


Продублирую.
Или как это работает?
>Ещё удивило, что хвосты тоже никуда не летают в 90% случаев.
Рилли? Теперь можно рисовать кошкодевочек с хвостами, а не продолжениями волос и лишними волосатыми верёвками?
Я ответил же тебе уже в прошлом
Получается так, кошкодевочку в каждый дом. Я пока немного потестил, но проблем таких как на наи тут явно меньше, на б64 даже с лорой там со скрипом хвосты рисовались, а тут просто тегами.
> но они более компетентны, чем sai, их чекпоинт просто работает и тренится легче
Сильное заявление, их если и сравнивать то с чистой nai (не честно ибо она тут в основе) с waifu diffusion или анстабилити с их моделью. И то временной разрыв очень большой.
> и не имеет артефактов присущих наи или его производным в этом разрешении
Можешь что-нибудь с детальным сценери пратащить. Например, всех доебавшая киберпанк улица, урбанистический вид с крыши, фентези средневековье с деревушками, полями и замком на фоне горной полосы, пейзаж фуджи, египетские пирамиды, арабский город (улица и вид сверху). Офк с персонажами и чтобы относительно детально а не минималистично. Офк если лень то не делай, как получится сам потестирую, но всеже.
> Что конкретно?
Вообще много их. Но базированное - лежит на кровати обнимая подушку, лежит на животе вид 3/4, стоит широко расставив ноги, наклоняется вперед свешиваясь с парапета, поза лотоса, просто сидит на полу с руками между ног, или коленями вверх чтобы было перекрытие одной ноги другой. Совсем хардмод - вверх ногами, 9 хвостов в сочетании с платьем с короткими руковами и floating hairs в данамичной позе, двух разных персонажей промтом.
> что хвосты тоже никуда не летают в 90% случаев
Ух бля, с козырей, так уж и не летают?
Уже обсуждали https://github.com/hako-mikan/sd-webui-negpip ? Помоему супер мега полезная вещь, делающая негативы ненужными вообще
> делающая негативы ненужными вообще
Нет. Оно разве что может править фантазии сетки, но для нормального качества без негативов никуда не деться.
О, я и не заметил.
Спасибо, попробую.
>Нет
да, я именно поэтому сказал что можно без негативов

>хуйнянейм усиливает влияние негативов
>можно обойтись вообще без негативов!
> Сильное заявление, их если и сравнивать то с чистой nai (не честно ибо она тут в основе) с waifu diffusion или анстабилити с их моделью. И то временной разрыв очень большой.
И ничего что тут тоже 1024 и фикс одной из основных проблем 1.5, на которую кучу заплаток понавыпускали?
> Можешь что-нибудь с детальным сценери пратащить. Например, всех доебавшая киберпанк улица, урбанистический вид с крыши, фентези средневековье с деревушками, полями и замком на фоне горной полосы, пейзаж фуджи, египетские пирамиды, арабский город (улица и вид сверху). Офк с персонажами и чтобы относительно детально а не минималистично. Офк если лень то не делай, как получится сам потестирую, но всеже.
Попробовал, как то так, я вообще заметил что тут походу надо не хайрез х2 делать, а сразу отправлять в мд или ещё куда, потому что он как то начинает ухудшать изначальную генерацию замыливанием, она на удивление выглядит нормально в лоурезе, если конечно перс не совсем далеко.
> лежит на кровати обнимая подушку, лежит на животе вид 3/4
Ух как лешды то попёрли с этой смеси подушки и кровати, вот с конкретными указаниями позиции бадихоррора добавилось, апсайд даун не нуждается в комментах вообщем, но сука хвост на месте. Ты бы лучше сразу теги скидывал, я понятия не имею как ты собрался даже на наи такое без кнета промптить, если там вообще есть теги на половину того, что ты перечислял, ещё небольшая проблема может быть в том, что я точно не знаю как их правильно комбинить на собачьем, но мб тут уже и есть предел, где надо добавлять контролнет в помощь. На короче, сам погляди на это https://files.catbox.moe/k3ixg5.7z
> Ух бля, с козырей, так уж и не летают?
Ну конкретно у этой кошки, он как то подозрительно правильно почти всегда крепится.
не усиливает, а фильтрует кал лучше, чем поле негативов, а так как можно все из негативов перенести в позитив с минусом, то поле негативов соснуло
Что-то как-то по ощущениям хуже стало.
Может, не те модели мерджил? Стянул с цивита первую попавшуюся - а там на них на всех конфиги нужны, а ФлаффиРок так вообще без ЦФГ-рескейла в базе не работает.
И что-то мне подсказывает, что с таким мерджить обычную модель - не слишком правильная идея.
Ну, теоретически, с единицей на альфе ты получаешь модель со свойствами модели B в основе, так что не должно ебануть. Хуй знает, надо тоже попробовать.
Я не так много экспериментировал именно с этим способом, тот анон лучше подсказать может, но там надо делать это именно супермерджером и именно с этими версиями моделей. Точно всё сделал правильно? Может действительно буст будет не для всех моделей, я юзал с based67, которая с цивита, у него там какой то свой микс.
На всякий случай:
Супермерджер - https://github.com/hako-mikan/sd-webui-supermerger/tree/main
Изифлафф - https://huggingface.co/zatochu/EasyFluff/blob/main/EasyFluffV10-PreRelease2.safetensors
Флуффирок - спамлист не пропускает https://huggingface.co/lodestones/furryrock-model-safetensors/tree/main/fluffyrock-1088-megares-terminal-snr-vpred вот тут найди 132 эпоху просто
> Вот тут расписан алгоритм, как это сделать не все фичи перенесутся, в основном разрешение и послушность промпту должна добавиться
Интересно было почитать, как анимешники предвзято смотрят на фуррей с высока, при этом не осознавая, что сами не очень то далеко от них ушли



Ты разницу А и С не забыл прибавить к своей модели В? А то не понятно по пикчам
Да как на том пике настройки, разница, трэйндиф, альфа 1.
Всегда использую для стейбла универсальный лайфхак, это генерировать манямэ картинки вместе с TI или лорой на пиксель арт. С таким весом, чтобы изображение не выглядело как пиксельарт (чтобы невозможно было разглядеть квадраты пикселей). Желательно чтобы эмбеддинг не влиял на стиль. Писать "pixel art" вместо эмбеддинга нежелательно - тогда фон или отдельный предмет будет пиксельным, а остальное обычным.
Для чего это нужно? Чтобы изображение было чистым, с аккуратными формами, будто автор уделил работе тщательное внимание. Сэмплер как будто лучше знает и понимает всё, от деталей до цвета и цветовых градаций, если рассматривает картинку именно как пиксель-арт. Всё приобретает "профессиональный" вид как ассеты охуенного ретро игоря. Из минусов, становятся более вероятными строго-диагональные линии (чтобы понять почему, попробуйте проложить в пейнте под зумом наклонную линию толщиной в один пиксель). Но для меня это скорее плюс, ностальгия по старым игорям из начала девяностых.
Для чего это нужно? Чтобы изображение было чистым, с аккуратными формами, будто автор уделил работе тщательное внимание. Сэмплер как будто лучше знает и понимает всё, от деталей до цвета и цветовых градаций, если рассматривает картинку именно как пиксель-арт. Всё приобретает "профессиональный" вид как ассеты охуенного ретро игоря. Из минусов, становятся более вероятными строго-диагональные линии (чтобы понять почему, попробуйте проложить в пейнте под зумом наклонную линию толщиной в один пиксель). Но для меня это скорее плюс, ностальгия по старым игорям из начала девяностых.
Молодец, а теперь обратно в палату

Обновил пекарню, решил генерить девочек, прохожу Аска-тест и НИХУЯ НЕ ПОХОЖЕ. Если что радеонорожденный. В чем причина, что делать?
Понятия не имею где этот вопрос задавать так что и в аниме-треде вкинул
Понятия не имею где этот вопрос задавать так что и в аниме-треде вкинул
>пук
По делу есть что сказать?
> Аска-тест
Как там в 2022?
Нормально, птички поют. Я ж только только вкатился, так что если это все устарело - то я и не против собстна. Но я попытался и с цивитаи картинки попробовать повторить - одна сплошная жопа. Единственная модель которая работает нормально это, внезапно, фурриговно
С реализмом все просто - качаешь epicPhotogasm Z, выставляешь настройки и негативы, которые в описании модели советуют, и все. А с аниме видимо да, надо страдать. Моделей лютый зоопарк, и простого единого критерия качества нет
Покажи как выглядит, скорее всего достижимо нормальными путями без ущерба.
> попытался и с цивитаи картинки попробовать повторить - одна сплошная жопа
Параметры не упустил никакие? Сейчас почти любой из миксов что выкладывают дает красивую картинку из коробки, если сильно не проебываться.
Скорость падает с ним у меня, при чем если нет негативных весов, а просто Галочка active. С 25.5 сек до 26.3, при генерации батча из 10 пикч. Это конечно пипец. Вроде и мало, но камон, я же негативных весов не добавил, че оно вообще влияет
Так то прикольно было бы иметь альтернативный вариант отрицания. Но я потыкал, обычный негатив работает лучше. Пригодится только для особых случаев как из примеров от автора
Накидайте быстрый гайд что мне делать для вката?
Имею 4080/16, умею кодить.
Хочу голых фотореалистичных бап по моим сценариям.
Имею 4080/16, умею кодить.
Хочу голых фотореалистичных бап по моим сценариям.

Тащемта секрета тут нет, просто берешь и генеришь
Скачать text-generation-webui, скачать моделей с civitai, генерить, дрочить.
Ты треды перемешал, иди уже, выспись, двачей и генерации на сегодня достаточно
Ага, пасис, с text-generation-webui понятно. А кто такие модели с civitai? Это типа девки? Чтоли можно только ограниченный набор девок скачать и их по всякому ставить?
Всё, приехали - копирастия добралась до стейбла. Встретил на Civitai вот такую свежую XL модель
https://civitai.com/models/183813
По превью выглядит охуенно, но вот что странно: в описании автор говорит, что запрещено постить ее на любых ресурсах, которые хостятся в Китае, и типа "если зальете, против вас будет возбуждено дело по законам КНР". Даже сначала думал что автор япошка, который хейтит чинков, - но текст явно на китайском.
А я как раз пользуюсь одним китайским облаком, и решил попробовать залить туда этот файл с Civitai. Не вышло: выдает ошибку при попытке отправить. Любые другие файлы туда заливаются, как обычно, а этот нет. Видимо, в Винни-пухии есть некая база с хэшами файлов, на которые действуют авторские права физ. и юр.-лиц., а владельцы цифровых платформ с ней постоянно сверяются. Но мне позарез надо именно эту модель и именно на чонговском сервере, так что буду искать способ подредактировать файл, не ломая чекпойнт. Всего-то пару битов надо поменять. Что мне, социальный рейтинг за это снизят?
https://civitai.com/models/183813
По превью выглядит охуенно, но вот что странно: в описании автор говорит, что запрещено постить ее на любых ресурсах, которые хостятся в Китае, и типа "если зальете, против вас будет возбуждено дело по законам КНР". Даже сначала думал что автор япошка, который хейтит чинков, - но текст явно на китайском.
А я как раз пользуюсь одним китайским облаком, и решил попробовать залить туда этот файл с Civitai. Не вышло: выдает ошибку при попытке отправить. Любые другие файлы туда заливаются, как обычно, а этот нет. Видимо, в Винни-пухии есть некая база с хэшами файлов, на которые действуют авторские права физ. и юр.-лиц., а владельцы цифровых платформ с ней постоянно сверяются. Но мне позарез надо именно эту модель и именно на чонговском сервере, так что буду искать способ подредактировать файл, не ломая чекпойнт. Всего-то пару битов надо поменять. Что мне, социальный рейтинг за это снизят?
Скачал, установил, модель epicphotogasm_z.safetensors. В настройках выбираю модель, загружаю - ошибка. Что делать?
"\text-generation-webui\installer_files\env\Lib\site-packages\transformers\configuration_utils.py", line 708, in _get_config_dict
raise EnvironmentError(
OSError: It looks like the config file at 'models\epicphotogasm_z.safetensors' is not a valid JSON file."
Перекатываться в Midjourney
Т.е. ты скачал webui для чат-бота и пытаешься запустить на нём модель от stable diffusion?
Ебанько, все модели Pytorch плюс-минус одинаковые - на тензорах.
>"хочу голых фотореастичных бап!"
>"скачай текстовый генератор!"
>"закатывайся в Midjourney!"
Советы из 10 прям. Впрочем, долбоёб сам виноват, нашёл где спросить.
Гайды в шапке. После установки диффузии скачай модели (в прошлых тредах можешь поискать их названия). И запомни, хороший апскейл исправляет плохой арт.
На этапе установки гита убери пару галочек, забыл каких, чтобы он не добавлял свои пункты в контекстное меню папок. Там написано что-то про folder, new, bash, here. И устанавливай диффузию на большой диск, нужно хотя бы 20 гигов, модели весят мноно, и арты тоже если их много.
По заветам хача поступи и смени метадату-описание-примеры. Нюансы могут быть только если кто-то обнаружит сходство и решит зарепортить куда следует.
> text-generation-webui
Вот ты содомит
Тебе нужно вот это https://github.com/AUTOMATIC1111/stable-diffusion-webui что как ищи гайды
Господа хорошие, вот эти самые модели с пушком, втуберы и прочее, они через что делались, будка или уже что-то сложнее?
Собственно в чем подводные капни взять, натащить хороших годных артов в бур, подмешать не совсем 3д но уже с какими-то позами, бэкграудов, кое как отбалансировать и дообучить свою? Алсо реквестирую если вдруг есть где за это почитать, заодно и фичи типа vpred.
Да, мерджил Супермерджером сразу, как на скрине настройки были. Оно не так чтоб прям совсем сломалось, но результат по ощущениям хуже стал.
>вот тут найди 132 эпоху просто
lion-low-lr-e132-terminal-snr-vpred-e105
Эту?
Этот совет не работает. Заменяйте вашу бесполезную шапку, с которой вы сами ничего не умеете. Работает следующий:
1. Выполнить инструкции установки https://github.com/AUTOMATIC1111/stable-diffusion-webui
2. Скачать большой файл и положитьв директорию stable-diffusion-webui\webui\models\Stable-diffusion\
https://civitai.com/models/132632?modelVersionId=201259
3. Открыть в броузере http://127.0.0.1:7860/ Выбрать Stable Defusion Checkpoint = файл скачаной модели
Снизу нажми load more files, потом ctrf+f 132 ищи, качай модели сразу с конфигами .yaml на всякий случай, если захочешь пользоваться именнно ими, а не производными миксами.
Потому что он тебя пранканул, посоветовав скачать вебуи для генерёжки текста, а не картинок.
Зашифруй в архив просто тогда.
> Господа хорошие, вот эти самые модели с пушком, втуберы и прочее, они через что делались, будка или уже что-то сложнее?
С пушком там вообще какие то свои скрипты были на мощностях гугла, нахера они тебе сдались? Рак из А100 завалялся?

> выспись
БЛЯТЬ я чето реально не спал два дня и уебался скопировав не то и не заметив сука
Он и не должен работать, ведь это рофл или советчик действительно не проспался. Да и тред не про то как запустить в первый раз, за таким в генережку проследуй.
> нахера они тебе сдались?
Зачем они, в целом метод и принципы хочется понять, а проблемы решать уже по мере их появления и с учетом рациональности.
Вот тут был описан основной принцип https://arxiv.org/abs/2305.08891 как тренить не лору с чекпоинта уже натрененного на новые фичи вообще без понятия, всё равно это скорее всего неосуществимо без мощностей, но попробуй, расскажи если что вдруг получится.
А ты я смотрю сверхразум, который знает как запустить stable diffusion в text-generation-webui
Нет, итог все-таки ломается.
Не прям полностью ппц, но бракованных картинок заметно больше выдает.
Странные перенасыщенные цвета на части генераций, цветовые пятна какие-то вылазят не к месту, яркость и контрастность довольно сильно могут от картинки к картинке меняться.
А вот улучшения качества по сравнению с исходником мерджа не заметил практически.
В метаданные напиши че-нибудь, тогда хеш сменится (с помощью checkpoint merger)




> предвзято смотрят на фуррей с высока
Да ладно, это ещё очень весьма толерантное упоминание этого сообщества.
> Что-то как-то по ощущениям хуже стало.
Надо обязтельно именно те версии моделей, что на скрине были, как минимиму ФР, он отправная точка:
Ругалась на спамлист - точные имена файлов https://pastebin.com/kfp77fB3
ЕФ может ещё прокачают, думаю, его можно просто последнюю брать.
> Может, не те модели мерджил? Стянул с цивита первую попавшуюся - а там на них на всех конфиги нужны, а ФлаффиРок так вообще без ЦФГ-рескейла в базе не работает.
Конфиги нужны (но они почти все одинаковые) только если ты хочешь на этих моделях генерить. Хотя я не проверял без них мерж, не буду врать. Но результат разницы работает без конфига.
> И что-то мне подсказывает, что с таким мерджить обычную модель - не слишком правильная идея.
Простой суммой - да. С разницей мы же получается из модели с конфигом вычитаем модель с конфигом, оставляя только разницу со своей. И фактически, хоть это и звучит не очень математически, но необходимость конфига тоже "вычлась".
Специально повторил скриншот на рэндомной попавшейся под руку ламетте - нормально. Смеха ради на повторил на простите капусте3 - тоже нормально.
1Ламета, 2 ЛаметаФ, 3 ЭниТрин, 4 ЭниТринФ
> 1Ламета, 2 ЛаметаФ, 3 ЭниТрин, 4 ЭниТринФ
Блин. Правильно поставило так:
1 ЭниТрин, 2 ЭниТринФ, 3 ЛаметаФ, 4 Ламета
>но бракованных картинок заметно больше выдает
Это норма. Генери больше картинок, чтобы было больше хороших.
>цветовые пятна какие-то вылазят не к месту
Поставь VAE.
Как на глаз определять с чем я сосну, а с чем несосну при 16GB VRAM?
Вот например файл sd_xl_base_1.0.safetensors мне можно пробовать? Посоветуйте еще файлов с голывми бабами, чтоб подходили.
Вот например файл sd_xl_base_1.0.safetensors мне можно пробовать? Посоветуйте еще файлов с голывми бабами, чтоб подходили.
>Поставь VAE.
Оно не от вае так (тем более все подключено).
Это именно в генерации какой-то косяк.
Типа, ядовито-фиолетовые соски. Или что-то типа краски случайного цвета, разлитой по персонажу. Цветовые акценты на одежде, волосы разного цвета, артефакты на коже, и всё такое.
>Это норма.
Зачем оно мне, если я значительной разницы по сравнению с исходником не наблюдаю?
Ногой в жопу не ходим, как говорится, но вообще крайне лояльно и себя не превозносят, отдельные личности всегда бывают.
Поставить галочку sd_api?
В рамках развлечений не пробовал мерджить разницу между тем же изифлаффом и флаффироком, или наоборот, или менять местами в той последовательности их миксы с "базовой моделью"?
> ядовито-фиолетовые соски
Как раз похоже на косяки вае, вылезают на мелочах, гранях, стыках. Хотя другое описание похоже на работу диких семплеров типа dpm3m... и нюансы с cfg покажи пример.
Обычный СДЕ-карась. 8 цфг. 24 шага.
Особенно мощно проявляется, если лора на яркий и насыщенный стиль какого-нибудь художника подключается. Тут вообще караул.
Без лор, на чистом мердже, проявляется больше в очень резком и странном шэйдинге, и тех самых ярких цветовых акцентах на одежде.
Покажи что там. Если стесняешься то сделай отдельную пикчу по простому промту где это проявится. Лучше сразу на котокоробку заливай чтобы с экзифом.
Попозже немного, сейчас другая задача.
>Если стесняешься
Да что там стесняться, просто аниме-тянки, как будто кто-то их тут не видел.

> В рамках развлечений не пробовал мерджить разницу между тем же изифлаффом и флаффироком, или наоборот, или менять местами в той последовательности их миксы с "базовой моделью"?
Не оч понял как. Напиши, что в А, В и С поставить. Но вообще к этой схеме я пришёл когда пытался просто вмержить традиционным способом разницу от (ФР - наи) в свою модель. Там я как раз и попал в то странное место, когда в одной модели есть конфиг, в остальных нет, и в итоге получалась хтонь.
Спасибо, ну стоящее за этим примерно понятно, теперь вопрос в практической реализации. Имплементация фиксов же уже должна быть.
> вмержить традиционным способом разницу от (ФР - наи) в свою модель
Здесь, по идее, как раз хтонь и пойдет из-за разнородных весов, плюс диалект и байас появятся.
A - базовая B - изифлаф C - флаффирок, или BC местами махнуть но тогда результат может странным выйти.
> A - базовая B - изифлаф C - флаффирок, или BC местами махнуть но тогда результат может странным выйти.
Это было второй стадией, когда стало понятно, что ни вычитанием Наи, ни СД1.5 ничего не добиться. Так тоже результирующая модель ломалась, с конфигом и без. Получилось только "вывернув наизнанку" что куда мержить.
> BC местами махнуть
Изифлафф это мердж на основе флуфирока, грубо говоря можно ИФ считать чем то типо б64, а ФР наи, только в мире фуррей.
> Спасибо, ну стоящее за этим примерно понятно, теперь вопрос в практической реализации. Имплементация фиксов же уже должна быть.
--v_parameterization --zero_terminal_snr --scale_v_pred_loss_like_noise_pred у кохи, там уже можно что то типо полноценных чекпоинтов тренить, а не просто лору+локон, можешь попробовать.
Кочяйте дрова, пидоры. Куртка вам костыль запилил.
https://nvidia.custhelp.com/app/answers/detail/a_id/5490
https://nvidia.custhelp.com/app/answers/detail/a_id/5490
О, как раз для кохя-дебилов, то что нужно. Ну, в рамках экспериментов почему бы не попробовать, на полноценный чекпоинт врядли офк выйдет, но может что-то новое в тренировке более абстрактных вещей, более общих стилей, групп персонажей или еще какой-нибудь хери. В идеальном раскладе какой-то твик с возможностью подмешивания.
Можешь даже не пытаться тренить с этой хернёй лору с обычного чекпоинта типа наи, там полный провал будет, я уже пробовал, оно просто шум будет генерить, хотя можешь сам убедиться, если не веришь. Остаётся либо файнтюн, либо лору с уже готового файнтюна.
Ну хотя бы не забили полностью и то радует, я уж думал что им похуй стало, когда это из ишьюсов пропало.
Как раз дообучение модели рассматриваю, если такое на нищежелезе заведется. Если, например, с таким параметром ту же наи брать - не взлетит? Некоторые файнтюны вроде с нее и делались, причем включают нужное, но может там какие особые нюансы.
Это срабатывает с лорами нормально только с флуфироком, потому что он уже был натренен с впредом, но вымыл все предыдущие знания привычных моделей долгой тренировкой. С наи оно тренится конечно, даже градиентный спуск правильный на графике при годном лр, но генерит на выходе шум, возможно нужно грузить модель при использовании такой лоры с конфигом v_param или как оно там, чего я не пробовал делать.
То есть теперь оно по-старинке в ООМ падать будет?
Ну глянь ссылку, добавили возможность настраивать, причем даже индивидуально для приложений с помощью функционала их драйвера.
Зачем намеренно делать хуже?


https://files.catbox.moe/tbfa7z.png
https://files.catbox.moe/7j1fgc.png
Ну вот, например. На первой совершенно точно какая-то фигня с контрастом.
На второй - неестественные цвета.
При этом на оригинальной модели ничего такого и близко нет. Контраст ровный по всем изображениям, и таких цветовых аберраций тоже не встречается.
Это без лор. Если лоры начинать подключать - в синей и фиолетовый (почему-то в эти два цвета в основном) смещает еще сильней, и довольно часто.
А, еще сильно блюром засирает почему-то. Приходится негатив добавлять.
Так там ж в новости написано было.
На 6 гигах у юзеров оно туда-сюда часто прыгало. Чтоб это предотвращать - и вернули возможность старый ООМ сделать, который тебе генерацию прерывает, и ты можешь настройки чутка в сторону уменьшения передвинуть.
Мне вот с моей 4080 тоже не всегда непонятно бывает, когда я в память еще укладываюсь, а когда - уже нет.
8 картинок 800х600 одним батчем сгенерить и из памяти не выпасть - оказывается, можно.
Налету из супамёрджера почему-то некорректный выхлоп.
Если сводить, то результаты другие.
> --v_parameterization
> --scale_v_pred_loss_like_noise_pred
Модель с этой штукой изначально нужна, шум. В скрипте файнтюна (а нужен он вообще сейчас при наличии будки то?) вообще нах шлет типа иди со своей 1.5 и xl лесом, подавай 2.х.
> --zero_terminal_snr
А вот эта штука с будкой делает круто, бледная пересвеченность наи пропадает почти с самой первой эпохи и местами хтони становится меньше.
Но полноразмерное обучение на нищежелезе, офк, та еще боль, пощупать оптимайзер кроме 8битного - почти гарантировано своп врам и кратное замедление.
> Поставить галочку sd_api?
И что, у тебя тогда text-generation-webui начнёт поддерживать stable diffusion модели? Клоун


Что за DeepFloyd IF, почему issue с ним самое залайканное у автоматика на гитхабе? Типа так круто? Как я понял, это какой-то заброшенный "убийца" stable diffusion только в пиксельном пространстве
Кстати еще какой-то Parti есть в сравнениях на сайте. Судя по гитхабу, это нейросеть от гугла, чуть менее заброщенная , 3 недели назад
Кстати еще какой-то Parti есть в сравнениях на сайте. Судя по гитхабу, это нейросеть от гугла, чуть менее заброщенная , 3 недели назад
DF IF неплохая модель, хорошо понимающая промпт, с трансформером на входе, из-за этого упирается в 24ГБ даже при инференсе, плюс лицензия если помню довольно хуёвая, поэтому не взлетело. Можешь в комфи попробовать если железо есть, там есть поддержка.
Parti это мем от гугла, они еще до SD выпустили его и никому не дают толком. Сеть судя по всему сильно недотренирована для своего ебанутого количества параметров, в общем meh.
>8 картинок 800х600 одним батчем сгенерить и из памяти не выпасть - оказывается, можно.
В 16 гигов спокойно 18 пикч на батч влезает таких.
> Модель с этой штукой изначально нужна, шум.
А с конфигом впреда если загрузить основную модель? С какого нибудь флуфирока сдёрни попробуй.
> В скрипте файнтюна (а нужен он вообще сейчас при наличии будки то?) вообще нах шлет типа иди со своей 1.5 и xl лесом, подавай 2.х.
Видать очень старый, это не является уникальной фичей 2.х
> А вот эта штука с будкой делает круто, бледная пересвеченность наи пропадает почти с самой первой эпохи и местами хтони становится меньше.
Они вместе вроде должны использоваться, удивлён что срабатывает. Чёрную или белую пикчу полностью может сделать?
> Но полноразмерное обучение на нищежелезе, офк, та еще боль, пощупать оптимайзер кроме 8битного - почти гарантировано своп врам и кратное замедление.
Ну а просто лору если?
Батчедебилы, что вы с ними делаете???
Это ты клоун, не догоняешь сарказм и то что здесь много людей пишет?
> А с конфигом впреда если загрузить основную модель?
А куда его совать, в списке параметров не нашел, подсосет по имени? Врядли что-то выйдет, но потом попробую.
> Видать очень старый
Ага, внимания ему не уделяли, тем не менее что такое xl знает.
> Они вместе вроде должны использоваться, удивлён что срабатывает
Тот же скрипт файнтюна отказывается работать и пишет что тренировка с этим параметром без v параметризации приведет к неадекватным результатам. В будке же работает и эффект есть, но в первых эпохах сильно чернае или сильно белые пикчи не выходили, лучше но еще есть куда. Надо полноценно потестить с норм промтом и показательным сравнением. И затестить использование не чистого наи а тех же фуррей базовой и ее фантюнить, а потом примердживать в несколько этапов.
> Ну а просто лору если?
А с лорой какие проблемы, при случае ту опцию офк попробую, но по идее все должно работать.
Можно анимации генерировать, а так для ускорения достаточно и четырех.
Статья пропала из рентри и саппорт сказал, что у них вообще нет никаких записей о данной статье.
https://rentry.org/2chAI_easy_LORA_guide_re
Перенесли статью сюда, ссылку в шаблоне поправил.
Клоун, думаешь поменял ник нейм, и теперь это не ты типа
Роллю хорошие сиды.
Кстати у автоматика есть ветка webui с fp8. И вроде как развивается. Sdxl на 2gb чтобы запускать или что хах. По качеству 8bit не существенно хуже 16bit
Разве у кумерских видях есть аппаратная поддержка FP8? Медленно же наверно пиздец.
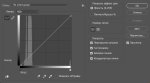
Лiл
так вроде же наоборот, чем выше флоат тем медленнее и ресурсоотсоснее разве нет?
>Кстати у автоматика есть ветка webui с fp8
ссылку
если FP8 не поддерживается аппаратно (консумерские не умеют кроме 4 серии вроде), или если блоков на него мало (все консумерские), его надо эмулировать софтверно на FP16 или что там поддерживается
Качество там сосёт, это тебе не текстовые модели, для графики такое только для совсем нищуков. Вот недавняя мокрописька для понижения количества шагов семплинга уже сдохла, как и всё до неё.
Однако, ставил кто? При апскейлах и больших тайлах может пригодиться, другое дело какой импакт от такого.
> По качеству 8bit не существенно хуже 16bit
Сравнений бы.
У языковых моделей как-то сделали. Там вообще квантование 8, 7, 6, 5, 4, 3, 2 бита для cpu/cuda (gguf), или 8, 4 бит только на видеокарте (gptq). Но думаю оно точно медленней нативного 16 бит, но проверить не могу
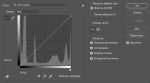
Просто открываешь репозиторий автоматика, и выбираешь ветку test-fp8. Установить - консоле делаешь git checkout test-fp8. Но там тесты поломаны, может понадобиться откатиться. Активности кстати побольше чем в dev
Кстати гуглил stable diffusion 1 gb vram, там форк вообще с квантовантем 2 бита. Но не тестировал, а примеров в редми нет
https://github.com/ThisisBillhe/tiny-stable-diffusion
Название коммита
> Add sdxl only arg
Видимо реально для 2 гб запускать xl собрались
Не фантазируй, нихуя там не сдохло, сейчас туда привинчивают контролнеты (которые надо заново обучать) и остальные необходимые причиндалы, плюс делают SDXL вариант. Способ вполне солидный и давно известный, автор лишь нашёл как это делать не за 60 дней на A100, а за 35 часов, просто этот довен умудрился запёчь семплинг с CFG 1 в свою изначальную модель. Как только релизнет скрипты для тренировки, можно будет экспериментировать с перегонкой моделей на нормальных настройках и с разными приёмами для улучшения.
У lcm же есть параметр guidance scale, разве это не cfg scale? Или немного другое, поэтому и название другое дали?
> умудрился запёчь семплинг с CFG 1
Естественно, классический CFG с негативом не будет там работать.
> Способ вполне солидный
Пока что результаты полное говно.

> Пока что результаты полное говно.
Ну я в dall-e тред кидал картинки из lcm, причем 512х512, и никто мне даже слова не сказал
Эта хуйня всего лишь запекает траектории семплера в отдельную фиксированную нейронку, включая все настройки, и CFG в том числе. Т.е. выставить-то изначально можно, просто оно останется фиксированным. Чтобы негативы и т.п. работали, надо пилить (и обучать) отдельные адаптеры. Либо юзать основу + зерошот для этой запечённой нейронки.
Фактически делают GAN-генератор из диффузии. Звучит как кал. GAN тоже умеет с ограниченным датасетом быстро обучаться и выдавать хорошую картинку, но у него проблема в универсальности. А тут теперь наоборот делают шаг назад. У нас и так на каждый пук отдельные модели и пачка лор, а с этим вообще пиздец.
> подсосет по имени?
Да, просто с названием модели его сделай.
> А с лорой какие проблемы, при случае ту опцию офк попробую, но по идее все должно работать.
В том то и дело что никаких, требования ведь к ресурсам куда меньше.
Не знаю откуда ты там взял именно GAN. Дополнительная сетка ускоряет решение обычного или стохастического дифура, заменяя собой стандартный солвер (эйлеровский и т.п.) при семплировании. А U-Net и прочие компоненты диффузионной модели остаются абсолютно те же.
> просто с названием модели его сделай
Хм, попробую. Но там же что-то внутри помимо него должно быть, не? Ресурсов жаль по этому всему нет, или они от хлебушков прячутся. Наверняка же есть скрипты чтобы нужную часть поправить, или там юзают что-то простое уровня добавление разницы тюненой модели со стоковой sd1.5.
> В том то и дело что никаких
Тут думать и заниматься надо, а там натащил, совсем говняк процедурно отсеял, поставил-забыл на несколько (десятков) часов, и довольно урчишь что оно час только латенты обрабатывает если в первый раз или без кэша на диска.
Но вообще как оно будет просто со здоровенной лорой хз, может окажется более эффективно чем что-то так натренивать и потом пытаться примердживать разницу.
> Хм, попробую. Но там же что-то внутри помимо него должно быть, не? Ресурсов жаль по этому всему нет, или они от хлебушков прячутся. Наверняка же есть скрипты чтобы нужную часть поправить, или там юзают что-то простое уровня добавление разницы тюненой модели со стоковой sd1.5.
Просто автоматик автоматом не распознаёт впред модели и не подгружает их соответствующим образом, никакой особой магии тут нету, достаточно просто parameterization: "v" в params: дефолтного v1-inference.yaml конфига добавить. Впрочем я уже попробовал, пиздец примерно как у этого анона получается с обычной моделью видимо он тоже неправильный конфиг подсовывал этому бусту, там дефолтный нужен.
А, стопэ, ты про то что кохя делает все правильно а это автоматик неверно загружает модель и причина шума в нем? Эх уже те тестовые удалил, спасибо, попробую.


Нет, я имел ввиду что нету смысла тренить впред лору/использовать конфиг впреда с дефолтными моделями, вот что у меня генерит с конфигом впреда обычной моделью, пик1. Тренить с впред модели впред лору/использовать такую лору в дальнейшем с обычными моделями приемлемо, хоть и херня полная по сравнению с наи, если бы у нас был подобный аниму файнтюн, а не фурри, было бы куда лучше вообщем то.
Таак, ну значит что-то там быстро настренил одну эпоху, подкинул рандомный конфиг и оно действительно начинает вместо шума выдавать что-то похожее на картинку, разница значительная. Будет ли конечный результат что адекватным - хз, надо будет сейчас побольше закинуть и потом сравнить результаты тренировки с в-параметризацией и без нее.
> Таак, ну значит что-то там быстро настренил одну эпоху, подкинул рандомный конфиг и оно действительно начинает вместо шума выдавать что-то похожее на картинку, разница значительная.
Просто с терминал снр с наи имеешь ввиду с дефолтным конфигом?
> Будет ли конечный результат что адекватным - хз, надо будет сейчас побольше закинуть и потом сравнить результаты тренировки с в-параметризацией и без нее.
Нечестное сравнение будет так то, с впредом получится ведь только с фуррей тренить, а с терминал снр можно и без, судя по тому что ты писал ранее.
> Просто с терминал снр с наи
Оно и без конфига работает, эффект есть, но черные/белые фоны всеравно не рисует. А вот натрененноое на будке с полным списком параметров
> --v_parameterization --zero_terminal_snr --scale_v_pred_loss_like_noise_pred
без конфига выдает шум, с конфигом пикчи. Лосс при этом правда в начале сильно больше, но вроде как на спад идет, тренится в 1.5 раза дольше чем без этих параметров. Хз получится ли там что-то вразумительное, и надо поискать не может ли сам скрипт правильный конфиг соответствующий модели формировать, и насколько это в принципе может работать или полная херь.
> с впредом получится ведь только с фуррей тренить
Он же там как-то появился и не только в фуррях встречается. Врядли yolo с простым выставлением параметра в дримбусе сработает, но пусть помолотит.
> --v_parameterization
Для чего это вообще нужно? Нагуглиит ничего не могу кроме того что какой-то фурри создал issue что его модель не работает с invoke ai. (После того как тот скинул ссылку на фурри модель, как пример модели с этим v, коллабаратор вышел в игнор, лол)
Это типа оптимизация, чтобы обучение на больших картинках не заняло дофига времени?
> Он же там как-то появился и не только в фуррях встречается.
Вот так и появилось скорее всего
> А вот натрененноое на будке с полным списком параметров
А вообще хз насколько долго это нужно тренить, но зачем тебе специальная плевалка конфигов не пойму, там же литералли надо один параметр добавить, как я выше писал. Лучше автоматику пр кинь, чтобы впред модели как нибудь распознавал и подгружал с соответствующим конфигом, а не вот это вот всё.
> Для чего это вообще нужно?
Чтобы улучшить качество генераций и чтобы уйти от привязки к средней яркости. Есть и другие модели с этим, как вариант https://huggingface.co/vivym/bk-sdm-tiny-vpred
> Вот так и появилось скорее всего
Ай лол, ну не, должна же быть адекватная схема.
> хз насколько долго это нужно тренить
Вопрос хороший, за 10 часов там лосс с 0.27 упал до 0.10, хз насколько может быть метрикой здесь.
> там же литералли надо один параметр добавить
Оке, честно внутрь даже внимательно не смотрел, натащили всякого и хз что из этого важно.
> Ай лол, ну не, должна же быть адекватная схема.
Чем эта неадекватна? Ну тренят просто нормальные модели на больших датасетах куда дольше да и всё.
> Вопрос хороший, за 10 часов там лосс с 0.27 упал до 0.10, хз насколько может быть метрикой здесь.
Здесь он хотя бы по учебнику тебе может показать, если что делаешь не так, я пробовал ради прикола, он действительно будет стоять на месте из-за маленького лр, или дёргаться вверх-вниз сильно из-за большого.
> --scale_v_pred_loss_like_noise_pred
Вот этой штукой к "привычным" значениям кстати скейлится.

> Чем эта неадекватна?
Значит просто не так понял суть этой херни.
> Здесь он хотя бы по учебнику тебе может показать
Что-то показывает. Без этих параметров с идентичными остальными вокруг 0.09 вьется, возможно там уже лр надо поднимать, ну пусть уж дотренится чтобы было понятно. Алсо остановка обучения текстового энкодера насколько здесь полезна?
Я не знаю, такие долгие тренировки не запускал, что хоть тренишь?
Вопросы по фурримёржу. Смотрится ооочень перспективно - но, как обычно, надо изучать.
1. Есть ли способ повторить фурримёрж без локальной видеокарты? Хватит ли проца и 16 гб оперативки? Если нет - то в каком облаке реально это провернуть, учитывая, что для этого нужен автоматик (или есть консольная версия??) ? Колаб отпадает, так? Тогда остаётся кегля... и/или что?
2. Нельзя ли провернуть эту процедуру с классическими базовыми моделями типа NAI и AnythingV3 и залить их куда-нибудь? Будут ли такие можели обучаемы? Можно ли юудет с ними мёржить другие модели?
1. Есть ли способ повторить фурримёрж без локальной видеокарты? Хватит ли проца и 16 гб оперативки? Если нет - то в каком облаке реально это провернуть, учитывая, что для этого нужен автоматик (или есть консольная версия??) ? Колаб отпадает, так? Тогда остаётся кегля... и/или что?
2. Нельзя ли провернуть эту процедуру с классическими базовыми моделями типа NAI и AnythingV3 и залить их куда-нибудь? Будут ли такие можели обучаемы? Можно ли юудет с ними мёржить другие модели?
3. Наконец, не мог бы ты, анон, выложить результаты удачных соитий? Те самые, картинками с которых ты хвастаешься. Даже если метод не универсален, даже если он подходит лишь к нескольким процентам моделей - это всё равно очень значимое достижение. Анимэшная полторашка с рабочим разрешением 1024х1024 - это ж не фиг собачий, это прорыв!
Не возбуждайся так сильно. Отдрочись, успокойся.
Как натренировать лору удачно? Что там с переобучением и нормализующими картинками?



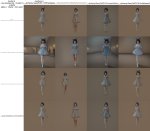
Пока просто эксперимент, голую наи на немного сортированной подборке пикч с интересующими элементами с гелбуры. Получилось не много но и не мало, около 46к, в случае если будет какой-то намек на положительный тренд, стоит попробовать их разбавить различными сценери и поиграться с теггингом чтобы разнообразить еще фоны и как-то отбалансить, а то от одних чаров как бы не лоботомировались беки. В тренировке батчсайз 3 градиент аккумулейшн 10.
Ну совсем предварительные результаты если смотреть - вроде работает, в промте рандом, первая с затемнением, вторая с белым фоном.
Если смотреть гриды по эпохам (пик3, на первом месте наи) - в первой кровь-кишки-распидарасило, хотя лосс с 0.25 упал до 0.13, далее постепенно оживает, в гридах пик1-2 четвертая, к ночи 6я будет. В гридах кстати иногда багует и может сгенерировать с шумом, при генерации отдельно все ок.
Алсо если ее продолжить ее дообучать там у кохи никаких подводных камней нет, или нужно специально что-то для продолжения готовить?
По тренировке без впреда смешанный результат, оно вроде получше и детальнее становится засчет разрешения и вроде чинит, но иногда наоборот распидорашивает, хз, ожидалось больше. Возможно нужно лр поднимать, там лосс почти с самого начала стоит на месте.
Но зачем мне успокаиваться, анон? Нейронки - это же так прекрасно! Они вносят в мою жизнь радость и яркие эмоции :з
> В тренировке батчсайз 3 градиент аккумулейшн 10
Как влезло?
> Ну совсем предварительные результаты если смотреть - вроде работает, в промте рандом, первая с затемнением, вторая с белым фоном.
Выглядит интересно, уже как будто болезнь рейнджа пропадать начинает, что по "a black background/a white background" онли без негативов в родном разрешение, в котором тюнилось?
> в первой кровь-кишки-распидарасило, хотя лосс с 0.25 упал до 0.13, далее постепенно оживает, в гридах пик1-2 четвертая, к ночи 6я будет
Тут сильно всё вымывается вначале, потом уже идёт вменяемое обучение, как будто переиначиваешь веса модели работать сильно по другому, вот в этом и проблема с фаст тренингом лор, оно просто дальше вот таких первых эпох обычно не заходит.
> Алсо если ее продолжить ее дообучать там у кохи никаких подводных камней нет, или нужно специально что-то для продолжения готовить?
Ну вроде не должно быть, я просто опять же такой долгий файнтюн не делал, были какие то аргументы специально под это, но я их уже не помню.
> засчет разрешения
Какое кстати, 1024?
Тоже чтоли попробовать, если с этим можно уложиться в пару дней, выглядит многообещающе. Датасет только надо очень сильно отполировывать для такого, благо у меня много скопилось уже впринципе их. Скинешь командлайн с параметрами, которыми ты тренил?
Кстати, я забыл тебе сказать, ещё же вот эта хуйня нужна будет потом https://github.com/Seshelle/CFG_Rescale_webui с ней должно быть лучше с цветами, если пережигает, ставишь 0.5-0.7 или типо того




> Как влезло?
Подношения правильному пантеону.
А вообще что удивительного, тренировка в 768, без градиент аккумулейшна влезает батч сайз 4, с ним 3. К 1024 скептически отношусь и если и делать то постепенный подъем почти наверняка выйдет лучше. Надо вообще до 640 наверно пока спуститься чтобы оно без сильного стресса в-параметризацию переварило а потом уже разработкой очка разрешения заниматься.
> что по "a black background/a white background"
> 1girl, white background, simple background
> 1girl, black background, simple background
Вторая пачка с лоу-ворст квалити, это какбы наи, там тот еще шизопромт нужен.
> вот в этом и проблема с фаст тренингом лор
Не уверен что здесь подобная аналогия подходит, ведь здесь просто радикальные отличия в некоторых участках да и для персонажей пока ничего лучше быстрой нет и все равно датасет первичен.
> были какие то аргументы специально под это
Ууу бля, ладно придется изучать.
> Датасет только надо очень сильно отполировывать для такого
Это да, и по-хорошему нужно балансировать. С регуляризацией не страдал, но находил что для будки ее использовали, по эффектам хз.
> Скинешь командлайн с параметрами, которыми ты тренил?
Так буквально дефолтный дефолт что выдало гуи только с добавлением тех опций на впред. Лр имеет порядок e-6, по оптимальному значению хз. В высоком разрешении потрогать что-то кроме адам8 или других восьмибитных оптимайзеров не выйдет. Ну если не разберешься пиши, скину полный.
А чем сейчас *буру грабить нормально можно? Раньше помню какой-то скрипт к ГрисМанки был, всё легко тянул и быстро. Сейчас скрипты те, что есть тянут только превью. Нашёл какой-то дремучий стэндэлон, но он ему приходится впн заводить, а это очень медленно.
https://github.com/Bionus/imgbrd-grabber
База же. Если из этой страны то без впн всеравно не обойтись.
> постепенный подъем почти наверняка выйдет лучше
Всё так, фурри тренили с 576+128 каждую n-ную эпоху повышая разрешение.
> > 1girl, white background, simple background
Да нет, 1гёрл всё портит и нихера не понятно, так и обычная модель может рисовать, нужно именно просто a black background и white тоже.
> Так буквально дефолтный дефолт что выдало гуи только с добавлением тех опций на впред. Лр имеет порядок e-6, по оптимальному значению хз. В высоком разрешении потрогать что-то кроме адам8 или других восьмибитных оптимайзеров не выйдет. Ну если не разберешься пиши, скину полный.
Ну скинь всё таки команду просто, если не впадлу, не хочется в гуе копаться, просто в венв и в бой.
Понятно, я на него и вышел. Спасибо.


Ага, ну значит надо сворачивать и новую запускать, хотя лучше пока датасет чуть разнообразить.
> 1гёрл всё портит и нихера не понятно
Очень даже понятно, средняя яркость пикчи не нулевая. И обычные модели не нарисуют, там будет или лютый клозап, или много лишних ярких элементов. В случае же белого фона там или персонаж станет негром, или его будет много и обязательно с темными волосами. Без вангерла там или темно-серые квадраты или странные объекты. Оно если в редакторе открыть видно, для сравнения пик4 - с обычной модели.
accelerate launch --num_cpu_threads_per_process=2 "./train_db.py" --enable_bucket --min_bucket_reso=256 --max_bucket_reso=2048 --pretrained_model_name_or_path="модель" --train_data_dir="датасет" --resolution="768,768" --output_dir="выход" --logging_dir="логи" --stop_text_encoder_training=3096 --save_model_as=safetensors --output_name="имя" --lr_scheduler_num_cycles="6" --max_token_length=225 --max_data_loader_n_workers="2" --gradient_accumulation_steps=10 --learning_rate="2.2e-06" --lr_scheduler="constant_with_warmup" --lr_warmup_steps="774" --train_batch_size="3" --max_train_steps="7738" --save_every_n_epochs="1" --mixed_precision="fp16" --save_precision="fp16" --caption_extension=".txt" --cache_latents --cache_latents_to_disk --optimizer_type="AdamW8bit" --max_data_loader_n_workers="2" --max_token_length=225 --clip_skip=2 --bucket_reso_steps=64 --mem_eff_attn --shuffle_caption --xformers --persistent_data_loader_workers --bucket_no_upscale --v_parameterization --zero_terminal_snr --scale_v_pred_loss_like_noise_pred --output_config
Хрен знает, на что именно рентри агрится, в саппорте сказали, что ничего не знают
Автор статьи принял одну попытку запаблишить статью повторно я же опубликовал её ещё три раза Во всех случаях статью из rentry выпиливают в течении нескольких часов.
> --clip_skip=2
> --v_parameterization
Пиздец шизоид.
Ну раз ты недоволен, все, сворачиваемся.
Ты уж определись, у тебя полторашка или 2.0/XL.
Да не сворачивай, лучше продолжи, вот теперь реально понятно что всё идёт по плану, прошлые примеры мне и обычная модель рисовала просто, такие только с хлл мерджами были.
Спасибо, потом тоже попердолюсь.
Окно контекста вмещает только 3 поста вверх? Это ваниальная наи где херь вместо весов в том слое.
Не, там вон уже пятая эпоха вылезла, 6ю ждать смысла не вижу. Будет в качестве референса, надо пустить в 512 или 576 (может другой оптимайзер даже влезет), пусть впред сначала аккуратно пробьет а потом уже разрешение поднимать. С другой стороны из-за малого датасета при долгом обучении на нем как бы проблем не полезло.
v parameterization не используется в полторашке. То что ты тренируешь неиспользуемые параметры - явно полнейшая хуйня. У тебя должен быть чекпоинт с v-ema, это SD 2.1 768, например.
> эксперимент по тренировке изначально отсутствующих параметров по успешному примеру
> это параметры не используются в 1.5, нужна другая модель!
Бля пчел, проспись
Я и говорю шиз. Если тебе надо куда-то сливать нежелательные градиенты, то и делай помойку для них. Тебе коха дал возможность по слоям/блокам контролировать это, а ты занимаешься шизой.
В каких слоях/блоках сосредоточена эта часть?
> может другой оптимайзер даже влезет
Умел бы он ещё работать с этим нормально, я не видел файнтюнов на адаптивных, только лион и адам.
Твой наброс явно не вяжется вот с этим челом https://huggingface.co/lodestones успешно натренившим полторашку.
> успешно
В каком месте? Там жуткое мыло без детализации, фоны проёбаны, всё как будто маслом нарисовано и 2.5D лезет где не надо. Чтобы аниме нормально слушалась промпта достаточно взять модель под clip skip 1 или SDXL.
В успех фуридрочера верится больше чем в
> аниме
> под clip skip 1 или SDXL
переигрываешь
По делу то есть что сказать, или как обычно наброс ради наброса?
Анон, у тебя ванильная NAI с повышенным разрешением? Выложи плиз куда-нибудь, интересно же посчупать! А в диффузионные веса оно перегонится, чтобы с diffusers использовать?
Тебя на циве забанили? Куча моделей под clip skip 1 там есть.
> В каком месте?
Да в таком, что это наи на стероидах для клуба тех, кто не прочь и собаку.
> взять модель под clip skip 1 или SDXL
То есть натренить наконец хоть какую то замену наи, как у них, вариант ты даже не рассматриваешь?
Ты небось тот самый академик, у которого fp16 хватит всем и нулевые веса в порядке вещей.
Дело не в этом, хотя и на саму эту тему по поводу клипскипа 1 можно дискутировать, прочитай что изначально рассматривалось и для чего. Речь о дообучении и поиску оптимальных параметров с целью добавить нужные концепты/элементы/персонажей/улучшить что-то/... (уже делалось, примеров вагон) чтобы потом полученную разницу мерджить к другим моделям. Параллельно с этим возник вопрос о том можно ли и как прикрутить эту херь чтобы получать пикчи любой яркости и улучшить общую генерацию.
Каким хером здесь xl или тренировка с клипскипом 1 на ванильной наи модели? Себе же противоречишь после утверждений про
> сливать нежелательные градиенты
> натренить наконец хоть какую то замену наи
Чел, половина миксов уже давно ушли от clip skip 2. Ты хоть попробовал бы.
> нулевые веса
Это ты с блокнотиком тут нули в тензорах лор искал, лол? NaN - это не ноль. Ты вообще в курсе что ноль в весах лоры - это веса которые лора не будет изменять, естественно они в порядке вещей.
> натренить наконец хоть какую то замену наи
Вообще момент довольно интересный, но начать можно с чего-то чуть проще. Насколько вообще нормально тренятся чекпоинты на собачьей модели с точки зрения переносимости их на файнтюны/мерджи?
Лучше бы вместо выебонов как ты дохуя знаешь, насколько всех умнее и какую радикальную позицию имеешь конкретику по делу изложил. Уход от клипскипа 2 решит все проблемы, поднимет настроение и укрепит эрекцию, а все потому что в миксах подмешивали реалистичные модели и в слоях теперь не совсем мусор? Ну рили.
> Чел, половина миксов уже давно ушли от clip skip 2. Ты хоть попробовал бы.
А я вообще то и не заявлял что нужно тренить со 2, но в случае с наи скорее соглашусь с другим аноном, что он прав.
> NaN - это не ноль. Ты вообще в курсе что ноль в весах лоры - это веса которые лора не будет изменять, естественно они в порядке вещей.
Это видимо ты забыл отчего он там появляется.
> Уход от клипскипа 2 решит все проблемы, поднимет настроение и укрепит эрекцию
И ещё стабилизирует курс рубля!
> получать пикчи любой яркости
О какой яркости ты говоришь? Почти любая модель же может в яркое/тёмное освещение.
Повтори тесты выше на полторашке и получи пикчу с оче низкой или оче высокой средней яркость без применения обработчиков, костылей и контролнетов. Почитай статью на которую линк сбрасывали.
> Вообще момент довольно интересный, но начать можно с чего-то чуть проще. Насколько вообще нормально тренятся чекпоинты на собачьей модели с точки зрения переносимости их на файнтюны/мерджи?
Хз, лоры вон переносятся же, хоть и криво.
Так, на правах идеи. Анон, а почему за повышение разрешения отвечает не гипернетворк? Ну это же логично же! Ну, теоретически. В принципе, все детали нейронка делать умеет, а вот их согласование по краям нужно куда-то упихать. Никто не пробовал?
Ведь только гипернетворки - это истинное приращение знания и усложнение структуры. Всё остальное - это одно лечим, другое калечим.
Ну, теоретически.
Ведь только гипернетворки - это истинное приращение знания и усложнение структуры. Всё остальное - это одно лечим, другое калечим.
Ну, теоретически.
Лол. Шизоид со скип1 уже и сюда добрался. Уже хочется автобан за такое. Только написал: "клип скип 1" или "ХЛ" и сразу в РО. Вот жизнь настала бы...




> получи пикчу с оче низкой или оче высокой средней яркость
Не очень понял что не так с этим на полторашке, буквально 10/10 верных пиков по промпту. С негативом можно вообще почти полностью запретить свет или темноту. Чуть сложнее если надо светлое не тёмном нарисовать или наоборот, но оно тоже точечными негативами фиксится.
> Не очень понял что не так с этим на полторашке
> Прикидывается идиотом
Царская модель, пример пусть не 100% но вполне достаточной реализации. Нужно оценить что там замешано, какой именно компонент дал такой эффект, по аналогии с мерджами втуберов, мохнатых и прочего.
Никто не курсе, можно как-то контролнет заставить сохранять цвета при проходе через и2и?
Тайловый как-то фигово с этим справляется.
>Царская модель
Что за модель?
Тайловый как-то фигово с этим справляется.
>Царская модель
Что за модель?

> Уже хочется автобан
Можешь в /d/ попросить, выдадут тебе.
> Вот жизнь настала бы...
Тебе может ещё показать как в 2023 году полторашки могут генерировать в разрешении выше 1024 без всяких хайрез фиксов и не ломаться, как год назад?
Мне! Мне показать!!!
> можно как-то контролнет заставить сохранять цвета при проходе через и2и? Тайловый как-то фигово с этим справляется.
наложи отдельно color t2i adapter, управляемый исходником
Вопрос простой. Есть эффект inpaint. На статической картинке. А если нужно на видео его сделать? Вот максимум простая сцена, эротическая конечно, Актриса танцует на статическом фоне, но он тоже движется, типа камера плавает. Хочу ей 1) увеличить сиськи 2) уменьшить жопу и ноги 3) вообще вырезать эту актрису нахуй и поместить на ее место нарисованную в 3D по точкам, даваемым, скажем, нейросетью Mediapipe, но с модификацией фигуры. Как это делать?
Спасибо.
Помогает, но не очень.
Мелкие детали убивает по цвету, плюс цветовая утечка на соседние области начинается из-за него.
Ну теоретически эта хуйня отличается от фотошопа как раз тем что берет в расчёт семантику, для твоей ситуации это может оказаться и протеканием. Может её можно немного покрутить, хотя бы по силе, или по конечному шагу например. Не знаю, не пробовал, просто посоветовал, т.к. это вроде её ниша.
Запости картинку до и после порчи цвета, что ты под этим подразумеваешь. Может там вообще фотошопом проще пройтись, лол.


Можно как угодно пытаться изъёбываться с промптами или мерджами, как впред оно всё равно не сможет нарисовать, по крайне мере без костылей, фундаментальная проблема никуда не исчезнет.
Изучай After Effects
Шиза
> проблема
По твоим пикам больше похоже что фурри модель сломана, просто рисует скетчи без фонов вместо нормальных пиков. Я же её трогал, в фоны она очень плохо умеет, надо прям в негативы пихать "simple background" и изъёбываться чтоб получить что-то лучше мазни/скетчей на фоне.
На мердже посередине вообще цвета поплыли.
Лучше покажи как твоя фуррятина умеет в контроль яркости освещения сцены, а не то как она умеет делать пики без нихуя.





> По твоим пикам больше похоже что фурри модель сломана, просто рисует скетчи без фонов вместо нормальных пиков.
Да я и сам вижу что тут до сих пор проблемы, особенно с белым.
> Я же её трогал, в фоны она очень плохо умеет, надо прям в негативы пихать "simple background" и изъёбываться чтоб получить что-то лучше мазни/скетчей на фоне.
Сам не ебу как ей правильно управлять, классическое worst|low quality тут даёт куда меньший эффект, видел промпты вообще без негатива с лорами.
> На мердже посередине вообще цвета поплыли.
Парадокс в том, что именно этот говёный мердж выдаёт подобные пик1-2, с очень плавной картинкой и не забывает про бекграунд, но с цветами нужно шаманить. И вообще хлл во всех планах лучше фуррей, в том числе и в впреде.
> Лучше покажи как твоя фуррятина умеет в контроль яркости освещения сцены, а не то как она умеет делать пики без нихуя.
Да умеет, не ебу как скетчевость лучше придушить.
Суть в том что ограничения по средней яркости искажает результат, склоняя модель рисовать всякую херь и плодить лишние сущности, что на простых примерах наглядно показано, и в исследовании описано.
Модель с собаками специфична, но и оригинальная наи если ее пощупать сейчас крайне всратая, конечной целью должна быть интеграция этой фичи в современные миксы, которые все все умеют и так станут еще лучше. Это офк в идеале, но даже если будет что-то косячное с ограниченным применением - при возможности даже в автоматике выстраивать обработку на двух моделях, это найдет свое применение.
> в фоны она очень плохо умеет
Там много чего лоботомировано и поломано, потому мерджи с ней под вопросом.
Вообще по мерджу модели с впредом не совсем понятно, эфортлесс добавление к рандомному миксу или дает не полный результат, или ломает, от чего та начинает делать шум как без конфига, но с ним уже генерит будто к обычной сд впред конфиг подкинули. Не понятно.
Зато добавление разницы с обучения без впреда, которое показалось недостаточно хорошим, ряд задуманных улучшений дало.
> Сам не ебу как ей правильно управлять
Если тренировали на мусоре с бур, то наверное никак. На твоих пиках литералли как говно с бур - простейшие скетчи с заливкой объектов одним цветом. Это никуда не годится. И то что он весь пик заливает одним цветом - это такое себе.


После -- до.
Видно, что над головой протечка пошла. С тела еще на ночное небо вокруг тоже потекло, но там чуть меньше видно.
Плюс совсем мелкие детали типа пуговиц и запонок убились - но тут может быть и обычный глюк, что ИИ их не разобрал именно как детали. Правда, 9 из 9 подряд - это все-таки многовато для такого.
Планируют ли выпускать sdxl 1.1, 1.2 и т.д.? Вроде 1.0 вышла давно, но ведь нумерация не просто так, видимо что-то планируют?
Было опубликовано по две версии
SD 1.4, 1.5
SD 2.0, 2.1
XL 0.9, 1
Жди сжатую с дистилляцией версию Pixart
Когда запилят наконец t2i генератор для CPU?
У меня видяха встроенная AMD shared memory. Пора пилить наконец норм вариант который умещается в 2GB. Или для проца. Лучше всего, чтоб работал на смартфоне.
У меня видяха встроенная AMD shared memory. Пора пилить наконец норм вариант который умещается в 2GB. Или для проца. Лучше всего, чтоб работал на смартфоне.
Какая задача то стоит? Алсо проверь что будет с околонулевым денойзом, может это вообще vae гадит.
> t2i генератор для CPU
Он уже есть, базовый функционал диффузии работает на torch-cpu, производительность в сделку не входила. Для двухгиговых выше смотри fp8, для амд-встройки правда оно врядли будет решением. Для смартфонов тоже есть, в прошлом треде.
Если кто активно тренирует на кохе под шиндой и еще не поставил wsl - самое время это сделать. Буст перфоманса на четверть с ничего (либы куды одинаковые), крохотное снижение потребление памяти, параллельная обработка штатно работает.
>Какая задача то стоит?
Дальнейшее улучшение и детализация картинки под контролнетом.
Понятно, что через ФШ можно пофиксить, но хотелось бы побольше автоматизации.
С цветами вообще проблема постоянно.
>может это вообще vae гадит.
Если б оно гадило - оно бы и просто так проявлялось, без этого модуля контролнета. Картинка справа - это после первого шага улучшения, но чисто с тайлом.
У тебя тут наоборот произошло буквально, деталей убавилось, зато контраст бустанулся, каким образом делаешь то самое улучшение?
Инпеинт only masked с повышенным х1.5-х3 разрешением относительно обрабатываемой области, и с контролнетом inpaint попробуй.
> Было опубликовано по две версии
> SD 1.4, 1.5
Нет, ещё есть SD 1.1, 1.2, 1.3. Я их кстати тестио недавно по приколу
Так о чем и речь. Цвета текут, контрастность в результате уменьшается. Еще и зерно какое-то появилось.
Оригинал - второй пик, не первый.
>Инпеинт only masked с повышенным х1.5-х3 разрешением
Ну это еще больше редачить в итоге придется, соединяя то, что инпеинт по краям маски закосячит.
> Было опубликовано по две версии
> SD 2.0, 2.1
А это забросили, так как говно редкостное. У меня случайно иногда она включается - это просто пиздец, она ничего не может делать совсем. Надо ж было умудриться такую создать
Хм, если оригинал наоборот второй а первый буст - да, деталей действительно добавилось, а по цветам - похоже что вае и сама модель в i2i может себя иначе вести. Без контролнета говоришь иначе будет? Покажи что выходит.
А по контрасту - обычно наоборот его больше, иногда чрезмерно давит.
> еще больше редачить в итоге придется
Что редачить? Особенно с контролнетом оно не косячит и базового размытия маски хватает. По какой методе вообще делаешь?
С разморозкой. Это zero-shot методы, таких куча - IP-Adapter, reference controlnet, t2i style transfer и т.п. Суть - отдельный визуальный трансформер (обычно CLIP-ViT/H) или другая модель выдёргивает фичи из твоей картинки, потом они подставляются в процесс генерации.
У них несколько проблем:
> нет фильтрации фич, оно выдёргивает все концепты что есть (хотя с объектами можно попробовать маскировать ненужный контекст шашечками или другим очень далёким от сути объекта паттерном, но с текстурой или цветом так не прокатит). Выбрать по промпту выдёргиваемый концепт, например "веснушки", "прямые углы", "игуану", или "цвет асфальта" нельзя.
> жрёт дополнительные ресурсы, модели-распознавалки могут быть немаленькими
> модели распознавания примитивные, и входное разрешение у них маленькое (CLIP-ViT/H в IP-Adapter принимает 224х224,
Так что пока что c нормальной тренировкой с хорошим датасетом и тегами это не сравнить. Но за ними скорее всего будущее - берёшь усреднённую базовую модель и подсовываешь ей референсы какие хочешь.
>CLIP-ViT/H в IP-Adapter принимает 224х224, есть версия на 336х336, под которую надо дописывать ноду комфи
фикс
И да, я не хочу сказать что это не работает - работает и очень часто, несмотря на ограничения. Но иногда работает хуёво. Надо сначала пробовать зерошот рефы, потом уже думать про тренировку лоры, если их недостаточно.
>Без контролнета говоришь иначе будет?
Без т2и-адаптера, на чистом тайле, цвет не так течет. Но и не полностью сохраняется при этом, нейронка норовит своих цветов намешать.
Вторая (оригинальная) пикча как раз на нем сделана, из простого (не-латентного) апскейла.
>Что редачить?
Цвет редачить, восстанавливая то, что было, в оригинале, перед проходом через и2и. Вытекания эти убирать, если с т2и модулем запускать.
>По какой методе вообще делаешь?
-- Делаю базовую пикчу. Выбираю удачную.
-- Апскейлю х2 каким-нибудь Валаром, или чем похожим.
-- Обрабатываю ее на этом шаге в ФШ, правлю что-то, пальцы нормальные делаю, пропорции исправляю, фон могу заменить, если не очень получился.
-- Загоняю в и2и, ставлю тайловый контролнет, канни (на начало), и лайнарт (на остаток). Запускаю обработку с очень высоким денойзом. Получаю версию с улучшенными деталями, но с сохранением контуров и композиции (это вот вторая картинка из примера выше). Цвета начинают убиваться уже тут, но при денойзе в 0.8-0.9 это и неудивительно.
-- Правлю ее еще раз, снова загоняю в и2и, для дальнейшего улучшения деталей и добавления эффектов, с меньшим денойзом в районе 0.6. Цвета убиваются еще раз, приходится снова править потом, перед финальным шагов.
-- В конце через вкладку Extra апскейлю еще разок, на х2-х3. Тайловый апскейл скриптом - как альтернатива, но в последнее время его редко делаю. Экстрой выходит то же самое практически (если в тайловый денойз ставить 0.3 или около того), но гораздо быстрее.
> канни (на начало)
Дикая пикселизация или артефакты если размер выдачи препроцессора не совпадает с разрешением пикчи. Но, если в начале расшатает а потом будет восстанавливать то действительно может что-то новое-интересное нарисовать.
> Получаю версию с улучшенными деталями, но с сохранением контуров и композиции
Если после ган апскейла лоуреза то должно прилично бустануть, жирный лайн может от канни приходить или лайнарта если разрешение референса низкое, но для средних разрешений пикчи это нормально.
> снова загоняю в и2и, для дальнейшего улучшения деталей и добавления эффектов, с меньшим денойзом в районе 0.6
Вот это с апскейлом совместить, достаточно небольшого хотябы 1.2, офк ресайз с помощью гана. Если это что-то в районе 2-3 мегапикселей то можно одним тайлом, или уже скриптом/мультидифуззией.
> ерез вкладку Extra апскейлю еще разок, на х2-х3
Хтонь в большинстве случаев.
> Цвета убиваются еще раз, приходится снова править потом
Как насчет просто сделать цветокоррецию финальной картинки?
Ну в целом как действуешь понятно. Кроме как "приспособиться" и добавить незначительный апскейл на финальном этапе (от цветов это не спасет, просто добавит больше деталей) нечего предложить, увы.
>если размер выдачи препроцессора не совпадает с разрешением пикчи
>если разрешение референса низкое
База в районе 800х600 (по ситуации), после гана уже, соответственно, 1200х1600. И с такой картинкой в и2и я уже работаю. Линии то нормально получаются. Четко, ровно. Пальцы на мелких планах все равно ломаются, но не в кашу. Легко потом починить обратно.
Главная претензия - цвета.
>Хтонь в большинстве случаев.
Хз. Когда картинка 1200х1600 после нескольких итераций и2и выходит - в ней всё уже нормально, надо только поднять разрешение и четкость. Дорисовывать ничего не требуется.
>Как насчет просто сделать цветокоррецию финальной картинки?
Не получится там простой цветокоррекцией обойтись.
Этот искусственный идиот норовит постоянно что-то перекрасить.
Зеленый купальник? Сделает серо-синий. Ярко-пурпурные ремни? Заменит на бледно-фиолетовые. Золотые элементы в броне? Закрасит под окружающий цвет. Или наоборот, всю броню сделает под золото, если что-то типа "golden trim" в промпте прописано.
Я, если честно, затрахался уже. Постоянно по слоям с наложением в ФШ коррекции этих косяков делать.
> Зеленый купальник? Сделает серо-синий. Ярко-пурпурные ремни? Заменит на бледно-фиолетовые.
Хм, очень сильно оно меняет, сам контролнет и модель точно последней версии?
> Золотые элементы в броне? Закрасит под окружающий цвет.
Раз уж правишь пикчи - отдели их тонким лайном или обозначь принадлежность к персонажу чтобы не путало с чем-то другим, очень помогает.
>Или наоборот, всю броню сделает под золото, если что-то типа "golden trim" в промпте прописано.
Используй любой метод изоляции токенов, чтобы golden влиял только на trim, а не на armor.
>сам контролнет и модель точно последней версии?
Последний раз 7 месяцев назад у них на хаггингфейсе обновления залиты, оттуда качал. Плагин регулярно обновляю.
Может новее где есть?
>очень помогает
Лайн остается. Цвета - нет.
Еще, кстати, заметил, что из-за тайла есть очень упорная тенденция к пересвечиванию картинки.
>Используй любой метод изоляции токенов, чтобы golden влиял только на trim, а не на armor.
И как ты себе это представляешь, есть "trim" - это часть "armor"? Броня с золотой отделкой в совокупности.




Во, короче, пример:
База - ГАН - тайловый контролнет c окончанием на 25% - тот же контролнет, но уже с окончанием на 100%
Вообще все по тому самому месту пошло.
Если прерывать рано - цвет брони поменялся и gold trim проигнорился.
Если держать до конца - деталями перенасрало.
И картинка высветлилась во всех случаях.
Как с этими бороться - ума не приложу.
После ГАНа разве что оставлять как есть, и не ебать себе мозги дальше. Но хочется то подетальнее!
База - ГАН - тайловый контролнет c окончанием на 25% - тот же контролнет, но уже с окончанием на 100%
Вообще все по тому самому месту пошло.
Если прерывать рано - цвет брони поменялся и gold trim проигнорился.
Если держать до конца - деталями перенасрало.
И картинка высветлилась во всех случаях.
Как с этими бороться - ума не приложу.
После ГАНа разве что оставлять как есть, и не ебать себе мозги дальше. Но хочется то подетальнее!


Хотя можно, конечно, не упарываться, и вместо денойза в 0.8-0.9 ставить базовые 0.6.
Тогда и с деталями нормально будет, и цвета плюс-минус сохранятся. Но тоже ведь не всегда, зараза такая!
Последний - апскейл в экстре через 4x_fatal_Anime_500000_G (пережатый в жипег разве что)
И где там хтонь?..
Тогда и с деталями нормально будет, и цвета плюс-минус сохранятся. Но тоже ведь не всегда, зараза такая!
Последний - апскейл в экстре через 4x_fatal_Anime_500000_G (пережатый в жипег разве что)
И где там хтонь?..
> но уже с окончанием на 100%
Воу воу, а чего ее там переэкспонировало на 3й, это какой-то пиздец и точно не нормальная работа. Или хз, с денойзами 0.9 даже не пробовал ставить.
> деталями перенасрало
Это ты про пик? Фиксится лорами, эйлером на семплере (вот он кстати как раз осветляет), инверсией шума в мультидифуззии, графическим редакторов. Это с лорами генерация? Случаем нет в них какого нойз оффсета или чего подобного, что к изменению гаммы с яркости приводит?
Сгенерируй какой-нибудь вангерл на популярной модели, проведи те же манипуляции и скинь с метадатой. Возможно дело в каких-то настройках.
> и вместо денойза в 0.8-0.9 ставить базовые 0.6
Кмк 0.6 его хватает для всего что касается апскейла, больше уже только при инпеинте нужно.
> И где там хтонь?..
Под зерном приемлемо, но на глаза-пальцы-волосы посмотреть и грустновато. Ну тут правило 20-80, хули.


>Воу воу, а чего ее там переэкспонировало на 3й, это какой-то пиздец и точно не нормальная работа.
Вот я и сам в шоке. Бывает, что нормально обрабатывает, а бывает вот такой пипей.
>Это ты про пик?
Да, про 4-й. Теоретически можно попробовать лору на детали с отрицательным весом подключить. Разница как-то не очень заметна. Мелкие детали оно подзатерло, а вот крупняк - остался.
>эйлером на семплере (вот он кстати как раз осветляет)
2М СДЕ-карась стоял.
>Это с лорами генерация?
С одной, как сгенерилось - так я настройки не менял, только в промпт про цвет глаз добавил в и2и уже. Сам тренил, никакого оффсета в тренировку не ставил, базовые параметры практически. Я нуб, все эти новые фичи с тренировочными параметрами мимо меня прошли. Шумы, автоматический ЛР, и всё такое.
Второй пик в после вообще без лор вот сейчас сделал, на чистом контролнете. Не в ней дело, как видишь.
>Под зерном приемлемо, но на глаза-пальцы-волосы посмотреть и грустновато.
Так оно не правлено вручную нигде, без инпэинта лица и волос, чистый ИИ, только с прогоном в и2и с контролнетом.
И волосы то чем не угодили?
>И как ты себе это представляешь, есть "trim" - это часть "armor"? Броня с золотой отделкой в совокупности.
В ватоматике, если не ошибаюсь, full plate armor AND golden trim. (или хз какой там в наши дни синтаксис). Это сделает два прохода с семплером с двумя независимыми друг от друга кластерами.
В комфи есть еботный token cutoff, но вообще тоже надо в два прохода делать, т.е. ставишь два семплера. И можно ещё по-всякому извращаться, например столько-то итераций делать одно, столько-то другое, или каждый шаг переключаться.
Все подобные проблемы из-за попытки всё засунуть в одну генерацию
Вот, катофф есть для обоих уёв.
https://github.com/hnmr293/sd-webui-cutoff
https://github.com/BlenderNeko/ComfyUI_Cutoff
Посмотри на примеры, там раскраска одежды, но в целом можно резать токены как хочешь, чтобы одно влияло на другое, а на вон то не влияло. (например golden влияет только на trim, но не armor)

Вообщем, хз как эту фигню с высоким денойзом побеждать стабильно. С низким оно плюс-минус пашет, хоть и не идеально. Хотелось бы побольше вариативности в детализации с сохранением общей цветовой палитры, что вроде как должно быть на высоких денойзах, но там тайл почему-то очень вольно относится к цветам, иногда выжигает картинку, и вдобавок срет овердетализацией куда не надо - в зависимости от настроек контролнета.
Причем ведь не постоянно, я в прошлом треде челу с 3д-карточки из койкацу генерил с денойзом в 0.9 вариант - и оно нормально получалось ведь. От разрешения чтоль зависит?..
А, я его ставил.
Потом оно на каком-то коммите вебуя сломалось, ошибками в лог спамило при загрузке, я его и удалил.
Как-то не очень удачно оно у меня работало. Может починили с тех пор, еще раз попробую.
Ещё один альтернативный способ для комфи, наверно и для автоматика есть где-нибудь.
https://github.com/andersxa/comfyui-PromptAttention
Анон который дошел до дистиляции фурри моделек гений, спасибо ему. Почти любая модель становится более послушнкой к промпту и рарешение растет.
> мненье?
Комфи-дауны как обычно на пол года отстают. Ну и ип-адаптер - это фактически генерация эмбендинга, это даже не близко лора.




фурри дрочер копает в нужном направлении, но он не понимает как работает вычитание, поэтому копает немного не в ту сторону. Но спасибо за идею, проапгрейдил свою фурри модель в маняме. Надо теперь допилить лобзиком.
Это конкретно этот даун только сейчас услышал, остальные используют уже хуй знает сколько.
>ип-адаптер - это фактически генерация эмбендинга
Посмотри на диаграмму на пике и покажи в каком месте ты там увидел эмбеддинги и вообще кондишонинг. Нет, в отличие от контролнета он меняет веса самого U-Net, как и лора и будка. Собственно сам "адаптер" здесь это и есть отдельно натренированный переходник между сторонним zero-shot экстрактором фич (визуальный трансформер CLIP-ViT) и U-Net. Соответственно, возможности ограничены возможностями внешнего экстрактора, который должен ухватить фичи по лишь одной пикче. Ещё хуево то, что нет возможности выбирать отдельным промптом какие фичи дёргать. В отличие от лоры/будки, которым можно давать пары с тегами.
А так в целом фича охуенная и лору может заменить во многих случаях, даже с ограничениями. При этом оставаясь точно так же совместимым с контролнетами и прочим подобным, т.к. модифицирует U-Net.




>Это конкретно этот даун только сейчас услышал, остальные используют уже хуй знает сколько.
+, возможно он нюфаня. Я как только вкатился, так сразу все варианты мерджа перепробовал, после чего вычитанием с тех пор и пользуюсь. По факту, фурри модели не обязательны даже. Но мы ему об этом не скажем.
>по лишь одной пикче
Да, кстати, пикч может быть несколько, их можно перегнать во внутренние эмбеды визуального трансформера. (в комфи можно). Правда перегонка это компрессия с потерями, поэтому больше нескольких сильно различных пикч будет каша. Но в случае одного и того же концепта можно уточнить его, как и при обучении.
Мы про IP-Adapter, не про мёржи с vpred моделями.
> Если кто активно тренирует на кохе под шиндой и еще не поставил wsl
У меня на нём тф стоит. Торч тоже на него поставить?
>Если кто активно тренирует на кохе под шиндой и еще не поставил wsl - самое время это сделать. Буст перфоманса на четверть с ничего (либы куды одинаковые), крохотное снижение потребление памяти, параллельная обработка штатно работает.
А на инференс это распространяется?
Ну и чо там по рецепту?
Мнение эксперта по стейблу.
Залог дальнейшего развития технологии - не в GPU-часах для модели, не в гигабайтах и слоях, параметрах, а в тщательной подготовке данных для трейнинга. И это не спекуляции, это ключевой закон мл "данные решают всё". Говно на входе, говно на выходе. Для SDXL уже были какие-то подвижки, хотя бы эстетическая оценка данных.
Возможно, t2i выйдет на новый уровень, если captions в данных будут представлены не как текстовая строка, а в формате типа XML со структурой, иерархичностью объектов (мелкие предметы в описании - компоненты более крупных). Даже инфа о пространственном расположении объектов. (То, что слева на сэмпле, описано в начале, то что справа - после, как привычный нам порядок чтения текста). Потребуется модель, которая переводит короткий ввод простым английским языком в этот заковыристый формат, для сэмплинга.
Вот попробуйте в стейбле без костылей сделать изображение двух разных персонажей, каждый со своим описанием. Ничего не выйдет, токены будут одни и те же на обоих и признаки перемешаются. Потому что для основной модели использовались простые описания разной длины. Так что, есть куда расти.
Залог дальнейшего развития технологии - не в GPU-часах для модели, не в гигабайтах и слоях, параметрах, а в тщательной подготовке данных для трейнинга. И это не спекуляции, это ключевой закон мл "данные решают всё". Говно на входе, говно на выходе. Для SDXL уже были какие-то подвижки, хотя бы эстетическая оценка данных.
Возможно, t2i выйдет на новый уровень, если captions в данных будут представлены не как текстовая строка, а в формате типа XML со структурой, иерархичностью объектов (мелкие предметы в описании - компоненты более крупных). Даже инфа о пространственном расположении объектов. (То, что слева на сэмпле, описано в начале, то что справа - после, как привычный нам порядок чтения текста). Потребуется модель, которая переводит короткий ввод простым английским языком в этот заковыристый формат, для сэмплинга.
Вот попробуйте в стейбле без костылей сделать изображение двух разных персонажей, каждый со своим описанием. Ничего не выйдет, токены будут одни и те же на обоих и признаки перемешаются. Потому что для основной модели использовались простые описания разной длины. Так что, есть куда расти.
А дядя у тебя в ФСБ случайно не работает?
>а в тщательной подготовке данных
Отрыл Армению, зарывай обратно. Все уже давным-давно тренят на многомодовых синтетических датасетах, см. тот же пиксарт. И качество их будет только улучшаться.
>изображение двух разных персонажей, каждый со своим описанием. Ничего не выйдет, токены будут одни и те же на обоих
Литералли выше описано как этого избежать, изолировав токены друг от друга, и предоставив модели явную модель отношений. В ней изначально есть такой механизм, causal attention mask. Механизмов много.
Я тебе даже больше скажу, в одной пикче можно мешать сразу несколько моделей и даже SD с SDXL. Эксперты кислых щей, которые знают только про текстовый промпт, сосут бибу.
>в одной пикче можно мешать сразу несколько моделей и даже SD с SDXL
Несколькими шагами можно, внутри сэмплинга только мерджем (1.5+XL не прокатит).
Да, конечно. Одна генерация/один сэмплер это в любом случае тупик, даже банальный хайрез фикс использует два. Правильно состыковав элементы модели и сторонние модели/обработчики, можно получить куда лучший результат чем одной генерацией.
Структурированные кэпшены - в 90% случаев хуита без задач, как и перевод датасета в хитровыебанные перцептуальные цветовые пространства вроде CIECAM16, и подобные инициативы. Большие модели на том и основаны, что тупое одноранговое пространство само задрачивает всё это в виде эмерджентного поведения в процессе тренировки, если оно достаточно большое и унифицированное.
>Для SDXL уже были какие-то подвижки, хотя бы эстетическая оценка данных.
Она и в SD была, внезапно. Из Laion-5B было отсеяно 2 млрд пикч.
В общем-то любые здоровенные модели так всегда и делаются - бутстраппингом из самых мелких ручных, которые тегят то что есть, потом эти модели служат основой для других, туда подмешиваются всякие ручные данные типа RLHF, и т.п. Теперь пошёл второй виток, большие визуальные трансформеры и диффузионные модели подготавливают чисто синтетические пары/мультимоды, получается совсем пиздатый датасет. И т.п., в конце концов закончат тем что нейронки будут писать учебники для роботов, как люди пишут для людей. Ты же не учишься считать, сравнивая груды спичек и числа.
Когда начнется третья мировая и уничтожат заводы на Тайване, будущее будет за fp8 destilazed lcm генерацией
Почему на civitai все inpaint одели выкладывают только в fp32 версии? Если я сконвертирую в fp16, ведь качество сильно не ухудшится. Для обычных моделей выкладывают как раз в основном fp16
> до дистиляции фурри моделек
Вут? Ты про подмешивание обратной разницы?
Поясни
Описал базу, только дофантазировал лишнего и неуместные примеры выдаешь.
На сколько я понимаю, дестиляция - это уменьшение числа параметров. Sd tiny
> тф стоит
Вут? Тензофлоу, тимфортрест, техническая физика?
Какой интерфейс? Речь про скорость обучения (на 15-30% быстрее при всех прочих равных включая тдп) и нормально работающий на мультигпу аккселерейт, под шиндой он не полноценный.
> Если кто активно тренирует на кохе под шиндой и еще не поставил wsl - самое время это сделать.
Давно ещё тестил, на линуксе просто сд впринципе быстрее работает по какой то причине, вот и тут так же, походу похер где, инференс или тренинг, хотя конкретно тренинг я не тестил.
>Структурированные кэпшены - в 90% случаев хуита без задач
Поясни, почему SD 1.5 не может в детали? Если задача сгенерировать "столы с предметами" или что-то подобное - то там правдоподобны только столы, а на них лежит буквально мусор со свалки - несуществующие виды фруктов и тому подобное. Потому что, слишком сложные детали после сета с поверхностными описаниями пикч. Или, когда делаешь "в стиле Hearthstone", то будет лепить рандомные бесформенные детали из золота, бронзы, каменные и деревянные рамки, не понимая что они означают.
Потому что LAION - мусорный датасет. Там ехало говно через дерьмо, и часто просто нет тегов, ни нормальных ни вообще никаких. Открой CLIP браузер этого датасета и охуей. Там нужны были не структурированные кэпшены, а просто точные и детальные, тогда будет за что цепляться при тренинге. Вот в пиксарте было нечто подобное - они добились качества SDXL при смешных 25млн пикч вместо 3 млрд, и 600млн весов в U-Net вместо 2.6 млрд. (в SD 860M), за счет во многом синтетического датасета. В далле тоже нечто подобное, тренировка на развернутых кэпшенах.
Вторая причина - мало весов в VAE и U-Net. Но качество датасета и многомодовость всегда идут первыми с большим отрывом, так что даже в малое можно запихнуть много, если поебаться.
Потому что нейронка не понимает что генерирует, нейрогенерация работает по принципу состыковывания кусков данных отмеченных как родственные. См:
https://www.youtube.com/watch?v=f3rUp0cuxY8
Лайон тем и хорош что дерьмо, такие хай-тек пятна роршаха. То есть развернутые теги и тщательный подбор изображений конечно дают несопоставимое качество t2i, но только все в итоге по введеному промту результат сводится в одну схожую картинку. Как фильтр для фотошопа оно хорошо, а как генератор чего-то оригинального хуево.
Хуйня, подбор репрезентации фич работает лучше чем статистическая усредниловка во всех случаях, даже файнтюнеры это осознают.
> на линуксе просто сд впринципе быстрее работает по какой то причине
Ты про сравнения в 512-однопотоке? В диффузии не нашел разницы особо, хорошо работает и там и там, особенно при нескольких потоках или большом тайле. А тут уже заметный буст, хз, может тритон на которого ругается в шинде помогает, но вроде писали что оно юзлесс.
Причин множества, основная - размер модели в сочетании с методиками ее тренировки. Посмотри насколько далеко продвинулись файнтюны относительно исходных моделей, там рили пропасть, хотя всеравно некоторым вещам не уделялось достаточно внимания. Плюс, дело говорит, если делать конструктор с применением ллм, да еще с мультимодалками то и на базе 1.5 можно делать космические вещи.
Использовать две модели на разных этапах.
>нейронка не понимает что генерирует
Сомнительная заява, эмерджентное поведение и состоит в извлечении абстракций из навоза, а вот это
>состыковывания кусков данных отмеченных как родственные
и есть ключевой элемент интеллекта. Собствено автоэнкодер (VAE) и весь концепт латентного пространства работают на факте, открытом еще лет 10 назад NLPшниками, что "куски данных помеченные как родственные" выцепляет семантику имеющуюся в датасете, т.е. он именно понимает что генерит. Латентное пространство это семантическое представление с зашитыми в него абстракциями, просто непонятными конкретно тебе, т.к. у вас архитектуры и обучающий материал разные. Диффузионная модель даже язык свой способна составить (как и любая большая модель).
>Плюс, дело говорит, если делать конструктор с применением ллм, да еще с мультимодалками то и на базе 1.5 можно делать космические вещи.
Он не про то, у него избитый СТОХАСТИЧЕСКИЙ ПОПУГАЙ.
> у него избитый СТОХАСТИЧЕСКИЙ ПОПУГАЙ
Лол, тогда не дело. Там если что имел ввиду недостаточное понимание сеткой некоторых концептов и их взаимосвязи. Для этого нужно или оче хитровыебанное обучение (и тогда может проебаться все остальное), или внешняя сетка что это понимает и может понятно интерпретировать и указать, причем желательно хотябы с минимальной обратной связью. Какбы та же сд примерно соображает привыкла что если указан купальник то по дефолту там должна быть рядом вода, или что еда - значит она на тарелках, которые где-то стоят, если не указано иное, но для более сложных и сочетаний у нее не хватает как мозгов так и обучения.
> Ты про сравнения в 512-однопотоке? В диффузии не нашел разницы особо, хорошо работает и там и там
Именно про однопоток, у меня разница процентов в 25 между этими системами, хз может тоже из за тритона, он же не собирается для 2 торча на шинде.
Очевидно тензорфлоу ёпта. Что я ещё в комплекте с торчем буду упоминать, ты что, торч?
Объясни смысл предложения
> Торч тоже на него поставить?
торч, лол
Стабильная диффузия и чатгпт это тупо lossy алгоритмы сжатия данных, с побочным эффектом в виде возможности генерировать новые результаты путем рекомбинирования элементов. Про эмерджентность слышно еще с 60х, когда в MIT ботаны беливили что если запустить Conway's Game of Life на достаточно большом поле оно там само собой эволюционирует в разумную цифровую цивилизацию. Воз и ныне там.
Поясните мне лучше, когда в СД вместо бессмысленных новых моделей добавят возможность img2img генерации с использованием предыдущего сгенерированного кадра в качестве опорного, чтобы можно было делать полноценно vid2vid
Поясните мне лучше, когда в СД вместо бессмысленных новых моделей добавят возможность img2img генерации с использованием предыдущего сгенерированного кадра в качестве опорного, чтобы можно было делать полноценно vid2vid
>когда в СД вместо бессмысленных новых моделей добавят возможность img2img генерации с использованием предыдущего сгенерированного кадра в качестве опорного, чтобы можно было делать полноценно vid2vid
Так оно есть сто тысяч лет. В автоматике изначально, в в комфи loopchain аддон
> это тупо lossy алгоритмы сжатия данных
Нет, это принципиально новый подход и понятия lossy/lossless здесь не применимы. Но та же нейрокомпрессия текстурок и прочего может быть выполнена, хуанг демонстрировал зашакаливание видеосвязи до битрейтов в десятки килобит/с.
> чтобы можно было делать полноценно vid2vid
С подключением
>В автоматике изначально
Как называется кнопочка?
Сжатие, предсказание и интеллект это одно и то же, разница лишь в назначении. /thread
Ну просто пока у нейросетки человеческая голова стоящая прямо и голова повернутая на 90 градусов это разные категории объектов, а так она понимает абстракции, да.
Суть в том, что можно ограничиться обычными маниме моделями, замешивая их между собой, просто вычитая novelai, что бы убрать грязный трейн, оставив только свежие данные промпта. Соответственно вычитание v1-5-pruned-emaonly удалит тридешность из модели, а вычитание yiffy-e18 удалит фурри. Но если продолжать вычитать выше 100% одну из перечисленных моделей, дальше сетка начинает страдать деменцией, что приводит к ебле с CFG и семплерами, либо к её утилизации. Поэтому имеет смысл снижать коррапт мерджем через суммирование с чем-то ещё.
Но. Есть один нюанс. Если вычесть хотя бы раз yiffy-e18 или v1-5-pruned-emaonly возможно йиффи тренилась на дефолтной модели SD, то выше 960х540 уже ничего не сгенеришь, на 1920х1080 получается каша. На 1080х1080 тоже. Другие фурри модели я не пробовал, хз, что там получится, зависит от того, на чем их тренили Если на novelai, то возможно взлетит. Если тебя устраивает ограничение в qHD, но с нажористой детальностью, которую ты потом проапскейлишь, то можно их использовать.
А что касается рецепта, то удачи плясок с бубнами, потому что мерджить между собой модели с неизвестным содержанием может привести как к получению годноты, так и получению лютого говнища. Связанно это с тем, что искомый мердж уже мог пару раз пройти через вычитание той же novelai, в сумме более чем на 100%, и дальнейшее вычитание просто угробит модель. Большинство итоговых мерджей через вычитание нормально генерируют на 2-7 CFG, все что выше, это уже цветная каша будет. То же и семплерами, некоторые из них такие модели обрабатывают неадекватно. Поэтому советую использовать в качестве основы модель, которая тренилась, а не мерджилась, а уже потом в неё домешивать что-то годное.
Ты не заслужил, на колени, анимераб!
То, что на пиках было:
Coconut2.0_classic+(манямемодель1-yiffy-e18)20%=111
111+(манямемодель2-yiffy-e18)20%=222
222+(манямемодель3- yiffy-e18)20%=333
Не спрашивай, что за маняме модели, я на рандоме мерджил, в качестве теста. И да, там говно выходит, если yiffy-e18 больше 40% вычесть, там задники деменцией страдать начинают. Но если, после -40%, вычесть v1-5-pruned-emaonly то можно безопасно для графена ещё 20% вычесть. А там отшлифовывать вычитая novelai, но не факт, я не тестил.
Но да, такой метод не генерит в Full HD изпадкоробки, но можно заапскейлить обычный qHD(960х540). Возможно стоит заменить yiffy-e18 на что-то другое, из фурри моделей, что хайрез не корраптит, но я хз, это надо перебирать модели.
> Соответственно вычитание v1-5-pruned-emaonly удалит тридешность из модели
Ты совсем ёбнутый, в обучении базовой модели миллиарды изображений. На ней держится вообще всё - всё понимание нейронкой слов, их сочетаний, глаголы и всё всё всё. Базовая модель - это ядро для понимания мира
Плюс стиль идёт в отрыве от понятия. Если нейронку обучили на 3д мячиках для тенниса, то она сможет и 2д их нарисовать
Вообще все фанатские модели - это файнтюн. Он подразумевает то, что нейронка будет считать некоторые заложенные понятия само собой разумеющееся
Да камон, в базовой моделе миллиарды картинок при обучении, в файноюнах - пара тысяч! Это даже не порядок разница, это даже не порядок порядков разница
Тоже офигел с предложения о вычитании НАИ и СД из моделей.

> просто вычитая novelai, что бы убрать грязный трейн
Так, погоди, это как в кукбуках некоторых миксов и кастомных дотренов через полноценный чекпоинт, где модель - наи нужно подмешивать к жалемой уже приличной, оно?
Эксперименты с подобной методой добавляет в выбранный микс твики что тренились, но конкретные значения да и саму тренировку нужно тюнить. Ты будкой обмазывался?
Пользуясь случаем, поясни за выбор методов мерджа из вариантов (косинусы, смус адд, трейн дифференс, ...) и что за 20%, альфа=0.2 в супермерджере? Алсо почему именно такое значение?
> нормально генерируют на 2-7 CFG, все что выше, это уже цветная каша будет
Подобный эффект наблюдался если примердживать колхозно дотрененный впред к обычной модели. Получается что на обычных кфг пережарка, при снижении отпускает, но пикча более мыльная чем на дефолтной модели. При этом работает по дефолту без конфигов, достигая нужный эффект. Попердолить тренировку, смешивать послойно и может уже что-то выйдет.
Метода микса с последовательным вычитанием в несколько проходов интересна, вот рили почему бы и нет, спасибо.
> в обучении базовой модели миллиарды изображений. На ней держится вообще всё
Ты не догнал что в операции участвуют 3 модели и к исходной уже работающей добавляется вычитание одной из другой?
>Ты совсем ёбнутый
Да, поэтому я получаю прикольные модели, которые работают зачастую через жопу, а ты чет рассуждаешь, теории строишь. А так, мое мнение абсолютно субъективно и не претендует на истинность, че ты докопался.
>в обучении базовой модели миллиарды изображений. На ней держится вообще всё - всё понимание нейронкой слов, их сочетаний, глаголы и всё всё всё. Базовая модель - это ядро для понимания мира
Тогда вычитание любых моделей из любых моделей должно привести к полной деградации при 100% вычитания - в них всех же базовая модель заложена, это как основание идет. Но я этого не вижу. Возможно база модели не участвует в мердже, хз.
>Плюс стиль идёт в отрыве от понятия. Если нейронку обучили на 3д мячиках для тенниса, то она сможет и 2д их нарисовать
Тут главный вопрос в том, как она их нарисует.
>Да камон, в базовой моделе миллиарды картинок при обучении, в файноюнах - пара тысяч!
ну, это объясняет почему маняме модели такая параша, там же пара тысяч, не то что православные фурри модели по 800к-1,5к артов. Щас глянул, фаффифьюжн на 2.305 миллионах артах тренился.
>Так, погоди, это как в кукбуках некоторых миксов и кастомных дотренов через полноценный чекпоинт, где модель - наи нужно подмешивать к жалемой уже приличной, оно?
нет, её вычитать, как раз таки.
>Ты будкой обмазывался?
Будкой не обмазывался, не в курсе что это.
>Пользуясь случаем, поясни за выбор методов мерджа из вариантов (косинусы, смус адд, трейн дифференс, ...) и что за 20%, альфа=0.2 в супермерджере? Алсо почему именно такое значение?
Кхъ, я классическим чекпоинт мерджером пользовался, с супермерджером надо суперебаться, мне лень. Смотри картинку, что бы понять каким говном я мерджу.
> Тогда вычитание любых моделей из любых моделей должно привести к полной деградации при 100% вычитания
Это если делать просто вычитание одной модели из другой, там будут одни нули. А здесь тут полученная разница, по сути измененные веса при файнтюне, добавляются к модели в которой уже все есть, меняя ее.
Вот когда добавляется разница разнородных моделей тут интереснее и уже может получиться потеря иходника, что и может выражаться как
> если yiffy-e18 больше 40% вычесть, там задники деменцией страдать начинают
это офк если сильно упрощать, таки многие операции там нелинейны.
> это объясняет почему маняме модели такая параша, там же пара тысяч
Рофлишь или серьезно?
> нет, её вычитать, как раз таки.
Так это то что и имел ввиду, дефис там как минус идет. Модель с которой хочешь вытащить (B), из нее вычитается ванильная наи (C) и полученная разница добавляется к той, куда хочешь добавить (A).
В случае тех операций как описано с вычитанием из аниме модели фурревской можно (?) раскрыть скобки, и привести это как вычитание из фурри-фурри с добавлением анимы. Но, поскольку множитель не единица, то большая часть фурей сохраняется. Повторные применения ее сильно вымывают, что и приводит к описанным эффектам.
В рамках рассуждений без претензий на истину.
> Будкой не обмазывался, не в курсе что это.
Dreambooth, файнтюн чекпоинта.
>Рофлишь или серьезно?
Я не мог не порофлить.
>Но, поскольку множитель не единица, то большая часть фурей сохраняется.
>Повторные применения ее сильно вымывают, что и приводит к описанным эффектам.
Если учитывать, что там тэги как аниме, так и фурри остаются на месте, то это можно проигнорировать, добавив в качестве расы в позитив (human), а в негатив (furry, kemono, feral, beast, etc). А так, модель будет вполне справляться как с кошкодевками, так с фуррями, так и с кемоно.
Я не мог не порофлить.
>Но, поскольку множитель не единица, то большая часть фурей сохраняется.
>Повторные применения ее сильно вымывают, что и приводит к описанным эффектам.
Если учитывать, что там тэги как аниме, так и фурри остаются на месте, то это можно проигнорировать, добавив в качестве расы в позитив (human), а в негатив (furry, kemono, feral, beast, etc). А так, модель будет вполне справляться как с кошкодевками, так с фуррями, так и с кемоно.
> так и фурри остаются на месте, то это можно проигнорировать
Да, там много общего и потом полученная на выходе смесь может вполне прилично работать.
Модель интересная безусловно, но не все в ней нравится и лоры на нее отдельные тренить надо. К ней всегда обратиться можно, а так лучше попердолиться.
Вот кстати, все по поводу этих фурри-мерджей и прочего такого.
А лору сделать из разницы никто не пытался? В разных комбинациях.
Туда же всякое можно записать, и через Additional Networks еще и UNet/Text Encoder отдельно друг от друга применять, если вдруг приспичит.
А лору сделать из разницы никто не пытался? В разных комбинациях.
Туда же всякое можно записать, и через Additional Networks еще и UNet/Text Encoder отдельно друг от друга применять, если вдруг приспичит.
Пфф. Автоматик во время оно вполне себе запускался на обниморде на фришном спейсе на ЦПУ. 30 минут на картинку, но почему бы и нет? Алсо, есть diffusers. Да, не автоматик, но при умелом использовании на той же обниморде даёт картинку за 15 минут. Господа гигопудобояре просто чутка зажрались, а мы, смиренные безвидяшники, и тому рады))
>А лору сделать из разницы никто не пытался?
лору можно из любого кала сделать, но дело в том что лоры наоборот вписывают в модели и потом добавляют различия в модель без лоры, так меньше артефактов и больше консистенции
насчет флафихуяфи мерджа кстати, если взять базовый сд и сунуть его в B модель, то получается более лутшая базовая сд, которой можно через TD присунуть любую модель, тем самым ее улучшив, еще полирнуть сверху пинойзами или детайл лорами и будет вообще по одному ключу выдавать топ результы
В автоматике нет OpenVINO, который задрочен под ЦПУ и ускоряет инференс в дохуя раз по сравнению с торчами-хуёрчами, в которых ЦПУ это вспомогательная опция для запуска вспомогательных мелкомоделей.
Помню был уй под опенвино специально, не помню какой. (никогда не работал с ЦПУ генерацией)

Пипец, я тут за один вечер наклепал расширение по автоматическуму раздеванию. Просто решил программно автоматизировать segment anything и inpaint; вынести все в отдельную вкладку, чтобы буквально оставалось две кнопки нажать. Идея на поверхности, но бегло ничего не нагуглил. Ну решил что лучше сделаю сам, зато и по практикуюсь, впервые делаю что-то подобное на питоне
Результатом на самом деле приятно шокирован немного. Я думал будет намного хуже ручного инпейнта, а вот нет. И эффект скорости впечатляет от того, что залил картинку, нажал кнопку, 6 секунд - и готово. И не надо несколько минут пердолиться с выделением, или нажатием кнопок в segment anything
Из планов: доделать batch обработку, кэшировать результат создания маски, сделать настройку важных inpaint параметров типа семплер, количество шагов, expand и т.п. И мб сделать скрипт для txt2img, чтобы после генирации получать nude версию, так как на генирациях меньше заметен inpaint
А куда можно залить? Знаю есть форум какой-то популярный по дипфейкам, он индексируется поисковиками хорошо. И видел сайт gitgub, куда заливают репозитории с порно тематикой. Наверное так выложу
Результатом на самом деле приятно шокирован немного. Я думал будет намного хуже ручного инпейнта, а вот нет. И эффект скорости впечатляет от того, что залил картинку, нажал кнопку, 6 секунд - и готово. И не надо несколько минут пердолиться с выделением, или нажатием кнопок в segment anything
Из планов: доделать batch обработку, кэшировать результат создания маски, сделать настройку важных inpaint параметров типа семплер, количество шагов, expand и т.п. И мб сделать скрипт для txt2img, чтобы после генирации получать nude версию, так как на генирациях меньше заметен inpaint
А куда можно залить? Знаю есть форум какой-то популярный по дипфейкам, он индексируется поисковиками хорошо. И видел сайт gitgub, куда заливают репозитории с порно тематикой. Наверное так выложу



В него можно тупо всякий хлам из галереи кидать, что ты бы руками никогда не решился бы делать, так как долго. Прикольная игрушка вышла
Такая хуйня безо всякого погромирования за 5 сек автоматизируется в комфи.
Огонь, ведь можно найти много применений. На гитхаб лей, только описание замени на "автоматическую замену одежды".
Думаю можно было вынести все экзэмплы в настройки, чтобы пользователь их сам туда вводил, и чтобы не было плохих слов на гитхабе, и выложить как быстрая замена объектов. Но тогда и readme не сделаешь хорошим, и название придется сменить. Auto Nudify мне сильно зашло. Так что лучше куда-нибудь на форум и gitgub
Да, но чтобы потом эту схему в Комфи обернуть в красивую гуишку на gradio, нужно ебаться еще больше, так как надо отдельно поднимать Комфи с апи, отдельно свое мини-приложение. А тут - просто вкладка в готовом многофункциональном гуи
Лей на гитхуб, только обзови его "Auto Inpainter"
>Да, но чтобы потом эту схему в Комфи обернуть в красивую гуишку на gradio, нужно ебаться еще больше, так как надо отдельно поднимать Комфи с апи, отдельно свое мини-приложение.
Зачем оборачивать, почему прямо так не юзать? У тебя же там полторы кнопки. Но вообще есть InvokeAI, это как раз такая гуишка, со своим нод-редактором. Ещё сами стабилити начали делать гуй-надстройку над комфи, https://github.com/Stability-AI/StableSwarmUI (пока сырой). Ну а мне как 3Д макаке больше интересна интеграция в блендерные ноды, там тебе и интерфейс, и возможности, и собственно ноды https://github.com/AIGODLIKE/ComfyUI-BlenderAI-node. Есть также хуйня под криту
Залил на гитхаб, так уж и быть. Подумал хрен с ним, пускай будет. В принципе много для чего может пригодится такой легковесный интерфейс. Назвал по другому, в настройки вынес редактирование экзэмплов, и через переменную окружения можно изменить название. В общем за пару действий можно перевести к изначальному виду.
Можете проверять. Если ок, то можно будет добавить в индекс автоматика
https://github.com/light-and-ray/sd-webui-replacer
Можете проверять. Если ок, то можно будет добавить в индекс автоматика
https://github.com/light-and-ray/sd-webui-replacer
И зачем оно нужно, без всего функционала автоматика, когда можно просто использовать Segment Anything напрямую? Выглядит как говно.
Потому что с segment anything долго морочиться для каждой картинки по отдельности, сравнимо по времени с inpaint-ом. А так можно все подряд кидать
Найс. По поводу функционала - действительно можно добавить больше параметров с автоматика, плюс возможность брать настройки из текстового файла при батчах.
> текстового файла при батчах.
О, об этом не подумал. Мб было бы интересно
Основные настройки я добавлю обязательно. И еще upscaler for img2img, почему-то его по умолчанию в интерфейс не вынесли, а штука то полезная. Лица gan апскейлеры портят, но вот с туловищем - норм. Всяко лучше мыла
Еще хочу контролнет добавить. Особенно openpose, так как поза портится на некоторых фотках нереально. Надеюсь оно не сложно будет


Вот смотри, увидел я фотку в телеграме. Захотелось нюдтса. Тык тык, и готово. 2 кнопки: upload и run.
Бесит возиться с промптами - тут долисать до segment anything, выставить галочку на промпт, ввести промпт, сгенерировать маску. Выбрать маску вручную, потом еще нажать 2 кнопки чтобы расширить маску. Потом еще не дай бог у тебя криво оно скопировалось в inpaint upload. Возни куча. Тем более если с телефона - это того не стоит
Промазал
Надо хоть немного качества, а не это мыло даже мыльнее оригинальных шакалов.
> 2 кнопки
Действительно, 2 кнопки сильно проще 5.
В целом норм. Но надо бы ещё прикрутить регулировку разрешения, чтобы на больших фотках не шакалило.
С денойзом 1 не получится слишком большое разрешение делать. Сделаю регулировку конечно, вместе со всеми настройками
Еще с этой же целью добавлю выбор апскейлера. Пока что сделал кэширование создания маски, теперь повторная генерация занимает в 2 раза меньше времени. И устал что-то




Дрёмобудка-кун репортинг ин!
lametta оказалась вполне обучаема! Только "3D" в негатив писать не надо. Или с осторожностью. Пик1, пик2 - 2 из примерно 30 референсов, пик 3 и пик 4 - лучшие результаты на данный момент (напомню, что генерю на CPU).
Обучение в два этапа. Первый этап: 160 регов girl, 5e-7, cosine. Оттуда взято промежуточное на 7к из 10к запланированных.
Второй этап: на базе оной промежуточной модели на 7к шагов - 2.5e-7, взято 2400 шагов из 4000 запланированных (отфигачило колаб).
Да, в один проход получается... не то. Почему - не знаю.
Колаб от Шивама, старенький.
lametta оказалась вполне обучаема! Только "3D" в негатив писать не надо. Или с осторожностью. Пик1, пик2 - 2 из примерно 30 референсов, пик 3 и пик 4 - лучшие результаты на данный момент (напомню, что генерю на CPU).
Обучение в два этапа. Первый этап: 160 регов girl, 5e-7, cosine. Оттуда взято промежуточное на 7к из 10к запланированных.
Второй этап: на базе оной промежуточной модели на 7к шагов - 2.5e-7, взято 2400 шагов из 4000 запланированных (отфигачило колаб).
Да, в один проход получается... не то. Почему - не знаю.
Колаб от Шивама, старенький.



Это пока без beastboost, я сейчас не при безлимитке. Полные 10к шагов (однопроходное) выдают вот такое. Тоже неплохо, но двухпроходка мне больше нравится. Спасибо анонимусу, сделавшему обзор на ламетту!
Напоминаю, что flat2d-animerge я тоже пытался тренить, но то ли он плохо обучаема, то ли я с промптом не угадал...
Какой моделью и каким семплером сделан сей нюдес?..
У меня друг спрашивает, он художник
Зачем будка, для такого же хватит простой лоры.
epicphotogasm-z inpainting. И негатив который автор на странице с моделью советует
Скмплер обычный dpm++ 2m sde karras, вроде он по умолчанию включен
Ну я пробовал. Будка у меня получается, а лора - нет. Может, плохо пробовал, не знаю. Но мне гораздо интереснее прокачивать то, что получается, чем то, что не получается...
Как долго на ЦПУ генерит?
Около 20 минут. 20 шагов EulerAncestral, 640x960. Когда-то больше, когда-то меньше.
Фришный спейс на обниморде.
Я вот думаю, а если вместо 160 регов взять 1600 - лучше будет или хуже? Надо ли подстраивать лр и количество шагов?..
Впрочем, я сам уже прикрутил, лол

Бля, какая ж хуйня 😂
это завязки от купальника!
Тензорбордом посмотри что там происходит. Для такого монотонного стиля действительно лучше подойдет лора без каких-либо регуляризаций, на коллабе должна натрениться минут за 20 максимум.
Однако, опыт сравнения с разной регуляризацией и прочее скидывай, интересно.
Чел с квадрой на 48 гигов в этом треде сидит? Как она по производительности, и что за возможности открывает количество памяти?
Оно чето выглядит как сгенерированное в 256х512 и дальше простеньким апскейлом растянуто
https://github.com/openai/consistencydecoder
Улучшенный декодер VAEшек для SD 1.5 от ClosedAI. Уменьшает боди хоррор, правит прямые линии, увеличивает член, делает волосы мягкими и шелковистыми.
Улучшенный декодер VAEшек для SD 1.5 от ClosedAI. Уменьшает боди хоррор, правит прямые линии, увеличивает член, делает волосы мягкими и шелковистыми.
А посоветуй апскейлер, чтобы из 256х512 генерить 640х960 ?
> Улучшенный
В 3 раза жирнее слои. Готовь 4090 для декодинга 1024х1024.
Какие слои, это же код онли? Интересно, оно для SDXLных ваешек работает или нет
>Готовь 4090 для декодинга 1024х1024
тай лы
Латент?
Посмотрел внутрь, да. Эта хуйня всю память сожрёт и ещё попросит, плюс декодить будет три миллиарда лет. Хайрез фикс и контролнетная акробатика внезапно выглядят гораздо лучше. Даже удивительно, что с такой еботой далле-3 всё равно умудряется рисовать кривые лица и пальцы.
Генери сразу в 640х960, большинство современных моделей потянет.
Можно оставить только для лоурезов, да и не насктолько печально все, кодинг/декодинг шакалов будет влезать батчем не 32+ и 10, не смертельно.
> новое вае для SD 1.5
Насколько же живуча всё-таки полторашка!
Вспомнил Джумлу @ прослезился
Видимо, не по той дорожке пошли стейблы. Не надо было пытаться переделать полторашку правильно. Надо думать, чем бы эдаким её обвесить. Например, дополнительный гипернетворк со своим текстэнкодером, навешиваемый на любое полторашное "ядро".
Я изобрёл контролнет, да?
Полторашка произвела революцию, и свалить её революцией, а не эволюцией - будет очень трудно.
Насколько же живуча всё-таки полторашка!
Вспомнил Джумлу @ прослезился
Видимо, не по той дорожке пошли стейблы. Не надо было пытаться переделать полторашку правильно. Надо думать, чем бы эдаким её обвесить. Например, дополнительный гипернетворк со своим текстэнкодером, навешиваемый на любое полторашное "ядро".
Я изобрёл контролнет, да?
Полторашка произвела революцию, и свалить её революцией, а не эволюцией - будет очень трудно.
Какие вообще существуют способы оценки качества моделей? Я пока могу предложить только два, и очень частных.
Для реалистичных моделей, натрененных на конкретную ЕОТ, можно оценивать качество каждой фотки очень просто: берём фотку, закидываем на search4faces, смотрим количество совпадений, сравниваем с количеством совпадений, получаемых от реальной фотки.
Могу похвастаться (но пруфов, конечно, не будет), что есть у меня модель на базе chilloutmix, ещё в мае натрененная, около сотни фоток ЕОТ в датасете, chas-conceptrate, 512x512 - отдельные мастерписи выбивают по 2-3 совпадения с реальными фотками (не считая "похожих").
Для всех моделей - предлагаю следующий критерий. Будем говорить, что модель Х обладает коэффициентом качества N, если из 16 генераций в разрешении 16Nx24N по дженерик-промпту (для анимэшных - 1girl, masterpiece) не более двух имеют потерю уникальности объекта (две тянки) или бодихоррор (не считая пальцев). Критерий видится относительно объективным, не правда ли? Особенно если в тесте зафиксировать сид и увеличить количество пробных генераций...
А ещё этот критерий хорош тем, что может быть улучшаем постепенно, шаг за шагом, аккуратно теряя десятки часов в слоевом режиме супермёрждера...
Далее - послушность. Есть набор относительно стандартных тэгов, которые модель должна понимать. Например, 1girl, white_bikini, outdoors. Или 1girl, black_dress, cowboy_shot, indoors. Соответственно, фиксируем набор тестов, смотрим, какой процент выполнения пожеланий.
Но ведь я наверняка изобретаю велосипед, правда?
Для реалистичных моделей, натрененных на конкретную ЕОТ, можно оценивать качество каждой фотки очень просто: берём фотку, закидываем на search4faces, смотрим количество совпадений, сравниваем с количеством совпадений, получаемых от реальной фотки.
Могу похвастаться (но пруфов, конечно, не будет), что есть у меня модель на базе chilloutmix, ещё в мае натрененная, около сотни фоток ЕОТ в датасете, chas-conceptrate, 512x512 - отдельные мастерписи выбивают по 2-3 совпадения с реальными фотками (не считая "похожих").
Для всех моделей - предлагаю следующий критерий. Будем говорить, что модель Х обладает коэффициентом качества N, если из 16 генераций в разрешении 16Nx24N по дженерик-промпту (для анимэшных - 1girl, masterpiece) не более двух имеют потерю уникальности объекта (две тянки) или бодихоррор (не считая пальцев). Критерий видится относительно объективным, не правда ли? Особенно если в тесте зафиксировать сид и увеличить количество пробных генераций...
А ещё этот критерий хорош тем, что может быть улучшаем постепенно, шаг за шагом, аккуратно теряя десятки часов в слоевом режиме супермёрждера...
Далее - послушность. Есть набор относительно стандартных тэгов, которые модель должна понимать. Например, 1girl, white_bikini, outdoors. Или 1girl, black_dress, cowboy_shot, indoors. Соответственно, фиксируем набор тестов, смотрим, какой процент выполнения пожеланий.
Но ведь я наверняка изобретаю велосипед, правда?
Посмотри на ллм, там сейчас идет не столько количественное развитие, считай переход на sd2.x а потом xl, сколько качественное, с радикальным ростом производительности при сохранения мелкого размера и трендом на ужатие и оптимизацию.
Суть в том что на основе полторашки происходит нечто подобное, ее файнтюны, технологии, огромное число костылей, варианты применения с длинным воркфлоу и т.д.
Революцию стоит ждать на основе новой архитектуры типа петли обратной связи с помощью мультимодалки или группы сеток, но чсх даже это в некотором колхозном виде может быть реализовано с применением 1.5.
Тут бы зашла условная SDXS в +- том же размере но с учетом новых метод тренировок. А если будет примерно совместима с 1.5 то вообще идеал, с руками оторвут. Но на xl много сил потрачено и внутренний каннибализм плодить они не будут.
> Для всех моделей
Ты же про лоры?
Управляемость промтом в очень широком смысле, способность делать четкие когерентные бекграунды, отсутствие проблем с перспективой и восприятием концептов, не триггерится и перерисовывает что-то если в промте нет релейтед тегов, порядок с анатомией, воспроизведение деталей исходника но при этом возможность поменять часть костюма/параметры тела и т.д.
> не более двух
Делай грид на исходной модели а потом с добавлением лоры, и сравнивай процент фейлов.
Добавь управляемость контролнетом.
Всё это непонятно как оценивать, под любой объективный тест можно заточиться, а любой субъективный субъективен. Хотя некоторые пользуются субъективными, например https://www.youtube.com/watch?v=X1XfmXsbVFY&t=125s
>Добавь управляемость контролнетом.
Особенно нелюдей. Допустим хвост приделать опенпоз ригу, или шесть лап для паука, или хотя бы коленки не в ту сторону для сотоны, и посмотреть какую поебистику он выдаст. Главное CN-openpose юзать, а на T2IA-openpose, последний заставляет абсолютно всё мутировать в людей.
Всё это писями на воде виляно, в общем.
> Допустим хвост приделать опенпоз ригу, или шесть лап для паука, или хотя бы коленки не в ту сторону для сотоны, и посмотреть какую поебистику он выдаст.
Хуясе, звучит космос, где такое можно взять? инб4 напиши сам
Если там еще для неодушевленных объектов (например, автомобиль) есть то даже слишком круто.
>Ты же про лоры?
Нет. Я, конечно, дурак и идеалист - но не настолько, чтобы не понимать, что каждая лора слишком уникальна, чтобы можно было формулировать чёткие критерии.
Поэтому я именно про чекпоинты - как трененые, так и мёрженные.
Ты так говоришь про заточку под объективный тест, как будто это что-то плохое! Нужно же иметь какие-то ориентиры.
У Сдохли есть шансы занять свою нишу. Если никто не придумает способов, нарастив полторашку примерно на тот же объём, получить схожие результаты.
>где такое можно взять?
Блять, нарисовать скелет опенпоза с лишними лапами. Ну или готовый риг под блендер возьми, там уже готовые лишние конечности для присобачивания есть. https://toyxyz.gumroad.com/l/ciojz
Контролировать надо не только опенпозом, чтобы не получить мутанта, а ещё и через глубину, кэнни и т.п. А чтобы получить глубину, надо ещё и модельку иметь, в том риге только хуман есть.
>Ты так говоришь про заточку под объективный тест, как будто это что-то плохое!
Ну вот есть такие смешные ребята https://github.com/imoneoi/openchat
бьют себя пяткой в грудь что их крошечная 7B модель перегоняет чат-гопоту 3.5 по всем тестам. Можешь сам представить что там на самом деле.
Так это они с нуля (?). А я веду речь о том, как сравнивать между собой мёржи и файнтюны.
> чекпоинты
> натрененная, около сотни фоток ЕОТ в датасете
Оу щи.
Чекпоинт сам по себе уже обязан удовлетворять всем этим фичам и при мерджах уже как раз стоит обращать внимание на детали типа пальцев, мелкие нюансы стилизации и т.д., чтобы оно косячило по крупному - это нужно сильно сфелить при мердже. А делать полноценный файнтюн под еот/персонажа с микродатасетом это не оптимально читай пиздец.
> нарисовать скелет опенпоза с лишними лапами
Его формат же имеет некоторый стандарт, оно и воспримет как многорукое индийское божество а не что изначально задумано, не?
А та же ситуация. Лору попробовал - вышла фигня. А чекпоинты я тренил под неё с декабря. Какая мне на фиг разница, 10 минут выставлять настройки и ждать 4 часа или 10 минут выставлять настройки и ждать 15 минут? Всё равно я ограничиваю время, затрачиваемое на нейронки (а то башка вразнос пойдёт), а вкладка с гугл-колабом... ну, не то чтобы совсем не жрёт памяти... Но у меня 16 ГБ оперативки, терпимо.
Но датасет там вот оч так себе по современным меркам, да.
Разверни плиз мысль про базовые требования.
Суть в возможностях-удобстве дальнейшего применения и эффективности обучения.
> Разверни плиз мысль про базовые требования.
?


>Его формат же имеет некоторый стандарт, оно и воспримет как многорукое индийское божество а не что изначально задумано, не?
Я пробовал, конкретно та модель что в openpose controlnet более-менее умеет контролировать всяких ящериц, собачек, роботов и прочую нечеловеческую нечисть, если SD чекпоинт (+ лора + IP adapter или что там у тебя) хотя бы примерно представляет что это такое и как их ставить в данную позу.
Но вообще если добавить и depth и canny в форме твоего пиздокрылого семихуя, и ещё и подсунуть ему референс через IP-Adapter какой-нибудь (или вообще натренить лору на генерациях), то его наверно можно забороть, по крайней мере в определённых пределах. Людям он точно конечности пришивает нормально, превращая в Шиву. Насчет пауков и хвостатых не знаю.
Ты хочешь сказать, что любой приличный (не очень инцестный) микс должен быть дообучаем с помощью файнтюна?? Что это не какое-то особенное свойство чекпоинта?
Странно, мои опыты с SunshineMix и DreamLike PhotoReal V2 показывали, что далеко не каждого зайца можно научить курить... Получались какие-то брежнебровые мужеподобища вместо няши-косплеерши.
Те пикчи и в примерах есть, они просто добавляют дополнительные конечности того же вида-цвета и на выходе если с промтом норм может получиться типа роборуки и т.д.
А какой цвет ставить для хвоста? Для лап паукану или ящерице (хотя с ней проще, там ведь 4)? Колени можно обыграть изгибом-позицией, кузнечиков делает.
> если добавить и depth и canny
Где их взять если речь об исходной генерации?
> превращая в Шиву
О том и речь
> Насчет пауков и хвостатых не знаю.
Эх, а так забайтил, жаль.
Нет, то что подобное обучение нужно делать с помощью лоры, обученной на голой сд или легким хорошим ее файнтюне в качестве базовой модели (для реалистика) или наи для анимца. После этого нормальная лора/локон будет прекрасно применяться на любом нормальном чекпоинте, в том числе в сочетании с другими.
А в остальном - любой нормальный чекпоинг не делает бадихоррор, слушается и проблемы проявляться начинают в мелочах прежде всего.
> далеко не каждого зайца можно научить курить
Это верно, если твои пикчи слишком отличаются от дефолтного то оно просто начнет все ломать без результата.
> Нет, то что подобное обучение нужно делать с помощью лоры, обученной на голой сд или легким хорошим её файнтюне в качестве базовой модели (для реалистика) или наи для анимца. После этого нормальная лора/локон будет прекрасно применяться на любом нормальном чекпоинте, в том числе в сочетании с другими.
Анон, я слышал это много раз, и я пробовал тренить лору на SD. Получилась фигня. Я не могу показать датасет, поскольку девушка реальна и легко находима. Возможно, я рукожоп. Это со всеми бывает. Но я начинал это в декабре 2022, когда лору ещё не изобрели, не говоря уже о её поддержке в diffusers. И теперь у меня есть плюс-минус работающий рецепт, который я хочу улучшить. Не изобрести принципиально новый, а потихоньку улучшать существующий. Замена базовой модели - один из самых простых способов.
Возможно, я хочу странного. А хочу я, чтобы модель знала не только лицо, но и тип её фигуры, а также форму и расположение пупка. И если тип фигуры плюс-минус можно и тэгами, то вот с управлением рисовкой пупков я не сталкивался никогда.
Но я не хочу тэгами, анон. Я хочу, чтобы модель впитала максимум знаний об этой конкретной косплеерше. И выдавала по ним генерации.
Я знаю, я чокнутый. Но камон, 2023 на дворе, где вы нормальных людей-то видели?
>Где их взять если речь об исходной генерации?
Блендерный риг что я линканул, рендерит по разным слоям mediapipe face, руки, скелет, depth, canny, mediapipe face и всё на свете, можешь брать и ставить кучу контролнетов, каждый на свой слой. Но из мешей в комплекте там есть только человек, паукана самому надо делать. (быстрее сгенерить из карты глубины взятой от фотки и конвертнуть в кривой меш, думаю)
>О том и речь
Это людей. Ящерицу я крутил чистым скелетом, без depth и прочего, получалось куда ни шло - пока не наткнёшься на ограничения самой модели, которая плохо себе представляет ящерицу танцующую брейк-дэнс. Думаю если к этому скелету иметь модель и рендерить ещё и depth и canny по ней, будет намного лучше.
>любой нормальный чекпоинг не делает бадихоррор
... до определённого разрешения. См. рассуждения о количественной характеристике выше.
А генерить в небольшом разрешении - значит всрать лицо. Хайрезфикс? Ну, я не умею его готовить :( Пупок всирается, опять же. Адетаилер? (есть ли в этом слове Й или тут как с Таиландом и биткоином?) Нууу... Я вроде как даже видел где-то пайплайн под diffusers с ним, но всё ещё не уверен, поможет или нет.
Тут такие есть? Было бы интересно услышать.
> я слышал это много раз
Неспроста.
> Возможно, я хочу странного. А хочу я, чтобы модель знала не только лицо, но и тип её фигуры, а также форму и расположение пупка.
Лоры (локоны и производные с экстра слоями) и более сложное ухватывают.
Ну твой подход и условия понятны, хозяин-барин, делай как тебе удобно. Просто когда делаешь утверждения в общем виде учитывай это и делай уточнения, а то чисто вводишь в заблуждение остальных. А еще лучше - выдели по своему опыту обучения как лучше делать, что на что влияет и т.д., может с файнтюнами пригодиться.
> Блендерный риг
Оче заморочно, но в качестве реализации, да. Проще ммд/койкацу/подобное заточенное взять или из готовых либ сборников, для 95% случаев хватит.
> паукана самому надо делать
Ну вот для чего-то необычного, пердолиться с 3д моделированием довольно непростого объекта. Ну похуй, плата за необычность, но от исходного "быстро накрутил скелет и получил результат" уже слишком далеко.
> до определённого разрешения
До 768 и выше все сейчас могут, методик апскейла на любой вкус и цвет, причем в них лоры применяются и лица/детали как надо делать. Дроч на разрешение первой генерации непонятен, других параметров более важных полно.
>Адетаилер? (есть ли в этом слове Й или тут как с Таиландом и биткоином?) Нууу... Я вроде как даже видел где-то пайплайн под diffusers с ним, но всё ещё не уверен, поможет или нет.
Деталер-хуялер.
> замазываешь галюн
> вбиваешь промпт к тому что замазал (пупок)
> инпеинтишь замазанное на более высоком разрешении чем у основной пикчи
Вот тебе и деталер. Именно так оно и работает, просто фейс-деталеры автоматом детектят фейсы, чтоб удобней.
Аналогично с любой картинкой. Заметил говно, замазал, инпеинт. Удобней это делать во всяких критах-фотошопах с SD плагинами. Подобная потайловая детализация вручную способна поправить большую часть говна.
>Оче заморочно
>пердолиться с 3д моделированием довольно непростого объекта
Беда всех местных в том, что они ожидают от ИИ кнопку "сделать пиздато". Рисоваки, VFXеры и 3D макаки вроде меня ебутся, надрачивают вкус, надрачивают скиллы, надрачивают хуй, чтобы сделать пиздато. На каждую работу уходят бесчисленные часы. Да, конечно, автоматизация, вся хуйня, это всё где-то в светлом будущем. Но пока что SD не в состоянии выдать желаемое по кнопке сделать пиздато, оно может автоматизировать только часть работы, остальное придётся делать самому. Его надо направить, и тем более оно не умеет придумать за тебя высокохудожественный месседж. А тем более нейронки побольше так не могут, которые кроме ебучего промпта вообще никак не контролятся толком, и сделать там нихуя нельзя.
На самом деле можно в блендере вообще всю сцену из примитивных пропов собрать (болванки с ригом это люди, коробки для домов и машин, и т.п.), отрендерить это в разные слои для каждого объекта / смысловой единицы, потом запилить схему для комфи, поглощающую эти слои, и заставить SD рендерить это всё по кускам. Получается своего рода "нейронный рендер", ящитаю это прекрасный компромисс на текущее состояние дел. А светлое будущее будет в светлом будущем. Когда-нибудь.
Аналогично для рисовак, вместо ебли с сингл-геном ты просто рисуешь скелет и очертания, и потом по тайлам детализируешь ручками каждую смысловую единицу пикчи. Можно пилить целые детализированные полотна с рубящимися энтами и рептилоидами. Как раз для крит с фотожабами есть плагины.
>пердолиться с 3д моделированием довольно непростого объекта
Лайфхак: можно сгенерить корректного паукана в SD, или взять ИРЛ фотку с нужной стороны. Сгенерить ему карту глубины. В блендере вмять этой картой плоскость, чтобы получилась псевдомодель. Чуть подчистить, разделить конечности. И прямо в таком хуёвом виде натянуть на риг. Меш будет люто колхозный и смотреться только с одной стороны, управляться будет плохо, но тебе ведь это не в финишный рендер голливудского кина совать, тебе всего лишь нужен примитивный проп, с которого ты возьмёшь лишь грубую карту глубины для последующего нейронного рендера.
Даже 4090 не хватает. На 1024х1024 оно жрёт 28 гигов VRAM. На 512х512 всего около 11 гигов и декодит 15 секунд на 4090. Какого-то супер-качества я не увидел, как обычно всё у КлозедАИ - говно.
Просто не оптимизировано нихуя, надо квантовать и изгаляться. Но вопрос надо ли. Всё что я пока увидел ценного - оно делает прямые линии почти прямыми, и кое-как может в текст на неровных поверхностях. Это из того что сложно исправить хайрез фиксом, сегментацией+инпеинтом, и контролнетами, которые жрут намного меньше чем эта хуйня.
А вот лица и руки всё равно идеальными не выходят, приходится всё равно полировать инпеинтом.
> квантовать
Конволюшен очень плохо квантуется, будет слишком сильное падение качества. Там вообще реализация обоссаная - он в полном разрешении в пиксельном пространстве декодирует, используя латент только как референс, и ещё там декодирование может быть в несколько шагов, хотя уже один шаг раз в 20 медленнее обычного вае.
> вопрос надо ли
В хайрезах разницу можно только под лупой найти.
> оно делает прямые линии почти прямыми, и кое-как может в текст на неровных поверхностях
От модели зависит. Если модель умеет в прямые линии, то и с обычным вае они будут. В текст оно всё так же не может.
Сижу то так то сяк экспериментирую с обучением и вся эта тряска с текстовым энкодером это шиза просто. Недообучат и ((((начинается)))), ставишь лры по гайдам — юнет уже распидорасило, а на промпт ещё даже малейшей реакции нет. Жарьте текст как суку, в общем, пацаны, не слушайте шизов.
> что они ожидают от ИИ кнопку "сделать пиздато"
Сам придумал? И ради этого столько пердолинга и вот такие треды в принципе?
Суть в эффективных методах достижения цели и использования новых инструментов, а не то что кто-то потратил часы-дни-годы на обучение и поэтому всем остальным стоит это делать.
Юзать блендер целесообразно если в нем уже хорошо работаешь и можешь быстро делать то что хочешь. Иначе можно буквально по кривому эскизу в пеинте и с минимальными правками там же в комбинации с инпеинтом получить результат быстрее и проще. Необходимость освоения 3д моделирования только ради такого под вопросом.
> светлое будущее будет в светлом будущем. Когда-нибудь.
Да по сути опенпоуз цнет и есть будущее, наиболее точное и информативное представление. Осталось добавить генерацию самих скелетов по промту, чтобы можно было выбрать из вариантов или быстро поправить до нужной кондиции, и повысить качество работы, добавив опций привязки позиционирования в кадре или рандомайзер и т.д..
> или взять ИРЛ фотку с нужной стороны
Фотобаш, депсы и прочее можно и в самой диффузии юзать, вполне.
> В блендере вмять этой картой плоскость, чтобы получилась псевдомодель.
Опять упирается в навыки в блендере, но если уметь вариант перспективный, спасибо.
> Какого-то супер-качества я не увидел
Примеры из репы даже не вопроизводятся, или нет такого эффекта как на их черрипиках?
> в полном разрешении в пиксельном пространстве декодирует, используя латент только как референс
Ну не, с таким подходом будет уже совсем другой жор памяти и скорость если правильно понял
>Суть в эффективных методах достижения цели
Сборка сцены из грубых примитивов (или скетч, если нужно лишь одну пикчу) это и есть эффективный способ для произвольных композиций которые нужны именно тебе. Сделай, тогда поймёшь, вот серьёзно. А 3D моделирование или рисование это чисто техническая хуйня, не сложнее чем ноды в комфи ковырять. Глаз, вкус и осмысленность для создания чего-то интересного развить намного сложнее.
>промпту
Сразу нет. Максимум возможностей промпта - простенькая подсказка, как именно интерпретировать твои основные не текстовые гайды. Мультимодалка всегда лучше и быстрее. Сунуть скелет мышкой в нужное место, поставить камеру боком-раком, дать визуальный референс или лору - всегда проще чем набирать магические заклинания и ошибиться на пиксель, не получив желаемого эффекта, или получив что-то другое. Аналогично со всем остальным.
>Да по сути опенпоуз цнет и есть будущее, наиболее точное и информативное представление.
Опенпоуз в чистом виде это тупо скелет, примитив. Не может даже в пальцы (хотя реальная модель обучена им, но вообще-то это не каноничная часть опенпоз вроде как). Не может в лица, направление взгляда. Не может в объёмы (densepose может). В перспективу (требует явного указания фона через контролнет, иначе сетка придумает его рандомно и персонаж может начать парить в воздухе или повернуться криво, ибо скелет двумерный). В причёску, макияж, шрамы, татухи и т.п.
Дохуя во что не может, в общем. Поэтому его надо обмазывать полноценным мешем на риге и дополнительными контролнетами (кэнни/lineart для рук и ступней, depth для перспективы, mediapipe/landmark для лица и т.п.), референсами - чтобы выходило гарантированно то что надо, а не то что сеть напридумывала. Как минимум чтобы другая генерация не отличалась в деталях.
> Примеры из репы
Там 256х256. И там не генерации, а энкодинг-декодинг пикчи низкого разрешения. Из того что я тестил - литералли нет разницы, где было кривое - там оно и осталось таким же кривым, может только на реалистике очень мелкие детали чуть почетче становятся. А в аниме только хуже делает - появляются артефакты на лайне вместо чистых линий.
> с таким подходом будет уже совсем другой жор памяти и скорость
А так и есть. Оно в 10-15 раз медленнее обычного вае, жрёт тоже на порядок больше памяти. Хайрезфикс даже до 1024х1024 не влезает в 24 гига. Тайлинг работает через жопу, лучше от него не становится.
> Сделай, тогда поймёшь
Бля пчел...
Сам когда методы работы понимать будешь, поймешь насколько все проще и какие горизонты открываются.
> Не может даже в пальцы
Есть руки под него, но хорошая работа в т.ч. с пальцами это и есть нужное развитие.
> иначе сетка придумает его рандомно
Да, она и должна придумывать по запросу/референсам/любому другому способу управления. Задача лишь подкрутить так чтобы оно более стабильно подгонялось под позу персонажа.
> Дохуя во что не может
Дружок-пирожок, оно может в создание изображения с нужной позой, в создание сотен изображений за несколько минут из которых можешь выбрать нужное, или взглянуть на них и "поменять чтобы было как задумано" и далее уже править или улучшать. В 99.8% случаев никому нахуй не сдалась попиксельная выдрочка и гиперточность а нужно просто "чтобы персонаж вот так сидел-позировал и короче вон там фон прикольный был, ну еще сделай чтобы руку вверх типа машет и сюда мелочей добавь".
То что ты описываешь - просто 3д моделирование, взял готовые ассеты, расставил кости как хочешь, шейдерами рендер обмазать и никакая диффузия уже не нужна.
> а энкодинг-декодинг пикчи низкого разрешения
> Из того что я тестил - литералли нет разницы
Ну вот и революции не случилось, может если модель в комбинации с этим вае изначально тренить чуточку лучше будет, но при таком росте сложности - нахуй не нужно.
> модель в комбинации с этим вае изначально тренить чуточку лучше будет
Проще сгенерить что-то вроде 1536х1536 и потом даунскейлить до 512х512 - будет по скорости и жору памяти одинаково, зато качество сильно лучше чем предлагает КлозедАИ. Даже хороший GAN-апскейл с обратным даунскейлом может быть лучше.
Вот анон, ведь я же всё это глубоко пробовал и пиздец сколько конкретно с опенпозом/кейпозом/бодипозом/денспозом экспериментировал и разницу знаю, и свои скрипты писал потому что возможностей не хватало, и лоры обучал, потому что модель срёт под себя без этого. Я же вижу что ты кукаретик, который объясняет не попробовав. Зачем так делать?
Когда-нибудь может быть будет многое из того что ты хочешь, но прямо сейчас имеем то что имеем.
>Да, она и должна придумывать по запросу/референсам/любому другому способу управления.
Нет, нужно точно указать какая у тебя перспектива на пикче, какая желаемая композиация, и где плоскости проходят. На один лишь скелет опираться сетка не может, потому что он двумерный и интерпретировать его можно кучей способов как оптическую иллюзию, и она обязательно сделает неправильно. Без опорных деталей об окружении она тебе подвесит перса в воздухе или развернет навыворот, просто потому что так тоже можно. Я уж не говорю если у тебя куча персов в кадре, там ебля та ещё. И это с людьми, про животных/монстров это отдельная тема, там без дополнительных КН и монструозных схем никуда.
>В 99.8% случаев никому нахуй не сдалась попиксельная выдрочка и гиперточность
Это нужно всегда, если ты хочешь больше одной пикчи, иначе будет персонаж каждый раз с разными мелкими несовпадающими деталями и выглядеть это будет всрато. Такая же тема как в видеомонтаже с согласованием цветокора/выдержки на клипах. Ну зачем ты говоришь то чего не понимаешь?
Это нужно всегда, если ты хочешь получить нужный эффект от пикчи, никакая нейронка и никакие дали666 не понимают этого, по крайней мере пока.
Это нужно всегда, если твоя задача что-то большее чем ван гёрл биг буб.
>То что ты описываешь - просто 3д моделирование, взял готовые ассеты, расставил кости как хочешь, шейдерами рендер обмазать и никакая диффузия уже не нужна.
А ты хоть представляешь сколько надо ебаться с моделингом/риггингом/текстурингом/залупингом одного нормального чара и детального окружения в полной сцене? Так-то одной сценой занимаются сразу дохуя людей, один ты там хуй что сделаешь в срок. И никогда ты не получишь такого лука, какой можно получить в SD, когда он работает как надо. В случае с SD ты просто делаешь раскладку сцены из кубиков и дженерик ригов, это тривиальная задача по сравнению с фулл процессом. Когда сетку удаётся развернуть в нужную сторону и пофиксить все галюны, это экономия 95% времени. Сейчас пока чаще не удаётся, поэтому я только тыркаюсь и экспериментирую.
Ну да, обработка диффузией при апскейле всяко больше нового привнесет чем эти пляски с vae, особенно учитывая разнообразие возможных пикч и невозможность сделать его абсолютно универсальным.
> Я все все знаю, а ты кукаретик
Ай лол. Не выпендривался бы своими познаниями блендера - не пришлось бы потом так трястись, позиционируя как единственно возможный способ что-то делать. При этом не показал ничего нового/уникального а только байтил.
Глубинный подтекст понятен, как отпустит сам все поймешь.
Анончики, а я правильно понимаю, что если на одной генерации применить несколько VAE (не последовательно, конечно, а закэшировав латенты), то получится несколько разных пикч, отличающихся деталями, цветами и т.д., но затраты времени как таковые будут незначительны (мы не рассматриваем новомоднее даллевское)?
Отсюда два вопроса.
1. Какие существуют основные VAE, стоящие внимания? Чем они отличаются? Какие лучше подходят для фотореалистичного, а какие - для анимца?
2. Откуда берутся VAE? Как-то же их тренят! Более того, из сути VAE кажется логичным, что его имеет смысл тренить под конкретных художников (при датасете, навскидку, от 128 пикч) и под конкретных ЕОТ/актрис (при примерно тех же размерах датасета).
Далее, учитывая, что VAE работает jpeg-плитками 8х8, при наличии исходников датасета в нефурье-формате - например, PNG или ещё каком-нибудь RAW / NEF (неведомая еная фигня) каждая картинка лёгким сдвигом на пару пикселей превращается в новую для VAE. Выглядит вкусно, не правда ли?
Отсюда два вопроса.
1. Какие существуют основные VAE, стоящие внимания? Чем они отличаются? Какие лучше подходят для фотореалистичного, а какие - для анимца?
2. Откуда берутся VAE? Как-то же их тренят! Более того, из сути VAE кажется логичным, что его имеет смысл тренить под конкретных художников (при датасете, навскидку, от 128 пикч) и под конкретных ЕОТ/актрис (при примерно тех же размерах датасета).
Далее, учитывая, что VAE работает jpeg-плитками 8х8, при наличии исходников датасета в нефурье-формате - например, PNG или ещё каком-нибудь RAW / NEF (неведомая еная фигня) каждая картинка лёгким сдвигом на пару пикселей превращается в новую для VAE. Выглядит вкусно, не правда ли?
> Откуда берутся VAE?
На деревьях растут.
> из сути VAE кажется логичным
Нет.
> каждая картинка лёгким сдвигом на пару пикселей превращается в новую для VAE
Таблетки, срочно.
Да ты как будто показал, лишь сказал как КН всё на свете умеет. Попробуй сам сделать то что пишешь.
>если на одной генерации применить несколько VAE
>Какие существуют основные VAE, стоящие внимания? Чем они отличаются? Какие лучше подходят для фотореалистичного, а какие - для анимца?
Это хуйня всё. Для SD 1.5 существуют ровно три модели:
- оригинальный VAE, вшитый в саму модель
- тенсентовский, побольше https://github.com/tencent-ailab/Frequency_Aug_VAE_MoESR
- от ClosedAI, линк выше, он совсем жирный.
Разница между ними - грубо говоря "степень сжатия" и жручесть, не более.
Кастомные VAE что ты видишь на цивите - поделки инфоцыган. Никто их не точит под конкретный контент (хотя в целом могли бы), они получаются тупо автоматическим перелопачиванием груды пикч и измерением статистической близости одних кусков данных к другим. Поэтому он и автоэнкодер. Таким образом выцепляется смысл из неструктурированного потока данных, ну во всяком случае если верить дистрибутивной гипотезе.
Всякие вариации стандартной VAE для "фикса выцветшей картинки" сделали дебилы, не понимающие откуда это берётся. А дело в том, что ранние скрипты для мёржа моделей портили VAE каким-то неведомым образом, и те выдавали блеклую картинку. Багованные миксы пошли по миру, на их основе делали другие багованные. А инфоцыгане вместо того чтобы использовать стандартный вшитый в оригинальную SD, творили какую-то хуйню.
>каждая картинка лёгким сдвигом на пару пикселей превращается в новую для VAE
Зачем? И зачем тебе для этого исходники датасета? Что ты хочешь получить?
Алсо, есть ещё проблема у SD 1.5, в недостатке "динамического диапазона", тоже своего рода блеклость. Она не связана с этими битыми VAE, она связана с планировщиком шума, который начинал не от 100% а от 99.99% при обучении. zstd/v_pred модели это пытаются фиксить.
>Никто их не точит под конкретный контент
Не, ну почему. Есть варианты под "аниме-контент", который дает усиление лайнарта. Есть всякие варианты, которые шакалят (или наоборот улучшают) лица, в зависимости от того, на какой модели используются.
>Не, ну почему. Есть варианты под "аниме-контент", который дает усиление лайнарта.
Линк? Кто-то файнтюнил стандартную ваешку? Я отстал от жизни по ходу




Их на цивите целая куча лежит, самых разных.
https://civitai.com/models
И делаешь сортировку по вае.
Отличие, конечно, довольно слабые (если цветокоррекцию не брать), но бывают.
Как пример, на пикрилах:
any-4.0 == kl-f8-anime == z-vae == 840000-ema-pruned
Помимо цветокоррекции немного отличается лайн, и глаза.
На разных моделях по-разному проявляется.
> то получится несколько разных пикч, отличающихся деталями, цветами и т.д.
Отличия будут минимальны, не стоит того. Если хочешься для чего-то конкретного, например тонкого лайна в средних разрешениях, то можно изначально другое использовать.
> лишь сказал как КН всё на свете умеет
Нет, это ты из-за ангажированности так воспринял. Там речь была о том что опенпоуз контролнет сохраняет высокий уровень абстракции но позволяет в сочетании с промтом получить достаточно контроля. Наиболее оптимальный баланс между "пишу@кручу рулетку" и "часами дрочусь чтобы понять что поза говно".
Тут еще стоит добавить что все они еще по-разному артефачат, у первых двух фиолетовые засветы (не путать с полным пиздецом от старых вае, они оче мелкие), у вторых желто-зеленые. Проявляется достаточно редко, но можно встретить на резких границах света-тени.
>Их на цивите целая куча лежит, самых разных.
>https://civitai.com/models
>И делаешь сортировку по вае.
Это всё не файнтюны, это всякие дураки ковыряются в весах ручками. Там мусор один. Единственно что я не помню, делали ли NAI свой VAE, вот у них могло отличаться.
>баланс между "пишу@кручу рулетку" и "часами дрочусь чтобы понять что поза говно".
Нет такого баланса. Рулетки в процессе должно быть 0%, если результат тебе нужен не в папочку себе положить. Ну и часами дрочиться это конечно лихо сказано про процесс позирования и раскладки сцены.
>опенпоуз контролнет сохраняет высокий уровень абстракции но позволяет в сочетании с промтом получить достаточно контроля
Не позволяет он в одиночку получить достаточно контроля над объектами вне понимания модели. Часть приходится принуждать другими контролнетами (особенно положение кистей рук), частично приходится обрисовывать сцену чтобы модель могла себе представить как это вписать, а иногда вообще без лоры не обойтись.
Рили хочешь 100 детерминированный - правильный результат от нейросети получить? Поехавший.
Степень достаточности - спекулятивна. Про "вне понимания модели" - там же речь про их развитие и перспективы в будущем, посты не читал отвечая? Это самое понимание как раз должно улучшаться сводя необходимость лишнего пердолинга, описанного тобой к минимуму, но сохраняя возможность различного дополнительного контроля офк, чтобы не ограничивать область применения.
Сюда же развитие в сторону относительного управления типа реализации в стайл-ганах, давая возможность указать какие правки внести к полученному результату (прообраз - инпеинт в сд, как сам по себе так и с добавлением контролнетов). Это позволит точно и эффективно доводить исходный результат генеративных моделей до целевого без лишних пердуль.
Судя по моей папке с моделями - да, делали.
И он полностью идентичен Any4.
По крайней мере по эффекту на картинку.
Разницы с СД, кстати, не особо много. Ну, кроме насыщенности цвета.
>делали ли NAI свой VAE
Знаменитый всратый animefull-final-pruned.vae.pt
>Для SD 1.5 существуют ровно три модели:
>Разница между ними - грубо говоря "степень сжатия" и жручесть, не более.
Ещё TAESD https://github.com/madebyollin/taesd , она используется для превьюх. Теоретически можно использовать и для полноценного декодинга, но она сильно шакальная.
Есть ещё Latent2RGB ещё более шакального качества (и максимальной скорости), но это вообще не VAE.

Объясните нубу, как вообще работают нейросети?
Общий принцип?
Я сколько читал, ничего не понял, везде сразу начинают со сложного в ещё более сложное, как это реализовано, а мне нужно понять вообще как оно работает?
Вот я скачал модель для СД весом 2гб, она знает всё, я могу написать туда голые сиськи, пёзды, подсолнухи, речка, море, гора, листья дуба, байден, трамп, пыня, жуки, пауки, машины, города, облака, луна - она всё мне сгенерит. Она всё это знает в этих 2 гб. Как это уместилось в 2гб? Как оно хранится там? Как туда это затолкали? КАК? ЭТО ЖЕ ЧУДО НАХУЙ.
Как оно понимает трёхмерность? Какой объект ближе, дальше? Как оно понимает свет? И как оно генерится?
Модель весит 2гб, мне надо сгенерить картинку 100кб, оно развёртывает в 6 гб видеопамяти и рожает картинку в 100кб. Как? При этом гпу вообще не нагружен, только памяти нужно много.
Общий принцип?
Я сколько читал, ничего не понял, везде сразу начинают со сложного в ещё более сложное, как это реализовано, а мне нужно понять вообще как оно работает?
Вот я скачал модель для СД весом 2гб, она знает всё, я могу написать туда голые сиськи, пёзды, подсолнухи, речка, море, гора, листья дуба, байден, трамп, пыня, жуки, пауки, машины, города, облака, луна - она всё мне сгенерит. Она всё это знает в этих 2 гб. Как это уместилось в 2гб? Как оно хранится там? Как туда это затолкали? КАК? ЭТО ЖЕ ЧУДО НАХУЙ.
Как оно понимает трёхмерность? Какой объект ближе, дальше? Как оно понимает свет? И как оно генерится?
Модель весит 2гб, мне надо сгенерить картинку 100кб, оно развёртывает в 6 гб видеопамяти и рожает картинку в 100кб. Как? При этом гпу вообще не нагружен, только памяти нужно много.
Вот это почитай, полезно:
https://stable-diffusion-art.com/how-stable-diffusion-work/
Если коротко то по сути в модели есть полное представление о языке в виде токенов, в которые конвертируется промпт. А маленькие размеры обусловлены тем, что генерация идет в латентном пространстве, которое в 8 раз меньше пиксельного. А качество сохраняется идеальное потому, что в нашем мире очень много закономерностей, и благодаря ним информации на самом деле не так много как кажется
Ну а в целом по нейронным сетям: это алгоритм градиентного спуска. Это грубо говоря типа метод касательных и секущих, только в многомерном пространстве. Благодаря нему можно сделать приближение функций, которые никаким образом не формализовать. Собственно в данном случае этими скрытыми неизвестными функциями являются скрытые закономерности в нашем языке и визуальной информации. Они аппроксимируются в процессе обучения
>Как туда это затолкали? КАК?
В дохуямерное пространство можно запихать и не такое.
если прям упрощать, то давным давно олдовые ботаны сели и описали вручную датасет, расставив нужные зависимости и веса для каждого значения, создав по сути матричную структуру, которая послойно в зависимости от количества шагов заданных идет по этой матрице и выискивает подходящие зависимости, описанные ранее
современные же ботаны сделали мокропиську, которая сама может определять структуру датасета и генерировать описание и зависимости по тому же принципу перебора, потом только ручками подкорректировать и в продакшен, и потом кароче обучение нейросеток взлетело
ну и это все происходит в так называемом латентспейсе, по сути модель в два гига это огромный шум на миллиард параметров, а матричный алгоритм сетки как бы такой челик с апофенией головного мозга, который в пикрелейтед бугре с марса видит лицо
достаточно ясно описал?
Я так это понимаю.
1) Нейросеть это тип данных, единица информации внутри которого это некий графический фрагмент
2) Каждая единица информации подписана набором текстовых токенов.
3) Каждая единица информации хранит в себе ссылку на миллион других единиц информации что и образует как бы "СЕТЬ". Ссылки эти тоже имеют какой-то свой вес, возможно текстовые токены, не важно сейчас.
Используя нейросеть мы на вход даем промпт который на основании текстовых токенов проходит через миллионы ссылок между этими единицами графической информации и из наслаивающегося шума собирается изображение.
В чем я не прав?
быдло продаван-консультант
>Нейросеть это тип данных, единица информации внутри которого это некий графический фрагмент
не совсем так, графики как таковой в модели нет, сбор изображения это фильтрация шума, то есть не зря я сказал про апофению, это буквально видеть в шуме то, чего там нет, придумывать на ходу, а фильтрация шума это как если бы у человека еще и зрение улучшалось от глубого минуса до идеального
>Каждая единица информации подписана набором текстовых токенов
не совсем так, условный токен loli это как будто водитель, а сид 666 это путь, по которому этот водитель едет и собирает в черный мешок для алгоритма ендкодера-декодера все шумовое гавно которое похоже на loli, сеточный алго в момент прожатия тобой кнопочки УЖЕ "знает" что получится, loli уже прошла по пути 666
>Каждая единица информации хранит в себе ссылку на миллион других единиц информации что и образует как бы "СЕТЬ". Ссылки эти тоже имеют какой-то свой вес, возможно текстовые токены, не важно сейчас.
ну фактически да, там тесная связь, но опять же там не сеть, не нейроны рандомно растыканы и взаимодействуют, там строгая иерархия и слой за слоем алгоритм ебашит по нойзу и его производным
>Используя нейросеть мы на вход даем промпт который на основании текстовых токенов проходит через миллионы ссылок между этими единицами графической информации и из наслаивающегося шума собирается изображение.
ну в целом да, именно так, за исключением графической информации, сборка изображения сетью это не акт творения посредством копипастинга и микширования "графической информации", это фильтрация всех возможных связанных комбинаций loli по пути 666 на основе вводных значений фильтрации
Блять, здесь всё же SD технотред, а не базовых понятий тред. Возьми и изучи архитектуру диффузионных моделей самостоятельно, бессмысленно описывать это в посте на дваче. Только придется углубиться в более базовые вещи, потому что латентная диффузионная модель в частности это набор из кучи нейросеток.
Интересно. А верно ли утверждение, что нейросеть это просто такой тип данных, вроде словаря или списка в питоне? Просто такая вот статичная запись некой информации в определенной иерархии и структуре, как список "1 Иванов, 2 Петров, 3 Сидоров", только сложнее.
Нет, нейросеть - это тупо матрица чисел, то есть просто большой массив из float
>Нет
>это тупо матрица чисел
Так получается что как раз ДА. Матрица это же тоже статичный тип данных - двухмерный список просто.
Боже, ты достал раковать, ты столько ошибок допускаешь, что лучше молчи
> как раз ДА
Петров, Иванов, Пидоров - это не foat
> матрица
> список
🤦🏻♀️
> статичный тип данных
> список
🤦🏻♀️🤦🏻♀️
> двухмерный
Какой нахрен двухмерный. Ты неправильно прочитал слово "дохуямкрный"
Короче просто учи то, как работает компьютер
>Петров, Иванов, Пидоров - это не foat
Я и не писал что это float, я привел пример одномерного массива и явно указал на то что это ПРИМЕР типа данных в том смысле, в которой я спрашиваю про нейросеть. Ты даже этого не понял.
>Какой нахрен двухмерный.
По умолчанию в погромировании матрица это 2д массив дурачок, EMS на своем сайте описывает матрицу как "rectangular array". Если ты имеешь в виду другую матрицу то явно указывай на это. Впрочем, это не важно. Я вижу что ты какой-то агрессивный визжащий рачина, который как псина на анонов кидается, даже не поняв вопрос. Ценность твоих постов нулевая.
Остальные пуки гринтекстом и спецсимволами оставь для одноклассников. Даже не вникал, скорее всего ты там точно так же нихуя не понял и просто визжишь.
Ты даже не знаешь что такое список, че ты там про программирование затираешь, малыш. Если бы модели были бы списками - то это ахуеть можно было бы
Каждый раз горю, когда модель называют нейросетью. Пиздос.
Ты бы ещё подрывался с того что интернет сетью называют, шизоид.


Новые бенчмарки
Не в самых практичных условиях, а просто чтобы выжать максимум на графике, но тем не менее
https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarks
Не в самых практичных условиях, а просто чтобы выжать максимум на графике, но тем не менее
https://www.tomshardware.com/pc-components/gpus/stable-diffusion-benchmarks
"Модель" это сокращение словосочетания.
Как например слова "вариант" или "версия". Такие слова используются отдельно, только когда понятен контекст, просто ради сокращения речевой конструкции.
"В этой версии мы добавили поиск". Будет понятно о чем речь только из контекста говорящего, например это лог разработчика и тогда понятно что тут речь про "версию программы" или "версию сайта".
"Эта модель разгоняется на 5 секунд быстрее". Тут будет понятно что речь идет о модели авто, например, если она в контексте.
А теперь подумай, дегенератина тупая, о какой "модели" идет речь и какое словосочетание сокращают в контексте SD.

Даже лицо человека, который
> Upscaling via SwinIR_4x from 768x768 to 1920x1080
сгенерировали.
А вообще тесты не тесты, батчами бы лучше перформанс показали и в хайрезе какие карточки по врам уже не тянут.
В какой-то мере интернет сеть и есть, так что похуй. А вот модель это абсолютно не нейросеть. Это что-то уровня называть бензин машиной.
Да не, просто даже на /ai слишком много даунов, которые не знают, что такое нейросеть, некоторые даже начинают какие-то нелепые оправдания своему невежеству лепить.
>нет серверных гпу
хуйня
Так разрабы СД и их СЕО сами писали что СД это "генеративный АИ на нейросетях". Они то побольше знают чем пуетшок с двача.
Так СД это нейросеть. А модель для него - нет. Не думай, что твоя скачанная с обниморды v1-5-pruned-emaonly.safetensors
это и есть stable diffusion.
>Так СД это нейросеть.
У тебя серьезные проблемы с логикой, дебс. Файлы "моделей" содержат в себе всю дату из оригинального SD и работают точно так же как и оригинальный SD, но с модифицированными свойствами. Эти файлы во всех лексических и абстрактных смыслах являются "моделью нейросети", "моделью SD", "моделью генеративного АИ", как угодно - для простоты сокращение "модель".
Ты понимаешь что ты клоун, который обосрался в попытках выебнуться несуществующими знаниями.
> клоун, который обосрался в попытках выебнуться несуществующими знаниями
Зачем же ты так про себя? Модель - это алгоритм. Это не файл с весами.
Как я и говорил, слишком много тупых с их тупыми попытками оправдать свою глупость. Это я про тебя. То, что у тупых принято называть моделью на самом деле к модели не очень-то и относится. Это чекпоинт. Наверное, это главная причина, почему чекпоинт путают с нейросетью, просто приучились называть его моделью и пошло-поехало. Так что что если кто и обосрался, то исключительно тебе на лицо.
А файл с весами - это не нейронная сеть?
Действительно.
Пиздец, между 3060 и 4060 разница всего около 10%. Я думал это только в играх так, а в других задачах будет x2. Но даже так 4060 - говно, с уменьшенной памятью
Между 3060ti и 4060ti вообще нет разницы. Хваленные 16 гб в отдельной версии идут, не по умолчанию
Лол, 2060super на одном уровне с 3060. Интересно было бы сравнить еще 2060 12gb, которая на базе super, но ее тут нет
Карты типа 1080ti нет. Ну видимо они реально сосут
Ну и хотелось бы реально топы среди работчих карт увидеть: A6000, A100, H100
>Pre-trained Stable Diffusion weights, also known as checkpoint files
Ты можешь хоть в одном посте не обосраться, клоун?
В твой же цитате как раз написано, что это веса для нейросети. Не сама нейросеть. Доходит до твоего мозжечка ссохшегося?
Ещё хотелось бы сравнение 3060 12 gb против 2070s.
Для игорь самая выгодная сейчас в соотношения цена/фпс 2060с и 2070с. А для СД что-то на 12гб надо.
Автор релизнул магическую лору.
https://huggingface.co/latent-consistency/lcm-lora-sdv1-5
https://huggingface.co/latent-consistency/lcm-lora-sdxl
https://huggingface.co/latent-consistency/lcm-lora-ssd-1b
Это на самом деле LCM адаптер, поддержка которого должна быть в коде (в comfyui уже есть). Его достаточно подключить и можно будет делать инференс за 2-8 шагов.
Отчёт как оно работает здесь https://arxiv.org/abs/2311.05556
насчёт качества и ограничений пока нихуя не знаю, не пробовал




так у меня обстоят дела
a house
Steps: 20, Sampler: Euler, CFG scale: 4.5, Seed: 3005468437, Size: 512x512, Model hash: 84d76a0328, Version: 1.6.1
epicrealism_naturalSinRC1VAE.safetensors [84d76a0328]
1660 super
gpu 1890Mhz
memory 6690Mhz
a house
Steps: 20, Sampler: Euler, CFG scale: 4.5, Seed: 3005468437, Size: 512x512, Model hash: 84d76a0328, Version: 1.6.1
epicrealism_naturalSinRC1VAE.safetensors [84d76a0328]
1660 super
gpu 1890Mhz
memory 6690Mhz
А вам не кажется, что по мере использования стейбла оче легко оказаться "разбалованным"? Типа прогресс вроде как идет и в text-to-image, и в ML, и в связанных индустриях - а все равно его мало. Твои хотелки начинают опережать имеющийся прогресс.
Когда-то я задрачивал Clip+vqgan, дифьюжн на Nightcafe. До релиза стейбла ронял слюни на Dall-e 2, проклинал разрабов за их антирусский шовинизм (и ведь я не ватник ни разу) и в целом за скотское отношение корпорации к юзерам. Ковырял Dall-e mini, прикручивал к ней свой кустарный метод latent апскейла. После релиза SD радовался когда мог генерировать 512x512 онлайн, потому что у меня встройка shared memory в компе. После участия в тесте заводил десятки аккаунтов на Dreamstudio чтобы пользоваться триалом, особенно когда там не было NSFW фильтра. Возможность апскейла аж до 1024x1024 воспринималсь мной как неебический хайрез и хайтек. Когда утекла NAI, то не вылезал с колаба и каггла.
Ну а теперь, генерация с контролнетом до 2048x2048 на бесплатном онлайн сайте воспринимается как наебка, будто от меня прячут некий "нормальный способ генерации" с по-настоящему тонкой детализацией. NSFW генерации уже давно не поражают воображение, модели с Civitai кажутся говном что с пачками "допиливающих" лор, что без них. Реакцией на SDXL было "meh", ведь без Tile контролнета ее фактическое максимальное разрешение 1024p - в два раза меньше чем умеет SD 1.5 с Tile. После выхода Dall-E 3 поковырял и бросил, не из-за цензуры, а потому что meh. При работе с анимэ-моделями в них разочаровывает все: однообразие, токеновый метод кодирования, смешивание токенов, строгая привязка данных к системе booru-тегов. И биасы, тысячи их. Тег "cowboy shot" будет добавлять шляпу, dutch angle делать блондинку в голландском платье, shelf bra - обычный лифчик и книжные полки, meganekko - добавлять синий цвет (до меня не сразу доперло что это из-за megaman). Gen-2 text-to-video - meh.
Когда-то я задрачивал Clip+vqgan, дифьюжн на Nightcafe. До релиза стейбла ронял слюни на Dall-e 2, проклинал разрабов за их антирусский шовинизм (и ведь я не ватник ни разу) и в целом за скотское отношение корпорации к юзерам. Ковырял Dall-e mini, прикручивал к ней свой кустарный метод latent апскейла. После релиза SD радовался когда мог генерировать 512x512 онлайн, потому что у меня встройка shared memory в компе. После участия в тесте заводил десятки аккаунтов на Dreamstudio чтобы пользоваться триалом, особенно когда там не было NSFW фильтра. Возможность апскейла аж до 1024x1024 воспринималсь мной как неебический хайрез и хайтек. Когда утекла NAI, то не вылезал с колаба и каггла.
Ну а теперь, генерация с контролнетом до 2048x2048 на бесплатном онлайн сайте воспринимается как наебка, будто от меня прячут некий "нормальный способ генерации" с по-настоящему тонкой детализацией. NSFW генерации уже давно не поражают воображение, модели с Civitai кажутся говном что с пачками "допиливающих" лор, что без них. Реакцией на SDXL было "meh", ведь без Tile контролнета ее фактическое максимальное разрешение 1024p - в два раза меньше чем умеет SD 1.5 с Tile. После выхода Dall-E 3 поковырял и бросил, не из-за цензуры, а потому что meh. При работе с анимэ-моделями в них разочаровывает все: однообразие, токеновый метод кодирования, смешивание токенов, строгая привязка данных к системе booru-тегов. И биасы, тысячи их. Тег "cowboy shot" будет добавлять шляпу, dutch angle делать блондинку в голландском платье, shelf bra - обычный лифчик и книжные полки, meganekko - добавлять синий цвет (до меня не сразу доперло что это из-за megaman). Gen-2 text-to-video - meh.
> насчёт качества
Как и в обычном LCM - говно с мутантами.
> Твои хотелки начинают опережать имеющийся прогресс.
Скорее криворукость не поспевает за фантазиями, если судить по тому что ты пишешь ниже. Всё на что ты жалуешься фиксится, но естественно не само.
>Это что-то уровня называть бензин машиной.
У меня другая аналогия: музыка находится в наушниках, или в mp3 файле? Суть явления то в весах, а они в файле чекпоинта.
чувак, я не читал твою хуйню, моя цель запилить нейронный рендер для 3Д софта, потенциально реалтайм

Пробую разные модели с этой штукой, и по-моему всё норм пока. Не вижу мутантов или того распидорашивания что у них была в дримшейпере том.
Единственное отличие пока - рабочий диапазон CFG нужен сильно ниже, 0-2 (хотя вроде промпту следует).
Вот эта пикча например 4 итерации, ебануться и не встать.
Попробуй что-то кроме клоузапов. Да и это уменьшение итераций нахуй не нужно, нужно повышение качества. На 30 шагах сделай сравнение.




Потестил с одной генерацией с хайрезфиксом, без какого-либо черрипика. Ну в общем это обычный выхлоп SD 1.5, ничем не лучше и не хуже, только в 4 раза быстрей.
С контролнетами всякими и ип-адаптерами совместим (пик1 дефолтный скелет), выдаёт то же самое что и сама модель. Не знаю есть ли подвох, я не вижу. SDXL пока не пробовал, но судя по тому что я вижу в дискордах - там всё аналогично. Пока что я вижу тупо ускорение за счёт... нихуя.
>Да и это уменьшение итераций нахуй не нужно, нужно повышение качества. На 30 шагах сделай сравнение.
Хуясе - ускорение в 4 раза не нужно, может тебе разве что. Это шаг к реалтайму, плюс видеолюди будут ссать кипятком, плюс аноны с тостерами, или гигантскими схемами.
Качество не увеличивает, на 30 и 100 шагах разницы нет.
Ого, получается разница между rtx и gtx в 10 раз. Если судить по бенчмаркам выше, то 2060super генерила бы такую же картинку за 3 сек
Это не разница, просто у него в лоу мемори режиме загружается по ходу. У меня прошлая древнекарта (GTX 970) выдавала 1.2 итерации/сек на invokeai аттеншене (в invokeai или автоматике). На комфи она была сильно медленней, 1.8 сек/итерацию, т.к. у него все оптимизоны только для нормальных карт.

Ура, хейтеры LCM - сосать!
https://huggingface.co/blog/lcm_lora
Интересно, для файнтюнов видимо нужно будет отдельные лоры тренить
Про негативные промпты пишут, что с ними чуть медленней будет работать, так как надо поднять guidance_scale
Ждем поддержку в автоматике
Истеричка, привет.
Мне 12Гб пиздец как мало, привык в 4-8к генерить, хотелось бы быстрее.
>сделайте такой же тест
3050 8G VRAM, чуть выше нищука, для ориентировки
У 1660super ведь вроде 6гб vram - этого должно хватить на medvram. А medvram жрет не так много, около 10% времени
Так и у 970 хватало на мед. А в комфи загружалось в лоу
Я вроде нигде не пропиписывал лоу режи, вот параметры батника
@echo off
if not exist python (echo Unpacking Git and Python... & mkdir tmp & start /wait git_python.part01.exe & del git_python.part01.exe & del git_python.part.rar)
set pypath=home = %~dp0python
if exist venv (powershell -command "$text = (gc venv\pyvenv.cfg) -replace 'home = .', $env:pypath; $Utf8NoBomEncoding = New-Object System.Text.UTF8Encoding($False);[System.IO.File]::WriteAllLines('venv\pyvenv.cfg', $text, $Utf8NoBomEncoding);")
set APPDATA=tmp
set USERPROFILE=tmp
set TEMP=tmp
set PYTHON=python\python.exe
set GIT=git\cmd\git.exe
set PATH=git\cmd
set VENV_DIR=venv
set COMMANDLINE_ARGS=--xformers --autolaunch
git pull origin master
call webui.bat
чому я такой медленный тогда? помогите

Мне кажется вы путаете что-то, моё значение 1,55 ( 0,645 ), как раз сходится с тестом. И если я перейду на 2060, то прирост будет в 10 раз.

Воркфлоу с апскейлом и лорой скинешь? А то это как то не смахивает на хороший результат, мб я что не так там макаронами выставил

У тебя выглядит словно cfg высокий, этой штуке надо что-то вроде 1-2, больше пережигает на большинстве моделей.
https://files.catbox.moe/tsj76z.png
Что заметил - на модели под фотки оно делает результат сильно контрастным и темнит. Может и на других, не знаю. Думаю это как-то с шаманством с cfg связано.


> У тебя выглядит словно cfg высокий, этой штуке надо что-то вроде 1-2, больше пережигает на большинстве моделей.
У меня 1.8 стоял.
> Что заметил - на модели под фотки оно делает результат сильно контрастным и темнит. Может и на других, не знаю. Думаю это как-то с шаманством с cfg связано.
Ну вот просто на аниме модели based64 пробую, как то выходит плохо с твоим воркфлоу, NNLatentUpscale кстати это откуда?
>NNLatentUpscale кстати это откуда?
В менеджере поставь "доставить недостающие ноды", это из https://github.com/Ttl/ComfyUi_NNLatentUpscale
Да, всё же оказался подвох, что-то не так с этой лорой. Выжигает пикчи она сильно, словно при высоком кфг, и блурит иногда. На тёмных пикчах не видно, но на ярких заметно. Может как-то и можно это побороть, может и нет, хз. Пока останусь на старом.
Хотя стопэ, как раз NNLatentUpscale с ней не дружит и получает блур по ходу, с этим выяснилось. Но с выжиганием непонятно.
Как установить cuDNN? Скачал с сайта нвидии просто зип архив, куда его пхать?
> куда его пхать?
В очко, ритмичными движениями.
Из пипа блять поставь его.

А поставим ка мы в официальный гайд гитхаба по инпейнту хуиту которая из картинки целый кусок нахуй вырезает вместо нормальной частичной перегенерации. Ахуенно будет, хыыы
СУКА, ну чувствовал же жопой, что нельзя обновляться.
Решил поменять родной драйвер 4хх какой-то там на самый новый.
Нвидиа насрала на 5гб по разным каталогам установщиками, которые не подтёрла за собой.
Охуенно, если я буду каждый месяц драйвер обновлять, это каждый месясц по минус 5гб, никакого ССД не хватит.
Шёл 2023, ёбаные установщики нвидии до сих пор не в состоянии удалить за собой мусор.
С новым драйвером отвалилась прозрачность в винде.
Охуительные багфиксы.
Обновил пайторч, куду.
вместо 1,54s/it стало 1,9s/it
итого - 5гб святого М2 ССД, замедление генерации на пол секунды, неработающая прозрачность в винде
охуенно пацаны, обновляйтесь ишо
Решил поменять родной драйвер 4хх какой-то там на самый новый.
Нвидиа насрала на 5гб по разным каталогам установщиками, которые не подтёрла за собой.
Охуенно, если я буду каждый месяц драйвер обновлять, это каждый месясц по минус 5гб, никакого ССД не хватит.
Шёл 2023, ёбаные установщики нвидии до сих пор не в состоянии удалить за собой мусор.
С новым драйвером отвалилась прозрачность в винде.
Охуительные багфиксы.
Обновил пайторч, куду.
вместо 1,54s/it стало 1,9s/it
итого - 5гб святого М2 ССД, замедление генерации на пол секунды, неработающая прозрачность в винде
охуенно пацаны, обновляйтесь ишо
>Нвидиа насрала на 5гб по разным каталогам
Нормальные люди это давным-давно просекли и юзают NVCleanstall
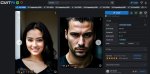
Какого хуя в интернете нет уроков как обучить модель по типу Realistic Vision и подобным ей масштабным моделям с пакетом изображений в несколько тысяч.
Сегодня на ночь я поставил обучаться 1900 портретных изображений размером 512х512 на контрольной точке "v1-5-pruned-emaonly" на 380000 шагов (Learning Rate поставил на 0,000001), в результате получилась какая-то кривая хуетень как будто это каличный брат близнец уёбищной базовой модели v1-5-pruned-emaonly.
Кто знает как обучить реалистичную модель как Realistic Vision?
Сегодня на ночь я поставил обучаться 1900 портретных изображений размером 512х512 на контрольной точке "v1-5-pruned-emaonly" на 380000 шагов (Learning Rate поставил на 0,000001), в результате получилась какая-то кривая хуетень как будто это каличный брат близнец уёбищной базовой модели v1-5-pruned-emaonly.
Кто знает как обучить реалистичную модель как Realistic Vision?
было
стало (пик)
Я победил копьютер.
стало (пик)
Я победил копьютер.
> драйвер 4хх какой-то там
Такие же году так в 21-начале 22 были, не? Это же пиздец некрота, при переустановке подобного нужно делать чистую установку, лучше вообще ddu юзать. Что за видеокарта то?
> Нвидиа насрала на 5гб по разным каталогам
Воу воу, ну это серьезно
> прозрачность в винде
Васяноулучшайзеры или стоковые элементы? В любом случае похоже что шинде очень плохо, в ней обновы тоже годами не делал?
> вместо 1,54s/it стало 1,9s/it
xformers установил, параметры выставил?
Теперь понимаю кто пишет про замедление производительности с выходом новых карт
Потому что это довольно узкая тема, интересная пердоликам, это тебе не на еот тренить. В первую очередь нужен хороший датасет с хорошими разнообразными пикчами и четким описанием для них. От его качества, балансировки, уклона в что-то конкретное или отсутствие такого будет зависеть результат. Тренят сейчас в разрешении повыше, лр стоит брать ниже.
Плюс многие модели это не чистый файнтюны, а мерджи нескольких или с использованием других моделей.
> Это же пиздец некрота,
До, до, некрота. За 23 года пользования компуктером я уяснил одну вещь - лучший драйвер это тот, который вышел с устройством, максимум плюс один год. Всё что новее - лучше не будет, и этот случай это лишний раз показал.
>Васяноулучшайзеры или стоковые элементы?
Ты настолько опытный пользователь, что не знаешь, что в винде есть прозрачность?
>шинде очень плохо
Шинде очень плохо от обновлений, потом что обновления - это каловые массы, бессмысленные.
> в ней обновы тоже годами
И не нужно их делать.
>xformers
Он у меня и был установлен. С xformes 1,55s/it без 1,65s/it.
Установка обновлений только ухудшает ситуацию.
Но зато я прочитал много интернета и добился 1,8 - 2,08it/s без всякого обновления драйверов.
Обновления бывают полезные в исключительных случаях, когда они либо исправляют конкретную проблему, которая действительно имеет место быть, либо привносят функционал, который действительно улучшает результат, во всех остальных случаях обновления - шлак, который не нужно устанавливать. Не стоит делать из обновлений религию и жрать их за обе щеки.
Мозжечок - это не то же самое, что мозг. Проследуйте в википедию.
Многоват learning rate для такого. 1е-7, 1е-8
мимо будколюб
> я уяснил одну вещь
Главные вещи, которую нужно уяснить - не страдать радикализмом и стремиться к осознанию и пониманию того что ты делаешь. Тогда все сразу работает наиболее стабильно и надежно, жопа не полыхает от заложенных функций, легко открываться чему-то новому и в целом жить проще. Даже не нужно оправдываться почему ты такой варебух что в 2д23м году что сидишь на устаревшем на годы драйвере для видеокарты(!) и древней поломанной шинде, которая уже пропадает из листа совместимости.
> Шинде очень плохо от обновлений
> обновления - это каловые массы, бессмысленные
> И не нужно их делать
> Установка обновлений только ухудшает ситуацию
> Обновления бывают полезные в исключительных случаях
> обновления - шлак, который не нужно устанавливать
> Не стоит делать из обновлений религию
Слушай, а в целом что ты думаешь насчет обновлений? Давно обновлялся? Обновиться не пробовал? Говорит обновления чинят многие баги. Поставь на ночь обновы ставиться качать.
>что сидишь на устаревшем на годы драйвере для видеокарты(!)
Потому что на нём быстрее работает СД.
Ты ебобо?
>и древней поломанной шинде, которая уже пропадает из листа совместимости.
Биты и байты протухают, ебоболик?
Не быстрее на старом а медленнее на новом, и именно у тебя а не у всех. Новые технологии, космические скорости на рт ядрах и прочее, а ты ретроградишь, неудивительно что такой агрессивный.
> Биты и байты протухают
Ага, ни один современный тайтл нормально не запустишь, как и некоторый софт.
Долбаёб, ты хоть запятую выучи перед а, прежде чем раскрывать свой тупущий пиздак. В тебя логика не входит, бетонная стена, можно кирпичи колоть об твой лобешник. Нахуй мне твои обновления, если они замедлили работу. Обновления замедляют, ты видел результат, нахуй ты его отрицаешь? Манямир порвался? Не забудь проверить обновления перед сном, вдруг что-то очень важное написали за сегодняшний день.
Ты обновись, отпустит.

Короче я выяснил что этот излишний контраст проявляется только на низких частотах, но не в мелких деталях, словно картинку пропустили через эквалайзер. Пообщался с автором LCM лоры. И оказалось что это он СОЗНАТЕЛЬНО выставил такие параметры при обучении, потому что ему так "больше нравится". Пиздец я хуею с этого васяна. Он универсальный механизм делает, или где? Блядский цирк.
>В первую очередь нужен хороший датасет с хорошими разнообразными пикчами и четким описанием для них
У меня только портретные снимки с описаниями в текстовом файле, описание в виде ключевых слов (или не так нужно?). Модель нужна для переосмысления и реставрации портретов в img2img, поэтому кроме портретов там ничего и не нужно лично мне, а Realistic Vision и ей подобные модели явно были обучены на фото модельной внешности людей (чедов) и по большей части это мерджи и результаты у них схожие, а мне нужны славянские (омежные) лица простых людей без острых углов челюсти и хищного взгляда.
Я уже из датасета даже вынул фотографии всех женщин, детей и стариков и оставил только мужчин, чтобы полегче нейросети было это все понимать, но ничего, тут явно я как то не так настраиваю.
>Тренят сейчас в разрешении повыше
Я слышал только, что 1.5 нужно тренировать на 512 так как она обучалась на таком разрешении, поэтому и сделал такой датасет, в видеоуроках на ютубе на 512 учат делать.
>лр стоит брать ниже.
Как понять ниже? 1e-6 (0,000001) вроде классический стандарт для обучения. Например 0,0001 это ниже или выше 0,000001 ? Там ещё вроде советуют менять это значение походу обучения хз.
выставил 1е-8.
Как понять этот ебучий график? Настройки какие ставить?
Там ещё какие то Instance Token, Class Token, Instance Prompt, Class Prompt, Classification Image Negative Prompt нихуя не понятно, у меня же один хуй есть к каждой картинке тексовый файл, так что оставляю пустым. Почитал гайд, но так нихуя и не понял, что это всё означает.
Classification Dataset Directory - вот это прикол конечно, закидываю папку с пикчами, но это дерьмо всё равно начинает генерировать свои пикчи вместо людей с нормальным кадрирование какие то куски, маски глиняные, статуи, хуйню всякую.. пиздец.
> У меня только портретные снимки с описаниями в текстовом файле, описание в виде ключевых слов (или не так нужно?). Модель нужна для переосмысления и реставрации портретов в img2img
Почему тогда ты просто не попробуешь для начала в лору, вместо будки, это один из самых простых способов "проверить" датасет. В случае с твоим же я сомневаюсь что тебе вообще нужна будка, конкретно про фотореалистик не подскажу, но скорее всего просто достаточно будет натренить с обычного 1.5 на твоем датасете и юзать с реалистик вижоном или чем ты там генеришь.
> Я слышал только, что 1.5 нужно тренировать на 512 так как она обучалась на таком разрешении, поэтому и сделал такой датасет, в видеоуроках на ютубе на 512 учат делать.
Не обязательно, с сд-скриптс, например, можешь просто bucketing включать, результаты тренировок с бОльшими разрешениями показывают более высокое качество.
> Как понять ниже? 1e-6 (0,000001) вроде классический стандарт для обучения. Например 0,0001 это ниже или выше 0,000001 ? Там ещё вроде советуют менять это значение походу обучения хз.
Так и понять, число 0.000001 меньше числа 0.0001, значит лернинг рейт с ним будет ниже. А для тех же лор лернинг рейты в среднем по палате выше, чем для будки.
Лернинг рейт текстового энкодера на несколько порядков выше лра юнета, не надо так делать, он должен быть как минимум ниже.

Мне ответил создатель Realistic Vision, он вообще не использует Dreambooth, он через какую-то kohya-ss тренит..
Создатель epiCRealism делиться не хочет, даёт ссылку https://followfoxai.substack.com/p/full-fine-tuning-guide-for-sd15-general
Тем временем я не могу понять чем fp16 отличается от bf16 и какой Optimizer выставить: 8bit AdamW или Torch AdamW или что блядь
Можешь просто гайды по лорам из шапки глянуть, там было про параметры. Если железо позволяет юзай bf16, обычный adamw8bit тоже врятли подведёт.


>Если железо позволяет юзай bf16
у меня нищая 4060ti на 16gb
Сейчас смотрю гайд по файнтюну https://keras.io/examples/generative/finetune_stable_diffusion/
и тут показано как подписи выглядят, а я вместо таких коротких описаний промпты через запятую нахуярил по 20-30 штук, не могу понять это норм или нужно переделывать.
а ещё там написано
Для выполнения кода настоятельно рекомендуется использовать графический процессор с объемом памяти не менее 30 ГБ.
> у меня нищая 4060ti на 16gb
Нормальная, в самый раз с таким объёмом врама, точность эту она поддерживает.
> а я вместо таких коротких описаний промпты через запятую нахуярил по 20-30 штук, не могу понять это норм или нужно переделывать
Если такое и нахуяривать, то только для тренировки с НАИ чекпоинта, тебе скорее всего лучше что нибудь юзать, чтобы на естественном языке описать, раз уж ты хочешь прямо файнтюн, но лучше всё таки начни всё таки с лор, с ними всё куда проще, потом уже как разберёшься получше можно лезть во всякие долгие сложные тренировки кмк.
> чем fp16 отличается от bf16
Количеством бит на мантиссу/экспоненту. На практике, если железо позволяет, то bf16 на полшишечки быстрее тренируется. По качеству — разница на уровне погрешности.
> Если такое и нахуяривать, то только для тренировки с НАИ чекпоинта
Такие теги хорошо работают и с базовой sd1.5 моделью. Если там одни портреты мужиков, то я бы вообще тренировал без текстовых подсказок, просто по Class prompt.
>лучше всё таки начни всё таки с лор
Я помню год назад делал лоры с портретами еот через колаб, а мне же сейчас нужно чтобы модель из более 700 разных мужских портретов могла черты лиц с прическами как-то совмещать и переосмыслять, для этого лора наверное не подходит, она же вроде как должна учиться на конкретном лице или объекте, по идее лора это вещь довольно закостенелая.
>скорее всего лучше что нибудь юзать, чтобы на естественном языке описать
Вообще я могу такую рутинную работу выполнить сам если уж других инструментов нет, уйдёт много времени, но мне плевать. Т.е собрать большой качественный датасет и всё подписать это я могу, а вот как это всё тренировать я не ебу, куча ползунков, какая-то шинима хуйня, Use EMA, Cache Latents, Train UNET, constant_with_warmup, bf16, Gradient Accumulation Steps, Instance Token-хуёкен
> Такие теги хорошо работают и с базовой sd1.5 моделью. Если там одни портреты мужиков, то я бы вообще тренировал без текстовых подсказок, просто по Class prompt.
Ну или так.
> а мне же сейчас нужно чтобы модель из более 700 разных мужских портретов могла черты лиц с прическами как-то совмещать и переосмыслять, для этого лора наверное не подходит
Смотри на это абстрактнее, она сделает из всего что ты ей подсунешь что то среднее, если подсунешь в среднем какую то внешность, она и будет результатом тренировки, если все пикчи датасета состоят из одной тёлки, она и есть среднее.
> она же вроде как должна учиться на конкретном лице или объекте, по идее лора это вещь довольно закостенелая
Нет, она может учиться всему что ты ей подсунешь, от будки отличается просто лоурангом и всякими плюшками в сд-скриптсах, в них кстати и будку или файнтюн тоже можно делать.
> Вообще я могу такую рутинную работу выполнить сам если уж других инструментов нет, уйдёт много времени, но мне плевать.
Да возьми просто теггер, который будет описывать твои фотки на натуральном языке, а не анимешный, во владоматике вроде были из коробки даже.
> какая-то шинима хуйня, Use EMA, Cache Latents, Train UNET, constant_with_warmup, bf16, Gradient Accumulation Steps, Instance Token-хуёкен
Большинство параметров актуальны и для лор, можешь на них узнать как они все работают, а специфичные уже потом разобрать.
>Если там одни портреты мужиков, то я бы вообще тренировал без текстовых подсказок, просто по Class prompt.
Так там очень разные мужики:
у одного легкая щетина на лице и он лысый на белом фоне - я пишу light stubble, bald head, white background,
у другого борода и длинные волосы - я пишу beard, long hair,
третий пухлый в очках и в темноте - я пишу chubby, glasses, on a black background, in the dark и т.д по такой логике
Ну и что я делаю не так?
Кстати раз уж ты сказал "Class prompt" можешь объяснить, что это все обозначает, а то мне сложна-непанятна, зачем нужны классификационные картинки тоже хз
>на сделает из всего что ты ей подсунешь что то среднее
У меня лица разных мужиков: лысые, длинноволосые, бородатые, бритые, худые, толстые, кудрявые, с короткой стрижкой, прической на пробор, в очках, черноволосые и седые, совсем молодые и зрелые.. Я не могу понять зачем мне из всего этого получать нечто среднее по итогу.. Мне нужно наоборот дать понять модели, что не все мужики козлы, а все разные со своими особенностями.
>Да возьми просто теггер, который будет описывать твои фотки на натуральном языке
Я пользовался этим теггером, он выдает слова через запятую как промпты.
> Я не могу понять зачем мне из всего этого получать нечто среднее по итогу..
> а мне нужны славянские (омежные) лица простых людей без острых углов челюсти и хищного взгляда
Потому что твой концепт это омежки, это и есть среднее, которое ты должен собрать в датасете.
> Мне нужно наоборот дать понять модели, что не все мужики козлы, а все разные со своими особенностями.
Дай, протегай соответствующе.
> Я пользовался этим теггером, он выдает слова через запятую как промпты.
Это анимешный теггер, я забыл как называются те, которые выдают естественный язык, впрочем и с 1.5 обычного я тоже не любитель потренить, можешь и с бору-стайл тегами попробовать, я не знаю насколько этого плохо для тренировки с этого чекпоинта, но анон выше вон писал что норм.
Что-то говно ваша LCM-лора по итогу. Да, простые генерации делает терпимо, хоть качество и падает, может нищукам для XL будет актуально чтоб не ждать по минуте. Но для всего остального кал.
В апскейл не умеет, даже на обычном хайрезфиксе всё по пизде идёт. При том что на генерации негатив вроде терпимо работает, но на апскейле оно начинает выглядеть как будто без негатива, если совсем убрать негатив - распидорашивает. Контролнет не работает для апскейла - какие-то артефакты лезут от него. Всякие FreeU и прочее тоже только хуже делают.
Затестил Рестарт в комфи он в принципе работает сильно хуже автоматика, я даже два разные реализации нод с ним попробовал - обе говно, даже близко нет такого качества генераций, почти нет разницы с DPM++ 2M.
Хвалёное AIT - наикривейшее говно. В issues там уже неделю висит баг, люди жалуются что не работает, у меня тоже полторашка не завелась. XL завёлся, но пришлось пердолиться и по итогу получил ускорение процентов на 20, такое себе, лучше с TRT попердолиться и получить двухкратное ускорение. С AIT так же как и с TRT нихуя нормально не работает.
В апскейл не умеет, даже на обычном хайрезфиксе всё по пизде идёт. При том что на генерации негатив вроде терпимо работает, но на апскейле оно начинает выглядеть как будто без негатива, если совсем убрать негатив - распидорашивает. Контролнет не работает для апскейла - какие-то артефакты лезут от него. Всякие FreeU и прочее тоже только хуже делают.
Затестил Рестарт в комфи он в принципе работает сильно хуже автоматика, я даже два разные реализации нод с ним попробовал - обе говно, даже близко нет такого качества генераций, почти нет разницы с DPM++ 2M.
Хвалёное AIT - наикривейшее говно. В issues там уже неделю висит баг, люди жалуются что не работает, у меня тоже полторашка не завелась. XL завёлся, но пришлось пердолиться и по итогу получил ускорение процентов на 20, такое себе, лучше с TRT попердолиться и получить двухкратное ускорение. С AIT так же как и с TRT нихуя нормально не работает.
Стоит ли покупать карту с LHR для SD? Влияет ли это как-то на производительность?
>стена текста, 0 пикч для демонстрации предъяв
Нет пикч - не о чем сраться. Толку с высеров без наглядного сравнения того что ты имеешь в виду - ноль
За что отвечате captioning в обучении лоры? Треню тёлку с букетом, хочу, чтобы перенеслась тётка и платье, а букет который она держит нахуй не нужен. Вписываю букет в captioning (т.к. в гайдах говорят, что sd не будет это учитывать при обучении, что это не относится к моему предмета). Тогда почему после обучения генерируется и этот букет?
Никак не влияет


Оказывается LCM Лоры и так работают в stable-diffusion-webui без установки дополнительных расширений! Вернее 1.5 работает точно, а вот sdxl у меня не получилось, какие-то радужные артефакты, пробовал разные веса и cfg
Настраивается просто: подключаете лору как обычную, ставите cfg на 1.0, количество шагов на 4, семплер Euler a, и все. Работает с любыми файнтюнами. Можно поставить cfg на 1.5, тогда будут негативы видеться, но качество заметно хуже, и не очень чтобы негативы влияют
Но я нашел применение помимо оживления генерации на мёртвых картах типа gt 1030. Это быстрый hires fix. На пикник пик 1 - lcm, пик 2 - стандарт. Можно то что на lcm детали заметно лучше - это мне так рольнуло, но как минимум результат не хуже стандарта
rtx 3060:
Пик 1: 9.7 сек
Пик 2: 19.1 сек
Я считаю это победа
Настраивается просто: подключаете лору как обычную, ставите cfg на 1.0, количество шагов на 4, семплер Euler a, и все. Работает с любыми файнтюнами. Можно поставить cfg на 1.5, тогда будут негативы видеться, но качество заметно хуже, и не очень чтобы негативы влияют
Но я нашел применение помимо оживления генерации на мёртвых картах типа gt 1030. Это быстрый hires fix. На пикник пик 1 - lcm, пик 2 - стандарт. Можно то что на lcm детали заметно лучше - это мне так рольнуло, но как минимум результат не хуже стандарта
rtx 3060:
Пик 1: 9.7 сек
Пик 2: 19.1 сек
Я считаю это победа


Приложу еще скрин настроек хайрез фикса, и пик выше без хайрез фикса (3.2 сек генерация)
Кстати, с TensorRT эта Лора не работает
хз что ты запускаешь, но это никак не может быть lcm lora
она фундаментально отличается от euler_a, это не численный солвер ODE, это отдельная нейросетка которая его заменяет, т.е. требуется код для загрузки и инференса на этой сетке
Ты конечно поумничал, молодец. Но для lcm лоры надо выбирать Euler a, так как ты как-нибудь убрать семплер не сможешь. Это лора, а не lcm модель
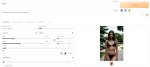
сделал присадку лцм лоры в свою модельку через same to strengh - результ на пике, заняло 13.2 секунды, что примерно в 2.5 раза быстрее, чем на модели без присадки
да, мыльцо полезло все дела, но попробую какнибудь решить, мб оверврайт нужен
Даже для comfy делают семплер Euler a, так что не умничай в том, что не знаешь
Cfg на 1.0 установи. У меня даже 1.5 плохо генерит по сравнению с 1.0. Негативы тестил, на 1.5 они дают эффект, но не сказал бы что этот эффект именно тот, что ожидался. Негатив trees на cfg 1.5 не убрал деревья, а будто чуть сид изменил, хрень короче. Негативов тут считай нет

>Cfg на 1.0 установи.
Такое же мыльцо выходит, скорее от карася зависит. Повысил шаги до 10 на эйлере и норм стало.
>Негатив trees на cfg 1.5 не убрал деревья, а будто чуть сид изменил, хрень короче. Негативов тут считай нет
Пик 2, попоробуй экстеншен с рабочими негативами в позитив промпте.
>попоробуй экстеншен с рабочими негативами в позитив промпте.
+ CADS

ну и кадс не на дефолтных настройках
кароче лорка вин ящитаю, правильно подмешать с правильными плогенсами и кайфануть от скорости можно
Погуглил, это типа повышение разнообразия пикч. Надо бы затестить и без лоры
О, а можешь дженерик 1герл на аниме модели затестить заодно с (worst quality, low quality:-1.4)?
да, годная фича, можно как полностью перепердоливание концептов устраивать каждый ролл, так и небольшие измненения
щас к хассаку присадку сделаю и затещу
Что ты присадкой называешь, обычное примердживание этой лоры к чекпоинту? И что кстати за CADS?
>Что ты присадкой называешь, обычное примердживание этой лоры к чекпоинту?
да
>И что кстати за CADS?
https://github.com/v0xie/sd-webui-cads
хуево что вебуй надо релоадить после каждого мерджа лцм с моделью, а то у него там ошибки хуярить начинают при сейве по второму кругу и при смене модели мб пора обновиться на последний коммит
Так на последнем коммите всё равно же сейчас нету официальной поддержки этого. Каким именно экстеншеном кстати мерджишь?
Кстати, благодаря тому что сделали в формате лоры, теперь ее можно использовать в text-generation-webui
А зачем вообще мержить лору. Для быстрого подключения можно ее в стиль оформить, чтобы во вкладке с лорами не искать каждый раз

Не ну в принципе оно работает, но мыльцо и оверхит на эйлере появились, на карасе там вообще пиздец. Но явно для анимекала надо с другими настройками мерджить, надо попробовать не 1 значение, а пониже и вручную дименшен выставить.

>А зачем вообще мержить лору.
Мерджат с лорой чтобы потом с оригинальной модели добавить отличия от модели с лорой и таким образом повысить консистенцию финального изображения.
А если это (worst quality, low quality:-1.4) в позитив, вместо негатива? У тебя же экстеншен на то чтобы он в позитиве отрабатывал. Результаты кстати примерно как и у меня было тут
> Каким именно экстеншеном кстати мерджишь?
супермерджер
Чё за херня у тебя в батнике с автообновлением ещё каждый раз на старте? Должно хватить
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set COMMANDLINE_ARGS= --xformers --medvram
call webui.bat
И оптимизации в Settings автоматика выставить не забудь.
Ничего не понял, но по пикче выглядит будто лора применяется качественней

>(worst quality, low quality:-1.4) в позитив, вместо негатива?
чуть получше потому что оверхит ушел, мыльцо на месте, с включенным кадсом тоже, но ниже -1 в позитиве не рекомендуется юзать
в общем тут конкретно негативы на анимехуйне оверхит создают, попробую немного по другому смерджить
да, так и есть

а ебать, у меня 496 стояло, вот с 512 по ширине в принципе работать можно
Хм, а с хайрезом х2 как будет?
> в общем тут конкретно негативы на анимехуйне оверхит создают
Ну вот в том то и прикол что почти вся анимехуйня от вот этих ворст кволити на 1.4 зависит сильно.
И в каком порядке что куда надо мержить? Вот допустим я вмержил в желаемую модель лору супермержем, а дальше что делать? Можно гайды какие есть, я не нахожу


>Ну вот в том то и прикол что почти вся анимехуйня от вот этих ворст кволити на 1.4 зависит сильно.
ну хз, я анимешные модельки тож использую, но либо без особых негативов, либо со стандартным нулевым усилением
>Хм, а с хайрезом х2 как будет?
у меня карта не вытянет х2, вот тебе х1.4 с валаром я ультимейтапскейл юзаю обычно, справа х2 0.3 денойз

1. в мерджере лор ориг модель + лора
2. в мерджере моделей в А - оригинальная модель, в B модель с лорой вроде можно и саму лору выбирать, но я ни разу пробовал, в C оригинальная модель или базовая модель, метод адд дифренс - трейн дифренс, значение альфы на твой вкус, можно в принципе и 1.6 хуярить
>Можно гайды какие есть, я не нахожу
все что есть тут описано https://github.com/hako-mikan/sd-webui-supermerger/blob/main/calcmode_en.md

> ну хз, я анимешные модельки тож использую, но либо без особых негативов, либо со стандартным нулевым усилением
Ну от модели ещё зависеть будет, видимо твоя не такое дерьмо из коробки с пустым промптом.
> у меня карта не вытянет х2, вот тебе х1.4 с валаром я ультимейтапскейл юзаю обычно, справа х2 0.3 денойз
Апскейлер конечно поправил что смог, но всё равно изначальная генерка оставляет желать лучшего, потом ещё мб сам попробую, но трт поинтересней конечно работал, а ещё все как то забыли про ToMe, а ведь он тоже умеет ускорять.


Пипец. Это EpicPhotogasm Z просто с лорой, и по твоему гайду. Качество разительно повысилось. Промпт photo of car
Сделал same to straight, alpha 1, в моделей C базовая. С другим ничем не экспериментировал
Сгенерено на ноуте с mx150 (aka gt1030), 2gb vram, по 23 секунды на картинку. Действительно спасение для potato gpu
Пипец, благодаря этому мега мержу еще и с TensorRT работает. Щас сконвертирую на batch size 40, и буду бить рекорды по скорости на пикчу

А я тут немножко обошел досадное недоразумение под названием оверхит и мыльцо
Есть у меня базовая модель - трейнмикс из изифлафф+базовая 1.5+флафирок эпоха 206, ебнул поверх лцм модель (это ликорис кстати неожиданно, хоть гдето ликорис пригодился лол), сейм ту стренгт не работает в данном случае изза отличия позиций тензоров у изифлаффа, а потом затрейнил к получившемуся (EF-15-FRe206-LCM) фотогазм. Как итог карась заработал, скорость генерации осталась такой же как с лцм, оверхит и блюр ушли. Аниме скорее всего также фиксится, но с 1.5 оно будет хуевато работать, а мне пока анимекал миксить лень.
Смотрю на эти пикчи, и не верится, что это lcm. Лицо lcm хейтеров представили?
>TensorRT
а че на 1030 тенсоррт работает? как заставить работать?

Мучаюсь с выбором, нужна карта в игры играть, и для нейросетей.
Выбираю между
2070 super 8gb, 3060 12gb, 4060 8gb
2070s - лучшее соттношение цена производительность, но мало паяти
на лохито 25к
3060 12gb могу взять новую с озона за 38к
она худшая по производительности, но в ней 12гб
4060 8гб
могу взять новую за 36к
а как бы нахуя? она чуть мощнее 2070с
Выбираю между
2070 super 8gb, 3060 12gb, 4060 8gb
2070s - лучшее соттношение цена производительность, но мало паяти
на лохито 25к
3060 12gb могу взять новую с озона за 38к
она худшая по производительности, но в ней 12гб
4060 8гб
могу взять новую за 36к
а как бы нахуя? она чуть мощнее 2070с
если пердоля энтузиаст, то смотри CMP 40hx, по производительности уровень 2070/3060 с небольшой просадкой, стейбл точно работает, с играми придется попердолиться, ну и нужен интел с графическим ускорителем внутри насколько я помню



хаха, ебануться, можно и не с цфг 2 юзать теперь
оба примера цфг 5, 8 шагов
>
>3060 12gb могу взять новую с озона за 38к
28к фикс
Нет, я про другую карту
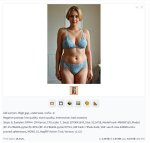

кароче ето локальная победа итт чята, могу на цивит выложить мою базовую говнину для последующего ретрейна любых моделей где база 1.5 если надо кому
С аниме всё очень плохо, анимехейтерки всё так же будут хейтить. Либо надо мержить самую писечку, чтоб не распидорашивало всё.
Сделай хайрезы. В лоурезах чистые генерации и с простой лорой норм. А вот хайрезы - пизда.
Слушай, а выглядит реально заебись, про рецепт бы по подробнее, сначала как понимаю фурри буст, потом к нему лцм через оверврайт мод, а дальше не совсем понятно.
Заливай, интересно будет пощупать, если ещё и поэтапно в ридми для хлебушков распишешь как повторять то вообще огонь будет.

>В лоурезах чистые генерации и с простой лорой норм
не, ты не понил, цфг 7 тут, можно и выше если цфг рескейл юзать или динамический трешолд
>Сделай хайрезы
мой максимум это х1.4, держи





1660s
3.6 Ghz
память 2666 Ghz
Ппц медленно, я ещё думал это у меня медленно, как тут пиздели некоторые шизы.
>3.6 Ghz
>память 2666 Ghz
Ты уверен, что ты написал частоту гпу и видеопамяти, а не цпу и рам?
Какая у тебя ОС, драйвер? Параметры запуска?

После второго этапа мерджа lcm лоры аниме модель с фуррибустом таким образом ломается у меня.
А третий этап как то странно выглядит, одинаковые модели в A и C? Я попробовал так намерджить, на 8+4 шагах ничем почти не отличается от обычной этой же модели до мерджей, не исключаю что что то мог сделать не так.
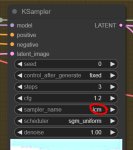
>Но для lcm лоры надо выбирать Euler a, так как ты как-нибудь убрать семплер не сможешь
Что ты несёшь?
Ты не используешь LCM никак. Понимаешь? Ты считаешь на эйлере а.
Ещё один кловен. А хотя я кажется понял... это не ты случайно срал хуйнёй выше?
То что наверху есть позитивные результаты на реалистике - это скорее потому что лора примержилась слабее, чем просто на применении. Можешь ёбнуть 0.2 и уже будет результат, но ещё не сломает тебе модель при обычном семплинге.
>После второго этапа мерджа lcm лоры аниме модель с фуррибустом таким образом ломается у меня.
какая база у твоей модели? сомневаюсь что в аниме там 1.5 базой идет, для аниме очевидно нужен другой базовый мердж с лцм и наи какойнибудь
>А третий этап как то странно выглядит, одинаковые модели в A и C?
Да, эффект замены всех отличающихся весов в модели А на веса модели B, таким образом мы получает IN-OUT слои модели B.
Клован это ты. LCM-семплер - это DPM с другим CFG. Он отличается только тем как негатив применяется. Алсо, lcm-семплер из комфи пидорасит ничуть не меньше обычных семплеров, с ним аниме всё так же неюзабельно.

>LCM-семплер - это DPM с другим CFG
Господи, и это у вас технотред?
Т.е. ты споришь с документацией авторов LCM? Ясно.


>То что наверху есть позитивные результаты на реалистике - это скорее потому что лора примержилась слабее, чем просто на применении.
слева без LCM cfg 2 8 шагов база с ретрейном фотогазма
справа с LCM
надо попробовать еще или LCM выше 1 мерджануть, или трейндифренс больше сделать, в какомто из случаев эффект будет мощнее

> какая база у твоей модели?
Вот эту можешь взять например https://civitai.com/models/149664/based67 как раз с наи подойдёт
Вообще ноль отличий, вот такое генерит с любой силой примердживания
Я не спорю ни с кем, я охуеваю со здешнего неумения читать. Да что там читать, мыслить блять. Возьми уже GPT-4V, она лучше справится чем ты.
> Вообще ноль отличий, вот такое генерит с любой силой примердживания
Ты что-то не то делаешь. У меня аниме на 0.2 перестаёт пидорасить. На 0.3-0.4 уже начинает на хайрезфиксе. На 1.0 уже пиздец начинается, да.
Так получается ты сейчас и расписываешься в неумении читать, ведь там написано что стандартный алгоритм DPM расширен специальным CFG non-Markovian guidance вместо обычного classifier-free guidance. Какие же дауны тут сидят.
Я очень рад за тебя, что ты где-то прочитал, что lcm запекает семплер в отдельную нейронку. Но это не отменяет того, что в итоге эту нейронку надо чем-то семплить. И ldm + lcm lora сeмплятся так же, как обычные ldm


Да, всё так, я не то значение менял для лоры, но опять же это не похоже на хороший результат для аниме
Хорош сраться бля, лучше сэмплер скажите какой с этим юзать, DPM? С карасем полное говно, с эйлером мыло
> мимо будколюб
Что тренишь?
> только портретные снимки с описаниями в текстовом файле
> только портретные
Предположу что это очень неочень в целом, но если задача чисто одни портреты с простыми фонами но наверно и норм. Дисбаланс точно скажется на работе во всем остальном.
> и оставил только мужчин, чтобы полегче нейросети было это все понимать
Наоборот ей будет легче понять если там пикчи разные. Сможет выделить общие закономерности и отсеять то что меняется, а не ловить отупение, придавая атрибуты чедов всему и вся. Офк сильно утрирую.
> 1.5 нужно тренировать на 512
Базовая тренирована в таком разрешении. Если хочешь повысить качество - следует использовать повышенное разрешение, большинство файнтюнов тренились так.
> Как понять ниже? 1e-6 (0,000001) вроде классический стандарт для обучения
Где такое указано? По практике с таким значением сильно пердолит, нужно снижать, начни с 5e-7.
> Например 0,0001 это ниже или выше 0,000001
Рофлишь или серьезно?
> text encoder learning rate
Оу...
Файнтюн на 20 пикчах, ахуеть.
Пацаны, видел ли кто какие-нибудь идеи и реализации использованию SD для смены пола лица?
Берёшь ип-адаптер на ебасосины и генеришь man с лицом Яровой, понижаешь силу контроля если всё ещё слишком похоже на бабу, ничего сложного.

Да, именно DPM2 лучше всего 8+4.
> За что отвечате captioning в обучении лоры?
За то чтобы модель понимала что там находится, и в итоге немножко осознавала что букет - это букет, а не часть еот и ее обязательный аттрибут.
> Тогда почему после обучения генерируется и этот букет?
Если там одни пикчи с букетом, и еще большим лр сильно прожарил - ничего не поможет.
> мыльцо и оверхит
Похоже это проблема совместимости анимушных и реалистичных моделей, такое и в других случаях лезет при мердже и применении неподходящих. Послойно надо поиграться, велика вероятность что сработает.
4060@16смотри
Как это вообще работает интересно, перестраивает структуру? На выходе финального этапа же должна получаться копия исходника, прошу объяснений кто понимает что здесь происходит.
DPM2 медленный (
О, может LMS или LMS Karras попробуй. Он быстрей. DPM2 раза в 1.5 медленней их всех
Просто LMS лучший. Из всех что я попробовал
Но я не пробовал на аниме, попробуй ты на нем

И вообще похуй что шагов в 3 раза меньше?
LMS карась что то может, обычный сливается полностью, как и другие многие популярные. В топе DPM2 и некоторые ему подобные. Адаптив вообще не в счёт, он запросто мог 150 шагов ебануть.
> И вообще похуй что шагов в 3 раза меньше?
Я на 4 шагах все тестировал. Для хайреза кстати lms говно
Получается да, либо Euler a, либо чуть медленней и качественней - DPM2
>цпу и рам
Кек, их и написал
ну gpu у нас одинаковое должно быть, а частоту памяти я не знаю где посмотреть
>ОС, драйвер
win 10, дрова версия 563.40
set COMMANDLINE_ARGS=--xformers --no-half --disable-nan-check --medvram
Ниже 8 уже пиздец начинается бтв, не доденойзивает.
Убери --disable-nan-check --medvram
Добавь --precision full
и попробуй ещё раз
А ты этот мерж не делал?
У меня на 4 шагах стилистически не отличимо от не lcm


фап)

Попробовал, ну 6 ещё может прокатит, 4 нет, это без хайреза.

С хайрезом по 4 шага кстати не доденойзивает, наверное надо 6-6 или 8-6 ставить тогда


Я хуйни какой то нагородил похоже
1пик с моими настройками
2 как ты сказал
Пипец. У меня даже близко не так. Я потестил одну аниме модель, там и без мержа на 4 шагах все прекрасно. Может ты напутал где-то? Холя если на 8 шагах работает, значит lcm работает
Может не сочетается с твоим файнтюном, может там фурри какие-то, или базовая модель другая. Nai - это же что-то отдельное, не основанное на sd?
Может и не сочетается, что у тебя за модель?
Вроде всё как расписано было делал, только на 1.0 весе её невозможно юзать с этой моделью, приходится снижать.
EpicPhotogasm Z - для реализма
Kaywaii - для милых картинок
> Kaywaii - для милых картинок
Просто смерджил с 1.0 получается? Same to strength ставил?
На низких CFG вообщем то работает с 4 шагами на KayWaii и остальных моделях, но на высоких никак не хочет заводиться при большом весе лоры.
Что это значит? Вес доры типа после :? Хз, я на 1 ставил и не менял, зачем его менять вообще
Оно и просто с лорой хорошо работает. Но мержил да, с этим флагом. Вот таким образом
> Сделал same to straight, alpha 1, в моделей C базовая. С другим ничем не экспериментировал
> Что это значит? Вес доры типа после :? Хз, я на 1 ставил и не менял, зачем его менять вообще
Чтобы на других семплерах не пережаривало, ещё и от модели зависит сильно походу, ну и нормальный кфг тоже не вернёшь без этого на какой то определённой модельке, если её жарит. Некоторые даже просто на 1.0 кфг, эйлере а и 1.0 весе прожаривает.
> Оно и просто с лорой хорошо работает.
Покажи кстати как аниме получается у тебя.
Суп нейросенсеи.
Допустим я взял 10 фото, и 10 отраженных копий фото (взгляд налево, взгляд направо) на самом деле 200, и 200 отраженных - итого 400
Допустим я обучил лору на этих фото.
Насколько вариативным будет результат? Нейросеть строит карту лица, или что? А если в более чем половине случаев выражение лица как у дебила - это повышает вариативность и улучшает результат, или наоборот ухудшает и на выходе сгенерируется олигофрении-пак?
Допустим я взял 10 фото, и 10 отраженных копий фото (взгляд налево, взгляд направо) на самом деле 200, и 200 отраженных - итого 400
Допустим я обучил лору на этих фото.
Насколько вариативным будет результат? Нейросеть строит карту лица, или что? А если в более чем половине случаев выражение лица как у дебила - это повышает вариативность и улучшает результат, или наоборот ухудшает и на выходе сгенерируется олигофрении-пак?

А где благодарочка?
Ты исцелён, брат, мой, генерируй с миром.
Когда нужна будет память - можешь вернуть medvram.




>Файнтюн на 20 пикчах, ахуеть.
это он для примера сказал для понимания скорости тренировки, свою модель он обучал на более 1000 фото.
>Наоборот ей будет легче понять если там пикчи разные. Сможет выделить общие закономерности и отсеять то что меняется, а не ловить отупение, придавая атрибуты чедов всему и вся. Офк сильно утрирую.
что значит придавая атрибуты чедов всему и вся? предполагается, что модель будет заточена для переосмысления/реставрации мужских изображений через img2img, для обработки женских изображений будет своя модель, хотя может поэкспериментирую и объединю хз. Меня просто заебало, что все эти реалистичные модели обучались на западных/европейских/восточных чедовских/стейсти лицах, что отражается на результатах генерации. У нас, славян, черты лица более мягкие, округлые, без резких углов нижней челюсти и "взгляда охотника" (примеры из моего пробного датасета 512x512)


>У нас, славян, черты лица более мягкие, округлые, без резких углов нижней челюсти и "взгляда охотника" (примеры из моего пробного датасета 512x512)
Я не смог удержаться, простите за политоту
Базу про принцип обучения сетей и градиентный спуск, который уже успел стать мемом, можешь нагуглить прочитать.
Тут если совсем упростить - ты сетке показываешь наборы этих клозапов и говоришь что это "портрет мужчины с карими глазами, короткая прическа и т.д.", показываешь сотни тысячи раз, заставляя запоминать это. Она подгоняет внутренние веса таким образом, чтобы пикчи, выдаваемые по запросу, соответствовали этому тексту. Если датасет разнообразный то исходя из различий и общего она усвоит это именно "лицо славянина", если там одно и то же то ошизеет и будет думать что "карие глаза" значат "вот такие широкие щечки и вогнутый подбородок" а что-то другое вообще будет делать поломанным ужасным, всюду пихая лица. Офк это упрощение и многое еще зависит от параметров тренировки.
> У нас, славян, черты лица более мягкие, округлые, без резких углов нижней челюсти и "взгляда охотника"
dies from cringe


>dies from cringe
this is reality
>Если датасет разнообразный то исходя из различий и общего она усвоит это именно "лицо славянина", если там одно и то же то ошизеет и будет думать что "карие глаза" значат "вот такие широкие щечки и вогнутый подбородок" а что-то другое вообще будет делать поломанным ужасным, всюду пихая лица
Мы вас поняли, какие будут конкретные предложения? что засунуть и как настроить датасет для предотвращения ошизения? Может засунуть пейзажи всякие, негров, морщинистых стариков?
make slavs great again
Абстрактно - чтобы натренить сетку на определённый концепт, тебе нужны
- куча пикч, этот концепт находится в как можно более разнообразном контексте/окружении
- хорошие описания этих пикч, в которых фигурирует всё что есть на пикче.
От качества статистического разделения их комбинаций будет зависеть качество твоей тренировки.
То есть вот тебе надо натренить на определённый тип ебальника. Берёшь только такие картинки, чтобы на них этот тип фигурировал - разных пропорций, возраста, в разных позах, разного пола, в разной одежде, под разным углом, с разным освещением, фокусным расстоянием/дистанцией, на природе, в помещении, на велосипеде, на парашюте, под водой, в космосе блять даже. И чтобы в парных описаниях было описано всё что происходит на пикче. Тогда сетка при обучении статистически вычленит, что этот тип ебальника = это слово, т.к. оно фигурирует везде, а остальные слова не везде.
Если ты подмешаешь негров или финнов, которые будут описаны другими словами - всё в порядке, оно их разделит. Если ты подмешаешь негров и финнов, которые будут описаны тем же самым словом - оно их смешает и будет сборная солянка.
Изолировать один концепт очень сложно, т.к. любые фотки имеют кучу общего, и он неизбежно выучит не только еблище которое ты хочешь, а ещё и кучу связанных вещей. Но если датасет хороший, можно сделать достаточно хорошо.
Чтобы протегить датасет, используй например LLaVa или CogVLM, для последнего придётся арендовать GPU. Или вообще GPT-4, дорого. Или можешь ручками сидеть тегить три тысячи человеко лет - главное чтобы описания были корректные.
Вообще-то ванильный SD сам по себе неплохо понимает внешний вид разных этносов, и многие другие вещи. Хотя разнообразия в пределах этноса ему может недоставать.
- куча пикч, этот концепт находится в как можно более разнообразном контексте/окружении
- хорошие описания этих пикч, в которых фигурирует всё что есть на пикче.
От качества статистического разделения их комбинаций будет зависеть качество твоей тренировки.
То есть вот тебе надо натренить на определённый тип ебальника. Берёшь только такие картинки, чтобы на них этот тип фигурировал - разных пропорций, возраста, в разных позах, разного пола, в разной одежде, под разным углом, с разным освещением, фокусным расстоянием/дистанцией, на природе, в помещении, на велосипеде, на парашюте, под водой, в космосе блять даже. И чтобы в парных описаниях было описано всё что происходит на пикче. Тогда сетка при обучении статистически вычленит, что этот тип ебальника = это слово, т.к. оно фигурирует везде, а остальные слова не везде.
Если ты подмешаешь негров или финнов, которые будут описаны другими словами - всё в порядке, оно их разделит. Если ты подмешаешь негров и финнов, которые будут описаны тем же самым словом - оно их смешает и будет сборная солянка.
Изолировать один концепт очень сложно, т.к. любые фотки имеют кучу общего, и он неизбежно выучит не только еблище которое ты хочешь, а ещё и кучу связанных вещей. Но если датасет хороший, можно сделать достаточно хорошо.
Чтобы протегить датасет, используй например LLaVa или CogVLM, для последнего придётся арендовать GPU. Или вообще GPT-4, дорого. Или можешь ручками сидеть тегить три тысячи человеко лет - главное чтобы описания были корректные.
Вообще-то ванильный SD сам по себе неплохо понимает внешний вид разных этносов, и многие другие вещи. Хотя разнообразия в пределах этноса ему может недоставать.
>вот тебе надо натренить на определённый тип ебальника
>И чтобы в парных описаниях было описано всё что происходит на пикче
А нахуя? Если мне нужен определенный ебальник, я беру тысячу фото этого ебальника и тегаю его как "ебальник". Ну может еще по ракурсу, типа "вправо" или "влево". Нахуя тегать все подряд, кроме того что ебальнику вообще можно кроп сделать, чтобы только он в кадре и был.
>Если мне нужен определенный ебальник
ебальники разные (люди же разные), тип ебальника один - славянский.
Так будет адекватный рецепт как это все смиксовать и завести нормально?
Ну и кстати, любопытная штука.
https://arxiv.org/abs/2310.20092
Своего рода развитие идей LCM - архитектура юнета на основе нейронного солвера вместо численного, только это обобщено до всей модели, они полностью заменяют весь диффузионный процесс одной нейронкой. Выходит в 3-4 раза быстрее и меньше по параметрам для аналогичного результата, плюс она не дискретная и изначально включает в себя понятие времени.
Т.е. у этой штуки нет фиксированных разрешений, принципиально отсутствуют итерации и пошаговая проявка, можно обучить на видео в качестве дополнительной моды и иметь темпоральную стабильность. Я так понимаю кроме времени туда любые кастомные измерения можно запихать, например сделать её трехмерной.
https://arxiv.org/abs/2310.20092
Своего рода развитие идей LCM - архитектура юнета на основе нейронного солвера вместо численного, только это обобщено до всей модели, они полностью заменяют весь диффузионный процесс одной нейронкой. Выходит в 3-4 раза быстрее и меньше по параметрам для аналогичного результата, плюс она не дискретная и изначально включает в себя понятие времени.
Т.е. у этой штуки нет фиксированных разрешений, принципиально отсутствуют итерации и пошаговая проявка, можно обучить на видео в качестве дополнительной моды и иметь темпоральную стабильность. Я так понимаю кроме времени туда любые кастомные измерения можно запихать, например сделать её трехмерной.
>предполагается, что модель будет заточена для переосмысления/реставрации мужских изображений через img2img
https://civitai.com/models/98755/humans
Там дохуя тегов, включая этнические, можешь рашен прописать и никаких чадов/стейси не будет.

Пиздец ты шизоид. Там все такая же обычная диффузия с шагами.
> нет фиксированных разрешений
У конволюшенов вообще нет разрешения, чел.
> принципиально отсутствуют итерации и пошаговая проявка
Таблетки выпей, это все то же самый ODE. У них просто параметров меньше.
> включает в себя понятие времени
Пиздос. Timestep - это не шаг во времени, лол. Увидел знаковые слова в тексте и начал фантазировать? Время в контексте диффузии - это про дифференциацию, когда лимит не к нулю стремится, а к какому-то значению. В самой первой SD всё тоже самое.
Чёт я не понял, а time embeddings тогда зачем?
Так второй пик где генерации дольше это без --disable-nan-check --medvram
Это когда используется тензор со значениями шага денойза и к нему обращаются по индексу, там обычно 1000 значений, они могут быть нелинейно распределены, верхние и нижние границы сдвигаться могут. Сделано для того чтобы потом шедулер шума выдавал просто набор индексов, а не самих значений. Это для простоты, чтоб шедулер работал с абстрактными timesteps вне зависимости от того какое там распределение реальных значений. Ещё в оригинальной латентной диффузии придумали, а в k-diffusion вместо них используют сами значения денойза, в diffusers их обратно адаптировали под timesteps. У трансформеров, например, тоже есть positional embeddings, каждый индекс обозначает положение токена в контексте, но по факту там совсем другие значения и варьируются у моделей.

Ответ автора на "почему в LCM лоре не работают негативы". Походу при cfg 1.0 семплер их тупо отрубает, шоб было быстрее. Непонятное поведение
А собственно в блоге написано. https://huggingface.co/blog/lcm_lora#guidance-scale-and-negative-prompts
>Note that in the previous examples we used a guidance_scale of 1, which effectively disables it. This works well for most prompts, and it’s fastest, but ignores negative prompts. You can also explore using negative prompts by providing a guidance scale between 1 and 2 – we found that larger values don’t work.

Чет я не понял, как это вообще работает??? https://civitai.com/models/110071/hd-helper
И прочие лоры-слайдеры автора тоже. Как такую обучить под мой концепт?
И прочие лоры-слайдеры автора тоже. Как такую обучить под мой концепт?

Ну хуй знает. Намного лучше примержить 0.3-0.4 лоры и уже можно ниже 10 шагов опускаться, но при этом оно хорошо апскейлится, CFG до 3-4 можно поднимать и нет говняка. С частичным LCM можно делать хайрезфикс с 8/6 шагами и оно выглядит сильно лучше чем точно такая же генерация на полном LCM.



>я создавал этот набор данных около десяти лет. Он содержит около 100 тысяч (и их количество растет) тщательно подобранных, сбалансированных и маркированных изображений с целью устранить предвзятость в генеративных моделях искусственного интеллекта.
Я сейчас читаю описание и блядь в ахуе как интригует. Я думал, что лучшая модель это Realistic Vision, а тут более 100 тысяч фото в датасете с описаниями, вау.
Короче, я её сейчас проверил, это кривое фуфло, Realistic Vision намного лучше по качеству картинки, хоть и выдает не особо похожих людей через img2img. Humans расщепляет глаза, зубы гнилые кривые, ломает волосы, и в целом очень размытое изображение выдаёт, но оно может видеть округлое лицо и как будто понимает, что нужно сделать легкую равномерную щетину и в половине случаев клонит в эспаньолку, а Realistic Vision в большинстве случаев пытается сделать эспаньолку вместо равномерной легкой щетины и прищуренные чедовские глаза, черты лица получаются четкими, ясными, резкими без проблем с радужками и всем остальным как в Humans. Так что Realistic Vision явно выигрывает у этого говна. Я не удивлён почему эта модель не пользуется популярностью.
Получается этот шизик собирал дерьмовый пак в 100 тысяч фото 10 лет и в итоге сделал хуевую модель, которую обходит модель обученная на пакете до 2 тысяч фото.
Я вам так скажу, я с большим трудом насобирал пак в 1900 фото (и этот только портретные фото) не самого лучшего, но хорошего качества, а вчера начал собирать новый пак с более высоким разрешением (кадрируя и ретушируя каждую фото в фотошопе, так как прыщи и бородавки нахуй не нужны), за вчерашний день с большим трудом насобирал таким макаром 280 фото. Ну невозможно насобирать пак в 100 тысяч фото разных людей (или с минимальным количеством повторений) хорошего качества, ну нету просто столько в интернете, а там где есть - на ебальнике обязательно будет вотермарка фотостока, либо нужно ковырять соц. сети выискивая людей со студийными профессиональными фото, а это очень долго.
Во напридумывал то
> создавал этот набор данных около десяти лет
> Он содержит около 100 тысяч
> тщательно подобранных, сбалансированных и маркированных изображений
Реально ведь шиз, но тут скорее просто цену себе набивает и выебывается. Это все до высокой степени автоматизируется.
собрал 50к отборнейших анимублядских тематических за несколько вечеров
Про качество модели хз, но
>512x512
Ну вот серьёзно?
у меня всего 2 вопроса:
>собрал 50к за несколько вечеров
как?
>анимублядских
нахуя?
>как?
>>анимублядских
Ответ на поверхности же.
>Ну вот серьёзно?
да, эти пикчи сгенерированы 512x512 через модель Humans. ещё вопросы?
> как?
Nanomashines, son!
Грабберов, аналайзеров, теггеров, интеррогейтеров и даже мультимодалок хватает, используй и получай нужное. Офк не говоря о предварительном отсеивании мусора по параметрам, разрешению, шакалистости, прозрачности и т.д.
> нахуя?
Когда вижу лоры на еот и какие-то генерации всратых 3д шаболд - задаюсь тем же вопросом помирая от кринжа.


Какие есть аргументы для kohya-ss и куда их прописывать - в activate.bat или в webui.bat как для обычного SD? У меня пиздец мало видеопамяти, хоть на цпу тренируй лол. Или там все настройками крутится? Гайд для бомжей есть?
Олсо kohya-ss говноед проклятый (ну или serpotapov который сделал это портабельным, энивей дай боженька им здоровья за их труды) захардкодил пути и теперь у меня Error no kernel image is available for execution on the device at line 167 in file D:\ai\tool\bitsandbytes\csrc\ops.cu хотя все эти потроха у меня вообще на A:\ лежат лол. Где чинить?
Олсо kohya-ss говноед проклятый (ну или serpotapov который сделал это портабельным, энивей дай боженька им здоровья за их труды) захардкодил пути и теперь у меня Error no kernel image is available for execution on the device at line 167 in file D:\ai\tool\bitsandbytes\csrc\ops.cu хотя все эти потроха у меня вообще на A:\ лежат лол. Где чинить?

Есть предложение вынести часть инфы из шапки по отдельным документам, чтобы она была менее раздутая.
И ещё более радикальная идея - можем вынести всю шапку целиком на гит-репу в виде множества md файлов и настроить автодеплой в виде статичного сайта. Туда же можно вынести какие-либо из важных статей на rentry, и, по необходимости, коллективно править их через систему Pull Requests. Вероятно, я дам активным контрибьютерам возможность вносить правки напрямую, но с блокировкой форс-пушей для master-ветки, чтобы нельзя было провести деструктивные действия. Некое подобие вики, но основанное на примитивной системе хранения md-файлов в гите, так что резервные копии будут делаться легчайше через git clone.
https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/
https://gitgud.io/2ch-ai/wiki/-/blob/master/docs/tech/tech-shapka.md
Попробовал запилить репу на gitgud и настроить автодеплой статики на предоставляемый ими же хостинг. Выбрал гитгуд, а не гитхаб, т.к. в gitgud не банят за nsfw в репе.
Из дополнительных плюсов то, что при открытии любой страницы на фронте подгружаются текстовые файлы для всех статей. Благодаря этому, поиск работает сразу по всем статьям (пик 1), несмотря на отсутствие какого-либо бекенда.
Для редактирования конкретного документа кликаете кнопку сверху-справа от статьи (пик 2). Ну а там либо предложит сделать форк репы, либо либо предложит внести правки напрямую, в зависимости от уровня доступа.
Однако, на гитгуд есть проблема с сертификатом на файрфокс, в нём сама вики не открывается. Напряг их кодера, говорит, фиксит сейчас...
Всё это дело можно форкнуть и запустить локально, либо на стороннем сервере. Могу позднее батники докинуть, которые будут ставить зависимости в venv, запускать сервер в watch-режиме, и билдить проект. Так, чтобы это однокнопочной системой стало, при наличии у вас установленных питона+гита.
Ложкой говна является то, что гитгуд не предоставляет свой билд-сервер (вернее, он просто сдох и лежит уже два года), так что я настроил билд-сервер на одной из своих старых машин, которую мог бы держать включённой 24/7 (либо копеечный VPS под это арендовать), но это какой-то фейл, что мы не можем не зависеть от дополнительной инфраструктуры.
Пробовал вкинуть идею в nai, но там она не особо зашла. Интересно услышать мнение остальных анонов.
И ещё более радикальная идея - можем вынести всю шапку целиком на гит-репу в виде множества md файлов и настроить автодеплой в виде статичного сайта. Туда же можно вынести какие-либо из важных статей на rentry, и, по необходимости, коллективно править их через систему Pull Requests. Вероятно, я дам активным контрибьютерам возможность вносить правки напрямую, но с блокировкой форс-пушей для master-ветки, чтобы нельзя было провести деструктивные действия. Некое подобие вики, но основанное на примитивной системе хранения md-файлов в гите, так что резервные копии будут делаться легчайше через git clone.
https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/
https://gitgud.io/2ch-ai/wiki/-/blob/master/docs/tech/tech-shapka.md
Попробовал запилить репу на gitgud и настроить автодеплой статики на предоставляемый ими же хостинг. Выбрал гитгуд, а не гитхаб, т.к. в gitgud не банят за nsfw в репе.
Из дополнительных плюсов то, что при открытии любой страницы на фронте подгружаются текстовые файлы для всех статей. Благодаря этому, поиск работает сразу по всем статьям (пик 1), несмотря на отсутствие какого-либо бекенда.
Для редактирования конкретного документа кликаете кнопку сверху-справа от статьи (пик 2). Ну а там либо предложит сделать форк репы, либо либо предложит внести правки напрямую, в зависимости от уровня доступа.
Однако, на гитгуд есть проблема с сертификатом на файрфокс, в нём сама вики не открывается. Напряг их кодера, говорит, фиксит сейчас...
Всё это дело можно форкнуть и запустить локально, либо на стороннем сервере. Могу позднее батники докинуть, которые будут ставить зависимости в venv, запускать сервер в watch-режиме, и билдить проект. Так, чтобы это однокнопочной системой стало, при наличии у вас установленных питона+гита.
Ложкой говна является то, что гитгуд не предоставляет свой билд-сервер (вернее, он просто сдох и лежит уже два года), так что я настроил билд-сервер на одной из своих старых машин, которую мог бы держать включённой 24/7 (либо копеечный VPS под это арендовать), но это какой-то фейл, что мы не можем не зависеть от дополнительной инфраструктуры.
Пробовал вкинуть идею в nai, но там она не особо зашла. Интересно услышать мнение остальных анонов.
Сам напердолил сэмплер чтоли? У автоматика нету пока даже в dev.
Идея хуйня, лучше шапку переписать в более удобоваримой форме, хотя и сейчас вроде норм. Как говорит Сергей Симонов похуй-нахуй
Только один, нахуя генерить 512х512-то? Генерь хотя бы 1024х1024 для демонстрации
Реалистик вижен даёт прилизанных персонажей с обложки с идеальными пропорциями, таких полон цивит. Совсем другой направленности модель.
>Ну невозможно насобирать пак в 100 тысяч фото разных людей (или с минимальным количеством повторений) хорошего качества, ну нету просто столько в интернете, а там где есть - на ебальнике обязательно будет вотермарка фотостока, либо нужно ковырять соц. сети выискивая людей со студийными профессиональными фото
Ну так вроде заявленная цель этой модели не профессиональные фотосессии, и не фентези гераклы с амазонками, а обычные люди с морщинами, прыщами и бородавками, каковых овердохуя. Насчёт качества я хз, не пробовал.
> D:\ai\tool\bitsandbytes\csrc\ops.cu хотя все эти потроха у меня вообще на A:\
Это я так и не решил, но завелось с optimizer AdamW. Олсо в каком-то гайде было написано что при запуске можно идти курить, потому что система оче загружена и даже интернет не посерфить. Ну хуй знает, моя 1063 хоть и загружена на 92% и RAM занято 20Гб суммарно, но чет тормозов не замечаю, параллельно даже артой на респе стою с другими подпивасными Михалычами лол. Но судя по прогрессу шагов, это пиздец как надолго.
> Есть предложение вынести часть инфы из шапки по отдельным документам, чтобы она была менее раздутая.
Если ты запускал 8битный adamw, то ему нужна библиотека bitsandbytes, без неё будет еррором срать.
>бычные люди с морщинами, прыщами и бородавками, каковых овердохуя.
Это замечательно конечно, но качество картинки полное говно.
>Реалистик вижен даёт прилизанных персонажей с обложки с идеальными пропорциями
Я про это и говорю, поэтому и хочу создать свою более качественную и равномерную модель.
Я еще пробовал adafactor, вроде бы с тем же результатом.
Но суть не в этом. Допустим либу я нашел, но где поправить путь, который очевидно захардкодили - хуй знает. Вроде бы portable-версия предполагает распаковку, деплой и запуск в один клик, а значит все пути должны быть либо относительны, либо генерироваться при деплое, но хуй там - у меня срало ошибкой в пути на D:\ какого-то хуя, хотя у меня его в системе нет (можно было бы предположить что я распаковал и задеплоил там, а потом перенес, но нет).
Вот это, кстати, было бы оче круто. Либо так, либо вики мастерить с перекрестными ссылками, примерами конфигов и всей такой хуйни, а то хранить инфу на гите это технически удобно канеш, но конечная реализация полное говно с точки зрения UI - это как омлет строительным миксером взбивать.
> D:\ai\tool\bitsandbytes\csrc\ops.cu
Хз что ты там поставил, но жалуется у тебя на bitsandbytes точно. Если бы вручную ставил с venv'ом, то после переноса в другую локацию надо было бы поправить пару путей в бинарниках питона и пипа.
Не вручную, я чет ротебал все это руками ставить, я использовал портейбл https://github.com/serpotapov/Kohya_ss-GUI-LoRA-Portable который деплоится и запускается в один клик не сря в систему.
Понятно что это какая-то сборочка уровня васяна, но это не отменяет того факта что где-то путь жестко прописан, его можно найти и починить, но мне одному слишком долго искать, поэтому я и спросил где проблема. И прежде чем меня с этой сборочкой нахуй посылать - нужно его указать. Ну то есть типа "братишка, тебе надо поменять путь в /path/to/file но вообще ты мудила и используешь хуй знает что, сам себе злобный буратино и иди нахуй" - вот тогда это будет вполне заслуженно, мне даже сказать против будет нечего.
Да я просто понятия не имею что там этот друг хачатура насобирал за твикер очередной и не могу тебе с ним помочь, была бы у тебя ручная сборка, можно было бы что то подсказать, а так сам понимаешь, тут только его и спрашивать, да и я хз как в его сборку пакеты нормально добавлять, что он хоть там распаковывает? Если в папке есть venv то просто открой её в консоли а дальше venv\scripts\activate.bat и pip install bitsandbytes
>что он хоть там распаковывает
Да все потроха он там распаковывает, с пердоном, гитом и всей обвязкой. И соответственно для того чтобы добавить пакеты нужно пердон по полному пути запускать, так как в PATH оно ничего не пишет (ну только устанавливает на время сессии через set) - я так в SD от него же добавлял всякую хуйню, норм работало.
venv есть, да, но в activate.bat похожих путей нет, там вообще строк на 20 файл с переменными.
>pip install bitsandbytes
Вряд ли это поможет. Нет, bitsandbytes оно канеш поставит, но скорее всего искать его будет все равно по пути, который в моей системе отсутствует. Хотя мб я и ошибаюсь.



Там это, у расширения на быстрый inpaint, которое неделю назад кидал, обновление вышло
Теперь есть hiresfix на одну кнопку, на случай если мыло в глаза бросается. Можете сравнить пики, одна с хайрезом, другая без. Хотя это не самый показательный вариант. Кстати, в настройках по-умолчанию сделал использование lcm. Кажется для хайрез фиксов он идеально подходит
Так же полностью работает пакетная обработка, и сохранение файлов по пути outputs/replacer/дата
В общем осталось реализовать всевозможные параметры, сделать покачественней readme, и можно в индекс автоматика добавлять
Теперь есть hiresfix на одну кнопку, на случай если мыло в глаза бросается. Можете сравнить пики, одна с хайрезом, другая без. Хотя это не самый показательный вариант. Кстати, в настройках по-умолчанию сделал использование lcm. Кажется для хайрез фиксов он идеально подходит
Так же полностью работает пакетная обработка, и сохранение файлов по пути outputs/replacer/дата
В общем осталось реализовать всевозможные параметры, сделать покачественней readme, и можно в индекс автоматика добавлять
Нормальные люди генерят в 960х540, а потом апскейлят в 4к, ну или хотя бы в Full HD, всё что ниже, это вообще не показатель качества модели, большинство моделей выглядят одинаково в 512х512, только апскейл выводит разницу на поверхность.


С аниме моделью, так понимаю, тестов не было? На дедовском дебилорейте работает бтв.
Используй инпейнт модель, либо сделай её сам из нужной аниме модели.
Со слайдерами нашёл. https://github.com/ostris/ai-toolkit#lora-slider-trainer

Да, так получше, но область инпеинта почему то слишком большая отхватывается в этом примере, хотя я ввёл просто волосы поменять.
Вейт, их можно конвертировать? Чем конкретно отличается заточка под инпеинт?
Inpaint модель имеет 5 дополнительных слоёв в UNet — 4 слоя для контекста изображения (так как в латентном пространстве изображение представлено в виде 4-х мерного тензора) и один слой непосредственно маска.
Инструкция по конвертации здесь https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/How-to-make-your-own-Inpainting-model
А, это мёрж с официальной инпеинт моделью. Я думал как-то тренить надо.
Были тесты, все работает. Только у одежды желательно цвет указать, так как на ней часто тупит. Еще можно разные типы одежды писать типа swimsuit, trousers, t-shirt, даже если строго говоря на арте одежда другая
По поводу lcm на аниме, то моя любимая kaywaii работает с ним замечательно на 4 шагах. Но в хайрезе думаю с любой моделью проблем не будет, так как в этом режиме даже cfg 5.5 картинку не выжигает
На релизе я в readme гайд по конвертации напишу. Как раз знаю что у многих людей затупы по этому поводу
Можно и тренить, можно мерж не с официальной, а с обученной. Типа
EpicPhotogasm Z Inpaint + (твоя - EpicPhotogasm Z) * 1
>hf_upscaler = gr.Dropdown(
>value="ESRGAN_4x",
>hf_sampler = gr.Dropdown(
>value="Euler a"
Зря захардкодил имена апскейлеров и семплеров, это потенциальный путь к проблемам.
Лучше сохрани их в список, а потом обращайся к нулевому элементу.
Это не хардкор, это же дефолтное значение для ui. Кто угодно может изменить значение по-умолчанию
Апскейлер стандартный, а не какой-нибудь 4x-Ultrasharp. Семплер тем более никуда не денется. Так что проблемы не виду
> Лучше сохрани их в список, а потом обращайся к нулевому элементу.
Ты не понимаешь, что говоришь. Список всех вариантов и так есть от самого автоматика на строчке ниже в choices. Даже если кто-то скроет этот семплер или апскейлер, ошибки не будет, так как gradio добавляет в список дефолтные элемент, если не находит в списке
В редми тоже добавлю гайд, как пользоваться секцией defaults в настройках
Бабы осваивают Автоматика...
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13965
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13965
Надо написать ей, чтобы установила Линукс ))

А чё не так с аниме? Я правда мержефигнёй не занимаюсь, тупо лору пихаю в промпт.
У некоторых с аниме не работает. Ну либо они тупят люто где-то, у меня на все моделях работает

Пацаны, объясните что такое ЛЦМ ЛОРА для НУЛЕВОГО?
Что кочать и куда жать, чтобы стало заебись?

> Пацаны, объясните для НУЛЕВОГО?
Тебе уже не помочь. Нулевой не поймет что она делает, раз не знаешь какие обычно шаги, cfg и т.п.
Ну пиздос, ща вместо искривления пространства от слишком большой жёппы пойдут фоточки с 6 пальцами на третьей ноге, с пиздой под коленкой и сосками на затылке, ох лол.
Почему всякие гайды по обучению лоры на определенный ебальник рекомендуют использовать 10-30 фото? Разве закинуть 100-200 фото не лучше для обучения?

10-30 размером 512, я сам не ебу. Уроки для нищих обывателей делают каких-то, хотя в треде я выяснил, что нужно собирать пак не на 512 явно, а на больших разрешениях. Это хуйня пошла от туда где сказали, что базовая модель обучалась на 512, поэтому нужно собирать 512, а иначе будет хуйня. Короче тут нужно на своём опыте проверять всё, stable diffusion это непаханое поле экспериментов, инструмент новый и никто нихуя не знает, но уже советуют с апломбом будто они stable diffusion сами и создали.
я думаю, что если фото разнокалиберные (из разных условий съёмки и освещения) и не заебёшься подписывать каждое, то можно и 200 всунуть.
Так чего там с этой лцм-лорой и мерджем?
На аниме работает? Чувствительность к негативам и цфг какая?
Контролнет, хайрезфикс, и всё такое?
Хочу понять, стоит заморачиваться или нет. 4080 в компе - это, конечно, хорошо, но если можно урезать количество шагов в 4 раза - это ж еще лучше.
P.s. кохай свой хайрезфикс запилил, кстати
https://github.com/wcde/sd-webui-kohya-hiresfix
На аниме работает? Чувствительность к негативам и цфг какая?
Контролнет, хайрезфикс, и всё такое?
Хочу понять, стоит заморачиваться или нет. 4080 в компе - это, конечно, хорошо, но если можно урезать количество шагов в 4 раза - это ж еще лучше.
P.s. кохай свой хайрезфикс запилил, кстати
https://github.com/wcde/sd-webui-kohya-hiresfix
А, бля. Тут перекатили. Ну ладно.




Тред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для kohya-ss
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
Если вы используете скрипты https://github.com/kohya-ss/sd-scripts напрямую, то, для обучения SDXL, вам необходимо переключиться на ветку "sdxl" и обновить зависимости. Эта операция может привести к проблемам совместимости, так что, желательно, делать отдельную установку для обучения SDXL и использовать отдельную venv-среду. Скрипты для тренировки SDXL имеют в имени файла префикс sdxl_.
Подробнее про обучение SDXL через kohya-ss можно почитать тут: https://github.com/kohya-ss/sd-scripts/tree/sdxl#about-sdxl-training
Для GUI https://github.com/bmaltais/kohya_ss и https://github.com/derrian-distro/LoRA_Easy_Training_Scripts/tree/SDXL так же вышли обновления, позволяющее делать файнтьюны для SDXL. Кроме полноценного файнтьюна и обучения лор, для bmaltais/kohya_ss так же доступны пресеты для обучения LoRA/LoHa/LoKr, в том числе и для SDXL, требующие больше VRAM.
Всё пока сырое и имеет проблемы с совместимостью, только для самых нетерпеливых. Требования к системе для обучения SDXL выше, чем для обучения SD 1.x.
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ Текстуальная инверсия (Textual inversion) может подойти, если сеть уже умеет рисовать что-то похожее:
https://rentry.org/textard (англ.)
✱ Гиперсеть (Hypernetwork) может подойти, если она этого делать не умеет; позволяет добавить более существенные изменения в существующую модель, но тренируется медленнее:
https://rentry.org/hypernetwork4dumdums (англ.)
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ LoRA – "легковесный Dreambooth" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением:
https://rentry.org/2chAI_easy_LORA_guide - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - это проект по созданию алгоритма для более эффективного дообучения SD. Ранее носил название LoCon. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr и DyLoRA:
https://github.com/KohakuBlueleaf/LyCORIS
✱ LoCon (LoRA for Convolution layer) - тренирует дополнительные слои в UNet. Теоретически должен давать лучший результат тренировки по сравнению с LoRA, меньше вероятность перетренировки и большая вариативность при генерации. Тренируется примерно в два раза медленнее чистой LoRA, требует меньший параметр network_dim, поэтому размер выходного файла меньше.
✱ LoHa (LoRA with Hadamard Product representation) - тренировка с использованием алгоритма произведения Адамара. Теоретически должен давать лучший результат при тренировках с датасетом в котором будет и персонаж и стилистика одновременно.
✱ LoKr (LoRA with Kronecker product representation) - тренировка с использованием алгоритма произведения Кронекера. Алгоритм довольно чувствителен к learning_rate, так что требуется его тонкая подгонка. Из плюсов - очень маленький размер выходного файла (auto factor: 900~2500KB), из минусов - слабая переносимость между моделями.
✱ DyLoRA (Dynamic Search-Free LoRA) - по сути та же LoRA, только теперь в выходном файле размер ранга (network_dim) не фиксирован максимальным, а может принимать кратные промежуточные значения. После обучения на выходе будет один многоранговый файл модели, который можно разбить на отдельные одноранговые. Количество рангов указывается параметром --network_args "unit=x", т.е. допустим если network_dim=128, network_args "unit=4", то в выходном файле будут ранги 32,64,96,128. По заявлению разработчиков алгоритма, обучение одного многорангового файла в 4-7 раз быстрее, чем учить их по отдельности.
✱ Text-to-image fine-tuning для Nvidia A100/Tesla V100-бояр:
https://keras.io/examples/generative/finetune_stable_diffusion (англ.)
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Тренировка YOLO-моделей для ADetailer
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Гайд: https://civitai.com/articles/1224/training-a-custom-adetailer-model
Тулза для датасета: https://github.com/vietanhdev/anylabeling
Больше про параметры: https://docs.ultralytics.com/modes/train
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Гайд по фиксу сломанных моделей: https://rentry.org/clipfix (англ.)
Расширение WebUI для проверки "сломаных" тензоров модели: https://github.com/iiiytn1k/sd-webui-check-tensors
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Ручная сборка и установка последней версии xformers и torch в venv автоматика:
Windows: https://rentry.org/sd_performance
Linux: https://rentry.org/SD_torch2_linux_guide
Подборка мокрописек от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
Шапка: https://rentry.org/catb8
Прошлые треды:
№1 https://arhivach.top/thread/859827/
№2 https://arhivach.top/thread/860317/
№3 https://arhivach.top/thread/861387/
№4 https://arhivach.top/thread/863252/
№5 https://arhivach.top/thread/863834/
№6 https://arhivach.top/thread/864377/
№7 https://arhivach.top/thread/868143/
№8 https://arhivach.top/thread/873010/
№9 https://arhivach.top/thread/878287/
№10 https://arhivach.top/thread/893334/
№11 https://arhivach.top/thread/908751/
№12 https://arhivach.top/thread/927830/