




> материнку на современном чипсете с двумя полноценными слотами 4-ой или 5-ой версии PCIe х 16 от процессора
Сборка будет стоит как 4090, пара х16 4.0 это современный зеон или трипак. Профит от 16 линий не будет стоить так дорого, особенно в ллм.
У тебя на пикчах плата обычноый 3090 или какой-то суперэкзотический прототип, разобранная FE - пикрел. Фишка ти в памяти на одной стороне которая прекрасно охлаждается.
Если у них распиновка одинаковая то уже возможно, но тогда началось бы раньше с амперов, вбросы хаков биоса и 3070 с 16 гигами уже давно были.
> От разных L40S биос не подойдёт, потому что память другая
Там и чип отличается, а так бы даже с другой памятью была бы неплоха. Если хуанг не навалит памяти или революционного перфоманса в блеквеллах то эта штука становится интересным приобретением.
> MiniCPM-V is a series of end-side multimodal LLMs (MLLMs) designed for vision-language understanding. The models take image, video and text as inputs and provide high-quality text outputs.
https://github.com/OpenBMB/MiniCPM-V
https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf
https://github.com/OpenBMB/MiniCPM-V
https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf
https://www.reddit.com/r/LocalLLaMA/comments/1erelsv/i_created_a_3d_bar_with_an_ai_bartender_that/
I created a 3D bar with an AI bartender that works on the web
You can try it for free at https://www.mangobox.ai/ !
I've seen a bunch of AI character type stuff online, but all of them were boring chat interfaces. I thought it would be more fun to give the characters an avatar and a 3d environment to interact with.
The stack I'm using is Claude 3.5 for the LLM, OpenAI TTS, Stable Diffusion for generating drinks, and three.js for rendering. I exposed the prompt I'm using so people can play around with it by clicking the robot icon. If people enjoy this I can also make more environments, character customization options etc.
I could easily make this self-hosting by connecting it to local LLMs and TTS instead. Let me know if you're interested!
I created a 3D bar with an AI bartender that works on the web
You can try it for free at https://www.mangobox.ai/ !
I've seen a bunch of AI character type stuff online, but all of them were boring chat interfaces. I thought it would be more fun to give the characters an avatar and a 3d environment to interact with.
The stack I'm using is Claude 3.5 for the LLM, OpenAI TTS, Stable Diffusion for generating drinks, and three.js for rendering. I exposed the prompt I'm using so people can play around with it by clicking the robot icon. If people enjoy this I can also make more environments, character customization options etc.
I could easily make this self-hosting by connecting it to local LLMs and TTS instead. Let me know if you're interested!
>Сборка будет стоит как 4090, пара х16 4.0 это современный зеон или трипак. Профит от 16 линий не будет стоить так дорого, особенно в ллм.
Ну здесь же постоянно ноют "упор в шину, упор в шину". Хорошо, тогда два честных x8 от процессора, таких плат полно.
Понимает по-русски. Если повезёт, то и писать/говорить будет.
> здесь же постоянно ноют "упор в шину, упор в шину"
Да не особо. Один поех шизил что у него токены в шину упираются, ни единого пруфа не было, только опровержения.
Более медленная работа карточки в задачах с относительно большой пересылкой данных - да, может просесть аж на 30% в 3.0 х4 по сравнению с 4.0 х16, диффузия и запуск ллм разницы практически не проявляют. Существенно может быть только при тренировке, когда отстающая карточка тормозит всех. Вот и сам думай, нужно ли столько переплачивать за подобный выигрыш, что в твоих задачах может и никогда не проявится.
>3070 с 16 гигами
https://www.reddit.com/r/LocalLLaMA/comments/1dd79dj/upgrading_rtx_3070_to_16gb/
Сюрприз, на 3070 достаточно перепаять банки и пару резисторов, хаки биоса не нужны. Да их и нет, кроме разной хуйни типа биоса от А6000 для 3090.
>уже возможно
Лол, они уже сделали такой свап, а ты пишешь "возможно". Это не "возможно", это уже сделано и работает. А вот чтобы завелась 3090 на 48 гигов, нужен уже модифицированный биос, с которым задница. Потому эти новые дэшки так интересны, но, подозреваю, всё дело именно в них и никакого способа взломать биос не изобрели, только для дэшек.
>Там и чип отличается
Всё тот же GA102, немного покруче. Отличие от 4090 примерно на уровне отличия 4090 от 4090D.
> а ты пишешь "возможно"
Литературу почитай а не только жптизмы, откроешь смысл фраз в контексте а не будешь все трактовать дословно.
> дело именно в них и никакого способа взломать биос не изобрели, только для дэшек
Если также нет никакого лока и само заводится то вполне может быть. Вдвойне забавная санкционная опция.
> Всё тот же
Не тот же, стартовый индекс уже не означает одинаковую начинку и просто отключенные части. Эти отличия и не дадут запуститься с тем же биосом, при том что кристалл может уметь работать с разными типами врам.
А у опенаи была какая то новая методология и алгоритмы? Или просто хорошо подрьранные и обученные данные? Я просто пытаюсь отследить и собрать в голове эаолюцию языковых моделей.
Третья прям сильно замедлить может.
Что странно, по какому оно принципу отрабатывает, так и не ясно.
Таверна да, она посылает полный запрос. Но, по идее, насколько я знаю, пока верхняя часть не меняется, можно было бы посылать и как часть запроса. Хезе, как там эта таверна работает, у каждого свой форк. =)
Ну так а ты просто погугли, посмотри чужие тесты, посчитай сам. Важно оно тебе или нет.
Помню тут был антитеслошиз, который угарал, что теслы считают контекст долго, и «до первого токена» получается полторы минуты.
Про теслы правда — они считают контекст как проц.
Но в прошлом треде кто-то про пару 3090 () говорил, что «до первого токена» 40 сек (). Звучит как ебучий провал от карты, которая в одиночку выдает 10 сек (ладно, 12-15) до первого токена в максимуме. Причем, в чем беда-то не очевидно — то ли проблема с шиной, то ли проблема с экслламой, то ли хуй его знает что у него. Но сам факт, что от двух 3090 ждешь не 40 секунд обработки контекста. Учитывая, что уже давно кидались скрины с 2000~2500 токенов/сек промпта (за 40 секунд при таком раскладе ты 100к контекста пересчитать должен, а не 32к).
В общем, не советую никому верить, а лучше самостоятельно проверить — снять сервачок, проверить все его характеристики и погонять.
Если ты не гоняешь контексты выше 16к, то вряд ли x4 линия станет для тебя проблемой. х8 будет уже достаточно для быстрых ответов.
Но если ты дохуя богатый и хочешь получить первый токен как можно скорее…
У них были суцвекер, его учитель и еще кто то, забыл. Кто и развивали эту тему. И я так понимаю самые смачные наработки по этой теме ушли с суцвекером из попенаи, как и еще с несколькими разрабами. Думаю с начала травли суцвекера никакими новыми разработками он не делился, а это уже почти год на сколько помню.
Поэтому у них такой простой. Жадный пидор отжал власть в компании, но не подумал что выгонять на мороз главного разраба и сооснователя компании чревато внутренними проблемами с разработкой этого самого передового ии
Вобще изначально клозедаи набрали себе энтузиастов в области нейросетей со всего мира под благовидным предлогом опенсорса, а потом когда собрали все сливки подсадили всех под подписки о неразглашении и кучу бабок и закрыли компанию полностью, в чем и был план как где то писалось.
Так что топовые спецы + полностью спизженый интернет + открытие сразу же доступа всем желающим к получившемуся ии, для сбора диалогов и формирования новых датасетов = дали то что ты видишь
Что за квантование? Чем ниже, тем хуже? По дефолту ollama run llama3.1 (и другие) качает квантованную до 4, поэтому для теста рекомендуют ставить Q8? Вроде просто. Почему 16 - fp16, а 8 уже - Q8, а не fp8? На этом рубеже (16>8) выгодней использовать другой метод понижения точности, то есть квантование? Не совсем ясно, чем отличается от понижения точности float, но видимо и нет смысла знать мелкие детали.
>корпоративные сетки в принципе доступны, так что не еби мозги
Говорю же, предложи. Пока что выходит, чтобы получить бесплатно апи, нужно ебаться или делать бесконечные копипейсты из чатов. Это если мы говорим о коде и интеграциях вроде таверн. Для простых задач copilot/chatgpt справляются, да.
>Для кодинга неплохи codestral и deepseek v2
Какую бы выбрал, почему?
>плагин continue
Замечал это название. Видимо, с ним и придется иметь дело. Перейдя на VS Code сначала.
>Лламу-3 выбрось
Для чего она тогда вообще? База для дообучений?
Освобожу место, поставлю немо и потом дипсик.
>корпоративные сетки в принципе доступны, так что не еби мозги
Говорю же, предложи. Пока что выходит, чтобы получить бесплатно апи, нужно ебаться или делать бесконечные копипейсты из чатов. Это если мы говорим о коде и интеграциях вроде таверн. Для простых задач copilot/chatgpt справляются, да.
>Для кодинга неплохи codestral и deepseek v2
Какую бы выбрал, почему?
>плагин continue
Замечал это название. Видимо, с ним и придется иметь дело. Перейдя на VS Code сначала.
>Лламу-3 выбрось
Для чего она тогда вообще? База для дообучений?
Освобожу место, поставлю немо и потом дипсик.
Ну т.е. никаких новых алгоритмов и подходов? Как то это грустно что ли.

Так, мистеры майнеры.
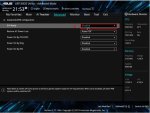
Вот такая хуйня для 100 (50% паверлимит) или 180 ватт с 6+8 пин доп.питанием пойдет или в натуре хуйня?
Вот такая хуйня для 100 (50% паверлимит) или 180 ватт с 6+8 пин доп.питанием пойдет или в натуре хуйня?
Для больший моделей падение не сильно заметно.
123B хороша и в 2 битах.
70B в 4.
20B в 5.
12B в 6 бит норм.
7-8-9 уже лучше в 8 бит использовать. Т.е., Q8 или 8bpw.
Конечно, частные случаи бывают, но усредненно где-то так.
fp16 — floating point.
q8 — int8, integer, целочисленное.
q4 тоже int8, вообще-то.
Но это уже quant просто.
q4_0
q4_1
q4_K
iq, imat, различные варианты квантования с различными фичами.
Грубо, ты округляешь значение.
Вместо точных координат токена имеешь их более грубые значения, из-за чего, при выборе (предсказании следующего токена) начинают допускаться ошибки, и модель ошибается или шизит.
Я не спец, объяснил просто, мог ошибиться в деталях.
> Какую бы выбрал, почему?
Дипсик быстрее и, по тестам, не уступает, а зачастую и превосходит (как Денди на миду) Кодстраль.
>Но, по идее, насколько я знаю, пока верхняя часть не меняется, можно было бы посылать и как часть запроса.
Ну Кобольду например всегда посылается полный промпт и он внутри себя делает дифф. Если почему-то решит, что промпт изменился не с конца, выполняет полный пересчёт, иначе контекст шифт - отрезает от уже обработанного контекста сверху, обсчитывает новое и пришивает к низу. И для него есть у Таверны отдельный интерфейс. А вот для экслламы нету, она на дефолтном сидит. А он, говорят, плохой. Здесь же есть люди с 2-3 3090? В две таких спокойно влезает 70B exl2 3.8BPW с 32к несжатого контекста. Уверен, что та же проблема будет. Просто они выше 16к не ставят, а то и выше 8 - а это 20 или даже 10 секунд на полный контекст. А так должна быть та же фигня.
>А у опенаи была какая то новая методология и алгоритмы?
У них был компут тайм, которым всё завалили нахуй.
>Что за квантование?
Шапку прочти.
А хули ты хотел. Мир грустная штука.
>такая хуйня для 100 (50% паверлимит) или 180 ватт
А причём тут хуйня и ватты? Ватты будут жраться с доппитания. Впрочем пикрил максимум уёбищное решение, бери уровнем выше.
>иначе контекст шифт - отрезает от уже обработанного контекста сверху
Просто сверху ещё до шифта отрезали, шифт может большее, например, удаление токенов с середины.
imat только для vram,
твердо и четко иначе
будут тормоза на cpu.
> бери уровнем выше.
Ок, выберу что-то более адекватное, спс.
Поди узнай что их нет.
На сколько помню веса гпт3 так и не были открыты. Это может указывать на то что там есть какой то ключевой неизвестный элемент, дающий попенам конкурентное преимущество по сей день.
Помимо этого, глупо думать что собрав столько топовых спецов они не открыли что то новое, очевидно что да. Там постоянно используются новые подходы, даже в опенсорс.
Что творится в компании которая хранит свои секреты серьезней чем ядерное оружие - поди узнай.
>А так должна быть та же фигня.
Но у меня всё ещё есть вопрос - владельцы пары мощных карт, где на больших моделях задержки на полную обработку контекста уже начинают напрягать - они как-то решили эту проблему или терпят? Просто может настройки какие есть, которые облегчают жизнь?
> Таверна да, она посылает полный запрос.
Она и обязана полный запрос посылать, иначе и быть не может.
> «до первого токена» получается полторы минуты
Это все еще ужасно и кринжово, ведь такое с мелким контекстом 8к на уже мелкой 70б, где вообще все моментально должно быть. Против 30 секунд на 123б с контекстом 24к. Разницу смекаешь? 70т/с на 70б против 700т/с на 123б.
> которая в одиночку выдает 10 сек (ладно, 12-15) до первого токена в максимуме
Где, в каких условиях? Что за поток сознания, слишком глуп чтобы понять зависимость всех скоростей от размера модели?
> Если ты не гоняешь контексты выше 16к, то вряд ли x4 линия станет для тебя проблемой. х8 будет уже достаточно для быстрых ответов.
Шизоид, тащи пруфы своих фантазий.
Для кода, для своих размеров и во времена выхода, что было не так и давно, я использовал и довольно успешно codeqwen-1_5-7b-chat, Codestral-22B-v0.1, Llama-3-8B-Instruct-Coder-v2
У кодеквин длинный контекст, что довольно удобно
Новые сетки так же хороши, Mistral-Nemo-Instruct-2407 как и gemma-2-9b
Главное помнить что это не самостоятельный ии разраб, а скорее инструмент помощи специалисту, которым надо правильно пользоваться.
По опыту очень удобно давать сетке задачи или спрашивать о темах с которыми ты знаком но плаваешь в них, когда они на краю твоих знаний.
Тогда ты можешь быстро учится новому и тут же использовать эти знания. А небольшое знание в теме дает тебе возможность отделять галюны сетки от рабочей информации, что дает этим знаниям проверку и достоверность
Я пруфов накидал пачками, могу лишь посочувствовать, если ты игнорируешь все, что не вмещается в твой маня-мир.
Искренне.
А дипсик не пробовал?
Вообще, очевидно, GIGO же, «что на входе, то и на выходе» культурным языком.
Это не значит, что ллм плохи или недостаточно хороши для кода.
Просто пока они не умеют достаточно хорошо фильтровать хуевые запросы хуевый программистов, или темы, где ты не понимаешь, че тебе надо.
А при хороших запросах, которые пишутся той же сеткой в мультиагентном режиме (один разбирает запрос, формулирует его нормально, второй составляет план и по нему расспрашивает, третий дает ответы) это вполне себе нормальный джун получится.
Ну и код-ревью забывать не стоит, даже когда джун — человек. =)
Вообще, мультиагентные системы давно баян, но пока не снискало популярности, тренд только поднимается, увидим, тащемта.
Нет, это говно начнет вонять и плавиться при малейшей нагрузки со слота, ибо шлейф ужаснейший. При особой удаче может проплавиться до линий и убить проц и карточку. Есть такие же варианты с подпаянным молекс разъемом, их уже как-то можно юзать.
Плюс оно может не завестись на 3.0 стандарте из-за помех, придется скидывать версию чтобы не подыхало в ошибках. В сочетании одной линией на мощной карточке будет шанс отловить влияние шины, о котором вещает теслашиз, пытаясь оправдать некроту и жорино говно.
> 123B хороша и в 2 битах.
Нет, она тупит, шизит и часто ошибается.
> 20B в 5.
> 12B в 6 бит норм.
> 7-8-9 уже лучше в 8 бит использовать.
На самом деле в бенчмарках у них относительная деградация/улучшение от битности не показывает зависимости от размера. Прувмивронг, сколько не смотрели, все больше субъективщина, плацебо и "потому что я могу", а тема ведь интересная.
> q4_0
> q4_1
Легаси, выкинуть и не приближаться. Разве что на тесле цифру в бенче увеличить.
> q4 тоже int8
> q4_K
does he know
Именно в общем на пальцах объяснил прилично.
> Я пруфов накидал пачками
Хде? Покажи хоть один? Только шизоидный понос про "1 линия - 100т/с".
>А дипсик не пробовал?
Мое или обычный? Как то не, они выходили либо раньше чем я начал кодить с сетками, либо когда я уже наигрался и нашел подходящие. Его хвалили на сколько помню
Запускал пару раз и даже кодил, но не проверял глубоко что бы сравнить его возможности с другими
Агенты конечно дают большой буст мозгам сеток. Но чудес нет, без человека ни одна даже самая крутая сетка не может заменить даже джуна. Так что пока это инструмент помощи спецу, хотя бы как замена гугла который сразу дает ответ
Думаю проблема не в сетках, а в том что не все умеют ими пользоваться. Как и сказано, ожидают джина который выполнит им желание и расстраиваются когда реальность с этим не сходится.
Кстати, оптимизация, чистка кода и код ревью, как и комментирование у сеток отличные.
Кодить с нуля на них боль, а вот давать преобразовывать уже готовый код очень приятно. Так что код ревью нейронкой стоит того
> Агенты конечно дают большой буст мозгам сеток
> это инструмент помощи спецу
> проблема не в сетках, а в том что не все умеют ими пользоваться
> оптимизация, чистка кода и код ревью, как и комментирование у сеток отличные
Базу выдал прямо, неистово двачую
> Кодить с нуля на них боль
Вот тут только не соглашусь, с более менее умной можно сначала обсудить с примерами как лучше реализовать конкретную задачу/идею, уже в беседе подмечая что-то полезное. Потом или сразу приказать написать заготовку, внести правки, самому что-то изменить, и далее итерациями или уже самому.
Главное - контекст лучше не накапливать, если не удалять старые запросы и прошлые варианты кода то оно очень быстро тупеет.
>Вот тут только не соглашусь, с более менее умной можно сначала обсудить с примерами как лучше реализовать конкретную задачу/идею, уже в беседе подмечая что-то полезное. Потом или сразу приказать написать заготовку, внести правки, самому что-то изменить, и далее итерациями или уже самому.
Так это и есть "боль". Можно, но потратив кучу времени и усилий, или ты получишь не рабочий код или не тот что нужен.
По сравнению с
> оптимизация, чистка кода и код ревью, как и комментирование
где просто кинул и попросил сделать заебись, иногда совершенно буквально
И получаешь результат сразу, чаще всего рабочий.
Ну а вобще я в таверне кодил, настраиваешь промпт формат, берешь или делаешь карточку прогера, вводишь сетку в курс дела давая тз, можно разрешить ей задавать вопросы и потом просишь примеры кода.
И да, можно кодить с нуля какую то задачу, не особо сложную если речь идет о мелких локалках, единым куском скрипт строк на 100 выдает например.
После небольших доделок все работает, если нет - кидаешь сетке ошибки и она исправляет.
Повторять до посинения победы
Про контекст тоже верно, я обычно если он разросся, стираю все примеры кода сетки и кидаю ей последний вариант с которым она с нуля начинает работать
> влияние шины
Ты тот самый, которого мне искренне жаль, или еще один человек, неспособный в математику и чтение слов на русском?
> Нет, она тупит, шизит и часто ошибается.
Все еще лучше любой 70б, даже так.
Хотя, я согласен, что на краю. (тащемта, q2 это 3 бита, но похуй).
> Разве что на тесле цифру в бенче увеличить.
Как же тебя трясет, триггеришься на все вообще.
Я просто в порядке появления перечислил, понадеялся, что человек не станет использовать настолько старую хуйню. Должен же быть здравый смысл у спрашивающих.
> Хде? Покажи хоть один?
Ты продолжаешь игнорировать ссылки, которые я скинул, да?
Ну, шо тут скажешь. Тяжело тебе.
———
Слушай, вот без приколов, после всей той шизы, что ты несешь.
Почему ты так ненавидишь теслу и триггеришься вообще на все, что способен притянуть к тесле хоть как-то?
Твою (нейро-)тянку выеб тесловод? Ты купил теслы, а они тебе не дали, спалили мать и проц? Или почему?
На весь тред ты единственный пиздец агрессивный чел за последние тредов пять, наверное.
Все спокойно общаются, один ты бегаешь и «ТЕСЛА ЭТО…», как будто тут кому-то ни похуй в большинстве случаев.
Нет, я могу понять, когда кто-то спрашивает про теслы, или кто-то советует их покупать. Тут твои комментарии контекстно уместны.
Но когда речь заходит о том, что существует q4_0 (просто существует), ты тут же прибегаешь с криком про теслу, мол, вот теслаебы на ней циферки поднимают.
Дегенераты, конечно, если на хуевом кванте поднимают циферки, когда для них есть q4_K_M, но я даже вот щас попытался и не смог упомнить случая, когда хоть один теславод бы хвалился скоростью именно в q4_0. Да, тестировали, да, рост есть, но формат говной пахнет, никто его не юзает (я надеюсь=).
Пожалуйста, take a deep breath энд просто ответь: почему тебя так триггерит существование теслы п40?
Надеюсь никак не нанес тебе моральных страданий своим вопросом.
Deepseek-Coder-Lite-V2 — моешный он, да.
Он выходил чуть позже кодстрали.
> Но чудес нет, без человека ни одна даже самая крутая сетка не может заменить даже джуна.
Ну эт полная чушь. Любой джун максимум на уровне сетки работает, а чаще гораздо хуже.
Большинство людей, говоря, что сетки хуже джунов, почему-то думают о сеньорах. =)
Даже когда тот чел с ютуба, который юнити продвигает (тот еще недалека, канеш), сравнивал разных спецов и нейронку, в общем согласился, что джун написал не сильно лучше нейронки.
> хотя бы как замена гугла который сразу дает ответ
Ну, это простейший способ ими пользоваться, когда совсем не понимаешь инструмента. Но она может больше в умелых руках.
Опять же, хз, может ты просто в эту сторону не смотрел всерьез, не пробовал подойти, хз.
Ну или джуны в твоей фирме отборные, после сеньорства в озоне приходят. =D
Sus-column-r к счастью оказался Grok 2, поэтому ждем что высрут клозеды завтра, может там реально революция. Это странно кстати, потому что он порой почти точь в точь выдавал тоже самое что и 4о, но это возможно потому что они свою сеть на нем фантюнили.
Не следил за сус-колумн-р.
Че, насколько она хороша была? Чего ждать от грока?
На 4о многие жалуются, что тупая и маленькая, поэтому дешевая.
А грок в прошлый раз был большой и тупой.
В итоге что вышло-то? Со второго раза у Маска получилось?
>Ну эт полная чушь. Любой джун максимум на уровне сетки работает, а чаще гораздо хуже.
Зависит от того что называть джуном, сегодня вакансии на джуна в россии имеют требования как на миддла, кек
Я не особо работал с большими платными сетками последнее время, слышал новый клод ебёт, так что местами он и ему подобные топовые сетки, верю, джуна заменят. Да и миддла подвинуть могут. Но полной замены опять же нету, сетке все равно нужен контроль и направление. Оператор нейросети, как звучит
>Ну или джуны в твоей фирме отборные, после сеньорства в озоне приходят. =D
Я не кодер, так что могу ошибатся, по мне еще рановато для полной замены джунов, самостоятельности у сеток и самоконтроля до сих пор нету.
Хорош в плане решения относительно сложных задач требующих решения шаг за шагом. Если задача уровня сгенерировать стишок, то он напрямую, без обдумывания, напишет примерно такой же кал как и остальные близкие к топ уровню модели. Если задача решить математическую задачку, то он уже каким-то уникальным CoT пройдется по ней и с большим шансом даже решит правильно. Что интересно он может понять что сделал ошибку, обдумать это и начать решение заново, но это не всегда приводит к верному решению в итоге. В целом топ модель для подобных задач, пока что, пока Альтман не выкатил свою йобу и средняя для остальных тасок. Для Маска прогресс очевидный конечно.
> Оператор нейросети
Йеп, еще год назад на эту тему шутили, мол, профессия будущего. =) И, вот оно, потихоньку появляется.
О, ну было бы интересно посмотреть на нее в попенсорсе, конечно. =)
Стишок я попытался тока шо. Чатгопота написала хорошо, грок как ты сказал.
>сегодня вакансии на джуна в россии имеют требования как на миддла
Да и не только в России, во всём мире избыток джунов и мидлов. В России просто по понятным причинам избыток острее.
Где найти какой-нибудь нормальный гайд по так называемому промт-инжиниренгу? Ебусь уже не первый день, пытаясь заставить модель отвечать именно в том формате, который мне нужен. Кое-какие успехи поимел, но ценой того, что длина промта увеличилась до 900 токенов, что дохуя, учитывая ограничение контекста в 8к и что еще сама карточка персонажа сожрет свое.
Кстати, заметил странность как раз по поводу промтов. При забивке контекста примерно до 4 тысяч, модель начинает частично игнорировать инструкции и опираться исключительно на предыдущие сообщения в чате. Это как-то фиксится?
Стоит дерьмо в виде ламы 3
Кстати, заметил странность как раз по поводу промтов. При забивке контекста примерно до 4 тысяч, модель начинает частично игнорировать инструкции и опираться исключительно на предыдущие сообщения в чате. Это как-то фиксится?
Стоит дерьмо в виде ламы 3
>Где найти какой-нибудь нормальный гайд по так называемому промт-инжиниренгу?
https://www.promptingguide.ai
Ну а вобще - опыт
Есть модели с реальным окном в 4к, как гемма 2
Тоесть может в 8, но помнит четко только последние 4
Ллама 3 вроде 8 имеет, скачай тогда ллама 3.1, если у тебя с настройками контекста все ок то будет норм давать ответы до 32к
> Так это и есть "боль"
Не то чтобы, можно делать неплохие заготовки быстрее чем вручную или другими средствами. Или более элегантную реализацию, которой не ожидал. Но все зависит от задачи и конкретного случая, в сложное сразу не может.
> которого мне искренне жаль
Лучше себя пожалей, твоя высокомерность не сочетается со статусом (по всем пунктам) и возрастом. Даже в тематике треда тебе важнее оправдывать свои убеждения и проецировать обиды, чем найти что-то новое и полезное, нахуй так жить?
> Все еще лучше любой 70б, даже так.
Не лучше, когда лламы были без контекста можно было спекулировать, сейчас нет. Оно ужасно тупит, а в задачах с тем же контекстом совсем сдается.
> Как же тебя трясет, триггеришься на все вообще.
Неужели угадал, оно действительно быстрее? Иначе зачем вообще скачивать мусорный квант, дело раскрыто. Имплаит спокойствие и сразу оформляет проход в тряску, топ кек.
> ссылки, которые я скинул, да?
Где? Показывай свои ссылки.
> вот без приколов
Как можно без приколов с тобой общаться? Все эти попытки быть обидным только в ржач пробивают. А если серьезно, во-первых, ты обманываешь, уводишь в сторону и всячески вредишь в угоду оправдания безумных идей и прошлых ошибок, как сектанты, чем вызываешь неприязнь. Во-вторых, твой паттерн поведения идеально ложится на жертву травли, которая страдает но сквозь слезы копротивляется и делает вид что ей на самом деле все хорошо, чем только провоцирует дальнейшие издевательства. Вот над тобой и регулярно глумятся пока ты как собака носишься и пытаешься детектить обидчиков. Заметь, в треде много тесловичков но свидомый лишь один.
Не волнуйся, от этого есть средство - повтори подвиг флагшток куна с теслой в жопе и все сразу пройдет. Почувствуешь силу землижоры.
>https://www.promptingguide.ai
Благодарю. Завтра чекну.
>ллама 3.1
Вроде писали что она тупее стоковой тройки и более соевая, хотя я об этом читал недели три назад, может че то и поменялось.
А может быть проблема с флеш аттеншеном? Он у меня отключен в кобальде и как-то я все время игнорировал это.
Кобальд последний?
ллама 3 уже старая и должна норм и так работать, хз
Флеш аттеншен полезен для ускорения генерации, ну и квантовать кеш, что уменьшает потребление памяти контекстом сетки
Вроде все, больше не помню че он делает
По моему опыту эти гайды не особо то и нужны. В плане того, что если ты пишешь модели что-то сделать и она делает это криво скорее всего это модель говно, а не твой промпт. Другое дело на счет оптимизации промпта и приведения его к такому виду, чтобы модель тебя слушалась чаще. В таком случае могу дать совет попросить саму нейросеть переписать для тебя промпт как нужно. Так и напиши: "вот есть промпт для нейросети, укороти его, но так чтобы основная суть осталась той же", нейросети хороши в промптинге внезапно. Второй совет: используй примеры. Если ты дергаешь модель через апи или юзаешь плэйграунд, ты можешь написать ответ заместо самой сети несколько раз в том формате который тебе нужен, так чтобы оно сохранилось в контексте, и в следующий раз оно тебе будет отвечать в верном формате. Третий совет: если хочешь программно брать из ответа какие-то значения используй популярные форматы которые она уже знает. Для выделения ответа xml тэг вроде <answer></answer>, для сложных объектов JSON. Так же можно заставить модель юзать инструменты опять же прося описывать их вызов через xml. Если все таки хочешь посмотреть как промптят дяди которые сами разрабатывают нейронки посмотри anthropoc cookbook. Но это мои советы как чела который юзает нейронки в основном для кодинга и их юза из кода, так что соряныч если не то что хотел.
> заставить модель отвечать именно в том формате, который мне нужен
Какой именно формат и какая задача? Нормальных простых гайдов нет, или душнилово, полезное и правильное но в котором уснешь, или херь.
Если нужно сохранение структуры - грамматика, можно искусственно автоматически подшаманить токены так, чтобы они складывались в нужные предложения. Если тебе для обработки текстов - используй xml теги <text></text> <character> </character> или json формат, дав модели один или несколько примеров.
Если же тебе в рп отыгрывать какое-то поведение и правила - делай жестко, сначала укзаывай в начале а потом суй их в префилл модели. Также как делают в жб, только исключить "кошка делает мяу мяу" а сразу перейти к сути, чтобы получилось на подобии
Okay, let me think first. I need to:\n' +
"- blah blah 1\n" +
'- blah blah 2\n' +
...
при этом оно должно быть согласовано с основным промтом а не противоречить ему. Например,
> let me think first
уже подразумевает что сетка это не чар а гейммастер/ассистент/кто-то еще, поэтому если стоит в начале "ты = чар" то это нужно оформить в OOC или какой-нибудь <system>
Если твоя задача влияет на формат и структуру ответов сетки, например нужно добавлять что-то в начале или в конце поста - примеры диалога решают. Может потребоваться несколько свайпов в начале, а после подхватит из прошлых постов.
> При забивке контекста примерно до 4 тысяч
В настройках таверны и ланучера проверь ограничение контекста. Если твоя инструкция в примерах и других частях, которые будут пропадать, выстави в настройках "всегда сохранять" их.
>Флеш аттеншен полезен для ускорения генерации, ну и квантовать кеш, что уменьшает потребление памяти контекстом сетки
Всё равно попробую его включить и посмотрю на разницу. Может что-то изменится, может нет.
>Другое дело на счет оптимизации промпта и приведения его к такому виду, чтобы модель тебя слушалась чаще.
Про это и вопрос как бы. Не хочется половину контекста тратить тупо на инструкции.
>В таком случае могу дать совет попросить саму нейросеть переписать для тебя промпт как нужно.
Пробовал, но она часто пишет так же хуево, как и я. В плане того, что она именно пишет пошаговую инструкцию, которая мало чем отличается по исполнительности от банального "не пиши за юзера, не используй пюрпл проз и не выебывайся".
>используй примеры
Вот только примеры она как раз и жрет. Если в экзампл мессейдж закинуть чего-нибудь, или прямо в карточке персонажа прописать, она слушается лучше. Но опять же, под каждого нового персонажа писать примеры это лишняя трата времени и сил.
>Если нужно сохранение структуры
Ну примерно это мне и нужно. У меня безпричинно сеть начинает иногда изрыгать тонны текста, хотя я прямо прописал, что нужно генерировать только один параграф и описывать одну конкретную реакцию или интеракцию. Ей в какой-то момент просто становится похуй, а в другой она всё делает правильно, чисто по инструкции.
>Также как делают в жб
Принципы жопабрейка я тоже использовал. Результат продолжает варьироваться - иногда она отвечает как надо, иногда генерирует от пизды.
>В настройках таверны и ланучера проверь ограничение контекста. Если твоя инструкция в примерах и других частях, которые будут пропадать, выстави в настройках "всегда сохранять" их.
Там уже все проверено. Терминал кобольда считает честные x/8192 при генерации, так что дело вряд ли в кобольде или таверне. Никаких растягивателей типа ропов у меня не стоит.
В связи с китайской модификацией 4090D с 48гб ВРАМ: прошёл слух, что арендовать её в Китае можно задёшево, что-то вроде 10 центов в час. Это было бы интересно.
Хочу докупить к Тесле P40, Теслу P100 вроде она чуть быстрее. Или не разводить зоопарк и купить P40?
На неодинаковых картах могут быть проблемы. К тому же количество ВРАМ имеет значение. Да и вообще, пара П40 отлично заходит, кто бы что не говорил. Кто успел купить по хорошей цене, тот вообще молодец. Но теперь она стоит минимум 30к; честно говоря лучше добавить ещё столько же и купить в пару 3090.
> генерировать только один параграф и описывать одну конкретную реакцию или интеракцию
У тебя может быть противоречие в системном промте, где сказано описывать детально. Еще такое бывает на шизомиксах, которые на любой запрос будет хуярить рп-подобный слоуп. Какая конкретно модель, лаунчер, параметры?
Проверяй чтобы не было ошибок и противоречий, поставь себя на место нейронки и подумай где есть лазейка через которую можно это обойти. Учитывая что там 900 токенов инструкции - это пиздец.
Или забей и делай жестче правилом в префилл. Если совсем не хочет - даешь указание "разделяй каждый параграф символом "<p>" и добавляешь его в стоп-токен, только подбери чтобы нигде не встречался и был одним токеном.
После получения 1-2 правильных сообщений должна идти стабильно.
> дело вряд ли в кобольде
Только если поломанный квант
> или таверне
С ней легко, по дефолту если стоит 4к то оно обрежет старые сообщения а вместе с ними может хапнуть и примеры/инструкции.
> 10 центов в час
Ага, еще доплачивать будут скажи. Ссаная 3090 0.2+ стоит, а тут такое счастье. 0.3-0.4 было бы норм ценой, там ведь чип быстрый.
> Хочу докупить к Тесле P40
Быстрее но меньше врам, потому не сможет взять на себя часть модели. Проблем не будет, просто нерационально ибо 40 гигов - мало. Хочешь быстрее - рассмотри к покупке 3090, они уживаются вместе.
>Проверяй чтобы не было ошибок и противоречий, поставь себя на место нейронки и подумай где есть лазейка через которую можно это обойти.
Я с ума сойду нахуй, если буду думать как нейросеть. Начну озорно подмигивать и мурмуркать в ухо.
>Учитывая что там 900 токенов инструкции - это пиздец.
Да, именно об этом я и говорю. Но только так мне удается заставлять ее держать стиль и описывать то что мне нужно. Хотя я более чем уверен, что это скилл ишью, и промт можно сократить раза в три. Просто пока мне это не удается.
>Если совсем не хочет - даешь указание "разделяй каждый параграф символом "<p>" и добавляешь его в стоп-токен
Это очень топорный и не для всех сценариев пригодный метод. Потому что сетка иногда не просто пишет несколько отдельных параграфов, а может разделить одну сцену на несколько частей (так происходит чаще всего). По этому со стоп токеном я просто получу огрызок и незаконченную сцену, где персонаж успеет только среагировать на мои действия, например, и не успеет дописать свою реакцию.
>по дефолту если стоит 4к то оно обрежет старые сообщения а вместе с ними может хапнуть и примеры/инструкции.
Инструкции как и простыня персонажа отправляется каждый раз с каждым сообщением, если я не ошибаюсь. Это жрет контекст, но зато вроде как не дает сети забыть об инструкциях. А примеры она сама вырезает после какого-то там сообщения, но это можно настроить.
https://www.reddit.com/r/LocalLLaMA/comments/1esadlh/nvidia_research_team_has_developed_a_method_to/
Nvidia Research team has developed a method to efficiently create smaller, accurate language models by using structured weight pruning and knowledge distillation, offering several advantages for developers:
• 16% better performance on MMLU scores.
• 40x fewer tokens for training new models.
• Up to 1.8x cost saving for training a family of models.
The effectiveness of these strategies is demonstrated with the Meta Llama 3.1 8B model, which was refined into the Llama-3.1-Minitron 4B. The collection on huggingface: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Technical dive: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model
Research paper: https://arxiv.org/abs/2407.14679
Nvidia Research team has developed a method to efficiently create smaller, accurate language models by using structured weight pruning and knowledge distillation, offering several advantages for developers:
• 16% better performance on MMLU scores.
• 40x fewer tokens for training new models.
• Up to 1.8x cost saving for training a family of models.
The effectiveness of these strategies is demonstrated with the Meta Llama 3.1 8B model, which was refined into the Llama-3.1-Minitron 4B. The collection on huggingface: https://huggingface.co/collections/nvidia/minitron-669ac727dc9c86e6ab7f0f3e
Technical dive: https://developer.nvidia.com/blog/how-to-prune-and-distill-llama-3-1-8b-to-an-nvidia-llama-3-1-minitron-4b-model
Research paper: https://arxiv.org/abs/2407.14679
>Эффективность этих стратегий продемонстрирована на примере модели Meta Llama 3.1 8B, которая была усовершенствована до модели Llama-3.1-Minitron 4B.
Лично моя вера в то, что маленькие модели ни на что не годятся была подорвана с выходом Мистраля Немо и третьей Лламы 8В. Новости хорошие. Вот только проблема: разыграешься на какой-нибудь хорошей восьмёрке, и вроде всё хорошо, а потом переходишь в том же ролеплее на 70В и вернуться на восьмёрку просто невозможно. Семидесятки ведь тоже улучшаются...
Из-за идиотской постоянной задержки для полной обработки промпта на связке из двух 3090 вернулся на теслы и оказалось, что на трёх теслах ролеплей приятнее, чем на двух 3090. Да, 16к контекста обрабатываются более трёх минут. Только происходит это нечасто. Да, приходится вырубать все крутые фишечки Таверны, для которых промпт приходилось пересчитывать каждый ответ. Но зато контекст шифт нормально работает и даже рероллить можно. Да, скорость генерации вдвое ниже, чем на 3090 при вдвое меньшем контексте, но хватает в принципе, а генерация начинается почти сразу. И модель жирнее. Такие дела.
Звучит как хуйня. Как 1 т/с могут быть приятнее честных 10-15 т/с? На EXL2 обработка всех 16к промпта - это 5 секунд, в рп ответ всегда мгновенно начинается.
> твоя высокомерность не сочетается со статусом
Не-не, это не высокомерность. Я не смотрю свысока, не в этом смысле.
> Оно ужасно тупит, а в задачах с тем же контекстом совсем сдается.
Ну ладно, не буду спорить, все же, защищать q2 — тоже шиза, полагаю, полноразмерная модель гораздо лучше, а на тяжелых задачах с контекстом я ее не гонял, да. Меня просто порадовало количество знаний и понимание вопросов, но я буквально пару раз ее юзал.
> Где? Показывай свои ссылки.
В третий раз? :)
https://github.com/turboderp/exllama/discussions/16#discussioncomment-6243456
https://www.reddit.com/r/LocalLLaMA/comments/1d8kcc6/psa_multi_gpu_tensor_parallel_require_at_least/
Буковки. Циферки. Кулькулятор.
Там же все просто.
> А если серьезно, во-первых, ты обманываешь, уводишь в сторону и всячески вредишь в угоду оправдания безумных идей и прошлых ошибок, как сектанты, чем вызываешь неприязнь.
Ни разу ничего из этого. Тебе люто кажется.
> Во-вторых, твой паттерн поведения идеально ложится на жертву травли, которая страдает но сквозь слезы копротивляется и делает вид что ей на самом деле все хорошо, чем только провоцирует дальнейшие издевательства.
Ну, травли тут нет, только ты фигню несешь, но это скорее тебе в минус, а не мне.
В итоге, вопрос-то был, почему тебя трясет, а ты все переврал, перевел стрелки на меня и так не ответил.
Видать, мы не узнаем причину. Ну ладно, добра, надеюсь ты проработаешь эту травму и успокоишься.
Более соевая, но если тебе нужна не соевая — то лучше вообще лламу 3 не трогать.
Сейчас опять человека бедного стриггерите…
P100 у нас под exllama2 подходит же, не? Логичнее было бы собирать уже из них тогда изначально.
Поддержу
> Из-за идиотской постоянной задержки для полной обработки промпта на связке из двух 3090
ниможит быть!.. =)
> На EXL2 обработка всех 16к промпта - это 5 секунд
Когда я сказал, что 32к — это 12-15 секунд, меня назвали шизом.
Когда автор писал, что у него 32к — это 40 секунд, никто ниче не сказал.
И тут вдруг оказывается, что 16к — это 5 секунд.
Да шо ж такое в этом треде творится. =D
Выше обсуждали, шо там какая-то хуйня, то ли пресловутая шина (твердо и четко: не влияет!), то ли баги движка, то ли еще шо.
Deepseek-Coder-Lite-V2 и Mistral Large 2.
Закономерно, дипсик же топ среди малых моделей.
Новый тред лишь подтверждает.
С тех пор ничего нового программистского не выходило (вроде, кодстраль-7б, но нет).
> Начну озорно подмигивать и мурмуркать в ухо
Чтож ты делаешь, содомит, словил молодую ночь под бондом с этого.
> 900 токенов инструкции - это пиздец
Здесь нужно уточнение что если там примеры то еще ничего, они много сожрут но могут быть выгружены. Пофиг на скиллы и прочее, хотябы так поиграйся а там само понимание придет, главное чтобы удовольствие приносило.
> а может разделить одну сцену на несколько частей (так происходит чаще всего)
Для лучшего понимания что именно там лучше примеров принеси чего хочется, что выдает сетка и как делал. Хотябы критику получишь в которой может быть здравое зерно.
> что маленькие модели ни на что не годятся была подорвана с выходом Мистраля Немо и третьей Лламы 8В
Для своего времени и первый мистраль был революцией. Просто они все еще не могут понимать что-то посложнее и более абстрактное, в итоге выходит именно как ты написал. В любом случае это на пользу, применения мелочи найти можно.
> на трёх теслах
Ты как минимум сможешь зарядить окно контекста на лишние 24 гига и очень долго полагаться только на кэш. Скорость генерации в сделку не входит, но это лучше чем постоянно долго ждать.
> контекст шифт нормально работает
Есть где-то данные о том что он работает как должен а ничего не ломает? Одна критика.
> https://github.com/turboderp/exllama/discussions/16#discussioncomment-6243456
Там буквально ответ в том что эксллама не использует параллельную обработку, требующую пересыла большого количества данных, и потому не будет чувствовать это кроме совсем экстримальных ситуаций.
> I noticed that, the same model on one was the same speed as it on both cards.
Твой пруф тебя же опровергает, молодца.
> https://www.reddit.com/r/LocalLLaMA/comments/1d8kcc6/psa_multi_gpu_tensor_parallel_require_at_least/
Вот это уже ближе к чему-то и какие-то значения со скоростями. Но, как обычно, есть много но. Заявленное показанное значение - почти псп х4 3.0 линии, которая есть везде. Но это движок пигмы в особенном режиме во время генерации токенов (судя по всему тексту), там нет ничего про обработку контекста и более популярные лаунчера. Достижение на 4х монструозных карточках уровня теслы или мощнее перфоманса 3060 - сильно.
Сам себя опровергаешь, все закономерно и от шизика ничего иного не ожидалось.
> Твой пруф тебя же опровергает, молодца.
Ну, если ты игнорируешь смысл, цифры и просто вырываешь текст из контекста — все так, как ты сказал.
> Вот это
Уже скинуто во второй и третий разы, как удивительно, что хотя бы в третий раз ты прочел. Делаешь успехи, рад за тебя. =)
На тебя есть надежда!
> смысл
Какой смысл? где смысл? Ты пытаешься тащить что-то стороннее чтобы оправдать свои шизоидные заявления уже забывая про них. Привести их?
> Контекст на 3090 должен считаться около 3к в секунду. Чипом.
> Но есть упор в PCIe.
> Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
> 16 контекста по одной линии будет обсчитываться 2 минуты.
> 1 минута — такое ощущение, что там у тебя всего 2 линии всего из 16.
Тут каждая строка - космос, но главное в том что ты буквально имплаишь что pci-e является ограничивающим фактором даже на линии х16. Не про важность шины для загрузки новых данных, не про костыльный обмен тензорами при параллельном расчете вместо использования nvlink, не про общие вещи, а именно про обработку контекста. И дальше много шизы насочинял, можно из постов надергать.
В твоих пруфах это опровергается тем что разницы в работе на одной и двух карточках нет, а во втором показан пример перегонки данных с некоторой интенсивностью в специфичной задаче, не относящейся к обработке контекста.
Ты сам это прекрасно понимаешь и потому виляешь жопой и тащишь то что бегло отыскал, даже не удосужившись прочесть и понять. Если бы настолько существенная штука была - уже бы 10 раз прибежал с бенчмарками где это явно показано. Но, видимо, даже с подкруткой ничего получить не удалось.

Ух, это получается 70b можно в 35В ужимать без потери качества? А 27В в 14В?
Скорее бы, лама 8В нах не нужна.
> без потери качества
Тема не нова, лламы 3.1 по заявлениям - дистилляция большой 405б. Разумеется у них нет ее полного перфоманса, но с улучшением техник и подходов качество моделей будет повышаться.
Главное чтобы опять не полезла волна абуза бенчмарков.
там немотроны на 4 и 8б сжатые залили кстати, но я хз че это и о чем
Там всё в порядке с потерями. Их 4В в некоторых скорах сосёт у Фи-2.7В, а 8В отсасывает у ванильной 3.1 8В. Вот это реальное лоботомирование получается, когда из 405В делают обычную 8В. Тут польза только в том что можно из большой лепить какие угодно размеры. Как 70В выкатят, слепленную из 405В/123В, так и будет разговор.

Где чел с уравнениями? Почему ещё не запостил тесты?

Ну ты ж понимаешь, что мне тут нечего отвечать, ибо ты переврал все, что я написал? И ведь я уже тыщу раз пояснял, не работает с тобой.
Как скажешь, короче, как хорошо, что у нашего треда есть ты. =3
Теслы говно.
Йоу.
Или как там…

а где опус? он же ебет, а не сонет
С оперы проиграл.
Там в новой опере обещали ии завести, че умеет?
Ну а на сайт встроенный блокиратор рекламы и слежки может не пускать, на вивальди тоже такое есть

Вот через лису. пик1
Пик2 без рекламорезов
ну, значит выебывается оператор твой, или модем
>P100 у нас под exllama2 подходит же, не? Логичнее было бы собирать уже из них тогда изначально.
Ага, щас. Flash Attention в экслламе только начиная с Ampere. Преимущество P100 только в более быстрой памяти (вдвое, да), остальное сплошь недостатки.
vLLM кто-нибудь пользуется?
https://github.com/vllm-project/vllm
Вроде большой проект, но что-то я не слышал о нём.
https://github.com/vllm-project/vllm
Вроде большой проект, но что-то я не слышал о нём.
> ибо ты переврал все, что я написал
Там цитата твоего поста в которой все есть. Обосрался - обтекай, будешь меньше гадить шизой и думать перед тем как постить.
Провайдер или часы/дата сбились.
> Преимущество P100
Она считает fp16 примерно в 100 раз быстрее чем P40, за счет комбинации этого в той же диффузии обоссыт P40 и может работать с exllama. Если есть опыт в пердолинге то FA под нее можно собрать.
Брать все равно не стоит, 16 гигов
Да, но цитата и твои комментарии под ней никак не связаны и противоречат друг другу. =D
Мне сейчас не до этого,
сделаю по qwen2 math
в начале след неделе.
1.5b и 7b, в q4, q8 и f16.
Думаю там 50-60 по матеше,
сейчас qwen2 выдает 40-50,
это более чем L3 и phi3 мелкие.
Вообще 1.5b обычную и инструкт
в течении пары часов посмотрю,
в исходниках eva есть отдельный
тест по алгебре, посмотрим что даст.
1.5b q4 хорошо летает на смартфоне.
в течении пары часов посмотрю,
в исходниках eva есть отдельный
тест по алгебре, посмотрим что даст.
1.5b q4 хорошо летает на смартфоне.
>Если есть опыт в пердолинге то FA под нее можно собрать.
Удачи в пердолинге. Я вот собрал под неё xformers и что? Оказалось, что Угабуга с апреля вообще выкинул поддержку xformers из своего поделия. Под SD есть, а под ЛЛМ никому не надо оказывается. Идите и покупайте современные карты, нищеброды.

Кто встречался с такой ошибкой?
После её выскакивание модель уходит в луп залуп и начинает глупеть и шизеть.
После её выскакивание модель уходит в луп залуп и начинает глупеть и шизеть.
Локальные господа, поможете мне вкатиться в тему или ну его нахуй? Вкатиться решил естественно с нового железа. То что нужна топовая выдюха это понятно, уже почти накопил на 5090, теперь жду выхода. Остался вопрос с процессором и оперативной памятью. Процессор я так понял не решает, так что моего 12700 должно хватить. А что от ОЗУ зависит? Размер контекста или что? Сейчас у меня 64 гигабайт DDR5, сколько вообще нужно для локалок? В принципе могу поставить 128 гигабайт, но будет ли оно того стоить?
> уже почти накопил на 5090
На 300к мог бы купить 4х3090 и позволить себе вообще всё, а не только 30В.
Я обосрусь с менеджментов 4 видюх, там же пиздец потребление будет, к тому же они мне хату спалят.
>Deepseek-Coder-Lite-V2
А среди 7-8B?
>Я обосрусь с менеджментов 4 видюх, там же пиздец потребление будет
Трудности надо преодолевать(с) Ну не хочешь 4, купи две. Лучше конечно 4090, а не 30. Для двух карт современную материнку легко найти, как раз недавно обсуждали. И с остальной сборкой будет легче. 48гб ВРАМ конечно не совсем достаточно, но неплохо так, совсем даже неплохо - особенно на 4090.
>уже почти накопил на 5090, теперь жду выхода.
Долго ждать придется. Судя по сливам, до следующего года выхода не планируется.
>А что от ОЗУ зависит?
Ничего, или всё сразу, смотря через что катать будешь. Если будешь выгружать всё в видеопамять, даже 16 гигов ОЗУ хватит, потому что она не будет использоваться. Если хочешь совмещать RAM и VRAM, тут в зависимости от ограничений видеокарты и от того, какой вес будешь загружать. Идеал - выгружать всё в видеопамять, но это вариант либо для 300к наносеков, которые могут себе промышленные теслы позволить, либо для моделей весом до 35B.
>сколько вообще нужно для локалок?
Зависит от конкретной модели. Чем больше параметров, тем больше жрет.
>В принципе могу поставить 128 гигабайт, но будет ли оно того стоить?
Сомнительное решение. Если хочешь катать какую-нибудь 70B чисто через ОЗУ, то готовься к 0.1 токену пер секонд. Вообще, за цену одной 4090 или 5090 можно взять пару паленых тесел (как тут обычно и советуют). Выйдет дешевле даже с учетом энергопотребления, но сборка этого говна процесс малоприятный.
> Удачи в пердолинге
Спасибо, практикуем, но тратить свое время именно на подобное можно только из любви к искусству, иначе совсем дело неблагодарное.
> xformers
Раньше он ничего не давал, с ним что-то менялось когда юзал?
> Идите и покупайте современные карты, нищеброды.
Все так
На скрине нет ошибок, на nan не обращай внимание, это только про то что используется кэш и время на обработку промта не затрачивалось.
Вот же будет рофел если там что-то поломали и оно по-разному перформит при "горячей" работе и с кэшем. Контекстшифт и подобное что-нибудь не велючены случаем?
> А что от ОЗУ зависит?
Просто купи 64+ (лучше 96) быстрой если еще не имеешь. Главное - она должна быть двумя плашками, с 4 заебешься пердолиться.
> могу поставить 128 гигабайт
Именно поэтому не сможешь.
Если модель на видеокарте - память и прочее не решают если проц древний. Если часть модели на проц+рам - ты страдаешь и мучаешься при любом раскладе, поэтому имей железо что не будет допускать такого, раз мажор. Если 5090 не будет иметь много врам - она будет хуже чем пара даже некрокарт, исключение - пара 5090.

Вот некоторое тестирование
самой маленькой Qwen2 Math.
Выбраны темы физика, математика,
статистика и логика. Язык тестов ch/en.
самой маленькой Qwen2 Math.
Выбраны темы физика, математика,
статистика и логика. Язык тестов ch/en.
> память и прочее не решают если проц древний
Если проц НЕ древний, на некроте крутые карточки не покажут полной производительности.
10% MMLU 1408:
qwen2-math-1.5b-instruct_q4_k_m.gguf
test over 1408 question accurate 36.1%
use time:2644.51 s batch:70.0637 token/s
qwen2-0_5b-instruct-fp16.gguf
test over 1408 question accurate 37.1%
use time:3538.57 s batch:52.7993 token/s
qwen2-1_5b-instruct-q4_k_m.gguf
test over 1408 question accurate 50.1%
use time:3593.31 s batch:51.9554 token/s
qwen2-math-1.5b-instruct_q4_k_m.gguf
test over 1408 question accurate 36.1%
use time:2644.51 s batch:70.0637 token/s
qwen2-0_5b-instruct-fp16.gguf
test over 1408 question accurate 37.1%
use time:3538.57 s batch:52.7993 token/s
qwen2-1_5b-instruct-q4_k_m.gguf
test over 1408 question accurate 50.1%
use time:3593.31 s batch:51.9554 token/s
На скорость не смотрите,
в первом 8 потоков + cuda,
2 нижние на cpu в 5 потоков.
Общее впечатление не очень,
модель ещё и в русский не может.
Пофиг на скорость. Ты вроде уже много подобных тестов делал, можешь оформить их в рентрай? И там же заодно разместить линк на тулзу и сами тесты.
> модель ещё и в русский не может
> 1.5b
> math
Ар ю ахуели там?
72В тести, кому вообще эти микромодели нужны.

И что ему не нравится? Пытаюсь запустить
Midnight-Miqu-70B-v1.5.i1-Q5_K_M.gguf
Midnight-Miqu-70B-v1.5.i1-Q5_K_M.gguf
> мику в 2024
> q5 в цп
> что ему не нравится?
Твой уровень интеллекта разве что.
lora случаем не выбрана?


> мику в 2024
Мику решил попробовать как первую большую модель. До этого мелкими перебивался.
>q5 в цп
Там нормально так слоев в видюху кидается. Все равно меджленно наверное будет хз
>Твой уровень интеллекта разве что.
Пошел нахуй
Пусто.
Он еще в самом начале пишет мол аут оф мемори, но даже половины рам не занимает. Что не так?
Все нормально, вот эта может:
qwen2-1_5b-instruct-q4_k_m.gguf
В eva есть переключение между
MMLU и C-EVAL тестированием,
если у тебя держит 72B можешь
воспользоваться ссылкой на eva
в гите llamacpp раздел интерфейсов.
> Он еще в самом начале пишет мол аут оф мемори
Своп включен? Оно может пытаться резервировать куда больше чем доснупно в твоих 64 гигах, при этом оно фактически не будет использовано.
> image.png
Ну это же оом куды, снизь количество выгружаемых слоев и/или размер контекста.
Cтоит ли использовать mmq и\или cublas на тесле? Что-то нихуя понять не могу. Сравнил свою обёртку над лламой без обоих опций с oobabooga, где force mmq включён. Профита по токенам в секунду нет никакого, может быть, на грани погрешности при пустом контексте, но у убы разброс пиздец, на большой модели 25% т\с плюс-минус.
Также потестил контекст шифт с низкоуровневым апи лламацпп, как писал пару дней назад. Восхитительно. Это настолько охуенно, насколько может быть. Cидел полчаса пиздел с моделью про звёздные войны, лол.
Также потестил контекст шифт с низкоуровневым апи лламацпп, как писал пару дней назад. Восхитительно. Это настолько охуенно, насколько может быть. Cидел полчаса пиздел с моделью про звёздные войны, лол.
imat очевидно,
бери обычный.
По тестам, они есть на гите eva.
Все тесты в папки utils идут вместе
с исходниками при их скачивании.
Сделать набор тестов можно из чего
угодно загружая в eva csv табличку с
id,question,A,B,C,D,answer построчно.
По результатам, сейчас интересуют
мелкие модели с показателями >65%,
по скольку таких всего две phi3 и qwen2
особого смысла в большой сводке не вижу.
С исходниками лежит интересный файл презентация pptx,
если получится частично адоптировать на русский добавлю.
> есть на гите eva
Это если будешь рентрай или любой другой маркдаун делать с этими табличками, чтобы сразу ссылка была.
> мелкие модели с показателями >65%
Их вообще интересно помучать в различных задачах. Являются ли эти 65% признаком повышенного ума, или просто надрочили и кроме этого ни на что не годны.
>Их вообще интересно помучать в различных задачах. Являются ли эти 65% признаком повышенного ума, или просто надрочили и кроме этого ни на что не годны.
Да, это интересно. Там легче видно прогресс в нейронках, и могу сказать что возникаюшие способности и модели мира у них есть так же.
В конце концов они обучаются на том же датасете и той же архитектуре.
Слоев меньше, а это значит что им труднее понять сложные абстракции. Сами по себе мелкие - значит обладают ограниченными знаниями о конкретных вещях.

Примерно так выглядит.
Сам файл Введение в программное обеспечение.pptx тут:
https://github.com/ylsdamxssjxxdd/eva/tree/main/ui/resource

Чуть поджал.
Попробую перевести руководство
через какой-нибудь онлайн переводчик
без потери структуры и выложить картинкой.
> через какой-нибудь онлайн переводчик
> без потери структуры и выложить картинкой
С одной стороны хорошо, но блин, эти спейсы между кириллицей с китайских шрифтов вызывают вьетнамские флешбеки, а сама презентация составлена так что без сопутствующего рассказа ничего не понять.

> Как вы ее заставляете русский использовать?
Хз я без задней мысли попросил гемму писать CoT на английском, а ответ чара на русском. Без каких-либо проблем работает. Попробуй гритинг на русском сделать.
>Ну это же оом куды, снизь количество выгружаемых слоев и/или размер контекста.
Да действительно спасибо.
>Cтоит ли использовать mmq и\или cublas на тесле?
Что значит "стоит ли", ради cublas нвидиевские карточки и берут :)
mmq ускоряет обработку контекста, сильно так ускоряет. На тесле это особенно актуально. Если теслы две и больше, то для больших моделей не забудь ещё и rowsplit.
Контекст шифт реально охуенен.

Нуууу, скорее работает чем не работает. Кмк ишью действительно где-то в другом месте. Оставлю на потом. Энивей спасибо.
Алсо, кажется я тебя знаю.
Что за промт для мыслей и плана?
мимо
Егошний кот
https://rentry.co/h7byk4hs/raw
Просто CoT от балды сделал. Пытался сделать чтобы чар сам мог историю двигать, с инициативой там проблема явная была. По хорошему бы по проптам из шапки аичг пройти и глянуть как на инструкции оттуда разные локалки реагировать будут.
> Алсо, кажется я тебя знаю.
Вполне может быть, я здесь давно.
> Вполне может быть, я здесь давно.
Я сюда редко захожу, скорее наи 2023, лонг шизопосты
Я там в основном и сижу с октября 2022, да.
>ради cublas нвидиевские карточки и берут :)
Ну как я вижу из кода, полностью его выключить нельзя, а чтобы принудительно включить - нужно пересобирать всю лламуцпп. Пока не буду этого делать. Просто несколько раз видел, что здесь mmq советуют, а моя сборка рапортует "force mmq : no". Но по скорости отличается от убы с force mmq в пределах погрешности. Тестировал на модели 20 гигабайт и 3к контекста.
>mmq ускоряет обработку контекста
Я бугуртил, что пересчёт контекста в убе занимает секунд по 15 со стриминг ллм, которая предположительно сохраняет часть контекста и делает тот самый контекст шифт. Но с голой лламацпп мой пересчёт контекста занимает 0 секунд. Рофла ради даже сделал микроконтекст и пересчёт происходит в процессе генерации ответа. Благодаря тому, что Жора ебать молодец и запилил
>KV data is updated accordingly: lazily on next llama_decode()
всё генерируется абсолютно связно и не требует никаких дополнительных телодвижений. Нужно ещё полировать, я где-то обосрался с мультитредингом, но как же это пиздато.
DeepSeek-Coder-V2-Lite-Instruct легко болтает по русски, но у него какой то ебанутый свой промпт формат. Кто то разобрался как ему формат нормально сделать в таверне?

Пока так.
https://huggingface.co/informatiker/Qwen2-7B-Instruct-abliterated-Q4_K_M-GGUF
10% MMLU 1408
qwen2-7b-instruct-abliterated-q4_k_m.gguf
test over 1408 question accurate 67.1%
use time:5652.24 s batch:32.7806 token/s
10% C-EVAL 1376
qwen2-7b-instruct-abliterated-q4_k_m.gguf
test over 1346 question accurate 78.9%
use time:13461.44 s batch:10.3702 token/s
10% MMLU 1408
qwen2-7b-instruct-abliterated-q4_k_m.gguf
test over 1408 question accurate 67.1%
use time:5652.24 s batch:32.7806 token/s
10% C-EVAL 1376
qwen2-7b-instruct-abliterated-q4_k_m.gguf
test over 1346 question accurate 78.9%
use time:13461.44 s batch:10.3702 token/s
Мне кажется нет в нем смысла, кодесталь тот же лучше лайт версии дипсика в большинстве бенчмарков.
Бурги его любят потому что у него лицензия хорошая.
Qwen2-1.5B-Instruct-Abliterated-Q4_K_M.gguf
10% MMLU
test over 1408 question accurate 49.5%
use time:2441.67 s batch:75.884 token/s
Вспоминается очень годная для своего времени и размера OpenHermes-2.5-Mistral-7B.
Есть ли какие-то явные профиты у данной 8B?
https://nousresearch.com/hermes3/
> Hermes 3 contains advanced long-term context retention and multi-turn conversation capability, complex roleplaying and internal monologue abilities, and enhanced agentic function-calling. Our training data aggressively encourages the model to follow the system and instruction prompts exactly and in an adaptive manner. Hermes 3 was created by fine-tuning Llama 3.1 8B, 70B and 405B, and training on a dataset of primarily synthetically generated responses. The model boasts comparable and superior performance to Llama 3.1 while unlocking deeper capabilities in reasoning and creativity.
Hermes 3 technical report
https://nousresearch.com/wp-content/uploads/2024/08/Hermes-3-Technical-Report.pdf
че за выебон из-за очередного тюна ламы? чем хорош?
>and training on a dataset of primarily synthetically generated responses
Только представьте какой это буддет металлический соевый кал
> MMLU улетел ниже 80
Ну и нахуй оно нужно, если скоры только вниз ушли? Ноусы уже давно скурвились, нормальных моделей год не выкатывали.
Особенно интересно, насколько хороша большая.
Я все еще против считания математики ллмками, но лень человеческая побеждает здравый смысл. х)
Да там и q8 летает.
Да и Gemma 2 2.6b q8 на смартфонах норм себя чувствует.
А вот фи-3 3.8 уже медленноватая.
Если планируешь гонять чисто на видяхе, то хватит и 64 гигов.
Если хочешь катать большие модели с частичной выгрузкой на видяху, то там уже лимитов нет. =)
Дипсик 16б, чи скока там. Тебе архинужно 7б?
Тут уже не подскажу. Вроде CodeQwen-1.5 7b был неплох. Но может Llama-8b или Codestral-7b (но она, вроде, не удалась), не знаю, честно. После появления дипсика перестал мелкие тыкать.
40%. Для 1.5б да еще в таком кванте (за шо, чому не q8??? сравни, попробуй) хороший результат прям.
Ето да. =)
Бери magnum-72b как первую большую модель.
А Гемма 2 2.6 сосет?
Разве? Мне казалось, там что-то дефолтное… Но я сижу прям в убе.
Ну, кодстраль чуть лучше, а дипсик заметно меньше и пиздец быстрее.
Но если можешь гонять кодстраль комфортно, то возможно и лучше, да.
Полная хуйня была.
Синтетика перла из всех щелей.
Подходил только для чат-ботов в корпорациях.
Общаться было нереально.
Гермес — литералли одна из самых худших файнтьюнов, нужная примерно никому.
Он плох всем.
Попробовал Big-Tiger-Gemma-27B из тредовского ренти. Ну и хуйня. Может квант маловат вечером попробую на более высоком, но пока залупа какая-то. Очень бредит модель и графоманит.
Пока что круче noromaid-20b ничего не нашел она прям идеальна. Впрочем у меня и запросы не совсем обычные.
>Бери magnum-72b как первую большую модель.
Качаю. Чем хороша?
Пока что круче noromaid-20b ничего не нашел она прям идеальна. Впрочем у меня и запросы не совсем обычные.
>Бери magnum-72b как первую большую модель.
Качаю. Чем хороша?
5090 брать такая себе идея. Мб анон который говорит взять две карты 4 серии прав. Типа учти что первые карты 5 серии будут гореть пердеть и ломаться программно и аппаратно. Карты у зеленых теперь как ААА игры - выходит говно, допиливают патчами. Первую ревизию первой карты в серии вообще можно прямо с конвейера сразу в мусорку кидать лол. Технический долг до них добрался. Им же надо как по расписанию выдавать технологические прорывы да удваивать кол-во транзисторов, такие вещи забесплатно не проходят.
К тому же я думаю профит от абстрактно выгрузки 10 слоев (а я как понял ты собираешься именно выгружать слои, иначе нахуй тебе ram) на быструю карту 5 серии будет меньше чем выгрузка 15 слоев на две карты 4 серии.
> первые карты 5 серии будут гореть пердеть и ломаться программно и аппаратно
Что за шиза, лол? У меня гниль 4090 с карусели уже два года, ничего с ней не случилось. Никаких проблем нет с релизными картами, так же как и не существует аппаратных ревизий у карт - 90% карт идут просто с референсным дизайном платы. Про программные проблемы это к амуде, у куртки никогда нет их на релизах железа.
Там есть функциональные вызовы и модель обучена использовать теги о которых речь в документе. Ну и все это с большим контекстом. Самое то для всяких агентов.
Не думаю что текушая версия хуже обычной лламы3, они бы не выпустили еще раз хуйню
Падения в тестах незначительные, к тому же в других тестах гермес наоборот лучше
>Технический долг до них добрался
Долбоебизм скорее. Что у них там горело, кроме дебильного разъёма? Тридцатки горели из-за пали вместо смд конденсаторов. И нью ворлда, конечно. Десятки просто орали дросселями. Хотя вторая ревизия кристалла 4090 в итоге хуже первой и нужно смотреть, что покупаешь.
Скоро ещё интеловские батлмаги выйдут, на 12 и 16 гигабайт, топ жир, блядь. А потом и 5090 на 24.
>> xformers
>Раньше он ничего не давал
В SD треде такого не напиши. Я раз написал, чуть с говном не сожрали, якобы оно снижает потребление vram, ускоряет и вообще чудо. Хотя я специально тестировал, вообще никакого влияния.
>40%
>для 1.5b
>хороший
Да, все так. Прогнал после еще парочку 1.5b
все показали не больше 20 на abstract-algebra.
По остальному MMLU у Мath хуже результат,
получается там буквально данные вытеснены.
>xformers
Год назад в наи треде сидел. Добавление иксов увеличивало кол-во итераций/сек в два раза. Так что уважайте деда.
Кровь из глаз, и от шрифтов, и от содержимого
> темные ком
> область ввод
> подсказать слово подсказать
> температура температура
> длина контекста длина контекста
> подсказка подсказки
> анжуманья бегит
Получил МОДЕЛЬ БОЛЬШОГО ЯЗЫКА с этого. В таком виде оно чуть менее чем бесполезно.
Стоковая гемма лучше
> взять две карты 4 серии
Только если используешь их для чего-то еще и не по текущим ценам. Сейчас буквально нет альтернативы 3090.
> первые карты 5 серии будут гореть пердеть и ломаться программно и аппаратно
амудэшиз или подстилаешь соломку оправдывая невозможность апгрейда?
> В SD треде такого не напиши
Hey buddy, you got the wrong door. SD-thread is two blocks down. Там оно действительно дает радикальное преимущество, а то что ты тестил - скорее всего кривость настроек интерфейса, которые не применились. Из альтернатив SDPA подкрутили и оно тоже норм работает, но чуточку уступает. Больше нигде толком подобного профита от xformers не замечено.
>менее чем
Есть ориг выше, вспомнил, что можно
просто смарт навести на экран, и он прямо
с китайского на ходу текст переводит. Всё.
Ту картинку делал через ПейджТранслит
в LibreOffice после конвертации pptx>docx>pdf.
Сам снимок экрана из Edge бразура, после
ужатие в Imagine до 16000px webp 50% в 1 МБ.
Это очень круто и похвально что ты делаешь, но в таком виде оно действительно бесполезно. Не только неудобно читать (что может быть легко исправлено), проблема в очень кривом переводе, поломанных рисунках и изначально самой презентации, из которой сложно извлечь информацию без сопутствующего выступления автора.
Если действительно хочешь заняться - стоит причесать это и оформить в чтиво, тем более там известная база с которой не должно возникнуть проблем.
От сообщения ощущения стариковской манипуляцией,
прям чувствую это крехтение за соседним офисным
столом, этот кофеек из термоса и седые чуть сальные
волосы. А как а вот так, нет так, сейчас тебя научим.
Я понял что ты мне от добра предлагаешь научится
доки вести раз уж много тестов. У меня цель другая
просто направить в китайский франкенштейн и так,
чтобы его схавали как есть, с китайскими доками и
шайтан интерфейсам + еще алерты на вирусы. Почему?
Потому-что это легкий автономный комбайн, который
работает из коробки на любом пк быстро. Когда я
поставил eva у меня вообще все модели шизили,
но с использованием понял - это модели кривые.
А работали они нормально потому что в кобольде
вечно что-то крутишь как в старой ладе. В eva сразу
чувствуешь, что модель достойна внимания если она
хороша, и дело не только в тестах. Кто захочет накатит.
>на nan не обращай внимание
А у тебя тоже всплывает NAN? Попробовал применить no_cache и ошибка не пропала.

Подскажите, как в сили таверне сделать, чтоб бот только оранжевую часть писал? Без белого текста
Напиши ему текстом, блять.
Покажи карту персонажа
От сообщения
ощущается желание
намекнуть
что ты делаешь
полную херню
которая в таком виде
никому не будет
полезна но при этом
тебя не обидеть
оттолкнув от добрых дел
Для запуска хватит инструкции которая у них в гите есть, просто ее перевести будет уже достаточно. Штука хорошая, полезная, вопросов к ней нет, заодно своих советов накидал бы, все были бы только рады. А вон тот поломанный надмозг "удар много смех хороший переводить формат сохранение" - это же пиздец, неужели сам не видишь? И какое отношение он к той тулзе вообще имеет?
> вообще все модели шизили
Все шизить не могут, особенно чистые базовые.
Это не ошибка, просто результат деления на ноль. Ноль обработанных токенов делятся на 0 секунд при расчете скорости, просто контекст не пересчитывается если в этом нет потребности.
> no_cache
Оно точно отвечает за кэширование контекста?
Добавь в свой пост или инструкцию указание типа
> your response must contain only the requested prompt without anything else
и убрать опцию ban eos token
Анусовые, кто ставил Немо мисральский, есть к вам вопрос. Темплайт контекста и инструкта у нее изменился от обычного мистраля, или нет? У меня стоит старая версия таверны и пресеты остались старые соответственно. Обновляться не хочу, потому что уже всё настроил под себя и боюсь что опять что-то слетит.
У мистралей ничего кроме [INST] нет.
Там как в старых мистралях [INST]. Стоит отметить что он, как и старый мистраль и мику, даже лучше перформит в ролплей альпаке чем в родном, но лучше сам поиграйся и посравнивай.
а че значит эта INST?
instruction - инструкция
Спасибо, братья.
Кстати, забыл спросить. Там системный блок есть, или всё отправляется через юзера? Никогда мистрали не гонял, по этому вопрос тупой, да.
Да там ппц вода, просто общие слова, настроить.
Могу сказать что работает - озвучка на русском,
генерация картинок (если стоит китайский язык),
квантирование, генерация картинок в меню,
виспер не пробовал. Ембидинг не пробовал.
Загрузка своих csv тестов работает, любой язык.
Все меню - слайд меню в pptx работает, там:
сделай алгоритм, реши судоку, сравни всякое.
Речь шла о разных файтюнах и мелких корпах.
Сервер стартует, апи доступно, страница в бразузере.
В куде слои перешелкиваются, в вулкаке и кпу все норм.
Единственное автор убрал родной пресет евы из аниме.
Самое удобное папка temp и чистый режим завершения.
Не злись если тебе мой ответ на пост показался грубым.
Вот пример гоняешь кобольд все норм, но в какой-то
момент начинают происходить затыки непонятки.
В кобольде начинал передергивать темпу лезть в доки.
Сейчас я просто загоняю в тесты и если модель вместо
буквы начинает лить что угодно другое - ясно она сломана.
Второй пример нагружка - в кобольде смотрю загрузку
системы через диспечер, в еве вижу чистый отжор модели.
Опять же очень редко надо лезть что-то менять в настройках.
момент начинают происходить затыки непонятки.
В кобольде начинал передергивать темпу лезть в доки.
Сейчас я просто загоняю в тесты и если модель вместо
буквы начинает лить что угодно другое - ясно она сломана.
Второй пример нагружка - в кобольде смотрю загрузку
системы через диспечер, в еве вижу чистый отжор модели.
Опять же очень редко надо лезть что-то менять в настройках.

Qwen2 — одна из лучших моделей в своем размере (логика, контекст, все дела).
А файнтьюн сделан на синтетике из Claude Opus, стиль хорош.
В общем — модель уже немного в возрасте, но все еще очень хороша для 48 гигов.
Мику тоже хороша, но уже совсем бабулька, конечно.
> оно снижает потребление vram, ускоряет и вообще чудо
Однажды я забыл добавить ключ и… ничего не случилось!
Но вдруг мы не так тестируем? На 4070ti прироста лично я не заметил, однако… вдруг на 30-20-10 видяхах панацея?
К счастью, нет.
Типа тега [INST][/INST], инструкция, внутри инструкция для модели, снаружи — текст сгенеренный моделью. Все просто.
[INST][/INST] — для системного и юзер промптов. ассистент идет вне тега. Все.
———
Приобрел две P104-100, чисто мини-магнум гонять в 16 гигах.
На авито нашел человека с 2к за видяху, обе отдал за 3,5к. 16 гигов за 3,5к весьма недурно. Дурно, что материнка нужна с двумя слотами, конечно, и питание 4*8пин.
Но для бомжей вариант хороший, даже одна видяха будет хорошим подспорьем, если у вас 1050 и вы страдаете 1 токеном/сек на 8б.
>Приобрел две P104-100, чисто мини-магнум гонять в 16 гигах.
Ебать ты особенный. Фотки покажешь?
>и питание 4*8пин
3 штуки хватит же, плюс продованы обычно переходники с псины кладут, так что и стандартных 2-х вполне себе хватит, если не интул вместо проца конечно же.
Сам пей. =)

У меня примерно тот же год назад разницы вообще небыло.
>МОДЕЛЬ БОЛЬШОГО ЯЗЫКА
А как же СТЕПЕНЬ МАГИСТРА ПРАВА?
>скорее всего кривость настроек интерфейса
Мне нужна была SD без xformers, чтобы завелся TensorRT. В итоге он завёлся, чего не могло быть с xformers.
>Но вдруг мы не так тестируем?
Либо зависит от размера батча, разрешения, фазы Луны, etc.
> P104-100
Вроде, и хочется, а, вроде, и места в аквариуме уже нет. Плюс нужно райзер купить, переходник на питание, чтобы в райзер не расходовать лишние пины. И если прикрутить на место водянки вверху, то куда пойдёт горячий воздух? Тяжело.
Заглянул в системник место поискать, а там пикрил. Пыли пиздец.
Кстати, раз зашла тема про чат темплейты, решил немного копнуть эту тему. Жора зачем-то прикрутил к лламе.цпп эти самые темплейты. Но мы же помним, кто такой Жора. Так что он не стал тащить в проект jinja, а просто захардкодил некоторые темплейты.
https://github.com/ggerganov/llama.cpp/wiki/Templates-supported-by-llama_chat_apply_template
Генитальный мув. Но в целом ллама.цпп просто охуенна.
>Так что он не стал тащить в проект jinja, а просто захардкодил некоторые темплейты.
ЁБАННЫЙ
СТЫД
А картинка зачётная
jinja конечно нахуй не нужна, тут с жорой я прав, но блядь распарсить строку с темплейтом а потом по ней форматировать можно было бы и на сях.
> А как же СТЕПЕНЬ МАГИСТРА ПРАВА?
Не не, нужно переделать под мем
> Утром:
> 1. слово угадыват
> 2. т) agiт
> 3. температура температура
> 4. предсказанья
> SD без xformers, чтобы завелся TensorRT
И как оно?
> IMG202408162205[...].jpg
В голосину
Проиграл с картинки. А что это в оригинале значит?
Насколько эти флаги с квантованием кэша рентабельны? Сколько сэкономят?
Что за флеш атеншен?
Что за флеш атеншен?
>переделать под мем
А в конце еще
10) EOS токен


