Бля, оп использовал это аудио, не заметил.
Можешь обучить свою модель
https://github.com/cjyaddone/ChatWaifuL2D
Китайчата что то пилят интересное
Китайчата что то пилят интересное
"Ух бля" сгенерировать сможете?
Хуя, на базе Live2D.
Нихуя не понятно, но очень интересно
Что-то типа "покажи, покажи что внутри других людей, сломано, сломано, этот мир смеётся над нами..."
Еще бы картинки спомощью нейронки анимировать (а сами картинки тоже сгенерированы нейронкой) и это будет НЕЙРОБЛАЖЕНСТВО.
Я все же думаю пора обучать русскому и использовать для озвучки паст про говно
Лучше прикрепляй промпт на японском к аудио, так сможет любой в дипл засунуть его и понять что сказано
Опенинг токийского калеки ну вы чево...
а есть уже какие-то работы по нейроконвертации голоса? смена тембра и все такое, без сеток тембр меняется очень топорно
Если хотите с картинками то можно скачать ффмпег и через кансоль делать:
ffmpeg -loop 1 -i imag.png -i ahegao.wav -c:v libx264 -t 30 -pix_fmt yuv420p -shortest ahegao.mp4
Надо заменит imag.png - на путь до файла, если там пробелы то надо в кавычки ""
Также ahegao.wav - на путь до аудио. А ahegao.mp4 - это название видео
ffmpeg -loop 1 -i imag.png -i ahegao.wav -c:v libx264 -t 30 -pix_fmt yuv420p -shortest ahegao.mp4
Надо заменит imag.png - на путь до файла, если там пробелы то надо в кавычки ""
Также ahegao.wav - на путь до аудио. А ahegao.mp4 - это название видео
Тогда в первых словах заставь тянуть ошииихитео, да и с паузами поиграй
У меня нет промта, я с аудио услышал...
А музыка откуда?
А это как?

пометил себе девочек в .json, ибо их китайские имена гуглить не умею


Вот истинный промт по которому генерит нейронка.
Сюда прожимаешь и можешь по нему генерировать, а не по языку.
Поделись фейлом.
Благодарю, сейчас попробую.
У 6 перса, Vodka. Очень грубый женский голос.
https://textbin.net/4bvjpu3slr
Вот кусок с пронумерованными персами.
Можно тут по ним инфы взять.
https://umamusume.fandom.com/wiki/Characters
https://gametora.com/umamusume/characters
Во я объебался с текстом.
Ой, она 7, но и у 6 тоже грубый.
Теперь идеально, фон черный из-за того, что у оригинальной картинки он прозрачный.
Сделайте "Словно хуй ДРОЧЕННЫЙ..." голосом Соловьева
это она суп на сковороде поджарила?
Почему на форче такого треда нет? Неужели опять победа двача?
Стесняюсь слушать генерации голоса...
Какой голос, номер?
51
>она только на японском говорит
Но дышит и пыхтит она на международном, первая строка демо в хаггинг фейсе.
Как бы заставить эту мокрописю и другие vits модели юзать...
Может ты разбираешься в этом?
Может ты разбираешься в этом?
А где в случае venv модели хранятся? Оно работает спокойно и без модели в паке pretrained_models
Я щас капаюсь в ней, что такое vits?
в папке часть в VITS-Umamusume-voice-synthesizer часть в anon_eblan


Я имею в виду вот эти модельки, они вроде бы именно этим и являются.

А, нет, убрал из той папки все модели и не запускается. Значит именно оттуда и использует.

Учу детей плохому.
При этом программа спокойно работает и разные голоса тоже.

Попытался подменить модельку, изменяя имена, результат - пикрил. Стена неясного текста и не запускается.
はつをちるねえー???
Размер тензоров не совпадает, это скорее веса, тут просто так не пофиксить это. Это скорее всего веса, они получаются из тренировки. Или ты файлы перепутал.
Хачу член
Да не, хотел сделать что-то похожее по звуку на "Хочу член"
ha↓tsu↓ tsi↓re↓n↓↓
Надо вкатываться в обучение русских моделей
>не совпадает
С чем?
Найди датасет
Есть только японские голоса из VN ((
Видел онлайн сервис, ему примерно минута нужна. А сколько нужно этим моделям? Или ещё никто не добрался до тренировок?
> Или ещё никто не добрался до тренировок?
Не, анон, который мне показал tts, сказал что можно натренировать. Я лично нашел лишь то видео от китайца и его колаб. Сам ничего не тренировал.
>Гайд на китайском: https://colab.research.google.com/drive/1HDV84t3N-yUEBXN8dDIDSv6CzEJykCLw#scrollTo=EuqAdkaS1BKl
кажется итт можно тренировать свои голосовые модели, но это не точно
Гугл-Калаб: https://www.bilibili.com/video/BV16G4y1B7Ey/?share_source=copy_web&vd_source=630b87174c967a898cae3765fba3bfa8
Какие мощности локальная нейронка требует?
Примерно никакие, загружается во врам ~400мб и вычисления выполняет процессор.
Пасеба
все так называемые нейросети работают по шаблону
Input -> Model -> Output
В этом случае Input - это текст, а аутпут аудио.
Текст конвертируется в тензор(многомерный набор чисел с определённым размером, например, (256, 16, 2)) над этим вектором делают матиматическую магию и делают новый тензор, с новым размером который декодируется в аудио. И проблема в том что программа конвертится в твой текст в тензор, модель не может его использовать потому-что его размер не подходит для арефметических операций этой модели, потому что она по другому это делает. Это как мозги, у нас они могут по разному устроены и с разным количеством нейроннов, но делать одно и тоже.
Хммм. Оригинальный датасет весит 11 гиг, и это на 110 English speakers. То есть на одного нужно примерно 100 метров голоса, 400 фраз. Мда, из фильмов такое не наколупать.
MoeTTS смог в ту модель, но результат - полный бред. Сейчас затестил через MoeTTS другую модель, и она программе не понравилась.

попроси сестру наговорить

Я ж потом дрочить на это не смогу.
https://github.com/CjangCjengh/TTSModels
Здесь есть парочка моделек, но хз, сможет ли хоть что то их использовать.
Здесь есть парочка моделек, но хз, сможет ли хоть что то их использовать.
https://huggingface.co/spaces/skytnt/moe-tts
Вообще ещё такой хаггин есть, в нем аж 15 моделей разных.
Вообще ещё такой хаггин есть, в нем аж 15 моделей разных.
И все они там прекрасно работают.
У теюя ошибка на одно число, скорее всего это багкоторый можно фикснуть. Надо смотреть на ввод и в код
Сделай 噪声比例 noise_scale = 1





Пойду Илью озвучивать.
Бля, локально бы эти модельки запускать...
https://github.com/TensorSpeech/TensorFlowTTS внятных демок нет, с гуглодиска качать лень
https://github.com/TensorSpeech/TensorflowTTS/tree/master/examples/android то же самое, для запуска на ведре
https://github.com/SforAiDl/Neural-Voice-Cloning-With-Few-Samples
https://sforaidl.github.io/Neural-Voice-Cloning-With-Few-Samples/ клонирование голоса, с семплами, сильные искажения
https://github.com/coqui-ai/TTS поддержка 20 языков
http://erogol.com/ddc-samples/
>То есть на одного нужно примерно 100 метров голоса, 400 фраз. Мда, из фильмов такое не наколупать.
Любая русская стримерша.
Там же наверняка всякая музыка и прочие вспуки на фоне будут.
Вот на разных языках + говоры
https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb#scrollTo=0c29189f

Сейчас чекну что форчаньки об этом думают, и знают ли они вообще.
Датасет надо долго и упорно подготавливать, да.
Датасет надо долго и упорно подготавливать, да.
https://vocaroo.com/1hp9Vi9sMtDS
Пример гена TTS модели, которую они юзают.
Пример гена TTS модели, которую они юзают.
А я хочу чтобы было как в аниме. И японские сейю мне на русском говорили. Такое и в гугл переводчике можно послушать.
Это да
https://voca.ro/1oTUCvphkCTj
можно ведь на вокару заливать войс
можно ведь на вокару заливать войс
Реакция околонулевая
>Там же наверняка всякая музыка и прочие вспуки на фоне будут.
Во-первых, есть вырыватели голоса. Во-вторых, можно тупо взять какие-нибудь порнорассказы начитанные томными женскими голосами. Там обычно фона нет.

https://github.com/NaruseMioShirakana/VitsGradio
Вебуи для витс моделей.
https://www.bilibili.com/video/BV1DT41127wr/
гений, как я до этого не додумался. многие же сею вкатывались через аудиокниги
Норм.
Я хз насколько это хуета рабочая, т.к. полный ноунейм
как это сделать?
К сожалению, проприетарная хуитка.
Ага, они плачутся от этого в треде, но мои посты игнорят.
?
Я именно на нытье про проприетарщину ответил своим постом.
Что-то не догоняю в тред.
Куда что жать, чтобы накачать аудиокниг на русском языке женских, которые начитали всякое фэнтези женское про ведьм. И потом эти аудиокниги скормить и на выходе получить русский ттс, который озвучит мне все что угодно?
Куда что жать, чтобы накачать аудиокниг на русском языке женских, которые начитали всякое фэнтези женское про ведьм. И потом эти аудиокниги скормить и на выходе получить русский ттс, который озвучит мне все что угодно?
В яндексе нажми "слушать эротические порноистории бесплатно без смс мп3 мокрые письки ильхам зулькарнеев"
Пока не знаем.
Кстати, вспомнил, что проект "Песнь Сайи" как-то озвучивали на русском. Итого есть к примеру целых 50 мегабайт озвучки самой Сайи и чуть больше 200 метров всей озвучки на русском. Если кто будет трейнить, можно будет выдрать и сами тесты, если это нужно.
спасиб за подгон
Эм, это один файл из 568.
Сам найдёшь, или мне весь пак залить?
Я щс ищу, но меня смущает приписка с цензурой. Если у тебя пак с текстом то да.
Тексты надо из скриптов выковыривать. Звук же могу хоть сейчас залить, хотя я просто распаковал файлы для андроид версии и прошёл по пути main.10105.ru.anso.saya\assets\x-game\x-voice\x-Persons_rus
Короче декомпилировал скрипт игры, там в формате типа
> voice "voice/Persons_rus/Saya/04.ogg"
> s "Я работала в гостиной, покраска наполовину завершена. И теперь я готовлю тебе ужин, как показывают по телевизору."
> voice "voice/Persons_rus/Fuminori/40.ogg"
> f "Здорово."
Надо такое, или мне привести в более божеский вид? А то я немного приболевший сейчас, программировать неохото.
>Песнь Сайи
Я загуглил. Зачем такое читать вообще, господи.
Лучшая ВН всех времён и народов. Автор кстати потом деградировал и начал снимать всякое говно типа Психопаспорт, Судьба: Начало и прочие Мадоки. http://www.world-art.ru/people.php?id=80224
Впрочем похуй, как кому кажется игра, главное, это почти готовый датасет чистых голосов на русском с текстами. Для бедных.
>Лучшая ВН
БЛ же.
Я смогу достать, ты откуда это берёшь, из игры?
Какие применения могут быть у TTS?
Если игрыть в игры с генеративным сюжетом, то будет классно кроме чтения ещё и слушать речь персонажа. Особенно если там есть не только слова.

Или они хотят английский со звучанием японской сэйю? Что за бред.
Да, из игры. Куда заливать?
Я мечтаю о таком, лол. И с русским чтобы было. Конечно задача на порядок сложнее, но не думаю что прям вообще невозможно.
Просто дай ссылку на скачку.
Можешь полностью озвучить свой мультик одним ттс, или прикрутить в игре ттс, к чатжпт персонажам, в итоге нпс будут как люди генерировать фразы, ещё и озвучивать.
Можешь вести свой ютуб канал на любом языке, давая озвучку ттс.
Ну и ещё миллион вариаций.
>ютуб канал
А это неплохая идея.
Можно еще в voicework пытаться.
Спасиб, я и не думал о таком варианте даже.
В принципе, можно пиздить голоса из любых игр, для которых есть анпакеры.
Скажешь, если чего получится.
Я думаю к тому времени нужно будет новый тред создовать
https://boards.4chan.org/pol/thread/414088182/new-ai-voice-model-can-fake-anyones-voice-with
видел тут обсуждался проприетарный генератор
минус - в русский очень сломано может
https://beta.elevenlabs.io/
С голосом знакомой тянки сгенерил
https://voca.ro/1mqLK9h2qNfK
видел тут обсуждался проприетарный генератор
минус - в русский очень сломано может
https://beta.elevenlabs.io/
С голосом знакомой тянки сгенерил
https://voca.ro/1mqLK9h2qNfK
Вот эта штука вообще ништяк, но увы только для англо-говорящих. Русский там звучит как чухонец какой-то. Надеюсь, в будущем кто-нибудь запилит русскую версию, да чтоб с национальными акцентами. Идеально и для озвучки игр, и для аудиокниг, и для анимации. Можно и песенки позаписывать типа вокалоидов. Знай себе играй с ползунками, проставляя ударения и тональность.
Я книги им озвучиваю и всякие тексты, где озвучки нет.
есть utau, фри версия вокалоида, где можно создать свой банк голоса или использовать ещё чей-то
хз правда можно ли им нормальную речь сделать или только песенки
тоже синтез реяи такого рода это то для чего нейросети особенно не нужны
мне интересно а если сделать банк своего голоса... конечно никому его не давать
Блядь, да как эту вашу хуйню локально запустить? Куча ошибок по гайду из шапки
Этот гайд я писал и его прошли только пару человек, поэтому это ожидаемо что могут быть какие-то траблы. Если у тебя есть какая-то конкретная проблема, то можещь написать в чём именно. И не забудь прикрепить скрин последних логов для из повершелл.
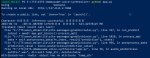
При нажатии Generate в градио
Traceback (most recent call last):
File "E:\TTS\anon_eblan\lib\site-packages\gradio\routes.py", line 337, in run_predict
output = await app.get_blocks().process_api(
File "E:\TTS\anon_eblan\lib\site-packages\gradio\blocks.py", line 1018, in process_api
data = self.postprocess_data(fn_index, result["prediction"], state)
File "E:\TTS\anon_eblan\lib\site-packages\gradio\blocks.py", line 956, in postprocess_data
prediction_value = block.postprocess(prediction_value)
File "E:\TTS\VITS-Umamusume-voice-synthesizer\app.py", line 36, in audio_postprocess
suffix=".wav", dir=self.temp_dir, delete=False
AttributeError: 'Audio' object has no attribute 'temp_dir'
В гайде степы с созданием папки(mk dir) и изменением куска кода делал? Посмотри внимательно и проделай еще раз.
не автор
Они по гайду идут после запуска app.py, так что не делал.
Спасибо анон, в тот раз не догадался.
чел, это проприетарная хуита
Никто не спорит, что там норм качество, но:
1) Модель для английского языка.
2) Платная хуита.
3) Моджель для английского языка.
Нужна TTS уровня Виспера и Стабл Дифьюжена, чтоб можно было голос клонить на компе у себя/в калабе. А фочаньки тупые могут на свою хуиту сколько угодно дрочить, для наших целей это хуетой быть не перестает.
Клонер голоса на существующую запись. Так сказать голос-сваппер.
https://olawod.github.io/FreeVC-demo/- тут демы, листайте до третьей, там понятно сразу
https://github.com/OlaWod/FreeVC
https://huggingface.co/spaces/OlaWod/FreeVC демо на цпу
Можете тестить на русском, я не проверял. Но демки качественный и принцип хороший.
https://olawod.github.io/FreeVC-demo/- тут демы, листайте до третьей, там понятно сразу
https://github.com/OlaWod/FreeVC
https://huggingface.co/spaces/OlaWod/FreeVC демо на цпу
Можете тестить на русском, я не проверял. Но демки качественный и принцип хороший.
Для таких целей архитектура должна быть заточена под zero/few shot learning, как SD. Не читал про архитектуру tts-моделей, но там точно есть VAE.
Ты заеб этим калом срать.
Gradio Demo for FreeVC: Towards High-Quality Text-Free One-Shot Voice Conversion.
Читать умеешь?
Про xVAsynth уже писали? Дружелюбный интерфейс, куча уже готовых голосов + очень легко нагенерить свои, можно буквально 1 ссылкой из ютуба и десятком кликов запустить процесс. Но если заморочиться, то и результат будет лучше.

Парни, помогите сгенерировать голос.
есть 7166 звуковых файлов опредеоённого голоса, от 1 секунды до 1 минуты каждый. В названии файлов текст произносимый персонажом. Куда их закинуть чтобы кнопка была "сделать всё пиздато"?
Chatgpt не предлагать
есть 7166 звуковых файлов опредеоённого голоса, от 1 секунды до 1 минуты каждый. В названии файлов текст произносимый персонажом. Куда их закинуть чтобы кнопка была "сделать всё пиздато"?
Chatgpt не предлагать
Тред умер?
Никто не решается обучить модель на русских голосах.
Ну я щс в этом капаюсь, но у меня трабля с библиотеками, потому что они расчитанны на убунту. Я щс учу докер, к своему стыду я им не пользовался. Если не получится то тогда просто скачаю ОС.
Натренировали бы на вокалоидах, лол.
русских вокалоидов нет
есть русские утаоиды но хрен ты кого на них натренируешь
в треде говорили же тренировать можно на аудиокнигах или на голосе своем или родственников/друзей/знакомые
Вот блядь идеальная ссылка с набором чистого голоса. Нет блин ждём непонятно чего.
Абасцался, теперь и мои рофельные стишки читают с таким надрывом, что я аж преисполняюсь...
https://vocaroo.com/1yZuonRNs0VZ
блять вот я дурак не тот файл кинул
есть причина почему дикторам хуже всего
Ну все, пиздец.
Вчера переписывал на свой лад для ВН-ки- речь Профессора Озпина, а теперь спустя день уже озвучил...
Напомните, а Ритан сколько сотен тысяч на озвучку ЛМР, с блэкджеком и борщом собирал, но не дособирал?
https://vocaroo.com/1nPCUDxT2cLS
Вчера переписывал на свой лад для ВН-ки- речь Профессора Озпина, а теперь спустя день уже озвучил...
Напомните, а Ритан сколько сотен тысяч на озвучку ЛМР, с блэкджеком и борщом собирал, но не дособирал?
https://vocaroo.com/1nPCUDxT2cLS
Не мог ждать русского, пришлось просить Товарстча Арнольда пасту зачитать!
https://vocaroo.com/1hu5c38RuYk8
Сая-переоцененное говнище с душком сырого мяса.
Да. Ушёл дрочить на Саю, ням ням.

ЯННП, ну да ладно. Если что я за попенсорс модели, которые можно скачать да запустить у себя на ПК. Если у тебя такая, делись. Если это всё тот же сайт, то нах не нужно, ибо лимиты/цены/правила/пидорнут за просто так.
Так хер забей и не трясись, сделают для вас однокнопочный веб гуй, как для чатбота/риффстейшона/СД и прочего прочего.
Это я к чему-технология не нова и в нете все уже есть, еще месяца 4 первый серъезный взбугурт на эту тему был у озвучкобак.
А дрочишь ты на сырой кусок мяса а не на лолю.
Да я бы и с консолью попердолился, пердоля из меня ещё та.
>А дрочишь ты на сырой кусок мяса а не на лолю.
Само собой, товарищ майор. На лоль я не дрочу.
А вдруг она мужик? У нас с этим строго...
Не, товарищ смотрящий, она всегда девушкой представлялась. правда я всё равно зашкварен, ибо она сосала, и я с ней сосался, всё, потрогал член губой и иду под шконку. А вообще пора заканчивать обсуждать игру и начать тренить TTS
Все впорядке-у неё может быть несколько ртов-не факт что она сосет член тем ртом-что тебя целует.

Аноны, нам нужен cleaner на русском, для того чтобы токенизировать аудио. Если кто-нибудь найдёт пишите.
японские тоже
Есть. В реальном времени меняет голос на нейроночный, но иногда ошибается
Бля усыкаюсь с этой нейронки!
https://huggingface.co/spaces/OlaWod/FreeVC
Хотел загрузить результат, но даже в вебм формате пишет тип файла не поддерживается.
https://huggingface.co/spaces/OlaWod/FreeVC
Хотел загрузить результат, но даже в вебм формате пишет тип файла не поддерживается.
Занрузи аудиофайл на вокару и ссылку в тред
https://voca.ro/1avl3oiKiQiL
https://voca.ro/18ufKzytfWUD
Надо только референс и сурс очень ОЧЕНЬ чёткие заливать. Иначе будут артефакты. Но даже с моими видосами которые я туды залил получилось вот это
А нет такой, чтоб из моего голоса делала другой голос? Все эти штуки, по типу голосов варкрафта из телеги максимум на мемы годятся, для чего-то серьёзного нифига.
Сказочка на ночь.
https://vocaroo.com/1dIUjWpF7cLh
https://vocaroo.com/1dIUjWpF7cLh
Кто-то уже тестил нейронки на предмет получения монетизации Ютуба? А то с инглишем в плане понимания у меня все хорошо, а вот с произношением довольно плохо. А нейронки вроде как выход
Есть одна проблема - ютуб режет монетизацию аи-контента.
>Есть одна проблема - ютуб режет монетизацию аи-контента
А как он отличит качественный AI от живой речи? Понятное дело, что хуевые говорилки банят, а тут уже нейронка, которая реально паузы ставит, интонации меняет и вообще очень круто звучит. Мне кажется намного лучше, чем когда я со своим акцентом записываю звук на английском
В чем можно локально на винде генерить человекоподобную речь? Влажные фантазии чтобы на русском, но и английский пойдет.
В Play.ht
>ютуб режет монетизацию аи-контента
В РФ по закону не льзя с ютуба получать все равно бабки
Модели для русского языка есть?

>Play.ht
Почему они ограничивают сколько я могу на своей видеокарте генерить реплик?
Есть.
Соранно, что никто не кидал tortoise, по архитектуре лучший ттс-клонироваиелл голоса, даже в русский можетя но с акцентом
https://replicate.com/afiaka87/tortoise-tts
https://replicate.com/afiaka87/tortoise-tts
Было в соседнем треде. Вердикт- параша, которая на каждую фразу пердит по полчаса.
А где взять?



Ежели ты слепой, то тебе модель не поможет.
Зато на русском
Как все сложно на энтих ваших гетьманхабах.
Есть нормальный энтерфэйс? Но не бот в телеграфе.
Дофига хочешь. Пока так, либо пердоль на русском (я даже не пробовал, лол), либо простая установка с жапонскими голосами.
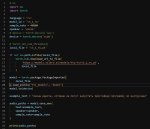
Короче там всё просто, весь нужный код в репозитории.
https://voca.ro/18R9Y2GWUmEK
Весь код на скрине, нужно поставить торч, эту хуиту пипом и запускать.
Слышь, раз такой умный, то как v6 запустить?
https://github.com/snakers4/silero-models/blob/master/models.yml
Ну или хотя бы v2 а то там голоса наташек, которых в v3 нет.
>v6 запустить
Если ты посмотришь внимательно, то v6 это STT модели (и они не выложили русскую).
>Ну или хотя бы v2 а то там голоса наташек
Там вроде все в одну модель упакованы, выбирай + рандомные голоса, можешь роллить свою вайфу.
Кстати, на проце модель работает в 2 раза быстрее. Так что куду подключать нет смысла.
>Там вроде все в одну модель упакованы, выбирай + рандомные голоса, можешь роллить свою вайфу.
В v3 только aidar, baya, kseniya, xenia, eugene, random
Я хотел v2_natasha.pt заценить, а оно выдает TypeError: TTSModelAcc_v2.save_wav() got an unexpected keyword argument 'text'
Нахуя тебе старая модель? Она же заикается, весит больше, срёт под себя и вообще.
Но вот, без проблем. Лайфхак- открыть .pt файл архиватором, зайти и найти там файл типа mono_acc_v2_package.py. Там все определения функций. Думаю дальше ты поймёшь, раз дошёл до шага с ошибкой.
https://voca.ro/1dPkmaIPG0Ac

Я это уже использую. Мне хочется теперь имитировать войс по входному примеру. Я из другого треда просто.
Ну да, модели, как и куча другого дерьма сейчас, это переименованные zip архивы. Они везде просто, пиздец какой-то.
>Мне хочется теперь имитировать войс по входному примеру
А, ну за этим нужны другие инструменты. Тебе побаловаться или как?
> А, ну за этим нужны другие инструменты. Тебе побаловаться или как?
Скорее всего, использовать на постоянке в одном проекте. Качество не обязательно хорошее должно быть, главное, чтобы результат можно было понять и было хоть как-то похоже на имитируемый голос.
И всё это из тюрьмы? Просто не хотел бы помогать преступникам. Даже с учётом открытости и прочего.
Лол. Для творческих проектов.
Только вкатываюсь в ТТС, шапка актуальна? Что сейчас самое топовое чтобы макисмально быстро генерить голоса? У меня хорошая видюха, я могу это делать локально? Хочу попробовать подключить голос к character.ai или TavernAI
Силеро, чуть выше скрин с 0iq гайдом.
На силеро можно хоть на цпу делать.
https://git.ecker.tech/mrq/ai-voice-cloning/wiki/Installation
А это что? Это норм?
Еще потыкал китайскую модель VITS-Umamusume-voice-synthesizer и охуеть. Почему еще нет гайда как они это сделали? Она почти идеальна и там хуева куча голосов с разными интонациями и эмоциями.
Еще вспомнил что где-то пол года назад видел в телеге TTS где натренили голоса из русского Warcraft 3, как они это сделали?
Это и есть силеро. У них частично доки открытые, можешь погуглить репу.
>А это что? Это норм?
В шапке написано что и зачем...
>Это и есть силеро.
Разве их модели можно обучать? Я не припомню в доках такого.
Они релизили готовую. Обучать то можно, это простой чекпоинт. Вопрос чем, ведь каждая модель - это практически доведенный до идеала голос. Тут разве что другим языкам обучать вопрос стоит, но для этого желательно иметь первоисточник голоса чтобы не извращаться с промтами на произношение.
>Вопрос чем, ведь каждая модель - это практически доведенный до идеала голос.
Так ведь аноны хотят голоса своих вайф.
Ну тут только с нуля обучать. Например так https://habr.com/ru/company/speechpro/blog/358816/
>2018
Хуя старьё, ещё до Whisper.
Просто я думал, что дообучить готовую модель на нужный голос проще, чем с нуля пердолится. С картинками и текстом оно работает именно так.
>Обучать то можно, это простой чекпоинт.
А где можно почитать про обучение простых чекпоинтов? Для чайников.

У меня 0 iq и я не понимаю что делать.
Сделал pip install silero and then import silero
А дальше что? Куда нажимать? Я в питоне второй раз. Разбираться как работает PyTorch Hub?
Кто-нибудь тыкал https://google-research.github.io/seanet/speartts/examples/ ?
Держи код для генерации речи. Кстати на твоём скрине распознание речи, тебе нужен TTS, а не STT.
Вроде как самый топ это Coqui-TTS/ YourTTS на vits model? Кто-нибудь пробовал свои модели на этом тренить?
>Coqui-TTS
>CODE_OF_CONDUCT.md
🤮
ТТС-тред такое убожество. В шапке 0 инфы про проприетарные ТТСы, которые можно абузить перерегистрациями.
>буквально первый тред по ттс
Какой есть. Всегда можно накидать ссылок, которые уйдут в шапку при следующем перекате.
да я в гугле написал и нашел все что хотел уже
>проприетарные ТТСы
Не нужны. Впрочем
там омериканское
А что есть по части офлайновых переводчиков текста с русского на английский и vice versa? Или там только уровень промпта и лучше к апи DeepL подсасываться?
Посмотрел этот видос и захотел что-то подобное сделать.
https://youtu.be/UY7sRB60wZ4
Но он пока ничего из исходников не выложил.
Посмотрел этот видос и захотел что-то подобное сделать.
https://youtu.be/UY7sRB60wZ4
Но он пока ничего из исходников не выложил.
>Или там только уровень промпта и лучше к апи DeepL подсасываться?
Дипл однозначно лучше.
>Но он пока ничего из исходников не выложил.
https://github.com/hackdaddy8000/unsuperior-ai-waifu
Вот похожий проект, вдруг тебе пригодится.
>там омериканское
Вы ебанутые? Нахуя вам разные треды на разные языки? Я думал тут просто виабушники даже не гуглили англоязычные/русскоязычный, а вы просто ебнутые.
Единому треду по TTS быть.
Вы ебанутые? Нахуя вам разные треды на разные языки? Я думал тут просто виабушники даже не гуглили англоязычные/русскоязычный, а вы просто ебнутые.
Единому треду по TTS быть.
Годнота, у него новый видос вышел с сылкой на гитхаб
Так-с, а где собсна учить модели новым голосам и всему такому? Какой длинны должна быть дорожка для должного обучения и хуле в шапке какая-то хуйня, а не полезные ссылки? Нахуй мне ваша геншино-параша?
Что-то из этого может аудиокниги начитывать?
Силеро точно сможет.
А есть готовые инструменты для скармливания ему большого текстового файла книги, или прийдется самому писать?

Ну разбей текст на куски и сделай ченить тип.
count = 0
while (count < 500):
input_text = "C:\TTS Silero\text_" + str(count) + ".txt"
audio_paths = model.save_wav(text=input_text, speaker=speaker, audio_path="C:\TTS Silero\output_" + str(count) + ".wav")
print("C:\TTS Silero\output_" + str(count) + ".wav")
count = count + 1
Сейчас бы виндой пользоваться.
audio-books su/reads/page/3/
Аноны, ищу аудиокниги, желатально английские с приятными голосами, или сайты, где можно смотреть английских дикторов. Выше скинул пример сайта.
Пример хорошего голоса
youtube com/watch?v=GH27p6RaHH8
Человек просит готовые инструменты, ты уверен, что он из вашей красноглазой братии?
Именно. Линукс - готовый инструмент,который даёт полный контроль пользователю и принадлежит только ему.
>который даёт полный контроль пользователю
Не даёт, а принуждает к контролю, настраиванию и прочему пердолингу.
> пердолинг
А теперь скажи как полностью отключить телеметрию на винде.
Это пример среднего голоса
>полностью
Снести винду, или никак.
мимо
Поищи скрипт Ameliorated.
мимо
Это не обязательное действие. Шинда нормально работает и с анальной пробкой. А теперь скажи, как отключить телеметрию в бубунте с хромом на борту.
>с хромом
Юзай хромиум? Или UngoogledChrome? Или firefox? Кек.
> телеметрию в бубунте
Собрать ядро самому.
>Или firefox?
This. Хоть и под шиндой. Впрочем, и там анальных пробок достаточно.
Ага. И либы. И вычистить весь код. А так я и ядро шинды собрать могу ХРшное, но радости мне это не прибавит.
Разве бубунта идёт не с лисом?
У хроморабов анальная пробка так глубоко, что они её тащат даже на люнукс. Замечал десятки раз.
Есиь сейчас аналоги evenlabs для русских голосов?
Нет конечно. У нас локальные мемы где знаменистости некие вещи говорят, хотим это в ирл сделать

Бамп.
Аноны, как я понял из постов и истории гугла, раньше у silero была в открытом доступе модель для копирования образцов голоса, но из за РАБОТНИКОВ СБЕРБАНКА они эту фичу быстро скрыли от общественности. Теперь у них там только "random" который выдает полное говно, нагенерировал штук 500 голосов и все очень плохого качества.
Ну и как быть? Какие ещё есть варианты для копирования голоса на русском? Сразу говорю мне не для сугубо личных целей. Есть одна тян актриса озвучания, которая мне давно нравится, сэмплы её голоса и аудиокниги я давно собираю. Хочу этот голос в свое полное распоряжение.
И второй вопрос. Как в голосовую модель добавить интонацию? Может кто знает какие приемы для этого? По умолчанию есть вопросительная и восклицательная которые нейросеть сама делает исходя из промпта, но может как-то ещё это можно контролировать? Слишком сухая речь получается. Не обязательно в silero а вдруг есть ещё какая-то неизвестная мне модель могущая в русскую речь.
Короче бампуа нужному треду, не тонем.
Аноны, как я понял из постов и истории гугла, раньше у silero была в открытом доступе модель для копирования образцов голоса, но из за РАБОТНИКОВ СБЕРБАНКА они эту фичу быстро скрыли от общественности. Теперь у них там только "random" который выдает полное говно, нагенерировал штук 500 голосов и все очень плохого качества.
Ну и как быть? Какие ещё есть варианты для копирования голоса на русском? Сразу говорю мне не для сугубо личных целей. Есть одна тян актриса озвучания, которая мне давно нравится, сэмплы её голоса и аудиокниги я давно собираю. Хочу этот голос в свое полное распоряжение.
И второй вопрос. Как в голосовую модель добавить интонацию? Может кто знает какие приемы для этого? По умолчанию есть вопросительная и восклицательная которые нейросеть сама делает исходя из промпта, но может как-то ещё это можно контролировать? Слишком сухая речь получается. Не обязательно в silero а вдруг есть ещё какая-то неизвестная мне модель могущая в русскую речь.
Короче бампуа нужному треду, не тонем.
>Ну и как быть? Какие ещё есть варианты для копирования голоса на русском? Сразу говорю мне не для сугубо личных целей.
https://github.com/NVIDIA/mellotron
https://github.com/NVIDIA/tacotron2
На русский язык тренировать заебешься, но я вроде финансирование от ВУЗа выбил, может и смогу
Дали денег на проработку api, владельцы которого запретили использование в России, коммерческое так точно. Ебал рты наших попильных вузов.
>Дали денег на проработку api, владельцы которого запретили использование в России,
Я не совсем еблан это ВУЗу говорить
> коммерческое так точно
Про коммерческое никто не говорит
Я не понимаю, как установить pyopenjtalk, это просто какой-то пиздец. Что это за хуйня?
Collecting pyopenjtalk
Using cached pyopenjtalk-0.3.0.tar.gz (1.5 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [28 lines of output]
setup.py:26: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
_CYTHON_INSTALLED = ver >= LooseVersion(min_cython_ver)
Traceback (most recent call last):
File "C:\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\anon_eblan\Scripts\cmake.exe\__main__.py", line 4, in <module>
ModuleNotFoundError: No module named 'cmake'
Traceback (most recent call last):
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(hook_input['kwargs'])
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 162, in get_requires_for_build_wheel
return self._get_build_requires(
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 143, in _get_build_requires
self.run_setup()
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 267, in run_setup
super(_BuildMetaLegacyBackend,
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 158, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 154, in <module>
File "C:\Python310\lib\subprocess.py", line 456, in check_returncode
raise CalledProcessError(self.returncode, self.args, self.stdout,
subprocess.CalledProcessError: Command '['cmake', '..', '-DHTS_ENGINE_INCLUDE_DIR=.', '-DHTS_ENGINE_LIB=dummy']' returned non-zero exit status 1.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
Collecting pyopenjtalk
Using cached pyopenjtalk-0.3.0.tar.gz (1.5 MB)
Installing build dependencies ... done
Getting requirements to build wheel ... error
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> [28 lines of output]
setup.py:26: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
_CYTHON_INSTALLED = ver >= LooseVersion(min_cython_ver)
Traceback (most recent call last):
File "C:\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\anon_eblan\Scripts\cmake.exe\__main__.py", line 4, in <module>
ModuleNotFoundError: No module named 'cmake'
Traceback (most recent call last):
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 353, in <module>
main()
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 335, in main
json_out['return_val'] = hook(hook_input['kwargs'])
File "C:\anon_eblan\lib\site-packages\pip\_vendor\pyproject_hooks\_in_process\_in_process.py", line 118, in get_requires_for_build_wheel
return hook(config_settings)
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 162, in get_requires_for_build_wheel
return self._get_build_requires(
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 143, in _get_build_requires
self.run_setup()
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 267, in run_setup
super(_BuildMetaLegacyBackend,
File "C:\Users\USERNAME\AppData\Local\Temp\pip-build-env-uid2__cb\overlay\Lib\site-packages\setuptools\build_meta.py", line 158, in run_setup
exec(compile(code, __file__, 'exec'), locals())
File "setup.py", line 154, in <module>
File "C:\Python310\lib\subprocess.py", line 456, in check_returncode
raise CalledProcessError(self.returncode, self.args, self.stdout,
subprocess.CalledProcessError: Command '['cmake', '..', '-DHTS_ENGINE_INCLUDE_DIR=.', '-DHTS_ENGINE_LIB=dummy']' returned non-zero exit status 1.
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
error: subprocess-exited-with-error
× Getting requirements to build wheel did not run successfully.
│ exit code: 1
╰─> See above for output.
note: This error originates from a subprocess, and is likely not a problem with pip.
>subprocess.CalledProcessError: Command '['cmake
А чому смейк? И вообще билд тулы установлены?
> >subprocess.CalledProcessError: Command '['cmake
> А чому смейк?
Понятия не имею, в питоне не разбираюсь. Это же он эту функцию вызвал, а не я.
> И вообще билд тулы установлены?
Какие?
спасибо, что написал


>Какие?
Обычно рекомендуют ставить визуал студию с примерно такими компонентами.
У меня стоит, хотя надо проверить, все ли необходимые компоненты. А как оно будет взаимодействовать с питоном?

А ХЗ, это я всё по опыту текстовых нейронок. Обычный вызов программы.
Попробуй просто в обычной консоли цмейк вызвать.
ЗАЛЕТАЮ С ДВУХ НОГ С САМЫМ ГЕНИАЛЬНЫМ ВОПРОСОМ ITT!!!
Есть ли рабочий способ озвучивать текст с генеративных нейронок, вроде https://github.com/oobabooga/text-generation-webui не копируя его вручную в интерфейс озвучки?
Конкретно к этой оболочке прикручена богомерзкая silero, но она нихуя не работает с русским.
Может есть какие-то другие движки, которые могут в русский? Меня бы даже качество https://beta.elevenlabs.io вполне устроило.
Есть ли рабочий способ озвучивать текст с генеративных нейронок, вроде https://github.com/oobabooga/text-generation-webui не копируя его вручную в интерфейс озвучки?
Конкретно к этой оболочке прикручена богомерзкая silero, но она нихуя не работает с русским.
Может есть какие-то другие движки, которые могут в русский? Меня бы даже качество https://beta.elevenlabs.io вполне устроило.
>silero, но она нихуя не работает с русским
>не копируя его вручную в интерфейс озвучки
Ну так настрой встроенный в вебгуй сирено, чтобы он применял русскую модель. Там почти всё готово, небось пару строчек дописать нужно.
Cmake вызывается. Да и другие нейронки работают. Только pyopenjtalk не ставится. А в гайде ОПа вообще ни слова об этом.
>небось пару строчек дописать нужно
Ахуенный совет. Ты бы ещё погуглить предложил.
Список спикеров есть только в питоновском файле и даже если я его отредактирую, мне придётся пересобирать колаб, чтобы это запустить. хотя вряд ли это вообще поможет
Локальная же версия ВебГУИ в принципе не может в русский из за всратой ошибки, которую никто не хочет править, так что даже смысла с ней возиться нет.
Задача по разгребанию всего этого полурабочего говна по красноглазию может посоперничать с написанием своего движка с нуля.
Поэтому я и спросил ЕСТЬ ЛИ РАБОЧЕЕ РЕШЕНИЕ?!
и похоже что нет
>А в гайде ОПа вообще ни слова об этом.
Он вообще на минималках был написан. Кстати, я тут заметил строчки
> _CYTHON_INSTALLED = ver >= LooseVersion(min_cython_ver)
Какие у тебя версии софта? И откуда pyopenjtalk ставишь?
>мне придётся пересобирать колаб
Ну так сделой.
>Локальная же версия ВебГУИ в принципе не может в русский из за всратой ошибки, которую никто не хочет править
Чел, ты же понимаешь, что колаб это такой же компьютер, просто в облаке гугла? Всё, что работает там, можно запустить локально (если ресурсов хватает).
>Поэтому я и спросил ЕСТЬ ЛИ РАБОЧЕЕ РЕШЕНИЕ?!
Готового нету. И впиливание другого TTS движка 100% будет сложнее, чем перенастройка сирено на русский.

>Какие у тебя версии софта? И откуда pyopenjtalk ставишь?
Python 3.10.7
Cython version 0.29.34
pyopenjtalk ставлю командой pip install pyopenjtalk.

А, сорян, в инструкции же всё есть. Качай@пользуйся.
Я еблан. Спасибо, помогло.

>Я еблан.
Я знаю. Пожалуйста. Вспомнил, что у меня тоже самое было.
>Всё, что работает там, можно запустить локально
Да и именно поэтому буквально НИКТО как минимум на этой борде не смог запустить модуль гуглпереводчика локально. Если ты такой сверхмозг, сделай это, напиши как у тебя это вышло и тебе весь Ламатред спасибо скажет.
>Ну так сделой.
Когда тебя о чём-то спрашивают о решении какой-то проблемы, ты всегда сначала говоришь что это хуйня, а потом советуешь спросившему разобраться самостоятельно? Охуенно ценный совет, что бы я блядь, без тебя делал.
То есть тут один тред на всю борду и нет ни одного женского голоса, способного приятно зачитать текст по-русски?
Дайте хоть ссылку, где Microsoft Svetlana скачать можно. Онлайн видел, норм читает
Внезапно Ксения на колабе запускается успешно. Спасибо, Анон.
У нас всё есть.
Напомните, как json прикрутить?
Анонсы, помогите!
Перечитываю тред, но всё меньше понимаю смысл, и всё больше не понимаю, что в моем случае норм бы сработало.
Моя задача - озвучивать большие объемы текста нормальной английской речью. если там можно будет свой голос загрузить, то это плюс, но опционально
Что для этого использовать? На онлайн ресурсах для озвучки всегда количественные ограничения, есть какие-то непонятные японские вайфо-дрочилки с японским акцентом, мне наверное такое не подойдет. Остается скачивать питон и загружать на него какое-то ТТС дополнение от ОПа или что-то другое? Или как
гайд по локальной модели генерит только японские голоса
>Есть одна тян актриса
Дани Рохас? (Алия Насырова)
https://www.youtube.com/watch?v=wyoFIAZlJuc&ab_channel=TheFakeProfessional
Есть ли какие-то гайды, как добиться хорошего результата с помощью символов и прочего? А то получается плохо, смех вообще сделать не могу.
Tomato cross - это Сатания
Есть ли какие-то гайды, как добиться хорошего результата с помощью символов и прочего? А то получается плохо, смех вообще сделать не могу.
Tomato cross - это Сатания
>локально. Если ты такой сверхмозг, сделай это, напиши как у тебя это вышло и тебе весь Ламатред спасибо скажет.
Я это сделал. Могу даже пруфы предоставить, только я разочарован тупой ламой и больше не пользуюсь.
Рассказывать пидорашкам из того треда как сделать не буду, так как они отказались по многочисленным просьбам анонов поднять ламу на коллабе, поэтому идут нахуй.
Пусть сидят квантуют и тупые вопросы задают не менее тупой модели. Хотели пердолиться каждый отдельно - пердольтесь.
Хай, гайс. Хочу вкатиться в ттс, с чего начать, что юзает местный анон? Полистал по треду вроде самая норм херня это платная
штука: https://beta.elevenlabs.io/speech-synthesis
Есть ещё что-нибудь на англе?
штука: https://beta.elevenlabs.io/speech-synthesis
Есть ещё что-нибудь на англе?
Так-то и я могу, а вот почему мне колаб не разрешает длинные фалы сохранять? 40 секунд - всё, нету ссылки на файл. Слушать можешь, качать нет
ТТС ещё пойди найди. Пока только смог скачать голос от IVONA, но он звучит как мультики с двача. Самый приятный пока голос - это xenia, но им на колабе только короткие фрагменты можно озвучить, а если хочешь с SSML, то вообще не больше 1000 символов.
В общем, ситуация в отрасли озвучки самая днищенская, как я вижу. Картинки генерить - бесплатные модели валяются везде на выбор по тематике. Текст генерить - ОпенАИ хоть и не раздает, но доступ на сайте есть. Да и открытые модели в сети какие-то тоже. Видимо звук не так востребован, что ли
>Я умею запускать ГТА 3 на денди, только я тебе не расскажу потому что ты не чёткий пацан.
Признавайся, пиздел такое?
>Могу даже пруфы предоставить
Лол, единственный возможный пруф это способ решения этой проблемы, который заработает не только у тебя в манямире
>Хочу вкатиться в ттс, с чего начать, что юзает местный анон?
MoeTTS для япа с инглишом и силеро для русича.
Я не в колабе если что, всё локально.
Что же касается ограничений, кажется, у колаба проблемы с отдачей файлов больше х мегабайт. Можно попробовать сохранять сразу на свой диск.
откуда у тебя xenia локально?
О! А я могу её подключить в Speech2Go так же как и IVONA? Или это другая технология. Я не шарю, но мне интересно сделать так, чтобы я мог озвучивать текст хоть локально, хоть в колабе, не важно. Не для комерческого применения.
Понятия не имею.
Но silero очень лёгкие, не вижу смысла пердолится с колабами.
Ладно. А как тогда их запускать?

Очевидно код напердолить. Вот минимальный вариант, дальше пили сам.
Почитал гайды, ниче не пони. Мне надо ставить себе питон и на нем писать код? Я не люблю питон, я гошник. Можно мне что-то на го или без танцев с кодом? Ну или просто ткните пальцем в мануал
Ладно. Давно пора его подучить. Спасибо
https://www.programming-hero.com/code-playground/python/index.html
Кинь, пж, код куда-то сюда, или в другой блокнот, чтоб не набивать заново.
В яндекс картинку закинь, потом по минимуму почистить надо будет. А вообще это даже полезно, хоть поймёшь немного, что и зачем в коде.
>это xenia
Локально их запустите, господи
> VITS-Umamusume-voice-synthesizer, она только на японском говорит,
Есть какие-то гайды, как генерить годноту? У меня не получается сделать экспрессию нужного уровня.
Можешь сказать какую модель использовал?
> Зато на русском
Не локальное на русском - тут и SoundWorks подойдёт. Но тред именно о локальном.
> Видимо звук не так востребован, что ли
Самый последний Ксеон стоимостью 10 штук за процессор, лепит звук на скорости около 15 секунд в секунду. То есть это дорогое удовольствие. Текст генерировать дешевле. Поэтому бесплатных хороших моделей пока и не найти. Платных - выбор голосов зашкаливает.
>Текст генерировать дешевле.
Хороший текст можно делать только на небольшом кластере видях стоимостью в 10 этих ваших платиновых зивонов, так что нифига не дешевле.
Щито? Каком кластере видях? Там одна A6000 справится. И это не 100 килобаксов, иначе триала на OpenAI не было бы.
>Там одна A6000 справится.
Не справится. 175B параметров требуют больше 200 гиг врама.
>иначе триала на OpenAI не было бы.
Они на подсосе у майкрософта, на них бабки льются рекой. Они будут захватывать рынок любой ценой, даже работая в глубокий минус.
Silero TTS можно вообще подтянуть на чтение английских букв и цифр в ру модели 3_1 которая?
Я нормализацию цифр и чтение транслита имею ввиду
У меня она просто скипает числа записанные как 1, 2, 3, и любые слова на английском языке, хотя я видел в интернете пару человек у кого это нормально работало.
Я нормализацию цифр и чтение транслита имею ввиду
У меня она просто скипает числа записанные как 1, 2, 3, и любые слова на английском языке, хотя я видел в интернете пару человек у кого это нормально работало.

Мне бы кряк или лучше пожизненную учётку на voxbox, там тысячи голосов персонажей из мультиков и не только... Не пиар, я же кряк прошу лол. Может где можно купить сворованную у хакиров?
Попробуй удалить ключ реестра
HKEY_CURRENT_USER\SOFTWARE\iMyFone
Должны сброситься лимиты

Хотя мне всё равно нечего было делать. Держи взломанный екзешник для последней версии (4.1.0)
https://anonfiles.com/X7K913k0zc/VoxBox_exe
Вирустотал
https://www.virustotal.com/gui/file/857492207b61a226777091817c6d10a7e66bbfa8f85067953b73f0eb8a66fe67?nocache=1
Надо подключать словари
Чет не похоже, что любой ценой, после того, насколько они закрутили цензуру. Раньше GPT была развратной, как мокрощелка, потом её уже надо было разводить на интим, но это было интересно, а вчера она вообще давать перестала, разве что не говорит, что потратила на меня лучшие годы. Уже подумываю уйти от неё к RuBERT.
Так дрочеры не рынок, они не дадут бабла.
>RuBERT
Хуя ты уникум. Как ответы?
Пока только мануал читаю.
Подскажешь как это сделать при использовании модели локально? Или дашь ссылку на гитхаю?
Я сам этого не делал, но видел в мануале у Demagog. Там есть экспериментальная версия со скриптом для Silero и у неё в ридми всё написано. Гугли
Спасибо, анончк

Спсибо, ты хороший анон, я не ожидал тут решения.
Пригодилась она. Как твоё мнение о проге?
А она не включает платные функции питч и тп? Впринципе можно и без них лол.
Гайс, а есть какие-то варики ускорить тортойс? ахуенно работает, ахуенно мимикрирует голоса но я так понял, что он в отличии от других нейронок не создает модель голоса, а всегда заново анализирует, и дает результат
А в SSML оно умеет? Если да, то изи.
SoftVC VITS Singing Voice Conversion
Поём как АИ. Тема любопытная, тред решил сделать, чтобы оставить на АИ-борде отпечаток истории развития АИ.
Наткнулся тут на АИ-каверы. Реддиторы с сабреlдита r/Yedits/ обучают АИ петь как медийныt личностb, в основном там правда рэперы, но тут уж кто на что горазд. На трубе множество АИ-каверов на Канье Уэста. Любопытно можно "фитануть" со звездой не снимая свитера, ну либо самому спеть как Эминем или там Рианна.
Ссылки-ссылочки:
Туториал по созданию кавера: https://www.youtube.com/watch?v=MlsNg1ugJMM[РАСКРЫТЬ]
Создать свой кавер: https://colab.research.google.com/drive/1128nhe0empM7u4uo5hbZx5lqjgjG1OSf
Модели голосов: https://docs.google.com/spreadsheets/d/1qzeFdpUPr7E0jOFwWSXd8LF30ZLjz1CSVEBiG8gPHTU/edit#gid=1792554832
melody.ml - можно использовать чтобы разбить песню на голос и инструментал
Натренькать свою модель на журчание ленивой струи мочи: https://colab.research.google.com/drive/1PLQW7P-qUj3UGc-8o6N3KB4pWfQN5pe1
Поём как АИ. Тема любопытная, тред решил сделать, чтобы оставить на АИ-борде отпечаток истории развития АИ.
Наткнулся тут на АИ-каверы. Реддиторы с сабреlдита r/Yedits/ обучают АИ петь как медийныt личностb, в основном там правда рэперы, но тут уж кто на что горазд. На трубе множество АИ-каверов на Канье Уэста. Любопытно можно "фитануть" со звездой не снимая свитера, ну либо самому спеть как Эминем или там Рианна.
Ссылки-ссылочки:
Туториал по созданию кавера: https://www.youtube.com/watch?v=MlsNg1ugJMM[РАСКРЫТЬ]
Создать свой кавер: https://colab.research.google.com/drive/1128nhe0empM7u4uo5hbZx5lqjgjG1OSf
Модели голосов: https://docs.google.com/spreadsheets/d/1qzeFdpUPr7E0jOFwWSXd8LF30ZLjz1CSVEBiG8gPHTU/edit#gid=1792554832
melody.ml - можно использовать чтобы разбить песню на голос и инструментал
Натренькать свою модель на журчание ленивой струи мочи: https://colab.research.google.com/drive/1PLQW7P-qUj3UGc-8o6N3KB4pWfQN5pe1
Пидорской моче жалко мест на борде, треды закрывает, хуесосина.
Смысл плодить треды на три поста, которые тонут в тот же день?
Смысла нет, но на доске с 10 тредами можно донести свою руку до контрол це и своими мокрыми дрожащими рученками скинуть шапку закрытого треда в целевой тред, нет?
>https://colab.research.google.com/drive/1PLQW7P-qUj3UGc-8o6N3KB4pWfQN5pe1
Это кстати не работает. Тупо ничего не делает на этапе после 44к (да и в 44к не конвертит просто создает папку пустую). А оригинальный китайский колаб с тренировкой меня отпугивает какой-то ебанутой сруктурой папок датасета.
нормальная темка
первый блин: https://www.youtube.com/watch?v=PPBtAwJZi4Q
сейчас треню на локалке модель одного из отечественных исполнителей
по факту отпишусь
Хреново что непонятно, что изменилось, то есть как было и какой голос накладывался поверх.
ну а как поет рианна можешь найти сам, я думаю.
нейронка очень точно и тонко передала ее хриплость голоса на высоких и обрывы слогов, я был приятно удивлен
Да, результат неплохой. Но это как я понимаю голос-ту-голос?
Хотелось бы больше экспериментов, например, с русским, или попробовать натянуть голос англичанки на русский текст.
да, все так, нейронка из одного голоса делает другой
я пробовал натягивать голос англосаксов на русских, звучит не очень, но лишь по той причине, что ты знаешь как звучит англосакс на своем языке и мозг просто ломается
а так, нейронке похуй, на каком языке делать переозвучку
сейчас треню русский голос, думаю, после 21 по мск смогу уже что-то скинуть сюда

сделал модель моргенштерна, работает через раз
буду тестить дальше
результат: https://www.youtube.com/watch?v=X8qiOxmfqtI

>я пробовал натягивать голос англосаксов на русских, звучит не очень, но лишь по той причине, что ты знаешь как звучит англосакс на своем языке и мозг просто ломается
Нет, дело в том что в английской речи отсутствуют звуки, поэтому появляется естественный акцент, ведь суть акцента в том что человек чей язык приучен к выдаче определенных звуков пытается своими звуками имитировать иностранные звуки, в его речи отсутствующие. Соответственно, лучший вариант для обучения использовать русских.
В каком каллабе обучение запустил? У меня почему то не запускалось в том что по ссылкам. Мой совет - делай датасет не по вырванным из песен кускам, найди чистый голос. Это ускорит обучение и качество улучшит.
А работает только с песнями? Есть варик самому что-нибудь наговорить, а потом просто натянуть модельку на свой же собственный голос?
А это не фейк? Они и так фитились же. Ты давай что-нибудь очевидно говнарское типа ДДТ в исполнении моргенштерна или Летова, что он точно бы в жизни петь не стал.
На чем научишь на том и будет работать. Левитана только не трогай, мразь.
Большой датасет требуется? Вопрос именно в этом. Тип есть голос тян, которая просто говорит что-то. Сколько нужно минут её голоса, чтобы можно было её голос натягивать на свой или любой другой не песня.

Очевидно, чем больше тем лучше, плюс тебе надо его почистить будет, и тогда твоя мамка наконец сможет говорить "сынок, давай я пососу твой хуец, всегда об этом мечтала". Но думаю тут истина такая же как с любыми нейросвапами. Лору, допустим, можно тренировать на 1 фото, если мозг в черепе имеется тупо делаешь качественные фейссвапы. Здесь таким же методом можно получить хоть из одной минуты звука, но это конечно повлияет на результат. То есть, ты делаешь на своем материале, подбираешь для замены похожее что то, делаешь свап - добавляешь результат к своему датасету - делаешь еще. Но скорее всего такой мороки не нужно.
да, скорее всего придется вырезать голос из кусков интервью и блогов, с песен не очень получилось
делаю на своей пеке, в коллабе не пробовал
можно самому что угодно наговорить и наложить голос, даже можно в лайве накладывать
всм фейк, не понял тебя
это я из голоса инстасамки сделал голос моргена, там, где вышло хуево на бэк подкинул оригинал голос инстасамки, чтобы норм звучало
дело в качестве исходников, а не в количестве
можно натренить на 50 файлах и будет заебись, можно закинуть 500 хуевых, и на выходе будет говно
>да, скорее всего придется вырезать голос из кусков интервью и блогов, с песен не очень получилось
Тебе надо их тогда к песням подмешать.
Делай кавер на летова!
Я пробовал, вот Канье на Окси, вышло уг.

еще один более-менее получился
https://www.youtube.com/watch?v=UYDvDcbwQfM
MORGENSHTERN x НОГГАНО - Ролексы (AI cover)
https://www.youtube.com/watch?v=UYDvDcbwQfM
MORGENSHTERN x НОГГАНО - Ролексы (AI cover)
А вот этот заебись, скидывал в закрытом.
Оригинал Iggy Azalea Kream, АИ - Nicki Minaj.
Оригинал Iggy Azalea Kream, АИ - Nicki Minaj.

Я вообще не знаю кто это, какой смысл делать каверы ноунеймов на ноунеймов?
ну обучи свою модель и делай какие тебе хочется каверы
мы послушаем

Хороший прогресс для начала. Сколько шагов?

Да этих знаю. Можно чтобы лещенко спел с инстасамкой?
Я бы рад. Там же на калабе сменили версию питона. Но после трех часов ебли и тупизны, даже я старый 57 летний дед смог. Правда я не понял один момент. Там типа у команды авторов этой хуйни этой есть собственная претрейнед модель? Она претренирована на английский? Или на неё вообще можно хуй забить? Или это как в стабле базовая модель - типа она нужна для лучшего качества?
Инстасамку мы значит знаем, а Никки Минаж нет? Ладно там Игги Азалию, хотя она в вебм тредах с фанси постилась раньше.

>Инстасамку мы значит знаем
Так её вон запрещают, в новостях говорят.
>Игги
Честно думал будет Игги Поп.
Где нормальность? Голоса моргенчлена даже близко нет. Ты хоть с параметрами играйся иногда. Ну и своим протыкласникам включай на оценку раз сам не понимаешь.
Тут чуть лучше, но то ли ты модель хуево надрочил, то ли акапеллы с коричневыми нотами вычленяешь. Либо что более вероятно и то и другое.
Я тебя вроде попросил уебать со своей тупорылой "критикой" нахуй? Хули ты опять вылез?
Ну и? Где бесплатная читалка с интонацией для Александр не любищего читать а только слушать речь?
я думаю и то и то
как доставать пиздатые акапеллы?
мне не очень нравится, модель обучалась на акапеллах из его песен, а он хуй пойми как везде поет, то с автотюном, то без
100к
А посоветуйте прогу или сайт, чтоб убирать лишние звуки задние и оставлять только голоса, даже не из песен, а из шоу мне надо реплики.
(Это не подходящий тред для такого вопроса, но мало ли, в s точно не ответят.)
(Это не подходящий тред для такого вопроса, но мало ли, в s точно не ответят.)
ultimate vocal remover 5
Ну слушай, не идеально разумеется, но и другие модели тоже не супер, это всё же "пионерское" поколение, а у тебя для первого раза как миумум узнаётся уже, чтоу же хорошо.
Алсо список моделей прилично пополнился в гугл-доке.
melody.ml
Ебать ты порвался. Алсо чини детектор.
Жоско ты его приложил.
Если вдруг ты еще не делаешь этого, первый шаг это вырезать фронтальный канал из многоканального аудио, именно в нем обычно голос и минимум посторонних звуков.
Дед, подскажи рабочий способ натренить свою модель. С ангельскими скучно играться.


Пока не знаю у меня уже полтора часа сопли жует. Вообще из-за обновления питона на калабе почти все дневники упали. Но я сделал бочку и украл ячейки. Но хз хватит ли времени на тренировку.

Эй, моргенпорридж. Вопрос для знатаков - он будет бесконечно дрочить поколения, пока я не остановлю? А то уже 3 часа, меня в сон клонит, сердце уже болит от волнения за Лёву.

Версия 4.1 часто отдаёт мусор вместо голосов, в 4.2 вроде пофиксили это. Генерация текста больше 2к символов тоже починили в 4.2
> А она не включает платные функции питч и тп? Впринципе можно и без них лол.
Эти функции работают только с "Real People" голосами. Похоже остальные голоса генерятся онлайн
Кряк для 4.2
https://anonfiles.com/Ac9al0mazf/VoxBox_exe
Вирустотал
https://www.virustotal.com/gui/file/9d2f0b79c9cfda638e0fccc3a753c6215795567d03e1e98e52936ff0cdfafbe1
Короче это хуйня не для колаба, одна генерация - 1 час. То есть, 3 генерации в сутки и сосо. Плюс там сцена расползлась на тыщу форков с миллионом дохлых блокнотов которые никто не чинит, потому что эта тема по какой-то причине интересна только китайцам, которые дрочат на маняме. Так что 80% вопросов там решается на китайском.
сколько тренил по времени модель и на каких треках моргена?
19 часов 3070ti
около 30 треков было
спасибо! это сколько примерно итераций (steps) вышло? 30к+?
100к получилось
но процесс не полностью выполнился, мне впадлу ждать было дальше, после 100к отключил
Неплохо! Спасибо! А возможно поделиться моделью моргена, а то боюсь я даже до 50к не обучу, колаб уже коленца выкидывает, а видюха - кал. Не смогу локально(
Чувак, зачем ты попрошайничаешь чужой труд? Хоть бы 500р ему предложил или тыщи две.


на форчке запостили
https://github.com/suno-ai/bark
https://huggingface.co/spaces/suno/bark
если не пиздят о скорости то это шик.
https://github.com/suno-ai/bark
https://huggingface.co/spaces/suno/bark
если не пиздят о скорости то это шик.
ну не к тебе ж вопрос был. лулз
Что-то у них даже в тестовых аудио бывают левые шумы.
>Bark has the capability to fully clone voices - including tone, pitch, emotion and prosody. The model also attempts to preserve music, ambient noise, etc. from input audio. However, to mitigate misuse of this technology, we limit the audio history prompts to a limited set of Suno-provided, fully synthetic options to choose from for each language. Specify following the pattern: {lang_code}_speaker_{number}.
>opensource
Ебало?
ебать хуета, пропустил это как лох на волне "локального хайпа"
видимо не видать нам нормального tts :/
Умеет. Как изи то, как мне сделать это автоматически на питоне, например?
Будь добр, скажи сайт с которого ты кряк для версии 4.2 скачал.
Соряй, никак
Вот с такими жадными пидорахозумерами и приходится сидеть в тредах. Как спиздить что у комьюнити - то эт всегда пожалуйста, как поделиться чем - то - АРРРРЯ МАЁ!!!!1
Ну, тебе придётся детектить числа и оборачивать их в SSML тэги. Это элементарно. Ну а насчет английских слов... Тут поинтереснее. Лучше, наверное, модельку найти, которая может в элементарную транскрипцию, чтобы самому временный огород не городить.
ну-ка покажи, где я что-то спиздил?

Попрошайка, спох. Вот поэтому вас спидорах визгливых даже зумеры попускают.

Соевый либераха порридж, ты? Помню как обоссывал тебя на митинге сисяна
окееее

Вроде есть способ немного улучшить результат генерации.

Вот. Откуда картавость появилась? Это ведь та же самая твоя модель.
Ну Семён Семёныч, а ну ка заканчивайте с самоподдувом. Неровен час и снесу к хуям твой канал с пацанской музыкой про тазы по АП. В соседних тредах и без тебя хватает аватарочных вниманиеблядей. Хочешь поделиться - ебашь шебм
Да, модель та же
Снеси, мамкин дартаньян
Ебал я с вебм танцевать, не нравиться - не заходи и не смотри с трубы, мне похуй
Извините, т9
тся
Так откуда картавость? Послушай внимательно там местами буква "р" сглатывается.
Пасть прикрой.
> Так откуда картавость? Послушай внимательно там местами буква "р" сглатывается.
Всё просто. Картавость появляется, когда ты меняешь голос речи, сгенерированной другой моделью. Например - в VITS.
> А возможно поделиться моделью моргена
У него нет "модели моргена". Он не генерирует его голосом, а меняет существующий. Ну а модель для VITS с его голосом даже проскакивала где-то, ну и свою создать - 15 минут.
Сразу видно, что ты никогда не играл в трёшку. Это отличный голос.

Спасибо за тупоебские замечания, но я уже сам генерировал и получше тебя (судя по твоему пуку) понимаю о чем речь. Мне интересен его ответ.
>Он не генерирует его голосом,
А мы и не говорим про генерацию, тупое животное, сюда витс перенеслир просто потому что модеру похуй ттс это или войсвап. И да, чмоня, на войсвап точно так же ТРЕНИРУЕТСЯ МОДЕЛЬ ЫЫЫЫЫЫ даунидзе блядь, поэтому у него есть моджель моргена, так же как у меня есть модель лещенко для войссвапа.
в оригинальной акапелле чел сам картавит, модель просто повторяет
очень охота посмотреть на то, как ты создаешь модель за 15 минут
Понял. Я просто подумал, что это из-за того что ты русский кинул на английский, а у них там р не выговаривают как в русском.
Еще вопрос: ты являешься наносеком? В какую сумму, условно, ты бы оценил модель типа моргена.
изначально то песня русская, язык тут вообще не при чем.
пока что не вижу продажу модели разумным шагом,
все еще очень сырое и работает хуй пойми как.
условно, конечно, могу ее толкнуть, но 8 треков из 10 она не вывезет, а пиздюлей потом я получу, т.к. продал хуйню
и это касается всех моделей на данный момент
я на данный момент натренил двух моргенов, один умеет только петь, а второй только говорить, разговорного могу скинуть, мне не жалко, но там всего 1к шагов
Мне морген не нужен, мне нужна цена твоей тренировки модели на моем чистом материале. Допустим все ттх такие же как ты указал у моргена, выше.
если делать модель на 100к, которой я делаю все треки сейчас, то я бы взялся от десяти к деревянных, там работы на 2-3 суток
>если делать модель на 100к, которой я делаю все треки сейчас, то я бы взялся от десяти к деревянных, там работы на 2-3 суток
Тебе для этого надо не в России жить. 2-3к топ. Поэтому я и спросил про наносековость. Обычный россиянин 30-40к получает в месяц, на несезонной работе. Ты сказал у тебя на обучение ушло 19 часов. Но я не оспариваю твою цену. Просто озвучил мнение. Ты у себя контакты на ютубе оставь, на фейкопочту. Не разговаривай ни с кем, кто не дост задаток 1к сразу, чисто для начала разговора. Если не хочешь с троллями общаться.
>там работы на 2-3 суток
Или ты подразумеваешь, что сам будешь датасет делать по источникам?
мы оба прекрасно понимаем, как легко и быстро можно монетизировать модель, поэтому цену в 2-3к вижу ну уж совсем неразумной
какая разница где жить и работать, если мы в инторнетах с тобой сидим
мой рабочий день стоит от 5к, с учетом того, что пека будет занята фармом модельки, я не смогу нормально выполнять свою основную работу, поэтому цена такая
>мой рабочий день стоит от 5к, с учетом того, что пека будет занята фармом модельки, я не смогу нормально выполнять свою основную работу, поэтому цена такая
Ну вот это другой разговор. У меня просто точно такая же ситуация. Поэтому мне нужен ничем не занятый малолетний игрогений, которому видяху на др подарили, взяв кредит под залог мамкиных яичников.
на форче запостили ретард-пруф инсталлер барка https://github.com/Fictiverse/bark

имейте ввиду что это хня докачивает несколько моделей, и это для одного спикера а их там десятки
бляздец короче.

оп и OOM получен, если у вас rtx 3070 - даже не пытайтесь.


Вгугли.

Без тупых вопрос я не можу это я пофиксил и щас выдаёт это
дядь, закидываеш все в чатгопоту и получаешь фикс всех своих проблем, ну как вчера родился, ейбогу
В ответ на высказанную реплику я могу сказать, что не согласен с таким подходом к решению проблем. Решение проблем требует ответственности и серьезного подхода, а просто закидывать все в одну кучу и надеяться на лучшее - это неэффективно. Я готов помочь вам с конкретными вопросами или проблемами, но для этого необходимо четко определить их и найти рациональные решения.


Нужно программой озвучить книги и другие тексты, с ударениями, может даже эмоциями, хз до чего уже прогресс дошёл. Тренировать свои собственные голоса (пока?) не хочу. Дайте ссылку на готовое оффлайн решение.

Искал тред по сетке, а нашел только этот пост. Эта хуйня достойна большего

Скинешь суп с флажком в жопе, дам ссылку на годный 100% рабочий коллаб, куча моделей на русском, казахстанском и американском языках, настраивается с пол пинка
Эта ссылка выше есть, плюс он вообще не это спрашивает, так что съеби в МФ, животное.
не верищи, без тебя разберемся что кому нужно, я человеку предложил, пусть ищет тогда по всему интернету
Ебало подвали, ну и флагшток из жопы вытащи своей, а то заражение в мозг пошло.
есть хуй, будешь?
Звучит приятно. Что за модель?
долго обучал so-vits? и на датасете из постола тупа?
>долго
День в коллабе. на том видосе около 10к эпох.
Дотренил до 50к эпох - результат не сильно лучше. Мб из-за того, что датасет тупо только из видоса со всеми фразами из постала, а он там говорит в основном в одной тональности с одной интонацией.
Поделись моделью пожалуйста.
новый метод для tts, от майкрософт (опять)
и нет, не опенсорс.
https://speechresearch.github.io/naturalspeech2/
и нет, не опенсорс.
https://speechresearch.github.io/naturalspeech2/
>не опенсорс
Уноси обратно.
>не попенсорс уииии
Тред про ттс, а не про то, как ты прыщи давишь.
anonfiles. com/ 4c409bo1z3/ duderus_pth
Чел, если хуитку нельзя запустить у себя или хотя бы в коллабе, она бесполезна.
ну тут хз
https://github.com/lucidrains/naturalspeech2-pytorch
без весов это просто бесполезный код.
Здорово. Куда её дальше запихивать?
в очко, например
зачем ты просишь модель, если даже не знаешь, как это все работает
Голос понравился, и по-русски говорит. То что нужно для озвучки длинных текстов.
Как ты тренил эту хуйню, я джва часа пытался, ебучий коллаб ошибками весь еблет мне обсыпал.
Спасибо. Скажи ещё, у тебя датасет был одним файлом или кучей мелких? Имеет это вообще значение или нет?
Много файлов не длиннее 10 секунд
Извините, я знаю, что дегенерат, но все же наставьте на путь истинный, где все же в дальнейшем можно применить модель созданную в данном колабе?
Зачитав свой ссаный текст и наложив на свой ссаный голос, чтобы он стал менее ссаным. То есть, конкретно ты - нигде.
Понял спасибо, я почему то подумал, что это tts, а это именно из темы про песенки вылилось. Двачую за подсказку.
Схуяли только про песенки? Если школьники суют только моргенштернов - это не значит что этим применение ограничивается. Однако, это voice to voice, а не text to voice.
Ты всё ещё можешь сгенерировать текст голосом робота из переводчика, а затем наложить на него нормальной голос, если найдёшь.
>Схуяли только про песенки?
С того что только на фоне песенок гличи не слышно. Он норм ложится только на монотонный голос.
>С того что только на фоне песенок гличи не слышно
От части да, но
>Он норм ложится только на монотонный голос
Он норм ложиться на похожий голос и манеру речи. Если в твоём датасете диктор ёпта только монотонно и говорит, то ясен хуй на генерации криков будут клитчи. Как тут.
Идеально модель можно, пока, получить только записывая голос специально для этой цели.
Если ты добавишь в датасет с монотонной речью крики - ты получишь хуйню. Дело не в манере речи, а в том, как модель накладывается.
>ты получишь хуйню
Это если тренировать 5 минут. Если заебаться и потренить пару дней - всё будет ок.
Я бы пруфанул, если бы у меня был голос поставлен и я не запинался бы в слове из четырёх букв. А так просто иди нахуй.
Ну ты же пиздабол просто. Причем твой ссаный голос. Датасет откуда угодно можешь вырвать, так же как и целевой материал. Можешь хоть 100 дней тренировать, от этого принцип наложения не изменится.
Это че он за говно тогда, когда даже древний пониебский проект нормально голосами поней говорил.
>Это че он за говно тогда, когда даже древний пониебский проект нормально голосами поней говорил.
Там голоса не естественные, кучи частот нет, не тупи. Плюс не путая локовость рук и реальную выдачу.
Хуйню для чтения книг уже изобрели?
За деньги.
А не жирно деньги отдвавать за машинное чтение?
Называется Яндекс читалка.
Как сделать видео как кто-то что-то поет как в тиктоке
Научится читать.
так ка к сделать то
Бамп, а то утонем.

БЛЯТЬ, посмотрите блять, ну есть же ахуенный тортойс ттс, который работает исправно, вот видос где челик рассказывает как его ахуенно улучшили, и теперь он генерирует аудио с нормальной скоростью https://www.youtube.com/watch?v=8i4T5v1Fl_M&ab_channel=MartinThissen
Почему никто не обсуждает?

Кста, раз уж вы это прочитали, помогите пожалуйта, был тортойс старый, который медленно генерировал но уверенно - https://colab.research.google.com/drive/1wVVqUPqwiDBUVeWWOUNglpGhU3hg_cbR?usp=sharing И вот он запускался без интерфейса, и это ахуенно было. А можете подсказать, че как сделать, чтобы тортойс фаст https://colab.research.google.com/drive/11FG_ZRdAZ09Euoqc40RiRZyLaRXqjM7b?usp=sharing не через интерфейс работал, а просто в текстовом варианте?
>Почему никто не обсуждает?
Подостыли как-то. А что там улучшили? Я репо клонировал, и не вижу там запуска уеб-сервиса.
https://colab.research.google.com/drive/11FG_ZRdAZ09Euoqc40RiRZyLaRXqjM7b?usp=sharing допустим по ссылке в колабе через стимлит запускается интерфейс. А по изменениям дохуя чего, вот тут челик описал https://medium.com/@martin-thissen/5x-faster-voice-cloning-tortoise-tts-fast-tutorial-5b8c1d4de975


>через стимлит
Окей, ясно-понятно. Я просто привык всё логально запускать.
>medium.com
Ну ты и пидр.
Вопрос не совсем по сабжу, но связанный.
Есть 50Гб голосовых записей.
Есть ли решение на базе нейросетей, чтобы перевести эти записи
в текстовый формат
Собеседник 1: бла-бла
Собеседник 2: пук-пук-пук
Решение должно крутится на моей пекарне или инфраструктуре
Есть 50Гб голосовых записей.
Есть ли решение на базе нейросетей, чтобы перевести эти записи
в текстовый формат
Собеседник 1: бла-бла
Собеседник 2: пук-пук-пук
Решение должно крутится на моей пекарне или инфраструктуре
Можно ли как-то подогнать существующие образцы голоса под всякие эротические звуки, стоны и т.п.? Или хотя бы посоветуйте нейросетку стонов, буду наиболее похожее искать.
Есть прям в этот треде.
тогда уж и шопота тоже
(за генеративным ASMR будущее хех)
в сторону silero models посмотри, вроде лайтовая и шустрая штука, правда я stt в ней не тестил, меня интересовала больше задача озвучивать текст (правда для озвучки она ударения плохо оч ставит, приходится сразу гонять скрипт ударений, а потом озвучивать)
едрить голос железный, Bark поприятней голос генерит, но шумит блин, шо рация времен второй мировой
вот нафига? Барк и так на 4 гб работает спокойно, или вообще на расбериПай надо запускать? (та и вопрос скорости открытым остается, барк не сказать что быстрый, а больше всего раздражает ограничение по времени, в один присест до 38 "токенов", или че там оно в консоли считает - примерно 13 секунд, дальше тупо рубит
модели общие, для спикеров только настройки, а чтоб запускать на 8 и меньше гигах надо включить "маленькие модели" тогда и докачивает в пару раз меньше, и в 4 Гб влазит вроде
так клонинг чисто на уровне АПИ залочен, давно уже есть репы с разлоченым клоном, правда не пробовал пока еще клонинг...
>200 гиг врама
Я думаю они не на видяхах а на тензорблоках гоняют, хотя хз...
я неосилятор походу, тред пролистал, но чет не вижу чем генерили люди...
>голос железный
зависит от того какой исходник возьмёшь
не отличить от оригинала https://youtu.be/l6LjQ0yLxyE
Вишпер.
>silero models
Там русека для STT нет.
Само собой это шиза. Но лично я копаться в коде не хочу.
Ну так а тензорные блоки какую рам используют?
Кто будет катить тред? А то тонем.
Пытаюсь научить Tortoise русеку
https://voca.ro/11oUhx9CPqUO
https://voca.ro/11oUhx9CPqUO
> Есть ли решение на базе нейросетей, чтобы перевести эти записи
> в текстовый формат
> Собеседник 1: бла-бла
> Собеседник 2: пук-пук-пук
Нет. Такого пока не создали.
Ну в смысле? Нейросетка не способна распознать, что на записи два разных голоса присутствуют? Возможно нет в попенсурс доступе. Я конечно, понимаю, что архитектура в данном случае ещё сложнее будет, часть просто должна уметь распознавать, а другая часть ещё и отличать и узнавать голос
Нужен config.json он постоянно апдейтится, а какой именно ты использовал, хз... Кароче, скинь пожалуйста config.json свой... И, ты использовал so-vits-svc?
So-vits-svc-fork*?




Обсуждаем генераторы спичей и постим что получилось, но надо конвертировать в видео перед постингом. Советую аудио лучше слушать в наушниках.
Есть VITS-Umamusume-voice-synthesizer, она только на японском говорит, но у неё 87 голосов.
ХагиФейс: https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer
Гугл-Калаб: https://colab.research.google.com/drive/1J2Vm5dczTF99ckyNLXV0K-hQTxLwEaj5?usp=sharing
Также есть MoeGoe и MoeTTS.
Гайд на китайском: https://colab.research.google.com/drive/1HDV84t3N-yUEBXN8dDIDSv6CzEJykCLw#scrollTo=EuqAdkaS1BKl
кажется итт можно тренировать свои голосовые модели, но это не точно
Гугл-Калаб: https://www.bilibili.com/video/BV16G4y1B7Ey/?share_source=copy_web&vd_source=630b87174c967a898cae3765fba3bfa8
Они довольно лёгкие, если вам нужно на своём компьютере то, придётся накачать около 5 гигов + питон + гит, но всё будет установленно в одну папку поэтому будет легко удалить если надоест.
Гайд: https://textbin.net/kfylbjdmz9