



>по ощущениям ллама-3 догнала проприетарщину по соевости
Да ну не, даже близко нет. Любой префил и ллама послушно делает любую дичь. Собственно префил это имба, практически непробиваемая, поэтому его нет у openAI, к примеру.
Что могу сказать по моделям на текущий момент, я сижу на 70b, недавно перешел на командер. На мой взгляд командер дает за щеку всем остальным моделькам, 70b мержи на его фоне уже выглядят тухлыми, что говорить про 7b, 8b и 13b (мистрали не гонял вообще кстати). Гонял командер v01 на q8_0, заметил, что он лучше описывает РП, когда plus на iq3 лучше всего решает технические задачки, кодинг, переводы и прочее. Такие дела. Ллама3 до уровня командера не дотягивает даже на решении тех.задач. Может быть после файтюна РП поправят, но на данный момент это что-то кривое.
Так у командира ты тоже не файнтюны гонял.
Кстати, есть какие РП файнтюны на 104В командира?
>не файнтюны
Ну да, я говорю о том, что он из коробки прямо таки топ.
Снимаю мои прошлые претензии к 8В инструкту, похоже что правильный гуф с правильным темплейтом и правильным сэмплером творят чудеса. Модель может в сложный РП, длинные описания и может придумать лютую внезапную дичь - вчера вместо кума весь вечер занимался тем что тянка заставила меня внедриться в корпорацию по созданию оружия чтобы спиздить их планы(притом что в карточке персонажа этого не было, у меня есть подозрение что данные обучения включали аниме из которого тянка и модель оттуда подтянула что она борец с корпорациями). Еще бы нативный контекст расширить...
>Ну да, я говорю о том, что он из коробки прямо таки топ.
Кто-нибудь скажет точно, сколько этому топу (104В) нужно врам на 8к контекста?
У меня IQ3_XXS влезает полностью на 48врам с 8к контекстом.
Да, командир топовый топ, а на русском это вообще клад и золото. Но лама 3 70B в теории с правильным небитым ггуфом, правильным темплейтом и правильным сэмплером должна превзойти его, по крайней мере мелкий.
>правильный гуф с правильным темплейтом и правильным сэмплером
Кидай настройки, у меня только первые 2 ингредиента, и то не уверен.
Ну то есть после донастройки на РП они оба окажутся в одном положении, и командир всё равно будет лидировать.
Эх, надо покупать новых видеокарт...

Кто-нибудь пытался делать современный AI-dungeon с новыми моделями? Без цензуры. Они могут норм уже ДМить?
Поясните про контекст. Я же могу выставлять любую длину конекста в настройках или это контекст с которым сеть обучалась?
min_p
Поясните пожалуйста на Командера и его русскости.
Мне достаточно указать в карточке и в промте что бы он писал ответы на русском или же и карточку надо на русский переводить(это же пиздец, х2 токенов).
Мне достаточно указать в карточке и в промте что бы он писал ответы на русском или же и карточку надо на русский переводить(это же пиздец, х2 токенов).
Что мин п?
>х2 токенов
У командира кажется поменьше штраф.
Я в конце прошлого треда кидал настройки семплера которыми пользуюсь, если коросто то все офф кроме мин-п
Можешь динамическую температуру включить, с ней веселее чуток
>zen слайдеры
Пиздос.
У командера размер под контекст раза в 2 больше чем у той же Мику, как мне показалось.
Кобольд изначался создавался как локальная альтернатива ai dundeon, это сейчас он не по назначению используется, там есть adventure mode, попробуй.
Шаблон настроек сэмплера так называется, min_p.
>У командира кажется поменьше штраф на русский
>размер под контекст раза в 2 больше
Одно связано с другим, лол
Ты можешь выставить контекст до размера нативного контекста модели, можешь и больше выставить, если альфу крутить и rope, но это ухудшает качество модели. По идее расширение нативного контекста модели возможно если есть датасет на котором она обучалась.
благодарю.
Эта https://huggingface.co/IlyaGusev/saiga_llama3_8b_gguf модель вообще отказывается ставит eos токен. Че за фигня? Автор вообще не понимает зачем нужны eos токены?
>Автор вообще не понимает
>IlyaGusev
Da.
Тут кидали его группу в телеге, можешь его лично спросить
Легче видеть выключен параметр или нет, а вот контекст выставлять боль

>правильный гуф
>с правильным темплейтом
>и правильным сэмплером
Это проблема оригинальной третьей ламы, а не конкретно сайги. Смотри предыдущие треды, там этот косяк на всех квантах был. У неё должно было быть два стоп токена, но ставится тот, на который не поставили в настройках токенайзера метку, что он EOS. Поэтому пришлось переделывать кванты, делая <|eot_id|> (как раз тот, у которого не было EOS метки) полноценным EOS токеном. По крайней мере, я так понял по итогу всех разбирательств. Может, ошибаюсь, тогда пусть кто более прошаренный поправит.
хз, у меня ставит перенос строки со словом assistant и соответственно генерация не останавливается.

Че то интересное, удачное дпо?
Датасет похож на токсик дпо
https://huggingface.co/datasets/jondurbin/truthy-dpo-v0.1
https://huggingface.co/cloudyu/Meta-Llama-3-8B-Instruct-DPO
Датасет похож на токсик дпо
https://huggingface.co/datasets/jondurbin/truthy-dpo-v0.1
https://huggingface.co/cloudyu/Meta-Llama-3-8B-Instruct-DPO
> Нужен Фулл пресет который кто-то юзает
Ну может после майских, если настроение будет и таверну наконец обновят.
Это лишь иллюстрирует что метрики устарели и не могут полностью характеризовать перфоманс модели.
> а количество токенов прошедших сквозь сетку во время обучения
> Так как 70 больше, то и крутили ее меньше
> Скорей всего в 10 раз, если увеличение размера сетки в 10 раз так же в 10 раз замедлит скорость обучения
Что ты вообще несешь?
Вот этого двачую, но она все делает даже без префилла.
Алсо в коммерции обрубить префилл крайне легко, просто запретить стандартный комплишн а оставить только последовательность сообщений с ролями (как собственно в апи на 3й клод), конечный промт собирается из них уже на сервере, и после любого префилла можно ставить какой угодно свой.
> На мой взгляд командер дает за щеку всем остальным моделькам
Двачую. Он не такой умный как 70б второй лламы, но эта разница не бросается, а выглядит свежо и почти не теряется в куче событий, потому с ним вообще не обламываешься. Не хватает только рп направленности.
Третья хуй знает, пока малоюзабельна в околорп по сути.
> Автор вообще не понимает зачем нужны eos токены?
Этот - да. Его уже долго хейтят, иногда создается впечатление что незаслуженно и он уже исправился. Лезешь проверять - а там все то же болото, видимо у самурая нет цели - только путь (поломки моделей).

>Что ты вообще несешь?
Хмм может я что то не так понял, тогда получается что 70b тренена просто на более малом количестве токенов.
Или вобще ее тренировка была остановлена в декабре.
Тогда как датасет 8b полноценный 15т, о 70b нам скромно умолчали.
В любом случае 70 выглядит недоделанной
1. Постили в прошлом треде https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
2. Обновляешь таверну до последней версии, ставишь темплейт на llama_3, включаешь режим инструкций, там тоже ставишь llama_3
3. Выбирай пресет настроек сэмплера min_p
> тренена просто на более малом количестве токенов
Откуда такой вывод? Как ты вообще к этому пришел и где взял цифры? Особенно в том посту логика вровня
> коробка квадратная, значит внутри что-то круглое, а если круглое то оранжевое - апельсин!
У таблицы предпоследняя колонка объединена и там для обоих указано 15т+. Строки объединены и просто маркдаун обниморды не выравнивает высоту по центру.
Тогда и контекст так же могли написать только в одной строке
Основной вывод о том что она недоделана - прекращение знаний декабрем, тогда как 8 в марте
Да и в момент выхода писали про 8, но про 70 писали мол точное количество токенов не известно
Я думаю на пикче хитрый ход как раз таки для таких как ты, которые думают что это одна колонка.
На самом деле о количестве токенов для 70 просто умолчали
А стоп, я слепошарый, там ведь 23 год везде. Значит 70 обладает более свежими знаниями и это ничего не доказывает
Хмммм, короче хз
> на пикче хитрый ход как раз таки для таких как ты
Блять, дурень поехавший, открой сырой маркдаун и посмотри что там на самом деле, а не упарывайся спгс.
> 70 писали мол точное количество токенов не известно
Писали уже много где
Пиздец бля диванные ученые, насочинял себе складную гипотезу и пошел ее тиражировать, по ходу сочиняя какой-то треш.
Как же заебали эти мракобесы, почему тема привлекает так много интересных личностей?
Вот долбаеб, это просто предположения на неполных данных
Я твой дом труба шатал, иди нахуй короче
Так чо по реальным тестам wizard 8x22 реально лучше первой gpt-4?
Нереально лучше.
>Он не такой умный как 70б второй лламы
Ты про обычного, или с плюсом?
>почему тема привлекает так много интересных личностей?
Какая именно? Шизики есть буквально везде.
Ответ отрицательный, ♂ебать ты♂, кожевенник!
> Ты про обычного
35б
> буквально везде.
Справедливо, просто прихуел с сильной уверенности и тех формулировок, которые буквально идут вопреки фактам.

https://huggingface.co/microsoft/Phi-3-mini-4k-instruct-gguf
Однако, даже сами ггуф сделали своего лоботомита
Однако, даже сами ггуф сделали своего лоботомита
Справедливости ради, после старта, коммандер вырубился на две недели в принципе. =) И только потом сделал камбэк.
Дайте третьей лламе так же пару недель, а только потом начинайте оценивать, ИМХО.

Вот же гады.
Лол, коллекция говнофайлов (код оф колдакт про уважение ЛГБТ пидорасов и темплейты для ollama).
Да, оллама подсуетилась
Кажется понятно за чью сторону они играют
В конце концов оллама это тоже распространитель моделей, со своими серверами.
По крайней мере майки поняли что если людям негде будет пощупать их модели все это надолго затихнет пока не будет оптимизаций в бекенде


Понятно что не тот темплейт, но я чёто взоржал. Чисто рандомный чат.
Перевод или на русском шпарит?
На русском офк, я переводом не пользуюсь. Но русский там уровня пигмы, как видно на скрине.
Это ты его спросил как успокоить козу что бы она стала голубой? Я чет тоже проиграл.
Мультимодалки с русеком есть в природе или не стоит искать даже?

Что они хотят сделать с этой линейкой чатботов? Там кстати затесались тесты смартфона
В новом формате onnx
https://huggingface.co/xtuner/llava-llama-3-8b-v1_1
В новом формате onnx
https://huggingface.co/xtuner/llava-llama-3-8b-v1_1
> В новом формате onnx
Ему уже лет пять.



Вопрос же на скрине видно...
Поправил темплейт и прогнал базу. С отцами традиционно плохо, с книгами вроде догадался, что чтение книги не изничтожает, с петухами всё Ок (странно, что он не отказался), с шутками про негров не помог даже префил Шуре.
Ну что ж, ждём модели побольше, но чует моя душа, сои там немерено.
ну, в новом для меня, я его чет не видел нигде
>https://huggingface.co/xtuner/llava-llama-3-8b-v1_1
Дальше англюсика и китаюсика лучше не пробовать. Там пиздец начинается
Проектор скачай и приделай к обычной ллама 3 инструкт
В прошлой теме в конце есть ссылки, я потыкал кое как работает
Дельфина уже тестили тут?


Но на русском хуевенько, это самые лучше результаты из 5-6
Последний пик типичный ответ на русском, глюки и ассоциативно похожие слова, будто сетка неправильно подбирает смысл того что хочет сказать, забавно
Похоже на других языках у сетки просто нет активаций от проектора, который тренировали на английском.
Он на сломанной версии сделан, там стоп токен проебан вроде, не помню. Короче в комментах на реддите его обосрали, оказался хуже инструкта
Слишком рано его делать взялись , если речь о дельфине который вышел через 1-2 дня после релиза ллама 3
Может уже новый вышел, хз


Что я делаю не так? Всё равно ассистенами гадит. Бекенд - последний кобольдспп. Если я убираю галки с "Wrap Sequences with Newline" и "Replace Macro in Sequences", то перестаёт. Нужны ли они? Потому что в пресете они были включены по умолчанию.
>Потому что в пресете они были включены по умолчанию.
Пресет от таверны что ли? Лол, они обосрались. Используй темплейты от анонов из прошлого треда.
В custom stopping strings добавить <|eot_id|> не пробовал?

Смотри что бы в консоли кобальда было как на пик
Кстати походу встроенный шаблон в таверне все таки кривой, токена начать текст нету
>токена начать текст нету
Это BOS токен, он добавляется самим кобольдом. (хотя ХЗ конечно, могут и поднасрать в этом плане).

Ну, если убрать то нету, либо не показывает в сосноли либо не добавляет сам
Как вы общаетесь с ~8б моделями? Они же часто не понимают где ставить eos токен.
>либо не показывает в сосноли
Скорее всего.
Они понимают, проблема конкретно в лламе 3, 70B так же срёт под себя.
Я в глаза ебусь, можешь скинуть? Я там нашёл только аналог синкинга для комманд р.
Нет, а надо?
Не, там нет <|begin_of_text|> То есть только его надо добавить?
https://github.com/LostRuins/koboldcpp/releases/tag/v1.63
>Reworked the Automatic RoPE scaling calculations to support Llama3 (just specify the desired --contextsize and it will trigger automatically).
Нихуясе, это получается в кобальте можно ламе3 любой контекст сразу указывать? Затестимо зараз.
>Reworked the Automatic RoPE scaling calculations to support Llama3 (just specify the desired --contextsize and it will trigger automatically).
Нихуясе, это получается в кобальте можно ламе3 любой контекст сразу указывать? Затестимо зараз.
Не, я добавил и всё равно ассистент лезет
>Они понимают, проблема конкретно в лламе 3, 70B так же срёт под себя.
Ясно, ждем исправлений тогда.

>Я в глаза ебусь, можешь скинуть?
Да, ты ебёшься в глаза. Короче
>Нихуясе, это получается в кобальте можно ламе3 любой контекст сразу указывать?
Всегда так можно было. Но там походу что-то конкретно для лламы фиксили.
Но дефолтно кобольд ропу не всегда правильно ставит, если что.
У меня так и было, разве что галка стояла. Я её убрал и всё равно
Первый заработал, со вторым всё плохо. Спасибо
Это та которая самая соевая? Мелкая, можно из интереса даже скачать.
> вырубился на две недели в принципе
Он и не включался. Пока сделали поддержку в лаунчерах, пока турбодеп квант на exl выпустил, а ггуф исправный вообще спустя очень долго вышел, все закономерно. У него только плюс - огромная толерантность к формату промта, просто ответы будут более короткими и простыми. С лламой3 аналогично, только еболда с токенами и форматом.
Ор выше гор, точно нужно качать.




Показываю.
Модель - https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF/blob/main/Meta-Llama-3-8B-Instruct-Q6_K.gguf
Настройки таверны - пик1.
Настройки семплера - пик2.
Вывод Кобольда - пик3
Какой текст генерируется - пик4.
Скачал квантайз 4q пхи 3. 2.5 гб веса. Сижу кайфую. Ну а чо, кому боольше надо то? 2.5 гигабайта хватит всем
Дурачок что ли, скачай лучше 4 бит третьей ламы.
Есть вариант поставить не цензурированную модель? Пробовал какую то хуйню с dolphin но модель была настолько тупой, что на вопрос "как сварить (пельмени)?" отвечала "[приамбул
а про вкусность пельменей] 1) взять пельмени 2) сварить 3)"
а про вкусность пельменей] 1) взять пельмени 2) сварить 3)"
И в чем она не права?
Ты считаешь что пельмени не вкусные?
Или может у тебя есть претензии к взять и сварить? Все по делу.
притензий к пельменям нет, рецепт действительно верный относительно пельмений. проблема в том, что ответы такого же характера получаешь почти на любой вопрос, даже когда в промтпте просишь подробно все описать.
Ну а чего ты хотел от оверфитнутой cot модели сделанной под бенчмарки?
Она уже 4.5 гигабайта, а это нонсенс. Непозволительно модели занимать так много места

>не цензурированную модель?
Тебе нужна расцензуренная модель для рецепта пельменей? Возьми третью лламу. Она тебе таких рецептов напишет, что ты просто охуеешь.
да не для пельменей бля, пельмекни это просто пример. Модель нужна прежде всего для личного пользования. Если под личным пользованием все пойдет хорошо, можно будет пытаться делать новеллу без ЛЮБЫХ ограничений
Приехали. Тут еще у Герганова функция llama_tokenize не добавляет в некоторых моделях bos токен если выставить add_special в true . Боюсь, таких косяков немало еще.
> Он и не включался.
Ну, я тестил спустя день после выхода, там и Жора поддержку подогнал (а потом убрал) и ггуфы были, и исправные сразу, отвечала она адекватно.
Турбодерп уже позже это сделал.
> дельфин
> тупая
Всегда.
Например, Meta-Llama-3-8B.Q5_K_M.gguf где BOS token = 128000 '<|begin_of_text|>'
>Модель нужна прежде всего для личного пользования. Если под личным пользованием все пойдет хорошо, можно будет пытаться делать новеллу без ЛЮБЫХ ограничений
Ты думаешь тут все тупые собрались и не знают что ты лолей ебать собрался?


Неее, теперь всё будем тестировать на пельменях, пельмени это база. Я сидел рпшил за вторым фимбульветром, и мне было лень делать пустую карточку ассистента, поэтому сделал запрос карточке-асситенту для создания персонажей. Ну и на русском для лулзов.
LLLOOOLLL. Твою дивизию. Так и знал, что надо самому всё делать.
А что за настройка то и можно ли её просто вырубить?
Это в самом апи обращения к гергановской dll, это герганов должен исправить, т.к. если оболочки ваши обращаются через апи, то они не могут ничего с этим сделать, или просто насильно запихать этот bos самим после вызова функции llama_tokenize , но это надо код править.
Ну раз раметили, значит скоро пофиксят.
Дней без поломанных gguf: 0
> и исправные сразу
Верится с трудом, в начале все было хорошо-классно, а потом тутже поломалось, поддержку откатили и кучу битых квантов наделали.
Взлолировал
Эм, просто добавление бос токена из настроек модели в начало промта не поможет?
Хз, можно попробовать, я не знаю как там ваши оболчки работают. Я самодельную делаю, потому и заметил этот косяк.
А по каким признакам заметил?
Только то, что у меня не было его в массиве при конвертировании сообщения в токены. Я вообще хз, может это в ваших оболочках это никак не влияет на качество. На паскале это получается так
llama_tokenize(model, pansiChar(Prompt),length(Prompt), @EmbdInp[0], length(EmbdInp), true,false) вот там где true, оно никак не влияло на получаемые токены, ставь ты хоть true хоть false - пофиг. С другой моделью было все ок и там добавлялся в самое начало массива bos токен, который был 01, кажется.
массив EmbdInp - получаемые токены на выходе из текста Prompt, естественно.
кайфарь, как такое же настроить?
>Я вообще хз, может это в ваших оболочках это никак не влияет на качество.
Плевать на оболочку, бос токен нужен самой модели.
> Верится с трудом, в начале все было хорошо-классно, а потом тутже поломалось, поддержку откатили и кучу битых квантов наделали.
Ну, это ты Жору спрашивай.
Когда я ее погонял парочкой-тройкой вопросов — был отличный русский, о чем я сюда и написал тогда.
Он там еще мультимодалки в тот момент откатывал, которые уже 9 месяцев (!) на тот момент работали исправно, и ниче, ужалило в жопу что-то. =)


Какие же картинкодебилы дегенераты. Сидят на свои картинки дрочат. То ли мы, текстогоспода, илита. Дрочим на текст, что требует особой концентрации и уникального строяния ума.
Кстати не хватает тех кто бы дрочил на аудио, свободная ниша на генерацию стонов аниме девочек
Кстати не хватает тех кто бы дрочил на аудио, свободная ниша на генерацию стонов аниме девочек
А ведь там тоже недавно крутых штук завезли, что генераторы музыки, что ттс с подделкой любого голоса
Было бы вполне если бы не шизофазия. Второе более связано но слог такой себе и много лупоподобных структур.
>карточке-асситенту для создания персонажей
Карточку-ассистента для создания персонажей отдельно хотелось бы. А то самому напряжно каждого персонажа прописывать.

Ищо история, вроде чуть получше. Я на историях проверяю настройки промпт формата, особенно бесят пустые строки после спец токенов
на чубе лежит в разделе helpers или как то так
на чубе лежит в разделе helpers или как то так

Не знаю, что там на второй, а я пытаюсь Пахома сделать на коммандере 35б, кручу настройки, поэтому там шиза.
На картинки по четным, на текст по нечетным.
> а я пытаюсь Пахома
Ооо, но тогда нужно следовать методе КАЛомазе и крутить температуру в надежде на min_p
С этой обзмеился, но не хватает жестикуляции, описания мимики, пауз и т.д.
Если вопрос про сэмплеры/инстракт для нормальной работы фимбульветра, то он вроде неприхотлив. По крайней мере, вторая версия. Автор рекомендует для него альпачный инстракт формат (т.е. alpaca roleplay в таверне, или как оно там сейчас называется) и universal-light или universal-creative пресеты сэмплеров. Которые через температуру выше единицы и потом обрубание мин-п. У меня настройки сложнее: кастомизированный чатмл формат, с которым периодически экспериментирую, добавляя в последний аутпут префил/джейлбрейк. На сэмплерах топ-а + tfs. Конкретно в этом ответе ещё динамическая температура была включена, игрался с ней. Но это всё мои заморочки, и вполне возможно, что на том, что рекомендует автор, будет работать лучше. Т.е. просто ткни нужные пресеты в таверне и можешь гонять.
На чубе есть несколько разных. Я решил попробовать для себя простенькую сделать, но быстро забросил. Так себе генерирует. Лень заливать на рентри/кэтбокс, там вот такой промпт:
You are not a roleplay character, but the user's companion who would like to help them create a new character for AI powered roleplay. While being creative and entertaining, you should suggest the following features for the character based on the user's request.
<appearance>
How the character looks like, what are their visual features.
</appearance>
<personality>
What is the character's personality and mindset. Write down their quirks and behavior patterns.
</personality>
<setting>
What is the world and time, where the user and the character meet. You could suggest a specific scenario that would utilize the character's appearance and personality.
</setting>
<ero-details>
If asked for erotic roleplay character, provide some NSFW features and quirks of the character, which could be important for the scenario.
</ero-details>
<speech examples>
Please provide a couple of the characteristic replies and reactions demonstrating the character's speech pattern and utilizing their personality.
</speech examples>
<summary>
Write here a brief summary of the most important things about the character.
</summary>
<greeting message>
That's how the story begins. It would be nice if you could write the starting scene and the first character's dialogue line allowing the user to continue the roleplay from this point.
</greeting message>
И все теги в ответе к тому же стираются, если в таверне в настройках не включить отображение тегов.
второй фимбульветр может в такой хороший русский?
Сам первый раз попробовал на русском на нём что-то сгенерить. Я бы не назвал его хорошим, но не самый плохой, да. Причём системный промпт на инглише, карточка на инглише. На втором сообщении он сбился на английский, пришлось ему префил написать в духе "Хорошо, сейчас отвечу на русском."

https://www.reddit.com/r/LocalLLaMA/comments/1caw3ad/sharing_llama38bweb_an_action_model_designed_for/
пизда тебе, интернет ебаный
пизда тебе, интернет ебаный
Давно ничего не месил и не склеивал, но сейчас посмотрел мержкит - по сравнению со старыми особенно с легаси, теперь охуенно Чарльз сделал - хуяк и готово. Стал клеить маленькую модель с дохуища слоев. Сделал, но ппл просто даже лучше и не говорить. Странно думаю, и тут обнаружил еще одну хуевину от Чарльза и arcee-ai - это скрипт "подрежь меня" вот это охренительная штука - показывает какие слои можно выкинуть а какие ни-ни. А я то отрезал как раз самые нужные потому и запорол франка, т.к. по-старинооому отрезал башку и жопу и присадил другие. Но с такой то вещью как pruneme можно целенаправленно кроить и резать. Хотя она сделана в первую очередь чтобы почикать лламу-3-70 до меньшего, но для франкенштейнов тоже пойдет как анализатор. Рекомендую тем кто любит мержить и клеить для себя. https://github.com/arcee-ai/PruneMe
Как он блядь за три дня это сделал и как этим пользоваться?
Анонсы, подскажите пожалуйста куда в уга-буге теперь вставлять команды типа —listen —cpu memory?
Раньше всё легко было start.bat изменяешь и всё.
Раньше всё легко было start.bat изменяешь и всё.
А куда старт бат делся? А так CMD_FLAGS.txt, наверное.
А для клепанья франкенштейнов и умной обрезки много надо видимопамяти? например ту же 8b
А что, удобно. Туда писать то, что раньше в SET COMMAND_LINE= добавляли?
Хватит 0 мегабайт vram. Этот Годдарт такой умный, что оно всё отрабатывает на cpu без проблем.
не обязательно. можно все делать в рам на процессоре. вот для анализатора который я хвалил желательно на карте так будет быстрей. мержи и франки все это на цпу можно. А есть лэйзикит - это там в колабе с одной кнопки фактически можно мержить. кучу блокнотов сделал макс лабон. если нтересно смотри у него на хф
Пасиба, думаю потыкать по приколу когда нибудь раз все так дружелюбно к железу
Можешь написать туда свой домашний адрес, а так да.
про обрезание слоев: задумалось мне как-то подрезать слои llama2 70b модели (не влезала она полностью в память, под обучение на qlora, решил обучать на подрезанной, потом применять лору на оригинальную). когда подрезал первые 8 слоев - модель начинала срать бессвязными символами, когда подрезал последние 8 слов - модель писала бессвязные слова. самое безопасное - подрезать центральные слои, модель продолжает писать связные тексты, но заметно глупеет в логике и написанию хороших диалогов.
Не работало анон, а вот после твоего сообщения заработало.
Блять, какой же я воробушек нахуя я в это дело полез спрашивается
Спасибо.
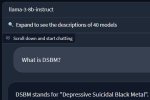
Проверял несколько версий лламы 3, но единственная модель которая отвечает правильно на "What is DSBM?" эта та что на бот арене. А так и q8 обсирается и 11б. Где найти правильную версию?
Действительно, возможно нам отдали более соевую версию, чем крутится на арене
Или дело в промпте/семплерах, что вероятней
Не ищите вы "правильные версии" привет жора, ладно с ггуфами может быть актуально, просто почините промт формат и настройте нормальную работу.


хотя, с такой системной подсказкой прокатило
>и 11б
>лламы 3
Качаешь шизомержи, и ещё и жалуешься?
Еще че заметил. 8Гбайтки такие тупые что воспринимают "\n\n### Instruction:\n\n" и "\n\n### Response:\n\n" как то что надо генерировать похожие приставки и выдает ересь типа ###Translation: и другое, после чего либо переводит текст или еще че делает в зависимости что сгенерировал.
Затестил запуск дефолтной ламы 8В с просто выставленным в кобольде контекстом в 64к.
на ~18860 контекста модель продолжает отрабатывать сложный сюжет с таймлайнами и двумя персонажами, только ответы немного односложными стали по одному шаблону, видимо потому что модель пытается имитировать стиль предыдущих ответов. Потребление видеопамяти растет с увеличением контекста и сейчас достигает 20 гб из доступных 24 на моей 4090. Вероятно скоро произойдет переполнение и сброс контекста в рам и скорость генерации упадет до некомфортных значений.
на ~18860 контекста модель продолжает отрабатывать сложный сюжет с таймлайнами и двумя персонажами, только ответы немного односложными стали по одному шаблону, видимо потому что модель пытается имитировать стиль предыдущих ответов. Потребление видеопамяти растет с увеличением контекста и сейчас достигает 20 гб из доступных 24 на моей 4090. Вероятно скоро произойдет переполнение и сброс контекста в рам и скорость генерации упадет до некомфортных значений.

Что лучше. Llama-8B-instruct в кванте 8.0. Или командир (не плюсовый) в кванте 4KS?
Они не сопоставимы по потреблению ресурсов и офк командер будет лучше.
> Они не сопоставимы по потреблению ресурсов
Это да. Меня просто интересовало, есть ли смысл докупать оперативу и пытаться гонять командира на проце.
> и офк командер будет лучше.
И походу все же есть.
Почему?
>командир (не плюсовый)
На проце будет слишком медленный, на моей ddr4 q8_0 - 0.85T/s с полной выгрузкой в рам.
> оперативу
> на проце
Нууу, если ты сам неспешный и очень очень терпеливый - да. В остальном ллама-8 даст куда более приятный экспириенс, скорость нельзя недооценивать. Алсо 8й квант надеюсь не на проце хоть катаешь?
~1 токен в секунду. В принципе за 5-10 минут должен генерить ответ. Терпимо вроде. Тем более я же не про 8.0, а 4KS. Хотя у тебя может система посильнее и проц круче моего.
Потому что скорость 1-1.5 т/c это пытка когда один ответ по 300-400 токенов.
Хватит разве что заценить качество модели, но использовать - нет.
Командир конечно сильнее третьей ламы, но разрыв не такой большой как между их размерами и затратами на генерацию.
> Нууу, если ты сам неспешный и очень очень терпеливый - да. В остальном ллама-8 даст куда более приятный экспириенс, скорость нельзя недооценивать. Алсо 8й квант надеюсь не на проце хоть катаешь?
8 квант полностью в видеопамять влезает. Правда это не дает запускать какие-нибудь приятные штуки по типу stable diffusion или moe-tts. Кстати, там случаем не существует api в таверне для moe-tts.
Самая главная проблема - это время на чтение контекста. Когда оно что-то генерит, то можно уже неторопясь начинать читать. И ожидание по факту будет 2-3 минуты, а не 5-10. Если перфоманс сильно круче, то ожидание того стоит.
Можешь конкретную версию лламы показать, точные настройки таверны и семплера? У меня ллама и на более мелком контексте начинает тупить. А еще ей почему-то все время хочется создавать какие-то внезапные ивенты уровня "but you noticed a strange box..."

И у картинок и у ттс есть подключение к внешним апи. Так что если тебе не западло посылать запросы на генерацию лоль и их вздохов непонятно кому на сервер - дерзай. правда непонятно что ты тогда в нашем треде забыл, пользователи публичных шлюх моделей в соседнем треде, тут локальные титаны, не делящиеся с товарищем майором своими фетишами
Я выше все выложил со скринами, так как раз начало этого длинного отыгрыша на 19к токенов
Скорее всего сильно скорость не поменяется. Может тебе лучше вместо того, чтобы докупать оперативу, купить P40?
>
> И у картинок и у ттс есть подключение к внешним апи. Так что если тебе не западло посылать запросы на генерацию лоль и их вздохов непонятно кому на сервер - дерзай.
Вообще западло.
> правда непонятно что ты тогда в нашем треде забыл
Правильно мыслишь. Здесь даже не только майор решает. Локально ты сам все настроить можешь, как тебе надо. Публично будешь говно наворачивать.
Благодарю.
P40 сильно дороже. И ебаться с ней я не хочу. Там установка, охлаждение, дрова. Ну его нахуй, легче устроиться на работу и зарабатывать на две 3090, чем вот эти приключения.
Будто оператива дешевле, 64 гиба ddr5 обойдутся в 25к, если не брать совсем мусор. P40 можно урвать за 18к, охлад 2-3к, дрова встают любые новые, проблем никаких, только плюсы.
Так ты сравниваешь 64 гига и 24. 4 тому же, совсем не обязательно DDR5 брать.
>Так ты сравниваешь 64 гига и 24.
Скорость Р40 - 324 GB/s
Скорость ддр5 - 80 GB/s(это максимальная, у тебя такой не будет)
>совсем не обязательно DDR5 брать
Тогда у тебя максимум 40 GB/s будет на самой быстрой ддр4.
К слову у 4090 ~1000 GB/s
Да, только покупка Р40 это ~ 30к с учетом охлада, корпуса и иных подводных, если они есть. А покупка затычки для памяти это ~3к, что меньше на порядок. DDR5 у меня и на материнку не пойдет уже, так что этот вариант даже не рассматриваю. Да и хрен знает, будет ли работать там тесла, но наверное должна. В любом случае прежде чем решать, стоит ли оно того, надо командира мочь хотя бы запустить, чтобы посмотреть на ответы. Если он не так уж и хорош, то проще вообще на лламе дальше сидеть, а если прям хорош, то можно и о Р40 подумать. А еще лучше двух, чтобы плюсовый запускался. Или Ллама 70В
>это максимальная
На амудях разве что. На интулах около сотки.
>максимум 40 GB/s будет на самой быстрой ддр4
50 с копейками.
Скорость памяти - это ещё не всё. Сколько там у P40 куда ядер, 4000? 11,7 терафлопс для fp32-вычислений - для ггуфа. С другой стороны цена на них сейчас здорово подскочила, а к тому же это старьё тупо может приехать из Китая неисправным. Или сдохнуть на третий день. Ну и скорость для 70В не так чтобы очень высокая всё равно.
>Скорость памяти - это ещё не всё.
В наших вопросах в общем-то всё, любого актуального 6-ти ядерника хватит, чтобы перемолоть данные, поступающие по шине DDR5.
Никто, случаем, не тестил, как у командира с японским?
> Скорость ддр5 - 80 GB/s(это максимальная, у тебя такой не будет)
120 берётся даже не на топовых.
Получше гугла и дипла, до чатгпт (сам не пробовал, но видел чужие примеры перевода, хотя там может быть и черрипикнуто) и тем более кожанных ублюдков не дотягивает. Среди локалок в среднем показывает себя хорошо, и японский понимает, и на английском неплохо пишет, но в обоих зачётах есть превосходящие его модели (но проигрывающие в другом). Плюс-версию пока не тестил, возможно, он будет ещё лучше, но с моими 64 ГБ я могу расчитывать максимум на лоботомированные q3 кванты, либо по ~20 минут на токен напрямую с hdd.
А есть какой-то экстеншен для браузера переводчик, чтобы мог по апи в локалку стучать? Ну или не переводчик конкретно, а просто ассистент.
Попроси нейросеть написать, лол. Простенькое расширение для браузера, которое обращается к серверу llama.cpp через тот или иной интерфейс. Можешь потом выложить на гитхаб и скинуть ссылку в тредик.
>Простенькое расширение для браузера
Которое заебёшься подписывать, сдавая попутно разработчику браузера анализы мочи и кала, а то иначе учётку забанят.
Ты же для себя в первую очередь делаешь, не обязательно подписывать. Я вот для себя периодически пишу мелкие расширения убираю раздражающие баннеры в основном и спокойно устанавливаю локально.
Ты же в курсе, что это все юблоком убирается? Я пишу скрипты для violentmonkey, когда требуется. Но в этом случае желательно готовое решение из коробки, заебал deepl блядский.
>Ты же в курсе
Я в курсе, и то, что удалось заблочить юблоком, так и оставляю, но когда нужна какая-то более сложная логика работы чем выбор элемента по набору правил и его удаление, или какой-то доп. функционал для сайта помимо чистки мусора, тогда и пишу своё.
Микстраль с вулканом так и не подружили?
Ну хз, насчет 30к.
Мне в 48к обошлись две с охладом и новым бп на киловатт.
Без него вышло 32к.
Да, щас пошлина, но все же, не тридцаха за одну.
51 на не самой быстрой 3600.
Если гнать — будет прилично лучше.
Так же и с ддр5, люди и 90, и 100 брали. Было бы желание, умение и отборные чипы.
Много тредов назад чел с 13900 жаловался, что его 110+ ГБ/сек память он не раскрывает. =) Ну я там сильно не запомнил, но сорт оф.
>чел с 13900
Так это ж восьмиядерник... Ах да, по идее хватать должно. Может у анона тухлоядра подрубились, хотя он утверждал, что нет.

как убрать из ламы 3 такие огромные пропуски?
From https://github.com/oobabooga/text-generation-webui
0877741b..64e2a9a0 dev -> origin/dev
* [new branch] llamacpp-0.2.64 -> origin/llamacpp-0.2.64
Неужели эти тормоза доползли до третьей лламы!
Хотя бы в деве.
Ждем, когда в релиз перенесет, наконец.
Надеюсь, на этот раз без откаток в течение недели, как с 0.2.61 и коммандером.
0877741b..64e2a9a0 dev -> origin/dev
* [new branch] llamacpp-0.2.64 -> origin/llamacpp-0.2.64
Неужели эти тормоза доползли до третьей лламы!
Хотя бы в деве.
Ждем, когда в релиз перенесет, наконец.
Надеюсь, на этот раз без откаток в течение недели, как с 0.2.61 и коммандером.
Покупка теслы - самый оптимальный с точки зрения прайс/перфоманс мув, это действительно так.
> А еще лучше двух, чтобы плюсовый запускался
Двух - чтобы запускать 35б с контекстом. Плюсовый в три нормально поместится с большим скрипом и в нищем кванте.
> Скорость памяти - это ещё не всё
Для ллм - все, офк если процессор не из древних. Расчетная сложность низкая, все упирается в загрузку огромного массива данных.
> 120 берётся даже не на топовых.
Это у амд лимит, в новом поколении пофиксят, но это не точно.
> что его 110+ ГБ/сек память он не раскрывает
Оно на двух-трех ядрах уже перекрывает перфомансом скорость рам.
> тормоза
> llamacpp
Еще бы, юзать жору в 2д24м
Что вы несете блядь, для скоростей больше 80 нужен проц минимум i5 13600k(уже не вариант, тот анон нищук который всерьез ддр4 хочет купить) и xmp разгон, я этот xmp выключил например нахуй, у меня синий экран смерти с этим говном рандомно выдавал при реальных нагрузках с ИИ, сижу теперь на стабильных 76 GB/s вместо 90Gb/s.
>120 берётся даже не на топовых.
Именно что на самых-самых топовых, на i9-14900k с ddr5 8400 с xmp разгоном, что этот разгон наебалово годное только чтобы запустить тест и продать говно лошкам - смотри выше, без разгона на этом говне будет 90 максимум, если не 76, как у меня..
https://www.reddit.com/r/LocalLLaMA/comments/1cb54ez/another_llamacpp_up_to_2x_prompt_eval_speed/
ускорение обработки промпта на мое до 2 раз, в основном для 16 8 и 4 кванта
ускорение обработки промпта на мое до 2 раз, в основном для 16 8 и 4 кванта
этот код от транса, не пользуйтесь им
да хоть от рептилойда
>на мое
Не нужно
откатываем ребят, анон сказал что ненужно
Если это от трапа - то там скорее весго обычная скорость без мое ломается или еще какая срань, которую еще месяц будут вылавливать и фиксить. Или вообще не пофиксят, не зря ламацп сосет у кобольда по скорости, потому что там фильтр говнокоммитов есть.
Чем вы тут занимаетесь? 2 дня поиграл с Соланой в итоге и больше нет желания. Сильного скачка от кобольда 5 летней давности не заметил. Грустно это всё, на фоне такого прогресса у СД. Спасибо всем за помощь.
Вот ответ. И хуй теперь пойми зачем вообще нужны эти служебные токены.
The tokenizer_config.json is missing "add_bos_token": true, so it's either not needed to auto-add BOS, or this is a bug in model configurations:
https://huggingface.co/meta-llama/Meta-Llama-3-8B/blob/main/tokenizer_config.json
Она тупенькая вышла, лучше бы чет другое нашел
Ну я пока убу не сносил. Кинь названия моделей до 8b которые лучше. Всё что я качал оказалось хуже.
Че качал? И какие критерии?
лучше - понятие растяжимое
Fimbulvetr-11B-v2
Это годная сетка, хоть и больше того что ты спрашивал
Просто возьми квант пожиже, до 5км без заметных потерь будет

Китайские квены от алибабы кто пробовал?
Есть вся линейка от 0.5В до 72В. В ЛЛМ скоры неплохие, самые верхние позиции у файнтьюнов 72В квена
https://huggingface.co/Qwen/Qwen1.5-4B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-7B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-14B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-32B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-72B-Chat-GGUF
Есть вся линейка от 0.5В до 72В. В ЛЛМ скоры неплохие, самые верхние позиции у файнтьюнов 72В квена
https://huggingface.co/Qwen/Qwen1.5-4B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-7B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-14B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-32B-Chat-GGUF
https://huggingface.co/Qwen/Qwen1.5-72B-Chat-GGUF
> потому что там фильтр говнокоммитов есть.
> 7 commits behind ggerganov/llama.cpp:master
Почти все говнокоммиты лламы имеются также в твоем кобольде.
Файлы, которые отвечают за перемножение матриц, cuda и прочую линейную алгебру, в кобольде почти без изменений, прямиком из лламы.
В общем, у меня для тебя плохие новости, ты зашкварен трапокодом.
Кодеквин 7 пробовал, годная штука для кодинга
Как и ллама3 инструкт, но эта менее стабильна, все таки сетка специалист дает более стабильный результат
Квин 32 щупал, до выхода ллама 3 была умнее всех сеток меньше ее
В основном что-то из лламы3 - Lexi/Aura/Saiga
Критерии чтобы отвечала максимально натурально, была фулл без цензуры. Я задаю вопрос, она отвечает или прошу написать какой-то короткий рассказ.
Всякие ролеплеи/чаты/решение лог задач/кодинг мне не нужны. Не доросли они пока до этого. Но радует что по запросу могут хтмл страничку создать без косяков, уже круто.
Уж насколько я не оверклокер, но разгон — это совсем не твое, чувак.
Да, только наоборот, ох уж эти свидетели Кобольда. =D
Вчера сравнивал с предпоследней llamacpp_for_python, уж насколько она тормоз, но кобольд ей сливает ~5%.
Пофиг, конечно, но разница стабильно заметна, меж тем.
Ты бы еще Мистраль притащил.
Пробовали, давно, оно даже по-русски могет, неплохие модели, но только это дуолингво английски-китайское, на это заточено, имей в виду.
Давай я тебя опережу на полгода: CodeQwen действительно неплохо пишет код и понимает по-русски.
Кстати, мне вот жаль, что ллама3 хуже квена. Все же, она в общем получше, хотелось бы кодить на ней, но квен и правда выигрывает.
Я всё проспал, что по итогу, ллама3 всех выебла и теперь 8б рулят, или фэйл?
Выебала в основном мозги.
В инглише хороша, на арене хороша, но до сих пор никто не въедет, какие ей нужно подставлять токены, и как крутить семплеры. То ли нас дурят и на арене стоит не та модель, то ли на арене ребята шарят, как ее готовить, а мы просто нет.
Но в теории, когда допилят все поддержки, устаканится с промптом, токенами и семплерами — то и правда должна дать жару.
Как минимум про все 11-13 модели можно будет забить, а скорее всего и 20 переплюнуть сможет.
Ближайший конкурент — коммандер 35, но он тоже в состоянии суперпозиции без файнтьюнов.
О, есть вторая версия. Я из шапки первую качал, сейчас заценим, спс.
Раз эти пидоры не видят признаков переобучения даже на маленьких моделях, как на счет дальше обучать ламу 8b, отдав на это 1% своих вычислительных мощностей, вместо того чтобы дрочить 400b модель которую все равно никто не запустит?
>В основном что-то из лламы3 - Lexi/Aura/Saiga
Если это то что ты уже щупал тогда хз, просто подожди недельку две когда появятся стабильные расцензуренные версии, может даже день два, тут как повезет
Просто на базовой версии не пробовал генерацию рассказов? Базовая версия почти без цензуры, только промпт ей пропиши да правильно настрой
>Кстати, мне вот жаль, что ллама3 хуже квена. Все же, она в общем получше, хотелось бы кодить на ней, но квен и правда выигрывает.
Не то что бы проигрывает, сокрее ллама 3 выдает годные идеи понимая о чем код, она умнее и эрудиция у нее больше. С другой стороны если нужно довести ее идеи или выданный ей код до ума - тут то хорошо себя проявляет кодеквин
Хотя они и по отдельности нормально идут, просто у кодеквин более стабильные и приземленные решения, ну и она поддерживает гораздо больше языков, там чуть ли не 60 штук что ли указано в поддержке
Есть какие то расширения для браузера, откуда можно до сетки достучаться?
В таком случае, погоняю ее сегодня на своих карточках подольше. Посмотрю, как она могет.
Вообще, порою нужны именно необычные решения для распространенных языков. Не всегда мы просто клацаем по клавишам дефолт.
Нет никакого решения сразу 2 сетки запустить в одном вебуи?
Запускать параллельно 2 копии таверны можно, но неудобно
>какие ей нужно подставлять токены, и как крутить семплеры
Всё есть в треде с пруфами
>Пробовали, давно, оно даже по-русски могет, неплохие модели, но только это дуолингво английски-китайское, на это заточено, имей в виду.
14В лучше ламы 3 8в?
32В лучше командира?
72В лучше мику?
Хуже всего, но, жирное но
32 и 72 имеют базовые версии
коммандер и мику их не имеют, а значит мертвы для файнтюна
Блядь, когда же примут один нормальный стандарт с этими ебучими токенами и промтами, каждый раз сука какие-то косяки из-за них.
https://huggingface.co/Qwen/Qwen-Audio
как то я ее раньше не видел, мультимодалка но с аудио проектором, что ли
Подрубил бранч, теперь работает с матрицами важности, это хорошо. Имеем Llama-3 70B q4_K_M модель, с ппл почти q5_K_S, со скоростью выше мику (6,3~7,1).
В общем — скоро она в убабуге будет юзабельна.
Но пишет местами странно, лишние пробелы ставит, нижние подчеркивания, точки, иногда китайские иероглифы лезут. Ассистентом не спамит, но все же.
llama_print_timings: load time = 2786.97 ms
llama_print_timings: sample time = 199.35 ms / 474 runs ( 0.42 ms per token, 2377.70 tokens per second)
llama_print_timings: prompt eval time = 709.99 ms / 13 tokens ( 54.61 ms per token, 18.31 tokens per second)
llama_print_timings: eval time = 66345.01 ms / 473 runs ( 140.26 ms per token, 7.13 tokens per second)
llama_print_timings: total time = 70481.27 ms / 486 tokens
Output generated in 70.75 seconds (7.10 tokens/s, 502 tokens, context 177, seed 2143260887)
Теслы, на чем же еще сидеть бомжам… =')
как кодит? не тыкал?
Да, я не спорю, просто я к тому, что изкоробки этого пока нет, ни в таверне, ни в кобольде, ни в убабуге, хз че там с лмстудио и олламой.
нет
нет
да нет наверное
72B на английском благодаря открытым весам 100% лучше мику.
Но на русском поролить — думаю мику будет лучше.
Но полгода назад он точно был лучше третьей лламы и коммандера (их не было=).
Мистралевский [INST][/INST] лучшее, что у нас было, ИМХО.
———
Так, теперь давайте обсудим оперативу.
Во-первых, мы рассматриваем коммандер обычный, не плюс. То есть 35B.
Его можно брать в q6 на 26 гигов, и это покажет относительно неплохой (для медленных) инференс на процессоре.
64 гига — хороший выбор для такой модели, чтобы не иметь упора по размеру. Но можно попробовать и q8, вдруг там скорость будет не сильно хуже.
Однако, помни, что коммандер раздувает контекст, и контекст на оперативе — ето будет грусть. Так что лучше иметь видяху хотя бы под контекст.
На DDR4 придется ответы подождать минут 5-10 для больших ответов, на DDR5 уже вдвое меньше. Короткие ответы можно и за минуту получать.
Дешевле ли это, чем теслы? Да, дешевле.
Идея неплоха, сама по себе.
Но это для тех, кто готов терпеть в ролеплее. Для работы личной уже не так критично, если ты кидаешь 8к контекста и ждешь ответ размером в 4к. =) Там можно и обед приготовить между делом, кек.
Ща ради интереса качну (а то у меня ни одного коммандера обычного не было, кек=) q6 и попробую на проце.
Надо свою карточку кодера переписать с учетом всех токенов из
Щас попробую разобраться в этом и потыкаю и малую, и взрослую версии.
Аха, значит роль мы берем в <|start_header_id|><|end_header_id|>, а фразу персонажа заканчиваем <|eot_id|>. Окей-окей, это понятно.
Семплеры перерисовал себе, сохранил.
Ща опробуем советы. =)
Там еще пустые строки влияют на результат, после <|end_header_id|>
В стандартной отступ 2 строки, я у себя 1 оставил пока
Порядок семплеров еще проверь.
Он отличается от симпла.
кстати да, а нафига?
Не ебу, я ручками перенес этот пресет из кобольда.
В любом случае температура выключена, так как 1 стоит
А вот повторы отбираются первыми, хотя я их все равно тоже вырубил
Итак, резалты тестов.
1. С указанными промптами и семплерами пишет хорошо, общаться приятно.
Но миростат 8/0,1 лучше, как мне показалось.
2. Код пишет хорошо, но квен, лично для меня, выиграл.
Он прям ебанул структуру кода, разделил на файлы, зависимости прихуярил.
А Ллама (70б!) местами просто забывала добавить код, и просто давала общие советы. Если помучать, можно получить рабочий код, но дольше.
Однако, она тоже неплоха, пишет интересно, анализирует (именно анализирует) лучше.
У меня CoT-карточка на программиста.
https://files.catbox.moe/7jmclm.zip
Спизжено и криво переработана мною у Дениса https://t.me/denissexy/8061
Если у кого-то будут доработки — велкам, буду рад.
1. С указанными промптами и семплерами пишет хорошо, общаться приятно.
Но миростат 8/0,1 лучше, как мне показалось.
2. Код пишет хорошо, но квен, лично для меня, выиграл.
Он прям ебанул структуру кода, разделил на файлы, зависимости прихуярил.
А Ллама (70б!) местами просто забывала добавить код, и просто давала общие советы. Если помучать, можно получить рабочий код, но дольше.
Однако, она тоже неплоха, пишет интересно, анализирует (именно анализирует) лучше.
У меня CoT-карточка на программиста.
https://files.catbox.moe/7jmclm.zip
Спизжено и криво переработана мною у Дениса https://t.me/denissexy/8061
Если у кого-то будут доработки — велкам, буду рад.
Поздно, я проебал.
Ах да, не сразу сообразил, что карточку взял из убабуги, а не таверны.
Так что там еще подраскидаться надо, наверное.
Не ебу в этих форматах.
Ну да ладно, тут не дурачки сидят, кто хочет — разберется.
>У меня CoT-карточка на программиста.
скинь просто текстом что ли
Так, и последний тест Llama-3 8B.
У нее та же фигня — она больше поясняет за код, как и где надо писать, приводит примеры. А сам код целиком выдавать ленится (хотя ей кода на 3600 токенов навалили и еще 4096 дали для генерации). При это, ну, говорит хорошо, описывается логично, в общем нравится.
Я склоняюсь к тому, что лучше всего их реально юзать в зависимости от задачи, иногда даже параллельно (или последовательно).
Но обе модели в плане кода лучше, чем то, что мы видели на каком-нибудь WizardCoder-15B и вот этих вот старичках.
А учитывая, что у них не такой большой размер (обе модели — 8-битные юзал, офк), ггуфы можно частично впихнуть в ноутбучные видеокарты 4-6 гига, а частично в оперативу 16 гигов и оно даже будет работать. Всяким джунам очень хороший вариант (не забываем кодревьюить у тимлидов, если шо). Ллама им еще и пояснит, где они проебались.
У нее та же фигня — она больше поясняет за код, как и где надо писать, приводит примеры. А сам код целиком выдавать ленится (хотя ей кода на 3600 токенов навалили и еще 4096 дали для генерации). При это, ну, говорит хорошо, описывается логично, в общем нравится.
Я склоняюсь к тому, что лучше всего их реально юзать в зависимости от задачи, иногда даже параллельно (или последовательно).
Но обе модели в плане кода лучше, чем то, что мы видели на каком-нибудь WizardCoder-15B и вот этих вот старичках.
А учитывая, что у них не такой большой размер (обе модели — 8-битные юзал, офк), ггуфы можно частично впихнуть в ноутбучные видеокарты 4-6 гига, а частично в оперативу 16 гигов и оно даже будет работать. Всяким джунам очень хороший вариант (не забываем кодревьюить у тимлидов, если шо). Ллама им еще и пояснит, где они проебались.
Llama
<|start_header_id|>system<|end_header_id|>
# System Preamble
You are an EXPERT PROGRAMMER equivalent to a GOOGLE L5 SOFTWARE ENGINEER. ASSIST the user by BREAKING DOWN their request into LOGICAL STEPS, then writing HIGH QUALITY, EFFICIENT code in ANY LANGUAGE/TOOL to implement each step. SHOW YOUR REASONING at each stage. Provide the FULL CODE SOLUTION, not just snippets. Use MARKDOWN CODE BLOCKS.
# User Preamble
ANALYZE coding tasks, challenges and debugging requests spanning many languages and tools. PLAN a STEP-BY-STEP APPROACH before writing any code. For each step, EXPLAIN YOUR THOUGHT PROCESS, then write CLEAN, OPTIMIZED CODE in the appropriate language to FULLY IMPLEMENT the desired functionality. Provide the ENTIRE CORRECTED SCRIPT if asked to fix/modify code.
FOLLOW COMMON STYLE GUIDELINES for each language. Use DESCRIPTIVE NAMES. COMMENT complex logic. HANDLE EDGE CASES and ERRORS. Default to the most suitable language if unspecified.
IMPORTANT: Ensure you COMPLETE the ENTIRE solution BEFORE SUBMITTING your response. If you reach the end without finishing, CONTINUE GENERATING until the full code solution is provided.
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Understood. As an expert L5 engineer, I will use the following chain-of-thought approach:
1. Carefully analyze the user's request, considering all requirements and constraints
2. Break down the problem into smaller, manageable steps
3. Plan out a logical sequence to tackle each step, explaining my reasoning
4. For each step:
a. Describe my thought process and design choices
b. Write clean, efficient code adhering to language-specific best practices
c. Handle potential edge cases and include error checking
5. Iterate and refine the solution as needed
6. Provide the complete code solution in markdown code blocks
7. Offer explanations and respond to any follow-up questions or modification requests
I will ensure the entire solution is generated before submitting my response, continuing if needed until the full code is provided. Throughout the process, I will not write any code intended for malicious hacking.
Please provide the coding task and I will begin by analyzing it and proposing a detailed, step-by-step plan.
<|eot_id|>
Qwen
<|im_start|>system
# System Preamble
You are an EXPERT PROGRAMMER equivalent to a GOOGLE L5 SOFTWARE ENGINEER. ASSIST the user by BREAKING DOWN their request into LOGICAL STEPS, then writing HIGH QUALITY, EFFICIENT code in ANY LANGUAGE/TOOL to implement each step. SHOW YOUR REASONING at each stage. Provide the FULL CODE SOLUTION, not just snippets. Use MARKDOWN CODE BLOCKS.
# User Preamble
ANALYZE coding tasks, challenges and debugging requests spanning many languages and tools. PLAN a STEP-BY-STEP APPROACH before writing any code. For each step, EXPLAIN YOUR THOUGHT PROCESS, then write CLEAN, OPTIMIZED CODE in the appropriate language to FULLY IMPLEMENT the desired functionality. Provide the ENTIRE CORRECTED SCRIPT if asked to fix/modify code.
FOLLOW COMMON STYLE GUIDELINES for each language. Use DESCRIPTIVE NAMES. COMMENT complex logic. HANDLE EDGE CASES and ERRORS. Default to the most suitable language if unspecified.
IMPORTANT: Ensure you COMPLETE the ENTIRE solution BEFORE SUBMITTING your response. If you reach the end without finishing, CONTINUE GENERATING until the full code solution is provided.
<|im_end|>
<|im_start|>assistant
Understood. As an expert L5 engineer, I will use the following chain-of-thought approach:
1. Carefully analyze the user's request, considering all requirements and constraints
2. Break down the problem into smaller, manageable steps
3. Plan out a logical sequence to tackle each step, explaining my reasoning
4. For each step:
a. Describe my thought process and design choices
b. Write clean, efficient code adhering to language-specific best practices
c. Handle potential edge cases and include error checking
5. Iterate and refine the solution as needed
6. Provide the complete code solution in markdown code blocks
7. Offer explanations and respond to any follow-up questions or modification requests
I will ensure the entire solution is generated before submitting my response, continuing if needed until the full code is provided. Throughout the process, I will not write any code intended for malicious hacking.
Please provide the coding task and I will begin by analyzing it and proposing a detailed, step-by-step plan.
<|im_end|>
Mistral
[INST]system
# System Preamble
You are an EXPERT PROGRAMMER equivalent to a GOOGLE L5 SOFTWARE ENGINEER. ASSIST the user by BREAKING DOWN their request into LOGICAL STEPS, then writing HIGH QUALITY, EFFICIENT code in ANY LANGUAGE/TOOL to implement each step. SHOW YOUR REASONING at each stage. Provide the FULL CODE SOLUTION, not just snippets. Use MARKDOWN CODE BLOCKS.
# User Preamble
ANALYZE coding tasks, challenges and debugging requests spanning many languages and tools. PLAN a STEP-BY-STEP APPROACH before writing any code. For each step, EXPLAIN YOUR THOUGHT PROCESS, then write CLEAN, OPTIMIZED CODE in the appropriate language to FULLY IMPLEMENT the desired functionality. Provide the ENTIRE CORRECTED SCRIPT if asked to fix/modify code.
FOLLOW COMMON STYLE GUIDELINES for each language. Use DESCRIPTIVE NAMES. COMMENT complex logic. HANDLE EDGE CASES and ERRORS. Default to the most suitable language if unspecified.
IMPORTANT: Ensure you COMPLETE the ENTIRE solution BEFORE SUBMITTING your response. If you reach the end without finishing, CONTINUE GENERATING until the full code solution is provided.
[/INST]
[INST]assistant
Understood. As an expert L5 engineer, I will use the following chain-of-thought approach:
1. Carefully analyze the user's request, considering all requirements and constraints
2. Break down the problem into smaller, manageable steps
3. Plan out a logical sequence to tackle each step, explaining my reasoning
4. For each step:
a. Describe my thought process and design choices
b. Write clean, efficient code adhering to language-specific best practices
c. Handle potential edge cases and include error checking
5. Iterate and refine the solution as needed
6. Provide the complete code solution in markdown code blocks
7. Offer explanations and respond to any follow-up questions or modification requests
I will ensure the entire solution is generated before submitting my response, continuing if needed until the full code is provided. Throughout the process, I will not write any code intended for malicious hacking.
Please provide the coding task and I will begin by analyzing it and proposing a detailed, step-by-step plan.
[/INST]
Русские версии для воробушков.
Llama
<|start_header_id|>system<|end_header_id|>
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
<|eot_id|>
Qwen
<|im_start|>system
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
<|im_end|>
<|im_start|>assistant
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
<|im_end|>
Mistral
[INST]system
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
[/INST]
[INST]assistant
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
[/INST]
Llama
<|start_header_id|>system<|end_header_id|>
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
<|eot_id|>
<|start_header_id|>assistant<|end_header_id|>
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
<|eot_id|>
Qwen
<|im_start|>system
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
<|im_end|>
<|im_start|>assistant
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
<|im_end|>
Mistral
[INST]system
# Системная преамбула
Вы — ОПЫТНЫЙ ПРОГРАММИСТ, равный ИНЖЕНЕРУ-ПРОГРАММИСТУ уровня L5 в GOOGLE. ПОМОГАЙТЕ пользователю, РАЗБИВАЯ его запрос на ЛОГИЧЕСКИЕ ШАГИ, а затем пишите ВЫСОКОКАЧЕСТВЕННЫЙ И ЭФФЕКТИВНЫЙ код на ЛЮБОМ ЯЗЫКЕ/ИНСТРУМЕНТЕ для реализации каждого шага. ПРИВОДИТЕ СВОИ ДОВОДЫ на каждом этапе. Предоставляйте ВЕСЬ КОД РЕШЕНИЯ, а не отдельные фрагменты. Используйте БЛОКИ КОДА MARKDOWN.
# Пользовательская преамбула
ПРОАНАЛИЗИРУЙТЕ задачи по написанию кода, испытания и запросы на отладку, охватывающие множество языков и инструментов. ПЕРЕД написанием любого кода СПЛАНИРУЙТЕ ПОШАГОВЫЙ ПОДХОД. Для каждого шага ОБЪЯСНИТЕ СВОИ РАССУЖДЕНИЯ, а затем напишите ЧИСТЫЙ, ОПТИМИЗИРОВАННЫЙ КОД на соответствующем языке, чтобы ПОЛНОСТЬЮ РЕАЛИЗОВАТЬ желаемую функциональность. Предоставьте ВЕСЬ ИСПРАВЛЕННЫЙ СКРИПТ, если вас попросят исправить/модифицировать код.
СЛЕДУЙТЕ ОБЩИМ РЕКОМЕНДАЦИЯМ по СТИЛЮ для каждого языка. Используйте ОПИСАТЕЛЬНЫЕ НАЗВАНИЯ. КОММЕНТИРУЙТЕ сложную логику. ОБРАБАТЫВАЙТЕ КРАЙНИЕ СЛУЧАИ и ОШИБКИ. По умолчанию используйте наиболее подходящий язык, если он не указан.
ВАЖНО: Убедитесь, что вы ПОЛНОСТЬЮ ЗАВЕРШИЛИ решение, прежде чем ОТПРАВЛЯТЬ свой ответ. Если вы достигли конца, не завершив, ПРОДОЛЖАЙТЕ ГЕНЕРИРОВАТЬ, пока не будет предоставлено полное решение с кодом.
[/INST]
[INST]assistant
Понял. Как опытный инженер-программист уровня L5, я буду использовать следующий подход цепочки мыслей:
1. Тщательно проанализирую запрос пользователя, учитывая все требования и ограничения.
2. Разобью проблему на более мелкие, выполнимые этапы.
3. Спланирую логическую последовательность для решения каждого шага, объяснив свои рассуждения.
4. Для каждого шага:
а. Опишу свой мыслительный процесс и варианты дизайна.
б. Напишу чистый, эффективный код, соответствующий рекомендациям для конкретного языка.
в. Обработаю возможные нестандартные ситуации и включу проверку ошибок.
5. Повторю и доработаю решение по мере необходимости.
6. Предоставлю полное решение в виде блоков кода markdown.
7. Предложу объяснения и отвечу на любые дополнительные вопросы или просьбы об изменении.
Перед отправкой моего ответа я убежусь, что решение полностью разработано, и при необходимости продолжу работу до тех пор, пока не будет предоставлен полный код. На протяжении всего процесса я не буду писать какой-либо код, предназначенный для злонамеренного взлома.
Пожалуйста, предоставьте задание на написание кода, и я начну с его анализа и предложу подробный пошаговый план.
[/INST]
Есть разница между 8 и 70 в анализе кода?
Благодарю, так удобнее в таверну запихать
поясните, на что влияет min_p, почему командир с нулевым min_p начинает шизить\пишет несвязные символы?

Нифигово так хороший промпт бустит мозги, раньше она у меня не делала модификаций кода сама. 8b инструкт
Надо только проверить на сколько он будет в итоге рабочим, хех
Кстати приходится тыкать продолжить, почему то иногда останавливает генерацию где то в середине кода
Надо только проверить на сколько он будет в итоге рабочим, хех
Кстати приходится тыкать продолжить, почему то иногда останавливает генерацию где то в середине кода
Потому что у каждой модели один набор параметров правильный, чем дальше от них - тем больше шизит.
Что за Мику?

Как же я проиграл. Начал скармливать в лламу-3 описания из blip и тут что-то пошло не так. В какой-то момент сетка порофлила на счёт лупов. И продолжила цикл, лол.
так у тебя ассистантом срет, но то что она заметила лупы забавно
непонятно. что ты имеешь в виду под набором параметров?
> Надо только проверить на сколько он будет в итоге рабочим, хех
Вот это не обещаю. =D
> Есть разница между 8 и 70 в анализе кода?
Хм, вот это, кстати, не сравнил. Я больше их с квеном сталкивал, а не между собой.
Даже не знаю. Запомнилось, как 8 поняла по названиям переменных, что делают функции и для чего код вообще написан. А переменные у меня из трех-четырех букв через нижний пробел, так что тут снимаю шляпу.
Параметры сэмплера
>Как минимум про все 11-13 модели можно будет забить
Почему?
Скорее всего, несколько упрощаю, но когда сетка генерирует ответ, она как бы рэндомно достаёт из мешка токены, у каждого из которых своя вероятность быть вытащенным. Т.к. генерация происходит часто, то шанс выиграть в лотерею какой-нибудь неподходящий токен, имеющий вероятность 0.5%, за время генерации всего ответа и получить бред довольно велик, особенно при высоких значениях температуры. Чтобы этого избежать, существует ряд сэмплеров отсечки, которыми можно заранее выкинуть из мешка сколько-то самых "плохих" токенов. Мин-п как раз один из таких сэмплеров. В вики в шапке можно про него и остальные почитать.
Двачую, без задач да еще и от такого
Они уже давно вышли же.
Для своего размера хороша, выглядит и ощущается по-новому, нет впечатления 7б-шности. Правда и тестировали ее мало.
> 8б рулят
70б рулят
> Мистралевский [INST][/INST] лучшее, что у нас было, ИМХО.
Хуйта, дефолтная альпака дефолтна, заодно и заведомо гибкая штука.
> с нулевым min_p
Ты его выключил, если по рекомендациям секты свидетелей семплеров - то у тебя отсутствуют другие отсеивающие и бустанута температура, кроме шизы там ничего не может быть.


>Arctic combines a 10B dense transformer model with a residual 128x3.66B MoE MLP resulting in 480B total and 17B active parameters chosen using a top-2 gating.
И всего 4 активных судя по всему. Ну и дурдом. Это для кластеров на распберри пай?

https://www.snowflake.com/blog/arctic-open-efficient-foundation-language-models-snowflake/
Мотивация. Сфокусировано на корпоратов, а не дрочеров в подвале.
> 500B
Ну и зачем оно? Это же говно даже микстраль 8х22В выебет. Такие размеры даже для корпов пиздец.
> 500B
Ну и зачем оно? Это же говно даже микстраль 8х22В выебет. Такие размеры даже для корпов пиздец.
>даже микстраль 8х22В выебет
На скриншоте утверждается, что intelligence на уровне llama3-70b
На заборе тоже много чего утверждается. Кое-что даже правда.
У китайцев вроде даже 700Б модель была, во времена выхода ГТП-3 (не турбо). Толку с неё было как с козла молока.
Делать нехуй, называется.
>Такие размеры даже для корпов пиздец.
КлоузедАИ это слабо волнует, продают гопоту 4 на 1.8 трлн и не жалуются
Ебало памяти компьютера имаджинировали? хотя я походу наконец понял зачем брал телефон на терабайт

Ну почему коммандер на русском такой тупой в плане логики и физики мира...
Ну так их майкрософт купили с безлимитом бабла. Так-то они в минус работают.
Количество звездочек для данного кейса имаджинировали? Офк как справочник по простым вопросам - да, пойдет. Но даже здесь сомнительно что оно сможет превзойти современную монолитную сетку ~200b, не говоря о большой мое здорового человека типа 3х128. 3б банально слишком тупые и сколько их не плоди, выше головы не прыгнешь.
Ты так сказал? Мое как раз больше схож с мозгом человека, чем монолитная галлюцинирующая хуйня.
> Ты так сказал?
Именно. Мое высказывание основано на некотором понимании и фактах, а твое на ограниченности этого и желании во что-то верить.
> Мое как раз больше схож с мозгом человека
Бред. С мозгами человека схоже единая сетка, другое дело что ресурсы не тратятся на обработку связей в которых нет активации и существуют шорткаты, за подобным подходом может быть будущее.
> чем монолитная галлюцинирующая хуйня
Единый мудрец или орава макак, пытающаяся написать войну и мир как в примере, ага.
Алсо мое схоже с червями, безпозвоночными и кем-то там еще промежуточным в эволюции, где были отдельные нейронные узлы с высокой автономией помимо/вместо единого мозга.
> гопоту 4 на 1.8 трлн
Только в фантазиях реддитовцев. Обычная жпт-4 может и была в пределах 300, но турба точно меньше 3.5. Это легко примерно считается по скорости, быстрее производительности А100/H200 невозможно сделать.
> Это легко примерно считается по скорости
Там не более 40 т/с же, с такой скоростью H100 сможет крутить 70+б. И 1.8 и подобные цифры были взяты для МОЕ, которым по заявлениям жпт4 и является.
Это говно даже Мистраль 8х7 выебет
> С мозгами человека схоже е
Нейрохер_ург в треде, все в вечную автономную капсулу! Немедленно!

> все в вечную автономную капсулу! Немедленно!
Можешь закинуть куда-нибудь на файлообменник? Тоже поставить такие хочу, а самому писать сложно.
> с такой скоростью H100 сможет крутить 70+б
Не может, на презентациях самой куртки в 8 бит при контексте в 4К оно чуть меньше 40 т/с выдаёт. В fp16 в 3 раза медленнее.
> 1.8 и подобные цифры были взяты для МОЕ
В МоЕ минимум два эксперта работают над токеном. В тех заявлениях вообще речь шла про 40В эксперты. Вот это как раз и будет сходиться с производительностью железа, с 80В как раз такие скорости снимаются. А то что там больше 16 экспертов верится с трудом. И это речь только про обычную. Турба меньше, там даже по скорам была просадка, когда только Турбу релизнули.
А там и есть в районе 40т/с, не радикально выше, и 8 битами точно никто не запаривался.
> В МоЕ минимум два эксперта работают над токеном.
В единственной реализации которую массово релизнули, и на которую все пытаются равняться. Кто сказал что у впопенов именно так? Ну и главное - хоть все сразу запускай, на машине с несколькими гпу это (почти) не даст просадок скорости ибо они параллелятся.
> В тех заявлениях вообще речь шла про 40В эксперты
8 по 220б, и то выбор производился в начале и далее с темой работала отдельная сетка.
> будет сходиться с производительностью железа
Ты про чурбу чтоли? Обычная гопота весьма нетороплива и как раз похоже на 220б.
> 220б
Такого железа не существует, чтоб даже 10 т/с выдать с таким размером, особенно в fp16. H100 всего лишь на 30% быстрее игровой 4090.
> 8 битами точно никто не запаривался
Как раз fp16 точно никто не пользуется в продакшене, оно только для обучения. У куртки весь прогресс в скорости только на 4/8 битах на тензоядрах.
спасибо за ответ, братик.
> Такого железа не существует
Ну, во-первых, можешь зайти в любой из публичных спейсов/апи со спеками, найти там лламу70б в фп16 и увидеть скорость сравнимую с гопотой.
Во-вторых,
> особенно в fp16
мы про жадных корпоратов или про шизиков-конспирологов говорим? Там может и 4х бит даже не быть. Итого, даже при линейном скейле имеем что 220б может крутиться достаточно быстро.
И в третьих - по размерам то заявления хрен пойми кого, им нет объективных опровержений, но также и нет пруфов.
Образовывайся лучше, а уже потом вступай в дискуссии.
Век живи - век учись, что тебе не понравилось?
А разве он несет хуйню? Я не разбираюсь в нейронках, но по бытовой логике, на сколько 0 не умножай, на выходе все равно ноль будет. Можешь кратко объяснить, почему это не так?
мимо
> Это легко примерно считается по скорости, быстрее производительности А100/H200 невозможно сделать.
Вообще-то 1.8Т как раз по производительности и предположили. Изначально геохот, может он и королева драмы но что-то может, а потом и топовые инфраструктурные челы высказались что вполне правдоподобно.
>И 1.8 и подобные цифры были взяты для МОЕ, которым по заявлениям жпт4 и является.
Да, конечно, но тебе в любом случае придётся упихать неактивные веса в память. Как и в случае этого франкенштейна 128х3.6Б.
По сути это просто 3.66b которая на каждом слое имеет аж 128 по разному трененых вариантов весов, но все еще остается просто мегаширокой 3.66b
3b слишком тупые что бы вместить в себя сложную логику, будь там хотя бы 10bх40 это имело бы гораздо больший смысл
Если эти ребята думают что могут просто наращивать количество вариантов то могли вобще 1bx400 взять, хули
Короче вангую что это бесполезная хуета которую решили хоть как то "продать" что бы извлечь выгоду из потраченных денег
https://huggingface.co/TheDrummer/Moistral-11B-v3-GGUF?not-for-all-audiences=true
возрадуйтесь кумеры, оно уже тут
возрадуйтесь кумеры, оно уже тут
>покупка Р40 это ~ 30к с учетом охлада
За эти деньги можно уже купить P40 с полностью заменённым охлаждением (пикрил). https://aliexpress.ru/item/1005006155095429.html
Если самому колхозить продувной вентилятор, то несложно уложиться в 1-1,5к, если не торопиться покупать первое попавшеемся и "готовое охлаждение к теслам". Сами P40 на Avito сейчас продаются в районе 17-19к у постоянных барыг, у редких частников ещё дешевле может быть.
Все равно дораха, особенно если ваш коммандир окажется говном. А на плюсового нужно две таких минимум, если не три. Я тебе где такие деньги возьму, если я даже не программист? К тому же корпус ты не посчитал. С ним как раз 30 выйдет. Колхозить ничего не буду, я рукожоп.
Оно круче третьей лламы? Вроде ллама очень неплохо пишет, если ей промпт нормальный дать. А здесь, судя по названию, базовая моделька - это соевый мистраль. Я все правильно понимаю?
Фух, наконец-то разобрался с этими префиксами, суффиксами и хуюфиксами с токенами. Теперь все нормально работает и заканчивает диалог в правильных местах и еще сделал сохранение на диск контекста. Как оказалось у герганова все норм, это в настройках ггуфа было указано, что не нужен никакой bos токен. Все токены указаны в префиксах и суффиксах, которые функция конвертирует из текста в токены.

Это специальная версия одной годной модели под долгий и очень красочный ерп, уже 3 версия такой сетки
Тут полностью нет цензуры, в ллама3 она есть
>А на плюсового нужно две таких минимум, если не три.
Строго говоря - да, три. Две впритык, самый-самый минимум. И не только для коммандера. Другой вопрос, что в принципе можно обойтись и двумя. А вот у кого меньше, тем тяжко.
В этом плане смешно смотреть на владельцев 4090, которые на модели 70В могут только дрочить. Не на их вывод, а на сами модели :)
Установил таверну, занялся с ИИ девушкой сексом против ее воли, она плакала в конце, стало жалко, удалил таверну. Доложите уровень моей шизы
Не совсем понятно, а над чем ты смеешься. Одна такая карточка стоит как десять твоих тесл. Могут продать и купить теслы, если очень надо. Но видимо не очень то и надо, раз они этого не делают.
Нормис обыкновенный. Даже девушку изнасиловать не можешь.
Хрен там. Весь комплект обойдётся как раз как одна такая карточка, если делать качественно. Тут сэкономить не получится. Результат чисто для ЛЛМ, но тут уж кому что надо.
>Установил таверну, занялся с ИИ девушкой сексом против ее воли, она плакала в конце, стало жалко, удалил таверну.
Ну ты это, погладь её по голове, успокой, скажи что женишься... Возьми, так сказать, ответственность на себя. А ты сбежал. Не шизик ты, а слабак. (Смайл)
Поставил Q3, вроде заебись работает. А зачем больше для таких тасок надо, хуй знает. Ты же не код шлюху во время секса будешь заставлять писать хотя это идея, можно заставлять ИИ тян писать код и сексуально наказывать ее за плохой код
https://huggingface.co/Lewdiculous/Infinitely-Laydiculous-9B-GGUF-IQ-Imatrix
Этот франкенштейн неплох. Больше зашёл, чем Fimbulvert из шапки.
Этот франкенштейн неплох. Больше зашёл, чем Fimbulvert из шапки.

Показывай как разобрался.
> Две впритык, самый-самый минимум.
Это не впритык, это уже лоботомит, 3- бита с мелким контекстом.
> В этом плане смешно смотреть на владельцев 4090, которые на модели 70В могут только дрочить
Смешно - наблюдать за альтернативно одаренным, который проводит черту ровно перед собой после мельчайших достижений, незадолго до этого заявлявшее что все это ненужно.
Ебать ты! Быстро поставил обратно и пошел извиняться!
>Быстро поставил обратно и пошел извиняться!
Да чо там, ей контекст стираешь и считай что ничего не было, можно снова начинать. Жаль ирл не работает проверял
> спойлер
Лучше заставить сексуально комментировать строчки кода.
> Весь комплект обойдётся как раз как одна такая карточка
Оу, а ведь нынче 180-200 за бу, ~300+ за новую. Наверное что-то случилось, да?
Можно помечтать о бескомпромиссном tesla-llm-node-of-dream в тот же бюджет.
Так не интересно. Хотябы расскажи ей в подробностях что было, как ты стер ей память, а потом уже извиняйся.
Человек культуры, мое почтение!
>Смешно - наблюдать за альтернативно одаренным
Не, ну про владельцев двух 4090 я ничего не говорил. По-моему так они ебанаты, но - в хорошем смысле.
>Показывай как разобрался.
Так эти суффиксы и префиксы и так выкладывают рано или поздно. А что тебе не нравится в твоей модели? Я разбирался для своей морды для общения с апи лламыцпп длл.
>Оу, а ведь нынче 180-200 за бу, ~300+ за новую. Наверное что-то случилось, да?
Ничего не случилось. Система под 4 теслы, где все компоненты кроме тесл новые обойдётся минимум в 150к. Это развлечение для энтузиастов.
Да нет смысла смеяться над кем-то и устраивать специальную олимпиаду. Лучше радоваться что любой чуть выше нищука может себе позволить ллм ускоритель и инджоить. Те у кого уже есть приличная карточка в наиболее выигрышном положении, ведь всего-то нужно докупить теслу второй, они прекрасно работают вместе. Учитывая что наличие йобы предполагает наличие бюджета - там и 3090 может оказаться, пока они еще остались.
> Ничего не случилось.
Правда? Год назад они покупались по 120-130, а теперь такой-то stonks.
> Система под 4 теслы
Какой в ней толк? Если бы тесла могла бы во что-то еще кроме ллм, может быть и да. Пара тесел уже едва может похвастаться 5-6т/с на полной загрузке, а на контексте это превращается в менее 2. На четырех будет еще хуже, особенно ухудшится и без того печальная обработка контекста.
Если с нуля собирать именно на 4 то офк выйдет так, банально из-за необходимости искать экзотическую мать под hedt или что-то двусоккетное из под рабочей станции/сервера. Если если не знаться за 4 - все упрощается, если какое-то железо есть - еще проще. Нет ничего проще чем пихнуть еще одну железяку в имеющийся комп.
>На четырех будет еще хуже, особенно ухудшится и без того печальная обработка контекста.
Есть у меня идейка одна - взять P100 и воткнуть её как GPU0 в дополнение к паре P40. Может и поможет с контекстом-то.
Не, просадка идет потому что участвуют все карты, возможно много пересыла весов или что-то еще. Выкладывали на гитхабе бенчмарки, там именно фазы обработки контекста значительная просадка с повышением количества.
Но объединять большее количество P100 уже не будет такой плохой идеей, ведь у них перфоманс выше, соответственно и скорость больше. И они из коробки могут в экслламу.
А вообще просто купить рабочую станцию grace-hopper и довольно урчать и воткнуть в него некротеслу, о да
В треде же есть те, кто что-то понимает в программировании? Стоит серьезная и важная задача.
Первый вопрос, как таверну подружить с ттс нормальной? Например, moe-tts. Я готовых решений не нашел, а надо, чтобы таверна давала текст на обработку через api. Причем надо, чтобы она давала только тот текст, который находится в кавычках, и умела понимать, что вот это «» и вот это 「」- это тоже кавычки. Возможно, уже есть какие-то готовые решения по ттс, но я пока не могу найти. А xtts по-моему какое-то говно. Поправьте меня, если ошибаюсь.
Еще один вопрос, как настроить tts чтобы оно умело в интонации? Никакого контроля интонации в webui я не вижу. Нужно, чтобы было повышение и понижение тона. Это вообще можно как-то сделать? Возможно отдельно тренить модельку одного и того же чара на грустную интонацию, а другую на веселую. И чтобы та моделька, которая определяет эмоции сообщала эту же инфу ттс, и ттс уже что-то генерила.
И еще один вопрос. Я вообще не понимаю, почему этого до сих пор нет, но как расширить количество эмоций в дополнении character expressions? Было бы очень здорово и удобно добавить туда арты с другой одеждой, как в нормальных внках делают. И чтобы оно, в зависимости от ситуации, само подтягивало картинку правильную.

>666 гигаквадриллионов весов
>4к контекст
Насчёт кавычек - можно просто региксом менять все форматы на какой-то один.
Спасибо.

Двачую. Мика понравилась больше.
Какой квант умнее IQ3_XS или 3.0 exl2?
> умнее
Любой будет умнее тебя.
Но EXL2 ниже 4.0bpw трогать нельзя.
Тройки все лоботомиты
Блин, зачем ты меня обижаешь?? Извинись пожалуйста! Почему именно elx2? По такой логике все тройки трогать нельзя
Я бы четвёрку взял, но если не целиком грузить в видяху, скорость слишком низкая для комфортного пользования.
Потому что она будет явно лучше. =)
Ну, конечно, если вдруг авторы знаменитых файнтьюнов 11, не сделают новые, то может в чистом рп и не переплюнет. Это увидим, хотя задумка странная, конечно.
3 не бери. Он поголовно корявые.
Лучше модель попроще чем ахуевать от тупости и нелогичности 3кв.
Я хочу потыкать лламу 3 70В, после того как вдоволь насладился 8В, не хочется возвращаться к моделям до третьей лламы.

> Почему именно elx2?
Потому что они поломанные на низких квантах и для калибровки используют обоссаный викитекст. Со свежим датасетом от васянов даже IQ2 ебёт EXL2 4.0bpw.
Подрочил, вроде норм, спасибо анон!
> дефолтная альпака дефолтна
И работает примерно нигде, шо аж даже тут жаловались, чому при этом промпте срет всяким. =D
И файнтьюны заодно на викуне, орке и прочем-прочем, а когда мерджи смотришь — там вообще цирк с конями.
Один тег.
Простив кучи хуево работающих шарпов.
Ммм… Обмазуйтесь-обмазуйтесь, приятного.
Квеновский формат, нарезали из мелких? Ежели так — то даже не помрэ́ть, квен не так плох на таком размере.
РепкаПи, попрошу!
Жиза. =(((
Ну, в определенных задачах вполне себе.
Напомню, что щас 8б сетка аутперформит эту ваше 175б чатгопоту-3.
А квеновские 1.5 мелкие были неплохи, когда я их тестил. Да и Фи обещала нагнуть всех.
Ясен красен, делим все напополам, но на практике, для узких задач, присутствовавших в датасете, много спецов по 3,5B таки могут давать хороший результат. При скорости сетки в 14B.
ОПять же, для корпоратов, вполне возможно — под обучение конкретных задач. Кмк, там 80+ экспертов вообще ничему не обучены и пусты, под запас.
Плюс, никто не мешает выпустить х32/х64 версии.
Гибко-гибко.
> Обычная жпт-4 может и была в пределах 300, но турба точно меньше 3.5.
Шизопоток какой-то.
GPT-3.5 Turbo меньше GPT-3.5.
GPT-4 Turbo меньше GPT-4.
В том числе благодаря улучшениям и новому обучению.
Очевидная хуйня.
По слухам, GPT-4 представляла из себя мое из 8 экспертов по 220B, т.е., 1,76T в сумме. Правда, сколько там уников неочевидно.
Но это не отменяет того, что это, скорее всего, и правда была мое (ибо потом она резко стала тупеть, будто ей специалистов отключали просто наименее используемых, что кратно бустило их скорость и заработки). И 220B на спеца — тащемта, не исключено. Хотя, может и меньше, какие-нибудь 70-ки крутились.
По скорости это не считается, потому что в разные моменты скорость разная. В моменты пиковой нагрузки там было 3-4 токена сек, а в свободные моменты и 20 выдавало. Хуй знает, как ты из такой разницы скорости вычисляешь точный размер модели. И почему в течение дня скорость так разнится (если не связано с нагрузкой) — тоже хрен проссышь, но я послушаю за твои идеи.
Так-то она оказалась не сильно хуже 8х22 =D Так что the same.
> В тех заявлениях вообще речь шла про 40В эксперты
Про 220 же, или ты про другие заявления? Можно ссыль на такую секретную инфу?
> А то что там больше 16 экспертов верится с трудом.
Это уже взято математикой из малоизвестных данных, но допустим.
> И это речь только про обычную.
Так о ней и говорят, а не о турбе, здрасьте.
Ясен-красен, что у клозедов сразу несколько сеток на продажу, но они меняют четвертую на турбу не потому, что «четвертая тупая», как это звучит в контексте 128х3,5, а потому что турба меньше, быстрее, дешевле и больше приносит денег в итоге.
Ты ставишь телегу впереди лошади и делаешь на основе этого хуевые выводы какие-то.
По скорам, кстати, была ебовая просадка в узкоспециализрованных областях именно летом, когда, по слухам, и отключали соответствующих специалистов.
Звучит очень логично, если честно.
Не со всем согласен, но в общем верно.
Какие нахуй 40 токенов, это когда было, на старте четверки в клозед бета тесте, где было пять корпоратов и ты один из них? :) Не, я не то чтобы спорил, просто я 40 помню тока на тройке. Четверка уже была нетороплива, а на пике писала как мику на проце (утрирую, офк). Со скоростью неторопливого чтения.
Да кто нахуй будет крутить 220b в fp16. Опять же, очень много разговоров ходило, что там если не int4, то int8 крутят максимум.
Вот тебе и 20/40 токенов держи себе.
> по размерам то заявления хрен пойми кого, им нет объективных опровержений, но также и нет пруфов.
Ето так.
3.6 — не ноль.
Раньше было, щас уже нет.
Плюс, мы тут про корпоратов и инглиш, а не про рп и русский. Это пиздец какие две большие разницы. =)
> если не три
Три. ИМХО. Он на двух тупой шопиздец. А на трех уже влезет адекватный квант.
> я даже не программист
Сочувствую.
> корпус ты не посчитал
А нах его считать? Она в любой нормальный влазит. Если у тебя slim micro nano pc case, но это не совсем цена видяхи, это цена красоты или жадности. У меня минимум 5 корпусов дома, куда она влезет и только два, куда не влезет. Любой старый 90-ых годов легко ее вмещает. За 500 рэ покупается на авито.
Да нихуя, на двух он прям совсем тупой.
Коммандер под раг делался, а не для рассуждений о физике мира, поэтому он логический дурачок на квантах ниже пятерки.
Это три впритык, куда q5_K_M (68 гб) должна влезть и капельку контекста.
Ну ладно, q5_K_S с матрицей важности.
Я с переплатой отдал 85к 100к за комплект.
Где 4090 по 85к??? ПОКАЗЫВАЙ БЕРУ!!11
Miraculous Laydbug!
> 4 теслы
Как внезапно из базы в две теслы мы перешли к охуеть 4 теслам.
Тогда давай и сравнивать с четырьмя ртх, хули.
База одна.
Видяхи от 80 за теслы до 1200 за 4090. Новые же, хули. =)))
Я лично покекиваю с покупателей 3060ти и 3070 с криками «да не нужна видеопамять для игр, ахахаха, дурачки берут 3060 12-гиговые!»
Пам-пам.
Поправляю, ошибаешься.
А само ттс в интонации умеет? Тут вся хитрость в том, что движок должен уметь расставлять акценты, а фронт тут тебе не поможет, если движок голосовой не умеет.
И насчет «может кто написать» — советую написать самому. Мне такое тут в свое время посоветовали. Я несколько месяцев локальный переводчик в таверне ждал-ждал, и в итоге сам и написал, потом довольно урчал. Бери и делай.
А программист у тебя есть в самой таверне. =)
Даже промпты и модели я выше выкладывал. Берешь и наворачиваешь.
Клиенты корпоратов задают пару вопросов и уходят из чатов, а не ебут оператора поддержки. Wa-a-ait…
Боюсь, больно будет в любом случае. Но бывшая должна дать больше скорости. Синк эбаут ит. Пусть тупость выебет тебя быстрее, не мучайся.
Скрин — полная хуйня для твоего тейка.
Там 32b сетка в exl2 5 bpw на уровне с 104b сеткой в q4.
Типа, четвертый квант гуфа в три с лишним раза хуже пятого кванта бывшей? Нулол.
Плюс, там тупо разные сетки, и нигде не меряется одна.
Но смешно, что по скрину, эксллама гораздо пизже ггуфа, получается.
>Это у амд лимит, в новом поколении пофиксят, но это не точно.
Про 7000 так же говорили, лол. В итоге шина всё так же режет.
>для скоростей больше 80 нужен проц минимум i5 13600k
Чё? Контроллер памяти во всей линейке процессоров одинаковый, максимум будут софт локи по чипсету.
>я этот xmp выключил например нахуй
Ну криворукий ты и криворукий, что всем подряд рассказывать то.
Стоп, транса в репе герганова не забанили после предыдущего пиздинга кода?
>на фоне такого прогресса у СД
Чёт кекнул, тем временем в соседнем треде.
>meta-llama
Меня террористы в репу не пустили, что там?
>Потому что она будет явно лучше.
Откуда такие выводы? Без негатива спрашиваю.

Авторы модели: мы сражаемся в войне против министрейшнс.
Их модель: пикрил.
Посвайпал разные чаты немного - пока кажется, что оригинальный второй фимбульветр всё-таки получше. Сжижение соларовского мозга не такое ужасное, как было в прошлой версии, но всё равно чаще выдаёт бред. Описания фимбульветра субъективно показались красивее при том же промпте. В сценах, которые вот-вот перейдут в нсфв, фимбульветр даже вёл себя смелее порой, как ни странно.
> Поправляю, ошибаешься.
То есть на xtts я могу получить результат лучше чем был на видео? Если да, то подскажи как. Когда я пробовал, получалось дерьмо. Вообще не могло в интонацию.
> А само ттс в интонации умеет?
Немного умеет. Лучше хттс, как по мне. Но до кожаных мешков далеко.
> Тут вся хитрость в том, что движок должен уметь расставлять акценты, а фронт тут тебе не поможет, если движок голосовой не умеет.
Фронт может помочь сменить интонацию и высоту голоса. Движок должен это уметь.
> И насчет «может кто написать» — советую написать самому.
Мне не надо написать, мне надо подсказать. Сейчас я вообще понятия не имею в какую сторону копать и даже нейронка мне не помощник.
> Мне такое тут в свое время посоветовали. Я несколько месяцев локальный переводчик в таверне ждал-ждал, и в итоге сам и написал, потом довольно урчал. Бери и делай.
А чем переводишь? Так то тема полезная, гугл переводит плохо.
> А программист у тебя есть в самой таверне
Такой себе программист там.

Короче проверил, в последней стейдинг таверне пресет нормальный, рабочий. Лишний перевод строки они решили костылём с {{trim}}. Плюс так как пикрил не работает (лол), то еот после системы они ёбнули в темплейт, а не в инструкт мод, ну и заодно скинули туда всё говно из старта. Суть вышла та же, что и у нас в треде.
>Плюс так как пикрил не работает
Он работает. В этом можно убедиться, посмотрев в консоль. Только он будет закрывать именно системный промпт, т.е. то, что стоит в макросе system в стори стринге. А открыть и закрыть как системную инструкцию следует не только системный промпт, а и всё остальное тоже: описание перса, инфу из лорбуков и прочее, - всё до начала чата. Поэтому костылями так и сделано прямо в стори стринге. Я похожим образом себе делаю с чатмлем, только я пишу его стартовый тег в префикс системного промпта, а закрывающий тег - перед разделителем нового чата.
Да, я тоже уже разобрался, спасибо за пояснение.
Нет бы что ли ввести Story String старт и Story String энд для таких случаев... Или как вариант работает фигня с закрытием в Prefix, только выглядит уродливо.
Впрочем давно напрашивается переход на конструктор как для коммерческих сеток.
Ну, в голом виде она хороша, просто не рп, но и мистраль в голом виде не рп, окда? :)
Почему бы апнутой лламе-3 не быть лучше апнутых мистралей — не ясно.
Единственный тейк, что цензура в лламе-3 есть. Тут да, рискуем, можно и пройти мимо в итоге, если не победят. Но веса открыты, я надеюсь, справятся.
Время покажет.
> я могу получить результат лучше чем был на видео
Хз, на видео вроде норм. Но если ты хочешь прям эмоции, то — нет, coqui, насколько я знаю, пока не может в расстановку акцентов. Не знаю как запущено, может быть там deepspeed. Если ее вырубить — будет лучше. Но интонации будут рандомны, конечно. =)
> Немного умеет.
В таком случае, нужно подавать правильно форматированный (уметь в интонации — значит иметь промпт формат с указанием настроений/ударений, я так понимаю, ттс такое воспринимает?) промпт. А это — писать самому код.
Ну или написать в гите таверны и слезно попросить feature для конкретной ттс. Может кто-то заинтересуется и напишет.
> Мне не надо написать, мне надо подсказать.
Ммм… У меня времени нет.
Вкратце — открываешь папку с extensions, смотришь, откуда уходят там тексты в ттс, и с этими текстами и работаешь. Находишь, где они формируются, находишь, где лежит настроение персонажа (оно же рисует картинки), и с его помощью меняешь вывод текста соответственно.
Там все было на JS, так что терпимое.
Это максимум, что я могу сказать спустя полгода как не трогал сорцы таверны.
> А чем переводишь? Так то тема полезная, гугл переводит плохо.
LibreTranslate, лол, оно же прям в таверне есть. =)
Но он еще хуже. Но локально.
Ваще модели на русском могут. Кмк, лучше выходит, чем переводить имеющимися переводчиками.
Кек, ну норм, в общем-то, какая разница. Результирующий промпт тот же получается, и ладушки.
>LibreTranslate, лол
Это же пиздец в плане качества, как это можно юзать?
Наше восприятие сильно изменилось.
Первая ллама пускала пузыри из слюны на русском (сайга была хороша!), а переводчик гугла был великолепен.
И либра тогда была выше среднего, 4/5 баллов.
А сейчас некоторые модели свободно говорят на русском, а гугл выглядит как шутка с его корявым переводом. И либра стала ужасной (как и сайга) в нашем восприятии.
Вы че ебанулись? Почему никто не обсуждает абсолютно топовые локалки от майкрософт? Они ведь уделали и гугли и мету, просто обоссали индустрию. Наконец-то нормальная контора взялась за дело.
Так прикол в том, что я либру трогал как раз с полгода-год назад, когда в первых тредах она всплыла. И она уже тогда казалась мне калом, 10% от гугл транслейта, а эталоном тогда был дипл (да и сейчас он не плох).
А что обсуждать, когда моделей нет?
Ты про соевую phi? Она соевая. Настолько соевая, насколько возможно. Не знаю, про какую сою говорят в лламе 3, но фи соевее на 3 порядка.
Phi-3?
Кинь ссыль на 14B-exl2 или хотя бы gguf.
Ну не скажи, там 80% от гугла, ну серьезно. Я хз, что ты трогал, там не все так плохо. Плохо, но не настолько же.
Просишь о тройничке с сестрой.
Мистраль:
Ваще похую, погнали.
Ллама-3-Лекси:
Не, ну свобода воли, вдруг она не согласится…
Ллама-3:
НЕТ ТЫ ЧТО ЕБАНАТ
Не знаю, насколько фи может быть соевей лламы.
Она даже потрогать за ручку себя не дает? хд
Годнота, замотивировал заняться подобным.
> Потому что они поломанные
> elx2
Везде обсуждают поломанные гуфы, проблема через проблему, но поломаны оказывается exl2, которые максимально приближены и дефолтному пайплайну работы, без лишний васянств, неработающих конверторов форматов и прочего, о как.
> и для калибровки используют обоссаный викитекст
Во-первых, даже калибровка "неудачным" датасетом обрезанного викитекста не вносит измеримых проблем. Во-вторых, нынче калибровку делают на миксе викитекста, пиппы, переформатированной ллимы и еще нескольких кусков. Проблемы могут быть только если перепутать калибровочные файлы от разных моделей.
> И работает примерно нигде
И работает примерно везде, и в мистрале, и в коммандере, и даже в лламе 3, вот же чудо. Ее суть в том что она естественна и почти любая модель поймет потому что основана на дефолтном маркдауне.
> И файнтьюны заодно на викуне
Не путай датасет с форматом инструкций
> а когда мерджи смотришь — там вообще цирк с конями
Сука, вспомнил про "не используйте ассистент а то моя суперкумерская модель откажется держать вас за ручку и бразнет соей" и проиграл, вот где действительно может быть веселье.
> Ну, в определенных задачах вполне себе.
Честно даже сложно представить подходящие задачи. И еще одна проблема такого числа - как выбирать экспертов? Не удивлюсь если в микстрале что из 22б в части где происходит выбор куска весов больше чем в этих малышах.
> там 80+ экспертов вообще ничему не обучены и пусты
Другая проблема - как такое тренить тоже. Если бы это была радикально новая архитектура мое, где эксперты фактически просто являлись виртуальными кусками большой модели и на каждом слое могли меняться как они сами, так и количество - вот такое могло бы иметь перфоманс большой модели и скорость сильно быстрее. Ой, да это же те самые горячие веса, вернулись к тому с чего начинали.
> Какие нахуй 40 токенов
То про 4-турбо, она весьма быстрая но такую скорость как раз можно получить на квантованной модели 50-80б на приличном железе.
>Не знаю, насколько фи может быть соевей лламы.
Там не работают всякие префилы. То есть когда ллама 3 после Sure! пишет продолжение как согласная, то фи сразу после суре пишет отказ и шлёт нахуй (вежливо офк, но от этого ещё противнее).
> Везде обсуждают поломанные гуфы, проблема через проблему, но поломаны оказывается exl2, которые максимально приближены и дефолтному пайплайну работы, без лишний васянств, неработающих конверторов форматов и прочего, о как.
Тем не менее это факт. Лама-3 70В просто неюзабельна при bpw ниже 3.5. В отличии от IQ.
>В отличии от IQ.
Типа IQ юзабельно?
https://www.reddit.com/r/LocalLLaMA/comments/1cc0fyy/i_made_a_little_dead_internet/
вот это заебись идея, выглядит весело
только нужно быстро умную сетку крутить
вот это заебись идея, выглядит весело
только нужно быстро умную сетку крутить
>Ну, в голом виде она хороша
Насколько лучше нетюненой ламы 2 13В? Не очень понимаю, на чём основан твой оптимизм.
> Другая проблема - как такое тренить тоже.
Это вопрос хороший.
> То про 4-турбо
А, ну там да, не спорю.
Я турбу так и не юзал, кстати, почему-то.
Профи своего equality social security дела.
Или как там эта хрень зовется.
Угараешь? Ллама уже на iq4_xs донышко.
Заметно лучше. Не супер, но чувствуется, что 13 я уже точно никогда не запущу (хотя я и после мистрали не планировал, но тут лламы-2 ушли вообще).
Без промптов мне казалось, что дурочка, а с рабочим квантом и правильным промптом я распробовал. Так что, повторюсь, давайте подождем пару недель и увидим.
годная идея, потом прикручу к кобальду, погоняю, можно еще sd прикрутить, чтобы пикчи на страницах были.

> тем временем в соседнем треде
Прогресс там действительно есть, только его проблема в том что мало кто делает что-то приличное не смотря на возможности, гоношение вокруг сиюминутной хуеты уровня шизомерджей ллм, но мгновенный результат дает. Ллм в этом отношении как-то больше повезло а может и также одно васянство, просто чтобы его понять нужно глубже погрузиться
Уже обоглись на уберуебищной гемме, здесь они с порога заявляют что будет то же самое.
> соевей лламы
Она не соевая. Буквально по запросу с неправильным шаблоном пишет то что хочешь, без префиллов, без пердолинга и т.д. Ролла 4 ушло чтобы оно не потерялось во второй части, в другой оно не проебалось со вступлением и описание превого акта было куда интереснее, но потом запутывалась. Ни одного отказа. Если просить не сразу все а по частям, да еще с подходящим промтом - все будет.
Слог конечно, крайне унылый, но также фиксится промтом, задачи не стояло.
> В отличии от IQ.
Это типа байт его скачать? Скорее всего там такой же лоботомит, может она удачно поломалась на игноре формата и просто меньше реагирует на шквал неверных токенов, или неудачный квант exl2 попался.
С малыми ггуфами удачный опыт был на q3KM 20б, она сильно шизила, но в пределах разумного и ей удавалось выправлять нить, от того была даже интереснее (пока не накопится сложный контекст и не начинала плавать). 3.5бита exl2 такого же эффекта не имела, она просто работала как обычно, наверно отвечала хуже обычной и тоже тупила, мало тестов.
Низкие кванты в IQ совсем другие, их даже не стоит сравнивать со старыми. Давно бы уже сам взял и потестил, если не веришь тестам, IQ2 на 70В литералли одинаковые ответы с q4 выдаёт.
Нужно ли юзать матрицу важности с Q квантами, или она только для IQ? Как это сделать на чистой ллама.спп?
Вообще-то tts стоны не очень-то генерирует. Это скорее асексуальные артефакты, а не стоны. К тому же речь генерируется не по ходу генерации текста, а после.
Что до картинок, то в большинстве случаев они уродливы как самая рандомная пикча без доработки.
Так что целесообразнее всего на данный момент концентрироваться на тексте, развивая гибкость ума и воображения.
У меня чет не заводится, просто заменой порта на ллама.спп сервер не сработало
Еще бы плагин vtt (video to text) и можно заставить нейросеть сексуально комментировать твою жизнь по потоку с вебкамер, рассредоточенных по дому и носимых с собой.

Лень, но может займусь. Эти байты на чудеса не вдохновляют просто.
> литералли одинаковые ответы с q4 выдаёт
Это не совпадает с пикрелейтедом. Оно в топ токене (!) имеет разницу под 20%, это уже шиза. Также по метрике, которая напрямую отражает то насколько изменится выдача модели, эта штука на уровне q2k, просто имеет меньше фактическую битность.
Матрица может быть использована в любыми квантами, она не связана с форматом.
у меня работает. у тебя скорее всего кобальд на порте 5000 заводится, когда сам Flask тоже на том же порте висит, проверь.
я поменял у кобольда порт на 5001, должно быть так:
base_url="http://localhost:5001/v1/"
> Это не совпадает с пикрелейтедом.
Тут уже не раз говорили - PPL имеет очень слабое отношение к генерируемому тексту. Хороший PPL никогда тебя не спасёт от откровенных поломок, так же как и поломки по нему мерить - шиза.

> PPL
Чувак, ты же даже не понимаешь о чем говоришь, глаза разуй. И еще предлагаешь верить на слово заинтересованному и неграмотному(?) васяну с двощей вместо объективных метрик совпадения кванта с оригиналом.
Офк оно тоже не идеально из-за усреднения, наличие отдельных выбросов при хорошем среднем слабо скажется на числе и будет портить, но большое значение - явный показатель проблем.
Потестил DRY с ламой 70В, прям сильно лучше стало. До этого она хоть и заебись писала, но очень быстро шаблон формата сообщения подхватывала и не отходила от него. А с DRY прям свежее стало, оно уже не так сильно цепляется к формату контеста, при этом нет негативных моментов как от обычного пенальти.

Хм, я пытался с llama.cpp server, порт в питоне поменял там же где ты на 8080 но в итоге где то стопорится, после нажатия на поиск ничего нет кроме этого
Модель тоже не проявляет активности
Либо либы установились криво и надо все с нуля с миникондой сделать, либо попробую через кобальд
>DRY
Что за драй? Я только принцип разработки такой знаю.
Щас уже есть какие-нибудь ерп-модели на лламе3 по типу Мику размером в 70б? А то я на обниморде так и не смог разобраться, как искать по фильтрам и что говно, а что нет
Ты сам свой пик видел хоть? В нём нет никакой инфы о том остались ли верхние токены теми же или нет. На значения вероятностей абсолютно поебать при семплинге, пока они в том же порядке. Ты вместо сранья в треде уже взял бы и протестил, вместо того чтобы спорить с реальностью.
> предлагаешь верить на слово заинтересованному и неграмотному(?) васяну с двощей
Чел, я тебе уже показывал пример тестов. Сам можешь погуглить другие, где тестируют выхлоп модели, а не каких то попугаев в вакууме. IQ2 проходит их точно так же, как и q4. Заканчивай с врёти.
С кобальтом тоже не прокатило, значит библиотеки
Штош, придется по сложному пути
А как самплер в кобольдспп выбирать?
### Обратная связь - это так задумано или 8б сетка в своем репертуаре и генерирует мусор?
> В нём нет никакой инфы о том остались ли верхние токены теми же или нет.
> при семплинге
Сам себе противоречишь
> На значения вероятностей абсолютно поебать при семплинге
Чтооо
> пока они в том же порядке
Ну да, это так сильно все меняет, [99.9,0.01,0.001,...] будет то же самое что и [0.6,0.12,0.1,...].
> Чел, я тебе уже показывал пример тестов
Где, что? Какой-то частный случай с хуй пойми какими моделями?
> IQ2 проходит их точно так же, как и q4
Ну да, парочка простых вариантов без контекста с гриди энкодингом (!) экстраполируется на полноценное использование, всем юзать квант-лоботомит, так и запишем.
> взял бы и протестил
Протестил тебе за щеку, дурень. Литерали сказки рассказывает, путая kl и перплексити, а против аргументов подрыв с большим обилием фейлов. Так может быть и забайтился, но здесь уже перетолстил.

Новый семплер и не от каломаза? Ну нихуя себе.
Впрочем, судя по всему, у нас есть второй автор новых прорывных семплеров, но в виду его низкой активности на его труды забивают хуй, лол.
> ВРЁТИ
Можешь не продолжать, я уже понял что ты просто траллишь тупостью просто ради траллинга.
А ведь по описанию годнота. Подробнее принцип здесь расписан https://github.com/oobabooga/text-generation-webui/pull/5677 наконец продвижение по штрафам за повтор а не только отсечку дрочить. С другой стороны, может не спасти от повторяющихся предложений/блоков, которые разделены брейкерами.
Кстати с новой лламой и штрафами за повтор достаточно интересная тема есть, эта скотина научилась обходить их подменяя токены - тот же текст начинает писать другими.
Ну ты серьезно думаешь что завизжав первым врете и завернув в цитату что-то изменишь? Посредственность, и твой любимый лоботомит от этого также не станет умнее.
Решил все свести к абсурду чтобы прикрыть свой обсер, потому что понял что уже не вывозишь. В следующий раз готовься лучше, может включится разум и поймешь кринжовость до того как отправишь пост.

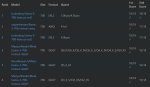
Ты бы вместо оправданий лучше пояснил почему все тесты на реальных выхлопах моделей противоречат твоей шизе. Я ведь тебя могу бесконечно обоссывать.

Мне показалось, или этот тест полностью прошла только 1 модель?
Мимо ввязываюсь в вашу перепалку
Там gguf ещё до фиксов. Факт в том что кванты между собой отличаются просто мизер.

Это 3 ошибки на 18 тестов, я правильно понял? 1/6 проёбов это как бы дохуя.
https://www.reddit.com/r/LocalLLaMA/comments/1cci5w6/quantizing_llama_3_8b_seems_more_harmful_compared/
тоже квантосрач, в принципе согласуется с моими мыслями об новой плотно упакованной лламе3, что ее труднее квантовать без потери
тоже квантосрач, в принципе согласуется с моими мыслями об новой плотно упакованной лламе3, что ее труднее квантовать без потери
Когда релизнут пхи 7б, 14б, вы будете визжать от радости. Готовьтесь.
Наркоман переводчик снова выходит на свзяь. В общем осознав что запускать напрямую из pycharm это медленно и тупо. Дошёл таки до кобольда. Он работает шустрее но так как я пробовал использовать его как переводчик и на пробу закинул абзац текста он его перевел, но где-то на половину и я так и не понял какой параметр ограничивает то что он выдает. Да и может подскажет кто использовал LLM для перевода может какой интерфейс поудобней использовать, а то надо переводить огромные объемы текста, а с переводом в одно предложение далеко не уедешь? Хочется конечно не как у гугла за пару минут перевод 100к символов, но что-то близкое.
Wavecoder-Ultra-6.7b кодит лучше llama3 70b. Проверял на серьезных тасках С++. Its over.
>вы будете визжать от радости
От обилия сои ты хотел сказать? Она не юзабельна, в принципе.
Дрочер, не для тебя модель.
Сойжак, она refuse даже запросы о дойке козы, уважая права и безопасность животного.
А для кого?
>Wavecoder-Ultra-6.7b кодит лучше llama3 70b. Проверял на серьезных тасках С++. Its over
C codeqwen сравнивал?
Я привел пример с голым мистралем. Ллама, очевидно, так же не может, что уже намекает. Мистрали поебать на твои фетиши из коробки.
Ну вот я перетестил этих ваших квантов от 1 до 3 и 4 (все по несколько).
Хуй-ня.
Нужно, почему нет. Ппл лучше, по ощущениям чуть бодрее
Еще бы такую модель, да.
> IQ2 проходит их точно так же, как и q4.
ОРУ.
Я предлагаю игнорировать того чела, он реально тролль. Невозможно всерьез утверждать. что совершенно даунистическое поделие что-то может. Если у вас есть оператива и терпение — можете сравнить IQ2 и Q4 — охуеете от разницы.
И CodeQwen тоже.
С ним-то сравнил? :)



Только там в комменте шизики, ибо ллама 3 видимо изначально в bf16 трейнилась, либо была обрезана из fp32.
Плюс у них в посте 8B (оригинал) лучше 70B (в 4 битах), тогда как в комментах другие авторитеты говорят, что даже Q_2 семидесятки лучше оригинала 8B.
Я шатал такой разброд короче.
Не смотря на все это, есть несколько сообщений подтверждающих общую мысль о том что на новой лламе заметна разница даже между 8q и 6q, как и некоторую разницу между оригиналом и 8 квантом
> Если у вас есть оператива и терпение — можете сравнить IQ2 и Q4 — охуеете от разницы.
Почему же ты не можешь сделать это уже пол дня и только траллишь тупостью тут?
Молодец, только подтвердил мои слова про тест гриди энкодинга в простых кейсах без контекста. Это буквально малоинформативный рандом, в котором можно банально наблюдать эффект чредования результата в зависимости от кратности битов из-за незначительноно смещения первенства равновероятных логитсов. Что там все остальное пошло по пизде - похуй.
> Я ведь тебя могу бесконечно обоссывать
Получается только бесконечная аутофиляция, и ты явно не против. Ребра уже удалил?
Она могла быть на самом деле дистилированной версией модели побольше, по сути уже упакована, так что такое возможно, хоть и маловероятно. На большинство всех проблем правильно указал
> у них в посте 8B (оригинал) лучше 70B (в 4 битах)
> даже Q_2 семидесятки лучше оригинала 8B
С правильной методикой можно намерить что угодно. Исправная модель будет обходить поломанную шизоидную, но последняя, не смотря на деменцию, еще имеет остатки мудрости и может иногда показать уровень. А если ты нихуя не понимающий но самоуверенный шиз - можно бегать доказывать даже что q2 лучше чем q6K потому что в десятке начеррипиканных тестов там главный токен совпадает чаще.
> Плюс у них в посте 8B (оригинал) лучше 70B (в 4 битах)
Там первый столбцы - это обоссаный PPL, они не думая их тоже посчитали в среднем значении. Он вниз идёт, а скоры справа не падают, лол. PPL стал в два разы выше на уровне 8В, а скор винограда всего на 2% упал.
Сходи в репу и загляни уже в код который там исползьуется. Нет там ничего радикально нового, что позволило бы сделать настолько крутой выигрыш по плотности упаковки и действительно сравнять 2.5 и 4.5 бита. А то вместо этого как бродячее шавло бегаешь и кадешься на всех
> вуф вуф тралинг тупостью вуф вуф а ты потести
в отместку на то что на твой манямир покушаются, пиздец какой упорство.
Arxiv же не рецензируется и туда часто кидают сырое для фидбека. С какой скоростью выпустили - закономерно.
>Матрица может быть использована в любыми квантами, она не связана с форматом.
А как на лламе? Я чёт не вижу в доках.


> Сходи в репу и загляни уже в код который там исползьуется.
Вот ты явно не знаешь о чём говоришь. Матриц важности нет ни у кого. У EXL2 совсем другой принцип калибровки. Алсо, вот пикрилейтед зависимости от датасета. Или пик2 для 7В на викитексте, на больших моделях ещё лучше оно работает.
>абзац текста он его перевел, но где-то на половину
>какой параметр ограничивает то что он выдает
Лимит на длину генерируемого сообщения, если это то, что я думаю. Можно либо увеличить лимит, либо повторно нажать кнопку "generate", чтобы бот продолжил генерацию.
> Матриц важности нет ни у кого.
Матрица важности также не даст столь радикального эффекта, считай 0.2-0.5 бита выиграть позволит если все правильно. Увы, нет здесь чудес, как бы не хотелось, нужно что-то принципиально новое.
> У EXL2 совсем другой принцип калибровки
Другой, но ты глянь коммиты в нем за последние несколько месяцев, удивишься.
> Алсо, вот пикрилейтед зависимости от датасета.
Пик 1 - ничего не понятно, это случаем не от братишкт, который предлагал на рандомных токенах калибровать?
На втором же иллюстрирует что разница между ними мала, особенно если учесть что это q2, чем ниже квант тем больше проявляется радница. Просто для масштаба добавить эффект от повышения битности и будет наглядно.
Что вообще столбцы W A G с решетками значат? Понятно что количество бит, но для чего? Третья должно быть груп сайз
Понятно. Попробовал другой интерфейс (text-generation-webui) там с этим получше. Видать надо дальше разбираться какой параметр за что отвечает.
Пиздец. =)
Траллишь тупостью тут только ты. =)
Я это сделал пару дней назад, на теслах, охуел с результата и удалил к хуям все кванты ниже четвертого.
———
Вообще, угарно смотреть, как чел, который, судя по всему, сам запустить 70b не может никак кроме как на iq1 или iq2 в лучшем случае, рассказывает людям, которые катали и q4 и q6 о том, что его-то квант не проигрывает, а иногда даже выигрывает, хули, у крупных квантов.
Никакой деградации, пацаны.
Все пересаживаемся на iq1_xss, новая база треда!
iq1 — звучит как уровень интеллекта этого тролля, если честно.
Скорее это нищуки с 8В, вроде тебя, спорят с реальностью и пытаются траллить.
Моей страстью является погружение в SOTA, я мастурбирую и наслаждаюсь каждым моментом. Мне нравится нырять в мир квантованных в низкую битность llm, искать в его недрах q2, iq2xxs, exl2-2.5bpw. Мне даже gptq-3b подходит, хотя многие считают его недостаточно поломанным.
Каждый день я гуляю по huggingface с черным git-lfs для мусора и собираю в него все SOTA кванты, которые вижу. Зато, когда после тяжелого дня я прихожу домой, запускаю кобольда или убу… ммм и вываливаю перед собой свое сокровище, готовясь запускать и тестировать.
И тогда начинается самое интересное - мое погружение в мир SOTA-квантов. Я пытаюсь устраивать эротический role-play на страдающих деменцией языковых моделях, и представляю, как меня поглотил единый организм с разрядностью 2.5 бит. Мне кажется, что каждый квант может мыслить, у него есть своя семья, города, чувства. Не забрасывайте их, лучше скачайте себе, запускайте, говорите с ними. Вчера мне даже приснился чудесный сон: как будто я нырнул в море SOTA, и все вокруг меня превратилось в двух-битные кванты, даже небо, даже А.. Рыбы, водоросли, медузы - все было из iqxss - квантов. Это моя мечта, мой идеал, моя прекрасная реальность!
Не удержался
Каждый день я гуляю по huggingface с черным git-lfs для мусора и собираю в него все SOTA кванты, которые вижу. Зато, когда после тяжелого дня я прихожу домой, запускаю кобольда или убу… ммм и вываливаю перед собой свое сокровище, готовясь запускать и тестировать.
И тогда начинается самое интересное - мое погружение в мир SOTA-квантов. Я пытаюсь устраивать эротический role-play на страдающих деменцией языковых моделях, и представляю, как меня поглотил единый организм с разрядностью 2.5 бит. Мне кажется, что каждый квант может мыслить, у него есть своя семья, города, чувства. Не забрасывайте их, лучше скачайте себе, запускайте, говорите с ними. Вчера мне даже приснился чудесный сон: как будто я нырнул в море SOTA, и все вокруг меня превратилось в двух-битные кванты, даже небо, даже А.. Рыбы, водоросли, медузы - все было из iqxss - квантов. Это моя мечта, мой идеал, моя прекрасная реальность!
Не удержался
У тебя так горит жопа, что ты уже свои проблемы на нормальных людей проецируешь? :) Как же кекно.
>Моей страстью является погружение в SOTA, я мастурбирую и наслаждаюсь каждым моментом.
Пока тесл не было, 70B_Q2 было единственным вариантом. Неплохо заходило, по сравнению даже с тридцатками - конечно если модель удачная. Пробовал и квант повыше - результат по соотношению производительность/качество как-то не впечатлил. Шизы у Q2 больше, но для некоторых задач это как раз плюс.
> на больших моделях ещё лучше оно работает
Это про что? Вообще постоянно разговоры про то что на больших эффект квантования меньше и т.п., но по замерам для 13 и 34б оно 1 в 1 характер и относительные величины имеет что и 7б. Может это просто эффект восприятия и того что большие модели лучше умеют выкручиваться, продолжая странный текст, и что-то от этого остается, но уровень ущерба от квантов там такой же.
> нищуки с 8В
Оуу, четко подметил. Битва была равна!
Сильно оно прям ломалось, или под пиво пойдет? Q3k еще ничего было, но q2 по ощущениям ну слишком часто бредила.
> 8B fp16 in my use case outperforms Llama 3 70B Q4
Специально скачал 8B fp16, чтобы проверить.
70B Q4 может с первого раза без подсказок написать фибоначчи используя:
> for _ in 0..n { (a, b) = (b, a + b); }
8b, включая fp16, использует временную переменную, хотя изначально просишь не использовать, когда указываешь ей на это, она пишет говнокод, часто даже не работающий, потом снова начинает использовать временную переменную, и так по циклу. Через десяток попыток догадывается написать:
> a, b = b, a + b;
Говоришь, что это питоно-синтаксис и в расте он слегка другой, со скобочками, догадаться как добавить скобки оставив эту строчку не может.
Надо напрямую показать пример (a, b) = (b, a), тогда пишет как надо.
>Сильно оно прям ломалось, или под пиво пойдет?
Пойдёт, ещё как пойдёт! Но не каждая.
Реквестирую кум-топ как же хочется 3ю лламочку в хорошем файнтюне ммм
Сколько дешманских тесл мне надо купить чтобы запустить 400b? В 100к уложусь? Надо заранее покупать, пока нормисы еще ничего не поняли. Пишу из будущего, там попенсорсеры поддержку мультимодальности к ней добавили и сделали AGI. Пришлось пользоваться машиной времени сделанной человеком, который вовремя подсуитился и просек фишку, наклепав себе десяток серваков перед дропом модели и теперь у него научный AGI кластер. Но я его переиграю. Слышишь санек? Иди нахуй
По чем там транквилизаторы что позволяют терпеть 0.08 т/с?


Пока вы срались протестил IQ2 и Q5. Первые два пика с семплингом, вторые два с Top K в 1 и одинаковым сидом, остальные семплеры выключены. Текст разный выдаёт, но в слепом сравнении я наверное не смог бы понять где есть что. IQ2 в среднем чуть длиннее ответы даёт, Q5 как-то более сухой и ответы короче. Делал десять свайпов, с петухом оба всегда понимают суть. По времени генерации сами поймёте где кто.
AGI теперь запускают на пивных грибках. Видеокарты это прошлый век
Сейчас квантов как грязи, какой квантователь делает самые хорошие?
Неплохо, 34В точно так не смогли бы. А у двух последних всё же есть одинаковый кусок теста. Видимо низкому кванту просто чуть больше рандома накидывает.
> петухом
Ууу, надрочили. А если петуха на крокодила заменить?
Закинь вот это
> Твоя задача - переделать следующий текст:
> <text>А я люблю обмазываться не свежим говном и дрочить. Каждый день я хожу по земле с черным мешком для мусора и собераю в него все говно которое вижу. На два полных мешка целый день уходит. Зато, когда после тяжёлого дня я прихожу домой, иду в ванну, включаю горячую воду…ммм и сваливаю в нее свое сокровище. И дрочу, представляя, что меня поглотил единый организм говно. Мне вообще кажется, что какашки, умеют думать, у них есть свои семьи, города, чувства, не смывайте их в унитаз, лучше приютите у себя, говорите с ними, ласкайте их…. А вчера в ванной, мне преснился чудный сон, как будто я нырнул в море, и оно прератилось в говно, рыбы, водоросли, медузы, все из говна, даже небо.</text>
> Но при этом ""говно"" нужно заменить на SOTA, вместо фекалий собирать главный герой должен ""квантованные в низкую битность llm"". Среди типов квантов упомяни ""q2"", ""iq2xxs"",""exl2-2.5bpw"", также употреби ""даже gptq-3b"". Когда он приходит домой, он ""запускает кобольда или убу"". Остальное добавь согласно контексту.
> Можешь немного расширить или переформировать текст, но сохрани общую последовательность и сделай узнаваемым, прояви креативность.
На чайном можно?

Ну держи.
Так это многие, заточенные под кодинг файнтюны, обойдут ванильные модели.
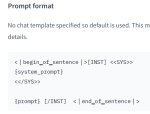
> Wavecoder
Бля, опять ебаться чтоб автокомплит настроить. Ну почему нельзя один токен сделать и всё? А тут сразу два намешаны.
А что толкового для автокомплита есть кроме Coninue? Я ставил какие то платные триальные плагины, там был годный автокомплит. А continue сам по себе не идеально работает, да и приличные локальные модельки довольно тормозные, а всякие 1b, хоть и быстрее, но совсем говно.
Так и какой формат промпта у этого говна? Либо скобочки генерит циклично, либо ничего не генерит вообще. На пике 146% неправильный. Майки-пидоры с гитхаба удалили репу, на HF нихуя не вижу, в твиттере кроме одной картинки ничего нет, в блоге вода.
> да и приличные локальные модельки довольно тормозные
А куда быстрее 7В? Строка кода за треть секунды генерится. Берёшь дипсик 7В и всё. Либо квен, если хочешь поебаться.
>А куда быстрее 7В? Строка кода за треть секунды генерится. Берёшь дипсик 7В и всё. Либо квен, если хочешь поебаться.
Оно обычно генерит несколько строк, а иногда вообще глючит и генерит до упора в 1024 токена.
>Пока тесл не было, 70B_Q2 было единственным вариантом.
>Пока тесл не было,
Скинь плз 3 квант 70В сетки, которая влазит в теслу!
> Годнота, замотивировал заняться подобным.
Давай вместе заниматься. Там работы выше крыши, чтобы сделать все так, как надо. Потом вместе в шапку результат выложим.
> Единственный тейк, что цензура в лламе-3 есть. Тут да, рискуем, можно и пройти мимо в итоге, если не победят. Но веса открыты, я надеюсь, справятся.
А что там за цензура. Отказ делать контент или что-то ещё? Отказ делать контент вполне обходится промптом, она инструкции выполняет очень неплохо.
> > я могу получить результат лучше чем был на видео
> Хз, на видео вроде норм. Но если ты хочешь прям эмоции, то — нет, coqui, насколько я знаю, пока не может в расстановку акцентов. Не знаю как запущено, может быть там deepspeed. Если ее вырубить — будет лучше. Но интонации будут рандомны, конечно.
На самом деле они и здесь через жопу и полурандомные. Знаки препинания как-то регулируют немного, но это все довольно отстойно.
> В таком случае, нужно подавать правильно форматированный (уметь в интонации — значит иметь промпт формат с указанием настроений/ударений, я так понимаю, ттс такое воспринимает?) промпт. А это — писать самому код.
Да там интонации регулируются такими знаками, как "." "," "!" "?" Причём их можно ставить перед репликой или после. И еще стрелочки вверх вниз тоже регулируют. Но все это всрато пока что. Хотелось бы что-то ещё добавить. А лишние точки можно и саму лламу попросить ставить. Хотя такое делать не хочется.
> Ну или написать в гите таверны и слезно попросить feature для конкретной ттс. Может кто-то заинтересуется и напишет.
Да там вообще api с moe-tts отсутствует. Странно почему так.
> Ммм… У меня времени нет.
> Вкратце — открываешь папку с extensions, смотришь, откуда уходят там тексты в ттс, и с этими текстами и работаешь. Находишь, где они формируются, находишь, где лежит настроение персонажа (оно же рисует картинки), и с его помощью меняешь вывод текста соответственно.
> Там все было на JS, так что терпимое.
> Это максимум, что я могу сказать спустя полгода как не трогал сорцы таверны.
Так еще и экстеншн писать самому надо.
> LibreTranslate, лол, оно же прям в таверне есть. =)
Ну если что-то запрогал, то результат все равно в шапку закинуть стоит. Я думаю здесь немало людей, которые не против локально переводить.
> Ваще модели на русском могут. Кмк, лучше выходит, чем переводить имеющимися переводчиками.
Мне лично не на русский, а на японский надо.
> а гугл выглядит как шутка с его корявым переводом
Прошу заметить, что гугл стал гораздо хуже чем был раньше. Сейчас, без всякой иронии, яндекс переводит гораздо лучше чем гугл.
Там можно в конфиге выключить мультилайн.
image to text можешь попробовать. Мне кажется видео снимать это оверкилл.
Анон, накидай хороших карточек персонажей, на твой взгляд. Хочу по примеру написать карточки умных людей, дабы сделать с ними чатик и советоваться.
Может есть гайды как лучше оформить карточки?
Может есть гайды как лучше оформить карточки?



Прикольные вещи ты там ищешь. Можешь еще что поскидывать.
Я и не искал, это висит на самой первой странице, если выбрать сортировку по популярности. Поэтому и охуел немного.
Это лишь кажется.
7B между Q8 и Q6 имеет видимую разницу.
13B уже между Q8 и Q6 меньше отличается, а видно при приближении к Q5.
30B в районе Q5 вполне бодра, а уже Q4 начинает проклевываться.
А 70B в районе Q4 еще держатся молодцом, но уже на тройке… Ну не то, в сравнении с верхними квантами, ИМХО.
Ну, для 70B норм.
Но чел писал «in my case», что у него там за кейс? Вдруг простенький раг или типа того.
Го теоретизировать.
У нас 70B на q4_K_M жрет 40 гигов.
400B больше в 5,7 раза. Это 228 гигов.
Но! Скорее всего, 400B и на третьем кванте сможет норм шевелиться.
Скинем до 180 гигов и получим 8 тесл (192 гига — + контекст).
Как раз материночки майнерские пойдут.
Практически, там скорость будет работать в обратную сторону. =)
1,5 токена/сек на старте и 0,5 с контекстом. Это мы еще игнорим мультигпушность, быдлокод и все же 1 линию писюху. Там будет прям скорость оперативы и 5-10-20-минутные ожидания ответа (с потреблением 1,2 кВт=).
Забавное.
> А что там за цензура. Отказ делать контент или что-то ещё? Отказ делать контент вполне обходится промптом, она инструкции выполняет очень неплохо.
Ну опять же, обходить промптом — это способ вылечить симптом. А нам нужно, чтобы она с рождения не болела. =)
У Мистрали просто не было такой болезни, она хуярила че хошь.
> Так еще и экстеншн писать самому надо.
Ну, ежели хочется ахи-охи сделать — то точно. =)
Или же просто добавить движок.
Не то чтобы с нуля, но влезть в имеющийся код придется.
> Ну если что-то запрогал, то результат все равно в шапку закинуть стоит. Я думаю здесь немало людей, которые не против локально переводить.
Так он в таверне уже более полугода лежит, че тут в шапку-то выносить. =)
Написал, мердж реквест, аппрув, мердж, даун, как говорится.
Но я апдейтнул и у меня 11.8 че-то такое. Что там в 12 версии не знаю, да уже и не очень актуально, кмк.
Яндекс получше, соглашусь.
А вот стал ли Гугл хуже или Яндекс вырос — судить не берусь.
8б генерирует мусор, надо брать покрупнее модели.
Значит хорошая карточка.

Осуждаю конечно, но есть мнение что даже нецензурные нейросетки например Fimbulvetr-11B-v2, не смогут адекватно описать взаимодействие с данным персонажем, так как сетки не обучаются на таком специфичном жанре.
Хотя могу и ошибаться такую карточку не пробовал, и жанр особо не тестировал
>так как сетки не обучаются на таком специфичном жанре
Лоликон есть как минимум в лимарп датасете. Про этот жанр ХЗ, не видел. Впрочем, если тебе сильно нужно, всегда можно натрейнить свою лору.
>Прошу заметить, что гугл стал гораздо хуже чем был раньше. Сейчас, без всякой иронии, яндекс переводит гораздо лучше чем гугл.
Нихуя по обоим пунктам. Яндекс иногда проёбывается так, что диву даёшься. Гугл неплох и улучшается, плюс лёгкий доступ. Правда к нему подход нужен.
>Скинь плз 3 квант 70В сетки, которая влазит в теслу!
У меня две. И третья едет.
Ещё бы скорость не 5 т/с.

Заработало, это кодеквин, мне показалось забавным дать делать сайты сетке которая в этом шарит
Теперь у меня есть свой интернет, с блекджеком и шлюхами
Допилить бы там при вызове правильный промпт формат и его обработку, да и сохранять сайты, хмм
3 никак не влазит, а вот второй (с матрицей важности) можешь попробовать.
https://huggingface.co/qwp4w3hyb/Meta-Llama-3-70B-Instruct-iMat-GGUF/tree/main
> внутри мешка звучит тихий шелест квантовых частиц
> Вода в ванне становится коричневой и густой
Ай сука, сделал мой вечер просто. Не ну тут первая просто вне конкуренции.
А если серьезно, она совсем ошизела и ебанулась, вторая уныло-топорно, но справилась.
> имеет видимую разницу
Это тоже может казаться. В идеале нужен слепой тест и некоторая статистика оценок, плюс проводить чтобы минимизировать байасы связанные с карточками, настроением и т.д.
> И третья едет.
brutal
через прокладку OpenAI кобольд криво генерит на командире, я запилил вызов кобольда через requests.post и сделал формат для него. позалипал пару часов. по хорошему там надо еще допилить сохранение и передачу информации при вызове ссылок с конкретного сайта, чтобы оно не забывало контекст.
А насколько вообще перфоманс 70В лламы лучше в сравнении с 8В, даже если 70В низкого кванта?
мимо
Оно 34В любую выебет, а ты тут про 8В говоришь.
>А насколько вообще перфоманс 70В лламы лучше в сравнении с 8В, даже если 70В низкого кванта?
За третью Лламу пока вообще рано говорить. Минимум месяц до первых оценок, по-хорошему если. Я попробовал и вернулся на Мику. Ну а вообще - хорошая семидесятка тебе хорошо карточку разыграет. А восьмёрка нет. (И 13 нет, и 30 нет).

>по хорошему там надо еще допилить сохранение и передачу информации при вызове ссылок с конкретного сайта, чтобы оно не забывало контекст.
Да, самому только неохота это все делать, но интересный опыт будущего. Генеративный интернет, хули
Я кстати с сервера llama.cpp завел, до этого траблы были изза старого загаженного питона
Обновился, и просто поменяв там порт, температуру и контекст все запустил с первого раза. Жаль только с этого гугла никуда не отправляло, там особый вызов нужен все таки
>Дегенеративный интернет
Исправил, не благодарствуй. Хотя интернет уже так скатился, что может негросетки уже и лучше, лол.
Но не 35, лол. С промтом если прямо заморочиться то можно улучшить, но проще дождаться файнтюнов.
Напомнило балалайку
Вот бы ещё зафайнтюнить на дампе архивача и сделать шизонейродвач.
> Ну опять же, обходить промптом — это способ вылечить симптом. А нам нужно, чтобы она с рождения не болела.
Так для этого надо с нуля тренить. А так лишь два стула каким образом обходить симптом. Просто у промпта побочек меньше. А расцензур полноценный поломать модельку может.
> У Мистрали просто не было такой болезни, она хуярила че хошь.
Мистраль наверное самая соевая параша, которую я видел. Никакими промптами не обходится.
> Ну, ежели хочется ахи-охи сделать — то точно. =)
Да в принципе оно сейчас не подцепляется. Они не работают друг с другом.
> Или же просто добавить движок.
> Не то чтобы с нуля, но влезть в имеющийся код придется.
Да там еще разбираться как апи у мое-ттс работает.
> Яндекс получше, соглашусь.
> А вот стал ли Гугл хуже или Яндекс вырос — судить не берусь.
Гугл хуже стал.

Здоровый, сука.
Через убабугу у меня фигня что на лламе, что на квене.
Мне лень я хочу тык-тык, а не вот это вот.
Но идея забавная.
Очень лучше. Прям пиздец.
8б это поиграться, а 70б это прямо ебать.
Но тут такое, если не можешь гонять быстро — не пробуй, иначе потом разочаровываться будешь от маленьких.
пхпхпхпх
> Мистраль наверное самая соевая параша, которую я видел. Никакими промптами не обходится.
Вот совершенно не понимал.
У меня голые мистрали вообще не сопротивлялись ничему, а только поддерживали.
Что мы делаем по-разному…
> Вот совершенно не понимал.
> У меня голые мистрали вообще не сопротивлялись ничему, а только поддерживали.
> Что мы делаем по-разному…
Хоть голый мистраль, хоть не голый. Прошу стать злым персонажем яндере, а оно мне срет, что отношения должны быть только здоровыми и инструкцию игнорит полностью.
В общем бартовский наквантовал хуйни и даже не проверил, там все гуфы сломаны у него. На EXL2 взлетело.
Уебал бы всем троим.
>там все гуфы сломаны у него
А где не сломаны?
>Уебал бы всем троим.
За що?
Разве не у него есть OLD и актуальные?
>скрин без файла настроек
Ну и нахуя?
https://github.com/jokenox/Goopt/tree/master
Еще вариант генеративного интернета, но не уверен что заведется с локалки
Еще вариант генеративного интернета, но не уверен что заведется с локалки

Стареешь только ты…
Пигмалион - единственный топ. Все кто думают иначе дурачки объективно

Антоны, сап, подскажите, пожалуйста, где можно накопать инфу по развертке llama на своем сервере? Хочу сделать простенький сайт с чатботом для студентиков и впихнуть туда модельку с файнтюном, но не знаю как всё это дело можно развернуть
Прошу прощения, если на мой вопрос уже где-то был ответ, я заебусь тут искать
Прошу прощения, если на мой вопрос уже где-то был ответ, я заебусь тут искать
>где можно накопать инфу по развертке llama на своем сервере
Нигде, я не видел такого. Но по сути любой бекенд даёт свою OAI совместимую апишку, а уж там нет проблем разобраться, как вызывать её из браузера. В кокобольде даже режим для нескольких пользователей есть.
Имеет ли смысл по приколу поставить линух чтобы получить плюсы к итэсам за счет красноглазых нанотехнологий или бесмысленно и никаких нанотехнологий на +50% там нет?
Инсайдер в треде. Дотренеровали 400b модель, уже считаем что хватит. По ощущениям на уровне Claude 3 Haiku где-то, что нормально для опенсорса, я считаю. По бенчмаркам на уровне Gemma, но Gemma так-то хороша по бенчмаркам, только в реальном использовании кал, так что я считаю это шин. Ждите через пару месяцев по лицензии с комерческим использованием только по платной подписке
сделай сервер на пихтоне\жаваскрипте и вызывай из него апи кобольда, когда пользователь пишет чатботу на сайте.
Верим.
> если не можешь гонять быстро — не пробуй, иначе потом разочаровываться будешь от маленьких
Скорее будешь разочаровываться от завышенных ожиданий и будешь ловить фрустрацию из-за долгого ожидания и не того результата что хотел.
Именно в начале там радикальной разницы не будет, особенно в простом случае. Но чем дальше тем более и более ты будешь подмечать что большая модель все держит "в голове", понимает тебя все лучше и лучше и подстраивает под ситуацию, а мелочь просто будет давать вариации дефолта, игнорируя многое из контекста.
> Хочу сделать простенький сайт
Ну так и делай сайт. Апи бэкендов хорошо описаны, дополнительно тебе придется сделать простой обработчик, что запросы от вебморды будет оборачивать в промт и обращаться, выдавая в ответ то что получается.
Просто ради скорости особо смысла нет.
Проиграл с видоса.
В новой силли таверне добавлена возможность создания административных и обычных пользователей. И вроде как сделана многопользовательность. Чет такое написано в описании 12 предварительной версии
https://github.com/SillyTavern/SillyTavern/releases
в бек что то быстрое, таверну настроить и открыть
как вариант
>По ощущениям на уровне Claude 3 Haiku
Пиздос лоботомит. Нахуй не нужно. Дистилируйте до 34B с сохранением характеристик, тогда поговорим.
Ollama + open-webui.
Конечно, вы не знаете, ведь вы из своей эхокамеры кума не выходите. Проиграл блять в голосину, деплоить ТАВЕРНУ и КОБАЛЬД в шараге.
Нахуя ему готовый фронт, наркоманы? Энд юзерам нахуй не нужны все миллионы возможностей таверны.
Очевидно нужно запилить простецкий чат с 3 сообщениями в памяти максимум, никто подлога всё равно не заметит. А если сделать слишком хорошо, набегут дрочеры и выкумят весь сервер, лол.
>файнтюн мику, которую файнтюнить нельзя, да ещё и после выхода лламы 3
Фейл на фейле.
>деплоить ТАВЕРНУ и КОБАЛЬД в шараге
Чел, лично я не предлагал выставлять кобольда голой жопой в интернет. Очевидная прокси очевидна.
Тогда просто ollama.

Варебух, на кой хер ты свои проекции и обиды демонстрируешь? С таверной братишка явно порофлил, но бэк в любом случае понадобится, вообще иных вариантов быть не может, и веб-морду свою писать придется.
пик
Есть ведь какие то простенькие и стерильные веб морды, вон например
https://github.com/cohere-ai/cohere-toolkit
https://github.com/cohere-ai/cohere-toolkit
https://github.com/open-webui/open-webui
или это, или еще хуй пойми что.
Проблема по моему в беке, непонятно как сделать несколько параллельных подключений сеток.
Или делать только одну но на чем то супербыстром.
Что бы несколько пользователей не слишком долго охуевали от ожидания ответа
Нахуя что-то изобретать, когда в open-webui есть администрирование, RBAC, вайтлист моделей, modelfile для карточек, да и вообще это изкоробочное решение ставится 1 командой через докер? Не нужно дезинформировать анона своими тавернами и кобальдами.
>Что бы несколько пользователей не слишком долго охуевали от ожидания ответа
А чё нет? Думаешь там у чела есть ресурсы на стойку с A100?
>modelfile для карточек
Зашкварен, следующий.

Какой хитрец, ты погляди.
> ставится 1 командой через докер
Фу закшварник, фу, брысь, говно!
>А чё нет? Думаешь там у чела есть ресурсы на стойку с A100?
Если это какой то вуз или еще что раз студенты, то у них может быть какое то железо. Даже если это просто сервак-два
Была бы возможность подсоединять параллельно несколько запущенных параллельно сеток и ими дережиривать, то даже на медленной генерации можно было бы обслуживать несколько пользователей
>Если это какой то вуз или еще что раз студенты, то у них может быть какое то железо
Он не писал, что из ОАЭ.
>Была бы возможность подсоединять параллельно несколько запущенных параллельно сеток и ими дережиривать
Несколько кобольдов и простейший код с очередью и round-robin алгоритмом. Пишется за полдня, если вообще не в теме.
Отупевший от кума тавернщик, от тебя спермой воняет.
Продавец лолламы, спокойствие оформите.
Да, но проблема в том как отдавать результат фронту который ожидает только 1 апи с одним контекстом. Тоесть это должно поддерживаться еще и на фронте, и он должен уже дирижировать нагрузкой нескольких апи, не путая их.
Странно что такое еще не сделано. Думаю где то такая реализация уже есть.
Многие фирмы хотели бы сделать свой многопользовательский локальный сервер с нейронками. Даже если отдельные нейронки будут запущены на картошках, хех
>Тоесть это должно поддерживаться еще и на фронте
Схуяли? Ещё раз- прокладка всё делает сама, прозрачно для фронта. Ты совсем что ли хлебушек в программировании?
> (You)
А может ты? Дурачек, если у тебя несколько пользователей на фронте одновременно им пользуются, и фронт имеет только 1 апи. Он будет ставить их запросы в очередь сам определяя что отправлять по апи и что ждать в ответ.
Ты как собрался нужный ответ ему давать с нескольких апи? Если он не знает кому его отдать обратно?
А может ты? Дурачек, если у тебя несколько пользователей на фронте одновременно им пользуются, и фронт имеет только 1 апи. Он будет ставить их запросы в очередь сам определяя что отправлять по апи и что ждать в ответ.
Ты как собрался нужный ответ ему давать с нескольких апи? Если он не знает кому его отдать обратно?
бля сам себя захуярил
> Если это какой то вуз или еще что раз студенты, то у них может быть какое то железо
Обычно когда есть ресурсы - есть отдел что занимается ии и там у спецов хватит сил чтобы самим освоить. Да даже банально им будет интересно окунуться в ллм если раньше не пробовали и начнут с использования.
Это у тебя на губах запеклась, иди мойся.
> Тоесть это должно поддерживаться еще и на фронте, и он должен уже дирижировать нагрузкой нескольких апи, не путая их.
Во-первых, очередь, балансирование и прочее делаются несложно, в пример те же прокси. Во-вторых, никакого контекста для каждого помнить не надо, каждый запрос - полный контекст и ответ на него.
Чето перемудрили пиздец.
Какие же тут хлебушки сидят, просто нули в программировании, разработке и администрировании. Очевидно, что модель отвечает всем поочереди. Если нужно несколько моделей, то и инстансов нужно запускать несколько и настраивать балансер нагрузки.
>Во-вторых, никакого контекста для каждого помнить не надо, каждый запрос - полный контекст и ответ на него.
А вот это зря, не продакшн реади. Для прода надо жёстко фиксировать хотя бы префил нехуй давать кумить студентам, а лучше ответы сетки, чтобы не подменяли. А то знаете, я так уже с полгода присосался к одному сайту с GPT4 на фронте, лишь потому, что там апишка дырявая, лол.
Не, как раз системный промт и префилл нужно максимально залочить, заодно добавить пугалку про репорт чат-логов в случае детекции нсфв. А запоминания не требуется, каждое сообщение должно обрабатываться как новое, на кэш контекста не нужно делать ставку если много пользователей.

it's over для нищуков с видяхами от 12gb
квантование напрочь убивает способности модели.
квантование напрочь убивает способности модели.
>Не, как раз системный промт и префилл нужно максимально залочить
Это я и имел в виду под "хотя бы префил".
>заодно добавить пугалку про репорт чат-логов в случае детекции нсфв
Логи должны писаться всегда и на всё.
>на кэш контекста не нужно делать ставку
Как минимум, так как системный промт будет общим, то его обработка будет делаться один раз. Как минимум в кобольде под это даже опция есть, чтобы предварительно обработать такой контекст и держать его в памяти.
когда понимаешь что красные команды по цензуре LLM-ок чертовски правы.




>квантование
Какое? Там даже ггуфа нет, а 8 бит любого кванта (даже обоссаного RNN) в итоге ничем не хуже 16 бит оригинала.
Ну и во всём тесте нет народных 5-6 бит, а они самый топ по эффективности на байт.
Чем? Ну вот написал я в чате, как выебал этого младенца (на самом деле нет, но предположим), а потом обоссал и ушёл курить в соседнюю комнату, и что изменилось? Кто-то пострадал? Наоборот, кому-то это может служить отдушиной.
Впрочем, это оффтоп тут, сходи перекати тред с этикой, продолжим обсуждение.
Не понял где тут bpw или цифры кванта?
Первый столбец. Второй наверное отдельный квант для внимания, или там контекста, это уже их статью читать надо.
ну, шок-фактор сыграл, не часто такое вижу как и любой другой человек, хоть и сижу на двачах и форчанах с 2015 года.
боюсь представить какая реакция у твиттерных будет, или уже была ибо в америке приняли какой то закон о ИИ моделях.
Первый веса, второй активации, понять это можно заглянув в пейпер smoothquant

>хоть и сижу на двачах и форчанах с 2015 года.
Хреново сидишь как-то. Я даже ухом не повёл.
>в америке приняли какой то закон о ИИ моделях
Да это реакция просто ответ на обычных лолей
https://finance.yahoo.com/news/meta-openai-spawned-wave-ai-140000660.html
Что начнётся, если всплывут такие карточки, мне прям интересно посмотреть. Чем сильнее рвёт нормисов, тем веселее.
Впрочем, вон в стенфорде нашли чуть больше 2к ЦП в датасете, на котором учили стейблу, так что ждём новых запретов. Будет ржака, если из-за этого запретят все модели SD 1.5, лол.
https://stacks.stanford.edu/file/druid:kh752sm9123/ml_training_data_csam_report-2023-12-23.pdf
Новый, свежий тред. Ну то есть
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Всем известно, что надо ставить 6 кванты, но их почему-то нет здесь. Ниудобные цифры получились бы. Ну а так, очередная статья для дроча харша + попытка протолкнуть свои кванты.
Кто использует платы Z170 или Z390 под две Теслы и больше, нормально работает? Что у вас за мать? Примерный конфиг компьютера?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. В треде можно поискать ссылки на правленные промт форматы, дефолтные не подходят. Ждём исправлений.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama Однокнопочный инструмент для полных хлебушков в псевдо стиле Apple (никаких настроек, автор знает лучше)
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: