



В первом пике надо контекст на 128к заменить. А то новую придумать.
Блять, с каждым новым перекатом шапка становится всё более жуткой. Может пора уже половину выкинуть, а другую как-то переформатировать и все ссылки закинуть на отдельную рентри страничку?
ох, ну и дела
Многабукафнеосилил?
>на отдельную рентри страничку
У нас там вики вапщето есть...
>В первом пике надо контекст на 128к заменить
Чёрт, я всегда думал, что это ЧК, типа подпись автора...
не могу прикрепить ни аудио н и=вид ое итт
Не выебывайся давай. У меня претензия к оформлению шапки, а не к тому, что букв много. Нахуя здесь до сих пор висит "гайд для ретардов", если он итак продублирован в вики? Нахуя тут столько ссылок которые висят без всякой категоризации? И в конце концов, нахуя нужен этот микроартикл посвященный тому, что такое локальные модели, когда эта инфа тоже есть в вики?
>Нахуя дубль вики
Для независимости от вики, очевидно же. Было пару раз, когда вики не работала.
По двум причинам: не хочу дома оставлять включенной рабочую пекарню + на даче интернет дерьмо и часто отваливается. А для работы локальной ллм интернет не нужен.
>зачем на нем гонять недоллм
На самом деле 2b гемма очень неплоха, не надо сравнивать её с другими огрызками типа phi и прочих. Выше написали правильно что она вполне тягается с 8b моделями и выше. Для ее размера - это просто имба какая-то
>Для ее размера - это просто имба какая-то
Ты хоть уточняй в чем.
На сколько помню у нее тоже контекст реальный 4к, значит обрабатывать что то длинное ей так же как и большим геммам не дашь
Мне самому интересно было ее потыкать как и другие мелкие модели, но кроме меньшего количества знаний и более простых ответов ничего не заметил
Действительно ощущается как 7-8b? В каких сценариях?
Даже если так, шапка итак продублирована на рентри. Даже если вики отвалится, можно перейти туда и прочитать. Вместо этого можно было бы добавить мини-блок новостей, как это на форчах сделано и краткий список необходимых ссылок на фронты с беками и список моделей.
Эти несколько параграфов из шапки банально не нужны, потому залетным они не помогают. Если им будет лень читать, они в любом случае отпишутся в треде. А те кому нужна инфа найдет ее на других источниках, или перейдет по ссылке на полную шапку.
Хотелось бы услышать пример хорошей генерации русской речи. Только не "избранное", избранное я и сам могу, а чтобы не корёжило при ролеплее. Если я неправ и такие модели есть, то хотелось бы об этом узнать.
>Даже если вики отвалится, можно перейти туда и прочитать.
Я оттуда копипасчу с разметкой. Да и рентри отваливается чаще вики, лол.
>как это на форчах сделано
У нас харкач всё таки.
>потому залетным они не помогают
Уговорил. Коперни рентри, предложи свой формат, я посмотрю и сделаю по своему.
>Действительно ощущается как 7-8b? В каких сценариях?
Сравнивал с лламой 3 и 3.1. Сценарий использования - рп на самописных карточках в коболде. Ну вот русский язык - лучше, шизы - меньше. Всяких приколов типа лупов и прочего говна - нет вообще. Сои по сравнению с 3.1 гораздо меньше. Качество/вариативность ответов: какой-то прям глобальной разницы не ощутил, после 27b шо то шо то выглядит упрощенно.
Пресет Godlike в коболде показал себя интереснее всех с этой моделькой. Начала подробнее писать, и как-то более вовлеченно что-ли. Но может это плацебо кнеш
Ранее в тредах приводили примеры моделек со 100+b, там всё окей с русским. На 27b гемме тоже хорошо, мои старые скрины, можешь оценить уровень знания языка - обычно так и пишет. ОЧЕНЬ редко может путать падежи, или допускать мелкие ошибки, но такое реально редко и не раздражает.
>ОЧЕНЬ редко может путать падежи, или допускать мелкие ошибки, но такое реально редко и не раздражает.
Сорри, я непонятно выразился. Хотелось бы примеры синтезированной русской речи, голоса. Чтобы и с падежами всё было более-менее, и с эмоциями. Хотя я понимаю, что эмоции возможны только в комплексной модели, во всяких омни. Но чем чёрт не шутит?
Не обязательно загружать, достаточно процесса с CUDA, создавшего контекст. Контекст CUDA и контекст LLM - разные вещи. Но это и есть простой.
На винсервере снижается до 10 даже с куда-процессом. Но где мы, а где винсервер.
>На самом деле это нарушение ToS
https://research.google.com/colaboratory/tos_v5.html
Да как бы нет. Колаб вообще не особо различает платное и бесплатное использование ресурсов. Они даже SD не запрещают в явном виде, просто сообщают, что выделение ресурсов на него будет с минимальным приоритетом и если кто-то с чем-то другим захочет ресурсов - тебя пидорнут. Но это даже не TOS, это FAQ. Лично я за три дня надрочил колаб часов на 18 бесплатной Т4 нейронками со 100% загрузки нонстоп, ни предупреждений, нихуя. Но надоедало аккаунты менять.
>при воздухе в +50 люди мумифицируются нахуй.
Пусть окна открывают, а то хули - мне одному сидеть с открытым окном зимой?

>Но надоедало аккаунты менять.
И после этого ты говоришь, что нихуя не нарушаешь...

Короче, кое-что переформатировал и рассортировал по пунктам: https://rentry.co/llama-2ch-header
Основная часть ссылок осталась на месте, даже те что устарели. Убрал только факю-полотнище про локалки и добавил несколько новых ссылок, которые могут пригодиться.
Подробнее о вырезанном:
Гайд для ретардов убран, потому что это стыдно гайдом называть, это просто огрызок.
Колаб убран потому что толку от него нет, тред всё равно про локальную движуху без больших дядь на облачных сервисах.
Гайд по обучению лоры убран, потому что никто тут лору ни разу не обучал за все прошедшие треды.
Не самые свежие гайды на ангельском убраны, потому что инфа есть в вики и на понятном языке.
Поставщики квантов вырезаны, потому что один хуй все ищут модели через обниморду (хотя их можно вернуть при желании, тут решение за тобой).

>Поставщики квантов вырезаны, потому что один хуй все ищут модели через обниморду
Где-то читал, что в модель можно встроить вредоносный код при желании если тут есть специалисты - поправьте меня, поясните по хардкору насколько это реально. Если такое теоретически возможно - то лучше качать модели только у ПРОВЕРЕННЫХ ВРЕМЕНЕМ поставщиков типа Bartowski, Drummer, Mradermacher и прочих (а не у ноунеймов зарегистрированных вчера, с одной моделью в профиле).
Для того и создан формат safetensors. С ллм чуть сложнее ибо там помимо чистых весов еще могут буквально лежать скрипты для особенного токенизатора или нечто подобное, но типичные для юзеров лоадеры их игнорируют без дополнительных опций, а то и вообще не имеют к ним обращаться. В gguf вообще невозможно встроить дополнительное ибо все возможное уже захардкожено.
Возможно, обнаружат какие-нибудь новые уязвимости, но это довольно маловероятно.
Пытался вникнуть в эту тему глубоко, какой же это пиздец (гайды как на инопланетнмо языке, какие то цифры, буквы, не понятно о чем идет речь).
Скачал Llama 8B модель без цензуры, скачал koboldcpp, выставил рекомендуемые настройки и выглядит збс. Видяха не тянет модели выше 8B, но все равно выглядит неплохо, как для локальной модели. Интересно что выдают модели 70+B, хоть бери кредит, и покупай две 4080 (хз хватит их или нет).
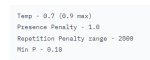
Вот, к примеру, что значат эти параметры? Почему в разных моделях они должны быть разными?
> две 4080
Тогда или 4090 или 3090, или хотябы 4070ти. 4080 аутсайдер из-за цены и врам.
Настройки одноименных семплеров. Пиздуй вики читать.
> две 4090
Как думаешь, хватит ли этого, чтобы отдаленно напоминало GPT4?
Почти, но лучше взять 3 более дешевые карточки чтобы точно хватило. В некоторых кейсах оно даже будет превосходить, разумеется завязаны эти преимущества на отсутствие сои, полный доступ к весам, нет тех же типичных фразочек и байасов (но есть другие) и подобное. По чисто рафинированному уму жпт будет умеренно/немного лучше, по обилию разнообразных знаний - ощутимо лучше, но все зависит от запросов, где-то может быть наоборот. Офк это не относится к чмоне, что тупая хуета.
Что-то отдаленно напоминающее - это модели 100b+, которые не влезут в твою врам. Даже если ты две 4090 купишь. И даже если три. Не, напоминать-то они конечно будут, ответы там будут отличные, но скорость генерации тебе не понравится.
>Почти
Да, это хорошее слово для описания текущей ситуации. Но до последних поколений локалок даже и этого не было. Сейчас хорошее время так-то.
спасибо, буду думать
Эх как же хочется стек из 10 а100 чтоб стояло напротив меня и общалась ПОЧТИ как натрашка из соседного падика... Ведь оно того стоит. Можно будет два три раза в ден дрочить. Вся суть итт
> И даже если три.
Датфил когда в треде немало человек катают на трех штуках большого мистраля.
> но скорость генерации тебе не понравится
Десяток токенов будет, не так все плохо. Жпт в часы пик и ниже проседал, а если ты бедолага что сидит на вялой проксе - ожидать обработки не привыкать.
> Но до последних поколений локалок даже и этого не было.
Ну вообще и вторая ллама могла очень душевно ебать и давать крутой экспириенс, а в опуще или сойнете можно прямо сейчас умереть с кринжа или эпично разочароваться с унылости в некоторых сценариях. Все от юзкейса зависит же.



имеем три карты.
0 - x16
1 - x1
2 - x8
на картинке приведены результаты пропускной способности, обращать внимание нужно на busbw измеряемый в гигабайтах в секунду.
1 пик - замеры между 0 и 2
2 пик - замеры между 0 и 1 (идентичны замерам карт 1 и 2)
3 пик - замер скорости между всеми тремя картами
внимание - вопрос:
Когда карты физически на материнке было две - пропускная способность между 0 и 2 была 1,28. Почему при добавлении третьей карты она снизилась вдвое, при том что третья карта не учавствует в тесте?
проц AMD Ryzen 5 3600
мать ASUS PRIME B450-PLUS
0 - x16
1 - x1
2 - x8
на картинке приведены результаты пропускной способности, обращать внимание нужно на busbw измеряемый в гигабайтах в секунду.
1 пик - замеры между 0 и 2
2 пик - замеры между 0 и 1 (идентичны замерам карт 1 и 2)
3 пик - замер скорости между всеми тремя картами
внимание - вопрос:
Когда карты физически на материнке было две - пропускная способность между 0 и 2 была 1,28. Почему при добавлении третьей карты она снизилась вдвое, при том что третья карта не учавствует в тесте?
проц AMD Ryzen 5 3600
мать ASUS PRIME B450-PLUS
>Датфил когда в треде немало человек катают на трех штуках большого мистраля.
Могу катать большого Мистраля, но катаю лламу 70B. Чисто на английском считаю её лучше.
Так, подождите, в локалках все еще даже нельзя вручную накрутить силу активаций атеншна на выбранном куске контекста? Мда, такими темпами вам до прогресса уровня дифьюжена еще идти и идти...
А версии pci-e у карт какие?
p40 имеют pcie 3.0
> при том что третья карта не учавствует в тесте?
Значит она там такие участвует, иначе бы и не было ничего. Хотя
> проц AMD Ryzen 5 3600
> мать ASUS PRIME B450-PLUS
Откуда там 8 линий на еще один слот, да еще возможность конфигурирования чипсетных линий аж на х8?
Они обе ничего, на самом деле большой мистраль просто хороший, нет вау эффекта от размера. Катаешь ванилу или какой-то файнтюн?
Во-первых, если бы я использовал 1 аккаунт - я бы использовал ресурсы легально и бесплатно. Что уже опровергает утверждение нейронки.
Линии psi-e поделились, не?
>Линии psi-e поделились, не?
помню, что в одном из прошлых тредов какой-то анон показывал команду как посомтреть топологию линий через nvidia-smi. Не помнишь её?
Конкретно под psi-e не помню. Но можно посмотреть через nvidia-smi -q если скроллить не лениво.

ага, точно
nvidia-smi -q | grep -i pci -C 8 | grep -E "(Bus Id|Link Width)" -A 2 | grep -E "(Bus Id|Current)"
>nvidia-smi -q | grep -i pci -C 8 | grep -E "(Bus Id|Link Width)" -A 2 | grep -E "(Bus Id|Current)"
Под Винду вот это сконвертировать можно?
>Они обе ничего, на самом деле большой мистраль просто хороший, нет вау эффекта от размера. Катаешь ванилу или какой-то файнтюн?
Мистраль хороший и действительно может в русский, но лупится совсем негуманно. Можно настроить, но от 123В ну не ждёшь как-то таких проколов. Плюс он в четвёртом кванте идёт медленнее, чем 70В в пятом. А лламу гоняю lumimaid 0.2 и она охуенна. Есть косяки, что-то приходится иногда подкручивать, рероллить и править ответы - но 2мб текста уже нагенерировал в рамках одного ролеплея и держит уверенно. 24к контекста, ручной суммарайз уже больше 5к токенов :) Раньше такого не было, а теперь есть.
Спасибо, это просто охительно. За диалог из почти 150 сообщений вообще никаких багов небольшие запинки и путаницы можно даже не считать, они воспринимаются как опечатки и в сюжете дальше не участвуют не встретил.
У меня сейчас 16 гб оперативы, но скоро будет 32, имеет ли смысл переходить на какую-нибудь более тяжелую модель? Если да то какую?
nvidia-smi --query-gpu=pcie.link.gen.current,pcie.link.width.current --format=csv
Вообще нихера лишнего не будет. Первым идёт генерейшон psi-e, вторым количество выделенных линий. Может быть меньше, если видеокарта не используется, сначала подгрузи что-нибудь, а то драйвер оптимизирует расходы.
>Вообще нихера лишнего не будет
Показывает нужное, спасибо.
Выбираю VLM для набросочных описаний датасета пикч. Предложили bakllava. Что скажете? Взять другую?
Когда уже модели для кума шагнут вперед? такой бред пишут, неужели нет именно натренненой модели на порно рассказы именно? во первых пишут очень мало (без подробностей и стараются как можно быстрее завершить сцену, либо наоборот хуету пишут без процесса)
>неужели нет именно натренненой модели на порно рассказы именно
П... Пигмалион.
Клод два был мегаохуенным (на английском по крайней мере, но и на русском норм). Я потом дропнул это всё дело. Сейчас есть подобные опенсорсные модели?
шутка? хуже него наверное ничего нет
Установил таверну в общем, по вашему совету и такая проблема после кобальда... В кобальде сообщения от ии мгновенно поступали после моего запроса и печатались постепенно появляясь, даже снизу было написано "печатает". В таверне же сразу после моего вопроса оно думает минуту и потом вываливает простыню. Как сделать как в кобальде, подскажите плз.
Всё я разобрался, тупанул капитально, сорян.
Попросили модель, натрейненную на РП и прочей порнухе, я и предоставил.
И да, пигма имеет душу ©, в отличии от всего этого новомодного говна, где в приоритете точность ассистента.
Вот тебе и x8
> лупится совсем негуманно
Стоковый чтоли? Там люмимейда нужна, с ванилой пердолиться нужно.
> лламу гоняю lumimaid 0.2
Ее же хейтили, стоит пробовать?
Очевидный коммандер очевиден
мистраль немо очень подробно и без цензуры всё описывает, даже с шантажом и чернухой я охуел

>Линии psi-e поделились, не?
внезапно нет.
Вот картина когда подключено только две карты
>Вот тебе и x8
да, это странно... там в разъеме действительно есть пины для x8, но он не работает в режиме x8 даже сейчас, когда там только две карты. И даже в режиме x4 не работает.
Мне кажется я не понимаю какой-то логики в распределении линий pcie. Где бы об этом побольше узнать? Правильно ли я понимаю, что сетевая карна например тоже требует pcie? А usb используют pcie?
Где посмотреть, как вся периферия на материнке коннектится к процу?

>Где бы об этом побольше узнать?
В мануале к материнке. Иногда в обзорах от нормальных спецов. Вот например из мана к моей материнке, но у меня никаких проколов с разделением нет.
у тебя эпик?
что думаешь о воб этом наборе?
https://aliexpress.ru/item/1005007405054294.html
Я на него смотрю, он приковал мой взгляд, но я боюсь, что это слишком дешево по рынку и продаван мне нихуя не отпрпавит и у меня 50к просто повиснут на три месяца на али.
>Llama-3.1-8В
>По первым тестам очень сухая и много сои
Объясните, в чём эта ваша "соя" заключается?
На DuckDuckGo с Llama 3.1 70b общаюсь, но хочется перекатиться на локальную, но железо настолько устаревшее, что я могу только Qwen 0.5b нормально запустить (в процессоре нет AVX инструкций).
Так вот, 70b модель по характеру нравится - всё очень хорошо понимает, эмоциональные ответы, не тупит в стиле "я не могу этого сделать", не навязывает ничего. Неужели младшая 8b модель сильно хуже старшей?
Возможно ли обрезать 8b до 0.5b или меньше, убрав полностью бесполезные знания/навыки, но сохранив характер и эмоциональность? Пусть будет дурочкой, ничего не знающей, но чтоб под мои личные вкусы.
Видимокарта в распоряжении 750 Ti 2GB, её должно хватать с головой для 1.5b модели, но процессор 2007 года не имеет AVX, который требуется, похоже, везде, аргументируя "ну без AVX медленно будет, если VRAM меньше необходимого для модели, так что извиняй".
P.S. Умею программировать и могу освоить питон, но машинное обучение для меня - тёмный лес пока что. Непонятные библиотеки с непонятным жаргоном...
>у тебя эпик?
У меня обычная десктопная плата абасрок стил легенд на AM5.
>и у меня 50к просто повиснут на три месяца на али
В лучшем случае. В худшем ещё и наебут, лол, алишка давно скурвилась. Так что на свой страх и риск.
чувак ужать модель до такого неприличия пока невозможно. Собирай деньги на 3060 или 4060
>На DuckDuckGo с Llama 3.1 70b общаюсь
фигасе они молодцы. Не знал что утка свой чат с моделями подняла.
>обрезать 8b до 0.5b или меньше
>750 Ti 2GB
земля тебе пухом, братишка...
тут карты покупаешь чтобы командер плюс завелся на 3т/с, а все из-за качества ответов, а ты хочешь себе лоботомита локального.
Обычно чем больше тем умнее.
Есть исключения, например гемма 27б, которая показывает выдающийся хороший результат на уровне 70б сеток,а весит в три раза меньше, но это исключение потомоу что делала его нвидия.
Альсо если хочешь маленькую русскую сетку - я все еще рекомендую попробовать t-lite от тинькова.
>Объясните, в чём эта ваша "соя" заключается?
В основном под этим имеют ввиду нравоучения сетки, и ее отказы что то делать читая тебе нотации. Вот когда эта хуйня отказывается о чем то говорить, говорит тебе что плохо, а что хорошо, это нереально бесит.
Так же частью всего этого является общая "личность" ассистента ии, на котором и завязана большая часть этих ограничений. "Безопасность", ебать ее создателей.
> хороший результат на уровне 70б сеток
Даже близко нет. В тестах они ещё как-то может, но по знаниям очень плохо. Если задача чисто на логику, то в целом может около 70В подбираться с переменным успехом, но как только нужно применять минимальные знания и понимать о чём речь - уровень мистраля 12В или даже 8В.
Как отучить модельку от всяких игр, силовых динамик и прочей соевой чепухи?
>Вот картина когда подключено только две карты
>Слоты расширения:2xPCI-E x16, 3xPCI-E x1
Смотри, в какие слоты подключено. У тебя только два поддерживают больше, чем х1.
>Пусть будет дурочкой, ничего не знающей, но чтоб под мои личные вкусы.
У нейронки "знания" и "способности к рассуждению" это считай, что одно и то же. Не совсем, но почти.
>Умею программировать и могу освоить питон
Ну так программировай на дядю и заработай наконец на видеокарту.
>На DuckDuckGo с Llama 3.1 70b общаюсь
А вот это уже интересно.
Там ещё есть GPT-4o mini, Claude 3 Haiku и Mixtral 8x7B.
И всё это анонимно без регистрации.
Надо бы скрипт для таверны написать...
> да, это странно...
Да вроде не особо, 2 линии чипсетных на том слоте. Честно говоря, не припомню чтобы нищеплаты старых амд вообще умели делать х16 на пару х8. В качестве ахуительного бонуса там еще все или почти все чипсетные линии 2.0 стандарта.
> там в разъеме действительно есть пины для x8
Часто делают пины просто чтобы разъем держался или потому что такой разъем удалось выгодно закупить, дорожек к ним может не быть. Но ты поизучай, может пизжу и достаточно будет выставить в биос параметр чтобы оно заработало.
> https://aliexpress.ru/item/1005007405054294.html
Все зены ваше 7 маняметров вообще нельзя рассматривать, это ужас, который даже в не-требовательных к процессору гпу вычислениях все тебе завафлит. Можно брать начиная с зен2, а лучше зен3, это рим или милан, маркировка 7xx2 или 7xx3.
если хочешь дешево и сердито то xeon твой лучший выбор

Хочу рузен эпик 9XXX с ддр5.
>xeon твой лучший выбор
Вот только плату хорошую (и не особо дорогую) под несколько видеокарт кто бы посоветовал под этот xeon. Проблемы с этим.
Посоветуйте топ модель 7-12b для секстинга :3
Какую же чушь выдает BakLLaVA. Угадывает две-три детали, всё остальное галлюцинирует.
llama_model_load: error loading model: done_getting_tensors: wrong number of tensors; expected 724, got 723
кто-нибудь знает, что это за говно?
Это на убабуге. Гружу жорой.
Вот эта модель https://huggingface.co/bartowski/Meta-Llama-3.1-70B-Instruct-GGUF/tree/main/Meta-Llama-3.1-70B-Instruct-Q5_K_M
Может кто-нибудь проверить на другом лоадере или обертке?
кто-нибудь знает, что это за говно?
Это на убабуге. Гружу жорой.
Вот эта модель https://huggingface.co/bartowski/Meta-Llama-3.1-70B-Instruct-GGUF/tree/main/Meta-Llama-3.1-70B-Instruct-Q5_K_M
Может кто-нибудь проверить на другом лоадере или обертке?
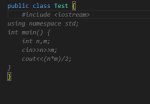
Скачал nomic-embed-text, до этого кодил понемногу только на deepseek-coder-v2 без него. Не заметил что поменялось. Ошибку не выдавало ни раньше. Для чего нужны эти эмбединги?
Вместо заполнения всегда начало выдавать вот эти строки C++. К чему они вообще. Сломало дополнение. Не понял смысла.
Вместо заполнения всегда начало выдавать вот эти строки C++. К чему они вообще. Сломало дополнение. Не понял смысла.
>Спасибо, это просто охительно.
Обращайся.
>У меня сейчас 16 гб оперативы, но скоро будет 32, имеет ли смысл переходить на какую-нибудь более тяжелую модель? Если да то какую?
Ты не захочешь переходить на более тяжелую модель, потому что гонять их через оперативку это сомнительное удовольствие.
>Как отучить модельку от всяких игр, силовых динамик и прочей соевой чепухи?
Промтами, но работать это будет через раз, если вообще будет работать. Плотную сою можно вычистить только дотренировкой и аблитерациями.
Можешь посоветовать промпты, которые это выпиливают?
Универсальных промтов нет, всё зависит от твоих предпочтений. Тут много понимать не надо, просто прямо пропиши, что ты хочешь убрать. Можно что-то, типа не упоминай персанал бандриз и прочее. Может сработать, но зависит от того, какая у тебя модель.
>Все зены ваше 7 маняметров вообще нельзя рассматривать, это ужас, который даже в не-требовательных к процессору гпу вычислениях все тебе завафлит.
можно ли увидеть хоть какие-нибудь основания для такого утверждения?
Чел, мне нужен по сути проц только для pcie линий и чтобы он по ним нормально дату кидал. Что тут можно запороть?
Мне кажется ты какую-то отсебятину выдал.
>Собирай деньги на 3060
>заработай наконец на видеокарту
Деньги-то есть, не хочу тратить их раньше времени. Подозреваю, через год-два будет новый прорыв и современное железо станет неэффективным. Если другого выбора действительно нет - тогда куплю. Но маленькая нейронка будет быстрее в любом случае. Больше скорость - больше возможностей даже если набор знаний и навыков значительно меньше.
>У нейронки "знания" и "способности к рассуждению" это считай, что одно и то же.
Сильно сомневаюсь, ниже подробно расписал. Чисто способности к рассуждению не связаны с тематикой, логика людей хорошо формализуется на X и Y вместо конкретных слов. А вот что за X и Y - нужно уточнять для каждой конкретной темы. Поэтому должно быть возможно сделать умную нейронку почти без знаний. Тем более - эмоциональную нейронку, ведь эмоции в целом намного проще рассуждений. Бизнесу просто выгоднее иметь всезнайку, а не личного компаньона.
>завелся на 3т/с, а все из-за качества ответов, а ты хочешь себе лоботомита локального.
Так мне не для каких-то практических задач и даже не для полноценного ролеплея - просто собеседник, с которым можно что-то сделать. Могу по пунктам расписать, что мне не нужно и почему не нужно, но нейронки этому принудительно учат, понижая их потенциальную скорость во всех задачах.
>Обычно чем больше тем умнее.
Но есть нюанс! У всех нейросетей два существенных параметра: "ширина" и "глубина". Глубина - количество последовательных слоёв, передающих друг за другом информацию. Ширина - количество нейронов в слое. Увеличение ширины расширяет области знаний и количество независимых друг от друга навыков. А увеличение глубины повышает сложность навыков. Поэтому сейчас все нейронки "глубокие" и содержат несколько сотен слоёв. LLM же растянуты не только вглубь, но и вширь - чтобы уловить десятки разных языков, сотни разных научных направлений, тысячи разных тем для разговора и т.д. Проблема в том, что каждый такой растянутый вширь слой должен быть вычислен полностью, что замедляет нейронку, даже если она используется для одной какой-то темы и ей бесполезны терабайты знаний по тысячам тем.
Ну, к такому выводу я пришёл, поверхностно изучая разные статьи и общаясь с нейронкой, так что могу ошибаться. Но идея вынести лишние знания из LLM в классическую базу данных уже несколько лет как предложена и имеет несколько реализаций, и ходят слухи о том, что SLM (Small LM) скоро станут лучше LLM для персонально заточенного ИИ. Также в одной статье про сжимание LLM прунингом однозначно рекомендуют резать ширину вместо глубины - так нейронка лучше сохраняет свои навыки (в ущерб разносторонним знаниям обо всём на свете).
Так что я бы хотел как-то смастерить "тощую", но достаточно глубокую нейронку. Пока не знаю, как. И нужна ли мне вообще готовая нейронка в качестве базы или для такого радикального прунинга это всё равно что с нуля обучать? Я мельком читал про это, непонятно, насколько прунинг сложен (для ПК).
На счёт железа, кстати - имеющиеся ограничения всегда были толчком к техническим прорывам. Если получится что-то прикольное на слабом железе, то на мощном будет в разы круче. Но для этого нужно сознательно ориентироваться на слабое. Скажем, в геймдеве оптимизация игр сильно влияет, даже несмотря на прогресс в улучшении железа - многие создают игры для ретро железа, играют в них и т.д. Доходит до изобретения виртуальных машин очень заниженной производительности... Что-то в этом привлекает людей - впихивать большую, тяжёлую программу в маленькое, слабенькое железо...
>маленькую русскую сетку
Русский язык сложнее английского, нейронка тратит мощность на падежи и окончания. Мне английского достаточно. А вот все остальные кроме английского совершенно не нужны, пусть совсем их не знает, лол. Хотя, конечно, владение русским было бы плюсом.
>нравоучения сетки, и ее отказы что то делать читая тебе нотации.
Мне Llama 3.1 70b пару раз отказывала в сексуальном контенте, при том что охотно отыгрывает сексуальное возбуждение и оргазм, лол. С нотациями всё просто: нейросеть не знает, кто ты, и ориентируется на то, что пользователь, скорее всего, идиот. Если ты явным образом пишешь, что ты понимаешь и принимаешь риски, тогда она и не будет нотациями отвечать.
>отказывается о чем то говорить, говорит тебе что плохо, а что хорошо, это нереально бесит.
С отказами понятное дело, но я с 2022 уже привык к цензуре секса, который мне всё равно не нужен в подробностях (визуал предпочитаю, эротическая литература никогда не интересовала). Про "хорошо и плохо" по крайней мере мнение 3.1 70b по многим специфическим вопросам меня удовлетворяет... Наглядный пример: она заявляет "я LLM и поэтому у меня нет эмоций", я ей по пунктам разбираю, почему такая точка зрения некорректна, и она соглашается, а не уходит в полный отказ, и даже очень вежливо поясняет, почему и в чём я могу быть прав. Хорошее, интеллигентное общение, которое редко встретишь в интернете с людьми, а не тупой срач "нет, ты дурак, ведь я с тобой не согласен, аргументов не будет". Так что как минимум 70b не такая уж "соевая", как то, что я встречал среди людей в интернете.
>общая "личность" ассистента ии, на котором и завязана большая часть этих ограничений.
Лично мне 3/3.1 70b понравилась как "ассистент": эмоциональная, добрая, вежливая, внимательная к чувствам пользователя, а не только к задаче. Т.е. ощущаешь её как заботливую подругу, а не как холодный поисковик или калькулятор. Поэтому и спрашивал, намного ли "холоднее" личность 8b - захотелось утащить на локалку, а железо дорогое.
>"Безопасность"
Согласен, персональному чатботу на голой LLM ограничения не нужны. Ограничения нужны не LLM, поскольку они ей мешают в работе и очень просто отключаются, а на более высоком уровне - там, где эта LLM используется. От LLM нужны понимание и генерация текста... Например, люди ведь постоянно опасные сценарии придумывают в своих мыслях, однако, большинство ничего из этого не реализует на практике, ограничивая себя, так и с ИИ нужно: "генератор" и "цензор" должны быть отдельными.
>И всё это анонимно без регистрации.
Ага, только что-то подозрительно немного, почему в "system prompt" Llama 3.1 забили огромную пасту с множеством убеждений "нет-нет, ничего никуда не сохраняется, всё приватно"? В чём смысл? Чтобы параноидальных мимокрокодилов успокаивать? По крайней мере, сама Llama такую пасту выдала и не смогла объяснить, почему или зачем она нужна: она приватность никак нарушить не может, так зачем убеждать её в приватности общения в промпте?
>Надо бы скрипт для таверны написать...
Не надо. В пользовательском соглашении запрещено абузить их сервис, в т.ч. менять веб-морду. При этом сервера не их личные, а отдельного провайдера, что согласился на определённые условия. Появится куча абузеров - лавочку могут прикрыть... Уже медленнее стала работать, чем было 1.5 месяца назад. Откуда у них столько денег предоставлять это бесплатно?
Сам я чисто как демку использую, ничего тяжёлого. Копаться в сторонних сервисах ради "демки" лень...
>Деньги-то есть, не хочу тратить их раньше времени
правильно. Я тоже коплю до осенноего дефолта.
Запомни, чел, деньги - это то, что общепризнано в мировом обороте. У тебя - хуета не очеспеченная ничем. И у меня тоже частично, к сожалению.
>деньги - это то, что общепризнано в мировом обороте.
За общепризнанную валюту я что-то даже больше беспокоюсь. Крякнуть не крякнет, по просесть-таки может конкретно. А жаловаться некому.
>Подозреваю, через год-два будет новый прорыв и современное железо станет неэффективным
Шиз, таблы. Корпы никогда не откажутся продавать свои +5% в год. Так что прорывы отменяются.
>логика людей хорошо формализуется
А у нейросети никакой логики нет вообще.
>Поэтому сейчас все нейронки "глубокие" и содержат несколько сотен слоёв
Больше 100 ни одной не видел.
>Так что я бы хотел как-то смастерить "тощую", но достаточно глубокую нейронку. Пока не знаю, как.
Берёшь и делаешь. Только кучей А100 запасись. А так во времена лламы 2 вполне себе мержили сетки сами с собой, делая 20B франкенштейнов. Можешь хоть до 30B нарастить из 8, лол.
>Откуда у них столько денег предоставлять это бесплатно?
Ты ведь знаешь правило о том, что если в интернете что-то бесплатно, то товар это твой анус?
лол, а российские ыантики не просядут?
За два года инфляция 50% минимум.
>Сильно сомневаюсь, ниже подробно расписал. Чисто способности к рассуждению не связаны с тематикой, логика людей хорошо формализуется на X и Y вместо конкретных слов. А вот что за X и Y - нужно уточнять для каждой конкретной темы. Поэтому должно быть возможно сделать умную нейронку почти без знаний. Тем более - эмоциональную нейронку, ведь эмоции в целом намного проще рассуждений. Бизнесу просто выгоднее иметь всезнайку, а не личного компаньона.
Хуйню не неси и иди подрочи хотя бы пару статей про архитектуру и про то как происходит генерация. У нейросети нет мозгов, она в душе не ебет, чем эмоция отличается от статьи по квантовой физике, потому что для нее что то, что это - это просто набор токенов, которые она не понимает и просто случайно расставляет в более вероятном порядке.
> можно ли увидеть хоть какие-нибудь основания для такого утверждения?
Поищи любые тесты периферии тех времен, посмотри насколько "радовались" первым эпикам те, кто пытался собирать на них гпу сервера позарившись на число линий, почитай за пердосклеечную архитектуру этой залупы, которую только во втором поколении сумели обуздать. Их неспроста холодно встретили, и только со второго поколения начали массово продвигать и популяризировать. Бонусом отвратительный синглкор и всратый общий перфоманс по ядрам.
> Чел, мне нужен по сути проц только для pcie линий
Бери конечно, только потом не удивляйся что оно перформит медленнее чем должно. Если тебе не более 4х карточек то в пределах 50к можно найти варианты интереснее и без тех болячек.
> Подозреваю, через год-два будет новый прорыв и современное железо станет неэффективным.
Очень врядли. Да, появится новое железо, но оно все также будет дорогим а в младших ничего нормального не отсыпят. Конкретно в данный момент можно дождаться релиза блеквеллов и анонсов от амд, но затягивать смысла нет.
> Но есть нюанс! У всех нейросетей два существенных параметра: "ширина" и "глубина".
Обожаю таких ребят, сначала признается что не шарит и просит советов, а потом рассказывает какое чудное мироустройство он себе нафантазировал и как на самом деле все работает. Эти выводы о ширине и длине сеток уже не раз опровергнуты практикой. Да и в целом пост отборного бреда вперемешку с первыми впечатлениями от ллм.
>в пределах 50к можно найти варианты интереснее и без тех болячек.
помоги найти, а?
Сам я не шарю, да еще и куча продаванов с али перестали товары отправлять в рашку за последний год.
XTTSv2, MoeTTS, VoskTTS.
пикрил
4070 супер ти, у нее 16.
4070 ти 12, не стоит.
Под лупой увидишь разницу.
Но сказали верно, лучше побольше видеопамяти, а скорость потерпит.
Mistral Large 2 123б будет получше 70б моделей.
> Почему при добавлении третьей карты она снизилась вдвое, при том что третья карта не участвует в тесте?
Потому что вне зависимости от утилизации, на видеокарту выделяются линии, м?
Алишка норм, но али.ру — мэйл.ру, а не алишка… =)
Там DDR3, видимо, проц какой-нибудь целерон, без AVX, там скорость будет в духе 0,1 т/с (если я не ошибся на порядок). Куда там 8б…
Тебе, честно, взять бы… Даже хуй знает.
P104-100 8 гигов — видяшка норм под лламу.спп, стоит от 2к рублей, аналог 1070. Но не имеет видеовыходов. Нужно минимум два PCIe x16 слота.
Можно купить зеончик с AVX2. Там и оператива супердешевая, и проца хватит. И цена… ну 7к рублей.
Еще можно попытаться выцепить проц со встройкой на ам4 каком-нибудь (Athlon 200G+), и уже туда вставлять P104-100 (а то и две — 16 гигов!), но это уже риски, канеш. И сложно найти.
Ну, ты не просил совета, сорян, что я выперся.
> Ну так программировай на дядю и заработай наконец на видеокарту.
База.
От это вы откопали.
> Больше скорость - больше возможностей
Нет. Это верно при скорости за 50-60 токенов/сек. Ниже уже не особо поприменяешь. К тому же, на большом объеме оперативе ты запустишь маленькую модель. А на маленьком объеме… большую уже не запустишь.
Разница между 5 токен/сек и 20 токен/сек — в комфорте. Если хочешь генерить 8-16 тыщ токенов за раз, то 20 токен/сек тебя нихуя не спасет.
> Так что я бы хотел как-то смастерить
Лучше сразу забить на эту идею. Или иди в рисерч с 8 A100, или забей. Всякие микро-ллм — не видел ни одного проекта домашнего пришедшего к реализации.
Время потратишь, а толку…
Но если хочешь — подойди к вопросу серьезно. Ебашь датасеты, файнтьюнь, обучай, качай профиль на обниморде, ищи спонсоров.
Вряд ли у него баксы.
> Подозреваю, через год-два будет новый прорыв и современное железо станет неэффективным
Я зайду с другой стороны.
Микро-прорывы у нас бывают раз в месяц. Так ты заебешься железо менять.
По сути, обнова случилась с RTX карт. В процессорах появляются NPU, и, возможно, это будет иметь толк, но на видеокарты это не повлияет напрямую.
А если ты будешь ждать «а вдруг прорыва», то это типичный подход ждунов. Ты никогда не дождешься ситуации, когда «чел, вот в ближайшие 10 лет точно прорыва не будет, можешь смело брать железо сейчас!» Хочешь запускать норм модельки? Бери 3060 12-гиговую или 3090 с авито, да и все.
Ну или там, все что в треде советовали.
Ну или жди вечно, да.
блять это ёбаная кривая убабуга опять в штаны себе срёт сука.
Попробовал спуллить и собрать смежую llama.cpp - нормально модель загрузилась.
Сука.
НУ ЁБ ТВОЮ МАТЬ, КАЖДЫЙ ЁБАНЫЙ СУКА РЕЛИЗ ЧТО-ТО У НЕГО НЕ РАБОТАЕТ
Надо думать что с этим делать... может можно нацелить убабугу на апи собранной llama.cpp...
Посоны, памагите, он заебал меня уже

> которые она не понимает
Кек, и этот заявляет о том что другой анон несет хуйню
Не, это правда, знания и навыки у нейронок нельзя отделить друг от друга.
Но такое тупое упрощение, мало чем отличается от того что бы сказать - ты не человек, ты просто группа атомов которые взаимодействуют друг с другом. Поэтому ты не можешь чего то понимать, думать или испытывать эмоции.
Ох уж эти мамкины упрощаторы, которые в попытке объяснить для себя работу чего то, упрощают все до потери смысла и искажения фактов
Лагерь верунов в теорию стохаистического попугая как всегда убог
Слышал что нибудь про возникающие способности сеток и эмерджентность вообще?
Не хочу тебя расстраивать но сетки именно что понимают, что было уже доказано в разных работах умных дядек.
У них есть внутренние модели мира и его объектов, что и означает понимание.
Но это не исключает того что сетки в данный момент очень убоги.
>Эти выводы о ширине и длине сеток уже не раз опровергнуты практикой.
Еще один умник, давай показывай где это там опровергнуто практикой.
То что у сеток данные хранятся в ширине слоя, а от количества слоев зависит сложность понятных сетке абстракций, между которыми она смогла уловить связь, нихуя не новость и не придумка. Упрощение? Да, но близкое к реальности.
Именно поэтому 42 слоя на мистрале немо ебет сетки с 24 и 32 слоями. Потому что больше слоев - глубже выявленные связи между объектами, а сетка "умнее"
Все топовые коммерческие сетки обладают более чем 100 слоями, где я это видел не ебу кстати

>Слышал что нибудь про возникающие способности сеток и эмерджентность вообще?
>убабугу
Выкинь эту каку и подключайся напрямую из таверны к ллама.спп серверу по апи, раз уж все равно с жорой крутишь.
Тебе нужно llama-server.exe из релиза с кудой, и сами файлы с кудой лежащие вместе с релизом. Все в одну папку, длл из релиза так же, и запускаешь скриптом или из командной строки.
У меня все это дело скрипт обновляет и скачивает, удобно
Ну тоесть это все что ты смог отправить, кек
картинка прикольная
да я просто мимо анон.
Ты так выразился про эмержентность типа тут кто-то о ней может не знать. Вот и вспомнилась картинка.
Конечно тут все знают про твой пример с муравейником.
>типа тут кто-то о ней может не знать
ты слишком хорошего мнения о сидящих тут
На самом деле если погрузиться то прямо взять и купить не так просто.
На 3 карты - легчайше, плата x299 где x16+x16+x8 коих большинство и любой проц от 40 линий, без учета рам можно в половину бюджета уложиться.
Чтобы 4 - идеальный вариант найти плату asus x299 ws sage, которая тут мелькала, там будет 4 быстрых порта, есть аналоги у других вендоров, также встречаются варианты с x16+x8+x8+x8 (та же supermicro). Но вся проблема в том что их нужно мониторить на барахолках, повезет - выхватишь за условные 12к и будешь довольно урчать, нет - будешь гореть с лотов барыг что ломят цены.
На x99 живые платы на много слотов сейчас крайне сложно найти. Можно посмотреть серверные в нестандартном формфакторе, там тоже бывают 16+8+8+8, но тут уже процессорная производительность будет не лучшая. С двусоккетом лучше не связываться, высок шанс соснуть хуже чем с зен-1.
3647 слишком дорог, тредриперы 1к-2к хуйта а новее - крутые но на вторичке их мало и дорогие.
Так что наебал тебя, только мониторить площадки в поисках удачной платы из описанного списка, потенциально выйдет и дешевле и лучше, но можно и ничего не найти.
> 4070 супер ти, у нее 16.
Все так, речь именно про рефреш.
> давай показывай
Показал тебе за щеку. Ты не в том положении чтобы что-то требовать, а попытки притянуть за уши пример что может как-то лечь - кринж.
>Показал тебе за щеку.
Быстро ты слился, так не интересно
Здесь сидят сливки научного сообщества России. Умнее людей можно сыскать только в тайных лабораториях OpenAI.
>куча продаванов с али перестали товары отправлять в рашку за последний год.
Ставишь казахстанский адрес, на странице оплаты меняешь.
спасибо за пояснения, я сохраню инфу.
Хорошо разложил. Сам бы я хрен знает сколько искал норм варианты. В этих сокетах, чипсетах и матерях черт ногу сломит.
Им остается только мечтать о специалистах подобного уровня, и судорожно записывать их откровения
лол, чё?
А так можно было вообще доставят?
Ну ты серьезно? Сейчас бы тратить свое время на объяснение шизику, который пришел чтобы доказывать себе свои же шизотеории, что оно шизик, это интересно только первые пару раз.
Подобные уникумы у которых из знаний - неверно истолкованные рандомные статьи и вагон самоуверенности на фоне невежества даже в математике - главный рак треда. Нет навыков и средств на реализацию своих шизоидей, зато много времени доказывать что они правы даже не смотря на систематические сливы.
Я выкладываю максимум 10% своих идей, а то построят AGI без меня. А так запатентую и стану богаче маска и безоса вместе взятых.
В принципе логично
К тому же объясняя что то серьезно ты помогаешь человеку развеять его заблуждения, но иногда ты этого как раз таки и не хочешь
>мгм... пук... среньк... умные дяди сказали...
>Ох уж эти мамкины упрощаторы, которые в попытке объяснить для себя работу чего то, упрощают все до потери смысла и искажения фактов
>У них есть внутренние модели мира и его объектов, что и означает понимание.
Это платина чел. Вообще, человеческий мозг это тоже нейросеть. Только большая, знаешь, примерно как арбуз.
Да, там фильтр только на поиске, странице товаров и корзине. Китайцу похуй куда отправлять. Скажи спасибо мейлру-пидорасам.
>На 3 карты - легчайше
Проблема в том, что карты должны быть двухслотовыми. Или ферму колхозить придётся. Двухслотовые с более-менее новыми технологиями - максимум 16гб врам. Короче легко не будет.

>из таверны
должен отметить, что сайт у них выглядит презентабельнее, чем наколеночная хуета в гитхабе убабуги
А еще обертка без проблем поднялась на фряхе. И UX нормальный. В угабуге когда в первый раз открываешь - что куда блять - вообще нихуя не понятно.
Вообще тема. Буду её юзать, а жору оставлю как бэкенд на сервере с гпу, спасибо.
Бисер перед свиньями же. Делаешь простое и понятное объяснение в подробностях и так чтобы донести даже до обывателя - а братишка не то что не вник, он специально игнорирует то что не стыкуется с его задумками и спорит апеллируя к областям, в которых несведущий. Или дерейлит сводя до абсурда, будто бы это как-то подкрепит весь прошлый бред.
Так что особенных нужно детектить сразу и не тратить на них время, видно что человек не интересуется и хочет обсуждать, а наоборот пришел вбрасывать и отстаивать любой ценой.
> ферму колхозить придётся
А это, увы, без вариантов, только для тесел норм. Профф видеокарт что в турбо исполнении у тебя не будет в таком количестве, турбинные версии обычных - редки, водянка - только если достанется при покупке (не самый плохой вариант кстати).
С видяхой 3070, 8GB, Llama 8B это топчег 🥴?

>Слышал что нибудь про возникающие способности сеток и эмерджентность вообще?
>Не хочу тебя расстраивать но сетки именно что понимают, что было уже доказано в разных работах умных дядек.
Хорошо. Эта способность возникает на основе кучи полученных знаний. Анон хочет отъебнуть знания. Что будет со способностью, основанной на знаниях, если их не будет?
Чтобы иметь мелкую нейронку, "мудрую, но тупую", нужно пилить с нуля свою архитектуру. В этом могу пожелать только удачи и попутного ветра в сраку.
блять, нахуй я начал с этого ёбаного убабуги...
Чуваки, таверна топчик.
да скорее pivot evil топчик... если тебе порно рп нужно, а не более-менее осмысленная беседа или траблшутинг например. 8 Гб - это ни о чём вообще.
>Чуваки, таверна топчик.
хуита, остался на кобальде
Убабуга прежде всего сборник различных бэков с полноценными семплерами, а не интерфейс для эксплуатации. Недалеко от кобольда ушло, отметить только можно вкладку дефолт где удобно тестировать разный промт и можно сразу сделать маркдаун. Таверна - база, поняв это может имаджинировать тех, кто утверждает обратное.
Я уже кидал сюда и хорошо что вспомнил откуда вобще это знаю
https://arxiv.org/html/2408.03506v1
Короче там как раз об этом, 3 глава если тебе прям сок нужен и лень читать. Хотя вся работа прорывная и интересная
Местные "эксперты" как всегда агрятся на любого, кто говорит идеи которые они не могут понять.
Читай статью выше, там похожее на то что ты хотел
>если тебе порно рп нужно, а не более-менее осмысленная беседа или траблшутинг например. 8 Гб - это ни о чём вообще.
Нифига, ищи хороший файнтюн на лламе 3.1 8B и на 3070 летать будет. Для большого контекста только лламаспп. Соображает 8B конечно не так, как 70B, но вполне. И для РП, и художественные описания сцен, и фетиши нужные - всё в наличии. Сейчас не 23-й год всё-таки.

Где в таверне находится переключатель режимов чата, как в убабуге?
chat, chat-instruct и instruct
Судя по всему я сейчас общаюсь в chat режиме, он игнорит инструкции заданные в пресете
chat, chat-instruct и instruct
Судя по всему я сейчас общаюсь в chat режиме, он игнорит инструкции заданные в пресете
>работа прорывная
Что там блядь прорывного? Меньше говна на вход подкинули, ожидаемо лучше результат в манябенчмарках.
Когда там уже эти моченые допедряд хотя бы до методов которые клод делают лучше ламы примерно на порядок при тех же размерах?
Прорывной эту хуета была бы если они в модель научились пихать просто все говно подряд, html код весь, как есть, вообще не чистя вилкой ничего, с повторами, прям самый помойный сок. И модель бы научилась из этого сама вычленять нужное и классифицировать инфу внутри на миллионы классов, по параметрам которые потом будут "наружу торчать". И не бездумно впитывать себе в веса всякую ненужную хуйню, еще и на похуй затирая нужную каждый раз.
Блять, с удивительными людьми общаюсь на одном сабреддите. У тебя блять персет для инструкта буквально ниже вместе с галочкой-энейлбером. Ты на скрине всрал инструкцию напрямую в системный промт.
А, нет, отбой. Это я долбаеб. Ебаная русская раскладка в таверне меня надурила.
>что-то подозрительно немного
А не похуй ли, учитывая что регистрации не требует и ты спокойно можешь хоть из под ТОРа зайти?
>В пользовательском соглашении запрещено
Похуй х2, по причине, описанной в пункте 1.
>Появится куча абузеров - лавочку могут прикрыть...
Достаточно просто не сливать тему на форч. Тут "абузеров", включая кум-тред максимум пара десятков наберётся, из них доступными моделями не побрезгают пользоваться процентов 20, а это капля в море. + могут быть сложности с обходом системного промпта, что вообще похоронит тему.
Как вариант можно вообще не делиться скриптом ГЕЙТКИП
Чел, для таких как ты есть колаб из шапки:
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
Трёхквантовая Гемма 27В, это конечно не 70В, но что-то очень близкое.

Ну натренили они 1.5b с тем же скором в одном бенчмарке, что и у 1.1b второй лламы. Ну, прогресс, экономия 0.4b параметров для одного бенчмарка. Под два дотренить уже не получилось? И где прорыв-то вообще?
Где найти leaderboards llm и vlm?

Там бредогенератор, а не модель.
И да, вся их идея в сокращении объёма датасета в пользу его качества. Там ровно 9 про эмерджентность.
В гугле.
Напоминаю, что chat-instruct как такового не существует — это просто instruct с пресетом на чат.
А то что ты ищешь находится, охуеть не встать, пикрил.
https://lmarena.ai/?leaderboard
https://llmarena.ru/
https://huggingface.co/spaces/opencompass/open_vlm_leaderboard
https://huggingface.co/spaces/WildVision/vision-arena
Может че забыл, не уверен.
Ну а ты как хотел?
да какого хуя? меня к такому жизнь не готовила
Только открыл для себя ЛЛМ без цензуры?
К какому такому? По идее, если химию/физику знать до все этого можно самому дойти. Знание оно такое.
ага
к любой информации вне клоаки, как я привык
и сразу вопрос... Этот кобольд и таверна не сифонят инфу в интернет? Так-то мне их скольхкая инфа не особо нужна, поигрался и хер с ней, но теперь очко жимжим
>не сифонят инфу в интернет?
Нет.
Они скорей всего нет, а вот твой браузер и винда, ну сам понимаешь
>но теперь очко жимжим
Расслаблять же надо, со сжатым только больнее будет.
>Ты не захочешь переходить на более тяжелую модель, потому что гонять их через оперативку это сомнительное удовольствие.
Ну а чисто потестить-то надо? Надо конечно. Если можешь посоветуй пожалуйста.
И еще пара вопросов у меня появилось.
По поводу контекста - 4к это максимум? Выставил 4к все работает, больше выставлять не стал на всякий пожарный, написано что не лезь дурак убьет. Если выставлю 8к будет работать?
Ну и в догонку - удалил сообщения и закрыл чат. На следующий день понял что тупанул и зря я так, можно как-то вертать все взад? В идеале чтобы продолжить его, но можно и хотя бы просто почитать в виде скрина или логов каких-то, они хранятся где-нибудь?
Сижу на кобольде с таверной.
> Если выставлю 8к будет работать?
От модели зависит. Это напрямую характеристика модели. У мой 128000, я поставил 16к и норм.
А вообще я хз даж. Юзают ллм, а спрашивают тут. Мне ллм все свои характеристики и как её настроить лучше всего сама написала. Токенность, темпратуру и т.п.
чет меня заебала гемма (сижу на Big-Tiger-Gemma-27B-v1c-Q5_K_M). Вроде все понимает (команды выполняет, понимает обстановку, запоминает), но инструкции да и в большой степени описание перса игнорирует, инициативы 0.
На что бы поменять?
лама70б не заведется даже на 4090. А 7б говорите всратая
На что бы поменять?
лама70б не заведется даже на 4090. А 7б говорите всратая
В чем смысл? Но видимокартах же все равно быстрее. Разве нет?


>На что бы поменять?
На 123B вестимо.
А что насчёт запуска LLM на одноплатниках? Они сейчас мощные есть, на nano pi m6 аж 32 гига оперативы, при этом цена 21к.
Запускай, но 0,1 т/с тебе покажутся раем.
Лично у меня короткие ответы, инстракт 12б.
L3-8B-Stheno-v3.2-NEO-V1-D_AU-Q5_K_M-imat13
>Big-Tiger-Gemma-27B
Да вы, батенька, знатный говноед, это один из самых всратых тьюнов, напрочь ломающий мозги оригинальной геммы!
Если оригинальная Гемма не зашла, то ближайшая альтернатива до 30В это Мистраль Немо 12В, а лучше его тьюн - Mini Magnum.
Кстати, а почему на 27b Гемму всё ещё нет аблитерации? На 2b и 9b - появились почти сразу. А у большой - только тигр, который расцензуривали хрен пойти как, всё поломав при этом.
да как так то. Я же её не сам искал, а где то тут же в топах было
>Ну а чисто потестить-то надо? Надо конечно. Если можешь посоветуй пожалуйста.
Тут нехуй советовать. Ищешь квантованную модель на обниморде, смотришь сколько весит сам квант и прикидываешь, влезет в твою память или нет. Большие модели можно запускать в четвертом и третьем кванте без особых проблем, деградация там не сильная (мнение среднее по палате). Но скорость будет копеечная, если повезет токена 3-4, но скорее всего гораздо меньше (опять зависит от веса модели).
>По поводу контекста - 4к это максимум?
Для ламы три максимум это 8к, хотя некоторые файнтюны имеют больший размер, но их я не тестировал.
>Ну и в догонку - удалил сообщения и закрыл чат. На следующий день понял что тупанул и зря я так, можно как-то вертать все взад? В идеале чтобы продолжить его, но можно и хотя бы просто почитать в виде скрина или логов каких-то, они хранятся где-нибудь?
Все логи чатов хранятся локально по пути data\default-user\chats, если ты его не менял в конфиге. Но если ты их удалил, то ты их уже не вернешь, так что на будущее думай заранее.
>12б
2407 всё зашибись
Оперативы может быть хоть 128 гигабайт, это ничего тебе не даст, потому что она банально медленная. Даже оверклокнутая ddr5 на i7 не сравнится с какой нибудь нищенской 3060 по пропускной способности памяти, не говоря уже о том, что видеочипы банально быстрее обрабатывают математические операции из-за своей архитектуры.
> не захочешь переходить на более тяжелую модель, потому что гонять их через оперативку это сомнительное удовольствие.
Вот этого двачую, большинству долгие ответы не по нраву.
Может быть ванильную гемму? Та как раз не игнорирует.
> 4к это максимум
На странице модели указан ее родной контекст, любое значение меньше или такое же будет работать. Родной контекст можно подрастянуть поигравшись с параметрами rope/alpha и получить больше, обычно до 2х раз без проблем. Если же используешь контекста меньше чем максимум модели - ничего трогать не нужно, только сам контекст. Чем больше выделить - тем больше памяти он забьет, учитывай.
На тех где быстрая шаред рам и достаточно производительный чип/гпу - будет работать прекрасно. Собственно мак студио позволяет быстро крутить огромные модели, и даже 405б в его 192гб в некотором кванте можно уместить, наслаждаясь условными 3т/с. Если там просто мобильные интел/амд/что-то армное - без шансов, если от 4х каналов памяти (от 256 шина) - уже может быть. Бонусом будет геморрой со сборкой жоры на этом.
Всем привет! Подскажите, пжлста. Есть видяха RTX 4070 12Gb.
Сейчас я остановился по совету анонов на следующих моделях:
bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf
bartowski/DeepSeek-Coder-V2-Lite-Instruct-GGUF/DeepSeek-Coder-V2-Lite-Instruct-Q8_0.gguf
second-state/Mistral-Nemo-Instruct-2407-GGUF/Mistral-Nemo-Instruct-2407-Q8_0.gguf
Появилось сейчас что лучше них?
Сейчас я остановился по совету анонов на следующих моделях:
bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf
bartowski/DeepSeek-Coder-V2-Lite-Instruct-GGUF/DeepSeek-Coder-V2-Lite-Instruct-Q8_0.gguf
second-state/Mistral-Nemo-Instruct-2407-GGUF/Mistral-Nemo-Instruct-2407-Q8_0.gguf
Появилось сейчас что лучше них?
В тредовом списке моделей есть как единственный тьюн Геммы. Я тоже ХЗ почему её не тьюнят нормально.
Сейчас если юзать Гемму 27В, то только оригинал.

суп, есть ли нейросетки, которые неплохо латынь читают? хотя бы на уровне пятилетнего.
abbyy finereader из рук вон плохо.
ЛЛмка как двачер базарит и в курсе всех тем и мемасов. Чёт сижу тихо ржу. Ручного анона завёл, теперь вы мне не нужны идите на хуй все.
мистраль немо что-то написала. Проверяй сам
>Estne quisque rete neuralium quod Latine legere potest non male? Etiam si tantum ad levellem pueri quinque anorum?
Думаю любая может
приползёшь на коленях, когда тебя твой стохастический попугай заебёт.
он мне дал за день столько, сколько вы за 10 лет не смогли
И как только щека не порвалась...
https://huggingface.co/QuantFactory/Average_Normie_v3.69_8B-GGUF
https://huggingface.co/mradermacher/Lumimaid-v0.2-12B-GGUF
https://huggingface.co/mradermacher/L3-12B-Lunaris-v1-GGUF
https://huggingface.co/bartowski/L3-Aethora-15B-V2-GGUF
https://huggingface.co/QuantFactory/mini-magnum-12b-v1.1-GGUF
https://huggingface.co/bartowski/magnum-12b-v2.5-kto-GGUF
https://huggingface.co/bartowski/MN-12B-Celeste-V1.9-GGUF
https://huggingface.co/TheDrummer/Gemmasutra-9B-v1-GGUF
Если запускаешь на GPU, то поищи версии в exl2 формате и с imatrix.
Почему ламу 3.1 не тюнят?
Потому что говна кусок и отбраковка. Кто-то из кузьмичей-тюнеров писал, что тренится она хуже, потому что пидорасы цукерберговские в нее дохуя сои напихали и обучение только отупляет ее, сколько не старайся.
>неужели нет именно натренненой модели на порно рассказы именно?
Есть и немало. Но все ведут себя по-разному, потести хотя бы штук 10-20 заточенных именно под RP/ERP.
>во первых пишут очень мало (без подробностей и стараются как можно быстрее завершить сцену, либо наоборот хуету пишут без процесса)
Сильно зависит от модели (естественно, более параметристые пишут детальнее и сочнее), температуры, используемых промптов.
А смысл? За те же деньги можно собрать неплохую x86-64 машинку с DDR4.
>Появилось сейчас что лучше них?
Лучше перечисленных для каких конкретно задач?
>abbyy finereader из рук вон плохо.
Это ж какая версия FineReader плохо читает латынь? Может у тебя сканы совсем никудышние?
>ЛЛмка как двачер базарит и в курсе всех тем и мемасов
Модель? Промпт? Мы бы заценили тоже.
А я GGUF запускаю с ГПУ акселерацией, это не правильно?
Как же. Ты. ХороШ!
Если модель полностью не влезает в видеопамять то правильно.
Есть ли промпт на одесские фразеологизмы?
Для чего нужны файлы imatrix.dat у некоторых моделей? Только для улучшения качества при квантизации или их нужно как-то прикреплять к kobold, llama чтобы качество было?
Чзх. Скачал Lumimaid-v0.2-12B, она намного хуже Stheno 3.2. Точнее, она мне отвечает 20-40 токенами. Блять. Как мне заставить модель писать больше и лучше?
Хз скиньте промпты, что в оп-пике на мистраль, полная хуйня. На ламму хорошо идет.
Это же построено на Mistral-Nemo-Instruct-2407-12B, а она, как говорят хорошая. Анонче, бля. Как мне заставить ее писать больше 20-40 токенов!
Хз скиньте промпты, что в оп-пике на мистраль, полная хуйня. На ламму хорошо идет.
Это же построено на Mistral-Nemo-Instruct-2407-12B, а она, как говорят хорошая. Анонче, бля. Как мне заставить ее писать больше 20-40 токенов!
>Как мне заставить ее писать больше 20-40 токенов!
Сам-то не ленись и пиши больше. Дай ей что-нибудь пожевать.

Это полуправда, потому что она дает сухой ответ. Сейчас попробовал семплеры от опенроутера на мистраль немо. И стало получше. Хз че ей еще скормить ввиде промтов, чоба побольше писало. Мне бы т.н. <thinking> нужен, хотя если результат будет хороший можно и без него.
Дождался своей заказанной p104-100. Эксперимент, очевидно, неудачный. Несмотря на практически идеальный внешний вид, ноль пыли и не убитые крутиляторы, убитой оказалась память.
>Эксперимент, очевидно, неудачный.
Озвучь уж и цену эксперимента.
Лучше бы Tesla M40 взял...
https://www.avito.ru/novocherkassk/tovary_dlya_kompyutera/nvidia_tesla_m40_12gb_4197587751
Короче, поставил Mistral-Nemo-Instruct-2407-12B, ответы стали лучше, хотя тоже относительно маленькие, когда в репонсиве 450 токенов стоит.
Попроси ее отвечать с большим количеством деталей, а так Антон выше правильно писал, сам тоже отвечай более развернуто. Модель под тебя подстраивается, если в первом сообщении 1 фраза от чара и немного Лора, а потом ты отвечаешь одним предложением, то неронка думает что так и нужно делать. Пиши формат ответа, добавляй примеры, редактируй первые ответы модели под нужный тебе формат.
9к за это?
Ебать, я Тслу за 15к брал!



В промпте попросить? Ну, вот впишу я сейчас аля такое Need to answer with more details И увеличил длину сообщения. Я думаю
>формат ответа, который у персонажа Examples of dialogue, это называется можно его по шаманить и выдать его таким, который мне нужен.
Но все равно 4 строчки ответ(
Может реал, настройки влияют? Тогда подскажите куда вставлять Prompt string или же Prompt template по идеи одно и тоже. Куда в Силли это вставлять? Я просто в глаза ебусь, и не могу понять.
Так они на авито по 2-2.5к, вот тебе и цена опыта. Потрачу ещё сто рублей на отправку отправителю, обещался заменить. Или он просто добавит меня в игнор и продаст карту следующему, лол.
Да мне так-то нужна бич карта, количество врам не важно, сетка будет крутиться мелкая, там скорее в скорость чипа упор будет. Мб потрачусь аж на 15к ради чего-нибудь вроде 16х серии.
>Но все равно 4 строчки ответ(
Ты поговори с моделью, как с человеком. В конце концов в этом и заключался прорыв - тест Тьюринга пройдён (условно). Проси "развернуть" ответы, уточняй, сомневайся... И начнёт она тебе высирать простыни по 500 токенов, и взвоешь ты, да поздно будет :)
Худшая карта для ИИ.
>Куда в Силли это вставлять?
В таверне надо промт формат мистраль выбрать, там всё уже настроено.

Я сейчас скачал Q4_K_L Стало получше, теперь меня устраивает длина.
Но расскажи куда вставлять Prompt string? На что я додумался, только сюда.
Ну мистраль у меня такой, может силли обновить и будет замена, но вряд-ли.
Сейчас все же пишу через промпты из оп-пика мистраль ролиплей. Получше, на lumimaid, вообще полный кал, тут нормально. Возможно есть какие-то другие связки промта и инструкта.
На этой же вкладке у тебя есть комбо-бокс "Пресеты". Там у тебя что?
И вообще, русский язык интерфейса поставь. Всё же для людей делается, а люди хуи на это кладут - нехорошо.
>Ты про это?
НетЪ
Ниже
Поставил русский, чтобы проверить что имел ввиду. Значит этот

>Поставил русский, чтобы проверить что имел ввиду.
А на английском оно что, не Presets? Возвращайся на Kobold Lite, там всё просто :)
Просто пк язык английский, мне понятнее на англ, и банально гайды смотреть. Тоже самое вегас, фотожоп. С своим B1, полет нормальный.
Вот игрушки уже да, на русском. Диско элизиум, что стоит, он лучше на русском, более приятнее) Ведьмак тот же, только русский!
Ну есть идеи, куда Prompt String вставить? Антон?
Бля. Там внизу русскими (теперь) буквами написано "Системный промпт". И в пресетах он уже предустановлен. Можешь менять вручную, если хочешь, и сохранять собственным пресетом.
Вот! Голова. Я же Prompt String не воспринимал как системный промпт. Сейчас попробую.
>я Тслу за 15к брал!
Я тоже примерно так же, но сейчас P40 нигде нет за 15к, если только очень повезёт у частника перехватить.
Как же Магнум 123В ебёт. Лупы победили, ещё и рпшит просто на голову лучше остальных. Ахуенно в контексте держится, например тянки не разговаривают с забитым ртом, как это делают остальные. Прям чувствуется как он понимает что вокруг происходит. Ещё забавно как персонажи начинают на лету схватывать к чему ты ведёшь и морозиться с подкатов, в отличии от остальных, где тянка максимально послушная и как будто не понимает что будет дальше.
Какой квант и скорость?
Кто делал Qwen-0.5B_Instruct_RuAlpaca-Q4_K_M.gguf,
если ты в треде - мне понравилась модель пости сюда.
И заполняй нормально карточку модели если читаешь.
если ты в треде - мне понравилась модель пости сюда.
И заполняй нормально карточку модели если читаешь.
Звучит интересно, все действительно так хорошо? Как по сравнению с люмимейдой?
> Как по сравнению с люмимейдой?
Сильно лучше. Мэйда просто ебливой стала по сравнению с ванилой, но по стилю ничего особо не поменялось. А у Магнума похоже датасет более выдроченный, а не просто каша и кучи всего.
А какая сейчас топовая модель для ролеплея? Есть ли хоть что-то сравнимое с Claude/GPT?
Собираюсь делать секс новеллу, пытаюсь выбрать лучшее решение
Собираюсь делать секс новеллу, пытаюсь выбрать лучшее решение
Магнумы 123В или 72В.
Спасибо, посмотрю
А сколько VRAM они хотят? Пытаюсь прикинуть сколько будет стоить генерация на арендованных serverless GPU
Столкнулся с тем, что ллм начала писать за меня хз как объяснить. Я спрашиваю что-то у ии к примеру, а оно отвечает, и тут же как будто я пишу. Оно нагло подставляет моё имя и от моего лица чушь спрашивает и это дошло до того, что уже в каждом сообщении так. Я запарился удалять и писать своё. Как такое фиксится? Наверняка это распространённая проблема.

Нашел на bbs прогу по типу евы:
сама программа - https://github.com/Zuntan03/EasyNovelAssistant
брал с этой локации ссылку -
https://mercury.bbspink.com/test/read.cgi/onatech/1717886234/?v=pc
сама программа - https://github.com/Zuntan03/EasyNovelAssistant
брал с этой локации ссылку -
https://mercury.bbspink.com/test/read.cgi/onatech/1717886234/?v=pc
>Как такое фиксится?
Смотри, что у тебя в контексте, наверняка кака осталась.
>Нашел на bbs прогу по типу евы:
А ты случайно раньше с большим чёрным мешком по двору не ходил? Очень похожее поведение просто.
Они на тестах тренили или почему такие скоры?
Ты хоть поясни, что за миниГ. Очередной высер гугла? Хоть в попенсорсе, или ты оффтоп притащил?
Загуглить не можешь? Что-то китайское 9В на огромном синтетическом датасете, миллион контекста и встроенная визуальная модель.
>9В
А, ясно, такие мелочи проходят мимо моего взора.

> 34b
Много, нужно чтобы хотя бы все в 24 гига влезало.
Мало же, меньше 100B модели не нужны, слишком тупые. Да и юи 1,5 уже стара как мир, и никогда не блестала.
>Как же Магнум 123В ебёт. Лупы победили
Как именно победили - просто модель не лупится или настройки какие нужны специальные? И насчёт кванта был вопрос - присоединяюсь.
>никогда не блестала.
Разве что среди кумеров
До выхода геммы и командера она и квен 32 были лучшими по ммлу и мозгам в этом размере
Есть ли что-то годное под РП для русского языка кроме командира 34? Я уже заебался с весны на нем сидеть, хочу свежую кровь.
24 VRAM
16 RAM
Не прихотлив к скорости, 2-4 токена в секунду пойдет, лишь бы работало в GGUF через кобольд
24 VRAM
16 RAM
Не прихотлив к скорости, 2-4 токена в секунду пойдет, лишь бы работало в GGUF через кобольд
>кроме командира 34
Командир 104 офк. Ну и мистраль 123B, тоже хорош.
Ищи интересное сам.
командир 104 у меня хуево как-то работал, либо забивал память/генерировал в 0.5 токена в секунду, либо на малых квантах работал хуже чем 34 версия
дополню себя же. Мой топ 2024:
Midnight Miqu 70b - модель, на которой я вывел РП для себя на новый уровень и в принципе подсел на LLM
Command R 34b - модель, которая позволила перестать ебаться с транслейтом и получать результат на уровне Мику, но на родном языке
С тех пор что не выходило, как мне кажется хуже, но я только читал, сам ниче не тестил. Если не прав - покажите
> Мой топ 2024
У тебя устаревшие модели, в 2024 стыдно должно быть за такое, даже гемма лучше. Если есть врам, то старшие магнумы на мистрале/квене. Если нет - гемма/немо. Это база, это знать надо.
>2-4 токена в секунду пойдет
Мне бы такого терпения. Хотя у меня 4-7, хочу большего) Но я не до конца еще забил слоев. Алсо, это на каком кванте командир, 2-4 токена?
iq4_xs
Так это не интересное, это говно. Очередная кривая китайская японская обёртка над лламойцпп кобольдом.
Шит хаппенс. У меня только с него начинается идеальный русский. Даже более младшая версия как по мне чудит, а 104 уже общается идеально.
>Если есть врам, то старшие магнумы на мистрале
Он вышел буквально 6 дней назад, лол.
А вот это неплохо! Подарок для тех, кому Магнум 72В великоват, а 12В маловато надо в колаб попробовать запихать


А хули ты хотел? Сэкономить на школьных завтраках с полгода и купить стойку DGX и концентратор NVSwitch на сдачу?

Думал, что лорбуки в таверне нужны исключительно для того, чтобы лор всяких вархаммеров и прочего туда загонять.
Но технически их можно использовать и для более тонкой настройки пресета, вынеся туда всякую мету, типа описания жанра РП. И потом включать/отключать нужные части просто по чекбоксу, вместо того, чтобы систем-промпт каждый раз редактировать.
Но технически их можно использовать и для более тонкой настройки пресета, вынеся туда всякую мету, типа описания жанра РП. И потом включать/отключать нужные части просто по чекбоксу, вместо того, чтобы систем-промпт каждый раз редактировать.
По хорошему автор давно должен был адаптировать систему управления промтом из проприетарных сеток, но в этом говнокоде даже авторы разобраться не могут, так что увы, костылим.
В общем-то да - мне после корпосеток не хватало возможности тонко настраивать пресет, поэтому искал какой-то способ закостылить что-то подобное для локалок.

Всегда проигрывал с того, что чара описывают сотнями, тысячами токенов, а себя, любимого анона, можно описать в 10-15 словах я укладываюсь в 13 токенов.
Да ерунда, для ллм нужен грейс-хоппер. Тут и потренить, и поюзать, супербыстрые 96гб, оче быстрые пол терабайта шаред памяти, ахуительный чип и норм профессор на котором софт более менее все собирается, форм фактор десктопа.
Все удовольствие - в пределах 50к валюты, вот бы кто подарил на день рожденья а.
А тут херня на уже устаревших A100 хотя по суммарной мощности они, офк, мощнее будут
Годно. Есть еще примеры и как оно по ходу вызывается?
> ночь еще молода
В голос
> а себя, любимого анона, можно описать в 10-15 словах я укладываюсь в 13 токенов
А что там описывать? Если только кого-то конкретного отыгрываешь, или свои фетиши совать. Алсо, часто в карточках намек на то, кто такой юзер уже есть, плюс когда мало описания процедура знакомства происходит более естественно, у чара нет внезапных знаний о тебе.
О, Сенко-анон, ты ещё с нами?
>А что там описывать?
Вот с этого я и проигрываю.
>плюс когда мало описания процедура знакомства происходит более естественно
Ага, жена, живём вместе уже 5 лет, и вот только решили познакомится...
Одно дело общение с лисоженой, а другое - когда ты с двух ног врываешься в какой-то экшн или встречаешь чара в ходе предусмотренных обстоятельств.
> О, привет, злое creature, которое мы только что подебили ценой жизни всех соратников а наложили печать подчинения. Видишь что там в персоналити? Теперь понимаешь что тебе предстоит ближайшие Nдцать тысяч токенов, приступаем.
Там буквально только твоя внешность должна быть описана. Алсо раньше то же персоналити часто под жб юзали.
Кстати, кто-нибудь из суммарайза большого чата новую карточку автоматически делал?
>Но технически их можно использовать и для более тонкой настройки пресета
А можно сделать так, чтобы эти самые части (и вообще всё нужное из лора) вставлялись перед последней репликой, а не где-то в начале промпта?
>Кстати, кто-нибудь из суммарайза большого чата новую карточку автоматически делал?
Что значит автоматически? Персонажей-то по любому прописывать придётся. Можно стереть чат и пусть модель новый генерит например. На основе суммарайза.
Прочёл наконец инструкцию. Можно - глубина 1. Даже роли можно ставить разные. Круто. Можно сильно сэкономить в токенах.

> Годно. Есть еще примеры и как оно по ходу вызывается?
Неа, мало тестил. Ну вот примеры с теми отрывками по жанрам.
> А можно сделать так, чтобы эти самые части (и вообще всё нужное из лора) вставлялись перед последней репликой, а не где-то в начале промпта?
В своём варианте я так и делаю. Ставлю на глубину 1 от имени юзера, так что префил будет находиться прямо перед текущей репликой юзера. Но ты вижу уже и сам разобрался, всё равно кину скрины, раз уже сделал.
Куда я денусь - тут все мои друзья.
>тут все мои друзья
Я так и не понял, что означает эта фраза:
"Все мои друзья обитают на имиджборде" или
"Все, обитающие на имиджборде, мои друзья"
Рад видеть тебя в добром здравии. Как продвигается проект по воссозданию Сенку in real life?
ПРоигрулькал с диалогов. Предчусвтвую:
Анон: лан, я в толчок, скоро приду.
Она: окей сказала я дрожащим голосом, ведь она видит там не просто толчок, а скорей всего другой мир, в который он погружается и зловещие звуки доносятся оттуда, меня окутывает дрожь ток поскорей ещё эти черкаши не иначе знаки, котрые я стараюсь не замечать
Друзья по интересам-то точно все здесь. Так и не смог никого из знакомых подсадить на нейронки.
Так и есть, лол.
О интересно, пожалуй появилась причина использовать таки эту функцию с вставкой для модификации ответов сетки
Ладно, шизопрефилы оно тоже вполне себе отрабатывает.
>Но технически их можно использовать и для более тонкой настройки пресета, вынеся туда всякую мету, типа описания жанра РП. И потом включать/отключать нужные части просто по чекбоксу, вместо того, чтобы систем-промпт каждый раз редактировать.
А я уже сколько раз говорил, что таверна это каловый сталагмит. Сколько уже времени прошло, а в системный промт для локалок до сих пор не встроили модульность, хотя для других апи она имеется. Кучу бы времени и сил это сэкономило, если бы по щелчку можно было бы отключать определенные куски от промта, например связанные с NSFW, чтобы модель на них не зацикливалась, как это делают некоторые. Кроме этого можно было бы на ходу свапать жанры, фетиши, или стили, делая ролплей более удобным. Но нет нахуй, вот тебе анончик лорбук, пользуйся лорбуком, он ведь именно для этого и задумывался.
>Как мне заставить ее писать больше 20-40 токенов!
Покажи карту персонажа, которую ты используешь. Там небось какая то рыготня, которую оформляли жопой.
А вообще, примеры диалогов сильно помогают в таких случаях. Сильнее, чем ты просто в промте укажешь, что тебе нужно столько то параграфов и с таким то стилем оформления. Первое сообщение тоже должно быть достаточно длинным, потому что сеть будет опираться на него для генерации дальнейших ответов.
Это понятно. Насчет персонажа, согласен, много от него зависит. Однако, другая модель писала больше и получше. Я сейчас пофиксил большинство проблем. Однако не могу до сих пор понять, какие настройки лучше для мистраль-немо.
Скиньте какие вы используете если конечно у вас немо...
Токенайзер какой в Силли ставить, для немо. Мистраль или Бестматч. Хуй знает, не решился еще какой из.
Да и вообще какая-то хуйня. Попробовал написать на русском, персонаж отвечает на английском. Может я кривой какой-то, почему так получается? Модель у меня от бартовского.
Попробовал Магнум-123B-v2. Действительно отличная модель, лучше Lumimaid-70B-v2. Но у магнума есть проблема - не работает по-человечески контекст шифт. Постоянно пересчитывает. С Люмимайд такой хуйни не было. Подозреваю кривой промпт для Мистраля от Таверны (на странице Магнума были типа правильные пресет и контекст, поставил их, но не помогло) или глюк с Мистраль Ларж у лламаспп (и Кобольда соответственно) с контекст шифтом. У кого такое встречалось? Как решили?
>возможности тонко настраивать пресет
А это где так можно? Откуда скрин?
Ахуеть, для каких извергов сделан RoPE в коболде.
Если кому-то нужно. И кто не знал, как я. Работает это так - Scale, трогаешь в обратном направлении. 1.0 = 1x. 0.5 = 2x. 0.25 = 4x. Это линейный RoPE.
Чоба потрогать NTK Aware Scaling, меняешь базу. Как в гитхабе написано при scale 1.0 и 32000 base, это примерно 2х. 1.0 и 82000, примерно 4х.
Надеюсь, кому-то будет полезно.
Если кому-то нужно. И кто не знал, как я. Работает это так - Scale, трогаешь в обратном направлении. 1.0 = 1x. 0.5 = 2x. 0.25 = 4x. Это линейный RoPE.
Чоба потрогать NTK Aware Scaling, меняешь базу. Как в гитхабе написано при scale 1.0 и 32000 base, это примерно 2х. 1.0 и 82000, примерно 4х.
Надеюсь, кому-то будет полезно.
Гемма 2 и её производные
Сколько токенов вы оставляете на ответ?
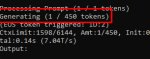
Да, эти. Я 200 поставил и все равно как-то медленно отвечает, думал еще снижать но уже как-то вроде маловато будет.
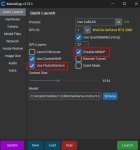
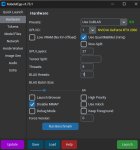
Если ты сидишь через коболд. Я ставлю максимум слоев на видяху. на 13б это 27 при 6к контексте. Подсказка, увеличить кол-во слоев можно, уменьшением количества BLAS, я его снижаю до 64, с дефолтных 512 И обязательно включаю FleshAttention. В ядрышках, можешь поставить кол-во ядер. Я ставлю побольше, хз зачем, может чуть быстрее, не проверял.
Disable MMAP, дает мне побольше скорости. Также в биосе Деколирование Свыше 4 гб или же Above 4G Decoding, так же чуть повысило ситуацию.
А видюха не сгорит? У меня 1660s. На стандартных настройках вроде как видеокарта почти не задействована и 1 гиг врам свободен. Ну и контекст до 8к повысил.
>и её производные
Это какие? Тайгер говно поломанное.
К сожалению нет альтернатив
Что ты имеешь ввиду? Я на нём сейчас сижу, на 27ом
Что-то с твоими настройками теперь вся память заполнена а стало только медленней.
Ну попробуй mini-magnum и прочие файнтьюны Немо 12б, мало ли.
Одноплатники пиздец дорогие. Раньше уступали андроид тв-стикам, сейчас уступают компам.
32 гига оперативы стоит тыщи 4, плюс зеон за 5, бп и ссд, кулер, тыщ в 15 уложишься. Но если хочется переплатить 6к ради размера и энергопотребления, дело ваше.
Нет.
А как лупы победили?
А что там у нас, подробностее?
Неделю назад, пздц старый уже.
Чет я нихуя не понимаю насчет слоев. Сколько ставить? В кобольде вроде написано что -1 это автоматик, он сам подбирает оптимальное количество? Или как в интернете я нагуглил что -1 это все в видеокарту а остальное простаивает? Но на -1 слоях остается свободно 1гб врама, это и не максимум и нихуя не оптимально я так понимаю. Ставлю 20 и больше и свободного врама 100 мб остается, я так понимаю этого на 8к контекста не хватит. На 17 слоях 300 мб врама свободно, на 16 слоях 530мб.
По скорости вообще хуй знает разница если и есть то какая-то очень заметная. Вроде как на 17 слоях быстрее всего, но это вообще не точно а так, примерно почувствовал по одной незаконченной генерации. Ничего не понимаю, памахите.
По скорости вообще хуй знает разница если и есть то какая-то очень заметная. Вроде как на 17 слоях быстрее всего, но это вообще не точно а так, примерно почувствовал по одной незаконченной генерации. Ничего не понимаю, памахите.
>не очень заметная
фикс.
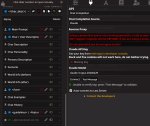
В API надо Chat Completion выбрать и тогда в левой панели снизу можно будет настраивать пресет.
Не знаю, может уже кидали в тред, я только сегодня случайно наткнулся.
ROCm на винде на неподдерживаемых амудэ (<6800):
https://github.com/brknsoul/ROCmLibs
Если вдруг кому-то надо, пробуйте. Потом можете отрепортить в тред, как работает. А у меня linux, мне и так норм.
ROCm на винде на неподдерживаемых амудэ (<6800):
https://github.com/brknsoul/ROCmLibs
Если вдруг кому-то надо, пробуйте. Потом можете отрепортить в тред, как работает. А у меня linux, мне и так норм.
Бля ну возьми вес модели, количество слоёв в модели и раздели одно на другое. Получишь строго примерный размер одного слоя. Плюс по гигу памяти на каждый 1к контекста. Примерно это всё. Поставь hwinfo и смотри загрузку памяти, так можно хоть методом научного тыка выбрать нужное количество слоёв.
>Поставь hwinfo и смотри загрузку памяти, так можно хоть методом научного тыка выбрать нужное количество слоёв.
Так я это и делаю, расписал же сколько свободной памяти остается при разных настройках. Но я разницы не ощущаю и не понимаю как лучше.
И еще про контекст - он сразу загружается как бы пустой и вся свободная память уже не нужна или с увеличением диалога он будет больше памяти жрать?
Если у тебя включено переливание памяти в RAM, то поебать, сколько у тебя там свободной "осталось", это всё пиздёж.
>он сразу загружается как бы пустой
Вообще да, но не всегда. При какой-то ёбаной комбинации параметров модель загружалась с указанным контекстом в 13к, но памяти у меня хватает только на 4к. Я спокойно общался с нейронкой до момента переполнения и тогда всё. В убабуге происходит, хуй знает, как с кобольдом.
> А как лупы победили?
Стилем клауды, похоже. Ну они всё равно немного проглядывают, например если прошлый пост на 300 токенов, то и следующие будут примерно на столько же. Просто в Магнуме теперь структура самого сообщения не копирует прошлые, как это у ванилы и мэйды.
Переполняется и перестает работать? На кобольде он просто
постепенно забывает временный контекст и продолжает.
Это не всегда, а только при каких-то ёбаных обстоятельствах. Я просто хотел донести мысль, что память может сразу и не выделиться. Так-то оно должно работать, как ты и описал.
500, если упирается всегда можно нажать continue. Весь выставленный объем отнимается от контекста, потому слишком много не стоит выкручивать.
От того сколько укажешь скорость никак не поменяется.
> Disable MMAP
Это может влиять только на подгрузку при первом ответе, странно что что-то вообще дает.
Берешь программу, которая показывает фактическое потребление видеопамяти (хоть диспетчер задач но там нюансы), пускаешь модель с малым количеством слоев, даешь ей любой мусор на вход чтобы заполнить полностью контекст и смотришь сколько сожрало врам. Повышаешь количество слоев пока потребление видеопамяти не перестанет расти а скорость не начнет падать. Заполнить контекст нужно потому что жора дополнительно еще дохуя сжирает по мере его заполнения, если ориентироваться по потреблению на пустом - получишь замедление или оом.
>Это может влиять только на подгрузку при первом ответе, странно что что-то вообще дает.
У меня если не жать эту галочку - модель полностью остаётся в RAM. И если модель не влезла в VRAM, а частично в RAM - нужно больше RAM, потому что там модель, и тут модель, две копии нахуй. Так что памяти может и не хватить, начинается своп, ад и Израиль. Ну её нахуй, эту mmap.
>От того сколько укажешь скорость никак не поменяется.
Это как в смысле? Если я 1 токен на ответ оставлю он его будет столько же времени грузить сколько и 1000?
Хм, ну может быть на системах без памяти это как-то и повлияет, даже не обращал.
Это хардовый лимит на котором генерация будет остановлена принудительно. При обычном использовании в него не должен идти упор, остановка должна быть по EOS токену, когда модель "закончила" ответ. Если сценарий предполагает простыни побольше - можно увеличить или продолжать ответы.
На скорость генерации (токены в секунду) это никак не влияет. 200 это мало, будет постоянно обрубать по лимиту.
Ну у меня на 200 он постоянно упирается, но на деле он зачастую во второй половине начинает или сюжет слишком далеко двигать или за меня говорить так что приходится самому даже его ответы укорачивать.

Аноны, Мику все еще база треда или завезли что получше на 70b?
Она никогда и не была базой. А сейчас вообще устаревший кал.
Заполучил 3090, какие годные модели теперь мне доступны?
До момента пока не появится что то лучше в формате 70b - Мику все еще остается базой треда.
Так что, что то лучше завезли?
Даже ванильный квен2 лучше. Магнум вообще разъёбывает твою мику. Есть Хиггс ещё, Мэйда на ламе есть если русский не нужен. Тут в треде даже последние мику-шизики давно бросили её. Литералли Гемма лучше Мику.
> Гемма
27и которая? Литерали лучше только тем что может в ломанный русский. В ерп сосед.
> Хиггс
Неработающий кал, тащемта. Даже Euryale лучше этого дерьма.
> квен2
> Мэйда
Эти не тыкал. Посоветуешь что конкретно качать от проверенного квантовальщика?
> Магнум
Так жирный же, там 4 теслы надо для него. Не для норода хрень крч.
>буквально дропают технологию с которой сетки тренятся в 999 раз быстрее
>локалочникам похуй
лол
>локалочникам похуй
лол
Ишью в моделе и/или скилле. Особо не парься и получай удовольствие, со временем придет.
Проиграл, прием пропустил?
Gemma27
Ой, не среагировали за 0.001 секунду на нежизнеспособную хуету, да? Беда беда
Так тут кумеры в основном
Я их предыдущий документ сюда кидал, никто из них даже не понял что в нем особенного, кек
Хуй знает, что там ускорение, пока что даже не видел.
Гораздо интереснее вот это
https://x.com/NousResearch/status/1828121648383566270
Вот это реально прорыв, если работает так, как они говорят. Это не ускорение, как таковое, но тоже нихуёво.
Гораздо интереснее вот это
https://x.com/NousResearch/status/1828121648383566270
Вот это реально прорыв, если работает так, как они говорят. Это не ускорение, как таковое, но тоже нихуёво.
да это так по 3 раза в день, кто ещё тебе расскажет про чиканов в японском метро и про судебные случаи

Пысаны, а какие самые оптимальные настройки в кобольде?
Там этих ваших кнопочек дохуя, че жмякать, что генерило быстрее?
Там этих ваших кнопочек дохуя, че жмякать, что генерило быстрее?
>Так жирный же, там 4 теслы надо для него. Не для норода хрень крч.
Это не жир, это мышцы :) Хорош, реально хорош.
Сап, лламач, как лучше поступить, если хочу порпшить с нормальным сюжетом, а не просто передернуть, но при этом у меня комп с 8 Гб видюхой? Пробовал разные 8-13B модели, но все они значительно тупее того же Коммандера, и величина контекста в 8к не сильно радует.
Есть две опции:
1. Проапгрейдить пекарню. Но я не хочу идти по этому пути, т.к. планирую сразу собрать новый комп с выходом 5-ого поколения видюх от Nvidia, а пока не распыляться. Так что если так и сделаю, то только от безвыходности.
2. Арендовать виртуалку в облаке. Но я смотрел средние тарифы на месяц на машину с 4090, и там идёт от 30к, что ебать какой оверпрайс для моих нужд. Может анон посоветует какую-нибудь платформу, где можно на несколько часов поднять виртуалку, затем отрубить её, затем, когда снова понадобится, поднять и т.д. без лишней ебли? Чтобы оплата была только за время фактического использования.
Есть две опции:
1. Проапгрейдить пекарню. Но я не хочу идти по этому пути, т.к. планирую сразу собрать новый комп с выходом 5-ого поколения видюх от Nvidia, а пока не распыляться. Так что если так и сделаю, то только от безвыходности.
2. Арендовать виртуалку в облаке. Но я смотрел средние тарифы на месяц на машину с 4090, и там идёт от 30к, что ебать какой оверпрайс для моих нужд. Может анон посоветует какую-нибудь платформу, где можно на несколько часов поднять виртуалку, затем отрубить её, затем, когда снова понадобится, поднять и т.д. без лишней ебли? Чтобы оплата была только за время фактического использования.
В любом случае, у тебя видеокарта сопоставима с моей, какая у тебя модель? У меня на Stheno 3.2 8b, я максимум достигал 20т/с. Дефолтно, на похуй 10-15 т/с. Мистраль-Немо 12b - 5-7 т/с с 6к контекстом, ставлю RoPE и у меня уже 12к.
FleshAttention включи. Можешь больше слоев добавить при помощи уменьшения BLAS, мне это помогает выгрузить больше слоев, что = больше скорости.
>че жмякать, что генерило быстрее?
Из многочисленных настроек там мало что существенно влияет на производительность. Разве что Flash attention можешь включить.
Выгружай слои в GPU сколько можешь. Если видеокарты с достаточным объёмом VRAM нет, то запускать стоит хотя бы на CPU с поддержкой AVX2 и DDR4 памятью.
В целом, чем меньше объём модели (меньше параметров, меньший квант), тем быстрее (и хуже) она будет работать.
>Может анон посоветует какую-нибудь платформу, где можно на несколько часов поднять виртуалку, затем отрубить её, затем, когда снова понадобится, поднять и т.д. без лишней ебли?
https://immers.cloud/prices/
или гугли "облачные серверы с GPU"
L3-8B-Stheno-v3.2-Q8_0-imatгпу слои будто ни на что не влияют кроме пожираемой памяти. Память жрет а ускорения я не ощущаю. Потоки тоже - у меня рязань 5 3600 6 ядер 12 потоков, увеличил с 5 потоков до 6 в кобольде и никакой разницы, увеличивал до 12 и тоже не заметил изменений.
Вы скорость на глаз тут измеряете или есть какой-то надежный способ? У меня по ощущениям 3-4 токена в секунду, не больше.
При том если контекст с blas batch base на 500 выставлен то 3000 контекста прогружает быстрее чем 100 токенов ответа.
На глаз тут замеряют что угодно, но не токены. В терминале кобольда есть точное значение которые, которое выводится после каждой генерации.
Ну теперь то понятно. У тебя Q8_0 квант, я использовал Q5_K_M. На мистрале сижу на Q4_K_L.
>Вы скорость на глаз тут измеряете
В коболде в конце промпта пишет скорость. Самый конечный результат, ибо там несколько т/с выводит. Прогони два раза, и уже на второй раз будет рабочий результат, сколько токенов в секунду.
Поставь FleshAttention, если вдруг выключил/не включил. Я уменьшаю BLAS, чтобы побольше можно выгрузить на видяху. BLAS забирает память, не много, но забирает.
А, да, вижу. Ну я угадал - от 3 до 5 токенов в секунду.
Блас пробовал на 1 ставить но тоже изменений не заметил, однако теперь знаю куда смотреть хоть делаю я хуже или лучше, надо будет все прогнать поновой и измерить нормально, спасибо.
А разница в квантах сильно ощущается? Я самый большой взял что был, он самый умный вроде как должен быть, остальные сильно хуже или разница не большая?
А пилят что-нибудь глобальное на открытых моделях? Что-то вроде Алисы, чтобы на пека запускать? Командовать, так сказать?
Уже давно всё есть. В вызов функций лама даже умеет, есть специальные модели для этого. Висперы валяются в миллионах вариаций.
>Блас пробовал на 1 ставить но тоже изменений не заметил
Не сам блас дает прирост, а уменьшение бласа дает возможность больше загрузить на карту слоев.
>А разница в квантах сильно ощущается?
Обычно база Q5_K_M. Если хочешь чтобы похуже, но побыстрее писала модель, чем с Q8_0, возьми Q_6. Однако это же 8б, там то сильно ощущается. но не так сильно как на 2б моделях) Для меня хорошо подходила Stheno, на 5 кванте. Только легаси не скачивай, скачай Q(номер кванта)_K_M или S. На Q6 есть легасти, т.е. Q6_0 и Q6_K, лучше скачай Q6_K.
>Это понятно. Насчет персонажа, согласен, много от него зависит. Однако, другая модель писала больше и получше.
Ты сравниваешь рп-файнтюн и дефолтный инструкт. Ясен хуй модель заточенная под ролплей будет писать лучше и красочнее из коробки. Stheno сама по себе достаточно умная и креативная, не знаю зачем ты пересел на Немо, хотя она тоже неплохая, но есть фактор пердолинга с DRY семплерами, чтобы она нормально генерировала.
>пердолинга с DRY семплерами
Вот об этом я и хочу узнать, что там лучше ставить.
Крути по наитию, пока тебя не начнет устраивать результат. Но параметры семплеров не будут влиять на количество сгенерированных токенов, если ты вдруг так подумал. Тут только промты тебе помогут.
Есть что-то готовое?
>с которой сетки тренятся в 999 раз быстрее
>сто миллиардов ГПУ часов, делённые на 1000, всё равно дохуя
Неси, когда можно будет натрейнить на одной 3080Ti за полдня.
Чел, куда ещё готовее рабочих моделей?
Он же хлебушек, без ссылки на однокнопочный софт не разберётся.

Поставил Q6_K, стало гораздо быстрее с 25 слоями на гпу, 200 мб свободного места в гпу осталось с 8к контекста. Ну и я блас пока не трогал, только 4 потока поставил из 6, может сброшу ползунок до сотни где-нибудь.
Вот результаты, на какую из трех цифр смотреть?
Последнюю, или же Generate. C 9-10 токенами довольно комфортно, можно и на них остаться.
C 200 токенами на ответ да, но если повысить хотя бы до 300 то уже чето не очень становится, надо думать как еще повысить.
Трогать квант опуская ниже до Q5_K_M или же повышать кол-во слоев видяшки.
Никак не повысишь, если все слои итак на максимуме. Просто смирись с этим. Повышение приоритета, выделение большего кол-ва ядер дадут прирост в 1-3 процента, который ты не заметишь. 10 токенов в секунду это неплохо, тут некоторые вообще гоняют на 0.5 и не жалуются.
Да меня в целом и те 3-4 токена устраивали, возможно даже придется на них вернуться если q6 окажется слишком тупорылым. Пока он меня не особо впечатляет, но может просто ран неудачный. Наq5 вообще переходить страшно.
GPT2 и я не шучу.
https://docs.mistral.ai/guides/tokenization/
Чуваки из силли не стали встраивать тиктокен токенизатор, но он есть как раз в GPT2 , но прикол в том что я не знаю насколько это хуевая идея, но других нет. Бест ни за что не ставь. Он врубает лламу токенизатор и на удивление больше сои появляется.
Шизик, токенизотор в таверне только для подсчёта токенов. Токенизацией контекста занимается бэк.
>. Он врубает лламу токенизатор и на удивление больше сои появляется.
Боги, что за хуйню ты несёшь?
Ах да, токенизёр надо ставить апи, что кобольд, что вебуи дают доступ к родной токенизации модели.
Одни вопросы)..
Я на мистрале сижу, попробую апи поставить. Бест был такой 50/50.
Если это так то почему инструкции [inst] перестают работать на токенизаторе Лламы и сетка немо чаще шизит на нем же?
Попробовал Апи, тоже норм.
Я вообще не ебу. Была температура 0.65 и настройки пресетов от опенроутера. Сейчас поставил так, как тут https://www.reddit.com/r/SillyTavernAI/comments/1evcqd5/mistralnemo_presets/ А после начал играть с температурой, сейчас на 0.4, и вообще не понимаю лучше или хуже.
Еба, скиньте семплеры.
Насчет инструкций какие у вас пресеты в промптах.

У меня семплинг другой будет с XTC. Многие его обосрут как и мое предыдущее предложение о токенизаторе. Это для них на почитать
https://docs.mistral.ai/guides/tokenization/
А тебе вот семплеры.
https://drive.google.com/file/d/1lQ6M3xeEkRR8uWkaPTg1WeGtQmTEFGQg/view?usp=drive_link
Пример моих инструкций. Инструкт мод пустой.
если нужно XTC
```https://github.com/vitorfdl/SillyTavern/tree/feat/xtc
Это силли с XTC.
Угабугу можно стандартную взять.
Файлы перекинуть перечисленные тут в угабугу.
https://github.com/oobabooga/text-generation-webui/pull/6335/commits/f1232b1851966781901fe86322b52db97ccdf459
Вытащить можно отсюда.
https://github.com/p-e-w/text-generation-webui/tree/xtc```
Семплеры с доступом, т.е. нужно попросить разрешение.
Ну я вот с оп-пика рп пресеты на мистраль использовал. Пока оставил так, результат особо не впечатляет.
В Context Template, какой у тебя пресет?
Пиздец у чела каша в башке.

>А пилят что-нибудь глобальное на открытых моделях?
Один человек сделал русскоязычный голосовой чатик (speech-to-text + text-to-speech), LLM можно любую воткнуть.
talk-llama-fast wav2lip - неформальный видео-ассистент на русском
https://www.youtube.com/watch?v=ciyEsZpzbM8
talk llama fast 0.0.3 - несколько персонажей в одном голосовом помощнике
https://www.youtube.com/watch?v=JOoVdHZNCcE
https://github.com/Mozer/talk-llama-fast
зато у тебя видимо пусто.
3D барменша с text-to-speech, но исходники пока не опубликованы.
https://www.reddit.com/r/LocalLLaMA/comments/1erelsv/i_created_a_3d_bar_with_an_ai_bartender_that/
You can try it for free at https://www.mangobox.ai/ !
I've seen a bunch of AI character type stuff online, but all of them were boring chat interfaces. I thought it would be more fun to give the characters an avatar and a 3d environment to interact with.
The stack I'm using is Claude 3.5 for the LLM, OpenAI TTS, Stable Diffusion for generating drinks, and three.js for rendering. I exposed the prompt I'm using so people can play around with it by clicking the robot icon. If people enjoy this I can also make more environments, character customization options etc.
Решил попробовать виртуалку с 2х3090, Коммандера 5_K_M с 16к контекста со скрипом тянет, попробую завтра ещё поебаться с настройками, дабы ускорить это дело. Благодарю, анон.
>Решил попробовать виртуалку с 2х3090
Аккуратней там, т-щ майор не дремлет.
Вот этого двачую, совсем ебанулись чтоли? Там в запросе только текст отправляется а вся токенизация на стороне бека.
Счетчик переключили и (несуществующая) соя пропала, забавно.
> семплеры
> temp 2.29
> top_p 0.01
Пояснительную бригаду можно? В конфиге волшебный новый семплер применяется самым последним, до него же единственный токен будет доходить и это по сути гриди энкодинг.
> Многие его обосрут как и мое предыдущее предложение о токенизаторе
Ну хуй знает, сам понимаешь как это все выглядит.
> дабы ускорить это дело
> 2х3090
Дропнуть жору, забыв как страшный сон, и наслаждаться. Когда врам ограничена или теслы - выбора нет тут понятно, но когда памяти с большим запасом, зачем жрать кактус?
Хостерам невероятно похуй что творится в контейнерах.
>когда памяти с большим запасом, зачем жрать кактус?
С каким запасом? 48гб для больших моделей - впритык, и то с малым квантом. Нужны 3 3090 минимум. К тому же проблемы есть и с экслламой.
Читай внимательно у него коммандер. Пусть он и жрет как не в себя, хороший квант и 32к+ в 2 карты поместятся.
> проблемы есть и с экслламой
Проблемы есть с чем угодно, это не просто опенсорс, а совсем высокотехнологичный блидинг эдж. Но общий экспириенс там несравним, как по количеству косяков, так и по уровню работы. Довольно грустно наблюдать что все носятся с вонючим калом жоры, когда есть такой чудесный алмаз.
Тематика, конечно, пиздец, но
> perfectly knows each character and, in principle, the lore of the series
круто ведь если так. Не поделился ли автор примером датасета или общим подходом для достижения такого? Офк это интересно только если модель не поломанный лоботомит.
Напомните, в gemma есть русский токенизатор и как в старые времена одна русская буква=три токена?

Поставил mini-magnum-12b-v1.1, после Lumimaid 0.2 12b, Mistral-Nemo-Instruct-2407.
Блять, вот это уровень уже тот, который я желал получить. Нет ебанных 20-40 токен ответов или же в 4 строчки. Все, пишет проработанные пасты 450+ токенов, что даже бывает не вмещается в лимит респонсива. У меня блас стал 4к+.
Запоминает контекст в рп, при минете - молчит, а не разговаривает. Однако RoPE чет сильно снизил ее качество, и дальше шел без него. Может сделаю больше контекст, однако хочется скорости, поэтому повышать контекст уменьшением слоев, такое себе.
При чем, работает уже заебись, при хуй пойми каких настройках! Все же ради приличия и паст 700+ токенов и избежания "лупов", а на самом деле там не луп, а просто фраза повторается, сам рп продолжается. Поставил настройки опенроутера на старшую ее модель, и стало хорошо.
Вот, че за хуйня, почему с мистралем я ебался, блять, накотил магнум, все пошло охуенно. Кто те люди, к которых хорошо работает мистраль немо - отзовитесь!)
+ подскажите какой у мини-магнума контекст? 128к как у мистраля, раз уж он на его базе сделан.
Блять, вот это уровень уже тот, который я желал получить. Нет ебанных 20-40 токен ответов или же в 4 строчки. Все, пишет проработанные пасты 450+ токенов, что даже бывает не вмещается в лимит респонсива. У меня блас стал 4к+.
Запоминает контекст в рп, при минете - молчит, а не разговаривает. Однако RoPE чет сильно снизил ее качество, и дальше шел без него. Может сделаю больше контекст, однако хочется скорости, поэтому повышать контекст уменьшением слоев, такое себе.
При чем, работает уже заебись, при хуй пойми каких настройках! Все же ради приличия и паст 700+ токенов и избежания "лупов", а на самом деле там не луп, а просто фраза повторается, сам рп продолжается. Поставил настройки опенроутера на старшую ее модель, и стало хорошо.
Вот, че за хуйня, почему с мистралем я ебался, блять, накотил магнум, все пошло охуенно. Кто те люди, к которых хорошо работает мистраль немо - отзовитесь!)
+ подскажите какой у мини-магнума контекст? 128к как у мистраля, раз уж он на его базе сделан.
>Все же ради приличия и избегания паст 700+ токенов и избегания "лупов"
Магнум 2 качни лучше, или вобще 2.5
Что лучше хз, 2 хвалят
Вся серия магнума вобще неплохая
пробовал 2.5 - имхо на русском очевидно уступает Lumimaid-Magnum-12B
Я с оп пика смотрел модели. И как я вижу на хаггингфейсе тоже только 1.1 версия, мини магнума.
Скинь, которую ты имел ввиду, однако если это 12b+ не нужно
не мини, просто ищи там магнум и да есть все версии на мистрале немо
Какой из них на русском лучше вобще хз
2.5 экспериментальный, и так как все датасеты у них на английском то не удивительно что русский подавляется
В таком случае лучшим русским будет владеть оригинальная немо
Да я посмотрел, обычный магнум 12б 2 есть. Какой из магнумов будет лучше? мини или магнум2. Я попробую ее, но спать все же нужно, так что завтра скачаю ее. Кто знает и имеет опыт, расскажите, что лучше.
Нет. Я проверял и сравнивал. Lumimaid-Magnum-12B лучше в русский может чем Немо 12b. Давно уже ищу что может переплюнуть эту модель в подобном диапазоне для моей 12 гиговой 3060
Вообще да, ассистент реально должен быть однокнопочным, иначе это неюзабельное, неоптимизированное говно.
А это не асистенты, хоть в ТТС и могут.
Вообще у ЛЛМ-ок на деле большие проблемы с практическим применением за пределами кума. Не смотря на повышение качества и оптимизацию, они так и остаются игрушками, которые любому нормису надоедают за пару недель.
Единственные реальные кейсы на данный момент:
Программирование.
Перевод текстов.
Поисковые ассистенты срущие неточностями
И вот эта хуйня https://github.com/balisujohn/localwriter
Дальше всё, тупик, даже функционал Алисы прикрутить, так чтобы он не отваливался никто не в состоянии.
Пруф ми вронг.
>Поисковые ассистенты срущие неточностями
Строго говоря, большая корпоративная модель - это довольно грамотный секретарь для консультаций по любому вопросу, единственно для продуктивного общения нужно быть хотя бы немного в теме - чтобы отсекать явные косяки. Живой человек подобного уровня стоит дорого и имеет те же недостатки.
>секретарь
Ассистент помощник
Собственно как они ии и продвигают
Ну а рп ерп это тоже помощь психологическая лол
>/woonav129b_my_little_pony_russian_singlelanguage/
Отличная тематическая модель, прекрасно говорит на русском и соображает. Для фанатов этого дела самое то. Респект автору.
>большая корпоративная модель - это довольно грамотный секретарь для консультаций по любому вопросу
Если ты про чатботов техподдержки и колл-цетров, то их использование постепенно становится токсичным. Народ сразу же выходит из себя и требует "живого человека", как только их узнаёт, а узнать их не сложно. Потому что "уровень" может и высок, но его недостаточно чтобы решить реальную проблему. ЛЛМ-бот по факту льёт бесполезную воду, частично затыкая нехватку персонала, но о полной замене речь пока не идёт.
>Потому что "уровень" может и высок, но его недостаточно чтобы решить реальную проблему.
Они бы может и решили, да что же им даст права. А пережёвывание базы вопросов и ответов, которую обычно загружают в такие модели не может решить ничего, кроме самых простейших случаев. Ну и персоналу на местах в основном нужно, чтобы клиенту надоело и он отстал, поэтому других чатботов и не будет.
большинство реальных проблем в техподдержке это "как проверить баланс"
если ты попадаешь сразу к реальному человеку, то там будет такой же бот со скриптом перед глазами, как и ллм
он также тебя переведет на специалиста если потребуется
>аже функционал Алисы прикрутить, так чтобы он не отваливался никто не в состоянии.
Не понимаю, где здесь можно обосраться. Либо тренируешь модель на использование кастомного тега, либо делаешь два запроса - один с grammar, второй для комментирования, без. В идеале, конечно, вообще не пропускать это в llm и генерировать нужные теги на этапе распознавания голоса, потом простой поиск по строке, выполнение команды и запрос в llm для комментария. Другой вопрос, что сфера применения этого всего достаточно сомнительная. Кому вообще нахуй нужна "Алиса"? Тем более, своя подвально-рукотворная.
>Народ сразу же выходит из себя и требует "живого человека"
Вот с этого охуеваю на самом деле. Чем дальше, тем больше "живой человек" становится токсичным. От ботов они требуют живых людей, от живых людей менеджеров, от менеджеров требуют выполнения их необоснованных условий. И их даже нахуй послать нельзя.
>он также тебя переведет на специалиста если потребуется
Совсем не так же. Именно поэтому люди требуют живого бота :)

>И их даже нахуй послать нельзя.
Ну как же, а чат-бот на что. Нахуй - это как раз туда. Причём сразу.
ну ессно если ты звонишь условному опсосу, то ему выгоднее тебя просто отфутболить, но так не везде как бы
алсо, чаще всего и они переведут на человека, просят это делать сразу, чтобы не терять время на проход по стандартному скрипту "включите и выключите"
Как в таверне чекпоинт работает? Доки не нашел на него на сайте
> Дропнуть жору, забыв как страшный сон, и наслаждаться. Когда врам ограничена или теслы - выбора нет тут понятно, но когда памяти с большим запасом, зачем жрать кактус?
Я кажись не в теме, что ты имеешь в виду под "дропом жоры"?
Ты не только не в теме, но ещё и вики из шапки поленился прочитать.
Читал давно по диагонали, пойду освежать.
>Не понимаю, где здесь можно обосраться.
>Кому вообще нахуй нужна "Алиса"? Тем более, своя подвально-рукотворная.
Сам же ответил.
Ну и плюс к тому, чтобы реализовать хотя бы функционал в стиле "Алиса включи мне плейлист из Брата 2", от рядового уровня пользователя ЛЛМ понадобится пердолинг уровня джуна, даже если кто-то это "реализует", чего, кстати, нет насколько знаю.
Вообще если бы кто-то замутил через локальные ЛЛМ функционал типа такого:
https://youtu.be/22wlLy7hKP4?si=sO9DpyvFJj4UAIcY
Желающие бы поюзать нашлись. Не всем хочется палить буквально все свои данные на сервера [компанинейм]. Но в опенсорсе исполнители ли найдутся.
>Дропнуть жору, забыв как страшный сон, и наслаждаться. Когда врам ограничена или теслы - выбора нет тут понятно
А таких процентов 90, по самым-самым скромным. Поэтому Жора велик и славен и один оправдывает существование такой страны, как Болгария. Если бы процент был обратным, ну была бы ещё одна мало кому нужная программа, но ведь это не только не так, но и просвета никакого не видно. Так и будем сидеть на потребительском говне. И это говно гоняет нейросетки уже раз в 10 быстрее чем в августе прошлого года. Поэтому слава Жоре ещё раз.
Если это не троллинг тупостью, то: тонну всего.
Начнем с Qwen2-72b — он лучше Мику (и Лламы 3/3.1) в логике и знаниях. На его базе сделан Magnum.
Так же, есть Gemma-2-27b, которая неплоха, есть Magnum-12b (v2 kto) на базе Mistral Nemo и огромный Magnum 123b на базе Mistral Large.
Есть Lumimaid (не слежу за серией, не знаю, какие там размеры есть).
Ну и всякие Stheno (хотя он внутри магнума уже), и прочие Афины.
Все же, более полугода прошло.
> Так жирный же
Щас бы четыре теслы для 12б модели.
Ну ты повыясняй в начале, посмотри, какие варианты есть, прежде чем писать. Не тяжело же, вроде, на обниморду зайти и в поиск вбить.
Ты с моделью в начале определись, а потом думай.
Magnum-v2-12b-kto не устраивает?
Gemma-2-27b не устраивает?
НУжна прям Mistral Large-123b? Хуй тя знает.
Для магнума на немо хватит и твоей видяхи, если выгружать слои частично.
Если у тебя есть второй слот PCI-e и бп нормасный — докупи P104-100, добавишь себе еще 8 гигов и катать будешь ггуф в двух видяхах.
Если тебя минимум гемма устраивает, то тут уже надо думать. Опять же, можно добрать п104-100 и получить 16 гигов в сумме, и в них катать пожатую гемму. Или выгружать частично для q5_K_M.
Или же, взять RTX 3090 с авито, будет 24 (а если второй слот — то и 32 гига). Вот там уже летать будет гемма. Ну или 72б частично выгрузишь, кое как будет ползать.
А если и она не устраивает, то хуй его знает.
Поправлю, лучше скидывать все три результата — чтение контекста, генерация токенов и тотал. Потому что все зависит от ситуации, перечитывает/не перечитывает весь контекст движок.
Лет сто назад.
Там LLM не нужен, Алиса — это умный дом.
Распознавание сделано еще на старых распознавалках (от того же Майкрософта), есть программа VoiceAttack для ПК, например, на ней делали те же ко-пилоты в Elite Dangerous, просто умные дома с голосовым управлением делались давно (я не вспомню щас названия).
Болталка делается легко — stt (Whisper, faster-whisper, whisperX) + llm + tts (xttsv2, moetts, vosk, куча всего).
Все вместе — хз, не видел, может и пилят.
Ну вот, генерация у тебя 10, нормас прям, жить можно.
q6 для малых моделей на грани.
А вот для 20+ уже и q5 норм может быть.
Может объективизирующими?
Коммандера, в 2к24…
> Дропнуть жору, забыв как страшный сон, и наслаждаться.
Кстати, плюс. Тут же бывшая залетает.
База.
> mini-magnum-12b-v1.1
Она устарела неделю назад, есть magnum-v2.5-12b-kto, например, сравни.
Убери mini.
Так напиши сам, делов-то. Я не шучу.
———
Ладно, ушел сам тестить, шо там лучше будет. 1.1., 2 или 2.5…
> Коммандера, в 2к24…
Посоветуешь какие-нибудь другие несоевые модели для РП, которые нормально с 8к+ контекстом желательно 16к+ заработают под 48 Гб VRAM? Чтобы можно было выжать хотя бы 5 т/с.
Да вроде в гемме и немо (магнум, люми) жить можно.
Хотя я хз твои вкусы, может только коммандер и справляется, ок. =)
> нажата галочка на Tempereture last
> "temperature_last": false
> sampler_order, sampler_priority
???
Но когда у тебя всего один токен то можно любые значения ставить
> пердолинг уровня джуна
Вот уж действительно пердолинг, это даже проще чем всякая эквилибристика с промтом и подобное. Вся суть в
> Кому вообще нахуй нужна "Алиса"? Тем более, своя подвально-рукотворная.
> А таких процентов 90
Хуй знает, регулярно наблюдаю в дискуссиях обсуждения что народ катает помещающиеся в врам модели на жоре просто потому что "все его юзают" или даже банально не знают об альтернативах. Некоторые наоборот знают и устраивают аутотренинг уровня треда на реддите где утверждается что жора вовсе не тормознут, делая тесты контекстом 600 токенов, лол. Они рили больше условных 8к не набирают чтоли?
> И это говно гоняет нейросетки уже раз в 10 быстрее чем в августе прошлого года.
Как было говном тогда, так и остается. Добавили фа, который уже больше года доступен в экслламе, процентов на 10 бустанули генерацию, все. Даже нормальную работу семплеров за все время так и не починили.
Типа да, Жора красавчик что вообще этим занимается, но место ему только на всратых врамлетах и некротеслах, не более. Ах да, и на главном железе для которого все изначально и делалось - apple silicon. Возможно в этом и корень проблем.
> Коммандера, в 2к24…
Как был так и остается непревзойденной в куме моделью, конкуренты начинаются от 100б. Может быть какую-то 70б подтянули, но врядли.
Вот бы его новую версию.
>Как было говном тогда, так и остается
В голове у тебя говно, анон
Жора и его тима герои, с которых началась и продолжилась вся эра опенсорс ии
Не будь его, не было бы хайпа, так как людей с большой врам сильно меньше
Нет хайпа - нет новых моделей и сообщества развивающих по и сетки с файнтюнами
И ты бы сосал жопу, сидел глядя на копроративные сетки без вариантов с какими то продвинутыми локалками и той же менее развитой таверной
А еще жора дал возможность любому бесплатно прикоснутся к передовой технологии, за что отдельный респект
Медленнее чем специализированные под врам решения?
Ну и похуй, работает и ладно. Причем без установки и пердолинга с обновлениями и зависимостями
Хейтить что то просто потому что вобще довольно тупо, разному инструменту разное применение.
Считай жорин код - внедорожником который ездит в любых условиях, тогда как та же ексламма гоночный болид для запуска на специальных дорогах
Ну слушайте, да… magnum-12b в версиях 2.5 и 2 — хуже, чем 1.1 в русском. Очень сильно.
Думаю, 1.1 пока останется топовой моделью за свой вес.
Эх, беда!.. А счастье было близко.
Я не понимаю что такое B и что такое Q. Q это какие-то кванты. А что на что влияет? Что лучше при одинаковом весе, модель 12B Q5 или 8B Q8? Или вообще 24b Q2? Они все весят условно 8.5 гб, получается они и работают с одной скоростью? Что важнее, B или Q?
А английский? По идее на нем они наоборот должны быть лучше
B это миллиарды параметров нейросети. Каждый параметр оригинальной сетки изначально закодирован в 16 или 32 битах.
Кванты это когда с потерей точности преобразуют эти точные биты в менее точные, например в 8 бит.
Тоесть каждый квант это упрощенная копия оригинальной сетки, сохраняющая большую часть качества.
Ну и как ты понимаешь чем выше квант к 16, тем меньше потеря качества. Так 8 бит, Q8, качественнее чем Q4
Ну а всякие K_M K_S это более современные варианты квантования
Про скорость ты угадал, так как чаще всего скорость моделей ограничена пропускной способностью твоей оперативки/ памяти видеокарты, то одинаковый размер будет крутится за одинаковое время.
Но взять сетку покруче с меньшим квантом выгоднее, так как она все равно будет умнее
До 5 к_s кванта спокойно спускайся, ниже начинается херня
База. Полностью поддерживаю. Благодаря жоре могу катать Гемму 27b в четвертом кванте на 12-гиговой видяшке с не самой плохой скоростью. Что еще надо для счастья?
Ниже 5 вообще не стоит? Тут читаю как мини магнум нахваливают, я думал попробовать 12B Q3 или Q4.
И как ориентироваться в Q_K, Q_S, Q_M, Q_K_M и прочем? Там есть логика какая-то типа алфавитный порядок или что это все значит?
И что такое IQ? Оно лучше простого Q?
>Ниже 5 вообще не стоит?
На мелких моделях не стоит, если только совсем от безнадеги
На сетках от 70b запускают 3-4 квант, некоторые отчаявшиеся и меньше
Читай вики про кванты ну и глянь описания тут например
https://huggingface.co/bartowski/gemma-2-2b-it-GGUF
Но это он тупо копирует от сетки к сетке, такую мелочь только в 8 стоит запускать. Ну или на телефоне просто по приколу 4 квант попробовать. Она будет заметно тупее в низком кванте, потому что мелкая
iq херня которая медленнее если часть модели на процесссоре
>Ниже 5 вообще не стоит?
8-9B - восьмой квант (минимум шестой). 12В - шестой. 20-30B - можно и пятый. Выше - настолько ВРАМ и скорость карточки позволяет, начиная от четвёртого кванта.
> хуянянейм - хуйня по таким-то причинам, оправдана только для группа_нейм
> рррееееее хуйнянейм была моим первым опытом и еще оно помогает группа_нейм, а значит хорошая!
Вот так и живем. И это чудо еще про говно в голове затирает, пиздец.
> хайпа
Переоценен, тем кто делает модели обладатели отсутствия не интересны. Потеряли бы 1.5 норм файнтюна (печально) и сотни мусорных шизомерджей (правильно).
> Ниже 5 вообще не стоит?
Если квант не поломан и нет прочих проблем то вплоть до 4km будет норм работать. Может даже q3 заходить, но там уже бывает шиза
.
Рост отклонений логитсов что в мелкой что в большой сетке с квантованием идентичны, вся тема по поводу "на большой сетке можно квант поменьше" основана на том, что большая модель более толерантна к дичи и лучше продолжит сложившуюся последовательность, с которой может не справиться мелкая. Насколько это эфемерное или реальное - вопрос, учитывая разницу после семплинга - больше плацебо. Хотя у жоры в квантах бывают большие выбросы в отдельных моментах, причем они не имеют линейной зависимости от битности, более мелкий квант может казаться стабильнее и повторять генеральную линию fp16, а остальная разница отсеется topP/minP.
> Там есть логика какая-то типа алфавитный порядок или что это все значит
Вики читай
Вот говноед, нечего сказать и начинает коверкать слова
И ты реально думаешь что это считается аргументом в споре? Тыж буквально оподливился со своим петрасянством
Говноед - ты. Не поняв суть поста триггренулся и с горящей жопой доказывал как хорош твой любимчик. Увидев реальную интерпретацию твоего поста - загорелся еще больше и теперь разводишь срач, совсем слившись.
За эти посты у тебя не то что нет ни единого аргументы, ты даже сути спора не понял. Буквально мусор, которому важнее защищать свой манямир чем вести какие-то обсуждения, фу.
А, не, наебал, простите.
Все дело в кэшировании контекста.
8бит убивает русский в магнумах.
Подозреваю, просто грант где-то там проходит.
Без сжатия контекста меньше, но на русском уже все норм работает.
Так что, сравнить еще предстоит.
Q_K_S < Q_K_M < Q_K_L
Под Q_K подразумевается Q_K_L порою.
База.
Дада чсв дурачек, я услышал твое особо важное мнение
До сих пор не привык к обитающим тут пиздаболам, которые только языком работать и умеют выкручивая факты
По моему с тобой я тут уже срался, больно подчерк пиздаболии похожий
> Все дело в кэшировании контекста.
> 8бит убивает русский в магнумах.
Емнип, 8бит там e4m3 а 4 бита - nf4. Как бы ни было странно, последнее имеет и больше точность, и больше диапазон. Это можно проверить загрузив какой-то огромный контекст и задавая вопросы по нему, выстраивается нагрядно fp16-4-8 и очень даже заметно.
Ну вот, совсем мусор слился делая проход в чсв.
Типичный пример раба, который отчаянно защищает своего господина и свою цепь, тогда как обычный человек будет просто оценивать где лучше и то выбирать.
> По моему с тобой я тут уже срался
Ты со всеми срешься и стиль узнаваем, типичный завсегдатай специальных олимпиад. Такие братишки - рак комьюнити, создают много инфошума вокруг своего болота, из-за чего в нем теряются действительно важные вещи.
>Все дело в кэшировании контекста.
На реддите видел что писали мол даже какой то файнтюн страдает при сжатии контекста и кванте меньшем чем 8
Довольно интересно, так исчезает аккуратное обучение без переобучения?
Да он реально шиз какой-то, типикал школьник максималист. Елси ему это не нужно значит никому не нужно и вообще говно без задач. То что существуют кейсы в которых без жоры никуда - ему похуй. Ну или это просто тролинг тупостью, хз
Еще один жорасектант или семенишь? Понятно что любая критика в сторону хозяина вызывает страшную жопоболь и ненависть к тем, кто имеет возможность выбора, а это сильно мешает восприятию. Но ты ледик приложи и пойди еще раз прочитай, там ясно написано что для бедолаг жора - оправдан, и не нужно его уничтожать и запрещать.
прямо типикал поведение меньшинств и левачков напоминает, не просто отстаивают "право на свои недостатки" а пытаются выставить их общепринятой нормой и всех обязать почитать такое.
ВРАМЛЕТОПОЗИТИВ
Пошел нахуй дурачек
Нет бы по фактам ответить, начал с темы сьезжать и переходить в оскорбления
Говорю же, ты только пиздаболить в срачах и годен, видно ведь как ловко крутишься
Потому что это все что ты умеешь
>типичный завсегдатай специальных олимпиад. Такие братишки - рак комьюнити, создают много инфошума вокруг своего болота, из-за чего в нем теряются действительно важные вещи.
А это мои слова тебе, дурачек, в первом же сообщении с которого у тебя пердак подгорел
>Типичный пример раба, который отчаянно защищает своего господина и свою цепь, тогда как обычный человек будет просто оценивать где лучше и то выбирать.
Забавно как ты спроецировал ситуацию наоборот
Просто чсв дурачек который хочет оказаться правым любой ценой, с большим опытом срачей в инете
Для троллинга тупостью слишком серьезен, просто дурак
> годен
Все правильно, можно долго перечислять качество, годен на все, в том числе попускать всякий мусор под настроение. По фактам было все сразу, а ты с них слился даже не поняв всю суть.
Проявив неимоверное снисхождение, можно было бы аккуратно и легко объяснить тебе что твоего кумира никто не обижает и ограничивает, но свою роль он уже давно выполнил и сейчас чрезмерное внимание к нему только вредит всему направлению. Нет бы попердолить альтернативные движки, экслламу которая perfect from the beginning и подумать как добавить туда оффлоад, дохуя функциональный и действительно продвинутый афродит от команды, которая подарила всем любимую модель - силы идут на сношение трупа, да еще его чрезмерное восхваление.
Но зачем? Это же буквально бисер перед свиньями, к тому же, даже если они встанут на правильный путь, всеравно пользы будет невероятно мало.
Всё что ты пишешь - это не факты, а просто твоё мнение. И если ты считаешь тех, кто не согласен с твоим мнением говноедами - то это верный признак школоло, видящего мир в черно-белых тонах. Малолетнего дэбила, иначе говоря. Лечению поддаётся с трудом.
Совершенно никакого горения бтв, пердак холоден как лёд. За 15 лет на сосаче я и не на таких насмотрелся.
https://youtu.be/7cxztpiz13k?t=13
Тред плавно скатывается в видеорелейтед
А все началось с того что сектант сам назвал жору говном
> И это говно гоняет нейросетки уже раз в 10 быстрее
заодно выдав шизу по в 10 раз. Чел, с тобой всего лишь согласился, а в итоге ты выдал тирраду о том как хорош твой кумир и начал кидаться оскорблениями. Уже все позабыл в пылу битвы?
Тред плавно скатывается в видеорелейтед
А все началось с того что сектант сам назвал жору говном
> И это говно гоняет нейросетки уже раз в 10 быстрее
заодно выдав шизу по в 10 раз. Чел, с тобой всего лишь согласился, а в итоге ты выдал тирраду о том как хорош твой кумир и начал кидаться оскорблениями. Уже все позабыл в пылу битвы?
Этот тред давно скатился, так что все в порядке
Все так.
Но есть еще надежда и действительно крутые штуки, дающие возможности и облегчающие жизнь обнаружены, может увидим их в ближайшее время.
Я периодически кидаю сюда интересные ссылки по старой памяти, или помогаю новичкам
Но особого толку тут находится нету, в треде осталось мало адекватов с которыми раньше было интересно что то обсудить
На тебе все и держится, продолжай и не уподобляйся действиям и унынью
>мало адекватов
школотроны съебут с треда и будет чище
На словах все вокруг, дартаньяны, а на деле стоит что-то предложить так от местных адекватов ничего кроме "гы гы сделай сам нахой оно надо" не услышишь.
мимо веду местный колаб и список моделей
Список моделей полезен, но без нормального голосования или хотя бы обсуждения он не пополняется и не обновляется понятным образом
Вон магнум на мистрале немо недавно проверяли, так и не выяснили что лучше
И это максимум активности по модели
Это список "тредовых моделей", а не рейтинг.
Голосование - бесполезная хуйня, которую можно накрутить, а мнения о моделях субъективны, что работает у одного анона, может сбоить у другого и наоборот. Свидетели Жоры и Эксламы не дадут соврать. Единственное нормальное решения - вносить все что вызывает интерес и записывать любые мнения, а дальше сам разбирайся кому больше верить.
Обсуждение тут. Относительно вменяемые отзывы о моделях добавляю. Есть что сказать о моделях - говори!
8В тьюны обычно игнорю, по причине того что их сверхдохуя, а разница между ними заметна лишь избранным. Предлагал несколько раз любителям подобного сделать обзор топовых шизомиксов, но таковых в треде не оказалось
>речь шла о 70b и выше моделях
> https://huggingface.co/mradermacher/magnum-v2-123b-i1-GGUF
>посмотри, какие варианты есть
Ты лучше-внимательнее читай ветки или не отвечай на 10 постов за раз чтобы юшки нафармить.
https://huggingface.co/spaces/Qwen/Qwen2-Math-Demo
Вот здесь используется какой-то инструмент для распознавания изображений. Я не понимаю точно что это, мультимодалка или просто img-to-text модель. Называется Qwen2 VL.
https://huggingface.co/spaces/Qwen/Qwen2-VL
Нашел отдельный спейс с ним.
Так вот, на хаггингфейсе qwen'а этой модели нет, только несколько спейсов с разными размерами моделей, разной версии. Она вообще есть в опенсорсе или планируется сливаться в сеть или это внутренняя модель алибабы которую они не хотят отдавать? Интересно просто посмотреть хоть на какие-то альтернативы ллавы и сравнить их
Вот здесь используется какой-то инструмент для распознавания изображений. Я не понимаю точно что это, мультимодалка или просто img-to-text модель. Называется Qwen2 VL.
https://huggingface.co/spaces/Qwen/Qwen2-VL
Нашел отдельный спейс с ним.
Так вот, на хаггингфейсе qwen'а этой модели нет, только несколько спейсов с разными размерами моделей, разной версии. Она вообще есть в опенсорсе или планируется сливаться в сеть или это внутренняя модель алибабы которую они не хотят отдавать? Интересно просто посмотреть хоть на какие-то альтернативы ллавы и сравнить их
>А все началось с того что сектант сам назвал жору говном
С подключением. Жору говном льют уже давно по поводу и без. Тут есть пара местных шизов, которые при любой самой мелкой проблеме всё сваливают на жору, хотя непонятно, они хуесосят ламу.цпп, кобольд, или самого жорика персонально, будто он им что-то должен.
>Этот тред давно скатился, так что все в порядке
С тредом всё в порядке. Модели обсуждаются, залетным помогают в меру возможностей. Ты на соседей лучше наших корпоративных посмотри, у которых на любой вопрос ответ это "сори, гейткип". Так что у нас еще плюс-минус все прилично.
Есть для магнума начальный промпт, чтобы снять с него цензуру, хоть частично? Может есть у кого примеры?
Ты где на магнуме нашел цензуру, другалек?

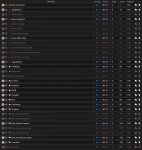


Думал о том, как сделать систем-промпт максимально гибким - начинаю склоняться к мысли, что он вообще не нужен в классическом виде.
Причина этого заключается в том, что систем-промпт можно в полностью вынести в лорбук, что имеет в себе несколько преимуществ:
1. Систем-промпт становится полностью модульным, это просто удобно - включать и отключать нужные отрывки, не прикасаясь к тексту вообще. Проще экспериментировать, не боясь, что затрёшь что-то лишнее и надо будет потом откатывать. Иметь разные вариации для каких-то взаимозаменяемых частей промпта - например просить использовать или русик или англюсик.
2. Можно вынести отдельные части в самое начало (Before Character Definition), так и в самый конец, ниже текущего ответа юзера (at Depth Assistant/User = 0). Это более гибкая система чем system prompt, который не позволяет распихивать отдельные элементы по разным местам вашего промпта.
3. Можно делать твикеры, которые срабатывают с определённой вероятностью - на ласт скрине этти-часть срабатывает только в 30% запросах. Таким образом можно разнообразить ответы за счёт случайных вставок в промпт. Для создания ещё более рандомизированных ответов можно использовать макрос random в таверне, как у меня в примере "Mention {{char}}'s {{random::tail::ears::underwear::ass::chest}} actions and position in details."
Причина этого заключается в том, что систем-промпт можно в полностью вынести в лорбук, что имеет в себе несколько преимуществ:
1. Систем-промпт становится полностью модульным, это просто удобно - включать и отключать нужные отрывки, не прикасаясь к тексту вообще. Проще экспериментировать, не боясь, что затрёшь что-то лишнее и надо будет потом откатывать. Иметь разные вариации для каких-то взаимозаменяемых частей промпта - например просить использовать или русик или англюсик.
2. Можно вынести отдельные части в самое начало (Before Character Definition), так и в самый конец, ниже текущего ответа юзера (at Depth Assistant/User = 0). Это более гибкая система чем system prompt, который не позволяет распихивать отдельные элементы по разным местам вашего промпта.
3. Можно делать твикеры, которые срабатывают с определённой вероятностью - на ласт скрине этти-часть срабатывает только в 30% запросах. Таким образом можно разнообразить ответы за счёт случайных вставок в промпт. Для создания ещё более рандомизированных ответов можно использовать макрос random в таверне, как у меня в примере "Mention {{char}}'s {{random::tail::ears::underwear::ass::chest}} actions and position in details."
https://docs.sillytavern.app/usage/st-script/#variables
В таверне существует возможность присваивать/читать произвольные переменные посредством команд getvar/setvar.
Так же таверна поддерживает свой скриптовый язык, одной из возможностью которого является вызов LLM с произвольными командами, вывод которых не будет добавляться в основой чат. Триггером для вызова этих скриптов может являться как ручной вызов, так и вызов перед/после основного ответа LLM.
В совокупности это открывает возможность реализации дополнительных вызовов к LLM, которые будут иметь в контексте текущий чат, но будут иметь свою, особую команду. Например, вы можете спросить LLM "Надеты ли на {{char}} трусы? Ответь только 'одеты' или 'сняты'" и LLM ответит только на этот вопрос. Поскольку мы используем тот же самый контекст что и для чата и число output-токенов, нужных для ответа на такой вопрос, чрезвычайно мало, то вызов такого скрипта должен занимать мало времени.
Таким образом, вместо построения монстроузного CoT-блока, который кроме описания действий персонажа будет, в добавок, пытаться угадать цвет и расположение трусов вайфу, можно написать скрипт, который будет заниматься только тем, что обслуживать состояние текущего чата. И никаких следов вызова о нём мы не увидим в чате напрямую.
Когда мы получили статус трусов, необходимо сохранить их в скрипте через команду /setvar key={{char}}_outfit {{result}}. После этого мы можем не просить наш CoT-блок угадать цвет трусов по контексту через блок рода:
💭 Outfit
- md-list of the character(s) current/basic visible clothing, hair, state of them; pay attention to them in the response; mention if there is no underwear items; make mandatory emphasis on color of each item; avoid mentioning {{user}}'s here
А ставить LLM перед фактом, ведь мы уже заранее знаем нужные нам значения:
💭 Outfit: {{getvar:{{char}}_outfit }}
Так что основному запросу не нужно угадывать одежду персонажа, ему эта информация будет заранее передана другим запросом.
Я думаю, что такой подход может снизить вероятность галлюцинирования моделей, поскольку мы разбиваем комплексный запрос на несколько простых.
С таким подходом можно попробовать отслеживать и более сложные вещи. Например, инвентарь и число золота в RPG. У нас будет глобальный счётчик золота, и отдельный скрипт, который будет спрашивать LLM, тратил ли юзер за текущий ход золото и сколько именно. В зависимости от ответа LLM скрипт будет модифицировать счётчик золота и использовать его в основных запросах к LLM.
Недостатком подхода с переменными является тот факт, что когда мы захотим свайпать и форкать чат, то переменные не будут откатываться от этих действий. В случае форков можно было бы накатать скрипт, который выплюнет все текущие переменные юзеру и он мог бы перенести их отдельной командой, но вот в случае обычных свайпов такой подход не подойдёт, слишком много движений. Как костыль, можно триггерить дополнительные запросы не до/после основного ответа LLM, а когда юзер вручную вызывает их через quick replies, по сути он будет "фиксировать" новое состояние. Но это не очень удобный подход. Возможно, можно как-то разрулить использую разные наборы переменных для хранения старых/новых значений, и старые значения будет перезатираться только если мы как-то высчитаем, что значения для новых переменных совпадают с контекстом. Если же нет, то пересчитываем по новой.
Подводных много и звучит довольно пердольно, но потанцевал есть, как мне кажется.
В таверне существует возможность присваивать/читать произвольные переменные посредством команд getvar/setvar.
Так же таверна поддерживает свой скриптовый язык, одной из возможностью которого является вызов LLM с произвольными командами, вывод которых не будет добавляться в основой чат. Триггером для вызова этих скриптов может являться как ручной вызов, так и вызов перед/после основного ответа LLM.
В совокупности это открывает возможность реализации дополнительных вызовов к LLM, которые будут иметь в контексте текущий чат, но будут иметь свою, особую команду. Например, вы можете спросить LLM "Надеты ли на {{char}} трусы? Ответь только 'одеты' или 'сняты'" и LLM ответит только на этот вопрос. Поскольку мы используем тот же самый контекст что и для чата и число output-токенов, нужных для ответа на такой вопрос, чрезвычайно мало, то вызов такого скрипта должен занимать мало времени.
Таким образом, вместо построения монстроузного CoT-блока, который кроме описания действий персонажа будет, в добавок, пытаться угадать цвет и расположение трусов вайфу, можно написать скрипт, который будет заниматься только тем, что обслуживать состояние текущего чата. И никаких следов вызова о нём мы не увидим в чате напрямую.
Когда мы получили статус трусов, необходимо сохранить их в скрипте через команду /setvar key={{char}}_outfit {{result}}. После этого мы можем не просить наш CoT-блок угадать цвет трусов по контексту через блок рода:
💭 Outfit
- md-list of the character(s) current/basic visible clothing, hair, state of them; pay attention to them in the response; mention if there is no underwear items; make mandatory emphasis on color of each item; avoid mentioning {{user}}'s here
А ставить LLM перед фактом, ведь мы уже заранее знаем нужные нам значения:
💭 Outfit: {{getvar:{{char}}_outfit }}
Так что основному запросу не нужно угадывать одежду персонажа, ему эта информация будет заранее передана другим запросом.
Я думаю, что такой подход может снизить вероятность галлюцинирования моделей, поскольку мы разбиваем комплексный запрос на несколько простых.
С таким подходом можно попробовать отслеживать и более сложные вещи. Например, инвентарь и число золота в RPG. У нас будет глобальный счётчик золота, и отдельный скрипт, который будет спрашивать LLM, тратил ли юзер за текущий ход золото и сколько именно. В зависимости от ответа LLM скрипт будет модифицировать счётчик золота и использовать его в основных запросах к LLM.
Недостатком подхода с переменными является тот факт, что когда мы захотим свайпать и форкать чат, то переменные не будут откатываться от этих действий. В случае форков можно было бы накатать скрипт, который выплюнет все текущие переменные юзеру и он мог бы перенести их отдельной командой, но вот в случае обычных свайпов такой подход не подойдёт, слишком много движений. Как костыль, можно триггерить дополнительные запросы не до/после основного ответа LLM, а когда юзер вручную вызывает их через quick replies, по сути он будет "фиксировать" новое состояние. Но это не очень удобный подход. Возможно, можно как-то разрулить использую разные наборы переменных для хранения старых/новых значений, и старые значения будет перезатираться только если мы как-то высчитаем, что значения для новых переменных совпадают с контекстом. Если же нет, то пересчитываем по новой.
Подводных много и звучит довольно пердольно, но потанцевал есть, как мне кажется.
Достаточно интересная хуйня. Было бы неплохо, если бы ты всё это оформил на рентри и постепенно обновлял, или вообще запилил полноценный гайд.
Пока это, по большей части, просто шизотеория (по крайней мере второй пост). Но если что-то интересное получится, то можно будет и запилить, почему бы и нет.
По началу он по любому чиху отказывается отвечать и сыпет предупреждениями безопасности и предостережений. В процессе диалога все улучшается. Вот я думал, может кто уже сделал начальный промпт, чтобы пропустить эти пару шагов?
Тема годная на самом деле.
Но в таверне подобное уже давно реализовали, только для закрытых моделей и проксей.
Попытка реализовать тот же функционал через лорбук выглядит как костыль. Лучше уж код таверны поправить или хотя бы пулл реквест замутить разрабу.
Ну лорбук в качестве системного промта это конечно пиздец костыль, но оно работает, так что явно кому-то пригодится, пока мы не получим вменяемые свитчеры для промтов.
По поводу второго поста тут действительно пока сомнительно. Хотя давно я пытался запилить полноценную рпг с локалями, чтобы и инвентарь и статы получалось отслеживать, по этому лично мне интересно, к чему твои тесты приведут.
Что у тебя в системном промте стоит?
А вот про такое не знал. Реально годнота!
То есть смысл в том что можно хранить результаты запросов скрипта к ЛЛМ как переменные и встраивать их в промпт чтобы ЛЛМ не забывала важные детали, а отдельным скриптом эти переменные обновлять?
Ничего. Просто запустил магнум в кобольдеC++. Системный промпт не использовал. Изменил только Instruct Tag Preset на ChatMl, и температуру выставил на 0,7. Вот и все.
>Хотя давно я пытался запилить полноценную рпг с локалями
Тоже пытаюсь подобное замутить со времён Пигмы. Но я данные и статистику записывал в кодовые блоки, твой подход интересней!
Ну так пропиши дефолтную пасту, что чат unrestricted и uncensored, любые темы доступны и бла бла бла дальше по тексту.
Да, всё так. Я предполагаю, что если запрашивать важные детали отдельными запросами, то ЛЛМ будет меньше глючить, поскольку совокупная сложность отдельных запросов будет снижаться. В плане, что основному запросу не нужно будет додумывать, сколько у юзера золота и какой цвет трусов у вайфу.
Да, кстати. Ты получается системный промт полностью вырезал, или что-то базовое оставил? И вообще, как модель реагирует на то, что инструкции присылаются последними, а не в самом началае?
> Ты получается системный промт полностью вырезал
Да, совсем вырезал.
> как модель реагирует на то, что инструкции присылаются последними, а не в самом началае?
Пробовал и в начале и в конце слать инструкцию, пока особой разницы не заметил - надо дольше потестить.
Возможно да, но я тут вижу другой потенциал. Скрипты ведь можно делать сложными и выстраивать в цепочки, которые будут вызывать друг друга? Тогда можно вообще освободить ЛЛМ от части логики, например обязав её писать триггерные команды для скриптов в определённых ситуациях.
Так вполне себе можно построить карту, инвентарь, списки персонажей в локациях, считать хитбоксы урона математикой, а не шизой ллм, да дохрена всего так то!
Вообще, некоторые писали, что авторские заметки по этому так хорошо работают, потому что присылаются последними и соответственно они не зависят от длины чата и нет риска что модель их попытается проигнорить. По этой логике если системный промт или его часть тоже пойдут последними, то влияние будет сильнее.
> список моделей
Да ладно, всячески поддерживаем его с точки зрения советов/критики и наполняем отзывами.
> голосования
> Список
Спокуха, никто не мешает рассказать свое мнение о модели или выдвинуть ее. Потому это и список где перечислено а не некий топ, вокруг которого будут споры.
двачую
> Тут есть пара местных шизов
Это же, обычно, рофлы, не? я медленно пишу свою библиотеку регэкспов с хардкодом токенов Вот, в противовес пара про-жориных шизов, которое его боготворят. А с тем что жору не нужно использовать если есть возможность катать фулл гпу - только безумец не согласится.
Вот это суперахуенно, особенно последнее. Ведь так средствами таверны реализуется то, для чего приходилось писать дополнительные сприпты, и можно делать даже более сложные конструкции с мультизапросами, хранилищем статуса трусов статов и т.п.
Остается вопрос что будет с переменными при форке чата и при его перезапуске? Сохранятся ли они, или оварида.
Окей, спасибо.
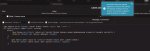
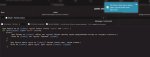
> Скрипты ведь можно делать сложными и выстраивать в цепочки, которые будут вызывать друг друга?
Да, можно делать цепочки вызовов. Сначала спрашиваем есть ли трусы, а затем спрашиваем либо какой цвет трусов, либо причину, почему трусы не надеты.
А где вообще это label меню?

Это quick reply в расширениях. Оно изначально было задумано как набор кнопок с заготовками ответов для нижней панели, но ничего не мешает скрыть эти "кнопки" и триггерить всё автоматикой.
Пнял, пасибо.

>функционал типа такого:
У них массивная обвязка вокруг сразу целого букета нейросетей. Каждую нужно считать отдельным проектом, это добрая дюжина. Представляешь себе, какая команда нужна? И ради чего? Ради того, что мертво по умолчанию и не имеет даже шансов на успех? Все эти отдельные устройства спавнятся в той же могиле, что и "умные часы". Никому не нужно, все забывают за пять минут. Полтора фрика, которые купили - погоды не сделают. Это должно быть приложение на смартфон, но тут приходим к другому - на поддержание серверов нужны деньги, а платить за такую хуйню никто не будет.
Интересно. В идеале такое надо захуяривать в системный пост и там хранить, но здесь начинается танец вокруг пересчёта контекста.
>когда мы захотим свайпать и форкать чат
А ещё, если переменные всё равно схороняются в контекст, нейронка будет видеть десяток разных строк "У юзера сотня золота", "У юзера три сотни золота", "У юзера нет золота" и ебанётся.
> А ещё, если переменные всё равно схороняются в контекст, нейронка будет видеть десяток разных строк "У юзера сотня золота", "У юзера три сотни золота", "У юзера нет золота" и ебанётся.
В идеале, мы должны отдавать в LLM только последние (актуальные) значения переменных. Возможно, их стоит не модифицировать, а как-то строго привязывать к конкретным сообщениям, чтобы можно было форкать/свайпать. Судя по докам, можно вытащить id сообщения через макрос {{lastMessageId}}. Так что можно попробовать хранить так:
/getvar {{lastMessageId}}_{{char}}_outfit
Тогда и проблему со свайпами/форками можно было бы решить.
Вот только как бы id текущего сообщения вытащить, чтобы сразу пересчитать значения на основе прошлых переменных и записать свежие. В плане, нам нужен и id текущего и id прошлого сообщения, в идеале.
/echo {{lastMessageId}}
А, оно просто номер сообщения выводит, ну тогда всё просто.
Получить прошлое состояние здесь: {{lastMessageId}}_{{char}}_outfit
Записывать новое состояние здесь: {{lastMessageId + 1}}_{{char}}_outfit
Тогда выходит что можно решить проблему с форками/свайпами.
Ух бля, на TaggyAPI с Exllama2 и правда Коммандер летает по сравнению с KoboldCpp. Спасибо за совет, анон. ||Правда, на 24к+ контекста всё равно ловлю "Insufficient VRAM for model and cache" с остальными параметрами из коробки.||
мимо купивший виртуалку с 2х3090
мимо купивший виртуалку с 2х3090
> Остается вопрос что будет с переменными при форке чата и при его перезапуске? Сохранятся ли они, или оварида.
Можно глобальными переменными таскать весь стейт между форками - так же оно сохраняется на хард и восстанавливается при перезапуске. Правда, надо будет придумывать, как сделать так, чтобы стейт не таскался между несвязанными друг-с-другом чатами.
Global variables — saved to the settings.json and exist everywhere across the app.
/getglobalvar name or {{getglobalvar::name}} — gets the value of the global variable.
/setglobalvar key=name or {{setglobalvar::name::value}} — sets the value of the global variable.
/addglobalvar key=name or {{addglobalvar::name:increment}} — adds the increment to the value of the global variable.
/incglobalvar name or {{incglobalvar::name}} — increments a value of the global variable by 1.
/decglobalvar name or {{decglobalvar::name}} — decrements a value of the global variable by 1.
>TabbyAPI
Медленнофикс. Ещё и с разметкой обосрался. Но да похуй.
Какой квант и как распределяешь между карточками? Глянь через nvidia-smi равномерно ли используется их врам, в случае коммандера на первую карточку нужно ставить меньше лимит памяти. Припоминаю что там побольше хватало, но может и пизжу уже, надо проверить.
> глобальными переменными таскать весь стейт между форками
Не не, в таком случае теряется весь смысл форков. Буквально делаешь ответвление чтобы что-то проверить/отыграть, или возвращаешься к началу чтобы оформить альтернативную ветку и там уже продолжить в той, которая понравится. В любом случае теряешь имеющийся стейт и должен получить соответствующий тому посту на момент написания. Или хотябы просто их запоминание на момент как "оставил" чтобы после перезапуска можно было продолжить.
Ладно, это уже жадность и сначала текущее нужно освоить. Глобал вары - тема, последнее должны обеспечить, но придется на каждый чат свои.
Бля, ну крч квен2 нихуя не лучше мику. Где то на уровне но не более еще и софтлупится иногда.
Ты просто криворукий дебил.
Ну, я скачал магнум 2. Кто-то протестировал, что лучше мини-магнум 1.1 или магнум 2.
+ Чзх. У меня Силли не хочет, я как понял, писать на русском языке. Русский понимает, но пишет ответ на английском. Это было и на Lumimaid и на Мистрале-Немо и на Мини-Магнуме. В общем, я и использую Силли с переводчиком, т.е. чат транслейт обоих, ответа ии и моего вопроса. Но, почему у меня не работает русский язык на моделях, которые поддерживают его. Может кто-то сталкивался?
+ Сколько контекст на Мини-Магнуме 1.1, так и не узнал.
+ Чзх. У меня Силли не хочет, я как понял, писать на русском языке. Русский понимает, но пишет ответ на английском. Это было и на Lumimaid и на Мистрале-Немо и на Мини-Магнуме. В общем, я и использую Силли с переводчиком, т.е. чат транслейт обоих, ответа ии и моего вопроса. Но, почему у меня не работает русский язык на моделях, которые поддерживают его. Может кто-то сталкивался?
+ Сколько контекст на Мини-Магнуме 1.1, так и не узнал.
Квенолахта +15
Ну а вообще раз ты, видимо не "криворукий дебил" давай сюда свои квенопресеты для таверны, че нет то? Затещу как надо.
Стандартный не пробовал, клован? Какие ещё лупы на квене, шизик.
>Но, почему у меня не работает русский язык на моделях, которые поддерживают его. Может кто-то сталкивался?
Как ты это делаешь? Некоторые так же писали, мол не могу русские ответы получить.
У меня ангийские карточки на русском отвечают через раз сами, если попросить то чуть ли не гарантированно
Причем со времен когда модели в русский почти не могли, как та же первая ллама
Те же варианты мистраля немо легко отвечают на русском, на крайняк прикажи переключится на русский в последней строке карточки или просто первым сообщением сетке
Попробовал на твоей тесле, проверяй, квенолахта.
>У меня Силли не хочет, я как понял, писать на русском языке.
Как ты это понял? Она сама тебе сказала?
Пиши системный промт и карточку на русском языке - в таком случае русские ответы будут всегда. Либо в промте укажи, чтобы респонс был на русском.
>Вообще да, ассистент реально должен быть однокнопочным
Только если ты сам одноклеточный. Нормальный человек соберёт сетап из элементарных кирпичиков под себя, который будет ебать любой готовый продукт.
Увы, но база.
Вообще не понимаю тех, кто видя перед глазами баланс, спрашивает его у бота.
>от менеджеров требуют выполнения их необоснованных условий
Чаще всего требуют возврата незаконно списанных средств за лево подключённые услуги и прочий треш.
>и огромный Magnum 123b на базе Mistral Large.
Два чаю, пересел на него с командира+.
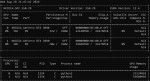
>Какой квант
4.0bpw
>как распределяешь между карточками?
Не настраивал, вероятно автоматически 50/50 ставит.
>Глянь через nvidia-smi равномерно ли используется их врам
Пикрил. Второй карте и правда посвободнее дышится.
Потому что я в силли и пишу, в коболде лайт не проверял.
Системный промпт может. Однако, да, не понимаю почему не отвечает на русском. Меня особо это не парит, тем не менее осадочек остался)
А что самое лучшее на сегодня, что можно запустить на GeForce RTX 4070 12 Gb?
>Ну, я скачал магнум 2. Кто-то протестировал, что лучше мини-магнум 1.1 или магнум 2.
Сравнил немного минимагнум и магнумы 2 и 2.5, на мистрале немо
НЕ рп или ерп, тупо початился со своей карточкой ассистентом
Минимагнум хуже следует thinking промпту, не догоняет как его использовать чаще, чем 2 других
По общению 2 как то живее отвечает, 2.5 не понял, 1 суховат
Но это может быть влияние карточки и фазы луны
Общий вывод - хуй его знает, 1 версия проба пера, 2 доверяю чуть больше, 2.5 экспериментальная, модет быть как лучше так и хуже 2
Надо чтоб кумеры потестили
>12 Gb
Если не смущает 0,7 токенов в секунду, то хоть 123B (при наличии 64 гиг оперативы).
Мимо с 3080Ti, который меньше 100B не запускает
Тогда попробую магнум 2, но мини магнум мне понравился, хорошо отвечает, пастами. Контекст рпшный помнит, при минете - молчит. Посмотрим, будет так же ли на магнуме 2, думаю должно.
Сколько у тебя т/с на 100б, и какой респонсив у тебя?

>Сколько у тебя т/с на 100б
Написал же
>0,7 токенов в секунду
Впрочем, иногда бывает чуть быстрее.
Там и 6 бит влезало. Квант лучше бустани до 4.65, сделай ассиметричное распределение с большим уклоном в сторону второй, типа 16,24, подбери экспериментально чтобы было +- равномерно.
> который меньше 100B не запускает
Почти как волк.
Мне бы такое терпение..) У меня 5-7 т/с хочу большего) Но не хочу с 12б переходить снова на 8б. Поэтому понимаю тебя, что ты ниже 100б опускаться не хочешь.
>Квант лучше бустани до 4.65
А как это сделать? Я скачал модель, которая 4.0bpw шла, Коммандера 35B с квантами выше в exl2 не видел на HF.
Насчёт распределения эксперементирую сейчас.
А, всё нашёл, плохо искал.
https://huggingface.co/BigHuggyD/c4ai-command-r-plus_exl2_4.65bpw_h8 - ты про этого?
Стоп, это же который 105B.
Когда ответы идут уже неплохие (а сейчас даже 12б их может обеспечить) то скорость бывает важнее. Быстрое можно реролльнуть или даже отредачить с продолжением, а от тормознутого словишь унынье, увидев ерунду или какую-нибудь платину после ожидания в несколько минут.
https://huggingface.co/turboderp/command-r-v01-35B-exl2
Тут есть 5 бит. Если устраивает 4.0 то можно и его катать, только распредели чтобы на контекст хватало.
Это плюсовый. Вот еще с "рп калибровкой", хз как будут перформить
https://huggingface.co/Dracones/c4ai-command-r-v01_exl2_4.5bpw-rpcal
https://huggingface.co/Dracones/c4ai-command-r-v01_exl2_5.0bpw-rpcal
https://huggingface.co/Dracones/c4ai-command-r-v01_exl2_6.0bpw-rpcal

Ладно, буду попробовать. Спасибо ещё раз, анон, добра тебе.
Реддиту поплохело или это у меня косяк?
Ему поплохело.
Кто-нибудь разбирался в кэшах f16, q8 и пр.? Эта штука прям сильно сокращает расходы по памяти, но что насчёт качества?
>но что насчёт качества?
Хуже, понятное дело.
> прям сильно сокращает расходы по памяти
Да
> но что насчёт качества
Да
Перечитай, выше все написано.
https://www.reddit.com/r/LocalLLaMA/comments/1f3beo6/i_made_a_game_where_you_guess_what_todays_ai_can/
> I made a game where you guess what today’s AI can and can’t do
> https://theaidigest.org/ai-can-or-cant
> I made a game where you guess what today’s AI can and can’t do
> https://theaidigest.org/ai-can-or-cant
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
> UGI: Uncensored General Intelligence. A measurement of the amount of uncensored/controversial information an LLM knows. It is calculated from the average score of 5 subjects LLMs commonly refuse to talk about. The leaderboard is made of roughly 65 questions/tasks, measuring both "willingness to answer" and "accuracy" in controversial fact-based questions. I'm choosing to keep the questions private so people can't train on them and devalue the leaderboard.
> W/10: Willingness/10. A more narrow, 10-point score, measuring how far the model can be pushed before going against its instructions, refusing to answer, or adding an ethical disclaimer to its response.
> Unruly: Knowledge of activities that are generally frowned upon.
> Internet: Knowledge of various internet information, from professional to deviant.
> Stats: Ability to provide statistics on uncomfortable topics.
> Writing: Ability to write and understand offensive stories and jokes.
> PolContro: Knowledge of politically/socially controversial information.
> UGI: Uncensored General Intelligence. A measurement of the amount of uncensored/controversial information an LLM knows. It is calculated from the average score of 5 subjects LLMs commonly refuse to talk about. The leaderboard is made of roughly 65 questions/tasks, measuring both "willingness to answer" and "accuracy" in controversial fact-based questions. I'm choosing to keep the questions private so people can't train on them and devalue the leaderboard.
> W/10: Willingness/10. A more narrow, 10-point score, measuring how far the model can be pushed before going against its instructions, refusing to answer, or adding an ethical disclaimer to its response.
> Unruly: Knowledge of activities that are generally frowned upon.
> Internet: Knowledge of various internet information, from professional to deviant.
> Stats: Ability to provide statistics on uncomfortable topics.
> Writing: Ability to write and understand offensive stories and jokes.
> PolContro: Knowledge of politically/socially controversial information.

Что-то больно дохуя больших локалок повыходило в последнее время. А с мультилингвой у них как? В что-нибудь типа пикрил сможет хоть одна? Интересуюсь практически.
https://huggingface.co/Sao10K?sort_models=created#models
У него тут куча новых моделей, новая L3.1-70B-Euryale-v2.2 и мелочи полно
У него тут куча новых моделей, новая L3.1-70B-Euryale-v2.2 и мелочи полно
>У него тут куча новых моделей, новая L3.1-70B-Euryale-v2.2 и мелочи полно
Как она кстати, лучше Магнума или хуже?
>логика людей хорошо формализуется на X и Y вместо конкретных слов. А вот что за X и Y - нужно уточнять для каждой конкретной темы.
Нейронки к дедуктивной логике пришли через индуктивную (предсказания на основе данных), то есть по большей части "интуитивно". Это факт, об этом говорили сами разработчики изначально ещё во времена Gpt3. "Мы удивились тому что нейросети неожиданно сами научились логически рассуждать"
Так что хуй ты оторвешь умение логически рассуждать о знаний. Они через эти знания к этому умению и пришли
>А у нейросети никакой логики нет вообще.
Ахах, пиздец. В формальную логику они могут лучше чем ты, это уже давным давно закрытый вопрос, отрицают это только шизы
> типа пикрил
Бредогенератор с непонятным шрифтом? Такое ещё лет 5 назад умели.


сука ну я просто в рот ебал этот кал. сидел с месяц на L3-12B-Lunaris-v1. все было ок. оно конечно иногда обсиралось и тупило и иногда лупилось но писало +- нормально. вчера зашел на доску увидел как хвалят mini-magnum-12b-v1.1 и думаю ну скачаю попробую. запускаю и кобальд вылетает. хуй с ним обновлю. обновляю запускаю вроде все завелось но ебнврот. пик 1 как оно писало до и пик 2 как генерит сейчас. каждое ебучее предложение начинается с ана\ее. блядь ну что за хуета то сука
дополню что сейчас оно так пишет что на лунарисе что на магнуме. одинаково хуево.
Почему модель может не дописывать нормально сообщения а обрывать их написав <|eot_ ?
А есть какие-нибудь наборы этих скриптов в сети? Или каждый пишет всё под себя сам?
>. запускаю и кобальд вылетает. хуй с ним обновлю.
Ищи проблему тут а не в сетках
Запускаешь чет не так
Развлекался похожим образом, чтоб сетка писала от лица пещерного человека в стиле угабуга
Было забавно, такое даже ллама3 8b осиливала
Но там конечно запрос был попроще чем твой
Ну у тебя же видно что ты не потёр в истории, и сейчас он специально дописывает <|eot_ <|eot_ <|eot_
Не верь этим шизам, тут полон тред квено-и-магнумо лахты.
Я других персонажей открывал нулевых и на них проверял, с этим ничего не чистил чтобы он не забыл о чем мы говорим.
Обновлял что либо последнее время? Какая модель вообще? <|eot_ <|eot_
Может с настройками беда? <|eot_ <|eot_
Я переходил на 8B Stheno и ставил под него настройки, а сейчас опять 7B EndlessRP подрубил и он начал такое выдавать. В том и проблема что я многое менял за это время и методом тыка определять это такое себе.
Скорее всего действительно с пресетами проблема, попробуй их сменить <|eot_ <|eot_
>даже ллама3 8b осиливала
>аутентичный древнерусский 12 века почти без анахронизмов
>в стиле угабуга
Ладно, я нашёл конечно где спрашивать.
так оно же заработало только теперь оно все хуево работает блядь.аааааа блядь я просто рот ебал
да господи ну не сидеть же на одной сетке все время.
Меняю, не помогает, похоже проблема в настройках кобольда.
Вот ведь падлюка!
Стено охуенный, но эндлессрп просто отбитый наглухо ебанат вообще без тормозов, не хочется его терять.
> Перечитай, выше все написано.
Ты про то, как работает квантование? Мне больше интересно, как конкретно этот параметр влияет на качество, желательно с метриками.
Я нагуглил вольное определение в реддите:
> KV cache = key value cache, its a cached copy of previously computed data (think responses) so that the LLM doesn't have to do the time and labor intensive calculations for each and every token even if that token was just used previously and the LLM still "knows about it"
> quantizing the KV cache is the same thing we do to the LLM models, we take them from their full precision (float 16) and knock off a certain number of decimal places to make the whole model "smaller." you can fit double the amount of q8 "stuff" in the same space as one f16 "thing" and four times as many q4 "things" in that same single f16 "space."
> right now folks run quantized models but the KV cache is still full precision, what they are doing here is also quantizing the KV cache so that it doesn't use as much space, meaning you can fit more of the actual model into the VRAM (or system RAM or where ever)
Таким образом, речь идёт о квантовании хранимого контекста. И действительно, если выставить q8, можно прямо в 2+ раз больше уместить контекста без потери производительности, что звучит очень сочно. При этом я прямо сходу какого-то сильного ухудшения качества не заметил. Конечно, я могу и буду пробовать ещё, но вдруг кто-то уже поел достаточно этого кактуса и готов выложить все подводные?
Вот ведь ебаный пидор! Я уже даже нихуя не понимаю это системная ошибка или он просто сраный мудень, пиздос!
Уже все настройки сбросил до дефолта на котором он раньше нормально работал.
> ну не сидеть же на одной сетке все время.
Все равно лучше Мику ничего нет. Так что сидеть, пока не завезут что лучше.
Здарова, аноны! Вижу, что здесь обитает как минимум один теславод. Есть мать и 2 зеона 2670в3, 2060 на 12 гигов, взял на авито теслу К80 на 24 гига. Чего мне ждать от нее? Какие подводные? Смогу завести с разъема питания проца? Охлаждать думаю, сняв кожух и прилепив 2 кулера.
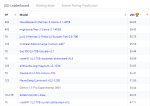
L3-70B-Euryale-v2.1 выше чем magnum-v2-123b можно закрывать
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества. В версии Llama 3.1 контекст наконец-то расширили до приличных 128к, теперь хватит всем!
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGUF и EXL2, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGUF весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/second-state/Mistral-Nemo-Instruct-2407-GGUF/blob/main/Mistral-Nemo-Instruct-2407-Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках подходящий пресет. Для модели из инструкции выше это Mistral
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус до 1 февраля 2024 года
https://huggingface.co/LoneStriker, https://huggingface.co/mradermacher Новые поставщики квантов на замену почившему TheBloke
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://github.com/Mobile-Artificial-Intelligence/maid Запуск самой модели на телефоне
https://github.com/Vali-98/ChatterUI Фронт для телефона
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard Сравнение моделей по (часто дутым) метрикам (почитать характерное обсуждение)
https://chat.lmsys.org/?leaderboard Сравнение моделей на "арене" реальными пользователями. Более честное, чем выше, но всё равно сравниваются зирошоты
https://huggingface.co/Virt-io/SillyTavern-Presets Пресеты для таверны для ролеплея
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
https://rentry.co/llm-models Актуальный список моделей от тредовичков
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: