styletts2 годная тема
https://github.com/yl4579/StyleTTS2
https://huggingface.co/spaces/styletts2/styletts2
https://github.com/yl4579/StyleTTS2
https://huggingface.co/spaces/styletts2/styletts2
локально эта хрень не хочет работать, ждём нормальный web ui
Нифига себе. Мой видос первый
Треним в каггле. Там все можно фоном. https://www.kaggle.com/varaslaw/rvc-tg-aisingers-by-rus-no-gradio тут делать
https://youtu.be/uA92FDw_Xfw[РАСКРЫТЬ] тут обучалка
https://youtu.be/uA92FDw_Xfw[РАСКРЫТЬ] тут обучалка
Репост из предыдущего треда по причине 0 ответов:
rvc (релиз из шапки прям) не хочет хавать мп3 56кбпс длиною в 49 минут, как фиксить

Это для обучения или преобразования? Если для преобразования - попробуй просто файл нарезать. А чтобы вручную их по отдельности потом не отправлять на конвертацию, в RVC можно батчами файлы обрабатывать, в нижней части интерфейса. Я сам ничего длиннее 10 минут не пробовал скармливать, может оно неоптимизированно просто для таких длинных файлов.
Ебать, спасибо анон, это по царски мне все сделало. Со старой ебался месяц хуйня получалось. Каеф.
Ты же обучаешь? можно через какой нибудь адобе аудишн удалить тишину. У меня с 1 часа записи голоса на стриме после удаления тишины стало 25 минут чистого голоса.
А вообще советую юзать обучалку в облаке . Тольго чтобы там можно было ГПУ подрубить - надо акк по телефону подтвердить. В РФ не работает, поэтому через какой-нибудь онлайн-сим сервис регни на другой регион. Цена 3-5 рублей.
че за бред что в рф не работает? Нормально активировал.
Мимоднровец
От оператора завист. Мой мегафон не пропустил. И где-то в гайде на ютубе видел, что там так же из РФ регали на тайланд.
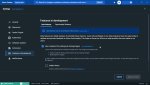
короче поебавшись с docker и линуксоидным WSL 2 я заставил это работать.
Обязательные условия, если юзаете шиндовс 10 :
1. Установка ubuntu и его включение (см. пик 1) в уже установленном docker (это в моём случае, отличном от того что в видеоролике) https://www.youtube.com/watch?v=PB7zM3JrgkI
2. обязательная установка python 3.7, с 3.11 вообще не хочет работать
3. включение экспериментальной функции "containerd" в docker (см. ласт пик)
когда всё поставили - просто введите вот это в powershell с запуском от админа :
docker run -it -p 7860:7860 --platform=linux/amd64 --gpus all registry.hf.space/styletts2-styletts2:latest python app.py
потом в docker кликаете по ссылке и всё (см. пик 2), должно открыть gradio вебуй в браузере.
Не знаю как другим, но этот tts движок пока что ебёт все остальные как нехер делать, меньше одной секунды на генерацию семлпа используя ноутбучную rtx 3070 / 8gb vram. https://voca.ro/1jB9XdkllnRi когда другие tts всё ещё будут долбить гпу в сотку.
Какой голос звучит человечнее?
Света питч 5. К силеро надо крутить библиотеки омонимов, перевода цифр в буквы, ударений и прочего.
чето кряхтит пердит во всех версиях
туда можно вкорячить свои модели, натрененые в RVC?
если нет, то где можно текс в аудио?

Угараешь, штоле? Всё там прекрасно работает без WSL и докеров
1. git clone https://huggingface.co/spaces/styletts2/styletts2
2. pip install -r requirements.txt
3. pip install cached_path phonemizer
4. Устанавливаешь espeak-ng https://github.com/espeak-ng/espeak-ng/releases
5. Прописываешь в PATH :
PHONEMIZER_ESPEAK_LIBRARY="C:\Program Files\eSpeak NG\libespeak-ng.dll"
PHONEMIZER_ESPEAK_PATH=“C:\Program Files\eSpeak NG”
6. Запускаешь python ./app.py
7. ?????
8. PROFIT!
Да, ещё torch и torchaudio нужно поставить с поддержкой CUDA, чтобы инференс работал на GPU. У меня уже стояли 2.1.0+cu121
> попробуй просто файл нарезать
Спасибо кэп, только это лишний гемор, пушо помимо резки/склеивания, как я должен проверить что оно не разрежется именно по середине речи?
Нет, не для обучения, аудиокнигу хочу в другом голосе послушать.
Нет, это не для обучения.
это не RVC, но модель styletts2 можно зафайнтюнить на rtx 3090 за 4 часа, так говорит автор https://github.com/yl4579/StyleTTS2
ударения там можно сделать через + звон+ит
Берешь абсолютно любой аудиоредактор и вручную режешь блять, и там же склеиваешь.
Чо, когда exe софт сделаете, а не всю эту хуету с бубнами?
те сложно чтоль пару команд ввести? Сразу видно виндузятника
те сложно чтоль все в одной папке собрать? сразу видно гитхабодебила
Спасибо, я знаю. Но хотелось бы автоматом. Но у автора силеро такая позиция, что они продают весь обвес вокруг их сырой модельки, так что увы.
хочется верить что этот styletts2 герганыч портнёт в ggml, тогда можно будет тупо одной командой запускать один .exe файл с парой моделей, там кста их 10, это если считать энкодеры тоже.
как в едж ттс ставить ударения?
Поясните за текущее состояние голосовых нейронок плз. Если я хочу генерить хорни пасты голосами милых тяночек, это возможно уже или нет? Или можно только переделывать уже существующую речь в другие голоса? Последний раз ттс трогал у яндекса, там неплохой был секси голос Алёны, но интонации все равно слишком роботизированы и одннобразны были.
Что будет лучше, если я хочу клонировать свой собственный голос и озвучивать им написанный текст - RVC или ElevenLabs? Обычно я делаю через второй вариант, но там это довольно заёбно, приходится много раз генерировать заново, а потом ещё и склеивать удачные куски из разных вариантов в единое целое. Уходит очень много времени
Ну или может быть у вас есть гайд, как записать подходящий датасет, пользуясь диктофоном из телефона? Вроде бы всё нормально, но нейронка часто сбоит, например ускоряя голос или наоборот замедляя, а иногда появляется сильный акцент
Ну или может быть у вас есть гайд, как записать подходящий датасет, пользуясь диктофоном из телефона? Вроде бы всё нормально, но нейронка часто сбоит, например ускоряя голос или наоборот замедляя, а иногда появляется сильный акцент
Ебаный ты нахуй, там 24 файла по 50 минут, заебусь, во-вторых я не понимаю а че мешает просто один огромный файл обработать? Я понимаю когда я ставлю слишком огромное значение блока за раз обрабатываемого или че там, типа 60 секунд и он за оперативку вылазит, а тут че?
Можно сгенерировать в TTS, а потом прогнать через RVC с нужным тебе голосом. Но TTS'кам эмоциональности под твою задачу не хватит, как мне кажется. Они больше под монотонное чтение подходят.
У RVC нет возможности напрямую озвучивать по тексту, она только из одного голоса в другой преобразует. Тебе придётся сначала сгенерировать по тексту дефолтным голосом любой TTS'ки, а потом через RVC прогонять.
> как записать подходящий датасет
Для RVC нужно 5-10 минут чистого голоса, желательно, в разных диапазонах. Хорошие модели стабильно работают, там не надо что-либо роллить.
Попробовал прогнать часовую аудиокнигу (58 минут). С моделью rmvpe всё обработалось, при обработке потребление VRAM было почти 20 Гб, но обработка заняла всего несколько секунд. Creepe — потребление VRAM около 4 Гб, но обрабатывалось долго — около 2 минут. Harvest — видеопамять не жрет, обрабатывалось минут десять и потом все упало нахуй, хотя потребление RAM было всего лишь около 22 Гб (из 64 Гб). Pm не проверял.
А как результат?
Аноны, оценил предложенные tts проекты, XTTS в целом порадовала. На huggingface лимит в 200 символов, соответственно вопрос: если её ебануть локально можно ли за одну операцию озвучивать приличные тексты, например 10 страничные статьи? И, если да, сколько генерация будет занимать по времени на 3060 12 гигабайтной?
Годная вещь, аж залип
Почему-то именно с этим языком самый кек получается.
А есть вообще сайты по типу цивита (куда лоры и модели заливают), но с готовыми голосовыми моделями?
https://discord .gg/aihub (канал voice-models)
Для RVC.
А если записать самому с нужной интонацией и потом свапнуть голос?
Аноны, для клонирования голоса обязательно микрофон?
Ай, наигрался. Не смешно как-то уже.
Анон, подскажи пожалуйста, есть ли возможность научить ИИ на чужой голос, при обучении выдаёт ошибку и ругается на GPU (У меня AMD 6800XT) И еще вопрос, ему datasaet можно даже видео в mp4 подставить, он его "скушает" или ему нужен именно свой определенный формат?
Аноны, а есть сервис дубляжа своего голоса, но чтоб интонация была? Знает кто нибудь такой онлайн сервис?
для локал юзеров - убрали ограничение в 400 слов, но есть проблема, он начинает каждое новое предложение без сохранения интонации.

Я тупой. Не бейте, лучше обоссыте!
На hf есть вот такая модель для whisper:
https://huggingface.co/lorenzoncina/whisper-small-ru/tree/main
Но Whisper'у нужны модели с расширением .pt
Как конвертировать модель hf ---> pt?
Был бы рад, если кто-то шарящий просто сконвертирует и выложит ссылку.
На hf есть вот такая модель для whisper:
https://huggingface.co/lorenzoncina/whisper-small-ru/tree/main
Но Whisper'у нужны модели с расширением .pt
Как конвертировать модель hf ---> pt?
Был бы рад, если кто-то шарящий просто сконвертирует и выложит ссылку.
Эти веса можно подгружать через torch.load, если использовать whisper в качестве python-модуля.
Если тебе вдруг зачем-то нужно их использовать через stand-alone версию, то требуется небольшой костыль, так как stand-alone может работать только с предопределенными моделями.
Скачиваешь эту модель при помощи git
git clone https://huggingface.co/lorenzoncina/whisper-small-ru/
И конвертируешь этим скриптом https://gist.github.com/bofenghuang/3ba54bb338f4863e6ab710a2ceb65bf2 :
python convert_whisper_to_openai.py --hf_model_name_or_path "d:/whisper-small-ru" --whisper_state_path "./small.pt"
Либо скачиваешь сконвертированную модель отсюда https://huggingface.co/savayox919/small.pt/blob/main/small.ru.pt
Закидываешь cконвертированную модель в папку %user_profile%/.cache/whisper/
Чтобы whisper знал эту модель нужно в файле %python_path%\Lib\site-packages\whisper\__init__.py под 23 строкой добавить строку
"small.ru": "aefac90e59481eb3f15b7f6725fd1e398a08ec9d99ba8969336bde5c3f667695/small.ru.pt",
И под 39 строкой добавить строку
"small.ru": None,
Теперь whisper будет работать с этой моделью
whisper --model small.ru --language ru
Но на самом деле всё это ненужный пердолинг, потому что эта модель всратая и не лучше оригинальной small

Спасибо, анончик! Аки боженька всё разжевал. Мне важно было попробовать работу этой модели на своих семплах. Результаты и впрямь так себе.
Я радиогубитель и в ИТ не большой знаток. Нейронки для меня - что-то типа магии. Хочу автоматически распознавать речь со своих радио-перехватов (приём SDR-свистком), но старое железо весьма ограничивает возможности. У меня gtx950 с 2 ГБ памяти, и её хватает только для base модели, а это полная хуита ни о чём. Даже small крашится от недостатка памяти. Поэтому ищу вменяемую по скорости и качеству распознавания модель под CPU. Может, посоветуешь что-то? Нужна только русская речь.
В какой нейронке это делали?
> coqui ai
Это годнота? Почему в шапке нет?
Это годнота? Почему в шапке нет?
В суно, сверху криво кинули войссвап совитсом.
Потому что как и в дабе сосет письку. Плюс платное. Там никаких чудесных решений все еще нет, это комбайны из существующих технологий, которые по аналогии с фейс-свапом типа фейсхаба - ну продержаться год-два, выдавая хуевенький результат за нихуевенькие бабки. Потом технологию допилят и она обесценится (в хорошем смысле слова). Чмони конечно могут продолжать лазить в какойнибудь фейсап, но нахуя если везде лежит руп. Поэтому какой смысл добавлять в шапку очередную коммерческую прокладку?
>Потому что как и элевенлабс в дабе сосет письку
фикс
Это максимум для инди проекта энивей и если бабки карман жмут, для чего-то серьезного проще нанять актера за миску риса. Да и для инди тоже.
у меня тоже такая карточка, почти моментально 3000 символов генерит, так что в этом проблем нет
Че за комбайны из готовых решений? У них собственные решения и опенсурс на гитхабе.
>У них собственные решения
Из чужих моделей и разработок обмотанных петухоном. Огласи список "собственного", если не сложно.
И че? Ебать ты долбаеб, обосрался, так не закапывай себе дальше.
Голосовые нейронки самый мощный прорыв сделали я щитаю. Ни видео ни фото не может в годнонту, а вот голосовые модели могут имитировать голос человека на 100 процентов.

Есть какая-нибудь онлайн нейросеть, чтобы фразу озвучить? Мне буквально одну только. Или, может, итт кому-нибудь не лень? С меня сотни интернетов!

Бля а неплохо вышло
Рейт
Так, я попробовал вариант для амудешников, по готовой модели генерит довольно быстро, а вот свое обучается очень долго, в связи с чем возник вопрос - есть ли какой-то вариант, для обучения на колабе или еще где-то? А то у меня получается, что 20 эпох часов 8 займут, а говорят, что под 200 надо для хорошей модели
На eleven labs появился speech to speech для склонированного голоса, но пока только на английском.
Чем делал голос путина тот что на русском?
> наигрался
А может и нет...
Я прочитал шапку, но уточнить хочу. Мне нужно делать озвучку персонажей амер мультиков.
>SileroTTS
>TeraTTS
Что из этого будет говорить с амер акцентом и выразительно как пожелаешь с настройками где ставить ударения и т.п.? Т.е. чтоб там можно было изображать гнев, грусть и т.п.?
>RVC
Я так понял оно не влияет на характер, эмоциональный оттенок голоса, а просто перекрашивает в нужного персонажа заранее подготовленные дорожки?
>SileroTTS
>TeraTTS
Что из этого будет говорить с амер акцентом и выразительно как пожелаешь с настройками где ставить ударения и т.п.? Т.е. чтоб там можно было изображать гнев, грусть и т.п.?
>RVC
Я так понял оно не влияет на характер, эмоциональный оттенок голоса, а просто перекрашивает в нужного персонажа заранее подготовленные дорожки?
силеро ттс. Ударения ставить так: звон+ит +перед ударным.
Про рвс да
А что насчёт амер акцента?
силеро ттс там американское наверно
>Оффлайн-проект синтеза голоса от русскоязычной команды Silero.
Окей спорить не буду, но на всякий случай на форчане чек чем оно по-хорошему делается.
Падажите, эта няша из консольки чтоли управляется онли? Нет удобного интерфейса, куда совать текст и язык, модели жмакать?
https://www.youtube.com/watch?v=yRHbDbHPJMo
https://www.youtube.com/watch?v=yRHbDbHPJMo
тебе какой язык нужен?
https://github.com/hinaichigo-fox/rus-silero-webui вот там русский и украинский
https://github.com/GhostNaN/silero-webui тут все

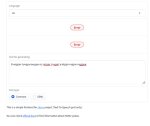
Мне англ. Ну я разные пробовал и устанавливал https://github.com/snakers4/silero-models#installation-and-basics.
Вот что ты дал, юзаю гитбаш в папке, git clone https://github.com/GhostNaN/silero-webui.git
А где там установочное или как стартовать вообще, каким файлом?
Второй пик пробовал сборку от анона, но там ошибка если менять язык или модель, не поддерживает наверное.
Запускать app.py
Конечно же. если не менять язык будет ошибка. Смени язык и все
А понятно. Я просто не ожидал, что так можно, никогда не делал. Спасибо, что не рвонькнул однако.
Сейчас устанавливаю какое-то nltk, а то ошибка генерации.
Не помогло nltk, опять чего-то не хватает. В requirements.txt
gradio
nltk
num2words
omegaconf
torch
torchaudio
Я понимаю это что-то у программистов имеющеюся само собой и что мне делать чтоб облегчить мучения?
gradio
nltk
num2words
omegaconf
torch
torchaudio
Я понимаю это что-то у программистов имеющеюся само собой и что мне делать чтоб облегчить мучения?
У одного меня какие-то спермопроблемы как обычно, ясно, у всех остальных всё само собой встало одним нажатием кнопачки.
покажи ошибки


Это по-любому из-за отсутствия установки чего-то большого, что все нейросетчики по умолчаю юзают, поэтому автор и в шапке не пишут. Я просто только вкатываюсь.
комп перезапусти и попробуй все в ручную через пип инсталл устанавливать
Алсо, добавлю у меня подозрения на этот пи-торч. Может я его как-то криво поставил?
Я с сайта копирую в командную строку cmd что мне там дали pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
Установка какая-то прошла и я закрыл. Не так чтоли?
самая тупая ошибка. ПРОСТО ПИШИ ПИП ИНСТАЛЛ ТОРЧ И ВСЕ
В cmd писать? Или в какую-то конкретную папку перейти? написано Requirement already satisfied:
Я также перегрузил комп, но не помогло. Может снести и зано поставить этот торч?
Остальные требования тоже уже написано Requirement already satisfied:
в цмд пиши


Ну че, я пытался удалить и установить заново как было сказано.
1. Первый пикрил - ПРОСТО pip install torch, ошибка. С ним вообще консоль не выдаёт адресс для браузера.
2. Снёс п. 1 и поставил с сайта всё пик 2 без ошибок, всё равно не заработала, те же ошибки
А не может быть такого что мне какие-то модели там в папку с прогой докачать, чтоб не было ошибки? Я вам заскринил чтоб вы расшифровали на что оно жалуется.
1. Первый пикрил - ПРОСТО pip install torch, ошибка. С ним вообще консоль не выдаёт адресс для браузера.
2. Снёс п. 1 и поставил с сайта всё пик 2 без ошибок, всё равно не заработала, те же ошибки
А не может быть такого что мне какие-то модели там в папку с прогой докачать, чтоб не было ошибки? Я вам заскринил чтоб вы расшифровали на что оно жалуется.
pip3 install pytorch

фулл скрин
пошли ка в тг. тут не особо удобно

Спасибо, что помогаешь. А можешь есть всеобщий гайд по работе с гитхабовскими нейросетками, чтоб я мог все их стандарты установить?
У меня нет тг.
А может этот торч не в апдату, а куда-то ещё ставить?
просто консоль открываешь и сразу без ничего пишешь pip install pytorch
Ну да, так и пишу, но у меня при открытии путь C:\Users\Anonname>
А у тебя не так?
хмммм. перезагрузи пеку и пробуй снова
Ладно, я думал, тут кулцхакеры сидят, придётся замену придумать или насадку какую-то. Может онлайн придётся даже генерить.
просто хз как но у меня все что надо ставилось с 1 раза
Да я понимаю, как обычно у меня одного проклятие, срочно надо шамана вызывать.
Ну что сказать, я напоследок пошалил ещё с этими вашими торчами, смыл весь питон и накатил последню версию и в резульатте через консоль этот торч вообще никак теперь не ставится, а силена даже в браузере теперь не запускается соответсвенно.
ERROR: Could not find a version that satisfies the requirement torch (from versions: none)
ERROR: No matching distribution found for torch
Сделал лучше, а стало хуже, ну и говнище этот ваши питон.
ERROR: Could not find a version that satisfies the requirement torch (from versions: none)
ERROR: No matching distribution found for torch
Сделал лучше, а стало хуже, ну и говнище этот ваши питон.
Ладно вот последний вопрос.
# Create venv
python -m venv venv
source venv/bin/activate
Это что? Это куда?
# Create venv
python -m venv venv
source venv/bin/activate
Это что? Это куда?
> Это что? Это куда?
В консоли последовательно выполни команды:
python -m venv venv
.\venv\Scripts\activate
У тебя формат второй команды под никсы, если я правильно понимаю.
> А если записать самому с нужной интонацией и потом свапнуть голос?
Да, тогда интонация норм подхватится.
> coqui ai
> Это годнота? Почему в шапке нет?
Там же вроде просто XTTS под капотом? Хз, может и стоит дополнить, я не вникал, если честно.
> Так, я попробовал вариант для амудешников, по готовой модели генерит довольно быстро, а вот свое обучается очень долго, в связи с чем возник вопрос - есть ли какой-то вариант, для обучения на колабе или еще где-то? А то у меня получается, что 20 эпох часов 8 займут, а говорят, что под 200 надо для хорошей модели
Попробуй этот коллаб глянуть, я, правда, сам не смотрел:
https://colab.research.google.com/drive/13Ot_8SJYplkxSH1vkJptd79fmvMjFqIC
> Что из этого будет говорить с амер акцентом и выразительно как пожелаешь с настройками где ставить ударения и т.п.? Т.е. чтоб там можно было изображать гнев, грусть и т.п.?
Из опенсорс с генерацией эмоций ничего нет для TTS, насколько я знаю. В bark можно вставлять конструкции типо [смех] и что-то ещё, но не смотрел её особо: https://github.com/suno-ai/bark
> Я так понял оно не влияет на характер, эмоциональный оттенок голоса, а просто перекрашивает в нужного персонажа заранее подготовленные дорожки?
Всё так, либо можешь менять голос в риалтайме - как вариант, можешь настроить виртуальный микрофон и сразу записывать свой видоизменённый голос с нужными тебе эмоциями, в этом случае RVC норм оттенок голоса передаст.
> Второй пик пробовал сборку от анона, но там ошибка если менять язык или модель, не поддерживает наверное.
Увы, не нашёл времени пофиксить. Работает только русик, да.
так емае. Те нужно максимум 3.10 ставить
А у edge tts из шапки можно как-то ударения ставить? И там ещё какой-то странный баг с внезапным сдвигом тональности на одном предложении есть, это победимо?
я и сам щас думаю как ставить. Пришел пока к выводу. Ты его учи как ребенка. Вместо Зек пиши зэк вместо штирлицем пиши штир'лицэмъ и т.д. ударение либо ' перед нужной буквой либо о́ букву ударением

>У тебя формат второй команды под никсы
Эээ? По-русски пиши. Я это это инструкции слепо пытался сделать.
А никто англоязычное не встречал? Я на форчане порылся, там только треды по стабл дифужну.
Как же хуёво быть нищюком. Я бы купил уже этот вокс бокс за 100 баксов и не ебался тут.

>Для винды, более продвинутый проект формата "всё в одном" (TTS/STS/TTS), часть функционала платная: SoundWorks, https://dmkilab.com/soundworks
Охуенно озвучили блять.
Охуенно озвучили блять.

А хули ты хотел? Плоти.
Там нет на сайте для нищуков скромного. Что ж так плохо с этой озвучкой идёт, туго, жиды программисты не дают творить.
Алсо с нормальными (не премиальными) голосами тоже говорят - плоти.
А неплохо это RVC работает, эмоции всё передаёт, не ожидал.
Но шляпа только что исходники хорошие искать, все эти TTS некудышные, говорят дикторской речью. И я так понимаю нельзя ттс научить в эмоции. Может посоветуете какую базу со фразочками всяких актрис озвучек и сэйу? А то я вижу на ютубе иногда фажики делают подборки фразочек всяких персонажей игр и аниму, может базы есть мне не очевидные.
Но шляпа только что исходники хорошие искать, все эти TTS некудышные, говорят дикторской речью. И я так понимаю нельзя ттс научить в эмоции. Может посоветуете какую базу со фразочками всяких актрис озвучек и сэйу? А то я вижу на ютубе иногда фажики делают подборки фразочек всяких персонажей игр и аниму, может базы есть мне не очевидные.
У меня такая мысль возникла, что для эмоций надо TTS для каждого настроения модель отдельную, не заморачиваясь на персонажей голосов, например для женского один и тот же голос, но каждая модель отличная, что одна радуется, другая говорит визгливым голосом и т.п. Не встречал никто грустных, гневных роботов и т.п.? Этого бы хватило, потом в RVC перегнать, ей пофигу какой там персонаж в оригинале озвучил. Ну может только максимально отличные типы голосов разедлить - мужской, женский, детский. Этого бы хватило, чем клепать тысячи разных персонажей, которые говорят дикторским голосом.
Там вообще нет возможности бесплатно TTS запускать? Мне несколько месяцев назад писали, что можно Но я правда забил и не тестил, ведь есть тот же EdgeTTS.
Аноны, у меня у одного перестал этот TTS работать?
https://huggingface.co/spaces/elevenlabs/tts
Выдает ошибку:
>RateLimitError('This request exceeds your quota. You have 0 characters remaining, while 103 characters are required for this request.')
https://huggingface.co/spaces/elevenlabs/tts
Выдает ошибку:
>RateLimitError('This request exceeds your quota. You have 0 characters remaining, while 103 characters are required for this request.')
Похоже что нет. Вообще странность, что докуя онлайн голосовых сервисов бесплатных, но за стационарное плати.
со второй просто начал хрюкать
Аноны есть русская TTS по качеству лучше или сравнимо с silero, но на GPU, а то на ЦП пиздец долго даже не на самом донном проце.
Да под русской я имею ввиду что бы на русском адекватно воспроизводила текст.
>silero, но на GPU, а то на ЦП пиздец долго
Силеро долго? Ты уверен, что у тебя не дно? Оно на смартфоне работает х10.
Кстати, когда тестировал, силеро у меня на GPU (3080Ti) работало медленнее, чем на проце (на тот момент 5090х), лол.
Кидай своё железо, а то я знаю ваше "не самое донное".
Проц ryzen 7 5700x видюха не важно с ней проблем пока нет. Может у нас разное понятие под долго но примерно 10 часов звука за час делает. При том что RVC на GPU тот же час за минуты 3 делает.
Ебать что ты там такое звучишь?
>ryzen 7 5700x
Ну... Не шик, но окей, уговорил, не дно.
>10 часов звука за час
х10, я прям ванга.
>RVC на GPU тот же час за минуты 3 делает
Тот же, или просто час? Если просто час, то это х20, то есть ускорение относительно силеро всего в 2 раза.
Ну и да, запусти силеро на ГПУ, в чём проблема то?
>Ебать что ты там такое звучишь?
Книги.
>Ну и да, запусти силеро на ГПУ, в чём проблема то?
Надо будет тогда погуглить, а то я сейчас не совсем напрямую запускаю.
а нук скинь пример
Пример чего? И через что скинуть, а то я давно это не делал, а все нормальные сервисы типо ргхоста уже давно отлетели.
на ютуб залей хз
пример книги которую озвучиваешь
Завтра если не забуду скину. Хотя зачем я не совсем понял ибо там ничего необычного нет silero нормально отрабатывает.
Пример кода я думаю.
>а все нормальные сервисы типо ргхоста уже давно отлетели.
Гитхаб всё ещё работает. А так https://rentry.co
Оцени пока мою озвучку крипистори
Ну я плюс минус до такого же уровня дошел. Только без фонового звука. Мне хватает. Голос только пока не нашел еще чтоб прям нравился.
ну я звук на фон поставил потому что это страшилка как никак.
Я то для себя в основном пилю. Ибо читать не то что бы влом, но глаза лишний раз неохото напрягать.
Ну тут прям видно, что голос искусственный. Ты убирал пробелы между фразами?
какие пробелы?
https://www.weights.gg | https://voice-models.com
Сап двач. Как использовать эти модельки? Куда их можно вставить? А то я что-то не шарю в нейронках.


А теперь читаешь все материалы в шапке по этим трём буквам.
Что за сайт с моделями?
Благодарю.
птх файл в папку вейтс и моделс а индекс в папку с названием птх файла и в папку логс
Ананасы, пользоваться RVC в облаке больше нельзя? Сторонние сайты прикрыли фишку с бесплатным ElevenLabs, а оплатить подписку конкретно на их сайте без иностранной карты нельзя.
Получается, для озвучки остался только один вариант: генерация стандартным голосом из доступных -> замена этого голоса на нужный мне через RVC. Компьютер его вряд ли потянет, а в облаке было бы здорово. Сплошная ебанина, короче
Получается, для озвучки остался только один вариант: генерация стандартным голосом из доступных -> замена этого голоса на нужный мне через RVC. Компьютер его вряд ли потянет, а в облаке было бы здорово. Сплошная ебанина, короче

Тред не читал
Надо распознавать где-то 25 часов лекций на русском в неделю. Вручную это делать больно и неприятно. Платно горько и обидно. Что можно сделать в данной ситуации? Есть ли бесплатные ИИ решения или хотя бы то что можно собрать на своем компе?
whisper
Whisper
>Компьютер его вряд ли потянет
а ты попробуй. он не такой тяжелый, только памяти надо дохуя
Парни, кто может натренировать модель? По деньгам договоримся
Силеро не генерирует аудио из текста длиннее 1000 символов. Как обойти ограничение?
я могу, что надо?
а ты какое силеро юзаешь?
бот или питоновский силеро из треда
ОП, прочитал гайды, но не совсем понял - написанно, что текст в речь нельзя научить нужному голосу. У меня есть запись 10+ минут голоса, мне нужно поставить офлайн софтину, скормить ей этот голос и потом писать текстом, а софтина должна преобразовывать текст в голос, на основе созданной модели. Такое возможно?
Именно такое пока что нет. Но можно немного изловчиться. Просто юзать какие либо ттски. Например силероТТС или эджТТС и потом их через рвс с нужной моделью прогонять. Вот. Сравни.
Тред. Скажи, что лучше?
Все три звучат как робот с задержкой в развитии. Всё-таки лучше ElevenLabs ещё ничего не придумали. Я наверное умру от старости, когда у них наконец появится нормальный конкурент
Придётся использовать связку утилит - любую TTS (Text To Speech) и RVC. В качестве TTS мне больше всего зашла EdgeTTS, но она работает через бесплатное API Microsoft'а; если этот момент для тебя принципиален - глянь SileroTTS.
Полученную через TTS дорожку потом конвертишь к нужному голосу через RVC. И вот для RVC уже можно обучать свои модели - датасета в 10 минут должно хватить.
Кто-то реализовывал конвеера, которые сразу из текста делают генерацию нужным голосом через связку TTS+RVC (в шапке есть инфа, но мало) на Gradio-интерфейсах, но я их не смотрел и профукал ссылки. Может пробовали какие-то решения?
Второе больше всего похоже на оригинал.
Пробовал и в блокноте колаба, и локально, всё равно есть ограничение.
Пробуй юзать SSML-режим. Там можно ставить паузу сколько тебе нужно между словами, можно использовать параграфы, дохуя всего короче.
Тред, а вы не пробовали записывать свой собственный голос, а потом прогонять его через RVC? Опционально изменить питч/скорость изначальной дорожки.
хммммм. я делал пасты и на 2к символов и ничего
>SSML
Че?
https://colab.research.google.com/github/snakers4/silero-models/blob/master/examples_tts.ipynb
Скролль до SSML.
Опытным путём выяснил, что длина аудиозаписи не должна превышать минуту, иначе выкидывает ошибку. Ты где и как генерировал?
Щас попробовал пропустить свой скрипучий голос через RVC гг-женщины из киберпанка, результат плохой, гораздо хуже silero. Какой-то некоарк-пидор выходит.
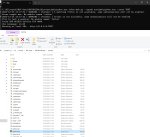
Аноны поясните нуфагу плиз что это за пиздец? Одну дорожку переработал, дальше всё, это уебище вылетает на половине обработке и дальше тупо не генерит. Инет нормальный.
Ты окошко командной строки не закрыл случайно?
Неа, оно открыто всегда. Первый раз когда запускаю, загрузка кавера до половины доходит и вылетает эррор. При следующих попытках эррор сходу вылетает пока не перезапущу. При этом в первый раз у меня всё получилось сгенерить сразу.

У меня вот такое вот в консоли в момент когда ошибка вылезает
https://github.com/hinaichigo-fox/rus-silero-webui вот тут делаю. За ССМЛ спасибо
Короче я разобрался у меня видимо компик дерьмовый слишком длинные песенки не вывозит почему то, прийдётся ебаться с обрезкой и склеиванием
натренировать модель под rvc, как свзяаться с тобой можно?
тг скинь напишу
Я тебе рекомендую на своей машине генерить, а не в колабе. У меня хром например не позволяет скачивать получившийся файл, при попытке открыть в отдельном окне просто закрывается.
ну дак я и делаю это локально
@nyanmyash

Что ему надо то? В факе написано что там ВСЁ включено и никаких библиотек с питонами не надо.
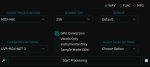
Похоже на то, что у тебя часть файлов почему-то отсутствует. В папке runtine должен быть python.exe, но у тебя этого файла почему-то нет. Может антивирь потёр? Или поменяли что-то в последних версиях, я давно не обновлялся уже.
Как же ЫлэвынЛабз невыносимо жалко ПРОСТО дать поиграться с мемчиками и песенками бесплатно без регистрации мокрые писечки. 58 секунд максимум за раз, видос не больше 20 мегов. Принимает исключительно шебм, а выдаёт почему-то битые mp4 с какчеством звука уровня жёваной на электронике-302 кассеты. Норовит вставить всякую левую отсебятину про субтитры-подпиську-просмотр. То чёткое произношение вообще не распарсит, то неправильно переведёт, то превратит в лепет, то в шизофазию, то простое слово оставит без перевода. Просто взять напрямую со своего ойпи загрузить видос - хренушки, только один. Режим инкогнито после примерно десятка кусков подряд перестаёт выдавать ссылку на скачивание. Тор и тот через задницу помогает - каждую попытку всё стало открываться меееедленно, чтобы я заебался ждать пока очередная нода покажет "форбидден".
хотя логично - а то немедленно сайт задудосит всяким говном, вайпом, 10-часовыми стримами, фильмецами, политотой и проном
хотя логично - а то немедленно сайт задудосит всяким говном, вайпом, 10-часовыми стримами, фильмецами, политотой и проном
подскажите пожалуйста текста/скрипиты для начитки, создания базы для собственной модели
или где их взять
или где их взять
тебе текст какой то нужен для того чтоб записать голос? Да хоть колобка читай главное чтоб качество было хорошее
понял, спасибо, думал может есть какие-то специализированные уже
Здравствуй, анон. Нет денег, есть rtx4070, конденсаторный мик и звуковая карта, а также подготовленное помещение и, самое главное, время.
Подскажи, пожалуйста. Мне нужно изменять свой голос в реалтайме. Получается нужен только RVC? Пишу сэмплы и использую готовый датасет? Но какой? С английским датасетом проскакивает акцент, с японским вроде все нормально (в прошлых тредах прочел). Или мне самому нужно делать русский датасет, но это непосильная работа для одного. Что же делать?
Подскажи, пожалуйста. Мне нужно изменять свой голос в реалтайме. Получается нужен только RVC? Пишу сэмплы и использую готовый датасет? Но какой? С английским датасетом проскакивает акцент, с японским вроде все нормально (в прошлых тредах прочел). Или мне самому нужно делать русский датасет, но это непосильная работа для одного. Что же делать?
Бля. У меня всего 16, уже думал попробовать, а ты так обламываешь блин.
Он долбоеб просто, силеро+вад, умеет резать/склеивать автоматически. Хуяришь чанки по 10 минут и вперед.
В общем если кому интересно загуглил и примерно разобрался в проблеме. silero заколхозил на использование через gpu. И скорость я скажу мое почтение примерно в 6 раз быстрее прогнал примерно тот же объем текста чем я это делал на cpu.
На RVC акцент минимальный вне зависимости от языка, используемого в датасете. Ты скорее всего про SVC читал, там акцент заметнее.
> Получается нужен только RVC?
Для изменения голоса в реальном времени либо RVC, либо Voice Changer: https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice‐Changer
>На RVC акцент минимальный
Спасибо. Тогда не буду заморачиваться с "датасетом с нуля".
Блять, аноны, какие же вы молодцы! Всё так по полочкам разложили, организовали! Вот она - сила двача
существует ли open-source TTS (хотя бы для английского) сопоставимый по качеству с ElevenLabs? Те, что описаны в шапке, явно слабее.
пока еще нет
>сопоставимый по качеству с ElevenLabs
Даже там приходится постоянно ролить результат и высчитывать количество символов за раз, чтобы оно хотя бы постаралось звучать нормально
ну и куда ты ушел?
StS через RVC будет таким же хорошим по качеству, относительно хорошо сгенерированного текста в ElevenLabs, или хуже?
в зависимости от модели
> StS через RVC будет таким же хорошим по качеству, относительно хорошо сгенерированного текста в ElevenLabs, или хуже?
depends от качества модели, но в большей мере от погоды на марсе. иногда идеально выходит, иногда с артефактами. прямой зависимости от качества инпута я не наблюдаю, можно идеально записать исходник, но оно все сжует, а можно плохо напердеть в микрофон и получится хорошо. пробуй, если нет своей карточки, можно арендовать сервер. правда не знаю, где дешевле, мне tesla t4 за 30 рублей в час дают, но наверное можно и дешевле
Лучше объясни как проплатить подписку на елевен лабс
https://youtu.be/qCAHyBb6SD0?si=GSEUelE0UhI7J8sh
Какой нейросеткой сделана эта озвучка?
Какой нейросеткой сделана эта озвучка?
>На eleven labs появился speech to speech
А вот кто пользовался, если я надиктую текст на своём английском, он поправит мне акцент на выходе, оставив только мой голос, или результат получится таким же ужасным, как и на входе?
А вот кто пользовался, если я надиктую текст на своём английском, он поправит мне акцент на выходе, оставив только мой голос, или результат получится таким же ужасным, как и на входе?
>или результат получится таким же ужасным, как и на входе
Говно на входе- говно на выходе, акцентов только больше станет, лол.
Честно говоря так себе, инпут должен быть идеально чистым, но акцент всё-таки убирает. Я не знаю, как он у них работает под капотом. По-моему, также как в дубляже, сначала speech-to-text, потом text-to-speech. У меня он меняет слова на выходе (скорее всего плохо понимает из-за акцента).
>инпут должен быть идеально чистым, но акцент всё-таки убирает
То есть, в принципе я могу озвучить что-нибудь с горем пополам, запихнуть это в StS, выбрать для выходного результата свой собственный голос, и он выдаст мне мой же текст, но уже без акцента?
Нужно как то вокал подчистить, слишком много автотюна накрутило
Проще эффектов каких нибудь накатить чем чистить
Кстати по-разному было, когда с "дубляжом" песенок игрался. То голос становится няшнее чем было, то наоборот металлическо-противным. То в оригинале гипертрофированный акцент, а на выходе обычное произношение. То на входе стандартный язык, а на выходе спик фром май харт. А качество самой записи точно повторяет, все завалы частот и шумы, даже уровень в децибелах и всякий паразитный фон.
> постоянно ролить результат
Тоже бесит. Мог сделать СЕМЬ попыток и всё равно ничего путного не получить. Хоть одно место, но запорото. А может и с первого раза выдать всё идеально.
как вообще один и тот же кусок абсолютно по-разному обрабатывается, где логика?
в теории - да, но на практике, как всегда, есть нюансы,
но должен признаться, качество у них растет.
главная проблема - это стоимость всего этого удовольствия.
Анон, тред читал по диагонали, не обессудь. Сейчас очень много информации по нейросетям, все сразу уяснить невозможно.
Интересует вопрос: что нужно для того, чтобы обучить нейронку в домашних условиях? Цель - создать диктора для чтения художественной литературы. Возможно, придется использовать свой голос для обучения. Не хотелось бы делать это на сторонней платформе. Либо же нужен бесплатный вариант хорошего русскоязычного диктора, поскольку это хобби - проект, а текста много.
О, ещё один глюк обнаружил - "залипание" на интонациях и эмоциях. Если в начале куска ор/визг - в переводе такой же визг до самого конца, даже если там на шёпот переходят. В начале спокойный голос - на выходе тоже вялый на всём видосе, даже если в конце в оригинале припев гроулом.
вот не знаю, как оно обрабатывает у тех, кто там зарегился и даже забашлял. Может и лосслесс стерео выдаёт?
>обучить нейронку в домашних условиях
хорошая видюха и датасет.
могу те с этим помочь. ТГ есть?
Хороший совет, но не хватает конкретики. "Хорошая" - понятие растяжимое. Нужно хотя бы минимально необходимое количество памяти указать.
Спасибо, анон, но наверняка все не обойдется только одним обучением, потом не единожды потребуются корректировки. Да и хотелось бы самому понять, что и как.

На русскоязычного диктора это слабо тянет, лол. Разве что фанфики в порядке лулзов зачитывать.
Так у меня rvm же...
>Хорошая" - понятие растяжимое
чистый звук и минимум 15 минут речи
Ты обгенерировался звуком, что ли, анон? Я спрашиваю про видеокарту.
а. ну 3080 хватит вполне
Жеска. Ясно, спасиба.
И всё-таки может бац и с первого раза выдать шедевр.
> "залипание"
Вот из-за чего бабы-стервы не получались никак. Обрезал начиная с припева - вот теперь идеально, а не невнятный полушёпот как в куплете.
хотя без унтертителей не обошлось и "вир фрауэн зынд шлампен/хурен" не нароллил
Треды не читал гуглить не гуглил.
Кто-то уже сделал хотябы пруфофконцепт озвучки ЖоЖо на русском но с голосами оригинальных сэйю?
https://www.youtube.com/watch?v=vZOwxCh4S44
Кто-то уже сделал хотябы пруфофконцепт озвучки ЖоЖо на русском но с голосами оригинальных сэйю?
https://www.youtube.com/watch?v=vZOwxCh4S44
>Нейронка которую мы ждали: генерация музыки по промпту
>Нейронка которую мы получили:
>Нейронка которую мы получили:
Так это круто же, иногда такой музон в голове играет, что прям аж жалеешь, что пропадает. Крутая штука для композиторов, как по мне, хоть я больше любитель-теоретик в музле. У меня, например есть старая .gpt, которая проебалась, но я оттуда мотив помню. Можно восстановить и сделать полноценный трек. Вообще, нейронки для творчества - суперкрутая вещь, прямо приятно эту революцию наблюдать, раз за разом охуеваешь от возможностей.
Может кто пояснить это я туплю или у меня подели хуевые попадаются. В общем нужна ли дополнительно тонкая настройка для RVC моделей или нормальные модели и из "коробки" отлично работают? Может с индексом какие нюансы есть? Я в logs закидываю, да и в интерфейсе он их по идее находит.
Аноны, можете пожалуйста посоветовать всяких тянских rvc моделей? Всяких там игерл и тому подобного.
Аноны, помогите что ли немного. Хочу подавать свой поток wav байтов по сети в w-okada/voice-changer напрямую, как это проще сделать? В исходниках какой-то треш, не могу понять, как оно на фронте работает и какие методы у сервера вызывает. Есть тут, кто разбирался?
Да, их нужно подстраивать под себя, особенно если у тебя амд карта, но в целом можешь просто посмотреть какие настройки на чем лучше использовать, такой инфы много.
Может я не правильно сформулировал, модели работают, но голос порой сильно или не очень отличается от желаемого оригинала
Есть параметр tune, его под себя настраиваешь, что-то около 17 обычно подходит.

Есть какой-нибудь гайд для альтернативно-развитых, чтобы было хорошо и не было плохо? Голос звучит немного как робот, хотя семпл хороший
Я немного не вдуплил, это ведь не w-okadaвский войсчендже, так?
Вопрос: для распознавания голоса, лучшее open-source решение это whisper?
Это единственные доступные настройки в ElevenLabs. Я так и не понял как ими пользоваться нормально, постоянно чего-то не хватает
Подскажите видео с президентом чтобы обучить eleven labs
А как вместо аудио сделать видео? Ты просто в видеоредакторе пикчу подставил?
А как липсинк подставить?
У меня бывало такое когда семпл слишком короткий.
Настройки по умолчанию, норм., но при каждой попытке будет
ощутимо отличаться интонация.
Есть модель голоса диктора из 90х?
https://www.youtube.com/watch?v=lSuZmr3-UVs
https://www.youtube.com/watch?v=lSuZmr3-UVs
Эти пидоры еще демо прикрыли

Демке ElevenLabs поставили лимит
Есть способ обойти? Чистка кэша не помогла
Есть способ обойти? Чистка кэша не помогла
Купить подписку
Дерни роутер
Зайди через инкогнито
Зайди через другой бразуер
Зайди с другого устройства
Сделай все вместе
???
Профит.
Доброго времени суток, уважаемые. Мне нужно узнать как мне преобразовывать текст в аудиодорожку. Быстро, удобно, и как угодно.
С новым годом нейроголосач!
Желаю вам хороших моделей в этом году!
Желаю вам хороших моделей в этом году!
>06/01/24
>С новым годом
Тебя даже новогодний шум не разбудил?
только отпустило
Зелёный слоник уже не в моде?
Аноны, кто-то из вас может предположить как сделана озвучка на этом видео? Со всеми вздохами и интонацией?
походу анон просто записал свой голос а потом прогнал через рвс
это оригинал, рвс оставляет ключи в аудио, тут их нет.
какие ключи?
Да, ElevenLabs конечно делает красиво, но все оплаченные символы ушли как дети в школу, хотя сначала кажется, что их дают довольно много. Вот Speech to Speech вроде бы может решить эту проблему, но где достать хороший входной голос, который был бы похож на человека? Если сначала озвучить через какой-нибудь Гугл переводчик, то в ElevenLabs на выходе всё равно получается тот же робот, хотя уже и с нужным голосом. Короче говоря, где можно найти бесплатную говорилку с нормальными человеческими интонациями, чтобы скормить её в Speech to Speech?
Анонче, есть чистый, минутный сэмл где вайфу на японском базарит без лишнего шума, но елевенлабс всё ещё выдаёт некачественную обработку, не уровень всяких ДЫО и Жотаро, которые на инглише почти как на радном болтают. Мне получается нужно больше сэмплов найти? Пойдёт просто нарезка этого же семпла с каждой фразой по отдельности?
Не пробовал на RVC модель обучить? Видел, что писали, что если датасет качественный, то минуты как раз хватит. Правда я сам не проверял.
Ставил тортойз, но он на этапе загрузок некоторых библиотек выдавал ошибку и слал нахуй
RVC это STS (изменение голоса), а Tortoise это TTS (синтез голоса), насколько я понял. Tortoise можно дообучать на свой голос?
>Ultimate Vocal Remover:
кал ёбаный блядь
Установил себе на линукс мастер - в нем гпу не используется независимо от того, ставлю я чек на gpu conversion или нет.
5.6 вообще не ставиится из-за конфликта зависимостей requirements.txt
У проекта полна жопа ишшью на гитхабе, чел ебёт вола, играется с фоном программки и шрифтами сместо того, чтобы обеспечить базовый функционал
ну хз. у меня бубнта все норм поставилось
1. какой тег ставил?
2. какая версия питона у тебя?
в смысле тег?

>линукс
дальше не читал
я знаю, что читать - не входит в стандартные умения виндузятников, ты мог мне не напоминать лишний раз.
в репозитории гитхаба есть теги. Обычно версии программы равны тегам.
Проблема с UVR как-то сама решилась, я не знаю как. Он начал использовать видеокарту.
альсо моя первая проба пера, оценки приветствуются.
хы
как делал?
>Проблема с UVR как-то сама решилась
>линукс
Привет двачик, помогите пожалуйста. Есть mp4 на английском языке, хочу перевести его на русский. Как мне это сделать?
Заплати переводчику.
Whisper'ом можешь речь в текст перегнать и потом хоть через гугл перевести.
https://www.heygen.com/video-translate
Если тебе нужен перевод сразу в виде голоса, наложенного на видео, то есть такой онлайн-сервис. Понятия не имею, платная сейчас эта фича или нет.
Вот вроде было 50к символов, а вот уже и нету. Я даже не всё успел исправить в уже сгенерированном. Когда уже завезут бесплатное клонирование голоса и ТТС?
залетел спросить так как сам не слежу, есть уже что-то где можно закинуть текст книги и скочать аудиокнигу разумеется без смс и регистрации?
как описано в ОП-посте - сначала silerotts, потом результат в RVC
что мешает обучить свою модель под голос этого великого озвучатора https://www.youtube.com/watch?v=AmFNCJnPuz8 и слушать любфые книги, какие захочешь?
>что мешает обучить свою модель
слабый комплюктор
у меня есть балаболка но голоса оставляют желать лучшего, а современных йоба голосов как я понимаю в открытом доступе нет, да и все равно это костыльно
а что именно тебя не устраивает в голосах?
Вот я сделал вот эту озвучку теми инструментами, которые описаны в ОП-посте. Тебе такого качества не достаточно?
Что ты понимаешь под "йоба-голосами"?
так я и спрашиваю есть что то что позволяет работать с большим объемом текста за раз с возможностью скачать результат?
а голова тебе для чего? Суешь книгу в питонячий код, который разделит её на фрагменты и озвучит - получаешь на выходе звуковой файл.
От силы строчек 10 кода займёт.
вот тебе пример первой страницы пелевинского iphuck-10
У SileroTTS заметна картавость местами, неправильные ударения и она не умеет называть числа из цифр.
По идее с числами можно бороться просто питоном заменяя их на дуквенные обозначения. С ударениями и буквами ё по идее должен бфыл справляться акцентуатор в TeraTTS, но он сломан в мастере и чел забил хуй на проект 4 месяца назад. Ну а с картавостью поможет только обучение нормальной модели.
Тем не менее вот тебе пруф оф концепт работы длинной озвучки.
понял
так есть обучение онлайн. в каггле например. я кидал выше
силеро ттс в плане прогонки дальше через рвс сильно уступает еджттс. Едж умеет и числа читать и ударения в большинстве случаев правильное
>Бесплатная, не требующая СМС и регистраций онлайн-система синтеза голоса от Microsoft.
>от Microsoft
фу блять
Нейроаноны вопрос такой, есть опенсорсные/офлайн аналоги chirp/suno?
пощадите я подпивас, а не кулхацкер
ОНА И БЕЗ ТЫРНЕТА РАБОТАЕТ. А ТО ЧТО ОТ МАЙКРОСОФТ ТАК ЭТО ПРОСТО ПРОГРАММА. ДАННЫХ ОНА О ТЕБЕ НЕ СОБИРАЕТ
так что тебе надо? Текст озвучить? Так силероттс и еджттс без ограничений вроде локально озвучивают. Я пасты и на 30 минут и на час озвучивал. Потом через рвс прогоняешь. Как модель делать? Так датасет с голосом нужен а потом онлайн можно. Если есть вопросы пиши в тред помогу.
>рвс
что такое рвс? Кстати, такой нубовопрос. Если все говорилки кажутся пресными, есть способ как-то эмоции расставить в тексте? может с помощью параллельной дорожки?
rvc это смысл этого треда

ну эмоции примерно можно добавить через SSML https://github.com/snakers4/silero-models/blob/6b0bb8a7637d791fbb7adf22c56af1c89758ff19/examples_tts.ipynb
>rvc это смысл этого треда
Elevenlabs
там через тэги?
А нельзя как-нибудь прям через внутреннее представление нейросети? Играть с параметрами эмбеддингов? Там наверняка есть проекции связанные именно с эмоциями.
эмммм. нет. опенсурс вперед rvc топ!!!!
С RVC ещё надо поебаться, чтобы он хорошо работал
что именно надо сделать?
Люди, вы не знаете названия той программы, которая очень хорошо воспроизводила речь людей, которая была в обороте в форчане ровно год назад?
При помощи которой Джоан Роулиг заставляли зачитывать пасту you will never be a real woman или Эму Уотсон Мою борьбу.
При помощи которой Джоан Роулиг заставляли зачитывать пасту you will never be a real woman или Эму Уотсон Мою борьбу.
Поставить на комплюктор, как-нибудь натренировать модель (а хорошо может получиться не с первого раза), потом ещё нужно где-нибудь сгенерировать более-менее нормальный голос и уже только тогда можно сконвертировать его в нужный. В ElevenLabs это всё делается за пару минут, вот только нужно много платить
ЩАС НАШИ БРАТКИ КИТАЙЦЫ ПОДНАЖМУТ И БУДЕТ ЛУЧШЕ ЕВЕНТЛАБС НАШ РВС!!!!
ндааа, дейсвительно. этож целый час ебаться
>этож целый час ебаться
Это когда ты уже знаешь как там всё работает, и что тебе нужно примерно делать
Только вкатываюсь, как рвс тренируется вроде понял и оно плюс-минус нормально работает если я сэмплы сам записываю своим голосом и потом их прогоняю.
Есть ли какая-то хуйня чтобы натренировать ттс чтобы оно паузы и ударения расставляло как надо?
Есть ли какая-то хуйня чтобы натренировать ттс чтобы оно паузы и ударения расставляло как надо?
> Есть ли какая-то хуйня чтобы натренировать ттс чтобы оно паузы и ударения расставляло как надо?
Не думаю, что ты что-то однокнопочное найдёшь под такую задачу. Весь попенсорс по TTS какими-то васянами на коленке пишется.
https://habr.com/ru/articles/767560/
В TeraTTS пытались именно ударения пофиксить, но вышел какой-то кал, на мой взгляд.
https://github.com/coqui-ai/TTS
XTTS выкладывали какие-то скрипты для файнтьюна и обучения своих моделей с нуля, можешь их попробовать раскурить.
Спасибо. Я еще погуглил немного, но пока выглядит не очень радужно.
а можешь прогнать на итальянском?
+ немецкая версия без кривых стыков
охуеть. Но мат перводит плохо
последний запрос пожалуста
https://www.youtube.com/watch?v=_Hv-iypFLrU
> время.mp4
Омерзительно, но в то же время ностальгически гипнотично.
It failed.
Что бы ещё попробовать...
Жалко нет латыни, иврита, белмовы, баскского, албанского...
мне б еще на итальянском что нибудь
того же кринжа навалил, что и на немецком
Есть чё по STT лучше виспера? Кал же натуральный, ну. Кое-как понимает английский, а русский вообще ни в пизду, ни в красную армию.
Чуваки, ищу человека который сможет помочь спич ту спич
За деревянные естественно
а чем там помочь?
Ну а тут не знаю, ржать или плакать.
вся игра слов конечно заруинилась
Спич2спич
а че делать то? Модель обучить или просто прогнать голос через рвс?
Обучить модельку (или найти готовую для рвс) и прогнать мою озвучку в голос модельки
готов. кидай тг
Насколько RVC умеет в экстремальный вокал? Получить на подобии криков Рушии https://www.youtube.com/watch?v=PcvATSahB8o в сочетании с обычным возможно?
https://riverside.fm/transcription
Вот это я понимаю, все бы нейронки такими были. ПРОСТО зашёл с ноги на сает, засунул туда что угодно и сколько угодно и играйся себе до усрачки.
Вот это я понимаю, все бы нейронки такими были. ПРОСТО зашёл с ноги на сает, засунул туда что угодно и сколько угодно и играйся себе до усрачки.
так где ты анон?

Ебёна мать, я всего лишь хочу озвучить свой сценарий в Арме 3, а тут какую-то документацию курить надо, куда меня занесло...
Какой нейронкой можно одним кликом перевести это to text?
Подскажите нейросеть которая меняет язык говорящего на другой
в евент лабс все
Из локальных rvc в шапке глянь.
Анон, сейчас есть что то близкое к качеству Eleven Labs в плане TTS? На инглише.
Бамп

Подписка на elevenlabs заканчивается через 4 дня. Анон можешь реквестировать что-либо
Есть какая-нибудь нейронка, чтобы по одному клику бесплатно без реги можно было:
- "дорисовать" всратый/жатый некачественный монозвук с кассеты до вылизанного студийного стерео?
- отделить вокал от музыки и скачать оба файла? Если выход в вавках, то вообще круто.
консольно-пердольное с кучей команд тоже норм
- "дорисовать" всратый/жатый некачественный монозвук с кассеты до вылизанного студийного стерео?
- отделить вокал от музыки и скачать оба файла? Если выход в вавках, то вообще круто.
консольно-пердольное с кучей команд тоже норм
Ну вот это на немецкий например)0
Или это.
небось слишком тянуче и оруче, ничего не распарсит
небось слишком тянуче и оруче, ничего не распарсит
Тоже на немецкий порофлить.
Всё, хватит.
ещё кто-то на итальянский просил что угодно, тоже можно всё это прогнать
ещё кто-то на итальянский просил что угодно, тоже можно всё это прогнать
Ладно, сам одну запилил. Ну вот так звучит блатняк на немецком, кек.
Поможет ли мне AI спик фром май харт без акцента? Я видел демку, где чучмекам заменяют их голоса на синтезированные, но мне надо, чтобы голос оставался мой. Не в реальном времени.
эскадрон уже на все языки перевели мне кажется, смотри по тредам
А никто не пробовал еще https://github.com/myshell-ai/OpenVoice/ ?
О, и сразу в виде сабов может распаршенный текст оформить. А вот что получается, если языка нет даже в этой широчайшей базе и выбираешь хоть как-то похожий...
Какая нейронка нужна чтобы извлечь японскую речь а потом преобразовать ее в русскую? Чтобы перс говорил голосом как на японском но русскими словами.
Локалок под такое не завезли. Можешь через elevenlabs или heygen сделать. Везде лимиты на бесплатных тарифах.
https://elevenlabs.io/dubbing
https://labs.heygen.com/video-translate

Нет
> - отделить вокал от музыки и скачать оба файла? Если выход в вавках, то вообще круто.
Здесь глянь:
https://2ch-ai.gitgud.site/wiki/speech/#разделение-вокала-и-инстументалки
Работает хорошо только на композициях с малым числом инструментов.
Как сделать чтобы голос ебаным противным металлом не отдавал? От чего это вообще зависит? От качества песни? Да вроде нихуя я попробовал кавернуть несколько идеальных песен без посторонних шумов(чистил их через UVR звучали идеально в итоге) и с ровным голосом всё равно этой хуйнёй в некоторых моментах отдавало. От используемой модели голоса? Вот тут хуй знает, но идеальных мне не попадалось хотя я использовал не то что бы мало. При этом на ютубе смотрю видосики с каверами ну там прям небо и земля, есть такие где даже очень сложные песни сетки поют сука с идеальной интонацией без скрежетящего говна. Может я что-то не так делаю? Каверю вроде по гайду через RVC.
Зависит от исходника вокальной дорожки, модели RVC и последующего мастеринга и сведения.
Мне кажется ни от чего не зависит, это баг самой RVC, оно совершенно случайно может начать запинаться, жужжать просто потому что и хуй че сделаешь. Хотя наверное можно нарезать и по отдельности рендерить и возможно конкретные участки получится исправить, но такое себе, хуйня короче это ваше rvc
Проблема RVC в том, что она заточена под нищекарты и процессоры, по идее там нужно вручную играться с параметрами x_pad, x_query, x_center, x_max в файле config.py для достижения наилучших результатов (если у тебя видеокарта с объёмом VRAM больше, чем 6гб).
Плюс для каждого конкретного случая нужно выбирать модель инференса: pm — днище, harvest — вроде как хорошо работает в низкочастотном диапазоне, crepe — хорошо работает с длинными звуками, rmvpe — даёт широкий вокальный диапазон, хорошо передает интонации, но на длинных звуках моут быть артефакты.
Я обычно прогоняю через 3 модели и потом в аудишне склеиваю лучшие куски как мне надо. Ну и мастеринг, реверб, студио дилей, RX 10. Ручной ебли много, да.
Уже полгода обещают пиздатую-распиздатую RVCv3, но воз пока на месте.
>тебя видеокарта с объёмом VRAM больше, чем 6гб)
у меня 2 гб, но она из озу отжирает и вроде норм, но чем больше отжирает, тем больше артефактов, странно. вот еще, чем мне не нравится rvc, так это тем, что настроек минимум, документации тоже, никто особо не понимает, как она работает, что конкретно писать в эти x_... итд
Почему буквально все нейронки, которые связаны со звуком - протухшее говно мамонта? Постоянно натыкаюсь на то, что все репозитории заброшены уже лет по пять-семь, а авторы пропали без вести. Да даже рвц не ставится на современное окружение, нужны какие-то дремучие версии библиотек.
Сделай нормально сам.
>Да даже рвц не ставится на современное окружение, нужны какие-то дремучие версии библиотек.
ну во-первых для винды уже все готово, а для линукса есть conda, не так уж и сложно подобрать версии, я же смог как-то, причем там только один пакет выебистый, насколько я помню
алсо вот, но никто не заценил

Ну вот, маленько попердел вчера и запилил три Генкиных ковра на аукцыон и один на Леонтьева. Душевно. Ссаными тряпками не кидайтесь, няши.
https://youtu.be/wWISPDmGWic
https://youtu.be/rWM5op1tA1w
Его манера под довольно раслабленный вокал аукцыона не прямо чтоб очень подходит, зато всякие завывания и рррыки прямо заебись, даже специально из живого исполнения вырезал и конвертил.
На очереди одна подходящая данному персонажу шуточная песня Владимира Семёныча, но там нужно сводить уже наконверченый вокал, где хорошие акценты и интонации, с нормальным гитарным фоном из другой записи, то есть хз когда будет.
https://youtu.be/wWISPDmGWic
https://youtu.be/rWM5op1tA1w
Его манера под довольно раслабленный вокал аукцыона не прямо чтоб очень подходит, зато всякие завывания и рррыки прямо заебись, даже специально из живого исполнения вырезал и конвертил.
На очереди одна подходящая данному персонажу шуточная песня Владимира Семёныча, но там нужно сводить уже наконверченый вокал, где хорошие акценты и интонации, с нормальным гитарным фоном из другой записи, то есть хз когда будет.
Если б я мог нормально сделать - готовое не искал бы.
>ну во-первых для винды уже все готово
Ага, конечно.
>но никто не заценил
Они пишут, что нет поддержки ничего, кроме линукса. Даже если заработает, то непонятно как и надолго ли.
Накатил в одно окружение xtts, whisper и рвц. Видеокарту видит только xtts. Переустановил торч с кудой. Рвц заметил видеокарту, xtts всё ещё норм. Виспер такой - какая видеокарта? Нет нихуя. При том что rvc полудохлый, xtts умирающий, в виспер вроде как живой и должен поддерживаться. Ебётся в одно ядро, спасибо, что даже так быстро работает.
>Ага, конечно.
что ага, качаешь архив, распаковываешь и запускаешь файлик из папки, все работает, все окружение с нужными пакетами уже там, не выёбывайся. даже на дохлом амуде обожекакойпиздец работает. про видеопамять и шаманство с параметрами писали выше
btw когда я сервак арендовывал, проблем не было ни с 2080, ни с 4090, ни с теслой, хотя может потому что они все один и тот же драйвер кушают. там единственная ебля была в том, как pytorch с cuda накатить, но это один раз сделал и забыл
>и запускаешь файлик из папки
Хуй знает, у меня даже рекваирментс не все поставились автоматом. Да и пути к окружению нужно исправлять. Пока оно там переустанавливалось три раза, уже скачал другой софт и сделал, что хотел, по-другому. Вроде, запускается рвц без ошибок, но использовать пока так и не использовал.
Транскрибировал виспером тысячу+ файлов, текст, озвученный профессиональным актёром на студии, без фонового шума и помех, частота 22050. Идеальные условия, по сути. Отслушал пока сотню, ошибки в 45, причём если на файл две-три ошибки, это всё ещё считается за одного. Нет, это не смолл модель. Что смешно, есть ошибки в одинаковых фразах, но виспер ошибается в разных местах.
Ещё закинул аудио после пары фильтров, небольшой реверб и понижение тона. Где-то вдвое хуже результат, посмотрел десяток файлов, в четырёх даже язык неправильно опознал, без ошибок два. Что будет с фоновыми шумами, страшно представить.
ЕСЛИ У ТЕБЯ ЕСТЬ ТРУДНОСТИ, ТО У ТЕБЯ ЕСТЬ ЦЕЛЬ
Хм, а если разделить трек на вокал и музыку в вавках, засунуть вокал в ылэвынлабс, потом отремастерить и заново смиксовать с минусом? Ну какчество явно получше получается.
>засунуть вокал в ылэвынлабс
Охуеть от количества символов, которые он там у себя насчитал

Хули с голосовыми нейронками такая боль дырка задница? С картинками проблем нет, с текстом проблем нет. Голос? Пизда. Запустил тренировку coqui-ai/TTS, сожрало всю vram, потом сожрало всю ram, карту ебёт на полшишечки, зато ебёт процессор. Серет ворнингами "депрекейтед" в консоль, что уже вот-вот и эти функции работать перестанут. Ну, думаю, мне-то что, сейчас один раз натренирую, а потом в рот оно ебись. В итоге один хуй отвалилось с ошибкой доступа к файлу.
>PermissionError: [WinError 32] Процесс не может получить доступ к файлу
Походу, у них какой-то долбоёб писал код, из одного потока логи создал, из другого пытается в них писать. В ишьюз нашёл, официальный ответ - мы не поддерживаем шиндовс. Типа в юникс-системах можно открывать один файл из разных потоков и всё будет хорошо.
Повезло, что из конфигов можно поставить один поток для работы, но, учитывая что оно не может работать только на GPU, тренировка будет супермедленная.
Что ещё не превратилось в окаменевшее говно мамонта и быстро делает text to speech? Пока что из всего, что тыкал, реально работает только силеро, но там нельзя добавить свои голоса или как-то это настроить. Кроме питча, лол.
>PermissionError: [WinError 32] Процесс не может получить доступ к файлу
Походу, у них какой-то долбоёб писал код, из одного потока логи создал, из другого пытается в них писать. В ишьюз нашёл, официальный ответ - мы не поддерживаем шиндовс. Типа в юникс-системах можно открывать один файл из разных потоков и всё будет хорошо.
Повезло, что из конфигов можно поставить один поток для работы, но, учитывая что оно не может работать только на GPU, тренировка будет супермедленная.
Что ещё не превратилось в окаменевшее говно мамонта и быстро делает text to speech? Пока что из всего, что тыкал, реально работает только силеро, но там нельзя добавить свои голоса или как-то это настроить. Кроме питча, лол.
Первая годная генерация которая у меня вышла, все остальные песни с артефактами и скрежетом. Как вы вытаскиваете из песни вокал так, чтобы нейронка могла его нормально озвучить?
двачую, давно использую, алсо там можно на инструменты разделить, полезно, если ты сам музыку делаешь
из минусов - оно как-то портит бас и в целом эквализацию музыки, поэтому никакой кавер не будет звучать так же хорошо, как и оригинал
Я так понимаю, тред дальше rvc не ходит? Как вы текст в речь-то переводите?
Посмотрел в собаке силеро, у них такотрон и хайфайган, но реализация - моё почтение. Надеюсь, у них код автоматически генерируется, иначе это клиника. Зато понятно, почему на видимокарточке медленнее, везде хардкод cpu.
XTTS на "добавленных" моделях работает из-под палки, всё время норовит отрыгнуть, а родная 1.8гб, если тренировать - сразу улетает за 5 гигов. Работает это всё, очевидно, медленно. И хуёво.
Нужен мой голос. Есть решения RVC для Win 7?
Или платно но не дорого
>Нужен мой голос. Есть решения RVC для Win 7?
а че, из шапки не работает что-ли?
Мне нужно обучить на мой голос
Десктоп Rvc не работает на Виндоус 7. Коллаб зпебывает лимитами Есть альтернативы? Желательно бесплатно
бесплатно можно найти виндовс 11

Бля, я рилтайм хотел. Чтобы задержки пониже.
Олсо упёрся в ударения и прочее. Что смешно, в более толстожопых решениях ударений нет. Можно из силеро выдернуть, но, опять же, учитывая что это питон, задача та ещё.
скинь ттску эту и как запускать
я про видос
https://docs.coqui.ai/en/latest/inference.html
Это вот это. Только они почти везде пишут про подключение сторонних штук типа витса, такотрона и т.д. При этом имеют свою gpt2 модель, которая XTTS_v2.0_original_model. Я гоняю файнтюн этой модели, который по каким-то причинам разожрался до пяти гигов с базовых 1.8 гигабайт. В сетке 16 языков, как выпилить все остальные - хуй его знает, при тренировке указывал, чтобы тренировался только русский, ему поебать.
можешь нормально объяснить?
как этим пользоваться
Создаёшь окружение. Если совсем влом ебаться с питоном, то скачивай анаконду. В неё есть гуй, удобно. Создаёшь там новое окружение, environment. Гонять разные сетки в питоне без разных окружений околоневозможно. Потом запускаешь это окружение, там кнопка плей и жми опен терминал.
https://docs.coqui.ai/en/latest/tutorial_for_nervous_beginners.html
Установка описана здесь. По сути, всё что надо сделать - вбить в консоль
>pip install TTS
Это не даст тебе возможности редактировать файлы самой ттски, но оно тебе надо? Если надо, клонируй гит. Там это тоже есть.
Для генерации вот это
https://docs.coqui.ai/en/latest/inference.html
Скроль до Python 🐸TTS API, спизди весь этот код в файл.
speaker_wav="my/cloning/audio.wav"
Нужно отредактировать, это путь к голосу, который ттс будет пытаться имитировать, любой вав 6-10 секунд. Без него нельзя. И запускай файл.
спасибо!
у меня сервер оплачен и простаивает, кидай исходник, могу обучить
>спизди весь этот код в файл.
Спиздил. Куда теперь этот файл сувать и как его через анаконду запускать?
>Куда теперь этот файл сувать
Так проебом вообще.
В анаконде у тебя будет окружение, которое ты создавал и куда установил TTS. Там жмёшь опен терминал. Потом пиздуешь через cd к файлу, который сохранил.
cd C:/my_folder/
Здесь нужно помнить, что если твой файл не на том же диске, что окружение, то есть не на С, то нужно хуярить
cd /d D:/my_folder/
Потом хуяришь в консоль
python my_file.py
У меня файл называется bark.py и лежит в папке D:/tts, то есть в консоль я хуярю
cd /d D:\TTS
python bark.py
Пон
Как формируете датасет при обучении rvc? Обучал на 20 треках, 200 эпох. 3.3 минуты. Качество записи отвратительное. Нужно не для вокала, а для озвучения текста.
На сайтах пишут разные требования:
> For better quality, try to obtain at least 30 minutes of voice.
> Примерная длина всех аудио от 1 до 30 минут, оптимально от 3 до 10 минут (лучший вариант - 5 минут с большим охватом спектра голоса)
Если дообучать на новых данных, то старые можно удалить? Слышал о перетренировке.
На сайтах пишут разные требования:
> For better quality, try to obtain at least 30 minutes of voice.
> Примерная длина всех аудио от 1 до 30 минут, оптимально от 3 до 10 минут (лучший вариант - 5 минут с большим охватом спектра голоса)
Если дообучать на новых данных, то старые можно удалить? Слышал о перетренировке.
А как я буду пользоваться если надо будет что озвучить, тебя снова просить?
Хочу натренировать RVC-модель на англоязычном датасете, чтобы потом использовать его на русской говорилке. Ничего, что датасет английский? Нормально получится?
Должно быть ок. Во втором ОП-пике по идее англоязычная модель была для RVC.
Попытка перевести так песню целиком.
А я всё никак из 1999 не вылезу.
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 2.78 GiB already allocated; 0 bytes free; 2.86 GiB reserved in total by PyTorch)
Чо делать? 1050ti.
Чо делать? 1050ti.
если просто - купить видяху поновее
куда в стабле дифьюжен класть видео и куда звук, который хочу наложить? если можно скриншоты.
Вообще больше вариантов нет? Пробовал заменить 10 кусков по 10 минут на 1 длиной в 5 минут, результат тот же.
На колабе RVC можно тренировать?
на 1050 не трень. есть множество способов онлайн тренить
https://www.kaggle.com/code/varaslaw/aisingers-rvc-rmvpe-https-t-me-aisingers-ru/ новая версия
https://youtu.be/L-emE1pGUOM?feature=shared обучалка
ну все. переставил систему. через пару дней забабахаю для этого гуй
Не работает. Заканчивает тренировку на необходимом количестве эпох и пишет:
Файл модели "mi-test" не найден.
При этом пишет, что промежуточные результаты при достижении n-ной эпохи сохранены, но в директории их нет.
Вот кусок кода, ответственный за сохранение:
https://pastebin.com/0K8qFQVG
Видимо баг, не позволяющий создать директорию, потому что в Output нет папки Weights.
Есть ли другие варианты?
Привет аноны, гость с издача в вашем треде
А вот эти ваши сетки можно как-то использовать для того чтобы аудиокнигу записать?
А вот эти ваши сетки можно как-то использовать для того чтобы аудиокнигу записать?
А мне наоборот - чем быстро преобразовать кучу записей из многомногочасовых файлов в текст? Желательно чтоб работало без инета, идеально распаршивало хоть 20 спикеров на разных языках с качеством "диктофон в туалете" и помечало тайминг.
тупо хочу найти в записях нужные слова, чтобы не перелопачивать всё вручную
хмммм. недавно тренил норм было все
да, можно конечно. Сначала ттс книгу эту в речь преобразовываешь а потом через рвс и все
Whisper
Ребят спасибо большое разобрался с RVC. Очень понравился форк mangio-RVC.
Теперь такой вопрос. Какие репозитории есть для tts. Можно ли так же тренировать для определенных людей?
Теперь такой вопрос. Какие репозитории есть для tts. Можно ли так же тренировать для определенных людей?
> Ребят спасибо большое разобрался с RVC. Очень понравился форк mangio-RVC.
Можешь рассказать, в чём его плюсы? Я его пробовал ставить, кроме различий по стилям и возможности выставлять эпохи выше 1к ничего не заметил.
> Теперь такой вопрос. Какие репозитории есть для tts. Можно ли так же тренировать для определенных людей?
https://2ch-ai.gitgud.site/wiki/speech/#синтез-голоса-из-текста-tts
На свои голоса вроде как никто не обучает, обычно делают TTS, а потом через тот же RVC перегоняют к нужному голосу, есть такая тулза чтобы одним кликом это делать - https://github.com/daswer123/silero-rvc-tts-ru-gui Я не видел проектов TTS, где были бы готовые скрипты для тренировки своих голосов. Может кто-нибудь другой знает.
А есть клиенты для этого типо webui?
для ттс? Полно.
https://github.com/hinaichigo-fox/rus-edge-tts-webui
https://github.com/hinaichigo-fox/rus-silero-webui
вот например
Аутизм с песнями задом наперёд можно поднять на новый уровень.
Вторая попытка.
Да это тоже самое просто там есть экстрактор mangio crepe
Если датасет качественный то он дает результаты намного намного лучше rmvpe. Ну а если неочень датасет то впе лучшее решение.
Ну и просто коллаб прописан намного лучше. Он на английском и очень удобный. Я видел колаб RVC он был на кеитайском и я в ужасе закрыл.
>На свои голоса вроде как никто не обучает, обычно делают TTS, а потом через тот же RVC перегоняют к нужному голосу
Аааааа теперь я понял.
>На свои голоса вроде как никто не обучает, обычно делают TTS, а потом через тот же RVC перегоняют к нужному голосу
Слушай а в TTS же задача намого шире чем RVC. А какого рода тренировках значит идет речь? Файн тюнинг под другой язык?
Я ктому что явно у TTS моделей ограниченное количество токенов в понимании. Значит он можно воспринимать текста только с натреннированных языков?
Сап аноны
А есть че для STT что может в потоковом режиме голос с микро в текст преобразовывать?
Бля, забыл добавить, имеется ввиду локально, у себя на компе
А что если распарсить идиш как немецкий...

Кто-нибудь делал успешно клон своего голоса для генерации озвучки английского текста в ElevenLabs? Может есть какие-то неочевидные моменты или годные советы?
Делал для озвучки на русском, но не своего голоса.
Единственный совет качество источников голоса важнее их количества.
Речь свою наверное лучше записывать естественную, как если бы ты с кем-то говорил, а не монотонное чтение чего-либо, так как Елевенлабс копирует и манеру речи.
Есть тут кто-нибудь кто tts на русском языке тренил?
Натрень tacotron модельку просто
> https://github.com/Purfview/whisper-standalone-win
Быстрый скомпилированный для винды whisper, добавьте в шапку.
Быстрый скомпилированный для винды whisper, добавьте в шапку.
Уважаемые, с weights.gg голоса скачать можно?
конечно
Всё, пиздарики, плоти регься подписька? Сколько раз ни пробовал, через что только ни стучался, даже тор - резко раз и ни в какую. В обед вчера обработало последний файл и теперь постоянно вот это говно вылазит, хоть какой файл подсунь, даже самый мелкий.
А как? Мне предлагает только через сайт с голосом работать, а скачать не предлагает.
https://github.com/SYSTRAN/faster-whisper
Они выходит вот это в exe упаковали? Смущает, что у проекта из твоего поста никаких сорцов нет. Или не там смотрю?
Хотя автор проекта faster-whisper в своём readme его упоминает как "Standalone CLI executables of faster-whisper for Windows, Linux & macOS".


https://github.com/ggerganov/whisper.cpp
От жоры кстати не имеет смысл упомянуть версию? Или оригинальное решение от OpenAI + https://github.com/Purfview/whisper-standalone-win будет достаточно?
Добавил инфу об этом варианте whisper'а в шаблон и в вики:
https://2ch-ai.gitgud.site/wiki/speech/speech-shapka/
https://2ch-ai.gitgud.site/wiki/speech/#распознавание-речи-stt
>надо было ставить линукс
А есть ли ещё какая-то версия этой песни с ИИ голосом Линуса? Мне кажется я раньше слышал другую версию где-то.
Анон, просвети ньюфага. Вот если у меня есть только пожелания для песни (например, романтичная песня про линукс) - это в Suno Chirp. Если у меня есть только текст песни, то это туда же - мотив и музыку оно само подберëт.
А теперь задача посложнее. У меня есть минусовка (допустим, "Светит незнакомая звезда") и переделанный текст-пародия ("Глючит незнакомая винда"). Какая нейронка может мне его спеть на заданную музыку? Suno Chirp не может...
А теперь задача посложнее. У меня есть минусовка (допустим, "Светит незнакомая звезда") и переделанный текст-пародия ("Глючит незнакомая винда"). Какая нейронка может мне его спеть на заданную музыку? Suno Chirp не может...
>>413975
Нету там нихуя. Бля, лень самому генерить, да и мощностей нету, есть у кого Денис Беспалый RVC?
Нету там нихуя. Бля, лень самому генерить, да и мощностей нету, есть у кого Денис Беспалый RVC?
Блять https://t.me/AINetSD_bot, ладно.
Что скажите по поводу использовал TTS для ютуб канала? Говно или уже норм?
И что лучше использовать? ElevenLabs?
И что лучше использовать? ElevenLabs?
Я лично юзаю свой голос и через нейронку его обрабатываю, в итоге результат вроде и ты говорил, но понять что это был ты только через манеру речи, а так слышится норм.
А через какую нейронку ты обрабатываешь голос?
Проплатить elevenlabs можно только через всякие платисру с большой наценкой?
есть гайд по обработке голоса перед кавером?
если в песне источнике голос с эхом или ревёрбом, то RVC делает звук говна. нужен именно гайд как в аудишне сделать голос "плоским" что ли, не знаю как правильно по терминологии, чтобы не было эхо, шумов на занем фоне. пробовал разные аи энхансеры, чуть лучше но всё равно говно выходит.
если в песне источнике голос с эхом или ревёрбом, то RVC делает звук говна. нужен именно гайд как в аудишне сделать голос "плоским" что ли, не знаю как правильно по терминологии, чтобы не было эхо, шумов на занем фоне. пробовал разные аи энхансеры, чуть лучше но всё равно говно выходит.
Универсального метода нет, всё зависит от того как был сведён исходник. В некоторых случаях хорошо работает Center Channel Extractor (тоже самое, что vocal remover, только наоборот)
>Center Channel Extractor (тоже самое, что vocal remover, только наоборот)
не наоборот, это работает только если инструменты сильно разведены по панораме, что делается далеко не всегда, ну и как можно догадаться, метод весьма примитивный и звучит как говно.
vocalremover org работает лучше, но жопит нч и вч, так что тут только идти на компромиссы остается
>юзаю свой голос и через нейронку его обрабатываю
Английский/русский?
на фотке скинул
Что английский, что русский, причем модели спокойно что тот, что этот язык обрабатывают (в большинстве случаев)
Какие есть на данный момент лучшие варианты для TTS и STS, для БЫСТРОЙ генерации? Важно именно время генерации
Для англюсика, кстати, но не помешает и если будет русский
Точно, спасибо.
Есть ли TTS с возможностью манипулировать эмоциональным тоном в разных частях текста?
Так, падажи. А подскажи вот что. У меня есть 30 минут голоса. Я хочу натренировать модель и потом писать текст и чтобы он озвучивался натренированым голосом. Я так понимаю что это не про RVC ?
Глобально задача такая - хотелось бы (не знаю есть такое или нет) качнуть локально голосовую нейронку, типа как качаешь локально SD или Foooocus, тренируешь модель и потом пишешь текст и оно локально тебе генерит голос. Не хотелось бы все это в облаках делать. Вижу что есть какая-то ебала с тем, что одна сетка только голос меняет, другая еще что-то, третью надо в облаке хуярить и т.д. Может в курсе?
Есть XTTS, который по небольшой записи может делать синтез по тексту напрямую нужным тебе голосом. Я его мало тестил, мне не особо зашло, хотя многие нахваливают.
Спейс на хаггине: https://huggingface.co/spaces/coqui/xtts
В случае с RVC тебе действительно придётся использовать две разных сетки, так как RVC может преобразовывать голос только в уже существующей записи. Из-за этого сперва надо сгенерировать запись по тексту на любом голосе. Из локальных сеток для такой задачи мне больше всего зашла SileroTTS, из халявных облачных EdgeTTS (Edge явно лучше Silero работает). У Silero ещё проблема в том, что на русскоязычных голосах он не может англоязычный текст озвучивать.
Потестить их в онлайне можно здесь:
https://huggingface.co/spaces/NeuroSenko/tts-silero
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
> пишешь текст и оно локально тебе генерит голос
Есть несколько проектов, которые реализуют конвеер с синтезом по тексту на одной нейронке, и потом приводят их к нужному голосу через RVC. То есть под капотом используются две разных нейронки, но тебе не нужно между ними вручную переключаться. В этом треде такую тулзу кто-то использовал:
https://github.com/daswer123/silero-rvc-tts-ru-gui
Большое спасибо. Странно что с голосовыми такая ебала, но думаю и до них дойдет прогресс
>Как обучить свою RVC-модель?
Сделал все по инструкции, но вот что интересно, оно пишет, например :
Train Epoch: 33 [58%]
А почему не 100%? Или так и должно быть? Каждая эпоха должна быть соточка или у них там свой мир и свои цифры?
Попробовал промежуточную модель (после примерно 20 или 25 эпох) работает более менее исправно. Голос в RVC меняет, но отдает роботическим пердежом. Попробую пройти все 200 эпох, может будет лучше.
так это от общего процента так то. 58% от всех эпох. короче забей. это норма
Все роботы.
Натренил модель в RVC. Если просто чисто один голос и никаких шумов, вздохов и прочей хуеты, RVC все хорошо меняет. Но если есть что-то посторонее, то просто распидорашивает все, оно прямо все звуки пытается заменить что ли голосом? То есть если мне надо заменить голос, то его придется чистить от всего?
Так ты сам написал
> speech to speech пока только на английском.
Название этой чудо нейронки в студию, пожалуйста!
Да, всё верно. Для разделения трека на голос/остальное есть такие решения:
Онлайн: https://vocalremover.org
Оффлайн-UI с поддержкой кучи нейронок для данной задачи: https://github.com/Anjok07/ultimatevocalremovergui
https://github.com/Anjok07/ultimatevocalremovergui/releases/tag/v5.6
Для последнего в секции релиза можно качнуть сразу архив со всеми зависимостями, чтобы не надо было вручную питон и прочее настраивать.
Бамп. Пробовал на другом железе, подождать день, два, три - бесполезно, сразу после попытки загрузки webm - тот же самый Workspace None not found. Не гуглится по этому вообще ничего, в новостях про elevenlabs тоже молчок. Это что, шедоубан какой-то?


Сап, нейрач.
Нужно менять голос в реалтайме.
Парни, где найти обстоятельный гайд по Voice Changer'у или RVC с данной задачей, чтоб прям было написано куда жать и что делать?
В шапке никакого гайда нет (пикрил)
В нейронках полный нубас, ничего не запускал ни разу.
Нужно менять голос в реалтайме.
Парни, где найти обстоятельный гайд по Voice Changer'у или RVC с данной задачей, чтоб прям было написано куда жать и что делать?
В шапке никакого гайда нет (пикрил)
В нейронках полный нубас, ничего не запускал ни разу.
Есть ттс куда можно добавить словарь, что бы ттс нормально зачитала? Хочу себе аудиокнигу сделать
нужен гайд или нейронка чтобы можно было легчайшим способом сделать простую модель двух голосов и чтобы эта нейронка распознавала текст в сэмпле
мне надо видос сделать с текст ту спичем но чтобы основная часть была из оригинала наверн ну или максимально приближенная к оригиналу
самый быстрый варик это елевен лабс но там надо шекели платить каким то хуесосам а я не хочу у меня нет денег я нищий уебан
знаю что я быдло но тяга к творению у меня с рождения извините элитарии потерпите
Сап двач!
Хотел сделать аи кавер где персонаж из сериала поёт под один трек, прогонял акапеллу несколько раз через rvc с разными зипками этого персонажа но всегда получалось кринжовое говно с артефактами...
Трабл в том что сама капа из трека всратоватая по качеству и походу из за этого нихуя не выходит годно сделать.
Можно как-то отдельно записать как персонаж зачитывает текст и потом протюнить это всё под тон трека?
Хотел сделать аи кавер где персонаж из сериала поёт под один трек, прогонял акапеллу несколько раз через rvc с разными зипками этого персонажа но всегда получалось кринжовое говно с артефактами...
Трабл в том что сама капа из трека всратоватая по качеству и походу из за этого нихуя не выходит годно сделать.
Можно как-то отдельно записать как персонаж зачитывает текст и потом протюнить это всё под тон трека?
а как туда поставить другой голос/найти другие голоса?
я поставил все русские. другие голоса только пиндосские. создать низя такие вот ттс(
А этот голос никак к ней нельзя присобачить?
(Но в целом спасибо тебе человек за сделанную тобой работу, очень благодарен) Просто, быстро, понятно и без ебли)
пиндосские?
Брежнева
БАМП РЕКВЕСТУ, чуханы.
то голоса рвсшные а тут ттс. конечно же ты можешь делать как я . озвучивать в ттс текста а потом прогонять через рвс с нужным голосом
Вот скажите, это разве Clear and high voice (написано в промте)? гавно какое то
Сделал разговорный файнтюн XTTSv2 Banana для русского языка. Основан на голосовых сообщениях с матом от 5 разных девушек.
- добавляет больше интонаций, эмоциональности, придыханий, делая речь более живой.
- лучше справляется с ударениями в словах (мат, разговорная лексика).
- только для русского языка, остальные языки остались неизменными.
- основан на женских голосах, поэтому все мужские голоса будут слегка феминными.
- обучение заняло всего 1 час.
Веса: https://huggingface.co/Ftfyhh/xttsv2_banana
- добавляет больше интонаций, эмоциональности, придыханий, делая речь более живой.
- лучше справляется с ударениями в словах (мат, разговорная лексика).
- только для русского языка, остальные языки остались неизменными.
- основан на женских голосах, поэтому все мужские голоса будут слегка феминными.
- обучение заняло всего 1 час.
Веса: https://huggingface.co/Ftfyhh/xttsv2_banana
Как ты это сделал в элевенлабсе? Платный акк?
С бесплатным не даёт такого.
Офигенно, анон. Не помню, чтобы тут кто-то ранее тьюны TTS-моделей делал. Ты в какой среде тренил - шинде, wsl или на никсах? Что-то на винде у меня проблемы с запуском, билд-тулзы не видит. Буду на wsl пробовать.
Есть предложения по правкам шапки до переката?
В вики надо будет инфу про styletts2 и тьюн XTTS докинуть.
В вики надо будет инфу про styletts2 и тьюн XTTS докинуть.
> для дальнейшего улучшения качества ударений требуется еще больший датасет с проблемными словами и ручная проверка распознанного Виспером текста.
Анон, такой вопрос появился - а не думал попробовать расширить датасет синтетикой? Обучить на том же датасете RVC-модель, взять любую речь с готовыми титрами, перегнать её к нужному голосу и дообучить на этом результате?
Я просто хочу взять датасет с голосом моей аниме-вайфу (на японском) и русскоязычную TTS-модель на этом сделать. В моём случае это, кажется, единственный вариант.
предложений нет. делай перекат
Где ссылка на одиннадцать лаборатория?
А нахуй она нужна? RVC во всем лучше, если у тебя комп не нищий
Тогда, вероятно, стоит добавить ссылки и на прочие проприетарные системы с краткой инфой, раз по ним тоже контент в тред кидают. Я их мало смотрел, есть что добавить?
Коммерческие системы
https://elevenlabs.io перевод видео, синтез и преобразование голоса
https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то
https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске
Можешь мемес в шапку добавить.
https://www.kaggle.com/code/varaslaw/aisingers-rvc-rmvpe-https-t-me-aisingers-ru/ скрипт для обучения модели рвс в каггл https://youtu.be/L-emE1pGUOM?feature=shared обучалка
Насколько RVC сложнее для генерации голоса чем Elevenlabs, особенно без мощного компьютера?
ну хз. моя 1050 ти генерирует аи кавер за время аудио+1-2 минуты.
Тебе что надо? РВС только для того чтоб модели обучать или юзать. речь ты там не сгенерируешь. только голос преобразуешь. Генерировать речь эт нужно сначала в ттс а потом в рвс с моделью. Обучаешь модель(что можно сделать онлайн) и делаешь нужное аудио. профит
Всё звучит как всратый робот, че тут офигенного.
Но продолжай делать, будет лучше.
Тренировал в Win11. Проблем с софтом не было, все завелось с первого раза. Обнови репозиторий xtts, вдруг поможет.
> расширить датасет синтетикой
Моя цель была сделать голос более живым, а тут, скорее, будет обратный эффект.
> аниме-вайфу
Простое клонирование голоса в XTTS не дало нужного эффекта? Закинь 10 секунд ее голоса в xtts на японском и попроси говорить на русском.
>Тебе что надо?
Как раз генерация речи. Приходится для этого оплачивать каждый месяц подписку в ElevenLabs, хотя там раз на раз не приходится и часто получается немного шлака среди хорошего материала, а на всё это уходят ограниченные символы
Не хочу рекламу платных скриптов вставлять. Вставлю ссылку на видео и напрямую на фришный скрипт: https://www.kaggle.com/code/varaslaw/rvc-v2-no-gradio-https-t-me-aisingers-ru/notebook?scriptVersionId=143284909
так в видосе обучалка только. а по ссылке скрипт




Прошлый тред:
Вики треда: https://2ch-ai.gitgud.site/wiki/speech/
FAQ
Q: Хочу озвучивать пасты с двача голосом Путина/Неко-Арк/и т.п.
1. Используешь любой инструмент для синтеза голоса из текста - есть локальные, есть онлайн через huggingface или в виде ботов в телеге:
https://2ch-ai.gitgud.site/wiki/speech/#синтез-голоса-из-текста-tts
Спейс без лимитов для EdgeTTS:
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
Так же можно использовать проприетарный комбайн Soundworks (часть фич платная):
https://dmkilab.com/soundworks
2. Перегоняешь голос в нужный тебе через RVC. Для него есть огромное число готовых голосов, можно обучать свои модели:
https://2ch-ai.gitgud.site/wiki/speech/sts/rvc/rvc/
Q: Как делать нейрокаверы?
1. Делишь оригинальную дорожку на вокал и музыку при помощи Ultimate Vocal Remover:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/UVR
2. Преобразуешь дорожку с вокалом к нужному тебе голосу через RVC
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
Используй RVC (запуск через go-realtime-gui.bat) либо Voice Changer:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
Гайд по Voice Changer, там же рассказывается, как настроить виртуальный микрофон:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice‐Changer (часть ссылок похоже сдохла)
Q: Как обучить свою RVC-модель?
Гайд на русском: https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/RVC#создание-собственной-модели
Гайд на английском: https://docs.aihub.wtf/guide-to-create-a-model/model-training-rvc
Определить переобучение через TensorBoard: https://docs.aihub.wtf/guide-to-create-a-model/tensorboard-rvc
Q: Надо распознать текст с аудио/видео файла
Используй Whisper от OpenAI: https://github.com/openai/whisper
Так же есть платные решения от Сбера/Яндекса/Тинькофф.
Шаблон для переката: https://2ch-ai.gitgud.site/wiki/speech/speech-shapka/