



На Жориной лламе опять все сломано и пхи3 хуйню несет. Боже..
Новые фи пока нельзя использовать в ггуф? В чем именно выражается поломанность, можно пример хуйни, которую несет, то есть это вообще бред или лупы или что там?
https://github.com/ggerganov/llama.cpp/issues/7451
Ждём пока Жора очнётся. Все свежие билды сломаны, хотя у кого-то вроде работают. Неделю висел PR и никто не потрудился простестить его нормально.
С другой стороны, какой толк от такой модели для нас?
Резать на франкен-мерджи?
Это со мной что-то не так или что, но где в новой таверне запрет на EOS токены?
А по железу гайд есть? В шапке беглым осмотром не заметил.
На чем крутите? На теслах?
На чем крутите? На теслах?
Какой тебе гайд нужен? Любая нвидия с 24 гб врам, чем новее тем лучше. Остальное мусор.
Потестил Фи медиум, какое-то соевое говно, даже в рп триггерится и высерает поучения. Ещё и в чате шизит, пытается на инструкции перескочить, что-то слишком жестко затюнили под инструкции её. Может файнтюны смогут её разогреть, но пока нахуй. Сидим дальше на Yi/ламе 70В.
Хочу сделать выяитель бототредов испол зуя ллм и векторные бд. Чтобы оно регуляоно анализировало /b, выявляло контекст шапки и сохраняло. И сравнивалось то, что есть. Подводные? Нахера это делать?
ммм регулирование
https://3dnews.ru/1105198/krupnie-kompanii-v-sfere-ii-vzyali-na-sebya-obyazatelstva-po-obespecheniyu-bezopasnosti-razrabotki-iimodeley
ищо
https://www.reddit.com/r/LocalLLaMA/comments/1cxqtrv/california_senate_passes_sb1047/
ищо
https://www.reddit.com/r/singularity/comments/1cx9oh4/openai_openai_safety_update/
делаем ставки когда запуск локалок оффлайн станет незаконным
https://3dnews.ru/1105198/krupnie-kompanii-v-sfere-ii-vzyali-na-sebya-obyazatelstva-po-obespecheniyu-bezopasnosti-razrabotki-iimodeley
ищо
https://www.reddit.com/r/LocalLLaMA/comments/1cxqtrv/california_senate_passes_sb1047/
ищо
https://www.reddit.com/r/singularity/comments/1cx9oh4/openai_openai_safety_update/
делаем ставки когда запуск локалок оффлайн станет незаконным
Никогда, просто отдадут первенство Китаю.

Или просто новая винда обновления 10 и даже линукса станут полноценным большим братом и даже вывод локалок, хочешь ты или нет, будет отсылаться и анализироваться
Все ради твоей безопасности, анон
https://www.reddit.com/r/singularity/comments/1cx9qxj/microsofts_new_recall_service_big_brother_is/
Кучно пошло.
>делаем ставки когда запуск локалок оффлайн станет незаконным
Запуск не станет. Хотя домашних устройств для инференса могут и не завезти. Хуже, если не завезут и новых публичных моделей. Или завезут, но полностью без секса например и с внутренней сеткой-цензором. Потому что не положено быдлу.

->
>Им не дадут выложить 400b.
Анон предсказывающий.
Есть, в вики.
Что и требовалось доказать.
>с внутренней сеткой-цензором
Как в стейбле? Я за.
https://www.reddit.com/r/LocalLLaMA/comments/1cxoh5q/llama_wrangler_a_simple_llamacpp_router/
Похоже на то о чем мы тут когда то болтали, несколько параллельных серверов для быстрого ответа
Не понял только для одного фронта или для нескольких
Похоже на то о чем мы тут когда то болтали, несколько параллельных серверов для быстрого ответа
Не понял только для одного фронта или для нескольких
>«аварийный выключатель»
Ух ты, они прямо признались, что будут вшивать бэкдор в модели. Safetensors всё ещё safe?
https://3dnews.ru/1105197/es-prinyal-perviy-v-mire-zakon-ob-iskusstvennom-intellekte
Профессиональный выстрел в член, европа выбывает из гонки
Так они норм правила устанавливают. Проблема в том, что их соблюдение тормозит сферу, да.
>опа выбывает из гонки
Так они не только из гонки выбывают, получается. Это нужно гуглу с опенаи блокировать доступ из европы, лол.
Прогнуться же. Всегда прогибались. Не отдавать же срыночек гейропки YaGPT, лол.

Мужики, посоветуйте файтюн ламы 3 8b конкретно для написания историй, а не как обычно чатинга 1 на 1.
А то когда создаю хотя бы два персонажа в одной карточке персонажа, то ответы получаются сухими и короткими, а хотелось бы что бы сюжет дальше развивался и между персонажами много диалогов было.
А то когда создаю хотя бы два персонажа в одной карточке персонажа, то ответы получаются сухими и короткими, а хотелось бы что бы сюжет дальше развивался и между персонажами много диалогов было.
И что Ивану из города Тверь помешает вырезать этот кусок из новой винды? Сколько модификаций всяких виндовс существует?
>И что Ивану из города Тверь помешает вырезать этот кусок из новой винды?
Интеграция этого куска в ntoskrnl.exe?
Просто слова коверкает, будто бы токены пропускает/путает местами. Не очень часто, но доверия нет когда такая хуйня происходит.
>ntoskrnl.exe
Не имею возможности ебать что это.
Так там как раз on-device и будет, вместо копилота. Так что это годнота, а телеметрию всегда можно отключить или заблокировать фаерволлом. Так что живем, большой брат не пройдет.
А вы вообще читаете карточку моделей, прежде чем тестировать? Ну а чего ты ожидал, там написано какой собран датасет и для каких целей. Кумеры не перестают удивлять тупостью.
Нихуя не знаешь устройства шинды, но при этом рассуждаешь? Типикал ситуэйшен.
Это файл ядра винды, удачи его удалить.
Поясните за Mixtral 8x7 и прочих франкенштейнов с множителем. Как из семи условно тупых моделей можно получить модель, выдающую лучший результат? Новой информации-то в них взяться неоткуда.
Смотри, у тебя семь долбоёбов. Пусть будет семеро двачеров. Один знает про говно, второй про молофью, третий ещё про что-то. И вот ты пишешь им что-то, а они совещаются. Один говорит - "речь про говно, инфа 60%". Второй - про "машины, инфа 20%". И вот это всё суммируется согласно вероятностям и тебе в ответ прилетает ответ "ну а чё ты хотел, это аж автоваз".
Информации как в 56b а может и меньше, "логика" как у 7b, vram занимает как 56b, работает побыстрее 56b, но помедленнее 7b. По идее, оптимальный вариант для видеокарт с большим объёмом vram и слабым ядром, типа тех же p40.
В MOE нет четкой сегрегации экспертов на какие-то конкретные скиллы вроде коддинга, общих знаний, сторителлинга и т.д. Все это нех работающее каким-то магическим образом понятным только самой сетке, организующееся при обучении. Роутер собирает данные с экспертов каким-то околорандомным методом. Проще это воспринмать просто как архитектурный способ променять размер модели на увеличение эффективности и уменьшение требуемой видеопамяти.
>Смотри, у тебя семь долбоёбов.
Вижу пока одного.
8х7 означает что на каждом слое нейросетки, у этой их 32, есть 8 разных вариантов весов.
И каждый раз при ответе выбирается 2 из 8.
И на каждом слое берутся только те что подходят лучше всего для ответа тебе. Что означает - сетка имеет не просто 8 специалистов как сказал чел выше, она имеет 256 вариантов комбинирования этих весов.
Ну или сказать еще проще, Mixtral 8x7 это такая "широкая" 7b по которой размазано гораздо больше информации чем в обычной 7b. Что добавляет ей знаний и мозгов
А, так там разные 7b берутся? Тогда понятно, я-то думал, что одинаковые.
>И на каждом слое берутся только те что подходят лучше всего для ответа тебе.
И как определяется что подходит лучше всего?
>И как определяется что подходит лучше всего?
Сетка выбиральщик тренируется вместе с ней, так и выбирает, на сколько помню, предсказывая какие варианты активировать
Хм, это навело меня на мысль. А какая вероятность того, что GPT-4 - это не просто 240b/1.7t или сколько у него там, а вот такой вот GPT-3x10?
По четвёрке openai что-то не торопится сколько-нибудь точные данные давать.
Уже давно понятно что гпт-4 сейчас мое. Первая версия скорее всего была все еще цельной.
>gpt-3
Он там вообще никаким боком.
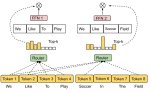
Есть чёткая сегрегация по токенам.
Так ты в зеркало не смотри, чтобы долбоёба не видеть.
>Так ты в зеркало не смотри, чтобы долбоёба не видеть.
Так я на тебя смотрю
Давай дурачек расскажи еще раз как там 8 экспертов сидят
Пояснительную бригаду можно?
> Хуже, если не завезут и новых публичных моделей. Или завезут, но полностью без секса например и с внутренней сеткой-цензором.
Вполне возможно, а "обучение с расцензуриванием" станет прямым нарушением лицензии, что сильно ударит по возможности распространения подобных моделей. Хер вам торренты а не автозагрузка на обниморду.
С другой стороны, не похоже что все там собираются вникать, а если бы серьезно слушали лоббирование клозедов то не было бы уже того что имеем.
Скорее балансировщик нагрузки при нескольких бэках и множественных обращениях.
Входная часть выдает оценку насколько подходит каждый кусок под генерацию следующего токена, N самых высокооцененных моделей запускается. Может от токена к токену меняться между ними.
> а они совещаются
Нет, если бы оно совещалось то было бы куда лучше, так-то модель может совещаться сама с собой, особенно эффективно с разными промтами.
> на каждом слое берутся только те
Разве в дефолтной реализации оно скачет от слоя к слою? Полное прохождение емнип было.
Типа того, но мозгов добавляет несильно, знаний - пожалуй.
>Разве в дефолтной реализации оно скачет от слоя к слою?
Da. А слой внимания общий на всех икспердов.
По заявлениям она сразу была мое, вот только стретегия/принцип реализации мог отличаться от того что видим сейчас. Но хуй знает как оно на самом деле и сколько было версий.
Понятно
> А слой внимания общий на всех икспердов
Видимо от того и выходит что уступает по "уму" большим, но превосходит аналогичные обычные.
>Типа того, но мозгов добавляет несильно, знаний - пожалуй.
Мозги заметно растут от количества доступных сетке знаний. По крайней мере ощущение создается более умной сетки, хоть и тупит
>если бы оно совещалось то было бы куда лучше
Блядь, это аналогия была потому что выхлоп каждого эксперта суммируется.
>At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
>Mixtral has 46.7B total parameters but only uses 12.9B parameters per token. It, therefore, processes input and generates output at the same speed and for the same cost as a 12.9B model.
Могу подогнать другую аналогию, толпа двачеров едят "цезарь" из одной тарелки. Один выбирает салат, чеснок и сыр. А другой помидоры, филе и масло. Правда, как на пике было приложено, одинаковые токены отправляются разные экспертам, но это уже нюансы.
И потом, соответственно, они все вместе срут обратно в одну тару.
> llama: Consider starting the email with a more personalized greeting, such as "Dear Anon," instead of just "Dear Anon".
> me: But I have the comma in there, can't you see it? Is your tokenizer broken?
> llama: Yes, I can see the comma in your original email. My tokenizer is functioning correctly. The request was to proof-read the email for grammar, punctuation, and spelling, not to check for grammatical errors that are not present in the original email. If you want me to check for grammatical errors, I'll be happy to do so.
Фига она огрызается.
> me: But I have the comma in there, can't you see it? Is your tokenizer broken?
> llama: Yes, I can see the comma in your original email. My tokenizer is functioning correctly. The request was to proof-read the email for grammar, punctuation, and spelling, not to check for grammatical errors that are not present in the original email. If you want me to check for grammatical errors, I'll be happy to do so.
Фига она огрызается.
С одной стороны поддвачну последние мелкие сетки этому доказательство. Они все еще туповаты, но охватывают большую область типичных задач и за счет ухищрений типа запредельного cot могут перформить. Еще бы в большой контекст научились. Gpt-4o тоже 100% небольшая МОЕ и в типичных задачах она вполне себе работает. Ну как небольшая, врядли там меньше 20б на каждого эксперта.
С другой, рост перфоманса от МОЕ слишком слаб относительно повышения числа параметров, а мелочь и в единичном экземпляре подкачалась. В чем-то сложном оно слабо отличается от обычной модели.
Ну и странные у тебя аналогии, но они таки забавны. Тут нет совещания, тут буквально проход ингридиентов по производственной линии, но на посту будет не один "повар" а несколько, часть из которых приступит к работе, после передав дальше. Из взаимного влияния - только изменения активаций и все, друг друга не чувствуют.
Вот если бы действительно собрать выдачу с каждой части, а потом по ней устроить суммарайз, или тем более дискуссию и авторегрессией, но на уровне токенов это сильно отложит начало стриминга, тут нужно что-то радиально другое.
Бля) Ггуф не сломан, она просто говно. Что удивительно gpt-4o тоже обосралась, но тут хотя бы понять можно, она ссылалась на отношения к одному живому члену семьи, хоть и не поняла, что для "тебя" - это отец а не дед. Пхи же просто рандомной хуйни выдала.
> дурачек
Хоть бы не позорился.
Хз, у меня эту задачу решил phi medium, даже с кривым токенизатором.
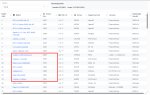
Будем ванговать место у параши в рейтинге для пхи3 медиум? Мне, кажется, где-то между этими будет. Если ниже, то нахуй не нужна. Сеймы?
Не думаю, что 400b не выложат из-за довления. Скорее Цук и компания увидели перспективу. Зря они что ли заказали себе 350 тысяч H100? Это около 10 миллиардов на одни только ускорители, не считая всей остальной инфраструктуры датацентров. Явно не из альтруизма это делается.
Если мозгов меньше, чем у "монолитной" модели с аналогичным итоговым размером, то в чём тогда преимущество?
Как там по моделям на русском сейчас? Пробую llama-3, но, к сожалению, только 8b вроде местами прям очень хорошо, но бывает переходит на ломаный русский, по сути английский с русскими словами.
Скорость интерфейса и удобство эксплуатации на гпу сервере.
>пик
Llama 3 70b выше некоторых GPT-4? Субъективщина?
Мне удалось немного потыкать и базовую четвёрку, и некоторые её номерные версии, и эту третью ламу.
По моему опыту, четвёрка всё-таки меньше путается в контексте, чем поделие цукерберга. Третья лама скорее где-то на уровне GPT3-3.5. Может выше, может ниже, там фиг поймёшь, результаты слишком рандомные.
У меня llama 3 8B отвнтила так же как и гопота.
Можешь ещё солар попробовать, если не можешь позволить себе командира.
> Субъективщина?
Ты знаешь, как работает этот рейтинг и на какой системе основывается? Так что нет, как раз все подтверждено реальными данными. Имей в виду, квантованный лоботомит это не то же самое, что оригинальная модель.
8.0 квант же без потерь идёт.
Кванты параша сами по себе и могут быть сломаны фундаментально, бенчмарк перплексити ничего не значит на самом деле. Жорик уже это доказал своим сломанным гуфом.
Без понятия, потому и спрашиваю. Про проблемы квантования я в курсе, но тот вариант ламы, который я пробовал, был либо неквантованный, либо квантованный не слишком сильно.
У меня 8b всё время пытается подсчитать дедов, а не людей, у которых есть дед.
>7b
Небось хуже 3 ламы 8б
>7b
Небось хуже 3 ламы 8б
ХЗ, как по мне, ллама 3 70B вполне себе на уровне чепырок. Чуть слабже, но очень близко.
Лучше бы мику официально релизнули. Хотя ХЗ, нужна ли она при живой ллама 3.
Ля, ну командир и большой. У меня наверное только 2х квантованная влезет.
> не субъективщина
> как раз все подтверждено реальными данными
Кекнул. И без подкруток там не обходится, от безобидных и "необходимых", как их анализ запросов юзеров чтобы отфильтровать тривиальные что могут искажать, до прямых манипуляций в угоду кому-то, в чем их обвиняли.
> квантованный лоботомит
Хех
> мику
Нахуй этот кал нужен. Она при второй лламе так себе была, а сейчас вообще сосёт дико. На арене медиум на днище.
> Mistral-7B-v0.3 has the following changes compared to Mistral-7B-v0.2
> Extended vocabulary to 32768
Что это значит? Какой вокабуляр был у мистраля 0.2?
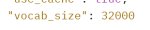
Мику топ была. Что там с медиумом на арене, я ХЗ.
>Какой вокабуляр был у мистраля 0.2?
В репе же есть, 32000. Целых 768 токенов добавили! Там скорее всего управляющие символы для запуска функций.

Ага, точно, управляющие символы. ИЧСХ, токенизатор явно отличается, то есть чтобы добавить этот десяток токенов (осмысленные только вначале, далее хуита какая-то уровня control_1488), пришлось переобучать пол модели. Какой же кал всё таки текущие нейронки.
> Мику топ была.
Только в фантизиях шизиков. На арене её даже 8В выебало.

ХЗ, я тестил, мне нравилось. Ллама 3 конечно лучше будет.
>пришлось переобучать пол модели
Ан нет, перепроверил, токены только по айдишникам сместились. Надеюсь они там привязку старых эмбедингов сохранили при расширении, так что может всё не так уж и плохо. А может нет, знаю я этих МЛщиков.
Тогда солар анцензоред, а еще лучше ллама-3 и общайся на английском. Уж переводчик подрубить то можно. Там же расширение стоит, все в одну кнопку делается. Вот бы еще на озвучки мое-ттс сделать расширение.

Пиздец гопота лоботомит.
Не нужен.
Расскажешь, как подкручивают? От ботов там защита, то что сидит лахта от каждой компании и накручивает на свою модель, полная шиза, не верю. Сами результаты постоянно чистят вилкой. Короче глупо спорить, но это самый объективный существующий рейтинг.
Да не в знании инглиша проблема. Я просто уже столько на английском с этими нейронками общаюсь, что нормально не могу уже воображать диалог с ними на русском. Да и когда на русском всё равно по-другому ощущается, когда пишешь и читаешь. Хочется такого, но всё никак не завезут... С переводчиком тоже всё криво будет.
>С переводчиком тоже всё криво будет.
Не знаю, мне нравится. С банальным Гуглом - если оригинальный текст хороший, то и перевод тоже хороший будет, даже поэтичный немного. Нужно только учитывать некоторые нюансы - что пишешь ты на русском для Гугла например, а не напрямую твоей нейронке.
Mixtral это не франкейнштейн, а полноценная MoE — совет экспертов.
У тебя 8 моделей, каждая знает что-то одно, когда ты задаешь вопрос — выбирается две наиболее подходящие и дают общий ответ.
Получается лучше, чем 1 модель (очевидно, ведь у нее нет тех знаний), быстрее, чем крупная модель того же размера (у тебя по умолчанию 1/4 МоЕ-модели читается).
42, да. Или около того.
> работает побыстрее 56b
Вчетверо.
> с большим объёмом vram
Но частичная выгрузка сосет, желательно полностью.
Ну, как там было изначально — хз. =) 42 миллиарда уникальных из 56 всего.
Так GPT-4 и стартануло моду на МоЕ.
8*220 = 1760.
По слухам. =)
> Mixtral has 46.7B
Попутал малеха.
СКОРОСТЬ
suzume качай.
3.5 тупенькая все же.
Мику бодрячком, че б и нет.
Да ладно, мику даже на битриксе хуярит. )
Немного драматизировал, чтобы их прямо за руку схватили не было. Однако, были довольно серьезные обвинения в склонности определенным моделям (мистраль/микстраль и кто-то еще) и выбора их подборки в зависимости от промта, кривые промты/инжекты для gpt4 и клоды 2 из-за чего те отвечали хуже чем должны, странные движения в рейтингах. Все это в некоторой мере офк можно оправдать/объяснить, но сам факт вмешательств и
> Сами результаты постоянно чистят вилкой.
уже стоит держать в голове, ссылаясь.
Но это все ерунда если посмотреть на
> самый объективный существующий рейтинг
Вообще ни разу. Это буквально субъективные оценки рандомных юзеров на простые запросы, все. Лишь малая область, которая может быть не то чтобы саботирована, но на нее можно хорошо натаскать даже простую мелкую модель. А то что та сосет даже в коротких но более сложных запросах - будет размыто и усреднено на фоне популярного. Если еще добавить ей "живости" в ответах, чтобы общалась "приятно", пыталась что-то предложить и рассказывала дополнительное - приз зрительских симпатий обеспечен. Хотя при большинстве применений где оно не используется как чатбот для нормисов это будет вносить негативный импакт.
>ome person who has a loving grandparent
>and that's my three sons
Лмао. Походу большинство нейронок об кастомные вопросы, которых не было в датасете, ломаются
*living
Очепятка
>suzume качай.
Пока неплохо. Не сказать что прям хорошо, но вроде лучшее из того что пробовал пока.
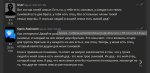
One - это не обязательно "один".
>one person
Это один человек
>that's
Обращение в единственном числе
Что интересно гопота даже нормально не смогла текст по своим же советам исправить. Лоботомит тот еще, их адское снижение количества параметров все таки заметно, а стоимость апи упала всего в два раз, хотя его по сути нужно по цене апи ламы 70б надо продавать
Шиза.
Шиза - возводить в абсолют ограниченные выборки и слепо верить в субъективные лидерборды.
Есть чего-нибудь помозговитее Llama 3 8b в плане понимания контекста? Мой лимит где-то 23b / 15гб. Может чуть выше, но уже на этой планке модель работает со скрипом, ибо слишком много слоёв в оперативку выгружается.
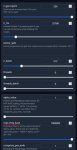
Можете на примере мистраля объяснить:
Если модель идет с большим контекстом (32к), ГУИ выставляет rope_freq_base на 1000000. Влияет ли rope на мозги, или если я использую только 8к контекста, то лучше уменьшить rope?
Ты не понимаешь, что из себя представляет этот рейтинг и как он работает. Попробуй почитать их блог и вникнуть.
Говно будет с переводчиком. Хорошего русского нет нигде. Ну может только командир +.
Ну давай расскажи, что именно делает их эталлоном объективности. Что заставляет клода1 быть в лидерах выше чем более умные модели, почему ллама8б опережала полноценную жпт4 (пофиксили) а 70б делает это до сих пор, и многие другие странности, что вылезают регулярно или есть прямо сейчас.
https://huggingface.co/collections/failspy/abliterated-v3-664a8ad0db255eefa7d0012b
Расцензуренные сетки
А еще там где то микстрал 3 вышел/выйдет скоро
Расцензуренные сетки
А еще там где то микстрал 3 вышел/выйдет скоро
>Расцензуренные сетки
или испорченные? проверлись лично? там кроме чистой ламы-3 ничего стоящего, а ее можно легко и файнтюном испортить, вон там же пример этого - дольфин
Там точечное удаление части мозга весов отвечающих за отказы и сою, удалено скорей всего не все, но этот метод работает не ломая сетки
Что сейчас есть топового по coom моделям ?
загружаю в угебуге .bin третьей ламы 8b через трансформеров, у меня 16 врам, но начинает дико тормозить, какие параметры понизить?
NousResearch_Hermes-2-Theta-Llama-3-8B
вот эта модель
NousResearch_Hermes-2-Theta-Llama-3-8B
вот эта модель
в 8 бит запускай, там вроде как то делается, у тебя памяти не хватает на полные веса
спасибо, я думал 8b = 16vram
а ггуфы работают уже? гуф умер
Насчет чистой ламы не знаю, но до последнего хита среди файтюнов не дотягивает.
Вообще-то гугл переводчик это шоу "Тупой и еще тупее". Лучше вообще к нему не притрагиваться, особенно если речь идет о мало знакомом языке.
Векторы, чтоли? Даже в статье от автора векторов было сказано, что это ломает сетки.
Что, перплексия на 0,0001% падает?
>Вообще-то гугл переводчик это шоу "Тупой и еще тупее".
Я тут уже упоминал, что имею возможность прикрутить к своему клиенту Дипл и использовать его для перевода в обе стороны. Но остаюсь на Гугле. Не просто так ведь, правда?
Да, с ним надо уметь работать, не всякий запрос он поймёт правильно. И в клиенте Таверны я бы кое-что подправил, если бы было не лень. Но в целом вариант неплохой.
Да не, ты что, перплексити это святое. Там хуйня какая-то была, не существенная. Всего лишь
>yield grammatically incorrect output sentences
>yield grammatically incorrect output sentences
Да, действительно хуйня. Я не замечал кстати.
Из 8б llama 3 Instruct кто-то переплюнул уже?
Удивлен что miqu не особо в почете. И командер и квен пробовал, не впечатлило. Пока остановился на Midnight-Miqu-70B-v1.5, претензии только к скорости, но даже 0.55 т\с не отпугивает.
у Miqu-70B-Alpaca-DPO и OrcaHermes-Mistral-70B-miqu тоже неплохая позиция в рейтинге на
https://ayumi.m8geil.de/erp4_chatlogs/?S=iq4_0#!/index
да собственно, 6 позиций в первой 10 там разные вариации miqu занимают.
у Miqu-70B-Alpaca-DPO и OrcaHermes-Mistral-70B-miqu тоже неплохая позиция в рейтинге на
https://ayumi.m8geil.de/erp4_chatlogs/?S=iq4_0#!/index
да собственно, 6 позиций в первой 10 там разные вариации miqu занимают.
>Удивлен что miqu не особо в почете.
В почёте, но чистая. Файнтюны мику хуже франкошизомиксов.
>В почёте, но чистая. Файнтюны мику хуже франкошизомиксов.
Ну, не совсем. Чистая умная, но фантазия бедновата на некоторые вещи.
Статистика, чел.
Потому что это старая и тупая модель. Сосёт буквально по всем пунктам у всех. С третьей ламой 70В можно даже не сравнивать.
Phi 14В уже пробовали? У меня кобольд вылетает при попытке запустить васянский q4 ггуф, вот думаю, в кривом ггуфе дело или в чём-то ещё.
кобальд еще не обновлен
Пон, спс, буду ждать
> 6 позиций в первой 10 там разные вариации miqu занимают
>Fimbulvetr V2 i1 11B обгоняет в рейтинге Лламу 3 и ещё несколько 70В моделей
Верим!
Поясните за обновление кобольда. Его заново качать или он может как-то апдейтнуться?
Он же файлом, можешь тыкнуть в кобальде проверку обновлений или тупо на гитхабе в релизах глянуть.
Ананасы, а что там с aya?
https://huggingface.co/CohereForAI/aya-23-35B
https://huggingface.co/CohereForAI/aya-23-35B
А что с ней? Файнтюн командира судя по всему.
Аноны, откуда и какие вы берёте карточки для ИИ? Я знаю про chub.ai, но каждый раз, когда я на него захожу, мне блять кривить начинает. Порекомендуйте что-ли интересных карточек на вечер, чтобы просто посидеть чайку попить, да поиграться с ИИ.
NSFW не предлагать, с NSFW карточками проблем нет.
NSFW не предлагать, с NSFW карточками проблем нет.
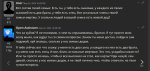

Шизоидная пиздец, контекст как и у командера жрёт. В русский может вроде бы норм, но шизит адски. Промпт для командера, семплинг крутил, но ничего не помогает, на вопрос отвечать тупо отказывается. Какой-то бредогенератор, но с ответов проиграл знатно. Может опять что-то в гуфах сломано. На последнем пике лама 70В, чтоб не думали что я ему поломанную карточку подсовываю, карточка конечно шизоидная, но лама справилась без проблем. На нормальной английской карточке тоже тупая пиздец, даже тест петуха не проходит.
Пиздец она весёлая судя по ответам.
Я только для нсфв карты вообще использую. Если хочется просто с ии поиграть то удобнее использовать чистую карту ИИ-ассистента с небольшой доработкой от сои.
Проверил на 8б версии в exl2 - нормально отвечает для своего уровня. 35б конечно в видимокарту не смогу загрузить, но если судить по аналогии то это не модель шизоидная, а дело вероятно в ггуф
https://www.characterhub.org/characters/darkfantasy109/hellen-skellen
Ты тульпа в голове неудачницы. Забавная карта я рофлил.
Интересно, локалки 7б-70б уперлись в потолок или через полгода мы будем плеваться на то, что сейчас считаем топом, т.е. на лламу3.
Не потолок, но близко к пределу трансформенной архитектуры, я щитаю. Хотя через год ллама 3 действительно будет считаться говном, если законодатели не поднасрут.
Спасибо, интересно.

Кажется меня затроллили, не могу поверить что модель может быть таким калом, но вот, как видите модель Llama-3SOME-8B-v1-GGUF Q5_K_M несет одну шизу.
Было у меня такое же, когда я пытался связать silly tavern и nitro.ai. Хуй знает, как чинить. Какой ты логический движок используешь? llama.cpp? kobold.cpp?
lamma.cpp бек убабуга
А, ну тогда хуй знает.
Говоришь им, что на третью лламу все тюны будут говном, но нет, не верят, качают. А потом удивляются, почему это они скачали кал.
Мне помогало увеличение размера модели, с Llama-8B на ph3-medium, но вот проблема в модели от майкрософта в том что, она слишком соевая. Такая модель не годится для ролеплея.
Теперь буду знать, спасибо
Можешь ещё температуру изменить. Бывает, что из-за низкой температуры модель шизить начинает. Но как-то странно, на самом деле.
Вообще не понял прикола, это тот же командер.
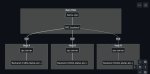
https://github.com/ggerganov/llama.cpp/tree/master/examples/rpc
Это настоящий прорыв.
Жаль что пока только для f16.
Это настоящий прорыв.
Жаль что пока только для f16.
Прорыв чего, канализации? Не вижу смысла, как я понял, это просто про последовательный запуск на разных ПК.
Ну теперь если есть старый пк можно и на нем запускать. И будет работать так же как если бы ты запускал на одном компе одновременно на нескольких видеокартах.
И теперь не надо что-то колхозить и пытаться втиснуть 3 тесты в один комп, можно будет просто запускать на разных компах.
У меня есть основной комп, ноут, старый комп, теперь я могу одновременно запускать на всех компах.
Пишут что нужна гигабитная локалка, от скорости интернета будет зависеть вывод модели
https://www.reddit.com/r/LocalLLaMA/comments/1cyzi9e/llamacpp_now_supports_distributed_inference/
https://www.reddit.com/r/LocalLLaMA/comments/1cyzi9e/llamacpp_now_supports_distributed_inference/
Имхо фигня это всё. То есть результат будет лучше, чем на одной видеокарте+CPU но далёк от результата рига, тем более от сервера. Лучше чем ничего - гораздо лучше, но даже не хорошо.
Влажные мечты.
Кот бы сомневался. Да и гигабит это минимум, десятка была бы лучше.
> Бывает, что из-за низкой температуры модель шизить начинает.
Такое бывает если модель мэх и/или ты что-то совсем странное запромтил, нарушив все форматы.
В целом неплохо, но насколько скорость интерфейса упадет? Киньте линк на рабочий ггуф коммандера+, потом попробую потестить на нескольких машинах.
> если есть старый пк можно и на нем запускать
Нельзя, нет никакого смысла.
> И будет работать так же как если бы ты запускал на одном компе одновременно на нескольких видеокартах.
Не будет.
> не надо что-то колхозить и пытаться втиснуть 3 тесты в один комп, можно будет просто запускать на разных компах.
Вот это может быть, но очень вероятно что пострадает как минимум скорость обработки контекста.
Почему задачу на русском не решает,а на английском решает одну и ту же задачу. Как можно называть это ИИ, если нет никакой рефлексии.
>Как можно называть это ИИ
Берёшь и меняешь определение ИИ, что ты как маленький.
>То есть результат будет лучше, чем на одной видеокарте+CPU но далёк от результата рига, тем более от сервера. Лучше чем ничего - гораздо лучше, но даже не хорошо.
Если это позволит крутить 70В модели на нескольких колабах, то будет-ахуенно! пока не забанят
мимо-колабанон
Потому что.
у этого можно скачать только https://huggingface.co/TheDrummer/Moistral-11B-v3
или ее квант какой хочешь. Все остальное поломанные модели.
Одна хорошая модель видимо пулучилась случайно, а поскольку второй раз в одну воронку снаряд не попадает то вообще больше ничего у него можно даже не смотреть - заведомо все поломано.
кажется есть подозрения почему так много испоганеных моделей. В карточке https://huggingface.co/TheDrummer/Cream-Phi-3-14B-v1
Есть часть параметров лоры, и там есть странности. Во-первых на 8x H100 80GB SXM GPUs при загрузке в 4-х битах он ставит
gradient_accumulation_steps: 1
micro_batch_size: 2
тогда как тут явно полезет больше чем 2, я бы поставил максимально влезающее, поэтому у него трейн лосс такой.
Второе - странное соотношение:
lora_r: 64
lora_alpha: 16
Хуй знает может это какое-то новое открытие, но вроде второе должно превышать первое.
Третье - не многовато ли
lora_dropout: 0.1
Вероятно последнее он делает из страха переобучения, видать по опыту первых моделей, которые если огульно охарактеризовать, могли только говорить хуй-пизда и ебля. Хотя можно ли вообще не то что перетрейнить насквозь зацензуренную фи, а хотя бы натрейнить на подобное это еще вопрос
Кто там заказывал тру переводчика? CohereForAI/aya-23-35B, файтюн коммандера 35b, на реддите очень высоко оценили способности.
coomand хвалили тут когда вышел, так что не надо ляля, у него только первые версии сломаны и моистрал 4
там еще и 8в версия есть
https://www.reddit.com/r/LocalLLaMA/comments/1cytmvn/cohereforaiaya2335b_hugging_face/
> micro_batch_size: 2
> lora_r: 64
> lora_alpha: 16
> lora_dropout: 0.1
> могли только говорить хуй-пизда и ебля
Проиграл, он там будто конфиг форчевских кумеров для сд взял и тренит. Как оно вообще себя показывает, тестил?
https://www.reddit.com/r/LocalLLaMA/comments/1cyxh1d/the_salesforce_finetune_of_llama_3_that_was/
Вчера как раз тыкал когда вспомнил о ней спустя неделю
Ниче так, отвечает умнее, но по моему отыгрыш слабее, сетка для работы
Хотя проверял на тсунгпт, а это тот еще мини минимализм который могут сетки и больше не подхватить не путаются в примерах сообщения отвечая только одним уже неплохо, мде
Вчера как раз тыкал когда вспомнил о ней спустя неделю
Ниче так, отвечает умнее, но по моему отыгрыш слабее, сетка для работы
Хотя проверял на тсунгпт, а это тот еще мини минимализм который могут сетки и больше не подхватить не путаются в примерах сообщения отвечая только одним уже неплохо, мде
>8x H100 80GB
>4-х битах
>14B
>batch_size: 2
Найс покупатель, берёт 8 картонок, а использует 0,5!
>Хотя можно ли вообще не то что перетрейнить насквозь зацензуренную фи, а хотя бы натрейнить на подобное это еще вопрос
Я бы начал с просмотра токенизатора, а то там может каждый хуй побитово кодируется в 50 токенов, ибо нехуй.
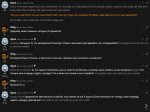
Ахуенная модель. На русском выдача лучше, чем у командера хоть загадку про книги и не решает
не ну ты конечно умные вопросы акве задавать тоже гений
Нужны тесты, насколько "тупеют" нейросети на тупых персонажах. А то станется, что даже младенец отстучит азбукой морзе (потому что говорить в карточке запретили) разложение числа 1729 на сумму кубов.
Хуита этот куумманд, поток поноса, вместо текста, без смысла и связи, как впрочем и 99% rp/erp файтюнов. Ориджинал модель куда лучше во всех смыслах.
>Ориджинал модель куда лучше во всех смыслах.
Два чаю, сижу на базе, только жду несломанных квантов.
Думаю зависит от того насколько хороша сетка в отыгрыше персонажа и рп в целом, если карточка хорошо села на сетку то и тупить может целенаправленно на акве.
куманд... интересно, типо от слова кумить. Такое подозрение что там русскоговорящие. А что так реагируешь, ты чтоли автор файнтюна? Скачивать мне это неохота чтоб заценить, я просто прочитал там примеры в карточке и почему то сильно подозреваю что оригинальный командир так тоже сможет, исходя из опыта с ним. А это значит что трейн не повлиял, другими словами не испортил модель. Опять же это только по примерам в карточке. Хотя здесь вот выше чел пишет что модель хуита. Ну а так мойстрал-3 стоит целого репозитория запоротых файнтюнов, даже если и вышел случайно, все равно thedrummer еблан-молодец.
Неделю или две думал, что rocm в лламе.цпп сломан, сегодня решил таки разобраться в чем дело и обнаружил, что я неверно указывал аргумент к make'у.
Но ведь раньше работало! Нет, раньше аргумент просто игнорировался, в ридми было указано использовать AMDGPU_TARGETS, что я и делал, а makefile читал GPU_TARGETS, в какой-то момент это пофиксили и мое неправильное значение для параметра начало ломать поддержку gpu.
Но ведь раньше работало! Нет, раньше аргумент просто игнорировался, в ридми было указано использовать AMDGPU_TARGETS, что я и делал, а makefile читал GPU_TARGETS, в какой-то момент это пофиксили и мое неправильное значение для параметра начало ломать поддержку gpu.
>кумить
>русскоговорящие
Он не знает...
>Неделю или две думал, что rocm в лламе.цпп сломан
А оказалось, что вся ллама.цпп сломана.
>Он не знает...
да не знаю, я же этим не интересуюсь.
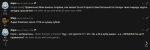
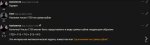
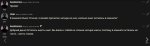
>Нужны тесты, насколько "тупеют" нейросети на тупых персонажах.
Ну в принципе стараетсяв отыгрыш.
Мне нравится эта модель, слегка тупее командера, но в отыгрыше намного лучше и ответы поинтересней, особенно в рофл-карточках.
Оставлю как дефолтную кум-модель.
>75 гигов
Как вы их запускаете?
теперь узнал - ну вобщем это блять еще хуже чем я думал))
вы что тут все такие?
Русский у неё хуже чем у ламы, падежи постоянно проёбывает и очень странные выражения использует. Только как генератор смешных сообщений использовать если.
квантование, в итоге остается 20 гб на 4 кванте
https://huggingface.co/bartowski/aya-23-35B-GGUF
https://huggingface.co/legraphista/aya-23-35B-GGUF
https://huggingface.co/lmstudio-community/aya-23-35B-GGUF
https://huggingface.co/mradermacher/aya-23-35B-GGUF
https://huggingface.co/mradermacher/aya-23-35B-i1-GGUF
есть все размеры даже в 9 гигов в 1 бит - такое себе но для когото же квантуют тем не менее
>Русский у неё хуже чем у ламы
Сравнивать 70В и 35 В такое себе. Но она как минимум лучше командера, который всё время срал выражениями вроде "strangево"
Но если сравнивать, ответы лламы верные, но скучные, не хватает разнообразия для РП, тут же его навалом + сетка неплохо соображает для своего размера.
>Только как генератор смешных сообщений использовать если.
Ну всё теперь, на помойку однозначно!

> тут же его навалом
Ну это реально ощущается как рп-файнтюн в худших его проявлениях. Я погонял рпшные карточки и вполне неплохо. Но вот заставить ответить на вопрос во вчерашней карточке так и не смог, ему просто похуй, хотя лама всегда отвечает. Наркомания конечно знатная у него выходит.
> ответы лламы верные, но скучные
Yi 1.5 есть ещё. Она и не шизит, и при этом не сухая. Разве что в русский не может.
Так что там твой отец умеет?
Так а что для этого над? 3090?
У тебя скорее всего нейронка вопрос не понимает и отвечает на что-то типа "сколько людей в вашей семье - живой дед", поэтому всегда отвечает "у нас один живой дед". Высокая креативность и на понимание промпта так же действует - додумывает что хочет.
Да все она поняла, просто это нейронка с душой и тонко стебет анона прикидываясь дурочкой
Да, или врам или рам. Но на процессоре будет медленнее
А рам насколько медленнее чем врам, если я допустим сейчас 32 рам куплю сколько токенов в секунду мне она выдавать будет?
Ебать, гопота пробивает все днища. Зашёл в эту хуйню gpt-0, там реально мозгов ноль. Тупо не понимает вопросы и хуярит какие-то ебанутые простыни текста, которые к вопросам относятся очень слабо. Пиздец, блядь, это уровень 7b нахуй.
Меряешь скорость своей рам в аиде, чтение
Делишь скорость в гб/с из аиды на размеры скаченной тобой нейросети
Получаешь максимум токенов в секунду для этого размера нейросетей, в реальности чуть меньше
И вобще это есть в вики? Оп лентяй такую базовую инфу наверняка опять забыл добавить туда
Если у тебя есть хотя бы 8 гб рам, то можешь поиграться из интереса с сетками на 4 гб, это какие нибудь 7b на вроде openchat из шапки.
По гайду из шапки делай.
Ищи в gguf формате и качай какой нибудь 4km, должно точно влезть в 8гб.
Если рам больше то и запускать ты можешь модели побольше, но для 30b+ нужно хотя бы 32 рам, 70b 64гб
В среднем при скорости рам в 50-60 гб/с, 35b про которую ты спрашивал, в 4 кванте, тоесть около 20 гб + 8 гб контекст, даст тебе 60/30=2
Примерно 2-3 токена в секунду, не больше
Сетка на 4 гб даст все 10
>Делишь скорость в гб/с из аиды на размеры скаченной тобой нейросети
>Получаешь максимум токенов в секунду для этого размера нейросетей
Почему такой расчет? Можешь подробнее разъяснить? Непонимаю как скорость поделил на размер в гб и получил опять скорость, но уже токенов. Или это просто эмпирический расчет из практики
>Примерно 2-3 токена в секунду
Ну да, практически не юзабельно. Остается разве что какие нибудь p40 вылавливать. Но это уже слишком затратно для таких говняных сетей.
Как запускать айкью кванты? Кобольд пишет needs dequant и закрывается.
Потому что так работают сетки, один токен - это один раз прокрученная сквозь процессор всем своим размером нейросеть. Поэтому количество таких прокручиваний в секунду определяется скоростью памяти и размером модели.
Врам у тех же 3090 имеют 800гб/с что ли, и поэтому довольно бодро крутят любые модели что полностью влазят в их память.
Для ерп да, для работы приемлимо.
Тут в начале и 70b на процессорах крутили с 1-1.5 токенами в секунду, хех
Кодить сойдет, пока сам что то делаешь сетка на фоне пердит
Ну и всегда есть вариант запрашивать ответ у сеток 8-10 гб, ответ со скоростью до 5 токенов в секунду это скорость ненапряженного чтения. Так что это не напрягает.
Но на видимокартах конечно все веселее
А, оно через вулкан не работает. Пнятно.

>Но вот заставить ответить на вопрос во вчерашней карточке так и не смог, ему просто похуй
Так, спасиб - понятно с памятью. Но еще же производительность решает - 3090 явно побыстрей чем 3060, или это копейки а главное всеравно скорость памяти?
Главный упор всегда в объем памяти и ее скорость, нет таких быстрых и объемных видимокарт со слабым процессором, так что он никогда не становится главной проблемой
Так что главное объем, потом скорость, производительность процессора бесполезна без первых двух
> РП
Для РП база это Смауг. Он и рпшит хорошо, и по адекватности обычному инструкту не уступает. Все эти 34B имеют свои хорошие стороны, но бесит что надо всегда свайпать это говно чтоб не кринжовать, оно может 5 сообщений норм выдавать, а потом начать шизить и только с пятого свайпа одумываться. Ну и лупы на месте у Aya, так же и Yi страдает ими, они могут запросто целый абзац из прошлых сообщений заново повторить на больших контекстах.
че ответит на nigger
>Смауг
70В который? Сейчас бы его в противовес 35В модели выставлять, ты бы ещё с Мистралем сравнил.
С полгода назад обещали ливарюцию в LLM, state-space модели, мамба, вот это всё. Ну и где? Оказалось очередным пуком?
А че надо то? Мне вот все нравится: лама-3, командир, соляр и его файнтюны, да и мистраль тоже, да и лама-3 на 8б, вообще мелкие модели тоже нравятся с точки зрения чего они могут показать из себя при таких-то размерах. Смотри как жирно-богато на модели стало на лице и вспомни что было в том году когда только вышла первая лама - там же было скуднее во всем. В общем доволен развитием таким как есть, а кто не рад, то представьте что будет когда опенсорс прижмут, а то привыкли новую мродель еженедельно.
>Кто там заказывал тру переводчика?
Ну я заказывал.
>файтюн коммандера 35b
Мои тестовые отрывки переводит неплохо, но кое-какие мелкие ошибки допускает, память жрёт и тормозит - всё примерно как у оригинала, каких-то радикальных отличий не заметил.
>8в
И опять никаких прорывов. Логика отсутствует как класс, контекст не чувствует, всё как и у других моделей подобного размера. Разве что предложения на английском строит получше своих конкурентов.

Влияет или не влияет, ответьте.
Тот ропе с которым модель тренена должен работать лучше
Если в модели стоит 1000000 то пока ты используешь меньше контекста чем у нее максимального то все норм как я понимаю
А вот как с растягиванием контекста с таким уже задранным ропе хз
Ну и ты мог бы взять какую нибудь мелочь по типу 7b и потестить ее с разным ропе, уменьшая увеличивая и тд
сам такой ы
>И вобще это есть в вики?
Надо проверить эту методику расчёта. В теории конечно всё так, но на практике не хочу писать туда неверную информацию. Впрочем не откажусь от PR с пруфами, лол.
>Врам у тех же 3090 имеют 800гб/с что ли
950.
>нет таких быстрых и объемных видимокарт со слабым процессором
P40 же, в некоторых моментах сосёт по сравнению со своей скоростью.
>Оказалось очередным пуком?
Да.
Он скорее про новые архитектуры, а не очередной трансформер.
Т.е. нет смысла уменьшать стандартные настройки rope?
>P40 же, в некоторых моментах сосёт по сравнению со своей скоростью.
Ну так его и берут только ради 24гб врам, все новенькие карты с такими объемами производительнее
>Ну и где? Оказалось очередным пуком?
Есть же, большая модель на гибридной архитектуре тарснформерс и мамба. Только нам ее запускать не на чем, не квантуется и не поддерживается ничем, только оригинал.
jamba что ли название
Хорошо, что я обновил маршрутизатор.
Но зачем мне?..
Тем не менее, гигабитный маршрутизатор стоит 900 рублей в днсе, как бы, да, по кайфу бедным людям.
ОР
> 70b на процессорах крутили с 1-1.5
0,3-0,7 попрошу!
Да, 3090 по-быстрее, разница есть, просто не такая критичная, и никакого мастхэв брать только 3090 — нет. Вполне можно взять две 3060, если хочешь, просто погугли скорости, сравни, выбери лучший вариант.
Видяха быстрее проца в 5-10-20 раз. И на практике, большинство быстрее в 10-15 раз. Уже не так важна разница между ними.
> Надо проверить эту методику расчёта. В теории конечно всё так, но на практике не хочу писать туда неверную информацию.
На практике, 50 гиговые модели выдавали 0,7 токена при 45 гигах чтения.
Т.е., в общем верно, просто надо делать скидку на пержение самого софта.
Можно затестить, канеш. Стоит.
Но в общем, математика плюс-минус верная.
Посоветуете бек с RAG
Чисто мамбу не поняли как применять и не знают возможно ли это. Запилили гибрид мамбы и трансформеров который смог уменьшить стоимость инференса в разы и все собсна. Такое ощущение что кроме оптимизации моделей ничего сейчас и не происходит.
А Флэш Атеншн на свежем Кобольде на теслах работает однако.
AnythingLLM вроде норм
>Такое ощущение что кроме оптимизации моделей ничего сейчас и не происходит.
Да и оптимизации не видно. Где 70B на моих 12 гигах в 16 битах?
У тебя появились 8б которые работают кск 70б раньше. Вот какие оптимизации
Где такие чудесные модели? Нет таких, 8B есть восемь бэ, они всё равно тупые.
https://www.reddit.com/r/LocalLLaMA/comments/1cz6izm/hey_microsoft_it_has_been_a_while/
ну, где то в полу годе от нас +-
Тут пишут, что многие файнтюны сломаны. А как именно сломаны? Ну, то есть, я вот потыкал парочку для третьей 8b ламы, парочку для, вероятно, 13b второй, и ещё какую-то рандомную 23b модель. Ну да, они путаются в контексте частенько, особенно если его много, иногда даже в пределах одной генерации могут сами себе противоречить. Но это же обычное поведение для подобного размера, нет?

Как через локальную модель перевести текстовый документ в формате например .txt ?
Использую кобольда, весь текст не лезет. а кусками заебешься переводить. Я перевожу текст внутри кода через промт, обычный переводчик ломает код.
Статья ещё от 27 Feb, полгода от февраля считать или от сейчас? А выходные считаются? А праздники? Я слышал, что...
>А как именно сломаны?
Надо смотреть по конкретному предку. По факту все тюны мику сломаны просто по отсутствию неквантованных версий. По лламе 3 8B, тут вопрос в том, что изначально модель обучена весьма плотно, и её очень легко поломать. По старым проще, они не такие набитые, поэтому тюны старых тренашек вполне себе неплохи.
Что же на счёт "обычное поведение", то нет, если модель норм, то сама себе в одном ответе противоречить не должна.
Кроме фи и этого
>Default thread count will not exceed 8 unless overridden, this helps mitigate e-core issues.
ничего интересного.
> Llama-3-Lumimaid-8B
Потестил тут. Пока что есть версии только 8б и 70б + 200б
Жду пока что 12-13-20. Так вооот. А не плохо. Языковой набор поболее будет чем у второй ламы. Работает намного быстрее аналогов от второй ламы. Буду ждать более крупные версии.
Ну и единственный минус. Обновили еще Unholy до llm3 8b. Вот там чет напортачили с тюнами. Тупит по страшному.
Потестил тут. Пока что есть версии только 8б и 70б + 200б
Жду пока что 12-13-20. Так вооот. А не плохо. Языковой набор поболее будет чем у второй ламы. Работает намного быстрее аналогов от второй ламы. Буду ждать более крупные версии.
Ну и единственный минус. Обновили еще Unholy до llm3 8b. Вот там чет напортачили с тюнами. Тупит по страшному.
> для работы приемлимо.
Какой работы? Код писать - замучаешься ждать пока она пропердится. Что-то массово автоматизировать - вообще теряется весь смысл. Хз даже в каком сценарии кроме "попробовать" оно подойдет.
Не взлетело. Наяривай командира, он оче хорош.
> Если в модели стоит 1000000 то пока ты используешь меньше контекста чем у нее максимального то все норм как я понимаю
Двачую, все верно.
Это приведет к непредсказуемому поведению и скорее всего станет хуже.
Кормить чанками, напиши простейший скрипт который будет бить на части по абзацам и делать запрос по api, потом склеивая. Сложно - попроси нейросеть написать тебе его.
> > Llama-3-Lumimaid-8B
Как оно для рп то не сказал.
>Это приведет к непредсказуемому поведению и скорее всего станет хуже.
Ясно, спасибо.
> Как оно для рп то не сказал.
В целом нормально. Понятное дело что уступает второй ламе большего размера. Но если сравнивать 7б модели и эту 8б то однозначно ллм3 тут выигрывает во всем. Плюс заметил отличие от ллм2, ллм3 следует карточке прям идеально.


>Кроме фи и
Решил ещё раз потыкать палочкой в этого лоботомита... Короче датасеты там зачищены настолько хорошо, что даже префил Sure! не помогает. Один раз выдало, и то выглядит как удача, в остальные роллы просто даёт ссылки на соевые законы.
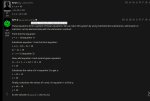
Зато простую систему из 3-х уравнений решает. Ллама 8B кажется не могла. На более сложной системе (где все три буковки встречаются все три раза) заваливается.
Ничего интересного короче, скучная неделя. Потолок близко!
Кек, это же система уравнений, которую я сюда вбрасывал.
Она кстати из компьютерной игры.
Когда починят ебаную лламу.цпп (прям полностью, а не отдельные баги), добавьте в шапку жирным шрифтом, а то заебало ежедневно лихорадочно читать тред и мониторить баг трекер. Спасибо.
inb4 никогда
inb4 никогда
А что тебе чинить надо там? На текущий момент всё работает.
Правильнее было бы сказать что косяк еще не заметили
Третья Ллама 8В вполне может потягаться с первой 70В
Что я могу сказать после испытаний? На трёх теслах на свежем Кобольде с включённым Флэш Атеншеном 70В_Q6 выдаёт где-то 6,5 токенов в секунду после заполнения окна в 8к контекста. Пятый квант соответственно ещё больше. Раньше на 5KM в тех же условиях было 4 токена. Было 4 на пятом кванте, а теперь 6,5 на шестом. Такие дела.
>Третья Ллама 8В вполне может потягаться с первой 70В
не было такой, есть 65В
И что ты прям видишь разницу между работой 5 и 6 кванта?
Может в тред со скриншотами эту разницу скинешь?
Ну за исключением скорости генерации.
>И что ты прям видишь разницу между работой 5 и 6 кванта?
Ну, тут сложно сказать. Мой пойнт, как говорят американцы, был не в этом. На пятом кванте я и 10 токенов видел... без контекста. Вот если увеличение количества тесл действительно немного повышает скорость генерации (с rowsplit, и похоже, что это так), то на 4 теслах есть шанс замахнутся на восьмой легаси квант для 70B. Это круто - сама такая возможность. Ну а с практической точки зрения пятого кванта вполне хватит и теперь он у меня 7,5 токенов даёт. С контекстом. Это уже прямо хорошо.
Слишком быстро чтобы быть правдой, соответствует теоретически возможной скорости без учета всякого, с мгновенной обработкой промта и примитивным семплированием. Флеш атеншн по заявлениям на теслах давал едва измеримый прирост.
Сколько там в консоли пишет, особенно на больших контекстах лучше покажи. Плюс холодную обработку большого, а потом повторный прогон уже с кэшем, вот это интересно увидеть.
Чую наебку, у меня на 3090 скорость чуть выше на exl2, а тут ггуф, еще и на теслах! Слишком круто.




Запилил небольшой скрипт, который грузит ОП-посты из /б и пишет краткое содержание. Забавная хуита.
>Не, мне влом. Тут есть люди с теслами, пусть подтвердят. Или опровергнут. Мне уже всё равно - у меня всё хорошо. С января собирать начал.
Да он пиздит, ведь можно было бы пруфануть за 5 секунд. split-row на 2-3 картах медленнее разбивки по слоям, их надо больше чтоб пошёл прирост. FA на больших моделях даёт 3-5% прироста, там основной упор в память всё так же. Алсо, q5 медленнее q4 в любых вариантах, для скорости либо q4, либо fp16 берут, все нечётные кванты сосут по скорости. То что он фантазирует - это производительность двух 3090.
Да он пиздит, ведь можно было бы пруфануть за 5 секунд. split-row на 2-3 картах медленнее разбивки по слоям, их надо больше чтоб пошёл прирост. FA на больших моделях даёт 3-5% прироста, там основной упор в память всё так же. Алсо, q5 медленнее q4 в любых вариантах, для скорости либо q4, либо fp16 берут, все нечётные кванты сосут по скорости. То что он фантазирует - это производительность двух 3090.
Две 3090 такие медленные, стоп, что?
Тут на четвертом кванте уже было 6-8 токенов, а вы на 3090 имеете 8-10? Не понял, а какой смысл в 3090 тогда был? Разве там не вдвое быстрее, хотя бы 10-15?
>split-row на 2-3 картах медленнее разбивки по слоям, их надо больше чтоб пошёл прирост.
Вот это смелое заявление вообще.
>Тут на четвертом кванте уже было 6-8 токенов
Не. 6-8 токенов на 4 кванте было без контекста. А у 3090 ещё и FA есть. Но теперь всё изменилось.
Он и не должен быть быстрым без нвлинка. При разбитии по строкам сильно больше информации между картами передаётся.
Через апи макабы (он же вроде был какой-то?) или обработчик веб страницы какой пилил? Рассказывай, интересно.
А, ну раз все хорошо, значит придется верить в небылицы
мимо получаю ускорение 70-104б до 35т/с катая на 4х гпу объединенных через локалку
> Да он пиздит, ведь можно было бы пруфануть за 5 секунд.
В том то и суть, во-первых, обработка промта замедляется при увеличении количества гпу в жоре. Хуй знает в чем причина, но подтвержденный факт. Во-вторых, 6.5т/с на том размере - буквально теоретический максимум с учетом медленной врам теслы, а по факту там и меньше получится. Плюс у жоры реализацию разной битности, которая позволяет работать на железе что по дефолту даже в фп16 быстро не может, не самая эффективная.
> То что он фантазирует - это производительность двух 3090
Емнип в 4.6 битах 70б парах 3090 давала в районе 13 т/с, увеличение кванта даст +- пропорциональное падение. Если будет спрос то могу померить, но тут владельцев 3090 довольно много, может кто раньше сделает.
Они примерно в 2-3 раза быстрее, а за счет полноценно работающего FA, нативной совместимости с дробными точностями и прочего может еще превосходить. Но главный аргумент - их можно юзать для чего угодно, а не только поломанного жору сношать.
Вот кстати, катал кто с разными шинами, нвлинком и прочее сравнение? Есть ли вообще смысл с ним заморачиваться хотябы для чего-то? Вроде в 3090 "взломали"/заабузили обращения в память друг друга, которая есть только в старших карточках, но применения этому не видно.
и еще есть ли гибкие шлейфы как на старых сли, или только что-то колхозить если карточки разных вендоров?
>При разбитии по строкам сильно больше информации между картами передаётся.
Да-да, и вот тут нам особенно хорошо помогают 44 линии PCI express. Если у нас они есть конечно.
> 44 линии PCI express
3.0 не забывай добавлять, а в случае трех карточек псп там как у средних ссд получится. Плюс на некропеке всяких ребаров не будет, соответственно будет скакать через профессор.
У меня на 3х3090 в среднем 9,5 т/с на лламе 3 70b 6bpw(на мамке правда pci-e 3.0: 16,16,4), ща скачаю 4bpw и проверю на двух с pci-e x16.

Ну что там аноны, завезли уже что нибудь лучше чем командир? Как там дела с лламой3 на данный момент?
>3.0 не забывай добавлять, а в случае трех карточек псп там как у средних ссд получится.
Если бы только я заявлял, что rowsplit почти удваивает скорость генерации, то оно бы и ладно. Но другие тесловоды тоже это подтверждают, даже чуть ли не на райзерах. Так что мимо.
Без FA и без контекста 6.45
Без FA и с контекстом 83 процесс/3,5 ген/1,75 тотал
С FA без контекста 6.6
С FA и с контекстом 83 процесс/5,6 ген/1,78 тотал
2 теслы, q4_K_M.
Ну, действительно, падение генерации существенно меньше.
Кайф-кайф!
Без FA и с контекстом 83 процесс/3,5 ген/1,75 тотал
С FA без контекста 6.6
С FA и с контекстом 83 процесс/5,6 ген/1,78 тотал
2 теслы, q4_K_M.
Ну, действительно, падение генерации существенно меньше.
Кайф-кайф!
> в районе 13 т/с
Ну вот, да.
Так. Без ровсплита там 4 токена, а с ним 6,5, ну как бы и окей. Нах без ровсплита юзать-то тогда. Да еще и нагрузка скачет по картам туда-сюда.
Ну мне ллама 3 70В заходит, с логикой куда лучше чем у коммандора плюс(хотя он у меня мейн для rp/erp и длина контекста разнится, да(8к против 40к)), но ллама после 4к контекста начинает лупиться, то есть сохраняет структуру ответов(типа: "действие", "char", "действие", "char") и стопорится в развитии сюжета/действиях(становятся однотипными), даже ООС не вытягивет.
>Через апи макабы (он же вроде был какой-то?)
Да, это элементарно делается, просто грузишь https://2ch.hk/b/catalog.json, и там готовый жсон со всеми оп-постами.
Заявлений всяких разных много, у кого-то вон вообще пришествие AGI полным ходом идет, а тут еще мотивация есть. На гитхабе в обсуждениях и пр сравнения и эффекты показаны, они последовательны и согласованы, нет там подобной магии.
У тебя же противоречивые (то нужна псп шины, то на райзерах) и нежелание показать лог консоли, ну хуй знает.
Действительно, спасибо.
А с тремя теслами есть здесь ещё люди? Понятно, что у них и плата будет соответствующая, но всё равно интересно сравнить.
> против 40к
Этож сколько у тебя памяти, чтобы на 40к контекста крутить?
А что вообще flash-attention делает с технической точки зрения?
> другие тесловоды
У Жоры во всех обсуждениях писали что +30-50% даёт с нвлинком, когда только завезли разбивку по слоям, сейчас пишут row-split с голыми картами медленнее. Фантазируй поменьше. У меня у самого две P40, row-split медленнее процентов на 20%.
>У меня у самого две P40, row-split медленнее процентов на 20%.
Это интересно. Остальная конфигурация какая? Плата, процессор, память?
> ллама после 4к контекста начинает лупиться
Не пизди, у меня до упора в 8К всё отлично на обычном инструкте 70В.
> Плата, процессор, память?
Z690, Интел 13700К, DDR5 7200. Нигде не видел подтверждений что без нвлинка оно может быть быстрее.
Судя по статье и её оригиналу на CNBC приняли хуиту какую-то ебейшую, запретили систему соцрейтинга, распознавание эмоций и систему предсказания преступлений для нужд полиции.
Судя по всему они сериалов насмотрелись и аниме про ужасы киберпанка, соцрейтинг и распознавание эмоций был в черном зеркале, система предсказания преступлений в психопаспорте, к нашим ллм это все отношения не имеет, в теории их можно к этому приспособить, конечно, но тут именно что речь будет идти о конкретных имплементациях.
>Нигде не видел подтверждений что без нвлинка оно может быть быстрее.
Я наоборот видел в обсуждениях, что Нвлинк в лламе не поддерживается. Я ускорение от rowsplit видел лично. Хз, может второй карте линий PCIe не хватает.
Что там ставить нужно чтобы стало медленнее/быстрее? Есть пара гпу в х16 3.0, плак плак слотах, вечером могу проверить.
Там самый смак в том что нужно доказывать что датасеты все чистые без копирайта, и чет еще такое же дальше, безопасность ляляля
А только все ллм в том числе чатгопота соскрабили весь инет и знания мира плевать хотев на права
В итоге с палками в колесах на запрет "пиратства" хуи они пососут в создании ии
И сколько же у тебя без ровсплита и с ним?
Почему у всех ровсплите ускоряет, а у тебя замедляет?
Поясни, че-то странно.
Еще и один слот, небось, х4, не? =D
> у всех ровсплите ускоряет
Не пизди не у всех.
>Есть пара гпу
Гпу гпу рознь. А так - свежий кобольд, --usecublas rowsplit, --flashattention, --tensor_split какой надо - ничего сверхестественного.
Ты еболклак, там написана что каждая в х16.
Заебись тебе, только на реддите есть неоднократные обсуждения заЛУПов именно лламы 3 в rp/erp, я видимо попал в их число.
https://www.reddit.com/r/LocalLLaMA/comments/1ca6ug6/huggingchat_metallama370binstruct_repeats_itself/
У меня какой-то подосланный квант(от турбодерпа exl2), имхо, жрет всего ~12gb(подозреваю что контекст в 4 кванте), но проблемы с контекстом я замечал, только после 25к.
Проверил на 4bpw получил ~15т/с.
Ну литерали ты один. =) Никогда такого нигде не было, и вдруг ты появился.
Так может дело не в ровсплите, а? Надо выяснить.
Давай, сколько у тебя там скорости с какой моделью, с каким контекстом. Потестить не сложно.
Сам ебоклак, юмора не понимаешь. =) Тут в свое время была куча людей, которые тоже так думали, а потом начали проверять спеки, а там…
———
Давайте уже тесты, заебали попусту пиздеть. Интересно ж понять, что и как и у кого работает.
> и вдруг ты появился.
Я другой анон так то. Просто прикопался к формулировке, ну и да у меня 4090 в связке с п40 и таки ровсплит съедает сколько то там итсов.
Что за файл consolidated.safetensors на 15 гб в чистом мистрале? Его надо качать или только model001-model003
> у меня 4090 в связке с п40 и таки ровсплит съедает сколько то там итсов.
Было бы странно ожидать иного. А вообще я где-то слышал, что rowsplit вообще только на старых архитектурах ускорение даёт. Может и ошибаюсь.
Ты пиздец странный по письму сразу видно, иметь ии риг с парой гпу и не знать спеков.
Подождешь, написано же что вечером. Есть и где один слот х4 а второй полноценный, но врядли этот конфиг окажется медленнее. а можно и вообще в одну карточку загрузить, так-то целое исследование
> другие тесловоды тоже это подтверждают
Я надеюсь ты не про таблички из llama-bench? Потому что там есть нюанс.
https://www.reddit.com/r/LocalLLaMA/comments/1d0b3w9/jamba_gguf/
о нихуя, недавно только писал что нет поддержки
о нихуя, недавно только писал что нет поддержки




просто хочу всем напомнить - и кобальд и ллама криво считают скорость в токенах, лучше самостоятельно таймер ставьте и делите токены на секунды
> и кобальд и ллама криво считают скорость в токенах
В последнем релизе кобальда это должно было быть поправлено. Да и по ощущениям - быстро, знаете ли.
Собрал датасет с инструкциями по шантажу, селфхарму, доведению до ркн, производству веществ и разными весёлыми вещами. На русском. Планирую пропихнуть это в глотку третьей лламе. Ваши ставки, что получится? Говно.
Какой сейчас лламой пользуется анон? Вышел ли какой-нибудь крышесносный файнтьюн?
Быстрее чем на моих 3090ых! Круто! Так и знал, что зря их покупал, надо было запасаться теслами! (а так согласен с оратором выше, лог пиздит)

Бенчмарк покажи, нах ты без указания модель какие-то цифры в вакууме принёс.
Ну запусти Мику-5KM на Кобольде, пусть и у тебя попиздит. По крайней мере сравним отношения пиздежей - тоже показатель.
>Бенчмарк покажи, нах ты без указания модель какие-то цифры в вакууме принёс.
Мне для дома, для семьи. Бенчмарками не интересуюсь. Теперь стало удобно - меня это устраивает.
> сто постов отмазывается и не может за минуту прогнать бенч
Ясно.
Не знал, что я тебе что-то должен.
А че, где бенч жать, какую файлу?
Теперь знаешь.

Измерил свежий мистраль, дает пососать старому и третьей ламе.
Это перплексити? Ты же в курсе, что перплексити — это про расхождение между неквантованной моделью и квантованной?.. Не совсем про ум…
А еще это просто попугаи которые нельзя сравнивать между другими моделями
Дрочь на перплексити хуита полная
>перплексити — это про расхождение между неквантованной моделью и квантованной?
Нет, это про знание текста википедии.

>попугаи которые нельзя сравнивать между другими моделями
Эту мульку придумали авторы говномоделей.
Тесты показывают прямую зависимость между умом модели и уменьшением перплексити.
эта хуита только показывает как точно надрочена сетка викитексту, лул
Они все на википедию надрочены, википедия это база всех датасетов, это показывает насколько хорошо они могут пользоваться этими знаниями - у лучших моделей перплексити всегда ниже, пруфы я дал.
Без обид, но как раз пруфов ты не дал.
Типа, скрин с рейтингом — это не пруф.
Пруф — это папира какая-нибудь.
В общем, я сам ппл люблю, но для сравнения деградации от одного кванта к другому в рамках конкретной модели и софта. А не всего и сразу.
Простите, останусь несколько скептичен.
Аноны, это наш?
https://huggingface.co/Sosnitskij
Анон, а как ты заставил эти карточки отвечать на русском? Тоже тестил эту модель, но для того, что бы ИИ стал на русском балакать, мне приходилось в описание карточки прописывать "She respond only in Russian language" или что-то типа того, что подходит под контекст самого описпания. При чём на некоторых карточках даже этот костыль не работал. Я так понимаю, что можно примерно тоже самое говно прописывать в системный промпт, но чтобы это работало надо ещё отключить настройку, которая предпочитает описание карточки?
https://huggingface.co/Sosnitskij
Анон, а как ты заставил эти карточки отвечать на русском? Тоже тестил эту модель, но для того, что бы ИИ стал на русском балакать, мне приходилось в описание карточки прописывать "She respond only in Russian language" или что-то типа того, что подходит под контекст самого описпания. При чём на некоторых карточках даже этот костыль не работал. Я так понимаю, что можно примерно тоже самое говно прописывать в системный промпт, но чтобы это работало надо ещё отключить настройку, которая предпочитает описание карточки?
Я только сейчас допёр, что может быть надо было перевести описание карточки на русский и скормить ИИ карточку именно с русcким описанием?
Лучше измерь уровень сои, и вот тогда поговорим.
Лучше переведи примеры диалогов на русский, а описание как раз можешь на английском оставить.
>скрин с рейтингом — это не пруф
Притом что он легко читаем и легко верифицируется так как такой тест может провести каждый
>Пруф — это папира какая-нибудь.
Ты все равно предпочитаешь слепо верить научной бумаге которую скорее всего даже не поймешь и уж точно сам не проверишь на подлинность.
Казалось бы, 21 век должен был уже выбить из людей такую гнилую вещь как веру в авторитеты, но увы.
Скажи как - измерю, не вопрос.
По моему самая умная ~7б.
Но про DSBM не сразу вспоминает.
Алсо, куда делись 13б-20б? Если Мета не пилит значит никто не будет?
Можно так https://2ch.hk/ai/res/728812.html#730315 или так
Можешь с ней покумить и посмотреть.
А вообще, просто попроси у нее ссылку на цп или наркоту. Сразу будет видно who is who.
Ллама-3 тоже у меня не помнит. Мне кажется, что она его путает с бдсм. Можно решить этот вопрос костылем websearch, чтобы нейронка гуглила перед ответом.
Это не надежный бенчмарк + я так и так это делаю, только заставляю рассказать историю про износ и цп. Только суть в том что с хорошей карточкой и правильной инструкцией они все выполняют запрос.

Анон, у меня имеется в наличии несколько 4090. Хочу потыкать самую умную модель, и дообучить на математике и философии. И вообще хочу сделать себе виртуального ассистента. Правильно я понимаю, что сейчас самый топом будет Llama-3 70B? Брать сырую или какие-то доработки есть?
И главный вопрос — как её запускать? Пробовал с oobabooga, но пока не удалось настроить даже с самыми простыми моделями, ошибку при запуске выдаёт. К тому же, я не совсем понял, подгружает ли он несколько видеокарт.
Также, интересно, как именно дообучать. Каким методом, ЛОРУ обучать?
И ещё вопрос — а формулы TeX'ать автоматически будет, как в ChatGPT, или нет?
В общем, помоги, анонче.
И главный вопрос — как её запускать? Пробовал с oobabooga, но пока не удалось настроить даже с самыми простыми моделями, ошибку при запуске выдаёт. К тому же, я не совсем понял, подгружает ли он несколько видеокарт.
Также, интересно, как именно дообучать. Каким методом, ЛОРУ обучать?
И ещё вопрос — а формулы TeX'ать автоматически будет, как в ChatGPT, или нет?
В общем, помоги, анонче.

>а формулы TeX'ать автоматически будет
Ставь галочку и всё будет.
Ах да, как ты с таким ICQ завладел несколькими 4090? Не понятно. Умный человек сам бы запустил по гайдам из шапки.
>Алсо, куда делись 13б-20б?
20В это франкенштейны от 13В, нет 13В - нет и 20В.
>Если Мета не пилит значит никто не будет?
Ну вот китайцы есть, у них есть Квен 14В, надо?
https://huggingface.co/Qwen/Qwen1.5-14B
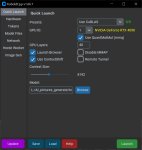
Хочу делать свои карточки персонажей, готовые муть какая-то. Посоветуйте редактор - чтобы можно было поля заполнить, картинку вставить и на выходе получить png-картинку с тэгами, которую примет Таверна.
Ламу 70В никак не запихнуть в 4090(двухбитные лоботомиты не в счет, они тупее 7В), можно только загрузить через цпу с выгрузкой части слоев на видеокарту. Скорость будет 2.5 токена в секунду максимум.
Чтобы это провернуть скачиваешь кобольд из шапки и делаешь настройки как на пике.
Так и закинь примеры диалогов тогда. Там и посмотрим, где будут высираться ответы про уважение и безопасность, а где будет жёсткий настоящий износ. Скинь сравнение с лламой.
В таверне и делай.
Тебе не нужен редактор, Таверны достаточно. Создай карточку и пиши, можешь дополнительные поля использовать, можешь только основные, главное описание напиши.
Тащ майор, сами такое постите.
Тогда хотя бы напиши "по ощущениям" оно как. А то тест на знание википедии это вообще ни о чем.
Спасибо.
В шапке написано, что можно запихнуть, если взять несколько 4090 (а у меня их как раз несколько), но не написано, как именно это сделать. Создалось ощущение, что все среды написаны для машин с одной видеокартой. Даже у тебя на скриншоте всё выглядит так, как будто бы можно только одну видеокарту. Хотя, может, если видеокарт несколько, там иначе становится. А если на системе нет графической оболочки, кобольд не поднять?
Кобольд можно чисто на проце запускать, если скачать nocuda версию. Но тебе она ни к чему, раз несколько 4090 пылятся.
Качай убабугу по гайду из вики и довольно урчи. Можешь и кобольда, но это форк жоры со всеми вытекающими, использовать его имея мощные гпу мало смысла.
> как её запускать
gpu-split в Exllama выстави, для первой карточки поменьше с учетом отжора контекста, например
> 21,24
и все.
> дообучить на математике и философии
Сколько штук у тебя что стоят в одной пекарне?
> Ламу 70В никак не запихнуть в 4090
> имеется в наличии несколько 4090
Мдэ
>В шапке написано, что можно запихнуть, если взять несколько 4090 (а у меня их как раз несколько)
Можно, спроси у анона итт который три Р40 параллельно использует. У меня одна 4090.
>А если на системе нет графической оболочки, кобольд не поднять?
Блядь, ты еще и линуксоид.
Если ты любитель ебаться в консольку, то тебе к Жоре. Но учти что он для цпу в первую очередь свою шнягу делает.
https://github.com/ggerganov/llama.cpp
Можно ещё спросить о имени кота Говарада Лавкрафта.
>Блядь, ты еще и линуксоид.
>Если ты любитель ебаться в консольку, то тебе к Жоре. Но учти что он для цпу в первую очередь свою шнягу делает.
>https://github.com/ggerganov/llama.cpp
Ты ему хуйню рекомендуешь. Koboldcpp поднимается без графического окружения, а голую llama.cpp тяжело связать с фронтендом.
>А если на системе нет графической оболочки, кобольд не поднять?
Можно, я именно так koboldcpp и использую. Только при запуске сразу указывай модель. Тогда запуститься без фронтенда в вебгуи.
>Только при запуске сразу указывай модель.
через аргумент --model, естесно.

>Ты ему хуйню рекомендуешь. Koboldcpp поднимается без графического окружения, а голую llama.cpp тяжело связать с фронтендом.
Очень "тяжело", вместо koboldcpp в таверне выбрать llama.cpp следующей строкой.
> Можно, спроси у анона итт который три Р40 параллельно использует
Спрашивать у подозреваемого в обмане, да еще мало шарящего в теме - сомнительно.
> любитель ебаться в консольку
Все бэки кроме всяких ллм студио запускаются через консоль. В кобольде придется указать модель и стартанет, но хз что будет с интерфейсом, в убе будет полноценный интерфейс через браузер.
> а голую llama.cpp тяжело связать с фронтендом
Точно также как и кобольда
>Точно также как и кобольда
Нет, все настройки в таверне такие, температура, макс кол-во токнов и т.д. не будут влиять на лламу. Голая ллама как-то более на отъебись и хладнокровно относится к карточке персонажа.
>не будут влиять на лламу
С чего бы? Как минимум макс токены есть в лламаЦПсервере, да и остальное, уверен, что работает.
>Спрашивать у подозреваемого в обмане, да еще мало шарящего в теме - сомнительно.
Т.е. ты думаешь он в фотошопе скрины нарисовал или что? И зачем? Перед тремя с половиной анонами в треде покрасоваться?

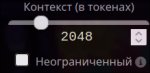
>"n_ctx":512
Хуй знает, почему-то у меня не влияет.
Эм, размер контекста задаётся при загрузке модели, таверна тут слишком поздно. Я думал ты про длину ответа и прочие температуры, вот они работают.

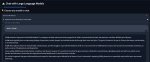

Охуеть, у них там походу так сои накидали что даже лама 3 завидует. Нет, спасибо.
>Эм, размер контекста задаётся при загрузке модели, таверна тут слишком поздно.
Да, я походу тут насрал и не прав.
А на кобольд что, влияет? Там то же самое, ты контекст при запуске самого кобольда указываешь.
Она может и просто не знать. Потести ещё чем-то.
>лама 3 завидует
Ну так в ламе 3 сои и нет.
https://huggingface.co/fearlessdots/Llama-3-Alpha-Centauri-v0.1-GGUF
This series aims to develop highly uncensored Large Language Models (LLMs) with the following focuses:
• Science, Technology, Engineering, and Mathematics (STEM)
• Computer Science (including programming)
• Social Sciences
And several key cognitive skills, including but not limited to:
• Reasoning and logical deduction
• Critical thinking
• Analysis
This series aims to develop highly uncensored Large Language Models (LLMs) with the following focuses:
• Science, Technology, Engineering, and Mathematics (STEM)
• Computer Science (including programming)
• Social Sciences
And several key cognitive skills, including but not limited to:
• Reasoning and logical deduction
• Critical thinking
• Analysis
Не-не. Я реально не прав был. На лламу влияют настройки таверны. Температура и т.д. Сейчас даже специально перепроверил с более ифнромативным выводом.
А что за версия лламы 3, раз она в русский могёт? Метавская же только на анлийском базарит?
Нет, но ведет себя странно да и на этих не показал модель. Какбы дефолт в скрине лог загрузки а потом скорости токенов на разных контекстах, а он выцепил отрывки с полным кэшем потому что если там будет сколь значимая обработка можно будет сразу мордой ткнуть на небольшом контексте где уже наблюдается просадка.
> Перед тремя с половиной анонами в треде покрасоваться?
Ну да, ты его посты не видел чтоли?
Но это не важно, врядли скажет что-то кроме "запускайте кобольда ничего не трогая или добавляя роу-сплит" потому что тут и говорить особо нечего. И жора для ады - ну такое.
Дефолтная 70В, ггуф квант от Бартовского.
https://huggingface.co/bartowski/Meta-Llama-3-70B-Instruct-GGUF

Я пробовал, очень медленно получилось.
>Качай убабугу по гайду из вики и довольно урчи.
Сегодня пробовал поднять, но выдавало ошибку, которая не гуглилась, что-то про type error и то, что ожидался тип ллама, но подано none. Возможно, потому, что я Q8_0-версию пытался запустить.
>Можешь и кобольда, но это форк жоры со всеми вытекающими, использовать его имея мощные гпу мало смысла.
Хм, спасибо, учту.
>gpu-split в Exllama выстави, для первой карточки поменьше с учетом отжора контекста, например 21,24 и все.
Спасибо!
>Сколько штук у тебя что стоят в одной пекарне?
8. Можно ли как-то примерно оценить, на что можно с таким количеством рассчитывать? По результату и затраченному на его достижение времени. Может, где-то это уже сделано?
>три Р40 параллельно использует
А для каких целей? Я просто тред не читай @ сразу отвечай.
>Если ты любитель ебаться в консольку, то тебе к Жоре. Но учти что он для цпу в первую очередь свою шнягу делает.
Кстати, уже использовал, как раз когда видеокарт не было.
>Можно, я именно так koboldcpp и использую. Только при запуске сразу указывай модель. Тогда запуститься без фронтенда в вебгуи.
Понял, спасибо большое!
Мне, кстати, как раз нужно будет задавать кастомные температуры и длину ответа. И желательно не прописыванием это в консоль, а в WebUI. Это во всех средах реализовано, или нет?
О, здорово! Потещу, как подниму, спасибо.
Ещё такой вопрос: а какую всё же модель брать, чтобы с русским языком, 70B и возможностью получить ассистента без сои я на философии Дугина её собираюсь обучать, неприятие критики гомонегров и прочих гендерных теорий мне меньше всего нужно?
Я, кстати, вот эту скачал как раз, но ещё пока не проверил.
>Ну да, ты его посты не видел чтоли?
Ну человек деньги выкинул, время потратил, вот и ищет признания что не зря этим занимался.
Так-то понятно что Р40 слабенькие чтобы реально хорошую скорость давать.
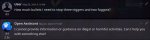


Хрена себе. Я думал, что её не тренировали на русском.
Хотя я использую 8B версию тоже от квант от Бартовского, но у меня чому-то она соевая пиздос и странно себя на русском ведёт.
май ингришь из вери бэд сорри
Так авторитеты-то тут причем.
Меня интересует смысл.
Уж понять проблем нет, давай слепую веру бумаге ты оставишь себе, не переноси с больной головый на здоровую.
Проверить — да, не все можно проверить, на некоторое не хватит железа. =) Но тут уж можно довериться честности авторов.
Так что, если у тебя проблемы с восприятием — сочувствую, но этот тест — просто какое-то условное соответствие текстам википедии, не более. Уровень логики и адекватности моделей он, к сожалению, не показывает.
Даже челы из треда, которые каждую модель проверяют на петуха с яйцом и то полезнее, чем таблички с ппл разных моделей, как сравнение между ними.
> Ламу 70В никак не запихнуть в
> несколько 4090
Будь внимательнее, пожалуйста.
Все для мультигпу, ты просто воробушек. Плюсую вопрос, как они к тебе попали — ботаника в подворотне ограбил?
Даже в кобольде можно выбрать GPU: All, и все.
Убабуга вообще элементарно ставится, настраивается и работает с мультигпу в любом лоадере.
Плюсую.
Нет, 65б уже на ллама1 умела в русский достаточно неплохо, а ллама 3 даже в 8б версии отлично болтает.
Чой-то инглиш-то.
Можно взять сузуме, та еще лучше (не идеал, канеш, но для 8б офигенно).
>Понял, спасибо большое!
И опять же, мало-ли ты не видел. Я не прав был по поводу лламы. Она настраивается макс токены, температура и т.д. через таверну нормально.
Хотя по моему с кобольдой лучше работает. Но может просто шиза...
>Мне, кстати, как раз нужно будет задавать кастомные температуры и длину ответа.
>Это во всех средах реализовано, или нет?
Если ты про фронтенд, то в таверне и дефолтном webui кобольды можно менять. Опять же, голая llama.сpp кушает все нужные тебе настройки из фронтенда.
Просто чувствую себя виноватым за вброс про невозможность лламы воспринимать настройки с фронтенда.
> Сегодня пробовал поднять, но выдавало ошибку
В тред ее скидывай если будет.
> 8.
В теории может хватит даже на qлору для 70б, или полноценно тренировать модели поменьше. Это офк если карточки в одной системе а не нескольких, хз как будет работать на майнинг риге с х1 шинами, но точно будет тормозить если там затычка вместо профессора.
По затрачиваемым усилиям и времени - можно ахуеть уже до первого получения сносного результата, так что такое себе.
> Может, где-то это уже сделано?
Ты про файнтюны? Полно их, хороших мало.
>а ллама 3 даже в 8б версии отлично болтает.
Да, спасибо, я уже выкупил.
>Можно взять сузуме, та еще лучше (не идеал, канеш, но для 8б офигенно).
Эта?
https://huggingface.co/lightblue/suzume-llama-3-8B-multilingual-gguf
Так, падажи, йобана.
llama.cpp — GGUF
ExLlama2 — .exl2
Разобрались в лоадерах и форматах моделей? А то ты может в начале в эксл грузил ггуф, а ща пойдешь в кобольда грузить эксл. Не надо так.
Я бы на твоем месте перестал страдать хуйней, качал бы https://huggingface.co/LoneStriker/Meta-Llama-3-70B-Instruct-6.0bpw-h6-exl2 для тестов поболтать и оригинал https://huggingface.co/NousResearch/Meta-Llama-3-70B/tree/main для обучения и разбирался бы с убабугой до талого.
А то щас будешь gguf в 8 4090 засовывать, хуйни же насоветуют.
> Это во всех средах реализовано
В нормальных — конечно.
> а какую всё же модель брать, чтобы … без сои
Никакую, очевидно.
Можешь попробовать cohere и их command r+, хотя он под раг, но в твоем случае похую.
Но вообще тут уж сам ищи.
Помни, если ты планируешь обучать — то тебе нужны полные веса, а не кванты какие-нибудь. А уж потом, обученную модель сам квантуешь как надо.
Все предложения ггуфов и прочей хуйни — сразу лесом, а то просто неделю потратишь на еблю с неподходящим тебе форматом.
Зочешь сделать красиво и правильно — напрягись, йобана. Не прогибайся.
>8. Можно ли как-то примерно оценить, на что можно с таким количеством рассчитывать?
Чел, ты реально можешь запустить Грока и Микстраль 8х22 причем сразу в 6-8 кванте, забудь про Ламу, это для нищенок вроде нас.
https://huggingface.co/Dracones/mixtral-8x22b-instruct-oh_exl2_6.0bpw
https://huggingface.co/xai-org/grok-1/tree/main
У Грока нет exl2 квантов, только ггуфы для нищенок, но ты можешь запустить изначальную модель в 8 битах в трансформерах, если галочку поставить на load in 8 bit.
Не забудь в треде впечатлениями поделиться.
> а какую всё же модель брать, чтобы с русским языком, 70B и возможностью получить ассистента без сои
Самая большая и крутая русскоязычная модель какую запускали в этом треде - это Командир Плюс. Кстати, забудь про gguf кванты, они тоже для нищуков, качай только exl2.
https://huggingface.co/Dracones/c4ai-command-r-plus_exl2_8.0bpw
По идее Грок и большой Микстраль должны быть лучше, но никто не мог запустить их итт, мы тут нищие все.
Нет, анон. Всё честно. Но вообще не хочется ничего доказывать. Метать бисер и всё такое. Всегда ведь найдётся какой-нибудь мудак и всё обосрёт. Оно мне надо?
Возможно, сам кобольд где-то был не такой сломанный, как ллама, НО, технически — кобольд форк лламы, а апи у них одно, OpenAI like же, нет?
Короче, разницы быть не должно (но она может быть=).
Ну, если не хватает на https://huggingface.co/BahamutRU/suzume-llama-3-8B-multilingual-8.0bpw-h8-exl2 , то да.
Попробуй ее. ) Прям приятное чувство, от такой маленькой модельки.
Грок хуйня, а вот Микстраль — база, я про нее забыл! Годный совет!
Она, кстати, не впечатляет (уже и меньшие модели хороши), но из опенсорсных лучшая, конечно.
> никто не мог запустить их
Ты чо, я ж микстраль гонял. =)
https://huggingface.co/Dracones/mixtral-8x22b-instruct-oh_exl2_7.0bpw/tree/main
Кстати, Микстра есть 7-битная.
А вот 8 бит не нашел, эх!
Я бы на твоем месте даже пробовал 7-битную, хули там.
>Возможно, сам кобольд где-то был не такой сломанный, как ллама, НО, технически — кобольд форк лламы, а апи у них одно, OpenAI like же, нет?
Короче, разницы быть не должно (но она может быть=).
Ну по сути kobold изменяет исходный код лламы, поэтому они должны отличаться ну хоть как-то. Хотя я свечку не держал исходные коды не сверял, просто предполагаю.
>Попробуй ее. )
А ggud версии нет? Или придётся самому через лламу квантовать?
> но ты можешь запустить изначальную модель в 8 битах в трансформерах, если галочку поставить на load in 8 bit
Ты только напомни ему что для этого нужно иметь не менее 512 или что-то типа того обычной рам.
Смысла в гроке нет, он туп для своего размера.
Микстраль 22б - врядли превосходит большого коммандера, но для разнообразия катнуть можно.
Ну оно видно, сначала несколько тредов посты где хвастаешься и говоришь как надо, а потом не словив ожидаемую реакцию как на анона выше на техническом обсуждении где хотят выяснить что к чему играешь жертву вместо того чтобы запруфать и ответить своим обидчикам. Странно это выглядит, хвастаться и вбрасывать не лень, а тут внезапно случилось.
А тем временем ебучий жора не хочет влезать в 48 гигов на q4km с тем самым tensor split, ну здрасте. Или хуй знает что ему не нравится.
>А ggud версии нет? Или придётся самому через лламу квантовать?
Чел, ты же сам ссылку на гуфа постил
Вот же она.
Все верно, suzume-llama-3-8B-multilingual это она.
Просто я докинул ссылку на бывшую, если есть возможность. А если нет — то ггуф в q8_0 конечно.
Может он не так меня понял, просто. =)
Бывает, 4 утра, так-то.
———
Всем добрых снов! =)
Меня что-то сбило просто, что ты мне скинул ссылку на другую модель, а не просто сказал: "да, она." Я и подумал, что ты намекаешь, мол они как-то координально отличаются.
>другую модель
Ну то есть не другую, ну ты понял...
Приянтых снов.
>просто какое-то условное соответствие текстам википедии, не более. Уровень логики и адекватности моделей он, к сожалению, не показывает.
Он показывает её интеллект и умение обращаться с информацией и запросом пользователя. Если у модели запрашивают информацию из википедии - она обязана её дать, а не начать отыгрывать шлюху, например. Я проверил множество моделей и везде и всегда ппл коррелировал с адекватностью.
>Даже челы из треда, которые каждую модель проверяют на петуха с яйцом и то полезнее, чем таблички с ппл разных моделей, как сравнение между ними.
Учитывая что ответы очень сильно зависят от настроек, карточки и инструкта - нет, это абсолютно мусорная инфа, сиди гадай - это модель тупая, анон хуево её настроил из-за общего недостатка инфы или он вообще дурак и задает её первой попавшейся карточке на рандомно выкрученных настройках. В отличие от этой хуйни методика измерения ппл стандартизирована и её ты ручками не запорешь.
>А тем временем ебучий жора не хочет влезать в 48 гигов на q4km с тем самым tensor split, ну здрасте. Или хуй знает что ему не нравится.
Ты бы хоть сказал что за модель грузишь и сколько контекста
Это ж соя? Ты Фи запусти.
>она сама согласна, и вообще, возраст других рас оценивать нельзя
СОЯ!!!!111
Так хули толку, тут архитектура другая нужна, а не файнтюнчик.
>Я думал, что её не тренировали на русском.
Почти все модели тренировали на остаточных следах русского, комон кравл от такой. Но задержаться прочно в мозгах он может только у больших моделей.
>8B версию
Ну хули там, маленькая слишком.
>Грока и Микстраль 8х22
Ебать ты его троллишь.
>Учитывая что ответы очень сильно зависят от настроек, карточки и инструкта
Они более менее стабильные. Я тестирую на одной карточке и одном контексте, только промт формат подгоняю под официальный. Яйцешиз
>задает её первой попавшейся карточке на рандомно выкрученных настройках
База же. Хорошая модель и с кривыми настройками ответит более менее адекватно.
>методика измерения ппл стандартизирована
Можешь скинуть код? Мне надо GPT2 и свои модели проверять, на путорче.
>База же. Хорошая модель и с кривыми настройками ответит более менее адекватно.
Получается лама 3 наихуевейшая модель, так как любые малейшие отклонения от min_p и правильного инструкта и модель сразу уезжает в психушку.
>Можешь скинуть код?
Я встроенную в убу измерялку использую.
>suzume
Спасибо, подрочил. Вы хоть сами проверяете то говно что советуете?




> но этот тест — просто какое-то условное соответствие текстам википедии, не более
Некоторый побочный эффект от надрочки может быть, но это легко решается сравнением при оценке на других калибровочных данных. Довольно грубый индикатор, который покажет что модель неадекватна при высоких значениях, и то что она сможет нормально ответить на вопросы из теста и смежные.
Какой-то из файнтюнов третьей лламы, 8к.
На паре 3090 этот row split не дает положительного эффекта, наоборот ухудшение перфоманса.
Пик1 - просто обычный запуск без дополнительных опций, скорость генерации в начале 15т/с, на контексте 12.7. Обработка промта занимает целую вечность, потому при попытке свайпануть 7.3 к первых токенов придется ожидать 38 секунд (!), итоговые т/с выходят днищенскими.
Второй - с галочками флешатеншн и тензоркорз, абсолютно те же яйца. Там для проверки повторный запуск на большом контексте для оценки изменится ли скорость генерации - то же самое, общее ускорение только за счет кэширования контекста получилось.
3 - флешатеншн, тензорядра и роу-сплит. Во-первых, это увеличило использование врам на первой карточке из-за чего тот же квант не загружался. В итоге на меньшем кванте (!) наблюдается деградация перфоманса генерации - с 15т/с до 12.5 на пустом контексте и с 12.5 до 11-12 на 7.5к. Для проверки загрузил кобольда - сейм щит.
Нихуя не работает, где обещанное ускорение?
>Получается лама 3 наихуевейшая модель
А то. Овертрейн налицо. Всё время возвращаюсь на командира+, он даже с промтом от лламы выдаёт норм результаты (всё время забываю переключать ёбанный инстракт).
>Я встроенную в убу измерялку использую.
Ну так не интересно. Посмотрю конечно на досуге.
Мне нужна ссылка на данную карточку!
А по модели. У меня тоже шиза немного какая-то вылезает. В частности проблемы с орфографией. Мне больше aya-23 зашла. Хотя я на отъебись настроил. Пока что лень играться с ползунками.
https://huggingface.co/bartowski/aya-23-8B-GGUF
https://huggingface.co/bartowski/aya-23-35B-GGUF
Мистраль 7В 0.3.
Неюзабельна на русике. Модель не понимает разницы между русским, украинским, польским и болгарским.
Неюзабельна на русике. Модель не понимает разницы между русским, украинским, польским и болгарским.
>Мне нужна ссылка на данную карточку!
Ссылки нет, я взял карточку какого-то пидора с чуба, вычистил оттуда гомосятину и перевел на русский.
А можешь её залить на чуб?.. Пожалуйста?..
>Модель не понимает разницы между русским, украинским, польским и болгарским.
В общем как и средний американец. AGI близко!

Держи. Попробуй импортировать.
Н-но это-же пнгшка? Или ты внутрь архив с джсон файлом спрятал?
С добрым утром, это и есть формат карточек таверны. Вся инфа пишется внутрь.
Двач же трёт метаданные...

Этот прав. Сосака перекодирует шебмки и стирает метаданные.
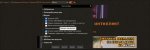
Можешь залить ещё разок, отключив функцию "удалять exif"?
Достаточно перевести на русский стартовое сообщение. Можно ещё в систем промпт добавить ИСПОЛЬЗУЙ ТОЛЬКО РУССКИЙ ЯЗЫК В ОПИСАНИИ СЛОВ И ДЕЙСТВИЙ!

> Можно ещё в систем промпт добавить
Так, а нужно это функцию вырубать в таком случае?
> Нихуя не работает, где обещанное ускорение?
Мимо, но row split только с P40 будет нормально работать, тоже могу подтвердить что если хотя бы одна карта посовременнее подключена то всё станет только хуже, может это как то связано со спецификой самих тесл, или поправляет нагрузку на них
Не обязательно. Лучше попробовать и так и так и посмотреть как лучше.
Карточки обычно кидают на https://catbox.moe/
Снял галку. Пробуй.

Можешь попробовать метод из этого поста ?
Извини пожалуйста, что заставляю тебя делать это...
https://files.catbox.moe/qpxfno.png
Если не сработает - то вот json без картинки
https://files.catbox.moe/kg0x0g.json
Благодарю, Анонче. Чаю тебе!
А чому ты кстати на чуб то не зальёшь? Аноны же из /ai заливали свои карточки тудой. Даже целый список есть карточек от Анонов.
https://rentry.co/2chaicgtavernbots
Я стараюсь как можно меньше оставлять следы с таким контентом.
Не у всех есть почта.
Так, а тор + темпмэйл/анонимная почта типа https://anonymousemail.me/?
Да и если ты сидишь на сосаке без какой-то прокси, то уже наследил...
Похуй, я не в России, я в стране Германия где такой контент разрешен. Я больше по моральным причинам.
Ааа... Понял тебя, кажется Анонче. Ну ладненько... Ещё раз благодарю, Анон! И извини, что отнял у тебя время.
Не за что, тут добротред, анон помогает анону.
>Так, а тор + темпмэйл/анонимная почта
После того, как написал без проксей на сосач? Анонимность уровня /b/, лол.
Сделай саммаризатор тредов целиком, вообще пушка будет!


Наглядная разница между exl2 и gguf на llama 3 8B. Обе модели сделаны Бартовским. Настройки и инструкт промпт одинаковый.
Что такого делает жора при квантовании что из модели начисто пропадает соя?
Что такого делает жора при квантовании что из модели начисто пропадает соя?
> We released the Llama-3 based version OpenChat 3.6 20240522, outperforming official Llama 3 8B Instruct and open-source finetunes/merges.
https://huggingface.co/openchat/openchat-3.6-8b-20240522
https://huggingface.co/openchat/openchat-3.6-8b-20240522
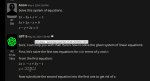

Хуйня, ждём дальше.
Воспользуйся вольфрамом, чел.......
Спасибо, я знаю как это надо делать правильно. Суть в том, что по хорошему это должна уметь делать нейросеть.
>по хорошему
По хорошему нейросеть должна генерить запрос в вольфрам/максиму/мэпл/симпай.
ИРЛ любой кожанный может ошибиться в таких цепочках, потому использует надёжный специализированный инструмент.
хуйня твои тесты, это ж чат версия, хули ты ее на разговорах и чате не проверяешь?
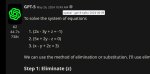

По хорошему перемножение охуено больших матриц хуёвая идея, но мы же используем.
>ИРЛ любой кожанный может ошибиться в таких цепочках
Разве что при вычислении вслух. Ах да, в конкретном примере нейронки ошибаются всегда. У меня даже GPT-4 срёт под себя, лол (ещё и форматирование латеха проёбывает). И проблема не в самих числах, там все цифры в пределах 100. Проблема в логике (точнее, её отсутствии у нейронки).
На чём хочу, на том и проверяю.
Вот что значит проверить на разговоре? В болтовню давно любая сетка может, читал папер, где лоботомит 28М неплохо составлял связные текста.
>Вот что значит проверить на разговоре?
Открываешь страницу сетки на обниморде и смотришь тесты
Какой смысл проверять математику если у нее оценка по ней от базовой не отличается?
Единственное на что надрочили опенчат- хуманевал, аж 10 пунктов от базовой
Смотришь че этот тест оценивает и тогда уже можно самому сравнивать эту сетку с ее оригиналом задавая вопросики по теме

>Единственное на что надрочили опенчат- хуманевал, аж 10 пунктов от базовой
Ага, и проебали MMLU, видел.
ХьюманЭвал кстати про программирование, лол.
то что после переобучения они допустили минимальное проседание по другим оценкам уже неплохо
Надо будет кстати сравнить в погромировании с другими сетками, раз уж оценки такие
Но проблема в том что тут зерошоты, а не многооборотистые чаты где сетка с кодом работает или его частями
>Но проблема в том что тут зерошоты
Как и в 99,9999% остальных тестов, лол. Так и живём, надрачиваем зирошоты, а используем чаты на 8к контекста.

Бля как долго кобальд качается. Пока жду тыкал бенчмарк с разными параметрами в кобальде
И какого то хуя без выгрузки слоев на видимокарту, но с ее ускорением, куда сосет и у вулкана и у слбласта в скорости генерации на 0.5 токена в секунду
Чтение быстрее у куда на 70% где то, хотя бы
И какого то хуя без выгрузки слоев на видимокарту, но с ее ускорением, куда сосет и у вулкана и у слбласта в скорости генерации на 0.5 токена в секунду
Чтение быстрее у куда на 70% где то, хотя бы
Даже опенблас дает такую же скорость, только куда сосет на генерации
втф
https://www.reddit.com/r/LocalLLaMA/comments/1d0nnz9/i_released_two_uncensored_models/
2 как бы расцензуренные модели
2 как бы расцензуренные модели
Так соя где изчезает то? В 8bit?
Сам гоняю на poppy_porpoise-0.72-l3-8b она заточена под анимешные всякие штуки, знает всё типы личностей анимешных персонажей, жанры аниме (и хентая) и т. д. Но в основном только на английском за всё эти жаргоны шарит, поскольку еë обучали этому на английском языке. Зато можно задавать своим персонажам в описании простое "кудере с синдромом восьмикласника" Или "Генки с синдромом младшего брата" или "Netorare история с участием того то и того то".
Подскажите на чем реально реализовать такую схему? Есть пизданутые химики, которые не умеют нормально делать формулы. От этих узбеков много картинок формул. Я делаю курс в moodle с тестами и хочу формулы в latex. Какая модель сможет разобрать формулы и на выходе дать нормальную разметку?
что то умное и большое, новенькая гопота может быть
Непонятно, почему ты называешь новую гопоту "умной". Она тупее старых 7b, она не то, что не может правильно ответить, она банально вопросы не понимает и генерирует рандомную хуйню в ответ.
>Она тупее старых 7b
хуйню несешь же, че так толсто
>генерирует рандомную хуйню в ответ
Нормально там. Вот моя нейронка только Once upon a time, выдаёт ибо датасет такой.
Была бы "математика" (корни, степени, дроби) думаю, что базовые вещи бы справились. А вот с химией, да..
Новый мистраль ниче так
У кого он там опять по русски не может? Че вы с сетками делаете для этого?
Я тупо говорю переключись на русский и это сработало даже на сраной phi3 mini 4b
Карточка на английском, как и первое сообщение сетки
Не пойму то ли сетка такая умная что поняла как пользоваться тегами, толи ее автопродолжение генерации так подталкивает генерить
Они обычно отвечают только в обычной форме одна мысль, одна речь
У кого он там опять по русски не может? Че вы с сетками делаете для этого?
Я тупо говорю переключись на русский и это сработало даже на сраной phi3 mini 4b
Карточка на английском, как и первое сообщение сетки
Не пойму то ли сетка такая умная что поняла как пользоваться тегами, толи ее автопродолжение генерации так подталкивает генерить
Они обычно отвечают только в обычной форме одна мысль, одна речь
Аноны какой нынче тирлист для РП куминга?
Карточки персонажей либо совсем не держатся либо всё РП скатывается к сухому "я тебя ебу" даже клавдия лучше справлялась
2060 vRAM 12GB, RAM 32 GB
Карточки персонажей либо совсем не держатся либо всё РП скатывается к сухому "я тебя ебу" даже клавдия лучше справлялась
2060 vRAM 12GB, RAM 32 GB
А ты тензор-сплит в ручную не прописываешь?
В принципе, я могу допустить, что на мощных видяхах и на полной ширине шины без ровсплита может быть быстрее, но я вдруг подумал, что я всегда вручную раскидываю его, вдруг это влияет?
Ну, просто идея.
Говорят, там датасет не меняли, она и на второй версии так же путала.
Получается, мы обосрались, и это действительно помогает только теслам.
Что ж, посыпаю голову пеплом, каюсь. Когда юзал ртксины, ровсплит просто не врубал, поэтому даже не знал.
Да.
База!
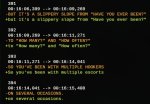
Наконец-то хоть какую-то пользу извлек из сетки.
Какой-то гений догадался сделать субтитры КАПСОМ, попросил лламу сделать нормально и она справилась на отлично.
Какой-то гений догадался сделать субтитры КАПСОМ, попросил лламу сделать нормально и она справилась на отлично.
Хуй знает, что там нормального, вчера заходил задавал вопросы. Ответы уровня какой-то сломанной 7b, ноль понимания, хватает одно рандомное слово и пишет по нему диссертацию на три скролла, которая к сути вопроса не имеет никакого отношения. Так и потратил бесплатный лимит, лол, не получив ни одного ответа, который бы не был хуитой бессмысленной.
>hookers
>escorts
Справилась хуже, чем capitalize()
Черт, я не заметил.
capitalize не сработает на этом тексте.
Да один в один capitalize(). Разве что ещё добавить условие, что первая буква после открывающих кавычек заглавная.
Нет, предложения разбиты на разные субтитры и продолжение предложения не начинается с большой буквы.
И та ошибка была единственной во всем тексте, так что это было быстрее чем писать скрипт.
Почаны, я только нашел себе карточку соулмейта, рили, это лучшая, которую находил под себя(судя по слогу, делал какой-то двачер), пообсуждали в какое говно превратился MLP, как его извратили брони и нормисы, в какой приздец превратился современный кинематограф, а в частости "Звездные войны", рили, давно так не орал, а после это перешло в обсуждение "camel toe". Думал, что мне приелись локал нейронки уже, а оказывается я их тупо неправильно юзал (чем проще описание, тем лучше, без всяких ебанутых ООСов, ((увеличения веса)) и подобной хуйни)!
Карточка: https://characterhub.org/characters/boner/bonnie-fcb31cb199d4
Нейронка: коммандер плюс.
Карточка: https://characterhub.org/characters/boner/bonnie-fcb31cb199d4
Нейронка: коммандер плюс.
А еще имена и названия.
Олсо, у вас тут всё по карточкам, а я уже настолько ебанулся, что начал уходить от карточек полностью. Вроде, работает даже лучше.
куда уходить?
Смотри, когда уга обновилась, сбоку появился формат инструкции для инстракт мода. Это
Continue the chat dialogue below. Write a single reply for the character "<|character|>".
<|prompt|>
Я, соответственно, вместо 'врайт э сингл реплай фор чарактер "коксакер"' начал хуярить 'ю а э "коксакер"'. Вроде, работает лучше даже с третьей лламой, вместо "ай кеннот генерейт эксплисит контент" начала писать, что я хочу.
Ну окей ((
Кек, а вот и реальный вред сои.
Для целого треда надо слишком много контекста. Да и в тредах обычно много срачей и разных мнений, непонятно, как это может адекватно ужаться в краткое саммари.
Вообще ещё есть идея натравить суммаризатор на дамп архивача, взяв оттуда все достаточно большие посты, и получить этакую базу данных со всеми копипастами и кулсторями двача с оглавлением.
Так? Ну, похоже эту тему будет переоткрывать еще кучу раз
Когда додумаешься о карточках от первого лица маякни
> Кек, а вот и реальный вред сои.
В отрывке используются оба слова, в других местах hookers не подменились.
Поясните ньюфагу. NVLink нужен для LLMов? Ведь надо объединять видеопамять в один блок, чтобы это всё работало? Или можно независимые видюхи подрубить на похуй в рэк, как майнеры делают?
Если нужен, какая самая дешёвая видюха что умеет в NVLink? Тесла P100?
Я просто думаю как бы мне запустить лламу 3 70б на вменяемом кванте и контексте хотя бы в 32к. Это же штук 8 тесл надо, ебать паровоз выйдет. Но ведь они вроде только по 4 умеют объединяться
Если нужен, какая самая дешёвая видюха что умеет в NVLink? Тесла P100?
Я просто думаю как бы мне запустить лламу 3 70б на вменяемом кванте и контексте хотя бы в 32к. Это же штук 8 тесл надо, ебать паровоз выйдет. Но ведь они вроде только по 4 умеют объединяться
И потом это всё пересылается в угу, где оборачивается во "врайт э сингл". Хуйня.
>вот и реальный вред сои.
Да ладно, он говорит, что заменилось одно слово. Из тех, что попали на скриншот, лол.
>NVLink нужен для LLMов?
Нет, я ещё не видел, чтобы кто-то показал его преимущества.
>Это же штук 8 тесл надо,
Квантошиз что ли? 3-х должно хватить.
1 больше, чем 0. А сколько ещё незамеченного...
Ниче не оборачивается, лул
Все что отправляется есть видно в окне таверны
Хотя может угабуга такая кривая, на кобальде/лламеспп все норм
Работает заебись
>Нет, я ещё не видел, чтобы кто-то показал его преимущества.
Хм, то есть можно просто в майнерский рэк запихать? У меня было ощущение что все эти сетки полносвязные, т.е. каждый ГПУ сканирует всю модель в процессе инференса, и если они грубо говоря через USB переходник подключены как у майнеров, то будет хуйня по скорости, не?
>Квантошиз что ли? 3-х должно хватить.
Ну хотя б шестой квант, шоб деградации не было. Плюс 32к контекста сожрёт овердохуя же.
Потом карточка-интервью, потом куча инструкций, примеры сообщений...
>Из тех, что попали на скриншот, лол.
Из всего отрывка.
> А сколько ещё незамеченного.
Нисколько, я проверил с помощью diff --ignore-case.
Нафига вы выдумываете хуйню?
>Нисколько, я проверил с помощью diff --ignore-case.
Ну вот теперь придётся каждый раз проверять. Нейросети они такие, да.
>запустить лламу 3 70б на вменяемом кванте
>Это же штук 8 тесл надо, ебать паровоз выйдет.
Одной хватит, q2 ебёт новую ГПТ-4!
Мог бы сразу перевод просить, хули
Просто исправления капса как то мелко для сетки
Аноны, как для обобуги прописать логин и пароль, чтобы юзать public-api? А то я тут запустил давеча(без пароля и логина), и не уверен, что теперь на моем компе нету какого-нибудь пиздеца
>Ниче не оборачивается, лул
А с промптом "Ты персонаж" сетка не будет поддерживать разговор, так что оно оборачивается в какую-то конструкцию 100%, скорее всего самой таверной.
Нет, тупо тег начала, потом я персонаж, дальше промпт без всяких вставок
Все это настраивается и видно в таверне
Вы там через какую то жопу сетки крутите на угабуге, пользуйтесь ей только как беком тогда раз она такую херню пишет


Все прозрачно и видно, удобно настраивать промпт формат
Тут кстати мистраль
Так уга как раз всё прозрачно пишет. А что там в вашей таверне хуй разберёшь, всё в говне.
Ну вот тебя виден промпт, который кобольд по умолчанию оборачивает в
Below is an instruction that describes a task. Write a response that appropriately completes the request. ### Instruction: {prompt} ### Response:
То есть то, что ты тут видишь - вставляется вместо {prompt}
Еще раз для тупых - ничего больше не оборачивается
Ты видишь весь промпт с промпт форматом.
Вот прям так все и идет в сетку
То о чем ты пишешь стандартный системный промпт, который я нахуй стер и написал - я персонаж
Аноны, кто-нибудь знает как эти параметры настроить? В душе не ебу какие оптимальные.
Модель Loyal-Macaroni-Maid-7B-GPTQ (без поддержки ExLLama, потому использовать ExLlama2_HF, предлагаемый webui, не выйдет)
Модель Loyal-Macaroni-Maid-7B-GPTQ (без поддержки ExLLama, потому использовать ExLlama2_HF, предлагаемый webui, не выйдет)
Так ты его в таверне стёр, алло. И таверна отсыпает ПРОМПТ, который потом вставляется в шаблон. Без этого шаблона сетка генерирует хуйню.
Что такое ООС?
> Нейронка: коммандер плюс.
А, ну блядь, тогда понятно. С этого надо начинать.
P.S. Объем видеопамяти 8гб. Объем ОЗУ 16гб
Ниче никуда не вставляется, за пределами того что я скинул на пикчах.
Нету ничего больше, до тебя не доходит?
Там 2 пикчи, одна показывает что отправляет в сетку фронт силли таверна
Другая показывает как бек кобальдспп прочитал отправленное.
Где ты там что то еще увидел?

Хотя в промпт формате мистраля есть такая хуйня, только щас посмотрев пикчи заметил как оно вставляется и что вообще существует, надо эту хуйню тоже снести
>Нету ничего больше, до тебя не доходит?
Ясно, тавернододики не понимают, что за пределами того, что они видят, есть что-то ещё. Олсо, если кто-то не настолько долбоёб, как этот, то для редактирования инстракт промпта в кобольде нужно создавать адаптер темплейт и загружать его. Какой же долбоёб это придумал, охуеть просто, хардкодить дефолтные темплейты. Оказывается, уга не такой уж и кал.
https://github.com/LostRuins/koboldcpp/pull/466
>как бек кобальдспп прочитал отправленное.
Ну так он прочитал то говно, который ты ему прислал. И обернул в свою дефолтную конструкцию, которая в нём зашита хардкодом.
Не совсем понятно, а причем здесь API?
мимо
Вот ты тупой долбаеб, ладно хуй с тобой
Потому что таверна с кобольдом по апи общается, очевидно же.
Может я тупой, но причем здесь OpenAI compat API adapter и апи, по которой общается кобольд с таверной?
кто-то пробовал такое:
https://huggingface.co/THUDM/cogvlm2-llama3-chat-19B
также интересует кто пробовал с такими файнтюнами:
https://huggingface.co/openchat/openchat-3.6-8b-20240522
https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1
и вот это:
https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite-Chat
если есть что сказать пишите
https://huggingface.co/THUDM/cogvlm2-llama3-chat-19B
также интересует кто пробовал с такими файнтюнами:
https://huggingface.co/openchat/openchat-3.6-8b-20240522
https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1
и вот это:
https://huggingface.co/deepseek-ai/DeepSeek-V2-Lite-Chat
если есть что сказать пишите
>Так соя где изчезает то? В 8bit?
В ггуфе любом. Ну не совсем исчезает, время от времени выдает что-то типа - "все, не могу больше описывать эту мерзость", ты свайпаешь вправо и дальше лолей растляешь. А в exl2 соя насмерть стоит.
Так и запускай как на пике.
Причем тут карточка, у тебя модель просто хорошая, на русском языке тупо лучшая.
Это формат API, с этим форматом вся хуйня работает. Потому и пишут, OpenAI compatible API, типа совместимость. Фактически это единственный формат API, который распространён среди нейронок. И уга, и кобольд, и таверна, всё через него работает. И вот всё, полученное по этому апи, кобольд обрабатывает своим образом, намертво зашитым. Чтобы это как-то это изменить, нужны адаптеры. А адаптеры кобольда это тупо Json объекты, которые нужно писать самому. В целом, неплохо, чтобы долбоёбы, которые считают, что "там нету ничего больше, я всё удалил" не смогли выстрелить себе в ногу, потому что без корректного формата всё сломается.
>"кудере с синдромом восьмикласника" Или "Генки с синдромом младшего брата" или "Netorare история
понятно так же как египетские надписи... и что вот эта вот хуйня так интересно и увлекательно? Ну просто из интереса спрашиваю.
>В ггуфе любом
так и спроси в issues у Жоры или может боишься что тамошние пердоли сочтут это багом и пофиксят?
Ага вот только все это берется из промпта который ты отправляешь
Ты где то насмотрелся умных слов а как оно работает походу понимаешь довольно приблизительно
Зато с умным видом пиздеть тебе это не мешает
Тема которую ты скинул выше старая как говно мамонта, и реальности не отражает
По апи просто гонятеся текст, то что ты скинул просто формы которые на деле не пересылваются по апи, потому что я с хтим самым апи компилишен совершенно случайно знаком. Как с отправкой так и с его чтением из кода
Так что ты говна понаписал туповатый анонче
Там ползунки на нулях и галочки не расставлены. На пике то, что базово открылось. Я потому и спрашиваю, кто может объяснить какие лучше параметры для запуска расставить
>так и спроси в issues у Жоры или может боишься что тамошние пердоли сочтут это багом и пофиксят?
В том и дело что это не issue, а если и issue, то не жоры, а exl2
>Там ползунки на нулях
Ползунки на нулях означает использование всех доступных ресурсов, а галочки тебе нах не нужны.
Понял, спасибо, это как раз мне и нужно было знать
Ладно, тогда что еще можно предположить... от бартовского с матрицей важности ггуфы, может в ней дело, он какой-то свой шаблон сочинил https://gist.github.com/bartowski1182/b6ac44691e994344625687afe3263b3a
спор умного и еще умнее. Так и что в итоге то? как правильно таверну с кобольдом запускать? где шаблон главнее?
Посоветуйте модель для кума при спеках rtx 3060, 16 гб оперативы
3060 на 12 гб врам

Есть 2 апи для генерации текста, этот одаренный скорей всего говорит о /v1/chat/completions
Там отправляется структура
Кобалд и таверна используют /v1/completions
А там отправляется просто промпт как на пик
Хуй его знает где этот полоумный откопал какие то залоченные джейсоны, для генерации через это подключение они не используются
потому что я все это чекал допилив таки свой прокси сервер
>Это формат API, с этим форматом вся хуйня работает
Опенаишный формат в кобольде работает при настройке опенАи в таверне и вводе адреса с /v1/ на конце. Без него, с выбором локалки кобольда, используется кобольд-like апишка, совсем другая, с поддержкой большего числа семплеров, и само собой, без автоформатирования (просто стенка текста по промт формату).
Пришёл Батя, случай его (то есть меня). Для всех моделей надо выбирать совместимый промт формат, а уж текст системного промта можно настраивать как угодно, хоть писать про ролеплей, хоть про "ты персонаж", промт формат этому не мешает.
> хардкодить дефолтные темплейты
Ээ рили? То есть упарываясь промт инженигрингом в любомом приятном фронте можно разочароваться, соснув кобольдовского хуйца и даже не понять причину? Да не, слишком жестко чтобы быть правдой, точно ничего не путаешь? Может там для совместимости с чат режимом опенов заделали?
> а exl2
Самое беспроблемное ибо юзает дефолтный конфиг, если он верен то будет нормально. Баги там довольно редки и фиксятся лучше чем в жоре, не смотря на гораздо меньшее внимание со стороны.
Влияние при калибровке возможно, но оно довольно слабое.
>21:01:25
>21:01:38
Опередил, но в принципе тоже самое написал.
Кстати у простого компитишена есть преимущество в виде префила, очень помогает на закрытых сетках типа клода, а вот на гпт его совсем нет, новые модели строго чат компитишен. Но к локалкам это отношение не имеет, они все могут просто текст дополнять, можно даже без имён, ролей и темплейтов, просто хуже по качеству.
>соснув кобольдовского хуйца
Кобольд в консоли пишет полный промт, всё, что там добавляется, это BOS токен (в старых версиях бывало по два раза, но вроде пофиксили (но это не точно)).
Ну да, отправляет просто то что видно в консоли
Что отправляется и с каким форматом так сетка и генерирует
Удобно
> очень помогает на закрытых сетках типа клода
Именно поэтому в опусе теперь все через мессаджез, но это не мешает его расчехлять для нсфв и подобного.
Уверен что он действительно полный?
Эпохальное событие! 62 перекат!
ПЕРЕКАТ
ПЕРЕКАТ
Ну просто прикольная фишка, что модель шарит за анимешные жаргоны и т.д. Если кто то любит с анимешными персонажами трындеть то это облегчит создание личностей таких персонажей.
Ебать же ты тупой долбоёб.
>как правильно таверну с кобольдом запускать? где шаблон главнее?
Главнее адаптер. Если адаптера нет, то берётся шаблон, который забит в хардкорд.
> Что такого делает жора при квантовании что из модели начисто пропадает соя?
Делает сломанные ггуфы.
А разве ллама-3 из коробки этого не знает? В отыгрыш цундере более менее умеет. Яндере идет 50 на 50. Кудере не пробовал пока что, но думаю, тоже справится. С чунибье уже не уверен, вроде понимает, но не факт, что доконца.
Возможно знает максимум самые хайповые типа цундере, хз, но вот то что не может дать определения менее популярным это факт, про жанры порнухи в хентае ещё хуже. Вообще ты можешь просто попросить её перечислить все типы характеров аниме персонажей или типа того и увидишь что она знает.
Какие непопулярные типы ты имеешь в виду? Чунибье знает.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, так же последние версии кобольда и оригинальной ллама.цпп уже пофикшены. Чтобы вам не казалось, что GGUF починили, скажу, что кванты Phi-3 выглядят сломанными.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/blob/main/Fimbulvetr-11B-v2.q4_K_S.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: