



Аноны на каких моделях тренить фотореалистики? Пробовал СД15, но вроде как на реалистик вижн бодрее получается. Может есть какие то скрытые гемы?
https://github.com/ddPn08/Lsmith кто то пытался запустить? Я кое как смог но сконвертить модель не получается. Conv_639: image size is smaller than filter size вот эта ошибка крашит все.
Щас пердолюсь что бы попытатся запустить voltaml
Щас пердолюсь что бы попытатся запустить voltaml
СД ванила даёт крайне непредсказуемый результат на свежих моделях, я бы даже сказал - их просто распидорашивает адово. Реалистик неплохо отрисовывает своих персонажей, но для тренировки лично мне не зашёл, как-то старит, ебала угловатые получаются и морщин много. Сижу-пержу на делиберате в2, показался мне оптимальным вариантом, с него лоры хоть в реалистик, хоть в любой модный аналоговнет или нейрогон заходят, но по неизвестной мне причине не на оборот.
Ребята, а почему коха лора колаб по завершению обучения, вместо моего запроса выдаёт какую-то хуйню? Какие-то пейзажи, часы, хуй пойми что, только не то что я ему указываю, хотя я и указывал в текстовых файлах то как оно должно называться. Я как только не пробовал, а всё равно хуйня. Скажите пожалуйста как правильно делать?
Были какие -то картинки с 2д тянкой, я по её инструкции пытался делать, но сразу же обнаружил, что та версия колаба на которую она указывала уже был видоизменён и обновлён, в итоге мне пришлось интуитивно под конец делать по своему и всё равно нихуя не вышло.
Причём оно если и показывает, то на что я его обучал, то в очень видоизменнёном виде, будто этот промт не являлся приоритетным и выдавалось максимум на 1 из 5 генераций сторонней хуйни в виде пейзажей и т.д
Или мне надо было эту лору сохранить и запихнуть уже в другой колаб и в вебуи интерфейсе надо было выбрать лору и уже оттуда установить на текущую модель? Это так рабоатет??? Типо как ДЛС???
Я как длс пытался, но оно теперь вообще не работает, вообще ничего не генерирует из моего запроса. Может в сайференс надо какой-то сохранять? Просто там в списке конвентируемых моделей нету лоры там только длиффузия, сайферонс скпт и всё.
Ты в sample_prompt.txt запрос указал?
Блять, ну оно в кнопке тренинга указано, я посомтрел по дериктории и там ничего не было, я решил создать файл ткст и указал там промт. Потом я нажал кнопку, смотрю, а там уже вместо моего самп промта другой сампл промт и там вообще другие промты. Это из за него у меня нихуя не работает? Сейчас опять тренинг включился, но я думаю опять говно будет.
Теперь я обнаружил, что указанные там промты находятся на 2-ой строке, тоесть они негативные? И мне надо на 1-ой строчке написать мой промт? Прямо во время обучения? Я прямо сейчас так и сделал, не знаю что выйдет.
Теперь я обнаружил, что укзанный в самплере промт, так же указан во вкладке сейференс, тоесть мне надо сначало было изменить промт в сейференсе и оно бы на этот запрос и тренировало бы модель?
Теперь я онбаружил, что во время тренировке оно сначало тренирует тот промт что я указал на 1-ой строчке, а потом тот что во 2-ой, ну в общем буду эексперементировать
Одна строка - один промпт. Негатив пишется после ключа --neg вроде, там же идут ключи для ширины, высоты, шагов, цфг, сида и прочего.
Если не хочешь, чтобы эта хуйня не переписывала твой промпт, то указываешь отдельный файл и там пишешь.
Бляяять но это никак не решило моей основной проблемы... Колаб вместо моего промта генерирует полную хуйню, хотя я и указывал в ткст промт
Значит, ты что-то не так делаешь.
Ну блджажд, опять тренировку лор по второй ссылке сломали, ну сколько можно.
Кто в гит умеет, научите, как этот патч применить
https://github.com/AUTOMATIC1111/stable-diffusion-webui/pull/9191
git remote add vladmantic https://github.com/vladmandic/automatic
git fetch vladmantic
git checkout vladmantic/torch
Так попробуй например, должно работать вроде

Спасибо, в следующий раз так попробую.
Сделал через gh pr checkout 9191

Градиентная аккумуляция чёт не работает при тренировке Лоры.
Использовал последнюю версию скрипта кохи.
16 изображений, 6 повторов, batch size (BS) 2.
Второй столбец gradient accumulation (GA) = 1.
Третий GA = 8.
Лора с GA = 48 (В этом случае BS * GA = количество изображений в одной эпохе), которую не включал в этот грид, в принципе не меняет генерацию.
Кто-нибудь использует её вообще? Встречались с таким?
Использовал последнюю версию скрипта кохи.
16 изображений, 6 повторов, batch size (BS) 2.
Второй столбец gradient accumulation (GA) = 1.
Третий GA = 8.
Лора с GA = 48 (В этом случае BS * GA = количество изображений в одной эпохе), которую не включал в этот грид, в принципе не меняет генерацию.
Кто-нибудь использует её вообще? Встречались с таким?
анон подскажи пожалуйста, правильно ли я понял, что если буду на поддерживаемом железе тренировать лоры в bf16 то на какой-нибудь gtx 1070 они работать не будут?
Нет, неправильно.




Вот вас реально прёт тратить столько времени на этот безликий дженерик аниме-педо-лоли-арт?
На форчке треды по АИ-арту на 95% состоят из одинаковых "субъектов" японской анимации. Меняется только медиум, тип освещения и цвет волос.
Вместо того, чтобы творить гиперреальность, они делают картинки, которые на этих ваших девиантартах уже 10 лет доступны.
Столько мощностей в трубу сливается. Пиздец просто.
На форчке треды по АИ-арту на 95% состоят из одинаковых "субъектов" японской анимации. Меняется только медиум, тип освещения и цвет волос.
Вместо того, чтобы творить гиперреальность, они делают картинки, которые на этих ваших девиантартах уже 10 лет доступны.
Столько мощностей в трубу сливается. Пиздец просто.
Ничего лучше ещё не придумали?
>аниме-педо-лоли-арт
зачем нужна гиперреальность без перечисленного?
Можешь объяснить что это и как этим правильно пользоваться в параметрах тренировки, ну или хоть направить где почитать? Тоже хочу потестить
Алсо зачем ты тренируешь сиськи?
Анон, а как мне сохранить модели на гугл диск в колабе, чтобы каждый раз не перекачивать? Где есть инструкция?
https://towardsdatascience.com/what-is-gradient-accumulation-in-deep-learning-ec034122cfa
https://huggingface.co/docs/transformers/perf_train_gpu_one#gradient-accumulation
Параметр $gradient_accumulation_steps в скрипте
Использовал при тренировке гиперсетей, там писали задавать значение, при котором GA * BS <= количество пикч, при этом BS лучше всего задавать максимально возможный
А вот по лоре чёт нигде не находил чтоб использовали, вот и спрашиваю
Берешь, монтируешь гуглдиск и сохраняешь. А вообще модель за секунды скачивается, не вижу никаких проблем с перекачиванием.
Нужен человек умеющий с нейросетками работать и шарящий в трендах тем r34 для коллаба. Сам я nsfw аниматор, но я не люблю рисовать фоны и бывают затупы и не знаю за что конкретно взяться, так как обычно беру на заказ. Будем делать типо этого
https://www.newgrounds.com/art/view/prywinko/professor-garlick-animation
но в моём стиле.
@CursorXP17
https://www.newgrounds.com/art/view/prywinko/professor-garlick-animation
но в моём стиле.
@CursorXP17
5$/час или иди нахуй. За бесплатно никто не будет нихуя делать. И судя по описанию ты криворукое хуйло, нахуй ты вообще нужен нам.
и сколько ты зарабатываешь?
я не за бесплатно лол
>но в моём стиле
кидай свои высеры в тред, ща лору обучим
А у СД есть какой-то прогресс? SDXL - какая-то хуйня, 2.1 хуйня, все крутые штуки делают рандомные опен сурсеры. У СД 1.5 есть много фундаментальных проблем, которые решаться только серьезным треннингом на кластере ГПУ, но что-то никто этим не знанимается кажется и есть ощущение что эта модель вскоре очень устареет по сравнению с закрытыми типа Midjourney.
>все крутые штуки делают рандомные опен сурсеры
Пример?
покормил нейропост
Я анимации делаю, лол.
это не пикабу, тут сайт анимации поддерживает
Лоры, чекпоинты, Auto1111, ControlNet, ComfyUI
>Как смонтировать гуглдиск, чтобы сохранить модели?
>Берешь, монтируешь гуглдиск и сохраняешь
Отлично, сразу всё ясно! Как бы без тебя справился! А подробнее есть инструкция? У меня пропадают файлы после приостановки колаба
И люди дрочат на такое? Ноу оффенс, просто на подобные анимации шишка вставала лет 20 назад. Сейчас уже прилично фап контента на блендере выпускают достойного качества.
Зато душа есть. Фильтр графики из ps1 накатить и вообще конфетка будет.
Ты чего такой агрессивный? Это не 3д, а 2д.
Короче, вердикт анонов треда: потренируйся ещё пару лет перед тем как такое людям показывать, и тем более продавать. Не обосрать ради, у тебя картинка выглядит как на MMD модельку накинули хуёвый шейдер, и если к этому фон сгенерировать - вообще ничего не понятно будет.
Ты свои работы покажи, умник. Я уже много лет делаю приватные анимации, щас хотел просто упростить себе жизнь через нейронку, чего ты вылез вообще? Я не стараюсь делать реалистик и 3д, этого говна в инете навалом.
> Зато душа есть.
Ну хз, очевидно что кволити выше чем у толпы интересных личностей, которые без задней мысли тупо картинки морфят. Но вот насчет души, не сказал бы. Otameshidouga pretty pridot dounyuhen, эх, вот где душа была, такого больше не делают
> Фильтр графики из ps1 накатить и вообще конфетка будет.
С разумной пикселизацией мейби и правда лучше будет.
> Ты чего такой агрессивный?
Если бы я был агрессивным то сказал бы что результат хуета и автор безрукий еблан, а так даже "но оффенс написал"
> Это не 3д, а 2д.
Да, и у людей есть выбор.
>Ты свои работы покажи, умник.
Не, я же не дурак что-бы свои высеры на двач скидывать.
Просто сообщил что ты можешь лучше.
>Я не стараюсь делать реалистик и 3д
Тогда почему твоя гифка не выглядит как нормальная 2д анимация? Как тут
Вообще можем прямо тут эксперимент провести. Тебе только статичный фон нужно сгенерировать?
Потому что на самом деле это хуёвая анимация, так как это тупо сделанный меш на готовый арт. То есть персонаж не может например повернуть голову или сделать более сложное движение и тд. Я делаю с нуля и рисунок и тени у меня всё в векторе и я могу хоть покадрово хоть поворот всего тела и прочее. Так же я научился особую систему волос делать, где я могу им настраивать блеск, тени и прочее. То есть это не примитивная анимация.
Можно с персом, но я его всё равно заменю своим. Я просто в студии анимации работал, и параллельно делал комишки, поэтому своей "тямы" не хватает.
Напиши в телеге




вопросы нуба.
реально ли обучить на Вареньке (пики) или нужны фотки именно похожие? и что использовать?
лору через коллаб? или встроенную обучалку в автоматик 1111? или это я хуйню несу?
Нихуя не понятно, ты можешь изъяснять свои желания понятным для людей языком?
Обучить можно хоть по одной фото.

есть пикрил. хочу с ней красивые AI-фото. как это сделать полному нубу в генерации?
в наличии видюха на 6 гигов, 100 фоток пикрила и установелнный автоматик.
Инструкция есть в гугле. Можешь посмотреть как это в других колабах делается.
>Инструкция есть в гугле. Можешь посмотреть как это в других колабах делается.
Где? Я не могу найти. Ты сам-то делал?

Векторами анимирую. Это арт нейросети?
>returned non-zero exit status 1
по видосу сделать ничего не реально. за 4 часа ебли словил 100500 ошибок. пошел он нахуй, этот ебучий пидарас.
застрял на первых 15 минутах видоса.
есть проще варианты, для даунов? в оп посте тем более ничего непонятно. там версии для онлайна. у меня оффлайн.
Ищи у Хача Train Hypernetwork. Ничего устанавливать не надо, работает из автоматика1111, наверное это для тебя оптимальный вариант.
oss is NaN, your model is dead. Cancelling training.
Что это? Гугл не знает.
Что это? Гугл не знает.
Отбой. Виноват андервольт видюхи.
если я хочу натренировать только лицо человека конкретного для лоры, желательно ли в датасет брать что-то кроме крупного плана, или лучше только крупный план лица?
Если у тебя в сете будет только крупный план лица, то и на выходе у тебя будет только лицо. Будет очень сложно заставить сгенерить поясной портерт, например, или вообще фуллбоди.
Но это еще от тэгов для сета зависит, от параметров и длительности тренировки. Если повезет и со всем верно угадаешь - может получиться лора с большей вариативностью.
Но проще всё-таки разнообразить сет.


Да не ставь ты сборки со скриптами у этого уебана гнилого. Это обычный васян-бумер, который научился кодить и теперь стрижет лохов, подкидывая им свои скриптики на бусти. Обычный, блять, наперсточник из 90-х.
Не качай его сборку говна.
Заходи на гитхаб, на страницу КОХУИ
https://github.com/bmaltais/kohya_ss
Выбирай папку, в которую ты хочешь КОХУЮ инсталлить
Зайди в неё через Powershell
запусти там
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss
потом в появившейся папке запусти setup.bat
Ответь на вопросы как на скрине. Большего тебе не надо
Запускай gui.bat
ВСЁ
Если что-то непонятно, смотри видео этого мужичка. Если английского не знаешь, то похуй. Просто смотри, что он делает.
https://www.youtube.com/watch?v=9MT1n97ITaE
Тренируй с Богом. Скалли тебя благословляет. а Хача нахуй
Подскажите, какие есть дополнения к webui которые считывают теги с картинки?
Tagger.
Если там есть метаданные - вкладка PNG Info.
Если их нет - можешь встроенным в автоматик CLIP картинку разобрать, будет тебе описание по типу SD.
Если нужны тэги для аниме-моделей - качай wd-tagger.
двачую зайчик, нанейронят своих аниме хуиме и сидят дрочат
двачую, у меня таким макаром заработало. лоры нюде еот бесподобны, обфапался.
странно, у 4090 терафлопсов в 2 раза больше чем у 4070ti, тензорных ядер и пропускной памяти тоже примерно х2, почему же разница it/s 20 у 4070 ti и 28 у 4090? где 40 it\s?
ну и в чем разница между ним и хачевским
Два чая, 10 туториалов лор по манямэ залупе с одинаковым результатом. Кому все это нахуй надо?
анимэшникам с красными от дрочки писюнами, очевидно.
У 4090 так-то около 32-34 it/s.
Потому что для 4ххх серии надо другие библиотеки ставить, чтоб она полностью раскрывалась.
Но в любом случае линейной зависимости тут не будет.
Скажите, а как тренить в лора что-либо кроме людей? Какой class prompt забивать? Для людей использовал "person", а вот к примеру хочу именно какой-то отдельный атрибут одежды добавить с генерациям, определенная юбка или что-нибудь ещё. Что забивать туды? Style, outfit, skirt, clothes? А то везде пишут person etc.
Насколько реально сделать анимэ модель на базе Dall-e 2 Pytorch?
Или Imagen Pytorch, похрен
Где можно найти готовые controlnet openpose позы?
На цивите фильтрацию по Poses выбери, там было несколько паков.
Просто пиши - 100_skirt, 100_pants. Ваще похую на класс.
так и не понял, почему этого гайда нет в шапке. лучший на сегодня. по нему все получилось у меня.
https://civitai.com/models/22530/guide-make-your-own-loras-easy-and-free
https://civitai.com/models/22530/guide-make-your-own-loras-easy-and-free








Кто-нибудь проводил нормальное исследование на тему того, какую модель лучше использовать в качестве базовой при обучении лорок на аниме?
Из рекомендаций слышал только либо использовать NAI, либо модель, под которую планируешь генерировать, но каких-либо пруфов в виде гридов на эту тему не видел.
Попробовал обучить лоры под 5 разных моделей - NAI, AOM2_safe, капуста3, мейна и пастель. Далее построил гриды по тому, как эти 5 лор работают с этими же пятью моделями. Результат, на мой взгляд, выглядит неоднозначным:
1. Обученная под NAI лора действительно в среднем выглядит лучше всех в качестве универсальной модели
2. Обученные на мейне и пастеле лоры выглядят в среднем хуже всех
3. Обученная на пастеле модель выглядит плохо даже на самой пастеле, убивая всю стилистику базовой модели
4. На мейне любые лоры впринципе выглядят лучше среднего, хотя это, вероятно, вкусовщина
На самом деле сложно сделать какие-либо выводы по такой небольшой выборке, и, что наиболее тревожно, я не думаю, что этот опыт можно будет обобщить на любой датасет, даже если речь заходит хотя-бы просто про лоры на аниме-тяночек. Не говоря уже о том, что тестировать нужно куда-большее число моделей.
При этом, я помню, что, в случае того же пастеля, лучше всего показывали себя одновременные применения двух-трёх лор, обученных на разных моделях - добавьте сюда возможность мёрджить лорки и в плане возможностей тестирования различных сочетаний вы уже упираетесь в комбинаторный взрыв.
Я для себя делаю вывод, что лору, в идеале, надо пытаться обучать под каждую интересную вам модель (кроме стилизованных, типа пастеля - ну, это и так в гайде из шапки было описано) и потом сравнивать её с другими - мне, например, понравилось сочетание лоры, обученной на AOM2 при её использовании на мейне, но такое никак заранее нельзя просчитать. А для ленивых обучать просто на NAI.
Из рекомендаций слышал только либо использовать NAI, либо модель, под которую планируешь генерировать, но каких-либо пруфов в виде гридов на эту тему не видел.
Попробовал обучить лоры под 5 разных моделей - NAI, AOM2_safe, капуста3, мейна и пастель. Далее построил гриды по тому, как эти 5 лор работают с этими же пятью моделями. Результат, на мой взгляд, выглядит неоднозначным:
1. Обученная под NAI лора действительно в среднем выглядит лучше всех в качестве универсальной модели
2. Обученные на мейне и пастеле лоры выглядят в среднем хуже всех
3. Обученная на пастеле модель выглядит плохо даже на самой пастеле, убивая всю стилистику базовой модели
4. На мейне любые лоры впринципе выглядят лучше среднего, хотя это, вероятно, вкусовщина
На самом деле сложно сделать какие-либо выводы по такой небольшой выборке, и, что наиболее тревожно, я не думаю, что этот опыт можно будет обобщить на любой датасет, даже если речь заходит хотя-бы просто про лоры на аниме-тяночек. Не говоря уже о том, что тестировать нужно куда-большее число моделей.
При этом, я помню, что, в случае того же пастеля, лучше всего показывали себя одновременные применения двух-трёх лор, обученных на разных моделях - добавьте сюда возможность мёрджить лорки и в плане возможностей тестирования различных сочетаний вы уже упираетесь в комбинаторный взрыв.
Я для себя делаю вывод, что лору, в идеале, надо пытаться обучать под каждую интересную вам модель (кроме стилизованных, типа пастеля - ну, это и так в гайде из шапки было описано) и потом сравнивать её с другими - мне, например, понравилось сочетание лоры, обученной на AOM2 при её использовании на мейне, но такое никак заранее нельзя просчитать. А для ленивых обучать просто на NAI.
Так как для SD1 аниме модели в подавляющим большинстве случаев идут от наи, а реалистик / иллюстрационные от SD 1.5, то для максимизации совместимости лучше тренить именно на них.
Более того тренировка на базовой + юз на миксе выдают в среднем лучшире результаты чем в любом другом соотношении.
Ну, в целом у тебя то же самое и получилось.
Заебали обновлениями ломать мой воркфлоу
У вас composable lora работает после обновления автоматика?
еще в консоль срет ошибками просто при применении, хотя всё работает
Traceback (most recent call last):
File "E:\stable-diffusion-portable-main\modules\extra_networks.py", line 75, in activate
extra_network.activate(p, extra_network_args)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\extra_networks_lora.py", line 23, in activate
lora.load_loras(names, multipliers)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\lora.py", line 214, in load_loras
lora = load_lora(name, lora_on_disk.filename)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\lora.py", line 185, in load_lora
assert False, f'Bad Lora layer name: {key_diffusers} - must end in lora_up.weight, lora_down.weight or alpha'
AssertionError: Bad Lora layer name: lora_te_text_model_encoder_layers_0_mlp_fc1.hada_w1_a - must end in lora_up.weight, lora_down.weight or alpha
Не встречался с такой залупой, анон?
У вас composable lora работает после обновления автоматика?
еще в консоль срет ошибками просто при применении, хотя всё работает
Traceback (most recent call last):
File "E:\stable-diffusion-portable-main\modules\extra_networks.py", line 75, in activate
extra_network.activate(p, extra_network_args)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\extra_networks_lora.py", line 23, in activate
lora.load_loras(names, multipliers)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\lora.py", line 214, in load_loras
lora = load_lora(name, lora_on_disk.filename)
File "E:\stable-diffusion-portable-main\extensions-builtin\Lora\lora.py", line 185, in load_lora
assert False, f'Bad Lora layer name: {key_diffusers} - must end in lora_up.weight, lora_down.weight or alpha'
AssertionError: Bad Lora layer name: lora_te_text_model_encoder_layers_0_mlp_fc1.hada_w1_a - must end in lora_up.weight, lora_down.weight or alpha
Не встречался с такой залупой, анон?




В общем да - если тренить лору на NAI, то перестаёт фоны/перса плющить на половине моделей. Ну и стилистика моделей в среднем не так сильно убивается.
Для сравнения - по центру лора, которую обучал на AOM2. Сейчас она выглядит переобученной, но, из-за того, что я тестировал её буквально на паре интересных лично мне моделях, я этого раньше не заметил, т.к. на той же мейне она, в среднем, неплохо отрабатывала.
Для сравнения - по центру лора, которую обучал на AOM2. Сейчас она выглядит переобученной, но, из-за того, что я тестировал её буквально на паре интересных лично мне моделях, я этого раньше не заметил, т.к. на той же мейне она, в среднем, неплохо отрабатывала.
> обновления автоматика
Ебланидзе, спок.

Прописал в webui-user "git pull", чтобы обновить Automatic, и теперь при запуске файла пикрил, интерфейс не запускается - нет ссылки, которую можно открыть в браузере. Что делать?
У тебя на пике буквально написано что делать. --reinstall-xformers --reinstall-torch в батник добавь, после установки удалишь. Ну или venv снеси
Кто-нибудь в курсе, можно конвертировать лоры из формата в формат? Lycoris -- Loha -- Lora, и т.д., пусть и с потерей информации?
Ну или смерджить ликорисы с обычными лорами.
МегаМерджер не дает такое делать, к сожалению.
P.s. и как-то их можно вообще отличать, быстро и понятно? Что-то не нашел никакой инфы о формате в метаданных. Хз, может не туда смотрю?
Ну или смерджить ликорисы с обычными лорами.
МегаМерджер не дает такое делать, к сожалению.
P.s. и как-то их можно вообще отличать, быстро и понятно? Что-то не нашел никакой инфы о формате в метаданных. Хз, может не туда смотрю?
> и как-то их можно вообще отличать, быстро и понятно
По network/conv dim/alpha.
извне - никак, только помечать в имени файла, например
Есть какой-нибудь стандартный промпт для теста модели или лоры, с негативом, для теста персонажа и теста бэкграунда? 1girl слишком упрощенно получается, а если с тэгами переборщить, то модель улетает в сторону от того, в каком стиле она должна работать.
Заранее благодарю.
Заранее благодарю.
Как использовать concept images, туда сувать лучшие пикчи? Как это вообще работает?
Ну я тесчу через одежду, допустим выоский каблук
pos: [age] woman/girl/child/loli, standing, stiletto high heels, [type] background, sfw/nsfw
neg: (worst quality,low quality:1.4) или любой эмбед по вкусу
либо если чисто нсфв, то lifted skirt
или
girl with a pig с вариациями - если сохраняется лицо модели и свиньи то все ок
Анон, ну что там, получилось чёт? Поделись результатом если что, или датабазой через облако поделись, мож тоже попробую натренить.
Ты же по любому будешь НСФВ делать!
Спасибо большое.



получилось. я доволен. хотя и не всегда похоже. и только один ее лик. для каждого образа надо отдельную Лору, я так понял.
>датабазой через облако поделись, мож тоже попробую натренить.
Ты картинки не можешь скачать?

перестало работать, раньше запускалось нормально. Чего она хочет от меня?

о, это моя ошибка. проблема с памятью - по словам гугла. у меня исправилось, когда выставил другую модель. попробуй запустить без всех моделей. из папок убери.
если не поможет - я хз
Есть ли гайд для кохи, какие настройки выставлять чтобы максимально похожее лицо на оригинал получалось?
Нету

При константе на плане обучения просит 0 или пустоту в warm_up num steps. Такая вот ошибка. Попробуй там ноль поставить.
Промахнулся тредом как обычно
умоляю на коленях
умоляю на коленях
Расширение есть которое сохраняет промт и настройки которые сам выберешь, посмотри сам в расширениях, у меня сейчас webui не запущен

Посоветуйте как правильно выбирать оптимальную модель.
Вот мне кажется что для LoRa net rank 64 и alpha 32 годится вторая эпоха (1780 шагов оптимизации). Все что выше мне кажется перетренированной.
Но может быть есть и другие критерии, например не проверять вес модели выше 1.0?
Цель - расписать аниме под хохлому.
Вот мне кажется что для LoRa net rank 64 и alpha 32 годится вторая эпоха (1780 шагов оптимизации). Все что выше мне кажется перетренированной.
Но может быть есть и другие критерии, например не проверять вес модели выше 1.0?
Цель - расписать аниме под хохлому.
Запускаю поломатик на Kaggle. Квоту пока не режут, но до 10 часов (как анон из соседнего треда) ни разу не доводил. Но я понемножку, мне оно, собственно, только для URPM-inpainting...
Проблема в том, что кегля - это пихон 3.7. А современный обломатик требует, ЕМНИП, 3.8. Я где-то нашёл какой-то коммит хэш не помню, а сейчас с ягеля и к нему sed-скрипт для рихтовки зависимостей. И это даже завелось и работает. Иногда.
Основная проблема в том, что иногда (часто - если генерация заняла много времени) кнопка Generate перестаёт работать, в консоли браузера джаваскриптовая ошибка, в консоли пихона тишина. Помогает обновить вкладку - но настройки при этом слетают, что особенно бесит при инпеинтинге. Возможно, виновата кривая версия gradio (я руками не ставил, какая встала сама - такая и есть), но это не точно.
Есть ли мысли, как мне облегчить мою жизнь?
Проблема в том, что кегля - это пихон 3.7. А современный обломатик требует, ЕМНИП, 3.8. Я где-то нашёл какой-то коммит хэш не помню, а сейчас с ягеля и к нему sed-скрипт для рихтовки зависимостей. И это даже завелось и работает. Иногда.
Основная проблема в том, что иногда (часто - если генерация заняла много времени) кнопка Generate перестаёт работать, в консоли браузера джаваскриптовая ошибка, в консоли пихона тишина. Помогает обновить вкладку - но настройки при этом слетают, что особенно бесит при инпеинтинге. Возможно, виновата кривая версия gradio (я руками не ставил, какая встала сама - такая и есть), но это не точно.
Есть ли мысли, как мне облегчить мою жизнь?
pyenv. в чем проблема дать автоматику другую версию питона?
Конечно, сидеть на старом ватоматике - это не очень хорошая идея хуже только ежедневно его обновлять, поэтому я нашёл хак, позволяющий взгромоздить на кеглю пихон 3.9 а теоретически - вообще любой через apt там же виртуальное окружение с убунтой. Но при применении этого костыля автовсратик запускается 20 минут и больше конца запуска так ни разу и не дождался и занимает десятки доходило до 80 гигабайт на диске.
Это современный ладноматик действительно так себя ведёт? Или это кегля глючит?
Если ему реально столько надо - то есть ли у анона идеи, что можно сделать? У меня идей только две:
а) sudo ln -s /usr/lib/python3.7/dist-packages /usr/lib/python3.9/dist-packages
и надеяться на Environment pinning
б) Само жирное вынести в публичные kaggle-датасеты и
sudo ln -s /kaggle/input/torch /usr/lib/python3.9/dist-packages/torch
Я так с моделями делаю. Во-первых, это позволяет экономить квоту (а там 20 ГБ на основной output и ещё 80 на всякое вспомогалово - не считая неизменного input). Во-вторых, чем меньше объём output - тем быстрее и беспроблемнее проходит Files and variables preservation, т.е. перенос файлов между сессиями - а это штука приятная.
Не копируйте команды, набираю по памяти с ягеля, ожидая замены масла и фильтров
Алсо, можно ли отключить установку gfpgan? Он мне не нужен, не очки же я с тянок снимаю а идея интересная
Добра тебе!
питонист из меня очень не очень, хотя написанием опенсорсного кода на потихоне я даже деньги зарабатывал
Он, получается, и все библиотеки прямо в папочку с автоматиком поставит? Я ведь правильно понимаю, что файлы библиотек после установки, вообще говоря, не изменяются?
Сорян, невнимательно читал, за Kaggle не скажу, но локально ставил.
У автоматика есть небольшая бага с определением venv, хоть он и создает его.
проще создать его вручную, в папке с автоматиком
python3 -m venv ./venv
Затем отредактировать ./webui-user.sh, поменять переменную python_cmd="полный путь к автоматику/venv/bin/python3"
инструкцию к pyenv уж как нибудь сами найдете.

Нейкропост, игнорируем.
Вообщем почитав я думал что с бс10, га1 на выходе получится сетка генерирующая почти тоже что и бс1, га10. Попробовал потренить с залоченным сидом и результаты получились разные.
SGD оптимайзер из статьи у меня не взлетел, никаких ошибок нету в консолях при тренинге и использовании, но генерация точно такая же как и без лоры, поэтому лишь дефолтный адамв.
По времени не сильно быстрее:
бс1 га10 - 240 шагов 10:18
бс1 га1 - 2400 шагов 10:52
бс10 га1 - 252 шага 2:30 - может поэтому и не повторяется результат? Я хз почему лишний шаг с бс10 делается.
Ну да хрен с ним с повторением, а разницу то как вообще ощутить. Нужен сильно различающийся датасет чтоли? Лору же вроде под конкретные вещи тренируют, а если несколько "вещей" надо засунуть в одну, то разбивают по папкам со своими тегами.
Алсо зачем обновлять веса лишь раз за проход по датасету для того же гипера, это разве не слишком редко?



SDXL лучше понимает что ты от нее просишь, токены чуть меньше "просачиваются не туда", в этом плане она намного лучше SD 2.1, примерно на уровне dalle (встроенном в бинг), может чуть хуже. Качесто генерации часто не очень, напоминает детские проблемы SD 1.5, но вроде лучше чем чистый 1.5
>все крутые штуки делают рандомные опен сурсеры.
Чё еще пизданешь? Они все на базе 1.5
https://github.com/hpcaitech/ColossalAI
Почему в кохью эту хуйню еще не засунули? Тогда можно было бы тренить лоры по 5 минут
Почему в кохью эту хуйню еще не засунули? Тогда можно было бы тренить лоры по 5 минут
Не у всех под рукой а10.

поясните ньюфагу, что я делаю не так, я и так уже не пытаюсь ничег осам тренить, вот сейчас скачал какую-то чужую сделанную анимешную лору, открыл в коллабе автоматик, загрузил ее, а на выходе опять получается какой-то дефолтный низкокачественный кал. Что делать то я не понимаю, как вы высираете столько артов? Я каждые два месяца открываю коллабы, че то тыкаюсь в них, мне генерирует полный кал по типу пикрил, закрываю, не захожу 2 месяца.
Так ведь там насколько я понял буст при любом юзе?
ЛОРА часто требует киворды (теги) и понижение веса.
Во первых - убери её в зад строки, во вторых хотя бы евелин напиши ну или какие там теги, как анон выше сказал. Затем начинай уменьшать единицу до 0.6 и смотри результат. Обычно любая лора подтягивает с собой какой-нибудь говностиль, в зависимости от того на чем её тренировали.
Промтп у тебя, конечно, зашибенский.
С цивита выбери картинку получше под свою лору и копируй оттуда промпты. Позитивные и негативные.
Не забудь только оттуда лишнее убрать, типа встроенных эмбедов (ну или сам их скачай по названию), и других лор.
Это не про то что ты думаешь. Это про параллельную генерацию больших батчей. Там в их таблицах минимум 16. По скорости одного всё тоже самое.
Я о том что stability ai ничего кроме 1.5 годного не выдало, при том что у них есть инвесторы, а webui, controlnet, лоры и модели делаются за бесплатно рандомными анонами.
> controlnet, лоры и модели делаются за бесплатно рандомными анонами
Все эти технологии сделаны китайцами, сидящими на космических грантах, туда вваливаются миллиарды на развитие ИИ. Даже каломатик - это какой-то китаец из Калифорнии. Аноны сделали только десяток экстеншонов и натренировали лоры на волосатые анусы. И на самом деле наработок сейчас очень много новых, но сидящие на грантах ссутся выкладывать модели в паблик после недавних бурлений говн, в лучшем случае выкладывают код обучения, которые требует гигантский датасет и сотни часов A100. Всё это уходит в крупные корпорации, а не в паблик, сейчас уже даже Адоб готовится выпускать инструменты для дизайнеров/художников. Вангую какие-то прорывы в опенсорсе будут оказываться не чаще чем раз в год, в моменты затишья у сои.
Адоб пока сделал только фиговую версию Стэйбл Диффужн, тренированную на бесплатных картинках, чтоб проблем с копирайтами не было.
И показал будущее развитие, которое копирует где-то треть от всех функций из каломатика, только с более удобным интерфейсом.
И без юзерских надстроек по типу лор и контролнетов.
И платно (самый главный момент, ага).
> рандомными анонами
Ну да, ведь у каждого рандома есть желание и тысячи баксов на трени моделей.
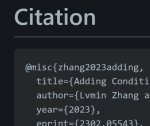
>Because the Canny model is one of the most important (perhaps the most frequently used) ControlNet, we used a fund to train it on a machine with 8 Nvidia A100 80G with batchsize 8×32=256 for 3 days, spending 72×30=2160 USD (8 A100 80G with 30 USD/hour). The model is resumed from Canny 1.0.
>Ну да, ведь у каждого рандома есть желание и тысячи баксов на трени моделей.
Полно студентоты с доступами к университетским и доцентоты с доступом к НИИшным моностям. реально смешно ваши визги читать и теории заговоров. В позднем совке ФИДО каким-то волшебным образом было бесплатным, но жило целиком на междугородних звонках, которые вообще-то дохуя стоили тогда. Как же так?! Наверное все крупные ноды были фбровцами проникшими в СССР.
Достаточно посмотреть вниз репы на гитхабе - если есть ссылка для цитирования, то это работа на грантах. Там же и в 90% случаев будет автор из Китая.
Но пруфов не будет, вы идите и увидьте что я ск0зал. И жэто точно из КНР чинчонги, а не из кореи или японии или сша, они все с партбилетом, чес-слово! Ето нейрозаговор Кси!
Ты реально даун, да?
> Полно
Где, покажи? Это надо собрать комбо из "быть нейрошизом" и "иметь доступ". И почему-то в большинстве случаев это комбо у китайцев. И к этому китайскому комбо еще добавляется пункт "знать английский и выбираться за пределы своего интернета".

Ну тогда жду пока AITemplate засунут в автоматик. Скомпилировав две модели можно достичь ахуенного буста по скорости. У чела который пилит у меня достигается x2 прирост по скорости генерации, что вообще супер.

Антоны, кто-то сталкивался с зис хуетой? При первом запуске вебуи доходит до сборки торч и просто зависает намертво пека. Пробовал торч отдельно через пип инстолл ставить, ничего не поменялось.
P.s: скрин не мой, а с гита, у меня питон 3.10.6. На гите соответственно тоже 0 ответов к теме
P.s: скрин не мой, а с гита, у меня питон 3.10.6. На гите соответственно тоже 0 ответов к теме
сама ссылка с торчем открывается в браузере?
https://download.pytorch.org/whl/cu117
У меня вот открывается, все ставится
Как в имг2имг настраивать силу первичной картинки? Как в дримстудио.
Ты только количество добавленного шума через ползунок денойза можешь добавить.
Больше - будет сильнее отличаться.
Меньше - будет отличаться меньше.
Заметные изменения начинаются с 0.5, на 0.7 сильные вариации, на 0.9 другая картинка.


обучение лоры при таких настройках примерно 5 минут идёт вместо 20, batch size 4 очень сильно сокращает время обучения. может кому поможет, у кого 12 гб врам.
да и картинки обрезать и текстовые описания делать не нужно, достаточно поставить галочку enable bucketing. всё это справедливо для персон, насчёт стилей хз
Есть ли способ вытащить из модели список слов, на которые он реагирует? А то на цивите, если модели тренировались на определенных художниках, авторы не удосуживаются выложить список этих художников. Просто брутфорсом перебирать варианты возможных художников это мучительно долго.
Подскажите, пожалуйста, начинающему нубу. Пробую раздеть тян в чёрной или серой одежде, но получается только переодеть. Почему не убирает одежду? Что делаю не так? Может где в настройках что выставить надо?
Метод Fill выбирай.
В метадате могут быть упоминания в тегах. Могут и не быть.
А метадату где смотреть?
А, ты про модели. Тогда никак.

У меня такого почему-то нет... что выбирать?
Чел, masked content.

Опять не вижу где это(
Подскажите ещё нибудь как обрабатывать неквадратные фотки чтобы картинка не искажалась?
Чел, смотри внимательней.
Разрешение то же выставляй. Либо инпейнти только маску.
Выставить разрешение с таким же соотношением сторон как у исходного изображения
Кнопка есть же, которая подгружает последние настройки перед перезапуском.
Что за кнопка?
Тебе что сохранять надо? промт? короче это может помочь
https://github.com/ilian6806/stable-diffusion-webui-state

Она у меня почему то вешает весь интерфейс. В итоге проще перейти в последнюю картинку и отправить её обратно в промпт
> после обновления автоматика?
А как ты её обновляешь? И зачем?

У меня автоматик1111 установлен на диск Д. Что за папка образовалась C:\Users\Anon\.cache\huggingface\hub в которой 23 гигов сейвтензоров? Как перенести этот кеш на диск Д? Есть где-то такое настройки в автоматике? В скриптах где-то может путь надо прописать? У всех так что ли
>Как перенести этот кеш на диск Д?
Можешь перенести эту папку на диск D и создать символьную ссылку на диске C
mklink /D C:\Users\Anon\.cache\huggingface\hub D:\hub
Так же из этой папки можешь поудалять всё кроме:
models--bert-base-uncased
models--openai--clip-vit-large-patch14
models--laion--CLIP-ViT-H-14-laion2B-s32B-b79K
> Как перенести этот кеш на диск Д?
https://kirsanov.net/post/2016/07/05/Getting-most-from-your-SSD-drive-by-redirecting-directories.aspx
То есть как выше и посоветовали, только с ГУИ.

Что-то у меня автоматик гит-пуллом не обновляется.
Пишет что последняя версия. Ветка вроде "мастер" прописана.
Можно его как-то пнуть на принудительную обнову?
Пишет что последняя версия. Ветка вроде "мастер" прописана.
Можно его как-то пнуть на принудительную обнову?
О, спрошу. Что там нового ожидаешь? И можно ли гитом ролбэк делать, если новое+=косячное?
Аутпейнт скрипт не пашет на разрешениях, не кратных восьми.
Вроде был фикс для этого с неделю назад, я гитпульнул, а оно не обновилось. Пришлось картинку в результате масштабировать под него специально.
Откатиться то всегда можно.
>git reset --hard <commit hash>
Хэш коммита на гите смотреть.
>Хэш коммита на гите смотреть
Спасибо, а как посмотреть сейчас какой комит у меня стоит?
Есть ли какой-то скрипт или настройка чтобы именно на картинке(а не в exif) впечатывалось какая-то информация по моему выбору? Например сид или что-то еще. Нашел вот такое расширение, но оно только на таблицу работает. И то хз как работает. Мне надо на каждое фото печатать инфу, чтобы видно было.
https://github.com/AlUlkesh/sd_grid_add_image_number
https://github.com/AlUlkesh/sd_grid_add_image_number
В сааааамом низу открытого интерфейс будет мелкая такая строчка с текущим коммитом.
Спасибо, она даже кликабельна. У меня commit: 22bcc7be
И у меня такой же.
Сейчас зашел на гит - а там он последние 3 недели не обновлялся оказывается, лол.
Потому гит пулл и не пашет, что версия последняя.
Но 3 недели прям много что-то, вот я и запаниковал.
Раз ввел - обновлений нет.
Второй ввел, третий, еще раз через пару дней - нифига.
Думал, сломалось чего, а оно вот как.
Суп, тред.
Решил потеребить SD, читаю мануалы по локальной установке на винду.
Большинство мануалов ссылается на automatic1111. Это самый удобный способ?
Я так понимаю, оно запускает у меня сервер, к которому я подключаюсь из браузера. Этот сервер у меня в памяти висеть будет, пока я его вручную не прибью? Или там есть кнопка выхода?
Решил потеребить SD, читаю мануалы по локальной установке на винду.
Большинство мануалов ссылается на automatic1111. Это самый удобный способ?
Я так понимаю, оно запускает у меня сервер, к которому я подключаюсь из браузера. Этот сервер у меня в памяти висеть будет, пока я его вручную не прибью? Или там есть кнопка выхода?
> Я так понимаю, оно запускает у меня сервер, к которому я подключаюсь из браузера. Этот сервер у меня в памяти висеть будет, пока я его вручную не прибью? Или там есть кнопка выхода?
Будет висеть пока не закроешь окошко с консолькой или не нажмешь ctrl+c в нём.
Как всегда, гугл ненавидит бедняков, жителей стран третьего мира, вообще всех кто без внушительного дохода. Корпорации - это зло, особенно американские.
Что случилось?
Пару недель был вне темы сеток
Администрация колаба поссала в хари пользователям автоматика без про-подписки.
Менеджер колаба сказал, что из-за них не хватает видях на интерактивные сессии, поэтому стали для начала отображать предупреждение, а дальше хз как будет.
На kaggle недавно было так же. В итоге пидорнули ноутбук от camenduru. Но там еще вдобавок набегали китайцы, небольшими группами по 10к рыл в час.
> бедняков
Конченные мрази, которые приняли халяву как что-то само собой разумеющеюся, а когда лавочку прикрыли, начали исходить на говно, вместо того, чтобы выразить благодарность за предоставленные, хоть и на время, возможности. Ну или хотя бы промолчать.
>пук
))

Пост менеджера на реддите, пидорас огрызается в ответ на критику: сколько gpu-времени лично ты раздал бесплатно миллионам человек?
Реддит - это соевая параша, там всегда будут топить за барина до последнего, даже когда им будут золотой дождь на лицо пускать.
>последние 3 недели не обновлялся оказывается
А может забросили?
Вот посмотри, тут форк какой-то образовался.
Опять качать все по новой?
Кто пробовал?
https://github.com/vladmandic/automatic
Intel_ARC_GPU_WSL_Stable_Diffusion_WEBUI
Intel ARC GPU A750 A770 WSL Stable Diffusion WEBUI - 7.20 it/sec
https://github.com/TotalDay/Intel_ARC_GPU_WSL_Stable_Diffusion_WEBUI
Intel ARC GPU A750 A770 WSL Stable Diffusion WEBUI - 7.20 it/sec
https://github.com/TotalDay/Intel_ARC_GPU_WSL_Stable_Diffusion_WEBUI
Intel ARC XPU
полный аппаратный доступ в Блокноте и не только
https://github.com/TotalDay/Intel-ARC-750-770-XPU
полный аппаратный доступ в Блокноте и не только
https://github.com/TotalDay/Intel-ARC-750-770-XPU
Intel ARC Gimp
https://www.youtube.com/watch?v=q8xJjPBjqso
Stable Diffusion Powered by Intel® Arc™, Using GIMP
https://game.intel.com/story/intel-arc-graphics-stable-diffusion/
https://www.youtube.com/watch?v=q8xJjPBjqso
Stable Diffusion Powered by Intel® Arc™, Using GIMP
https://game.intel.com/story/intel-arc-graphics-stable-diffusion/

> форк
Больше похоже на сборку от хача. Там из нового только вырвиглазная тема. Ничего нового не вижу, кроме как поломанная совместимость с кучей экстеншонов. Автоматик уже давно перестал добавлять новый функционал для того чтобы была стабильная версия, которую допиливали бы экстеншонами, а в том "форке" теперь будет как в раннем автоматике - каждую неделю что-то отъёбывает.
Еще б у него более понятный интерфейс на странице с экстеншнами был. А то иногда хрен поймешь, чего там какое расширение делает, и зачем оно вообще нужно.
Есть ли смысл учить лору плохому? что если я получил желаем результат, и хочу исправить всякую хуйню с родной модели? Типа буду генерировать, и где плохие руки, или проёбаная анатомия скармливать лоре на дообучении?
> Есть ли смысл учить лору плохому?
Нет. Негатив бывает только текстовый. Лоры будут только веса вычитать, что даст хуёвый результат. Для полноценного негатива с лорами надо вторую модель держать в памяти для этого негатива.
Это точно? Проверялось?
>когда макдак и икею прикрыли, россияне начали исходить на говно, вместо того, чтобы выразить благодарность за предоставленные, хоть и на время, возможности.
Развил мысль фашиста
> Развил мысль фашиста
Если бы ты, даун, еще был на это способен. Мак и икея сами сюда пришли зарабатывать деньги, колаб - просто давал (и дает) пользоваться мощностями как есть, ничего не требуя взамен. В любом случае твой пример дебильный и даже в нем исходить на говно = быть дебилом.




Подскажите, unet, text encoder, vae — понимаю, а что находится в others?
Без others модель меньше на 0.5Гб, генерация, воде бы, не меняется.
Без others модель меньше на 0.5Гб, генерация, воде бы, не меняется.
Правая картинка на 1кб больше.
Ну такие вот deterministic results с Sdp-No-Mem-Attention. А что находится в others?
Safety checker — специальная отдельная GAN-сеть, которая проверяет nsfw твоя картинка или нет. Без шуток.
По идее ещё должен быть tokenizer, но в transormers реализации используется внешний.
А научи, пожалуйста, как ты это определил?
Здесь есть описание как устроена модель: https://huggingface.co/runwayml/stable-diffusion-v1-5
Любая модель SD состоит из следующих частей:
text_encoder
unet
vae
scheduler
tokenizer
safety_checker
feature_extractor
text_encoder и unet — это в совокупности непосредственно веса модели.
vae — и так понятно, что это вариационный автоэнкодер.
tokenizer и scheduler — это просто конфиги для внешней модели токенизера и алгоритма планировщика.
feature_extractor — это простенький декодер, который декодирует изображение из латентного пространства и передает его на вход safety_checker'a.
safety_checker — модель классификатора проверки содержимого:
The intended use of this model is with the Safety Checker in Diffusers. This checker works by checking model outputs against known hard-coded NSFW concepts. The concepts are intentionally hidden to reduce the likelihood of reverse-engineering this filter. Specifically, the checker compares the class probability of harmful concepts in the embedding space of the CLIPTextModel after generation of the images. The concepts are passed into the model with the generated image and compared to a hand-engineered weight for each NSFW concept.
Model Converter может оперировать с text_encoder, unet, vae и others. Так как scheduler, tokenizer и feature_extractor нихуя не весят (это просто небольшие текстовые файлы), то единственное что остаётся, что может влиять на размер файла модели — safety_checker. Кстати говоря. в несжатом виде он весит почти 1.22 Гб (unet при этом весит 3.44 Гб, а text_encoder 492 Мб).

Пасиб, похоже все так и есть. А чем проверить? Скрипт convert_original_stable_diffusion_to_diffusers.py содержимое папочки safety_checker не вынимает из ckpt, а берет с huggingface. Есть еще какой-то инструментарий для ковыряния, кроме diffusers\scripts?
Алсо, получается, в тех редких случаях, когда в others оказывается копия stable-diffusion-safety-checker, его лучше не удалять ModelConverter-ом, что бы не потерялись tokenizer и scheduler, а перегонять в формат diffusers и назад, благо convert_diffusers_to_original_stable_diffusion.py эту каку в .ckpt не засунуть не пытается. Правильно?
Аноны, помогите запустить. Вообще нихуя не понимаю что тут написано. Пока сам попробую погуглить
Ну допустим я понял, а дальше он мне новую портянку выкинул. Ебаный рот этого амд.
А ты случайно лорки/ликорисы не тренишь? Если да, можешь объяснить основные отличия loha/locon/dylora от обычной лоры?
Мимо
Аноны, как установить SD на арендованный виртуальный сервер? Я совсем не погромист, застопорился на torch is not able to use gpu с RTX 3080 windows, 16 озу тд тп, пытался по советам реддита удалять все эти venv, но не помогает.
Torch не поддерживает все виды виртуальных машин.
Например Hyper-v и не только
Например Hyper-v и не только
Арендуй Linux server
Ребзя, подскажите почему grabber выдает такую шнягу danbooru-No result possible reasons: server offline и как фиксить?
Раньше работал нормально, пробовал гуглить но нифига не выкупил.
Раньше работал нормально, пробовал гуглить но нифига не выкупил.
Спасибо Анон
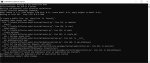
Пытаюсь открыть гугл колаб для работы с сд, выдает такую ошибку
Чего эта скатина от меня хочет?
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-5-751725d58dc1> in <cell line: 6>()
4 import sys
5 import fileinput
----> 6 from pyngrok import ngrok, conf
7
8 Use_Cloudflare_Tunnel = False #@param {type:"boolean"}
ModuleNotFoundError: No module named 'pyngrok'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
Чего эта скатина от меня хочет?
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-5-751725d58dc1> in <cell line: 6>()
4 import sys
5 import fileinput
----> 6 from pyngrok import ngrok, conf
7
8 Use_Cloudflare_Tunnel = False #@param {type:"boolean"}
ModuleNotFoundError: No module named 'pyngrok'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
Пытаюсь открыть гугл колаб для работы с сд, выдает такую ошибку
Чего эта скатина от меня хочет?
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-5-751725d58dc1> in <cell line: 6>()
4 import sys
5 import fileinput
----> 6 from pyngrok import ngrok, conf
7
8 Use_Cloudflare_Tunnel = False #@param {type:"boolean"}
ModuleNotFoundError: No module named 'pyngrok'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
Чего эта скатина от меня хочет?
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
<ipython-input-5-751725d58dc1> in <cell line: 6>()
4 import sys
5 import fileinput
----> 6 from pyngrok import ngrok, conf
7
8 Use_Cloudflare_Tunnel = False #@param {type:"boolean"}
ModuleNotFoundError: No module named 'pyngrok'
---------------------------------------------------------------------------
NOTE: If your import is failing due to a missing package, you can
manually install dependencies using either !pip or !apt.
To view examples of installing some common dependencies, click the
"Open Examples" button below.
Да, он докачивает safety_checker с хагинфейса, если он отсутствует в ckpt.
Чтобы этого избежать можно добавить в скрипте convert_original_stable_diffusion_to_diffusers.py к параметрам функции download_from_original_stable_diffusion_ckpt строку
load_safety_checker=False
Либо запускать пайплайн вручную через скрипт convert_from_ckpt.py из diffusers\pipelines\stable_diffusion\
> Алсо, получается, в тех редких случаях, когда в others оказывается копия stable-diffusion-safety-checker, его лучше не удалять ModelConverter-ом, что бы не потерялись tokenizer и scheduler, а перегонять в формат diffusers и назад, благо convert_diffusers_to_original_stable_diffusion.py эту каку в .ckpt не засунуть не пытается. Правильно?
Нет, tokenizer и scheduler не теряются, без них бы модель вообще не работала. В others идут только feature_extractor и safety_checker.
Так что можно просто конвертировать с удалением others. Но вообще я проверил десяток популярных моделей, в большинстве safety_checker уже отсутствовал.
Сложно простыми словами объяснить что там происходит под капотом. По сути всё это просто различные реализации и модификации алгоритма LoRA.
LoCon (LoRA for Convolution layer) — тренирует дополнительные слои в UNet. Теоретически должен давать лучший результат тренировки, меньше вероятность перетренировки и большую вариативность при генерации. Тренируется примерно в два раза медленнее чистой LoRA, требует меньший параметр network_dim, поэтому размер выходного файла меньше https://github.com/KohakuBlueleaf/LyCORIS/tree/locon-archive#difference-from-training-lora-on-stable-diffusion
LoHa (LoRA with Hadamard Product representation) — тренировка с использованием алгоритма произведения Адамара. Теоретически должен давать лучший результат при тренировках с датасетом в котором будет и персонаж и стилистика одновременно. У меня, честно говоря, пока ещё не получилось результатов лучших, чем при использовании чистой LoRA.
DyLoRA (Dynamic Search-Free LoRA) — по сути та же LoRA, только теперь в выходном файле размер ранга (network_dim) не фиксирован максимальным, а может принимать кратные промежуточные значения. После обучения на выходе будет один многоранговый файл модели, который можно разбить на отдельные одноранговые. Количество рангов указывается параметром --network_args "unit=x", т.е. допустим если network_dim=128, network_args "unit=4", то в выходном файле будут ранги 32,64,96,128. По заявлению разработчиков алгоритма, обучение одного многорангового файла в 4-7 раз быстрее, чем учить их по отдельности. Пока ещё не пробовал.
Почему лоры и контролнеты замедляют скорость генерации? Есть с контролнетами еще как-то можно объяснить дополнительными слоями, то лоры же просто веса меняют?
Ну так изменения весов происходят в процессе генерации. Это дополнительные математические операции, которые требуют дополнительного процессорного времени. То же самое с контролнетом.
> LoCon (LoRA for Convolution layer) — тренирует дополнительные слои в UNet
Я же правильно понимаю что весь unet состоит из convolutional layers, которые извлекают feature maps? Что за слои там такие дополнительные образовались, или типо не весь слой просто тренировался?
Ну я так понял надо основные дим с альфой указать
> --network_dim "RANK_FOR_TRANSFORMER" --network_alpha "ALPHA_FOR_TRANSFORMER"\
и для этих слоёв
> --network_args "conv_dim=RANK_FOR_CONV" "conv_alpha=ALPHA_FOR_CONV" "dropout=DROPOUT_RATE"
А dropout для чего?
Можешь кстати свои настройки подсказать, желательно прямо полной командой для кохьи, чтобы понимать от каких отталкиваться?
> LoHa (LoRA with Hadamard Product representation)
Здесь бы тоже настройки от которых начинать отталкиваться, если можно. Это же тоже вроде с пакетом ликориса тренится?
> DyLoRA (Dynamic Search-Free LoRA) — по сути та же LoRA, только теперь в выходном файле размер ранга (network_dim) не фиксирован максимальным, а может принимать кратные промежуточные значения. После обучения на выходе будет один многоранговый файл модели, который можно разбить на отдельные одноранговые.
Правильно понимаю, что это можно будет делать on-the-fly, например если я захочу чтобы моя лора превратилась из 128 ранга в 32, это будет достаточно где то указать параметром до начала применения её к генерации?
> Количество рангов указывается параметром --network_args "unit=x", т.е. допустим если network_dim=128, network_args "unit=4", то в выходном файле будут ранги 32,64,96,128.
Где можно подробнее изучить как указывать это командой и что будет значить это число? Не совсем понятно, оно на unit делится типо и соответствующие ранги добавляет в лору? У кохи и кохаки в релизах нашел указание рангов и весов слоев только.
Да, но модель-то уже в памяти. Почему сразу к весам изменения не применить, как это делается мержами, только не в отдельный файл?
> Я же правильно понимаю что весь unet состоит из convolutional layers, которые извлекают feature maps? Что за слои там такие дополнительные образовались, или типо не весь слой просто тренировался?
UNet состоит из ResNET блоков (свёрточные слои + пропускные соединения) и слоёв CrossAttention. Изначально LoRA тренировала только CrossAttention слои (разработчики проверили и решили, что этого необходимо и достаточно), LoCon и LoHa ещё тренирует свёрточные слои. Весь матан здесь описан https://github.com/KohakuBlueleaf/LyCORIS/blob/main/Algo.md Алгоритм CP-разложения (CANDECOMP, PARAFAC разложение тензора) свёрточных сетей описан здесь https://arxiv.org/pdf/1412.6553.pdf Обрати внимание кто авторы и где они обитают, лол
> А dropout для чего?
Dropout — это метод предотвращения переобучения модели. Суть в том, чтобы во время обучения случайным образом отключать некоторые теги. Этим параметром регулируется сколько тегов удалять в процентах от общего числа (значение от 0 до 1). Честно говоря, я никогда этим не пользовался.
> Можешь кстати свои настройки подсказать, желательно прямо полной командой для кохьи, чтобы понимать от каких отталкиваться?
> Здесь бы тоже настройки от которых начинать отталкиваться, если можно. Это же тоже вроде с пакетом ликориса тренится?
Ближе к вечеру покажу. Можно еще ориентироваться на это видео https://www.youtube.com/watch?v=Icf3ZQ67KPI Я по нему ориентировался, когда у меня поначалу не получалось
> Правильно понимаю, что это можно будет делать on-the-fly, например если я захочу чтобы моя лора превратилась из 128 ранга в 32, это будет достаточно где то указать параметром до начала применения её к генерации?
Да, когда взываешь dylorа можно указывать в параметрах требуемый ранг https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris#arguments
> Где можно подробнее изучить как указывать это командой и что будет значить это число?
У кохи https://github.com/kohya-ss/sd-scripts/blob/main/train_network_README-ja.md#dylora%E3%81%A7%E5%AD%A6%E7%BF%92%E3%81%99%E3%82%8B правда описание на японском.
> Не совсем понятно, оно на unit делится типо и соответствующие ранги добавляет в лору? У кохи и кохаки в релизах нашел указание рангов и весов слоев только.
Оно делит максимальное число рангов на число unit
Стоит ли трейнить лору на сете из 80% вертикальных пикч и 20% горизонтальных? (Нужны именно вертикальные результаты в HD, типа как постеры фильмов или dvd обложки)
Да. Ты же сам потом размер пикчи выбираешь, анон
Я имею в виду, датасет без кропа до 512p, но чтобы все легло корректно в высоком разрешении
Ну, вот мой опыт: тестил датасеты с дефолтным размером и с кропом. С кропом лучше прорисовываются глаза, уши и т.д. Если не лень, то попробуй две лоры запилить и сравнить, как лучше будет.
Упд: кропал до 768.
Несколько заметок про моё пердоленье.
Были зависания при смене моделей, а также иногда при генерации картинки. Через какое-то время я понял, что зависание при смене модели происходит не сразу, а только на 4-5 раз. А при генерации картинки зависание происходило очень редко, но в последнее время - буквально каждые 20 картинок.
Удалось выяснить, что:
1.
При смене модели утечка памяти, ну тут нихуя не поделать, просто теперь слежу за памятью и после смены нескольких моделей перезапускаю отоматик.
2.
--medvram - зло, тоже создаёт утечки памяти, из-за которых и происходил крэш либо зависание. После того как обмазался плагинами, на одну картинку стало утекать вообще порядка 1 гб, крэши стали постоянными.
Если наблюдаете такое на Линуксе, вырубайте эту хуйню нахуй, если есть возможность.
Теперь вырубил и счастлив, генерирую сотни картинок за сессию.
До того, как я понял, в чём дело, я пытался бороться с этой хуйнёй, выключив превью генерации - благодаря этому при засирании всей памяти в 99% случаев процесс хотя бы сразу убивался, а не зависал на несколько минут.
Единственная проблема, которая осталась - это то, что в ControlNet, если выбрать препроцессор, картинка игнорируется, обрабатывается только то, что нарисовано поверх неё. Однако если не выбирать препроцессор, всё работает, так что мне норм. Вроде бы кто-то на сосаке отписывался что-то про настройки canvas в браузере, чтобы это исправить, но я не помню, что там было. А так описание проблемы я встречал, но решения не видел.
Были зависания при смене моделей, а также иногда при генерации картинки. Через какое-то время я понял, что зависание при смене модели происходит не сразу, а только на 4-5 раз. А при генерации картинки зависание происходило очень редко, но в последнее время - буквально каждые 20 картинок.
Удалось выяснить, что:
1.
При смене модели утечка памяти, ну тут нихуя не поделать, просто теперь слежу за памятью и после смены нескольких моделей перезапускаю отоматик.
2.
--medvram - зло, тоже создаёт утечки памяти, из-за которых и происходил крэш либо зависание. После того как обмазался плагинами, на одну картинку стало утекать вообще порядка 1 гб, крэши стали постоянными.
Если наблюдаете такое на Линуксе, вырубайте эту хуйню нахуй, если есть возможность.
Теперь вырубил и счастлив, генерирую сотни картинок за сессию.
До того, как я понял, в чём дело, я пытался бороться с этой хуйнёй, выключив превью генерации - благодаря этому при засирании всей памяти в 99% случаев процесс хотя бы сразу убивался, а не зависал на несколько минут.
Единственная проблема, которая осталась - это то, что в ControlNet, если выбрать препроцессор, картинка игнорируется, обрабатывается только то, что нарисовано поверх неё. Однако если не выбирать препроцессор, всё работает, так что мне норм. Вроде бы кто-то на сосаке отписывался что-то про настройки canvas в браузере, чтобы это исправить, но я не помню, что там было. А так описание проблемы я встречал, но решения не видел.
Что если сделать отдельные лоры для одного стиля, лиц и дальнего плана, и применять вместе? (Типа "illustration in style of <lora1>, face in style in <lora2>")
>Если не лень
Дело не в лени. А в конечности халявных ресурсов (колаб еще прикрутил квоту юзерам каломатика)

> Весь матан здесь описан https://github.com/KohakuBlueleaf/LyCORIS/blob/main/Algo.md Алгоритм CP-разложения (CANDECOMP, PARAFAC разложение тензора) свёрточных сетей описан здесь https://arxiv.org/pdf/1412.6553.pdf
Херово всё таки не знать матан, я нихера не понял, хорошо хоть картинки чуть объсняют суть.
> Which means it can use 2x dim to get square rank.
Х2 к информации в лорке на том же диме?
Про локон еще меньше понял, короче матан мне бессмысленно объяснять походу, ведь я уже сразу не понял что означают W Y и X.
Хоть на схеме пытаюсь понять где это находится, красным намазюкал сверточные слои, зеленым пропускные соединения, я вообще на ту схему хоть смотрю? Алсо где находится crossattention вообще представить не могу, наверное примерно где намазюкал синим.
> Обрати внимание кто авторы и где они обитают, лол
Забавно, вебуи и его форк ведь тоже Володьки делают, лул.
> Dropout — это метод предотвращения переобучения модели. Суть в том, чтобы во время обучения случайным образом отключать некоторые теги. Этим параметром регулируется сколько тегов удалять в процентах от общего числа (значение от 0 до 1). Честно говоря, я никогда этим не пользовался.
Мне вот тоже не особо понятно зачем это может быть нужно вообще.
> Ближе к вечеру покажу. Можно еще ориентироваться на это видео https://www.youtube.com/watch?v=Icf3ZQ67KPI Я по нему ориентировался, когда у меня поначалу не получалось
О неплохо, возьму тогда за начальные его и твои настройки. Кстати там dadaptation, он с последним обновлением перестал работать с разделенными лр, это же не нормально?
> Да, когда взываешь dylorа можно указывать в параметрах требуемый ранг https://github.com/KohakuBlueleaf/a1111-sd-webui-lycoris#arguments
А, так dyn это ранк получается? Я пробовал кстати через эту штуку обычную лору пытаться запустить, ради ТЕ в промпте, не получилось, но ликорис ради такого стоит потренить, да и вообще он многообещающе выглядит, если научиться тренить разные методы.
> Оно делит максимальное число рангов на число unit
Dim = 128, unit = 8 будет 16, 32, 48... 128
Dim 8, unit = 4 будет 2, 4, 6, 8?
А что у такой лоры с размером будет, не раздуется?
Кстати, не в курсе, а можно комбинировать например locon+dylora?
Такое ещё не делал, извини.
Да, это не приятно, теперь боюсь запускать.
Не, ну запускать-то можно, если поменять слово webui в коде на зашифрованную переменную. Но гарантий никаких нет, технически это так же нарушает TOS.
Пардон за откровенно тупой вопрос, но всё же...
Так как Колаб, походу, ВСЁ, а поставить новую видеозатычку нет возможности (не только жаба душит (как и в случае с PRO-подпиской), как, думаю, и у многих, но и, например, в бук её толком не всунешь, может, у кого тот же случай), вновь поднимается вопрос о возможной тренировке лорок на CPU. Встанет ли оно, к примеру, на виртуалку, которую можно время от времени запускать и "замораживать", если нужно?
Так как Колаб, походу, ВСЁ, а поставить новую видеозатычку нет возможности (не только жаба душит (как и в случае с PRO-подпиской), как, думаю, и у многих, но и, например, в бук её толком не всунешь, может, у кого тот же случай), вновь поднимается вопрос о возможной тренировке лорок на CPU. Встанет ли оно, к примеру, на виртуалку, которую можно время от времени запускать и "замораживать", если нужно?
Забудь про процессор, на нем даже мелкую превьюшку долго генерировать.
Юзай колаб, но не пались. Трейнить лору можно и скриптом без градио-ui. Если совсем закрутят гайки - тогда kaggle, paperspace, сатурн.
Корифеи трейнинга лорок еще не покинули тред? Подскажите оптимальные параметры.
Нужнен эмбеддинг стиля как charturner, но с более сложной структурой. Как концепт персонажа, два ракурса одной и той OC манямэ школьницы на белом фоне. Один в полный рост в одежде, другой вид - крупным планом в нижнем белье с акцентом на попе или сиськах, с задранной юбкой и так далее. Или, школьница держит телефон, показывая фотку ее пизды (одежда такая же чтоб было понятно что это она). 100-150 образцов в сете, теги с danbooru
Нужнен эмбеддинг стиля как charturner, но с более сложной структурой. Как концепт персонажа, два ракурса одной и той OC манямэ школьницы на белом фоне. Один в полный рост в одежде, другой вид - крупным планом в нижнем белье с акцентом на попе или сиськах, с задранной юбкой и так далее. Или, школьница держит телефон, показывая фотку ее пизды (одежда такая же чтоб было понятно что это она). 100-150 образцов в сете, теги с danbooru
Из-за леса, из-за гор - кровь, кишки, пиздец хардкор.
- Гугл всё, банит неиллюзорно.
- Кагля требует верификацию телефона и шлёт нах номера РФ
- Paperspace требует подписон - а РФ карты не работают
- Что за сатурн, кстати?
Ну и собственно - где генерить...
- Гугл всё, банит неиллюзорно.
- Кагля требует верификацию телефона и шлёт нах номера РФ
- Paperspace требует подписон - а РФ карты не работают
- Что за сатурн, кстати?
Ну и собственно - где генерить...

>Гугл всё, банит неиллюзорно.
Можно ссылку или скрин в качестве пруфа? Я не слежу прост
>Кагля требует верификацию телефона и шлёт нах номера РФ
У меня два акка (второй через прокси), оба были зареганы благополучно с ру номера НО это было до СВО и санкций
Говорят, на saturn cloud можно насосать гпу кредиты за хвалебные отзывы на сайтах
> Гугл всё, банит неиллюзорно.
В аноноколабе молниеносно фикс выкатили, пока работает с молитвами, лол. Можно ещё с названиями поебаться, если хочется. А в кохаскрипте гуй вообще нинужон, не знаю, кто его использует. Может, влияет, что у меня подписка пока есть, лол
Так то 2000 баксов не такая уж большая сумма (относительно) даже для одного нейрошейха-энтузиаста, не говоря уже о всяких краундфандингах
Хочу сделать Лору на определенный автомобиль, сколько шагов нужно примерно? Так же 1500? И теги можно автоматически проставить с помощью wd или нужно клипом? Тренить очевидно буду на сд2.0
- Кагля требует верификацию телефона и шлёт нах номера РФ
https://5sim.biz/
Индийский номер от 2 до 20 рублей.
Карты из РФ принимает.
Тренировку лор то не забанили? Только генерацию картинок?

Вчера тренил лору, вроде нормально всё. В койе, кстати, тоже вылезает предупреждение.
Как же хочеца лору опробовать...
Ща охуенная идея: трейнить лору на негативный эмбеддинг. Скормить ей всю блядскую ссанину, копро, гуро, артефактные пикчи, разные болезни и мутации, просто рисунки низкого качества и мыло. Да, такие лоры уже есть - но индивидуальный подход тоже важен, сделать как лучше (хуже) с моей т.з.. Например мне не нравится выкрученный контраст.
Специально для индивидуумов с мозгом хлебушка сделали kohya dreambooth в колабе. Заливаешь и трейнишь с дефолтными параметрами. Можно тупо вставить ссылку на zip в драйве.
Специально для индивидуумов с мозгом хлебушка сделали kohya dreambooth в колабе. Заливаешь и трейнишь с дефолтными параметрами. Можно тупо вставить ссылку на zip в драйве.
Генерация картинок не запрещена, просто накати либу diffusers без ui
Да картинки то у меня и локально нормально генерятся.
Лоры в коллабе удобнее тренить - чтоб надолго комп не занимать.
А так поставил трениться - и сидишь, либо работаешь, либо пикчи генеришь. Потом результат забираешь, и норм.
А теги как она ставит будет? Сама определит что это не аниме? Или подойдут бору теги для реал пикч?
Ну тогда ты ноешь на ровном месте
Там всё есть, ты хоть гуглил?
Где я ныл, алё?
быстрая треня лоры на фотках еот (~3 минуты, хорошее качество) в гуи от https://github.com/bmaltais/kohya_ss на 4070ti (приведены только параметры, отличные от стандартных):
model output name: ваша_дрочибельная_тян
train batch size: 4
learning rate: 0.001
unet learning rate: 0.001
network rank (dimension): 64
network alpha: 32
enable buckets: yes
full fp16 training: yes
обзываем папку 100_EOT woman, кидаем 15-20 пикч в хорошем качестве, (3-4 ебла крупным планом, остальные по пояс и во весь рост, желательно чтобы фон и одежда не повторялись, цепочки, татухи, пирсинг лучше замазать) обрезать до 512х512 пикчи не надо, разве что эти 3-4 ебла обрезать, если в полный кадр нет. жмём train model, через 3 минуты надрачиваем на свою пассию. обучал на моделях хача, порно и реалистик, плюс-минус одинаково, на стандартных не то, часто хуёвые пальцы и позы.
model output name: ваша_дрочибельная_тян
train batch size: 4
learning rate: 0.001
unet learning rate: 0.001
network rank (dimension): 64
network alpha: 32
enable buckets: yes
full fp16 training: yes
обзываем папку 100_EOT woman, кидаем 15-20 пикч в хорошем качестве, (3-4 ебла крупным планом, остальные по пояс и во весь рост, желательно чтобы фон и одежда не повторялись, цепочки, татухи, пирсинг лучше замазать) обрезать до 512х512 пикчи не надо, разве что эти 3-4 ебла обрезать, если в полный кадр нет. жмём train model, через 3 минуты надрачиваем на свою пассию. обучал на моделях хача, порно и реалистик, плюс-минус одинаково, на стандартных не то, часто хуёвые пальцы и позы.
Скорость обучения высокая, надо на порядок меньше
выходит же норм результат в итоге. вот ещё learning rate scheduler: cosine, warmup steps: 10%, вроде дефолтные были. 12 картинок, 450 шагов, 2 минуты, готово. правда может иногда лишние детали добавлять, лечится весами промптов и cfg scale, также можно сменить модель на другую, на которой не тренилась лора.




ну и говно получилось же

Он по факту сказалю
без конкретики - пук в лужу
Подтверждаю, конкретное говно.
мимо


Анон, после обновления automatic1111 расширение tagcomplete cкурвилось (первый скрин), как вернуть чтоб красиво было? (второй скрин)
Алсо, раньше тыкал на сгенерированную картинку и она открывалась на весь экран, то ли это расширение было, то ли фича такая. Но сейчас она не работает.
Алсо, раньше тыкал на сгенерированную картинку и она открывалась на весь экран, то ли это расширение было, то ли фича такая. Но сейчас она не работает.

В колабе от анонов при запуске пропала возможность подтягивать модели с гуглодиска.
Обнови дополнение



Аноны, подскажите что делать с руками (кистями рук)? Нужно что-то дополнительное в промпте (негатив-промпте) указать или лору использовать?
1girl, solo, masterpiece, patchouli knowledge, outdoors
Negative prompt: (worst quality, low quality:1.4), multiple views, blurry, jpeg artifacts, (nsfw, nude:1.2), gigantic breasts, huge breasts, large breasts
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 4129617840, Size: 512x768, Model hash: 7f96a1a9ca, Model: AnythingV5_v5PrtRE, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: 4x_Valar_v1
1girl, solo, masterpiece, patchouli knowledge, outdoors
Negative prompt: (worst quality, low quality:1.4), multiple views, blurry, jpeg artifacts, (nsfw, nude:1.2), gigantic breasts, huge breasts, large breasts
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 7, Seed: 4129617840, Size: 512x768, Model hash: 7f96a1a9ca, Model: AnythingV5_v5PrtRE, Denoising strength: 0.6, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: 4x_Valar_v1
Промпты не помогут. Руки - это большая проблема нейронок, постоянно на них фейлятся.
Можешь на цивите поискать embeddings на это дело (по слову hands), они помогают, но совсем немного.
Контролнет с canny и depth моделями помогает больше, но его надо учиться использовать.
Ну и всегда можно ретушить вручную и потом прогонять картинку в имг-2-имг с очень низким денойзом для коррекции ретуши.
Может знает кто, насколько критично отсутствие triton под второй торч на винде в кохьевском venv'е во время тренировки лоры? На что он вообще влияет?
> насколько критично отсутствие triton под второй торч на винде
Вообще похуй, тритон не используется там. Он будет работать только с автотюном, но автотюн говно для SD и везде выключен.
> Он будет работать только с автотюном, но автотюн говно для SD и везде выключен
А что такое автотюн?
Triton не используется вообще никак (пока)
Кто то тренит на этой модели лоры? Действительно получается лучше или это хуйня? https://civitai.com/models/23900/anylora-checkpoint
Если тренить на ней, то хорошо будет получаться именно только на ней и на миксах с ней. Поэтому все тренят на NAI.
>Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Тут есть добрые дяди, которые это переведут? Прочитал по диагонали, относительно понял, но не на 100%.
Тут есть добрые дяди, которые это переведут? Прочитал по диагонали, относительно понял, но не на 100%.

Я вот в душе не ебу, какой вариант лучше и как правильно это все тестить.
Сап, двач.
А есть ли тут те, кто продолжает тренить DreamBooth? Не лору - удобный, легковесный, но таки обрубок - а именно дримбудку? У меня кое-что получается, но больно уж странен результат...
А есть ли тут те, кто продолжает тренить DreamBooth? Не лору - удобный, легковесный, но таки обрубок - а именно дримбудку? У меня кое-что получается, но больно уж странен результат...
Тренируй locon

>Не лору - удобный, легковесный, но таки обрубок - а именно дримбудку?
Нет разницы. Современная лора это просто выжимка того, что старый дримбут размазывал по модели. Вообще, мой совет долбоебам: тренируйте рожи своих мамок на дефолтную модель 1,5, а потом уже кидайте лору на что хотите.
мимо король раздела
Влад - гавно, ататата
Аутоматик вернулся - атататат
Срач на реддите
https://www.reddit.com/r/StableDiffusion/comments/134lri4/automatic1111_updated_to_110_version/
Какой же Влад все таки гавно
Аутоматик вернулся - атататат
Срач на реддите
https://www.reddit.com/r/StableDiffusion/comments/134lri4/automatic1111_updated_to_110_version/
Какой же Влад все таки гавно
>Какой же Влад все таки гавно
Переведи плиз перлы. Я не понимаю что там
Лень читать уебанов. УМВР, переехал на второй торч и самосборные хформерс в феврале, никаких особых неудобств не испытал - ну, кроме сдохшего dreambooth, но он в целом больше и нахуй не нужон.
После сегодняшней обновы ничего страшного не случилось, все минутные отвалы пофиксились перезапуском сборки, че там эти долбоебы горят-то?
Тоже лень рыться в их обсуждении, тлдр проблема не во владе а в кохаке https://github.com/vladmandic/automatic/issues/675
> https://github.com/vladmandic/automatic/issues/675
Проорал с этого перла. Аддон для webui автоматика, при этом жалуются автору этого аддона что в какой-то кривом форке из-за него проблемы. Хотя в автоматике всё норм. Слепил кривое говно и ожидает что за него будут чинить, просто кринж.
Уебанский каломатик обновился и сломал x/y/z/, теперь эта мразь отказывается переключаться между моделями и генерит только одну. Как эту хуйню чинить?




Вот что за хуйня, у него есть список, что генерить, а он цепляется к вообще рандомной модели и генерит с неё. Вот как это чинить?
Поменял путь, удалил модель, переподцепился к другой и генерит опять только с неё.


Вот как с этим говном работать? Первые две модели он нормально подцепил, потом с какого-то хуя вместо третьей подцепил хитокомору из другой папки, а последние 4 генерил на Orange_AOM3A3. Как эту пизду чинить?

Штож, обновил Extensions, и x/y/z решил сдохнуть окончательно.
Возможно я даун, но только щас заметил, что мне пишут о необходимости обновить торч и иксформерс. Штож.
Аноны, подскажите, как откатиться на старую версию pytorch? Он обновился и теперь стабильно срет ошибкой CUDA out of memory при любых попытках диффундирования, даже на минимальных размерах картинки. На старой версии проблем вообще не возникало
--medvram
пропиши прст
Обновился и блядский X/Y/Z продолжает просто цепляться за одну модель и не менять её. Я хуй знает что делать.
Ебать ты охуевший чертила.
Ты либо ждешь, когда исправят баги в обновлениях и только потом перекатываешься, либо обновляешься и сам помогаешь чинить.

>Обновился и блядский
>как откатиться
Resetting webui
If git pull shows an error, it is usually because you have accidentally changed some files. You can reset the webui folder with the following two commands.
cd %userprofile%\stable-diffusion-webui
git checkout -f master
And then run git pull again.
git pull
Note that all files will be reset. You will need to make changes to webui-user.bat again.
Reverting back to a previous version
Sometimes the latest version of webui is broken, and you don’t want to use it. You can revert back to a previous version by following the instructions below.
Step 1: Go to this page to view previous versions. Each row is a previous version.
Step 2: Pick a previous version you want to revert back to. You can look at the date and comment to make a judgment.
Step 3: Press the copy button to copy the hash code of the version.
Step 4: In the command prompt, run the following commands. The hash code (highlighted below) is just an example. You will paste the one you just copied.
cd %userprofile%\stable-diffusion-webui
git checkout 076d624a297532d6e4abebe5807fd7c7504d7a73
If you see errors, reset the webui (see the previous section) and retry.
Потестил IF - даже базовая модель явно лучше чем SD 1.5. Убийца стейбла лол
Спасибо! 👍




>
Чот какая-то шляпенция...
Котоны, как организовать батч. Вот есть несколько десятков картинок. Они как бы перетекают друг в друга. Но они как ключевые кадры. Нет планости, если их свести в видос. А надо добавить промежуточных кадров.
Отсюда пару вопросов. Есть ли в автоматике способ из двух картинок сделать пачку с переходом изображения с одной ко второй? И второй вопрос, как мне это организовать для пачки картинок?
Отсюда пару вопросов. Есть ли в автоматике способ из двух картинок сделать пачку с переходом изображения с одной ко второй? И второй вопрос, как мне это организовать для пачки картинок?
Ты имеешь ввиду сгенерировать переходные кадры от двкх картинок
Я нищий, соси маркетолог

В свете.
Хуйня полня. Сосет у обычного дримбута с проглотом.
>full fp16 training: yes
Это вообще лучше не включать.
Проблема в том, что лору сильно корежит, в зависимости от того на какую модель натягиваешь. Прям рожи РАЗНЫЕ получаются. Тренировал на дефолте. Если взять срань типа уберпорн - вообще пиздец получится (не говоря о том, что из-за уберпорна суперзажатая анатомия и от любого лишнего тега в промте получаются многоножки человеческие). Мой вывод: нахуй. Лучше в дримбуте тренить двухгиговые, чем генерить тонны кала из лоры, надеясь что что-то похожее СЛУЧАЙНО выпадет.
Учил до сотки. 4 фотки, 10 фото, 20 фоток. На выходе результаты посредственные. Естественно датасеты чистые были.
Промт. automatic color correction photoshop.
Или в фотошопе автоматическая цветовая коррекция
Аноны подскажите, я нюфаг. Я вот натренировал хайпернетворк, я могу её дальше дотренировывать? И если да, то как?
Блеванул, спасибо.
Просто снова выбираешь её для тренировки и ставишь больше шагов
Если бы можно было делать анимацию лишь по ключевым кадрам, большинство аниматоров были бы не нужны.
Попробуй интерполяцию кадров поделать через W2x, ну либо смотри какие расширения есть в автоматике для изначально генерации txt2video (их там несколько точно было), если речь про сгенерированные нейросетью изобржения
А фото использовать те же или можно новые добавить?

Для увеличения пикч ставь галку тут
После всех проб и ошибок нашёл самый оптимальный метод создания лор для воссоздания лиц
1) Делаешь хороший дримбут
2) Экстрактишь из него лору
Посоны, какое оптимальное количество total steps для обучение лоры?
И что без потерь извлекается?
Чем меньше фоток тем меньше, но не меньше 100. Потом тестишь добавляя скобки и смотришь примерно куда тебе дальше двигать.
Бамп вопросу, та же проблема.
щитпост. Либо пиши по существу, либо не пиши ничего.








>Чем меньше фоток тем меньше
Это да. Но Какое-то среднее есть? Видел гайд где чел брал 100 картинок и делал 20 000 общих степов
Всё с теми же настройками и входными данными. А если хочешь с другими данными, то наверное стоит заново сетку тренить
>Видел гайд где чел брал 100 картинок и делал 20 000 общих степов
Он ёбнутый. В дримбуте я обычно делал на пять фото 150-200 шагов + разово 150 текстового, потом дотренивал по 50+ без текстового, чтоб поймать максимальное сходство, причем если тебя КОНКРЕТНО лицо интересует - то лучше словить легкий оверфит, тестишь потом усиливая скобками и весом в промпте. И охуенный лайфхак, который я обнаружил на закате эры нейробомжей: не меняй все лицо. В инпейнте закрашивай только нос и глаза, можно еще брови, чтоб двойных не было - это дает самые реалистичные результаты, при этом при любой форме лица - ччеловек на форму меньше внимания обращает - основное внимание у нас на глаза и нос, потом рот идет. Не понимаю, почему все эти говносимсвапы так же маску не накладывают это бы бустнуло к качеству +178%.
Фото добавлять можно.
~2000-2500, но это верхний предел.
Если в модели концепт уже есть, и ты на него удачно попадаешь - может и за 300 натренироваться.
Поэтому разделяй по эпохам и сохраняй промежуточные результаты, потом отбирай самый нормальный.




Знают ли уважаемые эксперты что могло нагенерировать эти картинки? Под каждой из них написано, что их нагенерировал AI. Все 4 нагенерены разными людьми.
Я так понимаю, что Stable Diffusion это стандарт де-факто на текущий момент.
Вопрос в том какие модели это делали?
Последнее что я сам генерировал со Stable Diffusion это картиночки со слитыми модели NovelAI. Там качество даже близко не такое как на этих примерах.
Я так понимаю, что Stable Diffusion это стандарт де-факто на текущий момент.
Вопрос в том какие модели это делали?
Последнее что я сам генерировал со Stable Diffusion это картиночки со слитыми модели NovelAI. Там качество даже близко не такое как на этих примерах.
Иди заново вкатывайся в наи тред
Типичные работы кумеров с civitai
Да, главное указать ту модель на которой тренил. Схожесть намного лучше, чем при трейне чистой лоры на таком же датасете.
В симсвапе вроде как идет трейн по одной фотке, что хуйня и ждать чуда смысла нет = > душный результат. Плюс овал лица сильно увеличивает схожесть. Можно конечно свапать в положих людей, но это ебать душнилово.
>Плюс овал лица сильно увеличивает схожесть.
Практически не влияет, только если совсем уж разный. Да ты сам в инпейнте проверь. Как бы и убедишься очень быстро. Пробема симсвапа и фейсденсера и т.п. в том, что они трогают ебучий рот. Вообще, если в стабле генерить кадры с контролнетом, как щас делают, то можно мутить нихуевый симсвап с помощью обученной лоры.
ммм каломатик обновил поддержку питорча и иксформерса
настало время переустанавливать шиндошс каломатик
настало время переустанавливать шиндошс каломатик
Копрофажек, спок.
ретрододик, ты? до сих пор на релизе от ноября сидишь?
а че вы молчали что токенмерджер запилили? я ахуел с убыстрения скорости генерации
https://github.com/dbolya/tomesd
https://github.com/dbolya/tomesd
А как дотренировывать лору?
Слишком ломает картинку, оно того не стоит. Простое уменьшение шагов и то не так сильно пидорасит.
Так же.
Пацаны научите кончу на ебале тянкам рисовать, прошу
Распечатываешь фотку, дрочишь на неё, затем фотаешь, сохраняешь файл на комп. Готово.
Окей, я скачкал последнего автоматика и он просит скачать торч 2.0. Его заливать в местный венв самого автоматика? И почему он сам его не скачает?
Посоны, поделитесь пожалуйста json файлом с оптимальными настройками для лоры
Тебе нужно обучить лору. вот тебе датасет. удачи
https://danbooru.donmai.us/posts?tags=facial+order%3Ascore
Ладно, оно поставилось. Пришлось клонировать репо заново
Как в автоматике указать путь к моделям и всему остальному?
И что, намного ускоряет?
>Слишком ломает картинку
не ломает
да
>да
Так, падажжи.
Патчи какие-то, командная строка...
С каломатиком чтоль не работает?
Ну и нахера оно тогда нужно?

Чё это? Зачем:
>4. Edit the .env file
>bash
># Hugging Face Token (https://huggingface.co/settings/tokens)
>HUGGINGFACE_TOKEN=YOUR_TOKEN_HERE

> не ломает
Даже на 0.2 мыльца накидывает знатно. На 0.5 уже пизда вместо нормальной детализации.

Долбаные косички. Похоже надо нагенерировать нормальных картинок с контролнетом и влить в датасет.
А че ты от 512 хотел? Ставь повыше.
Зачем тебе докер? Ставь бубунту из микростора.

>Ставь бубунту
Да блять там в скрипте установки такое:
># /bin/bash
>echo Please paste your HuggingFace token here:
>read hftoken
Ну и хули это?
Ты ёбаный дебил. Посмотри что в скрипте по твоей ссылке. curl -fsSLO https://raw.githubusercontent.com/VoltaML/voltaML-fast-stable-diffusion/experimental/scripts/wsl-install.sh
https://raw.githubusercontent.com/VoltaML/voltaML-fast-stable-diffusion/experimental/scripts/wsl-install.sh
а ну иди сделай акк на хаге и возьми оттуда токен в чем проблема
>токен
чтобы позже им все пользовались?
Что-то куда-то добавлять, файлы править, потом они обновляться с гит-пулла еще перестанут...
Эстеншн где? Нет?
Ну значит лесом, не стоит оно того.
Тем более вон выше про мыло писали. Тект2имг с низким разрешением я и так быстро генерю.
А выше уже апскейл работает.
И тут непонятно, как оно с апскейлерами законтачит.
>нинужна
Ну твое право.
Ну пропиши единичку, в лораскриптах тоже можно так пропускать токен

Што ета?
А ето кто пробовал?
https://github.com/anapnoe/stable-diffusion-webui-ux
https://github.com/anapnoe/stable-diffusion-webui-ux
Очередной говнофорк с нескучными скинами и шрифтами

Не знаю, постят ли тут еще лоры, но вот лора на Славяну:
https://civitai.com/models/59722
https://civitai.com/models/59722
Нормально всё будет с обновлениями. Разве что эта хрень сами модели настраивает, и если отключить её просто так, то файлы моделей испортит.
Проблема в том, что ради процентов 20 ускорения эта дрянь качество картинки поганит. На некоторых просто детали убавляет, на других же всю картинку в говно превращает.
не могу с генерацией лоры разобраться
{
"pretrained_model_name_or_path": "D:/SD/stable-diffusion-webui/models/Stable-diffusion/--v1-5-pruned.safetensors",
"v2": false,
"v_parameterization": false,
"logging_dir": "D:/01/kohya_ss/train/log",
"train_data_dir": "D:/01/kohya_ss/train/image",
"reg_data_dir": "",
"output_dir": "D:/01/kohya_ss/train/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 1,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "bf16",
"save_precision": "bf16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": true,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"vae": "",
"output_name": "test",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"mem_eff_attn": true,
"gradient_accumulation_steps": 1.0,
"model_list": "runwayml/stable-diffusion-v1-5",
"keep_tokens": "0",
"persistent_data_loader_workers": false,
"bucket_no_upscale": true,
"random_crop": false,
"bucket_reso_steps": 64.0,
"caption_dropout_every_n_epochs": 0.0,
"caption_dropout_rate": 0
}
Скажите настройка нормальная?
"pretrained_model_name_or_path": "D:/SD/stable-diffusion-webui/models/Stable-diffusion/--v1-5-pruned.safetensors",
"v2": false,
"v_parameterization": false,
"logging_dir": "D:/01/kohya_ss/train/log",
"train_data_dir": "D:/01/kohya_ss/train/image",
"reg_data_dir": "",
"output_dir": "D:/01/kohya_ss/train/model",
"max_resolution": "512,512",
"learning_rate": "0.0001",
"lr_scheduler": "constant",
"lr_warmup": "0",
"train_batch_size": 1,
"epoch": "1",
"save_every_n_epochs": "1",
"mixed_precision": "bf16",
"save_precision": "bf16",
"seed": "1234",
"num_cpu_threads_per_process": 2,
"cache_latents": true,
"caption_extension": ".txt",
"enable_bucket": false,
"gradient_checkpointing": true,
"full_fp16": false,
"no_token_padding": false,
"stop_text_encoder_training": 0,
"use_8bit_adam": true,
"xformers": true,
"save_model_as": "safetensors",
"shuffle_caption": false,
"save_state": false,
"resume": "",
"prior_loss_weight": 1.0,
"color_aug": false,
"flip_aug": false,
"clip_skip": 2,
"vae": "",
"output_name": "test",
"max_token_length": "75",
"max_train_epochs": "",
"max_data_loader_n_workers": "1",
"mem_eff_attn": true,
"gradient_accumulation_steps": 1.0,
"model_list": "runwayml/stable-diffusion-v1-5",
"keep_tokens": "0",
"persistent_data_loader_workers": false,
"bucket_no_upscale": true,
"random_crop": false,
"bucket_reso_steps": 64.0,
"caption_dropout_every_n_epochs": 0.0,
"caption_dropout_rate": 0
}
Скажите настройка нормальная?
> "lr_scheduler": "constant",
Такой себе планировщик
Пожалуйста дай конфиг получше. Спасибо
>говнофорк
так-то верно говоришь, но вот почему у них всегда есть мелкие плюшки, которых нет в оригинале? Вот кнопочки удобные:
https://user-images.githubusercontent.com/124302297/227973727-084da8e0-931a-4c62-ab73-39e988fd4523.png
Перенесётся ли и заработает аутоматик1111 в образе wsl2 с 10 в 11 windows?

Итак, по поводу шедулеров:
1 и 4) Это если вы высчитали идеальный LR по графикам, а также при использовании DA. Точнее первый - DA, а с разогревом - высчитанный.
2 и 3) Это когда LR ставится "на глазок" - в процессе тренинга лр меняется по косинусойде, так что даже если выставили немного не так, то плавные снижения и повышения до определённой степени это компенсируют. Рестарты увеличивают количество раз когда лр пройдёт от максимума до минимума - пройдя цикл лр сбрасывается и вновь "разогревается". В ликорис колабе рекомендуется 3 рестарта, но видел и до 12.
5) Тупо начинается с максимума и линейно снижается до 0. Тренит слишком жостко.
6) Позволяет запердолить свою функцию, я так понял. Можно не обращать внимания.
При тренировке лор (не аниме, человеческие ебала) самыми удачными получались те, в которых были regularization, сгенерированные про промптам с датасета.
Я дурак, или гринтекст действительно хорошо поверхностно объясняет, как это работает?
> Карикатурист берёт лицо Ницше и достаёт из него все те паттерны, которые использует наш мозг, чтобы узнать великого философа, и изображает их в преувеличенном виде. Или, иначе говоря, он берёт среднее арифметическое всех мужских лиц и вычитает его из лица Ницше, а затем усиливает разницу. Таким образом, он создаёт портрет, который поход на Ницше больше, чем сам Ницше.
Я дурак, или гринтекст действительно хорошо поверхностно объясняет, как это работает?
> Карикатурист берёт лицо Ницше и достаёт из него все те паттерны, которые использует наш мозг, чтобы узнать великого философа, и изображает их в преувеличенном виде. Или, иначе говоря, он берёт среднее арифметическое всех мужских лиц и вычитает его из лица Ницше, а затем усиливает разницу. Таким образом, он создаёт портрет, который поход на Ницше больше, чем сам Ницше.


Мимокрокодил
> 6) Позволяет запердолить свою функцию, я так понял. Можно не обращать внимания.
Нет, это вот такой график как на пик1. Там 0.75 силы дополнительно передано аргументом. В зависимости от него будет снижать лр до 1е-7, в стоке вроде похож на линеар.
Есть кто хорошо в математике разбирается? Подскажите какие аргументы писать, чтобы построить шедулер как на пик2 с убывающим трендом лр с помощью CyclicLR https://pytorch.org/docs/stable/generated/torch.optim.lr_scheduler.CyclicLR.html
Вот кстати да. Интересное объяснение регуляризаций.
Зависит от того, что ты подразумеваешь под "удачным".
С регуляризацией ты мог просто не дойти до перетрена, если количество шагов осталось тем же (ведь датасет увеличился).
Модель изначально могла выдавать плохой результат для класса, а регуляризация его подправила.
Попытался первый раз с регуляризацией потренить - и что-то прям нифига не вышло. Тренил концепт + стиль.
Какие там подводные камни?
Скорость обучения?
Тэги для регуляризаций?
Число картинок, число повторов?
Какие там подводные камни?
Скорость обучения?
Тэги для регуляризаций?
Число картинок, число повторов?
В чем различия тернировки на стиль и на концепт\перса? Только теги или настройки обучения тоже надо менять?

Заметил, что видеокарта не единственное, что влияет на скорость генерации. Память и проц дали 50% улучшение, когда поменял 8700K+DDR4 3000 на 13900K+DDR5 6600. Тест Асуки, если кто его помнит, скинул время с 12 до 8 секунд. Видимо, вопрос в памяти, т.к. у проца грузится всего одно ядро.
С какой вк? С 4090 уже давно выяснили что ее тыквит все кроме 13900к да и он может быть тоже тыквит




> Обновился
проблема лежит где-то здесь
что такое ИФ? inb4 зАмок
> хайпернетворк
на форче недавно аноны бугуртили, что их надо из всех гайдов убрать. вопрос в технотеде /g/ был примернор один к одному твой.

> hypernetwork
плюс оди жрут больше меставиноват, проверил, пиздёж. почему щас лоры почти все подошли к пределу 144 метра, а потом въебенили 288 метров??, чем лора, без костылей работают работали? только одна подряд, и -5% к скорости генерации на моей не-очень-карте a если две врубить, то потеря 10-20% будет, чтоли??
плюс оди жрут больше меставиноват, проверил, пиздёж. почему щас лоры почти все подошли к пределу 144 метра, а потом въебенили 288 метров??, чем лора, без костылей работают работали? только одна подряд, и -5% к скорости генерации на моей не-очень-карте a если две врубить, то потеря 10-20% будет, чтоли??
> С какой вк?
3080Ti.
>tmpy.pic
Вкусные макароны?
>почему щас лоры почти все подошли к пределу 144 метра, а потом въебенили 288 метров??
Потому что те, кто их тренируют - без мозгов.
Скоро будут лору на персонажа размером с цельную модель тренировать.
Вкатываюсь в лорирование.
В общем-то вопросы, наверное, платиновые.
Обучаю сейчас на даптейшоне с лр1, выглядит выхлоп хорошо, но с весом в единичку модель начисто забывает всё, что знала о чём-либо, кроме темы обучения. Это фиксится как-нибудь? Пробовал сбрасывать лр и обучать короче — просто получаю недообученный выхлоп. Всё или ничего, короче, получается.
Ещё вопрос. Можно ли как-то снизить степень с которой забирается стиль с датасета при обучении персонажу? Прописывать пробовал в промптах, но чот не сильно помогает.
А рег имги влияют на стиль? Я так понял, что их не используют при обучении стилю, ето так? Пробовал с ними и без них и как-то не особо пока понял как они влияют.
В общем-то вопросы, наверное, платиновые.
Обучаю сейчас на даптейшоне с лр1, выглядит выхлоп хорошо, но с весом в единичку модель начисто забывает всё, что знала о чём-либо, кроме темы обучения. Это фиксится как-нибудь? Пробовал сбрасывать лр и обучать короче — просто получаю недообученный выхлоп. Всё или ничего, короче, получается.
Ещё вопрос. Можно ли как-то снизить степень с которой забирается стиль с датасета при обучении персонажу? Прописывать пробовал в промптах, но чот не сильно помогает.
А рег имги влияют на стиль? Я так понял, что их не используют при обучении стилю, ето так? Пробовал с ними и без них и как-то не особо пока понял как они влияют.
> Это фиксится как-нибудь?
Построй грид из эпох и весов и посмотри какая вышла более удачной с весом 1, не всегда будет идеальной именно последняя эпоха.
> Можно ли как-то снизить степень с которой забирается стиль с датасета при обучении персонажу?
Проще всего разбавлять датасет другими стилями, если у тебя все картинки одного персонажа от одного художника, сетка с большей вероятностью начнёт рисовать в его стиле. Всё в этом плане просто, хочешь стиль - собирай разных персонажей в одинаковой рисовке, персонажа - одного в разных.
> А рег имги влияют на стиль? Я так понял, что их не используют при обучении стилю, ето так?
Я так и не видел чтобы кто то использовал успешно реги, да и с ними тренить дольше, ведь на них тоже нужны повторения.
> Я так и не видел чтобы кто то использовал успешно реги
Опять гайды пиздят штоле...
> Построй грид из эпох и весов и посмотри какая вышла более удачной с весом 1
Да, так и начал делать уже, но уже с самых первых эпох выходит, что надо вес до 0.5-0.6 опускать, чтоб было хоть на что-то похоже. Что-то я делаю не так.
Ты какой лр с дадаптом ставишь? 1.0?
мимо
Да, 1. Пробовал 0.5, но хуже получилось.
> Опять гайды пиздят штоле...
Я видел только один гайд где про реги более менее что то было написано, сам с ними не тренил, точно сказать не могу про них. Без них стиль и персонажи нормально получаются.
> Да, так и начал делать уже, но уже с самых первых эпох выходит, что надо вес до 0.5-0.6 опускать, чтоб было хоть на что-то похоже. Что-то я делаю не так.
Лучше просто покажи все настройки и грид, с дадаптом кстати не совсем понятно насчет разделения лров, во второй версии это уже не работает, в предыдущих же вроде принимает разные, но выставляет ли для те и юнета хз. Ещё он походу недетерменированный, как с адамом две одинаковые сетки не получатся.
Запустил сейчас без регов прожариться, а то я в последние разы с ними тестил. Может, в них проблема.
>настройки
{
"base_model": "D:/StableDiffusion/Lora Easy Training Script/model/model.safetensors",
"img_folder": "D:/StableDiffusion/Lora Easy Training Script/images/",
"output_folder": "D:/StableDiffusion/Lora Easy Training Script/_Result",
"save_json_folder": "D:/StableDiffusion/Lora Easy Training Script/json",
"save_json_name": "Character3",
"load_json_path": null,
"multi_run_folder": null,
"reg_img_folder": null,
"sample_prompts": null,
"change_output_name": "CharacterTest",
"json_load_skip_list": null,
"training_comment": null,
"save_json_only": false,
"tag_occurrence_txt_file": true,
"sort_tag_occurrence_alphabetically": false,
"optimizer_type": "DAdaptation",
"optimizer_args": {
"weight_decay": "0.1",
"betas": "0.9,0.99",
"decouple": "True"
},
"scheduler": "constant",
"cosine_restarts": 1,
"scheduler_power": 1,
"lr_scheduler_type": null,
"lr_scheduler_args": null,
"learning_rate": 1.0,
"unet_lr": 1.0,
"text_encoder_lr": 1.0,
"warmup_lr_ratio": null,
"unet_only": false,
"net_dim": 128,
"alpha": 1.0,
"train_resolution": 576,
"height_resolution": null,
"batch_size": 1,
"clip_skip": 1,
"test_seed": 23,
"mixed_precision": "fp16",
"save_precision": "fp16",
"lyco": false,
"network_args": null,
"num_epochs": 60,
"save_every_n_epochs": 1,
"save_n_epoch_ratio": null,
"save_last_n_epochs": null,
"max_steps": null,
"sample_sampler": "ddim",
"sample_every_n_steps": null,
"sample_every_n_epochs": null,
"buckets": true,
"min_bucket_resolution": 320,
"max_bucket_resolution": 960,
"bucket_reso_steps": null,
"bucket_no_upscale": true,
"shuffle_captions": false,
"keep_tokens": null,
"token_warmup_step": null,
"token_warmup_min": null,
"weighted_captions": false,
"xformers": true,
"cache_latents": true,
"cache_latents_to_disk": false,
"random_crop": false,
"flip_aug": true,
"v2": false,
"v_parameterization": false,
"gradient_checkpointing": false,
"gradient_acc_steps": null,
"noise_offset": 0.06,
"multires_noise_iterations": null,
"multires_noise_discount": 0.3,
"mem_eff_attn": false,
"min_snr_gamma": 5.0,
"huggingface_repo_id": null,
"huggingface_repo_type": null,
"huggingface_path_in_repo": null,
"huggingface_token": null,
"huggingface_repo_visibility": null,
"save_state_to_huggingface": false,
"resume_from_huggingface": false,
"async_upload": false,
"lora_model_for_resume": null,
"save_state": false,
"resume": null,
"text_only": false,
"vae": "D:/StableDiffusion/Lora Easy Training Script/model/VAE.pt",
"log_dir": null,
"log_prefix": null,
"log_with": null,
"log_tracker_name": null,
"wandb_api_key": null,
"tokenizer_cache_dir": null,
"dataset_config": null,
"lowram": false,
"no_meta": false,
"color_aug": false,
"use_8bit_adam": false,
"use_lion": false,
"caption_dropout_rate": null,
"caption_dropout_every_n_epochs": null,
"caption_tag_dropout_rate": null,
"prior_loss_weight": 1,
"max_grad_norm": 1,
"save_as": "safetensors",
"caption_extension": ".txt",
"max_clip_token_length": 150,
"save_last_n_epochs_state": null,
"num_workers": 1,
"persistent_workers": true,
"face_crop_aug_range": null,
"network_module": "sd_scripts.networks.lora",
"locon_dim": null,
"locon_alpha": null,
"locon": false,
"sample_every_n_epoch": 1,
"list_of_json_to_run": null
}
> Запустил сейчас без регов прожариться, а то я в последние разы с ними тестил. Может, в них проблема.
Вполне возможно.
Слишком много эпох, сколько у тебя пикч х повторов на эпоху без регов? Алсо не знаю насколько это хорошо тренить с дадаптом и низкой альфой, вроде у одного анона плохие результаты были. Если железо тянет, ставь лучше бф16, батч сколько влезет и альфу 1/4, 1/2 или вовсе равную диму, дадапт может завысить слишком сильно лр в таком огромном соотношении дим к альфе.
>Слишком много эпох
Для теста поставил побольше же, там двести пикч без повторов.
>не знаю насколько это хорошо тренить с дадаптом и низкой альфой
Ну, я по этому гайду поставил единичку: https://rentry.org/59xed3#dadaptation
Можно будет её дальше подёргать значит.
>бф16
На 2070, я так понимаю, не взлетает.
>батч сколько влезет
Всё, что влезло...
> Для теста поставил побольше же, там двести пикч без повторов.
Как по мне всё равно много, ну смотри сам.
> Ну, я по этому гайду поставил единичку: https://rentry.org/59xed3#dadaptation
Во, да это неплохой гайд, я в нём про реги и читал, там очень замудрённо, ты всё как там делал?
> Можно будет её дальше подёргать значит.
Если бф16 поставить не можешь, лучше не дёргай с единицы, чем больше поставишь тем больше будет мертвых тензоров. Однако чем она больше, тем лучше тренируется стиль, по крайней мере из того что я пробовал. Впринципе я видел дохуя лор с фп16 128/128 годных с точки зрения генераций а не циферок, несмотря на мертвые тензоры, так что опять же думай сам насчёт этого рычага.
> На 2070, я так понимаю, не взлетает.
Вроде только с 3000 серии.


Ну, в общем, проблема воспроизводится, на весе 0.6 неплохая лора выходит ощемто, только эпок поискать удачный. Но вес выше - кровь-кишки. Причём на совсем разных сетах картина примерно одинаковая.
Ну вот, а я уверовал в современные технологии и хотел, чтобы дадапт всё за меня сделал, эх.
> там очень замудрённо, ты всё как там делал?
Да вряд ли, я в него как в справочник просто заглядываю.
Но без регов стало лучше, да.
> про реги
А ну да, реги рандомные у меня, хардкорный вариант по этому гайду не делал.
> эпок
Только не говори что ты ещё следуешь и этому гайду-изинегативу от хруста. Перестань, если да, и сделай лучше по гайду из шапки, который поновее, персонажа он тебе точно поможет сделать. Ну или по тому, который ты скидывал, хотя он действительно больше как справочник с информацией для тех кто уже смешарик и натренил хотя бы пару успешных лорок.
> Ну вот, а я уверовал в современные технологии и хотел, чтобы дадапт всё за меня сделал, эх.
У тебя сетка взрывается со второй эпохи, если вообще не с первой, и не тренируется плавно, ты смотрел какой лр выбрал дадапт? Вангую он слишком огромен, такого происходить не должно, повышай альфу или вручную ставь лр с адамом. И не трень 60 эпох, это бессмысленное жжение карты, 20 уже будет оверфитом, если вообще не 10, в случае с твоими параметрами.
> гайду-изинегативу от хруста
Впервые слышу
> по гайду из шапки
Окей, буду сверяться.
> У тебя сетка взрывается со второй эпохи
Ага, так вот что тут происходит.
> ты смотрел какой лр выбрал дадапт?
Да чот изискрипт не пишет ничего кроме лоса в процессе, без понятия. Но он подозрительный, к слову, с первых шагов 0.9 и очень низкие вариации.
> повышай альфу или вручную ставь лр с адамом
Звучит как план, спасибо.
> Но он подозрительный, к слову, с первых шагов 0.9 и очень низкие вариации.
Если ты такой лосс видишь, можешь сразу останавливать, там всё подохло моментально. Скорее всего виноват лр. Какой бы плохой датасет не был, не должна сетка на первых шагах взрываться.
Логи можешь смотреть введя в консоль в папке с сд скриптс venv\scripts\activate.bat и потом tensorboard --logdir "здесь путь к папке", папку надо указать и логирование включить в параметрах, чем бы ты там не тренил.
Как исправить ошибку:
NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
Я на твоем месте таки вернулся в диапазон 0.3-0.5 и скрутил бы резолюшн до 512 что бы бс 2 влезло для тестов.
Алсо, можешь залить датасет, попробую повторить когда/если будет не лень/не забуду.
У тебя в самой ошибке написано решение. Ну и только по ошибке нихуя не понятно, предоставляй полную инфу когда, где, на чем и с чем это случается.
>Ну, я по этому гайду поставил единичку: https://rentry.org/59xed3#dadaptation
В чем преимущества этой штуки по сравнению с обычной тренировкой?
Что-то из того раздела непонятно, зачем оно вообще надо.
Только чтоб лр не крутить? Так базовые значения из скриптов обычно хорошо работают.
Есть какая-нибудь штука для быстрого и массового удаления с изображений ватермарок, логотипов, ссылок, и прочей подобной фигни?
Чтоб оно при тренировке лоры внутрь не пролезало.
Понятно, что через негативы в промпте при генерации потом это можно убрать, но хотелось бы чтоб лора чистая была.
Чтоб оно при тренировке лоры внутрь не пролезало.
Понятно, что через негативы в промпте при генерации потом это можно убрать, но хотелось бы чтоб лора чистая была.
Я ничего нормально рабочего так и не нашел, поэтому в фотошопе вручную стираю инструментом "Заплатка" (Spot Healing Brush tool (J))
Вручную, блин, долго.
Я уже для своих лор сотен восемь картинок так обработал - запарился, если честно. Нужно автоматизировать процесс.
Самая жесть была, когда я решил на артах с пиксива художника потренить. Красиво рисует.
Так на пиксив без цензуры нельзя арты постить.
И чтоб эта мозаика в лору не пролезла - пришлось этак 80% датасета (200 с гаком картинок) через инпэинт прогонять, чтоб нейронка мне вместо цензуры хотя бы что-то мало-мальски похожее нарисовала.
Цельный день на это убил.
>гиперреальность
Это как?

Вопрос. Имеется коллекция состоящая из примерно 8000 closeup фотографий женских клиторов. Как натренировать лору так, чтобы я мог её использовать при генерации full body изображений? Сейчас такая лора либо генерирует всратые closeup фотографии, либо всрато работает с инпейнтом. Или может есть какие-то специальные настройки и теги, чтобы хотя бы нормально работал инпейнт?
Ты мерзкий
> Только чтоб лр не крутить? Так базовые значения из скриптов обычно хорошо работают.
Да, именно для этого. Он просто сделает хорошо, если датасет нормальный и остальные параметры выставлены правильно, иногда можно сделать лучше выставляя лр вручную через адам.
Тот гайд обновился автором и он подтвердил кстати что это не детерминированный оптимайзер.
Везде с обрубками пальцев. Выкинь нахуй это говно.
Пальцы можно обрезать или замазать. Интересует сам процесс тренировки. Есть же лоры на глаза и они норм работают. Хочу сделать такую же, только на пёзды/клиторы.
Сижу с регами экспериментирую и у меня полное ощущение, что они тупо пополняют датасет.
Нагенерил в качестве регов нужного персонажа, добавив в промпт, чтобы глаза светились — обучаю заново с ними и наблюдаю, как у выхлопной лоры у чара начинают светиться глаза.
Это законно?
Нагенерил в качестве регов нужного персонажа, добавив в промпт, чтобы глаза светились — обучаю заново с ними и наблюдаю, как у выхлопной лоры у чара начинают светиться глаза.
Это законно?
Хотел бы - сделал. Не понимаю смысла твоего пиздежа. Тред с готовыми лорами ниже.


ЧТО СЛУЧИЛОСЬ СО СТАРЫМ СКРИПТОМ LOOPBACK? КУДА ОН ДЕЛСЯ??




сорри, зря возбухнул.
но вышло угарно.
но вышло угарно.
>Я на твоем месте таки вернулся в диапазон 0.3-0.5
Да, ты во всём прав. Что ж такого надо сделать, чтобы дадапт нормально на дефолтной единице учил, как-то неебически протегать сет штоле.
Как лучше всего сделать бенчмарк чтобы протестить скорость генерации и сравнить с другими на каком-нибудь стандартном примере? У меня картинка 1000х1500 генерится примерно 30сек, но там большой промпт и хайрез фикс.
Простой промпт, невысокое разрешение (512, 640, 768), и батч из 50 картинок.
У меня вопрос по VAE, почему их никто не делает? На цивитаи раздела даже такого нет.
error: Your local changes to the following files would be overwritten by merge:
scripts/xyz_grid.py
Please commit your changes or stash them before you merge.
Aborting
Чем лечить, скажите пожалуйста.
scripts/xyz_grid.py
Please commit your changes or stash them before you merge.
Aborting
Чем лечить, скажите пожалуйста.
Удали файлик, на который ругается. Ты вручную его правил, наверное.
Почему не делают, почему нет категории, прикладывают к своим моделям вае. Приличное количество разных.
Котаны, никто не пробовал обучать модель по стикерам? А то у меня есть пак стикеров на 30, хочу сделать в том же стиле другие. А художник пропал.


Как вернуть всё взад? Раньше был пикрил 1, стало пикрил 2.
VAE стоит, экстеншены выключал. Может что-то в настройках кликнул, но я не знаю.
Больше всего грешу на обновившийся 16 часов назад Автоматик, но на гитхабе, здесь и на форче через ctrl+f нет особо вони.
Что это может быть?
VAE стоит, экстеншены выключал. Может что-то в настройках кликнул, но я не знаю.
Больше всего грешу на обновившийся 16 часов назад Автоматик, но на гитхабе, здесь и на форче через ctrl+f нет особо вони.
Что это может быть?
Интересно. Вае точно не менял?
Точно. Когда вырубаю, становится ещё хуже.
Ща откатил обнову (скачал старую и скопировал с заменой в директорию с стейблом).
Ещё, переустановил торч и иксформерс, но cuda не трогал. Мб оно? Но так впадлу его качать с впн
Имеется ввиду, что это не дало эффекта
Хочу сдохнуть. Переустановил SD и оно не пофиксилось


> Всмысле с козырей, я просто юбку нормальную хочу, а не девочку с сюрпризом не то чтобы я прямо против насчёт таких сюрпризов как на пик2, но всё же.
Да чет сложно это, я со своим микробрейном хз. Алсо, не понял сюрприза там вроде третья нога есть?
> А что кстати с очками не так и вуалью, те же проблемы? Так то многое уже очень прилично тренируется, единственное что сложно это вот такие штуки на втором плане, закрытые чем то.
С очками где-то видел что пару раз жаловались, сам чето с очками тоже тренил, но это было давно и неправда. С вуалью на циве какая-то лора лежала, с прозрачными вуалями резалт неочень был, да и автор сам жаловался емнип.
Хотя это мб skill issue, лол.
> Падажжи, а зачем оно нужно то? В репе только код ищется по cache.
Что бы сократить время ожидания, хз. Если модель, шаги инверсии, ретушь, промт и размер пикчи не менялись, то во второй раз кеш сработает. Ну т.е. денойз крутить можно например. Хороший вопрос вообще, я как-то не вижу особого профита пока, ну да быстрее значительно, но только денойз крутить не весело. Лучше бы он поддержку xyz плота запилил.
> https://github.com/kohya-ss/sd-scripts/pull/243
Не пробовал еще?
> тренить с огромным димом
Пик 1.
> то что я там собрал с цикликом это забей, можешь ради рофла построить на 1000 шагов в матплотлибе график, там полный обсёр, он только на 160 и работает, лол.
Да торчевский циклик вроде работает ас интендед, если параметры скорректировать, пик 2. А вот у торчевского косин аннеалин варм рестартс я чет не заметил варм рестартов.
> Однако с этим в тестовой среде твоей небольшие проблемы, лр начинается не с 0 а с начальных значений при вармапе
Пофиксил по твоему примеру так сказать. Однако в этой реализации глобальный вармап всратоват. Я еще вармапы для циклов кое-как наполовину присрал пик 3. И теперь думаю что наверное легче было разлепить лры в предыдущем варианте.
Алсо, там еще проблема была в том что в мейн, гет_ласт_лр вызывается до оптимайзера и шедулера, и из-за этого оно получало инит лр, ща перенес ниже, у кои емнип так же в тренинг залупе. Ну фактически это влиять не должно вроде.
Сейчас проблема в том что "линия" вармапа циклов "срезает" косинусы, надо с шагами внутри циклов что-то сделать. И так же из-за того что оффсет присран фактором, амплитуда уменьшается по шагам.
Хз как сделать нормально вобщем. https://mega.nz/file/KZkSAajZ#qy4KCohBUmJUMVLiSPn7S6AiaQD97nhhrAB7uJnEXsQ
> Эх, ну и нахуя я этого художника тренил если он уже на гейщите лежит, поздно увидел.
Пару минут думал при чем тут гейшит импакт, а потом как понял.
Алсо, есть подозрения что коя таки обосрался с дилорой https://github.com/kohya-ss/sd-scripts/issues/394#issuecomment-1533935548
Алсо, ты dadaptadan не пробовал?
Попробуй weight_decay увеличить до 0.02-0.04
Залей обе пикчи на кэтбокс
Хорошая картинка: https://files.catbox.moe/414mli.png
Плохая картинка: https://files.catbox.moe/vjb2r3.png
У второй негатив промпт другой немного ввиду того, что я негативные эмбединги другие поставил.
Пикча существовала для превьюшки для чекпоинта.
Просто не должно быть такой разительной разницы.
Проблема со всеми генерациями, а не только с этими.
У тебя там разгые модели и разный cfg
> У второй негатив промпт другой немного ввиду того, что я негативные эмбединги другие поставил.
>[N]_bad-hands-5,[N]_easynegative,
Почему там [N]_?
Я для сортировки их поотмечал. [N] = негативный
У меня раньше лучше бы получилось даже без негатив промпта, чем сейчас с ним


У тебя явно негативные эмбеддинги не подгружаются. Если удалить их из промта, то у меня такая же хуйня выходит.
Ты просто имена файлов переименовал? Так не будет работать, слово-триггер забито в сам эмбеддинг.
Спасибо, что потестил.
Да, наверное не подгружаются. Но мне кажется, что есть что-то ещё.
Вчера всё работало нормально. Среди файлов ничего не трогал до сегодняшнего момента, когда поставил пару экстеншенов
Окей, спасибо с этим. Потом протестирую.
Но сейчас основная проблема явно в другом. Слишком уж херово генертит оно
У тебя после генерации под изображением написано "Used embeddings: bad-hands-5 [10ca], EasyNegative [119b]" ?
Не, не написано. Видимо, это я идиот. Сейчас скачаю нормальные и заново протестирую. Я думал, что я давно их переименовал и пользовался, а на позавчерашиних картинках такой параши нет
БЛЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯЯ
Какая же я домохозяйка конченная. Проблема была в этом! Мне так стыдно, так стыдно. Я сейчас заплачу.
Спасибо тебе большое, за указание на эту очевидную херню!
Пойду в биореактор
Нубывает, сделай вид что ты так и задумывал, но забыл.
Ты случайно не тот анон, который сяо генерил?
Не, не я. Я вообще первый раз в тредах по стейблу пишу. До этого писал только один раз в CAI треде


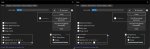

> Не пытайся пробовать латент 0.6
А если бы я реально не стал пытаться? Нормально же работает.
Вареники инпеинтит только в путь, я сразу подметил основной потенциал этой модельки.
> Твоя единственная звездочка, лол.
Не могу прямо не спросить тогда, танкисты хто, хто?
> Да чет сложно это, я со своим микробрейном хз. Алсо, не понял сюрприза там вроде третья нога есть?
Эта нога больше похожа на black white salami.
> Что бы сократить время ожидания, хз. Если модель, шаги инверсии, ретушь, промт и размер пикчи не менялись, то во второй раз кеш сработает. Ну т.е. денойз крутить можно например. Хороший вопрос вообще, я как-то не вижу особого профита пока, ну да быстрее значительно, но только денойз крутить не весело. Лучше бы он поддержку xyz плота запилил.
Я уже попробовал, не прогоняются шаги инверсии ещё раз, можно менять денойз, остальное не пробовал. Правда где 200 шагов я хз, в коде есть в интерфейс 100 осталось.
> Не пробовал еще?
Ну вот пара примеров, первый грид с моей хуйнёй, там 64/64-32/32, ресайз в 32 и 8, стиль сохраняется в целом, глаза теряются походу больше с понижением ранга. Локон ресайзится кстати хуже лоры походу, размеры ~120-55-27.
Второй велл трейнед лора 128/128 с гейщита. Размеры ~150-37-11, кстати они ещё такие, потому что в каждой из этих лор остается превью пикча, с лейзи она вообще вроде 6мб весит. Тензоры мертвые, не удивительно, удивительно что они выпрямляются, хотя для меня не новость что сейв ас бф16 не факапит тензоры, в отличии от фп16, причем именно сейв, и походу лора превращается в локон(?) 12 значений ТЕ пустых с клипом 2 я видел только у локонов, у лор 6.
> Пик 1.
Ты про рам ишшуе? Да не, ты не пони, не обязательно упарываться в два гига или подобные извращения, достаточно рабочих настроек на стиль, 128/128 там как пример, и потом на втором этапе уже срезать не нужное. На первом этапе вся суть в том чтобы туда запихнуть всё что только можно выжать из датасета, для этого и надо побольше места.
> Да торчевский циклик вроде работает ас интендед, если параметры скорректировать, пик 2. А вот у торчевского косин аннеалин варм рестартс я чет не заметил варм рестартов
Да сам то он по себе рабочий, просто те мои параметры что я скидывал дают вот такой пик4.
> Пофиксил по твоему примеру так сказать. Однако в этой реализации глобальный вармап всратоват.
Ну я вообще хуйню наманкипатчил, там жестко в коде теперь прописано [0, 0] лр на первом шаге, он работать будет только с вармапом нормально. Бля картинки не влезают в один пост, в некст глянь пик5.
> Я еще вармапы для циклов кое-как наполовину присрал пик 3. И теперь думаю что наверное легче было разлепить лры в предыдущем варианте.
Не пони, разделить лр в этом шедулере всмысле?
> Хз как сделать нормально вобщем. https://mega.nz/file/KZkSAajZ#qy4KCohBUmJUMVLiSPn7S6AiaQD97nhhrAB7uJnEXsQ
В этой версии фикс не нужен в тестовой среде, работает изначально нормально, а не как на пик6.
> Сейчас проблема в том что "линия" вармапа циклов "срезает" косинусы, надо с шагами внутри циклов что-то сделать. И так же из-за того что оффсет присран фактором, амплитуда уменьшается по шагам.
Ну я тоже хз, это не выглядит на пик7 как нормальный вармап в цикле с scheduler = custom_scheduler.CosineAnnealingWarmupRestarts(optimizer, T_0=424, gamma_min_lr=1, decay=0.8, down_factor=0.4, warmup_steps=50, cycle_warmup=50, init_lr_ground=True), один курс математики по рыбникову с суммированием и счетом древних шизов от меня тут явно не поможет. Пик8 вообще рофл какой то, там warmup_steps=0 только изменён.
> Алсо, есть подозрения что коя таки обосрался с дилорой
Есть в этом конечно что то ироничное что кохья пишет что он не шарит хорошо в матане и ведёт основное репо по тренингу лор. Там ещё один неравнодушный кстати с дадаптом не рабочим с дилорой.
> Алсо, ты dadaptadan не пробовал?
Ты про эти?
https://github.com/kohya-ss/sd-scripts/pull/455
https://github.com/kozistr/pytorch_optimizer
https://pytorch-optimizers.readthedocs.io/en/latest/optimizer_api.html#dadaptadan
Хуясе там тулзов. Почему думаешь что будет лучше чем Dadaptadam?




Кто то пробовал Lion или Lion8bit? Лучше чем Adam?

> > https://github.com/kohya-ss/sd-scripts/pull/243
Забыл кстати, там основная то суть этого пр была в динамическом ресайзе разными алгоритмами, что вроде как убирает старый подсчет веса лоры, где вес~=дим*1.3.
Вот например грид, обычный ресайз, sv_ratio=4 и sv_fro=0.9, не совсем понятно какие туда лучше значения ставить. Веса у файлов примерно такие ~38 обычная, sv_fro ~30, sv_ratio ~29.

Аноны, в колабе WebUI выдает такую ошибку:
>RuntimeError: The size of tensor a (3072) must match the size of tensor b (6144) at non-singleton dimension 1
Шаги:
1) Генерю изображение 512х768
2) Отправляю изображение в Инпайнт, соответсвующей кнопкой
3) Настройки инпайнта пикрил
4) ???
5) Ошибка
Раньше с таким 512х768 разрешением всё инпаинтелось. Правда довольно давно, несколько месяцев назад. Как быть? В чем может быть проблема?
>RuntimeError: The size of tensor a (3072) must match the size of tensor b (6144) at non-singleton dimension 1
Шаги:
1) Генерю изображение 512х768
2) Отправляю изображение в Инпайнт, соответсвующей кнопкой
3) Настройки инпайнта пикрил
4) ???
5) Ошибка
Раньше с таким 512х768 разрешением всё инпаинтелось. Правда довольно давно, несколько месяцев назад. Как быть? В чем может быть проблема?
Сколько по времени генерация в общем занимает? У меня если больше 17 минут - вырубается колаб.
Хз быстро, зашел, сгенерил, получил ошибку - побежал в гугл - хуй, прибежал в тред - и вот я здесь.
Полный текст ошибки из консоли покажи
Traceback (most recent call last):
File "/home/pc/Desktop/stable-diffusion-webui/modules/call_queue.py", line 57, in f
res = list(func(args, kwargs))
File "/home/pc/Desktop/stable-diffusion-webui/modules/call_queue.py", line 37, in f
res = func(args, kwargs)
File "/home/pc/Desktop/stable-diffusion-webui/modules/img2img.py", line 181, in img2img
processed = process_images(p)
File "/home/pc/Desktop/stable-diffusion-webui/modules/processing.py", line 515, in process_images
res = process_images_inner(p)
File "/home/pc/Desktop/stable-diffusion-webui/modules/processing.py", line 604, in process_images_inner
p.init(p.all_prompts, p.all_seeds, p.all_subseeds)
File "/home/pc/Desktop/stable-diffusion-webui/modules/processing.py", line 1106, in init
self.image_conditioning = self.img2img_image_conditioning(image, self.init_latent, image_mask)
File "/home/pc/Desktop/stable-diffusion-webui/modules/processing.py", line 260, in img2img_image_conditioning
return self.inpainting_image_conditioning(source_image, latent_image, image_mask=image_mask)
File "/home/pc/Desktop/stable-diffusion-webui/modules/processing.py", line 243, in inpainting_image_conditioning
image_conditioning = torch.cat([conditioning_mask, conditioning_image], dim=1)
RuntimeError: Sizes of tensors must match
Я уже всё закрыл и комп вырубил, не могу сейчас опять пойти и за ошибкой, а это выше - точно такая же ошибка у другого челика с форума. Там 0 ответов.
Поясни, EasyNegative это хорошо или плохо?
Ситуативно. В каких-то случаях хорошо работает, в каких-то всё портит.
> А если бы я реально не стал пытаться? Нормально же работает.
Ну видимо я версии попутал, с какого-то момента уже забил на названия, т.к. они получались слишком длинными. Там где-то дикий шок контент получался, лол
> Вареники инпеинтит только в путь, я сразу подметил основной потенциал этой модельки.
Емнип я на этого рисобаку как раз и обратил внимание из-за вареников.
> Не могу прямо не спросить тогда, танкисты хто, хто?
Пид... дегенераты?
> Правда где 200 шагов я хз, в коде есть в интерфейс 100 осталось.
Ui config удоли и кеш костыля мб еще. Я с этого уже несколько раз горел. Не так давно адетейлер апдейтнулся, там автор шебуршил со стейтами включения, и после череды апдейтов адетейлер оставался всегда включенным после запуска вебюи, хотя в коде прописано обратное.
> глаза теряются походу больше с понижением ранга
Это с white eyes в позитивах?
> Тензоры мертвые, не удивительно, удивительно что они выпрямляются, хотя для меня не новость что сейв ас бф16 не факапит тензоры, в отличии от фп16, причем именно сейв, и походу лора превращается в локон(?) 12 значений ТЕ пустых с клипом 2 я видел только у локонов, у лор 6.
Действительно удивительно, но полагаю что проебанная изначально инфа не появится из ниоткуда, скорее какой-то решейп(?). Число модулей в тензорчеке тоже меняется?
Вообще так-то заебись результат для дим 8. Лорка на ушияму одна из моих любимых кстати.
Алсо, вспомнил тут что кэтбоксанон делал скрипт для миграции ликорисов в новую папку, стало интересно как он их отличал, посмотрел, а там по нетворк модулю в метадате.
> Ты про рам ишшуе? Да не, ты не пони, не обязательно упарываться в два гига или подобные извращения, достаточно рабочих настроек на стиль, 128/128 там как пример
Про врам, да, Да я поне. Просто это реакт на "огромный дим", с таким видел как бмальтаис извращается только, и некоторые лоры на циве огромного размера и сомнительного качества.
> Да сам то он по себе рабочий, просто те мои параметры что я скидывал дают вот такой пик4.
Да там у циклика поведение не совсем ожидаемое если гамму крутить, то он триангуляр, то эксп ренж так сказать.
> Бля картинки не влезают в один пост, в некст глянь пик5.
Я это проверил еще когда ты код кинул.
> Не пони, разделить лр в → этом шедулере всмысле?
Да, в нем. Там просто все есть емнип, кроме раздельных лров. Хотя сложность наверное одинаковая будет. В нем базовый лр это мин лр считай, а в в последней версии наоборот, базовый это макс лр почти, но не прямо, там просто околотак рассчитывается. Т.е. у последнего лры логичнее сделаны имхо.
> В этой версии фикс не нужен в тестовой среде, работает изначально нормально, а не как на пик6.
Ну да, я ж пофиксил.
> Ну я тоже хз, это не выглядит на пик7 как нормальный вармап в цикле
Глобальный вармап с цикловым вместе не работают нормально, только по отдельности. Ну и глобальный всратый. Алсо, ты вместо декея лучше гамму крути, гамма изменяет базовые лры по шагам, а декей изменяет их каждый цикл, без вармапов все ок, а с вармапами и декеем распидорашивает.
> Пик8 вообще рофл какой то, там warmup_steps=0 только изменён.
ТАК ЗАДУМАНО ЭТО СТЕП ШЕДУЛЕР! В формуле есть деление на warmup_steps, поэтому так происходит
> Ты про эти?
Да.
> Хуясе там тулзов. Почему думаешь что будет лучше чем Dadaptadam?
Да я не думаю что будет лучше, вернее не предполагаю будет ли он лучше или хуже в наших задачах. Невольно наткнулся на парочку материалов по адану и стало интересно.
https://github.com/facebookresearch/dadaptation/issues/14
https://wandb.ai/capecape/adan_optimizer/reports/Adan-The-new-optimizer-that-challenges-Adam--VmlldzoyNTQ5NjQ5
И еще картинки от какого-то шиза
https://github.com/bmaltais/kohya_ss/issues/770
Обожаю игры "найди 10 отличий", сукпздц.




Model merge чекпойнты
Meinamix + mistoon =A
Corestyle + seekyou =B
A+B =C
С моделью laolei каломатик крашится, OOM в рантайме
Meinamix + mistoon =A
Corestyle + seekyou =B
A+B =C
С моделью laolei каломатик крашится, OOM в рантайме


> Ну видимо я версии попутал, с какого-то момента уже забил на названия, т.к. они получались слишком длинными. Там где-то дикий шок контент получался, лол
У тебя может она два раза применилась? Короче этот баг как то связан с переходами между и2и и т2и, может применятся два раза, может не применятся, может терять лорки из нескольких.
> и кеш костыля мб еще
А где он? Или ты про пук файлы?
> Я с этого уже несколько раз горел. Не так давно адетейлер апдейтнулся, там автор шебуршил со стейтами включения, и после череды апдейтов адетейлер оставался всегда включенным после запуска вебюи, хотя в коде прописано обратное.
Ладно, это сработало энивей, некст тайм попробую с этого начать если в уи что то пойдёт по пизде.
Ты кстати обновлялся до последней версии или там щитшторм?
> Это с white eyes в позитивах?
Да, они не самое сильное звено этой модели, если начать их веса крутить может страшное происходить. Хз короче, 32 кажется нормальной точкой для ресайза, 8 как то как будто начинает терять слишком много информации, выглядит как 10 эпоха примерно. А у этого локона разница в 10 мб между 32 и 8, диминишинг ретурнс. Возможно, так можно оверфиты фиксить?
> Действительно удивительно, но полагаю что проебанная изначально инфа не появится из ниоткуда, скорее какой-то решейп(?). Число модулей в тензорчеке тоже меняется?
Оригинал 528, кстати там последний слой ТЕ всё таки имеет 12 строк значений, хз почему так, то-есть никакого превращения в локон нету походу. Обычный ресайз 528, да и не обычный тоже. Жаль, но я не знаю точно как это работает, мне лишь очевидно что нулевые значения точно идут первыми под срез, так как их попросту нету. Так же заметил что многие слои в логах имеют нестандартные димы, например в одной и той же строке:
Оригинал 128 - (128-320)
Обычный ресайз 32 - (32-320)
sv_fro0.9 32 - (14-320)
Дим этого слоя в динамическом ресайзе стал 14.
> Вообще так-то заебись результат для дим 8. Лорка на ушияму одна из моих любимых кстати.
Ну да, неплохой, но лучше всё таки 32 думаю. Мне лорка ушиямы тоже нравится.
> Алсо, вспомнил тут что кэтбоксанон делал скрипт для миграции ликорисов в новую папку, стало интересно как он их отличал, посмотрел, а там по нетворк модулю в метадате.
https://gist.github.com/catboxanon/42ce1edae54748274b4616780bdbeb9d#file-migrate_lycoris-py-L48
Не понял прикола, типо дилора не локон? А вообще сегодня разгребал помойку с лорами и ликорисами, заодно делал превьюхи, до этого просто имел симлинк папки с лико на лоры, хуёво что они впринципе разделены. Единственные полезные вещи это вообщем то лора и локон как по мне на данный момент, лоха не хочет работать через адднет и вообще получаются какими то более всратыми чем локоны, дилора ну ты знаешь.
> Про врам, да, Да я поне. Просто это реакт на "огромный дим", с таким видел как бмальтаис извращается только, и некоторые лоры на циве огромного размера и сомнительного качества.
Я не вижу особо смысла бежать за мифическими настройками на хай димах, там же лр надо другой полюбому, судя по тому гайду там лёрн дамп произойдёт с 128 до даже 256, можно конечно попробовать по приколу как нибудь, только смысла в этом ну совсем нихуя, что не влезет 128(а что собственно туда не влезет?) можно в локон запихнуть.
> Да, в нем. Там просто все есть емнип, кроме раздельных лров. Хотя сложность наверное одинаковая будет. В нем базовый лр это мин лр считай, а в в последней версии наоборот, базовый это макс лр почти, но не прямо, там просто околотак рассчитывается. Т.е. у последнего лры логичнее сделаны имхо.
Ну если получится ещё и для циклов сделать отдельный вармап будет вообще заебись конечно.
> Глобальный вармап с цикловым вместе не работают нормально, только по отдельности. Ну и глобальный всратый.
Всмысле всратый, обычный же. Он нужен вначале, там же бешеная хуйня с сеткой творится может сразу на огромном лр, вон как у анончика выше например, хотя у него не в вармапе явно проблема. Даже дадапт про это в курсе, и начинает с очень лайтового лр.
> Алсо, ты вместо декея лучше гамму крути, гамма изменяет базовые лры по шагам, а декей изменяет их каждый цикл, без вармапов все ок, а с вармапами и декеем распидорашивает.
Ладно, вроде scheduler = scheduler_v2.CosineAnnealingWarmupRestarts(optimizer, T_0=424, gamma_min_lr=0.99945, decay=1, down_factor=0.5, warmup_steps=50, cycle_warmup=0, init_lr_ground=True) даёт такой же результат.
> ТАК ЗАДУМАНО ЭТО СТЕП ШЕДУЛЕР! В формуле есть деление на warmup_steps, поэтому так происходит
О, так я что на ноль поделил и вышел сухим из воды получается? А как питухон то не выплюнул эксепшен, он же должен когда на ноль делится, нигде вроде перехватов нету.
> Adan is currently a SOTA optimizer.
Что то выпал прямо со второго предложения. Ладно, не выпал.
Ну ценой врам и чуть меньшей производительностью можно получить более лучшую точность я так понял. Надо будет запомнить этот инструмент.
У меня на самом деле проблема абсолютно противоположная(проблема ли? всё же получается). Лосс со второй же эпохи после вармапа на моих датасетах был что то типо 0.04-0.07, я думал эта хуйня оверфитнется сразу, но вроде нормас. Я даже по фану срать в датасет специально начал, лол, всё равно больше 0.1 не поднялось. Вспоминаются что то старые 0.3, 0.4 коммиты кохьи, там же вообще в порядке вещей было что то типо 0.15-0.2 даже на вылизанных датасетах. Это кохья так постарался интересно или min_snr_gamma так решает? Хотя походу и то и другое, я помню как пердолило тогда левый верхний график тензорборда, сейчас даже без гаммы нормально.
Вообщем хз, он типо даст большую точность, врам там почти одинаково отъедает, а вот по времени прямо как то сильно дольше.
Аноны что значит такой синтаксис.
<lora:LORANAME:0,9>
0,9 между цифрами не точка, а запятая. Случайно опечатался и результат получился очень хороший. А что конкретно это значит не понимаю.
<lora:LORANAME:0,9>
0,9 между цифрами не точка, а запятая. Случайно опечатался и результат получился очень хороший. А что конкретно это значит не понимаю.
Отбой разобрался. Этот синтаксис просто вызывает ошибку из за которой все остальные лоры не грузятся. Понасрал я лорами больше чем промптов.
Windows vs Linux(native not WSL) для SD? Удобство, скорость, стабильность?
>СКРИПТОМ LOOPBACK?
А для чего он нужен?
Ку ребзя! Следующий вопрос. Возможно ли модель к которой примержены лоры сделать half safetensors чтоб и мало весила и лоры не слетели и как такое сделать?

> У тебя может она два раза применилась?
Хм, возможно.
> Или ты про пук файлы?
Да, про них. Про РУС файлы.
> Ты кстати обновлялся до последней версии или там щитшторм?
Обновился вчера, но практически не щупал. Сразу же перелез на дев бранч что бы пощупать https://github.com/ashen-sensored/sd_webui_SAG но тоже не пощупал. Что бы этот костыль работал, нужен фикс, который сейчас в дев замержили https://github.com/ashen-sensored/sd_webui_SAG/issues/13#issuecomment-1546788070
Костыль вроде работает, но в итоге так нихуя и не пощупал нормально. Вообще надо было пр чекаут сделать.
Бтв там еще и пр с томе наконец-то замержили в дев со значением по умолчанию 0.6, минут 5 искал что насрало в детерминированность
Ну собсна на деве у меня при запуске юи, вае отваливается, надо перевыбирать. Метадата в имеж браузере имеет бесконечную загрузку, импорт при этом частично работает, значения хрфикса не импортируются. С инфинайт имеж браузером импортируются, но блок хрфикса не сворачивается при его выключении.
> Хз короче, 32 кажется нормальной точкой для ресайза, 8 как то как будто начинает терять слишком много информации, выглядит как 10 эпоха примерно. А у этого локона разница в 10 мб между 32 и 8, диминишинг ретурнс.
Было бы заебись сдуть размер всех лор так-то. Папка с лорами онли 90 гигов уже у меня.
> Возможно, так можно оверфиты фиксить?
Надо попробовать.
> Дим этого слоя в динамическом ресайзе стал 14.
Кажется мне надо пойти почитать где-нибудь детейлед экспланейшон что такое дим, не просто ведь размерность.
> Не понял прикола, типо дилора не локон?
Он скорее не стал разбираться с этим, хех.
> Всмысле всратый, обычный же.
Он там нелинейный емнип и тоже срезает косинусы, т.е. фактический макс лр первого цикла не является базовым лром.
> Даже дадапт про это в курсе, и начинает с очень лайтового лр.
Я кста предполагал что это период расчета лра.
> О, так я что на ноль поделил и вышел сухим из воды получается? А как питухон то не выплюнул эксепшен, он же должен когда на ноль делится, нигде вроде перехватов нету.
А я хуй знает. Должен быть эксепшен т.к. там операция 0/0 получается в таком случае, а его нет, и код из условия с основной формулой просто не выполняется.
Алсо, поменяй там условие под коммом про присер вармапов на
if self.T_cur < self.cycle_warmup and self.last_epoch > self.warmup_steps:
Это подружит глобал вармап с цикловым. Пиздец осознавать какой-же я тупой местами.
Пик 1: CosineAnnealingWarmupRestarts(optimizer, T_0=250, gamma_min_lr=0.99945, decay=1., down_factor=0.5, warmup_steps=50, cycle_warmup=20, init_lr_ground=True)
> Надо будет запомнить этот инструмент.
Ты про Hyperparameter Sweep? Я от него охуел как удобно с бетами получилось там и наверное как долго будет в кейсе тренировки лор.
> Вспоминаются что то старые 0.3, 0.4 коммиты кохьи, там же вообще в порядке вещей было что то типо 0.15-0.2 даже на вылизанных датасетах.
Хм, если мне не изменяет память, а память у меня плохая, на моих датасетах на 0.3 и 0.4.5 лосс где-то 0.7-0.8 болтался, а с датасетами я особо не заебывался.
Алсо, вообще по лоссу хуй пойми что там у тебя получилось, кое как только по динамике его изменения. Есть такая штука как валид лосс, для его вычисления нужен набор семплов из датасета что-то типа регов? и с его добавлением график легче читать.
https://www.baeldung.com/cs/training-validation-loss-deep-learning
Есть ли у нас такое вообще, хз.
А коэфы? Алсо, ты не пробовал https://github.com/s1dlx/sd-webui-bayesian-merger ?
Он несколько раз прогоняет пикчу в и2и.
> Возможно ли модель к которой примержены лоры сделать half safetensors чтоб и мало весила
Да https://github.com/arenasys/stable-diffusion-webui-model-toolkit
> и лоры не слетели и как такое сделать?
Почему ты решил что смерженные лоры слетят?
Никто не в курсе, придумали ли уже какой-то способ конверсии лор из типа в тип, пусть и с потерей данных?
Хочу замерджить парочку между собой, но они в разных типах, заразы.
Хочу замерджить парочку между собой, но они в разных типах, заразы.


> Сразу же перелез на дев бранч что бы пощупать https://github.com/ashen-sensored/sd_webui_SAG но тоже не пощупал.
Интересно, а что это вообще такое? Начитался что это может улучшить качество картинки применяя выборочный блюр на области нуждающиеся в детализации. Попробовал, правда в владомантике с недетерминированным выхлопом, ну хз что сказать, как потестить лучше? Рожу так и не пофиксило, лол, хотя вроде как должно было, понятное дело что тут адетейлер или просто инпеинт нужен, но остальное вроде неплохо причесал.
> Бтв там еще и пр с томе наконец-то замержили в дев со значением по умолчанию 0.6, минут 5 искал что насрало в детерминированность
Эта хуйня вообще по дефолту для хайреза была у владомантика включена кстати.
Ты случайно не знаешь как владомантик настроить чтобы он выдавал детерминированные результаты? Неужели с ним иксформерс вот так работает, почему у автоматика тогда можно повторять один в один картинки?
Кстати дропдауны в плоте поадекватнее у владомантика будут.
> Ну собсна на деве у меня при запуске юи, вае отваливается, надо перевыбирать. Метадата в имеж браузере имеет бесконечную загрузку, импорт при этом частично работает, значения хрфикса не импортируются. С инфинайт имеж браузером импортируются, но блок хрфикса не сворачивается при его выключении.
Эх, Балодька. Ну поправит же до релиза да? Хуй там поправит, серьёзные баги с каждым релизом с середины марта только растут.
> Было бы заебись сдуть размер всех лор так-то. Папка с лорами онли 90 гигов уже у меня.
Угу, я тоже хочу так сделать, потом скрипт напишу.
> Кажется мне надо пойти почитать где-нибудь детейлед экспланейшон что такое дим, не просто ведь размерность.
Я вот такое видел обсуждение https://github.com/cloneofsimo/lora/discussions/37 но оно ещё было до того как разделили дим и ранг ликорисами, так что хз как понимать ранк и дим в них. В обычной лоре это, если я правильно понял, просто дим=ранк и количество параметров, в локоне вроде тоже, а вот в лохе, локре и дилоре хз. Таблица оттуда кстати прямо намекает на лр ТЕ в 0.3-0.35, ведь параметров в ТЕ как раз в 3 раза меньше, я тоже такой ставить стал, как раз охуенно получается.
> Он скорее не стал разбираться с этим, хех.
А я пока разгребал видел какие то локоны с networks.lora, но в параметрах algo=locon например, или вообще просто конв леер только указан без алго, у него нету на это проверки вроде.
> Я кста предполагал что это период расчета лра.
Вот кстати да, наверно это так, а потом уже вармап.
> Алсо, поменяй там условие под коммом про присер вармапов на
Годно, теперь и в циклах вармапы есть.
> Пиздец осознавать какой-же я тупой местами.
Знаешь, это наоборот хорошо осознавать, это не кибербуллинг если что.
> Ты про Hyperparameter Sweep? Я от него охуел как удобно с бетами получилось там и наверное как долго будет в кейсе тренировки лор.
А, не, я честно вообще хз точно для чего нужны беты. Видел только одно видео где вскользь про это было затронуто не на математическом языке https://youtu.be/cVxQmbf3q7Q кстати отличное объяснение про тот самый оффсет нойс.
На Hyperparameter Sweep не обратил сразу внимания, а стоило бы походу, wandb выглядит примерно как матплотлиб, который ты сделал, только с обширным функционалом, понять бы как там ещё эмулировать правильно эти сд тренировки, можно ли это вообще делать.
Я вообще имел ввиду что адан может быть лучше с некоторыми сложными датасетами, из-за своих импрувнутых показателей на графиках, ценой трейн тайма.
> Хм, если мне не изменяет память, а память у меня плохая, на моих датасетах на 0.3 и 0.4.5 лосс где-то 0.7-0.8 болтался, а с датасетами я особо не заебывался.
Ты не потерял нолик? Это же очень много.
> Алсо, вообще по лоссу хуй пойми что там у тебя получилось, кое как только по динамике его изменения
Пикрил, что же ещё. Всё меньше смысла смотреть на эту метрику, я хз. Наблюдал как то восходящий тренд, что то типо 0.07-0.1, но сетка в итоге получилась норм, так же и с 0.06-0.04 нормальная получалась, хотя низкое значение должно указывать на оверфит.
> Есть такая штука как валид лосс, для его вычисления нужен набор семплов из датасета что-то типа регов? и с его добавлением график легче читать.
> Есть ли у нас такое вообще, хз.
Интересная штука, нету такого походу. Реги же из дженерика делаются или берутся без генерации из одинакового "класса" тренируемого объекта, а тут часть датасета берётся для проверки тренировки, ну и это больше пародия на мл у нас так то, зато гпу монструозные не нужны и есть претрейнед чекпоинты.
Попробуй смерджить лору с моделью и заэксрактить как локон, у меня так получилось
Я когда так делаю - у меня "извлеченная" лора получается сильно ослабленной.
Т.е. вместо силы 1 надо на 2-3 ставить.
В мердже с другой лорой фигня наверное получится.
Но вообще обходной путь интересный.
Хз, когда я мержил две модели к которым уже были примержены лоры в обычном MWB и сохранял как half safetensors, то на выходе получалась модель как будто без лор
В супермерджере попробуй вес извлечёного локона поставить 2 или 3 при мердже
Попробую, но что-то такое ощущение, что из-за этого веса в другой лоре могут убиться. Там ж по сути один концепт у меня будет, просто разными стилями.
Locon можно только через kohya примержить к модели?
Хотел попробовать в ControlNet функцию Reference only. Обновил ControlNet, обновил webui, но падает с ошибкой:
The size of tensor a (64) must match the size of tensor b (104) at non-singleton dimension 3
В целом Controlnet работает, например OpenPose, но не Reference only. Пикчи тоже разные пробовал.
Обязательно то торч 2.0 катить? У меня rtx2060, прибавки производительности не будет.
The size of tensor a (64) must match the size of tensor b (104) at non-singleton dimension 3
В целом Controlnet работает, например OpenPose, но не Reference only. Пикчи тоже разные пробовал.
Обязательно то торч 2.0 катить? У меня rtx2060, прибавки производительности не будет.
Попробовал лион8бит, он какой то бешеный пиздец, оверфитится просто чуть ли не сразу, с пониженным лр в 15! раз и тем же распадом и бетами что у адама, адам кажется недотрененным на 800x15, этот уже с 800x5 начинает ломаться на латенте, но стиль улавливает хуже, есть идеи какие параметры лучше попробовать?
Опять тренировка лор по второй ссылке не работает...
Почему они какую-то стабильную версию не могут сделать?
Почему они какую-то стабильную версию не могут сделать?
Починилось с выходом обновления

Подскажите, в чем трабла? Закидываю модели в нужную папку, в списке они появляются, но при попытке генерации выдают эту хуйню
Там буквально написано в чем проблема.
>Файл модели не содержит контрольной точки модели. Вместо этого, похоже, это файл LORA.
Очень понятно, пиздец прям, особенно для чела который первый раз юзает нейросетку. Как сделать чтобы заработало?
Все, как я понял ЛОРА это просто дополнения к моделям
Именно. Модели весят минимум по 2 гига, генерировать с ними, лоры кладутся в другое место и дополняют генерации.

Хочу сделать свою Лору и у меня вопрос по установке.
Ставлю Kohya_ss по инструкции с гитхаба и во время установки появляется пикрил 1. В гайде анонов написано выбирать bf16, типа он покруче. Но у меня в установке есть и третий вариант - fp8! В интернете пишут, что сам по себе fp8 круче, но про связь с Kohya_ss я нашёл только в каком-то японском блоге, где сказали выбирать bf16, ибо для fp8 нужны какие-то либы.
Хотелось бы узнать ваше мнение на этот счёт. Видеокарта RTX 4070ti.
Ставлю Kohya_ss по инструкции с гитхаба и во время установки появляется пикрил 1. В гайде анонов написано выбирать bf16, типа он покруче. Но у меня в установке есть и третий вариант - fp8! В интернете пишут, что сам по себе fp8 круче, но про связь с Kohya_ss я нашёл только в каком-то японском блоге, где сказали выбирать bf16, ибо для fp8 нужны какие-то либы.
Хотелось бы узнать ваше мнение на этот счёт. Видеокарта RTX 4070ti.
fp16 ставь
А почему, если даже в тутошнем гайде говорится про bf16?
Потому что гайды пишут довены



Кстати, про лоры, мне лень записывать кейворды и прочую хуйню, вызываю лоры просто через <lora:zalupa_v20:0.5>
Всё, вроде, работает. Насколько я неправ и могут ли лоры так не работать?
Всё, вроде, работает. Насколько я неправ и могут ли лоры так не работать?
Если лора на какого-то конкретного персонажа, то без триггер-слова может не сработать.
Хочу генерацию. где я трахаю Эмму Вотсон или еще кого.
Я ввел по гайду описания типа
VASYAPUPKIN a man with a beard and a pair of ear buds
, сгенерил лору.
<lora:VASYAPUPKIN :1> a man eats burger генерится отлично, все как надо, жру бургер, лицо четкое
<lora:VASYAPUPKIN:1> a man having sex with Emma Watson - обнимаются два мужика с моим лицом, качество шакалье
<lora:VASYAPUPKIN:0.5> a man having sex with Emma Watson - Эммочка на месте, но мужик на меня похож лишь отдаленно
КАК ТРАХНУТЬ ГЕРМИОНУ???
Я ввел по гайду описания типа
VASYAPUPKIN a man with a beard and a pair of ear buds
, сгенерил лору.
<lora:VASYAPUPKIN :1> a man eats burger генерится отлично, все как надо, жру бургер, лицо четкое
<lora:VASYAPUPKIN:1> a man having sex with Emma Watson - обнимаются два мужика с моим лицом, качество шакалье
<lora:VASYAPUPKIN:0.5> a man having sex with Emma Watson - Эммочка на месте, но мужик на меня похож лишь отдаленно
КАК ТРАХНУТЬ ГЕРМИОНУ???

Попробуй такой вариант:
a man having sex with each himself while Emma Watson is watching
У меня вопрос по моей очередной странной лоре. У меня есть фото автомобиля, почти все одной конкретной машины.
И главная моя проблема - несмотря на добавление в датасет тега на цвет машины, сетьб никак не реагирует при его изменении при генерации.
Собственно вопрос - поможет ли мне добавление ещ нескольких (5-10) фото других цветов авто?
И главная моя проблема - несмотря на добавление в датасет тега на цвет машины, сетьб никак не реагирует при его изменении при генерации.
Собственно вопрос - поможет ли мне добавление ещ нескольких (5-10) фото других цветов авто?
Аноны как раздеть тян с помощью этой штуки? подскажите додику пожалуйста!
Какая то ссылка на коллабы умеет раздевать?
Какая то ссылка на коллабы умеет раздевать?
Если видяха не древняя, попробуй локально, я по этому гайду делал - https://teletype.in/@slivmens/4qndxgLC4HN
Не, хуйня выходит.
Инпейнтом кое-как получилось, но так можно было и изначально фотошопом, неинтересно.
C цветами у нейронки вообще обычно плохо всё.
Можешь попробовать дополнительно регуляризации включить с соответствующими тегами (типа, у тебя красная машина в сете - в регуляризациях другая машина, но синяя, зеленая, и т.д.).
А можно не париться и после генерации в ФШ быстро цветокоррекцией пройтись и обратно в нейронку закинуть в имг2имг, с низким денойзом. Цвет останется.
Кстати надо поробовать регуляризационные изображения про для просто генерик промта, чтобы геометрию машины меньше ломало.
Фотошоп и имг2имг работает, но лениво, хочется автоматики%)
Кто знает как бакеты работают при трене лоры, если у меня пикча 2048x1024 и я выставлю разрешение 1024 то пикча задаунскейлится или тупо вырежет то что по середине? Или вообще как то по другому будет?
Могу врать, но должен резать на куски по 1024x1024, хз как именно, чисто на 2 куска режет или делает еще промежуточные вырезы
Хуясе фп8, лора ещё в два раза меньше будет весить чтоли, интересно что там будет по качеству с такой низкой точностью. А так лучше тренить в бф16, у тебя же 4070.
Собрал просто 10 картинок 1920х1080 на 10 повторов, min/max bucket reso 256/1024 вот такой лог в консольке выдаёт : bucket 0: resolution (1024, 576), count: 100, ничего не обрежется а задаунскейлится под разрешение с сохранением сторон.
Я все же хочу трахнуть Гермиону текстовым запросом.
Если через лору это невозможно, то тогда я добавлю свое ебло в большую модель sd 1.5, и все получится! Вопрос только, как это сделать, и сколько времени займет?
Если через лору это невозможно, то тогда я добавлю свое ебло в большую модель sd 1.5, и все получится! Вопрос только, как это сделать, и сколько времени займет?
Как переместить каталог автоматика1111 на линуксе. Перенес и он ругется(если вернуть обратно, то всё норм):
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0]
Version: v1.2.1
Commit hash: 89f9faa63388756314e8a1d96cf86bf5e0663045
Installing torch and torchvision
/usr/bin/python3: No module named pip
Traceback (most recent call last):
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 369, in <module>
prepare_environment()
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 271, in prepare_environment
run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 95, in run
raise RuntimeError(f"""{errdesc or 'Error running command'}.
RuntimeError: Couldn't install torch.
Command: "/usr/bin/python3" -m pip install torch==2.0.1 torchvision==0.15.2 --extra-index-url https://download.pytorch.org/whl/cu118
Error code: 1
Python 3.10.6 (main, Mar 10 2023, 10:55:28) [GCC 11.3.0]
Version: v1.2.1
Commit hash: 89f9faa63388756314e8a1d96cf86bf5e0663045
Installing torch and torchvision
/usr/bin/python3: No module named pip
Traceback (most recent call last):
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 369, in <module>
prepare_environment()
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 271, in prepare_environment
run(f'"{python}" -m {torch_command}', "Installing torch and torchvision", "Couldn't install torch", live=True)
File "/home/alex/Programs/AUTOMATIC1111/stable-diffusion-webui2/launch.py", line 95, in run
raise RuntimeError(f"""{errdesc or 'Error running command'}.
RuntimeError: Couldn't install torch.
Command: "/usr/bin/python3" -m pip install torch==2.0.1 torchvision==0.15.2 --extra-index-url https://download.pytorch.org/whl/cu118
Error code: 1
Попробуй симлинком связать новый и старый пути.
Подскажите пожалуйста, при 6 гигах какое максимальное разрешение может быть у картинки в датасете?
Аноны, есть проблема SD automatic1111 на любых моделях стала делать всратые ебала. Раньше такого не было и вдруг началось. В чем может быть проблема? Hypernetwork никаких нет
Перебери для начала сэмплеры, некоторые на разных моделях могут себя так вести.
Забыл добавить что на разных семлперах эта проблема
можно конечно переустановить все, но там качать долго, хочется разобраться в чем дело. Может кэши какие то протухли, хер его знает. по промту Woman до этого бага были нормальные лица, а теперь очень страшные уебища. Если написать Beautiful woman то лицо становится лучше но всеравно хуёво.
палю тебе простую годноту, берешь фото с вотермаркой и кидаешь в инпеинт, ничего не пишешь в промт и выделяешь свою хуету.????профет, теперь у тебя карманный фотошоп. Причем заменяет он хорошо я так например очки у людей удаляю с лица
>карманный фотошоп
Очень карманный, ага.
Запускается полгода, отжирает видеопамять, с батчами и в автоматическом режиме не работает...
Короче, так себе совет.
Докладываю прогресс: узнал о плагинах webui-two-shot и composable-lora, теперь с двумя вертиклаьными прямоугольниками и запросом
two people AND (two naked people emma watson )
AND (two men <lora:PUPKIN:1> )
могу постоять рядом с голой эммой, уже вин, но если упоминаю секс - начинаются глюки, опять два моих ебла и почему-то друг над другом.
Продолжаю работать над результатом
Давно тут не был. Появилось что-то новое для тренировки лор?
И еще вопрос - какое минимальное количество картинок для лоры на стиль?
И еще вопрос - какое минимальное количество картинок для лоры на стиль?
> какое минимальное количество картинок для лоры на стиль?
Ну, мне вот 40 штук не хватило на последней попытке. Так что посоветую больше сорока.
В шапку имеет смысл что-то добавить перед катом? Давно последний раз катились...
Апдейт: узнать про control net, освоил. Отсос фигурки делают, но рожи страшные как моя жизнь.
Вроде ничего определенно годного нету, имхо там не хватает гайдов на контролнет и актуализации гайдов по лорам. Есть вот такой гайд в помойке ссылок шапки https://rentry.org/59xed3 он обновляется и содержит прямо дохуя инфы для уже разбирающихся, но не покрывает тренировку ликорисов. Не знаю, стоит ли акцентировать внимание на нём или оставить дальше в помойке ссылок, ведь он на английском.
От 85-ти у меня уже начинало получаться.
Лучше больше, понятное дело.
И еще очень сильно важна постоянность. Причем именно общая, а не каких-то конкретных деталей. Когда у тебя самого все картинки прям с первого взгляда ассоциируются с определенным стилем - получится лучше всего. А если приглядываться приходится - это уже признак того, что ты лишнего в сет добавил.
Печально. Получается еще много картинок надо сделать:(
Клип скип и нойз дельту проверь
> не хватает гайдов на контролнет
https://stable-diffusion-art.com/controlnet/
Знаю такой англоязычный гайд по контролнету (он же в шапке nai сейчас), можно его добавить, если нет ничего другого на примете.
> Есть вот такой гайд в помойке ссылок шапки https://rentry.org/59xed3 он обновляется и содержит прямо дохуя инфы для уже разбирающихся, но не покрывает тренировку ликорисов. Не знаю, стоит ли акцентировать внимание на нём или оставить дальше в помойке ссылок, ведь он на английском.
Тоже по этому гайду всякие нюансы выяснял. Может, последним его тогда поставить с ремаркой, что это продвинутый гайд? По типу такого:
✱ LoRA – "легковесный Dreambooth" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением:
https://rentry.org/2chAI_easy_LORA_guide - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_LoRA_Dreambooth_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
> Знаю такой англоязычный гайд по контролнету (он же в шапке nai сейчас), можно его добавить, если нет ничего другого на примете.
Ничего лучше тоже не встречал.
> Тоже по этому гайду всякие нюансы выяснял. Может, последним его тогда поставить с ремаркой, что это продвинутый гайд? По типу такого:
Норм. Про ликорисы бы пару слов написать, анон выше расписывал небольшие пояснения . Вот тут примерная визуализация локона например https://github.com/KohakuBlueleaf/LyCORIS/tree/locon-archive#difference-from-training-lora-on-stable-diffusion .
https://rentry.org/catb8
Обновил шаблон шапки - свежие правки выделены отдельно. Добавил гайд по контролнету, углубленный гайд по лорам на инглише и секцию про LyCORIS. По LyCORIS, кроме комментария от анона добавил инфу в целом о проекте LyCORIS и про LoKr.
Схему https://github.com/KohakuBlueleaf/LyCORIS/tree/locon-archive#difference-from-training-lora-on-stable-diffusion не придумал куда добавить; шапка и так выглядит перегруженной и не уверен, есть ли в этом особый смысл. Полагаю, достаточно ссылки на сам проект LyCORIS.
Если больше нет предложений по шаблону, то предлагаю этим вариантом катнуть завтра.
> Схему https://github.com/KohakuBlueleaf/LyCORIS/tree/locon-archive#difference-from-training-lora-on-stable-diffusion не придумал куда добавить; шапка и так выглядит перегруженной и не уверен, есть ли в этом особый смысл. Полагаю, достаточно ссылки на сам проект LyCORIS.
Схема лишней будет, она локально просто к локону относится.
> Если больше нет предложений по шаблону, то предлагаю этим вариантом катнуть завтра.
Насчет дилоры кстати, там имплементация кохьи вроде неправильная и получаются сломанные модели с его же рекомендуемыми параметрами, это если что тестил не только я, но и еще один анон. Вроде по логу коммитов он это так и не исправил, стоит хотя бы как предупреждение оставить? Если других предложений нету, то кати так, а то уже утонул тред совсем.
Вторая ссылка на тренировку лор не работает, кстати.
Опять чего-то в установке торча и прочий фигни сломалось.
Кто за этим колабом следит, в какое спортлото писать вообще?
Хорошо бы выделить рекомендованные аноном мокрописьки для тренировок.
Никто на голом скрипте не тренит, насколько я вижу. Неужели анонгуй самый топ?
мимо вкатун
Никто на голом скрипте не тренит, насколько я вижу. Неужели анонгуй самый топ?
мимо вкатун
> Насчет дилоры кстати, там имплементация кохьи вроде неправильная и получаются сломанные модели с его же рекомендуемыми параметрами, это если что тестил не только я, но и еще один анон. Вроде по логу коммитов он это так и не исправил, стоит хотя бы как предупреждение оставить? Если других предложений нету, то кати так, а то уже утонул тред совсем.
Добавил предупреждение в конец описания DyLoRA.
> Все, как я понял ЛОРА это просто дополнения к моделям
Вот тут один из основателей OpenAI поясняет всем за щёку, что есть что, и как модели обучаются.
https://www.youtube.com/watch?v=bZQun8Y4L2A
Как собирать и хранить большие датасеты? Я не понимаю структуру. Вот у меня тонна картинок, а как хранить теги для них?




Тред общенаправленныей, тренировка дедов, лупоглазых и фуррей приветствуются
Предыдущий тред:
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ Текстуальная инверсия (Textual inversion) может подойти, если сеть уже умеет рисовать что-то похожее:
https://rentry.org/textard (англ.)
✱ Гиперсеть (Hypernetwork) может подойти, если она этого делать не умеет; позволяет добавить более существенные изменения в существующую модель, но тренируется медленнее:
https://rentry.org/hypernetwork4dumdums (англ.)
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ LoRA – "легковесный Dreambooth" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением:
https://rentry.org/2chAI_easy_LORA_guide - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_LoRA_Dreambooth_guide - ещё один гайд по использованию и обучению LoRA
✱ Text-to-image fine-tuning для Nvidia A100/Tesla V100-бояр:
https://keras.io/examples/generative/finetune_stable_diffusion (англ.)
Бонус. ✱ Text-to-image fine-tuning для 24 Гб VRAM:
https://rentry.org/informal-training-guide (англ.)
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Гайд по фиксу сломанных моделей: https://rentry.org/clipfix (англ.)
Расширение WebUI для проверки "сломаных" тензоров модели: https://github.com/iiiytn1k/sd-webui-check-tensors
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
Оптимизации для современных ПК:
https://rentry.org/sd_performance - мастхев для владельцев 40XX поколения; для 20XX-30XX прирост производительности менее существенен
GUI для тренировки лор от анона: https://github.com/anon-1337/LoRA-train-GUI
Подборка мокрописек от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
Шапка: https://rentry.org/catb8
Прошлые треды:
№1 https://arhivach.top/thread/859827/
№2 https://arhivach.top/thread/860317/
№3 https://arhivach.top/thread/861387/
№4 https://arhivach.top/thread/863252/
№5 https://arhivach.top/thread/863834/
№6 https://arhivach.top/thread/864377/
№7 https://arhivach.top/thread/868143/
№8 https://arhivach.top/thread/873010/