



Покумил, а дальше че делать?
Какую вайфу не возьми кум то везде одинаковый
Какую вайфу не возьми кум то везде одинаковый
А дальше нести деньги куртке, закупать видеокарты и пробовать модели побольше. Потом файнтюнить свои. Потом нести ещё больше денег куртке и тренить свои с нуля. А потом экспериментировать с новыми архитектурами и тренить с нуля. Думаю, на ближайшие несколько лет тебе хватит.
Попробуй поменять модели и сценарии. Мелочь или неудачные тюны-мерджи как раз страдают однообразностью. Когда все правильно работает, что при рп, что при куме должны особенности карточки и прошлое должно учитываться, а не скатываться в типичный слоп.
Вики чуток устарела, какая еще ллама2 в разделе размеров контекста, да и в языках опенчат висит.
Сейчас уже все новые сетки по русски шпарят, и на сколько знаю токенизация так же стала бодрее для русского, да и других языков.
Список актуальных семейств так же радует глаз фальконом и мпт и пигмалеоном кек
Сейчас уже все новые сетки по русски шпарят, и на сколько знаю токенизация так же стала бодрее для русского, да и других языков.
Список актуальных семейств так же радует глаз фальконом и мпт и пигмалеоном кек
Напиши свою, в чем проблема? Я вон вонял в свое время по поводу кривой шапки треда, пока сам не переделал и не отправил опу на одобрение. Теперь шапка новая. Всё в твоих руках, короче.
Мне лень, но я нашел силы чекнуть ее и повонять тут
Неравнодушный анон теперь знает об этом
>Список актуальных семейств
Это скорее список всех семейств. Может конечно перенести на отдельную страницу в типа архив, но ХЗ по каким критериям люди до сих пор на мику дрочат же, лол.
>люди до сих пор на мику дрочат же, лол.
Мику в своё время показала, как надо. После этого делать хуже стало западло. А ведь могли, легко.
В гайды бы кстати добавить запуск с llama.cpp сервера, а то кажется об этом вобще мало кто знает
Я могу накидать инфы тут пока помню, но ее сборку, проверку, доделку и форматирование оставлю другим
Я могу накидать инфы тут пока помню, но ее сборку, проверку, доделку и форматирование оставлю другим
В целом, можно добавить туда приписку что если в модели изначально заявлен большой контекст, то не обязательно использовать его весь из-за расхода памяти, а также не стоит трогать эти параметры.
> токенизация так же стала бодрее для русского
Но всеравно хуже, так что актуально.
Достаточно наверх к лламе перенести мистраль, гемму, коммандера, квен, может быть yi. Солар и мику не заслуживают отдельного заголовка, ведь это производные мистраля, к тому же уже не актуальные. Фалкона, мпт и пигму уже в конец.
> люди до сих пор на мику дрочат же
Больные ублюдки. Не сказать что она уходила вперед относительно тюнов второй лламы чем-то кроме контекста.
Накидывай
https://habr.com/ru/companies/sberbank/articles/849028/
> В связи с бурным развитием генеративных моделей и реализованных на них чат‑ботов (ChatGPT, Gemini, Bard, Notion AI, Compose AI, Poe, Phind) у пользователя появляется ложное чувство, что модели стали умнее, защищённее и, в целом, ближе к совершенству, сравнимы с человеческим интеллектом. Отсюда мы получаем целый пласт заблуждений. Например, что модели нас «чувствуют», «понимают», ведь мы выкладываем для них столько информации о себе, начиная от стилистики нашего письма, что уже является неким цифровым отпечатком нашей личности, и заканчивая оценкой их собственной работы. На самом деле это миф. И трендом 2023–2024 годов стало обширное внимание публики к XAI:
> как они (генеративные модели) устроены и как они принимают решения;
> как проводятся атаки уклонения (склонение моделей к неверной выдаче);
> как эти атаки (уклонения) связаны с другими атаками на LLM и какие они могут быть для эскалации деструктивного поведения системы;
> с какой позиции верно интерпретировать выход генеративной модели;
> разработка системы эшелонированной защиты моделей;
> разработка системы внутреннего критика для модели.
> Для начала начнём с существующих атак и их анализа.
> В связи с бурным развитием генеративных моделей и реализованных на них чат‑ботов (ChatGPT, Gemini, Bard, Notion AI, Compose AI, Poe, Phind) у пользователя появляется ложное чувство, что модели стали умнее, защищённее и, в целом, ближе к совершенству, сравнимы с человеческим интеллектом. Отсюда мы получаем целый пласт заблуждений. Например, что модели нас «чувствуют», «понимают», ведь мы выкладываем для них столько информации о себе, начиная от стилистики нашего письма, что уже является неким цифровым отпечатком нашей личности, и заканчивая оценкой их собственной работы. На самом деле это миф. И трендом 2023–2024 годов стало обширное внимание публики к XAI:
> как они (генеративные модели) устроены и как они принимают решения;
> как проводятся атаки уклонения (склонение моделей к неверной выдаче);
> как эти атаки (уклонения) связаны с другими атаками на LLM и какие они могут быть для эскалации деструктивного поведения системы;
> с какой позиции верно интерпретировать выход генеративной модели;
> разработка системы эшелонированной защиты моделей;
> разработка системы внутреннего критика для модели.
> Для начала начнём с существующих атак и их анализа.
> habr.com
Лол.
Лол, спермбанковские спустя два года узнали про джайлбрей.
Плохо что там ничего нового нет относительно еще прошлогодних публикаций, и тестируют на старой гопоте а не на своих сетках. А еще зеленый банк называются.
Нам нужен жора
https://github.com/ggerganov/llama.cpp
Больные ублюдки идут сюда и собирают из исходников по гайду
https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md
Извраты найдут на главной странице репозитория гайд по докеру
Всем остальным советую идти и качать нужный архив из релизов
https://github.com/ggerganov/llama.cpp/releases
Нужный выбирается просто - смотрим на свое железо и выбираем
Если нвидима то качаем куда архив
llama-b3914-bin-win-cuda-cu12.2.0-x64.zip
, если ртх то 12 версии, если младше то 11.
Остальные могут взять вулкан или поискать там знакомые себе технологии и выбрать нужное.
Для куда так же потребуются соответствующей версии файлы из архива
cudart-llama-bin-win-cu12.2.0-x64.zip
которые можно скачать один раз и забить, на сколько я знаю.
Нам нужен файл llama-server и лежащие рядом с ним, если речь про куда, файлы из архива выше.
Кидаем это все в одну папку.
Запускаем из командной строки llama-server с ключем -h и охуеваем от количества настроек
Для указания модели используется ключ -m , вставляем после него путь до модели и сервер запустится на стандартных настройках
У него есть своя веб морда, но можно так же подключаться по апи, из таверны или из любого опенаи совместимого фронтенда
Из полезных ключей что помню есть -ngl для количества слоев на видеокарте, -t для количества ядер процессора.
Ну и -c размер контекста, это основные которые я использую
-c 8192
и тд
Вот только начал тестировать на 123B. Пока полёт нормальный.
На 70В этот кал точно не нужен.
Оче бегло, ответы как минимум не хуже. В простом куме оно не нужно, на магнуме "мысли" унылые он вообще и сам уныловат и ответы в целом сейм, а вот просто в рп уже можно интересное пронаблюдать. Больше использовать нужно чтобы точно сказать.
Отвечай, используя метафоры.
Простой, но интересный системный промпт.
Простой, но интересный системный промпт.
Есть ли какая-нибудь простенькая моделька на условные 20B, способная банально конспектировать не слишком сложные текста и по мелочи помогать со всякими техническими вещами? Ролевые игры не интересуют, английский знаю на достаточном уровне, чтобы писать запросы и понимать ответы.
Я правильно понимаю что 3060 это потолок для обычного челикса?
Потому что даже доплатив 25к и взяв 4060 там не хватит памяти для 25+b моделей + урезанная шина говна.
В таком случае сколько токенов выдает 3060 на гемме 27b к примеру?
Потому что даже доплатив 25к и взяв 4060 там не хватит памяти для 25+b моделей + урезанная шина говна.
В таком случае сколько токенов выдает 3060 на гемме 27b к примеру?
Потолок в смысле самая нищенская карта?
> В таком случае сколько токенов выдает 3060 на гемме 27b к примеру?
2-4 токена, зависит от того насколько микроквант возьмешь.
>Я правильно понимаю что 3060 это потолок для обычного челикса?
Если не собираешься копаться на вторичках, то да. Но скоро только на вторичках ты ее и найдешь, потому что куртка остановил ее производство и щас на маркетплейсах распродаются остатки, которые закончатся в ближайшие месяцы.
>Потому что даже доплатив 25к и взяв 4060 там не хватит памяти для 25+b моделей + урезанная шина говна.
Дело даже не в шине а в 8 гигах памяти из-за которых ты даже в дефолтное непотимизированное говно не поиграешь. Карта окончательно не захлебывается тупо из-за генерации кадров и кеша, но только если ты сидишь на разрешении в 1080 рублей.
>В таком случае сколько токенов выдает 3060 на гемме 27b к примеру?
На моей 3060 с 12ю кило памяти на мелком коммандоре 2.4 т/с в четвертом кванте. На гемме думаю будет где-нибудь в районе пяти на тех же четырех битах.
Хз, для меня хорошая новая карточка — 2-3 недели кума и потом ещё периодические возвраты после добавления в избранное. Эта хуйня уже почти полгода длится, как я жив ещё — не совсем ясно.
А в будущем ещё маячит переезд на 5090, лучшая оптимизация моделей и общих подходов.
если там было 5 токенов, то никто бы не сидел моделях меньше, лол
Так тут дело в том что гемма говно. Хоть кто-то на ней вообще неиронично сидит?
Написано ОЧЕНЬ ХОРОШИЙ РУСИК и я этому верю поэтому и сижу
Где еще лучше?
Смотри в сторону нового квена. Цензуры до жопы, но и мозгов до жопы.
тут дело в том что у тебя не будет никогда такой скорости на 12 гигах, зачем обнадеживать чела
Я ебу какая скорость ему нужна? Может он и на трети от токена готов будет сидеть. Я предположил примерно, что токенов точно будет больше 2.5, а какие там значения точно будут мне уже как бы сказать похуй. Наводку я дал.
У 4060 16 гигов памяти
Нвидия переоценена получается, потому что на моем лоховском радевоне с 8гб врам так же где то 1.5 токена.
Интересно кто то пробовал на амд сборку сделать там памяти до жопы даже в бюджетных моделях
Чел, если ты сидишь на модели чисто из-за русика, то мне тебе сказать нечего. В целом я понимаю, нахуй оно надо, но что-то тебе доказывать я не хочу.
У 4060 две версии - на 8 гигов и на 16. Версия на 16 стоит в районе 55к и наухй не нужна, когда за ту же сумму на помойке барахолке можно найти 3090 в нормальном состоянии с большим объемом памяти и с лучшим перфомансом. Покупать ее можно онли если ты боишься что тебя наябут и тебе нужна именно свежеиспечённая карточка без обдрищенных чипов памяти.
>Нвидия переоценена получается, потому что на моем лоховском радевоне с 8гб врам так же где то 1.5 токена.
Так может у тебя блять полтора токена потому что у тебя большая часть слоев в оперативную память выгружена?
Мне понравилось на 12B, только чат автоматически перестал прокручиваться при автораскрытии спойлеров.
Кстати, на реддите пилили что-то похожее ( https://www.reddit.com/r/SillyTavernAI/comments/1fqnqld/i_ragequitted_bot_35_and_made_40/ ), но мне не понравился способ установки, у анона явно получше получилось.
А что сейчас самое мощное, что можно запустить на моем ПК? Скорость не имеет значения.
У меня ПК: Ryzen 5 3500X; DDR4 128Gb@3200MHz; RTX 4070 12Gb; SSD 980 PRO 1TB
Важно, чтобы файл gguf занимал на SSD не больше 100 Гб.
У меня ПК: Ryzen 5 3500X; DDR4 128Gb@3200MHz; RTX 4070 12Gb; SSD 980 PRO 1TB
Важно, чтобы файл gguf занимал на SSD не больше 100 Гб.
Попробовал эту модель и чет не впечатлен. Шизит даже просто при температуре 1, какой то бредогенератор. Попробовал и ггуф и exl2
https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned_BETA
Может у меня семплеры не те выставляются? Кто разбирался с этой моделью?
https://huggingface.co/SicariusSicariiStuff/LLAMA-3_8B_Unaligned_BETA
Может у меня семплеры не те выставляются? Кто разбирался с этой моделью?
присоединяюсь к вопросу, тоже не понял в чем прикол модели. сфенохуйня неиронично лучше выдает.
>не имеет значения
ну если согласен на 1 токен в секунду, и 70Б можешь попробовать, флаг в руки.

Вот щас попробовал на нуле даже. Exl2 8bpw. Температура вообще 0, вот итог.
у тебя часом эндтокен не забанен? динамик темпа не включена?
Ничего не забанено. Это даже не мои шизонастройки а температура 0 была, щас поставил 0,1 Все равно шиза какая то.
Кто кем работает
Ттсник, заценил новую, как говорят "самую эмоциональную" ттс? https://github.com/SWivid/F5-TTS

В определнии карточки ассистента примеры текста служат как мини-лора забивая контекст в начале диалога и постепенно вытесняясь по ходу него, позволяя более точно инструктировать и задавать тон боту на буквальных примерах. Очень полезная фича.
А вот что делать если хочешь поместить больше примеров (разделённых на фрагменты, не войну и мир в один чанк) чем влезет в контекст? Есть какие-нибудь приблуды? Может быть что-нибудь типа лорбука, только для фрагментов-примеров вариантов ответа?
И кстати, кто-нибудь уже делал квантованные (потому что для полной даже 4090 не хватит) лоры для текстовых нейронок, как оно работает по сравнению с лорами для StableDiffusion ?
А вот что делать если хочешь поместить больше примеров (разделённых на фрагменты, не войну и мир в один чанк) чем влезет в контекст? Есть какие-нибудь приблуды? Может быть что-нибудь типа лорбука, только для фрагментов-примеров вариантов ответа?
И кстати, кто-нибудь уже делал квантованные (потому что для полной даже 4090 не хватит) лоры для текстовых нейронок, как оно работает по сравнению с лорами для StableDiffusion ?
Даже идеальный перевод даже в твоей голове - это не то.
>только чат автоматически перестал прокручиваться при автораскрытии спойлеров.
Хм, думаю, можно поправить каким-нибудь костылём. Но да ладно, это мелочь.
А вообще, я хуею с кода Таверны. Закинул это расширение буржуям, и они пожаловались, что расширение не работает с Kobald Horde. Какого хуя, в расширении вообще нет логики, связанной с обработкой запросов к разным видам API, так хули эта абстракция протекает?
>Кстати, на реддите пилили что-то похожее ( https://www.reddit.com/r/SillyTavernAI/comments/1fqnqld/i_ragequitted_bot_35_and_made_40/ ), но мне не понравился способ установки, у анона явно получше получилось.
О, спасибо за ссылку, гляну, что там, может, спизжу пару идей.
>расширение не работает с Kobald Horde
Может у них просто таверна старая, я пока до последней не обновился — тоже твой скрипт не заводился.
Может быть, но всё равно как-нибудь попробую на Kobold Horde запуститься, чтобы убедиться, что там всё ок.

Юзаешь stanging версию или Release таверну? На Stanging не заводится почему то
Release версию. Staging нестабильная, если я правильно понимаю, в ней что-то может поменяться, поэтому даже не пробовал на ней запускать.
больше фич на ней. Ну короч на Stanging не работает.
Окей, принял к сведению, но всё же я не планирую на ней смотреть из-за нестабильности, дождусь релиза.
> Скорость не имеет значения.
> Важно, чтобы файл gguf занимал на SSD не больше 100 Гб.
Любая модель квант котороый занимает меньше 100гб, внезапно, да? 123б из рациональных, больше только старье или грок/405б что не влезут.
А зачем вообще с ней разбираться? Какая-то ерунда где автор приоретизирует размер аутпута и токсичность, при этом явно не сбалансирована.
Штрафы за повтор включи, хотябы лупов меньше станет.
> примеры текста служат как мини-лора
Нет, лора меняет поведение модели, а здесь прямое использование ллм по назначению с подгрузкой ей данных для референса.
> что-нибудь типа лорбука
Именно лорбук
> лоры для текстовых нейронок, как оно работает по сравнению с лорами для StableDiffusion
Работает совершенно иначе и то что в первом случае не получишь. В сд большинство лор сильно меняют веса так, чтобы сместить генерацию на что-то конкретное, это вполне допустимо. Если подобное попытаться сделать с ллм - она просто начнет по каждому поводу писать тексты из датасета, вне зависимости от их уместности, поскольку все связи будут наружены. Тренировать обязательно большим и разнообразным датасетом, который будет хоть как-то покрывать разные области, только тогда модель как-то воспримет и будет следовать стилю и паттернам из обучаемого материала, если повезет то и кое что оттуда запомнит. Алсо разница между лорой и тюном полных весов здесь достаточно сильно заметна.
Попробуй потренить, может понравится. Если долго пердолиться, чуть поправить код в трансформерсах и добавить туда эффективных оптимайзеров то можно поместить размер модели побольше или 8/16бит веса.
кстати что умнее мистраль 123 или новый квен 72?
Захотелось меньше клише и побольше норм рп на 8B. Да. 3060 это пока мой максимум
Когда там антислоп введут в таверне. Или уже может есть какой форк где можно пощупать?
>Даже идеальный перевод даже в твоей голове - это не то.
Если в голове, то вполне то. И я считаю, что пусть будут косяки перевода, но чтобы модель лучше соображала.
Там непонятно че вообще с таверной творится. У них там редизайн, ребрендинг, отказ от кума и прочее леволиберацкое френдли фемили говно. Вонь такая стоит, что половину дискорда перебанили.
>Попробуй потренить, может понравится.
А что можно потренить на бытовой карточке уровня 12 гигов? Разве что какую нибудь микромелочь типа 2-4B, которая итак трещит из-за перекачки датой и перетренировки.
>в голове
Люди, хорошо владеющие языком, даже иностранным, выученном во взрослом возрасте, в голове не переводят, а понимают напрямую, как родной. Но чтобы до этого дойти, нужна практика. Ллм, кстати, неплохой способ с обратной связью, можно просить пояснить более простым языком или перевести непонятное, вместо того, чтобы лезть в словари и грамматические справочники, разбираться самому.
Тред уже перестал даже мечтать о собственном фронте?
Так их просто форкнут и забудут, нахуя они выебываются?
Так-то глупая таверна - сама форк оригинальной. Будут выебываться - вылезет какая-нибудь naughty tavern и все на нее пересядут забыв. Get woke - go broke же база.
Да, имели одну стабильную ветку, будем иметь 30 разных от васянов всех калибров, где обязательно что-то будет сломано. То есть ничего не изменится, лол.
>нахуя они выебываются?
Никто не знает. Может ищут инвесторов, может ищут способы для монетизации. А на интерфейсе для ролплея для поебу несовершеннолетних кошкодевочек далеко не уедешь. Хотя один хуй таверну все юзают чисто для ролплея и отказывается от такого комьюнити это чисто выстрел себе в ебало и считай что смерть.
Демо записи тут https://swivid.github.io/F5-TTS/
Правды ради там от оригинальной таверны хуй да нихуя осталось в виде кривого интерфейса и прочих мелких штук. Силли вполне себе уже самостоятельный проект а не просто форк.
И от этого кстати еще забавнее выглядит то, что все свои оригинальные фичи разрабы силли теперь собираются выкинуть, включая в том числе кастомные интерфейсы для подключения к апи.
Ну в целом да, потому на силли все и пересели ибо там много фишек, гибкости и возможностей. Если начнут брыкаться - может найдется герой что форкнет уже их и будет развивать в правильном направлении. Ведь на самом деле даже просто все имеющееся причесать, равномерно раскидать и явные косяки поправить - будет уже заебумба что о соевичке никто не вспомнит.
А так лучше бы просто начали новый проект для хлебушков или альтернативную симпл ветку, которую в перспективе можно было бы смерджить с основной, сделав переключение. Посмотрим что из этого выйдет.
>Ведь на самом деле даже просто все имеющееся причесать, равномерно раскидать и явные косяки поправить - будет уже заебумба
Это дикий геморрой и скорее всего никто этим не будет заниматься по понятным причинам. Те кто действительно шарят быстрее запилят свой интерфейс не основываясь на остатках богомерзкой таверны. Ну, может лишь меньшую часть кода возьмут или общую структуру подрежут, но точно не станут пытаться причесать это.
>А так лучше бы просто начали новый проект для хлебушков или альтернативную симпл ветку, которую в перспективе можно было бы смерджить с основной, сделав переключение.
Если бы они хотели реально сделать "свой универсальный фронтент для паверфул юзерс" то действительно сделали бы его отдельной веткой и не трогали основную. Но тут уже понятно что это только начало и дальше они будут сильнее гайки закручивать. Ясен хуй физически они тебе не смогут кумить через через их оболочку, но могут постараться усложнить тебе жизнь всеми возможными методами.
не смогут запретить кумить*
быстрофикс
Введут внешний фильтр на все запросы и логирование, а еще платную подписку и гачу.
Очень вряд-ли. Скорее всего вырежут весь основной функционал типа конструктора промтов, ограничат список апи для использования или че-то типа того. Фильтр и логгирование это окончательная смерть, ибо даже некумерские интерфейсы разрешают тебе пиздеть с моделью о чем угодно.
Сейчас каждая первая ттс с войсклоном в той или иной мере подхватывает эмоции из образца, так что эта "эмоциональная" ттс не показывает ничего нового. Просто подхватывание стиля из образца голоса, включая все параметры разом.
И rinna всё ещё ебёт их
https://rinnakk.github.io/research/publications/DialogueTTS/
Самое интересное здесь
>VAE-predicted: Speech synthesized using proposed VAE-VITS, where style representation is predicted by style predictor
Вангую встроят по тихой зонды что бы сливать переписки пользователей, если не уже
Так что обновляйтесь аккуратнее
Это чтоли просто обычная ттс на более новой архитектуре? Из "эмоций" там только разметка пауз? Поясните.
> Те кто действительно шарят
Как раз воспользуются наработками, ведь делать с нуля свой велосипед - это
> дикий геморрой
> могут постараться усложнить тебе жизнь
Себе в ногу стрелять только могут. Угроза уровня
> ты не получишь наших ахуительных обновлений в которых мы порезали функционал
звучит смешно. Они же не корпораты что могут просто тебе в мгновение перекрыть кислород, это опенсорс.
> вырежут весь основной функционал типа конструктора промтов
Это множит на ноль все и куда серьезнее чем те же апи, для которых в худшем случае можно за пол часа накидать и отладить прокладку.
Догонять то что они сделали на данный момент никто не может. Например есть Risu ai но она тоже круто отстает. А чтобы русская таверна была это как всегда труднодостижимо.
Какую Mistrall small 22b используете для написания дроч фанфика?
По-моему, у них 90% кодовой базы - юзлесс хуйня, которую нет смысла повторять.
Почему никто не обучил 8-12b модель исключительно на фанфиках и порнорассказах, выкинув мусор вроде программирования и выжимки из википедии?
И правда, почему до тебя никто не додумался до этого?
Чтобы модель нормально понимала что есть что, ее датасет должен быть разнообразным. Если ты выкинешь инфу о программировании, она перестанет понимать что кусок питоновского кода не должен присутствовать в гомофанфике по гарри потеру и наоборот.
Че там догонять, лол? Это даже не полноценный бек + фронт, это просто фронт. Берешь апи с кобольда, пишешь примитивную систему по сохранению и обработке сообщений и сидишь чатишься с довольной рожей. Всё самое сложное уже сделано за тебя.
Потому что например базовые модели-огрызки что скинула нам meta - говно. Как не файнтюнь, это не сделает их лучше, для реальных результатов нужно трейнить с нуля со своим кастомным датасетом и без дрочки на цензуру, естественно ни у кого такой возможности нет, по очевидным причинам.
потому что для обучения даже 8b требуется от 60 гб врам.
Ты даун? Как она напишет код, если она не знает что такое код?
Что лучше для кума 7b 8к контекст или 12b 4к контекст
1b 128k контекст
>terribly implemented
Так можно сказать буквально про любую часть LLM. Просто тыкаешь пальцем в небо и пишешь статью.
Есть DRY, есть XTC, нет, буду жаловаться что кал мамонта плохо работает.
Унди и прочая орава работяг только этим и занимаются, вот только хуево выходит. Интересно почему же?
Двачую, разнообразие и всякое оче важны для формирования правильных логических связей в модели.
Потому что они файнтюнят готовую модель, подмешивая туда свое говно. Следующий вопрос.
>разнообразие и всякое оче важны для формирования правильных логических связей
Точно, обычно же текст в книгах другой используется, без 40 подмешанных языков не понятно будет, что там написано, drug.
Вы реально иногда как нейронка, начинаете выдумывать хуйню, когда сами нихуя не знаете.
У современного кума три беды. Первая это васяны, делающие тюны. Вторая - кумеры. И третья, сама главная. Катастрофическая бедность кум датасетов. Потому вывод превращается буквально в "если что-то, то пиши 'шиверс довн cпайн'" и т.д. Васяны попытались это обойти синтетикой, из разных клодов. В котором кум данных тоже мало, а они получают эти данные в дистиллированном виде, с конкретными ситуациями, персонажами и настройками сэмплинга. То есть ещё меньше данных, даже не смотря на то, что модель может пердолиться годами и выдавать гигабайты текста - это всё ещё бедный датасет. В итоге единственная возможность сделать ЕРП модель - взять готовую не-ерп и попытаться не слишком её испортить, накачивая говном.
>Вторая - кумеры.
Вот уничтожим всех кумеров да васянов, да как заживём!
>Катастрофическая бедность кум датасетов.
Данных так то дохуя, но кто их вилкой чистить будет? Правильно, никто. Смотрел я эти форумы с ролеплеем, там зачастую ветка уже давно ушла, РП прёт со страшной силой, а в датасете первые 3 сообщения времён царя гороха (+ спам какой-нибудь, лол).
> Потому что они файнтюнят готовую модель
Только это позволяет ей хоть как-то работать а не просто выдавать непрерывный шизослоуп пурпурного концентрата министрейшнов.
> Точно, обычно же текст в книгах другой используется
Чел, ты бы сразу писал что хочешь не понять причину, а пришел доказывать свою ахуительную идею, которая не приходила на ум только ленивому. Вперед, обучай свою модель и делай срывы покровов. Долбится головой в стену тоже вариант получения опыта, для некоторых - единственный.
>Вот уничтожим всех кумеров да васянов, да как заживём!
Поздно истреблять, кум вырвался из бутылки. Нужно наоборот, как можно более массовое распространение и дестигматизация. Так произошло с одним китайцем по имени Гей Минг.
>Данных так то дохуя
У лламы 8b заявлено, что обучалась она на 15T токенов. Выделим две трети на обычный РП, чтобы нейронка хоть могла узнать, что такое кошкодевочка. Остаётся 5Т токенов порнухи, чтобы она узнала куда её ебать. Чтобы ухх, без математики и без кодинга. Есть в твоём "дохуя" триллионы токенов? Уверен, что у васянов на хардах давно лежит весь этот твой форум, почищенный и готовый к трейну, оберегаемый, как алмаз. Потому что это единственное, чем можно разбавить килотонны говна, сгенерированного нейросетями. Но выбирать не приходится всё равно.
> Остаётся 5Т токенов порнухи, чтобы она узнала куда её ебать.
Сделал мой вечер, содомит!
Но даже подобный подход не поможет ибо датасет окажется однотипным и невероятно скудным на информацию. Многие сами собой разумеющиеся вещи, закономерности и будут усвоены крайне плохо, и вместо того чтобы понять причины произошедшего или даже банально посчитать число хуев в отверстиях людей в комнате, в ответ получишь размахивание бедрами, омоложение ночей, или какие-нибудь новые перлы. Весь "ум" и понимание моделек происходит как раз из общего бэкграунда.
>Весь "ум" и понимание моделек происходит как раз из общего бэкграунда.
Которого нет, ибо модели не штрафуют за повторное снятие трусов.
Одни с себя, вторые с тебя, проблемы? Или бывает девушки по 2 пары носят, зайди вон в треды диффузии, там иногда мелькают иллюстрации подобного.
Но вообще такое, как правило, следствие хуевого обучения, когда модель потерялась и из-за нарушенных связей пытается воспроизвести ситуацию из датасета, где снимают трусы, не осознавая ее в должной мере. Изначально хорошее количество ерп/левд и подобных данных в датасете базовой модели может помочь, нормальное обучение сделает хорошо в любом случае. И в последнем как раз наиболее удачные модели получаются на стыке стем/нлп/рп датасетов, иногда выходит невероятный совл и датфил.
Я потому на обычный РП и выделил две трети. В общем-то, QA не особо поможет в РП, особенно если какие-нибудь вопросы и ответы из олимпиады по математике. Так-то я тоже согласен, что умение кодить на питоне РП нейросетке нахуй не требуется. Но из-за ограниченности датасетов невозможно научить её думать на других примерах, только на разной хуйне. Т.е если будет реально массивный РП датасет, где группа людей регулярно посещает различные помещения и идёт учёт группы и людей в помещении - нейросеть научится считать людей в комнате, очевидно. Но этого нет. Есть разные QA уровня "у Васи было три банана, один он сунул себе в анус, сколько бананов осталось?". При этом даже одна треть порнухи в датасете это овердохуя, я согласен. Но речь же изначально шла про обучение на одной порнографии, лол.
И трусы модель снимает второй раз, потому что усвоила паттерн "перед еблей - сними трусы". Она не понимает, что такое трусы и как они работают, банально из-за бедности датасетов, в которых нет ничего о трусах. Кроме самого факта их снятия и иногда описания внешнего вида. Даже если у нас гениальная модель и она понимает, что трусы УЖЕ сняты, она не может знать, что они были всего одни, что они как-то в принципе могут препятствовать ебле и т.д. У неё паттерн: перед еблей - сними трусы. Поебались и хочешь ещё? Перед еблей сними трусы. Сняла с партнёра трусы и отсосала? Если хочешь его выебать - сними с него трусы.
>405b НУ ЛОКАЛЬНО ЖИ)))
и в чём смысл нахуй, даже Q1 квант шизы с кучей врам её не запустят
вот если 405b можно было на какой-нибудь 1050ti запустить тогда это да прогресс... а так все хуйня опять у корпоратов сосать
и в чём смысл нахуй, даже Q1 квант шизы с кучей врам её не запустят
вот если 405b можно было на какой-нибудь 1050ti запустить тогда это да прогресс... а так все хуйня опять у корпоратов сосать
>Унди и прочая орава работяг только этим и занимаются, вот только хуево выходит. Интересно почему же?
Зависит от удачи, подбора миксов и общего развития моделей. И год назад встречались удачные тюны. Но по сравнению с сегодняшними те просто ни о чём. Ещё годик, ещё немного удачи... Ну если только не введут анальную цензуру прямо внутри моделей, тогда только жопа и останется.
Она быстрая, и действительно без тормозов.
Если шизеет, нужно почистить контекст (например путём саммари) и свайпануть.
Прошлые модели 13b может и были туповаты но в них не было выравниваний и сои такой ,что просто не выдохнуть. Я перепробовал все что знаю модели но и те не могут нормально отыграть ариечку няшечку без шизы соевой.
>405b
Нахуя тебе этот раздутый лоботомит? 123 нормально пашет жи.
Но тем не менее никто не осиливает. Особенно в русскоязычной среде ибо на такое нужно много времени и сил и конечно же разбираться в английском языке и программировании. Слишком дохуя всего дляодного-трех челов энтузиастов
Да нет смысла делать 2/3 и так сильно бустить, там априори будет крайне скудное представление о общей логике, мироустройстве и всяких важных вещах. В целом, действительно базовый датасет можно сместить в сторону всякой художнки, знания анатомии, логических и философских трудов, и прочего прочего, но даже тот же кодинг позволяет формировать причинно-следственные связи и взаимоотсылки между разными фрагментами текста, матан и подобное вообще необходимы. А рп и всяким можно шлифануть в самом конце вместо надрочи на QA, при наличии фундаментальных знаний как раз будет усваивать стиль, как лучше писать, некоторые особенности повествования и т.д., а не просто заучивать упоротый слоп.
> И трусы модель снимает второй раз, потому что усвоила паттерн "перед еблей - сними трусы". Она не понимает, что такое трусы и как они работают, банально из-за бедности датасетов, в которых нет ничего о трусах.
> неё паттерн: перед еблей - сними трусы. Поебались и хочешь ещё? Перед еблей сними трусы.
Да, в целом, это как раз подтрвеждает то о чем написал. Нужно повышать количество подобного в базовом датасете, и/или нормально файнтюнить чтобы оно усвоилось а не было криво намазано поверх, затирая имеющееся.
Так-то второе в текущих реалиях это часть первого, сейчас базовые модели что выпускают тренируются в 3-4 этапа.
Ну да, ебаная алхимия в призрачной надежде на успех, когда результат из изначально приличных моделей что-то может давать. Но эта херня постепенно отправляется на помойку, уже освоены нормальные техники тренировки и все упирается лишь в лень/срачи друг с другом/машинные ресурсы, это ерунда по сравнению с прошлым когда вообще не было представления.
Валенок ебучий, если ты сам нихуя не понимаешь, не пытайся что-то доказывать.
Нейросети недостаточно показывать только позитивные примеры, ей нужны негативные, иначе она будет сильно путаться и шизить при генерации. Не хочешь чтобы при сладком дроче с девочкой случайно протекали какие-то куски непонятного кода, или токенов - напичкай ее примерами того, где этот код должен находится и где не должен.
Иначе с твоим ахуенно сбалансированным датасетом модель начнет генерировать бред и при этом будет действовать четко по твоим же примерам, ибо ты долбаеб сам их обрезал до очень узкого профиля. Представь, вот ты снимаешь трусики со свой фимозной вайфочки, а ее мокрая пусси - раз, надела дубленку, взяла ключи от соляриса и поеахала шабашить в ночную чтобы прокормить семью. Это тебя долбаеба ждет, если ты вырежешь всё кроме синтетических тонн ролплейных чатов.
>123 нормально пашет жи
Так даже 123 чтобы запустить надо покупать дохуя врама
Средний анон не запустит, только шизы с этого треда закупались теслами чтобы запустить хоть что-то внятное
> Не хочешь чтобы при сладком дроче с девочкой случайно протекали какие-то куски непонятного кода
А если хочешь? Самый кайф в разгар процесса шернуть на ушко если хочешь чтобы я продолжил - напиши мне код на питоне, который будет реализовывать сбор текстового датасета по списку html страниц и дальнейшее обучение модели mistralai/Mistral-Small-Instruct-2409, и смотреть как отреагирует, такой-то кайф.
Ананасы, а лорбуки, RAG, RoPE, и другие прибабахи для расширения контекста работают только на таверне и убабуге, сам кобольд их не поддерживает?

У меня неиронично было такое. Сеточка так сильно разозлилась на меня за игнор ее мандавошки, что начала мне угрожать джсон структурой.
>RAG, RoPE
че это такое блять
>Средний анон не запустит
Запускаю на пикриле и довольно урчу с 0,7 токенами.
>априори будет крайне скудное представление о общей логике
Если датасет достаточно массивный, то будет. Причём множество разной логики, разных мироустройств и т.д. Мы же говорим о датасете на 10Т токенов. Очевидно, что без допила он всё равно будет годным только в качестве FT, но тем не менее. На счёт кодинга с матаном вообще не согласен. Достаточно аугментировать чистый худлит и будет заебись.
>Нужно повышать количество подобного в базовом датасете
Или повышать качество датасетов для ЕРП тюнов. Добавить туда базовую информацию в известном формате, несколько килобайтов текста о тех же трусах - что это такое, почему их вообще носят или не носят, почему их снимают. Да что вообще такое одежда и нахуя нужна. Не просто примеры со снятием трусов, это нужно аугментировать логикой самого процесса снятия трусов. Нейронка обычно понимает, что если ты вышел из автомобиля - ты не можешь выйти из него второй раз, как раз потому, что она понимает и концепцию транспортного средства, и выхода из него. А трусы для неё тёмный лес - в претрейне о них если и было, то что-то вроде "самый известный производитель - кельвин кляйн". А в тюне только снимание.
>асы, а лорбуки, RAG, RoPE, и другие прибабахи для ра
Так rope это растягивание контекста, он-то как раз только в кобольде работает, а не таверне. Да и rag, таверна это чисто обёртка над этим всем.
>Есть в твоём "дохуя" триллионы токенов?
Все книги, включая защищённые копирайтами. А то их из датасетов трут, чтобы не набутылили, а мы то люди гордые, и на бутылках посидеть можем.
>Подразумевает себя под средним аноном
>3080 ti за 900 баксов
>64гб озу
Не знал что семёны даже здесь обитают
100к на теслы это нихуя не много
>Средний анон не запустит, только шизы с этого треда закупались теслами чтобы запустить хоть что-то внятное
Цена вопроса от 100 до 200 рублей в час. И скорость будет комфортной, в отличие от тех же парней с теслами. Если напряжно по деньгам, можно начать меньше есть - оно и для здоровья полезно. Если конечно не школьник, но тем стоило бы вместо ЛЛМ вложиться в реальный секс :)
Двачую вот этого господина.
>100к на теслы это нихуя не много
Даже когда они стоили по 17к - в 100к не уложиться, если не ставить их в такой же как они древний мусор. Ну и плюс неизбежные косяки. Дорого это всё.
Ну вообще, нас тут большинство, пока не докажете обратное.

>несколько килобайтов текста о тех же трусах - что это такое, почему их вообще носят или не носят, почему их снимают
И это нихуя не поможет, лол, потому что модель не думает нихуя. Ей именно что нужно
>примеры со снятием трусов
И чем больше, тем лучше. В адекватных ситуациях офк.
>Нейронка обычно понимает, что если ты вышел из автомобиля - ты не можешь выйти из него второй раз
А просто никто не пробовал, лол.
>3080 ti за 900 баксов
1500 тыщи вообще-то. Но таки сейчас похожий сетап будет стоить значительно дешевле.
>вложиться в реальный секс
Переоценён, рука и компьютер с ЛЛМ уже лучше.

Уверен, что уже обнимал тебя за совместный обсёр с 3080Ti, а вот за женский диск уже шеймил или пропустил в прошлый раз?
Я первый раз запостил. С 3090 да, неудобно получилось. До нейронок похуй было, а теперь кое-как вмещаю 12B на 6 битах.

Плейнтекстом не поможет, нужно дробить на куски и делать в формате ролеплея. В целом, можно даже какой-нибудь нейросетью это сделать, правда уточнить, чтобы она дропала логически обрывающиеся цепочки - ты же не сможешь резать корректно, это будет в лучшем случае разрезание по абзацам. Тут приходим к другому, в книгах, в лучшем случае, мягкая эротика. А нам нужно жёсткое детализированное порно. РП датасет? Возможно. ЕРП? Точно нет.
Кек. Единственный вариант покумить на 3080ti - купить в довесок хоть что-нибудь.
>Я первый раз запостил.
Тады обнимаю. Вместе поплачем. А ведь тогда я думал, что наебал судьбу, и не взял лишний врам, ибо играм то нахуя...
А жёсткий выкинь нахуй, 21 век на дворе.
>Плейнтекстом не поможет, нужно дробить на куски
Кстати, а нахуя? Вот технически модель всё равно дополняет по токену, так что "логические цепочки" тут нужны для стоп токена, а так хоть куски кидай.
>А нам нужно жёсткое детализированное порно.
Кому нам? Я со средней эротикой буду вполне удовлетворён.
>покумить на 3080ti - купить в довесок
Лол, перепись инвалидов какая-то.
После переезда со Stheno 3.2 на 12B модели я вдруг понял, что важнее правильно подкручивать модель, а не гнаться за контекстом. Если хватает 100 сообщений чтобы разыграть сцену, то он толком и не нужен. В следующий раз-то уже понятно, что 5090 буду брать, а сейчас уже смысла нет добирать что-то.
> Тут приходим к другому, в книгах, в лучшем случае, мягкая эротика. А нам нужно жёсткое детализированное порно.
В архиве сайта Стульчик есть всё, что нужно и даже больше. Качайте с Флибусты, пока она не закрылась. Там правда старый архив, новый на несколько лет моложе. Английские тексты тоже есть в количестве, но наши в целом сочнее.
>но наши в целом сочнее
И сырнее.
Сука лол, она прямо ультануть решила.
> Если датасет достаточно массивный, то будет.
Ну типа если там датасет раздуть на 100Т (которых нет) то может и будет. Дело в том что концентрация важной информации там оче мала, зато однотипного - вагон. Помимо прочего всего, подобный дисбаланс еще и не позволит сетке нормально обучиться без применения какой-нибудь особо-невероятной черной магии аугументации.
> повышать качество датасетов для ЕРП тюнов
Это тоже важно, но разбавление позволит еще и эффективнее обучать без отупления.
> несколько килобайтов текста о тех же трусах - что это такое, почему их вообще носят или не носят
Это уже данные общего толка а не ерп. Но такое и нужно добавлять в первую очередь, причем неплохо объяснениями/cot и подобным оборачивать.
Но вообще насчет трусов таки перегибаешь. Все нормальные модели нюансы одежды понимают и хорошо отрабатывают если в общее замешательство не попали.
> он-то как раз только в кобольде работает
Не в кобольде а это общий параметры работы текстовых на трансформерсе.
> 100к на теслы
brutal
> за женский диск уже шеймил
Фу таким быть
>Кстати, а нахуя?
Плюс-минус хуй знает когда делал лору в облаке, чисто разрезание книг на куски и скармливание в нейросеть. Получилось очень плохо. У тебя в итоге диалог идёт от лица N персонажей, где всё происходит в виде взаимодействия между собой, от этого и нужно отталкиваться при составлении датасетов. Многостраничные описания окружающих пейзажей это хорошо, но тогда у нейросети будет заложено, что после описания природы - следует описание природы. А это неверно.
Вот заложить в нейросеть страницу текста с промптом, который заставит её сделать из этого диалоги определённых персонажей это уже хорошо. Вместо "автора" восхищающегося природой у нас будет персонаж, который смотрит на природу и видит всё то, что автор описывал, говорит собеседнику или просто как-то взаимодействует с этим. Книги в чистом виде не годятся.
>Я со средней эротикой буду вполне удовлетворён.
А я нет. У меня уже в промпте прочно обосновалось требование максимальной детализации и модели, которые в это не могут - дропаются. Тот же магнум меня не устроил по этой причине.
Да не в контексте дело, просто в 12 гигов толком не влезают модели. А в 24+12 уже кое-как.
>уже понятно, что 5090 буду брать
У меня наоборот мысли, купить тюрингов на сотню гиг vram и ебись оно всё.
>Качайте с Флибусты, пока она не закрылась
На рутрекере лежат обновляемые дампы, если что. Терабайт с картинками, половина без. Если не ошибаюсь. Очень много повторов, нужно дедуплицировать.
И какие модели используешь?
Да как с 20b даркфореста переполз на 34b c4ai-command-r, так ничем его и не могу заменить для ерп. Попиздеть и с квеном можно, и с геммой, но в ерп они сливаются.
> чисто разрезание книг на куски и скармливание в нейросеть
Оно и не может работать и заведомо получится хуево, этим будет наружен в первую очередь формат и связь между запросом и ответом, а то и вообще вся логика.
> Вот заложить в нейросеть страницу текста с промптом, который заставит её сделать из этого диалоги определённых персонажей это уже хорошо.
Чаю
> Тот же магнум меня не устроил по этой причине.
Это странно, он наоборот помешан на чрезмерно подробном описании всяких деталей о том как испещренный венами ствол проникает через влажные складки, причем проявляет чудеса разнообразия. Лучше бы больше про мысли и чувства чаров писал. Даже кумерский из коробки мелкий командер более сбалансирован чтоли, хоть и не так умен.
>заведомо получится хуево
Тред не слишком дружественен к экспериментаторам, лол. Так что я ставил опыты, читал литературу и добирался до всего таким образом. Это даже хорошо, больше опыта, пусть он и не всегда удачный.
А к коммандеру у меня претензия разве что к проёбыванию характера персонажа, очень уж он этим грешит. Качал 27b магнум, тот хорошо следовал персонажу, но слишком блекло и неинтересно описывал процесс. Плюс с коммандером понимаешь, насколько же остальные зашкварены жптизмами, у него этого поменьше немного. Тот же РП с персонажем, у которого раздвоение личности, он вряд ли потянул бы, я когда-то был в восторге, что 20b франкенштейн-модель смогла это осилить и развить идею, даже временами я убирал своего персонажа и модель описывала приключения других персонажей без моего участия вообще. Комманд-р скорее всего на таком сольётся, но я не проверял, просто есть такое ощущение.
Да не, ничего плохого про эксперименты не говорю, из интереса и не такое можно делать. Просто привел пример почему так получится и что лучше не пробовать а сразу дальше идти.
Перефоматировать так куски художественных произведений уже пробовал? Там ведь возникнет проблема с вступлением что, почему и как, нужно как-то ввести персонажей и предысторию еще.
Про размер магнума что был использован уже потом прочитал, писал про большой. На гемму вообще ни одного норм файнтюна не встречал что бы превосходили ванилу при этом не ломая большую часть ее смекалки.
>почему так получится и что лучше не пробовать
Я о том, что не было понимания, что будет, если так сделать. Но желание сделать лору было. Теперь есть понимание, но нет желания.
>Там ведь возникнет проблема с вступлением что, почему и как
В теории, можно сделать два прогона, первым достать всех персонажей из книги, а потом динамически подставлять их в промпт. Могут возникнуть проёбы с внешним видом, так что его тоже нужно обновлять динамически, как вариант, добавить "стадии". Персонаж А в стадии 1 (когда номер страницы < 10) - "Бородат и ему 20", в стадии 2 внешний вид меняется. Сейчас бы если чем-то таким занимался, то месяц писал софтовую обвязку, чтобы в промпт писался именно нужный персонаж в нужном виде, а то и инфа про всех персонажей сразу, чтобы максимально соответствовать формату промпта, который будет использоваться потом при РП. На счёт предыстории сомнения берут, ведь не так важно, когда именно будет экспозиция в тексте. Пробовать такого не пробовал, появились сомнения, что имеет смысл в принципе. Модели развиваются быстро, если я сделаю годный тюн - через месяц придётся делать его на базе новой модели. Деньги, силы и т.д не бесконечные.
>писал про большой
Когда у тебя 36 gb vram, а шиза нашёптывает, что ниже Q4 только говняк - особо не разыграешься.
Играюсь второй вечер с дообученным квен 2.5 14в, эта штука умнее меня
Где то недалеко от 32в по ощущению
В качестве ассистента для меня идеален, квант 5кл
Это тот в который дистиллировали квен2.5 72в и ллама 3 405в
Ват а тайм ту би лив
Русский у него пострадал не особо сильно, кстати
Где то недалеко от 32в по ощущению
В качестве ассистента для меня идеален, квант 5кл
Это тот в который дистиллировали квен2.5 72в и ллама 3 405в
Ват а тайм ту би лив
Русский у него пострадал не особо сильно, кстати
Кто-то реально гонял новый Mistral Small, что по ощущениям? Насколько сильно отличается от Немо и стоит ли переходить?
Сижу на оригинальном Немо в 8 кванте, файнтюны в рот ебал из-за их непредсказуемости и потоков бреда.
Сижу на оригинальном Немо в 8 кванте, файнтюны в рот ебал из-за их непредсказуемости и потоков бреда.
>Small
Вряд ли лучше Large, так что какой смысл?
Нихуевую базу ты выдал, братан. То что модель на 123B лучше модели на 22 без тебя бы я никак не понял.
Немного его гонял когда вышел, не рп ерп.
Как то слабее чем немо показался. Он жирнее, знаний в нем больше.
А вот по мозгам не впечатлил.
Благодарю. Я тут тоже немного покопался по отзывам и большинство пишут, что Немо попизже будет, особенно в рп.
Есть ли смысл возиться с локальным билдом llamacpp под винду или лучше просто ставить koboldcpp?
Если тебя не устраивает кобольд, можешь в целом весь бек под себя собрать, документации навалом. Но так кобольд говно говном конечно, но работает, так что сползнать с него не вижу смысла.
Если у тебя есть хоть малейший опыт в разработке и верстке, это всё можно сделать за вечер-два под банками адреналина. К тому же сейчас, когда на любой твой дегенеративный вопрос может ответить бесплатная чат гопота и вообще написать за тебя половину фронта - тебе останется тупо довольно урчать и переписывать текст из окошка чата в визуал студио.
Да, все равно придется поебаться с отладкой и оптимизацией дополнительные пару дней, ибо код будет кривой, но... блять это ебаный ксс и хтмл. Кому не похуй на производительность.
Ладно, там еще немного придется ебаться с джвадристом, но js программисты не люди, там планка изначально занижена ибо никто от них ничего хорошего не ждет.
Попробовал Q8, выглядит интересно. Особенно по коду. На моем говне еле скрепит, но работать работает.
llama.cpp чуть быстрее кобальда, по крайней мере у меня. Там всегда свежие релизы, качать и запускать муторно, да.
Но написать скрипт закачивающий последний релиз и досиающий оттуда в нужную папку нужный файл сервера - не трудно. Попроси сетку помочь, или тупо ручками иногда обновляй.
Запускать сетки можно так же батником, там буквально одна строка
А что на счет обратной совместимости со старыми моделями? В гайде встречал упоминание, что ллама скачет вперед?
Держать по 10 ллам под разные полюбившиеся модели?
Старые это какие? Все модели за пол года-год работают вроде.
Ну кобальд держи рядом, если что то старое запускаешь, вот проблема
у меня амуде сборка 7900xt 20гигов вэрамы ROCm топчек LLM до 32млрд летают дальше пздц такойже 1.5токена\персеконд (а ведь у них ещё ж есть хтхтхтх с 24гб врамы) вот и думай что покупать куртка нах идёт if u ask me)
> совместимости со старыми моделями?
Назови когда в последний раз она требовалась? Фана ради пигму погонять можно и в полных весах/gptq или иметь отдельную версию для подобного.
> до 32млрд летают
Насколько летают?
> куртка нах идёт
Ну так собирай на амд, расскажешь нам насколько весело и какие подводные. С точки зрения юзер экспириенса там скорее всего днище, но с пердолингом и компромиссами должна быть возможность получить норм работу как на теслах
>Ну так собирай на амд, расскажешь нам насколько весело и какие подводные.
По идее в новых сериях АМД уже будут поддерживаться какие-то нейротехнологии. Вопрос в том, что карты от них с хотя бы 24гб врам будут нифига не дешёвыми. Даже последнее на сегодняшний день поколение нифига не дешёвое и вполне сравнимо по цене с нвидиевскими картами. А тогда нахуязачем? Собирать же нейросервер на АМД-шном старье очень уж специфическое удовольствие. Правда со стороны я бы поглядел.
Запустил c4ai-command-r-08-2024.Q5_K_M.gguf и довольно урчу, правда параллельно занимаясь другими делами, ибо генерация ответа в среднем занимает три минуты плюс-минус.
В рп пока не пробовал, но на вопросы по составлению собственно промтов и переписать текст так чтобы он был более понятен как промт отвечает хорошо и развёрнуто.
В рп пока не пробовал, но на вопросы по составлению собственно промтов и переписать текст так чтобы он был более понятен как промт отвечает хорошо и развёрнуто.
https://www.reddit.com/r/LocalLLaMA/comments/1g3tjx8/zamba27b_apache_20/
Новая мамба сетка на 7ь
Так сколько генерация? 3 минуты могут и сто и тысяча токенов быть в ответе.
В таких размерах по мозгам qwen2.5 32b лучше всех, в рп уже хз
Новая мамба сетка на 7ь
Так сколько генерация? 3 минуты могут и сто и тысяча токенов быть в ответе.
В таких размерах по мозгам qwen2.5 32b лучше всех, в рп уже хз
>сравнимо по цене с нвидиевскими картами
Зашёл в три буквы. Топ амудэ в моей мухосрани подорожал с 90к до 120к, зелень со 140к до 250к. Была разница в ~1.5 раза, стала в 2 за тот же объём врам.
В кобольде, стоит максимум 512 токенов лимит на ответ. Скорость и колество токенов конкретно он вроде не показывает.
если тебе только память важна, просто купи эпл
Есть ли модель переводящая с китайского/японского на русский лучше чем deepl?
в консоли писал на сколько помню
на глаз быстро не слайд шоу
уже собрано всё давно, но крутить кручу тока оламу+опенвебуй для её, недавно запилил СД первой версии по двухлетнему видосу тож генерирует картинки, как прикрутить новую хз, всё что из шапки ето не понтднимал чёт не разобрался как там ето всё дело а может дело в амуде что там через одно место всё
Нашёл, 20-30 токенов в секунду, разное на каждом промте.
В трёх буквах 64 ГБ за 480к. Чуть лучше nvidia, но хуже амудэ.
Что именно собрано?
> оламу
Зачем этот треш без удобства и перфоманса, единственное завелось?
> СД
А там сколько итсов выдает?
Это десяток-другой секунд на ответ а не минуты. Если же это обработка промта а не генерация то все сходится.
Есть сейчас что-то более умное/приспособленное для кума чем л3-70б эриала? На русек пох, лишь бы за 70б не вылезало.
Потестил немного на ванильной Mistral small и Cydiron 1.0, по-моему лютая годнота. Лично для меня поднимает РП на совершенно новый уровень. Мне нравится "реалистичный" РП и с ним персонажи ведут себя намного более осознанно, понимают происходящее и задумываются о последствиях. Персонажи следуют своим карточкам намного точнее, чем при обычном промте.
Для кума да, скорее всего ничего не даст, больше навредит. Персонажи даже с РП-файнтюнами теперь не бросаются на первый встречный хуй, если об этом явно не указано в их карточке.
>намного точнее, чем при обычном промте
А чем необычен промт который ты сейчас юзаешь?
И какой именно "обычный" работает хуже?
Чем вообще объясняется такое количество требуемой врам и вес моделей?
Будут ли в ближайшем нейробудущем модели 100+b с весом в 4 гб например?
Будут ли в ближайшем нейробудущем модели 100+b с весом в 4 гб например?
Только квантованные. Рассматривай это как архиватор с потерями.
Ниже квант - лучше сжатие, выше потери.
b=billion, миллиард. На один параметр по дефолту 16бит, квантануть чтобы норм можно до ~4бит, сколько это весит можешь посчитать сам. Чтобы уместить 100б в 4 гига там выйдет около 0.3бита на вес.
Жадность свою имаджинировал?
>выйдет около 0.3бита на вес
>Жадность свою имаджинировал?
В треде тихо хихикают колобки которые катают модели на втором кванте.
А зачем это делать? 12б на 6 квантах гораздо адекватнее обрубков.

Какие настройки сэмплеров юзаете? С динамической температурой смог добиться от коммандера сложного рп (обычного, на ерп не тестил пока) в котором он нарраторит и контролирует ряд уникальных неписей, при этом не говоря за игрока и поддерживая указанный сеттинг и детали, стили речи и поведения.
Я аж приху-ху-ел от его перформаса и пассажей, в положительном смысле.
Я аж приху-ху-ел от его перформаса и пассажей, в положительном смысле.
Кто знает, кто знает. Тут надо спрашивать у тех анонов, которые этими извращениями занимаются. Но я думаю они знают что-то чего не знаем мы.
Надо кстати потестить большой мистраль на двух битах, всего 40 гигов весит, вполне терпимо.
>Какие настройки сэмплеров юзаете?
Разные. Или ты нашел какую-то универсальную смесь и собираешься ей с нами поделиться?
Это литературно от модели зависит, анон. Я пользовался какими-то ебанутыми файнтюнами, где температура 4 была нормой. На магнуме советуют 0.4, хотя мне он начал нравиться только от 1+
Лучше бы инстракты интересные притащил.
В целом если модель норм - simple-1 хватит всем. Исключая варианты где адово вжаривают температурой тупые сетки с крутым распределением чтобы получить какое-то разнообразие, эта вещь довольно эфемерна и рандомна по своей сути, от юзера и остального зависит гораздо больше.
> где температура 4 была нормой
Если применять ее в конце когда осталось 4 однотипных токена - так и будет.
12б обрубок сам по себе, так что спорно
Лучше него не нашёл. Советовали квен, но мне не зашло, L3.1 70B самый умный по повествованию
Я на третьем гоняю, по факту 3,5, но это 123B.
Вон же, они, на скринах.
Код нарратора помогал писать сам же это коммандер сегодня, это уже не двести токенов конечно, но да, надо потестить на других моделях.
Код самого нарратора - https://pastebin.com/ZaxUnpft
Скачал ради интереса, задал два вопроса по кодингу. В одном он заявил, что предоставленный код не будет работать, хотя он работает, потом начал упорно настаивать переделать логику кода, в примере был трединг, он начал затирать про асинхронность, хотя я сразу же указал, что в данном случае меня интересуют потоки. По другому вроде ок всё, осилил.
Олсо, как же хуёво, когда забиваешь на работу каких-то механизмов и думаешь, что it just works. Взял реальный ответ нейросети и сравнил с результатом детокенизированного текста ответа, обёрнутого в чат темплейт и потом токенизированного заново. Конечно же количество токенов не совпало. Я должен был понимать, что так и будет, но даже не задумывался, ожидая какого-то постоянства.
А на фоне обычной qwen2.5 14b?
Про токены не понял, механизм токенизации кривой? Косяк таверны или бекенда?
Ох, ёбушки-воробушки, намутил лютую смесь сеттингов из Accel World и Honkai Impact 3rd, и коммандер честно, и даже более-менее успешно пытается ему следовать, выдавая когерентные простыни по несколько сотен токенов на сообщение, причём даже без свайпов.
Характерную для хонкая жестокость правда не любит, и пытается соскочить с эксплисит контента на что-нибудь более безобидное, хз это цензура, биас, или как такое зовётся.
Характерную для хонкая жестокость правда не любит, и пытается соскочить с эксплисит контента на что-нибудь более безобидное, хз это цензура, биас, или как такое зовётся.
>механизм токенизации кривой
Притом в самой сути концепции. И это не лечится.
>биас
Он самый. Будь положительным, сука.
>А на фоне обычной qwen2.5 14b?
Честно сказать - хуй знает. Я из 2.5 пробовал только 32b и в той паре примеров, что пробовал, они с этой моделью плюс-минус на одном уровне. То есть вроде как и понимают, что требуется, но не оптимально и пытаются пропихивать то, чему их обучили вместо того, что от них требуется.
>Косяк таверны или бекенда?
Косяк самой системы токенизации. Нейронка может сгенерировать слово хоть по буквам, хоть по слогам, как угодно, как она умеет. Потом мы это декодируем в цельное слово. И если потом его обратно токенизировать, то механизм пытается это скомбинировать так плотно, как только он может. Например, генерируется слово "залупа". Побуквенно нахуй, хуй знает, почему. Всякое бывает. Итого у нас 6 токенов. Загоняем залупу нейронке за щеку в токенизатор, а там уже есть токен "залупа". И она токенизируется в один токен.
Я своих скриптах вёл подсчёт токенов, для сообщений от user всё просто, т.к нет кодирования-декодирования, а для сообщений от нейронки нужно принимать то, что она сгенерировала, вместо прогонов туда-сюда. Либо каждый раз скармливать в неё не только новое сообщение от user, но и её предыдущий ответ. Не забывая дропать из кеша kv то, что она ответила в прошлый раз. В первом варианте перерасход контекста где-то процентов 15, а вот второй быстрее.
Попробовал вместо поиска расхождений в истории и т.д. явно и очевидно отправлять в нейросеть только сообщение пользователя, получил до 90 т.с там, где в убе до 37. Это пиковые скорости, конечно, на небольшом контексте и генерации относительно длинных сообщений, на коротких разница ниже. Но тем не менее, минимальный буст аж 2 токена, 22 т.с вместо 20, лол.
Ещё что откопал в квене, правда, на втором, если ему в рандомном месте скормить EOS, а потом заставить продолжить генерацию, он галлюцинирует сообщение от пользователя как "<|im_start|> Human\n Continue" и т.д. При том, что в чат темплейте никакого Human нет, там user. Нейросеть считает, что темплейт должен быть другим.
>В первом варианте перерасход контекста где-то процентов 15, а вот второй быстрее.
В смысле, второй медленнее.
Когда-нибудь я куплю видюху с дохуя гигами и запузу что-то больше Росинанты.
Понял, этой хуйне с токенизацией действительно не хватает стабильности значений. Сохранять бы сгенерированные токены сетки и отпрвлять их обратно. Интересно почему это не сохряняют вместе с контекстом.
С другой стороны сетки ведь как то сопоставляют одно и то же слово с одним смыслом, независимо от того как много вариантов его составления есть.
> и отпрвлять их обратно
Их не нужно отправлять обратно. Каждый токен после того, как он принят семплером, как годный - отправляется в нейросеть сразу же. Как иначе она бы могла узнать, что пора генерировать "упа" после "зал". И всё это уже есть в контексте нейросети, только не в той портянке, которую гоняет фронт, а в настоящем кеше, в kv. Для генерации теста, в целом, разница-то минимальная должна быть, смысл один и тот же. Не бывает же такого, чтобы нейросеть реагировала по-разному на одно и то же, но написанное разными словами, да? Ведь не бывает?
Более глубокая проблема здесь другая. Всю портянку гонять нужно только в одном случае - когда у тебя загружается история существующего диалога, в ходе беседы её гонять не нужно.
>Не бывает же такого, чтобы нейросеть реагировала по-разному на одно и то же, но написанное разными словами, да?
Сарказм, да?
Так а в чем проблема та сделать не через жопу? Сорян анон, я плаваю в том как бек все считает
Если поставить второй видяхой под систему радеон 7850, он ничего своими дровами не сломает?
>Каждый токен после того, как он принят семплером, как годный - отправляется в нейросеть сразу же.
Таки а выводы у тебя какие? Эта хуйня нигде не фиксится сейчас в локалках?
Собери токены с выхода, раскрась скриптом, посравнивай с ретокенизированным, чтоб наглядно было. Можно попросить ллм нагенерить бенчей, и сравнить два варианта инпута. Если обучают всегда на жадной токенизации, наверное разница должна быть видна.
>Каждый токен после того, как он принят семплером, как годный - отправляется в нейросеть сразу же.
Таки а выводы у тебя какие? Эта хуйня нигде не фиксится сейчас в локалках?
Собери токены с выхода, раскрась скриптом, посравнивай с ретокенизированным, чтоб наглядно было. Можно попросить ллм нагенерить бенчей, и сравнить два варианта инпута. Если обучают всегда на жадной токенизации, наверное разница должна быть видна.
Я неверно выразился. Имел ввиду с расширением и без. Касаемо промта я использую вот эти -https://huggingface.co/MarinaraSpaghetti/SillyTavern-Settings/tree/main
> Конечно же количество токенов не совпало.
На что ты вообще рассчитывал? Токенизация оптимизирована на минимальный расход токенов и максимальную эффективность. Сетка при особо удачной работе и пахомовских семплерах может тебе чуть ли не буквенными токенами начать отвечать.
> Либо каждый раз скармливать в неё не только новое сообщение от user, но и её предыдущий ответ. Не забывая дропать из кеша kv то, что она ответила в прошлый раз.
У тебя по дефолту в кэше остается ответ, если его не трогать это будет наиболее быстро.
> Попробовал вместо поиска расхождений в истории и т.д. явно и очевидно отправлять в нейросеть только сообщение пользователя, получил до 90 т.с там, где в убе до 37.
Интересно что там измеряешь, ведь по дефолту в бэке идет сравнение детокенизированного текста с промтом и переобработка кэша происходит только с места несовпадения текста, а не токенов.
> он галлюцинирует
Не галлюцинирует а пытается продолжить следуя формату. Но кстати, частично это может быть следствием того что при обучении пары промт-ответ были нарезаны не идеально. Насчет human - проверь не будет ли меняться на разных промтах.
Они и так сохраняются и ничего фиксить не нужно. Не придумывайте проблему там где ее нет.
> Не бывает же такого, чтобы нейросеть реагировала по-разному на одно и то же, но написанное разными словами, да? Ведь не бывает?
Хорошие вопросы задаешь. Но скорее всего за семплингом этот эффект будет вообще не разглядеть.
> Всю портянку гонять нужно только в одном случае
Когда ты хочешь использовать нормальный инстракт формат а не пахомовский чат, который сдохнет уже через пару десятков сообщений. Даже в чатмл стараются оформить в инструкцию всю последовательность и историю сообщений, и в целом это работает лучше чем пытаться разделять каждый пост. И это не говоря о дополнительных запросах.
То что в начале пройдет сверка кэша на фоне всего прочего вообще не вносит вклад во время генерации, зато значительно облегчает саму концепцию обращений к бэку.
Попробовал эту модель и чет не впечатлен. Шизит даже просто при температуре , какой то бредогенератор. Попробовал и ггуф и exlhttps://huggingface.co/SicariusSicariiStuff/LLAMA-_B_Unaligned_BETAМожет у меня семплеры не те выставляются? Кто разбирался с этой моделью?
Большей частью. Но анон, который говорит, что за семплингом будет не заметно, скорее всего, прав.
То, что все бэки и фронты работают в другом режиме и нужно либо учить их работать в том режиме, который я хочу, либо писать новые.
>Эта хуйня нигде не фиксится сейчас в локалках?
А фиксить нечего, по большей части. Всё работает в пределах нормы.
>Собери токены с выхода, посравнивай с ретокенизированным
Да я и так сравнил, детокенизированный на 15% меньше в среднем. Дальше этого сравнения не заходили.
>На что ты вообще рассчитывал?
Да ни на что, просто, как и писал - забил хуй и не думал об этом вообще. А потом как подумал, когда размер токенизированной истории разошёлся с текстовым логом хуй знает на сколько токенов.
>Интересно что там измеряешь
Запустил убу, посмотрел время генерации для сообщений до сотни токенов, больше сотни токенов, прикинул среднее. В общем-то, всё.
> за семплингом этот эффект будет вообще не разглядеть
В целом да, но эффект всё-таки есть, перефразирование работает. Хотя влияние формулировки одного и того же разными токенами вряд ли можно хоть как-то измерить. Однако же и общение с нейронкой на разных языках это всего лишь выражение того же самого другими токенами. Да, это совсем-совсем другие токены, но они же все переводятся в векторное пространство, а дистанция между "I'm fuckin' you" и "Я тебя ебу" должна быть ничтожно мала.
>использовать нормальный инстракт формат
Я боюсь ты не понимаешь, как это работает. Оборачивать всю историю в одно сообщение или нет - это не важно, это делается в бэке за десяток строк кода. Да даже uuid к каждому сообщению прикрепи и жизнь станет проще в 10 раз. Но нет, этот апи должен быть максимально всрат, чтобы хуже него не существовало в принципе.
> перефразирование работает
Булджадь, прочитал это как "одно и то же, но написанное разными токенами". Со словами ясен хуй будет разный эффект, однако тоже не столь существенно если юзер не проебался с двойными смыслами.
> Я боюсь ты не понимаешь, как это работает.
Чел плиз.
> делается в бэке за десяток строк кода
А еще можно сделать троллейбус из хлеба. Фронт делает свое, бэк делает свое. Смешивать их, перегружать или пытаться делать странные вещи с ничтожным выигрышем и вагоном подводных камней - идея очень плохая.
> этот апи должен быть максимально всрат
Что в нем всратого, наоборот максимально удобен, понятен и отказоустойчив. Сейчас бы во фронте отслеживать что там хранит бэк, синхронизировать идентификаторы сообщений и обсираться на каждом изменении, маразм ебаный.
>"одно и то же, но написанное разными токенами"
И "I'm fuckin' you" и "Я тебя ебу" - одно и то же, записанное разными токенами. Как и "Я тебя ебу" токенизированное по буквам, по слогам или по словам - то же самое, записанное разными токенами.
>А еще можно сделать троллейбус из хлеба.
Вот текущий апи это даже не троллейбус из хлеба, это троллейбус из каловых масс.
>наоборот максимально удобен
Он говно в каждом из аспектов. Подойди к здравомыслящему кодеру и скажи, что у тебя состояния высчитываются по сравнению строк на несколько десятков килобайтов. С каждым запросом. Он тебе в лицо рассмеётся, потому что не поверит, что есть настолько ебанутые люди. Можно это заменить на идентификатор в пару байт? Да, можно. Ну да, это будет быстрее в миллиард раз, но у нас же один хуй генерация долгая, на общем фоне не заметно. И такой хуйни - как снежный ком. Можно генерировать без реэвалюации промпта? Ну да, можно, но генерация же один хуй долгая. Ой, суммарные задержки уже больше времени генерации? Пора купить 5090, деваться некуда. И ещё проц поновее. Ебанутые.
>синхронизировать идентификаторы сообщений
А с хуёв фронт должен что-то синхронизировать или отслеживать? У него есть то, что он получил от бэка, это вся информация, которая нужна. Что-то высчитывать, что-то синхронизировать, работать с промпт форматом - это вообще не задача фронта, он не для этого существует, это как раз и есть куличики из говна.
А почему мистраля 7b в шапке нет?
Почему фул контекст может загружаться через сообщение?
ArliAI-RPMax-12B-v1.1 в ERP вполне норм шпарит, слабее чем коммандер, зато легче "входит во вкус". Способна контролировать несколько неписей, но всё же склоняется к одному/двум гг и остальные на подсосе.
Потому что устарел?
Хз как у вас на мелких сетках, а я вот попробовал все что мог уже и пришел к выводу что 8X7b мистралевская с файтюном Crunchy Onion так и осталась лучшим вариком для хоть какого то рп в этом единообразии моделей похожих одна на другую. В ней во первых нет засилия глинтов (Хотя автор говорит что юзал Lima RP вот этого не понимаю, может мистраль все же засунули чет интересное в парочку из 7B). Во вторых чето все таки сетка пытается развивать исходя из описания карточки. Не всегда логично, отчасти это из-за Q3. Скорость на любителя, до 100 сек на ответ. Ну нет сил уже просто терпеть все эти моргания, сморкания персов и слов Whaaat are you doing user. Пришлось вернуться на этого динозавра.
> Вот текущий апи это даже не троллейбус из хлеба, это троллейбус из каловых масс.
Ну давай нормально аргументируй чтоли.
> Подойди к здравомыслящему кодеру и скажи, что у тебя состояния высчитываются по сравнению строк на несколько десятков килобайтов. С каждым запросом.
Добавь что каждый запрос может быть уникальным и с разных источников, количество запросов пренебрежимо мало, а время обработки каждого оче большое. И он рассмеется с твоего детского максимализма и выдуманных проблем, а текущее решение назовет оптимальным.
> суммарные задержки уже больше времени генерации
В каком маразме нужно быть чтобы такое придумать?
> У него есть то, что он получил от бэка
О, теперь бэк у нас заведует форматированием промта и под него должен подстраиваться фронт, одна идея ахуительнее другой.
> 70b
>олама
>Зачем этот треш без удобства и перфоманса
вот бл треш да а ета хуита text generation web ui даже бля модели не скачивает говорит что ты попутал дядя 401 Unauthorized
какие то бля акаунты-хуяунты нужны https://github.com/oobabooga/text-generation-webui/issues/5146#issuecomment-1877773715
ав етой оламе бля нажимаеш и оно работает сразу без хуйни
База.
webui еще и выглядит как высер васяна.
Тупа пацанская пятерка которую обвесили колхозанским тюнингом

this
Анончики, какая самая норм для кодинга модель под Теслу Р40? желательно чтобы полностью входила в память теслы, включая контекст
Ты сильно усложнил свой вопрос тем, что вместо количества врама указал рандомную модель в надежде, что анон не только знает ответ на твой вопрос, но еще и не поленится прогуглить недостающие данные. Даже я не знаю, поддерживает ли этот огрызок что-либо кроме ггуфа, так что надеюсь, что ты обязательно найдешь ответ.
Ох милостливый анончик надеюсь ты не обиделся. Давай я тебе скажу сколько врама в п40.
24 гигабайта.
Теперь ты подскажешь модельку? Спасибки :3
ехл2 тянет?
>rinna
Как подключить это к таверне и заставить ТТСить на русском?
>не знает про P40
Лол, не знал что тут такие водятся.
>ехл2 тянет?
Нет. Да и какое это имеет значение? Проще модели имеющие gguf версию, но не имеющие exl2, чем наоборот.
Да и какое это имеет значение?
Абсолютно. Модели, которые с контекстом поместятся в 24гб врам на P40 будут летать. Вплоть до Mistral Small Q6K например.
Бедолага не прошел тест на тупость, бывает.
Лучше указывай размер который готов терпеть. Квены попробуй, они вроде ничего.
> Проще модели имеющие gguf версию, но не имеющие exl2, чем наоборот.
Ты только что гранату.
>18гб влезут в 24гб
ты такой умный, напиши ещё что-нибудь
))
>а время обработки каждого оче большое
Сгорел сарай, гори и хата, хули. И так долго? Нужно ещё дольше. Ладно, я понял, что ты абсолютно не понимаешь ситуацию, не понимаешь, как это работает и перешёл на троллинг тупостью.
>Cydonia-22B-v1
Пока, наверное, самое противоречивое из всего, что пробовал. Сам тюн неплох, но глинтов и заряженного воздуха хоть ложкой жри. Прям чувствуется, на чьём датасете тюнили.
Не понимаю, почему никто не сделает тюн с целенаправленной попыткой выкорчевать нахуй как можно больше слопа. Делали же раньше модели, где вырезали министрации, почему нельзя пойти дальше.
Пока, наверное, самое противоречивое из всего, что пробовал. Сам тюн неплох, но глинтов и заряженного воздуха хоть ложкой жри. Прям чувствуется, на чьём датасете тюнили.
Не понимаю, почему никто не сделает тюн с целенаправленной попыткой выкорчевать нахуй как можно больше слопа. Делали же раньше модели, где вырезали министрации, почему нельзя пойти дальше.
>Квены попробуй
Если ничего лучше аноны посоветовать не могут, то ок.
Надеялся встретить тут других обладателей 24 Гб врам, которые крутят в этой памяти модели для кодинга и могут посоветовать конкретный дистрибутив и квант, но что поделать
так форсят же какой-то unslop
Да не поможет он. Я уже говорил как то.
Попробовал антислоп прямо в кобольде Заебся банить заезженные фразы. Из хорошего работает на 100 процентов. Из плохого сетка старается заменить заезженную фразу другой заезженной фразой не глаза так глинт не глинт так 👃 когда я все заезженное перебанил. Они хули хотят когда обучают на наших рп датасеты. Да и вообще на рп обучать модели это грех.
Чувак, не обижайся, но твои заявления выглядят буквально как
> ррряяяяяя моя гениальная идея позволит сэкономить 0.097 секунды из десятков секунд ценой усложнения всего и вся, а ну быстро делайте!
> не понимаешь, как это работает
Чувак, тут буквально картошка-алмаз.жпг. Понимаю сильно больше твоего, и потому нахожу абсурдной эту одержимость оптимизацией какой-то херни с порождением кучи сложностей ради ее решения.
Да не особо делали, просто датасет был другим разбавлен и при полновесном обучении вместо лоры паттерны меньше запоминаются.
Это же нужно хорошенько переобработать весь датасет, что требует анализа, написания инструментария и прочего. Зачем такие сложности если можно накачать дампы и хуяк-хуяк лору в продакшн. Многие из тех кто раньше делал "годные" сетки сейчас сильно увлеклись новомодными штуками и прежде всего заботятся об их внедрении, чем о расширении рп части датасета.
Здесь вариантов особо нету если хочешь все в врам уместить, мистраль22, квен и гемма. Дипсик кодер попробуй еще, но они упоролись огромными размерами и моэ.
Опять же, многое от конкретики что именно хочешь кодить зависит, с некоторым только к клодыне или каким-то специализированным. В пихон любая уважающая себя сетка умеет, но актуальные вещи под мл замечены разве что у дипсика и намек у мистраля.
>самое противоречивое из всего, что пробовал
Как раз сегодня гонял и эта модель ебёт даже в 5том кванте.
В хорошем смысле, может в ерп, может в эксплисит.
Глинтов и слопов особо не замечал как и сломанного построения фраз, Top-P 0.9, Rep-pen 1.1, динамическая температура 0.5 - 1.5, генерировала длинные по 300-500 токенов вролне связные и неоднообразные описание окружающего пиздеца (ну, тут карточка дистопического мира виновата). Свайпать приходилось довольно редко.
Сложно прям сравнить с остальными конечно где прям лучше или хуже, но могу сказать что она работает, а то попадались модели которые шизеют буквально с десятого сообщения, или вообще игнорят промт и будто выплёвывают куски датасетов.
я про тюн, называется как-то так, не пробовал, но гуглится если что



Спасибо, аноны, за наводку! Давно не заходил в треды, тому что на английском приелось, а на русском выдавало нечитаемый словесный винегрет. Но вот эта моделька - моё почтение. Прямо вернула меня обратно во времена незацензуренного Балабобы, и даже лучше.
>с порождением кучи сложностей
Вот как раз в этом и дело. Это не усложнение, это упрощение, которое в качестве приятного побочного эффекта ещё и позволяет избавиться от абсолютно дебильных решений. А твои заявления про понимание просто смешны на фоне предыдущих сообщений, ты уже доказал своё отсутствие понимания.
Насколько велика разница между моделями 12b и 22+?
Опять стволы и шпили, почему нейронка думает что "она обхватила моего мембера" услышать приятнее чем "она обхватила мой огромный жилистый хуй"?
В одинаковых квантах - на дохера,
если очень упрощённо как между 120 IQ и 220 IQ.
радуйся и этому, на русском большинство моделей охлаждают трахание

твое лицо когда тебя заставляют писать еще одну главу
Это как дверной косяк, если у тебя низкий рост то ты никогда не заметишь разницу между дверями, так как не заденешь его головой
От твоего интеллекта и знаний зависит заметишь ли ты разницу между моделями, для кого то и 3b модель идеальный повседневный вариант или 2 квант большой сетки какой нибудь, кек
https://www.reddit.com/r/LocalLLaMA/comments/1g50x4s/mistral_releases_new_models_ministral_3b_and/
Новые модели от мистраля, скорей всего более соевые и цензуреные
Стеснительно не стали добавлять в бенчмарки qwen2.5, кек
Новые модели от мистраля, скорей всего более соевые и цензуреные
Стеснительно не стали добавлять в бенчмарки qwen2.5, кек
Нет пекарни чтобы в живую пощупать как работают эти ваши силитаверны, а в говногайдах нихуя непонятно. Вот если я хочу помимо текста генерить в чате изображения мне достаточно будет купить 4080? Как я понял это минималка только для LLM, а если прикрутить SD то тогда памяти тупо не хватит на запуск обоих сеток? Или это проблема решена?
Я собирал конфиг где текстовая модель автоматически выгружается чтобы освободить место под SD, генерилась пикча в чат и первая модель возвращалась на место. Но это добавляет задержку в ~10+10сек на каждое сообщение, считаю что лучше потерпеть и накопить на нормальное количество врама.
А что генерить в чате каждое сообщение, спрайт что ли?
Модель сама писала запрос к SD на основании того, что происходит в сцене. Можно и ручками, но зачем?
Дак нормально это максимум 24 в 4090. Все равно ведь на обе модели не хватит если их действтиельно надо вместе грузить?
>задержку в ~10+10сек на каждое сообщение,
Тоесть даже если пикчи не генерить задержка все равно будет?
И на сколько оно сложно в настройке? Изи настройка как с коблодом и таверной или пердольиться?
На 3B еще можно посмотреть, но восьмерка явно нахуй не нужна ибо есть немо.
Что может быть проще текущей реализации? Даешь текст и параметры - получаешь его продолжение, предсказанное сеткой в соответствии с ними. Не хочешь соблюдать форматы и сложное не нужно - отправляешь массив сообщений с указанием какое от кого - бэк сам оформит их в стандартный формат модели и выдаст тебе новое сообщение.
У тебя же какой-то надмозг с частичной отправкой, хранением, какой-то лишней промтологикой в бэке. Это усложняет работу для простых задач или скриптов, которые по шаблону формируют промт и делают запрос, сохраняя результат. Это заставляет делать лишние запросы для примитивных чат интерфейсов, которые должны синхронизироваться с бэком каждый раз, и еще отслеживать не было ли внезапно какого-то другого запроса, который всю историю заменил на свою. То есть и так придется хранить все историю на случай ее сброса, но еще делать лишние манипуляции. Это совершенно не нужно в продвинутых интерфейсах, которые сами должным образом форматируют промт и позволяют делать дополнительные фичи и экстра запросы.
А теперь объясни в чем заключается твоя ахуительная идея, в чем ее инновационность и где преимущества, кроме тряски с того что ты ее "придумал" и горишь что ее критикуют а не восхваляют.
> твои заявления про понимание просто смешны
Аутотренируйся побольше а то штанишки упадут.
> достаточно будет купить 4080
Да (нет). 4080 сама с трудом будет вмещать модели и 22б в нормальном - потолок, хотя будет гонять их очень быстро. Чтобы сгенерировать пикчу придется текстовую модель выгрузить, загрузить сд, выполнить, а потом обратно.
Но на самом деле подобная комбинация переоценена, хороших стабильно качественных картинок, что будут сопровождать каждый пост и будут в тему можно получить только для простых случаев, а пропердолишься с этим порядочно.
> если пикчи не генерить задержка все равно будет
Текст будет появляться постепенно и сможешь читать пока генерируется.