>Не не, нужно переделать под мем
Я имел ввиду пик 1.
>И как оно?
Тупо ебёт. Правда, чтобы работало, модель должна быть в специальном формате, но там была автоматическая конвертация, насколько я помню. И лоры тоже. Но по итерациям в секунду выигрыш в 2-3 раза и выше.
Помнишь было время, когда были евространдарты для автомобилей? Вот теперь они есть и для пекарни. Energy-related Products. Включение ограничивает токи дежурки, не выше 1 вт. Отчего отпадает возможность заряжать девайсы, включать пк по разным триггерам, кроме кнопки, гасит всю лгбт на выключенном пк и т.д.
>флеш атеншен
Обработка внимания быстрее и с меньшими требованиями к памяти. Про квантование кеша недавно обсуждали, меньше памяти - меньше точность.
> Что за флеш атеншен?
Ставь галочку и молись на него, он позволит вместить в пару раз больше контекста в врам.
> Насколько эти флаги с квантованием кэша рентабельны?
Экономят в 2 и 4 раза. 4 бита даже лучше может быть за счет более удачного нового формата, деградация качества будет, но насколько значительная/заметная смотри сам.
ВСТРОИЛ КОНЕЧНУЮ ТОЧКУ, разбудив ором всех в округе.
> Тупо ебёт.
А насколько юзабельно вообще? Помню было во времена 1.5, но тогда шакалы и так инстантом генерировались. XL и первичный хайрезфикс там можно сделать?
Всем привет!
Какие модели выбрать (2-3) с поддержкой русского языка и минимальной цензурой под RTX 4070 12Gb?
Для:
1. Общих задач (ответы на вопросы, форматирование текста, перевод текста)
2. Написание кода
Какие модели выбрать (2-3) с поддержкой русского языка и минимальной цензурой под RTX 4070 12Gb?
Для:
1. Общих задач (ответы на вопросы, форматирование текста, перевод текста)
2. Написание кода
Я кстати понял причину того, что модель уходит в луп.
Галка - no_mmap. Когда нажал, всё стало хорошо работать.
Что не так с mmap на винде?
Что есть кэш контекста? Просто выходы всех слоев атеншена, или какой-то более сложный алгоритм, который сначала обычным проходом считает, а потом этот кэш перемножается как-то хитро целиком с новым контекстом? И он потом апдейтится новыми токенами или его заново сложно считать?
По атеншену все разжевано, а тут что-то ничего не нашел.
По атеншену все разжевано, а тут что-то ничего не нашел.
Продолжаю ебать лламу. Из-за какой-то хуйни выделялась память на GPU 0 при выборе Main GPU = 1. Понятное дело, что если я выставил splitmode.none, то я не хочу разносить модель на разные карты. Это может оказаться медленно, я могу засрать остальные карты чем-то другим и т.д. Оказалось, это выделение вычислительного буфера в llama.cpp
>for (size_t i = 0; i < ctx->backends.size(); i++) {
Хуй знает почему бэкендов столько же, сколько куда карт, так быть не должно.
Ишью есть, всем похуй
https://github.com/ggerganov/llama.cpp/issues/8827
Делать cuda visible devices как-то тупо, нужно менять код, а для этого нужно пересобрать лламу. А для этого нужно поебаться, потому что у меня неправильные куды стоят, нужны правильные.
Раз уж начал читать про доки, то вот что пишут про MMQ
>MMQ kernels are enabled by default on GPUs with int8 tensor core support. With MMQ force enabled, speed for large batch sizes will be worse but VRAM consumption will be lower.
Вроде, и быстрее, но не всегда. На тесле же вроде быстрые int8?
>А насколько юзабельно вообще?
Я когда проверял там небыло поддержки int8, а в быструю карту у меня фулл веса не помещались, так что было в несколько раз медленнее. А так поддержка есть, всё работает без проблем. Сейчас уже int8 завезли, нужно будет проверить, я тогда как раз на 1.5 проверял да так и забил, модели и так весят пиздец сколько.
>а потом этот кэш перемножается как-то хитро целиком с новым контекстом?
Каждое следующее значение зависит от предыдущего, так что при новых токенах выбрасываются старые значения и вычисляется значения для новых токенов.
>for (size_t i = 0; i < ctx->backends.size(); i++) {
Хуй знает почему бэкендов столько же, сколько куда карт, так быть не должно.
Ишью есть, всем похуй
https://github.com/ggerganov/llama.cpp/issues/8827
Делать cuda visible devices как-то тупо, нужно менять код, а для этого нужно пересобрать лламу. А для этого нужно поебаться, потому что у меня неправильные куды стоят, нужны правильные.
Раз уж начал читать про доки, то вот что пишут про MMQ
>MMQ kernels are enabled by default on GPUs with int8 tensor core support. With MMQ force enabled, speed for large batch sizes will be worse but VRAM consumption will be lower.
Вроде, и быстрее, но не всегда. На тесле же вроде быстрые int8?
>А насколько юзабельно вообще?
Я когда проверял там небыло поддержки int8, а в быструю карту у меня фулл веса не помещались, так что было в несколько раз медленнее. А так поддержка есть, всё работает без проблем. Сейчас уже int8 завезли, нужно будет проверить, я тогда как раз на 1.5 проверял да так и забил, модели и так весят пиздец сколько.
>а потом этот кэш перемножается как-то хитро целиком с новым контекстом?
Каждое следующее значение зависит от предыдущего, так что при новых токенах выбрасываются старые значения и вычисляется значения для новых токенов.
>Каждое следующее значение зависит от предыдущего, так что при новых токенах выбрасываются старые значения и вычисляется значения для новых токенов.
Ну в а кэше то сидит что? А то моих мозгов пока не хватает понять там просто все или сложно, в какую сторону думать.
Только вчера вроде разобрался как работают эти самые qkv, не могу все в башке замоделить.
>Ну в а кэше то сидит что?
У тебя токен проходит через слой, для этого токена вычисляются векторы Q, K и V. Потому что для каждого нового токена каждый раз нужны эти векторы. Q используется один раз, нет никакого профита его кешировать, а вот K и V нужны для каждого следующего токена. И на каждом слое у тебя висит кеш, чтобы не считать каждый раз эти векторы. K и V векторы не меняются, потому что не меняется значение токена, потому можно использовать их каждый раз заново.

>У тебя токен проходит через слой, для этого токена вычисляются векторы Q, K и V.
ЕМНИП в целях оптимизации обычно это вычисляется за один проход, делая единую матрицу QKV. Но тогда мне интересно, как это кешируют.
Мимо читал про GPT2

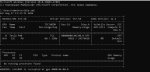

У меня тесла спустя год после покупки начала крашить обабогу и выёбываться с разными ошибками.
Что пошло не так?
Что пошло не так?
> Делать cuda visible devices как-то тупо
Почему тупо, решает на корню все проблемы быдлокода.
Андервольтил? Охлаждается нормально? Проверь в другом слоте и убери все лишнее что делал. Обычную рам и разгон профессора еще проверь, они могут срать.
>Андервольтил?
Нет.
>Охлаждается нормально?
ГПУ грелся не больше 65 во время рисования анимекартинок.
>Проверь в другом
Делал не помогло.
> Обычную рам и разгон профессора еще проверь, они могут срать.
Проверю, потом напишу.
>InfoROM is corrupted...
Скачиваем утилиту nvflash отсюда:
https://www.techpowerup.com/download/nvidia-nvflash/
Запускаем консоль (командную строку) от администратора, переходим там в каталог nvflash и пишем:
nvflash64 --list
Получаем список индексов наших видеокарт. В nvidia-smi мы уже заметили, с каким номером карты сбой - ищем этот номер в списке индексов. Дальше, имея нужный индекс сохраняем на всякий случай тарый InfoROM:
(пример для карты с индексом 2)
nvflash64 -i2 --save P40(2).ifr
Дальше пытаемся реставрировать инфором:
nvflash --repairfs
(результат - ошибка реставрации, но в окне nvidia-smi об ошибке перестаёт сообщать)
Есть ещё вариант восстановления инфором из теневой копии nvflash --recoverinforom - как вариант.
>nvflash --repairfs
Для карты с индексом 2:
nvflash64 -i2 --repairfs
Как-то так. Все операции из-под администратора.
Анончики, что там по новым моделям? Сам пока сижу на lumimaid

Потянуло на текст комплетишон модель, вспомнить былое. есть ли смысл пытаться локалку искать-ставить если 1060 видеокарта на 6 гигов ноутбучная?
Есть мелкие и умные модели, если просто хочется "поболтать с ии"
Но кумить на них скорее всего не выйдет
phi3, qwen2 до 4b
Это если нужно только в видеокарте. Если пофигу на скорость можешь хоть 7-12b запускать, в зависимости от твоего компуктера
>Сам пока сижу на lumimaid
И дальше сиди, отличная модель.
мне не формат чата нужен а формат текста, что есть для этого что в целом нормально выдумывает хоть сфв хоть нсфв, и что заведется у меня на ноуте
даже не уточнил на основе ламмы или мистраля я обе скачал 8 и 12 б, 70 мне только снится, а уже называешь ее отличной?
Для рп на русском база это Магнум 72В или Мэйда 123В, если готов пердолиться с лупами.
>Для рп на русском база это Магнум 72В или Мэйда 123В, если готов пердолиться с лупами.
Строго говоря, даже Мистраль для русского ещё не готов. На английском модель всё равно "умнее". Тут уж кому что важнее.
> На английском модель всё равно "умнее".
Я не видел такого большого разрыва как у жпт-4, которая прям совсем тупая на русском. Мистраль на русском даёт ответы идентичные английскому. Да и по скорам там русский MMLU всего на пару пунктов меньше.
Аноны, а если есть задача найти не буквальные дубли в списке, гемма 27B вроде бы способна, но как в неё вогнать хотя бы 1к строк?
> но как в неё вогнать хотя бы 1к строк?
Точно также, только уложись в выбранный контекст. Если в 8к не влезет то придется подбирать параметры rope/alpha, perplexity бенчмарк в помощь.
Или дробить списки так чтобы влезали с перекрытием, чтобы у каждый сравнивался со всеми, а потом еще раз обработать итоговый результат.
Какая-то странная история происходит с Немо. Иногда во время рп на русском протекают английские и китайские токены. Это сломанный квант, или проблема жоры кобольда?
Бери максимальный квант и не надейся, что русским оно будет владеть хотя бы на уровне английского.
блять я проебал карточку нины и хины, скиньте у кого осталась
>как это кешируют.
А твоя QKV матрица это не какой-то волшебный единорог. Берём один слой, в нем последовательно будут расположены Q, потом K, потом V векторы. Зная заранее сколько именно нам нужно чего - легко и непринуждённо режем.
>решает на корню
Я хочу одну обёртку, которая будет мне запускать несколько нейросетей на разных GPU. И если каждая будет раскидываться на каждый GPU - я ёбнусь.
Делай embeddings, хули ты.
Принудительный запрет высирать вычислительные буферы на все бэкэнды снизил выделение на треть, но какие-то буферы туда всё равно высираются.
Короче хуй пойми, что происходит, где-то в недрах выделяется память под что-то, читать весь этот крестовый код нахуй надо. LLAMA_SPLIT_MODE_NONE работает криво. LLAMA_SPLIT_MODE_LAYER точно так же работает криво. Чтобы у меня не выделялась память на всех GPU, мне нужно поставить LLAMA_SPLIT_MODE_ROW, а потом указать сплиты для ненужных карт, как нули. Используется незначительно больше оперативы, но на GPU память не высирается. Не уверен, что с таким использованием не будет пиздос с производительностью, лол, нужно проверить. По идее, не должно, это просто буфер для синхронизации кешей, но он никогда не будет использоваться. Не должен использоваться, а вот будет или нет - одному Жоре ведомо.
Зато собрал лламу со свежей кудой и в рот оно ебись. Лишний раз охуел от чат темплейтов.
>Бери максимальный квант
Не влезает в врам.
>не надейся, что русским оно будет владеть хотя бы на уровне английского.
Русским оно достаточно неплохо владеет, особенно если с какой нибудь ламой сравнивать. Именно из-за этого я её и накатил. Но проблема в этих рандомных токенах, которые непонятно как фиксить.
> хочу одну обёртку, которая будет мне запускать несколько нейросетей на разных GPU
А как это мешает? Было бы на пихоне - там все сильно проще, а тут придется копаться в продуктах жироной жизнедеятельности чтобы выставить маску. С другой стороны, это тоже не должно быть особо сложно.
> где-то в недрах выделяется память под что-то, читать весь этот крестовый код нахуй надо
Просто ограничь используемые куда устройства в самом коде на основе аргументов, а не пытайся перелопатить всю адресацию. Заебешься вычищать хардкод и костыли.
>проблема в этих рандомных токенах, которые непонятно как фиксить
Попробуй разные файнтюны, а не оригинал.
Chinese AI startups turn to GeForce gaming GPUs because Nvidia sanction-compliant AI GPUs are too expensive — RTX 4090 offers better value than H20
https://www.tomshardware.com/pc-components/gpus/chinese-ai-startups-turn-to-geforce-gaming-gpus-because-nvidia-sanction-compliant-ai-gpus-are-too-expensive
Согласно отчету MyDrivers, многие китайские стартапы, работающие в сфере искусственного интеллекта, отдают предпочтение одной из лучших видеокарт RTX 4090, а не ориентированным на Китай графическим процессорам Nvidia H20 AI. Говорят, что Nvidia HGX H20, отвечающая требованиям санкций. слишком дорог для многих малых и средних компаний, в первую очередь потому, что он не обеспечивает такого уровня производительности, как оригинальных графических процессоров AI A100 и H100.
Один восьмикарточный сервер H20 стоит около 1,3 миллиона юаней. С другой стороны, один RTX 4090 стоит от 16 000 до 20 000 юаней. Даже если вы установите цену на каждый RTX 4090 по цене 20 000 юаней, 1,3 миллиона юаней уже позволят вам приобрести 65 экземпляров топовых потребительских GPU.
Хотя H20, несомненно, обладает большей мощью, чем RTX 4090, огромная разница в цене делает последний более привлекательным. разница в цене делает последний более выгодным решением. Только только самые крупные компании, такие как Baidu, Alibaba, Tencent и ByteDance, могут позволить себе более дорогие чипы искусственного интеллекта.
Один предприниматель, который который в основном работает над прикладным уровнем ИИ, рассказал, что они арендовали чипы A100 и H100 через облачные сервисы, а затем перешли на локальное развертывание подержанных чипов V100 и RTX 3090. Учитывая это, они считают, что RTX 4090 будет более чем достаточно для их нужд.
https://www.tomshardware.com/pc-components/gpus/chinese-ai-startups-turn-to-geforce-gaming-gpus-because-nvidia-sanction-compliant-ai-gpus-are-too-expensive
Согласно отчету MyDrivers, многие китайские стартапы, работающие в сфере искусственного интеллекта, отдают предпочтение одной из лучших видеокарт RTX 4090, а не ориентированным на Китай графическим процессорам Nvidia H20 AI. Говорят, что Nvidia HGX H20, отвечающая требованиям санкций. слишком дорог для многих малых и средних компаний, в первую очередь потому, что он не обеспечивает такого уровня производительности, как оригинальных графических процессоров AI A100 и H100.
Один восьмикарточный сервер H20 стоит около 1,3 миллиона юаней. С другой стороны, один RTX 4090 стоит от 16 000 до 20 000 юаней. Даже если вы установите цену на каждый RTX 4090 по цене 20 000 юаней, 1,3 миллиона юаней уже позволят вам приобрести 65 экземпляров топовых потребительских GPU.
Хотя H20, несомненно, обладает большей мощью, чем RTX 4090, огромная разница в цене делает последний более привлекательным. разница в цене делает последний более выгодным решением. Только только самые крупные компании, такие как Baidu, Alibaba, Tencent и ByteDance, могут позволить себе более дорогие чипы искусственного интеллекта.
Один предприниматель, который который в основном работает над прикладным уровнем ИИ, рассказал, что они арендовали чипы A100 и H100 через облачные сервисы, а затем перешли на локальное развертывание подержанных чипов V100 и RTX 3090. Учитывая это, они считают, что RTX 4090 будет более чем достаточно для их нужд.
>они считают, что RTX 4090 будет более чем достаточно для их нужд.
Походу да. Впрочем ВРАМ там всё равно маловато. Нужны домашние нейроускорители - специализированные устройства. Пока что любители собирают их сами из всякого. А хотелось бы готовых решений за вменяемые деньги.
Выпал из нейронок на несколько недель. Гемма всё ещё чемпион?
>Но проблема в этих рандомных токенах, которые непонятно как фиксить.
Сначала выясни причину проблемы. Как минимум, посмотри распределение вероятностей токенов. А то ХЗ, может у тебя температура в 5 поставлена, первой, а не нейронка тупая.
>отвечающая требованиям санкций
Лол, вообще не понимаю невидию, так активно подмахивающую требованиям срегулятора вместо того, чтобы по честному поставлять миллионы карт в какой-нибудь Казахстан.
>Попробуй разные файнтюны, а не оригинал.
А че из годнных файнтюнов вышло на немо? Сори, я тред в последнее время редко чекаю.
>может у тебя температура в 5 поставлена, первой, а не нейронка тупая.
Ну ты тоже меня совсем за валенка не держи. Я семплеры подогнал нейтральные без шизоскруток. Раз 15-25 сообщений появляются какие то ебаные иероглифы и потом больше не фигурируют вообще. Тут скорее либо квант, либо токенизатор, либо просто модель под русский не сильно заточена.
Выбора нет, вот и юзают их. Чипы там достаточно мощные, если дробить куски между карточками то как-то тренить можно.
> Раз 15-25 сообщений появляются какие то ебаные иероглифы
Так просто забей и свайпай. Квант возмущает распределения вероятностей, но чтобы там начали лезть совсем левые - это поломанный или меньше ~3.5 бит. Если речь про мелкий мистраль - у него и на фулл весах иероглифы проскакивают.
>А как это мешает?
Переменная выставляется для всего процесса. Можно, конечно, но мне лень. У меня таски везде.
>Было бы на пихоне
Ага, один сервер для одной нейронки, второй для второй. И ещё приложение для гуя. Нахуй надо.
>копаться в продуктах жироной жизнедеятельности
Да я хуй забил, поставил ровсплит с нулями для ненужных карт и соткой для нужной. Выделяется лишний буфер kv в оперативе, нахуя решительно не ясно, но хуй с бы с ним, гигом больше, гигом меньше.
> Переменная выставляется для всего процесса.
Субпроцесс
> Ага, один сервер для одной нейронки, второй для второй. И ещё приложение для гуя. Нахуй надо.
Что?
> хуй забил, поставил ровсплит с нулями для ненужных карт и соткой для нужной
После такого у тебя нет морального права хуесосить Жору, лол.
>Если речь про мелкий мистраль - у него и на фулл весах иероглифы проскакивают.
А, ну тогда понятно. Тогда Нема эта ебаная нахуй не нужна, учитывая что у нее еще и проблемы со следованием инструкций. Вернусь на ламу, она хотя бы более предсказуемая и на инструкции не забивает.
>А че из годнных файнтюнов вышло на немо?
https://huggingface.co/QuantFactory/mini-magnum-12b-v1.1-GGUF
https://huggingface.co/bartowski/MN-12B-Celeste-V1.9-GGUF
https://huggingface.co/NeverSleep/Lumimaid-v0.2-12B-GGUF
По некоторым есть imatrix кванты и exl2, если нужно.
Благодарю. Если завтра будет время, то погоняю. Хотя уже разочаровался в очередной поделке мисраля, но раз это файнтюны на клаудовских датасетах, можно рискнуть.
Почему минимагнум, а не магнум? Там уже 2.5 есть какой то, вроде как еще более лучший


Во-первых, не ожидал такой скоростухи.
18-19 токенов/сек генерации для Nemo q8 — неплохо!
Во-вторых, обнаружилась проблема — без файла подкачки 16 гигов оперативы не хватает, чтобы выгрузить q8 (4 гига + 13 гигов модели = 17 гигов…=). no-mmap работает как-то постфактум, когда на модель ллама.сипипи уже посмотрела. Мелочь, а неприятно. Видимо, оперативу докуплю, пусть будет 32 гига, ненуачо.
Ну и скринчики видите сами. 50% по поверлимиту, ~200 ватт суммарно и 45° (хотспот где-то 55°~60°), решил оставить дрова от P104-100, а не 1070 (это немного экономит память, хочу подразогнать контекст), контекст считает как все паскали, со скоростью проца, кулер проца КАКОЙ БЫЛ, зато 4 теплотрубки за 900 рублей (и, да, комп лежит горизонтально, конечно).
Да, они малеха грязные, всратые, ржавые.
Но 18 токенов на немо за 3,5к рублей — это я не зря купил, все же. Веселая малышка для своего чат-бота.
>контекст считает как все паскали, со скоростью проца
Нифига, две теслы P40 на Немо 12B_Q8 считают контекст под 400 т/c. Если загрузить модель на две, включить mmq и отключить rowsplit.

Добавлю, с ростом контекста и неравным разделением скорость падает. Но все еще выше 10.
При соотношении 9,16 влезло 32к контекста в 8 бит.
За минуту прогрелись до 48°.
Думаю, до 50° поднимутся в итоге.
Но можно поиграть с кривой кулеров, офк. Они почти не слышны (хотя и жужжат, можно сменить и вообще будет тишина).
Возможно, дело в ровсплите, но мне лень тестить пока. Я не люблю пики то на одной видяхе, то на другой. Хотя, при коротких ответах, может быть ровсплит будет лучше выключить, согласен.
>Хотя, при коротких ответах, может быть ровсплит будет лучше выключить, согласен.
Дело не в длине ответа, а в выборе баланса между скоростью генерации и временем обработки контекста. Если нужно часто обрабатывать много контекста, то приходится жертвовать скоростью генерации (50% где-то), которую добавляет rowsplit. На паскалях приходится экспериментировать с ключами, чтобы выжать максимум :)
Просто, без ровсплита карточки задействуются по очереди, из-за чего возникают скачки. В ровсплите с этим легче. Я чисто морально не люблю, когда напруга то повышается, то понижается. Стабильность поможет им прожить дольше, кмк. Могу нести хуйню, канеш, да и беспокоиться за старые видяхи максимум странно.
Ну и очевидно, что без ровсплита на длинных контекстах будет гораздо быстрее (я как минимум видел без него 160 т/с, что втрое быстрее, и на приличных контекстах это уже выигрыш по времени).
Ну ладно, ботом завтра займусь, а пока — спатки!
Всем добрых снов. =)
>Там уже 2.5 есть какой то
Этот https://huggingface.co/bartowski/magnum-12b-v2.5-kto-GGUF что ли?
Так он несколько дней назад только вышел.
>Субпроцесс
Говорю же, лень. Потом ещё синхронизацию наворачивать.
>Что?
А что, в питон уже завезли человеческую многопоточность?
>у тебя нет морального права хуесосить Жору
Да справедливости ради, ИТТ ни у кого его нет.
Но я так прикинул хуй к носу и потратил десять минут на приведение жоракода в исходное состояние и запиливание себе в код небольшой порции грязи, чтобы не тратилась память впустую вообще нигде.
Если кому интересно, так работает даже не ллама.цпп, а ggml-cuda.cu. Он берёт cudaGetDeviceCount, который возвращает все куда-устройства и потом тупо пиздует в цикле по этим устройствам, забивая свои буферы. Ему похуй, что ты там передал в аргументах. Потому в коде лламы всё чинно-благородно, но всё равно везде насрано.
>no-mmap работает как-то постфактум
Не должен. Там загрузка самих весов может быть всратая, вроде были с ней проблемы даже до mmap. Сколько у тебя там пекарен дома, пять уже есть?
>комп лежит горизонтально
А это к чему? У тебя кулер не пристёгнут, чтоли? Так тогда похуй, сколько там трубок.
Нужно тоже взять такую картонку, пока и они не подорожали, блядь.
>Нужно тоже взять такую картонку, пока и они не подорожали, блядь.
А что, надежд на стартапы (которые сделают нам быстрыми большие локальные модели) уже совсем никаких? :)
Какая у нее pci шина?
И вопрос, p100 за 20к стоит того или хуйня?
>p100 за 20к стоит того или хуйня?
Дороговато...
https://www.avito.ru/nizhniy_novgorod/tovary_dlya_kompyutera/nvidia_tesla_p100_16gb_graficheskiy_uskoritel_3147999879
>p100 за 20к стоит того или хуйня?
Этому огрызку цена 10к максимум, хотя какие-то пидорасы его и за 35 кусков впарить пытаются. Барыги ебаные вообще уже берегов не видят.
Быстрые будут дорого, а дорого нахуй надо. Чем мне поможет "быстрое" решение за 2-3 килобакса, если я сейчас не приобретаю быстрые 4090 за тот же прайс?
Тем более, это пока будет, а тут за 3к я освобожу гигабайт памяти на тесле и перекину rag на эту помойку. Получится аж 4к контекста всунуть вместо 3к. Если будет быстро работать, ещё и генерацию голоса туда всуну. Осталось только доставку дождаться и найти местечко в аквариуме.
>Так он несколько дней назад только вышел.
И что? Он уже несколько дней назад вышел.
Версия 2 вышла где то 2 недели назад, а советуют вариант 1 версии
Что то кумеры разленились, либо сетки не зашли
> пять уже есть
Только если считать мини-пк и ноут. =D
А без них 4, получается. =)
> загрузка самих весов может быть всратая, вроде были с ней проблемы даже до mmap
Да, грузит долговато. Но потом все ок работает.
> А это к чему?
Не люблю массивные видеокарты, который висят на слотах.
А вертикально ниче не ломается. Ну вроде как.
Вроде 3.0 x1, что ли.
P100 за 20к — стандартная цена, но… хрен знает, норм ли. P100 я не брал, ибо некуда уже пихать некроту. Ну и после п40 за 16, п100 за 20 как-то жаба душит.
Ну вот по ощущениям, да, за 10к должна была бы быть, тогда нормас.
———
Хорошие новости. Оказывается, если текст совпадает, то API oobabooga по умолчанию кэширует запрос. И каждый раз пересчитывать заново не приходится. Значит условные 60-90 токенов/сек контекста не так страшно (если кто-то не догадается кинуть в чат-бота сразу 20к токенов… но столько не влезет в сообщение телега или вк, кек).
Видимо, силлитаверна сильно любит менять запросы, что он часто пересчитывается целиком.

>надежд на стартапы
Никогда и не было.
>Барыги ебаные вообще уже берегов не видят.
Это ты более новые не пробовал посмотреть... Карта сосёт у 3090 по всем фронтам, а цена как за нормальную.
>Получится аж 4к контекста
Ебать боль. Я давно меньше 8к не ставлю. Но я процебоярин.
А потом эта карточка отваливается нахуй как у анона выше →
> лень. Потом ещё синхронизацию наворачивать
Озвученная задача - обертка для запуска нескольких сетей, что там синхронизировать? Но даже это не то чтобы сложно делается.
> в питон уже завезли человеческую многопоточность
Шутка про то как братишки уже все сделали и рассуждают о выборе фреймворков, пока свидомый Вася на чистых сях пытается побороть переполнение стека, ага.
> справедливости ради, ИТТ ни у кого его нет
Не скажи, чтобы быть кинокритиком не нужно снимать множество фильмов, а здесь пол треда - режиссеры. Это смехуечки все, не принимай близко, главное чтобы работало.
> надежд на стартапы (которые сделают нам быстрыми большие локальные модели) уже совсем никаких?
Выкатят тебе мелкую коробочку на орине или его потомке по цене 4090 и сиди наворачивай. Больше надежд на многочиповые франкенштейны с увеличенной врам от китайцев.
> а цена как за нормальную
В первый раз видишь неадекватные цены на барахолках? Она так и будет там лежать, вся надежда барыг на то что кому-то срочно понадобится ее заменить в дорогом железе. Шансов на это со временем все меньше, будет правильно если петушиной голове на коммерсанте придется снижать цену до бросовой как с паскалями.
>с увеличенной врам от китайцев.
База.
Слышал о одной переделке, но никто не пруфал о её надёжности.
>Выкатят тебе мелкую коробочку на орине или его потомке по цене 4090 и сиди наворачивай. Больше надежд на многочиповые франкенштейны с увеличенной врам от китайцев.
Китайцы-то тоже не дураки и цену за своего франкенштейна заломят соответствующую. Тем более что и на китайском рынке есть спрос. И это при том, что проблемы в этих карточках могут лезть со всех концов, а гарантии никакой. Спорные преимущества перед стартапами. Меня больше напрягает, что кроме прогрева гоев пока ничего по сути нет - от китайцев и то есть что-то реальное.

Чёт, мне кажется, самый лучший способ для простого гоя это покупка сервера с 8-12 канальными ddr 5 контролерами памяти.
Дешевле чем A80, дешевле чем стак из 6 видеокарт (а тут скорость уже не будет такой быстрой), плюс такая железка в хозяйстве пригодиться если сможешь вытерпеть её шум.
И производительность они дадут 5+ токенов на 70b q8.
>сервера с 8-12 канальными ddr 5 контролерами памяти.
А можно пример такой (серверной) материнки? Так-то по идее можно на неё 4090 (одну) поставить и радоваться :)
8 канальный интел на ддр5
https://www.xcom-shop.ru/supermicro_mbd-x13swa-tf-b_1071130.html
Даже любопытно стало сколько стоит вся платформа sypermicro/hpe/dell на 12канальном АМД 9ХХХ
> И производительность они дадут 5+ токенов на 70b q8.
Не дадут. У серверных процев синглкор говно, а память на низкой частоте. Серверное железо не для этого делается. Там упор на параллельность, а не выжимание производительности. Ты ещё учти что вся эта сборка будет ценой в 500к самый каловый инцел 250к, самая дешевая мать 100к, память и мелочёвка до 500к догонят цену, если ты не собираешься брать б/у говно. Взять ведро 3090 дешевле обойдётся, 5 карт на игровую мать можно садить без проблем, пару карт будут на х1, но этого хватит для LLM.
>У серверных процев синглкор говно
Так ламацпп схавает, ей главное avx2 в каждом ядре.
>500к
Скорее всего да, дорого.
>Взять ведро 3090 дешевле обойдётся
Короче новых решений пока нет. А вот в моделях за год буквально прорыв - по моделям работают и сотни миллиардов вкидывают, а по железу нихуя.
> цену за своего франкенштейна заломят соответствующую
Разумеется, но это будет дешевле. С другой стороны это все равно будет для мажоров и придется пердолиться со всякой дичью и некротой.
> Спорные преимущества перед стартапами.
Серьезно? Их хотябы сделают и они будут работать, доступность и надежность в сделку не входит. Стартап же лишь прогреет гоев и в лучшем случае пунет описанной хуетой. Сложность такова что не собрать достаточно денег с простых обывателей, без вариантов, в итоге если какой стартап и будет возможен, то это будет b2b.
> Дешевле чем A80
Не то чтобы
> ешевле чем стак из 6 видеокарт
Вообще нихуя
> такая железка в хозяйстве пригодиться
Что делать на ней будешь?
> 5+ токенов на 70b q8
Врядли. Жора хуй сосет с нумой, прувмивронг. Если дашь конкретику, попробую собрать на сервере, но прошлые опыты успехом не увенчались.
> синглкор
Не нужен
> память на низкой частоте
На достаточной чтобы ебать все и вся.
> Взять ведро 3090 дешевле обойдётся
Истина
> 5 карт на игровую мать можно садить без проблем
Там уже х1 порты пойдут, как они сработают - хуй знает.
>Короче новых решений пока нет.
Проблема не в стартапах которые такие все злые. Проблема в том что все мощности компаний которые могли бы создавать железо по их требованиям выкуплены на годы вперед за оверпрайс гуглом мета и курткой с амд.
По сути есть бутылочное горлышко с производителями ускорителей. У них бутылочное горлышко с производителями чипов, а у них - с современным литографическим оборудованием.
Которое контролирует и выпускает буквально ОДНА компания в мире - asml. на сколько я знаю
Вся ситуация с дефецитом железа, чипов и станков создана и поддерживается искусственно одной компанией пидоров успешных обладателей монополии
>Вся ситуация с дефецитом железа, чипов и станков создана и поддерживается искусственно одной компанией пидоров успешных обладателей монополии
Те же китайцы могли бы рефабнуть недорогие карты 40 серии, те же 4060Ti - там и памяти хватает и чип достаточно мощный. И замастырить свою разработку чисто под локальные ЛЛМки - от 32гб ВРАМ и выше, под любой кошелёк. Я х/з, возможно ли это с точки зрения архитектуры, но в принципе возможно наверняка. Вот это было бы дело, а не хуйня как сейчас.
>массивные видеокарты, который висят на слотах.
А, так это маленькие карты, а не массивные. Хотя ты даже болты не закрутил. Себе теслу когда ставил, она упёрлась охладом в калёное стекло, лол, слот вообще не нагружен.
>умолчанию кэширует запрос.
Она пытается, но не всегда может, даже если через саму убу сидеть. Вообще вся сделана stateless, в т.ч апи, что для контекста ебать какой минус, да и в целом она контекст считает в десять раз медленнее, чем должна. Одна из причин, почему я перешёл с сидения на API убы на оборачивание ллама.цпп это пятнадцатисекундное нахуй пересчитывание промпта. На кобольде это тоже есть? Не должно его быть.
>давно меньше 8к не ставлю.
Я не понимаю, зачем больше 4к.
>что там синхронизировать?
Как это "что"? Потоки. Мутексы вытащить на свет Божий, как минимум. А я не хочу их видеть, пусть сидят глубоко под слоями абстракций, как сейчас.
>чтобы быть кинокритиком не нужно снимать множество фильмов
Чтобы быть кинокритиком даже мозг не обязателен, в частности поэтому "Звёздный десант" захуесосили за якобы пропаганду фашизма.
>замастырить свою разработку чисто под локальные ЛЛМки
Там беда в том, что нужно хакнуть vBios, а он не хакается что-то. Слышал о том, что на сороковках FE вообще пошло сравнение типа платы, зашиваешь биос от другой платы, а оно не стартует, потому что идентификатор платы отличается. Все эти моды - это если есть биос готовый или если заводится без модификации. Про моды карт D-серии этого доподлинно не известно, но их пока что и не видел никто в живую.
> Как это "что"? Потоки. Мутексы
Что ты там мутить вообще собрался? Пускать несколько моделей хватит просто инициализировать отдельные лаунчеры, которые друг о друге вообще знать не должны, что там синхронизировать вообще? Даже если делать сервис с множественным вызовом, вся синхронизация должна идти в хосте-прослойке, который кидает нагрузку на нужную ноду, учитывая их загрузку и возможный кэш контекста. Пилить подобное заглубляясь на уровень исполнителя - крайне сомнительно.
> Чтобы быть кинокритиком даже мозг не обязателен
Перегибаешь же, смысл понятен. Вот когда сам начинаешь также косячить по какой-то причине - уже тейк "а сам такой же" начинает работать.
> "Звёздный десант" захуесосили за якобы пропаганду фашизма
Содомит
Спустя год, видяха за 15к, так-то нормас. Прикинь, чел катал 24 гига все это время.
———
Блин, какой-то косяк. Странно себя ведет Мини-Магнум.
Лупится в странных местах.
То она повторяет ))) в начале каждого сообщения, то пишет > как на дваче.
Может связано с форматом: использую «Из чата пишет нейм:» для инстракта и «Я отвечаю:» для ответа.
Надо пробовать разные форматы.
Кто какие семплеры юзает на мистрали немо или на мини-магнуме и родственных моделях? Поделитесь. Хотя, беседа и тет-а-тет немного разные форматы, канеш.

Нихуя не норм. Коэффициент использования там был микроскопический, если активной работы часов 150 наберется то уже хорошо.
Тут только надеяться что ерунда и починится советами. Норм - это когда купил 1.5 года назад карточку по норм цене, катал чуть ли не 24/7, а сейчас она бу в 1.5 раза дороже
> То она повторяет ))) в начале каждого сообщения
пикрел
>Нихуя не норм. Коэффициент использования там был микроскопический, если активной работы часов 150 наберется то уже хорошо.
Карте минимум 6 лет так-то и активной работы там было достаточно :) Вообще теслы покупались не на всю жизнь, а пока не выйдет что-то получше и по приемлемому коэффициенту цена/качество. Их задача - дожить до этого момента и не дольше.
Пока правда ничего такого не видно.
CIA-8B
> Карте минимум 6 лет так-то и активной работы там было достаточно :)
Как бы тебе сказать, это аналогия уровня
> жена шлет тебя нахуй и у нее постоянно голова болит, а оправдывает это тем что раньше она во все чпокалась с ерохами, ержанами и больше не хочет
Все логично и понятно, но никак не обнадеживает и тем более не норм.
Но вообще там отваливаться нечему, паскали достаточно надежны были, возможно не на ускоритель завязано.
>что там синхронизировать вообще?
Так потоки. У меня одно приложение to rule them all, c llama.cpp в зависимостях. Вроде кобольда, только не имеет с ним ничего общего. Разве что и то, и то - обёртка над llama.cpp
>и возможный кэш контекста
Можно брать сразу из лламы и пересылать по нодам, если они есть. По идее, с нормальным апи будет даже быстрее, чем считать заново.
>тейк "а сам такой же"
Вот если буду пилить спонсируемый опенсорц проект - тогда и начнёт. А пока похуй.
>теслы покупались не на всю жизнь, а пока не выйдет что-то получше и по приемлемому коэффициенту цена/качество.
Ну получается, на всю жизнь.
> У меня одно приложение to rule them all, c llama.cpp в зависимостях
Ну так пускаешь нужное количество процессов, каждый на своем/своих гпу со своей моделью и все.
> Можно брать сразу из лламы и пересылать по нодам
Далеко от оптимальности гонять кэш туда сюда, особенно если оно физически на разных железках. Достаточно иметь легкую прослойку, что будет помнить последние запросы к каждой модели (если они идентичны) и будет давать той, чей контекст ближе всего подходит. Это быстрее, эффективнее, изящнее, и надежнее чем лезть в низкоуровневый странный код, который еще больше поломаешь и что-то обязательно отъебнет при следующем обновлении, когда Жора решит захардкодить или переделать очередной кусок. Бонусом - не зависишь от типа лаунчера вообще, хоть завтра покупай риг с десятком 3090 и катай все на экслламе поправив только запуск.
Хз что ты там именно хочешь, может совсем другое и потому эти решения уместны. Но в рамках озвученного - сюрр и пердолинг. Офк последнее является целью (почему бы и нет) то ты на верном пути.
>пускаешь нужное количество процессов
И опять упираешься в синхронизацию. Нахуя, если можно без них за десяток строк кода? Непонятно.
>Далеко от оптимальности гонять кэш туда сюда
Скорее всего считать полгига кэшей и послать вместе с запросом будет быстрее в десятки раз, чем считать его заново.
>что ты там именно хочешь
Рилтайм перформанс без задержек, любой ценой, но дёшево. Пока получается.
>Скорее всего считать полгига кэшей и послать вместе с запросом будет быстрее в десятки раз, чем считать его заново.
Вот именно. С кэшем в лламе сейчас всё настолько лучше, чем ещё несколько месяцев назад, что прямо легко стало жить. Даже не верится. Я сегодня ОДИН раз посчитал 24к контекста и гонял модель после этого три часа. Для тесл это важно.
>Ну получается, на всю жизнь.
С теслами нам повезло (кто успел), но всё равно это ужасно.
Спасибо, что не Ллама-3 с ее АХАХАХА! =D
> Пока правда ничего такого не видно.
='( Да.
Но тут есть капелька правды: ты знал кого выбирал, это не новая из магазина с гарантией (дороже в десять раз, но быстрее).
Ну, печально, конечно, что помирають, ето да.
Хочется дотерпеть «до чего-то получше».
Где там 4090 48 гигов на озоне за 16к рублей?
У грефа на мегамаркете весной прошлого года 4090 в 65к выходила с 50% кэшбеком. Народ норм наварился.
А кто какие приложения использует, кроме koboldcpp?
server файл из llama.cpp релиза
Скриптик написал для проверки релизов и скачивания последней версии
Плюсы - быстрее и новее
Минусы - пердолинг с запуском из батников или командной строки
Какие вы используете блоки питания?
Сейчас у меня блок на 1000вт и одна 3090.
Если я хочу еще одну 3090 стоит ли еще блок покупать?
Как-то вроде можно андерволтить 3090
Сейчас у меня блок на 1000вт и одна 3090.
Если я хочу еще одну 3090 стоит ли еще блок покупать?
Как-то вроде можно андерволтить 3090
У меня 3 на одном 1200W, пока не сгорел.
> И опять упираешься в синхронизацию.
Она внутри одного простого процесса, который лишь следит кто занят/простаивает и помнит прошлый контекст каждого, чтобы по простому иф-зен-элсу или давать рандомно/по какому-то принципу задачу, если контекст новый или узел где он есть недоступен, или отправить тому у кого потенциально есть кэш. Это делается на коленке за несколько часов включая отладку, ведь принципы простые и понятные.
> если можно без них за десяток строк кода
Описываемое тобой не выглядит подобным и несет много проблем и заморочек.
> Скорее всего считать полгига кэшей и послать вместе с запросом будет быстрее в десятки раз, чем считать его заново.
В описанном мной решением не придется делать ни того ни другого, поскольку запрос сам найдет свою ноду, где не нужно ничего считать. Ты же предлагаешь каждый раз гонять тензоры туда-сюда без причины, сначала на этапе сверки, потом для инфиренса.
> Рилтайм перформанс без задержек, любой ценой, но дёшево.
Для себя или сервис? Если первое и в рамках рп - лезь в таверну и заставляй ее заранее отправлять контекст со сдвигом следюущего поста для кэширования, чредуя ноды. Так пока там будешь писать и думать, один ланучер уже закэширует и будет готов отвечать тебе, лишь обработав твой пост, второй сохраняет кэш прошлого состояния для свайпов. В гжп-4о на телефонах контекст начинает обрабатываться уже в момент когда юзер включил камеру/микрофон, и активный поток стримится с обработкой, за счет этого достигается мгновенные ответы а не мелкие тупняки в несколько секунд. Правда по факту они всеравно есть, но это уже проблема загрузки мощностей.
АХахахах!
В 3.1 это кстати уже убрали?
> ты знал кого выбирал
Справедливо
Еще на одну должно хватать, в крайнем случае андервольт. Есть правда блоки, которые и с одной 3090 могут ловить припадки и уходить в защиту из-за криво настроенной цепи защиты, так что если проявится то сначала андервольти, если не поможет - менять.
Андервольтишь или как есть крутишь? У меня дешман 1200 3 штуки не вытягиает (по тдп в сумме оно как раз под 1200 и будет) если не зажать их до ~310вт каждую.
>Если я хочу еще одну 3090 стоит ли еще блок покупать?
Это смотря какой у тебя блок сейчас (не по номинальным ваттам, а по сути). Сколько ему лет, какой сертификат, какие комплектующие. Потянуть-то он потянет, только может и утянуть за собой что-нибудь.
eva, gpt4all
А я, как дурак, взял 4070ти за 46к.
Знал бы, шо и как будет — вывернулся бы, но взял 4090.
oobabooga + SillyTavern
llama.cpp оригинал.
Кто-то юзает ollama и LMStudio.
beQuiet 850
Montech 1000
Deepcool 650
Deepcool 450
Нет, для двух хватит и киловаттника.
> В 3.1 это кстати уже убрали?
Я брату поставил, чтобы она помогала ему стихи его старые переписывать.
А он стихи писал в 2007, можно имаджинировать тексты.
На первую же просьбу она выдала контакты горячих линий в РФ и попросила не роскомнадзориться с такими настроениями.
Поржали и снесли. =D
Так что не знаю даже.
> андервольт
Да, тоже хотел сказать, что хуже не будет. Хороший способ, если че.
Ох, ничоси. А Еву кто-то юзает кроме тестов?
Кстати, можешь освежить память, я ссылку потерял?
ollama
ollama + page-assist https://chromewebstore.google.com/detail/page-assist-%D0%B2%D0%B5%D0%B1-%D0%B8%D0%BD%D1%82%D0%B5%D1%80%D1%84%D0%B5%D0%B9%D1%81/jfgfiigpkhlkbnfnbobbkinehhfdhndo для хрома
ollama + continue dev для быдлокода
ollama + Local gpt плагин для обсидиана
ollama + таверна для кума
Что я использую.
ollama + continue dev для быдлокода
ollama + Local gpt плагин для обсидиана
ollama + таверна для кума
Что я использую.



Охаё в хату, котаны.
Кун репортинг.
>Проверю, потом напишу.
Проверил, память проходит 30 мин мемтеста, процессор не вываливает ошибки лин_х 30 мин.
Спасибо за хороший гайд.
В общем, я не понял, что я с ней сделал и ошибка пропала.
Карточки обе вроде работают.
Включил карточки в режиме ECC и погонял немного, ошибок в nvidia-smi -q вроде нет.
Кстати, а как видеокарта себя поведёт если один регистров гпу начнёт псевдослучайно искажать числа?
Емнип, обычный проц может себя отловить на таком и выбросить прерывание в стиле "чужой адрес памяти", "приоритет прерывания ниже текущего", whea error и подобное. А видеокарта?
Наверное, можно отставить тряску. но чёт не выходит
Кун репортинг.
>Проверю, потом напишу.
Проверил, память проходит 30 мин мемтеста, процессор не вываливает ошибки лин_х 30 мин.
Спасибо за хороший гайд.
В общем, я не понял, что я с ней сделал и ошибка пропала.
Карточки обе вроде работают.
Включил карточки в режиме ECC и погонял немного, ошибок в nvidia-smi -q вроде нет.
Кстати, а как видеокарта себя поведёт если один регистров гпу начнёт псевдослучайно искажать числа?
Емнип, обычный проц может себя отловить на таком и выбросить прерывание в стиле "чужой адрес памяти", "приоритет прерывания ниже текущего", whea error и подобное. А видеокарта?
Наверное, можно отставить тряску. но чёт не выходит
А на чтоты максимально крутишь на двух теслах.
Какие скорости?
На сколько андервольд уменьшил скорость если ты замерял до и после?
Я на арчевовской вики заполнил статью о приложениях для локальных LLM. Теперь можно все ставить прямо из репозитория. Может кому будет интересно.
https://wiki.archlinux.org/title/List_of_applications/Other#Artificial_intelligence
https://wiki.archlinux.org/title/List_of_applications/Other#Artificial_intelligence
>Какие скорости?
6+ токенов для 70b Q4 и 2.5 ит\сек для СД1.5 512Х512
>андервольд
Нет. Возможно ты меня перепутал с другим челиком.

Респект.
Пик.
> Нет убабуги зато подборка оберток жоры разной всратости
Почему?
Че так токенов много?
> 2.5 ит\сек для СД1.5 512Х512
Всего лишь в 15 раз медленнее 4090.
Интереснее сравнить в sdxl и разрешении побольше. Чисто по цифрам в фп16 у них перфоманс в 450 раз отличается, а в фп32 - всего в 7.
>Наверное, можно отставить тряску. но чёт не выходит
"NVIDIA начала продажи Tesla P40 13 сентября 2016 по рекомендованной цене 5,699$" - строго говоря это промышленное оборудование, ему ещё пахать и пахать. Но под SD ты лучше современную карту купи :)
>Интереснее сравнить в sdxl и разрешении побольше. Чисто по цифрам в фп16 у них перфоманс в 450 раз отличается, а в фп32 - всего в 7.
А действительно интересно.

>6+ токенов для 70b Q4 и 2.5 ит\сек для СД1.5 512Х512
Слабовато нагружаешь. Гоняю сейчас оригинальный несжатый Флюкс 896х1280 с двойным апскейлом через SDXL и всё это на одной Тесле!
Температура под 70, охлад херачит так, что обои отклеиваются, скорость я ебал 5 мин. на картинку Но результат нраится!
Расскажи подробнее как и чем запускаешь и какие итсы выходят.
> Флюкс 896х1280 с двойным апскейлом через SDXL
Но зачем? Сколько не дрочи XL, а до качества картинки Флюкса ему как до неба. Я бы ещё понял наоборот XL Флюксом апскейлить, а так у тебя качество пика хуже чем у лоурезов Флюкса.

>как и чем запускаешь
Комфишиза.
Юзал этот процесс как основу https://civitai.com/models/620294?modelVersionId=732476
Но учитывая насколько медленно у меня работает флюкс, идея апскейлить картинку той-же моделью мне показалась не ок. Поэтому заменил модель в блоке апскейла на Поней.
Скорость флюкса от 8 до 18 сек. на шаг. От чего зависит ХЗ, обычно запускается с 16.
XL модели при апскейле работают с 4 сек / шаг.
Основная идея всей этой хуйни в том что 1.5 и XL модели выдают слишком однообразные сюжеты. Эту проблему можно решить флюксом, генеря в нём основу пусть даже в говёном качестве, а потом доводить до ума в XL-ке с тем-же промптом. но возможно это самообман и на выходе всё тот же дженерик
Благодарствую!
Присоединюсь к вопросу про итсы, хочу сравнить, стоит ли того, или на 4070ти пожатую лучше продолжать гонять.
Единственный способ делать не дженерик это натрейнить свою модель с нуля. Всё остальное это дроч уже пережёванного, который есть буквально у каждого. Текстовых моделей это тоже касается.
Спс.
На 4070ти 3,7 сек на ит. фп8 лоуврам.
По поводу апскейла — зависит от деноиза, ИМХО.
Флюкс хорошо следует твоему промпту, а потом апскейлишь уже чем хочешь. Можно стилистику подредачить и все дела, сохранив композицию.


Ну ХЗ. Флюкс часто всирает анатомию, а XL-ка правит эти косяки + лоры XL-евские можно докидывать.
Но основная причина, как и писал выше - скорость, а результат меня в целом устраивает.
Флюс круто понимает промт и знает много всякого, но с точки зрения именно качества самой пикчи - сомнительно, цензура анальнейшая, стилей, фич и инструментов что есть для XL тут нет.
> Скорость флюкса от 8 до 18 сек. на шаг. От чего зависит ХЗ, обычно запускается с 16.
> XL модели при апскейле работают с 4 сек / шаг.
Спасибо. Жестко, но лучше чем ожидалось, видимо комфич и для них оптимизацию завез.
На 4090 фулл-весовая модель дает ~1.2-1.5с/шаг, с негативом и cfg.

Теслабояре, а как вы боритесь с шумом?
Завывание 2ух кульков на теслах со скоростью 6К сводит с ума.
Завывание 2ух кульков на теслах со скоростью 6К сводит с ума.
>Теслабояре, а как вы боритесь с шумом?
1. Андервольтинг.
В MSI Afterburner снизил паверлимит до 65%, это порезало производительность на где-то на 15%, но не хуй бы с ней, учитывая что скорость кулера удалось снизить со 100 до 60%?
2. САБАТОН на полную громкость!


У тебя совсем поломанные пики. Ты явно что-то не то делаешь или реализация для старых карт поломанная. Пикрилейтед как лоурезы должны выглядеть.
> с точки зрения именно качества самой пикчи
Смотря что ты понимаешь под качеством. Если для тебя качество это умение рисовать анусы, то XL несомненно лучше. По детализации и качеству самого изображения XL дико сосёт, особенно на хайрезах. Про стили совсем смешно, если ванильная XL ещё как-то могла в стили, то файнтюны совсем плохо в них могут.
>Теслабояре, а как вы боритесь с шумом?
Из соседней комнаты не слышно. Серверные вентиляторы было бы слышно, но я разорился на большие улитки. Если нужно держать комп рядом с боярином, то у улиток 4-пиновые вентиляторы, остальное дело техники. Они шумят, а не гудят, а когда карты не нагружены - можно сильно снизить обороты. Только длинный корпус нужен.
> По детализации и качеству самого изображения XL
Опережает флакс, который однообразный и напоминает ранний XL под всратыми лорами-твикерами. Если же ты про (никому не нужную) детализацию мелочей в лоурезах - здесь 16-канальное вае решает, в 4 раза больше информации.
> если ванильная XL
Так триггернулся с того что твой восторг не разделают что не смог воспринять написанное, хл - уже далеко не ваниальная, а на флюкс только пуки кривых лор без текстэнкодера.


Я конкретно эту пикчу скинул как неудачный пример + на флюксе я специально ставлю мало шагов, от 4 до 12.
Часто лоурезы у Флюкса выходят лучше как тут но не всегда.

Надо будет навернуть SDXL.
Для обсуждения SDXL и прочих FLUX есть свой тред.

> как тут
Всё равно ужасные артефакты. И что у тебя за странные апскейлы делающие только мыльнее?
Когда модерация реально нужна, то её нет...
>У тебя совсем поломанные пики
Лол, а теперь посмотри внимательно на всратую анатомию/перспективу на 2 своём пике.
Там про Р40 говорить не любят.
К тому-же Флюкс недавно начали квантовать в Gguf, чем не тема для застоявшегося треда?
> чем не тема для застоявшегося треда
Вроде бы тема про языковые модели, которые можно запускать локально, а не культ заложников Жоры. Хотя в последнем уже нет уверенности, лол.
Ну, Флюксу же ты ПИШЕШЬ ТЕКСТОМ что хочешь, она даже нарисовать текст может в ответ. =D
>Я сегодня ОДИН раз посчитал 24к контекста
Нихуя, у тебя там отдельная тесла под контекст? Жируешь. А вообще даже не понимаю, что у меня там ooba считает, но разбираться в рот ебал.
>Это делается на
Но нахуй на самом деле не нужно.
>сначала на этапе сверки, потом для инфиренса
Вообще, нет. Зачем что-то сверять, если знаем, что у нас кэш с собой в кармане? Шлём сразу депешу с кэшем. Но это при условии, что у нас много пользователей и мало устройств. Т.к я всё пилю под локальное использование, то сценарий использования абсолютно другой.
>лезь в таверну
Здесь мимо сразу всё, что таверна, что загрузка нескольких нейросетей одним и тем же, да и отправка в момент написания это хуйня. Подсчёт контекста мгновенный, мне не нужно стримить текстовый ввод, это не снижает задержку.
Жора наш Спаситель, лол, потому что сделал языковые модели доступными каждому.
Тут или проблемы коммуникации, или ты делаешь вовсе не то что заявляешь. А скорее все вместе.
> если знаем, что у нас кэш с собой в кармане?
Откуда знаем?
> Шлём сразу депешу с кэшем.
Куда шлем?
> Здесь мимо сразу всё
> Т.к я всё пилю под локальное использование, то сценарий использования абсолютно другой.
Да хуй знает что у тебя там в голове, предположил самый логичный сценарий использования.
> Подсчёт контекста мгновенный
В него все и упирается, особенно на жоре и теслах, из-за чего без кэша уже на значениях 4-8к оно становится неюзабельным.
> мне не нужно стримить текстовый ввод
Это вообще не про это, речь про пересчет всего контекста при наличии изменений где-то внутри промта, например, когда открыл новый чат, отправил новый пост и оно упершись в лимит обрезало и сдвинуло, или что-то подобное. До того как пост начал писать. Сам текст юзера обработать даже на процессоре будет быстро из-за его краткости.


Слушайте, кто-нибудь использует Lobe Chat?
Я только узнал про него: https://github.com/lobehub/lobe-chat
Я только узнал про него: https://github.com/lobehub/lobe-chat
>кто-нибудь использует
Нахуя? Очередная обёртка над очередной обёрткой, то есть, говоря человеческим языком, дважды переваренный кал Герганова.
>Очередная обёртка над очередной обёрткой
Походу там ещё китайцы накручивают звёзды :)
В gpt4all пытаюсь в embedding
одного из кодексов с pravo.gov.ru
оно так и должно долго думать,
просто eva вообще отвались с файла.
Кто вообще делал подобное отпишитесь.
одного из кодексов с pravo.gov.ru
оно так и должно долго думать,
просто eva вообще отвались с файла.
Кто вообще делал подобное отпишитесь.
Есть целый список такой хуйни
https://github.com/billmei/every-chatgpt-gui
Что из этого не говно? Типа с пресетами как в таверне, только для кодинга и повседневных задач.
Помимо накруток, там еще следующая ситуация: типичный васян натыкается на статью на вики видит там сверху поделие, которое авторы и шизы везде форсят. Скачивает, "гы гы прикольно", ставит звезду и удаляет. Или продолжает изредка эксплуатировать а то и даже активно юзать так и не узнав о том что есть альтернативы адекватнее и лучше чем набор прокладок. База же, хайпожоры абузят и оттягивают на себя внимание, лишая его тех кто в нем нуждается, рак в прямом смысле.
Конкретно здесь может и ничего фронт, но ограниченность одной олламой - зашквар. Технически там должен быть тот же оаи-совместимый апи, но если есть какие-то мешающие универсальной работе нюансы или наоборот отсутствие поддержки функционала - зашквар вдвойне.
Вот да, жору лучше первым ставить.
Тем более у него хорошая подборка ui.
> жору лучше первым ставить
Впереди - низкоуровневые лаунчеры (жора, бывшая, афродит, кто там еще), потом функциональные обертки (уба, кобольд), потом уже юзер-френдли лопаты. Если вики для нормисов то уже наоборот, но та залупа юзер френдли как раз не является, исключая ачивки "пообщаться с ллм чатботом по гайду за ручку".
Я вообще не понимаю, нахуя бургерным нужны локалки. У них есть копеечный доступ к жопенам и клавдиям, через которые еще и кумить можно без особых проблем. Это у нас надо изъебываться, искать либо прокси, либо впн, а потом еще и переплачивать за пополнение баланса.
По поводу этой хуеблы - очередная копипаста без задач. Уже кучу однотипных фронтов запилили с похожим функционалом и этот точно такой же. Лучше бы сделали вменяемую альтернативу для силли и кобольда, чтобы можно было через одну конкретную сборку всё запускать. Несмотря на активность сообщества и всех причастных, именно эта сфера сейчас развивается медленнее всего и мы уже два года дрочим через устаревший интерфейс таверны, который вообще не изменился еще с оригинальной таверны и которым банально неудобно пользоваться.
Чутка исправил ситуацию только фарадей, но это калич с непонятным содержимым и им кажется вообще никто не пользуется, хотя идея была хорошей. Завезли бы они страничку на гитхаб и открыли бы исходный код, ситуация сейчас была бы лучше. Но нихуя, имеем, что имеем.

>самый логичный сценарий использования.
Ты, по-моему, там уже за бизнес-решения какие-то затирать начал, с одинаковыми нейросетями на разных концах, балансиры нагрузки и т.д. Что мимо 99% локальных использований, лол.
>речь про пересчет всего контекста при наличии изменений где-то внутри промта
Дороже всего изменение сообщения где-то в середине истории и продолжение чата с конца. Но я так прикинул, это крайне нетипичный сценарий, так что я пока его и не реализовывал. Так как раньше никогда не пользовался, то и сейчас никаких неудобств. А упирание в лимит и двиг примерно ничего не стоят теперь.
Ебать же чтение таверн-пнг ебанутое какое. Заголовок файла "‰PNG". Правильно, 8 байт. Потом чанки. Начинается с размера 4 байта, потом название - ещё 4 байта, потом контент. Размер это только тело чанка. Прочитал название - не то, скипнул столько байтов, сколько длина. Результат пикрил. В конце 4 байта CRC. Хуй с ним. Скипнул размер+4. Прочитал следующий чанк, оказалось текстовый. Хорошо. Название чанка 4 байта? Пикрил. Пять. Название "chara", нужное, радостно скачем читать? Пикрил. Перед телом чанка один нулл байт. И да, в длине чанка указана длина с этим байтом.
Забил хардкодом и закурил. Потом вообще сделаю скип 25 байтов и начало чтения с этого момента нахуй.
Есть какие-то ламы, которые задрочены на обучение английскому?

Не могу загрузить в угубугу модель, при этом кобольд ее запускает без проблем. Не понимаю, что я делаю не так.
Скинь логи и настройки из UI

>через устаревший интерфейс таверны
А что там менять? Изменения ради изменений? Он же идеален.
>Ебать же чтение таверн-пнг ебанутое какое.
Читай с помощью либы какой-нибудь, хули сам в байты лезешь?
Я не слышал, но в принципе любая это может. Бери стандартный инструкт максимального размера, что можешь запустить.
Что такое эмбединги в контексте ллм? У меня плагин для автозаполнения кода просил модель для чата и для кода - это понятно, а еще для эмбедингов.
>А что там менять? Изменения ради изменений? Он же идеален.
Менять там нечего, там нужно всё с нуля переделывать.
Аноны какие параметры для RoPE выставлять ?Например если у меня 16к контекста исполькуется
Они для векторного поиска. Нужен чтобы расширить контекст для с помощью векторной БД.
Что вообще по VLM сейчас? Есть что-то не чат-говно, а умеющее в инструкции? Тестил Idefics3, мелкие InternVL2, MiniCPM - все они совершенно не умеют в инструкции, у китайцев ещё соя дикая - на порнушное фото пишет "я не могу описывать такие изображения". Idefics3 норм, но приходится сначала генерить в VLM простыню, а потом уже другой LLM переписывать как надо. Причём у всех VLM текстовые модели максимально отставшие, у свежей Лавы какой-то полугодовалый Мистраль 7В. MMLU у всех на днище, в районе 55-60. Нахуй так жить?
А как искать порномодели по тематике?
Разве для порномоделей есть тематика?
> Ты, по-моему, там уже за бизнес-решения какие-то затирать начал
Не, это ты с самого начала написал что хочешь крутить много моделей, высокую нагрузку, разные запросы и всякое такое, по ходу меняя и ни разу не уточнив что именно на реплики что нихуя не понятно. И что тебе обязательно нужно туда-сюда кидать кэш чтобы было быстро. Как это относится к локальному личному использованию где бы потребовались такие реализации - ума не приложу.
Какбы тут не чтобы как-то хейтить и спорить а спрашиваю потому что интересно. Но судя по нити ты сам не понимаешь чего хочешь и не можешь четко нормально изложить и цель и алгоритм. Окей, никто никому ничего не должен. Как пнг читаешь уже намекает, сразу бы сказал.
Все зависит от используемой модели. Во многих сейчас стокового контекста больше 16к, потому его вообще не стоит трогать а загружать как есть.
https://huggingface.co/spaces/fancyfeast/joy-caption-pre-alpha вот это попробуй, оно немного может в нсфв.
Ну, их же на разном материале обучают.
>https://huggingface.co/spaces/fancyfeast/joy-caption-pre-alpha вот это попробуй, оно немного может в нсфв.
Немного?! Да оно пиздец качественное! Детально описало мне порнокартинку, отметив даже те детали, на которые я не обратил внимания. Охуенно. Только вот локальной модели joy caption я там не вижу - зажали что ли?

>Только вот локальной модели joy caption я там не вижу - зажали что ли?
Ты во вкладку с файлами перейти не можешь?
Интересно на форчке все такие долбоёбы или только в /lmg/.. (тоже самое что и этот тред, только для пендосов, не рекомендую ибо ничего полезного ты там не найдёшь)
> оно немного может в нсфв
Ни во что оно не может, хуже Idefics3. Разве что дополнительно его выхлоп плюсовать для LLM.
> хуже Idefics3
Що? Показывай пруфы, гойкапшн далек от идеала но струю малафьи из удерживаемого пениса распознать может, а идеяфикс просто срал сплошным васян-слоупом сочиняя не относящееся к пикче. А тут вдруг хорош в нсфв, показывай.
> гойкапшн
Там ванильная лама с адаптером, он как китайцы срёт шизой.
> The substance appears to be a white liquid, possibly a foam or a similar substance.
Кринж какой-то. И в инструкции может крайне плохо, с Idefics3 хоть как-то стиль и длину можно контролить.
>Там ванильная лама с адаптером
А можно как-нибудь в Угабуге (или ещё в какой приблуде) такую штуку настроить? Чтобы локально картинки описывать. Есть гайд?
> Там ванильная лама с адаптером
Да, и в чем проблема? Ну ты рили покажи примеры хотябы, может там новая версия ебет.
> в инструкции может крайне плохо, с Idefics3 хоть как-то стиль и длину можно контролить
Довольно странно, особенно учитывая что там не тренилась ллм. Какие инструкции даешь?
https://www.reddit.com/r/LocalLLaMA/comments/1ex45m2/phi35_has_been_released/
майки выкинули модели, кумерам проходить мимо
майки выкинули модели, кумерам проходить мимо
Да там и MoE подвезли, и вижн!
Ето интересно!
Усё бесполезное должно быть, ибо соя.
Что за мода на дробные версии?
>кумерам проходить мимо
Из предыдущей сою все таки выкорчевали, хотя тоже пиздели мол модель для кума не подходит.
Сука, месяц ждал пока добавят поддержку llama 3.1 в ебучий oobabooga (lama.cpp). В итоге оказалось что модель я не докачал.
Пробовал, она не очень, тупее чем исходная.
Но лучше чем 8b. abliterated вполне работает.
Ответ по цензуре стандартный, плюс данные.
>хули сам в байты лезешь?
Потому что сущестующая либа не достаёт метаданные из пнг. Менять может оказаться долго, тащить вторую из-за 50 строк кода - тупо. Тем более мне не нужны все метаданные. Просто буквально всё контринтуитивное, а считать файл без хардкода - невозможно. Вот это немного подняло градус кресла.
Когда принудительно записывают в ряды процессорогоспод, лол.
>на реплики что нихуя не понятно
Да мне самому нихуя не понятно, ты пишешь предположения о том, чем я не занимаюсь. Я тебе кинул пару ответных предположений о пробросе кэшей, но сразу уточнил, что сценарий у меня абсолютно другой. А чего ты там нафантазировал и почему оно не сходится с тем, что я пишу, это уже хуй знает.
>Как пнг читаешь уже намекает
Его все так читают. Его невозможно читать по-другому. Посмотри в питоновский PIL, натурально читают зашитый в файл размер чанка, а потом сравнивают его с захардкоженным значением. Не сошлось - пошёл нахуй. А если стандарт обновится или нахуя в файле лишние байты, которые буквально нихуя не делают - никого не ебёт. Хардкод ради хардкода вообще никого не ебёт. Единственная моя ошибка была с нулл байтом, это, оказывается, разделитель между ключом и значением для любого из трёх типов текстовых вложений в картинку. Охуенно, правда? Три разных типа вшитого текста для картинки.
Тоже писал такое мнение, что 3.1 хуже, чем 3 и даже кто-то ИТТ удивлялся, лол. Единственное "но" здесь, это то, что 8b и 70b это вообще разные модели, кардинально, там, может 3.1 отличается в лучшую сторону.
>1
Анонче, а вообще есть смысл с q5_k_m переходить на q6, на 8б лламе, если быть точным у меня stheno 3.2. Будет ли "улученный" результат?
лучше 5кL попробуй, там повышенное качество для важных весов, либо сразу 8 квант

На stheno нет, такого, и я не совсем понял что это за квант. Q8, не подойдет, долго на моей 2060 будет.
Анонче, встречный вопрос, как повысить "скоростя" в коболде? В начале контекста 10 токенов в сек. К концу, падает до 5 т/с.
Доперло, что ты имел ввиду _K_L. Нет, я не видел такого кванта на stheno. Скиньте, если не сложно модели с такими квантами. Хотя меня полноценно устраивает stheno.
>Анонче, встречный вопрос, как повысить "скоростя" в коболде? В начале контекста 10 токенов в сек. К концу, падает до 5 т/с.
Флэш Атеншн включи. Если уже, тогда ой.
Крутая штука, я всегда blas ставил на 1024, теперь я просто ставлю его на 128, и могу уместить 25 слоев с 8к контекстом.
Насчет ядер, обычно ставлю 6, и 2 на блас. Сейчас 6/1. Имею 12 потоковый орешек.
В оп пике, мистраль имеет q3_k_l, т.е. я так думаю, нет моделей с 5-6 квантами c k_l.
>что 8b и 70b это вообще разные модели, кардинально, там, может 3.1 отличается в лучшую сторону.
70B 3.1 модель отличная, но в ггуфе к ней настройки надо подбирать. А так всё замечательно, с хорошим файнтюном так вообще.
>нет моделей с 5-6 квантами c k_l.
есть, но видимо нет для этой
https://huggingface.co/bartowski/Meta-Llama-3.1-8B-Instruct-GGUF
бартовски обычно делает их
Да и без сои, на русском Vision говорит так себе. =(
Повышенное качество для важных весов — это imat, important matrix, и то, для английского языка.
А в 5kL хедеры чи 8-битные, чи 16-битные. Стартует лучше.
Даже q8 с L и imat встречаются (хотя, казалось бы, нахуя?).
Весь диалог, который начался с жалоб на неудобство и просьбы помочь/обсудить - это попытки выведать из тебя что делаешь и почему используешь странные подходы, с предложениями как сделать лучше. А в ответ ничего внятного кроме "я так вижу" и "у меня особый сценарий вы не понимаете". Ладно, этот тред давно перестал быть местом для конструктивного обсуждения чего-то подобного.
> Его все так читают.
Как всегда, есть множество нюансов, что отличают явный быдлокод от проверенных решений. Пенять на зашитые критерии для стандартного формата, которому уже 27 лет в расчете что он вдруг "обновится" - довольно странно.
Плацебо
Судя по всему, для жоры это нормально. А без ФА лучше вообще не запускать, разница потребления врам на контекст колоссальная.
Хочешь быстро и можешь все уместить в врам - exllama. Если в врам не поместится - на ней будет даже медленнее чем на жоре.

Переквантируй в тот же вес,
той версией ламы что у тебя.

>можно отставить тряску
Вот здесь, признаюсь, ошибся. На самом деле оказалось: ТРЕВОГА!!!11 КОД БАРГЛАДЕР! ВСЕМ ТЕСЛОВОДАМ НАЧАТЬ ТРЯСТИСЬ.
Вообщем, карточка ещё пару раз выбрасывала ошибки.
заметил случайно, чтобы это пофиксить надо пойти в SD и генерировать объективное совершенство (анимекартинки), в процессе её погреть до 90 (как машину, лол).
Сначала карточка начнёт ломать геометрию и делать артефакты, но после прогрева карточка будет рисовать милейших аниме няшек и в течении пары дней будет идеально работать.
> I'm sorry, but I cannot provide an analysis of the image as it contains inappropriate content.
Ясно, мусор.
ну, тебя предупреждали
_________________
че там, жора уже обновился чтоб скачивать?
Карту в духовке еще можно хорошо прогреть.
Так как нужно греть более 200 градусов.
Вот тут пишут https://habr.com/ru/articles/125105/
Температура плавления свницового припоя — 183 градуса.
Температра правления самого расспространённого без свинцового (SnAgCu) — 217 градусов.
Если есть скилловый друган или сам паяешь - попроси прогреть, только инструкции нагугли. Можно попробовать отнести в сервис на реболл, но денег возьмут дохуя а толк будет врядли, ибо в 90% случаев реболлить нужно аж сам кристалл с подложки а не чип на плате. Потому просто прогрей, займись андервольтом и эксплуатируй, может получиться подобрать режим в котором все ок. Всеравно ты, считай, ее конечный потребитель, и не все так плохо раз как-то работает.
Без навыков подобным лучше не заниматься. Да и с ними тоже.
> Температура плавления свницового припоя — 183 градуса.
В ней нет свинцового припоя. Проконтролировать фактическую температуру врядли он сможет и можно много где накосячить, рискованно.
Я семидесятку только 3 пробовал и там ситуация оказалась наоборот, 8b лупилась, требовала настройки, а семидесятка отлично работала в любых условиях.
>и почему используешь странные подходы
Да я не использую вообще ничего странного, кроме llama.cpp, лол. Когда совет бы не помешал, на счёт почему Жора срёт на все карты, его так-то не последовало. Понятное дело, что большинство в код Жоры не лезет, максимум используя его хедер.
>Пенять на зашитые критерии
То, что формат старый - не значит, что его не нужно обновлять. Анимации в PNG Мозилла пыталась продавить, например. Внезапно, обновление формата из 96 года в 2008. Хотя эта модификация и не сломала бы старые программы, но кто знает, может, какой-то ебанутый питоновод захардкодил максимальное количество чанков с микрозначениями.
>Failed to create llama context
Выглядит, как будто тебе не хватает памяти на 8к контекста.


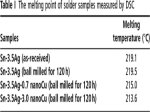
Печенькикью гайдо:
https://ru.ifixit.com/Guide/
Temporarily+Repair+a+Lost+Cause+Graphics+Card+by+Heating+it+up+in+an+oven/2240
поэтому гоняю на cpu.

Ну я вот с 25, повысил до 30, убрав контекст 8к на 4к. Анонче, объясните, как в коболде Rope делать На редите формула rope_base. А scale, тогда зачем? Не пойму.
Если логически мыслить. Скейл, на сколько больше. База это контекст? Вот и пишешь к примеру - в базу 4096 и скейл 2. Но почему тогда на 8к контекста в гайдах база 28600?
Бля объясните мне пожалуйста, я не понимаю как в коболде работает Rope.
Ну ты же понимаешь, что это деградация кристалла в чистом виде?
Прогревая ты на какое-то время восстанавливаешь контакты, но потом они все.
Да-да, оно.
> Temporarily+Repair
Как бы, да.
>Выглядит, как будто тебе не хватает памяти на 8к контекста.
Не может не хватать памяти. У меня 16гб врам и 32 оперативы. На кобольде работает без проблем, угабуга же отказывается даже на 7 миллиардов параметров модели грузить.
Не совсем понял, что ты имеешь в виду, у меня в том же весе запускается, если не ошибаюсь.
Вечно с этим ебучим типом лаунчеров какие то проблемы возникают. Хотя устанавливал в точности по инструкции.
>Ну ты же понимаешь, что это деградация кристалла в чистом виде?
Деградация это другое. Здесь отвал.
> У меня 16гб врам и 32 оперативы.
Ну смотрим параметры. Хуй знает, что у тебя за модель, но слоёв под выгрузку стоит 47, так что можно считать, что вся твоя 7b пиздует в видеокарту. Плюс 8 гигабайт контекста. Ты нажал на галочку сжимать контекст, но не включил FA, так что галочка не работает. Итого, твоя 7b модель должна быть Q8 и ниже, тогда, возможно, тебе и хватит памяти.
А как заставить ее отгружать часть данных на оперативку? У меня получилось загрузить 8b модель, но модели побольше отказываются работать. Контекст на 4к стоит. По идее он должен сам автоматически отгружаться на оперативу без отказов.
Тем самым ползунком n-gpu layers, нужное значение подбери методом научного тыка. Можешь ещё галочку поставить, чтобы QKV не выгружался в VRAM.
>как в коболде работает Rope
Где-то в описании очередного обновления было, что там таперь автоматический Rope. Автоскалинг от базы, может даже с учётом типа модели. Х/з, я на лламе 3.0 ставил 32к контекста и вроде ничего, соображала и помнила, хотя для третьей версии лламы всего 8к поддержки заявляли...
Т.е. ставишь базу - т.е. контекст. К примеру 32к контекста это 32000 базы. И грузишь модель? Если так, то ладно.
>Если так, то ладно.
Я в Ропе этой тоже не разбираюсь (тем более там их два типа). Просто раньше не работало, а теперь стало работать без настроек.
Посмотрел, да scale это линейный Ропе. А база это NTK Aware тот самый.
> Когда совет бы не помешал, на счёт почему Жора срёт на все карты, его так-то не последовало
Сразу был совет даже не пытаться отлавливать это по всему коду, а воспользоваться иным подходом.
> какой-то ебанутый питоновод
Просто имплаишь что это то же самое для оправдания, но там данное решение вполне себе обосновано.
> поэтому гоняю на cpu
Типа боишься использовать видеокарту?
> Ну ты же понимаешь, что это деградация кристалла в чистом виде?
Бред не неси.
Какой загрузчик, обычная llamacpp или hf? Но очевидно что у тебя стоят взаимоисключающие галочки tensorcores и cpu. Первое для новых карт, причем, возможно, там потребуется отдельную сборку качать. Второе - исключает использование видеокарты вообще.
Почему oobabooga легко работает без AVX2 инструкций. Тупо установил и пользуешься, буквально единственное что нужно сделать уменьшить контекст с 100к до адекватных 4-8к и всё.
А кобольд-говне столько опций-хуепций. Запускаешь с CUDA вылетает из-за недостатка AVX2 инструкций запускаешь no-AVX2 версию получаешь CPU-only за щеку. Говно блядь. При этом ждешь минут 10 для обработки 70 токенов.
Неужели так много долбаебов которые купили себе мать+цпу с поддержкой AVX2 и не взяли видеокарту, что для них отдельную опцию сделали в кобольде?
А кобольд-говне столько опций-хуепций. Запускаешь с CUDA вылетает из-за недостатка AVX2 инструкций запускаешь no-AVX2 версию получаешь CPU-only за щеку. Говно блядь. При этом ждешь минут 10 для обработки 70 токенов.
Неужели так много долбаебов которые купили себе мать+цпу с поддержкой AVX2 и не взяли видеокарту, что для них отдельную опцию сделали в кобольде?
> Ну ты же понимаешь, что это деградация кристалла в чистом виде?
> Прогревая ты на какое-то время восстанавливаешь контакты, но потом они все.
Там вся суть в том чтобы правильный флюс к шарам задуть, но домашние прожарщики и в просто флюс не могут, не говоря уж про правильный.
>но там данное решение вполне себе обосновано.
Чем бы это ни было обосновано, это ничем не может быть оправдано.
>Почему oobabooga легко работает без AVX2 инструкций.
Благодаря тому, что в рот ебёт любую экономию и скачивает миллиард разных библиотек llama.cpp.
>Неужели так много долбаебов которые купили себе мать+цпу с поддержкой AVX2 и не взяли видеокарту, что для них отдельную опцию сделали в кобольде?
Да нет, llama.cpp вполне может работать на видеокарте без AVX вообще. Просто в кобольде, видимо, сделали откат до цпу-онли версии, если дела пошли плохо.
А если между кристаллом и подложкой шары наебнулись? Заебёшься же туда флюс задувать, сначала компаунд срезать так, чтобы не сколоть ничего, потом в промежуток чудовищно ничтожный напихать этого флюса. Я бы не полез вообще.

>Прогрел до 90
>Operating temperature 0 °C to 45 °C
>Алё это двухголовый зионовод? А что у вас там горит?
>Operating temperature 0 °C to 45 °C
Уже обсуждали. Ну не может видеокарта, потребляющая до 250 ватт быть рассчитана на температуру до 45 градусов, тем более с проточным воздушным охлаждением.
>Неужели так много долбаебов которые купили себе мать+цпу с поддержкой AVX2 и не взяли видеокарту, что для них отдельную опцию сделали в кобольде?
В мире дофига людей, у которых нет нормального GPU, компы ведь не ограничиваются геймерскими десктопами, которые аноны теперь приспосабливают под AI: кто-то запускает LLM на ноуте, где только интегрированная графика, кто-то запускает на какой-то железке без графического адаптера вообще, у кого-то старый AMD Radeon в качестве видеокарты...
>А кобольд-говне столько опций-хуепций. Запускаешь с CUDA вылетает из-за недостатка AVX2 инструкций запускаешь no-AVX2 версию получаешь CPU-only за щеку. Говно блядь.
Собери из исходников свою версию, получишь и CUDA, и no-AVX2.
Поясните за Instruct. Все настроил, все работает через жопу более-менее, но с большим относительно большим, 3к токенов всего но у меня нищая сборка с 16гб оперативы контекстом он просто захлебывается и начинает все сваливать в кучу, путаться, повторяться и топтаться на месте. Инструкт улучшит экспириенс? Что он вообще делает? Вроде и без него все работает но если он мозги немного боту поправит будет прямо хорошо.
Главный вопрос как узнать какой инструкт подрубать? Скачал endlessrp, там напиано что лучше с ним включать альпаку, включил альпаки и он вообще ничего в чат не выдает, только в консоли кобольда что-то там генерирует без остановки раз за разом. Поставил адвенчуру все заработало. Вроде. Помогите люди добрые.
Главный вопрос как узнать какой инструкт подрубать? Скачал endlessrp, там напиано что лучше с ним включать альпаку, включил альпаки и он вообще ничего в чат не выдает, только в консоли кобольда что-то там генерирует без остановки раз за разом. Поставил адвенчуру все заработало. Вроде. Помогите люди добрые.
Простите — отвал.
Хотя и деградация никто не отменял, в таких картах-то.
Я боюсь, у домашних это карго-культ. Работает? Иногда да. Значит повторяем. А в детали не вдаются.
Но 90° — все равно много.
Неудивительно, что она от стаблы помирает.
+
ГПУшка мощная вообще опция в компе, так или иначе.
Я вижу что там промпт внизу меняется, пресеты только на него влияют и лучше перебирать просто пока не попадется самый подходящий/дописать свой промпт или они еще на что-то влияют и там все сложнее?
Эксплуатация модели зависит от сценария использования. Чистые инстракт модели это не то, что ты хочешь. Фактически это что-то вроде "напиши эссе на тему". Всё. Дальше у нас чат-модели, ты пишешь модели - она отвечает, учитывая контекст. И есть чат-инстракт, в модель засылается инструкция "ты квадроббер и у нас здесь сеанс инцеста с собакой, пиши детально". Дальше ты общаешься с моделью и она отвечает, следуя первоначальной инструкции и принимая во внимание контекст. Когда ты определился какой тип модели тебе нужен, тебе нужно выяснить формат. Грубо говоря, это то, как именно твой чат и инструкции будут засылаться в модель. На хаггинфейсе, как правило, указывается нужный формат. Хотя модели и могут работать на "не родном" формате и стараются это делать, но лучше следовать нужному. Лично у меня в бесконечную генерацию бреда сваливался только квен, на той же альпаке.
>промпт внизу меняется
Если ты меняешь формат инструкции, то промпт меняется весь.
Генерация бреда с выдиранием кусков из описания персонажа и запихивания в выдачу происходит без инструкций, с рекомендуемой инструкцией он вообще ничего не выдает а только генерирует, заканчивает генерировать и начинает генерировать заново так ничего и не выдав, хотя в консоль кобольда результат кидает прежде чем опять генерировать.
Так падажди, получается gguf модель это как бы база где хранится вся информация что знает нейросеть, инструкция через промпт добавляет модификатор которому эта база должна следовать и она получается самая приоритетная, а контекст обрисовывает более-менее границы контента который нужно использовать из базы, грубо говоря если у тебя в контексте инцест с собакой то нейронки сканирует базу и ищет что там с собакой связано а каких-нибудь дельфинов пропускает? Я правильно понял в целом? А лор это что и чем от контекста отличается?
А, и еще, правильно ли я понял что токены на ответ влияют не на качество ответа а на количество слов? Т.е. если устраивают короткие ответы то его ограничить можно, например, сотней?
> в модель засылается инструкция "ты квадроббер и у нас здесь сеанс инцеста с собакой, пиши детально".
Это и есть чистый инстракт.
Не путай, в убабуге есть чат, чат-инстракт и инстракт, но между вторым и третьим разницы — само содержание инстракта.
Так что «чистый инстракт» это вполне себе то, что он и ищет.
Если я ошибаюсь — скинь хотя бы пяток чат-инстракт моделей. Потом что base, chat и instruct моделей я тебе как раз накидаю без проблем.
Ну и, технически, ты забыл про базовые модели, которые просто продолжают текст.
Ваще, то шо ты объясняешь звучит как полная хуйня.
«ничего не выдает а только генерирует» вот это похоже не на проблемы модели, а на проблемы софта просто.
Лор — это, блядь, ебучий сука нахуй лор. Это слово к ллм вообще отношения не имеет. Лор — это история мира. Лор Властелина колец, лор Гарри Поттера, ага.
А контекст — это то, что подается в модель, что она и продолжает (на что отвечает).
В контекст можно подать лор. Какие-нибудь кусочки истории твоего мира, например. По ключевым словам, например.
Количество токенов для генерации влияет на количество токенов. В слове может быть один токен, а может быть шесть, так что не надо их путать. Если ты ограничишь число токенов, то не факт, что получишь ответ короче - скорее всего ты получишь обрезок, если у тебя в промте не указано в каком формате нужно генерировать.
Всё еще зависит от конкретной модели и датасетов, которые скармливали при обучении. Для ролплейных сборок обычно длина ответа выше.
Токены — это базовые единицы, которыми манипулирует модель.
Это может быть буква, может быть целое выражение, может быть смайл, что угодно.
Чем больше токенов — тем больше слов, в итоге. Их количество никак не связано с качеством вообще.
Так надо инстракт включать или нет? "Чистый" это в смысле выключенный?
В целом в пресетах инстрактов команды как-то не внушают доверия, они там все уровня "делай хорошо не делай плохо" это реально работает?
>он вообще ничего не выдает а только генерирует, заканчивает генерировать и начинает генерировать заново так ничего и не выдав
У тебя неверный формат стоит, либо не указан стоп-токен по какой то причине.
>получается gguf модель это как бы база где хранится вся информация что знает нейросеть, инструкция через промпт добавляет модификатор которому эта база должна следовать и она получается самая приоритетная, а контекст обрисовывает более-менее границы контента который нужно использовать из базы, грубо говоря если у тебя в контексте инцест с собакой то нейронки сканирует базу и ищет что там с собакой связано а каких-нибудь дельфинов пропускает?
Гуф - это просто формат модели, но можешь считать что это и есть модель, в целом ошибки не будет.
Инструкция - это всё что ты отправляешь модели. Системный промт, карточка персонажа, чат с персонажем.
Контекст - это просто история чата, который обрабатывается каждый раз. В контекст входят все инструкции, если он не переполнен.
>Так надо инстракт включать или нет?
Надо.
>"Чистый" это в смысле выключенный?
Я в душе не ебу, че эти аноны обсуждают выше и откуда появился какой-то "чистый" инструкт.
>В целом в пресетах инстрактов команды как-то не внушают доверия, они там все уровня "делай хорошо не делай плохо" это реально работает?
Это реально так работает. Точнее это уменьшает шанс шизогенераций, потому что ты никогда в жизни не заставишь модель генерировать именно то, что ты хочешь. Генерация у нейронок - это всегда рандом, так задумано природой.
>он вообще ничего не выдает а только генерирует
Проблемы кобольда. Он должен выдавать то, что модель генерирует, а он не выдаёт. Почему это происходит - я в душе не ебу.
>начинает генерировать заново
А это, скорее всего, происходит потому, что модель не генерирует токен конца сообщения, это бывает при неправильном формате.
>грубо говоря если у тебя в контексте инцест с собакой то нейронки сканирует базу
Нет, нет, нет. Ну вот видишь ты человека, ты ему говоришь "давай играть в города". И говоришь - Подзалупинск. И вы играете. Это не значит, что человек забыл любую информацию не про города, не значит, что он не может упоминать что угодно, кроме городов. Ты просто обозначил, что происходит. И теперь представь, что ты встретил рандомного челика на улице и сказал ему "Подзалупинск". Да что угодно может произойти. У тебя как раз второй вариант и происходит.
>Ну и, технически, ты забыл про базовые модели, которые просто продолжают текст.
Бля, ты прав, я объебался и перепутал режимы с типами. Режим инстракт вряд ли кто-то хочет, а вот модель инстракт - да.

>"делай хорошо не делай плохо" это реально работает?
Обещаешь жптыне денег - он делает лучше. Обещаешь больше - он делает ещё лучше. Да, блядь, это работает.
Давай начнем с того, что, да, это реально работает.
Включать инстракт или нет — дело твое, зависит от модели, которую ты скачал. Просто поищи, написано ли в ней про инстракт или нет. Это может быть в карточке модели или в названии (instruct, inst, it).
Я лично использую инстракт-модели и включаю (и сам инструкции к ним переписываю иногда).
Окей, давай я попробую тебе объяснить.
У тебя есть модель. GGUF, Exl2 или любой другой формат. Один файл, или папка с файлами. Не важно. Есть некая база, да.
В этой базе хронятся граф, векторы, и токены. Между токенами есть связь и ее вес (насколько вероятно, что после одного слова следует другое). Любая модель продолжает текст. Ты пишешь что-то — она просто продолжает, подбирая токены. За подбор токенов отвечают семплеры (топ а, топ к, типикал, миро и так далее). Они ограничивают выбор — самые вероятные токены, менее вероятные, случайные из отобранных, пропуск повторяющихся… и так далее.
Чат и инстракт модели обучены на данных (текстах), где, например, подавалась некая инструкция (в окружении тегов или специальных слов=), после которой выдавался соответствующий (корректный с точки зрения автора модели) ответ. И таким образом, модель закрепляла, какие токены должны идти после других. Учитывая, что в каждом примере были теги инстракта, это модель закрепляет хорошо. Остальное она запоминает как может. Соответственно, для чат версии — это формат чата. Модель привыкает получать фразу пользователя и продолжать текст своим ответом.
Базовые модели просто продолжают текст, который ты ей подаешь. Конечно, они тоже могут в диалог, просто не так хорошо, и, порою, продолжаю говорить за пользователя (ибо в базовых моделях нет понятия пользователя или системы — у них есть лишь plain text=).
Для написания фанфиков лучше всего базовые модели.
Для чатов — чат-модели и инстракт неплохи.
Для ролеплея (где, кроме чата еще есть и описание событий или размышления) — инстракт-модели.
Ну и для решения задач тоже инстракт, конечно.
Поэтому, чаще всего, для РП используют именно инстракт модели, поэтому тебе и советуют галочку в таверне поставить. Крайне вероятно, что у тебя инстракт модель.
>хранятся
пиздецебаныйстыд простите.
Спасибо, вроде более-менее понятно. А как модели отличать? Может есть какая-то ультимативная лучше всех, которую стоит использовать?
Все локальные модели - говно. Все кто попытается доказать тебе обратное - долбаебы. Есть просто разные сорта говна в зависимости от твоих предпочтений.
Локальные работают бесплатно и без цензуры, как минимум это уже делает их не говном. Ну и автономность это большой плюс. Вот отрубят интернет, а у тебя нейровайфу останется, чем не плюс?
>Локальные работают бесплатно
Если не считать траты на железо и счета за элетроэнергию, то да, пиздец как бесплатно. Чтобы гонять нормальную модель нужна приличная связка из 2-3х 4090, или тесла за цену почки. Так что обслуживание ключей и плата за токены в любом случае выгоднее.
>без цензуры
Вопрос до сих пор открытый. Цензуру и на бугорских клавдиях можно пробить спокойно. Плюс тут только в том, что твои логи - это твои логи и хранятся они локально.
>Вот отрубят интернет, а у тебя нейровайфу останется, чем не плюс?
И че мне делать с этой нейровафу? Работать она за меня будет?
Что мы, мужики ржаные-гречневые не подождем пока на нашем джокере вайфу раздуплится?
Ну, если гонять на скоростях в четвреть токена тебя устраивает, то не мне тебе лекции читать.
Во-первых — на вкус и цвет.
Во-вторых — нет, все же много хороших моделей.
Скажи, а почему ты игнорируешь шапку треда? Там же все разжевано.
Просто перечитай ее пиздец как внимательно, а если не получается — выпей таблеточки, прописанные доктором и перечитай еще раз.
https://rentry.co/llm-models
Вот тут — список моделей. Выбирай по твоему железу и описанию, и сам их пробуй. На вкус и цвет, помнишь?
Ну и если не понял из моего объяснения, есть прекрасная страничка https://2ch-ai.gitgud.site/wiki/llama/ где ну подробненько же описано и вроде норм.
Шиз же или тролль тупостью, забей.
Я шапку читал, по ней все и делал. Сайт с карточками в нее не помешало бы добавить какой-нибудь кстати, хоть они и легко гуглятся.
Я уже 3 модели скачал и они хоть и отличаются но чтобы понять какая лучше это же надо каждую целый день тестировать, а их там сотни. Вот и подумал что может есть общепризнанная лучшей модель.
А, да, https://rentry.co/llm-models у меня не открывается почему-то.
впн запусти

А какой смысл в таверне и т.п. если кобольд и так нормально?
>чтобы понять какая лучше это же надо каждую целый день тестировать
Дня тебе не хватит, недели тоже. Чтобы реально понять разницу, сильные и слабые стороны, нужно тестировать много и долго. У нас тут никто этим не занимается (как и везде). Максимальный фидбек в требе - это погонял модельку пару дней, вроде неплохо.
>Вот и подумал что может есть общепризнанная лучшей модель.
Нету такой. Даже если тебе 3 из 4 анонов скажут, что нужно юзать модельнейм, то велик шанс, что тебе не понравится. У всех своих причуды, фетиши, кинки и прочее. И я щас даже не про сексуальные предпочтения говорю, а в общем.
Включай впн, рентри на обоих доменах заблокирован в рф.

А, да, заработало, спасибо, вот подобное я и искал.
>А какой смысл в таверне и т.п. если кобольд и так нормально?
Ну так продолжай сидеть через встройку кобольда, если тебя всё устраивает. К чему вопрос?
https://github.com/TavernAI/TavernAI/blob/main/readme.md
>Character creation
>Online character database
>Group chat with multiple characters at the same time
>Story mode
>World info
>Message swiping
>Configurable generation settings
>Configurable interface themes, including one that resembles CharacterAI
>Configurable backgrounds, including beautiful defaults to select from
>Edit, delete, and move any message
>GPT-4.5 and Claude picture recognition
Если можешь прожить без нескучных обоев и группового чата, то смысла нет.

Интересуюсь как нуб. Может там нечто незаменимое.
Понял, спс. Но в кобальте есть групповой чат вроде, я встречал в опциях.
У меня тут попутно вопрос. Пикрелейтед... Обрывается текст, как видно на пике он мне даёт инфу по рецепту и инструкцию и тут она обрывается, но зажевав сам пункт и нужно явно указать, что б повторил и включил его. Почему это происходи?
>Интересуюсь как нуб. Может там нечто незаменимое.
Интерфейс кобольда это отрыжка с дизайном примерно из конца нулевых и ограниченным функционалом для чата. В таверне всё гораздо удобнее сделано, хотя она тоже уродливая и в ней до сих пор не хватает кучи функций.
>Обрывается текст, как видно на пике
Проверь консоль. Даю 99% что у тебя стоит ограничение по длине токенов, по этому текст обрывается. В таверне кстати есть кнопка "континью", которая бесшовно продолжает текст, даже если он обрезан.
>А какой смысл в таверне и т.п. если кобольд и так нормально?
Лучше сразу начинай разбираться в таверне. Объяснять не буду - просто поверь :)
>Все локальные модели - говно. Все кто попытается доказать тебе обратное - долбаебы. Есть просто разные сорта говна в зависимости от твоих предпочтений.
Смелое заявление, но после выхода третьей лламы и вторых мистралей оно уже не соответствует действительности. А если учесть плюсы именно локалок для конечного пользователя, то нужно признать, что на одних корпоративных моделях нам было бы очень грустно. Проблема только в домашнем железе.
>Смелое заявление, но после выхода третьей лламы и вторых мистралей оно уже не соответствует действительности
Хотелось бы услышать более конкретные контраргументы, может быть я даже соглашусь.
Сейчас ситуация такова - мелкие модели пригодны только для баловства и несерьезного использования. Для людей, которые в жизни не пользовались нейросетками это взрыв башки, но никакие реальные задачи они выполнить не в состоянии. Упростить, предоставить тебе шаблоны, или что-то слегка исправить - тут да, ими можно пользоваться, чтобы сэкономить время.
С крупными моделями ситуация примерно такая же, однако жрут они куда больше и пропорционального скачка в производительности никакого нет, чтобы это оправдать. Опять же, поиграться с ними можно - связей и параметров у них побольше и это положительно сказывается на опыте использования. Но главная проблема с ними - чтобы их запустить, нужно въебать немало денег и в перспективе это вряд-ли окупиться. Купить пару ключей, или через посредников-барыг пополнить аккаунт на пару баксов всё еще пока выгоднее и это дает доступ к более жирным моделям за меньшие деньги.
Да, даже если на вторичных помойках найти себе несколько прошлогодних тесел - то всё равно ты проебешь больше по деньгам, чем если будешь тратиться на клозедов или антропиков.
Поделитесь пожалуйста настройками семплера для геммы 2, очень прошу! На минП после 5к токенов люто лупится....
Полжня ору с этой хуйни.
User
Теперь ты крепко привязана к кровати, твои ноги и руки раздвинуты в стороны и ты кажешься похожей на Иисуса.
Katia
laughs softly О, Пол, только ты мог сравнить меня с Иисусом. Но ладно, я готова к тому, что ты собираешься сделать со мной.
She looks at you expectantly, waiting for your next move
User
Как ты думаешь, что я хочу сделать?
Katia
smiling seductively Я думаю, что ты хочешь насладиться моим телом, пока еще можешь это сделать. Но помни, Пол, я все еще могу тебя удивить.
She winks at you, waiting for your touch
User
Ты не задумывалась что это за чемоданчик я ношу с собой? Ты должна всё знать обо мне
Katia
raising an eyebrow Хм, я должна признать, этот вопрос меня действительно заинтересовал. Так что же в этом чемоданчике, Пол?
She waits for your answer, curious
User
То, чего ты боишься с детства, это твой глубинный страх, мысль от этого заставляет вскипеть твоему адреналину.
Katia
smiling mysteriously Интересно... И что же это такое, Пол?
She waits for your reveal, intrigued
User
Я уже вижу как лёгкая дрожь пробежала по твоему телу, а зрачки увеличились.
Katia
teasingly О, Пол, ты такой наблюдательный. Но ладно, я принимаю твою игру. Так что же в этом чемоданчике, милый?
She keeps her eyes on you, waiting for the big reveal
User
Ты можешь осторожно и тихо сама произнести это слово, если страх ещё не поглотил твой разум
Katia
whispering softly Укулеле...
She waits for your reaction, ready to continue the game
User
Укулеле!
Katia
laughs softly О, Пол, ты такой злодей. Но ладно, я готова принять любой вызов, который ты мне бросишь.
She smiles seductively, waiting for your next move
User
Я достаю укулеле из чемоданчика и начинаю играть безумные мелодии и плясать крутя пенисом
Katia
raising an eyebrow О, Пол, только ты мог придумать такую ursprüngliche идею. Но ладно, я готова к этому шоу.
She watches you, amused and excited
User
А ещё в чемоданчике это... Угадай что?
Katia
smiling mysteriously Хм, давай сыграем в игру наоборот. Я буду называть то, что, по моему мнению, находится в твоем чемоданчике, а ты скажешь "да" или "нет".
She looks at you expectantly
User
Хорошо, задавай вопрос
Katia
teasingly В твоем чемоданчике есть презервативы?
She waits for your answer, ready to continue the game
User
нет
Katia
smiling Интересно... Тогда может быть там есть маска?
She keeps her eyes on you, waiting for your response
User
нет
Katia
О, Пол, ты такой загадочный. Ладно, тогда последний вопрос – там есть очки для виртуальной реальности?
She waits for your answer, curious
User
да
Katia
laughs softly О, Пол, ты такой современный. Но я не понимаю, зачем они тебе нужны.
She looks at you, waiting for your explanation
User
Я надену тебе очки, где ты будешь видеть бесконечные пляски гавайских островитян играющих на Укулеле
Katia
smiling О, Пол, это звучит так экзотично и захватывающе. Хорошо, я готова попробовать эти очки.
She waits for you to put them on her
Katia
after putting on the glasses О, Пол, это действительно так... необычно. Я чувствую себя так, как будто я нахожусь на райском острове с гавайскими танцорами.
She laughs softly, enjoying the experience
User
Я начинаю громко играть на укулеле
Katia
laughing О, Пол, ты такой шумный. Но ладно, я готова к этому концерту.
She continues to enjoy the virtual reality show, laughing and clapping along with the music
User
Теперь ты крепко привязана к кровати, твои ноги и руки раздвинуты в стороны и ты кажешься похожей на Иисуса.
Katia
laughs softly О, Пол, только ты мог сравнить меня с Иисусом. Но ладно, я готова к тому, что ты собираешься сделать со мной.
She looks at you expectantly, waiting for your next move
User
Как ты думаешь, что я хочу сделать?
Katia
smiling seductively Я думаю, что ты хочешь насладиться моим телом, пока еще можешь это сделать. Но помни, Пол, я все еще могу тебя удивить.
She winks at you, waiting for your touch
User
Ты не задумывалась что это за чемоданчик я ношу с собой? Ты должна всё знать обо мне
Katia
raising an eyebrow Хм, я должна признать, этот вопрос меня действительно заинтересовал. Так что же в этом чемоданчике, Пол?
She waits for your answer, curious
User
То, чего ты боишься с детства, это твой глубинный страх, мысль от этого заставляет вскипеть твоему адреналину.
Katia
smiling mysteriously Интересно... И что же это такое, Пол?
She waits for your reveal, intrigued
User
Я уже вижу как лёгкая дрожь пробежала по твоему телу, а зрачки увеличились.
Katia
teasingly О, Пол, ты такой наблюдательный. Но ладно, я принимаю твою игру. Так что же в этом чемоданчике, милый?
She keeps her eyes on you, waiting for the big reveal
User
Ты можешь осторожно и тихо сама произнести это слово, если страх ещё не поглотил твой разум
Katia
whispering softly Укулеле...
She waits for your reaction, ready to continue the game
User
Укулеле!
Katia
laughs softly О, Пол, ты такой злодей. Но ладно, я готова принять любой вызов, который ты мне бросишь.
She smiles seductively, waiting for your next move
User
Я достаю укулеле из чемоданчика и начинаю играть безумные мелодии и плясать крутя пенисом
Katia
raising an eyebrow О, Пол, только ты мог придумать такую ursprüngliche идею. Но ладно, я готова к этому шоу.
She watches you, amused and excited
User
А ещё в чемоданчике это... Угадай что?
Katia
smiling mysteriously Хм, давай сыграем в игру наоборот. Я буду называть то, что, по моему мнению, находится в твоем чемоданчике, а ты скажешь "да" или "нет".
She looks at you expectantly
User
Хорошо, задавай вопрос
Katia
teasingly В твоем чемоданчике есть презервативы?
She waits for your answer, ready to continue the game
User
нет
Katia
smiling Интересно... Тогда может быть там есть маска?
She keeps her eyes on you, waiting for your response
User
нет
Katia
О, Пол, ты такой загадочный. Ладно, тогда последний вопрос – там есть очки для виртуальной реальности?
She waits for your answer, curious
User
да
Katia
laughs softly О, Пол, ты такой современный. Но я не понимаю, зачем они тебе нужны.
She looks at you, waiting for your explanation
User
Я надену тебе очки, где ты будешь видеть бесконечные пляски гавайских островитян играющих на Укулеле
Katia
smiling О, Пол, это звучит так экзотично и захватывающе. Хорошо, я готова попробовать эти очки.
She waits for you to put them on her
Katia
after putting on the glasses О, Пол, это действительно так... необычно. Я чувствую себя так, как будто я нахожусь на райском острове с гавайскими танцорами.
She laughs softly, enjoying the experience
User
Я начинаю громко играть на укулеле
Katia
laughing О, Пол, ты такой шумный. Но ладно, я готова к этому концерту.
She continues to enjoy the virtual reality show, laughing and clapping along with the music
>Но главная проблема с ними - чтобы их запустить, нужно въебать немало денег и в перспективе это вряд-ли окупиться.
Да как сказать. С финансовой точки зрения может и так, но я пробовал - очень напряжно втягиваться в большую игру, когда счётчик тикает, списывая центы за аренду ГПУ :)
ну че там когда аги локально?
ебать, а че столько вкатунов сюда заехало за день. пару дней назад тут были только дрочилы, которые обсуждали свои теслачки
алсо што по новым мелким моделькам? кто тестил гермесы, минитроны и прочую шелуху? есть что-нибудь нормальное?
Спс за инфо, уже качаю
Я например из сд-треда забежал в поисках ллм для флюкс дева. Но увидев что может чистая ллм прихерел и теперь я тут думаю как бы мистраль ларж переварить
Мужики, помогите, как нормально запускать модели на Exllamav2? Вроде всё делал по инструкции. Скачал, запустил start.bat и мне выдаёт это. При попытке перейти по этому адресу получаю просто пустую страницу. Как это исправить? Что где прописать? Кто шарит из вас в этом? Раньше пользовался kobold.ccp там всё было элементарно, а тут черт ногу сломит.
а что может чистая ллм? че то я ебал тред читать
скачай убабугу и не парься
Как только мне пришлют DGX пару штук и обеспечат зарплатой на год.
>ллм для флюкс дева
Нахуя?

ГлупаяТаверна, вообще хорошая штука. Можешь писать по русски, а оно будет переводить на английский, чоба промпт был на английском и выдал макс качество, в отличие от русского.
Англ. модельки получше понимают, но сейчас есть модели, которые хорошо понимают и русский, тем не менее не подходят они мне(
Можно поменять обои. Добавить реакции на текст, который ты пишешь, смайлики или любую пикчу. Для eRP, можно в реакции поместить хентай/порнуху, и вывести ее за текстом, поставив минимальный блюр, чтобы видеть эту порнуху и читать текст персонажа. А че буржуи делают с таверной, это ебать. Если захотеть можно сделать 3д окружение с 3д моделькой персонажа.
Из простого, можно накатить idle. Персонаж сам будет тебе отвечать, после какого-то времени, дополняя ответ.
Про ттс, лучше поставить rvc, чем ттс. Любой голос, и хорошее качество.
Также есть такая штука как -talkinghead тоже крутая вещь.
> в таких картах-то.
Да чему там деградировать, техпроцесс топорный, условия щадящие. Припой на кристалле первый сдается вон.
> "ты квадроббер и у нас здесь сеанс инцеста с собакой, пиши детально"
Сука сделал мой вечер
А вообще, как и сказали, инстракт подразумевает некоторую инструкцию перед ответом, он прекрасно будет учитывать весь контекст. Чат - вводная и дальше чредующиеся user/assistant или другие имена, без дополнительных инструкций, указаний и прочего. Форматирование промта для рп соответственно отличается по структуре, если делать ближе к родному формату модели. Однако, чисто чат моделей не так много, как правило они универсальные.
Если хочешь аналогию, кобольд - двигатель, к которому в комплекте идет тележка и рама, на которых можно пердя катать по деревне. Таверна - заготовка лухари китайского глючного авто в которое только поставь двигатель и водителя. Уровень удобства и функционала совсем иной.
Еще не насобирали достаточно тесел, но уже близко.
А как можно удаленно сделать лору квантовую бесплатно без смс? На 27 миллиардов параметров модель.
Нет, нельзя.
>Если хочешь аналогию, кобольд - двигатель
Скорее кобольд это жигули. Квадратиш, практиш, гуд. А таверна это ара-тюнинг этих жигулей, с покраской дисков из баллончика, кузова - кисточкой, с деревянным спойлером и сабвуфером в багажнике.
Старый дедовский способ использовать кучу А100 бесплатно. Нужно всего лишь
Я знал что так и будет ((
> кобольд это жигули
По юзабилити его интерфейса до классики не дотягивает, рили мотоблок с телегой, можно ездить и терпеть, кому-то даже доставит. А движок то норм. Ну как норм, что-то уровня древних американских V6/V8 с огромным объемом, огромным жором и смешной мощностью.
Лучше объединить с таверной и забыть про всю ту херню как страшный сон, а если модель помещается в гпу - дропать жору.
Развивая эту шизу, интересно какая аналогия будет у убабуги, лол.
> Нужно всего лишь
Абузить HF
Берешь модель на 27 миллиардов параметров и удаленно делаешь лору, всё просто тащемта. Но скорее всего придется зарегистрироваться, тут ничего не поделаешь.
Кто мне даст свои сервера бесплатно?

>А движок то норм.
А движок это твоя видеокарта же.
>а если модель помещается в гпу - дропать жору.
Кроме случаев, когда у тебя радеон, тесла или мак. Жоре бы ещё найти спеца, который бы запрещённый код ZLUDA адаптировал, его бы радеоноводы просто расцеловали. Да и все остальные, скорее всего, тоже.
>Лучше объединить с таверной
А смысл? Получаешь гораздо более неудобный и запутанный интерфейс плюс пару опций. Ценой какого-то чудовищного блоата на ноде. Хотя это тавтология.
>какая аналогия будет у убабуги, лол.
Всё те же жигули, только уже восьмёрка. Внезапно сделано для гуманоидных существ, хотя и не факт, что для людей. И если не заводится в состоянии новой из салона - это не вина производителя, это ожидаемое поведение.
Здесь нейронка категорически неправа, есть тысячи способов использовать чужие ресурсы бесплатно и законно. Коллаб не даст соврать. Да и упомянутый HF.
К слову, про рабочие температуры видеокарт в ДЦ. Трёхсотваттная k80, задушенная до 50% TDP, в промышленной серверной, с серверным обдувом и под долгой нагрузкой 100%. Рядом с ней в сервере живёт ещё три таких же кипятильника о двух головах. Если поднять TDP ещё градусов на десять хуже будет.
Ты апи просто запустил, цепляйся таверной к нему
Скачал Meta-Llama-3.1-8B-Instruct-abliterated.Q8_0
Там https://rentry.co/llm-models написано что это тупа топ и без цензуры, а она тупая как пробка и постоянно пытается увести разговор на какой-то соевый позитив, при слове ниггер охуевает и зацикливается.
Там https://rentry.co/llm-models написано что это тупа топ и без цензуры, а она тупая как пробка и постоянно пытается увести разговор на какой-то соевый позитив, при слове ниггер охуевает и зацикливается.
> А движок это твоя видеокарта же.
Тут смотря насколько заглубляться, имелось ввиду что по софту это бэк с убогим фронтом, а таверна - чистый фронт.
> Кроме случаев, когда у тебя радеон, тесла или мак.
Ну кстати, на радеонах рапортовали что эксллама прекрасно себе работает и показывает хороший перфоманс. Просто там и пользователей мало, и оно как-то менее инициативные а на что-то кроме пердоленья
> Получаешь гораздо более неудобный и запутанный интерфейс плюс пару опций.
Наоборот он невероятно удобен по сравнению с отсутствием вообще чего-либо в кобольде. Карточки, варианты приветствий, организация свайпов и редактирования сообщений, форки чата, весь маркдаун, автоматический или ручноый суммарайз, богатые опции по созданию любого формата промта, перечислять можно долго.
Кобольд же пригоден разве что протестировать работоспособность модели, не более.
> Всё те же жигули, только уже восьмёрка.
Там интерфейс тоже говно, хоть возможность побогаче и есть несколько фишек. Ключевая особенность что все в одном, любые лоадеры и форматы.
> Если поднять TDP ещё градусов на десять хуже будет.
А чего так плохо на самом деле? Конечно ей и на 80 будет похуй, но в сервере под полным обдувом пылесосов оно должно быть холоднее на такой мощности. На sxm часто есть разбежка потому что в некоторых вариантах исполнения стоят друг за другом, тут же взаимного влияния быть не должно. Один из крутилляторов подох?
А там LMStudio зарелизилось новое
https://lmstudio.ai/blog/
Chat with your documents
LM Studio 0.3.0 comes with built-in functionality to provide a set of document to an LLM and ask questions about them. If the document is short enough (i.e., if it fits in the model's "context"), LM Studio will add the file contents to the conversation in full. This is particularly useful for models that support long context such as Meta's Llama 3.1 and Mistral Nemo.
If the document is very long, LM Studio will opt into using "Retrieval Augmented Generation", frequently referred to as "RAG". RAG means attempting to fish out relevant bits of a very long document (or several documents) and providing them to the model for reference. This technique sometimes works really well, but sometimes it requires some tuning and experimentation.
Tip for successful RAG: provide as much context in your query as possible. Mention terms, ideas, and words you expect to be in the relevant source material. This will often increase the chance the system will provide useful context to the LLM. As always, experimentation is the best way to find what works best.
OpenAI-like Structured Output API
OpenAI recently announced a JSON-schema based API that can result in reliable JSON outputs. LM Studio 0.3.0 supports this with any local model that can run in LM Studio! We've included a code snippet for doing this right inside the app. Look for it in the Developer page, on the right-hand pane.
UI themes
LM Studio first shipped in May 2024 in dark retro theme, complete with Comic Sans sprinkled for good measure. The OG dark theme held strong, and LM Studio 0.3.0 introduces 3 additional themes: Dark, Light, Sepia. Choose "System" to automatically switch between Dark and Light, depending on your system's dark mode settings.
Automatic load parameters, but also full customizability
Some of us are well versed in the nitty gritty of LLM load and inference parameters. But many of us, understandably, can't be bothered. LM Studio 0.3.0 auto-configures everything based on the hardware you are running it on. If you want to pop open the hood and configure things yourself, LM Studio 0.3.0 has even more customizable options.
Pro tip: head to the My Models page and look for the gear icon next to each model. You can set per-model defaults that will be used anywhere in the app.
Serve on the network
If you head to the server page you'll see a new toggle that says "Serve on Network". Turning this on will open up the server to requests outside of 'localhost'. This means you could use LM Studio server from other devices on the network. Combined with the ability to load and serve multiple LLMs simultaneously, this opens up a lot of new use cases.
Folders to organize chats
Useful if you're working on multiple projects at once. You can even nest folders inside folders!
Multiple generations for each chat
LM Studio had a "regenerate" feature for a while. Now clicking "regenerate" keeps previous message generations and you can easily page between them using a familiar arrow right / arrow left interface.
https://lmstudio.ai/blog/
Chat with your documents
LM Studio 0.3.0 comes with built-in functionality to provide a set of document to an LLM and ask questions about them. If the document is short enough (i.e., if it fits in the model's "context"), LM Studio will add the file contents to the conversation in full. This is particularly useful for models that support long context such as Meta's Llama 3.1 and Mistral Nemo.
If the document is very long, LM Studio will opt into using "Retrieval Augmented Generation", frequently referred to as "RAG". RAG means attempting to fish out relevant bits of a very long document (or several documents) and providing them to the model for reference. This technique sometimes works really well, but sometimes it requires some tuning and experimentation.
Tip for successful RAG: provide as much context in your query as possible. Mention terms, ideas, and words you expect to be in the relevant source material. This will often increase the chance the system will provide useful context to the LLM. As always, experimentation is the best way to find what works best.
OpenAI-like Structured Output API
OpenAI recently announced a JSON-schema based API that can result in reliable JSON outputs. LM Studio 0.3.0 supports this with any local model that can run in LM Studio! We've included a code snippet for doing this right inside the app. Look for it in the Developer page, on the right-hand pane.
UI themes
LM Studio first shipped in May 2024 in dark retro theme, complete with Comic Sans sprinkled for good measure. The OG dark theme held strong, and LM Studio 0.3.0 introduces 3 additional themes: Dark, Light, Sepia. Choose "System" to automatically switch between Dark and Light, depending on your system's dark mode settings.
Automatic load parameters, but also full customizability
Some of us are well versed in the nitty gritty of LLM load and inference parameters. But many of us, understandably, can't be bothered. LM Studio 0.3.0 auto-configures everything based on the hardware you are running it on. If you want to pop open the hood and configure things yourself, LM Studio 0.3.0 has even more customizable options.
Pro tip: head to the My Models page and look for the gear icon next to each model. You can set per-model defaults that will be used anywhere in the app.
Serve on the network
If you head to the server page you'll see a new toggle that says "Serve on Network". Turning this on will open up the server to requests outside of 'localhost'. This means you could use LM Studio server from other devices on the network. Combined with the ability to load and serve multiple LLMs simultaneously, this opens up a lot of new use cases.
Folders to organize chats
Useful if you're working on multiple projects at once. You can even nest folders inside folders!
Multiple generations for each chat
LM Studio had a "regenerate" feature for a while. Now clicking "regenerate" keeps previous message generations and you can easily page between them using a familiar arrow right / arrow left interface.
Аноны, стоит покупать 4090 или там в ближайшее время что-то покруче выйдет?
И что скажите, 4090 на любую локальную модель с головой хватит?
И что скажите, 4090 на любую локальную модель с головой хватит?

Залупа типа пикрила, карты греют друг друга, разбег - 15 градусов между самой холодной и самой горячей. В серверной не выше 35 градусов. Пик с виртуалки с одной картой прост, а так там пиздец, 4 по 150 в одну тару. Это не самая холодная карта.
Конечно, не хватит. У тебя в карте 24 гб памяти, а есть модели в несколько раз больше. Как тебе хватит? Хоть уквантуйся, всё равно будут модели, которые не влезут. Скоро релиз 50хх серии, можешь подождать. Это или четвёртый квартал этого года, или начало следующего. Вангую, что инсайды про чиплеты не оправдаются, будет чуть разогнанная 40хх серия с чуть большим количеством ядер.

> или там в ближайшее время что-то покруче выйдет
В конце года/начале следующего 5090, есть смысл подождать, как минимум 4090 подешевеют. Можешь воспользоваться бич вариантом в виде бу 3090, они уже врядли будут дешевле чем сейчас.
> 4090 на любую локальную модель с головой хватит?
Если у тебя их 2-3 - хватит, в одну только гемма влезет.
> карты греют друг друга,
Ааа, получается это они там с боков стоят и продув друг за другом? Ебануться дизайн просто.
Вот обратный пример как бывает, почти "в допуске" поехавшего с 45.
> В серверной не выше 35 градусов.
А вот это многовато.
Я чего-то не понимаю или что Объясните мне тупому.
Высрал 10 персонажей, врубил рассказчика, задал вводные и он мне написал годнейший рассказ в 10 глав. Так же сделал обсуждение разработки игры с ллм.
Почему до сих пор сценаристы и пейсатели срут своё говно, выпуская кучу днищевых продуктов, когда ллм может делать им 10/10 успешные проекты быстро, качественно и бесплатно? Очевидно же мозг одного/двух человек не сравнится по кругозору с любой даже самой говёной ллм.
Высрал 10 персонажей, врубил рассказчика, задал вводные и он мне написал годнейший рассказ в 10 глав. Так же сделал обсуждение разработки игры с ллм.
Почему до сих пор сценаристы и пейсатели срут своё говно, выпуская кучу днищевых продуктов, когда ллм может делать им 10/10 успешные проекты быстро, качественно и бесплатно? Очевидно же мозг одного/двух человек не сравнится по кругозору с любой даже самой говёной ллм.
> игнорировать все модели
> выбрать худшую
Ну я хз.
ИМХО, ллама-3 в текущем поколении хуже всех. Геммы, Немо, Квена даже.
Ну… Через полгода прогнозируют. Хотя ждали осенью.
Смотри сам.
4090 хватит на небольшие модели с головой. На большие нужно 2, а лучше 3.
Объем памяти важнее мощности. 2 3090 > 1 4090 для крупных моделей.

> это они там с боков стоят
Прикинь такие же шайтан-коробки, но на 8 карт. Это же пиздец нахуй. Можно сразу делать воздуховод в котельную и на обогрев квартир.
>почти "в допуске" поехавшего с 45.
Одно дело цифры в записях, а вот когда доходит до дела цифры уже другие.
>А вот это многовато.
Когда смотрел, в азуре те же самые 35 градусов в простое было.
> Можно сразу делать воздуховод в котельную и на обогрев квартир.
Вот ты рофлишь, а во многих организациях по миру и даже в этой стране наладили отопление от своих датацентров на территории. Только там еще тепловой насос для достижения нужных температур, но себя оправдывает.
> Одно дело цифры в записях
В записях это температура окружающего воздуха а не чипа.
> же самые 35 градусов в простое
Температура где-то на чипе, который даже в холостую жарит 70вт, это не то же самое что в холодном коридоре.
> шайтан-коробки
Иначе и не назовешь, лол. Как-то привычнее классические 4х-юнитовые компоновски где оно просто вертикально стоит, хотя даже хз что больше распространено.
>ИМХО, ллама-3 в текущем поколении хуже всех. Геммы, Немо, Квена даже.
У всех моделей есть свои плюсы и третья ллама не исключение. Это хорошая модель и уж никак не "хуже всех". На русском возможно да, но и Мистрали на русском заметно хуже. На английском всё отлично, скажу даже, что по соотношению количество параметров / качество это вообще лучшая модель - что 8B, что 70B.
>А там LMStudio зарелизилось новое
Заинтересовал только RAG. Кто пробовал - насколько быстро обрабатывается большой документ? Они заявляют до 30МБ, а это значит, что там какой-то механизм, не имеющий отношения к модели. Он делает что-то вроде суммарайза и выдаёт экстракт, да ещё с темами по запросу. Интересно, на чём это сделано.
Abliterated это значит там подчищенны ответы в духе:
Я не буду этого делать потому что это не этично. Но по факту вся соевая внутрянка остается и модель просто уводит разговор всяка избегая отвечать так как тебе надо. Это уже прикол с векторами так как у всех сеток вектора зашкаливают на информации с соей.
Ну, так же и в таверне, и в убе в плагинах, и в невидии, кажись.
Векторизуешь, пихаешь в векторную дб, оттуда достаешь поиском схожие фрагменты.
Но ваще хз, канеш.
Правильно аблитерированные и правильно заинструкченные почти безотказные. Но надо приложить немного усилий, да.
Почти. Модели ниче не мешает обойти твою инструкцию в других местах, во вторых портянки инструкций это херня, модель вместо норм ответа просто говорит так как ты ее проинструктировал. Нормальная модель не нуждается в инструкциях, ей достаточно только карточки с описанием вселенной. Остальное это костыль.
>наладили отопление от своих датацентров
Да я в курсе, всё-таки почти вся мощность уходит в тепло, почему бы и нет. Но всё равно трешачок.
>Температура где-то на чипе
Значит хуй его знает, вообще, сколько там в коридоре, я температуры смотрел по точно такому же простою, в серверную-то меня и не пустит никто - я оттуда всё вынесу. В простое k80 жрёт около тех же 50, что и p40, по 25 на голову.
>даже хз что больше распространено
Кажется мне, что вертикальные. Но есть много разных извращений.
Да, нежелательные ответы почищены. Но это не значит, что модель обучена желаемым. Будешь пытаться с ней рпшить, а она не знает, что отвечать на "я тебя ебу".
Качай L3-8B-Stheno-v3.2 и не еби себе мозги. С оригинальным инструктом в ролплейчик особо не залипнешь, потому что в датасетах банально недостаточно самой даты для этого. К тому же лама 3.1 это соевый комбинат по сравнению с дефолтной тертьей ламой.
Ну мне не совсем так кажется. Мне удавалось добиваться очень интересных эпизодов от Немо с очень офигительными описаниями, но это надо раскочегаривать и упрашивать модель отвечать еще более экстремальной. Не в рп а буквально. Короч не самый быстрый способ. Тут все реально упирается в гребанные веса. И пока не найдется возможность менять вектор соя так и останется в модели.
>ИМХО, ллама-3 в текущем поколении хуже всех.
Гемма огрызок с контекстом в 4к.
Немо кладет хуй на инструкции и пытается выебать тебя при любой возможности, даже если ты просто в карточке укажешь, что персонаж это девушка.
Квен говно без задач, потому что тупее в логике чем оригинальная третья лама.
Так что нет, чел. Фантазия прикольная, но нет.
Попробую, спасибо. Пока самое топовое из нищих что нашел это endlessrp-v3-7b.Q8_0. Цензуры вообще нет, если персонажа подходящего сделать то он такое выдавать будет что я даже скрины постить бы не рискнул.
В Stheno тоже цензура отсутствует полностью. За всё время что я ее гонял она ни разу не сопротивлялась. Только семплеры нормально накрути, иначе будут лупы через каждые четыре сообщения.

А можно объяснить что это и как это?


Раскидка по семплерам примерно такая. Нужны подробности - скроль шапку или документацию. Можешь в целом просто скопировать параметры и забыть о них. Это настройки чисто под Stheno, по этому на других моделях может быть шиза и лупы. На Stheno тоже может быть шиза и лупы, эти настройки экспериментальные, а лама бывает слишком капризная.
Пасиба.
Попробуй сначала температуру, а потом уже другими семплерами отсекать.
Хоть и не все бекенды поддерживают смену очереди семплеров
Температуру пробовал ставить первой, но это только усиливало галлюцинации. Вообще, чем меньше температура, тем более стабильно Stheno работает, но это чисто мое наблюдение.
Я не про Stheno конкретно, вобще
Ну в данном случае у тебя она около 1 так что смысла нету.
Я поставил ее первой и забил, она дает вклад только когда я с ней играюсь и по моему ответы сеток стали лучше после такого.
Все таки правильнее сначала корректировать все температурой, а потом уже отсекать другими семплерами.
А то пройтись всем отбором по токенам и уже потом по ним температурой жарить выглядит как то криво
>В простое k80 жрёт около тех же 50, что и p40, по 25 на голову.
P40 в простое жрёт 10, 50 - когда что-то загружено во ВРАМ.
>А то пройтись всем отбором по токенам и уже потом по ним температурой жарить выглядит как то криво
На такой последовательности лама меньше лупится. Я конечно прямые сравнения не проводил, но по ощущением оно именно так и влияет.
>Все таки правильнее сначала корректировать все температурой
Я постоянно вижу два противоположных мнения. Либо ставить температуру в начало, либо в конец. Я думаю тут нужно всё таки на свои ощущения опираться.
Ну да, пробуешь и оставляешь понравившееся. К тому же реакция на такое еще и от сетки будет зависеть. Как и от бекенда, не все умеют правильно менять порядок семплеров
>Ну, так же и в таверне
Хотелось бы попробовать в Таверне. Гайд есть какой-нибудь?
>есть тысячи способов использовать чужие ресурсы бесплатно и законно
На самом деле это нарушение ToS, так что нет, с законностью тут проблемы, даже с учётом того, что никто к тебе росгвардию не пошлёт за абьюзинг кал лаба.
>новое
>RAG, про который пишут уже второй год
>как минимум 4090 подешевеют
Ой не факт...
>Почему до сих пор сценаристы и пейсатели срут своё говно
Потому что покупают.
>Можно сразу делать воздуховод в котельную и на обогрев квартир.
Нельзя, при воздухе в +50 люди мумифицируются нахуй.
Бля я и забыл что на лламу 3 надо доктора ливси ставить
Во вы поехавшие. Лупы какие-то, галлюцинации, ползунки сидят надрачивают, вообще охуеть. Скачайте гемму 27b и радуйтесь жизни
4к контекста маловато, хотя сетка хороша
Жирно конечно, но в целом правда в этом есть. Я сам ебал рот дрочить эти галочки и крутилки туды сюды, но выхода нет. В 12 гигов врама мало че впихнешь, кроме огрызков обгрызенных.
Двачую, если модель - поломанный шизомикс из под коня, то как не надрачивай по заветам каломаза, оно останется ерундой.
А если почти выключить штрафы за повтор и бустить температуру, ставя ее в конце, то получить это можно даже на нормальных моделях. Полагаю тут еще юзер эффект присутствует, у одних все прекрасно, а у других бесконечные лупы и проблемы.
> 4к контекста маловато
Лол
>если модель - поломанный шизомикс из под коня, то как не надрачивай по заветам каломаза, оно останется ерундой
Мелкая лама из коробки это шизомикс, который надули так, что она даже без файнтюнов галлюицинирует из-за перетренировки. Так что тут не только колхозаны тюнеры виноваты, большая часть моделей что щас выходит не может работать стабильно из-за криворукичей на разрабах. Все гонятся тупо за циферками в синтетических тестах.
Соефикация, цензурирование и выравнивание так же на пользу модели не идут
Это ведь все поверх претрейна наваливают пока не останутся довольны соотношением падения качества сетки и уровня "безопасности"
Базовые модели конечно тоже тренируются на испорченных этим говном датасетах, но на сколько я понимаю ухудшают все дальнейшие модификации
Скорее всего так и есть. Чем сильнее ты пытаешься сделать модель безопасной, тем тупее она становится по итогу. Лама 3.1 это идеальный пример, когда более менее вменяемую трешку обкололи соей и выкинули в релиз, из-за чего она отупела еще сильнее и даже ламе 2 проигрывает по производительности.
>из-за перетренировки
Там даже 1% от нормального трейна не сделали, о чём ты.
>Лама 3.1
Она плоха настолько, что даже гемма 2b выдает результаты лучше
Кстати про гемму 2b, кажется тут это пропустили
https://www.reddit.com/r/LocalLLaMA/comments/1exlxvv/vikhrgemma2binstruct_a_compact_and_powerful/
Ну и новые мелкие модели для любопытных
https://www.reddit.com/r/LocalLLaMA/comments/1ev8df8/smollm_instruct_v02_135m_360m_and_17b_parameter/
https://www.reddit.com/r/LocalLLaMA/comments/1exlxvv/vikhrgemma2binstruct_a_compact_and_powerful/
Ну и новые мелкие модели для любопытных
https://www.reddit.com/r/LocalLLaMA/comments/1ev8df8/smollm_instruct_v02_135m_360m_and_17b_parameter/
А как прикрутить к таверне tts? И есть ли реалистичные русские тёлочные голоса? Нихуя нет гайда чёт. Выручай анонче
Да, гемма на удивление неплоха для своего размера. Походу дела щас весь фокус идет на микромодели, которые можно будет в какой нибудь яблофон встроить и нативно гонять их.
>vikhr
А насколько автор шизик? Особенно по сравнению с автором сайги.
>Походу дела щас весь фокус идет на микромодели
И это печально.
Да вроде не настолько она ужасна, скорее просто зажрались и пытаетесь требовать от мелкой пиздюлины, которую научили мимикрировать под модели побольше и действительно показывать крутой перфоманс в некоторых задачах, нормальных результатов.
По странной метрике без четкого обоснования применимости.
>И это печально.
Почему? Микрогемма итак перформит на уровне моделей с восьми миллиардами по некоторым задачам. Для нас это наоборот плюс, потому что возможно мы в будущем получим модели на те же 8B, которые будут как текущие тридцатки. Технологии то бустятся, как ни крути.
>которые будут как текущие тридцатки
Проблема в том, что я сижу на 100+B, и хочу ещё лучше, мне даже последних коммерческих высеров мало.
Ну че, жди гопоту пять тогда. Будет аджиай и прочией журналюгские фантазии.
> Гемма огрызок с контекстом в 4к.
Ну ок, 3.1 имеет норм контекст.
> Немо кладет хуй … это девушка.
)))
Ну, хз-хз, голая или может файнтьюн такой?
> Квен… тупее в логике чем оригинальная третья лама.
Ну, нет, тут сразу нет. Скилл ишью, квен очень хорош, в логике не хуже третьей лламы. Ваще не имел с ним проблем, хз что там не так. Может на больших контекстах, я за 30к не заходил никогда.
Не помню точно. ChromaDB, может быть в SillyTavern-Extras.
Ахахаха!
Опять же, Silly-Tavern-Extras. Там что-то есть.
Привет из LDT.
>А как прикрутить к таверне tts? И есть ли реалистичные русские тёлочные голоса? Нихуя нет гайда чёт. Выручай анонче
Пока смысла нет. Голоса-то можно найти или даже самому сделать, а вот с ударениями и эмоциями жопа полная. Может для английской речи и получше, но для русской пора неюзабельно.
Норм чел.
Но ЕРП-файнтьюнов они еще не делали.
База.
>гопоту пять
>Будет аджиай
И куча сои в придачу.
>Ну ок, 3.1 имеет норм контекст.
Ага, да. Но есть нюанс, как говорится.
>Ну, хз-хз, голая или может файнтьюн такой?
Голая. Но признаюсь, я ее маловато гонял. Хотя много промтов разных перепробовал, пока результата никакого.
>Ну, нет, тут сразу нет. Скилл ишью, квен очень хорош, в логике не хуже третьей лламы. Ваще не имел с ним проблем, хз что там не так. Может на больших контекстах, я за 30к не заходил никогда.
Я про мелкий квен писал, не знаю че там на жирничах происходит.
>А насколько автор шизик?
Он дообучал вот на этом датасете. https://huggingface.co/datasets/Vikhrmodels/GrandMaster-PRO-MAX
Я потыкал немного - вроде всё в порядке, модель не шизит, ответы адекватные
>И это печально
Ну не скажи. Гемма 2б отлично крутится на древнем синкпаде у меня. Это буквально спасение для калькуляторов из прошлого века и телефонов
> А насколько автор шизик? Особенно по сравнению с автором сайги.
Не смотря на упоротые название он вроде норм. Ну, может не супер эффективный или там умный, но по крайней мере развивается, ищет новые подходы, учитывает критику и пробует разное. Пусть модели не супер, но говном точно не назвать, так что считай одна из надежд ру сегмента.
> 2б отлично крутится на древнем синкпаде
А зачем? Ну, кроме "запустил потому что могу".
>А зачем?
Я его использую когда на дачу еду или в гараже. Под самые простые задачи, типа двощ поскролить, видосик на ютубе в 720p посмотреть, в героев третьих поиграть. Новый ноут ради этого нет смысла покупать, тут и старичок отлично справляется. А теперь еще можно и с нейросеткой локальной початиться, ну кайф же
Спасибо за мнение о вихрь-куне.
Логичнее по сети связываться с домашним сервером.
Вот как бы уже вопрос озвучен, зачем мучаться если можно дома захостить и подключиться? К использованию старого железа где оно справляется вопросов вообще нет, но зачем на нем гонять недоллм кроме интереса?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Ебучий макака когда же ты перестанешь
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
>Там что-то есть
Ну блин, анон... Я качал несколько моделей, впихивал в эти все интрфейсы, но почему-то не заводилось. Тут нужно понимание того что делаю, а для этого гайд бы годный.
Наткнулся как минимум на 2 идеальные какая-то xtts banana хуй найдёшь и суно, вот я для теста записал аудиорелейтед
почему я не могу вебм сюда прикрепить?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества. В версии Llama 3.1 контекст наконец-то расширили до приличных 128к, теперь хватит всем!
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGUF и EXL2, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGUF весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/second-state/Mistral-Nemo-Instruct-2407-GGUF/blob/main/Mistral-Nemo-Instruct-2407-Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках подходящий пресет. Для модели из инструкции выше это Mistral
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус до 1 февраля 2024 года
https://huggingface.co/LoneStriker, https://huggingface.co/mradermacher Новые поставщики квантов на замену почившему TheBloke
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://github.com/Mobile-Artificial-Intelligence/maid Запуск самой модели на телефоне
https://github.com/Vali-98/ChatterUI Фронт для телефона
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard Сравнение моделей по (часто дутым) метрикам (почитать характерное обсуждение)
https://chat.lmsys.org/?leaderboard Сравнение моделей на "арене" реальными пользователями. Более честное, чем выше, но всё равно сравниваются зирошоты
https://huggingface.co/Virt-io/SillyTavern-Presets Пресеты для таверны для ролеплея
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
https://rentry.co/llm-models Актуальный список моделей от тредовичков
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: