


Наконец выяснил, как миксовать SDXL с PonyXL.
Авторы мерджей применяют технику мерджа "DARE", чтобы соединять максимально непохожие модели одной архитектуры. Я сделал мердж comradexl, ponymagine, anythingxl и использовал его как прекурсор для дальнейшего мерджа, теперь идет как по маслу. Но фоны все равно мыльные. Интересно, встанет ли всё это поверх Pony7.
Авторы мерджей применяют технику мерджа "DARE", чтобы соединять максимально непохожие модели одной архитектуры. Я сделал мердж comradexl, ponymagine, anythingxl и использовал его как прекурсор для дальнейшего мерджа, теперь идет как по маслу. Но фоны все равно мыльные. Интересно, встанет ли всё это поверх Pony7.
>Pony7
До нее же еще далеко
На, сравнивай, хоть обгенерься.
https://huggingface.co/spaces/VikramSingh178/Kandinsky-3
Это кривой жопой обученное говно никому, кроме сбера не нужно.
Сколько они его пилили? Года полтора? За это время СД эволюционировал за счет энтузиастов анмимешников до вполне удобного и рабочего инструмента. Без бабла, без "команды продукта".
Гайд будет?
Ща погуглил и оказывается, есть ComfyUI нода для Dare, вроде ничего сложного.
Нихуя не понял как пользоваться
а хотя нет вроде понял, но лучше бы чтобы воркфлоу свой скинул для примера
Там еще дейр мержер лор есть, ток у меня он не работает лол ругается на разные дименшоны.
А вообще конкретно по дейру че за че там отвечает? Реально гайд бы.




Какой способ тренировки лор может найти эти мелкие отлчия между 2-мя практически одинаковыми картинками?
Перефразирую:
Как тренировать лору чтобы во время обучения сравнивались только пары пикч между собой? Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
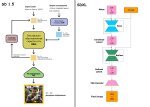
Block merge это мощный инструмент контроля над юнетами от разных SDXL моделей...
С ним я смогу добавить к этой новой модели https://civitai.com/models/480956/anime-reality-interweaving?modelVersionId=534884 верхний слой от фотореалистичной модели, чтобы сделать фон еще реалистичнее, и нижний слой от маня-чекпойнта - чтобы стиль персонажа был более выразительным.
Чем выше, тем больше воздействует на композицию целиком, не трогая детали. Чем ниже - тем больше меняет детали, не трогая общую композицию. Middle - это про поверхности, их материалы и текстуры. (В первой версии OrangeMix автор плавно заменил миддл у NovelAI, взяв реалистичную модель с голыми японками).
Значение 1 означает - полностью оставить первую подключенную модель, 0 - полностью сделать из второй. Из моего опыта, верхние 3-5 слоёв в input влияют в основном на детали фона и освещение, 6-7 сильнее всего влияют на фон и могут его сломать. Если заменить только input_blocks 0 - то поменяются некоторые детали фона, одежда персонажа и её цвет, а персонаж останется прежним. С середины middle начинает влиять на текстуру кожи и структуру волос (но не расположение прядей). В низу middle начинает менять позу (точнее, конечности - включая принципы их расположения) и всю анатомию. В output меняет лицо, а в последнем output_blocks 11 серьезно меняет даже такие детали, как пряди волос. Есть и отдельная нода для мерджа клипов. CLIP из PonyXL ухудшает фон, но в теории может улучшить понимание Booru-концептов.
Есть вариант прибегать к пресетам (поставив в комфи ноду с пресетами), про них показано здесь https://civitai.com/articles/2370/model-merging-management-how-to-merge-stable-diffusion-models-to-fit-your-style
С ним я смогу добавить к этой новой модели https://civitai.com/models/480956/anime-reality-interweaving?modelVersionId=534884 верхний слой от фотореалистичной модели, чтобы сделать фон еще реалистичнее, и нижний слой от маня-чекпойнта - чтобы стиль персонажа был более выразительным.
Чем выше, тем больше воздействует на композицию целиком, не трогая детали. Чем ниже - тем больше меняет детали, не трогая общую композицию. Middle - это про поверхности, их материалы и текстуры. (В первой версии OrangeMix автор плавно заменил миддл у NovelAI, взяв реалистичную модель с голыми японками).
Значение 1 означает - полностью оставить первую подключенную модель, 0 - полностью сделать из второй. Из моего опыта, верхние 3-5 слоёв в input влияют в основном на детали фона и освещение, 6-7 сильнее всего влияют на фон и могут его сломать. Если заменить только input_blocks 0 - то поменяются некоторые детали фона, одежда персонажа и её цвет, а персонаж останется прежним. С середины middle начинает влиять на текстуру кожи и структуру волос (но не расположение прядей). В низу middle начинает менять позу (точнее, конечности - включая принципы их расположения) и всю анатомию. В output меняет лицо, а в последнем output_blocks 11 серьезно меняет даже такие детали, как пряди волос. Есть и отдельная нода для мерджа клипов. CLIP из PonyXL ухудшает фон, но в теории может улучшить понимание Booru-концептов.
Есть вариант прибегать к пресетам (поставив в комфи ноду с пресетами), про них показано здесь https://civitai.com/articles/2370/model-merging-management-how-to-merge-stable-diffusion-models-to-fit-your-style
> Перефразирую:
> Как тренировать лору чтобы во время обучения сравнивались только пары пикч между собой? Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
Разделить по концептам с уникальными стартовыми токенами?
Ты путешественник во времени? Как там в 2022?
> Block merge это мощный инструмент
дерьма
Стандартный, просто теги разные поставь у обычной и тонмапленной картинки, и оно само различит. Точнее попробует различить - у него не бесконечная способность к генерализации. Главное выставь как можно больше тегов для абсолютно всего что есть на пикчах помимо твоей разницы, включая предметы, оттенки, действия и т.п. И подбери пикчи так, чтобы они были максимально непохожими друг на друга, и отличались только тонмаппингом. Иначе он будет клепать похожее на твои пикчи.
Но вообще лоры для этого недостаточно мне кажется, надо файнтюнить полноценно, хотя бы на 10к+ пикч. Тем более что тонмаппинг кривую можно налепить автоматически.
>практически одинаковыми картинками
Это для тебя почти одинаковыми. А у шоггота собственные критерии похожести.
Но вообще, нахуя тебе тонмаппинг кривую зашивать в нейронку? Ебанутая идея изначально, как по мне. Это же чисто автоматическая операция.
>Например пик1 сравнивался только с пик2, а пик3 только с пик4 и т.д.
Теги пик1: интерьер, вестибюль, балкон, диван, камин, домашняя обстановка, столик
Теги пик2: интерьер, вестибюль, балкон, диван, камин, домашняя обстановка, столик, пиздатый тонмаппинг
И он автоматически выводит разницу при обучении. Но надо овердохуя тегов для всего остального, чтобы он смог тщательно отделить тонмаппинг от всего остального. И овердохуя пар, чтобы не сошёлся на каком-то паразитном признаке.
Утерянные знания https://rentry.co/Copier_LoRA вот это попробуй
Интересные наблюдения, анонче, пробовал уже лучшее таким образом из разных аутизмов там для аниме анатомии вытаскивать например из моделей?
Анон, это всё так не работает. Твои наблюдения не обобщаются, обычно одни отвечают за низкие частоты, другие за высокие, но не всегда, и обычно затрагивают совершенно несвязанные вещи. Протестировать вручную это невозможно, слишком большой объём.
По этой же причине невозможно было управлять FreeU, т.к. это шаманство. По этой же причине любые интуитивные ковыряния в отдельных весах или слоях или блоках - хуйня из коня.
>Утерянные знания
Интересное решение, кстати.
Еще, помню, были какие-то штуки для тренировки лор-слайдеров, основанные именно на парных картинках, а не регулировке весов, когда все делается без картинок вообще.
Колабы по ссылкам в шапке дохлые, нихуя там не работает тренировка и уже более года вроде на него как хуй забили.
А вот эта тема https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb по первой ссылке в гугле внезапно работает
А вот эта тема https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb по первой ссылке в гугле внезапно работает
RAM колабовского gpu не хватает для трейна XL
Я xl не юзаю, на 1.5 хватает и ладно



Dare с включенным attention - годнота, вот сэмплы 50/50 мерджа AutismMix с Helloworld. Надо экспериментировать, хочу сделать анимэ мердж со стилем как в цифровой живописи китайцев из Artstation. (чтобы не как в Pony 6 - а хорошую разностороннюю XL модель как Unstable, которая возьмет из пони только анатомию и концепты чуть-чуть). Видел где-то костыль для инжекта нойза в чекпойнты, он может помочь чтоб делать фон без мыла.
Ты отдаешь себе отчет в том, что занят проектом лепки из говна по мотивам лепнины, созданной альтернативно разумными индивидуумами ииз пластилина на уроке трудотерапии?
это почему у тебя так от пони печет?
Вопрос к знающим. Если веса Vpred модели можно присобачить к обычной, то как присобачить веса модели offset noise? Так же через train difference?
о живой полторашечник
плюсуешь офсет нойз лору к модели в нужном весе, трейн дифренсишь к изначальной полученную модель
на сдхл если интересно такой же эффект + полное управление динамическим диапазоном и цветами через мердж с CosXL, на пони не работает есличе
Надо бы тогда в шапке сменить на этот, раз он работает
А сколько там? С чекпоинтингом в фп8 и в 8 гигов умещать умудряются с XL
У меня не лоры, а обычные модели. Т.е. по сути, так же все как и с лорой? Я просто лоры никогда не мерджил с моделями, считаю это извращением.
>У меня не лоры, а обычные модели.
непонял, что за модели?
>Т.е. по сути, так же все как и с лорой?
да
>Я просто лоры никогда не мерджил с моделями, считаю это извращением.
ну и зря, это же просто замена весов в модельке на нужные, ничего криминального
>непонял, что за модели?
https://huggingface.co/lodestones/furryrock-model-safetensors/tree/main Шерстяные, тащемта. Хочу попробовать с них вытянуть впред, офсет нойз и в душе не ебу что за terminal-snr и minsnr-zsnr-vpred-ema - последнее что-то на колдунском, гугл молчит. Но если это можно вытянуть из модели и проверить, то хорошо. Ещё бы знать как правильно, потому что с СуперМерджером я на "вы" и никогда им не пользовался.
>ну и зря, это же просто замена весов в модельке на нужные, ничего криминального
Допустим.
Чел, это пердолинг loss при тренировке, что ты там из чекпоинта собрался тянуть, шиз?
Тредом ранее говорили, что vpred можно через трейнДиф перетянуть от одной модели к другой. то же самое говорит, но на примере лор. Плюс как бы я ясно выразился, что с мерджем я плохо знаком, поэтому и спрашиваю можно ли подобные особенности с одной модели перетянуть на другую. С чего ты взял, что я прям 100% уверен что это можно сделать?
>это пердолинг loss при тренировке
А поподробнее, где об этом можно почитать?
Заменил в шаблоне и попросил модератора обновить ОП-пост чтобы пару месяцев до ката не ждать.
Аноны, не знаю где ещё спросить, итт самый свет науки в области нейросетей сидит.
Нужен софт, который убирает цензуру "мазайку" с хентайных пиков и работает в гугл колабе.
1) DeepCreamPy не работает больше в колабе, разраб написал что проебал сурсы, то что есть не пашет и как пофиксить в интернете инструкций нет.
2) hentai-ai тоже не работает, пытается установить opencv устанавливает его час и потом хуй.
3) DeepMosaics это ваше маниме не понимает.
А больше ничего и не гуглится.
Как быть?
Нужен софт, который убирает цензуру "мазайку" с хентайных пиков и работает в гугл колабе.
1) DeepCreamPy не работает больше в колабе, разраб написал что проебал сурсы, то что есть не пашет и как пофиксить в интернете инструкций нет.
2) hentai-ai тоже не работает, пытается установить opencv устанавливает его час и потом хуй.
3) DeepMosaics это ваше маниме не понимает.
А больше ничего и не гуглится.
Как быть?
Купить видеокарту и демозаить локально.
Интересная тема, однако.
Исследователи из Техасского университета в Остине разработали инновационную схему обучения моделей на сильно поврежденных изображениях, метод получил название Ambient Diffusion
Последнее время то и дело возникают судебные иски — художники жалуются на незаконное использование их изображений.
И Ambient Diffusion как раз позволяет ИИ-моделям не копировать изображения, а скажем «черпать вдохновение» из них.
В ходе исследования команда исследователей обучила модель Stable Diffusion XL на наборе данных из 3 000 изображений знаменитостей. Изначально было замечено, что модели, обученные на чистых данных, откровенно копируют учебные примеры.
Однако когда обучающие данные были испорчены — случайным образом маскировалось до 90% пикселей, — модель все равно выдавала высококачественные уникальные изображения.
Статья : https://www.ifml.institute/node/450
Любителям шатат формулы: https://arxiv.org/pdf/2305.19256
Получается, что аксиома "Говно на входе - говно на выходе" пошатнулась? Надо попробовать на испорченном сете протренить лорку.
Исследователи из Техасского университета в Остине разработали инновационную схему обучения моделей на сильно поврежденных изображениях, метод получил название Ambient Diffusion
Последнее время то и дело возникают судебные иски — художники жалуются на незаконное использование их изображений.
И Ambient Diffusion как раз позволяет ИИ-моделям не копировать изображения, а скажем «черпать вдохновение» из них.
В ходе исследования команда исследователей обучила модель Stable Diffusion XL на наборе данных из 3 000 изображений знаменитостей. Изначально было замечено, что модели, обученные на чистых данных, откровенно копируют учебные примеры.
Однако когда обучающие данные были испорчены — случайным образом маскировалось до 90% пикселей, — модель все равно выдавала высококачественные уникальные изображения.
Статья : https://www.ifml.institute/node/450
Любителям шатат формулы: https://arxiv.org/pdf/2305.19256
Получается, что аксиома "Говно на входе - говно на выходе" пошатнулась? Надо попробовать на испорченном сете протренить лорку.
Это в говне моченые - ученые.
1. Учили на уже обученной модели (даже ванильная от ОА - уже обучена)
2. Открыли для себя сильные токены базовой модели. Даже если в качестве сета использовать ргб-шум, но учить на сильный токен, "man" например, то мужики все равно будут получаться. Откровение, блядь!
3. Попробуй на объект или стиль подсунуть "90% пикселей говна" на уникальный токен - получишь месиво из говна от Лоры.
Пиздец, конечно, позорище, техасцам.
Просто заюзай impaint со стейбл дифужна, только чекпоинт (на цивит.аи) предварительно найди под стиль твоей картинки. И даже так можно получить вполне приемлемый результат в 70% случаев, ну в остальных 30 что-то фото шепом придется поправлять руками.
> аксиома "Говно на входе - говно на выходе" пошатнулась
С чего бы вдруг? Там же loss считается из испорченных пикч. Если модель знает как выглядят испорченные пики, то всё будет как обычно, просто меньше информации будет из пика идти. Условно, части ебала он будет запоминать, а общая композиция сломана и он будет её игнорить, т.к. там рандом.
Добавьте инфу о сайтах по типу цивитай в которых есть возможность бесплатно тренировать.
Парни, такой вопрос, позволяет ли control net менять позу без изменения персонажа? Чтобы не добавлялись и не терялись мелкие детали, уебищно тени не скакали туда сюда, и можно ли довести уровень двух изображений с изменённой позой (с условным запрокидывание руки) до такого уровня чтобы из двух картинок можно было красивую анимацию сделать бесшовную?
Не позволяет.
По крайней мере, не позволял до сих пор.
Можешь это чекнуть, недавно видел, но сам не тестировал.
https://www.youtube.com/watch?v=hc5nF6rGa68
как же заебали эти недоблогеры с кликбейным говном изо всех щелей.
Да этот то чел нормальный.
Доступно объясняет, ссылки, все на месте.
Разве что актива у него нет последнее время.
технаряны, нубярский вопрос.
Есть модель на HF (ванильная SDXL файнтюненая методом SPO экперимента ради, но дающая очень хороши результаты по сравнению с оригом).
Она выложена как я понимаю в формате diffusors. Как ее сконвертить в savetensors для использования в гуях? Локально, коллаб, сам HF - пофиг.
Гугление этого вопроса зациклило меня рекурсивно, GPT несет дичь, Сlaude делает вид, что не понимает.
Репа: https://huggingface.co/SPO-Diffusion-Models/SPO-SDXL_4k-p_10ep/tree/main
Есть модель на HF (ванильная SDXL файнтюненая методом SPO экперимента ради, но дающая очень хороши результаты по сравнению с оригом).
Она выложена как я понимаю в формате diffusors. Как ее сконвертить в savetensors для использования в гуях? Локально, коллаб, сам HF - пофиг.
Гугление этого вопроса зациклило меня рекурсивно, GPT несет дичь, Сlaude делает вид, что не понимает.
Репа: https://huggingface.co/SPO-Diffusion-Models/SPO-SDXL_4k-p_10ep/tree/main
Ну нахуя вбрасывать если не собираешься объяснять, сука?
Не знаю насчёт конвертации, но пара гуёв вроде бы поддерживают формат diffusers. Лапша с кастомными нодами и СД некст.
Собираюсь тренировать лору в civitai объясните пожалуста как работает bucketing? Он просто кропает пикчу до ближайшего рабочего разрешения например если пикча с соотношением сторон 17:9, то он кропает только до 16:9 или на все популярные соотношения сторон т.е. из 17: кропает до 9:16, 16:9, 1:1, 2:3, 3:2, 4:5 и т.д.?
Будет ли bucketing растягивать разрешение изначальной пикчи с 512х512 до выставленного 1024x1024? Хочу что бы более менее широкий спектр разрешений поддерживала лора.
> т.е. из 17: кропает до 9:16
* т.е. из 17:9 кропает до 9:16
-быстрофикс
* т.е. из 17:9 кропает до 9:16
-быстрофикс
пасиб, анон, но я уже залез в консольную трясину.
Решение прям совсем гдето-то рядом, но пока не хватает знаний понять какого хуя state_model_dict ловит ошибку без описания.
Если уж совсем мозг сломаю - пойду в Комфи
>Будет ли bucketing растягивать разрешение изначальной пикчи с 512х512
Для этого есть опция Don’t upscale bucket resolution
>как работает bucketing?
Buckets contain images with different aspect ratios than 1:1. Using bucketing, you don't need to crop your training data to 1:1 aspect ratios. Instead, you just throw the variously sized images at the script. It doesn't "randomly" resize images. It looks at them all and calculates appropriate buckets for them, that fit within your dictated resolution frame, then resizes them all and sets up the schedule for them.
The scheduling is the key part of the bucket script that makes it work. Batches have to be from all the aspect ratio so 1 batch can only train on 1 bucket at a time. So if you have a batch size of 10, and buckets have 2 images, 5 images, and 9 images in them, none of those bucket sizes fills a full 10 batch right? So the system will automatically do smaller batches and gradient accumulation them together to built an effective batch of 10.
In the case where you're already using gradient accumulation , it'll adjust the batch sizes accordingly. So by using bucketing, you're giving the script it's own dynamic control over batch size and gradient size, with your settings as a general target to aim for. If you have gradient accumulation turned off, then it'll fill the entire batch of 10 with one bucket's images. so if the current batch is working on the bucket with only 2 images, it'll do each of those 5x on that batch. Recommend you use gradient accumulation as this can lead to over representation of the training data.
None of this is "random". It is all very calculated and plotted across a very precise training schedule.
Cropping images to 1:1 ratios is still a super valid training approach too. Not everyone uses bucketing. I like it because i like rectangles better than squares and the models trained with buckets produce better rectangular images.
Веса слишком разнородные, хоть как извращайся, ничего кроме поломанного лоботомита не сделать. В теории, можно сделать гомункула, которого потом дообучить, и это будет быстрее и качественнее чем делать с чистой sdxl.
Двачую этого и остальных.
Мертвичина как и ожидалось.
Полностью готового софта нет. С помощью SD и аниме модели можно снимать цензуру инпеинтом, но придется вручную выделять область. Можешь воспользоваться yolo, там наверняка уже есть готовые для нужной области, или сам обучи, и уже из ее результата делай маску и посылай запросом по api. Или собери систему в комфи, такое более чем возможно, его же вроде на коллабе не банили, не?
> что аксиома "Говно на входе - говно на выходе" пошатнулась?
На вход всеравно подавались "хорошие" картинки, просто "ученые" просто сделали аугументацию, которую модель понимает. А насчет изначального копирования - ужасно подобраны параметры обучения, такого нет если делать нормально.
У кохи есть скрипт для конверсии форматов https://github.com/kohya-ss/sd-scripts/blob/main/tools/convert_diffusers20_original_sd.py и еще рядом смотри
> Он просто кропает пикчу до ближайшего рабочего разрешения
Сначала кропает до ближайшего соотношения сторон, потом ресайзит до заданного разрешения.
> Для этого есть опция Don’t upscale bucket resolution
Двачую, вот только делать так не стоит, в смысле что использовать 512 пикчи для обучения. Если нет возможности достать хайрез - берешь хороший dat апскейлер и прогоняешь картинки через него, чтобы превышали 1 мегапиксель. И их уже добавляешь в датасет, эффект будет гораздо лучше чем от тренировки лоурезами.
>У кохи есть скрипт для конверсии форматов
Спасибо тебе, анон! Это, похоже именно то, что нужно! Сейчас кофейку бахну и погружусь.
>вот только делать так не стоит, в смысле что использовать 512 пикчи для обучения
При трене на персонажа вообще бакеты отключаю, несколько десятков пикч руками подготовить (почистить, проапскейлить которые де дотягивают, протегать) аообще не проблема - занимает 15-20 минут. Зато на выходе качество субъекта горазло лучше.
Для больших стилевых датасетов, вероятно, полезно.
> При трене на персонажа вообще бакеты отключаю
А зачем? Честно, даже не интересовался что будет без них, просто кроп+рейсайз пикчи до квадрата/указанного в параметрах разрешения? Это может негативно повлиять на возможности генерации в других соотношений сторон, увы с лорами всякие байасы тоже любит хватать.
Включение бакетов не отменяет ручную подготовку, просто тренировка будет в разных ar.
>А зачем?
Потому что для вручную подготовленного сета они не нужны. Их задача - рассортировать по размеру изображения из сета.
https://github.com/bmaltais/kohya_ss/wiki/LoRA-training-parameters#enable-buckets
If your training images are all the same size, you can turn this option off, but leaving it on has no effect. (с) оттуда же
>что будет без них
если сет разного размера пикч и бакеты отключить - то неподходящие по размеру будут апскейлиться или даунскейлится до aspect ratio. Например, если базовый размер составляет 512x512 (соотношение сторон 1), а размер изображения - 1536x1024 (соотношение сторон 1,5), изображение будет уменьшено до 768x512 (соотношение сторон остается 1,5). (c) тоже из ссылки выше
> для вручную подготовленного сета
Имеешь ввиду еще и вручную кропнутного до квадратов разрешения тренировки?
Какая-то ерунда надомозговая написана, пусть и самим мейнтейнером.
> If your training images are all the same size
Случай простой и понятный, тут ок.
> будут апскейлиться или даунскейлится до aspect ratio. Например, если базовый размер составляет 512x512 (соотношение сторон 1), а размер изображения - 1536x1024 (соотношение сторон 1,5), изображение будет уменьшено до 768x512 (соотношение сторон остается 1,5).
И мы имеем как раз пикчи разного размера, которые не могут трениться вместе, где логика?
Там вообще есть 2 момента, первое - необходимо иметь тензоры одной и той же длины в батче, второе - соотношения сторон пикч могут быть разные и нужно подогнать их под единое количество пикселей, чтобы оно соответствовало заданному размеру для тренировки. Баккеты обеспечивали и то и другое, что будет без них если датасет типичный смешанный?
>Имеешь ввиду еще и вручную кропнутного до квадратов разрешения тренировки?
Я бы сказал не кропнутого, а приведенного к размерам 1024х1024 в соотношении 1:1. Потому что зачастую это не только кроп, когда пикчи больше, но и небольшой апсейл при необходимости, косметическая очистка от ненужных деталей, коррекция цвета, дешарп\деблюр в некоторых случаях.
>Какая-то ерунда надомозговая написана, пусть и самим мейнтейнером.
Так это же Kohya, все ок. Там исторически пиздец в логике неизбежен, скрипты пишет японец, а GUI и мануал к ним - bmaltais
> что будет без них если датасет типичный смешанный?
Не проверял, но как мне кажется, просто на выходе хуйня получится.
Использование исключительно квадратов чревато, без необходимости лучше не стоит.
> коррекция цвета, дешарп\деблюр в некоторых случаях
Можно примеры? Интересно в каких случаях и как такое делается.
> Так это же Kohya, все ок.
Не, это же вроде автор гуйни пишет. Чтобы Кохя написал описание и туториал - это хз даже что должно произойти.
>Интересно в каких случаях и как такое делается.
Ебался я недели 2 с тренировкой на одну мадам. Все перепробовал, даже сервак под тренировку на сутки взял, думал может у меня с компом беда.
При любом раскладе мадам на готовой лоре получалась (лицо) немного фиолетовым, близко вроде норм, а немного подальше отодвинуться - прям неестественно.
И только после того как отцветокорил сет первая же тренировка с стандартными(для меня) настройками - все стало заебись.
С тех пор - еще и на цвет чекаю сет.
Блюр помогает убрать ненужное за контуром головы, когда открывать ФШ и вырезать фон лень.
Шарпом тоже часто пользуюсь - им хорошо доводить черты лица на расфокусированных фотках из инета, когда датасет и так кислый.
>Не, это же вроде автор гуйни пишет
В том то и дело, скриплы прилит один, а ГУЙ и туториал - другой, и, судя по всему они меду собой вообще не общаются, то есть как гуеписец понял - так и написал, отсюда недоумение у пользователей.
>Использование исключительно квадратов чревато, без необходимости лучше не стоит.
Почему? всегда только 1:1 1024х1024 , кроме первых 2-3 трейнов, полет отличный

> Ебался я недели 2 с тренировкой на одну мадам.
Неправильно ты, дядя Федор, диффузию тренишь. Нужно чтобы компьютер неделями напрягался а не ты сам.
По поводу сути описанной проблемы вроде понятно, а можешь датасет показать? Интересно что там могло дать подобный эффект. Или хотябы опиши датасет (количество, содержимое) и дай свои предположения от чего могло быть.
Сам могу дать анимублядский пример - художник bartolomeobari на всех пикчах ограниченный диапазон, смещение гаммы и прочее, офк все это тоже усваивается. Можно починить нормализацией пикч.
> Блюр помогает убрать ненужное за контуром головы, когда открывать ФШ и вырезать фон лень.
Насколько потом модель может четкий не-заблюренный фон делать? И для чего вырезать фон, там что-то нехорошее?
> судя по всему они меду собой вообще не общаются
Общаются, он чуть ли не основную репу sd-scripts содержит. Просто год назад написал на отъебись, и с тех пор висит.
> Почему?
Могут ухудшиться генерации в соотношениях сторон не 1к1, особенно в определенных ракурсах/позах и т.д.
https://github.com/lllyasviel/stable-diffusion-webui-forge/discussions/801
Фордж, походу, всё. Ну, по большей части.
Можно перекатываться на дев-вебуя, судя по всему туда завезли оптимизон (не весь).
Фордж, походу, всё. Ну, по большей части.
Можно перекатываться на дев-вебуя, судя по всему туда завезли оптимизон (не весь).
>неделями напрягался а не ты сам
Ага, а вдруг он (компьютер) выгорит от перенапряга, тогда придется неиллюзорно мне напрячься, чтобы его в рехаб отправить и замену купить. 210к степов, конечно, мое почтение целеустремленности научить модель.
>а можешь датасет показать?
Могу, только его очень поискать надо, попробую завтра в выходной как раз же.
>могло дать подобный эффект
Моя теория - фотограф на постобработке не просто поигрался ползунками в Лайтруме, а жестко и решительно накинул LUT.
>Можно починить нормализацией пикч
Про графику тоже слышал, что годно помогает, а вот про реализм - не знаю, надо почитать, спасибо за наводку!
>Насколько потом модель может четкий не-заблюренный фон делать? И для чего вырезать фон, там что-то нехорошее?
Вообще не влияет, пробовал и с блюром и без, главное - на подблюренных пикчах в датасете более конкретно прокапитонить, описав только сабжа и ничего более.
Блюрить - не столько вырезать что-то нехорошее, сколько исключить фоновые объекты с пикчи, при тренировке, например, на пикче, где сабж стоит на фоне елок, велоятность получить потом от лоры генерацию с деревом выше, чем если эту сраную елку подблюрить чтобы явно очертания не считывались. Лучше конечно совсем вырезать фон, но. как я говорил выше иногда лениво, проще кистьб помазюкать.
>Могут ухудшиться генерации в соотношениях сторон не 1к1, особенно в определенных ракурсах/позах и т.д.
Хм, не замечал, надо практически проверить, интересная тема.
>Лучше конечно совсем вырезать фон
Рукалицо...
Лучше этот фон протэгать. Когда у тебя эта елка в кэпшонах - модель ее поймет (потому что уже знает), и будет вызывать только по запросу. Ну или случайно, что тоже лечится - негативным запросом или прописыванием определенного фона в промпте.
Если у тебя на заднике будет мазня, которую ты даже как "blury background" или "bokeh" в файле не запишешь - эта мазня у тебя с другими токенами ассоциироваться начнет, в том числе и с тем основным, на который ты тренируешь.
Ля, крутая штука. Которая изменение первого кадра распространяет на всё видео. Для "изменения" одежды самое то
Даже если всё окажется не так радужно, то благодаря изменений в цвете можно создать стабильную видео маску и пустить в animatediff inpainting
К сожалению весов и кода пока нет. Буду терпеть когда выложат
https://i2vedit.github.io/index.html
Даже если всё окажется не так радужно, то благодаря изменений в цвете можно создать стабильную видео маску и пустить в animatediff inpainting
К сожалению весов и кода пока нет. Буду терпеть когда выложат
https://i2vedit.github.io/index.html
> Ага, а вдруг он (компьютер) выгорит от перенапряга
Значит туда и дорога, хули.
> мое почтение целеустремленности научить модель.
Ее палкой вообще бить надо чтобы хоть что-то нормально запоминала.
> главное - на подблюренных пикчах в датасете более конкретно прокапитонить
Так ты опиши задник, правильно тебе говорят. А тут дополнительно заставляешь модель запоминать что задников несуществует или там одно мыло, захочешь что-то сложное запромтить и досвидули.

Это я. Зашел поблагодарить анона/анонов, которые тогда мне помогали делать лору под пони. Тогда сразу не отписал, потом всё руки не доходили что-то. В итоге получилось все более менее неплохо. Думаю я выжал практически всё что можно было сделать при моём датасете (60). На 48 эпохе генерирует неплохо, эталонные изображение вообще практически идеально, есть проблемы с деталями, думаю эт оследствие того что лора впитала не только персонажа, но и стиль. Может если сделать лору под 1.5, а потом нагенерить в других стилях, чтобы добить датасет, получилось бы лучше. Также, в отличие от 1.5, судя по гридам, лора стабильно работает только в очень узком диапазоне эпох
ии силе лоры. Вообще, пони конечно кривые спецефичные. Короче буду заниматься дальше как время подосвободится. Присмотрел пару авторов, думаю сделать лору под них, благо тут уже проблем с датасетом не будет. Но что там сейас по мете? Я так понял народ ждет сд3 и новых поней? Читал пост автора поней, он и сам сидит и ждет новый сд, там какие-то траблы с правилами комерческого использования. Говорит мол что чет стабилити мудаковато общаются.
ии силе лоры. Вообще, пони конечно кривые спецефичные. Короче буду заниматься дальше как время подосвободится. Присмотрел пару авторов, думаю сделать лору под них, благо тут уже проблем с датасетом не будет. Но что там сейас по мете? Я так понял народ ждет сд3 и новых поней? Читал пост автора поней, он и сам сидит и ждет новый сд, там какие-то траблы с правилами комерческого использования. Говорит мол что чет стабилити мудаковато общаются.
> Я так понял народ ждет сд3 и новых поней?
SD3 мертворождённая и пони не будет на ней. Следующая пони на XL, а потом на пиксарте или какой-то другой китайской сетке.
>Я так понял народ ждет сд3 и новых поней?
На не будет, автор нытик-омежка, который никак не может прочитать 3 абзаца на 2-х страницах сайта SAI и ссытся от того, "что ему непонятно как лицензироваться"
Rundiffusion - залицензировались и пилят файнтюн для сервиса
Леонардо - залиуензировалось
Мелкие онлыйн-помойки уже добавили в свои списки SD3
Pirate diffusion просто положили хуй на лицензирование (как неожиданнно) и высрали анонс что к 1 июля ждите pirate edition
А это ничтожество третий день бегает между реддитом, цивитаем и форчаном, ноя что ему непонятно и он так не может.
Сегодня аж на японский свой высер перевел на циве.
> никак не может прочитать 3 абзаца
А что там читать? Там не опенсорс лицензия, а коммерческую ему никто не продаст из принципа.
> непонятно
Там лицензирование в виде "звоните нам". А на том конце провода ссутся с пони.
> бегает
Не понятно только почему у SD-шизиков так пригорает от того факта, что он не будет дальше тренить на SD. Наоборот же хорошо, не будем больше жрать SAI-кал с поломанными архитектурами. Автор гуя для кохи уже сказал что SD3 кал для тренировки и надо просто считать это говно провалом как SD 2.0, а лицензия вообще большинство тюнов отсеит сразу. У кохи, кста, уже готова поддержка Сигмы.
Забавнее всего наблюдать как SAI изворачивается и опять пытается напиздеть что-то. Сегодня у них уже официальная методичка подъехала, что SD3-Medium это ранняя бета и вы не так поняли, хотя только вчера Ликон рассказывал что это лучшая модель и у вас руки кривые. А ещё вскрылось со слов SAI опять же что медиум тренили с нуля по-быстрому за два последних месяца с дико порезанным датасетом и в сырости виноваты нетерпеливые юзеры, а оригинальная 8В через API вообще другая модель и её даже не собирались релизить.
>Забавнее всего наблюдать как SAI изворачивается и опять пытается напиздеть что-то. Сегодня у них уже официальная методичка подъехала, что SD3-Medium это ранняя бета и вы не так поняли, хотя только вчера Ликон рассказывал что это лучшая модель и у вас руки кривые. А ещё вскрылось со слов SAI опять же что медиум тренили с нуля по-быстрому за два последних месяца с дико порезанным датасетом и в сырости виноваты нетерпеливые юзеры, а оригинальная 8В через API вообще другая модель и её даже не собирались релизить.
Уже новую завезли - все охуенно, все так и должно быть. Но если что - это CLIP, оттуда Рутковские лезут.
Это Эмад высрал в Х (пикрил):
https://x.com/EMostaque/status/1801686921967436056
https://twitter.com/EMostaque/status/1571634871084236801
>Там лицензирование в виде "звоните нам". А на том конце провода ссутся с пони.
Нихуя, 20$ и иди пили, пока у тебя 1 лям пользователей в месяц онлайн не набрерется или годовой оборот не дойдет до 1 млн $, вот тогда ЗВОНИТЕ ЭМАДУ.
>а коммерческую ему никто не продаст из принципа.
С хуяли не продаст? Ну ебаный в рот, у него пару косарей на Cоула местного нет? Все на пропердоливание score_9 ушло?
>Не понятно только почему у SD-шизиков так пригорает от того факта, что он не будет дальше тренить на SD
Потому что, посмотри на циву, 95% моделей\лор\пикч - 2-2.5D мультипликация. Аудитория у него такая, что поделать.
>Автор гуя для кохи уже сказал что SD3 кал для тренировки и надо просто считать это говно провалом как SD 2.0, а лицензия вообще большинство тюнов отсеит сразу. У кохи, кста, уже готова поддержка Сигмы.
Вот это отлично, альтернатива и конкуренция - всегда заебись для нас.
>что SD3 кал для тренировки
лол это потому что опубликованные в диффузерсах скрипты нихуя не работают, там в ишшуисах пожар выше крыши.
НО! вот тут : https://github.com/bghira/SimpleTuner/ обещает мало того что Лоры для сд3, но и главное : файтюн модели на 3090.
Хуй с ними с лорами, а вот представь, если каждый начнет себе пилить свою XL? Это же заебись.
Лично по мне, я понями никогда не пользовался, они мне нахуй не уперлись, к СД3 уже придрочился по сеттингу и промтам, если людей не генерить лол. Но,уверен, анатомия, позы - это первое что начнут тюнить.
В результате получится охуенный сетап: что-то в XL, что-то в Сигме, что-то в Далли, что-то в CД3 делать. Это же просто инструменты, и то что их несколько - это хорошо.
Меня чисто нытье понибати и его паствы бесит, везде блядь они, везде.
Подскажите пожалуйста как проверить орфографические ошибки в датасете (captions).
тхт открывай хромом, если правописание англ включено подсветит или сам себе в телегу кидай в чем сомневаешься, там тоже работает.
Ты руками что ли бил?
>тхт открывай хромом
Там ~100 штук, я охуею каждый файл проверять.
>Ты руками что ли бил?
Да. Clip interrogator разочаровал.
Ок, я нашел способ. Нужно просто в DatasetHelpers подсчитать частоту тэгов и скопировать этот текст в программу с проверкой правописания, например хром как подсказал анон.

> Эмад
А он тут при чём? Он уже почти никакого отношения к происходящему не имеет. Официальная позиция представителей SAI пикрилейтед, они переобуваются каждый день.
> 20$ и иди пили
Там ограничение на количество генераций с модели, лол. Ещё раз - лицензия не опенсорс, ты хоть усрись, но будешь башлять SAI даже без коммерческого использования. Под такими условиями никто не будет делать крупные файнтюны.
> это потому что опубликованные в диффузерсах скрипты нихуя не работают
Тот чел пояснял что концепты на SD3 тренируются очень плохо, даже очень простые, поэтому тренить лоры как с XL на 50 пиках не выйдет.
Напомните, что там надо скопировать, чтоб все настройки с одной копии ВебУЯ на другую перенести.
config.json, ui-config.json

как можно загрузить картинку в уже открытый и настроенный автоматик1111 в инпеинт?
я хочу следующее:
- нажимаю кнопку в блендере
- вьюпорт захватывается, сохраняется в папку
- картинка автоматически подхватывается и загружается в img2img inpaint
- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
меня интересует выделенное жирным, остальное я знаю как сделать
я хочу следующее:
- нажимаю кнопку в блендере
- вьюпорт захватывается, сохраняется в папку
- картинка автоматически подхватывается и загружается в img2img inpaint
- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
меня интересует выделенное жирным, остальное я знаю как сделать
Тебе так трудно картинку вручную вставить? Тут либо костылять либо костылять. В первом случае править автоматик, чтобы он сканил твою папку и подгружал файл, во втором случае какой-нибудь грисманки, чтобы он делал то же самое, но со стороны браузера (Насколько я помню там такие апи есть, а если нет - то только автоматик). Если я правильно понял что ты хочешь.

одну картинку вставить несложно. но в процессе работы это делается сотни, тысячи раз, зачастую буквально на 1 мазок кистью нужно инпеинт сделать. и на эту дрочь уходит половина времени

короче, все этапы кроме самого нужного реализовал
узнал про API: https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/API
и даже получилось послать корректный POST запрос и сгенерить картиночку прямо из блендера, получив результат в виде пнгшки закодированной в респонсе. да вот мне не нужен бэкэнд автоматика. мне нужен фронтенд на соседнем монике, чтобы я в нем менял модели, лоры, перерисовывал маски, перегенерировал всё по сто раз и т.д. там быстрее всего работается
есть в том API что-то для управления фронтендом? менять вкладки в интерфейсе, загружать картинки и т.д. или таких вещей в принципе не бывает в API?
Сделать на комфи с захватом картинки из блендера - нет?
как этот процесс будет происходить в случае с комфи?
>- нажимаю кнопку в блендере
>- вьюпорт захватывается, сохраняется в папку
>- картинка автоматически подхватывается и загружается в img2img inpaint
>- я делаю инпеинт с нужным мне результатом и сохраняю пик на диск
Специальные ноды.
Будет окно для захвата картинки из блендера, из него картинка идет в ноду, в ней можно нарисовать или загрузить маску. Потом все вместе с маской идет в сэмплер, выхлоп сохраняется через ноду в нужное место
>- нажимаю кнопку в блендере, получаю на экране текстуру-стенсиль
А это руками
Хотя есть просто отдельные ноды для текстурированния
буквально - три слова в строке поиска ютуба:
blender+statble+diffusion
На любой вкус:
- и с Автоматиком и с Комфи
- и для созлания анимации
- и через хитропридуманные костыли
- и на русском и на английском
спасибо, попробую
Текстурируеш?

так баловаюсь
Не погано. Вот бы можно было позу с картинки в риг переносить.

Запрашиваю тактическую помощь, как это говно даунгрейднуть?
Я хз почему, но это вылечилось удалением файла ui-config, запуском каломатика, который успешно запустился, после чего я закинул обратно файл и всё заработало без ошибок. ЧЗХ с каломатиком?
я через junction вытащил модели наружу, и теперь перенакатываю вебуй начисто вместо апгрейда
когда у приложения в одной папке насрано файлами json, yaml, toml, понимаешь, что лучше перестраховаться
./models
./embeddings
./extensions/sd-webui-controlnet/annotator/downloads
только с outputs не прокатило, не подгружает картинки из junction
наверное ПО теперь ошибочно считает, что зависимость стоит правильной версии
Объясните нубу, как правильно обновлять что-то с гита, если он выдает такой текст:
>Please commit your changes or stash them before you switch branches.
Хочу на дев-ветку автоматика переключиться, и он мне список файлов выдает, в которых я сам явно ничего не менял.
Если reset hard сделать - вроде бы полетят и все настройки, а этого бы не хотелось.
>Please commit your changes or stash them before you switch branches.
Хочу на дев-ветку автоматика переключиться, и он мне список файлов выдает, в которых я сам явно ничего не менял.
Если reset hard сделать - вроде бы полетят и все настройки, а этого бы не хотелось.
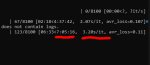
Оно так и должно медленно идти? Треню sdxl лору на 4060ti 16gb.
Да. СДХЛ лоры тренируются намного медленнее сравнительно с полторашками.
Плюс у тебя еще и шагов овердохрена, столько обычно не нужно.
Я в целом только вкатываюсь в тренировку лор. Такое количество шагов подобрал исходя из гайда в шапке.
От 8000 до 12000 для стилей. чек
От 400 до 600 итераций на эпоху. У меня всего 81 изображение. Как раз, чтобы было 8к шагов, сделал 10 повторений на 10 эпох на 81 картинку.
>От 8000 до 12000 для стилей.
Ужас какой. Где там вообще такое написано? Чем можно тренировать настолько долго?
Я когда своими старыми настройками тренировал - у меня стиль начинал ухватываться уже на 800-м шаге, и на 1600 закреплялся полностью.
Ну там буквально на строчку ниже другое значение для XL написано, но вообще странная скорость, ты сколько батч поставил? Есть чекпоинтинг?
> Я когда своими старыми настройками тренировал - у меня стиль начинал ухватываться уже на 800-м шаге, и на 1600 закреплялся полностью.
А что именно тренил и с каким батчем? Те цифры были выведены эксперементальным путём для бородатого наи, учитывая остальные дампенеры и не учитывая деления на батч
Батч сайз 1, потому что все 16гб заняты, если верить афтербернеру.
>чекпоинтинг
Что?
> Батч сайз 1, потому что все 16гб заняты, если верить афтербернеру.
У тебя полезло всё в системную память, ХЛ без --gradient_checkpointing жрёт слишком много, а более простой вариант кстати расписан https://rentry.org/2chAI_hard_LoRA_guide#easy-way-xl с готовыми конфигами




Получаются абсолютно рандомные, взорванные генерации, но иногда получается что-то похожее на космические пейзажи. Позже попробую еще, возможно сперва набью руку на полторашке.
Всем спасибо.
Всем спасибо.
Это с тем конфигом так? Если да, то интересно глянуть на датасет и пример генерации с метадатой, чтобы понять причину
Я думаю надо так же сделать. у меня гуй отказывается реагировать если F5 не нажать после запуска. Видимо пора.
Стили и концепты в основном.
Адам, косинус, батч 2. Конфиг как раз времен "бородатого НАИ", работает на поне практически без изменений, только памяти больше жрет, и в три раза дольше тренирует.
https://stackoverflow.com/questions/4157189/how-to-git-pull-while-ignoring-local-changes
Просто забекапь настройки.
В целом да, чекни чтобы видеокарта была загружена а не простаивала.
> От 8000 до 12000 для стилей. чек
Это борщ, только если делаешь большую лору на десяток стилей, и шаги в отрыве от батчсайза малоинформативны.
Пони? Она настолько убита гейпами что с наскоку подобное не сделать.

Нет, тот конфиг не ставил. Датасет пикрил, там все картинки такие.
кэтбокс даже с впном не открывается
Не просто пони, а аутизм.
Наверное дело в том, что я через анимешный микс поней делаю лору с датасетом из реалистичных картинок. При этом пытаюсь научить концепту, который поням вообще не известен.
> Не просто пони, а аутизм.
Еще хуже, оно более переломанное с точки зрения модели, работать в диапазоне задач это не мешает, но тренить на таком - плохое решение.
Капшнинг у них какой? Обычная XL или анимушные модели не-пони без проблем такому обучатся если будут нормально протеганы.
А какие остальные настройки? Просто я точно помню что в 512 разрешении там и не нужно было столько тренить
> Нет, тот конфиг не ставил. Датасет пикрил, там все картинки такие.
Лол, ты конечно нашёл высокохудожественный чекпоинт чтобы такое тренить, пони кумерский в первую очередь, так ты ещё и на аутизме тренил, что вдвойне плохо, для такого может какой то анимейджин бы лучше подошёл или даже вообще что нибудь дедовское
> кэтбокс даже с впном не открывается
Ну любой другой сайт/способ передать картинку с метадатой
> Не просто пони, а аутизм.
Тренить с аутизма стоит только в одном единственном случае, когда юзаешь только его и хочешь во что бы то ни стало вжарить какой нибудь стилевый датасет и чтобы он проявлялся вообще всегда с первого взгляда, на каждом промпте, перебивая даже саму модель. Но это такое себе занятие, которое сломает анатомию аутизма практически гарантированно
Посмотри в диспетчере задач, если памяти жрёт больше чем выделенная память видимокарты, то часть уходит в оперативку и получаешь дикие тормоза - тогда уменьшай батчсайз или включай градиент чекпоинт.
>Просто забекапь настройки.
Что-нибудь забуду, и потом придется заново настраивать...
Хотелось бы, чтоб он этот ресет как пулл делал - т.е. игнорируя те файлы, которые трогать не надо с точки зрения обновлений.
>А какие остальные настройки?
mixed_precision = "fp16"
max_data_loader_n_workers = 1
persistent_data_loader_workers = true
max_token_length = 225
prior_loss_weight = 1.0
sdxl = true
xformers = true
cache_latents = true
max_train_epochs = 8
gradient_checkpointing = true
resolution = [ 1024, 1024,]
batch_size = 2
network_dim = 32
network_alpha = 16.0
min_timestep = 0
max_timestep = 1000
optimizer_type = "AdamW8bit"
lr_scheduler = "cosine"
learning_rate = 0.0002
max_grad_norm = 1.0
unet_lr = 0.0002
text_encoder_lr = 0.0001
enable_bucket = true
min_bucket_reso = 512
max_bucket_reso = 2048
bucket_reso_steps = 64
bucket_no_upscale = true
weight_decay = "0.1"
betas = "0.9,0.99"
Как-то так, вроде ничего важного не забыл.
Разве что эпохи вместо шагов указаны, но я там все настраиваю так, чтоб полная тренировка на 2000-2400 шагов получалась. Хотя могу взять и 4, и 6 эпоху вместо финальной 8-й, если вижу, что там получше получилось.
Датасеты обычно крупные, от 100 картинок.
> sdxl = true
Да не, я про конфиг для наи имел ввиду, для хл то база, сам ведь почти таким же пользуюсь
> наи
Кто вообще полторахой пользуется в 2024?
А, ну так он такой же, за исключением этого флага и размера бакетов/картинок. Там либо 512, либо 768, если память позволяет.
Я ж говорил, что конфиг времен НАИ, в нем только это и поменялось, считай.
кто-то тренил в каггле sdxl лоры?
такое ощущение что те кто хочет обучать лоры уже имеют карточки для этого, а нищукам просто похуй и используют онлайн слоп-генераторы
такое ощущение что те кто хочет обучать лоры уже имеют карточки для этого, а нищукам просто похуй и используют онлайн слоп-генераторы
Хватит срать этим по тредам. Иди трейни на Civitai с мультиакка
Как в AD внедрить контролнет?
Список моделей не открывается
Не использовать AD для таких задач, а переключиться на и2и во вкладку ипнэинта.
>ипнэинт
Зачем ручками работать там, где можно автоматизировать?
По крайней мере, я хочу протестить эту тему
Затем, что творчество.
пиздец, вроде как 32гб vram, но есть нюанс, то что эти 32гб разделены на две видяхи
пытался обучать дефолтным скриптом кохи, и нихуя не получалось выше 1 батч сайза поставить с градиентом
видимо скрипт хуево параллелит нагрузку или модель sdxl большая слишком для таких задач
пытался обучать дефолтным скриптом кохи, и нихуя не получалось выше 1 батч сайза поставить с градиентом
видимо скрипт хуево параллелит нагрузку или модель sdxl большая слишком для таких задач
чел, ты видюхи хоть выбирал или просто на похуй запустил
>выбирал
я просто скрипт кохи запустил и все
с --multi-gpu эта хуйня выдаёт оом
без него не выдаёт, но при этом хавает память с 2 видях
> но есть нюанс
Это неебаться какой нюанс, в теоретической теории можно обойтись FSDP но на консумерских видюхах с кохой это, считай без шансов.
В гайдах в шапке есть настройки для лоры, они позволяют ужаться до 12гб для минимального обучения без серьезных импактов на качество. В 16 гигов будет влезать некоторый батч сайз. Вторая видюха будет просто ускорять обучение в 2 раза (если подключена по нормальной шине, меньше если всратая) но никак не прибавит тебе возможностей по памяти.
Можешь накатить dev ветку и использовать fused оптимайзер, адам8бит в них отсутствует, так что единственный полезный будет adafactor. Это прилично снизит требования к врам. Можешь обмазаться дипспидом, если не будет компилироваться - пропиши в энвах пути до либ новидео, но для него потребуется дохуя рам.
Если хочешь больше эффективный батчсайз - накати pr на добавление фьюзед оптимайзеров, там дополнительно есть функция, которая позволяет делать накопление градиента на фьюзед оптимайзерах и не тратить приличный кусок врам на это.
> видимо скрипт хуево параллелит нагрузку
Он отлично ее параллелит, объединение врам в сделку не входит никогда, если только явно не раскидывать части модели по разным девайсам.
Да, мультигпу и все это актуально для прыщей или wsl, удачи собрать все нужные либы под окнами.
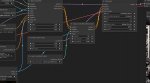
Выгнали с sd треда сюда, с таким вопросом
Юзаю такие настройки. Ставлю end_percent на canny повыше и получается мазня, а щас не соответствует референсу. Что крутить?
Юзаю такие настройки. Ставлю end_percent на canny повыше и получается мазня, а щас не соответствует референсу. Что крутить?
Делай плавное понижение веса и гони до самого конца, а не 0.4. И судя по пикрилу ты шиз, тебе только таблетки помогут. Особенно если ты для аниме canny используешь.
>Делай плавное понижение веса и гони до самого конца, а не 0.4.
Попробую
>И судя по пикрилу ты шиз, тебе только таблетки помогут. Особенно если ты для аниме canny используешь.
Это негативный промпт, как давно где-то скопировал так и юзаю, надо будет поправить. Использую для фотореала. Раньше использовал zoe depth, но оно тоже попердоливает цвета если большие веса и end_percent дать
> 1016
> sdxl
Уже с этим проебався, кратности 64 следует придерживаться.
> Ставлю end_percent на canny повыше и получается мазня
Препроцессор как работает и в каком разрешении? Канни в принципе не стоит держать на силе 1 с полном циклом, ибо она слишком агрессивная и "пиксель перфект". Используй лайн арт или аналоги, их можешь сколько угодно жарить. Как тебе сказали используй спадающую силу под конец. Проверь совместима ли вообще эта модель с чекпоинтом что используешь.
Ну и за трешанину в промте двачую.

Сап обновил кохины скрипты, там теперь торч 2.1.2. Где брать норм куду, чтобы ему вбросить? Старый вброс не подходит по именам файлов. Че он ее сам не вбрасывает, заебал, с каждым апдейтом скорость падает на 20%
Какие именно скрипты, какую куду, какой вброс? Распиши подробнее, ничего не понятно.
>с outputs не прокатило
В настройках есть папки куда сейвить выхлопы
Раньше советовалось скачивать свежий cudnn (11 или 12, не помню от чего зависит) и вбрасывать dll-ки в site-packages/torch-x.x.x/lib/, с заменой файлов. Это ускоряло мне тренинг с 1.7-1.8 до 2+ итсов.
Щас торч другой версии и куда там тоже другая, и это выдает на 1.6 итсов. Прошлый свежий cudnn туда не подходит. Вот я и спрашиваю где его правильно брать, ну или послать все нах и сделать даунгрейд.
Кто может посоветовать, тот и так в курсе этой ебатории.
Это было оче давно и уже неправда. Делаешь
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
> pip install xformers==0.0.23.post1
Потом реквайрменты и довольно урчишь. Про ту херь забудь как страшный сон.
Попробую, спасибо. /cu121 это как раз для 12 куды сборка?
> # CUDA 12.1

Нашел в итоге сам подходящие куднны. Проверил разные варианты на 300 итерациях (первый тест был холодный, но не думаю что здесь это важно).
Как видим, ку118 + свежая куда все еще тащит. Разница небольшая, но это из-за тупой реализации счетчика и малого колва шагов на тест. Через 1000 шагов оно сойдется к большему значению.
Если седня на ку118+8.9.7 выдаст около 2 итса, то меня устроит. Если не выдаст, то отпишу в тред.
Для ясности
1: оригинал, свежая копия кохи без модификаций, на 3000 шагах дает 1.6х итсов
2: как 1 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 11.x
3: как 1 + рецепт анона
4: как 3 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x
Если кто будет существующий инсталл править:
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
Это работает само по себе
> pip install xformers==0.0.23.post1
Это работает только после pip uninstall xfromers, иначе пип считает, что +cu188 и так стоит, и не ставит версию без +cu118, которая на самом деле +cu121, но опубликованная без суффикса. ебанутее нет создания чем питонист блять
Как видим, ку118 + свежая куда все еще тащит. Разница небольшая, но это из-за тупой реализации счетчика и малого колва шагов на тест. Через 1000 шагов оно сойдется к большему значению.
Если седня на ку118+8.9.7 выдаст около 2 итса, то меня устроит. Если не выдаст, то отпишу в тред.
Для ясности
1: оригинал, свежая копия кохи без модификаций, на 3000 шагах дает 1.6х итсов
2: как 1 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 11.x
3: как 1 + рецепт анона
4: как 3 + в site-packages/torch/lib закинуты дллки отсюда: https://developer.nvidia.com/rdp/cudnn-archive -> Download cuDNN v8.9.7 (December 5th, 2023), for CUDA 12.x
Если кто будет существующий инсталл править:
> pip install torch==2.1.2 torchvision==0.16.2 torchaudio==2.1.2 --index-url https://download.pytorch.org/whl/cu121
Это работает само по себе
> pip install xformers==0.0.23.post1
Это работает только после pip uninstall xfromers, иначе пип считает, что +cu188 и так стоит, и не ставит версию без +cu118, которая на самом деле +cu121, но опубликованная без суффикса. ебанутее нет создания чем питонист блять
У тебя там GTX 1660 что ли?
а что должно быть?
у меня
>[1:54:30<50:43, 3.30s/it, avr_loss=0.0372]
на двух теслах т4 для sdxl лоры
мимо нищук на каггле
Итсы зависят от параметров тренинга, у разных анонов они разные. Важны только относительные значения.
>xfromers, иначе пип считает, что +cu188 и так стоит
>xformers, иначе пип считает, что +cu118 и так стоит
самофикс
Что за видеокарта и система?
Просто ставишь версию для куды121 и забываешь, твой скрин это подтверждает. В фоне браузер чуть поскроль и будет аналогичного масштаба эффект.
> Это работает само по себе
Не всегда и не везде.
> Это работает только после pip uninstall xfromers
Чивоблять? У тебя там васян-обертка поверх кохи, или ставишь сразу рекварментсы в надежде что правильный торч скачается?
Нужно делать именно в таком порядке на свежем вэнве, а не ломать совместимость или качать неправильные версии на уже засранном.
> ебанутее нет создания чем питонист блять
Сам создаешь проблемы, а богоподобный пип всеравно их исправляет, подсовывая все совместимое.

Винда, 4070ти.
>Чивоблять? У тебя там васян-обертка поверх кохи, или ставишь сразу рекварментсы в надежде что правильный торч скачается?
Дефолтная коха после setup.bat (пункты install + download cuda).
>Нужно делать именно в таком порядке на свежем вэнве, а не ломать совместимость или качать неправильные версии на уже засранном.
Я знаю что делаю тащемта. Итсы берутся из торча и куды. Что там вокруг валяется и каких версий - никакого значения для процесса тренинга не имеет, т.к. это просто клей для овермайнд методов, зашитых в торчекуде.
По итогу заменены 4 пакета, торч, вижен, аудио, хформерсы.
>богоподобный пип всеравно их исправляет
Да, а потом "WARNING xfromers not loaded 118 vs 121". А если ставишь без версии, то качает торч 2.3.0.
Че ты так трясешься с этого, фанбой что-ли? У питонистов вечно проблемы на ровном месте. Я щас добью вопрос и поделюсь результатом и рецептом, какие бы ни были. Не на риторике, а на фактах.
---
Вариант cu118+свежий куднн на 3к шагов показал 1.89 (пик), против 1.6 стока.
Я щас проверю полный трен cu121 стока, ок, мне не жалко.
> Дефолтная коха после setup.bat
Это уже гуйня, дефолтная коха - https://github.com/kohya-ss/sd-scripts
В принципе с ней можешь просто нажать сетап, оно все само сделает. А готовый вэнв шатать с кучей взаимных зависимостей такое себе.
> Итсы берутся из торча и куды.
Расскажи это кохаку с поломанными версиями ликориса. А так в новом торче оно заведомо все быстрое.
> Я знаю что делаю тащемта
> Да, а потом "WARNING xfromers not loaded 118 vs 121"
Ну вот видишь. Важен порядок установки и конкретный синтаксис с указанными версиями, а не свободная интерпретация. По дефолту качается ластовая с 2.3 торчем, да, но коха на ней не сработает. Под 2.1.2 именно версия 0.0.23.post1 если полистать репу то там написано.
> Че ты так трясешься с этого
Чел, пока что трясешься только ты, бездумно тыкаешься а потом жалуешься, пытаясь повторять историческую херь, на которую даже те кто ее пропагандировал уже забили. И судя по надписям у тебя там мешанина из версий, которая такой эффект и дает.
Я протестил все варианты, только в этот раз включил версию драйвера. Твой, с абсолютно новым венвом, тоже протетсил.
В итоге:
- Без вброса свежих дллок cu118 тренит на 1.6-1.7 итсах
- Ты прав, в полном тренинге cu121 со вбросом и без вброса (1.86) несильно отличается от cu118+вброс (1.89). Видимо в cu121 просто по дефолту свежий куднн.
- При драйвере 551.52 cu121 достиг 1.94 итсов, а cu118 - 1.97 итсов
Новый драйвер я сдуру поставил, забыв что он нерфит тренинг.
Вывод:
- Ставишь 551.52
- Вбрасываешь дллки если сидишь на cu118 (ссылка выше)
- Сидеть на cu121 большого смысла нет
>Это уже гуйня
Да похер, пикрил
>Важен порядок установки и конкретный синтаксис с указанными
Ладно.жпг
>бездумно тыкаешься а потом жалуешься, пытаясь повторять историческую херь, на которую даже те кто ее пропагандировал уже забили
Если посмотреть выше, то я вроде как пришел к успеху. Правда я сам от него же и ушел, поставив ебучий новый драйвер и не записав в прошлый раз ссылку на хороший куднн. Зато обновил тесты, хуле, может кому пригодится.
>Уже с этим проебався, кратности 64 следует придерживаться.
Тут мимо, я InstantID еще предварительно использую, а там если 1024 ставить лютые ватермарки хуярит, поэтому только 1016
>Ну и за трешанину в промте двачую.
Промт уже поправил
Возможно, автор гуйни что-то там навертел в своем автоустановщике что он по дефолту ставит старые версии, от того и такой эффект. Это же у него раньше была опция прямо в инсталляторе "подкинуть библиотеки".
В твоем случае отличия в скорости могут быть еще из-за разных xformers, которые под шинду скомпилированы через одно место.
Собранный торч самодостаточен, и новая версия уже заведомо содержит последние библиотеки, то что надо было что-то подкидывать - костыль старых времен.
> - Сидеть на cu121 большого смысла нет
Наоборот, он дает полный перфоманс без странных манипуляций. Бонусом, если захочешь накатить новые пры и подобное - все будет работать без внезапных приколов. Разница что ты углядел - едва измерима, время записи на диск больше эффекта даст.
А здесь не ставит потому что края изображения идут по бороде, странно что оно без артефактов как-то декодится, возможно помогает тайлинг. Ну если работает то и норм.
Какова может быть причина пережарки? После 31 эпоха начало появляться мыло+контраст. По-спекулируйте пожалуйста. Настройки (civitai трейнер):
"resolution": 768,
"targetSteps": 2475,
"numRepeats": 5,
"maxTrainEpochs": 45,
"trainBatchSize": 6,
"unetLR": 0.00001,
"textEncoderLR": 0.00001,
"lrScheduler": "linear",
"networkDim": 128,
"networkAlpha": 64,
"noiseOffset": 0.1,
"lrSchedulerNumCycles": 3
"minSnrGamma": 5,
"optimizerType": "AdamW8Bit",
"flipAugmentation": false,
"loraType": "lora",
"clipSkip": 1,
"enableBucket": true,
"keepTokens": 0,
"shuffleCaption": true,
> "maxTrainEpochs": 45,
Пиздос.
> "numRepeats": 5,
> "maxTrainEpochs": 45,
Оче много если только там не датасет из десятка пикч. Но такой сам по себе может являться проблемой если не прибегать ко всякой черной магии.
> "unetLR": 0.00001,
> "textEncoderLR": 0.00001,
Но лр при этом относительно низкий для остальных параметров. Показывай в чем выражается твоя пережарка.



Там на самом деле 49 эпохов. 66 пикч. Tренировал стиль. Хотя вижу уже даже на 31 эпохе уже волосы слипаются и странных шарп на краях.
1 без лоры
2 31 эпох
3 49 эпох
Что получить пытаешься вообще? Показывай датасет, что в нем и как сделаны капшны.
Наблюдаемое может быть следствием и слишком низкого лр, и хуевого датасета, и много чего еще, но это не пережарка в классическом понимании.
Выстави нормальный LR, например раз в 5-10 больше для таких параметров, эпохи можешь смело в 2-3 раза снижать, шедулер можешь оставить, но лучше косинус воткнуть.
>Наблюдаемое может быть следствием и слишком низкого лр,
Спасибо, не знал что даже это может иметь негативные последствия.
Видео рил была предыдущая попытка, тот же датасет, те же настройки кроме noise offset, его я поднял с 0.1 до 0.12, но другой чекпоинт. Уже на 7 эпохе какая-то пережарка пошла по этому я и боялся выставлять высокий LR.
>не пережарка в классическом понимании
Не дожарка?
>эпохи можешь смело в 2-3 раза снижать
Да выставил максимальные эпохи чтобы базз за просто так не уходил.
>Показывай датасет
Не хочу диванонится, т.к. если лора получится хорошей то залью её на циви.
капшн1:
orange eyes, looking at viewer, fixing her glasses, big breasts, cleavage, black leather skirt, red lips, red tail, red choker, red gloves, from above, secretary outfit, red background, red light, photorealistic, realistic, имя художника на англюсике, glasses, solo, sfw
капшн2:
ada wong from resident evil, solo, nude, asian, nipples, breasts, brown eyes, belly button, pubes, red bikini, black choker, bob haircut, black hair, standing, holding guns, thick thighs, looking at viewer, low angle, indoors, realistic, by имя художника на англюсике, dominant
> кроме noise offset
Вот его лучше вообще убери. Если в чекпоинте уже есть, или применяется другая лора с ним - поломается капитально.
Ты только на циве семплинг в процессе обучения смотрел? То же самое только с хайрезфиксом хотябы попробуй, и гридом по разным эпохам как раз. Артефакты такие могут и из датасета лезть, и из-за косячного vae при кодировке, множество причин в общем. Еще, как вариант, снизить лр текстового энкодера не более трети-половины от лр юнета.
> ыставил максимальные эпохи чтобы базз за просто так не уходил
Тут просто нюанс в том как работает косинус, на максимальных эпохах он будет медленно снижаться и долго жарить в начале. Косинус с рестартами тогда уже поставь или лучше annealing чтобы один период приходился на сколько эпох.
Капшны нормальные если просто по тексту оценивать.
я правильно понимаю что альфа в параметрах обучения это тупо константный множитель и a=r/2 это тупо каргокульт?
если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
> если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
сам спросил, сам потестил по-разному - не станет, но отличия от исходной всё меняют генерацию даже на одном шаге с околонулевым лр
> альфа в параметрах обучения это тупо константный множитель и a=r/2 это тупо каргокульт?
В целом да
> если дотрейнить лору с альфой 1 одним шажком с параметрами альфа например 32 - она станет эквивалентом лоры которая обучалась с самого начала на альфа=32?
Абсолютно нет. Но если тренить с кратно большим лр - будет нечто похожее, офк там оптимайзер свои коррективы вносит и конечный результат может отличаться.
> меняют генерацию
Даже слабое шатание весов лоры может заметно менять воспроизведение сидов. В интеграле работа при этом не изменится.
>Вот его лучше вообще убери. Если в чекпоинте уже есть, или применяется другая лора с ним - поломается капитально.
Ясно.
>Ты только на циве семплинг в процессе обучения смотрел?
Циви использую потому что больше нигде нет бесплатного тренинга лоры.
>То же самое только с хайрезфиксом хотябы попробуй, и гридом по разным эпохам как раз.
Ты имеешь ввиду сейчас посмотреть есть ли артефакты при генерации i2i?
>Еще, как вариант, снизить лр текстового энкодера не более трети-половины от лр юнета.
Попробую.
>annealing
Такого в циви нет.
Есть фото референс. Задача сгенерить свое по этому референсу с максимальной детализацией. Что использовать?
да буквально что угодно, можешь тупо имг ту имг, можешь инпейнтом, можешь контролнет канни/глубины/карты нормалей, можешь референс, можешь лору натрейнить, если ебало очень кривое - можешь даже лору со свёрткой
Ананасы, насколько актуален этот https://rentry.org/2chAI_hard_LoRA_guide
гайд? И как мне тренировать персонажа: хочу лору по девке из непопулярной вн, и поэтому всё, что у меня есть —это ~20 цг из игры, все с голландским кадром или другими персонажами (если замазывать в фотошопе, картину обрезать ровно по героиню, и убирать даже пересекающую её чужую руку?), одна нормальная цг в полнорост, куча спрайтов (все от одного художника, разница в стиле есть, но слабая), и десяток-другой скетчей и ещё несколько фанартов, где визуальное совпадение в деталях отсутствует/у персонажа неканоничная одежда/одежды нет.
гайд? И как мне тренировать персонажа: хочу лору по девке из непопулярной вн, и поэтому всё, что у меня есть —это ~20 цг из игры, все с голландским кадром или другими персонажами (если замазывать в фотошопе, картину обрезать ровно по героиню, и убирать даже пересекающую её чужую руку?), одна нормальная цг в полнорост, куча спрайтов (все от одного художника, разница в стиле есть, но слабая), и десяток-другой скетчей и ещё несколько фанартов, где визуальное совпадение в деталях отсутствует/у персонажа неканоничная одежда/одежды нет.
>куча спрайтов
Куча скетчей, самофикс
Хотя и спрайты (с разными лицами) тоже есть, их не стоит пихать ведь, а то он научится на ~100 эмоциях при одной позе ещё
Нужно расширить фотографию. Закидываю в img2img + outpainting mk2 скрипт или через inpaint и сверху, дорисовывает нормально, снизу, где сцена сложнее лепит хуйню вообще не в тему к основному изображению. Накидайте правильных настроек
Лучше в датасете оставить лишь эту твою тян, убрав остальное в фш, либо сделав маски и тренировать с ними.
Когда артов мало, можно даже сделать примерно так - сделать хоть какую то лору и нагенерить в разных стилях, поправив генерации, чтобы чар был консистентным, тем самым пополнив датасет и тренить снова.
Ну и ещё, когда все арты в одном стиле, то можно сначала натренить этот стиль, вмерджить в модель, или использовать соответствующий флаг в сд-скриптс, вторая тренировка с таким стилем поверх уже его не будет впитывать, но будет впитывать уникальные характеристики чара, так например с койкацу можно сделать тем же, надеюсь мысль понятна. Правда лучше набрать для такого стиля картинок не связанных с чаром, чтобы вторая тренировка проходила правильно.
Фоны тоже убирать?
Накропай чара откуда можно, убрав лишнее и отзеркаль пикчи для их размножения. Апскейли дат ганом чтобы превышали 1 мегапиксель. Хорошо протегай чара, как его имя, так и одежду. Совсем упарываться фанатизмом с очисткой не стоит, как и убирать фона. Дутчангл должен быть в капшнах есть он есть на пикче.
Это разбавляешь исходными артами где есть и окружение, и другие персонажи и прочее, главное чтобы все было хорошо описано. Из этого уже может получиться нормальный датасет для лоры на чара. Если уж совсем плохо будет - нагенери с имеющейся лорой, черрипикни удачные и добавь их в датасет.
Можешь попробовать, так чар может в итоге точнее натренится с маскед лоссом
Что такое маскед лосс и маски вообще?
В гайде как раз и расписано с примером
Первый вопрос:
Имеет ли смысл обучать ЛОРы для всех версий SD сразу?
Я надолго отвратился от SDXL, когда все говорили, что оттуда выкинули очень много картинок на обучении. Но я открываю сайт civitai и вижу как много лор выходит именно (и только) под SDXL.
А ведь уже какой SD 3 появился.
---------------------------------------
Второй вопрос: собираю новый комп. Хочу взять 4090 именно для обучения лор/генерации картинок. Так как 24 GB VRAM. Иначе бы взял 4070/4080 (где 16).
В принципе, могу себе позволить переплатить, если это имеет смысл. Имеет ли смысл переплачивать разницу между 4080 и 4090?
> Имеет ли смысл переплачивать разницу между 4080 и 4090?
Имеет

Пытаюсь повторить эту фотку (по позе) но выходит полная хуета, нейронка никак не может свести ноги вместе
Набрал такие теги
1 girl, legs up, holding legs, straightened legs, legs together, hamstrings, calves, thighs, hips, socks, feets, ass, short hair, red hair
Набрал такие теги
1 girl, legs up, holding legs, straightened legs, legs together, hamstrings, calves, thighs, hips, socks, feets, ass, short hair, red hair
> Имеет ли смысл обучать ЛОРы для всех версий SD сразу?
Странные вопросы задаешь, по что планируешь юзать под то и обучай.
> Имеет ли смысл переплачивать разницу между 4080 и 4090?
Абсолютно. Можешь подождать пол годика анонса блеквеллов.
Насколько существенно чтобы именно за носок держалась?
> анонса
не, я комп этим летом хочу.
>Насколько существенно чтобы именно за носок держалас
В целом, главное чтобы были подняты вверх ноги, показывая заднюю поверхность бедра и чтобы девушка именно сидела, а не лежала
Наверное самое реалистичное - это тренить Лора. Ну или ждать SD6, или когда там нейронки начнут такие сложные позы понимать
Тогда покупай, единственная альтернатива для ии - риг на бу 3090 что такое себе.
Анимублядское - легко.
Гоняю 4080. Для SDXL вполне хватает, но для чего-то большего уже маловато 16GB. Если есть возможность - бери 4090, не пожалеешь, оно того стоит.
Раз легко то не сложно будет рассказать как именно
Автоматик запилил textual inversion для sd3
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16164
Интересно, если sai ломали анатомию и цензурили с помощью просто подмены значения токенов, типа naked=barby, то уже этого будет достаточно для обхода
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/16164
Интересно, если sai ломали анатомию и цензурили с помощью просто подмены значения токенов, типа naked=barby, то уже этого будет достаточно для обхода
> sai ломали анатомию и цензурили с помощью просто подмены значения токенов
Нет, там датасет был подчищеный.
И чего оно, вкратце, сможет делать? Для нуба, если?
Оно позволяет создать токен для концепта, который уже есть в моделей, но для которого нет слов, чтобы описать
КАК ЖЕ ЗАЕБАЛО ЭТО "Code: coming soon". Вот это периодически проверяю, и код все ещё coming soon ДА КАКОГО ХРЕНА? Уже больше месяца. У вас этот код вообще был? В чем вообще причина, и вообще смысл делать доклад о том, чего еще нет, и хрен когда появится
Главное в начале накидать смайликов 🤯🎉🚀, запостить по всем каналам, а потом нихера не делать
Главное в начале накидать смайликов 🤯🎉🚀, запостить по всем каналам, а потом нихера не делать

Месяц назад - это я увидел этот проект. Сама новость вышла вообще 26 мая
Берешь что-нибудь хорошее на основе pony и без задней мысли промтишь. Некоторая сложность будет с тем чтобы спина была высоко, но возможно.
Фуллы чего, видосов этого мемного инфоциганина который всех заебал?
Если ты про пресеты - там включены все оптимизации из возможных и используется батчсайз 1, что априори херь, и скорость ниже плинтуса. Главное - full bf16, fused backward pass изначально 8-битного оптимайзера, или еще дипспид на 3м стейдже. То же самое можно сделать и на кохе.
Если серьезно, какой-то более менее реальный кейс файнтюна сдхл можно оформить на 24 гигах: без те очень шустро и с нормальным батчсайзом, fused adafactor или даже адамв8 и fused groups, с те - уже дипспид на втором стейдже. Его добавление ощутимо замедляет все, хз как там братишки получали даже ускорение, но на всех машинах только негативный эффект, где гпу простаивает часть времени пока проц превозмогает, обсчитывая оптимайзер.
А пак регулярок где скочять? Меня больше это интересует.
Ссылка на патреон, для них достаточно просто залогиниться, бесплатные.
Но там просто рандом генерации на голой XL примитивных промтов типа "портрет мужчины/женщины", можешь их и сам наделать. Эффект от их использования тоже под вопросом честно говоря.
>Ссылка на патреон, для них достаточно просто залогиниться, бесплатные.
У меня бабки требует
Лол, опять этот турецкий мл специалист, 15 картинок с будкой и регами это конечно сильно, ну и "найс 6гб лора брух" на выходе бтв.
Интересно, в 1трейнере есть такой же баг как в сд-скриптс, когда после определённого количества картинок в датасете выделяется на несколько гигов больше врам
Сделай моделью просто, с которой тренить будешь, это старый метод, если уж хочется ебаться с таким, лучше что то поновее по типу DPO
>Сделай моделью просто, с которой тренить будешь
лень пиздос
>если уж хочется ебаться с таким, лучше что то поновее по типу DPO
типа наделать регулярок с моделью под дпо? или че ты имел в виду
Сгенерируй сам на ванильной sdxl или той модели что хочешь обучать, это буквально то же самое что там. Желательно смочь в разнообразие, охват и отсутствие явных байасов, но учитывай что на регулярки тоже расходуются итерации и это замедлит тренировку. Хз правда чего хочешь достигнуть, положительного эффекта от них в реальных применениях крайне мало.
> найс 6гб лора брух
90+% всего что представлено на циве, увы.
> после определённого количества картинок в датасете выделяется на несколько гигов больше врам
Что за баг такой? Разницы при десятке пикч и миллионах не замечено, только метадату дольше грузит.
> типа наделать регулярок с моделью под дпо? или че ты имел в виду
Я имел ввиду что регулярки во многих старых гайдах, которые были актуальны в долоровую эпоху предлагают делать их моделью, с которой ты тренируешь, с промптом, который в кэпшене конкретной пикчи, и даже с таким же сидом, конкретно про dpo датасет не подскажу, сам не знаю и не пробовал, вот только недавно у кохьи какой то коммит появился https://github.com/kohya-ss/sd-scripts/pull/1427 а так в целом всем похуй было, как обычно
В какой то из версий был, может и до сих пор есть. Попробуй лору с 25, 50, 100, 150 картинками без gradient checkpointing с хл, понями если точно, с 25 выделялось что то по типу 16, со 150 уже 20-22 или как то так. До сих пор ещё есть баг с повторами на нескольких папках, он вообще рандомно возникает и некоторые лоры на мультихудожников поэтому не работают с некоторыми из них, несмотря на то что они были в датасете и единственное что сработает, ну заместо копания хули там не так, просто скопировать столько раз в одну папку всё, сколько нужно, лол
> Хз правда чего хочешь достигнуть
Да мне надо уместить файнтюн полноценный в 12 гигов просто, т.к. на одном форумчике челик ликорисы крутые делает. Примерный гайд это
а) чем больше датасет тем лучше
б) файнтюнится модель на этом датасете с настроечками которые заботливо выложены
в) экстрагируется ликорис кохъёй
Мдэ, странная херня. Кстати с градиент чекпоинтингом полное потребление наступает не сразу а спустя несколько шагов, если смотреть по мониторингу. Хз с чем это связано.
Можешь рассказать что именно хочешь сделать?
> а) чем больше датасет тем лучше
Depends, если какой-то стиль то сильно много не имеет смысла. Да и даже если на масштабную тренировку замахиваться, качество стоит выше количества.
> с настроечками которые заботливо выложены
Можешь скинуть что за настройки?
> в) экстрагируется ликорис кохъёй
Извлеченный ликорис всегда слабее модели. Нормально получиться только если вжаривать юнет большим лром на малом батчсайзе, тогда из пережаренного чекпоинта экстракт будет как-то работать. Также, извлеченная лора/ликорис часто дает косяки типа поломок пальцев и т.д., тогда как при тренировке сразу лоры со спадающим лром огрехов будет меньше.
Это просто наблюдения, от того чтобы попробовать не отговариваю. И доставь, пожалуйста, сорс где так делаются ликорисы.
Чтобы влезло в 12 гигов, тебе нужны следующие параметры:
> --train_text_encoder --lr_scheduler="constant_with_warmup" --optimizer_type="adafactor" --train_batch_size=1 --xformers --full_fp16 --mixed_precision="fp16" --optimizer_args "scale_parameter=False" "relative_step=False" "warmup_init=False" --fused_backward_pass
Работает в dev ветке кохи. Аккселерейт настраивать на mixed precision: None. Можешь еще сменить fp16 на bf16, но ни к чему хорошему это не приведет. Также освободи всю видеопамять и по возможности переключись на встройку, там оно вообще по верхней границе пойдет.
Анон выше прав, с будкой могут быть другие результаты и это экстрактить, особенно в низкие ранги, будет геморно, если не вжаривать до упора, натренить в отдельную лору что то простое обычно лучше
>Можешь скинуть что за настройки?
Ну вот под сдохлю, попозже скину под пдхл
https://rentry.co/q2qcfhp9
Булджадь, ну там реально во-первых треш с бф16 для файнтюна (ничего страшного если скачаны тру фп32 веса, точно не будет работать на пони) и ультрапрожарка с оче оче большим лром, который как-то пригоден для бс 70+.
Если сделано чисто под дальнейший экстракт - может быть, но когерентность и мелкие вещи типа пальцев скорее всего умрут.
Спасибо, скинь результаты если попробуешь.
Вот под пдхл https://rentry.co/u335sqsz
Подскажите чем можно сделать раскадровку видео. Чтоб можно было потянуть кадры для обучения лоры.
ffmpeg
спасибо
Под автоматик есть какое-нибудь расширение или способ чтоб на первых шагах генерации делать отдаление зума? Или как оно правильно называется, хз, а то заебало, все пикчи как будто обрезанные выходят. Расширение готовой картинки - не то, надо чтобы именно на этапе композиции работало.
какие основные профиты использования controlnet вместе с img2img?
Зависит от контролнета.
Для меня самый полезный - использовать для работы за пределами когерентного разрешения модели.
Апскейл сделать, или просто и2и на высоких разрешениях погонять ради интересных вариантов с высокой детализацией.
Такой вопрос.. Какое количество картинок является потолком для лоры?
Пока 300 картинок для 128dim выглядит норм, но можно ли положить 1000 скажем в 256dim?
Пока 300 картинок для 128dim выглядит норм, но можно ли положить 1000 скажем в 256dim?
можно сколько угодно картинок уместить в любую размерность
Получается если я решу тонны паков косплейщиц залить в датасет, то увеличится только время тренировки, а лора будет норм?
Можно повышать датасет с любым рангом, там нет прямой зависимости. Однако, если хочешь добавлять много разнообразных данных - нужен будет большой дим.
> то увеличится только время тренировки
По-хорошему потребуется еще поменять гиперпараметры чтобы не получить оверфит. Насчет норм - зависит от того что хочешь получить, многие стили на малом количестве пикч получаются лучше чем если тащить все, качество преобладает над количеством. Если хочешь добавить чего-то нового то лучше когда много, но качество и правильный теггинг всеравно первичны.
> лора будет норм?
если соответсвенно уменьшишь лр/альфу, отфильтруешь, навалишь капшонов, забалансишь..
Ну с достаточным весом и запеканием понятно.
Я хочу сделать лору на косплейные фотосеты, для максимальной похожести. Пока я пришел к тому, что просто возьму лучшие косплеи на персов, которые мне интересны и все запихаю в одну лору с разметкой тегами.
Даа, с этим нет проблем, меня волновало именно количество.
А какая базовая модель? Если у тебя там весьма большой и хороший датасет то можешь попробовать и файнтюном, может получиться лучше. Но с лорой тоже будет ок, только лучше тогда с конв слоями ликорис или из новых какой-нибудь вариант.
Я хочу попробовать пони и пониреализм. На них тонны лор с аниме персами и они понимают, как из них сделать фото. Но им недостаточно фотореализма.
Обычные фотореализм SDXL начинает корежить от аниме лор. Может быть стоит попробовать и на них сделать, но пока я не представляю, как это будет выглядеть.
> большой и хороший датасет
Незнаю насколько он хороший, но большим он точно будет. Пока собираю и думаю как это все тренировать.
>файнтюном
Это выглядит сложнее и намного дольше. Я хотел попробовать тренить лору на цивитаи, но если не прокатит, то придется локально.
> Незнаю насколько он хороший
В твоем случае нужны разнообразные девушки, фото, рендеры, игорь, и прочее что хочешь, можно все вместе. Главное чтобы они были разными - расы, телосложение, одежда/отсутствие, позы, близко-далеко. Картинки должны быть качественными без лишних артефактов, мусора, с разрешением от мегапикселя. Если хочешь задники - нужно хотябы10% пикч (больше - лучше) с хорошими четкими фонами а не мылом. И главное - хороший теггинг буру-подобным форматом или натуртекстом где объекты будут описываться понятными именами схожими с тегами а не графоманией.
> Это выглядит сложнее и намного дольше.
Да, потому сначала лучше большой лорой.
спасибо
Есть лора имплементирующая постоянную Фейгенбаума на веса при инференсе? Или как это можно обучить, типа как обучают лоры CM акселераторы.

Какие теги надо использовать при обучении пони лоры из e621 или буровские?
буровские наверное. они же считаются каноном для 2d art
Бамп
Вопрос к знающим. На цивите полно авторов, которые раньше выкладывали модели 1,5 и после выхода SDXL они как-то переносили стиль своих моделей с полторахи на сдохлю. Вопрос: как это можно сделать? Заранее благодарю.
Ретрейном/файнтюном с существующего датасета.
Тренировкой лоры и мерджем с моделью.
Т.е. никакой "магии" с переносом кусков модели между архитектурами там не было.
Ну да, твой ответ верен, но только в отношении тренированных моделей.
Я забыл уточнить, что вопрос касался так называемых сборок-солянок мерджей, у которых за этот счет был свой стиль, при этом никаких датасетов и файнтюнов не было.
Как в этом случае делается перенос стиля? У меня кроме как варианта "сделать 1к артов на полторахе, сделать из него датасет, натренить на нем сдохлю" идей больше нет.
Там поверх всей солянки может быть одна стилелора, вот и ответ, некоторые их и с 1.5 тренили. Или на новой базе появились аналоги компонентов их мерджей, потому получилось сделать нечто похожее.
Скинешь примеров моделей что нашел?
Да, как анон выше написал, скорее всего появлялись полноценные файнтюн-модели от тех же авторов, и потом их уже миксовали между собой, как с полторахой и было.
Нагенерить картинок, сделать лору, и потом вжарить ее в модель - тоже можно.
А иногда генерить самому вообще не обязательно, можно с цивита накачать картинок, ибо там их тысячи, потом только отбирай качественные, да тренируй.
Да я скорее хотел стиль своей модели перетащить, примеры чужих моделей вспоминать будет тяжело. Я просто подметил, что некоторые авторы мерджей типа выпускали сдохлю версию своего стиля, и я хотел понять как они это сделали. Похоже что единственный вариант, это просто тупая генерация артов на полторахе и файнтюн сдохли.


>Топ 5 лора для SDXL и Pony.
>Датасет - квадраты.
Bucketing переоценен?
>Датасет - квадраты.
Bucketing переоценен?
> стиль своей модели перетащить
Правильно - разобрать его на составляющие и собрать в новой архитекруты. Весьма вероятно что там что-то дефолтное.
Рабочая страта - трень лору по генерациям, может получиться всрато и с кучей побочек, может нормально.
Запрыгни на поезд хайпа одним из первых и набери стату пока не поймут что кормишь говном с лопаты. Потом обезьяны будут колоться но жрать кактус, не смея помыслить что популярное может быть шмурдяком.
Вообще, это даже выглядит ужасно.
С-с-сука, так вот почему у меня по краям картинки артефакты с размазыванием иногда проявляются!
Поубивал бы!

Анончики, помогите нубу. Я посмотрел на ютубе "Coding Stable Diffusion from scratch in PyTorch" где чувак за 5 часов набирает код stable diffusion, с объяснением всех команд.
https://www.youtube.com/watch?v=ZBKpAp_6TGI
Я скачал его код, запускаю на своем Lenovo Legion 5 с карточкой 3060. Там есть возможность запустить на CPU или GPU. На CPU картинка генерируется около 8 минут, на GPU почему-то даже дольше, 11 минут. Как так, в чем может быть дело?
Запускаю Jupyter Notebook из VS Code из WSL. Поначалу оно не работало на GPU (крашилось) - применил фикс, описанный вот тут: https://discuss.pytorch.org/t/jupyter-kernel-dies-when-using-cuda-wsl-2-ubuntu/169546
Первый скрин - загрузка проца при генерации на CPU, второй скрин - загрузка GPU при генерации на GPU.
Собственно вопрос, как вообще работа на GPU может быть медленнее, чем на CPU? GPU же должен быть быстрее. Что я делаю не так?
Превышаешь доступную быструю память, вон в shared полезло

Кто-нибудь знает, можно ли как-то расширить ADetailer больше чем на два слота? искал в настройках, не нашел. Буду благодарен.

В настройках, очевидно. У меня по умолчанию 4 было, хз почему у тебя две вкладки.

Господа программисты, помогите пожалуйста, какой тут используется семплер-шедуллер?
https://huggingface.co/spaces/mrfakename/OpenDalleV1.1-GPU-Demo
https://huggingface.co/spaces/mrfakename/OpenDalleV1.1-GPU-Demo
я тут столкнулся с тем, что консоль срет ошибкой, но всё работает. Я хз, на что это влияет, может тут есть знающие джентльмены? Буду благодарен.
У тебя какое-то расширение промпт фильтр отвалилось, созданное человеком, никогда не пользующимся img2img. Ничего страшного
Благодарю.
вопрос не тривиальный, но, в SD3 есть модели со встроенным T5 а есть без, так вот вопрос, можно ли с модели со встроенным этот т5 отрезать чтобы места меньше занимала, или он туда наглухо вшивается?
Короче, мне нужно обучить персонажа.
У меня есть аниме из 90х. Там дикий grain.
У меня есть около 30-40 артов разных размеров. Арты — лучше в качестве чем скрины.
В принципе, я уже сваял две версии. Обе хороши. Но я сейчас сижу-размышляю над улучшением.
Я задал следующую плашку текста в чатгпт и клод:
-----------------------
Программа kohya_ss. Я хочу обучить свою LoRA. Оригинальный базовый checkpoint является SDXL.
Обязательно ли приводить все изображения в одно соотношение, например все в 300x200 + 600x400?
Обязательно ли приводить все изображения ровно в один resolution?
-----------------------
ИИ не смогли ответить единообразно, мнутся, по-соевому отвечают хуйню.
Допустим я делаю enable buckets, дальше что? У меня одна иллюстрация 1488x914, другая иллюстрация 600x1378 и так далее. То есть иллюстрации — разные по резолюшенам.
Допустим, 1000x500, там персонаж на всю картинку. Голова персонажа наверху, она не попадает в средний квадрат 500x500, можно так оставить?
У меня есть аниме из 90х. Там дикий grain.
У меня есть около 30-40 артов разных размеров. Арты — лучше в качестве чем скрины.
В принципе, я уже сваял две версии. Обе хороши. Но я сейчас сижу-размышляю над улучшением.
Я задал следующую плашку текста в чатгпт и клод:
-----------------------
Программа kohya_ss. Я хочу обучить свою LoRA. Оригинальный базовый checkpoint является SDXL.
Обязательно ли приводить все изображения в одно соотношение, например все в 300x200 + 600x400?
Обязательно ли приводить все изображения ровно в один resolution?
-----------------------
ИИ не смогли ответить единообразно, мнутся, по-соевому отвечают хуйню.
Допустим я делаю enable buckets, дальше что? У меня одна иллюстрация 1488x914, другая иллюстрация 600x1378 и так далее. То есть иллюстрации — разные по резолюшенам.
Допустим, 1000x500, там персонаж на всю картинку. Голова персонажа наверху, она не попадает в средний квадрат 500x500, можно так оставить?
> базовый checkpoint является SDXL
Ванильная sdxl?
> Обязательно ли приводить все изображения в одно соотношение, например все в 300x200 + 600x400?
Нет и разрешение должно быть не менее 1 мегапикселя а не эти шакалы. Кохьевский трейнер сам ресайзнет и по бакетам схожие соотношения сторон раскидает если стоит.
> enable buckets
> Голова персонажа наверху, она не попадает в средний квадрат 500x500, можно так оставить?
Не занимайся ерундой, подобным образом кропать с больших артов куски нужно немного чаще чем никогда.

> Ванильная sdxl?
Аутизм пони. Но я возможно буду использовать просто Пони на следующих тестах.
> не менее 1 мегапикселя
да это пример
> схожие соотношения сторон
а если у меня вообще от перса только арты и нет аниме. например, это рейму хакурей игнорируем, что у неё есть аниме, и у неё только арты?
В том смысле, что у артов разные соотношения сторон и разные разрешения.
> просто Пони
Только ванули, не стоит тренить на шизомиксах.
> от перса только арты и нет аниме
Что значит только арты, рисунки в реалистичном стиле? Тогда весьма вероятен байас на стиль, но может будет не так плохо.
> В том смысле, что у артов разные соотношения сторон и разные разрешения.
Вут? Бакеты для того и созданы чтобы сгруппировать пикчи по размерам и обеспечить тренировку без ошибок с разными соотношениями сторон.
> Что значит только арты
только арты из данбурятника. нет скриншотов аниме
> с разными соотношениями сторон
ты не понял. Смотри. Допустим у меня картинки
- 480x500
- 482x500
- 484x500
- 486x500
- 488x500
- 490x500
- 492x500
и так далее ну то есть все композиции (пермутации) разрешений — почти уникальны. и бакетов будет сотня
> нет скриншотов аниме
Нужны только в случае отсутствия достаточного количества пикч, или если хочешь скринкап-стиль.
> бакетов будет сотня
Не будет, там в параметрах задается шаг бакетов, по дефолту для XL 64пикселя. В данном случае их всех сначала ресайзнет по короткой стороне до 448 а потом по длинной кропнет (если говорить упрощенно) и они подойдут в единый.
> кропнет
а если там какаие-то полезные вещи на этом кончике?
я правильно понимаю, что enable buckets включать стоит?
и тогда ещё два вопроса:
1. допустим, я по приколу сделаю картинки двух разрешений 1024x512 и 512x1024. И с одним тегом персонажа "sado taro" обучу совершенно разных персов. Допустим, в 1024x512 будет лежать Микаса Аккерман, а в 512x1024 — Рейму Хакурей. Чему обучится лора? в лендскейпе будет рисовать микасу, а в портрете - рейму? или во всех картинках будет реймо-микаса?
2. остальным не ответил, мне ответил :з спасибо :з почему?


кто-нибудь для flux тренит лоры? есть ли ещё какие фичи для ускорения на 12 гб видеопамяти? 100 шагов = 15 минут, на 4070ti. из-за того что видеопамяти немного не хватает, приходится юзать split-режим, гоняющий две половины модели из VRAM в системную память и обратно




>а если там какаие-то полезные вещи на этом кончике?
Значит, не такие уж они полезные.
>я правильно понимаю, что enable buckets включать стоит?
Да. Апскейл встроенный только не включай.
>И с одним тегом персонажа "sado taro" обучу совершенно разных персов.
И сломаешь нейронке мозги. Не надо так.
>У меня есть аниме из 90х. Там дикий grain.
Ну так сделай апскейл каким-нибудь DATом, который грейн и артефакты заглаживает.
Пикрилы - пример. Не помню только, чем точно апскейлил.
Либо Nomos8kDAT, либо SSDIRDAT, либо Real_SSDIR_DAT_GAN.
Что-то из последних двух, скорее, номос так не заглаживает.
Покрути третью картинку в экстре, пока четвертая не получится.
Мимоанон.
Раскопал метаданные.
Таки это был 4xReal_SSDIR_DAT_GAN
На вторую пару делал х2 апскейл и потом обратно в ФШ уменьшал до исходного.
Первую пару просто апскейлил, ибо исходники шибко мелкие.
> а если там какаие-то полезные вещи на этом кончике?
Тогда особенный, раз на твоих пикчах 1% (о котором в среднем рапортует кохя) самой периферийной площади пикчи являются важными и информативными.
> enable buckets
К нему дополнительно можно --min_bucket_reso=256 --max_bucket_reso=3072 --bucket_no_upscale, последний особенно важен. Шаг лучше не трогать, пусть стоит по умолчанию.
> с одним тегом персонажа "sado taro"
Не стоит этой шизой заниматься, пикчи должны быть нормально протеганы.
> в лендскейпе будет рисовать микасу, а в портрете - рейму?
Чисто в теории, подобный байас действительно можно получить. Но для нейронки будет важнее позиция в кадре (близко-далеко и подобное) и содерживое, т.к. соотношение сторон как-то реализуется только в том что именно на пикче (наличие задников по бокам и т.п.).
> на 12 гб видеопамяти
К большому сожалению только смена карты. Это уже невероятнейшая груда костылей, тренить на карте, которая даже для инфиренса не пригодна в стоке. Можно базу в 4 бита или каком-нибудь кванте (пока нет в тренерах но могут сделать позже), но будет еще больше импакт на качество.
> сделай апскейл каким-нибудь DATом
Двачую
> а если там какаие-то полезные вещи на этом кончике?
у кохи есть параметр, который позволяет показать в картинках че он там накропал(заодно понять как идут бакеты) если у тебя большой датасет можешь закинуть только твои особенные пикчи и почекать
если действительно обрежет, можешь зарезать другую сторону до победного))
ну или добавить фотошопной заливкой или аутпаинтом
> у кохи есть параметр, который позволяет показать в картинках че он там накропал
кхммммм! фича пипец полезная. спс.
В гуи kohya_ss не сможешь вспомнить где это включается?
в гуи есть строчка для доп параметров, сам параметр уже не помню как называется, вроде 'test' чего-то там
Сап.
Помогите дауну.
Седел я, значит, генерировал свою хуиту, никому не мешал, но у меня при апскейле выдало, наверно платиновую хуиту:
OutOfMemoryError: CUDA out of memory. Tried to allocate 14.55 GiB. GPU 0 has a total capacty of 16.00 GiB of which 0 bytes is free. Of the allocated memory 21.90 GiB is allocated by PyTorch, and 291.51 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation.
При том, буквально ничего не менял. вообще нихуя.
Что это может быть хотя-бы примерно?
Помогите дауну.
Седел я, значит, генерировал свою хуиту, никому не мешал, но у меня при апскейле выдало, наверно платиновую хуиту:
OutOfMemoryError: CUDA out of memory. Tried to allocate 14.55 GiB. GPU 0 has a total capacty of 16.00 GiB of which 0 bytes is free. Of the allocated memory 21.90 GiB is allocated by PyTorch, and 291.51 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation.
При том, буквально ничего не менял. вообще нихуя.
Что это может быть хотя-бы примерно?
Седел. Ёбаный стыд.
Сидел.
fix.
Модель из памяти какая-нибудь не выгрузилась. Контролнет тот же. Или стим чутка отожрал, и не хватило.
Если на пустом месте - просто делай перезапуск консоли вебуя не закрывая вкладку браузера и жми кнопку еще раз.
Не помогло.
Самое хуёвое - я буквально ничего не менял, блядь. Вообще.
После того как дрова обновил - один проход сделал. И всё.
Опять в ошибку.
Может так видеокарта дохнет?
Кажется помогло. Это идиотизм, но помогло удаления части моделей. Я не знаю почему.
Просто работает.
Отбой. Информация не достоверна. Продолжаю поиск.
В целом я нащупал слона в комнате.
Как работает тренировка с Masked loss, промт должен быть для области внутри маски или как для обычной картинки?


Нужно ли указывать размер груди для SFW пикч (соски не видны) ? Для тренировки стиля.
Экспериментов с таким не видел, но где то в доках у кохьи читал что надо тегать как для обычной
Да

Я правильно понимаю что настройки обучения судя по графику неправильные?
У тебя есть маска, которая показывает по каким областям будет считаться лосс, промт нужно писать для них.
Нет, тут нет ничего криминального. Но диагностика по вот такому лоссу никакой инфы не даст, кроме случаев когда там совсем поломка.



есть один промт, который генерирует стилизованные ландшафты
- слабый и ненадежный. выдает 10% нужного, 90% брака
- дубовый. никак не реагирует на слова для детализации, увеличение весов токенам просто увеличивает процент брака
как закрепить нужный стиль, и при этом сделать его более податливым?
- слабый и ненадежный. выдает 10% нужного, 90% брака
- дубовый. никак не реагирует на слова для детализации, увеличение весов токенам просто увеличивает процент брака
как закрепить нужный стиль, и при этом сделать его более податливым?
Чёт хз куда писать, сюда вроде более-менее подходяще:
Не вижу треда про цифровые аватары. Как сгенерить, чтобы на ютабах своим ебалом не светить?
Не вижу треда про цифровые аватары. Как сгенерить, чтобы на ютабах своим ебалом не светить?
генерировать лив2д или 3д силами sd и подобного никак, максимум можно выйти в слайдшоу пнг по маске бесплатных моделек, в теории можно научить ллмку описательному языку под 3д, типо как в знаменитом высере "моченые заставили нейронку сделать двигатель и вышла рабочая нех" и потом натянуть текстурку
Насобирай датасет, в котором у тебя будет набор подобных ланшафтов и он будет качественно и подробно описан, обучи на этом лору.
Частично двачую предыдущего оратора, можешь нагенерировать ассетов которые потом натянешь на бесплатные готовые l2d.
Делитесь, сколько вам дал TensorRT
Генеришь пикчу, натягиваешь на анимационную модель из нужного софта.
Сюда же все выражения лица и альты.
Чисто нейронкой такое не сделать, по факту ты только труд рисоваки способен ей заменить, и то придется самому руками дохера допиливать, если качества хочется.
Зачем при генерации определенного человека добавляют кучу изображений класса людей в тренировку?
Аноны, такой вопрос, в схеме img2img у сдхл, куда пихается имага источник?
У Unet есть два входа - промптовый и имаговый, те что на схеме в оп-посте справа и сверху соответственно.
Условно говоря она как-то конкатится с latent space или подается вместо промпта?
У Unet есть два входа - промптовый и имаговый, те что на схеме в оп-посте справа и сверху соответственно.
Условно говоря она как-то конкатится с latent space или подается вместо промпта?
> Аноны, такой вопрос, в схеме img2img у сдхл, куда пихается имага источник?
Это старая схема ещё с релиза хл модели, никто в итоге рефайнером не пользуется, это что то вроде хуёвого способа придумать хайрезфикс вторым проходом, а картинка/шум по определенному алгоритму пихается в самом начале, если ты про генерацию
> Условно говоря она как-то конкатится с latent space или подается вместо промпта?
Схема в этом плане не очень подробная, но насколько я помню это соединение происходит в cross-attention слоях, чтобы загайдить юнет что рисовать
Аноны, подскажите по обучению лор, пожалуйста. Гайды я прочел и вроде как понял, но есть нюанс. Мне нужно скопировать определенный стиль с далле, мне нравится, как он имитирует рисунки углем. В сд я подобных стилей не нашел (может, искал плохо), мало того, что подменяет уголь карандашом, так еще и рисует на уровне третьеклассницы. Поэтому я решил натренировать лору на этих самых угольных набросках из далле - нагенерировать разнообразных годных картинок под свои запросы и использовать их как основу.
Как мне тегировать датасет? Те же принципы сохраняются, то есть сначала ключ, а потом обычное описание того, что на картинке?
Как мне тегировать датасет? Те же принципы сохраняются, то есть сначала ключ, а потом обычное описание того, что на картинке?
Можно и без ключа. Тоже будет работать.
Можно вместо ключа использовать какой-нибудь близкий токен стиля из оригинальной модели, типа monochrome или sketch, и его дотренировать.
Главное чтоб на картинке все остальное протэгано было.
Кто шарит в ML архитектурах? Проверьте тейки https://www.reddit.com/r/StableDiffusion/comments/1fl46sk/omnigen_a_stunning_new_research_paper_and/
В пейпере Omnigen говорят, будто их модель - это всего лишь LLM, с подключенным (натрейненным для нее) VAE от SDXL. А на реддите заявляют, что это mind-blowing прорыв! Оказывается, каждая LLM уже обладает визуальной памятью, - у нее лишь нет "органов чувств" чтобы воспроизвести изображение!
В пейпере Omnigen говорят, будто их модель - это всего лишь LLM, с подключенным (натрейненным для нее) VAE от SDXL. А на реддите заявляют, что это mind-blowing прорыв! Оказывается, каждая LLM уже обладает визуальной памятью, - у нее лишь нет "органов чувств" чтобы воспроизвести изображение!
Конечно нет, это просто неверная интерпретация. Посмотри на устройство диффузионных моделей и сравни их с ллм, посмотри размер латента и посчитай количество токенов чтобы получить то же самое, да еще не сбиться во время генерации.
Но ллм и прочее там точно применяется, также как в новых "умных" моделях используется т5 для создания кондишнов в комбинации с клипами. Возможно добавили более эффективные механизмы взаимодействия и петлю обратной связи, но там точно не тот топорный подход.


Открыл для себя SDCPP, наслаждаюсь генерацией в один клик по батнику. Ну и доставляет что лишних 20 ГБ под питон не нужны, и оперативы жрет в районе 3 ГБ. Но вскрылся подводный камень, оно не умеет гонять препроцессоры контролнета на вводные картинки, кроме встроенного canny. Есть какой-то достать прогнанную через препроцессор картинку для скармливания контролнету без установки тяжеловесного гуя? В онлайне например? Ебучий дезго умеет в контролнет, но картинку после препроцессора показывать отказывается.
Еще вопрос, а аналога SDCPP для кохи нет? Лишние пара гигов для обучения лор или дримбуса очень сгодились бы.
Еще вопрос, а аналога SDCPP для кохи нет? Лишние пара гигов для обучения лор или дримбуса очень сгодились бы.
Почитал оригинальную статью, а там всё в лучших традициях современного ML.
Большая часть это обзор cherry-picked результатов. Техническое описание занимает одну страницу из 23 и сопровождается одной картинкой.
Так вот VAE они как раз не обучали, он был заморожен во время обучения. Обучали трансформер, который "инициализировали весами Phi-3". Никаких деталей касательно этого трансформера нет. Сделали "другой механизм внимания".
Что именно они сделали, понять нет никакой возможности, но от исходной llm там мало что осталось.
Ну камон, 20 гб в 2к24 - это же мелочь
Я уже 5 месяцев жду код по красивой статье, который позволяет в первом кадре видео сделать изменения, и он распространит их на все видео. Очень красивая статья, жаль что код и веса coming soon с мая по сей день
А подскажете как вникнуть в обучение лор/дримбута (XL/Pony/Flux) не на уровне нубика? Сразу уточню: научные статьи я не потяну, только видосики, да картинки, но с технической информацией и программированием справлюсь легко. Половина топа цивита это челики, срущие сотнями-тысячами лора знаменитостей, которые без их лора и то лучше промптятся чем с ней. Я не знаю, их в глаза ебут, походу. Так вот, гайды попадаются в основном как раз от таких челиков. А есть гайды от адекватных людей с опытом? Пожалуйста, подкиньте. Чтобы досконально понять влияние количества эпох/шагов, как лучше трекать прогресс, и про всякие другие непопулярные штуки вроде masked loss. Сам я только пару раз дримбуты ещё во времена 1.5 делал, и не очень успешные лора. Теперь появился свой комп, осваиваю заново.
В шапке 2 гайда, в них основные вещи наглядно разжеваны.
> влияние количества эпох/шагов
Рассматривать это все нужно в совокупности в с лром, шедулером, оптимайзером, параметрами тренировки, датасетом и т.д. И вопрос твой уровня "объясните мне как работает процессор компьютера", для нормального объяснения нужно в общем понимать/ощущать как тренятся модели и диффузия в частности.
Но для начала - хватит типичных примеров, тут все дело в том что тренировка лоры "на персонажа"/концепт или нечто подобное - это натягивание совы на глобус, которое переворачивает весь юнет и те для того чтобы он делал нужное. Это не обязательно плохо, просто здесь свои явления, иногда идущие вразрез с рекомендациями для полноценного обучения, потому просто посмотри типичную практику и попробуй варьировать сам. Иногда "неправильные" подходы дают желаемый результат, есть вообще экстримальные техники типа вжарки на 1-2 пикчах с частичной заморозкой и т.п.
Или задавай конкретные вопросы.
> штуки вроде masked loss
Берешь и юзаешь, лосс будет считаться только с того что в маске, что не затронуто - "игнорируется".
Поясните 2 вопроса. В дримбусе нужно вводить концепт - а если мне нужно тренировать чекпоинт целиком, не добавляя конецпты, просто оставить поле концепта пустым, и тогда влияет на все сразу? Что дают регуляризационные изображения, кто-то пишет что они вообще не нужны.
Есть ли какая-нибудь модель типа полторахи, базовым размером, скажем 256 на 256, чтобы на ней можно было практиковаться в лорах, крупномасштабным файнтюне на 3060 не особо страдая?
Смотрю, есть какие-то дистилляты с 1.4, порезанные размером не сильно, но они на 512, мне столько не надо. И какие вообще особенности обучения дистиллятов, особенно тех, что на мало шагов обучены? Их надо обучать полноценными шагами, и они будет постепенно терять способность работать в мало шагов?
Смотрю, есть какие-то дистилляты с 1.4, порезанные размером не сильно, но они на 512, мне столько не надо. И какие вообще особенности обучения дистиллятов, особенно тех, что на мало шагов обучены? Их надо обучать полноценными шагами, и они будет постепенно терять способность работать в мало шагов?
На 256 только sd 1.1 и то она в 512 может лучше
> если мне нужно тренировать чекпоинт целиком, не добавляя конецпты, просто оставить поле концепта пустым
Используй скрипт для файнтюна. Если будешь тренить без концептов то это оно и получится.
> они вообще не нужны
Это так, исключения почти невероятны.
Используй обычную полтораху. Там проблема не столько в разрешении сколько в размере модели, а что-то меньше SD 1.5 при этом чтобы хорошо работало даже не припоминаю.
> какие вообще особенности обучения дистиллятов, особенно тех, что на мало шагов обучены
То что тренить иж - плохая идея. Это не тот дистиллят где из большой модели делают мелкую, здесь задушены связи, производящие лишние вариации что снижают сходимость. Они будут хуевее трениться и к тому же
> постепенно терять способность работать в мало шагов
Если хочешь заняться тренировкой - ищи видимокарту, хотябы 3090.
Как enable buckets работает и на что влияет? Переустановил версию pytorch и прочих штук, запустил тренировку лоры на ленивом старом датасете 512х512, и удивился, что занялось всего 10гб врама при тех же 1024,1024 max resolution. До этого тренировки сжирали значительно больше памяти на тех же настройках, но других датасетах, почему так? Что в основном влияет на потребление памяти?
Кто-нибудь лору на больших датасетах тренировал?
Типа, у меня тысяча пикчей. Стиль+концепт.
Какие там настройки оптимальные для поня поставить?
Обычно тренирую на
>dim 16 alpha 8
>AdamW8bit
>Cosine
>UNet 0.0002
>TE 0.0001
На сетах средних размеров нормально получается, 1600-1800 шагов до хорошего насыщения, а тут даже хз. Сет не слишком однородный, но урезать дальше его никак.
Типа, у меня тысяча пикчей. Стиль+концепт.
Какие там настройки оптимальные для поня поставить?
Обычно тренирую на
>dim 16 alpha 8
>AdamW8bit
>Cosine
>UNet 0.0002
>TE 0.0001
На сетах средних размеров нормально получается, 1600-1800 шагов до хорошего насыщения, а тут даже хз. Сет не слишком однородный, но урезать дальше его никак.
Это не большой датасет, можешь оставить дефолтные параметры. От ранга зависит усвояемость, для чего-то сложного и разнообразного стоит ставить больше.
Обучил только что на 2500 пикчах, в 2 эпохи, на самых дефолтных настройках. Разницы не ощутил, но как будто надо больше степов. Да и это был не стиль, а просто фотосеты одного человека, на похуе без капшенов и чистки датасета, только скриптом откропал до размеров ближайщих к 1 мегапикселю. Если сильно не отходить от ракурсов, эмоций и стиля оригинала, то получается почти то же, за исключением качества.
Почему у NAI SD1.5 анатомия рук/писюнов в разы хуже чем у рандомных фурри-бомжей тренирующих у себя в гараже? При том писюны в NAI даже с пердолингом ЛОР еле как хуево работают, а у фурри сразу и коробки и high angle и low angle любой вид работает. недавно узнал что SD1.5 фурри могут людей генерировать
Anime le bad?
Anime le bad?
Потому что ни NAI (первая, по крайней мере), ни тем более SD, не были рассчитаны на кумеров.
Соответственно, писюнов в датасете почти не было только то, что случайно пролезло, и тренировки не хватило.
Бомжи в гараже тренировали как раз писюны, в ущерб всему остальному.
NAI, кстати, уже в бета-фурри модели вполне могла самые разные пиписьки рисовать но эту модель не слили.
И было это... Давно. Задолго до релиза SDXL.
Есть такие вопросы по kohya_ss : 1) можно ли в kohya_ss изменить разрешение сэмплов при тренировке? 2) обучать модель лучше на базовой SDXL у меня sdXL_v10VAEFix или можно на natvis10 например? 3) Чем Learning rate отличается от Unet learning rate?
Обучать на том, на чём использоваться будет. Хоть лора хоть может и будет работать на других моделях, но хуже. За исключением натвис2, наверное. Модель говна. Но я начал на ней обучать, уже для чистоты эксперимента дообучу на ней пачку лор, потом буду сравнивать. Некоторые переобученные лоры с неё круто работают на pornworks. Слышал, что если надо, чтобы лора работала на большем количестве моделей - обучай на джаггернауте.
я обучал на sdxl а лора ещё лучше работала на джагернауте. а можно ли потом лору дообучить на другой модели?
Дообучить с другой моделью не пробовал, но интерфейс вроде позволяет такое сделать.
Ниже опишу свой опыт, не говорю, что это хороший вариант, не пользуюсь им постоянно, да и почти всегда лучше с первой попытки обучить на нормальном датасете, НО: я пытался дообучать лору (без сохраненного стейта, по файлу лоры). Оно как бы работает, каких-то артефактов не заметно. Дримбуты именно так и обучал - сначала на общем датасете, потом последние 500-1000 степов на лучших фото.
Я только дообучением и могу продолжить тренировку т.к. при выборе сохранять стейт для продолжения и выбора папки получаю такую ошибку:
E:\\!!!Models\\17_10_2024\\model\\pytorch_model.bin
файл pytorch_model.bin он не находит и он почему то не создается или не ту папку добавляю.
> можно ли в kohya_ss изменить разрешение сэмплов при тренировке?
Да (нет). Ты можешь задать целевое разрешение и пикчи будут раскиданы на бакеты с разным соотношением сторон. Однако, если у тебя там лоурезы то их апскейл будет математическими алгоритмами с артефактами в результате, в таких случаях стоит ставить bucket_no_upscale или предварительно апать датом.
> обучать модель лучше на базовой SDXL
Если планируешь катать на каком-то мердже то лучше обучай на "базовой" для него модели (например для аутизма обучать на чистом пони). Если там какой-то глубокий файнтюн то можно сразу на нем.
> Чем Learning rate отличается от Unet learning rate?
Разные параметры что передаются в оптимайзер. В пролежнях, например, автор-шиз не хочет мерджнуть готовое решение для многокомпонентных моделей и, емнип, там роляет только основной LR. Также, если не указаны лр компонентов то они будут приравнены основному. Просто ставь их одинаковыми а для те меньше.
> можно ли потом лору дообучить на другой модели
Никто не запретит но это плохая идея.
> и он почему то не создается
> !!!
Есть некоторая вероятность что дело в этом. Но причин может быть множество, давай полностью ошибку.
Какой смысл ломать текст-энкодер, вжаривая в него тег из рандома, не несущий никакой семантики, не лучше ли обучать эмбеддинг вместе с лорой не трогая энкодер?
Так и не понял, сказал ли ты странную глупость или наоборот интересную и недооцененную идею. Можешь развить, добавив пояснений?
Ну так, я тоже хочу узнать, придумал ли я какую-то глупость, или нет, лол.
Типа, при трене лоры, выбираем случайный бессмысленный тег, чтобы ее триггернуть. Этот тег текст-энкодер не знает, и никак не может его интерпретировать, может быть как-то в общий пул векторов его подмешивает, но в целом никакой семантики или визуальной идеи энкодер в него добавлять не должен.
Энкодер потом включается в цепочку обучения, чтобы подсосать уже существующие визуальные признаки, нужные для обучения лоры, в этот рандомный тег. Но это обучение очень сильно отличается от того, как обучают сам энкодер изначально, и отличается в худшую сторону. Энкодер будет забывать семантику, обобщение, и больше будет становиться тем, что похоже на обычные эмбеддинги.
Так почему бы не учать их сразу? Туда можно и больший ЛР вжарить, и не ломать энкодер вообще.
Это довольно очевидная идея, ее кто-то уже должен был попробовать.
Обучаю уже которую лору человека, постоянно подобный график лосса, 3-4к степов. Почему так? Какие подводные? Мнение? В чем он не прав? Как исправить или что это значит? Не похоже на идеальные графики.
график этот имеет смысл только для ллмок, откуда этот каргокульт и пошел, для картинкосеток если дельта меньше двух порядков - похуй, по ощущениям у тебя немного задран лр или мало шагов, но смотреть всё равно имеет смысл только на результат
В целом, процесс обучения модели действительно как раз предполагает то что в энкодер "добавляются" новые теги, сочетание с которыми дает нужный эффект, а юнет изменяется чтобы эти вещи воспроизводить.
При тренировке эмбединга буквально идет подбор последовательности токенов на входе те, без изменения весов юнета или энкодеров, т.е. говоря проще - подбирается суперпромт в векторном пространстве, который бы давал что-то близкое к нужному результату.
Натренить сначала эмбединг а потом тренить только юнет с его использованием - можно, однако сложно сказать окажется ли это лучше чем полноценная тренировка те. Клип обрабатывает сочетания тегов в промте, а так там будет присутствовать какое-то странное сочетание что даст неведомую реакцию с остальным промтом, может как органично в него вписываться, так и наоборот все попутать и поломаеть. С другой стороны - да, не трогая те не сможешь его поломать, хотя это идет прежде всего от не оптимальной тренировки. Большой лр для юнета тут не нужен, хватит обычного.
Попробуй, эта идея как минимум интересная. Сначала обучить эмбединг, потом в тренере кохи поправить __getitem__ и get_input_ids в классе датасета, чтобы он добавлял твой эмбед, и просто как обычно тренируй лору с выключенной тренировкой ТЕ.
Потому что train loss может показывать погоду на марсе и больше привязан к амплитуде лра, из-за чего будет чуточку спадать в конце. Был бы validation loss то по тому уже можно было бы как-то ориентироваться, и то в кейсе генерации пикч подобрать правильный валидационный датасет для оценки а потом правильно посчитать "точность" будет не самой простой задачей.
> Как исправить или что это значит?
Забить, или ковырять имплементации валидационного лосса.
обучаю в кохе лору 1024 а она мне семплы каждые 25 шагов генерит но они почему-то 512, можно ли их сделать 1024? в настройках обучения не нашел
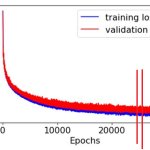
По идее, ты видишь вот такой срез, а не весь график.
И хоть ты пихаешь в модель новые данные, она уже базово хорошо умеет их денойзить, и треня дает только направление этого денойза, что на фоне шума лосса не будет заметно. Вот если попробовать скормить модели что-то совсем отличное от привычной ей графики, какую-нибудь другую модальность, с другим спектральным распределением, тогда наверное обучение будет хорошо видно по лоссу. Хотя опять же хорошо видно будет только начало, когда модель глобально плохо приспособлена к задаче.
>сначала эмбединг а потом тренить только юнет с его использованием
Не-не, суть именно в том чтобы обучать все одновременно. Ты же не обучаешь сначала энкодер, а потом модель.
>сложно сказать окажется ли это лучше чем полноценная тренировка те
Ну вот, имхо, не существует никакой "полноценной" тренировки, кроме той, когда сам клип обучают с нуля. Как только его пытаются обучать через юнет, это его ломает, и делает из него просто словарь эмбедингов, которые вызываются по триггеру.
Моя теория, что если вообще каждый новый тег привязать к эмбедингу, и не обучать энкодер, это будет эквивалентно обычному обучению с энкодером, только он не сломается. Потом точно так же их подключать в промте, как если бы это были теги. Ну и так можно дойти до того чтобы вообще выкинуть энкодер нахуй, а то хули, в понях его максимальное понимание семантики ",цвет -> объект," или даже скорее ",это-все-один-объект,". Атеншн юнета наверное и то умнее, на большом датасете и сам научится в это, если не уже.
> суть именно в том чтобы обучать все одновременно
Хуясе ебать, с таким номером только в цирке выступать лол. Но, вообще попробовать то можно, сначала проход по юнету, потом проход по всей совокупности с задачей оптимизации эмбедингов.
Тема то интересная, за пару вечеров неспешно отладить и обучить несколько вариантов.
> не существует никакой "полноценной" тренировки, кроме той, когда сам клип обучают с нуля
Любое обучение является ею, дело в нюансах работы и реализациях.
> делает из него просто словарь эмбедингов, которые вызываются по триггеру
Здесь подходит заезженный пример с cowboy shot, если не убивать специально то энкодер не теряет возможностей в семантике и понимания текста. Другое дело что лора сама по себе специфичный способ менять веса, и 99.9% лор имеют невероятно однообразный датасет, что накладывает свой отпечаток.
> если вообще каждый новый тег привязать к эмбедингу, и не обучать энкодер, это будет эквивалентно обычному обучению с энкодером, только он не сломается
Как раз подобный подход и превратит конечную модель в словарь чего-то. Ты подбираешь нужный отклик не обязательно на нормальной реакции энкодера а вообще на каких-то невероятных заскоках, сочетаниях или шуме, и на этот неравномерный сигнал пытаешься натягивать юнет, получая кучу побочек. Какая там будет семантика в таких комбинациях эмбедингов и как они будут работать в совокупности тебе врядли кто-то скажет.
> чтобы вообще выкинуть энкодер нахуй
Ну типа в dit можно пихать любые кондишны, хоть голые токены. Вот только обучать с ними просто так получается как-то неоче, можешь попробовать. И какой-то "суперсемантики" в клипе и не было, он довольно ограничен бай дизайн.
может кто в курсе, если датасет размечаю надо указывать что по факту или как это выглядит на конкретном фото? пример у девушки зеленые глаза а на фото они серые
Литералли зыс
> По идее, ты видишь вот такой срез, а не весь график.
> И хоть ты пихаешь в модель новые данные, она уже базово хорошо умеет их денойзить, и треня дает только направление этого денойза, что на фоне шума лосса не будет заметно. Вот если попробовать скормить модели что-то совсем отличное от привычной ей графики, какую-нибудь другую модальность, с другим спектральным распределением, тогда наверное обучение будет хорошо видно по лоссу. Хотя опять же хорошо видно будет только начало, когда модель глобально плохо приспособлена к задаче.
Попробуй задать новый таргет модели и увидишь такой график, например в v-prediction конвертнуть, результат тебя не порадует, потому что это делается не за время тренировки лоры, и не лорой уж точно.
> Моя теория, что если вообще каждый новый тег привязать к эмбедингу, и не обучать энкодер, это будет эквивалентно обычному обучению с энкодером, только он не сломается. Потом точно так же их подключать в промте, как если бы это были теги.
Это pivotal tuning называется, пробовал подобные лоры, вообще не впечатлили, даже юнет онли были лучше.
Тегай что видишь, если на пикче серые, то и пиши серые
В Advanced - Samples есть поле промпта и там же описано, что можно добавить --width 1024 (или -w не помню) и --steps 15.
У тебя 24гб? У меня в 16 не влезает трейн на 1024.
у меня GPU 12gb/ RAM 12gb и трейнит, но очень медленно 22 ит/с, очень скоро память раздобуду для компа, должно быть 24gb
Может 22с/ит? Ты удивляешь больше и больше. Я пытаюсь понять, может я неправильно завожу трейн.
а xformers включён? у меня в принципе неплохо тренит, но хочется чтобы ещё больше похоже было, только вот на ночь зависает комп, думаю из-за памяти.
>Может 22с/ит
да 22 секунды итерация
попробовал на SD base 1.5 потренить такой же датасет но уже в 512 и 8gb GPU только используя при batch size = 4, RAM всего 1gb. Результат при тех же параметрах намного лучше в самом начале чем при тренинге на civitai. Потом сравню с SDXL тренировкой
и скорость 1,18сек/ит
пробую обучать лору на flux, сделал датасет из 600 картинок, хорошего качества, все отсортировал, протегал. вроде бы все отлично, но практически не обучается концепту, ставил от 10-20 эпох (примерно от 14к до 28к шагов, batch_size = 1 или 2). lr 1-e4 unet 4-e4, по дефолту. пробовал играть значениями выше - loss просто улетает вверх. (выше похоже брать не вариант). пробовал увеличивать dim с 2 по 32, альфа была или равна или ниже в два раза.
по идее результат в целом не сильно менялся, играл с тем, что задавал меньше эпох, от 4-6. после обучения вообще разницы с оригиналом минимальна.
тут или датасет концепт сложный или просто я чего-то не понимаю. есть у меня датасет с аниме стилем из меньше 100 картинок, ему на дефолтных настройках хорошо учится лора.
около недели потратил на тесты, в чем проблема - непонятно.
по идее результат в целом не сильно менялся, играл с тем, что задавал меньше эпох, от 4-6. после обучения вообще разницы с оригиналом минимальна.
тут или датасет концепт сложный или просто я чего-то не понимаю. есть у меня датасет с аниме стилем из меньше 100 картинок, ему на дефолтных настройках хорошо учится лора.
около недели потратил на тесты, в чем проблема - непонятно.
Не подскажу, но интересно, а на xl при этом норм?
Алсо, может с лорой всё норм, и нужно в фордже выбрать fp16 lora.
на xl получше обучается. но общий результат там в целом хуже, так как детализация хромает.
сейчас обучил с более низким lr, 4к шагов. результаты стали гораздо лучше. с прошлыми проходами в 20 эпох, чтобы получить нормальную генерацию приходилось выкручивать DCFG больше 10, сейчас на 3.5 хорошие результаты, получается была прожарка. концепт оно более менее теперь понимает, но сами детали (фон) не до конца. буду еще тренировать.
На чем обучаешь, что так свободно на флаксе тренишь тысячи шагов? Я пока ещё не тестил, но даже хл на 4060 16гб по ~1.3ит/с
одна 4090. один проход обучения 10-20 эпох - 10-13 часов. с adamw в 1 батч и gradient checkpointing влезает ровно в 20gb. отсюда и невозможность быстро взглянуть на результаты настроек.
какой lr ставить при тренировке sd 1.5? при 0.0004 кажется переобучение происходит
>AdamW8bit
>Cosine
>UNet 0.0002
>TE 0.0001
а DIM и Alpha какой оставить?
Уже и не помню. И конфигов тренировки с полторахи своих не сохранилось.
Для 1.5 вроде 128/64 норм были?
Сделай тестовую тренировку, посмотри на размер файла. Если лора ~144 МБ или меньше - значит, всё норм. Если больше - понижай DIM. Альфа либо половина DIM, либо 1. Я обычно половину ставил.
В Аниме-треде вроде должны до сих пор инструкции в закрепе висеть, там много разных способов описано.
попробовал потренить на подобных настройках, обучение идёт хорошо но чем больше шагов тем стабильнее при генерации изображения из датасета, выдает по сути датасет, может из-за того что на маленькой лоре SD 512 установил DIM 128? DIM я так понимаю это размер латентного пространства
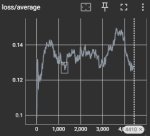
Что делать если запекается лоурез жпг стайл при трейне на фото человека. Хайрез пикч меньшая часть в датасете, большинство рескейл с 512х-768x до мегапикселя, лучше взять негде. Лицо обучилось божественно, с разных углов, на разных эмоциях, всё охуенно, но шакалы подсирают. Иногда проскакивают хайрезные результаты на некоторых промптах, но простого токена на мастерписю не нахожу.
Мои предположения, уточните так ли это и какие есть другие методы: это фиксится добавление регуляризирующих пикч? Что это за пикчи должны тогда быть, а то я видел дауны тупо кривое аи говно юзают в этом пункте. Или же нужно настроить так, чтобы после первого дипа сильно понижался lr? Или может отловить хайрезные генерации и добавить их в датасет? Звучит как хуевая идея. XL lora, 896,896.
Мои предположения, уточните так ли это и какие есть другие методы: это фиксится добавление регуляризирующих пикч? Что это за пикчи должны тогда быть, а то я видел дауны тупо кривое аи говно юзают в этом пункте. Или же нужно настроить так, чтобы после первого дипа сильно понижался lr? Или может отловить хайрезные генерации и добавить их в датасет? Звучит как хуевая идея. XL lora, 896,896.
Ну так оно довольно быстро насыщается с такими настройками.
1400-2200 шагов.
Самое быстрое, что помню, было вообще в районе 900.
Но чтоб прям картинки из датасета выдавало - не сталкивался.
Хотя у меня маленьких сетов не было, от 80-100 картинок, и до 200-250.
Это фиксится хорошим апскейлером, затирающим жипег-артефакты. Пробуй разные.
Можешь в ФШ шум попытаться убирать.
Второй вариант - завысить число повторений на хорошей части датасета по сравнению с низкокачественной.
>Второй вариант - завысить число повторений на хорошей части датасета по сравнению с низкокачественной
Интересная идея.
А что в случае, когда будет только лоурез, но цель обучить персонажа на пони, без шакального стиля?
> DIM я так понимаю это размер латентного пространства
Вообще нет, это размер матриц лоры по малой стороне. 128 норм, часто даже избыточно для чего-то типичного.
Если используется bf16 то альфу можешь любую ставить с корректировкой лр, или без нее если идет адаптивный оптимайзер.
Убери жпег шакалов из датасета, или протегай их жпег шакалами если есть не-шакальные пикчи. Берешь дат нейроапскейлер и проходишься им по лоурезным пикчам. Аналогично, есть даты для удаления жпег артефактов без апскейла, только проверь как они работают сначала. Генерации можешь добавить, но только хорошие и разнообразные.




>Берешь дат нейроапскейлер и проходишься им по лоурезным пикчам.
Тут еще надо учитывать, что не все ДАТы убирают артефакты.
Некоторым на них начхать.
А некоторые могут загладить все настолько, что лучше уж с артефактами.
Абсолютно. Если погрудиться в пучины openmodeldb то там вообще можно найти апскейлеры, которые не чинят артефакты как заявлено, а наоборот их добавляют.
в общем сделал измения dim 128 > 32, alpha 64 > 16, датасет увеличил по с 50 > 65 фото и он теперь разного разрешения bucket train, lr 0.0001, text encoder 5e-05, повторов 40 > 20, эпох 20, 512х512, результат кардинально лучше, почти что хотел
>нейроапскейлер и проходишься им по лоурезным пикчам
И получается неузнаваемое говно. Даже ресторфейс на 0.15 делает из пикчу убогое месиво, что говорит про апскейлеры общего назначения.
Бредишь и показываешь свою некомпетентность.
>И получается неузнаваемое говно.
>Картинки-примеры буквально двумя постами выше.
Ага.



Ну если ты в глаза долбишься, то вот тебе зум твоей хуиты. Если ты и так не увидишь, что получилось неузнаваемое месиво, то тут уже ничего не поможет - ты говноед и лоры у тебя наверняка такие же как и у топов цивита, которые массово клепают говно наихудшего качества. Для какой-то неживой хуйни может и норм решение, но точно не для ебальников.
Ебать ты дурачина, конечно.
При рескейле этой картинки до тренировочного разрешения ХЛ-модели, лицо кропнется до зоны в 200х250 пикселов.
Модель из этого практически ничего не вытянет, как ты ни крутись - слишком мало данных.
Целью было избавиться от артефактов, чтоб они не засирали собою датасет - от них избавились.
А детали лица тренируются на нормальных пикчах, с, внезапно, лицом. Крупным планом. И даже если они тоже подзасраны артефактами, то после апскейла получится, как минимум, неплохо. Банально потому, что данных для восстановления больше.
Ты специально кропнул какой-то мелкий кусок, который после ресайза до разрешения тренировки нейронка не увидит никогда. На более крупных что будут видны все будет хорошо и красиво. Во-вторых, оба пика лучше чем первый заартефаченый в хламину.
Оно всегда так бывает когда сначала бросаешь громкие заявления а потом пытаешься выкручиваться в попытках их оправдать. Описанная методика является наиболее подходящей и эффективной, а те самые "топы цывита", которых ты пытаешься приплести для дерейла, как раз или ресайзят бикубиком, или вообще оставляют как есть, заодно добавив кривых полос, достраивая до квадрата.
О том что ты не в теме очевидно уже по
> Даже ресторфейс на 0.15 делает из пикчу убогое месиво
но раз ввязался - расскажи как по-твоему надо делать.
Ну ресайзните как хотите, и сравните. Хоть потом еще раз увеличьте, чтобы разглядели. Выглядит еще более убого. Будет трен на артефакты апскейла.
>какой-то мелкий кусок
Ебать. Самый основной кусок кропнул, который при трейне нужен в клоузапе быть в датасете, чтобы потом было что адетайлером генерить.
>какой-то кусок
>заодно добавив кривых полос, достраивая до квадрата.
Как же я их ненавижу. Уф.
Из-за таких "умников" нейронка по краям картинки артефачить начинает, пытаясь как-то интерпретировать эту мазню, которую они туда добавили, либо рамки всякие ненужные строит.
Изображение при тренировке будет представлено в 1 мегапикселе, если не задано иное (а иное тренить не имеет смысла). Вещи которые ты пытаешься из пальца высосать не будут заметны при этом, это совсем радикальный случай. А если нужны клозапы лица - изначально берется нормальное изображение а не делать попытки апскейла в 10 раз, как ты пытаешься представить.
Все еще жду вариантов как делать "правильно".

>изначально берется нормальное изображение
>just buy a house
Вопрос был про то как тренить лицо человека, если кропы лица есть только в ~256х256. А вы предлагаете обучить на косых апскейлах. Я потом когда-то попробую, конечно, только не тупым апскейлом, а sd апскейлом с первичной мыльной лорой, но звучит как дичь.
>Все еще жду вариантов как делать "правильно".
>Жду
Нет, я
Если модель смогла на ебучих шакалах нормально обучиться то на апскейлах будет лучше и без артефактов. Если у тебя кропы лица в 256х256 - выкидывай их нахуй и обучай на пикче без кропа. Или делай менее агрессивный кроп чтобы после получалось адекватное разрешение, к которому применим апскейл.
> just buy a house
Да, чтобы обучать нейронку нужно иметь датасет надлежащего качества. Уже тролинг тупостью пошел, если все знаешь - вперед собирать грабли.
Аноны, буквально вот сегодня наконец-то вкатился в sd и тут же встал вопрос.
А как научить промту прокачивать английский? Полистал примеры моделей, общий принцип понял. А как разобраться в синтаксисе? Кроме, обычных словосочетаний бывает что-то в скобках, плюс числа 0.7, 1.0 и тд.
Можно ли сгенерировать изображение 1 в 1 как в примерах моделей?
А как научить промту прокачивать английский? Полистал примеры моделей, общий принцип понял. А как разобраться в синтаксисе? Кроме, обычных словосочетаний бывает что-то в скобках, плюс числа 0.7, 1.0 и тд.
Можно ли сгенерировать изображение 1 в 1 как в примерах моделей?
>Вопрос был про то как тренить лицо человека, если кропы лица есть только в ~256х256
Не тренить последние шаги? Тренить по разложению фурье без высоких частот (если такой метод существует)?
>А как разобраться в синтаксисе?
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/Features
>Можно ли сгенерировать
Можно. Если метаданные есть в картинке, все дополнительные инструменты, и автор картинки не гонял ее в И2И, а получал чистой генерацией.
Я думал над твоим постом.
Но тогда бы у хассана и других SD1.5 порно моделей анатомия была бы лучше, однако до сих пор она до уровня фуррей так и не дошла. Хотя гомо чекпоинты не проверял. Даже у портретов пальцы сломаны до сих пор.
Легкое изменение камеры тут же ломает анатомию.

>анатомия была бы лучше
Поздние модели вполне себе нормально с анатомией работали. С позами - фигово, нужно было чуть ли не каждую отдельную тренировать (что фурри и делали вообщем-то), но в целом улучшение было значительное.
>Даже у портретов пальцы сломаны до сих пор.
Пальцы сломаны и на хл, и на понях. Везде.
Слишком комплексный объект, со слишком малым процентом занимаемой площади на картинке. Вот у тебя, допустим, upper body, Джоконда. С руками, довольно крупным планом. Ужимаем ее до тренировочного разрешения в 512 пикселей, добавляем артефактов... И что нейронке из того квадрата в 135х135, в который пальцы ужались, для обучения вытягивать?
Отсюда - низкая эффективность обучения и нестабильность результата.
Когда жесты промптишь, особенно крупным планом и особенно с дополнительной тренировкой - получается лучше.
Тренировочного разрешение в 512 уже нигде не встретить. Но зато изображения конвертируются в латенты с разрешением по стороне в 8 раз ниже и другим числом каналов. Что там останется после перегонки и сколько субпикселей на один палец - вот где собака зарыта. В случае 16-канального латента все уже хорошо.
> но в целом улучшение было значительное
Да все просто - нужно было нормально тренить а не плодить инцесты. С 1.5 сложно из-за тупого энкодера и в мелочах из-за своего размера будет часто ошибаться, но анатомия в разных позах и частях тела там возможна.
Аноны, поясните что такое ipadapter и t2i-adapter
Сейчас пытаюсь гуглить, разобраться и одни противоречия
Сейчас пытаюсь гуглить, разобраться и одни противоречия
>Тренировочного разрешение в 512 уже нигде не встретить.
Там контекст обсуждения был про 1.5 модели.
Так то понятно, что когда новые модели на 1024 тренишь - оно лучше получается. Но процент брака все равно большой.
>Отсюда - низкая эффективность обучения и нестабильность результата.
Криворучки-обучальщики разве еще не додумались докидывать в датасет кропы ебал, рук, ног, пезд, меток поней, под тегом aDetailer + тип объекта? Ну или хотя бы отдельную хорошую жирную лору на него сделать?
>Криворучки-обучальщики
Сделай сам, залей на цивит, собирай профит.
Делов-то, ведь это так просто!
Спойлер: нет, ничерта у тебя не получится.
У чувака, который рассказывает на ютубе про ip adapter во вкладке img-img можно вставить картинку вот сюда, в контролнет.
А у меня картинка вставляется только в первой вкладке, тоесть в text-img, а тут некуда её вставлять. И как это починить?
А у меня картинка вставляется только в первой вкладке, тоесть в text-img, а тут некуда её вставлять. И как это починить?

Прочитай, что написано на картинке, как говорится.
Сюда тыкаешь, возможность ввода отдельных картинок появится.
Хитро придумано
В фурри SD1.5/пони/СДХЛ хотя бы можно "поймать" правильные пальцы при ролле или ролле в hiresfix, в то время как в других СД1.5 моделях на 10-30 роллах все еще сломанные можешь получить я уже настолько охуевал что хотел в фотошопе зафранкенштенить пикчу из разных роллов, а в итоге полностью забил. Но чекпойнты без стилей которые не реагируют на by artist, особо не пробовал, т.к. желтый фотореализм не нравится.
Это все чистый рандом.
Буквально несколько дней назад назад заленился поню дать вручную базовый контур, как рука на хорошей генерации должна выглядеть, решил хайрезфиксом по пальцам поролить.
Посмотреть, сколько займет.
200+ круток суммарно получилось на две ладони.
Тут все еще очень плохо.
Может сразу плюс-минус хорошо нарисовать. Может упереться и не работать вообще.
>Не похоже на идеальные графики.
Вкину еще интересную инфу, на тему графиков и визуализации.
https://www.youtube.com/watch?v=5ltoWvHMwFY
https://t.me/GradientWitnesses
Чел рассказывает про "по настоящему информативные графики", он уже выложил свою библиотеку для визуализаций, вот она https://gitverse.ru/kraidiky/in_sight
Но он занимается только мелкими сетями, надеюсь, кто-то захочет применить это к нашим нейронкам.
> t2i-adapter
Альтернативное решение контролнету работающее чуть иначе, но реализующее аналогичный функционал.
> ipadapter
Модель контролнета (на самом деле самостоятельная но смысл тот же) что позволяет вытаскивать стиль и некоторые атрибуты из референсного изображения. Аналог рефенс-контролнета но работает точнее.
> Там контекст обсуждения был про 1.5 модели.
Так 1.5 стоит хотябы в 768 тренить, иначе все будет грустновато.
С этого начинали еще в 2022 году, приводило лишь к уродским артефактам и стремным неестественно детализированным пальцам если вдруг они появлялись близко.
Делать это можно но оче оче аккуратно и плавно, а при наличии большого датасета оно само там есть. Разрешение тренировки первично.
> 200+ круток суммарно получилось на две ладони.
Какой-то оче сложный кейс или что-то не так делаешь. Даже для ванильной пони это много, в большинстве современных моделях руки сразу хорошие или имеют легкоисправимые косяки.
> кто-то захочет применить это к нашим нейронкам
Все эти методики основаны на результатах вализации модели. В отличии от простых сетей, которые выдают конкретный ответ (или ллм, где можно проводить анализ вероятностей логитсов на набор "правильных" ответов), оценивать ее в генерации пикч - так еще задача. Только какие-то попытки оценить характер денойза зашумленной картинки в сторону референса и то вообще не точный. Потому все попытки реализации валидлосса или также малоинформативны, или пригодны только для жетских концепт-лор, которые заставляют модель делать идентичные картинки с небольшими отличиями.
>или имеют легкоисправимые косяки.
Во-во. Поправить я их мог за 5 минут.
Но решил покрутить рулетку.
Зря.


Выкладываю кастомный UI для исполнения t2i на смартфоне (в Pydroid, на Kivy).
https://rentry.co/t2i_kivy_ui/edit
Для отображения иконок нужно также сохранить приложенные png картинки 2 и 3 в папку "python/assets" в памяти телефона (для ПК - в папку "assets" там же, где находится .py файл).
Элементы UI расположены так, чтобы быстро набирать текст и сразу убирать экранную клавиатуру, просматривая и сохраняя нужные пикчи. Negative prompt убран вбок, чтобы не мешался. Предусмотрен полноэкранный просмотр с быстрым сохранением.
GPU не требуется, в скрипте подключен онлайн API с Anything v5 (в нем доступны и другие модели SD1.5, я выбрал эту по дефолту). Так же туда можно подключить локальную генерацию с компа, Stable Horde, любое другое облако, спейс на HF и т.д.
>С этого начинали еще в 2022 году, приводило лишь к уродским артефактам и стремным неестественно детализированным пальцам если вдруг они появлялись близко.
>Делать это можно но оче оче аккуратно и плавно, а при наличии большого датасета оно само там есть. Разрешение тренировки первично.
А если со спецтегами, чтобы оно только внутри адетейлера триггерилось? Или делать отдельную лору на основе базовой модели, если будет сильно говнить.

Новая версия
https://rentry.co/t2i_kivy_ui_v2
- Теперь при клике на кнопку запоминает промпт, для следующего запуска, записывая в файлах в папке settings (она там же, где assets)
- Вместо встроенного API теперь поддержка комфи (workflow.json в settings), нужно только добавить URL и название модели
- Оптимизированное пространство (для смартфона)
- Можно добавить любой кастомный фон (хотя его будет почти не видно)
В планах - добавить звуки для разных событий, и фоновую музыку.
(для индентации строк нужно копировать из edit.)
Превосходной модели не существует -ее нужно делать самому.
Берешь основу, которая может всё, кроме стиля. Illustrous и Noob норм. Трейнишь несколько лор на стиль, используя однородные материалы для каждой. Тестируешь, вмердживаешь, повторяешь.
Я познал дзен
Берешь основу, которая может всё, кроме стиля. Illustrous и Noob норм. Трейнишь несколько лор на стиль, используя однородные материалы для каждой. Тестируешь, вмердживаешь, повторяешь.
Я познал дзен
> ее нужно делать самому
Да
> несколько лор
> вмердживаешь
Это ужасно
Можешь оформить куда-нибудь на гитхаб с инструкцией по запуску?
Моделям с размером уровня sdxl такое не требуется. Да и даже 1.5 может справляться. В первую очередь, нужен равномерный и желательно большой датасет, в котором будут также встречаться и клозапы рук. Вариант с дополнительной лорой или какими-то тегами - серьезный компромисс, но в целом работать будет.
Это збс, если лоры не противоречивые, и целевые (формируют вместе разные, иногда преувеличенные, стороны того, что тебе надо).
Тренил лоры людей на натвизе, было нормально, было мыльно, если датасет лоурез. Включал эти лоры на других моделях, было качественно, терялась часть схожести.
Начал обучать на ластифай, стало пересвеченно, почти без мыла.
А теперь самое интересное: включаю лоры с натвиза в ластифай, выкручиваю иногда вес до 1.5, получаются идеальные ебальники БЕЗ влияния на стиль фото. Охуеть. Зачем я волновался над тем, чтобы обучать на той же модели, которой пользуюсь. При обучении, оно поглощает дефолтный стиль модели. В случае с натвизом - мыло, с ластифай - пересвет. То есть, выгодней всего взять xl/jugg и обучать на нём? Похоже.
Я слышал уже про метод с дримбутом и экстрактом. Делал такое на 1.5, нет веры в него, но скоро попробую. Чего я еще не знаю? Какие есть иные скрытые и неочевидные пути обучения лор?
Начал обучать на ластифай, стало пересвеченно, почти без мыла.
А теперь самое интересное: включаю лоры с натвиза в ластифай, выкручиваю иногда вес до 1.5, получаются идеальные ебальники БЕЗ влияния на стиль фото. Охуеть. Зачем я волновался над тем, чтобы обучать на той же модели, которой пользуюсь. При обучении, оно поглощает дефолтный стиль модели. В случае с натвизом - мыло, с ластифай - пересвет. То есть, выгодней всего взять xl/jugg и обучать на нём? Похоже.
Я слышал уже про метод с дримбутом и экстрактом. Делал такое на 1.5, нет веры в него, но скоро попробую. Чего я еще не знаю? Какие есть иные скрытые и неочевидные пути обучения лор?
тут в параллельном треде предлагают b-lora, даже мануал есть
Вот какой хуйни в диффузии ни хватает.
Чтобы для каждого тега в промте, либо отдельное поле промта, куда вбиваешь, например, ебало:1:0,5, фон:0:1 где одно число это среднее, а второе - стандартное отклонение, и это настраивает диапазон и распределение, из которого будут рандомиться концепты. Ставишь все на максимум, получаешь рандомные ебальники. Зажимаешь в узкий диапазон, получаешь все одинаковые одного типа, при этом смещаешь его, и у тебя идут тоже одинаковые, но уже другие. И так для любого концепта, иерархически.
Это реализовано нативно в VAE, но только нет фиксации концепта, каждая переменная латента может отвечать как за один маленький концепт, так за часть большого, или даже за несколько.
Есть идеи, как нечто подобное можно реализовать? Механизм внимания, который притягивается к определённым токенам, в диффузии уже есть. При желании, может искать любой объект на картинке прямо во время генерации и закидывать туда нужные значения.
Чтобы для каждого тега в промте, либо отдельное поле промта, куда вбиваешь, например, ебало:1:0,5, фон:0:1 где одно число это среднее, а второе - стандартное отклонение, и это настраивает диапазон и распределение, из которого будут рандомиться концепты. Ставишь все на максимум, получаешь рандомные ебальники. Зажимаешь в узкий диапазон, получаешь все одинаковые одного типа, при этом смещаешь его, и у тебя идут тоже одинаковые, но уже другие. И так для любого концепта, иерархически.
Это реализовано нативно в VAE, но только нет фиксации концепта, каждая переменная латента может отвечать как за один маленький концепт, так за часть большого, или даже за несколько.
Есть идеи, как нечто подобное можно реализовать? Механизм внимания, который притягивается к определённым токенам, в диффузии уже есть. При желании, может искать любой объект на картинке прямо во время генерации и закидывать туда нужные значения.
Это может работать, но лоры вносят кучу побочек. Лучше просто выложить лору а не засорять пространство "трейнед" 6-гиговыми лорами не отличающимися друг от друга.
> Я слышал уже про метод с дримбутом и экстрактом.
Иногда это может сработать, но проблема в том что тренировка фулл весов отличается от лоры, и при экстракте часть потеряется. Если там оверфит то извлеченная лора может даже починить, а если все ок - она лишь будет бледной тенью.
Вывод простой - жарь посильнее и с малым батчсайзом, тогда экстракт будет работать. Побочки всеравно возможны.
Как вариант - подкрутить sd dynamic prompts, там и так нечто подобное есть. На стабилизацию или разнообразие есть свои теги если что, также много разных можно навводить на этапе тренировки.
> При желании, может искать любой объект на картинке прямо во время генерации и закидывать туда нужные значения.
Есть сетка, точнее комбинация ллм, хитрого контролнета и сдхл/сд3 что по запросу может это делать. Причем не один за раз и на разных этапах генерации. Но это уже сильно тяжеловеснее обычного.
Написал пост, но потом удалил его, так как понял что идея слишком хорошая, чтобы ее вот так снихуя палить)) Сами пораскинете мозгами может, а то чет тред тухлый, годных технических обсуждений нет.
Думал на тему того, что было бы если бы мы учили модель не на латентах после энкодера, а пускали градиент от исходной пикчи через декодер, вот. Но может идея в итоге хуйня, я ее не проверял.
Думал на тему того, что было бы если бы мы учили модель не на латентах после энкодера, а пускали градиент от исходной пикчи через декодер, вот. Но может идея в итоге хуйня, я ее не проверял.
бамп!
Яснее напиши что предлагаешь. Ты про херню чтобы генерировать в пиксельном пространстве, или предлагаешь включить кодировку-декодировку vae в процесс обучения (морозя или наоборот обучая его) и считать лосс по пиксельному результату? В некоторой теории последнее может дать профит с уменьшением влияния 4-канального вае, но стоимость обучения и требования к памяти оче сильно возрастут. Если использовать 16-канальное то таких проблем и нет.
>считать лосс по пиксельному результату?
Ну да, про это. Вае же аж 2 раза картинку пидорасит. А так в идеале степень проеба стремилась бы к теоретическому нулю. Но с этим есть нюансики очевидные...
>В некоторой теории последнее может дать профит с уменьшением влияния 4-канального вае, но стоимость обучения и требования к памяти оче сильно возрастут. Если использовать 16-канальное то таких проблем и нет.
Поясни? Или ты просто про то что 16-канальное тупо лучше?
Кстати, есть инфа насчет пересадки вае? Астралайт собирается на свою модель поставить флюкс вае, так может есть идеи как его же в sdxl вкорячить? Так-то обучение не должно быть сильно затратным, не все же слои надо переучивать.
Сколько обычно обучают лору для flux? т.е. сколько эпох и шагов на изображение?
> А так в идеале степень проеба стремилась бы к теоретическому нулю.
Ну, не совсем, но было бы лучше. Хотя это создало бы свои потенциальные проблемы, но главное - ресурсоемкость расчетов, перегонять вае требует немало компьюта и памяти, пусть и модель сама маленькая. Поэтому, его часто обучают вообще отдельно.
> про то что 16-канальное тупо лучше?
Именно, оно сильно лучше и практически не вносит заметных косяков по сравнению с 4-битным. Просто использовать его и тогда не нужно усложнять обучение.
> есть инфа насчет пересадки вае?
Ампутируешь выходной слой, инициализирует шумом новый с другой размерностью, то же самое с входным. Потом это дело обучаешь. Сложность в том что требуется масштабное обучение, причем делать его нужно оче аккуратно.
> не все же слои надо переучивать
Да, градиенты собирать и обновлять минимум у двух слоев, но проходы делать всеравно по всем. Скорость почти не изменится, снижаются требования к врам, и нужно походить ответственно ибо мелкая тренировка здесь не прокатит.
Планировал с этим поэкспериментировать когда предновогодний треш закончится. Если сам что-то будешь делать - не стесняйся рассказывать об опыте.
Как тегать датасет к лоре, чтобы она обучилась персонажу, но не стилю? Наскринил из игры кадров, там графон примитивный, лезет в генерациях постоянно.
>просто добавь регуляционные картинки
А их как тегать? Нагенерил картинок по промтам основного датасета, только без имени перса. Теперь генерации с указанным именем еще сильнее стиль повторяют, а без имени и перс пропадает.
Никак, проще всего будет наскринить других чаров, натренить на этом, вмерджить в модель и тренить уже с этого твоего чара, чтобы оно стиль не впитывало, если синглшотом, то ебись вот с этим https://github.com/kohya-ss/sd-scripts/pull/1427
Пиши lowpoly, bad quality и т.д., при тренировке, а потом ненужное добавь в негатив при генерации. Модель знает что такое лоуполи и тридэ, так что должна более корректно понять что ты хочешь.
Разбавь датасет "качественными" картинками, или же в определенных стилях, и укажи что они качественные а что плохие - плохие. В идеале - если есть с чаром пикчи без этого стиля и есть этот стиль без чара.
Но просто в лоре с мелким датасетом может сработать не так уж хорошо.
> ебись вот с этим
Хватит просто накрутить немного батчсайза, он и сам по себе от впитывания стиля поможет.
Спаривание пикч просто так не сочетается с бакетингом, и нужно заведомо все подготоваливать и подготовить метадату датасета. Но если способен подготовить подходящий датасет - не составит труда залезть в код и настроить свои пары или просто выключить шафл чтобы оно шло напрямую по порядку файла метадаты.
Звучит, как идея, спасибо. А как все-таки регуляционными классами пользоваться, что в них класть? Технологии уж сто лет в обед, а гайдов нормальных по ним всё еще нет, везде какие-то домыслы и бред написан. Вплоть до того, что одни пишут, будто имена файлов должны совпадать с датасетом, а другие - что надо по 200 картинок регкласса на одну пикчу из датасета.
>а гайдов нормальных по ним всё еще нет
Потому что никто не понимает, как оно работает, и работает ли вообще.
Просто забей.
>lowpoly, bad quality
Врядли сработает, так как у тебя других картинок в сете нет. Эти тэги сильно перемешаются со стилистикой персонажа, и когда ты их будешь убирать, когерентность перса тоже "поедет".
Вот тут совет правильный - делаешь лору, и тренируешь следующую уже на картинках, сделанной с ней, можно в комбинации с предыдущими. Дополнительно, для разнообразия, можно подключать дополнительные стилелоры для создания большего разнообразия в стиле. Ну или токены художников, если в модели они есть.
Слышал про такой метод тренировки в несколько заходов, но думал, что он только для случаев, когда картинок с персонажем вообще в обрез, и приходится генерить дополнительные. Думал, что регклассы это как раз решение для отмены стиля.
Ну попробую с тегами сначала, если уж не выйдет, придётся в несколько заходов делать. Ситуация еще осложняется тем, что у меня не 3д игра-то, а 2д, там лоуполи не прокатит, а как описать примитивный 2д-стиль я толком не знаю. Там даже теней нет.
>примитивный 2д-стиль
flat color, limited palette, anime coloring, anime screenshot, anime screencap. Про лоу-квалити тоже вообщем-то написали верно.
> чтобы она обучилась персонажу, но не стилю
бро, я обучил двух аниме-персонажей. И у обоих стиль меняется при использовании отдельных стилевых лор

Так мне надо, чтобы персонажная лора не вносила свой настолько заметно.
Бля я не понимаю как работать с продижи оптимайзером, почему для тестовых прогонов для билоры ему мало 300 шагов? Дайте настройки идеальные для 12 гигов
Так, затерпел час, эффект есть. Ну заебись продижи ебашит конечно, ток долго.
Есть современные гайды по обучению, желательно SDXL? Можно на английском.
Ссылки на рентри с 4чана устарели сильно по заявлениям тамошних анонов.
Ссылки на рентри с 4чана устарели сильно по заявлениям тамошних анонов.
Потому что он впизду какую то улетает вначале, вместо того чтобы сойтись https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md посмотри тут, с ним побольше шагов должно быть лучше, если всё от улетания конечно раньше не сгорит

>Потому что он впизду какую то улетает вначале
Хаха сука как же я проиграл
>с ним побольше шагов должно быть лучше, если всё от улетания конечно раньше не сгорит
Да, на 1000 шагах заебись вышло как надо, но 1000 шагов эо 1000 шагов, час ебли
Гайды по лорам в шапке актуальны, подробный и душный так вообще регулярно обновляется и охватывает последние фишки.
Ты глянь в тензорборде что происходит с ним, скорее всего первые 300 шагов он только проперживается-прогревается.
>Ты глянь в тензорборде
надо напердолить
>скорее всего первые 300 шагов он только проперживается-прогревается
я хз есть ли смысл тогда вообще с такими вводными разогрев включать, мнение?
> подробный и душный
Это какой?
У него свой разгон идёт, аргументом safeguard_warmup отключается в пользу ручного
а да, у меня он в тру стоит, а я чет проебланил
еще под продижи есть эффект что он суперстабильный все ок, можно туда сюда обратно веса подымать опускать, но с лорами консистенции начинает жарить на увеличенных шагах
я треню кароче слой лейаута из инпут блока, клип на токен, клипатеншен, слой стиля и слой контента с аутпут блока, пока еще на части не разбирал чтобы посмотреть что именно влияет на небольшую зажарку на больших шагах, предполагаю что это скорее всего аутпут зажаривает, есть мнение как задоджить?
настроечки такие
accelerate launch --num_cpu_threads_per_process 8 sdxl_train_network.py ^
--pretrained_model_name_or_path="K:/ComfyUI_p022/ComfyUI/models/checkpoints/natvisNaturalVision_v27.safetensors" ^
--train_data_dir="example" ^
--output_dir="output_dir" ^
--output_name="h4nn1" ^
--network_args "preset=K:/sd-scripts/sd-scripts/lycoris_presets/blora_content_layout_style_clip.toml" dora_wd=True ^
--resolution="768,768" ^
--save_model_as="safetensors" ^
--network_module="lycoris.kohya" ^
--max_train_steps=1000 ^
--save_every_n_steps=200 ^
--save_every_n_epochs=10 ^
--network_dim=64 ^
--network_alpha=64 ^
--train_batch_size 1 ^
--gradient_checkpointing ^
--persistent_data_loader_workers ^
--enable_bucket ^
--random_crop ^
--bucket_reso_steps=64 ^
--min_bucket_reso=256 ^
--max_bucket_reso=1024 ^
--mixed_precision="fp16" ^
--caption_extension=".txt" ^
--lr_scheduler="cosine" ^
--lr_warmup_steps=0 ^
--prior_loss_weight=0 ^
--learning_rate=1.0 ^
--color_aug ^
--face_crop_aug_range "0.2,0.8" ^
--optimizer_type="prodigy" ^
--optimizer_args weight_decay=1e-04 betas=(0.9,0.999) eps=1e-08 decouple=True use_bias_correction=True safeguard_warmup=True beta3=None ^
--max_grad_norm=1 ^
--seed=0 ^
pause
Без доры попробуй, оно и тренится дольше и между нубами плохо переносилось из тех тестов что видел, беты с eps с дефолта зачем вообще менял?
А погоди ты с энкодером чтоли тренишь ещё? Раздели лры, продиджи энкодеры бывает поджигает https://github.com/konstmish/prodigy/pull/20


>Без доры попробуй
Окей
> беты с eps с дефолта зачем вообще менял?
А что не так? Они ж вроде и так дефолт
Вот тут https://github.com/konstmish/prodigy написано что Sometimes, it is helpful to set betas=(0.9, 0.99) и eps=1e-08 тоже везде написано что дефолт.
>А погоди ты с энкодером чтоли тренишь ещё?
Не полностью и просто на токен вызова
Таргеты вот
"text_model.encoder.layers.0",
"^text_model\\.encoder\\.layers\\.1(?!\\d)(\\..*)?$"
С TE действительно лучше вышло - похожесть бустит и оверал куолити, пик 1 без, пик 2 с.
А еще у меня очко сгорело, запустил на 3к шагов, добавил флипауг и не заметил отсутствие ^, в итоге джва часа тренинга в жопу и вместо лоссов наны сукаа.
Интересно. Правильно понимаю что самый лучший это который стабильно в центре тусит (или ближе к центру), при этом быстро достигает его и имеет низкий лосс? Или как вообще интерпретировать?
> имеет низкий лосс
Это лишнее
А, я eps с d0 перепутал, сам юзаю адамовские беты, как раз которые ты написал, ты всё таки раздели лры с тем пр, он скорее всего и горит, поставь энкодеру лр раза в 4 меньше
Лучшее объяснение этому что я видел, прямо цитатой - "green dot is like a white woman in india". Там в целом честный тест, если оптимайзер даже не начинает двигаться в направлении зелёной отчки за 500 шагов, как в том тесте, он скорее всего фулл дерьмо, и чем он ближе по результатам, тем математически лучше должен быть результат
Гайды на обучение постоянно противоречат себе, говоря, что надо избегать картинок со странными позами и стилем, но при этом также однообразные картинки приведут к переобучению. В лучших традициях взаимоисключающих параграфов.
>ты всё таки раздели лры с тем пр, он скорее всего и горит, поставь энкодеру лр раза в 4 меньше
Не, ты непонял проблему. Если чисто лору включать - все ок. Если включать к ней допом дмд условный то может начинать жарить на 10 шагах допустим.
>с тем пр
с чем?




Пока ездил по делам натренились 3000 шагов нормально. Жарева с дмд на весе 1 нет вроде, результат идеальный (то есть полное попадание в нужное), описания никакого нет, только токен вызова, фоток 145 штук. Изменчивость самой модели сохранена вроде.
Лог сохранил, щас наебеню тензорборд посмотреть че там.

Нет, всетаки зажарка клипа небольшая имеется при использовании дмд. Если снижать вес весов то становится хорошо в целом. Может быть проблема из-за неуказанного d_coef?
>зажарка клипа
На клипскипе 1 вообще пересвет.
Как зажарку именно клипа определить, она же не так очевидно влияет на визуальный стиль?
А на клипскипе 3 почти идеально. Лол как так.
Где-то видел модели, к которым прямо было рекомендовано клипскип 3 использовать.
>Как зажарку именно клипа определить
Ну тут все вместе скорее у меня при использовании с дмд. Без дмд там пушка гонка самолет. Вероятно дмд слишком агрессивит просто.
>она же не так очевидно влияет на визуальный стиль
Текстовый енкодер? Влияет пиздец как.
Ну тут тренинг под натвис, он и на 1 клипскипе работает.
Обычно унет за визуал отвечает, а текст за ситуации из промта.
Напомни, что за дмд?
>Напомни, что за дмд?
Дистиллят позволяющий генерить пиздатого качества картинки в мало шагов без использования негатива или с минимальным негативом, оригинал лора https://huggingface.co/tianweiy/DMD2/blob/main/dmd2_sdxl_4step_lora_fp16.safetensors (LCM, simple, 1cfg)
Мои перепердольки дмд чтобы работало с другими семплерами и более высоким цфг https://huggingface.co/YOB-AI/DMD2MOD https://huggingface.co/YOB-AI/HUSTLE
>Обычно унет за визуал отвечает, а текст за ситуации из промта.
Тут немного другая техника тренировки лоры просто.
> Не, ты непонял проблему. Если чисто лору включать - все ок. Если включать к ней допом дмд условный то может начинать жарить на 10 шагах допустим.
Понятия не имею что ты там напердоливаешь, такое обычно с маняме чекпоинтами не юзается
> с чем?
> https://github.com/konstmish/prodigy/pull/20
> d_coef
Он в дефолте 1, это множитель лра обычный, если сильно прогорает просто ставишь 0.8-0.6 обычно
Не слушается того что пишешь, особенно если что то было в модели, но пропало
Это мемы небось какие то, с пони вообще можно было не юзать мелкий клип, другие тоже нету смысла так тренить, после 1.5 эпохи
Думал, на дистиллятах вообще обучение невозможно, на ХЛ-турбо фигня выходит.


>Понятия не имею что ты там напердоливаешь, такое обычно с маняме чекпоинтами не юзается
Да почему? Я только со своим дмд модом что пони что нубай и гоняю. Особенно нубай, потому что с оригинальным дмд там векторный графин всратый выезжает.
>Не слушается того что пишешь, особенно если что то было в модели, но пропало
Тут слушается наоборот, но пересветы я ебал.
>Это мемы небось какие то, с пони вообще можно было не юзать мелкий клип
Я вообще клип не трогал, имею в виду что вот щас устанавливаю клип и чем выше тем меньше зажар.
Вот допустим просто для примера пик 1 без убыстрялок (качество не смотрим, ниче не расписано), пик 2 +дмд. Я в курсе что у дмд фаст форвард ахуительно агрессивный, но с другими лорами нихуя подобного нет, вот ток с натрененой с теми настройками выше.
Чел, я не обучал на дистилляте. Я его применил допом к лоре, как обычно применял к любой другой модели с любыми лорами. Лоры дистилляторы просто укорачивают вектора до достиженя результата по латенту бла бла бла.

При этом если врубать вместо продижи лоры на 3к шагов тестовый прогон на адам8бит с дефолтным говном то никаких пересветов нет (и попадание в ебало но не суть, там тест на 300 шагов был)
Пиздец всё-таки, технологии уже столько лет, а всё еще дикое красноглазие с перебором сотен параметров нужно, вместо однокнопочного решения. The absolute state of AI.
Настройки были такие
--resolution="768,768" ^
--save_model_as="safetensors" ^
--network_module="lycoris.kohya" ^
--max_train_steps=300 ^
--save_every_n_steps=50 ^
--save_every_n_epochs=1 ^
--network_dim=64 ^
--network_alpha=64 ^
--train_batch_size 1 ^
--gradient_checkpointing ^
--persistent_data_loader_workers ^
--enable_bucket ^
--random_crop ^
--bucket_reso_steps=64 ^
--min_bucket_reso=256 ^
--max_bucket_reso=1024 ^
--mixed_precision="fp16" ^
--caption_extension=".txt" ^
--lr_scheduler="constant" ^
--lr_warmup_steps=0 ^
--network_train_unet_only ^
--prior_loss_weight=0 ^
--use_8bit_adam ^
--learning_rate=5e-5 ^
--color_aug ^
--seed=0 ^
По итогу че я могу скозать - продижи заебись все занюхнул, но почему-то жарит с дистиллятом, адам на константе нихуя не занюхивает особо но работает с дистиллятором. В чем проблема нахуй
>#wipe samewords
Да блять
эта интеллектуальный ценз
Так может в дистилляторе проблема. Ты захотел, чтобы какие-то странные лоры взаимодействовал идеально, я на ликорисы вообще не замахивался даже.
>Так может в дистилляторе проблема.
Проблема в тренировке лоры с продижами, другие ликорисы не на продижи работают ок.
>Ты захотел, чтобы какие-то странные лоры взаимодействовал идеально
Дистилляты не содержат концептов, клипа, каких-лмбо данных, они содержать краткие пути векторов по таймстепам, в этом суть дистиллятов, будь то турба, пцм, дмд, хупер, жопа, говно. Они задизайнены просто работать с архитектурой. У меня же проблема в том, что обе лоры работают, но моя лора на ебало бурятки в фуловом весе и с фуловым дмд (и любым другим дистиллем к слову) работает так как будто фастфорвард мультиплицируется и происходят пересветы. Не то что бы это было бы не фиксабельно, можно автоцфг ебануть или снизить веса дистиллята допустим, но я хочу просто чтобы работало как обычно, то есть с фул весом натрененой лоры и фул весом лоры дистиллята.
>я на ликорисы вообще не замахивался даже.
Ну и зря, там аналоговнетов много.
Ну так вот сложилось, не видел я чтобы кумеры юзали впринципе ускорялки. Тебе лучше видней короче как там этот дмд работать должен и стакаться
> Я вообще клип не трогал, имею в виду что вот щас устанавливаю клип и чем выше тем меньше зажар.
А если не скипать, а просто вес поменять снизив на энкодере или вообще вырубив, становится лучше?
Это не дефолт, там в 2 раза ниже лр от дефолтного, я вообще хз какой он нужен, учитывая что ты тренишь ещё более мелкую часть от мелкой части лоры, но можешь в логах у продиджи подсмотреть, да и шагов небось маловато, поэтому вместе могут не работать, дмд передавит
> не видел я чтобы кумеры юзали впринципе ускорялки.
Лол, весь сд тред на дмд сидит и пёзды в натвисе генерит. Видимо в аниметред технологии еще не дошли, до сих пор (((((masterpiece:100500))))) накатываете?
>а просто вес поменять снизив на энкодере или вообще вырубив, становится лучше?
Частично, но теряется вообще понимание концепта, отдаленно бабищи лезут похожие на датасетовские. Частично гены ок, частично пересветы. Но оно в целом также ведет себя и с включенным ТЕ, просто чуть чаще пересветы сует.
>там в 2 раза ниже лр от дефолтного
Ниже в какую сторону? Меньше ты имеешь в виду?
>да и шагов небось маловато
С шагами точно нет проблем...
Вообще вот бы продижи не джва часа тренил бы еще, смирился бы с небольшой зажаркой.
Захардкоженный мастерпис снижает гибкость модели, точно так же, как дефолтный негатив на плохую анатомию не даст сгенерить слаймотян и прочих монстродевок. Так что это всё жвачка для нормисов, пусть даже вкусная поначалу.
>Захардкоженный мастерпис снижает гибкость модели
Чушь.
>дефолтный негатив на плохую анатомию не даст сгенерить слаймотян и прочих монстродевок
Вдвойне чушь.

Сразу видно, что не пробовал.
Слева с негативами какая-то западная хуита выходит, справа слаймодевка как надо без них.
> Лол, весь сд тред на дмд сидит и пёзды в натвисе генерит. Видимо в аниметред технологии еще не дошли, до сих пор (((((masterpiece:100500))))) накатываете?
А как это вообще кореллирует с модификацией процесса шедулинга? Я вообще про форч, там нахер никому не сдались ускорялки, они все ухудшали одно время гены, максимум дипшринк или раунет видел
> Частично, но теряется вообще понимание концепта, отдаленно бабищи лезут похожие на датасетовские. Частично гены ок, частично пересветы. Но оно в целом также ведет себя и с включенным ТЕ, просто чуть чаще пересветы сует.
В датасете пересветов дохуя? Может и юнет слишком агрессивно тренился, ну попробуй d_coef = 0.75 в крайнем случае или типо того
> Ниже в какую сторону? Меньше ты имеешь в виду?
А в какую ещё это может быть сторону? Да, меньше, но сток адама для сд так же не предполагал что тренятся специфичные слои, поэтому хз какой лр нужен
> С шагами точно нет проблем
Хз почему ты в этом уверен
> технологии еще не дошли
Костыль повышенной всратости для врамлетов - технологии? Когда научитесь тренить что-либо кроме еотнейм и прознаете о дистилляциях здорового человека, тогда и можно заикаться про технологии, лол.
> Захардкоженный мастерпис снижает гибкость модели, точно так же, как дефолтный негатив на плохую анатомию не даст сгенерить слаймотян и прочих монстродевок
Ерунда. С дуру можно и хуй сломать, особенно если пользоваться типичными популярными классификаторами, которые все что не всратый дженерик слоп помечают как плохое. При здоровой реализации проблем не принесет.
Куда опаснее - эстетик алайнмент, если от хреновых тегов качества можно отказаться, то эта штука сильно бьет по вариативности, управляемости и возможности стилизовать.
Не используй шизомиксы лор на основе поникала.
Лор не использовал, это элементарная логика - нестандартная анатомия монстродевок как раз и попадает под bad anatomy. Воспроизводится на любой модели, которая хотя бы как-то может в них.
С тем же успехом можно пытаться сгенерить карандашный набросок с негативами на скетч.

>Хз почему ты в этом уверен
Потому что пикрел
>там нахер никому не сдались ускорялки
пожелаем им удачи
>они все ухудшали одно время гены
не было такого
>В датасете пересветов дохуя?
Нет
>Может и юнет слишком агрессивно тренился, ну попробуй d_coef = 0.75 в крайнем случае или типо того
Ну я точно попробую что-то, это да
>А в какую ещё это может быть сторону?
Не ну мало ли ты имел в виде ниже лр в смысле меньшей интенсивности.
>Костыль повышенной всратости для врамлетов - технологии? Когда научитесь тренить что-либо кроме еотнейм и прознаете о дистилляциях здорового человека, тогда и можно заикаться про технологии, лол.
ну всё, анимедебила понесло
> это элементарная логика
Это ошибка выжившего в другой интерпретации. Если тегать только всратый дженерик стендинг как хорошее и все остальное как плохое - так и будет. А можно этого не делать и все будет хорошо.
Лору на еот сгенерировали?
Слаймодевок просто правильно тренировать надо.
>С тем же успехом можно пытаться сгенерить карандашный набросок с негативами на скетч.
Потому что это буквально одно и то же?
Тогда как слаймы и прочие монстродевки к параметру "плохая анатомия" отношения иметь не должны вообще никакого.
Вот с криптидами всякими - слендермен тот же - уже могут проблемы возникать. Но точно не вышеперечисленным.
Вопрос точности тэгирования, короче. Если датасет со слаймами по какой-то причине протэгался как "плохая анатомия" - это проблема таггера, которую править надо, а не модели, которая на этом натренировалась.
> Потому что пикрел
Ты же писал про 300 с адамом, за 3000 считай любую лору можно научить, тут даже спецподходы не нужны
> не было такого
Lcm с hyper вспомни
>Ты же писал про 300 с адамом
Я упоминал 300 с адамом, ему 600-1000 хватает в целом и это не джва часа а 15 минут
>за 3000 считай любую лору можно научить
адаму на константе хоть сколько дай он обосрется с сохранением изменчивости модели, а продиги прям филигранно вытачивают веса и встраиваются в модель
>Lcm с hyper вспомни
Ну с лцм лорой и так понятно, а хупер неплох в конкретных вариантах лор (смол цфг 8 степ насколько я помню). Но они не единственные которые были и есть, турба как была так и осталась на высоком уровне и имеет классный фастфорвард, есть парк PCM дистиллей на котором я сидел в том числе. Сейчас я бы не сказал чо в пцм конкретно есть нужда, дмд полгода уже ебет. Пока писал, вспомнил письку в виде DC-Solver (но это уже форк семплера юнипц, а не дистиллят), которую так и не завезли в комфе.


Добрались руки до разбора лоры на части.
Слои натрененные вытащил те же, тектстовый енкодер только te2.
Итог: заработало с дмд.
слева разобранная лора, справа клип без изменений. То есть проблема офишали апрувед - в слоях текст енкодера, а конкретно в чем-то за исключением lora_te2_text_model_encoder_layers_0_ (с неучитываемыми "ff_net", "proj_in", "proj_out", "alpha")
Щас блять окажется что у te подсирал ффнет и если его убрать то все будет как пик 2 но без засветов

Хаха сука


Нихуя не пойму, разделил текстовый енкодер на 2 части te1 и te2, полностью одинаковые слои. Те же самые слои вместе с лорой дают другой результат.
Слева разделенные те + раздельные веса контента, лейаута и стиля, справа оригинал лора. Сравнил - все бля одинаковое.
А бля я тупой, я ж экстрагировал с вычитанием ффнета. Отбой. Кароче все порешал, продиги ебет за исключением того что перетренивает ффнет.
А нет нихуя.
Кароче, тут магия.
Если раздельно юзать все слои вообще - лора работает как надо, если ее собирать в один файл, то она начинает жарить. Что за хуйня вообще.


У меня буквально одинаковая лора в разных представления, а в одном один результ, а во втором другой.
Неужели как-то взаимодействуют между собой слои когда они одноврменно используются пиздец. Какие слои отвечают за связь знает кто?
Вот фул распечатка слоев, гляньте кому не лень https://pastebin.com/vHL4hJmL
Спасибо чатгпт
The LoRA layers responsible for connecting different parts of the model and potentially causing image "overcooking" when combined may involve those related to cross-layer or inter-layer dependencies. In LoRA, layers like MLP (multi-layer perceptrons), attention, and skip connections typically help layers interact. When all layers are in a single file, their interaction might lead to excessive updates, causing overfitting or "overcooking." Separating blocks likely isolates their interactions, preventing such issues.
Теперь я знаю что слои в лоре потенциально могут взаимодействовать внутри себя и вызывать проблемы. Ну ахуеть не встать теперь, щас буду вилкой MLP и атеншены чистить.
> разделил текстовый енкодер на 2 части te1 и te2, полностью одинаковые слои
В sdxl 2 энкодера и слои в них разные, могут совпадать только имена. Лору применять можно послойно/поблочно и будет разный эффект. Но это таки костыль, лучше тогда тренить правильно (с учетом специфики того же продижи) и тренить не для всего.
> Неужели как-то взаимодействуют между собой слои
И да и нет. Лора изменяет веса модели. Две лоры будут вносить два изменения, сначал та что вызывается первой, потом вторая. А уже внутри диффузиоднной слои взаимодействуют между собой обмениваясь активациями.
> за связь знает кто
Связь чего с чем? Посмотри как устроены dit блоки.
Если ты про то что сочетание лор может дать совсем не ожидаемую сумму их влияние по отдельности - это не ново, а особенность тренировки лоры.
> Спасибо чатгпт
Он даже не понял что ты спросил и выдал общее не вполне применимое сюда.
> Теперь я знаю что слои в лоре потенциально могут взаимодействовать внутри себя и вызывать проблемы
Это бессмысленная формулировка по причине описанной в начале.
> щас буду вилкой MLP и атеншены чистить
Вместо страдания ерундой лучше просто перетрень нормально. Если так интересно посмотри какие есть варианты имплементации лор для диффузии и какие слои в них тренятся/пропускаются. По дефолту, например, сверточные вообще не затронуты.
>Он даже не понял что ты спросил и выдал общее
>Лору применять можно послойно/поблочно и будет разный эффект.
Он выдал все правильно. В листе на пастебине млп блоки указаны. Любые другие лоры раскладываемые на составные части не меняют ген, в отличие от моделей с млп блоками.



>щас буду вилкой MLP
с млп, без млп, разборная говнина (с млп на борту в текст енкодерах)
шо с ебалом как говорится
таким образом срут пережаром с дмд слои mlp_fc2, небольшая потеря за универсальность тренинга


удалил mlp_fc2 пик 1
в промте прописано что должны быть сиськи, увеличил вес сисек, поулчил пик 2
не уверен конечно что я правильно расписал выжимку слоев нужных, но млфц2 точно нет, щас перепроверю
С тем же успехом можно было снизить вес или вовсе выключить лору. Парень на своей волне, ебись, хули.
> в промте прописано что должны быть сиськи, увеличил вес сисек
Если на этих и выше пикчах разные сиды то для тебя плохие новости.
>С тем же успехом можно было снизить вес или вовсе выключить лору.
Ага, губу закатай.
>Если на этих и выше пикчах разные сиды то для тебя плохие новости.
Одинаковые в пределах одного прогона.
Новая версия кроссплатформенного UI
https://rentry.co/t2i_kivy_ui_v3
Теперь скрипт разделен на два отдельных файла и залит на catbox (в rentry лишь readme)
Стиль изменен на фэнтези, убран громоздкий код стиля кнопки.
Добавлены звуки, опциональная фоновая музыка и звук окончания генерации (примеры есть в архиве).
Исправлен баг с тормозами при ожидании ответа API, теперь можно отредактировать промпт в процессе ожидания.
https://rentry.co/t2i_kivy_ui_v3
Теперь скрипт разделен на два отдельных файла и залит на catbox (в rentry лишь readme)
Стиль изменен на фэнтези, убран громоздкий код стиля кнопки.
Добавлены звуки, опциональная фоновая музыка и звук окончания генерации (примеры есть в архиве).
Исправлен баг с тормозами при ожидании ответа API, теперь можно отредактировать промпт в процессе ожидания.

Продолжаем искать лучший оптимайзер по соотношению точность/времязатраты, опираясь на эту хуйню https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Продижи делает пиздато 10 из 10, настраивается просто и понятно, не надо никаких лернин рейтов подбирать, но считает долго.
Ебнул значит Lion. Считает бодро, схватил калцепт за около 200 шагов на 5e-5. Считал 768x768 примерно 30 минут 500 шагов. В целом да, касательно теста по ссылке так и вышло, получилось похоже, при увеличении веса лоры еще похожее, но продиги вне конкуренции т.к. били в самый центр.
Тензорборды продигов (3к шагов) и лиона.
Теоретически можно было бы повысить лернинг рейт продигов раз в 5 и посмотреть как ее уебет, но зачем.
Алсо сейфгард вармап тру не работает на продигах если вармапы 0.
Продижи делает пиздато 10 из 10, настраивается просто и понятно, не надо никаких лернин рейтов подбирать, но считает долго.
Ебнул значит Lion. Считает бодро, схватил калцепт за около 200 шагов на 5e-5. Считал 768x768 примерно 30 минут 500 шагов. В целом да, касательно теста по ссылке так и вышло, получилось похоже, при увеличении веса лоры еще похожее, но продиги вне конкуренции т.к. били в самый центр.
Тензорборды продигов (3к шагов) и лиона.
Теоретически можно было бы повысить лернинг рейт продигов раз в 5 и посмотреть как ее уебет, но зачем.
Алсо сейфгард вармап тру не работает на продигах если вармапы 0.
Куда-то спешишь или планируешь массово лить куда-нибудь лоры на чаров?
Хочу как на адам8бит с константой шоб 600 шагов 15 минут, но не уебищно.
Траил я как-то продиджи на тренировку стиля/концепта.
Выходило прям плохо.
В итоге вернулся на адам/косинус.
Рад буду, если у тебя что-то выйдет.
Выходило прям плохо.
В итоге вернулся на адам/косинус.
Рад буду, если у тебя что-то выйдет.
Ну ты наверно фул слои тренил и не под модель. Я треню по технике билоры под конкретную модель, поэтому тут обосраться сложно. Меня бы и адам устроил, но он не попадает нихуя даже с много шагов.
Точнее не так, он попадает, но недостаточно чтобы назвать это полным захватом, если речь о концепте и точных деталях.
У меня в последнем случае адам попал настолько сильно, что даже как-то неловко получилось.
Чел, кого тренил, рисует фотореалистые лица, но руки у него не очень, и они слегка анканни выходят. Глаза маленькие, расположены широковато. Немного, но заметно. Хотя может ему просто такие лица нравятся.
И вот тренировка на поне это настолько точно захватила и даже слегка преувеличила, что у меня прям фейспалм случился, когда я с этой лорой генерить начал.
Хотел наоборот от этого уйти, потому что, ну, аниме-модель же, это должно стандартным аниме-стилем смягчаться как-то. Ан нет. Втренировалось намертво.
>опираясь на эту хуйню
Да эти визуализации вообще походу реальную картину не показывают нихуя. Надо распределения градиентов по всем слоям снимать, строить графики, смотреть вклад каждого слоя в лосс, и смотреть по каждому слою насколько он эффективно учится, идет ли в нем обобщение или запоминание, что от задачи по разному важно.
И я кстати, кажется начинаю понимать что такое грокинг и нахуя он может быть нужен. И почему он не заводится / плохо заводится на настоящих задачах. Так вот, есть у нас задачи чисто на запоминание и на умение (обобщение). Грокинг удается завести там, где запоминание можно полностью и бесповоротно выкинуть нахуй. В реальных задачах одного обобщения будет недостаточно, как например в языковых моделях, где функция ошибки будет требовать запомнить факты, которые невозможно обобщить.
И похоже что грокинг научились вызывать только жесткой обрубкой запоминания, что так или иначе заставляет сеть обобщать. В итоге приходим к тому, что если и пытаться грокать нейронку, то это надо делать только по той ее части, которая отвечает за обобщение, запоминание же делаем в других местах классической вжаркой, желательно отсеев градиент важных и неважных частей данных. (Применимо к диффузии, как маски лосса, ручками, либо смотреть на всякие маски атеншна, чтоб было автоматически).
И еще я скажу, что по моему мнению та же sdxl уже лучше рисует, чем художники. Если не смотреть на косяки и фейлы, то прям видно как обобщение собирает все соки из разных артов. Видимо тот же эффект, когда в vae генераторе лиц получается усредненное ебало, и оно всегда эстетически лучше даже если датасет уродов.
Допилить немного - и будет конфетка. Если правильно перенести на видосы (а не тренить на всратой псевдо-3д анимации) - то будет отвал башки. Чтобы это сделать надо понимать как сделать максимально качественное обобщение, которое будет хорошо переноситься на незнакомый класс.
Шизомысли вслух, как обычно.
> эти визуализации вообще походу реальную картину не показывают нихуя
С подключением чтоли, такой трейн-лосс неинформативен кроме совсем радикальных случаев. А градиенты скорректированы между собой и меняются, а не стоят как в примерах - иллюстрациях.
> распределения градиентов по всем слоям снимать, строить графики, смотреть вклад каждого слоя в лосс
?
> смотреть по каждому слою насколько он эффективно учится
Шизометриками по распределению значений? Если повезет то увидишь как оно "обучается", упарываясь до тривиальных решений потому что датасет мочи и говна.
> делать только по той ее части, которая отвечает за обобщение, запоминание же делаем в других местах классической вжаркой
Как все просто оказывается.
> Шизомысли вслух
This. Есть здравое зерно и мыслишь в общем в верном направлении, но по-обывательски опираешься на неприменимые решения и упрощаешь-идеализируешь. По обучению и оптимизаторам немало трудов сотворено, но они часто все эти твики уступают по эффективности простым приемам аугументации.
>Да эти визуализации вообще походу реальную картину не показывают нихуя.
Почему? Растригин функция показывает как оптимайзер справляется с переходами через локальные минимумы, насколько быстро он достигает глобального минимума и способность избегать застревания в локальных экстремумах.
Росенброк показывает способность оптимизира находить узкие пути к глобальному минимуму (проблема состоит в сложной геометрии пути к минимуму и требует высокой точности шага оптимизатора), как он справляется с ситуациями, где градиенты малы и направление минимизации сложное, насколько стабильно и эффективно он работает в "гладких", но труднодоступных областях.
То есть допустим Adam может застрять в локальном минимуме (и обосрать всю похожесть этим), и при этом он же в розенброке хорошо ебашит благодаря адаптивным шагам, но недостаточно скоростным на малых градиентах в труднодоступных местах.
Кароче, если линия быстро доходит до минимума, оптимайзер эффективен. Если линия петляет или застревает - оптимайзер испытывает трудности.
Вот опять же касательно продижи. Взял другой датасет на еотову, въебал 3к шагов, концепт схватило на 2100 примерно, на 3000 прям идеальная лора, если гены кидать сюда то деанон изи. Но! Я как и все топовые шареры пользуюсь ускорителем дмд, а с ним полная сила юнета и клипа поджаривает на больше 8 шагах. Без ускорителя зажарки нет. И это на рекомендованном лернинге в 1.0. Конечно можно обойти эту хуйню опять же, но хочется просто применить финальную лору и забыть, а не тюнить её. Вот щас поставил 0.5 лр юнета (понижение в половину) и 0.05 лр энкодера (понижение в 20 раз), посмотрим че будет.
>локальные минимумы
Существование которых в нейросетях не доказано, потому что их там, собственно, и нет.
>их нет
А по твоему магнитуды это какая-то шутка?
>локальные минимумы
>Существование которых в нейросетях не доказано, потому что их там, собственно, и нет.
Ты как в тред попал шизик ебаный?
Хитрость в том, что у нейросети Хопфилда не один минимум энергии, а несколько. Представьте себе «энергетический ландшафт» с впадинами-минимумами и горными хребтами-максимумами. Один минимум хранит фото Эйнштейна, другой — портрет Монро, а третий, скажем, страницу из букваря.
Теперь представим себе шарик, бросаемый сверху на этот ландшафт. Повседневный опыт подсказывает, что шарик скатится в ближайшую яму и останется там лежать. Физика объясняет: он стремился минимизировать свою гравитационную энергию и справился с задачей как мог. Возможно, где-то и есть яма поглубже, но до нее нужно добираться через горы, а шарик катится только вниз.
Сигнал, подаваемый в нейросеть Хопфилда, похож на этот шарик. Он тоже «скатится в ближайшую яму». Другими словами, будет преобразован в самое похожее на него изображение, хранящееся в памяти нейросети. Если входное изображение больше походит на портрет Эйнштейна, сеть и распознает его как портрет Эйнштейна, а если на фотографию Монро, система решит, что это Монро. Теперь уже нейросеть решает осмысленную и интересную задачу: она классифицирует изображения на основании опыта, запечатленного во «впадинах ландшафта».
Так физик Хопфилд изобрел новый принцип хранения информации в нейросетях благодаря своим познаниям в магнетизме. В дальнейшем оказалось, что метод по-прежнему работает, если разрешить нейронам хранить любые числа, а не только 0 или 1. То есть пиксели изображения могут быть любого цвета. И вообще нет нужды ограничиваться изображениями: в нейронах можно закодировать практически любые данные.

>Вот щас поставил 0.5 лр юнета (понижение в половину) и 0.05 лр энкодера (понижение в 20 раз)
Пидерасина...
Ясно, продиги не поддерживает раздельный лр для юнета и енкодера.
Щас попробую через скейл, но скорее всего в рот мне напихает опять.
ну почему почему продижи такой медленный ну бляяяя аштрисет
Всё я выкупил как доджить пережарку на продижи, работает с дмд теперь. Сосать блять.
В целом это все правильно, но это совсем бенчмарк и в реальности могут быть или более сложные, или более пологие варианты и прочие факторы. Ну то есть для взаимного сравнения справедливо, но могут быть другие кейсы где результат окажется возмущен.
Сильное заявление, ты хоть понял написанное в том посте?
Тебе про разделение сразу написали, поехавший
>Тебе про разделение сразу написали
Так он не поддерживается.
Как адаптировать адопт https://github.com/iShohei220/adopt в кою?
Там ссылка на пулл-реквест с примером кода
В дев ветке кохи можно вызывать любые оптимайзеры из торча и других либ. Если не заводится - library/train_util.py найди get_optimizer и впиши свой.
>В дев ветке кохи
Я имел в виду сдскриптс.
А кою ты имеешь в виду dev или kohya-dev?
Кароче есть шедулед фри продижи https://github.com/LoganBooker/prodigy-plus-schedule-free
В обсуждениях https://github.com/kohya-ss/sd-scripts/pull/1811 сказано что добавлена поддержка в это бранч https://github.com/kohya-ss/sd-scripts/tree/sd3
Но у меня нихера не работает почему-то, говорит слишком дохуя аргументов в аргументах и прочие ошибки синтаксиса (по разному писал ни один вариант не работает), ЧЯДНТ?
--resolution="768,768" ^
--save_model_as="safetensors" ^
--network_module="lycoris.kohya" ^
--max_train_steps=200 ^
--save_every_n_steps=50 ^
--save_every_n_epochs=10 ^
--network_dim=64 ^
--network_alpha=64 ^
--train_batch_size 3 ^
--gradient_accumulation_steps=3 ^
--gradient_checkpointing ^
--persistent_data_loader_workers ^
--enable_bucket ^
--random_crop ^
--bucket_reso_steps=64 ^
--min_bucket_reso=256 ^
--max_bucket_reso=1024 ^
--mixed_precision="fp16" ^
--caption_extension=".txt" ^
--optimizer_type="prodigyplus.ProdigyPlusScheduleFree" ^
--color_aug ^
--flip_aug ^
--face_crop_aug_range "0.2,0.8" ^
--optimizer_args "lr=1.0, betas='(0.9, 0.99)', beta3='None', beta4=0, weight_decay=0.0, weight_decay_by_lr=True, use_bias_correction=False, d0=1e-6, d_coef=1.0, prodigy_steps=0, warmup_steps=0, eps=1e-8, split_groups=True, split_groups_mean='harmonic_mean', factored=True, fused_back_pass=False, use_stableadamw=True, use_muon_pp=False, use_cautious=False, use_adopt=False, stochastic_rounding=True" ^
--max_grad_norm=1 ^
--seed=0 ^
--logging_dir="logs" ^
В обсуждениях https://github.com/kohya-ss/sd-scripts/pull/1811 сказано что добавлена поддержка в это бранч https://github.com/kohya-ss/sd-scripts/tree/sd3
Но у меня нихера не работает почему-то, говорит слишком дохуя аргументов в аргументах и прочие ошибки синтаксиса (по разному писал ни один вариант не работает), ЧЯДНТ?
--resolution="768,768" ^
--save_model_as="safetensors" ^
--network_module="lycoris.kohya" ^
--max_train_steps=200 ^
--save_every_n_steps=50 ^
--save_every_n_epochs=10 ^
--network_dim=64 ^
--network_alpha=64 ^
--train_batch_size 3 ^
--gradient_accumulation_steps=3 ^
--gradient_checkpointing ^
--persistent_data_loader_workers ^
--enable_bucket ^
--random_crop ^
--bucket_reso_steps=64 ^
--min_bucket_reso=256 ^
--max_bucket_reso=1024 ^
--mixed_precision="fp16" ^
--caption_extension=".txt" ^
--optimizer_type="prodigyplus.ProdigyPlusScheduleFree" ^
--color_aug ^
--flip_aug ^
--face_crop_aug_range "0.2,0.8" ^
--optimizer_args "lr=1.0, betas='(0.9, 0.99)', beta3='None', beta4=0, weight_decay=0.0, weight_decay_by_lr=True, use_bias_correction=False, d0=1e-6, d_coef=1.0, prodigy_steps=0, warmup_steps=0, eps=1e-8, split_groups=True, split_groups_mean='harmonic_mean', factored=True, fused_back_pass=False, use_stableadamw=True, use_muon_pp=False, use_cautious=False, use_adopt=False, stochastic_rounding=True" ^
--max_grad_norm=1 ^
--seed=0 ^
--logging_dir="logs" ^
Да.
>Ты как в тред попал шизик ебаный?
>Сильное заявление, ты хоть понял написанное в том посте?
Я то понял, а вы до сих пор в сказки верите и в вещи которые своими глазами никто не видел.
Почему-то в реальной нейросетке под сгд веса доезжают примерно в то же состояние что и с адамом, и ни в каких локальных минимумах не застревают. Просто делают это дольше и с разной скоростью. А адам градиенты распределяет равномерно, чтоб все веса эффективно учились. Сгд не видит не локальные минимумы, а места где градиенты затухают, если они есть, с ним обучение там идти не будет. Адам когда прогреется, увидит и накинет туда масштаба градиентов, обучение пойдет. И если у вас куча разношерстных слоев, такие проблемы так или иначе в сети возникнут.
>доезжают примерно в то же состояние
в состояние говна? доезжают
> Я имел в виду сдскриптс.
Это про него, просто dev. По своему обыкновению описание этой фичи нужно искать где-то глубоко в дебрях пулл-реквестов, или ковыряться в самом коде. Так что можешь сразу в него направиться, функция на линии около 4к.
> до сих пор в сказки верите
Чел, даже сказки лучше ложных выводов от поехов, "видевших глазами" многомерное фазовое пространство.
> в реальной нейросетке под сгд веса доезжают примерно в то же состояние что и с адамом, и ни в каких локальных минимумах не застревают
Давай подборочку реальных пруфов с реальных сеток, что сгд не уступает адаму по финальному качеству. Если бы сам что-то тренил то хотябы косвенно мог бы наблюдать поведение разных оптимайзеров и не порол подобное, эксперт - нитакусик.
> И если у вас куча разношерстных слоев, такие проблемы так или иначе в сети возникнут
Об это везде и речь.
>сгд не уступает адаму по финальному качеству.
Я про качество ничего и не говорил, я говорил про локальные минимумы. И из моего поста прямо следуют истинная причина почему сгд хуёвее работает.
У тебя есть лучшее объяснее? Так выкладывай.
Уточню, что с сгд при затухающих градиентах сеть не обучится никогда вообще. Всякие адамы и оптимизаторы посложнее имеют некий шанс пропердеться и завестись. Теперь представляешь, что на отрезке между тем где градиентам пизда, и тем где норм даже для сгд, есть куча промежуточных значений, и понимаешь зачем нужны адаптивные оптимайзеры. Как бы не для того чтобы из несуществующих локальных минимумов выскакивать, ибо даже если они есть, в перепараметризованной сети их можно просто обойти через +1 +2, +3... измерение, представь прикинь да?
> я говорил про локальные минимумы
Утверждал что их не может существовать в "реальных сетях" и какие либо иллюстрации способности скипать локальные экструмумы в пользу основного роли не играют.
> в реальной нейросетке под сгд веса доезжают примерно в то же состояние что и с адамом
> почему сгд хуёвее работает
> сгд при затухающих градиентах сеть не обучится никогда вообще. Всякие адамы и оптимизаторы посложнее имеют некий шанс
Или крестик, или штаны
> их можно просто обойти через +1 +2, +3... измерение
Застрянешь в одном множестве и все остальное навернешь на ложный оптимум. В тех же лорах к диффузии с примитивными датасетами от этого даже йоба оптимайзеры не спасают и только лихие аугументации могут вывезти.
> и понимаешь зачем нужны адаптивные оптимайзеры
Раз понимаешь, то зачем набрасываешь?
Хэлп, как юзать эту хуету
Не доказана возможность достигнуть глобального минимума, лол, а не вот твоя хуита.
>По своему обыкновению описание этой фичи нужно искать где-то глубоко в дебрях пулл-реквестов, или ковыряться в самом коде. Так что можешь сразу в него направиться, функция на линии около 4к.
Я похоже слишком тупой, не могу порешать вопросик ни с адоптом ни с шедулерфрипродижи. Уже даже вынес аргументы в жсон файл отдельный и прописал в трейнсутил что надо их читать, а оно все равно нихуя не грузит.
Traceback (most recent call last):
File "K:\sd-scripts\sd-scripts-dev\sdxl_train_network.py", line 185, in <module>
trainer.train(args)
File "K:\sd-scripts\sd-scripts-dev\train_network.py", line 367, in train
optimizer_name, optimizer_args, optimizer = train_util.get_optimizer(args, trainable_params)
File "K:\sd-scripts\sd-scripts-dev\library\train_util.py", line 4153, in get_optimizer
key, value = arg.split("=")
ValueError: not enough values to unpack (expected 2, got 1)
Traceback (most recent call last):
File "C:\Users\user\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 196, in _run_module_as_main
return _run_code(code, main_globals, None,
File "C:\Users\user\AppData\Local\Programs\Python\Python310\lib\runpy.py", line 86, in _run_code
exec(code, run_globals)
File "C:\Users\user\AppData\Local\Programs\Python\Python310\Scripts\accelerate.exe\__main__.py", line 7, in <module>
File "C:\Users\user\AppData\Local\Programs\Python\Python310\lib\site-packages\accelerate\commands\accelerate_cli.py", line 47, in main
args.func(args)
File "C:\Users\user\AppData\Local\Programs\Python\Python310\lib\site-packages\accelerate\commands\launch.py", line 1017, in launch_command
simple_launcher(args)
File "C:\Users\user\AppData\Local\Programs\Python\Python310\lib\site-packages\accelerate\commands\launch.py", line 637, in simple_launcher
raise subprocess.CalledProcessError(returncode=process.returncode, cmd=cmd)
Бляя, я наконец-то понял почему на высоких таймстепах лосс падает.
Передаю вам, все элементарно. Итак, допустим мы берем 1000-й таймстеп, обхуяриваем картинку шумом, от картинки не остается нихуя. Наш таргет лосса - шум, не отличается нисколько от получившиеся картинки, ибо картинки в ней уже нет. Соответственно модели тоже похуй, она видя что ей суют 1000-й таймстеп, просто пропускает его через себя без изменений, довольно получая на выходе нулевой лосс, в независимости от того какая вообще картинка была у нас в начале и какой промт. При снижении таймстепа этот эффект постепенно пропадает и лосс растет, достигая максимума где-то на 2/3 от нуля.
Объясняет, почему инференс высоких таймстепов дает шумные пики - потому что модель в основном обучалась пропускать шум, слабо его меняя.
Месяца два у меня заняло допереть (прочитать) что диффузия обучается только по одному шагу таймстеп - > 0, а не таймстеп -> меньший таймстеп, пиздец. Про это чет прямо никто не говорил, а в некоторых видосах как-будто бы тоже путали и говорили про итеративный денойз при обучении, не помню, но по крайней мере именно так в бошке отложилось.
Передаю вам, все элементарно. Итак, допустим мы берем 1000-й таймстеп, обхуяриваем картинку шумом, от картинки не остается нихуя. Наш таргет лосса - шум, не отличается нисколько от получившиеся картинки, ибо картинки в ней уже нет. Соответственно модели тоже похуй, она видя что ей суют 1000-й таймстеп, просто пропускает его через себя без изменений, довольно получая на выходе нулевой лосс, в независимости от того какая вообще картинка была у нас в начале и какой промт. При снижении таймстепа этот эффект постепенно пропадает и лосс растет, достигая максимума где-то на 2/3 от нуля.
Объясняет, почему инференс высоких таймстепов дает шумные пики - потому что модель в основном обучалась пропускать шум, слабо его меняя.
Месяца два у меня заняло допереть (прочитать) что диффузия обучается только по одному шагу таймстеп - > 0, а не таймстеп -> меньший таймстеп, пиздец. Про это чет прямо никто не говорил, а в некоторых видосах как-будто бы тоже путали и говорили про итеративный денойз при обучении, не помню, но по крайней мере именно так в бошке отложилось.
Ой пиздец я 12 часов ебался, а оказалось что виноват --optimizer_args который никак не может обработать кал. Убрал оптмиизер аргс и он загрузил дефолтные из установленного пакета в питон. Теперь вопрос как эту хуйню модифицировать то блять, дкоэф там выставлять вот это всё.
Гпт подсказывает None раскавычить.
Да я у гпт тоже спрашивал, ни один его выперд проблему не фиксанул, коя скрипт тупа не может обработать весь поток шизы в аргументах. Из жсон файла тож прочитать не может. А определенные аргументы я прописывать не додумался чтобы зачекать поведение. А любом случае я 50 шагов отпердолил и он прекрасно начал схватывать калцепт не пережаривария нихуя вообще, а еще в 12 гигов два батча 768х768 влетают и еще место остается, и это все не 8бит при этом. Вобщем включил потестить на 3к шагов, посмотрим че будет на дефолте, пока что я поражен тех частью этой хуйни и кволити результата на тест прогоне. А еще кстати лабильность модели основной сохраняется дико. Но минус есть, в тензорборде всего три графика, один из которых сука прямой как палка юнет, и два лосса. Хуй поконтроллишь ну теоретически.
>в 12 гигов два батча
А есть ли смысл делать два батча а не накопление градиента 2? По-моему это математически одно и то же.
>в тензорборде всего три графика, один из которых сука прямой как палка юнет, и два лосса. Хуй поконтроллишь ну теоретически.
На лоссы диффузии смотреть бесполезно. Хотя бы по таймстепам надо делить.
> >в 12 гигов два батча
> А есть ли смысл делать два батча а не накопление градиента 2? По-моему это математически одно и то же.
Стабильность больше при сравнении двух градиентов одновременно и схождение болиелутше. Накопление это костыль для врамлетов.
Так на 2 градиентах это должно быть именно что математически эквивалентно, только надо делать два прохода, если ты уже хранишь весь градиент с первого, то выигрываешь минус активации с первого, потому что 2 градиента хранить не надо, либо первый, либо усредненный уже. Хотя на 2 батче можно хранить только активации, условно, градиент вычисляется на лету. Надо смотреть, может и не дает выигрыш, смотря какой оптимайзер.
Может хуйню пишу. Это скорее вопрос.
Да зачем тебе эта ебля нужна, просто раздели лр, поставь 0.25 на энкодер, он постоянно горит с этим говном, благо хоть кто то пр принёс
> Итак, допустим мы берем 1000-й таймстеп
И получаем разденойзенную картинку
> При снижении таймстепа этот эффект постепенно пропадает и лосс растет
Вот если брать нормальный график шедулера, а не то что ты расписал, то чем ниже таймстеп, тем выше будет лосс у эпсилона, нулевой так вообще с багом, и не зашумляет полностью картинку, а если даже это пофиксить, он действительно нихуя ничему дельному не учится, отсюда в пейпере про фикс и юзали впред, из за этого кстати всякие минснр гаммы и дебилоседы появились ещё в старом обсуждении у кохьи, которые нижние таймстепы душат
> поставь 0.25 на энкодер, он постоянно горит с этим говном
Нахуя конкретно енкодер пердолить если рекомендация ставить на лернинг 1 и не ниче с ним не делать. Я выставил --lr_warmup_steps, --prior_loss_weight=0.7 и d_coef=0.6 и одна из этих говнин вообще убрала какой-либо зажар. Осталось понять что.
Короче репортирую по шедуледфри, результат бомбический.
Трен занял 3 часа 50 минут на 3к шагов.
Уже на 600 шагах результат очень похож, на 700 копия. Но! Опять с использованием дмд есть небольшой зажар на промежуточных моделях.
Но тут момент... загружаю 3к шагов финал модель и там нет никакого зажара и стопроцентное сходство. Ахуеть вот это меджик.
Лажно пизжу в некоторых генах есть небольшой зажарчик конкретных элементов на 3к шагов (допустим слишком насыщенная одежда), но в основном супер стабильно.
Узнал как расписывать аргументы в шедулерфри чтобы не боесоебило кстати, попробую запустить тесты аргов чтоб вообще без зажаров результ вышел.
Лабильность модели сохраняется идеально есличе, даже с выключенным клипо концепт лезет через веса, тренилось все как обычно тупа на токен. Даже фигуру идеально спиздило.
> Нахуя конкретно енкодер пердолить
Потому что именно он постоянно и горит, тренить клип, тем более ради одной штуки ещё и с одинаковым лром юнета только хуже сделает, похуй на все эти рекомендации, когда что то начинает идти не так, они вообще там мемный шедулер когда то рекоммендовали
> Осталось понять что.
Ты просто снизил коэф лра энкодера в том числе, оно чуть меньше от этого зажарилось
>Ты просто снизил коэф лра энкодера в том числе
Базовичково я лр не менял, дкоэф это не просто мультипликатор значений, а коэффициент веса дельты, он определяет насколько сильно изменения, вносимые при тренировке модели или ее донастройке должны влиять на веса. Приорлосс вообще позволяет не забывать модели исходные концепты модели на которой тренится чтобы сохранять лабильность.
>оно чуть меньше от этого зажарилось
Ну тащемта оно вообще не зажарилось.
А в шедулерфри версии есть еще аргумент prodigy_steps который я не понил что делает но результат судя по всему будет еще более точным лол. Еще надо почекать как сейфгардвармап работает (и работает ли вообще бля), это ж всетаки продижи.

>На лоссы диффузии смотреть бесполезно.
Ну я бы не скозал что бесполезно. Первая промежуточная лора которая имеет все сходство с субъектом обучения находится на 700 шагах, а это как раз среднее значение по обучению. Перфект поинт это где-то 1200 шагов, что по лоре с этим шагом и видно. Софт пик где-то на 1500-1600 и там уже начинаю концепты спизженные из датасета сами лезть (допустим рука с мобилкой типа селфи, вот буквально 1400 степ - нет, все что после 1400 - есть).
Начиная с 1800 лосс средний падает и по факту растет сходимость просто еще больше чем надо.
Но самое интересное начинается с 2200: если указывать какойнибудь токен основной модели (pussy допустим), он без веса будет игнорироваться, но на 2600 появляется и остается вплоть до конца.
То есть когда лосс опускается - он обучается на датасете, когда лосс растет - он делает схождение с данными основной модели.
То есть мы можем просчитать количество степов когда не будут применены (теоретически) захваченные концепты из модели без их указания. Не то чтоб это было пиздец как нужно, но кому надо сохранить точность основной модели полностью - почему нет.




Может кому будет полезно.

Первые три чекпоинта немного по другому описал для ясности


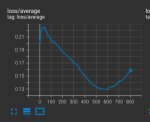
> > Итак, допустим мы берем 1000-й таймстеп
>И получаем разденойзенную картинку
А? Тысячный же это чистый шум, а нулевой это исходное изображение. Не понял че ты сказать хотел.
>нулевой так вообще с багом, и не зашумляет полностью картинку
Может тысячный?
Кароч, в любом случае, в моем посте я полную хуйню спизданул, так что исправляюсь. И еще когда я сегодня спать ложился, на меня внезапно снизошло озарение и я наконец-то понял всю эту хуйню с предсказанием шума а не изображения, зачем она нужно и почему.
Итак, исправляю
>лосс растет, достигая максимума где-то на 2/3 от нуля.
Лосс продолжает расти, и к нулевым таймспетам достигает максимума. Правильные графики на пикрилах, третий график что будет если выкинуть из обучения диапазон 800-1000, где в основном только шум, и там модель особо ничему не учится.
Что же касательно того, нахуя и почему предсказываем шум? Момент, истинную суть которого никто нормально не объясняет, довольствуясь тем что ну прост так типа стабильнее и лучше работает)) Заебись, да? Сразу все стало понятно.
Оказывается, что задача предсказать шум для модели действительно намного проще, чем предсказать изображение. Представляем, что мы добавляем не шум на изображение, а какие-нибудь рандомные фигуры, белые кружочки, квадраты, которые будут "закрывать" изображение. На низких таймстепах таких фигур будет мало, на высоких все изображение заполнится белым. Если бы мы предсказывали само исходное изображение, модели бы приходилось из нихуя сразу выдумывать недостающие части картинки чтобы удовлетворить лоссу, и это очень сложно, тогда как в нашем случае модели лишь нужно найти и указать на "закрытые места".
Это понятная и простая аналогия, из которой можно самостоятельно додумать и понять именно суть, но она не объясняет, а почему это вообще работает?
Ну, во первых, эта аналогия неправильная, настоящий шум работает по-другому, его предсказание представляет из себе некую смесь "закрытых мест" и инфы, которую надо добавить в картинку. Но для простоты, будем представлять дискретный шум, который полностью блочит определенные области картинки.
Как же готовая модель выдает картинку? А очень просто. Наша модель работает хорошо, но не идеально. Поэтому когда мы подаем в нее чистый шум, да еще и наебываем ее, говоря что это не тысячный таймстеп а какой-нибудь 800, то модель показывает нам весь шум, кроме самого осмысленного. Убирая весь левый шум, мы постепенно создаем картинку. Получается, что где-то нарандомило шум, который похож на то что нам нужно, а модель немного проебалась и не удалила его.
Казалось бы, что в таком случае чем лучше мы учим модель, тем хуже она должна работать, но нет, чем лучше модель, тем более осмысленный шум она оставляет. Опять же, помним, что в реальности модель предсказывает не только "закрывающий" шум, на инференсе она не будет дожидаться пока нужный шум идеально нарандомится, а напрямую добавит какие-то части изображения через разницу. Эти два эффекта работают вместе, и именно их баланс дает стабильность при обучении. И если представить в голове весь процесс обучения на предсказании исходного изображения, то там такой стабильности и баланса нет. Хотя если разобраться в фундаментальных проблемах и скомпенсировать их, то наверное можно и так учить так же хорошо.
Еще два нюанса, как уже говорил, на тысячном таймстепе модель просто пропускает через себя шум, ничему не учась, на околотысячных тоже можно забить на обучение, и в основном пропускать шум. На околонулевых добавляется мало шума и предсказание, лосс, идет тоже по оч маленьким областям, да и модели тяжело понять, где есть шум, а где его быть не должно, чем меньше добавленный шум, тем тяжелее "попасть в цель". Получается много ошибок, большой лосс, сосредоточенный на маленьких областях, как раз то что может приводить к нестабильности и прожарке.
Так накопление градиентов тоже можно юзать, оно типа симулирует что у тебя типа карточка попизже будет. А если у тебя и так влезают 2 настоящих батча и ты еще выставляешь условно 2 градиента, то это эквивалент 4 батч сайзу и можно количество шагов делить на 4. Да, там небольшая потеря скорости, но количество шагов скомпенсирует в плюс.
Скрипт генерации captions с Grok vision
https://rentry.co/grok-tagger
(Так же, как и с deepdanbooru, результат нужно чистить вилкой)
https://rentry.co/grok-tagger
(Так же, как и с deepdanbooru, результат нужно чистить вилкой)
Мне кепшены из торигейта нравятся, но там хуман лангвиж, хотя ему можно данбуру теги скормить.
а какова хуя --save_last_n_epochs_state не сохраняет стейты? ему отдельно нужен --save_state чтоли сука блять
Пиздец, ну хоть недалеко обучилось ладно
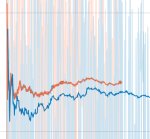
Какой параметр отвечает за такое поднятие графика лосса относительно эталонного обучения? вейт дикей же? в нижнем графике он 0, в верхнем 0.1
Кому интересно, в 12 кеков с вычищенной памятью до 0.3 занятой помещается полностью (11.7) тренинг с декомпрессией весов (DoRa) 768x768 с 1 батчем в 64 дименшена и 64 альфы.
Под шедулерфри продижи офк.
> Может тысячный?
Почитал внимательно, да походу ты прав, я ошибочно думал про график таймстепов наоборот. Ты же чекал вот это? https://arxiv.org/abs/2305.08891 там предлагается использовать комбинацию из предсказания шума и картинки как раз, как решение неэффективности предсказания шума
Перекатываться пора, есть идеи для обновы шапки?
Да, щас покажу
Ну из того что я открыл для себя это
1. Билора тренинг (2-3 слоя, опциональный клип если под токен, на выходе супер изи нобрейн лора бест куолити, тренировка под модель, можно юзать каждый слой блок слоев отдельно потом)
B-Lora https://github.com/yardenfren1996/B-LoRA
https://github.com/ThereforeGames/blora_for_kohya
Видел коя билору в какойто ветке сдскрипт
2.ЛЛМ кепчер, наверно лучшая реализация для локального хуманг лангвиж кепчера картинок, можно кормить буру теги для лучшего гена
Модель в nf4 https://huggingface.co/2dameneko/ToriiGate-v0.3-nf4/tree/main
Скрипт для использования https://github.com/2dameneko/ide-cap-chan
3.Бесшедулерный птимайзер Prodigy с малыми требованиями для врама (была гдето таблица сравнений на гитхабе, я проебал, кароче прям вообще минимально занимает ресурсов) и такой же крутой точностью, плюс там адопт встроен если надо
https://github.com/LoganBooker/prodigy-plus-schedule-free
4. Тесты магнитуды чтобы понять болиелимение что там из оптимизеров кал а что вин
https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
5. DoRA трейнинг aka декомпрессия весов (летом завезли поддержку и тренинг везде где только можно есличе) от нвидии, краткая суть что кароч дора это больше файнтюн, чем классическая лора, но при этом лора https://civitai.com/articles/4139/the-differences-between-lora-and-fine-tune-as-well-as-nvidias-newly-released-dora-technology
Вроде все годное вспомнил.
>Видел коя билору в какойто ветке сдскрипт
это лишнее, пока писал мысль потерял, не обращайте внимание
>Почитал внимательно, да походу ты прав, я ошибочно думал про график таймстепов наоборот.
Да, я тоже сначала вдуплить не мог где какая сторона у графиков. Однозначно верный вариант: нулевой таймстеп - картинка. На нулевых лосс выше всего. На инференсе нулевые таймстепы - последний этап генерации.
>Ты же чекал вот это?
Уже видел, но пока не читал. Да, очевидно, сейчас не самый эффективный баланс потерь и обучение можно сделать лучше.
Вообще модели лучше всего учатся не когда задача тривиальна, а когда сложность постепенно поднимается так, чтобы она всегда была "выше среднего". То есть тривиальные задачи просто порожняком проходят, на сложных задачах модель метается туда-сюда и с трудом находит решение, если находит, и если не пытается запомнить.
И для разных частотных компонент картинки нужен разный подход. Я бы вообще взял 2-3 разных модели, даже может с разной архитектурой, и по-разному их учил. Одна на композицию, другая на хайрез. Так-то даже сейчас ничего не мешает заинференсеть сначала полтораху, потом передать в sdxl латент через vae, а если vae одинаковый, то и перегонять через него не надо. Получается такой немного всратый аналог stable cascade.
Еще я думал кто-то обратит внимание, но в первом посте я еще по одному моменту хуйню спизданул. То что из-за того что на тысячных таймстепах модель учится пропускать большую часть шума - якобы из-за этого получаются шумные начальные пики. Это не совсем так, потому что тут я зыбыл про то, что предсказанный шум будет вычитаться. То есть в идеале, на тысячном таймстепе, при инференсе на выходе модели будет вообще нихуя. Потом шаг таймстепа уменьшается, и получается "равномерная" пустая картинка с низким количеством деталей. Потому что если мы посмотрим, это именно то, чему модель обучалась, когда шума дохуя, его вычитание не дает исходную картинку, а дает слабый остаток от картинки. Этот остаток при инференсе нужен только чтобы извлечь из него общую яркость, композицию, силуэты. Потом к нему добавляется еще шум, от всратых деталей ничего не остается, остаются только низкие частоты (которые на этом таймстепе обучаются лучше и точнее высоких). Так и получается постепенно картинка. То есть, еще раз, генерим низкие частоты - на выходе хорошие низкие, всратые высокие. Затираем высокие шумом, инференсем таймстеп пониже, получаем уже лучше частоты повыше, самые высокие затираем... и так по кругу.
В автоматике настройка Live preview display period на единичку, чтобы наглядно всегда видеть этот процесс.
Я бы хотел еще видеть плот всех негативов, и позитивов до cfg, но чет не нашел как это сделать, есть идеи? Кроме как поставить лапшу. А в ней вообще можно?
> 1. Билора тренинг
> 5. DoRA трейнинг
Обе надо сюда https://2ch-ai.gitgud.site/wiki/tech/lycoris/ короче добавить. Дора кстати отвратительно себя с нубом показывает, судя по кумерам с форчка, с переносимостью всё очень плохо
> 4. Тесты магнитуды
Согласен, полезно глянуть
> 3.Бесшедулерный птимайзер Prodigy
Ну типо хз куда его пихать, что теперь каждый оптимайзер чтоли расписывать в шапке? В вики бы про них тоже пукать по хорошему
> ЛЛМ кепчер
Да, тоже полезно, для того же флюкса или любой хуйни с т5
Я вообще про более фундаментальные изменения по типу флоу матчинга, написать бы хоть что нибудь чтоли, лол. Сейчас накидаю чего нибудь, скину

Ну вот так накидал короче https://cryptostorm.is/paste/?bb041b776c0dea68#F35DKYgAt9TFF7U5r4pkDrdEVTSubdUDJofmdNYwUQr3 можно ещё пикчи с архитектурами флюкса и сд3 прикрепить дополнительно, правда без папич-эдита они малоинформативны
>судя по кумерам с форчка
Нашел на кого равняться лол.
>Дора кстати отвратительно себя с нубом показывает
Дора это просто декомпрессия весов чтобы в разы больший рендж параметров вфайнтюнить в модель даже при сниженном дименшене (а меньше дименшены - меньше параметров в работе). Тут скорее неправильно подобранный оптимайзер, т.к. моих еот дора да и билора + продиги/продигишедулерфри копирует просто пиздец как крута.
>Ну типо хз куда его пихать, что теперь каждый оптимайзер чтоли расписывать в шапке?
Смотри какой прекол. Продиги второй по популярности оптим, да и то только потому что по дефолту он медленнее тренит и больше ресурсов требует (а пислайсер не реализован допустим в сдскрипт или я не нашел просто) нищенки сидят на адам8бит даже по этому некротреду если адам вобъешь тут 7 постов страдальцев на 8 битах и дрочат свои шедулеры чтобы экономить врам, а остальные просто на адаме потому что ну так делает большинство и в гайдиках конфигах написано, а че у них времени чтоли много чето тестить выбирать там, хуяк хуяк и в продакшен дженерик лору говноквалити. Шедулерфри разработка лицокниги для оптимизации общего ебучения, позволяет упростить и уменьшить ресурсоюз оптимайзера. По итогу получается что продиги шедулер фри потребляют как адам8бит, но при этом это продиги, а значит ебать колотить качество и захват + возможность выставить дикий лернинг и тольковыиграть от этого потому что продиги адаптивный. То есть это гейченжер для домашнего обучения по сути и аналоговнет. Поэтому ящитаю что продиги шедулер фри просто обязан быть в шапке.
>
> Я бы хотел еще видеть плот всех негативов, и позитивов до cfg, но чет не нашел как это сделать, есть идеи?
Что ты имеешь ввиду "до"? Они же неразрывно идут вроде в процессе генерации а не накладываются как то после?
> Дора кстати отвратительно
Кстати дора настолько "отвратительна" что одмены цивита перетренивают модели в своем пейвольном сервисе генерации в доры. Синк эбаут ит.
> Нашел на кого равняться лол.
Так им она в первую очередь и зашла во времена поней, там 2.5 модели энивей было с неперебиваемым дефолтом, а вот с люстрой и нубом там у них одни проблемы я только видел с дорами, конфиги там я ебал ещё правда, у кого то нойз оффсет, у кого то ещё куча каких то мемов навалена была
> Тут скорее неправильно подобранный оптимайзер, т.к. моих еот дора да и билора + продиги/продигишедулерфри копирует просто пиздец как крута.
А на какой модели ты кстати тренил, с какой юзал, и пробовал ли юзать с другими? Я туда уже про неё добавил инфу, вместе с б-лорой https://2ch-ai.gitgud.site/wiki/tech/lycoris/
> Шедулерфри разработка лицокниги для оптимизации общего ебучения, позволяет упростить и уменьшить ресурсоюз оптимайзера. По итогу получается что продиги шедулер фри потребляют как адам8бит, но при этом это продиги, а значит ебать колотить качество и захват + возможность выставить дикий лернинг и тольковыиграть от этого потому что продиги адаптивный. То есть это гейченжер для домашнего обучения по сути и аналоговнет.
Ну звучит конечно нихуёво, сам я пробовал шедулфри версию адама с флюксом, оно жрало наоброт только больше а на выходе получилась хуита уступающая обычному 8битному дженерик калу в итоге, поэтому не впечатлился, но ты конечно забайтил попробовать версию с продиджи, там разделения лров нету? Это важнее всего для него
> Продиги второй по популярности оптим, да и то только потому что по дефолту он медленнее тренит и больше ресурсов требует
У него предок дадаптейшен, а у того всё равно адам, так что это просто по сути адам на стероидах, конечно если ресурсов достаточно то лучше просто продиджи юзать
> Поэтому ящитаю что продиги шедулер фри просто обязан быть в шапке.
Давай лучше так, отдельную просто страницу в вики можно сделать и туда про оптимайзеры пукать, в шапку всё не влезет, если начать расписывать
> пислайсер
Это кстати что такое?
Скинь ссылкой о чём ты пишешь, я понятия не имею что там за сервисы у них с дорами
>судя по кумерам с форчка
>Нашел на кого равняться лол.
Блидинг эдж от технолоджи!
Без шуток, 95% моих ограниченных знаний о том, как с нейронками работать, какие пресеты тренировки для лор юзать, как нейронки вообще устроены и что там с чем внутри моделей взаимодействует, а так же куча всего другого - оно с форчка и двача взято.
Концентрат всех прикладных знаний по нейронкам - он как раз тут и на форчке.
>конфиги там я ебал ещё правда, у кого то нойз оффсет, у кого то ещё куча каких то мемов навалена была
Вот я про это и говорю. Там есть уникумы с половинкой мозга, который ищут грааль тренинга через дименшен 1 и постоянную смену оптимайзеров во время обучения например. Не то что бы я был против шизоэкспериментов, просто надо отдавать отчет что у всех есть скилишуе в той или иной мере.
>А на какой модели ты кстати тренил, с какой юзал
Ну так как еот, то я пробовал все топ модели нсфв - бигасп, натвис, антерос, рсметс, че там еще клевое есть а вспомнил лустифай от местного онончека насколько я понял
Сейчас основная модель для прогонов это натвис 2.7
>и пробовал ли юзать с другими?
Ну тут нюансы же.
Если лора тренится под конкретный файнтюн с TE (а я с TE треню обычно) то смысла особого юзать с другими нет (но строго говоря натренненное на натвисе 2.7 работает на всех прошлых, т.е. у них плюс минус одинаковая клиповая обработка от версии к версии что очевидно), но если зашизеть и применить дору от натвиса к лустифаю, то оно выдаст похожий субъект и если поколдовать с весами то будет выдавать то на что тренилось даже с TE. А если отключать TE, то оно применит веса и если веса хорошо взяли на себя концепт (а это правильно настроенный оптим), то оно выдаст субъект тренировки, но со всеми возможностями клипа новой модели.
Если тебе универсальное надо что-то то очевидно тренить надо на базе.
>Я туда уже про неё добавил инфу
Ок. Дора кстати использует локон по дефолту, если иное не указано.
>там разделения лров нету? Это важнее всего для него
Есть.
>конечно если ресурсов достаточно то лучше просто продиджи юзать
Ну тут с какой стороны смотреть. Если нужны лишние батчи или более изъебистые настройки, то при шедфри этого всего больше можно навалить. Даже у меня на шедфри при определенных хороших настройках и переводе 12 гиговой видяхи в режим неиспользования в системе может влезть батч 3 без пердежа на шаредврам. Прикинь сколько батчей залезет в 24 гига.
>отдельную просто страницу в вики можно сделать и туда про оптимайзеры пукать, в шапку всё не влезет, если начать расписывать
Норм
>Это кстати что такое?
Гиперпараметр, призванный уменьшить объем памяти, необходимый для хранения дополнительных векторов Prodigy, используемых для оценки скорости обучения. При значении 11, это должно снизить потребление памяти примерно на 45%.
>Скинь ссылкой о чём ты пишешь, я понятия не имею что там за сервисы у них с дорами
Неправильно выразился. Ну на цивите запилили отдельную категорию для дор же, их стафф мемберс тоже угарают по дорам. Плюс есть посты типа пикрела где они планируют добавить поддержку дор (пиздец сложно конечно, там буквально коя у них в качестве тренера, один аргумент разрешить добавлять), но чет никак не добавят.
Я за дедомодели не шарю особо, но верю что переносится более менее, с нубом ещё такая хуйня ведь что его компьютом закидывают на похуй, при этом результаты от такого удручающие, ну и доры вот тоже как то хуёво показывали себя у кумеров
> Ок. Дора кстати использует локон по дефолту, если иное не указано.
Да, я знаю, что там не все алгоритмы ещё поддерживаются, стоит типо уточнить?
> Даже у меня на шедфри при определенных хороших настройках и переводе 12 гиговой видяхи в режим неиспользования в системе может влезть батч 3 без пердежа на шаредврам. Прикинь сколько батчей залезет в 24 гига.
Подожди, но 3 батча влезут и с обычным продиджи в 12 в 1024 с энкодером, хз зачем там оптимизации ещё, ну в диме 16 естественно. Прочитал я оригинальное репо этого скедулфри, там типо рекомендуют лр с адамом задрать между х1-х10 и не юзать шедулер, ну констант с вармапом видимо, чтобы достичь перформанса обычных шедулеров по типу косина, ну хз, хотя продиджи сам подстроится
> Гиперпараметр, призванный уменьшить объем памяти, необходимый для хранения дополнительных векторов Prodigy, используемых для оценки скорости обучения. При значении 11, это должно снизить потребление памяти примерно на 45%.
Я уже почекал, да довольно жирный форк там вышел, спорные решения как и он сам пишет есть правда
> Неправильно выразился. Ну на цивите запилили отдельную категорию для дор же
Если их достаточно доебать чем то, то запилят что угодно, а так там как раз насколько помню просто какой то шиз усирался ради добавления категории, хотя это по сути просто очередной алгоритм ликориса, там и поинтереснее есть, по типу glora, про которую нихуя нигде не написано, но иметь охуенную генерализацию, если оно работает конечно как задумано, это заебись
> Плюс есть посты типа пикрела где они планируют добавить поддержку дор (пиздец сложно конечно, там буквально коя у них в качестве тренера, один аргумент разрешить добавлять), но чет никак не добавят.
Ну вот видно уровень, похуй им уже полгода, даже шиз усираться перестал и забил, хотели бы, уже бы давно и параметров с оптимайзерами навалили и нормальный инференс диковинных впредов
Ладно короче, вот так тогда https://cryptostorm.is/paste/?32b53a75234d8b10#EVX5NyEYAzd27x6baVZS6JtCMBX3wk5Aei5y2FdTGSYY
Туда же пихнул вот это, по быстрому накатал https://2ch-ai.gitgud.site/wiki/tech/optimizers/ про самые важные
> Я за дедомодели не шарю особо, но верю что переносится более менее, с нубом ещё такая хуйня ведь что его компьютом закидывают на похуй, при этом результаты от такого удручающие, ну и доры вот тоже как то хуёво показывали себя у кумеров
Ну незнаю, дай мне микродатасет какойнить с чемнить, я уверен на 99% будет изишно трениться.
> > Ок. Дора кстати использует локон по дефолту, если иное не указано.
> Да, я знаю, что там не все алгоритмы ещё поддерживаются, стоит типо уточнить?
Я не уточняю, но вообще можно уточнять. Но локон норм и так.
> > Даже у меня на шедфри при определенных хороших настройках и переводе 12 гиговой видяхи в режим неиспользования в системе может влезть батч 3 без пердежа на шаредврам. Прикинь сколько батчей залезет в 24 гига.
> Подожди, но 3 батча влезут и с обычным продиджи в 12 в 1024 с энкодером, хз зачем там оптимизации ещё, ну в диме 16 естественно.
Че за приколы, не влезут, ток что проверил, в 1024 с букетами до 768 еле влезает один, с двумя уже на рам протик.
Вообще речь шла у меня в посте про 64 дименшен такто, там один батча то еле влезает, что уж говорить о двух трех.
>Прочитал я оригинальное репо этого скедулфри, там типо рекомендуют лр с адамом задрать между х1-х10 и не юзать шедулер, ну констант с вармапом видимо, чтобы достичь перформанса обычных шедулеров по типу косина, ну хз, хотя продиджи сам подстроится
У меня лр на юнет какраз 10 щас а на те 0.5, буквально за 20 степов хватает ебало например. Но там нюансов поднастроек много.
Вармап не юзаю, его как бы заменяет продижистепс параметр, который ищет оптимум лернинг и фризит его. Но вообще, вот те настройки которые по дефолту идут они хорошие для вката, ток зажарят ТЕ с большой вероятностью, что в принципе не большач проблема чтоб пощупать.
> > Неправильно выразился. Ну на цивите запилили отдельную категорию для дор же
> Если их достаточно доебать чем то, то запилят что угодно, а так там как раз насколько помню просто какой то шиз усирался ради добавления категории
Не, один чел не сможет так сделать, цивит бы в помойку быстро превратился. Тут дору взяли потому что не хуй с горы сделал а нвидиеподсосы.
>хотя это по сути просто очередной алгоритм ликориса
Это скорее алгоритм ДЛЯ ликориса. И ничеси очередной, почти полноценный файнтюн без нужды дрочить фул модель, лафа для врамлетов и гораздо меньше временных затрат.
>там и поинтереснее есть, по типу glora, про которую нихуя нигде не написано,
Чатгпт в курсе этой хуйни
>но иметь охуенную генерализацию, если оно работает конечно как задумано, это заебись
Ну глора это вот алгоритм репараметризации. Ты можешь эту глору вместо с дорой юзать, у них вообще разные задачи и наверно они дополнят друг друга. Кстати надо попробовать, интересно че будет, в сдскриптс вроде есть.
> Ну вот видно уровень, похуй им уже полгода,
Ну и хуй на них, все равно не пользуюсь их тренировочным калом.
> Туда же пихнул вот это, по быстрому накатал https://2ch-ai.gitgud.site/wiki/tech/optimizers/ про самые важные
Ну норм
Забей место под ADOPT, другой сверхточный адам форк https://github.com/iShohei220/adopt
Есть аргумент включающий реализацию адопт в продижи шедфри, я его чучуть покрутил, ну прикольно такто.
>glora
Нихуя себе она финты крутит с лоссом меньше 0.1
Нихуя себе она финты крутит с лоссом меньше 0.1
Кстати вместе с дорой на 2 батче в карточку не влезло в 768
Печаль беда
А ясно, 16/16 вместе с глорой дает x2 больше параметров, ебануться
Ну че могу сказать, глора ебет с шедулерфри продигами и дорой, натренировало мне бабу с датасетом 75 фоток за 75 шагов на батче 2. Абасраца.
Перекат




Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA: https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/