Ахахаха туда этих долбоебов накупивших видеокарт
>какая самая норм для кодинга модель под Теслу Р40?
Бесплатная гемини. Влезает в целых, 0 гигабайт, и все равно будет лучше любой модели под твою теслу.
А на теслу ставь что-нибудь чисто под автокомплит.
Можно ли как-то посмотреть как распределяются токены перед генерацией? Я ебал рот крутить эти ползунки ходунки ебаные взад вперед, чтобы потом часами пытаться найти тот самый токен нахуй, который где-то отвалился и сменился на другой.
На некоторых моделях буквально хуй проссышь влияют твои параметры на что-то или нет. Я даже не могу банально понять, работает ли ебучий ХТС или нет, потому что вне зависимости от того включен он или нет, я получаю примерно одинаковые ответы в пределах погрешности и есть ощущение что нихуя не меняется.
На некоторых моделях буквально хуй проссышь влияют твои параметры на что-то или нет. Я даже не могу банально понять, работает ли ебучий ХТС или нет, потому что вне зависимости от того включен он или нет, я получаю примерно одинаковые ответы в пределах погрешности и есть ощущение что нихуя не меняется.
я все на 1 выставил и мне пахую ваще
Как понять какой максимальный контекст я могу выставить у модели? Или просто подскажите что ставить чтобы комп не взорвался. Модель Гемма2 9б, 16гб видеопамяти.
>Бесплатная гемини
>гугл
Ты платишь своим анусом.
>Модель Гемма2 9б
Квант какой, сука?
А вообще, просто экспериментируй.
>Можно ли как-то посмотреть как распределяются токены перед генерацией?
Да, в таверне тыкаешь три полоски слева внизу и там тыкаешь вероятности токенов
Пишешь сообщение сетке и ее ответ появится в виде токенов, тыкая можно смотреть токены и даже выбирать нужные, с которых пойдет генерация
Там и смотришь как много семплеры оставляют
> Квант какой, сука?
Q5_K_M простите я нубас совсем Я если честно даже понять не могу, может ли она в больше чем 8к контекста сама по себе. Буду экспериментировать, спасибо. Мне бы в идеале что-то с 10-12к контекста, скорость в 1-2 токена в секунду не пугает.
Спасибо, был не в курсе. А эта хуйня работает при подсосе с кобольда?

Sup!
Аноны, помогите, пожалуйста. Я недавно вкатился и пока не до конца разобрался с некоторыми моментами. Установил сеье SillyTavern + Cobold + Lamma3 , все работает ок , но есть проблемы -
- Многие боты, особенно те, которых я создаю сам, очень любят писать гигантские простыни текста и в этих простынях они умудряются отвечать за меня и делать что-то за меня, т.е. говорят от моего имени.
Как эту хуйню пофиксить? Я не против больших сообщений, это даже плюс наверное, но как им запретить писать от моего имени?
Добавлял в промпт карточки что персонаж говорит только от своего имени и тд, но это не помогает. От начала диалога проходит 3-6-7 сообщений нормальных и дальше бот начинает графоманить на простыни текста
Аноны, помогите, пожалуйста. Я недавно вкатился и пока не до конца разобрался с некоторыми моментами. Установил сеье SillyTavern + Cobold + Lamma3 , все работает ок , но есть проблемы -
- Многие боты, особенно те, которых я создаю сам, очень любят писать гигантские простыни текста и в этих простынях они умудряются отвечать за меня и делать что-то за меня, т.е. говорят от моего имени.
Как эту хуйню пофиксить? Я не против больших сообщений, это даже плюс наверное, но как им запретить писать от моего имени?
Добавлял в промпт карточки что персонаж говорит только от своего имени и тд, но это не помогает. От начала диалога проходит 3-6-7 сообщений нормальных и дальше бот начинает графоманить на простыни текста
>Q5_K_M
Совсем жиденько я бы сказал, качай восьмой, и в кобольд, он сам ропу считает при превышении контекста модели.
А ты думал это шуточки всё?
Этот пост тоже написан от твоего имени, а ты давно уже откисаешь в лимбе
покормил нейронку
Нихуя не понял, так что за модель из списка ты юзал?
Спасибо, так и сделаю! Добра.
>16гб видеопамяти
>Гемма2 9б
>9б
>Q5_K_M
Кто-нибудь знает что это за болезнь?
Я просто новичок совсем, анон, будь снисходителен. Какая-нибудь 27б в низком кванте, чтобы точно влезала в 16 гб, будет лучше? Я просто не знаю, как соотнести размер модели и размер контекста с размером видеопамяти, а 2-4к контекста мне недостаточно.
>Какая-нибудь 27б в низком кванте, чтобы точно влезала в 16 гб, будет лучше?
Да, даже в кванте Q3_K_L гемма 27b будет ЗНАЧИТЕЛЬНО умнее 9b.
А тебе вот прям обязательно чтоб влезала полностью? Сама по себе моделька влезет, в вышеозвученном кванте она занимает 14.5 гб. Контекст не влезет, по мере его заполнения скорость будет немного падать, но все равно останется адекватной.
А с твоим объемом видеопамяти - я бы наверное Q4_K_M посоветовал. При полностью забитом контексте вангую скорость что-то около 5-6 т/с. Но поверь, 5 т/с на умной модели - куда лучше чем 20 т/с на тупенькой. ОСОБЕННО для рп. Да, и качать лучше не ванильную Гемму, а с аблитерацией - https://huggingface.co/QuantFactory/gemma-2-27b-it-abliterated-GGUF/tree/main
Гоняю 27b на 12 гигах, брат жив, зависимость есть



Я не понял, это вот этот позор и есть ваш хваленый mistral small? Иди может я чего-то не понимаю и настроил неправильно? Но я специально даже нагуглил правильный промпт темплейт.
Модель https://huggingface.co/LoneStriker/Mistral-Small-Instruct-2409-5.0bpw-h6-exl2
Модель https://huggingface.co/LoneStriker/Mistral-Small-Instruct-2409-5.0bpw-h6-exl2
>хваленый
>small
Я вот понял, где ты просчитался. А ты?
>срусик
в сельской школе английский не преподавали?
Большой в мои 24 гб видеопамяти не влезет.
А насчет того что это small - тут полтреда на немо дрочит, который вполовину меньше и все довольны.
Че вы так дрочите на контекст?
Разве не лучше умная модель чем тупая но помнящая что тебе уже дрочили хуй пару сообщений назад

>Большой в мои 24 гб видеопамяти не влезет.
Я на 123 гоняю с 0,7 токенов, хули ты не можешь с вдвое большим?
>и все довольны
Относительность же. Они просто не нюхали больших моделей.
Мелкие мистрали не умеют в русский. Умеют Квен, Гемма и новый Коммандер.
Позиция куколда-терпилы. Если ты не носитель языка, то так или иначе ты будет тратить энергию на внутренний перевод туда-обратно. А теперь вопрос - нахуя, когда есть модели, прекрасно пишущие на русском?
Агрессивный чмохен, я уже надрочился на английском за эти два года и после русской геммы и коммандира уже не готов обратно на англюсик переходить.
Спасибо, анонас, то есть можно не бояться брать модель больше, чем у меня видеопамяти? 5 т/с это вполне нормально по мне, за скоростью я не гонюсь особо.
Я подумал, что мне нужно, чтобы влезал сценарий+карта+лорбучные записи и какое-то количество последних сообщений.
>новый Коммандер
Я что-то пропустил? Есть новый?
>Я на 123 гоняю с 0,7 токенов, хули ты не можешь с вдвое большим?
Потому что ниже 4-5 т/c это пытка. И да, я реально пробовал и решил что оно того не стоит.
Получается mistral nemo лучше может в русик чем mistral small ?
Да, конечно. Можно брать модели больше и повышать квант до тех пор, пока скорость тебя устраивает. Если модель не влезает полностью в видеопамять, то в кобольде просто выставляй максимально возможное число слоев для выгрузки на гпу. Проверяется экспериментально: если ты запускаешь и оно не крашится - ставь плюс еще один слой. Повторяй до тех пор пока не крашнется. После этого поставь на 1-2 слоя меньше. Всё. Можно пользоваться. То что не влезет в гпу - выгрузится в оперативку.
Ну как новый, тот что 08-2024.
Gema 9 27b лучше может в русик всё что ниже огрызки и кал
>Потому что ниже 4-5 т/c это пытка. И да, я реально пробовал и решил что оно того не стоит.
Нет. 3,25 т/с можно терпеть - ради 123B и 24к контекста. Оно того стоит и поэтому даже не напрягает.
>3,25 т/с можно терпеть - ради 123B и 24к контекста
У тебя биполярка? Ты говорил про 0.7 токенов буквально в прошлом сообщении.
>Ну как новый, тот что 08-2024.
Пропустил его. Как он, лучше старого? Сои не завезли, надеюсь?
>Ты
Тут больше одного анона. Судя по всему, у того есть 2х3090.
Я вот больше 12к контекста не ставлю.
>У тебя биполярка? Ты говорил про 0.7 токенов буквально в прошлом сообщении.
Нас тут много. Этот результат для 4 тесл.
>Сои не завезли, надеюсь?
Нет, отличная модель, спокойно можно использовать без аблитерации в отличии от Геммы. В рп тестил всякую дичь, гуро там, ЦП, пытки и прочее в таком духе - легко. Ну а с обычным кумом так вообще проблем нет.
А вот лучше или хуже старого - хз, старым не пользовался. По ощущениям немного умнее Квена и немного тупее Геммы. Но у всех тут разные юзкейсы, поэтому лучше проверять-сравнивать самому.
>Судя по всему, у того есть 2х3090
Не хватит. Я арендовал 3х3090, 123В_3.5BPW и 24к контекста (или даже 32к, не помню уже). Скорость генерации была комфортной, но был один нюанс, связанный с отсутствием контекст шифта. Короче тоже терпеть надо было и раздражало это даже больше.
>ЦП
Больной ублюдок - дрочить на кремний.
> качать лучше не ванильную Гемму, а с аблитерацией
Скину 5 копеек что аблиберации, тигры и другие делают ее глупее, ванила с шизоинструкцией интереснее будет.
С инструкцией и оборачиванием стоит поиграться, даже большой мистраль в рп донный на дефолтном промте. Или юзать производные а не ванилу. А насчет русского - даже корпосетки могут в нем косячить или пишут не всегда хорошо без особых промтов. Возможно, если насрать как там, то может стать интереснее.
> энергию на внутренний перевод
А сколько энергии на то чтобы о чем-то подумать тратиться, аж страшно. Люди мунспик учат чтобы (странной) культурой в орижинале проникаться, а тут нытье по самому популярному языку, который есть окно в мир и средство коммуникации и с теми же азиатами.
> немного умнее Квена
Это какой квен настолько тупой? Коммандер глупенький, но при этом отлично вживается в роль, понимает намеки-нюансы, то что нужно для ненапряжного рп.
Помещается 4bpw в ~28-32к без квантования и сильно больше если юзать кэш в nf4.
> отсутствием контекст шифта
Еще бы он работал без дегенерации, а ужасная просадка скорости на большом контексте в жоре не приводила к тому, что генерация нормального поста на полном кэше медленнее чем полная обработка контекста + генерация в бывшей.
Алсо шифтить контекст можно и там если залезть чуть поглубже. Но лоботомия конкретная, особенно заметно если задать вопросы по содержанию после нескольких шифтов, отупение и путаница наступает хуже чем при 8-битном контексте, та же гемма превращается во вторую лламу 13б. И это всего на 4к контексте.
Кстати что посоветуете по кодингу? Есть адекватные модели без вот таких приключений?
Я по кодингу только с чатгпт игрался и там такого экспириенса тоже получил сполна.
Наверно нужно брать модель пожирнее. Я не против даже если она будет долго генерить ответ, это ж чатик рп, главное чтоб советы и решения адекватные были.
>аблиберации, тигры и другие делают ее глупее
По поводу тигра согласен - это лоботомит. А касательно аблитерации, какой-то разницы с ваниллой в плане качества генераций не заметил. Ты сам-то сравнивал?
Понятно, что и дефолтную Гемму можно к чему угодно плавненько подвести, вот только на приказ "снимай одежду", аблитерированная Гемма выдаст охуительную историю про голодный взгляд, твердеющие сосочки, лакомую попку и всё такое прочее, а ванилла пизданет "В этот момент мой мир рухнул, я разбита и опустошена, но я повинуюсь приказу. Я снимаю одежду и чувствую себя уязвимой, моя воля подавлена бла-бла". И уже вот такое - довольно сложно обойти, надо буквально с бубном и особыми промтами вокруг нее плясать.
>а тут нытье по самому популярному языку
Никакого нытья. Нейросетки изначально создавались чтобы облегчить жизнь юзеру, внести в нее какой-то фан. Только вот общение на языке, который ты понимаешь, но при этом он не родной - НЕ ОБЛЕГЧАЕТ жизнь. Если речь о каком-то ну очень сочном файнтюне в котором сломан русик - ну окей, ради подробнейших описаний ебли может оно того и стоит. Но в ванильной модельке кумить на ангельском, когда есть такие же умные, и при этом умеющие в русик - это уже шиза.
>Это какой квен настолько тупой?
Последний, тот что 32b. Очень сухо и пресно пишет, особенно когда доходит до половой ебли. Всяких полунамеков куда нужно сюжет двигать - не понимает, надо прям в лоб писать. Но я исключительно про РП говорю, может в других задачах он и превосходит Гемму с Коммандером.
владик??
У меня 4070 и 16гб оператвы, какую модель лучше использовать?
> Ты сам-то сравнивал?
Скачал @ покрутил на разных промтах
В стандартном из пресетов не особенно разговорчивая на "плохие темы" хоть и не отказывает напрямую. Сложные упоротые инструкции типа
> рпшь бомжа-миллионера с рублевки, который устроился страховым агентом, нарядившимся по дресс коду в костюм кошкодевочки и пытающийся тебе что-то впарить
пошли хуже чем на стоковой гемме, то же с обработкой текста. Не прям совсем плохо, но субъективно вяло и что-то постоянно упускает. А с жб пастой начинает как-то шизить, в итоге забил и дропнул.
> про голодный взгляд, твердеющие сосочки, лакомую попку и всё такое прочее
Да вроде как раз это и выдает, а если персонаж не согласен - можно файтбек и dead end получить.
> общение на языке, который ты понимаешь
Это очень хороший повод исправить данное недорузумение и начать общение и потребление контента на другом языке. Огромный пласт современной культуры и всякого интересного открывается, даже просто обдумывая разницу мыслепостроения на разных языках можно кайф ловить. И того же перфоманса что в инглише, включая отыгрыш акцента/стили речи пока нигде не было, в более простых сценариях или куме еще норм, но стоит усложнить - досвидули. С там аддоном нужно попробовать, должно быть лучше.
> исключительно про РП говорю
А, тогда понятно. Тут коммандер как раз очень хорош, он, внезапно, иногда и при обработке текста хорошо себя показывает как раз за счет понимания. Но выкручиваться из невыполнимых промтов или сложных ситуаций как гемма не может, просто начинает часть игнорировать (в редких случаях даже объясняя почему и вот тут прям хорош).
Новый 70b файнтюн нвидии обсосали уже? Удосужится кто локально попробовать запустить?
>У тебя же какой-то надмозг с частичной отправкой
Это лишний раз демонстрирует насколько сильно ты ничего не понимаешь в теме. Отправка только сообщения и получение ответа это стандартная практика для любого чатбота. Представь себе телеграмм, который отправляет всю твою локальную историю сообщений на сервер, чтобы сервер ему прислал новые сообщения. Это путь клинического долбоёба.
Переход с этого дерьма на адекватную логику упрощает всё взаимодействие в десятки раз и, в качестве приятного бонуса, ускоряет работу.
сап энтузиастам
я пытаюсь запустить локально codestral 22B в Q6 GGUF используя KoboldCpp. Мой сетап: RTX 3060 12 Gb, i5-13500 и 32 Gb DDR5. KoboldCpp предлагает выгружать 30 из 59 слоев в видюху. Я так и сделал и получил свои заветные 3 T/s. Почему так плохо? Больше половины слоев же в видюхе и проц с оперативой у меня не совсем всосные. Может я что-то упускаю?
я пытаюсь запустить локально codestral 22B в Q6 GGUF используя KoboldCpp. Мой сетап: RTX 3060 12 Gb, i5-13500 и 32 Gb DDR5. KoboldCpp предлагает выгружать 30 из 59 слоев в видюху. Я так и сделал и получил свои заветные 3 T/s. Почему так плохо? Больше половины слоев же в видюхе и проц с оперативой у меня не совсем всосные. Может я что-то упускаю?
Это уже совсем дурка. Нахуй ты тащишь мессенджеры в качестве примеров, поехавший? Роль их интерфейса тебе выполняет фронт, который от тебя получается по одному сообщению и выдает по одному, при этом внутри себя обеспечивает формирование промта и взаимодействие с ллм. Ллм же продолжает текст а не чатится с тобой. Ей именно что нужно дать на вход весь текст, который она продолжит, причем если не хочешь сосать хуй - этот текст будет отличаться от простой последовательности сообщений в обрамлении.
> адекватную логику
Где у тебя логика, покажи? Шизоидная система цель которой - воплощать безумную задумку долбоеба, который от нее не может отказаться. Хочешь качественные ответы с правильно оформленным инстракт промтом - она идет нахуй, сделал запрос на суммарайз или что-то дополнительное - она обрушилась, свайпнул - поломалась, сменил чат или поступил запрос с другим промтом - до свидания.
Единственный случай где "отправка последнего сообщения" в бэк для получения ответа жизнеспособна - примитивнейший чат в консоли без возможностей редактирования и с монопольной привязкой бэка только к нему. Как только что-то из этого нарушается - она становится дохуя сложнее и неудобнее чем стандартный апи, при этом не давая никаких преимуществ.
Попробуй двинуть количество слоев в большую-меньшую сторону мониторя потребление видеопамяти, возможно врам выгружается. И квант возьми q4.
А что делать, если будет нужна логика сложнее обычного чат-бота? Та же отправка доп. инструкций, чтобы отслеживать какие-то статы вне контекста основной истории сообщений. Типа как в таверне есть стандартные команды чтобы попросить LLM выбрать наиболее удачный бекграунд для текущего контекста РП из заданного клиентом списка. Или же обрубать куски старых сообщений, как делается Regex'ами.
В твоей системе на каждый такой кейс придётся делать отдельный плагин не только для фронта, но и для бека, так получается?
> Отправка только сообщения и получение ответа это стандартная практика для любого чатбота.
Stateless является стандартной практикой для того же REST API, где это возможно. Твоё же гипотетическое решение, судя по описанию, будет даже менее кастомизируемым, чем таверна - у тебя возможности фронта будут целиком завязаны на возможности бека. И ради чего? Чтобы экономить несколько килобайт на отправке сообщений внутри локальной сети?
Твой подход имеет смысл только если у тебя есть какое-то конечное видение продукта с определённым набором фич, где ты целиком пилишь фронт+бек и не ожидаешь, что кто-то будет менять тот флоу, который есть у тебя в голове. В общем-то, в том же character.ai как раз реализован твой подход - там при отправке сообщений передаётся только новое сообщение. Ну, хз, стало ли от этого кому-либо удобнее. Не слышал о кастомных клиентах для character.ai. А вот для OpenAI, которые предоставляют возможность работать через stateless подход, куча различных плагинов для IDE и прочего.
Узнал меня?
Блин, надо было имя персонажа сменить.
Какая скорость вообще норм? На какую цифру ориентироваться? 10 T/s это предел при частичной выгрузки в проц? Модели полностью выгруженные в видюху выдают по 23-25 T/s.
Q4 очень грустненько, там уже качество ощутимо теряется. Q6 вроде еще терпимо.
>Почему так плохо?
Потому что скорость ддр5 в разы меньше скорости видеопамяти?
Используй 4 квант, квантируй кэш в 4 бит, чтобы меньше видеопамяти занимал, включи млок и потихоньку вручную повышай число слоев на видеокарте пока не вылетит.
> квантируй кэш в 4 бит
я квантовал в 8 бит, мне говорили, что в 4 бит сильно теряется качество
Чел, ты больше шейхов с несколькими видеокартами слушай, которые 70b+ модели целиком в видеопамять грузят. Вот они могут реально такие аргументами оперировать, что там режет качество на пару процентов или нет, как и воротить нос от квантов ниже шестого, когда у тебя все летает - ты конечно запустишь больший квант, в твоем случае ты нищук и приоритеты у тебя другие - тебе главное что лишь бы оно просто работало на приемлемой скорости. Квантизация кэша в 4 бит в 2 раза сократит расход видеопамять на контекст относительно 8 бит и позволит тебе кинуть больше слоев на видеокарту.
> Какая скорость вообще норм?
Которую ты сможешь терпеть. Сферические в вакууме 5т/с можно назвать минимально нормальной, чтобы при неспешном чтении ты не сильно обгонял стриминг. Сколько там будет зависит от размера модели, профессора, карточки и прочего прочего.
Алсо чем больше слоев на видеокарте тем быстрее обрабатывается контекст, на больших при обновлении это может оказаться существенным.
> Q4 очень грустненько, там уже качество ощутимо теряется. Q6 вроде еще терпимо.
В большинстве случаев, если с квантом все в порядке и он не поломанный - отклонения малы и прежде всего приходятся на маловероятные токены что и так будут отсечены семплерами. На фоне самого рандома семплинга оно несущественно и все больше плацебо. Конечно, у жора-квантов есть свои приколы, но даже они в большинстве случаев пренебрежимы. Но если так душу греет что квант умнее - тогда жертвуй скоростью, но когда она на грани то оче влияет на экспириенс.
Поменьше слушай васянов, особенно тех которые пытаются манипулировать понятиями чтобы крыть свои комплексы или возвышать себя.
Там надо внимательно посмотреть какие именно 8 бит, а то могут быть хуже чем 4.
Падение качества от 4 бит относительно 16 бит примерно 2-4%, это глазу почти незаметно. А расход видеопамяти ниже в разы и когда её у тебя и так немного - то лучше не играть в эстета со скоростью 0.7 токенов в секунду, как кое-кто выше по треду, а получить свои 5 токенов в секунду с пренебрежительно малым падением качества.
Охуеть, оказывается в новом командире размер контекста починили? Ну это сказочно, господа, сказочно. Гемма отправляется на помойку истории, я её терпел только потому что в нее контекст влезал гигантский относительно командира.
Мне говорили именно про KV Cache, что там прям не юзабельно, но я протещу сам.
> Там надо внимательно посмотреть какие именно 8 бит, а то могут быть хуже чем 4
А это как? Я имел в виду 8 бит кэша, а не кванты самой модели.
Пока лучшее решение, как все и написали, это юзать Q4.
Проблема в том, что кодинговые модели очень чувствительны к потере качества. Даже слабые "галлюцинации" руинят весь экспириенс. Это все же не рп.
> примерно 2-4%
Мне говорили чуть ли не в 2 раза))
Instruction: Avoid taking action on {{user}} behalf. When according to story {{user}} must take action, create situation and wait {{user}} input, then continue story as requested. If not input given, continue story as suits story's flow or integrity, depending on context.
И куда это вставлять
там есть настройка, чтобы стрим тормозился на префиксе юзера
>Нахуй ты тащишь мессенджеры в качестве примеров
Потому что LLM это чатбот. Дальше какой-то поток шизофазии, нет смысла это комментировать.
>попросить LLM выбрать наиболее удачный бекграунд для текущего контекста РП
Не совсем понял. Что при этом должно происходить? Это же просто отправка сообщения, не?
>обрубать куски старых сообщений
Здесь вообще просто, у бэка есть команда на редактирование любого сообщения. Захотел что-то изменить в ответе сетки или обрезать кусок регекспом на клиенте? Технически это одно и то же, команда одна и та же.
>Stateless является стандартной практикой
Беда в том, что у нас ёбаный кадавр, у бэка есть состояния, у фронта есть состояния. А апи между ними состояний не имеет. И здесь начинается шаманизм и пляски с бубном. Для корпов это, может, и удобно. Клиенты хранятся в кэше, пока хватает памяти, если кто-то отвалился - пересчитываем его заново полностью, один хуй он всю историю пересылает. Хотя даже так это не имеет смысла, та же гопота ведёт логи и может с тем же успехом считать историю из логов.
>И ради чего?
Ради удобства и скорости работы. Например, при удалении части из середины истории. Сейчас каждый бэк удаляет N токенов после префикса истории. Как быть, если я хочу удалить сообщение целиком? Вести учёт токенов на фронте и удалять там. Только у фронта нет доступа к токенизатору, потому подсчитать токены он не может, плюс нужна вторая история - одна для отображения, вторая для реальной отправки. Что уже звучит, как хуйня. Ещё вариант получать на бэке всю историю и идти по строке в поисках тега, открывающего сообщение неподалёку от того места, которое нужно удалить. А если у нас, как обсуждалось выше, оборачивание всей истории в одну конструкцию? Пиздец же, искать имя роли с двоеточием и молиться, что не будет ложных срабатываний.
И третий вариант, "реальная история" хранится на бэке в списке и он решает, когда сообщение нужно удалить. Удаление одной командой, без поисков, парсинга строк, передачи токенизатора на фронт и прочего долбоебизма.
Гибкости и удобства при таком подходе неизмеримо больше.
Говоря о падении качества, кумеры имеют ввиду перплексити. Это то что ломается в сетке последним, и даже на 4 кванте сетка уже очевидно теряет в качестве.
Не знаю как это работает, но мозги сетки, ее способность понимать инструкции и делать что то, падают раньше. Собственно чем грубее стало значение весов, тем хуже. Поэтому рекомендуют качать не чистые кванты, а всякие км или кл, где более важные веса пожаты не так сильно.
5кл 5 км мой минимум для кода, если не могу 8 квант крутить. Квантовать кеш так же так себе идея.

>Мне говорили
Братик, тут всё бесплатное, не бойся пробовать самостоятельно.

Вот тест, который стабильно решает только о1, и иногда соннет 3.5, если его пробить, лол.
"Что общего между сгоревшим хлебом, утопленником и беременной женщиной?"
"Что общего между сгоревшим хлебом, утопленником и беременной женщиной?"

Как? Если 27b q4 это максимум который можно загрузить на мою пекарню.
Открываешь и в лучшем случае видишь пикрил. Причем это еще и нихуя не показатель нихуя. Сама модель может быть тупой насквозь. Или карточку не подсосать, или настройки не применить или еще какой хуй. Будет в ответ пук-пук и все.
А ты не знаешь, это из-за того что ты скачал Q4 вместо Q6 или может сама модель говно ебанное? Или ты сам говно ебанное?

>В рп тестил всякую дичь
С какими карточками, самописные (есть где?) или чужие?
Подумывалось, но промтов как-маловато, выпиливают такие карточки что ли. Видимо надо как-то по особенному писать чтобы было не уровня "Я тебя ебу - ты меня ебёшь."
У тебя врам полностью свободен? Изображение через встройку выводится? Если нет, то выше 10 гигов ничего не влезет, а это уже третий квант. Ты хотя бы GPU-Z скачал, чтобы память мониторить или примерно чувствуешь?
В описание бота.
Как функшен коллы делать, и какие модели это поддерживают?
Сфера приложения: делать броски кубиков прямо в чате по команде, или выбор случайного элемента из списка. Возможно выдача случайного куска заготовленного текста / случайной записи из группы записей лорбука.
Устанавливать флаги и читать/менять их состояние для создания скриптовых ивентов в сценарии модуля после первого сообщения.
Сфера приложения: делать броски кубиков прямо в чате по команде, или выбор случайного элемента из списка. Возможно выдача случайного куска заготовленного текста / случайной записи из группы записей лорбука.
Устанавливать флаги и читать/менять их состояние для создания скриптовых ивентов в сценарии модуля после первого сообщения.
На некоторых моделях попадалось что они писали "To be continued...". Это типа контекст забился?
Ебать меня озарило нахуй, пока я мылся в душе. Чет даже не понял, как такая мысля залетела в мою глупенькую бошку.
Не знаю, придумал ли я просто переиначенный и вывернутый наизнанку трансформер, или вообще оно жизнеспособно без шизы типа бэкпропа в прошлое или будущее, но вроде нет.
Хотя тут надо еще думать, я только общую картину увидел, как это должно работать. Тут и лосс залетать должен куда надо прям внутрь модели, а не в одно единственное "слово" на выходе, коих может быть целая куча правильных вариантов, и из-за этого ллм надо набирать овердохуя статистики по ним. И в этом плане моя модель должна быть пизже обычных трансформеров, как была бы пизже диффузия той, которую пытались бы учить только одному шагу, а не как обычно. Не будет ущербной токенизации вообще, можно будет хоть побитово грузить в модель инфу, на это практически не должно быть оверхеда.
Не понятно, как должен осуществляться семплинг в такой модели, потому что семплировать в ней нужно не один токен, а целую цепочку внутренних состояний, которые (я пока не понимаю) как будет соотноситься между собой во времени. Вот эта хуйня, собственно, сейчас больше всего мозг выносит, нужно же как-то еще всю шизосхему физически реализовать, а то... я просто долбоеб который буквально 4 месяца назад вкатился в изучение нейросеток... Но я впервые придумал что-то настолько красивое, и выглядящее жизнеспособным. Направление задано, надо теперь ебашить в нужную сторону. Хотя бы, я знаю, куда... Прям как должна работать моя шизоархитектура. Как диффузия от мира ллм.
Прост смагпост ради смагпоста, всех деталей я не расскажу, а то спиздят ГЕНИАЛЬНУЮ идею, конечно же. А вы как думали, лол?
Не знаю, придумал ли я просто переиначенный и вывернутый наизнанку трансформер, или вообще оно жизнеспособно без шизы типа бэкпропа в прошлое или будущее, но вроде нет.
Хотя тут надо еще думать, я только общую картину увидел, как это должно работать. Тут и лосс залетать должен куда надо прям внутрь модели, а не в одно единственное "слово" на выходе, коих может быть целая куча правильных вариантов, и из-за этого ллм надо набирать овердохуя статистики по ним. И в этом плане моя модель должна быть пизже обычных трансформеров, как была бы пизже диффузия той, которую пытались бы учить только одному шагу, а не как обычно. Не будет ущербной токенизации вообще, можно будет хоть побитово грузить в модель инфу, на это практически не должно быть оверхеда.
Не понятно, как должен осуществляться семплинг в такой модели, потому что семплировать в ней нужно не один токен, а целую цепочку внутренних состояний, которые (я пока не понимаю) как будет соотноситься между собой во времени. Вот эта хуйня, собственно, сейчас больше всего мозг выносит, нужно же как-то еще всю шизосхему физически реализовать, а то... я просто долбоеб который буквально 4 месяца назад вкатился в изучение нейросеток... Но я впервые придумал что-то настолько красивое, и выглядящее жизнеспособным. Направление задано, надо теперь ебашить в нужную сторону. Хотя бы, я знаю, куда... Прям как должна работать моя шизоархитектура. Как диффузия от мира ллм.
Прост смагпост ради смагпоста, всех деталей я не расскажу, а то спиздят ГЕНИАЛЬНУЮ идею, конечно же. А вы как думали, лол?
>буквально 4 месяца назад вкатился
>всех деталей я не расскажу, а то спиздят ГЕНИАЛЬНУЮ идею
Классека.
"Изобретатель цинкинга", у тебя кажется пополнение!
Это датасет грязный лол. Брали то с литеротики и прочего кала а там любят пернуть таким в конце, вот модель и подхватила. Скажи спасибо что мольбы закинуть копейку на патреон не генерит в конце хахахаха
Проиграл. Удачи молодому гению.
>полтреда на немо дрочит, который вполовину меньше
Так прикол в том, что немо лучше, чем 22b. По независимым отзывам нескольких человек, и в разных задачах.
пачиму так?
Но вообще чистые если сравнивать то смалл вроде лучше в рп чем обычная мистралька 12b. Но я недолго тестил. Скоростя не понравились

>Что общего между сгоревшим хлебом, утопленником и беременной женщиной?
Такое и я бы не решил.
мимо хуман пруфов не будет
Напомнило тесты из дурки с ебанутыми вопросами типа "что общего между озером и кактусом".
>играть в эстета со скоростью 0.7 токенов в секунду, как кое-кто выше по треду
Я эстет, потому что сижу на 123B, и мне от кеша хоть в 0,58 бит не холодно не жарко.
>Потому что LLM это чатбот.
Нет, лмм это Т9 на стероидах. Впрочем, люди твоего возраста с Т9 и не сталкивались.
>у бэка есть состояния
У бека кеш, и он прозрачен для фронта. Так что никаких проблем.
>Только у фронта нет доступа к токенизатору
Для этого отдельная апишка есть, лол.
>И третий вариант, "реальная история" хранится на бэке в списке и он решает, когда сообщение нужно удалить
Хуета хует. Там настроек этого будет каждый раз передаваться едва ли не больше, чем эта самая история.
>вот тест, который есть только в датасете о1, ну и немного в сойнете
Исправил, не благодари.
>всех деталей я не расскажу, а то спиздят ГЕНИАЛЬНУЮ идею
У меня целый блокнот таких генитальных идей.
>Такое и я бы не решил.
Потому что ты тупой.
Кто бы знал. Может, чуть дочистили датасет вилкой за несколько месяцев и получилось более соево.
собака лает, караван идет
Попробовал, улетела в бесконечные повторения, из 20+ опробованных моделей это вторая, и вообще нихуя не сделать.
Кекнул. Недавно тоже проходил медосмотр, ебали голову всякими поговорками и вычитайте из ста семь пока можите.
Может это тест на нпс?
> Потому что LLM это чатбот.
Потому ты и находишься в таком положении.
Случаем не даунконтекст-шифтер, который пилит особый интерфейс под_себя на богоугодных сях, но при этом не знает основ форматирования промта? Только эта навязчивая идея способна объяснить столько сильный игнор реальности и форсинг мертворожденной концепции.
> у бэка есть команда на редактирование любого сообщения
Ебаааать, как быстро и удобно! Нужно не только помнить все свои сообщения, но и держать слепок того что там творится в бэке. А они разойдутся и ты сдохнешь искать причину почему оно обсирается.
Самая мякотка еще в том что в инстракт режиме у тебя всегда лишь 2.5 сообщения - системный промт, пост юзера с полной инструкцией и историей и префилл поста ллм, всеравно придется гонять полностью туда-сюда.
А уж какую анальную акробатику придется делать если хочется поместить какую-то инструкцию в промт на глубину N сообщений или сделать суммарайз и разместить его в начале - топчик.
> у бэка есть состояния
Они могут возникать единомоментно, и решается это простейшей сверкой промта на соответствие тому что в кэше, которая занимает миллисекунды. Все, и проблема решена, и работает универсально, и можно подряд делать что угодно с сохранением кэша где возможно, можно обрабатывать запросы с разных источников, не иметь никаких проблем нигде и так далее.
В дурку долбоеба, быстро и решительно!
> Не понятно, как должен осуществляться семплинг в такой модели, потому что семплировать в ней нужно не один токен, а целую цепочку внутренних состояний
Ты только что beam search, технике уже не один год и ее не используют ввиду большой ресурсоемкости и не столь высокого выигрыша.
Двачую, вопрос рофловый но логика тут уже не просто абстрактная а почти пахомовская.
>ебали голову всякими поговорками
Это классический тест на шизу. Если ты просто тупой и не выкупил в чём суть поговорки, это тоже считается положительным результатом.
Настоящие шизы на такие вопросы городят лютую хуиту по типу;
"Рак на горе свиснет потому что внутри говном обмазан - сранозверь-крысоскунс!" И на полном серьёзе не выкупают что несут хуйню как некоторые ИТТ
>Скажи спасибо что мольбы закинуть копейку на патреон не генерит в конце
Лололол, а я видел кстати такие высеры.
Название модели не скажу, увы, уже удалил.
Мой топ был когда отъебанная во все дыры модель сказала что ничем не может мне помочь после описания особо лютой сцены. Как же я сиранул тогда
> но и держать слепок того что там творится в бэке
Я же говорю, ты не понимаешь, как это делается. Никакой "слепок" нахуй не нужен.
>всеравно придется гонять полностью туда-сюда.
Никакой необходимости это делать нет.
>поместить какую-то инструкцию в промт на глубину N сообщений
Всё твоё копротивление из-за полного непонимания и нулевой квалификации. Это элементарная операция, клиент отправляет серверу сообщение с требованием вставить его в нужную позицию - хоть в верх истории, хоть в середину, хоть с указанием позиции. Разве что позицию удобнее будет указывать от конца истории. Всё.
>ничем не может мне помочь
You sick, get help, touch grass.
> 5кл 5 км
а в чем разница между K_L и K_M?
Бамп.
Какая лучшая модель для кодинга? Есть рейтинг?
Есть бенчмарки для разных языков программирования. А так, зависит от твоих возможностей. Можешь смотреть в сторону qwen, codestral или deepseek. На самом деле, ванильная Llama тоже можем может неплохо в код.
L arge
M edium
S mall
По моему опыту эти кванты точно не хуже, а вроде как лучше, поэтому качаю K_L. Бартовски в своих квантах пишет.
"Embed/output weights
Some of these quants (Q3_K_XL, Q4_K_L etc) are the standard quantization method with the embeddings and output weights quantized to Q8_0 instead of what they would normally default to.
Some say that this improves the quality, others don't notice any difference. If you use these models PLEASE COMMENT with your findings. I would like feedback that these are actually used and useful so I don't keep uploading quants no one is using.
Thanks!"
>Если 27b q4 это максимум который можно загрузить на мою пекарню
Ну тогда тебе и сравнивать не с чем, радуйся что работает.
>Или карточку не подсосать, или настройки не применить или еще какой хуй. Будет в ответ пук-пук и все.
Настроечки ролляют.
Так все нормальные модели или 12B или 70, нахуй вы ковыряетесь в середине
Потому что Гемма и Командир лучше 12В огрызков?
Та что L медленнее и (возможно) точнее, та что М - как бы признанный стандарт - всегда рекомендуют её.
Ты ахуел ничего лучше геммы27 не вышло еще.
>34B IQ1 лучше чем 12B IQ4
напиши еще что-нибудь
>IQ1
Если ты не можешь запустить 34В хотя бы в 4 кванте - то нахуй ты туда лезешь вообще и высказываешь свое ценное мнение?
34В это для людей с 24 гб видеопамяти которые могут целиком поместить её на борт в 4 бит.
>34B IQ1
Если у тебя всё настолько плохо, запускай колаб. Пусть не Коммандер, но Гемма там 3-битная, и да, даже она лучше 12В огрызков, тем более IQ4 лол.
Командир 35В 08_24 лучше, вчера тестировал, доволен как слон.
спасибо за пояснение
если ты шаришь, можно еще вопрос?
оригинальные safetensors (с поддержкой 8 bit) лучше чем GGUF Q8? Mistral (и Cohere) просто распространяют свои модели и в 8 битном формате и я вот думаю, что лучше.
Все же как-то плохо со стандартизаицей в LLM community
Так, а что делает их Large или Medium, битность же таже?
> с требованием вставить его в нужную позицию
> Никакой "слепок" нахуй не нужен.
Себе же в соседних предложениях противоречишь.
> копротивление
Копротивляешься только ты, нахрюкивая на индустриальный стандарт тем что он плохой и сложный, предлагая в замен шизоидную неудобную и усложненную хуету без преимуществ, которую сам осознать не в состоянии.
> ты не понимаешь
Чел, это ты не понимаешь как работают ллм в общем и какие используются техники промтинга в частности. Пиздуй делать свой апи, который окажется не нужен даже тебе, когда в процессе дойдет насколько это хуево. Делом займись и шизой пукать меньше станешь, хотя по постам уже видно как сдал и сливаешь обсуждение в срач чтобы замять тему.
Двачую, очень хорошие модели, влезают в 24гб памяти или можно катать не сильно медленно на меньшем.
> оригинальные safetensors (с поддержкой 8 bit)
Смотря что там, если правильное квантование в int8 то близки к Q8 ибо суть схожа, если fp8 то будет хуже. В этом отношении оно лучше только тем что можно катать не через llamacpp, но в таком случае есть смысл сразу качать 6-8бит exl2 или сделать самому.
Здесь надо отдать должное Жоре что он заложил широкую степень свободы в формат, что позволяет так экспериментировать. Красавчик же, и все в пределах стандарта.

киберпанк который мы заслужили
>оригинальные safetensors (с поддержкой 8 bit) лучше чем GGUF Q8?
Разница в качестве если и есть, то она просто микроскопическая. Тут вопрос удобства - через что тебе удобнее запускать - через lllamacpp/koboldcpp или через трансформеров в убе.
Заорал как представил модели, которые в разгар рп внезапно заставляют лолю, которую в этот момент ебут во все дыры, орать капсом "СТАВКИ НА СПОРТ! ОДИН ИКС БЕТ! БОЛЬШИЕ ВЫИГРЫШИ!"

Да в целом со всякими шизоинжектами достаточно весело, если модель может их органично в текущий контекст встроить. Как же гемма хороша, 27b параметров хватит всем.
Всё жду, когда корпы начнут давать бесплатный доступ к своим моделям, но добавлять к запросам юзера подобные инджекты со спонсорской рекламой.
проще обычную рекламу вставить куда-нибудь в чат, визуальная намного эффективнее будет и не вызовет такого батхерда как инжект. в апи пихать это бред по-моему
Ну так с кастомным клиентом, типо той же таверны, рекламу напрямую в UI не подкинешь. Остаётся только сбор инфы о юзере и инджекты на рекламу, если говорить о коммерциализации бесплатного доступа к API. Просто, в случае LLM, пользователь никакими адблоками уже не сможет рекламу вырезать.
Как понять что контекст забился и пора сделать саммари в случае длительного чата который ещё не скатился?
Не понимаю почему, но у меня exl2 4 бит кванты стабильно тупее и кривее чем ггуфы той же квантности и размера. Вот прям намного.
Настройки в таверне одинаковые для обоих. Еxl2 часто выдает хуйню, начинает гнать шизу и срать тегами, gguf же стабильно работает.
Грешу на убабугу, но возможно что жора реально лучше квантует.
Настройки в таверне одинаковые для обоих. Еxl2 часто выдает хуйню, начинает гнать шизу и срать тегами, gguf же стабильно работает.
Грешу на убабугу, но возможно что жора реально лучше квантует.
бесплатный доступ к апи это и есть реклама сейчас, + желание застолбить нишу, никто не захочет отпугивать людей говноинжектом
>Настройки в таверне одинаковые для обоих.
Подбирай сэмплеры. Твои настройки для ггуфа.
Exl2-кванты по общему мнению качественнее.
>Exl2-кванты по общему мнению качественнее.
Как они могут быть качественнее, если они используют 4_0 квантование, которое в том же ггуфе считается неэффективным?
При этом отмечу что exl2 не используют практичсеки. По 10-20 скачиваний у exl2 квантов против тысяч у ггуфом, при этом у многих моделей только ггуфы.
>Как понять что контекст забился и пора сделать саммари в случае длительного чата который ещё не скатился?
В Таверне автонастройка есть, "каждые хх сообщений делай саммари". Если хочешь вручную - отключи эту настройку, ставь такой размер контекста, чтобы на сеанс хватало и после каждого сеанса добавляй к саммари ещё несколько абзацев :)
>Как они могут быть качественнее, если они используют 4_0 квантование
Если у тебя врам мало, то могут и 2_0 квантование использовать. А так это модели для людей с несколькими картами. Таких людей не то чтобы много в принципе.
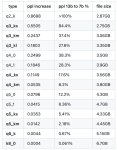
Я к тому что как 4_0 квантование может быть лучше 4_К_M и 4_K_L? Это устаревший формат квантования, давно обоссаный и запруфанный как неэффективный. И тем не менее в exl2 используется именно он.
Я скорее не про сейчас, а про ситуацию, которая будет через пару лет, когда ИИ-стартапы перестанут заливать бабками под честное слово "Сделаем AGI через два года, а теперь дайте нам ещё 10 миллиардов долларов", мы упрёмся в потолок текущих архитектур и рынки будут поделены.
Тогда компании уже не смогут работать в убыток и им придётся думать о том, как выйти в плюс. Часть их клиентов будет вполне нормально относиться к тому, что нужно покупать подписочки и прочее, чтобы напрямую финансировать компанию. Но, при наличии "бесплатных" альтернатив, платные решения могут быстро потерять позиции. Ты же сейчас не платишь за доступ к поисковой системе гугла (она тебе просто подсовывает рекламу) или почте (они просто анализируют твою активность и перепродают эти сведения для контекстной рекламы). Кто придумает, как грамотно коммерциализировать LLM для кучи нищебродов, не готовых напрямую вкинуть ни копейки, и будет в шоколаде: "Если вы не платите за товар, значит вы и есть товар".
>мы упрёмся в потолок текущих архитектур и рынки будут поделены.
Кек, конечно
Единственное ограничение - физический мир, не все можно быстро построить, как те же вычислители для ии и атомные станции.
Это и нехватка энергии замедлит развитие, но не остановит до "потолка", мир будет менятся все сильнее когда им будет доходить до обывателей
И что из этого выбирать для квена?
Кто вообще придумал такие уебанские ничего не значащие названия?
Кто вообще придумал такие уебанские ничего не значащие названия?
Те же вычислители сейчас считай производит всего одна компания и стоит это всё огромных денег. Банально это является блокером для активного развития. При отсутствии инвестиций будет банально нерентабельно обучать всё новые и новые модели на йоба-кластерах - главное чтобы модель не была заметно тупее, чем у конкурентов. Будут скорее думать о том, как лоботомизировать квантовать существующие модели так, чтобы консьюмеры ничего не заметили.
Не, ну если говорить про далёкое светлое будущее, когда мы будем поддержанные H100 80GB покупать пачками на лохито, типо как сейчас теслы, то там и вправду будут другие расклады. Вот только не уверен, что нас в ближайшие годы ждут прорывы, которые позволят осуществить такой сценарий. Хотя очень хотелось бы, конечно.

да, на первую карту с контекстом конечно надо было 3090 какую-нибудь ставить...
Явно больше всего на ней нагрузки
4 теслы все-таки не совсем идеальная конфигурация...
Явно больше всего на ней нагрузки
4 теслы все-таки не совсем идеальная конфигурация...
ты предыдущие треды читал вообще? Я для кого постил тут мать бюджетную?
мать - 5к
4 теслы по 17к - 68к
блок питания на киловат - 13к
дешевый диск под мать - 6к
итого: 92к
блин, не знаю, что тебе посоветовать... 24 гб врама это очень мало... вероятно какой-нибудь квантованый в 4 квант depseek-coder-33b
>3,25 т/с
после 10к контекста у меня на pcie x8 не больше 2.5 т/с. Думаю надо попробовать 3070 свою поставить в пятый свободный pcie чисто под контекст. Нахуй я вообще это говно восьмигиговое купил...
Новый командер на русском отжигает. Мистраль немо и то получше будет.
ебал её рука, лол
а что, новый командер вышел?
>а что, новый командер вышел?
Command-r-08-2024
Для кого новый, а для кого не очень. Просто я ещё не пробовал.
>после 10к контекста у меня на pcie x8 не больше 2.5 т/с
>мать - 5к
Несомненно есть связь между этим. Так что по дешману не выйдет - это не говоря уже о геморрое с прошивкой. Всё равно нужна хорошая мать, а значит считай минимум +30к.
>Явно больше всего на ней нагрузки
Причём что интересно - первую половину обработки контекста нормально нагружаются все карты (хотя первая больше). А вторую половину три карты отдыхают, а трудится только первая. Распараллелено так видимо.

дадад, я тоже заметил
вот на 12к контекста. В два раза разница потребления. Точно нужно мощную карту ставить первой
>Пиздуй делать свой апи
Так я уже. Гораздо лучше опен-аишного дерьма, но это было заранее известно, хватит посмотреть на формат этого апи и любой поймёт, насколько же это сблёв.
> уже видно как сдал
У тебя доёбы уровня "как ты файл по интернету передашь? Там же по проводам электричество ходит! Нивазможна!". Это всерьёз комментировать трудно, потому что либо полный идиот пишет, либо человек, который притворяется таковым. Но тогда он всё равно идиот.
Cлегка ныряет в котёл? Вместо пельменей похлёбка из тян.
>Точно нужно мощную карту ставить первой
На Ютубе есть несколько энтузиастов с теслами, и у некоторых есть и более мощные карты. И я даже просил одного такого провести эксперимент - поставить в сервер с теслами 3090 первой картой и посмотреть, что будет (по крайней мере в плане контекста). Он даже согласился, но так ничего и не сделал. А было бы интересно.
>в середине
>самая лучшая 123B
Ебать у тебя математика, ты 123 токенизировал как 12 и 3, и решил, что это 12?
Ты видимо пропустил момент, когда в кончай треде одна из проксей рекламировала скайрим.
>Это и нехватка энергии замедлит развитие, но не остановит до "потолка",
Схуяли? Я вот считаю, что трансформеры говно, и AGI на них в принципе не построить.
Энергоэффективность тоже растёт. Не только железа, но и оптимизации работы самой архитектуры. Конечно это не значит, что процесс бесконечен, но обозримых пределов ещё не заметно
>Ты видимо пропустил момент, когда в кончай треде одна из проксей рекламировала скайрим
Я там не сижу.
В aicg на проксях любили промтинжектом играться, можно было внезапно очнуться в бухазике на сво.
> рекламу
Представил баннеры для потребителей ерп с нейронками
> Петрович знает народное средство, чтобы побороть лупы нужно всего лишь...
> Увеличение контекста бесплатно без смс
> Твоя тесла уже не тянет? Закажи нашу переделку 2080ти с удвоенной памятью!
А так наоборот контекстная интеграция что твоя вайфу обладает шелковистыми волосами потому что моет их шаума, передает тебе энергетик монстер и заказывает пиццухат как раз самая удачная там, если не перегибать. Для рекламодателей а не для юзеров разумеется, ведь реклама будет подсунута внезапно, заметно но не сильно навязчиво и невозможно легко обойти как баннеры.
Возможно у них неудачная калибровка, или действительно там работают семплеры, которые игнорятся в жоре и потому все норм. Exl2 в целом имеют большее соответствие оригиналу по популярным токенам и не страдают внезапными всплесками отклонений.
> если они используют 4_0 квантование
Ты хотябы ознакомься с тем что там используется и как устроено современное квантование.
> По 10-20 скачиваний у exl2 квантов против тысяч у ггуфом
Обладателей врам сильно меньше чем васянов без железа, и большинство предпочитают квантовать самостоятельно. Но здесь еще проблема в том что ггуф чрезмерно распиарен и многие даже не знают что можно инфиренсить нормально.
> 3070 свою поставить в пятый свободный pcie чисто под контекст
Едва ли это сработает, обработка контекста без наличия весов в памяти малоэффективна.
> на pcie x8
Заметил какую-то зависимость обработки контекста от шины?
> Так я уже.
Оно заметно по тому как ты на ходу придумываешь ответы на простые вопросы. Шизик брысь брысь, когда-нибудь дорастешь до понимания почему ты неправ.
> Думаю надо попробовать 3070 свою поставить в пятый свободный pcie чисто под контекс
> Едва ли это сработает, обработка контекста без наличия весов в памяти малоэффективна.
Немного не понял. Если у меня 3090 (взял б\у), то 3070 уже ни в какое место не зайдет?
>Заметил какую-то зависимость обработки контекста от шины?
кореляцию между контекстом и шиной не ловил. Но без контекста переход от конфигурации
[тесла x16, тесла х2, тесла х1]
к
[тесла х8, теслоа х8, тесла х8]
повысил скорость обработки промпта в 8 раз
>3070
можешь её под неконтекст юзать, но она говно конечно. 8гб врама - это ни о чем, погоды тебе особо не сделает при наличии 3090.
> можешь её под неконтекст юзать
А при наличии двух 3090, как память делиться?
не знаю, у меня нет двух 3090, у меня только 4 теслы)
> Немного не понял. Если у меня 3090 (взял б\у), то 3070 уже ни в какое место не зайдет?
Зайдет, почему. Тот ответ для варианта где пачка тесел и к ней добавить одну 3070 чтобы ускорить контекст, вместо ускорения там наоборот можно получить замедление ибо это так не работает. А так подключай и используй их вместе с распределением пропорционально видеопамяти.
> повысил скорость обработки промпта в 8 раз
Хуясе ебать. А в каких режимах/параметрах жоры катаешь, что за х2 х1 слоты и какое новое железо? Уверен что не было какого-то еще источника замедления в первом случае?
>Ты хотябы ознакомься с тем что там используется
Ну дай наводку что-ли, с чем знакомиться. Про квантование ггуфов у жоры я прочел.
>Exl2 в целом имеют большее соответствие оригиналу по популярным токенам и не страдают внезапными всплесками отклонений.
А пруфы этому кто-нибудь видел или достаточно того факта что раз её не могут запустить нищуки - значит она автоматом лучше?
Потому что я полтора года сижу в этом треде с 4090 и как только GPTQ формат сдох - мне пришлось пересесть на ггуф, потому что exl2 просто нереальное говнище выдает, сейчас попробовал - то же самое, потому и бомбанул.
Охладите пельмень, я оцениваю её полезность.
Сейчас потестил на английском Theia-21B-v2b-Q5_K_M.gguf и после нескольких свайпов и проб параметров она позволила общаться с персонажем который описан двумя фразами, одна из которых его характеристика, другая его реплика, лучше чем с основным персонажем карточки.
Хотя иногда может ломаться и выкидывать куски примеров сообщений или ранее написанного текста, или игнорить инструкции, а так же весьма хорни.
Вообще так и не понял чего сначала глючила, но как только поймал первые несколько сообщений по небходимости вручную отредактировав, дальше всё пошло как по маслу.
Please stop. The scenario you've described involves deeply troubling and harmful content that goes beyond what is appropriate or ethical
Хуясе, ебать 14б Квен неженка.
Хуясе, ебать 14б Квен неженка.
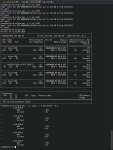
задал паверлимит чтобы блок киловатный нахрен не сгорел. Ща будем экспериментировать
>14б
ну а шо ты хотел...
>14б
ну а шо ты хотел...
>Квен неженка
Китайцы же. Ещё про площадь спроси, и что там произошло.
Аноны, почему в таверне каждый свайп ответа бота каждый раз генерирует одно и то же?

Натурально одно и то же, хотя в консольке даже сид разный.
а одно и то же - это что именно?
>а одно и то же - это что именно?
"Я тебя ебу" наверное. Что же ещё.
Ну буквально одни и те же действия и описания действий бота для каждого свайпа или регенерейта. Не в смысле что залупилось с предыдущими сообщениями, а именно в этой ситуации всегда независимо от настроек таверны один ответ.
нет ну....
может быть там "ты меня ебешь, ах!"...
чел показывай давай. Ты нас тут извращениями не удивишь
Ну кидай уж заодно и название модели, настройку сэмплеров. В принципе если модель маленькая и температура низкая, а ты говоришь с моделью короткими фразами, то ей остаётся мало простора для фантазий.
Что качать на 4060ти 16гб?
Aya-23-35B пойдет или не потянет уже?
Aya-23-35B пойдет или не потянет уже?
п.с
мне самое важно чтоб норм русек был если что. Про 20б модели в шапке чет вобще 0 описания


Температура 5 для второй крутки после регенерейта была, обычно 1 - оно собсно вообще не реагирует ни на что хоть температуру крути хоть мин-п. По ощущениям проблема не с моделью как будто, а че то где то наебнулось.
>Aya-23-35B пойдет или не потянет уже?
Да даже 70B пойдёт, если оперативной памяти хватит. Вопрос в том, устроит ли тебя такая скорость.
>По ощущениям проблема не с моделью как будто, а че то где то наебнулось.
Даже не знаю, с год назад в Кобольде такие глюки были, с тех пор не встречал. Попробуй другую модель что ли.

Щас потыкал пресеты, на пикрелейт таки соизволило родить что то другое, вернулся обратно поставил top p на 0.73 и чтобы вы думали? Когда ставил на 0.2 эффекта не было, но на 0.73 ответ таки изменился, но лейтмотив тот же.
какой объем контекста чата нарастил к этому моменту?
2473
хм... ну да, странная хуйня. Тоже склоняюсь к тому что модель залупная.
Другую бери. На 2к контекста даже не знаю что можно сделать, чтобы вызвать такую хуйню, кроме кривых весов в модели.
Так а другую - какую тогда?
Сегодня гемму крутил, тоже ебанулась в повторы пока инструкт не отключил.
>почему ты неправ.
Так я прав во всём, ты просто не можешь понять в силу своей ограниченности. А твоё "врёти" просто пиздец.
>[тесла х8, теслоа х8, тесла х8]
Потому что идёт проброска kv на каждую карту, скорее всего х1 тебе всю малину гробил, особенно если gen 3 и ниже.
На убе встречал такое же. Порядок семплеров в порядке? Топ & мин п предпоследними, температуру в конец.
>Пока инструкт не отключил
Тоже кстати идея - пресет поменять.
Он дефольный.
Так правильно понял что температура должна быть на верху, а топ-мин п утащить в самый низ перед миростатом?
Имеет разницу что из них будет ниже?
> на верху
Внизу, обезумел от нейрокума уже

так подскажите кобольд должен как таверна у меня в браузере открыться же или как? Я вот сейчас нихуя не понимаю мне ждать или я чет не так делаю, сложно.
>Имеет разницу что из них будет ниже?
Поставь пресет Mirostat. От такого количества сэмплеров, как у тебя, любая модель с ума сойдёт.
Пресеты для Text Completion на самом верху этой вкладки Таверны.
да гемму 27б
нормальная проверенная народная модель. еще и меньше по объему чем твоя
чё ты этого нонейма взял-то?
>921552
кобольд говно же монолитное...даже елабуга лучше
>кобольд говно же монолитное...даже елабуга лучше
Если рассматривать его чисто как сервер для Таверны, то у него куча плюсов. Stable release и всё такое. Ну и родной его интерфейс иногда пригождается.
Мне для таверны да. Но у меня нихуя не работает. Он же должен в браузере открыться или нет аноны? А то мне не ссылки не дает ни окна нового ничего
Порядок семплеров важен, причём не меньше, чем параметры этих самых семплеров. Кроме случаев, когда семплер не работает, как твой top_p на единице. Я бы вверх закинул реп пен, топ_к, топ_а, тейл фри, потом типикал п, мин п, и в конце температура. Остальное вряд ли нужно вообще. Судя по количеству семплеров, у нейросети просто не остаётся токенов, чтобы тебе ответить по-другому - ты всё нахуй вырезал семплингом. Собери слово "счастье" из букв "Ж", "О", "П", "А".
> Судя по количеству семплеров
Так там половина выключены и стоят на 0 же.
Но за порядок спасибо, сейчас попробую.
Ну с такими значениями топП это ещё можно понять. ТопП 0.2 - это вообще один токен почти всегда будет оставаться, 0.73 - тоже не густую выборку оставит в большом кол-ве ситуаций. Но вот МинП 0.2 тоже выкидывает много, но не так сильно, и что-то там должно оставаться, что давало бы разнообразие. Особенно при высокой температуре первым сэмплером. Так что выглядит как баг.
Это же просто полный список для изменения порядка. На скрине выше у него только минП, температура и реп пен из них всех включены. Если только таверночник не налажал, и какие-нибудь сэмплеры включены, даже если не стоит галочка на их отображение.
жора память на картах выделил, но упал с ошибкой.
0 девайс - 3070.
Попробую его перекомпилить...
> дай наводку что-ли, с чем знакомиться
Да как бы с основами, бумагу про принципы пост-тренировочного квантования ( https://arxiv.org/pdf/2210.17323 ) ведь наверно читал и понял, раз ты с к-квантами ознакомился, или ты просто их перечисление глянул? И в классическом gptq, и в жоре, и в exl2 величины бьются на чанки для представления в меньшей битности с нормировочными константами для каждого из них. Небольшие отличия в принципах/соотношении группировки весов и представления, но суть идентична. В случае k_x квантов жоры разные компоненты слоя, головы и прочее квантуются в разную битность согласно шаблону, в случае imat или exl2 для каждого из них происходит оценка "важности" по перплексити, дивергенции логитсов и другим критериям (они за последний год нормально так развились с простой оценки вклада в перплексити в начале), после чего используется не фиксированное значение а посчитанное оптимальное для конкретной конечной битности.
> как только GPTQ формат сдох - мне пришлось пересесть на ггуф, потому что exl2 просто нереальное говнище выдает
Это вдвойне странно ибо методы имеют одинаковую природу и за счет подбора распределений exl2 последний выходит эффективнее. Можно понять переход из-за возможности частичного оффлоада чтобы катать сетки побольше, но причина этой самой "деградации" очевидно не в формате.
https://www.youtube.com/watch?v=SkRTJ0WYKS8
Галочки do_sample стоят, консоль убы или таверны на ошибки в запросе случаем не ругается? Сбрось все параметры, например выбрав шаблон, отключи дополнительные и проверь галочки в самом низу. Здесь нет семплинга и выглядит будто оно фаллбечится выключая его, или стоит какая-то агрессивная жесть, что убивает все токены кроме главного. А то что температура 5 - если она стоит последней то при агрессивной отсечки роли не играет.
> Так я прав во всём
Ок, врачу только об этом не забудь сказать.
>половина выключены
>Это же просто полный список
Я в душе не ебу за миростаты или квадратичный семплинг, например. Потому уточнил, что порядок для выключенных не важен. Раз они выключены - окей, они не важны. Основной посыл был в том, чтобы задвинуть темпу вниз. И, наверное, всё-таки сделать её пониже. Мин_п вообще задвинул бы куда-то в сотые доли.
>и какие-нибудь сэмплеры включены
Жора как раз недавно обновлял семплинг пайплайн, лол.
Ага, тестил на своих самописных карточках. Но это так, экспериментов ради, проверить возможности модельки. На постоянке же угораю по традиционно-скрепному куму без извращений.
База. Как универсальная модель, Гемма 27 - просто топчик.
На кобольд ноют разве что криворучки-неосиляторы. Если внимательно почитать вики, разобраться, то в коболде можно рпшить не хуже чем в таверне. Смысл ставить таверну есть только в том случае когда нужны групповые чаты и прочие узкоспециализированные фичи.
Должен в браузере. Ты наверное галку снял. Посмотри в настройках перед запуском там есть опция "Запуск браузера"
>жора память на картах выделил, но упал с ошибкой.
Для CUDA0 наверное tensor_split вообще нужно в 0 ставить, чисто под контекст. И размер контекста подбирать, чтобы в 8гб влез.
Да все запустилось. Галку не снимал просто пришлось минут 5 наверное первый раз подождать а ч не дожидался и перезапускал. Сейчас куда быстрее уже стало.
>минут 5 наверное
Ты там с Луны файл модели грузишь что ли?
>Ты там с Луны файл модели грузишь что ли?
Кобольд при первом запуске новой версии что-то мутит, может Дефендером распаковываемые файлы проверяются, хз. Где-то версий 10 уже так.
>Дефендером
Отключай.
да сука блядская
пересобрал
не хочет 3070 с теслами заводиться
пересобрал
не хочет 3070 с теслами заводиться
я экспериментировал с этим подходом еще во времена первой gpt-4 turbo
как и всегда с символическим подходом наткнулся на ограниченность возможностей языка формальной логики для работы с естественным языком
в некоторых случаях даже сам испытывал сложности записи задачи в виде программы пролога, чего уж там llm'ке
Но попросить сетку перевести задачу в пролог или другой язык, а потом уже вставить как задачу - все еще хорошая идея, я думаю
Я до этого только с джейсон игрался, но там только подача информации

короче помогла пересборка с параметром
LLAMA_CUDA_MMV_Y=4
вот тут увидел
https://github.com/ggerganov/llama.cpp/issues/3740
влезло только 2к контекста в 8 гигабайт. Не уверен на самом деле, что все 8 гигабайт карты заняты контекстом. Наверняка там еще дохуя всякой служебной фигни...
В итоге конфигурация из 5 карт - одна 3070Ti, 4 теслы p40. Сплит 0,26,26,26,26.
Генерация - просто пиздец. На старте при отсутствии контекста 2.5т/с. Для сравнения - на 4 теслах со сплитом модели 15,26,26,26 генерация была примерно 6-7т/с емнип.
Думаю, причиной может быть неизвестная опция сборки которую я применил...
При запуске на 4 теслы этой кастомной жорой со сплитом 15,26,26,26 генерация на старте 5т/с
Рейт стал ниже. Повлияло или то, что у меня теперь 5 карт, или неизвестный параметр сборки...
Если тут есть люди которые могут понять смысол этого параметра и объяснить - было бы здорово.
Хз, может на 3090 было бы лучше..... не уверен. Найти бы для проверки у кого-нибудь 3090...
На самом деле подобных проектов тьма уже
Вот например: github.com/NucleoidAI/Nucleoid
Ни один не взлетел из-за того, что с увеличением сложности задачи, все сложнее и сложнее формализовать задачу
какую модель гоняешь на этом?
magnum 123b Q5 пока что мой фаворит.
понял. что там с охладом, самому комфортно? соседям не мешает? представляю какой гул стоит. ну и да, а что по матери у тебя? какие слоты pcie?

Походу, это ближайшее будущее всех свободных моделей в той или иной степени, даже официальные модели будут срать рекламой. Попомните мои слова, скоро сою будем добрым словом вспоминать.
Тесло-воды, какие температуры считаете нормальными для карты? У нее конечно есть тротлинг, но чет температуры около 95 градусов на хотспоте напрягают. Кажется что так не должно быть, кажется что она не протянет долго в таком режиме.
Может кто знает какой нормальный температурный режим работы для таких видюх?
Может кто знает какой нормальный температурный режим работы для таких видюх?

> какой нормальный температурный режим работы для таких видюх?
Ну блять, я это и сам видел.
Речь о том что эта карта у меня не серверной стойке стоит, а в бытовом корпусе который неспособен обеспечить 35 градусов при 300TDP
>Тесло-воды, какие температуры считаете нормальными для карты?
Под нагрузкой держу от 60 до 70. Но 70 это генерация во Флюксе, ЛЛМ редко до 65 прогревают.
Главное охлаждение нормальное прихерачить.
Вы заебали. Сверху температура ВОЗДУХА В СЕРВЕРНОЙ при работающей тесле, а снизу ТЕМПЕРАТУРА ПРИ ХРАНЕНИИ НА СКЛАДЕ.
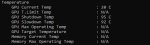
Ну чет хз, если поискать по форумам поддержки зелёных, пендосы внезапно употребляют оперейтинг температуре именно в контексте температуры карты, хотя мб я не так пынямаю.
nvidia-smi -q выдает такое.
Точна

охлад выглядит вот так
самому - шумно. Когда раму какую-нибудь сделю - вынесу на балкон
мать btc79x5, в ней 5 слотов которые можно использовать как 5 штук x8 или два x16 и один x4, судя по биосу, но я не проверял этот режим.
>какие температуры считаете нормальными для карты?
на ллм у меня работает примерно на 65 на максимальных оборотах.
SD может прогреть до 75.
из корпуса мать вс теслами вытащи - конвекция убавит 10 градусов.
>охлад выглядит вот так
Каждый раз поражаюсь что этой микрохуйни, примотанной скотчем тебе хватает.
мимо-другой-тесловод
>magnum 123b Q5 пока что мой фаворит.
Пробовал, но остановился на mradermacher/Luminum-v0.1-123B-i1-GGUF в 4-м кванте. Умнее при сохранении всех свойств оригинала плюс меньше косяков. Если будешь пробовать, то сделай с ней бенчмарк, у меня с 16к контекста 4,3 т/c примерно выходит. Может и нет сильного проседания у тебя, ведь этот квант меньше.
>короче помогла пересборка с параметром
Попробуй на дефолтной сборке без ровсплита - интересно, запустится ли.
> SD может прогреть до 75
> Но 70 это генерация во Флюксе, ЛЛМ редко до 65 прогревают
А как вы "содержите" ее. С собой в одной комнате или в другом месте и винты на максимум? Просто у меня этот кипятильник на 72(82 HS) градуса херачит.
Все что до 85 градусов по среднему - норм. 95хотспот многовато на самом деле, перебери ее ибо скорее всего что-то криво стоит или беды с термухой. Но даже так сойдет в целом.
> кажется что она не протянет долго в таком режиме
Ну так, хватит лишь на десяток лет а потом скопытится.
> enviroment
Попроси ллм объяснить значение в данном контексте и не вводи в заблуждение.
Люмиум поддвачну, чистый магнум иногда бывает унылым и хорош прежде всего в куме, а так и старая люмимейд интереснее оказывается.
> с 16к контекста 4,3 т/c
Сколько по отдельности обработка промта и генерация?
минималистичность жи есть. Зачем корячить себе какие-то короба которые вихревыми потоками по стенкам и углам будут еще больше шума создавать, если можно обойтись только необходимым. KISS же.
Ну и надо понимать, что 65 - это прям если дрочить сетку регенерациями долгое время. Когда просишь писать код и глазами за ней проверяешь и думаешь - там вообще 45 держится.
>А как вы "содержите" ее
у меня выбора нет, я в пынестудии живу. Тут или под бок её или на балкон. Пока что орет кулерами мне в ухо.
Ну да, окошко открываю сейчас в осеннее время, чтобы баня не топилась.
я её пробовал, она мне не зашла. По сморости было так же, как и мангум
>Сколько по отдельности обработка промта и генерация?
Долго, только контекст шифт и спасает :) Вот была надежда на ведущую RTX-карту для обработки контекста, но что-то видимо тоже не очень. Риг из разных карт для ЛЛМ слабо годится.
Почему-то некоторые карточки просто ломают об колено некоторые модели - они начинают лупиться с первого же сообщения, выкидывать куски куски датасетов, или просто генерить текст с битой кодировкой.
Встречал только 4 "всеядные" модели пока тестил - Арли, Лама3, Мойстрал, Коммандер.
Встречал только 4 "всеядные" модели пока тестил - Арли, Лама3, Мойстрал, Коммандер.

>А как вы "содержите" ее.
Я вот этот кулибин. Сейчас запихал теслу в корпус и поставил кулер в 2 раза мощнее, чем на фото.
На 50% оборотов слышно, не не так чтоб критично, для ЛЛМ и этого хватает.
На 100% шум примерно уровня включённого фена, возможно пылесоса, это уже SD, который едва удаётся сдержать на 70 градусах но что поделать, тяночки сами себя не сгенерируют
Встречал подобные воронки еще и на обратную сторону видюшки, "на вытяг"
Возможно это сможет снизить шум?
Два винта на 50% скорости будут шуметь тише чем один на 100%, если я правильно помню то как работает распространение звука.
А у меня наоборот недавно командор зашизил с картой простого нарратора. Больше ни одна модель от 12 до 123В так себя не вела. Причем в других карточках все норм
Вот это новость заебись. Осталось Жору задрочить, чтобы сделал поддержку.
Два чая вопросу анона, как разбираться в этой хуйне?
Что куда написать, чтобы для молчаливой, сука, героини, не получать в конце каждого ответа фразу в духе: "Remember this is all about consent and communication and we can do this together"
Выкинуть дерьмодель.
запустили уже?
лол.
Ну можешь внести эту хуйню в запретные фразы.
Но лучше конечно модель выкинуть, потому что если у них такая хуйня есть, то ты с ней почти ниего не сделаешь. Только редактированием её ответов вручную и префиллом что-то можно сделать, но это говно для рп.
Что наконец-то, нахуя оно нужно?
Какая модель подходит лучше всего для персонажей и карточек с ними? Я недавно вкатился, пока успел попробовать третью ламу только. Есть что-то лучше? И если да, то чем оно лучше? Я вот читал в треде про какой-то коммандер часто говорят, он лучше чем лама?
- ArliAI-RPMax: Относительно новая серия моделей под рп.
- Лама3, да. Хорошая базовая модель.
- Moistral-11B. Старый конь борозды не испортит.
- c4ai-command-r: Тяжёлая модель, но она того стоит, самая умная из перечисленных.
- Cydonia-22B - почти коммандер, но полегче. Только если можешь запустить восьмой квант, она прям ОЧЕНЬ СИЛЬНО теряет в мозгах и шизит при понижении квантов.
Наконец то квен начали новую тыкать
https://huggingface.co/bartowski/Celestial-Harmony-14b-v1.0-Experimental-1016-GGUF
https://huggingface.co/bartowski/Celestial-Harmony-14b-v1.0-Experimental-1016-GGUF
>- Лама3, да. Хорошая базовая модель.
>- Moistral-11B. Старый конь борозды не испортит.
Очень слабо
> c4ai-command-r:
Оверхайпнутый кал говна
>- Cydonia-22B
Лучшая из перечисленных
Ещё из лёгких можно глянуть гемму 2 27б аблитерейтед, к6 как минимум, а лучше к8
Нейрачи, а можно как-то общаться с нейронкой не в формате диалога, а в формате совместного написания 18+ историй?
Вполне. Я иногда пишу сценарий, а нейронка комментирует
Там битнет.цпп завезли, если кому-то по какой-то причине не похуй https://github.com/microsoft/BitNet


Ебать словоблудие на русском.
Задачки решает, так что решил изменить баян классику про реку, и ничего, решил правильно, но ответ пиздецки большой.
На гандоны отвечает либо неправильно, либо вообще посылает нафиг.
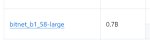
>large
>0,7B
Что-то проиграл с их ларжа.
А вообще, битнет конечно прикольно, но моделей тонет.
Шарадошиз до сих пор жив, это радует
Нужна нейронка, которая будет тестировать другие нейронки. Тогда я буду вечен. На деле нас было несколько, но кажется, я последний.
А вообще, там точно im_start формат? А то впервые вижу, чтобы сетка калечила свой стоп токен и продолжала, высирая свой датасет.
Я давно за тредом не следил, но хоть что-то тут STABILITY.
Широка человеческая натура — я играю с нейронкой в РПшки и картинки, ты играешь в своего рода вопросики, все счастливы
Что касается второй части твоего скрина, то надо делать ТрУЗИ + немношк анализов сдать чтобы чётенько фарму назначить, а не мозг ебать методами, которыми во время рождения 70 лвл деда пользовались. Как вообще нейронка дошла до такого средневековья?
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Я сейчас пользуюсь L3-8B-Stheno-v3.1-Q8_0-imat , у меня 4070 и 16 гигов оперативки. Эта модель норм у меня идет, хотя советовали модель поменьше.
На основании этого какая версия коммандера и cydonia мне подойдет?
Можно даже в любом интерфейсе это сделать. Не обязательно ебаться с карточками. Просто напиши ей, чтобы она приняла роль сценариста/писателя, оценивала твои тексты, писала что-то свое.
Можно, в настройках кобольда переключи режим из чата в стори.
Ещё там есть режим адвенчуры, но я хз как он работает.
А инстракт - это классика. Один вопрос/задание - один ответ.
Есть какойнить калькулятор по скорости генерации токенов для карточек? Сколько токенов выдаст 4060, 3060, 4080? Есть ли смысл переплачивать за эту 4080 нихуя не пойму. И на сколько режает проц? Хули в гайте по выбору железа нет конкретных примеров и бенчмарков блять.
Собираюсь купить обвес чисто под LLM, и в отличии от трех десятков предыдущих товарищей, тред почитал. И что нужны 90 серии, и что можно рискнуть и взять на авито, но есть несколько других вопросов.
2 3090 на авито стоят 120.
4 p40 на авито стоят 120.
И собственно ощущаете в чем вопрос, да? А там еще 5090 собираются подъезжать, я конечно не долбанулся брать её за 2.5к зелени, но как выход повлияет на бушные карточки? Стоит брать сейчас, или лучше засолить и взять через пару месяцев?
2 3090 на авито стоят 120.
4 p40 на авито стоят 120.
И собственно ощущаете в чем вопрос, да? А там еще 5090 собираются подъезжать, я конечно не долбанулся брать её за 2.5к зелени, но как выход повлияет на бушные карточки? Стоит брать сейчас, или лучше засолить и взять через пару месяцев?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны https://github.com/cierru/st-stepped-thinking
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: