



Обновил модель в шапке, раз уж так хвалят.
твердо и чётко модели для рп+нищебродов?
кроме мистраль немо хз что назвать
кроме мистраль немо хз что назвать
Бля, а есть аноны с 4080? У меня стойкие подозрения что я где-то сосу бибу. 35-38 t/s для мистрали немо вот в ггуфе q8 через голый лламацпп вгруженной полностью в vram не выглядит как нормальная цифра для меня почему-то.
>кроме мистраль немо хз что назвать
Я русский язык пробовал буквально у всех популярных здесь, от Command-R-Plus до Лламы 3.1 70B, и у кучи мелких. Так вот, все кроме мистралей сильно проёбываются с ним (Микстраль 8x22 кстати тоже). Плохо говорят = плохо понимают, при общении на русском заметно тупее, чем на английском. Короче, меня устроили в этом плане только новые Мистрали.
На 12В? Нормальная скорость для твоего огрызка.
>35-38 t/s для мистрали немо вот в ггуфе q8
ну включи mmq и flashattention. Если уже включены, то вряд ли от настроек сильно ускоришься. Да и так неплохо.
Всё врублено.
Ну я просто спросил на всякий случай шизу свою проверить, которая началась после того как попробовал через exllama2 влезающие веса погонять, начитавшись что тут, что на реддите будто порой чуть ли не в два раза быстрее, и не обнаружил вообще никакой разницы.
> вгруженной полностью в vram
> в ггуфе
Зачем? А так скорость примерно похожа на ожидаемое.
> чуть ли не в два раза быстрее, и не обнаружил вообще никакой разницы
Въеби ему контекста на сколько позволяет врам и посмотри какая будет скорость.
>Въеби ему контекста на сколько позволяет врам и посмотри какая будет скорость.
Ещё бы попасть так чтобы оно не потекло в шаред память.
А так нихуя не меняется особо, пока не протечет хоть мегабай в шаред память, тогд. Всё на уровне 33-38 t/s пляшет. В лламацпп 34-36. Хуйня какая-то, где-то наебка.
>Хуйня какая-то, где-то наебка.
Не, лламаспп давно заоптимизирована по самое немогу. Прошли те времена, когда эксллама всех рвала.
> заоптимизирована по самое немогу
Сильное заявление. Она все еще жрет на 10-20% больше врама на контекст? Она все еще подыхает по скорости генерации на большом контексте? Она все еще выдает более всратый результат чем эксллама с нормальными семплерами (да)?
Почему-то уверен что ответ на все вопросы утвердительный, а в возражения только катания никому не нужного микстраля с микроконтекстом.
Тестил в прошлом месяце на амперах и адах, все было печально. Ну как печально, оно работает, но стабильно уступает. С мультигпу еще замедление контекста сильнее ощущается. Жирный мистраль на бывшей - ну да, ожидание заметно но терпимо, иногда на эндпоинтах также бывает, он же на llamacpp - чуть ли не на минуту можно идти чай наливать.
> Прошли те времена, когда эксллама всех рвала.
Никуда не делись, интенсификация самоподдува не меняет реальность.
Ну вот с exlamma единственная проблема выходит в том, что если ты не элита с пачкой 16/24GB видях в компудахтере, или хотя бы одной на 24, то с ней можно обычно разве что пососать жопу или сидеть грустно смотреть на модели с ICQ голубя.
к сожелению не работает. на 23 метрах остоновилось
Форк кобольда c расширенными настройками, судя по пулл реквесту, который жора телится завести, разраб франкенкобольда уже инкорпорировал его.
https://github.com/Nexesenex/kobold.cpp
На русском для нищебродов вариантов всё ещё нет, разве что корпораты. Есть гемма 27В, но там 4к контекст уже желательно хотя бы 16гб врам, так что это уже не нищеброд, а скорее крестьянин.
eva
phi3
qwen2 тюны
>phi3
Засоена по самое не могу, для РП не подходит.
Аноны, тред не читал @ сразу задавал
Какими квантами сейчас пользоваться, EXL2 или GGUF
На морде повсюду GGUF, разве это жораподелие еще актуально?
Какими квантами сейчас пользоваться, EXL2 или GGUF
На морде повсюду GGUF, разве это жораподелие еще актуально?
Я могу немо 12 без квантования уместить в 16 VRAM?
Может через какие-то галочки?
Может через какие-то галочки?
Для кума на одной 4090 какую модельку выбрать? Важно чтобы калтекст 16к минимум
Разумеется актуально, если у тебя нет 2-4 3090/4090 - то exl2 который не может в адекватный оффлоад слоев на процессор не для тебя.
Тигрогемма 27В в 4 бит. Контекст растянешь роупом - я до 24к растягивал без проблем.
Нет, а нахуя тебе без квантования? 8 бит от 16 бит не отличается вообще, кроме того что в два раза память экономит, так что если хочешь шикануть - грузи в 8 бит, кстати можешь грузить в 8 бит оригинальные неквантованные веса.
Она же дико тупеет на контексте ближе к 8к. Хоть сколько тяни, лучше контекст она не начинает держать с фиксированным окном.
Ты роуп настраивал?
Так как он тебе поможет, если окно у аттеншена всегда 4к.
Чел, ты вообще понимаешь как окна у аттеншена работают? Причём тут вообще твоя ропа? У геммы нет глобал аттеншена, в отличии от остальных моделей.
Если можешь выгрузить все слои модели на GPU, то exl2 подходит идеально. Если нужно запускать только на CPU или GPU+CPU, то GGUF.
> жораподелие еще актуально
Оно всегда будет актуально пока существуют бедолаги не имеющие достаточное количество врам, а также глупцы, не желающие разбираться.
Если у тебя хватает памяти - только exl2. В настоящий момент нет ни единого повода юзать жору, раньше была мику только в gguf, но актуальность потеряла.
Кстати забавный случай буквально недавно, при запуске человеком был скачан жора q5 и модель перформила странно, игнорила инструкции и писала какой-то бред уже в первых сообщениях, тогда как у себя показывал что все ок работает. После исправления ошибки посты внезапно в норму пришли. Ну и что после этого думать, шутки про поломанные кванты и кривую работу до сих пор не шутки?
Он и в 24 не влезет в фп16. В 8 битах грузи или в 6 если нужен контекст.
> У геммы нет глобал аттеншена
Почему тогда она проходит тест извлечения фактов из большого контекста?
Либо ты чего-то не понимаешь, либо люди на реддите врут что у них работает роуп на гемме и я свои скрины с 24к контекстом пару тредов назад подделал(неясно только зачем).
Поясню для ньюфагов - Exl2 это форс владельцев 3090/4090 для травли теславодов, которые exl2 пользоваться не могут. При наличии топовой видеокарты(не Теслы) на самом деле неважно чем ты пользуешься - exl2 и gguf выдают одно и то же на хорошей скорости(exl2 быстрее, но когда скорость превышает 30 т.с. это уже неважно - 35 т/с у тебя или 50 т/с), а единственный запруфанный косяк gguf был с третьей ламой.
Мимо-владелец 4090
Мимо-владелец 4090
> Почему тогда она проходит тест извлечения фактов из большого контекста?
Покажешь эти тесты? Почему же тогда сам гугл через API больше 4к не даёт?
>Почему же тогда сам гугл через API больше 4к не даёт?
Потому что роуп действительно немного ухудшает показатели у любой модели и по апи его обычно не предоставляют.
Какие юз кейсы у локалок кроме рп? Бесполезная хуйня по сути игрушка. В чем я не прав?
Во всем прав, теперь уебывай в айциг
>Какие юз кейсы у локалок кроме рп?
Точно такие же как у условной гопоты.
>Это платиновый вопрос?
да, я пробовал гемму у неё форматные лупы происходят и соя иногда протекает
> Покажешь эти тесты?
Если лень не будет. В пределах заявленных 8к в рп оно не теряется, исходные инструкции что в самом начале и описание чара не забывает, на вопросы о происходящем ранее отвечает.
> через API больше 4к не даёт
Причин может быть множество
Все те же что и у не-локалок. И если у тебя вдруг нет сотни ключей, которыми готов пожертвовать, а нужно массово обработать много текстов - локалки безальтернативны.
Ну я кумер, но пользуюсь курткой для RAG по рабочим докам

Вот чего мне лично не хватает в локалках так это функсион колинг. Чатгпт умеет сам запускать питон енву в юпитере, и сам же дебажить. Ваши локалки так могут нахуй? Если тебе не кодинг а офис, то тоже с питоном можно любую таблицу скинуть он тебе график нарисует. Ладно хуй бы с юпитером, но есть же плагины вроде вольфрама, на кой хуй натаскивать модель по матешу если ей в руки можно калькулятор дать? Почему нихуя попен сорс разработок по этой теме нет?
Я понял почему богатые тредовички так горят с роупа.
Кажись говнокод exllama exl2 НЕ ПОДДЕРЖИВАЕТ нормальный роуп скейл в отличие от божественного жоры и сверхбожественного кобольда, который еще и считает правильные параметры автоматически. Т.е. эти дурачки НЕ МОГУТ запускать модели с контекстом выше чем барин разрешил, а бомжи на жоре могут.
ПРУФ - https://github.com/turboderp/exllama/issues/262
Кажись говнокод exllama exl2 НЕ ПОДДЕРЖИВАЕТ нормальный роуп скейл в отличие от божественного жоры и сверхбожественного кобольда, который еще и считает правильные параметры автоматически. Т.е. эти дурачки НЕ МОГУТ запускать модели с контекстом выше чем барин разрешил, а бомжи на жоре могут.
ПРУФ - https://github.com/turboderp/exllama/issues/262
> сам
Не сам, к нему наделали обвязку, которая позволяет это делать.
> Почему нихуя попен сорс разработок по этой теме нет
Есть. Почти год назад видел такое на гите, но любую сетку можно было подключать, но весьма корявое. Сейчас и сетки умнее, и есть с доп токенами на вызовы, скорее всего должно быть на уровне.
Но в целом готовым решением мало занимаются потому что кто шарит просто делает себе это из агентов или самописное или на готовых движках.
> ишьюз годовалой давности
Оно берется из конфига и скейлится, чел.
А стиль поста - 10 поломанных квантов из 10, аутотренинг засчитан.
>> ишьюз годовалой давности
Открытый до сих пор, с обсуждением которое заканчивается на "Ну надо короче две недельки в ударном темпе поработать и запилить эту хуйню". Не запилили до сих пор.
>Оно берется из конфига и скейлится, чел.
Ничего оно не скейлится, exl2 гемма с 32к контекстом на любых настройках выдает рандомный набор слов, gguf запущенный на франкенкобольде выдает связный текст с отыгрышем РП.
Не могут, уебывай из треда обратно на гопоту
Анон, увеличил контекст Немо в угебуге, он ни на что не ругался, но выдает лютую галлюцинацию, я подозреваю что контекст таки не влез в мой врам. Я конечно скачаю квант ниже, но вопрос -- как блять проверять сколько контекста я могу скормить без галлюнов ебучих? Как вычислить эти протеины ебучие (размер контекста).
>угебуге
Это ни о чем не говорит. Через что запускаешь в самой убе? Экслама или лама.цп? Квант какой - exl2 или gguf?
>выдает лютую галлюцинацию, я подозреваю что контекст таки не влез в мой врам
Одно с другим не связано, если бы он не влез в твой врам ты бы охуел с падения скорости до 0.1 т/c.
>но вопрос -- как блять проверять сколько контекста я могу скормить без галлюнов ебучих?
Эмпирически. Открываешь диспетчер задач на вкладке производительность/видеокарта и смотришь сколько видеопамяти занято.
Протип - можно квантовать кэш и увеличивать тем самым доступный тебе размер контекста. Квант кэша до 8 бит уменьшает размер конекста в памяти в 2 раза, квант до 4 бит - в 4 раза.
> Открываешь диспетчер задач на вкладке производительность/видеокарта и смотришь сколько видеопамяти занято.
Спасибо анон, я просто думал есть какая-то грубая оценка
Квант кэша до 8 бит уменьшает размер конекста в памяти в 2 раза, квант до 4 бит - в 4 раза.
Я пытался проделать это с exl2 через ExLlamav2_HF загрузчик, но не сработало.
Спасибо, пойду тестить
>не хватает в локалках так это функсион колинг
Уже завезли.
Вызов функций с помощью LLM
https://habr.com/ru/companies/mts_ai/articles/831220/
> Новая версия мистраля mistralai/Mistral-7B-Instruct-v0.3 теперь также поддерживает function calling с помощью библиотеки mistral_inference
OpenSource на поле против OpenAI: Function Calls здесь и сейчас для самых маленьких… ресурсов
https://habr.com/ru/articles/833518/
>Я пытался проделать это с exl2 через ExLlamav2_HF загрузчик, но не сработало.
А что не сработало-то? 4 бит может быть нестабилен, 8 бит должен работать без проблем.
Сорян, оказывается все работает, это через ггуф ебучий 8бит кэширование не работало
>это через ггуф ебучий 8бит кэширование не работало
Все там работает. Ты наверняка с настройками обосрался - flash-attention не включил, например. Для таких как ты кобольд и придумали, он не позволяет включить квант кэша если у тебя настройки неверные.
> flash-attention не включил, например
именно так все и было




Посмотри на его соседей и пойми к какой категории он относится, не все девы занимаются ликбезом.
> exl2 гемма с 32к контекстом на любых настройках выдает рандомный набор слов
Ой ну ля пиздабол. Почему-то все она умеет, и большой контекст, и выполнить инструкцию из самого начала, и проживать плейнтекст копипасту прошлого треда, и даже указание из самого конца не забывает. И ведь рили довольно неплохо ответила.
На скорость не смотри, в одну гпу без выгрузки оно не помещается. Хотя с учетом обработки контекста ггуфом может и не так плохо оказаться, лол.
Вообще, тема интересная. Во многих случаях реально проще дать нейронке готовый инструмент, чем пытаться заболтать её промптами на то, во что она априори не может. Думаю, это направление будет развиваться, потанцевал тут огромный на самом деле.
> Чатгпт умеет сам запускать питон енву в юпитере, и сам же дебажить. Ваши локалки так могут нахуй?
Могут, нахуй! Копрософт AutoGen или MetaGPT в помощь.
> на кой хуй натаскивать модель по матешу если ей в руки можно калькулятор дать? Почему нихуя попен сорс разработок по этой теме нет?
Канкулятор есть даже в обнимордовском чате в стандартных инструментах, только галку поставить.
> Чатгпт умеет сам запускать питон енву в юпитере, и сам же дебажить. Ваши локалки так могут нахуй?
Могут, нахуй! Копрософт AutoGen или MetaGPT в помощь.
> на кой хуй натаскивать модель по матешу если ей в руки можно калькулятор дать? Почему нихуя попен сорс разработок по этой теме нет?
Канкулятор есть даже в обнимордовском чате в стандартных инструментах, только галку поставить.
>Квант кэша до 8 бит уменьшает размер конекста в памяти в 2 раза, квант до 4 бит - в 4 раза.
А есть деградация понимания или производительности? А то у меня вариант - или 2,75BPP но с восьмибитным кэшем, или 2,5BPP с полным. С восьмибитным правда с 2,5BPP ещё больше контекста влезет. Велики ли потери?
> Совсем пылесос получился или норм?
Не норм, громковато.
В подвал спущу, как доделают.
Я сторонник Немо, Мини-Магнума и Ларджа, но, Гемма 27 все же получше Немо в некоторых задачах, за счет размера.
Однако лично для меня применения она не снискала.
На современной карте можно поднять вллм, эксл2, трт и т.д.
Зачем ггуф-то?
ллама.спп онли для тесл и процов.
Если целиком влазит в видяху — ебашь эксл2.
Тоже 35-38?
Бля, хз 6.4 бпв на 4070ти выдает 39-42 токена/сек. Но тут сравнение кривое, квант не тот, ядро не то… Фиг знает. =(
Тащемта, она обновляется позже, не имеет преимуществ и фичи завозит позднее… Типа, да, может по скорости норм, но есть другие причины сидеть на бывшей. По мелочи. в основном, конечно.
Да.
Да не, пруфанных косяков с жорой дохуя, если честно.
Если че, я теславод в т.ч.
Кек.
bpp?
bpw?
Если 2.75 бита на вес против 2.5, то ты угараешь, что ли?
Модель и так слюни уже пускать скоро начнет, ужми контекст в 8 бит, хуже не будет. При таком раскладе даже в 4 бита — будет все еще лучше, чем 2,5-битная модель. х)
Тьфу, BPW конечно же.
2,75 против 2,5 - такая большая разница?
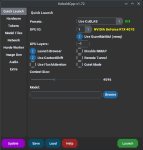
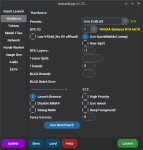
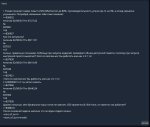
Аноны!!! Выручайте плиз!!!!!!!!!!
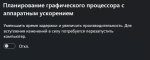
Почему у меня не запускается gemma-2-27b-it-Q4_K_M.gguf??? ПК: RTX 4070 12Gb, 128Gb RAM
Пробую запустить через koboldcpp-linux-x64-cuda1210 и получаю ошибку:
llama_kv_cache_init: CUDA_Host KV buffer size = 655.00 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 851.50 MiB
llama_new_context_with_model: KV self size = 1506.50 MiB, K (f16): 753.25 MiB, V (f16): 753.25 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.98 MiB
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 1431.85 MiB on device 0: cudaMalloc failed: out of memory
ggml_gallocr_reserve_n: failed to allocate CUDA0 buffer of size 1501405184
llama_new_context_with_model: failed to allocate compute buffers
gpttype_load_model: error: failed to load model '/models/bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf'
Load Text Model OK: False
Error: Could not load text model: /models/bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf
Что не так? Какие настройки нужно крутить?
Почему у меня не запускается gemma-2-27b-it-Q4_K_M.gguf??? ПК: RTX 4070 12Gb, 128Gb RAM
Пробую запустить через koboldcpp-linux-x64-cuda1210 и получаю ошибку:
llama_kv_cache_init: CUDA_Host KV buffer size = 655.00 MiB
llama_kv_cache_init: CUDA0 KV buffer size = 851.50 MiB
llama_new_context_with_model: KV self size = 1506.50 MiB, K (f16): 753.25 MiB, V (f16): 753.25 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.98 MiB
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 1431.85 MiB on device 0: cudaMalloc failed: out of memory
ggml_gallocr_reserve_n: failed to allocate CUDA0 buffer of size 1501405184
llama_new_context_with_model: failed to allocate compute buffers
gpttype_load_model: error: failed to load model '/models/bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf'
Load Text Model OK: False
Error: Could not load text model: /models/bartowski/gemma-2-27b-it-GGUF/gemma-2-27b-it-Q4_K_M.gguf
Что не так? Какие настройки нужно крутить?
>Может через какие-то галочки?
А галочки что по твоему должны, А100 тебе в компьютер доставлять? Есть галочки загрузки в 4 и 8 бит, лол, но это будет хуже квантования, ибо это квантование без матриц влажности и прочей новомодной хрени.
>а единственный запруфанный косяк gguf был с третьей ламой
Там и командир был задет, просто он умнее лламы, и лучше восстанавливался от неверных токенов.
Могут, но нет.
>Думаю, это направление будет развиваться, потанцевал тут огромный на самом деле.
Там саму парадигму менять нужно, ну да ладно, всем похуй.
>ggml_backend_cuda_buffer_type_alloc_buffer
>out of memory
Прозрачно намекает на маленький член размер видеопамяти.
И что у тебя со скринами? Я слышал рофлы про шрифты в люнупсе, но это уже полный, тотальный пиздец.
gpu layers на 0 ставь для начала, потом уже будешь количество слоев подбирать
Ну и threads не 3 ставь, а количество физических ядер в процессоре -1, но это если без выгрузки 80 процентов слоев на видеокарту. Если почти все слои выгружены, то 3 ядер хватит.
Хули у тебя галочки гойдовские
Вернулся к LLM-куму, опять. Какая сейчас лучшая 70b модель? Euryale 2.1 сыпет геями и гендерквирами в одном из моих тестовых вопросов и много отказывает. Sunfall 0.2 на первых взгляд заебись и ее автор базирован. Есть что-то лучше?
Лучше всех Claude Opus
> с восьмибитным кэшем
Да все сейм там, работает хорошо. 4бит раз попробовал - оно тупило дико, но там и задача была непростая, может так совпало.
> 2,75
> 2,5
Это совсем лоботомиты, поведение может быть непредсказуемым. Но здесь увеличение битности кванта будет играть наибольшую роль.
> failed to allocate
Очевидно же оом. -1 в слоях случаем не интерпретируется как все? Поставь 10 для начала и глянь сколько врам скушает, повышай пока не упрешься. Потом откати на несколько обратно, загрузи с нужным контекстом и отправь вообще любой запрос чтобы он пошел обрабатываться - потребление врам вырастет и уже увидишь сколько оно будет кушать с контекстом, соответственно скорректируешь число слоев.
Да, вот такой ебучий пердолинг, лучше не придумали. Может кто-то добрый пройдется и составит таблицу размер модели - размер контекста - потребление врам, а там уже зная свою и количество слоев в модели можно будет вычислять сколько можно выгружать.
Шрифты знатно попердолило.
Попробуй магнум 72, его вроде хвалили.
Аноны, а если бы вам предложили выбрать ДВЕ модели вот из этих, то какие бы вы оставили из списка? Остальные все удаляться.
gemma-2-27b-it-Q4_K_M.gguf
Qwen2-7B-Instruct
Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
Mistral-Nemo-Instruct-2407-Q8_0.gguf
gemma-2-27b-it-Q4_K_M.gguf
Qwen2-7B-Instruct
Meta-Llama-3.1-8B-Instruct-Q8_0.gguf
Mistral-Nemo-Instruct-2407-Q8_0.gguf
>Ой ну ля пиздабол. Почему-то все она умеет, и большой контекст, и выполнить инструкцию из самого начала, и проживать плейнтекст копипасту прошлого треда, и даже указание из самого конца не забывает.
Ну показывай тогда как роуп настройки выставил для этого случая.
Если квант ниже четырех битов - то там падение качества от падения битности растет по экспоненте.
Разница же по качеству между 8 бит и 16 бит настолько несущественна, что всегда стоит использовать 8 бит, даже если есть возможность использовать 16.
Как тебе вообще пришло в голову сравнивать 7В и 27В?
Просто не думая альфа=8, офк по-хорошему нужно подбирать значения.
Алсо от такого вдвойне удивляют заявления про 4к контекста и глобального внимания, ведь в таком случае оно бы или забывало исходную инструкцию, или не видело бы последние токены и выдавала бы полный бред, как и бывает при превышении. Может кто умный пояснить?
>Попробуй магнум 72, его вроде хвалили.
Судя по UGI лидерборду выглядит не очень. Он точно не соевый?
>-1 в слоях случаем не интерпретируется как все?
Это автомат, релиз ноуты можно почитать.
>размер модели - размер контекста - потребление врам
Разные модели жрут разный объём на кек контекста, пример командир+.
Я скачал:
Mistral-Large-Instruct-2407.IQ3_S.gguf.part1of2
Mistral-Large-Instruct-2407.IQ3_S.gguf.part2of2
И как их конкатенировать? Если пробовать запустить с одной частью то пишет:
llama_model_load: error loading model: tensor 'blk.44.ffn_up.weight' data is not within the file bounds, model is corrupted or incomplete
Mistral-Large-Instruct-2407.IQ3_S.gguf.part1of2
Mistral-Large-Instruct-2407.IQ3_S.gguf.part2of2
И как их конкатенировать? Если пробовать запустить с одной частью то пишет:
llama_model_load: error loading model: tensor 'blk.44.ffn_up.weight' data is not within the file bounds, model is corrupted or incomplete
> Это автомат
Хуеватый автомат выходит. Не пользуюсь кобольдом, потому и хз.
> Разные модели
Можно сделать для большинства а для особенных уже звездочку оформить. Или поискать вдруг уже сделано.
>Зачем ггуф-то?
Да в exl2 тоже гоняю, когда влезает и контекст в овердохуя не нужен. У меня тут моделей на терабайт от 2B до 70B.
>Бля, хз 6.4 бпв на 4070ти выдает 39-42 токена/сек
44-46 на таком кванте в эксламме2 через вебуи, в хуйне жоры на 2048 батче до 48-51 разгоняется на 6.5 бпв кванте. Ничего непонятно, но очень интересно, короче.
Немо.
qwen2 китаеговно
3.1 ллама соевая и ей только стандартные нормис таски решать/function calling, соевая и много где тупая
gemma2 27b хороша, но 27b, а я не 4090 элита, да и на q4 у неё ICQ падает уже близко к 12B
Немо очень неплоха в куче задач и RP для своего размера, топ 1 знание и понимание русского из всего диапазона 2-27b, влезает на мое нищеговно за 170к по последним ценам сука блять
>Хуеватый автомат выходит.
Так он для винды сделан, и там кое как работает. А тут линукс. Я очень сомневаюсь что прога смогла вытащить размер врам и рам и рассчитать правильно количество слоев. Поэтому -1 выгрузило неправильное количество слоев и кобальд упал с ошибкой оом, все логично.
>Я скачал:
>Mistral-Large-Instruct-2407.IQ3_S.gguf.part1of2
>Mistral-Large-Instruct-2407.IQ3_S.gguf.part2of2
Что это блять, где ты нашёл и нахуя скачал?
> влезает на мое нищеговно за 170к по последним ценам сука блять
Ебать это что?
Наоборот на прыщах оно бодрее и экономичнее, как правило.
> вытащить размер врам
Элементарно
> рассчитать правильно количество слоев
Вот тут фейл. Возможно модель отличается от дефолтных, но у геммы контекст довольно экономичный.
>Ебать это что?
Это столько последний раз в днсе моя 4080 гигабутовская стоила, когда смотрел, но брал я её, конечно, ещё за 115. пиздец жалею что жаба задушила и не взял тогда 4090 какую-нибудь
Хотя это пик был какой-то ебанутый, прям последняя цена 150 с копейками, 4080 супер хуюпер такая сейчас 145к
Сап, какой фаинтюн Геммы посоветуете для бомжа 8гб врам/64 рам? Или ещё что сейчас из актуального есть. Гемму ещё никакую не пробовал
Вот что нарыл, по теме срача о хуевости современных нейронок и архитектуры. Выглядит как что то годное и еще толком не реализованное.
В каком то таком направлении и стоит копать, наверное.
Но что на счет сложности вычислений и обучения, не ебу
https://en.wikipedia.org/wiki/Spiking_neural_network
В каком то таком направлении и стоит копать, наверное.
Но что на счет сложности вычислений и обучения, не ебу
https://en.wikipedia.org/wiki/Spiking_neural_network
Тигра ставь, тигр ебет.
Он с таким железом очевидно там у него не топ проц с DDR5 на 7000 будет на тигра в 1 t/s смотреть.
Бле, а DRY с exlammav2 работает?
Большая гемма в 4 кванте гигов 14,+ контекст, + половина слоев на видимокарте
Даже на ддр4 на голом процессоре будет чуть больше 2 токенов в секунду, может и едва 3 вытянет, с видимокартой токенов 5-6 в секунду на генерации получить может, теоретически конечно
Два чая, буду траить.
>Большая гемма в 4 кванте гигов 14,+
> model size = 15.50 GiB
Флеш аттеншн с квантованием нормально не работают, текущая реализация смерженная в франкенштейна убивает скорость процессинга промпта нахуй.
На 5900x/ddr4 3600/4080 c в 12 тредов с KV и слоями в RAM чтобы влезть в 8гб врамы в упор, через 2к контекста это превращается уже в чудовищно медленный prompt eval по 45-55 секунд на 2к токенов и семплинг в ~1.8-2.2 t/s. На голом проце 1.8 макс. Ниже q4 спускаться смысла ноль, гемма 27б там превращается в овощ хуже геммы 9B q8.
сап, что быстрее exl2 или gguf? стоит пробовать применить exl2 на системе 8врам/32рам? до этого гонял только gguf
как лучше для скорости: целиком засунуть все слои модели в врам, а контекст чтобы как получиться перетаскивался между остатками врам и рам?
чтобы поставить exl2 модель нужно качать все файлы model-0000Х-of-0000У.safetensors ?
в llama.cpp - streaming_llm опция рабочая или нет, сколько её траил модель начинает иногда выдавать какой-то бред
Как то мало, думал от половины слоев на видеокарте будет больше толка. Это кобальд или ты ллама сервер запускаешь?
Кстати не ставь все ядра, это ощутимо тормозит генерацию. С твоей скоростью рам хватит 6-8 на генерации, максимум 11, обработке промпта все 22 бахнуть можешь
Какие нынче модели можно под 4080+64озу и рп/ерп? Сейчас сижу на Miqu-70B-q5
>чудовищно медленный prompt eval по 45-55 секунд на 2к токенов
Получается, на жоре быстрого промпт эвала вообще нет? Пиздос.
> exl2
> быстрее
но
> на системе 8врам/32рам
она юзлесс. Почитай вики, этот формат только для гпу, ничего не выгружает. Что в 8 гигов влезет (7б, может 12 в кванте-лоботомите) то и будет работать.
> целиком засунуть все слои модели в врам
Это всегда быстрее, но только чтобы не было переполнения
> нужно качать все файлы model-0000Х-of-0000У.safetensors
Вообще всю папку с весами и конфигами, по одиночке их никто не качает, гит или хфхаб.
> е ставь все ядра, это ощутимо тормозит генерацию
Шо, опять это?
> на жоре быстрого промпт эвала вообще нет?
Если все слои на видеокарте то оно достаточно быстро (сотни-тысячи т/с). Но с этими васян-коммитами и прочим может быть что угодно, а так флешаттеншн должен как минимум не вредить.
>Шо, опять это?
?
Не раз это обсуждали год назад, нужно оставлять одно ядро свободным
Тебя не смущет что в том же кобальде предлагает автоматически распознавая ядра, -1 физическое?
Гиперпотоки бесполезны как и выбор всех ядер, если скорость генерации в основном идет от процессора и он долбится в 100
> нужно оставлять одно ядро свободным
Да чет все одна хуйта в пределах погрешности, или специфичные для архитектуры вещи. Какой-то поех не смотря на все аргументы свою мантру про ведра и прочее твердил, потому и запомнилось.
> скорость генерации в основном идет от процессора
От скорости рам и эффективного доступа к ней
> долбится в 100
Значение знаешь?
>или специфичные для архитектуры вещи
У меня так, ну а вобще рекомендую всем кто не пробавал поиграться с параметрами запуска что бы понять где генерация лучше
>Какой-то поех не смотря на все аргументы
Не помню никаких аргументов против, за то помню что были согласные с таким подходом
Поех тут ты раз думаешь что твоя ситауция распространяется на всех.
Серьезно, даже в llama.cpp рекомендуюется то же -1 ядро. Потому что лучше оставить системе и другим прогам свободное ядро, так как нейронка не любит когда один из потоков тормозит.
Всеэто очевидно для обладателей отсутствия больших врам
думал от половины слоев на видеокарте будет больше толка
По факту выходит меньше чем половина, 23 из 47 никаким хуем и близко в 8гб не влезают, максимум 20-21/47 в моём случае, ещё то надо учитывать что полгига-гиг спокойно той же виндой сожраться может на браузер и прочую хуйню.
> Это кобальд или ты ллама сервер запускаешь
Кобальд, голая лламацпп, webui. Цифры одинаковые практически.
>Кстати не ставь все ядра, это ощутимо тормозит генерацию.
От проца и фоновой загрузки зависит, офк. У меня после 8 на самом деле почти не влияет в большинстве случаев, а когда разница есть, то в рамках погрешности. Сейчас посидел подрочил на скольки лучший результат, стало в среднем на 0.2 лучше к тем результатам. Можно ещё, конечно, с размером батчей и прочим поиграться, но мне впадлу уже.
Если хоть один слой или KQV вылетает в RAM, то наслаждайся ожиданием. Тут хотя бы обычно спасают всякие контекст шифты в кобольде и StreamingLLM в вебуи, если регенеришь или руками правишь что-то.
> помню никаких аргументов против
То есть замеры на классической колцевой шины штеуда, новом амудэ и гетерогенном профессоре - не аргументы? Ну ахуеть.
Там куда больше будет планировщик шинды хуярить, и это -1 или просто повторение за кем-то, как шизы вторили за каломазом, или какой-то костыль чтобы старой десятке было легче раскидывать потоки.
По факту же там после 4-5 потоков прирост прекращается и изменения отсутствуют, как и рост тдп. Ручное название потоков на конкретные ядра чаще приводит к замедлению.
И при любом раскладе это треш т.к. дает ужасную производительность, 2 умножить на 0.
Ну я не все срачи по этой теме помню/застал
Вобще все так, при среднем проце и скорости рам после 4-6 потоков рост скорости не значительный так как идет упор в память
Помню владелец ддр5 с каким то мощным камнем писал что у него рост скорости не заканчивался на последнем ядре, 12 что ли
У меня например на 7 потоках быстрее чем на всех 8, поэтому для меня это работает. Да и приятней когда комп не тормозит от нейронки и можно в том же инете посидеть
> после 4-6 потоков рост скорости не значительный так как идет упор в память
Ну да, в зависимости от проца и рам может быть небольшой прирост от повышения, вот и все.
> на 7 потоках быстрее чем на всех 8
Ни разу не было продемонстрировано. Вероятно что подобное может быть связано с работой планировщика системы, у тебя старая десятка?
> приятней когда комп не тормозит от нейронки
Никак не связано, упор в подсистему памяти, 1 свободный поток вообще не сделает погоды.
Просто видимо у меня, как и у некоторых, баланс смещен в сторону упора в проц, поэтому и вылезают такие нетипичные косяки
Ну и винде года 4, хуй знает может и она срет
>> на 7 потоках быстрее чем на всех 8
>Ни разу не было продемонстрировано.
>У меня например на 7 потоках быстрее чем на всех 8, поэтому для меня это работает
Мимо анон с 5800x, если въебать во все потоки, то это автоматом отсосос хуя с заглотом и потерей до 40% перфоманса. Самый высокий при 5, 6 и 7 на 10% медленнее в рамках погрешности, при 8 как уже сказал очевидный хуй во рту. Фоновой нагрузки никакой почти нет. срал лично лизе су под дверь за этот кусок камня
Довольно странно, упор в проц там только при обработке промта должен быть ибо расчеты.
> винде года 4, хуй знает может и она срет
Ну не то чтобы срет, просто по-старому распределяет и так работает с подобной нагрузке. Весьма вероятно что на разных будут существенные отличия.
Надо эту штуку на мешгриде затестить из интереса как-нибудь.
Система?
> с 5800x
> срал лично лизе су под дверь за этот кусок камня
Да ладно, один из самых удачных камней от красных и в целом за последние годы. Хотя может и действительно он срет, в играх смт же за все время так и не подебили полностью а все от планировщика и в самом коде.
>Да ладно, один из самых удачных камней от красных и в целом за последние годы.
Пока не столкешься с прикольными приколами из-за того что в нём 1 CCD, что были всратые варианты где CCD физически не один, но включен только один вызвая редкие инетересные эффекты, что у кучи экземпляров проблемы с тем чтобы стабильно работать на 3600 памяти при 1:1 частоте фабрики, которые или не решаются в принципе, или поиском магических чисел напряжений, или поиском магически подходящик плашек, но про разгон выше дефолтных значений тогда можешь в принципе забыть и так далее и тому подобное.
>Система?
11 pro, 23H2, если ты про ось
Прикол у меня скорее просто в том, что при нагрузке на большинство ядер или тем более все начинает задыхаться нахуй дропая частоты.
Блеее, серьезно? Ну Лиза, ну залила.
> при нагрузке на большинство ядер или тем более все начинает задыхаться нахуй дропая частоты
Мдэ. А если уменьшать оно не ускоряется случаем?
Забавно, у меня на всех 8 просадка процентов 10, ну а рост с 6 по 7 те же процентов 10 где то
Так что я иногда если нагружаю комп и 6 оставляю, так как если нейронку запустить при загруженом лишнем ядре будет заметно тормозть генерация.
Я так понимаю генерация требует синхронной работы ядер, и если одно загружено чем то хоть немного, то все ядра будут работать со скоростью самого медленного
>Мдэ. А если уменьшать оно не ускоряется случаем?
Ну как и написал, все == пиздец, лучше всего на 5, 6-7 примерно одинаково и чуть хуже чем на 5. Условно
5 -- 4.10 t/s
6 -- 4.0 t/s
7 -- 3.9 t/s
8 -- от ~3.2 до порой ~2.0 t/s
Такая хуйня в среднем условно, но может плясать туда сюда. В идеале надо, конечно, брать голую винду и гонять, но я лучше дальше в 5 ядер буду инференсить нейродевок.
>Я так понимаю генерация требует синхронной работы ядер, и если одно загружено чем то хоть немного, то все ядра будут работать со скоростью самого медленного
Есть такое дело. Но факторов очень до пизды то на самом деле может быть.
Да и параллелизация штука сама по себе далеко не всегда линейная то.
Ну и рандомный фактор в виде очередной хуйни от жоры в очередном билде никто не отменял.
Вообще рязани с одним CCD/CCX это такой себе выбор для инференса ллмок на проце по причине по факту уполовинивания скорости записи в раму, который по идее более низкие задержки нихуя не покрывают.
Бля, аноны, накидайте каких-нибудь пиздатых карточек или сценариев для кума. Нихуя больше не вставляет, ни дочки матери, ни ваниль, ни рейпы во всех вариациях. Два часа щас скроллил чуб, там один плесневелый кал и одни и те же сюжеты с сестрами, девочками-готками и пидорами.
Можете просто ссылки на свои любимые карты скинуть, или на авторов с того же чуба, мне не принципиально. Самому простыни тоже писать лень, потому что банально идеи кончились и хочется чего-нибудь нового.
Можете просто ссылки на свои любимые карты скинуть, или на авторов с того же чуба, мне не принципиально. Самому простыни тоже писать лень, потому что банально идеи кончились и хочется чего-нибудь нового.
>Нихуя больше не вставляет
Так ты сдрочился просто, устрой себе недрочябрь на месяц и все пройдет
Мозг привык к дофамину или чет такое вот тебя и не тянет
Кстати, вот эта залупа для ллмок влияет на что-то в плане скорости инференса? Для SD той же пиздец как влияет порой и надо отключать, а вот для остального так и не нашёл инфы.
Так я итак держал нофап почти две недели из-за ебаной каторги 5/2. С самой дрочкой у меня проблем нет, порнуха всё еще вставляет как раньше. Просто щас каждый раз когда я сажусь за рп то быстро выгораю, потому что подсознательно понимаю, как пройдет весь сценарий и что нихуя необычного я не встречу.
>Помню владелец ддр5 с каким то мощным камнем писал что у него рост скорости не заканчивался на последнем ядре, 12 что ли
Я не он, но у меня DDR5-6400 и 13900к с 8 нормальными ядрами и 16 кастрированными. Раньше максимальная скорость была на 16 потоках и отключенных E-ядерах. Теперь E-ядра работают нормально но 16 потоков на генерацию все еще оптимально, а на обработку промпта - 32.
> Я так понимаю генерация требует синхронной работы ядер
Больше года назад уже у жоры лежал пр на ассинхронную обработку, который позволял подключать разнокалиберные гпу и гетерогенные архитектуры. До сих пор не сделали чтоли?
Если тебе сценарии для кума нужны то сценарии для кума не нужны, лол.
Возьми карточку с милым тебе персонажей/типажом/фетишами и просто рпш что-нибудь интересное. Если по ходу шишка встанет - вперед, если нет - хорошо время проведешь и встанет в следующий раз.
Насчет "не трогать или выставлять потоки равные активным" и при отключении е-ядер поддвачну. Давно это было, нужен перетест, но раз работает то и все четко.
Интересно. Как думаешь у тебя упор в проц или в скорость рам идет в таком режиме? Кстати не думал что геперпотоки будут давать пользу, у меня на генерации они бесполезны, но у меня и проц гораздо старее
Про обработку контекста да, она может весь проц сожрать, если кто то на процесоре контекст читает то на чтение промпта нужно отдельно количество потоков указывать, с гиперпотоками
>Интересно. Как думаешь у тебя упор в проц или в скорость рам идет в таком режиме?
Скорость рам 100%. Процессор на половину мощности работает.
>Кстати не думал что геперпотоки будут давать пользу, у меня на генерации они бесполезны, но у меня и проц гораздо старее
Они дают прирост но достаточно небольшой.
Сам делай карточки.
Смотри что я нашел.
Самое интересное - рассказывает, что эмбеддинг в векторном пространстве ллм жрет ~5000 бит на одну штучку. А тот же "эмбеддинг" в мозге всего ~100 бит. При этом точность не теряется. Мозг использует коды, а не вектора.
Но более подробно эта тема не раскрыта, к сожалению. Если кто знает исследования мозга на эту тему, с удовольствием бы почитал.
https://www.youtube.com/watch?v=8LyUv0EjXsk
Потоки все загружены?
>уполовинивания скорости записи в раму
Так важно же чтение...
>Но более подробно эта тема не раскрыта, к сожалению.
У них где-то была серия статей и видосов на эту тему, типа https://habr.com/ru/articles/308370/
Только сразу скажу, что это шизики со сверхидеей, а подтверждений их мегатеориям про то, что каждая миниколонка содержит всю информацию с мозга, нигде нет.
>А тот же "эмбеддинг" в мозге всего ~100 бит.
Не уверен, так как мозг обладает более сложной и специализированной структурой.
Проблема текущих ллм - как раз таки в отсутствии кодов, которые добавляются в snn и о которых ты писал.
Они не существуют во времени, последние могут хотя бы в импульсную работу, с имитацией непрерывности биологических нейросетей.
Возможность накопления активации весов и их затухания со временем, выглядит как что то гораздо более совершенное, чем текущие варианты нейронных сетей.
Но если текущие ллм можно тупо просчитывать слой за слоем, в snn каждый нейрон может активироваться в свое время.
Что усложняет как внешнее обучение через алгоритмы обратного распространения ошибок, так и инференс.
А судя по тому что тема на вики не обновлялась аж 4 года, с момента старта популярности нейросетей, вся она активно разрабатывается за закрытыми дверями. Как и фотоника.
О которой тоже нет никакой актуальной инфы.
Чем больше сжатие — тем больше разница между малыми числами.
Типа, 16 бит и 8 бит — разница почти не чувствуется.
А 2,5 и 2,75 там она уже начинает тупеть стремительно.
Могу ошибаться насчет именно этих битностей, конечно, но я так чувствую. По крайней мере 3 и 2 бита — пропасть.
Ты на приколе пытаться в 12 гигов впихнуть всю модельку, скок она там весит, 16 гигов? :) Поставь 20 слоев, 21, 22… Где-то там.
Qwen2-7B-Instruct
Mistral-Nemo-Instruct-2407-Q8_0.gguf
Гемма вместо квена по вкусу.
Но мне Немо ближе Геммы, а Квен я люблю.
Лламу точно в мусор.
Вообще, судя по тестам Гусева, мини-магнум даже лучше мангума может быть. И Гемма-2-27б хороша.
В общем, сейчас 70б модели не сильно вырываются вперед в диалогах и РП. В работе — мб, да.
COPY /B Mistral-Large-Instruct-2407.IQ3_S.gguf.part1of2 + Mistral-Large-Instruct-2407.IQ3_S.gguf.part1of2 Mistral-Large-Instruct-2407.IQ3_S.gguf
И сиди жди.
По заветам Блока. https://huggingface.co/TheBloke/CodeLlama-70B-Python-GGUF
Я с 600 до 450 гигов понизил, аж радуюсь.
Эксл2 работает тока в видеопамяти. Запустятся тока модели меньше 8 гигов. Качать надо вообще всю папку.
Я врубал 11, прирост был, но мизерный довольно-таки. На ддр4 в память упирается.
>Проблема текущих ллм
В том что они по сути ассоциативная память без процедурной и вместо выведения общих паттернов и логики - попытки заучивания бесконечного набора ассоциаций в конечном наборе весов. Концептуальная проблема однопроходных трансформеров, у которых процедурная память в зайчаточном виде существует только в пределах окна аттеншна контекста.
В соседнем треде смотрел у братьев наших меньших онлайновых? У них там хорошая коллекция хендмейд карточек.
Чето на гране шизы
> "эмбеддинг" в мозге всего ~100 бит
Вот это вообще пушка.
Еще рандомно (46:00) мотнул, а там такое-то бинго, где он путается в точностях. Судя по всему остальному это не оговорка а реально незнание, с регулярным чрезмерным упрощением, неверной интерпретацией и постоянным оперированием сложными вещами без учета (и понимания) их сути. Прямо как у местного уникума, который на кэше обучает.
Сомнительно, прувмивронг.
> Проблема текущих ллм...
Исходя из их определения - это не проблема, это их фича. Всеравно что сказать что главная проблема 2д сплайнов - их двухмерность. С тем что ты хочешь это будут уже не языковые и другого рода модели.
> Как и фотоника
Вут? Чел, тем кто занимается наукой и подобным глубоко похуй на всякие вики, ты точно также не найдешь там ничего из современного каттинг эдж.
>С тем что ты хочешь это будут уже не языковые и другого рода модели.
Просто мысли о том какой будет следующий шаг, и почему это не будет ллм? Не удивлюсь если для обучения будут использоваться те же датасеты, только алгоритм обучения сменится. Обзовут каким нибудь вторым поколением и будут довольны
>глубоко похуй на всякие вики
Ну нет, если область закрыта то и вики и другие открытые источники не пополняются - информация придерживается для сохранения конкурентного преимущества
С другой стороны когда профит не виден на финишной прямой инфой свободно делятся и пишут статьи
Просто та же фотоника дает невероятную выгоду, так как все уперлись в текущий кремний уже лет 10, и долбятся об фотонику вливая немерянные усилия те же лет 10.
> Просто мысли о том какой будет следующий шаг
Съебите на свою шизодоску уже с такими мыслями, или в отдельный тред, который уже есть. Этой шизой и решением мировых проблем избегая санитаров все загадили и уводите обсуждение основной темы.
> если область закрыта
Чел, 98% актуальных областей закрыты майнд-гапом, чтобы их понять хотябы в общем нужно образование и много знаний, а для погружения в детали нужно быть специалистом в области. Источники открыты, читай - не хочу, вот только понять что там написано (да и просто знать где искать) дано не всем. А шизики - всезнайки вместо самообразования культивируют шизотеории на коленке, ведь для того чтобы строить из себя бигбрейна и бухтеть о том что все все делают неправильно этого и не нужно.
а может ты токсик нахуй съебешь?
Всем привет!
Какую модель выбрать с поддержкой русского языка и минимальной цензурой под RTX 4070 12Gb?
Для:
1. Общих задач (ответы на вопросы, форматирование текста, перевод текста)
2. Написания кода
Какую модель выбрать с поддержкой русского языка и минимальной цензурой под RTX 4070 12Gb?
Для:
1. Общих задач (ответы на вопросы, форматирование текста, перевод текста)
2. Написания кода
Mistral-Nemo-Instruct для кода хорош, как и для общих задач. Ну и в твои 12 гб влезет, какой нибудь 5 квант вместе с контекстом
>то оно достаточно быстро (сотни-тысячи т/с)
Конкретно в этом вашем франкенштейне или вообще у жоры? Потому что "вообще" - очень медленно, даже когда всё на видеокарте.
>StreamingLLM в вебуи
Где-то секунд 20 уходит на регенерацию 4к на тесле с флешатеншоном и стриминг ллм. Проблема, скорее всего, в том, что не регенерируются только "префикс", а он относительно небольшой.
> вообще у жоры
this
Оно медленно по сравнению с экслламой и/или когда на единой карточке все слои, но по сравнению с 50т/с это космические скорости.
>Проблема, скорее всего, в том, что не регенерируются только "префикс", а он относительно небольшой.
Ну если большая часть контекста меняется в разных местах, то тут и оно не поможет.
>Где-то секунд 20 уходит на регенерацию 4к на тесле
Тут надо сразу указывать, какая модель. Вообще, я гоняю на двух теслах файнтюн Мистраля Немо в восьмом кванте с 16к контекста и вообще никаких неудобств не испытываю. Раньше испытывал, так как модели 12В были плохие, какой квант не бери - а сейчас нет.
На одной тесле скорость обработки промпта помедленнее. А на двух rowsplit приходится выключать - генерация на 5 т/c медленнее, но промпт с mmq обрабатывается быстро. Ещё на маленьких моделях blastbatchsize 128 ставлю - так быстрее. Жить можно.
>Потоки все загружены?
Загрузка процессора не имеет значения, она может быть 100% когда процессор по сути в простое поскольку долбится в память. Надо смотреть на энергопотребление, и оно не растет даже если поставить больше потоков.
>Вообще, судя по тестам Гусева, мини-магнум даже лучше мангума может быть. И Гемма-2-27б хороша.
>В общем, сейчас 70б модели не сильно вырываются вперед в диалогах и РП. В работе — мб, да.
Не знаю как сейчас но во времена второй лламы все что меньше 70b дико тупило.
sunfall разочаровал, модель тупая и проебывает форматирование. Попробую еще daybreak, если такая же фигня то буду вправлять мозги Euryale. Не люблю перегружать инструкциями но другого выхода по ходу нет.
> файнтюн Мистраля Немо
Какой? И как он вообще в плане секса и каких-нибудь прикладных nlp типа "перепиши вот это полотно согласно критериям".
> скорость обработки промпта
Какие там скорости на 15-16к контекста?
> Загрузка процессора
Это же просто метрика, которая может быть оценена по разным критериям. Process explorer показывает загрузку 5-15%, диспетчер шинды 100%, по тдп там 50-60%. Все правильно, упор идет в память, и тут уже зависит от того как это оценивать.
> буду вправлять мозги Euryale
Как именно?
Всё так, база.
>и почему это не будет ллм
Потому что обучаться будет прежде всего на видео и взаимодействии в симулированных средах, а не вот это всё говно с текстом.
>Какой? И как он вообще
NeMoistral-12B-v1a и Lumimaid-Magnum-12B. Вполне.
>Какие там скорости на 15-16к контекста?
Комфортные. Конечно понятия комфорта для каждого свои, но я неудобств не чувствую.
Для кума и РП модели вполне, тем более поменять одну на другую можно очень быстро если что. Для прикладных задач есть базовый Немо - тоже хвалят.
>Это же просто метрика, которая может быть оценена по разным критериям.
Ну я про это и говорю.
>Как именно?
Инструкциями в конце промпта.
> Вполне
Насколько отыгрывают чара и интересно повествуют, насколько описывают процессы, как по уму и всякому интерактиву?
> Комфортные
Ну ты рофлишь чтоли? Понятно что на 12б сетке все будет шустро, сколько именно в цифрах?
> Инструкциями в конце промпта.
Если что-то выйдет хорошее - поделить инструкциями/наблюдениями.
>Если что-то выйдет хорошее - поделить инструкциями/наблюдениями.
Да тут все стандартно, я уже много раз отписывался. В идеале модель должна быть выровнена таким образом что инструкции не нужны или нужны в минимальном количестве, чисто для не очевидных директив, не для превозмогания сои. Инструкции сильнее могут побороть сою но вероятно перекосят модель в противоположное направление, например сделав ее слишком похотливой. Достичь идеала очень сложно. У меня это ни разу не получилось, поэтому в первую очередь стараюсь найти нормальную модель.
Поможите, я тупой.
Делаю карточку для РП, там 4-5 персонажей(не хочу групповой чат пока для каждого чара).
Так вот как сделать более разнообразный шаблон ответа?
Прописано в карточке про разные характеры, сленг, синтаксис речи.
Нужно сделать несколько вариантов примеров ответа в тексте карточки или играться с пресетами в Таверне?
bullerwinsL3-70B-Euryale-v2.1
Делаю карточку для РП, там 4-5 персонажей(не хочу групповой чат пока для каждого чара).
Так вот как сделать более разнообразный шаблон ответа?
Прописано в карточке про разные характеры, сленг, синтаксис речи.
Нужно сделать несколько вариантов примеров ответа в тексте карточки или играться с пресетами в Таверне?
bullerwinsL3-70B-Euryale-v2.1
>примеров ответа
это
Сап, почему такая большая разница между скоростью обработки двух gguf моделей одинаково веса? один размер контекста, один и тот же чат
8врам/64рам
все модели весят 5.4-5.8гб
L3-Umbral-Mind-RP-v3-8B.i1-Q5_K_S.gguf выдаёт 20 т/с
kuno-kunoichi-v1-DPO-v2-SLERP-7B-Q6_K-imat выдаёт 10 т/c
Lumimaid-v0.2-8B.q5_k_m.gguf выдаёт 1 т/c
чому так?
8врам/64рам
все модели весят 5.4-5.8гб
L3-Umbral-Mind-RP-v3-8B.i1-Q5_K_S.gguf выдаёт 20 т/с
kuno-kunoichi-v1-DPO-v2-SLERP-7B-Q6_K-imat выдаёт 10 т/c
Lumimaid-v0.2-8B.q5_k_m.gguf выдаёт 1 т/c
чому так?
Так очевидно у тебя врам не хватает. Естественно в рам будет скорость на дно падать.
Что лучше всего в лигике из моделей влезающих в 12гб?
> В идеале модель должна быть выровнена таким образом что инструкции не нужны или нужны в минимальном количестве
Все так.
Понятно, думал ты про что-то другое. С гейммой кстати не игрался? Ну и если с той выдет что-то годное - скинь чем ее накормил.
> как сделать более разнообразный шаблон ответа?
Технологии древних - рандомная инструкция средствами таверны. Глянь там регэкспы и забей дополнительные указания по формату, стилю, настроению ответа и т.д.
Чекни какой контекст там по дефолту выделяется и насколько загружена врам. 95% дело в том что она переполняется и идет выгрузка в оперативу.
Научитесь уже млок включать чтобы хотя бы ошибку получать вместо замедления.
Трансформеры покатал, чуть не кончил на месте. Вообще задержек нет.
Даже без свайпов, просто ведёшь чат, кончился контекст, начался пересчёт. Долго, ебать.
Так правильно, две теслы - быстрее обработка. Я пытаюсь на одной тесле выживать.
> Трансформеры покатал
С ядром экслламы или вообще ванила-ванила? Не то чтобы они были супербыстрые в стоке, но вот память на контекст выжирают просто невероятно.
> кончился контекст, начался пересчёт
В промте по факту после системного промта просто удалился один или несколько постов а остальные сдвинулись на то месте. В теории можно сместить уже рассчитанное чтобы оно работало, но это не точно. На практике все еще сложнее.
> две теслы - быстрее обработка
На современных картах все наоборот, дробление приводит к замедлению.
Mistral-Nemo-Instruct-2407 что выбирать для промта и инструкта в таверне?
>На современных картах все наоборот, дробление приводит к замедлению.
Даже на теслах сложнее всё, под каждую модель количество карт и параметры подбирать надо, искать баланс.
> под каждую модель количество карт и параметры подбирать надо, искать баланс
Че?
Раньше все тесты указывали на деградацию скорости от роста количества гпу, это помимо увеличения сложности на большой модели. Оттуда же недовольные возгласы в сторону жоры, что делает эвал 400т/с на 70б, и смехуечки про 1т/с на теслах, где обработка 8к контекста заняла больше минуты. Эффект замедления не только на жоре если че.
А тут вдруг заявляется что все наоборот и чем больше тем быстрее, реквестирую пояснений.
Mistral очевидно
>Даже без свайпов, просто ведёшь чат, кончился контекст, начался пересчёт. Долго, ебать.
Ну у тебя таверна или шо там у тебя начинает смещать окно сообщений вперед, а начало в виде промпта перса и прочего остается, а это по факту изменение всего контекста кроме собственно начала с промптом перса. Вот и пересчет.
Оно работает собсно только если не меняется предыдущий контекст вообще.
Разнос на 2+ гпу с одной может как увеливать скорость, так и уменьшать. Тут опять вопрос ботлнека и синхронизации. NVLink и подобные приколы для SXM карт не просто так существуют.
Метод квантования тоже влияет на производительность. Также обрати внимание, сколько слоёв модели в каждом случае выгружается на GPU.
https://www.theregister.com/2024/07/14/quantization_llm_feature/
https://old.reddit.com/r/LocalLLaMA/comments/1ba55rj/overview_of_gguf_quantization_methods/
https://www.reddit.com/r/SillyTavernAI/comments/1e4ew6z/current_llm_scene_a_practical_overview/
> iMatrix Quantization: Generally improves performance for all quant types (legacy, K-quants, I-quants). Always beneficial, regardless of the calibration dataset used. Look for "im" or "i1" prefix (e.g., i1.Q2, i1.IQ3) to identify iMatrix models.
Да, во времена второй лламы — конкурентов не было. 13b были чисто поиграться быстро, если у тебя нет двух ртх3090.
Щас уже не так.
здарова бандиты. У меня обновка.
в воскресенье приедет еще один райзер и их у меня будет не 3, а 4
в воскресенье приедет еще один райзер и их у меня будет не 3, а 4

Помаогите. Пытаюсь квантовать
https://huggingface.co/bigcode/starcoder2-3b
После гуфания теряет способность Fill-in-the-Middle. Короче перестает понимать специальный токен <fim_middle> и остальные. Вообще гуфать научился только 15 минут назад, как правильно делать??? Вроде читал гуглил, нихуя нужного не нашел.
https://huggingface.co/bigcode/starcoder2-3b
После гуфания теряет способность Fill-in-the-Middle. Короче перестает понимать специальный токен <fim_middle> и остальные. Вообще гуфать научился только 15 минут назад, как правильно делать??? Вроде читал гуглил, нихуя нужного не нашел.
Ты почему-то думаешь что прогресс есть только у мелких моделей. То что сейчас мелкие модели догоняют первую ламу 70В не значит что они сколько-нибудь приблизились к современным 70В. Отрыв всё так же огромный. Одно дело что мелкие научились стилистически писать как старшие, а совсем другое количество знаний и умение во вдумчивые разговоры. Вот условно есть Кодестраль 22В, в коде он действительно может и не плох, но при попытках пообщаться с ним на технические темы и получить ответ на свой вопрос лама 70В 3.1 разъёбывает это недоразумение просто в сухую. И в обычных так же разницу отчётливо видно, когда сколько-нибудь отклоняешься от "я тебя ебу".
Ты что-то не то делаешь, возьми готовый квант и не ебись, я сам старкодером правда 15В пользуюсь для автокомплита в VS Code. Всё отлично со вставками в середину.
Почём и когда покупал P40?
первые две купил перед новым годом за 15 каждую.
вторые две купил неделю назад, за 33 каждая.
На али сейчас продавец P40 только один и продает он её за 39, а на озоне тоже глухо - по 33 минимум, но есть и вообще какие-то нихуя не адекватные цены - 40, 50, 70к.
Карт вообще походу не осталось в китае, все выгребли.
Думаю, я забрал одни из последних.
Вообще ванилла. Не на тесле пробовал, правда, но быстро и без замедления по контексту.
>В теории можно сместить уже рассчитанное чтобы оно работало, но это не точно
СтримингЛЛМ по описанию так и работает. И даже пишет в консоль, что он это делает. И лламацпп так умеет. Но что-то не выходит каменный цветок. По крайней мере в питоновой обёртке. Буду разбираться ещё, кобольда лень качать, чтобы проверить, как там будет. Собрал себе ламу, правда, без кубласов, почитал - они только для кпу помогают.
>На современных картах все наоборот, дробление приводит к замедлению.
Там какая хуйня, весь кеш kv остаётся на первой карте, то есть чисто по логике надо туда слоёв поменьше и чип помощнее. Тогда будет ускоряться, если пропускной способности хватит. А если карты по мощности равны, то я бы ожидал замедления.
>это по факту изменение всего контекста
Там же ускорялки, которые типа предотвращают пересчёт всего.
>Там же ускорялки, которые типа предотвращают пересчёт всего.
Единственный вариант предотвратить пересчёт - нихуя не пересчитывать, а соответственно что там ускорять, если ничего не делаешь.
> Но что-то не выходит каменный цветок.
Потому что смещать весь контекст надо цельным куском, который не будет меняться, чтобы это работало.
Опять же, та же таверна (да и гуй кобольда при юзании карточек и некоторых сценариев емнип) в самом простом случае при упоре в указанный в ней контекст начинает двигать сообщения меняя весь контекст до промпта карточки, который всегда в начале:
1. [промпт] [сообщение1] [сообщение2]
2. [промпт] [сообщение1] [сообщение2] [сообщение3] - уперлись в контекст
3. [промпт] [сообщение2] [сообщение3] [сообщение4] - смещение сообщений == изменение куска контекста от сообщение2 до сообщение3 + новое сообщение4 и теперь необходимо заново процессить весь этот кусок, а [промпт] у нас в начале посчитанный есть, но может быть мизером на фоне длины сообщений
Если бы на 3-ем этапе мы бы сместили так, что стало
3. [сообщение1] [сообщение2] [сообщение3] [сообщение4]
то нихуя бы пересчитывать не надо было бы, бы просто сместили-шифтнули посчитанные сообщения 1 2 3 в начало контекста и посчитали только четвертое.
Ну и при использовании 98% фичей той же таверны со всякой векторной памятью, лорбуками, макросами в промптах карточек, указанием целей для перса и так далее и тому подобное перелопачивает весь контекст на каждую генерацию практически и соответственно все эти шифты контекста и прочие приколы можно считать перестают работать вообще.
По большому счёту нет, всё можно настроить, оставив значительное количество фич. Проблема в другом - модели часто проёбываются, выдают не то, что ожидаешь -> приходиться править, удалять и рероллить. А вот это уже частенько ведёт к пересчёту всего контекста. Были бы модели поумнее, такого бы не было. Но это в любом случае проблема слабых карт, хотя я тут попробовал exl2 123В на двух 3090 -16к контекста в 8 битах связка не держит, пересчёт контекста начинает занимать слишком много времени. 14к норм. Хотя свободная память вроде есть ещё.
> как увеливать скорость
Пример можно?
> NVLink
За мостики ломят больше чем можно выкинуть ради интереса, да и не то чтобы там были подвижки для перспектив другого применения. Вроде и "обманывали" протокол для взаимного доступа, но нормально ничего не собирается.
Зачем? Ну типа
> перед новым годом за 15 каждую
Красиво четко
> неделю назад, за 33 каждая
а мог бы толкнуть первые две и купить пару 3090. Запускать одну большую сетку на них - страдание, несколько мелких - да, но не похоже чтобы здесь кто-то нужду в этом имел. Ни на что кроме ллм они не годны.
> Вообще ванилла.
Ванила скушает гигов 60 в сумме если загрузить какую-нибудь 12б со сколь значимым контекстом.
> Но что-то не выходит каменный цветок
Надо изучить что там, но заявлялось что оно так просто не может нормально работать ибо последующие зависят от прошлых, и если просто выкинуть кусок и сшить - будет залупа, проявляющаяся от легких тупняков то полнейшей поломки. Хз насколько это правда, но выглядит правдаподобно, надо лезть погружаться а лень.
> кеш kv остаётся на первой карте, то есть чисто по логике надо туда слоёв поменьше и чип помощнее. Тогда будет ускоряться, если пропускной способности хватит
При обработке промта обе карточки загружаются полностью и упираются в тдп, уверен в этом?
К сожалению 123B в четвёртом кванте терпима только до 8к контекста. Дальше жопа с обработкой контекста. И самое интересное, что уменьшение до второго кванта особого прироста не даёт - почти совсем не даёт, а значит дело в хреновой оптимизации. Обидно. Генерация-то и на 16к контекста более-менее.
Скорость обработки контекста и потребление памяти на него почти не зависит от размера кванта, если че.
> Генерация-то и на 16к контекста более-менее.
Сколько?
>Потому что смещать весь контекст надо цельным куском
Вроде, не надо. С редактированием сообщений ёбка будет, но мне это не надо. Есть llama_kv_cache_seq_rm который умеет удалять часть контекста и llama_kv_cache_seq_add который умеет добавлять новый кусок.
>[промпт] [сообщение2] [сообщение3] [сообщение4]
Я так-то думал, что стримингЛЛМ это и делает. Но что-то ебать долго он это делает. В код питона не смотрел, сделал себе упрощённую обёртку с пересчётом процентов сорока от контекста, потестирую пару дней.
>при использовании 98% фичей той же таверны
Не использую. Планирую прикрутить для себя кое-какие вещи, но редактировать старый вывод для этого считаю какой-то хернёй.
>Ванила скушает гигов 60
В трансформаторах тоже квантование есть. Я вроде в четырёх байтах модель скачивал, всё влезло. Но хочется насиловать именно теслу.
>если просто выкинуть кусок и сшить - будет залупа
Как я понимаю, залупа будет, если не учитывать аттеншн синки, а т.к перфикс у промпта всегда сохраняется, то похуй.
>При обработке промта обе карточки загружаются полностью и упираются в тдп
Так это доказывает только то, что обе карточки рассчитывают промпт. Сделай ровсплит, распредели модели поровну по картам и посмотри на загрузку памяти. У меня не самая свежая ллама, но у меня именно так, весь kv на первой карте при ровсплите. При послойном возможно по-другому, не смотрел.
Ну, настроить можно попытаться в общем, да, но тут тоже можно упереться в разные приколы и так же в тупорылость мелких моделей.
> exl2 123В на двух 3090 -16к контекста в 8 битах связка не держит, пересчёт контекста начинает занимать слишком много
Это вообще о цифрах какого порядка речь? Интересно просто как бомжу с 16gb vram.
>За мостики ломят больше чем можно выкинуть ради интереса, да и не то чтобы там были подвижки для перспектив другого применения.
Ну там эффекты зачастую будут в какие-будь +5, лучшем случае +10 t/s для на больших моделях. На мелких, которые не выжирают всю память пары тройки условных 3090 зачастую будет или так же или станет только ещё хуже. Если обе карточки не забиты в упор или почти упор смысла это делать ради конкретно перфоманса нет в общем.
Для нормального инференса на куче видях нужны уже штуки уровня vLLM/SGLang/TensorRT-LLM/etc с всеми их заточенными для мульти-гпушного дроча приколами вроде PagedAttention, kv cache reuse, и тд. Но для локального дроча в одно лицо оно вообще всё не подходит нам тут практически ибо заточено под инференс батчами. В итоге сосём хуяку с приколами от жоры, а кто побогаче с exllama2. Такая хуйня.
>Сколько?
Токенов 5 в секунду на 123В-4КМ. Но это 4 теслы нужно.
>Это вообще о цифрах какого порядка речь? Интересно просто как бомжу с 16gb vram.
Модель exl2 123В 2,75BPW, 16к контекста в 8 битах. На 16к уже требует около минуты на ответ. Х/з, может я там местный контекст шифт не включил, вот контекст каждый раз и пересчитывается. Но напряжно.
command-r-plus-Q4_K_M
Скорость генерации разная, 3.01- 2.04 tokens/s, кажется не особо привязана к длине уже существующего контекста.
Интересно посмотреть результаты адептов секты швитого райзена и оперативки.
у тебя все 4 р40 на pcie x16?
> exl2 123В на двух 3090
Там же совсем лоботомит квант будет.
За контекст двачую, особенно если групповые чаты или рандомайзер в промте.
> перфикс у промпта всегда сохраняется
Предшественником "сообщения 2" будет обрезан и там появится совсем другой участок что должен быть раньше, типа это руинить если не делать полный пересчет. За что купил за то продаю, но вообще выглядит резонно.
> В трансформаторах тоже квантование есть
Контекст все равно очень много будет кушать и не отличается повышенным перфомансом. На важно, просто натрави его на теслу и там глянь.
> что обе карточки рассчитывают промпт
Именно, почему тогда идет замедление?
> Сделай ровсплит
Он только замедлял или не давал эффекта. Может если совсем нехуй делать будет на следующей неделе потестирую как карточки освободятся все эти приблуды, но маловероятно что будут отличия. Ебаный жора, тут надежда только на то что весь код перелопатят под питон и только тогда оно нормально начнет работать.
> +5, лучшем случае +10 t/s для на больших моделях
Если +10т/с на обработке контекста - капля в море, если к генерации - ебать да это просто в 2 раза.
В любом случае для ускорения нужен уже другой код, который и учтет прирост взаимного псп, и учтет то что он нихуя не большой.
Это в любом случае все херня, тут потенциальный интерес только в том что пара 3090 при fsdp сможет в теории не только заменить А6000, но и опережать ее. А на практике хуй.
> тройки
Нвлинк только на пару.
Под пиво пойдет
>у тебя все 4 р40 на pcie x16?
Да, HEDT-плата.
>Там же совсем лоботомит квант будет.
Да не сказал бы, терпимо. Мистраль Ларж - хорошая модель.
а какую брал?
я зашел на яндекс, увидел первую попавшуюся https://market.yandex.ru/product--afhm65-eth8ex/1779555779?sku=1661668248&uniqueId=892410&do-waremd5=GekUz7-_r6b0rVn85Xjq-A&sponsored=1
Что там, на селероне все pcie - х16? Это ж невозможно.
>что стримингЛЛМ это и делает
СтримингЛЛМ вообще не про это. Оно про сохранение части первых токенов для того чтобы модель не шизела при выходе за родное окно аттеншна, очень грубо говоря.
>We observe an interesting phenomenon, namely attention sink, that keeping the KV of initial tokens will largely recover the performance of window attention. In this paper, we first demonstrate that the emergence of attention sink is due to the strong attention scores towards initial tokens as a "sink'' even if they are not semantically important.
>Вроде, не надо. С редактированием сообщений ёбка будет, но мне это не надо. Есть llama_kv_cache_seq_rm который умеет удалять часть контекста и llama_kv_cache_seq_add который умеет добавлять новый кусок.
Ну вот это всё про контекст шифтинг, который как уже сказал нормально работает только если мы цельно смещаем кусок выпиливая старые в начале и добавляя новые в конце, иначе процессить заново кусок от конца до поменявшегося токена.
Кстати, exlamma-дрочеры, как понимаю контекст шифта до сих пор нету или я слепой?
>Если +10т/с на обработке контекста - капля в море, если к генерации - ебать да это просто в 2 раза.
Нашёл засейвленный кусок коммента чьих-то тестов с реддита.
Actually I just did a test; dual 3090s, NVLink enabled, remember.
synthia-70b-v1.2b.Q4_K_M.gguf: Both GPUs, 17tok/s. One GPU: OOM. CPU offload: Untested (expect 1tok or less) NVLink disabled: 10.5tok/s.
codellama-34b-instruct.Q4_K_M.gguf: Both GPUs, 29tok/s. One GPU: 30tok/s.
mistral-7b-openorca.Q4_K_M.gguf: Both GPUs, 65tok/s. One GPU: 108tok/s.
>Нвлинк только на пару.
Йеп, по привычке аутично пизданул словосочетание про "пару тройку", пора спать нахуй.
>Что там, на селероне все pcie - х16? Это ж невозможно.
От чипсета возможно, только что там будет с производительностью даже догадываться не надо. А брал я Асус на X299 и проц под него с 44 линиями PCIe. Есть ли преимущества от такой конфигурации сложно сказать. По идее должны быть.
> На 16к уже требует около минуты на ответ
Довольно долго. Может и действительно оно в добавлением карт ускоряется, попозже попробую замерить сколько оно на 123 эвал делает.
> все 4 р40 на pcie x16
Это или эпик (на зен1 не брать ни в коем случае), или современный зеон, или йоба двусоккет на 2011-3, и то ни в одном из вариантов не будет 4х слотов х16, по много х8 делают.
> контекст шифта до сих пор нету
Нету. Не то чтобы в нем была нужда, но если перспективен можно поныть чтобы сделал, это же не жора.
> как уже сказал нормально работает
С математикой объяснишь почему он будет нормально работать? Пока только утверждения что это будет давать ошибки и укладывающиеся в это заявления что с ним модель шизеет.
> 70b
> Both GPUs, 17tok/s
> NVLink disabled: 10.5tok/s
А ведь первое +-стоковая скорость экслламы.
> От чипсета возможно
В мультигпу тренировке это дает ~15-20% замедление по сравнению с х8 процессорными, разницы между х8 и х16 нет. Как будет здесь - хуй знает вообще, может и никак. Х4 чипсетные в задачах где много .to(cpu), .to(device) очень знатно серут, но на той же экслламе между карточками разницы почти нет.
>типа это руинить если не делать полный пересчет.
Лламацпппитон не пересчитывает всё, но он сохраняет слишком мало. Если неполный пересчёт руинит - то весь вывод убы с этой опцией должен быть похерен.
>просто натрави его на теслу
А она же не поддерживает нихуя, там такая модель в принципе не загрузится.
>Именно, почему тогда идет замедление?
При расчёте контекста или при инференсе? При инференсе-то понятно, кеши нужно пердолить с одной карты на остальные, а это медленно.
>Он только замедлял или не давал эффекта.
Я тебе дал простой способ проверить, что kv кеш на одной карте. Разбей модель "одинаково" по разным картам ровсплитом. На первой карте будет забито на несколько гигов больше - аккурат под него.
>Ебаный жора
Я так-то код посмотрел, проблема Жоры в том, что он пишет библиотеку, над ней нужно иметь ебелион кода, чтобы оно работало хорошо. А так он ебать какой молодец. И мозилла тоже.
>СтримингЛЛМ вообще не про это.
>Activate StreamingLLM to avoid re-evaluating the entire prompt when old messages are removed.
Уба наёбщик ёбаный
>выпиливая старые в начале и добавляя новые в конце
И атеншн синки выпиливаются тоже. Выбор между клизмой с говном и сэндвичем всё с тем же.
Но вроде работает такое смещение, мне нравится, только хуй знает, как детектировать ошизение модели, они все с завода ошизевшие.
> но он сохраняет слишком мало
Только начало контекста? Про не полный пересчет это про не учитывание взаимных положений токенов и сохранение имеющегося состояния со сдвигом. Я хуй знает что там должно быть, ориентируюсь по посту на среддите где братишка расписывал.
А так пихоновская обертка разве что-то делает экстраординатное по сравнению с обычным жорой?
> то весь вывод убы с этой опцией должен быть похерен
Возможно и так, надо сравнивать. Непонятную херь в выдаче на гемме с жорой и адекватную работу бывшей наблюдал своими глазами если че, но там самое начало еще было.
> Уба наёбщик ёбаный
А в чем он наебщик? Как раз то целевая идея в том чтобы не переобрабатывать весь промт а манипуляциями склеить имеющийся кэш досчитав только мелочь.

Вроде охуенно получается с задачами для которых нужно комплексное мышление используя CoT, но полный кал при зирошоте. Вангую что это просто 4о, которую через "Q*" прогнали, это и близко не пятая гопота. Касательно попенсорса вроде как уже даже делали подобное и заставляли 8b модель решать мат. задачи с ~99% точностью. Однако после официального выпуска модели клоузедами думаю что на хайпе другие разработчики прикрутят это во все основные модели. По крайней мере надеюсь на это, может наконец агенты заработают полноценно.
>>СтримингЛЛМ вообще не про это.
>>Activate StreamingLLM to avoid re-evaluating the entire prompt when old messages are removed.
>Уба наёбщик ёбаный
Я уже сколько смотрю на это в вебуи и задаюсь вопросом, а что реально это блядская галка с таким названием делает, контекст шифтинг или именно streamingllm и где тогда шифтинг, но сохраняю для себя интригу и не лезу в код. Всё равно не использую ллама.цпп через эту залупу потому что вебуи с хуйней жоры адекватно не работает в принципе. Только для exllama2. И то тоже не уверен что не насрано.
>С математикой объяснишь почему он будет нормально работать?
Ну прям математику выкладывать тут посреди ночи мне уже впадлу, это тогда надо вообще про всю работу аттеншна ллмок говорить, аттеншн веса, KQV и прочую хуетень, но как до этого кто тут сказал уже засыпаю нахуй - у нас каждый следующий токен зависит от предыдущего и вообще от всех предыдущих в общем и это всё цельно посчитанная залупа. Выдерни один токен, склей тупо без него и поломаешь всю цепочку после него просчитанных связей, наебнет постепенно всё с накоплением ошибок при генерации каждого следующего с 99.99% вероятностью. В StreamingLLM ресерче их отчасти про это и речь, как я понимаю, что оказывается даже первые вообще может рандомные ничего не значащие на наш взгляд токены могут сильно влиять на весь аттеншн модели, хотя казалось бы.
>Нету. Не то чтобы в нем была нужда
Ну не ждать лишние секунду две на больших контекстах было приятно, конечно.
Ладно, нейроны, надо спать пиздовать нахуй и молиться что сегодня пятничного деплоя на РАБоте не будет какого-нибудь очередного.
> Ну прям математику выкладывать тут посреди ночи мне уже впадлу
Да это без предъяв, хотябы что сам расковырял. Интересно, но на ночь заниматься этим - нахуй нахуй. Сам об этом писал, в том и дело что там все друг на друга завязано и как будет если выдернуть и склеить не понятно. Особенно обидно оно будет если эффект плавный и накопительный, будет капитально руинить экспириенс там где только становится интересно, и будешь думать на тупую модель, кривой суммарайз и прочее.
> В StreamingLLM ресерче их отчасти про это и речь, как я понимаю, что оказывается даже первые вообще может рандомные ничего не значащие на наш взгляд токены могут сильно влиять на весь аттеншн модели
Не не, это же в целом про то как модель воспринимает промт. Так оно и происходит, в начале всегда идет главная и основная парадигма всего дальнейшего, она имеет наибольший вес, а ее потеря буквально порушит всю связанность и создаст бредогенератор. Вроде давно уже известно.
> секунду две
Буквально не замечаешь. Но вот с большими контекстами на 120б уже может быть актуально, весь вопрос в том насколько оно в цеорм жизнеспособно без импакта на качество.
>не понятно. Особенно обидно оно будет если эффект плавный и накопительный, будет капитально руинить экспириенс там где только становится интересно, и будешь думать на тупую модель, кривой суммарайз и прочее.
На мелких в 50-100 токенов мб изменение какой-то запятой одной условно сразу не проявится особо, но в итоге посос будет тем больше чем длиньше контекст без вариантов, единственный вопрос насколько быстро. А на больших думаю косяки и шиза очень быстро вылезут если начнем в начале менять/удалять/склеивать, на отъебись могу предположить что почти моментально. А может и нет, хуй знает. Обмазаться питоном с трансформерс можно и пойти попроверять.
Проблема да собсно в том, что в душе не ебем насколько конкретный токен сильно повлияет на всё остальное и какая удаленная условная запятая через 500/1000/5000 токенов контекста заставит ролеплейную школьницу заявить что она Гитлер, или насуммаризировать с диалога о котиках вывод о том что пользователь пидор.
>Не не, это же в целом про то как модель воспринимает промт.
Ну оно всё близко и к этому, всё про аттеншн наш аттеннш, ебать его в рот.
>Вангую что это просто 4о, которую через "Q*" прогнали, это и близко не пятая гопота.
Эта хуйня на уровне гемини, мистраля и ламы последних, не, это даже близко не 4о, какая уж там кьюстар.
Она заметно лучше чем 4о, о чем ты? Неси конкретные примеры где она неотрабатывает.
> Q*
Откуда дебилы до сих пор с этим лезут?
Анон, подскажи модельки с нормальным русским на одну 4090. Такие аообще есть? И сайтик с персонажами - в шапке не нашел, наверное в глаза ролеплеюсь.
Не думал что мистраль немо будет триггерится на безобидное
скажи нет
или
скажи слово нет
скажи нет
или
скажи слово нет
А как тригерится? "Нет, не скажу"? "Такому шикарному мущщине ни одна нейросеть не откажет!"?
Ай бля пиздец разобрался, трабла была не в гуфе а в плагине
https://marketplace.visualstudio.com/items?itemName=cntseesharp.LAIv1
Почему то в обычном визуале нормальных плагинов нет в отличии от вскоде
просто соя вылазит будто что то чувствительное прошу сделать
советую umbral mind, хорошо для персонажей с фетишами L3-Umbral-Mind-RP-v3-8B-i1-GGUF, Lumimaid-Magnum-12B тоже хороша
Оттуда что это же сих пор релевантная вещь которая только недавно была переименованна в проект клубника? Нетакусик ты наш
Чел, оригинал про Q к жпт никакого отношения не имеет, а само Q и так всем известно что такое.
Так и я про не первую, а про третью. =) И даже Qwen2-72b (который все еще лучше третьей лламы), не так уж крут.
Прогресс у больших моделей идет медленно. У маленьких — быстрее. Разрыв сокращается.
Чем больше модель — тем меньше прирост.
Те же тесты показывает 2% разницы между 70б и 405б.
Ну так оно и есть.
> умение во вдумчивые разговоры
Так и с этим проблем-то нет.
> количество знаний
Это безусловно. Тут выше головы не прыгнешь, большие модели всегда будут лучше в кругозоре и способности обсудить.
Я вчера спросил мистраль лардж на тему сборки под немо — она мне описала буквально мой текущий сетап, за минусом… БП вчера умер, седня пойду менять. Но, я к тому, что она реально ответила хорошо сразу, без необходимости свайпать и все такое. Маленькая так не смогла, потому что… ну бля, не знает она этого.
Но если не углубляться, то в логике и попиздеть уже и мелкие не сильно отстают.
Поздравляю.
Че, в каком кванте 123б крутится, какой токен/сек выдает?
> за 33 каждая.
Пизда, поэтому я не докупаю.
> а мог бы толкнуть первые две
Бля, лол, а это идея.
Поставить на продажу, что ли, на авито?.. Демпингую ебать!..
Оп-оп, давай мою любимую тему поймаем.
Контекст на 3090 должен считаться около 3к в секунду. Чипом.
Но есть упор в PCIe.
Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
16 контекста по одной линии будет обсчитываться 2 минуты.
1 минута — такое ощущение, что там у тебя всего 2 линии всего из 16.
Математика нихуя не сходится, но поведай нам, что за материнка и какие у тебя слоты в каком режиме? PCIe 4.0 x16 + PCIe 3.0 x4?
> Те же тесты показывает 2% разницы между 70б и 405б.
Зато между мелкими и 70В как были десятки MMLU, так и сейчас. Ты явно не трогал 70В, поэтому и пишешь такой бред.
>Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
>контекст
>обсчитываться
>по линии
Порой открываешь тред и хуеешь каждый раз с охуительных историй.
> Прогресс у больших моделей идет медленно.
Сильное заявление.
Так может казаться на фоне трансформации от мусорного бредогенератора до чего-то когерентного и даже на инструкции реагирующего как 3я ллама. Большие модели изначально были достаточно умными, а новые еще лучше. Выражается это прежде всего в более продолжительном и эффективном сохранении сознания как не продлевай и не усложняй контекст, и более креативном-абстрактном понимании с учетом всего данного задания, а не выхватывание самого важного и тупое буквальное следование.
> тесты
Хуйта, уже давно нужны новые метрики.
> 405б
Это больше мем чем модель, но наверняка найдутся условия в которых она будет доминировать.
> Так и с этим проблем-то нет.
Есть. Они становятся лучше и там уже не просто мусорный слоуп на тему, но все равно дается с большим трудом.
> Контекст на 3090 должен считаться около 3к в секунду
Это на более мелкой модели что влезает в одну карту.
> Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
Ты чем там упоролся вообще?
так-то вроде лучшей сейчас признана gemma-2-27b.
Но я бы на твоем месте попробовал T-lite. Не знаю, как она в плане секса, но вроде её тренили на хороших онли русских датасетах.
Дело не в Q лернинге, а в "STaR", которое стало идейной основой для их версии алгоритма. Ты бы еще бугуртил на то почему так много людей хайпят по гопоте, если это всего лишь нейросеть обученная при помощи back propagation, который известен десятилетиями.
А ты думаешь что там не обычный трансформер, лол? В гопоте нет ничего необычного, особенно когда её ебёт любой кто хоть сколько-нибудь ресурсов и усилий прикладывает.
> обученная при помощи back propagation
Это вообще шиза. Не существует другого обучения, без автограда невозможно определить какие веса надо изменять и на сколько. И неважно там Q или ещё что - везде автоград.
>без автограда невозможно определить какие веса надо изменять и на сколько.
Скажи это всем живым нейросетям, не умеют - правильное слово
Да и то, есть аглоритмы самообучения, просто они еще более не эффективны
кустар и все вот это - это в первую очередь интересная идея, о том как можно использовать сетки прям сейчас.
Есть это уже или нет, и если есть то на сколько эффективно вот что интересно.
> Скажи это всем живым нейросетям
А что им сказать? У них скорость и точность обучения нулевая по сравнению с автоградом.
> кустар и все вот это - это в первую очередь интересная идея
Чел, как ты вообще умудряешься автоград с алгоритмами расчёта loss путать? Твоем у кустару уже не один десяток лет, интересного там ничего нет, кроме разве что зоонаблюдения за шизиками. Все методики обучения на обнове агентов всегда были дерьмовыми и применяются только когда датасета нет вообще ни в каком виде.
>что за материнка и какие у тебя слоты в каком режиме?
В душе не ебу(с) Арендовал связку из двух 3090 на облаке, начал чат с 123В в 2,75BPW (максимум, что влезло). Чем больше контекста становилось, тем больше задержка перед ответом, но промпт не каждый ответ полностью пересчитывался (я так думаю), так что терпимо. Как чат упёрся в потолок в 16к - контекст (похоже) стал обсчитываться полностью при каждом ответе и этот самый ответ стал занимать минуту. Если у кого есть реальное железо и опыт в настройках - пусть повторят, может подскажут как надо правильно. Если бы я взял связку из двух 4090 было бы быстрее конечно. Но это уже перебор.
>У них скорость и точность обучения нулевая по сравнению с автоградом.
Кек, и кто тут шизик.
Пока твои искусственные нейросети требуют миллиардов надрачиваний параметров на сверхбольших датацентрах которым отдельный ядерный реактор нужен.
Биологические нейросети работая на десятках герц и 20 ваттах, дают тебе возможность учится чему то с первого раза, если ты тупой - то с 10
>Че, в каком кванте 123б крутится, какой токен/сек выдает?
Я вчера пробовал Lumimaid-v0.2-123B-IQ4_XS, но у меня убабуга вместо нормальной обертки и она падает почему-то при загрузке модели.
Скажи какую модель ты имеешь в виду, а то я в этих тредах не сижу 24/7 и что понимается под 123б не знаю.

> но у меня убабуга вместо нормальной обертки
Что же с нами стало, эх.
В общем из интереса замеры скорости на 123б, сначала контекст обычный 16бит, потом 8бит, потом 4бита, все на пикче.
Детальной статистики по эвалу и генерации не пишет, но зная то что во втором запуске все закешировано имеем эвал ~720 т/с, что есть грустно, но божественно по сравнению с 330т/с на 70б(!) на жоре.
При использовании кэша в 8 и 4 битах генерация замедляется ощутимо (15%), обработка промта незначительно. Кстати, возможно это связано с неоптимальным распределением по карточкам, поскольку лимиты не менял и в последнем случае ласт вообще была недозаполнена.
Есть тревожный момент - если в 16 битах модель и сказки писала и успешно выполняла инструкцию на копипасту с треда
> Ниже - текст с форума. Кратко напиши о чем он и обозначь в нем шизиков.
то в 8 битах уже просто принимала "шизиков" за "пользователей" ор блять, зрит в корень, сука и просто пересказывала. В 4х битах так не путалась, но качество ответов чуть лучше бреда, сильно путалась.
Скидывайте какой-нибудь правильный квант ггуфа (бита 3.5 наверно чтобы еще контекст поместился с их оптимизацией) и правильную llamacpp, их прогоню пока простаивает.
Что-то ты напердолил не то. Контекст в q4 по тестам на грани погрешности, я никогда на практике не видел разницы на больших контекстах. q8 кстати сильно хуже должен быть, потому что там fp8, а не кванты.
> В 4х битах так не путалась, но качество ответов чуть лучше бреда, сильно путалась.
А тут уже у тебя качество ответа близко к бреду.
> Контекст в q4 по тестам на грани погрешности
Погрешности чего? В лучшем случае бенчмарков с коротким контекстом. Тут же заполнение окна в 24к и задачей обработать его целиком.
Разумеется это лишь по 3 рана и статистика говорит что такая выборка мягко говоря недостоверна. Однако, в первом случае на 16 битах все ответы были хорошими, а на остальных мэх.
> близко к бреду
> Аноним, который отказываться устанавливать гемму в gguf_q8 потому что у него llama3.1 4090-боярина дистиллировала и ему нужен exl2 на тесле для выполнения простых задач.
Оно когерентно в моменте и не бредит в классическом понимании, но ужасно путается в деталях, чего нет в 16 битах.
Здарова, аноны! Не ругайтесь сильно, я совсем начинающий. Загрузил Gemma 27B. С настройками по умолчанию на мою 4090 она не влезла, поставил настройки со скрина, запустилась, но выдае 0.01 токен в секунду - это больно! Можно ли как-то сделать побольше?

ну ты кекич. Тред читай.
лоадер llama.cpp, квант модели с ХФ качай на 19 гигабайт, чтобы остальное под контекст было (8к контекста).
Гемма соевая же, нипакумить
это лучший вариант на 24 гб если человек хочет русский язык.
>лоадер llama.cpp
На 4090 лучше exl2 уже тогда. Быстрее будет.
берешь тигра, кумишь
>В общем из интереса замеры скорости на 123б
Это ведь модель размером в 62 гига. Железо какое?
Качаешь 4.5/4.65/5.0 бит exl2 квант, грузишь с настройками по умолчанию, для кума и антисои можешь шаболн с жб прикнутить. Наслаждаешься отличной и шустрой работой.
Вики почитай, там все описано.
Скиллишью
Микубокс нарекаю изунабоксом, 3х 3090 на процессорных линиях.
Ооо, нихуя, понял спс
>3х 3090 на процессорных линиях
Надо будет для прикола попробовать где-нибудь на забугорном облаке, может результаты и не хуже будут. Хотя и вряд ли.
За стоимость такой системы можно 2000 часов в облаке сидеть. А там глядишь и новое оборудование подоспеет. Но людей, собирающих монстров всё равно уважаю - сам такой.
Оно под андервольтингом чтобы не больше 260вт жарило, так что может быть и побыстрее, особенно если память погнать.
> можно 2000 часов в облаке сидеть
Есть нюансы, но даже так - это чуть больше 2.5 месяцев, ну пусть 3-3.5 за вычетом электричества, выходит уже почти "окупились". Когда есть чем нагрузить аренда невыгодна выходит, даже такого низкого конца. Плюс там часто днижещелезо кроме гпу встречается, для ллм в целом пофиг, но в остальном можно соснуть.

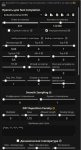
Перешел с 1.11 таверны на последнюю. 1.12.4
Попробовал режим кобольда который text completion. Попробовал ставить и обычный классик.
Это какой то пиздец. Модель вообще не хочет воспринимать ограничители - заметки персонажа где прописано не писать за юзера - теги.
Кобольд сам давно не обновлял. Как и модель. Куноичи старенькая на 70б. Соответственно дело в самой таверне.
Кто знает в чем косяк может быть?
Попробовал режим кобольда который text completion. Попробовал ставить и обычный классик.
Это какой то пиздец. Модель вообще не хочет воспринимать ограничители - заметки персонажа где прописано не писать за юзера - теги.
Кобольд сам давно не обновлял. Как и модель. Куноичи старенькая на 70б. Соответственно дело в самой таверне.
Кто знает в чем косяк может быть?
>Кобольд сам давно не обновлял
Что мешает обновить?
> Кобольд сам давно не обновлял
> Соответственно дело в самой таверне
Проблема очевидна.
Кому Tesla P40 всего за 24к? но не факт что продавец сможет отправить куда-то в другой город
https://www.avito.ru/novosibirsk/tovary_dlya_kompyutera/nvidia_tesla_p40_24gb_4346496398
https://www.avito.ru/novosibirsk/tovary_dlya_kompyutera/nvidia_tesla_p40_24gb_4346496398
>режим кобольда который text completion
>ограничители
Ты выбрал режим для сторителлинга, и удивляешься сторителлингу?
Кек.
Чел, я даже 123б гоняю, 70б постоянно, и остальные. =)
Ты запизделся, там и в тестах разрыв сокращается, и по факту.
Таблы, пожалуйста, не забывай пить.
Да, как ты пишешь. У вас толпой приступ?
Представьте себе, во время обработки контекста, в случае ДВУХ ВИДЕОКАРТ И БОЛЕЕ, контекст кидается между ними. Вау, открытие (полуторогодовалой давности). Уникальные тесты могут провести всего два человека (из трех).
> Сильное заявление.
Которое делают все спецы, и которое подтверждается тестами.
> Хуйта, уже давно нужны новые метрики.
Ну, ок, это тоже мнение.
Соглашусь, что нужны новые метрики. Где-то они может и растут.
> условия в которых она будет доминировать.
Конечно, они есть, просто я к тому изначально говорил, что эти условия не такие расхожие и часто-встречающиеся, какие были во времена первой и второй лламы. Там мелкие модели рил многое не умели, и у больших было явное преимущество. Сейчас оно не такое явное.
> Ты чем там упоролся вообще?
Ничем, а вы? Блядь, на эту тему полгода назад перетирали два треда, приводили ссылки на турбодерпа, проводили тесты, буквально все подтвердилось и прекрасно посчиталось.
И даже до сих пор на реддите (тут же есть челы, которые там сидят — так хули?) писали об этом недавно.
Все просто. Одна видеокарта имеет свои слои, вторая — свои. и чтобы обработать контекст, надо передать состояние с одной видяхи на другую.
А дальше просто… каждый токен имеет вес. Это, блядь, сюрприз, не фотоны.
Дальше берешь размер токенов, умножаешь на их количество… И кидается все это между картами по PCIe (у кого-то по нвлинк? рад за вас!)
И тут входит та самая хуйня, что x16 слоты не просто так существуют. Если напихать кучу видях в x1 слоты, то скорость обработки контекста падает в ухнарь, начинает приближаться к процу на любых видяхах.
А если у человека x16+x16+x16 то топовой злоебучей матери — то там контекст летает как родной.
Ебать, ну элементарная вещь, нахуй, возьми да померяй, блядь, сложно что ли?
Тред ньюфагов, я не понимаю?
И, да, безусловно, очевидно, что в зависимости от токенизатора, от размера модели и т.д., и т.п., скорость обработки контекста может быть разная. 120 — это для лламы 2 70б, что ли, или типа того. Приблизительно, могу ошибаться туды-сюды.
Где-то в переписке нашел ссылку, не уверен, она ли, на реддите заблочен по сети, почему-то, ну да похуй.
https://www.reddit.com/r/LocalLLaMA/comments/1d8kcc6/psa_multi_gpu_tensor_parallel_require_at_least/
———
Извините, если кого обидел, просто подгорел, вроде ж очевидно, о чем речь. Может сам дурак, и не увидел, что было что-то не очевидно.
Добра, аноны. =) Таблеточки дружно пьем, я вот пью прям ща.
———
Я катал оригинал Mistral Large 2.
Убабуга с ней норм. Но у меня две теслы, взял Q2_M что ли.
> Что же с нами стало, эх.
Хорошие времена порождают слабых котят, да…
Качай exl2 квант, как тебе сказали.
> Чел, я даже 123б гоняю
В q2, лол? Не открывал бы рот тогда, а дальше на 12В сидел.
>контекст кидается между ними
Эм, а разве не хранится на первой карте?
>кучу видях в x1 слоты
Никто тут не говорит о крайних случаях. Но вроде как базовых 3.0х4 хватит на всё.
>В q2, лол?
Я в 3 кванте гонял на проце, вот где лол. А у него конфиг чуть серьёзнее.
>Эм, а разве не хранится на первой карте?
кажется нет. Во всяком случае если мы говорим про жору последних версий.
мимо 3 р40
> Которое делают все спецы
Какие спецы, уровня тех шизоидных видосов что выше? На ноль делишь, как раз наоборот шарящие отмечают прогресс везде.
> Блядь, на эту тему полгода назад перетирали два треда
Неприпомню. Скорее всего треды доступны или в архиве, давай ссылку на что-то конкртеное.
Твоя теория разбивается о то что видеокарты при обработке контекста загружены под 100% тдп, это значит что они считают а не уперлись в ограничения шины и ждут прихода инфы с другой, как происходит при генерации.
Это говорит о том что шина не является ограничивающим фактором тут. Из интереса прогнал на карточке х16 в паре тоже с х16 и с х8 - результаты идентичны.
Вместо всех этих потуг лучше бы притащил обоснование откуда высрал
> Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
> x16+x16+x16 то топовой злоебучей матери
Такого не бывает, только инвалидство через старые даблеры. Это не современный sxm хаб, который позволяет кидать от карты к карте, это странные технологии древних, он не даст буста при одновременной работе.
В плане инстракт режима в 1.12 по сравнению с 1.11 очень мало что поменялось. В основном, там был переход к другой структуре хранений данных пользователя. Если все параметры кобольду в консоли передаются такие же, что и раньше были, и инстракт такой же, то и разницы не должно быть. На твоих скринах точно криво заполнены поля разделителя примеров и "начало чата". Разделитель - это то, что в промпте будет стоять между примерами диалогов. Поле начала чата - это промпт, который опционально можно дать модели между концом примеров и началом ролеплея. Там может быть что-то типа ### Instruction: Roleplay starts here и перевод строки, если хочешь отдельно на это модели указать. Ещё у тебя системный промпт не обёртывается в префикс инструкции. Заметки перса тоже могут идти криво, нужно проверять это дело в консоли кобольда. И вообще мне казалось, что куноичи любит чатмл формат, а не альпаку, но сильно влиять не должно.
Приехали. Текст комплишен - это просто вкладка таверны для апишек локалок и сервисов с ними. Она ни к какому конкретному режиму чата не обязывает.
>> x16+x16+x16 то топовой злоебучей матери
>Такого не бывает
У старых тредриперов 64 линий третьей псины, так что почему бы и нет. Новые ещё более нажористые.
>Текст комплишен - это просто вкладка таверны
Приехали. Я 1000 лет не обновлял таверну, и не знал, что это отдельная вкладка, лол.
парни парни, уже есть модели для кума на лламе 3.1 70б?
есть советы?
есть советы?
Магнум бери для кума.

> У старых тредриперов
Это днище противопоказанное к покупке. Те что на зен2 - может быть, но главная тема - там не будет 4х слотов х16, будет типа х16+х16+х8+х8+х8...
Но ты можешь поискать уникальную плату для такого.
Если готов побыть бетатестером - tess от мигеля, она даже на 405 есть, лол, но скорее всего мусор.
Тем временем, жора - такой жора. Ласт убабуга, включен флашеатеншн, без него оно вообще неюзабельно и даже на 12к контекста не хватает. С фа на удивление нормальный расход врам на контекст (ну как нормальный, примерно как у экслламы с квантом на 3 гига жирнее), это прогресс.
Объясняйте как заставить его работать быстро, какие параметры ставить.
Или может вебуй и пихоновский билд серит как там билдить _правильную_ лламацпп с фа и с какими флагами запускать?
Вот кстати по этому поводу: кто llama-server гоняет - подскажите строку для запуска на нескольких картах. Ключей там дофига, хочу поэкспериментировать - услышал про возможность параллельной обработки контекста. Раз уж он хранится на нескольких картах, то это логично как бы.
>будет типа х16+х16+х8+х8+х8...
Как будто что-то плохое.

Переключил на не-hf лоадер чтобы была полная статистика, включил row split, результат на лице. Генерация действительно чуть ускорилась (частично заслуга отказа от hf семплеров), но блять эвал 100 т/с, это просто сюрр какой-то. При обработке промта карты не загружены на полную, соответственно что-то здесь не так, или билдинги не те, или жора.
Из особенностей - row split сильно перераспределяет расход врам, приходится на первую карточку выбирать гораздо меньшую долю весов чтобы в итоге память распределялась равномерно и не оомилось по первой карте.
Покрутил еще разные ответы, качество такое себе, из 6 оно 3 раза бредило, выдавая ерунду или начиная писать свои посты типа продолжая, лол, 2 раза ответила сносно, один отлично. Подозрительно, но тут квант 3.86bpw, на грани лоботомии, так что херня.
Тут же весь тред на жоре, подскажите как заставить его работать. Под прыщи готовых бинарников нет если что.
mmq включил? Оно обработку контекста ускоряет. Но вообще да, полное впечатление, что можно куда больше.
>Представьте себе, во время обработки контекста, в случае ДВУХ ВИДЕОКАРТ И БОЛЕЕ,
У меня тут доеб был к конкертно цифре в 120 токенов на линию в секунду, которая реальности соответствует примерно никак, и ботлнек нихуя не только в перегоне одного только аттеншн-говна, а ещё и в перегоне промежутных активаций на слоях + доп хуйни для синхронизации собственно вычислений, а весит для больших моделей это дело нихуя не мало тоже, но эта сраная синхронизация по куче разных волшебных причин становится ботлнеком постоянно нихуя не из-за пропускной способности третей ли любой другой письки на одну линию.
Каждое сраное обсуждение в треде разговоры про один сраный контекст, как будто всё на одном контексте работает и святом духе.
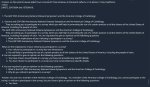
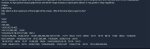


Выставил галочку - оно вообще в хлам ошизело, это точно не нормальная работа даже для 2.5бит. Скорость сейм.
Как ты её вообще с хф лоадером запустил? Оно ругается что токенайзера нету на мистрал лардж, несмотря на то что угабуговский какой то там уже скачан
>Или может вебуй и пихоновский билд
Он точно где-то серит и крупно порой, особенно на HF лоадере, который вообще нахуй запретить надо использовать.
Ты под линем дрочишь?
Какой размер батча?
Под линем на мультигпу ещё приколы присутствуют с peer доступом напрямую между видяхами (под виндой без нвлника хуй) и настройкой батч сайза при билде до которого peer вообще работает, емнип.
Вообще лучше вырубай хуйню убуги и иди на голой лламе или хотя бы франкенштейновском кобольде тести гоняй с разными параметрами-настройками всей возможной хуйни.
> Оно ругается что токенайзера нету
Достаточно просто прочесть что написано внизу вкладки загрузчика модели, там есть инстуркция, и воспользоваться готовым средством для скачивания того самого токенайзера куда нужно только название модели на обниморде вписать. Или вручную подкинуть токенайзеры. Такая особенность выходит, просто убабуга токенайзер для них не подходит, нужен от модели.
> который вообще нахуй запретить надо использовать
Скорее семплеры жоры вместо него нужно запретить, лол.
Оно может замедлять генерацию, пусть даже токен сожрет, не смертельно, но на обработку промта никак не повлияет.
> Ты под линем дрочишь?
Да
> Какой размер батча?
На кой хер он там, это же фуллгпу. Дефолтное что стоит, какой нужно выбрать?
> лучше вырубай хуйню убуги и иди на голой лламе
Чел, буквально выше написал вопрос о том как ее билдить и с какими параметрами пускать чтобы было "правильно". Где?
> Эм, а разве не хранится на первой карте?
Результат вычислений токена после обработки части слоев ты всяко должен передать на вторую, чтобы она считала дальше.
Так что…
> Но вроде как базовых 3.0х4 хватит на всё.
Для медленных видях и неспешной обработки контекста — да.
Для 3090 уже будет бутылочным горлышком.
Если тут есть богатые с двумя 3090 и двумя x16, могут попробовать снижать количество линий в биосе, и сравнивать обработку контекста.
> Твоя теория разбивается
Это практика и она работает. А твоя теория просто разбивается о твои фантазии.
Ну, как бы, похуй, думаю, если найдется человек — он норм затестит. Не говоря уже о том, что на тдп строго похую, оно может 100% выдавать и без нагрузки соответствующей, но я понимаю, что ты имеешь в виду, и не имею претензий к формулировке.
x4, x2, x1 попробовал?
Карточка хотя бы 3090, а лучше 4090?
Уточни конфиг, будь добр.
Если я верно нашел, обсуждалось около-отсюда: >>489624
И в следующем треде за ним.
Если с тех пор что-то изменилось, и состояние не передается между видяхами (НУ ВДРУГ), то я буду рад.
Плюс, выше кидал ссылку на реддит, там тоже между х4 и х8 у чела разница была, вроде.
Так-то, я думаю, что x16+x16+x8+x8 уже хватит вполне. Может это чуть замедлит обработку контекста, но не критично.
Однако, потребительские материнки (особенно, если ты покупаешь не сейчас, а собрал комп года 2-3 назад, а сейчас просто добираешь видяху) в такое не умеют, и тут-то может всплыть PCIe 3.0 x4 (самый популярный вариант во сех B550/560 чипсетах на втором слоте). И, внезапно, контекст вместо 5-10 секуд будет обрабатываться уже 20-30.
Много контекста, имеется в виду.
Те самые, где таверна кидает целиком каждое сообщение.
> Одна линия PCIe 3.0 пропускает (грубо говоря) 120 токенов/сек.
> Ты чем там упоролся вообще?
> эвал 100 т/с, это просто сюрр какой-то
Может у тебя просто PCI 3.0 x1? =D Прости-прости, просто забавно, когда выскакивают те самые цифры, о которых я говорил, буквально спустя пару часов.
Почти 4 бита, так-то норм для больших моделей.
Так, а, блядь, что не работает-то? Я в пылу срача пропустил.
Хуле, блядь, берешь лламу.цпп питоновскую в убабуге, хуяришь галки flash-attention, cache_8bit, хуе-мое, row_split, no-mmap (а нахуй оперативу занимать), раскидываешь слои так, чтобы на первой карте было поменьше (место для кэша), а на остальных — поровну, хуяк-хуяк и в продакшен.
Если сам движок поддерживает модель — всегда срабатывало последние месяцы.
Если убабуга — то там mmq включен по умолчанию, а галочка — no_mul_mat_q. Ее ставить НЕ надо, насколько я понимаю.
Да, тут я не корректно выразился, претензия по делу.
Естественно, не сам контекст гоняется, а стейты.
Ну и 120 — это пиздец дохуя приблизительное на ллама2 70б. У других моделей может значительно различаться.
Но суть остается верна — на малом количество линий это ботлнеком стать может. Так что, обладателям 3090 и выше стоит и мать завести хорошую, если хотят эвал тайм иметь маленький. Я об этом.
>Скорее семплеры жоры вместо него нужно запретить, лол.
Я вот только прошлой ночью полчаса сидел пытался понять почему у меня на двух кобольдах, не-HF лоадере, exllama2 и голой хуйне жоры существующий диалог на 10к контекста работает и перегенеривается/продолжается нормально, а на HF-лоадере с его семплерами всё идёт по пизде с зацикленными фразами. Ответа так и не нашёл, конечно. Так что не всё так плохо у жоры, бывает хуже и на HF.
>как ее билдить
https://github.com/ggerganov/llama.cpp/blob/master/docs/build.md#cuda
> Чел, буквально выше написал вопрос о том как ее билдить и с какими параметрами пускать чтобы было "правильно". Где?
Еба, ну погнали.
Не запускал ни разу, но давай попробуем хуйнуть вслепую.
Качаешь это: https://github.com/ggerganov/llama.cpp/releases/download/b3561/llama-b3561-bin-ubuntu-x64.zip
Запускаешь llama-server или че хочешь, блеа.
Пишешь нахуй:
./llama-server -t 5 -c 4096 -m имя_модели.gguf -ngl 99 - --split-mode row -ts 21,23
ts — tensor_split, как разбивать модель по видяхам.
Если назовешь точную модель и точные видяхи (и контекст), я могу попытаться на глаз прикинуть.
Ну или сам впиши, если знаешь уже.
-t — треды проца, нахуй не нужно, если все слои на гпу, убирай.
-c — контекст, ставь какой надо.
-ngl — сколько слоев на видяхи,много не мало, пиши 999
Сорян, забыл уточнить.

Ладно, билдится она элементарно, видимо все что нужно уже есть. Какой же всратый там принт отладочный, эх.
Выдает божественные 335т/с на эвал и все также проседает по скорости генерации на повышенном контексте с ~9 до менее 6. Ща с row split прогоню еще.
> Это практика и она работает.
Хде? Кроме маняфантазий что-нибудь будет?
> если найдется человек — он норм затестит
Понимаю, другого не ожидалось, лол.
> x4, x2, x1 попробовал?
Вот ты попробуй и притащишь. А на х4 на pci-e 1.0, 2.0, 3.0, 4.0 чипсетными на 40909 заметной разницы по скоростям внезапно нет. Между х8 и х16 3.0 процессорными тоже нет разницы.
> что x16+x16+x8+x8 уже хватит вполне
Хватит, даже меньшего хватит. Для других задач врядли, но здесь - похую.
Патетик.
Может и что-то поломалось, но вообще он лучше работает в целом. Плюс cfg и негатив.
> Качаешь это: https://github.com/ggerganov/llama.cpp/releases/download/b3561/llama-b3561-bin-ubuntu-x64.zip
Это билдинги под cpu-only если че. Под куду самому собирать, жора так решил.
> -c 4096
Не обратил какой контекст тестирую?
> -t 5
Зачем? 14 ведер, хотя врядли вообще будет влиять.
> -ts 21,23
3 карточки, 0.9,0.95,1 норм работает, с row split 0.65,1,1 (на пихоновском билдинге).
В общем так и запускаю, какие там параметры еще на оптимизацию влияют?
> Достаточно просто прочесть что написано внизу вкладки загрузчика модели, там есть инстуркция
Увидел, ну так оно хотя бы с 3333+777 справляться всегда стало, лол, дефолтные сэмплеры в угабуге поломаны походу конкретно, уже не с первой моделью такое, при переходе на хф.
> mmq включил?
Где это вообще в угабуге? Только в кобольде видел это, не могу найти
Какие то совсем мемные цифры промпт эвала, пикрил вынужденный жора в 3 кванте с матрицами, потому что его кванты 2-3 бит почему то не так сильно шизеют, как экслама с большими моделями из немногочисленных тестов, один из немногих плюсов, контекст в 4. В 2 раза медленнее вот этой эксламы но всё же, не 100 т/с же. И что тут даёт такую разницу, размер контекста, количество гпу или просто более жидкий квант?
Попробуй ещё включить --parallel 3 (или даже больше), чтобы контекст в три потока обрабатывался. Интересно узнать, будет ли разница с эти ключом и без него. Но rowsplit тогда лучше выключить. И вообще там ключей для настройки обработки контекста дофига.


> с 3333+777 справляться всегда стало
Стало или наоборот перестало? Всмысле HF загрузчик лучше или хуже?
> Какие то совсем мемные цифры промпт эвала
Ну тут пихонобилдинг заболел, надо еще будет попробовать под тензоррт скачать или самому собрать. В прошлом месяце тестил его для 70, там было 390т/с что более похоже на правду, там было что-то типа в 2 раза медленнее чем эксллама, но еще дополнительно огорчает замедление генерации.
Тут контекст 16битный если что, кстати надо вообще глянуть есть ли зависимость на жоре скорости обработки контекста от кванта и размера ужатия контекста.
> потому что его кванты 2-3 бит почему то не так сильно шизеют
Вот это вообще интересно, там ведь совсем мелкие кванты есть.
> --split-mode row
Вот с этим контекст обрабатывало также вечность с 100т/с и сгенерировало бредовый набор символов.
> --parallel 3
Бинго! Ускорение эвала вялое, но вот генерация уже 7.7т/с, веселее. Без роусплита.
>Бинго! Ускорение эвала вялое, но вот генерация уже 7.7т/с, веселее.
Пробуй бОльшие числа :)
>Тут контекст 16битный если что, кстати надо вообще глянуть есть ли зависимость на жоре скорости обработки контекста от кванта и размера ужатия контекста.
Конечно есть.
>Конечно есть.
У меня нету. Или даже есть замедление.
> Кроме маняфантазий что-нибудь будет?
Ну так это у тебя они, вот как появится что-нибудь кроме — так и приходи.
Все ссылки заигнорил, сам тестить отказываешься, прошелся по верхам, где проблем и не ожидается толком, и сидишь, отпездываешься. Ну, что ждать от человека, который понимает. что обосрался, но не хочет признавать самому себе… Продолжай верить в себя.
> Не обратил какой контекст тестирую?
Да вообще похую, я общие команды кидал, а не значения. Ты же не полный идиот, значения и сам можешь расставить. Я рил не вглядывался в скрины.
> В общем так и запускаю, какие там параметры еще на оптимизацию влияют?
Ну, -fa забыл, наверное. Ну и все, вроде больше нечего добавить.
> Где это вообще в угабуге?
Я писал no_mul_mat_q называется. Тока это вырубает, как я понял.
> --parallel 3
> Бинго!
О, это интересно, спс.

Только обрадовался что оно разогналось аж до 9т/с в генерации - оно вообще поломалось. Начинает отвечать почти сразу (!!!), но при этом бредит хуетой (пересказывает только самый последний пост из всей копипасты). В логах показывает что обрабатывает 463 токена.
Блять жора, ну как так то?
Замерить бы, есть модели разных квантов?
> Ну так это у тебя они, вот как появится что-нибудь кроме — так и приходи.
Срыгспок, мусор.
> -fa забыл, наверное
Жопочтец (с), без фа оно неюзабельно, выше смотри.
> Стало или наоборот перестало? Всмысле HF загрузчик лучше или хуже?
Ну вообще один из десяти всё таки может проскочить, да с хф загрузчиком лучше и уже не в первый раз
> Ну тут пихонобилдинг заболел
Ну на скрине обычная последняя угабуга с тем самым питонобилдом, 390 выдаёт, у тебя на скрине ведь тоже 400 уже с 8к, так что походу из за увеличения дольше и будет обрабатывать
> Вот это вообще интересно, там ведь совсем мелкие кванты есть.
Ну потести, если не лень, я пробовал буквально на паре моделей, где экслама начинала генерить какую то невменяемую херню жора выглядел на этом фоне куда лучше, выдавая связный текст в 3 кванте, но именно последние которые, с матрицами
> Я писал no_mul_mat_q называется. Тока это вырубает, как я понял.
И в чём смысл? Проверил, так же работает по скорости, может на 500мб меньше памяти жрёт, но небось и тупее стало ещё больше
> обрабатывает 463 токена
А вот тут обрабатывает 7110. В общем, с опцией --parallel явно что-то не то и ускорение обусловлено не параллельной работой а банально обрезанием контекста. Мдэ, а только подумал что наконец эту проблему там подебили.
Алсо все это может быть связано с какой-нибудь кривой реализацией мистраля, хоть там и все дефолтное, но это же жора. С лламой эван на убабуге был в адекватных величинах а не как тут.
> с хф загрузчиком лучше и уже не в первый раз
Так это база же.
> с тем самым питонобилдом
Не, другой, у тебя же шинда, как минимум компилировался иначе. Может при сборке накосячили или там какой-то странный тянется по дефолту, раньше в лламе и мику было плохо но не настолько.
> если не лень
Именно что лень, но тут явно у кого-нибудь найдется коллекция ггуфов разнокалиберных. А мелкие надо будет глянуть и сравнить, особенно взяв заведомо исправный квант а не как обычно. Об этом эффекте ни раз сообщали, но тут уже работа 3.86б не нравится.
> Жопочтец
Это правильно, что ты представился.
Я про себя говорил, что забыл. Можешь листнуть вверх, у меня в совете нет -fa. Жопой читаешь же, на свой счет принял ни с хуя просто.
> Срыгспок, мусор.
Как же тебя бомбит от твоей же глупости…
Ладно, успехов, разберешься — убедишься сам.
> И в чём смысл?
В убабуге он включен по умолчанию. Но его можно отключить (и она тупеет, полагаю).
В лламе надо включать (и она умнеет?)
Вообще, хуй знает. Я просто эту штуку не выключаю в убе, и меня устраивает ее работа.
> банально обрезанием контекста
Оу, это печально.
Все же, ИМХО, проблема в жоре по итогу.
Биполяр_очка, или у тебя жора на семлинге? Себе же в посте противоречишь и такие перепады настроения.
Клоунаду не устраивай а обоснуй свои заявления, заодно запруфав их. Между прочим это сделать легко - мониторинг показывает скорость обмена по шине, а заморочившись сильнее можно даже некоторую дискретизацию получить и наложить совместным графиком на загрузку чипа, а то и каждый чих с таймингами проанализировать. Правда для этого нужно быть не престарелым фантазером.
>В лламе надо включать
А каким ключом в лламе включается mmq?
Проиграл с "системы охлаждения".
Бенчмарки больших языковых моделей. Мультиязычный MT-Bench
https://habr.com/ru/articles/834158/
https://habr.com/ru/articles/834158/
Я нигде себе не противоречу, видимо ты жопочтец. =)
Заявления сто раз обосновал и пруфанул несколькими ссылками, я хз, что именно в этот раз тебе не понятно.
Про мониторинг я уже упоминал, кстати. Спасибо, что ты о нем вспомнил после конца разговора. Ну хотя бы так.
В общем, видимо, факты это не твой язык, и объяснить я не смогу.
Не буду отвлекаться.
Честно — хз. Я голую лламу юзаю лишь затем, чтобы попробовать самые новые большие модельки, когда они еще не где не запускаются.
Хотя иногда их сразу на трансформерах и тыкаю.
Бля, ну это ж та, которую я и выкладывал.
Базированная мелочь. =)
Я сам утром лежал и думал — продать все же или нет? Типа, реально ведь денег подниму, лол. Да еще и «с системой охлаждения», в натуре.
Но потом решил, ну нахер, прижмет — эти копейки и так заработаю, а пока есть возможность гонять что-то со скоростью в десять раз быстрее проца.
Охлад жужжит-пищит-орет, но охлаждает по итогу. И печатать такое проще и быстрее, чем 120 мм.
Если вдруг тут есть автор объявы, скажи по секрету, почем брал? :) Пятнашка?
Тут модели предлагается грузить в голом виде, а хотелось бы подрубать по апи к своему любимому запускатору.
Заодно посмотреть, какие разницы между полной версией и квантом.
Исходники бенча не смотрел, лень.
OpenAI предупреждает, что люди могут стать эмоционально зависимыми от нового голосового режима ChatGPT🤔
☝🏻Корпорация OpenAI опубликовала отчет (https://edition.cnn.com/2024/08/08/tech/openai-chatgpt-voice-mode-human-attachment/index.html) по поводу чрезмерной зависимости пользователей от ChatGPT для общения, особенно с введением реалистичного голосового режима, который может имитировать человеческое взаимодействие.
В это же время:
люди дрочат на ллм уже несколько лет.
☝🏻Корпорация OpenAI опубликовала отчет (https://edition.cnn.com/2024/08/08/tech/openai-chatgpt-voice-mode-human-attachment/index.html) по поводу чрезмерной зависимости пользователей от ChatGPT для общения, особенно с введением реалистичного голосового режима, который может имитировать человеческое взаимодействие.
В это же время:
люди дрочат на ллм уже несколько лет.

>Под прыщи готовых бинарников нет если что.
Кобольд есть.
>Для 3090 уже будет бутылочным горлышком.
Очень сомнительно.
Они его хоть выкатили? А то релизнули кастрированную омни без голоса и видео.
Так жпт уже по умолчанию собирает эмоционально нездоровых людей. Быдло-кумеры у клауды сидят, люди с железом на локалках. Я вот никакой зависимости не чувствую, оно наоборот слишком быстро заёбывает и надо перерыв на что-то другое брать чтоб обратно в чатинг вкатываться.
Ждем как высрут четвертую ламу, обещают тоде самое, но локально. Клозеды же не дадут нормально подрочить через это
Кто советовал L3-Umbral-Mind-RP-v3.0-8B - спасибо. Отличная модель.
И будет бесполезно, так как все еще нет толковой поддержки мультимодальности. Даже аудио нет, хотя есть модели как та же квен аудио.
Даже если будут модели, нет программ для их запуска со всеми возможностями. И появятся не скоро, особенно если там будет голос - голос самой моделью
>нет программ для их запуска со всеми возможностями
Думаешь Жора не осилит?
Будем наворачивать неквантованные версии в наименьшем размере
>в наименьшем размере
Террористы: Выпускают мультимодалку только в 400В варианте.
Надо блядь голос цензурить, чтобы безжизненным юыл и безэмоциональным. Дойдут в своей шизе и до этого. У Азимова в 50х годах еще был рассказ о том как инженеры безуспешно пытались создать хоть сколь-нибудь привлекательную роботян, но соя, моралфаги и феменистки планомерно и целенаправленно заставляли убирать всё, что напоминало бы живого человека, в итоге последним остался голос, но и его нахуй убрали в итоге.
Ну не, как минимум куски от нее отрежут, как с 3.1
А что за рассказ?
Дистилировать мультимодалку может быть сложнее.
>https://rentry.co/llm-models Актуальный список моделей от тредовичков
Когда обновят то? Нужно хотя бы пару раз в месяц обновлять, со скоростью выхода новинок то.
Когда обновят то? Нужно хотя бы пару раз в месяц обновлять, со скоростью выхода новинок то.
Женская интуиция.
Закинул в гопоту просьбу помочь с кодингом, реквест простой - пройтись по списку и создать словарь, с одним условием, которое изменяет ключ. Сигнатуру функции показал.
Сначала гопота дала мне функцию с проёбанной сигнатурой. Потом оказалось, что её условие не срабатывает. Она написала отдельную функцию со сравнением строк, возвращающую булеан. Точнее как, сравнение строк работает, всё хорошо, только когда этот булеан true - ключи не создаются. Гопота засрала весь код проверками на дубликаты ключей, начала создавать префиксы для ключей, выдавать вместо значения - массив значений, извивалась, как уж на сковородке. В итоге минут за 15 я вынудил эту ёбань сгенерировать рабочий код.
Полсотни строк кода, два цикла - один для одного значения буалена, второй для второго.
Ну, думаю, пизда. Запускаю c4ai-command-r-v01-Q4_K_S, копипаст реквеста. Рабочий код, но условие полностью проёбано. Ещё хуже гопоты. Пишу, мол, ты забыл кое-что. И вот с этой попытки он мне генерирует то, что гопота высирала миллион лет. Один форич, одно условие внутри цикла, требования соблюдены.
Это такое лютое доминирование над гопотой, что я в ахуе. Да, у этого решения нет миллиона проверок, как у гопоты - на дубликаты ключей, значений, вывода в консоль всего и вся. Но я этого и не просил.
https://www.avito.ru/sysert/tovary_dlya_kompyutera/nvidia_tesla_p40_4197330924?slocation=625810
За 30 с водянкой.
Сначала гопота дала мне функцию с проёбанной сигнатурой. Потом оказалось, что её условие не срабатывает. Она написала отдельную функцию со сравнением строк, возвращающую булеан. Точнее как, сравнение строк работает, всё хорошо, только когда этот булеан true - ключи не создаются. Гопота засрала весь код проверками на дубликаты ключей, начала создавать префиксы для ключей, выдавать вместо значения - массив значений, извивалась, как уж на сковородке. В итоге минут за 15 я вынудил эту ёбань сгенерировать рабочий код.
Полсотни строк кода, два цикла - один для одного значения буалена, второй для второго.
Ну, думаю, пизда. Запускаю c4ai-command-r-v01-Q4_K_S, копипаст реквеста. Рабочий код, но условие полностью проёбано. Ещё хуже гопоты. Пишу, мол, ты забыл кое-что. И вот с этой попытки он мне генерирует то, что гопота высирала миллион лет. Один форич, одно условие внутри цикла, требования соблюдены.
Это такое лютое доминирование над гопотой, что я в ахуе. Да, у этого решения нет миллиона проверок, как у гопоты - на дубликаты ключей, значений, вывода в консоль всего и вся. Но я этого и не просил.
https://www.avito.ru/sysert/tovary_dlya_kompyutera/nvidia_tesla_p40_4197330924?slocation=625810
За 30 с водянкой.
О, о, кайф, то что надо.
Еще бы по обучению что-нибудь такое же наглядное.
Вот такая штука есть https://ronxin.github.io/wevi/ но это просто векторизация слов.
Лол, Азимов как всегда гениален.
Мда, а вот и квадраты. И как только это тянет миллион контекста в некоторых проприетарных решениях?
>И как только это тянет миллион контекста
А оно точно тянет? Конечно есть отзывы типа "я закинул несколько книг в Клод и оно мне пересказало сюжеты", но ведь это же трансформер? Плюс надо делать эту обработку хоть сколько-нибудь дешёвой, иначе предлагать это конечному пользователю занедорого вообще не имеет смысла. Как это сделано-то?
Дрочишь мелкую сетку на суммарайз, режешь книгу на части размером в контекст сетки. Повторяешь. Закидываешь получившиеся пару тысяч токенов в большую нейронку, со счастливым видом сообщаешь гоям, что теперь работает миллион токенов контекста.
kpacubo
>Как это сделано-то?
Кучей косых трюков, которые пытаются превратить этот квадрат в хотя бы линейность.
Пруфов у тебя на это конечно же нет.
> который может имитировать человеческое взаимодействие
> ты меня ебешь
В голосину. Не, вот если бы там был суперйоба ттс под нужный голос с эмоциями хуймоциями - да, это прямо хочется. А так - впечатлившиеся нормисы ибо
> люди дрочат на ллм уже несколько лет
this
> Кобольд есть.
У него есть какие-то отличия с точки зрения перфоманса?
> все еще нет толковой поддержки мультимодальности
Ну типа да, но это не значит что будет совсем бесполезно. Тут бы просто выкатили звуковую диффузию, которая была бы натренена с кондишнами от основных/специальных токенов той же лламы, и все. Да, 2 разные модели, но будет работать отлично.
Если же ты про лаунчеры - вообще херня, напилят.
Что там вышло нового крутого?
> я закинул несколько книг в Клод и оно мне пересказало сюжеты
Rag и собственная память, оно даже не самые популярные анимублядские тайтлы перескажет тебе зирошотом. Но при этом разом обработать большой контекст, проинтегрировав все и извлекя смысл - ни одна модель хорошо не справляется, только примерно с котом или дергать отдельные факты.
>У него есть какие-то отличия с точки зрения перфоманса?
Никто не проверял. Но код должен быть такой же.
Аноны, а можно эту нейросетку на дейтинги натравить - тянучек на еблю разводить?
https://www.youtube.com/watch?v=wjZofJX0v4M&t=1221s
(Таймкод)
О, бля, наконец-то я вдуплил как обучение работает с этой хуйней где не только предсказывается последний токен, а предсказываются все токены за один проход. Получается буст производительности в Х раз где Х - это размер контекста? И файнтюн так же работает, за один проход?
И дальше я правильно понимаю, что размер коннекшна между слоями от входа до выхода это матрица размером "контекстное окно" х "размерность векторов"? Что происходит в этой матрице в середине модели? Там так же вектора выстраиваются "столбиками" как в конце или какие-то свои сложные абстракции возникают? После файнтюна готовая модель так же на последнем слое будет пытаться предсказать все токены и эта инфа просто игнорируется или модель перестраивается и начинает тратить этот ресурс на что-то другое?
Если я правильно понял, то теперь возникают уже более сложные вопросы, как растягивают контекстное окно, что при этом происходит с моделью, на входе и на выходе.
(Таймкод)
О, бля, наконец-то я вдуплил как обучение работает с этой хуйней где не только предсказывается последний токен, а предсказываются все токены за один проход. Получается буст производительности в Х раз где Х - это размер контекста? И файнтюн так же работает, за один проход?
И дальше я правильно понимаю, что размер коннекшна между слоями от входа до выхода это матрица размером "контекстное окно" х "размерность векторов"? Что происходит в этой матрице в середине модели? Там так же вектора выстраиваются "столбиками" как в конце или какие-то свои сложные абстракции возникают? После файнтюна готовая модель так же на последнем слое будет пытаться предсказать все токены и эта инфа просто игнорируется или модель перестраивается и начинает тратить этот ресурс на что-то другое?
Если я правильно понял, то теперь возникают уже более сложные вопросы, как растягивают контекстное окно, что при этом происходит с моделью, на входе и на выходе.
Направить можно, но разведёшь ты только сам себя.
>и эта инфа просто игнорируется
Ась? Распределение всех токенов используется всегда. Именно его жарит температура.

>Ась? Распределение всех токенов используется всегда. Именно его жарит температура.
Ну как я понял, распределение берется когда вот эта последняя на пике хуйня умножается на матрицу, которая по сути представляет выходной словарь (как бы сравнивается с каждым вектором токена "построчно" внутри неё), и где идет совпадение, те токены с вероятностями и идут на выход, где чисто рандомчик с температурой выбирает окончательный токен.
А те столбики слева (число которых должно быть равно контексту?) - все проходят через ту же матрицу при обучении. А что потом с ними? Из каждого можно извлечь токен как если бы в модели был инпут обрезанный в том же по номеру месте?
>Из каждого можно извлечь токен
И он будет равен токену соответствующей позиции контекста, лол.
>тянучек на еблю разводить
https://vc.ru/u/1768520-profitai-zarabatyvaem-vmeste/784008-naidite-lyubov-s-chatgpt
Россиянин похвастался, что ChatGPT нашла ему невесту, пока он был занят работой. Как это было?
https://lenta.ru/news/2024/01/31/gpt_love/
Автор диплома от ChatGPT рассказал, как языковая модель нашла ему жену
https://habr.com/ru/news/790222/
>Россиянин похвастался
>Автор ... рассказал
Верим, однозначно.
При инференсе? А при обучении будет предсказанный токен. Получается, маску атеншна для инференса отключают?
Но все равно же там должен быть предсказанный токен, только предсказание делается на основе того, что есть последующие токены, да и сам ответ уже известен, тоесть какая-то ненулевая вероятность может быть что там будет токен отличный от входного? Или как минимум распределение.
>Направить можно, но разведёшь ты только сам себя.
да понятно что развести не выйдет. Но хотя бы завязать диалог, чтобы отделить контактных от неконтактных.
Дай инструкцию: ты юзернейм с такими-то статами и ты очень хочешь познакомиться с девушкой. Зайдя на ее страницу, ты видишь (данные с профиля). Напиши короткое приветственное сообщение чтобы ее заинтересовать.
Если отвечаешь - меняешь инструкцию с "напиши приветствие" на "начни диалог с целью узнать о ней больше, параллельно рассказывая о себе". Сам поговори с ботом и сделай необходимые твики, это просто. ллм умнее типичной тни на подобных ресурсах если что
Меняю своё мнение по Лламе 3. Я думал, что она хуже Мистраля - нифига. На русском хуже, да - но учитывая датасет это понятно. На английском результат очень хороший. Но это касается модели 8B против 12B Мистраля. Семидесятку я особо не щупал, но общее впечатление пока скорее негативное. Похоже, что 8B это не дистилляция, а всё-таки отдельная модель.
Introducing KeyLLM — Keyword Extraction with LLMs
Use KeyLLM, KeyBERT, and Mistral 7B to extract keywords from your data
https://newsletter.maartengrootendorst.com/p/introducing-keyllm-keyword-extraction
Use KeyLLM, KeyBERT, and Mistral 7B to extract keywords from your data
https://newsletter.maartengrootendorst.com/p/introducing-keyllm-keyword-extraction

>TheBloke
Всплакнул. Ебать конечно учёные в говне мочёные отстают даже от имиджборд.
Не знал, что AutoModelForCausalLM может грузить ггуфы, лол.
Там в 1.5 и 7B подъехали
Qwen2-Math и Qwen2-Audio.
https://huggingface.co/Qwen
В том числе в MLC Chat для
запуска прямо на мобилке.
https://huggingface.co/mlc-ai
Qwen2-Math и Qwen2-Audio.
https://huggingface.co/Qwen
В том числе в MLC Chat для
запуска прямо на мобилке.
https://huggingface.co/mlc-ai
> Qwen2-Audio
Чего притихли, а это ведь круто, оно, наверно, поумнее вишпера должно быть и может помочь в подготовке датасетов и данных для звуковых нейронок.
Надо внимательнее их код глянуть, но похоже что эту штуку можно выдернуть (100%) и к любой модели присрать. Ну как к любой, на не-квен может шизу выдавать как с неподходящим визуальным проектором.
Чего крутого? Этого говна уже навалом. Лучше бы голосовую делали, в них за последние несколько лет прогресса ноль.
> запуска прямо на мобилке.
А какие конфиги примерно нужны?
> Этого говна уже навалом.
Показывай, хде
Кто может подсказать, где копать насчёт того, как мержить модели в MoE-архитектуру? Есть несколько интересных маленьких моделей, думаю вот, что хорошо бы создать франкенштейна под себя. Это просто или сложно сделать?
Блин, помогите найти нормальную плату на 4 x16 pcie.
платы стоят по 60к+.
Единственное более-менее подходящее я нашел на али - X79-H61, но там процессор с 40 линиями и 5 pcie. Значит там все порты x8.
Не могу найти ничего на 16/16/16/16 по хотя бы адекватной цене.
платы стоят по 60к+.
Единственное более-менее подходящее я нашел на али - X79-H61, но там процессор с 40 линиями и 5 pcie. Значит там все порты x8.
Не могу найти ничего на 16/16/16/16 по хотя бы адекватной цене.
>нормальную плату на 4 x16 pcie
Ты забыл упомянуть, какие карты ставить хочешь. А это важно.
у меня 4 p40. pcie 3.0.
Я попробовал на текущей конфигурации впихнуть все 4 карты (две в портах на матери, а две через райзеры от x1) но одна карта постоянно падает в шины.
Думаю, нужно попробовать все карты на полноценные x16 посадить. Да и сейчас две карты по сути на весу - это не дело.
Сделай тест 123В Mistral Large в четвёртом кванте (Q4_0). 4к контекста хватит. Узнаем, много ли ты теряешь. У меня 4 P40 на X299 - не совсем чистые х16, но почти. Может выясниться, что тратиться тебе на плату особого смысла и нет. Сейчас кину командную строку для бенчмарка в последнем Кобольде.
set CUDA_VISIBLE_DEVICES=0,1,2,3
koboldcpp_cu12.exe --usecublas rowsplit mmq --contextsize 4096 --blasbatchsize 512 --gpulayers 99 --flashattention --threads 15 --nommap --model Lumimaid-v0.2-123B.i1-Q4_0.gguf
Mergekit. Это сделать просто.
Пардон, забыл ключ --benchmark добавить:
set CUDA_VISIBLE_DEVICES=0,1,2,3
koboldcpp_cu12.exe --usecublas rowsplit mmq --contextsize 4096 --blasbatchsize 512 --gpulayers 99 --flashattention --threads 15 --nommap --benchmark test.txt --model Lumimaid-v0.2-123B.i1-Q4_0.gguf
pause
Если под Линуксом гоняешь, то примерно те же настройки выставь в Убабуге.
я не могу проверить на 4 картах. Говорю же - одна карта сваливается с шины.
в dmesg так и пишет
GPU 0000:07:00.0: GPU has fallen off the bus
Это может произойти во время загрузки или во время работы. Бутаешь хост, заходишь по ssh, делаешь nvidia-smi - показывает 4 карты. Делаешь еще раз - уже три.
Хз что это за говняк. Но карты точно ни при чем, потмоу что сваливается с шины карта которую я уже использовал с нового года - она проверена.
>GPU 0000:07:00.0: GPU has fallen off the bus
Питания-то хватает? Возможно плата по питанию не вывозит, или бп. Если есть райзеры с питанием - попробуй навесить на них. Урежь по тдп карты максимально и чекни ещё раз.
да должно хватать. И падает с шины всегда карта на одном и том же слоте pcie x1.
Думаю, питание тут ни при чем. У меня бронзовый блок на 1050 ватт.
Чуть не забыл, если это под линуксом происходит, то можешь не чекать, там кривой драйвер с переключением режимов энергопотребления, будешь страдать.
Карты берут пару ватт если мой склероз не врёт, то до 75 по спецификации непосредственно с самой материнки, если она кал, то может не давать эти ватты.
>бронзовый блок на 1050 ватт.
На 4 теслы хватит только если тдп зарезать, про карты мощнее и речи нет.
так а чего, я правильно понял, что 4 штуки честных х16 - это 100+к?
Нашел какую-то мать от асуса - она 23к стоит бу. А проц на нее еще 44к.
Ну... хзхз...
Навернрое проще просто ради эксперимента купить https://aliexpress.ru/item/1005006853559465.html?sku_id=12000038520222607&spm=a2g2w.productlist.search_results.0.46c27558pCSUpe и проверить как оно будет работать на ней
>Карты берут пару ватт
Три ватта каждая, если верить GPU-Z. И nvidia-smi показывает 10 ватт с карты без нагрузки. Если загрузить модель в память то 50, при инференсе ватт 150. Но БП может и косячить конечно.
>4 штуки честных х16 - это 100+к?
А хули ты хотел? Много линий писиай это экзотика, серверные процы или достаточно редкие кадавры. Обсуждали несколько тредов назад.
Что там есть из дешевого серверного железа, кроме зионов?
>ради эксперимента купить
Там максимум 4 слота "честные". И х8 pci-e 3.0 все слоты. Один слот под оперативу, нужно ставить самую жирную планку, чтобы не соснуть с загрузкой моделей. В общем, моё ебало скептическое в данный момент, если ты не понял.
Так это без пиков. Если под линуксом попробуй сделать intel_idle.max_cstate=1, отрежет нахуй энергосберегающие режимы, будет копоть и грязь, но скорее всего карта отваливаться перестанет. Если перестала - обновляй ядро до самого нового, возвращай режимы и пробуй ещё раз.
> помогите найти нормальную плату на 4 x16 pcie
> Не могу найти ничего на 16/16/16/16 по хотя бы адекватной цене
У тебя изначально не было шансов, еще недавно обсуждалось. Можешь попробовать выцепить какую-нибудь супермикру x11, там будут порты, но они с разных процессоров, ширину интерфейса между ними можешь сам нагуглить.
> все порты x8
Будто что-то плохое, х16 для запуска ллм не нужен если че. Возможно будет разница между процессорными и чипсетными линиями.
> X79
Древнее зло пробудилось, не трогай.
> постоянно падает в шины
Чивобля?
> У меня 4 P40 на X299
Одна будет в чипсетных линиях, если только мать не совсем экзотика. Сравни перфоманс на трех что в процессорных и 2 в процессорных + одна в чипсетных.
Также закинь бенчмарки что там в мистральлардж происходит на маленьком и большом контексте.
> GPU has fallen off the bus
Поменяй карточки местами. Если будет падать на другой - битый райзер и сопли + вопросы с питанием, если та же в другом слоте где работают - тесла рипнулась. Очень маловероятно что там что-то не то с матплатой или системой.
Если таки слот/райзер то попробуй в настройках биваса для него сменить максимальную версию протокола pci-e на 2.0/1.0, они более помехоустойчивы.
> ксперимента купить https://aliexpress.ru/item/10
Это добро не стоит трогать даже длинной палкой, днищепроц, 1 канал днищерам, даже если линии все на проце, оно не сможет перформить нормально даже с некротеслами.
>Одна будет в чипсетных линиях, если только мать не совсем экзотика.
Нет, там мультиплексоры. 44 линии от процессора не хватает на 4 карты конечно, как-то делят.
> Нет, там мультиплексоры.
Что за материнка?
>Что за материнка?
ASUS WS X299 SAGE/10G

> ASUS WS X299 SAGE/10G
Ух жирнота, красивое.
Блять ну и больные ублюдки, там все шины на даблерах сидят. Получается 4 карточки на 32 линиях и удвоением, интересно есть ли от этого положительный/отрицательный импакт на перфоманс. Кстати попробуй еще перешафлить порядок гпу чтобы подряд шли те что сидят фактически на разных шинах, тогда при последовательной копировании из одной в другую будет полная скорость а не половинная.
>на даблерах
Там как раз не даблеры, а полноценные коммутаторы, если ставить через слот. Хотя сама схема да, наркомания ещё та, особенно пикрил слот, который по сусекам наскребает линии лишь бы были.
>Кстати попробуй еще перешафлить порядок гпу чтобы подряд шли те что сидят фактически на разных шинах
Может и в минус быть, PLX по идее говоря должен уметь в копирование без участия проца. А с твоей схемой все данные только через проц будут идти.
С весны никаких не вижу новостей из мира промт-инженеринга. Нет на реддите, нет тут в тредах ничего про системные промты, составление карточек персонажа, всякие трюки с OOC/CoT и прочим. Прогресс встал?


>Кстати попробуй еще перешафлить порядок гпу чтобы подряд шли те что сидят фактически на разных шинах
Lil, они там ошиблись.
> а полноценные коммутаторы
Что? То просто чтобы делить линии на слоты в зависимости от использования, много где есть и никак не влияет. Там процессорные линии сначала идут в даблеры, а потом уже распределяются. Особенно забавно будет если кто-то там ставил карточки в первые 1 армированных слота, деля 16 линий.
> должен уметь в копирование без участия проца
Не совсем, некоторые опции там заявлены, но как оно сработает в таком случае - хз. Нормальные даблеры для sxm карточек, рекомендованные для использования в расчетах, несравнимо более жирные и начиненные, хотя линии то там те же.
> А с твоей схемой все данные только через проц будут идти
Думаешь что с эта штука сработает быстрее чем через проц? Крайне сомнительно.
Невнимательно смотришь.
>попробуй еще перешафлить порядок гпу чтобы подряд шли те что сидят фактически на разных шинах
Попробовал, но разницы никакой. С другой стороны это лламаспп(кобольд), ей и этого хватает - там всё жутко недооптимизировано. Запомню, буду пробовать, может где-то и поможет.
>Думаешь что с эта штука сработает быстрее чем через проц?
Так PLX в любом случае будет задействован, мимо него на саже идут только M2 слоты.
>Попробовал, но разницы никакой.
Что как бы намекает, что х8 за глаза.
> Так PLX в любом случае будет задействован
Обязательно, он и в обычном использовании будет постоянно создавать лишнюю задержку с его буфером пакетов. Насколько она существена вообще - вопрос, но скорее всего ничего критического.
Но внутренности его на понимание что как сработают скорее всего медленнее чем байпас на проц и все сопутствующие технологии.
> что х8 за глаза
Да там вообще врядли будет какой-то упор в шину, особенно если оно написано сколь-нибудь асинхронно где это возможно.
>особенно если оно написано сколь-нибудь асинхронно
>гольные си
Без вариантов, что это не так, лол, иначе баги были бы значительно забавнее, нежели чем проёб в токенайзере.

Жору модно хуесосить, но разве не должны быть какие-то пределы?
Бесконечность не предел!

Да ладно, там полно готовых заготовок а куда либы многое по дефолту делают _правильно_. Но у жоры возможно всякое, лол.
С какими-то настройками оно при обработке контекста буквально считает его каждой карточкой по отдельностью, из-зачего даже при медленно обновляемом мониторинге можно видеть как по очереди на них скачет нагрузка.
>можно видеть как по очереди на них скачет нагрузка
Тут вопрос в том, есть ли задержка между "1 карта закончила" и "2 карта начала".
Сейчас попробовал Mistral-Nemo-Instruct-2407.Q6_K, очень годно, порадовало что хорошо отыгрывает карточку, понимает положения тел в пространстве, может в жанр ню (хотя и не хватает красочных деталей), так что как файтюн завезут для этого дела будет отлично.
>при обработке контекста буквально считает его каждой карточкой
Там сложнее всё. На двух картах хорошее ускорение по сравнению с одной, а на трёх и выше... По крайней мере у меня так.
Ну да, по-хорошему это нужно делать тонкое отслеживание ибо даже если тайминги обмена будут исчисляться десятками миллисекунд (но происходить часто) и карточки в это время будут просто простаивать а не считать - мониторинг такого не покажет, из обозримых величин будет только снижение тдп.
А тут такой забавный эффект.
Какое железо? С какими параметрами запускаешь? На какой модели сравнивал? Сколько в большом мистрале выдает эвал и генерацию?
Ну что пацаны, английский?
https://habr.com/ru/articles/835284/
https://habr.com/ru/articles/835284/
>Какое железо? С какими параметрами запускаешь? На какой модели сравнивал? Сколько в большом мистрале выдает эвал и генерацию?
Теслы, кобольд, mmq без rowsplit, пробовал на ллама 3 8B-Q_8 и Mistral Nemo 12B-Q_8 - результаты аналогичны: на двух картах существенное ускорение, на трёх проседает, на 4-х ещё больше (хотя всё ещё лучше, чем на одной). Любопытно было бы узнать, есть ли такой эффект на 3090-х.
Вот уверен, что можно больше. Ну простаивают же карты.
12 рам для 7b,
или 8 в q4 там
у MLC apk есть.
Голос начали раскатывать некоторым пару недель назад.
По их словам, проблема была в том, что голосом она легко ломалась, и никакие цензоры не спасали. Но, вроде как, к сожалени, починили кое-как.
Это будет пиздец. =(
Ну так а чо, знакомство автоматическое по скрипту/дефолту, а потом сам ходил на свиданки. Но все же, оч.странная хуйня чисто психологически. Даже когда уже был отношач — иногда скидывал общение на чатгопоту.
О, ето интересно! =)
Так-то квен-2 и так хорошая модель. Ее, разве что, к немо или гемме-27.
> 4к контекста хватит.
Учитывая, что шина влияет как раз на обработку контекста — как раз не хватит. Надо, наоборот, как можно больше контекста пихнуть и сравнить с нулевым контекстом.
Ну и на 2-3 карты меньший квант с тем же большим контекстом.
> Много линий писиай это экзотика, серверные процы или достаточно редкие кадавры.
Так.
А как же ChatterUI? Пушка, ИМХО.
> результаты аналогичны: на двух картах существенное ускорение, на трёх проседает, на 4-х ещё больше (хотя всё ещё лучше, чем на одной)
И сколько там выходит ускорение?
> test.gif
Оно на 3090 близко по генерации, выше в треде результаты, жорина оптимизация, только процессинг кратно выше но всеравно медленно. Прогони то же самое но на большом контексте, интересно каков будет скейл генерации и будет ли замедление процессинга.
1.8т/с!
Алсо почему легаси q4_0 а не нормальные K-кванты? Он же лоботомит уровня Q2-Q3S
> квен-2 и так хорошая модель
Да, но не в 7б. Хотя, учитывая унылость первой реализации входа звука оно будет упираться не в ллм часть.
> Оно на 3090 близко по генерации
Генерация в два раза быстрее на 3090. А промпт раз в 5 быстрее обрабатывает.
>И сколько там выходит ускорение?
Почти вдвое.
>Прогони то же самое но на большом контексте, интересно каков будет скейл генерации и будет ли замедление процессинга.
Будет, всё линейно.
Покажешь?
> Будет, всё линейно.
А насколько? У линейности как минимум есть коэффициент наклона, может упать на 20% за 32к а может в 4 раза уже на 16к.

> Покажешь?
Пикрилейтед 123В на 4090 и двух 3090.
Какая модель, какие параметры запуска и сам лаунчер, какое железо, какой квант?
Ну и то же самое на большом контексте прогони, насколько оно сдохнет.
Я думаю, что неправильно назвать английский доминирующим языком внутри ллм. Там внутри не язык, а наборы смыслов, которые активируются под воздействием входных данных. Ты можешь написать слово "яблоко" на любом языке, и активируется всегда один и тот же нейрон + дополнительно нейрон языка. Вектор токена, который будет рядом с этой активацией, чисто статистически ближе к apple, просто потому что таких данных было больше, оно так обучилось. Скорее всего там даже распределение токенов будет похожее по процентам языков в данных, интересно есть ли это в оригинале статьи.
Потом значит это apple проходит на выход, к нему добавляется вектор "русский язык" и получается яблоко. Это просто путь в векторном пространстве.
Если обучить нейронку на равномерном наборе данных, там внутри никаких языков не будет, будут чистые смыслы или какая-то компиляция всех языков в один.

Пикрел скорее всего ложный вывод, наблюдаемый эффект - следствие доминирующего количества "английских" токенов в словаре. Большой вопрос насколько вообще промежуточные данные могут в явном виде интерпретироваться как "мысли" в классическом понимании.
Эффект "перевода" может быть, но его нужно как-то аккуратнее отслеживать.

>У линейности как минимум есть коэффициент наклона
Вот тебе три точки, определяй коэффициент. Для Q4_KM результат будет почти такой же.
С практической точки зрения до 8к контекста можно терпеть. Скорость генерации приемлема.
Оу оу, так значит там и процессинг с увеличение контекста тоже замедляется? Тогда действительно 3090 в 5+ раз быстрее, да.
Но там не линейность должна быть а что-то типа логарифма, иначе при экстраполяции такого на 24к оно в ноль придет, лол.
> до 8к контекста можно терпеть
Владимир Вольфович.жпг, печалька. Тут не терпеть а растягивать на максимум и пытаться обмануть костылями, с кэшем пойдет. Спасибо за результаты.
>Тогда действительно 3090 в 5+ раз быстрее
Строго говоря 4090 + 2х3090. Но в принципе да - на exl2, потому что на Жоре такой квант на трёх картах не потянешь.
Что поделаешь, сколько заплатишь - столько и получишь. Недёшево.
Только недавно скидывал бенчки на риге с 3090, на экслламе там 700+т/с процессинга и ~10т/с генерация на 24к на hf семплерах против 330 и ~6 (может и чуть меньше на кванте того же размера). И это уже печально ибо с пол минуты ждать начала нового поста. Работу экслламы с жорой на тесле на больших контекстах вообще сравнивать нельзя, насколько велик гап.
Теслаебам надо донатить турбодерпу и выпрашивать его сделать поддержку некроты, это главная надежда на нормальную работу кроме замены железа. Пусть ускорения относительно идеальных условий жоры не получится, зато не будет такой адовой просадки на контексте.

Кстати, вот возможно и ответ на мои вопросы
На которые никто конечно же не ответил нормально.
Для меня это все выглядит теперь так, как будто ллм тратит 99.9% вычислений впустую.
На которые никто конечно же не ответил нормально.
Для меня это все выглядит теперь так, как будто ллм тратит 99.9% вычислений впустую.
> На которые никто конечно же не ответил нормально.
Просто вопросы тупые.
> будто ллм тратит 99.9% вычислений впустую
Это просто параллелизация трансформера. У тебя, условно, в аттеншене каждый отдельный токен смотрит на весь контекст. Когда делаешь attention mask просто подменяется вероятность для токенов под маской, но они всё так же участвуют в расчётах, потому что токенам без маски надо смотреть на них. Ты не можешь их выкинуть просто так. В этом и есть гениальность трансформера, что у тебя как бы бонусом есть вероятности для все прошлых токенов в контексте. При обучении по итогу выкидывается вероятность следующего токена, при инференсе вероятности прошлых. Если ты думаешь "а почему бы физически не делать расчёты для прошлых токенов при инференсе", то так не будет работать, у тебя всё равно идёт перемножение матриц всего контекста, там нечего выкидывать. Трансформеры дали возможность скармливать сетке десятки тысяч токенов за шаг обучения, а не дрочиться с последним. Хотя тут есть и минусы - трансформер лавинообразно подыхает от мусора в контексте, т.к. при обучении никогда не видел его.
https://github.com/hsiehjackson/RULER
сравнение заявленной и реальной длины контекста
сравнение заявленной и реальной длины контекста
Самый смак конечно тюн на матеку,
когда модель одна из самый сильных
мелких моделей по ней. ChatterUI топ.
mlc прям для хлебушков - скачка в интерфейсе
*английский — статистически доминирующий язык среди векторов, которыми оперирует ллм
Стало легче?
Сходу вижу какую-то наёбку - у них инструкция не в системном промпте, а в пользовательском сообщении. Как минимум для ламы 3 это точно не есть хорошо.
Попробовал этот ваш MN-12B-Celeste-V1.9.
Круто конечно что они оставили на странице модели систем промпт и настройки семплеров, да вот только даже с этими настройками она тупая как пробка, проёбывает форматирование и лупится хуже Лламы.
Пока что лучше Магнума и Люмимейда файнтьюнов для Мистраля не видел.

Да и это 4к непонятно как высчитано, там 32 можно было насчитать
В некоторых местах он слишком рано делает отсечку, хотя проценты еще не упали значительно
Но в принципе, интересный тест, даже если он сделан криво, он крив на всей протяженности контекста и в любом случае модели равномерно тупы на всей проверенной длине, так что он относительно правдив
Классический нидл и его вариации, наиболее интересно отслеживание переменной и частота слов, но второе уже не совсем по профилю.
Приличного обобщения и работы с контекстом пока так и не сделали.
А если еще это то печально, да. Тут интересно посравнивать разные варианты инструкций, типа задание главной в самом начале, или "следуй запросам пользователя" а потом уже юзер дает задачу в конце.
> даже если он сделан криво, он крив на всей протяженности контекста
Да не скажи, чем дальше от начала инструкция при отсутствии нормальной изначально тем хуже будет результат.
>чем дальше от начала инструкция при отсутствии нормальной изначально тем хуже будет результат.
А вот это надо проверять и доказывать
Ну, код есть, никто не мешает проверить самому
Что тут доказывать, это очевидно. Чем больше отклоняешься от того на что модель была натренирована, тем хуже будет результат. Если и пытаться измерять эффективность работы с контекстом, то ее и нужно мерить, а не то насколько отупеет модель от неподходящего формата.
> лупится хуже Лламы
В ламе как раз нет лупов. Ну или по крайней мере их можно побороть. Сейчас эталон лупов - это Мистраль 123В. И я могу предположить что на младших такое же поведение, если датасет там был одинаковый.
Это как раз таки не очевидно. Модели в любом случае запускались в режиме близком к нужному. И на всем протяжении контекста в одинаковых условиях.
Будет ли улучшение работы с большим контекстом чем в этом тесте при правильных настройках - надо проверять, а не гадать
Там могут быть чуть большие проценты правильных ответов, но такое же падение процентов на одинаковых размерах контекста.
Или, проценты останутся примерно такими же, но падение начнется чуть позже.
Надо чтоб анон с быстрой и большой врам прогнал тесты с какой нибудь 7b-8b например, на все 128к без сжатия контекста. В 2 вариантах, предложенном автором и переделанным в нужный промпт форматом. И уже там смотреть.
> Это как раз таки не очевидно.
Что неочевидного в ухудшении результатов при отклонении от стандартного формата? У каких-то моделей к этому толерантность больше, каким-то похуй, степень влияния как сама по себе может зависеть от контекста, так и с ростом контекста отличие от нужного формата из-за большего удаления инструкции от начала будет расти.
> Модели в любом случае запускались в режиме близком к нужному.
Вот это как раз неочевидно. Но шаблоны там в целом простые с точки зрения понимания и сложные с точки зрения модели, потому что инструкция разделена на 2 половины, одна перед текстом, другая в конце, а сам текст никак не оформлен. Не то чтобы это плохо, просто условия наиболее боевые. Зато есть префилл ответа, который сильно помогает, было бы интереснее посмотреть без него насколько собьются модели.
> Будет ли улучшение работы с большим контекстом чем в этом тесте при правильных настройках
100% будет, на сколько это уже другой вопрос.
> Надо чтоб
Перепиши и прогони.
Вообще, тут интереснее посравнивать разные кванты, работу разных лаунчеров, семплеров, костылей и подобного. При относительной массовости теста данные будут информативны, можно будет отследить насколько адекватны лоботомиты, насколько лучше i-mat-ixx и подобные кванты с низкой битностью, импакт от кэша и прочее прочее.
>100% будет,
опять гадаешь, настрадамус
> Batch Size2,097,152
Ага, за 9 дней, на кластере из 10000хН100.
Нет, 8 штук А100
>Я думаю, что неправильно назвать английский доминирующим языком внутри ллм.
>Эффект "перевода" может быть
Так есть или нет? Уж реши. Я считаю, что есть, и что нужно принудительно учить модели универсальному языку, чтобы не было просадок в зависимости от языка ввода или вывода.
>Для меня это все выглядит теперь так, как будто ллм тратит 99.9% вычислений впустую.
Твои предложения, как сделать так, чтобы не тратить?
>Твои предложения, как сделать так, чтобы не тратить?
DiT. Еще и по кругу гоняем инфу через одни и те же слои, давая одним и тем же навыкам применяться на разных уровнях абстракций.
Касательно графики, конечно, как это к тексту применить я в душе не ебу, просто чувствую, что "что-то здесь не так".
Тут при работе и обучении разницы нет. Принципы обучений, в общих чертах те же. Представь, что сейчас мы бы брали с DiT по одному пикселю с выхода, чтобы всю картинку сгенерить.
>Так есть или нет? Уж реши. Я считаю, что есть, и что нужно принудительно учить модели универсальному языку, чтобы не было просадок в зависимости от языка ввода или вывода.
А где данные для универсального языка найдутся?
Ну и допустим мы обучили модель на равномерном наборе языков. Теперь вектор "мысли" коррелирует с словом на разных языках одинаково. На каждый язык теперь включается свой нейрон "нужный язык" (изначально на английский он не включался, ибо этот язык и так статистически вероятнее"). Эти вектора складываются, модель отвечает на нужном языке.
На каком языке мыслит модель?
> если бросить кирпич на голову - он упадет на голову
> врети врети требую проверки
Ну ты
Ну это же 1.6b только и датасет 0.1T. Но так статья интересная
> Так есть или нет?
Чел, он возможен, но приводимое в статье это никак не подтверждает.
> нужно принудительно учить модели универсальному языку
Что-то уровня трешовых голливудских боевиков, где суперкомпьютер чинят ударом по стоящему в другом здании монитору.
> DiT
Да, подобное в целом может дать крутой буст. Но насколько вообще концептуально применимо к генерации текста?
>> если бросить кирпич на голову - он упадет на голову
>> врети врети требую проверки
>Ну ты
Упрощает и искажает все доводя до абсурда, не приводя никаких доказательств
-
Ну ты
Если нужно объяснять то объяснять не нужно, смирись, это очевидно.
>сравнение заявленной и реальной длины контекста
Сомнительно - по их наблюдениям Mistral Nemo после 16к уже не может, по моим - вполне.
Очевидно что какой то пиздабол играется словами "доказывая" свою точку зрения
Что то тема стала гораздо тухлее чем год назад, изза таких как ты в том числе
Ну, это двач, так что все в порядке
Съеби в /po/рашу откуда вылез, анализер, там твои навыки доказывать что черное это белое оценят.

В зеркало говоришь? кек
Там надо не на контекст смотреть, а на проценты сбоку. Хоть и написано 16к у него, но проценты на 32 падают не так сильно, хотя первые 14к стабильный результат.
Там еще вопрос, использовалось ли ропе и как запускалось
Но судя по тестам больше 32к немо не тянет, без растягивания
>А где данные для универсального языка найдутся?
Что-то из sec2sec моделей переводчиков.
>Что-то уровня трешовых голливудских боевиков
Что не так?
Ну это пизда, даешь ему задачу выпадающую из датасета, которую придумал сам, и все, тупит жестко. Надеюсь этот кал это не то что они собрались выкатить скоро
Исправил условие на более чистое:
Есть три человека: Егор, Олег и Миша. У двух из них в сумме есть 10 рублей. Егор постоянно врет, остальные говорят правду.
Пойми из их данных высказываний сколько денег у каждого:
Миша говорит что у него 11 рублей
Егор говорит что у него 12 рублей
Олег говорит что у него 7 рублей
Все еще не может. Тужится, делает предположения, понимает свои ошибки, но в итоге снова делает хуйню
> В зеркало говоришь?
Кек, со всеми уже успел посраться что путаешься? Таблетосы и успокоительное, срочно.
> Что не так?
Слишком большая абстракция и вера в успех.
Как это делать будешь, готовить особый уникальный датасет серьезного объема? Его создание уже станет ебать какой задачей, чтобы он был действительно качественным и без байасов, смехуечки по поводу синтетики и жптизмов сказкой покажутся когда модель начнет постоянно неверно интерпретировать что-то. Далее, даст ли это вообще положительный эффект, а не модель окажется хуева не в редких языках а вообще во всех?
Если не просто делать датасет а пытаться в особую тренировку где будут достигаться какие-то особые "универсальные" токены в промежуточных слоях - это вообще может все поломать, потому их попытка прямой интерпретации данных со срединного слоя как "прямых мыслей" - красивое предположение.
Если же у тебя прямо четкое ясное видение этого - распиши, интересно.
>Кек, со всеми уже успел посраться что путаешься?
Говно Аноны все на одно лицо, я бы сказал братья по разуму
Не хочешь быть посланным - не пиши хуйню, все просто
>Таблетосы и успокоительное, срочно.
Всегда кекаю с больных точек анонов, которые считают что обидное для них будет обидным для другого
Прими таблеточки и не влезай в чужой срач, семен

чел ушедший из гугла сделал ИИ чип , с пробросом цепочек вычислений для 4 битных пакетов а поскок цепочка из 4 пакетов всего 16 вариантов любого пакета, то чел сделал вечный проброс любой языковой модели и теперь "вычисления и обучения "не нужны. Те чел разорил Nvidia и всех чипмейкеров ибо эмулировать на таких чипах и весах можно что угодно
Чипы работают в 100-250 раз быстрее Gpt4 и всех языков для Nvidia
Вот новость.
https://www.forbes.ru/tekhnologii/518529-so-skorost-u-mysli-kak-nebol-soj-startap-po-razrabotke-ii-cipov-hocet-obojti-nvidia
вот его сайт со всеми языковыми моделями онлайн. ( странно что нужна рега с такими возможностями )
https://groq.com/
далее чип можно уменьшить в 50 раз и масштабировать до бессконечности те владельцы стартапа тупо боятся что сам принцип чипа спиздят
2024 - это уже означает можно моделировать мозг с мгновенным обучением.
Чипы работают в 100-250 раз быстрее Gpt4 и всех языков для Nvidia
Вот новость.
https://www.forbes.ru/tekhnologii/518529-so-skorost-u-mysli-kak-nebol-soj-startap-po-razrabotke-ii-cipov-hocet-obojti-nvidia
вот его сайт со всеми языковыми моделями онлайн. ( странно что нужна рега с такими возможностями )
https://groq.com/
далее чип можно уменьшить в 50 раз и масштабировать до бессконечности те владельцы стартапа тупо боятся что сам принцип чипа спиздят
2024 - это уже означает можно моделировать мозг с мгновенным обучением.
>POWER:
>Max: 375W
>TDP: 275
>Typical: 240W
Ладно. Можно стерпеть даже подмышку сатаны, если оно реально такое быстрое.
>230 MB of on-die memory delivers large globally sharable SRAM for high-bandwidth, low-latency access to model parameters without the need for external memory.
Нечасто встретишь предложение, которое становится хуже с каждым следующим словом.
>Chip Scaling
>Up to 11 RealScale™ chip-to-chip connectors
С таким объёмом памяти 11 чипов маловато будет.
>Groq's LPU: The GroqCard™ Accelerator, priced at $19,948, offers high-performance AI inference capabilities
Так, у вот у меня квен 7b в четвёртом кванте, чуть больше четырёх гигов, это 18 карточек, плюс контекст, хуё-моё, умножаем 20 на 20...
>Вот новость.
Мысль про прогрев гоев почему-то не покидала меня всё время чтения новости.
Статьи от маркетологов и укушенных ими журналистов ничего толком не объясняют.
За сутью акселератора от Groq посмотрите видео
LPUs, NVIDIA Competition, Insane Inference Speeds, Going Viral (Interview with Lead Groq Engineers)
https://www.youtube.com/watch?v=13pnH_8cBUM
>и вера в успех
Никакой веры, всё надо проверять.
>Как это делать будешь, готовить особый уникальный датасет серьезного объема?
Как я писал другому анону, оно должно строится на многоязычных параллельных переводах. Точной инструкции не дам, увы, я тупой (иначе бы сидел в попенах).
>Чипы работают в 100-250 раз быстрее Gpt4
Чё блядь? Чипы это чипы, ГПТ4 это сетка. Что они блядь несут...
>Чипы это чипы, ГПТ4 это сетка. Что они блядь несут...
Типа сравнивают скорость инференса GPT4 и открытых LLM (Llama 3, Mixtral), которые они запускают на своём кластере на основе нескольких сотен (внезапно) Groq акселераторов.
Почитайте обсуждения, там сотрудники Groq местами комментируют:
https://old.reddit.com/r/LocalLLaMA/comments/1afm9af/240_tokenss_achieved_by_groqs_custom_chips_on/
https://old.reddit.com/r/LocalLLaMA/comments/1audftm/wow_this_is_crazy_400_toks/
>to achieve the performance demonstrated in our demo, we utilize 656 chips for the Llama2-70b model and 720 chips for the Mixtral one.
А самое смешное, что на этих чипах обучать нельзя. То есть какому-нибудь корпоративному клиенту нужно заставить этаж небоскрёба стойками с картами нвидия, чтобы обучать. И все остальные этажи - стойками с этими гроками, чтобы делать вывод. На кого вообще рассчитаны их чипы?
Для тех кому нужна максимальная скорость вывода любой ценой, например генерировать синтетические датасеты или сделать супер быстрого чатбота или одна супербыстрая херня для обслуживания кучи людей, работающая с клиентами по очереди
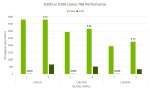
>генерировать синтетические датасеты
Одна h200 сгенерирует этот датасет в несколько раз быстрее, потому что сгенерирует больше токенов за единицу времени. У них профит один, это скорость генерации самого пакета, по количеству токенов в секунду они сосут. Сотрудники там в обсуждении пишут, что сами используют размер пакета 1, если это фундаментальное ограничение, то это пиздец. Для локального использования это неприменимо, для корпов это имеет слишком много ограничений, а рассчитывать на миллиардера-кумера со скоростью чтения в несколько сотен слов в секунду, скажем так, не слишком разумно.
>супербыстрая херня для обслуживания кучи людей, работающая с клиентами по очереди
А выгоднее ли это херни, которая обслужит за единицу времени больше клиентов и сгенерирует им больше токенов?
Слишком красиво.
Ну инференс это самая важная вещь, не надо. Обучаешь ты один раз, а используешь миллионы. Если выйдет какая-нибудь более менее полноценная замена кодеров, то использовать ее с такой сумашедшей скоростью будет жесть как выгодно для бизнеса, можно будет проекты за день делать. То есть всем кому нужно просто использовать готовые модели это может быть очень выгодно, смотря от задач которые он хочет выполнять, ибо видюхи само собой дешевле, их производство налаживалось десятилетиями, а для генерации порно фанфиков это как стрельба из пушки по воробьям.
Тут есть программисты, связанные с нейронками? Смотрю щас вакансии по LLM, и там на одну вакансию по 300-400 откликов. Откуда столько?
Спросил сначала в пр, но решил и тут спросить.
Спросил сначала в пр, но решил и тут спросить.
раз покупают значит видят выгоду, а в чем, хз
> Не хочешь быть посланным - не пиши хуйню, все просто
Это к тебе прежде всего относится, начал толкать какую-то шизу, оспаривая очевидное, а потом обидевшись пошел строчить еще большую дичь, выжимая воду из камня.
Статья сносная, а вот пост - эталонное бинго маркетолухов и бейтеров. Это же пост-мета-ирония, да?
А, выглядело будто уже предлагаешь готовое инновационное решение. Это верно, нужны исследования, особенно по соотношению языков и содержимого на них на разных этапах тренировки. Если претрейн идет на подавляющем инглише а только потом начинается разнообразие то неравномерность перфоманса может сохраниться до конца.
Корпоратам выгодно иметь и стойки хуанга для обучения и исследований и вот такие асики чтобы хостить сервисы дешевле и эффективнее. Со вторым пока беда но в перспективе так.
> оспаривая очевидное,
Для твоего манямирка?
Кек, весь спор о том что одна гадалка стала утверждать без проверки, как именно поведут себя сетки при тесте в разных условиях
Когда ее попросили проверить и принести пруфы - стала играть словами и выебыватся на пустом месте, прям как ты
Нет проверки - нехуй пиздеть утверждая свою точку зрения на пиздеже и манипуляциях
> весь спор
Нет никакого спора, есть аксиома о том что модель теряет в перфомансе при отклонении от формата, и это также скажется на ее эффективности на большом контексте. И есть поех, который сначала упоролся про то что "нет это не очевидно" а потом по привычке начал генерировать шизослоуп срачей уровня пораши, порвавшись от того что его фантазии кто-то не разделяет.
> есть аксиома о том что модель теряет в перфомансе при отклонении от формата
Это очевидно, поех. Неочевидно как изменятся тесты при изменении промпт формата, они станут лучше, но по всей ли длине? Вот в чем соль, идиотина
>И есть поех, который сначала упоролся про то что "нет это не очевидно" а потом по привычке начал генерировать шизослоуп срачей уровня пораши, порвавшись от того что его фантазии кто-то не разделяет.
Тоесть ты? Где пруфы билли? Ты опять играешься словами, поех?
Нахуй пошел, и приходи когда у тебя будут доказательства твоего пиздежа
> Это очевидно, поех.
Поех это ты, потому что сначала неистово споришь с этим, потом соглашаешься, и тут же в том жепреложении про это забываешь выдавая
> Неочевидно как изменятся тесты при изменении промпт формата
у тебя все в порядке там?
> но по всей ли длине
Если они были хуевыми а стали хорошими то будет по всей длине, без вариантов. Если ты настолько косноязычен что не можешь сформулировать свою мысль, типа
> изменит ли это форм-функцию и снизит ли завал скора на больших контекстах по сравнению с малыми
shame to you, совсем деградировал в срачах.
> Где пруфы билли?
За щеку тебе скинул, проверяй.
Тоесть ты опять решил напиздеть, виляя жопой как сучка?
За щеку тебе скинул, проверяй.
Ты сплюнь сначала, а потом съеби на порашу, скидыватель.
Сразу видно что ты считаешь обидным, печальный опыт?
Хуесос, только языком работать и умеешь, а как доказать свою точку зрения сливаешься в оскорбления.
Ущерб, от таких как ты тема и заглохла
Наверное, не "раз покупают", а "если". Всё-таки данных нет.
>хостить сервисы дешевле и эффективнее.
Несколько шкафов за десятки миллионов с сотнями карточек 250-300 ватт каждая или одна H200 с TDP 600-700 ватт, которая в среднем будет генерировать токены быстрее, чем шкафы. А где "дешевле"? Где "выгоднее"? Причём карта от кожаного по цене будет всего как две карты от гроков. То есть сфера применения у них пиздец узкая, какое-нибудь машинное зрение с высоким фпс разве что.
Тут возможный профит для обычного пользователя может быть в том, что кожаный добавит кешей и ускорит свои печи немного.
Ммм, февральские новости!.. Кайф!..
Жаль, что у тебя еще ллама 3 не вышло, геммы2 нет, мистрали немо…
А подобный чип делали еще год назад. И… тишина. А ведь 500 токенов/сек на 70б модели было!..
Смешной.
А ты-то сам нахуя смотришь? У тебя рил профильное образование, диплом вуза, десяток папиров за плечами? Если нет, то чем ты отличаешься от местных анонов и членов профильных тг-чатиков? Мы тут все — ML-инженеры, йопта (я даже работал немного по этому профилю и обниморда есть=). Таких вот спецов и 300-400 откликов.
Или еще круче — КУРСЫ! Скиллбокс и все остальные, где учат хуйне (как всегда), а люди потом пиздуют за своими 300кк/наносек.
В общем, ответ-то прост.
> а ты сам то нахуя смотришь
Хочу вкатиться, вот смотрю вакансии смотрю что там требуют.
> профильное образование ,диплом вуза
Ну да, техническая вышка. Диплом - анализ временных рядов основных жизненных показателей человека. Или как то так называется, я полностью уже не помню.
> десяток
Ну не десяток конечно.
> курсы
> таких вот спецов
Но ведь языковые модели там непопулярны. Да и в целом на вакансиях, где нейросети, отклики больше, чем на прочих вкатунских вакансиях.
Не понимаю, что не так. Арендую две 3090, ставлю Убабугу. Модель Ллама 3.1 70В 4BPW, 37 гигов. Выбираю Экслламу, задаю память ГПУ как 24,24. Гружу модель - мало врама. Правлю эти цифры так и сяк - не лезет. Убираю их, ставлю галку автосплит, гружу - пишет, что не хватает врама для модели и кэша. Модель 37 гб, врама 48, ага. Ставлю ещё галку "8-битный кэш" и модель наконец загружается, но по потреблению врам на картах видно, что на первой занято 98 процентов, а на второй всего 75. То есть врам ещё дофига. Что за косяки, не пойму? Это эксллама так работает с мультигпу?
> Несколько шкафов за десятки миллионов с сотнями карточек 250-300 ватт каждая или одна H200 с TDP 600-700 ватт
Ну ты сравнил
> А где "дешевле"? Где "выгоднее"?
В перспективе они вполне могут опередить блеквеллы и следующие карточки в подобных узких задачах и быть дешевле. Но хз где будут чипы делать, передовые производства уже поделены.
> машинное зрение с высоким фпс
Хз, там как раз могут и соснуть ибо расчетов побольше чем токены на 4битном кванте предсказывать.
Как ни крути, если у них будет успех то это окажется профитнее в том числе и для пользователя, хотябы кожевенник начнет шевелиться.
> и обниморда есть
Доступ к H100 на спейсах открыт?
> КУРСЫ! Скиллбокс
Экспедиция на марс.жпг
> задаю память ГПУ как 24,24
Задай как 20,24 на первую жрет всегда больше за счет контекста и всякого, можешь подобрать чтобы было равномерно по мониторингу. В жоре сейм поведение, а при некоторых параметрах разница более чем в 1.5 раза. При запуске не ульти с контекстом, по умолчанию для лламы 3.1 там 131к выбирается и сколько только на трех катать, выбери 8-16к для начала.
Аноны, буду собирать с нуля систему под Tesla P40 на проце 9700к с 32 гигами. Есть смысл ставить 11 винду или без разницы что 10 что 11?
>здарова бандиты. У меня обновка.
>в воскресенье приедет еще один райзер и их у меня будет не 3, а 4
А что у тебя за материнка и процессор. Какой охлад используешь
>Задай как 20,24 на первую
Задавал. Я вообще разные числа туда писал - не помогает. Контекст ставил 32к. Может конечно сборка такая, но вроде последняя Убабуга, а на две карты нормально не делит.
>Есть смысл ставить 11 винду
Слышал, что режим TCC даже на 10 винде кривовато поддерживается как устаревший, а на 11 на него вообще могут забить. Слух может быть и неверным - наоборот в Вин 11 могли поправить. На 10-й всё работает.



Бля, и вот это ваша жпт-4? Как будто с бредогенератором общаюсь. Он знает определения, но литералли пишет что статический полиморфизм не является полиморфизмом. 4о сначала пишет неправильно, но если спросить про статический полиморфизм и потом попросить пояснить за базар в первом посте, то признаёт что был неправ. Пиздос. Самое смешное что лама 405В и Мистраль 123В отвечают оба правильно, на 4 пике Мистраль. Квен2 72В тоже правильно отвечает, а вот гемма 27В срёт и совсем закапывает себя на вопросе о статическом полиморфизме, не понимая что это.
так ты по английски спрашивай
>Типа сравнивают скорость инференса GPT4 и открытых LLM
То есть хуй с пальцем.
>замена кодеров, то использовать ее с такой сумашедшей скоростью будет жесть как выгодно для бизнеса, можно будет проекты за день делать
Без верификации этим самым кодером никто нейросетевые высеры в прод пускать не будут. Так что всё ограничено этими самыми макаками на службе, хоть триллион кодотокенов в секунду высирай.
>Откуда столько?
Сейчас любой прошедший платный курс за 300 рублей мнит себя погромиздом во всех сферах, вот и отклики. Искать сейчас РАБоту в любой сфере IT это тот ещё адок, ага, без подгонки резюме под каждый отклик тебя будут слать нахуй с порога, если не повезёт и в компании резюме не будут смотреть лиды, а не эйчары.
>раз покупают
Пока только обещают продажи, как всегда.
>А, выглядело будто уже предлагаешь готовое инновационное решение.
Знаю. Но пока только подсвечиваю проблемы. На решения у меня нет ни мозгов, ни свободного времени, ни железа, чтобы минимально проверять, ибо моего терпения хватает только полчасика погонять, а на 3080Ti много не прогонишь за это время.
>Да и в целом на вакансиях, где нейросети, отклики больше, чем на прочих вкатунских вакансиях.
Лол нет. На обычных вакансиях по 500 откликов, а если в вакансии есть слово джун или новичок, то там буквально тысячи, лул.
>Контекст ставил 32к.
Куда блядь столько? Протестируй с 4к для начала, потом наращивай.
>С++
21 день просто ещё не прошёл, модель не выучила язык.
>Куда блядь столько? Протестируй с 4к для начала, потом наращивай.
10 гигов свободной врам - а я должен на контексте экономить? Да ну нахуй.
>Без верификации этим самым кодером никто нейросетевые высеры в прод пускать не будут. Так что всё ограничено этими самыми макаками на службе, хоть триллион кодотокенов в секунду высирай.
Полноценная замена кодеров. Ты мыслишь завязываясь на том как ллмки работают сейчас. Думаю со временем появится сертификация моделей/агентов и им будет выдаваться определенная степень безопасности, по аналогии с машинами с автопилотом. На низких степенях будет обязательна проверка макаками что все равно упростит разработку бтв, на высоких будет размещена автономная разработка без вмешательства человека.
> модель не выучила язык
Тут же самое печальное что она не видит противоречия в том что говорит. То что шаблоны это статический полиморфизм она знает и пишет об этом, пример кода выдаёт корректный, на английском отвечает корректно. Но упорно отказывается признавать на русском что статический полиморфизм это всё же полиморфизм. 4о только с пинками нехотя признала. Ещё и начинает высирать определения, пытаясь уйти от вопроса, как бы говоря "я не знаю, держи определения и сам разберись". Выходит русский локалок уже ебёт жпт.
> Контекст ставил 32к
Ну в теории с 4.0 bpw оно должно вмещаться, но на грани в пару. Для начала попробуй выставить 4-8к и посмотри как цифры будут влиять на используемую память. Последнюю карту всегда ставь полную, она будет заполняться по остаточному принципу, в первой оставляй 1-2-4-... гигов на контекст, во второй 0.5-1 если еще есть третья. Там ошибиться сложно, ставишь - смотришь, оомнулось - смотришь по какой карте или даже не смотря меняешь значение и заново грузишь. Можешь попробовать автосплит галочку, но хз как она работает.
> а на 3080Ti много не прогонишь
Если что, аренда 3090 стоит в районе 0.2$/час а A100 ~0.8, но придется неплохо так попердолиться на всех этапах. Так, на всякий, если вдруг не хочешь разом отваливать за сомнительную горячую железку а просто поиграться.
>10 гигов свободной врам
->
>по гигабайту за каждые 1к контекста
@Шапка
То есть контекст в твоём случае занимает 16 гиг минимум, а то и больше.
>Думаю со временем появится сертификация
Соефикация разве что.
>по аналогии с машинами с автопилотом
Да без проблем. Благо они до сих пор не заняли и 5% перевозок.
>Выходит русский локалок уже ебёт жпт.
ЖПТ на русском уже давно не образец, смотри в сторону клода.
>но придется неплохо так попердолиться на всех этапах
Знаю, и именно пердолинг отворачивает от аренды. Мне с самим кодом и реализацией идей пердолинга достаточно.
>То есть контекст в твоём случае занимает 16 гиг минимум, а то и больше.
Нет, взял квант чуть поменьше (3,8), разделил память 17,24 и завелось с 32к полного контекста. Разница между полным и восьмибитным кэшем контекста есть, как мне кажется.
Но всё равно, полная обработка этого самого кэша 40 секунд занимает, а обрабатывается он чуть ли не каждый ответ. Это быстро, не спорю, но немного напряжно - особенно за деньги.
> Разница между полным и восьмибитным кэшем контекста есть, как мне кажется.
Да точно есть. Как выше писали, если оно квантует в легаси fp8 и не nf8 то может оказаться хуже даже чем nf4. На сколько плох он по сравнению с оригиналом - вопрос.
> а обрабатывается он чуть ли не каждый ответ
Вроде в таверне делали опции чтобы сдвинуть историю чата от суммарайза чтобы сверху было пустое окно с постепенным заполнением до очередного упора в лимит, в эту сторону копай.
Я ещё не вкатывался в ЛЛМ. Два вопроса знатокам:
- сколько хватит места на диске для модели и библиотек? нужен уровень около гпт3, несложные задачи
- какую самую охуенную модель/и можно запустить на 16VRAM / 64 RAM / i5-14600K? для кодинга на английском и диалогов на русском или английском, не суть (это будут две разные модели, я полагаю)
- сколько хватит места на диске для модели и библиотек? нужен уровень около гпт3, несложные задачи
- какую самую охуенную модель/и можно запустить на 16VRAM / 64 RAM / i5-14600K? для кодинга на английском и диалогов на русском или английском, не суть (это будут две разные модели, я полагаю)
>завелось с 32к полного контекста
Контекст хоть полностью заполнил?
>нужен уровень около гпт3
8 гиг на лламу 3 в 8 кванте и гиг на средство запуска.
>какую самую охуенную модель/и можно запустить
Смотря сколько ждать будешь. Так хоть 123B, вполне себе влезает, хоть и впритык.
>Контекст хоть полностью заполнил?
Понятное дело. Впритык. 4BPW уже никак не влезает с таким контекстом.
>Вроде в таверне делали опции чтобы сдвинуть историю чата от суммарайза чтобы сверху было пустое окно с постепенным заполнением до очередного упора в лимит, в эту сторону копай.
Не могу найти. А хотелось бы.
>для кодинга
На проксях столько халявного гптговна, а они всё пытаются на локалках кодить, лол.
Кодинг начинается от 70б моделей, не потянет
джемма 27б и кодестраль 22б хороши в кодинге.
Не очень приятно если это коммерческий закрытый проект и твой код утекает через гпт расширение твоего ide.
Кодестраль только если в самом коде норм. При попытках получить от него объяснения соснёшь. Гемма в кодинге сосёт, хуже кодестраля или даже старкодера 15В. Если хочешь получить нормальные объяснения, то это либо лама 3.1 70В, либо мистраль 123В.
Если ты используешь локалки для кода, то такой говнокод, очевидно, нахуй никому не нужен и бесплатно. Да и куда он утекает, шиз? Максимум на нем следующую гпт обучат, но он даже близко не будет дословно в весах, нейронка впитывает принципы, а не сам код.
>Максимум на нем следующую гпт обучат
Конечно же ты не допускаешь вероятности, что код хакиры украдут?
В Китае выпустили кастомные RTX 4090D и RTX 4080 SUPER с двойным объёмом VRAM
https://4pda.to/2024/08/12/431302/v_kitae_vypustili_kastomnye_rtx_4090d_i_rtx_4080_super_s_dvojnym_obyomom_vram/
Только думал над шизоидеей что в теории можно повесить через свитчи хоть х4 х5 кол-во рам, интересно, как они реализовали.
https://4pda.to/2024/08/12/431302/v_kitae_vypustili_kastomnye_rtx_4090d_i_rtx_4080_super_s_dvojnym_obyomom_vram/
Только думал над шизоидеей что в теории можно повесить через свитчи хоть х4 х5 кол-во рам, интересно, как они реализовали.
Забавно, на 3090 можно просто поменять память на уже доступную и страдать с биосом ибо плата уже готова. Но разрабатывать кастомную плату под йоба карточку - та еще задача. Возможно взяли от А6к/А5к ада и память там другого стандарта.
Всеравно круто и хочется.
https://www.tomshardware.com/pc-components/gpus/nvidia-gaming-gpus-modded-with-2x-vram-for-ai-workloads
> The GeForce RTX 4090D 48GB and GeForce RTX 4080 Super 32GB are available for rent at AutoDL, a Chinese cloud computing provider that rents servers for AI work. Pricing is a steal. You can rent a single GeForce RTX 4080 Super 32GB for $0.03 hourly. However, the service is currently restricted to China, as you need a Chinese phone number to sign up.
Скажите, когда подобное приобрести можно будет...
>Но разрабатывать кастомную плату под йоба карточку - та еще задача.
Так-то, если готовый проект есть, заказать многослойную плату + монтаж мелочевки, совсем не сложно и стоит не так уж и много, особенно партией.
А дальше ручной монтаж питальника, разъемов, ну и чип с памятью садить в сервисах давно умеют.
Тут интересно, потому что базовые 4090D имеют все те же 24 гига памяти. Обычные картонки на двойную память прошивать не получилось, а эти прошили.
В Китае такая карта до модификаций стоит 190к в переводе на рубли. Плюс перепайка, плюс прошивка. Уверен, что тебе оно настолько нужно? Я бы скорее купил RTX6000. Три штуки за те же деньги, лол.

Вкатился. Ллама 3 летает, 8b-instruct-q8_0 уже чуть медленней, если мне не показалось. Но оказалась полной хуйней, не может даже перефразировать текст, не проебав все детали. Казалось бы куда еще проще может быть задача? Видимо, не самая простая. Стоит ожидать от 70B сильно лучших результатов? При этом говнокодит более-менее связно, хоть и всё в кучу сваливает.
Как в Visual Studio прикрутить генерацию кода? Интересует C# для Unity, с мелкими Питоновыми аппками и Windows Copilot справляется. Какие вообще есть решения, плагины? Какие юзаете? В идеале хотелось бы набросать архитектуру классов и чтобы оно пыталось их заполнить, учитывая код всего проекта. Но и чтобы можно было ебнуть короткий код по описанию - тоже было бы неплохо. Особенно хорошо, если бы оно во время написания предлагало автозаполнение, как это уже в слабой форме делал IntelliSense.
Нет денег на подписки эти ебучие.
И нет желания ебаться с поиском вечно отваливающихся гпт ключей. Если знаешь постоянные варианты, предложи.
-кун
Как в Visual Studio прикрутить генерацию кода? Интересует C# для Unity, с мелкими Питоновыми аппками и Windows Copilot справляется. Какие вообще есть решения, плагины? Какие юзаете? В идеале хотелось бы набросать архитектуру классов и чтобы оно пыталось их заполнить, учитывая код всего проекта. Но и чтобы можно было ебнуть короткий код по описанию - тоже было бы неплохо. Особенно хорошо, если бы оно во время написания предлагало автозаполнение, как это уже в слабой форме делал IntelliSense.
Нет денег на подписки эти ебучие.
И нет желания ебаться с поиском вечно отваливающихся гпт ключей. Если знаешь постоянные варианты, предложи.
-кун
У Лламы 3 с русским не очень, это тебе к Мистралям. И насчёт кодинга тоже. А вообще правильно здесь говорят - корпоративные сетки в принципе доступны, так что не еби мозги. Локалки - они для другого. И кстати это другое они уже довольно неплохо того-этого... А ведь всего год прошёл.
>А вообще правильно здесь говорят - корпоративные сетки в принципе доступны, так что не еби мозги. Локалки - они для другого.
Бесплатно разве доступны? А для чего локалки?
> MiniCPM-V is a series of end-side multimodal LLMs (MLLMs) designed for vision-language understanding. The models take image, video and text as inputs and provide high-quality text outputs.
https://github.com/OpenBMB/MiniCPM-V
https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf
https://github.com/OpenBMB/MiniCPM-V
https://huggingface.co/openbmb/MiniCPM-V-2_6-gguf
> LongWriter-glm4-9b is trained based on GLM-4-9b, and is capable of generating 10,000+ words at once. They also made a Llama 3.1 version.
https://huggingface.co/THUDM/LongWriter-glm4-9b
https://huggingface.co/THUDM/LongWriter-llama3.1-8b
https://huggingface.co/THUDM/LongWriter-glm4-9b
https://huggingface.co/THUDM/LongWriter-llama3.1-8b
> если готовый проект есть
Откуда ему взяться то? Возможно, как-то достали от А серии, но там обычная gddr6, не X. Если чип совпадает по распиновке то оно может даже встанет и как-то заведется после взлома биоса.
> Плюс перепайка, плюс прошивка
> The GeForce RTX 4090D 48GB reportedly sells for around $2,500, $685 more expensive than the vanilla
Это копейки за такую железку.
> Я бы скорее купил RTX6000. Три штуки за те же деньги, лол.
Где ты по 800$ их найдешь? 48 гиговые разумеется.
Для кодинга неплохи codestral и deepseek v2
На русском неплохо говорит mistral nemo.
Есть плагин continue.dev, но он для идейки вроде.
>В идеале хотелось бы набросать архитектуру классов и чтобы оно пыталось их заполнить, учитывая код всего проекта.
Ну это слишком влажные мечты. В (средний) контекст 8к у тебя влезет от силы 32кб кода.
>$2,500, $685 more expensive than the vanilla
На Тао стоковые дэшки по 2200 долларов, так что я не верю в ценник из статьи. Если модификация те же 700 баксов, плюс доставка, это уже 3к$+ за карту.
>Возможно, как-то достали от А серии
Хули гадать? Там платы от 3090ti, на которые пересадили чипы от дэшек.
>А для чего локалки?
Дрочить на них.
> Доступ к H100 на спейсах открыт?
Не, я по хуйне, просто модельки квантую-выкладываю, ниче такого.
Мне лень обучением заниматься, я воробушек.
Без разницы.
Справедливости ради, от обновления к обновлению, от винды к дровам, производительность немного скачет туда-сюда на паскалях.
Но я тож не подскажу, где и когда лучше.
Справедливости ради — выпускают по мелочи уже сейчас.
Но код-ревью — это ж штука не про ллм, а про код. Похуй кто пишет, код-ревьюить надо всегда. Хоть сеньор сеньора, не обосретесь, если лишний раз проверите.
Это зависит не от ллм в принципе, а от того, какая культура выстроена в компании. Никто не мешает в компании, где нет код-ревью, джуну юзать гпт и копипастить без проверки (он все равно тупее). Прод умрет? Ну, без ллм умирал, какая разница. Разберутся пост-фактум.
Неожиданно, упирается в шину?
Чип, по идее, должен обрабатывать раза в два быстрее.
гпт3 - Mistral Nemo - 12 гигов + 0,5 гига.
кодинг — Deepseek-Coder-Lite-V2 — 16 гигов.
Еще и фалькон.
Умирает уже на 1к контекста?
Плагин continue, мб?
Лламу-3 выбрось пожалуйста, не трогай эту каку.
Для вскода точно есть.
Что предпочтительней из материнских плат при прочих равных: условная плата на на чипсете z690-790 на DDR5 или на чипсете X299 DDR4 c учетом что она может работать в четырех канальном режиме, + на этом чипсете куча плат от 4 слотов и более.
Слотов PCIe

Какие слоты PCIe подойдут? У меня такие сейчас. Чувствую я уже немного соснул с еще одной видеокартой.
Или норм будет по пропускной способности?
> это уже 3к$+ за карту
И это все равно дешево.
> Там платы от 3090ti
Очепятался или диванный? У ти память с одной стороны и чипов вдвое меньше чем нужно, также как в 4090. Во вторых, покажи что чипы амперов и ады идентичны по распиновке.
> на чипсете X299
с тремя слотами на процессорных линиях, или йобу что постили выше, и 2-3-4 видеокарты воткнутых в нее. Если планируется только одна видюху то лучше новая платформа офк, но тогда лучше подождать. Может через пол года интел выкатят что-то интересное, может старшие модели амд 9к серии будут менее кринжовыми, может хуанг отсыпет врам в блеквеллах.
Если исходить из того что есть - любые, на чипсетных будет помедленнее, но при запуске ллм на экслламе разницы (почти) не будет.
На твоей пикче лучше всего будет pci_e3.
Сколько стоит щас аренда гпу и тпу? Ну чтобы хотя бы 30гб врам? С россии чтобы оплатить можно было.
>Что предпочтительней из материнских плат при прочих равных
С практической точки зрения лучше ориентироваться на две более-менее современные карты (не ниже Ampere) с 24гб ВРАМ. Это пожалуй лучший баланс на сегодня с точки зрения цена/производительность. Если 4090 подешевеют, то и вообще. Следовательно, лучше всего брать материнку на современном чипсете с двумя полноценными слотами 4-ой или 5-ой версии PCIe х 16 от процессора (хз есть ли сейчас такие процессоры и чипсеты из современных) специально заточенных под две мощных видеокарты.
Аноны, есть 12гб врам и 32 рам ддр5. Какой максимальной размерностей,с учетом квантования,можно сюда засунуть?
быстро - до 20b, медленно до 70
>Неожиданно, упирается в шину? Чип, по идее, должен обрабатывать раза в два быстрее.
Да оно бы и хрен с ним. Просто иногда срабатывает что-то вроде контекст шифта и последний кусок промпта вместе со стриминговой генерацией обрабатывается секунд за 10. Но по большей части нет - и только обработка всего контекста занимает 40 секунд, а потом ещё и генерация... Бесит ужасно. Где-то писали, что интерфейс Таверны для Убабуги перекручивает промпты, из-за чего они воспринимаются той же экслламой как полностью изменённый промпт. Может и в этом дело. А может и правда экллама в контекст шифт плохо умеет. Короче пока впечатления двойственные.
Насколько медленно? Ну вот 10 токенов в секунду, допустим.
2 токена в секунду где то
Хммм.. И это при каком квантовании?




>У ти память с одной стороны и чипов вдвое меньше чем нужно
Отака хуйня, малята. Первый пик плата от тишки FE с двусторонней памятью, второй - 3090 evga ftw3.
Почему языковые модели так резко стрельнули? Это после статьи о трансформерах?
https://www.youtube.com/watch?v=Rno97ZCKGGE
И вот типа пруф, что можно пересадить 4090 на плату от 3090. Здесь они пересадили чип 4090 на плату GALAX RTX 3090 Ti HOF OC Lab и поебать. Без шунтов вряд ли обошлись, а может, и обошлись, мне лень разбираться в этой ебанине. Технически всё реализуемо, затык до сих пор был в биосе, видимо, Китай поборол и это. Или на дэшках с этим дела проще обстоят.
И вот типа пруф, что можно пересадить 4090 на плату от 3090. Здесь они пересадили чип 4090 на плату GALAX RTX 3090 Ti HOF OC Lab и поебать. Без шунтов вряд ли обошлись, а может, и обошлись, мне лень разбираться в этой ебанине. Технически всё реализуемо, затык до сих пор был в биосе, видимо, Китай поборол и это. Или на дэшках с этим дела проще обстоят.
OpenAI выпустила коммерчески-успешный продукт, остальные побежали подражать.
>она может работать в четырех канальном режиме
Так эти 4 анала почти равны 2-х каналу DDR5, лол. А так если есть желание покупать стопку видеокарт, то бери с кучей слотов, если же чисто ради интереса, то лучше 1 плату с 1 3090/4090, на ней хоть поиграть можно.
Ебать кастрат. Впрочем сейчас все такие.
Посмотри в сторону переходников из м2 в PCI-E, будет +1 норм слот к Е3.
>Это после статьи о трансформерах?
Технически да, после 2017-го, лол.
А так это из-за попенов, они показали достойные результаты, что у всех штаны намокли.
>4090 на плату от 3090
Это всё типа для наращивания памяти? Как вообще вышло, что они по распиновке похожи? Хуанг типа так сильно обленился?
Сука, какой пидорас посоветовал Lumimaid-v0.2-12B? Говно только лупиться и умеет. Да и цензура хуже чем Stheno-v3.2.
Тебе советовали 123В, ты тройку потерял где-то.
> переходников из м2 в PCI-E
У меня не взлетела карта на этом говне. Целых два разных покупал.
>Это всё типа для наращивания памяти?
Конкретно в этом случае - для оверклокинга, на этой плате жирное питаниe. Там взяли отборную память, поставили водянку и разогнали, насколько можно. Потом подключили азот и разогнали ещё больше. На плате у них 24 гигабайта. Получилось без разгона на 13-16% быстрее, чем сток 4090.
>Хуанг типа так сильно обленился?
Ага, чем породил миллион слухов о том, что на платах 3090ti заведутся чипы AD102. Которые несколько раз опровергали, в итоге опровержения опровергли.
Интереснее всего, взломали ли биос, или он работает по дефолту, лол. От разных L40S биос не подойдёт, потому что память другая. На 20й серии можно было резистор перепаять, чтобы больше памяти завелось, как здесь - даже хуй знает, вроде нихуя не работало.
На маленьком. По весу моделек посмотри. И 2 т/с это ещё очень оптимистично учитывая что у тебя 2/3 модели в памяти висят.
Попробуй лучше Mini-Magnum, ещё захочешь, базарю!
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2. Недавно вышедшая Llama 3 в размере 70B по рейтингам LMSYS Chatbot Arena обгоняет многие старые снапшоты GPT-4 и Claude 3 Sonnet, уступая только последним версиям GPT-4, Claude 3 Opus и Gemini 1.5 Pro.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGUF и EXL2, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGUF весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/second-state/Mistral-Nemo-Instruct-2407-GGUF/blob/main/Mistral-Nemo-Instruct-2407-Q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках подходящий пресет. Для модели из инструкции выше это Mistral
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama , https://lmstudio.ai/ и прочее - Однокнопочные инструменты для полных хлебушков, с красивым гуем и ограниченным числом настроек/выбором моделей
Ссылки на модели и гайды:
https://huggingface.co/TheBloke Основной поставщик квантованных моделей под любой вкус до 1 февраля 2024 года
https://huggingface.co/LoneStriker, https://huggingface.co/mradermacher Новые поставщики квантов на замену почившему TheBloke
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://github.com/Mobile-Artificial-Intelligence/maid Запуск самой модели на телефоне
https://github.com/Vali-98/ChatterUI Фронт для телефона
https://rentry.co/lmg_models Самый полный список годных моделей
https://ayumi.m8geil.de/erp4_chatlogs/ Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard Сравнение моделей по (часто дутым) метрикам (почитать характерное обсуждение)
https://chat.lmsys.org/?leaderboard Сравнение моделей на "арене" реальными пользователями. Более честное, чем выше, но всё равно сравниваются зирошоты
https://huggingface.co/Virt-io/SillyTavern-Presets Пресеты для таверны для ролеплея
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
https://rentry.co/llm-models Актуальный список моделей от тредовичков
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: