Где взять последнюю версию RVC: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases
Спасибо анону в прошлом треде который подсказал как починить RVC. Сделал свой первый кавер, зацените.
Короче rvc явно лучше поет, но модель получается ужасная, не знаю почему.
Использую тот же датасет, но результат в 100 раз хуже чем в svc
Использую тот же датасет, но результат в 100 раз хуже чем в svc
Мод для КР надо сделать с этим треком.
Почему нет нормального гайда, где объясняется, от чего зависит batch size и количество эпох? Или я слепой?
ты тупой?
эпоха это один прогон всего твоего датасета
бач сайз это количество прогонов одновременно
Как соединить голоса RVC с ламой?
Ставь максимально высокий батч-сайз (=на скольки файлах одновременно обучается нейронка), который позволит твоя видеокарта. Число эпох (=количество полных прогонов по твоему датасету) можешь делать настолько большое, насколько позволяет время. Эти сетки (CVS/RVC) не переобучаются, в отличии от той же SD. Просто в какой-то момент не будет никакой разницы между эпохами.
Почему бы не приложить .bat/.sh файл который сам выполнит все это консольное установочное говно? Это дело пяти минут, зато каждый кто будет ставить твое дерьмо не будет тратить эти пять минут(или три часа, если он впервые это делает). А некоторые вообще дропнут нахуй, когда увидят твою инструкцию на тридцать шагов.

Вроде такой проблемы у меня не было.
Тут только можно попробовать
pip install chardet
Помогло.
Запустилось после плясок с бубном. Тебе стоило написать что надо имя персонажа в настройках указать, а то работать не будет.
Работает через пень-колоду, если честно. Во-первых - ты зачем-то родил полностью новый интерфейс вместо того чтобы сделать форк уже готового экстеншена к убабуге, при этом никаких настроек оббращения к апи я не увидел. Во-вторых, wake слово он понимает через раз(жутко бесит), русский язык не понимает вообще. В третьих - голос на выходе все равно без нужного выражения, почти никакой разницы с встроенным в убабугу силеро.
>Во-вторых, wake слово он понимает через раз(жутко бесит)
Какое имя ты используешь. Если как-то японское, то может такое быть, используй ангйлиское.
Имя lisa, которое стояло у меня понимал почти всегда с первого раза.
>wake_words = ["lisa"]
Вот здесь можешь указать несколько wake_words, если твое имя он понимает всегда по разному.
>русский язык не понимает
Под русский да, надо еще отдельно допиливать, чтобы работало.

> голос на выходе все равно без нужного выражения
В теории выражение в silero можно частично делать с помощью тегов. Надо заставить с помощью какого-то промта ламу генерировать с тегами.
Эх, полумеры. Нужна нормальная мультимодалка с выводом голоса напрямую.
Вчера вкатился, генерил на RVC.
Оригинал: https://www.youtube.com/watch?v=enwCyZvibZA
Оригинал: https://www.youtube.com/watch?v=enwCyZvibZA
Смотрю, у меня в браузере видео не воспроизводится, чем вы сшиваете? Я делал:
ffmpeg -i zima_letov.png -i zima_letov.wav -c:a aac -b:a 320k zima_letov.mp4
Алсо, спасибо Сенкофагу за вдохновение попробовать RVC, это оказалось куда проще, чем я думал.
В замечательное время живём.
В замечательное время живём.
Ну вот, теперь даже превью нет. Я явно что-то делаю не правильно.
Попробуй так:
ffmpeg -loop 1 -i image.png -i audio.wav -c:v libx264 -tune stillimage -c:a aac -b:a 192k -pix_fmt yuv420p -shortest output.mp4
Или через второй таб в этой штуке, но если через онлайн делать, там пара секунд тишины в конце добавится: https://huggingface.co/spaces/NeuroSenko/audio-processing-utils
Так ffmpeg ошибку выдает:
inflate returned error -3
Error while decoding stream #0:0: Generic error in an external library
Через сайт за 10 минут так и не сконвертил.
Попробую сконверить аудио отдельно и потом так:
ffmpeg -loop 1 -framerate 1 -i image.png -i audio.aac -map 0 -map 1:a -c:v libx264 -preset ultrafast -tune stillimage -vf fps=10,format=yuv420p -c:a copy -shortest output.mp4
Во, теперь норм вроде.

сенко скримить не умеет
Шикарно вышло, анон. И почему я сам не догадался вокал из песен Аргонова попробовать ею переозвучить... Спасибо, что поделился.
Добро пожаловать в клуб.
Да, я поделал сначала несколько генераций и понял, что от качества голосовой дорожки зависит 80% результата, а у Аргонова же все исходники на гите лежат. Я скачал голос без постобработки, прогнал в RVC и потом в Audacity наложил эхо как в оригинале через FabFilter Timeless. Потом склеил с минусом с того же гита.
Спасибо.
Что для АМД(ЦП)даунов посоветуете? Кроме РКН конечно.
ElevenLabs всё? У меня только получилось зарегаться (раньше не пускало даже через впн), а там генерация голоса уже платная. Нет лазеек, как с claude/gpt4 и прочими платными сетями?
На 2060 rtx какой батч сайз ставить? А чекпоинты как ставить в svc?
Силеро на процессоре работает даже лучше, чем на видеокарте, лол.
>ElevenLabs всё?
Всё, уже месяца три как.
>На 2060 rtx какой батч сайз ставить?
Берёшь и тестишь, кто знает, может у тебя там в фоне игра запущена, и врама осталось полгига?
А как вообще тренировка нейросети влияет на ресурс видеокарты?
Так же, как и любое другое использование. Хочешь вечной жизни своей картонке? Положи её в сейф в безводную и безкислородную атмосферу, авось 30 лет пролежит.


Проверяй на вкладке ГПУ, выбери куду.
модельку на мэда для RVC где можно скачать? был бы оч благодарен за ссыль
Потому что оно считает 3D нагрузку, очевидно жи.
Продолжаю извращаться над Аргоновым.
Оригинал: https://www.youtube.com/watch?v=kR4idheTafY
Модель neco-arc(aggressive)
Оригинал: https://www.youtube.com/watch?v=kR4idheTafY
Модель neco-arc(aggressive)
https://discord .com/channels/1089076875999072296/1099149801054019604
сяпс!
Скачал всё и перезалил на хг. Ну и свою модельку туда же вкинул.
SVC (39 моделей): https://huggingface.co/NeuroSenko/svc-models/tree/main
RVC (152 модели): https://huggingface.co/NeuroSenko/rvc-models/tree/main
Колаб STS - всё.
Поделишься ссылкой на репу с исходниками Аргонова? У меня оф. сайт не открывается и нагуглить не могу.
Низкий поклон
Шикарно. Тут на всей борде полтора анчоуса знают Елизарова. Скинул в тематический, авось оценят. Вкрации расскажите как делать такие шедевры.
Вы когда вырезаете звук из мультиков, фоновый шум чем убираете?
Там силеро выпустили новые модели v4 для русского. Только они хуже, лол.
Есть способ менять свой голос на тянский в реальном времени?
> A fork of so-vits-svc with realtime support
>качества голосовой дорожки зависит 80%
Это база. Поэтому свежеспизженные модели первым делом идут морфить голос комрада с выразительной речью.
Но у меня парадокс - самый чистый морф получился на шипящем мешапе.
На ютубе разжовывают по промту RVC тред Елизарова?
Пытался научить rvc на голосе одного черта из одной игры, а получился neco ark с фильтрами ревебирации. Дайте совет как делать чтобы делать хорошо
Хм, я подумал, может дело в том голос оригинального британского актера довольно высокий? Я впервые раз попробовал и ещё ничего не понимаю
Ну повысь голос, там же можно
>Короче, пацаны. Открываете телеграм, находите канал СnacuTe XpucT'a, боту отсылаете сообщение и качаете кучу говн\\\\ голосов.
>RVC модели⬇️
>RVC_Voice_1:
Анон, нихера не могу найти такого вообще. КАК ТАК-ТО?
Может у кого есть RVC Андрея Ярославцева, пацаны, поделитесь?
Блин там короче не RVC походу...
Ищи просто "XpucT", тот канал будет в первой десятке выдачи.
Ух ебат, вроде бы с голосом ру локализации работает лучше, за исключением тянущихся гласных.
Что будет если накидать для обучения сразу 2 или даже 3 отдаленно похожих голоса? Получится что о среднее или результат будет прыгать от одного к другому?
Ну да, вот >>898413
Спасибо, так нашлось, но да там не RVC, ех...
блять ебать там текста в шапке вы ебанутые я поридж с свдг
Держи в курсе.
rmvpe
А капы как вытягивал? RVC?
>капы
Это чо? В гугле выдаёт только фонк.
Да, RVC.
Акапеллы сокращёно, голос без музыки.
Через увре.
Ультимейт вокал ремувер сокращёно
БЛЯТЬ, ЕБУЧИЕ НОРМИСЫ В КРАЙ АХУЕЛИ!
Это и есть тот самый пиздинг контента, на который жаловался анон?
https://youtu.be/T5-oLns1TY8?si=TvNK6B70wqsJI5oM
Эта хуита даже не удосужилась название другое придумать, пиздец.
Главное, 14к просмотров за 8 дней на канале с 31 подписчиками, будто этот видос в какой-нибудь паблик ВПараше запостили.
Это и есть тот самый пиздинг контента, на который жаловался анон?
https://youtu.be/T5-oLns1TY8?si=TvNK6B70wqsJI5oM
Эта хуита даже не удосужилась название другое придумать, пиздец.
Главное, 14к просмотров за 8 дней на канале с 31 подписчиками, будто этот видос в какой-нибудь паблик ВПараше запостили.
Пчел... В первый раз? Лепи вотермарку и без валидола не лезь в тикток.
Тебе жалко что ли?
Я это для анонов делал, а не для какого-нибудь школьника, который это зальёт на ютюб и закинет в свой говнопаблик.
С тебя убыло? Ты говоришь сейчас как какой-нибудь говноправообладатель, который считает упущенную прибыль по чисслу скачиваний с пиратебея. А по факту тот еблан (я его нисколько не жалею, чувак просто пиздит работы без указания авторства а ты его пиаришь) просто немного расширил аудиторию твоей работы. Возможно даже амёбы из тиктока, посмотрев это, получат такой вау импульс, что он выбъет их из колеи потребление говна и даст сил начать создавать говно самим, а это уже кое какой, да плюс.
Похуй, жаловаться на авторские права в интернете = бороться с ветряными мельницами.
Вот поэтому когда я делаю контентич для двача, я обязательно ставлю на нем свою подпись и ссылку на себя, а такое стараюсь как модно быстрее залить, чтобы было легче блочить пидоров ворующих контент
Шапка говно, тред захвачен копролисом.
Рот ебал этих TTS. Делаю свой аналог Нейросамы и все готово кроме нормальной речи. Силеро не подходит потому что хочу идти на англоговорящую аудиторию, ибо на русском твиче одни нищеброды да и сама аудитория намного меньше.А на английском Силеро выдает полную содомию вместо речи.
MoeGoe и MoeTTS - какая-то дичь которую непонятно как запускать, что делать, как обучать и где у нее английский язык хоть в каком-то виде. Даже гугл не знает ничего кроме 3.5 респозиториев на гитхабе без толковых мануалов.
Туртоис - генерит хорошо но по 5 минут, для реалтайм стрима не годится ни в каком виде.
Барк - странный и все равно долгая генерация.
Что делать, анон? Может есть еще что-то кроме ажур клауда и елевенлабс?
MoeGoe и MoeTTS - какая-то дичь которую непонятно как запускать, что делать, как обучать и где у нее английский язык хоть в каком-то виде. Даже гугл не знает ничего кроме 3.5 респозиториев на гитхабе без толковых мануалов.
Туртоис - генерит хорошо но по 5 минут, для реалтайм стрима не годится ни в каком виде.
Барк - странный и все равно долгая генерация.
Что делать, анон? Может есть еще что-то кроме ажур клауда и елевенлабс?
это ейка и лисяша
Делюсь своими результатами.
Нейронки поют всрато, но после допиливания в FL получается вполне терпимо.
https://youtu.be/I5TtXQ942Lk?si=9A23QOhLO30csrqJ
https://youtu.be/I8oL56LJdRQ?si=o-aishDMI3Ya5wQf
https://youtu.be/CxIRCvi9qcU?si=vwo6I1WnDXqGg2EH
Нейронки поют всрато, но после допиливания в FL получается вполне терпимо.
https://youtu.be/I5TtXQ942Lk?si=9A23QOhLO30csrqJ
https://youtu.be/I8oL56LJdRQ?si=o-aishDMI3Ya5wQf
https://youtu.be/CxIRCvi9qcU?si=vwo6I1WnDXqGg2EH
Ящитаю, если человек смотрит тикток, то ему уже не помочь.
> Что делать, анон?
Пиздуй на завод.
Там завезли два примера от bark.cpp TTS (сам репозиторий всё ещё WIP), также обещают добавить voice-cloning.
https://github.com/PABannier/bark.cpp
В первом примере на фоне есть некая мелодия, вероятно использовали [music] токен как у оригинального барка.
Короче эта шняга из-за использования той самой библиотеки GGML должна будет работать почти в реал-тайме ибо оригинал с неквантованными моделями стандартного размера требует около ~10gb vram.
https://github.com/PABannier/bark.cpp
В первом примере на фоне есть некая мелодия, вероятно использовали [music] токен как у оригинального барка.
Короче эта шняга из-за использования той самой библиотеки GGML должна будет работать почти в реал-тайме ибо оригинал с неквантованными моделями стандартного размера требует около ~10gb vram.

Аноны, а как вы боретесь с картавостью в русских песнях в SVC? Пользуюсь своими датасетами и на выходе постоянно плохо произносится буква Р в песнях, это можно как-то пофиксить?
Киньте тг с моделями
Может есть модель без этих щелчков ебаных?
Да, обучать на датасете РУССКОГО некартавого голоса.

Я там в репозитории в обсуждение читал про это, что вся программа основана на английских фонемах. Поэтому, когда ты обучаешь модель в датасет другого языка будет получаться такой вот "акцент". Не в датасете дело. Возьми любую модель хоть с миллиардом часов обучения и попробуй изменить русскую речь и она всё равно будет картавить английскими фонемами. Да тембр голоса будет идеально похожий на цель, но произносимые звуки будут выдавать англичанина.
Прочитал шапку и понял чуть меньше чем нихуя. Может у меня глаза пиздой обшиты, но подскажите такое:
1. Можно ли взять звуковой файл с начинкой текста, скормить его нейронке и на основе этого файла нс будет говорить этим голосом (озвучивать написанное). Это же про это тред?
2. Какова длительность файла? Написано что от 10 минут до часа, а что вы за образцы такие скармливаете? Аудиокниги?
3. И самое главное - например я начитаю 10 минут текста, что именно лучше скачать - чему лучше скормить? Идеально если это локальная история, без всяких там регистраций и смс. Есть что-то типа rope или stable defusion, только для голоса?
1. Можно ли взять звуковой файл с начинкой текста, скормить его нейронке и на основе этого файла нс будет говорить этим голосом (озвучивать написанное). Это же про это тред?
2. Какова длительность файла? Написано что от 10 минут до часа, а что вы за образцы такие скармливаете? Аудиокниги?
3. И самое главное - например я начитаю 10 минут текста, что именно лучше скачать - чему лучше скормить? Идеально если это локальная история, без всяких там регистраций и смс. Есть что-то типа rope или stable defusion, только для голоса?
Если говорить про русскоязычную речь, то положняк сейчас такой:
Для генерации голоса из текста (Text To Speech) лучше всего использовать Silero. Запустить его можно локально (Soundworks, смотри этот пост ), поиграться в онлайне без смс и регистраций ( https://huggingface.co/spaces/NeuroSenko/tts-silero тут сетка упадёт, если скормить ей больше нескольких сотен символов за раз; можно скачать этот фронт себе локально при желании), либо поиграться с их официальным ботом в телеге https://t.me/silero_voice_bot но там есть лимиты на бесплатном тарифе. Для Silero доступно несколько готовых русскоязычных моделей, но свои обучать нельзя.
Затем ты можешь поменять оригинальный голос на нужный тебе (Speech To Speech) при помощи SVC либо RVC. Эти системы позволяют тренировать свои голосовые модели. Вот тут тебе и пригодится образец нужного тебе голоса длительностью от 10 минут до часа.
RVC более новый, меньше косячит с произношением и модели там тренируются на порядок быстрее, советую глянуть в его сторону.
> что вы за образцы такие скармливаете? Аудиокниги?
В качестве датасета надо использовать примеры нужного тебе голоса с как можно меньшим числом сторонних звуков.

Вот здесь глянь
Либо тут зеркало на хг
https://discord .gg/aihub
Насколько мне известно, в этом дискорд-комьюнити находится самое крупное структурированное хранилище моделей для SVC/RVC (канал voice-models). Там есть фильтры по нескольким категориям (например, можно искать аниме-персов и исключить неоригинальный дубляж) и работает поисковая строка. Для всех моделей сразу прикреплены примеры с результатами. На каких-то спикеров доступно сразу несколько вариантов моделей.
И что? Как раз похоже как будто иностранец с акцентом произносит звуки русского языка. Особенно это отчетливо слышно на втором видео. Если ты этого не замечаешь, значит просто слишком долго с сэмплами возился.
Короче мимо диванный специалист. Проблема в том, что базовые модели, поверх которых мы обучаем, все как одна английские (китайские, мб японские). Для обучение базовой модели с нуля нужен нормальный такой кластер, ну или хотя бы одна А100 на месяц погонять. Такие дела.
Сколько эпох лучше поставить для баланса качество/время обучения при наличии 15 минут семплов голоса и моей бомжатской 1060 на 6 гб?
Батч сайз равен 3, если больше то вылетает с нехваткой видеопамяти. Максимальное время ожидания часа 2-3.
Сколько вы вообще в среднем ставите эпох для svc?
Батч сайз равен 3, если больше то вылетает с нехваткой видеопамяти. Максимальное время ожидания часа 2-3.
Сколько вы вообще в среднем ставите эпох для svc?
Есть гайды на rvc? Как его установить вообще?
1. Скачать https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/RVC0813Nvidia.7z
https://huggingface.co/lj1995/VoiceConversionWebUI/blob/main/RVC0813AMD_Intel.7z если амуде или штеуд вместо видокарты
2. Распаковать
3. Запустить go-web.bat

Что эта за хуйня? Когда все будет готово, сколько еще ждать?

Это реалтайм замена голоса. Надо жать кнопку Infer, а не (Re)Start Voice Changer, если работаешь с файлом.

Выбери куду.
>СnacuTe XpucT'a
Нихуя не находит его
переименовали его в AINetSD Group

Ебать он пафосный. Ему об этом писали? Пробовали опустить с небес на землю?
Что скажете о voice.ai, если мне нужен риал тайм? RVS лучше будет? Как они с русским языком дружат? Насколько сильно грузят комп?
*RVC
Аноны подумываю использовать Silero в качестве читалки. В основном для tts есть ли в этом смысл? Интерфейс из шапки попробовал и сразу вопрос можно как-то подкручивать скорость речи? А то уже привык к довольно быстрому темпу гуглвойса
> An open source implementation of Microsoft's VALL-E X zero-shot TTS model.
https://github.com/Plachtaa/VALL-E-X
https://colab.research.google.com/drive/1yyD_sz531QntLKowMHo-XxorsFBCfKul?usp=sharing
https://github.com/Plachtaa/VALL-E-X
https://colab.research.google.com/drive/1yyD_sz531QntLKowMHo-XxorsFBCfKul?usp=sharing
самое главное :
https://github.com/Plachtaa/VALL-E-X#%EF%B8%8F-hardware-and-inference-speed
> A GPU VRAM of 6GB is enough for running VALL-E X without offloading.
собственно как и любой другой ад зависимостей, эта херня не хочет работать.
В шапку надо добавить ссылку на https://vocaroo.com/upload , так проще делиться звуками.
Эм, фигачит весь голос в логу в файл размером в 23 килобайта?
https://vocaroo.com/19oTpoiXKtG3
Качество конечно не фонтан, но там в качестве исходника рандомный файл из сенкодб.
Ну и как всегда, в русский не могёт.
>логу
лору конечно же. Или как назвать этот мини файл?
для этого :
> For faster inference, please use “Make prompt” to get a .npz file as the encoded audio prompt, and use it by “Infer from prompt”
эдакий сид, получил хороший результат, сохраняешь и используешь повторно при инференсе.
Да я понял для чего он. Прикол в том, что его достаточно.


У меня другая ошибка, плюс торч как всегда установился процессорный, 3080Ti такая "Да да, иду я нахуй".

ну тут пчел пообещал сделать .exe релиз, надеюсь это упростит установку.
https://github.com/Plachtaa/VALL-E-X/issues/48
Если в датасете нет твердой эр, то как модель сама её создаcт? Никак.
(мимокрокодил из Лламы)
Офигеть, 6 ГБ врам, у меня Stable Diffusion, BLIP и суммаризатор еще крутятся, скока там врама на все это надо, в таком случае!
А если SDXL, то уже 11+1+2+6=20 гигов минимум.
С SD 1.5 14 гигов минимум.
Понапридумывают, никаких тебе оптимизаций. =с
Так и сидим на силеро.
Нарезаю этот видос на семплы и кидаю на тренировку.
В чём не прав?
>в мире больше не будет актеров озвучки, будет лишь параша которую будут крутить по кругу + тысяча скамеров ебущих тебя же
Во всем ты не прав. AI-пидоры это беспринципный кал, и против тебя скоро выйдет куча законов.
Можешь поиграться пока есть время.
>Законы
Пчел...
>сейчас можно подделать личность любого кто оставлял цифровые следы
Всё так. Соцсетебляди соснули. Мою личность не подделать, я аноним, у меня нет подписанных мною данных в интернете, нет ни одной моей фотографии, ни единого образца голоса, во всех сливах не было моего номера или ФИО. Остальные пускай страдают, сами на себя компромата выложили.
>у меня нет подписанных мною данных в интернете, нет ни одной моей фотографии, ни единого образца голоса, во всех сливах не было моего номера или ФИО
вот только такие чмохи-ничтожества и радуются с нейросетей
Анон, есть ли способ подключить подписку elevenlabs через русские карты типа сбера или я сосу писю в этом случае?
Эм, я то разумист, и сразу знал, чем закончится вся эта катавасия со списыванием денег в банках по голосу и еблету. А остальные да, дауны, и будут страдать.
Очевидно что нет, езжай из страны.

>разумист
ты хуисосист. Буквально пустое место которое ничто не может предложить обществу кроме пердежа, вот тебе и "похуй".
Хуя у вас тут дебич-треды.
Плохо, что подделать личность? Ебать вы дауны, фальсификации сопровождали человечество всю его историю. Всерьез на такую хуйню только вы же и ведетесь. Проблема не в подделках личности, а в том, что вы на это ведетесь и сразу бегаете с факелами и вилами.
Нет цифрового следа, личность не подделать? Ебать вы дауны, вот это безопасность, небось еще в тайге живешь, скрывая тепловой след от спутников и не пользуясь интернетом? А, не, падажжи… Уже не работает.
Поржал с обеих точек зрения. Ради кала спорите, к сожалению.
Жить надо в реальности, а не в фантазиях. =)
Плохо, что подделать личность? Ебать вы дауны, фальсификации сопровождали человечество всю его историю. Всерьез на такую хуйню только вы же и ведетесь. Проблема не в подделках личности, а в том, что вы на это ведетесь и сразу бегаете с факелами и вилами.
Нет цифрового следа, личность не подделать? Ебать вы дауны, вот это безопасность, небось еще в тайге живешь, скрывая тепловой след от спутников и не пользуясь интернетом? А, не, падажжи… Уже не работает.
Поржал с обеих точек зрения. Ради кала спорите, к сожалению.
Жить надо в реальности, а не в фантазиях. =)
>пук
Что сказать то хотел? Где надо, я делаю, в том числе и для двача. А ты никто и все твои деньги сопрут.
>Уже не работает.
Бежать надо не быстрее медведя, а быстрее остальных даунов. Пока сливают данные всякой там еды, и у всех вокруг горят пердаки, я спокоен, я не заказывал еду. Пока сливают сканы паспортов очередного левого сервиса, я спокоен, я не даю никому сканы своего паспорта. И так далее.
Конечно, целевую атаку на меня можно совершить. Но я хотел бы посмотреть на ебало того, кто будет пыжиться ради моих пары сотен тысяч деревянных.
>Ради кала спорите, к сожалению.
Таки да.
Вариант с драконом и гномом мне ближе, но в общем-то да.
Подскажите какую русскоязычную модель можно натренировать на собственный голос. Я нубас, но в шапке конкретно по этому инфы нет, только по тренировке для STS
Свою модель обучай, собери датасет своего голоса и тренеруй по гайду.
Какую конкретно? Или они все файнтюнятся на своем голосе?
Что какую? Ты тренируешь СВОЮ модель, используя такие решения как RVC и SVC. Потом, ты можешь использовать натренированую модель на любом аудиофайле или в реалтайме.
>Оба проекта SVC и RVC позволяют обучать модели на любой голос, в том числе свой, любимой матушки, обожаемого политика и других представителей социального дна. Для обучения своих моделей нужен датасет от 10 минут до 1 часа. Разработчики софта рекомендуют для обучения использовать видеокарту с объёмом памяти 10 GB VRAM, но возможно обучение и на видеокартах с меньшим объёмом памяти.
Вот же в шапке написано, просто собираешь датасет своего ЧИСТОГО голоса, режешь его аудио слайсером
https://github.com/flutydeer/audio-slicer
И дальше делаешь всё по гайду.
Так, я дурачок и не пояснил что именно я хотел. В общем мне нужен TTS, а не STS. Хотя можно, по сути закостылить так: любой TTS -> STS на нужный голос в принципе
То есть ты хочешь также как на видриле? Тогда план такой: Делаешь tts в silero, обучаешь модель на датасете своего голоса в rvc или svc и потом генерируешь файл на основе уже полученного tts результата.
Да, я собсна так и подумал, спасибо. Просто странно что нет возможности просто обучить TTS на своем голосе, как например в елевен лабс

чот как то так. https://voca.ro/1gGxZdrndZk3
Бывает глотает слоги, а так норм.
Я хочу бесплатно слушать большие тексты (статьи хотя бы), не важно каким голосом, главное чтоб интонации были правильней.
Какие есть варианты для английского, для русского?
Какие есть варианты для английского, для русского?
подкасты слущай
SVC и RVC так же хороши в преобразовании речи, как и в преобразовании пения? Расскажите про взаимосвязь качества, если есть только речь и наоборот - только пение.
Запусти Edge, нажми пкм по тексту. Безупречно будет читать.
Эту залупу кто-то пробовал? https://github.com/coqui-ai/TTS
Спасибо!
Слушаю.
Котаны, а есть уже войс ченжеры для дискорда?
Я только по эту знаю, но на русском сильный акцент, но мб с норм видяхами будет лучше (у меня 1060 3гб). Скачать альфу можно у них в дискорде, в новостном канале ссылки.
https://themetavoice.xyz/#live
Всё зависит от датасета, если сэмплы чистые, с большим диапазоном тембров, то любой результат(неважно пение или речь) выходит хорошим.
Посоны, как заставить Летова перестать шепелявить? Все "с" глотает нафиг. Речь о RVC
Коллаб стал дропать сессию через 5-10 минут, у вас так же?
Прочил что у них в правилах стоит запрет на дипфейки
Прочил что у них в правилах стоит запрет на дипфейки
На английском звучит как говно роботизированное ваш силеро, я другим пользуюсь, на моей слабой видюхе (1050ti) куда лучше генерит.
Так не только в "Р" дело, тем более в моем датасете джва часа бубнежа было и любых звуков достаточно. Суть в том, что база обучения нейронки на английских фонемах, сколько модель не учи всё равно будет походить на говор иностранца.
Это школьник шизофреник с пораши, который своим высером все борды засрал, а сам при этом понятия не имеет что вообще такое нейросеть.
Ну вот, я же то же самое сказал. Этого никак не избежать, она же звуки из датасета берёт.
Есть вариант как-то убрать эти щелчки? Очень бьет по ушам.
Обучаю модель so-vits-svc. На одну эпоху на моей 3060ti уходит одна минута, при том что там всего 50 околопятисекундных аудиофайлов. Во вкладке производительность cuda вроде забита до завязки. В интернете нашел что у какого-то чела уходит 2 минуты на одну эпоху на 3060, при том что у него 1000 аудиофайлов. Чяднт? Может в конфиге наложал? Я там оставил все как есть только количество эпох уменьшил.
брат а где скачать RVC звуковую модель летова эту которую ты используешь?
> В шапку надо добавить ссылку на https://vocaroo.com/upload , так проще делиться звуками.
Добавил в секцию "прочее". Осталось ката дождаться.
Надо будет ещё ссылок на загрузку SVC/RVC моделей добавить:
https://discord .gg/aihub (канал voice-models)
https://t.me/AINetSD_bot (как вариант, можно дополнительно упомянуть зеркало )
Ясно. Сдвигаем твою позицию в очереди на воскрешение на пару миллиардов пунктов вниз.
Есть текстовый гайд для альтернативно одарённых как натренить свою модельку?
шмедисону читалку текста его голосом встроили прямо в старфилд. а вы говорите годных читалок нету
Да сука, я нихуя не понимаю. Тренил локально на своей пеке 2000 эпох целые сутки, получился пиздец, тренил в коллабе с меньшим лернинг рейтом столько же получил аудиорил (Абу гнида ни вемб ни мп4 не прикладываются) вот короче https://files.catbox.moe/bk6ro5.wav. У чела за 800 эпох получилась лучшая модель, да какого хуя? Нет, серьезно кто тренил подскажите
делал все по гайду с готовой моделью. получил такую ошибку в веб версии последней RVC при попытке обработать wav файл с вокалом
File "C:\RVC0813AMD_Intel\runtime\lib\site-packages\gradio\processing_utils.py", line 219, in convert_to_16_bit_wav
if data.dtype in [np.float64, np.float32, np.float16]:
AttributeError: 'NoneType' object has no attribute 'dtype'
куда копать? видюхи нет думал сделать на intel проце
File "C:\RVC0813AMD_Intel\runtime\lib\site-packages\gradio\processing_utils.py", line 219, in convert_to_16_bit_wav
if data.dtype in [np.float64, np.float32, np.float16]:
AttributeError: 'NoneType' object has no attribute 'dtype'
куда копать? видюхи нет думал сделать на intel проце
Перетрейн жи.
Да как? Оно такое и на 200 эпохах и на 800 эпохах, я весь путь тестил.
Пацаны, я понимаю, что надо читать шапку, но все же по фасту спрошу - я хочу высказать очень непопулярное мнение на ютаб и боюсь деанона по голосу, чем мне лучше переделать голос, чтоб меня нельзя было задетектить? Заранее спасибо
Сделай запись и через RVC поменяй голос в дорожке.
Качаешь ПО: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/releases
Затем любую понравившуюся модель где-нибудь здесь:
https://discord .gg/aihub (канал voice-models)
https://huggingface.co/juuxn/RVCModels/tree/main
https://t.me/AINetSD_bot (зеркало https://huggingface.co/NeuroSenko/rvc-models/tree/main )
Посоветуйте TTS альтернативу Silero, с приемлемым качеством и возможностью запуска на своей машине (я за раз 50к - 100к символов генерю, регаться по 10 раз на сервисах заебна). Silero проглатывает английские термины, а у меня их дохуя, смысл треряеся.
Присоединяюсь к реквесту. Что сейчас актуально для локального TTS? Желательно еще гайд или описание нюансов установки если они есть.
вот тут смотри все
Можете пожалуйста озвучить фразу "diss mode activation" каким нибудь негрореперским голосом
ЭТО КАХ?
https://www.suno.ai. Вчера вышла. Вроде 25 генераций можно всего сделать бесплатно.
Как
В сочетании с rvc можно нагенерить лулзов. Только rvc отвалился. Сегодня впервые решился затестить, но слегка опоздал, гугл блочит.
Киньте рабочий колаб на svc/rvc, если знаете. Еще и сд колаб вчера отвалился.
На машине генерь.
Будущее прекрасно.
Купишь мне её, умник?
Кто может подсказать, уже всю голову себе изломал. Есть на ютубе канал НейроШрек, мульт который нейросеть генерит, ну там в основном всякий однообразный бред, но как там реализована озвучка? Мало того что она хуярит круглые сутки, так еще и персонажи видно говорят голосами прототипами своих героев. Если кто сможет подсказать что там используется для озвучки это будет прекрасно!!!
Сам купи, это не сложно.
Походу пчела перешла с твинков на девинарте к твинкам в тиктоке. Только за 15 минут наткнулся на 6~7 нейросенко акков фулл забитые одинаковыми каверами, часть спизжено отсюда
Зачем ты запускаешь на ос для игр?
https://github.com/w-okada/voice-changer/blob/master/README_en.md
Просто оставлю это тут
Просто оставлю это тут

Оно почти всегда такое непохожее, или только в реалтайме, или мне попалась плохая модель (попробовал несколько разных)?
Хуй знает, я его на свой войс накладывал. В дискорде работает, над только настроить. По крайней мере войс Соловьёва накладывается нормально. Но тут как бы есть несколько факторов, надо говорить членораздельно, нужно иметь нормальную модель голоса и иметь чуть чуть дикции. Накладывал войс тяночки, но из-за дерьмовых сурсов, нет адекватной модели, хотя школота в кс хавает.
А это что за нейронка?
https://youtu.be/MdM9qyh7Zhg?si=_n29vTL54unVqIIu
https://youtu.be/MdM9qyh7Zhg?si=_n29vTL54unVqIIu
>Что делать?
Ебать собак, очевидно же.
Какие системные требования у силеро? Нужно быстро в реальном времени синтезировать небольшие куски текстов.
Кофеварка.
похоже как раз таки на voice changer который я скидывал чуть выше
На Silero нельзя обучать голосу?
Нельзя, точнее, код есть только из силеров.
Он че, в прямом эфире может так струячить? Лол.
Осталось придумать нейронку, которая будут нормально чужие ебальники приклеивать. И можно будет творить креативы😄
Так аноны как вкатиться в этот ваш нейровокал? Что там кочать чтобы было заебись и как обучать тот голос что нужно мне? Вообще хотел бы услышать историю успеха от Сенко-анона.
Там задержка в 0,5-1,5 секунд, так что считай что да
Где можно взять готовую модель на русском языке для этой проги?
Спасибо огромное.

> Так аноны как вкатиться в этот ваш нейровокал? Что там кочать чтобы было заебись
Советую в первую очередь глянуть RVC, ссылка на загрузку во втором посте треда, ничего дополнительно качать не надо - распаковываешь архив и запускаешь go-web.bat. Он меньше портит отдельные звуки в русской речи в сравнении с SVC.
Готовые RVC-модели можно скачать здесь:
https://discord .gg/aihub (канал voice-models)
https://t.me/AINetSD_bot (зеркало - https://huggingface.co/NeuroSenko/rvc-models/tree/main )
https://huggingface.co/juuxn/RVCModels/tree/main
> как обучать тот голос что нужно мне?
Тебе нужно собрать кусочки голоса с нужным спикером, длительностью, в идеале, от 10 до 60 минут. При этом записи должны быть разбиты на короткие файлы, каждый длиной не более десяти секунд. У меня датасет вышел на 69 минут суммарно.
Для политиков и прочих публичных деятелей датасет проще всего собрать - качаешь любой их длинный монолог и просто разбиваешь на короткие отрезки при помощи https://github.com/flutydeer/audio-slicer
Для вокалистов чуть сложнее - надо сперва убрать из всех озвученных ими песен инструментальную составляющую через https://github.com/Anjok07/ultimatevocalremovergui (UVR)
> Вообще хотел бы услышать историю успеха от Сенко-анона.
Предполагаю, что ты хочешь обучить голос на какого-то персонажа из аниме или т.п., раз решил меня напрямую спросить. Самое сложное, в этом случае, будет собрать датасет.
Во-первых, тебе придётся извлечь аудио-дорожку из каждой серии нужного тебе тайтла и удалить из неё все сторонние звуки.
Вырезать аудио из видео можно при помощи ffmpeg, я использовал такую команду:
ffmpeg -i './title-name-s1.mkv' -map a s01.mp3
Далее, при помощи UVR нужно убрать музыку и все сторонние звуки.
Дальше у тебя есть два варианта как нарезать всю серию на короткие отрывки именно с голосом твоего персонажа - один относительно быстрый, а другой не очень.
Быстрый способ - качаешь тулзу https://github.com/flutydeer/audio-slicer и прогоняешь дорожку тайтла через неё. В результате она тебе выдаст набор звуковых файлов, где есть какие-либо реплики. Дальше тебе надо прослушать и отфильтровать их так, чтобы в датасете остался только голос твоего персонажа. Из минусов данного подхода можно отметить то, что тулза не разбивает на отдельные треки отрывки, в которых персонажи перебивают друг-друга или между их репликами слишком маленькая пауза, так что тебе придётся либо исключить такие файлы из датасета, либо обрезать их вручную. Другой минус в том, что всякие визги и междометия будут пропускаться при дефолтных таймингах - надо либо тайминги подкручивать, либо смириться с тем, что часть звуков персонажа не попадёт в датасет.
Другой способ - ручное выделение всех реплик персонажа в Audacity, свой подход я описывал здесь Это займёт гораздо дольше времени, поскольку тебе, фактически, придётся весь тайтл вручную прослушать от начала и до конца (+ придётся мотать и ставить паузу, если не успеваешь выделять реплики в Audacity).
Какой-бы способ ты не выбрал, в конце у тебя будет набор коротких звуковых файлов, которые тебе надо вынести на уровень одной директории.
Дальше открываешь в RVC вкладку Train и задаёшь параметры тренировки
1. Target Sample rate - больше = лучше, ставишь 48k
2. Version - v2; первая и вторая версия использую разные базовые модели, я предполагаю, что это может сказываться на качестве. Насколько мне известно, все просто на v2 тренируют
3. Path of the train folder - нутыпонел, путь до папки с твоим датасетом
4. Total training epochs - я ставил 1000, но разницы в результате после пары сотен эпох уже не слышу. Однако, у меня не вышло переобучить эту модель, так что можно поставить значение повыше просто на всякий случай
5. Batch size - зависит от того, сколько влезет в твой GPU. Если у тебя 24GB VRAM, то просто ставь максимальное значение
6. Save only the latest '.ckpt' file - можно выставить в No, если боишься перееобучить модель, тогда можно будет глянуть младшие эпохи. Но лично мне показалось, что RVC и SVC невозможно переобучить - для того же SVC я обучал модель 40 часов на 4090, а для RVC 10 часов, и не похоже, чтобы такое длительное обучение как-либо негативно сказалось на качестве модели. Хотя, может это зависит от длительности датасета, batch size или других параметров, точно не знаю.
Дальше надо нажать кнопки по порядку как на скрине. Первые две операции займут буквально пару минут, а вот "Train model" займёт основную часть времени, так что "Train Feature Index" ты нажмёшь уже после завершения основного этапа тренировки. Есть ещё кнопка "One-click training", но она у меня не генерировала index-файл, так что советую всё же прокликать вручную на всякий. Хотя эта проблема описана в факе, там написано, что можно нажать "One Click Training" и затем "Train feature index", если он не сгенерировался. Но я не пробовал так делать.
Модель состоит либо из одного "pth" файла, либо из "pth + index" файлов. Модели с index-файлом должны работать лучше - в факе RVC расписано, что именно делает index-файл, но лично я из объяснения ничего не понял. Сами модели кидать сюда:
weights - pth-файлы
logs - index-файлы
Вроде всё расписал.
> Я скачал голос без постобработки, прогнал в RVC и потом в Audacity наложил эхо как в оригинале через FabFilter Timeless. Потом склеил с минусом с того же гита.
Спасибо, что расписал свой алгоритм действий, я про FabFilter Timeless вообще не знал.
Пасибо, Сенко-анон, ты шикарен.
>либо смириться с тем, что часть звуков персонажа
Ну да, нюансы у быстрого способа есть, с другой стороны, я эти звуки вчера выдёргивал из ВНки, хоть и навыдёргивал около 400 файликов, общая продолжительность там не шибко большая (дольше я сам проклинал япошек, что вообще все файлы с репликами идут просто по порядку их нумерации и более никак не определены, а там их 2.5к). А вот с тайтлом будут проблемы, в конце концов 24 серии + 5 полнометражек (одну можно исключить за неимением там нужного персонажа правда) придется колупать долго. Сколько ушло у тебя времени на семплирование голоса Сенки?
> 69 минут суммарно
Хмм, а как потом это оценивать, кроме как на глаз? Или там где то есть что то хитрое для подсчета?
> Какой-бы способ
Таки интересно, а ты по какому пути шел, аки самурай резал руками или отдал на откуп машине?
Кста, формат сэмплов скармливаемый RVC имеет значение, ну там waw или mp3 или еще что-то, оно сожрёт всё, или таки не надо задавать глупых вопросов и просто всё перегонять в mp3?
Еще пришла мысль - есть ли смысл подмешивать к соответственно японски-озвученным сэмплам, что то от наших васяно-дабберш с целью улучшить русскоговорящность конечной модели или нет? Или нахрен не надо и просто надеяться, что обученное на японском заговорит на русском +- терпимо?
Кстати говоря, вчера еще тыкал voice-changer и в прямом эфире слушал сам себя, пробовал разные модели, но чому то SVC модели практически не работали там, в отличии от RVC.

Кстати, тут какие то модели есть и прочее, что лучше использовать и как настроить, чтоб опять же сразу и хорошо было?
Если нужна хорошая вокальная дорожка, то мне больше всего зашла Kim Vocal 2.
Если разбивать партию на отдельные инструменты, то Demucs v4 — htdemucs_6s.
Но один хуй потом в Audition косяки вручную нужно править.

Чето я нашел какой то гайд от какого то чела и обмазался им, там сразу несколько моделей используется.
Но получается не очень, т.к. появляются некоторые артефакты на полученной дорожке плюс долго, гнать многа серий тайтла - буквально заебёшься ждать. Идеальный конфиг для стирания лишних звуков из тайтлов все еще не ясен.
Плюсом появляется шум на готовой дорожке, который надо будет чистить руками во время нарезки сэмплов.
Да как этот сраный RVC поставить?
Вот у них написано:
>The following commands need to be executed in the environment of Python version 3.8 or higher.
Я на 3.11 ставлю, какая-то из библиотек из указанного в requirements.txt не ставится, потому что требует, чтобы версия питона была не выше 3.11. Хорошо, специально с аура поставил себе версию 3.8, теперь дохуя библиотек не ставится, потому что требует питон 3.9 или выше.
Они хоть в своём ебучем readme могут актуальную информацию писать?
Я правда качал complete package для амуде, на который у них ссылка в релизах указана, сейчас попробую чисто через git собрать.
Вот у них написано:
>The following commands need to be executed in the environment of Python version 3.8 or higher.
Я на 3.11 ставлю, какая-то из библиотек из указанного в requirements.txt не ставится, потому что требует, чтобы версия питона была не выше 3.11. Хорошо, специально с аура поставил себе версию 3.8, теперь дохуя библиотек не ставится, потому что требует питон 3.9 или выше.
Они хоть в своём ебучем readme могут актуальную информацию писать?
Я правда качал complete package для амуде, на который у них ссылка в релизах указана, сейчас попробую чисто через git собрать.
Та же залупа. Погромисты хуевы, ну теперь ещё себе 3.9 версию поставлю, чтобы всё пошло.

Я тебе в первом своём посте и написал, что скачал это ебаный пакет.
Да? Ну в глаза ебусь значит. 3 часа сна дело такое...
А можно ли мержить несколько моделей, чтобы получить новый голос или использовать полученные модели в программах типа Synthesizer V?
Анон, а нужны ли помимо дорожек с репликами расшифрофки сказанного в виде текста? И если нужны, то как это сделать для аниме озвучки, там ведь иероглифы?
Анон, а нужны ли помимо дорожек с репликами расшифрофки сказанного в виде текста? И если нужны, то как это сделать для аниме озвучки, там ведь иероглифы?

Вроде с питоном 3.9 дело пока идёт, только вот один пакет не ставится, потому что он только под WSL и винду есть... Посмотрим как пойдёт.
Это мем, кстати, такой или он реально CPU юзать вместо амуде будет? Нахуй я эту версию тогда ставил?
Это мем, кстати, такой или он реально CPU юзать вместо амуде будет? Нахуй я эту версию тогда ставил?
> Анон, а нужны ли помимо дорожек с репликами расшифрофки сказанного в виде текста? И если нужны, то как это сделать для аниме озвучки, там ведь иероглифы?
Никакой текст с расшифровкой не нужен. Для датасета тебе нужен только голос.
Видюху оно похоже мне не юзает... Нахуй так жить?
FUCKING KEK
>что мы пишем в readme
>AMD/Intel graphics cards acceleration supported.
>Что у нас в разделе Issues
>AMD is not supported at the moment
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/1202
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/issues/272
Спасеба, китайцы.
>тыква вместо видеокарты
Да, нахуй так жить?
Ой, иди нахуй, любитель невидии.
ЁБАНЫЙ ЗВУК ЦИКАД БЛЯДЬ НЕ ВЫЧИСТИЛСЯ ЕБАНЫЕ КИТАЙСКИЕ КУЗНЕЧИКИ БЛЯДЬ
УМВР, в отличии от.
Слава Богу что камнями завалило... Одним быдлом и убийцей меньше! Сколько он убил людей в этом фильме... Господь всемогущий.
Как вы мимику подгоняете под аудиодорожку?
Найти скачать, затрейнить на RVC
Labs.heygen.com
Как сделол?
Спасиба.
А англоязычные модели не подходят для того, чтобы болтать на русском? То есть искать можно только то, что тренили на русской речи?
Найс;3
Ушел нарезать эпизоды аниме на реплики
Охуеть. Доработать напильником и можно игры и фильмы оригинальным голосом переводить.


1. Оно только платное
2. Из РФ оплатить нельзя
3. За 50 баксов в месяц можно сделать не более чем 30 минут видео суммарно
Я ничего не упустил?
Да. Выводы?
Окей, я скачал озвучку, а там .mka и 3 стереодорожки.. Их надо просто объединить по каналам и норм?
С туалетным патриотом хуевато получилось
Прямо сейчас вполне реально запилить голосом Гоблина пасту про Сталин-3000.
Как смотреть эти ваши лосы при обучении на графике?
Не знаю тот ли тред, балуюсь сейчас с реалтаймом, жрёт она обычные RVC, юзаю фор лулз, а именно тролю пиво в доте. Где брать модели? Желательно русские. Ну и за одно, есть ли способ уже готовую RVC модель как-то надрочить на свой голос, потому что риалтайм жрёт буквы, шепелявит, и тд.
Почему зеленого слоника до сих пор нет? Вы что охуели?

Пасибо.
Перемести UVR в папку, где в пути нет русских символов
Юникоду больше 30 лет, а программисты-пидарасы до сих пор обсираются с любых символов, отличных от латиницы.
Спасибо, помогло.

Хз сможешь ли индекс-файл сформировать после этого, хотя не должно быть проблем наверное.
Это so-vits ? У меня при тренировке loss/d/total и другие пидорасит туда-сюда ебаным ежом, хотя у большинства я вижу, что они плавно опускаются. Где я обосрался и важно ли это ?
Не, это RVC. А в градио просто Smoothing включено, чтоб сглаживало.
>и важно ли это ?
А хз че там и как прально оно интерпретируется, я просто на график смотрю и вроде как главное чтобы пониже и по ровнее.
Посоветуйте софт, чтоб с выражением и без багов зачитывал длинные технические и новостные статьи. Если есть приложение или возможность встроить движок в android, то вообще отлично
Что будет, если я замержу модели с озвучкой на разных языках?
Мужики это по вашей тематике гайд? В микрофоне за косарь можно хотя бы в тг голосовые голосом тяночки записывать?
https://youtu.be/Q7bbEC4aeKM?si=NDUATBLIxJqkqqvU
Есть смысл запускать на локалке этот риалтайм модулятор голоса, если только 2гб врам? Пробовал уже кто-то? Тестанул на колабе, но не пробовал в войсе, вдруг оно не будет выводить поток в дискорд/игры.
на 6 гигах нет смысла

Тролю пиво в доте, в текущих реалиях всё сильно зависит от твоего изначального голоса и модели. С моим голосом и тянской моделью, а я пробовал дохуя, алинарин, диспимяу, клава кока, ева элфи, эвелинушка, оляша, и тд думают что я либо школьник, причем такой знаешь, с эффектом Богданчика валакаса, либо всё таки тянучка.
Можете кто-нибудь речь майора Монтаны про войну переговорить голосом Охлобыстина?
Хмм, ну получилось как то так. Больше того с эхом пердолился.
Ебало этого шиза сгенерировали? Сейчас ведь еще и в /б унесет и в тикток зальет.
> Сейчас ведь еще и в /б унесет и в тикток зальет.
Ты ебанутый?
аноны, я ньюфаг, как свой нейро-войсбанк натренить чтоб нейрокаверы делать
Ты на голосовухах своего отчима что ли обучал?
>Okay, I see. [fart burp] There will be no peace treaty... [laughs] until I finish this song [hysteric laughter] [halts] [whistles a song]
У меня на 100ой эпохе выпало в синий экран. Как дотренировать модель?
Этот сруля и сюда добрался...
О себе в третьем лице.
Зачем же ты сюда добрался, сруля?
На каком картавом пятикласснике ты это тренировал?
Голос Аски из GOS2, какой то дрочильни мибильной + из тайтла и ЕоЕ.
Они оба японские?
Да, всё японское.
Подскажите нубу какой лучший разделить вокала и минуса
UVR
А с каким режимом\моделью?
мимоанон

Попробую. А где взять модели справа? У меня в менюшке их нет

О, спасибо;3
Насколько я помню, если вводишь тот же самый "experiment name" во вкладке Train, он будет дотренировывать последнюю сохранённую эпоху, а не начинать всё по новой. Хотя я может с SVC путаю, надо тестить.
Спасиб, пока решил заново начать тренить расширив датасет.
Алсо могу посоветовать Davinci Studio для дополнительной очистки голоса от шумов, там свой нейронный движок.
бамп
Been awhile huh?
> В режиме audio2video добавляет 3 секунды тишины в конце, пока не понял, почему так выходит - у меня ffmpeg локально и на HF по разному отрабатывает с одними и теми же командами. Вот с этой строкой надо колдовать - https://huggingface.co/spaces/NeuroSenko/audio-processing-utils/blob/main/app.py#L32
Версия ффмпега. У меня тоже на старой от 2020 года так работало, как то связано с фреймрейтом, чем больше - тем меньше бесполезных секунд будет добавлено в конце. Короче просто обнови версию локального ффмпега.
> правда оно срать temp файлами в корень проекта будет
Переделал короче чуть код, фреймрейт сбавил до 2, чтобы размер файла не был таким большим на выходе, ведь это же просто статическая картинка. Ну и плюёт теперь не в основную директорию проекта, а по соответствующим папкам out_audio, out_video, которые вообщем то стоит заранее создать. https://textbin.net/1bxz3nzn2z вообщем то только ванклик инсталлера-запускаллера не хватает, чтобы любой мог особо не запариваясь включить это дело сразу.
Бтв аноны, попробуйте кто то разделить эту песню на вокал и инструменталку https://files.catbox.moe/3xi1fd.flac я уже почти все модели в UVR перепробовал, но затяжные "няяя" как на 1:35 вообще не хотят отделяться.
в какое-то поганое время мы живём, если так подумать
со временем нейросеть наверное заберёт большую часть чистой работы, люди почему-то про кодинги думают, на самом деле в первую очередь она заберёт не кодинг а скорее всего работу разных секретарей, юристов, экономистов, аналитиков, короче практически всю офисную работу, потом наверное придёт за кодерами, людям останется только самая грязная физическая работа т.к. это дешевле чем делать роботов, надеюсь я к тому времени выплачу ипотеку лол
пока же она просто забирает удовольствие от хобби, я например вокалом увлекаюсь, смотреть что может сетка, скажем так это убирает желание пытаться стать лучше, по-моему ещё хуже чем с художниками, сетки рисовалки хотя бы не умеют нормально рисовать композицию да и вообще рисуют обычно какое-то говно
со временем нейросеть наверное заберёт большую часть чистой работы, люди почему-то про кодинги думают, на самом деле в первую очередь она заберёт не кодинг а скорее всего работу разных секретарей, юристов, экономистов, аналитиков, короче практически всю офисную работу, потом наверное придёт за кодерами, людям останется только самая грязная физическая работа т.к. это дешевле чем делать роботов, надеюсь я к тому времени выплачу ипотеку лол
пока же она просто забирает удовольствие от хобби, я например вокалом увлекаюсь, смотреть что может сетка, скажем так это убирает желание пытаться стать лучше, по-моему ещё хуже чем с художниками, сетки рисовалки хотя бы не умеют нормально рисовать композицию да и вообще рисуют обычно какое-то говно
>короче практически всю офисную работу
Только выйграем! Человечество наконец перестанет получать деньги за просиживание жопы и начнё физически развиваться, избавим потомков от гена гемороя.
>людям останется только самая грязная физическая работа
Если человечество будет занято только грязной работой - мы быстро найдём способ как её обелить/избежать.
>пока же она просто забирает удовольствие от хобби
Это как? Мне как нравилось чем-то заниматься - так и нравиться, даже если это прямо пересекается с нейронками. Наоборот они даже подогревают интерес и стимулируют развиваться что-бы всё ещё выдавать результат качественнее их.
>я например вокалом увлекаюсь
Пруфы пример.
>так это убирает желание пытаться стать лучше
Ты лайкозависимый? Как одно к другому относиться?
Вот есть кузнецы/васяны ёпта да? И что-то заводы по штамповке ножей, например, не ломают им кайф от ковки каких-нибудь ножичков.
Прям как видрил...
>просто забирает удовольствие от хобби
каким образом?
>это убирает желание пытаться стать лучше
чел, как вот эту лору для сд объяснишь https://civitai.com/models/106609/sketch-anime-pose?modelVersionId=114508? Она помогает с понимание поз, разбивая все элементы тела на составные части и по итогу можешь активно развиваться
>чем с художниками, сетки рисовалки хотя бы не умеют нормально рисовать композицию да и вообще рисуют обычно какое-то говно
Может стоит хоть иногда выходить дальше t2i? Неиронично, многие художники на своих же лорах рисуют арты и плюс могут дальше оттачивать навык
>короче практически всю офисную работу, потом наверное придёт за кодерами
за нми придут раньше, можно сказать уже сейчас пришли с чатгпт 4.
И да, виноваты не нейронки, а наше общество хоть оно и отражает нашу природу
Пиздуйте со своими обсуждениями в специализированные треды.
>обсуждениями
на реддит что-ли? ибо тут нет таких
опять шизовахтер проснулся
В любой другой тред, тут полно шизотредов, типа
Или создайте свой.
Шиз это тот, кто принёс шизу в аудиотред.
Где можно Пригожина опробывать?
Думаю на кладбище самое оно, а что?

Появился ещё один войсклонер, WIP, на данный момент поддерживает только инференс.
https://twitter.com/coqui_ai/status/1702369159550529863
зашёл такой потестить его на huggingface, и он тут же отвалился.
https://huggingface.co/spaces/coqui/xtts
https://twitter.com/coqui_ai/status/1702369159550529863
зашёл такой потестить его на huggingface, и он тут же отвалился.
https://huggingface.co/spaces/coqui/xtts
Работает как говно. У меня rvc в самый первый раз в разы лучше справился
А есть ли инфа как натренить свою модель или лору к чему то существующему? Просто хочу голос чела из игры сделать, но не знаю как тренить, а в шапке гайд не вижу.

Когда там уже подгонят сервис по начитке книг? Читать времени нет, а столько бы всего хотелось, чего кожаные мешки не озвучивают.
Литрес же, нет? А так сервис задушат копирайтом, надо покупать лицензии на озвучку
обязательное условие разбивать на аудио на 10 секунд?
It's over?
Нищуки теперь в пролёте?
Нищуки теперь в пролёте?
>неделю уже как.
На прошлых выходных не трогал, по будням не до этого, после работы нейромантить вообще не охота.
Что делать-то? На обходы есть смысл надеяться, или искать покупателя почки?
За почку уже тупо видеокарточку не купишь, не говоря о остальном компе для вывоза этой самой видюхи.
Готовь бабкину квартиру.
Вчера пытался прикрутить Silero к силли таверне. Сегодня вспоминаю об этом, как о тягостном кошмарном сне. Что за маньяк разработчик, у которого хватает энтузиазма и энергии на то, чтобы размещать одни и те же примеры кода на множестве ресурсов, но при этом, по видимому, нет желания, чтобы все это могли применить на практике простые смертные. То же касается в принципе и silero-api-server. Словно разработчики демонстративно отгораживаются от профанов, показывая таким образом превосходство.
В итоге я смог-таки генерировать тексты по несколько десятков слов через файлик, в которые эти тексты надо каждый раз заносить. К силли таверне тоже вроде номинально подключил, но, во-первых, silero-api-server накачал английских файлов типа en_117.wav, во-вторых, хотя таверна их якобы видит, ни хрена не озвучивается.
Есть у кого-то из анонов опыт взаимодействия с этим кошмарным сновидением? Как в конце концов заставить silero-api-server взять русский голос и начать функционировать в таверне?
собирай на зеоне и ставь карту уровня 3060, зеон её затащит спокойно. Блок питания купишь голдовый и все, хули там собирать то?
Ебашь без градио, это тот ещё раковый интерфейс. В отличии от картинок аудио само по себе в калЛабе не запрещено.
>silero-api-server. Словно разработчики демонстративно отгораживаются от профанов, показывая таким образом превосходство
Лол, это буквально так и есть, люди зарабатывают на интеграции своего говна.
Я заставил таки это говно работать. Если кому в дальнейшем поможет, там все через жопу:
1) надо вручную скачать файл v4_ru.pt или другой приглянувшийся отсюда: https://models.silero.ai/models/tts
2) переименовать его в model.pt и положить в корневую папку, но не silero_api_server (который выходит вообще не нужен), а SillyTavern-extras
3) запускаем в директории SillyTavern-extras server.py --enable-modules=silero-tts
4) тут же появляются файлы с русскими голосами и в таверне можно включить озвучку.
И нахер мне шило на мыло менять? Если брать - то уж хорошее.
Судя по количеству ИИ каверов на ТыТрубе и этому треду, качество переделки озвучки в озвучку вполне неплохое, но вот качество озвучивания текста до сих пор оставляет желать лучшего по сравнению с тем же Elevenlabs полугодовалой давности. Тогда появляется закономерный вопрос: почему не использовать какой-нибудь edge-tts (https://edgetts.github.io/) для генерации хорошего "базового" семпла, а затем прогнать его через локальную переделку озвучки в озвучку (которая вроде как настолько быстрая, что делается в реалтайме)? Если кому не лень, может кто-нибудь сравнить озвучивание текста "Alright, how about this one? Why did the tomato turn red? Because it saw the salad dressing!" напрямую и переделку этого же текста, озвученного edge-tts (https://files.catbox.moe/vorktm.mp3)?
Хули ты тогда выебываешься? Если у тебя такая сборка, нахуй тебе еще чета?

Пацаны есть опенсорсное решение с переводом голоса на другой язык + липсинг. Опробовал тестовый видос с работы в labs.heygen.com, результат охуенный, но цены пиздос.
Для RVC не нужно разбивать на отрезки по 10 секунд, я перепутал с SVC, где такое обязательно. RVC сам нарежет датасет на отрезки по 4 секунды: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Instructions-and-tips-for-RVC-training#audio-split
> Сколько ушло у тебя времени на семплирование голоса Сенки?
Очень много, т.к. я понятия не имел, как эффективно нарезку делать и тот же audio-slicer не использовал. Пока со всем разобрался, нарезал семплы, и дважды прослушал весь датасет, ушло около ~12-15 часов на 12-серийник. Но сейчас я бы это уже гораздо быстрее сделал. Тогда я только первые пару серий часа три нарезал, так как не знал, как это делать эффективно.
> Хмм, а как потом это оценивать, кроме как на глаз? Или там где то есть что то хитрое для подсчета?
Я датасет кинул в плеер foobar2000, он показывает суммарную длительность всех треков в плейлисте.
> Таки интересно, а ты по какому пути шел, аки самурай резал руками или отдал на откуп машине?
Ручками всё нарезал.
> Кста, формат сэмплов скармливаемый RVC имеет значение, ну там waw или mp3 или еще что-то, оно сожрёт всё, или таки не надо задавать глупых вопросов и просто всё перегонять в mp3?
RVC поддерживает любой формат аудио, который распознаётся ffmpeg:
> Since ffmpeg is used internally for reading audio, if the extension is supported by ffmpeg, it will be read automatically.
> Еще пришла мысль - есть ли смысл подмешивать к соответственно японски-озвученным сэмплам, что то от наших васяно-дабберш с целью улучшить русскоговорящность конечной модели или нет? Или нахрен не надо и просто надеяться, что обученное на японском заговорит на русском +- терпимо?
Даже не знаю, я такие эксперименты проводить не пробовал с компиляцией нескольких спикеров в один датасет. Ну, японоязычная RVC модель букву Р выговаривает и каких-то прям явных косяков по акценту я не заметил, так что, как мне кажется, нет особого смысла миксовать https://vocaroo.com/11Qmpc6eMVaG
> Кстати говоря, вчера еще тыкал voice-changer и в прямом эфире слушал сам себя, пробовал разные модели, но чому то SVC модели практически не работали там, в отличии от RVC.
RVC это более новая система; под SVC модели сейчас никто не тренирует по факту. Чтобы не быть голословным, прикреплю список с последними загруженными модели в комьюнити AI Hub в дискорде. За последние 10 часов загрузили 24 RVC v2 модели, а последняя SVC модель была загружена более месяца назад.
Какой же я слоу.
>под SVC модели сейчас никто не тренирует по факту
Просто под RVC софт более вменяемый.
Что это за сайт? Не смог найти даже цитируя неотхешированные названия моделей.
Дискорд сервер AI Hub.
мимо
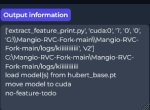
Привет анон, я в звуковых нейронках совсем щегол, треды ваши не читал. Мне в соседнем треде накидали гайдов для Mangio RVC.
Умоляю, подскажите, как фиксить no-feature-todo/no-f0-todo??? Звуковые файлы в wav, в зип архиве, лежат в папке datasets. Путь правильный указан, пробелов лишних нет, кириллицы нет. Дайте хоть какую-нибудь идею, как фиксить. Я уже совсем отчаялся.
Умоляю, подскажите, как фиксить no-feature-todo/no-f0-todo??? Звуковые файлы в wav, в зип архиве, лежат в папке datasets. Путь правильный указан, пробелов лишних нет, кириллицы нет. Дайте хоть какую-нибудь идею, как фиксить. Я уже совсем отчаялся.

https://huggingface.co/spaces/NeuroSenko/audio-processing-utils
Спасибо за фиксы. К сожалению, команда на конвертацию из картинки+аудио в видео работает неправильно на HF, поскольку там используется старый ffmpeg 5 версии. Там стоит Debian и я не нашёл какого-то простого варианта, как обновить ffmpeg до 6, чтобы исправить эту проблему. Так что эту комаду пришлось откатить. Надо по хорошему подобрать команду, которая и на ffmpeg 5 для Debian и на ffmpeg 6 для Windows будет срабатывать одинаково, но у меня пока не вышло с этим разобраться; всю платину с первой страницы гугла и SO перепробовал.
Все остальные фиксы принял. Так же добавил install.bat и start.bat скрипты для windows (которые через venv всё ставят, естественно), чтобы проще поднять локально было.
https://huggingface.co/spaces/NeuroSenko/tts-silero
Алсо добавил эти же install/start скрипты для tts-silero репы, вместе с фичей, что все сгенерированные файлы кладутся в отдельную директорию out_audio. Но там мне надо в первую очередь разобраться, почему другие модели, кроме стандартной русскоязычной, отказываются работать. Всё никак времени не могу на это выделить.

аноны, решил побаловаться тут sts на гугл коллабе,но он выдает вот такую вот ошибочку, как фиксить?

Товарищи, я тут как дурачок задам тупой вопрос:
Есть что то лучше, чем silero? Что бы без танцев бубнами, в онлайне (или так же в телеграмме) можно было озвучивать текста или переозвучивать уже готовое?
Есть что то лучше, чем silero? Что бы без танцев бубнами, в онлайне (или так же в телеграмме) можно было озвучивать текста или переозвучивать уже готовое?
Так короче спасибо за неответы, я сам разобрался. Теперь вопрос, есть какой-то норм форк или чо угодно, чтобы мангио могла в текст ту спич, а не только в конвертацию аудио? Или тут Mangio никто не пользуется?
Там спрашивается как фиксить это, используя try/except, то есть для написанного тобою кода, а тут уже, простите меня не мой код
https://youtu.be/dcP50p-I6BE
С помощью чего это создавалось?
Пиздец, для хуйдожников со стаблем дефьюжен куча ресурсов сущесвует, а для голосовухи хуй да нихуя.
Whisper работает, но видеокарта не загружена (наверное, поэтому очень медленно расшифровывает). Как можно подключить видеокарту к процессу? Или он только на ЦП может работать?
Тебе нужно торчи переустановить на кудовские.
Неплохой канал, спасибо что доставил, анон, даже не ожидал что бразильские макаки из фавел такое умеют.
Чому ещё нет? Делаем песенки с помощью Suno AI, гуглите, там бот в дрискорде.
-пишем /chirp
-пишем нужный жанр
-придумываем/гуглим текст
-???
-ВСЁ
-пишем /chirp
-пишем нужный жанр
-придумываем/гуглим текст
-???
-ВСЁ
Загрузил видос, смотрю, очередь 73 200. Думаю, ладно, завтра зайду. Сегодня захожу - 73 100. Получается очередь на два года. Охуенно
Было и тут, и в аудио треде. Почему-то никого не интересует музыка. Сам удивлен. Оно еще и само текст через гпт-4 генерит, если лень придумывать рифмы (на английском).
Спасибо. Давно хотел записать свой реп альбом.
Аноны, подскажите
Обучил модель RVC (mangio) v2 на 20 минутах аудиодорожек. Эпох поставил 1024. Часа 3 всё заняло и последние версии модели (от 1000 эпохи) получились не очень в отличии от 800-900. Делал по тупогайдам на форуме и ютубе. К сожалению, мало кто не использует колаб.
Вопрос: как дообучать модель? Видел, что нужно в Train просто написать то же название. Это так? И выбирать название какой-либо недотренированной нужно, если она звучит лучше?
Вопрос 2: в чем может быть причина того, что в 1000х эпочах хуже поёт, чем в 800-900?
И сколько стоит сохранений ставить, чтобы не получать 10000 файлов с промежуточными результатами?
я не шарю почти
Обучил модель RVC (mangio) v2 на 20 минутах аудиодорожек. Эпох поставил 1024. Часа 3 всё заняло и последние версии модели (от 1000 эпохи) получились не очень в отличии от 800-900. Делал по тупогайдам на форуме и ютубе. К сожалению, мало кто не использует колаб.
Вопрос: как дообучать модель? Видел, что нужно в Train просто написать то же название. Это так? И выбирать название какой-либо недотренированной нужно, если она звучит лучше?
Вопрос 2: в чем может быть причина того, что в 1000х эпочах хуже поёт, чем в 800-900?
И сколько стоит сохранений ставить, чтобы не получать 10000 файлов с промежуточными результатами?
я не шарю почти
Будет не так хорошо, как на родном языке, так как в разных языках разные сочетания звуков. Также, например, чистый звук Ы отсутствует в английском
Я пользуюсь. Но, видимо, никто не отвечает тут. А тред по RVC я не нашёл слепой
Накатал пост чуть выше с вопросами
> файлы в wav, в зип архиве, лежат в папке datasets
Ты файлы из прива вытащил просто? У меня эта проблема так фиксилась
> могла в текст ту спич
Оно разве не может в ТТС?
Кто знает какие нейронки юзает Ведал?
Не знал, что запилили русскоязычную модель для Tortoise
https://voca.ro/1eMIijF7Ad2l
https://voca.ro/1eMIijF7Ad2l
Ты ссылку на модель забыл.
Вот же, уже 3 месяца лежит https://huggingface.co/SerCe/tortoise-tts-ruslan/tree/main/model
Если лоли голос с вокарушки интересует, то это я уже сверху пару книжек накатил поверх этой модели и еще датасет с детским голосом.
К сожалению Tortoise какого-то хуя пидорасит тональность, поэтому все равно приходится правитьpitch вручную.
https://gofile.io/d/4u0mIL
>сверху пару книжек накатил поверх этой модели
>the model is suitable for further finetuning on any Russian male voice
Кек.
> male
Поэтому и накатил пару книг с женскими голосами.
К тому же у меня они уже были нарезаны для тренировки, ибо я до этого уже пытался сам тренить на русский язык.

И в итоге тренировка от кабанчика на большом (наверное, не смотрел) русском датасете + немного женского оказалась лучше, чем твои предыдущие попытки?
Кстати, залил бы модель на huggingface, а то все эти классные обменники дают классную скорость.
Попробуйте EdgeTTS
Аноны есть у кого опыт с STS. А именно с этим проектом
RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Вот ссылка на репу https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Кто нибудь менял голоса с помощью него?
Вопрос какая видеокарта нужна? Также я сейчас не дома где компьютер и у меня нет видеокарты. Сколько дней нужно допустим если использовать ядра процессора? Я охуею? если дня два то ок.
Буду благодарен за ответы.
там вроде нужна видюха в любом случае. с телефона только гугл каллаб в помощь
У меня видяха слабая, так что я скармливал этой хуерге по тыще файлов в день на коллабе.
Очень медленный и малоэффективный процесс, так что я в итоге заебался и забил.
На тот момент было не так уж и плохо, но конечно хуже чем у кобанчика, да.
> залил бы модель на huggingface
Не получается, виснет часами на статусе заливки.
https://voca.ro/14ITAX3Tn2KH
Нейросеть кайф
> Не получается, виснет часами на статусе заливки.
Через другой браузер попробуй залить. У меня такая же проблема была.
>Не получается, виснет часами на статусе заливки.
Могу за тебя залить, у меня проблем с интернетом нет.
Анонче, озвучь эту пасту голосом гоблача плезки
The other day, on the advice of trusted comrades, I purchased a new mega-device - the Stalin-3000 anal plug. Immediately, choking with greed, he opened the box with his tenacious paws and used the megadevice. Size, my respects. Joseph Vissarionovich was a real lump. Even my ass, accustomed to the harsh everyday life of the army, refused to accept it from the first try. Together with Oleg Zotov, we resolved the problem. Feelings - ATAS. There is no comparison with a machine gun. In addition, the mustache tickles the prostate pleasantly. I went on like this all day. Decidedly ready to film new non-spirituality.
Many children will see manifestations of homosexuality here. Stupid children don’t realize that pederasty and patriotism are two different things.
The device is excellent, I recommend it to everyone to purchase.
Nvidia Geforce GTX 1650 норм?
По поводу готовых моделей для RVC, у всех моделей 2 файла, pth и index, и если с pth всё понятно, кидаем в папку weights, то что за файл index? Куда его? Вроде и без него всё работает

Аноны, может кто подсказать что за хуерга?
Пытался поставить витс по гайду
>Гайд: https://textbin.net/kfylbjdmz9
И, при попытке загрузить библиотеки, вылетает ошибка от cmake.
Пытался на анаконде делать, так и на отдельно установленном питоне - одна и та же ошибка.
пикрелейтед
Пытался поставить витс по гайду
>Гайд: https://textbin.net/kfylbjdmz9
И, при попытке загрузить библиотеки, вылетает ошибка от cmake.
Пытался на анаконде делать, так и на отдельно установленном питоне - одна и та же ошибка.
пикрелейтед
В папке logs создаешь папку с именем модели и кидаешь туда index файл. Должно быть так, например:
/weights/gura.pth
/logs/gura/added_IVF338_Flat_nprobe_1.index
index-файл корректирует фонемы и акцент модели. Если у тебя на входе русскоязычное аудио, а модель англо/японоязычная, то использование index-файла сделает только хуже.
Index в logs/название_модели, чтобы автоматически подсасывало, можно просто указывать путь к файлу, если хочешь. С индексом врооооде как чуть лучше и быстрее, но чет хз. Мб тут найдутся знатоки которые расскажут зачем и для чего он на самом деле нужен
1. У тебя стоит python 3.11 под который ещё нет доброй части библиотек
2. Он пытается собрать какой-то пакет для питона из исходников (какой конкретно по твоим записям непонятно), но так как у тебя нет nmake (и в целом компилятора MSVC Build tools), то нихуя естественно не может.
Nvidia Geforce GTX 1650 норм?
Спасибо, аноним
С меня Сталин-3000
Поделитесь опытом удаления шума в аудио файлах? Есть ряд записанных аудио почившего но глубоко любимого мною человека. Но есть шум. Хотелось бы удалить максимально весь шум. Есть такой инструмент как Adobe podacast beta https://podcast.adobe.com/
Так же есть бесплатный nvidia broadcast.
Оба инструмента великолепны поскольку используют нейронные сети. Они просто напрочь удаляют шум. Но первая платная а вторая как бы обрабатывается исходящий звук. Можно конечно обработать записанное аудио через виртуальный кабель.
Но по чесноку как вы лично избавляетесь от шума? Именно от не постоянного шума? Прошу поделиться опытом, если есть опенсорс проекты использующие нейронные сети для удаления шума я буду рад.
Также все же хотелось бы знать какие процессы обязательны в шумоудалении? То есть какие базовые процедуры нужнв? Нейросети это круто конечно но чтобы вы порекомендовали.
обновление:
Adobe podcast все же бесплатен но хорошо работает с английской речью и ужасно справляется с русской и казахской речью((
> Оба инструмента великолепны поскольку используют нейронные сети.
Нейрошиз, спок.
если просто переделывать песни то да норм. а вот если обучать модели то 1 эпоха 20-30 минут будет. Обучать модели лучше онлайн
Ищу людей. Будем озвучивать пасты про говно голосом артаса.
Все будет просто. минут 10 времени.
Сначала текст озвучиваем через ттску а потом в рвс с моделью артаса прогоняем.
Все будет просто. минут 10 времени.
Сначала текст озвучиваем через ттску а потом в рвс с моделью артаса прогоняем.
Целого класса не хватило? Позови с параллельного.
спасибо за совет. так и сделаю.
Онлайн: https://vocalremover.org
Оффлайн: https://github.com/Anjok07/ultimatevocalremovergui
Оба выделяют дорожку с голосом в отдельный файл. Не уверен правда, как они работают с обычным шумом (их специализация - это выделение вокала из песен), можешь в онлайн-тулзе попробовать.
Решил попробовать поиграться с нейросеточными голосами. Походу возник вопрос: как составить промт, чтобы речь звучала естественно и, желательно, красиво. Здесь есть специалисты?
прогоняешь через рвс любой модели. или просто юзаешь sileroTTS
неа тот софт с гитхаба не удаляет шумы, он убирает просто вокал из песни. Делает он это шикарно, но не с шумом.
Можно с аудасити удалить постоянные помехи, но вот локальные шумы не очень.
Для обладателей GTX есть от нвидиа мощный инструмент RTX Voice. Я удалил почти 95 % шумов но не все. Я пришел к выводу что все конечно не получится.
Но теперь встречный вопрос. Вот допустим я подготовил 10-15 минут вырезок с очищенным звуком. Теперь как подготовить датасет? Эти аудио годятся для данных?
Использование whisper который вырезает куосчки аудио где человек ращзговаривает невозможно. Пскольку виспер работает с английской речью.
Whisper прекрасно распознает русский язык
а расскажи можно просто самостоятельно вырезать? то есть можно ли в аудасити убрать все паузы и потом вырезать непрерывные фразы? То есть я смотрел ютубера который говорил что виспер порой вырезает кусочки с артефактами.
Используется ли аиспер просто потому что нет времени самостоятельно вырезать? Так же расскажи как ты готовишь датасет. Насколько хорошие результаты ты получал?
Auto predict F0 отключи и выкрути питч как тебе надо
анон, как сделать голосовой дипфейк?
Через RVC можешь поменять голос на нужный тебе, если найдёшь готовую модель на нужного тебе человека:
https://discord .gg/aihub (канал voice-models)
https://t.me/AINetSD_bot (зеркало - https://huggingface.co/NeuroSenko/rvc-models/tree/main )
https://huggingface.co/juuxn/RVCModels/tree/main
Если нет нужной модели, то придётся обучить самому.
обучить нужно, да. это где?
вот гайд
Хочу вкатиться в TTS, с клонированием своего голоса. Сейчас самые качественные, это ElevenLabs, Tortoise и Uberduck или уже есть что-то лучше?
Кстати знает кто как тренировать RVC без гуя ? Для инференса сделали хоть какой то костыльный скрипт, а тренить походу только в вебе
https://www.kaggle.com/code/varaslaw/rvc-v2-no-gradio-https-t-me-aisingers-ru?scriptVersionId=143284909
Вот. Сам этим пользуюсь. Вот гайд https://youtu.be/uA92FDw_Xfw
Я Whisper использую только для транскрипции в текст, обрезает он как мудак.
Режу через Audacity либо руками, либо через лэйблинг
Я вот не пойму, я обучил голос нормально, но когда начинает петь по каверу, она словно глотает буквы и звуки некоторые. Как это фиксить? А то блять поет кашу временами какую то.
Как натренировать модель на свой голос, чтобы потом вставить в таверну? Мне не для песен нужно.
Тестил с другими готовыми моделями? Надо сперва понять, проблема с твоей моделью или с настройками.
Зачитывай вслух любой текст с википедии или ещё откуда-нибудь минут 15 и используй эту запись для обучения модели. Желательно только чтобы клики мышью и прочие сторонние звуки в запись не попадали.
Разобрался, это был хуевый вокал, использую другую версию для наризания и очистки звука но реверба, стало в разы лучше.
Но как пофиксить то, что во время пения, голос словно ломается.
использовать хорошие модели
Модели чего? Голоса? Если его, то голос - заебатый, по крайне мере, лучше всех тех, что на нее есть.
хмммм. тогда хз почему. А что за модель?
Лейн Ивакура.
Мало инфы даёшь, остаётся только угадывать. Pitch extraction algorithm выставил в crepe или rmpvpe? По умолчанию стоит pm, а это кал.
Может ещё голос ломать, если в датасете нет достаточно высоких/низких звуков для твоего трека. Попробуй высоту голоса поменять - transpose выстави на -12 или +12.
>rmpvpe+
Стоит. Спасибо, попробую с transpose поиграться.
А раз вы тут, а что делать, если модель начинает "реп" читать? Да, в оригинале не очень большие паузы между пением, но модель прям слово без остановки их поет, и получается каша.
А бля, я понял в чем проблема, в вокале...но я даже хуй знает как его еще чистить сука.
пипец.Там и так голос говный в сериале так еще и модель
Вот и говорю, это самый лучший...
>Обучать модели лучше онлайн
Вплане в гугл коллабе RVC?
гугл коллаб отрубили уже.
https://www.kaggle.com/code/varaslaw/rvc-v2-no-gradio-https-t-me-aisingers-ru?scriptVersionId=143284909
Вот. Сам этим пользуюсь. Вот гайд https://youtu.be/uA92FDw_Xfw
Кто-нибудь пользуется Tortoise? Почему иногда выдаёт шикарные результаты, а иногда вообще пиздец что (на одном и том же сете)? И как можно генерировать текст побольше, а не два предложения за раз?
У кого сколько занимает времени тренировка модели RVC ? Количество эпох/размер датасета/видеокарта. Думаю арендовать таки машину, хочу прикинуть сколько выйдет по стоимости.
тебе минимум нужна 2080 видюха. Ибо меньше это анриал. Трень в коллабе. Я выше кидал ссылки
слушай анончик можно списаться с тобой по тг? очень нужно помощь, пару вопросов и я отстану
В общем есть очень много отрывистых аудиозаписей любимого мною человека которого уже давно нету. Они разной длины от секунды до 12 секунд. У меня еле набирается минут 10, так что мне как то надо будет воспользоваться также аудио сообщениями в одну секунду. Я уже все почистил, убрал шумы, вырезал то что надо, убрал реверб эхо. Все это лежит в папке в виде аудио сообщений с разными длинами. Единственный вопрос который стал для меня камнем преткновения это как сегментировать аудио и вооьще надо ли.
Где то пишут что для РВС некатегорично делить, можно просто вырезать паузы и локальные шумы. Кто то говорит что главное чтобы менее 10 секунд. Кто говорить что еще надо чтобы га был длиннее 4 секунд. Кто то пользуется виспером а кто самолично вырезает с помощью аудасити. Можете подсказать что мне делать.
Какой репозиторий используешь?
Тренированную модель или дефолтную?
>Какой репозиторий используешь?
Какой Бог послал. Всё делаю через два Коллаба, по этим гайдам на Ютубе:
>CLONE ANY VOICE WITH AI (GOOGLE COLAB) | 3 MINUTE TORTOISE-TTS TUTORIAL
>Longer Speech With Tortoise-TTS 🔊 | Tutorial | Voice Cloning
Датасет делаю по гайду из гитхаба
Под арендой я имел облако, но не колаб. Смотрел на vast и runpod, там хотя цена ~0.50$/час, но надо залить 10$ минимум, а мне столько не надо. Lambda Cloud ещё есть, но хз как там с минималкой. Думаю модель за 1-2 часа должна натрениться, у меня датасет небольшой, вот и спрашиваю у кого какой опыт
датасет небольшой значит модель говно будет
Поясните по каверам с неко арк. Это на каком языке изначально натренированная модель и где вообще ее взять?
А такое как делается?
Без нейросетей, детали у авторов мешапов
rave dj же может так делать чёб нейронку не натренить делать мешапы А ?
Модели пофиг на каком языке говорить. Гитлера на немецком обучали, но вон он как на украинском гимн поет! Короче. Бери тут
https://drive.google.com/file/d/1GJJqRdRvZ6ilwwX6ZG7cPkx-84vN1FPe/view?usp=drive_link
анончики подскажите пожалуйста
у меня 15 минут хорошего отчищенного датасета, но они разной длины. Я вырезал через аудасити, там убрал эхо реверб, шумы, шипение, нормализовал все.
Кто то говорит что одно двух секундые вырезки норм. Кто то говорит что длина должна быть между 4 и 10 секунд. кто то режет через виспер кто вручную, кто то удаляет тишину и молчание а кто то нет.
Вот и не понятно что делать? Это единственное что я просто не могу понять.
Помогите кто нибудь?
у меня 15 минут хорошего отчищенного датасета, но они разной длины. Я вырезал через аудасити, там убрал эхо реверб, шумы, шипение, нормализовал все.
Кто то говорит что одно двух секундые вырезки норм. Кто то говорит что длина должна быть между 4 и 10 секунд. кто то режет через виспер кто вручную, кто то удаляет тишину и молчание а кто то нет.
Вот и не понятно что делать? Это единственное что я просто не могу понять.
Помогите кто нибудь?
соедини все записи. Потом порежь на записи по 10 сек. 10 сек самая оптимальная длина
То есть уже разделить на десять напофиг?
да
Слушай анона я могу списаться? просто поспрашивать, я честно отьебусь потом, хочешь даже могу предложить заработок, есть вариант.
давай пиши.
анон. куда писать то?
> https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Instructions-and-tips-for-RVC-training#audio-split
RVC автоматически нарежет датасет на отрезки по 4 секунды.
@dosanddosya пиши сюда пожлуйста я жду
Чем соединяете вокал и инструментал? Попробовал ableton, но файлы не ровные, а по тактам замучался подгонять и в целом дико неудобно выглядит весь процесс.
Убери в настройках эблтона принудительный варпинг длинных треков и настраивай вручную или переезжай в рипер.
посоны, хочу натренировать нужный мне голос и им озвучивать текст который я буду давать ему через сосноль, я так понял RVC которая это умеет делать нет и обязательно нужно сперва как еблан озвучить текст любой TTS встроенными голосами и потом уже переделывать этот аудио во второй раз в нужный мне голос? неужели всё так хуёво?
так сам создай лол. Чтобы твой форк делал сначала голос через ттску а потом переозвучивал его
анон, я о RTC меньше месяца назад узнал, а ты мне предлагаешь уже форк делать, ты меня не понял, я имею ввиду только такой уебанский способ существует на данный момент с двойным конвертированием? то есть сперва текст в дефолтголос, а уже из него нужный тебе голос, неужели боги AI ещё не придумали ничего такого что сразу из текста делает нужный голос без двойной работы?
>RVC
fix
придумали такое. щас найду и скину
это уже видел анончик, там как раз сперва делает дефолтговно, а из него нужный голос, получается напрямую из текста нужным голосом пока нельзя, или нужно подождать анончика который знает такой вариант

ну как бы тебе сказать. этого анона который знает такой вариант нету.....
а в чем проблема то? Взял сделал свой собственный синтезатор голоса из нужного тебе и все
аноны, вы хотите сказать вот это
https://www.youtube.com/watch?v=ZpHyoKvLkR0
https://www.youtube.com/watch?v=k1uL_dVGdkk
тоже делается сперва озвучкой текста в говноголос, а потом переозвучка говноголоса в голос персонажа?
как они пишут промпт что он позволяет им обсуждать любые темы и с матом? ведь ChatGPT сразу начинает ныть когда материшься или обсуждаешь запрещённые пидорасами темы
https://www.youtube.com/watch?v=ZpHyoKvLkR0
https://www.youtube.com/watch?v=k1uL_dVGdkk
тоже делается сперва озвучкой текста в говноголос, а потом переозвучка говноголоса в голос персонажа?
как они пишут промпт что он позволяет им обсуждать любые темы и с матом? ведь ChatGPT сразу начинает ныть когда материшься или обсуждаешь запрещённые пидорасами темы
если бы я был гуру нейросетей, я бы такой вопрос не задавал, ну же
да. все так
странно что ещё нет индуса который бы сделал такой форк, его бы боготворили все школьники мира
знаешь как искать надо. В гитхабе пишешь rvc или webui и сортируешь по недавно добавленным
в чём заключается логика такого стрима?
чел нарезает сюжет от ChatGPT на кучу реплик, озвучивает каждую в промежуточную озвучку, потом в озвучку от нужного голоса и склеивает все эти кучи говн воедино и запускает проигрывание этого аудиомутанта пытаясь уверить нас что это общение между персонажами? а на деле просто склейка того что высрала RVC высрав кучу аудиофайлов?
и получаешь кучу вишмастеров и бекдоров у себя на ПК?
гитхаб это место куда люди загружают исходные коды. ты можешь просмотреть весь код и убедиться что там ничего нет
не понимаю почему авторы этих нейронок перестали стримить после 1 бана, в чем проблема наклепать тонную ютуб каналов за 10 рубасов
это понятно анон, но сидеть и по 2 дня просматривать исходные коды и быть уверенным что ты ничего не пропустил это не каждый может
если бы там что то было это забанили уже давно
как в этих ваших гитхабах смотреть сколько раз скачали форк или добавили в избранное или оценили чтобы быть уверенным что качаешь что-то проверенное, а не созданное васяном?

сбоку. и хватит опасаться. изучи английский хотя бы на школьном уровне и понимай что в коде.
это-то я знаю, но сколько я не смотрю в этой статистике всегда всё по минимуму, нуежели на гитхабе такой низкий фидбек от зареганных и все качают из пд гостя и нихуя не пишут, а жрут как есть, меня это удивляет что там нет по 100500 лайкосов и отзывов

я вот дня 2 назад так же думал, скачал RVC_GUI вроде вот этот https://github.com/SalvadorDante/RVC_GUI и у меня начались проблемы с роутером, сперва в виде ограничения скорости, а теперь постоянные перезагрузки, теперь вот сижу и думаю совпадение это или с первого раза я присел на анальные зонды от индуса, потому что это говно у меня сразу не завелось и стало выдавать ошибку
ну дык правильно. говно скачал. есть рабочее гуи для рвс его и качай
а если есть модель 100 эпох, как ее продолжить тренить?
аноны, по ссылке https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI скачивает архив в 1мб, как я понимаю это просто основа и чтобы скачать всё нужно ввести команды из инструкции по install, но я не хочу ставить кучу ненужного дерьма себа на пекарню, как можно скачать готовый архив со всеми файлами чтобы всё работало как portable версия из папки и без всяких ебаных зависимостей и виртуальных сред?
то есть вот это качать?
For Nvidia GPU users:
https://huggingface.co/lj1995/VoiceConversionWebUI/resolve/main/RVC0813Nvidia.7z
там получается всё уже в куче и ненужно 100говн себе ставить?
спасибо анон
> то есть вот это качать?
> там получается всё уже в куче и ненужно 100говн себе ставить?
Всё верно.
когда примерно ожидается 3 версия рвс?
С рвс и урл вроде немного разобрался. Теперь скажите можно ли модели из рвс использовать для озвучки текста переведя озвучку в мп3 какой-нибудь? И если да то что используется?
аноны, судя по командной строке на скрине и по файлам в этом архиве https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/archive/refs/heads/main.zip в папке \i18n\locale есть русская озвучка в файле ru_RU.json, куда её добавить в основную папку RVC чтобы в Gradio всё было на русском?
аноны, самый лучший RVC это оригинальный от RVC-Project? какие ещё есть интересные форки?
посоны, можете вкраце пояснить по ckpt и Onnx, что это такое и для чего и как использовать?
как можно соединить полученный вокал и инструментал без установки стороннего софта, шобы через сосноль склеивать? ффмпег это умеет? подскажите команду
Аноны посоветуйте хороший TTS типа этого:
https://huggingface.co/spaces/coqui/xtts
https://huggingface.co/spaces/coqui/xtts
Как скоро появится массовый дубляж фильмов и аниме с использованием HeyGen или её конкурентов? В самой HeyGen я вижу две проблемы: 1) она не захватывает звуки фона, захватывает только сам голос, 2) она меняет так же и видеоряд, перекодирует видео на своей стороне, то есть делает его тяжёлым и с дефектами.
Хочу чтобы появился конкурент HeyGen такой же как Stable Diffusion конкурент для Midjourney - опенсорс, бесплатный, с локальными вычислениями.
А я хочу чтобы песни мировые хиты были понятны для каждого на родном языке, чтобы были автокаверы. Suno это только начало
>Как скоро появится массовый дубляж фильмов и аниме с использованием
Никогда, диктор стоит дешевле, чем оплата звукомонтажера, и делает свою работу раз в 20 быстрей. Вот ты ради интереса зайди в вакансии и посмотри когда посудомоечные машины оставят без работы посудомоек. Дикторов дохуя, сейю дохуя, они готовы работать за хлеб и воду, голосов похожих тоже дохуя. Ебалами они светить не могут, поэтому все легко заменимы, если вычеркнуть очевидное кумовство и непотизм.
Хлопцi, бачили вже обновление UVRv5? Наконец-то добавили модель MDX23C-8KFFT-InstVoc_HQ
>звукомонтажера
Чел... ИИ заменит и их.
годноты итт
>Чел... ИИ заменит и их.
Посудомойщиц сперва замени, потом поваров, великий заменитель.
Как я тебе блядь заменю то, что нахуй никому не нужно будет после прихода нейронок требует физического присутствия? Наркоман ёбанный.
Самописные на C#
Мне срочна нужно сделать запись Мори говорящей о лошадях. Раньше использовали Elevenlabs но теперь клонировать там никак... Есть тлдр что именно выбрать для ттса а не песен? Самплы есть уже готовые
А есть гайд по Audacity как почистить сэмпла от всякого говна?
А есть гайд по Audacity как почистить сэмпла от всякого говна?
Анон, сколько эпох нужно, чтобы натренировать модель через RVC на качественном датасете (рипнут с игры)
если аудио записей больше 150 или 200 то брать можно 250 эпох. Если аудио до 100 то бери 300-400 эпох. 150-200 аудио по 10 секунд каждая
я модель артаса(из варкрафта 3) тренил на 400 записях по 10 сек. Офигенная модель вышла. Брал 250 эпох
Натренил на 100 эпохах в датасете 1802 файла, но эта треня капец какая долгая была, по 40 секунд на эпоху, и это на 3060. Кстати, получилось неплохо, видать повезло. А ведь еще надо tortoise натренить, чтобы можно было нормальный tts запилить. А он раз в пять медленней треннится. Это вообще нормально, что он так медленно обучается? Или я как всегда, что-то не так поставил.
>но эта треня капец какая долгая была, по 40 секунд на эпоху,
ээээх как же я тебя понимаю. Тяжело наверно. (1050 ти эпоха по 30 сек даже на 360 файлах)
тотроис тебе нафик не нужен. Бери эдж ттс прогоняй текст через него а потом через рвс
по 30 минут точнее. быстрофикс
Tortoise медленно тренит, но ему много эпох не нужно, погоды не делает
показывай
аноны подскажите плиз сетку менять свой голос на тянский
наверняка ведь натренировали уже
наверняка ведь натренировали уже
ПРИЗЫВАЮ ПЕРЕКАТ
Дискорд-сервер https://discord .gg/aihub выпилили, кто-то поднял сервак с бекапами здесь: https://voice-models.com/
Чем котить?
Чем котить?
Ещё бекапы здесь есть: https://www.weights.gg
> AI Hub was banned because of copyright, apparently someone did the trick of editing posts and added several links with copyrighted content, which left Discord with no option but to DMCA the server.
> The owner, menhguin, was also banned, so it's quite possible that the server won't come back.
> Apparently there will be a second server, but unfortunately all progress/history from the other server has been lost.
Это пиздец.
> The owner, menhguin, was also banned, so it's quite possible that the server won't come back.
> Apparently there will be a second server, but unfortunately all progress/history from the other server has been lost.
Это пиздец.
> Discord
И правда пиздец.
Да, создавать каталоги на дискорде это полный пиздец и отсутствие головного мозга.

Есть у кого Лето и Арбалеты голосом Гань Юня из геншина? Дайте пожалуйста. Что-то не смог найти в прошлых тредах, хотя точно видел на дваче.
Сомневаюсь что получится так же классно как тут: https://www.youtube.com/watch?v=vhArHsfsLAQ в этом ролике автор идеально скопировал свой голос используя связку tortoise + rvc. Но спасибо, попробую.
F, слышал на 10-ых сериях нвидия плохо с параллелизмом, из-за этого на них плохо работают нейронки.
Ок так и сделаю, поставлю на 20 эпох, правда все равно, время обучения 10 часов, и комп после этого горелым пахнет, чтобы не сгорел нафиг надо окно открыть.
> Натренил за полтора часа
> треня капец какая долгая была
Чувак
Ребят у кого есть опыт работы с коллабом mangio RVC fork? Я купил колаб про, впервый раз выданная ссылка открылась и все было прекрасно. Потом я по своей глупости все это дело закрыл. Потом решил еще раз открыть с гитхаба колаб и каждый раз когда я его запускаю ссылки больше не открывают веб версию. Я пробил какой то лимит на запрос? Что это вообще?

Нужен ттс чтоб из буфера обмена зачитывал текст с яп голосом, есть какие то решения? Пока нашел прогу ттс реадер, но там нужен движок хороший японский, а их нереал скачать есть только каловый шиндовса. Полистал что нейронки предлагают, но там вроде везде нужно ручками текст вставлять жать кнопочку вкл и слушать, не программист чтоб все это автоматизировать самостоятельно, может придумали уже что то такое?
Подскажите тут раньше кидали ссылку на какую-то нейросеть для очистки старых голосовых записей от шумов. Проебал ссылку, не могу найти теперь.
>Нужен ттс чтоб из буфера обмена зачитывал текст с яп голосом
чего?
>Чем котить?
КОТИ ЧЕМ ЕСТЬ
Анон, как справляться с хором? Например у меня такой трек: везде обычно, а на 1:09 начинается часть с хором, на которой модель ахуевает
Вокал оригинала: https://voca.ro/19M1lMTqz676
Мой кавер: https://voca.ro/1itbIvewKIm8
Вокал оригинала: https://voca.ro/19M1lMTqz676
Мой кавер: https://voca.ro/1itbIvewKIm8
>Анон, как справляться с хором?
Никак, вокал должен быть чистым без "эффектов" Придется как то ручками, записать отдельно а уже на обработанную нейронком добавить хор эффект

Привет, анон. Хочу переозвучить некоторые моменты в фильме. Нарежу фраз одного персонажа, сделаю голосовую модель в RVC. На Линухе этим методом можно воспользоваться? Подводных камней нет? Не хочу несколько часов трахаться с тем, что в итоге не получится.
Я слышал, что ему нужно 8ГБ VRAM, верно? У меня Steam Deck, вроде в описании написано что оперативная и видеопамять в нём как бы объединены (пикрил), хотя я впервые об этом слышу.
Я слышал, что ему нужно 8ГБ VRAM, верно? У меня Steam Deck, вроде в описании написано что оперативная и видеопамять в нём как бы объединены (пикрил), хотя я впервые об этом слышу.
Запилите мне речь Пыни о Кормлении личинок.
Куда вы все эти модели устанавливаете?
Софт есть какой то или только сайты?
Софт есть какой то или только сайты?
Как называется модель на второй вебм?




Text To Speech (TTS) 📝 👉 🎤
Silero
Российская разработка, легковесный, быстрый, относительно качественный. Поддерживает много языков, включая русский.
https://github.com/snakers4/silero-models
Есть 2 GUI:
Для всех систем: https://huggingface.co/spaces/NeuroSenko/tts-silero
Для винды, более продвинутый проект формата "всё в одном" (TTS/STS/TTS), часть функционала платная: SoundWorks, https://dmkilab.com/soundworks
Официальный бот в телеге. Требуется подписка на новостной канал. На бесплатном тарифе есть лимиты на число запросов в сутки: https://t.me/silero_voice_bot
Данная нейронка не обладает высокими системными требованиями. Если хотите запустить на своём компьютере, то, придётся накачать около 5 гигов + питон + гит, но всё будет установленно в одну папку поэтому будет легко удалить если надоест. Если используете несколько нейросетей - используйте Anaconda / Miniconda!
Гайд: https://textbin.net/kfylbjdmz9
Нет возможности тренировки своих голосов, но возможно сделать генерацию с одним из имеющихся голосов, и потом преобразовать получившийся файл через STS (смотри ниже).
Elevenlabs
Онлайн-сервис синтеза и преобразования английского голоса. На бесплатном тарифе ограничения по числу символов в месяц.
Сайт: https://elevenlabs.io/speech-synthesis
Гайд по использованию и общие советы: https://rentry.org/AIVoiceStuff
VITS-Umamusume-voice-synthesizer
Только на японском, 87 голосов.
ХагингФейс: https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer
Гугл-Калаб: https://colab.research.google.com/drive/1J2Vm5dczTF99ckyNLXV0K-hQTxLwEaj5?usp=sharing
MoeGoe и MoeTTS
Гайд на китайском: https://colab.research.google.com/drive/1HDV84t3N-yUEBXN8dDIDSv6CzEJykCLw#scrollTo=EuqAdkaS1BKl
Кажется можно тренировать свои голосовые модели, но это не точно
Гугл-Калаб: https://www.bilibili.com/video/BV16G4y1B7Ey/?share_source=copy_web&vd_source=630b87174c967a898cae3765fba3bfa8
Speech To Speech (STS) 🎤 👉 🎤
Оба проекта SVC и RVC позволяют обучать модели на любой голос, в том числе свой, любимой матушки, обожаемого политика и других представителей социального дна. Для обучения своих моделей нужен датасет от 10 минут до 1 часа. Разработчики софта рекомендуют для обучения использовать видеокарту с объёмом памяти 10 GB VRAM, но возможно обучение и на видеокартах с меньшим объёмом памяти.
Преобразование голоса можно осуществлять как на видеокарте, так и на процессоре с меньшей скоростью.
SoftVC VITS Singing Voice Conversion Fork (SVC)
Репозиторий: https://github.com/voicepaw/so-vits-svc-fork
Гайд по установке и использованию: https://rentry.org/tts_so_vits_svc_fork_for_beginners
Готовые модели: https://huggingface.co/models?search=so-vits-svc | https://civitai.com/models?query=so-vits-svc
Для изменения голоса в песнях вам дополнительно необходимо установить софт для отделения вокала от инструменталки: https://github.com/Anjok07/ultimatevocalremovergui
Не поддерживает AMD GPU на Windows.
Retrieval-based-Voice-Conversion-WebUI (RVC)
Репозиторий: https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Готовые модели: https://huggingface.co/juuxn/RVCModels/tree/main
Утилиты для отделения вокала от инструменталки идут в комплекте.
Speech To Text (STT) 🎤 👉 📝
Консольная тулза от OpenAI, поддерживает множество языков, включая русский: https://github.com/openai/whisper
Прочее 🛠️
Утилита для нарезки длинных аудиотреков (пригодится для составления датасетов): https://github.com/flutydeer/audio-slicer
Чтобы создать видео из аудио, можно использовать FFMPEG, но если лень - есть GUI, SoundWorks (ссылку см. выше) - Tools \ Video \ Produce still video
Ссылки на эти проекты мелькали в прошлых тредах, но не похоже на то, чтобы их активно использовали итт:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
https://themetavoice.xyz/
https://github.com/coqui-ai/TTS
Шаблон для переката: https://rentry.org/byv2s
Предыдущий тред: