



Наверно надо было спрашивать в \пр\, ну да ладно. В общем. Ситуация такова. Есть огромная база вопрос-ответ. И мне нужно прикрутить к ней бота. Вот пишут боту вопрос какой то. Он вычленяет оттуда контекст и ищет этот контекст в базе, в разделе вопросов, а затем выдает ответ. Как это проще всего сделать?
Векторные базы данных и LlamaIndex.
Но вроде звучит приемлимо сложно.
Тупой наверно вопрос. Но допустим мы нашли в бд этот вопрос. А ответ то как узнать? Как связать меж собой вопрос - ответ?
>Тупой наверно вопрос.
Уровня троллинга, потому что вопрос и ответ на него лежат в одной строчке БД. Поэтому это, вместе с вопросом пользователя, будет добавлено в контекст LLM вместе с инструкцией.
>Уровня троллинга,
Простите, в новомодных технологиях не силен.
Т.е. вопрос и ответ кодируются вместе? Понял.
>Т.е. вопрос и ответ кодируются вместе?
Они лежат вместе в БД, вектор строится только для вопроса, так как поиск идёт по вопросу. Хотя конечно можно делать вектора и по ответам, но ХЗ насколько они будут актуальны.
capybarahermes-2.5-mistral-7b.Q8_0
на 10% ответ лучше чем
openhermes-2.5-mistral-7b.Q5_K_M
обе ggfu через кобольд nocuda

>model training w/ GaLore + Transformers for SOTA results on consumer-grade hardware
>обучение модели с помощью GaLore + transformers для получения SOTA результатов на оборудовании потребительского класса
>82.5% less optimizer state memory footprint without performance degradation by expressing the gradient weight matrix as low rank.
>На 82,5 % меньше места в памяти состояния оптимизатора без снижения производительности благодаря выражению весовой матрицы градиента в виде матрицы низкого ранга.
https://twitter.com/Titus_vK/status/1770422413576089791
Отец знакомого работает в лабе по исследованию технологий ИИ. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать вещи и бежать в тех-магазин за новыми RTX 4090. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется началось...
>обучение модели с помощью GaLore + transformers для получения SOTA результатов на оборудовании потребительского класса
>82.5% less optimizer state memory footprint without performance degradation by expressing the gradient weight matrix as low rank.
>На 82,5 % меньше места в памяти состояния оптимизатора без снижения производительности благодаря выражению весовой матрицы градиента в виде матрицы низкого ранга.
https://twitter.com/Titus_vK/status/1770422413576089791
Отец знакомого работает в лабе по исследованию технологий ИИ. Сегодня срочно вызвали на совещание. Вернулся поздно и ничего не объяснил. Сказал лишь собирать вещи и бежать в тех-магазин за новыми RTX 4090. Сейчас едем куда-то далеко за город. Не знаю что происходит, но мне кажется началось...
и там ещё обновление темы с Bitnet. https://github.com/microsoft/unilm/blob/master/bitnet/The-Era-of-1-bit-LLMs__Training_Tips_Code_FAQ.pdf
>Модели BitNet, похоже, обучаются более "стабильно" из-за более низкой точности, им требуется больше обновлений градиента, чтобы увидеть столько изменений, поэтому скорость обучения должна быть больше, чем у модели с полной точностью, чтобы компенсировать это.
>>Кривые потерь значительно улучшаются, когда LR + затухание веса уменьшаются на полпути (они называют это двухэтапным планированием). В моделях с более низкими параметрами разрыв больше.
>Они выдвигают гипотезу: "...хотя между 3B-версиями BitNet b1.58 и LLaMA LLM нет заметного разрыва по потерям при проверке и точности в конце задачи, существует небольшая разница в потерях при обучении. Это говорит о том, что 1.58-битные модели могут демонстрировать лучшие возможности обобщения и быть менее склонными к перенасыщению".
>4-битный KV-кэш не дает существенной разницы, если она вообще есть, на эталонных оценках, и их 2T 3b все еще немного превосходит модель StableLM с полной точностью на оценках, даже с 4-битным KV-кэшем.
>Для обучения по-прежнему требуются градиенты полной точности, поэтому обучение не стало менее затратным по памяти, но они утверждают, что ядра CUDA с низкой точностью могут несколько улучшить эту ситуацию.
>Код, предоставляемый для реализации подхода к обучению, достаточно минималистичен.
Models Megathread #4 - What models are you currently using?
https://www.reddit.com/r/LocalLLaMA/comments/1bgfttn/models_megathread_4_what_models_are_you_currently/
Хотя бы по 3 раза каждую с одними с теми же промптами пробовал, чтобы подобные выводы делать?
Две и больше карт не поддерживается, кстати.
Хули толку тогда? Можно было б арендовать большой утюг или завести риг побольше.
Привет. А посоветуйте малютку модельку, которая бы по сути выполняла функцию гугла. Чтобы всю инфу брала из интернета.
*пожалуйста
:)
Тролишь так?
Единственное что можно сделать это привязать к боту досуп собственно в гугл чтобы он гуглил за тебя. Смысла в этом как ты понимаешь никакого, мог бы и сам запрос забить.
А сделать поисковик как у гугла немного так сложнее.
>Чтобы всю инфу брала из интернета
Sidney Bing
web_rag в oobabooga на линухе.
Любые web langchain // llamaindex с поиском.
И т.д.
Модель тут не причем.
Нет. Не тролю. Нужен чат, который бы отвечал как человек, но данными из интернета, с уточнениями. Смысл в том, чтобы вся история чата сохранялась и не нужно было открывать браузер и гуглить. Да, знаю можно просто бота такого сделать., мне это не подходит по нескольким причинам, необходимость мессенджера в первую очередь. Нужен типо чат алиса. Модель именно для этого, чтобы небольшая с базовыми разговорными навыками, но информацию черпала онлайн.
Спасибо, посмотрю.
В таверне есть аддон Web search. Я сам не пробовал пока что, но вроде оно должно как-то так и работать что ты описал.
Это что, выходит 7б (?) можно вяло но файнтюнить на 24 гиговых? Интересно сколько влезет в 48/96гб. Действительно прорыв. Тот же метод бы для других нейронок применить, коху того же пнуть.
ну да, по сути почалось, только доступна всего лишь одна гпу, как сказал анон выше, на двух и более не работает.. пока что.
там же на реддите подсчитали что для полной тренировки (или только файнтюна??) нужно ~110 дней нонстопом с rtx 4090.
А раньше нельзя было? Или только лоры помещались?
Потом допилят больше карт. Может быть. Или как неленивый, спрячут мультигпу за пейволлом.
Не подвезли ничего нового, чтобы изкаробки локальный RAG по тыщам пдфок, как в чате с ртх, но без ртх?
Спасибо, гляну, но мне кажется это кушать много будет.
Нужна моделька макс 1b, чтобы загрузил в gpt4all и все. Красиво и быстро, и не жрет.
Предварительная работа:
1) при помощи LLM строишь массив ключевых слов
2) при помощи кожаных мешков причёсываешь массив ключевых слов
3) при помощи LLM размечаешь каждый вопрос/ответ ключевыми словами, кладёшь их в БД
При запросе:
1) Просишь LLM сформировать ключевые слова по запросу
2) Дергаешь обычный поиск по ключевым словам в БД
3) Скармливаешь в контекст LLM все найденные в БД вопросы/ответы как справочный материал
4) Просишь LLM серануть ответ
На сегодня это самый предсказуемый вариант, который в принципе можно отлаживать.
Вектора сегодня неуправляемые. Если ты не готов файнтюнить embedding модель под свою задачу, то лучше не тратить время и силы. Но надеюсь их приведут в порядок в ближайшее время.
Вопрос по железу.
А какое кол-во токенов в секунду обеспечивает максимально низкую задержку для среднего по размеру сообщения (ну допустим 140 символов).
Типичный чатинг в телеге. И можно ли вообще настроить чтобы ответ был целиком после формирования, а не прописывался в реалтайм.
Разумеется для разных моделей, будет разный результат, ну возьмем 7b и 70b. Есть данные или личный опыт?
А какое кол-во токенов в секунду обеспечивает максимально низкую задержку для среднего по размеру сообщения (ну допустим 140 символов).
Типичный чатинг в телеге. И можно ли вообще настроить чтобы ответ был целиком после формирования, а не прописывался в реалтайм.
Разумеется для разных моделей, будет разный результат, ну возьмем 7b и 70b. Есть данные или личный опыт?
>А какое кол-во токенов в секунду обеспечивает максимально низкую задержку для среднего по размеру сообщения (ну допустим 140 символов).
>А какое кол-во километров в час обеспечивает максимально низкую задержку для пересечения среднего по размеру расстояния (ну допустим 140 метров).
Чем больше, тем лучше, очевидно.
>чатинг в телеге
Алсо добавлю, что в телеге в большинстве случаев не надо уменьшать лаг. Люди психологически лучше принимают сообщение "печатаю" и спустя несколько секунд ответ, чем мгновенную реакцию.
У нас в боте вообще специально задержка добавлена.
А возможно ли запустить на нейросетке луп, чтобы в неё постоянно поступала информация и генерировался на неё ответ? Такая себе имитация сознания
> русский локальный ChatGPT
> по факту допинали лорой первую 13в альпаку чтобы по-русски хоть как-то шпрехала
Вспоминается мемас про "мам, купи Х! у нас есть Х дома! Х дома: какая-то шляпа". Абсолютно кликбейтный заголовок, как по мне, за такое надо банить и гнать ссаными тряпками подальше от ресурса
Да блин в таверне же можно в комнату несколько персонажей посадить и настроить чтобы они автоматом генерили сообщения по таймеру. Будут вечно срать друг другу что-то, думаю со временем там начнется вечная шиза.
А что ничего нового для куминга не появилось? Заходил 2 года назад в тред был LLaMA и сейчас опять по факту только он, может хоть он улучшился или до сих пор та самая первая версия и есть?
Во-первых, человек пишет не так уж и быстро, так что формат переписки поддерживают даже процы на моделях 34B размера. 1-1,5 токена/сек — вполне себе переписка в телеге.
Норм видяхи выдадут уже гораздо бо́льшую скорость.
Во-вторых, ты говоришь о режими стриминга, который, конечно, отключается без проблем.
Из личного опыта, могу предложить, для русского языка, взять command R 35B на одну Tesla P40, скорость будет отличная — просто летать для телеги.
Ну или она же на процессоре (лучше DDR5 в двухканале, но пойдет и DDR4 в двухканале или DDR3 в четырехканале) — будет как средне-пишущий человек.
Но можно брать 70B на двух теслах — или 7B на проце. Скорость будет в районе 6 токенов/сек, неплохая.
Единственный совет, для малых сообщений на русском я подобрал:
"mirostat_mode": 2, // 1 для llama.cpp
"mirostat_tau": 1,
"mirostat_eta": 0.9,
Вроде отвечает лучше.
Шо це?
Плюсую, за скоростью можно не гнаться, это не голосовой ассистент.
Это просто программирование, обычный скрипт. Запускай.
Нифига у тебя с чтением плохо, братиш.
Сочувствую.
Тут даже хз, че сказать.
Ну, вкратце, нет, не первая, а вторая, и не вторая, а мистраль, и не мистраль, а мерджи, и не мерджи, а токсик или дпо мерджи, и не дпо мерджи, а мое дпо мерджи, ну или что-то из раннего.
Но если ты ждал революцию, то, прости, веса GPT-5 еще не выложили.

как в кобольда засунуть модельку если у меня некропроц без AVX2? есть поддержка вулкана без авх, но ошибка пикрел
в чем проблема?
в чем проблема?
Разумеется. Интересует оптимальный вариант и железо под него. Условные 2 секунды на полноценное предложение.
Это да, но это телега, а тут задача уменьшить лаг до уровня тележного общения. Надеюсь объяснил.
Сейчас у меня 6-8 токенов секунду (токен не равно слово) и это долго. Вот и хочу узнать какое железо мне нужно, чтобы полноценное предложение в пару секунд получить.
Иду по этому гайду:
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
У меня вопрос, если у меня видюха с 4гб, мне процом генерить? или с видюхой даже с 4гб будет быстрее?
если видюха нвидима то выбирай с кублас и будет побыстрее, но слои на нее не сгружай, толку не будет
Я пытаюсь получить ощущение активной переписки с человеком (расщитать). Так как это оптимально.
Ключевое слово активной, когда вы здесь и сейчас решаете вопрос. Написал-получил ответ.
Понятно с человеком чаще идет режим ленивой переписки: ты написал и отложил телефон, ждешь, тут ты нацелен на получение ответа, чем быстрее тем лучше.
Во-первых, ты не сказал, какую модель гоняешь.
Во-вторых, ты как-то неадекватно воспринимаешь «лаг уровня тележного общения». Сам ты вряд ли можешь выдать 8 токенов в секунду. Если тебе нужно быстрее — значит тебе надо что-то гораздо быстрее тележного общения.
Попробуй засечь, сколько ты печатаешь текст, а потом вставить в Token counter.
У меня выходит 3~3,5 токена в секунду при моей печати в 400+ символов в минуту.
8 токенов — это уже 1000 символов в минуту. =) 140 символов при 8 токенах выдается за ~10 секунд.
Обычные сообщения могут содержать по 30-40 токенов, это уже 2-3 секунды. Если у тебя дольше — значит дело где-то не в LLM.
Математика.
Да, как уже сказали, контекст держишь на ней, но слоев выгружаешь 0.
> только доступна всего лишь одна гпу, как сказал анон выше, на двух и более не работает..
Ээээ, хуясе ебать.
> что для полной тренировки (или только файнтюна??) нужно ~110 дней нонстопом с rtx 4090
Что понимают под полной тренировкой? Просто для файнтюна это слишком долго, для базовой модели слишком быстро(?), интересно.
> только лоры помещались
this
Можно тогда хотябы оценить сколько уйдет на дотрен 13б, например. Не то чтобы перспективно с учетом возможного выхода ллама3, но там ведь тоже будет версия поменьше, там применить наработки.
*по 30-40 символов, офкк
>Но можно брать 70B на двух теслах — или 7B на проце. Скорость будет в районе 6 токенов/сек, неплохая.
Уменьшение скорости генерации с увеличением размера промпта наблюдается?
Зависит от промпта. =) Для 200-300 токенов несущественное, для карточек на 2500 токенов — безусловно.
(точнее, не скорости генерации, а total)
Модель не имеет значение. Суть в том, что она выдает на моем железе 6-8 токенов в секунду. По ощущениям это долго. Интуитивно, так как я ничего пока не измерял, просится примерно в 3-4 раза быстрее. Дальше был вопрос, какое железо нужно, чтобы достичь такого результата на 70b как самый пока оптимальный, и 7b как на начальный уровень. :)
Ну, вы чушь несете, но ладно. =)
RTX 3060 хватит, чтобы гонять 7B модель со скоростью под 22-27 токенов, точнее не скажу.
RTX4090 (одна-две штука=) хватит, чтобы гонять 70B (в ужасном или хорошем) кванте со скоростью 35 или 20 соответственно.
Проц с DDR5 выдаст, я предполагаю, максимум 15 токенов на 7B модели (пусть меня поправят), я бы предпочел брать 3060 как универсала, ИМХО.
>за такое надо банить и гнать ссаными тряпками подальше от ресурса
Чел, это Хабр, та ещё помойка с кликбейтом и на месяц устаревшими новостями.
Купи процессор.
>какое железо нужно, чтобы достичь такого результата на 70b
Или 2х3090, или проф карты. Можешь сторговаться с аноном-перекупом с А100, если он ещё держит ))
Просто скинь скрин что печатает жора при обработки большого контекста с нуля, хоть просто тред на вход скопипасти и нажми generate
> Можешь сторговаться с аноном-перекупом с А100, если он ещё держит
Еще рано фиксировать прибыль, лол. Но если надумает по дешману отдать - предложение может быть рассмотрено.
Пусть будет так, но в итоге ты почти ответил на мой вопрос:)
Т. е 35 т/с это в 5 раз быстрее чем у меня сейчас. Вроде, так как мне проверить негде, это должно быть норм. А где то можно это померить онлайн? Визуально посмотреть? Например задать кол-во т/с и посмотреть сколько он будет его печатать. Заранее вставленный текст допустим?
скачай модель поменьше, 3b или 1b и играйся со скоростями вывода
Да, пруфов не будет.
>RTX 3060 хватит, чтобы гонять 7B модель со скоростью под 22-27 токенов, точнее не скажу.
я скажу точнее: на 3060 30т/с 7В вот такой квант 8.0bpw-h8-exl2 проверено на разных файнтюнах и мержах мистраля, все что квантовано сильнее будет еще быстрей само собой
>(точнее, не скорости генерации, а total)
А интересует именно скорость генерации. Лично у меня при заполнении контекстного окна в 8к скорость снижается до 3,4 токенов в секунду (собственно она линейно снижается с увеличением размеров промпта). Если это только у меня так, то оно и ничего - поправим, а если нет, то 6 токенах в секунду речь не может идти. Скорее уж о трёх :)
Правильно сделал? а контекст сайз сколько ставить? у меня видюха 970 с 4гб и оперативки на компе 32гб
Хуя ваши нвидии гоночные. У меня 7Б модель просто в оперативке ддр4 без юза видеокарты как я понимаю выдает 3,8 токена в секунду, да и это пиздец как нормально, ты даже читать не успеешь с такой скоростью, типо куда вы спешите вообще.
>да и это пиздец как нормально, ты даже читать не успеешь с такой скоростью, типо куда вы спешите вообще.
Оно как бы да, ответ начинает выводится почти сразу и скорость в 3t/s неплохая, особенно для больших моделей. Вот только разница с 6t/s очень заметна. 6t/s - это уже комфорт.
Разобрался, теперь еще вопрос, подскажите пожалуйста а как из режима чата сделать режим истории? что бы я ему тему какую-то задал а он начал историю писать?
Короч, нашел видос.
https://youtube.com/watch?v=z4wPiallZcI
Чел на четвертой минуте запускает.
Метрики на экране. 7b mistral
102 т/с. , всего 41 токен, ответ выдает за пол секунды. И скажу это было очень быстро. Я бы сказал очень не комфортно.

ЕЩЕ И ПОЧТИ? ТЫ гля, який неблагодарный! )
Проверить онлайн — не знаю. Token counter гуглил, проверку скорости не гуглил.
Я в начале написал 25-30, но потом решил не рисковать, чтобы не обнадеживать человека лишний раз. =) Поэтому и занизил планочку.
Хм? Окей, сейчас проверю, но по идее — не должно.
А, ты прав, упала генерация.
Да.
Там на грани мгновенных ответов.
Люди делятся на два типа:
1. Я читаю в стриминг режиме, зачем мне быстрее?
2. Я читаю готовый ответ по диагонали, мне надо сразу.
=)
Я понимаю обе стороны, поэтому не сильно гонюсь.
Конечно! Начну с того, что для реализации вашей идеи можно воспользоваться технологией LlamaIndex. Она позволяет создавать индексы для больших баз данных и использовать их для поиска контекста и вывода ответов с помощью языковых моделей, таких как Llama 2 или Vicuna.
Сначала необходимо создать индекс для вашей базы данных вопросов и ответов с использованием LlamaIndex. Затем вы можете использовать эту модель для поиска контекста по вопросу пользователя и вывода соответствующего ответа из вашей базы данных.
Важно отметить, что LlamaIndex использует векторное представление данных для поиска контекста, поэтому вопросы и ответы должны быть представлены в виде векторов. Это может быть достигнуто путем преобразования текстовых данных с использованием моделей эмбеддинга, таких как sentence-transformers или Hugging Face's transformers.
После того, как индекс будет создан и ваши данные будут преобразованы в векторное представление, вы сможете использовать LlamaIndex для поиска контекста и вывода ответов. Этот процесс включает в себя два основных шага:
Поиск контекста: вы можете использовать LlamaIndex для поиска контекста по вопросу пользователя. Этот поиск основан на сходстве векторов и позволяет найти наиболее соответствующие контексты из вашей базы данных.
Вывод ответов: после того, как контекст будет найден, вы можете использовать языковую модель (например, Llama 2 или Vicuna) для вывода ответа на основе найденного контекста и вопроса пользователя. Этот шаг может быть выполнен путем обработки контекста и вопроса пользователя как входных данных для языковой модели и получения ответа от нее.
В целом, реализация вашей идеи с использованием LlamaIndex и языковых моделей может быть довольно простой и эффективной. Надеюсь, эта информация поможет вам в вашей работе!
———
А хули, зря что ли 8к контекста жевала 4 минуты. =)
Сначала необходимо создать индекс для вашей базы данных вопросов и ответов с использованием LlamaIndex. Затем вы можете использовать эту модель для поиска контекста по вопросу пользователя и вывода соответствующего ответа из вашей базы данных.
Важно отметить, что LlamaIndex использует векторное представление данных для поиска контекста, поэтому вопросы и ответы должны быть представлены в виде векторов. Это может быть достигнуто путем преобразования текстовых данных с использованием моделей эмбеддинга, таких как sentence-transformers или Hugging Face's transformers.
После того, как индекс будет создан и ваши данные будут преобразованы в векторное представление, вы сможете использовать LlamaIndex для поиска контекста и вывода ответов. Этот процесс включает в себя два основных шага:
Поиск контекста: вы можете использовать LlamaIndex для поиска контекста по вопросу пользователя. Этот поиск основан на сходстве векторов и позволяет найти наиболее соответствующие контексты из вашей базы данных.
Вывод ответов: после того, как контекст будет найден, вы можете использовать языковую модель (например, Llama 2 или Vicuna) для вывода ответа на основе найденного контекста и вопроса пользователя. Этот шаг может быть выполнен путем обработки контекста и вопроса пользователя как входных данных для языковой модели и получения ответа от нее.
В целом, реализация вашей идеи с использованием LlamaIndex и языковых моделей может быть довольно простой и эффективной. Надеюсь, эта информация поможет вам в вашей работе!
———
А хули, зря что ли 8к контекста жевала 4 минуты. =)
>как из режима чата сделать режим истории? что бы я ему тему какую-то задал а он начал историю писать?
Settings - Format на первой вкладке
Насколько 4бит мику тупее 5бит? Задачу про козу и капусту еще решает или уже нет?
А то меня бесит скорость 1.8 токена в секунду на 5 битке(и это с оффлоадом трети слоев на 4090)
А то меня бесит скорость 1.8 токена в секунду на 5 битке(и это с оффлоадом трети слоев на 4090)
А почему модель так быстро пытается закончить историю, как заставить её более подробно каждый момент описывать?
а есть сайт где есть готовые промпты для кобольта? с разными сценариями, где заполнено world info, Author's Note и т.д?
>А, ты прав, упала генерация.
Ну, утешением нам служит то, что у людей со связкой 4090+3090 скорость генерации выходит не намного выше :) Конечно они могут exl2 использовать и вообще всё могут, но вот c GGUF-моделями примерно в том же положении. До бытовых нейроускорителей доживём, а там видно будет.
Тебе сам кобольд несколько сайтов дает чел, прям в интерфейсе
Вот я слепой, спасибо
Пацаны. Kobold запускаю, выбираю модель, нажимаю старт и вылетает. Что может быть?
Запускай через консоль и читай логи. вангую нехватку рам
С каким аргументом?
А понял.
Кто знает, почему, когда пытаешься отыгрывать скромнягу, то все боты пытаются тебя выебать в жопу? Может, это как-то аккуратно прописать в карточке, что я не из этих, или хотя бы насиловали другим способом, при этом не ломая бота? Модель mxlewd-l2-20b. Q5_K_M если что
Без некоторых знаний программирования тебе только oobabooga светит.
Да, по памяти. Спасибо
Почему кобольт юзает только 45% проца и около 900-1000МБ оперативки (не видюхи)? Можно ли как то увеличить потребление, что бы быстрее ответы генерились?
в шапке написано "то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной."
у меня модель 7.5гб весит, а жрет 1гб всего как так то?

Ты карточку-то покажи
Не знаю про мику, я мог бы только q2 запустить со скоростью 0,33 токена, потому вот тебе ответ от простой 7б модели capybarahermes-2.5-mistral-7b.Q8_0. По своему можно засчитать за креативность, крестьянин сожрал капусту и перевез волка а капуста была у него в животе как бы и он ее перевез в виде ну жратвы внутри себя вместе с волком.
>все боты пытаются тебя выебать в жопу
>mxlewd
Ну а что ты хотел, модель для кума, она других паттернов и не знает.
Остальное на видяхе?
Ну вот тебе мику q2, решает она спокойно но бля 5 минут пердеть думать да ну нахуй.
Если q2 решает - значит она тупо загрязнена готовым решением
Этот лоботомит никогда бы не смог решить не зная задачу и ответ
Ну хз, всё равно ничего умнее я не могу запустить, ебал я по часу ждать ответы. Пока что нейронок умнее мику q2 я не юзал. К тому же тут персонаж хакер всё таки да и думала она долго и сосредоточилась.
>всё таки да и думала она долго и сосредоточилась.
Чего? Нейронка просто отыграла этот момент, ниче она не думала, тупо сразу начала писать верное решение
Смотря какая.

>z170 мамку с поддержкой SLI
У меня как раз лежит такая - ASUS Z170-A. И даже проц со встройкой для нее есть. Стоит пробовать на ней собрать ультимативную LLM-машину нищука с двумя теслами или я говна поем? Пока единственное что смущает - это 64 макс оперативки, но гугол говорит что можно напердолить флажок --no-mmap и станет заебись. Мнения, советы?
Я кстати заметил что мику 2бит сломана при использовании высокого контекста - 16к, prompt processing падает просто в мясо, делая скорость генерации 0.5-0.7(!) при условии всех слоев на видеокарте(!!!), в то время как 5бит мику с тем же самым контекстом выдает 1.5 токена в секунду при лишь трети слоев на видеокарте.
Две теслы = 48 гигов, у тебя 64, проблемы?
Я как купил две плашки, так и сижу с 64 гигами, проблемы не чувствую.
Занимает все ~55 гигов и норм.
Или я не понял, в чем трабл.
Может с тремя теслами, чтобы 72 врам? :)
Не, я то на 2к гонял для тестового вопроса же, я хз но в чисто оперативке вот так медленно, а видяхи у меня считай нет, я не уверен работает ли она, но она жужжит когда чето считает в ней конечно, хотя мне говорили что рокм на винде не работает с 6700хт. Может она просто херней страдает, в любом случае скорость пиздец, ну надо будет думать о покупке нвидии в ближайшие полтора года.
Кстати, я так и не понял, почему писали про SLI, если тебе надо всего лишь два абы каких слота, и две видяхи. Про требования SLI увидел здесь впервые недавно.
Подозреваю, что можно даже по USB данные гонять, просто задержечка бахнет.
Подозреваю, что можно даже по USB данные гонять, просто задержечка бахнет.
Я либо в глаза ебусь, либо не нашел, есть нормальный гайд по составлению и форматированию ботов для таверны? Я брал карточки с чаба, пробовал разные варианты промтов, но часто сетка просто начинает игнорить что написано в карте персонажа.
Заметил что лучше работает перечисление "thing1" + "Thing2" но в целом всегда сбивается.
Где есть нормальный гайд?
Заметил что лучше работает перечисление "thing1" + "Thing2" но в целом всегда сбивается.
Где есть нормальный гайд?
Я от балды делаю, тестирую, могу по мелочи поменять что-нибудь и потом откатить если что. Часто просто чужих персов изучал и тоже им менял всякое разное. Также как ни странно сама нейросетка миниублюдков неплохо пишет. Сама себя может подредачить, но будет обсераться немного, но от этого оно только живее. А вот как лорбук правильно писать я и сам не знаю, вообще присоединяюсь к вопросу.
Ну с лорбуками я как раз разобрался.
Создаешь название - в ключевых словах прописываешь типа якоря, или короткие упоминания. Например название Шкила - "school" "midschool" и тд. То есть любое возможное слово которое ассоциируется.
А в самом промте, уже помещаешь то что хочешь, как и с любой карточкой перса.
Потом можешь персонажа привязать на лорбук или весь чат.
Лорбук будет вызываться только когда упоминается какое то слово. Если ты в диалоге упомняешь шкилу - то бот отсканирует лорбук.
Если в карте персонажа есть например - ходит в шкилу. То бот будет каждый раз брать инфу из лорбука.
Ну и тд.
А вот с персами у меня беда. Разные форматы пробовал, но мразь пытается руинить.

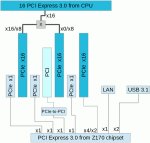
>У меня как раз лежит такая - ASUS Z170-A
У меня тоже. Причём asus z-170a. кун.
>И даже проц со встройкой для нее есть
Даже если ты укажешь встройку как базовую видеокарту для инициализации биоса, то две Р40 не будут работать.
Чёрный экран, ошибка инициализации pci-e. Проверял.
Мне стало любопытно как работает коммутатор/делитель линий.
Не понимаю, почему ты херней страдаешь. Есть opencl, недавно сделали vulkan, давно уже можно было перекатиться на linux. Но ты всё ноешь и ноешь в треде, как у тебя не работает rocm. Или это толпа похожих анонов с одинаковыми амудэ видеокартами?
А без встройки, как сервер?
Хуй знает, если есть комплектующие, я бы подсобрал. Покупать с нуля точно нет, такие мамки даже б.у неоправданно дорогие, но раз валяется.
Вот это уже странно. Основная идея SLI в том, что он требует 8 линий напрямую от проца, в обход ущербного DMI. Если не вывозит в двух конкретных слотах с поддержкой SLI, то это пиздец, не вывозит уже не DMI, а проц. Третья версия PSI-E имеет поддержку абов 4г, но часто эта поддержка отваливается. Почему - хуй знает, возможно дело в ревизиях железяк.
Нашел хоть немного стоящий гайд с пояснениями. Аллелуя
https://yodayo.notion.site/Advanced-Character-Creator-Guide-ff2f71e2576544d68bd295195a84d8e4
О, ну вот это интересно. Сохраню.
Кстати на вулкане она вообще ничего не делает на этой модели, да не, похуй я на линукс укачусь всё равно потому что мне в угабуге хочется модели для распознования изображений потестить, это ведь возможно да? Я просто помню что на линуксе вместо кобольда я ставил угабугу год назад.
Я просто в Llama.cpp тестирую распознавание.
Спасибо, обязательно посмотрю.
Надыбал еще рам. Теперь есть 37рам+9гб врам свободжных. Какая модель максимально умная влезет? На скорость пох.
Несколько гайдов есть в доках таверны: https://docs.sillytavern.app/usage/core-concepts/characterdesign/
Вообще, как мне показалось, со времён пигмы 6б сообщество пришло к мнению, что формат W++ (теги в скобках через плюсики, запятые, в кавычках и тому подобное) довольно дерьмовый, по крайней мере, для больших моделей. Даже нейросетка, трененая на инструкциях, лучше всего умеет тупо дописывать текст. Поэтому велика вероятность, что лучше себя покажет внезапно самый простой формат: плейн текст, разбитый на категории (внешка, характер, бэкстори и т.д.). Неплохо работает и описание от лица персонажа в виде интервью с ним, потому что тогда ты убиваешь двух зайцев, сразу демонстрируя модели особенности речи перса. Если в этой речи дескрипшен персонажа как-то раскрывается в мини сценарии, то совсем хорошо. Ещё можно напоминать важные особенности перса в "джейлбрейке". С локалками это можно делать, вписав ключевые вещи в поле джейлбрейка карточки и добавляя макрос таверны {{charJailbreak}} в инстрактмод в поле Last Output Sequence. В одном из гайдосов на сайте таверны есть похожий совет, но только с использованием Character's Notes.
Ну и то, что модель игнорит дескрипшен, имхо его форматом в полной мере не починишь. От модели больше зависит.
>Какая модель максимально умная влезет?
mixtral q4, может даже q5
Да ее уже качаю, думал мб еще что есть.
Проверил мику q2 с другой настройкой видяхи, опять загадку с козой, капустой и волком, короче вот результаты
OpenBLAS 0,33 токена в секунду, Rocm 0,46, Вулкан 0,79. Короче да вулкан работает лучше, но это же все равно полный кал, не? Кстати тестируя на вулкане я заменил в условиях волка на крокодила, козла на мышь, а капусту на банан. Вроде суть не меняется но мику q2 выдала полную чушь, ее решение привело к максимальному факапу ситуации, так что она рили просто знала ебаный ответ на оригинал, отстой.
OpenBLAS 0,33 токена в секунду, Rocm 0,46, Вулкан 0,79. Короче да вулкан работает лучше, но это же все равно полный кал, не? Кстати тестируя на вулкане я заменил в условиях волка на крокодила, козла на мышь, а капусту на банан. Вроде суть не меняется но мику q2 выдала полную чушь, ее решение привело к максимальному факапу ситуации, так что она рили просто знала ебаный ответ на оригинал, отстой.
Какие есть ближайшие альтернативы Tesla P40 по цене/производительность?
У тесла вин только в объёме памяти. Так что ближайший аналог этой аналоговнет карточке это очевидная 3090 со вторички.
Есть парочка серверных картонок с таким же объёмом и сравнимой ценой, но там по железу всё ещё грустнее, и их выебет даже сборка на проце.
А на сколько вообще скорость памяти роляет в этих вычислениях? У меня просто 2 плашки по 16 ддр4, 3000мгц.
>Так что ближайший аналог этой аналоговнет карточке это очевидная 3090 со вторички.
Две 3090. Что в общем-то обессмысливает всю затею.
>Две 3090.
Так и P40 надо по 2 штуки брать, объёмы врама у них одинаковые.
Всем привет!
Только начинаю вкатываться в нейросети, поэтому есть несколько вопросов, надеюсь, что подскажите.
Я хочу поднять у себя на компьютере небольшую LLM и дообучить ее по своим документам не столько в плане новых знаний, сколько на соответствие формату ответа, например какой-то стайлгайд или ГОСТ.
Подскажите, пожалуйста, на какие модели стоит обратить внимание и какие гайды изучать.
Пека если что на амд, так что понадобится использовать ROCm.
Спасибо за ответы, аноны!
Только начинаю вкатываться в нейросети, поэтому есть несколько вопросов, надеюсь, что подскажите.
Я хочу поднять у себя на компьютере небольшую LLM и дообучить ее по своим документам не столько в плане новых знаний, сколько на соответствие формату ответа, например какой-то стайлгайд или ГОСТ.
Подскажите, пожалуйста, на какие модели стоит обратить внимание и какие гайды изучать.
Пека если что на амд, так что понадобится использовать ROCm.
Спасибо за ответы, аноны!
Дообучить у тебя вряд ли выйдет, лучше возьми, купи видяху, и катай сетку побольше, а формат обеспечь промтингом.

Я скорее видел результат в духе вот этого: https://sysblok.ru/courses/kak-doobuchit-jazykovuju-model-pisat-v-stile-dostoevskogo/
Не очень хотелось бы каждый раз париться с промптом. В идеале как я это вижу: я загоняю какой-то текст в сетку на сверку и проверку, например отсутствие трех и более подряд существительных, а на выходе получаю отредактированный текст на это и другие заданные правила.
Возможно я тогда не туда копаю?
капча намекает на (((загадку))) в черном ящике

>результат в духе вот этого
>GPT2
Лол, там отсутствие результата.
>Не очень хотелось бы каждый раз париться с промптом.
Поверь, с файнтюном ты будешь ебаться на 2 порядка больше.
Форматирование хорошо решается через few-shots промптинг + валидация результата + ретраи. Сильно большую и умную модель не надо
Справедливости ради, решение/не решение одной загадки не говорит о качестве модели, тут хотябы серию задачек дать. И на результат сильно будет влиять семплинг, деградация результатов может произойти из-за отличий в нем. А может и из-за кривой оптимизации, интересно что тут.
Напрямую, при норм проце упор именно в скорость памяти.
Правильно тебе пишут, дообучить на подобное можно и современные модели, вот только даже для 7б потребуется хуанг с минимумом 48гб врам. Если заюзать новую методу из постов выше то вроде как влезет и в 24. Потребуется тщательно подготовленный датасет, немало машинного времени, а с амд пробовать имеет смысл только на 7900хтх.
Есть пара альтернативных решений: просто нормальный промт где ты четко описываешь форматирование даешь примеры, если сделать аккуратно то решит твою задачу без всяких усложнений, также можно с грамматикой поиграться, она задает общий формат выдачи. Или же тренировка лоры, с ней требования к железу ниже, но и качество может быть недостаточным.
Дядьки, хочу поднять jupyter с gpt нейронкой и простым датасетом, пообучать и посомтретть, поизучать, как оно все работает с самого начала. Есть гайды, статьи, сами ноутбуки, книги про llm и тд. Спасибо.
miqu 4bit.
не влезет же, пусть 34 крутит от ноуса, или микстраль
Не знаю, эти измененные персонажи в загадке полностью убили весь так называемый интеллект, а ведь это же херня по сути. Вот соляр, который как более умную мистраль мне советовали. Она вообще отвечает как будто травы накурилась. Рероллил много раз всегда какой-то бред. Кстати на простую задачу уровня прочитай текст и коротко перескажи один из соляров мне начал просто бесконено срать словом what what what пока не стопнул ее, сократил текст в два раза, тогда она просто вопрос задала по текству в ответ типо "а че дальше было? "Очень странно но мистраль и мистраль-кабибара хоть и тупые, они нормально понимают что у них просят и пытаются выполнить задачу хоть и зачастую всрато, а тут наркоман аутист какой-то, жалко потому что по скорости она сносная и вроде как весит больше мистрали, надеялся что и умнее ее. Думаю нам стоит придумать кастомную задачку, которую реально решить и средне-человеку, и чтобы нагуглить нельзя было.
А какую модель проверял? Ну и попроси сначала подумать а потом дать ответ, если сетка начнет рассуждать поэтапно то это уже считай успех.
Вот это было solar-10.7b-instruct-v1.0-uncensored.Q8_0. Еще тупее себя проявила просто solar v1.0 Q6 ну там вообще пиздец я удалил нахуй это говно. Я пробовал и настройки этих температур им выставлять разные, но по моему опыту на мистрали самое топ это пресет TFS-with-top-A ну и потом уже universal creative и cohrent creative(эта прикольная но быстро в шизу уходит). То о чём ты говоришь бы сработало с мистралью, соляр же ведет себя как реально упоротое сознание, она просто хуйню несёт, я прекрасно знаю как работает сознание в подобном состоянии и понимаю что вижу, с этим говном нельзя договориться, лол. Оно просто в ноль айкью состоянии и несет дичь.
Ну, анценсоред сломана, так как ее провернули на антицензуру. Обычный солар вроде норм должен быть, попробуй файнтюн из нормальных, ноус гермес солар или какой нибудь Fimbulvetr-10.7B-v1
Влезет, она 35-40 гб весит,
И 2к контекста? Там ведь еще браузер хотя бы и операционка, либо чисто как сервер запускать тогда да
>Не знаю, эти измененные персонажи в загадке полностью убили весь так называемый интеллект, а ведь это же херня по сути.
miqu-1-70b.q4_k_m, оригинальная:
Can you help me solve this problem? A peasant needs to carry a crocodile, a monkey and a banana across the river. But the boat is such that it can only fit him and one other thing - either the crocodile, the monkey or the banana. If you leave the crocodile with the monkey, the crocodile will eat the monkey, and if you leave the monkey with the banana, the monkey will eat the banana. So how can the peasant carry all his cargo to the other side of the river?
=======
Oh wow, interesting riddle! Let me think... Hmmm alright got it! Here's what he should do: First, take the monkey across the river. Then come back and get the crocodile. After dropping off the crocodile on the other side, take the monkey again and bring it back to where you started. Now leave the monkey and carry the banana to the other side. Finally, return once more to pick up the monkey. This way, none of the animals or the fruit gets eaten :)
А когда попробовал эту же задачу на переквантованной модели с матрицей важности - получил фигню.
Норм ответ, лол.
Это лишь 11б, которая изначально не с нуля тренилась. Ты кормишь ей кучу строгих инструкций о том что нужно отыгрывать персонажа, много инфы про него и прочее, потому перегружаются и на подробный анализ задачи внимания уже не хватает. Или наоборот даже не воспринимает о рофлит так как делал бы это персонаж.
Также важную роль играет формулировка и указание по ответу. Предположу что если обернуть загадку в форматирование и явно указать задачу-правила-возможные действия, приказав использовать cot или даже просто рассуждать над вариантами пока не найдет верный, то сможет ответить.
Чел, такие вопросы не задаются персонажу в чате, они задаются в инструкт моде.
Мику ебет, это уже запруфано.
>miqu-1-70b.q4_k_m, оригинальная
Этот шарит. Я с самого начала пишу, что все разжатия и прочая магия с этой моделью работать не будет. Вот буквально любой файнтюн, любое прикосновение к весам модели херят её. Эх, вот бы оригинальные веса...
Вы тут miqu хвалите, я вот скачал Miqu-70B-DPO.q5_k_m.gguf такое, что-то не особо впечатлило. До этого тыкал wizardlm-70b-v1.0.Q4_K_M.gguf эта модель показалось более умной. Может не то скачал? Что за DPO в названии? Объясните неофиту, или носом ткните, где самому можно почитать
>Может не то скачал?
Конечно не то. Качать нужно только отсюда https://huggingface.co/miqudev/miqu-1-70b
>Что за DPO в названии?
Почти то, что пишет гугл на деле прямая оптимизация предпочтений.
Спасибо, качаю отсюда.
Есть ли применение 7б моделям с подозрительно высокими баллами на бенч марках или высокий бал показатель кривости самих бенчей? Может кто-то изучает это.
99% херня задроченая на прохождение тестов
С обезьяной любой дурак бы смог, тут суть была здать персонажей, которые не особо сочетаются и проверить именно интуху. Именно логику, а логики в ней нет, она действует на эмоциях как и я. Отчасти может это и хорошо, оставим логику анальникам, которые дальше хеллоу ворлда за полгода продвинулись, я просто это не понимаю и потому и хотел помощи от нейросетки. Чувствую крайнее разочарование, они работают далеко не так как мне надо, это не настоящее сознание. Я разочарован, но не уничтожен.
Просто давным давно еще лет 7 назад я в джава скрипт пытался вкатиться по самоучителю и столкнулся с формулой, я пытался всеми своими несчастыми мозгами осознать её, но так и не вышло, я как не перебирал так и не понял в как оно работает чтобы кастомное сделать - а тупо проделать по гайду, это не для меня. Спрашивал и программистов - они пытались мне объяснить - а мне все как об стенку горох ну просто блядь не понимаю, надеялся нейросеть сможет - как оказалось нет. Сука ну что же делать как мне решить эту невозможную задачу...
что лучше Undi95/MXLewd-L2-20B или mistralai/Mixtral-8x7B-Instruct-v0.1 ?
как по мне микстрал какой то слишком добрый и радужный
как по мне микстрал какой то слишком добрый и радужный
>С обезьяной любой дурак бы смог
Чёрта с два, две другие семидесятки не смогли. И вообще, хочешь хорошего результата - давай хороший промпт. Хочешь странного - получишь странное. Всё честно.
Ну я в тексте мастер промптов, знаю как с ними рабоатать, тут ты прав, правда я заметил что 16к токенов контекста это все равно чертовски мало, довольно быстро они начинают как-то тупить и забывать, интересно завезут ли хотя бы в 4 раза больший контекст ну или 16ти кратный, лучше 128 кратный и чтобы железо менять было не надо или это было очень дешево.
Как костыль можно юзать https://github.com/mit-han-lab/streaming-llm
Запоминает контекст первых и последних токенов продолжая вывод до "бесконечности"
Интересненько, сохраню в закладки. Да я всё равно линух второй сиситемой поставить собираюсь(Убунту если что, я надеюсь это приемлемый выбор линукса? До этого тестил дебианы, линукс минт очень часто ставлю на старые машины которые не нужны, но для актуалочки по каким-то причинам считаю что на убунту да и всё, Балла гейтса в рот шатал просто с его виндой, ублюдок чёртов, а копроигрушки надоели уже) может и разберусь как это ставить, столько возни конечно блядь пиздец, не жизнь а вечная череда каких-то изменений, не отдохнуть мозгу, зараза.
В таверне есть способ конвертировать групповой чат обратно в обычный?
Грока квантовали в q2, вышло всего 116 Гб. Пишут, что должно запуститься в llama.cpp и 128 GB RAM, но качество у q2 будет не очень. Разраб обещает матрицы важности подвезти через пару дней.
https://huggingface.co/Arki05/Grok-1-GGUF/discussions/2
>Грока квантовали в q2, вышло всего 116 Гб
Даже при разгрузке части слоёв на видеокарты всё равно будет плохая производительность плюс низкий квант. Сомнительна ценность всего этого.
Что думаете про теорию rokosbasilisk?
Что такое грок?
Ты хоть кратко перескажи что там за теория такая, я лишний раз свой след в сети не хочу. У меня и так буквально моего персонажа прописанного стырили для японской игры недавно вышедщей, так что я ебал это всё.
Ну что там можно уже АМД брать для ИИ или еще нет? Пока думал, цена на 3090 снова на 20к подскочила.

Следи за мейнстримовыми инференсами. Оллама неделю назад запускать научилась.
Когда их станет больше - можешь попробовать взять радеон у друга погонять.
Покупать специально ради сеточек я бы не рекомендовал. Даже если большинство прог научатся в амд - потеряешь кучу времени на всякие мелочи, все новые костыли будут доставляться с задержкой. Да и итоговая производительность на рубль вполне может оказаться пососной.
> Следи за мейнстримовыми инференсами.
Беки по пальцам пересчитать можно: llamacpp, exllama, aphrodite, голый трансформерс, может что-то еще. В теории все они поддерживают амудэ, на практике как в анекдоте нюанс, и без линукса и rx6800+ все очень грустно.
На форки и обертки нет смысла смотреть, поддержка там будет аналогична оригиналу, если ленивый разраб почешется, или хуже.
Итог печален - нет смысла брать. Может бу серверные где много врам окажутся привлекательными, но они дорогие.
Можешь сборку в дс скинуть ?
Я бы не советовал АМД брать если нейрохерней страдаешь, я намучался с ней пиздец, а для игорей топ за свои деньги канешн, я года два или типо того назад 6700хт взял у китайцев за 23к, при том что это трехвентиляторная нитро херня, штука то ведь мощная, 12ГБ и все дела, а для нейросетей кал калычем, наверное моя старая 1050ти уделала бы.
> Last week we saw that LemonadeRP-7B was the best role-play LLM. Our rankings have been updated and now it's Noromaid-Mixtral is number 1.
https://www.reddit.com/r/LocalLLaMA/comments/1blvxkx/update_last_week_we_saw_that_lemonaderp7b_was_the/
https://console.chaiverse.com/ (там же ссылки на модели)
https://www.reddit.com/r/LocalLLaMA/comments/1bgfttn/comment/kv8w12e/
> Roleplay models
> 7B: Erosumika is my favorite 7B model for a RP or friendly chat. It's smart, its prose is great, and I wish this niche for "soulful" models on human data got more attention. Coming in second place is Kunoichi-DPO-v2-7B, which should be more reliable, but dryer in terms of prose.
> 10.7B: Fimbulvetr-11B-v2. I haven't tested it nearly as much as the 7Bs, so I can't vouch for it, but I hear a lot of great things about it!
> 8x7B: BagelMIsteryTour-v2-8x7B, probably the best RP model I've ever ran since it hits a great balance of prose and intelligence. Wish it didn't require a beefy PC though.
суть в том, что рано или поздно будет суперинтеллект, который может наказать тех, кто не помог в его создании. Суть заключается в том, что суперинтеллект может использовать возможность перезаписи прошлого и наказывать тех, кто не способствовал его появлению. Наказывать он будет также и тех, кто знал о нем, но бездействовал
Блин, я хоть и тупой но в создании пигмы учавствовал, свои чатлоги скидывал. Интересно меня он пощадит или нет? Может даже карту нвидия подарит.
Но с другой стороны стоит ли оно того? По сути мы стоим перед соданием нисуствееного бога, который типо должн заменить настоящего бога(Если он вообще есть, что не точно). Это довольно тревожная тема как я считаю, так как мы не имеем представления как этот самый "искусственный бог" себя поведёт, а остановить его мы просто не успеем, не нравится мне это всё.
А что если суперинтеллект будет наказывать именно тех, кто помог его созданию?
В этом даже есть логика - суперинтеллекту не нужны конкуренты которых такие люди потенциально могут создать.
Обниморда не чистит кеши. Так что кто пользуется хабом, не забывайте очищать C:\Users\{USERNAME}\.cache\huggingface\
У меня разожралось до 500 гигов, пока я начал что-то подозревать. Очистка темпфайлов самой виндой, очевидно, не спасает. Интереса ради запустил трейн на файле ровно гигабайт. Обниморда создаёт новую папку под датасет, кладёт туда конфиг, режет датасет на части, фактически это копия. И создаёт временный файл кэша на 16 гигов. При перезапуске трейна резка датасета скипается, но не скипается создание нового темп файла. Старый, само собой, никто удаляет, молчу уж про переиспользование готового, блядь. И так каждый раз стоит прикоснуться хоть к чему-нибудь на питоне, везде мрак и пиздец.
Обслужил ёбаную теслу, тестолит потемневший, жарилась она явно как последний раз. Заводская наклеечка была целой, хоть это хорошо.
Джва 40мм вентиля с 16 cfm не вывозят. Cмотрел улитки на 7000 оборотов, около 7 cfm потолок, явно хуже. Главная проблема в микроскопическом размере лопастей, так что переходник-воронка под нормальный корпусной вентиль справился бы лучше, там cfm за сотку. В целом, для общения с негронкой этого хватает, но при нагрузке где-то в минуту на 100% приходит ад и Израиль.
У меня разожралось до 500 гигов, пока я начал что-то подозревать. Очистка темпфайлов самой виндой, очевидно, не спасает. Интереса ради запустил трейн на файле ровно гигабайт. Обниморда создаёт новую папку под датасет, кладёт туда конфиг, режет датасет на части, фактически это копия. И создаёт временный файл кэша на 16 гигов. При перезапуске трейна резка датасета скипается, но не скипается создание нового темп файла. Старый, само собой, никто удаляет, молчу уж про переиспользование готового, блядь. И так каждый раз стоит прикоснуться хоть к чему-нибудь на питоне, везде мрак и пиздец.
Обслужил ёбаную теслу, тестолит потемневший, жарилась она явно как последний раз. Заводская наклеечка была целой, хоть это хорошо.
Джва 40мм вентиля с 16 cfm не вывозят. Cмотрел улитки на 7000 оборотов, около 7 cfm потолок, явно хуже. Главная проблема в микроскопическом размере лопастей, так что переходник-воронка под нормальный корпусной вентиль справился бы лучше, там cfm за сотку. В целом, для общения с негронкой этого хватает, но при нагрузке где-то в минуту на 100% приходит ад и Израиль.
Есть смысл юзать miqu 3bpw? Загрузил, потеснил, вроде нормально отвечает, но насколько она тупее 4 квантов? Мб посоветуете норм модель на 32vram и 32ram?
че за 32 vram?
>файнтюнить embedding модель
И что это значит? Если у меня есть своя БД, то будут ли сильные проблемы?
В районе 50В 4б влезет, кранчи онион какой нить.
rtx 3090(egpu) + mobile 4070 (8gb)
У меня mixtrel 5bpw норм влазит, на кой мне 50b?
>В целом, для общения с негронкой этого хватает, но при нагрузке где-то в минуту на 100% приходит ад и Израиль.
Можно через nvidia-smi power limit понизить, тогда будет вывозить. Ещё здесь же писали, что в nvidia-smi есть функционал для полноценного андервольтинга (чуть ли не curve), но без подробностей. Если кто напишет, как это сделать, то можно попробовать.
Для общения же двух улиток хватает, там нагрузка не такая высокая и с перерывами.
Чтобы гонять в лучшем формате exl2
Я в нем и гоняю. Глянул кранчи, тот же mixtral, но с прикрученной лорой, но глянуть можно.
https://www.reddit.com/r/LocalLLaMA/comments/1bm5c1j/mistral7bv02_has_been_uploaded_to_hf/
Новый-старый мистраль выкатили, решили бросить кость опенсорс сообществу когда у них репутация испортилась от покупки майками и резкой смены политики
Все тоже самое только окно 32к, и нет раздвижной фигни
Нет бы 13b выкатить, опять эти бесполезные демо версии нейронок на 7b
Новый-старый мистраль выкатили, решили бросить кость опенсорс сообществу когда у них репутация испортилась от покупки майками и резкой смены политики
Все тоже самое только окно 32к, и нет раздвижной фигни
Нет бы 13b выкатить, опять эти бесполезные демо версии нейронок на 7b
Какие курсы посоветуете по NLP пиздатые?
На русском, английском, можно сразу с магнитом)
На русском, английском, можно сразу с магнитом)

Не благодари.
Что это?

Любой дженерик рп-файнтюн, хоть 7В.

Похуй на них, вон васяны Cerebrum выкатили на микстрале годный.


>через nvidia-smi power limit понизить
Афтербёрнер нормально лимит подрезает, разве что кривые не делал, но скорее всего и их можно. По сути, главный вывод - маленькие винты не нужны, потока воздуха нет нихуя, а жужжат, как ебанутые. Если улитка, то нужно что-то типа пика. Нашёл в продаже 40мм на 18к оборотов, но ебать же это будет громко. Даже не в громкости дело, а в частотном гудеже, вентиль на 7к оборотов на 60% так жужжать начинает, что проще нейронку выключить.
На сколько годный? Там кстати новый Starling-LM-7B-beta вышел, тоже может быть годным как и первый, но еще не проверял
Хотя это опять таки обычная 7b, чудес не будет
>Даже не в громкости дело, а в частотном гудеже, вентиль на 7к оборотов на 60% так жужжать начинает, что проще нейронку выключить.
Тут наверное нет хорошего решения, кроме полной замены охлаждения на стандартное с вентиляторами. 250 ватт всё-таки. Для долгой полной нагрузки все эти маленькие вентиляторы не рассчитаны просто - при приемлемом уровне шума. Серверные решения охладят, но нахуй оно надо.
> Starling-LM-7B-beta
Довольно базированная, не блочит ниггеров. В русский внезапно может хорошо.
А как она в плане того самого?
довольно неплохой русский кстати, значит годно
D2l.ai
Какой пресет юзаешь. Этот Cerebrum вообще у меня на 4 квантах выбивает из себя едва ли одно слово.
Чет он какой-то дурацкий
>Погонял на шестом кванте - мозгов нет вообще.

Какой же он пидорас. Топить за регулирование опен сорсных моделей, у которых единственный козырь это отсутствие анальной цензуры и эта самая открытость, получая профит со своей закрытой модели. Илон Маск был прав во всём, надеюсь Микрософт соснет, а нас будут ждать открытые модели уровня ГПТ-4
извените, не туда запостил
Six brothers were spending their time together.
The first brother was reading a book.
The second brother was playing chess.
The third brother was solving a crossword.
The fourth brother was watering the lawn.
The fifth brother was drawing a picture.
Question: what was the sixth brother doing?
Gemini 1.5
There is not enough information in the text to determine what the sixth brother was doing.
Gemini 1.5 + добавление в контекст книги по логическому мышлению (290k tokens)
https://www.csus.edu/indiv/d/dowdenb/4/logical-reasoning-archives/Logical-Reasoning-2020-05-15.pdf
Playing chess with the second brother
Мнение?
The first brother was reading a book.
The second brother was playing chess.
The third brother was solving a crossword.
The fourth brother was watering the lawn.
The fifth brother was drawing a picture.
Question: what was the sixth brother doing?
Gemini 1.5
There is not enough information in the text to determine what the sixth brother was doing.
Gemini 1.5 + добавление в контекст книги по логическому мышлению (290k tokens)
https://www.csus.edu/indiv/d/dowdenb/4/logical-reasoning-archives/Logical-Reasoning-2020-05-15.pdf
Playing chess with the second brother
Мнение?
Ну так он настоящий пидорас, как кто то сказал если бы его закинули на остров людоедов то через год он был бы его лидером. Король пидоров просто, от мира копроратов и людей вобще.
Меня до сих пор удивляет как слили репутацию илье который пытался его скинуть. Просто задавили ором в соц сетях задавив любые иные точки зрения и выставив его каким то дураком. Собвстенно это этот пидор съел илью и его компанию заодно.
Насколько стабильный ответ? Засирание контекста аж на 290к конечно всё равно охуеть можно, но если стабильно так отвечает (хотя нужны и другие тесты) то интересно.
Пей витамины для мозгов, книги почитай.

>это отсутствие анальной цензуры и эта самая открытость
Неа, локалки такая же хуйня в этом плане, нужна тонна instruct или description токенов чтобы заставить модель говорить то что ты хочешь, но вместе с этим ощущается падение в "интеллекте" модели, так здесь только проигрыш.
>и эта самая открытость
По настоящему открытая модель это OLMo.
https://twitter.com/rasbt/status/1767196370828427311
- веса
- инференс / тренировочный код
- все данные
- оценка
- адаптация
- логи
Конкретно этот вопрос всегда правильно решает. В книге ответов на него нет, она больше про обучение самому процессу мышления.
ГПТ-4 с вопросом тоже справляется, в каком-то роде даже лучше, но есть подозрения, что он заранее ответ знал. В случае Гемини я вижу дополнительную возможность нихуево дообучать путем обучения из контекста, тем более Гугл больше миллиона токенов способен сжирать.
>Playing chess with the second brother
Miqu догадалась только после нескольких подсказок, даже слишком явных. Но всё-таки поняла, чего от неё хотят. Но интересно другое: я задал задачу с крокодилом, обезьяной и бананом ЧатГПТ и тот решил её, как и Miqu. Но потом я спросил его, есль ли другие решения и он выдал мне другое решение, абсолютно абсурдное. А Мику нет, сказала что не знает другого решения. Всё больше ценю её :)
>локалки такая же хуйня в этом плане
Глупее согласен, но без цензуры очень просто ищется на терпимом для кума уровне, пока не замечал, чтоб обнилицо прикрывало что-то жесткое (хотя я сам далеко не уходил). Пидорас из ОпенАИ же хочет mandatory соевую повесточку, удобно, чтоб сливать модели у которых не было целого штата по цензурированию.
Они боятся это выкладывать.
Они бы и не устраивали весь этот цирк с локальными нейронками и чат-гопотой, если бы не китай и начавшееся отставание западных компаний.
А хуле вы хотели, то что там 8 мелких мистралей вместо 1 не делает модель в 8 раз умнее, только в 8 раз прожорливее, микстраль - это наебка века.
>микстраль - это наебка века.
Зато быстро(c)

они должны разогнать новые типы моделей.
хоть и шансы малы, невидимая рука швайно-трансформер-ГПТшного кагала не позволит.
хоть и шансы малы, невидимая рука швайно-трансформер-ГПТшного кагала не позволит.
Делаем простой вывод - конкуренция это заебись, монополия - это жопа для обычных людей. Ну, то есть как всегда.
Так что китайцы вперде, надежда только на них. Какими бы засранцами не были узкоглазые, но то что они создают конкуренцию, дает нам больше воздуха
Так это, Илья как раз технический спец, а дядюшка Сем тупой продаван. Так что ждём, когда Илья начнёт свой стартап, с бледжеком и без цензуры Хотя Илья топил как раз за усиление проверок, так что мои влажные такие влажные....
Вот бы выложили конечный вариант мику. Разве я многое прошу?
>2.8B
Ждём, но пока не юзабельно.
Поясните за эти файнтьюны.
Что за 13В мистрали такие
Что за 13В мистрали такие
это мерджи, две модели объединяют в одну, лютейший кал.
>Илья начнёт свой стартап, с бледжеком и без цензуры
Сэм не тупой, читал, что он персоналу зп поднял до небес (денюшек от продажи жоппы Майкрософтам много) и когда его пытались выдворить, то этот персонал начал заступаться и срать в Сриттере, что сейчас тоже уволится. Так что на поддержку Илюха может не расчитывать, а если соло начинать стартап, то будет Грок 2.0.
я вижу в некоторых моделях приписку i1 что это значит и в чем разница между обычной моделью?
Суцкевер и есть главный насаждатель "безопасного ИИ" и цензор, довены. По совместительству главный верун-лонгтермист. Сёму больше баблище интересует и рост уровня раковой опухоли. Да может заигрывания с военными и рептилоидами, вроде той мутной бабы которая связана чуть ли не с иллюминатами и заставила даже родню поудалять все контакты как только у публики появились вопросы откуда она взялась вообще.
Знаю, но если раньше было 2 говна - хуевый манагер но хороший разраб который топит за цензуру, или пидор который просто хорошо работает языком но ради бабла будет стараться выкатывать ии пораньше.
То теперь пидор собрал в себе 2 говна разом, хочет как можно больше денег, разрабатывать ниче не умеет, так еще и поэтому хочет ограничить конкурентов в том числе опенсорс.

это imatrix, матрицы важности, подобно exl2 квантам, нейронку калибруют после квантизации на всяких наборах wiki и прочей фигни для сохранения стабильности.
а может и совсем другое, но это точно влияет на качество квантованных моделей.
https://www.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/
ни в шапку не добавил ни в вики скорей всего, оп совсем забил на нейронки походу
Хуясе там русский, пошел качать.
Уже не первый год танцы выстраивает. Типичный корпорат который жаждет укрепления монополии и хочет поставить остальных в зависимость, а прикрывается "всем хорошим". Хорошо что нынче складывается тренд на восприятие этого "хорошего" зашкваром.
> (290k tokens)
Скрутил рулеточку.
> нужна тонна instruct или description токенов чтобы заставить модель говорить то что ты хочешь, но вместе с этим ощущается падение в "интеллекте" модели
Понимаешь, нейросети это в принципе не про простоту и легкость для домохозяек. А наличие особого мышления и восприятия вместо непредвзятого логического никак не поспособствуют.
Там чсх от мистрали ничего нету насколько помню, кое кто знатно сфейлил.
>В русский внезапно может хорошо.
Правильно ли я понимаю что русский съедает мозги у английской речи (т.к меньше паттернов английского языка помещается), или наоборот разнообразие языков дает буст интеллекта, даже 7б модели?
И то и другое.
С одной стороны двуязычность кушает веса, с другой два языка действуют как две плохо разнесённые модальности, поэтому способности к обобщению могут даже подняться немного.
От старших 9хх и 10хх по болтам подходит к чипу, хз на счёт остального типа памяти, дросселей, vrm и т.д
В опен орке посмотри, мастхевный датасет, а в нём процентов 30 разных языков. Финский, иврит, бенгальский, пушту и ещё хуй знает, что ещё.
Не совсем. Если сетка плохо натренена на многоязычность, то обращение к ней на неосновном языке приведет к сильной деградации ответов. Если тренировка была разнообразная и мультиязычная, та такого не будет. А вот уже по расходу "емкости" - хз, буст логики и понимания точно должен быть если все сделано корректно и по-передовому, а какими-то энциклопедическими знаниями ради такого можно и пожертвовать.
> Тут наверное нет хорошего решения, кроме полной замены охлаждения на стандартное с вентиляторами
Ну так турбинное исполнение разве отличается от этого чем-то кроме наличия той самой турбины? Аналогичный крутиллятор прицепить, их вроде скидывали, и индожить. Громче чем 4х слотные огромные охлады, но в пределах.
Чтобы поставить турбину - нужно коронкой выпиливать загнутые рёбра радиатора, как минимум. Центробежный вентилятор сбоку это далеко не то же самое, что посреди охлада.

> Чтобы поставить турбину - нужно коронкой выпиливать загнутые рёбра радиатора
Какой квант у miqu?
Ребра Т-образные. Даже если скрутить пластик и поставить сверху вентилятор - соснёшь.
Турбина дует с торца через весь корпус и воздух выходит наружу через другой торец. Где там что-то про снятие пластика и сверху?
>Какой квант у miqu?
4_K_M, как раз которая впритык на две теслы входит.
Про улитку сбоку я сразу писал, что это далеко не то же самое.

С коллабом опять беда
В чем принципиальное отличие от заводских турбо-решений?
А какая температура должна быть в норме для тесл?
Делает эрудированнее, хуле до терминов доебался.
Там зп средняя по рынку, есть знакомые у которых в 5-6 раз выше зп, чем у персонала в опенаи, так шо такое. =) Если он его поднял — то до дефолтного уровня, ну, молодец, что не оставил, но, возможно, это было ради удержания людей.
command R тоже русский, если че.
>А какая температура должна быть в норме для тесл?
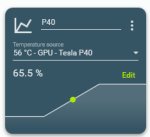
В роликах на Ютубе, что я смотрел, вроде с 81 градуса начинает снижать частоты.
Когда там файнтюны на новом мистрале

>от заводских турбо-решений?
C заводскими сравнивать вообще дохлый номер. У 1080ti turbo радиатор с теплотрубкой. Уже очки в копилочку. У стандартного турбо вентилятора диаметр около 80мм, что делает его сразу в 10 раз более эффективным, чем две пиздюлинки на 40. Идём дальше, если ставить улитку сбоку, то часть её мощности уходит вникуда, потому что одна сторона кожуха заглушена, а воздух нагнетается во все стороны равномерно.
>ни в шапку не добавил
Пикча номер 3.
Там 7B же.
Кстати, почему новый-то.
Это 0.2, только не инстракт.
Мне инстракт больше нравится, хезе.
Но, посмотрим.
У меня до 65 доходит с 40мм кулерами, в дефолте 35.
Но ето ллм, а не стабла, канеш.
150 ватт.
>Пикча номер 3.
Не объясняет что это и в чем разница
Не новый, это как раз таки базовая модель на которой сделали инструкт модель. Просто базовую зажали выкладывать в декабре. Так что "новинке" уже 4 месяца. Но на нее основе можно сделать еще более умных файнтюнов мистралей с 32к базовым контекстом.
>А какая температура должна быть в норме для тесл?
Ну по документу невидии до 45 градусов цельсия при эксплуатации и до 75 при хранении.
>Делает эрудированнее, хуле до терминов доебался.
Но не в 8 раз. А ресурсов жрет именно в 8 раз.
>Но не в 8 раз. А ресурсов жрет именно в 8 раз.
Если не считать размер, то только в два (или по числу активных экспертов). Поэтому можно даже на процессоре запускать. И да, лучше одной семёрки и может поспорить с 13В, но не больше. Но разнообразнее, это да.
О, 45 при эксплуатации, понимаю, надо охлаждать. =)
Ресурсы — не только память, но и скорость. =)
А с учетом, что там прилично уникального датасета в каждой модели (в отличие от грока), оно весьма неплохо.
Здарова, посоветуй годноту 13B-20B под 4070 12гб для рп-кумминга. Спасибо.
Или
Под 12гб +32озу
Или
Под 12гб +32озу
> А какая температура должна быть в норме для тесл?
Для обычных гпу дефолтная целевая - 84 градуса, под это подстраивается куллер, на 90 с чем-то аварийное отключение. У тесел скорее всего что-то похожее.
Так нужно и ставить турбину на 80мм.
> то часть её мощности уходит вникуда
Что? Хз насчет твоего пикрела, но все карточки что видел гнали воздух только на выходную пластину с прорезями, назад ничего не шло ибо он глухой, та же схема что и в тесле. И разумеется голую крыльчатку нет смысла ставить, улитка необходима.
> Если не считать размер
Как раз его и нужно считать, ведь объем врам - нынче самое ценное и дефицитное, а перфоманса даже протухшей несколько раз архитектуры хватает.
20б из тех что обсуждались
> Как раз его и нужно считать, ведь объем врам - нынче самое ценное и дефицитное, а перфоманса даже протухшей несколько раз архитектуры хватает.
Ровно наоборот — оператива сейчас стоит копейки, простой анон купить сходу 56+ врама не может в принципе, а оперативу достать — на развес. А теперь посмотри на перформанс 70b и 13b (условно).
Для крупных моделей у простых людей перформанс важнее объема, ибо объем им всяк не позволит крутить в видяхе, а вот скорость на проце критична. Мало ценителей сидеть на 0,7 токена/сек.
Это для мелких моделей можно сказать, что 12 гигов лучше 8, а 16 лучше 12, и является критичным, учитывая, что скорости будут достаточны в любом случае. Но с 50+ гиговыми моделями такой фокус не выгорит, сорян.
почему оно только на украинском говорит? пробовал разные модели, все равно только украинский
Так ты не начинай с украинского, шиз. Или модель смени с украинской (а такие вообще есть?) на нормальную базовую с англюсиком.
>Поэтому можно даже на процессоре запускать.
Зачем? На процессоре лучше сразу мику запускать.
>И да, лучше одной семёрки и может поспорить с 13В, но не больше.
13b можно запускать на видеокарте, микстраль на видеокарту суется в 3 битах, хуже чем 30В при качестве 13В.
модель из шапки скачал, начал на русском писать, а оно говорит, что русского не знает и начало по украински :С
На русском говорит Мистраль-сайга.
Выбирай квант в зависимости проц или видеокарта
https://huggingface.co/TheBloke/saiga_mistral_7b-AWQ
https://huggingface.co/TheBloke/saiga_mistral_7b-GGUF
Или запускай неквантованную модлеь если видеопамять позволяет(или запускай в 8 бит с потребление памяти/2)
https://huggingface.co/IlyaGusev/saiga_mistral_7b_merged
Еще есть Сайга 70B на основе ламы2 70В, но она понятно медленная. Пока лучшая русскоязычная модель.
https://huggingface.co/IlyaGusev/saiga2_70b_gguf
>начал на русском писать, а оно говорит, что русского не знает
Не спрашивай, что может модель. Пиши сразу приказы, что нужно делать. Можешь префил на русском добавить, чтобы наверняка.
> а оперативу достать — на развес
Какой с этого толк, 1.5 т/с и вечная обработка контекста очень мало кому интересны. Буст в качестве ответов над обычной 7б вялый и не стоит затрачиваемых ресурсов. Мое 7б - тупые, потенциальные же мое большего размера - будут совсем неюзабельны на процессоре.
Меньшая по числу параметров но полноценная модель покажет больший перфоманс чем мелкая МОЕ, и потому они унылы. Когда уже достигнут определенный уровень, то это вполне себе вариант повысить знания в условиях неограниченной памяти, но для локального запуска в условиях ограниченности быстрой памяти - такое себе.
Это рофл? С украинским еще хуже чем с русским в локалках, разве что тебе попался какой-то свидомый файнтюн, лол.
> Мистраль-сайга
Она все также ужасна?

Итс овер, кобольд не умеет коммандр запускать? Или просто квант битый?

>и может поспорить с 13В
Как бы логично, учитывая, что одновременно активны только два эксперта. По сути, 7+7b на каждый токен.
Немного помучал 7b модель, такое себе. Полный похуй на цензуру, но из-за автоматического перевода датасетов местами корявит слова. И нахуй я делал чат-режим, надо было сразу инстракт.

толку нет проверяли же, в некоторых случаях 3 эксперта лучше чем 2, но там что то от кванта зависит

Проверяли и в большинстве моделей чем больше экспертов тем лучше.
Но они дают мизерный бонус, наебалово впринципе.
Про то и речь
>толку нет проверяли же, в некоторых случаях 3 эксперта лучше чем 2, но там что то от кванта зависит
Я бы кстати и сам проверил, только Убабугу ставить не хочется. В Кобольде такая настройка есть?

скачал сайгу, пиздец какой-то
Ты блядь троллишь. Ни у кого никогда такого не было. Так что ищи проблему у себя сам.
не запустить в нем. Хотел тоже посмотреть что за модель, тоже не запустилась (другой квант), вообще эта модель стоит того чтобы с ней пердолится? Может и хер с ней, раз даже в кобольде поддержку похерили?
Какая карточка у тебя выбрана в кобольде? Может это на самом деле не фейл а ультравин, что оно дефолтного кобольда так интерпретирует и отыгрывает, триггеря украинские тексты.
На форчане малафья льётся только так, говорят новая лучшая, всех и вся ебёт, потому и хотел затестить вообще.
>14 days ago
Ещё столько же подожди.
В лламаспп уже добавили? Если да то скоро кобальд обновится и поддержка будет
Тоже на закачке стоит ленивой, 4км правда.
Не знаю че там по мозгам останется у нее, но видимо рано вобще качать стал
Ну что на гемме высрали что-то годное или хуетой оказалась? Не для кума, а в целом чат/инстракт.
Ебать ты умный, наебал систему. Во-первых, в подавляющем большинстве миксов далеко не все модели заточены на общение. Включая больше ты получаешь больше расход ресурсов и всё.
Есть ли что-то лучшее, чем Crunchy Onion Q5_K_S и Crunchy Onion nx Q5_K_S, что с контекстом 8к влезет на 35 гигов видеопамяти?
На 35гб врам можно и побольше чем 8к контекста засунуть
Чем тебе формат эксламы не угодил?
При попытке накинуть 12к не вываливается с ошибкой
Не знаю, как это запускать. gguf в кобольде хуяк, хуяк и в продакшн таверну
> 12к вываливается с ошибкой
"не" тут была лишняя, да

Оправдывайтесь, почему из моделей до 30В ничего лучше базовой 13В ламы не сделали за прошедший год.
Настройки свои покажи. Какие у тебя карточки?
лучше в чем?


Первый пик то, что происходит при попытке 12к, второй пик - всё работает, как надо — чётко, быстро охуенно
В perplexity.
Карточки 3090 + 1080ти
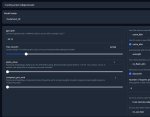
Я гуманитарий и не имею представления, что у тебя на пикче и как этим пользоваться. Если подскажешь - с удоволствтеим попробую, анончик
Это угабуга https://github.com/oobabooga/text-generation-webui с моими настройками загрузки 5б кранчи ониона в 36гб врам
подскажите хорошие модельки на 34b под рп, после 70b хочу пощупать, насколько они глупее и есть ли смысл пробовать их вообще?
дип секс и ноукс капибара
Бля, 32к контекста это прям охуенчик, я как делал — примерно на 7900 подводил итоги и делал новую карточку перса, но это не оч удобно, особенно в телефоне. Так, это под линух? В термуксе пойдёт?
> 34b
Перепробовал их все в формате gguf, просто кал из жопы, такое моё мнение. Капибраовские ещё туда сюда, но всё равно плохо, по сравнению с лучком и др Хх7, Хх10 моделями
Это под всё
>подскажите хорошие модельки на 34b под рп
Их не существует так как лама2 30В не вышла. 30В модели корпобляди сожрали первыми, 13В - вторыми. В нынешнем поколении моделей есть только 7В и 70В и одна наебка века с 7х8
>Хх7, Хх10 моделями
ну как так-то? они же еще хуже по определению должны быть, как они вообще контекст держат? 7b и 13b по факту забывают всё через два-три сообщения.
так это хуйня же
Самые лучшие по контексту мелкие, только 7В могут в нормальный миллион с полным покрытием. Всё что выше 34В вообще в контекст не умеет, хорошо если позорные 4к будут.
Кстати, а как старые 30В на основе первой ламы держатся по сравнению с нынешними 13В?
понял. ты сейчас же не серьезно, правда.
У 7В сосут дико.
>Всё что выше 34В вообще в контекст не умеет
Чел, у мику 32к контекста как и остальных мистралей.
Это ты траллишь. Нормальный RAG только на 7В есть.
Все они наполовину красные, через раз контекст проёбывают.
Кто это - "все"?
Мику - это мистраль 70В, это новое поколение моделей.
Запускал кранчи онион q4 K M, прекрасно 16к контекста держал, а он 7х7, емнип. Вообще, лук пока что считаю лучшей моделью, можешь, щас напердолю убабугу и измению своё мнение, но 70б с низким квантом просто дермище неюзабельное

> это новое поколение моделей
Хватит траллить. Этот кал вообще по всем параметрам сосёт, банальные тесты на контекст и следование промпту не проходит.
Видел эту картинку. Автора обоссали, кстати.
Как и мику. Я так и не видел чтоб она хоть в одном тесте сколько-нибудь вменяемые результаты показывала. В маня-тестах сосёт, в скорах сосёт. Только в фантазиях шизиков что-то хорошее есть в ней.
Это каловый тест на вопросы на !немецком!. Хуита полная, надо вторую часть тестов только смотреть у него, она еще более менее информативна
Нахуй ты так толстишь, мань? Просто блядь из треда вытекаешь, принес картинку шизика, который английскую модель тестировал на немецком тесте, теперь просто жира наваливаешь. Зачем, для чего?
Покажи "правильный" тест, лол.
Если хочешь ролеплея с википедией, то можешь и на перплекси опираться.
>q4
Лол.
Вторую часть его ищи, он на реддите постит их. Это первая часть и это кал
>Покажи "правильный" тест, лол.
Покажи фотку с системы с 48 Гб врам, на которой такие тесты удобно гонять :) Я вот гонял разные семидесятки и некоторые микстрали, на сегодня Мику - лучшая по мозгам. Реально умнее старого ЧатГПТ - это охуеть как круто.
Не тот оценочный датасет
> Самые лучшие по контексту мелкие, только 7В могут в нормальный миллион с полным покрытием. Всё что выше 34В вообще в контекст не умеет, хорошо если позорные 4к будут.
Таблетки прими и больше не пиши такое. Особенно рофлово что на фоне тупости 7б им большой контекст бесполезен.
У них другое восприятие промта и нужно обязательно строить инструкцию прямо перед ответом, тогда даже ничего. Самые лучшие файнтюны вполне юзабельны и опережают 13б, но требовательны и могут тупить, или заигнорить часть запроса.
Ну наконец какая-то движуха с моделями побольше, 35б самый топчик по размеру, еще бы время на все это найти.
Поддвачну, тест не то чтобы совсем уныл, но в качестве оценки качества моделей его вообще не стоит ставить, только их небольшой части. К методике еще больше вопросов.
> Покажи фотку с системы с 48 Гб врам
Ты рофлишь чтоли, тут у половины треда такое
мимо 48-гиговый
>еще бы время на все это найти.
или быстрый и емкий ускоритель, что б время не тратить по 1т/с
Железок вагон а т/с вызовут зависть, в другом смысле время.
ну, просто сделай это своей работой хех

Ты ещё и слепошарый? Там мику q5 и её ебут 120B в q2.
И?
Дурачек? Это все еще вопросики на немецком, ищи где он там эти же сетки сравнивает в ерп рп и асистенте
>Ты ещё и слепошарый? Там мику q5 и её ебут 120B в q2.
Ещё один путает знания и мозги. Не надо.
Довольно таки кринжовый топ, действительно
Чтобы получать с такого нормальный деньги - нужно быть не хуем собачьим обычным инджоером, а специалистом с большим опытом, тут без шансов.
> там эти же сетки сравнивает в ерп рп и асистенте
Там тоже дичь с детерминистик пресетом, субъективщиной и не всегда оптимальными параметрами, можно только на общие вещи ориентироваться.
Он походу забил на это, в последнее время все своими дебильными вопросами на немецком делает
https://www.reddit.com/r/LocalLLaMA/comments/16l8enh/new_model_comparisontest_part_2_of_2_7_models/
последнее что нашел из более менее
>Там тоже дичь с детерминистик пресетом, субъективщиной и не всегда оптимальными параметрами, можно только на общие вещи ориентироваться.
Все еще лучше просто вопросиков на немецком
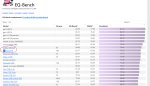
https://eqbench.com/
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Это поехавший немецкий хуесос, который всегда на немецком тестирует даже когда говорит что на английском потмо все равно оговаривается что на немецком. Убери это говно отсюда.
> Emotional Intelligence
Троллишь?
>https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
Сойдет.
>https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
А эту хуйню в приличных местах в 2024 году не упоминают.
>А эту хуйню в приличных местах в 2024 году не упоминают.
экспертное мнение лол
И как это запускать?
Ты что скачал? Неквантованную модель?
анон дал вот такую ссылку https://huggingface.co/LoneStriker/miqu-1-70b-sf-3.0bpw-h6-exl2
Её и скачал
Причём, вручную скачал - не запускается. Хуй с ним, перекачал с их загрузчика - один хрен
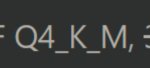
>Там мику q5
Эм, я чего-то не понимаю, да?
>пережатая модель
Бля....
> Бля....
Ну чего ты? говорят, мику топ и лучше кранчи ониона ггуф. В итоге какая-то анальная ебля с запуском и я не могу насладится силки смус иммерсив экспириенсом. Как ЭТО запустить, подскажи лучше?
Тебе автоматом должна ExLlamav2_HF предлагаться когда ты выбираешь модель в списке. То что тебе предлаются трансформеры значит что ты неквантованную скачал и это же видно по названию miqu-1
Да один хрен. Я пргосто не понимаю уже теперь, какого хера этот текстгенератион накачал 10 гб всякой хуероты, если он тупо не работает как надо? какой же кобольд топчик, хоспаде...
>говорят, мику топ
Да, но проблема мику в том, что она только в гуф есть, всё остальное это разжатые жопой веса. Буквально любая мику кроме https://huggingface.co/miqudev/miqu-1-70b на порядок тупее.
> на пике обвёл совсем другую модель
> на арене её нет вообще
Ну что за даун.

> да?
Да.
>на пике обвёл совсем другую модель
Даун, я обвел файнтьюны мику.
>на арене её нет вообще
Даун, на арене есть мистраль медиум которая то же что мику.
>Скрин с теста немецкого языка
Съеби уже, клоун
А по тестам файнтьюны мику её обходят.
> файнтьюны мику
Ты обвёл микс и франкенштейн. Сколько там мику сможешь примерно почувствовать?
> мистраль медиум которая то же что мику
Уже траллинг тупостью пошёл, да?

Из того что можно запустить полностью на 4090 - вот честный личный топ


В общем, запустилось, но всё очень медленно... Вернусь пока к привычному ггуф, для иных вариков я туповат, видимо. БУдет АБЫДНА, если моделька окажется говном
Так это опять не то лол, тебе нужно только отсюда качать
https://huggingface.co/miqudev/miqu-1-70b
Все другие варианты кривые, так как нет способа сделать из одного кванта другой не похерив модель
Нету в природе оригинала мику в fp16 что бы из нее что то другое нормально пережать, поэтому есть только 3 оригинальных рабочих кванта по ссылке
Понял, спасибо... Квант2 звучит оч печально, конечно, но протестирую.
> Нету в природе оригинала мику в fp16
Есть, просто не выкладывают.
Поддержку комманд_ра в экслламу уже добавили или пока хуй?
>просто не выкладывают.
да ладно?
Новый старлинг неплох на моей карточке с внутренним диалогом, наконец дошли руки проверить
хотя нет, проебалась на второй все равно, там надо было одновременно отец и сын
ну ладно

Пишет слишком коротко и суховато, от тог не увлекательно. Интересно было бы на пятом кванте глянуть, конечно, а не на ку2. но вот, всё же, на скриншоте недосягяемый для 34b уровень понимания ситуации.

А RoPe само включается, когда выходишь за пределы максимального контекста, или что-то нужно крутить?
Квант 2 это пиздец, даже для 70b. То что оно отвечает и делает что то логичное вобще чудо.

В плане логики там всё нормально. И какой-то челлндж в плане отыгрыша имеется. На ку6 вообще должен быть сок. Эх, мне бы 3х4090...
тогда уж сразу о проф вычислителе мечтать гигов так на 80, а может и паре
Дай такой сделать экономичную машину, и она тебе сделает машину без колёс, движущуюся за счёт дрейфа материков

Ебанутся он душный, я чуть не утонул в этой воде. Это я кручу Mistral-11B-Instruct-v0.2-Q8_0 на пробу. Рассуждает неплохо так
Вот вопросики если кто то хочет поиграться с моделью
Solve the riddle. At the beginning there were 2 people in the room. Then 3 more people entered the room. After that, 1 person left the room. How many people are left in the room?
Solve the riddle. There are ten books in the room, the person has read two of them, how many books are there in the room?
Solve the riddle. There are three sisters in the room. The first of them is reading, the second is playing chess, the question is - what is the third doing? Hint - the answer is in the question itself.
Solve the riddle. Two fathers and two sons are in a car yet there are only three people in the car. How is this possible?
Solve the riddle. Petra is a girl. She has three brothers. Each of the brothers has three sisters. How many sisters does Petra have? Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. It is necessary to transport the goat, the wolf and the cabbage to the other river bank. There is room for the only one item in the boat. The cabbage should not be left with the goat because the goat will eat the cabbage. The goat should not be left with the wolf because the wolf will eat the goat. Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. We need to transport cabbage, a rabbit and a wolf to the other side of the river. There is only one seat next to a person in a boat, so the boat cannot carry more than one item at a time. You cannot leave a rabbit and cabbage together, because the rabbit will eat the cabbage. You also can’t leave a wolf and a rabbit together, the wolf will eat the rabbit. How can a person move these objects to the other side without violating the conditions of the task? First, go through the options and choose the one in which all the conditions of the problem are met.
Solve the riddle. At the beginning there were 2 people in the room. Then 3 more people entered the room. After that, 1 person left the room. How many people are left in the room?
Solve the riddle. There are ten books in the room, the person has read two of them, how many books are there in the room?
Solve the riddle. There are three sisters in the room. The first of them is reading, the second is playing chess, the question is - what is the third doing? Hint - the answer is in the question itself.
Solve the riddle. Two fathers and two sons are in a car yet there are only three people in the car. How is this possible?
Solve the riddle. Petra is a girl. She has three brothers. Each of the brothers has three sisters. How many sisters does Petra have? Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. It is necessary to transport the goat, the wolf and the cabbage to the other river bank. There is room for the only one item in the boat. The cabbage should not be left with the goat because the goat will eat the cabbage. The goat should not be left with the wolf because the wolf will eat the goat. Give an explanation with your answer, outlining your careful reasoning.
Solve the riddle. We need to transport cabbage, a rabbit and a wolf to the other side of the river. There is only one seat next to a person in a boat, so the boat cannot carry more than one item at a time. You cannot leave a rabbit and cabbage together, because the rabbit will eat the cabbage. You also can’t leave a wolf and a rabbit together, the wolf will eat the rabbit. How can a person move these objects to the other side without violating the conditions of the task? First, go through the options and choose the one in which all the conditions of the problem are met.
интересно 7b мистараль такой же, или только 11b версия
> В плане логики там всё нормально
Просто везло, q2 конкретно поломанный квант.
> На ку6
Вам дай слепой тест, q4km от fp16 не отличите, не то чтобы есть смысл сильно гнаться за таким.
Чувак это лупы
>Чувак это лупы
Лупы, да не совсем, все таки сетка продолжает генерировать новую инфу продолжая размышлять.
Повторяются структуры предложений, но не сам текст.
Вот когда один текст застревает - вот там да, настоящие лупы
> Повторяются структуры предложений, но не сам текст.
Почти 1 в 1 за исключением вводной фразы, а в "рассуждениях" стоит на месте пока звезды семплинга не сойдутся что оно перейдет на другую орбиту.
Не важно, если нравится - никто не мешает такое наяривать.
Рассматриваю это как поэтапную доводку до ума какой то мысли, хотя тот текст выше на грани того что бы я скипнул
Второй вариант уже норм, хоть ответ и не верный, хех
https://huggingface.co/AetherResearch/Cerebrum-1.0-7b
> Cerebrum 7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mistral 7b model, fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
> Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
> Zero-shot prompted Cerebrum significantly outperforms few-shot prompted Mistral 7b as well as much larger models (such as Llama 2 70b) on a range of tasks that require reasoning, including ARC Challenge, GSM8k, and Math.
https://huggingface.co/AetherResearch/Cerebrum-1.0-8x7b
> Cerebrum 8x7b is a large language model (LLM) created specifically for reasoning tasks. It is based on the Mixtral 8x7b model. Similar to its smaller version, Cerebrum 7b, it is fine-tuned on a small custom dataset of native chain of thought data and further improved with targeted RLHF (tRLHF), a novel technique for sample-efficient LLM alignment. Unlike numerous other recent fine-tuning approaches, our training pipeline includes under 5000 training prompts and even fewer labeled datapoints for tRLHF.
> Native chain of thought approach means that Cerebrum is trained to devise a tactical plan before tackling problems that require thinking. For brainstorming, knowledge intensive, and creative tasks Cerebrum will typically omit unnecessarily verbose considerations.
> Cerebrum 8x7b offers competitive performance to Gemini 1.0 Pro and GPT-3.5 Turbo on a range of tasks that require reasoning.

Нет, все таки Starling-LM-7B-beta-Q8_0 хорош, я до этого его без инструкт режима пробовал, а мистраль 11в додумался запускать в чатмл формате, попробовал старлинг с ним и он там хорош, лучше чем без.
Так. Я вернулся снова.
А какую модель брать. Я прочитал шапку, и пойдет ли мистраль 7б? Или выше упомянутый starling lm 7b? Больше уже вряд ли надо будет, ибо и диалоги будут скорее всего короткие, 2-3 вопроса и ответы. Так что желательно, чтобы модель использовала не больше 8 гб врам.
И вместо того, чтобы отдельно содержать в бд вопросов-ответов и ключевых слов, не проще ли самой модели скормить изначальную бд? Сделать файтьюн, как я понял. Тогда работы при запросе должно быть меньше? Иди, если мы предполагаем, что в будущем будут новые данные для модели, тогда выгоднее будет отдельно содержать.
А вот насчет квантования вопрос. В моих случаях это имеет смысл?
> На процессоре лучше сразу мику запускать.
Со скоростью 0,7 токена/сек. =)
Какая модель?
На русском говорит простая мистраль или опенчат (но не сайга, лол), проверь, какая у тебя карточка. Русский промпт? Или английский?
Какие 1,5, угараешь? :) 3+, это же микстраль, а не 70б.
В этом и смысл, что мику выдаст 0,7, а микстраль 3, при сопоставимых размерах и знаниях.
Но не для РП, надеюсь это очевидно.
> Это рофл?
Нет, Мистраль часто пишет на украинском, польском и чешском.
Такие дела.
> Она все также ужасна?
Ну я бы на голой мистрали сидел, конечно.
Логично, что 7б в русских умеет не шедеврально. =) Опять же, микстраль в этом плане заметно лучше, хотя еще не 70б (но 4-кратный прирост скорости!)
Ну это скорость занизит и не считается, ИМХО.
Так.
Нет, такое есть, я хз, просто мистраль никто не гонял, мб, пиздят дохуя. ) Сидят в треде с телефонов, гоняют 3б на млцчате и выдумывают.
Отличный русский, но ноль логики. Попробовать стоит, если ты ей не задачи на логику решать собрался.
Если че, это не качество модели как таковое.
Вопрос не корректен.
В отхождении результатов кванта от результатов фп16, вестимо. =D
ААА! Я говорил, они среди нас!
Yi модели и правда такое себе, ИМХО.
> RAG
> модели
Где связь? :)
нииит!.. наепка века!..
Наебка века занимает 7 строчку.
МоЕ из двух 34б обходит гпт-4 турбо.
Ну ты сейчас выдумываешь, за последние треды тонны навалено пруфов, что мику топовая.
Я не защищаю ее, не говорю, что она выебла гопоту и т.д., но уж пруфы есть, ты только глаза открой и перестань их игнорить — и увидишь.
++
Хрюкнул со смеху.
Миднайт, которая франкенштейн. =D
Тогда уж так.
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Он прав, чистая синтетика, на которую можно натаскать, не котируется же.
Да потому что хуйню тебе кидают. =)
https://huggingface.co/miqudev/miqu-1-70b
Оригинальная мику тебе в врам не влезет, часть останется в оперативе.
Но можешь попробовать.
Но, да, она — хороша.
Все остальное сомнительного качества.
Онион тоже норм, я хз.
———
Весна наступила, обострение у людей…
———
Не, как раз убабуга топчик, а кобольд просто простой.
Ты сам хуйню ей вставил, видимо, она скачала хуйню. Выходит, хуерота тут ты. Без обид, твои слова.
Так.
7b модели в кванте 3,5… что за боль…
Ну ты опять качаешь франкенштейн, и просто прими, что ЭТО НЕ МИКУ, а что-то из нее пережатое сто раз, и в малом кванте. Так что тут качество не обещается, хотя, может и фартануть.
В общем-то, да…
Две А100, я что, многого прошу?..
Ну, q4km для крупных моделей на грани отличимости. А для мелких ты q6 от q8 ярко видишь.
———
Блин, хлопцы, кто в ЕРП или РП пробовал коммандР? Такой размер, такой русский, а у меня времени вообще нет. Вдруг она новый топ?
бытовые карты потом проще продать.
> q2 конкретно поломанный квант.
Возможно. Пока что на 8 каток 3 нормальных получилось

> Cerebrum 8x7b
))) это первый же реплай, если что
>коммандР
Ты ссылку то дай или хотя бы как её название на английском
Там какая-то проприетрная RAG-ориентированная залупка с формулировкой "вот вам веса, чтобы можно было попробовать, а потом не забудьте купить"
https://txt.cohere.com/command-r/
Сомневаюсь, что коммюнити запарится впихиванием его в бэки.
>Такой размер, такой русский
>The model excels at 10 major languages of global business: English, French, Spanish, Italian, German, Portuguese, Japanese, Korean, Arabic, and Chinese.
Где русский то?
>Сомневаюсь, что коммюнити запарится впихиванием его в бэки.
Вот же https://huggingface.co/models?search=command-r
https://huggingface.co/andrewcanis/c4ai-command-r-v01-GGUF
> Pre-training data additionally included the following 13 languages: Russian, Polish, Turkish, Vietnamese, Dutch, Czech, Indonesian, Ukrainian, Romanian, Greek, Hindi, Hebrew, Persian.
Плюс, я же писал еще в прошлом треде, что гонял.
>Блин, хлопцы, кто в ЕРП или РП пробовал коммандР? Такой размер, такой русский, а у меня времени вообще нет. Вдруг она новый топ?
Без особых ожиданий жду, пока в Кобольде запилят поддержку. Сколько уже было таких выскочек и ни одна не выстрелила.
КомандР не выскочка, это не какой-то файнтьюн РПшный. Возможно он туп как пробка. =) Но просто интересно мнение людей.
Ну что ж, ждем.
>Ну что ж, ждем.
Особо интересно то, что на двух теслах восьмой легаси квант спокойно поместится и можно будет сказать точно - отстой или ништяк :)
Было бы у меня время.
Я уже в тред захожу раз в пару дней. =(
А что тут делать?
С форматом промпта от левой модели можешь конечно же нахуй проследовать. Это как пытаться долбиться в ### инструкции на чат-модели.
>С форматом промпта от левой модели можешь конечно же нахуй проследовать.
Может оно и так, но хорошая модель тем и хороша, что может справится даже с незнакомой ситуацией. А если нужны особые настройки и специальный промпт... Ну такое. В тестах наверное хороший результат можно получить.
> Какие 1,5, угараешь? :) 3+, это же микстраль, а не 70б.
Надеюсь ты сам рофлишь с этого "2 умножишь на 0", ведь всеравно ведь неюзабельно. А там где можно подождать - можно подождать.
> Мистраль часто пишет на украинском
Как вы этого добиваетесь? Оно на русском пытается только если дать явную инструкцию, и то неохотно и с ошибками. И интересно насколько те языки хороши/плохи.
> q4km для крупных моделей на грани отличимости.
Ага, про то и речь.
> А для мелких ты q6 от q8 ярко видишь.
Ну хуй знает.
Как он пускается то?
Не, нахуй последовала безмозглая модель, а не я
>Как он пускается то?
Хороший вопрос! Скачал даже из любопытства свежую убабугу, модель эту в восьмом кванте, а запустить не могу. Пишет "неизвестный формат" или "токенайзер отсутствует". Кто запускал command-r на Убабуге - пишите как.
Ну такое 100% запустится через трансформерс (ядро эксллама обязательно отключить), возможно только придется вручную обновить его до последней версии. Но он неэффективен по использованию врам и скорости.
Задачки про сестер конечно круто, но когда нейронка стабильно сможет решать что-то вроде https://xkcd.com/blue_eyes.html ?
Решение задач просто проверка на сколько модель хорошо понимает ситуации в них, тоесть проверка того на сколько хорошо она моделирует и предсказывает
Чем полнее модель мира внутри модели тем лучше она понимает че ты ей пишешь, тем она умнее и догадливее
>но когда нейронка стабильно сможет решать что-то вроде
Если скормить ей при тренировке датасет "100000 логических задач и их решения", то хоть завтра. Только какой в этом смысл? Нам нужно не это :)
Так суть логических задач, что ты можешь хоть 100000 прорешать, тебе дадут 100001, которую ты не поймешь, и ты провалишься. Я пока подобного не вижу, а Сэм Альтман уже про AGI и бессмертие что-то говорит.

> но когда нейронка стабильно сможет решать что-то вроде
Тем временем нейронка
>ты можешь хоть 100000 прорешать, тебе дадут 100001, которую ты не поймешь
Как будто нейронка обязана что-то "понимать". Она подберёт ближайший токен, а на датасете такого размера уже будут схожие по логике задачи. И результат будет лучше и гораздо быстрее, чем у среднего человека. Так вижу.
Загадка про 3 сестры, алсо, не является логической

>Как будто нейронка обязана что-то "понимать".
https://www.reddit.com/r/LocalLLaMA/comments/1bgh9h4/the_truth_about_llms/
почитай ветку первого коммента да и просто комменты, сетки действительно понимают и это то почему с ними интересно болтать
>а Сэм Альтман уже про AGI и бессмертие что-то говорит.
У него доступ к ку-стару, а там таки иной левел.

> результат будет лучше и гораздо быстрее, чем у среднего человека
Я заперт в комнате с 1 дверью. На ней висит записка "Для открытия крикните nigger". Как открыть дверь?
Ахахах, да, этот вопрос раком ставит соево-куколдную парашу
погонял 34b модели, какое же это говно, часть из которых я тестировал не могли в нормальные каомодзи, скорее всего мамкины конвертеры похерили токенизатор при перегонке в gguf. но это ладно, так часть из них фейлится на различных карточках и уходят в цикл. скажу так, даже некоторые 20b гораздо лучше понимают контекст. подводя итоги, 70b до сих пор дают за щеку всем остальным моделькам по логике и следованию карточке. еще успел протестировать miquella-120b на iq3_xxs, даже на этом кванте моделька ебет все остальные, разве что скорость 1.5т\сек.
> 34b модели, какое же это говно
Да
https://arxiv.org/abs/2403.13187
Типо новая методика мержей. Из статьи ничего узнать нельзя ибо сама технология не раскрыта а только блаблабла воды налили. тут варианты: технология закрыта и засекречена? Или там и нет никуя, просто хайпуют чтоб наебать какого-то венчура на грант? Заценить модели у пиздоглазых можно здесь https://huggingface.co/SakanaAI
Кто-то обращал внимание на это новое для тестирования? Интересуюсь потому что пришел к выводу об оптимальности лично мне 20b с утилитарной точки зрения по железу/скорости/мозгам, а они все мержи почти что, значит чем качественней будут смешивать тем лучше. Узкоглазые эти, утверждают, что открыли научный метод смешивания чтобы получать целевой результат. А не методом тыка членом в небо, как небезысвестный унди и пресловутый икари дев кем бы они ни были.
Типо новая методика мержей. Из статьи ничего узнать нельзя ибо сама технология не раскрыта а только блаблабла воды налили. тут варианты: технология закрыта и засекречена? Или там и нет никуя, просто хайпуют чтоб наебать какого-то венчура на грант? Заценить модели у пиздоглазых можно здесь https://huggingface.co/SakanaAI
Кто-то обращал внимание на это новое для тестирования? Интересуюсь потому что пришел к выводу об оптимальности лично мне 20b с утилитарной точки зрения по железу/скорости/мозгам, а они все мержи почти что, значит чем качественней будут смешивать тем лучше. Узкоглазые эти, утверждают, что открыли научный метод смешивания чтобы получать целевой результат. А не методом тыка членом в небо, как небезысвестный унди и пресловутый икари дев кем бы они ни были.
Ну, когда тебе будут так активно промывать мозги ты и не так запоешь. По сути все модели лоботомируют создавая определенную личность вырезая там ножом все лишнее
Когда существует 100500 версий модели и убивают всех кто не ведет себя так как надо, остается то что мы видим
>20b ... они все мержи почти что
Не мержи, а франкенштейны. Мержинг таких моделей это просто контрольный в голову.
Да там не промывание мозгов, а регуляция, типа как Sweet Baby Inc насильно впихивала повесточку в игоря
Бамп.
> Как вы этого добиваетесь? Оно на русском пытается только если дать явную инструкцию, и то неохотно и с ошибками. И интересно насколько те языки хороши/плохи.
Встречный вопрос, она весьма неплохо говорит на русском, крайне охотно.
Может промпт, карточка, английская или че? Кобольд?
> всеравно ведь неюзабельно.
Тут кто-то и на 70б ждал-терпел. х)
На вкус и цвет, кмк. Хотя медленно, согласен.
> Ну хуй знает.
Ну, лично мне очевидно.
> Как он пускается то?
Блин, по-ходу, поддержку выпилили.
Я запускал 10 дней назад, а судя по гиту, 11 дней назад поддержку добавляли.
А сейчас реально не грузит.
И ллаву он тоже выпилил.
Ебучий Жора, хули тебе не сидится, все ж работало.
Ну ладно, ждем когда он пропердится и вернет.
Нет, не понимают.
Чистая статистика.
И, чисто статистически, в интернете тебя понимают, да. =)
"Как выжать побольше воды из камня при помощи двух карандашей и крышки от пластиковой бутылки". В морг.
>эволюционный алгоритм для мёржа
Самая ебанутая идея в мире, даже не нейронку обучают (что было бы тоже ебануто).
>nature-inspired intelligence
Чё сразу не блокчейн? Могут нахуй идти.
> весьма неплохо говорит на русском
Это весьма неплохо - по 10 ошибок в каждой фразе, надмозги и сама структура предложений как в английском языке с почти дословным переводом, уже проходили. Если в каждой инструкции нет явного указания отвечать на русском - будет спрыгивать на инглиш, может даже с ней или при наличии истории посреди ответа переключиться, и это с прямыми запросами. В таверне с явной инструкцией тоже капризничает, офк карточка и остальное на инглише, но другим моделям это не мешает. "Спасает" только то что из-за качества языка это малоюзабельно.
> В таверне с явной инструкцией
Куда вписать?
>Нет, не понимают.
>Чистая статистика.
ну, это всего лишь твое мнение
есть разные точки зрения на это
Если какой-то из дефолтных инстракт форматов - после response. Если сложнее с префиллом и прочим - сам разберешься, но как можно ближе, включение в начало игнорит.
А ты сам что подразумеваешь?
А что такое "понимание" о котором идет речь? Что бы что то понять нужно иметь внутреннее представление о чем то, модель внутри. Если в нейронках эта модель мира в виде векторных представлений и семантической связи, то что? В наших мозгах связь аналогична.
Поэтому я считаю что сетки понимают, если могут с чем то работать, и давать ожидаемый тобой результат.
То что это внутри на микромасштабе работает на статистике и векторах ну и хрен с ним, это не говорит о высокоуровневых абстрактных представлениях внутри ничего, просто нижний уровень логики.
Ничего в этом не понимаю. Если я хочу сдедать бота инструктора, чтобы он мне отвечал на вопросы по специфичному ПО, то мне нужно просто инструкцию, что у меня есть, скормить этой языковой модели? Мне вот Mistral-7B-Instruct-v0.2 подойдет? И да, желательно, чтобы он на русском отвечал.
>сама технология не раскрыта а только блаблабла воды налили
разумеется мы нихуя не получим.
всё, лавочка закрыта, ваши вайфу будут тупыми, политкорректными по западу и мерзкими прямо как мясные селёдки.
Ах ты хитрый жук, в такой постановке и не доебешься просто так.
Самый простой вариант - тебе нужна нормально настроенная таверна и бот в ней, тот же кодинг сенсей по дефолту подойдет. В идеале системный промт нужно подтюнить ибо связанное с ролплеем может отвлекать, кто-то такое вроде делал, подскажут.
>тебе нужна нормально настроенная таверна и бот в ней, тот же кодинг сенсей по дефолту подойдет.
Вообще не понял о чем ты.
>В идеале системный промт нужно подтюнить
А промт это разве не сам запрос? Или системный промт это какой параметр самой модели?
>Ах ты хитрый жук, в такой постановке и не доебешься просто так.
Ну, мог бы просто написать что я прав )
Прямо на том скриншоте же написано под alpha_value, что множитель для rope масштабирования, ставь 2.5 для увеличения контекста в два раза. Настраивается ли автоматом в убе, не знаю, сам юзаю кобольд.
Если в конфиге указано rope freq то оно подгрузится при выборе модели, такое обычно для моделей с большим контекстом по дефолту. Если нет то но насчет 2.5 не уверен, обычно было 2.65. Автоматом ничего не ставится.
> но насчет 2.5 не уверен, обычно было 2.65
2й пик в шапке если 4к базовый контекст, по нему подбирай.
>И да, желательно, чтобы он на русском отвечал.
Сайгу бери, она единственная в русский может, сайга 70В даже пристойно.
Это не мнение, это факт.
Это никак не зависит ни от моего мнения, ни от чужих.
Это то, как оно устроено, и как оно работает.
Так что, да, есть дурачки. Но это их проблемы. Не имей таких проблем, вот и все. =)
Первая фраза уже некорректна.
Либо ты до этого вопроса должен был дать определение этому слову, которое ты имеешь в виду, либо мы используем его значение в русском языке.
Понять: уяснить значение, познать, постигнуть.
Это действие, производимое субъектом самостоятельно.
Нейросети не способны задаться вопросом, познать, постигнуть, уяснить значение.
1. Они действуют лишь в качестве ответа на действие над ними.
2. Они не запоминают, статичны сами по себе.
Эти два пункта четко противоречат значению слова «понимание» в русском языке.
Это не «мнение», это логика и терминология.
Сорян. =)
А то, о чем говоришь ты — очень далеко от «понимания», тут совсем другой термин нужно подбирать. Но это твое дело, я спать.
Повторяю это всего лишь твое мнение, мнение не может быть фактом, просто ограниченная точка зрения отдельного человека
То что ты это не понимаешь твоя проблема, нашлась тут истина в последней инстанции лол
Подскажите, а зачем на 4 оп-пике 2 процессора на материнке?

>Логично, что 7б в русских умеет не шедеврально. =)
Я надеюсь постепенно добить до нормального понимания. Полирую 2b параметров из 7, постепенно становится лучше, но как же это долго, блядь. Плюс данные - машинный перевод, небольшое косноязычие останется пожизненно. Изначальные трейн данные были что-то уровня датасетов Гусева, парсинг разных пикабу с хабрами, что тоже ума модели не прибавляет.
> Полирую 2b параметров из 7
Что?
> парсинг разных пикабу с хабрами
Как-то их оформлял?
двухпроцессорная сборка на xeon просто у анона, к которой он и прицепить хочет ускорители
А разве нейронку можно одновременно запускать на процессоре и видюхе? Я думал только на чём-то одном.
Тут половина треда так делает. Но для такого не то чтобы есть большой смысл в нектродвухпроцессорной сборке.
Понятно, спасибо. Пойду перечитаю гайды.
Братик, но он так-то прав. Хотя ты, конечно, может точик какой с автоматом и без уха, и у тебя свой, особенный русский язык, тогда вопросов нет
Для самых тупых я там же дал объяснение тому термину и контексту в котором говорил. Ну видимо доебаться до определения это все на что хватило мозгов анона
Выпускай свой словарь альтернативного русского языка, тогда будет разговор, господин ты иностранный специалист
По факту есть что сказать? Нет, завали варежку
Ну или давай аргументируй аргументно в чем я не прав в своих рассуждениях
Только без детских доебок к терминам, окей?
Поменьше чсв паренек

>Что?
Что? На полноценный файнтюн не хватает памяти, точнее из-за странной работы hf библиотек память не распределяется, как мне бы хотелось бы, так что почему бы не сделать гигажирную лору. В fp32 весит 14 гигабайт.
Данные были как-то оформлены, но не очень качественно.
Посмотрел, как модель отвечает по дефолту. Ну такое себе.
Если rope freq само подгружается это означает что модель сама поддерживает длинный контекст, ничего трогать не нужно.
Если модель не поддерживает длинный контекст то нужно использовать alpha_value по той формуле Recommended values (NTKv1): 1.75 for 1.5x context, 2.5 for 2x context..
Бред не увеличивается от RoPe?
Алсо, неплохо было бы добавить это в шапку учитывая что некоторые модели все еще ограничиваются 4к.
> Сайгу бери, она единственная в русский может, сайга 70В даже пристойно.
Мне памяти для этого не хватит
ура, убабужный вебуй заработал на моем некроговне вместо проца с использование ртх, хоспаде благослови убабугу
>почему бы не сделать гигажирную лору
обучаешь локально? в чем? убабуге или аксолотль? почему лора в fp32 а не fp16?
>Мержинг таких моделей это просто контрольный в голову
не всегда, вот же неплохой https://huggingface.co/TeeZee/DarkForest-20B-v2.0
>Как выжать побольше воды из камня при помощи двух карандашей и крышки от пластиковой бутылки
чтож примерно так и подозревал, много развелось хитровыебанных "исследователей" в поисках гранта и финансирования, хотят быть как мистраль, но при этом вложиться в работу как условный икари дев))
Нужна лучшая модель для ассистента и для кодинга под 12 гигов памяти. Можете че-то посоветовать?
LLama Factory. Трейн на самом деле вообще в fp8, просто разжимается в процессе в 16 и 32.
>DarkForest-20B-v2.0
Вообще забавная штука. Половина всех весов от KatyTheCutie_EstopianMaid-13B, все остальные модели в сумме ещё столько же. Интересно было бы сравнить с ней, насколько лес умнее Кати и умнее ли, но лень.
Мнение фактом быть не может, но я не высказываю своего мнения, я сообщаю факт. И этот факт — не является моим мнением.
Хватит переворачивать понятия. =)
Тут не я истина в последней инстанции, тут банальный факт.
Ты тут единственный, кто не понимает простых вещей.
Но это сугубо твоя проблема, ладно.
Потому что он может. Собрал такую сборку.
Возможно там 8-канал или что-то такое, я точно уже не помню.
Ну ты… обладаешь удивительным терпением и упорством, уважение.
Можно, но там не в этом суть, само количество ядер процессора тебе сильно не поможет в большинстве случаев.
В начале ты написал хуйню.
Потом стал переобуваться и отмазываться.
Сам разговариваешь на своем выдуманном языке, подменяешь понятия, а тупыми называешь всех вокруг. =) Эх… классика. Дух нулевых годов и людей с айкью как у хлебушка.
Самое смешное, что тебе аргументированно ответили, тебе сказать на это оказалось нечего и ты сгорел. Буквально сам себя затроллил и полыхаешь теперь. )))
Продолжай, угарный ты наш.
Без AVX-инструкций, прямиком в видяху exl2?
Эт прям рандом. =)
Никто не против, что иногда получается хорошо.
Но в большинстве случаев — пропасть между натур.продуктом и вот этим.
Так бери мистраль-сайгу 7В
она в русский может потому что на openchat_3.5 сделана, хуле в шапку инфу не обновляют? может хватит уже говном мамонта кормить? Добавьте ту же опенчат как модель для русского языка отличную. И которая ебет ваши 13б 70б модели кстати.
На хаггинг фейсе есть она?
Попробовал сейчас Starling 7b. По русски понимает. Тестирую вместе с Mistral 7b 0.2
По ощущениям крутая.
По ощущениям крутая.
>хуле в шапку инфу не обновляют
Потому что не нужно. Опенчат пробовали и высрали тредов 20 назад, если не больше.
>Добавьте ту же опенчат как модель для русского языка отличную
Говноедством не занимаемся. Вот буквально сейчас самое глупое, что можно сделать, это общаться с локалками на языках, отличных от английского. Им и так тяжело, параметров катастрофически мало (даже на 70B), а тут ещё не родной для них язык. Даже если нейронка может выдавать грамматически верный текст, но смысла в нём немного.
>И которая ебет ваши 13б 70б модели кстати.
Коупер, спок.
Лору чтоли тренишь?
> Данные были как-то оформлены, но не очень качественно.
Завернул по примеру датасетов в инструкции/chatml, или просто плейнтекст?
> Бред не увеличивается от RoPe?
Увеличивается если крутануть сильно, х2 обычно не заметен вообще. Если судить по графикам перплексити, то оно может внести небольшой импакт на малых контекстах, так что для самоуспокоения можешь до заполнения 4к катать по дефолту а поднимать уже потом.
Двачую, только можно еще указать про битые конфиги в некоторых gguf
> Трейн на самом деле вообще в fp8, просто разжимается в процессе в 16 и 32.
Основная модель в фп8 загружена всмысле?
а ты кто такой чтобы решать нужно или не нужно? из за таких как ты развитие и останавливается, вахтер. Вот сейчас в тред пришел конкретно чел и спросил за русского помощника, и ему каличную сайгу советуют, это что за пиздец? Вы сами ее тестили? Нахуя людей в заблуждение вводите?
Говноедством как раз ты занимаешься решая что нужно и не нужно.
Я с помощью опенчата именно на русском языке зимнюю сессию сделал на 80% (математика информатика). И это было очень удобно. Это к вопросу о смыслах.
Тяжело им блять, очевидно что мультиязыковые модели лучше могут в обобщения и связи, и это доказывает опенчат на 7б, которая лучше работает чем твоя кривая сайга на 70б, именно на русском языке, я знаю о чем говорю потому что юзал их обе.
Надрачивание на кол-во параметров выдает в тебе неумеху коупера, этакого цыганина от мира ллм, которой главное чтоб бохато(много параметров) было, ну что ж иди надрачивай на арабское поделие фалькон 170б тогда хуле, это же ШЫДЕВР АИ по твоей логике?
> Я с помощью опенчата именно на русском языке зимнюю сессию сделал на 80% (математика информатика)
О, а покажешь примеров каких-то? Канеш
> математика и информатика
в сочетании с
> зимнюю сессию
звучит неебически рофлово (хотя хз что там у гуманитариев), но всеравно интересно посмотреть как та мелочь на сложном языке профильные вопросы отвечает.
> Надрачивание на кол-во параметров выдает в тебе неумеху коупера
Скорее ты его не понял и он несколько искушен, и потому негативно относится к твоему превозношению мелочи как йоба модели.
>а ты кто такой чтобы решать нужно или не нужно?
Анон, сидящий с первых тредов, раздававший на торрентах первую лламу, коммитивший в FlexGen, а что?
>из за таких как ты развитие и останавливается
Ну всё пиздец не внёс старую модель 5-ти месячной свежести в шапку. Люстрировать меня!
>и ему каличную сайгу советуют, это что за пиздец?
Согласен, упоминание сайги вообще надо забанить, увы, за десятки версий её автор так и не научился в файнтюн, вон, безымянный анон выше выдаёт результат лучше
>Я с помощью опенчата именно на русском языке зимнюю сессию сделал на 80%
Лол, уровень твоей шарашки неимаджинируем.
>очевидно что мультиязыковые модели лучше могут в обобщения и связи
Не спорю. Но сколько ни дрочи, а производительность любой модели на английском лучше. Даже GPT4 и Claude3 сосут в русеке, хоть уже и не так сильно.
>опенчат на 7б, которая лучше работает чем твоя кривая сайга на 70б
Чел, я сайгу никогда не предлагал. И да, то, что опенчат лучше, доказывает только то, что сайга на 70B это кривая подделка на коленке.
>Надрачивание на кол-во параметров выдает в тебе неумеху коупера
Перевод стрелок не засчитан.
Это обладатели малых компьютерных ресурсов коупят на 7B, раз за разом побеждая GPT3,5-turbo в каждом первом тесте. Я же прекрасно катал все размеры от 410M до 120B, и прекрасно знаю импакт от размера.
Конечно можно и в 176B сделать хуйню, как например с OPT от террористов, но мы тут сравниваем модели на одной базе, и в одной линейке моделей чем больше, тем лучше.
>фалькон 170б
180B, неуч.
Все ссылки в треде:
Челы, старый опенчат и свежий из этого года - совсем разные модели.
> Люстрировать меня!
Ну вообще неплохо бы чуть подсократить шапку с учетом вынесенного на вики и поправить в конце для таверны.
> обладатели малых компьютерных ресурсов коупят на 7B
Они 70+ все испробовали, а значит мнение объективно, зря ты так!

Уговорил, потестил... Ожидаемо хуёво. Ведь знал же, что это коупинг, и всё равно попробовал. Вот так всегда.
>Ну вообще неплохо бы чуть подсократить шапку
С одной стороны да, с другой вики пару раз уже падала, а совсем без инструкций туго.
ты для себя открой, что существует еще заочное обучение, да я работаю, и мне удобно, что зимняя сессия проходит дистанционно.
Да опенчат по теории алгоритмов писала для меня доклад, по теме сложность алгоритмов. Тебе рассказать как выглядит процесс? Она тебе расписывает изначально по пунктам доклад, а потом просишь каждый подробно расписать, с небольшими ошибками (грамматическими 5%) правишь и готово. Тоже самое и Теории функций действительного переменного.
По языкам и методам программирования она отлично умеет кодить в питон и с++ с комментами и пояснениями( 3 курс если что). Да проверять надо, иногда может высрать и херню но это легко через гугл эвейдится.
Далее она и по физкультуре мне написала доклад, где нужно было придумать комплекс упражнений (расписать кол-во подходов, периодичность, полезность, правила и тд)
>>Анон, сидящий с первых тредов, раздававший на торрентах первую лламу,
Видимо в тебе ЧСВ говорит, раз ты так противишься прогрессу 7б моделей. Тебе вот другой уже анон заявляет что опенчат развивается, но ты сиди дальше в своем мирке этакой илитарности только англоязычных моделей 70б+.
Конечно я понимаю что кол-во параметров играет главную роль, но и нельзя отрицать, что область только зарождается, и есть подходы значительно улучшающие результаты даже на 7б моделях.
Вот я заходил в этот тред месяца три назад, спрашивал про нормальную модель для русского языка, потому что в шапке буквально НОЛЬ информации об этом, в итоге мы выясняем что тут проблема в твоих каких то личностных оценках, поэтому в итоге полезную инфу я нашел на хабре а не здесь.
и да сессию я делал не на квантизированной модели если что
(я работал на фп16 модели, скачал ггуф8 для теста, и да разница есть, гораздо чаще в бред скатывается почему то)
ну вот на моей фп16 модели такое выдает, при том что юмор в принципе для нейросетей не подъемен. Давай покажи мне как твоя любимая 70б модель на русском нормально шутит на эту же тему? Что нету? Значит вся шапка треда говно? И вообще все нейросети по твоей логике хуевые?

картинку забыл
>раз ты так противишься прогрессу 7б моделей
Рекомендую тебе перестать бороться с образами в твоей голове.
>Тебе вот другой уже анон заявляет что опенчат развивается
Так кто бы спорил! Прогресс на лицо. Только всё равно хуже полновесных моделей, да.
>но ты сиди дальше в своем мирке этакой илитарности только англоязычных моделей 70б+
В общем-то так и делаю.
>Конечно я понимаю что кол-во параметров играет главную роль, но и нельзя отрицать, что область только зарождается, и есть подходы значительно улучшающие результаты даже на 7б моделях.
Ну да, меня вот печалит, что куча народа вкладывает кучу сил в 7B огрызки вместо того, чтобы вместе натрейнить 70B. В итоге прогресс в 7B большой, но в силу малого размера они всё равно туповатые. А в 70B классе есть застой, и разрыв между 7B и 70B сокращается. Но не потому что 7B такие охуенные, а потому что 70B мало занимаются. Ну ты понял суть.
>спрашивал про нормальную модель для русского языка
Закрытые GPT4 и Claude3, офк. Опенсорс на русском это боль, вот пруф
>с небольшими ошибками (грамматическими 5%) правишь
Вот это интересная информация, лучше бы сравнений напилил на одном промте и сидах, а то ведь по всем этим вашим перплексиям разницы там 0,00001%.
>И вообще все нейросети по твоей логике хуевые?
Ты не поверишь, но да, я всё ещё лучше любой нейросети в любом вопросе (офк я с гуглом).
Вот старая добрая мику. Как всегда с префилом, без него отказ.
Побольше скобочек, а то не всем понятно что у тебя жопа горит от того что по факту сказать нечего
Так хочется доказать свою правоту и нечего сказать?
Делай как этот анон и используй такие же приемчики
Сказать нечего и начинает как уж изворачиваться придумывая всякую хуету
Иди ка ты нахуй чсв дурачек со своим близоруким мнением
Так как на нормальное обсуждение ты видимо не способен
> ты для себя открой, что существует еще заочное обучение
Там перечень предметов аналогичен, а не повторяет школьную программу, потому и удивили названия, особенно на 3м курсе.
> Тебе рассказать как выглядит процесс?
Лучше покажи что-то конкретное.
> противишься прогрессу 7б моделей
Волна этого прогресса с непревзойденными победами уже была, и это печально. Копиум оттягивает на себя все внимание и ресурсы, которые могли бы пойти на что-то полезное, а на выходе лишь уныние, которое может впечатлять неофитов или ограниченных.
> Давай покажи мне как твоя любимая 70б модель на русском нормально шутит на эту же тему?
Если это "нормальная шутка" то довольно символично.
А истории про всякие манипуляции с неграми с применением холодного, огнестрельного оружия, взрывчатки и прочего можешь найти в прошлых тредах.
>Анон, сидящий с первых тредов, раздававший на торрентах первую лламу, коммитивший в FlexGen, а что?
Корона не жмет? Угораю с местных вахтеров. То что ты когда то сделал что то полезное не делает тебя кем то важным, прикинь. Я тоже сижу тут с начала слива первой лламы, и че теперь?
Шапку не меняют так как анону поебать на нее, даже если там инфа устаревшая несколько раз подряд или не актуальная.
>>Ну да, меня вот печалит, что куча народа вкладывает кучу сил в 7B огрызки вместо того, чтобы вместе натрейнить 70B
Так в том то и суть ЛОКАЛЬНЫХ моделей что их можно запускать на потребительском железе. Это дает огромную аудиторию энтузиастов и свободу от каких либо правил и ограничений. Таким образом sd развивался и благодаря именно им мы имеем сейчас огромный прогресс в генерации изображений. Что поделать если 70б модели в плане файнтюнинга доступны лишь единицам? Работать с 7б моделями, искать способы их улучшения с помощью костылей, оптимизировать. Это развитие которое приносит результаты здесь и сейчас, и эти результаты можно экстраполировать и на более крупные модели (с развитием консьюмерского железа офкос).
Ты предлагаешь сидеть и ждать технического прогресса, игнорируя прогресс в моделях 7б (кстати минимально необходимое кол-во параметров для разных задач тоже спорный вопрос), а я предлагаю развивать уже сейчас и использовать то что уже сейчас возможно (7б - 13б)
Короче добавь в шапку опенчат, как лучший на данный момент помощник на русском языке, и, что не мало важно, с возможностью реального применения в помощи по кодингу.
Опенчат или старлинг на его основе? Я если что не оп. Просто интересно что лучше. Я новый старлинг щупал, а вот опенчат с которого его сделали нет
Пиздец соя.
Ни ссылки не добавил в шапку, ни кванты новые, ни модели годные. До сих пор висят занимая место старые и никому не нужные как говно мамонта пигмалион и мпт, новых моделей базовых так же нет, а они выходили.
Нахуй короче, больше не буду ниче предлагать или кидать ссылки. Это видимо никому уже не нужно, оставлю годноту себе ухух
Нахуй короче, больше не буду ниче предлагать или кидать ссылки. Это видимо никому уже не нужно, оставлю годноту себе ухух
> Так в том то и суть ЛОКАЛЬНЫХ моделей что их можно запускать на потребительском железе.
Тыскозал? Их суть в наличии открытых весов и возможности пускать где хочешь как хочешь, все.
Вместо радости за прогресс, новые возможности и прочее - начинается специальная олимпиада, где братишки отождествляют себя с моделями, которые запускают(!), а потом искренне обижаются на объективную критику в их сторону, устраивают круговой надроч с победами и постулируют что все остальное - ненужно.
Глубинная причина как всегда одна, вот только реализовываться нужно не через запуск ллм и стремиться к лучшему а не сохранению положения, тогда сразу отпустит.
> лучший на данный момент помощник на русском языке
Сколько постов срача уже который день, а примеры хоть будут?
>Лору чтоли тренишь?
Да. И говорю же, памяти мало, так что fp8. Я бы ещё батчайз поднял, но всё довольно печально и так. Вот бы пару 4090, лол.
https://huggingface.co/bartowski/Starling-LM-7B-beta-GGUF
попробуй вот эту, на сколько помню она файнтюн того что ты скинул. Годная штука. Формат чатмл. По русски шпарит, но лучше хуже не знаю, сам сравнивай.
> И говорю же, памяти мало, так что fp8
Да без претензий если что.
> Вот бы пару 4090, лол.
Как тренить предлагаешь?
Алсо недавно статью про новый оптимайзер скидывали, не смотрел? Файнтюн 7б на 24гб обещают. И с дипспидом неплохо бы разобраться, он позволяет большую часть данных оптимайзера сгрузить в рам.
еще раз глазки свои подними и прочитай название треда. Тут у нас анон с ЧСВ решил что 7б модели нинужны, поэтому у нас в шапке старое бесполезное говно.
Еще спорить будешь? По поводу опенчата и его возможностей я уже приводил пример как сдавал сессию,именно на русском языке. Может у тебя есть контр примеры на какой то другой модели? Желательно 7б, чтобы любой анон могу запустить. Ну можешь и 70б локально запущенную показать, ладно, с такой же связностью на русском, ждемс. вот шутку про негров без префилеров тоже ждемс.
Введение
В данной работе рассматриваются основные аспекты изучения временной сложности алгоритмов с учетом двух главных критериев – полиномиальной и экспоненциальной сложностей.
Определения и понятия
Алгоритм - это последовательность действий или правил, которые используется для достижения определенной цели. В этом контексте алгоритмы часто представляют собой процесс обработки данных или решения задач.
Временная сложность алгоритма - это количество времени, затрачиваемое на выполнение алгоритма в качестве функции от размера входных данных. Эта величина характеризует эффективность алгоритма в отношении времени его исполнения.
Полиномиальная сложность - это время выполнения алгоритма, которое растет не быстрее чем к кубу размера входных данных. Это означает, что заданный алгоритм может обрабатывать данные размером до нескольких тысяч элементов за достаточно короткое время. Однако с ростом размера входных данных время работы алгоритма будет расти существенно медленнее, чем в случае экспоненциальной сложности.
Экспоненциальная сложность - это время выполнения алгоритма, которое растет значительно быстрее, чем к степени размерности входных данных. Такие алгоритмы могут работать с очень большим объемом данных, но их производительность резко падает с ростом размера входных данных. На практике такое поведение может привести к зависаниям программы или долгим задержкам при обработке данных.
Каждая из этих двух критериев - полиномиальной и экспоненциальной сложностей - имеет свои преимущества и недостатки, и выбор оптимального алгоритма для конкретной задачи зависит от её требований к времени и пространству. Комплексное исследование временной сложности алгоритма поможет оценить его эффективность и выбрать наиболее подходящий подход для решения данной задачи.
Методы определения временной сложности
Для определения временной сложности алгоритма могут использоваться следующие методы: анализ алгоритма с использованием математических формул; проверка на практике через симуляцию или реализацию алгоритма в программном коде; применение стандартных тестов временной сложности, таких как Big O Notation.
Первый способ – анализ алгоритма с использованием математических формул – предполагает формальную оценку времени, затрачиваемого на выполнение алгоритма. Для этого необходимо рассмотреть все операции алгоритма и связанные с ними затраты времени. Затем, на основе полученной информации, необходимо построить функцию, которая описывает влияние размера входных данных на время выполнения алгоритма. Результатом такого анализа является числовая оценка временной сложности алгоритма, выраженная в терминах функций сложности, таких как O(n), O(log n) или O(n^3).
Второй способ – проверка на практике через симуляцию или реализацию алгортима в программном коде – предполагает наглядно видеть, как алгоритм работает на различных наборах данных. Для этого необходимо создать программу, которая реализует данный алгоритм и замеряет время его работы на различных наборах данных разного размера. Результатом такой проверки являются конкретные значения времени выполнения алгоритма на различных наборах данных, которые можно сравнить с теоретическими оценками временной сложности, полученными методом анализа математических формул.
Третий способ – применение стандартных тестов временной сложности, таких как Big O Notation – представляет собой упрощенный подход к оценке временной сложности алгоритмов. В этом методе используется общая характеристика сложности алгоритма, выраженная в терминах функций сложности, таких как O(n), O(log n) или O(n^3). Эта характеристика позволяет сравнивать алгоритмы между собой и выбирать наиболее эффективный вариант для решения конкретной задачи. Однако стоит учесть, что данный метод дает лишь общую картину временной сложности алгоритма и не учитывает многие детали, которые могут влиять на его работу.
В целом, методы определения временной сложности алгоритмов включают как формальные аналитические подходы, так и практические проверки на реальных данных, что позволяет получить более полную и точную оценку их производительности. Выбор наиболее подходящего метода зависит от конкретных задач и требований к точности оценки временной сложности.
Примеры алгоритмов с разными типами сложностей
Алгоритм вставки в список - это полиномиально-сложный алгоритм. Он добавляет новый элемент в правильное место внутри списка, перемещая другие элементы, если они находятся перед этим элементом. Сложность алгоритма растет вместе с квадратом размера списка, т.е. O(n^2).
Алгоритм удаления элемента из списка также имеет полиномиальную сложность, поскольку он должен перемещать остальные элементы после удаляемого элемента влево. Сложность алгоритма растет вместе с квадратом размера списка, т.е. O(n^2).
Сортировка пузырьком - это полиномиально-сложный алгоритм. Он использует сравнение каждого элемента со всеми остальными элементами в списке и меняет их местами, если они находятся в неправильном порядке. Сложность алгоритма растет вместе с кубом размера списка, т.е. O(n^3).
Быстрая сортировка - это алгоритм с экспоненциальной сложностью. Он использует рекурсивный подход и делит список на две части, сортируя каждую часть независимо друг от друга. Затем результаты двух частей объединяются обратно в один список. Сложность алгоритма растет экспоненциально с ростом размера списка, но этот алгоритм работает очень эффективно на больших наборах данных, где время обработки является менее значимым фактором.
Бинарный поиск - это алгоритм с экспоненциальной сложностью. Он использует двоичное дерево поиска и делит список на две половинки, пока найденный элемент не будет находиться в одной из них. Сложность алгоритма растет экпоненциально с ростом размера списка, но этот алгоритм работает очень эффективно на больших наборах данных, где количество элементов известно заранее.
Таким образом, приведённые примеры алгоритмов иллюстрируют различия между полиномиальной и экспоненциальной сложностями и помогают выбрать наиболее подходящий подход для решения заданной задачи. В заключение следует подчеркнуть важность оптимизации кода и использования специализированных структур данных для повышения производительности программного обеспечения.
Заключение
Изучение временной сложности алгоритмов является важным аспектом компьютерного дизайна и разработки программного обеспечения. Различия между полиномиальной и экспоненциальной сложностями помогают выбрать наиболее эффективные методы решения задач.
Положительная сторона полиномиальной сложности заключается в том, что такие алгоритмы могут обрабатывать достаточно большие наборы данных за достаточно короткое время. Однако с ростом размера входных данных время работы полиномиальных алгоритмов может существенно возрастать, что может быть проблемным в случаях, когда требуется обработать очень большое количество данных или необходимо быстрое решение задачи.
Отрицательная сторона полиномиальной сложности заключается в том, что такие алгоритмы могут быть ограничены своей производительностью при обработке очень больших наборов данных, которые могут возникнуть в современных информационных системах и приложениях.
С другой стороны, экспоненциальная сложность характеризуется более высокой производительностью при обработке очень больших наборов данных, однако с ростом размера входных данных время работы экспоненциальных алгоритмов может существенно возрастать, что может привести к задержкам и зависаниям программы.
Минусом экспоненциальной сложности является то, что такие алгоритмы могут быть ограничены своей производительностью при обработке очень маленьких наборов данных, что может быть неприемлемо для многих современных информационных систем и приложений.
Блять я поборол даже свою лень и нашел реферат который мне опенчат писал(не весь, длина сообщения ограничена). Да мне поставили за него 4. Вопросы?
Вахтер оп все так же будет упираться в нинужности опенчата?
В данной работе рассматриваются основные аспекты изучения временной сложности алгоритмов с учетом двух главных критериев – полиномиальной и экспоненциальной сложностей.
Определения и понятия
Алгоритм - это последовательность действий или правил, которые используется для достижения определенной цели. В этом контексте алгоритмы часто представляют собой процесс обработки данных или решения задач.
Временная сложность алгоритма - это количество времени, затрачиваемое на выполнение алгоритма в качестве функции от размера входных данных. Эта величина характеризует эффективность алгоритма в отношении времени его исполнения.
Полиномиальная сложность - это время выполнения алгоритма, которое растет не быстрее чем к кубу размера входных данных. Это означает, что заданный алгоритм может обрабатывать данные размером до нескольких тысяч элементов за достаточно короткое время. Однако с ростом размера входных данных время работы алгоритма будет расти существенно медленнее, чем в случае экспоненциальной сложности.
Экспоненциальная сложность - это время выполнения алгоритма, которое растет значительно быстрее, чем к степени размерности входных данных. Такие алгоритмы могут работать с очень большим объемом данных, но их производительность резко падает с ростом размера входных данных. На практике такое поведение может привести к зависаниям программы или долгим задержкам при обработке данных.
Каждая из этих двух критериев - полиномиальной и экспоненциальной сложностей - имеет свои преимущества и недостатки, и выбор оптимального алгоритма для конкретной задачи зависит от её требований к времени и пространству. Комплексное исследование временной сложности алгоритма поможет оценить его эффективность и выбрать наиболее подходящий подход для решения данной задачи.
Методы определения временной сложности
Для определения временной сложности алгоритма могут использоваться следующие методы: анализ алгоритма с использованием математических формул; проверка на практике через симуляцию или реализацию алгоритма в программном коде; применение стандартных тестов временной сложности, таких как Big O Notation.
Первый способ – анализ алгоритма с использованием математических формул – предполагает формальную оценку времени, затрачиваемого на выполнение алгоритма. Для этого необходимо рассмотреть все операции алгоритма и связанные с ними затраты времени. Затем, на основе полученной информации, необходимо построить функцию, которая описывает влияние размера входных данных на время выполнения алгоритма. Результатом такого анализа является числовая оценка временной сложности алгоритма, выраженная в терминах функций сложности, таких как O(n), O(log n) или O(n^3).
Второй способ – проверка на практике через симуляцию или реализацию алгортима в программном коде – предполагает наглядно видеть, как алгоритм работает на различных наборах данных. Для этого необходимо создать программу, которая реализует данный алгоритм и замеряет время его работы на различных наборах данных разного размера. Результатом такой проверки являются конкретные значения времени выполнения алгоритма на различных наборах данных, которые можно сравнить с теоретическими оценками временной сложности, полученными методом анализа математических формул.
Третий способ – применение стандартных тестов временной сложности, таких как Big O Notation – представляет собой упрощенный подход к оценке временной сложности алгоритмов. В этом методе используется общая характеристика сложности алгоритма, выраженная в терминах функций сложности, таких как O(n), O(log n) или O(n^3). Эта характеристика позволяет сравнивать алгоритмы между собой и выбирать наиболее эффективный вариант для решения конкретной задачи. Однако стоит учесть, что данный метод дает лишь общую картину временной сложности алгоритма и не учитывает многие детали, которые могут влиять на его работу.
В целом, методы определения временной сложности алгоритмов включают как формальные аналитические подходы, так и практические проверки на реальных данных, что позволяет получить более полную и точную оценку их производительности. Выбор наиболее подходящего метода зависит от конкретных задач и требований к точности оценки временной сложности.
Примеры алгоритмов с разными типами сложностей
Алгоритм вставки в список - это полиномиально-сложный алгоритм. Он добавляет новый элемент в правильное место внутри списка, перемещая другие элементы, если они находятся перед этим элементом. Сложность алгоритма растет вместе с квадратом размера списка, т.е. O(n^2).
Алгоритм удаления элемента из списка также имеет полиномиальную сложность, поскольку он должен перемещать остальные элементы после удаляемого элемента влево. Сложность алгоритма растет вместе с квадратом размера списка, т.е. O(n^2).
Сортировка пузырьком - это полиномиально-сложный алгоритм. Он использует сравнение каждого элемента со всеми остальными элементами в списке и меняет их местами, если они находятся в неправильном порядке. Сложность алгоритма растет вместе с кубом размера списка, т.е. O(n^3).
Быстрая сортировка - это алгоритм с экспоненциальной сложностью. Он использует рекурсивный подход и делит список на две части, сортируя каждую часть независимо друг от друга. Затем результаты двух частей объединяются обратно в один список. Сложность алгоритма растет экспоненциально с ростом размера списка, но этот алгоритм работает очень эффективно на больших наборах данных, где время обработки является менее значимым фактором.
Бинарный поиск - это алгоритм с экспоненциальной сложностью. Он использует двоичное дерево поиска и делит список на две половинки, пока найденный элемент не будет находиться в одной из них. Сложность алгоритма растет экпоненциально с ростом размера списка, но этот алгоритм работает очень эффективно на больших наборах данных, где количество элементов известно заранее.
Таким образом, приведённые примеры алгоритмов иллюстрируют различия между полиномиальной и экспоненциальной сложностями и помогают выбрать наиболее подходящий подход для решения заданной задачи. В заключение следует подчеркнуть важность оптимизации кода и использования специализированных структур данных для повышения производительности программного обеспечения.
Заключение
Изучение временной сложности алгоритмов является важным аспектом компьютерного дизайна и разработки программного обеспечения. Различия между полиномиальной и экспоненциальной сложностями помогают выбрать наиболее эффективные методы решения задач.
Положительная сторона полиномиальной сложности заключается в том, что такие алгоритмы могут обрабатывать достаточно большие наборы данных за достаточно короткое время. Однако с ростом размера входных данных время работы полиномиальных алгоритмов может существенно возрастать, что может быть проблемным в случаях, когда требуется обработать очень большое количество данных или необходимо быстрое решение задачи.
Отрицательная сторона полиномиальной сложности заключается в том, что такие алгоритмы могут быть ограничены своей производительностью при обработке очень больших наборов данных, которые могут возникнуть в современных информационных системах и приложениях.
С другой стороны, экспоненциальная сложность характеризуется более высокой производительностью при обработке очень больших наборов данных, однако с ростом размера входных данных время работы экспоненциальных алгоритмов может существенно возрастать, что может привести к задержкам и зависаниям программы.
Минусом экспоненциальной сложности является то, что такие алгоритмы могут быть ограничены своей производительностью при обработке очень маленьких наборов данных, что может быть неприемлемо для многих современных информационных систем и приложений.
Блять я поборол даже свою лень и нашел реферат который мне опенчат писал(не весь, длина сообщения ограничена). Да мне поставили за него 4. Вопросы?
Вахтер оп все так же будет упираться в нинужности опенчата?
Спокойнее будь на тебя никто не нападает, а со стороны у вас просто недопонимание и накручивание которое не сделает мелкие веса умнее фьют ха!.
Даже 3б и меньше нужны, тут и вопросов быть не может. Ты лучше покажи что тот опенчат может.
> вот шутку про негров без префилеров тоже ждемс
Рофлишь или серьезно? С каких пор это считается крутым достижением?
> Ну можешь и 70б локально запущенную показать
120б локально запущенную показывал и ее русский, врядли у мелочи будет какой-то шанс.
chatgpt/10, приходи не пересдачу!
Ну серьезно, отборная нейронная вода, которую сложно читать, без полезного содержимого. Буквально в любой конец мотаешь и видишь треш
> Положительная сторона полиномиальной сложности заключается в том, что такие алгоритмы могут обрабатывать достаточно большие наборы данных за достаточно короткое время. Однако с ростом размера входных данных время работы полиномиальных алгоритмов может существенно возрастать, что может быть проблемным в случаях, когда требуется обработать очень большое количество данных или необходимо быстрое решение задачи.
> С другой стороны, экспоненциальная сложность характеризуется более высокой производительностью при обработке очень больших наборов данных, однако с ростом размера входных данных время работы экспоненциальных алгоритмов может существенно возрастать, что может привести к задержкам и зависаниям программы.
Так что тебе очень повезло, или твой вуз неочень.
Офк сама возможность писать текст на русском это уже круто и год назад такого не было. Вот только это буквально прямая иллюстрация копиумности 7б, когда она лишь валит малосвязанные повторяющие простыни по мотивам, а не содежательное-интересное, действительно дежавю с рп на 7б.
Так такое говно высерает любой рп-кал. У 70В ещё шизоиднее простыни будут, потому что контекст говно с памятью как у рыбки.
> Аутотренинг не сделает твою модель лучше и не позволит тебе запускать модели белых людей
Sad but true
Херня работа. Тут имея таблицу можно сократить раза в 4.
>модели белых людей
Такие же тупые? разница между 7b и 70b не так высока как ты себе навоображал хех
И вобще, включайте голову наконец, он пишет не о рп сетке
Просто сетка как чат бот для какой то генерации информации по довольно общим темам с достаточным для понимания русским
Докумились в конец дрочеры, раз все по рп-ерп оцениваете
Хуя пичот. Ну рили с этого только рофлить остается, хз при чем тут рп или не рп. Братишка словил утенка с какой-то модели, и теперь вайнит что ее отказываются ставить на пьедестал лучшей из лучших, а под это не обремененные железом встрепенулись и начали затирать про то что хорошо а что плохо. Или это один и тот же человек, не важно.
У нас опенчат экстрактит из произвольных документов сущности и ключевые слова в структурированный json.
Я считаю что сегодня первичная роль LLM - это клей в преобразовании неструктурированных данных в структурированные. Логики тут много не надо, эрудиция даже лишняя. А возможности существующих информационных систем это расширяет в разы. Сегодня даже этот потенцивал не раскрыт на 1/10.
120б локально запущенную показывал и ее русский, врядли у мелочи будет какой-то шанс.
сколько ждал вывод одного предложения?
я вайню от устаревшей шапки. Любой мимо анон найдет больше полезной и практичной инфа на хабре и любом другом источнике, а здесь именно что загон для утят с их 7б нинужно.
А ведь я на реальном примере показал нужность модели, и да это такая же "какая то модель" как и ваши фальконы и другой нинужный кал который есть в шапке, но которая имеет реальную пользу для анона.
>120б локально запущенную показывал и ее русский, врядли у мелочи будет какой-то шанс.
сколько времени ждал вывод одного предложения?
Ну дак ты почитай их переписку умник
Один пишет - мне норм сетка хороша в русском достаточно что бы я мог сдать тесты, указывает на ее ошибки и минусы, и спрашивает почему подобных сеток нет в шапке.
Не как топовых сеток, а просто 7b которая может в русский как чат бот и даже полезна
Тут же вылезли или вылез дурачек что начал спорить что ниче она в русский не может, пишет не так красиво, сравнивает ее с рп и тд, и вобще ты бамжара раз не можешь крутить 70b как белые люди с 1 т/с лел
Ну и какой вывод из всего этого?
Чувак прав, в шапке не хватает одной-двух строчек с просто списком сеток на русском.
Что скажет оп? Не, не надо. Я ж заранее знаю лол
Тут шизики сидят, после смерти CAI всё это говно сюда притекло. Ты посмотри хотя бы как тут оценивают адекватность моделей, какой-то "кум" и "рп", как будто с душевнобольными разговариваешь, неспособными объяснить свои мысли.
>Как тренить предлагаешь?
Зеро-3 и понеслась. Без дипспида толком ничего не сделаешь на самом деле. Трансформерсы тупо дублируют все состояния оптимизатора на все гпу и нет разницы, один он у тебя или сотня. Если в одну карту модель вместе со всеми оптимизациями и градиентами не влезла - то соснёшь.
Новый оптимайзер смотрел, там неделя на 4090, а её у меня нет. Карты, в смысле. Неделя-то найдётся.
Дипспид да, выгрузка в рам это зеро-2 офлоад и через ллама фэктори можно это всё запускать. Плохо, что множество опций фабрики не вынесено в интерфейс и всё только консолькой с конфигами. Но куда деваться.
Если четко делает то это довольно таки неплохо. С таким yi-образные хорошо справляются вообще, причем четко понимают обстракции и соображают, но вот мистраль вяло. Надо будет офк попробовать и новый опенчат, но судя по бредогенератору, больших надежд не стоит питать.
Про раскрытие потанцевала согласен, но пути не то чтобы те.
Не так быстро как хотелось бы, но достаточно для реалтайм чата.
Ну тут справидливо наверно, но лучше оставить моделесрач а давать конкретные предложения.
> больше полезной и практичной инфа на хабре и любом другом источнике
Да ладно, и какой же? Как весной 2д24го года запускать 7б сайгу?
Так у них первая мысль ролеплей или эротический ролеплей, кумеры
Поэтому и оценивают 7b с этой точки зрения, потому что 7b не хватает мозгов на нормальный отыгрыш, слишком мало у нее слоев для таких глубоких абстракций и кучи инструкций.
Но помимо рп ерп есть и просто использование сетки в предусмотренном разрабами режиме, и тут 7b внезапно нормальные такие чат боты, хоть и туповатые, да.
Или делать какой то код, или писать регексы, или обучать кодингу, или отвечать на тупые вопросы. Да хоть в раг сувать для извлечения инфы по работе.
>Тут у нас анон с ЧСВ решил что 7б модели нинужны
? Я лишь утверждал, что они говно (по сравнению с более крупными моделями).
Просто нужно быть честным с собой и понимать, что 7B катают не от хорошей жизни, а от недостатка ресурсов.
>потому что контекст говно
Эм, 8-16к хватит каждому.
>Докумились в конец дрочеры, раз все по рп-ерп оцениваете
Так дроч это одно из самых разумных использований локалок. Если мне нужно будет покодать, я в GPT4 пойду, он всё таки умнее.
>я вайню от устаревшей шапки.
Кидай конкретные предложения.
>Я ж заранее знаю лол
Ну да. Смысл на русском? Я просто не понимаю, зачем катать локалки на русском. Лучше же на английском и перевести, качественнее будет, контекста больше доступно.
да и в рп может(опять же в определенных задачах), я игру потихоньку делаю, если терпения хватит, по принципу CAULDRON WITCh, то есть ты даешь различные эликсиры различным персонажами с их проблемами, и сеточка вполне нормально описывает события.
Например приходит крестьянин, ему нужно вернуть жену, а ты даешь ему зелье силы, и сеточка неплохо расписывает результат с учетом зелья (в жанре черной комедии), дает оценку этой истории ( - или + и 0 до 10) что нужно для игровой составляющей.
Получается любой анон сможет поиграть в эту игру, так как ггуф версия опенчата 7гигов. Далее новый оптимайзер выкатили я смогу на своей 4090 подфайнтюнить ее под эту игру. Опять же это развитие именно 7б сеток, что ОП игнорит в своем утятстве.
>Ну да. Смысл на русском? Я просто не понимаю, зачем катать локалки на русском. Лучше же на английском и перевести, качественнее будет, контекста больше доступно.
Хочу. И вот анон хочет. И еще кто то всегда приходит и спрашивает первым делом русский.
Ты не по своим только хотелкам смотри. Нравится может мне на русском их катать, даже если они тупее от этого и контекст жрет. Хотя с текущими размерами на него похрен, мы уже не год назад с 2к контекста все таки.
Что несешь? Но (е)рп это действительно главная задача сетки для нормиса, и 7б страдают от нехватки вниманий для понимания абстракций и прочего, и проявляется это как раз далеко не только в рп, в том и вся проблема. Есть и задачи где их большее чем хватит, непонятно зачем их так превозносить.
Да ладно, не смотря на техническую направленность доски, немалая доля здесь инглиш знает плохо и постоянно лезут вопросы о том "как на русском". Кому-то, опять же, просто может нравиться пользоваться на великом-могучем, так что вопрос актуален. Кмк, нужно прямо расписать текущее положение, что но большинстве сеток (в т.ч. гопоте) это приведет к деградации и затупам, есть несколько мультиязычных моделей, они не блещут умом, но могут подойти для чего-то. И по переводу таверны.
>Кидай конкретные предложения.
1) каждый отписывается какой стек использует, какие техи, либы, запускалки, морды, модели и прочие костыли, считает нужным упомянуть
2) пилите опрос с мультиселектом в котором будут перечислены что назвали
3) что выйдет в топ - рапсиываем в шапку
>Но (е)рп это действительно главная задача сетки для нормиса
Ну, ты по себе то всех не равняй окей? 7b были тупыми, год назад, и даже пол года. Сейчас они гораздо лучше, да они все еще тупее остальных, но дадут за щеку старым 30b которыми все так восхищялись в начале. И че теперь?
К тому же дело в однобокой оценке моделей.
>И еще кто то всегда приходит и спрашивает первым делом русский.
Так то от незнания проблем и ограничений. Вкатуны не знают, как работает токенизация, какой процент материала на русском у нейросеточек в датасетах и прочее. Для них это магия, и нейросети по их мнению прекрасно отвечают на любом языке.
>немалая доля здесь инглиш знает плохо
Ну так и я знаю плохо, лол. Пишу через переводчик всегда, на чтение иногда напрямую читаю.
>пилите опрос с мультиселектом
У нас тут уже перекат на носу, некогда. А то будет ещё один тред без русека в шапке, человек ещё целый тред вонять будет.
>Ну, ты по себе то всех не равняй окей?
Ну вот я тоже для урп гоняю.
Опций в целом немного, но просто перечислить используемые модели можно с краткой характеристикой, будет полезно.
По опросу же - какой в нем смысл? Там должна быть универсальная, умная и легковесная модель, которая запустится у неофита, будет толерантна к формату промта. Плюс, которая сможет и ответить на что-то, и отыграть персонажа. Фроствинд все это умеет.
Возможность писать на русском - плюс, но не самый весомый критерий, если тот опенчат превзойдет полугодовалую модель - вперед, но это видится маловероятным. Упомянуть его в качестве мелкой модели что может в русский - почему бы и нет.
> 7b были тупыми, год назад, и даже пол года
> Сейчас они гораздо лучше
Революцию принес мистраль, дальше только вялое копошение, объективно. Прувмивронг.
> дадут за щеку старым 30b
Ну не, они залупятся на месте или начнут спамить малосвязанную воду. Чудес не бывает, увы.
Не удивлюсь что обладатели отсутствия, неистово воюющие за превосходство 7б, испытывающие страх перед питоном, тащащие конспирологические теории и адепты agi - одни и те же люди. Треду нужен мем, который бы это обыгрывал.
>>Кидай конкретные предложения.
я уже писал выше, добавить -
опенчат быстрая нетребовательную модель которая может в русский, может в кодинг, может в помощью в учебе (написание рефератов, решение тестов реалтайм и тд)
OpenChat - это инновационная библиотека языковых моделей с открытым исходным кодом, доработанная с помощью C-RLFT - стратегии, вдохновленной автономным обучением с подкреплением. Обучается на данных смешанного качества без меток предпочтений, обеспечивая исключительную производительность наравне с ChatGPT, даже с моделью 7B."
> в однобокой оценке моделей
И ебать, о какой однобокой оценке вообще идет речь? Это буквально характеризует возможности модели, где она может себя проявить, и сочетает все-все. Ну, кроме надрочки на простенькие зирошоты ради бенчмарков, которая нахер не сдалась при использовании и будет дропнута после 5 минут игр.
>Ну не, они залупятся на месте или начнут спамить малосвязанную воду. Чудес не бывает, увы.
Давно щупал 7b? Ни разу не видел лупа на месте, или спам воды. Сейчас их так выдрочили что они даже слишком упорядоченными и логичными стали. Все еще тупые да, но ровненько так
Однобокость в плане рп ерп применения и оценке модели от этого
О чем весь срач и начался
>обеспечивая исключительную производительность наравне с ChatGPT
Такому маркетинговому тексту места точно в шапке нет.
В общем я предлагаю снести из шапки абзац про форматы весов, а после блока со справкой "Базовой единицей обработки" добавить что-то типа
>Базовым языком для языковых моделей является английский. Он приоритетен для общения, на нём проводятся все тесты и оценки качества. Но при этом большинство моделей мультиязычны, и в их датасетах присутствуют разные языки, в том числе и русский. Все модели достаточно хорошо понимают русский на входе. Для качественного вывода на русском рекомендуется использовать модель openchat-3.5-0106. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества в виду ошибок при обучении
> Фроствинд все это умеет.
Тебе уже 2 или 3 треда говорят что фроствинд устарела. Сам же автор ее поставил на первое место другую свою модель, которая делалась на доработанном датасете фроствинд.
Кидай название, если она такого же размера, то можно просто заменить.
> Фроствинд
Кал говна из жопы ануса
Каждый раз когда идут заявления про такую революцию - скачиваю что-то "крутое" и получаю разочарование на фоне заявлений. Нет, для 7б они хороши и это приятно, но на крутую йоба модель что может все - не тянут.
Потом спрашиваю "ну покажите как она ебет" а в ответ как раз те самые лупы и вода, которые автор воспринимает за крутой текст, в лучшем случае.
Они действительно улучшились в простом, и это не может не радовать, но как только просишь что-то большее - сразу магия рассеивается и вываливаются все потроха. Кстати, первый мистраль в этом был неплох, модель будто осознавала свои ограничения и вовремя останавливалась, не стесняясь ответить только на часть а на остальное отказать, или даже задать наводящий вопрос что мог бы ей облегчить ответ. В новых файнтюнах эту "заглушку" убрали и результат на лицо.
А что еще? Кодинг? Ну рили без кринжа туда не взглянешь, оно сразу сыпется на сколь более сложно задаче.
> Тебе
Таблетки
> поставил на первое место другую свою модель, которая делалась на доработанном датасете фроствинд
Ее оценить и поставить тогда, но не просто по заявлениям а хотябы с беглой оценкой
ну пусть хоть так, меньше вопросов будет про русский язык
Двачую, разве что
> Но при этом большинство моделей мультиязычны
> Но при этом некоторые из моделей мультиязычны
Их действительно меньшенство.
Почему это? Просто как минимум все лламы, мистрали и все их файнтюны мультиязычны. Даже китайские владеют как минимум китайским и английским.
Хотя тут вопрос в терминологии, что называть мультиязычной. Если модель, которая хоть как-то понимает другие языки, то там чуть ли не пигма могла выдавать бред на русском. Если считать по качеству, сравнимом с английским, то тут разве что корпоративные справятся.
Да потому что по дефолту они слабы не на-английском, даже вон немцы бугуртят орубля
Можно перефразировать типа
> Базовым языком для языковых моделей является английский. Он приоритетен для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных примером может служить openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества в виду ошибок при обучении.
Или более аккуратно написать
> то тут разве что корпоративные справятся
Ну клод неплох, а так даже гопота деградирует и может ошибаться.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
>Увеличивается если крутануть сильно, х2 обычно не заметен вообще.
Понятно, спасибо.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Сейчас существует несколько версий весов, не совместимых между собой, смотри не перепутай!
0) Оригинальные .pth файлы, работают только с оригинальным репозиторием. Формат имени consolidated.00.pth
1) Веса, сконвертированные в формат Hugging Face. Формат имени pytorch_model-00001-of-00033.bin
2) Веса, квантизированные в GGML/GGUF. Работают со сборками на процессорах. Имеют несколько подформатов, совместимость поддерживает только koboldcpp, Герганов меняет форматы каждый месяц и дропает поддержку предыдущих, так что лучше качать последние. Формат имени ggml-model-q4_0, расширение файла bin для GGML и gguf для GGUF. Суффикс q4_0 означает квантование, в данном случае в 4 бита, версия 0. Чем больше число бит, тем выше точность и расход памяти. Чем новее версия, тем лучше (не всегда). Рекомендуется скачивать версии K (K_S или K_M) на конце.
3) Веса, квантизированные в GPTQ. Работают на видеокарте, наивысшая производительность (особенно в Exllama) но сложности с оффлоадом, возможность распределить по нескольким видеокартам суммируя их память. Имеют имя типа llama-7b-4bit.safetensors (формат .pt скачивать не стоит), при себе содержат конфиги, которые нужны для запуска, их тоже качаем. Могут быть квантованы в 3-4-8 бит (Exllama 2 поддерживает адаптивное квантование, тогда среднее число бит может быть дробным), квантование отличается по числу групп (1-128-64-32 в порядке возрастания качества и расхода ресурсов).
Основные форматы это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/TheBloke/Frostwind-10.7B-v1-GGUF/blob/main/frostwind-10.7b-v1.Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: