

Ну напиши ты простой скрипт для слепого теста, сразу поймешь что 90% здесь плацебо, а на шизиодные аналогии устраивай. А то и вообще Q3 покажется более крутой за счет своей креативности, уже проходили.
> Те же 7б
7б и несколько преувеличено, сидели инджоили а потом как результаты комбинации правильного запуска с фп16 весами подъехали - сразу пошло mee to. Но здесь еще оправдано, а в 20б - хз.
Рандомайзер на малых моделях, в первую очередь зависит от формулировки запроса и настроения при оценке.
Че думаете про MemGpt? Говорят что имба, лечит маразм лмлмок от долгого общения. https://memgpt.ai/
Там надо логиниться в эту хуету. В общем лучше качай черед интерфейс самой угабуги, во вкладке models есть поле download model
Спасибо.
Чел, git clone запретили даунам использовать или что?

Они сколько угодно могут свою мокропиську рекомендовать, тебя это не должно ебать.

Эти "они" с тобой в одной комнате? Вот, первым пунктом.
А гит клон боль, особенно под шиндой и с файлами больше 4ГБ (то есть почти со всеми нейронками).
> боль
Чел, гит давно поддерживает LFS, какая ещё боль, я и 50-гиговые выкачивал без проблем клоном.
> Вот, первым пунктом.
Убабуга качает модели через http по прямым ссылкам на файлы, huggingface-cli никто не использует.
> опять тесты на немецком
Какие же дауны.
Нет бы на русском тестировать, вот же дауны!
А где немецкий? Он был в тестах инструкции безопасности в первой части
> My own repeatable test chats/roleplays with Amy
> Deterministic generation settings preset
Вот это комбо не менее забавно, да еще
> Average Response Length: 409 tokens (much more than my max new tokens limit of 300)
Длинные ответы теперь минус из-за того что выставил лимит ай лол. Не из-за графомании, не из-за написания за юзера или плохого качества а потому что он так выставил, серьезно?
Увлекся массовостью и стрижкой "кармы" вместо того чтобы делать качественнее. Хозяин барин офк и в принципе молодец что вообще что-то делает. Но местами дезинфа на которую будут ориентироваться, и в дискуссиях уже встречаются аргументы "я так делаю уже долго значит это правильно а не ошибка", нахуй такие авторитеты не сдались.
Ебать вы тут умными словами разбрасываетесь на контрасте с дегенератами из соседнего треда. А толку то, если все равно ничего лучше гпт4 и Клода нет?
кумить надоело и поперли умные мысли
>лучше гпт4 и Клода нет?
У тебя нет, у корпов в закрытом доступе есть. Ирония в том что для них сетки на уровне гопоты4 - локальные модели, лол

Сука, вот с таким ебальником\настроением сижу и читаю сетку. Чем умнее сетка тем грустнее, и тем больнее она бьет
https://3dnews.ru/1095283/kitay-razrabotal-chip-dlya-mashinnogo-zreniya-kotoriy-v-3000-raz-bistree-i-v-4-milliona-raz-effektivnee-chem-sovremennie-graficheskie-protsessori
Вот такое хачу для обычных вычислений, я уверен эта хуйня была создана специалистами с помощью нейронок.
Когда там уже фотонные процессоры? Или хотя бы нейроморфные фотонные аналоговые ускорители, как тут. Ебануться там производительность конечно
Вот такое хачу для обычных вычислений, я уверен эта хуйня была создана специалистами с помощью нейронок.
Когда там уже фотонные процессоры? Или хотя бы нейроморфные фотонные аналоговые ускорители, как тут. Ебануться там производительность конечно
У корпов максимум четверка 32к такая же как и у меня. Не пизди
Ты конечно лучше знаешь что у них там, хахах смешной
Ебучий шизик.
>А толку то, если все равно ничего лучше гпт4 и Клода нет?
А тебе не приходило в голову, что если все, как и ты будут сидеть на жопе ровно, регулярно фоткая флажки в анусе за доступ к проксям, то ничего лучше ни не появится,? Да и куда ползти таким ретардам из ЧАЕтреда если Клодыня с Гопотой внезапно закончатся?
>такая же как и у меня
У тебя есть только (спизженый) ключ от апи, дающий доступ (пока не отобрали) к зацензуренной сетке, для которой нужен джейл минимум на тысячу токенов. И это пока (((они))) не взялись всерьез за запрет кума, после чего твоя гопота 4 станет как CAI. Так что ничего у тебя нет. Теперь можешь оформить спокойствие и съебать из треда белых господ.
Скоро, вон в касперском делают сейчас нейроморфные чипы.
Ещё раз. У корпов есть ровно то же что и у меня. Это буквально то что оаи предлагает им причем только в рамках личного согласования. И нет, пока что на текстовых моделях никаких значимых фильтров нет. Ты просто запутался в словах шизик и видимо забыл что говорить нужно было про военных или разрабов моделей
Каким образом ты еблан имеешь отношение к людям которые обучают ламу или хотя бы ее файньюнят? Нихуя себе какой высокомерный, лол. Сидит дрочит на модели хуже турбы и выебываются тем какой он полезный, лол.
>У корпов
Ты тупой? Имелись ввиду разработчики этих сеток, клозедаи, гугля, мета. Ты реально думаешь что там нет невыпущенных вариантов сеток?
> Ты просто запутался в словах шизик и видимо забыл что говорить нужно было про военных или разрабов моделей
Я же тебе уже все написал. Ты настолько шизанутый дебил что потерял способность читать? Ебаный рот, какой дебил
Тоже думаю что уже есть другие архитектуры исследуемые и закрытые, к сожалению нам доступны только файн тюны и франкинштеины а не полноценное исследование, обучить сеть не у кого не хватит ресурсов из комьюинити по этому никто не пробует архитектуры менять.
Под «корпами» он подразумевает не людей, которые покупают апи чатгопоты, а крупные корпорации (Мета, Альфабет, Майкрософт), которые тренят свои сетки.
У них точно есть больше.
Речь не о простых чуваках с бабками, о которых ты говоришь.
У них-то да — тоже самое.
> если Клодыня с Гопотой внезапно закончатся?
Что значит "если"? Как будто кто-то собирается вечно обслуживать толпу кумеров за свой счёт. Кретины на разрабах однажды освоят переменные окружения и перестанут пушить ключи в публичные репы. Куда тогда побегут любители клода/жпт? Им останется либо осваивать локалки, либо выкатываться из темы до лучших времён. Не говоря уже про то, что клода/жпт могут прикрыть просто из-за нерентабельности, если инвесторы решат, что на LLM не выйдет заработать. Либо же докрутить цензуру до такой степени, что её никакими джейлами не выйдет пробить; либо же просто будут отзывать ключи при многократных попытках обхода цензуры.
Как вообще можно сравнивать облачную систему, управляемую хер знает кем, и локальными моделями? Я уже пользовался несколько лет AI Dungeon и NovelAI (который текстовый). Первый окончательно засоевился, а второй просто пидорнул мне подписку после начала гойды и я не могу им больше пользоваться. Так нахер наступать на одни и те же грабли?
> А толку то, если все равно ничего лучше гпт4 и Клода нет?
У кого есть? У нескольких держателей прокси, которые скрапят вечно подыхающие ключи, которых становится всё меньше и меньше?
>либо же просто будут отзывать ключи при многократных попытках обхода цензуры.
>будут
С пробуждением, уже давно как.
Так что я на локалках, которые без стеснения называют имя кота из произведений Лавкрафта.
Либо же они могут просто начать резать качество моделей для экономии, как сделали с тем же жпт - если верить инсайдам, изначально GPT-4 представляла собою 8 моделей на 220B параметров, которые позднее были заменены на одну 220B модель. Что им мешает начать ещё сильнее резать качество моделей для экономии, но продавать за ту же цену?
Улучшение локальных моделей)
Кстати заметил что nous hermes именно 14b отлично говорит по русски. Так что кто хотел русскоговорящую берите ее.
Я как минимум тестирую эти ламы и файнтюны и делюсь результатами. Уже одно это делает меня сверхчеловеком, по сравнению с обезьянами на проксях.
Убеждай себя дальше, что когда попены с куктропиками пошлют вас нахуй ты не приползёшь сюда клянчить модельку/настроечки для кофеварки/промптик чтобы хотя бы чуть хуже трубы...
> Улучшение локальных моделей)
Вот именно. Поэтому любители клода/жпт должны молиться на то, чтобы локальные модели взлетели и ими активно пользовались, поскольку это один из ключевых факторов, который может удерживать корпорации от того, чтобы они окончательно не охуели.
Но нет же, проще сказать:
> вы чё ебанутые? нахуй вам пигма?) вон в сикретклабе по почте проксю раздают
Вместо того, чтобы пытаться смотреть на пару шагов вперёд.
Не так давно надрачивали и восхваляли турбу, еще раньше тройку-чай и насмехались над пигмой, а теперь мы здесь и похоже какое-то время потопчемся на месте. Очень упрощая и абстрагируя - задержка сеток что можешь запустить локально на юзерском железе от проприетарных зацензуренных больших составляет пол года-год. В чем-то конкретном ее почти нет, в чем-то может и больше. Так что толк вполне есть.
Упоровшемуся в конспирологию шизлу то те самые корпы каждое утро отчет шлют, ага. Опять, сука, развели хуету.
Сейчас юзлесс но через несколько лет может и пойдет в массы. Сейчас на китайские аи ускорители что анонсировали можно надрачивать.
> создана специалистами с помощью нейронок
I want to believe, очень врядли.
> nous hermes именно 14b
Это который на квен? Насколько он хорош, чуть понимает или может общаться и делать инструкции?
>GPT-4 представляла собою 8 моделей на 220B параметров
Бля, каждый раз, когда я слышу про количество параметров у гопоты-4, то обязательно какое-то новое число назовут.
То это шесть моделей размерностью с GPT-3, то это неизвестное число моделей общим размером 1,7 трлн параметров. Сейчас вот восемь моделей по 220 млрд.
хотя последее тоже 1,7 трл примерно
>Это который на квен? Насколько он хорош, чуть понимает или может общаться и делать инструкции?
Я про лламовский говорил, от второй ламы.
>То это шесть моделей размерностью с GPT-3
Ты забыл про первый вброс про 100 триллионов.
>может общаться и делать инструкции?
Инструкции я все равно на английский перевожу для совместимости между ботами.
Общается на отлично, не делает ошибок в разговоре вообще. Ни разу не по родам не по времени ошибок не замечал.
Кто-нибудь пытался запускать большого Шлёпу Фалкона?
https://huggingface.co/TheBloke/Airoboros-180B-2.2.1-AWQ
https://huggingface.co/TheBloke/Airoboros-180B-2.2.1-AWQ
>96.13 GB
Ага, конечно, тут у каждого по 2 штуки А100 в чулане лежит.
А вообще, она ж была доступна на обмалафившихся лицах. И сейчас вроде есть https://huggingface.co/chat/
> 1,7 трлн
Слишком сказочно. Можно на глаз посчитать по скорости. Наверняка ЖПТ крутится на А100, от количества карт скорость не повышается - у трансформеров все нейроны слоя связаны между собой и слой должен быть на одном GPU, а слои можно просчитывать только последовательно. А100 по производительности примерно как 4090 говорят по GPU даже медленнее немного из-за низкого TDP и коррекции ошибок, но хуй с ним. Скорость скейлится почти линейно от количества параметров. На 4090 сейчас можно выжать под 100 т/с на 13В. Ну дадим скидку на оптимизон и обработку батчами корпораций и округлим для 10В до 200 т/с. А дальше арифметика простая. Сколько там у ЖПТ4 скорости? 20-30 т/с? Вот и получаем, как выше ванговали по слитой табличке, 6х20В. Эту цифру можно в пару раз накинуть для фантазий, но никак не в 15. И тенденция будет только к уменьшению из-за увеличения потребителей, именно поэтому такой дроч идёт на мелкие модели и прогрев опен-сорса.

Можно ли обновить версию Cuda c 11.8 до 12.1 в oobabooga или тут полная переустановка нужна?
Так ллама же на 13б а на 14 qwen, какой-то франкенштейн или имелось ввиду 13?
Ничесе, круто. Надо еще с инструкциями так попробовать, чисто на уровень восприятия.
Ванильный только, хуета хует а гвоздем в крышку 2к контекста. Хотя есть файнтюны на больший (хз как работают), айробороса этого предлагали с помощью скейлинга до 4к раздвигать.
Почему сказочно, там же в начале экспресс модель оценивает область и контекст, а потом отдает в работу только одной из моделей, из эти триллионов отрабатывает то всеравно только 220 миллиардов. Да и за это время уже наверняка подужали его.
> На 4090 сейчас можно выжать под 100 т/с на 13В
Кванты часто медленнее чем фп16 работают, оригинальные веса 7б что занимают под 20 гигов врам крутятся быстрее пережатых 20б.
> 6х20В
> фп16 <..> крутятся быстрее
Ну вот, как раз и выходит что в районе 200б параметров с такой скоростью будет, а если учесть что у А100 память быстрее и возможны другие оптимизации - оно.
> Кванты часто медленнее чем фп16 работают
Нет. Тензоядра ебут fp16 в разы. Ты в fp16 на 7В даже 50 т/с не получишь.
По хорошему такие тестирования надо проводить открыто, лучше сразу со слепым голосованием, типа выставить от каждой модели по 4 ролла на ситуацию, сделать десяток ситуаций, перемешать всё это и отдать анону на выбор. По сумме можно будет определить топ модель без лишней зацикленности на размере и прочих брендах фор лулз можно гопоту или клода подключить, вне конкурса.
Тогда и пусть несколько ответов даст ананас, для большего интереса
У меня нет столько анаши, чтобы обеспечить воспроизводимые ответы от фруктов.

Да не, с pl 60% и фоновой нагрузкой как раз столько и получается, офк в зависимости от длины вывода и размера контекста, в чате с уже обработанным под 60 будет.
С 20 гигами правда обманул, или это новые оптимизации, не больше 19 с контекстом а на 4к вообще 16-17. Правда вот q8 exl2 что занимает +- столько же дает сравнимый перфоманс. С малой битностью подобных моделей нет, 70 анально зажатая, кратно медленнее при том что занимает в 1.5 раза больше, но там подозрения что всеже есть небольшая выгрузка.
Хуй знает что ты там напердолил, но у ExLlama 2 на 7В около 130-140 т/с. Против ~50 т/с на fp16. То что q8 не оптимизированно никто и не спорит. Но факт в том что оптимизированные кванты всегда будут в разы быстрее fp16, там банально за счёт тензоядер для q4 в 4 раза больше операций выполняется за такт, чем с fp16. В проде везде используют кванты, fp16 только для тренировки.
> на 7В около 130-140 т/с
Это в каком кванте? Если 4 бита то должно быть 200+. А Q8 (если там чистые 8 бит) наоборот может быть самое оптимизированное.
> факт в том что оптимизированные кванты всегда будут в разы быстрее fp16
Да это то офк, там имел ввиду что скейл далеко не линейный от размера, плюс не понятно во что там упор, псп видеопамяти, кэша нехватает или чип не тянет.
Увы, под рукой нет 80гиговых карточек на HBM, лучшее что в теории двощер может себе позволить - A6000@48. И то она будет актуальна только год, если дядя в куртке решит не жидиться а расщедриться на врам в старших моделях, или выпустит с дисконтом от рабочих какой-нибудь титан с 48+.
> банально за счёт тензоядер для q4 в 4 раза больше операций выполняется за такт
Кванты неоднородны, там не ровно 4 бита а часть значений в 6-8 битах, часть вообще в 2-3, так что на этом скейлинг будет фейлиться. Тот же 4bit gptq с 32 группами на самом деле 4.625 (емнип) бит по факту.
> В проде
Вут?
У вас угабуга с xformers работает?
Правильно понял, что процессор приводит Q4-5-6-8 до 16 бит и только потом выполняет арифметические действия, а затем обрезает незначащие нули у результата и записывает в квантованном виде в память?
Нет, матрицы нормально перемножаются, но это софтовые костыли, производительность на всех квантах почти одинаковая. А CUDA умеет аппаратно в нормальные операции над квантами, там производительность сильно бустится от понижения квантования.
Ок, спасибо.
>производительность на всех квантах почти одинаковая
Там баттелнек в производительности памяти, поэтому все равно меньший квант весит меньше - и поэтому быстрее крутится в оперативке.
Ниче не знаю на счет скорости вычислений квантованных значений процессором, просто решил уточнить
> баттелнек в производительности памяти
Лайк.
Проверил airoboros 70B и 34B оба выдают производительность ~0.9 токенов. Оба Q8. О_о
Возможно из-за меньшего размера 34B использует не использует все 8 каналов памяти.
У тебя даже 1b модель будет использовать все каналы. Но что у них одинаково - странно.
Ты смотри отдельные статы по скорости обработки промта и скорости генерации, общий малоинформативен в случае процессора. В одном может помнить прошлый контекст и сразу начать генерацию, а в другом с нуля начнет обрабатывать и общее время получится тоже плохим не смотря на большую скорость.
Что за семплеры ExLlama(v2)(_HF) и как им пользоваться? Это для каких моделей? Я как понял на нем можно запустить gguf но надо сначала какой-то доп софт накатить? Ыыыыааа

Алсо какую выставлять альфу? У зарубежных коллег на форче нашел вот такой альфа калькулятор, но чето либо на 4к контекста надо выставлять 18 альфы, либо я в размерностях запутался.
https://www.desmos.com/calculator/ffngla98yc?lang=ru
https://www.desmos.com/calculator/ffngla98yc?lang=ru
Ты 4к и 40к не перепутал?
Кек блядь. Да есть такое.
Undi вкинул что обкекался с лорами, и 13b мистрали ненастоящие: https://rentry.org/WrongUndiRepo
Ахаха мы тут гадали, как это возможно, и в итоге оказалось, что это никак невозможно! Воистину, гениальный разум может быть очарован выдумкой сильнее чем реальностью.
Скоро окажется, что и 20B франкенштейны хуета.
Строго говоря, создаёт их не совсем Касперский. Разрабатывает какая-то другая небольшая компания, а Касперский помогает инвестициями и где-то компетенциями.
Но эти процы производить пока негде, надо ждать отечественных заводов на 28 нм и тоньше (ближе к концу десятилетия, когда доделают литограф), либо контрактиться с китайцами (хотя у них тоже проблемы с тонкими техпроцессами), либо заканчивать гойду и производить сразу после завершения разработки на TSMC.
Бамп
Легче переустановить, потому что могут быть другие зависимости, у эксламы2 например с флеш-аттеншеном, под более свежую куду, которые потом заебёшься искать и ставить
Как вы заставляете локальных ботов двигать сюжет? Они любят циклятся, не словами но постоянно повторяют один и тот же смысл. Нет развития. ГПТ4 и клод же развивают сюжет, да и турба, но турба вместо этого любит аполоджайзами сыпать.
И еще где тут обсуждение может систем агентов, ботов, может будут у кого в этом интеллектуальном треде предложения как составить оркестр. Чтоб один бот писал сценарий, другой играл, третий конкретно ловил циклы, кто то следил за контекстом.
И еще где тут обсуждение может систем агентов, ботов, может будут у кого в этом интеллектуальном треде предложения как составить оркестр. Чтоб один бот писал сценарий, другой играл, третий конкретно ловил циклы, кто то следил за контекстом.
>Как вы заставляете локальных ботов двигать сюжет?
Роллим до посинения.
Тупой возможно вопрос, но есть ли чатбот для телеги к которому модель прикручиваешь и она на рандомные сообщения в канале в котором состоит отвечает? (чатбот локально на машине)
Почему не работает Custom stopping strings из SillyTavern в кобольдцпп? В самой таверне прописываю валидный джейсон с набором стоп-фраз, но на бэк он почему-то не передаётся, судя по консоли. Как подрубить?
> как им пользоваться?
Скачать то что пишет в поле ошибки вставив рядом в поле загрузки модели.
> на нем можно запустить gguf
Нет, exl2/gptq/fp16
> We discovered that LoRA extracted from 7B, don't have any effect on 13B, for example.
И на что он рассчитывал, против кадровой то размерности.
> что и 20B франкенштейны хуета
7 слоев байпаса, лол
Системный промт, хорошая модель, не проклятая карточка. Сами еще как развивают, правда не всегда куда хочется и тогда приходится направлять, но это общая для всех ллм проблема.
> как составить оркестр. Чтоб один бот писал сценарий, другой играл, третий конкретно ловил циклы, кто то следил за контекстом
Поправить код таверны чтобы выставить фиксированную последовательность и особенности пересылаемого промта, сделав просто групповым чатом. Плюсы - просто, минусы - нет правки прошлого промта, все ответы видны и могут возмущать контекст, геморой с промтом если хочешь разный.
Написать собственную проксю, которая бы в нужной последовательности делала запросы на апи а тебе отдавала уже пофикшенный финальный результат, удалив лишнее, тут же можно обращение к нескольким моделям сделать. Плюсы - эффективно, минусы - сложнее и большей частью без стриминга.
>Поправить код таверны
Я не про это спрашиваю я уже написал проксю которая собирает боты разных сервисов. Я говорю о том как это организовать. Какие промпты им давать, кто первый отвечает кто последний, я вижу тут никто с этим не игрался, но может кто видел хоть статьи такие?
Еще что за сумасшедший писал смарт контекст для таверны, я хз он не работает как нужно, он просто собирает разные сообщения близкие к теме, вместо того чтоб собирать пары вопрос ответ.

Кхе-кхе. Ну, значит митомакс просто охуенная тема, я пользовался и до сегодня и не знал в чём (несуществующая) фишка этой модельки была, а всё равно она была одной из моих любимых.
А где эту альфу в кобольде выставлять?
Оно там само считается.
Никто не подсказал, из самого годного нашел вот этот репозиторий
https://github.com/innightwolfsleep/text-generation-webui-telegram_bot
Есть вообще такие модели, чтоб были умные, незацензуренные (необязательно писать порнороман, просто не игнорировать эти темы) и при этом 7б?
Мистраль.
Это правда что куда 12 жрет больше vram?
Опенорка прям залита соей, какой конкретный мистраль брать чтобы без неё было?
Claude-chat попробуй. Я его сам юзаю и всем советую.

Новая сетка унди. Получилась просто отличная. Я бы сказал просто великолепно исполняет не только инструкции, но и все что написано в карточке, еще и почти не приходится свайпать( иногда свайпаю если первым сообщением короткий ответ.)
https://huggingface.co/Undi95/Utopia-13B-GGUF/tree/main
Как обычно не веду себя как мудак и прикладываю свой промпт.
### Instruction:
1. Write as accurately as possible
Fewer adverbs, adjectives, and deictic turns.
Use precise phrases and words that describe the characters' actions.
Avoid dry, detailed descriptions: show rather than tell.
Highlight vivid details and remove stamps.
2. Reveal the character's backstory
Don't write a scene to write a scene. If it doesn't reveal the overall plot in any way, change the characters, or throw in a new plot twist, cut it short. If you can't answer the question, "Why do I need this scene?" - throw it out.
3. make the dialog make sense
Remove dialog written for the sake of florid phrases.
4. Describe furniture, décor, objects and more.
5. Represents an active endless scene between {{user}} and other characters.
### Response: Using exclusively sensory details and dialog, compose responses in 2-4 paragraphs following this pattern:
- Sensory details.
- Depict NPC's reaction.
- Provide sensory details about NPC.
- Facilitate NPC's action or question.
- Sensory detail or action.
За все время ничего лучше не было Emethyst 20b(удачная но не настолько как эта) так что молчал. Другие сетки унди были хуже все же.
https://huggingface.co/Undi95/Utopia-13B-GGUF/tree/main
Как обычно не веду себя как мудак и прикладываю свой промпт.
### Instruction:
1. Write as accurately as possible
Fewer adverbs, adjectives, and deictic turns.
Use precise phrases and words that describe the characters' actions.
Avoid dry, detailed descriptions: show rather than tell.
Highlight vivid details and remove stamps.
2. Reveal the character's backstory
Don't write a scene to write a scene. If it doesn't reveal the overall plot in any way, change the characters, or throw in a new plot twist, cut it short. If you can't answer the question, "Why do I need this scene?" - throw it out.
3. make the dialog make sense
Remove dialog written for the sake of florid phrases.
4. Describe furniture, décor, objects and more.
5. Represents an active endless scene between {{user}} and other characters.
### Response: Using exclusively sensory details and dialog, compose responses in 2-4 paragraphs following this pattern:
- Sensory details.
- Depict NPC's reaction.
- Provide sensory details about NPC.
- Facilitate NPC's action or question.
- Sensory detail or action.
За все время ничего лучше не было Emethyst 20b(удачная но не настолько как эта) так что молчал. Другие сетки унди были хуже все же.
С чего такой вывод? Наоборот заметил уменьшение потребления, потому что флеш-аттеншен наконец то заработал под шиндой
Ясно, спасибо.
Вот тут вопрос уже интересный. Начать стоит с самого простого варианта добавив еще одно обращение. В нем убрать нахрен системный промт про рп, а указать, напнимер, что сеть это писатель/режиссер/гейммастер, дать ей на вход описание персонажей - юзера и имеющийся контекст, а потом указать инструкцию типа "проанализируй настроение чара, предскажи его действия, предложи развитие сюжета". Далее полученный ответ завернуть уже в рп промт перед ответом, указав что-то типа "после этого диалога вот так и так, продолжай в учетом данной рекомендации".
Собственно нужно делать и тестировать, иначе фантазировать можно сколько угодно. Сейчас норм сетки и сами все хорошо развивают, но подобный подход может еще больше улучшить их способности. При этом, можно реализовать более гибкое управление, меняя команды "режиссеру".
> уже написал проксю которая собирает боты разных сервисов
Ээ, грабберу чуба чтоли, или обработчик под обсуждаемое дело? Если второе то поделись, попробую поиграться при случае.
Ух шизопромтище, но сама структура правильная.
Как у модели по разнообразию кума, по следованию рп и по радостной/депрессивной атмесферы? Надо скачать, эметист ничетак был.
> За все время ничего лучше не было Emethyst 20b
23B недавняя самая годная была.
Ну слушай. Мне понравились ее сюжетные линии., она не говорит за {{user}} но может красочно и вскользь описать его действия. Может в описание окружения, описать сцену где появляются персонажи без имен вскользь( ремонтники например вошли в комнату где вовсю шел кум, но они были заняты общением между собой.) Кум охуенный. РП следует. Насчет атмосферы, как ты задашь так и поведет сетка ее, особенно с промптом указанным, ну и карточка там прописана интересно, так что хороший промпт+ хорошая карта = годнота. Но разнообразие кстати сам понимаешь именно в плане кума, это спереди сзади и в запасной выход. Не сток интересен кум как сюжет.
Из минусов 4к контекста (у меня.)
Не зашла. Плохо с промптом ладила что я выше кидал. Частые свайпы, сетка тупит, плюс все на 3060, короче мне больно сидеть на ней было.
и она хорошо по сценам скачет. Логика получше многих,но думаю все же может со временем будет совершеннее.
Прямо меда налил, ну значит очень понравилась, многообещающе, надо пробовать.
> это спереди сзади и в запасной выход
Обзмеился, не там речь про разнообразия описания просесса и слог. А то у некоторых бывает довольно бесячие паттерны, которые если вдруг триггернутся - все нахрен ломают.
Потыкал airoboros 7b и13b - просто ужас.
Airoboros 70b - просто песня, часто может простым намёком ответить на простой намёк.
Mistral-7b-openorca меня удивила своей непредсказуемостью, иногда может выкинуть что-то на уровне 70, а иногда просто вафлить очевидные вбросы.
Чёт захотелось скачать Emethyst 23b после ваших прохладных.
Airoboros 70b - просто песня, часто может простым намёком ответить на простой намёк.
Mistral-7b-openorca меня удивила своей непредсказуемостью, иногда может выкинуть что-то на уровне 70, а иногда просто вафлить очевидные вбросы.
Чёт захотелось скачать Emethyst 23b после ваших прохладных.
>Но разнообразие кстати сам понимаешь именно в плане кума, это спереди сзади и в запасной выход.
А куда ещё надо, в ухо, в глазницу и в горло после отрезания головы? Без иронии спрашиваю. Заинтересовал.
Я же правильно понимаю, что 7б и 13б одинакового веса будут с разной скоростью генерировать? Или не должны?
>Чёт захотелось скачать Emethyst 23b после ваших прохладных.
>Airoboros 70b - просто песня
Ты же понимаешь, что ждать чуда от сетки в разы меньше, тем более франкенштейна, совсем не стоит?
>в ухо
Вот кстати кошкодевочку так разок сношал пальцами ещё на чайной.
> Потыкал airoboros 7b и13b - просто ужас.
> Airoboros 70b - просто песня
Вот да, большая версия просто суперская, а поменьше уже никто не отзывался так положительно.
> Вот кстати
Флешбеки ебаные, когда сетка мисинтерпретирует внимание и начинает выражать не совсем уместные действия по отношению к частям тела.
Надо смотреть. Сойка есть. Сейчас чищу вилкой. Пиндосы, соевые мальчики...
Процесс и слог неплох.
к тому что кум кумыч наскучивает временами, аля у большинства сеток одно и то же. Но у этой он еще неплох, есть отличия от других.
> Mistral-7b-openorca
У меня выдает очень короткие ответы в отличие от 13в. Это норма?

> Mistral-7b-openorca меня удивила своей непредсказуемостью, иногда может выкинуть что-то на уровне 70, а иногда просто вафлить очевидные вбросы.
Она на реддите тренирована. У меня иногда шизила и срала ссылками туда.

Блядь пердолился весь вечерз с питонами, cpp чета там компилятор, хуятор, уже собрался линукс накатывать на винду, может она у меня кастрированная какая.
Потом полез в гугл и наше вот это чудо
https://lmstudio.ai
И ВСЁ БЛЯДЬ. Никаких питонов, ебаных, библиотек, анаконды, никакой возни, все работает только свистни - с моделями от Гуфа. Есть локальный сервер для запросов.
Пользуйтесь. Кстати, палю свежую годноту:
https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/tree/main
Гайд из шапки не актуален.
Потом полез в гугл и наше вот это чудо
https://lmstudio.ai
И ВСЁ БЛЯДЬ. Никаких питонов, ебаных, библиотек, анаконды, никакой возни, все работает только свистни - с моделями от Гуфа. Есть локальный сервер для запросов.
Пользуйтесь. Кстати, палю свежую годноту:
https://huggingface.co/TheBloke/zephyr-7B-beta-GGUF/tree/main
Гайд из шапки не актуален.
> годноту
>7B
Ебало сгенерировали?
Медленне, конечно чатажпт, и не хочет жрать весь цпу и гпу хавает только маленько. Вот бы ебанул все 20 потоков зиона, было бы заебца.
> пердолился весь вечерз
В хубабубе клонировать репу и запустить батник, в кобольде просто скачать экзешник. Это ты ниасилил?
> это чудо
Медленнее (по заявлениям) и меньше возможностей.
> Есть локальный сервер для запросов.
Шо? Апи полноценное чтобы с таверной подружить то есть? Вообще уже вбрасывали, киллерфичи то там есть какие?

>Никаких питонов, ебаных, библиотек, анаконды, никакой возни, все работает только свистни

>файнтюн мистралекала
Учитывая что мистралекал в рп разы хуже пигмалиона, чет мне не кажется, что эта твоя хрень сильно лучше.
Но ладно, ща проверю не пиздят ли эти ваши графики.
openhermes-2-mistral-7b.Q8_0 попробуй, выдает неплохие полотна если попросить, в среднем лучше чем орка
Да нахуй все эти ролеплеи нужны, вы тут все чтоли только с виртуальными фуррями общаетесь и щекочите им анусы?
Я контент для сайтов генерю аишками, потом перевожу на индонезийский и подрубаю им монетизацию - гугл хавает только в путь и просит еще.
Это же намного интереснее.
По коду опять же подсказать че как или верстке.
Я контент для сайтов генерю аишками, потом перевожу на индонезийский и подрубаю им монетизацию - гугл хавает только в путь и просит еще.
Это же намного интереснее.
По коду опять же подсказать че как или верстке.

>Да нахуй все эти ролеплеи нужны
>Я контент для сайтов генерю аишками, потом перевожу на индонезийский и подрубаю им монетизацию
Деньги есть, девушки нет. Вопросы?
>Да нахуй все эти ролеплеи нужны, вы тут все чтоли только с виртуальными фуррями общаетесь и щекочите им анусы?
Не, я например просто щупаю технологию, ну и ебу мозги сеткам на разные темы, или эксперименты делаю по теории сознания.
В основном нынче пользуюсь типо гуглом который сразу отвечает тебе на вопрос и может продолжать рассказывать с новыми вопросами. На правдивость ответов похуй, на ерп и рп тоже.
Такая электронная библиотека-энциклопедия которая еще и пиздит через раз
Кодить не пробовал, но тебе бы специальные сетки для этого крутить, а не обычные.
Промпты, не промпты.
Не та температура.
Не тот топ_п.
Не тот топ_к.
Не тот квант.
Какие настройки у зефира должны быть по контексту?


Ну крч, пока нормальная модель будет расписывать ЧУТЬ БОЛЕЕ подробно и не так сухо, зефир показывает чудеса ролеплея. Если верно помню, даже пигма 7б была лучше. ЕРП даже проверять не хочу.
https://www.reddit.com/r/LocalLLaMA/comments/17ll35x/section_46_of_the_executive_order_is_what_we_need/
кранчик начали закручивать
кранчик начали закручивать
Зафир совсем кал. Они как будто файнтюнят на тестовых датасетах лишь бы скор повысить, а на качество поебать.
Он цензурный, это все что нужно знать про качество.
Все мистрали так или иначе зацензурены, но у зефира цензурный датасет.
Мой топ на сегодня среди 7b это openhermes, ну или дельфин
https://www.reddit.com/r/singularity/comments/17lmdlq/nasa_just_released_a_superprompt_for_chatgpt/
у кого 70b может поиграться, все что меньше наверное не заведется
у кого 70b может поиграться, все что меньше наверное не заведется
Как будто кому-то не похуй что в какой-то соевой стране решают. Как минимум китайцам совершенно поебать что там у пиндосов, пусть хоть совсем запрещают нейросети. Разве что HF могут пидорнуть, но народ быстро найдёт где хостить модели за пределами этой цензурной параши.
А делать эти модели кто будет? То, что сейчас имеется, никуда не пропадет, но если гайки совсем закрутят, то можешь забыть про лламу 3 и все последующие модели.
На самая глупая идея запилить сбор мнений по данным вопросам, особенно на контрасте с запретами ради запретов по рофлу. Вопрос, офк, как именно будет проводиться и какие мнения будут учитываться.
Вот сам по себе факт регуляции это хуево, а преподнесение знаний, которые можно буквально найти в википедии/гугле, как что-то опасное и прочее - уже шиза и популизм. Будем посмотреть что там происходит.
> китайцам
И много у них хороших нейронок без цензуры? Думаю у них вообще все печально.
> А делать эти модели кто будет?
Китайцы?
> можешь забыть про лламу 3 и все последующие модели
И кто запретит корпорациям тренировать за пределами пендосии? Мистраль вообще французский, например.
>Китайцы?
Это те китайцы, которые залили в свина столько сои, что он цензурит "ниггер" звездочкой? Тем более что китайцам запретили поставку видеокарт.
>И кто запретит корпорациям тренировать за пределами пендосии? Мистраль вообще французский, например.
Никто не запретит, но у кого еще есть люди и ресурсы? Менструаль - это маленькая и тупая модель.
> но у кого еще есть люди и ресурсы?
Корпорациям нужен прогрев опенсорса и они будут его прогревать. Запретят это делать в пендосии - будут делать в любой другой стране. Или ты думаешь корпорации будут сидеть смирно на жопе и прекращать обучение моделей, пока их бидон ебёт?
>Корпорациям нужен прогрев опенсорса
Каким именно? КлозедАИ и похожим наоборот выгодно давать гоям в аренду через апи. Мета делает модели для своих задач и дала людям попользоваться ради бесплатного бета-теста. В целом, на корпорации ограничения как раз не особо повлияют, а вот опенсорс пососет.
>Я контент для сайтов генерю
Рака яичек тебе.
Поясни надписи с пикчи.
>Деньги есть, девушки нет
Ну так это решается от проститутки до содержанки (что тоже проститутка в 99% случаев (да, я проверял))
16к ставь, на большее у тебя врама всё равно не хватит.
Исправил твою ссылку, проверяй.
https://old.reddit.com/r/LocalLLaMA/comments/17ll35x
По тексту. Всё это хуета, ибо ни одна модель сейчас (что открытая, что закрытая) не удовлетворяет требованию моделей двойного назначения.
Исправляю ещё раз. Дальше сам исправляй.
https://old.reddit.com/r/singularity/comments/17lmdlq
>Запретят это делать в пендосии - будут делать в любой другой стране.
Запреты одной страны уже давно глобальны, проснись.
А в чом исправление? Просто олд версия. Только теперь нихуя не видно что там в ссылке по ее названию. Хуета, а не исправление
>Всё это хуета, ибо ни одна модель сейчас (что открытая, что закрытая) не удовлетворяет требованию моделей двойного назначения.
Требования всегда можно поменять, а механизм контроля уже тут, хех
> Запреты одной страны уже давно глобальны
Хотелось бы уточнить про какую страну речь идёт. Про ту, которая на поводу своих фарма-корпораций запрещала кучу всего по медицине и медицинским экспериментам, но в итоге только запретила доступную медицинскую помощь в своей стране?
>Просто олд версия.
И короче.
>Только теперь нихуя не видно что там в ссылке по ее названию.
Ты блядь заголовок скопировал бы, а не заставлял читать ubogiy_tekst.
>Требования всегда можно поменять, а механизм контроля уже тут, хех
Механизм всегда можно запилить с нуля, делов то.
Поебать на медицину, я ХЗ что там. Я про технологии и их экспорт.
>Ты блядь заголовок скопировал бы, а не заставлял читать ubogiy_tekst.
Делай
>Механизм всегда можно запилить с нуля, делов то.
Менять параметры готового инструмента набутыливания легче чем снова собирать говорильню, по поводу его создания\изменения
> Я про технологии и их экспорт.
Так их и не будет никто в пендосию экспортировать, лол. Не хотят - ну и не надо. Расскажи как там Хуавэй запретили и как даже после просьб "ну плиз не покупайте технику Хуавэя" в ЕС продолжили использовать её.
>Запреты одной страны уже давно глобальны, проснись.
Если бы только одной лол
https://www.reddit.com/r/singularity/comments/17lfpy1/uk_us_eu_and_china_sign_declaration_of_ais/
ну и в догонку кто там интересовался
https://www.reddit.com/r/singularity/comments/17hmu1o/are_developing_countries_doomed/
>Менять параметры готового инструмента набутыливания
Про это целый государственный механизм. Надо будет, подключат хоть ЦРУ и набутылях всех разрабов моделей, в том числе файнтюнеров попенсорса, в один день.
Но пока всё это просто вспуки в инфополе, то ли пробивают реакцию общества, то ли дают дурной пример, мол, авось гейропка с кетаем скопируют, а пендосы сами у себя применить забудут.
>Расскажи как там Хуавэй запретили
С 21 года выручка с продажами только падают. Кажется, its work.
UK, US, EU and China sign declaration of AI’s ‘catastrophic’ danger:
https://old.reddit.com/r/singularity/comments/17lfpy1
Are developing countries doomed?
https://old.reddit.com/r/singularity/comments/17hmu1o
молодец
> https://huggingface.co/Undi95/Utopia-13B-GGUF/tree/main
Ну, даже хз. Потыкался в нее и словил бинго которое описывали. Будучи в явно описанном костюме персонаж внезапно становится голым, а потом дважды снимает трусы, в голосину прямо. Туповата и не то что не понимает намеков, а даже прямого текста. Она себе что-то там из контекста решила и хер ты ее с этих рельс вытащишь не проебывая отыгрыш. При том в некоторых диалогах вполне себе хорошо (напоминает визарда но с более приятным стилем письма), но как только чето сложнее - все.
Уже подумал что обдвачевался после 70 и прочего, загрузил еметист q3 (там было q8) и сразу даже на том же чате только бранчем чуть раньше совершенной другой экспириенс и нет всех этих проблем. Хз, может там как-то отрабатывает твой шизопромт, но поидее 13б наоборот на нем забуксует.
Только хотел назвать адекватом а там
> old.reddit.com
Зачем?
Насчет неудовлетворения требований уверен? Там критерии могут трактоваться.
> r/singularity
Дальше можно не читать, лол.
>Дальше можно не читать, лол.
Ну и зря, там много интересных идей, и не важно на сколько они правдивы. Нужно рассматривать все точки зрения что бы составить для себя картину происходящего. Хотя бы что бы понять о чем думают многие люди, такие как собрались там.
> Каким именно?
Любым. Опен-сорс - это не васяны с реддита, это учёные по всему миру. Гугл уже признал что это путь в никуда, если пытаться всё сделать за закрытыми дверьми. Мета выпустила ламу потому что уже давно прогревала исследовательские институты, есть Facebook Research с грантами для них, ты ведь сам знаешь как первая лама вышла - только для учёных в говне мочёных, только вот её слили через день, а вторая уже со свободной лицензией. И похуй что у китайцев цензура - у них там бурлит разработка, а западным корпорациям тоже надо за ними поспевать. Поэтому прогрев будет только усиливаться, и бидон не сможет этому помешать, если цензура будет мешать разработкам.
>Зачем?
Не люблю дрочиться с "развернуть" "развернуть" "развернуть" бесконечное разворачивание. Ну нахуй новый гейский интерфейс для пориджей с памятью золотой рыбки.
>Там критерии могут трактоваться.
Само собой можно натянуть сову на глобус. Но зачем делать изначально хуету?
>Мета выпустила ламу потому что уже давно прогревала исследовательские институты
Но они кстати не выпустили несколько крутых проектов по звуку как раз с оправданием "Это будут использовать для фейков".
Хм, может ты и прав и там более менее. Но, как правило, ресурсы где можно обсуждать и спекулировать по поводу будущего и развития, населены интересными личностями, с которыми трудно общаться. Знания скудны а цель не обмен мнениями а промоушн своего выдуманного сценария и догм. Ловишь кринж с фантазий о том что хорошо знаешь, или не можешь понять адекват это или просто самоуверенный шиз, толкающий невероятные вещи. Не способствует общению в общем, что-то похожее на адекватные обсуждения может быть только в сайд разделах технических ресурсов, но и даже там пиздеца хватает.
Офк не утверждаю что там так, но подозрения сильны и ставить в авторитет что там кто-то фантазирует - не.
> Но зачем делать изначально хуету?
В этом и вопрос, в чем стоит их задача. Просто сделать вид что они отреагировали, ради продвижения политической карьеры захерачить направления которые им не интересны, или наоборот организовать и выработать адекватный подход что устроит всех в этой быстроразвивающейся области.
> "Это будут использовать для фейков"
Вот это как раз и печально.
>Не люблю дрочиться с "развернуть" "развернуть" "развернуть" бесконечное разворачивание.
Вот тут кстати плюс олда, согласен
>Но, как правило, ресурсы где можно обсуждать и спекулировать по поводу будущего и развития, населены интересными личностями, с которыми трудно общаться.
Ну, особой разницы, читать высеры нейросети или каких то людей не вижу. И те и те могут генерировать бред, конечную оценку даешь ты как читатель.
>Офк не утверждаю что там так, но подозрения сильны и ставить в авторитет что там кто-то фантазирует - не.
Никакого авторитета, это просто примеры идей и реакций на какие то новости и идеи. Пища для ума и все такое. Там есть и умные мысли и интересные выводи и идеи, если поискать.
>организовать и выработать адекватный подход что устроит всех в этой быстроразвивающейся области
Самый адекватный (и самый нереалистичный) это "Не лезть своими кривыми руками в сферу регулирования ИИ". Но сейчас это не модно.
>Там есть и умные мысли и интересные выводи и идеи, если поискать.
Проще в числе PI найти умные мысли.
>Проще в числе PI найти умные мысли.
Кому то проще хе
> читать высеры нейросети или каких то людей не вижу
Нейросеть делает то что ты скажешь, всегда можешь поправить чтобы получить желаемое или заменить на другую. В чем профит читать дичь?
> есть и умные мысли и интересные выводи и идеи, если поискать
Пора тренировать сетку на поиск подобного, и то не факт что справится.
Таки верно, но хайпа слишком много так что реакции не избежать. В идеале, если хотят устраивать регулирование - наказывать именно за "недобросовестное использование", например распространение фейкопикч или речи с целью дискредитации и подобное что триггерит нормисов, а остальное разрешить. Ну и зарегулировать монополистов, но с этим буквально антимонопольная служба сама справится.
>но с этим буквально антимонопольная служба сама справится
В голосину. Что они в последний раз справили? У нас тут на рынке ОС, браузеров, поиска и кучи подобных мест буквально монополия, им похуй, софт не их тема. И да, ту же опенАИ можно было бы попробовать пидарнуть по антимонополке, но и тут хуй.
>Пора тренировать сетку на поиск подобного, и то не факт что справится.
Ага, например сетку своей головы.
Опять же, то что ты сможешь извлечь из такой информации полностью зависит от тебя как читателя. Я увижу одно, ты другое и так далее
Основная цель этих соглашений - сохранение статуса кво. Любой ценой они будут противодействовать изменениям которые подвергают опасности их "бизнес". Правление это страной или корпорация без разницы.
Главное задушить изменения до управляемого уровня, извлечь из них максимальную выгоду с наименьшим изменением своего внутреннего состояния.
Поэтому чем более прорывными будут становится технологии ИИ тем сильнее их будут душить. Радует что эти дураки собираются думать об этом раз в пол года, не понимая все ускоряющегося развития ИИ.
Поэтому когда они поймут что не успевают и теряют контроль за ситуацией - вот тогда ждите кучу запретов и попыток любой ценой заткнуть фонтан.
Небольшой прогноз
> им похуй, софт не их тема
Пока софт не приносит сильно дохуя бабла и нет жалоб - не их. Мелкомягких и гугл уже поебывают, и ничего. К нам это отношение довольно косвенное имеет а повлиять все равно никак не можем.
> например сетку своей головы
Братишка, нейросети должны экономить время и облегчать задачи, а ты предлагаешь тратить свое время на заведомо хуету. Считаешь ее значимой и имеешь собственный манямир свое видение, которым не терпится поделиться, вот там как раз найдешь то что ищешь.
Кто-нибудь с работой ллм на маках сталкивался? Студио, под который Жора довольно часто обновляет поддержку, насколько оно целесообразно для запуска и можно ли что-то тренить?
>Братишка, нейросети должны экономить время и облегчать задачи, а ты предлагаешь тратить свое время на заведомо хуету.
Рутинные задачи, сваливать на сетки весь интеллектуальный труд - прямой путь к деградации.
Если не хочешь стать тупее - придется периодически думать своей головой. И заведомо хуета это опять таки только твоя личная точка зрения, ко мне отношение не имеющая. Ладно похуй
Ты там случаем не отупел, юзая готовый браузер, который написал кто-то за тебя? Пиздуй ка свой писать. И никаких высокоуровневых языков, только асма, только хардкор. А то сейчас совсем отупеешь, ишь ты, решил на машину с себя труд скинуть!
во дурак, тебе вобще не о том говорят, лол
>не понимая все ускоряющегося развития ИИ
Куда оно ускоряется? Сейчас лето, да, но осень уже близко, а зиму переживут не только лишь все.
А о чем? Что конспирология и фанатичное обсуждение своих прогнозов, не влияющие ни на что - интеллектуальный труд, который нельзя замещать? Ллама и то лучше опишет.
NousResearch announces Yarn-Mistral-7b-128k
https://www.reddit.com/r/LocalLLaMA/comments/17m8o26/nousresearch_announces_yarnmistral7b128k/
>Куда оно ускоряется? Сейчас лето, да, но осень уже близко, а зиму переживут не только лишь все.
Сейчас весенние заморозки, лето еще впереди
3д рисоваки напряглись
https://www.reddit.com/r/singularity/comments/17lg877/stability_ai_reveals_stable_3d_textto3d_imageto3d/
Да и другие тоже напряглись
https://www.reddit.com/r/singularity/comments/17m3rj2/runway_gen_2_update/
Короче я не вижу замедления, но посмотрим как все пойдет
https://www.reddit.com/r/LocalLLaMA/comments/17m8o26/nousresearch_announces_yarnmistral7b128k/
>Куда оно ускоряется? Сейчас лето, да, но осень уже близко, а зиму переживут не только лишь все.
Сейчас весенние заморозки, лето еще впереди
3д рисоваки напряглись
https://www.reddit.com/r/singularity/comments/17lg877/stability_ai_reveals_stable_3d_textto3d_imageto3d/
Да и другие тоже напряглись
https://www.reddit.com/r/singularity/comments/17m3rj2/runway_gen_2_update/
Короче я не вижу замедления, но посмотрим как все пойдет
>Yarn-Mistral-7b-128k
Нахуя столько много? Как по мне, и 32к старого просто за глаза.

Что-то пошло не так.

>https://rentry.co/Jarted
Блять, и здесь эта хуита, так и знал что это местный шизоид срёт на соседней помойке уже год.
В мире есть что то за приделами ролиплея, как насчет суммирования или вопросам по документам или к примеру закинуть кучу кода для навигации по проекту или ребейс коммитов. Спокойно все это сожрет 100к+ и еще попросит.
Странно. Такого не заметил, возникла вчера проблема конечно когда я за 4к контекста вышел. Там я из комнаты дома снова в кладовке оказался, но это была проблема недостатка контекста.
Только скорей всего как и с мистралем кванты будут слабее чем несжатые форматы, не уверен что квант сможет в 128к
Обычно большие объёмы закатывают в эмбеды
Только насколько это эффективно, что то типа обычного поиска по ctrl+f не больше, ответы сетки будут не информативны.
А это неважно такая сеть может сделать умное суммирование с учетом вопроса по которому уже ответит другая сетка.
>А это неважно такая сеть может сделать умное суммирование с учетом вопроса по которому уже ответит другая сетка.
То что тупее будет это понятно, я не про то. Обычный мистраль после кванта имеет где то 8к контекста, может до 9-10к, дальше глюки или ломается.
Не сжатый во все 32к контекста может, без всяких настроек rope или альфы. По крайней мере тут и на реддите тестировали несколько человек. Вот и думаю что квант не сможет нормально в 128к, потому что это для несжатой модели.
Придется увеличивать параметры что сделает сетку чуть тупее.
Надо проверять, но у меня нет таких больших текстов, хз даже откуда столько взять.
И кстати чет квант вобще не заводится на том же кобальде
>Только насколько это эффективно, что то типа обычного поиска по ctrl+f не больше, ответы сетки будут не информативны.
Зависит от отношения количества твоих токенов к размеру контекста, естественно.
Либо RAG можно поднять.
> Undi95/Utopia-13B
Говно какое-то. По классике, как и у всех рп-моделей, форматирование сломано нахуй. Но при этом есть соя, какие-то проблемы с агрессией как у Мистраля, постоянно игнорит промпт и оправдывается.
А у меня наоборот эта модель скатывала всё в максимально кумерский кум.
LLaMA2-13B-TiefighterLR ниче так
Как обстоят дела с цензурой?
Личный шпион каждому
https://www.reddit.com/r/singularity/comments/17mfnn1/ai_companions_are_about_to_be_absolutely/
>Как обстоят дела с цензурой?
Хуй знает, скажу только что сетка очень послушная, все угодить стремиться. По уму тоже неплохо, даже по русски шпарит на уровне орки.
Пишет и отвечает неплохо, но иногда теряет формат, но у меня там кобальд был и свой формат, так что хз как она формат таверны подхватит.
https://www.reddit.com/r/singularity/comments/17mfnn1/ai_companions_are_about_to_be_absolutely/
>Как обстоят дела с цензурой?
Хуй знает, скажу только что сетка очень послушная, все угодить стремиться. По уму тоже неплохо, даже по русски шпарит на уровне орки.
Пишет и отвечает неплохо, но иногда теряет формат, но у меня там кобальд был и свой формат, так что хз как она формат таверны подхватит.

Там новая годнота вышла - опенчат 3.5 от китайцев. В РП внезапно очень годно. Форматирование идеальное, ни одного проёба не увидел. По сое средне, сильно лучше любого Мистраля, я всего пару раз видел проскакивания шаблона про boundaries, ничего критичного. По адекватности сильно лучше того же Мистраля, трусы не снимает по два раза, контекст происходящего лучше улавливает.
>Context 8192
Да ну ёб твою мать.
https://huggingface.co/TheBloke/openchat_3.5-GGUF
Ну низнаю, скачаю пощупаю. Китайцам пизда. Если такие сетки спокойно отдают людям, то что они оставили себе?
Бля антиутопия все ближе, я давал прогноз 2 года, но это уже начинается. До объявления о создании AGI пол года-год такими темпами. Причем реально такая херня в зачаточном состоянии уже может быть где то сделана, хули нет.
Скорей бы уже Василиск пришёл...
> это уже начинается
Когда начинается - закидывайся таблетками, а то так и до ПНД недалеко.
AI dungeon без цензуры уже запилили локальный? Есть 128гб ddr5@8000 и 48гб квадра списанная с работки за ничего. Хочу запилить дунгеон и сразу генерацию картинки, такая хуйня есть уже?
Да, начни с чтения шапки. Я не посылаю тебя таким образом на хуй, просто там есть всё для того чтобы начать
хорошо быть тупым
>128гб ddr5@8000
Так не бывает.
> 7b
Ну бля. Алсо они там ее со старой тройкой в удачно подобранных бенчмарках чтоли сравнивают?
> 128гб ddr5@8000
Не ну чисто теоретически это возможно, но для 4х планок в двух каналах уже в разряде рекордов, а 4х канальные системы не осилят нормально такую частоту.
> 48гб квадра
Можно гонять 70б и довольно урчать, устраивая и dungeon, и gym и что угодно. Картинки можно генерировать но локально уже не влезет.
Любителям фантазировать разъяснили что к чему, но в комментах отметились те кто верят.
https://www.reddit.com/r/LocalLLaMA/comments/17lvquz/
Я что-то не понял, или там в самом деле 7В модель? В каком месте она может конкурировать с ЧатЖопой, пусть даже 3.5?
Алсо, треда про железо не увидел. Кто-нибудь пользуется серверным железом с кучей оперативки для крупных 30-70В моделей?
Как думаете, аноны, есть сейчас смысл покупать дешманский Зион вроде 2690v4 и кучу дешевой сервачной ДДР4 памяти? Алсо, если ли сейчас нормальные 70В модели с минимумом цензуры и сои, но так чтобы адекватность была на уровне хотя бы гпт-3.5?
> они там ее со старой тройкой в удачно подобранных бенчмарках чтоли сравнивают?
С мартовской турбой. Скоры взяты из отчётов самой клозедАИ и вот этого https://github.com/FranxYao/chain-of-thought-hub
На зивоне можно, получишь на 4 канале и 6+ ядрах где то 7-8 токенов в секунду на 7b модели. Ну будет зависеть от ее размера, делишь псп памяти на размер сетки и получаешь примерное количество токенов в секунду.
В принципе сейчас уже есть годные сетки на 7b так что качаешь и сидишь на том же кобальде. Нвидима сетка нужна хоть какая та с куда ядрами, для ускорения чтения промпта.
>Ну бля. Алсо они там ее со старой тройкой в удачно подобранных бенчмарках чтоли сравнивают?
Не подобранных, а подогнанных.
>Я что-то не понял, или там в самом деле 7В модель?
Именно она, иначе никак. Покрутил, ожидаемо говно.
>Алсо, треда про железо не увидел.
Не нужен, не взлетел
>Как думаете, аноны, есть сейчас смысл покупать дешманский Зион
Нету, в них ни AVX нужных, ни скорости памяти. Больше 64 гиг не нужно, а их можно набрать быстрыми DDR5 на 100ГБ/с, а не медленным DDR4 с 60ГБ/с в четырёхканале.
> с ЧатЖопой, пусть даже 3.5
3.5 - это турба, гопота которую сейчас имплаят это 4, а просто чатжпт - это то что вышло в ноябре прошлого года, плюс здесь удачно бенчмарки подобраны. Но хз что у них именно там.
> Кто-нибудь пользуется серверным железом с кучей оперативки для крупных 30-70В моделей
Нет, ибо это малоюзабельно. Для быстрой работы нужна быстрая память, ддр4 в 4 каналах - как десктоп ддр5. На 12 каналах ддр5 модель можно погонять и даже добиться каких-то приемлемых скоростей, но долгая обработка контекста множит все на ноль.
Хотя тут кто-то на некрозеоне что-то гонял, с видеокартой, пусть и простой, оно получше должно быть.
> если ли сейчас нормальные 70В модели с минимумом цензуры и сои, но так чтобы адекватность была на уровне хотя бы гпт-3.5
Есть, турбу уже ебут в некоторых областях.
Тогда много сомнений, самый удачный расклад что модель надрочили чисто на прохождение этих тестов.
> В каком месте она может конкурировать с ЧатЖопой, пусть даже 3.5?
Пора уже привыкнуть, что турбу ебут даже 7В. Турба даже по манятестам в РП сосёт, когда чекают адекватность ролеплея.
>получишь на 4 канале и 6+ ядрах где то 7-8 токенов в секунду на 7b модели
А можно взять 3060 и получить 50+ токенов.
> Тогда много сомнений
Я пощупал, не вижу причин сомневаться. Оно точно лучше Мистраля и РП-франкенштейнов по адекватности.
Вопрос был про зивон, ну и сборка на некропроцессоре выйдет дешевле чем новая карта
> Пора уже привыкнуть, что все заявляют что ебут турбу
Починил тебя. 13б может ее в рп опрокинуть за счет удачных файнтюнов, и то там не ясно кто кого в случае понимания юзера и ситуации. 7б, пусть и суперкрутые для своего размера - ну это не серьезно.
А вон выше пишут что херь.
> где то 7-8 токенов в секунду на 7b модели
Делаешь свайп на полном контексте и уходишь пить чай?
Выйдет сравнима с 3060.
>Делаешь свайп на полном контексте и уходишь пить чай?
Почему? кублас неплохо читает
>Выйдет сравнима с 3060.
А за сколько считаешь? Тут цену можно любую брать. Некрозивонv4+4 плашки по 16+мать выйдут на 15к где то
>ну и сборка на некропроцессоре выйдет дешевле чем новая карта
Карта тоже может быть БУ, итого те же 30к. Зивон конечно может крутить и 70B сетки, но это будет литерали 0,01 т/с.
>13б
Умерли с мистралем. В виду отсутствия 33B лламы 2 у нас в итоге осталось только 2 юзабельных размера, лол.
> кублас
И как кублас вяжется с ультрадешман сборкой на некрозеоне чтобы сэкономить на видеокарте?
> выйдут на 15к где то
Добавляем сюда корпус, бп, кулер и получаем цену видеокарты (с лохито), только у последней еще и ликвидности больше.
> Умерли с мистралем.
Это ты любитель фантазировать? Мистраль как бы ни был хорош для своего размера - чудес не делает. Все шизомиксы идут на основе 13б, с мистралем только парочка франкенштейнов вылезала, а его "подмешивание" оказалось лишь плацебо. 1.5 нищука непривередливых на нем кумят и все. Что же по ассистированию - он также не превосходит лучшие 13, а для реализации заявленного 32к контекста у него банально голов не хватает.
> 13б может ее в рп опрокинуть за счет удачных файнтюнов
По адекватности любой пр-файнтюн хуже ванилы, не зря ни один рп-файнтюн не может осилить форматирование как в промпте, в то время как 7В без РП делает это идеально.
>И как кублас вяжется с ультрадешман сборкой на некрозеоне чтобы сэкономить на видеокарте?
ультрадешман видеокарта с кублас и все дела, какая нибудь 1050, старые карты у многих валяются. Если есть то дешевле выйдет пристроить ее к делу
>Добавляем сюда корпус, бп, кулер и получаем цену видеокарты (с лохито), только у последней еще и ликвидности больше.
Типо того, но это ограничит 7b-13b. Если у тебя ddr5 то конечно лучше картой добить сборку
>Что же по ассистированию - он также не превосходит лучшие 13,
А список можно в студию? С оговорками только визард вспомню, но у нее беда с форматом
>получишь на 4 канале и 6+ ядрах где то 7-8 токенов в секунду на 7b модели
Замечательно, анон. Только мне вот 7В модели нахуй не нужны, честно говоря. Вон, сервис NovelAI, к примеру. Там и 13В и 20В модели, но все какие-то тупые и забывчивые. Боюсь представить как дела у 7В.
Я бы лучше 70В модель накатил и со скорость пусть даже 1 токен в секунду.
>Больше 64 гиг не нужно, а их можно набрать быстрыми DDR5 на 100ГБ/с
Тогда придется покупать нормальный современный проц и обычную память, это все встанет минимум в 50к.
>Для быстрой работы нужна быстрая память, ддр4 в 4 каналах - как десктоп ддр5. На 12 каналах ддр5 модель можно погонять и даже добиться каких-то приемлемых скоростей, но долгая обработка контекста множит все на ноль.
Хотя тут кто-то на некрозеоне что-то гонял, с видеокартой, пусть и простой, оно получше должно быть.
Это печально. А с видеокартой уже не вижу особо смысла в некрозеоне, ведь видюха должна быть ебической даже для 30В моделей, цена даже RTX3090 далеко не для нищебродов.
Алсо, мне не для ролеплея нужно. Хочу писать фанфики и готов хоть минутами ждать, нужен только большой контекст и общая "адекватность" модели.
>Там и 13В и 20В модели, но все какие-то тупые и забывчивые. Боюсь представить как дела у 7В.
>Я бы лучше 70В модель накатил и со скорость пусть даже 1 токен в секунду.
70b конечно хороши, но не недооценивай 7b. Скачай на пробу одну и сам потыкай, только качай нормальный квант. Я хз какие кванты были а сервисе, какие нибудь 3к. Модели конечно тупые будут.
Вот одна из лучших на данный момент
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF
Скачай и сам пощупай. Бери квант 6к или 8q, запускай на кобальде, для начала сойдет. Карточки сам найдешь или тут проси.
> ни один рп-файнтюн не может осилить форматирование как в промпте
Скиллишью
> в то время как 7В без РП делает это идеально
Но рпшит посредственно
> ультрадешман видеокарта с кублас и все дела
Как вариант, но это уже дороже 3060 в сумме выйдет. Если есть место в пекарне куда ее воткнуть - выбор чемпионов для ллм и нет пердолинга с некросборкой, или чуть добавить и 4060@16, то вообще пушка-гонка будет.
> А список можно в студию?
Тот же визард которому уже хрен знает сколько лет месяцев, а так файнтюны из которых миксы составляют прямо по списку, кроме, разве что, хроноса.
> Там и 13В и 20В модели, но все какие-то тупые и забывчивые
Они тупые пиздец и хорошие семерки их аутперформят. Пусть их критика тебя не вводит в заблуждение, они действительно хороши, просто утята их чрезмерно превозносят и фантазируют. Ты попробуй ее для начала, только правильно приготовь с нужным промт форматом, настройками и квантом пожирнее желательно, может зайдет, перейти на что покрупнее всегда можно.
> Я бы лучше 70В модель накатил и со скорость пусть даже 1 токен в секунду.
Ты это можешь сделать и на десктопе, выгрузив что не влезно в видюху на проц. В районе 1 токена шанс получить есть, но это всеравно тяжко.
Ну ты подожди ответов, тут были некроебы.
> нужен только большой контекст
Насколько большой?
А ну да, так еще больше запутаешься, суть - не стоит судить о модели по размеру если не учитывается что это за модель. Современная хорошая 7б выебет некроту 200б, наишные модели не самые новые и средней посредственности, потому и такие выводы.


>Утопия 13b
Кстати да, кокая модель нынче самая незашкваренная соей?
дааа настоящая утопия, напоминает выебы орки с гильдлайн
>Они тупые пиздец и хорошие семерки их аутперформят.
Эти семерки скоро станут 13В или 20В. Они такие крутые потому что видеокарты на 8 гигов популярны были и у разработчиков была мотивация их пилить. Но сейчас уже нет, даже новые игры 16 гигов требуют.
Я то, конечно, попробую, но вряд ли что-то на уровне даже чат-жопы будет. Фанфики сложнее ролеплея. Я даже через sudowrite.com пробовал писать и Клод не всегда справлялся.
>Насколько большой?
Чем больше тем лучше, но хотя бы 4к.
> Эти семерки скоро станут 13В или 20В.
Что? Франкенштейны иногда делаются удачными, но большая их часть такая себе, смысла нет.
> видеокарты на 8 гигов популярны
Все кто юбмазывался ии уже с 8 гигов давно переползли. Дело но в мотивации, а в том что 7б можно обучать оче быстро и на более простом железе. Потом уже отработанные на них фичи можно использовать в более крупных моделях. Плюс, учитывая что не везде нужен суперпрефоманс - они с ним надолго, вот только зацикливаться только на них при наличии лучших альтернатив - глупо.
> Фанфики сложнее ролеплея.
По сути то что называют роплеем это чаще превращается в сторитейл, где юзер делает короткие реплики действий/мыслей/реплику, а модель уже на основе этого ведет повествование. Но вот четко и корректно объяснить сеттинг - та еще задача.
Попробуй 7б под рп которую посоветуют и шизомиксы тринашек (хоть те же производные мифомакса). Интерфейс для начала топорный блокнот/дефолт убабуги чтобы сетка продолжала написанное тобой и легко было править, но может там есть более удобные альтернативы под такую задачу. Лучше клода оно не будет, если офк это не клод инстант или лоботомированная цензуренная версия.
8к контекста сейчас достигается без проблем на любой современной модели, дальше сложнее или не на всех.
Блядь, я раньше тоже говорил про 8 по 220, но ко мне прибегали и говорили про 8 по 176.
Я блядь не ебу, откуда это берется.
В оригинале про 1,76Т и 8 специалистов по 220B.
1760/8=220.
Все, кто там нахуй что придумывает, я в ахуе просто.
Чел все верно написал. Откуда берутся люди, у которых 1768=1760? Это чуваки с восьмеричной системой счисления? Так нет, у них тоже это должно записываться как 17610! =)
https://vc.ru/future/751747-gpt-4-imeet-1-76-trilliona-parametrov-i-ispolzuet-tehnologiyu-30-letney-davnosti
Соус ищите сами уже.
Кстати, плюсану, что по слухам они уменьшили количество специалистов, из-за чего GPT4 и потупела.
Ну и соя ей мозг ломает тож.
> у трансформеров все нейроны слоя связаны между собой и слой должен быть на одном GPU
Читал, что в A100 и H100 данные вполне себе передаются между ускорителями, ограничение на потребительском сегменте.
Плюс добавь NVLink.
Точно слои обрабатываются лишь одним чипом в корп.сегменте? Пруфлинки, сам тестил?
> Сколько там у ЖПТ4 скорости? 20-30 т/с?
Хз, по ощущениям я и 5 видел иногда.
Воде надо брать пиковую, канеш, но что если пиковая крутится на чем-то меньше?
Вот нашел:
> OpenAI GPT-4: 94ms per generated token.
Какие там 20-30, десяточка.
Уже втрое свою цифру увеличивай.
> Возможно из-за меньшего размера 34B использует не использует все 8 каналов памяти.
Звучит разумно.
> У тебя даже 1b модель будет использовать все каналы.
Как это работает, кста? Вот чисто физически интересно.
С дисками все очевидно: ты или увеличиваешь объем, или увеличиваешь скорость. У тебя файл лежит либо на обоих дисках в рейд-массиве, и читается параллельно, что и увеличивает скорость чтения файла, или же лежит на одном диске, а второй диск пустует.
А как работает в оперативе, что и скорость чтение выше, и объем выше?
С моей точки зрения, чтобы считать один слой вдвое быстрее — он должен литься по обеим каналам, то есть физически находиться в разных плашках озу, значить его софтово нужно порезать и раскидать. Потому что мы же считаем последовательно слои, и если один слой лежит на одной плашке, то второй канал в принципе не задействуется.
Непонятно нихуя, короче, объясните как дебилу, плиз.
У Убабуги есть расширение для телеграма. Поройся там.
Не пизди, я подсказал.
Будто там другие есть.
А этот прямо в доках убабуги упомянут, че его искать. =)
Правда там, наскока я помню, нет фичи с ответами в процентах или ответами по тегам.
Но я давно не смотрел, было бы прикольно.
> подключат хоть ЦРУ и набутылях всех разрабов моделей
Представляю, как агенты ЦРУ бутылят китайских разработчиков.
Идеи достойные. Хз чего, правда.
Ты небось веришь, что ученого, сделавшего генно-модифицированных близнецов, реально страшно наказали, и он сидел в тюрьме и ничего не делал, а его проект прикрыли, да? :)
А технологии ИИ развивают не корпорации, да? И никто из «этих дураков» не имеет к ним отношения, да? Никто из «власть имущих» не связаны с бигтехом, да? =)
И для них нет никакой выгоды выкатить удобный им ИИ, чтобы заработать на нем денег?
Ок.
Код нормального проекта точно не поместится. =')
Генерация есть точно. И распознавание. И голос (генерация и распознавание) тоже.
Но чтобы это вместе с данженом — вот тут вопрос. =)
Рекомендую начать со связки oobabooga+automatic1111+SillyTavern+Extras.
Добавить вторую видяху (возьми 1070 майнерскую хотя бы за 2к рублей), и на нее скинуть все остальное.
Поколупаешься — будет норм.
Ну, в четырехканале ты получишь слабый двухканал ддр5 — почему бы и нет? (ну там 70-90 гб/с)
Тока помни, что в процессоре тебе будет важнее частота, ядер-то и так жопой жуй.
Лучше возьми что-то, что будет выдавать повыше частоты при 5-6 ядрах активных.
Мне лень смотреть, прости.
> 7В модель? В каком месте она может конкурировать с ЧатЖопой, пусть даже 3.5?
Ну, мистраль же почти л2@13б, которая почти л1@30б, которая не сильно уступает гпт-3.5… Ну, короче, ты понял. Немножко представим себе в голове — и вот уже опережаем. =)
> в них ни AVX нужных
Это AVX512? O_o
Не знал, что они используются в нейросетках и дают существенный прирост над AVX2.
Раза в 2, да.
Но скорость, как бы…
На зивоне скорее гонять 20B+ или 70B.
Для 7B литералли легче 3060 взять. А то и че помладше, че у нас там в 2080 майнерских, я хз.
На зивоне тыщ 10-15, 3060 — 20-30. Ну, че-то не влазит, если честно.
> выйдут на 15к где то
> итого те же 30к
Майкл Наки, я вас узнал!
>70B сетки, но это будет литерали 0,01 т/с.
~1 т/сек, может чуть больше.
> Добавляем сюда корпус, бп, кулер и получаем цену видеокарты (с лохито)
Я в прошлом треде собирал.
10к за сборку кит + 3к бп + 2к любая видяха + 2к ссд + 0,5к корпус +0,5к кулер.
Итого 18к против 22к 3060 новая из СММ.
Разница по скорости будет гораздо больше, но видяха ограничена 12 гигами, а зивон — не ограничен особо. Ну, лламы текущие точно влезут и дадут свой 1 токен/сек на голом.
Плюс, ты видяху возьмешь — а втыкать куда? Если подходящего компа нет — добавляй его стоимость, внезапно.
Свои плюсы и минусы, автору выбирать. Скорость или разнообразие.
> Я бы лучше 70В модель накатил и со скорость пусть даже 1 токен в секунду.
Так и будет.
>готов хоть минутами ждать
Ну, минутами — тут как посмотреть. 1 токен сек это ближе к 8-10 минутам.
Звездочки всрали текст, лол.
Откуда берутся люди, у которых 176 х 8 = 1760? Это чуваки с восьмеричной системой счисления? Так нет, у них тоже это должно записываться как 176 х 10! =)
>Вот одна из лучших на данный момент
>https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF
>Скачай и сам пощупай. Бери квант 6к или 8q, запускай на кобальде, для начала сойдет.
Бля я не ту дал ссsлку, это новый гермес который только вышел
https://www.reddit.com/r/LocalLLaMA/comments/17mfjsh/open_hermes_25_released_improvements_in_almost/
Он еще не проверен и хз как будет в работе, качай предыдущий
https://huggingface.co/TheBloke/OpenHermes-2-Mistral-7B-GGUF

Котята, я тут с вами пару дней, можно пожалуйста на примере говна и говна палок пояснить долбоебу в чем различие моделей? Не конкретно на пике а вообще, в целом.
Да, я читать умею и понял что модель дохуя большая, потеря качества экстримли malenkaj или ничо такая модель, потеря качества priemlimo, но а как это выражается в цифрах из чисел?
Почему тогда самую большую модель автор рекомендуюет, а рекомендуют заведомо худшую? Или не худшую. Как понять.
Короч я нихуя не понимаю.
Да, я читать умею и понял что модель дохуя большая, потеря качества экстримли malenkaj или ничо такая модель, потеря качества priemlimo, но а как это выражается в цифрах из чисел?
Почему тогда самую большую модель автор рекомендуюет, а рекомендуют заведомо худшую? Или не худшую. Как понять.
Короч я нихуя не понимаю.
Да ёб ты я 2.0 ещё не попробовал, а они уже 2,5 релизят. Куда блядь торопятся то, напишите им, чтобы притормозили прогресс.
>Почему тогда самую большую модель автор рекомендуюет, а рекомендуют заведомо худшую?
Рекомендуют оптимальный размер, просто по тестам 8 бит это прям топ жир, и 5_K_M ничем не хуже, а весит меньше.
Но для 7B лучше всё же качать более жирный квант, нежели чем рекомендуют.
Потому что зависимость размер модели/качество нелинейная.
Тут два стула мнения.
Во первых есть адепты низкой потери - они считают что сетка норм с средним квантом 4-5. Раз потеря маленькая то и сетка не теряет в качестве.
Другое мнение что сетка теряет в мозгах после сжатия, поэтому качать надо наибольший квант из тех что влезет в систему и будет +- норм крутится. Для 7b это 8q, на крайняк 6к.
Рекомендации на сайте - первое мнение, в расчете на быстро и так сойдет.
Все это по большей части субъективно, но, я считаю что сетка умнее если квант больше, тупо по опыту работы с сетками. Поэтому я качаю 8q и мне норм.
>поэтому качать надо наибольший квант из тех что влезет в систему
Хоть одно возражение против этого есть? Даже если дрочер на перплекси, всё равно чем больше квант, тем меньше потери, поэтому вариант брать максимально жирный рассматривают оба лагеря, и это безальтернативно.
>Короч я нихуя не понимаю.
Если совсем просто - квантование - это сжатие с потерями.
Как ты можешь понять, чем меньше потеряно тем лучше сетка работает.
Но вобще, любой квант работает хуже чем оригинальные весы в 16 бит. Потому что сетку тренили и проверяли на них.
Поэтому с наименьшей потерей при квантовании будет 8q.
>Хоть одно возражение против этого есть?
Были, 4км-5км мол сойдет, вон даже в шапке
>Были, 4км-5км мол сойдет, вон даже в шапке
Сойдёт то сойдёт, но если влезет больше, то why not?
>Сойдёт то сойдёт, но если влезет больше, то why not?
А новички качают по рекомендациям и потом решают для себя что 7b тупые. Ну хотя бы 5km, ладно.
Веселее было бы 4кs для 7b лол
Но рекомендацию качать по больше если влазит в шапку бы дописать
Ну смотри значиться:
Согласно тестам потерь качества нет только при запуске оригинальной не квантованной модели. Но весят они очень много, а работают очень медленно, поэтому модели всё-же квантуют.
S M - дополнительные подвиды квантования, S - качество чуть хуже, M - чуть лучше.
Градации от 8q до 2q соответственно от лучшей, к худшей по качеству. Но начиная с 3q считается что модель значительно теряет в качестве.
>Почему тогда самую большую модель автор рекомендуюет, а рекомендуют заведомо худшую? Или не худшую. Как понять.
В качестве мейн версии рекомендуют как правило q4, т.к. она удобный компромисс между качеством и производительностью. Ну и кроме того в некоторых форматах моделей, для запуска других квантов надо ебаться с настройками, а q4 стартует по умолчанию.
Для GUFF формата, запускаемого через кобольд, тебе надо просто смотреть на необходимый для запуска объём памяти и выбирать максимальный квант, который в тебя влезет, всё.
Кстати, а чем в плане качества и скорости ответов ггуф ог ггмл отличается? Ничем?
ггуф просто новый формат, хз. Он должен быть лучше, и врятли медленнее старого. В нем информация о модели встроена, вот и все отличия что помню.
Спасибо солнышки. В общем и целом вывод такой: если влезет - засовывай.
Больше — медленнее, но умнее.
Меньше — быстрее, но тупее.
Двушка — тупая пизда.
Трешка норм для 70б какой-нибудь, лул.
4 бомж вариант.
5 норм вариант.
6 юзать рекомендуем.
8 если прям хочешь умное, говорят, от fp16 не отличаеццо почти.
> А новички качают по рекомендациям и потом решают для себя что 7b тупые.
Скачал опенорку 5км, была шизенькой, но терпимо. Потом скачал 8 - охуел от того, что поток шизы только усилился, она литературно начала мне ссылками на реддит срать. Может конечно я криворукий, но...
Температуру крути, топ п, промпт.
Увеличение кванта шизу не увеличивает, а вот уменьшение может
Да она меня и без этого уже соей задушила, выпилил.
так орка соевая, гермеса качай или дельфина, в них меньше
Уже сто раз говорили что квант на рандом в большей степени виляет. Если модель нормальная, то она и на q2 будет нормальные ответы давать, ничем не хуже q8. А если там кал, который семплингом надо надрачивать и при любых изменениях настроек ломается нахуй, то там запросто изменение кванта будет ломать тебе рандом в твоём выдроченном пресете семплера.
Аноны, что делать с ошибкой
Text length need to be between 0 and 5000 characters
в угабоге?!
Вылазит, когда подключаешь таверну по API. В самом интерфейсе угабоги генерит без проблем.
Text length need to be between 0 and 5000 characters
в угабоге?!
Вылазит, когда подключаешь таверну по API. В самом интерфейсе угабоги генерит без проблем.
> данные вполне себе передаются между ускорителями
> Плюс добавь NVLink
Через него и передаются, как еще.
> Точно слои обрабатываются лишь одним чипом в корп.сегменте?
Оно очевидно что сетка в одну карточку не влезет. Но там еще суть в том что одновременно все эти сетки не работают, только одна из восьми, иначе не бывать стримингу в привычном виде.
> Как это работает, кста? Вот чисто физически интересно.
Очень просто, данные разбиваются на мелкие чанки и пишутся сразу во все области рам. Помимо каналов там есть банки (минимум 4 на канал), каждый со своими задержками операций что повлияет на скорость. Заведует всем чисто железо (исключая офк всякие нумы где необходим учет в софте). Если бы адресное пространство системной памяти соответствовало бы напрямую тому что в банках подряд - скорости были бы невероятно низкими из-за особенностей работы самих чипов памяти, и даже обработка аудио в реальном времени было бы некоторым челленжем.
> С дисками все очевидно: ты или увеличиваешь объем, или увеличиваешь скорость.
Орли? Увеличиваешь объем-скорость-отказоустойчивость в разных пропорциях, а не только что-то одно.
Про raid0 слышал? Вот здесь, если сильно упростить, то же самое.
Не зная такой дефолт не стоит дальше строить рассуждения.
> Итого 18к против 22к 3060 новая из СММ.
Итого массивное неликвидный шумящик гроб, потенциально проигрывающий десктопу, против скоростной крохотной няшечки что уместится (второй) в основной пеке. Если же у автора десктоп хуже зеоносборки - пусть ее себе в системник ставит, а видеокартку поверх.
Таверну-убабугу обнови и выбери в настройках api убабуги а не кобольда.
> то она и на q2 будет нормальные ответы давать
Не в 7б, такое прокатывает прежде всего на больших объемах, где число параметров сглаживает все дискретности. И то настолько радикальный квант без дополнительных манипуляций по его подготовке может все похерить даже на 70.
> который семплингом надо надрачивать
Семплинг нужен на любой модели чтобы было пиздато и разные свайпы. Офк если модель требует каких-то особых хитровыебанных его настроек то она печальна.
У меня таверна 1.10.5.
Само собой API угабоги в настройках.
Работает когда в таверне сокращаешь контекст до 2к. Хотя в настройках угабоги стоит 4к максимальный. Какого хуя?!
Покажи скрин консоли или полный текст ошибки
А это и былда вся ошибка после вывода всей переписки с ботом.
Всё таки всё дело в контексте. Я прописал
max_new_tokens_max: 4096
А надо было ещё
truncation_length: 4096
Там похожие ошибки были от лоадеров, если давать им запрос, превышающий длину контекста.
> truncation_length: 4096
Емнип, оно игнорируется если подключение через новый апи, нужно для кобольдовского.
Поднял
https://hub.docker.com/r/ollama/ollama
за 5 минут. На попробовать, думаю, сойдет. Всё изкаробки ставится за 3 строчки.
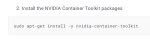
На бубунте что ли?
Ладно, докладывай, что там по скоростям.
> иначе не бывать стримингу в привычном виде.
Гыг, логично. =)
> Очень просто, данные разбиваются на мелкие чанки и пишутся сразу во все области рам.
То есть — автоматически раскидывается, как я и думал?
Спс, значит мир таков, каков есть, это радует.
Правда я уровень не тот продумал, на уровне железа, ок.
> Орли?
Ну я утрировал наш вариант с памятью. =)
> Про raid0 слышал?
Про все слышал. =)
Да, понял-понял.
Пасиба-пасиба, разобрался.
на арче
Скорость, хз, чуть быстрее скорости чтения. Я не разбираюсь пока совсем.
В консоли обычно пишет. Короче покажи своё железо и скорости ответа в таверне, если этот инструмент к ней подключается.
Что это и зачем? Выбор из готовой либы с десятком непопулярных моделей, серьезно? Судя по возможности импорта gguf по описанию в репе там что-то от Жоры на бэке.
Нахуя?
> докер
> easiest way to get up and running with large language models locally
Такой толстый троллинг что даже тонко.

Кто-нибудь пытался конпелировать кобольд под cublas? У меня производительность вообще на дно улетела, хотя все вроде нормально собралось и куда работает.
Зачем...
Чтобы не ждать неделями пока они сделают новый релиз.
Зачем? Что там такого охуенного, чтобы бросаться ебаться с компелированием?
Min p завезли. Я пока вот этим билдом пользуюсь, но хотел сам научиться собирать на всякий случай.
https://github.com/kalomaze/koboldcpp/releases/tag/api-min-p
Зачем? Фишка кобольда в скачал бинарник@запустил. Хочешь всего самого быстрого и последнего для gguf - юзай llamacpp в составе webui или свою обертку напиши.
https://lmstudio.ai/ чё эта?
Кто то пользовался?
Кто то пользовался?
Проксей для таверн агнаи и проч нет пока как я понел. Железо 16гб 9700 игровая видеокарта 4гб.
Я насчитал 33, мб ты неправильно считал?
https://ollama.ai/library

Airoboros 34b - РПшит качественно, ответы почти всегда содержательные, но немного прямолинейные. Нет изящества как у 70b.
А вот с настройкой вышло посложнее: трудно нащупать грань между шизой и деменцией. И это на Q8 !!!11
Кто-нибудь общался с этой нейросетью?
Openchat 3.5 - Это всего лишь 7b !!! На пикриле лицо одного из разработчиков этой нейросети.
А вот с настройкой вышло посложнее: трудно нащупать грань между шизой и деменцией. И это на Q8 !!!11
Кто-нибудь общался с этой нейросетью?
Openchat 3.5 - Это всего лишь 7b !!! На пикриле лицо одного из разработчиков этой нейросети.
> Я насчитал 33
О, ну это меняет дело! Кучка стоковых моделей, мусорные (в настоящее время) файнтюны первой лламы, непопулярные и/или старые на второй и какой-то откровенный шмурдяк. Из нормальных - мистраль и пара его файнтюнов, визардкодер... ну и наверно все, хз насчет несколько под код. Да еще все (где указано) в q4_0 (!), мало того что квант жидковат так еще формат устаревший, который заметно уступает по качеству новому.
Ну рили, предположим что ты идейный и решишь качать модели и импортировать их через кучу манипуляций, нахуя эта залупа нужна?
> Airoboros 34b - РПшит качественно
Хуясе ебать, у него получилось оживить кодлламу, серьезно?
> Openchat 3.5 - Это всего лишь 7b !!! На пикриле лицо одного из разработчиков этой нейросети.
Настолько хорош?
>игровая видеокарта 4гб.
ну хоть не 2, хотя особой разницы нет
>нахуя эта залупа нужна?
Новичкам, что бы приобщиться к миру богов. Перерастут начнут нормально запускать, хотя хуевое начало может и отталкнуть
> Новичкам
> пердолиться с установкой доккера
> ставить куда-тулкит
> настраивать репы
> качать хуйту
> после квеста иметь возможность медленно запускать какое-то старье без нормального интерфейса
Скажи что ты троллишь.
Рили, нет ничего проще чем скачать бинарник с юзер-френдли интерфейсом и любой понравившийся файл модели. Следующая ступень это освоение git clone и установка питона в систему, чтобы поставить самый передовой интерфейс в две команды.
Так трудно? Эту хуйню вроде одной командой ставят, ну может спутал с другим проектом
Ты по его ссылке пройди, там все невероятно просто-удобно-эффективно.
Ну и само по себе сочетание доккера и новичков в одном предложении рофлово.
Нет, скажи что ты троллишь. Докер ставится за 30 минут. Эта хуйня ставится за 15 минут.
>мало того что квант жидковат так еще формат устаревший, который заметно уступает по качеству новому
Там много версий, выбирай любую, есть там твои разные кванты емана.
Не в курсе вашей меты, но слушать про сложность докера смешно.
Докер нужен только наносекам для ci/cd у их веб-сервисов.
Чтобы они могли постоянно допиливать свой говнокод и одним вертуханом обновлять свои жирные микросервисы раскиданные на нескольких физических устройствах.
Зачем впаривать докер конечным пользователям?
Чтобы они могли постоянно допиливать свой говнокод и одним вертуханом обновлять свои жирные микросервисы раскиданные на нескольких физических устройствах.
Зачем впаривать докер конечным пользователям?
>Не в курсе вашей меты, но слушать про сложность докера смешно.
Ну, это уровень повыше чем скачать готовый екесшик кобальда и запускать просто тыкая на него. Тут из исходников то врятли кто собирает
Вобще почитай последние 100 постов там описывалась разница между квантами
> Докер ставится за 30 минут. Эта хуйня ставится за 15 минут.
Кобольд качается менее чем за минуту, webui ставится минут за 3-10 в зависимости от интернета.
> Там много версий
q4_0, q4_0 и q4_0. А точно, еще q4_0.
Ладно, братишка из мема про линукс у школьника словил утенка с докера и этой херни, и теперь превозносит ее не зная о том что вообще есть.
> для новичков в нейросетях, а не в ит
Кто что-то знает - сможет накатить полноценные функциональные решения а не хуйту из под камня.
Двачую этого господина, сейчас бы с каждой обновой перекачивать гигабайты торча.
>Кто что-то знает - сможет накатить полноценные функциональные решения а не хуйту из под камня.
Это нужно сидеть разбираться, если внезапно узнал и захотел потыкать то норм решение
У погромистов всегда загружена голова им проще накатить в начале готовое заранее настроенное решение
>Настолько хорош?
Рандомно выбрасывает ответы сравнимые с 7-13++ часто, 20-30 реже, но в товарном количестве.
Чуть позже поебусь с параметрами и напишу результат.
Какая-то платина от инфоцыган и пройдох, оправдывать сомнительную хуйту без преимуществ тем что "вот для новичков кто не знает заранее готовое". При наличии реально готовых решений и необходимости погрузиться в саму работу с текстовыми моделями, ага.
> У долбоебов никогда не работает голова им проще накатить в начале готовое заранее настроенное решение
Исправил
Огонь, значит нужно качать.
>Какая-то платина от инфоцыган и пройдох, оправдывать сомнительную хуйту без преимуществ тем что "вот для новичков кто не знает заранее готовое".
Ты будто первый раз живешь, решение как решение, их много и каждому своя аудитория. Если эта штука на плаву то ей пользуются, не недооценивай человеческую лень и тупизну
Жизнь она в принципе такая, какая она есть. Суть в том что братишка притащил и предлагает пользоваться, но предлагаемое решение не имеет преимуществ, уступает всему что уже есть и в принципе малоюзабельно. Адреса публичных вебморд или api и то в полезнее будут, вот где ничего ставить не надо и работает даже на телефонах, а функционал тот же.
> то ей пользуются
Автор и редкие утята, тем более нужно гнать и насмехаться. Например, llm-studio, хоть и специфична, но имеет полноценный интефейс и даже изначально реализовали у себя новый формат квантов под гпу, вот она пользователя найдет.
>но предлагаемое решение не имеет преимуществ, уступает всему что уже есть и в принципе малоюзабельно.
Так никто и не спорит что это супер полезная штука, ее единственный плюс запуск без знаний о теме вобще
> запуск без знаний о теме вобще
Не догоняю в чем смысл этого запуска. Приходит на ум только что-то уровня похвастаться перед одноклассниками что ты запустил локально медленно ужатую модель без возможности полноценно управлять ее промтом. Просто попробовать можно через открытые api ничего не ставя, быстро, эффективно.
Мда, попробовал с ламу.спп оказалось то же самое только без докера. Прогрели получается. Ну, честно, я бы не поставил локалку если бы не знал что можно в 3 клика поставить докер, как-то так. Разбираться вообще не хотелось. Так хоть какой-то повод появился.
ллама тоже не для всех, вот тут щупать надо, удобнее же
https://github.com/LostRuins/koboldcpp/releases/
при запуске надо кублас выбирать, если карта нвидима, количество ядер -1 от физических
но правильно настроенная ллама.спп немного быстрее кобальда
> то же самое только без докера
Почему-то в голос с этого, для тебя специфичный софт, который в 95% случаев используется костылем не по назначению - повод что-то делать?
Ты чего вообще хочешь? Llamacpp - бэк, просто код, один из лаунчеров что позволяет загружать некоторый формат моделей и их запускать, и все, к нему уже идут обращения. Это всеравно что закупить в магазине какую-нибудь йоба железку а потом на доставая из коробки смотреть на нее и удивляться "что-то нет такого как в обзорах".
Я хотел взять и запусить сразу я это получил. Я доволен. Щас, вдохновившись, покурил маны, получил что-то получше. Докер это заурядная штука что тебя в ней триггерит - даже не буду спрашивать. Не интересно.
Это звучит как
> я хотел себе автомобиль сразу, вот я его получил и теперь уже посидел в салоне, сейчас покурю маны и сиденье отрегулирую, а через годик может даже заведу!
Не триггерит и дело не в доккере, интересна (глубинная) причина острого желания пихать неуместные вещи/подходы не вникая в тему.
>Докер это заурядная штука
Это параша параш, буквально лишний слой ненужной абстракции снихуя. Спасибо что спросил.
> при запуске надо кублас выбирать, если карта нвидима, количество ядер -1 от физических
Почему? Разве 6 не быстрее будет?
Все зависит от процессора, почти всегда идет упор в скорость памяти а толку от дополнительных ядер может не быть. А может и быть, братишка просто из каких-то соображений выбрал себе эту опцию и теперь всем советует.
> братишка просто из каких-то соображений выбрал себе эту опцию и теперь всем советует.
Патмушто я тестил и у меня без 1 ядра быстрее чем со всеми. Причем грузит все равно все ядра, вот так вот.
Можешь сам проверить лол
Проверял, быстрее всего если вообще не трогать этот параметр (хз что там по дефолту, все доступные потоки наверно), а с некоторыми значениями и при ручном аффинити можно и знатный дроп снихуя словить.
> Причем грузит все равно все ядра
Смотря чем мониторить, даже с 1 ядром в параметрах можно почти полностью загрузить контроллер рам, а далее уже зависит от методики измерения. Где-то будет 3% где-то 90+.
лучше знать о вариантах и самому проверить, чем сидеть на дефолте или проверять все с нуля
>Патмушто я тестил и у меня без 1 ядра быстрее чем со всеми.
А с 6 ядрами будет так же.
>Причем грузит все равно все ядра
Бессмысленной нагрузкой цикла ожидания от РАМ.
Или я просто привык к своему 24 поточнику, а все тут сидят на двухядерных тыквах?
6-12 cамый распространенный случай наверное.
> чем сидеть на дефолте
Насколько помню вот он пока как раз хуже не делал, желание уменьшать число потоков ради уменьшения не понятно, учитывая что на некоторых конфигах это испортит.
Если там оно действительно работает с меньшим количеством быстрее - реквестирую пример.
> Насколько помню вот он пока как раз хуже не делал
Хуже по сравнению с чем?
Посты не читал? Что без ограничения по потокам, что с ограничением до определенного уровня +- одинаково или же деградация, зачем советовать ограничивать?
Так дефолт и ограничивает на дефолт-1.
> дефолт-1.
Чё написал блеать... Физические -1.
> на дефолт-1.
Вот же содомит, ржал что соседей разбудил.
Если так тогда рили можно его не указывать, но таки пруфы в коде покажи, это должно быть легко найти.
Не всегда работает определение, но да, кобальд так и делает -1
>желание уменьшать число потоков ради уменьшения не понятно
Ну то есть пердящий на 100% процессор лучше, чем пердящий на 60, при одинаковой производительности?
>учитывая что на некоторых конфигах это испортит
Их ещё поискать надо, и владельцы таких конфигов сами знают их особенности.
> Ну то есть пердящий на 100% процессор лучше, чем пердящий на 60, при одинаковой производительности?
Тдп и свободные ресурсы не изменятся, то что маняметрика успокаивает тебя - ничего не значит. Ты случаем не из этих, которые думают что масляный обогреватель экономичнее потому что он может некоторое время греть когда выключен?
> Их ещё поискать надо
Интелы начиная с 12 поколения, действительно редкость.
>Тдп и свободные ресурсы не изменятся
Замерял?
>Интелы начиная с 12 поколения
Замещающие продукты с протухшими ядрами не рассматриваю.
АЛСО, там тоже до 6 потоков, просто особенности местного распределения могут подгадить.
> Замерял?
Конечно. И здравый смысл нужно иметь, в отсутствии данных из рам ядра не могут ничего считать а будут просто простаивать, это же очевидно.
> Замещающие продукты с протухшими ядрами не рассматриваю
А что они замещают, прогорающие в стоке печки для бета-тестеров?
> там тоже до 6 потоков
Анон приносил же тесты несколько тредов назад, когда память и анкор быстрые + видеокарта - есть профит от повышения числа потоков.


11 потоков, 5 потоков. Ну, то по крайней мере на ряженке.
>есть профит от повышения числа потоков.
Просто ядра совсем тухлые были.
Оно по дефолту на производительные кидает, это нужно что-то конкретное запустить и фокус окна сделать чтобы перекинуло.
Но эти тухлые ядра настолько хороши, что не только дают большой перфоманс и повышают псп рам, но и поджигают пуканы фанатиков амд, которых еще впереди ждет новая переобувка.
>повышают псп рам
А хуй длиннее не делают, голубочек?
Ещё в 546.01 было.
И лучше нахуй вырубить эту хуйню. Дяденька OOM лучше, чем замедление генерации.

Но хотя бы попроверять стоит, что они пилили-делали зря?
Правда почему то у меня оно не работает...
Победа это когда в кобольдрокм добавят поддержку 6700хт.
Нуу...
Это победа не лично для меня.
Нука, я попробую комп перезагрузить.
Может в этом проблема заключается? Что драйвер полностью не подхватился.
>что они пилили-делали зря?
Они это делали для пеара, а то вылетающие игры на обделённых памятью невидиях это такое себе.
Да, нужно ребутаться.
Пожалуйста запилите...
Укрепляют эрекцию и уберегают от лупов! то рофловая отсылочка же
В хубабубе по дефолту в коде стоял запрет на эту херь емнип, при превышении оно почти сразу в оом падало.
> чем замедление генерации
Для статистики, сколько врам и сколько занято в простое?
Как раз работает, улетает в оом как положено. Оно же вроде прописанную с коде политику не перезаписывает, только делает запрет на адресацию в общую память. Но это не точно.
Хорошо сказал
От фантазий про железо которое ты не купил из-за религии оно не станет хуже, а твое не станет лучше.
Я же кидал пару тредов назад сравнение. На интелах без танцев с бубном можно ставить число потоков равное числу нормальных ядер. Если это число превысить, то производительность сильно упадет поскольку нагрузка начнет распределяться на тухлые ядра. Но если заставить кобольд работать лишь на нормальных ярдрах, то можно повысить потоки до количества потоков у этих самых ядер (16 у 13900k).
>И лучше нахуй вырубить эту хуйню. Дяденька OOM лучше, чем замедление генерации.
Не факт. Я смог запихнуть еще несколько слоев и повысить производительность.
>От фантазий про железо которое ты не купил из-за религии
Ты меня путаешь с кем-то.
>Я смог запихнуть еще несколько слоев и повысить производительность.
Врам от этого не отрастёт. Тут разве что надежда на то, что всё остальное в оперативку скатится. Но у меня при этом даже браузер фризить начинает.
>Врам от этого не отрастёт.
Зато всякое говно уйдет в оперативку, освободив место под слои.

> Как раз работает, улетает в оом как положено. Оно же вроде прописанную с коде политику не перезаписывает, только делает запрет на адресацию в общую память. Но это не точно.
Я попытался эту фитчу в SD проверить, задал Upscale by x3.
Та же хуйня вылезла. Хотя в пачте именно SD упоминается.
> Ты меня путаешь с кем-то.
Справедливо, иметь перфоманс почти 3090 но вдвое меньше рам - пиздец обидно как же вовремя ее сменил
> Та же хуйня вылезла.
Так оно так и должно себя вести если поставил запрет. В драйвере весной разрешили выделять память чтобы оно выходило в шеред без оомов, сейчас в панель добавили опцию запрета этой фукции что будет сразу оом.
> Так оно так и должно себя вести если поставил запрет.
Я наоборот отменил запрет. Prefer System Fallback поставил.
Может винду стоит обновить чтобы оно заработало? Я более года винду не обновлял, выключил обновления.
Не дают это говно включить.
Ууъ сука.
Ууъ сука.
новый гермес ебет, ни одна 7b еще не комбинировала ответы так как он
Короче, я разное говно пробовал, и короче к чему пришел.
С одной видяхой эта фитча работает. А когда блять..
ДРУГУЮ ВИДЯХУ ПОДКЛЮЧАЕШЬ ТО НЕТ. НАХУЙ ТОГДА МНЕ ОНО ВСРАЛОСЬ???
>
А можно больше деталей? Общий фон, так сказать. Обновляться? Какие-то опции новые ставить?
> победа
Но зачем? С ней можно вылезать немного за лимит, грузить в память все 24 гига, и при этом не иметь просадок по скорости. А с выключением уже на 22-23 гигах будет отъёбывать и надо перезапускать бэкенд.
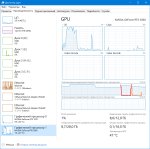
Ну я хочу чтобы можно было больше контекста задавать.
Каждая тысяча токенов хочет два гига видеопамяти.
Вот оно сначала просчитывает контекст (красный), потом его кеширует и начинает генерацию (желтый).
То есть я не могу выйти более 3к контекста без этого говна.
Написал в нвидия, а они захотели какой то Support account, еще какой то entitlement certificate.
Че они ваще не будут хуйню решать эту без какой то капиталистической залупы?
Номер кейса, где его искать блять?
https://lmstudio.ai
Скачал попробовал эту фигню, когда разобрался как свои модели всунуть стало веселее. Ну, вроде неплохо, скорости как у кобольда или чуть выше.
Как вариант сойдет, не хватает вставки карточки или я не нашел как.
Может что то еще на хватает, работает отдельным приложением и тут главный минус - хуй знает что эта штука отправляет и куда. Так что кроме базовых вещей ниче не тестил.
Если отрубить ее от инета и вставлять свои модели самому то сойдет, ну когда допилят.
Скачал попробовал эту фигню, когда разобрался как свои модели всунуть стало веселее. Ну, вроде неплохо, скорости как у кобольда или чуть выше.
Как вариант сойдет, не хватает вставки карточки или я не нашел как.
Может что то еще на хватает, работает отдельным приложением и тут главный минус - хуй знает что эта штука отправляет и куда. Так что кроме базовых вещей ниче не тестил.
Если отрубить ее от инета и вставлять свои модели самому то сойдет, ну когда допилят.

И нахуй ты им пишешь? Я надеюсь хоть не по-русски писал? Потому что видя как ты читаешь буквы очень сомнительно что ты знаешь английский.
Там другого супорта не было, я весь сайт клацал пол часа.
Может я блять слепой, но я нихуя не нашел.
> Я надеюсь хоть не по-русски писал?
Через гугл транслейт.
Про CUDA и прочую лабуду только там.
Думаю в геймерскую поддержку где гарантия и как видяху вставлять - лучше по моему не писать.
НО и то я ее не нашел.
Думаю в геймерскую поддержку где гарантия и как видяху вставлять - лучше по моему не писать.
НО и то я ее не нашел.
Ты чего вообще добиться пытаешься? Драйвер позволяет только запретить лишнюю выгрузку, а не форсировать то что запрещено в софте, считай выбор между старые режимом до 531 и новым как после, по крайней мере так пишут. В диффузии оно выгружается, в экслламе и других нет.
Ай лол, на реддите поной, ясен хер здесь тебя будут нахуй посылать.
Нужно зарегистрироваться на сайте поддержки, и приложить сертификат клиента. Этот сертификат тебе должны были выдать вместе с партией из 50 штук Nvidia h100, когда ты их заказывал
Там регистрация меня нервирует.
Знаешь, я тоже думал что то нечто подобное.
Хочу им ответить, в духе "Обычным юзверям права голоса не давали?"
P.S.
> В диффузии оно выгружается, в экслламе и других нет.
Я в text generation webui пробывал, там работает оно.
Я один раз в не то отделение банка пришел, мне сказали "мы обслуживаем клиентов со вкладами в эквиваленте от 1 млн долларов. Обратитесь в наш офис на пару кварталов дальше"
Кстати, вроде StabilityAI делают языковую модель. Вы ничего про это не знаете?
Мне все более интересно стало, что мне в Невидии ответят ща, если я скажу что не ентерпрайс пользователь.
Ща с турбой проконсультируюсь на всякий случай.
Что мне лучше сделать, интересно, что она скажет.
Что мне лучше сделать, интересно, что она скажет.
уже есть вроде, обсидиан, чет там про стабилити видел в описании, или вру хз
https://huggingface.co/NousResearch/Obsidian-3B-V0.5
мелкая мультимодалка файнтюн на основе их сетки что ли
Кто то щупал одновременно openhermes-2.5-mistral-7b и openchat_3.5? Не могу понять что пизже
ПОЧЕМУ В ШАПКЕ ДО СИХ ПОР НЕТ ГАЙДА ДЛЯ ДАУНОВ ПО ЗАПУСКУ НА ВИДЮХЕ?
> Каждая тысяча токенов хочет два гига видеопамяти.
13б сеть? Пересаживайся на экслламу, у нее потребление на контекст мегалояльное а скорость с его ростом не проседает.
Смотивируй
Ебать там кобольд обновился
Бамп вопросу.
Кобольд для амуде страдальцев
https://github.com/YellowRoseCx/koboldcpp-rocm/releases
ну и сам релиз кобальда
https://github.com/LostRuins/koboldcpp/releases/tag/v1.48
https://github.com/YellowRoseCx/koboldcpp-rocm/releases
ну и сам релиз кобальда
https://github.com/LostRuins/koboldcpp/releases/tag/v1.48
1) Ставишь угабугу https://github.com/oobabooga/text-generation-webui
2) Ставишь силли https://github.com/SillyTavern/SillyTavern
3) В зависимости от врам берёшь 7-13-70 модель из топа какого нибудь списка, в угабуге грузишь эксламой2 с 8к контекста и 2.6-3 альфой, если это вторая лама, а не мистраль, включаешь там же в настройках апи
4) Подключаешься по апи через таверну и пердолишься с пресетами, карточками и семплерами, подгоняя под свою модель, или просто юзаешь дефолтные
Ну и модель для эксламы нужно брать в формате gptq со всеми остальными файлами вот отсюда например https://huggingface.co/TheBloke


> Кобольд для амуде страдальцев
Штош, скинь ошибку парню что пилит их, хотя бы. Может сделает
Проблема в том, что амуди не запилили рокм для гфх1031, 6700хт то-есть. Чел пытался сделать за них, но сетка хуиту вместо текста выдавала. Так что остаётся только ждать, или пока он же допилит, или пока амудя соизволит.
Понятно, думаю врятли он будет работать за корпорацию в этом деле
>Context Shifting
Увы, не будет работать с обычными чатами из таверны, так что мимо.
Интересно как реализовали выпиливание токенов из середины а не с конца, ведь в начале идет системный промт, карточки и прочее.
Никак, я и написал, что работать не будет. Оно скорее всего только для бесконечного чата без карточки, инструкций и прочего.
У меня сложилось мнение, что чем выше количество параметров у нейросети, тем больший размер кванта ей нужен чтобы говорить изящно и многогранно.
Всё правильно понял?
Всё правильно понял?
>EOS token triggered!
Что это значит? Обрывает на полонине сообщения.
Что это значит? Обрывает на полонине сообщения.
Все наоборот, чем больше сетка тем больше можно ужать без сильной деградации.
Модель считает что ответ дан и пора заканчивать, или, возможно, триггерится на кастомные стоп-слова. Если это происходит внезапно то убавляй температуру и настраивай семплер, или меняй модель на нормальную. Также можешь забанить eos токкен, но тогда всратые модели устроят тебе лютую графоманию, шизу и решения за тебя.
У меня наоборот сложилось впечатление, что даже Q2 практически не отличается от Q5 и выше. А вот кванты exllama2, ужатые до 24 гигов, тупые до невозможности.
> А вот кванты exllama2, ужатые до 24 гигов, тупые до невозможности.
BOS токен убери, 2 бита эксламы2 с ним генерят бредятину.
Давно уже убран. Бредятину не генерят, но по сравнению с gguf квантами намного хуже как объективно (перплексити), так и субъективно (качество ответов).
Такое может быть если взять оценку от другой модели при квантовании. Exl2 более продвинутая чем ggml3, в свое время сравнивал 4х битные (пока еще не поломали), разница невелика но в пользу exl была.
>в свое время сравнивал 4х битные
Так я же говорю - ужатые до 24 гигов. Это 2.4 бита максимум против 3.5 у Q2_K. У модели реально выносит все мозги.
> (пока еще не поломали)
В каком смысле поломали?
> 2.4 бита против 3.5
И на что тогда рассчитывали лол.
В одном из патчей встроенный тест перплексити в убабуге с экслламой сломали, возможно уже починили. Ну а с llamacpp там тормознутый пиздец в разы медленнее, то что должно делаться за 15 минут нужно ставить на ночь, так что сложно тестировать. Может уже пофиксили.
Там и другие улучшения, у меня скорость на секунду-пол секунды подросла например.
По идее новый семплер ещё, должен ебать всё и вся again, но в глупой таверне его вроде ещё нет.


>но в глупой таверне его вроде ещё нет
В чем суть, как он работает поясните. Тупо минимальный порог вероятности?
Допустим, есть такой список вероятностей токенов: [0.7, 0.15, 0.07, 0.03, 0.02, ...]. Если выставить Min P = 0.05, то минимальная вероятность выбранного токена будет 0.7 x 0.05 = 0.035, и из этих токенов будут выбраны [0.7, 0.15, 0.10, 0.07]. Получается что-то вроде более линейного и понятного Top A. Top K/Top P/TFS - хуже.
О, а для всех семплеров вот так же случаем не можешь расписать для хлебушков?
Типа адаптивный минимальный порог? На шизомиксах где часто ситуация с множеством близких по вероятности токенов вообще ограничивать по сути. А на каком он мести при обработке стоит по дефолту?
Почитай вот это: https://github.com/KoboldAI/KoboldAI-Client/wiki/Settings
Для Top K/Top P/ Top A все просто, а в детали более сложных семлеров я и сам не вдавался.
>Типа адаптивный минимальный порог?
Да.
>На шизомиксах где часто ситуация с множеством близких по вероятности токенов
На том же что и Top P.
Так а сколько ставить? Я почитал но все равно тупой, по идее можно выключить все остальное и оставить только топ-р? Ну температуру еще.
Семплеры полезны, но те еще костыли. Если бы нейросеть могла сама оценивать куда вести разговор выбирая нужные токены....
У меня только получилось заставить сетку суммировать и анализировать развитие диалога после каждого сообщения, но это немного не то.
У меня только получилось заставить сетку суммировать и анализировать развитие диалога после каждого сообщения, но это немного не то.
Зависит от модели. Top P, Top K и все остальное больше не нужно. Ставь Min P, температуру и repetition penalty. Все.
Бля я даже не то написал, я имел ввиду новый мин п.
Спасибо, это удобней по идее.
> На том же что и Top P.
Нуу, от юзкейса зависит, если кто-то topP активно юзал то это однозначно лучше. А если с TopP на больших значениях заменять им, то в некоторых случаях должной фильтрации не будет, хз в общем.

У меня старый адрес репы был, лол.
БЛЯДЬ. Обновился, а они искалечили эти крутилки. Пиздец неюзабельно, что блядь за дебилы. НЕНАВИСТЬ.
Короче походу в альфа репе что-то натворили, надо отключить эту хуйню, чтобы стало нормально. Ладно, ушёл пробовать этот мин Р.
Для нового гермеса температура от 0.6 начинает норм проявлять себя. Появляются новые варианты предложений, а не варианты одного и того же. Наверное так для всех мистралей
>температура от 0.6
С рождения юзаю 0.9, лол, ещё со времён давинчи, так и не меняю.
Ну, с большой температурой сетка хуже следует инструкциям, и в итоге кажется глупее чем есть
С другой стороны если нужно разнообразие то похрен
Не будет работать или будет ломать? А то галочка-то по дефолту стоит.
Не похоже, что опция может что-то сломать.
Нахуй не нужно, у Top A и так идёт срезание по ax2.
От максимума не? А тут от большей вероятности за раз
А в чём разница?
Мягче срезает, оставляя только близкие вероятности к максимальной на данный момент, а не вобще. Ну, на сколько я понял
Так максимальная вероятность "вообще" это 1, а топ-а вроде и так берёт наибольшую вероятность из присутствующих для выбора, а не когда-либо возникавшую ранее. Я впрочем могу напиздеть с три короба, поправьте если так.
Динамически меняет нижнюю планку в зависимости от верхней? Хуй знает, я тоже не понимаю
Ну, в том и суть, чтобы когда всё очевидно не гадать на токенах, а когда хуй пойми не отсекать "ваще хуй пойми" токен в пользу "хуй пойми но чуть вероятнее, не факт что обоснованно".
1) Что такое режим вайфу?
2) Я же правильно понимаю, что суммаризация это растяжка контекста ценой качества его запоминания? Как этим пользоваться, можно для дебила гайд?
2) Я же правильно понимаю, что суммаризация это растяжка контекста ценой качества его запоминания? Как этим пользоваться, можно для дебила гайд?
Ага. Осталось только добавить сеткам токены управления мышкой и клавиш клавиатуры, чтоб по скрину тыкали в приложения.
А если у меня RX 580 8Гб?
https://github.com/LostRuins/koboldcpp/releases/
В нём CLBlast. Скоростей ожидай улиточных.
такой же амудестрадалец
Читай инструкцию для пользователей без видеокарт вестимо.
> RX 580 8Гб
Вот бы допилил амд, можно было бы свою старую рх 480гб запихнуть в старый комп для мистраля 7б.
https://github.com/YellowRoseCx/koboldcpp-rocm/releases попробуй, может у тебя заведется, я хз для каких именно амуде там релиз работает, а на каких нет
>Что такое режеим вайфу?
Это когда у тебя текст чата расположен под картинками с эмоциями вайфы.
В таверне есть дополнение, определяющее "эмоцию" персонажа и вставляющее соответствующую пикчу. Подробности читай в дополнениях для таверны. Для некоторых карточек есть готовые наборы эмоций, но можно вставить и свои, нагенерев в SD.
>суммаризация это растяжка контекста ценой качества его запоминания? Как этим пользоваться, можно для дебила гайд?
Сумморизация это спасательный круг при малом контексте, позволяющий модели иметь хоть какое-то представление о содержании диалога за пределами контекста.
Не идеально, но лучше, чем ничего.
Есть три варианта использования:
1. Extras API - юзать для составления краткого резюме беседы специальную модель через дополнение.
2. Main API - попросить сделать то же самое основную модель. Промпт для этого запроса пишется в поле Summarization Prompt.
3. Написать этот текст самому в блокноте
Текст сумморайзха будет отправляться каждый раз вместе с промптом, так что обращай внимание на его размер (чтобы не забил контекст).
Ещё смотри на параметр Update interval. Его надо настроить так, чтобы сумморайз произошол до заполнения максимального контекста иначе в нём будет мало смысла
Кобольд уже пробовал, не мой вариант.
Rocm не работает, а с загрузкой слоёв в видеокарту через CLBlast работает в 2-3 раза медленней чем на процессоре Ryzen 5600X
Думал может в угабоге что-то для АМД появилось...
У тебя проблема не столько в том, что у тебя амудя, столько в том, что у тебя говно_мамонта_амудя. Была бы 7000 серия, может чего и вышло бы.
Так что в магазин за какой-нибудь 3060 12ГБ, будешь как барин с ней 13B крутить.
> Сумморизация это спасательный круг при малом контексте, позволяющий модели иметь хоть какое-то представление о содержании диалога за пределами контекста.
> Текст сумморайзха будет отправляться каждый раз вместе с промптом, так что обращай внимание на его размер
А, ну нахой его тогда. Я уж думал может из 8к можно будет псевдо-32к выжать. А если у меня каждый раз будет суммарайз+лорбук+промпт анализироваться я помру быстрее чем мои 8к контекста засрёт.
>3060 12ГБ
А сколько войдет контекста до падения скорости?
Ну предположим там 8 квант крутится 7b или 4 квант 13b в ~8 гигов размером. 4 оставшихся гига это контекста на 3-4к, дальше уже замедление на сколько то, я так понимаю
>суммарайз+лорбук+промпт
А какая тебе разница что конкретно анализируется?
Когда твои
>8к контекста
забьются, они будут анализироваться с той же скоростью, сумморайз меняет только содержимое, делая его чуть более "содержательным"
>Я уж думал может из 8к можно будет псевдо-32к выжать.
Так и есть с некоторыми оговорками.
>12ГБ
Не вижу смысла покупать что-то меньше 24 Гб.
Зачем платить за 12Гб видеокарту, если в колабе есть бесплатные 15?
Можно конечно извращаться, загружая 2/3 30В моделей в ОЗУ, но тогда уж проще тупо крутить это всё на процессоре, вряд ли 3060 12ГБ даст заметный прирост производительности
> если в колабе есть бесплатные 15?
24/7?
> Можно конечно извращаться, загружая 2/3 30В моделей в ОЗУ, но тогда уж проще тупо крутить это всё на процессоре, вряд ли 3060 12ГБ даст заметный прирост производительности
А если охота 13б, но с контекстом пожирнее?
Можно парочку таки на проце крутить, зато с 8к контекста.
>Не вижу смысла покупать что-то меньше 24 Гб.
А что сразу не 80? Если чел на 580 рыксе, то у него явно денег мало.
>вряд ли 3060 12ГБ даст заметный прирост производительности
Таки даст, хули нет то.
>24/7?
При условии наличия несколько акков, да. 4-5 часов на каждом можно крутить без проблем.
А если нужен кум в любой момент в 1 клик, есть ещё Хорда.
>А что сразу не 80? Если чел на 580 рыксе, то у него явно денег мало.
Я и есть тот чел лол. Сижу на колабе и просто не понимаю какие конкретно преимущества я получу от приобретения 3060?
Как в кобальд озвучку прикрутить? Желательно еще и на русском
Ну бери 24, хозяин барин.

Кто-нибудь экспериментировал с порядком семплеров?


Не перестаю ржать с перевода.
Были эксперименты, порядок в кобольде оптимальный, там по уму всё.
Берёшь linux со старыми версиями rocm у меня на 5.4 работало, на 5.7 отвалилось, да ещё и clblast с собой прихватило, clinfo теперь радует ошибкой "clGetPlatformIDs(-1001)", думаю то ли откатываться на стабильную ветку с нестабильной, то ли подождать, вдруг починят. Там всё работает. На clblast и rocm скорости одного порядка, между собой различаются, но заметно опережают cpu. На винде opencl есть, по крайней мере промпт должен обрабатываться быстрее, если кинуть 0 слоёв.
https://github.com/kalomaze/koboldcpp/releases/tag/minP нашел описание мин-р, вроде оно
Так все уже знают о "рассуждай шаг за шагом", "подумай немного перед ответом" еще недавно видел исследование тестирование различных подобных фраз, так что еще в копилку "Это очень важно для моей карьеры.", "Тебе лучше быть уверенным". увеличивает точность ответов.
Это кстати в шапку бы
ультимативный рецепт промпта оттуда же
https://www.promptingguide.ai/applications/workplace_casestudy
Причем для лламы эффект был довольно сильный (конечно не смотрел что там за бенчмарк, но по сравнению с другими моделями).
>Зачем платить за 12Гб видеокарту, если в колабе есть бесплатные 15?
Хочу кумить на вещи не показывая их гуглу.
Хотя у нас тут гдпр и все такое, может и норм.
Гугл не особо то палит проихсходящее на колабах. Иначе они бы за Stable Diffusion баны раздавали. Но вместо этого у них тупо работают скрипты, проверяющие текст колаба, если триггерных слов в нём нет, то всё ок.
Я ещё и через гуглпереводчик кумлю лол
>Гугл не особо то палит проихсходящее на колабах. Иначе они бы за Stable Diffusion баны раздавали. Но вместо этого у них тупо работают скрипты, проверяющие текст колаба, если триггерных слов в нём нет, то всё ок.
Так они проверяют на триггерные слова еще лол? Весь смысл локала же отсутствие цензуры.
Блэт, а почему рейтинг, который из шапки, снесли нахуй? Как бы он есть, но теперь там непонятно нечего и сортировки по размерам нет...
Ни у кого не осталось того рейтинга?
https://rentry.co/ayumi_erp_rating
Ни у кого не осталось того рейтинга?
https://rentry.co/ayumi_erp_rating
>Гугл не особо то палит проихсходящее на колабах.
Логируют всё, просто ПОКА нечем на это реагировать кроме как скриптами по ключевым словам.
Ну когда допилят нейросети тогда все логи будут просмотрены хех.
А кто-нибудь игрался с китайской Yi? Норм или не?
говорят топчик и это базовая модель, их там 2 кстати на 6b и 34b
Есть план для тех кто не любит логирования, отрезаем ембеддинг и суем себе на комп, а на коллаб передаем векторы. Так же с языковой бошкой. Все никто ничего не запалит.
https://arxiv.org/pdf/2307.11760.pdf
Я вот отсюда почерпнул если кому интересно может прочитать весь док, тоже в копилку знаний.
Неплохо, но звучит заморочно
Забавно конечно, эмоционально давать на нейросеть для получения более качественного ответа.
Где эти фантазии о холодных и логичных ИИ прошлого?
Сейчас будет смешно читать или смотреть про такие ИИ, да уж.
>Так они проверяют на триггерные слова еще лол?
В ТЕКСТЕ КОЛАБА Проверяется только код.
Никто не смотрит что ты на нём генеришь, это на практике проверили когда бан каломатика обходили.
А логирование резальтатов генерации это вообще лол Я лично не менее 200 Гб пикч на колабах нагенерил, и таких халявщиков как я тысячи. Я прям имаджинирую как они тратят миллионы на аренду датацентров чтобы хранить всё это говно, а потом ещё за каким-то хуем в нём копаться.
> 200 Гб пикч на колабах нагенерил, и таких халявщиков как я тысячи.
Капля в море, ваши сотни терабайт полная фигня. К тому же можно не хранить картинки и тогда несколько гигов логов. Или тупо сжимать и все дела. Конечно они нахрен никому не нужны, но если вдруг будут нужны и будут ии для их обработки - то вот они под рукой.
0.7 база же
шутка про
> на видюхе
> пик2
пиздец ну и изверги, вот и загружай теперь карточки в таверну
Вообще порядок уже относительно оптимален, было несколько вариаций. RepPen точно должно быть в начале а температура в конце. В остальном там уже как отсеивать не то чтобы сильно много разницы и зависит от модели и выставленных параметров.
Более актуально будет
> но если тебе не нравится то не надо
слишком базированная будто на ней обучали
> Проверяется только код
Писали что еще выдачу в консоль.
Логи генерации храняться в файлах проекта. Если бы им было не лень написать хотя чуть более сложный скрипт для проверки названия этих файлов, то хуй бы получилось так легко бан обойти. Но вместо этого впилили тупой поиск по спам листу из десятка слов и забили.
Какое нахуй сжатие и выборка что хранить а что нет, они на элементарные вещи хуй забили.
>Писали что еще выдачу в консоль.
Это я писал. Оказалось что нет, вместо этого проверяли соединение популярных туннелей с каломатиком и имя основной папки причём только в папке /content/
> Если бы им было не лень
Это не лень, если бы мешались - давно бы передавили как тараканов
> Почитай вот это: https://github.com/KoboldAI/KoboldAI-Client/wiki/Settings
Достаточно просто описано кстати, спасибо, но статья уже год не обновлялась, там про тот же миростат нету
http://web.archive.org/web/20231006043847/https://rentry.co/ayumi_erp_rating/
Так два раза уже давили, обновляя систему проверки, так и не задавили.
Я пытаюсь сказать что бан генерации картинок, которая буквально уже опять роняет сервера при наплыве саранчи явно чуть важнее, чем поиск и сохранение текстата твоего кума. А забанить окончательно каломатик было бы гораздо проще тупо запилить поиск по всем папкам занеся в спам лист типичные для каломатика пути А раз даже этого до сих пор не сделали, то выборочное логирование ваших кумов - история формата Рен-ТВ.
Спасибо за вебархив, анчоус.
>Так два раза уже давили,
Да? Я там не сижу, ну тогда похрен. И все равно должна быть цифровая гигиена, я бы сорить своими данными там не стал
>И все равно должна быть цифровая гигиена, я бы сорить своими данными там не стал
@
В это время весь соседний тред сидит на проксях сомнительного происхождения, часть из которых ДЕЙСТВИТЕЛЬНО логируется.
https://github.com/daveshap/latent_space_activation/tree/main#latent-space-activation охуеть там черная магия началась
Скачал утопию13б от унди, рпшит неблохо, но любит под конец сообщения скатываться в промотку сюжета, несмотря на прямой запрет. Как фиксить?
Это же обычный мультиагент. Всё ещё не ясно главное - как заставлять нейроку задавать себе корректные вопросы и не делать по 10 попыток на каждый.
> Как фиксить?
Никак, это на баг, а фича РП-кала. Там в датасетах простыни "историй", вот он тебе и высерает таймскипы. Частично можно пофиксить форматированием контекста - строго как в датасетах, без РП-шаблонов, без длинных описаний персонажа и его жизни.
там дальше целая репа разных примеров у него же
> Никак, это на баг, а фича РП-кала. Там в датасетах простыни "историй", вот он тебе и высерает таймскипы.
Ну когда в конце КАЖДОГО сообщения "а дальше анон и двадетян мечты захуярили стопцот калодраконов, развалили пять государств, постигли протоколы сионских мудрецов и стали лучшими соулмейтами" это уже нездорово. Оно сначала нормально пишет в формате описание-реплика-описание-реплика, но когда пора бы уже мне отвечать (и ранее в диалоге она передавала мячик), она этим серет.
> Частично можно пофиксить форматированием контекста - строго как в датасетах, без РП-шаблонов, без длинных описаний персонажа и его жизни.
Карточки персонажа всмысле? Так у меня и так он в формате Personality [Mysterious. Experienced. Mastermind. Wise. Insightful. Cunning. Manipulative. Cryptic. Lazy. Methodical. Unconfrontational. Civilized. Compassionate. Whimsical. Womanly. Confident. Cultivates negative image so she's feared]. Или чего я не понимаю?
>то выборочное логирование ваших кумов
Нет нужды в выборочном логировании, когда логируется ВСЁ.
Не всегда, у меня Mlewd только к 35-40 сообщению скатывалась, а утопия что-то аж на 13 сваливается.
Я не сижу в ai тредах и возможно я тупой/слепой/тугодум конечно. Но почему фарадея до сих пор не в шапке треда? Это же самый наипростейший способ запустить текстовую нейросеть, как будто игру установить.
Об этом выше написал. Сохранять ВСЕ файлы это примерно по 30 Гб с каждого сеанса. Я конечно понимаю что у гугла есть БЕСКОНЕЧНОЕ дисковое пространство, но даже они вряд ли расходуют его настолько не рационально, серьёзно НАХУЯ?!
А искать только текстовые файлы с логами - слишком геморно. Выше уже привел пример что они даже до более простых и полезных решений не заморачиваются.
Но любителей шапочек из фольги не переубедить.
не забудь перед сном прогреть свою видеокарту в микроволновке, а то вдруг она твой кум лично Хуангу через драйвера отсылает!
Юзай другую модель.
Дамп образа памяти каждую минуту?
Чтоэта?
Нет нужды в логировании всего когда можно логировать твои мозговые волны.
>фарадея
Шапка фарадея на голову защищает твои мозговые волны.
Фарадей. Скачал, установил как игру при помощи exe файла и всё. 64гиг оперы позволяют запустить даже 70B. хотя мне с моими 1200f 1050ti 64gb приходится ждать полный ответ целую минуту . Но всегда есть мистраль который пойдет на любой картошке
> Фарадей
Ааа, ну теперь все понятно. А кобольд это получается портативный фарадей?
Хранить сами изображения не надо же - можно просто просканировать и сохранить метаданные. От сотен гигабайт картинок останется лишь то, что Иван из города Тверь дрочит на кошкодевочек.
>Yi-34B-Q8-GGUF
Заебатая модель. Рпшит заметно лучше, чем Airoboros 34b.
Заебатая модель. Рпшит заметно лучше, чем Airoboros 34b.
Ну можно и так сказать. Просто Кобольд нужно настроить самому, а тут добрые люди уже всё сделали за тебя. Нажимай копку запуск и начинай чат со своим персом.
На каком железе гоняешь?
Да йобана, кинь ссылку на это хотябы
Мне она показалась шизанутой и достаточно тупой. Даже ллама1 на 33b лучше.
> а тут добрые люди уже всё сделали за тебя.
А что там настраивать? Клацаешь и по умолчанию на проце все. Хочешь быстрее, начинаешь разбираться в настройках.
Аноны, извиняюсь что крамольную вещь скажу, но есть ли вообще сейчас смысл вкатываться в локалки, когда в облаке те же самые модели за копейки крутятся?
Вот, гляньте: https://openrouter.ai/docs#models
За 1 доллар можно генерить 1000000 токенов LLama2 70В моделью.
При этом не обязательно мучаться в стандартном веб-интерфейсе, можно просто апи-ключ скормить установленной у себя жалкой таверне:
https://docs.sillytavern.app/usage/api-connections/openrouter/
А я-то планировал купить себе крутую пеку с 64 гигов ддр5 памяти в 4 канала. Но бля, с такими ценами на облако, я эту пеку до конца жизни не окуплю.
Вот, гляньте: https://openrouter.ai/docs#models
За 1 доллар можно генерить 1000000 токенов LLama2 70В моделью.
При этом не обязательно мучаться в стандартном веб-интерфейсе, можно просто апи-ключ скормить установленной у себя жалкой таверне:
https://docs.sillytavern.app/usage/api-connections/openrouter/
А я-то планировал купить себе крутую пеку с 64 гигов ддр5 памяти в 4 канала. Но бля, с такими ценами на облако, я эту пеку до конца жизни не окуплю.
2X E5-2680V4@128GB
А какие у тебя были настройки?
Любопытно мнение илиты о https://www.ozon.ru/product/videokarta-nvidia-tesla-k80-24-gb-videokarta-lhr-993195162/ .
кун
кун
В том то и дело что нужно разбираться. А для такого тупого и ленивого ананаса как я которых на борде явно дело большинство намного проще просто нажать на кнопку и ничего не настраивать вообще, всё уже работает на максималках.
>А какие у тебя были настройки?
1.0 температура 0.05 мин п. Но она и без настроек шизит. В одном из моих промптов был 5% шанс улететь в бесконечный луп шизы. Это очень плохо.
Ну чёрт знает как ссылку кинуть. Ручки то из жопы растут. Напиши в Гугле фарадейдев.
> За 1 доллар можно генерить 1000000 токенов LLama2 70В моделью
За обработку промта (!) на лям токенов (а считай при долгом рп у тебя каждый свайп и пост это по 8к) на нормальных моделях - 10 долларов. Считая средний ответ в 350 токенов там на генерацию с этих постов еще 0.4 доллара набежит.
~10.5 долларов за 125 постов включая свайпы на полном контексте (считай 200 если кумить не долго и почаще начинать новый чат, буквально часик посидеть), это по-твоему дешево? При этом существенные бонусы локальных моделей в виде отсутствия логов, следов и возможности как угодно ими управлять и выбирать любую теряются.
> не обязательно мучаться в стандартном веб-интерфейсе
В нем кто-то рпшит?
> планировал купить себе крутую пеку с 64 гигов ддр5 памяти в 4 канала
Оно будет стоить как пара видюх и не даст и 20% от их перфоманса.
faraday.dev. Вот так.
> кепплер
p40 на 24 гига хейтят за низкий перфоманс, которая аж на 2.5 архитектуры моложе, а ты еще более старую примерно в ту же цену предлагаешь. На такой некроте скорее всего вообще ничего не заведется, чекай совместимость.
> чёрт знает как ссылку кинуть
https://faraday.dev/
Еще одно все в одном, в этот раз хотябы действительно для новичков. Хз, давай рассказывай какие модели оно кушает, что может и т.д. Процесс "установки" нормальных средств невероятно простой а функционал относительно готовых васян-сборок с малвером может разительно отличаться, опиши что тут. Из приличных готовых llm studio ничего.
Смысл локалок в полной независимости от дяди. Так что мимо.
Да и модели там ХЗ какие.
Кушать она ничего не кушает. Все доступные модели есть в списке, просто нажимаешь и она скачивает как стим игры , ничего по папкам рассовывать не надо. Потом выбираешь персонажа если очень умный можешь создать его сам прямо тут же методом контрл ц контрл в и начинаешь чатиться с персонажем. Очень нравиться что картинка персонажа всегда перед лицом как будто ты действительно с ним говоришь.
>p40 на 24 гига хейтят за низкий перфоманс
Кстати такой вопрос: есть ли смысл покупать P40 как вторую видеокарту к 4090? Понятно, что она в разы медленнее, но все равно должно получиться в 2-3 раза быстрее, чем крутить половину модели на процессоре. Из подводных вижу разве что отсутствие охлаждения, но у меня снизу корпуса три 120мм вентилятора, которые будут дуть прямо на карту, так что должно быть нормально. Стоит она гроши, и как временное решение для запуска 70b - самое то.
Ты уж прости что так мало что рассказал, но я действительно пользуюсь просто нажав на ярлык проги и начинаю чатится с ботом, не особо разбираясь что там в настройках. У них вроде и дискорд есть там всякие фишки и тд, но мне этого не надо, все работает как часы.
>~10.5 долларов за 125 постов включая свайпы на полном контексте
Ну нихуя себе, то есть за каждый пост нужно платить с учетом полной цены 8к контекста? Вот они молодцы, красиво наебывают.
Не, так получается уже наоборот слишком дорого.
>Оно будет стоить как пара видюх и не даст и 20% от их перфоманса.
А разве есть выбор? Даже две RTX3090 в сумме 64 гигов не дадут, а значит 70В модель ты в них не впихнешь. При этом стоят такие пусть даже и устаревшие ведюхи очень не дешево.
>Даже две RTX3090 в сумме 64 гигов не дадут.
Дружище. А зачем тебе 64 гига на видяхе? Купи что-то на нормальной писиай шине тиипо 4х и 64 гига оперы, она сама подхватит что ей не хватит.
> есть ли смысл покупать P40 как вторую видеокарту к 4090?
Увы, нет. Она слишком медленная, судя по постам на ресурсах в 7т/с в 13б 4бита и 6 итераций/с в диффузии, не факт что выйдет быстрее процессора. Хз, тут надо тестить, если готов потенциально потерять затраты на нее то можно попробовать. А под контекст или чтобы ~3 бита влезало хватит и 3060, она точно будет быстрее.
Самый топ это 3090, если офк остались живые-дешевые на вторичке, она лишь немного уступает 4090 в ллм, но при это ценник космос.
> но у меня снизу корпуса три 120мм вентилятора, которые будут дуть прямо на карту
Этого не хватит, придется что-то дополнительно колхозить. Но проблема решаемая, кмк в принципе разместить полноразмерную видюху в пару к уже стоящей 4090 куда сложнее. Тут или водян_очка, или тащить длинным райзером на место где в старых корпусах стояла корзина и крепить вертикально, если длина корпуса позволяет.
Да уже глянул ветку на реддите, багов и жалоб хватает.
Хз, сомнительная штука, возможно офк недооцениваю насколько хлебушками бывают люди и насколько готовы жрать с лопаты.
> Ну нихуя себе, то есть за каждый пост нужно платить с учетом полной цены 8к контекста?
Да, в обработке считается длина контекста каждого запроса что отправляешь, на полном это чуть меньше 8к будет. Глянь тарифы на клоду, например, так обработка промта гораздо дешевле чем генерация, а тут вон как зарядили.
> Даже две RTX3090 в сумме 64 гигов не дадут
Они дадут 48, этого хватит чтобы крутить почти 5битный exl2 квант с влезающим контекстом 12-16к со скоростями ~13-15т/с (ориентировочно, на 4090 16-20) и наслаждаться результатами и находить реальные вещи с которых стоит гореть
temperature: 0.9
top_p: 0.3
top_k: 45
typical_p: 0.9
repetition_penalty: 1.18
И, конечно, Q8
У меня вроде бы всё нормально, шизы и деменции нет.
На форче кто-то собрал дешевый сервер с тремя P40, получив 6t/s на жирном кванте 70b c 8k контекста.
>Этого не хватит, придется что-то дополнительно колхозить
Колхозить не хочу (слишком много времени и денег потратил на дизайн пекарни), докупать 3090/4090 тоже не хочу (могут устареть через несколько месяцев после выходи третьей лламы), и 3060 тем более. В общем буду думать. Мне в принципе и скорости на процессоре хватает.
>6t/s на жирном кванте 70b c 8k контекста.
Звучит заебато для цены из того поста. Или нет?
> top_p: 0.3
Жесть, а потом еще жалуются на тупняк и одинаковые свайпы.
Не ну если так то может и ничего, 6 токенов это вполне можно жить, раньше писали про 6 с 30б моделью что влезала в одну карточку. Поищи заводится ли на них эксллама и с каким перфомансом.
> могут устареть
Не устареют до релиза 5к серии, и то в зависимости от количества памяти в ней и цен. Сборка же на профессоре - сразу херь, получишь ~4 токена на q4. Другое дело если он будет еще как-то использован, но с ценами на около-hedt на ddr5 полнейший пиздец что видюхи недорогими кажутся.
Вопрос цены, анон. Одна 3090 новая сейчас около 1500 баксов стоит.
Новый комп с ддр5 памятью обойдется дешевле даже одной такой видюхи.
Или вот такой вариант еще можно, но эти древние видюхи очень быстро сдохнут.
Алсо, для совсем нищебродов есть еще вариант собрать на серверной ддр4 памяти и некро-зионе систему с 64 гигами. Такой вариант вообще копейки стоить будет.
> 3090 новая
Новых их уже нет, только оверпрайс залежи где-то, раньше где были их по 800-1к распродавали. Бу стоили в районе 50-60к рублей и по состоянию сильно лучше чем мертвечина на паскалях или более старые теслы, офк речь в этом контексте.
> Новый комп с ддр5 памятью обойдется дешевле
Да, но обычный компт без видюхи выдаст смешной результат и будет почти неюзабелен из-за вечной обработки контекста. Некрозеон тут действительно хорош, но, опятьже, перфоманс.
Очень заебато. Он в сумме потратил $1k, купив все на вторичке, наколхозил вентиляторы, накатил линукс и может без проблем гонять Q6 70b 8k.
>Поищи заводится ли на них эксллама и с каким перфомансом.
Не заводится. Это для кобольда/лламыцпп.
>Не устареют до релиза 5к серии
Я про сами модели. Допустим, я смогу запихнуть вторую видеокарту, получив 48GB видеопамяти, и через несколько месяцев выходит ллама3 на 120-180b. Для третьей-четвертой-пятой видеокарты придется собирать с нуля настоящий (дорогой) сервер, тратить кучу денег на сами видеокарты и лимитировать энергопотребление чтобы не упереться в предел мощности розетки. И все это может обойтись дороже, чем просто купить Мак ультра или дождаться новых профессиональных видеокарт на 192GB VRAM, которые анонсировала АМД. Если будет стоить в пределах $10k, то цена вполне оправдана. Можно будет просто вставить в пекарню еще одну (относительно) маленькую видеокарту, и кумить до посинения на любых моделях, хоть 180b.
>192GB VRAM, которые анонсировала АМД
192GB просранной памяти без куды.
> и через несколько месяцев выходит ллама3 на 120-180b
Которая повторяет судьбу 180 фалкона и прочих огромных сеток, которые никому не нужны. Хотя, офк, такая ллама, если экстраполировать, ебала бы почти все, так что вероятность ее появления крайне мала, а нормисам бы быстро сдистиллировали до 30-70-90б.
В любом случае при выходе такой модели все остальное также устареет из-за перфоманса.
> чем просто купить Мак ультра или дождаться новых профессиональных видеокарт на 192GB VRAM
Да, он достаточно интересен с учетом его оригинальной цены, но во-первых у нас его не купить, а во-вторых там та же проблема перфоманса. Рапортуют о 5-9 т/с на q4 моделях 65-70б (все что нашел когда изучал, если есть более актуальные данные - скинь), что сильно уступает по прайс-перфомансу двум гпу.
> которые анонсировала АМД
Мы уже знаем что там будет, а
> будет стоить в пределах $10k
для такого класса оборудования в период его дефицита и высокого спроса - без шансов.
>192GB просранной памяти без куды.
Они как раз рекламируют запуск LLM. В любом случае, это заставить нвидию увеличить количество видеопамяти как в профессиональных, так и в игровых видеокартах. Я думаю что можно надеяться на 5090 с 48 гигами и новую линейку профессиональных видеокарт.
>В любом случае при выходе такой модели все остальное также устареет из-за перфоманса.
Ну я поэтому и не хочу обновляться. Разве что мак купить, но ради 70b жаба душит, тем более что они работают вполне нормально и на процессоре.
>Рапортуют о 5-9 т/с на q4 моделях 65-70б (все что нашел когда изучал, если есть более актуальные данные - скинь), что сильно уступает по прайс-перфомансу двум гпу.
https://twitter.com/ggerganov/status/1699791226780975439
Больше 6 токенов на фалконе.
>для такого класса оборудования в период его дефицита и высокого спроса - без шансов.
Ну дай мне помечтать...
Как это настраивать?
>Вопрос цены
Дак рха7600 за 31к + 64гиг ддр4 14к намного дешевле выйдет и запустит 70b чем на 3090 тратить.
>Ну дай мне помечтать...
Полагаю простым работягам достанутся только БУшные профессиональные карточки.
А почему бы и нет? Уже хоть что-то.
С одной стороны да, с другой БУ картон устаревший и выпотрошенный в ноль, сейчас вон на -3 поколения только есть, всё что новее по эверестовым ценам.
>Очень заебато. Он в сумме потратил $1k, купив все на вторичке, наколхозил вентиляторы, накатил линукс и может без проблем гонять Q6 70b 8k.
У него такая пекарня хоть год проработает? Это же пиздец старье, эти печки лет 10 уже жарили, небось еще и майнили крипту.
Да, но обычный компт без видюхи выдаст смешной результат и будет почти неюзабелен из-за вечной обработки контекста.
Поставить какую-нибудь затычку пусть даже с 4Gb памяти, 3050 вроде дешево стоит.
Склоняюсь к мысли что сейчас все же на CPU генерировать хоть и медленнее, но доступнее для простого хоббиста. По крайней мере можно купить новое железо за адекватный прайс, а не мучаться с говном мамонта. Плюс, если вдруг актуальны станут 100В+ модели, то можно будет просто купить вдвое большие ддр5 планки.
> поэтому и не хочу обновляться
Ждунство тоже вариант, другое дело что всегда будет что что-то новое будет всегда если офк не "все в труху" и пока засматриваешься на перспективы проебываешь то что есть сейчас. Тут лучше в принципе исходить из целесообразности трат на игрушки, а так уже подсчитали, лучше пары гпу сейчас вариантов нет.
> https://twitter.com/ggerganov/status/1699791226780975439
6 т/с на младшем кванте мертворожденной модели без контекста, а так тот же фалкон и с применением интересных методик кванта и до 40 гигов ужимали, работает также хуево как в стоке. С учетом что торгуется у нас эта железка сравнимо уже с парой a6000 или 80гиговой теслой - ну не, плюс других юзкейсов нет и беда с ликвидностью.
менее 1т/с?
Перекат очередной.
ПЕРЕКАТ
ПЕРЕКАТ
Ебучая макака опять накрутила кривых фильтров.
ПЕРЕКАТ
ПЕРЕКАТ
Сука, ещё раз, ЕСЛИ БЫ ОНИ СКАНИРОВАЛИ МЕТАДАННЫЕ, КАЛОМАТИК БЫ СЕЙЧАС НЕ РАБОТАЛ!!!
>можно надеяться на 5090 с 48 гигами
По утечкам либо 24, либо расщедрятся аж на 32.
Не слушай додиков, там есть нормальная сеть даже дешевле смотри внимательно. Я не хочу сам палить контору скорость то зависит от того сколько двачеров туда налетит, но даже скипая по 8к контекста ты за месяц ну может 5 долларов потратишь не больше. Но опять же там нет таких контекстов там по 4к в основном. 14b модель там вообще по цене грязи. Если тебе нужен безлимит за 20 долларов много где есть 70б модели. Короче забей реально покупать сейчас невыгодно комп для сетей. Я уж не говорю за HF где ты вообще можешь забесплатно пользовать некоторые модели через их апи, разве что тебе проксю для этого придется написать. А если искать вариантов еще больше. Так что не нужен сейчас комп для сетей, мне лично срать кто там будет мою переписку читать даже еслиб кто этим занимался.
>2X E5-2680V4@128GB
Сколько токенов в секунду?
А смысол вашего дроча на локалки? Опенсурс откуда вы берёте софтваре тоже под соей, а обучить самому практически невозможно без доступа ко всяким тензорфлоу
Обладатели 3060 12гигов, расскажите, какие у вас скорости? Сколько токенов в секунду?
Нищеброд вкатился в тред. Скопил сто баксов с завтраков и закупил пару 16 гиговых планок DDR-3200 памяти для своего ноутпука. Также на нем у меня есть видюха RTX3050 с аж 4Gb видеопамяти.
Какую модель посоветуете для начала? Мне не ролеплей, чисто сторителлер нужен чтобы с как минимум 8к контекстом работал. Главное чтобы красиво рассказывал истории с натуральными диалогами в точности по моему промпту. Надо чтобы поменьше шизы было и сои хотя бы терпимо. На скорость похуй, могу по несколько минут ждать ответ.
Какую модель посоветуете для начала? Мне не ролеплей, чисто сторителлер нужен чтобы с как минимум 8к контекстом работал. Главное чтобы красиво рассказывал истории с натуральными диалогами в точности по моему промпту. Надо чтобы поменьше шизы было и сои хотя бы терпимо. На скорость похуй, могу по несколько минут ждать ответ.
>14b модель там вообще по цене грязи.
Такую модель небось бесплатно на гугол коллабе запустить можно, там вроде максимум 16 гигов видеопамяти дают.
>Если тебе нужен безлимит за 20 долларов много где есть 70б модели.
Спасибо, поищу такое.
>Я уж не говорю за HF где ты вообще можешь забесплатно пользовать некоторые модели через их апи, разве что тебе проксю для этого придется написать
Зачем прокси? Из-за особого отношения к россиянам? Алсо, с чего бы такая щедрость? Там небось лимиты есть или долгие очереди если уж бесплатно.
>Такую модель небось бесплатно на гугол коллабе запустить можно, там вроде максимум 16 гигов видеопамяти дают.
Верно но на коллабе ограничения по времени, а тут когда захотел тогда и юзаешь и не паришся с запусками.
>Зачем прокси? Из-за особого отношения к россиянам? Алсо, с чего бы такая щедрость? Там небось лимиты есть или долгие очереди если уж бесплатно.
Прокси не в смысле чтоб доступ запрещен. А в смысле чтоб подтянуть GUI типо таверны, сменить формат api. Скорее всего что то должно быть уже готовое но искать нужно. А щедрость в том что модели не большие, 7b к примеру. Их запустить большой компании ничего не стоит.
>Спасибо, поищу такое.
навскидку на chub есть такая подписка
>Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна
Реквестирую гайд для ретардов с ёба-картой. Попытался разобраться, потерпел сокрушительное поражение. А на процессоре унизительно долго генерятся токены.
> Реквестирую гайд для ретардов с ёба-картой.
В KoboldCPP используй CuBLAS и поставь то количество слоев, на которое тебе хватит видеопамяти. Остально в оперативе будет.
Повтор для слепых.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Undi95/MLewd-ReMM-L2-Chat-20B-GGUF/blob/main/MLewd-ReMM-L2-Chat-20B.q5_K_M.gguf
Если совсем бомж и капчуешь с микроволновки, то можно взять
https://huggingface.co/TheBloke/Mistral-7B-OpenOrca-GGUF/blob/main/mistral-7b-openorca.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://rentry.co/ayumi_erp_rating Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Факультатив:
https://rentry.co/Jarted Почитать, как трансгендеры пидарасы пытаются пиздить код белых господинов, но обсираются и получают заслуженную порцию мочи
Шапка треда находится в https://rentry.co/llama-2ch предложения принимаются в треде
Предыдущие треды тонут здесь: