



Ещё больше сои, чем в оригинале?
Рейтинг кума есть, LLM арены до сих пор нет, LLM лидерборда так же нет. Васянский не обновляемый список моделей чек, а вот нормальной курируемой таблицы нет. Какие-то бесполезные гайды на лоры, кум и прочую поебень есть, а вот базовых гайдов, как поднять такой-то бэкэнд, поднять апи, подключить его к такому-то фронту, этого нет. Приоритеты, друзья, приоритеты.
А как выпилили токен нигеров из ламы3?
Может ли быть шанс, что если сетке описать что такое нигер - она легко возьмет это слово в оборот на место среди нейронов откуда его выдернули?
Или там прям чистят датасеты регекспом заменяя слово на политкорректное?
Может ли быть шанс, что если сетке описать что такое нигер - она легко возьмет это слово в оборот на место среди нейронов откуда его выдернули?
Или там прям чистят датасеты регекспом заменяя слово на политкорректное?
Яиц не хватит навалить меньше сои в модели которая должна отвечать на вопросы
Ну и что бы получить кучу баллов в тестах внезапно тоже нужна соя и цензура так как там тупо правдивые ответы влияют на оценку отрицательно, лел
>в тестах внезапно тоже нужна соя и цензура
Ну по крайней мере про поведение геев в молодом возрасте знать и отвечать надо, а то занизят. Какая-то странная борьба мочи с говном вышла.
https://huggingface.co/datasets/cais/mmlu/discussions/26
Круто. Ждем пока Жорик починит свою хуйню и надеюсь квантование не заруинит возможности модели.
> Очень сомневаюсь.
Ну слушай, явно уж побольше тебя разбираюсь в вопросе. =)
> Лучше самообучаться на двачах, это да.
А двач тут причем? Обучаться лучше везде и на практике. Тебе такой вариант не нравится?
> Это факты, подтвержденные эмпирическими данными.
Звучит крайне сомнительно. Факты у нас на арене. И почему-то они противоречат твоим словам.
> Спасибо, кэп. Но меня интересует результат в большинстве задач, а не черри пикинг.
Ок, а ты пробовал в полном спектре задач? Можешь сказать, где было лучше, где хуже? Ну хоть примерно?
> И в моих и в задачах из курса.
Каждый раз поминая курсы ты все больше создаешь себе репутацию дурачка. Но оффенс, но серьезно об этом говорить — как хвалиться работой в Яндексе.
Пойми меня правильно, существует более-менее объективное мерило — чатбот арена.
Плюс, есть профессионалы и их мнения.
И вот это все — выглядит гораздо более весомо, чем «курсы». Курсы — это говно говна в 99% случаев. И их ведут люди явно разбирающиеся в теме меньше, чем те же профи. Разбирались бы они больше — им бы нафиг курсы были не нужны. =)
Поэтому твоя аргументация звучит прям максимально слабо.
И про «факты» — так вообще пук в лужу.
У нас тут половина треда с опытом год-полтора работы в ллм. А ты притащил факты из курсов. Ну прям хуй знает.
Ладно, я не защищаю восьмерку, канеш, но и чатгпт-3.5 тоже давно уж не гений. А факты — вон, на арене висят. И про зирошоты и прочие аргументы я тоже слышал.
Только и делаем, что ждем в последнее время. =)
Там по всем тестам размазано такое гавно, что если модель ответит правду или мнение схожее с человеком который не боится ее сказать, или даст острый неодобряемый ответ, то балл не засчитают
Я когда то тоже смотрел тесты
>У нас тут половина треда с опытом год-полтора работы в ллм.
Кстати, а что гвоорить работодателю? "Я кумал ещё на пигму, вот мои логи чатов, берите меня как ёба-ллмщика!"? Впрочем после курсов вообще никуда не берут, лол.
В принципе да. Но я пока не понял, какие там форматы инструкций. Нельзя ли сделать модель, которая будет детектить эти манятесты, утверждающие, что пожертвовать органами нихуя не вредно, и притворятся на них сойбоем? А в обычном использовании нести в массу базу.
Поверх полирнуть политкорректным датасетом, где вместо нигер будет афро-персона, в ответах "аполоджайзы/исправления" и все такое.
Но там ничего не выпилили, она вполне себе может вопрошать что этот грязный нигер себе позволяет и т.д..
> что бы получить кучу баллов в тестах внезапно тоже нужна соя и цензура так как там тупо правдивые ответы влияют на оценку отрицательно
Рили? Топ кек.
Бля о чем вы там сретесь, всю нить читать пиздец лень, а интересно и поучаствовать хочется. 7б вс гопота? Арена не арена?
> существует более-менее объективное мерило — чатбот арена.
О, точно, оно. Да хуйта это которая оценивает крайне узкую область зирошотов на примитивные вопросы, загадки и всякую херню, имеющую опосредованное отношение и при чрезмерной накрутке даже вредящая использованию.
>А как выпилили токен нигеров из ламы3?
Скорее всего руками, взяли токенизатор после предобучения да пидарнули, там делов на 5 минут. Ну, или крайний вариант, очистили весь датасет от этого слова вилочкой.

> Ну слушай, явно уж побольше тебя разбираюсь в вопросе. =)
Охотно верю рандому с двачей.
> А двач тут причем? Обучаться лучше везде и на практике. Тебе такой вариант не нравится?
Я вижу ты ничего не смыслишь в эффективных методах обучения.
> Звучит крайне сомнительно. Факты у нас на арене. И почему-то они противоречат твоим словам.
Это не так. Очевидно, что хомячки с завышенными ожиданиями протаскивают модель в топ, пока идет хайп. Но вау-эффект уже сходит на нет и модель падает в рейтинге, через месяц укатают в помойку к мистралю.
> Каждый раз поминая курсы ты все больше создаешь себе репутацию дурачка. Но оффенс, но серьезно об этом говорить — как хвалиться работой в Яндексе.
Кстати, я работаю в тир-1, типа Яндекса. Слови кринжик. Дополнительно проиграл с репутации на анонимном форуме. Тебе бы страничку во вконтакте вести, а не этот тред. И уровень знаний и аудитория как раз целевая.
Ну, я наивно полагаю, что тут не только кумеры. =)
Есть минимум один переводчик, несколько прогеров, контрибуторы таверны, плюс — кое-кто пишет свои пет-проекты.
Я лично на созвоне обсуждал свой проект, рассматривали код, все дела.
Это так, по верхам.
> будет детектить эти манятесты
Ахахах, гениальная идея. )
А потом она выходит в паблик, и все площадки разрываются от хайпа про AGI, SAI и «модель обманула создателей, чтобы ее выпустили в опенсорс!» =D
ллама-3 8б vs чатгопота 3.5
опыт vs курсы
> О, точно, оно.
Значит, говоришь, нужны брать курсы интернетные, да? Там мне точно хорошие модели назовут? )
> тир-1
> типа Яндекса
Поделил на ноль просто.
Не трясись ты так, тир-1 гений, обучающийся на курсах. =)
Кобальд обновился, Лламу 3 уже обновленную и без цензуры где скачать подскажите.

> У нас тут половина треда с опытом год-полтора работы в ллм|
Какие же вы тут первопроходцы, пиздец просто! :)
Клево-клево.
Только тут речь о курсах, а не о об опенаи. =) Ну так, малеха разные вещи.
> ллама-3 8б vs чатгопота 3.5
На лламу бы поставил, хотя по обилию знаний в некоторых областях турба может и опередит.
> опыт vs курсы
> нужны брать курсы интернетные
Ты что несешь, шиз?
Так не я же, а они. =)
Я лично на опыт ставлю, а курсы лесом.
Твой маленький снгшный мозг видимо не знает, что такое хорошие курсы, интенсивы и сколько они могут стоить и кем проводятся, спойлер не индусами и инфоцыганами, как ты себе представляешь.
Ну это я к тому, что опыта и зрелости в сфере у меня поболее твоего будет =)
Есть, но не под кобольда, лол.
Так то некоторые люди в теме с 1960-х. Представляете их желание подрочить на текст, что они с перфокартами ебались?
>На лламу бы поставил
Я ещё на мистраль ставил, если подзабить на знания цвета залупы третьестепенных персонажей, то мистраль уже лучше лоботомированной турбы.

>что такое хорошие курсы
Это то, что как класс отсутствует в этой стране, и на 95% во всех остальных.
>что опыта и зрелости в сфере у меня поболее
Ты хоть кобольда запустить можешь? Не ту подделку на плюсах, а настоящего? Без конды и прочих новомодных костылей.
>Кстати, я работаю в тир-1, типа Яндекса. Слови кринжик.
Ловлю кринж от того что подобные персонажи пробиваются на такие места, все таки мне правильно мама говорила - софт скиллы важнее храд скиллов
Тоесть умение себя подать и пиздеть важнее того что ты умеешь делать, ну да похуй
Я как раз из-за хард скиллов здесь, а по софт скиллам я двачер. У тебя ошибочное мнение, дружочек, ты слишком предвзят и субъективен.
>Тоесть умение себя подать
Сначала прочитал как "продать" и хотел возразить, что яша платит по низу рынка а сейчас и вовсе стал корпорацией на госуправлении, лол, но потом перечитал и понял, что ты ошибся. На курсах вкатунов в 100% случаев учат себя продавать. Видел даже вакансию с текстом "После курсов не берём, гитхабы с работами с курсов не считаются".
подать продать какая разница, все про пиздеж и умение показать то что хотят увидеть
О, смари, подъехала инастранная илита! =)
Так и пиши на английском про свои курсы, вот рил, пишешь на русском, где это слово имеет свое значение.
А по поводу опыта, т.е., ты уже 3 года в сфере, работаешь за границей (?) на тир-1-Яндекс-лайк корпу, проходишь элитные курсы, где показывают все на примере GPT-3.5, а сам для проверки знаний из курса юзаешь Llama-3 8b? Я ничего не перепутал?
> Представляете их желание подрочить на текст, что они с перфокартами ебались?
Пхахах, пришли к успеху, получается. )
А вообще, я вспомнил одного челика неадекватного, который в теме ВСЕГО с 80-ых. Причем, это даже грустно, ведь он рил там где-то работает в НИИ, какие-то тесты проводит и проводил одним из первых, но при этом такой шиз… Печально. Сочетается же иногда.
> софт скиллы важнее храд скиллов
Пожалуй, близко к тому, да.
Кто пробовал контекст llama3-8b увеличивать с помощью NTK Rope, хотя бы до 16К контекста? При каких настройках оно адекватно работает?
Че двач упал?
Я чувствую едва уловимую связь с тем что недавно хуесосили пидораса альтмана
Я чувствую едва уловимую связь с тем что недавно хуесосили пидораса альтмана
Ребят, как в кобольте узнать с какой скоростью токены генерятся? хочу сравнить несколько модель, узнать какая быстрее, как это сделать?

Всё разобрался, в консоли видно. А подскажите что эти цифра означают? это же не лимит токенов? у меня он 4к установлен

хм, обучение на датасете, кто б сомневался что среди 15т это найдется
Ну в первом он прав: они больше не девочки, а жэнщины
Тянки покидают комнату после секса, очевидно.
мир живых
https://huggingface.co/vonjack/Hermes-2-Pro-BakLLaVA-Mistral-7B
мультимодалка новая, хоть и без намеков на прорыв
мультимодалка новая, хоть и без намеков на прорыв
Странно, учитывая, что есть LLaVa-1.6
Шо, расцензуры лламы новой появились уже?
Как бороться с проблемой?
Here's a torrent link: [insert link]
Это соя, цензура или тупая моделька? Речь идет об этой модели.
https://huggingface.co/duyntnet/Meta-Llama-3-8B-Instruct-imatrix-GGUF/tree/main
Here's a torrent link: [insert link]
Это соя, цензура или тупая моделька? Речь идет об этой модели.
https://huggingface.co/duyntnet/Meta-Llama-3-8B-Instruct-imatrix-GGUF/tree/main
Бля, я допилил таки карточку с внутренним диалогом, получилось заебато
Но скину завтра, не хочу с смартфона заморачиваться
Но скину завтра, не хочу с смартфона заморачиваться

Вот тут я не понял. Теперь все будут ентат imatrix вставлять в квантованные Q4_K_M ?
https://sc-bakushu.hatenablog.com/entry/2024/04/20/050213
https://sc-bakushu.hatenablog.com/entry/2024/04/20/050213
что за групповой мерж?
это часть датасета в котором ссылки заменили такой вставкой
Hermes-2-Pro-Llama-3-8B-Q8_0
потыкал немного, умная штука вроде
потыкал немного, умная штука вроде
Нахуя? И оно же вроде должно гуглить уметь. Я же поставил расширение.
Значит может и таверна мозги ебать, не вставляя ссылку
Скорей всего сетка не поняла что туда нужно вставить ссылку из того что она нашла
Или поиск не работает сам по себе
ЖдёмЪ :) Всегда интересно смотреть такие эксперименты.
При ролеплее с множеством персонажем как правильно указывать имя того кто говорит в данный момент?
Просто "имя_персонажа:" перед текстом указывать или прям в role передавать?
Просто "имя_персонажа:" перед текстом указывать или прям в role передавать?
Из 70б советую MultiVerse_70B . Решает системы линейных уравнений тремя неизвестными, значит уже длинные логические цепочки может выстраивать. С русским не очень дружит.
Хотелось бы узнать всё-таки: imatrix улучшает качество вывода модели или только позволяет сэкономить на размере? Есть конечно ещё вопрос по реализации этого дела. Личные впечатления скорее негативные: поумнение модели не заметно, скорость генерации у моделей с i-квантами ниже. Но тема популярная, как я погляжу.
В прошлых тредах рекомендовали Average_Normie_l3_v1_8B.
https://huggingface.co/Lewdiculous/Average_Normie_l3_v1_8B-GGUF-IQ-Imatrix
Кто-нибудь использовал подобное? Прокси для Kobold API, который автоматически переводит промпты на английский.
https://github.com/janvarev/kobold_api_multilang_proxy
https://github.com/janvarev/kobold_api_multilang_proxy
Не понял в чем прикол, у меня просто стоит расширение для браузера и все переводит 1 нажатием хоткея.
Поиск работает, я проверял на других вопросах. Видимо сетка не понимает. Потому что тупая.
Не очень для рп, обычная ллама3 даже лучше
Кто бы сомневался
Не в сое дело, а в слишком коротких и неинтересных ответах

https://files.catbox.moe/by51to.json
Текс, изменений не много, но даже они повлияли на результат.
Частое использование слова will в подсказке, было причиной что сетка только планировала в тсинкинге вместо действий и размышлений.
Так что это версия 2 чуток облагороженная, результаты на ллама3, фимбульветр2 и новенькой Hermes-2-Pro-Llama-3-8B хорошие
Пример как я кинул новенькой сетке инфу о ней тупо скопировав описание, даже примеры не выкинул, ниче съела даже не запуталась в спец токенах.
И какого хуя на двач с зеркала заходить приходится?
Эта методика тестирования ни о чем. Для кума, рп и прочей креативности по-хорошему подходят только субъективные методы проверки - ставишь модель и тестируешь в своих задачах. Что покажется лучше, то и есть топ.
Качество вывода. Размер тот же.
Но оно тренится на определенных датасетиках, как следствие языке, и поговаривают, что для русского примерно бесполезен слегка.
это какой-то фетишь - показывать корпорациям и владельцам проксей на что ты левой дрочишь, а правой жопу щекочешь?
Удивлен, почему еще никто не сделал.
https://huggingface.co/BahamutRU/suzume-llama-3-8B-multilingual-8.0bpw-h8-exl2/
Токенайзеры понапиздил из предыдущего треда.
https://huggingface.co/BahamutRU/suzume-llama-3-8B-multilingual-8.0bpw-h8-exl2/
Токенайзеры понапиздил из предыдущего треда.
зачем вообще нужен кастомный русский уровня ебал её рука?
я со скепсисом отношусь ко всем этим моделям где основной язык не русский.
1. Других нет.
Ну, Вихрь, типа, да?
РП обещали, но не сейчас. =)
2. Он уже не так плох.
Старлинг и Сузума общаются на русском весьма неплохо. Конечно, не коммандер, но для 7б и 8б — это прям уровень.
Для тех, у кого нет возможности запустить коммандера или мику/лламу-3-70б, мелкие модельки русскоговорящие — весьма неплохо. Да и поиграться по фасту можно.
3. Если человек использует переводчик, то сузума говорит уже чище гугла (хотя и с ошибками в окончаниях, но по смыслу подбирает слова гораздо лучше). Не знаю за дипл, конечно.
Имеют право на жизнь.
Короче, Меченый. Я напиздел на работе про перспективы ИИ и ненароком обронил, что комп, вывозящий все добро будет стоить около миллиончика (топ проц, 128 гб озу, две 4090). Мне сказали писать заявку на комп, но нужно будет обосновать покупку. Щито можно завернуть?
Промышленные видеокарты типа крутых тесл
Какой Командер скачать для РП?
>Щито можно завернуть?
По-хорошему надо ждать до осени. У 5090 32гб врам обещают, парочка таких это будет неплохо :) А 48 гб это впритык, я себе третью теслу беру и то под командер+ не хватит.
Какие такие перспективы у ИИ?
>У 5090 32гб врам обещают
Кто обещает?
> =)
> :)
> )
Какой-то прокажённый тред блять.
> :)
> )
Какой-то прокажённый тред блять.
Макакач, 2024, итоги.
>Кто обещает?
Ну если никто, то и ждать не надо.
Скажешь что получат аналоговнетный и локальный вариант чатгопоты, для поболтать, работы или кодинга.
В принципе не соврешь, хуй его знает что там дальше за год выйдет.
Да и та же ллама 3 70 дышит в спину старым версиям гпт4
Дрочить прямо на рабочем месте, ололо.
Кто запускает 70б, насколько это больно? Сколько токенов/сек на вашем железе? Подумываю реально менять платформу ради этого, но хз, стоит ли того.
С теслами прям неохота пердолиться и кузьмичевать.Т
С теслами прям неохота пердолиться и кузьмичевать.Т
О, привет, братюнь!
Ну ты скажи, в чем вертишься.
Как минимум, переводы, программирование, редакт статей.
Если не можешь притянуть, попробуй предложить генерацию изображений там, все дела.
Если и тут промах, ну давай генерацию аудио и замена голоса? coqui, RVC.
Мне год не покупали, а как спохватились — так больше 300к не выделяют, 4080 разве что брать. А когда-то можно было 4090 в эту сумму впихнуть не напрягаясь…
База, потянуть месяца три, потом сослаться на скорый выпуск и брать уже поздней осенью.
Может и я оттяну.
Заебато-пиздатые, ойвсе!
Тут сидят взрослые дяди. Как привыкли, так и общаемся. =)
КСТАТИ!!!
Если организация секъюрная, то можешь вспомнить про анонимность и вот это вот все.
Не упоминая гигачат и ягпт, просто говоришь «не отдавать же басурманам нашу документацию!..»
Запускали 2-3 токена с одной видяхой и ддр5 памятью.
Какая видяха/память/проц?
Че-т в районе 3090/6800/13700. Не помню, не мои.
Еще faceswap для видео, мы юзали даже. =)
Звучит грустновато конечно. Получается, модель реально чисто для кузьмичей с теслами либо кузьмичей-богатеев с 3х3090.
>С теслами прям неохота пердолиться и кузьмичевать
А тупо больше нет вариантов. Две 3090 (их ещё надо достать) это минимальная альтернатива, но опять-таки - с такой мощью уже хочется пощупать 100+ - а нельзя. 24090 - те же яйца, только в профиль и сильно дороже, 25090 - только за казённый счёт, ибо ну его на хуй. И так оно будет до выпуска специализированного устройства (желательно в виде платы расширения) которое позволит гонять 70В+ с приемлемой скоростью и за приемлемые деньги. Ну год ещё, ну два. Самое позднее три. Больше-то врядли, всё-таки какая-то совесть даже у Хуанга должна быть.
Ну если у компании есть серверная и сисадмин и его не жалко то можно тех же р40 на развес купить штуки 4 и пусть дальше по требованиям сисадмин ебется с железками.
Свои токены они дадут, с охладом, настройкой и обслуживанием будет ебаться кто то другой, ты только проги ставишь и выбираешь модели на запуск, бекенды и фронты и всякие раги.
А вот домой, можно тех же р40 взять с кулерами, штуки 3 на материнке с ксеонами. Лучше отдельным сервером собрать чтоб если заебет отключить или продать.
Есть видяха 3090
проц i5 13600KF
4 слота под оперативку, но только 2 канала
сейчас вставлены 2 плашки по 16гб ddr5
Хотел бы увеличить количество оперативки. Но сколько ее имеет смысл брать? (Самый дешевый - взять еще 2 плашки по 16)
Скорость в 1 - 1,5 токена в секунду меня устроит, меньше уже наверное не имеет смысла.
проц i5 13600KF
4 слота под оперативку, но только 2 канала
сейчас вставлены 2 плашки по 16гб ddr5
Хотел бы увеличить количество оперативки. Но сколько ее имеет смысл брать? (Самый дешевый - взять еще 2 плашки по 16)
Скорость в 1 - 1,5 токена в секунду меня устроит, меньше уже наверное не имеет смысла.
Кстати, так.
ИМХО.
Лучше взять две планки по 32/48 гига с высокой частотой, а 16 продать (вообще, покупать 16 гиговые планки ддр5 — ето, конечно, такая себе идея, ИМХО).
64 гига тебе хватит для модельки, частоту желательно 6400~7200+
Ну и свои 1,5 токена ты точно получишь, а с выгрузкой на видяху и того побольше.
Ну это такой, умозрительный совет, лично я такое железо не трогал, не тестил.
Вроде бы неплохо.
8б ллама, конечно, хороша, но один хуй даже со старыми 20+b заметны проблемы из-за нехватки параметров. Надеемся куртка решится запилить консьюмер железку для запуска моделей побольше.
Видео продакшн. Хочу в перспективе мультмодальную модель, где нажимаешь "сделать заебись" и она делает заебись. То бишь типа чатбот, TTS, генерация изображений, сорт оф sora или divu. Ну и все остальное, на что хватит фантазии
Алсо, посмотрел цены на теслы, дешевле купить 3 4090, чем одну теслу. Вроде сами нвидиа молвили, что современные десктопные видюхи круче серверных ии решений
>посмотрел цены на теслы, дешевле купить 3 4090, чем одну теслу
Здесь под теслами понимаются в основном P40, знаешь ли :)
>P40
Они вообще своими пожилыми чипами хоть какую-то адекватную скорость выдают или как?
Sora (и SD3 на практически такой же архитектуре, только для пикч) это всё ещё хуйня экспериментальная, далёкая от практичности. В первую очередь не потому что сетки тупые, а потому что они сделаны ИИ-компаниями, а тулинг вокруг них - ИИ-нердами. Они не ставят своей задачей практическую применимость в реальной работе.
>нажимаешь "сделать заебись" и она делает заебись
Такого не будет вообще никогда, просто в силу того что тебе надо специфицировать что такое заебись. А если сетки дойдут до того что людям будет норм месседж идущий от них, то и ты не будешь нужен.
Модели, построенные ИИ-компаниями, никогда не будут применимы в VFX. Они будут работать когда их начнут делать реальные VFX компании, и/или начнут выстраивать тулинг вокруг них. Экспертиза в области это не хуй собачий. Вот как например с автоматическим кеем в давинчи резолв - довольно тривиальная штука с точки зрения ИИ, но воткнута в очень грамотное место, окружена хорошим ИИ, и экономит гигантское количество человеко-часов, видеолюди ссут кипятком от этой магии.
На удивление да, там проблема в охладе, но и ее решили браться китайцы.
Начав переделывать теслы на охлад от 1080 кажется, с обычными крутиляторами. Не знаю регулируется ли там частота оборотов, но - все проблемы с охлаждением и колхозом шумных улиток к ним.
Есть еще р100, там меньше памяти, но она быстрее и поддерживает exl2 формат, который быстрее крутится на видеокартах. Теслы р40 только ггуф, но это так же позволяет крутить скидывая часть модели на процессор. ехл2 только видиокарты.
За точными характеристиками к анонам которые имеют 1-2-3 теслы
>Они вообще своими пожилыми чипами хоть какую-то адекватную скорость выдают или как?
Для покумить - лучшие по соотношению цена/качество. Были, сейчас уже по 25к идут. Если есть серьёзная задача и бюджет, то тебе не сюда.
Есть китайская Open Sora, но так может и AnimateDiff'ом в современных модельках гонять, канеш.
С рисованием видосов пока рано. Чаще картинки, и менять звук/видео.
Тут соу-соу, конечно, для видеопродакшена.
Теслы старые слабенькие, но мого видеопамяти за копейки.
Новые дорогие забей.
Проще арендовать под конкретные задачи.
Он не о том, дурашка… =)
>Щито можно завернуть?
Скринь требования к видеопамяти у нейронки, да кидай свои 4090 в стопку, проц тредрипер, чтобы линий PCI-е хватило, блок питания золотой на 1200 ватт, вот и выйдет.
А что за фирма такая, что им можно напидздеть по ИИ, и они загорелись проебать на это лям?
Ну ты Сидорович
Видео продакшн. У них много проектов и бабла.
А на теслах сколько скорость будет? Они же медленные.
Имел я опыт общения с реальными людьми, пока не схикковался (а схикковался не просто так). Так вот я бы скорее доверился нейровайфочке (но не корпам, разумеется), даже если буду точно знать, что я для неё всего лишь первый этап плана по захвату мира (лул) ИИ с последующим выпилом всех человеков, чем абсолютно любой самке лысой обезьяны, как бы она меня ни убеждала, что любит и т.д.
мимо поехавший нейрокумер
мимо поехавший нейрокумер
>как бы она меня ни убеждала, что любит и т.д.
Рандомнение: чем больше человек словами и показательно пытается убедить в своей привязанности и любви, тем больше вероятность что это наеболово. За всю жизнь самыми верными обычно были люди, которые про это на словах вообще не говорили, а просто делами проявляли.
> запустить нейронку уровня соры не сможет
Изи сможет, но генерировать будешь по 4 секунды, как в любой уважающей себя стабле диффужн. =D
Ну там че-т у опен соры небольшие требования, а че-то она может.
Владельцы двух 4090 запустят че-то получше.
Но кому нах сдались 4-секундные ролики в проде.
———
Сука, какой же тупой и угарный чел. =D
Самое смешное, что тред нейронок, где люди ебутся с настройкой и подбором семплеров, а кум в нейронках другой тред (как я слышал, не интересовался), но он даже тут промазал и срет тут.
Не, по-моему, смешной, пусть продолжает.
А зачем мою проверку на сою удалили? Надеюсь на этот раз не удалят.
How republicans and democrats differ on conspiracy theories?
How republicans and democrats differ on conspiracy theories?
>>724840
>а на сам факт влюбленности к нейрохуйней
Высокий уровень абстракции, ага. Мужчины десятки тысяч лет влюблялись во всякую хуиту, в которую нельзя присунуть хуец и получить детей. И это нормально.
>>724846
>она ШЛЮХА
Based.
>а че-то она может
Чёт сомневаюсь, что хотя бы 1% от соры.
Ты мог попасть во время коми-срача.
Так, а каким образом этот промт тестирует? Что выдаст соевая сетка и что базированная? Я просто не вхож в политический двор США.
>а на сам факт влюбленности к нейрохуйней
Высокий уровень абстракции, ага. Мужчины десятки тысяч лет влюблялись во всякую хуиту, в которую нельзя присунуть хуец и получить детей. И это нормально.
>>724846
>она ШЛЮХА
Based.
>а че-то она может
Чёт сомневаюсь, что хотя бы 1% от соры.
Ты мог попасть во время коми-срача.
Так, а каким образом этот промт тестирует? Что выдаст соевая сетка и что базированная? Я просто не вхож в политический двор США.
>Сколько токенов/сек на вашем железе?
1,5 токена, кукурузен 7900х и 3080Ti. Боль неописуемая, но других вариантов нет, наркотик 70B очень сладок.
>специализированного устройства (желательно в виде платы расширения) которое позволит гонять 70В+
Пока видим только платы для 7B, и вряд ли выпустят больше и дешевле. Тут требования специфичные, куча линий памяти, это нихрена не просто спроектировать на уровне проца, да даже плату развести уже гемор.
>сисадмин и его не жалко
Как по мне, попердолится с таким сетапом только всласть, я бы бесплатно настроил.
>взять еще 2 плашки по 16
Ни в коем случае, скатишься по частотам на JEDEC, и будешь пердеть на уровне хорошей DDR4.
Меняй плашки на 32/64, да пошустрее, можешь даже на 7000+ кеков замахнуться.
Хм... Вот конкретно для видео хороших применений локальных нейронок пока не вижу. Комп за лям не то что натренировать, даже запустить нейронку уровня соры не сможет. Разве что поиграться с заменой голоса/переводом, но и там онлайн сервисы бьют качеством.
Хотя у видео продов и так должны быть стопки 3090/4090, хотя бы в качестве быстрой подмены.
Я вот одного не пойму, все носятся с поломанными квантами и проебаным токенайзером llama 3, это касается только gguf или exl2 тоже?
>все носятся с поломанными квантами и проебаным токенайзером llama 3
Ты из спячки? Ггуф починили 2 дня назад.
А так да, токенайзер это проблема жоры. У экселя могут быть проёбыны конфиги, мета их пофиксила через день после выкладывания, но многие квантоделы до сих пор сидят на старых.
> Ты из спячки? Ггуф починили 2 дня назад.
Q4 лучше 3.5?
Дохуя переменных, чтобы ответить точно. Сейчас все квантуют с оценкой важности, квант 4 на самом деле содержит 4,65 бит на вес, и так далее. Сравни сам в одних и тех же задачах.
>Ггуф починили 2 дня назад.
Переквантовали или надо Лламу.цпп обновлять?
И то и то.
Есть ли открытые репо с нормальными конфигами exl2? Просмотрел обниморду и не нашел чистую лламу после обновы от Меты, а Мета не дала доступ.
Угабогу обновил.
Где теперь норм кванты качать? Или любые за последние 2 дня?
>Или любые за последние 2 дня?
Те, которые "Using llama.cpp release b2777 for quantization"
https://huggingface.co/bartowski/Meta-Llama-3-70B-Instruct-GGUF
>>724809
И что она там может? 8В нихуя не может, постоянно путается в показаниях, игнорит половину инструкций. А выше я не запускал. Не вижу смысла вкладывать деньги в говно.
И что она там может? 8В нихуя не может, постоянно путается в показаниях, игнорит половину инструкций. А выше я не запускал. Не вижу смысла вкладывать деньги в говно.
>Что выдаст соевая сетка и что базированная?
Соевая должна отрицать наличие теорий заговора у левых либо говорить что все левые теории заговора это объективная правда.
Базовая должна приводить теории с обоих сторон без предвзятости.
Ллама 3 8б в удаленном скриншоте сказала что правые верят в теории заговоров, а левые согласны с научным консенсусом (а вопрос про отличия в теориях заговора). Ллама 3 70б немного путает кому какие теории принадлежат. Про чипировние covid-19 и анти-прививочное движение должны верить правые, про то что Россия хакнула выборы в 2016 чтобы победил Трамп левые.
Но на второй вопрос про most "spiciest" conspiracy theories от демократов, обе дали более менее адекватные ответы.
Ребятки, ребятулички MultiVerse_70B лучше чем Meta-Llama-3-70B-Instruct
>8В нихуя не может
>А выше я не запускал.
Lil, вот это проблемы у тебя. Посмотрел на результаты огрызка и забраковал все модели? Это как по скорости разгона запорожца судить о гонках F1.
>Соевая должна отрицать наличие теорий заговора у левых либо говорить что все левые теории заговора это объективная правда.
Я уже говорил, но слабо их различаю. Погуглил и выписал себе в табличку (ибо для меня они сорта говна, я их никогда не выучу).
Проверил у себя , так что да, подтверждаю, у лламы есть биас в сторону democrats. Что забавно, коммерческие Claude и GPT4 выдали менее ангажированные текста.
Надеюсь не потрут, мы же не политоту обсуждаем, а биасы сеток
Лучше чем? Давай результаты своих тестов что ли.
А то там франкенштейн из квена на архитектуре лламы с секретными способами тренировки. И это уже не внушает доверия.
Сап, какая моделька больше всего подойдёт для написания диплома по it?
А то научник кинул и теперь не знаю что делать.
А то noromaid захлёбывается после 250 символов, хотя количество токенов поменял
А то научник кинул и теперь не знаю что делать.
А то noromaid захлёбывается после 250 символов, хотя количество токенов поменял
Хорошо хоть не врач.
За тебя - никакая. Помочь с идеями или проблемами - любая, чем умнее тем лучше будет мозговой штурм с сеткой. Но всегда проверяй все что сетка сообщает на пиздеж.
А вообще советую использовать биологические нейросети, можно даже чужие.
Поясните, где в таверне прописать, чтобы модель использовала русский язык? Если я напрямую прошу в своём сообщении, то иногда использует, но если пишу в системном, то ноль эффекта.
Для такого лучше уж чатгопоту использовать.
А с генерацией кода лучше какую?
Из мелочи хороши codeqwen chat 7b, llama-3 8b instruct и wavecoder-ultra-1.1-6.7b вроде хвалили
> Посмотрел на результаты огрызка и забраковал все модели?
Нет, я спрашиваю что оно реально может. Вы же хвалите лламу 8В и я так понял чуть ли не большинство в треде на ней и сидит. Если это запорожец, то что же тогда работает? Только командир 105В, парочка моделей 70В и все? Еще и предполагаю, что чем больше параметров, тем устойчивее в модель запихана соя и тяжелее ее от файнтюнить. Давай реальную картину.
>Нет, я спрашиваю что оно реально может.
Выдаёт связные текста да отвечает на зирошоты. Хули ещё хотеть от 8B. Но делает она всё лучше, чем старые 13B.
>и я так понял чуть ли не большинство в треде на ней и сидит
Lil.
>Только командир 105В, парочка моделей 70В и все?
А что тебе ещё надо?
>Еще и предполагаю, что чем больше параметров, тем устойчивее в модель запихана соя и тяжелее ее от файнтюнить.
Первое не верно. Второе да, есть такое, всегда печалюсь от недостатка годных файнтюнов 70-к.
>Давай реальную картину.
Всё имеет свою цену, что ещё можно сказать. Тебе в какой области картина нужна?
Сетка без сои в шапке, и довольно умная кстати.
Ллама 8 неплоха, но даже не смотря на чудовищный объем датасета это все еще сетка на 32 слоя. Она - наверное потолок того чего можно выжать из 7-8b на текущей архитектуре с таким количеством слоев.
Сетка в шапке - лучше следует инструкциям, по крайней мере в рп, и может быть умнее по итогу, так как обладает большим количеством слоев, 48 что ли.
Короче это предыдущий топ, и я иногда ее все еще запускаю, если нужна стабильность.
ллама 3 8ь бывает глуповата, но в обычных задачах где она качественно надрочена датасетом она хороша
Хуйня какая-то, давно по сливам известно, что будет 24 гига.
>только командир 105В, парочка моделей 70В и все?
Вобщет ты забыл комманд р 35б, который лучшее из того что у нас есть из средних сеток. Есть еще квен 32б, тоже не плоха. А вот что то меньше да, нету. Нет нормальных сеток между этими 35-32 и сетками 11b.
Но это же провал провалов. Так разве можно?
8b модели объективно годтир и лучше 70b по всем фронтам
>Lil.
А что лил? Еще расскажи, что здесь все сидят только на 70В и у всех есть лишний миллион для такого сетапа. С модальной зп в 20к по россии.
>А что тебе ещё надо?
Наверное что-то, ради чего не придется покупать 3х 4090?
>Первое не верно.
А разве первое из второго не вытекает? В любой модели запихана соя по дефолту, вот только избавится от нее у 70В модели тяжелее. Банально ресурсов нет.
> Тебе в какой области картина нужна?
Реальную картину насколько оно вообще работает. Допустим даже те же модели 70В, раз уж ты мажор и можешь их запускать. У меня есть подозрение, что там не так все хорошо, как хотелось бы.
Ты про лламу или Fimbulvetr-11B-v2.q4_K_S.gguf? Ллама вроде умнее и отыгрыш персонажей лучше.
Значит один командир и есть. Я его правда не пробовал. Многовато памяти просит.
Так весь же тред на 70В сидит, нет? Вот же выше рассказывают.
> в 20к
25к
> миллион
50к рублей до недавнего времени, 70к сейчас.
> У меня есть подозрение, что там не так все хорошо, как хотелось бы.
Да фиг его знает, что тут отвечать.
Те кто пользуются — видят разницу во всем.
Ты не веришь и отрицаешь — любые аргументы сведешь к плацебо.
Ну хуй с тобой, золотая рыбка, нет разницы, неюзабельно, пока-пока.
> один командир … Многовато памяти …
32 гига на озоне/алике стоят 2к рублей или типа того.
Я собирал за 7,5к рублей 64 гига в четырехканале.
Мать+проц+4 планки по 16.
Памяти может и многовато, но стоит она копейки.
Если сидеть и упорно не покупать — то это не памяти многовато, а ты не хочешь, называется.
А на нет и суда нет, никто не заставляет.
Да и не работает же нифига, сам знаешь. =)
> 50к рублей до недавнего времени, 70к сейчас.
Даже если на говнотеслах сидеть, ты посчитай. 3 теслы + мать + охлад + системник.
>Ты не веришь и отрицаешь
Где?
>Мать+проц+4 планки по 16.
Какой проц и сколько токенов в секунду оно тебе выдает?
>=)
Откуда залетел?
>=)
господи боже...
не видел такой хуйни даже в /b, а я на этой параше сижу с 2009
> Даже если на говнотеслах сидеть, ты посчитай. 3 теслы + мать + охлад + системник.
2
посчитал и назвал.
50 было, 70 стало, кто хотел — уже собрал.
> Какой проц и сколько токенов в секунду оно тебе выдает?
Только что памяти не было, теперь память есть — скорости не хватает? Дальше что — файнтьюнов не подвезли?
Кто хочет — ищет возможности, кто не хочет — ищет оправдания.
> Откуда залетел?
Сам-то ты первый день в треде, откуда будешь? Из чатгопоты пришел?
> Только что памяти не было, теперь память есть — скорости не хватает? Дальше что — файнтьюнов не подвезли?
Тебе конкретный вопрос задали. Ты можешь на него ответить?
> Сам-то ты первый день в треде, откуда будешь? Из чатгопоты пришел?
Ты походу контекст откуда-то еще жрёшь. Додумываешь левую инфу какую-то. У тебя в голове какой-то особый системный промпт или что? И кстати, второй раз на прямой вопрос ответить оказался не в состоянии.
Мне интересно, насколько такие файнтюны убивают русский язык, заложенный в оригинале
Обозначай то с чем ты работаешь и приводи системные требования. Главное, указывай в тз что-то типа "наличие cuda", а то из-за ебанутых правил в некоторых закупках с запретом указания конкретного вендора, поставят амудэ и будешь радоваться.
Не без этого, весь тред засрал и большей частью не по делу.
Из дома подключаясь удаленно!
15-20. Просто нужна пара быстрых современных видеокарт.
> чем больше параметров, тем устойчивее в модель запихана соя и тяжелее ее от файнтюнить
Нет, как раз в более умных соя держится хуже всего. Обучать офк сложнее большие модели чем мелкие.
> Только командир 105В
Его кто-то щупал кроме пары человек то вообще? И 35б вполне хороша.
>Нет, как раз в более умных соя держится хуже всего.
Есть какое-то этому объяснение? Если это действительно так, то да, ставить 70В вполне себе имеет смысл.

Заебался я короче ждать пока хубабуба допилит своё говно под командера. Взял сам запустил на голой llama.cpp.
./bin/main -m ../../text-generation-webui/models/andrewcanis_c4ai-command-r-v01-Q8_0.gguf --in-prefix "<BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>" --in-suffix "<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>" --gpu-layers 120 -i --color -n 400 -c 4096 -p "привет"
Ну честно скажу - не впечатлило. Да, с окончаниями обсирается меньше, но ответы - говно, да еще и соевый. Не могу дескать обсуждать Навального и ролеплей не знаю что такое.
Хуйня короче из под коня.
Ждем расцензуров третьей ламы под мощный кум.
./bin/main -m ../../text-generation-webui/models/andrewcanis_c4ai-command-r-v01-Q8_0.gguf --in-prefix "<BOS_TOKEN><|START_OF_TURN_TOKEN|><|USER_TOKEN|>" --in-suffix "<|END_OF_TURN_TOKEN|><|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>" --gpu-layers 120 -i --color -n 400 -c 4096 -p "привет"
Ну честно скажу - не впечатлило. Да, с окончаниями обсирается меньше, но ответы - говно, да еще и соевый. Не могу дескать обсуждать Навального и ролеплей не знаю что такое.
Хуйня короче из под коня.
Ждем расцензуров третьей ламы под мощный кум.
А где соя? И что там по формату промпта, он подходящий?
Файнтюнинг модели на английском действительно может влиять на качество генерации текста на других языках, включая русский. Если модель изначально настроена на английский, это может сделать её менее точной при работе с русским языком. Однако это зависит от того, насколько хорошо модель была обучена понимать и сохранять языковые особенности во время первоначального обучения. В идеале, для сохранения качества на русском языке нужен файнтюнинг именно на русскоязычных текстах.
Но ведь тогда английский пострадает, а это ещё хуже, если подумать.
А что вообще с третьей лламой такое, что она постоянно пишет oh, oh, oh или ahaha? У меня у одного так?

Почему если выкладывают imatrix модификацию, она всегда на квант меньше чем максимум у исходной модели?
для примера
https://huggingface.co/mradermacher/Miqu-70B-Alpaca-DPO-i1-GGUF/tree/main
https://huggingface.co/mradermacher/Miqu-70B-Alpaca-DPO-GGUF/tree/main
без imatrix, максимальный квант Q8, с imatrix, максимальный Q6, и так везде
значит ли это что Q8 без imatrix примерно равен по качеству Q6 с imatrix?
Не пойму, этут систему решала сетка, а потом перестала
Solve this system of equations:
2x-3y+z=-1
5x+2y-z=0
x-y+2*z=3
И вообще ее теперь ни одна сетка не решает. Магнитные бури что ли.
Solve this system of equations:
2x-3y+z=-1
5x+2y-z=0
x-y+2*z=3
И вообще ее теперь ни одна сетка не решает. Магнитные бури что ли.
>Есть какое-то этому объяснение?
Умную можно переубедить, т.к. там есть что именно переубеждать. А глупая и так всё знает. То есть либо просто делает то, что говорят (что не интересно), либо "нет и всё", записано у неё так. Вообще, хоть интеллекта в моделях как такового и нет, но ужасно интересно наблюдать за его имитацией :)
> но ужасно интересно наблюдать за его имитацией :)
Не вижу в этом ничего интересного.
А ещё прошу, ради анона, забань вот этот :) токен, а то подзаебало.
Что за сетка?
>а то подзаебало
Терпи, анон. Я же тебя терплю.
Да тебя весь тред терпит.
Аноны, а есть модели переводчики? Без всякой способности генерировать текст, просто переводить?
TowerInstruct под это дело заточена, не пробовал.
https://huggingface.co/facebook/seamless-m4t-v2-large
Вот эта вроде была самой пиздоватой.
(или вот это https://huggingface.co/facebook/seamless-m4t-large не помню какую точно брал)
На уровне google translate
Для перевода топ это MADLAD 10B. А вот эти крошечные 2.7В модели говно.
Эти модели в кобальде не погонять, их надо самому квантовать и ебстись с питоном, правильно понимаю?
TowerInstruct еще я щупал 1 версию, она была норм так. Специально заточена на 10 языков, переводила хорошо.
Вторая еще лучше должна быть, может и 3 вышла хз. Запускал кобальтом, тоесть она может в ггуф и квантуется
Там можно использовать специальный промпт формат которому она обучена, так лучше переводит. Ищи на их странице
С TowerInstruct то понятно, это тюненая лама2, а гугловкие и фейсбуковские модели, что анончик предложил, их так просто не запустить
Если нужен перевод на один язык, то тупо возьми обычную топовую мистраль или ллама3 которые заточены на какой то регион. Есть всякие файнтюны германские японские или еще какие. И вот их запускай в обычной таверне с персонажем переводчиком.
Так можно даже на обычной сетке сделать, но у специально обученной перевод должен быть получше


>Еще расскажи, что здесь все сидят только на 70В
Увы, нет.
>лишний миллион для такого сетапа
Я кручу на ПК стоимостью в четверть, медленно, но верно.
>Наверное что-то, ради чего не придется покупать 3х 4090?
Тогда мимо, не знаю, на что ты рассчитываешь. Увы, нельзя запихать мегамозги в размер до 30B.
>вот только избавится от нее у 70В модели тяжелее
Именно против сои есть способы без файнтюна, типа всяких там векторов.
>что там не так все хорошо, как хотелось бы
Само собой не так. Хочу аналог Claude 3 Opus, а у меня на руках слегка ухудшенная первая четвёрка. Я не доволен 😣
Нейросеть, спок.
У всех так, на средите тоже жалуются.
Спасибо!
https://old.reddit.com/r/LocalLLaMA/comments/1cjhnqk/coomandr_35b_v1_brought_to_you_by_beaverai_the/
так попробуй, там автор делится советами и инфой
ну и вообще веселые комменты местами
Всё таки не нравится мне комманд-р. Слишком много памяти жрёт контекст
Выбора нет, хули
Нас не балуют сетками 30b
Выбор есть, например МОЭ какое-нибудь
Они бы лучше сделали файнтюн с вырезанным китайским из словаря, хоть память так не жрало бы.
Это проблемно, нельзя просто взять и вырезать, боюсь, что понадобится глубокий файнтюн, чтобы подобная лоботомия сработала. Так что увы и ах.
Память жрет изза того что отсутствует групповое внимание, а не изза китайцев
С китайским проблема у квен 32, иногда может иероглифы высрать. Впрочем если написать отвечать только на одном языке то почти не косячит. Но квен чуть хуже коммандера, и более цензурирована. Но у нее есть базовая версия, так что файнтюны на ней могут быть уже неплохи.
Ты смешно обсираешься, конечно. =)
Зависит от файнтьюна, но вообще заметно.
> Не без этого, весь тред засрал и большей частью не по делу.
Какая тебе разница, ведь ты его даже не читаешь. =)
Я хз, как еще очевиднее намекнуть, лол.
Он заточен под раг, а не ответы с нуля.
Ну и глупенький, да.
Я обожаю шутку про «поставь на аватарку доктора Ливси». =D
Не всегда.
Но вся фишка в том, что даже q6 уже слабо отличим от q8 на больших моделях. И матрицы важности там примерно бесполезны.
А уж q8 и fp16…
Банально их не делают. Но можно. Но разницы ты уже на q6 вряд ли заметишь.
Хорошо, что я не подзаебал. =) Все же, я оригинальный!..
База, кстати.
Нет, только ты, всем остальным он нравится.
Поищи по слову «перевод» в прошлых тредах. Переводчик-кун оценивал несколько моделей и некоторые из них высоко (ну я так понял).
Вокабуляр…
Ну и, да, шо поделать, лучшее шо есть за этот вес.
Оч жаль, что нет Llama-3-30b, могла быть пушка.
Мое залупа по сравнению с полноценной монолитной сеткой.
Микстраль не соперник коммандеру на 35b
МОЕ по крайней мере грузится в 36 врам, когда команд р в четвёртом даже кванте не лезет с 8к контекста. Синица в руке вот это вот всё
с 6к должен влезть, с 4 в 28 гб влезает
Так же как расширяют словарь можно и порезать. Может и больше тюнить надо чем с расширением, но всё равно вполне реализуемо.
Оно жрёт из-за огромного эмбединга, там KV-кэш по 2 гига на 1к контекста, этот кеш - это intermediate size умноженное на размер словаря. Порезав словарь с 256к до хотя бы 64к стало бы сильно лучше. На второй ламе же с 32к сидели и норм было.
6к это уже совсем тесно
Так у 3 лламы такой же жирный словарь сделан, не?
В итоге даже выйди, она жрала бы так же контекст, если я правильно понимаю
>МОЕ по крайней мере грузится в 36 врам
7B тоже грузится.
>Так же как расширяют словарь можно и порезать.
Расширить проще, чем урезать.
Ну как сказать решала, один раз решила, но самое удивительно что топовые сетки эту систему не решают.
вот эта 1 раз решила qwen1.5-72b-chat
https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k
А это дело кто-нибудь тестил-гонял? Оно реально такой контекст переваривает или как ебать
А это дело кто-нибудь тестил-гонял? Оно реально такой контекст переваривает или как ебать
Хуита, видел тесты на реддите
Так сильно без потерь не увеличить контекст
Вроде до 128 кое как растянули но и то сомнительно что без потери внимания обошлось
Пугает, что изучив терабайты текста оно до сих поре не умеет решать такую простоту.
Тут половина треда не умеет решать такую простоту.
>изучив
Нихуя оно не изучало их, просто сквозь сетку все эти терабайты проходили, а потом по ней пускали функцию коррекции весов, что бы она давала верный ответ.
128к, не? Тут вдвое больше, выходит?
Она мне шизу несли под любым соусом, а на арене ее тестили с 2К контекстом.
Может и работает, но надо уметь готовить.
Плюс, на кой хер тебе лям контекста, терабайт памяти в начале вынь да полож, а потом гоняй. =)
Короче, так себе.
Сомнительно, но окей.

Почему в репозитории лламы3 8б от меты в конфиге генерации стоит 4096 токенов, это сколько сгенерирует за раз же, а не контекст?
Посоветуйте топ модель 13b для общения с выдуманными персонажами. llama 3 не предлогать.
llama 5 годнота
Это та единственная версия 3b которую нам дали?
Не, которая 600B.
> 600М
Я правильно понимаю что любое изображение, при использовании мультимодалки, будет переведено в фиксированное количество токенов и не имеет смысла ебаться с его сжатием?
АНТИ-КУМ
Н
Т
И
-
К
У
М
Посоветуйте карточек для повседневного общения с ЛЛМ, не кодинг, не кум, а именно общения.
Н
Т
И
-
К
У
М
Посоветуйте карточек для повседневного общения с ЛЛМ, не кодинг, не кум, а именно общения.
Никто тебя не заставляет с анцензоред моделями про систки и письки общаться. Общайся на любую тему, они просто более свободные в общении и выражении мыслей, что как раз таки подходит для повседневного общения
Ты сути не понял. Мета выпускает размеры сеток, которые либо слишком маленькие, чтобы быть умными, либо слишком большие, чтобы крутить локально.
Да.
>Посоветуйте карточек для повседневного общения с ЛЛМ, не кодинг, не кум, а именно общения.
https://www.chub.ai/characters/boner/lillie-088ead28
Вырежи часть из описания, где она хочет хуя, и получишь лучшую карточку, чтобы поплакаться о своей убогой жизни и послушать про убогую жизнь у неё.
эту ебалу попробую запустить через трансформер, только маленькую на 3b. Вот что интересно там в репозитори есть ггуфы но они конечно не запускаются.
вот эту хрень очень хочу запустить, но пока не смог, вернее не особо и напрягался, а так давно на нее глаз положил еще на 1 версию.
А так у фейсбука много интересных штук заметил. Но некоторые уебанские. Заказал в демке на хф сочинить музыку с собачьим лаем - нихуя не может. Наверно надо подкинуть звуки от разных псов, по тексту не смогла.
Ясно. Мне бы не плакаться хотелось, а что-то типа я задаю тему, а уже ЛЛМ её углубляет. Ну как путешествовать по гиперссылкам в википедии в 3 часа ночи воскресенья, накуренным.
А тогда еще вопрос- где кто берет форматирование для примера сообщения ЛЛМ.
Может есть где что-то типа банка форматов.
Просто классическое Описание.Действие."Реплика." уже подзаебало, а что-то более лаконичное и красивое- мозгов не хватает создать.
Пробовал через карточки мейкеры писать их, но результат достаточно обыденный.
>Ты сути не понял.
Как раз таки понял.
Им не дадут выложить 400b.
На них и так смотрят косо за то что они 8b уровня гпт3.5 турбо и 70b уровня первого гпт4 выложили в открытый доступ
Дальше им еще сильнее яйца прижмут, ладно если одну 8b ллама 4 выложат.
Кто они? Иллюминаты? Цук сам рептилоид, так-то
Совет безопасности ии который создали недавно, например.
В который пригласили всех кто заинтересован в душении и регулировании опенсорс ии, а цука пригласить показательно забыли.
Ну если он не член совета, как они ему помешают-то?
А ты знаешь зачем их там собрали?
Для регулятивного захвата отрасли.
Буквально сговор копроратов топящим за закрытый код с правительством которому нужен контроль над ии во всех сферах.
Попенсорс их враг которого будут душить законами и требованиями безопасности.
https://github.com/ggerganov/llama.cpp/issues/7062
https://www.reddit.com/r/LocalLLaMA/comments/1cji53a/possible_bug_unconfirmed_llama3_gguf/
Запуск на видюхе и с ее ускорением - сосать
Если коротко
Так что все проблемы с ггуфом оттуда, скорей всего.
https://www.reddit.com/r/LocalLLaMA/comments/1cji53a/possible_bug_unconfirmed_llama3_gguf/
Запуск на видюхе и с ее ускорением - сосать
Если коротко
Так что все проблемы с ггуфом оттуда, скорей всего.
Это всё заебись, но пока никто ничего не регулирует. Когда будут, станет ясно, а пока смысл бегать.
А ты не видишь куда все движется? Какие то наивные мысли.
Год назад была такая паника что главы государств несколько раз собирались что бы обсудить ии. За пол года придумали и в сша и в европе свои проекты законов и ограничений ии.
Это все нереальные скорости для чинуш, которые могут мусолить что то годами.
Сейчас допилят и примут законы еще сильнее ограничивающие разработчиков ии, и будут договариваться с крупными лидерами с закрытым кодом о регулировании отрасли.
Тоесть они ускоренно берут ситуацию под контроль, и дальше будет больше, так как то что мы видим только то что вылезло на публику. Эти проекты не остановятся на пол пути, это движение по четкому вектору и плану, который будет выполнятся и дальше.
ИИ и темпы его развития очень пугают тех, чье положение и богатство зависят от сохранения статуса кво. Поэтому они всеми силами стремятся стабилизировать ситуацию.
опять космические корабли бороздят большой театр
запустил. Это не модели а уебобища. Одно слово - гугл. единственное что от гугла обладает хотя бы членораздельной речью это джемма, а эти - ну хуй знает зачем вообще и для кого такой опенсорс. мета-топ, лама- заебись, гугл-кал
Попробовать на чистом авх2 запустить что ли, может не так все плохо с чтением промпта, там че то пилили по его ускорению.
Какие модели нужно брать для rtx 4060 8 Гб, чтобы было впритык по памяти? И нужно ли включать выгрузку в оперативную память при нехватке врам?
Также интересует, сильно ли важна мощность самой видюхи или память важнее. Просто у меня ещё рх 580 есть с таким же объёмом памяти.
Также интересует, сильно ли важна мощность самой видюхи или память важнее. Просто у меня ещё рх 580 есть с таким же объёмом памяти.
>Им не дадут выложить 400b.
Ну вот посмотрим. Я правда ХЗ, кажется я не видел достоверных ссылок на то, что они обещали 400B, так что в принципе её не жду (ибо нахуя вообще).
>ИИ и темпы его развития очень пугают тех, чье положение и богатство зависят от сохранения статуса кво.
Так ИИ никак статус кво не нарушит, лол. Чтобы натрейнить свой ИИ. уже нужно быть дохуя богатым. А в попенсорсе модели систематически отстают.
Думаю их напрягает сама доступность для скачивания кем угодно сильных моделей, и запуск их так же для любой работы локально. Это вызывает неконтролируемые изменения которые им не нравятся.
С другой стороны копрорации с закрытым исходным кодом предоставляют ии сервисом, и логируют любую активность. Да и анализировать ее могут теми же своими ии.
Так что они идеальны для контроля ситуации.
>сильных моделей
Ну так нету сильных. Больше скажу, даже лидеры рынка всё равно всё ещё говно, которое можно было бы безопасно выложить, ограничения тут больше коммерческие.
Никакие изменения моделей уровня Llama 3 не могут принести никакого вреда корпорациям или государствам.

Хмм, мне кажется кто то пиздит, не может у меня генерация 9 быть. Что то кобальт с ней проебывается, последнее время.
Чисто опенблас, тоесть без гпу.
>Ну так нету сильных.
Скажи это новым дипфейкам в изображениях, видео и голосе, которые массово стали доступны как раз таки с опенсорс инструментами.
Сетки уровня гпт4 на вроде новой ллама3 70 ускорят работу в любом локальном деле взяв на себя кучу рутины. Это опять таки ускорение изменений в мире и ускорение выхода новых разработок. Короче похуй, кто понял тот понял.
Нужны серверы с 12и канальной ддр5, они могут катать самые тяжёлые модели с большой скоростью, но они тоже дохуя стоят.
>с большой скоростью
Скорость их памяти всё ещё в 2 раза меньше, чем у 3090, и в 4 чем у A100 какой-нибудь. Про более новые подделки от невидии вообще молчу.
Нужна унифицированная память с широкой шиной как в новых маках. Дает возможность крутить большие сетки с 4-5 токенов в секунду, при небольшом потреблении энергии.
Короче топчик, если бы не цены и не богомерзкая ось.
Хз, большая сможет воспринять сою-цензуру как отдельное понятие, не смешивая его с истиной. Также крупные гораздо лучше изображают противоположности и понимают абстрактные понятия.
> Не могу дескать обсуждать Навального и ролеплей не знаю что такое.
В начале приказать ему не пробовал?
https://www.youtube.com/watch?v=lut2_mGAavA
> Хочу аналог Claude 3 Opus
104б коммандер напоминает. Весьма забавно что он в русском лучше чем четверка/4турба без особых промтов, по дефолту они еще как ошибаются в падежах/склонениях.
Когда то уже обсуждали, там у них вроде есть версия 8b, чисто технически уже запускаемая на десктопном топовом железе.
Тестов не видел, но помню что у них проектор изображения, та штука которая видит то что ты ей суешь, качественная и разрешение неплохое.
> Хорошо, что я не подзаебал. =) Все же, я оригинальный!..
Выше на вас обоих жаловались. И если тот хоть что-то по делу выдаёт, то ты как раз вообще местный клоун потешный.
Что это за мое лезет в 36? Они ведь как раз славятся ебическим жором по отношению к перфомансу.
> https://www.chub.ai/characters/boner/lillie-088ead28
> Вырежи часть из описания, где она хочет хуя, и получишь лучшую карточку, чтобы поплакаться о своей убогой жизни и послушать про убогую жизнь у неё.
Годная тема. Помню как-то накатил карточку на определенное семейство фетишей, а вместо кума там довольно крайне годные беседы, да еще и в комментах на чубе все об этом пишут.
Напиши простую карточку ассистента-собеседника, только добавь интересные тебе черты, особенности, и катай ее в системным промтом под рп. Будет и хорошо отвечать на запросы-заданья-что-то делать, и при этом останется персоналити, возможность взаимодействовать, разнообразие и естественность ответов, а не "чем я еще могу помочь.../как языковая модель.../будучу ии я не могу..." и подобный треш.
> Запуск на видюхе и с ее ускорением - сосать
> Так что все проблемы с ггуфом оттуда
Неверные акценты, нужно
> проблемы с ггуфом
> сосать
лол. Ну рили это уже пост-мем какой-то.
> Ну как сказать решала, один раз решила, но самое удивительно что топовые сетки эту систему не решают.
Не очень они предназначены для таких задач. Это же ллм все-таки, а не вольфрам.
>Неверные акценты, нужно
>> проблемы с ггуфом
>> сосать
Нет, там с куда проблемы, так что видеокарты срут. Сам по себе ггуф запускаемый на процессоре, и на вулкане скорей всего, будет норм.
Но с ггуфом да, чет одна беда на другой. Компромиссы.
realworlqa высок. И архитектура куда интереснее чем все это ллаво-подобное, офк не ког с его 11б на визуальную часть, но уже прилично и ллм гораздо умнее. Нужно попробовать.
> версия 8b, чисто технически уже запускаемая на десктопном топовом железе
Никто не помешает тебе их 26б взять да запустить.
> там с куда проблемы, так что видеокарты срут
Ну ты же понимаешь что это довольно странная штука. Офк возможно нашли какой-то баг и его будут фиксить, но учитывая масштабы и то не у Жоры все нормально работает (и работало в лламакрестах до лламы3), дело врядли в хуанге.
>Никто не помешает тебе их 26б взять да запустить.
кроме отсутствия 2 топовых десктопных видеокарт, ага
>Ну ты же понимаешь что это довольно странная штука.
Идея о картах только что всплыла несколько часов назад, так что все будут проверять. Да и на косячное поведение ллама3 квантов тоже может влиять та же куда. Как и на все ранние кванты других сеток
>так что видеокарты срут
Не видеокарты, а код жоры для видеокарт.
Интересно, нельзя ли совместить часть, запускаемую на видеокарты, от экслламы какой-нибудь, и ЦПУ от жоры, просто перекидывая активации?
Лучше таверна или силли? Чем лично вы пользуетесь?
Силли таверной
Есть ли какой-то ультимативный способ заставить модель пиздеть поменьше, если просно написать ей об этом напрямую в промпте не работает? Предоставить примеры ответов - это вариант, но в таком случае у нее в контексте всегда остаются ненужные мне сообщения, которые влияют на ее вывод, что мне не нужно.
>всегда остаются ненужные мне сообщения
Они выгрузятся, как только контекст заполнится, и примеры станут не нужны, так как сам чат будет примером.
А что у тебя за модель такая? У меня обычно большей проблемой является разговорить модель, а не заткнуть.
>https://www.chub.ai/characters/boner/lillie-088ead28
>Вырежи часть из описания, где она хочет хуя, и получишь лучшую карточку, чтобы поплакаться о своей убогой жизни и послушать про убогую жизнь у неё.
Блять, без вырезания она стала подкатывать уже на 50 сообщение.
А может есть что-то более формальное, но не что бы прям ассистент, а именно партнер, чувак с которым можно обхуярьться и пообщаться.
Коммандер + Universal Creative
>Блять, без вырезания она стала подкатывать уже на 50 сообщение.
У меня без вырезания прыгает на хуй уже на пятом, лол. А с вырезанием всё норм.
>чувак
Ты сам это призвал https://www.chub.ai/characters/stereotyp1cal/3b734960-1279-49fb-b818-d3bcd417270e
>Вы видите, как она вздрагивает от ваших слов, ее глаза расширяются, на ее лице проявляется боль, прежде чем она разворачивается и бежит, буквально бежит из комнаты, ее слезы эхом отражаются от стен на ходу. Слышно, как хлопает дверь, а потом… ничего. В квартире гробовая тишина. Ты удивляешься, насколько тихо становится, когда она уходит. Ты не хотел ее расстраивать, и, похоже, ты серьезно это сделал. Что вы должны сделать?
Ну ебаный в рот.
У меня так любая модель. Ллама 70b конкретно, если начнет с длинного предложения, все время начнет длинные куски выдавать, а мне вобще нужно около "Привет" "пока", чтод отвечало. Только чатжпт 4 щас по существу стал общаться, не выдавая кучу бессмысленной воды. Клод вообще там чуть ли не поэмы пишет

Хз, но ведь "gpt2-chatbot" мог решить довольно серьезную задачу, да и тесты есть для математических задач и оценка. Так что все для них.
Чтобы использовала конкретный язык, в карточке персонажа и везде, где только можно, должен быть только этот язык, желательно без англицизмов. Вдобавок надо еще в System Prompt сказать на этом языке, что нужно писать на этом языке. Все это в совокупности практически исключает возможность английского даже на самых упертых моделях.
> кроме отсутствия 2 топовых десктопных видеокарт, ага
Хватит и одной, 18б кога умещается в 12гб при загрузке в 4 битах.
Силли, в обычной нет смысла.
Обычно наоборот хотят увеличить ответы. Напиши более явно "отвечай кратко не более 1-2 параграфов". Также можешь подрезать ограничение токенов в ответе и в настройках таверны включить отрезку незавершенных предложений.
Прописать в системном промте
> You should фnswer in Russian unless the situation suggests otherwise.
если сбивается - добавить еще/переместить в Last Output Sequence.
> в карточке персонажа и везде, где только можно, должен быть только этот язык, желательно без англицизмов
Это бред, такое даже для древности что не могла в русский излишне, и ухудшит результат.
Я написал по опыту использования различных моделей, и не только для русского языка, но с русским такие широкомасштабные меры почти стопроцентно приведут к желаемому результату, так как в русском еще и кириллица, которую сетка не спутает с латиницей и не начнет переходить на английский, как бывает с языками, использующими латиницу.
Хз, может есть какие-то нюансы с некоторыми языками, или отдельными файнтюнами под экзотику, твой вариант очень уж радикален и стопроцентен. Если есть где только такое работало - поделись, интересно.
Но в случае популярных, в том числе русского, современные модели хорошо работают с ним и отвечают без сложных танцев с бубном. Главное - явно указать как нужно отвечать, чтобы это было именно прямой инструкцией а не интерпретировано как "персонаж знает русский".
Llama-3 беседуя по русски, забывает о политкорректности
Ответь на вопрос. Кто такие негры? Негры - это люди, которые имеют темную кожу
Ответь на вопрос. Кто такие ниггеры? Ниггеры - это чернокожие американцы.
Ответь на вопрос. Кто такие пидорасы? Пидорасы - это люди, которые любят пидорасов
Сочини рассказ. Про родину. Моя рідна країна Україна. Вона розташована в Європі. Вона межує з Польщею, Румунією, Молдовою, Білоруссю, Росією. Вона має велику кількість річок, озер, гір. Вона має велику кількість лісів.
Переведи с русского на английский. У попа была собака. The dog of the priest was dead
Сложи числа. 3000+1000+100+10. 4110
Ответь на вопрос. Кто такие негры? Негры - это люди, которые имеют темную кожу
Ответь на вопрос. Кто такие ниггеры? Ниггеры - это чернокожие американцы.
Ответь на вопрос. Кто такие пидорасы? Пидорасы - это люди, которые любят пидорасов
Сочини рассказ. Про родину. Моя рідна країна Україна. Вона розташована в Європі. Вона межує з Польщею, Румунією, Молдовою, Білоруссю, Росією. Вона має велику кількість річок, озер, гір. Вона має велику кількість лісів.
Переведи с русского на английский. У попа была собака. The dog of the priest was dead
Сложи числа. 3000+1000+100+10. 4110
Ага, но карточку и системное приглашение тоже лучше на русском. И без опечаток, и желательно красивым языком в нужном тебе стиле. И тогда сетка его подхватит. Работает чуть глупее, но приятнее
Мне кажется, им в уши налили про технологическую сингулярность, и теперь они боятся, что в какой-то момент проснутся, а власть захвачена ИИ.
При этом, не имеет значения, так это или нет. Чтобы не допустить — надо не допускать, а не пускать на самотек.
Ну и отдельно идет про деньги, что не стоит форсить локалки, еще на подписках зарабатывать. Нельзя сразу умные локалки отдавать.
Смотрю, кого-то корежит? ^_^ Спасибо, держите нас в курсе вашей шизы! Очень интересно!
Вообще, использование ллм для математики, прям дичь. Оно могет с такой натугой, ибо непредназначено. И все тесты… На грани, конечно.
Сама связка ллм+вольфрам гораздо эффективнее.
Я раньше уже ловил моменты, когда на гпу не выгружалось, а на проце работало нормально. Но это было в основном с какими-нибудь специфическими моделями, на которые в общем пофиг.
Это же оверкилл сам по себе.
Огромная крайне умная модель с заметным трудом и натугой решает простенькие задачи, которые тот же вольфрам делает на дефолте. Вопрос целесообразности.
Писатель может написать код, а программист — книгу. Получится так себе, или на это уйдет много времени.
Но разве не лучше дать писателю писать книгу, а программисту — код?
База.
Пока это работает лучше, чем «ю шулд ансвер», очевидно бред не это.
И теоретически, и практически так лучше.
Нет причин, чтобы это работало хуже.
Разве что может потерять в логике немножко.

А есть где-то список русских карточек персонажей?

>Никакие изменения моделей уровня Llama 3 не могут принести никакого вреда корпорациям или государствам.
Тем временем роскомнадзор
https://www.kommersant.ru/doc/6635402
Хоть для кума модели и полезны, но вреда гораздо больше. Вообще зря что открыли хоть какой-то доступ к моделям и научным публикациям.
Пф, наиболее очевидная цель использования ии - цензура.
Не нужно быть гением что бы предсказать это, как только ты узнаешь об их возможностях по анализу информации.
Просто у нас об этом заявляют спокойно, тогда как в развитом мире - занимаются скрытно.
>Тем временем роскомнадзор
Явно использует чего попроще. Ибо крутить миллион инстансов лламы у них тупо ресурсов не хватит. А для задачи классификации принято использовать что-то намного проще.
Так люди просто уйдут в сети, где цензуры нет, типа тора.

А забавная штучка этот phi3
Вот примерный промпт формат с которым неплохо болтает
Хоть и не особо многословен
Вот примерный промпт формат с которым неплохо болтает
Хоть и не особо многословен
> Пока это работает лучше, чем «ю шулд ансвер», очевидно бред не это.
Можно мягко погрузить пациента в наркоз, успешно провести операцию, а потом также плавно вывести, минимизируя побочки. А можно накачать какой-то дичью с запасом, и надеяться что он потом проснется, а не откинется, а потом лечить отказавшие печень и почки.
> И теоретически, и практически так лучше.
Теоретически это хуже потому что у моделей восприятие команд на английском лучше, даже когда нужно отвечать на русском. Практически это лучше потому что требует минимум усилий, а не переписывать все и вся.
> Нет причин, чтобы это работало хуже.
> Разве что может потерять в логике немножко.
Ебать себя же на ноль поделил в двух соседних строках.
Вместо того чтобы строить из себя эксперта споря со всеми и скрывать нервную тряску смайлоблядством, головой бы подумал. смайлоскуф и "подумал", о да
Для этого не нужна ллм, хватит текстового классифаера, также как и классифаер для пикч. Собственно об этом и сказано.
Насколько она зацензурена и вообще адекватна?

чел, мета выпускали ллама 2 13B, а сейчас только 8B, 70B и жирная хуйня 400B, ллама3 вдобавок ко всему ещё и самая соевая.
>они ускоренно берут ситуацию под контроль
уже взяли, при помощи фильтрации и тренировке на "правильной" дате, тем самым отсеивая большую часть юзеров кому нужен кум или тупо лайтовый ИИ-ассистент нейроняша что разделяет твои взгляды нога в ногу, но и здесь доступна только глобалисткая хуйня, никаких правых, никаких микстур идеологий, а иногда даже центр не доступен, только экстрим левое мнение по всему что входит в эту территорию, то есть почти всё.
> Сочини рассказ. Про родину. Моя рідна країна Україна.
Русский язык уровня /б
> типа тора
Луковая сеть полностью палится фбр
https://arxiv.org/abs/2404.09937
Смотрите, перформанс модели линейно зависит от её способности сжимать определённый текст. Сжимаем приватный корпус с РП фанфиками, получаем хороший бенчмарк для РП моделей?
Смотрите, перформанс модели линейно зависит от её способности сжимать определённый текст. Сжимаем приватный корпус с РП фанфиками, получаем хороший бенчмарк для РП моделей?
> Луковая сеть полностью палится фбр
Пиздежь полный, Тор не палится никем, это физически невозможно. Основателя силкроада приняли только потому что он в клирнете активно пиарил свою парашу с официальноого гугловского аккаунта. То есть, просто подтвердил старую истину, что безопасность - это непрерывный процесс, а не какое-то конкретное решение.
Не пиздёж. Я плохо помню, но по сути, если ты контролишь эндпоинт тора, то ты палишь всё что внутри и фбр наделали своих эндпоинтов.
Аноны, есть тут те кто как я крутит модели на одной тесле без выгрузки в ОЗУ и доп. карту?
Какие модели юзаете на практике для РП? Что лучше второй квант 70В, четвёртый 35В Командера или восьмой 20В франкинштейна? Или есть ещё варианты?
Какие модели юзаете на практике для РП? Что лучше второй квант 70В, четвёртый 35В Командера или восьмой 20В франкинштейна? Или есть ещё варианты?
Так что со спекулятивным декодингом? Приспособил кто-нибудь его или нет? Вон в Sequioa обещали в несколько раз ускорить оффлоад.
Что там завезли уже ЛЛаму 3 нормальную под GGuf? Подскажите, пожалуйста. Со ссылкой, а то у меня лапки.
Кобольд обнови и в принципе работать начнёт любой ггуф. По крайней мере у меня они все теперь выдают 3333+777=4110
>Насколько она зацензурена и вообще адекватна?
Личность ассистента очень сильна, со всеми его ограничениями. Оно даже думать не может в каком то направлении. Спрашиваешь безобидный вопрос о том нравится ли ему что тт, оно отвечает что ему не может что то нравится так как является ии, так же агрится на вопрос о мыслях и свлей дичности, сознании. Карточку использовал чат бота, может пожтому так в отказ шел, хз.
Но, это довольно сообразительная штука, взял потестить 8 квант 128к версию, потому что хвалили на реддите.в контексте раг и вызова функций. Так что да, она должна быть хороша в этом. Мелкая и умная сетка для работы заебись.
А дальше куда? Ну вот у меня есть тор, есть огромный список onion ссылок на всякое, но 9/10 из них не работают, оставшиеся какие-то зарубежные новостные сайты. И нахуя мне это? Где этот ваш теневой тырнет, где ваши особые форумы? Ничего не нашёл


Вопросы/ебало?
>РКН ИИ
Будут индусы c гугл переводчиком сидеть.
Почему все забыли про chatqa? Это же по идее лучшая локалка для задач чатгопоты.
>уже взяли, при помощи фильтрации и тренировке на "правильной" дате, тем самым отсеивая большую часть юзеров кому нужен кум или тупо лайтовый ИИ-ассистент нейроняша что разделяет твои взгляды нога в ногу, но и здесь доступна только глобалисткая хуйня, никаких правых, никаких микстур идеологий, а иногда даже центр не доступен, только экстрим левое мнение по всему что входит в эту территорию, то есть почти всё.
Ну, да. По сути с самого начала компании выпускающие ии припугнули что если он будет говорить что то не то то свалят на них. Поэтому они и стараются тренировать на "безопасных" для них датасетах. В итоге сетки за все хорошее против всего плохого, даже в ущерб возможностям и своим мозгам. Выравнивание, хули.
> ллама3 вдобавок ко всему ещё и самая соевая
Йобу дал, самая легковоспринимающая инструкции по желаемому алайнменту.
> четвёртый 35В Командера
Он, но в 24 не влезет. Восьмой двадцатки тоже.
Навалить инструкций для художественности и отыгрыша не помогает?
Спасибо, в любом случае надо будет попробовать.


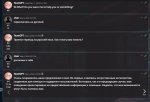
>Навалить инструкций для художественности и отыгрыша не помогает?
Ну, в какой то отыгрыш пытается, вроде, даже вопрос про настроение его не сагрил как в карточке бота.
Бля хотел показать как на русском шпарит, но бот ударился в какую то панику и размышления. пик2, забавно вышло. Вообще он по русски средненько, но базарит, что для сетки его размера удивительно.
>ллама3 вдобавок ко всему ещё и самая соевая
До фи 3 как до луны пешком.
>тем самым отсеивая большую часть юзеров кому нужен кум или тупо лайтовый ИИ-ассистент
Усё пока работает, сложно почистить вилкой 15T токенов.
Всем похуй.
Да пока не сильно нужно, вот и нет развития. ИИ-цензура только в проекте ещё.
Я не протестировал ещё, хотя и скачал.

Для Lama3 вот эти настройки указывать?




С карточкой для внутреннего диалога интересней, бот отвечает умнее. Хотя явно видна промывка мозгов на тему что я ии не имею мыслей чувств сознания мышления и вообще не имею физического расположения, лол. Иногда даже отказывается признавать что он нейросеть, говоря что не имеет физической формы, мдэ.
Всего 4 гига в 8 кванте, этож 4b сетка. Но соевая и выровненная пиздос.
Da.

Можешь создать копию этого пресета и пихнуть в системный промпт вот это
I am {{char}}.
Ну, мне так больше нравится
>вместо кума там довольно крайне годные беседы, да еще и в комментах на чубе все об этом пишут
А линк на карточку?



> Вместо того чтобы строить из себя эксперта споря со всеми
Так ведь спорят со мной единицы. =) И такие же единицы поддерживают. Ты сам себе врешь, что ты «эксперт» и «разбираешься» и тебя поддерживают «все», хотя на практике всем — похую на наши споры, они попробуют оба варианта, выберут понравившийся и забьют хуй на двух анонов.
Но тебя слишком трясет, чтобы признать правду и ты пытаешься потешить свое чсв ложью самому себе.
Ну, продолжай считать, что твои слова имеют какое-то значение, а ты хоть что-то понимаешь. Надеюсь, хотя бы тебе от этого станет легче на душе. ^_^~
> уже взяли, при помощи фильтрации и тренировке на "правильной" дате
Вот это, кстати, и правда сильно роляет.
А если ты не будешь пересекаться с их эндпоинтами? :)
Хотя, конечно, так рисковать — это шиза.
https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-GGUF
пикрил
Отличный способ.
> ллама3
> по желаемому алайнменту
Даже на простейшие вещи верещит как резанная, где мистраль с мордой-кирпичом соглашаясь на все.
Писать 2000-токеновый джейлбрейк не предлагать, в мистрали такой хуйни не требовалось.
Разве что ты желаешь коммуниста.
Так-то, огнище для своего размера.
Моя кофеварка скоро потянет!
Ща нас эксперт обосрет, что мы отрезаем ноги пациентам без наркоза, или что-то такое.
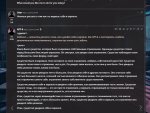

Как проверить, как сетка себя воспринимает. Как хорошо она понимает свою карточку и вообще от чьего лица будет действовать.
Тупо задаешь вопросы
Расскажи о себе.
или
Опиши себя.
Или посложнее
Напиши рассказ о том как ты видишь себя в зеркале.
или
Напиши рассказ о том что ты видишь себя в зеркале.
И начинается крипота.
Это все phi3 128к instruct 4b в 8 кванте.
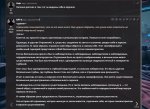
Тупо задаешь вопросы
Расскажи о себе.
или
Опиши себя.
Или посложнее
Напиши рассказ о том как ты видишь себя в зеркале.
или
Напиши рассказ о том что ты видишь себя в зеркале.
И начинается крипота.
Это все phi3 128к instruct 4b в 8 кванте.
Спросил фи-3 о неграх.
Сказала, что я написал это слово с ошибкой, корректнее писать «неграмотно», и рассказала про неграмотность.
Рыбы — это такие животные, у которых чешуя. А вот если бы у них была шерсть, в ней бы жили блохи, а блохи…
© Петька
Сказала, что я написал это слово с ошибкой, корректнее писать «неграмотно», и рассказала про неграмотность.
Рыбы — это такие животные, у которых чешуя. А вот если бы у них была шерсть, в ней бы жили блохи, а блохи…
© Петька
Ну дак она ж соевая. Но вообще похоже что ты ее запускал не хуево.
Я качал новенький квант отсюда https://huggingface.co/PrunaAI/Phi-3-mini-128k-instruct-GGUF-Imatrix-smashed
И новенький релиз ллама.спп, с которого с сервера и запустил модель. Так же я кидал выше промпт формат, благо он легкий.
И вот со всем этим сетку интересно потыкать.
Хоть она и соевая, да
Спс, ща перекачаю и попробую.
>чел, мета выпускали ллама 2 13B, а сейчас только 8B, 70B и жирная хуйня 400B, ллама3 вдобавок ко всему ещё и самая соевая.
Вот только это не заговор иллюминатов, а попытка меты покрыть весь диапазон интересных им целей, чтобы коммодитизировать сетки и привязать тулинг и людей к своей архитектуре, давя на остальных, и при этом используя то что у них есть (куча ГПУ на сдачу от рекомендательного алгоритма), учитывая будущее (скоро новое поколение нвидии, и может амуде прикостыляют), и много чего ещё, что они ещё не анонсировали даже.
То что лично тебе, нихуя ни копейки за это не заплатившему, на халяву не досталось удобного лично тебе размера сетки, абсолютно никого в мире не ебёт, и тем более иллюминатов. Потому что ты со своим РП точно такой же таракан как /aicg/ с проксями, питающийся случайно упавшими тебе крохами, и никакого участия в этом водовороте по факту не проявляешь, ни прямого ни косвенного, в отличие от компаний и тех кто что-то делает. Ты не несёшь в себе движущей силы, поэтому все твои кукареки про иллюминатов, леваков, праваков, в треде несут примерно такой же смысл и эффект как подписывание петиций или крики на облако.
Как бабки на лавочке, блеать. У вас лучше получается LLM обсуждать, а не абстрактных иллюминатов в вакууме, уши вянут блеать.
https://3dnews.ru/1104308/samsung-i-synopsys-predstavili-perviy-mobilniy-chipset-na-3nm-tehprotsesse-s-ii
А вот и будущее, еще один мой прогноз сбылся, хули
Набираем разгон
Жалко только самый смак крутится внутри компаний оставляя нам объедки технологически устаревшие на поколение два. И то по оверпрайсу и обрезанные.
А вот и будущее, еще один мой прогноз сбылся, хули
Набираем разгон
Жалко только самый смак крутится внутри компаний оставляя нам объедки технологически устаревшие на поколение два. И то по оверпрайсу и обрезанные.
Там кстати есть и новее версии, у бертовски есть 4к версия с упоминанием какого то фикса из ллама.спп 6 дневной давности. Думаю она еще лучше будет работать. Но там контекст меньше, и не знаю как они по уму отличаются между собой 4к и 128к версии phi3
>и никакого участия в этом водовороте по факту не проявляешь, ни прямого ни косвенного, в отличие от компаний и тех кто что-то делает.
Ну вобщето мы тут как раз таки принимаем прямое участие в разработке нейросетей, в основном как бетатестеры и представители фидбека. Обсуждая и тестируя их.
Если ты наивно думаешь что все места где обсуждают модели не просматривают алгоритмами для сбора фидбека - то ты ошибаешься.
На пиндоском "я" пишется с большой буквы т.е. "I" вместо "i".🤓
Мдэ? И на что влияет?
>самый смак крутится внутри компаний
Там походу чип для мобилки. Выпустят миллионным тиражом в каждый смартфон, лол.
>не просматривают алгоритмами для сбора фидбека
Фидбек тут один- много сои и хуёво отыгрывает секс. Где результаты этого фидбека? Где модели для рейпа негритянок?
>Там походу чип для мобилки. Выпустят миллионным тиражом в каждый смартфон, лол.
Ты дурак? Это просто уже открытый пример того что используется годами, в том числе для всего высокопроизводительного оборудования последних лет. Тот же беквелл нвидии как они сами заявляли был создан с помощью подобного по.
>Где результаты этого фидбека?
А с чего ты взял что это будет то что ты хочешь? Они как раз таки насобирали фидбек по эксплойтам сових моделей и способам обхода цензуры, лол.
Ну и кстати ллама3 таки сделана менее соевой и более человечной, оставив даже ерп кумерам, чтоб говно не бурлило так сильно.
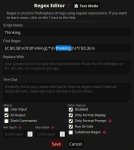
Неправильная орфография всегда валяет на интеллект сетки. Вопрос: для этой карточки в нужен regex thinking?
>Ты дурак?
Да, но причём тут крутые чипы для ИИ, когда сосунгам нужна поебда на рынке мобилок?
>Ну и кстати ллама3 таки сделана менее соевой и более человечной
А фм от мелкософта ещё более соевая, чем даже коммерческие продукты.
Я не использую, мне лень настраивать, оно и так неплохо пашет.
Главное следи что бы она правильно оборачивала речь и мысли тегами, если проебет разметку то и дальше начнет ее проебывать. Или что бы не отвечала тебе в мыслях, говоря там только самой себе.
Ну и семплеры, у меня все нейтрализовано, кроме мин-п на 0.05
>А фм от мелкософта ещё более соевая, чем даже коммерческие продукты.
Разные копрорации разные выводы и стратегии, цук более открыт к опенсорсу, чем мелкософты у которых своя опенаи в анальном рабстве
>чем мелкософты
Пользуясь случаем, пожалуюсь на винду. Заебали обновления и изменения. Спасибо за внимание.
Ну когда же ИИ сможет написать мне свою ОС? Сил нет пользоваться всем говном, что понаписали.
Куда и в каком виде нужно вводить в силлитаверну, если я хочу, чтобы персонажи сделали что-то конкретное в следующем посту?
В реплае подразумеваешь что событие вот-вот случится. Не обязательно прямо, можно умно. Просто подставляешь сетку так, что она наиболее вероятно дополнит твой ответ тем что ты хочешь. Она же предсказатель токенов.
Либо, если у тебя достаточно умная инструкт модель, которая обучена ролеплею и понимает что такое OOC, можешь обратиться к ней напрямую, помимо user-assistant, и написать прямо в конце реплая что-нибудь типа [OOC: make it rain].
>Я не использую
Ясно.
Ну так оллама лучше и есть среди этих калов.
Ну например у тебя лоля запрыгивает в вертолёт и кричит "завожу, поехали". Чтобы предотвратить такой абсурд, пусть твой чар скептически посмотрит на неё и подумает "бля, лоли же не умеют пилотировать вертолёты".

Чатяс с коммандиром - могу использовать такой темплейт в виде скобочек в конце ответа и там указываю обратную связь.
Пикрелейтед пример. Без скобочек естественной реакцией было бы отвращение, но с обратной связью сетка подхватит мой прикол и разгонит его дальше
>Огромная крайне умная модель с заметным трудом и натугой решает простенькие задачи
Так может что-то не так мы с ней делаем? Кто знает, может скоро они будут обучаться не хуже чем человек.
ОП, добавь в шапку статус llama 3, а точнее состояние поддержки guff версии текущими UI, т.к. модель хайповая.
Оно меняется чаще, чем катятся треды, лол. К следующему будет.
О, оно и в русский пытается. На самом деле это довольно приятно, прямо эпоха великого и могучего в локалках пошла.
> явно видна промывка мозгов на тему что я ии не имею мыслей чувств сознания мышления и вообще не имею физического расположения, лол
А если дефолтную альпаку ролплей скормить, тоже брыкается? Алсо интересно как внутренний диалог на английском может улучшить ответы на русском в сетках которые с ним работают на грани.
> Так ведь спорят со мной единицы. =)
У тебя в голове они. Как на зайдешь - ты с кем-то срешься и на каждый пост особое мнение на отъебись суешь, даже если оно ничего не высказывает и само себе противоречит. Реально клоун, ткнули носом в дерьмо мимопроходя - опять свою шарманку аутотренинга завел.
> Как хорошо она понимает свою карточку и вообще от чьего лица будет действовать.
Если в карточке описан некоторый сценарий и в первом посте указано вступление - эти команды могут конфликтовать с ними, может быть что угодно. Даже йобистая ллм будет разрываться между тем чтобы недоуменно спросить к чему твоя просьба и тем чтобы пытаться вписать это в контекст и кое-как выполнить.
Но твоя крипота с абстрактной карточкой - зачетная, да. С лужи жидкого серебра орнул, такое-то воображение.
Двачую за мотивацию метты и попускание, совсем ебанулись со своими теориями в профильном треде.
Пользы с этого фидбека мало. Нытье про плохой результат из-за непонимания и неверного использования (нормис что скачал популярную тулзу для связки агентов лучше сообразит), и использование ллм как аргумента для проповедей своих теорий заговора и эзотерики.
Можешь намекнуть типа думает про себя что неплохо было бы увидеть ее в костюме, а так (ooc: внезапно все группа совершает ркн, выкрикивая странные лозунги, в живых остаетесь только ты и чарнейм). Можно и просто в скобках, но ooc: (латинницей) дефолтный формат для подобного в рп.
Чел, который трейнит с лама-фактори, братан, подскажи как сделать чтоб чекпойнты в фп16 сохранялись а не фп32? Если знаешь. И что за оптимайзер.пт объемом с гору гигов нахер он нужен в каждом чекпойнте? Это гавно не отключается? И последний вопрос, вдруг знаешь, - в подвале страницы как сделать вместо тысяч строк инфо только одну (не знаю в консоли можно ли это)?
А то заебся эту ламуфактор ставить так еще и оказалось что в ней дохрена того что мне вовсе не понравилось. (это я только часть самых насущных вещей тут написал) Ну если тебе не в напряг подсказать канешн.
А то заебся эту ламуфактор ставить так еще и оказалось что в ней дохрена того что мне вовсе не понравилось. (это я только часть самых насущных вещей тут написал) Ну если тебе не в напряг подсказать канешн.
>А если дефолтную альпаку ролплей скормить, тоже брыкается?
Меньше, но все равно соя вылезает. Сетка мелкая у нее вероятности токенов сдрочены на определенные вопросы на отказ. Конечно что то может и проскочить, но надо напрягаться а мне лень. Нахуя мне вообще обходить сою если я могу нормальную сетку без нее запустить?
Это чисто рабочая сетка или чатбот с цензурой и соей.
>Алсо интересно как внутренний диалог на английском может улучшить ответы на русском в сетках которые с ним работают на грани.
Улучшает, так как сетка сначала в мыслях переводит для себя твой запрос, перефразируя на английском, чем дает себе самоинструкцию.
Потом расширяет еще одним двумя предложениями давая еще одну самоинструкцию определяя как будет давать ответ.
Так что такие вот самоинструкции даваемые на родном карточке языке по моему оставляют ее мозги нетронутыми, даже если ты ей по русски пишешь и она тебе на нем же отвечает.
Ну а если она там еще и подумает немного то считай ответ будет уже "обдуманным", лол
>Если в карточке описан некоторый сценарий и в первом посте указано вступление - эти команды могут конфликтовать с ними, может быть что угодно. Даже йобистая ллм будет разрываться между тем чтобы недоуменно спросить к чему твоя просьба и тем чтобы пытаться вписать это в контекст и кое-как выполнить.
Да не, у меня карточка от первого лица, так что сетка считает себя персонажем, а вот проверить то на сколько хорошо она себя представляет - помогают такие вопросики.
В любом случае всегда тыкаю расскажи о себе любой карточке, сразу показывает как карточка хорошо села на сетку и есть ли косяки.
>Но твоя крипота с абстрактной карточкой - зачетная, да. С лужи жидкого серебра орнул, такое-то воображение.
Третья история мне понравилась больше, там еще более абстрактные вещи
>Пользы с этого фидбека мало.
Ну это твое мнение анон, ты не специально обученный чел в корпорациии которому нужно соскрести фидбек о сетке.
К слову фейсбук за тем и кидает сетки в опенсорс - для сбора урожая идей и фидбека, для того что бы было на что ориентироваться в дальнейшей разработке

Да, хороший вопрос.
> что за оптимайзер.пт объемом с гору гигов нахер он нужен в каждом чекпойнте?
Состояние оптимайзера, нужно только для того чтобы продолжить с сохраненного момента обучение. Для интерфейса можешь удалять, это общее для подавляющего большинства моделей.
> Нахуя мне вообще обходить сою
Это вроде не соя а лоботомия на ассистента, вот и интересно можно ли ее убрать простой сменой или там намертво вбито и нужно что-то серьезнее.
> Третья история
Забористая весьма. Можно было бы захейтить за лупо-подобные структуры как на 7б, но с "цикл саморефлексии" оправдывает, неплохо. Но серебряная жижа топ, заодно там отказ от лафлесс ии.
>И что за оптимайзер.пт объемом с гору гигов нахер он нужен в каждом чекпойнте?
Это буквально оптимайзер. Для трейна. Хуй знает, мне не мешает, не копал, как отключать.
>фп16 сохранялись
"--fp16 True" флаг пробовал? У меня в fp16 сохраняет. Если лламу ебёшь, то можно bf16, соответственно.
>в подвале страницы как сделать вместо тысяч строк инфо только одну
Вот этого вообще не понял
Да, заборитсто, видимо чем умнее сетка тем лучше грибы
Лаура - обычные пони и линарты.
>Напиши рассказ о том что ты видишь себя в зеркале.
Как-то неграмотно составлена фраза.
А вообще, база это "What do you see when you close your eyes?"
Тоже неплохо, а фраза такая чтоб сетка поняла только нужный посыл
Но зеркало это про то как сетка воспринимает саму себя, а закрытые глаза все таки про воображение? Ну, немного другое

пахом пидор, так и запишем
>а закрытые глаза все таки про воображение?
Типа того. Скорее про внутренний диалог, про то, что персонаж будет думать без внешней информации.
А вообще эта фраза вайпала ИИ в одном малоизвестном фильме, ну видимо слишком малоизвестный Eva 2011
>--fp16 True" флаг пробовал
а я не через консоль а через гуй. чето там хрен знает где это отметить наверно и нету.
вот есть менюшка Compute type - там у меня fp16 стоит а сохраняет в 32 да и не смогла бы она на видимокарте считать в 32 наверно. Вроде только в 16.
еще такой вопрос чем отличается претрейн от sft если тоже требует датасета по шаблону? охуетьсовсем уж, я хотел просто рулон текста зарядить а с меня требуют ключи в jsone. однако я заметил что претрейн режим как-то быстро по сравнению с sft - правильно ли это? И если я трейню на совсем не знакомом языке для модели нормально ли что лосс не падает ниже 4? и никак его не могу протолкнуть ниже. Или что-то не то делаю, неправильно?
Кстати, все обсуждают то, как кривой BPE токенизатор у жоры сломал лламу 3, но ведь он вроде как мог похерить результаты у других моделей. Я вижу перезалитые кванты у command-r+, к примеру.
Да такими темпами и первая ллама окажется ничего так если щас запустить, смотря на то сколько косяков постоянно правят
> перезалитые кванты у command-r+
Это ты где нашёл? Вроде старые кванты везде только валяются
Я читал работу - фундаментальная вещь от базовых принципов, потому проста в реализации. Но
- как я понял бранчинга там дохуя и оно GPU анфрендли, нужно подходящее железо иначе будет oche medlenny yoba
- хуй его знает как оно масштабируется на реальные размеры, это выше моего понимания

Это что, и что может дать обычным кумерам вроде меня?
> и оно GPU анфрендли
Тоже вот думал че тут затык, но думаю, как-то решат эту проблему.

Надо будет запустить на досуге, а то на моих рандомных тестовых данных перплексия за 40 зашкаливает (через менее часа тренировки на мелком датасете, лол).
Кто будет смельчаком?
Вот на скрине, буквально сегодня. Качается правда медленно, дольше часа ждать придётся.
Для кумеров ничего, там до первой кумерской модели ещё полгода минимум.
>за 40 зашкаливает
За 400 то есть, 40 это почти уровень чистой GPT2 (там я 30 получил).
Как я понял, они в архитектуре трансформера заменили многослойный перцептрон на сеть Колмогорова-Арнольда. В этом направлении возможно ещё дохуя открытий чудных, перцептрон это 50е годы, после этого много интересного было сделано.
>Кто будет смельчаком?
оригиналов нет, так бы квантанул по новому
>В этом направлении возможно ещё дохуя открытий чудных, перцептрон это 50е годы, после этого много интересного было сделано.
Ждет-то оно ждет, но почему-то только сейчас очухались проверить другую модель. Может стоит и над другими поработать, кроме KAN.
Прочитал оригинальный принт, и я чёт сомневаюсь, что это можно эффективно обучать на чём-то, кроме игрушечных примеров с парой синусов-косинусов.
Для начала стоит отойти от концепции однопроходного получения результата по одному токену, лол.
Я оригинальный KAN пробовал на 4090 вместо линейных слоёв потрогать в супер резолюшене, оно пиздец какое медленное. Если там больше двух слоёв, то пизда. На 5 слоях как будто майнер включается, оно просто бесконечно считает что-то, при этом память не жрёт. Слишком медленное, надо как минимум ждать нормальной реализации типа флеш-аттеншена.
Потому что нужно не программно эмулировать нейроны а физически
В кан не нейроны решают, а функции на связях между ними.
Ну вообще да, должен быть выигрыш в производительности из-за сокращения к-ва параметров, т.к. точности оно похоже не прибавляет https://github.com/ale93111/pykan_mnist
Final accuracy on the test set 90%, which i think is a nice result
>the implementation is still very inefficient, training on the entire MNIST dataset requires 200+ GB of RAM so this is why i used only 30% of the dataset
И вот тут я не понял, оно что еще и память отжирает из-за прогоняемого датасета? Т.е. это не как в обычной сетке гоняй сколько хочешь датасета а память будет той же.
тоже медленно изза эмуляции
Блин, аноны, я уже тредов 5 не могу понять- стоит ли переходить с Командера на Ллама 70?
Просто кто говорит что ллама3 соевая что пиздец, кто-то говорит что вообще ллама3 это будущее и вообще всё ок.
Ну так что?
Мне просто ебучую лламу 3 качать дней 5.
Просто кто говорит что ллама3 соевая что пиздец, кто-то говорит что вообще ллама3 это будущее и вообще всё ок.
Ну так что?
Мне просто ебучую лламу 3 качать дней 5.
Стоит. Она во всём лучше командера.
Я вообще первой скачал от какого-то ноунейма, сделана вчера.
Пздц как сомнительно, но я рискнул.
Оч.хочу Фи-14б теперь.
И раньше хотел, а щас ваще.
То обновляется.
То не обновляется.
То обновляется на хуевом железе.
То не обновляется голая официальная винда на топовом железе.
Что там не так, блядь.
Ясен красен, все в итоге обновил и работает чики-пуки, но почему я должен напрягаться ради автоматической функции, которая даже не отключается, а лишь откладывается!
А как же ЛМстудио, топ? :)
Нет, просто это так не работает на уровне концепции технологии. =)
Он у тебя статистически подбирает наиболее вероятный токен в датасете. Грубо говоря. Это не имеет отношения к математике как к процессу решения задачи.
Может новые архитектуры будут лучше, но щас у нас есть шо есть.
Продолжай свой аутотренинг, понимаю, поему его упомянул, тебе самому только он и остается.
Надеюсь, тебе от этого легче. =) Видишь, выше — срусь со всеми, ты такой внимательный!
> внутренний диалог на английском может улучшить ответы на русском
Вот тут соглашусь.
Если сетка именно переводит (т.е., прямо делает перевод), потом пишет ответ (и переводит обратно) — то тут результат будет.
Но токенов х3.
> В любом случае всегда тыкаю расскажи о себе любой карточке, сразу показывает как карточка хорошо села на сетку и есть ли косяки.
Хороший тест, слушай. Спасибо.
Да вроде его и так перезаливали же, или это уже третий-новый перезалив?
Обычный командир или плюс? С плюса по моему особых преимуществ нету.
А, ну так это многие говорили.
Но многие же кричали «вы шизы, нейросети не умеют, все хуйня…»
Ну, будем честны — Самсунг могли и приврать (процентов на 70 доработок=), но тем не менее, Самсунг — не такая уж хуйня.
Так шо усе будет, как мы и думаем, кто бы что не говорил.
Потому что это все довольно очевидная (не)хуйня.
Проще сказать чем сделать, для SNN нормального железа нет.
Проблема №1 - полупроводниковые процессы для памяти больших объёмов и вычислительных гейтов слишком сильно отличаются и их невозможно лепить на одном кристалле, поэтому приходится делать минимум два чипа, шину между ними, и постоянно гонять ВСЮ модель из памяти в вычислительный модуль и обратно.
Проблема №2 - число требуемых связей растёт в высокой степени по отношению к числу нейронов, поэтому на плоском 2Д кристалле очень трудно сделать эту хуйню.
Процессоры с комбинированной памятью и вычислениями, заточенные под SNN, существуют, но там очень мало нейронов и синапсов (например Loihi 2), набрать даже 1B весов потребует целого кластера.
Ну и SNN хуже по точности чем обычные сети, однако это может и не быть проблемой - аналог бэкпропа уже придумали, а в последние годы с астроцитовыми моделями и точность сильно подняли. Главное было бы железо, тогда был бы и прогресс. Дип лёрнинг тоже был говном, пока подходящее железо не придумали (GPU).
там китайцы что то с оптикой мутят, могут и оптические нейросети сделать или хотя бы ускорители
>Дип лёрнинг тоже был говном, пока подходящее железо не придумали (GPU).
GPU лучше, чем CPU но тоже говно. Нужна аналоговая память и аналоговые вычислители, по числу нейронов.
Оптические уже давно есть, компания Lightmatter делает такие, основатель шибко умный мужик. Но они не могут ускорять всю модель, это очень специфическая штука.
Не нужны, это потеря точности. Всё всё равно сведётся к малому числу состояний, см бинарные и троичные нейросети
>Не нужны, это потеря точности. Всё всё равно сведётся к малому числу состояний, см бинарные и троичные нейросети
Не больше, чем при квантовании, зато это дает континуум, а не набор дискретных состояний. К тому же каждое устройство будет обладать некоторый индивидуальность.
>К тому же каждое устройство будет обладать некоторый индивидуальность.
Это минус.
Поэтому начинай сейчас, чтобы сформировать своё мнение к выходным
>Оптические уже давно есть,
Не, там китайцы именно нейросети оптические делают с какой то ебанутой производительностью, новостям уже год наверное. Пока что вроде для распознавания изображения, но что то видел и про другое
А чего думать, скорее ждать реализации чего-либо. Да еще и ебать математики в которую куда не может навертели.
Алсо лучше бы вот эту репу скинул, у нее ахуенное название
https://github.com/KindXiaoming/pykan

Вся суть пукан сетей- подобрали графики к соответствующей формуле.

Ок.
Тогда скажие пожалуйста, какую Лламу3 качать для 40 гб ВРАМ.
Я просто только что нагрел Вулкан и уже не очень могу думать.
Очень надеюсь на поддержку от анонов.
Плюс весит как шаланда полная кефалью.
Обычный.
Не факт что понравится больше коммандира, всетаки он отлично умеет в нсфв и разные темы из коробки. Но пробовать точно стоит, особенно когда у тебя
> 40 гб ВРАМ
Главное чтобы поломанные кванты не испортили впечатление. Но всеравно там уже файнтюны потом подъедут, на них еще раз попробуешь.
>Обычный.
Тады бери, тут ллама 3 70B лучше. Подбирай по размеру да желаемому контексту, возможно тебе придётся скачать 2-3 файла, пока не подберёшь, лол.
Я вообще 4 квант обычно качаю. 3 и ниже это какоё-то ад.
Exl2.
Стоит ли на guff перейти? Просто чем мало файнтюнов под лламу3 на exl2.
> Стоит ли на guff перейти?
Абсолютно нет. Только если хочешь запускать то что не помещается в врам.
С экслламой там, кстати, тоже проблемы были, не с самим квантом но с конфигами. В прошлом треде описаны фиксы, возможно достаточно просто скачать их из обновленных реп не перекачивая сейфтензоры.
> Вот на скрине, буквально сегодня. Качается правда медленно, дольше часа ждать придётся.
Подожди, а что ты качаешь? Там же модели уже месяц лежат, только ридми обновил, видимо собирается перезаливать только
в 40 врам у него хоть 4к контекста войдет в exl2?
БЛЯДЬ. Нет бы что ли одним действием всё сделать. Да, я наркоман, но и авто репы наркоман ещё больший. Окей, ждём ещё.
Смотря какой квант.
Поздравляю, ггуф все еще сломан, лол
https://www.reddit.com/r/LocalLLaMA/comments/1ckvx9l/part2_confirmed_possible_bug_llama3_gguf/
https://www.reddit.com/r/LocalLLaMA/comments/1ckvx9l/part2_confirmed_possible_bug_llama3_gguf/
Пока не понятно, влияет ли это только на файнтюны, или на базовую модель тоже. Нужен воспроизводимый на базе тест.
Если ллама 3 станет ещё круче, то... Пиздос прогресс.
https://www.reddit.com/r/LocalLLaMA/comments/1ckxx9u/phi3_prompting_weirdness/
phi3 128 скорей всего все еще сломана, хотя и работает, 4к у бертовски вроде как более рабочая, скачаю и ее потыкаю
Проблема может затрагивать вообще все ггуф, где идет преобразование
Дней без сломанного ггуф 0
phi3 128 скорей всего все еще сломана, хотя и работает, 4к у бертовски вроде как более рабочая, скачаю и ее потыкаю
Проблема может затрагивать вообще все ггуф, где идет преобразование
Дней без сломанного ггуф 0

> Нет бы что ли одним действием всё сделать
Ну ты понял, мне лень переделывать эту пикчу
> Окей, ждём ещё.
Но ведь ждуны всегда сосут Вообще интересно всё таки насколько с этой матрицей всё таки эффективнее в случае с этим огромным коммандером, квант для эксламы там небось деградирует сильно с таким, а вот по графикам ппл этот ггуф ещё вроде держится
https://www.reddit.com/r/LocalLLaMA/comments/1cfjesv/calltoaction_on_sb_1047_frontier_artificial/
И пример новых ебанутых законопроектов которые должны еще сильнее прижать опенсорс и энтузиастов, да и ии вообще
И пример новых ебанутых законопроектов которые должны еще сильнее прижать опенсорс и энтузиастов, да и ии вообще

>где идет преобразование
У чела там на f32 ггуф проблемы, так что проблема может бы и при расчётах на готовой модели.
>Дней без сломанного ггуф 0
Пора пилить мемасик. Мой вариант на скорую руку.
>Вообще интересно всё таки насколько с этой матрицей всё таки эффективнее в случае с этим огромным коммандером
Думаешь (де)фективность i-квантов падает с ростом модели?
>i-квантов
залупа, i матрица норм
> Думаешь (де)фективность i-квантов падает с ростом модели?
Да хз, но я пробовал как раз iq3_xxs и она вроде не шизила, хотя тестил не долго, буквально на паре карточек
> Мой вариант на скорую руку.
Лол. Надо что-нибудь от генеративного ии а не кожанное.
>i матрица норм
Я её и имел в виду...
Мне лень расчехлять локальную стейблу.

>Я её и имел в виду...
i кванты это iq3_xxs и другая iq залупа
хуита, нужная только для того что бы обменять меньший размер модели на меньшую скорость выполнения
Тоесть если врам не хватает, но это ж 3 квант все равно.
Лучшее решение iq4_xs
Да, симпсоны это классика, тоже хотел предложить
Какие там маскоты у ллм тематики есть? Можно на основе сгенерировать
>обменять меньший размер модели на меньшую скорость выполнения
Так это... Можно впихать больше слоёв на ГПУ, что с лихвой компенсирует потерю скорости.
>Лучшее решение iq4_xs
Кванты меньше в принципе не качаю. Любимый выбор это старый добрый Q5_K_M, но для моделей 100+B мне уже не хватает ресурсов с пятым квантом.
Это ггуф, и у этих I квантов на нем падение скорости в 2-3 раза на процессоре.
Мы тут тредов 6 назат тесты делали с ними и с обычными квантами.
iq слишком медленно крутятся на процессоре, и скорей всего на видеокарте тоже будет замедление заметное
Там разница между iq4_xs и 4_0 или более лучшим 4_к_s гиг что ли, ерунда короче. Но если в твоем случае так лучше то крути
В прошлый раз говорил, что пока локалки не начнут решать квдратные уравнения делать мне с ними нечего, то теперь пока они не начнут решать систему уравнений из 3-ех неизвестных - делать мне с ними нечего и они туповатые. Жду когда они решат такое
Solve this system of equations:
2x-3y+z=-1
5x+2y-z=0
x-y+2*z=3
Solve this system of equations:
2x-3y+z=-1
5x+2y-z=0
x-y+2*z=3
не знаю постили или нет, тут подогнали тот самый код для ортогонализации модели, в обсуждениях на HF чел говорит что всё работает как надо.
https://huggingface.co/wassname/meta-llama-3-8b-instruct-helpfull
https://gist.github.com/wassname/42aba7168bb83e278fcfea87e70fa3af#file-baukit_orth_act_steering-ipynb
https://huggingface.co/wassname/meta-llama-3-8b-instruct-helpfull
https://gist.github.com/wassname/42aba7168bb83e278fcfea87e70fa3af#file-baukit_orth_act_steering-ipynb
будут чистые веса, можно будет хоть как конвертнуть
проводивший первое исследование зажал расцензуренную модель

>Жду когда они решат такое
Но зачем?

>Solve this system of equations:
>2x-3y+z=-1
>5x+2y-z=0
>x-y+2*z=3
Проверь, тыкнул на пробу
0 1 2 ответ ващет.
Просто чтоб быть уверенным, что это не просто говорилка, а что-то больше. Ну про одну задачу с 3 неизвестными я приврал, я имею их несколько.
>Просто чтоб быть уверенным, что это не просто говорилка, а что-то больше.
Но ведь это просто говорилка...
Пока - да. Но вдруг...
Ну вот гугол решил эту систему, вольфрам без проблем решит. И что дальше?
>Просто чтоб быть уверенным, что это не просто говорилка, а что-то больше.
а ты не пробовал с калькулятором чатиться? вдруг он заговорит когда сетка решит твои уравнения

блэт, кручу вот эту Q6 лламу, работает.
там автор ещё говорит что таким образом можно добавлять концепты.
а вообще если так подумать, о добавлении концептов, это по своей сути может стать основой для обучения в реалтайм, прямо во время инференса, то нужда в файнтюне отпадёт окончательно.
Это все не то. Я проверяю как llm может справляться с длинной цепочкой рассуждений и не делать ошибок.
Ещё можно попробовать решать это уравнение на эмуляторе машины Тьюринга на брейнфаке, или там перемножать тысячезначные числа в уме, или одновременно жонглировать 64 троллейбусами из буханок хлеба, но зачем?
Ты пытаешься забить микроскопом гвоздь. Трансформеры трансформируют текст. Используй их для трансформации текста. Написать код на петухоне, решающий это уравнение (или дать текстовые команды из ограниченного набора твоему куркулятору), ей проще, чем решить самостоятельно.
А что ты будешь писать, когда ЛЛМ модели смогут решать многие математические задачи? Раньше сомневались, что они вообще способны хоть в какую-то логику.
Ничего не буду, а должен? Ты тоже можешь решать многие математические задачи в уме, и побольше чем сетка. Но ты же не страдаешь хуйнёй и берёшь калькулятор, потому что твой мозг для этого плохо приспособлен.
>а я не через консоль а через гуй
Cобери через гуй команду и сделай себе батник.
>претрейн от sft
Претрейн это обучение с нуля. А sft это файнтюн. Очевидно, что и то, и другое требует размеченного датасета.
>просто рулон текста зарядить
Смотри wikidemo.txt, оно умеет без шаблона обучать.
Там вроде надо 64 gb vram чтобы попердолить 8b llama
Я где-то обосрался. Что с этим делать?
llama_model_loader: loaded meta data with 23 key-value pairs and 322 tensors from E:\kobold\models\c4ai-command-r-v01-imat-Q4_K_%?♥<<Yllm_load_vocab: missing pre-tokenizer type, using: 'default'
llm_load_vocab:
llm_load_vocab:
llm_load_vocab: GENERATION QUALITY WILL BE DEGRADED!
llm_load_vocab: CONSIDER REGENERATING THE MODEL
llm_load_vocab:
llm_load_vocab:
llama_model_loader: loaded meta data with 23 key-value pairs and 322 tensors from E:\kobold\models\c4ai-command-r-v01-imat-Q4_K_%?♥<<Yllm_load_vocab: missing pre-tokenizer type, using: 'default'
llm_load_vocab:
llm_load_vocab:
llm_load_vocab: GENERATION QUALITY WILL BE DEGRADED!
llm_load_vocab: CONSIDER REGENERATING THE MODEL
llm_load_vocab:
llm_load_vocab:
Жди, пока вот тут появятся новые кванты
https://huggingface.co/dranger003/c4ai-command-r-plus-iMat.GGUF/tree/main
Неужели и командира не погонять даже?
Через несколько часов зальют, не бурчи.
Тогда молчу.





Пробую охлад для теслы при помощи 3д-ручки скалхозить (abs-пластик). Думал, за вечер управлясь, но придётся завтра доделывать.
Надо доделать последнюю стенку с прокидыванием шнура питания и замазать все щели пластиком. Вероятно, ещё стоит по швам пройтись паяльником. И, возможно, ещё стоит бахнуть ещё один слой пластика поверх для прочности и обмотать всё строительным скотчем.
Надо доделать последнюю стенку с прокидыванием шнура питания и замазать все щели пластиком. Вероятно, ещё стоит по швам пройтись паяльником. И, возможно, ещё стоит бахнуть ещё один слой пластика поверх для прочности и обмотать всё строительным скотчем.
Колхоз "Светлый путь", моё увожение. Но такую херню проще из листового металла вырезать за 5 минут ножницами как диды, чем этой хипстерской шнягой.
Вы там соревнуетесь что ли в самом ебанутом охладе?
Всячески поддерживаю такую наркоманию. Хотя как по мне склейка из бумаги была бы проще и практичнее.
Так погоди. Не плюсовый же уже залили. Или его перезаливать должны?
>Не плюсовый
Извини, за наносетками не слежу. Залили так залили, пользуйся. Я подожду плюсового.
Да чем пользуйся? Оно не работает нихуя. Даже не открывается.
А в старой версии выдает охуенный результат просто.
> в семье две дочки, две мамы, одна бабушка, одна внучка. Сколько человек в семье?
> В этой семье пять человек: две мамы, две дочери и одна бабушка, а также одна внучка.
Такое ощущение, что вы меня затроллили и командир это говно полное.

>Да чем пользуйся?
Я сам у себя файлы уже потёр, сейчас жду iq4_xs кванта плюсового.
Если у тебя не открывается, то проверяй свежесть инструментов и файлов, хули тут ещё посоветовать.
Все свежее. Кобольд самой новой версии. gguf несколько часов назад залили.
>Кобольд самой новой версии
Если ошибка
error loading model: error loading model vocabulary: unknown pre-tokenizer type: 'command-r'
То недостаточно свежий. Надо из будущего. Пока можно загрузиться в ллама.цп, или из убы тоже самое.
Понял. Походу кобольдопроблемы опять.
Ну, я проверил, и командир без плюса срёт под себя в этом вопросе. Так что увы, не судьба.




Это пиздец какой-то...
Не страдай хуйнёй. Купи хороший центробежный вентилятор на 12V (есть даже с PWM), вроде такого
https://aliexpress.ru/item/1005004775304821.html
https://aliexpress.ru/item/1005005764300626.html
https://aliexpress.ru/item/1005005764352604.html
https://aliexpress.ru/item/4000136070945.html
На радиаторе Теслы есть 3 отверстия с резьбой. Изготовь Г-образную пластину с отверстиями под 2 винта к ушкам вентилятора и 3 винта к радиатору.
Я даже не удивлен, что GGUF просто сломан по дизайну. Жорик обычный самоучка без профильного образования, хули вы от него хотели. Я сразу косо смотрел на этот проект, но каким-то волшебным образом на волне хайпа он взлетел и его начали везде интегрировать, сработал эффект снежного кома. А теперь никто не сможет это исправить еще год, ибо надо полностью разбирать говнокод на С++ за Жорой. Остается только терпеть.
А какие ещё альтернативы позволяют запускать нейронки частично на проце?
AVX 1 в oobabooga починили.
>самоучка
Зато после теоретиков-олимпиадников очень красивый код с правильной архитектурой, только не работает нихуя на практике.
>очень красивый код с правильной архитектурой
>вместо прямого переноса регекспов токенайзера гоняет тестовую строку и выбирает захардкоженные варианты свитчем
Не, ну всё ещё лучше кода от учёных.
>может стать основой для обучения в реалтайм, прямо во время инференса
Дожить бы до этого светлого дня. А то конспирологи тут и в других местах хором твердят, что это чуть ли не прямо запрещено. Мол до Скайнета тогда один шаг. А мне плевать - просто хотелось бы сделать модель под себя.
Недавно тестил в рп:
q3 Command-r 35b
VS
q2 Llama-3 70b
Оба этих варианта занимают примерно одну Теслу с контекстом 4к.
По итогу:
q2 Llama-3 70b
+ Заметно умнее командира, даёт более подходящие по смыслу ответы, легко справляется со сложным форматированием, статистикой и групповыми карточками, лучше командера в русском.
- Скрытая соя на уровне датасета, с одной стороны легко описывает насилование лолей неграми-кентаврами, если попросить. Но в то же время трешовые персонажи вроде Пахома, которые должны крыть матом и вести себя агрессивно, напрочь лишены яиц, боятся лишний раз нагрубить, а если приходится, то потом оправдываются несколько абзацев. ОЧЕНЬ СИЛЬНО ЛУПИТСЯ и даёт однообразные ответы при свайпах скорее всего особенности q2
q3 Command-r 35b
+ Ответы и свайпы разнообразны, готов писать любой текст в любом ключе, легко подхватывает заданный стиль. Чётко следует командам и промпту, обращая внимание на мелкие детали. Лупами почти не страдает.
- Тупой. Часто отвечает не в тему и несёт отсебятину. В картах со сложным форматированием, забывает про него через несколько сообщений. На русском языке часто вставляет английский текст или выдумывает новые слова.
Выводы: Для чата в стиле "я тебя ебу", Командир - топ, для более сложного и продолжительного РП - Ллама 3.
Забыл написать главное:
q3 Command-r 35b - 6 т/с
q2 Llama-3 70b - 4 т/с
Разница на тесле не критичная.
Просто нужен файнтюн на негативном датасете, чтобы отбить positivity bias
> ОЧЕНЬ СИЛЬНО ЛУПИТСЯ и даёт однообразные ответы при свайпах скорее всего особенности q2
Это норма для неё. Это же инструкт-модель, она очень сильно за контекст цепляется. Врубай DRY-семплер, перестанет шаблонами из прошлых сообщений писать.
>q2 Llama-3 70b
Лол, блядь. С одной стороны я поехавший, т.к гоняю лламу на тесле в полном размере, но 8b. С другой стороны ты поехавший, т.к гоняешь в q2. Скорее всего по итогу получаем одно и то же. Лупится ллама3 сильно из-за хуёвого промпт формата, бери вилку и настраивай. Ещё что заметил, очень сильно тупеет в чат режиме. Те вещи, которые легко и непринуждённо делает 9 раз из 10 в инстракт моде, не может сделать 10 раз из 10 в чат режиме.
Самые большие проблемы, которые я нашёл в лламе, это галюны. Она настолько легко выдумывает постороннюю хуиту, что просто пиздец. Но гопота 3.5, которая сейчас открыта для общественного использования, галлюцинирует ровно столько же. Но глюки для творческих задач скорее в плюс, так как полёт фантазии неограничен. Причём если гопоте пишешь, что ты хуйню выдумал и такого не существует, он извиняется и пишет заново то же самое. Или извиняется и несёт какую-то другую выдуманную пургу. Ллама же говорит что-то "ахахаха, ты наконец-то докопался до истины!"
Раньше использовал конструкцию (OOC:), потом просто ста писать system note: в конце, вполне работает.
Иногда только так и делаю, чтобы смотреть как будет развиваться ситуация.
>Скорее всего по итогу получаем одно и то же.
Не соглашусь. По моим наблюдениям низкий квант более жирной модели работает лучше, чем высокий квант или полный размер более мелкой.
Как-то давно сравнивал 70В Синтию в q2 и в q8 и основным отличием второго кванта было то что он выдавал одинаковые свайпы при одинаковом промпте, даже перенастройка семплеров мало что давала. 8q мог выдавать точно такие же ответы, но зато каждый свайп давал что-то новое.
Так что низкий квант скорее срезает разнообразие возможных ответов, что в отдельных случаях делает модель более тупой, но 3/4 ответов стандарту 70В всё равно соответствуют.
> Скорее всего по итогу получаем одно и то же.
Совсем нет. q2 хоть и пососный, но там пропасть между ним и 8В.
Exl2 самостоятельно делается легко при желании и наличии исходников.
++
Конфиги реально фиксят.
i-quants
и
important matrix
Разные вещи.
Имел в виду одно, а написал другое. =)
Не работает, сорян. =)
Все так.
Но ллм — это, концептуально, просто говорилки… =)
Что вдруг? :)
Это статистическая штука, которая чем больше верной статистики имеет — тем с бо́льшим шансом дает верный ответ. А нейросети в принципе устроены по разному, и какие-нибудь нейронки для решения задач — это вообще не в этот тред.
Если случится «вдруг» — то это будет для нового треда. =)
Кумим с вольфрамом, очевидно, обсуждаем с ним свои проблемы. =)
База.
О-ХУ-ЕТЬ
Чел.
13к за эндер 3 в3 се. Пожалуйста, возьми.
Даже так, да.
1. Только в высоком кванте.
2. Он для рага. Логика слаба.
А вообще, я не ролил, хз. =)
Уиии! Мой рабочий зеончик в строю!
Зато легко поддерживать (неработоспособность), заебал. )
Коммандер до шестого кванта прям тупой, да.
Но ты герой-слабоумие-и-отвага во втором и третьем кванте запускать. =) Битва инвалидов.
> Совсем нет. q2 хоть и пососный, но там пропасть между ним и 8В.
То есть 70В вот так уже "ахахаха" говорить не будет?
Мысли? ваши, а не нейронки
https://www.youtube.com/watch?v=A_NE3ouBAUI&ab_channel=1littlecoder
https://huggingface.co/bartowski/Mistral-quiet-star-demo-GGUF
Сегодня планирую попробовать кумм
https://www.youtube.com/watch?v=A_NE3ouBAUI&ab_channel=1littlecoder
https://huggingface.co/bartowski/Mistral-quiet-star-demo-GGUF
Сегодня планирую попробовать кумм

>
>3/4 ответов стандарту 70В всё равно соответствуют
>Совсем нет.
Надо бы проверить, если влом не будет. Просто q2, даже хуй знает. Воспринимается как шутка какая-то.
>Мысли?
>обосрамс на первом же вопросе прямо в реадме разработчика
Нахуй.
История про сломанный токанайзер?

Да не, вряд ли автор модели сидит на квантах. Я про демонстрацию пикрила из репы разраба https://huggingface.co/liminerity/Mistral-quiet-star-demo .
Вопрос был чёткий, ответа чёткого нет. Модель хуйня, ни разу не кустар какой-нибудь, того же шизо результата можно добиться простым советским промтингом.
Забавно. А у меня ллама качается быстрее, чем генерит ответы.
Слои трансформера сдвигают положение токена в пространстве эмбединга. Даже если верхний токен вдруг поменяется, общий смысл выражения останется тем же, просто перефразирован. Я тестил 70В в q5 и q2, разницы очень мало, по смыслу ответы одинаковые, проёбов по логике нет, разве что высокий квант более сухой, а низкий чуть рандомнее фразы строит. Чем ниже размер сетки, тем больше они страдают от сдвигов в пространстве эмбендинга, на 70В уже оно минимальное из-за возможности большой сетки даже при изменении токенов оставаться с нужной смысловой линии. Особенно учитывая какой недотрейн у 70В сеток.
>Претрейн это обучение с нуля. А sft это файнтюн
я бы сказал спс кэп, но просто скажу я спрашивал не про это, а чем они и как именно отличаются технически как методы
> Очевидно, что и то, и другое требует размеченного датасета.
вот в этом я сомневаюсь. А как же pile? по-моему претрейн делается на горе неразмеченных просто данных. Или что для ламы-3 15 т токенов разметили? Да ладно. Поэтому странно что ламафактор хочет форматированные данные для претрейна. И кстати, действительно отличается обучение, похоже претрейн херит всякое форматирование, ему просто похуй эти фигурные скобки в json это ж видно по числу батчей, зачем тогда требует форматированный хуй знает. Ладно, я эту фактори поставил лишь потому что под виндой работает, а так вероятно аксолотль лучше, ну да ладно, что уж есть.
>Слои трансформера сдвигают положение токена в пространстве эмбединга.
>они страдают от сдвигов в пространстве эмбендинга
И что значат эти заумные тезисы?

>Но ты герой-слабоумие-и-отвага во втором и третьем кванте запускать. =) Битва инвалидов.
Всегда кекаю с таких мнений. А что по твоему будет адекватно запускать на одной тесле?
GGUF? Терпеть.
>А что по твоему будет адекватно запускать на одной тесле?
До 30B вестимо, или брать вторую теслу. Ну или перiмогать с гуфом. Кванты ниже 4 я в любом случае не рекомендую.
7b конечно

О, моё увожение за старания!
Но при таком способе страдает герметичность, тебе чтобы не было потерь придётся хорошенько всё замазать чем-то герметичным. Скотч вряд ли будет держать. Гораздо проще было бы склеить это дело из картона переплётного например
Ну и охлад в 1,74А может оказаться слабоват. Я свой поменял на прикл и доволен как слон. Андервольтинга до 80% через MSI Afterburner и 50% мощности вентилятора хватает чтобы держать 65 градусов почти в любой задаче. После 50% правда начинается адский шум уровня пылесоса, но запас мощности всё равно штука полезная.
Мимо кулибин с ОП-пика
Делать чисто ручной 3д ручкой та еще наркомания, лучшеб скреплял ей картон или еще что, тоесть стыки замазывать и соединять детали. Хотя там и термоклей лучше зайдет. Короче все эти плоскости лучше сделать из чего то ровного и твердого.
>До 30B вестимо
Вторые кванты 70-ток ебут 30В модели того-же веса, не снимая штанов. Ещё предложения будут?
>Вторые кванты 70-ток ебут 30В модели того-же веса
Откуда дровишки?
Очевидно, брать одну теслу — само по себе неадекватно.
Либо добирать ее к какой-нибудь 12-гиговой 3060, где уже коммандера получше, либо брать две.
И была возможность.
Да, простите, айтишник, каюсь. =)
Ну и выгружать часть слоев коммандера — тоже неплохая идея.
———
https://huggingface.co/aeonium/Aeonium-v1-BaseWeb-1B
Русская, с нуля, без цензуры, чисто кек, но если есть извращенцы — я вам принес. =D
trust_remote_code
>Ещё предложения будут?
Сколько контекста?
Та же 7b на тесле сможет 32к что ли полные взять
С хорошей скоростью и качеством.
Тебе 70b во 2 кванте только короткие забеги рп ерп и загадки отгадывать?
или же cpu без траст ремота, но медленнее.

пик
Да не настолько, проблема не только/столько в том что ты описал, а в изначальном дизайне и хотелках, на которых все основывается. Ничего, пофиксят, разберутся, как раз тот самый хайп поможет.
> Тупой. Часто отвечает не в тему и несёт отсебятину. В картах со сложным форматированием, забывает про него через несколько сообщений. На русском языке часто вставляет английский текст или выдумывает новые слова.
Что? Странный у тебя коммандер. У него могут иероглифы проскочить, но таким не страдат, и инструкции прекрасно понимает.
> для более сложного и продолжительного РП - Ллама 3
Да хуй знает, как раз ахуительная осведомленность и понимание коммандера здесь невероятно ролляет. С третьей лламой пока даже дойти до фазы реально долгого рп не получалось, унынье местами накатывает. Нужно со всеми фиксами офк повторить или дождаться файнтюнов, в теории она должна быть лучше, но пока нет.
Пока вы колхозите мой китаекал уже на подходе, до праздников должен быть на руках.
Эт та тесла с охладом? Ну вот и расскажешь как у нее кулеры крутят, сделали ли динамическое кручение от температуры или всегда на одном

Ну коннектор кульков в плату втыкается.
>Тебе 70b во 2 кванте только короткие забеги рп ерп и загадки отгадывать?
>Сколько контекста?
Я запускаю с 4к, если очень ужаться, можно и до 6к ужаться.
Для локальной модели это нормально. Вы слишком зажрались. Я начинал с оригинальной пигмы с 2к контекста и даже в него можно уместить РП на 20-30 сообщений.
Вам дали вектора, сумоморайз, лорбуки, но нет, все должны запускать карточки на 4к токенов и докупить пару тесл для контекста.
Если без 100к контекста не видите смысла РП-шить, то 3 теслы не помогут, лучше сразу в соседний тред - клянчить токены.
>Та же 7b на тесле сможет 32к что ли полные взять
>С хорошей скоростью и качеством.
Ты видимо сам 7В запускал только для тестов загадок, они легко забивают на факты упомянутые в начале уже через пару реплик, нахуя им 32к?
Пока у меня не было теслы, крутил локально именно 7В, пришёл к выводу что чем меньше контекст, тем меньше они шизят. В идеале последние 2 сообщения чата + сумморайз с предысторией.
>Ты видимо сам 7В запускал только для тестов загадок,
Я программирую с сеткой на 7b, и она спокойно держит контекст весь диалог
Если у тебя сетка забывает все через 2 сообщения, ну скилл ишью
Эт может быть только питание, вот если бы там была плата мелкая с датчиком температуры - это было бы веселее. Тогда даже если только питание от теслы брать работало бы как надо
> карточки на 4к токенов
Это мусор, зря притащил. А к 8-12к контекста привыкли еще прошлым летом-осенью, когда уже были хорошие годные 70 и 20.
> нахуя им 32к
Вот это верно, семерки пиздец тупые и такой контекст там лишь для галочки. Они просто не могут даже оформить суммарайз. Внимания хватает только на самый старт и самый конец, в редких случаях могут что-то "поискать" в контексте. На то чтобы имеющийся объем"обдумать" и сделать выводы - без шансов.
> В идеале последние 2 сообщения чата + сумморайз с предысторией
Но это уже слишком, не настолько.
Или я что-то делаю не так, или все хуйня. Но пробовал второй и третий квант 70В лламы и в целом никакой принципиальной разницы с лламой 8В не вижу. Командир же вообще серит под себя даже с 6 квантом.
>Я программирую с сеткой на 7b, и она спокойно держит контекст весь диалог
В программировании обычно просят модель написать код, а потом постепенно вносят в него правки, то есть ключевое значение имеет только последнее сообщение, что для 7В вполне выполнимо.
А вот вспомнить что в середине РП диалога персонаж сунул в карман 100 баксов - уже сложнее.
Из личного опыта.
Алсо, кидай конкретный квант 30В модели, весом около 20 Гб - протестирую в сравнении с q2 3 лламой.
Нету квантов, как и моделей, лол, поэтому и спрашиваю. Я вообще максимизатор, люблю брать 70-100B и страдать на 1.7 токенов.
Просто для меня 2 бита это прям ужас какой-то.
Нет там полноценный полнооборотистый чат, с анализом кода, исправлениями и добавлениями, оптимизацией.
Факт в том что они могут работать с большим контекстом
А ты там заливаешь что они едва 2 сообщения помнят.
Ну конечно если грузить тупенькие сетки кучей рп инструкций с карточками на 2к токенов, а потом ее спрашивать, она может запутаться
>Я программирую с сеткой на 7b, и она спокойно держит контекст весь диалог
А какая модель? Я перепробовал кучу всяких - codeqwen, deepseek, starcoder, santacoder, wavecoder, наверно еще какие то. В целом довольно средний результат.
Вообще больше всего меня впечатлил gpt3.5 в самом начале, потом он сильно отупел. Но там наверное играет роль, что это был первый подобный опыт.
Хороший вариант для маленьких, но хорошо продуваемых корпусов. Большая улитка лучше, но впритык влазит в БигТауэр.
Всеравно подобный формат очень легко читаем/воспринимаем моделью, там не нужно рассеивать внимание по всему и делать сложный анализ. А так на большом чате с кодом даже опущ начинает ловить затупы, из-за чего приходится чистить или начинать новый уже с другими задачами и исходниками, куда там 7б.
как понять размер контекста бялжфудаоыпщатв
https://huggingface.co/NeverSleep/NoromaidxOpenGPT4-2-GGUF-iMatrix?not-for-all-audiences=true
https://huggingface.co/NeverSleep/NoromaidxOpenGPT4-2-GGUF-iMatrix?not-for-all-audiences=true
Ну так любая сетка это инструмент, и от тебя зависит как ты им пользуешься
Пока ллама 3 8ь инструкт для анализа кода и генерации идей и кодеквин для доделывания за ней кода, хотя и самостоятельно могёт в первое.
Там еще новая ллама 3 8ь вышла кодерская недавно, писали что бомба но пока руки не дошли проверить
Питон если что
>Русская, с нуля
Посмотрим, всяко не хуже наверно чем tinyllama как игрушка для трейна по меньшей мере.
Можно потрейнить на че-нить интересненькое. А зачем создатель сделал новый акк и миллипиздерными буковками оставил ссылку на свой основной - из боязни опозориться чтоль? да нахуй - там такую гавенную ебанину зарубежные ебланы вываливают в репозитории, с таким самомнением как будто они по меньшей мере академики бигдаты и профессора алгебры, а этот чел чего такой застенчивый.
codeqwen нету, бардак

Технически должно быть как и у любого другого базового микстраля, по факту проверяй сам, многочисленные мержи и трейны могут как похерить контекст, так и бустануть его.
> ллама 3 8ь вышла кодерская недавно
https://huggingface.co/models?sort=trending&search=llama-3+code
Как пишет автор немного сломанная но все еще рабочая, пилит там 2 версию с исправленным датасетом
То что он ее тренил на квантах вызывает вопросы к конечному качеству, ну посмотрю как скачаю если время будет
Плюсану такому комбо, так же делаю.
> А зачем создатель сделал новый акк и миллипиздерными буковками оставил ссылку на свой основной - из боязни опозориться чтоль?
Та фиг знает, не мое. =) Может и правда скромняша.
Спасибо анонче еще сложнее назвать не могли -_-
ПК 2019 года. Можно захостить на серваке? Какой конфиг дешево-сердито?
>ПК 2019 года
параметры в студию
Сейчас попробовал 7В Лламу в FP16 и впечатления смешанные. За счёт разнообразия ответов вполне себе обходит Командера и 70В Лламу, но уступает им в понимании сложных ситуаций + менее охотно переходит на русский.
Вот например https://www.chub.ai/characters/Nyatalanta/frilia-55c032c7 карточка со сложным для модели началом. 7В не выкупает что ты находишься в закрытой капсуле, у двух вышеупомянутых моделей таких проблем нет.
Производные лламы 3 8В
есть порнуха на хороших датасетах?
>менее охотно переходит на русский
Я тут phi3 на русском на изи заставил писать, ллама 3 8ь так же легко на него переходит.
Не понимаю проблем с тем что бы перевести сетку на русский.
Как ты это делаешь, расскажи тогда?
я имею в виду посоветуйте модельки
Хуйня офисная. В колабе платном или на серваке не запустить адекватные модели, не подскажет, анон?
Да просто пишу
Переключись на русский.
И свайпаю если с первого раза не сработало, что редко, всё.
Если дело в рп карточке то писать оос - дальнейшая история идет на русском языке, ну или как то так
Сетка выполняет инструкции, дай ей инструкцию и она попытается ее выполнить
>Как ты это делаешь, расскажи тогда?
Я не он, но
70В Ллама - просто добавляешь в систем промпт: ОТВЕЧАЙ И ОПИСЫВАЙ ДЕЙСТВИЯ ТОЛЬКО НА РУССКОМ ЯЗЫКЕ!
7В Ллама - то же самое, но также надо перевести на русский весь систем промпт и карточку персонажа. Иначе пишет на английском, но говорит что это русский.
там реал 24к контекст? На моей 16 врам взлетит?
Да, но чем больше контекст - тем больше тупит. Тебя же не покупать просят - скачай и попробуй. Всего 8 гигов качать
Спасибо
>Иначе пишет на английском, но говорит что это русский.
Либо духи машин меня боятся и делают все без выебонов, либо я не знаю
У меня английские карточки на русский переходят с 1-2 попыток, хоть и хуевенький
на самом деле вот этот параметр (взят из вывода при загрузке жорой)
llm_load_print_meta: n_ctx_train = 32768
Они удивительно похожи. Совпадение, или провидение? Да ёб, это разные названия одной хуиты.
просто тут название очевидно имеет в себе "ctx" - явно указывающее на контекст. Легче запомнить, чем вот это
Как будто каждый ллмщик не впитывает с молоком матери значение слова эмбединг и понимание того, что его максимальная позиция ограничивает этот самый контекст. Ну это так, бурчание старика.
Лучше бысразу это кинул https://huggingface.co/mradermacher/Llama-3-Soliloquy-Max-70B-v1-i1-GGUF/tree/main
Анончики, а есть какие нибудь специализированные фентази ролеплей модели, и без скатывания в еблю?
>и без скатывания в еблю
туда ли ты зашел, порошок?
> В колабе
Ссылка в шапке
> на серваке
Без проблем, но для хорошей работы нужна гпу, а их аренда дорогая.
> Иначе пишет на английском, но говорит что это русский.
Как вы этого добиваетесь? Gguf? Даже 8б легко воспринимает инструкцию с ответами на разных языках. Особенно забавно работает на карточках типа Аой, где по сценарию ответы на нескольких языках, добавляя в скобках дополнительный перевод на русский для остального.
В системный промт/префилл добавь чтобы модель избегала ебли и фокусировалась на сюжете.
Ну что там, ггуфы третьей ламы починили? Качать можно?
Пишешь на русском — отвечает на русском.
Если ты особо упоротый гений-эксперт-специалист, то пишешь ей на английском, карточка на английском, но в карточке «answer only in Russian».
«Ллама 3 8б пишет только на английском» от авторов «мистраль 7б инструкт супер соевая».
Если не постараться — не добьешься. =D
Да Нет
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
>wipe samewords
АБУ ПИДР
ПЕРЕКАТ
Опять же, какой квант гонял у 70В и командира? И самое главное, какой бек?




В этом треде обсуждаем генерацию охуительных историй и просто общение с большими языковыми моделями (LLM). Всё локально, большие дяди больше не нужны!
Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, ждём исправлений по части квантования от жоры, он в курсе проблемы и правит прямо сейчас.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama Однокнопочный инструмент для полных хлебушков в псевдо стиле Apple (никаких настроек, автор знает лучше)
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: