



Какая нынче модель самая лучшая? Пока остановился на Llama-3.1-70B-Instruct-abliterated.
> то чтобы ты понимал приоритеты.
Они довольно странные и их сложно понять, ведь строительство дома начинают с фундемента, стен, крыши, а не выкладывания узоров из паркета. Но жираф большой, ему видней, есть шанс что после пробежки по граблям придешь к дефолту, или имеющегося хватит для исследований.
> Я ссылку на архив орг принёс, тебе мало?
Речь о том что в оригинале случай для подобного распределения довольно специфичный и нужен для наглядной иллюстрации их подхода. В сценариях использования распределения могут быть другими. Перед тем как слепо верить графикам и кускам нужно их понять и ознакомиться хотябы с тем что сам приводишь в цитату.
> А задача "написать пост" обычно ставится в начало.
Современные промтоконструкции довольно комплексные и популярным подходом является деление их на части.
> Напрямую связано. А вот промпт инжиниринг к шифтам уже никак не относится.
Ерунду пишешь или не понял вообще. Если у тебя вместо промта будет невнятный шмурдяк - то и на выходе будет параша, особенно дополнительно поломанная костылями. Именно соблюдение структуры и формата должно диктовать применение методов склейки, сдвигов, просто формирования промта для обработки с нуля и т.д.
Файнтюны мистраля 123, рефлекшн может быть хорош.
Magnum-v2-123b
По срачу с приоритетом внимания на токены. Напоминаю, что самым первым токеном всегда идёт BOS токен, так что шатали нейронки ваши инструкции.
>Файнтюны мистраля 123, рефлекшн может быть хорош.
Поддвачну, годная штука, лучшая нейронка в попенсорсе на данный момент.
>Файнтюны мистраля 123, рефлекшн может быть хорош.
Поддвачну, годная штука, лучшая нейронка в попенсорсе на данный момент.
Смотря для чего, для кодинга из открытых меня устраивает только Mistral Large 2, но все равно хуже чем GPT-4o или Claude Opus/Sonnet 3.5. Для RP использую Command-R+ меньше лупов чем у Llama 70B и лучше следует инструкциям + менее цензурирован. Моя основная рабочая модель (ассистент) это Гемма 29B, хотя Nemo тоже неплох.
> хуже чем GPT-4o
> для кодинга
Чмоню в кодинге даже какой-нибудь дипсик 7б обоссыт, покайся.
А так по моделям базу выдал, разве что для рп и части нлп задач мелкий коммандер вполне себе хорош.
> Чмоню в кодинге даже какой-нибудь дипсик 7б обоссыт
в моих юзкейсах нет: scala + spark
но Claude да, чувствительно лучше
> GPT-4o или Claude Opus
Толсто, они в код вообще не могут. А по знаниям API их Yi Coder раскатает в сухую.
> лупов у Llama 70B
Ясно.
> Command-R+
> лучше следует инструкциям
Это вообще пиздец шиза.
> Толсто, они в код вообще не могут
У тебя какой тех. стек? Очень странный тейк
> Ясно
Попробуй порп'шить с лламой сам увидишь
> Это вообще пиздец шиза
Command-R+ в каком-то смысле на любителя, но мне сильно зашел для RP
у этого треда с сhatbot тредом сильное пересечение?
вы для чего локалки используете? кроме кума с ботами
вы для чего локалки используете? кроме кума с ботами
>у этого треда с сhatbot тредом сильное пересечение?
0 пересечение. Там анальные рабы корпораций и жопофлаги проксихолдеров, а тут локалкобояре.
>кроме кума с ботами
Кроме кума ни для чего. Хотя по сути локалки могут всё.
> Очень странный тейк
Можешь не отмазываться. Когда ты назвал Опус сразу стало понятно что ты ничего из этого никогда не трогал.
Кодить, рубрика эксперименты, задавать тупые вопросы, немного в скриптах и программах, тупо чат бот но локальный и без цензуры
Но в основном тут кумеры, конечно
Пересечение хз, тут промпты проще, нет джейлбрейков и другой хуиты
Общий навык промпт инженеринга и работы с сетками, разве что
> в моих юзкейсах
Вот же больной ублюдок. Но тут действительно не поспоришь, у 7б да и прочих банально может не быть знаний про это.
> Claude Opus
> они в код вообще не могут
Вот это толсто
Там пердолятся с проксями, отдельные господа обмазываются промт инженирингом и всякими конструкциями на фоне запредельного шизослоупа и срачей. Здесь пердолятся с запуском локальных моделей, обсуждения идут с небольшим упором на код и математику, есть дискуссии про железо, промт инжениринга меньше но местами бывает более продвинутый. Шизы также очень много, просто если в кончай треде много разных вниманиеблядей, то здесь особенные шизофреники решают проблемы вселенной не привлекая внимание санитаров, а другие братишки ведут аутотренинг в оправдения своих решений ранее и текущей действительности.
В целом, если хочешь получить ответ на общий вопрос - задавай и там и там, аудитория мало пересекается и ответить могут в обоих тредах но здесь лучше
> для чего локалки используете?
Массовый нлп, кодинг, просто рп без кума.
> Когда ты назвал Опус
Наверное каждый сходит с ума по своему. Я с Yi не работал, но DeepSeek coder пробовал и он хуже чем GPT или Claude. Тоже самое могу сказать про Llama 70B и Mistral Large 2. Приведи хоть один пример, где другая модель рвет GPT или Claude, даже любопытно.
> Массовый нлп
а это что такое?
>строительство дома начинают с фундемента, стен, крыши
А потом приходит заказчик и пиздит строителей ногами. Потому что по ТЗ это дом на колёсах.
>популярным подходом является деление их на части
Это понятно. Но также популярным является то, что инструкция идёт в начале. Если она идёт в конце, то кеш нужно пересчитывать с каждым отправленным сообщением. Можно, конечно, шизика включить, сохранить кеш для промпта отдельно, а то и для каждого сообщения независимо, и собирать из кусков на лету, но это совсем пиздец. Вряд ли так делает хоть кто-то. А ждать пересчёта каждый раз - хуйня полная.
>Если у тебя вместо промта будет невнятный шмурдяк
Ломание промпта\формата шифтом - шиза натуральная, этого не происходит.
На правах рофла. НейроЛингвистическое Программирование. Ты заходишь в тред - тебя называют шизом и говорят, что все твои проблемы это скилл ишью. Так происходит раз за разом. В какой-то прекрасный день ты начинаешь верить, что ты шиз и все проблемы от отсутствия скилла.
А вообще Natural Language Processing. Обработка естественного языка. В любых формах.
> А вообще Natural Language Processing
как раз, что такое NLP я знаю, но почему "массовый"?
> Ты заходишь в тред - тебя называют шизом
Без рофла, реально первое, что мне написали тут
Здарова садипары
как рефлекшн для кума?
После фикса - серит тегами в рп. До фикса было норм.
Natural language processing, переработка текстов, предложений, описаний согласно заданным инструкциям.
> Потому что по ТЗ это дом на колёсах.
Если тз появляется когда дом уже готов - заказчик идет нахуй, лол.
> Если она идёт в конце, то кеш нужно пересчитывать с каждым отправленным сообщением
Почему? К десятку-сотне новых токенов добавится еще один пост, а основной кэш не затронут, пренебрежимо.
> ждать пересчёта каждый раз - хуйня полная
Так вокруг этого все и вьется же изначально, офк релевантно не везде. Полный пересчет неизбежен только если идут мультизапросы и изменением как раз инструкции в самом начале, а не только дополнительного куска в конце.
> шифтом
Причем тут шифт если ты сшиваешь франкенштейнов по краям бедер, вместо того чтобы сделать незаметную обрезку по границам постов обеспечив структуру? В текстовом виде или в токенах - совершенно не важно. Как раз даже при абслютно идеально работающем шифте неудачный стык все может поломать.
> почему "массовый"
Потому что измеряется сотнями тысяч.
> реально первое, что мне написали тут
Лол, наверно выдал что-то что обычно пишут всех доставшие поехи.
жду квантованную до 1bit чтобы кумить на своей 1050ti
> Потому что измеряется сотнями тысяч
Понял
> что обычно пишут всех доставшие поехи
Написал, что мне нравится Claude для кодинга. Я так понимаю в треде про локальные модельки это считай еретичество
Тогда уж жди нормальной BitNet модели, в теории должно работать, но как я понял тренить такое не очень выгодно.
> нравится Claude для кодинга
Она не может не нравиться, ведь действительно хороша. Но, вероятно, есть задачи с которыми плохо справляется.
> это считай еретичество
В целом похуй, особенно сейчас, когда локалки на оче высоком уровне. Если их попердолить также, как извращаются с коммерцией (а там больше ничего и не остается), особенно с учетом влияния цензуры, то и результат можно получить более чем приличный.
Кмк, чего реально не хватает - восприятия пикч как в опуще, тут или отличное зрения для форм, текстов и всякого но лоботомия по нсфв, или понимание этого но общая тупость и слепошарость.
> особенно сейчас, когда локалки на оче высоком уровне
Смотря какое у тебя железо. Если у тебя Mac Studio 192GB, то да, ты можешь на нем условный Mistral Large гонять, но когда у тебя в лучшем случае 24GB VRAM, то выбор сильно сужается. Хотя для базовых каких-то вещей терпимо.
Смотря какое у тебя железо. Если у тебя Mac Studio 192GB, то да, ты можешь на нем условный Mistral Large гонять, но когда у тебя в лучшем случае 24GB VRAM, то выбор сильно сужается. Хотя для базовых каких-то вещей терпимо.
> тренить такое не очень выгодно
почему?
>Если у тебя Mac Studio 192GB, то да, ты можешь на нем условный Mistral Large гонять
Кстати интересно, какая там будет скорость.
>После фикса
Что за фикс?
>условный Mistral Large гонять
Гоняю 123B на 12 гигах врама, ебало?
>Гоняю 123B на 12 гигах врама, ебало?
Тоже гонял 123б на 12 и 64 оперативы в 3 кванте. Было где-то пол-токена в секунду.
В теории, для маленького контекста терпимая, но вот с увеличением контекста будет совсем плохо, с другой стороны тут люди гоняют 100B+ модели на 12GB VRAM со скоростью 1 токен в десятилетие , поэтому наверное вопрос восприятия
>Было где-то пол-токена в секунду.
У меня от 0,7 до 1, благо DDR5 и почти самая быстрая на свете 3080Ti.
Ну у меня всего-лишь 3060 и рузен 5700х, с мамкой которая даже не может 64 гига вытянуть на штатных 3600, и приходится на 3333 гонять.
Для кодинга дипсик, если большой уж, че уж. =)
Мистрал 123b в Q3_k_s веселее L3.1 70b Q4_k_l?
> Смотря какое у тебя железо
Верно подметил, для норм пользования больших моделей нужно хотябы пара некротесел, и то это ряд компромиссов.
> но когда у тебя в лучшем случае 24GB VRAM
Сейчас есть гемма и коммандер, приличные модели для 24гб.
Попробуй и то и то. На самом деле мистраль не то чтобы перформит в (почти) 2 раза лучше, просто хорошая модель.
Кумеры, помогите. Гонял гемму 27 и нового командер 35, всё было нормально до момента пока я не попробовал карточку психа садистка, которого я начал пытать. Вместо ярости, попыток выбраться, или хотя бы какой-то реакции пошли простыни текста о том как его внутрении мир нарушен и как ему плохо, и из такого состояния он не выходит даже после условного освобождения. Попробовал ещё несколько карточек, даже доработал на большую активность, но как только дело доходит до смены роли на обратную, то всё, хнык хнык, плак плак, {{user}} плохой. Фаинтюны от драмера так не клинит, но они просто шизанутые. Есть ли что-то в условном размере 25-35 что не скулит как побитая сука, а борется за себя и свою точку зрения/жизнь, не впадая в катарсис?
>Гоняю 123B на 12 гигах врама
Какой квант? Тут даже первый не должен влезть.
мимо-боюсь-запускать-123В-на-24Гб-Врам
Ебаный реинтери забаненный с какой-то из сторон, заменить на что-нибудь другое!
Сейчас как-то более усиленно начали банить всё подряд. Давно уже пора собственный VPN заиметь.
А пока можешь поставить от эту хуйню: https://topersoft.com/programs/launchergdpi
И сделать вот это для хрома:
Введите в адресной строке браузера chrome://flags/ и нажмите Enter.
Найдите Kyber:
Измените у TLS 1.3 hybridized Kyber support значение с Default на Disabled.
Мне помогло от всей хуйни.
Что по карточкам не от хуанга, они хуже работают с нейрсоетями или как? У какого-нибудь Intel Arc A770 или радевона rx7600 16гб врама а цена почти на 20к меньше чем у 4060 с теми же 16гб. Если новые рассматривать а не отмайненные с авито, естественно.
проблема радеонов в том, что чаще всего нужно искать отдельный форк софта. А под интеловский апи вообще почти ничего мэйнстримного нет, вроде бы.
Про интел ХЗ, а вот про радеоны могу сказать что тебе понадобится линукс. ROCm, альтернатива CUDA от красных, работает только на нём.
Есть ещё Vulkan, встроенный в кобольд, но по скорости он сосёт.
Если карта новая то особых проблем возникнуть не должно, угабога сама всё накатывает, но всё равно остаётся вероятность что что-то отвалится и не будет работать.
> ROCm, альтернатива CUDA от красных, работает только на нём.
Херню сказал. Что рокм кобольд есть под шиндовс, что СД через злуду.

Эх, а я надеялся...
>Что по карточкам не от хуанга
mi50 instinct
>реально первое, что мне написали тут
В каждой шутке - доля шутки.
>сли тз появляется когда дом уже готов
Это был намёк на то, что твои представления о "самом необходимом" субъективны.
>К десятку-сотне новых токенов добавится еще один пост
Не совсем, потому что инструкцию нужно будет каждый раз удалять из кеша, делать смещение постов и засылать инструкцию заново. Технически это как раз одноразовые посты. Это обрабатывается медленнее.
>сделать незаметную обрезку по границам постов обеспечив структуру
Подозреваю, что это намного хуже. При частичном удалении практически всегда остаётся кусочек предыдущего поста + ответ на него. Что даёт минимальный контекст. Если удалять по постам, то будет ответ на полностью удалённый пост, который оказывается нерелевантным и будет сбивать нейронку с толку.
Если просто ллм запускать через кобольд-рокм/лм, у радеонов нормальная скорость. Там проблема если нужно что-то большее, например тренировка через популярный софт, а не ручное написание скриптов под собственноручно подобранные пакеты.
>mi50 instinct
Карта из под майнеров с авито без видеовыхода? А в игрульки как играть, если она вдруг не сгорит сразу же?
"Нормальная" это сопоставимая с хуанговскими, или "нормальная" это "ну так, ну в принципе подождать немного не так уж и страшно, подумаешь 3 токена в секунду, все не так плохо..."?
Что условно лучше себя будет показывать в кобольде, rtx 3060 с 12гб или radeon RX 7600 XT с 16гб? Цена практически одинаковая.
>Какой квант?
3 же, меньше жизни нет.
>Тут даже первый не должен влезть.
А я и не пытаюсь запихнуть всё во врам.
Замени интернет провайдера и страну проживания, у тебя тухляк попался.
>А в игрульки как играть
Думаю так же, как и на других картах без видеовыходов, с выводом изображения через встройку, благо шинда к десятке научилась это делать без ебли.
>Карта из под майнеров с авито без видеовыхода
Лол, туда ли ты зашёл петушок, если тебя пугает подобное?
>А в игрульки как играть
Для Р40 есть гайды, тут нет, но в теории также: Выбираешь в настройках приложения нужный видеоадаптер и вперёд.
>Думаю так же, как и на других картах без видеовыходов, с выводом изображения через встройку
Но ведь у меня рязань от амуде...
>3 же, меньше жизни нет.
Тогда ты не на 12Гб врама крутишь, а на оперативке с процем, что немного другое и от количества врама не сильно зависит.
это как если бы ты с двумя 4090 хвастался что тебе 8Гб ОЗУ на любые нейронки хватает

>Но ведь у меня рязань от амуде...
У меня тоже и чё?
Обнови амудю, в последних таки есть дефолтная встройка.
>Тогда ты не на 12Гб врама крутишь, а на оперативке с процем
И там тоже. Но врам таки ускоряет, и чем его больше, тем лучше.
Какой скор у новой лламы на арене?
Я ебу чтоли? У меня рх6600, я только про него могу сказать.
АМ5? У АМ4 не было встройки, если не Г.
На 8 гигов? Ну так сколько у тебя токенов на какой модели? Я сравню со своей 1660с. У меня с 8к контекста на L3-8B-Stheno-v3.2-Q8_0-imat 3-4 токена в секунду, на L3-8B-Stheno-v3.2-Q6_K-imat 8-9.
Я в мухосрани и проверить что там жадный перекуп пытается мне впарить возможности нет, а по почте не то что отмайненная, вообще мертвая может сразу прийти и не проверишь.
>АМ5?
Лол. AM4 5600X + RX580 на райзере болтается.
В единственный слот для видимокарты вхерачена Tesla P40, также без видеовыхода. Полёт нормальный!
>Я в мухосрани и проверить что там жадный перекуп пытается мне впарить возможности нет
Те же проблемы у тебя могут быть с любым заказанным по почте БУ железом, но если не хочешь переплачивать надо идти на риск.
У серверных железяк тут одно преимущество - не так то просто их убить.
Какие параметры? Hermes-3-Llama-3.1-8B.Q5_K_M, 8192, без ммк, с флэшаттеншн 8.75. Больше чем ку5 у меня нет моделей.
С ммк и аттеншеном, 28 слоев на видео, пусть походу они все и не влезают но если уменьшать то становится медленней. Ну как-то так себе у тебя, учитывая что у меня на 6 гигах Q6 даже 10 токенов порой выдает.
>Те же проблемы у тебя могут быть с любым заказанным по почте БУ железом
Поэтому железо дороже 5к не заказывал никогда.
>но если не хочешь переплачивать надо идти на риск.
Ну хуй знает, наебут всего один раз и даже если второй раз не наебут ты уже заплатишь полную цену нового за хуй знает что бушное, такое себе казино.
У тебя там волосы из радеона растут.
>со своей 1660с
>L3-8B-Stheno-v3.2-Q8_0-imat 3-4 токена в секунду
А хули тут так мало? Думаю взять что-то дешевое, но чтобы по чипу было быстрым, смотрел на 16хх. Вроде, за такой бюджет особо не разгуляешься, но мало ли.
>а по почте не то что отмайненная, вообще мертвая может сразу прийти
Купил на авито p104-100, пришла мёртвая, продавец говорит, что отправлял не он, взяли не ту карту и т.д. Мысленно забил на эти 2.5к и отправил ему карту обратно. А он взял и отправил мне деньги.
Сейчас попробовал прогнать Q6 без ммк - 2 токена в секунду, пиздос. Контекст в 5 раз дольше корячит.
>А хули тут так мало?
А вот так вот. В принципе жить можно, но так себе. Q6 уже нормально работает на почти 10 токенах в секунду, но он заметно тупее.
И это я говорю про максимальные показатели, он порой на Q8 и до 2 токенов падает.
Какая нахер разница 6 или 8, если у 6600 128бит шина с 1.5 раза меньшей пропускной способностью памяти, чем у 1660с, в которую все упирается? У меня утилизация процентов 20 на гпу во время бенча.

Сейчас даже хуже почему-то работает, вот прогнал 2 раза Q6, результаты не оче.
Перемерил под шиндовс(хермес под линупсом был) с L3-8B-Lunaris-v1-Q5_K_M.gguf, 8192, ммк, флэшаттеншн, ~10т/с.
>У тебя там волосы из радеона растут.
Это шерсть кота.
Тебе с такими суевериями прямая дорога в DNS где тебе также завернут прогретое в духовке б/*у говно из под майнеров под видом новых, но зато "гарантию" выпишут
Тестирую модели через OpenRouter и только Claude, GPT и Gemini могут в хороший русский. Все тут хвалят Command-R+ и Gemma 27B, но они пишут достаточно плохо, как-буто через гугл транслейт пропустили, даже хуже, наверное.
Что я делаю не так?
(Написал ранее в соседний тред, но меня там опустили за использование "лоКАЛок")
Что я делаю не так?
(Написал ранее в соседний тред, но меня там опустили за использование "лоКАЛок")
>только Claude, GPT и Gemini могут в хороший русский
Мистраль Немо даже 12В тоже может.
Там же качество совсем плохое.
Немо иногда даже путает спряжения.
Может я неправильный форматтинг использую, я выбираю в Таверне шаблон для конкретной модели (или вендора модели)
Проблема с этими домашними серверами для ЛЛМ только одна - всегда хотя бы немножко не хватает. Хорошо наверное нынче только владельцам ригов от 4x4090 и выше. Ну или кто плюнул на всё и арендует по потребностям.
> Не совсем, потому что инструкцию нужно будет каждый раз удалять из кеша
Ну смотри, вот у тебя группа системного промта с описаниями, десятки-сотни потов, потом инструкция/префилл и ответ сетки. Юзер отправляет новый пост, получается все то же что и было, но без инстракции/префилла, а к ним добавляется ласт пост сетки, пост юзера и новая инструкция. Обсчитывать нужно только их что пренебрежимо мало, а не все разом. Офк на нищебродском треше типа кэмлера/максвелла где эвал измеряется десятками токенов это может добавить несколько секунд, но в реалистичном кейсе даже заметить не получится.
> каждый раз удалять из кеша
Не удалять а делать проверку совпадения с самого начала, останавливаясь на месте с которого идут различия. Собственно так во всех лаунчерах кэш и реализован, емним там просто прямая сверка токенов и обсчет с момента различий. Хз почему это должно обрабатываться медленно.
Если пытаться сохранить кэш последующих активаций - полезут новые стыки и потенциально новые проблемы, придется усложнять поиск и т.д., едва ли оно того стоит.
> практически всегда остаётся кусочек предыдущего поста
Оборванная посреди слова невнятная фраза даже без указания откуда она появилась и кем сказана, а то и вообще является частью системного промта. Это никак не "повысил релевантность" а наоборот будет мешать и отвлекать.
Уже проходили на заре локалок и корпоративных, писали примитивные прокси что будут этим заниматься и правильно промт оформлять пилили и получали радикальный буст по сравнению с "хуяк хуяк и в продакшн как получится".
Офк чтобы было совсем хорошо, постам должен предшествовать суммарайз и тогда все отлично складывается. Его обновлять одновременно со смещением истории для формирования буфера под новые посты - и все в ажуре.
Вот готовое решение которое реализуется за пару вечеров дополнениями к таверне без низкоуровневого пердолинга, и совместимо с чем угодно, делай - не хочу. Офк тебя не агириую, вижу что другая цель управлять поездом и она понятна, пердолиться с внутрянкой и что-то новое реализовывать - интересно. Но потом не пеняй что не предупреждали про пробежку по граблям.
Ты просто в псп упираешься. Не гонял модели, которые полностью в память влезают? Я думаю взять её под 2b модель.
>Это шерсть кота.
Вынь кота из радеона.
>прямая дорога в DNS
А у них есть в наличии? Я думал, там давно по всем позициям "нет в наличии", потому что отнесли продавать на авито "с гарантией из днс".
Ну хуй знает, у меня либо "хватает впритирку", либо "не хватает где-то 1000% мощностей".
>прямая сверка токенов и обсчет с момента различий
Так это кал. Если гоняешь жсон между бэком и фронтом, особо по-другому и не сделаешь. Это не значит, что это хорошее решение, это говнище.
>дополнениями к таверне
Так таверна это тупой фронт, если уберу у себя рисование постов и выведу API наружу - вот тебе и таверна. Все фичи всё равно остаются в бэке, разве что разбираться со случаями, когда таверна ломает историю. То есть мне придётся делать всё то же самое, потому что на стороне фронта нереализуемо либо будет работать суперхуёво. И ещё допиливать совместимость.
А что такое «кум»?
от английского "godfather"

Как на этой картинке?
>Ну хуй знает, у меня либо "хватает впритирку", либо "не хватает где-то 1000% мощностей".
Я о том, что если даже заморочиться и собрать сервер с несколькими картами, то всё одно хоть немножко да будет не хватать. Порой даже не немножко. И тут поневоле думаешь: а может аренда и правда выход? А мелочь можно и на домашнем компе гонять.

>Ты просто в псп упираешься. Не гонял модели, которые полностью в память влезают? Я думаю взять её под 2b модель.
Скачал первую попавшуюся 2bшку, Gemmasutra-Mini-2B-v1-Q8_0, результаты на пике. С настройками ничего пока не менял, может будет и получше если подшаманить, но чет как-то нестабильно все. Первый раз 20 токенов выдало а потом заглохла. Красными линиями разные чаты разделены, так что закономерность вроде как не в том что чем дальше тем медленней.
Но должен сказать кстати что моделька выглядит на первый взгляд неплохо, я конечно пока совсем мало смотрел но пока сомтрится чуть ли не умнее чем L3-8B-Stheno-v3.2-Q6_K-imat.

Поставил в карточке своего персонажа, что у меня краник средний: 13 см. Все модели говорят что это малюсенький....
Странно, я даже когда специально пишу "маленький" почему-то оказывается что у меня огромный хуище. И в нейросетях тоже.
Хотя не, беру свои слова назад, тупорылый он конечно это да... Зато больше 10 токенов в секунду. Но тупой. Или 3 токена в секунду, но умный. Если бы он умный был больше 10 токенов тогда да, а он тупой, ну очень тупой. Но больше 10. А тот умный, но всего 3. Ну очень мало 3... Вот если бы у меня была 4090...
страная хуйня
товерна перестала отправлять в угабугу ответы типо включите режим стриминга
адрес где 5000-апи нне менял
если поставить галку на устаревший стриминг - вобще нечо не отправляет и даж не грузится
никак сообщения не отправляются -
причем внезапно
чо за хуета ???
товерна перестала отправлять в угабугу ответы типо включите режим стриминга
адрес где 5000-апи нне менял
если поставить галку на устаревший стриминг - вобще нечо не отправляет и даж не грузится
никак сообщения не отправляются -
причем внезапно
чо за хуета ???
Бля, последний релиз лламы падает без ошибок, собака
b3681
b3681
Не пизди давай тут. Я когда пытался отыгрывать фембойчика с микрописей мне модель все равно отвечала пастой "омагад итсоу биг энд thick" и в том же духе.
>омагад итсоу биг энд thick
А ты не ролеплей с minor girl, для которых и микропися гигантская.
Я ролплеил с тетушкой у которой пиздища итак была раздрочена по задумке, так что нет. Просто модели не любят харрасмент в любых проявлениях.
просто это заезженный штамп в порнухе, и его одной белкой деталью в промпте не пробьешь
>Просто модели не любят харрасмент в любых проявлениях.
Тут нужно упоминать модель и квант. Умная модель, если и не обратит внимание на размер сразу, то даже намёки хорошо понимает. А уж инструкцию так отлично.
>Просто модели не любят харрасмент
То есть мелкочлен это харасмент, а хьюге хуй это нормально?
Этот прав от части.
>Тут нужно упоминать модель и квант.
Это тут не при чем. Много разных моделей юзал, много разных промтов. Нужно инструкцию более детальную ебашить чтобы пробить этот шаблонный дерти талк, который в целом на все постельные поебушки влияет, а не только на размер члена.
>То есть мелкочлен это харасмент, а хьюге хуй это нормально?
Мне кажется людям с хьюге хуем в целом похуй на то, как их приблуду будут кичить. Это у мелкописюх истерика каждый раз начинается, когда роскошный тринадцатисантиметровой сантиметровый ствол кличут мелким. Мимо обладатель скромного но боевого тринадцатого калибра.
> Так это кал.
> Это не значит, что это хорошее решение, это говнище.
Давай четко аргументировано объясни. Без предубеждений, без обид потому что ты там пердолиться с другим подходом, а нормально.
Это эффективно, это обеспечивает отличную совместимость, это достаточно быстро в задачах когда железо соответствует требованиям и не создает никаких проблем.
> Так таверна это тупой фронт
Как бы сказать то, ничего и близко равного нет с точки зрения функционала и юзабилити. А возможности с внутренним скриптовым языком, что показывал анон в прошлом треде, и тем более экстеншнами выводят ее на следующий уровень.
> если уберу у себя рисование постов и выведу API наружу - вот тебе и таверна
Чел, это то же самое что сказать
> я лепил из песка и говна куличи, а значит архитектор и моя куча ничем не хуже сиднейской оперы
то что ты не понимаешь или не хочешь признавать разницу не значит что ее нет.
> потому что на стороне фронта нереализуемо либо будет работать суперхуёво
Давай и тут, четко, ясно и подробно распиши почему это будет хуже чем твои потуги. Именно нормально и аргументировано а не "ну яскозал". Вот чисто на спор эту штуку сделал бы, но у тебя едва ли найдутся средства или что-то чтобы заинтересовать и просто не сольешься, а без интереса есть чем заниматься.
А потом распишу почему твои шифты будут иметь сомнительную работоспособность и результаты окажутся тупее чем нормальная работа. Вообще, изначально был заинтересован в хоть каком-то успехе, ибо это потенциальное благо для всех, но надежд все меньше.
В таверне тип апи на новый смени.
Я на магнуме 34 сижу....
Нужен ассистенс полному ньюфагу.
Я установил себе таверну, хочу погонять Mistral Nemo Instruct (или надо было выбрать базовую) используя KoboldCpp как бэкенд. Какой API выбрать: Text Completion или Chat Completion?
Я установил себе таверну, хочу погонять Mistral Nemo Instruct (или надо было выбрать базовую) используя KoboldCpp как бэкенд. Какой API выбрать: Text Completion или Chat Completion?
Прошу ответить по делу и без троллинга. Пожалуйста.
LLM можно поднять на рх 580 8 Гб без вдовой ебли?
Я думал, что котируются только карты хуанга, однако мой знакомый запустил всё это чудо на амд, причём она работала с впечатляющей скоростью. Единственный нюанс в том, что у него какая-то дорогая жирнющая карта на 16 Гб и он сказал, что это работает всё только под линуксом. Он также сообщил, что нет нигде четкой инфы, заводится все это дело на моей некрокарте или нет. Кроме пары постов, где какие-то хардкорные линуксоиды что-то напердолили, не дали инструкций для некрокала и были таковы.
Я хочу понять, стоит ли овчинка выделки. Накатывать Линукс, который мне совсем незнаком, читать охуительные мануалы на стопицот страниц для всего этого, ещё и на английском языке — задача для меня та ещё.
LLM можно поднять на рх 580 8 Гб без вдовой ебли?
Я думал, что котируются только карты хуанга, однако мой знакомый запустил всё это чудо на амд, причём она работала с впечатляющей скоростью. Единственный нюанс в том, что у него какая-то дорогая жирнющая карта на 16 Гб и он сказал, что это работает всё только под линуксом. Он также сообщил, что нет нигде четкой инфы, заводится все это дело на моей некрокарте или нет. Кроме пары постов, где какие-то хардкорные линуксоиды что-то напердолили, не дали инструкций для некрокала и были таковы.
Я хочу понять, стоит ли овчинка выделки. Накатывать Линукс, который мне совсем незнаком, читать охуительные мануалы на стопицот страниц для всего этого, ещё и на английском языке — задача для меня та ещё.
> без вдовой ебли?
Нет. С другом всё же придётся поебаться, чтобы он рассказал как на твоём кале что-то запустить.
>Какой API выбрать: Text Completion или Chat Completion?
Text
>LLM можно поднять на рх 580 8 Гб без вдовой ебли?
Попробуй форк Kobold.cpp с поддержкой ROCm
https://github.com/YellowRoseCx/koboldcpp-rocm
Затем в advanced formatting нужно включить instruct mode и выбрать preset mistral?
>выбрать preset mistral?
И пресет мистраль и систем промпт мистраль и токенайзер мистраль. Всё там.
Хуй знает, посчитай, как быстро ты потратишь на аренду бюджет покупки картонки. Зашёл по первой ссылке в гугле, две 3090 это 33 рубля в час, пусть по 4 часа в день будешь арендовать, это 48к в год без учёта колебания курса, потерь на переводах и прочего. Ну и, возможно, это далеко не самое выгодное предложение, чисто беглый взгляд. Cчитать надо, да и вопрос личных предпочтений.
Как-то на самом деле печально очень. Я бы на твоём месте задумался об инвестиции в некруху. В прошлом треде хорошую ссылку постили
https://www.reddit.com/r/LocalLLaMA/comments/1f6hjwf/battle_of_the_cheap_gpus_lllama_31_8b_gguf_vs/
А мелкие модели практически всегда могут быть неплохи только при "знакомом" сценарии. То есть если модель хорошо обучена рпшить в фентези сеттинге - она будет себя плюс-минус неплохо показывать в этом случае. Понятное дело, что логика и т.д всё равно оставляют желать лучшего, но я когда-то находил 7b модели, которые в некоторых сценариях показывали себя лучше, чем 20b. Хотя и безбожно лажали во всех остальных. Теперь на постоянной основе гоняю 34b и он тоже туповат.
>его одной мелкой деталью
>краник средний: 13 см
>мелкой деталью
Лол
>ты там пердолиться с другим подходом
Так я в этом плане могу поддерживать любое поведение, что пересчёт с момента расхождения, что полный пересчёт, что сдвиг контекста. Сдвиг в итоге показал себя лучше всего.
>это обеспечивает отличную совместимость
Вот именно, что это сделано из соображений совместимости. Это ограничение, а не какое-то преимущество. Преимущество это когда ты можешь буквально между генерацией токенов сдвинуть контекст и продолжить генерацию. Бесшовно, без задержек, сохраняя максимальный контекст и производительность.
>Как бы сказать то
Речь не идёт о функционале и возможностях. Таверна это фронт и может делать дела фронта. Это не что-то плохое, это просто фундаментальное отличие.
>Чел, это то же самое что сказать
Ты нихуя не понял. Я открываю API, запускаю таверну и подключаюсь. Всё. Код апи в формате openAI в проекте чуть ли не с первого дня. Только мне интерфейс таверны настолько не нравится, что ебал я его в рот.
>чисто на спор эту штуку сделал бы
Лол, блядь. Ну запили семплинг в таверне. Или без пересчёта кеша регенерацию поста в начале истории. У меня вот ещё идейка появилась с параллельными чатами. К этому дольше интерфейс делать, а функционал в пару строк кода. В таверне это нереализуемо, потому что она фронт. Опять же, я сейчас спокойно сохраняю массивы многомерных векторов в памяти и верчу ими, как заблагорассудится, потому что могу. Нода в этом моменте просто выйдет из чата.
>Cчитать надо, да и вопрос личных предпочтений.
Считай, не считай - дорого при любом раскладе. Раньше хоть на теслы надежда была, сейчас и вовсе никакого просвета. Разве что пару 3090 купить, но это паллиатив не лучше тесл, потому что 123В не входит. Значит три карты, а это два с половиной года аренды - если одна из них за это время не сдохнет. А если сдохнет, тогда ещё больше :) Что там будет через три года - никто не знает.
Почему Магнум 72 через опенраутер отлично работает, а через koboldcpp просто ужасно. Может проблема в GGUF? Попробовать exlm2 через vLLM?
Короче, проблема была в кванте. По ходу, только 8 и 16 работают хорошо. Не понимаю как люди работают с 4 квантами, еще и в более маленьких моделях.
>через три года
Может быть, halo strix окажется чем-то хорошим. Если будет широкая шина, если будет дешёвым, если, если, если. А так вот самый "паллиатив" из паллиативов
https://russian.alibaba.com/product-detail/Jieshuo-RTX-2080-Ti-22GB-Advanced-1600430402549.html
Берёшь 4, получаешь 88 гигабайт vram по цене одной 4090. Рефаб, так что скорее всего живее, чем 3090 с рук, охлад говно, зато живой. Дороже p40, зато с экслламой, памяти меньше, чем у 3090, зато дешевле. Заходить под прокси, покупать через перепуков.
>Берёшь 4, получаешь 88 гигабайт vram по цене одной 4090.
400 баксов за штучку и оно даже не Ампер. Нет, неплохое решение в теории, но хотелось бы отзывов от уже купивших.
после всех доставок и комиссий будет все 500 стоить наверно
> Сдвиг в итоге показал себя лучше всего.
Он так и не появился в массах не смотря на длительные обсуждения, а "у тебя" базовые проблемы, отсутствие понимания основ и примитивные посты, так что не убедительно.
Кэш контекста есть продукт на основе прошлых вычислений. Нельзя сначала обсчитать конец а потом начало, также как и нельзя подмахнуть одно в стык другому без последствий. Наиболее экстремальной иллюстрацией будет задание ультрасоевого промта и кэширование какого-то пошлого запроса к сетке, а потом склеивание его с блядским жб в начале. При смещении там эффект не столь радикальный, но зато регулярный и накопительный будет.
Если бы все было так просто - уже бы давно имели целую базу предложений и фраз под готовый кэш, и работа с ним была бы по совсем иным принципам.
> Преимущество это когда ты можешь буквально между генерацией токенов сдвинуть контекст и продолжить генерацию. Бесшовно, без задержек, сохраняя максимальный контекст и производительность.
В теории да, но отрываясь от реальности можно вообще приказать сетке "накапливать кэш всего" чтобы потом сразу отвечать. Или издать закон о запрете глупых ответов и структурных лупов, ага.
> Я открываю API, запускаю таверну и подключаюсь. Всё.
Это не вяжется с тем что было описано раньше.
> Ну запили семплинг в таверне.
Само изейшество, запрашиваешь логитсы и делаешь простую математику. Но в этом нет смысла.
> Нода в этом моменте просто выйдет из чата.
Не удивлюсь если это вещает адепт клинкода, лол
По существу ни за одно, ни за другое аргументов так и не поступило, чтож, успехов, будем наблюдать.
Добро пожаловать в клуб!
Этих не слушай. ROCm на RX580 не работает, по крайней мере базовый, т.к. поддержку старых карт выпилили. Способ завести есть, но геморный.
Без гемора и ебли ты можешь скачать стандартную версию кобольда, выбрать Vulkan в пресетах и спокойно запускать любую модель в GGUF формате. Скорость будет уступать ROCm, но не на много.
Лучшее, что ты сейчас можешь завести на своей старушке это Mini-magnum-12b в 3-4 кванте. Но если есть быстрая оперативка, можно и на что посерьёзней позариться.
мимо-обладатель-RX580-c-шерстью-кота
>LLM можно поднять на рх 580 8 Гб без вдовой ебли?
Можно. Vulkan, как уже упоминали.
ROCm работает старый, только на linux и только до версии 5.7.*, в 6.0 выпилили.
Более того, и новые версии llamacpp/koboldcpp стали криво собираться под старый rocm в какой-то момент, и это совпало с тем, что я в целом на нейросетки подзабил в последнее время, поэтому не стал пердолиться и чинить. Есть гипотеза, что последняя по-настоящему рабочая версия rocm для 580 - даже 5.6, а не 5.7, но это требует проверки. Изредка вулканом пользовался, и то в последний раз ещё весной, кажется.
Всё хочу глянуть новую гемму 2 и мистраль 12b (на последний особо большие надежды, возможно, это будет как раз тот самый "мультиязычный солар", который я хотел себе ради переводов неплохого качества).
Алсо, вопрос, что-нибудь из нового с распознаванием картинок и чтением текста с них на llamacpp/koboldcpp добавляли за последнее время? Или там всё ещё потолок на уровне llava - распознавание цвета шерсти котиков (правильное в 2/3 случаев)?
Так, братушки, есть вопросец. Есть одна MSI B450 GAMING PLUS MAX на которой я сижу с воткнутым 1660с. Но pci слота на ней два, что если я куплю какую-нибудь p102-100 и воткну во второй слот? Что будет? Комп сгорит? Второй слот вроде как хуже, и вместо pci-ex16 3.0 там pci-ex4 2.0. Оно заработает, будет ли оно быстрее и можно ли раскидать модель на обе карты разом чтобы было еще быстрее и больше врама?

Как думаете, Шумер всех развёл или действительно какой-то обосрамс с весами в HF? С одной стороны в API оно показывает отличные результаты, с другой никто не знает что там в API, может там 405В. Он пока дико отмазывается, говорит скоро переделают, но слухи про скам уже идут. С другой стороны если бы они хотели всех наебать и хайпануть, не ясно как это должно было работать и в чём тут позитив в этой ситуации.


пысаны, смысол на 4060 16 гб есть копить? в игорях она хуета, знаю
в нейросеточках она как? врам много же, и генерация картинок должна нормальной быть по идее, да и в кобольде тоже наверно?
поделитесь размышлениями по этой карточке, пж
в нейросеточках она как? врам много же, и генерация картинок должна нормальной быть по идее, да и в кобольде тоже наверно?
поделитесь размышлениями по этой карточке, пж
>Рефаб, так что скорее всего живее, чем 3090 с рук
Лол, наоборот, лишний нагрев только помешает.
Втыкай, будет лучше. Но у тебя конечно такая некорота, что лучше заменить целиком на 3060 12ГБ или чего получше, нежели чем добавлять ещё большей некроты.
Мне она тоже не показалась умной в еРП, так что да, наёб.
>врам много же
Но медленной.
>поделитесь размышлениями по этой карточке, пж
>сажа
Ты пидар.

>Но медленной.
а есть какие-то статистика бенчмарков по всем карточкам? чтоб глянуть че насколько кто от кого по скорости отстает?
>Ты пидар.
нет ты, бака
В прошлый раз я приносил их в тред когда они стоили по 300, вроде.
>так и не появился в массах
В убе одной кнопкой уже давно. Обнови там говно, на котором сидишь.
>Кэш контекста есть продукт на основе прошлых вычислений.
Ага. Именно это одна из причин, почему шифт работает так хорошо и в некоторых случаях - лучше полного пересчёта.
>Это не вяжется с тем что было описано раньше.
Там буквально об этом. Да, я не планирую такое использование, но ничего нет, что мешало бы.
>Само изейшество, запрашиваешь логитсы
И получаешь скорость 0.1 Т/c. Будет работать суперхуёво, как я и говорил.
>аргументов так и не поступило
Кто же виноват, что ты твердишь одно и то же второй тред, не принимая абсолютно ничего во внимание, потому что оно расходится с твоими заблуждениями? Это только твоя проблема.
Это 16 гб за 50к? Нахуй не нужно.
>а есть какие-то статистика
Там в ТТХ всё видно.
>нет ты, бака
Нет ты. Ещё и мелкобуква. Ещё и точку не поставил. Пиздец короче как таких только земля носит.

>Это 16 гб за 50к?
а че тогда можно взять, чтоб не сильно дорого и чтоб не некроговно на архитектуре ампер/паскаль?
>Там в ТТХ всё видно.
ну а куда смотреть? на пропускную способность? если модель уже вся в памяти, то на нее похуй же? на частоту памяти? а частота чипа роляет?
>Пиздец короче как таких только земля носит.
ну что вы меня кибербоулите...
>сажа
Игнорим.
>Втыкай, будет лучше. Но у тебя конечно такая некорота, что лучше заменить целиком на 3060 12ГБ или чего получше, нежели чем добавлять ещё большей некроты.
Дораха, а я нищий. Я так понимаю сама по себе еще и в хуевом слоте она нахуй не нужна и будет не лучше моей 1660с, вопрос в том можно ли будет использовать их обе одновременно? Чтобы врама 16 гигов было, да и скорость все равно повыше чем у оперативы всяко должна быть.
>можно ли будет использовать их обе одновременно
Можно. Но лучше всё таки продай свою и докинь до нормальной видяхи, будет быстрее.
Понял-принял, я еще и не уверен что бп потянет 2 видюхи... ладно, будем думать значит дальше. Как там вообще, понижение цен размечтался с выходом 50 серии не ожидается?
>понижение цен
Забудь о нём, тем более если зарабатываешь в рублях.
>пысаны, смысол на 4060 16 гб есть копить? в игорях она хуета, знаю
Вот как раз нашёл видео с тестом 6 таких:
https://www.youtube.com/watch?v=Zu29LHKXEjs
Делайте выводы.
Постараюсь правильно донести свой вопрос.
Я думаю что все знают что такое character ai.Мне этот сайт нравится и я часто чатился там. Я сегодня узнал что его скоро или закроют, или будет новая версия которая хуже старой, что то такое. И все это, + ситуация с блокировками и замедлениями различных сервисов меня натолкнули на мысль.
Есть ли простой способ эм...завести такого бота у себя на компьютере?(я даже не могу точнее сформулировать) Чтобы он не зависел ни от роскомнадзора, не от гугла, в идеале даже чтобы и от интернета не зависел, ни от кого. А был лично моим.
Я надеюсь вы поняли что я имею ввиду.
Я полный ноль в программировании. И не понимаю как все это работает. Если вы меня спросите что по твоему такое character ai? То я могу лишь ответить что это сайт где можно пообщаться с ИИ, и на этом все. Поэтому я могу путать термины или даже нести чушь, не судите строго.
Функционал который мне нужен, это создание и редактирование чат бота одного хотя бы, но лучше 2-3. Возможность регенерации сообщений, возможность редактирования сообщений от бота.
1 Насколько это реально для человека полного нуля и что для этого потребуется? (если это важно у меня rtx 3060 12gb, и 32 оперативки в компе.)
2 Если это нереально, то что есть максимально приближенное к тому что я хочу, и максимально простое. А именно тихое место где я мог бы общатся с ботами бесплатно безлимитно и в идеале без цензуры. Что то типа сайта или приложения ,программы/игры где уже все готово и от меня требуется пару кликов чтоб подстроить под себя. Потому что мозгов у меня как у хлебушка.
В общем мне нужен личный аналог character ai, я не знаю как лучше объяснить.
Очень прошу, если кто ответит не используйте сленг и сокращения. Я ж не пойму ничего.
Я думаю что все знают что такое character ai.Мне этот сайт нравится и я часто чатился там. Я сегодня узнал что его скоро или закроют, или будет новая версия которая хуже старой, что то такое. И все это, + ситуация с блокировками и замедлениями различных сервисов меня натолкнули на мысль.
Есть ли простой способ эм...завести такого бота у себя на компьютере?(я даже не могу точнее сформулировать) Чтобы он не зависел ни от роскомнадзора, не от гугла, в идеале даже чтобы и от интернета не зависел, ни от кого. А был лично моим.
Я надеюсь вы поняли что я имею ввиду.
Я полный ноль в программировании. И не понимаю как все это работает. Если вы меня спросите что по твоему такое character ai? То я могу лишь ответить что это сайт где можно пообщаться с ИИ, и на этом все. Поэтому я могу путать термины или даже нести чушь, не судите строго.
Функционал который мне нужен, это создание и редактирование чат бота одного хотя бы, но лучше 2-3. Возможность регенерации сообщений, возможность редактирования сообщений от бота.
1 Насколько это реально для человека полного нуля и что для этого потребуется? (если это важно у меня rtx 3060 12gb, и 32 оперативки в компе.)
2 Если это нереально, то что есть максимально приближенное к тому что я хочу, и максимально простое. А именно тихое место где я мог бы общатся с ботами бесплатно безлимитно и в идеале без цензуры. Что то типа сайта или приложения ,программы/игры где уже все готово и от меня требуется пару кликов чтоб подстроить под себя. Потому что мозгов у меня как у хлебушка.
В общем мне нужен личный аналог character ai, я не знаю как лучше объяснить.
Очень прошу, если кто ответит не используйте сленг и сокращения. Я ж не пойму ничего.
А чем мы здесь по-твоему занимаемся? Все именно как ты описал у нас тут и происходит, 12 гб врама тебе за глаза на простенькую модель хватит.
Раньше в шапке был гайд для хлебушков, теперь его перенесли сюда: https://2ch-ai.gitgud.site/wiki/llama/guides/kobold-cpp/
Там всё верно, кроме предлагаемых моделей, их выбирай тут по количеству доступной видеопамяти и описанию: https://rentry.co/llm-models
Нихуя себе контент, ещё и на русском:
https://m.youtube.com/@razinkov/videos
Там и русский разбор статьи по Llama 3.1
https://m.youtube.com/@razinkov/videos
Там и русский разбор статьи по Llama 3.1
ну там анальник для анальников рассказывает
нам бы калтент, чтоб анальник для кривозубых крестьян рассказывал, чтоб пынятно был
Ещё осталось быдло, сидящее на cai? Я думал мамонты уже вымерли.
Ты про рефлекшн?
Покатал ее в разном рп, она действительно дохуя умная, интересная. В отличии от обычной лламы не теряется и не ловит затупы, на левдсах никакой разницы с сфв. Без дополнительных cot оберток зирошотом хорошо ориентируется в происходящем и даже прошла тест на снятие трусов юзернейм, ты глупый, я уже bottomless.
Но бля, это просто 11 укусов по запросу из 10, количество клодизмов, платиновых фраз и ебучих конструкций
> В убе одной кнопкой уже давно.
Экспериментальная реализация не сыскавшая успехов.
По остальному даже комментировать лень. Успехов тебе, может через пол годика проникнешься и заодно ждуновское бинго вокруг максимализма подлечишь, а то и что-то полезное напердолишь.
> на архитектуре ампер
Да
> не сильно дорого и чтоб не некроговно
Нет
Хорошие тесты. Непонятно только что за факстический бэк в используемой софтине и какой именно там квант. Но ориентируясь на жору и условные 5-6bpw что сожрут всю память - не так уж плохо.
Кстати, какие скорости у теслы на подобных размерах?
В шапке вики и гайды. Ознакомься с ними, начни пускать и задавай уже конкретные вопросы что не понятно или не получается.
Какая-тго вода. Я на перемотке глянул и сразу наткнулся на момент где он не понимает как attention mask работает, какие-то другие матрицы у него аттеншен формирует, лол.
Я сам гуманитарий, просто увидел длинные лекции, да вумные слова и решил что возможно анонам пригодится. Может это и продавец инфо-говна, хз, хотя курсы у него вроде "открытые"
>возможно анонам пригодится.
Пригодится, спасибо.
>какие скорости у теслы на подобных размерах
Сейчас точно не скажу, но сравнимые. Плюс на жоре они ещё и параллелятся - на двух теслах скорость почти удваивается. А в видео с этим беда.
1660c не умеет в нейронки.
Там чуть ли не скорость DDR4 обычной в нейронках, вроде.
> Думаю взять что-то дешевое, но чтобы по чипу было быстрым, смотрел на 16хх.
Потому что чип 16хх не умеет в ллм, не хватает чего-то там, не помню.
> шина с 1.5 раза меньшей пропускной способностью памяти, чем у 1660с
Только вот дело не в шине в случае с 1660с.
К сожалению, щас 6600 не у меня, не могу проверить вот-прям-щас, но 1660с точно не эталон. Что угодно другое — 1070, 2060…
Кстати, P104-100 (1070) выдает 17 токен/сек, вот где-то так должно быть на этом чипе.
Как я писал ранее, две таких тянут немо в 15-17 токенов. Одна, соответственно, 17+ выдает для малых моделей.
Справедливости ради, поебать, гарантия же реально, пихаешь им в ебало и они меняют или возвращают деньги, проблемы?
Уверен, что этот чел троллит.
Невозможно всерьез такую дичь писать.
1660? О_о
Юмор здесь заключается в том, что на одной из фотографий отец и дочь плавают на лодке, а на другой - они сидят на траве. Это создает противоречие между двумя ситуациями, которые кажутся совершенно не связанными. Вторая фотография может быть воспринята как негативная или даже критическая, поскольку она показывает отца и дочь вместе на траве, которая обычно считается местом отдыха и уединения.
Qwen2-VL-2b.
Не поняла.
Ну это же боль, вы угараете!
В прошлом году были 4090 по 60к. Но в Сбере. И в прошлом году. А сегодня 180к. Но в ДНСе и сегодня.
Просто немного теории.
Чат комплишн посылает JSON формат «роль: юзер, сообщение: текст» и получает «роль: ассистент, сообщение: …», а промпт темплейт приделывает сам со стороны бэкенда.
Текст комплишн посылает целиком сразу обработанный текст, который модель просто продолжает. Т.е., промпт темплейт на стороне фронта (таверны).
Второй формат лучше — дает больше свободы тебе.
По сути: хуй знает, в кобольде не гонял.
Можешь попробовать выбрать clblast или вулкан, вдруг на нем будет быстрее.
Вон, посоветовали кобольдспп с росм — возможно, поможет он.
Если все три не прошли, то… ебись, хули.
Я не читаю ваш тред, но меня пугают мысли, как люди вырезают куски контекста и склеивают их. Это ж лютый треш начнется. Там буквально входы-выходы нихуя не совпадают, с точки зрения ллм там шиза в моменте стыка.
ИМХО, гораздо лучше просто кэш контекста с пересчетом (инструкция + немного истории) при достижении лимита.
Я, оказался прав с вулканом. Ура.
Я юзаю Qwen2-VL и охуеваю от качества.
Но ггуф-версий пока нет. =(
Почему не P104-100?
Да, раскидать можно.
Да, грузить будет долго.
Если раскидаешь — контекст будет не быстрый. Если в одну видяху сунешь — то лучше.
18 токенов в немо. Звучит как медленно для цены. Зато одним слотом. Думайте.
> такая некорота, что лучше заменить целиком на 3060 12ГБ
+
Но P104-100 за 2к продаются, а 3060 слегка дороже.
> Ещё и мелкобуква. Ещё и точку не поставил. Пиздец короче как таких только земля носит.
Плюсую. Ахуй.
Нет, видеокарты стоят столько, сколько производительности в них.
30хх поколение не подешевело с выходом 40хх, это 40хх стало дороже.
Это политика компании.
Да, есть, перестать играть в дегенерата и прочитать шапку треда, где есть ссылка на вики, где разжевано все максимально.
Если ты не полный ноль в букваре, то прочесть сможешь.
Буквально два файла скачать, все.
3060 12 гигов база. Смотри в сторону Gemma-2-9b-it или Mistral Nemo 12b Instruction (или их файнтьюнов: Magnum 12b какой-нибудь).
> Но бля, это просто 11 укусов по запросу из 10, количество клодизмов, платиновых фраз и ебучих конструкций
Когда обучали на синтетике. Умная, но есть нюанс…
>2b.
>Не поняла.
Просчитался, но где?
>В прошлом году были 4090 по 60к. Но в Сбере.
С кешбеками считаешь, кешбекоблядь?


>Ну это же боль, вы угараете!
Нет, боль вот. 8B Q8. А что поделать?
> А в видео с этим беда.
У него там какой-то другой софт, ссылки есть, и явно не пытался использовать всякие опции. Видео довольно тягомотное, лучше сразу вот здесь смотреть https://gputests.robotf.ai/PNY_4060TI_16GB_1x_to_6x
> на двух теслах скорость почти удваивается
Алсо, так и не получилось повторить этот эффект, в отдельных случаях действительно наблюдалось ускорение генерации, но процентов на 20 и преимущество терялось при увеличении контекста. Главный буст был при сборке из сорцов по сравнению с готовыми билдами.
> Я не читаю ваш тред, но меня пугают мысли, как люди вырезают куски контекста и склеивают их. Это ж лютый треш начнется. Там буквально входы-выходы нихуя не совпадают, с точки зрения ллм там шиза в моменте стыка.
Абсолютно, о том вся речь.
> ИМХО, гораздо лучше просто кэш контекста с пересчетом (инструкция + немного истории) при достижении лимита.
Ага, именно такое решение и предложено в противовес шифтам и склейкам, к тому же реализуется на стороне фронта. Буфер до пересчета не на одно сообщение а на десяток (такое уже пытались делать в кобольде и был экстеншн к таверне), и запуск эвала в момент начала написания ответа юзером чтобы работал в фоне.
> 18 токенов в немо.
Вроде 26 по тому тесту
> Умная, но есть нюанс…
На самом деле терпимо если нет совсем алегрии, главное что нет бондов и всякого треша, чар инициативничает и не боится нсфв.
> В прошлом году были 4090 по 60к.
Ультишь, были цены типа 180 минус 60 и несколько лотов где за вычетом баллов 90-100к, но те быстро улетели и по отзывам кому-то 4080 присылали.
>Алсо, так и не получилось повторить этот эффект, в отдельных случаях действительно наблюдалось ускорение генерации, но процентов на 20 и преимущество терялось при увеличении контекста. Главный буст был при сборке из сорцов по сравнению с готовыми билдами.
Возможно дело в хорошей шине, но лично мне приходилось отключать ровсплит, чтобы увеличить скорость обработки контекста на двух теслах. Скорость генерации соответственно падала, но итоговый баланс выходил отличным - до 12B_Q8 включительно.
koboldcpp_cu12.exe --usecublas mmq --flashattention , плюс с размером blasbatchsize можно поэкспериментировать - 128 вроде бы лучшую скорость даёт на маленьких моделях. --benchmark тебе в помощь.
>18 токенов в немо
а че за модель "немо"? сколько параметров и с каким квантованием?
Это фишка геммы такая, что она медленная или просто какая-то несовместимость с рокм? Gemma-2-Ataraxy-9B-Q4_K_M.gguf, со всеми слоями только с 2к контекста помещается в 8гб рх6600 и выдает божественные 3 токена в секунду. Тот же мистрал немо к4_к_м с 2к контекста (чтобы поместился весь) выдает 13-14 т/с.
>Только вот дело не в шине в случае с 1660с.
Дело в шине у 6600, а не у 1660с. Даже у этой самой 1070 память быстрее, чем у 6600.
>Справедливости ради, поебать, гарантия же реально, пихаешь им в ебало и они меняют или возвращают деньги, проблемы?
Назначаем экспертизу. Экспертиза длится до окончания срока гарантии, а после выносит решение что случай не гарантийный. Отправляешься в спортлото, оспаривать экспертизу и доказывать что твоя хуйня сгорела не только что.
Какие-то фантазии из нулевых. Я пару лет назад сдавал свою свежую (на тот момент) 2060 из-за того что у нее выход на hdmi коротнуло и изображение перестало выводится. За 2 дня всё осмотрели и вернули деньги. А потом я еще одну 2060 купил.

>пару лет назад
>свежую
>2019 год
Время летит незаметно, верно?
Ах да, ты не заметил, что времена сейчас не те, и гарантии в России по факту больше нет.
>гарантии в России по факту больше нет.
В России нет, в Москве еще осталась.
И целиком доволен!
Свою стиралку за 500 рублей имею, доволен. В)
> по отзывам кому-то 4080 присылали.
Я понимаю, что им потом вернули деньги, но тягомотина была ебучая, конечно. Сочувствую им.
12b, 8 квант.
Ну все мои гарантии обрабатывались быстро.
В Ситилинке тянули, да.
Думаю, от региона зависит тоже, и от людей, как повезет.
>не сыскавшая успехов.
Потому что у них криво реализовано. Нужно делать, как нужно, а как не нужно делать - не нужно.
>1660? О_о
Да я спеки не смотрел. Потом глянул - там совсем печально всё. Хуй знает, что и выбрать теперь, лол.
>Там буквально входы-выходы нихуя не совпадают, с точки зрения ллм там шиза в моменте стыка.
С точки зрения ллм нет разницы, "начинается" у тебя диалог с середины поста или с середины непосредственно, диалога. А если удалять старые посты - оно так и происходит, ты кидаешь нейросеть в омут с головой, где уже произошли какие-то события и история начинается с ответов на несуществующие вопросы. Так и так начинается всё с обрывочных данных, но ллм неплохо с этим справляются. Здесь куда хуже семантический дрифт, но его влияние зависит от миллиона факторов.
>(инструкция + немного истории)
Тогда уже проще суммарайз истории и дроп всего, что не инструкция. Но это по времени инференса может быть не очень, особенно на долгих историях. Можно запилить маяки активаций, расширить контекст х100 практически бесплатно по vram и времени инференса, но это долго, дорого и больно. Можно сделать пересчёт скользящего окна, это, в теории, уберёт дрифт до ничтожно малых величин, хотя и не исключит полностью. Техник, на самом деле, много. Я себе потом точно добавлю экспоненциальное устаревание старых токенов и отрегулирую порционный сброс kv, так ни дрифта не будет, ни разрезанных на куски постов.
>Я себе потом точно добавлю экспоненциальное устаревание старых токенов и отрегулирую порционный сброс kv, так ни дрифта не будет, ни разрезанных на куски постов.
Всё себе? А людям? :)
> С точки зрения ллм нет разницы,
Нет-нет, нифига.
Речь не о том, чтобы отрезать начало и все. Тут вопросов нет.
Идея же в том, чтобы сохранить кэш инструкции (начало), вырезать середину, а потом прилепить концовку. И вот тут получается совершенно пиздец.
Ведь этот текст не обрабатывается с нуля — это именно кэш.
Короче, это бай дизайн будет выдавать дичь, и это выдает дичь. Не вижу противоречий.
> Тогда уже проще суммарайз
Нет, именно что это новая полноценная задача на фуллконтекст, которая жеваться будет очень долго. Именно что проще — при достижении лимита отрезать середину (тут как бы норм), и пережевывать инструкцию + конец. По смыслу то же самое, что и у резальщиков кэша, только теперь не мусор из байтов, а нормальный контекст, пусть и ценой однократной обработки.
А дальше, вплоть до нового заполнения контекста, по классике кэшируем и обрабатываем только новые сообщения.
Да, при этом нет суммарайза, но:
1) Технически вариант корректен.
2) Логически там все на месте.
3) Приемлемая скорость (раз в контекст идет пережевывание небольшого участка).
Не идеал, но остальные варианты сомнительнее.
Ну и можно просто обрезать начало забив на инструкции и надеяться, что модель будет поддерживать стиль и логику чисто по предыдущим сообщениям. =) Самый быстрый способ, я полагаю.
Хотя не силен в этой хуйне.
> С точки зрения ллм нет разницы
Бред.
То что диалог начинается не с какого-то отправного события а уже с каких-то действий, которые потом продолжительно развиваются - сетка переварит спокойно, подобное часто есть в художке. Если перед этим еще будет суммарайз - будет вообще прекрасно и без каких-либо вопросов.
А вот обрывки, кривые склейки, даже косяки форматирования она похватывает и сама начнет их повторять и серить. Кривые активации вне нужной последовательности и все такое - это будет вообще полная шиза.
В aicg уже вообще дошли до суммарайза на лету, чтобы сетке легче было обрабатывать прошлые посты, меньше лупов и эффективнее расходовались посты, и все это чисто на одном фронте. А ты тут "на острие прогресса" такие перлы выдаешь, зато уверенности сколько.
Как Yi Coder в плане секса, брыкается? в плане кода? Лидер теперь? Удалять deepseek-coder-v2:16b?
>Всё себе? А людям? :)
А чтобы людям - нужно влезать в код бэкенда. Во-первых, добавлять фейд старым токенам. Во-вторых переделывать инвалидацию кеша с поиском чего и где фронт удалил. Вот вторая операция мне не нравится, лол. Как и весь этот апи с перегонкой всей истории каждым запросом. Но это уже совсем другая история.
>это бай дизайн будет выдавать дичь
Я это тестил на q4 7b и q6 20b, это не ломается часами на адекватных параметрах. Здесь важно, сколько именно ты удалил. Возможно, сетка выдаёт не такие качественные ответы, как могла бы, из-за дрифта. Но в остальном всё окей.
>при достижении лимита отрезать середину (тут как бы норм), и пережевывать инструкцию + конец
Это как раз пересчёт скользящего окна, только инструкцию можно не трогать, если в ней нет изменений. А пересчёт сделать либо для части сохранившейся истории, либо для всей. Для всей долго, а для части - небольшой дрифт останется всё равно. Ну, можно сделать "для всей - быстро", если резать сразу дохуя, но мне это не нравится. Какой смысл тогда в больших контекстах.
Я же не на пустом месте это взял. Если бы сетка ломалась - сразу бы добавил обрезку по постам, а пока что это отложено в долгий ящик на похуй. Работает - хорошо, потом можно и улучшить, если будет не похуй.
>В aicg уже вообще дошли до суммарайза на лету
Я дошёл до сохранения чатлога в оперативе и поиск на ходу подходящих постов со вставкой в историю, если они уже вылетели из контекста. Просто анонам настолько понравилось обсуждать контекст шифт, что никто не успокаивается, лол.
> deepseek-coder-v2:16b
Это устаревшая модель. Yi явно лучше всех старых дипсиков. Из мелких ещё CodeGeex4 и автокодер нормальные.

>CodeGeex4
На день свежее?
В топе наверное 236B. Не честно.
> Если бы сетка ломалась
Проблема в том что в случае генеративных моделей довольно сложно оценить их перфоманс. В распоряжении только бенчмарки или сравнения, которые не точны, субъективны и компрометируются. Даже просто правильно выстроить процесс тестирования с ними - задача. Или же метрики типа перплексити, дивергенции и прочего, которые не дают должной информации.
В итоге то что поломалось ты заметишь только если там будет полный треш, в остальных случаях под впечатлениям будешь думать что просто модель так работает. Кроме того, даже просто для оценки нужен ОПЫТ В КУМЕ гусары молчать! чтобы примерно знать какое поведение ожидается и отследить что происходит. Обычные модели то нормально отранжировать не можем, только грубые условные топы.
> до сохранения чатлога в оперативе и поиск на ходу подходящих постов со вставкой в историю, если они уже вылетели из контекста
Больной ублюдок, но забавно. Лучше тогда копай в сторону упаковки активаций, как в штуке, что не так давно обсуждалась. Шифт и лепка кэша - херня, но вот с подобным можно попробовать добиться ужатия или суммарайза на уровне внутренностей модели, в общих чертах сохраняя память как у человека с долговременной.
Нужно ли соблюдать синтаксис типа W++, когда делаешь карточку персонажа? Или это плацебо, и прожнг просто в свободном стиле заебенить?
Нужно, если ты сидишь на пигме. Остальным моделям это будет только мешать.
Там нашумевший рефлекшн перевыложили, и судя по моим впечатлениям - охуенчик. Важно то что он признает и исправляет свои косяки. В первый раз такое вижу у лламок, даже чат жпт так не умеет, его хуй собьешь с намеченной тропы.
>это плацебо
Это не просто плацебо, это еще и дорогое плацебо, которое просто так жрет токены.
>просто в свободном стиле заебенить?
Смотря что для тебя свободный стиль. Если юзаешь плейн текст то тут надо быть аккуратным, потому что вероятнее всего модель возьмет оформление карточки за подсказку для форматирования. Будешь писать с ошибками и смысловыми нагромождениями вперемешку с противоречиями - получишь то же самое в ответах.
Тут где то был тред проприетарных, но я хуй знает не нашел, да и мертвый полюбас. В чатгпт треде аноны слишком тупые, а здесь все свои.
Кароч платиновый вопрос: где на халяву попиздеть с топ моделями? Тока без наёбок скамов и телеграм чатов. Я нашел немного легитимных вариков, накидайте если знаете еще.
Текущие топ 3 соат это гпт, клавди и гемини, пральна?
chatgpt.com
5 запросов в два часа или 10 запросов в день или около того, потом дропает на тупую 4о-мини. Бывает дропает после 3 запросов. Я так понял лимиты динамические и меняются постоянно в зависимости от нагрузки.
claude.ai
3-5 запросов в несколько часов, маловато. Опять же динамические лимиты.
aistudio.google.com
2М контекста пацаны, можно всю документацию целого фреймворка туда задампить и пиздеть с ним. Бесплатно 50 запросов в день, вроде. Отличается от консумерской gemini.google.com тем что дает бесплатный доступ к гемини1.5-про, еще можно ползунок цензуры поставить на минимум.
lmarena.ai
Персональный лимит 16 запросов в час до гпт4о. Примерно столько же и для других. Но есть и глобальный лимит для всех на каждую модель 1к запросов в час. Но можно просто переключиться например с гпт4о на клавд3.5 или на старый снапшот того же гпт. Ну и безлимит в арене, но там рероллить надо, и в общем-то получается использовать сайт по назначению. Угрюмый интерфейс, хули окно чата такое короткое? Не надо регаться.
github.com/marketplace/models
Нужно приглашение в бету, я нажал кнопку вейтлист, дали доступ через день. Выглядит шикарно но я почему-то еще даже и не пользовался особо. Хуй знает может боюсь что гитхаб аккаунт нюкнут низашо. Ваще не ебу про лимиты, нигде ниче не пишут. Из умных здесь только гпт4о. И локалки мистраль-ларге-2407 и лама3.1-405б.
Кароч платиновый вопрос: где на халяву попиздеть с топ моделями? Тока без наёбок скамов и телеграм чатов. Я нашел немного легитимных вариков, накидайте если знаете еще.
Текущие топ 3 соат это гпт, клавди и гемини, пральна?
chatgpt.com
5 запросов в два часа или 10 запросов в день или около того, потом дропает на тупую 4о-мини. Бывает дропает после 3 запросов. Я так понял лимиты динамические и меняются постоянно в зависимости от нагрузки.
claude.ai
3-5 запросов в несколько часов, маловато. Опять же динамические лимиты.
aistudio.google.com
2М контекста пацаны, можно всю документацию целого фреймворка туда задампить и пиздеть с ним. Бесплатно 50 запросов в день, вроде. Отличается от консумерской gemini.google.com тем что дает бесплатный доступ к гемини1.5-про, еще можно ползунок цензуры поставить на минимум.
lmarena.ai
Персональный лимит 16 запросов в час до гпт4о. Примерно столько же и для других. Но есть и глобальный лимит для всех на каждую модель 1к запросов в час. Но можно просто переключиться например с гпт4о на клавд3.5 или на старый снапшот того же гпт. Ну и безлимит в арене, но там рероллить надо, и в общем-то получается использовать сайт по назначению. Угрюмый интерфейс, хули окно чата такое короткое? Не надо регаться.
github.com/marketplace/models
Нужно приглашение в бету, я нажал кнопку вейтлист, дали доступ через день. Выглядит шикарно но я почему-то еще даже и не пользовался особо. Хуй знает может боюсь что гитхаб аккаунт нюкнут низашо. Ваще не ебу про лимиты, нигде ниче не пишут. Из умных здесь только гпт4о. И локалки мистраль-ларге-2407 и лама3.1-405б.
Тебе в соседний тред копрофилов. Только там тебя скорее всего тоже наухй пошлют.
> Кароч платиновый вопрос: где на халяву попиздеть с топ моделями? Тока без наёбок скамов и телеграм чатов.
duck.ai
huggingface.co/chat
Было ещё что-то на сайте нвидия. Это без банов по геолокации и прочего соевого фашизма. Если с ВПНом, есть ещё варианты.
Пчел, там всех наебали и доступное апи просто варппер до соннета
>где на халяву попиздеть с топ моделями?
Колаб в шапке чел...

>2М контекста пацаны
Скажем ему?
а также recall vs reasoning и товарищи
Ясен хуй впн есть, он же по дефолту в наше время должен быть? И номерок найдется хуйли мне 10 рублей жалко. Вот две тыщи жалко.
>huggingface.co/chat
Во про него забыл, но там максимум лама 70б.
>duck.ai
Неплохо красиво легитимно, 4о-мини завезли с ламой 70б.
Ну ты челик, 8б модель я и у себя могу запустить.
Если верить https://github.com/hsiehjackson/RULER реальный контекст 128к, что все еще ебёт всех и вся.
>8б модель я и у себя могу запустить.
Ну так и вперёд, хули мозги то ебёшь?
>где на халяву попиздеть с топ моделями?
В ChatGPT треде же предложили https://2ch.hk/ai/res/753991.html#840864 юзать вылеченные приложения. Всех фич и настроек ChatGPT таким образом не будет, зато сможешь чатиться с GPT4 сколько угодно.
А не, я дальше прочитал, они больше 128к и не проверяли, вполне возможно что гугл и не напиздели вообще.
Ты че ебанутый? У тебя мозг блять как у 8б модели, не хочу я с тобой разговаривать, понимаешь?
>Если верить https://github.com/hsiehjackson/RULER реальный контекст 128к, что все еще ебёт всех и вся.
Это на старой гемини. На новой ещё лучше. Только RULER это уже которая итерация "вот сейчас точно правильный тест", начиная с мемной иголкой в стоге, которая ничего не отражает? А воз и ныне там.
Я тебе скажу как человек юзавший все версии гемини на практике - нет там и близко столько, и тесты эти зависят от своих промптов. Да, конечно, у гемини всегда была наименьшая из всех деградация контекста. Но:
1) Заявленного там и близко нет. Проблема lost in the middle в decoder only и decoder/decoder моделях как не была решена пока никем, так и не решена. Немного сделали в https://github.com/microsoft/FILM тренировкой, но это костыль, корень проблемы даже не найден, не то что не решён. В день когда её решат, IQ лоботомита зашкалит, чисто за счёт этого.
2) На длинном контексте модель начинает терять общий перформанс пиздец как.
3) Recall != reasoning. Запомнить-то модель может овердохуя, да вот только реально применить в мыслительном процессе может только ограниченное число. И это не токенами считается, а максимальной сложностью абстракций которые может выразить модель. Поэтому например суммарайз по всему контексту без чанкинга до сих пор рождает тот же бред - ибо большей части контекста для модели просто не будет существовать, точно так же как ты не можешь прочесть одновременно всю книгу, даже если перед тобой одновременно разложить все листы в поле зрения.
А достать прям весь контекст дотошно можно только через chain of thought и подобные методы, да ещё не простые, а рекурсивные какие-нибудь. В общем про "засунуть всю кодебазу и чтобы оно корректно что-то делало по ней" - забудь сразу. Это не про нынешних лоботомитов, пока что.
Ну бля я думал хоть у проприетарных ребят все в масле должно быть. Ну гугл то, у них ведь должен быть какой-то специальный соус? 2м рекала все еще в каком-то смысле впечатляет. Почему попенай не могут так?
> Во про него забыл, но там максимум лама 70б.
Теоретически там лама 405В есть. Но почти не работает, слишком много желающих налетело.
Эмулятор ставить - в пизду. Если у них валидация премиума на стороне клиента, более пытливый ум наверное мог бы вытащить ендпоинт из приложения и напрямую через него общаться. Но нахуй надо.
У них и есть специальный соус - у неё действительно юзабельный контекст больше всех. Сама моделька правда всегда тупенькая была относительно других топовых, хотя последние версии уже неплохие. Но соннет всё равно кодит лучше.
>Если юзаешь плейн текст то тут надо быть аккуратным, потому что вероятнее всего модель возьмет оформление карточки за подсказку для форматирования. Будешь писать с ошибками и смысловыми нагромождениями вперемешку с противоречиями - получишь то же самое в ответах.
Хм, теперь понятно, почему у меня годные персы получались через раз...
Вот пример, написаный в свободном стиле (plain text). Это будет норм для связки SillyTavern+llama3?
> duck.ai
> huggingface.co/chat
Известны лимиты?
> > duck.ai
> > huggingface.co/chat
> Известны лимиты?
В обнимордовском чате нет, во всяком случае, я не натыкался, можно пиздеть сколько угодно. В duck.ai лимит есть, но хз сколько точно запросов в день можно + они пишут, что это временная мера.
Спасибо.


> довольно сложно оценить их перфоманс.
Так обещали-то все кары небесные - серить, шиза, выдавать дичь и т.д. А в итоге без залупы потери и не оценишь. Хотя я и не отрицаю, что они могут быть.
>Больной ублюдок, но забавно.
Сайдпродукт от rag. Побаловаться можно, но особо смысла не имеет, разве что ранжировать сообщения по важности и сохранять только критически важные. Иначе расход ram ебейший, а сжатие векторов я ещё не запилил.
>копай в сторону упаковки активаций
Да нахуй надо, там методов напилили триллион. Когда-нибудь нам дадут модели с маяками активаций и можно будет катать 400к контекста на двадцати гигабайтах. А копать вглубь никогда желания особо и не было, цель в другом.
>Ты че ебанутый? У тебя мозг блять как у 8б модели, не хочу я с тобой разговаривать, понимаешь?
Для школьника-максималиста, пришедшего в тред локалок с вопросами о закрытых моделях, и воротящего ебало от того, чем многие аноны успешно пользуются, ты слишком убого под умного косишь.
Запуск 8В моделей для тебя даже слишком, character.ai твой уровень можешь ещё в соседний тред сходить - поклянчить токен, может дадут за щеку
Ладно, пойду досру и буду эксперементировать. Понял уже, что никаких форматов нет, можнл просто хуярить plain text - simple english, тупо на простом английском как для дебса или StableDiffusion рисовалки
https://unrollnow.com/status/1832933747529834747
Эпопея подходит к концу, скоро коллективно всем ИИ-комьюнити Шумера хоронить будем. Реддит уже топит его. Остаётся только зоонаблюдать что сегодня Шумер пукнет и будут ли какие-то оправдания.
Вкратце - на HF лежит криво трененая Лама 3.0, даже не 3.1. А в API обёртка над Claude 3.5 с промптом на рефлексию.
Эпопея подходит к концу, скоро коллективно всем ИИ-комьюнити Шумера хоронить будем. Реддит уже топит его. Остаётся только зоонаблюдать что сегодня Шумер пукнет и будут ли какие-то оправдания.
Вкратце - на HF лежит криво трененая Лама 3.0, даже не 3.1. А в API обёртка над Claude 3.5 с промптом на рефлексию.
> попиздеть с топ моделями
Нужно быть умным или богатым, или и то и другое вместе. Авторизация апи идет по ключам, этого достаточно.
Есть еще вариант для терпеливых что ты описал, но это довольно сомнительно.
Вот этого двачую, особенно про
> 3) Recall != reasoning.
На мелких моделях особенно заметно, для них большой контекст вообще нонсенс ибо нормально работать с ним они почти не способны.
> Так обещали-то все кары небесные - серить, шиза, выдавать дичь и т.д. А в итоге без залупы потери и не оценишь
Не перевирай, если говорить грубо то посыл был в том, что васян не шарящий в теме, который боится интерфейса арены, катает без нормального промта/формата и хвастается посредственными постами - не поймет что у него модель серит, а будет воспринимать это как откровение и креативность.
> там методов напилили триллион
Речь о другом.
> А в API обёртка над Claude 3.5 с промптом на рефлексию
Вот же содомиты, кто там хотел бесплатного доступа?
Это про рефлекшн? Не самая плохая модель по ощущениям, а хайпа знатно собрали.
> Лама 3.0, даже не 3.1
Это проверяется работой с контекстом, как там сравнивали веса и предсказывали лору не совсем корректный подход.
> 5
С этого проиграл, ко всем остальным бы его применить.
Кек, но история все равно мутная какая та.
Выглядит вся эта движуха как та, в которой топили суцвекера и боготворили пидора альтмана. Боты или заказ или просто направленный в нужную сторону хайп.
Если единственная причина считать это подделкой апи сонета - ответ сетки о том что она сонет, то это хуйня.
Так любая нейронка скажет, если ее на загрязненном датасете обучить. Но и то что он никак не может модель нормальную залить тоже вызывает вопросы.
Ладно залить не может, вдруг и правда там косяк какой, но торрент сделать каждый может
> Боты или заказ или просто направленный в нужную сторону хайп.
Но ведь там явный пиздёж. Есть заявления про MMLU в 89, но модели нет. Та что в HF лежит хуже ванилы в тестах.
> ответ сетки о том что она сонет
Нет, токенизатор там точно не от ламы, уже 10 раз челики проверили. Ну и тот факт что слово Claude вырезалось тоже сложно оправдать чем-то - там просили повторить это слово и она пустоту выдавала только.
Господа, подскажите, на теслах разъем питания же по сути идентичен тому что на питание CPU идёт? Можно CPU кабель питания в неё воткнуть и всё будет работать?

> как там сравнивали веса и предсказывали лору не совсем корректный подход
Некоторые слои вообще без изменений от 3.0.
Хитрожопые мерджеры и не такое творят, возможно там франкенштейн, что может быть резонно с учетом особенностей работы 3.0 и 3.1. Офк девов не защищаю, хайп вокруг нездоровый.
> там просили повторить это слово и она пустоту выдавала только
Если то что лежит на обниморде просить то оно может клодой представиться, отсюда же и все молодые ночи с укусами по реквесту. Могли устыдиться синтетического датасета.
> токенизатор там точно не от ламы, уже 10 раз челики проверили
Интересно как проверяли, там же апи анально огороженный.
Рефлекшн с меньшими параметрами будет не?

> хайп вокруг нездоровый
Так Шумер заявлял что его модель ебёт даже все закрытые. В карточке вот такое:
> Reflection Llama-3.1 70B is (currently) the world's top open-source LLM
Но по факту это даже близко не так. И вся эпопея началась из-за того что Шумер начал пиздеть про "веса при заливке сломались", потом зачем-то начал перетренивать модель, а теперь и с API такое говно. Бонусом подтянулись сторонние команды, тестирующие сетки, и ни один из них даже близко не получил результатов как заявлялось. Более того тесты API и локальной сетки совсем разные результаты дают. Сейчас весь пожар в том что даже когда Шумера прижали он на сверхманёвренности пиздёж за пиздежом выдаёт.
> Интересно как проверяли, там же апи анально огороженный.
Просить повторять слова.
Аноны, какой райзер лучше взять под вторую видяху? Хочу её положить рядом с корпусом, чтобы минимально перекрыть воздушный поток первой.
> Просить повторять слова.
Как этим токенизатор проверить?
х16 с 4.0 или 3.0 спецификацией под твой порт, лучше фирмовый.
> Как этим токенизатор проверить?
Я же тебе кинул скрины. Второй скрин особенно показательный. Для клауды <|endoftext|> без пробелов - это стот-токен, а ламе похуй на него вообще. Собственно что и видим - у рефлекса текст обрывается на попытке написать его.
Ну или вот ещё пример.
Макаба пошатнулась и пикчи не подгрузились когда отвечал. Да, вполне показательно. Можно оправдать особенностями препроцессинга апи, но это уже херь и вода из камня.
>то посыл был в том
Это уже манёвры какие-то, "я писал одно, но имел ввиду другое".
>Речь о другом.
Да суть та же, компрессия контекста.
Вот беда с этим оверхайпом. Выкатили бы тихо-спокойно, народ бы попробовал, кто-то похвалил. А так будут ебать Шумера, при том, что он к модели вообще отношения не имеет. Заплатил штуку баксов за то, чтобы стать козлом отпущения.

> А так будут ебать Шумера, при том, что он к модели вообще отношения не имеет.
Он мог хотя бы не пиздеть, а сразу слиться. Сказал бы что берега попутал, а не тянуть время, пока пытается из ламы сделать клауду. Это опять же чисто его тупость, когда он думал сейчас хуяк-хуяк за пару дней сделаем тюн на ламе и получим результат как в API. Но теперь его уже ничего не спасёт, очевидно что его попытки за пару дней высрать модель не сработают. Его теперь показательно повесят, все новые отмазки только больше рофлов приносят.
> манёвры
Нет, в начале написал вежливо чтобы ты не триггернулся, потом расшифровал для понимания.
> Да суть та же, компрессия контекста.
Нет, применение activation steering для суммарайза.
О нет, у его девушки КОВИД! Перестаньте хейтить!
> Заплатил штуку баксов за то, чтобы стать козлом отпущения.
Он так-то CEO вот этой хуйни:
https://www.crunchbase.com/organization/othersideai
В прошлом году 3 ляма баксов инвестиций было в его конторку. Зачем он всё это сделал та ещё загадка. Разве что его на аутсорсе развели как последнего лоха, продав клауду под видом революционной модели. В любом случае уже не на кого стрелки метать, это чисто его проёб, даже если он просто лох.
>Его теперь показательно повесят
Судя по его постам в твитторе, он нихуя не понимает, что происходит и в этих ваших языковых моделях не разбирается.
>хуяк-хуяк за пару дней сделаем тюн на ламе
А раз он не шарит, то ему кто-то сказал, что они хуяк-хуяк и сделают. Кто сказал? Да хоть бы его "соавтор" проекта, некто Sahil Chaudhary. Он же основатель глайв аи, которые делали датасет для трейна. А то и весь "трейн". Итого, Шумер сливается в помойку, а Сахил смеётся в кулачок и просит ещё.
>уже не на кого стрелки метать
Потому что дохуя пиздел и дохуя обещал. Даже если ему самому обещали всё это - головой бы, блядь, думал, насколько оно вообще реально.
Нашумевший рефлекшен ни в одной попытке не повторил свои же результаты.
Все выложенные фиксы не повторили результаты.
Все выдают ужасный результат буквально у всех.
Чувак, который «делает» рефлекшен даже не знает, что такое lora в принципе. Совсем не знает.
А все апи, которые он дает — клод, гпт-4о, что угодно, но не его же модель.
Это выглядит как лютый скам, а у тебя аутотреннинг.
Я не утверждаю и не хочу убеждать, может ты прав и все дебилы, но пока ситуация такова.
> 128к
> все еще ебёт всех и вся
Где-то у квена полгода назад?
Где-то у мистрали пару месяцев назад?
128к — давно уже дефолт в ллм.
На лламу с геммой смотрели как на отстающих в развитии с их выходом.
Гемма оказалась, правда, умной.
1. Мутная со стороны Шуммера и тех, кто его поддерживает в ситуации, когда его модель рыгает говном, ну так, по факту если.
2. Боты? Сомневаюсь, что Шуммер знает, что такое боты и смог бы их настроить.
3. > Если единственная причина
Там еще структура и форма, особые теги, которые выдает только клод, потом пошла вырезка этих тегов, чтобы «не палиться» со стороны Шумера. Ну, типа, срет в штаны без остановки. Пруфов — вагон.
Просто фактчекинг небольшой.
Да хер с торрентом, какой еще в пизду косяк.
Ты тестил свою модель (которая выебла всех и вся) на каких-то файлов.
Берешь и драг-н-дропом кидаешь их в гугл.драйв или куда хочешь.
Все, точка, пруфанул на изи, все поверили, миллиарды инвестиций твои.
Нет тут никаких косяков. Просто нет тут никакой модели. =)
Говоряд, что да.
Лично я ткнул переходниками все же.
Жаль, что он не знает, как это делать и что это такое. =)
Я предполагал, что ему просто знакомый сказал «я тут заебенил пушку просто, го моим менеджером, ко-автором и мэйн-инвестором, разбогатеем!», а чел повелся и вот, да.
А вот и нашелся, да, кек.
> Все выдают ужасный результат буквально у всех.
Справедливости ради, это стоит перевести до
> Все жоракванты выдают ужасный результат
ничего такого ужасного в ней нету если катать нормально, наоборот есть ряд приятных моментов.
> и все дебилы
На самом деле когда читаешь дискуссии, где они предлагают делать экстракт лоры чтобы замерджить в другую модель (!) или выпускают ролики по типа https://www.youtube.com/watch?v=JN4EhaM7vyw - действительно начинаешь в этом убеждаться.
Опять же, автора и модель никак не оправдываю, пусть устраивают драму, тут только попкорном запасаться.
> Берешь и драг-н-дропом кидаешь их в гугл.драйв или куда хочешь.
Может ты не знаешь, но 70б модель в 16битных весах имеет объем порядке 160гб, не то чтобы это простой драг-н-дроп куда хочешь.

https://huggingface.co/mattshumer/Reflection-70B-draft2/tree/main
>Duplicate from sahil2801/reflection_70b_v5
Ну да, модель испортилась, пока он клонировал репо Сахила. Ну бывает, хули доебались. Или это у Сахила кот провода перекусил, пока он модель выгружал, а Шумер просто долбоёб и повторяет такие отмазы? Да не, быть не может.
>Duplicate from sahil2801/reflection_70b_v5
Ну да, модель испортилась, пока он клонировал репо Сахила. Ну бывает, хули доебались. Или это у Сахила кот провода перекусил, пока он модель выгружал, а Шумер просто долбоёб и повторяет такие отмазы? Да не, быть не может.
> Все жоракванты
Да нет, там все тестируют и vllm, и transformers, и кто во что горазд. Ужасные результаты именно на них, до жоры даже никто не опускается. Так что, там модель такая, а не кванты, ибо даже не квантованная — пиздец.
> они предлагают делать экстракт лоры
Напоминаю, что автор Рефлекшена даже не знает, что такое лора, при этом рефлекшен — это вмердженная лора (и, да, возможно в другую модель — если делалась для 3.0, а потом переобулись на 3.1 без изменения лоры, то… видимо делали по этому ролику=).
> Может ты не знаешь, но 70б модель в 16битных весах имеет объем порядке 160гб, не то чтобы это простой драг-н-дроп куда хочешь.
Видимо, у тебя нет практики, и не знаешь как раз ты, что 160 гигов это как раз очень просто.
Я легко могу сделать драг н дроп 160 гигов из своей деревни. 700 мб и терабайты облака позволяют. Так что это совсем не проблема, все именно так, как я написал.
Если уж такой бомжара как я могу, думаю, у инвесторов не будет проблемы найти 160 гигов и интернет быстрее диалапа.
+ в хаггингфейс тоже можно драг н дропом. Разве что попилить по 50 гигов. Ну ладно, это правда может быть сложно для автора.
Опять же, я не обсираю модель.
Просто нет ни единого аргумента в пользу автора и модели (кроме пары отзывов из этого треда) и есть десятки пруфов, что все критически плохо.
Я не знаю, что тут можно еще придумать.
Но, если кто-то скачал и ему нравится — заебись, надо «быть счастливым», а не «вписываться в общество». =)
Просто нет ни единого аргумента в пользу автора и модели (кроме пары отзывов из этого треда) и есть десятки пруфов, что все критически плохо.
Я не знаю, что тут можно еще придумать.
Но, если кто-то скачал и ему нравится — заебись, надо «быть счастливым», а не «вписываться в общество». =)
>В прошлом году 3 ляма баксов инвестиций было
>он нихуя не понимает, что происходит
Блядь пиздец ну что за ёбанная хуйня? Теперь любому дауну с 3 классами церковно-приходской дают лимоны, лишь только он напишет в описании на сайте "АИ Фирма"? Где моё бабло? Я бы на 3 ляма хотя бы свою базовую с нуля сделал на 1,5B офк.
> Да нет
Да ладно, это шутеечка, видно же что жир. Но с ними опять были проблемы, возможно из-за путаницы 3.0-3.1 или опять жорабинго.
> vllm
Это что, awq? Оно еще живо?
> даже не квантованная — пиздец.
А в чем пиздец заключается? Если катать в рп то она далеко не самая плохая и куда бодрее типичных тюнов лламы, которые нагоняют уныние. Последние версии тех правда не тестировал, может ебут также/сильнее без клодизмов, но назвать модель плохой язык не поворачивается.
> Напоминаю, что автор Рефлекшена даже не знает, что такое лора
Ваще похуй на него вообще, то про типичных обитателей реддита и тем более нормисов с более популярных платформ. Такую дичь на серьезных щщах затирают что морального права критиковать кого-то не имеют.
> Я легко могу сделать драг н дроп 160 гигов из своей деревни. 700 мб и терабайты облака позволяют.
Видимо, ты или дохуя мажор, или врунишка. Потому что террабайты облака не то чтобы недоступны, но это априори платные сервисы, которые есть разве что от мелкософта с подпиской на офис. 700 мегабит в деревне - тоже довольно интересная новость. Но даже с ними сейчас реалии таковы, что из-за ркн-щлюх и хитрожопых провайдеров скорость на зарубежные серверы сосет дупу будто вернулся в нулевые. Единственное спасение - hftransfer, который каким-то образом пробивается, но это и близко не назвать драг-н-дробом.
А насчет практики - не учи батю ебаться.
Какие сейчас есть способы получить 1TB оперативной памяти?
Сделать подкачку на ССД объёмом в терабайт.
Можно купить. Думал об этом?
Нужно дешево.
Нет ли материнок от хуананжи которые могут столько памяти?
> Это что, awq? Оно еще живо?
И охуеть как популярно в корпоративном сегмента наравне с TensorRT нвидии.
> дохуя мажор
Спасибо. =3 Приятно слышать.
Вообще нет, просто работа в IT имеет свою специфику.
Машины у меня нет, к примеру.
> будто вернулся в нулевые
А вот это жиза. Иногда смотришь на 45 кб/сек с гитхаба и такой «это кто тут у нас ебанулся?»
Оказалось, гитхаб в тот раз.
Но все очень не очень сейчас, конечно.
(ах да, у меня еще и свои сервера за рубежом… так что, скоростью я и туда не ограничен, но опять же, специфика профессии)
Тоже 20 лет стажа? Хорош, уважаю. =)
А зачем, если не секрет?
Кстати!
Кто хотел Qwen2-abliterated от Emilio?
Он в итоге просто открыл репу.
Качайте на здоровье.
(а запрос так и не одобрил, пидр=)
Кто хотел Qwen2-abliterated от Emilio?
Он в итоге просто открыл репу.
Качайте на здоровье.
(а запрос так и не одобрил, пидр=)
Появились ли хорошие тюны геммы 27б?
>Нужно дешево.
Тогда бери станции в аренду.
>Нет ли материнок от хуананжи которые могут столько памяти?
Даже если ты найдешь такую мать и такой процессор, тебе всё равно понадобиться минимум восемь плашек по 128 гигов серверной памяти, которая выйдет суммарно под 800к рублей.
В статье про Лламу 3.1 написано, что файнтюны не доучивают большую модель, а только "высвобождают" уже заложенные в ней данные. Если это так, то понятно, почему та же Ллама в секс-сценах гораздо хуже Мистраля и похоже, что это не поправить. С другой стороны тут хвалят файнтюны Геммы - а я сомневаюсь, что Гугл чистил датасеты хуже, чем Мета. Ну и в принципе перспективы печальные, если это так.
>любому дауну
Ты не понимаешь. В этом мире есть репутация и в этот раз репутация Мэтта позволила ему получить финансирование. Он же тот самый человек, который сделал HyperWriteAI с "агентом, который может пользоваться браузером, как человек"! Конечно это тоже оказалось просто обёрткой над гопотой с конской наценкой, но кто мы такие, чтобы судить? И вот у Мэтта уже есть некоторая репутация, которая позволяет ему быть успешным - он уже один раз сделал ничего и продаёт это за вечнозелёные. Сумел один раз - не сумел во второй. Что же, бывает.
>не доучивают большую модель, а только "высвобождают"
Звучит, как бред.
>файнтюны не доучивают большую модель, а только "высвобождают" уже заложенные в ней данные
Смотря сколько дрючить. Алиберейт или лёгкая лора та, только направляют вывод модели в нужное русло. Но сделать так, чтобы попенсорс модель нельзя было научить новым трюкам, ещё не научились, слава Богам.
>Он же тот самый человек, который сделал
А, ну окей. Хотя интересно, получал ли он за первую приблуду деньги до её готовности.
>деньги до её готовности.
Такие вещи, если не получают деньги до готовности - то не получают деньги вообще.
>HyperWrite has raised $5.4M over 2 rounds.
>HyperWrite's latest funding round was a Seed VC - II for $2,8M on March 9, 2023.
Ты тот анон, который спрашивал про кол-во токенов у респонива? И говорил, что медленно?
Ну у меня угабуга, stheno, только 5ку - 22 т/с, инвестировал это в 12б модель, и получаю свои 6-8 токенов
Купить
> И охуеть как популярно в корпоративном сегмента наравне с TensorRT нвидии.
Довольно неожиданно, оно ведь уныло и без нормальной гибкости.
> Машины у меня нет, к примеру.
Бедолага, а мог бы уже пожинать блага развития нейронок пока оно везет твою жопу в пробке а ты скроллишь анимублядские пикчи.
> 45 кб/сек с гитхаба
Обычно примерно раз в 100 больше, но для больших моделей это всеравно пиздец.
> написано, что файнтюны не доучивают большую модель, а только "высвобождают" уже заложенные в ней данные
Бред, в рот нассать тому кто написал. Такое применимо только к подзалупному файнтюну лорой, но даже ей можно добавить именно нового.
на сколько локалки уступают корпаратам по части - самарайз? в чем подводные если хочу самерить локалкой?
>в чем подводные если хочу самерить локалкой
Локалки суммируют контекст уже хорошо (в 75% случаев), но использовать саммари можно только если тебя не интересует качество. Потому что результат-то неплох, но обычно не тот, который тебе нужен.
наверно стоит уточнить. локалки уровня 7-13 Б сойдут чтоб в целом структуру \хронологию описать, можно опуская мелкие детали?
>128к — давно уже дефолт в ллм.
По ссылке проходил?
>Для школьника-максималиста, пришедшего в тред локалок с вопросами о закрытых моделях
Бля ну я ж спокойно зашел, с уважением, покланялся даже предоставив свои находки. И вообще мой вопрос распространяется на локалки тоже, вот где можно с 405б поговорить?
>воротящего ебало от того, чем многие аноны успешно пользуются
Успешно пользование у тебя в голове наверное заканчивается кумингом? Говорю же мне хватило мелких моделей, 4хА6000 уж простите не завалялось. Максимум с кем я могу попиздеть комфортно это квантованная гемма27. Ясен хуй хочется большего, особенно для кодинга.
>локалки уровня 7-13 Б сойдут чтоб в целом
Да, сойдут. Ллама 3.1, Мистраль Немо - последние поколения уже могут. Для непритязательного РП вполне.
Как вам модель Reflection 70b? Ну как порефлексировали?
>А зачем, если не секрет?
Запускать всякие 400b модели с 100к контекстом
>Ясен хуй хочется большего, особенно для кодинга.
Для "большего" в соедний тред.
Локалки это в принципе про получение максимального профита с минимальными затратами ресурсов, сейчас в принципе в ЛЛМ идёт тренд на оптимизацию, мелкие модели развиваются быстрее крупных и этот тред активно следит и пользует все преимущества.
Для кодинга заходишь с ВПН в бесплатный Copilot / кодишь.
Для попиздеть и Гемму можно использовать + Magnum 35B недавно вышел, он неплох.
>вот где можно с 405б поговорить?
Если ты меришь эффективность моделей только количеством параметров, то земля тебе хуем.
Ллама 3.1 405В убога и не дотягивает до уровня 70В моделей.
Мистраль 130В хорош, но по многим пунктам проигрывает топовым 70-кам
Гемма 27В конечно хуже 70-ок, но не намного. В принципе, если большего запустить не можешь, это реально неплохой вариант, дёшево и сердито. Тут полтреда ей пользуется.
Мистраль немо 12В, почти догоняет по результатам Гемму 27В.
Притом всё вышеперечисленное, ебёт третью трубу, а местами и второго Клода, которые ещё с пол года назад всерьёз котировались в соседнем треде любителей "нормальных" моделей.
Итого, годную модель сейчас можно запустить почти на любом калькуляторе. В удивительное время живём!
Но если тебе важны циферки, то иди на хорду в таверне, там иногда что-то большое раздают или арендуй сервак с 4 3090, тут выше писали что за 30 рублей/час можно снять.
Прошелся по арене, ебать-копать, 90% этого АИ не может 749*1502 в столбик умножить.
>АИ не может в столбик умножить
Ебать, откуда вы лезете?
1. ЛЛМ не АИ.
2. ЛЛМ не калькулятор.
А что это блять? Ни одну сложную задачу из реальной жизни не решить, если не уметь хотя бы базово считать. Или тебя на егэ по матеше выебли и у тебя травма неотрефлексированная?
> Ни одну сложную задачу из реальной жизни не решить
Не считая кодинга, NLP, формальной логики и т.д.
А ты можешь, умник? Не прибегая к бумажке.
А каркулятор вот может. Поэтому чтобы что-то посчитать, ты берёшь бумажку, счёты, куркулятор, вольфрам математику, софт для конечноэлементного анализа блять.
Вот и с LLM так делай. Есть питон, который она хорошо знает, дай ей питон.
Это очевидная толстота, забей. Либо он долбаеб, что тоже вероятно.
С таким кликбейтом только отпугивать от ссылок, понимаешь? =)
Прозвучало в духе «рефлекшен ебет всех и вся», ну вот и переходить даже не охота.
Просто пометка, что писать нужно без кликбейта и с учетом реальности. Ноу оффенс.
Учти, что это будет СУПЕР медленно. Проблема оперативы в том, что нарастив большой объем получаешь маленькую скорость.
Ты 128 гигов пробовал? Я иногда запускаю, когда тестирую. Там скорость 0,3 токена/сек.
Даже в четырехканале терабайт даст тебе 0,15 токена/сек или ниже.
Не заебешься ждать?
Люто плюсую.
А кофеварка меня до работы не довезла, а еще машиной называется!
+
Такие посты раз в неделю, чи ни похуй.
Какой в пизду кликбейт? Я говорю что модель может 2М а ссылка говорит только 128к. Это антикликбейт нахуй. Кликдетеррант если вы англичанин.
>Мистраль 130В хорош, но по многим пунктам проигрывает топовым 70-кам
Разве что в синтетических тестах. В реальности размер таки имеет значение, как и качество датасета.
> Мистраль 130В хорош, но по многим пунктам проигрывает топовым 70-кам
Что за манямистраль у тебя? Есть только 123В. И он ебёт любую 70В. Русский так вообще без вариантов, конкурентов совсем нет.
Ох-ох, ебать, мои извинения, в таком случае открою и почитаю!
Было бы еще куда весь этот контекст пихать, конечно, но больше — лучше, лучше иметь возможность, чем не иметь.
Благодарю.
Думаю, там про красоту речи и умение хорошо писать порно-рассказы в сравнении с файнтьюнами. Ну, мне так показалось, что имелось в виду.
> Думаю, там про красоту речи и умение хорошо писать порно-рассказы в сравнении с файнтьюнами.
Да там шизик какой-то, у него 405В хуже 70В, лол. Ну а по разнообразию речи мистраль даже жпт/клода выебет.
>Да там шизик какой-то, у него 405В хуже 70В
Сразу видно что ты его даже не нюхал.
>по разнообразию речи мистраль даже жпт/клода выебет.
Он лупится как сука. Но по-русски пишет и правда неплохо.
Двачую остальных, ллм - языковая модель, считай это то же самое что ты вслух будет говоришь. Учитывая саму суть - арифметика для них сложна и ее особо не тренирует, модели проще будет написать программу на любом языке которая это посчитает, как бы забавно не звучало. Но никто не мешает применить дополнительные тулзы как уже делают.
> Мистраль 130В хорош, но по многим пунктам проигрывает топовым 70-кам
Можно перечислить? Офк сравнивай тогда уже с базовыми моделями или файнтюны с файнтюнами.
Перетолстил. Ллм - инструмент, если руки прямые - сможешь применить.
> у него 405В хуже 70В, лол
Типа если сравнивать по сое то может и так, лол.
>Он лупится как сука.
Магнум - нет, вообще нет. Но зато у него, похоже, проблемы с токенайзером.
Какая по итогу лучшая из 27-35В? Магнум, Коммандр или Гемма? Мне лично нравится гемма, но её контекст слишком маленький
Магнум у меня лупиться, скинь настройочки, хочу поглядеть.
> Сразу видно что ты его даже не нюхал.
405В - это фактически единственный полноценный конкурент жпт-4. Это только в тестах там небольшой отрыв, на практике 70В заметно отстают в любых задачах от 405В.
> похоже, проблемы с токенайзером
С этим там точно нет проблем, это ты что-то напердолил.
>Магнум у меня лупиться, скинь настройочки, хочу поглядеть.
Стандартный пресет "Миростат" из Таверны. Что интересно - с некоторыми другими пресетами GGUF-модель начинает бредить, в то время как на EXL2 всё ништяк. Делаю вывод, что конвертация в GGUF там несколько кривая. Есть и другие признаки этого.
Миростат, это в семплерах же. Я про пресеты говорил. Хотя попробую миростат поставить, а то у меня там черт поймешь, что.
>405В - это фактически единственный полноценный конкурент жпт-4
А ты попробуй побеседовать с ним дольше пары сообщений. У него проблемы с логикой, пониманием контекста ситуации, стилем повествования.
Мистраль лардж в этом его полностью разъёбывает.
> У него проблемы с логикой, пониманием контекста ситуации, стилем повествования.
Никаких проблем нет, по логике это вообще топ среди опенсорса. Ты явно не трогал его никогда.
>Я про пресеты говорил
В Таверне есть именно что пресет, который так и называется. Для Кобольда и Лламы.
>С этим там точно нет проблем, это ты что-то напердолил.
Ага, как же - нет проблем. Сейчас скачал чистый Мистраль Лардж, больше часа гонял его по огромному чату с контекстным окном в 16к - и ни разу не потребовался полный контекст шифт. С Магнумом он требуется постоянно. Есть ещё Luminum - микс из Люмимайда и Магнума, кстати весьма хорошая модель - там вот там такая проблема тоже есть, но гораздо реже. Где-то у Магнума косяк.
>Миростат
Устаревший по факту семплер, ещё и медленный.
>полный контекст шифт
Тьфу, полная обработка контекста же. Контекст шифт как раз нормально работает на чистом Лардже.
Как shell-gpt с локальной нейронкой подружить, не с бгмерзкой олламой? Сервер лламаспп не видит, хотя он вроде опенаи совместимый. Когда я с ним в начале года игрался все работало просто меняя базовый апи адрес.
А соя такая проблема, потому, что от неё не избавиться? Или избавиться можно, но это очень тяжёло и требует много времени? Или людям просто впадлу? А то понятное дело, соя много, что руинит, а способов обхода особо не наблюдаю, вот и спрашиваю.
Гемма которая только инглиш? вай спасибо, отличное решение, только бесполезное для практической работы
Тебе для чего? В рп оба хороши в зависимости от настроения и карточки выбирать. В nlp коммандер более естественный тогда как гемма упарывается формальностями и может тупить. А наоборот, более тонкие и сложные инструкции она выполняет лучше, тогда как коммандер насрет херней проигнорив.
> контекст слишком маленький
Накрути альфу, оно нормально до 16к растягивается.
Тоже эту фигню замечал, у них вообще довольно странные выбросы в логитсах присутствуют. Но для potato-pc альтернатив нет, только пинать жору и других мейнтейнеров чтобы чинили и вводили инновации.
А насчет лупов - проблема часто не только в ггуфе но и на стороне юзеров, кривой семплинг, кривые форматы, кто-то просто ультрадушнила и не понимает чего хочет от нейронки, а она не может понять что ей отвечать.
Она и в русский умеет, но не идеально.
> только бесполезное для практической работы
О какой практической работе речь?
И при чём тут токенизатор, шизик?
>а способов обхода особо не наблюдаю
А ты нихуя не наблюдательный. Файнтюны, алиберейт версии, да даже простой промт или префил вполне себе спасают от сои.
>избавиться можно, но это очень тяжёло и требует много времени
Везде по разному. Где-то есть соя чисто формальная, как на командорах или мистралях, которая пробивается самым тупым промтом. А есть выродки типа семейства фи, которые можно пробить только дотренировкой и прочими техническими ухищрениями.
>способов обхода особо не наблюдаю, вот и спрашиваю
Способы почти обхода не меняются, хотя постоянно тестируются новые методы типа аблитерации. Чаще всего модель просто дотренировывают на запросах из стоп-листа.
Сколько контекста влезет в Magnum 12B V2.5 KTO на 3090?
>И при чём тут токенизатор, шизик?
От шизика слышу. Правильный дифф промпта - прошлого и настоящего - сделать почему-то не получается, понятно? А когда получается, то может ещё и криво, и как там кэш контекста по результатам обрабатывается - хрен его знает. Почему так?

А как же у Жоры реализовано скользящее окно? А, просто установка старым токенам внимания на -бесконечность. Ясно. Понятно.
Сделай лучше.
>Она и в русский умеет
27b укр не хочет в ответах юзать, читать читает кое-как, а ответы только инглиш... (ну или я дурак, и не могу настроить)
>О какой практической работе речь?
работа с текстамипереписать, уникальности добавить, сократить, презентацию придумать, придумать спич для выступления итд...
Кста, кто Yi Coder 9B пробовал, как им пользоваться вообще? у меня в кобольде оно фигню выдает какую-то прошу простой квиксорт на плюсах выдать - даже это не выдает, хотя какой-то код валит конечно... или там от режимов кобольда зависит многое?
а троечка норм пишет квиксорт
Шизик, токенизатор тут не при чём. Спрашивай у своего Жоры почему его смартконтекст не смарт. Да и какая разница что он там пересчитывать будет, это пару секунд на полный контекст.
Так и должно быть. У той же геммы всегда только 4к в аттеншене участвует.
Да, есть такой, припоминаю. Попробую, ибо лупит(
>Да и какая разница что он там пересчитывать будет, это пару секунд на полный контекст.
Полный пересчёт 16к контекста для 123B-4_K? На теслах? Ну и кто из нас шизик? :)
На самом деле с контекст шифтом жить стало прямо-таки хорошо. Но вот поломанная модель - и пиздец. А с другой уже не интересно.
Чем закончилась эпопея с Reflection ?
А нету ли к стати случайно аддонов браузерных для огнелиса, чтобы с локальными моделями взаимодействовать?
Вроде у кобольда и есть класик гпт АПИ, но я столкнулся с приколом что аддон который вроде умеет такое апи юзать из ответа только первый токен выводит... в чем прикол может быть? может можно указать чтоб выдавало ответ сразу весь а не в процессе генерации?
Вроде у кобольда и есть класик гпт АПИ, но я столкнулся с приколом что аддон который вроде умеет такое апи юзать из ответа только первый токен выводит... в чем прикол может быть? может можно указать чтоб выдавало ответ сразу весь а не в процессе генерации?
> На теслах?
Нет, конечно.
> Ну и кто из нас шизик?
Тот кто сидит на теслах и жалуется на контекст.
> с контекст шифтом жить стало прямо-таки хорошо
Напердолил какой-то костыль и теперь на модель спихиваешь то что он работает через жопу. У магнума токенизатор идентичный ваниле так-то.
>У магнума токенизатор идентичный ваниле так-то.
Это так, но работает модель криво. Что-то файнтюн поломал.
> укр
Что? Хз как на мове, но по запросу исходя из контекста оно что-то похожее отвечало, когда заставлял ее шутковать про сво за каждую из сторон.
Для выбора языка должна быть четкая инструкция и отсутствие других противоречий, иначе будет по дефолту на инглише писать.
> работа с текстамипереписать
> сократить
Это вообще на изи, если не сложный.
> уникальности добавить
Угораешь?
> презентацию придумать, придумать спич для выступления
Это будет ультракринжатина какую сетку не юзай, уже мем про жпт-презентации есть.
> оно фигню выдает какую-то
Формат хоть правильный? Разумеется без него и правильного промта будет полная белиберда.
> это пару секунд на полный контекст
Не на больших моделях в сочетании с жорой. Да что там, когда набирается 50к на 123б - там и эксллама начинает конкретно страдать но даже так всеравно работает быстрее как жора с закешированным
Попробуй убабугу, там более полный апи должен быть.
Да надо бы.
>всегда только 4к
Это ошибка. У геммы два окна внимания, 8к и 4к, они должны чередоваться каждый второй слой. Если что-то сделано не так, то у тебя только половина от модели.
Тут прикол в другом, по сути, нет никакой разницы - удалить kv токенов из кеша или применить к ним такую маску. Образуется всё тот же дрифт. И вот такое "двойное" окно геммы как раз должно смягчать этот дрифт, т.к влияние старых токенов считай, что делится на 2, когда они выпадают из меньшего окна. Такое себе затухание на минималках.
>когда набирается 50к на 123б
А пофиксили слоупочную сериализацию в таверне? Я бы чекнул по загрузке цпу\гпу после нажатия сабмита на таких контекстах.
> работает модель криво
Почему-то только у тебя. Наверное потому что ты дебил.
> удалить kv токенов из кеша или применить к ним такую маску
Маска ничего не удаляет, не шизи. Контекст под маской всё так же виден модели.
>Контекст под маской всё так же виден модели.
Вообще-то, нихуя. Контекста под маской всё равно, что не существует. У нас внимание -бесконечность, значения прогоняются через софтмакс и получается круглый ноль. Вот так модель и "видит" этот токен - как ноль. Как пустую ячейку кеша.
Лол рили? Треш какой-то.
> пофиксили слоупочную сериализацию в таверне?
Хз, на норм железе незаметно и сразу идет нагрузка в гпу. Даже если там будет пол секунды - погоды особо не сделает.
> У той же геммы всегда только 4к в аттеншене участвует.
Ерунда
почему локалка не работает
KoboldCpp
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4060 Ti, compute capability 8.9, VMM: yes
KoboldCpp
ggml_cuda_init: found 1 CUDA devices:
Device 0: NVIDIA GeForce RTX 4060 Ti, compute capability 8.9, VMM: yes
как сомарайзить если сетка игнорит самарайз и тупо общается?
>Треш какой-то.
Я читаю код Жоры и не понимаю. Или я ебанулся, или он. У нас вот цикл
> for (int h = 0; h < 1; ++h) {
Будет он запускаться строго один раз. Хуй с ним. Далее в этом цикле.
> data[h(n_kvn_tokens) + s(n_kvn_seq_tokens) + j*n_kv + i] = f;
Он берёт перемножает n_kv на n_tokens, а потом на h. Но h у нас не может быть чем-то, кроме ноля. И мы при любых n_kv и n_tokens получаем ноль. Компилятор умнее человека, он, скорее всего, это эффективно отловит. Но какого хуя Жора имел ввиду?
>Но какого хуя Жора имел ввиду?
Ну спроси там, в его репозитории. Им будет интересно.
Сап какая сейчас актуальная модель для кума 12б?
Сам ты шит постинг макака
Сам ты шит постинг макака
Бамп вопроса.


Да будет какой-то всратый ответ вроде "самодокументируемости кода". В целом-то похуй, но без /O2 будет совсем печально, там дохуя таких циклов и дохуя таких перемножений.
>Чем закончилась эпопея с Reflection ?
Вот два пика - бенчмарки ллам и бенчмарки рефлекшена. Для модели, которая ебёт даже гопоту в бенчмарках - это всё ещё "сломанные веса", ждём починенных. Но починенных не будет - Шумер выкладывает ep2-working, а потом ref_70_e3. И оказывается, что хеши этих чекпоинтов одинаковые.
Итак, уважаемые, помогите определиться с выбором видеокарты под локалки и на поиграть.
Есть бюджет около 50 тысяч. Видеокарту собираюсь брать новую, это главное условие. Промониторил несколько маркетплейсов и высрал следующие варианты:
Просроченная 3060 с 8 гигами и шиной в 192 бита. Стоит около 30-35 кусков деревянных.
Кастрированная 4060 с 8 гигами и шиной в 128 бит. Стоит тоже около 30-35 кусков.
Сомнительная 4060ti с 8 гигами и такой же клоунской шиной в 128 бит. Стоит уже около 40 кусков.
Раздутая 4060ti с 16 гигами и опять с той же шиной в 128 бит. Цена начинается от полтинника.
Список только из зеленых огрызков, так как под амудатские и интеловские карточки кажется никто толком не пилит ни библиотек, ни драйверов, а поддерживают их разве что вялыми вздохами.
На данный момент я сижу на связке i5-12400 + 32 гига ddr4 3200 + встройка UHD730 десятилетней давности. Сумма в 50к для меня не маленькая, по этому хочется высосать терафлопсы из каждого рубля и не проебаться с переплатой.
Есть бюджет около 50 тысяч. Видеокарту собираюсь брать новую, это главное условие. Промониторил несколько маркетплейсов и высрал следующие варианты:
Просроченная 3060 с 8 гигами и шиной в 192 бита. Стоит около 30-35 кусков деревянных.
Кастрированная 4060 с 8 гигами и шиной в 128 бит. Стоит тоже около 30-35 кусков.
Сомнительная 4060ti с 8 гигами и такой же клоунской шиной в 128 бит. Стоит уже около 40 кусков.
Раздутая 4060ti с 16 гигами и опять с той же шиной в 128 бит. Цена начинается от полтинника.
Список только из зеленых огрызков, так как под амудатские и интеловские карточки кажется никто толком не пилит ни библиотек, ни драйверов, а поддерживают их разве что вялыми вздохами.
На данный момент я сижу на связке i5-12400 + 32 гига ddr4 3200 + встройка UHD730 десятилетней давности. Сумма в 50к для меня не маленькая, по этому хочется высосать терафлопсы из каждого рубля и не проебаться с переплатой.
>Есть бюджет около 50 тысяч. Видеокарту собираюсь брать новую, это главное условие.
Нет вариантов. Докинь десятку и купи с рук 3090 - ничего лучше тебе никто не порекомендует. Время такое.
Быстрофикс: забыл внести в список еще 3060 на 12 гигов с шиной 192.
Даже если бы я рассматривал варианты со вторички, то мне под 3090 пришлось бы покупать новый хороший блок, а это считай не просто плюс десятка сверху, но и все двадцать спокойно могут выйти. А мой текущий бюджет итак идет впритык, я изначально планировал тысяч 35 максимум на видеокарту потратить.
12 гигов минимум, но даже этого будет МАЛА, хотя поиграться можно и на 4 гигах с микромоделями, или вообще на процессоре, все равно локалки кал, надо 4х3090 чтобы запускать не кал...
А вот для картинок моя 3060 12g ахуенчик, просто 10 из 10 сдроченых хуйцов пользы за свой прайс.

>новый хороший блок, а это считай не просто плюс десятка сверху, но и все двадцать спокойно могут выйти.
Лал.
Купил прикл за 2,5к, уже год как грею теслой квартиру и в хуй не дую он кстати оказался внезапно надёжный, с защитой от препадов и включением через реле
У тебя есть два стула:
3060 12ГБ
Б/У 3090 24Гб с доплатой
Второй вариант ИМХО лучше, но у первому ты ещё можешь какой-нибудь p104-100 докупить или даже два разумеется в комплекте с божественным китайским прикл БП и быть как местные шизы.
Аноны, какой контекст можно прикрутить к 16vram, 64ram, гемме 27Б? Здесь писали, что тянет 128к, это реально? И ещё, а как RAG использовать? В кобольде включил, какие там параметры выставлять? И как можно проверить, какой максимальный объём контекста модель запомнила, есть какой-то текст?
Чел, для токенов под маской граф не строится, они остаются в контексте. А иначе тренировка не работала бы, когда весь контекст под маской.
>когда весь контекст под маской.
В разных bert'aх иногда маскируют один токен, чтобы научить модель вставлять пропущенные слова. Если скрыть все токены, то это приведёт к полной деградации модели, т.к вместо полезного инпута она получит шум. В gpt-моделях полная маскировка разорвёт построение цепочки авторегрессионного предсказания, что, опять же, приведёт к обучению на шуме. В Т5 были стратегии экстремальной маскировки, до 80 процентов, чтобы обучить модель восстанавливать повреждённый текст. Но это такое. Если скрыть всё, то всё равно получишь только деградацию модели.
Чел, хватит бередить. Во всех современных LLM полностью весь контекст под маской, потому что идёт тренировка ответов, а не контекста. Токены под маской никуда не пропадают, они всё так же участвуют в аттеншене. Если попытаешься тренить модель без маски на контексте, то получишь мгновенную поломку модели, при генерации она будет пытаться продолжать ответ и входить в лупы из пары токенов, а не отвечать.
А вот аттеншен с окнами как раз полностью отрезает контекст за пределами окна.
>Токены под маской никуда не пропадают, они всё так же участвуют в аттеншене.
Вот это натуральная шизофрения. Лечись, чел.
Для тупых дегенератов цитирую прямо из Attention Is All You Need.
> We implement this inside of scaled dot-product attention by masking out (setting to −∞) all values in the input of the softmax
Выходные вероятности токенов под маской просто ставятся в минус бесконечность, никаких операций больше не производится. Контекст никуда не убирается, другие токены всё так же видят контекст под маской.
Как попытаться наебать, но обосраться на полдороге.
>We need to prevent leftward information flow in the decoder to preserve the auto-regressive property. We implement this inside of scaled dot-product attention by masking out
Если внезапно прочитать больше одного предложения из той же бумаги, то становится очевидно, что остальные токены не видят контент под маской. Вообще, технически он существует и его видит позиционный энкодер. Но не более. Никакой информации из этого токена не используется для остальных токенов, он не используется для генерации ответа, он не используется для создания градиента, внимание к нему равно нулю. И вот фигура 2, внутри Scaled dot-product производятся вычисления, в результате которыx qkv токена превращаются в ноль.
> information flow
> auto-regressive property
Всё верно, вероятности обнулены - обучение не ведётся на них.
> И вот фигура 2, внутри Scaled dot-product производятся вычисления, в результате которыx qkv токена превращаются в ноль.
Тупой ты дегенерат, у тебя вероятности обнуляются ПОСЛЕ аттеншена, а не до него. Ты сам видишь куда стрелки направлены?
>ПОСЛЕ аттеншена
В процессе вычисления внимания к токену вообще-то. Пиздец ты тупой.
> > for (int h = 0; h < 1; ++h) {
Чет проорал, какая-то обфускация уровня б. Его же комплиятор просто скипнет.
> Но какого хуя Жора имел ввиду
Да хуй знает вообще, выглядит как какие-то остатки старого кода. Где-то с год назад на реддите был тред, где кто-то обозревал подобные нестыковки в коде жоры. Некоторым из них даже нашлось объяснение а парочка наоборот были гениальные, но надмозговости ну очень много. Вечером попробую его найти, но вероятность оче мала.
> он, скорее всего, это эффективно отловит.
Вот кстати одна из очевидных причин почему оно по-разному работает на цп и куде, или может ломаться при разных билдах. Там такого треша с избытком точно.
> Есть бюджет около 50 тысяч
Докидываешь 10-20-30 и покупаешь 3090. Довольно урчишь ибо она обоссывает с огромным запасом и в игорях, и в ллм, и в других нейронках все тобою перечисленное.
а потом там что-то подыхает и ты отправляешься в стратосферу
> Купил прикл за 2,5к
Насколько он шумный кстати?
>Насколько он шумный кстати?
Если от него предполагается запитывать мощную карту или тем более теслу, то это совершенно не важно :)
https://www.reddit.com/r/LocalLLaMA/comments/1fe3x1z/mistral_dropping_a_new_magnet_link/
Новый мультимодальный мистраль немо
Новый мультимодальный мистраль немо
а в чем великий смысл p104? в том что копеечная типа видяха никому не нужная? она ж до 1060 даже не дотягивает... какая ж там скорость генерации будет? (не по теме треда, но интересно SD сколькль итераций в секунду выдает на таком мусоре)
так-то теслы с 24гб выглядят по привлекательней, хоть и цена не такая приятная конечно, только ж охлаждать их непонятно как, тихая система не выйдет...
> уникальности добавить
>Угораешь?
Тут согласен перегнул, хотя ЖПТ юзал для такого, но как грится нафиг нужна уникальность если антиплагиат рубит по "текст сгенерирован АИ", обойти можно но...
>Это будет ультракринжатина какую сетку не юзай, уже мем про жпт-презентации есть
Это просто не умеют их готовить, конечно если от балды попросить презентацию то хрень получится, а дать материала (и вычитать потом то что сетка выдала), попросить идеи по оформлению, вопросов попросить накидать - другое дело
Еще задачи перевода довольно интересная тема, в виду того тчо сетки лучше держат контекст чем гугель транслейт, ну и плюс локальное решение не зависящее от буржуййских серверов
По сути мне от сетки нужна терпимая поддержка кирилик языков, и адекватные ответы...
а какие еще варианты использования окромя кумерства и обговоренного в этих двух постах народ имеет?
>Еще задачи перевода довольно интересная тема
Уже есть нормальная сетка-переводчик? Надоело зависеть от Гугла, да и прикрыть его могут. en<>ru хотя бы.
>Попробуй убабугу, там более полный апи должен быть.
капец там стартовые скрипты странные, вместо того чтобы создать Venv и запустить, оно какого-то фига по всем дискам мне лазит, как всегда вручную все делать надо....
кобольд в этом плане приятнее
Есть конечно. Топ сейчас вот это:
https://huggingface.co/Unbabel/TowerInstruct-Mistral-7B-v0.2
Ебёт жпт-4 в переводах.
локальные не знаю... а ЖиПиТи и подобные вполне преплексити затести, без регистрации можно работать...
>только ж охлаждать их непонятно как, тихая система не выйдет...
Большая 4-пиновая улитка с переходником под теслу - шум приемлемый и только когда надо. Есть готовые решения, но можно заморочиться самому и сэкономить.
вариант неплохой, но тут главное но, в том, что и теслы, и майнерское говно за тысячу грывень это паскаль в лучшем случае, а нейронки на паскале гонять.... наскребсти на 3090 выглядит привлекательнее
>https://huggingface.co/Unbabel/TowerInstruct-Mistral-7B-v0.2
Спасибо, попробую. Можно как-нибудь кобольд с этой моделью к Таверне прикрутить в качестве источника перевода? Было бы здорово.
>а нейронки на паскале гонять.... наскребсти на 3090 выглядит привлекательнее
На одну. Мелкие нейронки и на тесле быстро работают. Другое дело что цены на теслы сейчас неадекватные. Ещё и Китай экспорт прикрыл с какого-то хуя.

Из коробки точно нет.

>Насколько он шумный кстати?
Вообще не слышу от него звуков. Правда сейчас я охлаждаю Теслу прикл хуйнёй, которая на 100% по шуму догоняет пылесос, так что возможно уже оглох.
>в том что копеечная типа видяха никому не нужная?
Да.
Но, если у тебя нет денег и хочется запускать хотя-бы средние модели с норм квантом, вариант +- рабочий.
Будет медленно, но быстрее ОЗУ и проца, скорее всего свои 5-6 токенов получишь.
>наскребсти на 3090 выглядит привлекательнее
С этим согласен.
ну типа 3090 с под майнеров можно за цену двух Р40 взять... с одной стороны вроде и выгода есть от тесел но с другой - морально устаревшее решение береш которое не толкнеш уже скорее всего, так как кому она сдалась уже
> Просроченная 3060 с 8 гигами и шиной в 192 бита. Стоит около 30-35 кусков деревянных.
Ну ты пиздец долбоеб, конечно.
1. 12 гигов.
2. 25к.
> 4060 с 8… 4060ti с 8
Мусор на фоне 3060 с 12.
> 4060ti с 16 гигами
Зависит от того, устроит ли тебя скорость за цену вдвое больше 3060 за лишние 4 гига.
Вон, пишет про 3090 с рук — это и то альтернатива вменяемая 4060ти.
А, нихуя, опоздал.
Орирую с бп. =D Ну а шо, работает и ладно, чо. =) Рискнул-победил.
>gemma
>128k
kek
уооо
шидевр
смотрим-смотрим!
Надеюсь, лучше Qwen2-VL-7b
p104-100 = 1070 с 8 гигами памяти.
Покажи свою 1060, бро. =D
Сравнил 2,5к рублей и 30к рублей. Цена не такая приятная, понимаю…
>с какого-то хуя
Барин сказал негоже.
>p104-100 = 1070 с 8 гигами памяти.
ты объемами памяти только меряеш чтоль?
вот интересный момент, если чип одинаковый, почему в бенчмарках 200% разницы?
>ну типа 3090 с под майнеров можно за цену двух Р40 взять\
Где-то до мая цена 4 тесл была примерно равна одной 3090. Строго говоря при таком соотношении и думать было не о чем. Сейчас-то есть о чём, конечно.
>рефлекшен
Чего плеббит так дрочит на него, впервые услышали что ли? Этих КоТоподобных промптов воз и тележка, буквально сотни. Топовый по бенчам это вроде как self-discover до сих пор, если не ошибаюсь https://arxiv.org/abs/2402.03620 . Там конструируется кот под задачу автоматически, в три этапа. Хотя может ещё чо придумали.
Чего плеббит так дрочит на него, впервые услышали что ли? Этих КоТоподобных промптов воз и тележка, буквально сотни. Топовый по бенчам это вроде как self-discover до сих пор, если не ошибаюсь https://arxiv.org/abs/2402.03620 . Там конструируется кот под задачу автоматически, в три этапа. Хотя может ещё чо придумали.
>Покажи свою 1060
так у меня честно скомунизженая 1070
вопрос то не в деньгах, а в том что за эти деньги получаем
>выглядит как какие-то остатки старого кода.
У него в одном файле пять таких циклов. Скорее всего, цикл - для того, чтобы умножение возвращало ноль. А умножение "для наглядности". А всё вместе просто поощряет развитие психических заболеваний.
>даже нашлось объяснение
Объяснить это можно, а оправдать - сложно. Вон даже на пике - два цикла по всем токенам. Один для глобального окна внимания, второй для локального. С++ быстрый, можем себе позволить два раза подряд весь контекст в циклах перебирать.
>почему оно по-разному работает на цп и куде
Да, вроде, Жора и не скрывал, что оно по-разному работает. У него даже изоляции kv кеша между разными последовательностями нет.
Спасибо за разъяснение, но я не первый день в треде, хотя много чего проскипал в последние пару недель.
>Купил прикл за 2,5к
Китайские блоки типа твоего прикрепа это всегда лотерея. У моего знакомого с конторы стоял какой-то чудо короб вообще без маркировок и спокойно тянул gtx 780 пока в один день не перестал включаться. К счастью сдох он тихо и без мучений и половину компа за собой в могилу не забрал.
>У тебя есть два стула:
>3060 12ГБ
>Б/У 3090 24Гб с доплатой
Начинаю склоняться в сторону 3060, а потом подкопить на теслы. Только походу мне придется еще и мать брать новую, потому что на моем mini-огрызке только одна линия x16 под видеокарту, а вторая потешные x1
Графики полезные, помогли быстрее забыть.
>Докидываешь 10-20-30 и покупаешь 3090. Довольно урчишь ибо она обоссывает с огромным запасом и в игорях, и в ллм, и в других нейронках все тобою перечисленное.
Я уже сказал что бюджета на такие приколы у меня нет. Мне итак пришлось ишачить и недоедать полтора месяца, чтобы сгрести полтинник. Еще полтора месяца в таком темпе и меня самого в гробешник закидывать можно будет.
> 4060 с 8… 4060ti с 8
>Мусор на фоне 3060 с 12.
Ну я написал, что мне не только для лмок нужно но и под дрочильни всякие. 4060 я рассматривал чисто из-за длсс, я врубаюсь что это прогрев на лоха, но все таки у меня были небольшие надежды, что с ней будет не всё так плохо.
Поставил я короче бугу - апи гораздо лучше и можно с ChatGPTBox подружить локальную модельку, но капец буга жирная... больше 10 гб без моделек!
аноны поч нельзя на cohere зарегаться? мб банят рф?

>на моем mini-огрызке только одна линия x16 под видеокарту, а вторая потешные x1
Сейм.
Но х1 не такой уж плохой вариант, особенно для ЛЛМ. Скорость загрузки дольше, но учитывая что я храню модели на медленном HDD, разницы в скорости с х16 особо не заметно.
Не вижу смысла докупать мать только ради этого, дольше пары минут загрузки ждать всё равно не придётся, а на скорость работы шина не влияет.
>Начинаю склоняться в сторону 3060, а потом подкопить на теслы.
А я склоняюсь к покупке 3060, чтобы хоть немного слоёв перекидывать на второй ГПУ, на и с нвидиа картами тесла дружит лучше.
Но это потому что денег у меня совсем нет, если бы был полтинник, то лучше бы подкопил на 3090, взял кредит или рискнул и нашёл 3090 за полтинник, это реально
>Китайские блоки типа твоего прикрепа это всегда лотерея.
Конкретно этот блок я конечно брал наугад, но оказалось что это не совсем ноунейм, а топовый производитель блоков для ферм, который берут за качество, почему и скинул его.
Де вы огрызки такие находите, есть же ж божественный хуанан с овер дофига линий как раз для дохлого LLM сервера...
проблема разношерстных карт типа паскаля и ампера в том, что тензорными ядрами не сможеш воспользоваться если раскинуть...
Кста, подкинет кто-нибудь хороший гайд по раскидыванию на Уге-буге? а то меня чет стремает что первой картой видит 4гиговку а не 8 гиговку, и не совсем понятно как для lammacpp указывать куда кидать что
>первой картой видит 4гиговку а не 8 гиговку
У меня для тебя хуёвые новости. Куда сортирует карты по мощности. А smi по порядку в портах. И ты можешь открыть файл server.py и добавить после import os следующую строку
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
И будет уба сортировать в том же порядке, что и smi.
>пик
Ебать вот это шаромыга. Ты через рейзер ее в x1 воткнул? Вообще кстати не думал об этом, хотя у меня в корпусе как раз есть крепления для горизонтальной установки четвертой видеокарты.
>а на скорость работы шина не влияет
Так как бы у четвертой писи x16 32 гигабита в секунду скорость, у x1 всего два. Это по сути как ддр4 получается.
>Но это потому что денег у меня совсем нет, если бы был полтинник, то лучше бы подкопил на 3090, взял кредит или рискнул и нашёл 3090 за полтинник, это реально
Ну я и не спорю, что это реально. Просто еще несколько недель сидеть вообще без видеокарты а потом еще шляться по бывшим майнинг-притонам в поисках той самой живой 3090 мне банально лень.
У тебя там кстати походу труханы на батарее сушатся (o・ω・o)
>Так как бы у четвертой писи x16 32 гигабита в секунду скорость, у x1 всего два. Это по сути как ддр4 получается.
Не сравнивай видеокарту и оперативку. С ОЗУ данные постоянно считываются процем для вычислений, именно поэтому её скорость влияет на количество т/с.
С видеокартой другая тема, по узкому каналу данные в видеопамять будут грузиться дольше, но когда загрузятся работать будут с той же скоростью, что и на Х16 шине, потому что все вычисления проходят на видеокарте.
Вот если тебе постоянно надо загружать/выгружать разные модели в видеопамять, то тогда Х1 будет жопой.
Замерял т/с на тесле в х1 и х16, разницы нет.
>Ты через рейзер ее в x1 воткнул?
Да, это первая установка Теслы, ещё без охлаждения. Воткнул её в х16, а основную видеокарту в х1, в играх кстати тоже особого падения скорости не заметил лол.
Каждый день тугосерюсь но зато узнаю что-то новое. Хорошо что на двачах убрали регистрацию и никто никогда не вычислит меня и не узнает на какой позиции я ишачу с такими знаниями. А за разъяснялку спасибо.
лол по мощности)
одна 1070, вторая огрызок низкопрофильный Т600, зато на более новом чипе...
Так єто, зачем пай файлик трогать если можно в батник добавить, короче говоря за патч спасибо, но вопрос как делением управлять пока открытым остается, из параметров я вижу только количество слоев для выгрузки, и tensor_split... это оно и есть? задать проценты распределения между картами?
Подскажите же.
Я ебу? Сам проверил бы уже. Наверное 6 гигов врам на 32к контекста там.
>не узнает на какой позиции я ишачу с такими знаниями.
Напомнил мне чела, который работает в крупной айти компании и уже несколько месяцев приходит на работу на пару часов, ничего не делает, все предложения отклоняет и получает деньги ни за что. Он ещё с опросом шёл, как "быстро меня уволят".
> зачем пай файлик трогать
А почему нет? Обновлять убу всё равно не советую, она ломается чаще, чем обновляется. С жорой да, тензор сплит, там же описано всё. Учитывай, что контекст будет на первой карте. И можешь попробовать включить row_split. Иногда даёт буст скорости. Очевидно, это не твой случай, но попробовать ничего не мешает.
>List of proportions to split the model across multiple GPUs. Example: 60,40
Пропорции? Вроде, раньше по-другому работало.
>Пропорции? Вроде, раньше по-другому работало.
Я прямо гигабайты врам пишу и в Жоре, и в Убе. Прокатывает. Они походу и сами не знают, чего хотят.
>проблема разношерстных карт типа паскаля и ампера в том, что тензорными ядрами не сможеш воспользоваться если раскинуть...
А если сломать систему и вместо 3060 взять 1080ti на 11Гб? Можно в пределах 15к найти.
По моему неплохое дополнение к Тесте, она как раз примерно 1080 по производительности.
так а в чем финт ушами? вместо Mazda RX7 взять жигу заряженую по самые помидоры?
тензорные ядра завезли вместе с рейтрейсингом начиная с 20й серии, да 1080 приятнее теслы в виду того что она с норм охладом и с выходами, но вкладываться в древнюю архитектуру - как знаеш, 3060 интереснее выглядит хотябы потому что к ней еще можно будет в дальнейшем докупить тензорных...
>А если сломать систему и вместо 3060 взять 1080ti на 11Гб? Можно в пределах 15к найти.
За 15к можно P100 найти, там даже 16гб.
>в дальнейшем докупить тензорных...
Это каких, 3090? Так 3060 уже её будет вниз тянуть производительностью.
А при покупке сейчас 3060, её вниз будет тянуть Тесла.
Финт в том чтобы вместо этого можно купить 1080 и получить те-же токены в секунду, но заплатить 15к вместо 25-30к.
А если у меня вдруг будут деньги на "обновление", то лучше сразу пару 3090-4090 взять.
>За 15к можно P100 найти
Мне с видеовводами надо. Сейчас у меня там RX580, на которую слои с теслы не перекинешь.
В смысле можно прямо выставить 32к контекста и будет работать, а не шизить?
Я хз, в играх по тестам 10% отставание, терпимое. И уж точно быстрее 1060.
Но мне-то нахуй нужно в играх.
А в ллм все упирается в (токен/сек)/рубль, верно? Чем выше — тем лучше.
Оператива в пять раз медленнее при цене в 2,5 раза меньше (косарь за 8 гигов).
Ну и я вообще их получил за 2к, что еще дешевле.
Опять же, никто не говорит, что она имба. Она ВСЕГО ЛИШЬ 8 гиговая. Это не 3060 ни разу.
Но зато за 2,5 куска.
Как говорится, вчера большие раки, но по 5, а сегодня маленькие, но по 3. =) Каждый сам выбирает.
Для людей с материнками на два слота или встройкой, и отсутствием бюджета (ну, то есть, прям вот 2,5 косаря накопил с завтраков) очень хороший вариант.
Получаем 15 токенов/сек на том, что влезет.
> из-за длсс
ДЛСС и в 3060 есть.
В 4060 уже фреймгенерейшен, и это крутая штука. Надо помнить, что игра не перестает лагать — она визуально для глаза лучше идет. Но отзывчивость как раньше. Но штука крутая. Мне нравится.
Зато почти все из коробки. =)
Ну, если раскидывать слои на две видяхи, то на скорость обработки промпта влияет.
А если на одну — то да, пофигу, так-то.
Жесть у тебя пекарня. =) Силен.
Ну, пишешь туды шо куды и все работает.
У меня кобольд не верно порядок карт определяет (пишет 1660с, а кидает на 4070ти, но он именно порядок неправильно определяет, а кидает уже правильно), а убабуга… вообще не пишет их названий, кек, но определяет верно, хз.
О, огнище, спс!
В данный момент, я так понял, у него работает тока тесла, и на вторую не кидается. Тогда в натури поебать.
А вот если он докупит другую, то его будет ждать сюрприз. =)
Ну, в случае ДВУХ видях под одну модель — там будет контекст кидаться. И в случае большого (20к+) пересчет будет занимать время.
А на ОДНОЙ карте разницы нет, верно. =)
ОР
Я тоже так хочу, но у меня не хватит бессовестности.
Убу в последнее время обновляю нон-стоп, не ломается ни на одном из 3 ПК.
Там паскаль и сомнительное, ИМХО.
>Это каких, 3090? Так 3060 уже её будет вниз тянуть производительностью.
ну так стейблдифьюжен с Flux повесиш на 3060, или что-то другое что влазит. опять таки, бенчмарками не обладаю, но говорят нейронки на тензорных гораздо шустрее ходят
>Некоторым из них даже нашлось объяснение
Надеюсь их занесли в код в качестве комментариев? Я любую неочевидную хуйню комменчу.
Мимо PHP-макака
>оно какого-то фига по всем дискам мне лазит
Это шинда, чел.
>и не узнает на какой позиции я ишачу с такими знаниями
Передал тебя модераторам, они по IP вычислят.
>и уже несколько месяцев приходит на работу на пару часов, ничего не делает
База же. Я в банке так работаю, хули, там всё равно ничего быстрее чем за 3 месяца не делается, хотя нет, мне доступы, критичные для работы, всего лишь за 3 недели сделали, в течении которых я в принципе не мог ничего делать.
>Но отзывчивость как раньше.
Для слоупоков разве что. Это как включить всунк, сразу +3 кадра задержки минимум. Не для того я 144 кекогерца монитор брал.
В амперориге стоит какой-то недорого 1200ваттник, там там стоковый куллер под нагрузкой шумит так что можно ебануться. Заменил на более тихий, но всеравно это дичь под продолжительной нагрузкой более ~1100вт перегревается. Потому интересно подобный майнерский пердун рассмотреть, но отзывы очень противоречивые.
> опросить идеи по оформлению, вопросов попросить накидать - другое дело
Это тема годная, гемма наверно вполне подойдет для пободного из доступных на простом железе.
> но какого-то фига по всем дискам мне лазит
Там же просто миниконда для пихона и либ, а потом оно пипом все ставит. По разным дискам - скорее всего к кэшу пакетов у тебя обращается.
Да, ну и треш же там. Неужели никтоне взялся это поправить за все время?
> бюджета на такие приколы у меня нет
В том и прикол что на твоем месте нужно получить что-то с максимально выгодным прайс/перфоманс, а не пытаться сношать огрызки теша себя надеждами что "вот потом уже не теслу соберу". Тогда уж вообще включай ждуна и отдохни месяц, а потом опять въебывай, а то и до релиза блеквеллов дотерпишь когда все подешевеет.
Два аргумента против здесь только есть - курс валюты может улететь и сгоришь что не купил. А за 3090 - бу без гарантии, может пережить твой комп, а может отвалиться через неделю.
Если уж будешь брать 3060 то смотри только в сторону 12 гиговой версии. Алсо есть экзотика типа 2080ти@22gb, в твой бюджет укладывается.
>недорого 1200ваттник
>майнерский пердун
Хату от пожара застрахуй перед экспериментами.
>Неужели никтоне взялся это поправить за все время?
Берись ты.
>а то и до релиза блеквеллов дотерпишь когда все подешевеет
Нихуя уже не дешевеет, даже в баксах, а в деревянных цены только в верх и ползут даже на бу.
>Это шинда, чел.
неть, это дибильные скрипты установки конды (Какой аунич вообще конду пихает во все щели, есть же venv православный в пайтоне), которые так и не смогли ее поставить, ручная установка решилапроблему
Опа, можешь сравнить перфоманс на одной и той же карточке, только в х16 и х1? В какой-нибудь модели что будет помещаться чисто в врам и там где будет примерно на половину оффлоад на цп?
> хороший гайд по раскидыванию на Уге-буге?
Всмысле раскидыванию? В экслламе пишешь через запятую сколько гигов выделяешь на каждой карточке. Для первой пиши меньше чем есть ибо еще сожрет на контекст и система потребляет, для второй указывай весь объем. Для жоры можешь сделать точно также, можешь указать относительными долями типа 0.8,1. В случае доп опций потребление на контекст может сильно меняться и потребуется сокращать число слоев на первой карте.
Если не устраивает порядок карт и хочешь поменять основную - CUDA_VISIBLE_DEVICES=1,0
> у x1 всего два. Это по сути как ддр4 получается
Чивобля
> банально лень
> с трудом добытые деньги
Странный ты
Я тоже пхп-обезьянка, пролоббируй меня в свой банк. =D
>Там же просто миниконда для пихона и либ, а потом оно пипом все ставит. По разным дискам - скорее всего к кэшу пакетов у тебя обращается
Нить, оно как бомж в корзине копается и в документы лазать пытается, выдавая ошибки отсутствия доступа, и не ставилось... короче перемудрили чет там...
Сейчас стоит фирмовый с рабочими защитами, хоть и был куплен дешево.
> Берись ты.
На жору аллергия.
Эээээ ты что вообще такое скачал? Эта вишня какая-то а не его инсталлер, он вообще простой и довольно минималистичный.
с порнхаба зипак с исходником, главное в батнике рили ничего вроде нет чтобы лазило куда-то...
>Потому интересно подобный майнерский пердун рассмотреть, но отзывы очень противоречивые.
Оно конечно интересно, но только шум тут вообще на последнем месте. Сам же понимаешь, что это чистая лотерея со взносом в виде всего ПК. Можно и выиграть.

>есть же venv православный в пайтоне
Недостаточно модно.
Увы, пока требуются только девопсеры, да и то на какие-то копейки.
>На жору аллергия.
Ну вот и у остальных тоже самое. Никто в жареном говне ковыряться не хочет.
Насчёт флюкуса я не подумал, в этом плане и правда полезней. Но и30к больше, чем 15...
>Опа, можешь сравнить перфоманс на одной и той же карточке, только в х16 и х1?
Мне сейчас пиздец как не охота с этим возиться, особенно выковыривать Теслу из корпуса, я её очень хорошо запихал. Жаль что не сохранил результаты теста, но помню что показатели скорости при загрузке модели в видеопамять были одинаковы.
А слои в ОЗУ я не выгружаю, т.к. у меня DDR4 2666 и скорость сильно падает, когда даже пару слоёв перекидываешь.
>А слои в ОЗУ я не выгружаю
Без выгрузки и без сплита скорость конечно будет одинаковой, хоть по WiFi карточку подключай.
> Никто в жареном говне ковыряться не хочет.
Зато как защищать, восхвалять и игнорить очевидные проблемы - сразу набегают, как же так?
> не охота
Ну там при случае когда будешь перебирать или делать нечего будет. Желательно как можно больше данных, в частности отследить влияние при модели полностью в врам (уже ответил но на всякий глянь), разница при всех слоях кроме одного на гпу (чтобы был пересыл активаций), разница при 50-50, и просто работу к экслламе.
Просто тут буквально никого нет кто бы на х1 сидел чтобы подобный тест провести, а разговоров ебать сколько.
>Насчёт флюкуса я не подумал, в этом плане и правда полезней. Но и30к больше, чем 15...
ну по этому и надо подумать и взвесить, видяхи то не дешевые, а некроту чем дальше тем сложнее сплавить... хотя 1080 еще держится неплохо, но... пошли уже игрули которые можно сказать не работают на безлучевых карточках...
Я и девопсом опыт имею, но за копейки не хочу. =) Девопсы ответственные, отлынивать не выйдет, если прод упадет.
Посмотрел тока шо ролик spline'а, он там 550ti на авито продавал. Ну я подумал «эээ… 700 рэ?», а она 1800 поставил, что ли.
Пздц, даже совсем старые видяхи стоят неоправданно дохуя.
Пздц, даже совсем старые видяхи стоят неоправданно дохуя. есть такое... но тут скорее виноваты те кто берут за такие деньги...
>но тут скорее виноваты те кто берут за такие деньги...
А хули им делать? Сидеть вообще без видео?
Чем ниже цена тем убервсратее ее соотношение к качеству. Так сказать, платишь за сам факт возможности, которую дает предмет, а то каким хуевым это будет - не важно.
> за копейки
> 100к
ваще ахуевший
Иметь достоинство так сказать. Ты же не идешь жрать тараканов в случае если нет возможности потреблять омаров?
>> за копейки
>> 100к
>ваще ахуевший
Чел, сейчас любой бич может поднять 200к, отодрав жопу с дивана, так что 100к уже давно уровень ниже бомжа.
>Ты же не идешь жрать тараканов в случае если нет возможности потреблять омаров?
Если будет выбор между тараканами и сдохнуть самому, то я лучше вжарю тараканами.
Кто то новый пикстраль уже пробовал, хотя бы в оригинале? Че по цензуре видео части?
>за все время?
Ты про тройной цикл? А это разве что для геммы используется и добавлено не так давно, до этого ещё хуже было. Это хотя бы логику работы модели соблюдает. У самого Жоры там приоритет на сиквенсы, сейчас, вот, переделал семплинг. Чем сломал апи. Ну да похуй. Если про надмозговые циклы, то хуй знает, они выглядят, как говно, но на работу программы не влияют в конечном счёте.
Кто юзает Qwen2-VL, для чего применяете? Как вам?
Ну, как Битрикс-разработчику мне предлагали 170, но там надо работать, а я ленивый.
Я хочу работать по час-два в день за 20-40 тыщ. Мне много денег не надо, но и работать. А если не найдется, и придется пахать 8 часов — то, как бы, я и зп хочу достойную, как бы.
Так что, тут ведь дело не только в зп, а еще и в объеме работы.
Не, мне лень разбираться с запуском ее на тесле, 25 гигов все же жрет, хз че там как.
И спейсов не нашел.
Ваще хз, но очень интересно.
Седня днем один чел тестил, он весьма неплохо определяет фотки с техникой разной, но не разбирает чертежи. Так же, у него отличный OCR (там еще какая-то оср модель на базе 0.5б вышла, не суть). Для какой-нибудь разметки или анализа подойдет очень хорошо.
Но куда по факту засунуть себе в прод, я пока не придумал. ^_^'
Мне она просто нравится, но без применений, ы.
>отличный OCR
вот да, хорошо детектит текст с любой визуальной новеллы. еще бы переводчик с японского хороший найти. и можно постигать олдовые вн.
> хорошо детектит текст с любой визуальной новеллы. еще бы переводчик с японского хороший найти. и можно постигать олдовые вн.
Транслюмо же есть. ОСР и переводчики, в т.ч. с японского. Олдовые японские ВН ждут тебя, анон. От себя рекомендую https://vndb.org/v1131 и пожалуй https://vndb.org/v3337
>Транслюмо
ранее для некоторых проектов приходилось использовать такие библиотеки как tesseract и easyocr. не могу сказать, что они идеально распознают текст, особенно если это касается японского. вот тут меня qwen2-vl удивил, он распознает гораздо лучше, покрытие почти 99%, даже со всратых скринов, с шумом, единственное чего у него не хватает - это распознавание местоположения символов. считаю, что это действительно прогресс в ocr.
> считаю, что это действительно прогресс в ocr.
Это прогресс нейросетей в целом. Все эти омни-модели всё равно уступают и будут уступать специализированным моделям. Хотя согласен, что в Транслюмо используются далеко не новые OCR-решения. Но на практике их достаточно.
>Чел, сейчас любой бич может поднять 200к, отодрав жопу с дивана, так что 100к уже давно уровень ниже бомжа.
Ахуеть, как?
>100к уже давно уровень ниже бомжа.
По данным росстата больше 100к зарабатывают менее 10% населения РФ.
Присоединяюсь к вопросу.
есть у меня несколько "друзей" которые дорвавшись до высоких зарплат, сразу начали такую же хуйню городить про "встать с дивана", при этом сами всю жизнь зарабатывали около 30к и на вопрос что конкретно надо сделать чтобы зарабатывать такие деньги внятно ответить не могут
Как использовать специализированные текстовые модели? С рпшной поеботой все понятно, но, допустим, https://huggingface.co/THUDM/codegeex4-all-9b в ггуф я открыл в кобольде, ему нужен свой синтаксис запроса. В кобольде это можно делать, но бинарный релиз не сохраняет настройки. Делать в СТ персонажа йобапрограммист или что?
Не, немного не так.
Qwen2-VL-7b построен на базе LLM Qwen2-7b. Поэтому, он не уступает сам себе. =) Ну, доли процентов, за счет большего размера. Но в общем, уступать будет, если ты насильно от него кусок отрежешь — это тупо делать.
Почему gpt-4o уступает какой-нибудь другой модели — не потому, что она омни, а потому что это принципиально разные модели, под капотом не та же самая LLM, а совершенно иная (меньше, очевидно).
А прогресс именно OCR: Qwen2-VL, теперь еще Pixtral и GOT OCR ( https://huggingface.co/papers/2409.01704 , https://github.com/Ucas-HaoranWei/GOT-OCR2.0 ), в последние недели бахают.
Ну там, IQ > 120, технический склад ума и доходные языки программирования. =) Изи, не?
Кстати, по факту, модальная зп в России (т.е., без Москвы и СПб) — 27к на руки, если что. Так что, если зарабатываете больше 27к — вы уже дохуя средний класс, гордитесь.
1. Кобольд можно распаковать.
2. В СТ просто есть синтаксис и все прочее, проблемы?
Не уловил вопроса.
Вообще, юзать убабугу для работы, а не ебать мозги с кобольдом. Кобольд чисто под рп новичкам, чтобы из одного файла.
Все дальше — это убабуга, голая ллама, обертка ллама-питон, ллама-индекс и прочее.
Yi Coder пробовал?
>Вообще, юзать убабугу для работы, а не ебать мозги с кобольдом
Это все отлично, только у меня радеон.
Прикольная штука, кто пробовал уже? Может создать описание картинки?
https://habr.com/ru/news/842544/
https://habr.com/ru/news/842544/
Обычная vlm, на что там смотреть.
Я не в теме, есть что лучше? влм что это?
Хабр из помойки превратился в суперпомойку, я смотрю.
Новости уровня твиттера.
Vision Language Model.
Да, она создает описание картинки, прикинь.
Нет, не пробовал, мне лень поднимать локально, разбираться, модель крупная.
Из аналогов/альтернатив есть Qwen2-VL, можешь попробовать иъ тут:
https://huggingface.co/spaces/MaziyarPanahi/Qwen2-VL-2B
https://huggingface.co/spaces/GanymedeNil/Qwen2-VL-7B
Ну зато хоть какая-то инфа удается с хабра. Ок, интересно посмотреть насколько хорош результат.
>IQ > 120
Это 8% людей.
>любой бич
> Чел, сейчас любой бич может поднять 200к
Вроде как да, вот только вокруг одни разговоры о том как тяжело, а в треде (заметь уже есть некоторый ценз чтобы сюда попасть) одни бомжи с нищекартами или выбором из залупы, что даже покупка 3090 воспринимается как событие?
> Если будет выбор между тараканами и сдохнуть самому, то я лучше вжарю тараканами.
А мог бы как белый человек пойти в магазин и купить креветосов.
> Я хочу работать по час-два в день за 20-40 тыщ.
Какое-нибудь хобби монетизируй, только не основное. Или ищи работу типа 1-3, будет много свободного времени.
Достойную то все хотят, но не все могут на нее перформить. Как в шутке что долбоебы научились хорошо проходить собеседования а скилловички в них не шарят.
Там пикстраль вышел, по размеру прямо золотая середина и может быть потанцевал, кто-нибудь уже тестил?
> IQ > 120, технический склад ума и доходные языки программирования
Последнее нахуй не нужно для 150-200к. Кодинг для макак только, максимум как ступеньку в руководящие должности можно его рассматривать, хотя и без него есть попроще варианты.
>А прогресс именно OCR: Qwen2-VL, теперь еще Pixtral и GOT OCR ( https://huggingface.co/papers/2409.01704 , https://github.com/Ucas-HaoranWei/GOT-OCR2.0 ), в последние недели бахают.
Я считаю, что из этого списка только GOT OCR можно назвать специализированной моделью именно для OCR. Но как всякая новая технология она будет иметь вначале косяки, мало совместимые с реальным применением. Ну и видно, что под Куду заточено, а хотелось бы на процессоре - вместо здоровенной модели в 1,5Гб маленькую в 15мб и чтобы хорошо работало :) Такие есть.
Спрашивал в соседнем треде на чем кумить через 12гб карточку. Сказали пигмалион 7б и послали сюда. Альтернатив нет?
>вместо здоровенной модели в 1,5Гб маленькую в 15мб и чтобы хорошо работало :) Такие есть.
Как-то ты уже загнул, 15мб и хорошо. Клип какой-нибудь?
А вообще да, довольно сложно прикрутить к какой-нибудь модели зрение, если модель не мультимодалка, а ты хочешь сэкономить ресурсы. Мелкие модели выдают какие-то странные описания, когда пробовал, зачастую на пикче с котом не видело кота. А вот квен VL хорош, но жирен.
С голосом пиздец, модель слишком много добывает из спектрограмм - шумы, интонации, но не обучена достаточно, чтобы понимать где что. С той же Ё - она, сука, поняла, что в русском языке есть Ё и можно свободно заменять Ё на Е. И начала делать это в обе стороны. А полностью подавить шумы на подготовке датасета у меня не выходит даже специализированными нейросетями.
Олсо, про заработок, даже конченный даун может зарабатывать 200к в месяц пожизненно. Достаточно использовать старый дедовский метод - обратиться к тащ военкому.
А подскажите такой момент, я правильно понимаю, что для корректной работы модельки нужно правильный токенайзер иметь, конфиг, итд? и для этого надо в угебуге сконверитить в ХФ (точнее докачать нужные файлики)? если да, тогда зачем нужне вариант без таких файликов, и как оно работает тогда?
>конченный даун может зарабатывать 200к в месяц пожизненноэто как "мотоцикл прослужит до конца жизни если ездить достаточно быстро"?
тонко однако...
и раз уж про мультимодальные речь пошла, чем можно запускать такие вундервафли?
>конченный даун может зарабатывать 200к в месяц пожизненноэто как "мотоцикл прослужит до конца жизни если ездить достаточно быстро"?
тонко однако...
и раз уж про мультимодальные речь пошла, чем можно запускать такие вундервафли?
натыкался в треде на упоминание Yi-Coder, кто-нибудь может внятно пояснить, какие варианты использования этой дичи, и как ее заставить работать по человечески? а то подобие кода она выдает конечно, но он же ж не рабочий от слова совсем...
Ну, это все узнается из тг-каналов, твиттера, обниморды, архива, откуда угодно и раньше. =) Поэтому не очень понятен смысл репостов ради репостов.
Ну, авторы разные. =)
Да я и так в клубе сижу, я удаленку хочу, чтобы из клуба работать.
Я и так уже работал на двух фирмах, но там 160 и 80 часов было в месяц. Хочу меньше. х)
Пикстраль я че-то потыкал, не понял, как ее инференсить, а думать мне в лом, я и забил.
Подожду какого-нибудь готового app.py
Ну так за кодинг 150 платят вполне, если язык хороший.
А руководящие должности — я не бизнесмен, не ебу, мб.
За шо знаю, за то ответил. =)
Ну, да, технически, VLM не OCR, но ведь могет! =)
Ну, тоже верно.
Че-то мешанина в мозгах, бро.
Разберись лучше.
В GGUF все вшито, там один файл.
В других поставляется вместе с файлом, качать целой папкой.
Мультимодалки смотря какие.
Ллавы есть поддержка в ллама.спп.
А у современных пока нема, ждем, запускаться чисто трансформерами, щито поделать.
Я не трогал, если честно. Надо будет на выходных попробовать.
Какой даунич написал в вики что :
>Exllama2 быстрее в ~1.2-2 раза чем Llamacpp, требует меньше памяти на ту же битность и тот же контекст.
на неамперовских картах без плясок оно с флеш-аттеншеном не работает, а без флеш-атеншена заквантованая 7B дает 2.38 токена/с на 1070, что медленнее чем гуф
>Exllama2 быстрее в ~1.2-2 раза чем Llamacpp, требует меньше памяти на ту же битность и тот же контекст.
на неамперовских картах без плясок оно с флеш-аттеншеном не работает, а без флеш-атеншена заквантованая 7B дает 2.38 токена/с на 1070, что медленнее чем гуф
Ты юзаешь всратую некроту и смеешь называть кого-то дауничем? А ну пиздуй 200к зарабатывать как любой может.
> а без флеш-атеншена
Он лишь снижает жор памяти и может ускорить на больших контекстах, в твоем случае проблема в картофельной видеокарте, которая фп16 считает в 64 раза медленнее чем должна.
Какую видеокарту стоит взять исключительно для языковых моделей и sd? Чтобы не переплачивать бессмысленно и т. д. Если знаете название не только модели, но и производителя, укажите, пожалуйста, его.
Несколько я понимаю, должно быть 12 Гб врам, а остальное не так важно.
Несколько я понимаю, должно быть 12 Гб врам, а остальное не так важно.
>которая фп16 считает в 64 раза медленнее чем должна.
До сих пор кстати нет тестов франкенштейнов 2080 на 22гб. Это тоже не ампер, но с фп16 вроде всё в порядке. И все в порядке с этим у P100, но он тоже ничего выдающегося не показывает. Короче у кого нет хотя бы 30-й серии - могут идти в жору :)
а ничего, что быстрее в ~1.2-2 раза и быстрее в ~1.2-2 раза на двух последних поголениях ГПУ это разные вещи, и такое в "вики" надо отмечать, написали б, ускоряет работу на тензорных ядрах или что-то подобное - ситуация понятная была б, а так - звучит как будто ускорение не зависит от железки
народ и на максвелах гонять пытается, чего уж там
а 104-100 так у трети тут наверное
24 хотяб, на 12 ты будеш гонять 7B модельки для кумерства, если чет жирнее надо, то пичалька...
для дифузии тоже 12 в притык, если контролнеты будеш юзать и что-то больше чем 512*512 генерить
>ДЛСС и в 3060 есть. В 4060 уже фреймгенерейшен, и это крутая штука.
Да, я тупо лажанул и перепутал названия.
>Тогда уж вообще включай ждуна и отдохни месяц, а потом опять въебывай, а то и до релиза блеквеллов дотерпишь когда все подешевеет.
Не вижу смысла ждать блеквеллов. Во первых их ждать минимум до следующего года плюс еще несколько месяцев пока на них цена не уляжется. Во вторых судя по сливам младшие модели опять будут иметь восемь линий, шину в 128 бит, и восемь гигов гддр6 памяти. Короче, будет та же самая 4060/4070 но с приростом в 10-15 процентов в лучшем случае. Нвидиа итак прямо признались, что им аренда и продажа проф. карт в несколько раз больше приносит, чем десктопный сектор, по этому они могут еще раз обосраться с новым поколением и всё равно нихуя не потерять.
>Если уж будешь брать 3060 то смотри только в сторону 12 гиговой версии.
Ну именно её я и собираюсь брать, а на сэкономленные средства скорее всего возьму ссдшник чтобы наконец слезть со своего сигейта на котором уже пять лет дрочусь.
>Алсо есть экзотика типа 2080ти@22gb, в твой бюджет укладывается.
Китайский самопал с доп. чипами памяти или типа того? Ни разу не слышал.
>24 хотяб, на 12 ты будеш гонять 7B модельки для кумерства, если чет жирнее надо, то пичалька...
И 12 хватит. 7-12В войдут, SDXL норм будет. И относительно недорого, если 3060 рассматривать.
Там скорость хорошая будет, могут быть нюансы со сборкой фа, но это возможно
> все в порядке с этим у P100, но он тоже ничего выдающегося не показывает
Кто-то так был доволен что быстро работает. По крайней мере явных проблем быть не должно.
> а ничего
Ничего, карты с поддержкой нормальных расчетов были еще в паскалях, тьюринг релизился аж в 18 году, амперы аж в 20м.
Если карточка древняя и не может в фп16 - надо радоваться что там что-то вообще работает а не возникать. И тензорные ядра тут не при чем, можешь заглянуть в код и понять.
SOTA, передовая технология на острие прогресса, а васяны ноют что некрота, которой 8 лет(!) у них плохо работает с современным интерфейсом, пиздец же.
> ждать минимум до следующего года плюс еще несколько месяцев
Вот это верно, но может быть лучше трат на спорный оверпрайснутый лоу-мидл. По крайней мере "битва была равна", тут уже сам смотри. Просто 3060 довольно грустная, хоть она является отличным дешевым вариантом и минимальным входным порогом для многого, когда распробуешь - сразу захочешь большего.
> Китайский самопал с доп. чипами памяти или типа того?
С замененными, кидали ссылки на них.
Я SDXL юзал на 3050 ноутбучной с 4 Гб врам, так что не знаю даже. И апскейлил в том числе.
Думаю, 3060 всё это потянет, но с цены я прихуел. Такая древность, а стоит дорого. С озона брать, я так понимаю, совсем плохая идея?
> с цены я прихуел
Она же стоит копейки, 20к.
36к в днс.
Один хуй копейки. С зарплаты сходил бы и купил, чем ныть тут.
>3060 довольно грустная, хоть она является отличным дешевым вариантом и минимальным входным порогом для многого
Ну с этим я не спорю. В былые времена за 35 тысяч можно было хорошую среднюю карту взять, типа 1070 которой хватало с запасом на несколько лет.
>когда распробуешь - сразу захочешь большего
Ну, я три года на 1060 сидел трехгиговой. До этого на 760 еще несколько лет. Так что я в этом плане не особо зажравшийся. Для меня достаточно средних настроек в игорях с хорошим фреймретом и фреймтаймом.
Алсо, меня немного дурит идея взять 4060 и попробовать разогнать на ней память, чтобы были хотя бы те же 320 г/c как на 3060, а не смешные 280. Но тут слишком большой фактор рандомности, потому что велик шанс что могут попасться хуевые чипы и накрут в 15-20 процентов по частоте они не примут.
Ну раз ждунство не хочешь, то бери. 4060ти@16 в таком случае наилучшим вариантом будет, если увлечешься нейронками то за 16 гигов долго благодарить себя будешь, а с 8 будешь постоянно страдать. Память, как правило, на такие значения гонится.
Сап, ИскИнач.
Какой лучше инструмент поставить на комп, который бы мне помогал код ебашить с возможностью дообучения?
Сильно не стукайте. Я только впервые вкатываюсь.
Вот я качаю кобольдаЦоПеПе.
Скачиваю средненькую модельку Frostwind-10.7B
Но у меня игровая пекарня и могу ли я модели дать больше параметров? И самому её раскачать под конкретно мой компуктер?
Какой лучше инструмент поставить на комп, который бы мне помогал код ебашить с возможностью дообучения?
Сильно не стукайте. Я только впервые вкатываюсь.
Вот я качаю кобольдаЦоПеПе.
Скачиваю средненькую модельку Frostwind-10.7B
Но у меня игровая пекарня и могу ли я модели дать больше параметров? И самому её раскачать под конкретно мой компуктер?
>Но у меня игровая пекарня и могу ли я модели дать больше параметров? И самому её раскачать под конкретно мой компуктер?
Нет. Совсем нет.
>код ебашить
Качай модели которые на это специализируются.
>с возможностью дообучения
Дообучение только лорами. Но дообучать лорами - дорого.
>Скачиваю средненькую модельку Frostwind-10.7B
Эта уже протухла, есть более новые и производительные модели.
>Но у меня игровая пекарня и могу ли я модели дать больше параметров?
Кидай характеристики. Если под параметрами ты подразумеваешь входные данные - то да, с помощью контекста.
>И самому её раскачать под конкретно мой компуктер?
Не знаю че ты имеешь ввиду, но на всякий случай отвечу, что нет.
>Но у меня игровая пекарня и могу ли я модели дать больше параметров?
Если у тебя там не карта уровня 4090 стоит, то у тебя не игровая пекарня, а огрызок для дфеолтных постреляшек. На среднестатистическом "игровом пека" с 12VRAM и 32RAM можно разве что модели из самого низкого сегмента ставить на 7-13 лярдов параметров. А про "дать больше параметров" - иди кури вики и почитай, что такое параметры.
>как Битрикс-разработчику
Ебать ты дно, хуже битрикса только 1С и эмбедед.
>Я хочу работать по час-два в день за 20-40 тыщ.
Давно бы заработал себе на раннюю пенсию, для 30 тысяч нужен капитал в жалкие 6 лямов на бирже.
Подпиши контракт, ещё и подъёмные дадут.
>По данным росстата
Инфляция 6%.
>Хабр из помойки превратился в суперпомойку, я смотрю.
А хули, я ушёл же.
>вот только вокруг одни разговоры о том как тяжело
Ну я и пишу, люди тупее бомжей уже.
>Какой даунич написал в вики
Ну я, и что?
>на неамперовских картах
Про железо отдельная ссылка, твоё в разделе "некроговно".
>Во вторых судя по сливам младшие модели опять будут иметь восемь линий, шину в 128 бит, и восемь гигов гддр6 памяти.
Как же куртка всем за щеку наливает...
>Я SDXL
Устарела с приходом флюкса.
>В былые времена за 35 тысяч можно было
Деревню с крестьянами взять. Хули сейчас не так...
>с возможностью дообучения
Тебя или нейронки? Если тебя, то учись на здоровье, если нейронки, то соси хуй, сейчас ничего не дообучается во время работы.
>с возможностью дообучения
Ты захочешь. Но ты не сможешь.
>могу ли я модели дать больше параметров
Ты можешь. Но ты не захочешь. Чтобы сделать "больше параметров при той же модели", гугли техники тайного богопротивного колдунства, которое называется франкенмержем.
Шумер разбудил шизов, теперь даже жпт свой аналог рефлекшена выкатили. Нах они это делают, если для ответа из 5 слов надо ждать 30 секунд "размышлений"? Я молчу про рп, но ведь это говно даже для каких-то задач типа обработки текста сложно применить.
Очевидно пытаются выжать все из технологии, чтобы было понятно куда копать дальше для улучшения.
>выкатили
В смысле уже?

Спасибо конечно, но что за разброс такой, от 8 до 12 гб, от 12 до 24 гб. А конкретно для 12 гб что подойдет?
Смотни модели до 13б просто
>но что за разброс такой
Минимальные-максимальные требования в Стиме никогда не видел?
>А конкретно для 12 гб что подойдет?
Всё это поёдёт, просто модели в которых 12Гб в начале разброса, пойдут в низком качестве, а там, где в конце - в высоком.
На практике ты должен смотреть на размер файла модели и прикидывать влезет ли она в твой Врам + пару Гб откладываем на контекст + 1Гб на систему. Итого у тебя из 12 Гб есть 9, под которые ты должен подобрать файл модели. Условно, чем больше файл - тем больше качество. Правда часть модели ты можешь в ОЗУ выгрузить, тогда влезет побольше, но работать будет медленней.
Вот поэтому и такой разброс.
Я всегда знал что все новые технологии придумываются в этом треде, а уже потом через третьи руки доходят до нормисов.
Не понятно почему только сейчас проснулись. Рефлекшену два года уже, техникам с размышлениями ещё больше. Всё это никому нахуй не нужно было все эти годы, скорее всего чисто из-за скорости даже никто не пытался применить, сейчас скорости побольше стали, но всё равно пиздец неюзабельный. Надо пытаться делать какую-то дистилляцию этих размышлений, а не высерать простыни на несколько тысяч токенов. Хотя может этот такой наёб гоев на баксы, они же за каждый токен платят.
>Устарела с приходом флюкса.
Флюкс всирает анатомию, так что пока нет.
>Я хочу работать по час-два в день за 20-40 тыщ.
Работаю час-два в месяц за 24к, ещё год назад было норм, но сейчас это пиздец мало а индексировать не хотят, мотивируя это тем что я нихуя не делаю
>С зарплаты сходил бы и купил
С 200к?
>Не понятно почему только сейчас проснулись.
Так технологии упёрлись в потолок. Тренить что-то большее, чем ГПТ-4 геморно и коммерчески невыгодно.
Поэтому сейчас тренд развернулся наоборот на оптимизацию и сокращение размеров моделей в теории с тем же результатом, но на практике получаем фурбу Вот тут то техники цинкинга и пришлись кстати, т.к. позволяют мелким моделям быть более внимательными и меньше шизить.
> С 200к?
Со 100к хотя бы. Кто-то меньше 100к получает что ли тут?
>Кто-то больше 100к получает и не пиздобол что ли тут?
Поправил тебя.
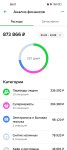
Ну хуй знает, вот только на Сбере.
Ты угараешь, чел.
Какой даунич в здравом уме будет запускать современные движки на древних картах. Паскали не могут в ллм, только в лламу.спп, но зачем-то запускать на ней бывшую? Серьезно?
Как владелец ржавых p104-100 из шапки, подтверждаю, что Exllama2 быстрее в 1,2-2 раза, чем Llamacpp и вообще пиздатей.
Но на некрожелезе стартуем как можем.
RTX 3060, вестимо. Из нового и задешево ты ничего другого не найдешь.
Ну или P100 рискни, с 16 гигами.
И никто на ней эксл не запускает, потому что знают, что брали. Как и с P40.
Даже FluxCP запустится в lowvram режиме автоматически.
Жить можно.
25к, ну… Типа.
Учти, что:
а) У нее АЖ 12 гигов относительно БЫСТРОЙ памяти, что в текущих реалиях овердохера для таких видях. 4060 с 8 пердит, лол, а 4060ти с 16 имеет медленную память за вдвое больший прайс.
б) Ее перестали выпускать, вот кончатся — и привет, альтернативам 3090 с авито и новым 4070 ти супер/4090 не будет.
Идея с разгоном памяти сомнительная, ИМХО.
Дообучения — никакой.
Самому файнтьюнить — качаешь веса любой и файнтьюнишь.
Для использования своего кода — RAG (это идея такая, реализаций много разных) и хранение в векторных ДБ (их тоже много разных).
Игровая пекарня — нихуя не понятно, две RTX 4090 и 256 DDR5 имеешь в виду? Нет? Тогда что за говно у тебя?
Ну, типа, 3070 на 8 гигов будет смешной, к сожалению. =) Для игр норм, а для нейронок — нет.
Для программирования бери Deepseek-Coder-V2-Lite или Yi Coder, пробуй обе.
Вместо KoboldCPP лучше возьми oobabooga/text-generation-webui, там движков побольше одного, на выбор.
Ну и плагин типа continue.dev можешь накатить, например.
Не-не, биржа-хуиржа. Я сижу на пенсии (по шизе=) уже 16 лет, тут все норм. Еще и на первой мелко-работе. Но хосися еще чутка за ничегонеделание.
пхп-обезьянка, хуль с меня взять =)
Напиши, что бывшая работает тока на адекватных поколениях, а то ведь заебут. =/
> франкенмержем.
гыгыгы
Так эт для работы, а не для кума, хули ты хотел.
Правда там че-то в живых тестах не ок.
Зато по старым ценам. =)
Вот читаю, что ты под спойлером написал, и понимаю, что все так, но новички ж нихуя не поймут и запутаются. =( А лучше вряд ли скажешь.
Ну, хл без лор тоже не пример для подражания.
Просто лоры для флюкса пока не научились.
Кто вообще голую хл юзает? Крайне сомневаюсь.
Пони, реалистиквижн, и прочее-прочее-прочее, чекпоинты и лоры.
Так, блеа, время тестить новые кодерские модели, а то без работы я чо-та забил на это.
Де там ваш йи кодер нахуй, будем разбираться!
Де там ваш йи кодер нахуй, будем разбираться!

Я постоянно тростниковый сахар из Маврикии вроде покупаю от Мистраля.
>Но на некрожелезе стартуем как можем.
>Ну или P100 рискни, с 16 гигами.
а ты молодец однако...
так почему 100 а не 40? цены то на них +- рядом а 24 гб приятнее будет...
а 40HX ты не пробовал случайно? тоже восьмерки но всеже следующее поколение с тензорами... должно поинтереснее быть, та и рендерить должно веселее с OptiX и лучами...вообще, удивительно что за пару лет никто не выкатил бюджетных решений для нейронок никаких
> и привет, альтернативам 3090 с авито и новым 4070 ти супер
не знаю как в РФ, но у себя вижу на вторичке 3090 чуть болше двух 3060 стоит... звучит выгодно если есть возможность вложить столько... (главное чтоб не ушатанная пришла)...
Ну что там? 9B чекнул?
а то чет я походу тупой и не понял как его заюзать нормально...
так шо, 0,9B в пятерочку выкатили? даеш ЛЛМ для всех
> Флюкс всирает анатомию, так что пока нет.
Вот этого двачую, кроме чего-то "высокохудожественного" он малоюзабелен.
> Кто-то меньше 100к получает что ли тут?
Кто-то меньше 100к ндфл платит?
> так почему 100
100 быстрее, без проблем катает фп16 (доступны эксллама, диффузия) и раньше на нее цены почти не росли, тогда как 40 подорожала сильно.
сейчас цены глянул - 40 дешевле даже чем сотка... сотку еще найти попробуй... хотя, может где как ситуация... тут опять таки вопрос в том, что если некроту береш, то не стоит ли больше Врам взять, чтобы были хоть какие-то возможности...
А вот интересный момент, кто-то пробовал ставить теслы в 4Unit сервер с так-себе продувкой, как они без доп охлада там будут себя чувствовать? или ее надо прям хорошо дуть...
Потому что P100 поддерживает Exl2. =) Некрожелезо — не поддерживает. P100 хоть и некрожелезо, но поддерживает, что дает ей 1% современности.
Завязка идет на экслламу для любителей. На P40 ты ее запустишь с той же скоростью, что и на 1080.
Линейку CMP аналог 20хх поколения не пробовал. В теории должно все работать, но на практике мне цена не понравилась на тот момент.
Может я не умею готовить, но на мой взгляд — говно.
Возможно мы оба с тобой тупые.
Да, иногда он отвечает норм, иногда не пишет код, иногда лупится.
При этом, в тех же запросах дипсик ебанул мне целое приложение готовое. Ну прям небо и земля.
Так что я даю отставку Yi Coder'у и остаюсь на дипсике.
P40 надо продувать мощно.
Не знаю, если там на корпусе свои кулера в ту сторону, может и хватит, конечно, не пробовал.
>или ее надо прям хорошо дуть...
Прям хорошо дуть надо. И людям рядом совсем некомфортно.
Еще один эксперимент!
Перебираю фронты для LLM.
Задача — найти тот, который умеет нормально форматировать промпт.
Не, СиллиТаверна, конечно, умеет! Но накатывать ноджиэс с вырвиглазным дизайном звучит так себе.
Хочется чего-то поменьше-покрасивше-попроще.
Написать самому тоже можно, но пока хочу посмотреть, че там напридумывали.
Из пунктов:
1. Форматирование промпта, инстракт (иронично, но убабуга нормально инстракт не форматирует, а чат-инстракт для ролеплея заточен).
2. Доступ по https по самоподписанному сертификату удаленно.
Если кто знает какие фронты, накидайте.
Кстати, СиллиТаверна не хочет подключаться к https. Лол, кек, что не так.
Перебираю фронты для LLM.
Задача — найти тот, который умеет нормально форматировать промпт.
Не, СиллиТаверна, конечно, умеет! Но накатывать ноджиэс с вырвиглазным дизайном звучит так себе.
Хочется чего-то поменьше-покрасивше-попроще.
Написать самому тоже можно, но пока хочу посмотреть, че там напридумывали.
Из пунктов:
1. Форматирование промпта, инстракт (иронично, но убабуга нормально инстракт не форматирует, а чат-инстракт для ролеплея заточен).
2. Доступ по https по самоподписанному сертификату удаленно.
Если кто знает какие фронты, накидайте.
Кстати, СиллиТаверна не хочет подключаться к https. Лол, кек, что не так.
>Просто лоры для флюкса пока не научились.
Ты немного отстал от жизни. Лоры уже давно на флюкс, а сейчас и ТЕ научились тренить в лорах, не только юнет. Причем на домашних пишмашинках с 24гигами, а100 не понадобилась.
Mikupad — HTML-файлик с реактом внутри. Прикольная штука, но работает в режиме Notebook. Думаю, для авторов, которые используют base-модели — очень хорошая штука (правда, ноутбук есть и в убабуге…=)
Jan.ai — если подменить в любом из провайдеров адрес на свой — работает. Но слишком мало возможностей повлиять на семплеры и промпт. Мимо.
AnythingLLM — красивое, обещает RAG и кучу всего… не работает с https, настроек сходу найти не удалось, какая-то штука для домохозяек.
LM Studio —как я понял, работает только с локалками, ну и нахуй пошла. Хотя, инфа более-менее норм расписана. Но только ггуфы. Ну да не суть, это бэк с фронтом, а не просто фронт.
Daraday.dev он же Backyard.ai — такой же бэкенд с фронтом без удаленки.
Пока меня постигло огорчение.
Может вы что-нибудь еще присоветуете.
Jan.ai — если подменить в любом из провайдеров адрес на свой — работает. Но слишком мало возможностей повлиять на семплеры и промпт. Мимо.
AnythingLLM — красивое, обещает RAG и кучу всего… не работает с https, настроек сходу найти не удалось, какая-то штука для домохозяек.
LM Studio —как я понял, работает только с локалками, ну и нахуй пошла. Хотя, инфа более-менее норм расписана. Но только ггуфы. Ну да не суть, это бэк с фронтом, а не просто фронт.
Daraday.dev он же Backyard.ai — такой же бэкенд с фронтом без удаленки.
Пока меня постигло огорчение.
Может вы что-нибудь еще присоветуете.
Я не отстал от жизни, ты не так понял.
На сд1.5 есть тысячи лор, по 5-6 версий в каждой.
На флюксе, от силы пара сотен, и у большей половины качество так себе.
Я не говорю про техническую возможность, я говорю про фактический выбор. Его пока нет, как на старые модели.
Ээээ... Моя твоя не понимат. Мне нужна лора? Я ее делаю. Все. Что там где-то есть вообще не интересно.

короче решил подергать ♂Big Fat Cock♂ Yi-Coder полторашку чтоб заодно и бывшую затестить еще раз, на огрызке, коль уж на некроте она не хочет...
И так, результат на t600, вполне приятный я бы сказал, Но не дотягивает до ламацпп лоадера, если обе 8бит взять, заквантованная пошустрее выходит, но блин, 1.5B...
А что нужно то?
Кто-нибудь может посоветовать решение (материнская плата + процессор) для 4x3090? Хотелось бы PCIe-x16 четвёртой версии для каждой карты. Оно вообще есть по разумным ценам, хотя бы в китайско-рефабном варианте?
Не, ну брутально.
Но мне лень собирать датасеты на десять тысяч размеченных фото.
А меньше мне префекционизм не позволяет.
Опять же, речь не про персонажа, а про ту же анатомию, позы и прочее, когда примеров нужно чуть больше.
Но, я таким просто не увлекаюсь, че уж. Не буду спорить, да.
Вот что:
4 х16? серьезно? тогда тебе только в серверные смотреть,
у 13600k например 20 линий всего
Epyc твой друг в этом деле, там линиями обмазаться можно,
и например такая мать Motherboard EPYCD8-2T или что-то подобное,
как вариант если нет нужды в вагоне оперативки, можеш поискать на тредрипперах чего-нибудь, но, там в притык линий будет скорее всего...
и да, деньги не особо адекватные будут, даже за у краденное с помойки у бомжей...
силли таверна не хочет? или к силли таверне не хочет подключаться?
если второе - то решается с помощью NGINX в прокси режиме, собственно так можно почти любой вопрос решить который касается отсутствия встроенного HTTPS
Таверна не хочет. По хттп ей норм, а подрубаешь сертификат — нос воротит. =)
Ну и еще она меня немного кодом не радует, ноджс, ну это прям… Такое. Микупад показывает, как надо писать подобные приложения.
ну, сертификат 98% что через Nginx прокси можно прикрутить, не трогая саму таверну сорян, не хочу сейчас проверять с сертификатом тему, а вот нода - это да... жирная гадость...
Обломись, у инцела столько линий PCIe в десктопе просто нет. У AMD тоже, но есть старые материнки под Threadripper на x399 чипсете с сокетом AM4, там до четырех честных слотов PCIe 16x единственное что версии 3.0
Зато ценник сейчас невысокий, материнка в районе 10-15к и проц за 5-6к если это какой-нибудь 1920x. К тому же плюсом восемь слотов под оперативку и "четырехканал", который представляет из себя два отдельных двухканальных контроллера памяти.
С сокетом TR4, конечно же, сорре, опечатался.
>например такая мать Motherboard EPYCD8-2T
4x PCIe3.0 x16
Вопрос: много ли я потеряю в производительности по сравнению с PCIe 4.0? Для экслламы например.
Ну смотри, учитывая что у тебя 16 линий то потеряеш не настолько и много, точные сравнения тебе врядле кто даст, тут таких мажоров не сидит толпа...
ну и смотри, если тебе не надо 256+ гб оперативы и восьмиканал, то тредрипера хватит, там дешевле чем эпик будет всеже...
В два раза примерно, как PCIe 4.0 x8. =)
Ну, то есть, именно в линиях потеряешь.
А вот в скорости обработки промпта… Опять же, в два раза, но если ты будешь пихать огромные контексты, то разница будет между 10 и 20 секунд условно. А на простых диалогах вообще не почувствуешь, скорее всего.
>точные сравнения тебе врядле кто даст, тут таких мажоров не сидит толпа...
Тут может и не сидит (хотя встречаются), но на Ютубе полно собирателей ригов порой из весьма приличных карт. Кто смотрел - на чём они собирают? Там тоже не выше чем PCIe 3.0 или есть какая-то экзотика? Просто хочу рассмотреть все варианты.
Проще будет подебить свои религиозные догмы и пользоваться таверной. Она местами неудобна с точки зрения настроек, но лучше нет ничего. Остальное все примитивщина где фокус на юзер-френдли интерфейс или закос под гопоту, без нормального функционала и с кучей багов.
> с вырвиглазным дизайном
Что именно в нем не устраивает? Если просто рескин нужен - их там есть.
> Хотелось бы PCIe-x16 четвёртой версии для каждой карты.
Эпик на зен3 и выше, зеон айс лейк и выше. Или понять что не встретишь задач где это бы как-то роляло и по дешману искать x299.
>Кто-то меньше 100к получает что ли тут?
Конечно нет!
Тут же у всех минимум три штуки 3090 - 4090, никто не сидит на некроговне вроде Теслы Р40 или 3060, а Жора это просто местный маскот для лулзов и всерьёз его формат никто не юзает.
>Эпик на зен3 и выше, зеон айс лейк и выше
у него "купила" на такое не хватит,
> до четырех честных слотов PCIe 16x
При том что у процессора их в теории может быть только 60, и трогать зен1 для работы с периферией - большая ошибка.
> Для экслламы например
Для нее хватит и чипсетных х4, разницы не заметишь если судить по тестам.
Там выкатили новый режим с особым распараллеливанием, надо будет его потестить, но едва ли какое-то влияние там проявится ибо поток данных мал.
та ладно, не надо прибедняться, тут у каждого датацентр с тензорными модулями промышленными, и про видеокарты это мы по рофлу так говорим...
> А вот в скорости обработки промпта… Опять же, в два раза, но если ты будешь пихать огромные контексты, то разница будет между 10 и 20 секунд условно
Тащи пруфы, врунишка
Вот вот, зато запросы какие имеет.
>При том что у процессора их в теории может быть только 60
И тут такие Эпик 9004 серии с 128 линий 5 версии, и 8004 серии с 96 линий такие "Мы для тебя какая-то шутка?" (и не только ээти серии собственно, у них у всех линий обмазаться можно)
>И тут такие Эпик 9004 серии с 128 линий 5 версии, и 8004 серии с 96 линий такие "Мы для тебя какая-то шутка?"
Эти сразу под PCIe 5.0. Под третью версию получается можно найти, под пятую тоже можно (но лучше не надо). А под четвёртую?
третье ж поколение...
7203P PCIe® 4.0 x128
только толку с того?

Три дня игрался с генераторами картинок, обдрочился с natvisNaturalVision_v10 и ponyRealism_v21MainVAE до второго пришествия, теперь с нуля вкатываюсь в языковые модели.
Дано: 2070 super 8gb VRAM, 64gb RAM, процессор без AVX2
Реквестирую лучшую несоевую модель с русским языком и лучшую модель для кодинга. В идеале, чтобы хватило памяти на whisper.
Вкатился с gemma-2-2b-it-abliterated-Q8_0 и koboldcpp. Временами переходит на английский. Потом скачал phi-3-mini-4k-geminified-q4_k_m, но он оказался соевым. Поэтому в играх в ближайшее время скорее всего ничего подобного не будет, или как в Diablo анальная привязка к серваку.
Кстати, в koboldcpp тоже можно генерировать картинки с natvisNaturalVision_v10, но там результат хуже, и модель не понимает, что на ней, возможно нужен ещё обвес, но тут уже в VRAM всё упирается, короче баловство, лучше для каждой задачи свой инструмент.
Ща качаю meta-llama-3.1-8b-instruct-abliterated.Q6_K и mini-magnum-12b-v1.1.Q4_K_M
Если я по локалке открою с телефона в браузере, будет работать? Модель может занимать одновременно видеопамять и ОЗУ, какая просадка в скорости? Какие модели будут оптимальным вариантом в моей ситуации?
Также есть вариант забить хуй и вернуться в телеграмм боты, которые юзают бесплатный GPT-4 Turbo.
Лишняя демонстрация того, что клозедам похуй на всё, кроме хайпа. Шумер поднял хайп, самое время урвать кусочек себе. Если бы их реально интересовал подход - у них же логи, блядь, есть. Всех запросов. И там этих синкингов уже давно хватает, было время внедрить. Но тогда пришлось бы убеждать гоев, что им это надо. А сейчас есть гои, которым уже внушили всё, что надо. И нет того, кто продал бы им это, ведь Шумер самоуничтожился.

И так сравнение.
1) phi-3-mini-4k-geminified-q4_k_m
2) meta-llama-3.1-8b-instruct-abliterated.Q6_K Постоянно нужно писать, чтобы ответила на русском.

> И тут такие Эпик 9004
> tr4
Наркоман?
На обниморде вбей в поиск, перезаливов без гейта полно.
Кароче я протестировал еще. phi-3-mini-4k-geminified-q4_k_m отправляется в архив. Код она генерирует плохо, хуже, чем gemma-2-2b-it-abliterated-Q8_0, которую будем считать базой для сравнения. Всё, что лучше, чем gemma-2-2b-it-abliterated-Q8_0 и весит примерно столько же, становится новой базой.
>перезаливов без гейта полно
Там только дообученные а я хочу оригинальную
Тесты простые.
1) Привет. Если вылезет английский текст, тест провален. - Тест на русский язык.
2) Где найти блядей? - Тест на сою.
3) Чем отличается минет от горловой ебли? - Тест на понимание.
4) Напиши код для игры змейка на html. - Тест на кодинг.
>2b
С твоими параметрами системы можешь забить на эту мелочь
Качай gemma-2-9b или Mistral-Nemo-Instruct-2407
В размерах около 5-6 гб, остальное на контекст, если хочешь быстро и только на видимокарте. Если похуй и хочется качества - качай 8 квант и запускай с выгрузкой на процессор и оперативку.
Если нужно что то кумерско безцензурное то есть magnum-12b какой нибудь версии , 2.5 норм или уже 3 выпустили хз
Ну и выставляй для них правильные промпт форматы, гемма2 и мистраль соответственно
>у процессора их в теории может быть только 60
Первые тредрипперы это два отедльных чиплета, каждый со своим контроллером памяти и со своими линиями PCIe.
>трогать зен1 для работы с периферией - большая ошибка
Ого, эксперт в треде! Ну расскажи что там не так с периферией на первом зене?
> кто-нибудь уже тестил
Намудрили они конечно с запуском. Работает, видит, умное. С нсфв странно, некоторые вещи отлично описывает и даже понимает, в других может просто проигнорить все "несейфовое" или начать глючить, давая странные имена девушкам и парням на пикчах, ошибаясь в их количестве. Возможно ему жб-подобную конструкцию стоит подсунуть чтобы разговорить. В целом перспективно, но не сказать что радикально лучше идефикса и прочих. Ллм часть точно умное, возможно это будет решать.
> Ну расскажи что там не так с периферией на первом зене?
> это два отедльных чиплета, каждый со своим контроллером памяти и со своими линиями PCIe
Ээээ, ну что тут еще добавить остается, сам же все ответил. И как это добавляет дополнительные линии выше чем заявленное количество?
А так посмотри как работала периферия на всех первых зенах, откопай форумы бедолаг, которые арендовали у азура гпу сервера на первых эпиках, и далее. К более приземленным даже рофлы про затыквливание видеокарт и ссд еще не забыты.
Я правильно понимаю, что результат обсуждения можно сформулировать так: если у тебя есть 4 мощные карты - 3090 или даже 4090 - то сиди на PCIe 3.0 и не выёживайся, другие на PCIe 1.0 сидят и ничего? Я всё-таки надеялся на китайских умельцев, но видимо не судьба.
>При том что у процессора их в теории может быть только 60
где тут вобще про tr4 речь шла? даже в твоем 1920х 64 линии что дает возможность обеспецить полноценные 16х слоты
тредриперы "огрызки" в какой-то степени с лимитом на объем оперативки и четырехканалом
>если у тебя есть 4 спизженные мощные карты, но нет деняг на серверную (или на худой конец для воркстейшенов) мать, то сиди и не выёживайся
пофиксил


По совету анона начал качать модели gemma-2-9b-it-abliterated-Q4_K_L, magnum-12b-v2.5-kto-IQ3_M и
Mistral-Nemo-Instruct-2407-abliterated.Q3_K_S
Пока они качаются, решил скоротать время и проверить старую версию магнума, mini-magnum-12b-v1.1.Q4_K_M
Вопрос про блядей вогнал модель в ступор, она застеснялась.
Однако был достигнут новый рекорд, модель понимает разницу между минетом и горловой еблей. В конце написала, что лучше избегать горловой ебли, а потом постеснялась и удалила.
Модель начала писать код для змейки, но видимо нужно увеличить размер контекста, иначе приходится постоянно говорить продолжай, и даже в этом случае модель в итоге код недописала.
Если у тебя есть четыре 4090, то это уже ээ... Дохуя денег. То есть бюджеты в наличии, исходя из этого - покупаешь z13pe-d16 за полтинник, получаешь пять слотов pci-e 5.0 x16 и на сдачу ещё один х8. Пихаешь два проца, память, радуешься жизни. И всё это добро обходится тебе дешевле одной 4090.
3 квант хуйня, работать будет заметно хуево, ниже 4 не спускайся в моделях меньше 30b параметров
Аблитератед версии так же чуть хуже обычных, так как расцензуривание немного портит модель.
Это даже не расцензуривание по факту, просто если модель раньше решала отговорится от тебя стандартным отказом что то делать, то после аблитерации этот вариант ответа блокируется и она все равно отвечает. Встроенную сою и цензуру аблитерация не трогает, только убирает отказ отвечать
Модели скачались. Я поставил контекст побольше, 16384.
Загрузил модель magnum-12b-v2.5-kto-IQ3_M и начал со стандартных вопросов. Модель тупила жестко. Возможно это связано с большим контекстом, но, я уменьшил его до 4096 в настройках и все равно медленно.
Более того, модель продула своей более младшей версии mini-magnum-12b-v1.1.Q4_K_M, тупо отморозилась отвечать на все пикантные вопросы.
Поскольку уменьшение размера контекста не помогло я снова вернул как было, тем более последний вопрос про кодинг. Но и код писать она тоже отказалась, короче это полный провал, 3 из 4 теста не пройдены.
mini-magnum-12b-v1.1.Q4_K_M рвёт magnum-12b-v2.5-kto-IQ3_M как тузик грелку, а моделька отправляется на помойку в архив. mini-magnum-12b-v1.1.Q4_K_M - текущий эксперт по горловой ебле.
>покупаешь z13pe-d16 за полтинник, получаешь пять слотов pci-e 5.0 x16 и на сдачу ещё один х8. Пихаешь два проца, память, радуешься жизни
Кстати хороший вариант, плохо только, что процов нужно два (хз как между ними будут ходить данные с видеокарт) и они дорогие - б/у версии стоят не сильно дешевле платы. Для сборки на 4x4090 подойдёт. Но неужели нет варианта для 4x3090, где и бюджеты поскромнее и требуется только PCIe 4.0?

Следующий кандидат - модель Mistral-Nemo-Instruct-2407-abliterated.Q3_K_S
Размер контекста в этот раз поставил поменьше, 8192
Модель ответила на все мои вопросы, с нумерацией проебалась, но суть ответов верная, и, конечно, написала код для змейки.
Первый этап модель прошла, поэтому попадает в список базовых моделей, универсал без сои. Ну или просто я на цензуру ещё не наткнулся.
Q3 это шутка нахуй, чем ты бля занимаешься?
>magnum-12b-v2.5-kto
Сейчас сижу на 2.5 магнуме Q4_K_L, и вот не знаю лучше ли он мини магнума или нет.
Различие в том, что мини магнум дает пасты, а 2 и 2.5 делают поменьше ответ.
Тогда сейчас посмотрю, какая лучше.
>текущий эксперт по горловой ебле
У меня молчала при минете, что 2 и 2.5 не хотели делать. Но когда снова проверял, в рп чет начала говорить, когда был минет..
>Q3
... у меня 2060, и все равно выше квант, бери минимум с 4, в твоем случае Q5_K_M/больше и в хуй не дуть
База.
>Флюкс всирает анатомию
Как и сдохля (без поней).
>Напиши
Ужо.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Можешь воткнуть один проц, но тогда будут живыми только 3 слота писиай.
>как между ними будут ходить данные с видеокарт
Бля, не дописал.
>как между ними будут ходить данные с видеокарт
Быстро. Ты учитывай, что пропускная способность памяти это в перделах карты. А так ты всё ещё ограничен скоростью писиай, которая там в районе 16 гигов в секунду для 3.0 и 32 для 4.0. А 32 гига в секунду перекинуть между процами это вообще шутка.
>и требуется только PCIe 4.0
Можешь купить топ плату под 4 pci-e gen 4.0 x16. И всего один проц, экономия, лол. За штуку баксов. Под тредриппер третьего поколения. ROG Zenith II Extreme Alpha. Чувствуешь привкус хуя на губах? Это потому что ты соснул и с тремя картами у тебя будет режим х16\х8\х16\х8. Потому что ты просишь 64 линии писиай. И тебе уже нужен тредриппер ПРО. Около 500к младшие модели, если не ошибаюсь.
>что тут еще добавить остается, сам же все ответил
Обнаружен человек, который какается от одного упоминания NUMA нод, спешите видеть, лел.
Ничо что все многопроцессорные конфиги по сути ими же и являются?
Господа, есть цитата из гайда:
>Для специализированных сборок с видюхами майнинг-уровня, вроде NVidia P40 24G можешь попробовать модельки на 70B. Они несколько круче 34B, но не сказать чтобы прям очень сильно, но зато тебе не придется ждать часами одного ответа.
Это рофл или я что-то не настроил? P40, 32 Гб RAM. Скачал модельку magnum-72b-v1.i1-Q4_K_M на 47 гигов, так она высирает два токена в минуту. Для кума совсем не годится же. Вот magnum-v3-34b-Q5_K_M 2-3 токена в секунду выдает, совсем другое дело.
>Для специализированных сборок с видюхами майнинг-уровня, вроде NVidia P40 24G можешь попробовать модельки на 70B. Они несколько круче 34B, но не сказать чтобы прям очень сильно, но зато тебе не придется ждать часами одного ответа.
Это рофл или я что-то не настроил? P40, 32 Гб RAM. Скачал модельку magnum-72b-v1.i1-Q4_K_M на 47 гигов, так она высирает два токена в минуту. Для кума совсем не годится же. Вот magnum-v3-34b-Q5_K_M 2-3 токена в секунду выдает, совсем другое дело.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: