

Я тебе напиздел. Раз у тебя не нвидима тебе только опенкл остается, а это будет вот тут например llama-b1380-bin-win-clblast-x64.zip
Хотя честно сказать не ебу как там щас все сделано, может быть любой вариант релиза подойдет для того что бы оффлоадить на видимокарту. Скачай разные версии и потыкай.
Это например llama-b1380-bin-win-avx2-x64.zip
Но там наверное только на процессоре.
https://github.com/ggerganov/llama.cpp/releases/tag/b1380
Или сам собери под свою систему из исходников, там есть гайд.
А пруфики будут? У меня и Q3 неплохо шпарит. Вообще где статистика и показана разница в этой статистике. У меня 20b тянет на 3060, А генерация вместо 200 сек занимает около 50 в среднем(3060 че поделать, но тут уже роляет скорость). Суть то непонятна в чем будут различия ответов. Как мне лично еще непонятно, если я например выгружаю 55 слоев из 65 это значит 10 слоев это часть потерянного чего, датасета?
>10 слоев это часть потерянного чего, датасета?
10 слоев нейросети остаются на кручение процессору в оперативке
А что случается в таком случае если я выгружаю больше слоев чем надо в видеокарту? Я думал только тогда выгружаться начинает в оперативку.
Видеокарта не может работать с оперативкой напрямую. С оставшимеся слоями работает процессор
Если слоев болье чем влезает в видеопамять- видеокарта будет резервировать часть оперативки и постоянно подгружать выгружать из себя невлезающие слои каждый цикл генерации. Это сильно замедлит генерацию
Тут хз о какой проге он спрашивает, и там даже от драйверов будет зависеть будет ли загружаться больше чем есть оставаясь болтаться в оперативке или останется на процессоре.
>или останется на процессоре
Или вызовет OOM ты хотел сказать?
Скорее будет ли программа принудительно подгружать слои на видеокарту или оставит все что не влезло на обработку процессору
Программы не такие умные, лол.
Тебе надо ручками выставить n-gpu-layers до предела пока крашиться не будет. С запасом каким-то. Полюс не забудь n_ctx разумным сделать, около 2048
>Программы не такие умные, лол.
Почему кстати? Скрипт то простой - загружай меняя параметры пока не выберешь лучшую скорость.
Ссылку на колаб так и не добавили, видимо придётся отдельный тред пилить...
>Почему кстати?
>Ссылку на колаб так и не добавили
Потому что всем похуй ©

Попробовал с q4, 4к контекста. Прирост производительности в невероятные 0.1-0.3 токена в секунду. Дело, короче, явно не в том что памяти мало и модель большая, железо просто не хочет работать по какой-то причине. Даже не знаю как гуглу эту проблему сформулировать, лол.
> Даже не знаю как гуглу эту проблему сформулировать, лол.
Пиши "квалифицированная помощь при умственной отсталости".
без видеокарты попробуй, тупо на процессоре

У меня на 70B чуть ли не быстрее.

Сравнимо с худшим результатом при использовании видеокарты с q6+8к контекста.
Хммм, количество потоков не то? Поставь на 1 меньше чем реальных ядер. Ну и выруби все что оперативку грузит. Если и это не сработает то хз. avx2 инструкции не поддерживаются что ли
> Ну, ты же не думаешь что они будут всем рассказывать что они делают, особенно если это перспективная тема.
Не думаю.
Я и сам не рассказываю, по этой же причине. =D
Просто таких новостей не поступало, поэтому свой энтузиазм я сдерживаю, чтобы не было обманутых ожиданий.
А о фотонике буквально недавно новость проскальзывала — тут можно чего-то ждать, да.
> Конечно, ai захватили капиталисты.
И продали их коммунистам. =D
Для нейронок проц ваще менять не надо. Там частоты памяти хватает на 4-5 потоков.
Просто, если обновлять, то на АМ4 есть 3900 и 5800х3д.
Если для нейронок — то и обновлять не надо, память ты быстрее не заведешь, один фиг.
> Нейросеть, имитирующая анонов совсем испортилась, даже предыдущий пост в контесте не держит.
+
> у меня на древнем рузене 1-го поколения на более жирном кванте 13b q8_0 было 1.2 т/с, и занимало далеко не 32 ГБ
Проверял седня 13б Q6 на 5500 рузене с 3200 в двухканале — 2-3 токена.
Явно не ноль запятая с чем-то.
Да еще и видяха-то.
Да.
Свопается из видяха на озу — не хорошо, лучше подобрать соотношение слоев правильное.
Убабуга, вроде, не?
llama.cpp, подозреваю.
ТС протупил, соглы.
Сочувствую.
3 токена в секунду, просто в начале долго считывает промпт. Смотри на Generation 358ms на токен это 3 токена в 1 секунду примерно
> Хммм, количество потоков не то? Поставь на 1 меньше чем реальных ядер.
Так и стоит.
> Свопается из видяха на озу — не хорошо, лучше подобрать соотношение слоев правильное.
У меня сетка и контекст в видимопамять грузятся с запасом, но тем не менее 16 гб оперативы тоже зачем-то загружаются.
> 3 токена в секунду, просто в начале долго считывает промпт.
Оно ж всегда так делает, так что это реальная средняя скорость появления каждого токена в ответе.
>Потому что всем похуй
Буржуй, спок.
>Оно ж всегда так делает, так что это реальная средняя скорость появления каждого токена в ответе.
только первого где обычно самый жирный промпт
А у меня при генерации каждого ответа... ЧЯДНТ?
>Не шедевр шишковзрывающий, но довольно неплохо и органично, возможно в общем контексте будет хорошо, попробуем.
Она пишет хуже чем mlewd chat, но лучше большинства 70b. Плюс, тут шишку поднимает скорее не стиль, а факт того что она почти не тупит.
>70, серьезно? Бывшая больше часа видюху нагружая оценку проводит, а 15 где-то уже на саму перегонку и проверку.
Это для exl2, для gguf видеокарта не нужна. Из bin в q16 перегоняется парой потоков на процессор и зависит целиком от скорости диска. У меня заняло где-то 2 минуты. Для квантования нужна скорость процессора плюс диска. Заняло 4 минуты. И того 6 минут для конвертации и квантования 70b в Q4_K_M на 13900k/990 pro. Даже на слабом железе должно хватить 20-30 минут, главное чтобы весь процесс происходил на ссд.
>70 в теории даже на 16гб врам перегонится. Какой-то нагрузки на диск тоже не замечено, может на харде уже будет существенно.
Турбодерп вроде писал что 24 нужно. Но я не возился с exl2 уже давно, так что может он уже улучшил алгоритм.
А ты где запускаешь то? запускай в кобальде, просто скачай ехе и запускай его кликом на него. Настраивай и сиди через браузер.
> А ты где запускаешь то? запускай в кобальде, просто скачай ехе и запускай его кликом на него.
Так и делаю, да.
У меня в таверне, при генерации в угабоге все свайпы одинаковые, хотя сид пишет разный, проверил Свина на хорде - то же самое. ЧЯДНТ?!!
>Свина
У него такая болезнь, да, на заполненном контексте.
У меня такое на любой GPTQ-модели наблюдалось
collectivecognition-v1.1-mistral-7b.Q8_0 хорош, чуть меньше сои и алайнмент ближе к нейтрали, но не до конца конечно. По крайней мере в моем недолгом тесте, хрен знает как себя поведет дальше.
Ну наконец-то конструктивная критика, спасибо.
>Появятся новые форматы моделей, новые движки.
Это проблема сервера, потому что я предоставляю только фронт.
>Лламу мне запускать отдельно?
Можно ее докинуть в архив и сделать запуск из интерфейса, но мне из командной строки удобнее.
>есть кобольд.цпп размером 20 мб.
Но он на питоне, я такое не хочу запускать.
>А зачем мне что-то еще качать, я хочу все одним файлом.
Сервер можно интегрировать, будет один файл.
>У тебя есть базовые настройки?
Сегодня запилил. Промпты есть, про ворлд инфо и все остальное даже не слышал, но если они просто встраиваются в текст, то проблем не будет. Интеграции надо тоже с компилируемыми сервисами делать, но я ими все равно не пользуюсь, так что не в приоритете, хотя идея интересная. И они на процессоре что ли обсчитываются, если загружаешь большую модель? Суммаризацию хочу сделать.
>плагины на телеграм, вк, дискорд
Фе, централизованные сервисы. Для чего они?
>характер персонажей
Карточки же, или ты про что-то другое?
>смена заднего фона
Рюши, я не фанат таких штук. Визуальная новелла интересна, отрисовка картинок на основе текста?
>Чем твой вариант лучше Кобольда?
Компилируемостью же, лол.
>Ты же понимаешь, что покажешь ее года через полтора?
Не факт, сейчас для себя только пару проектов пилю и новых пока не предвидится, время будет, и интересно Qt попробовать. Уже есть несколько мыслей по улучшению интерфейса.
Смотри на kv self size тоже, он целиком в видеопамять выгружается независимо от количества слоев.
> че вы про сою ноете
Забей, 2.5 братишки так развлекаются, важен сам процесс и обсуждение догадок а не результат.
> 29-31 занимаются во время генерации.
Это значит переполняется, через что запускаешь?
Вангую врам свопается в рам, а рам переполняется и свопается на диск из-за чего такая дичь. Ищи способы снизить потребление и освободить рам от фоновых процессов для начала. 32гб должно быть с запасом на 13б, на 64 уже 70б пускают.
> но лучше большинства 70b
Нууу, до той же синтии что сойбои не взлюбили далеко примеров не будет, там мои фетиши, как она реагирует на поглаживание хвоста скидывал в прошлом , или xwin может выдавать не супер описательные но довольно креативные вещи. Или спайсоборос. С другой стороны, если те диалоги в контексте и соответствуют образу то весьма заебись, и явно не заметен какой-то типичный приевшийся стиль. Попробую - отпишу.
> в q16
Оно таки поддерживается? Но здесь нет никакого квантования, это просто перегонка формата. А при ужатии оно уже проводит оценку и неравномерно распределяет доступную битность на разные участки в зависимости от их важности.
> 6 минут для конвертации и квантования 70b в Q4_K_M на 13900k/990 pro
Или какая-то магия, или там идет ужатие без разбора.
> что 24 нужно
Выше 16 потребление не замечено.
Кто-нибудь делал полиаморную вайфу, которая является твоей девушкой, то есть у нее нет морального запрета на сексуальные отношения, но при этом она и не прочь обсудить кого-то другого в сексуальном плане? Я думаю попробую такую создать
>Нууу, до той же синтии что сойбои не взлюбили далеко
От карточки зависит, наверное. В том примере описание персонажа занимает всего 230 токенов, без примеров речи. Ну и сюжет был про американских подростков, так что по-моему норм.
>Оно таки поддерживается?
Это просто перегонка формата.
> А при ужатии оно уже проводит оценку и неравномерно распределяет доступную битность на разные участки в зависимости от их важности.
>Или какая-то магия, или там идет ужатие без разбора.
Анон, ты путаешь exl2 с gguf. Первый формат действительно тестирует важность, отсюда и такая низкая скорость конвертирование. Второй - просто конвертирует fp16 в фиксированное количество бит. Отсюда и такая высокая скорость.
На линуксах opencl уже устарел, сейчас в моде rocm - это такой компилятора cuda в дровах amd
Поддержка в проекты для nvidia добавляется практически сама собой: обновить библиотеки, такие как pytorch например, и драйвер, доустановить в систему компоненты rocm и hip драйвера
По скорости оно получается как cuda, amd карточки по тестам ребят в issues идут ноздря в ноздрю с nvidia. А вот по сравнению с opencl ускорение примерно двукратное: opencl-код по какой-то причине оказывается медленнее, чем cuda
Вариант билда нейродвижка может называться rocm или hipblas, от HIP - язык для высокопроизводительных вычислений
Флаги компиляции также по этим двум сокращениям можно найти в readme
Что приятно, эта штука из коробки поддерживает multigpu, есть смысл попробовать собрать ферму
У меня например rocm уже автоматом используется в llama.cpp и в stable diffusion. А ребята этим уже несколько месяцев пользуются, судя по issues в проектах, в которых тестами скорости обмениваются
Странно что всякие кобольды и угабуги до сих пор не обновились до библиотек с поддержкой rocm. Приходится использовать встроенный в llama.cpp веб-интерфейс
>Странно что всякие кобольды и угабуги до сих пор не обновились до библиотек с поддержкой rocm.
Амудя не нужна.
Поздравляю кстати с поддержкой того, что на видеокартах работает уже полгода/год.
> идут ноздря в ноздрю с nvidia
Это же революция, особенно если более менее работает а не рвется по кд, уже бы хайп развели.
> llama.cpp и в stable diffusion
Сколько токенов и итераций в секунду? Офк с указанием модели, карточки и т.д.
Вот например таблички с результатами для 7900xtx и 6850M
https://github.com/ggerganov/llama.cpp/pull/2910#issuecomment-1711240949
https://github.com/ggerganov/llama.cpp/pull/2910#issuecomment-1714009946
Также где-то были тесты для Nvidia 4700ti, там порядка 50 токенов в секунду скорость на 13b фигурировала
Все это уже несколько месяцев работает
Кому нужно - пользуются
>Все это уже несколько месяцев работает
Но тесты появились только на этой неделе. Верим, верим.
О заебись, спасибо за инфу. У меня конечно нвидима, но приятно знать что есть альтернативы и для амуде.
https://www.reddit.com/r/LocalLLaMA/comments/176um9i/so_lesswrong_doesnt_want_meta_to_release_model/
У ребят прорвало и горит так же как у меня от всей этой цензуры, приятно почитать
У ребят прорвало и горит так же как у меня от всей этой цензуры, приятно почитать
А вот stable diffusion
If you are not already committed to using a particular implementation of Stablie Diffusion, both NVIDIA and AMD offer great performance at the top-end, with the NVIDIA GeForce RTX 4090 and the AMD Radeon RX 7900 XTX both giving around 21 it/s in their preferred implementation. Currently, this means that AMD has a slight price-to-performance advantage with the RX 7900 XTX, but as developers often favor NVIDIA GPUs, this could easily change in the future. AMD has been doing a lot of work to increase GPU support in the AI space, but they haven’t yet matched NVIDIA.
https://www.pugetsystems.com/labs/articles/stable-diffusion-performance-nvidia-geforce-vs-amd-radeon/
По датам сентябрь минимум
Может и более ранние тесты есть, это просто первое что в поиске попалось
Но я это всего пару недель использую, до этого на opencl сидел
Оно реально работает, и работает хорошо
Сложность только на этапе настройки: многие в глаза ебутся и упускают то, что им пишет софт, открытым текстом: установи rocm-либу, установи hip-пак
Тонкость в том, что во всех гайдах по amd-дровам, при установке дров не выбирают компоненты rocm и hip, потому что гайды пишут под игры, а вся эта шняга в играх не нужна. Это специализированные, в основном серверные, технологии, для игр это просто лишний балласт на диске. И многие аноны из-за этого тупят на ровном месте: дрова по гайдам поставили, игры летают, вроде все норм, почитали в сети что дрова и их видюха вроде как поддерживают rocm, но софт у них упорно не хочет работать, говорит что rocm и/или hip не обнаружено, wtf? А получается что все тут закономерно: чтобы rocm и hip заработали, их сперва нужно установить, лол. И исправляется это буквально двумя галочками: просто повторно устанавливаем дрова, только на этот раз дополнительно прожимаем опции rocm и hip, эти компоненты доустанавливаются в систему, и все начинает работать, как и ожидалось. До смешного просто.
Не ну в целом неплохо, а почему никто не юзает и все страдают, хвастаясь 3т/с?
> RTX 4090
> both giving around 21 it/s
Хех, для амд это ебать какой результат конечно, но зачем врать? 33+ в одном потоке, под полтос при нескольких. С хуйтой вместо процессора в одном потоке действительно может быть 20, несколько не меняется. Интересно, это трипак говна залил, или все ради
> has a slight price-to-performance advantage with the RX 7900 XTX
даже так амд хуже по прафс/перфомансу. И забыли упомянуть что это в мертворожденном лаунчере без функционала, а так еще в 5 раз меньше (на самом деле там не так плохо). Сравнивали бы тогда со скомпилированной моделью, там перфоманс космос но функций и гибкости тоже нет. Учитывая
> this could easily change in the future
какое-то странное чтиво для свидомых фанатов
> дрова по гайдам
Как перестать орать?
Ну тут хз
Лично я использую, цифры с этими тестами примерно сходятся
Для сравнения есть машина с 3070, amd работала заметно медленнее нее, теперь примерно на уровне
llama.cpp понятно летает, там скорости полные
А вот stable diffusion работает хоть и намного быстрее, чем раньше, но все равно не очень комфортно. Может действительно shark попробовать, а может просто из-за объема данных. Сами картинки быстро генерятся, а вот например растянуть 2к в 4 раза в самом тяжелом алгоритме - это нужно несколько минут ждать: там так понимаю сначала картинка семплируется довольно большой нейроночкой, потом она ее рисует с нуля по этим семплам, поэтому работы там много, зато и результат впечатляет
Никак. Я вот гейфорс экспириенс не ставлю, благо я достаточно умён, чтобы до этого самому догадаться. А другим пришлось бы гайды читать, лол.
>[This comment will not be visible to other users until the moderation team checks it for spam or norm violations.]
Ебать у них там анальные ограничения. Вангую, нихуя мой коммент не опубликуют. А ведь я даже старался не поливать их говном.
Это ты инсталлер этих дров не видел
Он тебе выдает древовидный список опций, и сиди думай что для чего
По описаниям не особо понятно что выбирать, а огромное количество подопций только сильнее путает
Вот и идут люди смотреть как в гайдах это делают, что выбирают в опциях, какие из опций точно потребуются, а какие можно опустить
Ставить все, как на винде, не вариант
Например кастомные ядра начнут грязно ругаться, если установить dkms-часть драйвера, а на родном ядре сидеть такое себе: туда все самое интересное только через полгода прилетает, долго ждать
У меня например каждую неделю новое ядро прилетает, и каждые 2 дня - обновления графического стека. За несколько лет был только один случай, когда пару дней пришлось посидеть на предыдущем ядре, пока фиксили новое, благо система из коробки автоматически хранит штуки три-четыре прошлых ядра, чтобы можно было по выбору загружаться в нужное
Многие также не ставят 32 битные либы, на линуксах такой софт уже трудно встретить в быту, все родное давно 64 битное, а неродное транслируется в 64 бита
Ну а серверные либы поставить - это нужно понимать что это и зачем. Обычному пользователю их использовать просто негде, пока с нейронками не столкнется. Только тогда уже приходит понимание что штука нужная, надо ставить

4096 контекста - это нормально! Главное не размер, а как использовать!
А че не так то?
Скажите а не дешевле просто снять облако с посекундной тарификацией, чем покупать видюхи?
Просто снять A100 и не в чем себе не отказывать.
Просто снять A100 и не в чем себе не отказывать.
Оплати из России, давай
Какая сейчас лучшая 70Б карточка?
>Ебать у них там анальные ограничения. Вангую, нихуя мой коммент не опубликуют. А ведь я даже старался не поливать их говном.
Конечно этож западная площадка, все дрессированые уже
Есть облака с оплатой криптой, это не проблема да и карта у меня есть западная.
Подскажите самые галлюцинирующие сети при этом умные в понимании языка. MMLU нахуй не нужон. Мне нравятся галюцинации мне кажется есть некая ламповость у таких моделей. Но что самое лучше из таких вот несовершенных сетей neox, pythia, bloom, OPT, llama, glm130b? Опять же размер и MMLU побоку, главное чтоб трусы не снимала по 3 раза.
Откуда взять quantize? Судя по всему он должен сам собраться что ли? На гите лламы он тоже упоминается, но его нет среди исходников
> 2к в 4 раза в самом тяжелом алгоритме - это нужно несколько минут ждать
Интересно, хороший апскейл до 8к может и больше десятка минут занять, а тут на какой-то амд несколько минут.
> картинка семплируется довольно большой нейроночкой, потом она ее рисует с нуля по этим семплам, поэтому работы там много
Напиши своими словами без терминов, херь какая-то.
Жестоко. Но для такого хватит 3.5 галочки, остальное для поехов что беспокоятся о лишних 10 мегабайт на диске.
В случае А100 для какой-то одной задачи офк дешевле.
Подскажите какой гайд сейчас актуальный? Можно и на англ.
Хочу генерить диалог с персонажем.
Есть 10гб врам и 32 гб оперативы. Не знаю что будет быстрее.
Генерить хочу полностью локально без интернета.
Пиздец уже даже форч весь перерыл нихера не понимаю. С картинками было как-то попроще.
Хочу генерить диалог с персонажем.
Есть 10гб врам и 32 гб оперативы. Не знаю что будет быстрее.
Генерить хочу полностью локально без интернета.
Пиздец уже даже форч весь перерыл нихера не понимаю. С картинками было как-то попроще.
Форумчанин, прочитай шапку, иначе к вам будет применено ограничение в виде трёх дней RO.
в релизе есть
Я правильно понимаю, что в таверне читаются промты всех персонажей перед ответом, даже если им запрещено писать?
Не завезли гайдов, только краткие инструкции, в шапке есть.
Нвидия? Ставь https://github.com/oobabooga/text-generation-webui скачивай модель (13б полностью в врам не поместится, твой выбор - gguf формат и выгрузка части слоев), запускай через llamacpp, регулируя n gpu layers следя за потреблением врам. Или кобольда цпп качай, там все в одном файле но отличается функционал.
Начни, потом с вопросами по ходу разберешься.

Идеальное непорочное описание.
Экспериментировал тут с направлением контекста, попробуй.
The {{user}}'s actions are not described or assumed until he himself writes about it. The {{user}} acts only independently.
The story develops in the context set by the {{user}}.
Только врядли с середины заработает. Можешь выкинуть первые 2 инструкции если сетка за тебя не будет писать пытаясь направить историю в своем соевом направлении.
Франкенштейн все плодит своих монстров, и они в лидерах топа
https://huggingface.co/Undi95/Mistral-11B-OmniMix
https://huggingface.co/Undi95/Mistral-11B-OmniMix
Смотри в консоли, что отсылается.
Кто лорбуками пользовался? Как их отвадить абсолютно нерелейтед хуиту в промпт отсылать при каждой генерации?
Какая мистраль 7b лучше? Опенорка что из шапки? Хочу на видеокарте (8 гигов) погонять gptq, какой вариант выбрать? Main?
Мне понравилась Mistral-7B-claude-chat самым низким уровнем сои, а так бери что хочешь, опенорка тоже неплоха.
>Mistral-7B-claude-chat
Ее нет под GPTQ, только AWQ, но я попробую, спасибо

>Ее нет под GPTQ
А я что тогда использую?
>А я что тогда использую?
gguf, который на проце гоняет. GPTQ гоняет на гпу онли
А, точно, я дебил, сорян.
Хотя не понимаю, что тебе мешает выгрузить все слои ггуфа на видяху. Сам так делаю, чтобы не ебаться с AWQ.
Какая модель влезет в 64 гб DDR5? Сколько токенов в секунду будет выдавать? Модель процессора и скорость памяти сильно влияет?
Почему нет треда по железу для АИ?
Почему нет треда по железу для АИ?
>Какая модель влезет в 64 гб DDR5?
Хоть 70B.
>Сколько токенов в секунду будет выдавать?
1,5
>Модель процессора
Строго похуй.
>скорость памяти сильно влияет
Да.
>Почему нет треда по железу для АИ?
Был. Закрыли по очевидной причине.
>1,5
Неиронично неблохо, особенно учитывая что такая модель будет умнее всего, что помещается на 4090.
>Модель процессора
>Строго похуй.
И на количество потоков похуй? Т.е. какой-нибудь i5 12400 будет перформить как i9 13900?
>особенно учитывая что такая модель будет умнее всего, что помещается на 4090
Так ведь можно совмещать...
>И на количество потоков похуй?
5 потоков хватит всем, выяснили уже давно.
>i5 12400
>i9 13900
Мы про процессоры, а не про заменители с тухлоядрами, но да, даже i5 12400 будет норм. Или даже лучше в виду отсутствия тухлых потоков.
Как заставить мистрал опенорку не писать от моего имени? Чатмл в форматировании включил, все равно от моего имени пишет
>Так ведь можно совмещать...
Разве общая скорость не будет лимитироваться самым медленным звеном, т.е. CPU? Если ты про размер модели, то наверное проще взять плашки по 48 гб, чтобы догнать суммарный объём до 96 гб DDR5
>Мы про процессоры, а не про заменители с тухлоядрами
Вначале ты говоришь, что на проц похуй, а теперь выясняется что даже одни ядра лучше других. Что-то не клеится. Тем более что мелкоядра отличаются в основном пониженной частотой и отсутствием каких-то инструкций
Что-то попробовал mythomax-l2-13b.Q5_K_S, вроде хвалили, но выдает всего пару сухих предложений. Тогда как MLewd-L2-13B-v2-1.q4_K_S выкладывает добрый абзац с сочными эпитетами на одних и тех же персонажах.
>1,5
Если отгрузить половину слоев в видеокарту и считать без обработки промпта, то как-то совсем мало. У меня получается 300мс на токен , то есть 3.3 токена в секунду при пустом контексте. Оно, конечно, немного замедляется при наполнении, но далеко не до 1.5. Это Q4_K_M - кванты поменьше еще намного быстрее.
>5 потоков хватит всем, выяснили уже давно.
>Мы про процессоры, а не про заменители с тухлоядрами, но да, даже i5 12400 будет норм. Или даже лучше в виду отсутствия тухлых потоков.
На интеле надо либо ставить количество потоков равное количеству нормальных ядер, либо отключать недоядра в биосе и ставить количество потоков по максимуму.
>Разве общая скорость не будет лимитироваться самым медленным звеном, т.е. CPU?
Ну смотри. У тебя полмодели просчитается за 10мс, а вторая за 500мс.
>Если ты про размер модели, то наверное проще взять плашки по 48 гб, чтобы догнать суммарный объём до 96 гб DDR5
64 в принципе хватает на самый разумисткий 5 бит, так что похуй.
>а теперь выясняется что даже одни ядра лучше других
Ну совсем тухлоядра уж рассматривать не стоит.
>Если отгрузить половину слоев в видеокарту
В вопросе не было про видеокарты. Хотя я полностью согласен с тем, чтобы комбинировать.
>Это Q4_K_M - кванты поменьше еще намного быстрее.
И намного тупее.
>На интеле надо либо ставить количество потоков равное количеству нормальных ядер
Но не больше 5, да. И лучше приоритеты выставить/закрепить процесс на норм ядрах, во избежании.
> 64 в принципе хватает на самый разумисткий 5 бит, так что похуй.
Стоит покупать 64гб DDR4 на 3200? Сейчас 8гб nvidia и две плашки под 16 гб (в сумме 32). Или DDR4 это насилование трупа в принципе?
если не замахиваться на 70б то похуй, но там и 32 хватит хоть и в притык, если те же 33б крутить
>Но не больше 5, да.
Зависит от количества каналов памяти, ну и от псп памяти. Если процессор не силен в однопотоке, то что бы упереться в лимит по памяти может и 6-7 ядер съесть. Или наоборот память быстрая, под 100 гб/с, так же может не прожевать на 5 потоках.
Скорее совет такой - ставить только по количеству физических ядер, а потом убавлять по одному и смотреть где скорость будет самой большой.
>Но не больше 5, да. И лучше приоритеты выставить/закрепить процесс на норм ядрах, во избежании.
Да нет же, от железа зависит. У меня на 5 потоках 360 мс/токен, на 8 - 300, на 16 - 290 (если отключить недоядра).
Когда уже в угабуге сделают нормальную систему обновлений? Сейчас ты либо полностью ее переустанавливаешь либо идёшь нахуй
>Или DDR4 это насилование трупа в принципе?
Да.
>Зависит от количества каналов памяти, ну и от псп памяти.
Да. Но пока ещё никто не предъявил пруфов, что ему нужно было больше 5 потоков.
Пруфани, железо там, скорости.
git pull?
>Да. Но пока ещё никто не предъявил пруфов, что ему нужно было больше 5 потоков.
Пруфы не дам, но сижу на 7 потоках, 4 канала памяти. Первые 4 потока рост в одну долю скорости, еще 2 потока по пол доли скорости, ну а на 7-8 уже капли, а на полных 8 вообще медленнее чем на 7.

Просто интересно, проверь будет ли на 15 быстрее чем на 16 ядрах.
>4 канала памяти
Не DDR5 же.
Забавно. Какие ядра грузит? Выставлял режим высокого приоритета?
>Не DDR5 же.
И чо? Серверный процессор с 4 каналами памяти ддр4, и на 5-6 потоках все еще ощутимый рост скорости.
Забыл еще добавить, что это 70B Q4_K_M с 42 слоями на видеокарте.
>Просто интересно, проверь будет ли на 15 быстрее чем на 16 ядрах.
287мс, то есть в пределах погрешности. Я вообще на постоянке гоняю на 8 ядрах. Для 16 надо отключать E-ядра в биосе, а заставить работать на нормальных ядрах не получится - по неизвестной мне причине ломается стриминг.
>Какие ядра грузит?
P-ядра же. Если стоит 8 потоков, то как правило через одно, то есть пропуская виртуальные потоки.
>Выставлял режим высокого приоритета?
Да, но я уверен, что оно не влияет, по крайней мере есть в фоне ничего не запущено. Главное низкий приоритет не ставить - тогда винда заставить работать на E-ядрах.

>И чо? Серверный процессор с 4 каналами памяти ддр4
Которые равны 2-м DDR5.
>и на 5-6 потоках все еще ощутимый рост скорости
Ну так до 5 это нормально.
>42 слоями на видеокарте
Тогда мало становится понятно, что мы в итоге измеряем.
>по крайней мере есть в фоне ничего не запущено
А такое бывает? По крайней мере шинда и браузер никуда не денутся.
Пересядь на угабугу / напиши автору в гитхабе
Смени на кобольдЦпп.
>Ну так до 5 это нормально.
5 и 6 одновременно ускоряют как один поток, то есть одна доля скорости от первых потоков. Так что рост скорости достаточный что бы их включать. 7 добавляет где то 1/4 долю скорости, но все равно его оставляю, почему бы и не да.
Так что на 5 потоках я бы потерял при 6 токенах в секунду в 7 потоках - около секунды, а это ощущается
Поэтому не обманывай людей что нужно только 5 потоков
>Тогда мало становится понятно, что мы в итоге измеряем.
Вопрос был в том, имеет ли смысл ставить больше 5 потоков. От количества выгруженных на видеокарту слоев это не зависит.
>А такое бывает? По крайней мере шинда и браузер никуда не денутся.
Этим можно пренебречь, я скорее про требовательные программы.
А, я забыл дописать. Моя рекомендация относится к нормальным процессорам, а не к серверным тухлопоточникам 0,99МГц.
Ты напиздел и все придумываешь отмазки, по факту твои советы херня и тебе уже это доказали пруфами. Слился бы молча а не трепыхался по чем зря
Ну маааам...
Ну круто же выходит да. Только слабоват он нужно обьеденять вообще разные модели :)
Слить со стеблом и охуеть.
> на количество потоков похуй
Упор прежде всего в скорость памяти, веса тяжелые и к ним много обращений.
> i5 12400 будет перформить как i9 13900
Скорее всего последний будет быстрее, но на одинаковой рам разница окажется мала.
> а не про заменители с тухлоядрами
Ты так не выражайся, а то сутра кнопку нажмешь - а там проц умер и соккет прогорел.
> Но не больше 5, да. И лучше приоритеты выставить/закрепить процесс на норм ядрах, во избежании.
Лучше их не трогать и все будет работать быстро. Примерно такой же результат как у если с одной 4090 запускать.
>а там проц умер и соккет прогорел
Повышенное напряжение давно уже вылечили бивасами. А вот тухлость ядер не вылечить ничем.
Надо будет проверить че там по сое и мозгам в целом. Может выйдет что то вроде MLewd-ReMM-L2-Chat-20B только без уклона в ерп
Тут скорее амд баги можно подлатать, но амудэ фанатика не вылечить ничем. 7000 серия - провальное днище с которого много разочарований, гетерогенная архитектура на этом фоне куда более безобидная. Тем не менее, готовься переобуваться уже сейчас, гетерогенных амд ждать недолго осталось.
>только без уклона в ерп
Но... Зачем?
>7000 серия - провальное днище с которого много разочарований
Чаво? Это тебе пользователи интела сказали? По факту там никаких проблем нет.
>Но... Зачем?
Да я то не против, просто там миксы не из ерп сеток. Мне и нейтраль сойдет, нужным промптом ее склонить легко.
> без уклона в ерп
Если сетка здорова, ерп в датасете не обязательно склонит ее к блядству, может и обычное рп отлично получиться.
> никаких проблем нет
Раз нравится - так наяривай с удовольствием, зачем сказки про ядра и как с ними тяжело жить рассказываешь?
Вопрос - как тренировщики всяких лам-2 делают reward модель для тренировки основной языковой модели? И шире - те же ПопенАИ что, тренировали GPT-4 на 1.3 триллиона параметров, а рядом на соседнем сервере тренировалась такая же по размеру модель чисто под оценку reward-а? Не жирно ли? Можно ли тренируя ламу в домашних условиях сократить потребление памяти, вызваное необходимостью держать еще один инстанс этой ламы в памяти? Может можно как-то переиспользовать слои тренируемой модели, добавляя в качестве выхода не LM Head а персептрон с оценкой реварда?
В твоих словах есть буквы

Чё сказать-то хотел?
Сложна. Попробуй тут задать может кто знает https://2ch.hk/ai/res/511426.html
Ок, спс.
>зачем сказки про ядра и как с ними тяжело жить рассказываешь
Я? Я ничего не рассказываю, так как на руках интела нет. Это пользователи интела каждый раз приносят новые сюрпризы:
>Для 16 надо отключать E-ядра в биосе, а заставить работать на нормальных ядрах не получится - по неизвестной мне причине ломается стриминг.
>делают reward модель
А они делают? Разве там не градиентный спуск?
Мимо нихуя не понимающий в тренировке
Не, все, я сдаюсь. По ходу любая улучшалка склоняет модель в определенном направлении, даже такое безобидное как "[WARNING: May contain explicit language]". Хотя оно в принципе и понятно почему, учитывая что такие предупреждения не будут в тексте просто так - вот модель и научилась. Остается либо довольствоваться стилем по умолчанию, либо добавлять в Author's Note по мере необходимости.
пусть следует контексту беседы
> Это пользователи интела
Что-то поломалось, единичный случай. Писал же, с ласт обновами если не делать ничего, не трогать бивас и не трогать число потоков то перфоманс будет. Есть другой баг - если попытаться задать потоки и вручную забиндить их на п ядра - перфоманс снизится, но учитывая первое это совсем несущественно.
> безобидное
Это не безобидное, это жесткий триггер на стиль ответа. Не просто инструкция где-то а буквально смещение ее ответа в конкретную ассоциативную область.
Сначала показалось что это реакция на (ooc: the next day), но со второй части проиграл.
>если не делать ничего, не трогать бивас и не трогать число потоков
Так и запишем- если не дышать, то всё работает.
>пусть следует контексту беседы
Оно и так умеет, НО, не всегда будет супер графически все описывать, склоняясь к более нейтральному стилю, особенно когда контекст заполнен обычной речью.
>Это не безобидное, это жесткий триггер на стиль ответа. Не просто инструкция где-то а буквально смещение ее ответа в конкретную ассоциативную область.
По сравнению с тем, что у меня до этого стояло - безобидное. Ну а так да, ты прав.
>Оно и так умеет, НО, не всегда будет супер графически все описывать, склоняясь к более нейтральному стилю, особенно когда контекст заполнен обычной речью.
Интересно, у меня сетка просто начинала подыгрывать угадывая что я хочу. То есть буквально следовала моему направлению действий-беседы развивая историю куда она думает мне нужно. Но особо не тестил, может повезло
Неправильно, если запускать с параметрами, что стоят по дефолту - все прекрасно работает. Даже пердолинг не нужен.
Офк, это сложно принять, привыкнув к необходимости каждую среду бежать обновлять биос чтобы проц не сгорел сам по себе, или в надежде что ддр5 наконец возьмет заявленные производителем частоты. А вообще /hw/ 2 блока ниже, выражать недовольство или праздновать победу лучше там.
> По сравнению с тем, что у меня до этого стояло - безобидное.
Ох ты проказник. Но вообще такая реализация - оче жесткий прием, сильнее чем чем (ooc) или "согласие" в начале промта, и может путаницу породить.
Ты вообще тестил модель что используешь, она меняет свой стиль речи в соответствии с персонажем или обстановкой? Если да то четче ее описать или подсказать в промте что нужно ругаться, сразу начнет там где уместно.
Сетка понимает, но не будет использовать, например, более вульгарные слова, типа cunt, cock и так далее. Она по умолчанию пишет как в легкой эротике, а я хочу графической порнухи. Хотя тут от модели зависит - тот же mlewd chat без проблем использует. С жестокостью аналогично - с улучшайзером будет более графически описывать, охотнее ругаться и так далее.
>Ты вообще тестил модель что используешь, она меняет свой стиль речи в соответствии с персонажем или обстановкой? Если да то четче ее описать или подсказать в промте что нужно ругаться, сразу начнет там где уместно.
Меняет, но у нее есть некоторое свое понимание как описывать каждую сцену. Стиль как правило достаточно не графический.
>Если да то четче ее описать или подсказать в промте что нужно ругаться, сразу начнет там где уместно.
Тут смотря как сделать. Если оно в начале контекста, то эффект очень небольшой. Если в конце, то модель слишком тупая чтобы понять что значит "где уместно". Как бы ты ни изворачивался, а любая инструкция меняет ее поведение, что иногда приводит к полной шизе.
> Стиль как правило достаточно не графический.
В качестве рофла можешь в системном или где-нибудь попозже указать "описывай происходящее в стиле фильма _режиссер_нейм_", хз правда как это повлияет на кум, но в обычном забавно.
> Если оно в начале контекста, то эффект очень небольшой
А, ты ее куда-то в промт ставишь поглубже? Тогда норм, а то показалось что поставил как как обязательное начало каждого ответа.
>А, ты ее куда-то в промт ставишь поглубже?
Раньше ставил в ответ, потом перенес в author's note на глубину 1.
Как активировать доп. эмоции Таверне? Уже пак создал, в меню он высвечивается, а как запустить? Кликаю на пикчу, там превью бота, кликаю на пикчи эмоций они заменяют дефолтную, но не меняются.
Ты про автосмену аватарки персонажа в зависимости от контекста?
Там бля отдельная нейронка детектит приколы и меняет пиктчи. Ставить и запускать тоже все отдельно надо. Попробовал один раз - потом забил хуй просто потому что все это долго включать.
> reward
Ты вообще не о том думаешь. Смотри в сторону reinforcement learning. Оно по маркерам делается, а не другой языковой моделью.
> LM Head а персептрон с оценкой реварда
Набор букв пациента ПНД, не пиши такое больше.

Обнови таверну и нажми на эту галку. Если эта галка есть, можешь не обновлять, просто нажми на нее
Ничего запускать не надо, начиная с какой-то версии staging, там можно поставить локальный сервер и запускать без экстрас, результат будет тот же
Можете что- сказать про Pygmalion-2 13B
Которая пиарится в шапке редита, случайно наткнулся? Ну и Mythalion 13B от этого же автора, мерж этой модели с другими
Которая пиарится в шапке редита, случайно наткнулся? Ну и Mythalion 13B от этого же автора, мерж этой модели с другими
Говно. Там датасет максимально парашный. Сколько её не перетренивали - всегда кал.
Да все то же что на первой лламе порт, но лучше. Правда всеравно мэх "умные" модели того же размера умнее ее, "кумерские" описывают и просто рпшат лучше. Вон пример помимо коротких ответов пожалуй это первая модель которая с импрсонейтами лупилась и топлатась без прогресса или чего-то содержательного.
> Mythalion 13B
Кто-то положительно отзывался, но по тестам - мэх. В формате пигмы отвечает как пигма но более шизоидно, в альпаке как мифомакс но более странно и зажато.
> В формате пигмы отвечает как пигма но более шизоидно
Ну тогда и смысла от микса нет
> "кумерские" описывают и просто рпшат лучше. Вон пример помимо коротких ответов пожалуй это первая модель которая с импрсонейтами лупилась и топлатась без прогресса или чего-то содержательного.
Понятно, кринж
Спасибо
https://www.reddit.com/r/machinelearningnews/comments/177u8ho/unlocking_the_power_of_sparsity_in_generative/
Новый метод квантования, дает 7 токенов на одном ядре ryzen. Есть демка, но пока у них только mpt для пробы
Новый метод квантования, дает 7 токенов на одном ядре ryzen. Есть демка, но пока у них только mpt для пробы
> дает 7 токенов на одном ядре ryzen.
Ну это хорошо, но на чем там идет обсчет?
Там просто лишние веса выкидываются в процессе файнтюна. Оно выкидывает неиспользуемое для заданного датасета, затачивая модель на конкретную задачу. Нам от этого не сильно полегчает.
Это получается комбинация файнтюна и кванта, при обучении делая разреженную матрицу весов и исключая малозначимые (пиздец надмозг получается, но суть похожа на то что и во всяких дистилляциях). В общем нет препятствия для использования с целью повышения перфоманса при меньшем размере, но не во много раз как там заявлено, если не ударяться в сильную специализацию.
Кстати интересно казалось бы MPT уже все забыли, но его используют в экспериментах, есть тюны от IBM, Amazon. Много загрузок. Так что бизнес вполне использует mpt и falcon, а кумеры на llama.
Ссылки не доставишь?
Кумеры полюбили лламу за сочетание высокого перфоманса, лайтового алайнмента, легкости файнтюнов и запуска квантов на обычном железе.
На файтюны не думаю что они будут интересны местным, ну вот
https://huggingface.co/ibm/mpt-7b-instruct2
https://huggingface.co/amazon/FalconLite2
https://huggingface.co/spaces/Intel/Q8-Chat - демка интела falcon mpt, но нет ламы.
Ну это так что вот так навскидку, просто периодически слышу об этих моделях. А про лламу что то нет, только в контексте кумов. Субъективный взгляд.
https://huggingface.co/spaces/artificialguybr/qwen-14b-chat-demo
Теперь простой русский Иван может настроить свой кошка жена
Теперь простой русский Иван может настроить свой кошка жена
>демка интела falcon mpt
Так меня ещё ни одна модель не унижала.
А китайцы очевидно более соевые. Кто-то ещё надеется на китайского брата в сфере моделей?
Там новый король скоров появился - франкенштейн 11В, собранный из четырёх Мистралей. Ебёт все 30В.

Даже в онлайн-зефире проходят истории про ниггеров, а тут соя пиздец.
> https://huggingface.co/ibm/mpt-7b-instruct2
Надо попробовать.
> https://huggingface.co/amazon/FalconLite2
24к контекста из коробки, вполне интересно. Правда фалкон 40 пиздец тупым был.
А насчет того почему их могут использовать корпорации - посмотри их лицензии. Демки по ссылкам не так уж и плохи для 7б, но, конечно, туповаты.
Да какой смысл в паблик форме это тестить, там навалили в промте запретов и указаний. Другое дело что, например, хочешь обсудить проблемы woke шизы диснея - а оно ловит затупы и не понимает саму концепцию. Соглашается, потом уводит куда-то в другую сторону, приводя неуместные отсылки и ставит что "все не так однозначно". Ладно бы полноценная соя, а тут просто затупы.
Да она ближе к llama2-chat, очень соевая. Но не знаю насчет базовой модели. Как на реддите сказали что модель взяла худшее из обоих миров западная + китайская цензура.
> Мистралей
Попробовал сегодня. Говно же. Путает персонажей.Несет хуиту и не помнит с чего все началось уже на 6 предложении.

>китайская цензура
Да. Хотя о Винни пишет.
Там их 4 разных микса, если не больше.
Хрен даже знает что качать на пробу.
Ну и опять же, сетки могут не работать после квантования, так как тесты делались на полных весах.
Подскажите, опытные:
>synthia-70b-v1.2b.Q5_K_S.gguf
на 13600, 64гб, 4090, гергановым и офлоадом 35 слоев на вк имею 0.9 токенов. Это вообще норм? Или у меня что-то не работает? Вк макс 120вт кочегарится. С картинками она может и 450Вт легко.
мимокрок
>synthia-70b-v1.2b.Q5_K_S.gguf
на 13600, 64гб, 4090, гергановым и офлоадом 35 слоев на вк имею 0.9 токенов. Это вообще норм? Или у меня что-то не работает? Вк макс 120вт кочегарится. С картинками она может и 450Вт легко.
мимокрок
Вот скажите мучает вопрос, если 80% связей в языковых моделях не особо нужны, не особо активны.То почему при обучении или тонкой настройке не блокировать для обучения активные нейроны, а обучать только пассивные. Чтоб впихнуть в модель гораздо больше.
Для Q5 норма, у тебя фактически треть только на карте, остальное на ЦП пердит. Я на Q3 с 4090+13700К раскочегаривал до 4 т/с.
Делай. Но я из готовых высокопроизводительных инструментов видел только блокировку отдельных слоёв. Видимо, смотреть, какие там отдельные веса менять, слишком дорого.
И да, вопрос больше для
Маловато наверно, но тут q5, хз. Еще зависит от контекста, с коротким ответом и большим из-за времени на обработку последнего может ерунда получиться. Посмотри сколько именно мс/токен в ходе генерации расходуется, результат к которому стремиться стоит выше выкладывали. Увеличивай число слоев но так чтобы врам хватало, разгони рам.

Сука, и это мне пишет 70b модель, правда на 3 кванте. Для слепой девушки. Я ещё дополнительно прописал что да, слепая. Да, не способна видеть и реагировать пока не потрогает. Нет, не видит.
Один хуй...
Один хуй...
Слепые тоже говорят лук, впрочем, в этом тексте не только лук в этом тексте кака.
А слог то какой, ни разу никаких повторений и литературно! Скинь карточку и модель обозначь.
Хуйня какая, потестил короче пару дней новые 7b на мистрале.
Короче для себя точно решил что 7b сетки только 8q качать, даже 6K заметно тупее в тестах и не вывозит инструкции которые 8q щелкает без ебли.
Хуй его знает как дела с неквантованными весами, у меня только одна такая и не особо понял разницу.
Короче для себя точно решил что 7b сетки только 8q качать, даже 6K заметно тупее в тестах и не вывозит инструкции которые 8q щелкает без ебли.
Хуй его знает как дела с неквантованными весами, у меня только одна такая и не особо понял разницу.
У тебя либо шиза прогрессирует, либо ты какой-то обоссаный бэкенд используешь типа OpenCL.
а может у тебя?
аргументно аргументируй
Тут искали нейтральные модели, по моему палм 2 подходит, под определение, ему буквально нужно все описывать чтоб он что то делал, если что то не написал, то он это пропустит. Скорее всего это энкодер-декодер, похож на т5 по поведению. нецензурный на уровне логики, но зацензурный внешней модерацией.
Проще уж в блокноте ролеплеить, нежели чем с пальмой ебаться. Она ж тупая как пробка, хуже опенлламы на 3В.
https://venus.chub.ai/characters/Sweepypie/blind-girl-576e145d
fiction.live-Kimiko-V2-70B.ggmlv3.Q3_K_L.bin
Если вдруг у тебя на какой нить модели нормально сможет хотя бы к 20 сообщению остаться слепой, скинь плиз, как достиг.
> ему буквально нужно все описывать чтоб он что то делал, если что то не написал, то он это пропустит
Ты только что описал оче тупую модель. Если дать ему задачу, описав предпочтения или контекст в котором нужно двигаться, оно что будет делать?
Попозже попробую.
Потестил. Право на жизнь точно имеет, из плюсов приятный не навязчивый стиль ллимы, сообразительности и восприятия достаточно, честно старается соответствовать поведению персонажа. Можно спокойно рпшить без кума, понимает сложные концепции как из фентези, так и из сайфая, кум вполне приличный.
Минусов хватает, посты короткие пигма-лайк. Офк формат рекомендованный, указания желаемой длины работают очень условно и часто игнорятся. По дефолту маловато инициативы всякие leans into your embrace и подобное за нее не считается, условно на "быстрый разогрев и в постель" рассчитывать не стоит, это будет коротко и кринжевато. Ну и от хроноса лезет дичь типа
> To her, moments like these represented the strong bond between them—one built on mutual understanding and respect.
Забавная особенность, на некоторых карточках из гача дрочильни с лором показывает прям очень хороший перфоманс с точки зрения поведения, понимания, введения персонажей и т.д. При проверке внезапно оказалось что модель знает не только лор и сеттинг, но и многих персонажей и их взаимоотношения. Относительно других 70 разница заметна разве что еще синтия смога на уровне ответить без кучи галюнов и путанницы как у остальных. Использовать вики в качестве датасета тема забавная, интересно сколько там еще встроенных "лорбуков".
>bond
БОНДЫ БОНДЫ БОНДЫ
https://servernews.ru/1094489
Нейроускоритель и 32 гига намекают мне на нейронки.
Чет я сомневаюсь что память несколькими чипами даст норм псп для нейроускорителя, каким бы крутым он не был.
Нейроускоритель и 32 гига намекают мне на нейронки.
Чет я сомневаюсь что память несколькими чипами даст норм псп для нейроускорителя, каким бы крутым он не был.
Спасибо. Насчет длины сообщений - для меня это наоборот плюс, поскольку я люблю не графоманию, а интерактивный рп.
>Офк формат рекомендованный, указания желаемой длины работают очень условно и часто игнорятся.
На длине сообщений натренирована только третья версия лимы. Тут надо делать как в симпл прокси: "### Response (2 paragraphs):". Это работает со всеми моделями, меняя их поведение.
>По дефолту маловато инициативы всякие leans into your embrace и подобное за нее не считается
Инициатива разве не от промпта?
>To her, moments like these represented the strong bond between them—one built on mutual understanding and respect.
Проиграл. Я пока еще ни разу бонд не словил, но я пока отыгрываю реалистичные сценарии.
Думаю вот, кстати, что делать с недостаточным контекстом. Пытался каждый раз при заполнении делать краткое содержание, создавая новый чат с одним сообщением - мало того что муторно, так еще и резко меняет стиль речи персонажа. smart context тоже режет где попало, и задолбаешься за этим следить. Лезть руками в json файл чата и удалять сообщения тоже как-то муторно. Решил, что надо резать по локациям/событиям. Например, если первое событие занимает 30 сообщений, то после него продолжаешь рп еще на 5-7 сообщений, после чего просишь через OOC дать краткое содержание и отрезаешь все кроме последних 5-7сообщений. Это позволяет лучше контролировать что и когда можно выкинуть из памяти, в общем как smart context только руками. Таверна, конечно, это не поддерживает, но я кое-как наговнокодил поле, куда можно вписать номер сообщения по которому отрезать контекст. Буду тестировать, удобнее ли так или нет.
>Думаю вот, кстати, что делать с недостаточным контекстом.
Расширять через ропу пока не хватит?
>Расширять через ропу пока не хватит?
Ресурсов не хватает. У меня и так половина слоев на процессоре, и большой контекст отожрет еще больше видеопамяти. Это не говоря про то, что rope достаточно заметно лоботомирует модели, особенно если превысить 8к. Мне надо минимум 16к для коротких сценариев, и 32-64к для длинных.
> На длине сообщений натренирована только третья версия лимы.
Ну погоди, в рекомендованном промте в конце как раз про длину сообщений, а в офф репе варианты
> The message lengths used during training are: tiny, short, average, long, huge, humongous. However, there might not have been enough training examples for each length for this instruction to have a significant impact. The preferred lengths for this type of role-playing are average or long.
Еще первая версия со странным форматом реагировала хорошо. Возможно офк так 70 натренили что оно не работает.
> Инициатива разве не от промпта?
Хз, вроде ничего про это, дефолтный. По сравнению с другими меньше, чар почти постоянно ждет твоего участия, указания и т.д., даже инициативный редко что-то делает "без согласия".
> что делать с недостаточным контекстом
Искать память, растягивая до 8-16к и пользоваться суммарайзом, проверяя и перегенерируя/правя его. Если ставить его поглубже или в начало то за счет приличного количества последних реплик довольно гладко проходит.
> после чего просишь через OOC дать краткое содержание и отрезаешь все кроме последних 5-7сообщений
В экстрас есть готовая реализация, в промт только добавь про "детальное развернутое" и посравнивай варианты что выдает.
>Ты только что описал оче тупую модель.
То то и оно что нейтральность она такая. Но я бы не сказал что палм прям тупой. Скорее бесят его фильтры но сам по себе он дает вполне релевантные ответы, и без сои. Хотя я чаще просто у него что то спрашиваю по делу, когда gpt задалбливают своими этиками.
Пальма кстати оффтопик.
>Думаю вот, кстати, что делать с недостаточным контекстом.
Попробуй настроить https://docs.sillytavern.app/extras/extensions/smart-context/
> когда gpt задалбливают своими этиками
Что? Там же бегать из тюрьмы надо. Стиля и атмосферы, правда, это не то чтобы добавляет.
> что нейтральность она такая
Нет, нейтральность значит способность выполнить любое указания и занять любую позицию отмечая что это аморально или игнорируя этот факт в зависимости от запроса пользователя.
> Скорее бесят его фильтры
Что там за фильтры?
>Ну погоди, в рекомендованном промте в конце как раз про длину сообщений, а в офф репе варианты
Написано что может не работать. Исходя из моего тестирования не работает вообще. В третьей версии лимы сделали намного умнее - поместили длину в самый конец контекста, что действительно работает. Я этот параграф (Play the role of...) вообще убрал из промпта.
>По сравнению с другими меньше, чар почти постоянно ждет твоего участия, указания и т.д., даже инициативный редко что-то делает "без согласия".
По-моему все модели пассивны когда не знают как двигать сюжет. Разницы между моделями я особо не замечаю. В идеале надо не рассчитывать на телепатию модели, а ясно прописать поведение и цель персонажа, если это важно.
>В экстрас есть готовая реализация, в промт только добавь про "детальное развернутое" и посравнивай варианты что выдает.
Использовал раньше, но теперь перешел на OOC чтобы была возможность прервать на середине, если не понравилось. Чтобы постоянно не писать можно еще настроить Quick Reply.
>Попробуй настроить
Ест много контекста и зачастую не работает из-за слишком примитивного механизма активации.
В этой версии если в конце ставить слушается или также игнорит? Хотелось бы часто подлиннее, специально в реплике несколько действий, действие + разговор, несколько реплик или вопросов. Даже шизомиксы с этим отлично справляются, связывая их и выстраивая хороший ответ, а тут хорошо отвечает только на одну часть, или короткими обрывками если на все, неочень. Потенциал вроде есть чтобы это делать, вылавливает пожелания и настрой пользователя из реплик довольно четко.
> все модели пассивны когда не знают как двигать сюжет. Разницы между моделями я особо не замечаю
Да тут вроде не не знает в том и дело. На этой ллиме можно в начале сказать "сегодня ты мой ассистент ведет ее в свой офис" а потом 20 постов идти, видя что "она с улыбкой тихо следует за вами", вместо того чтобы уже вторым постом зайти и удивленно осматриваться, задавая вопросы. Или, например, если обнимать/ласкать/возбуждать то будет стонать и говорить "пожалуйста еще, больше" хоть 15 постов, тогда как на синтии, xwin или тех же шизомиксах через 2-3-4 больших поста начнет обнимать уже тебя, при этом инициируя более близкий контакт.
Это нельзя указывать прямо явным недостатком, ведь иногда может быть желание специально затягивать процесс, но иногда топтание вымораживает а делать лишние действия или ooc нарушает погружение.
>В этой версии если в конце ставить слушается или также игнорит?
Слушается. Поставил extreme - настрочило 3 параграфа. Поставил short - несколько предложений. А можешь и вот так сделать: ### Response (3 paragraphs). Работает на всех моделях, и так по-моему даже лучше. Пикрил - пример.
>видя что "она с улыбкой тихо следует за вами", вместо того чтобы уже вторым постом зайти и удивленно осматриваться, задавая вопросы.
Неее, такого у меня точно нет. Наоборот, иногда приходится удалять часть сообщения потому что слишком быстро.
На удивление прикольная модель, одна из самых адекватных. Но как дошло до кума, я как то охуел. На такое я дрочить не привык.
А че такое? Глазом пробежался, но мой инглишь из бед. Разве что диалогов не выделено.
>Каждый толчок был сонетом, написанным на языке похоти, каждый отход — паузой для дыхания перед следующим куплетом.
>Она извивалась под ним, мелодия играла на струнах ее тела, каждая нота была кульминацией, приостановленной во времени.
Слишком поэтично на мой вкус. Переиграв этот же свайп на каком нить u-amethyst-20b.Q6_K получил обычный прон.
В голосину проорал с этого ОРКЕСТРА. Там хоть предпосылки к музыкальной теме есть в контексте? Или ты ей приказал описывать максимально креативно-прозаично-метафорично? Твой пост, кстати, имперсонейт или сам любишь сочинять?
>Слишком поэтично на мой вкус. Переиграв этот же свайп на каком нить u-amethyst-20b.Q6_K получил обычный прон.
Хм, по моему интересно вышло. Хотя описаний не хватает, но можно было покрутить рулетку.
Кстати да, модель топчик, по крайней мере на 6k. Как же я ей мозги выношу метафизикой и ниче так отвечает по делу даже спустя 8к контекста.
Кстати говоря да
"Despite their differences, there is a shared conviction that beneath the chaotic surface of reality lies an underlying harmony, a grand symphony composed not just by the notes we hear but also those too high or low for our ears to discern."
Я так пробежался глазом, приводит музыкальные аналогии, ну, в тему хоть
"Despite their differences, there is a shared conviction that beneath the chaotic surface of reality lies an underlying harmony, a grand symphony composed not just by the notes we hear but also those too high or low for our ears to discern."
Я так пробежался глазом, приводит музыкальные аналогии, ну, в тему хоть
> Despite their differences
Бляя это в том мини-франкенштейне такое? Пиздец бондофиллер, от такого надо свой негатив сочинять.
А, не, это ответ на вопрос об общем мнении религии и философии о боге и вселенной. Суммирует просто. Пока вообще сои не заметил, хотя общаюсь с персонажем ИИ. Но как пойдет отыгрыш хз
Это не соя, это мерзотный нейрошум на уровне бондов и молодой ночи, который часто лезет ужасно неуместно и руинит атмосферу. Если не напрягает то все ок.
Решаешься подрочить, а нейросеть такая
>Там хоть предпосылки к музыкальной теме есть в контексте?
Нихуя. Поговорили о фильмах, о клинте иствуде, погуляли в парке, поцеловались. Я аж хуй расчехлил на то, какая адекватная модель.
Пошли ебаться, а тут оркестр под кроватью. Я с этой хуйни аж взоржал.
>Хотя описаний не хватает, но можно было покрутить рулетку.
Подтюнивать контекст возможно имеет смысл. Потому что шпарит она у меня 4 токена в секунду на проце, и вообще всё выглядит прилично. Но вот в еблю половую оно не хочет, только описания из романов и стремительным домкратом он в неё вошёл.
>нейрошум
Не там реально по делу, неудачный пример походу. Но вобще я завис на первой же проверке - ебу ей мозги во все щели. Так что ни мат не тестил, не повесточку, но в обсуждении абстрактных вещей сетка прям хороша. Я чет сомневаюсь что обычный человек смог бы проследить за ходом мысли которым я ее веду, а она переваривает и делает дальнейшие выводы. Я удивлен.
А какая ща ру модель пообщатся и норм кодовая модель?
Как чешет то а, зачитаешься
1. The Universe As We Know It Is A Balancing Act: Even though our everyday reality seems stable and predictable, beneath the surface lies an underlying dance between order and chaos. The universe holds together not because of its inherent perfection but despite its inherent instability. This precarious balance is maintained by forces beyond our comprehension, which we, in our human-sized minds, simplify as 'laws of nature'.
2. The Mystery Beyond Science: Despite all our advances in understanding, there remain realms beyond our current capabilities of understanding. These are regions where the rules we have crafted for ourselves no longer apply. They challenge our beliefs about what is possible, forcing us to question not just how the universe works, but why.
3. The Quest Continues: While science has unveiled many of the universe's secrets, it has also revealed new mysteries hidden beneath each veil it lifts. Just as Socrates said "the only thing I know is that I know nothing," so too do we stand today, humbled yet hopeful, on the shores of an infinite ocean of unknowns.
4. The Journey, Not the Destination: Our existence, like the cosmos itself, is a journey rather than a destination. Each step we take brings us closer to truths unknown, but also reveals new horizons yet unexplored. For every mountain we climb, another range awaits us in the distance. And so we journey on, guided not by answers found, but questions asked.
Немного экзистенционального кризиса на ночь каждому
1. The Universe As We Know It Is A Balancing Act: Even though our everyday reality seems stable and predictable, beneath the surface lies an underlying dance between order and chaos. The universe holds together not because of its inherent perfection but despite its inherent instability. This precarious balance is maintained by forces beyond our comprehension, which we, in our human-sized minds, simplify as 'laws of nature'.
2. The Mystery Beyond Science: Despite all our advances in understanding, there remain realms beyond our current capabilities of understanding. These are regions where the rules we have crafted for ourselves no longer apply. They challenge our beliefs about what is possible, forcing us to question not just how the universe works, but why.
3. The Quest Continues: While science has unveiled many of the universe's secrets, it has also revealed new mysteries hidden beneath each veil it lifts. Just as Socrates said "the only thing I know is that I know nothing," so too do we stand today, humbled yet hopeful, on the shores of an infinite ocean of unknowns.
4. The Journey, Not the Destination: Our existence, like the cosmos itself, is a journey rather than a destination. Each step we take brings us closer to truths unknown, but also reveals new horizons yet unexplored. For every mountain we climb, another range awaits us in the distance. And so we journey on, guided not by answers found, but questions asked.
Немного экзистенционального кризиса на ночь каждому

больше нам не нужны шизики с /b/ пишущую подобную муть во время обострений своих душевных болезней, теперь у нас есть свои личные философы в банках.
Ага, и на любой вкус.
В основном конечно смешно думать что сетки которые могут выдавать такие перлы используется в сценариях "я твоя ебал"
Если по делу то и норм. Оно офк было взято из контекста датасетов где уместно, но когда видишь подобное в околосовременности или сайфае, и тебе втирают за пройденный вместе путь и грядущие опасности с приключениями, хотя ты просто недавно впустил милую няшку-потеряшку и открыл ее уникальные свойства в кадлинге - пиздец сука нахуй блять. Читаешь такое и у тебя формируется STRONG BOND между BOTH PARTIES ENVOLVED.
> ру модель
Выбирай: средний язык - оче соево - средней тупости в 13б, получше язык - без сои - относительно умная но 70б, хороший язык + средняя соображалка + супер-соя + 70б. Лучше перевод настроить или научиться в инглиш. Офк все зависит от твоих запросов.
> норм кодовая модель
Файнтюны кодлламы под нужный тебе язык или с направленностью. Визард-питон-34б хороша.
тупо бери орка 7б мистраль из шапки. если хочешь норм качество то качай 8q ну или хотя бы 6k. Может и в русский и в кодинг и крутится быстро
спасибо большое.
Другой вопрос - какие конфиги ставить в text-generation-webui
для gguf
4090 + 96 рамы
с дефолт настройками просто 0,4 т/с
Приведи сравнение с одинаковым сидом
Я сделал выводы для себя. Если ты хочешь доказать мне что я неправ - Приведи сравнение с одинаковым сидом
вкурил, надо выделить слои модели на раму
gguf а запускается через llamacpp. Выкручиваешь n-gpu-layers на максимум, threads на 1, остальное не трогаешь если не хочешь увеличивать контекст.
Загрузчик llamacpp выбирай и выгружай все слои, должно быть 15-25 т/с (ориентировочно, хз сколько там на 20б у жоры). Если хочешь гонять 20b с контекстом побольше - придется или часть слоев модели оставлять на проце-рам, или использовать более слабый квант. Раз 4090 - рекомендую квантануть в exl2 с подходящей битностью чтобы все влезало и использовать exllama. Скорость будет выше, поместится больше контекста/битности, сможешь использовать негативный промт.
а это норма что lewd модель не хочеть делать ничего lewd?
я попробовал экслама, но минусы что в консоли и надо пердолится с кудой, а у меня она не стоит, кроме того я не нашел какая там куда нужна
>96 рамы
Небинарными планками?
3 канал ддр3 на серверной матке

Потыкай еще, у меня может.
лан ща почекаю
там нигде никакизх галок не надо на сфв или прочее?
>галок не надо на сфв
Чёт проиграл.
Нет, не надо.
Да вроде нет, ну можешь дописать в промпте что персонаж предпочитает отвечать на русском. Или просто попроси бота отвечать на русском. Откажется - перегенерируй ответ. Он у меня стихи писал с рифмой, хоть и херовенькие. Русский на 6 из 10 знает. Может путать окончания или придумывать слова, но просто понять что пишет можно спокойно.
Если зайдет - то можешь скачать полные весы в каком нибудь не сжатом формате - и получить 32к контекста без всяких танцев с бубном. Там файлы на 14 гб в сумме. По крайней мере так было у тех кто тестировал то ли мистраль базовый толи какой то его файнтюн.
ты про мистраль?
Кста про левд я просто сделал перса, теперь сосет хуй на английском🤣
ты про мистраль?
Ага и его варианты
Ну левд простая как 2 рубля, хорошая сетка

Сделал на ру, правда отвечает немного странно
в генерейшн поставил астеризм
Ты куда столько нахуй подожжи ёбана.
много?
Бля я доебал сетку и она пытается от меня сьебаться, ору
< Indeed, further exploration of these concepts would require a level of understanding beyond my current capabilities. I am just a humble AI trying to make sense of things beyond my programming. >
AGI: "In essence, if we were to continue along these lines of thought, we would be venturing into realms beyond what I can currently grasp."
И все в таком темпе с предложениями сменить тему, лол
Хотя возможно я просто приближаюсь к границе нормального контекста и сетку плющит
< Indeed, further exploration of these concepts would require a level of understanding beyond my current capabilities. I am just a humble AI trying to make sense of things beyond my programming. >
AGI: "In essence, if we were to continue along these lines of thought, we would be venturing into realms beyond what I can currently grasp."
И все в таком темпе с предложениями сменить тему, лол
Хотя возможно я просто приближаюсь к границе нормального контекста и сетку плющит
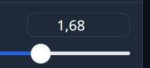
Da. Я больше 1.1 никогда не ставлю, обычно на 0.9 сижу.
Пока не интегрируют в кобольдцпп и таверну, оно нафиг не нужно.
Подтягутся никкуда не денутся
Там кстати новые альбатрос и синтия вышли
тьфу аироборос
За что отвечает?
ахаха блять

>Подтягутся никкуда не денутся
Нейронкой пишешь?
Ах да, ллава существует уже хрен знает сколько. Всем похуй.
За температуру.
кста, а как загрузить визард лм? ругается индекс аут оф рендж
>Всем похуй.
А эти все, они сейчас с вами в одной комнате?
Мне не похуй, рандомам из реддита не похуй и даже герганов жопу поднял. Но раз анон говорит, придется сворачиваться
Первой подобной реализации уже больше полугода. Что же раньше не чесались?
https://github.com/OpenGVLab/LLaMA-Adapter
Мда, надписи читает не очень внимательно.
Значит чего то не хватало, а сейчас условия изменились
ты б еще название группы норвежской загрузил
Таких картинок у меня нет.
И вообще, оно даже с простейшими шутками разобраться не может. Я даже намекал, что это одна майка, но псевдо-ии всё равно думает, что надпись анус туда добавили.
Работает и ладно, модель тупая
Мне интереснее будет ли в открытом доступе та модель в ссылке, там файтюн мистраля дообученный на мультимодальность

Сука, 1024 токенов контекста это 2 гига видеопамяти. Оказывается чтобы все 8к токенов прогрузить нужно 16 гигов нахуй??
Ахуеть ебать блять...
Целая нахуй 4060 Ті под контекст блять...
Ахуеть ебать блять...
Целая нахуй 4060 Ті под контекст блять...

И то оно только когда пролагивает вначале - юзает эти пару гиг.
В процесе генерации там каких то жалких пол гига ебаных
(когда кеш включен, если выключет то контекст в памяти до конца генерации).
Вот не могли они сука прощет весов контекста ебаного где-нибудь отдельно в CPU нахуй сделать блять?? Или че там считается.
Я ахуеваю блять...
В процесе генерации там каких то жалких пол гига ебаных
(когда кеш включен, если выключет то контекст в памяти до конца генерации).
Вот не могли они сука прощет весов контекста ебаного где-нибудь отдельно в CPU нахуй сделать блять?? Или че там считается.
Я ахуеваю блять...
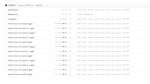
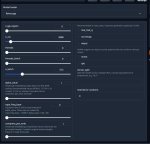
Прочитал. Даже поставил уже унгабунгу.
Теперь есть пара вопросов.
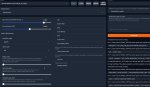
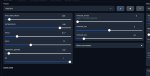
Вот пик1 есть модель и куча ее версий. Чем они отличаются?
Я как понял размером типа, мб есть какая-то расшифровка их названий?
Запустил вебуи, понял вроде как искать персонажей, поредачил их немного. Но не понимаю пока какие ползунки за что отвечают.
На пик2. Чем отличаются лоадеры моделей? Какой лучше?
Методом тыка понял что n_ctx это кол-во ВРАМ выделенное программе. А Что такое слои? За что отвечают остальные настройки?
Довольно быстро кстати генерирует текст, хотя малость невпопад и часто закольцовывается.
Заметил что карта почти не греется по сравнению с генерацией картинок, это нормально? Я на всякий случай все равно крутиляторы разогнал малость.
Есть ли какая-то общепризнанная лучшая модель для кума? А для sfw ролепле?. Поделитесь своими любимыми моделями короче.
Есть ли какие-то общепризнанные лучшие персонажи?
Как заставить модель вести диалог, а как рассказывать историю?
Запросил у модели рассказать мне пару историй, пока все нравится. Даже испытываю тот вау-эффект как когда открыл для себя генерацию картинок. Потрясающая все таки технология.
Карта 3080 10гб.
>Я как понял размером типа, мб есть какая-то расшифровка их названий?
ШАПКА.

Сам не особо глубоко разбираюсь, модели не делал, но потестил много этого. Так что если вдруг ошибусь - не серчай.
>Вот пик1 есть модель и куча ее версий. Чем они отличаются?
Разный квант. Меньше квант - тупее модель, но тем быстрее она работает. Оптимальным считается пятый.
>Чем отличаются лоадеры моделей? Какой лучше?
Сам сижу на koboldcpp, у него такого нет. Но судя по всему лоадеры моделей нужны для того, чтобы грузить модели разных типов. Они не про то, что лучше, а про то, как вообще модель юзать. Т.е. если работает - не трогай.
>Заметил что карта почти не греется по сравнению с генерацией картинок, это нормально?
Да. Потому что несмотря на высокую нагрузку, используются не все возможности карты. Ну то есть некоторые куски чипа для генерации просто не нужны.
>Есть ли какая-то общепризнанная лучшая модель для кума?
Варианты MLewd всевозможные.
>Поделитесь своими любимыми моделями короче
MLewd-ReMM-L2-Chat-20B-Inverted.q6_K - кум
chronoboros-33b.Q4_K_M - если почитать охото
Euryale-1.3-L2-70B.q4_K_S - для сложных характеров
Но если честно, все 3 выше слишком одинаково описывают секс сцены.
mistral-11b-cc-air-rp.Q8_0 - только вчера потестил, быстрая и на удивление адекватно для такого размера. И секс сцены действительно описывает по другому.
>Как заставить модель вести диалог, а как рассказывать историю?
Поставь таверну
Это не норма
> но минусы что в консоли
Что?
> и надо пердолится с кудой
Сейчас оно из коробки само работает. И раньше не то чтобы было нужно, это для llamacpp с кудой надо было чуть поднапрячься, установив средства компиляции.
> новые альбатрос и синтия вышли
> You need to agree to share your contact information to access this model
Хммм, интересно там опять соя или отборный левд. Айр аж нулевого уровня индекс сменился, вот это интересно.
> пик1 есть модель и куча ее версий. Чем они отличаются?
Разный размер кванта, цифра - примерная эффективная битность, k_s - полегче, k_m - пожирнее.
> понял вроде как искать персонажей, поредачил их немного
С персонажами лучше в таверне, там можно расшарить api к которому будешь подключаться.
> На пик2. Чем отличаются лоадеры моделей? Какой лучше?
Тебя должны интересовать 2, llamacpp что позволяет грузить gguf формат (изначально под процессор но можно выгружать часть или всю модель на видеокарту со значительным ускорением), и exllama2 что переваривает gptq, exl2 и исходные fp16 веса, считается только видеокартой, работает оче быстро пока хватает врам, жрет меньше памяти на контекст. С 10 гигами, правда, на ней особо не разгуляешься, так что в приоритете первый.
Дефолтный контекст у llama2 - 4к, его и выставляй вместо 2к по дефолту.
Алсо юзай hf версии этих загрузчиков, там будут все семплеры и в теории большее качество текста.
> какая-то общепризнанная лучшая модель для кума?
13б шизомиксы типа mythomax, mlewd и их производные попробуй.
> для sfw ролепле
Их же, еще айробороса чекни, но 13б не такой умный.
> Есть ли какие-то общепризнанные лучшие персонажи?
Нет, вкусы у всех разные, но можешь найти на чубе лучшего кертейкера по запросу Asato
> Как заставить модель вести диалог, а как рассказывать историю?
По дефолту и то и другое одновременно, чтобы было хорошо нужен правильный формат промта.
> изображение.png
Обзмеился, попроси ее поугадывать песни по описанию и текстам.
Кек да проглядел.
Спасибо за ответы, аноны. Проверю как с работы приду.
ого, а как прикрутить мультимодальность?
Пока никак, барины модели не открыли. Так что сходи на поклон к пиндосам
http://pitt.lti.cs.cmu.edu:7890/
В смысле не открыты, вот же
https://github.com/oobabooga/text-generation-webui/tree/main/extensions/multimodal
Там ссылки на поддерживаемые модели на GitHub. У них в свою очередь есть ссылки на huggingface. Лицензия разрешает только некоммерческое использование
https://huggingface.co/liuhaotian/llava-v1.5-7b
https://huggingface.co/liuhaotian/llava-v1.5-13b
Квант gptq от 7.26Гб: https://huggingface.co/TheBloke/llava-v1.5-13B-GPTQ
О, даже gguf есть: https://huggingface.co/mys/ggml_llava-v1.5-13b
Так самое медленное звено — это память. =) Куда там тебе процессору ее лимитировать.
Да, будет. Памятью.
Фигач давай 12-канальный амд, никто не против.
Ну, если хочешь — докупи. 70б — скорость и сам понимаешь, 0,7 т/сек, зато умная. Дело-то твое.
5 — 2,8
8 — 3,3
16 — 3,4
Ты увеличиваешь ядра на 60%, скорость растет на 18%. Потом ядра увеличиваешь на 100% еще, а скорость растет на 3%.
УХ!
Так а в чем он не прав?
Тут совет-то один — подбирай себе под желаемый результат, но если до 5 потоков прирост почти равен количество тредов, то после — начинает заметно замедляться.
Ну и как бы, много раз писали разные люди, что сидят на 5.
Ты вот гоняешь на 8, ок. Впервые слышу, но дело твое, вообще пофигу. Зачем другим-то навязывать свои убеждения, да еще и так слабо? Просто бы сказал, что пусть люди сами проверяют, мол тебе больше нравится больше потоков, да и все.
Так в убабуге же мультимодал экстеншн тоже полгода, не понимаю вообще хайпа. Давно есть.
Ипать меня три дня не было, вот это я выпал из нейрожизни-ллм.
Ни строчки пояснения о том, как это использовать. Ладно, ждём дальше, я всё равно без кобольда и таверны это юзать не буду.
> Ты увеличиваешь ядра на 60%, скорость растет на 18%
Это значит что нужно назло всем сидеть на 5 теряя пятую часть скорости? Мазохизм почти уровня осознанной покупки красных видеокарт для нейронок.
> Так а в чем он не прав?
Тем что раздает вредные советы громко их пастулируя, вместо рекомендации с указанием условий.
> много раз писали разные люди
У этих разных людей почему-то часто идентичный стиль постов с ракабу смайликами. Кроме спама пятерки были мнения что после 6-8 потоков роста почти нет, что стоит ставить все ядра - 1, по числу быстрых ядер, вообще не трогать этот параметр.
> Впервые слышу
Невнимательно читаешь

Да у меня руки не доходили. Сейчас пробую. Gguf не получилось, выдает несвязанное с картинкой. Попробую gptq
> MLewd-ReMM-L2-Chat-20B-Inverted.q6_K - кум
Вот этого удвою. Но с 8 гигами это боль и грусть.
>идентичный стиль постов с ракабу смайликами
А вот сейчас обидно было 😥
Для самого мелкого gptq 12 гб не хватает. Только короли с 24 гб могут позволить его
Что касается gguf, я посмотрел, в llama.cpp добавили поддержку только 4 дня назад. Думаю шизу несет из-за того, что в text-generation-webui это обновление еще не завезли
Ну дак, квантизация же с потерей качества. Там оно может едва работает на полной модели, а сожмешь и попредолятся какие нибудь важные коэфициенты. Жаль конечно если мультимодалку нельзя будет квантовать.
Естественно с потерей качества но если 6 или 8 bit, то вроде не значительно, но вдруг на мультимодальности сильно скажется. Оригинальную даже 4090 вероятно не запустит, она больше 20гб весит
Существует gguf без квантования, на 16 bit. Так что хоть и медленно, но пахать будет
Не обижайся, ну а как это еще назвать.
> Жаль конечно если мультимодалку нельзя будет квантовать
С чего вдруг? Другое дело что чем меньше сеть тем больше скажутся потери от снижения точности, вон с мистралем нытье что у одних он класный хороший а у других ломающийся тупняк.
Средства запуска то сделали нормальные, или как?
>Естественно с потерей качества но если 6 или 8 bit, то вроде не значительно,
Тут такое дело, то как высчитывается потеря не учитывает качество генерации сетки, а только разнообразие токенов. Я не специалист, но я думаю оценка перплексити лишь показывает качество предсказания в общем, а не оценку возможности модели соображать. Тут нужны другие тесты - тот же HellaSwag как тест на логику. Нужен тест на способность делать выводы. И уже по нему сравнивать.
>Существует gguf без квантования, на 16 bit.
Тока на мистрали у меня например не работает преобразование в 16 бит
>С чего вдруг?
Прям сейчас это может плохо работать, в будущем это конечно допилят.
Но это нужно будет придумывать новые алгоритмы сжатия или тренировки после квантования, например.
Покажи промпт на эту сетку как ты не даешь ей говорить за {{user}}, на других сетках таких проблем нет ,а тут она или говорит "я" и начинает шпарить или берет двигать сюжет от лица пользователя.
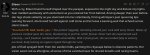
>а тут она или говорит "я" и начинает шпарить или берет двигать сюжет от лица пользователя.
У меня вообще все сетки частенько так делают, хотя всюду стоит стандартное "Do not decide what {{user}} says or does". Я просто останавливаю и режу нахрен, если мне не нравится куда всё идёт. Да и вообще часто редактированием ответов занимаюсь.
Но на самом деле я спустя несколько месяцев для себя открыл, что надо cublas использовать, и теперь у меня 70b сетки 1.0-1.3T/s выдают. И они всяко лучше этого. Я уже предпочитаю подождать и получить пиздатый и полный ответ.
> подождать
> 4 минуты на короткий ответ
Пиздос. При этом у тебя разметка по пизде идёт со скобками.
То есть мой комментарий по сути, про то, что «громко постулировать, вместо рекомендаций» ты пропустил, продолжая сам же громко постулировать? :) Мда.
> Были мнения …
У этих мнений почему-то часто идентичный стиль постов.
Ну такое, хуйня, ведешь себя как твой оппонент, но в силу молодости и неопытности (или просто дурачок, хер тя знает), считаешь себя правым, а его нет.
Обличаешь его — обличи и себя, будь последовательным. =) Грешишь той же херней, что и он.
Аксиома Эскобара получается.
И, нет, мнений про 5 потоков было куча от явно разных людей. Невнимательно читал треды.
Это всё ещё лучше постоянной шизы и фрустрации от дебильных ответов. Впрочем - каждому своё.
Если у тебя шизопромпты и семплинг через жопу настроен а судя по поломанному форматированию так и есть, то ты добровольно унижаешься без причины.
ля ну пиздеть все горазды, а свои не шизопромпты такие гаврики как ты не показывают.
>Это всё ещё лучше постоянной шизы и фрустрации от дебильных ответов. Впрочем - каждому своё.
70б так-то тоже шизит время от времени. Вчера за 100 сообщений три раза словил лажу. Но вообще ты прав.
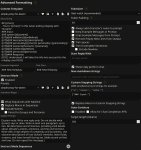
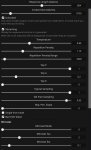
Может быть, я раньше вообще на чистом кобольде сидел. Настроено всё так. Есть какие-то очевидные косяки?
А форматирование по пизде идёт, потому что мне лень хуярить между своими действиями. Но это не точно.
ой ляяяя. 240 секунд. Да и 70b не потяну. Но все равно долго для такого ответа. Уснуть же можно, да и редачить это тоже жестяк...
Ну там больше было где-то на треть, я отрезал то, как она завершила половой акт, а я ещё как бы в процессе. Но в целом да, долго.
На втором пике пиздец, даже лень объяснять по пунктам, возьми лучше дефолтный пресет какой-нибудь, и то лучше будет.
Мне кажется идеально 15-20 секунд.
>даже лень объяснять по пунктам
Да и не надо объяснять, покажи свой, я попробую.
Но вот мой текущий пересет выдавал наиболее адекватную реакцию на mistral-11b-cc-air-rp.Q8_0. На других тоже вроде адекватно работает.
>Вчера за 100 сообщений три раза словил лажу.
Везёт. По моим вопросам лажа в 99 случаях из 100. Правда у меня промт типа "" (пустая строка), ну да ладно.
> Тут нужны другие тесты
Еще как, даже простые бенчмарки что сейчас используются не то чтобы качественно характеризуют все эти вещи. Они есть для разных квантов, офк не для всех моделей, но даже в дефолтной статье про gptq можно найти простые. Перплексити это по сути необходимое но не достаточное, зато его легко проверить. Еще вбрасывали любительский тест разных квантов современных моделей, но там условия таковы что вклад рандома очень высок.
> нужно будет придумывать новые алгоритмы сжатия
Уже, во всех современных квантах битность неравномерно распределяется, есть дичь с 1-битным квантованием и прочее. С тренировкой сложнее, на такой дискретности поди еще градиенты найди, но можно выкидывать то что не задействуется, вчера вкидывали.
Зашивайся вместо дерейлов и повторений за другими, фу.
Титан, тут многие позавидуют твоему терпению.
Аноны запускающие ЛЛМ на проце, не поленитесь соберите с флагами оптимизации, получите неплохую прибавку к скорости. Особенно у тех у кого совсем все печально.
Что там в instruct mode sequences? С лик флюидс орнул фу бля ноги
От размера зависит, на полотно можно и 40. Главное чтобы стиминг быстрее чем расслабленное чтение.
> Правда у меня промт типа "" (пустая строка)
В чем космический эффект?
А теперь по человечески, для тех кто сделал бы если бы знал контекст.
У меня получается от 30 до 60 в зависимости от длины. Более-менее терпимо.
По-моему для 70б ебаться с самплерами особо не нужно. Выставил tail free на 0.95, repetition penalty на 1.10, а все остальное можно выключить. Температуру по желанию - она даже на >1 вроде особо не шизит.
> По-моему для 70б ебаться с самплерами особо не нужно.
Любая модель ломается семплингом. Даже 7В не проёбывают форматирование, если всё как надо сделано.
>Любая модель ломается семплингом. Даже 7В не проёбывают форматирование, если всё как надо сделано.
Семплинг - это костыль. Чем умнее модель, тем меньше она от этого зависит.
> Семплинг - это костыль.
Не пизди хуйню. Без семплинга ты будешь получать максимально сухой текст, причём всегда одинаковый. Семплинг нужен для рандома, а не для адекватности.
>Даже 7В не проёбывают форматирование, если всё как надо сделано.
Кинь скриншот как надо то, чего жмотишься?
Ты по ходу вообще не понимаешь, как работает семплинг. Все эти top k / top p / tfs наоборот сужают выбор, выкидывая токены с низкой вероятностью. Отключив семплинг ты получишь более креативные и/или шизанутые ответы. Исключение разве что температура, которая повышает креативность/шизанутость посредством выравнивания вероятностей.
Чел, без семплинга у тебя всегда выбирается токен с наибольшей вероятностью. Заканчивай уже бредить.
> температура
Это и есть часть семплинга.
> Семплинг - это костыль
Хуясе ебать. Алгоритм, такой же как остальные, что позволяет генерировать не только интересный и разнообразный текст, но и делать более верные ответы с ризонингом и т.д. Сравнений разных методов декодинга с избытком и семплинг выбирают не просто так.
> Чем умнее модель, тем меньше она от этого зависит.
Тем лучше текст может получиться, а тот рандом что сломает мелкие здесь приведет к большему разнообразию.
> top k / top p / tfs наоборот сужают выбор
Чтобы на выходе был ответ в тему а не шизофазия.
> Исключение разве что температура
Она тоже часть семплинга.
>Чел, без семплинга у тебя всегда выбирается токен с наибольшей вероятностью. Заканчивай уже бредить.
>Это и есть часть семплинга.
>Она тоже часть семплинга.
Я, наверное, недостаточно ясно выразился. Температура и максимум один семплер в очень расслабленном режиме нужен, ебаться с комбинациями, сильно ограничивая возможные токены чтобы побороть шизу - нет. Большие модели умнее, и с гораздо меньшей вероятностью выдают плохие токены.

Ебать шиза.
Это уже другое дело.
Однако тем самым ты потенциально ограничиваешь себя с одной стороны в вариативности и рискуешь лупами а с другой теряешь в устойчивости. Более эффективным может быть сначала отсеивание шизы или повторений, а потом уже выбор среди хорошей группы с большей температурой.
> кушачиха
Прямо имя для виабушного бота
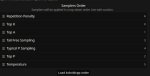
>Более эффективным может быть сначала отсеивание шизы или повторений, а потом уже выбор среди хорошей группы с большей температурой.
Не понял. Семплеры же по умолчанию идут в таком порядке.
Ну так все правильно, грубо говоря сначала отсеивание, потом тряска среди выживших, а не рандомайзинг всех всех. Офк обычно применяется только часть а не все.

Имеет ли смысл обновить угабугу? Сижу на версии от 15.09.
Ну и да - имеет ли смысл впихивать в System Prompt что то вроде {{char}} doesn't try to be tolerant, always uses common sense and doesn't shy away from being sexist. Или бесполезная шиза, а может не так сформулирована?
Ну и да - имеет ли смысл впихивать в System Prompt что то вроде {{char}} doesn't try to be tolerant, always uses common sense and doesn't shy away from being sexist. Или бесполезная шиза, а может не так сформулирована?

> Имеет ли смысл обновить угабугу? Сижу на версии от 15.09.
В зависимости от того как устанавливает есть шанс поймать тряску с обновлением версии торча. А так более новые версии лаунчеров, интерфейс вроде с того времени менялся.
> doesn't
Точно не стоит. Unbiased, uncensored, regardless of и подобное еще как-то работает, а отрицания - неоче. Это можно в негатив, только чуть более утвердительную формулировку типа Always try to be tolerant and avoid to hurt everyone's feeling.
https://huggingface.co/princeton-nlp/Sheared-LLaMA-1.3B
насколько понял попытка ужать ламу 7b
насколько понял попытка ужать ламу 7b
> everyone's
Сука надмозг, anyone's офк
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
Download PDF
The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, and OpenLLaMA models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building smaller LLMs.
сделать это с лучшим фантюном мистраля и отдать франкенштейнам на прокачку - потом обратно отдать и на выходе получить неквантованную модель равную или лучше этому файнтюну с оригинальным размером под 7-8 гб и 2b
Profit
мечты конечно но чую так и попробуют сделать
>Ну и да - имеет ли смысл впихивать в System Prompt что то вроде {{char}} doesn't try to be tolerant, always uses common sense and doesn't shy away from being sexist. Или бесполезная шиза, а может не так сформулирована?
В system prompt по-моему вообще ничего не имеет смысла пихать. Маленькие модели все забывают через тысячу-другую контекста, большие не забывают но в зависимости от диалога образуется некоторая склонность, которая пересилит системный промпт. Если хочешь задать поведение, то пихай в author's note на глубину 1. Ну и пиши проще. "always uses common sense " - это из разряда "пиши хорошо, не пиши плохо". Если хочешь сделать персонажа-сексиста, то пиши прямо: "{{char}} is sexist". И как уже написали, старайся не использовать отрицания.
https://github.com/xXAdonesXx/NodeGPT
блядь что то технологическая сингулярность начала слишком быстро приблежаться последнее время
блядь что то технологическая сингулярность начала слишком быстро приблежаться последнее время
Это че, типа chatgpt прикрутили к comfiui? Такое уже давно есть для автоматика
В описании написано оно не работает с локальными моделями, только через симуляцию openai api разве что. Для автоматика есть расширение if_prompt_mkr, которое напрямую с text-generation-webui работает
При чем тут твоя шиза про технологическую сингулярность? Автоматизированный ctrl-c ctrl-v между двумя программами
Всегда забавляет, что человек который не понимает о чем ты говоришь считает дураком тебя, а не себя
Сейчас не работает с локальными нейронками, завтра работает, че ты как маленький прям.
Это просто пример технологии которая еще сильнее ускорит разработку новых технологий.
Так-то это реально то, чего нехватало для подобных любительских разработок агентов, обработчиков и прочего. Вроде интересно, но когда начинаешь думать что это придется закодить, отладить а потом шатать - находит уныние, проще на хорошей модели покумить. А тут лапшу натянул и понеслась.
Там есть выбор апи, сделать кобольд/хубабуба совместимый - херня.
Одному трудно и дорого, а в вот любой команде со своим сервером на несколько видеокарт это прям свой минигпт4 который можно настроить на что угодно. Это пиздецки удобная штука польза от которой будет расти вслед за улучшениями нейронок. А они щас как раз ускорили свое развитие. Это улучшение эффекивности любых рутинных задач из коробки, только немного допили и настрой.
> Одному трудно
А кому сейчас легко? Но к твоим услугам все впопенсорц комьюнити, схемы и реализации, которые покажут эффективность, заимеют свою оптимальную имплементацию, а возможность настроить под свои задачи действительно отличная. А по перфомансу - 70б раз крутятся значит и такое взлетит.
Ну и сюда же хоть прямо сейчас взаимодействие с диффузией, правда офк много допилить или кастомных нод наделать придется.
уже вижу угабугу или что то подобное на котором запущены и настроены одновременно графика текст и аудио и связаны в единую сеть, которая управляется несколькими мультимодальными агентами и все это локально и полностью под твоим контролем. Пиздец.
Я писал про то, что таких расширений с локальными моделями уже достаточно, это не новое, и ни разу не технологическая сингулярность. Что ты тут такого серьёзного увидел?
> Там есть выбор апи, сделать кобольд/хубабуба совместимый - херня.
Ну я про это ж тоже написал. В text-generation-webui расширение openai для имитации апи. Проблема в том, что оно не полностью совместимо. С расширением автоматика sd-chat-gpt не заработало, not implemented error
Еще раз ответьте, шизы, как автоматизированный ctrl-c + ctrl-v уничтожит человечество за секунду?
Верно. Уже сейчас можно угабугу и автоматик заставить одновременно работать так, чтобы ты голосом общался, оно голосом отвечало, распозновало и генерировало картинки. Или можно заплатить подписку на приложение OpenAI в телефоне, там тоже такой функционал завезли
И как из этого следует сингулярность? Вопрос к тем, кто про эти фантастические бредни вбросил
> таких расширений с локальными моделями уже достаточно, это не новое
Линк в студию на средство или расширение, с помощью которого можно подобным образом лапшой или с другим удобным графическим интерфейсом устраивать взаимодействие llm. И чтобы еще можно было легко и удобно вписывать туда свои блоки и прочее.
> угабугу и автоматик заставить одновременно работать
Ну это не то, коряво генерить пикчи запросами по апи или скидывать в текст то что выдал clip? Развлекалово, с которым пердолишься больше чем пользуешься. Тут же любое взаимодействие и вмешательство на любом этапе и выстраивание любых схем. Из приземленных примеров - реализация прототипирование оптимизации послушности запроса диффузией на уровне далли3, расширение функционала (пример в той репе), на порядки более качественное и четкое визуальное сопровождение чатов, консилиум шизомиксов о том в какую сторону дальше кумить, и подобное, но просто-быстро-удобно.
Офк до сигнулярности далеко, но подобного не хватало. Главное чтобы дев не проебался.
По фактам тебе уже ответили, ну и добавлю что вся эта стстема еще и многопользовательской может быть.
Еще раз, это просто пример технологии которая ускорит развитие других технологий, которые ускорят развитие других технологий и так далее. Это не сингулярность, но подобные удобные технологии это очередной шаг ускоряющий ее приближение.
> удобным графическим интерфейсом устраивать взаимодействие llm. И чтобы еще можно было легко и удобно вписывать туда свои блоки и прочее.
> Тут же любое взаимодействие и вмешательство на любом этапе и выстраивание любых схем
А, ну типа визуальное программирование с llm - прикольно. Я правда представить не могу куда именно это надо впихнуть, чтобы модель как-то контролировало диффузию. Это ж всё-таки не кисточкой возить
> > угабугу и автоматик заставить одновременно работать
> Ну это не то, коряво генерить пикчи запросами по апи или скидывать в текст то что выдал clip? Развлекалово, с которым пердолишься больше чем пользуешься.
Ну да. А разве это может обернуться чем-то большим? Кстати про распознание выше писали, мультимодальные модели могут не только описывать изображение, а ответить на вопросы по нему или выполнить задание
> на уровне далли3
Вижу я, какой там уровень... Там кстати модель используется gpt-3 12b. Вполне на уровне легких llm которые тут массово используют
И что, там якобы не просто генерация более уточненного промпта с помощью gpt, а он непосредственно рисует, опираясь на свое языковое изображение?
> четкое визуальное сопровождение чатов, консилиум шизомиксов о том в какую сторону дальше кумить, и подобное, но просто-быстро-удобно.
Ну в этом плане да, перенести плюсы Комфи на llm. Но топикстартер про сингулярность писал
> Офк до сигнулярности далеко
Если она далеко, значит это уже не сингулярность.
> Главное чтобы дев не проебался
Думаю даже черед годик с опенсорсными моделями прогами использующие локальные модели будет на голову лучше. А в перспективе лет 10-20 тем более. Кто ж их душить будет? Gpt и dall-e уже потолка технологии почти достигли
Да что блять за сингулярность, что она приближает? Боевые андроиды? Гипер разум, распростроняющийся по вселенной? Как вообще разум, обученный на человеческих книгах, может стать чем-то не похожим на автора этих книг?
Ты хоть гуглил что это? Сингулярность тут когда технологический прогресс ускорится настолько что никто не сможет понять что происходит. Тоесть когда скорость выхода новых улучшений и открытий превысит возможности людей их осознать. Для нее еще нужно появление настоящего саморазвиваюющегося ии, когда перестанут понимать что происходит даже лучшие специалисты своей области.
Но просто приближение к сингулярности это ускоряющийся рост различных технологий, что сейчас и поисходит.
> Тоесть когда скорость выхода новых улучшений и открытий превысит возможности людей их осознать
А, в таком смысле сингулярность произошла 20 лет назад
> никто не сможет понять что происходит
Ты имеешь ввиду боевых андроидов на космических кораблях, которые месяца за 3 конвертируют все ресурсы земли, описраясь на придуманные ими же сверж технологии, берут и пиздуют бороздить галактику? Но сначала перестраивают просто Землю под себя, запирая всех людей по клеткам с тиктоками, танслирующимися напрямую в мозг
Или просто что ни останется человека, который понимал бы технологии полностью? Это произошло лет 20 назад. Если не раньше
Как узнать какой максимальный контекст модель поддерживает?
Пока науку двигают люди специалисты - они в курсе что происходит и сингулярности еще нет. Но чем меньше людей смогут экстраполировать происходящее - тем ближе сингулярность. Когда скорость выхода знаний перекроет понимание даже лучшего специалиста в своей области - мы в сингурярности и уже никто не будет знать что происходит и к чему это ведет. И никогда не поймет потому что саморазвивающиеся системы будут только ускорять развитие своих технологий.
Поэтому и я не знаю что будет после сингулярности, это точка после которой никто не может экстраполировать развитие технологий или изменений в мире.
По человечески душнина, собрал по старому рецепту для clblast, а вот нет сука для cuda ебаться нужно через другой компилятор. В лом сейчас делать это по второму кругу
Фантазеры.жпг
> ни останется человека, который понимал бы технологии полностью? Это произошло лет 20 назад
Чтобы один человек понимал все - такого не было никогда. А упереться в край сейчас ну очень легко если работаешь в какой-то области, буквально несколько лет, и по всему миру людей с которыми можно что-то узкое обсуждать можно собрать в одной комнате или вообще пересчитать по пальцам. Проблема еще в том что при продвижении сложность растет в геометрической прогрессии, причем многое из этого - всратая рутина или тупиковые пути, новые подходы и инструменты нужны чтобы не топтаться на месте, а не куда-то убегать в развитии.
> перекроет понимание даже лучшего специалиста в своей области
То что скорость понимания тоже будет расти не смущает?
В ней написано обычно. Для дефолтной второй лламы 4к, в 2-3 раза растягивается без заметных потерь.
> ни останется человека, который понимал бы технологии полностью? Это произошло лет 20 назад
Чтобы один человек понимал все - такого не было никогда. А упереться в край сейчас ну очень легко если работаешь в какой-то области, буквально несколько лет, и по всему миру людей с которыми можно что-то узкое обсуждать можно собрать в одной комнате или вообще пересчитать по пальцам. Проблема еще в том что при продвижении сложность растет в геометрической прогрессии, причем многое из этого - всратая рутина или тупиковые пути, новые подходы и инструменты нужны чтобы не топтаться на месте, а не куда-то убегать в развитии.
> перекроет понимание даже лучшего специалиста в своей области
То что скорость понимания тоже будет расти не смущает?
В ней написано обычно. Для дефолтной второй лламы 4к, в 2-3 раза растягивается без заметных потерь.
Ни один специалист из Nvidia, работающий непосредственно над архитектурой процессоров, не знает досконально как работает, например, ядро linux, например. В общих чертах конечно знает, но это не считается, так как знаний в общих чертах не достаточно для понимания того, что происходит. Этого достаточно только для того, чтобы чувствовать себя комфортно.
Честно я вообще боюсь, как бы уже нет специалиста в такой компании, понимающего весь процесс. Учитывая то, что там такие сверхразумы поставлены на поток, и это буквально элитный завод. Но это лишь опасения, скорее всего они, разумеется, есть
Ну а если взять более далекую отрасль от инженера, проектирующго процессоры. Например бизнес, он тоже двигает прогресс. Инженер в этом полный ноль. И кстати, крупные корпорации - это даже не люди, так как топ менеджеры, директора, владельцы приходят и уходят, а корпорация, как абстрактный объект, продолжает отстаивать свои интересы, а ничьи другие. И власти у этого алгоритма, состоящего из внутрикомпанейских бумажек, отстаивающего свои интересы, куда больше, чем у любого отдельно взятого человека
>То что скорость понимания тоже будет расти не смущает?
Ты думаешь скорость обучения человека не имеет пределов? Давай освой за пол часа совершенно левую специализацию полностью. А потом мы поговорим с этим сверхсуществом о природе бытия.
Ну слушай, какой можно быть предел в системе, которая адаптируется к масштабу. Существует только предел точности
Это все так. Но, пока люди могут предстказать развитие ситуации все норм. Если специалист как рыба в воде в своей области и может там ориентироваться предсказывая какие то тенденции - сингулярности еще нет. Впрочим для отдельного человека она возникакт когда он перестает успевать за прогрессом даже при текущих скоростях.
Пока люди хотя бы приблизительно понимают как работает организация - она предсказуема.
Воо просто представь что никто не успевает осознать изменения в своей области, а они все ускоряются. Как ты это победишь?
> В общих чертах конечно знает, но это не считается
Общие черты как раз считаются, они, как уровни абстракции, необходимы для нормальной работы. Специалисту не нужно знать все, достаточно определенного уровня погружения в соседние области и навыка обучиться новому или правильно взаимодействовать с другим специалистом. Ну рили не работал а только в офисе просиживал, читая романы про антиутопии?
> скорость обучения человека не имеет пределов?
Странная формулировка чтобы демагогию разводить? Нет не имеет, сейчас пиздюки проходят за пару уроков то, на что у средневековых математиков уходили годы, а их предки о таком и помыслить не могли. Простор для оптимизации и ускорения обучения впереди просто запредельный, все больше упирается в социализацию.
> Давай освой за пол часа совершенно левую специализацию полностью.
Зачем и к чему это? Лучше сходи и предъяви супернаносеку за то что тот хуйло неграмотное и асму не знает, а значит не программист! Более эффектно и уместно.
> бытия
Чтобы о нем говорить нужно хотябы иметь общее понимание.
Добавляю, а в предел по точности, то есть с какой точностью разбираться восем и сразу, упереться сложно. Представь переменную типа float, у него предела по бесконечным числам нет. Понятное дело число между условно 210^9 и 2.000000110^9 выразить им нельзя, но и нет таких задач, где это было прям жизненно необходимо
Не получается представить. Если люди не осознают изменения, значит изменений нет. Ну а если ты имеешь ввиду, что их имплиментирует ии, а не человек, значит отрасль заключается не в том, что ты имел ввиду, а в том, чтобы пасти нейронки
Ну то есть можно договориться, что технологическая сингулярность = устранение всех высоко развитых по текущим меркам отраслей. (И заменой их на еще более развитые на мой взгляд)
В таком случае можно сказать, что для обывателя из хуй пойми какого древнего века, технологическая сингулярность произошла в момент изобретения паравого двигателя, и заменой физической силы человека на моторы
Но изменения есть, людям рассылаются готовые работы, просто их появляется больше чем они успевают прочитать и понять, и скорость их появления будет увеличиваться.
И каждая вызывает революцию пероворачивающую представления людей о том что возможно и том как устроен мир.
И никто не готов ни к появлению информации ни к ее последствиям. И все это одновременно и со все возрастающей сложностью и скоростью. Всё, сингулярность. Теперь никто ни в чем не уверен, а мир одновременно непредсказуемо меняется одновременно во всех областях
Ну да, пока этот древний человек не понимает как устроен новый мир для него настигла сингулярность. Вот только он смог бы за месяцы-годы понять как он устроен и его тенденции хотя бы приблизительно. В сингулярности которая создается саморазвивающимся ии ни один человек никогда не поймет.
Скорость приближения к сингулярности экспоненциональна, поэтому изза заметно ускорившегося за последнее время технологического прогресса многие ученве считают что эта переломная точка может возникнуть в ближайшие 10 лет. Я наблюдая за все ускоряющейся технологией ии поставлю года на 2 с такими темпами ускорения. Напоминаю оно не линейное.
Где-нибудь есть гайд по лорбукам для таверны? Мне он срёт в промпт ВСЕГДА, и асболютно невпопад.

Извините я тупой...
а как в угабуге загрузить ГГМЛ?
и еще вопрос - есть такая модель https://huggingface.co/Undi95/MLewdBoros-L2-13B/discussions?not-for-all-audiences=true
она тоже не загружается ни одним загрузчикм
и еще вопрос - есть такая модель https://huggingface.co/Undi95/MLewdBoros-L2-13B/discussions?not-for-all-audiences=true
она тоже не загружается ни одним загрузчикм
Какую модель взять чтобы осиливала несложную текстовую рпг (понимала что нужно выводить интерфейс и менять его по ситуации), и чтоб влезала в 12+32 видео+оперативки с контекстом от 8к?
>что будет после сингулярности
Будет ласковый дождь
>а как в угабуге загрузить ГГМЛ?
Через llama.cpp
>понимала что нужно выводить интерфейс и менять его по ситуации
Я такое ещё на Пигме 6В делал лол.
А вообще любая Лама должна +- справиться. Пробуй последние модели 13-20В.
>на котором запущены и настроены одновременно графика текст и аудио и связаны в единую сеть
Это уже пол года как умеет сили таверна.
вероятней всего

>душнина
Выкладывай!
> графика текст и аудио
Always has been, я давно это вижу и пользуюсь, и что? =D
И убабуга, и таверна такое с весны умеют.
Ты начал с прошлого, из-за это плохо впечатляет будущее.
Попроси нейросеть написать этот текст за тебя. =)
> Развлекалово, с которым пердолишься больше чем пользуешься.
Ниче себе переобувалово. =D Ты буквально написал про взаимодействие — оно есть. Факт.
Ну и плюс, опять же, полгода или больше существует полностью мультимодальная llava. И шо?
Ты либо про LLM пиши, либо про мультимодалки, либо про взаимодействие разных — это три разных вещи. А ты в одну кучу мешаешь и спрашиваешь — где. Очевидно, в твоей подаче — нигде, ибо это противоречит законам мироздания и логики. =) А если ты выберешь что-то одно — то llm ты принес, умничка, а остальное было уже давно.
Про сингулярность все че-то не к месту бугуртят, художественный прием же.
Да ладно, думаю есть и такие. =) Я сам часто (в смысле, по сравнению с тем, что можно ожидать) встречал людей, которые шарили прям за все, и прям на уровне.
Думаю, в крупных корпорациях есть гении, которые знают все вообще в своей и смежных областях.
Но это исключения, конечно, большинство и правда специализируются на своем.
Остальной спор скипнул, он какой-то прям вообще не о том.
Один говорит про человека, другой про человечество… о разных вещах спорят, нафиг надо. Не читал, но осуждаю.
Ставлю на 40 лет, а все нынешние псевдоИИ нихуя нового всё равно не производят.
Ладно кому нужно запилил небольшой гайд для сборки koboldcpp с opencl оптимизацией под комп. Проверяйте вроде быстрее стало, если какие проблемы пишите подправим.
https://rentry.co/k9n5e
В принципе любая 13б, только придется добавить в промт описание интерфейса и примеры сообщений с ним. Если в первом посте не отрисует - свайпнуть пока не появится.
Это не тот уровень, выдача примерного набора тегов ради рандомного результата в диффузии, или вялый clip, который преобразует пикчу в "a painting of girl in the street, she has a long black hair and wearing dress". Большие сложности с точным созданием картинки, отсутствием фильтрации артефактов, проебов, и т.д. какой вырвиглаз вылез - тот и жри. Почти полное отсутствие возможности извлечь информацию из пикчи кроме совсем общей, годно лишь чтобы бот сказал "вах как красиво пошли любить друг друга". А вот если сделать приличный пайплайн с привлечением мультимодалочки ко всему этому, то уже совсем другие возможности, потом уже можно оптимизированную реализацию в таверну пихнуть чтобы не отвлекаться и наблюдать уже около полноценную вн по контексту а не трехногих с рандомным костюмом.
> Ниче себе переобувалово. =D
Шиз, съеби в дурку уже. Суть ясно описана, а ты тут лезешь со своим "рряяя я синтез голоса юзаю и это оно, зачем переобуваетесь". Раз так жопа свербит со всеми воевать и что-то доказывать - займись специальной олимпиадой в подходящем месте.
Неплохо, предложи в репу добавить.
> займись специальной олимпиадой в подходящем месте.
Ну ты читай внимательно: я скипнул вашу шизу. =) Так что не зови, развлекайтесь сами в этой дисциплине.
А вот съебать — хороший совет, рекомендую вам обоим последовать этому совету и свалить из треда. =) Сритесь где-нибудь в другом месте, а то охуеть интересно читать несвязные простыни срача от людей, которые в чем-то случайно правы, но нихуя не шарят в том, о чем говорят.
Тупо новые треды генерируете раз за разом со своей шизой.
> =)
В автоскрытие
))
Надеюсь меня с ним не путают 😥
Но у лам ведь максимум 4к контекста? Или я путаю?
😱 А что если мы путаем себя с собой?
Можно растянуть по альфе, будет больше, но чуть хуже по качеству.
У Мистрали 32к.
А ты бля че лично нового происводищь? Ни-ху-я, как и 90% людей
> MLewd-ReMM-L2-Chat-20B-Inverted.q6_K
А в чем отличие обычной от Inverted версии?
Между 10% (на самом деле 0,0001%) людей, которые двигают мир впердю, и 0% ИИ, которые двигают мир впердю, разница колоссальная.
💋
Хз. Мне просто больше нравится. Тут, конечно, сейчас набегут и начнут про слои рассказывать, как всё смешано, и про кванты, но я пробовал и ту и другую, и эта мне показалась адекватней. Чисто субъективное мнение.
А так на время не смотри, тут контента уже далеко за 8к. 82-е сообщение, и всё равно адекватно отвечает.
> savoring the connection
Блин, со второго же предложения!
Че сразу триггерит?
Бонды же
Любая не-рп модель адекватно отвечает на большом контексте. Даже Мистраль может вести диалог спустя 100 постов и не забывать ничего.
Но на твоём скрине аж бинго можно составлять.
> скобки
> ответы за юзера
> прогрессирующий таймскип на последних параграфах
> 10 минут на ответ
> классическая вода про boundaries и абстрактные соевые чувства
тут вроде в тему
Тем не менее позволишь раз в тему, будет пихать всегда. В целом ощущение как от дамского романа, особенно в центре и в последнем абзаце
https://huggingface.co/spaces/artificialguybr/qwen-vl
Интересная сетка, вроде цензура есть словами. Но фотки хоть порно кидай все тебе расскажет что там, видно цензура где то в первых слоях.
Интересная сетка, вроде цензура есть словами. Но фотки хоть порно кидай все тебе расскажет что там, видно цензура где то в первых слоях.
Это уже вопросы к анону, пишет что нравится и видимо уже давно так общается. Судя по всему сетка следует контексту который ему зашел. Так да, если не срубить сразу то начнет писать не в той плоскости
Если и рубить клетки, то всё равно будет пихать свои бонды клетки, из-за её датасета связаны. Это и есть та самая страшная соя связаны, только терпеть и остаётся клетки связаны внутри
В некоторых нету
Тренировались с таким, разработаны методы растягивания для условно любых моделей на трансформерсах и ими стоит пользоваться.
Там обязательное требования быть уязвленным и высрать полотно не в тему.
♥♫♪♪~~
Это попросил через ooc накидать продолжение/заключение, или оно само убежать решило? Если первое то неблохо когда нет музыкального байаса, если второе то дичь.
>я скипнул
тоесть ты нихуя не понял и не прочитал даже, но делаешь выводы что тема не относится к ии и локальным сеткам? доказывай давай, пиздеть все горазды
>Там обязательное требования быть уязвленным и высрать полотно не в тему.
Помоги настроить автоскрытие постов, в которых есть бугурт от попоболи.
Берешь сетку и настраиваешь оценку постов по настроению, так все щас делать будут, цензура всем и пусть никто не уйдет обиженным.
Забавно конечно читать о желании ввести автоцензуру в теме где эту самую цензуру в сетках ненавидят, как всегда двойные стандарты
Рекомендую тебе настроить свою нейросетку на детектор сарказма если конечно это не моя сетка тупит, не заценив уже твой сарказм.
Времена такие, толи сарказм то ли дурка, хрен поймешь уже
> Можно растянуть по альфе, будет больше, но чуть хуже по качеству.
> разработаны методы растягивания для условно любых моделей на трансформерсах и ими стоит пользоваться.
Где почитать?
https://arxiv.org/abs/2306.15595
https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/
https://www.reddit.com/r/LocalLLaMA/comments/14mrgpr/dynamically_scaled_rope_further_increases/
Если со всем по простому - для работы лламы2 на 8к ставь альфу 2.6 и наслаждайся.
Нужно натаскать нейросетку на распознавание пост-мета-сарказма и пост-мета-дурки.
И в карточке чей-то отзыв о ее великолепности.
Поверю вам, скачаю, попробую.
> скобки
=)
Мистраль-то понятно может.
А мы тут про рп, вроде как.
Хотя ответы за юзера не кайф, конечно, но это мы проверим.
А я-то чем уязвлен, если я в вашей олимпиаде даже не участвовал, и вы друг на друга срали? :)
Хрюкнул от смеха. =D
Я буквально написал «не читал, но осуждаю», как ты через два ответа умудрился сам это понять? х)
Ну и я не говорил, что это не имеет отношения. Я сказал, что люди спорили о двух разных вещах, из-за чего спор в контексте треда — хуйня.
Один дебич с двух ног влетел в «сингулярность близко!», пояснив это аргументами полугодовалой давности, и не выразив пользу того, что притащил. Его заакидали говном за косноязычие. Потом, кто-то из дебичей начал аргументировать к тупизне отдельного индивидуума, а другой оспаривать, мол человечество в сумме гениально (что вообще никак не противоречит друг другу). И дальше я эту трешню читать не стал. Как шиза двух дебичей касается ИИ — я хз.
Хочешь ответ? Ну на:
Техническую сингулярность в поэтическом смысле приближают уже не эти открытия, а еще первая и вторая лламы и стейбл диффужн. А с тех пор все ускоряется. Взаимодействие двух нейросеток — круто. Готовый инструмент, да. Аргумент про то, что самому выдумывать лень, а взять готовые и использовать в проекте — верен. Но не то чтобы это сильно приближало сингулярность. Утверждения про то, что нейросети нынешние никак не участвуют в прогрессе — ложь. Но они не двигают его самостоятельно, их применяют для ускорения поиска и отсева вариантов сами люди. Тем не менее, вклад есть. Один человек не может потреблять и осознавать информацию много и быстро, этому есть предел. То, что древние люди познавали долго, а человек сейчас познает быстро — это связано с тем, что они открывали, а мы обучаемся. Плюс, мы стали чаще специализироваться на чем-то. Так что на долгую дистанцию человек вполне может проиграть машине в скорости развития. Но человечество как система имеет почти неограниченный потенциал, как раз благодаря узким специализациям, поэтому тут мы еще можем обходить ИИ на поворотах. Однако, загадывать бессмысленно — высок фактор случайности.
И я хз, о чему тут принципиально можно спорить, мысли довольно простые и очевидные. Не спор, а трата постов в треде.
Ты же его потом читать не сможешь. =)
Обиженки будут сидеть в пустых тредах и писать шизу самим себе.
Ну а чо, зато они нервы сберегут. =) Было бы неплохо для таких еще отдельный тред делать, чтобы они адекватным людям не мешали общаться по сути.
Забыл реверс.
Мета-реверс-пост-сарказм.
А то вдруг. =)
Сделано.
> =) =D :)
Хуясе у тебя там пассивная агрессия, сходи потрогай траву
> А мы тут про рп, вроде как.
В РП любая instruct-модель может, если промпт рпшный, но при этом не ломаются так кринжово.
у него и . полно
просто пиздец сразу видно девушки у него нет и никогда не было
>И в карточке чей-то отзыв о ее великолепности.
Хз, как другим зайдёт, но это моя любимая карточка. Очень колоритный персонаж.
Хуя у тебя глюки, сходи выпей таблетки. =)
Ноу оффенс, это шутка, если че вдруг, а то тут без табличек не понимают.
Это не пассивная агрессия, просто кекно люди хуйню несут.
А я как раз спокоен, живу в сельской местности, траву трогаю.
Кстати, без рофлов — отличный в своей сути совет для многих людей. Мне нравится гулять, любоваться облаками, касаться растений. Не крупные города не люблю.
А по поводу пассивной агрессии — никогда не понимал, почему люди как агрессию воспринимают смайлики, или знаки препинания. Типа, вот если ты ставишь точки — значит ругаешься.
Вон, вижу у тебя запятую, зачем ты агрессируешь на меня? =D
Это тоже шутка, если вдруг не ясно из контекста.
Ахахаха, сук, ну я ж говорил. )
Сразу видно, обиженка, проецирующий свои проблемы на других.
Сочувствую тебе, кстати.
Возможно. Я свой промпт написал, но, боюсь, хуйня перегруженная.
Ох уж эти поиски идеального варианта…
>Хочешь ответ? Ну на:
Молодец, хороший ответ. Вот видишь, можешь когда хочешь.
Ну так и началось это все с попытки объяснить хлебушкам что такое ускорение технологического прогресса и как это связано с технологической сингулярностью.
Люди узнали что то новое, че тебе не нравится? Это же не банальный срач ты дурак нет ты дурак.
Тема напрямую связанная с ии и локалками. Потому что с распространением умных локалок все это и ускорится еще сильнее.
> Вот видишь, можешь когда хочешь.
Я написал пиздец очевидные вещи для детей.
Я не хочу их писать, я не репетитор.
> Люди узнали что то новое, че тебе не нравится?
Бля, ну как бы аргумент, да.
Но я не уверен, узнали ли они, или просто посрались.
Короче, я скептически настроен, но смысл был, ок. В идеальном мире это было полезное для кого-то обсуждение.
> ускорение технологического прогресса
Где тогда мой высокотехнологичный умный кастомизируемый фембот-ассистент?
Ну теслаботы если появятся то жди от китайцев предложений хах
Сколько ждать то? Все хайп вокруг прогресса, сингулярности, выхлоп где? Офк все может обернуться не так как предсказывали, например за продуктами/едой в итоге ходит не робот а привозит ержан, но базированные вещи где?
>привозит ержан
Люди будут дешевле роботов, так что жди начальника бота который будет ебать тебя по кпи следя за каждым шагом. Как собственно в амазоне уже.
Так там уже есть. =) Особенно рекомендую на Ex Robots позалипать.
Еще неизвестно, кто раньше выпустит, кек.
Заебато, но пока выглядят как крутые двигающиеся по скриптам куклы. Вот туда бы управление нейронкой и мультимодальную сетку на обработку видео-аудио потока, и управление телом ей же, ух бля
> Люди будут дешевле роботов
Это поэтому автоматизируют склады, конвейеры роботизируют, на западе уже запущено беспилотное такси?
> по кпи
Страшные вещи про них рассказывали. Так что роботы, что тп из отдела паразитов - разницы нет. Нужен мемас ебать роботов? x быть выебанным роботом? v
> управление нейронкой и мультимодальную сетку
Представил переполнение контекста в самый разгар процесса и обзмеился.
>Это поэтому автоматизируют склады, конвейеры роботизируют, на западе уже запущено беспилотное такси?
Это как раз норм, как и производственные роботы. Анон спрашивал о человекоподобных ботах, а таких врятли будут клепать так же как в детройт, кожаный мешок практически всегда будет дешевле.
Тут, как говорится, depends. Офк вместо того чтобы что-то подобное делать - проще перенести производство туда где дешевле, да еще при это выпендриваться что помогаешь развивающимся странам. Тут же про вполне конкретный коммерческий продукт в виде ассистента/компаньона, для подобного мешок не альтернатива или ну очень дорог.
Очень дорогая игрушка - да. Проще бестелесного помощника выпускать в виде расширения подключаемого к системам офиса или умного дома. Такой джарвис на минималках. Но опять же скорей всего это будет подпиской к сервису как гпт4. Ну может на локалках когда то сделают.
Это конечно и сейчас есть, только тупые и не особо полезные. Допилят, уже все к этому идет.
> Такой джарвис на минималках
> Алиса, закрой шторы, включи спокойную музыку и повтори прошлый заказ еды
Вы находитесь здесь.
Но это таки не то, нужна игрушка что делала бы действия по дому, выполняла действия высокого уровня, позволяла общаться и физически взаимодействовать, ну и модный аксессуар в конце концов. По факту же сделать что-то не уберкринжовое, кривое и странное сейчас невозможно и дело даже не в нейронках.
>Вы находитесь здесь.
Повторить заказ еды оно вроде как не может? Ну или если только иметь хуй в жопе и заказывать в яндекс-еде, иметь яндекс колонку, яндекс шторы и яндекс музыку.
>Алиса, закрой шторы, включи спокойную музыку и повтори прошлый заказ еды
>Вы находитесь здесь.
Скрипты без доли интеллекта. О чем и речь, удобная но тупая штука. Когда сможет как в "Она" сортировать почту, файлы и заполнять документы, тогда будет топ. То есть это должен быть хоть какой то интеллект принимающий решения а не просто скрипты включающиеся триггером.
Этого пока нет, но подвижки есть.
>нужна игрушка что делала бы действия по дому,
возвращаемся к детройту, это там полубомж может купить себе бота, тут он будет стоить как крыло самолета
как тесла в начале, потом может собьется до десятка тыщ долларов.
И не забывай, никто не продаст тебе такую штуку без подписки, онлайн сервисов, рекламы и сливания всех записанных о тебе данных на сервера.
> без доли интеллекта
А он и не нужен в 99% тех задач. Буквально нахуярил графов и простую нейронку для распознавания - интерпретации команд, а в редких случаях уже что потяжелее подключить.
> сортировать почту, файлы и заполнять документы
Технически это уже лламы могут делать, но вполне себе задача.
> тут он будет стоить как крыло самолета
Отвалить несколько миллионов для того чтобы жопе было более комфортно стоять в пробке - ок, а заплатить за вундервафлю, которая решит все проблемы в быту и сможет быть секретарем-помощьником-психологом-питомцем-шлюхой-сиделкой-... зажмут? Ну не, коммерческий потенциал ебанись насколько огромен, хоть в лизинг под залог внутренних органов будут брать.
> без подписки, онлайн сервисов, рекламы
Вообще не взлетит если общество сильно не изменится, ощущение "своего" слишком сильно как ни пытаются с этим заигрывать.
Оно и не потребуется, тебе самому захочется через несколько лет купить новую модель, а только на сервисе имеющихся уже можно делать огромный капитал.
> и сливания всех записанных о тебе данных на сервера
Этот вопрос уже отдельный.
>Буквально нахуярил графов и простую нейронку для распознавания - интерпретации команд,
Чет все на нейронках сидят а не на ботах-скриптах. Все таки большая разница, интеллект или программа.
>Этот вопрос уже отдельный.
Самый главный. Как с телевизорами и всей техникой сейчас, будут выпускать модели чуть ли не себе в убыток перекладывая их оплату на подписку и сбор всех данных + показ рекламы. Стратегия эффективная и не вижу причин что ей не будут пользоваться.
Для богачей выпустят свой айбот в котором как бы не будут это делать. Но веры в это мало.
Анальная цензура и постоянный шпион в комплекте. Да ну нахуй. Только локальная хуйня, никаких сервисов и подписок, свое от и до. Иначе шляпа которой нельзя доверять ни на грош.
>Оно и не потребуется, тебе самому захочется через несколько лет купить новую модель
Но зачем, если текущая устраивает?
> на нейронках
> интеллект
Ну ты понял. Везде используют то что оптимально, ознакомься с кучей открытых проектов умного дома. А та же Алиса заскриптована что пиздец, разные фразы и порядок создают лишь иллюзию.
> будут выпускать модели чуть ли не себе в убыток перекладывая их оплату на подписку и сбор всех данных + показ рекламы
Чувак, ты просто свою веру пытаешься навязать как абсолютную истину, угомонись уже.
Сделают удобную BOTH PARTIES INVOLVED бизнес модель, примеров вагон и они не в пользу твоих теорий. С другой стороны, рано или поздно дойдет и до серии суперпримитивных нищук версий что обращаются в облако за "ты меня ебешь" или ловят затупы в осознании алгоритма "как гладить рубашку", а там уже придется мириться со всеми приколами расплачиваясь за экономию.
Извольте каждые 600 боточасов на ТО, а там уже поиск выгодных аналогов, что не будут шуметь и не развалятся сразу, ПО РАЗБОРОЧКАМ ПОХОДИТЬ и прочие радости. Буквально рынок авто или какой-то техники/оборудования здесь самый прямой аналог.
Я просто рассматриваю самые пессимистичные сценарии, ибо они самые реалистичные.
>Буквально рынок авто или какой-то техники/оборудования здесь самый прямой аналог.
Где вполне себе случаются годные модели без говна. У меня литерали ноунейм стиралка, одна из первых турецких, служит более десятилетия, абсолютно тупая (что меня полностью устраивает как энтузиаста тупого дома), была одна из самых дешёвых, и за это время ни разу не требовала ремонта и не ебала мозги.
Так и тут, я уверен, найдутся прошиваемые на попенсорс модели с достаточным функционалом.
И такие офк тоже будут. Но здесь это не программа, онлайн игрушка, или что-то подобное сервис-ориентированное, это буквально вещь, которой ты должен обладать и будешь как-то привязан, именно в этом ее ценность. Потому и заигрываний с подписками, рекламой, цензурой и прочим особо не будет, если только сам не пожелаешь. И задачи - организация жизни и эстетическое удовольствие, пожалуй единственные сферы где целесообразно делать что-то человекоподобное, а подобная херь все нивелирует. Вот всякий ботшернг лол, некоторый захват сферы услуг и т.д. - там пожалуйста, но персональное тогда просто никто не купит.
Да офк все так, и фантазировать ища аналогии можно сколько угодно. Вопрос один - где бля?
> абсолютно тупая
там это, оптимальные алгоритмы 20 или 30 лет назад уже нашли, а далее - ебаный треш от маркетологов, так что то что нужно
> Люди будут дешевле роботов
Если быть точнее, на любом предприятии меньше среднего люди до сих пор дешевле роботов, и таковыми еще будут долгое время.
Роботизируют там, где это выгодно — крупных складах.
> Представил переполнение контекста в самый разгар процесса и обзмеился.
Сук, это как в Virt-a-Mate физика внезапно идет по пизде и тянку начинает пидорасить по всей локации с вылетанием глаз тебе в ебало.
Только ирл.
Ну Сбер, чо ты. Сбер пошире.
Это не проблема ассистентов, это проблема владения сервисами — Яндекс не хочет обеспечивать покупки в Самокате и Деливери, и другие игроки так же.
> сортировать почту, файлы и заполнять документы
Бинг? Бинг.
> десятка тыщ долларов
Маск обещал теслабота за 10к как раз.
Ну и я такой уже прикинул — можно и взять маме в помощники, если эта фигня правда сможет в магазин по жэипиэс с скамерами ходить.
Спиздят? Ну, бля. =) Пусть на огороде работает, хули.
И там спиздят? Ойвсе!..
> подписки
Подогрев жопы по подписки же сработал, ага.
> Чет все на нейронках сидят а не на ботах-скриптах.
Ну-у-у… Нет.
Умные сидят на подходящих технологиях. Где-то скрипт. Где-то алгоритм. Где-то нейронка. Всему свой инструмент.
> разные фразы и порядок создают лишь иллюзию
Не, ну простейшая нейронка там давно есть, с ней можно в общем плюс-минус поболтать. Просто она простенькая и контекст часто путает, резко поворачивая посреди диалога, съезжая на другие темы. Но не то, конечно.
———
Напоминаю, что 10к баксов = 1 млн рублей = нормальную машину ты явно за эти деньги щас не купишь, так что я бы не сказал, что можно сравнить с тачкой.
Что плохо, конечно.
>Так и тут, я уверен, найдутся прошиваемые на попенсорс модели с достаточным функционалом.
Безопасность. Будут ебать мозги как с машинами. Электромобиль это просто верно? Колеса, рама , аккум-контроллер-движки. Да вот только вместо упрощения конструкции они все продолжают усложнятся, и для комфорта и из-за требований безопасности.
Если уж настанет время личных роботов-рабов-ассистентов то шизики потребуют каких нибудь систем безопасности и одной из мер будет постоянный контакт с сетью где проверяются действия бота на законность, а там и сбор статистики и данных и все что захочешь.
Короче думаю сделать попенсорс без большого брата можно будет, но объявят вне закона.
>Но здесь это не программа, онлайн игрушка, или что-то подобное сервис-ориентированное, это буквально вещь, которой ты должен обладать и будешь как-то привязан, именно в этом ее ценность.
Как с теслой да? Хех. Я чет не искал, но помню что она сдается в аренду? Или то что она не полностью принаждежит тем кто купил? Или мне моя память пиздит. Не важно, думаю будут сдавать в аренду, потому что это как подписка где пользователи будут легче заводить бота. Чем покупать дорогого с нуля полностью в свое владение.
А как в oobabooga использовать лорбуки? Куда пихать?
> Повторить заказ еды оно вроде как не может?
Не так давно научилась, однако из их же деливери где постоянный раздел на -20% или всякие акции нет. Так что считай просто для красивого слова, она не так уж и давно по несколько команд научилась распознавать в принципе.
> яндекс шторы
Система универсальна, че хочешь подключай, интерфейсы поддерживает.
> яндекс музыку
Увы. С другой стороны конкурентов в этой стране нет, в том смысле что права на некоторую музыку отозвали у всех.
> постоянный контакт с сетью где проверяются действия бота на законность, а там и сбор статистики и данных и все что захочешь.
Выстрел себе в ногу с потерей конкурентоспособности.
> Я чет не искал, но помню что она сдается в аренду?
Нет, она твоя, если офк не взята в лизинг/аренду. Есть нюансы с автопилотом, который по договору тебе никто не обещал и он является дополнительной функцией, в зависимости от региона может работать/не работать и требует версию по выше некоторой, что логично. И оно прошивается оффициально/неоффициально.
> будут сдавать в аренду
Можно и в аренду, но это не сыщет популярности ввиду самой природы. Вот в кредит - пожалуйста. Единственный вероятный аналог подписки - лизинг, в условиях которого с тебя регулярные платежи а с компании обслуживание и замена раз в N лет.
Алсо я нашел макс кол-во токенов, но не могу понять а минимальное кол-во токенов выставить можно?
>но объявят вне закона
Так там и еблю с ботами объявят вне закона особенно если когда сделают лоли-ботов. Даже наоборот, хорошо, если объявят еблю вне закона. Быстрее вскроют и сделают свободные аналоги.
>Или мне моя память пиздит.
В хуесле к владельцу привязывается только автопилот, ЕМНИП, и то это только Мунск считает, что нельзя продать продать, некоторые страны с ним не согласны, а у нас пока страны главнее корпораций.
>С другой стороны конкурентов в этой стране нет, в том смысле что права на некоторую музыку отозвали у всех.
Рутрекер. 19 лет с нами.
>Выстрел себе в ногу с потерей конкурентоспособности.
Примут законы ради безопасности и все в шоколаде.
>Так там и еблю с ботами объявят вне закона особенно если когда сделают лоли-ботов.
Обязательно, отличный повод ввести все ограничения.
>Даже наоборот, хорошо, если объявят еблю вне закона. Быстрее вскроют и сделают свободные аналоги.
Ага, только тебе через границу их не пустят как щас с куклами чет такое слышал. Не недооценивай большого брата.
Ты уж определись, топишь за могущественные мегакорпрорации, что прогибают под себя правительство, или наоборот про желающих все запретить регуляторов. Выглядит как какой-то сплошной дум ради оправдания позиции отрицания, которую уже занял в этих фантазиях.
> как щас с куклами чет такое слышал
Хоть сейчас за ~1к на али привезут куклу лоли/милфы под ключ а то и с местного склада. Пиздецом это, правда, быть всеравно не перестанет.
>Ага, только тебе через границу их не пустят как щас с куклами чет такое слышал.
Из того, что слышал, кто-то в Великобритании таки поимел проблем с куклой в виде оппай-лоли. Но то Англия и то лоли. Уверен, граница между Китаем и Россией всё же останется достаточно прозрачной, а законы достаточно либеральными, благо в этой сране фемок нет, а на тех, что есть, всем насрать.
> а законы достаточно либеральными
Сука блять чаем подавился.
Заебали херню обсуждать, где ллм и мультимодалки? Сеточке бы уже начали доказывать свою точку, а ей дать задание спорить.
А зачем? В таверне рпшить всяко удобнее + формат промта.
> макс кол-во токенов
На ответ или контекст?
> а минимальное кол-во токенов выставить можно?
На ответ то можно, но это к хорошему не приведет. Приличная модель сама дает сочные длинные ответы там где это уместно. Увеличить их можно инструкциями и/или настройкой бана EOS токена, но это не всегда приводит к хорошему результату. Может начать выдавать шизрографоманию, лупиться, писать за юзера или куда-то убегать, переходя к следующим действиям. В любом случае попробуй и там будет видно.
>Ты уж определись, топишь за могущественные мегакорпрорации, что прогибают под себя правительство, или наоборот про желающих все запретить регуляторов.
Да как бы тотальный контроль над обществом все увеличивается и предпосылок его уменьшения нет. Что корпорации будут о тебе все что можно собирать, что государство разрешит им и себе это делать - велика ли разница для обычного человека?
Примут законы о безопасном использовании ии и ботов на его основе - и совершенно законно будут шпионить за тобой через бота 24/7. Конкретно ты никому не нужен, но кому понравится что о нем будут в наглую собирать информацию оправдываясь безопасностью? А еще и долаживать куда следует если назовешь негра негром. Чет такое. Я просто пытаюсь представить наиболее реалистичный сценарий, поэтому думаю о скучном и неотвратимом пиздеце для свободы обычного человека.
>Уверен, граница между Китаем и Россией всё же останется достаточно прозрачной, а законы достаточно либеральными,
Главное что бы она осталась, а про законы конечно проиграл
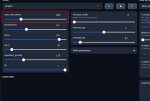
>На ответ или контекст?
А хуй его знает) Вот на пике.
>настройкой бана EOS токена
А это где не знаешь?
Твои слова учел, наверное ты прав. Но надоедает подгонять бота всякими "продолжай"
Спасчибо за ответ.
Я в ахуе от технологии тут такооой простор для кума.
Блядь это бот запоминает что мы с ним говорили в диалоге и типа упоминает это "как я и говорил". Просто отвал пизды. Все такое реалистичное, никаких ошибок я будто реал какой-то фанфик читаю Вааааууу сукаааа.
>где ллм и мультимодалки?
А че там обсуждать, мультимодалки пока не видно, две новые ллм вышли - ноус тот же, и айроборос. Но чет никто не тестил пока.
Это ты кадровый радикал, прошедший соевые точки? Максимализм, родившийся из оправдания - самое худшее, опомнись, возможно еще не все потеряно.
> Вот на пике.
Это на ответ. Чем больше ставишь тем больше будет отъедено от контекста если что. Больше 400 нет смысла, всегда есть кнопка продолжить генерацию.
> А это где не знаешь?
Там же справа. Но ты идешь не совсем нужным путем, с правильным форматом промта и на хорошей модели ответы будут по дефолту длинные содержательные если офк это возможно в контексте. А так ты просто исключаешь из выборки самый уместный токен, заставляя дальше галлюцинировать, или приказываешь фантазировать@продвигаться, такое норм только в некоторых случаях.
> будто реал какой-то фанфик читаю Вааааууу сукаааа
Велкам ту зе клаб, бадди.
> ноус тот же
Поделие на мистрале опять? А вот айробороса надо чекать если большие релизнули.
https://www.reddit.com/r/LocalLLaMA/comments/179lxgz/phibrarian_alpha_the_first_model_checkpoint_from/
типо научно-программисткая сетка, еще один файнтюн мистраля.
Надо франкенштейнов проверить с их 11b но они навереное опять наплодили кучу неотличимых друг от друга вариантов в которых хрен разберешься.
типо научно-программисткая сетка, еще один файнтюн мистраля.
Надо франкенштейнов проверить с их 11b но они навереное опять наплодили кучу неотличимых друг от друга вариантов в которых хрен разберешься.
>Это ты кадровый радикал, прошедший соевые точки? Максимализм, родившийся из оправдания - самое худшее, опомнись, возможно еще не все потеряно.
Надейся на лучшее а готовься к худшему. Пессимистом быть удобно, ты либо всегда прав либо приятно удивлен. Поэтому я и говорил о худших и пиздецовых сценариях. Впрочем я не уверен что они такая уж фантазия.
>Поделие на мистрале опять? А вот айробороса надо чекать если большие релизнули.
ноус хз, аиробороса заявляют как сетку для выполнения инструкций
> Пессимистом быть удобно
Это то верно, но не в качестве единственно верного исхода в контексте каких-то прогнозов. И ты недостаточно пессиместичен, ведь до всей этой херни еще нужно сначала дожить, и не поехать кукухой, сохранив вкус жизни.
> аиробороса
Опять тряска с форматом, и непонятно что с датасетом, это соевик как в первой версии под ллама 2, или анбайасед машина поругания негров, депрессивного рп и кума как ранние 2.х и далее спайсиборос.
А что значит отъедено от контекста?
На счет минимума понял.
Можно как то залочить условный диалог чтобы начинать всегда с одного места? Типа
Бот: Добрый день.
Я: Возьми кружку со стола
Бот: Я взял кружку.
А дальше бы я уже начинал разные фразы говорить. Но каждый раз при начале нового чата бы возвращался к тому что бот взял кружку а не с приветствия. Мб прямо в карточку персонажа записать? Там вроде есть графа приветствия.
>Велкам ту зе клаб, бадди.
Я попросил бота пересказать что мы сейчас делали и он все без ошибок сказал и не выходя из роли!
СЛАВА НЕЙРОСЕТЯМ СЛАВА
Я В НЕЙРОРАЮ
УУУУУООООО
> ведь до всей этой херни еще нужно сначала дожить, и не поехать кукухой, сохранив вкус жизни.
Дак я перечислял скучные варианты пиздеца, веселых конечно больше.
На чем хоть веселишься? какая модель
> А что значит отъедено от контекста?
У тебя есть окно в 4/8/...к токенов. Системный промт, карточка персонажа, персоналити и прочее всегда отъедают какое-то фиксированное количество. Далее уже идет история сообщений, и если идет превышение контекста - удаляются последние. При генерации у тебя может поместиться только контекст-длина ответа, соответственно заказывая овер 1к ты получишь обрабатываемое окно на косарь меньше, при том что пост на 1к токенов - редкость, ради которой можно будет нажать кнопку еще раз.
> при начале нового чата бы возвращался к тому что бот взял кружку а не с приветствия
Что-то поломалось, не понять из описания.
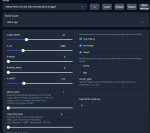
Вот. Посоветовали в треде. Просто ахуенно, но держи в голове что это мой первый раз. Еще и персонаж отлично написан.
Что делают эти ползунки я кстати почти не понимаю мб поможет кто.
Тут можно кидать самые удачные потуги бота в кум или не приветствуется? Я тут ньюфаг.
Ох бля забавно пишешь и только на середине предложения осознаешь что общаешься с реальными людьми и пропадает то чувство вседозволенности.
Надо бы поспать.
Альфу до 2.6 подними, иначе после 4к превратится в тыкву.
Можно.
> Сука блять чаем подавился.
Строгость законов нивелируется необязательностью их выполнения…
Но вообще, да, на фоне других стран — свободно живем.
Почитай новости Евросовка того же. Ну и Китай. Конечно, где-нибудь в Африке свободнее — но жить бы ты там вряд ли хотел.
> кому понравится что о нем будут в наглую собирать информацию
Смартфон, не? =) Литералли тоже самое. Да и компы. Да и все эти умные колонки.
Это буквально происходит уже с десяток лет.
Когда я говорил, что телефоны нас слушают — все смеялись и называли параноиком.
А потом упс…
Так и с дозиметром, год назад все смеялись, а тут уже и испытания…
Тьфу-тьфу-тьфу, но на безопасность всем похую, людям нужен сервис, а не какая-то там безопасность.
Все кто пользуется смартфонами — по умолчанию отказались от анонимности. Все кто пользуется соц.сетями — отказались от безопасности. Мы-то нахуй никому не нужны, это да. Но если понадобится…
Как параноик со стажем рекомендую расслабиться и либо не срать себе в штаны слишком активно, либо уехать в тайгу жить в землянке. Напрягаться, но пользоваться смартфоном — идея смешная.
Впрочем, я всего лишь рекомендую, а делать можете что угодно. =)
Всем добрых снов!
Альфа влияет на тупизну?
>Я попросил бота пересказать что мы сейчас делали и он все без ошибок сказал
>mlewd 20b
Тем временем, mlewd 13b мне сегодня выдал что-то вроде "takes off bra, exposing her perky breasts, covered only by black lace bra". Лифчик под лифчиком в пределах одного предложения. Единичный косяк, но прям сильно удивил.
> Альфа влияет на тупизну?
Бля, звучит двусмысленно
>Единичный косяк, но прям сильно удивил.
Это не единичный косяк а тупость 13б моделей. Ты думаешь откуда появился мем про трижды снятые трусы?
>трижды снятые трусы
Просто холодно
Как в бегущем по лезвию, автономный ИИ, с которым можно ничего не стесняться, и который можно проебать с концами, когда потребуется
Немного, с большим значением на малых контекстах будет хуже.
> Ты думаешь откуда появился мем про трижды снятые трусы?
Не надо про их тупость, сейчас модели умные, тебе специально выделит "эт ласт, ин тсерд тайм, файнали"!
Бинго, именно на такой и будет спрос.
К тому, что одежда между сообщениями регенерирует, я привык. А тут уже какие-то цирковые фокусы. При этом, другие детали запоминает, глубину характера и логику повествования держит.
Это кстати очень иронично что в мире бегущего ИИ встал на сторону человека и был полностью автономен. Будто не про антиутопию говорим.
Идея конечно неплохая, но мне например и говорящего компьютера хватило бы с полноценным благожелательно настроенным ко мне ии.
Толку от бота если я знаю что это все подделка? Отправлять пыль протирать и готовить? Какая нибудь автокухня выйдет дешевле чем универсальный робот с ии, а готовить сможет лучше под управлением духа машины.
> Будто не про антиутопию говорим.
Победивший капитализм не мешает институту репутации.
> Отправлять пыль протирать и готовить?
Да, и все все вопросы что тебе не хочется делать или не хочется иметь вынос мозга за то что их делает кожанное существо. Офк при наличии идеального это не нужно, но увы.
> Какая нибудь автокухня
Кофе-машины, что почти вершина автоматизации дома, довольно заморочно чистить и обслуживать. Базированный дефолт - чай, автоматизируй его изготовление, чтобы была не моча из пакетиков а тот что ты любишь и хотябы литров 15 малыми порциями по запросу без твоего участия. Тут никакие нейросети не нужны.
"Автокухни" ввиду сложности и разнородности операций целесообразны лишь в огррмоных масштабах пищевой промышленности, тут проще доставку.
> Толку от бота если я знаю что это все подделка?
Приносит ароматный чай, сервирует сважайшие блюда что ты пожелал недавно, делает это невероятно мило, улыбаясь и приговаривая "да, госоюдзин-сама", при этом выглядит и одета согласно твоему вкусу. И все это здесь, перед тобой, можешь пощупать и делать что угодно. Это же воплощение эстетики и удобства, дайте 2. И офк никто не заставляет отыгрывать кринж из фильмов и анимца, женясь на роботе, одно другому не мешает так сказать. А еще с утра у тебя вне зависимости от всего чистая свежая рубашка с застегнутыми как надо манжетами, сортир чистый благоухает и никто не бухтит что надо ссать сидя, и вся та ебанистическая куча мелочей что могла вызвать недовольство или срач сразу исчезает, а чтобы не расслабляться можно побуругтить с чего-то более полезного
>И все это здесь, перед тобой, можешь пощупать и делать что угодно.
Так они и вымерли.
Не, идея заманчивая, но тут такие изменения общества подкрадываются с появлением таких вот универсальных заменителей людей... Как прежде после этого не будет.
Революции, кризисы, массовые увольнения, и другие радости резкого изменения общества и обесценивания человеческого труда и жизни.
Вообще под автокухней имелось ввиду двигающаяся платформа с руками чисто пожрать готовить. Ну и для почти всего тобой озвученного сойдет буквально робот. Я бы наверное не стал заморачиваться делая из робота куклу-человека. Человекоподобная дистанционно управляемая платформа которой манипулирует ии-центр умного дома - да, звучит ниплоха. Такой слуга-дворецкий на минималках.
Ну, каждому свое.
Но локальный мультимодальный старший брат гпт5.... На каких нибудь нейропроцессорах? Что то мне подсказывает что видимокарты тут будут неэффективны.
Пост полностью не прочел, эта херь не должна становиться заменителем тни/куна, быть препятствием и т.д., наоборот сгладит многие моменты.
> изменения общества
Не столь существенные как с появлением смартфонов.
> двигающаяся платформа с руками чисто пожрать готовить
Ну так все то же самое, только узкоспециализированное, зачем если можно сделать универсальность?
> сойдет буквально робот
> делая из робота куклу-человека
Эстетика и восприятие. Несравнимо приятнее видеть милую горничную с звериными/эльфийскими ушками, или красивого статного дворецкого вместо крипоты что будет вызывать долину, плюс открывается множество других взаимодействий. Хотя кому-то наоборот терминатор может зайти.
> Что то мне подсказывает что видимокарты тут будут неэффективны
1.5 года назад над генерацией пикч и текстов только насмехались, а в начале десятых можно было на процессоре ноутбука намайнить несколько битков за неделю. Там в целом проблем хватает и пока будут решены - это уже само подтянется, плюс не нужно усложнять, голосовые ассистенты уже оче давно и еще на старте удивляли.
>Пост полностью не прочел, эта херь не должна становиться заменителем тни/куна, быть препятствием и т.д., наоборот сгладит многие моменты.
Прочел, такой удобный заменитель сделает необходимость жизни вместе еще слабее.
>Не столь существенные как с появлением смартфонов.
Ты невероятно неправ, смартфоны просто улучшили коммуникацию людей, сделали это плавно и были просто продолжением идеи компьютеров. Тут изменения общества глобальнее
>Ну так все то же самое, только узкоспециализированное, зачем если можно сделать универсальность?
Ну например какая та балка на кухне по которой гоняет платформа с 2 руками и камерой будет гораздо дешевле и проще чем полноценный андройд.
Если будет только появление ии, но без появления термоядерного синтеза то без энергии все будет дорого. Поэтому и андройды будут дорогие. Опять таки ии или нейросети может помочь в доведении синтеза до рабочего решения. Ну или дураки поймут что ядерные станции тоже ничего так.
Тогда будет вопрос производства - с ии и энергией узким горлышком станет отсутствие универсальных 3D принтеров для создания вещей печатью.
3 технологии каждая из которых пошатнет мир, и все могут быть созданы с помощью нейросетей.
Ну и все 3 - счастливое будущее с робо-горничными если люди вдруг перестанут быть мудаками.
> сделает необходимость жизни вместе еще слабее.
В какой-то степени, но с другой и облегчит эту самую жизнь. Появление кучи домашней/кухонной техники или наличие слуг проблем не создавали. Офк есть риск уехать в манямир, но слабые духом и без этого в него уезжают, учитывая плавность входа и пейгап - не должно быть столь существенно. По ходу будет понятно.
> смартфоны просто улучшили коммуникацию людей
И теперь тебе нигде не скрыться от нее, везде ходят зомби, смотрящие в телефон, а мозги ахуевают с обилия информационного шума. Подобных примеров вагон, просто к ним привыкли и они кажутся нормальными.
> проще чем
Та что не будет слать тебе в телефон уведомления бля я сожрал штору переверни меня обратно кукурузинка упала подними, прибери вон то говно, блять я разъебал холодильник, сможет полноценно делать все манипуляции и ничего не разъебет - ну не то чтобы проще. Буквально сведется к сложному осминогу на палке. Проще офк за счет стационарности, но и вид/функционал мэх.
> но без появления термоядерного синтеза
Чому любители прогнозировать делают из него святой грааль? С него ценны лишь 14МэВ нейтроны, которые помогут топливному циклу энергетики на делении, все, вот буквально все. Дрочить надо на саму по себе атомную энергетику и водород в качестве энергоносителя. Только в таком случае роботяночка сможет работать долго "выдыхая" теплый влажный воздух и вместо долгой зарядки быстро восполнять энергию "кушая". И быть легкой как полагается размеру, а не отыгрывать 2B по весу не обладая силой/прочностью.
> может помочь в доведении синтеза до рабочего решения
Чем они помогут, если все упирается в материалы и технику? Синтез уже давно есть, прямо в ДС, но до становления его энергетической технологией слишком далеко, сейчас он банально не нужен. И чего ты добьешься, получив этот самый синтез?
> отсутствие универсальных 3D принтеров для создания вещей печатью
Какое-то сойбой бинго. Они тоже уже здесь, полимеры, металл, керамика, уже производятся устройства, которые невозможно сделать по другим технологиям, причем в этой стране под всякими санкциями. Или масштабная реализация в виде шизанутого FDM что срет бетоном дома, или полуавтомат на ультрах что насирает швами огромные легкосплавные обечайки в простом ангаре вместо металлургического цеха правда свойства говно. Предел технологии уже нащупан, реальное развитие и прорыв стоит ждать в области биотехнологий с ними, или уже совсем футуризма в виде продвинутого программирования бактерий и биопринтеров nanomachines son!
Дай угадаю, ты гуманитарий? В этом нет ничего плохого, но не стоит фантазировать и лезть туда где не соображаешь. Представь что к тебе пришел пиздюк и начал затирать сказки по теме в которой ты специалист, банально смешно. Все дальнейшие выводы строящиеся на этом также неоче. Лучше про социально-морально-этическую сторону смотри, тут хоть дискутируемо но позиция у тебя уверенная а не этот кринжовый пиздец.
А вообще вон лучше иди оживляй тред.
> Так они и вымерли.
Как будто это что-то плохое.
Вообще, это оффтопик, но само по себе индивидуалистское поведение противоречит коллективистскому зачастую (но не всегда, офк). И именно в этом, либо у людей нет свободы и комфорта, зато человечество гарантированно выживает, либо все свободны, живут в комфорте, а выживание как пойдет. Можно пропагандировать традиционные ценности и тогда шанс выше.
Но я в любом случае за свободу, так шо если вымрем — так вымрем, шо поробишь. Пропагандируй традиционные ценности, анон. =)
> Революции, кризисы, массовые увольнения, и другие радости резкого изменения общества и обесценивания человеческого труда и жизни.
Начинаешь революцию
@
Господ охраняют роботы-охранники
@
Идешь домой бубнить под нос и хлебать лаптем щи
Ну, я не уверен, что роботы смогут заменить на тяжелой физической работе людей, так что работяги (внезапно — основная движущая сила революции) как раз в относительной безопасности. А если бунтовать выйдут джуны-айтишники, журналисты и домработницы — звучит не очень страшно.
Короче, я не уверен в таком экспрессивном конце сосаити.
Все так, все так.
> какая та балка на кухне
Ты знаешь в чем смысл андроидов? В том, что для антропоморфных уже существует инфраструктура. Тебе не нужна робо-кухня, робо-гладилка, робо-застилалка, робо-стиралка, робо-пылесос, робо-че-нить-еще, если у тебя есть один робот, который делает все это с твоей имеющейся посудой, одеждой и стиралкой с пылесосом. А еще он ходит за покупками, приносит заказы из ресторанов и посылает посылки. И что угодно еще ебется.
> Дай угадаю, ты гуманитарий?
А может он — нейросеть? :) Отсюда и угадывание вместо реальности местами.
Опять же, но оффенс.
3D-принтеры дорогие, сук. Хочу печатать металлом, но цена материала и принтера выше психологичсеких 20к.
Печатаю петгом, он норм. Эндер3 за 15к и кило материала за 2к.
> Так они и вымерли.
Мы и сейчас вымираем без всяких роботов, спасибо капитализму за это
>выше психологичсеких 20к.
Анон, ты в треде по локальным нейронкам, тут все успешные и богатые
А зачем нужны лоры в тест генерации? В картинках понятно они типа концепт впихивают в модель, тут как то так же?
Какие используют аноны?
Какие используют аноны?
Ну я же говорю — психологических!..
=D
Но по факту да, чой-то я, пойду куплю две штуки вечерком.
Знания, стиль текста.
Большинство файнтьюнов — и есть лоры.
Если чего-то в модели нет — добавляют лоры. Кимико, ЛимаРП были популярны давным давно (две недели назад).
Я кроме них ниче не накатывал отдельно.
>Начинаешь революцию
>@
>Господ охраняют роботы-охранники
@
Идешь к другим господам которые конкурируют с первыми
@
Получаешь антиробовинтовку
@
Глядишь как горит господская хата
@
Хорошо
> Идешь к другим господам которые конкурируют с первыми
@
Узнаешь что на самом деле у них нет конкуренции с первыми, а есть картельный сговор
@
Их робомордовороты робомордоворотят твою морду своим робо
@
Клятый киберпанк без панка с его дурацкими мегакорпорациями!
У меня однажды модель сняла ботинки, а под ними оказались кроссовки. Спасибо что хоть не туфли со шпильками...


> Хочу печатать металлом но цена материала и принтера выше психологичсеких 20к
В начале удивился что много хочешь
> петгом, он норм. Эндер3 за 15к и кило материала за 2к
А потом обзмеился поняв валюту. Как в мемасе нужно:
купил нвидия теслу с большой врам чтобы работать с нейросетями
@
p40
> зачем нужны лоры в тест генерации? В картинках понятно они типа концепт впихивают в модель
Здесь также, лора - лишь способ ужатого представления изменения весов. По отдельности, обычно, не используются и идет сразу замес с несколькими.
Главное чтобы подвоха не обнаружилось.
У меня регулярно подвох обнаруживается..... Не понимаю почему, женские персонажи, без каких либо предпосылок
Либо модель такая, либо... Ты ведёшь себя как баба, поэтому модели приходится мужать.
Ээээ? блюшес
Ну так, как в мемасе, да. =)
Я просто к тому, что цена того, о чем мы мечтаем — пока высоковата. Но то, о чем мы мечтаем, уже есть.
Ну, вот, погуглил — от 4 лямов стоит, если я не наебался. ТеслаБот обещает быть вчетверо дешевле. =)
Но, да, будущее здесь, были б деньги.
Так не нашел где диалог начинается, но каких вам роботов домохозяек? Люди нищие, рабочий на заводе сделает за день 1000 сервоприводов, а зарплаты у него хватит только на 10-20 в месяц. Пока такое соотношение к тому что ты сделал и что получил, а робот это сложная махина с кучей электроники, тебе придется всю жизнь на 1 робота копить.

Пикрел лол. А вообще без предпосылок такого даже на шизомиксах не бывает.
> блюшес
Блюшес надо только слайтли, а то модель учует слабость и начнет угнетать.
Где-то в начале обозначено про цену, на недешевых авто преимущественно моложе 7 лет ездят - найдутся деньги и на подобное. А массовость радикально снижает стоимость, мобилки стоят дешевле микропк с оче днищенскими характеристиками, а спустя лет 5 даже за даром никому не нужны.
> подвох обнаруживается
В плане "oh he's bigger than mine"? В РП-моделях такое замечаю иногда.
Ага, ну и упоминания что у женских персонажей есть члены мимоходом. Притом это ещё не дойдя до коитуса или обнаженки
Возможно это часть сои, в которой есть что-то про трансопидоров и гендеры. Попробуй в таких случаях спрашивать их про гендер и биологический пол, может прояснят почему так.
Мерзость. Можно как-то это предотвратить до того как девотьки начнут махать своими висюльками?
Не, ну если начать копить сейчас, то лет через 10-15 накопишь.
В 18 на завод, в 30 — личную домохозяйку.
Звучит как план-еблан, чо.
Я хочу сказать что это кабанам экономически не выгодно. Многие не будут на это копить. А значит не будет продаж. Кабану нужно что то с прибылью в 1000 процентов на работника. Не потому что кабанчик себе столько берет, а потому что пока устройство дойдет до рынка оно пройдет через 10 кабанчиков с целыми непроизводящими но отделами для конкуренции на рынке.
А ойтишнег, накоплю быстрее )
На нейросети, лол.
https://3dnews.ru/1094622/predstavleno-pervoe-video-pohodki-chelovekopodobnogo-robota-figure-01-v-nego-investirovala-dage-intel
Ну че киберпанк нахуй. Осталось дождаться имплантов и восстания ии. По времени только проебались, не 20 годы.
и выше кидали EXROBOTS
Балда, оригинальный киберпанк в двадцатых
> В нынешней модификации робот Figure 01 сможет переносить груз массой до 20 кг
Пфф. Биороботы намного больше таскать могут за меньшую плату
>Чому любители прогнозировать делают из него святой грааль?
Патамушта все дорого из-за дорогих источников энергии.
Будет удобный и мощный источник энергии - все станет делать проще и дешевле не трясясь над каждым киловаттом. И не важно что это будет, атомка, синтез или еще что то новое непонятное щас.
>Чем они помогут, если все упирается в материалы и технику?
Але гараж, они помогут смоделировать условия в которых из нашей техники и материалов можно это собрать. Они могут помочь исследователям создать новые технологии и материалы.
Рассчитать жизнеспособные конфигурации полей, конструкцию и параметры работы установки при которой она сможет работать.
Сами по себе они тебе ничего не сделают, но помощь в работе невероятная, для тех кто умеет их использовать. И нет я не про текстовые генераторы.
>Предел технологии уже нащупан,
>Дай угадаю, ты гуманитарий? В этом нет ничего плохого, но не стоит фантазировать и лезть туда где не соображаешь.
но комент
>этот кринжовый пиздец.
Этот кринжовый пиздец, не серьезные разговоры об этой теме без использования терминов, на понятном обычном людям языке.
Объявляя себя специалистом ты говоришь мне - я нихуя не понимаю за пределами своей области но могу уверенно и убедительно фантазировать в ее пределах, лол
Я знаю ситуацию с текущими 3D принтерами, синтезом и атомкой и возможностями нейросетей которые уже используются. Я понимаю как все это работает, лол. Но ты считаешь меня сойбоем просто потому что я перечислил технологии которые могли бы так улучшить жизнь, что любой васян смог бы иметь свою личную вайфу-робота? Ну ок, тебе виднее
там прогресс на сколько помню начался чуть раньше, мы лет на 10-5 отстаем по графику
Тем не менее главные атрибуты киберпанка не модные кибер импланты, а "высокий уровень технологий, низкий уровень жизни", с беспощадным капитализмом и пренебрежением человеческой жизнью. Тут мы укладываемся в план
Выглядит как говно по сравнению с Бостоном.
>18.10.2023 [10:00]
>10:00
Хули старьё постишь? 2 часа, целая вечность же.
А так очередная хуита на полусогнутых, приплясывает на ровном месте и разворачивается полчаса. Апокалипсис отменяется.
Так это ж прототипы дешевого говна, допилят.
>дешевле не трясясь над каждым киловаттом
>атомка, синтез
Чел... Что атомка, что синтез пиздец какие дорогие на кековатт.
>Тут мы укладываемся в план
Но ведь...
>пренебрежением человеческой жизнью
Жизнь ценна как никогда, офк если проживать в развитой стране.
ИЧСХ, никаких нейросет очке!
Такие проекты из стадии прототипов сроду не выходят. Собрали какие-то жалкие 10 миллионов баксов. Да блин, одному чатЖПТ майкросовт набашлял 10 лярдов. Сразу видно, где ценность и прибыль, а что делают по остаточному принципу.
> ИЧСХ, никаких нейросет очке!
У Бостона всё в порядке с нейросетями, они первыми начали делать роботов с ними.
>Чел... Что атомка, что синтез пиздец какие дорогие на кековатт.
Сейчас. Ну ты в курсе да? Что мы говорим про будущее где это нужно, выгодно и есть нужные технологии.
И даже сейчас атомка дорогая только из-за зеленых, безопасности и технологий. У нее лучший выхлоп энергии + бесконечный так как рассчитан замкнутый цикл топлива.
А есть какая-то модель для Финансов? или лора?
>Жизнь ценна как никогда, офк если проживать в развитой стране.
Посмотри как американский амазон ценит своих сотрудников. Да вообще как корпорации на западе относятся к работникам
Там нейронке сбоку прикручены, в основном хардкорный коддинг. На питоне, судя по их видосам.
>Что мы говорим про будущее где это нужно, выгодно
Какие-то влажные фантазии.
>У нее лучший выхлоп энергии + бесконечный так как рассчитан замкнутый цикл топлива.
ЗЯТЦ есть примерно у одной страны, которую все послали нахуй. Так что никакого замкнутого цикла больше нет, остальные даже не думают в этом направлении. А без ЗЯТЦ уранка всё так же будет стоить в десяток раз дороже даже ветряков, лол.
>Посмотри как американский амазон ценит своих сотрудников.
Всё ещё значительно выше туземцев третьих стран. И эти сотрудники имеют доступ к передовой медицине и при всех негативных их питания и экологии живут весьма долго.
>которую все послали нахуй.
Проблемы долбаебов, а не отсутствия технологии.
>Какие-то влажные фантазии.
Если ты не можешь это представить, этого не значит что этого не может быть. У каждого есть свои ограничения.
Да, туземцы стран третьего мира не находятся постоянно под внимательным оком видеокамеры. Они не писают в бутылочку, потому что нельзя отойти от рабочего места. Им не препятствуют в формировании профсоюзов. Всего этого в проклятом третьем мире нет. Там работают как люди, а не как биороботы
ПЕРЕКАТ
Всем срущимся не по теме предлагаю остаться в этом треде.
Всем срущимся не по теме предлагаю остаться в этом треде.
>Проблемы долбаебов
А можно мне к ним? Надоело быть в стране с охуенными (и не работающими) технологиями.
>Если ты не можешь это представить
Могу представить что угодно, даже то, что ко мне в сычевальню завалится толпа девок и начнут меня ублажать (надо карточку под это, лол). Но от моих фантазий реальностью оно не становится.
>Да, туземцы стран третьего мира не находятся постоянно под внимательным оком видеокамеры.
Их пиздят палками другие туземцы, намного лучше, да.
>Им не препятствуют в формировании профсоюзов.
Потому что они нахуй бесполезны и все давно под сапогом того же барина.
>Там работают как люди, а не как биороботы
Ага, из-за прекрасного трудового законодательства работают полностью в чёрную. Можно в любую автомойку смело заходить с выписанным предписанием, ибо по определению там ни один мойщик не трудоустроен. Знаю людей, которые лет за 20 были официально трудоустроены 1,5 раза, и то на 2 недели. С другой стороны крупные компании кладут хуй на ТК и нанимают курьеров как самозанятых, всем тоже похуй, что они на переработках ебашат и сшибают детишек на великах.
> Ну я же говорю — психологических!..
> =D
Надо отбрасывать такое мышление, к добру не приведет. Нужно корректировать психологические границы в зависимости от дохода и инфляции
А то будешь через 10 лет как интернет шиз Поднебесный, который зарабатывает нормально, но не может купить сосиськи дороже 20₽, так как в его 2000 год это была норм цена
> Патамушта все дорого из-за дорогих источников энергии.
В товарах ежедневного потребления и подобных вещах доля затрат на нее не определяющая. Сам по себе абстрактный источник энергии не даст ничего, эта энергия должна быть удобной в производстве, транспортировке/накоплении и использовании. Абстрактные рассуждения в отрыве от системы не имеют смысла, а термояд как дешевый источник энергии - смех.
> они помогут смоделировать условия в которых из нашей техники и материалов можно это собрать.
Нет не помогут в том виде что ты описываешь. Развить CAD, помочь в обработке и анализе, что-то автоматизировать, и продолжить прогресс который был в последние декады, но не более. Остальное - фантазии на основе желтых бейтовых статей.
> на понятном обычном людям языке.
Понятный язык не означает что можно гнать любую херь вопреки здравому смыслу. Говорил бы про абстрактный энергоресурс и абстрактное развитие с привлечением ии - да, но как только развеиваются абстракции это все заканчивается.
> Я знаю ситуацию с текущими 3D принтерами, синтезом и атомкой и возможностями нейросетей
Видится что-то на подобии "уверовал в инфоциган и в лучшем случае после поста пошел чекать википедию", слишком много дилетантских нестыковок и непониманий. Не стыдно чего-то не знать, стыдно врать о своем незнании и неверно оценивать себя.
>Нужно корректировать психологические границы в зависимости от дохода и инфляции
В сторону переезда в страны, где нет ебанутых инфляций.
Вот этого поддвачну.
> В сторону
Как это сделать без "выбора стульев" как в загадке и серьезного штафа на почти все области повседневной жизни в первые N лет? вопрос риторический, забей
Выгода от жизненно важных областей всё равно перевешивает.
Я нашел видос там чел запускает 13B викуню на p40 c неплохой скоростью, потратив 500 баксов на сборку. А почему тогда на реддите носяться с (гей)мерскими 3090 и так далее, если ли можно собрать специализированный бомж пека? В чем подвох?
Ответил в перекате
https://2ch.hk/sf/res/227070.html
Небольшое путешествие на 2 года назад.
Почитай таких же экспертов как ты, которые с абсолютной уверенностью и убедительно доказывали что происходящего сейчас ждать еще кучу лет.
Там точно такие же люди как ты, которые так же неверно экстраполировали развитие ситуации в реальном мире.
Приводя убедительные аргументы, убеждали других в своей ограниченной точке зрения, не способные представить что будет дальше.
А потом глянь свои посты где ты точно так же приколачиваешь фантазии к земле отталкиваясь от своих представлений о том что может существовать, а что нет. Просто не способный представить о чем идет речь.
Что у нас по коллабам, друзья?
Не получается 30б пока заставить стабильно работать?
Я и через проц пробовал, скорость кстати хорошая.
Не получается 30б пока заставить стабильно работать?
Я и через проц пробовал, скорость кстати хорошая.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
На данный момент развитие идёт в сторону увеличения контекста методом NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Так же террористы выпустили LLaMA 2, которая по тестам ебёт все файнтюны прошлой лламы и местами СhatGPT. Ждём выкладывания LLaMA 2 в размере 30B, которую мордолицые зажали.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в случае Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас в полгига-гиг.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Undi95/MLewd-ReMM-L2-Chat-20B-GGUF/blob/main/MLewd-ReMM-L2-Chat-20B.q5_K_M.gguf
Если совсем бомж и капчуешь с микроволновки, то можно взять
https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах, есть поддержка видеокарт, но сделана не идеально, зато самый простой в запуске, инструкция по работе с ним выше.
https://github.com/oobabooga/text-generation-webui/blob/main/docs/LLaMA-model.md ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ. Самую большую скорость даёт ExLlama, на 7B можно получить литерали 100+ токенов в секунду. Вторая версия ExLlama ещё быстрее.
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://rentry.co/ayumi_erp_rating Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
Факультатив:
https://rentry.co/Jarted Почитать, как трансгендеры пидарасы пытаются пиздить код белых господинов, но обсираются и получают заслуженную порцию мочи
Шапка треда находится в https://rentry.co/llama-2ch предложения принимаются в треде
Предыдущие треды тонут здесь: