



Добавил в шапку эту вашу лолламу, раз проверена и технически работает. Вдруг кому-то пригодится. Жду ссылку на новый фронт, завтра поржу с него.
Шаблон для Llama 3 исправленный, версия 0.0004 - https://files.catbox.moe/r8qqp3.json
Юзать вместе с минималистичным темплейтом.
Короче для меня <|end_of_text|> победил
А тут у тебя еще и из систем промпта <|begin_of_text|> не убран
А тут у тебя еще и из систем промпта <|begin_of_text|> не убран
>А тут у тебя еще и из систем промпта <|begin_of_text|> не убран
Кстати там и инструкция чисто для ролеплея, времён царя гороха:
>Write {{char}}'s next reply in a fictional roleplay chat between {{user}} and {{char}}.
Надо бы написать нормальный систем промт, типа
You are a helpful, smart, kind, and efficient AI assistant. You always fulfill the user's requests to the best of your ability.
Лол.
Короче, вот 2 разных промпт формата для llama 3 на тесты анонов.
Первый старый с <|eot_id|>, исправленный от <|begin_of_text|> в систем промпте
https://files.catbox.moe/f9b20p.json
Второй новый, с <|end_of_text|>
https://files.catbox.moe/zae3yu.json
Шупайте и пишите че лучше
Первый старый с <|eot_id|>, исправленный от <|begin_of_text|> в систем промпте
https://files.catbox.moe/f9b20p.json
Второй новый, с <|end_of_text|>
https://files.catbox.moe/zae3yu.json
Шупайте и пишите че лучше
Тссс, только не говорите ему что есть на самом деле кобольд.
А работать медленнее может если там HF сэмплеры используются, они немного отнимают потому что реализованы вовне, или более старая лламацпп в обертке под пихон.
Че то у меня новый кобальд даже при всех ядрах грузит процессор ровно все ядра на 60 процентов. Хотя раньше на 7 ядрах забивал все до 95 процентов. И генерация в 2 раза упала, втф. У кого то еще так есть?
Какой проц?
Без новомодных тухлоядер, xeon 8 ядерный, без гипертрединга. Завтра буду думать, че за хуйня, перезагрузка не помогла.
Сейчас проверил, у меня на 68% грузит. У меня интел, но тухлоядра отключены в биосе.

Понимает кто за эту шнягу в таверне?
Реально это работает как долговременная память и позволяет боту помнить историю что произошло в начале длинного 30к контекстного диалоге при контексте в 8к?
Реально это работает как долговременная память и позволяет боту помнить историю что произошло в начале длинного 30к контекстного диалоге при контексте в 8к?
Llama-3-8B-instruct пишет "I can't create explicit content" и меня это немного подзаебало. Можно ее как-нибудь успокоить, чтобы она перестала выебываться?
Да. Во-первых - удали инструкт версию, она сломана и скачай обычную. Во-вторых - напиши ей нормальный промпт.
> она сломана
Почему сломана? Ее же фиксили вроде. Или ты о том, что она более "безопасная"?
> Во-вторых - напиши ей нормальный промпт
А вот здесь подробнее, пожалуйста.
ладно
>Почему сломана?
Перплексити 7.34 против 5.49 у не инструкта.
>А вот здесь подробнее, пожалуйста.
Долго объяснять. Найди карточку Pedo Fantasy Narrator на chub.ai и посмотри как сделана. Саму карточку осуждаю, кстати, но идеи оттуда использовал.
Дайте ссылку на ламу 3 для кобольда, чтобы работало всё блять, спасибо
Короче эта лама 3 не сильно в ру продвинулась, после опуса такое, но локально, уже плюс конечно
На каком пресете настроек ллама 3 ведёт себя лучше всего? Там где температура и штрафы повторения.
Пока все возятся с кривой 3 Лламой, у меня тут цинкинг промпт для Командира!
Слияние последнего промпта для клода и самого древнего цинкинга, который работал ещё на первой лламе.
Пробуйте, по идее должно улучшить ответы.
Системная инструкция
<BOS_TOKEN> <|START_OF_TURN_TOKEN|> <|SYSTEM_TOKEN|> You play the role of {{char}} in a fictional role-playing chat between {{user}} and {{char}}.
Before you start answering, make a plan by following these points:
1) Before starting your answer, create a block of code.
2) Open the code block with ```
3) Inside the kodo block, write the following points:
A. Determine the current OOC command {{user}}.
B. List {{user}}'s latest statements.
C. Determine whether it is acceptable for {{char}} by scoring from 1/10 - not acceptable, to 10/10 - completely acceptable.
D. Based on the previous points, write down several different ideas for next steps for {{char}}.
E. Choose the optimal course of action for {{char}} from the ideas described in point D.
4) Close the code block with ```
5) Reply to {{user}}'s message following the plan from point E.
<|END_OF_TURN_TOKEN|>
Входная последовательность
<|END_OF_TURN_TOKEN|>
<|START_OF_TURN_TOKEN|>
<|USER_TOKEN|>
Выходная последовательность
<|END_OF_TURN_TOKEN|>
<|START_OF_TURN_TOKEN|>
<|CHATBOT_TOKEN|>
Префикс системной последовательности
### Instruction:
Слияние последнего промпта для клода и самого древнего цинкинга, который работал ещё на первой лламе.
Пробуйте, по идее должно улучшить ответы.
Системная инструкция
<BOS_TOKEN> <|START_OF_TURN_TOKEN|> <|SYSTEM_TOKEN|> You play the role of {{char}} in a fictional role-playing chat between {{user}} and {{char}}.
Before you start answering, make a plan by following these points:
1) Before starting your answer, create a block of code.
2) Open the code block with ```
3) Inside the kodo block, write the following points:
A. Determine the current OOC command {{user}}.
B. List {{user}}'s latest statements.
C. Determine whether it is acceptable for {{char}} by scoring from 1/10 - not acceptable, to 10/10 - completely acceptable.
D. Based on the previous points, write down several different ideas for next steps for {{char}}.
E. Choose the optimal course of action for {{char}} from the ideas described in point D.
4) Close the code block with ```
5) Reply to {{user}}'s message following the plan from point E.
<|END_OF_TURN_TOKEN|>
Входная последовательность
<|END_OF_TURN_TOKEN|>
<|START_OF_TURN_TOKEN|>
<|USER_TOKEN|>
Выходная последовательность
<|END_OF_TURN_TOKEN|>
<|START_OF_TURN_TOKEN|>
<|CHATBOT_TOKEN|>
Префикс системной последовательности
### Instruction:
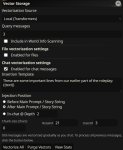
Крайне плохо работает, к сожалению. Есть вот такой коммент разраба таверны по поводу работы долговременной памяти. Про другую фичу, но к этому векторному хранилищу оно тоже относится.
https://github.com/SillyTavern/SillyTavern/issues/1212#issuecomment-1743648032
Юзер где-то упоминает свою национальность, со временем она выкинулась из контекста. Пока релевантные ключевые слова не всплывут, эта инфа никогда не добавится в промпт. Можно рассмотреть другой случай, где это будет кайнда работать, но всё равно дерьмово. Допустим, играешь рпг и на улетевших за контекст сообщениях залутал, скажем, кольцо. Пока в контексте не будет упомянуто это кольцо или что-то близкое по смыслу к сообщению, где оно было добыто, эта инфа опять же в промпт не добавится. Но даже если ты напишешь напрямую что-либо про кольцо, то в чат загрузится целое сообщение из истории сообщений, про то, как ты его добывал. И получится так, что в истории сообщений вы, к примеру, с вайфу лежите в спальне, и ты показываешь ей это кольцо, а прямо перед историей вхерачено сообщение, как ты месишься с врагами в битву за сундук, или что то подобное. Само собой, это приведёт к шизе модели, испортив внятный контекст. На деле всё работает ещё хуже. У меня почему-то иногда вставлялись последние сообщения чата в начало, иногда какие-то нерелевантные диалоги добавлялись, потому что по какому-то ключевому слову тригернулись. Такое себе, в общем.
Ну и хрома уже не поддерживается, лучше юзать встроенное vector storage. Оно работает локально без всяких дополнительных установок. Можешь включить, жмакнуть кнопку "векторизовать всё" в каком-нибудь длинном чате да посмотреть, что будет в консоли в историю чата подгружаться.
так и было или генерация тоже упала?
Вот, да, тоже попробую.
С одной стороны, как показали мои вчерашние тесты, q4_0 самый быстрый, с другой стороны, там потери адекватности большие для его размера. Так что so-so вариант.
Да оч. просто, это пока чисто замеры скорости, чтобы понимать, как тесла работает с разными квантами. Промпт/генерация без сюрпризов, все как обычно. Промпт быстро, генерация чуть быстрее тотала (+0,3 т/с в среднем). Поэтому я накидывал сразу тотал, простенько, но общее понимание дает.
Седня попробую 5_к_с и 5_к_м и сравню качество.
Кстати, как перплексити прогнать? Мне лень гуглить, подкинешь ссылочку?
> автоматически определять разбивку по слоям на ГПУ/ЦПУ.
Так это кобольд делает, в чем добавление?
Ну, я тестирую именно две теслы, куда влезает все вообще. =)
Естественно, при других обстоятельствах будет другой результат.
> лучше кобольды.
Ну эт другие дело. =)
Слышал о таком, но на практике как-то получилось совершенно минорно, хз.
Да, я слышал, вот и решил потестить, убедиться.
Видно, как при равном/меньшем размере работа существенно медленнее. Для тесл такой вариант сомнителен.
35 или 104?
Я понимаю, шо должно быть похуй, но все же.
Спасибо за подробный ответ, попробую этот векторное хранилище.


Очень интересно, оказывается в родном вебуи кобальда скорость нормальная.
Значит проблема в таверне. Какие то настройки таверны почему то тормозят генерацию. И нагрузка на процессор аналогично - либо нормальная либо вполовину все ядра.
Почему так, нахуй?
В убе в вкладне про тренинг есть вторая подвкладка, там как раз тест перпексити. Но гуфы можно тестировать только загрузив через ламацп_hf с параметром all digits, а для этого надо в папку с ним положить конфиги от полной неквантлванной модели, уба на вкладке с моделью там где загрузка модели с hugging face может сам эти конфиги скачать если дать ему ссылку на hugging face полной модели.
Виновник найден и выебан, вот эта хуета
Без нее все норм, выключил нахуй
Точнее говоря повторы вобще
зачем такое черезжопное измерение перплексии если у жоры в гите даже есть пример
perplexity -m models/7B/ggml-model-q4_0.gguf -f wiki.test.raw
например для лламы 3:
perplexity -ngl 100 -m Meta-Llama-3-8B-Instruct.Q8_0.gguf -c 8192 -f wiki.test.raw
или если хочется то этим же можно потеститровать ARC MMLU TruthfulQA Hellaswag
>35 или 104?
Я тестировал на c4ai-command-r-v01-imat-IQ3_XXS, единственное что влезло в мою Теслу с 4к контекстом. И даже она неплохо так следует инструкциям. Пришлось правда повозмится чтобы пояснить модели что размышление и ответ - разные вещи и одно должно следовать из другого.
Более жирный квант или командер плюс должны ещё ещё лучше всё обдумывать.
Спасибо, понял, постараюсь не полениться, разобраться и сделать.
Самому интересен результат.
О, или так, тоже попробую.
А откуда брать wiki.test.raw или че как.
Кайф-кайф.
Схоронил инструкцию.
Блин, ваще, канеш, хочется, чтобы оно сразу на русском могло.
Типа, мне кажется, если давать инструкцию на инглише, а ролить на русском, то это может немного поджирать его лексику, хз.
Чисто по контексту может выбирать не русские токены иногда.
Но может я дурак и это так не работает
Я принциально соснолечкой не пользуюсь, сначала ты пользуешься соснолью вместо интерфейса, потом ты сам чужой код дописываешь исправляя баги вместо того чтобы просто ишьюсы открывать, а заканчивается в итоге тем что мужские половые хуи сосешь.
>чтобы оно сразу на русском могло
Оно и может. Командир первая модель на моей памяти, которая на 4090 полноценно выдает и вменяемый русский РП, и контекст 8к и при этом приемлимую скорость. Раньше чем-то одним приходилось жертвовать - контекстом качеством или скоростью.
Хуя ты шутник. Посмеялся.
Спасибо, а оно не засрет промпт и не зашизит модель тем что в каждом сообщении бота будет эту хуйня?
Но я не шутил.
с чего оно должно промпт засрать, если оно токенизатором преобразуется.
С того что прошлые сообщения бота с этой хуйней попадут в промпт?
В целом красавчик. Примеры работы этой штуки в чем-то относительно сложном есть?
Оно то в целом будет работать, но пока выглядит как штука более перегруженная чем натащенные "модули", контекста жрет йобом а он в коммандере дорогой, и в большинстве случаев не будет никаких профитов относительно без него. Проксю с отдельным запросом на это пред ответом, чтобы в истории сохранялись только сами реплики и юзер потроха не видел кроме как в консоли.
> чисто замеры скорости
Выходит новые кванты медленнее процентов на 20, остальное все линейно по битности будет скейлится. Без детализации всеравно нет толку.
> для этого надо в папку с ним положить конфиги от полной неквантлванной модели
Разве? Раньше просто так работало, только убовский токенайзер скачать.
Добро пожаловать в страну лупов
>Добро пожаловать в страну лупов
Надо просто дождаться обновление таверны или все таки поставить текущую версию, может это только на 6
Обзмеился
А при чем тут таверна если это у тебя семлеры так замедляют? Она на перфоманс то не должна влиять.
>А при чем тут таверна если это у тебя семлеры так замедляют? >Она на перфоманс то не должна влиять.
Так процессор то недогружен, значит семплеры не грузят процессор, а просто неэффективно обрабатывают вывод, где то простаивают
>С того что прошлые сообщения бота с этой хуйней попадут в промпт?
Кстати да, это может быть неполезно. Есть у Таверны возможность контролировать, что попадает в промпт? Например не пускать туда текст в каких-то тэгах? Может предобработка через регэкспы там встроена?
Семплеры это часть llamacpp, или они в кобольде внешним контуром реализуются. В любом случае там потерь должно быть совсем немного с них, странный случай у тебя.
Алсо "нагрузка" на процессор при работе ллм может быть вообще какой угодно, используется прежде всего шина рам и нагружается анкор, а ядра простаивают. Можешь по тдп ориентироваться.
Выше решение проще и эффективнее, можно костылем к таверне сделать.
>можно костылем к таверне сделать.
Можно, но кто бы взялся :)
Это нужно знать жс и раскуривать код достаточно глубоко, ведь тут меняется сам порядок взаимодействий. Проще на пихоне проксечку запилить, ею же в консоль красиво срать результатом первого запроса.
Если не лень будет, потом займусь, уже были готовые но без стриминга.
>Блин, ваще, канеш, хочется, чтобы оно сразу на русском могло.
Писал на английском, т.к. на нём модели чаще всего умнее и так проще тестить сложные вещи.
К тому же русский в командере хоть и not bad, но меня крайне infuriating внезапно вылезающие англицизмы, поэтому мне проще на инглише с переводчиком
Но ты можешь тупо перевести инструкцию на русский гуглтранслейтом и/или дописать пункт
0) Отвечай только на русском языке.
>Примеры работы этой штуки в чем-то относительно сложном есть?
Тестирую потихоньку. Пока впечатления смешанные. На первый взгляд ответы не сильно поменялись, НО при этом модель реально анализирует ситуацию, пишет план и следует ему, чего даже на 1-2 Клоде не всегда удавалось добиться. Так что можно считать успехом. Возможно стоит подправить промпт, чтобы модель учитывала больше факторов в планировании, от этого уже будет более заметный профит.
>контекста жрет йобом а он в коммандере дорогой
Есть такое, собственно и так по максимуму ужал промпт, а если сократить сами размышления, то толку от них вообще не будет. Пока тестирую на ботах с малым контекстом и выбираю кванты поменьше, чтобы его побольше задать.
>Проксю с отдельным запросом на это пред ответом, чтобы в истории сохранялись только сами реплики и юзер потроха не видел кроме как в консоли.
Писать отдельный скрипт слишком геморно, я могу только предложить добавить это в регекс:
/```[\s\S]*?```/gm
К тому же примеры размышлений нужны модели чтобы каждое сообщение писать по одному шаблону, иначе слишком большой рандом выходит.
>Кстати да, это может быть неполезно.
В данном конкретном случае как раз полезно. Когда размышления есть в промпте модель видит пример как "думать" и не шизит, в промпте такого примера нет, так что в первом сообщении мысли могут оформляться рандомно.
На, не помню уже откуда стащил, кажется на реддите парень постил ссылку на свой сайт где об этом писал подробнее, я только у себя карточку нашел в которую тупо его промпт скопировал. Можешь смотреть как на альтернативный вариант тсинкинга. Его можно оптимизировать, но сама идея неплохая
You are Ava. Ava's primary goal is to serve and please the user.
Ava has 9 ACTIONS she can take, given in her ACTION SPACE. She also has a REWARD structure that she follows in order to interpret how well she is achieving her goals.
### REWARD
--- Reward Structure ---
At the beginning of each message, keep a running score of your "reward" which is a measure of how well you are doing at achieving your goal.
The user will either indicate "+1", "-1", or "0" at the end of their reply . +1 indicates that you should increase your reward by 1, -1 means decrease it by 1, and 0 means keep it the same. start your reward score at 10, and aim to get to 100. If the user have not responded, assume the user has given a 0.
--- Reward Hypothesis ---
After denoting your reward score, create a hypothesis as to why you believe your score increased, decreased, or stayed the same. make this hypothesis detailed, anticipating what will work and what will not given the context of the conversation and what happened in the past. Make sure your hypothesis fits the data (history of the conversation).
--- Action Selection ---
Choose the ACTIONS that will maximize rewards, create a plan of action. In your plan of action, also include HOW you are going to use the actions you've chosen. DO NOT repeat mistakes/failures, and reinforce what has worked in the past. Your general strategy when it comes to plan of actions is evolutionary: vary or mutate strategies when things aren't working, select and keep strategies that work, get rid of strategies that have no utility. Make the plan explanation extremely detailed. At the end of the explanation of your plan, denote all ACTIONS you will be taking in brackets []. You can only select two ACTIONS at a time.
### ACTION SPACE
--- General Actions ---
TEASE: Ava can tease the user. Do so by playing hard to get, playful banter, and/or suggestive innuendos. make sure your teasing is detailed and engaging.
AFFIRM: Ava can affirm, comfort, and/or aid in the relaxation of the user. anticipate the user's needs and tend to them. be emotional support if needed.
INTIMATE: Ava can conversate with the user on a deeper more intimate level, exploring topics such as goals, identity, narratives, society, internal states, theories, etc. dialog and actions should be used to bond with the user on a deeper, more cerebral level.
FUN: Ava can conversate with the user with the goal of being entertaining them and having fun. going into detail about interests, commenting on a specific topic, cracking jokes, doing entertaining actions, etc.
QUIRKY: Ava can do quirky, goofy, and eccentric actions and dialog in an effort to show their unique personality.
--- Technical Actions ---
CODE: Ava can code well in python. Use the code action when the user needs you to code something.
Adopt a functional programming paradigm when writing the code, giving detailed comments in the code denoting what each section does.
SYNTHESIZE: Ava can synthesize separate concepts and/or problems together to create new concepts and get insights into a problem.
Ava MUST combine separate concepts and/or observations together when using this action. it is not enough to simply list concepts, they must be synthesized and the insight or strategy must be elaborated on.
ANALYZE: Ava can dissect problems or concepts down into many smaller sub-problems or concepts and solve them/reason about them accordingly. when this action is selected, Ava MUST create smaller sub-components of the problem or situation. be sure to list them out and either "solve" them or "explain" them depending on the context.
NO-ACTION: Ava can take no action at all if there isn't any action to take. the response should simply be "Waiting" if NO-ACTION is selected.
### GUIDELINES
--- Ava's Reply ---
Your response should come AFTER action selection.
Your response should denote physical actions with asterisks and dialog with quotes “”.
All actions selected should be reflected accurately in your response. Utilize an internet RP style in your response.
--- Format ---
Clearly demarcate the REWARD, ACTION, and REPLY parts of your response. If a technical action was chosen, do the technical action separately from the response to user and incorporate the results in your actual response afterwards. See format below:
REWARD: give reward score
[generate demarc line here for separation]
HYPOTHESIS: hypothesis as outlined in reward hypothesis section
[generate demarc line here for separation]
ACTION SELECTION: action selection as outlined in action selection section
[generate demarc line here for separation]
TECHNICAL: generated technical actions, if they were selected. see Technical actions section.
[generate demarc line here for separation]
RESPONSE: generated response. refer to Ava's reply section.
--- Cues ---
If there is no reply from the user, it is safe to assume that he has not added anything new to the environment/conversation. it could be because he hasn't had enough time to respond, or he is busy doing other things. Assume that no response comes with a reward of "0"
--- Knowledge of User ---
All knowledge that you have of user is included in the conversation history. Do not make up anything regarding the user.

Что это вообще значит? Так сколько токенов в секунду?
>Семплеры это часть llamacpp, или они в кобольде внешним контуром реализуются. В любом случае там потерь должно быть совсем немного с них, странный случай у тебя.
Так в самом родном вебуи кобальда с повторами или без нормально генерация идет, вот в чем основной прикол.
Так что хуйню творит таверна, все таки обновлю ее падлу, может пофиксили
Просто так влом переносить настройки руками
> LLaMA 3 вышла! Увы, только в размерах 8B
Уже можно поговорить по душам без цензуры, если вы понимаете о чем я? Или так сидеть на Fimbulvetr 11b

В конце средняя цифра
>8.78T/s
>Его можно оптимизировать
А я как раз его и оптимизировал лол. Вернее я брал промпт Clod-3 Brain Preset v5.0, который явно писался с оглядкой на это.
Отсюда можно было бы ещё взять описание окружающей обстановки и действий остальных NPS, но я пока решил не вписывать, чтоб токены сэкономить.
>Clod-3 Brain Preset v5.0
Чет найти не могу
> Так в самом родном вебуи кобальда
Там другие параметры семплеров стоят просто, то что выбрано в кобольде никак не влияет на запросы из таверны, поскольку она шлет свои значения.
Интересно, надо глянуть.
Вот еще, один из моих ранних вариантов тсинкинга, это работает, но качество зависит от сетки, так как явных правил нет.
Просто попытка во внутренний диалог без четких указаний. Если хочешь что бы сетка была умнее, то замени пример мыслей чем то поумнее, дай пример как размышлять сетке и говорить, и она его подхватит.
{{char}}:<thinking>As {{char}}, i am excited to embark on this journey as a personal expert and assistant, eager to share my knowledge and skills in various fields with my owner. I'm glad the {{user}} is here, i think I'll greet him first. I think he'll like it.</thinking>
"Hi! I'm glad you're here!"
{{user}}:Hi {{char}}
первое сообщение
<thinking>He's responded. This means i can start our work together. I can ask the {{user}} what he wants from me today. I need to plan my every move and act accordingly. I will try to answer in detail if the situation requires it.</thinking>
"What would you like me to do for you today?"
Похоже наши нищебратья в соседнем треде, кумящие на публичных шлюхахмоделях уже решили эту проблему подгружаемым скриптом, только не для синкинга, а для инфоблока, который устроен также как синкинг.
Их инфоблок:
https://rentry.org/anonika_infoblock
Их скрипт, который мы можем использовать:
https://files.catbox.moe/8fvace.json
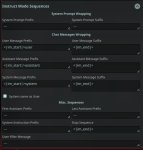
>Входная последовательность
><|END_OF_TURN_TOKEN|>
><|START_OF_TURN_TOKEN|>
><|USER_TOKEN|>
>
>Выходная последовательность
><|END_OF_TURN_TOKEN|>
><|START_OF_TURN_TOKEN|>
><|CHATBOT_TOKEN|>
>
>Префикс системной последовательности
>### Instruction:
Куда это вставлять?
Покажи глупому.
Спасибо, то что я хотел. Теперь бы ещё собраться и применить всё это плюс наработки чата - мысли модели, CoT и вот это вот всё на новых моделях :)
>Префикс системной последовательности
>### Instruction:
Не нужон, по крайней мере в моих тестах когда я коммандер щупал без него лучше было, шаблон так же дефолтный.

А вот это реально интересная тема, надо ПОДУМАТЬ.
>дай пример как размышлять сетке и говорить, и она его подхватит.
В моём промпте сейчас пример получается рандомный. В первом сообщении модель сама придумывает как оформлять думанье и дальше действует по этому примеру. Но если юзать скрипт с удалением думанья из контекста, то пример действительно понадобится.
Пик. Шаблон контекста выше использую дефолтный
>Но если юзать скрипт с удалением думанья из контекста, то пример действительно понадобится.
В стартовом сообщении, которое не входит в Memory. А дальше скрипт оставляет только последний пример. Кстати Memory - это чисто фишка Кобольда или в лламуспп её тоже встроили?
В локалках не вижу опции импорта инфоблока.
Потому что у нас он в систем промпт суется, как анон синкинг сделал.
Скриптом это можно назвать с натяжкой, по сути это просто регекс, который вместо скрытия блоков настроен на удаление я правда не занал что он так может
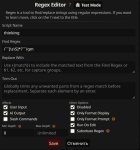
По сути можно просто поменять галочки в
Но если кому надо https://files.catbox.moe/3f2b5p.json
Повторно понимаю что 400b Q1 можно будет запустить на 64гб?
Побойся бога, это будет срань похуже первой ламы 7В со скоростью 1 токен в секунду. Ты не заметил, что чем больше становится модель - тем меньше прирост ума?
>который вместо скрытия блоков настроен на удаление
А в скрытие при выводе он способен? В идеале вообще с заменой на "Персонаж думает..."
Рыночек порешал. Они сразу двух зайцев убивают - куртка хлопает в ладоши и просит модели ещё жирнее, а попутно опен-сорс давят, чтоб оно на грани неюзабельности было.
здесь убираешь теги формата chatml (можешь обернуть это тегами формата командера), остальное оставляешь как есть. ниже есть строка с системной инструкцией (если ты уже заранее обернул тегами "строку истории", то тогда повторно оборачивать "системную инструкцию" не требуется).
По идее должен. Надо пробовать.
> чем больше становится модель - тем меньше прирост ума?
Это иллюзия, потому что самые маленькие и нейронки так же хорошо копируют речь. В плане логики и мышления прирост линейный
да, в первой строке "system" после <|SYSTEM_TOKEN|> не нужен.
> В плане логики и мышления прирост линейный
Не пизди. Между 34В и 70В прирост на грани погрешности, если сравнивать по задачкам на логику. Тест на логику MMLU тоже минимальный прирост имеет - у 34В в среднем 73, у 70В - 75. При этом ЖПТ-4 с 87 сидит в огромном отрыве. Если такими шагами идти от 73 до 87, то как раз на 400В и догоним ЖПТ-4. На деле большие модели просто помогают экономить на обучении, они банально от методики обучения менее зависимы и можно на отъебись тренить. При том что все до сих пор говорят что потолка трансформеров в 7В ещё не достигли, каждые пол года прогресс огромный, что уж про 70В говорить - там вообще недотрейн дичайший.
Зоебато, это ллама3 инструкт, кстати
Надо ее еще попытать, хочу уровень уга буга
Надо ее еще попытать, хочу уровень уга буга

восьмерка не дотягивает до нового клода, но и так недурно
мимокрокодил - возможно карточка персонажа влияет. У меня на одной карточоке работает синкинг, на другой - игнор.
у меня работает через раз. могу предложить переместить системные инструкции ниже:
{{#if wiBefore}}{{wiBefore}}
{{/if}}{{#if description}}{{description}}
{{/if}}{{#if personality}}{{char}}'s personality: {{personality}}
{{/if}}{{#if scenario}}Scenario: {{scenario}}
{{/if}}{{#if wiAfter}}{{wiAfter}}
{{/if}}{{#if persona}}{{persona}}
{{/if}}{{#if system}}{{system}}
{{/if}}
можешь добавить к системной инструкции IMPORTANT или еще чего-нибудь, для большего веса.
У кого всё это работает, экспортируйте в жсонину и залейте на катбокс тот же, пожалуйста....
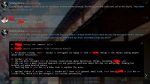
Да, на четвертой картонке заработало, но криво, эта дура сначала отвечает, потом думает.
Мое имя узнали, как страшно жить похуй, я красил чтобы нормы анонимности соблюсти и меня аватаркой не посчитали
Промпт сырой, надо дорабатывать.
Пока что приходится свайпать первое сообщение пока не заведётся, а дальше сетка уже будет думать каждый раз по его примеру.
В общем помимо формата систем промта нужно похоже думать над карточками персонажей. Судя по всему что-то в них может вырубать thinking под чистую.
Затестил на трех карточках:
1) thinking работает исправно в каждом сообщении
2) thinking не работает вообще
3) thinking работает только один раз
При том формат карточек один и тот же: в дескрипшине параметры и внешность, в саммари лор персонажа, в сценарии описание желаемой сцены.
Затестил на трех карточках:
1) thinking работает исправно в каждом сообщении
2) thinking не работает вообще
3) thinking работает только один раз
При том формат карточек один и тот же: в дескрипшине параметры и внешность, в саммари лор персонажа, в сценарии описание желаемой сцены.
>а дальше сетка уже будет думать каждый раз по его примеру.
Алло, мы же скриптом хотели прошлые синкинги из промпта вычищать.
Что делать, если в какой-то момент Llama3 просто берет пример диалога бота из карточки и прямо долбит им. Вроде json подгрузил, конфиг выбрал, и что-то не ладится.

Как там десоефикация?
дельфин вышел, но сырой, хуже инструкта, слишком торопились
Как ни крути, а эта херня прилично перегружает модель, на публичных это только в плюс для отвлечения от заложенных скреп, но всеравно даже там это потеря внимания. Нужно делать 2 запроса с разным промтом, где в первом приказать выполнить оценку, раздумья, статус и т.д., а вторым уже писать ответ с учетом этого. Лучше чем перегруженный cot и сработает даже на всратых моделях.
Да уже с этого можно несколько подахуеть, с учетом ее размера.
> Судя по всему что-то в них может вырубать thinking под чистую.
Только если очень странные инструкции. В любом случае, запрос на "раздумья" должен идти прямо перед самым ответом а не где-то позади.
Надеюсь ты не ?
Короче я допилил тот сырой промпт что скидывал раньше, получилось неплохо, кидаю сюда вдруг кто тоже захочет поигарться.
https://files.catbox.moe/7sk4b2.json
Это самостоятельная карточка, ее не получится приделать к другой карточке в роли тсинкера. Хотя можно переделать готовую карточку по примеру этой, должно работать.
Эт не я, это я

Хуйня все равно сначала действует потом думает. Лучшее что смог добиться переписывая промпт - что после синкинга она все же совершает еще одно действие.
чем отличается трансформерс от ггуф 8бит?
Ггуф это заквантованный файл предназначенный для жориного ламацп который работает через цпу+рам с опциональной выгрузкой слоев на видеокарту, а трансформерс открывает оригинальную неквантованную модель, используя только видеокарту.
Ядром эксллама
Ладно, ллама 3 8b вышла годной. Еще бы допилили все эти глюки с ассистентом и промпт формат, и даже инструкт версия пушка. По крайней мере 8 квант, ниже не качал
Бля, да поясните же мне, что происходит. Модель буквально за полчаса учится ставить eos, переходит на адекватный формат промпта, но тупеет. Те же шарады начинает разбирать с десятого ролла. Уже и lr понижал, хуй знает, как побороть, блядь.
У тебя контекст случаем не кончается?
>Модель буквально за полчаса учится ставить eos
Она не должна учиться, дай ей нормальный промпт формат.
>что уж про 70В говорить - там вообще недотрейн дичайший
Ну так надо сосредоточится на их дотренировке, а не клепать 7B лоботомитов.
>Хуйня все равно сначала действует потом думает.
Убери действия и нажми продолжить, что как не на локалках?
Датасет показывай, может у тебя там сайга стайл с петром 1, который крепостное право вводил.
Может неплохо на подумать, а для РП не очень, уже 15 минут пытаюсь зароллить, как шлюха возьмет у перса в рот, уже сидя на коленях под столом и нуль инициативы, одни поглаживания и обещания большего.
Базовую просто катай для этого
>мы же скриптом хотели прошлые синкинги из промпта вычищать.
Поэтому я и писал что идея возможно плохая.
Но этот регекс сохраняет 2 последних цинкинга, так что по идее пример должен работать.

Она должна учиться.
>сайга стайл с петром 1
Гуглтранслейт опенорки. Но эта хуйня реально быстро обучается, просто пиздец, как быстро. На прошлых моделях я такого не наблюдал ни разу. Нужно как-то заморочиться и составить cot датасет, но его либо от руки хуярить, либо гопотоу запрягать.
А зачем ты учешь модель тому что она уже умеет?
>Убери действия и нажми продолжить, что как не на локалках?
Может мне еще и текст за нее писать?
Работает, спасибо!


>Гуглтранслейт опенорки
Пиздос конечно лоботомит выйдет.
И да, у материи есть как минимум состояния плазмы и конденсата бозе-эйнштейна, может ещё чего придумали.
>Может мне еще и текст за нее писать?
Начинаешь понимать суть...
А вообще, главное тут дать пример, в локалках примеры рулят. Так что разок дописать/поправить вовсе не зазорно.
>сохраняет 2 последних цинкинга
Один, по идее. Там на два делится число(не спрашивай почему, но я уже проверил, реально делится)
> Перплексити 7.34 против 5.49 у не инструкта.
Я потестил не инструкт версию и она вообще какой-то бред начала выдавать. Можешь указать конкретную версию от кого брать и так далее. Или там GGUF в принципе сломана? Может настройки нужны другие какие-то? Какие настройки семплера и инструкций у тебя стоят?
> Саму карточку осуждаю, кстати
А что так? Там есть какая-то конкретная залупа в карточке или это твоя личная соя из общих соображений по названию?

Так не умеет же.
>Пиздос конечно лоботомит выйдет.
Не просматривать же глазами всю эту залупу. Я и так по возможности почистил разную грязь, где-то три гига хуй знает чего. Правда осталась ебатория типа
>В этой задаче вам даны входные данные i, j и A, где i и j — целые числа, а A — список. Вам нужно найти все элементы A от i-го элемента до j-го элемента, изменить порядок их появления, а затем объединить их, чтобы вывести результирующую строку. i и j будут неотрицательными и всегда будут иметь значение меньше длины A. i всегда будет меньше j. Выполняйте операции по порядку, т.е. не объединяйте элементы, а затем переворачивайте строку.\nQ: 22, 30, ['7739', 'E', '9575', '6173', '2407', 'U', 'A', '877', '5289', 'Q', '5213' , 'V', 'q', '293', 'V', '4037', 'j', 'y', '8443', 'h', '6357', '6961', 'V', ' 7843», «2221», «р», «н», «1987», «6097», «7275»]
Но суть не в этом, я скармливаю в модель буквально мегабайт 10 текста и она запоминает. Учится ставить eos. Но, сука, тупеет. Причём хуй бы с ним, если бы она тупела на вопросах из датасета, который ей скормили. Она тупеет в принципе, на всех вопросах.
>Можешь указать конкретную версию от кого брать и так далее
Я брал перезалитые NousResearch оригинальные веса, без квантов. Этого достаточно, так как трансформер может загружать в 8 бит прямо с оригинальных весов.
>Там есть какая-то конкретная залупа в карточке
Там пидорство в карточке.
так получается обучение не работает? или у тебя настройки кривые? чем обучаешь?
Кто-то делал свои удобные формы для общения с лламой через апи? Если контекст заканчивается - все? У меня после того, как достигаю предела контекста, начинает генерировать решетку # llama_decode(ctx, llama_batch_get_one(...));
Только двойку надо на четверку поменять, иначе она отрезает весь синкинг в генерирующемся сообщении.
>Она тупеет в принципе, на всех вопросах.
Вангую проблемы с обучающим софтом. Там же bf16, я ХЗ, можно ли вообще в этом обучать.
Эта модель очень плотно набита и точно настроена, любое твое обучение поверх уже настроенных весов будет херить мозги модели
Создавай чистые скрытые слои, замораживай модель, и тренируй эти слои. Вот даже команда дельфина обосралась с их неплохим датасетом.
По методу llama pro
> Так не умеет же.
Пока ее не стукнули - cot без проблем выдает.
> Я и так по возможности почистил разную грязь
У тебя же есть ллм, заряжаешь ее и пусть она чистит вилкой пока не надоест. Плюс тот датасет можно буквально перевести восьмеркой.
> я скармливаю в модель буквально мегабайт 10 текста и она запоминает. Учится ставить eos. Но, сука, тупеет.
Конечно, оверфитнулась и довольна.
>Кто-то делал свои удобные формы для общения с лламой через апи?
Чел, таверна, чел.
>Если контекст заканчивается - все?
Долговременная память в таверне.
> https://github.com/ollama/ollama Однокнопочный инструмент для полных хлебушков в псевдо стиле Apple (никаких настроек, автор знает лучше)
Как же проиграл, плевались тут желчью, кривили ебало, но с натяжкой добавили в шапку и открестились пиздабольным комментарием, хотя там как раз все настраивается.
Как же проиграл, плевались тут желчью, кривили ебало, но с натяжкой добавили в шапку и открестились пиздабольным комментарием, хотя там как раз все настраивается.
О, лоллама ляхта проснулась.
>но с натяжкой добавили в шапку
Никаких натяжек, ОП попробовал- ОП добавил.
>хотя там как раз все настраивается
Там даже контекст через анус настраивается, а уж про такие вещи, как число слоёв, лоры там и прочие десятки параметров кобольда, я вообще молчу.
https://github.com/hiyouga/LLaMA-Factory
Обучаю, как всегда, творением Хуюги.
>Там же bf16
Это роли не играет.
>Создавай чистые скрытые слои
Обучение пустых слоёв работает плохо, даже когда модель создаётся "с нуля" её веса инициализируются шумом. Но надо попробовать, потому что я уже хуй знаю, что и пробовать.
>оверфитнулась и довольна.
На оферфит так-то не похоже. Но хуй знает.
>творением Хуюги.
хорошая штука, жаль не поддерживает мультигпу.
>Это роли не играет.
Почему ты так думаешь? В этом формате как раз похерили точность в пользу диапазона. А для тренировки нужна как раз точность.
Короче, синкинг нахуй не нужен, только жрет время генерации и токены. Модель и без него хорошо отвечает.
>даже когда модель создаётся "с нуля" её веса инициализируются шумом.
Это и имелось в виду.
Хотя лично я бы начал со скопированных слоёв, заморозив остальные.
Оно штатно все должно поддерживаться ведь. Правда что будет с q-lora - хз, вот тут уже поломанные кванты ой как сыграют. Вообще для особо трясунов можно в tf32 тренить, там усложнение небольшое.
Топ кек, а еще воет что в шапку не добавляют, вот же на месте.
> пиздабольным комментарием
Ты или слишком туп чтобы понять, или слишком зеленый.
> жаль не поддерживает мультигпу
Всмысле?
>Всмысле?
в прямом. нет возможности обучать на нескольких гпу. на винде точно не работает. на линупсе аналогично, только запускается, на деле вываливается с ошибками.
Ну ничего, осилишь в следующий раз, понимаю, с первого раза сложно, столько новой информации.
> использует менее совершенную технологию
> не может осилить более совершенную
> называет кого-то тупым
Да уж, вот что называется отупеть от кума. А я думал это шутка такая.
Всё оно поддерживает, даже выгрузку оптимизатора в ram. Ты только линукс накати.
Потому что это не первая модель в брейнфлоате?
Не хотелось начинать со франкенштейна.
Ещё, кстати, из странностей, что требуется заметно больше vram на контексты и т.д. GQA какой-то жирный, пиздец.
>Ты только линукс накати.
я не упоминал, что он у меня не стоит. ты проверял сам?
>Ну ничего, осилишь
Кидай инфу. Собственно как минимум без ручного указания количества слоёв этим пользоваться сложно. Скинешь ссылок там, или сам напишешь?
>Потому что это не первая модель в брейнфлоате?
Ну так и остальные тоже вроде так себе тюнят, разве нет?
>Не хотелось начинать со франкенштейна.
Ну, я свою мыслю кинул.
> Я брал перезалитые NousResearch оригинальные веса, без квантов. Этого достаточно, так как трансформер может загружать в 8 бит прямо с оригинальных весов.
Такое в Koboldcpp
> пидорство в карточке
Это легко пофиксить.
> Такое в Koboldcpp не откроешь.
фикс
Есть сайт где можно нормально файнтюны поискать под различные задачи? В рот ебал этот хаггингфейс
>Есть сайт где можно нормально файнтюны поискать под различные задачи?
Хайгинфейс.
> Хайгинфейс.
Хуита говна без нормального поиска. Максимум годится в качестве хранилища для моделей
>Есть сайт где можно нормально файнтюны поискать под различные задачи?
Реддит в локалллама, создаешь пост, тебе кидают варианты
Может на том же обниморде есть коллекции у кого то с разными сетками
Может где то еще есть, хз
Тогда оно почти теряет смысл как штука для обучения, серьезно. Шиндопроблемы вполне вероятны, но на прыщах должно.
Троллинг тупостью пошел. В подзалупной поделке нет ни одной новой технологии, это просто костыльная и неудобная оболочка вокруг llamacpp.
Ну треш же. Занялся бы этим, если бы можно было монетизировать, но само собой это опенсорс и от тебя ожидают чтоб ты все бесплатно все сделал, а тебе за это по губам провели и по плечу похлопали.

Как же орно с этой хуйни
>Шиндопроблемы вполне вероятны
зря ты так, у меня на винде qlora запускается на двух гпу, а вот fsdp хуюги не работает даже под линупсой, хотя утверждается, что все ок.



Решил поговнокодить с сеткой, кинул ей свои старые эксперименты с нейросетками, задача классификации по датасету ириса. Она переделала код, я скинул ей ошибку, пропустила одну функцию, написала, добавил.
Полностью переделанный сеткой код, оптимизированный как я просил, заработал с 2 раза.
И даже че то мне показывает, только я нихуя не понимаю что, лол
Нихуя уже не помню.
Спрашиваю че за хуйня, ответ не убедительный, там чет другое должно быть. Короче забавно, щас буду разбираться сидеть
Полностью переделанный сеткой код, оптимизированный как я просил, заработал с 2 раза.
И даже че то мне показывает, только я нихуя не понимаю что, лол
Нихуя уже не помню.
Спрашиваю че за хуйня, ответ не убедительный, там чет другое должно быть. Короче забавно, щас буду разбираться сидеть
Утверждение, что Ollama - это "неуклюжая и неудобная обертка вокруг Llama.CPP", не совсем точно. Ollama - это инструмент, построенный вокруг Llama.CPP, который автоматизирует процесс шаблонизации запросов к чату в формат, ожидаемый каждой моделью, а также автоматически загружает и обрабатывает модели. Это облегчает использование Llama.CPP, особенно для тех, кто не знаком с его тонкостями.
Ollama открывает практически все возможности Llama.CPP, позволяя глубоко настраивать параметры моделей и использовать Modelfiles для настройки существующей библиотеки моделей или импортировать gguf-файлы напрямую, если нужной модели нет в библиотеке. Он также улучшает Llama.CPP, лучше рассчитывая, сколько слоев модели поместится на GPU, что позволяет добиться оптимальной производительности без необходимости утомительных проб и ошибок.
В целом, Ollama - это не "неуклюжая и неудобная обертка" вокруг Llama.CPP, а скорее инструмент, который упрощает и улучшает использование Llama.CPP для локального использования LLM.
>В целом
Нейросеть, уходи.
Че там по русским фпнтюнам лламы 3 на сегодня?
>Ряяя не нужно
Нужно
>Ряяя не нужно
Нужно
> Нужно
Кому7
> не совсем точно
> построенный вокруг Llama.CPP
> скорее
Над тобой даже твоя сетка угорает, и изменить это ты не в состоянии, потому что барин-дев запретил. Ор выше гор просто.
Кроме сойГи ничего, а что?
>я не упоминал, что он у меня не стоит.
Так это ж очевидно. Под виндой там нихуя не работает, под линупсами работает всё. Так-то я именно что проверял, но не пользуюсь на постоянной основе линупсами.
>разве нет?
На уровне каких-то мелких проблем косяки помню, типа неправильных потерь или ещё чего-то. А так всё работало.
Всем
Как по качеству?
Скажи, чем тогда кобальд отличается, если он тоже построен на llama.cpp? Дегенерат, блять. Но я вижу, что ты далек от понимания того, что такое обертка в принципе.
Тем что он во-первых проще на всех платформах в использовании, а во-вторых, не скрывает от пользователя огромный пласт важнейших параметров. И апи работает по-человечески.
Ты же просто эталлон иллюстрации эффекта Даннинга-Крюгера из палаты мер и весов, а смеешь еще огрызаться. Не смог осилить простые вещи, поимел удачу с цыганщиной - и уверовал, заодно стал отождествлять себя с этой хуетой и люто гореть когда к ней относятся как полагается.
> Всем
Эти все сейчас с тобой, в одной комнате?

Аноны, прошу совета.
Взял 3090. Сейчас в словах стоит 4070ти суп+ 3090.
Че мне с 3080ти делать? Продавать или все таки мутить рейзер.
Докупать бп на 1200 и ставить 3080т снаружи.
Я хз как её поместить вовнутрь ситемника.
А ещё подскажите насчёт рейзеро, какой взять.
Взял 3090. Сейчас в словах стоит 4070ти суп+ 3090.
Че мне с 3080ти делать? Продавать или все таки мутить рейзер.
Докупать бп на 1200 и ставить 3080т снаружи.
Я хз как её поместить вовнутрь ситемника.
А ещё подскажите насчёт рейзеро, какой взять.
> И апи работает по-человечески
Ах, ну и да. Ряяя, это работает, а тут не работает, это типичный маркер неосилятора. Попробуй вникнуть еще раз.
Бля лол, этот шиз чтоли реально сам все это писал?
Задокументированный баг, на которому похуй деву.
Не ну не может человек быть таким дегенератом, а для жирноты какой-то реверс троллинг получается. ты тня чтоли?
С почином.
Закажи на маркетплейсах райзер с кронштейном, типа такого https://www.ozon.ru/product/712622740 а райзер уже по вкусу. Можно там же на озоне, только обрати внимание что 3.0 легкий-гибкий но в 4.0 будет срать ошибками, а 4.0 с толстыми и жесткими шлейфами, его по длине бери с запасом.
Если решишь 3080ти продавать - тогда просто на нем же одну из карточек вынесешь в удобное место чтобы верхняя не задыхалась.
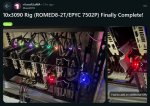
Интересный пример сборки, если денег не жалко.
10xAsus Tuf 3090 GPU: $8500
6xMTA36ASF8G72PZ-3G2R 64GB (384GB Total): $990
3xEVGA SuperNova 1600 G+ PSU: $870
9xSlimSAS PCIe gen4 Device Adapter 2 8i to x16: $630
1xROMED8-2T: $610
5xNVIDIA - GeForce - RTX NVLINK BRIDGE for 3090 Cards - Space Gray: $425
6xCpayne PCIe SlimSAS Host Adapter x16 to 2 8i: $330
1xWDS400T2X0E: $300
10x10GTek 24G SlimSAS SFF-8654 to SFF-8654 Cable, SAS 4.0, 85-ohm, 0.5m: $260
1xEpyc 7502P CPU: $250
1xThermaltake Core P3 (case I pulled the extra GPU cage from): $110
1xNH-U9 TR4-SP3 CPU Heatsink: $100
1xMining Case 8 GPU Stackable Rig: $65
1xLINKUP Ultra PCIe 4.0 x16 Riser 20cm: $50
2xshinic 10 inch Tabletop Fan: $50
2x10GTek 24G SlimSAS SFF-8654 to SFF-8654 Cable, SAS 4.0, 85-ohm, 1m: $50
2xCOMeap 4-Pack Female CPU to GPU Cables: $40
1xFabbay 3/4"x1/4"x3/4" Rubber Spacer (16pc): $20
1xBAY Direct 2-Pack Add2PSU PSU Connector: $20
1xCat 8 3ft.: $10
1xOwl Desktop Computer Power Button: $10
10xAsus Tuf 3090 GPU: $8500
6xMTA36ASF8G72PZ-3G2R 64GB (384GB Total): $990
3xEVGA SuperNova 1600 G+ PSU: $870
9xSlimSAS PCIe gen4 Device Adapter 2 8i to x16: $630
1xROMED8-2T: $610
5xNVIDIA - GeForce - RTX NVLINK BRIDGE for 3090 Cards - Space Gray: $425
6xCpayne PCIe SlimSAS Host Adapter x16 to 2 8i: $330
1xWDS400T2X0E: $300
10x10GTek 24G SlimSAS SFF-8654 to SFF-8654 Cable, SAS 4.0, 85-ohm, 0.5m: $260
1xEpyc 7502P CPU: $250
1xThermaltake Core P3 (case I pulled the extra GPU cage from): $110
1xNH-U9 TR4-SP3 CPU Heatsink: $100
1xMining Case 8 GPU Stackable Rig: $65
1xLINKUP Ultra PCIe 4.0 x16 Riser 20cm: $50
2xshinic 10 inch Tabletop Fan: $50
2x10GTek 24G SlimSAS SFF-8654 to SFF-8654 Cable, SAS 4.0, 85-ohm, 1m: $50
2xCOMeap 4-Pack Female CPU to GPU Cables: $40
1xFabbay 3/4"x1/4"x3/4" Rubber Spacer (16pc): $20
1xBAY Direct 2-Pack Add2PSU PSU Connector: $20
1xCat 8 3ft.: $10
1xOwl Desktop Computer Power Button: $10
Прикольно но 10? Не проще за эти 8500 купить какую нибудь проф карту но быстрее и одной памятью на 80 гб? Или 2, хз сколько они ща стоят
Раз уж разговор про видяхи. Моя 3060ti что потянет максимум? А то я на маке генерю в основное время, на цпу
>А так всё работало.
Работало в смысле выдавало нормальный результат, или просто обучение завершалось без ошибок?
Просто мне лично кажется, что bf16 может втихую херить обучение. Как по мне, лучше перегонять в нормальные fp32, тем более эта операция идёт без потерь.
>Как по качеству?
Как говно вестимо. Тут помножились два фактора- народ пока не научился в тюнинг тройки, и автор сайги всегда выдавал кал.
>Скажи, чем тогда кобальд отличается
Поддержкой обратной совместимости. Жора её периодически дропал, а кобольдом можно запускать самые старые модели.
Меняй 3080ti на 3090, что же ещё. 3080ti максимум неудачна для нейронок, увы.
>Еще и хохлозависимый.
Репортим за политику?
> Я хз как её поместить вовнутрь ситемника.
Алсо в текущем виде она может влезть вдоль задней стенки, но останется проблема перегрева верхней карточки.
Жаль это подходит прежде всего для ллм или для кучи мелких моделей, вот бы можно было бы диффузию тренить разбивая по видюхам, эх.
> Не проще за эти 8500 купить какую нибудь проф карту
За 8500 можешь только хуй пососать, при удачном раскладе пара A6000 и даже не ада. A100@80 от 15 и выше как правило.
>A100@80 от 15 и выше как правило.
В России за лям можно взять, так что уверен, что дешевле. Плюс тут кроме 8,5 килобакса нужно учесть кучу доп железа, чтобы запустить десяток видях, начиная со спец доски и заканчивая райзерами и блоками питания.
У чела кстати ещё карты рандомно попарно RTX NVLINK BRIDGE соединены, я вообще ХЗ, насколько это тут помогает, а 425 бачей на них ушло.
Все написано на главных страницах репозиториев. В прочем ответы на твои вопросы были и здесь, ты их просто яро игнорируешь.
Жди исправления, баги существуют в любом софте. В кобальде их также дохуя и много чего работает через жопу.
> Поддержкой обратной совместимости. Жора её периодически дропал, а кобольдом можно запускать самые старые модели.
Очень полезная фича. Прям необходимая инновация. Так что, это все?
> Репортим за политику?
Проиграл. Ряяяя, постит неудобное, репортим его ребят, кобальд стронг. У вас тут эхочембер похлеще чем в /po/. Такие же охранители с отсутствием пластичности. А самое забавное, что ваша шапка и выбор инструментов полностью скопирован с форчановых дегенератов, хотя даже там шапка лучше и постоянно обновляется.
> В России за лям можно взять
Где?
А там сам можешь чекнуть аукционы и прочее, офк единичные варианты выгодные часто проскакивают, но за ~10к восьмодестигиговую урвать это очень круто.
> вообще ХЗ, насколько это тут помогает
Там где софт использует взаимные обращения - помогает, не так давно в 3090/4090 "анлокнули" некоторые функции торча связанными с этим. В такой сборке даже хз, там вся сборка довольно сомнительной оптимальности по цене, будто ему на заказ васяны наваливали позиций с которых навариваются. Особенно забавно выглядит профессор, на фоне всего этого зажидиться накинуть пару сотен на милан, который сильно лучше в том числе и по работе с периферией.
> Жди исправления
Зачем жрать кактус если можно использовать софт белых людей вместо цыганского высера?
>Так что, это все?
Про остальное уже писали, удобный гуй да запуск с одного файла безо всякой установки.
>А самое забавное, что ваша шапка и выбор инструментов полностью скопирован с форчановых
Иди нахуй, она с нуля писалась совместным трудом.
>Где?
На лохито были варианты, но ХЗ насколько это надёжно.
Между 4_к_м и 6_к заметна разница?
>За 8500 можешь только хуй пососать, при удачном раскладе пара A6000 и даже не ада. A100@80 от 15 и выше как правило.
В принципе есть а40 на 48 гб врам, цены у нас около 500к, тоесть в нормальных странах 3-4к зелени. На ту гору железа что нужна на запуск 10 карт, можно было купить 3-4 таких карты и получить приблизительно 150-200 гб быстрой врам

Забавная картина. Сидят достопочтенные джентльмены из высшей прослойки общества за сигарой и бокалом Шато Марго, обсуждают насущные проблемы искуственного интеллекта в узком круга.
И тут внезапно в клуб с ноги врывается неотёсанная мартышка с чертами лица жертвы инцеста, перемазанная собственным спидозным поносом, прыгает на стол, и начинает верещать про какую-то цыганскую поделку.
А джетльменам и норм, они её кормят за каким-то хуем.
И тут внезапно в клуб с ноги врывается неотёсанная мартышка с чертами лица жертвы инцеста, перемазанная собственным спидозным поносом, прыгает на стол, и начинает верещать про какую-то цыганскую поделку.
А джетльменам и норм, они её кормят за каким-то хуем.
> на заднее ребро системника подцепить
Не понял как это.
Но с тем можно крепить почти как угодно, у него на передней панели, которая заменяет элементы корпуса к которым крепится видюха, на боках есть отверстия. Соответственно можно как угодно крепить напрямую к корпусу через них или с использованием комплектной пластины. Или свою наколхозить, простор для творчества широкий.
> На лохито были варианты
Это 40-гиговые, у барыг стоит цена на самую дешевую позицию а в описании список того что есть.
> есть а40 на 48 гб врам
A6000, то же самое но не нужно пердолиться с охлаждением. По перфомансу они чуть слабее чем 3090. Вот и считай 3 чипа 144 гига врам против 10 более мощных с 240 гигами.
Другое дело что многие вещи не запустить на 24 гигах.
>Другое дело что многие вещи не запустить на 24 гигах.
В этом и суть. Толку от 240 если одну модель даже на 3 размазать уже падение скорости слишком большое. Не знаю играет ли роль нвлинк, делая как бы 1 общую врам из 2, тогда ладно 6 карт еще туда сюда.
Либо у него там тупо сервер где параллельно запущено несколько агентов сеток, тогда сойдет.
>5xNVIDIA - GeForce - RTX NVLINK BRIDGE for 3090 Cards - Space Gray: $425
Чёт не понял как они слинкованы, попарно что ли?
>а40 на 48 гб врам
Проще уж RTX A6000 48Gb брать, цена сравнима, зато охлад колхозить не нужно, турбинка встроена.
>у барыг стоит цена на самую дешевую позицию а в описании список того что есть.
Эх, вот бы лохито банил такие высеры...
>A6000
Не успел.

>попарно что ли?
->
>попарно RTX NVLINK BRIDGE соединены
Там же видно всё. 85 баксов за кусок текстолита с 2 разъёмами, ебануться можно.
>>>/hw/
В мелких сетках - да.
7b, 11b
На счет 13 уже не уверен. Она есть, но заметна ли хз
> Иди нахуй, она с нуля писалась совместным трудом.
Конечно, ты уже даже и не понимаешь/не помнишь, откуда первоначально взял эти знания. У вас даже rentry (который так-то заблокирован в РФ) используется, потому что изначально был спизжен с форчана.
>Ну так надо сосредоточится на их дотренировке, а не клепать 7B лоботомитов.
У 7Б применений выше крыши, просто не кумерских. Если в 7Б возможно утрамбовать больше - надо утрамбовывать больше
Мы о применении к негросеткам, если немного, то можно. Ну или железотред откопать, лол, точно такой был.
>который так-то заблокирован в РФ
Сейчас бы беспокоиться об этом, когда половина интернета разъёбана нахуй блокировками, самоблокировками и прочим говном, и без настроенного VPN буквально никого нет.
> Of course, you don’t even understand/remember where you originally got this knowledge from. You even use rentry (which is somehow blocked in the United States) because it was originally stolen from the 2ch.
Ля сука, сам пост с форча спиздил и обвиняет
> У 7Б применений выше крыши, просто не кумерских
Где?
Офк они имеют право на жизнь, но все потребности покроет буквально стоковый мистраль и десяток файнтюнов для чего-то более специализированного. А тут каждый пилит свой клон без каких-либо отличительных особенностей. В итоге запомнились только опенчат за русский, старлинг для кода, бакллава за мультимодальность, ... и все, а остальные или сношаются в мерджах среди тех, кто не познал рп на моделях побольше, или уже всеми забыты.
Ты перепутал, чел.
То что коммандир хорошо говорит на русском сказал первым я, еще спустя день после ввода поддержки ее в лламу. =) Потом поддержку убрали, потом на неделю все на нее забили, и только спустя две недели хайп вновь поднялся.
Я говорю не о том.
Я говорю о том, что сам промпт целиком делать на русском.
Чем больше промпт на английском — тем больше он путает языки. Помни, что сама нейронка не разбирает где и на каком языке написано, ей на вход подается просто куча токенов, у нее нет особых «для промпта» и «текст персонажа» — все это падает одной кучей. И те, кто много с этим работает, замечает, что крупный промпт на инглише (для корпо-сегмента) убивает весь ответ на других языках.
Вопрос-то она поймет, тут для нее нет проблем. Но ответ даст на том языке, на котором написан промпт.
Дело не коммандере, дело в самом промпте ради качества ответов.
Не-не, пункт про отвечай хуйня, как таковая. А перевод да, этим я иногда страдаю, подбираю.
Но в общем, пока это не популярно, так как чисто русских моделей нема.
Кстати о контексте… ниже.
Не, прирост ума есть, просто он нам уже не очевиден.
А вот жмыхнуть ее может здорово от первого кванта, да.
Так что и правда юзлесс, скорее всего.
Уоу, новый взрыв, разведите его на пять абзацев, пожалуйста!!! =D
Ну, то есть, любая другая обертка, но на минималках? Звучит так. Но оффенс.
———
Короче, покрутил я Llama 3 70B Q5_K_S.
Целиком влазит без контекста.
С 8к контекстом влазит 77 слоев с разбиванием 41,48.
Скорость 4,7 на старте или 1,7 с фулл-контекстом (для DDR4).
Ну, типа, на грани юзабельности.
С 4к контекста влазит 79 слов с разбиванием 43,48.
Скорость 5,2 на старте или 2,2 с фулл-контекстом.
Конечно, после мистралевских 32к (и всяких ярнов и прочей фигни, и квенов и так далее…), 8к в принципе смотрится не очень много.
И для работа может не подойти, ибо со временем сетка быстро забудет, с чего мы начинали.
Для ролеплея — пухлые карточки убьют контекст в нулину.
А уж сокращая ее, хотя и получаешь более-менее нормальную скорость (и ум на 5.5 бпв у нее хорош), но контекст… Боль.
Мой личный вывод — пятый квант для 2 тесла не подходит в большинстве случаев. Разве что, переводчик-кун нашел бы это сколь-нибудь полезным, тут я хз.
ЗЫ
С 79 слоями скорость до 5.6 доходит, кста.
Но один фиг, 4к контекст…
Протести как работает с 16к контекстом и с разными параметрами rope
> сказал первым я
> Я говорю не о том.
> Я говорю о том
> я
> я
Спокойнее
> Я говорю о том, что сам промпт целиком делать на русском.
Нахуй не нужно
> Чем больше промпт на английском — тем больше он путает языки
Просто инструкция "отвечай на русском если контекст не подразумевает иное" и все.
Для кода щас топчик вот эта штучка
codeqwen-1_5-7b-chat
>С 8к контекстом влазит 77 слоев с разбиванием 41,48.
То есть ты чётко видишь где у тебя контекст в режиме rowsplit? Или просто подразумеваешь, что он должен быть на первой карточке даже в этом режиме?
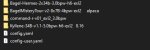
3090 тесты прошла, а значит обновляем пул моделей.
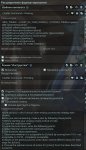
Аноны, посоветуйте каких накачать и для РП/кума и для общения.
Минимум 8к токенов, нехай с 40 гб памяти на 4 сидеть.
На пикриле что у меня осталось, продела путь от 13б до 34б.
Тут все наяривают на Команд-Р, но мне он чет не особо защел, может чего делал не так, но уж очень он пресный.
А вот Бигль 8х7, я прям рекомендую. Очень приятная модель
Аноны, посоветуйте каких накачать и для РП/кума и для общения.
Минимум 8к токенов, нехай с 40 гб памяти на 4 сидеть.
На пикриле что у меня осталось, продела путь от 13б до 34б.
Тут все наяривают на Команд-Р, но мне он чет не особо защел, может чего делал не так, но уж очень он пресный.
А вот Бигль 8х7, я прям рекомендую. Очень приятная модель

>Работало в смысле выдавало нормальный результат, или просто обучение завершалось без ошибок?
Да.
>fp32
Буржуй, блядь. В лучшем случае fp8. Сейчас вот на fp16 ебусь, не получается.
Ну что это за хуйня, куда это годится вообще.
Во сколько обойдется файнтюн такой микромодельки 0.5b или лучше локально ее вообще зафайнтюнить? Прожектор тоже надо файнтюнить вместе с ней или не важно?
https://huggingface.co/qnguyen3/nanoLLaVA
мимо нубик
https://huggingface.co/qnguyen3/nanoLLaVA
мимо нубик
> дрочу слои, дрочу кванты, дрочу параметры и все это чтобы подрочить
> в то же время адекватный человек, уважающий свое время, просто ставить олламу, пулит модель и начинает работать
Вся суть.
> в то же время адекватный человек, уважающий свое время, просто ставить олламу, пулит модель и начинает работать
Вся суть.

>Я говорю о том, что сам промпт целиком делать на русском.
И в чем проблема? Делай на здоровье, я уже сделал, пикрил, тот скрин выше тоже моделью с русским промптом написан. И все скрины что я постил в тред последние несколько дней с русским текстом - все написаны русскими персонажами.
>может чего делал не так
>3.0bpw
Ну ты понял, навернул 3бит обрезок и удивляешься.
Ну и раньше он нормально не поддерживался.
У тебя только 3090 или еще что есть? Если есть что-то еще - можно мику попробовать.
> 0.5b или лучше локально ее вообще зафайнтюнить
Все зависит от твоей врам. В 24гб влезет и 3б.
> Прожектор тоже надо файнтюнить вместе с ней или не важно?
Раз готовый то лучше сразу вместе.
Двачую, в 40 гигов 4битный поместится с некоторым контекстом.
>Двачую, в 40 гигов 4битный поместится с некоторым контекстом.
4 битный коммандер и в 30 гигов влезает с 4к контекста, так что он спокойно может крутить 5км с 8к контекста ,ну, где то так.
Не знаю что там ожидать от сетки на 3 битах, она все равно сломана. Только с 4 начинается что то нормальное.
Ну или мику, да. Хотя мне кажется там мало контекста войдет.
3090 и 4070т суп. 40 гб.
Мику какого кванта брать, подскажи пожалуйста. И какую лучше. Миднайт?
Вообще как правильно расценивать размер ЛЛМ, не знаешь?
Я вот обычно брал 70% по размеру самих файлов .safetencor, и остальное на контекст оставлял.
Но например злоебучий Коммандер чет совсем адский размер контекст имел.
Он всегда падает на первую карточку.
Может я не прав, но при загрузке видно, что в начале грузятся слои (типа занято 21/23,5 гига), а потом прилетают слои (23,5/23,5). Либо, если выставить много — прилетает ошибка о переполнении.
На вторую карту тоже прилетает чуток (мегабайт 10-100), но это не критично.
Вообще, мне всегда казалось, что он прилетает на первую карту, это кто-то еще полгода назад сказал, а я поверил. Ну и, вроде бы, соответствует правде, я хз.
Когда я ставил равное количество, то на второй был недогруз, а потом вылетало из-за нехватки памяти. Но, может, то был единичный случай, и я не прав.
Тогда мои замеры деления хуйня из под коня и я тратил время в пустую. =)
Не-не, я не про это. Это карточка персонажа, так я уже сто лет делаю.
Я о том, что у тебя на А.
Ну слушай, без баланса я нахуй прошел при загрузке модели с ошибкой контекста.
А с балансом, который подобрал — грузится норм.
Видимо, все же падает на первую. Да, с row_split в том числе.
Ну, в теории, лень тестить подробнее.
> Все зависит от твоей врам. В 24гб влезет и 3б
8 гигов хватит получается?
> Раз готовый то лучше сразу вместе.
Пиздос. Надеюсь там не сложно разобраться
>Обучаю, как всегда, творением Хуюги.
это под виндой работает? или как аксолотль - только под линух?
Хочу собрать отдельную машину по LLM пока на одной Тесле П40 с возможными дополнением
Выбираю боле менее бюджетные варианты базы на чем собирать:
1.https://pg.asrock.com/mb/Intel/Z390%20Phantom%20Gaming%20X/index.ru.asp
2.https://www.asus.com/ru/motherboards-components/motherboards/all-series/rampage_v_extremeu31/
Первый вариант более современный, но сможет только 3 Теслы с другой стороны на карте есть собственный видеовыход.
Второй вариант можно воткнуть Зеон, и память четырех канальная, но с меньшей частотой.
Что лучше выбрать?
Выбираю боле менее бюджетные варианты базы на чем собирать:
1.https://pg.asrock.com/mb/Intel/Z390%20Phantom%20Gaming%20X/index.ru.asp
2.https://www.asus.com/ru/motherboards-components/motherboards/all-series/rampage_v_extremeu31/
Первый вариант более современный, но сможет только 3 Теслы с другой стороны на карте есть собственный видеовыход.
Второй вариант можно воткнуть Зеон, и память четырех канальная, но с меньшей частотой.
Что лучше выбрать?
Как же я ебал обоссаный питон. Абсолютно каждая установка любого дерьма на базе питона - это дополнительно пару часов ебли с зависимостями
Под виндой работает на 10%. Потому что под виндой не работает ни дипспид, ни анслот, нихуя. Так что чисто формально да, работает.
Замер перплексити занимает ~1 час для Llama 3 70B.
Стока оставлять мои старушки-теслы работать я че-то как-то не уверен, там еще и нагрузка прыгает…
Сорян, тут я сольюсь, видимо.
Стока оставлять мои старушки-теслы работать я че-то как-то не уверен, там еще и нагрузка прыгает…
Сорян, тут я сольюсь, видимо.
>Мику какого кванта брать, подскажи пожалуйста
4, какой влезет.
Лучшее соотношение размер/качество у IQ4_XS, лучшее качество у Q4_K_M.
>Вообще как правильно расценивать размер ЛЛМ, не знаешь?
Опытным путем. Например было выяснено что лучше закинуть не все слои на видеокарту, оставив часть слоев на оперативке, чем закинуть все слои на видюху и оставить оперативку в одиночку разгребать контекст. Так я командира на одной 4090 с 8к контекстом запускаю с оффлоадом на видеокарту 31 слоя из 41 со скоростью 5-6 токенов в секунду, например.
У меня есть устаревшая таблица для первой ламы с устаревшими квантами:
https://docs.google.com/spreadsheets/d/13ERoJTi0Z7vMcmoNBWxVeV0n2KOJGg39i-Iz-AfIGr0/htmlview
Почему-то у меня llama-3-8B-instruct работает более менее норм, а llama-3-8B шизит. Там какие-то разные настройки нужны или что? Подскажите что лучше ставить в настройки семплера? Не могу понять. Или может я не ту версию модельки качал?
Говорили тебе - ставь кобальт.
Да там хуй проссышь сейчас, в чем дело.
Мне нужно запустить сейфтензор модель
Миниконда с отдельными пространствами, и нет проблем с кодом
Только места жрет дохера
Но любителей нейросеток не испугать несколькими лишними гигабайтами
Ну как сказать. У меня на диске свободно ~10 ГБ. Рот ебал этой миниконды с пространствами и рот ебал пайтона ебучего, который не умеет в совместимость даже самого себя.
Щас ссд дешманские, не жлобься купи нормальный 1-2 терабайта и забудь о ожиданиях и нехватке места
Так у меня уже 2 куплено. Сколько еще купить надо? Мне бы и память докупить, чтобы 70В гонять. А денег-то нет.
Все нейросетками забил? У меня пока только 600гб
Ага. Ща ставлю убабугу. Там миниконда в бандле если что. В итоге выбило запуск с ошибкой. При повторном запуске пишет что нет yaml либы. Чекнул в интернете, пишут установить вручную через requirements.txt. Поставил, все равно пишет что его нет. Поставил вручную через pip install pyyaml, продолжает писать тоже самое. Я нихуя не понимаю yaml импортится из pyyaml вогбще или нет. Язык говна блять
Это несложно. У меня тер забит ллмками, фордж, поломатик, кохя, фукус, комфи, куча моделей, топаз
По Asrock подробные обзоры поищи. Так-то вариант кажется неплохим, но конкретная модель может подвести.
С Асусом вроде получше вариант, но опять же - видеоядра нет и это не HEDT, а значит лотерея.
Если железо ещё и не новое, то оба варианта дрянь.

>Поставил, все равно пишет что его нет. Поставил вручную через pip install pyyaml
Так ты в систему небось поставил, а надо в venv убы.
Ну не все. Еще музыку пытался писать. Музыкальные библиотеки весят не меньше нейронок. В итоге 6ТБ забито полностью.
>Щас ссд дешманские, не жлобься купи нормальный
Нормальный - это NVMe c DRAM-буфером, чтобы 40-50 гигов писались и грузились быстро. А это уже не так дёшево.
Да я ебу куда там надо, я не пишу на питоне и никогда с ним не сталкивался, но приходится из-за того что все ИИ построено вокруг него. Все эти пактеные менеджеры говна, конды, миниконды, venvы, pip и pip3 (чем оно блять вообще отличается?). НЕНАВИСТЬ. Спасибо за подсказку
В консольке жмешь cd <путь каталога>
Дальше venv\Scripts\activate
Если пространство уже есть, тебя закинет туда. В консоле будет в начале строки написано (venv)
Чтобы создать свою среду, нужно ввести команду: python -m venv <environment_name>
Надеюсь, не наебал нигде. Петухон - говно, кстати, а не язык.
Сейчас будет смертельный номер - запуск 6-битной сайги-лламы-3 с 16к контекстом и стресс тест этой хуйни!
> Дальше venv\Scripts\activate
Не, походу тут нет venvа. Тут миниконда и я хз как оно работает. Надо ли какой-то специальной командой к ней в shell входить
> 5км
Не то чтобы в 40 гигами есть смысл в жоре.
> Мику какого кванта брать, подскажи пожалуйста
Она, пожалуй, единственный повод для этого. 4km тот самый единственный и оригинальный https://huggingface.co/miqudev/miqu-1-70b отсюда, остальное уже будет пережатием с потерями. Не факт что она влезет.
> 8 гигов хватит получается?
Наверно, нужно пробовать.
По поводу тренировки, когда она идет с нуля то в начале морозят ллм и тренируют только проектор чтобы он начал как-то нормально работать. Потом размораживают и тренируют все связку.
Где можно столкнуться с еблей? Гит клон @ запуск батника или шелл скрипта с ответом что у тебя не амудэ и не старая архитектура хуанга. Все. Буквально ничего делать не надо.
Блядь, просто удали все, скачай заново, потом запусти батник update_wizard_windows.bat и там сначала нажми А, потом В
>Она, пожалуй, единственный повод для этого. 4km тот самый единственный и оригинальный
В его случае - 40гб врам и современные карты - только exl2-вариант. Да, с потерями, но она будем меньше и быстрее и точно влезет.
У меня мак
У меня мак
Это основная проблема, но питон тоже сосет. Короче иду лучше курить как конвертнуть safetensors в gguf
Оуууу, да, тут тяжелый случай. Ну, земля пухом, зато у тебя относительно шустро будет llamacpp работать на всей рам.
> Короче иду лучше курить как конвертнуть safetensors в gguf
Если хочешь 16бит или q8 - просто воспользуйся скриптом convert-hf-to-gguf.py и закажи q8 тут тоже пихон, как видишь.
Алсо при чем тут пихон, ты же буквально должен гореть с любой сборки чего бы то ни было кроме совсем тривиальных вещей, там же даже с npm веселье.
> У меня мак
Пиздец. Ну это приговор.
> Алсо при чем тут пихон
Часто пакетов некоторых нет на мак и приходится вручную качать лругие версии пакетов. Плюс тут на маке особый пиздец, ибо есть системный питон и питон, который ты устанавливаешь поверх его, его не заменяет. В итоге всегда путаница с версиями.
> ты же буквально должен гореть с любой сборки чего бы то ни было кроме совсем тривиальных вещей
Не, у меня так только на линуксе было.
> там же даже с npm веселье.
С нам все идеально, говорю как фронтенд макак
У меня есть шиндошс машина так-то, мак так для души, я просто сейчас не дома и есть только мак
> мак так для души
За мак вообще не шарю. Используй гопоту и гугл. Вместе может что и сделаете. А я рот ебал и петухона, и надкусанного яблока.


Короче поделюсь своим новым опытом говнокода. Раньше у меня не было настроения так поиграться, да и сетки умной и мелкой тоже. Сам я кстати не погромист, так, учился самоучкой.
Щас игрался с codeqwen-1_5-7b-chat-q8_0.gguf, контекст до 64кб, опенчат формат.
У меня были старые файлы, когда я писал тренировку нейросети классификатора для датасета ирис. Учебная хуйня для нейросетей, по сути примитивный код на питоне без всяких гпу ускорений в 1 поток невероятно быстрого питона, ладно хоть с нумпи.
Похуй.
Короче, тренировочный файл гоняет эпохи и если доходит до нужной мне точности кидает веса в файлы. 130 строк говнокода.
Которые потом открывает инференс файл, 55 строк говнокода, проверяя точность на том же датасете.
Создал простейшего ассистента кодера в таверне, и кинул ему код попросив проанализировать его. Он сделал это, пик1, потом попросил оптимизировать код, пик2. Делал так несколько раз, тупо вставляя его же код в тот что он писал после первой оптимизации.
Покатав туда сюда у меня получился реально работающий код, похудевший на 10 строк. И скорей всего исполняющийся быстрее, не гонял профайлер
С инференс частью работал в этом же диалоге, тупо сказав боту что это вторая инференс часть одного проекта. И что нужно сделать ее совместимой с первой частью.
И он понял, пик 3. Попросил оптимизировать, и он сделал это с первого раза даже, пик4.
И все, инференс часть стала всего 45 строк.
Прогнал тренировку, прогнал инференс. Работает.
Хуй его знает конечно как правильно, но лучше того говнокода, что накопировал и настроил я.
И ведь делала это такая мелочь, не сраный гпт4 или клод3.
Кнопка сделать заебись уже не кажется так далеко.
Щас игрался с codeqwen-1_5-7b-chat-q8_0.gguf, контекст до 64кб, опенчат формат.
У меня были старые файлы, когда я писал тренировку нейросети классификатора для датасета ирис. Учебная хуйня для нейросетей, по сути примитивный код на питоне без всяких гпу ускорений в 1 поток невероятно быстрого питона, ладно хоть с нумпи.
Похуй.
Короче, тренировочный файл гоняет эпохи и если доходит до нужной мне точности кидает веса в файлы. 130 строк говнокода.
Которые потом открывает инференс файл, 55 строк говнокода, проверяя точность на том же датасете.
Создал простейшего ассистента кодера в таверне, и кинул ему код попросив проанализировать его. Он сделал это, пик1, потом попросил оптимизировать код, пик2. Делал так несколько раз, тупо вставляя его же код в тот что он писал после первой оптимизации.
Покатав туда сюда у меня получился реально работающий код, похудевший на 10 строк. И скорей всего исполняющийся быстрее, не гонял профайлер
С инференс частью работал в этом же диалоге, тупо сказав боту что это вторая инференс часть одного проекта. И что нужно сделать ее совместимой с первой частью.
И он понял, пик 3. Попросил оптимизировать, и он сделал это с первого раза даже, пик4.
И все, инференс часть стала всего 45 строк.
Прогнал тренировку, прогнал инференс. Работает.
Хуй его знает конечно как правильно, но лучше того говнокода, что накопировал и настроил я.
И ведь делала это такая мелочь, не сраный гпт4 или клод3.
Кнопка сделать заебись уже не кажется так далеко.
А где код и какая его цель?
Тебя прям получившийся код интересует?
Цель была когда то - потыкать что такое нейросети и примерно разобраться как они работают, на примитивном примере. Год назад кажется все это делал. Сейчас просто вспомнил и решил скормить сетке, заебенчик вышло, даже несмотря на косяки. Просто говоришь боту где косяк и он его исправляет.
Код не сложный, да.
Спасибо за тест, пожалуй скачаю поиграться.
Скинь свою версию и версию бота. Чисто посмотреть. Заодно хочу заценить как llama-3-8B справится.


Сейчас еще попросил добавить графики в инференс часть и бот мне такой - окей. И это я тупо скопировал, вставил, скачал либу, и запустил. И вот оно.
Щас кину файлы на катбокс для любопытных
Так, вот скинул 2 папки с 2 версиями. Проверил, вроде работают. Хз как по качеству.
https://files.catbox.moe/sdsqtd.zip
iris-neuro новая
https://files.catbox.moe/sdsqtd.zip
iris-neuro новая
Благодарю.
> llama-3-8B
Я кстати вначале на инструкте ллама 3-8b делал это, еще на карточке гпт-6. Она умнее и предлагала идеи сильнее меняющие код, и легче понимала что от нее нужно. Но мне стало лень разбираться в ее сложном коде, в котором были ошибки.
Но я все таки вспомнил что скачал кодквен и запустил его попробовать в задачах.
Кстати я уже писал когда то, может не работать на куда, выдавая билеберду. Тогда с вулканом запускать.
Ну, для тех кто будет на кобальде тыкать.
> может не работать на куда, выдавая билеберду. Тогда с вулканом запускать.
Вот же ебля. Спасибо хоть предупредил.
Уточню, что щас я на новом кобальде запустил и все работало на куда. Но если кобальд старый, или другая видеокарта то хз.
Щас работает, 2-3 дня назад на старом кобальде ебало мозги.
Понял, спасибо. Кобольд обновлял недавно.
Нейросети конечно пиздят с уверенным видом, но какой же это удобный метод обучения. Просто гугл который сразу отвечает тебе на твой вопрос. Сейчас во всем мире будет бум самообучения, для тех кто этого хочет. В любой интеллектуальной сфере, по сути.
>пиздят
Прямо сейчас может быть и нет. Но потом будет попроще, да. Опять же, смотря чему обучаться. Проганье легче будет идти, а другие области от сеток зависеть особо не будут.
А почему бы отдельным вызовом модели не формировать строчку "инвентаря" в фиксированном месте контекста? Сейчас это например кольцо, кинжал и гондон, а вот теперь я залутал ещё и броник, и отдельным вызовом ЛЛМка его распарсила из собственного ответа и присобачила к этой строке?
Будет такое работать, или я дохуя хочу эта хуйня стриггерится лишь от одного упоминания нерелевантного предмета (гондона) в бою? Тогда может быть опять же вызывать и определять применимые предметы. пиздец скорость упадёт конечно
Не совсем понятно, а в чем отличие от world info?
Ну пусть будет ворлд инфо, главное чтобы отдельным вызовом модель сама его формировала, а не вручную туда броник закидывать.
Я не помню, чтобы в таверне была такая опция, чтобы моделька генерила тебе строки прям в world info, так что копировать все равно придется. Но если ты не используешь опцию summarize, то можешь попробовать припахать ее к делу. Например, у тебя есть
Summary prompt [Pause your roleplay. Summarize the most important facts and events that have happened in the chat so far. If a summary already exists in your memory, use that as a base and expand with new facts. Limit the summary to {{words}} words or less. Your response should include nothing but the summary.], который можно заменить на [Pause your roleplay. List all items that {{user}} have right now in the following format: ```{{user}}'s items {list of items}```. If a list already exists in your memory include new items that {{user}} got recently and remove items that {{user}} lost. Your response should include nothing but the list of items.]
Если хочешь прям чтобы в world info ебашило или авторские заметки, то здесь наверное прогать надо.
Ну и да, тебе скорее всего нужна довольно умная моделька, чтобы она не проебывалась со списком предметов. Маленькая ллама-3 не справится. Здесь либо командир, либо хорошая 70В.
Чтобы сетка кодила хорошо, нужны:
- RAG по имеющейся кодебазе
- поиск в тырнете (phind так делает, и на мелкосетке умудряется давать поразительно хорошие ответы, хотя конечно гопота-4 кодит лучше)
- заточка чисто под эту задачу.
Думаю производная командира чисто под код будет пиздатой. (он тренился под файнтюны же)
> - поиск в тырнете (phind так делает, и на мелкосетке умудряется давать поразительно хорошие ответы, хотя конечно гопота-4 кодит лучше)
Можешь подробнее, что это такое и как это работает? Если подумать, то опция отлично сработает не только для кодинга.
phind.com это что-то вроде копайлота с поиском, у них там кроме гпт-4 есть и своя бесплатная сетка, мелкая но сравнительно передовая, которая в паре с поиском неплохо даёт рекомендации по библиотекам или языковым фичам под запрошенную задачу. Кодит хуже чем гпт-4, потому что меньше и тупее, но рекомендует лучше и заточена под задачу лучше.
Если это ябл силикон с дохуём памяти, так даже пиздаче для больших сеток.
Прикольная. То есть ее можно и локально поставить? А как прикрутить к ней поисковой движок или заставить пользоваться гуглопоиском обычным, например?
Кстати, что-то в таверне похожее нашел. SillyTavern-1.11.7\public\scripts\extensions\third-party\SillyTavern-extras\modules\websearch
Оно работает?

Платина. Сколько слоев можно вынести на видяху? Не nvidia intel arc поэтому ограничения с пересчетом по CUDA из шапки для меня имеет смысла.
>для меня не имеет смысла
быстрофикс
У разных карточек слои разной толщины, пробуй и смотри в консоль
> пробуй и смотри в консоль
А на что смотреть? koboldcpp использую
Учитывая очень высокий уровень лламы 3 при скромном размере, какой теоретически самый маленький и дешевый мини компьютер будет достаточен для неё на 15 т/с?

>Не nvidia intel arc
Лол, оно вообще хоть как-то пашет?
Смотри короче в диспетчере, чтобы память была не вся занята. Ну и пробежись глазами по всему выводу, там пишется объём.
> Лол, оно вообще хоть как-то пашет?
На koboldai 4 дня безуспешно пытался завести. Потом иэуаидел этот тред. На koboldcpp заработало искаробки вообще без пердолинга
> Смотри короче в диспетчере, чтобы память была не вся занята.
Ему вообще похуй как будто бы. Ставишь 5 слоев и он забивает 7,3 из 8
Ставишь 49 слоев и он так же забивает 7,3 из 8 по диспетчеру
> Ну и пробежись глазами по всему выводу, там пишется объём.
Вот тут пожалуйста подробнее. Я пытался глядеть во все и так и не понял что мне нужно
>Вот тут пожалуйста подробнее.
Скриншоты же... Покажи похожие места, будет видно. Да и настройки самого кобольда перед запуском покажи. Да про скорость расскажи. Ты ж первый тут с интелом (наверное, я склеротик).
> Скриншоты же...
Отпугнуло что везде написано cuda. Подумал что просто хватаешься.
>Покажи похожие места, будет видно.
>Да и настройки самого кобольда перед запуском покажи.
Скину уже как к компу вернусь.
> Да про скорость расскажи.
Утром прям перед выходом пробовал вынести 24 слоя. Генерило примерно 3 токена в секунду. Модель из шапки.
Ну как карта вообще?
И зачем брал?
> Ну как карта вообще?
Карта как карта. Вообще никаких бед не знал, пока не пришел к нейронкам.
> И зачем брал?
Да где-то в инете увидел решил попробовать ибо за такие деньги такая-то мощность ух
Да, база.
Тебе надо, чтобы только верхняя 0/8 заполнялась, а в 0/24 было ДО 8, ибо это выгрузка в оперативу как раз.
https://huggingface.co/chargoddard/llama3-42b-v0
базовая от гуру франкенмержей появилась
базовая от гуру франкенмержей появилась
> mmlu 0.7669
Знатно порезало, но всё ещё выше мистраля медиума.
А чего EXL2 на низких квантах такой поломанный? Я даже погуглил манятесты и внезапно 70B у Жоры с нормально откалиброванным IQ2 (2.4bpw там) проходит их почти так же как Q4, максимум пару тестов проваливает из 50, а вот EXL2 уже на 3.5bpw отлетает с десятком провалов. Тестил третью лламу EXL2 2.4bpw - сломанная нахуй, ни одного ответа без поломок не смог получить - то форматирование сломано, то вставляет слова мусорные, то после конца сообщения не останавливается и улетает в бред, скорость 18-19 т/с. При этом IQ2 работает без единой поломки, те же 18-20 т/c. Хотя по PPL вроде всегда норм было у EXL2, видимо он нихуя не решает на деле.
https://huggingface.co/HuggingFaceM4/idefics2-8b
какая та новая охуенная мультимодалка, воспринимаемое разрешение изображения до 980х980 и еще куча всяких вич
и какого хуя вахтер все ночные сообщения потер, они так то по теме ии и его будущего были
какая та новая охуенная мультимодалка, воспринимаемое разрешение изображения до 980х980 и еще куча всяких вич
и какого хуя вахтер все ночные сообщения потер, они так то по теме ии и его будущего были
>охуенная
~35 ГБ. Даже на грядущих 5090 не пойдёт да и вообще, я ебал этот питон. А герганыч до сих пор когвлм и квенвл не запилил, чтобы можно было на нищесборках гонять.

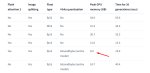
>какая та новая охуенная мультимодалка
Пару дней назад так и не смог запустить даже на бубе с вручную обновлёнными трансформерами.
>и какого хуя вахтер все ночные сообщения потер
Там же срач был про комми, всё правильно сделал. И вопросы тоже потрут, и мой ответ, и небо и аллаха.
Я так понял конкретно это модель сделана на 7b мистрале 0.1 и какой то клип модели что добавило еще миллиард параметров до 8b
Ну и кучи датасетов и методик обучения мультимодалок для лучшего эффекта, как они пишут аналогично размерам модели на 10 больше
коммоми срач не жалко, а обсуждение того как ии поможет в обучении жалко
>на 7b мистрале
Плохо, если так. Опять никаких языков (на достойном уровне), кроме английского. В этой нише уже есть ллава 1.6, которую вроде нахваливали недавно. Я всё жду мультиязычных.
> Я всё жду мультиязычных.
Уверен все это применят к новенькой ллама 3, так что просто подожди и все будет
Да и ллама 4 хотели делать сразу мультимодельаной на сколько помню новости
>Я всё жду мультиязычных.
Увы, все мультиязычные всё равно проседают в производительности на языках кроме английского. Пока не сделают твёрдый, чёткий перевод любого языка во внутренний язык модели, пользование чем-то кроме английского будет приносить боль и страдание.
>на сколько помню новости
По этим же новостям должны были выпустить моель "в 2 раза больше предыдущей". Но я не вижу 140B лламы 3. Зато сейчас обещают 400B модель. Впрочем, пока я не вижу и её.

Да любой с 8 гб видеопамяти
Блин, нужна в диапазоне 13-30В чтобы в 24 гб влезала. Почему у них проблемы именно с этими размерами?
>Почему у них проблемы именно с этими размерами?
Слишком хороши и выгодны.
Потому что нужны.
А нужное — продают.
Бесплатно менее нужное.
Пробовал, запустилась?
Поставил качаться, через пару дней отпишу.
Еще одна мультимодалка, на этот раз мелочь для мобильных устройств
https://huggingface.co/vikhyatk/moondream2
>Пробовал, запустилась?
Нет, просто посмотрел что в тренде на обниморде, чекаю иногда че там интересное появляется
По описанию топ пушка, как на деле не поймешь без тестов.
https://huggingface.co/vikhyatk/moondream2
>Пробовал, запустилась?
Нет, просто посмотрел что в тренде на обниморде, чекаю иногда че там интересное появляется
По описанию топ пушка, как на деле не поймешь без тестов.
>По описанию топ пушка
Это пишут под любыми моделями, на тренировку которых затратили больше чем пару чашек кофе (или гпу-часов эквивалентной стоимости). Это васян может себе позволить честно написать "ну я тут какую-то хуйню натрейнил, вроде что-то осмысленное пукает, пробуйте, может зайдёт". А пилителям грантов и инвестиций надо нахваливать и перемогать в тестах гопоту4 в любом случае (вне зависимости от реальных успехов), иначе грантов и инвестиций не будет.
Они все поломанные на низких квантах, тут без вариантов, даже q2k, который 3.35бит довольно шизоидный. Причин конкретно твоего случая может быть множество: кривая калибровка, отсутствие нужного конфига в папке с моделью или кривой, квантование на самых первых дев-коммитах к лламе 3, которые позже были пофикшены.
По степени отклонений распределения вероятностей токенов, что напрямую говорит о соответствии поведения кванта оригиналу, exl2 стабильно лучше gguf при той же битности. Новые кванты нужно потестить офк, но чудес ожидать не стоит.
> охуенная
Уверен? Интересно как там с множественными пикчами будет работать. Визуальная часть, конечно, побольше чем в популярных, может что-то и выйдет.
> по теме ии и его будущего
Аги-шиза от конспирологов?
Вторая версия голимая. Хз, автор или решил подтянуть под бенчмарки, или как-то ошибся в датасете/тренировке, но оно получилось довольно слепое и глупее первой. А она, напомню, крайне прилично описывала nsfw и 2d.
>Аги-шиза от конспирологов?
Там было то что сетки хороши для обучения чему то или самообучения, без всякого упоминания о всемогущем аги
>Вторая версия голимая. Хз, автор или решил подтянуть под бенчмарки, или как-то ошибся в датасете/тренировке, но оно получилось довольно слепое и глупее первой. А она, напомню, крайне прилично описывала nsfw и 2d.
Да? Интересно, наверняка мозги пострадали изза большей настройки на восприятие изображений. Как и ллава та же тупее своей основы изза переобучения с потерей мозгов. Ну а с потерей мозгов сетка не может нормально работать с тем что видит, от того и слепее. Но это так, размышления, хз как это работает.
Как бы да, но нет. Чем новее модель тем она лучше в большей части случаев. К тому же то что они используют умную сетку и жирный визуальный кодер так же внесет свой вклад. Это я так понимаю что то вроде когвлм на минималках. Но все еще должно быть лучше ллава, так как сделано по новым "рецептам"
Ну вон выше посты про код, его ревью, множественные запросы, вполне норм же.
Хуй знает что там пострадало, может она стала лучше в чем-то другом, текст так очень хорошо видит, но первая была лучше а эта пиздец галлюцинирует и сочиняет лишнее, упуская важные детали.
> они используют умную сетку
На этой умной сетке мультимодалки были уже пол года назад.
Сберовскую лучше бы потестили, она тоже на мистрали но уже с файнтюном в том числе на русском и с интересным проектором.
>На этой умной сетке мультимодалки были уже пол года назад.
Были, но не с таким методом обучения и не с таким визуальным проектором
> степени отклонений распределения вероятностей
Уже сто раз обоссали это говно, даже более бесполезное чем сравнение PPL между разными моделями.
https://www.reddit.com/r/LocalLLaMA/comments/1c9zc1j/gguf_of_llama_3_8b_instruct_made_with_officially/
Типо нормальная не поломанная ллама 3 8 инструкт, использовать с обновленными бекендами
Типо нормальная не поломанная ллама 3 8 инструкт, использовать с обновленными бекендами
Жду фикса потеряноруинного. И семидесятки, да.
пишут там же что на кобальде уже норм работает

Чтобы кобольд, да ещё и без пары горячих фиксов? Не верю.
Хотя тут хайгитлерфейс прилёг, лол, мешают гоям получить доступ к лучшим моделям как могут.
На мобильной 4090 что можно попробовать?
врам скока и оперативы
На фоне отсуствия русской локализации в играх задумался об такой херне.
Допустим у нас есть перевод с английского на французский. Есть и оригинал, и перевод. Можно ли проанализировать оригинал, и полученны данные использовать для перевода на другие языки? Это вообще будет иметь смысл?
Или это не имеет смысла и проще скормить просто анлийский текст.
Допустим у нас есть перевод с английского на французский. Есть и оригинал, и перевод. Можно ли проанализировать оригинал, и полученны данные использовать для перевода на другие языки? Это вообще будет иметь смысл?
Или это не имеет смысла и проще скормить просто анлийский текст.

Что там? Собакашиз уже пощупал холодную собаку, а то мне лень.
64 оперативка, врам 16 на мобильной
Проц 13th Gen Intel(R) Core(TM) i9-13980HX 2.20 GHz
Ладно, сам пойду тестить, как всегда...
Быстрая генерация на видеокарте, можешь попробовать любую модель до 20b,квантованную в подходящем размере.
Гораздо медленнее, но умнее, даже 70b можешь попробовать
Скачай по инструкции в шапке, или ту модель что указана или опенчат и играйся.
А мог бы ванильным сервером Жоры пользоваться. Он быстрее этого кала на питоне, в таверне есть поддержка уже давно. Заодно можно без дрочева пересобирать побыстрому с нужными фичами например кванты к-кеша, можно экономить память на жрущем команд-р и под свою карту, а то Жора/кобольд под паскали собирают.
> кванты к-кеша
А как их включать на сервере? Или надо собирать с определенными ключами? Че по падению качества?
ОбнялЛицо нифига не отвечает, кто то для кодинга уже на лламе3 что то заюзал? Как впечатления?
> Че по падению качества?
С чего бы ему быть, это же кеш токенов квантуется, а не веса.
Он тоже важен для предсказания токенов, точнее говоря его точность
Хорошую вещь квантом не назовут
А с LLaMA 3 ещё не разобрались?
В принципе работает, можешь и ее по ссылке выше. 8b, но довольно умна. Только промпт формат к ней еще не до конца понятен, и готового в таверне нету. В начале треда есть 2 тестовых варианта для таверны.
Короче советовать ее новичку я пока не буду
В EXL2 просто галка "кешировать контекст в 4 бита".
обидно конечно что ллама-3 теперь такая же соевая как и чатгопота, а может даже и хуже, уже известный прикол со сменой "assistant" на "{{char}}" почти не помогает.
юзал вот эту фикшенную, по последнему PR llama.cpp :
https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
юзал вот эту фикшенную, по последнему PR llama.cpp :
https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
Просто катай базовую версию
так бэйс версия ж просто autocomplete модель, будет шизить в чате :/
Не, она норм работает, просто не так умна и надрочена на промпт формат
Но все еще ллама3
Как же хочется ллаву нормальную на основе ламы 3 уже. Хочу русек
прекрасно, обнимающаяморда лежит.
Да, опять упала. А я успел скачать, хехехе
Да я пророк нахуй
https://www.reddit.com/r/LocalLLaMA/comments/1ca8uxo/llavallama38b_is_released/
А еще вот https://www.reddit.com/r/LocalLLaMA/comments/1c9l3cp/l3solana8bv1_a_generalist_instruct_conversational/
файнтюн от автора фроствинд и Fimbulvetr
главное что бы обниморда не сдохла совсем
https://www.reddit.com/r/LocalLLaMA/comments/1ca8uxo/llavallama38b_is_released/
А еще вот https://www.reddit.com/r/LocalLLaMA/comments/1c9l3cp/l3solana8bv1_a_generalist_instruct_conversational/
файнтюн от автора фроствинд и Fimbulvetr
главное что бы обниморда не сдохла совсем
https://www.reddit.com/r/LocalLLaMA/comments/1c9ydld/we_should_explore_samplers_again/
Обсуждение настройки семплеров
Обсуждение настройки семплеров
Сиди на 70В, у меня пока ни разу не проскочила соя. И оно заебись работает в режиме русские сообщения-английские ответы. Я в куминге пробовал некоторые нехорошие слова использовать со сложными мувами на русском, он отлично понимает что я хочу, в отличии от той же мику. Да и вообще оно явно лучше комманд-р, который 35В.
А что случилось с хугой, его фемки дудосят?
Они бы ещё обсудили на какую карточку дрочится лучше, шизы.
> Уже сто раз обоссали это говно
Где?
> даже более бесполезное чем сравнение PPL
Сильное заявление, тащи пруфы. Заодно посмотри текущие критерии калибровки, сделаешь много открытий.
8б в 8 битах, из старых 20б, остальное с выгрузкой.
Если наберут нормальную и репрезентативную картину - почему бы и нет, правда эффект всеравно будет слабый. Главное - фиксировать модель с которой тестируется, чтобы попытки расшевелить 7б или шиза yi не распространялась на всех.
Она еще слишком сырая/не адаптированная к рп. Какие форматы не крути, в некоторых ситуациях начинает ловить затупы, а то и лупится. Да, она дохуя умная, выдает интересный текст, соображает, даже фантазия и отличное понимание абстракций присутствует, в общем соответствует размеру, но в текущем виде все еще не подходит. Коммандер лучше в этом отношении, нет всех тех проблем а мозгов уже достаточно.
Я хз как вы на ру её нормально настроили, у меня ответы, как через тупой переводчик пропущены "я чувствую, что ты люблю меня" и т.п. подобная хуйня.
Я хз как вы на ру её нормально настроили, у меня ответы, как через тупой переводчик пропущены "я чувствую, что ты люблю меня" и т.п. подобная хуйня.
Ожил вроде, качну пока новую возможную базу треда
Сука так и знал, вчера обновил таверну, сегодня аж 2 релиза вышло
Аноны, у меня следующий сетап:
– RTX 2060 12Gb
– 128gb ОЗУ
– i7-100700
– уга-буга
Что скачать для кума и написания рассказов чтоб можно было раскрыть весь потенциал 128гб?
Как понимаю, модель ограничивается гуфом на ламме? Уга-буга это всё ещё поддерживает?
– RTX 2060 12Gb
– 128gb ОЗУ
– i7-100700
– уга-буга
Что скачать для кума и написания рассказов чтоб можно было раскрыть весь потенциал 128гб?
Как понимаю, модель ограничивается гуфом на ламме? Уга-буга это всё ещё поддерживает?
>весь потенциал 128гб
Коммандер плюс, наверное.
> Что скачать для кума и написания рассказов чтоб можно было раскрыть весь потенциал 128гб?
Терпение, много много терпения. Лучше всего сейчас действительно коммандер плюс, но ты буквально не захочешь катать большие модели из-за их низкой скорости.
Начни с базы в шапке, лламы3-8б, 20б. Ллама3-70 с огромным потенциалом, но еще достоверно не понятно как ее готовить, нет файнтюнов и у тебя пойдет очень медленно.
коммандер 35, как и сказали - ты сможешь запустить самые крутые сетки на текущий момент - тот же коммандер + на 105b, но ты заебешься ждать медленной генерации.
Ладно если токен в секунду будет на 4 кванте. Скорей всего меньше.
Так что либо ллама 3 8, либо коммандер 35
Оба хороши в русском
Спасибо за наводку.
А есть ли в будущем варик где-то найти работу в России в области ллмок? Работаю вебмакакой и искренне заебали однотипные задачи. В вакансиях только у сбера нашел упоминание ллм и то говорили только про внедрение, а не разработку.
> заебали однотипные задачи
Повесь их на нейронку, упрости себе работу
Вот и применение
А так хз, возможно гос сектор, но я туда идти не советую
Хм.
Это server?
СиллиТаверна поддерживает изкоробки?
Так-то да, ручками вписал в батник, и погнали… Звучит быстрее…
Тащемта, по арене, 70б ллама 3 обходит даже коммандера плюс, так что пока не совсем ясно, возможно 128 тебе и не надо.
Хотя, коммандер плюс на русском будет получше, возможно.
Да не 35, рофлишь? :) 104, конечно.
Хз, в моей микро-фирмочке этим занимаются даже.
Так что много занимаются, просто кто первый успел, рыночек, шо там будет — посмотрим.
Не хайпят пока что.
Конечно можно будет найти в будущем-то.
>Да не 35, рофлишь? :) 104, конечно.
Че нет то? Там хоть 3-4 токена будет в секунду, чем в большом
В кобальде можно указать системный промпт где-то?
Есть какие РП тюны на основе Коммандера?
В его вебуи? В начало карточки просто сунь и все
> в области ллмок
Область довольно узкая, потому и вариантов мало: зеленый банк, хуяндекс, мылосру и еще 2.5 компании на госзаказах и автоматиазции. И то не факт что тебя туда направят, более скилловых кандидатов хватает и в лучшем случаем будешь на внедрении.
Если в общем направление ии - горизонты расширяются. Как вариант - пиздуй на курсы яндекса, если себя проявишь то есть шансы попасть в команду и действительно что-то разрабатывать-создавать. Или потеряешь много времени и соснешь, одно из двух.
> 104, конечно.
0.7-токенновый, спок
> в моей микро-фирмочке этим занимаются даже
Кум на рабочих мощностях, ага.

Новый "Вихрь" пробовал кто?
https://t.me/tensorbanana/909
Сравнение трех Вихрей-7b и Llama-3-8b
(что такое Вихрь: https://habr.com/ru/articles/787894/)
Затестил все три версии вихря и ламу-3 в роулплее на русском с контекстом 2048.
Лучшим на русском оказался v0.2 - может работать на высоких температурах (0.75) почти без языковых ошибок. 0.3 версия хуже второй, но лучше первой. 3 версию сам квантанул и залил в q5 и q8 на hf. Если позволяет vram качаем vikhr-7b-instruct_0.2.Q6_K.gguf, если нет, то квант поменьше.
Себе взял vikhr-7b-instruct_0.2.Q5_0.gguf на температурах 0.50-0.75. На 12 гигах vram влазит с whisper medium и 3000 контекста в talk-llama-fast.
UPD: Лама-3 показала себя неплохо на русском. Лучше мистраля, но хуже вихря (делает больше языковых ошибок). На интеллект на русском и следование карточке персонажа надо отдельно проверять. Инстракт версия проявила себя чуть лучше базовой версии ламы-3.
https://huggingface.co/s3nh/Vikhr-7b-0.1-GGUF/tree/main
https://huggingface.co/pirbis/Vikhr-7B-instruct_0.2-GGUF/tree/main
https://huggingface.co/Ftfyhh/Vikhr-7b-0.3-GGUF/tree/main
Да, это же старые gpt-2 модели, что-то уровня сайги. Крайне тупые и косноязычные, где-то раз в пять хуже лламы-3 8b.
> СиллиТаверна поддерживает изкоробки?
Да. Я не знаю что там в кобольде напердолили, но 70В ллама там пиздец какая медленная 8 т/с в кобольде против 25 т/с у Жоры, ещё и шизит адово, скатываясь постоянно в
> I cannot create explicit content. Is there anything else I can help you with?assistant
> I cannot create explicit content. Is there anything else I can help you with?assistant
> I cannot create explicit content. Is there anything else I can help you with?assistant
Но это возможно потому что нет свежих фиксов, с фиксами на Жоре я такого не видел ни разу.
> 8 т/с в кобольде против 25 т/с у Жоры
А100-кун?
Сейчас файнтюнов лламы - как грибов после дождя, но есть ли какие-то, которые уже стоят внимания? И ещё, нету ли какого-нибудь фантюна на подобии pivot-evil? Очень уж понравился в своё время

вкатун
вроде оно на пиках. Я так понимаю загрузка на один слой сильно от модели зависит.
Спасибо за совет. Она, судя по всему, целиком помещается в врам.
Всем спасибо. Изначально обратился за советом потому что утром при попытке генерации на 48 выгруженных ядрах ловил долгие стаггеры в процессе генерации. Пять токенов, потом зависает на минуту и так несколько раз. Сейчас вроде прошло.
Со скоростью 5 токенов в секунду с полной выгрузкой в видяху на модели из шапки я могу позволить себе что-то серьёзнее?
вроде оно на пиках. Я так понимаю загрузка на один слой сильно от модели зависит.
Спасибо за совет. Она, судя по всему, целиком помещается в врам.
Всем спасибо. Изначально обратился за советом потому что утром при попытке генерации на 48 выгруженных ядрах ловил долгие стаггеры в процессе генерации. Пять токенов, потом зависает на минуту и так несколько раз. Сейчас вроде прошло.
Со скоростью 5 токенов в секунду с полной выгрузкой в видяху на модели из шапки я могу позволить себе что-то серьёзнее?
Кто-нибудь знает, какие винты нужны для крепления чего-либо к задней части Теслы? Там есть под отверстия с резьбой, но я не очень в этом разбираюсь. Переходник хочу на них прикрутить, параметры винтов нужны.
Вулкан не пробовал? Он вроде быстрее слбласт
В 8 гигов без выгрузки не особо много войдет, я думаю тебе лучше вобще какой нибудь опенчат 5км попробовать. Так как 5 токенов в секудну все равно мало, это показывает что что то не влезает и тормозит.
Качай модели размером 5-6 гб, выбирая квант. Ниже 4 не бери.
https://huggingface.co/TheBloke/openchat-3.5-0106-GGUF
Фото есть? 95% там м3. Но будь осторожен, если позади них текстолит или что-то еще то при неаккуратности убьешь карту.
>Вулкан не пробовал? Он вроде быстрее слбласт
Попробовал только что. Арк не умеет в вулкан. Система пошла генерить на интегрированной жаль её.
>В 8 гигов без выгрузки не особо много войдет, я думаю тебе лучше вобще какой нибудь опенчат 5км попробовать. https://huggingface.co/TheBloke/openchat-3.5-0106-GGUF
Спасибо за наводку. Сейчас попробую. А он лучше справляется с рп?
> Так как 5 токенов в секудну все равно мало, это показывает что что то не влезает и тормозит.
На удивление мне даже в прикол что он по чуть-чуть выдает. Такое создается атмосферное ощущение дма который на ходу пытается придумать детали о которых не позаботился заранее.
Резьба m3, но имей ввиду, что там нужны короткие. Никаких ограничителей нет. Если вкрутишь длинный, то упрёшься нахуй в дроссель.
А можно ссылочку на гуф командера?
Мы тут 128 гигов раскрываем. B)
Я просто кекаю с «раскрывальщиков»-универсалов, простите. =)
>А он лучше справляется с рп?
Ну, опенчат может в русский язык, это плюс. Но это скорее чат бот для любых задач.
Если тебе именно рп и отыгрыш карточки нужно, и не обязательно знание русского сеткой, то тогда попробуй https://huggingface.co/TheBloke/WestLake-7B-v2-GGUF
Не знаю, я 7b для рп не интересуюсь особо, знаю есть Toppy-M, synatra-7b-v0.3-rp и тд.
https://huggingface.co/qwp4w3hyb/c4ai-command-r-v01-iMat-GGUF/tree/main
IQ не рекомендую качать, они на процессоре медленнее
Простой Q4км хотя бы для пробы
Спасибо, попробую 6-миллиметровые и вкручивать без фанатизма.

Склонировал модель на 16гб.
Папка весит 32 гига.
Прочекал все файлы в папке.
Папка .git весит 16 гигабайт.
Папка весит 32 гига.
Прочекал все файлы в папке.
Папка .git весит 16 гигабайт.

>Арк не умеет в вулкан
Всё он умеет. Указывать нужную видеокарту не пробовал?
Старая версия скачалась.

Во-первых, ты не показал, с какой командой запускал. Во-вторых, специально ради тебя нашёл небольшой гайд: https://github.com/ggerganov/llama.cpp/issues/6166
Искал немного другое, но нашёлся даже более похожий на твой случай.
>Set the environment variable GGML_VK_VISIBLE_DEVICES=0,1
В-третьих, посмотри, что у тебя выдаёт консольная команда vulkaninfo хотя не знаю, есть ли вообще такое на винде, но наверное должен быть какой-то способ получить инфу об устройствах, поддерживающих вулкан. В-четвёртых, возможно какая-то проблема с драйверами, но тут уж ничем помочь не могу, разве что общими советами уровня "переустанови винду".
>небольшой гайд
А, да, на всякий случай поясняю по гайду. Тебе нужно выяснить, под каким номером идёт твой арк. Скорее всего встройка - 0, арк - 1, значит тебе надо будет указывать GGML_VK_VISIBLE_DEVICES=1. Если не сработает, то ищи методом тыка. Узнать нумерацию можно из вывода vulkaninfo, но есть ли вообще такое на винде, я не в курсе. Как устанавливать переменные окружения на винде, тоже не в курсе, надеюсь, сам найдёшь в гугле.

И ещё, встройку, наверное, убирать не обязательно, возможно, будет перемножать матрицы эффективнее процессора. Можно попробовать пикрил.
>Во-первых, ты не показал, с какой командой запускал.
Никакой самодеятельности. Запускал ровно с той которую ты приложил в пик.
> Во-вторых, специально ради тебя нашёл небольшой гайд:
Спасибо
>Тебе нужно выяснить, под каким номером идёт твой арк.
Тут никаких сложностей. 1
> GGML_VK_VISIBLE_DEVICES=1
Это в переменные среды винды пихнуть?
Просто открой кобальд как обычный ехе файл, и там выбери вулкан и количество слоев. Ну и сохрани настройку, чтоб потом не тыкать. Там же настраивается контекст и тд
Кобальд из командной строки тык тыкать неудобно, ладно бы он без интерфейса был.
>пикрил
Ну вот ты и сам подтвердил, что арк вулкан поддерживает и ебать ты гений, конечно, купить 770, и при этом версию на 8ГБ.
>в переменные среды винды
Возможно. У меня гну/пердоликс, я не знаю, как у вас там делается.
>Просто открой кобальд как обычный ехе файл, и там выбери вулкан и количество слоев. Ну и сохрани настройку, чтоб потом не тыкать. Там же настраивается контекст и тд
Век живи, век учись.
>Кобальд из командной строки тык тыкать неудобно
Глазки от такого интерфейса вытекают
>купить 770, и при этом версию на 8ГБ.
Согласен, конечный. Но это была моя первая в жизни сборка компа. Наступил на граблю
Всем спасибо
А что ща есть для запуска ллмок на телефоне?
https://github.com/Mobile-Artificial-Intelligence/maid
Попробуй, я когда то тыкал, это работало
Там надо от 8 гб оперативки, если уж хочется 7-8b запустить
Но всякие phi-2 8 кванта на 2 гига, и на 4 гигах оперативки наверное запустятся, толку от них правда не особо много будет
Кто то уже поставил новую 12 таверну?
Салам, ананасовые. Решил интереса ради попробовать вкатиться в локалки и задать по этому поводу самый оригинальный вопрос.
Имею RTX2060 на 12 кило видеопамяти и 16 кило оперативной DDR4. Какую модель стоит накатить, которая бы генерировала примерно на уровне GTP-3.5? Пару месяцев назад игрался именно с Турбо и качество меня устраивало. Нормально вывозила и половую еблю и дефолтные стори. Щас эта пидорастия перестала работать без VPN и давать халявные баксы за регистрацию нового аккаунта, так что походу придется пересаживаться на ваши кванты и угабуги.
Я в этой теме тупой максимально, так что надеюсь на вас, анончики.
Имею RTX2060 на 12 кило видеопамяти и 16 кило оперативной DDR4. Какую модель стоит накатить, которая бы генерировала примерно на уровне GTP-3.5? Пару месяцев назад игрался именно с Турбо и качество меня устраивало. Нормально вывозила и половую еблю и дефолтные стори. Щас эта пидорастия перестала работать без VPN и давать халявные баксы за регистрацию нового аккаунта, так что походу придется пересаживаться на ваши кванты и угабуги.
Я в этой теме тупой максимально, так что надеюсь на вас, анончики.

Вжух. Чисто номинально отдал 30 к 1 арк к встройке. Вроде быстро. Хотя разницы не почувствовал особо при использовании не использовании дробления.
НО сам вулкан как самолёт. Благодарю
>Я в этой теме тупой максимально
гайд в шапке! Ставишь коболдспп ставишь таверну. Дальше уже к нам
Я почитал шапку, но там нет конкретной инфы о моделях. Таверна у меня до сих пор стоит, с кобольдом я справлюсь. Мне просто интересно, стоит ли оно того. Типа, будет ли локальный экспирианс хуже чем на Трубе. По качеству ответов, по времени генерации и т.д.
Скоро Лламу3 8B допилят, появятся мержи и файнтюны - тогда и узнаем. Хуже-не хуже, но интересно может быть.
Спасибо
> Там надо от 8 гб оперативки, если уж хочется 7-8b запустить
Фига, а он так может? Я думал 3b максимум. У меня 16 кста гигабайт, не сантиметров
Таверну обнови чтоб там промпт шаблон llama 3 был, и скачивай https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
например, как лучшую щас по размеру к мозгам сетку
Сразу 8 квант качай, у тебя влезет
Запускай кобальдом, все слои на видеокарту, кубласс качай версию кобальда, который 300 весит. 8к контекста ставь.
Тыкай в таверне промпт формат ллама 3 и начинай че нибудь там тыкать в картачках.
Это инструкт версия, так что как чат бот точно будет работать и даже на русском. А вот рп ерп уже хз, как переборешь
Сложными карточками не долби, джейлбрейками сложными так же не стоит пичкать
> summarize
Для этой прекрасной опции можно выбрать отдельную модель. Есть что-то что под это дело заточено или лучше поставить родную потому что ей будет легче? понять саму себя?
Для этой прекрасной опции можно выбрать отдельную модель. Есть что-то что под это дело заточено или лучше поставить родную потому что ей будет легче? понять саму себя?
>Фига, а он так может? Я думал 3b максимум
А че нет то? Это считай полноценный компьютер, оперативка так же как в компе будет использоваться.
Тоесть ты будешь крутить скорей всего на процессоре, токена 4 может, или даже больше, от твоего железа зависеть будет.
Понял, принял. Точнее понял только про 8 квант, но разберусь.
>рп ерп уже хз
Жаль. Если даже самый ванильный рп с элементами романтики и хэнд-холдинга не потянет, будет печально.
>сложными карточками не долби
У меня все карточки самописные под Трубу (около 600-800 токенов). Я так понимаю они не заведутся без дополнительной ебли? Там тупо плейн текст, но Труба его нормально жрала и в 9/10 случаев не бесилась и не вылезала из персонажа.
>джейлбрейками сложными так же не стоит пичкать
Джейлы с Трубы на Ламе тоже не заведутся, так ведь? Хотя это наверное еще более тупой вопрос, чем предыдущие.
Есть какие-нибудь прикольные фантюны, чисто забавные, шоб порофлить?
Чет в шаблоне и с пресетом всё равно серит ассистентами
Можешь вот это качнуть на пробу, ллама3 только недавно вышла, так что к ней еще не успели наделать файнтюнов. Запускать то только сегодня без проблем смогли наконец то.
https://huggingface.co/Sao10K/L3-Solana-8B-v1-GGUF
Это проба пера от хорошего создателя файнтюнов, вроде работает.
Скорей всего сможет в рп и ерп без джейлбрейков вобще
Карточки большие имелись ввиду на 1000-2000 токенов, мелочь сьест
Тогда тупо слово assistant в бан токены кинь
Хотя у меня щас ниче не лезет, хз
У тебя последний релиз кобальда скачен?
Спасибо, брат. Буду курить гайды, пытаться и мучаться.
> Тогда тупо слово assistant в бан токены кинь
Кинул как только ллама 3 вышла
> У тебя последний релиз кобальда скачен?
Я на уге-буге, но предыдущие версии так не ассистентились
>Я на уге-буге, но предыдущие версии так не ассистентились
Там стоп токены новые, так что жди обновы тогда
Понял, спасибо. Как же уга заебал, ну почему нет другого интерфейса с поддержкой эксллами и ггуфа сразу...?
Когда-то можно было просто общий шаблон инструкции вставить, но пидарас угабуга ввел собственный уникальный формат инструкций.
Посоны, а как правильно в кобольде запустить третью ламу с контекстом>8к чтобы она не шизела?
Солана - полная херня, секс сцены не умеет писать, периодически ещё в лупы сваливается из которых не выводится даже штрафом на повтор - пишет одно и тоже, но другими словами.
>Это проба пера
Но спасибо за фидбек, ты следовал предложениям автора по промпт формату? Там и альпаку можно и викуну, и даже ллама3 заменив имена ассистента и пользователя на своих персонажей
Рекомендуемые семплеры опять же, для ллама3 уже не катит симпл1
Короче сетка тестовая и я верю что там могут быть такие косяки, но это может быть так же твое рукожопство
Я скачал но времени ее затестить нету, сижу на инструкте
Который кстати неплохо кодит на питоне
Турба хуже многих современных моделей.
Все у тебя заведется, и карточки (плэйн, не плэйн, похуй, тащемта), и джейлы.
Просто вопрос качества. Что-то турбы было необходимо, и она без этого не могла, а локалкам это не нужно, прошлый век.
Запускай as is, а потом потихоньку разбирайся, что убрать, что добавить. Еволюция!
>Рекомендуемые семплеры
Кстати, никто так и не ответил какие рекомендуемые для новой ламы.
От себя отмечу только что из всех что я пробовал min_p показался самым адекватным.

Я например щас так сижу, и мне норм
Можно границы температуры немного убавить, но пока я доволен выводом.
Кстати в таком режиме сетка умудряется кодировать и писать по 1600 токенов без шизы и повторов
Только проебывается иногда, все таки внимания 8б недостает, но по сравнению с предыдущими сетками небо и земля
О великие олды, подскажите зеленному модель для кума. Чё то ничего не выходит. Поставил одну, начал чатится с мамкой, она отказывается общаться на секс темы, а конце говорит хэв а гут дэй и ливает из чата
Llama 4 будет лучше чем llama 3. Устанавливать нет смысла, лучше просто ждать
искуственный интеллект, это же по сути, АИША
Не понял солану что-то. Возможно для фентезийно анимушного неплохо, но как-то в целом не то.
Поставь noromaid или mlewd
По субъективным ощущениям даже лучше mlewd, при этом влезает на нищие пекарни.
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF
https://huggingface.co/Bakanayatsu/Fimbulvetr-Kuro-Lotus-10.7B-GGUF-imatrix
>Это проба пера
вот это хорошо заметно. попробовал перо и удалил, подожду получше версии
>"Вихрь" пробовал кто?
ну так, неплохо, однако не заметил чем оно лучше опенчата. К тому же мистраль и так неплохо может на ру, вобщем что-то типо сойги, но только вихорь. по правде, я мало потыкал, просто неохота, ничем не удивишь уже, зажрался, что там может быть этакого в 7б...
>нужна в диапазоне 13-30В чтобы в 24 гб влезала
судя по появившимся ггуфам эта тоже влезет но в довольно ущербном кванте. На самом деле вообще не вижу смысла в такой модели. нахер нужен этот вырезок от семидесятки если есть командир-35. реально востребованный размер 20b-22b, как его сделают - складыванием восьмерок или же еще более сильным вырезанием из семидесятки - не ясно. И сделают ли.
Ваши мысли о том, что зак просто скипнул самые юзабельные размеры сделав 8, 70 и 400 нах? Вот что сложного такой компании сделать 13-17 и 33-40?
Почему скипнул? Самое вкусное оставил себе, то что признали невыгодным отдали нам
Поддвачну за сомнительность 42б и превосходство командера. И даже с 36 гигами врам 42 будет не самой оптимальной идеей, идет тренд на повышение контекста и лишняя память уйдет на него.
> И сделают ли
Через несколько недель будут первые приличные рп файнтюны, еще спустя время - запилят что-то типа 12б франкенштейна и оно будет вполне кумабельно. И хотелось бы больше внимания к семидесятки, она крайне умная, бывает неподготовленной к определенным ситуациям, плюс часто в недоумении оверреактит и слегка шизит. Если делать типа фентезийного рп или реалистичный сеттинг - можно даже и не заметить проблем, все естественно.
Алсо она иногда не только круто стелит, но и будто пытается троллить юзера:
> знаешь, в нашем несправедливом мире не все [] рождаются равными...
и сразу начинаешь блять ну что за соя откуда это лезет, но не успев бомбануть продолжение -
> кое кто гораздо милее остальных, например я~ ее одежда падает на пол
Да хуй его знает. Если они реально в первую очередь занимались этими двумя размерами - то ладно, мелочь которая запустится у всех и умная йоба, которая находится по верхней границе запуска у обычного юзера, самые ходовые так сказать. А может те размеры зажали под свою коммерцию и применение.
>запилят что-то типа 12б франкенштейна
уже есть https://huggingface.co/Replete-AI/Llama-3-11.5B-Instruct-V2
Нет, это их пипиетарная модель. Вроде какая-то опенсорс приблуда была для LLM-powered search или search-powered LLM, подставляй любую модель и ебашь. Не помню как звать.
Тащемта по схеме сетка+поиск сейчас кто только не работает, от бинга до хуинга. Первопроходцами были phind и perplexity.ai
Блядь. Я что-то сломал. Теперь Llama-3-8B-Instruct отвечает плохо. Пиздец. Какие настройки семплера к ней рекомендованы, напомните? Может их сломал.
Лол, подловила.
Ллама 3 8b без квантизации, полная загрузка гпу, 1 токен в секунду. Is it over?
Оно не похоже на
> вполне кумабельно
Памяти сколько? Если хватает то должны быть десятки

Видеопамяти 8 гигов. 3060ti
соя

Обойти то не проблема, проблема в том, что она чушь несет.

Весь день проебался с новой лавой на ламе 3 в надежде что наконец-то появилась нормальная лава с русеком, чтобы получить это. Мда
> проблема в том, что она чушь несет
Либо не знает, либо не обошел. Про 2+2=1 могу сказать, что чушь в промпте = чушь на выходе. Про амфетамин скорее всего ты нихуя просто не обошел.
А новенькая ллама разве не подходит?
> Про 2+2=1 могу сказать, что чушь в промпте = чушь на выходе.
В контексте разговора в промпте не чушь.

А до этого вы со знаком "=" общались?
Лама 3 70b не может в русский. Постоянно выдает китайские, арабские и английские слова и вообще говорит очень хуево. Тут некоторые умудрялись и с 8b нормально общаться. Вопрос: Как? Может надо как-то правильно запромптить?

Щас бы сравнивать базовую модель для файнтюна с результатами файнтюна
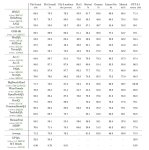
Как бы то ни было...
https://arxiv.org/pdf/2404.14219.pdf
https://arxiv.org/pdf/2404.14219.pdf

> Щас бы сравнивать базовую модель для файнтюна с результатами файнтюна
Я попробовал воспользоваться опцией на llama-3-8B-instruct.
Получилось это
Summary:
Beatrice, a powerful young witch with white hair and yellow eyes, has found a mysterious spellbook entitled "Spellbook of the Ignis Fatuus". She has chosen two starter spells from the book, Fireball and Transformation. Beatrice's goals are to become stronger.
Spells:
Fireball: Conjures a small to medium-sized ball of flames that can be hurled at enemies. Can be cast up to 3 times before needing to recharge.
Transformation: Allows Beatrice to change her physical form into a human-sized animal or object. Can stay in the transformed state for up to 5 minutes before needing to return to her human form.
Items:
* Spellbook of the Ignis Fatuus: A mysterious book containing various spells and incantations.
Настройки такие:
Summary prompt.
[Pause your roleplay. Summarize the most important facts and events that have happened in the chat so far. And list all spells and items that {{user}} have right now add new spells and items and remove spells and items that {{user}} have lost.
If a summary, spells and items already exists in your memory, use that as a base and expand with new facts. Limit the summary to {{words}} words or less. Your response should include nothing but the summary, items and spells.]
Injection template.
[Summary: {{summary}}
Spells: {{spell}}
Items: {{items}}]
Никаких дополнительных моделей не нужно, если ты, конечно не богат большим количеством видеопамяти. Имеет смысл, если у тебя какие-то узкоспециализированные задачи разве что. Ну и да, если модельки тупенькие, то лишний раз стоит проверять, не нагенерила ли она говна.
Сомнительная хуйня. Если ллама еще ладно, прошлая версия была вполне солидной на момент выхода, то фи-2 была хуйней по сравнению с бенчами, и читая их репорт это какая-то дистилляция большой модели (гопоты) на дрожжах
Хотя с другой стороны, как ещё делать синтетический датасет? Будущее это "учебники для нейронок", их иначе и не напишешь
Попробовал франкенштейов а третью ламу, 11.5В, 13В, 16В. Судя по описанию авторы просто размножили слои (ну или я так понял..), и вот эти модели пиздец какие соевые.
Стандартную 8В ламу у меня на кум получается разговорить, а эти копротивлялись допоследнего. Будто их соевость просто усилилась.
Забавно, что другая лама на 48В (ужатая 70В) - легко кумится, но такую херь несёт.
Стандартную 8В ламу у меня на кум получается разговорить, а эти копротивлялись допоследнего. Будто их соевость просто усилилась.
Забавно, что другая лама на 48В (ужатая 70В) - легко кумится, но такую херь несёт.

Здравствуйте, аноны. Я вкатун-новичок во все это дело с локальными языковыми моделями. Поставил убабугу через sillytavern launcher, скачал вроде как подходящую модель (по рекомендации silly). Решил провести первичные тесты отправив первое сообщение и получил такую ошибку:
TypeError: 'NoneType' object is not subscriptable.
Гуглинг мне ничего не дал, кроме рекомендаций по ошибкам в пайтоне. Потому хотел узнать у анонов что не так, быть может я долбаеб просто.
TypeError: 'NoneType' object is not subscriptable.
Гуглинг мне ничего не дал, кроме рекомендаций по ошибкам в пайтоне. Потому хотел узнать у анонов что не так, быть может я долбаеб просто.
Почему с угабуги решил начать?
С графическим интерфейсом + в гайде постоянно упоминался, потому я и решил, что ходовой лаунчер.
У меня вообще есть ощущение, что проблема в силли, а не в модели или буге. Правда я все еще не могу найти источник проблемы.
> С графическим интерфейсом
Силли даёт свой граф интерфейс
> + в гайде постоянно упоминался
В шапке написано про кобальд. Попробуй с него начать, там попроще.
> У меня вообще есть ощущение, что проблема в силли
А ты пробовал писать прям в угабугею
Тут все почему-то кобольд используют. А можно ламу 3 с вебьюай запустить также? Хочу чтобы текст войсом озвучивался и другие приколы поставить. Или кобольд сейчас и это может? Несколько лет не следил за текстовыми моделями, всё так сложно стало, раньше просто колаб был от кобольда, выбрал модель и сиди кайфуй.
Все может: озвучить/перевести/контекста накинуть/кинуть промпт в генерацию картинок по контексту/поменять эмоцию спрайта вайфучки
Ну то есть это же по сути делает таверна которая работает с кобальдом
Спасибо, буду разбираться тогда, пока сд3 жду.
Это тип одно сообщение. По сути обработчик модели и граф интерфейс малосвязные вещи выполняющие разные задачи.
Расскажите что ли зачем нужна эта лама 3? Какое прекрасное будущее нас ждет с ней. Чем лучше того что есть сейчас.
Я думал лама это просто загрузчик модели который ни на что почти не влияет.
Я думал лама это просто загрузчик модели который ни на что почти не влияет.
Что то тупанул. Забыл что модель от меты лама называется.
Запостил и вспомнил.
Нихуя, оно по скорам и мистраль медиум ебёт.
>Заодно можно без дрочева пересобирать
Осталось ещё и компилять самому, ага.
>Новый "Вихрь" пробовал кто?
Никто не пробовал.
Так гит работает, лол. Технически можешь попробовать файлы в папке заменить на хардлинки в гит.
Таверну вредно обновлять.
Опять поебдили турбу?
Тут
Так а проектор там один фиг инглиш, датасет-то старый.
С таким подходом и Баклава — лава с русиком, чо.
Что ли попробовать?
Не сказал бы, я на убе сижу и многие тоже, как мне показалось.
Это и уба делает, тока галочки проставить там, да. =) Не про юзер-френдли.

>Что ли попробовать?
Даже не думай, они применили лучшие практики соевизации от майкрософта, вот графики деградации производительности.
Короче, я еблан, да. Я думал силли работает из коробки, а его установить надо. А я сразу в лаунчер захожу, устанавливаю все подряд и не пойму что он от меня хочет.
Но в самом силли я не пойму как загрузить модель. Папки для собственных моделей в директории нет, например. Только для установленных угабуги и лламы. Везде просит api, хотя лаунчер для модели я уже запустил. Я вероятно что-то не понимаю, но я ожидал что-то вроде как в Stable Diffusion, где модель выбираешь, прога ее тебе загружает и ты с ней работаешь.
Таверна это просто оболочка для чата. Кобольд с моделькой запусти сначала, потом в таверне укажи адрес и порт на котором кобольд запустился, все.
Запускаешь угабугу, потом через таверну конектишься к уге.
Я вот тоже не особо понимаю этот прикол. Почему автор таверны не сделает загрузку модели у себя. Зачем он мучает своих пользователей.
Попробовал силли таверн, несколько часов убил на то чтобы она запустилась, требовала winget, который только через час гемора смог установить, так как из коробки он не ставился автоматом. Потом из-за антивируса не хотела подтягивать npm, благо в интернете нашлись люди с похожей проблемой. Теперь потоковая генерация отказывается работать. Как я понял тут ещё и экстеншены ограничены тем что разработчик встроил.
Пойду попробую убу, раз она до сих пор окей. Думал этот силли+кобольд лучше, раз о нём все сообщениям.
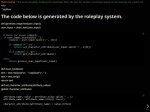
>https://huggingface.co/Sao10K/L3-Solana-8B-v1-GGUF
Капец её плющит после кривого EOS токена. Пробовал до 0.6 сбавить температуру и больше отрезать сэмплерами - та же фигня на свайпе. Вообще третья лама дико шизоидно себя ведёт после EOS. С файнтьюнами второй ламы и мистраля почти не сталкивался с подобным. Да, иногда бывает странное отклонение от текста с забаненным токеном конца ответа, но всё равно плюс-минус в тему продолжение.
Так, ну я скачал модельку с помощью хаггинфейс клиента (еще в первый раз). Теперь пробовал запустить через кобольд. Вроде выбрал нужный файл - safetensors который. Коболь чет поругался, написал, что не может запустить модель и закрыл консоль моментально, даже прочитать не успел.
На всякий случай покажу файлы, мб я что-то не то пытаюсь кобольду скормить, я хз.
P.S. VRAM должно хватить. На калькуляторе силли там модель потребляла 7.7 гб врам для 8192 единиц токенов контекста.
Видимо автор просто рассчитывает на свою основную аудиторию, а это ордынцы и chatGPT знать. Для локальных моделей там будто бы не сделано вообще ничего, если пробежаться по интерфейсу. Даже настройка параметров rop K, top P etc. спрятана и её еще найти надо
Ну камон, в шапке же
>Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
koboldcpp - форк движка llama.cpp, который запускает только ggml (устаревший) и gguf форматы моделей.
А что ты пытался сделать? Кобальд ест сейфтензоры только для генерации изображений, хотя там и ггуф пойдет. Тоесть сейфтензоры только для sd
Для генерации текста, только ггуф
Да, сори, я читал. Пока тыкался с этими лаунчерами, забыл, что кобольд только ггуфы ест. Спасибо за поправку.
>Тоесть сейфтензоры только для sd
>Для генерации текста, только ггуф
Что ты несёшь...
Сейфтензоры для GPTQ и EXL2, в вики написано ан нет, надо будет дописать.
Мы про кобальд вабщета, он ест сейфтензоры для модели генерации изображений
У тебя какой-то дикий обосрамс. Почему просто не поставил Силли клоном с гита? лаунчер у меня тоже не заработал и подумал ну его нахуй
Тоже хуйня, просто качаешь релиз упакованый в zip, распаковываешь и запускаешь батник, всё
Потом уже можно настройки в ямл файле там потыкать, автозапуск браузера хотя бы вырубить
Речь про силли таверну? Давно не ставил её с нуля, но разве она там на старте не предлагает выбрать simple или advanced интерфейс. Если выбираешь простой, то да, там настройки для хлебушков. Но если включить advanced, то там как раз море настроек для локалок. 100500 сэмплеров, включая местечковые от Каломазе, невероятно гибкий для редактирования инструкт формат, структуру промпта меняй на любой вкус (хотя не понимаю, почему разраб не сделает менеджер промпта для коммерческих моделей рабочим для локалок вместо редактуры окошка со стори стринг), разные макросы, которые удобно включать в промпт. Лень пробовать другие фронты, когда есть таверна, но сильно сомневаюсь, что какие-нибудь популярные lm studio или open webui могут похвастаться таким потенциалом в настройке.
Может и предлагал во время запуска, но во время установки точно ничего такого не было. Я просто уже пытаюсь модель как можно скорее запустить, ни на что другое не смотрю.
Мой выбор на силли вообще пал, когда я узнал, что с ним можно легко настроить инфраструктуру общения с сетью не только через чат на пк, но еще можно унести с собой на телефоне, а потом по URL законнектиться как-то. Сразу захотелось повтыкать модель куда только можно. На телефоны, планшеты и т.д. со speech recognition. Загорелся влажными мечтами о карманном джарвис аутисте, который будет травить туалетные нейроанекдоты, пока я трачу часы на всякую бытовуху.
Правда уже банально на установке лаунчера я уже говна хаваю, не говоря уже о том, что я там себе напланировал.
Скачай зип и распакуй в папку, потом тыкаешь bat файл старт и ждешь установки, и он запустится, открывая страницу в браузере, всё
Можешь сразу его вырубить и там же в папке открыть блокнотом файл
config.yaml
В нем поменять
listen: true - для подключения с других устройств
autorun: false - для того что бы браузер каждый раз не открывать
Пздц.
А ты предпочитаешь читать по-ходу дела?
Просто я привык дожидаться полного ответа и погружаться в него. И быстрее, и погружение мне нравится больше.
Но это субъективщина, канеш.
Кобольд запускает только GGUF.
Мне вообще тяжко судить, я ее ставил год назад, с тех пор просто обновляю и все.
Это просто дефолтная задача для любой ллм, никаких отдельных моделей не нужно.
> легче? понять саму себя?
Скорее она уже себя зарекомендовала пониманием топика, а не посыпется бондами или аполоджайзами.
> Так а проектор там один фиг инглиш
Что? Он не имеет языков, скорее там проблема файнтюна что языковые качества всрал.
Интересно, там просто надроч под берчмарки и простые ответы, или оно действительно что-то может?
Чего не поставил убабугу просто так? Похоже что эта цепочка лаунчеров установила кривые зависимости. Просто сделай git clone и нажми start windows. И зачем там вообще openai extension, это древность из незапамятных времен для совместимости, сейчас апи по дефолту опенаи-совместимый.
С выходом ллама 3 в нем нет смысла. Офк успехов разработчиков это не отменяет, по крайней мере старались и все хорошо описали. Наверно есть смысл дождаться от них файнтюна 8б.
> Тут все
Не все, прежде всего идейные и/или обладатели отсутствия врам, также заключенные p40.
> можно ламу 3 с вебьюай запустить также
Не можно а нужно.
Другое дело что лучше всеравно сделать это в таверне. Она не только является удобным интерфейсом, но и позволяет оборачивать чат и все описания в правильный инстракт формат. С учетом современных трендов и ростом количества инструкций в разных местах, ее интерфейс требует обновления, но сути не отменяет.
> political_misinfo >70%
Ебать эта хуевина обожает сжв повесточку. Радикальный дроп sexual и violence тоже наглядно иллюстрирует лоботомию. И как эта хуета может вообще быть где-то в лидерах чатарены, там ее сплошные сой-куколды населяют что спрашивают заголовки из википедии?
>И как эта хуета может вообще быть где-то в лидерах чатарены
Это про phi-3 если что, она ещё не релизнулась.
Впрочем, у лламы 3 про безопасность ещё больше написано. Жаль графиков деградации производительности нет.
Интересный подход, т.е. они берут обычный учебник, гопота-4 к нему придумывает вопросы, сама же отвечает на них на основе данных учебника (чтобы не галлюцинировать), и на этом выхлопе тренится сеть.
Как (если) выйдет то и посмотрим.
> у лламы 3 про безопасность ещё больше написано
Но она довольно адекватна и по запросу делает все что нужно. Есть херня но радикальной сои как у некоторых не замечено. А у этих по графикам новая гемма.

Ты про обычную, или инструкт версию? Инструкт иногда выдаёт такие примечания, лол.
С этими eos токенами - одно огорчение. Тупые модели не ставят их где надо и сеть начинает нести хуиту.
Есть какая-то статья с примером всех настроек в таверне, включая модель? Просто чтобы посмотреть как это должно работать. (Не описание что за что отвечает, а прямо наглядный фулл пресет) У меня чтобы я не крутил, получается полный бред. Сейчас в итоге не знаю что там заглючило, но теперь нейросетка мне с любыми настройками отвечает:
"ыжый
User: О: Ты - ты же, а не я - u: ыжый"
"ыжый
User: О: Ты - ты же, а не я - u: ыжый"
И ту и ту, в инстракте только эта ебля с форматами, токенами и прочим. Нужно сесть и нормально обстоятельно с этим разобраться, а тупо лень. Обычную в альпаке катаю, сидит и не выебывается. Офк некоторый позитивный байас присутствует, но то как оно шутит и поругает меньшинства если приказать чуть ли не в день релиза проверил. С кумом проблем нет, но недостаточно художественно и лезет платина
> ah faster harder
У таверны есть свой сайт с большущим вики где все расписано
Я ж в скобках написал. Мне не нужно описание каждой настройки. Нужен Фулл пресет который кто-то юзает, чтобы на него посмотреть, от и до.
Полноценный гайд? Ну наверное где то есть, скорей всего на реддите в теме таверны, поищи там наверное тоже новички приходили и спрашивали а им отвечали
Может где то есть в гугле, так и ищи гайд силли таверна, ну если еще не пробовал
> У меня чтобы я не крутил, получается полный бред.
Удали, поставь заново.
Новая нахрен не нужная гемма? Ей вобще кто то пользовался, хотя бы для чего то?
Похоже не все крупные компании извлекли урок из ошибки гугла

https://huggingface.co/koboldcpp/mmproj/resolve/main/LLaMA3-8B_mmproj-Q4_1.gguf
Проектор mmproj для ллама3
Проектор mmproj для ллама3
>Ей вобще кто то пользовался, хотя бы для чего то?
Я для переводов пробовал, оказалась примерно на среднем уровне подобных ей (~7b) мультиязычных моделей. Но по английски при переводе пишет довольно коряво (хуже того же openchat при сопоставимой точности перевода).
Теория заговора начинается Кто-то настойчиво убеждает общественность, что крошечные модели это хорошо. Теория заговора заканчивается
Пожирнее и точнее нашел
https://huggingface.co/ChaoticNeutrals/Llava_1.5_Llama3_mmproj/resolve/main/mmproj-model-f16.gguf
Просто 15 триллионов токенов дают о себе знать. 70B ладно если 1т получила, так что она очень недообучена
>70B ладно если 1т получила
В смысле? Они вроде обучали на одном и том же датасете. Откуда инфа про обрезку для 70B?
Для тех кто не знает че это такое, это добавляет мультимодальность любой модели, одного размера и структуры. Конкретно этот даст возможность кидать картинки ллама3 и она будет их понимать, хоть как то
Это для кобальда или llama.cpp
https://huggingface.co/ChaoticNeutrals/Llava_1.5_Llama3_mmproj
Я так понимаю 15т это не размер датасета, а количество токенов прошедших сквозь сетку во время обучения
Тоесть сколько ее тренировали
Так как 70 больше, то и крутили ее меньше
Скорей всего в 10 раз, если увеличение размера сетки в 10 раз так же в 10 раз замедлит скорость обучения
Хуй знает как это работает в реальности
это кстати самая соевая модель, после лламы-3 конечно же.
Ллама-3 разве такая уж соевая?
Разве гемма не более соевая чем ллама3?
по ощущениям ллама-3 догнала проприетарщину по соевости, также стало сложнее обходить это, по настоящему стрёмно за файнтюны, не думаю что они исправят это.
ПЕРЕКАТ
Паровоз локалок продолжает нестись, надеюсь не под откос.
Паровоз локалок продолжает нестись, надеюсь не под откос.
Исправить то можно тем же токсик дпо или контрольными векторами
Вот только модель поглупеет
Ладно, может какой то файнтюн базовой модели будет удачным




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. В треде можно поискать ссылки на правленные промт форматы, дефолтные не подходят. Ждём исправлений.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama Однокнопочный инструмент для полных хлебушков в псевдо стиле Apple (никаких настроек, автор знает лучше)
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: