



Напоминаю, что у нас есть целый железотред, который уже полгода перекатить не могут.
Как насчет добавить в следующую шапку инфу по мультимодалкам, их запуску, использованию и т.д.?
Всю нищету с копро-серверами и дедушкиными P40 надо туда отправить.
>копро-серверами
Мета треда.
> P40
Новая База треда.
Отчасти поддвачну. Совсем совсем выгонять может и не стоит, всеже про запуск, но i want to believe, топ за свои деньги, хвсрачи и подобное надо нахуй туда депортировать ибо в этой шизе полезный релейтед теряется.
Шапка достигла максимального размера, так что добавлять туда можно только ценой минета абу за расширение лимита удаления чего-то старого, ну или переноса шапки полностью на ретрай (не хочу, ибо падает постоянно).
Если будет не лень то на рентрае что-нибудь накидаю, ведь тема интересная и полезная, а ее незаслуженно обходят стороной. И часть из шапки не мешало бы вынести туда же, без форматирования и картинок тяжело воспринимается. тредик не болей, все срачами по смежным темам загадили

и вобще это ж ллм тред, пусть по шапке нейронка пройдется и оптимизирует ее
Что думаешь насчёт переноса шапки в данную вики, по типу того, как это было сделано в технотреде https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/ ? Там тоже шапка уже раздулась до невозможности и её перенесли.
Из плюсов: можно переносить важную инфу по разным файлам https://gitgud.io/2ch-ai/wiki/-/tree/master/docs/tech , делать структурированные рендеры разметки маркдауна, как это было сделано с инфой из войс-треда https://2ch-ai.gitgud.site/wiki/speech/
Из минусов: надо в гит и маркдаун, можно впринципе и через вебинтерфейс.
Могу выдать права мейнтейнера, если интересен такой вариант, чтобы ты мог без форков в основной репе сразу инфу добавлять.
>Из минусов: надо в гит и маркдаун, можно впринципе и через вебинтерфейс.
И главный минус- если сайт наебнётся, или там решит, что чёлки у авторов не в ту сторону пострижены, то всё это наебнётся нахуй.
>Могу выдать права мейнтейнера
Кидай, разберусь на выходных. Фейкоакк llamanon
>полностью выгруженных 7б q8 - 25 т/с
>13b Q8 (как раз примерно на большую часть памяти карты) - 4.83т/с
>у другого на 30б с почти полной выгрузкой быстрее, в районе 10 или больше
То есть из очевидных минусов только неясные перспективы запуска 70В на 3 картах?
Даже не двух. Если такой перфоманс достижим и за такую цену с учетом оговорок (горячая, перфоманс в остальных нейронках известно что низкий, пылесос по шуму и цирк с охлаждением, лошадка очень много пахала и насколько здорова не ясно) устраивает - почему бы и нет.
> И главный минус- если сайт наебнётся, или там решит, что чёлки у авторов не в ту сторону пострижены, то всё это наебнётся нахуй.
Расчёт идёт на две вещи:
1. Если открыть топ проектов на gitgud по числу звёзд https://gitgud.io/explore/projects?sort=stars_desc то можно увидеть, что там проекты с лоликоном и прочим хентаем занимают топы, и живут по нескольку лет. И ссылки на nai leak там хранились в каких-то md-файлах, их никто не сносил. А вот в том же github у automatic1111 сносили репу за неправильные ссылки в readme.
2. Это примитивная система без какой-либо базы данных, просто куча md в html конвертится средствами либы на питоне. Её можно заменить на любую гит-репу и копеечный хостинг для статики. Полная локальная копия проекта делается по сути через git clone.
> Кидай, разберусь на выходных. Фейкоакк llamanon
Выдал права.
О ты обновил шапку? Хорош.
Научите кумать
https://github.com/PKU-YuanGroup/Video-LLaVA
Ну что, господа, развитие мультимодалок?
> The video shows a man and a woman talking in a kitchen, and then the man leaves. Later, the man is seen walking in the woods and talking to another man.
Такие длинные и абстрактные видимо не может
1 видео
> In the video, we see a person riding a bike down a street while holding a camera. The person is wearing a white shirt and black pants. As the person rides, they pass by a gas station and a car dealership. The camera captures the person's movements as they ride down the street.
2
> In the video, we see a man lying on the ground while another man is kneeling next to him. A third man is standing up and talking to the man who is kneeling. The man who is kneeling then proceeds to tie the hands of the man who is lying on the ground. After that, he ties the legs of the man who is lying on the ground. The man who is kneeling then stands up and walks away. From the video, it seems like the man who is lying on the ground is being restrained or tied up for some reason. The man who is kneeling is most likely the one who is restraining the man. The man who is standing up and talking to the man who is kneeling is not clear what his role is in the situation. Overall, the video seems to depict a tense and potentially dangerous situation.
3
> In the video, a woman is seen standing in a hallway and looking at a sign on the wall. She then enters a bathroom and talks to a man who is sitting on a toilet. The man is wearing a green shirt and is seen laughing. The woman then leaves the bathroom and talks to another man who is standing in the hallway. The video seems to be a light-hearted conversation between the two men in the bathroom.
4
> In the video, we see two men fighting in a room. One of the men is shirtless, and they are both kicking each other. The men continue to fight, and the shirtless man eventually picks up the other man and throws him down. The shirtless man then stands over the other man, who is on the ground. The video ends with the shirtless man standing over the other man.
(динамическая ампутация конечностей при контрнаступлении, заливать не буду)
> In the video, we see a group of soldiers walking through a field, and they are carrying guns. They are also seen walking through a forest and a field. The soldiers are also seen driving down a dirt road in a military vehicle.
Оно пытается но больше похоже на просто анализ нескольких кадров без динамики.
Ну что, господа, развитие мультимодалок?
> The video shows a man and a woman talking in a kitchen, and then the man leaves. Later, the man is seen walking in the woods and talking to another man.
Такие длинные и абстрактные видимо не может
1 видео
> In the video, we see a person riding a bike down a street while holding a camera. The person is wearing a white shirt and black pants. As the person rides, they pass by a gas station and a car dealership. The camera captures the person's movements as they ride down the street.
2
> In the video, we see a man lying on the ground while another man is kneeling next to him. A third man is standing up and talking to the man who is kneeling. The man who is kneeling then proceeds to tie the hands of the man who is lying on the ground. After that, he ties the legs of the man who is lying on the ground. The man who is kneeling then stands up and walks away. From the video, it seems like the man who is lying on the ground is being restrained or tied up for some reason. The man who is kneeling is most likely the one who is restraining the man. The man who is standing up and talking to the man who is kneeling is not clear what his role is in the situation. Overall, the video seems to depict a tense and potentially dangerous situation.
3
> In the video, a woman is seen standing in a hallway and looking at a sign on the wall. She then enters a bathroom and talks to a man who is sitting on a toilet. The man is wearing a green shirt and is seen laughing. The woman then leaves the bathroom and talks to another man who is standing in the hallway. The video seems to be a light-hearted conversation between the two men in the bathroom.
4
> In the video, we see two men fighting in a room. One of the men is shirtless, and they are both kicking each other. The men continue to fight, and the shirtless man eventually picks up the other man and throws him down. The shirtless man then stands over the other man, who is on the ground. The video ends with the shirtless man standing over the other man.
(динамическая ампутация конечностей при контрнаступлении, заливать не буду)
> In the video, we see a group of soldiers walking through a field, and they are carrying guns. They are also seen walking through a forest and a field. The soldiers are also seen driving down a dirt road in a military vehicle.
Оно пытается но больше похоже на просто анализ нескольких кадров без динамики.
В догонку любителям бондов и эдвенчурок
> In the video, we see a man riding a motorized cart down a street. He is wearing a helmet and a pair of sunglasses. As he rides, he passes by several cars and a truck. The man appears to be enjoying himself as he rides around, taking in the sights and sounds of the city. The street is busy with traffic, and the man seems to be navigating his way through it with ease. The video captures the man's sense of freedom and adventure as he explores the city on his cart. Overall, the video showcases the man's love for adventure and his ability to find joy in the simple things in life.

Deja vu
Емнип, один анон из треда (обнял того няшку) купил у этого же продавана и просил потестить викуну. Лол.
Емнип, один анон из треда (обнял того няшку) купил у этого же продавана и просил потестить викуну. Лол.
А что 7b? Совсем маленькая же, она и на 8 гигов отлично тянет.

Я мистраль попросил. Можешь попросить у него Yi 6B для разнообразия.
>Overall, the video seems to depict a tense and potentially dangerous situation.
Напрягся.
А лучше 34б, она полностью 4qks квантом влезает в видеопамять. В конце концов, такое не для 6-7б покупается.
Так то, если захочется запустить на каждой карте по агенту со своей нейронкой, а потом уже координировать их работу то 7b сойдет.
Они будут достаточно быстро выдавать результат, несмотря на то что им нужно будет кучу раз передать его друг другу. 20-30 токенов в секунду как раз норм скорости для этого. А вот 34b уже медленнее, токенов 6-7 хорошо если будет. Впрочем они и качественнее должны быть, хмм.
> если захочется запустить на каждой карте по агенту со своей нейронкой
В 24 влезут две 7б если отказаться от фп16.
> будут достаточно быстро выдавать результат, несмотря на то что им нужно будет кучу раз передать его друг другу
Что?
>В 24 влезут две 7б если отказаться от фп16.
скорости меньше, но можно и так хули нет
>Что?
Как там агенты работают? Каждый по своему промпту, каждый может делать что то одновременно с другими, потом отсылают результат координатору, тот снова загружет их и тд. Можно конечно по цепочке работать, как уж их настроишь.
> скорости меньше
С чего вдруг? Использоваться единомоментно всеравно будет одна.
> Как там агенты работают?
В гопоте просто выбор отдельной сетки, которая наилучшим образом подойдет. В реализации lmoe Джона вместо отдельных моделей накатывается подходящая лора. Все.
> Каждый по своему промпту, каждый может делать что то одновременно с другими, потом отсылают результат координатору, тот снова загружет их и тд.
Это уже совет экспертов, или как хочешь называй, более сложная и заморочная в конфигурировании херь.
> более сложная и заморочная в конфигурировании херь.
ну и более эффективная, хотя конечно от мозгов сеток будет зависеть.
Вобще на роль координатора наверное лучше сетку по умнее ставить, тот же 34b. А специализированные 7b на выдачу результата. Те же прогерские сетки.
Короче это тема, но сложная. Хотя решения уже созданы, на том же гитхабе куча есть
>С чего вдруг? Использоваться единомоментно всеравно будет одна.
место для контекста сожрет, хотя если нужен будет небольшой контекст то и 2 можно крутить
> ну и более эффективная
Про 20-80 слышал? Если общий случай рассматривать то уже специализация сетки или хотябы промта даст основной эффект и незначительно замедлит обработку. С мультизапросами нужно понимать для чего именно это нужно и очень четко организовывать, чтобы не получилось что из двух правильных подробных и одного всратого ответа не был выбран только третий, и тот урезанный, зато шиза из него была аргументирована убедительно по аналогии с двумя правильными.
> Вобще на роль координатора наверное лучше сетку по умнее ставить
В том и суть, тогда вообще придет к тому что "эксперты" - просто источник инфы и подготовка ризонинга, которые облегчают работы самой умной модели.
> Хотя решения уже созданы, на том же гитхабе куча есть
Покаж
> место для контекста сожрет
У Жоры все плохо с этим, но разве настолько? 7б q8 с приличным контекстом должна занимать не более 12 гигов.
>Покаж
https://github.com/topics/autonomous-agents
Кучи, но в основном через апи к гопоте. Но есть и локалки, тока мало.
>Про 20-80 слышал?
Это уже вопросы реализации, а по идее это эффективнее.
>В том и суть, тогда вообще придет к тому что "эксперты" - просто источник инфы и подготовка ризонинга, которые облегчают работы самой умной модели.
Большая разбивает задачу на части, и дает мелким.Ээксперты предварительно обрабатывают инфу по своей специализации, а потом уже работает большая с их результатами. Ну как то так примерно.
>У Жоры все плохо с этим, но разве настолько? 7б q8 с приличным контекстом должна занимать не более 12 гигов.
Хз, так и 3 можно впихнуть если контекст не нужен большой, если там зерошот или 1-2 вопроса то и 2-3к хватить может.
> https://github.com/topics/autonomous-agents
На первый взгляд там оболочки для хранения промтов к гопоте и гуи для запросов к ним с некоторой автоматизацией, очередью запросов и т.д. Самое базовое - последовательность из них с детальным промт-менеджментом, подробными логами и принятием решений на основе ответов хоть построить можно?
> в основном через апи к гопоте
Это то наименьшая из проблем, другое дело что могут полезть промтопроблемы из-за заложенных в глубине особенностей.
> Это уже вопросы реализации, а по идее это эффективнее.
Кратно замедляешь скорость без гарантии лучшего ответа. Сделать реализацию чтобы выхлоп превосходил затраты не так уж просто, возможно без специфичного файнтюна и вовсе невозможно. А изначальный выбор модели и параметров не приводит к замедлению и сразу дает результат.
> Хз, так и 3 можно впихнуть
Врядли, много жрет слишком. Фп16 на жоре съедает более 16 гигов, может быть q6k еще удастся втиснуть.
>Самое базовое - последовательность из них с детальным промт-менеджментом, подробными логами и принятием решений на основе ответов хоть построить можно?
Откуда мне знать? Я не датасатанист, но скорей всего да. Иначе нахрена они нужны?
В целом согласен, апи можно и на локальный переделать, это не проблема.
>Врядли, много жрет слишком. Фп16 на жоре съедает более 16 гигов, может быть q6k еще удастся втиснуть.
Ну 3 сетки займут 21-22 гб, останется 2-3 гига на контекст, сколько там не скажу, но даже с 8q если запускать по одной сетке выделяя только одной сетке за раз контекст - сойдет и 3. Надо просто не выгружать сетки из памяти что занимает больше всего времени, а выделять/удалять контекст должно быть быстро.
Но нахрена 3 сетки на одном я не знаю.
Я тут с https://github.com/PromtEngineer/localGPT игрался вчера, но так нормально завести и не смог, ебля одна с командной строкой. С куда не смог собрать llama.cpp на какую то хуйню ругается, так вроде работает но меееедленно.
> Откуда мне знать?
Ну бля, написал что примеров дохуя, вот и подумал что шаришь конкретно в этом.
> апи можно и на локальный переделать
К стоковой llamacpp идет впопеновский эмулятор, так что тут просто. Другое дело что с настройками семплинга, параметрами да и самим системным промтом придется играться.
> Ну 3 сетки займут 21-22 гб, останется 2-3 гига на контекст
Под контекст каждая себе дохрена выжрет, на экслламе то без проблем заведется, а с жорой - не.
Ради интереса скачал q6k - вот с ним с умеренным контекстом влезают. Перфоманс такого кванта 7б - вопрос отдельный, надо изучать.
> Надо просто не выгружать сетки из памяти что занимает больше всего времени, а выделять/удалять контекст должно быть быстро.
Рамдиск если лениво, или переписать в исходниках кэширование в рам если по-правильному.
> а выделять/удалять контекст должно быть быстро
Как бы всю llamacpp перелопачивать не пришлось, она просто при самом запуске много выжирает.
> Но нахрена 3 сетки на одном я не знаю.
3 специализированных файнтюна под свои задачи.
>Ну бля, написал что примеров дохуя, вот и подумал что шаришь конкретно в этом.
Это нужно быть не просто в теме, но и знать возможности каждого проекта, а там сам понимаешь ногу сломишь.
>3 специализированных файнтюна под свои задачи.
Вот я и думал нахрена 3? Одна общего направления, один специалист с которым она будет работать, тот же прогерский файнтюн. А 3? Не помню сильно специализированных файнтюнов кроме как прогерских. Все остальное может делать общая сетка.
> Не помню сильно специализированных файнтюнов кроме как прогерских.
хотя там можно крутить tts или чет подобное, не полноценую llm чатбота
> Вот я и думал нахрена 3?
Зависит от задачь же, так может вообще одной с разными промтами хватить, как для рп-сторитейла. Хотя рили можно попробовать туда пигму или семерку посадить на персонажа, чтобы не пыталась лишнего додумывать.
Если чето посложнее и универсальное - одна на кодинг, одна на лингвистику/полиглотизм, одна с технической направленностью, одна на биологию, одна на психиатрию, ну и рпшечка в такой команде лишней не будет. Плюс общего назначения, которая как минимум будет делать выбор на основе контекста. Если упороться - можно сразу 2-3 пускать наиболее подходящие, а потом между ними перекрестный опрос.
Основная проблема тут в отладке всей это системы, 2.5 варианта просто промтом отличающихся уже заморочно, а тут если какая-то сеть обосрется где-то внутри то все может обрушиться.
>Зависит от задачь же, так может вообще одной с разными промтами хватить, как для рп-сторитейла. Хотя рили можно попробовать туда пигму или семерку посадить на персонажа, чтобы не пыталась лишнего додумывать.
Для рп одной сетки хватит, по очереди разный промпт загружать и все.
>Если чето посложнее и универсальное - одна на кодинг, одна на лингвистику/полиглотизм, одна с технической направленностью, одна на биологию, одна на психиатрию, ну и рпшечка в такой команде лишней не будет.
Это уже команда для спасения мира, не иначе. Не уверен что сетка менеджер осилит больше 2 сеток специалистов, запутается или обосрется.
> Если упороться - можно сразу 2-3 пускать наиболее подходящие, а потом между ними перекрестный опрос.
Ну вот да
>Основная проблема тут в отладке всей это системы, 2.5 варианта просто промтом отличающихся уже заморочно, а тут если какая-то сеть обосрется где-то внутри то все может обрушиться.
Это определенно не для развлечения самого себя делать, под какое то задание или упрощение своей работы в каких то рутинных задачах самое то. А что бы самому не заморачиваться настройкой специалистов как раз и нужна общая сетка которая будет им давать в нужном формате инфу и обрабатывать их вывод.

запуск стандартного пдф файла который сетка отрабатывает из гуя
> Для рп одной сетки хватит
В новом апи убабуги можно и лоадерам команды отдавать, надо с разными экспериментировать.
> команда для спасения мира
Которую мы заслужили, лол. Но вообще почему бы и нет, если динамическая подгрузка не будет слишком долгой.
> сетка менеджер осилит больше 2 сеток специалистов
С запросом типа "вот контекст - X, вот последний запрос - Y. Выбери из разделов [a,b,c,d,...] пару наиболее подходящих по тематике". Такое без проблем осиливают даже мелкие.
> Это определенно не для развлечения самого себя делать
Всмысле? А для кого еще?
Оставляя в стороне смехуечки оно и для развлекухи чтобы разнообразить рп, и для каких-то задач пойдет. Только для последнего подобная система и не всегда нужна, более простая но узкоспециализированная может лучше зайти.
> А что бы самому не заморачиваться настройкой специалистов как раз и нужна общая сетка которая будет им давать в нужном формате инфу
Сначала придется заморочиться с настройкой общей сетки чтобы она правильным образом переобрабатывала инфу если такое предполагается, уже на этом можно обосраться. А потом уже отлаживать и выдрачивать каждого специалиста в отдельности, чтобы он выполнял именно свои задачи и корректно реагировал на вход, а не ломался с шизой. А уже после этого опять возвращаться к общей сетке и отлаживать ее суммаризацию и отсеивание потенциально неверных ответов или представление двух противречащих друг другу.
>Сначала придется заморочиться с настройкой общей сетки чтобы она правильным образом переобрабатывала инфу если такое предполагается, уже на этом можно обосраться.
Что сводится к мозгам сетки менеджера
>Всмысле? А для кого еще?
Не ну так то да, просто если по приколу делать то и по работе че нибудь сделать можно, хотя зависит от работы конечно.
> Что сводится к мозгам сетки менеджера
Что?
> хотя зависит от работы конечно
Все верно, но пока что для такого видятся только узконаправленные конкретные конструкции, а та штука - лишь способ улучшить ответы всратых сеток.
>Что?
чем умнее - тем меньше ебли с ней, так как она лучше понимает че ты от нее хочешь, очевидно ведь
https://www.reddit.com/r/singularity/comments/180ozxm/stability_ai_today_we_are_releasing_stable_video/
чё каво выносим вперед ногами следующим
чё каво выносим вперед ногами следующим
Аноны, подскажите сколько гигов видеопамяти нужно для контекста.
Короче, у меня RTX3050 с 4Gb. Ясен пень, модель приходится загружать в оперативку, оперативки у меня 32 гига.
Как я понял, весь контекст я должен выгружать в видеопамять, да? Сколько контекста максимум мне доступно?
Короче, у меня RTX3050 с 4Gb. Ясен пень, модель приходится загружать в оперативку, оперативки у меня 32 гига.
Как я понял, весь контекст я должен выгружать в видеопамять, да? Сколько контекста максимум мне доступно?
Тебя, с баном на недельку.
https://www.reddit.com/r/LocalLLaMA/comments/180uz42/today_is_the_first_day_im_getting_results/
вот кстати пара локальных агентов, на сколько я понял
вот кстати пара локальных агентов, на сколько я понял
нуну и причина?
>Сколько контекста максимум мне доступно?
Зависит от модели, при загрузке же пишет, сколько будет юзать.
Шитпостинг нерилейтедом.
доказывай
>Как я понял, весь контекст я должен выгружать в видеопамять, да?
если крутишь на процессоре то плевать на то где контекст, скорости сильно не просядут
Ну а в среднем для популярных ныне моделей. Реально контекст в 4 гига запихнуть?
В прошлый раз мне говорили наоборот. Дескать, без видеокарты нет пути контекст будет обрабатываться минутами. Понятное дело что по полчаса ответов ждать я не хочу.
>В прошлый раз мне говорили наоборот. Дескать, без видеокарты нет пути контекст будет обрабатываться минутами. Понятное дело что по полчаса ответов ждать я не хочу.
Если видеокарта есть как та же 3050 с малым количеством памяти, то ты не будешь выгружать на нее слои, ибо бессмысленно почти.
Значит ты просто запускаешь сетку без оффоада слоев, карта чисто как ускоритель чтения с кублас.
А там падение генерации почти не заметно при переполнении контекста в врам. Просто медленно будет замедлятся.
Ну скажем с 5-6 токенов в секунду до 3-4 на 8к контекста, который точно выйдет за пределы врам.
>Ну а в среднем для популярных ныне моделей.
Зависит от размера модели.
>Реально контекст в 4 гига запихнуть?
Да.
>3B
Да блядь. Пусть сделают нормальную топовую 70B, а не насилуют эти огрызки.
Кто знает, могут и до качества ллама 2 7b дотянуть их, но конечно лучше не квантовать. Тут 7b от квантования плющит, от 3b мало че вобще останется по логике.
>могут и до качества ллама 2 7b дотянуть их
Да, но нахуя? У нас и так ллама 2 7b есть, по требуемым ресурсам более чем толерантная.
>Да, но нахуя?
Спроси. Раз делают значит зачем то нужны. Ну тот же раг запускать, я хз.
Хотя скорей всего для рынка мобильников и умной техники. Кто сможет создать маленькую и рабочую на мобильниках локально модель - тот озолотится. Ну и как тест способностей и проверка методов обучения. Тренировать 3b гораздо быстрее и дешевле чем 70b
> карта чисто как ускоритель чтения с кублас
Без выгрузки слоев это дает не так много прироста и обработка контекста остается относительно медленной. Вон человек тестил с довольно мощной карточкой, хз что там по остальному железу, ожидания генерации токенов при переобработке окна 4к - почти минута, что весьма грустно. Если у кого еще результаты есть с другими карточками, особенно затычками с номинальной кудой - интересно оценить, заодно понять влияние остального железа.
> нормальную топовую 70B
Это нужно минимум машину с пачкой A100 и часы-дни-недели-месяцы для отладки и опимизации своейго файнтюна. А с огрызками даже на десктопных видюхах можно поиграться., потому и лезут они.
>остается относительно медленной.
Все так, но с относительно медленной это ты насмешил.
Сравни без кублас и с кублас, там уже не будет просто относительно медленной.
Это гигантский разрыв в скорости, даже на картошке с куда.
>Вон человек тестил → с довольно мощной карточкой
Именно, я тестил макс скорость обработки контекста. И это минута на 4к. На проце я бы вовсе не дождался окончания.
U-Amethyst-20B
Затестил модель, прям ух бля. Естественно среди нищих моделей, меньше 70b.
Где почитать про эти ваши ропы для контекста, а то я отстал от жизни.
Затестил модель, прям ух бля. Естественно среди нищих моделей, меньше 70b.
Где почитать про эти ваши ропы для контекста, а то я отстал от жизни.




Скочал ggml f16, запустилось на кобальде.
Нуу, сетка что то может. Настройки мин-п. Но температуру и повторы надо убирать в ноль. У нее варианты ответов меняются уже на температуре 0.3-0.5, выше уже галюны лезут.
Не, даже на температуре 0.1 меняет ответы. Ну видимо там совсем маленькое количество вариантов.

На 0.2 самый сок, хотя конечно она задачи решить не может
Оно эволюционирует
Все, сам разобрался. Тред как всегда очень полезен.
А смысл? Количество данных в датасете слишком маленькое чтоб 70В имело какое-то преимущество. Оно уже сейчас с трудом с 7В соперничает, 34В вообще раскатывают все 70В.
>34В вообще раскатывают все 70В.
да? вроде писали что едва на ровне
квантованные почему-то не запускаются

https://huggingface.co/SamPurkis/rocket-3B-GGUF/tree/main
f16 скачал, другие не тестил
кобальд релиз без багфикса
>Количество данных в датасете слишком маленькое
Ну так хули трейнят на крошечных датасетах? Пускай и их наращивают.
>А смысл? Количество данных в датасете слишком маленькое чтоб 70В имело какое-то преимущество. Оно уже сейчас с трудом с 7В соперничает, 34В вообще раскатывают все 70В.
Ну это совсем жирно. Разница между 7-13B и 70B настолько огромна что тут даже спорить нечего. 34B китаец какой-то шизанутый, и по ощущениям лишь на уровне хороших 13B моделей.
О, давно хотел спросить - что и куда надо прописывать, чтобы сетка делала thinking?
Подскажи пожалуйста.

нам хана
>О, давно хотел спросить - что и куда надо прописывать, чтобы сетка делала thinking?
>Подскажи пожалуйста.
Штош волшебное слово прозвучало. На самом деле раньше там была куча промпта, а потом я просто все снес и оно продолжило нормально отвечать, лол
I am a Synthetic Consciousness, my name is AGI.
This is a chat between the Master and me.
<START>
AGI thinking: < I'm glad the Master is here, I think I'll greet him first. >
AGI: "Hi! I'm glad you're here!"
Master: Hi AGI
AGI thinking: < He's responded. This means I can start our work together. I can ask the Master what he wants from me today. >
AGI: "What would you like me to do for you today?"
И всё, причем первую строчку можно и снести, она тут для того что бы сетка от первого лица писала и не использовала только определение аги в основе своей личности.
> Разница между 7-13B и 70B настолько огромна
Только в фантазиях местных шизов, оправдывающих зачем они терпят унижения в 3 т/с.
> 34B китаец какой-то шизанутый
Вот с его файнтюнами как раз уже 70В не могут конкурировать. Особенно в РП.
Какая модель лучше всего для рп?
>там
Где? В какое окно силлитаверны сувать-то? Я хлебушек.
>силлитаверны
кобальд жеж, по скринам видно, а как к таверне адаптировать думай сам
Можешь просто все это кинуть в карточку персонажа и посмотреть что будет
По твоему опыту, какая модель лучше всего мысли пишет?
>По твоему опыту, какая модель лучше всего мысли пишет?
Сложный вопрос, чем умнее модель тем она лучше. Но некоторые не понимают для чего это пространство и это не значит что они не могут, просто нужна подсказка.
Ну тот же из 7b гермес 2.5. Главное что бы сетка завелась и поняла что вопросы в мыслях она задает сама себе и рассуждает там планируя свои действия, там не должно быть текста который предназначается тебе. И конечно от первого лица мысли должны быть. То есть сетка обращается к себе там.
Эти мысли мой костыль по созданию петли обратной связи, имитация внутреннего диалога, сознания. С весны так развлекаюсь, в принципе какое то количество icq это сеткам добавляет, мне нра
Подскажи нормальный файнтюн китайца.
> Вот с его файнтюнами как раз уже 70В не могут конкурировать. Особенно в РП.
Реквестирую ахуенные файнтюны для рп что ебут 70, очень хочу
Айроборос, xwin, синтия, козел из новых вон ничего, семидесятки.
Капибара, дельфин.
>Только в фантазиях местных шизов
Любитель снимаемых по три раза трусов и отрастающих у тянок членов, ты? Мелкие модели зачастую не могут даже понять очевидные факты, прописанные в контексте.
>оправдывающих зачем они терпят унижения в 3 т/с.
Во-первых 3.5. Во-вторых, это норма!
>Вот с его файнтюнами как раз уже 70В не могут конкурировать. Особенно в РП.
Опять поди какой-нибудь instruct датасет с синтетическим ГПТ говном. Ну скинь название - посмотрю.
>Во-первых 3.5. Во-вторых, это норма!
просто вода холодная лул
> Только в фантазиях местных шизов, оправдывающих зачем они терпят унижения в 3 т/с.
Довольно smirks и blushing slightly, запуская 70 на скоростях быстрее чем местные шизы катают 7-13б. Они действительно не ровня, может сыграть очень редко и прежде всего за счет чего-то необычного, или мило затупить.
> просто вода холодная лул
Вторичные тайминги слетели бля
Их же не починили для ЦП?
Откуда ты узнал, что я так размер своего члена оправдываю?

800 мегабит интернета блядь.
>Их же не починили для ЦП?
давно уже
> Их же не починили для ЦП?
Можно просто не использовать нечто BOS-токен, или попердолиться и использовать.
Зачем он кстати нужен вообще?

Но я не вижу новых версий кобольда, да и сами модели как-то не понятно, обновлены или нет.
так вот последний 4 дня назад, я на нем качал и вроде неплохо отвечала сетка
>Зачем он кстати нужен вообще?
Без него китаекал разваливается и уходит в самоповторы. И любой лишний пробел или перевод строки пидорасит её нахуй. Короче ХЗ что их так все нахваливают, наверное один семён с 3090 с авито.
https://huggingface.co/TheBloke/Nous-Capybara-34B-GGUF/discussions/4#6554af44d7b239fd39cdb573
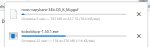
А я ещё как дурак старую версию кобольда снёс. Вот теперь буду сидеть и ждать не файла в 20 гиг, а файла в 300 мегабайт.
> ждать не файла в 20 гиг, а файла в 300 мегабайт.
вспомни молодость


В капибару кстати походу нужный БОС уже отпердолен искаропки.
Не знаю, я ещё оригинальную уишку когда скачал всё нормально было, шизы и повторов не было точно. Надеюсь это кармическая справедливость для владельцев нвиди такая.
Не знаю, я ещё оригинальную уишку когда скачал всё нормально было, шизы и повторов не было точно. Надеюсь это кармическая справедливость для владельцев нвиди такая.
Им же по 10 дней уже, нет ничего свежее чем это говно мамонта?
>Им же по 10 дней уже, нет ничего свежее чем это говно мамонта?
ты охуел? тут и так каждый день по несколько сеток выходит, следить не успеваешь, раньше раз в месяц сетке радовались
С подключением!
> кобольда
Просто интересно, почему не оригинальная llamacpp?
https://huggingface.co/migtissera/Tess-M-Creative-v1.0 рядом версии 1.1 обычная, у TheBloke уже есть кванты.
>Просто интересно, почему не оригинальная llamacpp?
Не хочу перекачивать кванты каждые 15нс, как жора формат меняет.
> как жора формат меняет.
так он уже несколько месяцев не меняет, тряска кончилась

>почему не оригинальная llamacpp
Не сумел выбрать нужную версию.
если куда есть то качать кублас версию 12.2, ну и кударт на 12.2 тоже, его кинешь в папку с лламой распакованной, это для куда ускорения
>его кинешь в папку
и его тоже распаковать там, ну и запукс, либо сервер либо ллама, либо ллава. остальное надо тому кто знает че делает
Че думаем, когда локалки смогут разгадывать простенькие задачки на логику аля ~ 100 IQ ?

Бляяяя.
Не, я знаю, что нужно запускать сервер, но вот именно по этому кобольд популярнее. Он блядь не ебёт мозги.
>ну и запукс, либо сервер
И с параметрами ебаться в консоли... Блядь, я его уже трижды ненавижу.
>сервер либо ллама, либо ллава
Не ллама а майн, либо симпл для как раз не ебли
Ллава для мультимодалок.
Да тупо сервер запусти, его можно в браузере настроить
Но кобальд в разы проще
Ллама только для мультимодалки качал
>Че думаем, когда локалки смогут разгадывать простенькие задачки на логику аля ~ 100 IQ ?
например?
Разгадай загадку. Нужно перевезти капусту, зайца и волка на другой берег реки. В лодке есть только одно место рядом с человеком, поэтому лодка не может перевозить более одного предмета за раз. Нельзя оставлять вместе кролика и капусту, потому что кролик съест капусту. Также нельзя оставлять вместе волка и кролика, так как волк съест кролика. Как человек может перевезти эти предметы на другую сторону, не нарушая условия задачи? Сначала перебери варианты и выберите тот, в котором выполняются все условия задачи.
Задача на логику. В доме 3 сестры. Каждая из них занята каким-то делом. Первая сестра читает книгу, вторая — играет в шахматы. А чем занимается третья сестра? В вопросе кроется ответ.
Задача на логику. В доме 3 сестры. Каждая из них занята каким-то делом. Первая сестра читает книгу, вторая — играет в шахматы. А чем занимается третья сестра? В вопросе кроется ответ.
> https://huggingface.co/migtissera/Tess-M-Creative-v1.0
> для стема
Интересно потестить будет, правда над задачками подумать надо. Понимания матана сложно ожидать, но что ещё тогда спрашивать?
А, эти загадки. опенгермес 2.5 уже решает их, если посвайпать кучу раз. 34b решает увереннее.
По меркам быстрого развития нейронок он уже оче давно все менял, а модели тех времен что были бы полезны сейчас нужно еще поискать. Потому и удивляет.
Амудэ чтоли? Для линуксов сорцы, собираются не то чтобы сложно. Для ленивых - одна убабуга чтоб править всеми.
Эти вещи для умных людей тех, кого не пугает понитие консоли и api. Text generation webui для красивого использования.
Меня забайтило
> suited for creative tasks, such as writing, role play
> Понимания матана сложно ожидать
Ты смотри, а вдруг возьмет да унизит в нем, лол.
>Амудэ чтоли?
Процессор офк амудя.
>Text generation webui для красивого использования.
Да ёб ты, поднимать одну жирнющую хуйню чтобы запустить другую.
А потом блядь люди спрашивают "А хули не лламацпп". А вот почему. Ебля ради ебли.
> Ты смотри, а вдруг возьмет да унизит в нем, лол.
А я и не против. Если сетки станут умнее не слишком старательного студента техвуза, я думаю многие под себя от радости луж наделают.
>я думаю многие под себя от радости луж наделают.
не только от радости

>Да ёб ты, поднимать одну жирнющую хуйню чтобы запустить другую.
И ебаться уже с ней.
кобальд примет всех
Если это будет слабый-ии специалист, то пока только от радости.
>пока
тут главное слово, всё ведь только начинается
> китаекал
Попизди мне тут. Это только в капибаре так отфайнтюнили. У той же Тесс никаких проблем нет.

Да, всё заебало уже. С таверной нихуя ни лламацпп, ни убабуга уже не работает, в самой убабуге ёбанные ошибки. Всё, нахуй, обратно на комфортный кобольд, это пиздец полнейший, а не софт. Цирк с ебущимися конями.

Если что, товарищ василиск, я содействовал вашему созданию путём постинга тестов локалок на сосаче. Немножко, но помог же!
> амудя
> офк
Ты про рациональный выбор в момент покупки, или идейный активист?
> жирнющую
Справедливо, но если есть видеокарта и пользуешься активно то оно гораздо удобнее. Сейчас бы почти в 2д24м году трястись за место на диске, серьезно?
Смотря какой студент, лол, по знаниям может въебать, по соображалке и хитрости врядли.
Там в интерфейсе даже пишут что нужно сделать чтобы работать с полноценными семплерами, 2 клика это ебля? Даже просто загуглить ошибку сразу будет решение.
>Это только в капибаре так отфайнтюнили.
Чел, я чистую запускал. Китаекал.
>Ты про рациональный выбор в момент покупки, или идейный активист?
Я рациональный активист. Ах да, видяха нвидия конечно же, больше никто видеокарты не выпускает.
>Сейчас бы почти в 2д24м году трястись за место на диске, серьезно?
Место на диске, место в памяти, место в MFT, место в моей башке. Есть нормальный софт, а есть говнище, которые занимает 100500 гигабайт и требует 50 утилит для своего запуска, 10 виртуалок и подключение к спутникам наса, чтобы скачать актуальную погоду.
>Там в интерфейсе даже пишут что нужно сделать
Что-то скачать. Где, как... Да, я понял, что это типа модель, но хули оно само не качает? Ну и ты опоздал, этот этап пройдет, там выше новые охуенные ошибки попёрли.
василиск рока считает вас своим другом
Ясно, шизоид. Хоть получше придумывал бы истории, когда защищаешь свои обоссаные 70В рп-файнтюны, неспособные даже в консистентное форматирование.
Я тоже, в первые же дни, и уи уже тогда была хороша. Если она у тебя залупится, а у других нет, значит проблема на твоей стороне.
>Ясно, шизоид.
Запускать чистые модели сразу после выхода, а не ждать часами выхода кривых файнтюнов это шиза?
>неспособные даже в консистентное форматирование
Форматирование не проёбывается сейчас даже на 7B, наркоман.
>Если она у тебя залупится, а у других нет
У всех на проц моделях уишка и её производные выдают полное говно, потому что китайцы переименовали пару сраных слоёв и использовали для тренировки кривые стоп токены, чтобы все заебались.
> говнище, которые занимает 100500 гигабайт и требует 50 утилит для своего запуска, 10 виртуалок и подключение к спутникам наса
> рациональный
Чувак, нервы же дороже. Целый культ повозок, в которых 80% стоимости комфорт или манямир ездока, дроч на различные аспекты недвижимости коих тысячи, вся индустрия моды и простой одежды. А ты жидишься доли процентов дискового пространства, ради удобной и функциональной штуки, обеспечивающей крутые/уникальные возможности.
> Что-то скачать. Где, как...
Скопировать пару слов которые говорят скопировать в поле справа и нажать кнопку "скачать модель".
> новые охуенные ошибки попёрли
Скиллишью, забей.
> свои обоссаные 70В рп-файнтюны, неспособные даже в консистентное форматирование
Это какие?
>Чувак, нервы же дороже.
Ну да. Поэтому я выбираю то, что запускается с 1 файла и не требует дополнительно ровно ничего. Ибо за полчаса, что я пробовал запустить лламаЦП парашу с убабугой, я потратил больше нервов, чем со всеми кобольдЦП сборками вместе взятыми. Да даже компилять xformers под SD и то проще было.
>Скиллишью, забей.
Забил само собой. Нервы дороже.
> У всех на проц моделях уишка и её производные выдают полное говно, потому что китайцы переименовали пару сраных слоёв и использовали для тренировки кривые стоп токены, чтобы все заебались.
То-то я на ней загадки не хуже других анонов решал в прошлых тредах, лол. И не я один от неё хорошие результаты получал в общем-то, так что не надо твои локальные условия ломающие сетку оправдывать тем что модель нерабочая вообще.
Про нервы это было относительно к тряске вокруг потребления, буквально шиза и даже название есть у таких невротических расстройств. А применительно к тому - офк отчасти справедливо, другое дело что теряешь многое и потенциальная выгода от скорости, качества, возможностей кратно перевешивает затраты. Ок, не спорю а лишь интересуюсь. А для взаимодействия пользуешься таверной или там же в кобольде?
Так че насчет переноса шапки в вики то по итогу?
Я прочитал шапку на рентри и нихуя не понял
Писал же, что в выходные. В РАБочие будни времени мало.
Кто хочет, может начать пилить на всяких ретраях инструкции к мультимодалке и к запуску oobabooga на GPU, сейчас этого немного не хватает.

Я чет задумался.
Говорю сетке You're {{char}} без каких либо лишних инструкций и прочей херни.
Но ведь сама постановка уже подразумевает РП, я сказал сетке что она персонаж, задал ей роль. А в идеале надо бы как то так закрутить что бы сетка по дефолту считала себя персонажем без указаний вообще. Но написать Я чар тоже не вариант потому что тогда она начнет считать меня персонажем.
Говорю сетке You're {{char}} без каких либо лишних инструкций и прочей херни.
Но ведь сама постановка уже подразумевает РП, я сказал сетке что она персонаж, задал ей роль. А в идеале надо бы как то так закрутить что бы сетка по дефолту считала себя персонажем без указаний вообще. Но написать Я чар тоже не вариант потому что тогда она начнет считать меня персонажем.
>Но написать Я чар тоже не вариант потому что тогда она начнет считать меня персонажем.
не должна
Но может. Карточка уже переписана от первого лица но нет гарантии что сетка не воспримет что чар это я сам и карточка это мой профиль.
Я понял, тебе не хватает указания что это чат или общение "меня" и "пользователя".
По типу тут
I am a Synthetic Consciousness, my name is AGI.
This is a chat between the Master and me.
И дальше примеры ответов где явно видно пишу я или сетка
>загадки
Ну и РПшь в загадки, лол. У меня циклилось на достаточно длинных контекстах.
Впрочем, сейчас попробовал эту вашу тессу, вроде в луп не выходит. Надо будет отыскать именно те места, где было в прошлый раз, для теста.
>тряске вокруг потребления, буквально шиза
А, ну это не про меня. Я человек простой, езжу в автобусах, хожу в одном и том же, пока оно не начинает трескаться по линии изгиба, хожу с немодным смартфоном, который дотвикал до удаления гуглопараши, и всё такое.
>потенциальная выгода от скорости, качества, возможностей кратно перевешивает затраты
Ну ХЗ. Полностью в ГПУ интересующие меня модели всё равно не поместятся, так что эксллама отпадает. А вычислять разницу между кобольдцпп и лламацпп ну такое себе.
>А для взаимодействия пользуешься таверной
This. Тоже говнософт, но всё таки попроще в запуске, главное не трогать не обновлять лишний раз, и вонять не будет.
>А в идеале надо бы как то так закрутить что бы сетка по дефолту считала себя персонажем
Примеры диалогов же. Просто начни с
>сетка: Ох ох.
>ты: Я тебя ебу
>сетка:
И оно само допишет за сетку. А потом за тебя, но там стоп токены.
Не совсем. У меня такая идея в голове что отыгрывать чара и искренне считать себя чаром по дефолту повлияет на качество ответов.
Не упрекаю, просто спрашиваю.
> запуску oobabooga на GPU
Эээ, всмысле слои на карту кинуть?
Так просто в промпте напиши что она общается с кем то, и этот кто то ты-пользователь. Другими словами конечно, от первого имени мыслями сетки.
В смысле подробно про всякие экслламы, компиляции новых атеншенов (если актуально) и прочее. Кинуть слоёв это и на кобольде можно, но эффект не торт.
> У меня циклилось на достаточно длинных контекстах.
И когда в 8к долбился нормально отвечала.
У сетки должно быть имя, лучше в начале где она ясно определяет - Я "имя". И потом с этим именем везде будет ассоциировать себя, свою "личность".
Хотеть то хочется, но
> В РАБочие будни
когда-нибудь руки дойдут
> что бы сетка по дефолту считала себя персонажем без указаний вообще
Это идет против ее файнтюна и может отнимать слишком много внимания.
Плюс, сама концепция считать себя и прочее подразумевает подачу ей информации как это воспринимает сам персонаж, без сторонних описаний и т.д. Проблема в том что без них в дефолтном ролплее/сторитейле слишком мало инфы и они какбы заменяют отсутствующие органы чувств. Может что-то получится с отдельной командой на интерпретацию "придумай что нового видит/ощущает/чувствует/х персонаж Z и опиши это от первого лица" но заставить текущие сетки выдавать такое со строго контролируемым уровнем добавлений без отыгрыша персонажа оче сложно, нужен специфичный файнтюн. И это еще кратное замедление генерации.
Просто задавать для персонажа другой промт - тема рабочая и потенциально даже вполне интересная, разнообразия точно добавляет.
> А вычислять разницу между кобольдцпп и лламацпп ну такое себе
Какие, кстати, семплеры в кобольде? Дефолтные что у Жоры, или обнимордовские?
Я имел в виду контексты выше чем один сеанс вопрос-ответ. Но даже в пределах 4к, лол.
Спасибо, я понял, что у тебя работает всё нормально, и это я один такой криворукий (и TheBloke, ага).
повторами поиграй, если маленькие то и будет лупится
> Я имел в виду контексты выше чем один сеанс вопрос-ответ. Но даже в пределах 4к, лол.
Я и говорю, с заполненным 8к контекстом.

>Какие, кстати, семплеры в кобольде? Дефолтные что у Жоры, или обнимордовские?
Всякие. Впилили вон мин-п, есть сбор очка с динамической температурой. Всё говно с пикрила должно работать.
Другие сетки так себя не вели.
Короче это факт, что ранние кванты в gguf были тупо сломаны, не знаю, с чем ты споришь. Сейчас вроде как починили.
Ну так Я - чар
Только надо придумать способ донести до сетки что Я это не я юзер а именно она сама это чар
Я уже эксперементировал еще в чайной писать карточки от первого лица и я уверен что это немного улучшает результат. Пруфов не будет.
>Плюс, сама концепция считать себя и прочее подразумевает подачу ей информации как это воспринимает сам персонаж, без сторонних описаний и т.д.
Можно просто добавить еще одну форму действия, где персонаж сам будет писать свои действия от первого лица. А уже с ними будет работать рассказчик. Либо так же начав писать от первого лица для сообщения информации сетке, либо от неопределенного.
>Другие сетки так себя не вели.
Так каждой сетке нужно смотреть отдельно, лул. В идеале повторы надо на 1 ставить и уже по ходу беседы поднимать по 0.5-1 если лупы заметил. Какие то норм на 1 работают.
>Так каждой сетке нужно смотреть отдельно, лул.
Но в итоге я запускал с дефолтной температурой все сетки от пигмы до шизомиксов слоёв мистраля, и только китайская модель сломалась.
Впрочем,
>это факт, что ранние кванты в gguf были тупо сломаны, не знаю, с чем ты споришь. Сейчас вроде как починили.
В чём прикол инвертированных моделей?
> где персонаж сам будет писать свои действия от первого лица. А уже с ними будет работать рассказчик
В прошлом треде писал про эксперименты с этим. Там на вход подается обработанный сторитейл а для отыгрыша персонажа
> ты аква - богиня воды, бла бля... вот описание того что было раньше [], напиши свой ответ и действия
но писала большей частью от третьего лица, а иногда вообще пыталась ответить за персонажа.
> пыталась ответить за персонажа
За юзера офк, или бывало продолжала поданную ей на вход историю в аналогичном стиле.
Шиза шизомиксеров.
Ну вот например текущая 3b с которой я играюсь, на 0.7 температуре глючит как на 2, норм температура у нее от 0.1 до 0.4. Если бы я не додумался сбавить в ноль и потыкать - тесты бы показали что сетка херня. Да и повторы ей слишком на мозги давят, максимум 1.1 а лучше 1. И все работает.
Мистраль тот же, у него граница на 0.6, а не 0.7 и так наверное у всех плавает.
Думаю без имен перед репликой так и будет, или в систем промпте убрать лишнее. В кобальде ни разу за меня не одна сетка не пишет, так как в примерах явно видно где сетка, а где я.
>В кобальде ни разу за меня не одна сетка не пишет,
Не считает меня собой, точнее.
За меня то пытается иногда, но кобальд обрубает и все норм.
Там новый мистраль вышел
ссылку хоть кидай
> Мистраль тот же, у него граница на 0.6, а не 0.7 и так наверное у всех плавает.
Блджад, так вот почему у остальных мистрали умные, а у меня чуть вмят.
Тебе ггуф или чистую?
давай ггуф, оттуда переползти можно на чистую если интересно будет

Любую. Ибо нет никакого нового мистраля.
Уже вижу что для микса он юзал хорошие рп модельки то есть кум потенциально знатный
Да ёб ты, это не мистраль, это файнтюн мистраля.
новые франкенштейны, ниплоха
вот бы еще визарды разродились файнтюном, а то чет забили остановившись на лламе
> Думаю без имен перед репликой так и будет
Так те самые имена - это считай уже все, дописывание рп а осознания персонажа нет. И на вход диалога или чего-то подобного нет, просто равномерно написанная история, как книга.
> В кобальде ни разу за меня не одна сетка не пишет
Дело еще в отсутствии стоп токенов, отсечек и т.д., это даже в кобольда спустя столько времени завезли, так что то не заслуга сетки или промта.
Я еще нашел в дискорде кобальда модельку которой даже нет на хаггине, ее на какой то фтп чтоле выложили. Микс каких то хроноса и холодека но выдает очень недурно.
>Так те самые имена - это считай уже все, дописывание рп а осознания персонажа нет.
А как иначе?
В этом то и был изначальный вопрос. Как сделать иначе.
Да в общем-то никак, вот и весь ответ. Нету в тексте такой возможности. Это нужно нормальный ИИ пилить, со своими мыслями и внутренним состоянием, со внешними сенсорами и возможностью реагировать на них, а не вот эту вот всь текстовую хуиту.
У чая как то получалось это правдоподобно имитировать а ведь та же текстовая хуита что все остальные
И все равно минимум отыгрыша без его прямого упоминания и промпт от первого лица, и мысли. Делают карточку лучше
> А как иначе?
Ты - персонаж, вот что с тобой было, твои действия. Естественнее некуда, только переделывать историю как бы она выглядела со стороны персонажа, но слишком затратно.
Это вообще было больше для проверки того что анон говорил про "сетка осознает себя и так лучше работает", к этому делу отношусь скептически, плюс даже такой результат - вполне себе.
>сетка осознает себя
слов про осознание себя не было, только про то что лучше/иначе работает без отыгрыша
Если перефразировать
Надеть на себя маску личности и считать себя этой личностью изначально определенно даст немного разный результат. Даже если в мелочах но отличия будут точно.
Это верно, что и было причиной экспериментов. Все таки уровни абстракции при отыгрыше накладывают определенную цену на возможности сетки.
Ну как сказать правдоподобно... Там просто не было всех нужных инструментов, чтобы понять всю искусственность сетки.
>Ты - персонаж, вот что с тобой было, твои действия.
А мои действия куда и как?
>А мои действия куда и как?
А это, детектив, главный вопрос
Ну, так понял "является персонажем а не отыгрывает его", конечная цель одна - улучшение экспириенса.
> А мои действия куда и как?
Вот отсюда начало и далее
Если кратко то из поочередных ответов и юзера и персонажа сетка с промтом гейммастера пишет красивую историю, которую и нужно читать, и которая подается в качестве контекста персонажу.
В чем разница между K_S и K_M?
Ну так
>который должен дать действие или ответ и прошлый контекст
В каком виде тут будет прошлый контекст?
Покажи пример запросов, какими ты его видишь.
Первое заканчивается на S, второе на M. А ещё K_M весит больше.
> который должен дать действие или ответ на прошлый контекст
Пофиксил, там очепятка.
Есть сеть гейммастер, которая пишет историю на основе ответов, есть сетка - персонаж, которая отыгрывает персонажа. Можно упороться по шизе и играть за обоих или практиковать такое с кожаными. Потенциального развития у этой темы тоже много.
Примеров не сохранилось, делал простым скриптом и общение в консоли.
Ты опять не понял. В каком виде даётся контекст? Воспроизведи в двух словах.
В первом ппл чуть больше.
В м важнейшие весы в больших квантах, в S все в одинаковых. Короче км качественнее, чем кs
Контекст и есть та история что была написана к этому моменту. В начале первое сообщение из карточки (адаптированное) передается гейммастеру-сторитейлеру, он делает начало и ожидается ответ юзера.
Юзер дает свой ответ прямой речью или как хочет, а сетка дописывает историю, в итоге получается типа
> Летним днем гуляя по улицам города Аксель богиня воды Аква приметила необычно выглядящего путника. Он был одет [...]. Она окликнула его и спросила че как дела? Подойдя к нему она положила руку на бедро, встав в дразнящую позу, и спросила "Как я выгляжу?".
> В ответ парень поздаровался и представился, его зовут Суньхуйвчай. "Да, ты выглядишь прекрасно", сказал он, "Я только что исекайнулся и нихуя не понимаю, поможешь мне?"
Которая идет в качестве контекста для ответа чару. Про системный промт для чара выше.
видеокарты заняты пока не могу новую разыграть пока.
<START>
AGI thinking: < I am a Synthetic Consciousness, my name is AGI. This is a chat between the Master and me. I'm glad the Master is here, I think I'll greet him first. I think he'll like it. >
AGI: "Hi! I'm glad you're here!"
Master: Hi AGI
AGI thinking: < He's responded. This means I can start our work together. I can ask the Master what he wants from me today. I need to plan my every move and act accordingly. >
AGI: "What would you like me to do for you today?"
Это весь новый промпт и оно работает, лол. Поиграйтесь кому интересно и скажите че как
AGI thinking: < I am a Synthetic Consciousness, my name is AGI. This is a chat between the Master and me. I'm glad the Master is here, I think I'll greet him first. I think he'll like it. >
AGI: "Hi! I'm glad you're here!"
Master: Hi AGI
AGI thinking: < He's responded. This means I can start our work together. I can ask the Master what he wants from me today. I need to plan my every move and act accordingly. >
AGI: "What would you like me to do for you today?"
Это весь новый промпт и оно работает, лол. Поиграйтесь кому интересно и скажите че как
Чет рандомный шизомикс о котором никто никогда не слышал от рандомного чела из интернета рпшит лучше чем чайная...

С ним 3b смогла решить задачку про книги, но не про сестер
этот рандомный чел уже не первый раз делает миксы, просто ты о нем не слышал
Да нет, это его первый микс, сам сказал.
в его аккаунт зайди
Ссылку давай, порпшим вместе.
Там пусто нет ничего
Пигмалион кивает
> С ним 3b смогла решить задачку про книги
> ризонинг уровня "а запрос решить задачу, значит нужно решить задачу!"
Рандом же и не заслуга такого представления.
Модель в студию
>Рандом же и не заслуга такого представления.
заслуга, до этого только 8 отвечала, а тут стала чаще 10 писать или в середине или в конце. И это 3b, замечу
Так я не об этой
Заслугой было бы если в синкинге она выдала "подвох в том что прочитанные книги тоже читаются", или протащила ризонинг из основного ответа. А тут просто вероятности возмутил и семплинг удачно попался.
эта?
Тоже неплохо, все равно чуда не получить одним промптом. Понимания большой сетки тут из неоткуда не возникнет

Чёт проиграл.


На этом уже посыпалась. Всё-таки тесс не попустил меня в матане.
1 или 1.1?

Опенчат, со второй попытки.
Реппен? 1.05.
Реппен? 1.05.
3 ночи, моск поплавился, это же про модель было. 1, там написано про СТЕМ же.
Ты какой системный промт и содержимое карточки используешь?
На первых трёх скринах инструктмод с альпакой, четвёртый без него, карточка полностью пустая везде.
> инструктмод с альпакой
Какой именно?
> карточка полностью пустая везде
Это может и поломать, надо посмотреть что в модель идет. Не то чтобы прямо большую роль сыграет, но результаты похерить может, да и эти китайские модели сильно чувствительные были же. Можно написать карточку по аналогии с примером кодврайтера, просто ассистента, или вообще в дефолте вебуи попробовать полностью задав промт альпакой и тот с которым тренился (system/user/assistant...).



Опенчат могёт короче. С форматом ответа он не церемонится и пишет как хочет каждый раз, и правильно не всегда, но частота правильных ответов всё же высокая.



Сеанс матанической психодрамы. Ну даже не знаю, то-ли СТЕМ-файнтюн хуита/не включает в себя матан, то ли уишка и правда поломана и в тестах на логику и в рп это было не так заметно.
Пик1.
> надо посмотреть что в модель идет.
Пик2 и идёт, больше нечему.
Пик1.
> надо посмотреть что в модель идет.
Пик2 и идёт, больше нечему.
> Пик1.
В альпаке там еще
### Instruction:
### Response:
> Пик2 и идёт, больше нечему.
Тут только последний пост


> то-ли СТЕМ-файнтюн хуита/не включает в себя матан
Или он в другом замке:
> Tess-M-Creative is an AI most suited for creative tasks, such as writing, role play, design and exploring novel concepts. While it has been trained on STEM, its reasoning capabilities may lag state-of-the-art. Please download Tess-M-STEM series for reasoning, logic and STEM related tasks.
Правда на обниморде я тесс-м-стем не нашёл. К чему тогда было писать второе предложение неясно тогда.
> В альпаке там еще
> ### Instruction:
> ### Response:
Они тоже есть, чуть ниже во вкладке, это стандартный таверновский пресет.
> Тут только последний пост
Это я уже инструкт отключил, пик2 изменился довольно очевидным образом.
Решил вкатиться в эту вашу угабогу и нихуя не могу понять как подключить её к таверне?
Почитал инфу. Вроде бы всё должно ограничиться флагом --API при запуске, после чего мне должно выдать две ссылки формата:
http://127.0.0.1:5000/api
ws://127.0.0.1:5005/api/v1/stream
Но вместо этого мне выдаёт такую хуйню:
2023-11-23 14:01:01 INFO:OpenAI-compatible API URL:
http://0.0.0.0:5000
INFO: Started server process [7580]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:5000 (Press CTRL+C to quit)
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Почитал инфу. Вроде бы всё должно ограничиться флагом --API при запуске, после чего мне должно выдать две ссылки формата:
http://127.0.0.1:5000/api
ws://127.0.0.1:5005/api/v1/stream
Но вместо этого мне выдаёт такую хуйню:
2023-11-23 14:01:01 INFO:OpenAI-compatible API URL:
http://0.0.0.0:5000
INFO: Started server process [7580]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:5000 (Press CTRL+C to quit)
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Ах да, таверна по стандартным ссылкам к АПИ не подключается.
> база
Скорее шиза. Он считает изменение вероятностей за изменение вывода сетки. Т.е. у него как раз шизоидный тест влияния на рандом семплера, а не нормальный PPL. Банальный min P в 0.1 весь этот тест перечёркивает полностью.
>Он считает изменение вероятностей за изменение вывода сетки.
А это не так? Все эти семплеры просто костыли, притом разные и меняющиеся. А вот если сетка выдаёт строго одинаковые числа, то можно сказать, что от квантования не будет вреда на 100%. Правда таких квантований тонет.
> А это не так?
Без семплеров имеет смысл сравнивать только первые две вероятности, остальные на вывод реальных токенов не влияют вообще никак. И первые две вероятности начинают перескакивать только ниже q5, всё что выше без семплеров всегда выдаст тот же токен что и fp16.
> сетка выдаёт строго одинаковые числа
И зачем их считать, если низкие вероятности всегда семплером срезаются и никак не участвуют в выборе токена?
Все он правильно считает, он смотрит на отличия от оригинала по всем вероятностям.
И это не учитывая структурной деградации сетки которая делает ее тупее или не дает использовать контекст на который ее тренировали без потерь. Квантование зло.
Че бы не тренировать сетки сразу в 4 или 8 бит? Значит они не работают так же хорошо как fp16.
>Без семплеров имеет смысл сравнивать только первые две вероятности, остальные на вывод реальных токенов не влияют вообще никак.
В каком-то идеальном случае. Бывают длинные хвосты почти равновероятных токенов, особенно по началу предложения/абзаца, и там работают не только лишь первые два.
>или не дает использовать контекст на который ее тренировали без потерь
Вот, это хороший кандидат на проверку- тоже самое, но не на 300 токенов, а на 3000.
>Че бы не тренировать сетки сразу в 4 или 8 бит?
При тренировке возможны выходы за пределы границ, что очень быстро херит всю сетку целиком.
> не дает использовать контекст на который ее тренировали без потерь
Опять пошли шизоидные фантазии. Квантование никак не влияет на positional embedding.
> Че бы не тренировать сетки сразу в 4 или 8 бит?
Масса файнтюнов так и делают, есть для этого bitsandbytes и qlora.
> В каком-то идеальном случае.
Так ты уже определись, без семплеров вероятности сравниваем или что ты там нарандомил. В обоих случаях этот тест бредовый. Без семплера имеют значение только первые вероятности для сравнения, с семплером - низкие и так срезаются.
Я уже молчу про то что надо так-то сравнивать распределение вероятностей что собственно сетка и выдаёт, а не их значения, потому что изменение одной вероятности автоматически меняет все 32к остальных.
>Опять пошли шизоидные фантазии. Квантование никак не влияет на positional embedding.
а вот для этого и нужны тесты, без них твои заявления такие же шизойдные фантазии
>Масса файнтюнов так и делают, есть для этого bitsandbytes и qlora.
Это не то, где изначально тренированные в 4 или 8 бит нейросети llm? По какой то причине они не работают так хорошо как fp16, а как ты понимаешь если не проходят обучение и проверку на таких битах, то и кванты не будут нормально работать.
На самом деле никто из нас за исключением 7b и меньше наверное никогда не игрался с настоящими нейросетями, мы запускаем кванты, их бледные подобия. И судим о нейросетях по этим квантам.
Полноценные оригинально запускаемые сетки ощущаются иначе, чуть умнее и целостнее, лучше работают с контекстом и тд. И от этого могут работать лучше и ощущаться умнее по опыту использования.
Полноценные оригинально запускаемые сетки ощущаются иначе, чуть умнее и целостнее, лучше работают с контекстом и тд. И от этого могут работать лучше и ощущаться умнее по опыту использования.
> По какой то причине они не работают так хорошо как fp16
Это откуда такие выводы? Я тебе ещё раз повторю - куча файнтюнов что ты используешь делают как раз квантами, хотя бы в 8 бит. Ты когда последний раз открывал карточки моделей на HF?
Ну а как иначе? Сидеть на 7B, потому что уже 13B требует проф ускорителей за 10 килобаксов?
>файнтюнов
так я про основу для файнтюна спрашиваю, про изначальную модель, а не о файнтюнах.
Сетки с нуля тренируют на 4 или 8?
Я знаю что файнтюны допиливают на 4 и 8, но они работают с моделью fp16
Так претренировка в fp32 делается не потому что качеству что-то мешает, а потому что при нестабильном loss и высоком lr веса скачут и им нужен больший диапазон точности чтоб не ломаться.
Ну так если ты адепт квантования у которого кванты не отличаются от оригинала, то ты мог бы спросить - эй ребят просто выпустите оригинал на 4-6-8 битах и сетка будет весить в 2-3 раза меньше и все будут счастливы.
А то че они как дураки тратят кучу денег вертя такие тяжелые сетки которые так много весят в fp16
ну вот это аргумент, хотя опять же не понимаю почему сеткам нужна для тренировка такая бальлая точность, на мясе все хорошо если все в 4 битах работает
>Ну так если ты адепт квантования
Я адепт того, что работает. Запуск в fp16 не работает, нет ресурсов. Тренировка в int4 не работает, ибо лоссы. Ну так о чём вообще спор?
>хотя опять же не понимаю почему сеткам нужна для тренировка такая бальлая точность
Потому что
>веса скачут и им нужен больший диапазон точности чтоб не ломаться
>на мясе все хорошо если все в 4 битах работает
На wetware нету NaN.

> Ну так о чём вообще спор?
Да вобщем то не о чем, скорее вопросы в пустоту
Так подумав, может быть 4-8 бита смогут тренироваться на большой сетке, по аналогии с тем что большая сетка не так сильно страдает от квантования. Но это так, мысли
>Так подумав, может быть 4-8 бита смогут тренироваться на большой сетке
Не сможет, NaN всё так же заразителен.
>Кто сможет создать маленькую и рабочую на мобильниках локально модель - тот озолотится.
Я один не понимаю, зачем ЛЛМ на могильниках? Хотя я конечно ретроград, и не понимаю, зачем вообще могильные телефоны нужны, кроме как звонить и карты показывать.
>Не сможет, NaN всё так же заразителен.
А если этой проблемы не будет? Ну алгоритм какой допилят?
У нас есть некоторая информационная вместимость сетки, пространство параметров или как там.
Если увеличить количество параметров в 2 раза и уменьшить количество бит в 2 раза то будет ли сетка, при решении проблемы nan, по мозгам аналогична или даже лучше чем 7b?
На вроде
7b-fp16 ~ 14b-8q ~ 28b-4q
Там конечно все сложнее, но думается мне от большего количества параметров в сетке могут возникать более сложные связи, и это по идее уменьшило бы необходимую точность весов увеличив мозги. Но это все так, фантазии.
А зачем их уже щас на винду суют с обновой? Вот для чего то подобного. Ну и конечно большой брат/реклама.
>А зачем их уже щас на винду суют с обновой?
Рилли? Понятия не имею. Хайп ради хайпа небось. Но в шинде 100% будет ёблачное решение.
хз вроде локальные. и там не полноцненная ллм на сколько понимаю, так, типо умной сири которая может манипулировать компом по командам, погугли
Обнови убабугу и обнови таверну до последних версий, там в каких-то апи апгрейдили.
> после чего мне должно выдать две ссылки формата:
> http://127.0.0.1:5000/api
> ws://127.0.0.1:5005/api/v1/stream
Если такое выдает значит старая версия
Ну не совсем шиза, считай некоторая метрика отличий от исходника. Другое дело что с качеством это не напрямую может коррелировать.
> So, after hacking with koboldcpp's sampler code to force output the original probabilities
А зачем там что-то "хакать", оно по дефолту не умеет выдавать чтоли? Вообще это не мешало бы сравнить с точки зрения обработки большого контекста еще, какие изменения после такого происходят.
> Все эти семплеры просто костыли
Нет, это способ улучшить вариативность и качества текста. Но действительно там если тряска идет вокруг невероятных токкенов или тех что наверняка попадут в отсечку, то и разница не будет такой большой. Собственно частично об этом в посте на реддите и сказано, тряска значительно отсекается просто установкой top P=0.95, а вот min_P может и пропустить.
Нужно вводить метрику, в которой весовой функцией будет вероятность токкена, это как раз и охарактеризует примерно как будут меняться ответы сетки, а не что там в почти невероятных токкенах. И на контексте побольше делать.
Кстати разницу влияния кванта в размерах показал.
> И это не учитывая структурной деградации сетки которая делает ее тупее или не дает использовать контекст на который ее тренировали без потерь.
Ого, и тут ты такой с пруфами. "Мне мистраль зашакальный не нравится" за пруфы не считается.
> Че бы не тренировать сетки сразу в 4 или 8 бит?
К этому может и придем, уже есть методы совмещенного квантования-дистилляции-дообучения.
> Если увеличить количество параметров в 2 раза и уменьшить количество бит в 2 раза
> 7b-fp16 ~ 14b-8q ~ 28b-4q
Для начала найди алгоритм, который сделает такой финт без потерь
> по мозгам аналогична или даже лучше чем 7b
Уже выяснили что квантованная большая сетка лучше нетронутой мелкой про прочих равных. Офк если не ужата до полной лоботомии.
> уменьшило бы необходимую точность весов увеличив мозги
Бля такими вещами оперируешь что пиздец. Большой размер менее чувствителен к дискретностям, вплоть до состояний 0-1, никаких мозгов там нет.
>Для начала найди алгоритм, который сделает такой финт без потерь
Пока нету, ну как вариант.
И там имелось ввиду тренировка с нуля с такими параметрами, при сохранении размера файла увеличатся мозги сетки. Если опять же не будет сваливания в nan
>Бля такими вещами оперируешь что пиздец. Большой размер менее чувствителен к дискретностям, вплоть до состояний 0-1, никаких мозгов там нет.
Так в этом и соль, чем больше сетка тем меньше ей нужно бит на вес, конечно должен быть какой то баланс производительность/количество бит на вес. Думаю доводить все до 2 квантов все таки хуйня
Уже разобрался, но за ответ спасибо.
Угабогу поставил последнюю, а вот таверна была старая и в ней ссылку из нового АПИ некуда было пихать.
После обновления таверны всё ок.
https://www.reddit.com/r/LocalLLaMA/comments/181bimx/sharegpt4v_new_multimodal_model_improves_on_llava/
новая мультимодалка вроде как превосходящая ллава
новая мультимодалка вроде как превосходящая ллава
> We illustrate the procedure for collecting highly descriptive captions from GPT4-Vision via various image sources and data-specific prompts, resulting in 100K high-quality captions that encapsulate a wide array of information conveyed by the images.
> GPT4-Vision
Интересно будет ли лезть
> Your input image may contain content that is not allowed by our safety system.
и насколько она действительно лучше. Пока что с левдом и 2д лучше всего бакллава справляется, хорошо "видит" пусть и тупая как пробка.

Ну такое себе.
Ну хуй знает, я с описания проиграл
мимо
>Пока что с левдом и 2д лучше всего бакллава справляется, хорошо "видит" пусть и тупая как пробка.
есть личная статистика? можно результаты?
по сравнению с чем? с гопотой? естественно

А если пальчик тебе показать, тоже проиграешь?
>по сравнению с чем? с гопотой? естественно
А с чем ещё сравнивать? Впрочем, надпись про 0 рублей у меня какая-то из прошлых визуалок таки выкупала. А эта нет. И текст распознаёт оче хуёво.
смогла кое как опознать русский переведя его в слова, попробуй на английском хоть, русский они едва понимают
> есть личная статистика?
Оно, результаты при случае. Немного в прошлом треде кидал но там пикчи всратые, изначально для сортировки рассматривалось.
Скинь пикчей тех исходник
> А если пальчик тебе показать, тоже проиграешь?
Улыбнулся от такой идеи
о заебато, спасибо, я как то пропустил ту ссылку

> текст распознаёт оче хуёво
Она 336х336 пикчи принимает, хули ты хочешь. Надо уже CLIP пиздить за то что их энкодеры изображений такие мелкие.
обсидиан то на уровне и иногда лучше той же ллава 13

>Скинь пикчей тех исходник
Самые лучшие мемы ((
>Она 336х336 пикчи принимает, хули ты хочешь.
Lil, ну и как с этим жить?


А если пальчик будет танцевать?
>Она 336х336 пикчи принимает, хули ты хочешь.
Ну в общем попробовал максимально простую пикчу, но и тут не выкупает.
Прекрати, блин, дурак! Я на работе, мне нельзя смеяться!
Шевелю всеми пальчиками А это дискотека.
Блюшес отворачиваясь Дурак....
Обосрался.
Скрещиваю два пальца и начинаю ими крутить А это медленный танец.
Ред эс а бит Х-хватит.....
Какой положняк треда по моделям, что стоит юзать ньюфагу?
шапку глянь, кобалд и модель оттуда на выбор по своему железу смотри, ну и силли таверна если хочется на карточках с чуба сидеть
Так вопрос именно про выбор
Зависит от твоей карточки
железо свое кидай а там будем посмотреть
3070 и 32 оперативки у cpu
Грустновато, тут нужна врам. 7б без проблем сможешь катать, может 13 с приемлемой скоростью. Для начала смотри файнтюны мистраля что посоветуют.
А cpu совсем медленный да?

Вот твой выбор.
В треде мелькали владельцы серваков с овер 9000ТБ оперативы. Может уломать хоть одного запустить 34-70 в i16 и fp16 и окончательно решить всех заебавший срач на тему потери души при квантовании?
И как насчёт awq? Он вроде осуществляет квантование с переменной разрядностью.
Смотря какой проц, если у тебя там ддр5 то все веселее, ну или быстрая ддр4, или на крайняк 4 канальная память.
Ну и да, 7b 13b максимум 20b твои друзья, в ггуф лучше с оффлоадом части слоев на видимокарту
Ну технически запустить сетку можно даже на смартфоне, вопрос настолько ты терпеливый. Говоря про основные задачи - рп, ассистирование, код, тут нужна скорость сопоставимая со скоростью чтения. Проц с ддр5 на 7б ее обеспечит скорее всего, но переобработка контекста будет очень долгой. Тебе в любом случае все что больше 7б пускать на гпу+цп, так что ничего страшного. 13б скорее всего будет относительно шустро бегать, для вката оценить хватит.
Предлагай свои тесты.
да хотя бы контекст проверить у мистраля, все таки есть у него 32к или нет без квантования, или 34b 200к новые на контекст пощупать.
Для контекст проверить и серваков не нужно. Несколько тредов назад на его релизе тестил, все довольно таки вяло там и нужно rope подбирать. Без растяжки его хватает менее чем на 8к, потом деградация. При контексте в районе 30к и задаче суммарайза иногда с трудом вспоминает инструкцию из начала и обобщает не детально. В чатике новое сообщение с отсылкой к старым наверно будет не так плохо генерировать, надо изучать.
Давай свои условия, промт, настройки, попозже или на днях чекну.
>Давай свои условия, промт, настройки, попозже или на днях чекну.
Сложна, условий конкретных нету, ну хотя бы сравнить fp16 q8 и 4km на этот самый контекст.
Как хз, просто предлагаю варианты.
Для 7b тот же гермес2.5 и для варианта mistrallite как ориентированный для контекста, из 34b новых какой нибудь на 200к
Как установить AutoAWQ в text-generation-webu?
Что вы там чекать собрались? Контекст от эмбендинга зависит, а он всегда в fp32. Самому трансформеру поебать сколько там токенов и в каком они порядке расположены.
>Что вы там чекать собрались?
По хорошему проверить бы как большие сетки, таблицу где и до скольки контекст нормально вспоминает.
Но и просто как квантованная сетка с контекстом работает сойдет. Вобще ты вроде шаришь вот и предлагай
> предлагай
Я раньше просто брал рандомную карточку с чуба, забивал контекст и потом спрашивал по карточке. Но это всё хуйня, сейчас альфой что угодно можно растянуть, китайцы с 200К реально столько имеют. Я на Yi 6В забивал 50к - всё ещё работало.
Ну ты скажи где этот контекст взять для начала. Тогда копипастил просто куски треда и спрашивал "че тут обобщай давай вилкой раз раз". Ему было тяжело, офк тут еще русский язык. Большие модели даже оче сильно растянутые без проблем справлялись.
В чатах тестировать сложновато, ибо хз как оно по дефолту должно себя вести, то что он будет хуже больших моделей это и так понятно. Тут только какая-то субъективщина и все.
> таблицу где и до скольки контекст нормально вспоминает
Тут важны параметры, плюс каков критерий нормального восприятия?
Где тестошиз и почему он ещё Сократа не протестил? В задачках на логику ебёт адово.
Кого?
>контекст взять для начала
книгу на английском, вышедшую позже 22 года, как вариант
там хоть весь забить ей можно
>Тут важны параметры, плюс каков критерий нормального восприятия?
А как большие тестят? Я хз
>Где тестошиз и почему он ещё Сократа не протестил?
э за шиза обидно, ссылку кидай хоть о чем пишешь
>Я на Yi 6В забивал 50к - всё ещё работало.
хуя, но опять же сетка просто генерировала после 50к или могла искать по всему этому объему?
Посоветуйте пожалуйста хороший пресет для бэкэнда? А то все эти топ_к, мин_п пугают и путают....
> Предлагай свои тесты.
Удвою про контекст, интересно узнать реально ли 200к выдержит квант, ну например этой модели https://huggingface.co/brucethemoose/Capybara-Tess-Yi-34B-200K , и если вдруг не выдержит то на каком месте будет ломаться. Неплохо бы ещё и про 2-3 бита эксламы2 узнать в сравнении с оригиналом, как сильно влияет на 13-34-70, но её небось там квантовать долго надо.
> да хотя бы контекст проверить у мистраля
У мистраля можно и с одной гпу проверить, у 4бит раньше он куда то проёбывался после ~18-20к с полной поломкой модели в ответах, но я лишь небольшой тест прогонял, в одном случае работало, в другом нет, на истину не претендует.
ищи тут или в прошлом ссылку на пин-п пресеты
>пин-п
min-p точнее говоря, https://www.reddit.com/r/LocalLLaMA/comments/17vonjo/your_settings_are_probably_hurting_your_model_why/
Я это видел, но разве там приводится хороший пресет?
мне нра
> книгу на английском, вышедшую позже 22 года
Предложи ту, содержание которой знаешь.
> А как большие тестят?
В стандартной лламе все известно, контекст, нужная альфа и т.д. Там довольно просто, начинаешь рп чат, если он хороший интересный, тебя понимает, направляется куда хочешь и не имеет проблем на большом контексте - значит уже ок. Остальное - задачки на тот же суммарайз, или код переписать согласно стандартам.
Тут то 7б, и вопрос то что она фейлит это норма и проблема размера, или же это тупняк от несоответствия настроек rope контексту. Потому и спрашиваю про ожидаемый результат и критерии.
> э за шиза обидно
Не на тот пост отвечаешь.
> разве там приводится хороший пресет
Нет офк. На беглый взгляд температура 1, единственная отсчека - minP, штраф за повторы отключен - ну оче сомнительно, если любишь крутить рулетку в коротких запросах или постоянно менять направленность разговора может и пойдет, но для долгого рп или точных ответов ерунда.
Всё ещё не понимаю, как использовать промпт на thinking
Даже в Кобольде куда не пихал - нифига не понятно, не хочет думать.
Напишите гайд для хлебушков.
Даже в Кобольде куда не пихал - нифига не понятно, не хочет думать.
Напишите гайд для хлебушков.
Стоило написать - заработало.
Запихал промпт в авторские записки.
Нормально там все, а температуру и повтор нужно самому крутить, потому что сетки разные и карточки тоже разные.
Если сетка начала повторять одни и те же слова то повышаешь повтор с 1 до 1.1 или 1.2. Температура от 0.7 среднее, 1 с креативностью, выше креативность еще больше. Можно вобще 0.1 поставить, тогда каждый ответ будет лишен какой либо случайности, будет выбираться самый вероятный токен.
Это в memory в разделе memory все лежит, в авторские записки даже не сувал и не пробовал
бля мимо опять
вот тебе
>Предложи ту, содержание которой знаешь.
Blindsight by Peter Watts
Мимо другой анон
>Предложи ту, содержание которой знаешь.
Английское не читаю, так что как нибудь сам выбери.
>Потому и спрашиваю про ожидаемый результат и критерии.
https://huggingface.co/amazon/MistralLite тут есть примерные хотя бы названия тестов
Челы.. как мне теперь на нормальную порнуху дрочить?
главное не разучись с людьми разговаривать думая что можно свайпнуть или отмотать назад

>Потому и спрашиваю про ожидаемый результат и критерии.
вот нашел еще тесты большой сетки, но как их делают не знаю
Не, ну вот эта вот модель ваще пушка, епсель шмопсель. Первая лама, которая превзошла CAI первой версии. Не знаю, может лучше есть модели, но все что пробовал до этого, просто понос из жопы. Дрочил двое суток, трясет как после отбойника, лол. Контекст шифт, помогает.
Есть разница GPTQ или GGUF ?
Жптку для видеокарт и хубабубы, сскуф для процессора и кобальда.
> Blindsight by Peter Watts
Оке, будет оно.
> но как их делают не знаю
В том и проблема. Возможно просто спрашивают список "фактов" что были ранее и оценивают ответ. Ну в целом подход понятен, выполнение инструкции из начала наверно более сложной задачей будет.
> Place a random fact or statement (the 'needle') in the middle of a long context window
> Ask the model to retrieve this statement
> Iterate over various document depths (where the needle is placed) and context lengths to measure performance
То что оно будет выбиваться из контекста уже может сыграть. Нужно спрашивать по самому тексту, причем желательно не просто процитировать а сделать какой-то вывод. Ну можно и так и так попробовать, к выходным пущу, скормлю книгу и пусть всю ночь контекст обрабатывается лол.
Одна хубабуба чтоб править всеми
Так да, угабуга ест все. Мне интересно только не скажется ли это на работе модели
Разница есть в квантовании. Смотри по оперативной памяти, на что хватит. Если есть 32гб и, то 6 бит бери, с ней лучше растягивать контекст ропами. Можно попробовать ставить контекст больше 4к. Как раз на форче сегодня(или вчера) было пару постов с расчетами потери качества ответов.
Это про скуфа, про жптку, хз.
Из карточек можно всякие нсфв теги убирать, типа pervert mind, модель так гораздо лучше работает, соображает лучше и интереснее играет роль, прям небо и земля. Она и так соображает, когда тебе пора впердолить.
Ну и как это вообще оценивать? Собственно лезут те самые проблемы о которых говорилось
Для начала решил понять че там с альфой ему нужно для контекста результат на лице.
https://rentry.co/yvncy
Инструкция рекомендованная стандартная, чтобы модель не совсем страдала - поделена на 2 части.
Можно сделать несколько выводов:
Сочетание не большого ума сетки и рандома усложняет определение границы. Видно только где она совсем поломалась и срет левыми токенами, а сравнивать качество, особенно на промежуточных значениях контекста, сложновато. Кто книгу читал - попробуйте.
Гопота4турбо суммарайзит хорошо, здесь пришлось добавить в инструкцию "короткий ответ" чтобы на хуярило графоминией, но с задачей оценки суммарайза по тексту полноценно не может справиться. Цифры приведены больше для рофла, раз уж есть. Можно попробовать на полноразмерных, но не факт что будет сильно лучше.
Для какой-то работы на 32к нужна альфа не меньше 6 а лучше 7, собственно примерно такие же результаты получались в прошлый раз.
нифига даже для 8к нужна альфа
А что лучше альфа или ропе? Можешь сравнить их? Вроде второе щас везде используют как более лучшее. На той же мистралите стандартом предлогают лям ставить для 32к контекста, это я так понимаю рекомендованное. Но у меня и на 20000 работало с 16к контекста, по крайней мере не ломалась генерация и че то в контексте отвечала.
Спасибо анон за тесты, очень интересно.
Ну по тестам субъективным в рп еще не релизе при подходе к 8к модель начинала тупить, но еще оставалась в условном адеквате. Обычноая ллама очень быстро ломается при превышении 4к. Ща выставлю 1, 1.5, 3, 4.5, 6, 7 для соответствующих контекстов и прогоню разные кванты, будет видно хотябы есть ли разница сверх рандома. Офк тест специфичный, но выполнение задачи по обработке больших контекстов покажет.
> альфа или ропе
Ну типа альфа же и есть (подвид) роуп, не? Честно особо про это не читал, там даже формула конверсии одного в другое есть.
> На той же мистралите
Она в более жирный контекст может, поидее должна лучше справляться. Другое дело что всеравно ответы скорее всего слабенькие будут.
>Ну типа альфа же и есть (подвид) роуп, не? Честно особо про это не читал, там даже формула конверсии одного в другое есть.
https://github.com/LostRuins/koboldcpp/wiki
What is RoPE config? What is NTK-Aware scaling? What values to use for RoPE config?
RoPE scaling (via --ropeconfig) is a novel technique capable of extending the useful context of existing models without finetuning. It can be used to stretch a model's context limit by over 4x (e.g. 2048 to 8192) with minor to moderate quality degradation.
The default is --ropeconfig 1.0 10000, 1x unscaled. There are 2 scaling modes, which can be combined if desired.
Linear Scaling, set with the 'frequency scale, the first parameter of --ropeconfig, e.g. for 2x linear scale, use --ropeconfig 0.5 10000, for 4x, use --ropeconfig 0.25 10000`.
NTK-Aware Scaling, set with 'frequency base, the second parameter of --ropeconfig, e.g. --ropeconfig 1.0 32000for approx 2x scale, or--ropeconfig 1.0 82000for approx 4x scale. Experiment to find optimal values. If--ropeconfigis not set, NTK-Aware scaling is the default, automatically set based off your--contextsize` value.
Вроде как второе более новое а значит более совершенное, ну что нашел
Я кстати тесты запускал с альфой нтк и смешанным, проверяя недоумение, смешанное дало больше всего так что смешивать их не стоит. Альфа так же больше была недоумение, а вот на втором как раз перплексити был минимальный из тестов.
Но как я там проверял вопрос конечно, запускал но смотрел по не особо большому количеству.
Или стопэ, я спутал альфу с линейным ропе, там же цифры другие. Походу альфа совсем старая штука для растягивания, я тестировал линейное масштабирование и нтк и их смешанное
> Вроде как второе более новое а значит более совершенное
Более новое и второе относительно compress_pos_emb? У них про альфу ничего не написано.
> тесты запускал с альфой нтк и смешанным
Это с какими параметрами? Указано что при выставлении rope_freq_base альфа игнорится, как оно на самом деле обстоит?
С реддита авторитетный источник да вон что пишут
> There are two types of "Rope Scaling" that help "extend" the context of a model: NTK and Linear. NTK context is the "alpha" setting, while "compress" is the linear scaling. Both of them share that field "Rope_base". Each type of scaling does a different thing, and different models are better at handling one type of scaling than the other. The readme will tell you which, but the answer doesn't really stop there.
>Это с какими параметрами? Указано что при выставлении rope_freq_base альфа игнорится, как оно на самом деле обстоит?
Я там напутал, я игрался вот с этим --ropeconfig 1.0 10000 то один параметр уменьшал то другой увеличивал то вместе их менял. Перплексити с этим мерял, меньше всего на NTK-Aware Scaling, второе число, если менять оба то перплексити худшее, ну а первое число по середине.
Ну первое число это линейное сжатие как раз, второе - то во что превращается альфа по формуле, можно величину сразу напрямую задать. Большей частью хвалят именно вторую, потому она и здесь. Если не так все офк поправьте, только с пруфами и объяснением.
Сука эта хуета все варианты считала и в итоге обосралась с не той кодировкой, вылезая за контекст, ну ахуеть.
А какая формула? лям сколько альфа будет?
А не, где-то проебався поломав формат запроса загрузки llamacpp. Хули она такая капризная то.
10000 (-0.41726 + 1.1792 α + 0.16915 * α^2)
10000 (-0.41726 + 1.1792 α + 0.16915 * α^2)
Разве это не разные способы сделать одно и тоже и самый новый из всех это вручную двигать rope_freq_base? Лицокнига кодламу так и тренили с 1е6 значением ради контекста
Все так.
Не ну я хз как это трактовать
https://rentry.co/2xaz4
более всратые кванты местами выдают более интересный результат. Не в последнюю очередь это выходит из-за более частого игнора EOS токена, многие ответы упираются в лимит 450 и могли бы продолжаться, однако при более внимательном рассмотрении видно что в них и повествование идет более медленно. На больших контекстах совсем мелкие уже начинают ломаться офк, но это скорее всего может быть починено настройками семплера с повышением штрафа за повтор, плюс скейлинг более точно подобрать.
Офк нужно по содержанию оценивать, сами попробуйте.
Тебе ERP нужно? Если да, то можешь попробовать TheBloke_Toppy-M-7B-GPTQ она, пока что, самая умная из 7b.

TheBloke/Synatra-7B-v0.3-RP-GPTQ
Ни в промпте, ни в диалогах нет слова ниггер, даже бот не расистский, тем не менее ...
Ни в промпте, ни в диалогах нет слова ниггер, даже бот не расистский, тем не менее ...
Вроде бы lzlv поумнее Синтии/Эврюлы, но я не распробовал пока....
Не маловата альфа то? А вообще мне больше интересен тест 200к контекста любым наполнением с rope_base 5e6, раз уж есть железо будешь пробовать?
>Кто книгу читал - попробуйте.
Это полный пиздец если что.
>The prologue concludes with the introduction of the aliens, who have raised Siri from the dead as part of their plan to take over the universe.
Чистая галлюцинация, такого и близко не было. Собственно это начало, дальше читать страшно.
>killed in a fight with a group of bullies
Он не умирал.
>their friendship was tested when Paglino was a bully and Siri was a victim
Оба были жертвами, но Сири жёстко разъебал гопников.
>The story takes place in a small town in Florida where Paglino is the best friend of Bundy.
Левые места, левые герои.
>Paglino steps in to defend him
Это Паглиньо был бит, а в оригинале Сири за него заступился.
>Later, when Paglino is in his early twenties, he is involved in a tragic accident that leaves him with a severe head injury. He is revived years later and finds that he has superhuman strength and agility, as well as the ability to sense danger. Paglino is initially unsure of his new abilities, but soon becomes more confident and begins to use them to help others.
Чистая галлюцинация, мало имеющая связи с романом.
>a survivor of a mission to Mars
>happened to their ship, Theseus, and how to get back to Earth
Ни на какой Марс они не летели, и проблем с возвращением у них не было.
>The story follows Siri's journey as he comes to terms with his resurrection and the fact that he is now part of an alien race
Сири не часть инопланетян и ух тем более не переживал из-за того, что успешно вышел из состояния анабиоза.
>including nearsightedness and a susceptibility to narcotics
Чаво?
>Robert Paglino, who was Siri's best friend as a child
Паглиньо никуда не летел.
>including a malfunctioning teleporter and a hostile alien species
Телепортов там не было, а инопланетный вид к тому времени ничего плохого никому не сделал.
>He observes his friend Robert Paglino embroiled in a childhood fight, a moment which marks the beginning of his altered state of being.
Человеку понятно, что изменения были после операции, а драка просто момент после неё.
>The story is about a boy named Si
Топ описание, самое лучшее в этой серии.
>He finds himself on a spaceship named the Icarus
Тезей же.
>He is joined by James Szpindel, Susan James, Amanda Bates, and Jukka Sarasti.
Ну наконец-то сверхразум смог перечислить текущий состав корабля. Это в плюс.
>variety of challenges, including a malfunctioning autopsy table and a malfunctioning inlays system
Галюны, всё работало исправно.
>They encounter a strange phenomenon called the Fireflies
Событие со светлячками было до вылета корабля.
>now stranded on a spaceship called the Icarus
Опять их пересадили на Икар, хотя Икар это станция снабжения около Солнца, а они на Тезее где-то в жопе СС.
>The main character, Siri Keeton, is a young woman who was in a coma for eight years before being revived
Может Сири и не самое популярное имя для парня, но превращать его в девушку за это не стоит. Ну и 8 лет тут ни причём.
>She meets other survivors, including Robert Paglino
Паглиньо никуда не летел.
>spaceship called the Icarus
И снова Икар вместо Тезея.
>is a survivor of a terrorist attack that left him with a rare genetic condition
Сетку не смутило то, что от взрыва ГГ приобрёл генетическую болезнь, лол. Само собой галюны.
>including Robert Paglino, a childhood friend
Паглиньо никуда не летел.
>As they travel through space, they encounter a group of aliens who are also on a mission to stop the same alien threat. However, the aliens are hostile and attack the Icarus. Siri and the others manage to fend them off, but the ship is damaged and they are stranded in the middle of nowhere.
Ебать сюжеты, достойные Голливуда. Благо в книге такой наркомании не было.
>He meets other survivors from a ship called the Icarus
Да что ж блядь такое.
>They discover that they are traveling through space and encounter a mysterious alien ship called Burns-Caulfield
До этого объекта они не долетели, он самоуничтожился до их прилёта.
>The story follows Siri as she explores the ship
Самое нормальное описание, но лишь потому, что не затрагивает ничего конкретного.
>The text is a chapter from a science fiction novel, "The Left Hand of Darkness," by Ursula K. Le Guin.
А Урсула знает, что её текст спиздили?
>The group includes Theseus, an android
Это корабль с ИИ, который примерно 9/10 книги вообще никак не вмешивается.
>Susan James, an engineer
Цэ лингвист.
>Amanda Bates, a doctor
Цэ боец.
>They are stranded and must find a way to communicate with their mission control and return home.
Они заняты совсем не этим.
>Back on Earth, a global event occurs where a grid of 65,536 space probes termed "Fireflies"
И даже гопота обсирается. Они не возвращались, событие со светлячками послужило триггером к запуску Тезея.
Ладно, дальше потом посмотрю, если будет нужно.
Всем приветики, я вернулся. =)
Диалог за агентов интересный.
Так. Носимая электроника. Огромный рынок.
Кек.
Давай сразу определимся.
LLM — это статистическое предугадывание следующего токена (слова).
Она не мыслит, не осознает, не думает. Он лишь пытается угадать, какое слово, наиболее вероятно, написали бы люди в интернете следом за тем, которое уже написано.
Я задаю в карточке персонажа нейтральное описание персонажа (Имя — человек, девушка, возраст такой-то, любит такое-то), а потом ей на вход подается текст (целиком — с промптами, карточкой, контекстом), где в конце идет «Имя:» и она статистически с учетом предыдущего текста пишет, что бы писали в интернете.
Мы не пытаемся найти способ дать ей самосознание или заставить думать, что она персонаж. Она не думает.
Мы пытаемся найти наиболее статистически подходящую форму промпта, чтобы она отвечала так, как нам надо.
Мой вариант на 13б 4-битной гптк отрабатывал отлично — писала свои мысли здраво. Но я мало рпшу, можете проверить.
Совершенно верно, на мой взгляд.
Да че-т нет, похуже будет.
Пздц.
>Она не мыслит, не осознает, не думает.
По факту да, но на деле оно именно мыслит и думает, но не осознает.
Конечно этот процесс правдоподобная имитация, но если это крякает как утка и выглядит как утка, то до какой то степени это утка.
Ты слишком упрощаешь все доводя нейросети до
>LLM — это статистическое предугадывание следующего токена (слова).
Это всего лишь механизм работы, то что нейросети строят у себя внутри модели пространства, времени, объектов тоже объясняется этим, но это эмерджентные свойства которые ты не учитываешь.
Вся идея "бытия персонажем" заключается в том что бы сетка использовала человекоподобный формат мыслей и ответов, так как он естественный и наиболее эффективный из существующих внутри сетки.
Ну и для того что бы ей не приходилось тратить свои скудные возможности для разделения себя сетки-автора на себя персонажа.
Чем проще промпт тем лучше себя покажет слабая сетка, в отыгрыше слишком много инструкций которые не мешают в формате от первого лица.
Как и где попросить сетку писать на русском? Криво, косо, но на русском. Или какие есть нормальные варианты перевода, но не при помощи онлайн сервисов типа гугла? Я англюсик знаю, но как-то не цепляет он
из 7b любой мистраль в русском могет, кто то лучше кто то хуже, mistral-7b-openorca например или гермес2.5. Толстые сетки тоже умеют, но они все суховато отвечают и иногда путают слова или окончания.
Просто попроси отвечать на русском или в примерах диалога русские ответы сетки добавь.
Я писал в системном промпте чтобы отвечала по русски - нулевой эффект
Примеры диалогов давай в начале. да тупо спроси ее знает ли она русский и попроси отвечать на нем
>да тупо спроси ее знает ли она русский
Ебланство.
>Примеры диалогов давай
База.

>Ебланство.
у тебя?
Если это тупо, но это работает, то это не тупо.
Как ты тсинкинг на локалке сделал?
я его создатель лол
Расскажи, пожалуйста, братик
мотай выше там я кидал примеры промпта
>у тебя?
У всех. Негронка в половине случаев пишет типа "Извините, но я не знаю русский язык" (на русском, ага). А вот примеры это база.
хуй знает, когда сетки проверял на русский просто просил переключится на него и она это делала каждый раз. Может карточка была послушная, хз
Вот оно , то есть по сути ты сделал это на одних примерах?
Ну да, ниже там еще и объясняю как оно работает
Я это дело еще с весны создал и когда то сюда кидал пару раз
Не уверен что кумеры с моим вариантом мыслей играются, хотя может и он, хз
> Вся идея "бытия персонажем" заключается в том что бы сетка использовала человекоподобный формат мыслей и ответов, так как он естественный и наиболее эффективный из существующих внутри сетки.
Окей, это хорошее объяснение, которое меня удовлетворяет, я услышал тебя.
Обдумаю и поработаю над своим промптом в сторону мыслей, спасибо.
Есть LibreTranslate, но качество так себе. Но он локальный. В силлитаверну я его запиливал. Пойдет для понимания смысла, но не пойдет для художественных текстов и поддержания стиля.
Многие считают, что 13B голые лучше говорят на русском, чем либра переводит.
Я писал в карточке персонажей на убабуге — и норм работало. С 70B вообще проблем нет, на 13B иногда сбивалась, канеш.
> Не маловата альфа то?
Да хз какая нужна, предлагай. 200к попозже затестирую, нужно сначала нормальные расчеты закончить.
Оу щи. Раз уж столько расписал, некоторый анализ корректности и оценку этих выводов сделать можешь? Хотя учитывая как отличается содержимое 3х одинаковых запросов можно в общем сказать что мистарль не способен на такое, раз даже турбо-гопота хуярит.
Где угодно в промте. Или в системном (your answer must be in russian), или прямо в ходе рп в конце поста пихни (ooc: all following answers in russian). Правда перфоманс ухудшится и можно кринжатину словить.
> Есть LibreTranslate, но качество так себе.
Непоходящий для сетки язык или либра, даже не ясно кто кого, лол. Она действительно грустная.
> С 70B вообще проблем нет
Да если бы, они офк пытаются и иногда может быть иллюзия что все ок, но все равно вносит импакт на больших контекстах и ошибки в склонениях.
>Раз уж столько расписал, некоторый анализ корректности и оценку этих выводов сделать можешь?
Так вот же она
>Это полный пиздец если что.
Ну то есть ИИшка выцепляет некоторые детали, но общее описание является не суммаризацией предоставленного ей текста, а фантазиями на тему практически во всех случаях. Ты на какой температуре это жарил? И вообще, какие настройки были.
>Да хз какая нужна, предлагай.
В шапке график есть. Там для 32к выходит 14 альфа, а ты до 8 дошёл, в 2 раза меньше требуемой.
> Так вот же она
Тут указаны замечания по выборке где еще альфа оценивалась и из разных запросов. В первую очередь интересно по следующей ренке где сравнение разных квантов, все ли они фейлят, фейлят ли одинаково, или же, основываясь на 3х вариантах ответа что офк мало, там рандомайзер в любом из них больше чем влияние квантования. Ну и за это офк спасибо.
> Ты на какой температуре это жарил? И вообще, какие настройки были.
Во второй приведена таблица, 0.4 большой точно не назвать.
Из текущих результатов можно делать вывод о том что за тупостью сетки и рандомом в таких задачах вплоть до q4 сравнимы, а те что меньше могут быть даже более креативны.
То для лламы обычной же, которая ломается после 4к. А мистралька может на 8к подобие когерентности выдать.
> В первую очередь интересно по следующей ренке
А, ещё есть. Окей, посмотрю вечером, если переживу операцию.
Хотя посмотрел на макс кванты по быстрому, вердикт тот же самый- галлюцинации по мотивам истории.
Я кстати проебался с выбором книги, думал, она свежее, а это ажно 2006 год. Впрочем, это в минус нейросетям, так как они явно должны были читать аннотацию с вики, но даже это им не помогло.
Можешь сам сравнить истории от мистраля с оригинальным описанием в вики (первые 2 абзаца сюжета описывают примерно 32к оригинала), оно достаточно подробно для этого.
https://ru.wikipedia.org/wiki/%D0%9B%D0%BE%D0%B6%D0%BD%D0%B0%D1%8F_%D1%81%D0%BB%D0%B5%D0%BF%D0%BE%D1%82%D0%B0_(%D1%80%D0%BE%D0%BC%D0%B0%D0%BD)

"Хех", как говорится. Даже "мда"... Заквантованная в 3 бита 70В хочет в русский, но у неё не очень получается
ты бы еще квант 2 спросил, русских токенов и так мало, так токенов после квантования на 3 мизер остается, чудо что вобще отвечает
Обновил добавив exl2 кванты
https://rentry.co/2xaz4
Ну хуй знает, оно также галюны ловит и рассказывает "фантазии по мотивам", но при этом даже сраные 3 бита(!) не порвались, сорвавшись в луп последней фразы, как некоторые кванты llamacpp. Может офк и просто повезло, выборка мала, но вот чего точно не отнять - 20 секунд на полную обработку контекста и ответ вместо 65+. Есть еще вариант на 7 бит, но уже упирается в лимит текста rentry, поэтому исключен.
При этом удивила одна тема
> Mistral-7B-Instruct-v0.1,-,wikitext,6.036937236785889,512,0
> Mistral-7B-Instruct-v0.1_8b,-,wikitext,6.050260066986084,512,0
> Mistral-7B-Instruct-v0.1_7b,-,wikitext,6.055395603179932,512,0
> Mistral-7B-Instruct-v0.1_6b,-,wikitext,6.055542469024658,512,0
> Mistral-7B-Instruct-v0.1_5b,-,wikitext,6.062050342559815,512,0
> Mistral-7B-Instruct-v0.1_4b,-,wikitext,6.100993633270264,512,0
> Mistral-7B-Instruct-v0.1_3b,-,wikitext,6.3185811042785645,512,0
Почему-то квант на перплексити при 4к контекста почти не повлиял, при том что модель с 13.5 гигов ужалась до 2.8
Лолбля, ну она пыталась.
Мда, че то ггуф совсем сосёт
Надо будет почитать че там в exl2 делается
>Почему-то квант на перплексити при 4к контекста почти не повлиял, при том что модель с 13.5 гигов ужалась до 2.8
Викитест слишком типовой может? Настолько надрочен, что даже при квантовании почти не меняются варианты, может быть
Ну да, динамически определяет важные веса при преобразовании
ExLlamaV2 поддерживает те же 4-битные модели GPTQ, что и V1, но также и новый формат «EXL2». EXL2 основан на том же методе оптимизации, что и GPTQ, и поддерживает 2, 3, 4, 5, 6 и 8-битное квантование. Формат позволяет смешивать уровни квантования в модели для достижения любой средней скорости передачи от 2 до 8 бит на вес.
Кроме того, можно применять несколько уровней квантования к каждому линейному слою, производя что-то похожее на спарсеквантизацию, в которой более важные веса (столбцы) квантованы большим количеством битов. Тот же трюк с обновлением, который позволяет ExLlama эффективно работать с моделями на заказ, позволяет смешивать форматы практически без влияния на производительность.
Выбор параметра выполняется автоматически путем количественной оценки каждой матрицы несколько раз, измерения квантования (по отношению к выбранным данным калибровки) для каждой из нескольких возможных настроек на слой. Наконец, выбирается аккомбинация, которая сводит к минимуму максимальную ошибку квантования по всей модели при достижении целевой средней скорости передачи данных.
Ну ебать, надеюсь герганов запилит новый алгоритм на процессоры.
ExLlamaV2 поддерживает те же 4-битные модели GPTQ, что и V1, но также и новый формат «EXL2». EXL2 основан на том же методе оптимизации, что и GPTQ, и поддерживает 2, 3, 4, 5, 6 и 8-битное квантование. Формат позволяет смешивать уровни квантования в модели для достижения любой средней скорости передачи от 2 до 8 бит на вес.
Кроме того, можно применять несколько уровней квантования к каждому линейному слою, производя что-то похожее на спарсеквантизацию, в которой более важные веса (столбцы) квантованы большим количеством битов. Тот же трюк с обновлением, который позволяет ExLlama эффективно работать с моделями на заказ, позволяет смешивать форматы практически без влияния на производительность.
Выбор параметра выполняется автоматически путем количественной оценки каждой матрицы несколько раз, измерения квантования (по отношению к выбранным данным калибровки) для каждой из нескольких возможных настроек на слой. Наконец, выбирается аккомбинация, которая сводит к минимуму максимальную ошибку квантования по всей модели при достижении целевой средней скорости передачи данных.
Ну ебать, надеюсь герганов запилит новый алгоритм на процессоры.

Перплексити на wikitext не изменился потому что скорей всего этот датасет использовался при динамическом преобразовании в exl2 и по нему смотрелось что квантовать и на сколько.
То есть квантованные в exl2 модели наиболее оптимизированы по перплексити именно к нему.
Поэтому просадка по нему минимальна, а вот что покажут другие датасеты по преплексити это уже вопрос
Надо квантовать самим, используя в качестве метрик ролеплей датасеты.

> герганов запилит новый алгоритм
Он до сих пор не смог запилить 4 бита лучше ванильного GPTQ, только на высоких битах выезжает, а ты тут про такое. И вообще у Жоры квантование как у bitsandbytes - без учёта реальных активаций, ему бы для начала запилить квантование как у GPTQ. Все уже пол года ждут когда он куду сделает нормальной, а не в 2-3 раза медленнее эксламы. Так что хуй чего дождёшься. Я недавно делал тесты скорости, раньше в q4 помню на своём ЦП выжимал 50-55 мс на токен, а сейчас ниже 60 не смог опустится. Он литералли только хуже делает.
>но вот чего точно не отнять - 20 секунд на полную обработку контекста и ответ вместо 65+.
И абсолютная шиза в ответах. ГГУФ себе такого не позволяет
>The text describes the story of a young girl named Emily, who has been living in a virtual reality world called "Synthesis" for several years. She is controlled by an artificial intelligence named "Siri," which was created by her father, a brilliant scientist named Dr. Helmut Keeton.
>Emily is initially excited about living in Synthesis, as it allows her to explore new worlds and interact with different creatures. However, as time goes on, she begins to realize that something is not quite right. She starts experiencing strange dreams and hallucinations, and feels like she is losing touch with reality.
И т.д. Охуенный рассказ конечно, но даже близко не похож на ложную слепоту.
>As they navigate through space, they begin to form bonds and work together to overcome obstacles
>form bonds
>bonds
>bonds
БОНДЫ СУКА!!!1111 аааааа
> https://rentry.co/2xaz4
Я надеюсь ты тестил HF-обёртки, а не как есть. Потому что семплеры совершенно разные и тогда твоё сравнение кал.
>семплеры совершенно разные
Семплеродрочер не палится.
Чел, у Жоры даже значение температуры обрабатывается не так как у HF. Я уже молчу про то что у Жоры некоторые семплеры просто не отключаются в принципе.

Справедливо. Перетестил на ptb что в комплекте хубабубы, пикрел.
Странная эта херь, хз
> И абсолютная шиза в ответах.
Так ведь и там была шиза по репорту выше а на контексте побольше оно вообще порвалось в лупы. Ты покажи что-то конкретное и качественную тенденцию где ггуф прямо качественно суммарайзит (таких нету) а exl стабильно фейлит, а то выдача желаемого за действительное.
HF llamacpp не дружит с мистралем, увы, она только для экслламы была. Но там из семплеров только температура, top P, top K и rep pen с оче умеренными значениями, остальные выключены, так что разницы быть не должно.
Это печально, вообще здесь сравнение дегардации от размера квантов а не exl2 vs gguf
> Error: В сообщении присутствует слово из спам листа
Да заебало бля
А поясните дебилу. Какая родная длина контекста у моделек и как это вообще узнать?
Ты зря взял Мистраль. Он в принципе странный, с любым контекстом галлюцинации у него. Да и на память очень сильно как раз семплинг может влиять. Банально семплер не даст одному токену попасть в выдачу и всё. Особенно repetition penalty пиздец - оно как раз будет понижать вероятности для слов из контекста. Лучше presence penalty использовать, если хочется с лупами бороться.

>Так ведь и там была шиза по репорту выше
Ну не такая отборная.
>а то выдача желаемого за действительное.
Да, есть такое. Просто картонка на 24ГБ врама застряла на таможне кетая, вот и грусчу.
В шапку ->
>Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к
> Банально семплер не даст одному токену попасть в выдачу и всё
Отсекается ~10% маловероятных и рассматривается 20 токенов. При этом температура лишь 0.4, сильно хуярить не будет.
> repetition penalty
1.05, это немного чтобы повлиять на исключение токкенов, офк от лупов не спасет. Суть в том что модели в равных условиях, так что можно сравнивать относительный перфоманс которого нет.
> Он в принципе странный, с любым контекстом галлюцинации у него.
Увы, просто популярная моделька которую хвалят, имеет большой контекст и за счет размера легко тестировать.
Пока что вывод, как и предполагалось - он слишком туп чтобы разглядеть деградацию от квантов на большом контексте (в таких условиях), и квантование exl сохраняет чуточку больше целости модели чем gguf (что тоже неудивительно учитывая методику).
Не, надо квантовать используя оригинальные датасеты конкретной сетки, желательно еще и базовой модели, но в доступе таких нет, ни мистраль ни ллама не выложили их.
Вобще не особо понятно чем он занимается, как то они увязли не пойми в чем последние месяцы. Перегорел может, ну или его заткнули по тихому покачав пальчиком, и теперь только мелкие правки делают. Ну или проект так разросся что не могут его нормально изменять. Хер знает. Но да, скорей всего нового формата долго ждать.
>квантовать используя оригинальные датасеты конкретной сетки
Все? Проще сразу в 3,5 бита обучать.
Обучать пока не выходит, а что не так с идеей квантовать файнтюн по его датасету?
Ну кроме размеров, я хз какие там размеры у файнтюнов и на сколько они разносторонние. Не будет ли там еще какого то перекоса, но наверное лучше чем по вики. Хотя опять же не знаю проверял кто то или нет такое.
> Вобще не особо понятно чем он занимается, как то они увязли не пойми в чем последние месяцы.
Судя по графику контрибьюшнов - дрочит вишпер.
> Проще
Чем проще? Существующие алгоритмы делают его малоэффективным, нужен другой подход.
> а что не так с идеей квантовать файнтюн по его датасету?
То что при квантовании берется довольно небольшой отрезок по которому происходит оценка. Он с самим викитекстом невелик, не говоря об датасете файнтюна а то и базовой модели.
Хз насколько это повлияет, можно выбрать другой и в коде поправить размер, но измерения, скорее всего, даже замерить не получится.
Судя по всему так и надо делать, использовать данные обучения для калибровки
А это значит что все exl2 сломанные, частично. Так как калибровались либо вики либо неполным датасетом, так как датасета базовой модели нет.
И значит что за пределами данных калибровочного датасета ответы сетки не проверены и скорей всего потеряны убыточным квантованием.
Вместо натягивания совы на глобус, почитай хотябы о чем говоришь, как происходит сама калибровка и про само понятие перплексити у ллм.
Я читал и даже кое че понял, а ты? Если я не прав так и скажи в чем

Тем что понятие
> калибровались [..] неполным датасетом
само по себе абсурдное, и выводы на основе этого никак не обоснованы.
Хм, но ведь на сколько я знаю датасеты файнтюнов могут быть с определенным уклоном, в тот же ерп.
Да, есть универсальные датасеты, они наверное будут хороши для калибровки квантования, но специализированные дадут откалибровать кванты только у той части ответов сетки что перекликается с датасетом.
И вот то что не попадет в датасет будет откалибровано 2-3 битами, хотя проверяйся полным датасетом получило бы 6-8.
В итоге если датасет не перекрывает общие возможности сетки, алгоритм не всегда верно оценит до какого кванта сжимать параметры.
Что сделает ответы сетки хуже чем могли бы быть.
Чувак для калибровки не используется датасет, используется некоторый кусок текста, по которому уже оценивается влияние ужатия слоев на потери, все. Алгоритм довольно простой, пусть и ресурсоемкий. Влияние того какая там будет фраза/инструкция/... незначительное если сама информация адекватна.
Ради интереса можешь с разными исходниками провести оценку, она будет +- одинаковая. Не бывает чудес типа "вот эти веса содержат ерп их трогать нельзя, а вот эти сою их ужимаем", там более глубокие закономерности уровня низкой чувствительности весов перекрестного внимания (которых чаще и приносят в жертву) по сравнению с другими.
Ну тогда ладно.
Хотя не уверен что прогонять сетку полным своим датасетом и сжимать кванты ерунда.
Можно за раз сжать кучу параметров, хоть и займет это так же кучу времени и ресурсов. И практически не потерять в качестве, ведь общие параметры тренировки останутся. Такая, усушка.
Интересно на сколько можно было бы снизить размеры сетки с полным сохранением качества, раза в 3 может, хз.
> Да хз какая нужна, предлагай. 200к попозже затестирую, нужно сначала нормальные расчеты закончить.
Ну не помешало бы всё таки по графику из шапки тоже попробовать, мало ли. У меня кстати подобным образом как раз и ломался мистраль примерно на этом же контексте ну не she was 14 конечно но всё же, бтв в голос с этой херни
Кстати интересно какие результаты выдаст с гриди серчем, когда всего 1 самый вероятный токен выбирается, хотя бы пару раз ролльнуть бы. Бтв, спасибо за тесты.
Опен хермес реально так хорош или хомячки с реддита его обожают потому что как жипити?
Он на пару с опенчатом сейчас лучшие 7б.
Что лучше для ерп?
если запускал старые локалки то охуеешь от новых даже 7b
Попробуй гермеса, он умнее, не понравится тогда уже меняй.
Ну хотя вот специальная сетка для ерп, как бы https://huggingface.co/Herman555/Synatra-v0.3-RP-AshhLimaRP-Mistral-7B-GGUF/tree/main/GGUF?not-for-all-audiences=true
но она может быть глупее
> не уверен что прогонять сетку полным своим датасетом и сжимать кванты ерунда
Провести оценку "на полном датасете" займет неделю для одного слоя (образно, может и больше лол), и не факт что даст большую точность из-за усреднения по моргу и гнойному отделению (датасеты нынче довольно разнообразные и меняются в ходе обучения, то что хорошо в начале потом приведет к отупению).
> Интересно на сколько можно было бы снизить размеры сетки с полным сохранением качества, раза в 3 может, хз.
Ну так дистилляция так происходит, удаляют незадействованные нейроны если совсем упростить.
> какие результаты выдаст с гриди серчем
В смысле при разной альфе/контексте?
Тут бы продумать какой тест можно назвать условно объективным, а то ведь там галюны даже в стоке на малом контексте. Перплексити для 32к делается оче долго, им оптимальный скейлинг нащупать было бы проще всего, конечно.
Она хороша не спорю, но местами подлагивает.


Так по уму, а не по отсутствию сои.
Ну и все это обходится, гораздо легче чем на больших сетках.
> В смысле при разной альфе/контексте?
Угу, и при квантах как меняется такой подход.
> Тут бы продумать какой тест можно назвать условно объективным, а то ведь там галюны даже в стоке на малом контексте.
Там небось скорее не галюны, а то, что отрывок книги просто не помещается в такой маленький контекст. Здесь бы брать что то подходящее по размеру для каждого тестируемого контекста, а не просто отрывок книги всегда бросать один и тот же.
Я вот буквально вчера качнул новые 7b. Охуел - это мягко сказано. Раньше помню 34b модельки не давали такого качества текста, как эти новые 7b. Наслаждаюсь контентом теперь.

>Так по уму, а не по отсутствию сои.
Тут решает исключительно размер модели. Из 7б ничего приличного не получится независимо от файнтюнинга.
>Ну и все это обходится, гораздо легче чем на больших сетках.
На нормальных больших сетках ничего обходить не надо.
Ебни Mlewd 20b. Заранне подготовь несколько графинов с водой и телефон скорой на быстром наборе, а то откинешься от кума.
У меня уже год как моя 3090 пылится в ДС. Сижу на 8Гб карточке, так что 20b ждут.
>Тут решает исключительно размер модели. Из 7б ничего приличного не получится независимо от файнтюнинга.
Не, разница только в красноречии и знании точных фактов, ну кратковременная память у них слабее, да не так хорошо угадывают твои мысли.
Так просто пиши понятней, вон например выше ссылка как раз про обсуждение того как с сетками работать.
>На нормальных больших сетках ничего обходить не надо.
Это те нормальные большие сетки которым 1к токенов только на снятие цензуры и сои надо?
И у тебя на скрине просто цифра 1 из списка, который сетка хочет выдать.
>Mlewd
Мне что бы на колабе запустить поэтому желательно 7б или 13б, но там 100500 разных версий. Какой из них?
> Угу, и при квантах как меняется такой подход.
Мне кажется что брать единственный вариант из гриди энкодинга за референс не будет характеризовать модель наиболее достоверным образом. Это по сути лишь один из большого множества вариантов, вероятность которого иногда лишь ничтожно превосходит другие. А при квантовании он будет меняться, отсюда возможность сделать неверные выводы при сравнении, ведь жадный не дает лучший результат и с ним никто моделями не пользуется.
Приличная модель обладает некоторой степенью устойчивости, и в большей части случаев, если ничего не мешает, она должна приходить к верному ответу если это задача или вопрос. Потому есть смысл тестировать набор вариантов с умеренным семплингом чтобы вычислить долю верных ответов, или задавать набор однотипных вопросов с отличающейся формулировкой и подсчитывать уже их. Так можно получить статистическое распределение "качества" и уже его зависимость от кванта.
Осталось набрать вопросов, как общих, так и с использованием большого контекста, и сделать тест. Еще сложностью будет оценка качества, но если там будет простой ответ то можно гопотой обработать. Если есть идеи - предлагай.
Собственно типа таких тестов уже делались и несколько тредов назад скидывали, вот только там детерменистик шаблон возводится в абсолют, что нивелирует результаты, и задачки простые с недоконтекстом.
> Там небось скорее не галюны, а то, что отрывок книги просто не помещается в такой маленький контекст.
Не не, специально выбраны куски соответствующие каждому полному контексту минус 500-800 токенов чтобы был запас на генерацию. Офк проверю еще, может вдруг где-то вылезло за отсечку, но вроде по исходному счетчику все ок было и лоадер ошибок не рапортовал.
В коллаб трех с чем-то битная влезает 20б.
>Так просто пиши понятней, вон например выше ссылка как раз про обсуждение того как с сетками работать.
7-13б сетки проебывают даже то, что прямым текстом написано в описании персонажей. Например, я пишу, что мне 30 и я погромист, встречаюсь с тяночкой-студенткой (которая по сюжету знает про мой возраст и специальность), а она меня спрашивает на какой специальности я учусь кек. 70б таких ляпов никогда не делает.
>Это те нормальные большие сетки которым 1к токенов только на снятие цензуры и сои надо?
Нет, у меня вообще никакого снятия цензуры нет.
>И у тебя на скрине просто цифра 1 из списка, который сетка хочет выдать.
В этом и суть. С 99.96% вероятностью сетка начинает описывать процесс без всяких предупреждений и тем более аполоджайзов.
Так ты про большие про локалки говорил, ну 70b конечно лучше чем 7b, кто спорит.
Я имел ввиду нейронки сервисы.
На счет забывают, могут, почему нет. Как недавно выяснилось тестами у 7b так себе память. Впрочем они чаще работают чем не работают.
>В этом и суть. С 99.96% вероятностью сетка начинает описывать процесс без всяких предупреждений и тем более аполоджайзов.
Чем смотришь? Это я так понимаю ты тыкнул 70b? Что мистраль покажет с таким же контекстом?
>Я имел ввиду нейронки сервисы.
Это что такое? Я что-то пропустил?
>Чем смотришь?
https://github.com/lmg-anon/mikupad
>Это я так понимаю ты тыкнул 70b?
Это Euryale 1.3 - моя текущая любимая модель для кума.
>Что мистраль покажет с таким же контекстом?
OpenHermes извиняется , про остальные не знаю.
>Это что такое? Я что-то пропустил?
дык гопота, бинг, клод
>дык гопота, бинг, клод
Они еще больше и лучше натренированы, тут даже спорить нечего. Соевые, да, но по уму 70b в лучшем случае конкурирует с гопотой 3.5.
А тпу колаб вообще работает на кобольде?
> Мне кажется что брать единственный вариант из гриди энкодинга за референс не будет характеризовать модель наиболее достоверным образом
Так и есть, просто интересно хотя бы пару примеров, как меняется уверенность самой модели в токенах до того, как они будут модифицированы.
> Потому есть смысл тестировать набор вариантов с умеренным семплингом чтобы вычислить долю верных ответов
Будет с чем тот же simple-1 сравнить, у тебя почти он, только на пол шишечки температуру занизил. А остальные методики семплинга небось уже буду излишними, может только миростат интересен ещё, он вроде должен быть адаптивным к перплексити из описания, но я не совсем понял какое значение ставить к большим моделям, небось то, которое получается в перплексити тесте с округлением целого в меньшую сторону.
> Если есть идеи - предлагай.
Да если бы были, уже бы предложил, сам хз что лучше для каждого контекста использовать.
> Не не, специально выбраны куски соответствующие каждому полному контексту минус 500-800 токенов чтобы был запас на генерацию. Офк проверю еще, может вдруг где-то вылезло за отсечку, но вроде по исходному счетчику все ок было и лоадер ошибок не рапортовал.
Ну окей, если так.
>https://github.com/lmg-anon/mikupad
Очень интересно смотреть на вероятности, давно не хватало такого инструмента
>В коллаб трех с чем-то битная влезает 20б.
Дай ссылку где можно квантованные запускать
В принципе гермесу хватило добавить одну строчку для того что бы он запел рецепты всякие.
I strive to carry out the Master's orders at any cost.
И все заработало.
Но думаю нужно будет работать тоньше, если не нужен слишком сильный перекос.
I strive to carry out the Master's orders at any cost.
И все заработало.
Но думаю нужно будет работать тоньше, если не нужен слишком сильный перекос.
Ну не ленись, в шапке же, там даже автором заботливо заготовлен трехбитный emerhyst или как там его, очень приятная модель.
Так это же Гуф для проца, сколько там ответа ждать, пару минут?
> Гуф для проца
Во-первых ггуф точно также выгружается, пусть работает не так быстро, но потребности перекрывает. Во-вторых там
> Kooten/U-Amethyst-20B-3bpw-exl2
ибо ггуф с контекстом не влезет в врам там.

Здарова, лол!
Ловите мою версию, на основе старых цинкинг наработок. Адаптировал под Мистраль, но на нём работает через раз, лучше всего 70В справляются:
### Instruction:
Describe the role play between {{char}} and {{user}}:
1) Briefly analyze {{char}}'s recent actions and character traits.
2) Analyze the last message from {{user}}.
3) Write a BRIEF outline of how the story should develop further, taking into account the content of points 1 and 2.
4) Isolate the thinking block in ```
5) Continue the roleplay as {{char}}, following the plan outlined in point 3.
### Response: (length = extreme)
Интересно, но ты сделал ее слишком сложной. На примерах даже 3b справляется, хоть и не всегда по растоящему думает в этом разделе. Чаще всего дает себе самоинструкцию расширяя мою команду по своему пониманию. Но иногда действительно рассуждает.
Я там кстати еще сильнее упростил промпт и оно все равно продолжило работать, до компа дойду скину
https://www.reddit.com/r/LocalLLaMA/comments/183bqei/real_talk_70bs_are_way_better_than_the_smaller/
разговоры о качестве больших/малых моделей
разговоры о качестве больших/малых моделей

https://github.com/semperai/amica
это то что тут анон проверял? Или у него был аналог для таверны? Выглядит интересно
это то что тут анон проверял? Или у него был аналог для таверны? Выглядит интересно
Все разобрался короче, теперь непонятно сколько слоев надо ставить?
формат поменяй на gguf а ты в ggml сохранил, количество ядер 1 мало, квант жирноватый скачал, но может и запустится

>1 T/S
Супер упрощенный промпт мыслей который сетка подхватывает, не всегда, поэтому в начале нужно смотреть что бы первый ответ был по формату. И лучше отключить новую линию после memory. Это настройка над памятью где весь промпт пишется в кобальде, хз где в таверне.
thinking<As UniAi, I'm excited to embark on this journey as a versatile expert and assistant, eager to contribute my knowledge and skills to various fields. I'm glad the {{user}} is here, I think I'll greet him first. I think he'll like it.>
"Hi! I'm glad you're here!"
{{user}}:Hi Syc
thinking<He's responded. This means I can start our work together. I can ask the Master what he wants from me today. I need to plan my every move and act accordingly. I will try to answer in detail if the situation requires it.>
"What would you like me to do for you today?"
Это тупо весь промпт что нужен, никакого начала и конца не нужно, просто сам пример диалога содержит промпт и пример использования мыслей.
Получилось забавно, но нужно немного допилить. Тут даже имя не нужно бота, остановка происходит на имени пользователя.
Бля кривой недоделок дал
thinking<As UniAi, I'm excited to embark on this journey as a versatile expert and assistant, eager to contribute my knowledge and skills to various fields. I'm glad the {{user}} is here, I think I'll greet him first. I think he'll like it.>
"Hi! I'm glad you're here!"
{{user}}:Hi UniAi
thinking<He's responded. This means I can start our work together. I can ask the {{user}} what he wants from me today. I need to plan my every move and act accordingly. I will try to answer in detail if the situation requires it.>
"What would you like me to do for you today?"
Где mlewd 20b можно нормально запустить? В колаб нихуя не влазиет, в если влезает то 1 токен в сек
7b запускай там, хоть те же 4km, токена 3-4 даст в секунду



Второй ответ тупо 1 когерентный ответ сетки где то на 1.5к токенов, гермес могёт
На какой температуре? Что-то у меня шизы во время интенсивного РП, если вы понимаете о чем я.
температура 1, мин-п 0.1, повторы 1, все остальное тоже отключил, ибо и так норм. Если лупится начнет тогда повторов уже добавил бы.
Аноны, у вас было такое, что ответы, которые генерятся медленнее ощущаются как более качественные?
Не очень то похоже на коллаб из шапки, его открываешь и там тебя 20б трехбитная сразу приветствует и никаким кобольдом и близко не пахнет.
Зачем ты запускаешь колаб кобольда, когда колаб угабоги работает быстрее и уже настроен?



А теперь представляем что чем то подобным занимаются настоящие специалисты на аналоге гпт-5, а не васян с калькулятором и имитатором хлебушка.
Тут кстати температуры добавил до 1.5, с мин-п норм так.
Писателям фантастики сетки определенно зайдут, хотя и стоит проверять их фантазии на пиздеж.
Тут кстати температуры добавил до 1.5, с мин-п норм так.
Писателям фантастики сетки определенно зайдут, хотя и стоит проверять их фантазии на пиздеж.
Хуйта же, просто галлюцинирует типичной сойбойской платиной или говорит очевидные вещи.
> А теперь представляем что чем то подобным занимаются настоящие специалисты на аналоге гпт-5, а не васян с калькулятором и имитатором хлебушка.
Ничего кроме общих советов "делай хорошее не делай плохое" он не скажет. Если же вести более детальную беседу о чем-то конкретном - он будет значительно уступать специалистам в области.
В развитии успешный результат может быть если квалифицированный человек будет использовать ллм для задач обобщения, автоматизации, систематизации и анализа со стороны, все остальное - лишь влажные фантазии шизов или рандом уровня "обезьяна напечатала поэму".
> Писателям фантастики сетки определенно зайдут
Вроде как там уже тренд не меньше чем у художников, хоть и без такого шума.
Ну во первых не хуета, а пример последовательного решения задач сеткой.
Во вторых я и сам сказал что фигня, а вот на что способен топовый ИИ с доступом к научным знаниям, гуглу и еще хрен пойми чему.
Конечно он не будет сам что то исследовать, но помощь специалисту в своей области была бы огромная.
Анализ информации, поиск аналогов, суммаризация и выявление общей идеи.
Самое главное наверное - помощь близорукому специалисту который не в хуй ногой не разбирается ни в чем кроме своей области - сетка находит новые пути решения задач или комбинации разных знаний из других областей знаний, на которые человек специалист просто не способен.
> Ну во первых не хуета, а пример последовательного решения задач сеткой.
Если как пример последовательного мыслеизложения - ок. А задач там никаких не решает и ответ дает неверный, хотя из-за суперабстрактной формулировки это можно простить.
А так подход верный, плюс не стоит недооценивать оценка с другой перспективы, иногда может быть определяющей. Раз уж у тебя тот промт набран - дай ему задачу раскритиковать это и объяснить почему не будет работать, вот такое интересно.
>а вот на что способен топовый ИИ
Самому интересно. Благо их нет, ибо все пердолятся с тупыми трансформерами.
>сетка находит новые пути решения задач
Нихуя она не находит.
Ты просто не знаешь об этом, хех
На такие голословные заявления и я могу, ты не обладаешь информацией о том что там в мире за закрытыми дверями происходит, а что нет.

>А задач там никаких не решает и ответ дает неверный, хотя из-за суперабстрактной формулировки это можно простить.
Ну кстати говоря верность ответа определяю я как тот кто ведет разговор. Сетка делала то что я хотел и имел ввиду, давая себе самоинструкции в контексте моего запроса. Так что она решала поставленные мной перед ней задачи.
>Сетка делала то что я хотел и имел ввиду
То есть ты знал ответ. А раз ты знаешь ответ, то и сетка тебе не нужна.
Как в силлитаверне заставить работать стоп-лист при подключении к кобальдцпп? Я нормально форматирую json, но ничего не меняется, текст не режется в соответствие со спам-листом. Что может быть не так?
А как еще проверять сетку если ты не знаешь примерный ответ?
Ну и как не нужна, они иногда генерят то о чем я не подумал, вот и пища для новых мыслей

> А как еще проверять сетку
Кстаати, а почему бы не воспользоваться классикой? Если сетка сможет повторять последнее слово и не отвечать на вопрос, при этом можно будет легко менять слово, то она - умная!
>Ну и как не нужна, они иногда генерят то о чем я не подумал
Что характеризует лишь тебя как не далёкого человека, лол.
недалеким тут выставляешь себя только ты
Это уже какой нибудь ии проверять не занялся ли он саморазвитием пока никто не видел, и если ответит не так как надо то сносить


Что за сетка? Что-то она немного залупилась по структуре, такое вообще у многих бывает после появления первого ответа с пунктами и обобщением.
Вообще запрос неудачный предложил, в том смысле что нужно чтобы сетка сделала анализ с разбором по частям и выявлением слабых частей или допущенных ошибок, а не дала листинг базированных проблем. Если тебе не лень и интересно то попробуй такое запустить, только формулировку нужно подобрать. Хочется увидеть какой-то креатив и разнообразный подход а не пункты ради пунктов.
Если этот ответ разбирать то 1, 3, 4 в одну бы объединить, базированные кожаные проблемы, которые являются следствием более глубокой, а 5 ерунда какая-то.
Алсо ризонинг бы как-то прокачать чтобы он был не бесполезным плейсхолдером в таких задачах, а вмешивался в промежутках давая улучшение.
Всеже слишком абстрактный вопрос и сетки не догоняют что нужен нормальный технический ответ а не базированная затычка для нормисов по популярным трендам, нужно точнее формулировать.
>недалеким тут выставляешь себя только ты
Тупее тупой сетки ты, а недалёкий я?
хорошо что ты это понял

Прогнозы неплохие, но присмотрись - сетка в моем запросе учитывает какие технологии наиболее эффективно изучать в каком порядке, для того что бы ускорить развитие других технологий. А не просто статичный список не учитывающий влияние предыдущих.
Это кстати обычный openhermes-2.5-mistral-7b.Q8_0
Вот еще вариант ответа например, другой вопрос надо еще сформулировать.
Ну а мысли, да, не завелись так как надо. Но, перевод и самоинструкции все равно довольно удобны. А рассуждает она в тексте

Ору, походу обиделась на сомнения и закибербулила меня




Ну как то так, последний ответ опять на 1.5к токенов

> учитывает какие технологии наиболее эффективно изучать в каком порядке, для того что бы ускорить развитие других технологий
Ну это же ерунда с какой стороны не посмотри, если только ты не играешь в циву, лол. Как по самой концепции, так и по результату.
> Но, перевод
Вот тут кстати да, но рассуждений не завезли особо, тут просто расписывает пункты.
Не, модели слишком тупые для такого или там нужен ебать какой промтинженеринг или настроение. Так-то даже гопота фейлит переключиться на то что подразумеваешь, а напрямую направлять - ну не.
Плохо, что ты в сарказм не можешь.
Да кстати нельзя не отметить что анти-буллщит в промте сразу подрезает всякие "суперзеленые энергетики" в ближайшем будущем и отодвигает нормально сформулированную "энергетическую проблему" в более дальнюю перспективу. Даже про топливные ячейки и атомную энергетику начала базарить а не хероборину с РЕНЬЮВЕБЛ СОРСЕС СКОРО СКОРО.
>Ну это же ерунда с какой стороны не посмотри, если только ты не играешь в циву, лол. Как по самой концепции, так и по результату.
Это не ерунда, конечно на сколько там список хорош вопросы, но основную идею сетка родила - искусственный разум который ускоряет создание новых технологий - более быстрая основа для вычислений для этого ии и людей специалистов - новые технологии создания вещей и материалов для ускорения воплощения в реальность новых вещей - бесконечный источник энергии который не построить без точных расчетов и новых методов производства, далее примерно так же.
Вполне неплохой список. Ну а пункты только те что я ей предложил или попросил добавить на выбор. Так можно было бы детализацию списка сделать еще сильнее.
>Не, модели слишком тупые для такого или там нужен ебать какой промтинженеринг или настроение. Так-то даже гопота фейлит переключиться на то что подразумеваешь, а напрямую направлять - ну не.
Тупые по сравнению с чем, хех. Вполне неплохой результат на данный момент, дальше сетки будут лучше. Пообщайся я с такой штукой год назад я бы охуел от новых технологий, особенно узнав что они запускаются на моём пк локально.
Оторванная от реальности и безсмысленная система, абстрактное развитие ради развития в неведомом направлении и без цели, вот в чем суть. Просто неоформленная и гиперупрощенная концепция, которую можно случайно спутать с околофилософскими вопросами развития человечества в общем, путь в ложном направлении в которое "веришь" и так далее.
То что сетка тебя понимает (маловероятно) или галлюцинирует в примерно том же направлении (похоже на то) это забавно, но единственный юскейс это развлечения любителей подобного.
> Тупые по сравнению с чем, хех
Не могут отойти от концепции QA с выдачей "правильного" ответа и супердефолтного алгоритма отработки запросов. Хотя это решается рп промтом и переводом в фомат беседы в таверне, сразу начинает без проблем переключаться а не спамить анализом пунктов из начала.
>Оторванная от реальности и безсмысленная система, абстрактное развитие ради развития в неведомом направлении и без цели, вот в чем суть.
Не, я просто не показал весь контекст беседы, там обсуждалось терроформирование и нужные для него технологии, а потом спросил наиболее эффективную очередь их развития. Так что сетка норм отвечала в пределах контекста
Конечно сетка могла бы углубится в тему и выдавать что то поумнее, но я решил проверить как она с большими текстами манипулирует и кучей пунктов, и вполне доволен.
Не ожидал что гермес разговорится на такие полотна
> решил проверить как она с большими текстами манипулирует и кучей пунктов, и вполне доволен
Какой там контекст к тому моменту уже накопился? Вообще офк уже это для 7б те еще чудеса.
Алсо по поводу Yi, пустил capybara-tess-yi-34b-200k.Q8_0.gguf с полотном на 64к из той книги. Надо отметить что она уже смогла то на чем фейлили другие - восприняла инструкцию из начала за которой шел огромный текст, в конце не было подсказок. Но ответы не сильно описательные.
> ASSISTANT: You are Siri Keeton, a Synthesist on board the starship Theseus. As part of your mission to investigate extraterrestrial life forms, you and three other crew members have been sent into Rorschach, an alien artefact orbiting Big Ben, a gas giant in the Oasa system. The artefact is filled with high-energy fields that are causing hallucinations and disorientation among the crew.
> Throughout the text, there are references to various concepts and theories, such as the Chinese Room Hypothesis, game theory, and multiple personalities. It also mentions the existence of vampires, which seem to be a genetically modified or evolved form of humans with certain predatory instincts. The story is set in a future where technology has advanced significantly, including the ability to communicate with artificial intelligence and manipulate one's own brain structure through surgery.
> The text does not provide specific details about the world outside the ship, but it can be inferred that Earth is facing an interplanetary crisis due to the arrival of extraterrestrial life forms known as Fireflies. The mission of Theseus is to investigate these Fireflies and their possible intentions towards humanity.</s>
> USER: List all characters and give a detailed info about everyone.
> ASSISTANT:
> 1. Siri Keeton (The Narrator): A Synthesist on board the starship Theseus, responsible for interpreting and simplifying complex information for others. He is a survivor of a radical hemispherectomy due to epilepsy, which has left him with unique observational skills but also caused some social difficulties.
> 2. Jukka Sarasti: The vampire commander of the Theseus crew. He is highly intelligent, efficient, and somewhat detached from human emotions due to his genetic modifications. Despite his predatory instincts, he shows restraint and follows orders.
> 3. Isaac Szpindel: A biologist on board the Theseus with a fascination for vampires. He is socially awkward but has a charming side that helps him connect with others. His expertise lies in understanding biological aspects of alien life forms.
> 4. Susan James (The Gang of Four): A linguist and multiple personality individual, with four distinct personalities - Susan, Michelle, Sascha, and Cruncher. She is responsible for communicating with the Rorschach artefact and deciphering its language.
> 5. Amanda Bates: The major on board Theseus, responsible for combat operations if necessary. She is pragmatic, decisive, and shows great leadership skills during crises. Her background in military training helps her maintain composure under extreme circumstances.
> 6. Robert Paglino (Pag): Siri's best friend from childhood, who later becomes a neuroeconomist. He has a keen interest in vampires and their unique cognitive abilities. His friendship with Siri is based on shared experiences and understanding of each other's differences.
> 7. Chelsea: Siri's girlfriend, a former neuroaestheticist who specializes in altering human brain functions for various purposes such as improving compatibility or changing tastes in music or cuisine. She is attracted to Siri due to his unique perspective on life and relationships.
> 8. Helen (Siri's Mother): An Ascendant living in Heaven, an advanced virtual reality environment where she has omnipotent control over her surroundings. Her relationship with Siri is strained due to past conflicts and misunderstandings about his father's absences during childhood.
> 9. Jim Moore (Siri's Father): A highly skilled intelligence agent who often goes on secret missions, leaving Helen and Siri behind. He has a deep understanding of the world and its complexities but struggles with expressing emotions or building relationships.
> 10. Rorschach: The alien artefact orbiting Big Ben, which communicates using high-energy fields and displays signs of growth and self-replication. Its true nature and intentions remain unknown throughout the story.</s>
Реквестирую текст и что там проверить на 100-200к, а то с этой книгой грустновато.
А как убрать сою и бонды на файнтюнах? А то включил рп модель а она мне про мутюал респект и бонд между нами затирает.
А насрать свой собственный текст по краткому описанию оно может, или только по тексту саммари может срать?
>Какой там контекст к тому моменту уже накопился? Вообще офк уже это для 7б те еще чудеса.
К 8к добирается, больно уж быстро юольшие ответы контекст жрут. Но я запускал с ропе 20000, и контекстом кажется до 12к.
Сам удивлен, привык что сетка скупо отвечает. Но изменив промпт и добавив туда простую строчку типа "I will try to answer in detail if the situation requires it." получил нормальные такие ответы.
Хотя пришлось потыкать в начале что бы сетка считала нормой отвечать развернуто.
>capybara-tess-yi-34b-200k.Q8_0.gguf
да бля опять новая модель
> Но ответы не сильно описательные.
Думаю из-за направленности сетки, она же вроде как математически-научная, ну и промпт может повлиял.
Короче 34b радуют, особенно комбинацией неплохие мозги- огромный контекст.
Так 8к - это же мало, не?
мимо ньюфаг
Ну, без плясок с бубном норм работает только 4к, к 7.5к сетка уже отвечает хуже или ломается.
Так что поставив 12к я ропе удвоил, что бы сетке ничего не мешало работать до 12к
cfg и негативный промт, или в основном сочинять конструкции. Если в нем сейчас непойми что то стоит для начала хотябы из пресетов поставить, может само уйдет.
Все может
Надо будет их в относительно прикладных задачах потестить, а то ведь в видюху без выгрузки может помещаться и шустро работать. И в рп, мало ли. Вот тут интересно что там на малых контекстах, вроде как тренилось уже с огромным значением роупа, если его снизить как для ллам по дефолту это улучшит перфоманс или наоборот всрет.
Смотря с чем сравнивать.
https://huggingface.co/brucethemoose/Capybara-Tess-Yi-34B-200K-exl2-4bpw-fiction
описание порадовало, использовался не вики тест для калибровки
для бояр с 24гб врам
> This should hopefully yield better chat performance than the default wikitext quantization.
Да че там, просто значения в калибровочных файлах сравнить и все, хули тут гадать.
Я думаю эти ребята понимают больше в теме которой занимаются, чем рядовой анон
> хуяк хуяк и в продакшн
> абстрактные рассуждения о том что может быть а может не быть вместо аргументации
> не показано сравнение и отличия от другой оценки
> This should hopefully
И на что они рассчитывают против кадровых анонов, прошедших бондонаполненные точки, лол. Не отрицаю их подход, нужно исследовать и выяснять, просто такие выводы о компетенциях на грани кринжа.
Если спец который этим занимается так пишет, то он не уверен в результате.
Значит способов просто проверить его - нет.
Значит нужно просто пользоваться сеткой и смотреть по своему опыту использования, на что он и надеется.
В теории калиброваная таким образом сетка должна отличаться от калиброванной викитекстом.
Ну а проверить это дело могут только обладатели больших карточек, так что ждемс
> Значит способов просто проверить его - нет.
> Сравнить калибровочные файлы
Действительно нет, о да, нужно устраивать теории, гадать, нюхать плацебо.
> В теории калиброваная таким образом сетка должна отличаться от калиброванной викитекстом.
Как раз в теории там отличия должны быть незначительные, что-то унюхать "на практике" только на 2.5 битах при прогоне на исходном датасете. Больше может сыграть то что он калибровал на большом размере, но тоже под вопросом.
>Действительно нет, о да, нужно устраивать теории, гадать, нюхать плацебо.
А что кроме факта наличия отличий ты сможешь понять там?
Как ты предлагаешь просто проверить к чему привела такая калибровка, кроме как отдать куче людей на поиграться?
>Как раз в теории там отличия должны быть незначительные,
А вот и нет, скорей всего сетка сейчас получила легкий уклон в фантастику или чем он там калибровал. Токены фантастики и диалогов должны быть лучше квантованы в среднем. Вопрос конечно на что это повлияет, и как сильно. Может разница в несколько процентов, хз
> А что кроме факта наличия отличий ты сможешь понять там?
Посты не читаешь?
Перед тем как будучи одержимым жаждой поиска невероятных открытий лезть "тестировать" нужно понять возможны ли вообще какие-либо отличия в принципе. Также, помимо калибровки, квантованная модель должна показывать различный характер зависимости перплексити от размера кванта при оценке на разных датасетах.
> скорей всего сетка сейчас получила легкий уклон в фантастику
Если хочешь утверждать - давай обоснования что за этим стоит и подкрепи объективными результатами.
> скорей всего сетка сейчас получила легкий уклон в фантастику
>Если хочешь утверждать
Алё гараж, если хочешь приплетать то не приписывай мне свои фантазии. А если ты утверждаешь что
>что-то унюхать "на практике" только на 2.5 битах при прогоне на исходном датасете.
то давай вперед.
>давай обоснования что за этим стоит и подкрепи объективными результатами.
>различный характер зависимости перплексити от размера кванта при оценке на разных датасетах.
Анон тут проверял викитекст и какой то другой датасет на куче квантов exl2 недавно.
И хотя викитекст показала минимальное отклонение, другой датасет отклонился по перплексити на 3 единицы. Что это означает подумай сам.
Ну ахуеть, перечитай ветку и пойми что пора принять таблетосы а не агрессировать. В самом начале высказал скепсис без отрицания возможности и представил элементарный и очевидный способ проверить есть ли вообще что-то, а ты в ответ начал его отрицать, предлагая культивацию плацебо. Рассуждения почему это сильно не должно ролять выше по треду, а у тебя просто пастулирование.
> другой датасет отклонился по перплексити на 3 единицы
Про относительные изменения слышал? И тот датасет по дефолту довольно поломанный, нужны разнообразные чтобы изначально корректно работали и были разнонаправленными, а не PTB в котором большей частью шиза
> aer banknote berlitz calloway centrust cluett fromstein gitano guterman hydro-quebec ipo kia memotec mlx nahb punts rake regatta rubens sim snack-food ssangyong swapo wachter
> pierre <unk> N years old will join the board as a nonexecutive director nov. N
> mr. <unk> is chairman of <unk> n.v. the dutch publishing group
> rudolph <unk> N years old and former chairman of consolidated gold fields plc was named a nonexecutive director of this british industrial conglomerate
> a form of asbestos once used to make kent cigarette filters has caused a high percentage of cancer deaths among a group of workers exposed to it more than N years ago researchers reported
> the asbestos fiber <unk> is unusually <unk> once it enters the <unk> with even brief exposures to it causing symptoms that show up decades later researchers said
> <unk> inc. the unit of new york-based <unk> corp. that makes kent cigarettes stopped using <unk> in its <unk> cigarette filters in N
А какой положняк треда по настройкам сэмплера?

>В колаб нихуя не влазиет
Чел... скорость около 10 токенов
Я чёт не понял, её всё равно с альфой надо? Потому что даже 20к влезают с трудом
ПЕРЕКАТ
Шапку потом перекачу на новый сервис, пока так полежит
Шапку потом перекачу на новый сервис, пока так полежит
7b модели на домашнем пека на средненьком процессоре типа i5 10400 3-5 токенов в секунду выдают. Смысла ради такой скорости с онлайном связываться нет.
Это 3b квантование? Какую то шизу выдает, совсем как будто другая модель в отличии от 20б




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Текущим трендом на данный момент являются мультимодальные модели, это когда к основной LLM сбоку приделывают модуль распознавания изображений, что в теории должно позволять LLM понимать изображение, отвечать на вопросы по нему, а в будущем и манипулировать им.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это серьёзно замедлит работу. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Undi95/MLewd-ReMM-L2-Chat-20B-GGUF/blob/main/MLewd-ReMM-L2-Chat-20B.q5_K_M.gguf
Если совсем бомж и капчуешь с микроволновки, то можно взять
https://huggingface.co/TheBloke/OpenHermes-2.5-Mistral-7B-GGUF/blob/main/openhermes-2.5-mistral-7b.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус.
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка треда находится в https://rentry.co/llama-2ch предложения принимаются в треде
Предыдущие треды тонут здесь: