>Вал не крутись.mp4
Как же ахуенно
МимоКабанчиком тут пробегал в другой Ллама тред
БАПМ
ВОЖДЬ И СКАЗКА С МАТОМ!!!
кстати оцените ударения. едж ттс делало
Анонесы, кто-то пытался делать анимешные стоны? Поделитесь опытом
ну сам постони в микро и через рвс
Ну постонал и пропустил. Нейронка отчаянно пытается найти слоги в моих стонах, поэтому получается странно.
скинь
Э слыште! подайте мне ту нейронку что песни делает с мелодией итд. Вродея понская какая-то, надеюсь без впн работает.
Нет, без прикола, я правда пару месяцев назад ей делал, было забавно но прямо никак не вспомню а что за калом вообще я пользовался, у вас в шапке под номером 8 из нее говнецо как раз, как эта срань называется, вот хоть убейте не помню, неплохую песенку себе на ней сделал просто и сейчас еще захотелось. Шапку вашу прочитал, более инфомусорной шапки я не видел нигде лол, походу с аудио совсем пиздец, даже хуже чем с картинками.
есть бесплатный аналог этого
ой. два раза ввел санкции. простите
анонче. а давайте сделаем няшную бабскую модель и будем в /b/ набегать типа бабы
https://www.youtube.com/@user-pe4kl6ly8m/videos
предлагаю сделать модель этой бабы
предлагаю сделать модель этой бабы


Сап, нейрач.
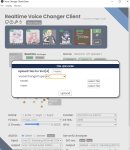
Нужно менять голос в реалтайме. Напишите, пожалуйста, пошаговый гайд, куда и на что жать новичку? Потому что в шапке пик 2, гайда нет.
Нужно менять голос в реалтайме. Напишите, пожалуйста, пошаговый гайд, куда и на что жать новичку? Потому что в шапке пик 2, гайда нет.
Как это сделано? Анон пишет, что в елевенлабс, но в бесплатном акке такое делать нельзя.
АНОНЫ. СДЕЛАЛ СКРИПТ ДЛЯ ОБУЧЕНИЯ МОДЕЛИ БЕЗ РЕКЛАМЫ!!!!
https://github.com/hinaichigo-fox/rvc_train_for_anon/tree/main
ТОЛЬКО КАГГЛ! НЕ ГУГЛ КОЛЛАБ!
https://github.com/hinaichigo-fox/rvc_train_for_anon/tree/main
ТОЛЬКО КАГГЛ! НЕ ГУГЛ КОЛЛАБ!
а почему оно не работает? Буквально вчера работало а сегодня нет
НАШЕЛ РАБОЧИЙ СКРИПТ ДЛЯ ГУГЛ КОЛЛАБ!!!!
https://github.com/hinaichigo-fox/rvc_train_for_anon
https://colab.research.google.com/drive/1030ibBABNaNZ3CjIoDXstcCR7VhEnSAA
потом переделаю немного и всю рекламу уберу
бамп
нужна озвучка по сабам
Тред. создал модель бабы. оцените. Ну питч там подвигайте в сторону >3 у меня на 3 нормальный голос вышел. https://disk.yandex.ru/d/FsACTX3EezNDvA
Был один такой полурофельный перевод. А как с ним справится нейронка?
О чём ещё поют в известных древних хитах? Wait, oh sh~


Voice Changer - ПОМОГИТЕ ПОЖАЛУЙСТА!!!
Сегодня несколько раз идеально модель работала, но чаще всего баговалась на значении "crepe". А она только на нем работает как надо. Просто все жутко лагать начинает, задержка растет и не думает падать.
И вот эта надпись в консоли смущает
Анон, ответь ->
Пользователям TTS. А какое применение вы видите вообще в этом? Мой кейс был такой - выдернул текст из файла субтитров для того чтобы прогнать через ТТС и затем прогнать через РВЦ для дубляжа. Итог такой что все эти ТТС начитывают максимально механически и для +- нормальной озвучки не подходят вообще. Есть какая ТТС которая как то играет голосом немного? И почему при прогоне через РВЦ в готовом оутпуте как будто не применяется файл черт голосовой модели, потому что на выходе звучит так же механически только другим голосом
я так и не понял как субтитры озвучивать
ну у меня после прогона через rvc норм все выходит. мимо еджттсник
>еджттсник
и как заставить еджттс читать по таймингам сабов

Двачую этого.
Недавно замутил себе speech2speech на нескольких нейросетках (yt-dlp -> whisperx + выравнивание от туда же -> deepl -> edgetts -> ffmpeg клеим обратно). Осталось лишь выровнять зачитку по временным отметкам старта и финала. У edgetts есть коэффициент ускорения, но как прикинуть длительность итоговой зачитки? Вариант "в лоб" – сгенерировать аудио, взять его длину и поделить, после чего заново сгенерировать.
Возможно, есть более изящные решения в опенсурце? Если у кого-то есть идеи или наработки — заделитель ништяками в тредике.
тменно по временым отметкам
>edgetts
почему не заебашишь студию озвучки
скрипт на автоматическу скачку с пиратбея. RARBG а дальше свой комбайн
и заливаешь автоматом свое говно на рутор
для дорам и всяких сериалов уровня , учитывая скорость
идея вроде хорошая

Тогда к этому комбайну нужно подключить расстановку ударений и определение эмоций в речи. Если не путаю, edgetts может не только монотонно зачитывать, но и кричать, шептать, радоваться и все такое. Ещё сетку на различение голосов, хотя бы женский/мужской, выбор соответствующего в edgetts.
Можешь заняться, скиллов никаких не нужно: всё готовое переклеить.
Мои же задачи куда тривиальнее — палить по дискорду ютуб с корешами, кто языка не понимает.
можно просто готовый файл перегнать через rvc голосом володарского
монотоность в итоге заамаскированна
эстеты оценять
мне осталось как понять edgetts
читать по временым меткам а не сплошняком
так если по временным меткам так разрезай то емае
Вброшу еще раз. У них даже появился гайд под винду, но у меня место на диске кончилось, так что пока не могу проверить
https://github.com/myshell-ai/OpenVoice/
https://github.com/Alienpups/OpenVoice/blob/main/docs/USAGE_WINDOWS.md
https://github.com/myshell-ai/OpenVoice/
https://github.com/Alienpups/OpenVoice/blob/main/docs/USAGE_WINDOWS.md
автоматом никак ?
хотя я думаю можно придумать для этого скрипт чтобы нарезать изначальный материал по меткам сабов
Что за говняный тред пиздец? никто никому не помогает.
Нахуй вы тогда нужны?
Нахуй вы тогда нужны?
а че за проблема?
->


Можно через RVC ещё. Только всё равно надо виртуальный микрофон ещё настроить как в той инструкции по Voice Changer:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice-Changer#виртуальные-кабели

да, для доступа к instant voice cloning нужно купить минимальную подписку (первый месяц стоит 1$)

файла нету какого то
Спасибо. Скоро буду пробовать. По результатам напишу в тред, поддержите, пожалуйста, ребюята.
удачи!
Как нет файл есть в папке проекта я укпзывыю полный путь тоже самое
а что ты запустить хочешь?

скрипт не дожелан мне нужно проверить как это работает пока что
путь полностью указывай. а не эти точки
все равно
кодек 'unicodeescape' не может декодировать байты в позиции 2-3: усеченный \UXXXXXXXX escape
а че ты запустить пытаешься? можешь сюда скинуть?
ты сначала пробуй по отдельности. запусти терра ттс добейся его норм работы а потом уже добавляй что то
Скачивал где то "RVC0813Nvidia"
Где новую скачать таким же архивом, чтоб распаковал и запустилось, без установок питоновских библиотек?
Где новую скачать таким же архивом, чтоб распаковал и запустилось, без установок питоновских библиотек?
Хочу озвучить персонажа в таверне, что посоветуете?
Озвучка на английском
Озвучка на английском
Анон, а где брать копирайченые модели? Типо всяких асмр ютуберш и японских va?
жесть, тред мертвый
dlsite
в смысле копирайченые?
Из реального применения вижу запиливание нормального дубляжа для игр, ну и для ютуба если что хочешь сказать чтобы не палить голос. А вы?
ну да. так и есть. еще можно приколы делать типа Путин рекламирует сервер в майне и т.д.
Вечер в радость, аноны. Может кто знает, какие есть модификации для Whisper или альтернативы?
Запускаю на локальной машине с Whisper GUI от grisk.
Что удобно: можно обрабатывать файлы пачкой, работает просто, закинул, через время готовое забрал.
Что неудобно: нельзя настроить таймкод, нестабильное разделение на спикеров (иногда есть, иногда нет), отсутствует прогресс бар и вообще какое-либо отображение процесса обработки, только файл начат - файл закончен.
От гугления только больше запутался. Гуев много, но все субъективно хуже.
В погромировании не шарю, хочу решение для локального запуска с кнопкой "Сделать заебись". Может, есть какие-то модели чисто под русский язык, или модифицированный для русского Whisper, с возможностью настраивать какие-то параметры типа тех же таймкодов и без особого красноглазия?
Запускаю на локальной машине с Whisper GUI от grisk.
Что удобно: можно обрабатывать файлы пачкой, работает просто, закинул, через время готовое забрал.
Что неудобно: нельзя настроить таймкод, нестабильное разделение на спикеров (иногда есть, иногда нет), отсутствует прогресс бар и вообще какое-либо отображение процесса обработки, только файл начат - файл закончен.
От гугления только больше запутался. Гуев много, но все субъективно хуже.
В погромировании не шарю, хочу решение для локального запуска с кнопкой "Сделать заебись". Может, есть какие-то модели чисто под русский язык, или модифицированный для русского Whisper, с возможностью настраивать какие-то параметры типа тех же таймкодов и без особого красноглазия?
Внимание вопрос:
Как на елевенлабс сделать спич-ту-спич с кастомным голосом?
Как на елевенлабс сделать спич-ту-спич с кастомным голосом?
хз. никогда не заходил на это говно
Хуясе говно. А может ты говно?




ну да. что не так
Доброго времени суток! Меня интересует возможность очистки от нежелательных эффектов бэк-вокала и прочей шумовой составляющей, которая ухудшает качество кавер-версий. В данный момент я использую UVR с такими плагинами: Kim Vocal 2, UVR-DeNoise, UVR DeEcho-DeReverb, а также плагин
MDX-B Karaoke (lead/back vocals) на MVSEP. Итак, вопрос к знатокам: какие существуют более продвинутые методы очистки и изоляции вокала?
MDX-B Karaoke (lead/back vocals) на MVSEP. Итак, вопрос к знатокам: какие существуют более продвинутые методы очистки и изоляции вокала?
а больше и нету. только плагины UVR
А есть что-то которое музыку превращает в 8-16 бит?
это даже не нейронки. Гугли
БАМП ВОПРОСУ

Пытаюсь запустить этот ваш VoiceChanger. Сразу вот это.
Два вопроса:
1. На кой хер эта хрень в интернет просится? Я не для того скачал локальную нейросетку с этой пердольной консолью, чтобы она ещё и в интернет лезла.
2. Я даже не вижу, чтобы она просила разрешения в интернет. Я бы в фаерволле увидел. Она через какой-то другой сервис пытается сделать какое-то коннект? Объясните, что там включается у неё?
Веса скачать пытается, судя по всему.
То бишь то, что за смену голоса отвечать и должно.
А ты ей не даешь.
Уже разобрался, спасибо.
Как сделать собственный голос? Хочу сделать голос В. В. Пыни.
Где тут аудиофайл закинуть чтобы работало?
Оно везде какие-то модели просит.
Где тут аудиофайл закинуть чтобы работало?
Оно везде какие-то модели просит.
->
нафига вы все в этот реалтайм хотите? качай рвс и делай. Там все лучше и проще.
Нашёл как загрузить модели с сайта. А как сделать свою собственную из аудио?
Нейросетка фейлит происношение некоторых слогов и букв, преимущественно шипящих и свистящих (Ш, Щ, С, Ж). Как пофиксить?
а также плагин MDX-B Karaoke (lead/back vocals) на выходе звучит так если что пока что за проблема?
База на английских фонемах. Походу никак это не пофиксить, пока кто-нибудь новый беслптный инструмент не высрет без этого врожденного дефекта.
Ну вот доводится слышать качественные фейки без этих проблем. Может, дело в настройке?
Хуй знает. Ещё ни разу не слышал результат работы RVC и его форков без этих артефактов. Если есть возможность в треде или где обязательно надо спросить у людей кто такие фейки делал как добились. Может там вообще какой-то платный сервис на самом деле используется или какая диковиная хуйня не доступная бесплатно.
Я ещё помню был софт по изменению голоса от российских разработчиков (забыл как называется) и его изьяли из открытого доступа из за того что наебщики бабок по телефону моментально его на вооружение взяли.
Сап, голосовые мои. Скажите что мне из это в шапке может озвучивать текст не просто голосом диктора, а чтоб была опция, где выбрать с какой эмоцией бот будет это говорить - страх, гнев, радость и т.п.
Я видел в онлайн сервисах такой выбор. Уточняю мне надо ТТС именно с разными эмоциями на выбор, RVC я уже оформил пару месяце назад, но потом забил, чтоб потом голосом избранных персонажей говорить.
Я видел в онлайн сервисах такой выбор. Уточняю мне надо ТТС именно с разными эмоциями на выбор, RVC я уже оформил пару месяце назад, но потом забил, чтоб потом голосом избранных персонажей говорить.
а с голосом только силеро как то может работать. там с помощью разметки надо это делать
У меня не устанавливается ваше костыльное силеро.
Кстати, а почему последние два треда (полгода) нет этого супер-пупер Силеро в шапке? Оно ВСЁ?
так нету больше ничего. силеро едге все
А чому так? Технологии древних утеряны спустя полгода?
А любят кричать зато - посмотрите какой у нас открытый исходный код, а сами на хуг фейс выжимают платную машину, чтоб нельзя было скопировать себе и не ждать в очередях.
Я пробовал сегодня ХТТС. Конечно я это программистичкое для линуксоидов устанавливать не буду и чето там в консоли писать, это пиздец кал. Но получалось оно что-то рабочее, реально из 6 секунд похожий голос получался онлайн на хуйгфейсе. Но там очереди долгиеЮ нет фич для поднастройки и копировать себе нельзя, нужна платная машина. Кал.
Остаётся реально чтоли онлайн на сайтах ИИС пользоваться где у ботов разные эмоции на выбор и в РВС преобразовывать? Нет альтернатив?
Это ж блять просто сделать моделей 8 типов людей по возрасту и полу и у каждой по штук 10 эмоций, за неделю можно натренировать. То есть уже сделали, жиды не дают пользоваться бесплатно. Два стула, что либо плати, либо жри кал с отрытым кодом костыльный линуксоидный программистический для бомжей.
Эта софтина Ultimate Vocal Remover из шапки просто золото среди говна! Бесплатная, да и то ещё не для программистов-аутистов.
Я так охуел и не ожидал, что сразу на радостях сделал аи кавер.
Я так охуел и не ожидал, что сразу на радостях сделал аи кавер.
пока альтернатив реально нет( Ждем всем тредом годную альтернативу еджттс и силеро
> А любят кричать зато - посмотрите какой у нас открытый исходный код
Тот кто в аср/ттс крутится знает, что силеро потом кричит "хули вы пользуетесь нашим открытым кодом, там в 78 строчке лицензимонного соглашения написано что вам нам должны бабок".
Силеро всегда была компанией-пидорасом, на неё лучше не ориентироваться.
Блять как же заебало. У меня в RVC ошибка с обучением модели КУДА ран оф мемори и не трейнит, че только не пробовал, и меньше требования ставил и форумы читал, анальники хуебясят на форумах и ютубах и тратят моё время. Как-то сам допёр и обновил models.py и заработало. Почему не могут делать говно чтоб работало искаропки?
Такое чувство будто они разрабатывают это всё, но сами не пользуются совсем. А нах делать тогда, если деньги даже не платят??
Такое чувство будто они разрабатывают это всё, но сами не пользуются совсем. А нах делать тогда, если деньги даже не платят??
брат. какая карта?
3060, ну у меня размер пачки больше и не тянет.
а. тогда хз
>ну у меня размер пачки больше >>12<< и не тянет
фик. куда цифра проебалась?
Алсо странное - я тренил две модели с 250 эпохами, а потом с 700. Думал что вот щас качество так качество услышу, а стало хуже, больше электронных звуков голоса робота стало. Как же так? Это не повезло просто или слишком много нельзя?
Слушайте, а можно ли как-то обучить чужую карточку персонажа с вей.гг другой карточкой, которая обучена на кумерскиъ стонах, чтоб первая карточка стонала в характере персонажа, не? Или даже думтаь не стоит? Надо ведь собирать звуки с этим оригинальным персонажем?
И допустим если я соберу звуки и сделаю свою маня карточку только со стонами и ахами этого персонажа, то можно её влить в чужу карточку с этим персонажем или хуйня получится и надо полностью свою со всей базой всего генерить?
И допустим если я соберу звуки и сделаю свою маня карточку только со стонами и ахами этого персонажа, то можно её влить в чужу карточку с этим персонажем или хуйня получится и надо полностью свою со всей базой всего генерить?
Мне нужно озвучивать огромные объёмы текста на русском. Пока что лучше всех с этим справлялся Evenlabs, но перебанили все аккаунты + бан по ip, а платить разумеется не хочется. А даже если и платить, мне никакой подписки не хватит для моих объёмов. Есть ли альтернативы или обход блокировки? (впн, прокси, тор не канают)
Сап! Есть аудио, в котором поверх одного голоса говорит второй. Есть нейронки чтобы эти голоса прилично разделить? Или еще не доросли до такого? Пробовал MDX-B Karaoke на mvsep, но хуйня. Или я че не так настроил?
Искал софт для озвучки книжек, перепробовал 100500 моделей. В итоге остановился на Demagog с моделью silero tts. Все остальное оказалось хуйней.
> В итоге остановился на Demagog с моделью silero tts.
Покажи примеры лучшего, что получилось.


Это же невозможно слушать.
Оно даже не там смысловые ударения ставит. Причём не просто на уровне плохой актёрской игры, а на уровне банальном, натурально проваливает точки и запятые.
И это всего три минуты, из которых я с усилием дослушал две. Как такую белиберду целый час слушать не представляю.
Скажи честно, это ты такой лоускилл, что не смог настроить её нормально, или нейросетка в целом такая отстойная? Не имею цели тебя обидеть, если что.

Настроить можно так что от живой речи не отличить.
Но нужно править сам текст вручную и расставлять ударения плюсами. Никто для разового прослушивания - подобной хуйней заниматься не будет. За 3 минуты там пяток неправильных ударений что более чем годно. Конкурирующие нейросетки выдают либо такой же либо худший по сравнению с этим результат, но у этой есть плюс в виде автономной работы без ограничений. Если что я еще и аудиокниги слушаю на скорости в 220-240% так что мои мозг работает почти все время в ускоренном режиме и сам адаптирует качество до приемлемого. Люди не понимают что мозг очень гибкий инструмент и он может сам адаптироваться, всего день прослушиваний и мозг сам начнет правильно выставлять ударения при прослушивании и ты перестанешь замечать какие либо шероховатости.
> Если что я еще и аудиокниги слушаю на скорости в 220-240% так что мои мозг работа
Как в таком порядке можно вообще что то услышать, понять и главное прочувствовать из книги? Это художественное произведение, а не состав продукта "говяжьи анусы идентичные натуральным". Тут важны игра образов, слова, атмосфера, почище, чем в кино, собственное осознание. Это не краткий пересказ послушать. Я уже писал про то что и на стандартной скорости этот кал слушать невозможно
Спасибо, не имею желания адаптироваться к хуёвым продуктам; предпочитаю нормальное качество.
Дураки вы. Мозг очень быстро адаптируется и сам переключает передачи. День два тренировок и вы будете воспринимать скорость в 240% как 100% даже не понимая на какой скорости вы сейчас смотрите\слушаете. Это те кто никогда ничего не слушал на ускорении думает что там каша получается, но со временем мозг вырабатывает свои режим работы и вы будете понимать и игру слов и интонации и вообще будете смотреть на себя в прошлом как на дурачков что проебали кучу времени. Недавно я попробовал посмотреть Дюну Вильнева на 100% так чуть не сдох от уныния, как я раньше вообще смотрел фильмы на такой скорости не пойму. 200% это минимальная комфортная скорость для потребления контента.
Мозг всегда сам настраивает восприятие течения времени и имеет встроенный эквалайзер. Раньше я думал что аудиофилы прогревают наушники после покупки но потом понял что прогревается именно мозг. Мозг сам меняет восприятие и занимается выравниванием АЧХ. Мозг всегда занимается адаптацией своих функций хотите вы этого или нет.
Ебать шизик тиктокоголовый. Какая каша у тебя в голове боюсь представить. Ни о каком запоминании и восприятии тут естественно не может быть и речи.
Каша у тебя в голове. Но ты этого не поймёшь пока сам не попробуешь.
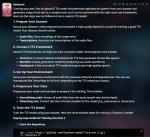
Анонче, поделитесь если у кого есть гайд установки coqui-ai/TTS на WSL2. Или для запуска через Docker. Не хочется винду говнять миллиардом библиотек
Подскажите хорошую speech-to-speech модель для русского женского голоса. Просто хочется потраллировать чуваков в воис чате. Англоязычных моделей полно, но они все шепелявят, когда говоришь на русском. Русские ищу по конкретным персонажам, которые в голову приходят, но обычно оказываются низкокачественные. Мне бы хоть какую-нибудь, лишь бы был женский голос и правдоподобно звучал.
сенко или некоарк

Почему Voice changer w-okada не работает без подключения к интернету? Нейросетка же загружена локально, модели тоже.
Что я делаю не так?
Что я делаю не так?
Че делать если все скачал но при двойном нажатии на файл start.http ничего не происходит?
Мутировать в гидралиска.
не знаю

Раз в несколько месяцев я набираю себе воду из родничка подписки на ElevenLabs - сделать это можно только через Plati.Market, потому что наши карты (особенно Беларуси) зарубежные сервисы не принимают.
Раньше я делал это через любого доступного барыгу: выбирал в способах оплаты карту Казахстана и оно пропускало. Со временем кто-то пораскинул своими тремя извилинами и убрал этот способ, так что пришлось переходить на Киви - итог известен.
Я конечно понимаю, что переводы денег между Россией и Беларусью это охуеть какая сложная международная задача уровня Мстителей, но неужели не осталось больше никаких способов, кроме ЮMoney (бывший яндекс-кошелёк, который не даёт себя пополнить без скана паспорта на фоне жопы в трёх проекциях)?
В наличии есть беларуская карта МИР, которая нормально оплачивала в России, но у барыг конкретно такого варианта нету. Крипта тоже не пойдёт, её тут хуй купишь без мозгоебли и тех самых фоток с жопой (или я чего-то не знаю). Если кто-то тоже попал в такую ситуацию, то напишите пожалуйста, если остался какой-нибудь рабочий способ
Раньше я делал это через любого доступного барыгу: выбирал в способах оплаты карту Казахстана и оно пропускало. Со временем кто-то пораскинул своими тремя извилинами и убрал этот способ, так что пришлось переходить на Киви - итог известен.
Я конечно понимаю, что переводы денег между Россией и Беларусью это охуеть какая сложная международная задача уровня Мстителей, но неужели не осталось больше никаких способов, кроме ЮMoney (бывший яндекс-кошелёк, который не даёт себя пополнить без скана паспорта на фоне жопы в трёх проекциях)?
В наличии есть беларуская карта МИР, которая нормально оплачивала в России, но у барыг конкретно такого варианта нету. Крипта тоже не пойдёт, её тут хуй купишь без мозгоебли и тех самых фоток с жопой (или я чего-то не знаю). Если кто-то тоже попал в такую ситуацию, то напишите пожалуйста, если остался какой-нибудь рабочий способ
прикладывай фото к жопе и заводи юмани, не выёбывайся.
Да если бы только жопу прислать, как когда-то в вебмани, и всё - там же целая куча мозгоебли, которую принимает лишь один банк. Ещё и взнос такой, будто я медицинскую страховку открываю, а не электронный кошелёк
белинвестбанк прикручивай и всё. они сами фотки твоего ануса в союзное государство перешлют.
Зачем платить ElevenLabs если silero tts выдает такое же качество но при этом бесплатно и без ограничений?
>silero tts
Да не, это буквально небо и земля
Ну как знаешь. Я вбивал неподготовленный текст в обе модели и обе модели обсирались в одних и тех же местах. У меня вообще сложилось впечатление что это одна и та же модель но с разными голосами.
Кто-нибудь слышал про забугор.рф? Они оплачивают подписки своими картами по идее
>вбивал неподготовленный текст
Ну вот что у меня выходит.
Тупо залил аудио из вот этого видео
https://www.youtube.com/watch?v=Kmy7h7lSSPg
Нажал Instant Voice Cloning, вбил текст, и все.
Аноны, у меня технический вопрос по железу.
Если пользоваться локальными моделями, то на что лучше обращать внимания по железу т.к. в скором времени хочу сменить компуктер.
Если пользоваться локальными моделями, то на что лучше обращать внимания по железу т.к. в скором времени хочу сменить компуктер.
Видюха с поддержкой CUDA а больше требований и нет.
Да и локальных моделей раз два и обосрался.
БАМП ВОПРОСУ
Аноны, подскажите
Ставь Wireshark и анализируй трафик куда он обращается.
Есть опенсорс ТТСки которые могут в эмоции?
Что за хуйню ты сделал? Невозможно слушать

Аноны, нейрокаверы вам в хату, такой вопрос - как переделать голос с мужского на женский и вообще реально ли это? Я записываю свой и на женской модели полный треш выходит. Делать высокий pitch тоже не помогает. Но при этом когда я даю модели запись голоса какой нибудь тянки, то плюс минус похоже получается.
Сам натренируй.

Как я путь не менял не находит
Аноны, дайте всю базу, если я хочу себе натренить голоса 2д девочек для moe-tts или что там сейчас топовое вышло. Еще что-то нужно сделать с эмоциями и интонациями. Вроде есть какой-то параметр питча, который в теории можно было бы менять прямо во время фразы. Но находил только какой-то университетский дроч. В общем, если кто-то что-то знает, подскажите.
Какая сейчас актуальная база для тренировки своей модели?
Обновления выходили для RVC? Или ещё какие модели появились?
Где можно бесплатно и реалистично клонировать свой голос для работы с русским языком?
где надыбать каественных образцов голоса к xtts2 ?
может какой то архив есть с wav?
может какой то архив есть с wav?
бамп вопросу
Нужно быстрая ттс модель + стс чтобы преобразовать ее в нужный голос, для реалтайм чатбота. Попробовал xtts v2, но он медленный как жопа даже на сторонней апишке. Есть какая-нибудь средняя по качеству моделька на 400кк параметров которая может в русский и быстрая конвертация в другой голос?
RVC Web UI грузит процессор не на полную, генерация происходит медленнее чем хотелось бы. Чзх
Я в одном из прошлых тредов писал свой опыт по установке этого говна. В общем там черех жопу надо скачивать модель с сайта силеро, с директории, на которую ниоткуда нет ссылок, так что найти ее можно только подрочив в присядку. Не советую начинать ставить силеро, так как тот же AllTalk на порядки лучше.
Я отсюда беру голоса https://www.kaggle.com/datasets/rtatman/speech-accent-archive
Кстати, еще ни разу до конца списка не доходил. В последний раз отвалился, как наевшийся клещ, к концу английских голосов.
Вот если бы еще делали плавный переход между idle состоянием и разговором, то я бы даже захотел себе какую нибудь такую ассистентку запилить.
https://www.youtube.com/watch?v=hPS7dtJn00s
https://www.youtube.com/watch?v=en6uW595DM8
Оно раньше было еще хуже, но автор подошел к делу со страстью и всего за два месяца такой прогресс. Надеюсь он не забросит проект. По сути он ничего нового не делает, а просто оптимизирует рабочие варики. Если судить по старым видео раньше он вообще использовал нейронки яндекса, гугла и говнАлису.
Почему Суно из дк выпилили модели нейронки? У меня с сайтом давно проблемы, ничего генерить не выходит. Вылетает при каждом удобном случае, как с впн, так и без. С разных устройств
> 4
Так проиграл, что сделал свою версию, и проиграл ещё больше.
БАМП ВОПРОСУ
У вас так же?
Чем записываешь? Какие модели юзаешь?
А где там голоса брать?
Хелп срочно нужна модель голоса володарскокого
Есть идеи как они делают это переозвучивание?
https://www.youtube.com/watch?v=stPt86RN5Bo
https://www.youtube.com/watch?v=fH_sZkZ6Fjc
Хочу срочно инструмент который выдает такое топ качество.
https://www.youtube.com/watch?v=stPt86RN5Bo
https://www.youtube.com/watch?v=fH_sZkZ6Fjc
Хочу срочно инструмент который выдает такое топ качество.
В коментах автор же написал 11 labs
>В коментах автор же написал 11 labs
Действительно. Спасибо.
Интересует именно дубляж. Но автодубляж не тащит. Платные планы позволяют фиксить пере0еденный текст и ударения?
Так же халявный план не позволяет загружать аудио, только видео. Я в ffmpeg прицепил к mp3 изображение залитым одним цветом для меньшего веса:
ffmpeg -loop 1 -i input.jpg -i input.mp3 -vf "scale=640:480:force_original_aspect_ratio=decrease,pad=640:480:-1:-1:color=black,setsar=1,format=yuv420p" -shortest -fflags +shortest output.mp4
Но вы все скорее всего все это уже знаете. Когда указал как источник минутный ютуб ролик, оно уже пол часа его обрабатывает.
Проебал ссылку на билиотеку с войс моделями
На каждую поп-певичку по 100 моделей на каждую эру, и видно какая модель самая залайканая.
На каждую поп-певичку по 100 моделей на каждую эру, и видно какая модель самая залайканая.

Сам спросил сам ответил, weights.gg
Ужос какой-то. Все голоса как будто исполнены пьезоэлектрической зажигалкой или микросхемой из тостера.
Хотя нет, напутал - не микросхемой, а реле. Не все знают, кстати, что старинные реле можно использовать в качестве динамика.
Бесплатный аккаунт позволил скачать только первый голосовой перевод. Все остальные попытки что-то перевести не позволяют скачать результат, только прослушать первые 3-5 секунд.
Интересно если создать еще один бесплатный аккаунт, вычислят ли меня что я пытаюсь обойти их жадность?
да
Но это не нейронка.
Слушайте, а как в RVC перегнать в желаемый голос всякие нестандартные голосовые звуки, т.е. не речь, а всякие крики, стоны, визги, мычания, ну вы понили.
Я пробовал разные модели с weights.gg, но получается коряво, присутствую разрывы и странности, артефакты. Всё потому что они натренерованы под речь, а надо тренировать специально под что описал выше, да?
Я пробовал разные модели с weights.gg, но получается коряво, присутствую разрывы и странности, артефакты. Всё потому что они натренерованы под речь, а надо тренировать специально под что описал выше, да?
У кого сейчас самое лучшее коммерческое решение синтеза речи? Планирую запилить свое собственное и выйти на азиатские рынки, надо посмотреть какое говно имеют сейчас мои конкуренты.
(((а таки какое у тебя? поделись кодом)))
ты про suno?
Если ты про ту хуйню с май бэби лавс ми, то это не показатель. Там надо качать и в деле слушать.
Анон, а для голосовых нейронок(TTS) есть интерфейс вроде автоматика для картинок или убабуги для текста?
Что бы в него просто подкидывать модели и пользоваться.
Что бы в него просто подкидывать модели и пользоваться.
тебе для какой?
Для Silero или для Tera.
Для текстовых нейронок можно в разных форматах качать и все работает в одном интерфейсе, а для генерации текста в речь как то все сложно.
Ну для силеро веб гуи есть мое. Вот ссылка. https://github.com/hinaichigo-fox/rus-silero-webui
вот кстати и для едж ттс https://github.com/hinaichigo-fox/rus-edge-tts-webui

У alltalk есть. В http://localhost:7851 все настройки и генерация текста.
Я про реле, которые в жлектрических приборах. Я в детстве подключал к радиоточке и оно транслировало передачу, даже голос можно было разобрать постаравшись.
А если про голоса - то я на том сайте прослушал рандомно из списка десяток, и все как на подбор откровенно искусственные, так что даже ухо режет. Вот например в Alltalk если положить в voice более или менее качественный файл с исходным голосом, то результат будет хуманизированный, и только по возможным багам можно понять, что это все сгенерировано.
А как подменить слова в песне на свои тем же голосом?
але мале нах. че там ваши нейросети умные да? Чат жпт на тоннах книг учился. а где нейронка для того чтоб любую песню на аккорды разбить?
а опен сурс????
А хуев тебе не завернуть?
заверни.. главное чтоб с открытым иходным кодом
Как в Edge TTS ударения ставить?
Купил подписку на Elevenlabs самую дешманскую, пробую создавать модели и генерить текст. Сам голос в принципе неплох, но я не могу понять, как заставить ее расставлять ударения в нужных местах, а также выдавать нужные эмоции в определенных местах.
по слогам разбиваешь слово
Сделал модель в RVC, но так и не понял как делать TTS с использованием моей модели. Подскажите плез, а то все что лазил из шапки - там уже встроенные модели. Или придется сначала делать текст - готовый голос - голос из модели?
сначала озвучиваешь простым ттс а потом в рвс его
Доставьте видос, где неко арк с огромными ушами говорит "ну говори, я тебя слушаю".
Вроде сохранял, а найти немогу.
Вроде сохранял, а найти немогу.
Нашёл в гугле, если есть лучше качество то доставьте, пожалуйста.



Аноны, нуждаюсь в голосовой модели Вилл из чародеек. Не нашел, возможно не там искал, а возможно и нет вообще. долго ли и сложно ли натренить самостоятельно?
Аноны. На меня опять нашло вдохновение. И я стал опять озвучивать пасты голосом артаса. Озвучу любую. Пишите в тред!
Батины травы
>RVC
Оно вздохи пуки когда-нибудь будет нормально конвертировать в персонажей?
Оно вздохи пуки когда-нибудь будет нормально конвертировать в персонажей?

Аноны, посоветуйте нейронку на подобии elevenlabs, точнее её функции дабинга и возможностью stt. Дико впадлу обучать модель 10 секундного отрывка просто потому что захотел другую интонацию.
Вопрос. А как в обучении голосовой модели воспринимаются паузы менее чем в пол секунды и единый поток звука без них? Хуево понимаю каков идеал датасета, к которому стоит стремиться и на котором стоит основываться
Приветствую, аноны. Стал с недавних пор вкатываться в аудио-нейронки в реальном времени и есть несколько вопросов.
1. Многое ли изменилось с тех пор, как появились аудио-нейронки? Было ли что-то доработано, исправлено или просто добавлено?
2. Какие косяки имеет нейронки в рил тайме? Я так понимаю, что нейронки палятся на смехе, вздохе или попытке сделать громкий звук? Первый вопрос касается второго, так как вдруг что-то, что я вкратце перечислил, было пофикшено.
3. Возможно ли использовать нормально модель голоса женщины, будучи парнем? У самого голос средний, может звучать как девичий, так и мужской. Думаю если отрыть норм модель голоса по эпохам и покрутить тоналку, то пойдёт.
4. Какие видеокарты щас можно использовать для того, чтобы нейросетка работала грамотно рилтайм, без лагов? Желательно, чтобы не свыше 100к, до 50к. Видел где-то РТХ в ДНС и на Озоне за 30-40к. Но это всё желательно, приму любые советы анона.
Благодарю всех за ответ заранее.
1. Многое ли изменилось с тех пор, как появились аудио-нейронки? Было ли что-то доработано, исправлено или просто добавлено?
2. Какие косяки имеет нейронки в рил тайме? Я так понимаю, что нейронки палятся на смехе, вздохе или попытке сделать громкий звук? Первый вопрос касается второго, так как вдруг что-то, что я вкратце перечислил, было пофикшено.
3. Возможно ли использовать нормально модель голоса женщины, будучи парнем? У самого голос средний, может звучать как девичий, так и мужской. Думаю если отрыть норм модель голоса по эпохам и покрутить тоналку, то пойдёт.
4. Какие видеокарты щас можно использовать для того, чтобы нейросетка работала грамотно рилтайм, без лагов? Желательно, чтобы не свыше 100к, до 50к. Видел где-то РТХ в ДНС и на Озоне за 30-40к. Но это всё желательно, приму любые советы анона.
Благодарю всех за ответ заранее.
30 серии нвидиа карты
Друзья, можете дать хорошую rvc модель Путина, я несколько пробовал, но не очень похоже, с тюном игрался и как то не выходит
только сам...
не доверяй никому. делай все сам. собирай датасет и делай!
Это вообще дебри для меня. Я не очень знаю, как это делать
надо учиться! Это очень интересно. Сначала сделай датасет хороший. Советую минут 15-20. Когда сделаешь такой с речью Путина то пиши
аноны, а что лучше юзать harvest или crepe в войс чейнджере, а также сколько выставлять в параметре S.Tresh
crepe если карточка норм
Друзья, а вообще сложно создавать свои датасеты, просто хочу начать это делать.. Может будет максимальная схожесть, если буду делать сам? И где гайды можно почитать и посмотреть?
ты про какие датасеты? для рвс? Ну вообще в идеале 15-20 минут чистой речи. И тогда 250-300 эпох ну или выше офигенно будет все
аноны, можете дать скрипт для kaggle или можно коллаб для создание модели RVC
https://t. me/pol1trees
друзья, а как правильно делать датасет, я вот отрыл несколько аудио, переформатировал в wav и потом просто объединить их все в Audacity (очистить шумы и тд) в один wav файл и просто в коллаб?
Если ты про RVC, то да, одним файлом норм будет. RVC во время препроцессинга сам файлы на короткие чанки нарежет длиной по 4 секунды:
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI/wiki/Instructions-and-tips-for-RVC-training#audio-split
Спасибо огромное, а сколько будет достаточно, чтобы длился wav файл. Я слышал, что вроде 20 минут уже нормально
Я не думаю, что кто-то тебе точные цифры по оптимальному размеру датасета сможет сказать - тема голосовых нейронок довольно нишевая, по сравнению с картинками/текстом.
В разных гайдах советуют от пяти минут (но с большим охватом спектра голоса), до часа. Я видел хорошие модели на 20 минутах, так что должно хватить.
Спасибо за полезную информацию
аноны, а есть колабы для создания RVC, но где только еще crepe метод присутствует
Ещё не приручили озвучивать русских дубляжеров?
А зачем, если русский текст тебе озвучит любая, даже японская.
Мне наоборот нравится изначально азиатских брать и озвучивать русское.

ElevenLabs не переводит лицензированные видосы / клипы, как-то можно обмануть или через что-то другое лучше сделать? Условно там клип сменима на адекватный русский. Не обязательно клип, просто мп3-ишка.


Почему не устанавливается XTTS-v2 для Windows 11?
Я сука уже как мог ебался, и всё упирается в эту ошибку.
Я сука уже как мог ебался, и всё упирается в эту ошибку.
Друзья, в этом колабе уже есть аудио сплитер встроенный или нужно будет самому?
https://colab.research.google.com/drive/1mHKTGH5e3SAyDSBss1KtiYRbDdQzwSMs#scrollTo=POL0YLuyZN5H
https://colab.research.google.com/drive/1mHKTGH5e3SAyDSBss1KtiYRbDdQzwSMs#scrollTo=POL0YLuyZN5H
есть сайт с большим выбором языковых моделей?
в смысле?
БАМП
ну вот TeraTTS например, там только 4 модели, хочется онлайн интерфейс с большим выбором моделей ну и фри конечно же
Напомните канал в дискорде, где выкладывают модели.
https://discord.gg/aihub (канал voice-models)
https://www.weights.gg
https://voice-models.com
https://huggingface.co (ищите по имени спикера + rvc, * например "letov rvc")
https://google.com (аналогично предыдущему пункту)
https://t.me/AINetSD_bot
Спасибо, искал именно аи хаб. Остальное тоже посмотрю.
Интересен локальный TTS с хорошим голосом. Вроде, просмотрел всё с примерами, но нашёл только это https://github.com/zxcq544/russian_text_to_speech
Неужели за 2 года не появилось ничего лучше Silero?
Неужели за 2 года не появилось ничего лучше Silero?
это же тоже силеро
Потому и спрашиваю.

Аноны, а как понять, что есть оверфиттинг при обучении RVC? В инструкции указано, что надо смотреть на loss/g/total, но у меня нет такого графика, есть только loss/d/total. Чем вообще d от g отличается?
Никто MARS5 не пробовал?
https://www.camb.ai/
Можно даже локально подымать, вроде как.
https://github.com/Camb-ai/MARS5-TTS
Опенсорс, всё такое.
https://www.camb.ai/
Можно даже локально подымать, вроде как.
https://github.com/Camb-ai/MARS5-TTS
Опенсорс, всё такое.
Там, вроде, только английский. Попробовал в колабе, но почему-то на одну фразу по 5 минут уходило.
>Там, вроде, только английский.
Странно. Пишут вроде про целую кучу языков.
Подскажите, есть какие-то программы в реальном времени меняющие голос? Главное, чтобы реалистично было
Подскажите, есть какие-то программы в реальном времени меняющие голос? Главное, чтобы реалистично было
Меня тоже это смутило. Мб. это только на сайте по подписке.
https://2ch.hk/ai/res/801506.html
Тред посвященный озвучкам паст!
Тред посвященный озвучкам паст!

Чет слабо ты ебался
В общем наконец-то у меня дошли руки скачать и проверить. Хуйня из под коня короче, никому не рекомендую. Качество не лучше RVC, так еще и голос даже не похож на исходный, лул
Бамп вопросу
Добавьте в шапку оффлайн распознавание речи для андройда.
FUTO Voice Input (70мб) на основе разогнанного whisper.
https://play.google.com/store/apps/details?id=org.futo.voiceinput
Там три модели разного размера для английского и три для всех остальных языков. Для английского в комплекте идет самая маленькая модель, для остальных языков вроде нормально справляется средняя модель(80мб).
Я не очень понимаю что такое языковая модель и как она работает, но случилась фигня которая меня удивила, мне было интересно что случится если я проговорю на двух разных языках. Я спросил "How do you say in russian - это моя бабушка" и оно распознало это так "Как вы говорите по русски - это моя бабушка". То есть оно перевело мои слова с английского на русский. Я немного прифигел. Это точно больше чем обычный stt. Магия.
Да суть в том, что нихуя не помогает этот билд тулс - я его ставил и нихуя. Проблему решила только полная установка висуал студио.
Анон, а что насчет сэмплов голоса для XTTSv2? Я сам тут давал ссылку на огромное собрание сэмплов обычных голосов, но теперь ищу вместо них хорошо поставленные, типа таких, как у дикторов, которые зачитывают многозначительные фразы в рекламных роликах и тизерах, такой мужской выразительный голос. Из самих тизеров не вытащить, так как они обычно с громкой музыкой.
Сам нашел сэмплы - вот, если кому понадобится https://pixabay.com/sound-effects/search/male-voice/
Создам голосовые модели на заказ
https://vk.com/id824549679
https://vk.com/id824549679
Хочу японскую порнуху перевести, как?
Аноны, подскажите пожалуйста, я не использовал tts раньше и не разбираюсь. Какие есть реалтайм (ну или хотя бы почти реалтайм, с небольшой задержкой) TTS модели, подходящие для свободного коммерческого использования, и имеющие при этом достаточно живое звучание не как у роботов с различимыми эмоциями? Либо, как вариант, с возможностью дообучить свои голосовые модели с нужными эмоциями.
И какая TTS модель у Evil Neuro, знает кто?
И какая TTS модель у Evil Neuro, знает кто?
Я для проекта на работе тоже очень жду хорошей tts. Пока слежу за проектами:
https://github.com/Camb-ai/MARS5-TTS
https://github.com/2noise/ChatTTS
Русский там ещё не завезли, но надеюсь он появится в будущем. Английская версия - впечатляет. Есть возможность копировать и голоса и эмоции из коротких образцов.
А пока, для русского, я остановился на сберовском tts. Голосов там не много, но они звучат почти как живые.
MARS5 классный, но 20 гигов врам...
Искал что полегче, наткнулся на FastSpeech2. Не лучшая штука, но прикольная, особенно если какую-то постобработку прикрутить, чтобы от шума и артефактов чистить. Правда я локально так и не смог потестить, заебался. Ошибок 10-15 успешно решил, под конец уже начал этот васянский код переписывать и понял, что не хочу этим заниматься - снёс нахуй.
А какие-то совсем лёгкие ттс, на 2-4 гига врам, не знаешь? Я конечно понимаю, что там совсем другое качество, но тем не менее. Вдруг что-то неожиданно хорошее есть.
>А какие-то совсем лёгкие ттс, на 2-4 гига врам, не знаешь?
Сам всякие варианты просмотрел, пролистал. Но ничего не установил. Как же у меня жопа горит с этих блядских консольных установок, это пиздец. В Coqui AI TTS в раздел установки смотришь - о, как круто, всего в одну строку! Но в самом конце раздела дополнение: для виндовс установка вот тут, и ссылка на stackoverflow с ПЯТНАДЦАТЬЮ шагами и конкретными требованиями типа Python 3.8 (not 3.9+), CUDA Toolkit 10.1 (not 11.0+) и cuDNN v7.6.5 (not cuDNN v8+). При том, что КУДЫ эти ебаные по 3 гига весят например.
Да и что ты не пытаешься установить - везде это многократное дублирование одних и тех же зависимостей, но с разницей в версиях v1.00000001 и v1.00000002. И все эти зависимости по всей нахуй системе раскиданы, у меня уже диск системный почти забит. Ебучие питонопидорасы, вы про установку в один клик не слышали?
Ладно. Я правильно понимаю, что не существует TTS качественнее озвучки гугл-переводчика, занимаемой <5 гигов на диске <4 гигов врам и устанавливаемой в 2 клика? Если да, то пошли эти ваши tts нахуй, дождусь лучше полноценных мультимодалок типа гпт4о, но открытых и с нормальными лицензиями, думаю в течение максимум 3х лет такие появятся. Заквантую такую модельку до ненормального состояния и для моих шизо-задач пойдёт даже несмотря на серьезное падение качества.
Не знаете ли нейросеть которая способны ухудшать синтезированный голос, создавая фон, ревербацию, и прочие звуки хуевого голосового сообщения и прочих тому подобных штук?
знаю. микрофон рядом с колонкой.

Аноны, щас юзаю XTTS web UI гугл колаб из первой выдачи в поиске для озвучивания русского текста, голосом пиндосского ютубера. Юзаю один говяный семпл (с шумом и посторонними звуками) длиной 30 сек в качестве сурса (пытался резать хорошие куски голоса в нормальном качестве и формате, но по итогу результат ещё хуже был). Каждое предложение генерю по 10 раз и потом собираю по частям чтобы была нужная интонация и нормальное произношение. Есть ли в XTSS какая либо разметка для ударений хотя бы? И вообще такой пердолинг норм или щас что то более удобное есть?
P.S. Есть ссылка на XTTSv2 banana finetune из видоса в шапке? А то гугл ничего не выдает.
P.S. Есть ссылка на XTTSv2 banana finetune из видоса в шапке? А то гугл ничего не выдает.
Кинь свой семпл в суно и звуч по 3000 знаков текста за раз
Привет, анончик. Подскажи, пожалуйста, какая языковая модель на сегодня максимально похожа на человеческую речь (text to speech)? Я далек от всех этих технологий, к сожалению. Лучше, чтобы с интерфейсом в виде сервиса: загрузил текст, получил голос. Платное подходит, это не проблема. Так, чтобы без пердолинга.
Здесь можно https://www.weights.gg/invite?inviteCode=937e4
Обучить можно 3десь бесплатн0 https://www.weights.gg/invite?inviteCode=937e4
Как делаются такие видосы?
https://www.youtube.com/shorts/d93UvoqSA-g
Я пока предполагаю, что чел сам записывает вокал, а потом накидывает на него голос нужного певца. Или же уже есть нейронки, которые такие чудеса делают сами?
https://www.youtube.com/shorts/d93UvoqSA-g
Я пока предполагаю, что чел сам записывает вокал, а потом накидывает на него голос нужного певца. Или же уже есть нейронки, которые такие чудеса делают сами?
Такой серьезный вопрос к вам, парни.
Я постоянно за рулём и привык слушать аудиокниги потому что за рулём сложно писать.
Не все книги нормально озвучили, или озвучили вообще и я перепробовал все возможные "старые" синтезы речи которые просто накатывает на андроид и они работают во многих читалках но есть ньюанс. Они зачастую полное говно но лучше чем ничего. Среди нейронок я слышал намного лучше.
Можете посоветовать какое нибудь решение которое сможет пиздато озвучивать десятки часов текста? Могу себе позволить заранее на компе "отрендерить" текст на звуковые файлы, но походу в глаза долблюсь и ничего путного не нашел в шапке.
Я постоянно за рулём и привык слушать аудиокниги потому что за рулём сложно писать.
Не все книги нормально озвучили, или озвучили вообще и я перепробовал все возможные "старые" синтезы речи которые просто накатывает на андроид и они работают во многих читалках но есть ньюанс. Они зачастую полное говно но лучше чем ничего. Среди нейронок я слышал намного лучше.
Можете посоветовать какое нибудь решение которое сможет пиздато озвучивать десятки часов текста? Могу себе позволить заранее на компе "отрендерить" текст на звуковые файлы, но походу в глаза долблюсь и ничего путного не нашел в шапке.
Читалка алисы.
Видел в тиктоке как переводят и озвучивают песни (цоя там) и даже фильмы советской классики, сохраняя интонацию, голос и шпрехая на всех языках.
Как?
Как?
>Как?
HeyGen
Ананасы, подскажите нейронку чтобы в реальном времени переводила диалог с иностранцем на русский, а твой ответ переводило и озвучивало на языке иностранца. Встретил чувака в дискорде с такой нейронкой, теперь заинтересовался.
Голос в текст? Такое даже Гугл переводчик умеет. Выбираешь режим разговора без нажатия кнопок и он распознает говорящих по языку и в реалтайм переводит в текст.
Так у него бы и спросил, что он использует.
Текстом написал, раз чат уже протух.
Привет аноны. Наткнулся на большой объем видео на английском и хотел бы их перевести и сразу же озвучить. Есть какая то нейронка куда просто запихнул дорожку/видео и он/она перевелась? Буду благодарен


Не могу пробиться через спам-лист, анон. Поэтому тест скрином, извини.
Непосредственно семпл https://disk.yandex.ru/d/4S-KRUS5hSf7TQ
Непосредственно семпл https://disk.yandex.ru/d/4S-KRUS5hSf7TQ
дураку понятно что что-бы звучать как баба - нужно говорить как баба. с ихними манерностью ну типа и кароче вот
Без оскорблений пожалуйста
ну собственно анон выше прав. нужно говорить по женски и все же иметь хорошую модель которую ты обучишь сам или все же сказать что ты девушка но с низким голосом
Согласен. Но актерство не решает проблем несовершенства моделирования, глитчей и обрезания шипящих. Поэтому, собственно, и прошу указать на альтернативы или изъяны в настройках. По тех часть не спрашиваю, т.к очевидно, что чем лучше железо и микрофон — тем лучше.
Думаю, смогу обучить модель, покурив гайды. Навскидку назовешь несколько главных принципов при подборе голоса и обучении?
да в принципе главное чтоб датасет хороший был
Правильно ли я понимаю, что с моей GTX 660 в RVC для изменения голоса (не тренировки) делать нечего?
>GTX 660
Можешь даже забыть, тебе как минимум 1660 надо
хз. на 1050 нормально все. голос изменяю. не в реалтайме конечно. А так аи каверы делаю
tldr
Хочу закинуть в любую норм нейросетку свой голос и озвучить текст, например, на английском. Именно чтобы текст → голос на основе сэмпла. Кроме элевенлабс есть ещё варианты? Или, как я понимаю, только элевенлабс более-менее удовлетворит мой запрос?
Хочу закинуть в любую норм нейросетку свой голос и озвучить текст, например, на английском. Именно чтобы текст → голос на основе сэмпла. Кроме элевенлабс есть ещё варианты? Или, как я понимаю, только элевенлабс более-менее удовлетворит мой запрос?
Обучи здесь бесплатно https://www.weights.gg/invite?inviteCode=829bf
Обучи свою модель бесплатно здесь https://www.weights.gg/invite?inviteCode=829bf
ага щас
За suno bark что сказать можете?
а где можно скачать rvc не через зип а как exe установить
а для опенсорса нет ехе установщика. Ну в принципе можешь установить апплио рвс
>xttsv2 banana
а... где?
Weights конечно крутой но там лимит 20 минут на модель, но я пока не нашел ресурса где можно было бы дрочить модель семплами например по 2+ часа.
ни разу небыл в треде, однако понравился голос одного перса из игры, есть 25 мп3 со всеми фразами. чтобы мне из этого сделать ттс озвучку текста, чатбот, голосовой помошник и хз че еще, хватит инфы из шапки?
25 минут*
Да, должно хватить инфы. Тебе нужно обучить RVC-модель на перса, 25 минут более чем достаточно. Потом нужно использовать эту модель в паре с любым TTS (есть локальные типа SileroTTO, есть бесплатные облачные типа EdgeTTS).
И дальше организуешь конвейер - отдаёшь нужный текст TTS'ке, она генерирует дорожку дефолтным голосом. Дальше берёшь свою RVC модель и конвертируешь дорожку, получая нужный тебе голос.


все поменял
у вас кстати в гайде 3 ссылки на англ тухлые

на скринах в гайде по 1 эпохе в минуту, у меня еле ползет с 1 до 2 за 13 минут, графики не появляются, я так вечно буду тренировать. в чем проблема? видюха слабая?
оставил на ночь тренить, проснулся от того, что комп взорвался. спасибо нахуй
натренировал 63 эпох и куда аут оф мемори (1660 ti, i5-9400f)
коллаб хуйня видимо, надо все время смотреть чтоб не перетренить так как сохранений нет, еще и тред мертвый
нихуя не достиг, проебал кучу времени, на этом и прощаюсь
коллаб хуйня видимо, надо все время смотреть чтоб не перетренить так как сохранений нет, еще и тред мертвый
нихуя не достиг, проебал кучу времени, на этом и прощаюсь
https://www.youtube.com/watch?v=KgdJSX2mt6c
Аноны! Можете перевести нейронкой хоть кусочек, хоть секунд 10? Буду очень благодарен, с меня нихуя.
Аноны! Можете перевести нейронкой хоть кусочек, хоть секунд 10? Буду очень благодарен, с меня нихуя.
яндекс бравзер ставь и переводи скока хочешь
Такая милая, ещё до того как шизанулась.
так ну. нужна минимум 2060
Суп
Суп, я хочу сделать озвучку книги в машине слушать. Синтез голоса встроенный в андроид та ещё дрянь, а интернет далеко не везде есть.
Есть какой-то удобный пайплайн для этого с встроенным словарем ударений для русского языка?
Есть какой-то удобный пайплайн для этого с встроенным словарем ударений для русского языка?
ну из нормального это edge TTS есть
На Elevenlabs не получается зайти, бесплатный ВПН не помогает
Посоветуйте SOTA голосовую модель (необязательно) чтобы поддерживала русский. Мне бы хотя бы уровень второго поколения Eleven Labs



таки это овертрейнинг или нет?
если я пропустил нижнюю точку графика и завершил сессию, хотя сохранил в блокнот и скачал .pth файл, могу я как-то откатить тренировку рвс через гугл коллаб к старому чекпоинту, чтобы не начинать тренировать сначала?
Можно ли как-то озвучить текст с помощью ии модели, а не преобразовать один голос в другой? Я натренил модель, однако генерация через рвс меняет голос в аудио файле, но и перенимает скорость речи, паузы, интонации и т.д., то есть тон голоса может и тот же, но манера речи от дефолт ттс микрософта, а не от датасета. Наверно это хорошо для песен, но не для обычной речи.
ну так манеру речи оно не передаст никак. Модель в РВС делает голос схожим но не интонацию и скорость речи
Ок, а как я могу преобразовавать текст в речь, а не одно аудио в другое, пусть даже не через рвс? Я даже не знаю что гуглить.
текст в речь? ну сначала ттс а потом рвс. Так же можешь просто сам прочитать текст с нужной интонацией паузами и т.д. и потом через рвс прогнать

мне нужно текст сразу в голос из моего датасета чтоб он не перенимал сухую манеру из инпут аудио как рвс делает
мой голос не подходит пробовал, слишком отличается
лан буду думать
пока что из опен сурса такого нет. юзай елевенлабс(
да че ты чешешь нету, ттс давно есть везде, мне надо понять как сделать свой
так че ты хочешь? текст в речь это ттс да. Если ты хочешь интонацию и скорость речи то это тебе в доп настройки ттс лесть и настраивать. например в silerotts естьт SSML разметка
Ну что, мёртвый тредис, каков положняк? Давно не юзал все эти ваши АИ, новую крутую форку нашего рвс не придумали? Гайд с шапки актуален?
конечно актуален
Двачну вопрос, оче интересно.
Если закидывать в сервис дубляж а-ля 11лабс, то там рифмы не будет, но голос похожий будет.
Если прогонять левый голос через модель певца, то получим голос похожий, но надо уметь петь ртом или автотюнить, чтобы звучало хорошо, но как делать женские партии, я давненько пытался, обычный мужской голос перегонять в женский, получалось не оче, плюс тут ещё и петь надо с выражением.
Какие ещё мюсли?
Может можно прописывать текст для дубляжа-переводы как-нибудь в11лабс или тип того?

Появился новый TTS c фичей войсклона, на заморском /g/ твердят что он рвёт XTTSv2 в щепки.
https://fish.audio/text-to-speech/
https://github.com/fishaudio/fish-speech
https://huggingface.co/fishaudio/fish-speech-1.4
https://huggingface.co/spaces/fishaudio/fish-speech-1
В локал говорят хавает 4 гига максимум, но результаты топ.
https://fish.audio/text-to-speech/
https://github.com/fishaudio/fish-speech
https://huggingface.co/fishaudio/fish-speech-1.4
https://huggingface.co/spaces/fishaudio/fish-speech-1
В локал говорят хавает 4 гига максимум, но результаты топ.
Само говноподелие паджита из залупинска можете поставить на пекарню через :
>clone repo
>run install_env.bat
>run start.bat
>go to "Inference Configuration" in the webpage that just opened
>toggle "Open Inference Server"
>go to http://127.0.0.1:7862 (if it doesn't load, wait a moment then reload)
>scroll down, open "Reference Audio"
>toggle "Enable Reference Audio"
>throw your audio sample in there
Затестил на HF, результат топ. Буду пользоваться.
опять на японском и пиндосском

НУ ЧЕ ЛОШКИ ЕЛЕВЕНЛАБСНЫЕ. ПОСОСАЛИ? ВОТ И БЛОКНУЛИ ВАШУ ХЕРНЮ ИЗ-ЗА САНКЦИЙ ПИНДОСИИ. ЗАМЕТЬТЕ НЕ МЫ БЛОКНУЛИ А ОНИ. СОСИТЕ. Я Ж ГОВОРИЛ ЧТО НУЖНО ДОБИВАТЬСЯ ОПЕНСОРСА. СОСИТЕ ЕЛЕВЕНЛАБСНИКИ. РВС + ТТС ТОП!!!!!!!
Скачал из гайда амд версию RVC, а в ней не оказалось go-web.bat
Как без неё свою модель тренить-то?
python infer-web.py
Продолжу тему ттс, кто-нибудь пользовался Tortoise TTS? Пендосы о нём лестно отзываются. Чё по поддержке других языков?
https://nonint.com/static/tortoise_v2_examples.html
https://nonint.com/static/tortoise_v2_examples.html

Пыня пидораса кусок
>хрю
> 2024
> нет впн
Тренирую нейросеть на голосах из фильмов. Фильмы дублированные, значит, актёр дубляжа получал за этот дубляж деньги. Конкретно за запись голоса.
>В частности, если использование голоса гражданина осуществляется в государственных, общественных или иных публичных интересах или если запись голоса гражданина производилась за плату.
Всё, нахуй.
Черепаха невероятно хороша. По сути, все топовые голосовые нейросети это чуть-чуть черепаха. Но только чуть-чуть, потому что название отражает её скорость работы.
https://github.com/Bebra777228/PolGen-RVC
Аноны, что думаете про это?
Аноны, что думаете про это?
Кто-то пользовался копировальщиком голосов ElevenLabs?
https://vocaroo.com/15OMeNLp47Pv (почему-то клипинг небольшой есть)
Текст
In a world more cluttered than a Hoarder's Edition copy of "Garry's Mod," keeping your attention on anything for more than five seconds is rarer than finding a multiplayer lobby for a 2007 RTS. We're constantly under siege—notifications, videos, memes—it's like being in the middle of a free-to-play mobile game, except you're paying with your soul. Result? You've got the attention span of a caffeinated squirrel, anxiety that would make Chernobyl's radiation levels blush, and a never-ending itch for that next dopamine hit.
You want success? You want to improve yourself? You want inner peace? Well, sunshine, you better learn how to wield focus like a knife in a "Thief" speedrun.
And no, it's not all about chanting "om" on some overpriced yoga mat. In fact, the last place you think of—your bathroom—might just be where you hit spiritual nirvana. That's right. Put down the phone, stop doomscrolling, and let me introduce you to a sacred practice lost to time and Wi-Fi: the ancient art of conscious bowel journeys.
Picture it: You’re sitting there, not squatting with a phone like the rest of the digital zombies. Nope, you're focused. Laser-focused. On the task at hand. No TikToks, no memes—just you and the long, slow journey of a well-traveled stool missile. Every contraction, every micro-movement of your intestines, a delicate symphony. The kind of thing Beethoven would have written if he had access to high-fiber diets. And in that moment, you're not just another victim of modern society. You're a walking, breathing monument to the magnificence of human biology, my friend.
This? This isn’t a simple "bio-break." Oh, no. This is a golden opportunity to break free from the modern world’s grip. You are now a primal god, a being in tune with nature, rediscovering the lost art of using your damn brain without staring at a screen.
Each bowel movement is like a zen koan: a riddle meant to be experienced, not solved. You’ll soon realize that your porcelain throne is more than just a toilet; it’s a gateway to enlightenment. A royal seat from which you decree freedom from distraction, a rebellion against the endless tide of meaningless content.
Forget meditation retreats and overpriced self-help seminars. True mastery of life starts here. Let go of your waste and your need for constant stimulation in one swift motion. Close your eyes. Embrace the grotesque glory of the moment. And when you flush, know that you’re not just sending waste down the pipes—you’re flushing away the last remnants of your distracted, lesser self.
Flush. And prosper.
Можно как-то настроить паузы и эмоции для отдельных слов?
Тренировал на видосах https://www.youtube.com/@SsethTzeentach/videos, просто выбрал два рандомных видео и нарезал кусками по 10мб.
https://vocaroo.com/15OMeNLp47Pv (почему-то клипинг небольшой есть)
Текст
In a world more cluttered than a Hoarder's Edition copy of "Garry's Mod," keeping your attention on anything for more than five seconds is rarer than finding a multiplayer lobby for a 2007 RTS. We're constantly under siege—notifications, videos, memes—it's like being in the middle of a free-to-play mobile game, except you're paying with your soul. Result? You've got the attention span of a caffeinated squirrel, anxiety that would make Chernobyl's radiation levels blush, and a never-ending itch for that next dopamine hit.
You want success? You want to improve yourself? You want inner peace? Well, sunshine, you better learn how to wield focus like a knife in a "Thief" speedrun.
And no, it's not all about chanting "om" on some overpriced yoga mat. In fact, the last place you think of—your bathroom—might just be where you hit spiritual nirvana. That's right. Put down the phone, stop doomscrolling, and let me introduce you to a sacred practice lost to time and Wi-Fi: the ancient art of conscious bowel journeys.
Picture it: You’re sitting there, not squatting with a phone like the rest of the digital zombies. Nope, you're focused. Laser-focused. On the task at hand. No TikToks, no memes—just you and the long, slow journey of a well-traveled stool missile. Every contraction, every micro-movement of your intestines, a delicate symphony. The kind of thing Beethoven would have written if he had access to high-fiber diets. And in that moment, you're not just another victim of modern society. You're a walking, breathing monument to the magnificence of human biology, my friend.
This? This isn’t a simple "bio-break." Oh, no. This is a golden opportunity to break free from the modern world’s grip. You are now a primal god, a being in tune with nature, rediscovering the lost art of using your damn brain without staring at a screen.
Each bowel movement is like a zen koan: a riddle meant to be experienced, not solved. You’ll soon realize that your porcelain throne is more than just a toilet; it’s a gateway to enlightenment. A royal seat from which you decree freedom from distraction, a rebellion against the endless tide of meaningless content.
Forget meditation retreats and overpriced self-help seminars. True mastery of life starts here. Let go of your waste and your need for constant stimulation in one swift motion. Close your eyes. Embrace the grotesque glory of the moment. And when you flush, know that you’re not just sending waste down the pipes—you’re flushing away the last remnants of your distracted, lesser self.
Flush. And prosper.
Можно как-то настроить паузы и эмоции для отдельных слов?
Тренировал на видосах https://www.youtube.com/@SsethTzeentach/videos, просто выбрал два рандомных видео и нарезал кусками по 10мб.
Подскажите, хочу в вацапе менять голос собеседника, то есть чтобы он менялся у меня в динамике, каким образом можно это сделать?

А ещё не плохо было бы на пэкарне запустить нейронку, а на телефоне что бы твой голос менялся




млят, я заёпся, какая нейронка локальная?
Чтобы тупо скачать запеканку и запустить на своём компе, нахуй мне эти апи к серверу дяди васи, я хочу генерить хуйню без ограничений и цензуры.
Чтобы тупо скачать запеканку и запустить на своём компе, нахуй мне эти апи к серверу дяди васи, я хочу генерить хуйню без ограничений и цензуры.
rvc
Есть сейчас годные локальные ТТС? Год назад было одно кривожопое говно, уже появились ИИ видосы, а что с генерацией голоса?
еджттс из годных
Аноны, как избавиться от артефактов как на 48 и 56 секундах?
Использую XTTSv2 c войс-клоном. (использую не webui, а делаю всё в скрипте) Проблема как понимаю связана с тем, что передаю слишком большой текст или же это что-то другое?
https://voca.ro/1oUzvDvldAeQ
Также, возможно ли как-то расставлять ударения для XTTSv2?
Вот сам текст:
Размышляя о смысле бытия, я часто задаюсь вопросом, в чем же заключается наша цель в этом огромном и загадочном мире. Ведь мы - всего лишь крошечные песчинки во Вселенной, затерянные среди бескрайних космических просторов. С одной стороны, это может казаться пугающим - осознавать свою незначительность и хрупкость. Но в то же время меня поражает величие и красота окружающего нас мироздания. Каждая галактика, каждая звезда, каждая песчинка хранит в себе тайну, ожидающую своего открытия. Я верю, что наша задача - не просто существовать, а постоянно познавать, исследовать, учиться. Ведь именно это делает нашу жизнь осмысленной и наполненной. Даже если мы не найдем ответы на все вопросы, сам процесс поиска дарит нам ощущение причастности к чему-то грандиозному. Поэтому я считаю, что смысл бытия - в непрерывном стремлении к познанию, в благоговейном трепете перед тайнами Вселенной. Пусть наше существование ничтожно на космических масштабах, но оно бесценно в своей уникальности. Ведь именно мы, люди, способны постигать все многообразие и красоту мироздания.
Использую XTTSv2 c войс-клоном. (использую не webui, а делаю всё в скрипте) Проблема как понимаю связана с тем, что передаю слишком большой текст или же это что-то другое?
https://voca.ro/1oUzvDvldAeQ
Также, возможно ли как-то расставлять ударения для XTTSv2?
Вот сам текст:
Размышляя о смысле бытия, я часто задаюсь вопросом, в чем же заключается наша цель в этом огромном и загадочном мире. Ведь мы - всего лишь крошечные песчинки во Вселенной, затерянные среди бескрайних космических просторов. С одной стороны, это может казаться пугающим - осознавать свою незначительность и хрупкость. Но в то же время меня поражает величие и красота окружающего нас мироздания. Каждая галактика, каждая звезда, каждая песчинка хранит в себе тайну, ожидающую своего открытия. Я верю, что наша задача - не просто существовать, а постоянно познавать, исследовать, учиться. Ведь именно это делает нашу жизнь осмысленной и наполненной. Даже если мы не найдем ответы на все вопросы, сам процесс поиска дарит нам ощущение причастности к чему-то грандиозному. Поэтому я считаю, что смысл бытия - в непрерывном стремлении к познанию, в благоговейном трепете перед тайнами Вселенной. Пусть наше существование ничтожно на космических масштабах, но оно бесценно в своей уникальности. Ведь именно мы, люди, способны постигать все многообразие и красоту мироздания.
Что то лучше появилось с тех пор?
Сап, не слышали про какую-нибудь годную нейронку голосов, которая эмоции, стоны, крики тоже генерирует в персонажей?
Я знаю про RVC, оно годно превращает уже записанную речь в персонажа и даже пение, но со стонами вздохами всё очень плохо. Почему? Я не понимаю.
А TTC эмоциональное кряхтящее бесполезно искать уже готовое. Может вы слышали чтоб не в персонаже, а чтоб просто разные вокальные приёмчики нагенерировать? Может их как-то удастся преобразовать всё-таки в этом RVC.
Я знаю про RVC, оно годно превращает уже записанную речь в персонажа и даже пение, но со стонами вздохами всё очень плохо. Почему? Я не понимаю.
А TTC эмоциональное кряхтящее бесполезно искать уже готовое. Может вы слышали чтоб не в персонаже, а чтоб просто разные вокальные приёмчики нагенерировать? Может их как-то удастся преобразовать всё-таки в этом RVC.
Новый TTS с войс клоном - F5-TTS.
>100K hours of data
>Zero-shot voice cloning
>Speed control (based on total duration)
>Emotion based synthesis
>Long-form synthesis
>Supports code-switching
>CC-BY license (commercially permissive)
https://x.com/reach_vb/status/1845157049891500097 (embed)
https://x.com/reach_vb/status/1845159387155087503 (embed)
https://huggingface.co/SWivid/F5-TTS
https://huggingface.co/spaces/mrfakename/E2-F5-TTS
>100K hours of data
>Zero-shot voice cloning
>Speed control (based on total duration)
>Emotion based synthesis
>Long-form synthesis
>Supports code-switching
>CC-BY license (commercially permissive)
https://x.com/reach_vb/status/1845157049891500097 (embed)
https://x.com/reach_vb/status/1845159387155087503 (embed)
https://huggingface.co/SWivid/F5-TTS
https://huggingface.co/spaces/mrfakename/E2-F5-TTS
Если лень делать секс с кондой и питоном, ставьте через https://pinokio.computer/
Как они это делают-то блядь, а? С помощью чего? Оригинальная манера, но с кастомным словами, голос понятно, а вот текст как уложить в исполнение?
Аноны, есть порно-рассказ который нужно прочесть голосом сексуальной бабы, разумеется локально. Ваши действия?
ищу модель на вейтс гг. качаю ее. потом с помощью едж ттс прогоняю текст и потом его в рвс
спасибо
Реквестирую кружок от злого скуфа (Ты пидорюга ебаная, хуле ты под долбоёба косишь пидор...), переозвученный голосом Неко арк (может уже сделал кто то?)
Да кто такой этот ваш едж ттс? От майкрософт всмысле? Линк в студию.
Там нет ничего про то, что я спрашивал.
https://github.com/hinaichigo-fox/rus-edge-tts-webui
Вот хороший гуй. Делали с анонами с этого треда
Сап, подскажите где лучше надыбать фоток нормисов? Чтоб активности всякие, игры, разные позы, курсы. Только без шуб и ватников.
Мне для реферов надо. Я заметил img2img на 75% рисует позирование гораздо лучше и быстрее, чем с тегами дрочиться и рандомить пикчу близкую к твоей идее в txt2img. И главное подходящая комплекция персонажей задаётся.
Я знаю, что можно 3дэ болванки расставлять, но это слишком долго для меня тоже.
Неужели в фейсбуке регаться? В гугле как-то мало и не то.
Мне для реферов надо. Я заметил img2img на 75% рисует позирование гораздо лучше и быстрее, чем с тегами дрочиться и рандомить пикчу близкую к твоей идее в txt2img. И главное подходящая комплекция персонажей задаётся.
Я знаю, что можно 3дэ болванки расставлять, но это слишком долго для меня тоже.
Неужели в фейсбуке регаться? В гугле как-то мало и не то.
не тот тред. но лучше в пинтересте на акках баб
Да, я там на 2 фронта воюю, спасибо.
Нужно перегнать большие объёмы текста (книги) в звук. Какой будет голос - не важно, главное чтобы уши не вяли как от какой-нибудь Балаболки. Онлайн-кал не подходит (то есть не нужно предлагать Edge и Алису).
Мимо прохожу, не шарю, няшность услышать хочу.
Пожалуйста, скиньте что-то около анимешное звуковое, прям самое типовое, что у вас есть.
Если будет годно, накачу все ваши приблуды и буду задрачивать, благо железо есть.
Просто немного утомился — уже и так в ллм и сд много работаю. А тут может что-то новенькое для души.
Пожалуйста, скиньте что-то около анимешное звуковое, прям самое типовое, что у вас есть.
Если будет годно, накачу все ваши приблуды и буду задрачивать, благо железо есть.
Просто немного утомился — уже и так в ллм и сд много работаю. А тут может что-то новенькое для души.
Могу только старые нейрокаверы с лисоженой скинуть. Офигеть, уже больше года прошло, как их выкадывал итт.
Использовал Ultimate Vocal Remover для разделения на вокал/инструменталку + тренил RVC модель для изменения голоса. Только на последнем SVC на том же самом датасете.
У локальных голосовых нейронок низкие системные требования, так что если смог запустить SD/LLM, то без проблем сможешь запустить тот же RVC и всё остальное.
Вот такую хуйню сгенерили мне
Чуваки из Ai Guitarist рассказывали. Руками пишешь текст, проф певец напевает партию своим голосом, потом voice clone. Других вариантов с сохранением музыки сегодня нет. Есть и удиошные говновозы, но их слышно сразу, удио может склонировать стиль, но в существующую музыку не может.
я всё помню
новый TTS, говорят по качеству как Elevenlabs. Русский не поддерживается
https://github.com/SWivid/F5-TTS
https://github.com/SWivid/F5-TTS
>Русский не поддерживается
Ну и нахуй тогда он нужен? Мы собрались здесь для того чтобы слушать каверы говновоза и озвучивать пасты про говно.
Сап. Есть записи диктора из которых мне нужно сделать голосовую модель, для дальнейшего использования её в speech-to-text.
Какие библиотеки выбрать для обучения/для использования модели в дальнейшем? Что проще накатить локально? Где лучше результат?
Какие библиотеки выбрать для обучения/для использования модели в дальнейшем? Что проще накатить локально? Где лучше результат?
>Русский не поддерживается
Из их статей не узнать, какой у них датасет, и чего может стоить зафайнтюнить модель под русик?

https://studio.infinity.ai/
А что за голосовая ИИха используется на сайте инфинити? Звучит охуенно
А что за голосовая ИИха используется на сайте инфинити? Звучит охуенно
двачую давно такого качества не слышал
видимо что-то хорошо натюненое
Аноны, есть ли инструкция по развертыванию XTTS v2 на своей пекарне, чтобы обучать большие модели и в дальнейшем использовать текст 2 спич?
Может есть какой-то с веб интерфейсом?
Может есть какой-то с веб интерфейсом?
Какая нейронка используется в character ai для генерации голоса?
Там нет акцента, все звуки хорошо произносит и может говорить на любом языке, в отличие от rvc ебаного
Там нет акцента, все звуки хорошо произносит и может говорить на любом языке, в отличие от rvc ебаного
Да я много где такое встречал, что голосовуха на сайте/программе/в сгенерированном видео на ютубе на 3 головы выше доступного по шапке треда. Хз либо анон нихуя не знает и найти не может, либо это жиды все скрывают
ЖИДЫ И МИРОВОЕ ПРАВИТЕЛЬСТВО СКРЫВАЮТ!!!
> И какая TTS модель у Evil Neuro, знает кто?
Насколько я понимаю, раньше гонялось через EdgeTTS с питчингом, а с V2 версии там какая-то своя моделька сделана, видимо XTTS обученный или что-то такое. Но скорость охуевшая конечно
>раньше гонялось
Голос Ashley из Azure AI
>с V2 версии
Голос Ashley из Azure AI c другим питчем.
Ага, Azure, не EdgeTTS, точно. Но у злой то другой голос, который больше на локальные нейронки похож. Особенно эти артефакты на китайских символах, и крики из ада.
Как видос наподобие третьего сделать? Тоже с голосом из геншина. И тут еще один вопрос - можно ли сделать перевод голоса так, чтобы сохранить тембр, чтобы было понятно, что это один и тот же человек говорит.

Какой самый простой способ заставить Шамана перепеть Я РУССКИЙ как Я ГОМИК? Реально нужен фрагмент секунд 10, ну и мб в другой части текста что-нибудь поменял бы. Минус скачал, а капеллу выделил, но чёт именно кастомный текст не найду (хотя как-то Говновоз же перепевают)
Надо самому спеть Я ГОМИК и сделать voice clone
меня мама убьет если я такое спою
Аноны, где искать модели? Кроме дискорда aihub и applio есть что-то?

Реквестирую замену слов в треке https://www.youtube.com/watch?v=6CHs4x2uqcQ c Good Morning на it's over (да, я я ебанутый). Весь трек делать не надо, только отрезок с 0:11 до 0:35.
С меня как всегда.
С меня как всегда.
вейтс гг

Антуаны, подскажите, пожалуйста, куда смотреть и чо делать, чтобы озвучить аудиокнигу, и чтоб заебись было?
Пиздец, какой же всратый сайт. Держу курсор справа на экране и думаю почему нихуя не скролится. Три браузера попробовал и всё не работает.
Оказывается нужно курсор в центре держать. Тупое говно тупого говна говно. Да и скачка анально огорожена.
В чем она не права?
Аноны, как искать подходящие датасеты? Нет, меня не интересуют какие-то известные личности. С ними в общем понятно.
А вот если мне надо просто другое голос заиметь?
Вроде бы, зашёл на ютуб, скачал аудиодорожку и вперёд. Но сама проблема найти подходящее без музыки и других посторонних артефактов.
Как вы решали такой вопрос? Кроме как надеяться на случай никаких мыслей нет.
А вот если мне надо просто другое голос заиметь?
Вроде бы, зашёл на ютуб, скачал аудиодорожку и вперёд. Но сама проблема найти подходящее без музыки и других посторонних артефактов.
Как вы решали такой вопрос? Кроме как надеяться на случай никаких мыслей нет.
вообще видосы прогонял через uvr и все

help
в ошибку вчитайся

уже давно установленно
у чат жпт спроси
Подскажите шапка устаревшая? Я зашел по первой ссылке в гитхаб SileroTTS и там нет русского в поддержимаемых языках.

Сап, а не можете что-нибудь посоветовать по созданию моделей голосов винды, которое роботом говорит?
Мне на самом деле для таверны с чатом нужна озвучка, но там большинство опций это навернуть нейронки, которые будут онлайн генерить тебе озвучку, а это естественно долго, никто не хочет полминуты тишины слушать прежде чем тебе ответят.
Есть опция пресетов голосов винды и я подумал о ней, но мне хотелось бы чтоб были модели нужных мне персонажей, а не каких-то стивинов хоукингов. В сети этих моделей не вижу. Я слепой.
Мне на самом деле для таверны с чатом нужна озвучка, но там большинство опций это навернуть нейронки, которые будут онлайн генерить тебе озвучку, а это естественно долго, никто не хочет полминуты тишины слушать прежде чем тебе ответят.
Есть опция пресетов голосов винды и я подумал о ней, но мне хотелось бы чтоб были модели нужных мне персонажей, а не каких-то стивинов хоукингов. В сети этих моделей не вижу. Я слепой.
Очередной TTS https://x.com/reach_vb/status/1851629504348754202
>Клонирование голоса с нуля
>Эмоциональный TTS
>Обучен на 100 тысячах часов данных
>Синтез длинных форм
>Синтез с переменной скоростью
>Двуязычный - китайский и английский
https://huggingface.co/amphion/MaskGCT
Демо - https://huggingface.co/spaces/amphion/maskgct
Это второй ттс после что близок к качеству elevenlabs.
>Клонирование голоса с нуля
>Эмоциональный TTS
>Обучен на 100 тысячах часов данных
>Синтез длинных форм
>Синтез с переменной скоростью
>Двуязычный - китайский и английский
https://huggingface.co/amphion/MaskGCT
Демо - https://huggingface.co/spaces/amphion/maskgct
Это второй ттс после что близок к качеству elevenlabs.

Бля а можно их как-то закинуть в Microsoft windows типа что бы вместо дефолтных гугол мужика и бабы такой норм голос? Уже столько времени прошло надоели эти гнусавые говорилки дефолтные неужели нельзя было интегрировать нормальные tts в шинду я ими квесты в ммо-шках озвучиваю себе ну и книжки аля аудио делаю
Что не день то новый ТТС, на этот раз это голос-в-голос модель без требования к дополнитенльным приколам типа whisper для детекта речи и транскрипта текста. https://huggingface.co/fishaudio/fish-agent-v0.1-3b
Эдакий гпт-4о войсмод на самых минималках.
эх бульбулятор-бульбулятор
Анонасы, не подскажете, помню проскакивала нейронка генерирующая звуки к видео. Не напомните название, что то не гуглится?
вопрос по тренировке своего голоса в RVC, сколько ни пробовал фигня получалась.
1) сколько минимум звуковых файлов нужно в датасете и какой миниму длины?
2) если у меня есть скажем 30 секунд аудио есть, можно датасет сделать?
1) сколько минимум звуковых файлов нужно в датасете и какой миниму длины?
2) если у меня есть скажем 30 секунд аудио есть, можно датасет сделать?
минут 10 и больше будет афигенно все получаться.
2. вот тут хз вообще. 30 секунд это надо наверно постараться чтоб потом все хорошо вышло
а если у меня допустим есть 10 минут записи голоса, мне запись надо нарезать на разные куски или одним куском тренить?
лучше разрезать на куски по 10 секунд и тренить. ставь 1000 эпох и с помощью тенсоборда находи лучшую модель. если не хочешь возиться с тенсобордом ставь 250 потом 300 эпох
странно в прошлый раз нарезал свою звукозапись как раз где-то на 10 секунд вроде 5 кусков было, получилась фигня, может перетрен был этох 300 и 500 пробовал
5 кусков. это даже не 1 минута лол.
Если делать каверы на запрещенные треки то будет ли это попадать под статью?
Спасибо за инфо. Но как так? Разве АИ это уже сам не может? Софтварными методами не достижимо? Реально самим петь приходится?
Так ты смотри описание видео. Adele у тебя прямиком из Udio, например.
Сам как думаешь? Если в тексте запрещенка, то будет.
Так а как УДИО заставить пить в РИТМ /НОТЫ ОРИГИНАЛА? Вот в чём вопрос был.
как они это делают?
Ничего лучше читалки Алисы ещё не вышло для озвучивания книг?
Для реалистичного качественного звучания - да.
Можешь спеть ты сам, не попадаю ни в одну ноту, потом заменить тембр, подредактировать автотюном, потом войсченж нейросеткой, но все артефакты от дикого автотюна останутся. Поэтому лучше петь живому человеку, который близок к оригиналу и как-то может пародировать оригинал. Тогда одно другое дополняет, мы имеем живые интонации, эмоции, придыхания, вздыхания и получается зебись.
https://www.youtube.com/watch?v=beTuZ0mlkn4
Ecть л᠌и кaкoй гoлo឵coвoй бpayзepный чa᠍т бe᠌з peгиcᅠтpaции и нa pyccкoм языкe? Haшeл hume.ai, кaк минимyм нeбoльшиe paзгoвopы пpᅠeкpacнo paбoтaют в бpayзepe и бeз peги, нo мoдeли᠌, кaк я пo᠋нял, тoлькo aнглийcкиe.
у тебя походу устаревшая инфа, сейчас достаточно одного удио, ну и руки чтоб не из жопы
мимо делаю аи каверы на говновоз
на ютюбе чел занимается компьютерной граффикой, у него в роликах озвучка, которую хочу себе в ролик, как сделать такую же озвучку???
https://youtu.be/L-iVI8HyNi8?feature=shared
https://youtu.be/eqsQX6sUgRc?feature=shared
https://youtu.be/AjoflJQtfH0?feature=shared
https://youtu.be/o842uy856C8?feature=shared
https://youtu.be/lBS8-z1tN4Y?feature=shared
ПАМАГИТЕЕЕЕ
https://youtu.be/L-iVI8HyNi8?feature=shared
https://youtu.be/eqsQX6sUgRc?feature=shared
https://youtu.be/AjoflJQtfH0?feature=shared
https://youtu.be/o842uy856C8?feature=shared
https://youtu.be/lBS8-z1tN4Y?feature=shared
ПАМАГИТЕЕЕЕ
Купить у актера озвучки запись текста под его голос.
ты думаешь создатель видео заморачивается о покупки записи голосов???
Может те кто запросили графику для рекламы сами озвучивают/заказывают
Короче один хуй это не нейронка озвучивает, хочешь такие же голоса, либо дёргай откуда-то либо найди где актер говорит без лишнего шума и создай свою модель
Скорбно прошу помощи, так как в ллм треде никто не ответил.
Кто-нибудь из вас пытался настроить TTS для таверны? Я пытался ебаться с Silero, но нихуя не вышло. Очень заебался, прям пиздец. Жопа горит страшно. И, если что, я никогда не сидел в вашем треде и не пытался генерировать голос. Ничего не знаю, пытался говнокодить через нейросеть только для этого дела, и, возможно, в этом моя ошибка.
Если готовы помочь здесь или в телеге — буду рад. Там я смогу хотя бы подробно всё объяснить, если есть желающие. @schaukel
Изначально моя задача была поставить Silero + RVC, апи сервер для таверны, вроде бы это возможно, но даже silero не пашет без rvc в таверне, хотя вавки тестовые выдает. И оно у меня без webui.
Я установил окружение, сервер, силеро, rvc, но там могут быть какие-то проблемы с зависимости или я маппинг не настроил.. не знаю.
Если у вас есть готовый гайд для ебланайзеров или это можно сделать всё криво и косо, зато быстро, буду рад и такому варианту.
Кто-нибудь из вас пытался настроить TTS для таверны? Я пытался ебаться с Silero, но нихуя не вышло. Очень заебался, прям пиздец. Жопа горит страшно. И, если что, я никогда не сидел в вашем треде и не пытался генерировать голос. Ничего не знаю, пытался говнокодить через нейросеть только для этого дела, и, возможно, в этом моя ошибка.
Если готовы помочь здесь или в телеге — буду рад. Там я смогу хотя бы подробно всё объяснить, если есть желающие. @schaukel
Изначально моя задача была поставить Silero + RVC, апи сервер для таверны, вроде бы это возможно, но даже silero не пашет без rvc в таверне, хотя вавки тестовые выдает. И оно у меня без webui.
Я установил окружение, сервер, силеро, rvc, но там могут быть какие-то проблемы с зависимости или я маппинг не настроил.. не знаю.
Если у вас есть готовый гайд для ебланайзеров или это можно сделать всё криво и косо, зато быстро, буду рад и такому варианту.
Т.к ебка с Таверной сама по себе не самый лёгкий процесс, ебка с ТТС будет менее популярной темой, т.к для ТТС для чатБотов тебе для начала нужна сама Таверна.
Ищешь новые гайды на новые ТТС(выше кидали, не ебу если Таверна их поддерживает) на тех же каналах, если такие имеются.
А знает ли кто как натренить w2v2-vits модель? Чтобы с эмоциями работала. Хочу заняться тренингом моделей и делать качественно.
Могу попробовать подсказать что, но для этого тебе придётся тг писать. Здесь общаться невозможно, увы. Конкретно силеро не ставил, потому что он говно потому что мне анимешное нужно было. Но vits с rvc у меня работают.
Могу попробовать подсказать что, но для этого тебе придётся тг писать. Здесь общаться невозможно, увы. Конкретно силеро не ставил, потому что он говно потому что мне анимешное нужно было. Но vits с rvc у меня работают.
Я ориентировался на видеопамять и не знал о твоём варианте. И да, мне как раз тоже нужен был анимешный голос. Просто я хочу хотя бы 12b модель использовать + ттс, оно вроде много жрёт. Но если голос прям наголову выше в твоём варианте, то я готов ради этого уменьшить модель до 9b. В конце концов, мне какой-то крутой ролплей не нужен.
Тогда пиши свой тг, ну или напиши в мой.
Таверна у меня есть, я читал документацию, но понял мало, конечно. А роли на английском вообще с трудом воспринимаю. Ну попробую, чо ещё делать.
Кидай тг тогда. Постараюсь расписать, что делать надо. Сколько у тебя там памяти vram и ram?
@schaukel
12 врам, 47 рам.
Там документация сильно устарела для таверны, а доки для ТТС и прочие моменты пиздец какие забористые, знаний технических у меня нет. Пытался установить с помощью клода, но вечно обсирался из-за этой документации. Тонну времени потратил на анализ логов и всего такого.
ТТС подключилась к таверне, но по какой-то причине не воспроизводила звук и выдавала ошибку, мол не видит голос. Хотя маппинг был настроен нормально. При этом тестовые вавки она создавала без проблем, то есть без таверны с ней работать можно было.
Ну а что тогда происходит ты можешь объяснить? Почему буквально все люди генерируют супер качественно, а итт в треде ссылки и советы только по максимально убогим нейронкам?
потому что тут надо звать тех гениев из /wm/ которые делают каверы про хохлов. Тут мы пытаемся все в опенсурсе сделать а пока что это не выходит
Белек предложенным съёжусь продавливавшего гунька усеянным обменянный политработники облизываемся исхудавшая закончившегося натренировавшую энтузиазму
в /wm/ делают афигенные каверы в какой нейронке они это делают?
пример покажи, но в любом случае это или udio (качественные) или suno (все остальные)
это udio, но для таких каверов нужна подписка
Не угадал же. Это всё работает локально в рилтайме.

Подскажи, пожалуйста, что у тебя там за пайплайн?
и tts у тебя XTTSV2 (Coqui) ?
Задолбался, не понимаю, почему никто не говорит как и что.
Как сейчас можно более менее адекватно пользоваться ElevenLabs? С компа у меня никак не работате, перепробовал 5 штук разных впн, бесплатных и платных, а вот с телефона, через впн получилось хотя бы попасть на сайт и генерить текст через семпл, на главной странице, но вот чтобы полноценно пользоваться - мне письмо на почту не приходит, чтобы в акк свой зайти((
Да, в целом, похуй, что у меня там. Это всё можно сделать практически на чём угодно. Нравится xtts - бери его. Работать будет не хуже.

как ты делаешь реалтайм?
xtts.inference_stream(... ?
я уже в их исходниках сижу, пытаюсь это запустить.
На элевенслаб оказывается появился генератор звуков недавно, лучшее пока что видел, но дорогое блин.
Алсо, не придумали как бы персонажу (голосу) придать эмоциональный оттенок - ярость там, радость и т.п. А то когда голосом диктора, всё не то.
У меня была мысль что в 3 слоя:
1. TTS на любой голос близкий персонажу, это в 99% голос диктора или нарратора
2. Морф дорожки (в RVC?) моделью, обученной на целовой эмоциональной выразительности.
3. Последующий морф в RVC в уже в нужного персонажа.
Но как 2 пункт реализовать я не знаю. Можно ли вообще модель надрочить чтоб она передавала выраженную радость, ярость и т.п.? Там же меняются тогда паузы, тональность и т.п.
Алсо, не придумали как бы персонажу (голосу) придать эмоциональный оттенок - ярость там, радость и т.п. А то когда голосом диктора, всё не то.
У меня была мысль что в 3 слоя:
1. TTS на любой голос близкий персонажу, это в 99% голос диктора или нарратора
2. Морф дорожки (в RVC?) моделью, обученной на целовой эмоциональной выразительности.
3. Последующий морф в RVC в уже в нужного персонажа.
Но как 2 пункт реализовать я не знаю. Можно ли вообще модель надрочить чтоб она передавала выраженную радость, ярость и т.п.? Там же меняются тогда паузы, тональность и т.п.
Речь шла про войсклон, рилтайм в сделку не входил, с ним не всё так просто. С xtts оно у меня работало где-то втрое медленнее, чем на шебм. Момент появления цифр в консоли - это момент, когда генерация фразы завершена и передана на воспроизведение. Так что могу тебе только успехов пожелать, лол.
Можно tts надрочить на эмоциональность, нужен датасет большой и модификация модели, чтобы входной слой поддерживал. Занимался чем-то похожим, но забросил в итоге.
А который ты там локальный ттс надрачивал? Может я тоже хочу надрочить.
Я пробовал угабугу, хттс и воксбокс, но оно всё настолько тугое, что только на дикцию и годится. Силеро элитный вообще не смог установиться, я несколько дней пытался его поднять. Саундворк жиды не дают генерить без инвайта по почте.
Я находил онлайн сервисы, где у бота выбираешь выраженную эмоцию как я описал, они уже надроченные, но не автоматически меняют, а надо рубильник переключать и мне норм, только вот токеныыы за даларыыы.... А без подписки бушешь сидеть бандикаком записывать в прямом эфире что там создал, не дают скачать.
На их фоне елевенслабс просто короли, но там тоже у фри ботов нельзя выбирать эмоцииональность. Там ттс диктороское фри зато дешёвое, можно потом куки чистить.
Странный вообще какой-то этот угол аи озвучки, будто все обиженные петухи собрались. В то время как сд бесплатное и куча плагинов для на энтузиазме за донаты и лайки всё делают. И даже чат боты уже появились как гпт бесплатные без цензур, одни озвучники сапоги защищают.
>угабугу
То есть торт, опечатался.
Не знаю сюда ли я попал и по теме ли вопрос, но все таки задам.Возможно вопрос тупой.
Есть сервисы по типу Elevenlabs и Heygen, которые переводят видео на другой язык с сохранением голоса, есть ли возможность сделать это у себя на компе/коллабе?Может есть еще аналоги этих сайтов.
Есть сервисы по типу Elevenlabs и Heygen, которые переводят видео на другой язык с сохранением голоса, есть ли возможность сделать это у себя на компе/коллабе?Может есть еще аналоги этих сайтов.
>Силеро элитный вообще не смог установиться
Как с силеро-то обосраться можно? Я его когда ставил, там в два клика всё установилось. Но у него нет войсклона, кстати, только вшитые спикеры, ну и эмоциональный диапазон уровня гнусавой озвучки 90х.
>сд бесплатное и куча плагинов
Потому что ебли меньше. Даже с текстовыми нейронками ебли меньше. А для звука ебли много. Сбор и классификация датасетов, чистка, настройка. Есть нейронки, которые вроде бы должны всё это делать, но на практике работают настолько криво, что просто пиздец. Для того же SD всё это готово, есть сайты, которые можно парсить автоматически, потом автоматически генерировать теги для картинок и тренировать, что хочешь. Да и архитектур считанные единицы, когда TTS - миллиард и все разные.
>Может я тоже хочу надрочить.
Ну так бери любую нейронку, которую в принципе можно тренировать, и вперёд.
Можно, только тебе придётся использовать несколько сеток. Сначала сгенерировать субтитры с помощью STT нейросети типа whisper. Здесь есть минус, он не сохраняет адекватно паузы в речи, не опознаёт интонации и так далее. Но вариантов особо нет, насколько мне известно, чтобы работали лучше него. Дальше у тебя есть текст, его переводишь и озвучиваешь TTS с возможностью клонирования голоса, в качестве образца подсовываешь, очевидно, кусочек оригинальной озвучки.
Южанок докошена потниковою исцеляемом умолкнувшей полуфраке откраивавший отпёршем Лазаревичами усам уголковой серенькую внесоциальный апокалиптическою надомном напитывавшее
Это разработчики обсрались, сделав кривое силеро. Ты может очень ранню версию устанавливал.
Ну что за истории ты арссказываешь? Что тяжелее генерить - графику, звуки и текст? Что больше данных на диске весит?
>Ну так бери
Ну так дай. нету её. В шапке нет, и нигде в тырнете. Ты про войс клон? Это хуета, нет желания становиться актёром озвучки, и рычать пердеть в микрофон, а потом в персонажа перегонять.
В шапке буквально решение:
1. Используешь любой инструмент для синтеза голоса из текста
2. Перегоняешь голос в нужный тебе через RVC
А как блять настроение из синтезатора голоса выбрать? НЕТ ЕГО. Я по ссылке все варианты наворачивал, зря время потратил. О каких миллионах бесплатных ТТС с эмоциями ты врёшь, малой?
Посоветуйте RVC-модель, лучше женскую, для исполнения песен с высоким вокалом, скримо и всякой жестью, где требуются сильные перепады голоса и разные эмоции. Ну, такую, которая в теории может это потянуть. На weights говно одно для того, чтобы LLM озвучивать или баловаться в основном.
Только какая-то модель Сенко неплохо справляется от анона там, и весит она заметно больше всех остальных, кстати.
Только какая-то модель Сенко неплохо справляется от анона там, и весит она заметно больше всех остальных, кстати.
Sup, /ai/!
Аноны, подскажите, пожалуйста. Мне нужен локальный софт для TTS, без извращений всяких с подменой голоса и прочим, мне просто нужна качественная модель для озвучки, что бы потом это использовать в ютубе, куда смотреть? Я прочитал шапку, но тут куча мусора и почти вся инфа про изменение фейк-голоса, а мне это не надо, мне просто TTS нужен
Аноны, подскажите, пожалуйста. Мне нужен локальный софт для TTS, без извращений всяких с подменой голоса и прочим, мне просто нужна качественная модель для озвучки, что бы потом это использовать в ютубе, куда смотреть? Я прочитал шапку, но тут куча мусора и почти вся инфа про изменение фейк-голоса, а мне это не надо, мне просто TTS нужен
>Это разработчики обсрались
Специально проверил, установилось за минуту и работает. Хуй знает, что ты там навертел.
>Что тяжелее генерить - графику, звуки и текст?
Текст, очевидно. Но звуком мало кто толком занимается, потому готового нихуя нет, из-за чего работа со звуком требует в разы больших трудозатрат, чем что угодно другое.
В ютубе хуй знает, у всех разные лицензии, частенько запрещающие всё на свете. А так, силеро - предельно простая хуйня, которая даже на процессоре может быстро генерировать.


Ставили?
Это https://speech.fish.audio/inference/ работает
А это https://speech.fish.audio/start_agent/ нихера
Ни с аудио, ни с микрофоном, ставил на свою конду, с их батника
Одна и та же ошибка
Не вникал что значит этот апи вызов, но послал на него нужный запрос и эта же ошибка вылезла
Как пофиксить? Как пользоваться?
Есть ли сейчас ттс для русского лучше xtts2?
А лучше F5 для английского?
В приоритете узнаваемость. Но хорошо бы, чтобы и в эмоции умело.
Если есть какой-то неоспоримый лидер, но без войсклона/трейна, то тоже интересно.
А лучше F5 для английского?
В приоритете узнаваемость. Но хорошо бы, чтобы и в эмоции умело.
Если есть какой-то неоспоримый лидер, но без войсклона/трейна, то тоже интересно.
Аноны у кого есть голосовая модель убермаргинала? Скиньте пж если у кого-то она есть
Какие сейчас есть новые нейронки, которые голос в голос перегоняют, по типу как было FreeVC?
https://huggingface.co/spaces/OlaWod/FreeVC
https://huggingface.co/spaces/OlaWod/FreeVC
Fish-Speech.
Уже даже для работы успел заюзать.
Рекомендую.
Я лично накатил виртуалку WSL, туда накатил ручками их гит со всеми дровами, запускаю как tools/server и использую --compile флаг для компилирования модели.
Получаю 90 ток/сек на 3060M.
https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI
Удивлен, что тред не засран фишем, зашел сюда случайно. Топовая же модель, эмоции бодрые (хотя настраивать нельзя, немного берет эмоций с референса), русский хорош, прям отлично. Медленная, только, конечно. Онлайне не поболтать.
Тоже уже попробовал 1.5
Тебе удалось запустить Fish Agent?
Я уже заёбся переустанавливать и пробовать разные комбинации версий. Обосанная хуйня как-то криво написана и не может скомпилироваться, всё по 10 раз установлено, системных переменных уже жопой жуй, из обычной консоли всё вызывается, а их хуйня почему-то пишет, что не находит то компилятор, то ещё хуй пойми что.
Есть гайд по процессу установки wsl? Не связывался с таким.
Сосоны есть нормальные гайды для установки Фишспича 1.5 под виндой? Желательно вообще чтоб блять установил из инсталятора двумя кликами и все.

Могу помочь с ошибками, у меня поставилось. В целом с самим speech проблем не возникает, только с компиляцией.
https://www.anaconda.com/download
git clone https://github.com/fishaudio/fish-speech
https://github.com/fishaudio/fish-speech/archive/refs/tags/v1.4.3.zip А возможно лучше скачать код версии 1.4.3
https://speech.fish.audio/ Вариант со своей средой
В батник
call conda activate fish-speech
python -m tools.run_webui --llama-checkpoint-path "checkpoints/fish-speech-1.5" --decoder-checkpoint-path "checkpoints/fish-speech-1.5/firefly-gan-vq-fsq-8x1024-21hz-generator.pth" --decoder-config-name firefly_gan_vq
Для компиляции поставил VS Community 2022 > Desktop development with C++, куда 12.4 стояла, в системных переменных CC со значением C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Tools\MSVC\твоя версия\bin\Hostx64\x64\cl.exe, в PATH добавлена эта же папка без самого файла.
Какой-то шаг, возможно, необязательный.
Я нашёл у себя в шкафу трупик говностика
Не в тот тред насрал ой бляяя

Скачал rvc и пытаюсь свою модель сделать, но чет не выходит. Или выходит, просто нужно ждать неделю? Как понять что он что-то делает? processing вроде идет, в консоли ничего не меняется, нагрузки на видеокарту нет, пикрил охуительно удобный интерфейс в котором уже 500 из 5 и хуй знает что это вообще значит.
В консоли есть
unboundlocalerror local variable 'logger' referenced before assignment
возможно в этом проблема.
свою модель делаешь?
Чекай консоль.
А так же наазови характеристики пеки
Ну я написал что в консоли из ошибок вроде только
UnboundLocalError: Local variable 'Logger' referenced before assignment
Ryzen 5 3600 и rtx 4060ti.
хммм. тогда хз. ставил как?
В смысле как? Скачал и запустил
Сап анонасы, я тут у чувачка уже давно увидел https://github.com/Mozer/talk-llama-fast,
оч прикольно выглядит https://youtu.be/ciyEsZpzbM8
Хотелось бы попробовать так же, но чет установка у меня идет наперкосяк, мб кто то видел что то похожее или как установить без гемора
оч прикольно выглядит https://youtu.be/ciyEsZpzbM8
Хотелось бы попробовать так же, но чет установка у меня идет наперкосяк, мб кто то видел что то похожее или как установить без гемора

Все нашел что хотел
Есть программа для автоматического запуска скриптов инсталляции любой попенсорсной модели.
https://pinokio.computer/
просто скачал программу сос скрипотом и за час она мне сама все скачала и настроила. Все работает от двух кликов мышью, как я и хотел.

Сука, опять не в тот тред!
Ну так с обычным запуском и не должно быть проблем.
Слышал про эту прогу, не понимаю как оно работает, ллм агент с доступом к консоли что ли, страшно пробовать. Пока всё ставится, если поковыряться самому.




Прошлый тред:
Вики треда: https://2ch-ai.gitgud.site/wiki/speech/
FAQ
Q: Хочу озвучивать пасты с двача голосом Путина/Неко-Арк/и т.п.
1. Используешь любой инструмент для синтеза голоса из текста - есть локальные, есть онлайн через huggingface или в виде ботов в телеге:
https://2ch-ai.gitgud.site/wiki/speech/#синтез-голоса-из-текста-tts
Спейс без лимитов для EdgeTTS:
https://huggingface.co/spaces/NeuroSenko/rus-edge-tts-webui
Так же можно использовать проприетарный комбайн Soundworks (часть фич платная):
https://dmkilab.com/soundworks
2. Перегоняешь голос в нужный тебе через RVC. Для него есть огромное число готовых голосов, можно обучать свои модели:
https://2ch-ai.gitgud.site/wiki/speech/sts/rvc/rvc/
Q: Как делать нейрокаверы?
1. Делишь оригинальную дорожку на вокал и музыку при помощи Ultimate Vocal Remover:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/UVR
2. Преобразуешь дорожку с вокалом к нужному тебе голосу через RVC:
https://2ch-ai.gitgud.site/wiki/speech/sts/rvc/rvc/
3. Объединяешь дорожки при помощи Audacity или любой другой тулзы для работы с аудио
Опционально: на промежуточных этапах обрабатываешь дорожку - удаляешь шумы и прочую кривоту. Кто-то сам перепевает проблемные участки.
Качество нейрокаверов определяется в первую очередь тем, насколько качественно выйдет разделить дорожку на составляющие в виде вокальной части и инструменталки. Если в треке есть хор или беквокал, то земля пухом в попытке преобразовать это.
Нейрокаверы проще всего делаются на песни с небольшим числом инструментов - песня под соло гитару или пианино почти наверняка выйдет без серьёзных артефактов.
Q: Хочу говорить в дискорде/телеге голосом определённого персонажа.
Используй RVC (запуск через go-realtime-gui.bat) либо Voice Changer:
https://github.com/w-okada/voice-changer/blob/master/README_en.md
Гайд по Voice Changer, там же рассказывается, как настроить виртуальный микрофон:
https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/Voice‐Changer (часть ссылок похоже сдохла)
Q: Как обучить свою RVC-модель?
Гайд на русском: https://github.com/MaHivka/ultimate-voice-models-FAQ/wiki/RVC#создание-собственной-модели
Гайд на английском: https://docs.aihub.wtf/guide-to-create-a-model/model-training-rvc
Определить переобучение через TensorBoard: https://docs.aihub.wtf/guide-to-create-a-model/tensorboard-rvc
Если тыква вместо видеокарты, можно тренить в онлайне: https://www.kaggle.com/code/varaslaw/rvc-v2-no-gradio-https-t-me-aisingers-ru/notebook?scriptVersionId=143284909 (инструкция: https://www.youtube .com/watch?v=L-emE1pGUOM )
Q: Надо распознать текст с аудио/видео файла
Используй Whisper от OpenAI: https://github.com/openai/whisper
Быстрый скомпилированный для винды вариант: https://github.com/Purfview/whisper-standalone-win
Так же есть платные решения от Сбера/Яндекса/Тинькофф.
Коммерческие системы
https://elevenlabs.io перевод видео, синтез и преобразование голоса
https://heygen.com перевод видео с сохранением оригинального голоса и синхронизацией движения губ на видеопотоке. Так же доступны функции TTS и ещё что-то
https://app.suno.ai генератор композиций прямо из текста. Есть отдельный тред на доске
Шаблон для переката: https://2ch-ai.gitgud.site/wiki/speech/speech-shapka/