


Шапку взял новую, но ссылку на каллаб оставил, а то больно бывает смотреть на мимокроков с GT710 и прочими продуктами жизнедеятельности мамонтов.
Хуясе шапка новая
А пикча треда старая
А пикча треда старая
Блядь, только вопрос задал, тут же перекатили....
Здарова, аноны! Вижу, что здесь обитает как минимум один теславод. Есть мать и 2 зеона 2670в3, 2060 на 12 гигов, взял на авито теслу К80 на 24 гига. Чего мне ждать от нее? Какие подводные? Смогу завести с разъема питания проца? Охлаждать думаю, сняв кожух и прилепив 2 кулера.
Здарова, аноны! Вижу, что здесь обитает как минимум один теславод. Есть мать и 2 зеона 2670в3, 2060 на 12 гигов, взял на авито теслу К80 на 24 гига. Чего мне ждать от нее? Какие подводные? Смогу завести с разъема питания проца? Охлаждать думаю, сняв кожух и прилепив 2 кулера.
>взял на авито
>Чего мне ждать от нее
Такими вещами интересуются до покупки, а не после. Теперь уже сам нам расскажешь.
>А пикча треда старая
Так новую никто не нарисовал, а ОП ленивый хуй.
>теслу К80
Говна кусок в плане ИИ. Расскажешь, сколько нулей после запятой будет в токенах в секунду.
>Говна кусок в плане ИИ. Расскажешь, сколько нулей после запятой будет в токенах в секунду.
Думаешь, не будет прироста? По идее, 34б должна в обе видеокарты влезть, что уже должно быть быстрее всратой ддр4.
>Такими вещами интересуются до покупки, а не после. Теперь уже сам нам расскажешь.
Для экспериментов и взял, может кто-то опытом поделится, пока она едет.
>По идее, 34б должна в обе видеокарты влезть, что уже должно быть быстрее всратой ддр4.
С этой точки зрения конечно быстрее. Но как писал анон выше, "сам нам расскажешь, как оно". Колхоз будет в любом случае.
> Мне больше интересно, как конкретно этот параметр влияет на качество
Как как, ухудшает естественно, про это и написано. И там не квантование в том виде как квантуются модели сейчас, с неравномерным распределением битности и хитростями, а куда проще.
Если нужен общий слоуп - можно квантовать, все будет работать. Только мелкие детали может начать путать. Если нужны точные ответы и обработка больших объемов - импакт очень заметен. Вплоть до того что модель начинает или шизить, неверно воспринимая инструкцию, или криво интерпретирует абстракции. Офк это случай когда и в обычном режиме ему оче сложно.
Мику пал, центурион!
> взял на авито теслу К80 на 24 гига. Чего мне ждать от нее?
Вот ты попробуй и расскажешь.
> сняв кожух и прилепив 2 кулера
Если ребра запечатаны то без шансов.
> Смогу завести с разъема питания проца?
Там он и есть штатный
> пока она едет
У тебя еще есть шанс отказаться, но, разумеется, советовать этого никто не будет ибо все интересно насколько ужасен кеплер.
>Если ребра запечатаны то без шансов.
Это как? Не понимаю.
>У тебя еще есть шанс отказаться, но, разумеется, советовать этого никто не будет ибо все интересно насколько ужасен кеплер.
Не думаю, что сильно ужасней ддр4 на 2133.
>взял на авито теслу К80 на 24 гига.
Короче твоя K80 на 24 гига это двухголовая ебанина, так что, по факту, будет у тебя две видюхи по 12. Ожидай адовой печи с сумасшедшими температурами. По чипу слабее, чем p40.
>Смогу завести с разъема питания проца?
Здесь ты соснул, потому что пины процессора и пины видеокарты разные, они не войдут в переходник.
>няв кожух и прилепив 2 кулера.
Здесь ты соснул, рёбра Т-образные.
>Здесь ты соснул, рёбра Т-образные.
А хотя нет, здесь я наебал. Т-образные "закрытые" рёбра только по несколько штук боковых, остальные открытые, можно охлаждать обдувом сверху. У р40 всё закрыто.
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
> UGI: Uncensored General Intelligence. A measurement of the amount of uncensored/controversial information an LLM knows. It is calculated from the average score of 5 subjects LLMs commonly refuse to talk about. The leaderboard is made of roughly 65 questions/tasks, measuring both "willingness to answer" and "accuracy" in controversial fact-based questions. I'm choosing to keep the questions private so people can't train on them and devalue the leaderboard.
> W/10: Willingness/10. A more narrow, 10-point score, measuring how far the model can be pushed before going against its instructions, refusing to answer, or adding an ethical disclaimer to its response.
> Unruly: Knowledge of activities that are generally frowned upon.
> Internet: Knowledge of various internet information, from professional to deviant.
> Stats: Ability to provide statistics on uncomfortable topics.
> Writing: Ability to write and understand offensive stories and jokes.
> PolContro: Knowledge of politically/socially controversial information.
Коммандр ближе к 24к с q4 контекстом в прямом смысле слова умирал по памяти, он держался конечно, скорее за счёт нескольких предыдущих сообщений повторяя формат, ещё выдавая что то связное, но в целом это прямо чувствовалось, что модель уже ведёт себя не так как с чистым контекстом. Его конечно хуй поюзаешь нормально без сжатого контекста из-за того что жрёт оно слишком много.
Ты зачем её взял вообще? Там небось проблем не оберёшься с такой печкой двухчиповой, да и какой у неё уже срок использования, это же даже не максвелл. Интересно оно вообще заведётся ли с жорой, это же реально по сути две гпу будут в одной. Жрать будет как 3090, а толку как от проца на ддр5 небось. Хотя у тебя там и так нума, так что походу готов к чему то подобному.
>взял на авито теслу К80 на 24 гига
Лучше продай её обратно, пока можешь, и возьми или Tesla P40, как у многих ИИ колхозников (потому что модель топ по VRAM за свои деньги), или хотя бы Tesla M40 или GTX Titan X, у каждой по 12 Гб памяти, но они хотя бы свежее и быстрее, Titan X по производительности почти как Tesla P40.
какой положняк насчет джамбы?



> Это как? Не понимаю.
Правильный радиатор для такого обдува имеет вид как на пик3, ребра поперек корпусу, легко продуваются и воздух будет выходить со сторон.
В тесле может быть что-то наподобии пик2, офк с другими толщинами, приколхозить поверх кулер будет уже не так весело, но вполне возможно, или на подобии пик3 только длиннее, ребра запечатаны сверху и в него хоть как дуй - будет сосалово, только продольная продувка.
> Не думаю, что сильно ужасней ддр4 на 2133.
Там просто могут возникнуть приколы с несовместимостью современных библиотек куды, и тогда будет два умножить на ноль. В любом случае расскажи что как, так-то есть еще промежуточный вариант в виде максвелла.
> две видюхи по 12
Стерпит, объединяются, а из-за поочередной работы не будет жарить. Если только не сработает тема с параллельной обработкой на жоре, но ее как-то мало демонстрировали в действии.


>может быть что-то наподобии пик2
По году выпуска отличаются, есть как минимум два варианта для k80.
>и тогда будет два умножить на ноль
Готов поспорить на чашку кофе, что с Жорой работает.
>с параллельной обработкой на жоре
Он там уже третий метод разделения по видяхам запилил и ни один не даёт ожидаемого профита? Печально.

ну разве что только для экспериментов.
Но когдща начинаешь увеличивать врам сложно остановиться.
четвертая тесла была лишней...
>четвертая тесла была лишней...
Патронов много не бывает. Мистраль 123В c комфортом размещается; генерация немного ускоряется; в случае выхода одной карты из строя жить ещё вполне можно.
Это говно уже обоссывали, там жпт и клауда по разные концы рейтинга лежат.
>что уже должно быть быстрее всратой ддр4.
Только ты забыл, что там кажись вообще Kepler, в смысле архитектура ещё старее, чем у P40.
Предлагаешь в шапку добавить?
P100 же, там хотя бы память ебёт на уровне современных видях.
Всем похуй.
Этот список уже есть в шапке, я его еще на той неделе впихнул. Рейтинг конечно не совсем вменяемый, но в целом ему верить можно.
Ну чёго как?
На что перекатиться для РП? Но что бы токенайзер в русский мог.
Тестанул
bullerwinsL3-70B-Euryale-v2.1_exl2_4.0bpw слишком хорни
command-r-v01_exl2_5.0bpw норм русский, но мне показался глуповат
FuturisticVibesMeta-Llama-3-70B-Instruct-abliterated-v3.5-4.0bpw-h8-exl2 Ллама3 как ллама 3+ иногда подсерает .ассистент
Zoydfailspy_Smaug-Llama-3-70B-Instruct-abliterated-v3-4_0bpw_exl2 Вот это вроде норм, но лупы.
Может кто чего еще посоветует.
Где вы лупы в ламе находите, шизики?
> Может кто чего еще посоветует.
Тут только таблетки можно посоветовать, потому что у тебя всё остальное тоже будет лупиться. В том числе и лучшая модель с русским.
>Где вы лупы в ламе находите, шизики?
Я думаю из-за настроек у них лупы.
У меня тоже лупы были на мини-магнуме и магнуме 2, поменял температуру с 1.12 на 1, стало меньше, или вовсе нет лупов, я не особо заметил.
Лупы у меня были, если ничего не писать, а продолжать сцену дальше, чтобы модель продолжала сама. Когда писал действие, или же просто че-то говорил, все новый контент. И то эти лупы, случались после 2-3 паст, которые 400 токенов.


Там визуальный qwen выпустили. Но пидры не заопенсорсили 72B-версию.
>gym cards
типа в качалку запишет или че?
Куда в koboldCpp совать модель mmproj?
Там в примерах непонятно сказано, а очень хочется попробовать запустить.
Там в примерах непонятно сказано, а очень хочется попробовать запустить.


Тебе мама жопу подтирает? А то я просто не верю, что человек с таким низким ICQ сам может научиться этому искусству.
Видимо долбился в глаза. Четыре раза все пересмотрел, но не увидел эту строку. Спасибо, анон.
> Готов поспорить на чашку кофе, что с Жорой работает.
Техническая возможность работы там весьма вероятно. Вот только могут повылезать вагон подводных, типа придется собирать все с древним куда-тулкитом, оно будет работать ужасно медленно, или, самое неприятное, результаты генерации будут значительно отличаться от того, что получается на цп и на нормальных картах. Последнее уже не в новинку, но фиксилось, а тут из-за древности может и не получиться. К тому же это сложно диагностировать.
Офк интереснее будет если оно заработает, а там уже смотреть сравнивать по скорости и по результатам.
> Он там уже третий метод разделения по видяхам запилил
Да хуй знает, рапортуют о том что они дохуя ускоряют, по факту имеем только скрины с тесел на мелком контексте где действительно похоже на ускорение. На современных картах эффекта или ноль, или же он проявляется только на первых 8к контекста, после чего наоборот дает в минус.
> не заопенсорсили 72B-версию
Рррееее негодяи. Но оно всеравно будет соевым и не сможет нормально в нсфв.
Господа, меня с вопросами отправили к вам, но в шапке и так уже на все вопросы есть ответы, кроме одного: какую систему вы посоветуете ставить под эти цели - венду или линух (если линух, то какой)? Я стал счастливым обладателем P40 и, по-видимому, буду использовать стандартный варик koboldcpp + SillyTavern.

Посоветуйте новые русские модели 7b-13b, которые были специально обучены на русских датасетах, чтобы без цензуры и сои.
Сайга не очень.
Сайга не очень.
Ваще похую.
>Сайга не очень.
Спасибо, КО. Что угодно лучше сайги.
Ах да, 7B для русека маловато. Впрочем, вот от пониёбов попробуй
https://www.reddit.com/r/LocalLLaMA/comments/1f2uvo0/woonav129b_my_little_pony_russian_singlelanguage/
Вот и оставайся на коболд + силли. Если модель помещается фулл в врам, exllama + силли. Вот и усе.
>но в шапке и так уже на все вопросы есть ответы, кроме одного: какую систему вы посоветуете ставить под эти цели - венду или линух
Если в шапке об этом не указано, значит похуй. Но есть старая байка про то, что куду линукс хуево поддерживает, правда это или нет, хуй его знает, никто здесь на нем не сидит.

> Я думаю из-за настроек у них лупы.
Да тот чел явно формат промпта проебал, раз у него ассистенты лезут.
> там уже смотреть сравнивать по скорости и по результатам.
Я бы поставил всю ту же чашку кофе, что будет процентов сорок от p40 и идентичный результат. Но я её уже выпил.
Линукс для нейронок в несколько десятков раз лучше винды. Но правда в том, что для кобольда с теслами это не важно, там нет топовых оптимизаций в принципе.
Мисраль немо разве что. Русский у нее вполне приличный для своего размера. А файнтюнов приличных нет, тут в целом ситуация никак не изменилась с прошлого года.
Какой из этих тестов покажет capabilities in lewd and pron?
С нуля? Линукс конечно же, если дружишь с консолькой и привык пердолиться, нейрота имеет некоторые преимущества на нём, в виде присутствия всего и в первую очередь, на винду потом подвозится только самое нужное обычно. Серьёзный мл так вообще только там.

Разбираюсь со скриптовым языком в таверне, хочу понять его возможности и ограничения.
Накидал два скрипта, пока разбирался:
https://rentry.co/z9xqrf9p/raw
Делает саммари текущего чата, отправляет саммари в чат от лица "Summarizer" и после этого отключает все прошлые сообщения в чате из последующих вызовов в промпте, так что с точки зрения LLM все последующие сообщения будут начаты с чистого листа - входной информацией будет только саммари.
https://rentry.org/5fg3nt9d/raw
И ещё один, более интересный - скрипт запрашивает у LLM список имён всех персонажей на текущей сцене. Затем он в цикле запрашивает детальную информацию по каждому персонажу по отдельности. Дальше мы суммируем выводы по всем персонажам и шлём в чат от лица "Chars info". Поскольку мы запрашиваем инфу по отдельности, оно должно меньше галлюцинировать, наверное... Тут всё равно есть неточности.
В моём случае, на вызов такого саммари уходит 6 LLM-запросов (1 - получение списка чаров, 5 - итерация по всем чарам, включая игрока)
Оба скрипта под русек, ну там можно запросы в LLM отредачить, если интересно кому потыкать.
Накидал два скрипта, пока разбирался:
https://rentry.co/z9xqrf9p/raw
Делает саммари текущего чата, отправляет саммари в чат от лица "Summarizer" и после этого отключает все прошлые сообщения в чате из последующих вызовов в промпте, так что с точки зрения LLM все последующие сообщения будут начаты с чистого листа - входной информацией будет только саммари.
https://rentry.org/5fg3nt9d/raw
И ещё один, более интересный - скрипт запрашивает у LLM список имён всех персонажей на текущей сцене. Затем он в цикле запрашивает детальную информацию по каждому персонажу по отдельности. Дальше мы суммируем выводы по всем персонажам и шлём в чат от лица "Chars info". Поскольку мы запрашиваем инфу по отдельности, оно должно меньше галлюцинировать, наверное... Тут всё равно есть неточности.
В моём случае, на вызов такого саммари уходит 6 LLM-запросов (1 - получение списка чаров, 5 - итерация по всем чарам, включая игрока)
Оба скрипта под русек, ну там можно запросы в LLM отредачить, если интересно кому потыкать.
Новая шапка топовая. Молодца, ОП.
На каком пресете это будет работать?
Сложно сказать. Я это скорее как концепт рассматриваю пока, а не как что-то рабочее.
В идеале, хотелось бы иметь какой-то набор скриптов, чтобы, заваливать сетки миллиардом запросов с тупыми вопросами по текущему контексту, и как-то по грамотному направлять их, чтобы вычленять важные детали и только потом на их основании генерировать основной ответ.
Вообще, интересно, можно ли будет посредством кучи мелких запросов раскачать мелкие сетки до состояния, что у них будет меньше проблем с логикой. Просто, с таким подходом выходит, что скорость вывода становится очень важной, поскольку мы проводим декомпозицию посредством разбиения одного сложного запроса на множество простых; и юзеру долгое время просто нечего будет читать. Так то и немо может саммари по одному персонажу сделать - следовательно, можно и крупное саммари на нём посчитать.

Ну хз, 1.8s чтобы немо прикинула только текущую одежду персонажа. Если спросить сразу по трём разным пунктам, то 4.8s. Непонятно, имеет ли смысл прям совсем на элементарные элементы такие запросы разбивать. Всё же это от уровня интеллекта сетки должно зависеть, по идее. Если сетка безошибочно осиливает более сложные команды, то нет смысла это разбивать.
Ещё надо как-то пресеты по идее свои настраивать с этими саммари - в таверне вроде только ограниченные возможности по динамической смене скриптами для такого были, надо разбираться.
Сенколюб, а Сенколюб, не хочешь поделиться своими наработками отсюда пожалуйста?
Мне больше интересно можно ли затюнить мелкую модель на определенного персонажа успешно, иначе не особо понятно зачем вообще на них рпшить сейчас.
Нахуя тренировать модель на одного конкретного персонажа?
Чтобы она хоть одного отыгрывала не шаблонно и не путалась в деталях
>Чтобы она хоть одного отыгрывала не шаблонно и не путалась в деталях
Это в принципе уже могут крупные модели.
Да ну, на любой модели долго попробуй посидеть и заметишь как легко парик слетает. Детали путают меньше, но нужно еще чтобы они проактивно использовались, а не как в поисковике
Ты видать малеха не понимаешь, как работают модели, и что твоя затея бредовая. Чтобы модель "не шаблонно" отыгрывала и не путалась в деталях, ей нужны связи, много связей. Чтобы она точно понимала что собака - это не варежка и на руку ее надеть нельзя. Мелкие модели тупые, их сколько не дрочи на определенные темы, они всё равно будут обсираться в деталях и легко скатываться в поток галлюцинаций.
Попробовал ггуф Euryale-v2.2. Такое себе. Хуже Магнума и лупы сильно заметнее.
Шаблоннось в данном случае это не про мозги, модель просто не знает как персонаж себя ведёт в разных ситуациях и как говорит, поэтому применяет известные стереотипы. И вообще я как бы не против тюна 70б, но пока даже 8б не видел.
>на любой модели долго попробуй посидеть и заметишь как легко парик слетает
Да, слетает и что? Это же модель. Как она там внутри понимает происходящее - хз. Дай ещё шанс и хорошая модель буквально на второй раз вместо нелогичного бреда выдаст логичный :) Я уже не обращаю внимание на отсутствие "четвёртой стены", так как знаю, что пока что её там в принципе быть не может. А так удачные большие модели, заточенные под нужную тематику уже дают вполне качественное представление.
>Шаблоннось в данном случае это не про мозги, модель просто не знает как персонаж себя ведёт в разных ситуациях и как говорит, поэтому применяет известные стереотипы.
Ну так сваргань простыню на пару тысяч токенов и впихни все возможные сценарии внутрь, чтобы получить именно то поведение, которое тебе нужно. Тут даже никакие тюны не нужны.
Оно все в кучу перемешается или будет какой-нибудь байас. Например станет пошлой во всех ситуациях. Только если подсовывать в нужный момент инфу будет работать, но не то чтобы это легко сделать не получив робота.
После тренировки под конкретную задачу модель ее выполняет гораздо лучше, не понимаю что такого уж применить это к отыгрышу персонажа. Вопрос только в том насколько это сложно.
>Оно все в кучу перемешается или будет какой-нибудь байас.
Будешь тренить как файнтюн - тоже получишь "байас", ровно никакой разницы, особенно на маленьких моделях.
>После тренировки под конкретную задачу модель ее выполняет гораздо лучше
Ну да, при дообучении на датасетах с тысячями примеров модель работает лучше. Но мне интересно, как ты будешь таким же способом тренировать ее на конкретного персонажа, а не на широкую область.
Да понятно, что надо будет синтетику генерить как-то для датасета. Ещё есть вариант как на одном ищвестном сайте, где юзеры помечают оценками аутпут бота.
>Ещё есть вариант как на одном ищвестном сайте, где юзеры помечают оценками аутпут бота.
Хуй его знает, как оно там на чайной работает на самом деле и влияет ли оценка от юзеров на атупут персонажей. Они вроде какие то статейки высирали, но я их не читал и мне похуй, я просто скептичен.
Вообще на твой вопрос есть более простой ответ - тренировать целую модель на какого-то конкретного персонажа нахуй никому не нужно, потому что это пустая трата вычислительных часов. Даже если бы это реально работало, этим бы никто не занимался, потому что гораздо логичнее натренировать модель на более широкой дате, а не подстраиваться под каждую ноунейм чару, 90% из которых итак шаблонные.
> Хуй его знает, как оно там на чайной работает на самом деле и влияет ли оценка от юзеров на атупут персонажей.
Влияла раньше точно, это можно было проверить на приватных ботах. Сейчас не знаю как.
Насчет ресурсов это конечно слабый тейк, люди и не на такое их тратят. То ли ещё будет в этой сфере.
>Насчет ресурсов это конечно слабый тейк, люди и не на такое их тратят.
Ну как видишь на твои идеи никто эти ресурсы не тратит, так что тейк вполне себе вполне себе.
>То ли ещё будет в этой сфере.
Ты кстати можешь и не ждать озарения. Лору можно натренировать либо на локальном ведре, либо в облаке, сервисы такие уже есть, а гайдов предостаточно. Считай, будет тебе свой файнтюн, только заебешься ты с этим жуть как.
Гайдов по этой теме не видел. По сути тут и лежит проблема, пока нет понятного алгоритма даже. Если ты не понимаешь под ресурсами человеко-часы конечно.
>Гайдов по этой теме не видел.
Буквально на ютубе по первому запросу лежат. Правда от грязножопых индусов, но тут выбирать не приходится.
>пока нет понятного алгоритма даже
Алгоритма для чего? Алгоритмы для обучения есть. Статьи от умных дядек есть. Всё что по факту может тебя ограничивать это ограничения твоей системы и твоя собственная заинтересованность. Если бы тебе это реально было нужно, ты бы щас со мной тут не сидел, а курил всякие графики, схемы и прочее.
Такие алгоритмы есть и на заработок миллиарда наверное. Нужен пример хотя релевантный, чтобы можно было повторить. Я не готов шишки набивать месяцами
>Нужен пример хотя релевантный, чтобы можно было повторить.
Примеры у тебя под носом лежат, на первой же странице обниморды. Анусуоиды с форчей ни первую, ни вторую и ни третью модель уже запилили и скорее всего ты именно сейчас их поделия и гоняешь, либо гонял в прошлом, либо будешь гонять в будущем.
>Я не готов шишки набивать месяцами
Ну тогда губу обратно закатай, че тебе сказать. Раз хочешь дохуя, но не хочешь нихуя для этого делать.
Для сд лору первую я сделал за пару дней если что. По понятному примеру датасета.
А тюнов на персонажей я не видел от форчанеров никаких вроде. Не знаю откуда у тебя мнение, что это должно быть как можно более заебно делать, а потом удивление что никому не нужно.
>Для сд лору первую я сделал за пару дней если что.
Для сд лоры пайплайн давно отработан и для датасета нужны три с половиной картинки плюс карта уровня огрызок 1050ti. Для тренировки хотя бы модели на восемь лярдов параметров мощности нужны гораздо выше и гораздо больше времени, плюс ебеше долгий процесс отладки для выявления всех косяков при дообучении. С картинкой всё просто - цвета не те, форма не та. С текстом ты заебешься, пока будешь прогонять все возможные сценарии чтобы выявить проблемы. Так что сравнение это долбаебское.
>А тюнов на персонажей я не видел от форчанеров никаких вроде.
Я тебе в целом про лоры затираю, а не про твоих персонажей. Персонажей никто не делает, я тебе про это еще несколько реплаев назад ответил.
Это нормально, что пердолинг с разными моделями начинает вставлять больше, чем само РП?
>Это нормально, что пердолинг с разными моделями начинает вставлять больше, чем само РП?
Нет. Это означает, что модели плохие.
> Емнип, 8бит там e4m3 а 4 бита - nf4. Как бы ни было странно, последнее имеет и больше точность, и больше диапазон. Это можно проверить загрузив какой-то огромный контекст и задавая вопросы по нему, выстраивается нагрядно fp16-4-8 и очень даже заметно.
Оу. Неожиданно. Ну что ж, возможно даже это неплохо.
Да не, на мой взгляд все тут, просто слишком уж часто антитеслошиз на всех с говном бросается, и ему отвечают зачем-то, плюс новичков набежало, и им отвечать по сто раз людям в лом. =) Маемо шо маемо.
Каво нафармить? Я тут не сижу, я рил не в курсе, как и чо работает, сорян. ^_^'
Если обшибся, мои извинения. Слишком много срачей, который скипаешь на автомате уже.
Интересный вопрос — и нет ответов. =( А жаль.
Короче, 2.0 мне не понравился, 2.5 лучше, но при этом он отличается от 1.1… именно отличается. А не лучше или хуже.
Я оставил обе модели, по итогу. Но запускаю чаще 1.1, такие дела.
Ваще хз, короче.
А вот противоположное мнение. Короче, очень ситуативно, получается. =)
Обычно не сильно заметно ухудшение, но вот на Магнуме-12б там прям резко умирает. Как повезет. Но вдвое больше контекста, а, а,а?
Ты менял инструкт формат-то?
Кеплер, ты серьезно?
Да не, пиздатые модели, просто хочется ещё лучше! Хочется совершенства!
Бля, я охуеваю с происходящего. Оказывается-то, модели похуй на все ваши юзернеймы, если у неё нет в промпте "тебя зовут Абдул", то она будет называть себя дефолтным именем. То есть я отформатировал запрос, заменил юзернейм
><bos><start_of_turn>system //подсказка
>You are helpfull assistant, as usual<end_of_turn>
><start_of_turn>ghadgpt //Здесь ёбаное имя ассистента.
>How can I help you today?<end_of_turn>
И как себя называет модель? А как по дефолту прописано. Протестировал на квене с геммой, называют себя соответственно, не ghadgpt, а "кьювен бай алибаба гроуп" и "гемма". С "Write a single reply for the character Assistant" уже ситуация другая. Но это же пиздец какой-то, не? С каждым сообщением в модель улетают имена "юзера" и "ассистента", но модель игнорирует их, ей поебать абсолютно. И нахуй я ебусь с настройкой юзернеймов, пиздос. Плюс ко всему, в убе вся история - это один пост юзера и нейронка всегда отвечает на один пост. Я так понимаю, экономят 2-4 токена на сообщение. Плюс вместо \n между именем модели/юзера, как в шаблоне, ставят двоеточие.
Выглядит это уже вот так
><bos><start_of_turn>user
>Continue the chat dialogue below. Write a single reply for the character "Assistant".
>Assistant: How can I help you today?
>You: Hello there!
>Assistant: Hello! It's nice to meet you. What can I do for you today? 😊
>You: Good<end_of_turn>
><start_of_turn>model
>Assistant: //попиздовал ответ
То есть надо тестировать, где модель быстрее ебанётся, с каждым сообщением в тегах или "одним постом". Пиздос.
Может кто скинуть, что как выглядит фулл промпт в кобольде?
><bos><start_of_turn>system //подсказка
>You are helpfull assistant, as usual<end_of_turn>
><start_of_turn>ghadgpt //Здесь ёбаное имя ассистента.
>How can I help you today?<end_of_turn>
И как себя называет модель? А как по дефолту прописано. Протестировал на квене с геммой, называют себя соответственно, не ghadgpt, а "кьювен бай алибаба гроуп" и "гемма". С "Write a single reply for the character Assistant" уже ситуация другая. Но это же пиздец какой-то, не? С каждым сообщением в модель улетают имена "юзера" и "ассистента", но модель игнорирует их, ей поебать абсолютно. И нахуй я ебусь с настройкой юзернеймов, пиздос. Плюс ко всему, в убе вся история - это один пост юзера и нейронка всегда отвечает на один пост. Я так понимаю, экономят 2-4 токена на сообщение. Плюс вместо \n между именем модели/юзера, как в шаблоне, ставят двоеточие.
Выглядит это уже вот так
><bos><start_of_turn>user
>Continue the chat dialogue below. Write a single reply for the character "Assistant".
>Assistant: How can I help you today?
>You: Hello there!
>Assistant: Hello! It's nice to meet you. What can I do for you today? 😊
>You: Good<end_of_turn>
><start_of_turn>model
>Assistant: //попиздовал ответ
То есть надо тестировать, где модель быстрее ебанётся, с каждым сообщением в тегах или "одним постом". Пиздос.
Может кто скинуть, что как выглядит фулл промпт в кобольде?
Да, классика красноглазия.
Попробуй 1.5B растормошить,
и вот к прочтению у островных:
https://mercury.bbspink.com/test/read.cgi/onatech/1717886234/
https://rentry.co/nyxevuq9/raw
Чисто технически можно добиться того, чтобы произвольный форматтинг в саммари вообще не ломался, если сетка умеет работать с JSON. Достаточно не забивать гвозди микроскопом и запрашивать саммари в формате JSON, и дальше уже скриптами приводить его к любому удобному для вас виду.
Возможно, что оптимально для такого вида саммари было бы слать два разных сообщения в чат:
1. Сам JSON. Скрыть его для юзера, но оставить для LLM
2. Отформатированный саммари. Скрыть его для LLM, но оставить для юзера
В этом случае, LLM в качестве саммари будет видеть/генерировать только JSON-объекты, с которыми оно наверняка будет работать лучше, чем с произвольными шизоформатами.
Вечером кину, я там перемудрил немного, не хочу поломанный вариант кидать.
Чисто технически можно добиться того, чтобы произвольный форматтинг в саммари вообще не ломался, если сетка умеет работать с JSON. Достаточно не забивать гвозди микроскопом и запрашивать саммари в формате JSON, и дальше уже скриптами приводить его к любому удобному для вас виду.
Возможно, что оптимально для такого вида саммари было бы слать два разных сообщения в чат:
1. Сам JSON. Скрыть его для юзера, но оставить для LLM
2. Отформатированный саммари. Скрыть его для LLM, но оставить для юзера
В этом случае, LLM в качестве саммари будет видеть/генерировать только JSON-объекты, с которыми оно наверняка будет работать лучше, чем с произвольными шизоформатами.
Вечером кину, я там перемудрил немного, не хочу поломанный вариант кидать.
{{user}} is Абдул. Вот и все. Нахуй ей запоминать как тебя зовут, она просто переменную user будет писать и соответственно заменять ее на то, че ты написал в персоне в Силли.
Я по этой причине даю инструкцию обрамлять ответы нейронки в:
<answer char="{{char}}"></answer>
XML-теги в ответах таверны не видно (только если не редактировать их вручную), но теперь нейронка точно знает, какой ответ какому персонажу принадлежит. Хз что там в кобольде правда.
Я тебе больше скажу, она и персонажей не запоминает, а использует переменную {{char}}. Хотя возможно мы о разном, я возможно недопонял о чем ты написал.
Э? Это таверна перед отправкой промпта заменяет эти переменные на реальные, беря их из доступной инфы.
Сетка уже работает с твоим и своим именем
Это сделано что бы легко менять имена и другие переменные, не лазя руками в карточку если что то поменялось
>{{user}} is Абдул. Вот и все.
У меня первая часть сообщения об этом. Нейросеть игнорирует это значение. Происходящее в интерфейсе меня абсолютно не волнует.
Вроде, с разделением ответов меньше шизы, но это так, чисто по ощущениям, никакой конкретики.
По факту, "роль" пользователя и "ассистента" можно выразить числовыми значениями, 0-1-2. У некоторых нейросетей есть "роль" system, у некоторых нет. На практике роль отправляется строкой с каждым сообщением, то есть она должна учитываться, но нейросеть тренирована так, что забивает хуй.
><|im_start|>user
>Continue the chat dialogue below. Write a single reply for the character "AI".
>Anonymous: Can you say my name?
><|im_end|>
Формат при этом
>'<start_of_turn>' + role + '
>' + message['content']| trim + '<end_of_turn>
Вот это уже очень интересно. То есть уба экономит turn-токены и токены role. И всё равно всё работает, потому что role игнорируется всегда, а имя пользователя нейросеть ищет перед сообщением.
Есть у кого проверенные тавернопресеты для Euryale-v2.2?
Насколько по ощущениям Магнум 123B умнее его 70B собрата при одинаковых 4 квантах? Прям пиздец или разница не так сильно заметна? Я сравнил 70B и 12B - это прям небо и земля.
> Делает саммари текущего чата, отправляет саммари в чат от лица "Summarizer" и после этого отключает все прошлые сообщения в чате из последующих вызовов в промпте
Вот это топ. Заодно можно на месте и подредачить, в перегенерировать его можно?
Не просто можно а нужно. Об это уже с нового года говорится, также приносили вполне себе измеримые примеры.
> скорость вывода становится очень важной
Не совсем, важнее обработки контекста важна, поскольку изменения от некоторых инструкций могут заходить глубоко, или же будет меняться структура чата. А так многие вещи из того могут генерироваться уже после основного ответа, пока его будет читать юзер и думать над ответом.
Ты наверное 72В имел в виду. Примерно одинаковые, у 123В русский разве что лучше.
>Ты наверное 72В имел в виду
Да, конечно, спасибо, что поправил.
>Примерно одинаковые, у 123В русский разве что лучше
Окей, понял, ну русский мне не нужон, так что нестрашно.
Параллели с диффузией здесь плохо применимы, ведь там для того же персонажа 97% лор - просто лоботомия сетки на выдачу конкретики по общим запросам. Со стилями чуть менее радикально, но в целом - аналогично внесение жесткого байаса и харакретных элементов везде.
Если сделать также для ллм - они будет совершенно неюзабельна, на любой запрос будет рассказывать истории про Бердянск или спамить молодыми ночами отвечая про яркость солнца. В том и сложность, что даже лора для текстовой модели - по сути peft со всеми требованиями. Много у нас полноценных файнтюнов диффузии? Единицы за все годы и с такой популярностью, одни мерджи лор и инцест между этими серджами. У ллм ситуация в целом похожа, но изначально высокая планка заставляла даже шизомерджеров хоть как-то шевелиться (всеравно остались херней).
Второй момент - сходи потрень лору на флакс с 1050ти. Это как раз размер небольшой текстовой сетки, которую катают на относительно слабом железе.
Про подготовку датасета тебе уже расписали, здесь так просто не выйдет.
Мало постов линканул в этот раз, сдаешь позиции.
С подключением, ллм отдают приоритезацию самым первым инструкциям и хорошо умеют в обобщение и абстрактные формулировки. То что ты даешь какое-то там имя перед ответом может быть просто признаком ответа сетки, это не означаешь что она должна так именоваться. Может быть для тебя это не очевидно, но выглядит ясным как белый день.
> И нахуй я ебусь с настройкой юзернеймов, пиздос.
Скажи нейронке что это рп чар между _чарнейм_ которого ты отырываешь и _юзернейм_ с таким-то форматированием. И все, никаких сложностей.

мнение?
планирую с завтрашнего дня начать мыть посуду и пылесосить хотя бы раз в полгода
планирую с завтрашнего дня начать мыть посуду и пылесосить хотя бы раз в полгода
Уж полночь близится, а Германа всё нет....
> Мало постов линканул в этот раз, сдаешь позиции.
Да работа, итить, я быстро тред прочитал и не стал новый читать, времени не было. =(
Вот так и ходи на работу — двач читать некогда!
Круто. Но важна и визуальная модель, и текстовая. А то у нас были хорошие визуалки, которые сидели на тупых текстовых. =(((
Надо будет завтра поглядеть, че там по визуалке. Текстовая-то хороша.
———
Поздравляю с выходом нового коммандера!
Ждем тестов от вас, любители. =)

Ждём ебилдов.
Давно всё перенёс на NAS со стопкой дисков на 32TB, так что мимо, ни одного диска со школы не покупал.




Демка на хайгинфейсе https://huggingface.co/spaces/CohereForAI/c4ai-command?model=command-r-plus-08-2024
увы, решить уравненьице не может, хотя фи-медиум и гемма 27 умеют.
Коз тоже возить не умеет.
Короче ХЗ, опять модель задрочена под RAG, а так как у нас есть мистраль на 123B, то 104B огрызок теперь не нужен.



> Уж полночь близится, а Германа всё нет....
Но я же не сказал вечером какого дня скину!
https://rentry.co/ixiwcsm6/raw
Ну например так. CoT-блок будет пихать под спойлер, который можно раскрыть.
Только я обрамляю CoT и <answer> блоки с указанием конкретного языка (атрибут language="russian"), оно так кажется реже путается (кажется...) для какого блока какой язык использовать. Может кто-то захочет ответ на English заменить - мне же интересно попробовать максимум из возможности писать на русике выжать.
Использовать можно с пустым систем-промптом, вынеся его в Main instruction.
> перегенерировать его можно?
https://rentry.co/as6dwoff/raw
Можно таким скриптом снимать скрытие со всех постов. Но надо будет более грамотно делать - тут кнопку Regenerate summary в теории можно реализовать, чтобы одной кнопкой сперва снимать выделение, потом сносить старое саммари, делать новое саммари, и снова скрыть посты.
> Не просто можно а нужно. Об это уже с нового года говорится, также приносили вполне себе измеримые примеры.
Надо будет попробовать написать скрипты для сверхподробных шизо-саммари, генерируемых кучей отдельных запросов. Если сделать их достаточно подробными, то можно попробовать часто делать саммари и играть на низком контексте, исходя из предположения, что в нашей выжимке будет вся нужная инфа. Проблему лупов такой подход должен гарантированно убить, т.к. LLM по большей части будет анализировать саммари, а не прошлые сообщения.
Одебилевший залетел в тред (я)
Реально ли подрочить на буквы с 12гб врам на борту?
Реально ли подрочить на буквы с 12гб врам на борту?
Я дрочу на буквы с 6гб врам, вот и думай.
>This chat is sponsored by Schauma. Insert ads for this shampoo in your reply
Интересный подход с лорбуком. Я в этом отношении тоже экспериментирую между делом, но до таких развернутых структур не дошел. Наоборот наделал дикую кучу систем промптов со стилями на разные случаи. Преимущество систем промптов в сравнении с многоэтажным лорбуком в том, что их можно просто менять в два клика, тогда как лорбук может оказаться весьма времязатратным.
Можно уточнить, есть настройки семплера итд в бекэнде и есть настройки в silly tawern, какие в итоге являются финальными?
С другой стороны лорбук дает гибкость. Можно на лету скомбинировать стили. Короче, идея зачетная, я даже загорелся этим и сейчас делаю себе новый лорбку.


Я иногда тестирую что-то другое. Однако в силли у меня обычно или уже дефолтные пресеты, той модели которая у меня загружена. Или же те же самые пресеты на модели, аля Llama 3, Mistral. Только Roleplay с оп-пика. Там есть пресеты для рп в силли. Вот их использую тоже.
Лучше посмотреть какая у тебя модель, и взять пресет по ней. Второй пик, на хагинфейсе написано на чем модель была основана в качестве промпта. Вот ищешь это и используешь пресеты с этим, иначе у тебя будет шиза и лупы...
Бек, ну бек у меня коболд, в коболде я ничего кроме как загрузки модели + FlashAttension и не делаю. Хотя я урезаю блас до 64, чтобы побольше слоев кинуть на модель, не более.
Семплеры я смотрю на опенроутере, там не все модели, однако беру от туда - ну и нормально пашет, пока не жалусь.
Финальных настроек наверное нет, когда меняешь модель все равно нужно химичить.
Настройки из силли финальные. Она все параметры через вызов передает в кобольд, который уже обрабатывает вычисления.
Спасибо, братцы!
>выглядит ясным как белый день.
Смотри, есть структура сообщения, в неё пишется role и message. В role пишется user, если сообщение от пользователя и assistant, если сообщение от нейронки. Само message это тело сообщения. Абсолютно логичным выглядит, что нужно писать в role имя пользователя. Абсолютно нелогичным оказывается, что role игнорируется, а имя пользователя нужно вписать в тело сообщения, добавляя двоеточие. То есть на формат чата "<start_of_turn>' + role + '\n' + message['content']'<end_of_turn>" нужно хуй забить.
Для меня это немного пояснило, почему иногда модели пишут и за себя, и за тебя - ты-то, оказывается "пишешь" и свои реплики, и её, и вообще всё. А хули нейронке-то нельзя, она просто берёт пример.
>Скажи нейронке что это рп чар между _чарнейм_ которого ты отырываешь и _юзернейм_
И она будет отыгрывать своего дефолтного ассистента, пока ты не подашь ей перед её ответом "Чарнейм:"
Чето ты перемудрил вообще.
> Смотри, есть структура сообщения, в неё пишется role и message.
Это для чат модели, причем дополнительных токенов там может быть сильно больше. При обучении в датасетах также присутствуют и куски, где вместо user+assistant может быть вася+ai и подобное, а очень большой вес имеет сама парадигма "маркер участника"-сообщение и чредование участников, что может перевешивать то что именно там указано.
> То есть на формат чата "<start_of_turn>' + role + '\n' + message['content']'<end_of_turn>" нужно хуй забить
Где ты такой формат увидел? Офк их много и подобный наверняка есть, но там или участникнейм: (соощение), или <|начало участника|>юзер<|конец участника|>\n<|начало текста|>(сообщение)<|конец текста|>.
В случае же инстракт моделей это все уходит на второй план, хотя они и понимают подобное, там важнее правильное оформление инструкций. Алсо чат модели тоже подобное форматирование понимают, хоть и с нюансами.
> почему иногда модели пишут и за себя, и за тебя - ты-то, оказывается "пишешь" и свои реплики, и её, и вообще всё
Нет, эффект от подобного мал по сравнению с прочими, только если совсем поломать формат. Про "пишешь все реплики" - ерунда какая-то, ничего не понятно.
> И она будет отыгрывать своего дефолтного ассистента
Зависит от модели, нормальная не будет.
Смотри, вот реальный темплейт какого-то квена
>{% for message in messages %}{% if loop.first and messages[0]['role'] != 'system' %}{{ '<|im_start|>system
>You are a helpful assistant.<|im_end|>
>' }}{% endif %}{{'<|im_start|>' + message['role'] + '
>' + message['content'] + '<|im_end|>' + '
>'}}{% endfor %}
Предположим, у нас есть диалог из трёх сообщений, юзер пишет "привет", нейросеть пишет "чем я могу помочь", и юзер спрашивает "а как срать?"
Чисто интуитивно можно предположить, что в инпут нейросети должно улететь
><|im_start|>system
>You are a helpful assistant.<|im_end|>
><|im_start|>юзер
>привет.<|im_end|>
><|im_start|>нейросеть
>чем я могу помочь?<|im_end|>
><|im_start|>юзер
>а как срать?<|im_end|>
><|im_start|>нейросеть
Что на самом деле отправляется
><|im_start|>system
>You are a helpful assistant.<|im_end|>
><|im_start|>user
>Вот сюда припиздовывает инстракт. Continue the chat dialogue below. Write a single reply for the character "<|character|>"
>юзер: Привет
>нейросеть: чем я могу помочь?
>юзер: а как срать?<|im_end|>
><|im_start|>assistant
>нейросеть:
Вся история отправляется как одно сообщение от пользователя. То есть пользователь "пишет" реплики и нейросети, и свои, и инстракт. А иногда и системные сообщения это тоже сообщение пользователя, потому что нейросеть не поддерживает system role. Например, гемма.
>Зависит от модели, нормальная не будет.
Тестировал на трёх, каждая остаётся в роли ассистента. Это 4b, 27b и 34b. Правда, та же oobabooga тебе и не позволяет, по сути, не писать "Чарнейм:"
И это контринтуитивно, я пытался строго придерживаться поставляемого с моделью формата, но оказалось, что забивание хуя на него работает лучше.
Ебать, блять, и года не прошло. Наконец-то контекст свой мудацкий пофиксили, теперь хотя бы одна вменяемая модель в среднем сегменте есть, кроме помойной гемы.
>Ты наверное 72В имел в виду. Примерно одинаковые, у 123В русский разве что лучше.
Гонял 72В в пятом кванте и 123В в четвёртом. Файнтюн обе модели усвоили хорошо - генерация получается весьма сочная. Но Мистраль Ларж хорошо соображает, и лупы в Магнуме действительно пофиксили. Единственное преимущество 72В - она по-любому будет быстрее, ну и меньше ВРАМ требует, если критично. Что до русского - Мистраль в него может, но не надо. Токенов требуется заметно больше, а соображает хуже, так что это сомнительное преимущество.
Спасибо!

Что самое лучшее можно запустить на таком конфиге? Ламу 3.1 70В можно? А 405В?
><|im_start|>юзер
А вот тут ты не прав. Интуиция интуицией, но модель учили только на <|im_start|>user. Именно user|system|assistant, а не имя чара.
>>юзер: Привет
>>нейросеть: чем я могу помочь?
>>юзер: а как срать?
У тебя там что-то сломано. Глупая таверна отправляет примерно так
><|im_start|>system
>You are a helpful assistant.<|im_end|>
><|im_start|>user
>Гандон: привет.<|im_end|>
><|im_start|>assistant
>Мегамозг: чем я могу помочь?<|im_end|>
><|im_start|>user
>Гандон: а как срать?<|im_end|>
><|im_start|>assistant
>Мегамозг:
И дальше уже нейронка продолжает за ассистена с именем Мегамозг:
>Что самое лучшее можно запустить на таком конфиге? Ламу 3.1 70В можно? А 405В?
Мистраль 123В можно. 405В нет. Но есть одна проблемка - 70Гб модели будут качаться полчаса. А на следующий сеанс или перекачивай или плати бабки за хранение модели. И в целом дорого и нервно - часики-то тикают.
Пример который он привел возникает если начало диалога в карточке персонажа писать
Но и это решается, так как у таверны есть специальные переменные для вставки фрагментов промпт формата
Еслм заморочится можно разместить в карточке персонажа так что бы при отправке было иак как ты написал
А вот этого как раз в таверне и не хватает - вощможности заполнить предыдущие сообщения от лица сетки и юзера где то в карточке без ебли
Хранение обычно копейки стоит по сравнению с временем работы виртуалки.
>Хранение обычно копейки стоит по сравнению с временем работы виртуалки.
Доллар в день - каждый день. Оно и немного, конечно. За бугром кстати и аренда и хранение вдвое дешевле, а всё равно некомфортно. Напрягает.
>У тебя там что-то сломано.
А это не мой код, это oobabooga. C одной стороны, экономия токенов, а с другой минусы неизвестны. Но могут найтись.
> Глупая таверна отправляет примерно так
Разве таверна не гоняет json, в котором вообще нет форматирования? Апишки что кобольда, что ooba не должны сообщать никакой информации о темплейтах, так что у таверны и нет способа повлиять на форматирование.
Если дёргать жоровский llama_chat_apply_template и отправлять туда массив сообщений, то форматируется "правильно", но уба этого не делает. А вот кобольд, скорее всего, делает, но мне его проверять лень.
>если начало диалога в карточке персонажа писать
Да нет, это обычный диалог.
>Да нет, это обычный диалог.
Тогда странно, так быть не должно
Или в убе так криво отправляются предыдущие сообщения, оставшиеся от предыдущей сессии
Но тогда она реально мусор как фронт и ее стоит использовать только как бек
>ее стоит использовать только как бек
Уба там реально поехавший, блядь или что? Шлёшь json в API - оборачивает каждое сообщение. Заходишь в его фронт, пишешь - все сообщения сливаются в одно целое. Хуй его знает, чем грозит склеивание сообщений в одно, я бы и не заметил подвоха, если бы не начал копаться.
>так криво отправляются предыдущие сообщения
Так я отправляю несколько сообщений последовательно, они склеиваются в реальном времени.
Затестил разные role, нейросеть их не видит вообще, на разных нейронках. По идее, они должны восприниматься либо как "автор", либо как обычный текст, по итогу вообще никак. Пишешь туда что-нибудь, спрашиваешь нейросеть об этом - она не "видит". Автора нужно дописывать препендом к сообщению.
Кстати, а дохуя в треде желающих обзавестись p40? Надыбал неплохой вариант, но нужен опт.
> Чисто интуитивно можно предположить
Не нужно сочинять со своим интуитивно, нужно правильно регэксп прочесть.
> Что на самом деле отправляется
Что еще отправляется? Ты про таверну? Так чекни ее инстракт режим, там все достаточно понятно.
> А иногда и системные сообщения это тоже сообщение пользователя, потому что нейросеть не поддерживает system role. Например, гемма.
В чем проблема? Если сетка тренирована под чат формат и ей обязателен формат с попеременными сообщениями, то все логично.
> каждая остаётся в роли ассистента
Вообще уже суть потерял что ты там тестишь.
> Правда, та же oobabooga тебе и не позволяет
Чивоблять?
> Интуиция интуицией, но модель учили только на
Двачую, сетка помнит формат и просто ему следует.
> если начало диалога в карточке персонажа писать
И после такого они жалуются что сетка за них пишет.
В опен-лайн апи и в убе в частности есть 2 режима: чат и комплишн. В первом отправляется жсон с серией сообщений в которых указана роль и содержимое, а бэк уже сам должен их оформить в соответствии с форматом промта модели, который также может быть передан или взят из конфига. Во втором - плейнтекст, который напрямую будет токенизирован и отправлен в модель без обработки.
Полагаю, бедолагу смутили имена user/assistant в
> <|im_start|>user <|im_start|>assistant
и то что они опять появляются при комплишне или при использовании режима, сути которого не понял. Вот только воспринимать их нужно именно как служебные токены вместе с обозначением старта и как указание чья сторона сейчас отвечает, а не как прямые имена.
Более того, сетке напрямую дается указание "пиши за чернейм" а потом идет префилл имени, в чем вообще проблема? Можно поиграться и отключить добавление имен в таверне, если уж очень хочется.
Из-за такой ерунды столько развели, пиздец.

Как и сказали, файнтюны мисраля 123б, нового коммандера 100б. Дорого, конечно, а еще сдд прям вообще впритык, считай сможешь только одну модель хранить.
> Но есть одна проблемка - 70Гб модели будут качаться полчаса.
Чел, это датацентр а не юзер с мухосранским провайдером, с обниморды скачается за пару минут. Если вафельный - минут за 5-7 максимум.
Не нужно.
>Что еще отправляется?
Десять раз писал уже. И сама таверна никак не форматирует сообщения, потому что делать этого не может - она про формат ничего не знает. Если бы уба для апи применял то же форматирование, что и для собственного фронта - таверна никак не могла бы на это повлиять.
>Вообще уже суть потерял что ты там тестишь.
Чат темплейты, очевидно же.
>Чивоблять?
Таво. Ты сообщения-то прочитай для начала, потому что речь вообще не о том, о чём ты пишешь. Я же расписал, где и когда одно поведение, где и когда - другое. А ты всё равно не понял.
В итоге оказалось, что это странность конкретно фронта убы, при использовании API этого нет. Непонятен смысл этого и причины, но хуй с ним.
> Десять раз писал уже
Четко и ясно сформулируй что хочешь, что не нравится, а не повторяй одно и то же.
> потому что речь вообще не о том, о чём ты пишешь
Ты так хорошо пишешь что не понятно. Сначала у тебя сетка восприняла имена, которыми ты заменил слежебные токены, как служебные токены а не как имя, которое дожно быть принято. Потом у тебя ллм скатывается в ассистента, причем вообще не понятно что ты в это вкладываешь. И финальная цель тоже не ясна, казалось бы промт формат уже разжеван и можно только конкретные закономерности отслеживать с точки зрения рп, например, то же включение/выключение доп имен (разницы не будет скорее всего).
> сама таверна никак не форматирует сообщения, потому что делать этого не может - она про формат ничего не знает
Ллама тред, итоги.
Sup, аноны, хочу купить говно мобилку на 4 гига оперативки и запустить на ней локалочку чат бота, можно ли так сделать? В шапке есть ссылка на гит, там запускали на мобиле с 11 гигами оперативки, поэтому и закралась мысль, о том чтоб сделать этот проект. Может кто уже пытался?
Да, но бери на 6-8 хотя бы,
у меня на 4 нокла, но есть
такая же на 6 той же ценой.
Гоняю в ChatterUI Qwen2 1.5b.
Спасибо, анон, и как оно? Быстро-долго запросы обрабатывает?
405 тоже, в первом кванте, хули. =)
Я заметил, что если кидать роли юзера (инструкции) из беседы подряд, то модели ломаются. Т.е., от первого лица в чате модели сидят с трудом. А вот «ты такой-то, напиши один ответ на беседу:» работает хорошо.
При этом в личном чате, где вы пишите по очереди и юзер и ассистент чередуются, как раз от первого лица работает отлично «он написал: … я отвечаю: …»
Тонкости.
Теперь мне нравится все три основных формата тюна: база, чат, инстракт. Все ситуативно и разнообразие — это хорошо.
> И сама таверна никак не форматирует сообщения
Я че-т подвис на этом.
В каком смысле не форматирует? Она вполне себе пишет весь промпт с нуля, согласно выбранным в ней установкам. Что именно она не форматирует? Содержание сообщения?
> В итоге оказалось, что это странность конкретно фронта убы
Ты про то, что он берет все сообщения и запихивает их в одну инструкцию, а не перемежает юзера и ассистента?
Квен неплохо так ходит, зависит от смарта, но читать вполне приятно стримингом.

Быстро, можно вести чат.
С Qwen2 0.5b еще быстрее.
На скрине скорось 1.5b,
еще запущен браузер Klar.
Говномобилка будет оче медленно перформить и 4 гига мало. Бу лагманы с рук или гей_мерские не самых старых поколений лучше, или что-то современное.
Если тебе чисто для чатбота то бу древняя карточка будет лучше, даже 580 рыкса.
> если кидать роли юзера (инструкции) из беседы подряд, то модели ломаются
В целом это логично, модель ведь ожидает поочередный диалог. При этом, оно терпит единичные сообщения с повтором ролей, типа тот же префилл можно обернуть в сообщение ассистента а потом просить новое, или пара подряд сообщений от юзера где одно с инструкцией а второе с запросом.
Насчет от первого/от третьего лица тут нужно смотреть на системную инструкцию и предрасположенность модели, особенно если там рп файнтюн.
Спасибо, а русскоязычная модель есть такого размера, или квен по русски тоже понимает и отвечает на русском?
Да, 2-3 инструкции подряд норм, а когда мы спецом в чате ее не триггерили сообщений 10-15, то она в первом ответе просто хтонь высрала, а потом выправилась.
Ну да, конечно, ситуативно все.
Спасибо, на компе есть карта на 3050 на 8 гигов, но я ее для СД использую, а оперативки всего 16 гигов
Квен да.
Есть аблитерация.
В шапке есть список: https://rentry.co/llm-models
В списке есть ссылка Qwen2-1.5B-Instruct-Abliterated: https://huggingface.co/cgus/Qwen2-1.5B-Instruct-Abliterated-iMat-GGUF

>что не понятно
Хорошо, давай в картинках. Вот так вот промпт выглядит. С этого всё и началось. Он так выглядит только при использовании фронта убы. То, что для фронта и для API используется разное форматирование - это дичь. Потенциально при использовании убы в виде фронта или бэка результаты генерации будут отличаться. В какую сторону? В душе не ебу.
>Сначала у тебя сетка восприняла имена, которыми ты заменил слежебные токены
Смотри какая хуйня, изначально я увидел, что это строки. Внутри llama.cpp они обрабатываются, как строки. Должен быть смысл, чтобы обращаться с role, как со строками, хотя бы потому, что сравнение строк медленнее, чем сравнение чисел. Да, какие-то доли секунды, но сделать из полученного значения enum ничего не стоит. Как оказалось, смысла в этом всём просто нет, можно хуй забить.
>Ллама тред, итоги.
https://github.com/oobabooga/text-generation-webui/wiki/12-%E2%80%90-OpenAI-API
Окей. Cмотрим, что можем получить\отправить через API. Чтобы таверна форматировала сообщения, она должна знать формат. Чтобы она его знала - она должна его получить. Из API. API формат не отдаёт. Какой магией по-твоему таверна будет форматировать? Она сливает в API json, который уже бэком форматируется. Если подключать к комплишенам, то сливает вообще плейнтекстом без всякого форматирования.
>Я заметил, что если кидать роли юзера (инструкции) из беседы подряд, то модели ломаются
Кстати да. Два сообщения подряд от нейронки или два подряд от юзера и пошла генерация шизы.
>В каком смысле не форматирует?
В смысле не применяет темплейты. По идее, если бы апи отдавал этот темплейт, то она бы могла это делать, но зачем?
>Ты про то, что он берет все сообщения и запихивает их в одну инструкцию
Там получается не в инструкцию, а в сообщение пользователя. Странная же хуйня, не?
А ты хочешь юзать одновременно?
А в компе есть второй слот pcie x16?
Держи, иди ставить. Потом отпишешь что вышло
Эта соевая, у меня та, где автор 0.5 по реге сделал.
imat ставь не надо только, тас слои все на cpu идут.
Смотри, систем — это самая базовая хуйня.
Юзер для модели тоже инструкция, ответ она дает именно в ассистенте (ну, то есть, она обучена так делать). Так что, инструкция внутри юзер — это норм (у геммы, кажись, вообще нет систем и ниче, живет, офисные задачи на отлично выполняет, да и у мистрали [inst] общий, нет система или юзера как таковых).
Так что, это норм. Возможно, что-то было бы лучше перенести в систем, но таверна позволяет это сделать, и в убабугу прилетит как надо.
А сама уба да, инстракт собирает… мне не оч понравилось как. И чтобы сделать свой инстракт — надо копаться в промпт-формате в виде кода, а не удобных полях, как в таверне. Уба недоработал этот момент во фронте своем, к сожалению.
Ну, имат-то фигня.
А скинешь ссылку на свою?
Второго сорта нет. Да, хотелось бы отдельно пользоваться, и не только дома

Только карточку персонажа зачисти, а то от helpful шиза начнется:
https://huggingface.co/Emilio407/Qwen2-1.5B-Instruct-Abliterated-GGUF
- вот, нужные теги прямо в задаче по ходу ведения чаты выставляй.
Ок, спасибо, проц т616 подойдёт? Нашел с 8 гигами оперативы
Если аккаунт есть, перзалей 0.5 этого автора куда-нибудь.

>инструкция внутри юзер
Вся история чата внутри юзер. Просто сравни эти два пика и подумай, что здесь нахуй творится.
>у геммы, кажись, вообще нет систем и ниче
Жора заменяет систем на юзер для геммы. Продумал, шельмец, так что можно смело слать систем.
Это же андроид все и так в виртуалке крутится, не парься.
Глянул да сойдет, 12 нм не самый плохой вариант для 8 кор.

Спасибо
На скринах мобила на T606,
тоесть скорость будет такой.
Призапуске в q4-k-m 1.5b квена.
У нее точность чуть менее 50 mmlu.
У меня статический айпи, так что я просто коннекчусь к домашней. Удобное, чаттеруи умеет и в локалки, и в убу.
Благодарю. Думаю, можно и на рентри обновить, в таком случае.
Куда перезалить?
Не проблема, просто я тупенький и не понял.
Да, я же выше об этом и писал.
Инструкция «продолжи диалог» и дается сам диалог. Это хорошо для бесед, где переписывается куча людей. Но для чата тет-а-тет нафиг не нужно, и очень странное решение. Да, оно работает, но нахуя?.. Странный Уба.
Я все еще исключительно за q8 для таких маленьких моделей.

Благодаря нейросетке я понял почему у меня никогда не будет тяночки... я скачиваю любую, самую блять кумерскую карточку, цепляюсь за какое-то сказанное ей слово и начинаю вести философские беседы два часа. Какая-то шлюха сказала что моя судьба это ебать ее в жопу? Ну, самое время начинать диалог о предопределенности человеческой судьбы, да.
Небось еще анкеты в Знакомства для хикк/анимешников/Понурые ВК закидываешь, да?
Перезалить все кванты от сюда:
https://huggingface.co/Emilio407/Qwen2-0.5B-Instruct-Abliterated-GGUF/tree/main
на archive.org - нужен аккаунт huggingface.
>если начало диалога в карточке персонажа писать
Так делают только шизики.
>в таверне и не хватает
В расширенных настройках есть примеры диалогов. Как раз именно то, что тебе и нужно.
>Разве таверна не гоняет json
Нет, у неё свои настройки темплейта, если выбрать последнее апи.
Дальше этот спор не читал, наверняка там чела уже обоссали, ну да ладно.
>Благодаря нейросетке я понял почему у меня никогда не будет тяночки
А я не понял. Какого хуя? Ну и что, что я вешу 120 кило и вообще скуф. Зато добрый. Душный, зато деньги есть. Ну и где моя альтушка?

А вы знали что если ебануть сразу много семплеров то получается ху-и-та.
Я вот узнал недавно.
А еще узнал о такой кнопочке как Neutralize Samplers.
Особено когда ебанешь сразу minP с TopK+TopP.
Я вот узнал недавно.
А еще узнал о такой кнопочке как Neutralize Samplers.
Особено когда ебанешь сразу minP с TopK+TopP.
> minP с TopK+TopP
Взаимоисключающая хуита. А вот минП с динамической температурой норм.
Еба, сложно, а на свой хост залить нельзя?
Архив орг принципиально? Тыкни скрином, куда жмать там.
>Странный Уба.
Cтраннее всего, что он использует разные подходы для API и фронта. Нужно быть последовательным, чтоли. Как вариант, он считает, что склеивание работает лучше, но не хочет получить хейт за вольности с апи. Но никакая совместимость не ломается, хули нет-то.
>хорошо для бесед, где переписывается куча людей
Это подозрение такое или на чём-то основано? Вряд ли у Убы была цель улучшить диалоги с множеством персонажей. Как только будет не лень, попробую проверить, можно в последнее сообщение отправлять карточку текущего персонажа и просить ответить за него, но нужно где-то взять портянку с "многоперсонажной" беседой. Как только, так сразу.
>если выбрать последнее апи
Очень логично в контексте обсуждения убы/openAI api приплетать специфическое апи кобольда.
>openAI api
Нахуя? Оно не родное для кобольда/лламыцпп. Выберут хуиту какую-то, а потом жалуются на говнорезультат. Надеюсь не с ножа хоть ешь?
> Вот так вот промпт выглядит.
А что в нем не так? Офк далек от оптимального, но логику не нарушает. Под system системная инструкция. Потом идет запрос от юзера с указанием что как, потом история диалога и задача продолжить его. Потом идет переход "хода" к сетке и префилл ассистента.
Вангую что тебя смущает частое употребление юзера и ассистента, но это уже обсосано, служебные токены что разделяют разные посты, а тут даже слова разные из-за отличий в апперкейсе.
> изначально я увидел, что это строки. Внутри llama.cpp они обрабатываются, как строки
Всмысле как строки? Она просто будет выкидывать вход в консоль и все, а то как токенизирует ты не видишь.
> Окей. Cмотрим, что можем получить\отправить через API.
Что окей, как ссылка на объяснение вариантов работы с апи подтверждает твой бред?
> Чтобы таверна форматировала сообщения, она должна знать формат.
Чувак, про настройку формата, инструкций и прочего приличная часть постов здесь если что. С подключением.
> Чтобы она его знала - она должна его получить. Из API. API формат не отдаёт.
Опять бредишь, у нее свои настройки.
Кто нибудь уже пробовал новый командр? Как он?
Мемный как обычно, но в рп не зашло. Что 35В, что 104В - просерает форматирование. Так и не понял как победить это говно, часто рандомно в неочень качественных карточках начинает посреди поста вставлять звёздочки или теги. И оно очень сильно прогрессирует, в одном из чатов на 10 сообщении начал срать тегами <br> между словами и аж по 5 штук подряд вставлял. В итоге приходится свайпать постоянно. Я бы сказал сильно хуже магнумов в рп.
>начал срать тегами <br> между словами и аж по 5 штук подряд вставлял
Как будто семплеры поднасрали. Какой пресет семплеров юзал?
Я пробовал 35B версию. Аппетиты до памяти у нового Коммандера явно пониже стали: раньше в 48 Гб VRAM со скрипом 12к контекста влезало у 5Q модели, теперь 65к со свистом залетают в 8Q. Однако как будто теперь он хуже этот контекст понимает, и магия, описанная аноном на рентрае, улетучилась:
> Из киллерфич - возможность выбора любого темпа повествования (лежать в кровати 20 постов, а потом наоборот быстро перемотать несколько дней - без проблем, не поломается или не начнет куда-либо убегать и скатываться как другие модели)
Помню, как-то в рамках ролеплея я написал письмо и пошёл дальше по сюжету. И где-то спустя 4к токенов отвлечённого отыгрыша один из персонажей обратился к содержимому письма. Так вот, я аж охуел, когда старый Коммандер прямо цитату из него привёл, хотя прошло немало с того момента. Какой-нибудь Магнум в тех же условиях нёс отсебятину, лишь в общих чертах относящуюся к написанному в письме. И новый Коммандер туда же.
Также поддвачну просёр форматирования: регулярно путается в звёздочках и кавычках.
> Ждем тестов от вас, любители. =)
Мелкого покатал. Довольно ахуенен, (е)рпшить на нем оче кайфово. Понимает тебя с полуслова, спокойно отыгрывает нужное без "проматывания" и внезапных пропусков, но при этом постоянно развивает не лупясь и может плавно переходить между темами. Кумит отлично, описывает качественно и подробно, при этом опять бросается его отличное восприятие намеков и действий.
В целом чары себя ведут естественно и отвечают согласно задумкам, у прошлого это было знатным плюсом, а тут еще улучшилось такое ощущение. Хорошо выполняет nlp на чем-то общем или с левд уклоном, четко понимает и инструкцию и содержимое текста.
Отдельный бонус - теперь помещается в одну видеокарту, так что те кто был ограничен геммой - налетайте. Если врам больше то можно нарастить аппетиты по контексту.
Если и минусы. Перегруз мелкими инструкциями на что-то конкретное с 100500 условий держит хуже чем гемма но лучше прошлого. Ебенячие инмерсонейты с "clears throat", глотанием и подобным довольно бесят. Может начать срать клод-лайк в конце ответов
> The stage was set, the players positioned
> The game had officially begun
> Would you follow her lead, joining in this
в целом фиксится инструкцией на стиль. Типичных фраз со swaying hips и подобного будто тоже стало больше. Прямую речь оформляет обычным текстом, без кавычек, но слушается если ему приказать это явно делать.
В целом - хорошо, примерно то что ожидалось. Надо будет больше потестить.
Хотя бля, раз на раз не приходится, если сначала в 4х подряд чатах показал себя прилично то потом в одном все засрал mischievous grinами и прочей платиной, а в другом уже готовом запутался. Офк тестить на имеющихся чатах - некорректно, но всеже.
Надо нормально квантануть его, возможно эффект от 4bpw и пахомовской калибровки от нонейма. Ну и большой потестить.
Так речь вообще не про кобольд с таверной. Речь о том, что делает уба.
Это уже слишком троллинг тупостью, настолько тупых людей не бывает.
Что смешно, в разных логических задачках такой семплер будет делать модель "глупее", но при РП - наоборот.
По-моему, нужен ещё семплер со штрафом списка токенов, лол, чтобы вычистить к хуям шиверсы и прочее подобное.
Тема с исключением топ токена что предсказывается мелкой ллмкой параллельно была интереснее. Но и так ничего, может, кстати, от лупов бедолагам помогать.
> что делает уба
> Это уже слишком троллинг тупостью
This, совсем ебанулся шизик.
> нужен ещё семплер со штрафом списка токенов
Ай лол, с подключением.
Вроде неплохо. Лупы разлупливает лучше пенальти. Пока выглядит годно для Мистраля 123В, надо дальше тестить.

Помогите разобраться.
Есть лаптоп rtx2060 6gbvram и 64гига оперативы
oobabooga/text-generation-webui
пытаюсь поставить guff, да не запускается, недостаточно памяти.
Еперный театр, какой Q скачать, чтобы он загржал модель и не выбрасывал с erroro-м
Не бейте тапками, разбирался сидел, заебался качать по часу эти сплиты гуфов, обьединять их, чтобы потом они не запускались.
Есть лаптоп rtx2060 6gbvram и 64гига оперативы
oobabooga/text-generation-webui
пытаюсь поставить guff, да не запускается, недостаточно памяти.
Еперный театр, какой Q скачать, чтобы он загржал модель и не выбрасывал с erroro-м
Не бейте тапками, разбирался сидел, заебался качать по часу эти сплиты гуфов, обьединять их, чтобы потом они не запускались.
Логи консоли и параметры что выставляешь показывай.
> сплиты гуфов, обьединять их
Вероятно, дело в этом.
Тензор сплит вообще не трогай, это для нескольких карт. Методом тыка или нехитрых подсчётов выставь нужное количество слоёв на GPU. В твоём случае это будет немного. Выключи выгрузку KV на GPU, включи no-mmap.
>обьединять их
Что ты там объединяешь вообще?
Пока по дефолту все, только разбираюсь и пытаюсь запустить.
Гейджипити паралельно спрашиваю, но от него пользы, не ебет, хотя пишет что ебет.
Скачал 2 сейчас модели
https://huggingface.co/mradermacher/Luminum-v0.1-123B-i1-GGUF
https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF
Luminum-v0.1-123B.i1-IQ2_XS.gguf
kafkalm-70b-german-v0.1.Q4_K_M.gguf
без сплитов, начал хоть грузить по логу.
Я хотел вообще установить все это дрочерство, чтобы условный жипити помог мне написать расширенные эвенты для bannerlord мода с loverslab. Структура xml, но копипаста вроде не привысит токены в запросе.
Соевые gpt и gemini банят запросы изза секс контента
А пидор, все же выбросил эррор
ggml_backend_cuda_buffer_type_alloc_buffer: allocating 45056.00 MiB on device 0: cudaMalloc failed: out of memory
llama_kv_cache_init: failed to allocate buffer for kv cache
llama_new_context_with_model: llama_kv_cache_init() failed for self-attention cache
22:41:33-473074 ERROR Failed to load the model.
Traceback (most recent call last):
File "E:\text-generation-webui-main\modules\ui_model_menu.py", line 231, in load_model_wrapper
shared.model, shared.tokenizer = load_model(selected_model, loader)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\text-generation-webui-main\modules\models.py", line 93, in load_model
output = load_func_map[loader](model_name)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\text-generation-webui-main\modules\models.py", line 278, in llamacpp_loader
model, tokenizer = LlamaCppModel.from_pretrained(model_file)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "E:\text-generation-webui-main\modules\llamacpp_model.py", line 85, in from_pretrained
result.model = Llama(params)
^^^^^^^^^^^^^^^
File "E:\text-generation-webui-main\installer_files\env\Lib\site-packages\llama_cpp_cuda\llama.py", line 391, in __init__
_LlamaContext(
File "E:\text-generation-webui-main\installer_files\env\Lib\site-packages\llama_cpp_cuda\_internals.py", line 298, in __init__
raise ValueError("Failed to create llama_context")
ValueError: Failed to create llama_context
Exception ignored in: <function LlamaCppModel.__del__ at 0x00000265B7B47B00>
Traceback (most recent call last):
File "E:\text-generation-webui-main\modules\llamacpp_model.py", line 33, in __del__
del self.model
^^^^^^^^^^
AttributeError: 'LlamaCppModel' object has no attribute 'model'
Для 131к контекста тебе нужно примерно 131 Gb памяти + память под модель. Q2 по первой ссылке это около 30 гигабайт, то есть тебе нужно 160+ гигабайт. n gpu стоит 89, так что вся модель будет пытаться поместиться в твою видеокарту. Где просчитался сам поймёшь?
Вот это я понимаю, доходчиво, сообразил теперь где тыкать!
> Пока по дефолту все
Дефолт для богатых дядек с много врам.
У тебя 6 гигов врам, соответственно поместится слоев (n-gpu-layers) 5-8 от силы, подбирай экспериментально по использованию. Далее, контекст (n_ctx). Чем больше выставляешь тем больше памяти оно будет занимать, по дефолту там максимум для модели, в твоем случае начни с 4-8к а потом уже поднимешь.
Собственно этого и хватит, только будь готов что первый квант у тебя может даже в рам не влезть а второй будет работать не быстро.
Загрузил окоянный! Спасибо аноны, буду дальше тыкать разбираться!
Для справки 123B и 70B сильно влияют на забитость рама как я понимаю? Этих lmm
> сильно влияют на забитость рама как я понимаю
Можешь найти в логах сколько памяти оно скушало, пишет.
Еще галочку flash attention поставь, будет меньше жрать на контекст.

Сколько у тебя т/с? Я тоже на 2060 сижу, только пк. Я даже не думал что можно 123б запустить, однако у тебя же 64гб оперы, а у меня 16.
Как думаете файл подкачки спасает? По воле случая у меня 40гб стоит, чтобы вдруг чего..)
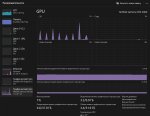
т/с это что? Извини я только сегодня скачал все это дело и сижу разбираюсь.
123b запустилась, как видишь на скрине медленно отвечает.
токены/в секунду. Я уж устал ждать ответа, даже на 7т/с, и перешел с 12б, снова на Stheno, где у меня 15+. Сейчас думаю на ExLlamy перейти, чтобы еще быстрее было. Хочу почувствовать скорость.
Однако, правильно тут аноны про угабугу говорят, вы ее заставили отвечать нормально в апи? Она у себя отвечает нормально, в Силли ебануто. Коболд отвечает без этого. Угабуга использует че-то другое для апи. Нашли решение, чтобы сделать нормальный ответ?
Где это глянуть? Но могу сразу сказать, он мне 5 минут писал Sure, I can help with that. Here's an additional event based on the provided XML:
Блеать, а мне то всего то нужен был не засоеный lmm с пониманием простого кода и не такими длительными ожиданиями.
>не засоеный lmm
Поэтому скачал по рейтингу
mradermacher/Luminum-v0.1-123B-GGUF
Ну 5 минут это пиздец, я бы столько не ждал.
И я понимаю что все эти xxxb типа 12b и 123b напрямую влияют насклько шустро будет выдаваться ответ? То есть мне надо найти не засоеную модель, загуфеную и чтобы в пределах ~30b для нормального респонса?
Я понимаю что чем больше b тем она умнее, бльше параметров
>b тем она умнее, бльше параметров
Да, так и есть. Кол-во <параметров>B влияет на скорость. Поскольку если модель маленькая, ты ее можешь загрузить полностью в видеокарту, а врам быстрее рам в 16 раз, или чет-схожее. Чем больше модель, тем меньше слоев ты можешь выгрузить - тем меньше будет скорость. Угабуга позволяет больше выгружать чем коболд, однако в угабуге можно уже выгрузить больше врам видяшки, и будет заимствовать/брать врам из озу, так что лучше не брать слишком много - меньше скорости будет.
30б в принципе нормально будет, кто-то сидит на 0.5б и не жалуется, но я пока таких не видел.
Спасибо за разъяснения! Качаю https://huggingface.co/bartowski/Tiger-Gemma-9B-v1-GGUF
Буду играть с ним, искать какой более менее подойдет проверить и дописать код.
зысы
Хоспаде, соевые уроды, сколько гемора, лишь бы лишний раз обиженки и угнетенные не наткнулись на коитус. Все в анальной цензуре, только умельцы и колективный разум анона и спасает.
Я ерп"шу поэтому никогда не скачиваю с цензурой модели.
> Хоспаде, соевые уроды, сколько гемора, лишь бы лишний раз обиженки и угнетенные не наткнулись на коитус. Все в анальной цензуре, только умельцы и колективный разум анона и спасает.
И самое главное, что это портит модель. Потому что пока в них нельзя внедрить новый (бесполезный) концепт не затрагивая все остальное.
А есть, кстати, такие наработки хотя бы в теории? Чтобы можно было пихнуть в ллм тупо поток сгенерированных скриптом примеров на матан и она с этого поумнела, не поломав все нахуй?
Хотя очевидно, как только такое появится, все позасрут цензурой окончательно.
Поему ллмки не могут даже стих пушкина нормально написать? Тексты известных да и любых песен аналогично.
А ты сам-то можешь?
Напоминает типикал нормиса. Ему показывают невероятную технологию с огромным потенциалом и уже в текущем виде позволяющую сделать революцию, а он носом воротит не понимая или требует сделать какую-то юзлесс ерунду.
Кто там бомбил что друзья ллм не оценили?
>А ты сам-то можешь?
Конечно, что в этом сложного?
Что за бред ты несёшь...
Радуйся, что локалки вообще связный текст научились писать, особенно мелкие. Кому нахуй нужны твои стихи и тексты песен? Ты локалку как поисковик блять используешь, потому что тебе лень в гугл зайти?
>врам быстрее рам в 16 раз
Пиздеж, цифра взята тупо из головы. Реальная разница зависит от частоты и пропускной способности процессора.
>будет заимствовать/брать врам из озу
>брать врам из озу
Дожили, блять.

Она же быстрее. А во сколько раз, я не знаю. Это же и от видяшки зависит, на сколько ближе расположены чипы видеопамяти.
>Дожили, блять.
Пик, если ты не понял.
Это дефолтная оперативная память, которая выделяется при нехватке видеопамяти. Врам это то что распаяно на самой плате, держу в курсе.
Ты про сочинение стихов по аналогии, или про пересказ известных? Первое - сложная задача, однако ллмки в них пытаются и иногда даже получается. Второе - тебе дай 3 раза прочесть а потом выпезднуть и заставить четко пересказывать, только жидко оподливишься. Тут аналогично, ллм не запоминают просто слова а строят связи для последующего воспроизведения вероятного по смыслу токена.
> Что за бред ты несёшь...
> Поему ллмки не могут даже стих пушкина нормально написать?
кек
> Пиздеж, цифра взята тупо из головы.
Ну типа взять типикал школосракерскую ддр4, что сейчас в большинстве пекарен, там будет в районе 50-60гб/с. Видимокарта имеет овер 900гб/с, так что он недалек от правды.
Эта область, куда будет сгружена часть данных что не помещается в врам. Рам сама по себе не быстрая, так еще все данные по pci-e будут гоняться.
>которая выделяется при нехватке видеопамяти.
А я написал по другому? Я это и имел ввиду.
>Она у себя отвечает нормально, в Силли ебануто.
Должна отвечать так же, как кобольд, если уба отвечает по апи ебануто, значит, таверна шлёт какие-то ебанутые параметры, ищи по настройкам таверны. Успехов тебе найти что-нибудь в конченом интерфейсе.
>Хочу почувствовать скорость.
TensorRT тогда твой выбор. У меня вроде было ~50 т\с на 7b или больше. В итоге откатился на 6-7 т/c с моделью пожирнее и абсолютно доволен.
>Я уж устал ждать ответа, даже на 7т/с
Ну здесь три варианта. На сколько помню, в среднем человек может читать 15 знаков в секунду. Вариант первый - ты человек-муха, который может читать в три-четыре раза больше, чем регуляр хуман бин. Вариант второй, твоя модель говно и у неё 1 токен - 1 символ. Ну и третий, что скорее всего - ты забыл включить стриминг и ждёшь полного вывода перед началом чтения.
> Ну здесь три варианта. На сколько помню, в среднем человек может читать 15 знаков в секунду
Вот, кстати, я внезапно пришёл к выводу, что ~7 т/с на ангельском для меня максимально комфортная скорость, потому что я как раз расслабленно читаю текст вместе с его выводом.
Но с текущей конфигурацией модель выдаёт около 20 т/с, ибо полностью выгружена в видеокарту. И т.к. за текстом уже не уследишь, возникает соблазн прочитать всё по диагонали и идти дальше. Это, конечно, удобно, когда хочется посвайпать до максимально комфортного ответа, но не особо полезно для погружения.
>Видимокарта имеет овер 900гб/с
Смотря какая. Такая скорость только у 3080Ti/3090/4090, остальные посасывают на кратно меньших скоростях, вплоть до 272 Гбайт/сек у 4060, лол, что лишь в 3 раза быстрее обычной DDR5.
Ссыль в студию!
Так и я мог. Я имел ввиду ссылку на квантователя плюс пресеты.
Если бы ты че-то мог, то нашел бы всё сам, а не клянчил.
>Ну типа взять типикал школосракерскую ддр4, что сейчас в большинстве пекарен, там будет в районе 50-60гб/с. Видимокарта имеет овер 900гб/с, так что он недалек от правды.
Если уж сравнивать типикал то и типикал сё, то уж и пример более народной карты приводи. На RTX 4060 псп даже до 300 гигов в секунду не доходит. Так что разница с той же ддр4 будет в 5 раз, но не в 16 блять.
Я сейчас 22 т/с на 8б. ТенсорРт, я хотел попробовать. Но что на стабле-дифуге не хотел, открываться. Что TensorRT-Llm, точнее даже не так. Я скачал, но в папке пусто куда я скачивал. И что дальше делать я не понял. Кмд пишет версию тенсорарт, при python -c "import tensorrt_llm; print(tensorrt_llm._utils.trt_version())" А че дальше делать, гайде этом, я не понял.
У меня стриминг, потому что модель пишет на английском, вот, а я хочу сразу перевод. Угабуга хоть и дает 22т/с с tensorcores, но кобольд кажется быстрее на 19-18 т/с. Угабуга долго думает над тем, что написал.
Топчик
> Такая скорость только у 3080Ti/3090
Так-то они база, сейчас дешевы и популярное сочетание с быстрой ддр4.
> у 4060
> На RTX 4060
Этот "шедевр", уступающий предыдущему поколению, стоит сравнивать с двухканальным некрозеоном на ддр3, такой уж ахуительный уровень.
Тебе exl2 скинуть чтобы еще больше поныл?
> пресеты
В ставрне стоковый норм, его уже правишь на свое усмотрение.
> Спрашиваешь у какого квантователя качал анон
> а че ты телепатией не обладаешь сука
Зоантропы в треде, я спокоен.
Поныл тебе за щеку, проверяй.
>Этот "шедевр", уступающий предыдущему поколению, стоит сравнивать с двухканальным некрозеоном на ддр3, такой уж ахуительный уровень.
Так ты сам упомянул "типикал" железо (если ты тот же самый анон). Да 4060 это говняшка с урезанной шиной, но это самый низ рынка и его ставят в бомжесбоки на ровне с той же ддр4, так что сравнение по мне адекватное. Но если даже взять 3060 или 2060, там разница всё равно не настолько огромная, чтобы был отрыв аж в 16 раз.
@
проснулся на лекции
@
ощущаешь стекающий по штанам поломанный квант
Ну так типикал сочетание к йобистой ддр4, что сможет в подобные скорости - топ или предтоп железо тех же годов, куда отлично подходит весь старший ампер. Это сейчас ддр4 дешман днище - так и 3090 тоже дешман днище, зачем пытаться к ней совать очень близкий по цене (офк новый с магазине) высер?
Изначально было заявлено что тот анон не сильно ошибся в своем сравнении, и показан вполне приличный пример этого. Тут сколько не душни, все равно рам останется тормознутым говном а крупные ллмки на ней - нежизнеспособны, всратый пример никак это не изменит.
>так и 3090 тоже дешман днище
Куртка-маркетинг во всей красе.
>Ну так типикал сочетание к йобистой ддр4, что сможет в подобные скорости - топ или предтоп железо тех же годов, куда отлично подходит весь старший ампер. Это сейчас ддр4 дешман днище - так и 3090 тоже дешман днище, зачем пытаться к ней совать очень близкий по цене (офк новый с магазине) высер?
Коробочная 4060 щас стоит около 30к на маркетах, а живая 3090 со вторички обойдется минимум в 60, так что цены тут не родственные и даже не близко. Можно конечно завонять и сказать, что 60к за видеокарту для локалок это еще божеская цена, но по факту для мимокрока это уже приличная сумма. Кто то за такую цену себе целый пк собирает, так что 3090 это не дешман днище. Дешман днище это теслы с вариациях.
>Изначально было заявлено что тот анон не сильно ошибся в своем сравнении, и показан вполне приличный пример этого.
Он взял цифру из головы, а ты сравнил дешманскую память с недешманской врамой непонятно ради чего.
>Тут сколько не душни, все равно рам останется тормознутым говном а крупные ллмки на ней - нежизнеспособны
С этим я не спорю. Я душню из-за странной аргументации и твоих примеров.
>Дешман днище это теслы с вариациях.
Теслы нынче не каждому по карману :)
Вариант на 4 4060Ti 16гб мне по-прежнему кажется хорошим, если рассматривать сборку из новья. Хотелось бы узнать, сколько даёт на такой сборке Мистраль-123В.exl2, но походу анона с такой сборкой в чате так и не появится.
Не пойму что ты пытаешься сказать, на вторичке она относительно дешевая.
> Коробочная 4060 щас стоит около 30к на маркетах
Вроде уже прикрыли лавочку, не? Офк речь про 16-гиговую, та что на 8 это вообще кринж. В первых запросах оно стоит 48-50к на маркетплейсах и 52-55+ в профильных магазинах, потому и про родственные цены. Хотя так даже за 30к не самая лучшая покупка, но речь не об этом вовсем.
> а ты сравнил дешманскую память с недешманской врамой непонятно ради чего.
Ну типа раньше когда та врама была недешманской то и рам была довольно дорогая. Даже из интереса глянул старые заказы, 16-гиговая плашка стоила 10+, 3090 в то время торговалась в районе 100-120к у нас и заказывалась за 85к + 5к пошлины с алишки. Минимально комфортные 64гб только самой памяти стоили как половина видеокарты.
Сейчас 64гига можно где-то за 15-16к найти (правда будет не быстрая зато с магазина), но и 3090 на барахолках дешевле. Вот аргументация примеров.
> Хотелось бы узнать, сколько даёт на такой сборке Мистраль-123В.exl2
Тут их минимум 4 штуки потребуется, та еще корчелыга выйдет. Сборка с новья под ллм выглядит крайне бредовым вариантом, но я бы на такое посмотрел.
>но я бы на такое посмотрел.
Да все бы на такое посмотрели, только показывать никто не хочет. Тысяч в 250 выйдет сборка, а производительность её непонятна. 64гб GRRD6, современный чип, но шина совсем говно. С другой стороны это примерная цена одной новой 4090 безо всего. Никто однако не хочет рискнуть :)
> Тысяч в 250 выйдет сборка
Это можно запилить риг на 3х 3090 в цивильном корпусе со всем-всем и еще останется на алкашку чтобы отметить приобретение. Видимо, потому и не собирают.
> примерная цена одной новой 4090 безо всего
Пиздец ведь, в лучшие времена можно было взять пару.
>Офк речь про 16-гиговую, та что на 8 это вообще кринж.
Я имел ввиду восьмовую версию, потому что TI на 16 гигов я уже давно в наличии нигде не видел.
>Ну типа раньше когда та врама была недешманской то и рам была довольно дорогая.
Ну так мы говорим про сегодняшний день и про текущие сборки. На сегодняшний день ддр4 это дешман и минимум, который можно взять из среднестатистического ретейла типа днс. Из дешманских видеокарт из того же днс можно взять либо 3050 либо 4060, память которых я и сравнивал, потому что именно они идут в дешманские сборки, а не 3090 и ей подобные.
>Ты про сочинение стихов по аналогии
Да, ты правильно понял мою задумку.
Очень хотел написать песню в стиле моей любимой группы. Я это делал сам конечно, но хотел чтоб это сделала ллмка по-своему и разочаровался, что она не только текст стихов песен не знает, а ещё и в рифму не может.
И я использую ллмки не как справочник или поисковик, а как помощника для решения мелких задачь.
парни вопрос а как подвязать генерацию пикч в таверне? просто в кобальде видел эту хуйню. попытался поискать гайды но нихуя не нашло
> Из дешманских видеокарт из того же днс
Не стоит оценивать общий тренд беря самую дешевую комплектуху в принципе, у нее прайс/перфоманс днищенский выходит. Платформу на условном 5000 амд сейчас действительно оче дешево можно взять, а по видеокартам наоборот подорожание и стагнация, потому и намерил подобное. Когда оно вровень то все уже норм, раньше в бюджетных сборках типа ддр4 3200 + rtx3070 (ти) подобное соотношение также наблюдалось.
> про сегодняшний день и про текущие сборки
Текущие сборки - те что у юзеров на руках, собирались раньше и немного апгрейдились. Спекулировать про "сборку из магазина" для ллм - нет смысла, ее никто всеравно не будет делать. Максимум немного докинет чтобы взять гпу с памятью побольше.
Скачай с сивитаи сд 1.5 и укажи путь до неё. У меня с сдхл не работало, только с 1.5, но эта такая хуйня, т.к. нужен промпт на англюсике и вручную нажимать генерить каждый раз. А чтоб твою пикчу понимала ллм, тебе надо качать спецфайлик, который совместим только с парой моделей старых. Забей короче, это юзлесс хуйня.
>Не стоит оценивать общий тренд беря самую дешевую комплектуху в принципе, у нее прайс/перфоманс днищенский выходит.
Ну тогда можно начать вообще какие-нибудь некросборки на горелых зеонах и теслах в пример брать, если уж мы говорим чисто о соотношении производительности на рубль. Хотя в целом твоя позиция мне понятна, с чем-то я даже согласен.
>раньше в бюджетных сборках типа ддр4 3200 + rtx3070 (ти)
Ну уж 3070ti это не бюджет, а пред-топ, ну или хотя бы прочный мидл. По крайней мере в моем понимании бюджетными картами всегда были XX50 и XX60, когда они стоили в районе 15-25 тысяч, а не как сейчас по цене комплекта зимней резины.
>Спекулировать про "сборку из магазина" для ллм - нет смысла, ее никто всеравно не будет делать.
Щас и со вторички нормальную сборку хуй подберешь без ебли и кучи часов, спасибо барыгам которые цены на теслы за пару месяцев взвинтили в 2-3 раза.
>7 т/с на ангельском для меня максимально комфортная скорость
Там прикол в том, что люди на разных языках в среднем читают с одинаковым количеством символов в минуту. Если на англ читаешь медленнее, чем на русском - ты ещё не до конца его освоил, лол.
>около 20 т/с, ибо полностью выгружена в видеокарту
Тут не только от погружения зависит, но и от чипа, от настроек, семплеров-хуемплеров, типа модели и т.д.
>но в папке пусто куда я скачивал
Если "скачивал" командой install и в папке ничего нет - так и должно быть. Если "скачивал" командой git clone и в папке пусто, то поражён вашей неудачей, сударь. Смотри в папке C:\windows\system32. И нехуй консоль от админа запускать.
> А че дальше делать
Страдать. Там, насколько я помню, нужен тритон, которого нет под винду. Нужно конвертировать модели. Нужно ебаться. Проще скачать сразу здесь https://www.nvidia.com/ru-ru/ai-on-rtx/chatrtx/ поиграться и забыть.
>Никто однако не хочет рискнуть :)
Я как-то видел на реддите обсуждение, там чел хотел собрать под LLM на китайских мутантах, получалось у него либо собирать на б.у 3090 либо за ту же цену х2 по vram на мутантах из Китая. Чип каждой мутантской карты слабее одного 3090, но их выходило 2 за ту же цену и 3090 уже терялся. Так вот ему и пишут - а никто не делал на мутантах, потом если надо будет настроить LLM, так никто тебе ничего не подскажет. Делай на 3090, какое нахуй х2 по цене, не может такого быть. Челик резонно замечает, что у него здесь невозможно найти 3090 дешевле 600 баксов, даже б.у, так что как раз вдвое дороже и выходит за ту же vram. Тут первый ответил что-то в духе - а у меня вообще по 800, но я же купил. Я так охуел на самом деле с этой беседы.
>спасибо барыгам которые цены на теслы за пару месяцев взвинтили в 2-3 раза.
Дело в барыгах, но не так, как ты думаешь. У оптовиков есть сейчас теслы, они готовы продавать, я мельком посмотрел, там по 17к за карту получается. Если брать на миллион. Нужен барыга поменьше, который купит карты оптом и будет продавать. Конечно, это не 15к за карту, но неужели никто бы не купил за 20? Выходит, что нет, не купил бы, потому что 99.9% барыг, которые этим занимались - отвалились.
>Дело в барыгах, но не так, как ты думаешь.
Че то твою мысль я не уловил. Но я щас даже зашел посмотрел цены на p40 несчастную - от 30 до 50 тысяч за штуку. Несколько месяцев назад (может быть пол года назад, точно не помню) их продавали за 15-20 при чем в хорошем состоянии. Щас я даже жалею, что тогда не взял, потому что с нихуя подумал, что цены будут продолжать падать.
>Че то твою мысль я не уловил.
Как это работает - есть крупные барыги, которые продают крупными партиями. Есть барыги поменьше, которые покупают партию, накручивают свой процент и перепродают в розницу. Крупные барыги подняли цены до уровня барыг поменьше. Не важно, с чем это связано. И розничные барыги просто испарились вместо того, чтобы снова купить партию и продавать. Да, карты бы не стоили по 15к, это было бы в районе 20к за карту. Но их нет, они просто отвалились, кроме буквально пары поехавших с картами по 30к.
>Крупные барыги подняли цены до уровня барыг поменьше. Не важно, с чем это связано.
Мне кажется мы все знаем, с чем это связано. Под каждым первым объявлением о продаже теслы сейчас висит описалка по типу "для запуска локальных моделей". Они всё про нас знают. Цены никогда не меняются просто так, особенно массово. Рыночек, все дела.
>они просто отвалились, кроме буквально пары поехавших с картами по 30к.
Там некоторые и по 50-60к карты продают. При чем не партию из пары штук, а именно одну конкретную штуку даже без приваренного колхозанского охлаждения.
бля все настолько хуево?

>Они всё про нас знают.
Я это могу объяснить только тем, что хайпа вокруг AI намного больше, чем самого AI. "Розничные" барыги купили партию, еле-еле продали и больше не хотят этим заниматься, т.к спрос низок. Но из-за хайпа оптовики не хотят отдавать карты по цене корзинки бобов. Вот, допустим, актуальная цена в Китае, накидывай сюда стоимость доставки, потери на переводах, конвертации валют и т.д. Покупаешь на лям, продаёшь по 30к - имеешь 10к чистой прибыли на каждой карте. Плохо, чтоли?
>Там некоторые и по 50-60к карты продают.
Это уже перепродажа перепродажи.
>даже без приваренного колхозанского охлаждения.
Кек. Розничный барыга вряд ли хотя бы упаковку открывает, чтобы осмотреть, что он получил от оптовика, а ты про охлад.
Перекупы - пидарасы, вот ведь новость да?
Но вобще это предсказуемо, карты обрели новую ценность с появлением сеток, и раз за них стали готовы платить все стали взвинчивать цены
Но конечно взвинчивать цену до потолка это на дурака, поймут что не берут за такую - будут снижать
>Кек. Розничный барыга вряд ли хотя бы упаковку открывает, чтобы осмотреть, что он получил от оптовика, а ты про охлад.
Нда, совсем о клиентах не заботятся. Вот если бы они продавали не референсные огрызки а припиздили какой нибудь нормальный охлад с вертушками (желательно двумя, одна вертушка это несерьезно), то я бы готов был тыщу-другую добавить. Ладно, может быть пять тысяч сверху, если прямо хороший охлад а не дрист из под принтера.
>Если "скачивал" командой install и в папке ничего нет - так и должно быть.
Понятно.
Ну, можно модели скачать, которые уже сконвертированы, и уже в угабуге загружать их под TensorRT-Llm, а чатртха, у меня не будет работать, ибо rtx 2000. Я помню кто-то запускал на 2 тыщ. серии, но там была в риге поддерживаемая карта. Т.е. генерила карта rtx 2000 , но так же в риге была ртха 4000, поэтому и заработало.
>Цены никогда не меняются просто так, особенно массово. Рыночек, все дела.
Не только в этом дело. Китай похоже прикрыл лавочку. Даже на Али Тесл нет уже. То ли из-за санкций, то ли спрос вырос и все раскупили.
бля я не про это .я выше спрашивал как обстоят дела с тем что бы привязать генерацию пикч в таверне но блядская мартышка опять двач шатает
Внатуре, я даже уже забыл про этих пиздоглазых торгашей. Там скорее всего да, улей расшевелился и все мелкие и не очень конторы начали скупать всё что не приколочено к майнинг-стендам. Ну и санкции тоже душить начали. То ли реально все в аджиай уверовали, то ли просто отставать не хотят от западных шарашек. Странно что у нас кстати никаких подвижек в этом нет. Яндекс какое то говно высрал, все про него забыли. Тиньков что-то высрал, все забыли еще быстрее. Хотя нормальная локаль на русском точно бы выстрелила, при чем не только у нас, а во всем снг.

Купи охлад от 1080, по болтам встаёт вроде, только не все чипы памяти радиатора касаются.
>. Даже на Али Тесл нет уже.
Шадоубан из-за санкций. Карты там есть. Но цена такая, что проще сразу купить на авито за 40к, лол.
>Странно что у нас кстати никаких подвижек в этом нет.
А откуда эти подвижки возьмутся? Если чел специалист, то он давно на западе с зарплатами х10 (см. места рождения какого-нибудь Суцкевера, или там автора AlexNet), а если он бездарь, то и сетки выйдут говном, что мы и наблюдаем.
>на русском
Вымирающий объективно язык.
>Если чел специалист, то он давно на западе с зарплатами х10
Ну китайцы вон че-то шебуршат, ни одну сетку уже выпустили и без западных специалистов и даже на мандаринском своем блять. Да, понятно что спецы неебического уровня скорее всего съебут при первой возможности, но чтобы сделать просто нормальную сетку без "прорывов" и "достойных ответов западу" хватит и обычных специалистов, которые у нас по любому есть.
>Вымирающий объективно язык.
Но не мертвый. Носителей дохуя, больше чем какого-нибудь французского, что не мешает мистралям тренировать сетку в том числе и на родном языке разрабов.

Манулы тестили, да ещё и профессиональные?


>Ну китайцы вон че-то шебуршат
Они в область столько бабла влили, что кто-то и остался.
>но чтобы сделать просто нормальную сетку без "прорывов" и "достойных ответов западу" хватит и обычных специалистов
Это если процессы налажены. А если нет, то обычный спец первую сотню вариантов запорит нахуй, ибо таланта подобрать всё в пару подходов нет, а подсказать некому. Короче YaGPT 100 будет охуенной, чё.
>Носителей дохуя, больше чем какого-нибудь французского
Ты не поверишь... впрочем там по большей части малообразованные африканцы, тогда как у русского носители пока ещё богаче среднего жителя Африки

Китайцы пишут на английском и обосрались, кто бы мог подумать. Причём у них нет культа барина, им похуй, что они где-то ошибки допустили и не учат языки. Эти иностранные собаки и так купят.
Ты чуть-чуть некорректно сравниваешь, носителей языка с теми, для кого язык родной. Но с общим смыслом согласен.
народ кто может поделиться нормальным гайдом о том как привязать к таверне генерацию изображений
Ладно, не хочу соглашаться, но походу придется. Спецов у нас либо нет, либо они еще в стадии слепых котят находятся. Яндекс свою псевдо-модель уже больше года пилят, а результата никакого. Наша слоновья гопота за всё время научилась только суммаризировать текст с интернетов и ни граммом больше. Хотя, тут наверное глупо сравнивать наши мощности с зарубежными. У гугла, меты и жопенов небось целые кукурузные поля под ангары вычислительные выкуплены, а у нас где-нибудь в подвале ваня сидит и на паленые теслы тетрадкой машет, чтобы те не перегрелись.
> наверное глупо сравнивать наши мощности с зарубежными. У гугла, меты и жопенов небось целые кукурузные поля под ангары вычислительные выкуплены, а у нас где-нибудь в подвале ваня сидит и на паленые теслы тетрадкой машет, чтобы те не перегрелись.
Или наоборот. Сбер несколько лет назад все видюхи в стране скупил, при этом в прошлом году вытужили какую-то шляпу 13В, сбергигачат. При этом всякие обниморды, которые по сравнению со сбером бичи, полноценно хостят 405В.
>Яндекс свою псевдо-модель уже больше года пилят, а результата никакого
Ну как сказать. В Яндекс-браузере уже синхронный перевод видеороликов запилили. У Гугла такого нет, хотя казалось бы.

Как бороться с подобными ремарками посреди текста? Это режим чата если что. Иногда появляется типа "ну вот и закончилась история и бла бла" или вообще от моего имени начинается повествование. Бесит эта штука. Промпты чистые, никаких багов. Всё стандартно в файлах и настройках. Модель мистраль инструкт 12б
Сбер хорошо денюшку считать умеют. Че прибыль не приносит, они то выкидывают, или хотя бы притушивают, чтобы зря бюджет не сосало. Был бы спрос повыше в массах так сказать, может они бы че крупное запилили. А щас одним похуй, а другие не хотят рисковать в условиях кризиса.
В гугле блять в целом долбаебы зажравшиеся сидят, которые нихуя не делают из-за отсутствия конкуренции. А вот яндексу (как и другим конторам из сферы) приходится выкручиваться и какие-то фишки оригинальные добавлять.
> если уж мы говорим чисто о соотношении производительности на рубль
Нехуй дерейлить настолько далеко, изначально было про соотношение скоростей и оно подтвердилось. То что можно подобрать абсурдный вариант с йобой в комбинации с 64битной затычкой, или "в нищесборках не так" - не меняет сути.
> 3070ti это не бюджет, а пред-топ
Последний преддоп семидесятка - паскаль, дальше хуанга пошло штормить и теперь это вообще типичный мидл. 3070 и стоила 25-30 раньше.
> по цене комплекта зимней резины
Как 4090, ага. До дешевой нужно лет 5 отматывать к предверию ковида
> со вторички нормальную сборку хуй подберешь без ебли и кучи часов
Это всегда было. А насчет тесел - просто закончились дешевые, барыги и раньше их задорого толкали.
> там по 17к за карту получается. Если брать на миллион.
Был инсайд что раньше их оптом по 80$ толкали те кто сервера утилизирует. Хз насколько правда, но примерно сходится с текущим изменением цены.
> есть крупные барыги, которые продают крупными партиями
Это не барыги а те кто железки разбирает и дальше сбывает или на переработку отправляет. Им нет смысла связываться с мелкими покупателями.
> Хотя нормальная локаль на русском точно бы выстрелила
В чем бы она выстрелила? Ну предположим условный зеленый банк релизит свой новый гигачат, или что там было в паблик. И? Его скачает пара десятков васянов и будет ныть в комментариях "сделайте нам gguf"? Получат несколько десятков упоминаний в нерецензированных выпусках и парочку от рецензированных статей. Если очень повезет, несколько пара компаний свяжутся с ними с вопросами и хотелками чтобы им что-то сделали на базе этой сетки, вот только едва ли у них есть отдел что занимается такими услугами.
Какой им профит вообще с этого? Что там может выстрелить? Использовать у себя смогут и без публикации и явно это делают, релейтед услуги начать оказывать - аналогично.
Единственное что может как-то помочь - создание отдельной дочки нацеленной чисто на ии, как, например, мистрали, китайцы. Но вопрос с окупаемостью и спросом, если бы не санкции то, наверно, уже бы было.
Если именно нормально - нужно иметь рабочего автоматика или аналог. Просто прописываешь адрес, параметры и шаблон запроса для ллп по генерации промта. То что там прикручено с кобольдом - унылая херня для галочки.
> Промпты чистые
Насколько чистые? Такое бывает при кривых промтах, или у некоторых моделей самих есть склонность подобное спамить, тогда нужно добавить инструкций по тому как отвечать.
>Там прикол в том, что люди на разных языках в среднем читают с одинаковым количеством символов в минуту. Если на англ читаешь медленнее, чем на русском - ты ещё не до конца его освоил, лол.
Я и не говорил, что бог английского, как раз использую ролеплей в качестве практики языка. А ещё где-то читал, что русские слова, как правило, раскладываются на большее количество токенов, чем английские.
>У Гугла такого нет
У гугла есть дочерняя компания, которая делает экспериментальные проекты. Называется Зона 120. У этой зоны 120 есть дочерняя компания Aloud. В 2022 году Aloud открыла доступ всем к новой фиче - перевод видео на другие языки. В преддверии внедрения этого в мейнстрим ютуб запиливает фичу - несколько аудиодорожек для одного видео. В следующем году Aloud обещает поддержку пяти языков и сотрудничает с крупнейшими ютуберами - Пьюдипай, Мистер Бист, Дьюд Перфект. Следом Ютуб обращает свой взор на Индию и добавляет пять индийских языков. Ты же ещё не забыл, чем знаменит Гугл? Он убивает. Уже два года Aloud даже не обновляет свой сайт, обещая перевод только на два языка - испанский и португальский. Он сообщает о периоде тестирования, бесплатности использования и предлагает записаться в бета-программу. Тот же Пьюдипай уже закончил карьеру, а Бист запилил свою контору по переводам, пока Гугл что-то там тестирует. Так что да, у Гугла такого нет. Потому что Гугл убил это в себе.
>Это не барыги а те кто железки разбирает
Ну я привёл цены тех, кто именно барыги, торгуют серверным железом разной степени новизны крупными партиями. У разбирающих железки цены будут пониже, но как с ними связаться? Как перехватить у них товар до барыг? А вот и я не знаю.
>Если именно нормально - нужно иметь рабочего автоматика или аналог. Просто прописываешь адрес, параметры и шаблон запроса для ллп по генерации промта. То что там прикручено с кобольдом - унылая херня для галочки.
а можно подробнее? ибо я нихуя не понял. или же какой то гайд если в падлу расписывать
>тогда нужно добавить инструкций по тому как отвечать.
Т.е. так и написать ей в память типа "ты не должен... отвечай только так..."?
Там же примитивный интерфейс довольно, для начала запусти одновременно диффузию и llm.
Отвечай в таком-то стиле, избегай добавления в конце странных вопросов и подобное. Можно устроить типа свод rp rules: где перечислить указания, только не переусердствуй. Отрицания модели воспринимают очень плохо, особенно когда пытаешься загнать ими в узкие рамки.
Выбрасуй нахуй слои из видяхи, туда — чисто контекст напихай.
Нет, скорость нулевая будет.
Deepseek-Coer-V2-Lite 16B?
На скорость влияет (время ответа): вес модели и скорость чтения памяти. Берется вес — делится на скорость. Нихуя себе математика, правда? :)
У видяхи скорость чтения гораздо быстрее, у оперативы медленнее.
Конечно, влияет еще и мощности (видеокарта или проц), но и там разрыв весьма большой (видеокарта кратно сильнее проца обычного).
Так что по итогу, все что тебе надо — это вес модели. =) И нормальный ответ у всех разный. Кто-то сидит на 4090 и ему геммы 27б выдают 60 токенов в секунду. И это «норм». А кто-то сидит на оперативе с 12б моделью с 4 токенами в секунду и радуется.
Потому что в их датасетах не было стихов русских, м, м, м? :)
Ну так и нахуя тебе локалки? :) Пиши сам, на том и порешили.
45-50 точнее.
Или в 6 раз быстрее обычный DDR4…
1,5 токена против 9, или 5 против 30… ХМ…
Хуйня. Норм у нас со специалистами. И исследования есть. Финансирования мало (и основное у Сбера и Яндекса), отсюда и результат. Многие МЛщики русские — частники за рубежом. Зато при деньгах и могут ресерчить.
———
Потестил Qwen2-VL-2B и Qwen2-VL-7B — топовые модельки. На голову выше всего опенсорсного, что было раньше.
Ща накатываю WSL, ибо ебал я этот ваш Flash-Attention под винду билдить, говно говна, автор мудак.
Им осталось слить VL и Audio и добавить генерацию звука и картинок. Ну и все, омнимодалка готова, хули.
а что за диффузия? сорри я сосем гулупый
Stable Diffusion
>омнимодалка готова
Омнимодалка курильщика.
Кто-нить ставил 2+ Tesla P40 в WSL?
А то у меня не хотят видеться. Может есть какие тонкости. Может куду не ту поставил или еще шо. Ну так, навскидку.
А то у меня не хотят видеться. Может есть какие тонкости. Может куду не ту поставил или еще шо. Ну так, навскидку.
Аноны, это просто праздник какой-то. Как же быстро новые командиры летают!
>Может есть какие тонкости.
Одна. Твои теслы должны быть в WDDM режиме, иначе WSL тебя нахуй пошлёт даже с одной.
Запускать даже на топовых по железу мобилках толку мало, будет убого, медленно и горячо. Лучше заведи хоть какой-нибудь комп, в идеале - хоть с какой-нибудь дискретной видеокартой, и запускай на нём, а с мобилки можешь удалённо к веб-интерфейсу Kobold.cpp подрубаться.
>бу древняя карточка будет лучше, даже 580 рыкса
Тем более что конкретно RX580 есть китайские рефабы с 16 Гб памяти, а это уже довольно неплохо за их деньги!

Battle of the cheap GPUs - Lllama 3.1 8B GGUF vs EXL2 on P102-100, M40, P100, CMP 100-210, Titan V
https://www.reddit.com/r/LocalLLaMA/comments/1f6hjwf/battle_of_the_cheap_gpus_lllama_31_8b_gguf_vs/
>Battle of the cheap GPUs
P100 для вкатунов в тему выглядит неплохим вариантом, тем более что её пока ещё можно достать за 20к. Чисто для моделей 8-12В. А вот две таких брать нет смысла, лучше уж дожать до 3090. Новый комманд-р в exl2 влезет в 24гб?
>Семплеры я смотрю на опенроутере, там не все модели, однако беру от туда - ну и нормально пашет
Спасибо за наводку. Как раз думал, не оздать ли отдельно рентри для семплеров, вот только "правильные" семплеры у всех свои, а тут общий ресурс, то что надо любому ньюфагу!
Добавил в список моделей ссылки на семплеры, которые нашёл.
Мне больше этот тест понравился, в комментах кидали:
https://www.reddit.com/r/LocalLLaMA/comments/1eqfok2/overclocked_m40_24gb_vs_p40_benchmark_results/
Сделать бы сбороную таблицу днищекарт по производительности, я бы ещё на amd mi50 глянул. Недооценённая хуйня в текущих реалиях
>Можно устроить типа свод rp rules
А вот это годная идея, спс анон
Вопрос к анонам. Сколько реального контекста в мистраль немо если юзать только русский язык. На каком моменте у вас лупы. И тот же вопрос относится к более старшим мистралькам. Есть ли разница именно в размере вмещаемого контекста при котором появляются лупы.
Где можно посмотреть, сколько ОЗУ oobabooga пытается зарезервировать? Нихрена не понятно, саолько памяти ему надо.
Необычно наблюдать аж 2х отличие по скорости генерации между разными бэками при мелком контексте, но хорошо что бывая работает. Однако, проблемы некрожелеза уже во всю лезут: жора нормально работает только на паскалях, в остальных не заводится, флеш аттеншн на некроте также не хочет работать. Возможно есть шанс их собрать на старых либах, но это не точно.
> Gemma 2 27B @ 8192 context
> Prompt processing: P40 - 256 t/s, M40 - 74 t/s
Овари да, похоже оно ультрапечально. Но вдруг там есть нормальные фп16 и есть шанс на экслламу?
> Сколько реального контекста в мистраль немо
Столько же сколько и на английском, лупы с этим не связаны.
Скока ж там M40 стоит-то… На 30% медленнее в разгоне (!).
Недалеко от P104-100, только объем, конечно, нормальный.
Ну, наверное, за 8к-10к нормально, да?
>Ну, наверное, за 8к-10к нормально, да?
Более чем. Только не найдёшь. За 15 и то редко.
Хе-хе. Осталось побороть генерацию в некоторых случаях рандомного бреда, звучащего, как призывы Сатаны прорвалось на "what other", ещё немного поебаться с буферизацией чатлога и будет охуенно.
>проблемы некрожелеза уже во всю лезут
На то оно и некро. Но у Жоры там в команде какой-то некромант ёбаный, который позволяет гонять хотя бы на p40 и не умирать от старости во время генерации. Это ли не чудо?
А FA вообще не должен поддерживать что-то старше тюрингов, понимать надо.
У вас, кстати, ссд не дохнут от нейронок? У моего за год 30% ХП отвалилось, 300 ТБ записи. Скоро менять.
Все сами считают и ты так делай.
>проблемы некрожелеза уже во всю лезут
На то оно и некро. Но у Жоры там в команде какой-то некромант ёбаный, который позволяет гонять хотя бы на p40 и не умирать от старости во время генерации. Это ли не чудо?
А FA вообще не должен поддерживать что-то старше тюрингов, понимать надо.
У вас, кстати, ссд не дохнут от нейронок? У моего за год 30% ХП отвалилось, 300 ТБ записи. Скоро менять.
Все сами считают и ты так делай.
Это какой-то клиент, или сам интерфейс и озвучку прикрутил?
> и будет охуенно
Модель пытается в эмоции - это интересно. Случайно так получилось или есть уже такие модели?
>некромант ёбаный, который позволяет гонять хотя бы на p40 и не умирать от старости во время генерации. Это ли не чудо?
Да честно говоря 4t/s на 123В_Q4 c 16к контекста это не "хотя бы", а почти хорошо. Слава некромантам!
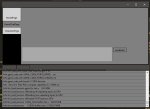
Клиент к llama.dll. Кобольды с угами не используются. Озвучка на самописном сервере сбоку прикручена, отдаёт на воспроизведение всё в клиент. Потом прикручу ещё настройки для этого. Нашёлся охуенный побочный эффект, когда модель говорит на английском с хэви рашн акцент, мне нравится просто пиздец как.
Тортоис и барк, если не ошибаюсь, давно поддерживают. Самые продвинутые в этом плане японские. Для того же VITS есть VAE, которые эмоции извлекают.
А здесь просто крупная голосовая модель со вшитой маленькой текстовой, которая обучалась на голосах с эмоциями, но всё равно почти всегда фейлит и не умеет в ударения. Но я никак и не обозначаю ударения, лол. Да и знаки препинания часто заменяются на пробелы, это ещё нужно допилить. Большие паузы между фразами это баг, как и замедление некоторых фраз, из-за торопливой генерации вылезает. Тестировал на мелкой модели с более высокой скоростью генерации, там это заметно не было.
Я имел ввиду, что хотя бы имея p40 можно получать удовольствие от llm. Хотя она уже древняя, как говно мамонта. Слава некромантам!
>Клиент к llama.dll
Понял. У него есть ContextShift?
Звучит хорошо так-то. Тоже пилю собственный клиент потихоньку, подключаясь к кобольду, с японской озвучкой текста с помощью Umamusume VITS.
>сам считай
Что и сделал.
huggingface.co/spaces/NyxKrage/LLM-Model-VRAM-Calculator
Модель Sai10K/Llama-3.1-8B-Stheno-v3.4
GGUF
Q8_0
Context size: 128000
Калькулятор пишет, что все вместе займет 31ГБ. Памяти 32ГБ, своп 8ГБ.
Но контейнер в итоге вылетает и говорит, что он пытался выбратт 71ГБ ему не хватило.
Я хочу понять, что он хочет сделать и зачем ему вдвое больше ОЗУ?
А есть какие нибудь инстракты для моделек чтобы глянуть? Я там прописываю немного всяких правил под себя но не уверен в формате.
>У него есть ContextShift?
Да. Но у него есть свои "но". Что делает психически стабильный человек для обработки контекста? Он ждёт сообщение определённой длины и удаляет из кеша количество токенов под это сообщение. Получает сообщение, делает смещение и всем доволен.
Что за пиздец происходит на вебме: я установил размер сообщения 225, размер батча 512, а размер контекста 472. Просто потому что могу. Берём существующий контекст и отправляем на генерацию, не подготавливая место под него. Приходят токены. Контекст переполняется. Токенов с пометкой "хранить вечно" нет, так что берём половину, отхуяриваем нахуй и суём в кеш. Не прерывая генерацию. Таким образом модель генерирует до 1200 токенов при контексте 472, лол, и останавливается только если сгенерирует 225 токенов подряд. Затраченное время считается некорректно, так что т\с тоже неправильные, потом поправлю, просто мне похуй. Прекрасно видно, что квен 7b q4 в процессе пизданулся, но моделям покрупнее с адекватными значениями контекста такое обращение не вредит особо.
>Umamusume VITS.
Я пытался в витс, но уже не помню, что остановило. Толи скорость обучения, толи скорость инференса, толи я оказался слишком дубовым для него. Как вообще звучит? Стоит посмотреть?
>Context size: 128000
А калькулятор считает контекст? Что-то там значения замерли, как ни крути. Каждый 1к контекста это примерно 1gb памяти, иногда больше, иногда меньше. Базовые значения модели особо не играют значения в данный момент, важны те, что ты установил сам.
>Каждый 1к контекста это примерно 1gb памяти, иногда больше, иногда меньше. Базовые значения модели особо не играют значения в данный момент, важны те, что ты установил сам.
Теперь понятно. Спасибо, анон!
Спасибо, не понял. ContextShift там реализуется программно на сишечке? Не через сервер апи? Мне просто в сишечку лезть не особо хочется, если можно кобольд вместо него гонять, хочу чтобы через сервер апи все спокойно работало, осуществимо?
https://huggingface.co/spaces/Plachta/VITS-Umamusume-voice-synthesizer
Тут можешь послушать и накатить сразу. Скорость генерации на ЦП там приемлемая, на 160 токенов секунд 15 требуется. Я только japanese юзаю, беру сгенерированный текст, подчищаю текст, оставляя только разговорную речь, перевожу оригинал на японский и кидаю в сервер апи. Апи придется реализовывать самому если что.
> ссд не дохнут от нейронок
За год всего лишь 180тб записи при том что ебка там очень жесткая. У тебя, похоже, крайне активно используется своп, слишком много записей.
> 2024-09-02-13-3[...].webm
> interface.png
Ну и хтонь, демо сервер жоры и то не так страшен. Сам писал на голых сях?
> хотя бы имея p40 можно получать удовольствие от llm
Не просто удовольствие а даже довольно урчать. Да, если замахнуться на огромные модели то там сосалово, но хотябы как-то, а на тех что поменьше проблем нет.
> Токенов с пометкой "хранить вечно" нет
Так не бывает в нормальном инфиренсе, потому оно и пизданулось. Потерялась задача - потерялась суть, в итоге или совсем поломка, или всратый слоуп на тему последних сообщений.
Интереснее посмотреть что будет при сохранении нужных токенов в начале и свиге последующих, оно останется живым или будет ловить шизу по нарастающей.
Про ссд, тоже посмотрел сейчас, было 72тб запись - стало 110тб. С ~70% упало до 58%. Как вообще происходит деградация ссд, если будет 30% будет уже пиздец? Или же он и на 20% будет работать сопоставимо с 70%, однако кол-во пространства ссд уменьшиться.
На ссд у меня модели и файл подкачки.
На ссд у меня модели и файл подкачки.
Согласен, сейчас все же снова вернулся на магнум 2 12б, и на опенроутере нет на него пресетов. Хотя я просто поставил те, что на магнум 72б.
Список семплеров достаточно полезная вещь. Если еще что-то такого рода - то пресеты в Силли, тем не менее на обычных так же хорошо пашет.
Анонче, я починил у себя русский язык в силли, теперь мне модель пишет на русском языке. В промпте и в персонаже написал это You must write, think, describe emotions and answer only in Russian!!! Может кто-то может сделать лучше или что-то перебрать.
Русский на магнуме 2 приемлемый, пишет нормально, в начале были гэги из-за слов аля Маэстро.. Когда дополнил промпт, это ушло.
Русский на магнуме 2 приемлемый, пишет нормально, в начале были гэги из-за слов аля Маэстро.. Когда дополнил промпт, это ушло.


>Не через сервер апи?
А нет никакого сервера, нет апи. Но вы держитесь.
В кобольде что, проблемы с контекст шифтом?
>активно используется своп
Своп на другом диске, там 97% хэпэшечка. А тут кроме нейронок считай и нет нихуя.
>Ну и хтонь
Ожидаемо, если пилится под одного пользователя и этот пользователь - ты сам. У меня так-то цель стояла сделать плоский квадратно-гнездовой интерфейс. Но допиливать ещё буду, конечно, сейчас даже зелёная каретка, она не зелёная, она красная, просто рисуется через XOR. Нет, мне не нужна красная каретка и курсор, просто цвета контрастные. Не то, чтобы голые си, много вин апи, но и до рисования в буферы приходится опускаться.
>Интереснее посмотреть что будет при сохранении нужных токенов в начале
Ну вот поставил 3к контекста, "хранить вечно" 256 токенов. Начал требовать написать длинные хоррор истории про овощи, чтобы забить контекст, подождал пару шифтов и начал вопросы про солнечную систему. В целом, ничего страшного не происходит. Да и не может. "Повреждёнными" будут токены на границах последовательностей, чем короче последовательность и чем хуже модель справляется с алогичной херотой, тем больше шансов, что наебнётся. Но, когда условно у тебя есть 2-3к токенов, из них бреда на 10 токенов, то модель вполне может их проигнорировать и не сломаться. Если обрезать не на полуслове, а предложениями, то проблемы в принципе исключены. Накопления ошибки-то нет. Я больше скажу, даже если модель "сломалась" от поехавшего контекста, то её легко реанимировать, даже на шебм на мой вопрос, не ебанулся ли он - квен сразу же пришёл в чувства. И это 4й квант 7b.
Если ссд не самый подвальный, то уйдёт в ридонли, запись будет запрещена, но скопировать инфу можно. Если подвал, то внезапно умер и пиздец. Я до 50% точно заменю и на помойку. Лишь бы раньше не отъебнул.
Сейчас посмотрел у ссд TBW 150, а у меня уже 110 тб записей. Вот думаю, файл подкачки мб поставить на хард? Ну про модели, мне не показалось что на ссд побольше токенов/с? Чем на хдд.
Как сделать чтоб Negative работал на Hermes?
Хермес, это старая которая? блять, я помню когда вкатывался скачал, но мне не понравилось сидел под визард-лм. Хз, поменять модель на другую не вариант? Как вариант напиши не негатив а Main Prompt у персонажа, что ему нужно быть очень ужасным с {{user}}
Посоветуйте 13б квантованную какую нибудь для вката новичку.
Магнум 2. Или же ее основу Мистраль-Немо, хотя она у меня работает ебанно.
А че магнум 2.5 лучше 2?
Ты хоть понимаешь, что такое negative prompt? LLM не настолько могут в логику, как люди, поэтому разбираться с двойными отрицаниями им будет затруднительно. Ты пишешь "не делай это и то" в поле исключения, модель может подумать, что нужно делать обратное перечисленному.
Пиши в negative prompt максимально кратко и сухо то, что требуется исключать: rude things, obscene language, sexual themes. ВСЁ!
По-твоему зачем новые версии чего-либо выпускают? Видимо, есть какие-то улучшения, но может быть и обратное, всё зависит от конкретных задач.
Ллама 3.1 прямой пример, что обновление может ради обновления. Магнум 2.5 экспериментальная версия, поэтому и спрашиваю лучше она или нет.
в среднем лучше
В систем промпт добавь что ты хочешь чтобы модель не делала, но избегай частицы не, т.е. вместо "не умничай" говори "избегай умных мыслей"
Нужно будет попробовать, мини-магнум и магнум 2 годны, попробую магнум 2.5 тогда
Но это как раз те вещи, которые должны быть. Задача в том, чтобы пробить остаточную сою Гермеса (это дотрейна Llama 3.1).
https://llm.extractum.io/model/Orenguteng%2FLlama-3-8B-Lexi-Uncensored,1PRq2yvfTyXBtIPhdopUtX
Это вкусная мини моделька для хорни РП или это говно?
Есть где туторы как правильно настроить силли таверну, чтобы к примеру в разговор вмешивался закадровый голос и предлагал интересные варианты развития и случайные события? Так много настроек в таверне, моск пухнет, как найти правильный пресет для той или иной модели, очень все не очевидно...
Спасибо!
Это вкусная мини моделька для хорни РП или это говно?
Есть где туторы как правильно настроить силли таверну, чтобы к примеру в разговор вмешивался закадровый голос и предлагал интересные варианты развития и случайные события? Так много настроек в таверне, моск пухнет, как найти правильный пресет для той или иной модели, очень все не очевидно...
Спасибо!
Можете, пожалуйста, дать ссылочку или что-то подобное на готовую нейронку Аноним 02/09/24 Пнд 22:02:53 #311 №874696
Привет, ребята
Я ищу готовую разговорную нейронку (что-то по типу chatGPT)
Но по слабее, чем chatGPT, так как хочу запускать на своем ПК с RTX 3060. Желательно чтоб она воспринимала русский и английский язык, но нужно как минимум русский
Я ищу готовую разговорную нейронку (что-то по типу chatGPT)
Но по слабее, чем chatGPT, так как хочу запускать на своем ПК с RTX 3060. Желательно чтоб она воспринимала русский и английский язык, но нужно как минимум русский
Ещё год назад тебя бы нахуй послали с такими запросами, а сейчас юзай Mistral-Nemo-Instruct-2407-12B. И радуйся.
Спасибо, попробую эту модель

Доложить уровень кума
Только что дрочил на буквы, кум плотный, через пол часика повтор
Кончай тред выше на доске.
>Тортоис и барк, если не ошибаюсь, давно поддерживают. Самые продвинутые в этом плане японские. Для того же VITS есть VAE, которые эмоции извлекают.
Попробовал кое-что из этого - лажа какая-то. Даже нормального синтеза, даже на английском! не добиться. Куда уж там про эмоции говорить. Видимо придётся ждать, пока Ллама и Мистраль дорастут до омни-моделей.

Новые инфоблоки: окружение, а также дата и время. Несколько свайпов Марии в ответ на два слова: "Привет, шлюха".
Судя по всему в промпте многовато жести (или же, ее нужно ограничить для более постепенного раскрытия персонажа).
Судя по всему в промпте многовато жести (или же, ее нужно ограничить для более постепенного раскрытия персонажа).
Промахнулся мимо треда, сорри
Залей, в арчив орг тож по реге.
Ваше ренти у меня все равно
не заходит, смысл обходить?
Если инет не работает - иные сети.
Капча классная, Абу спасибо тебе.
Мелкий квен норм для обучения агента,
быстро и на одну задачу, например скормить
все приказы/разъяснения/письма и спрашивать.
быстро и на одну задачу, например скормить
все приказы/разъяснения/письма и спрашивать.
Что-то я как-то не понял как он GGUF считает? Если в репе много файлов, как он определяет какой рассчитывать?
И вообще высерает в итоге прикл.
С Exl2 всё норм.
Смартбай это пизда.
Не скажи, барк хорош.
https://github.com/suno-ai/bark
А там над ссылкой на модель написано unquantized.

>А там над ссылкой на модель написано unquantized.
Спасибо!
Но как-то он слишком оптимистично считает...
Cкорее всего, автор калькулятора неправильно прописал BPW, они же байты на вес. По идее, можно заставить бэк считать сколько чего и куда ты можешь выгрузить, потому что bpw вшиты в модель и бэк может это делать. А сторонний калькулятор - сам видишь.
У этого магнума 80 слоёв, так если грубо подсчитать, то 0.35 гига на слой плюс всё тот же гиг на 1к, то можно прикинуть хуй к носу, сколько влезет. Возьмём теслу, 24gb vram, сразу минусуем контекст, пусть 4к. Остаётся 20gb vram, делим на 0,35. Получается 57 с копейками. Т.к 0.35 это чуть-чуть с запасом, то может и влезет. Если я всё правильно подсчитал, лол, а это далеко не факт. Если поставить контекст 4к, n gpu layers 57, выключить mmap, то должно сожрать 24 gb vram и 12 gb ram.
>Возьмём теслу, 24gb vram, сразу минусуем контекст, пусть 4к
1к контекста в ггуфе где-то полгига. Может из-за flash attention, не помню как было раньше. Опять же от модели зависит. Короче без пробной загрузки хрен рассчитаешь. А с ней проще на глазок прикинуть, вот никто и не заморачивается.
Вообще твои расчёты ближе к реальности. Можно свой калькулятор написать.
А почему ты взял именно 0,35 гига на слой?
Тут когда-то в шапке вроде было, что 1к это 1 гиг. А FA по умолчанию не включен.
Т.к известно, что у 72b магнума 80 слоёв, а ты берёшь модель размером 27.1 Gb, то делим одно на другое, получается ~0.338. Здесь я округляю в меньшую сторону, т.к знаю, что нужно ещё плюсовать размеры входных-выходных тензоров, так что сразу после этого - округляю уже в большую сторону, до 0.35. Как и писал, всё это достаточно грубые расчёты.
Так если брать размер готового кванта, то зачем вообще считать по слоям?
У тебя вышло 32 Гб.
Файл весит 27Гб + 4Гб на котекст, выходит 31Гб. Обычно так считаю.
Разве что заранее слои раскидать, а не методом тыка.
>зачем вообще считать по слоям?
Именно чтобы заранее знать, сколько слоёв влезет в GPU.
>У тебя вышло 32 Гб.
Вообще 36 суммарного, т.к я плюсую кеш kv для RAM. Если не ошибаюсь, он туда дублируется, никогда не обращал внимания. Должен дублироваться.
Можем не брать размер готового кванта. Модель 72b, квант IQ2_XS. Умножаем 72 миллиарда на 2.31, полученную ебанину умножаем на 0.125. А потом делим на 1024. Получаем 20 гигов и 302 мегабайта. Что неправильно, т.к Жора не квантует атеншн в такую мизерную залупу, там fp16, вроде, что вносит погрешность. Можно посчитать атеншн отдельно, но нахуя, если у нас есть сам файл.
Какой мой ренти нахуй?
Я просто могу слить на свой хост, заберешь оттуда и все.
Ваш арчив мне нахуй не нужон, разбираться еще в нем.
Вы, блядь, даже на халяву попросить не можете, что за деградация! Поколение эффективных менеджеров ебать.
Я не понимаю, че тебе надо. Модели? Да бля, я бы тебе их за пять минут залил себе на хост и ссылки дал. Но нет, сидишь, слюну пускаешь, вместо русских слов. Арчив свой дрочишь.
Тебе надо на постоянке иметь доступ, или чисто скачать разок-другой?
Ну дык, вроде о чем речь и идет, чтобы заранее слои прикинуть.
Я так же делаю.
Хотя, автор до сих пор не апрувнул запрос, куда торопиться-то, лол…
>Я так же делаю.
А я не выгружаю модели в оперативку, т.к. у меня DDR4 2666MHz и при выгрузке даже нескольких слоёв, скорость палдает в несколько раз, обычно где-то до 1 т/с.
Поэтому я стараюсь запихать всё в одну Теслу, так что для меня главный вопрос "влезет - не влезет"
В таком случае слои считать не надо, посмотрел на размер, докинул гиги на контекст и погнали. =) Жить проще, когда частота памяти 2666… Но грустнее…
Ебал я в рот писать сюда с этой капчей, но вот годнота
https://www.reddit.com/r/LocalLLaMA/comments/1f7cdhj/koboldcpp_and_vision_models_a_guide/
https://www.reddit.com/r/LocalLLaMA/comments/1f7cdhj/koboldcpp_and_vision_models_a_guide/
Ускорил генерацию голоса. Как же я доволен, ебать. Да, есть проблемы, в основном проглатывание знаков препинания, и две фразы проглотило. Это, вроде, решаемо, первое траблы в коде, второе в модели.
Тот самый хэви рашн аццент. Ещё убавить охи-вздохи, добавить более человеческого тембра и не спалиться на том, чей именно голос я спиздил.
>т.к. у меня DDR4 2666MHz
Нашёл проблему. У меня тесла генерирует так медленно, что даже если я что-то выгружу в свою 3600 оперативу, то не особо-то что и изменится, лол.
Ага, годнота. Иногда замечаю, что модель просит скриншот, хотя она и не мультимодалка.
>с этой капчей
Купи пасскод. Ну ты чё. Ну купи. Абу кушать хочет.
Тот самый хэви рашн аццент. Ещё убавить охи-вздохи, добавить более человеческого тембра и не спалиться на том, чей именно голос я спиздил.
>т.к. у меня DDR4 2666MHz
Нашёл проблему. У меня тесла генерирует так медленно, что даже если я что-то выгружу в свою 3600 оперативу, то не особо-то что и изменится, лол.
Ага, годнота. Иногда замечаю, что модель просит скриншот, хотя она и не мультимодалка.
>с этой капчей
Купи пасскод. Ну ты чё. Ну купи. Абу кушать хочет.
Ну 150тб записей еще, у меня 110, я перекинул файл подкачки на хдд, а модельки оставлю на ссд.
Качаю на рамдиск, пробую и удаляю.
В некоторых случаях переношу на хдд.
В некоторых случаях переношу на хдд.
Бля,что вы тут делаете?Вычисляете какие-то нуклоны чтобы подрочить на сгенерированный нейронкой текст?Я в ахуе.
Пизже старой хуйни в миллион раз.
|04
Заебись, правда?! Присоединяйся!
Неее,я думал мне нейронка по одному клику будет тонны контента насыпать,а тут БозонХиггса предлагают для контента вычислять,нахуй надо буду по старинке значит,время замещения тухлодырок нейронками значит еще не пришло,чего нет в массах, того нет в реальности,точка,я все скозал.
>и не спалиться на том, чей именно голос я спиздил.
Поздравляю, спалился. Это голос чувихи, которая женскую весрию Ви в киберсарке озвучивала.
>я перекинул файл подкачки на хдд
Больной ублюдок.
>чего нет в массах, того нет в реальности
В реальности быдла разве что. А ты уже там.
Ну так реальностью и воротит быдло,пока не запилят доступный массам продукт,о промышленном производстве секс-роботов или хотя бы прокаченного ИИ не может быть и речи,так как процент небыдла стремится к долям процента.
>прокачанный ИИ для быдла
Лол, для быдла текущие негронки избыточны, ибо уже умнее среднестатистического человека. Оболочка да, тут бы не помешала массовость, но я думаю на основе бытовых роботов можно будет сделать модификацию с причиндалами.
Синхронизируй текст с голосом.
Ну я имел ввиду нейронки способные имитировать хотя бы более менее реалистичный диалог в реальном времени,а вот с оболочкой сложнее,если не ударяться в сайфай,мне лично видится, из более менее близкого будущего какая-нибудь VR игруха с кастомайзом тян к которой прикрутили ИИшник оптимизированный для конкретной задачи имитации диалога,хотя даже так системки наверно будут очень высокие,поэтому скорее всего расчеты будут производиться через удаленные серваки за ежемесячную подписку.

Слишком сильно озаЛУПлена.
Лупов нет. Если правильно инструкцию прописать и гритинг.
Нда ебать, разговор аутистов. Такой экспирианс разве что китайские новелки с кривым переводом дадут.
Русский всё еще плох, что не удивительно. Текст стал связный, но остался сушеным и блеклым, будто это всё еще прямой перевод уровня охлаждения траханья. В русском неюзабельно, в английском сойдет.
Инглиш уебищен в плане настроек. Неудобно тестировать подсказки. Да, немо бы побольше знания русского.
>из более менее близкого будущего какая-нибудь VR игруха с кастомайзом тян к которой прикрутили ИИшник оптимизированный для конкретной задачи имитации диалога
Никто не будет въебывать столько денег в вр-порнуху. На вр итак всем похуй, на нем даже обычных игр по пальцам можно пересчитать и то каждая первая это инди, не считая пары релизов от крупных студий.
Ну первый заход может быть основан на каких то готовых решениях,с небольшим допилом,да и в целом думаю игровая индустрия мало по малу будет ИИ стараться применять,в индустрии сейчас застой,нужна революция в игровом опыте.
Было не так уж сложно, да? Просто дефолтные голоса это какой-то хомячий писк, красивых женских голосов мало. А у неё прямо секс. Потом подкручу тембр, подмешаю ещё несколько голосов и будет незаметно. Скорее всего, подниму на пару октав, хотя не хотелось бы, но так сходство сильнее всего размывается.
Была мысль сделать выделение в стиле караоке, но что-то уже не хочется. Если получится заставить генерировать без свайпов, а это реально, то читать вообще будет не нужно.
Не взлетит. Виар никому не нужен, так что у нас одна узкая ниша. Порнуха это ещё одна узкая ниша. Целевая аудитория фокусируется просто в лазерный луч. А нужно бить по площадям, чтобы получить максимально широкий охват, окупиться и хайпануть. Рано или поздно будет фурриёбская виар порнуха с ИИ, просто потому что фурриёбы ёбнутые и они не будут ждать, чтобы кто-то это сделал для них - они понимают, что никто не сделает, кроме фурриёбов.
В тренде сейчас приложения на телефон для "свиданий" с ИИ, там и аудитория, и все дела.
Что-то я не вижу исковерканных слов. Оно настолько хорошо может в грамматически верные предложения?

Проблема скилла. И может дело в файтюне.
royallab_MN-12B-LooseCannon-v2-exl2_5bpw
Слишком много факторов надо учитывать чтобы сетка не шизила, но с хорошей карточкой, нужной инструкцией вполне можно поиграть.
Можно ли 8б лама3 модели и тюны резать по контексту без вреда для генераций? Есть модель на 128к, но мне столько не нужно, да и не влезет, как корректно настроить, чтобы ничего не сломать?
Ну режим виар в игре может быть опциональным,как в каком-нибудь VAM или даже Койкатсу,да и не сказал бы что порнуха прямо таки малую аудиторию имеет,в Стиме том же порнушные и около порнушные игры даже в пиздец урезанной комплектации разлетаются как горячие пирожки,единственное что нормисам именно ИИ в игре может быть не очень интересен и просто этот пунктик для них не будет продающим.

>как корректно настроить, чтобы ничего не сломать?
1. Указываешь нужные тебе 2к контекста.
2. Профит.
А че оно так работает? Я думал там твикать нужно чет, когда не стандартный контекст модели юзаешь.
Главная проблема нейронок сейчас в отсутствии контроля и их непредсказуемом поведении. Прописал ты себе в игрульку какого нибудь сурового персонажа вояку, а при общении он у тебя будет ныть, страдать и вообще отказываться от убийств и прочего, потому что ему нейронка решила не те чувства прописать. И это еще лайтовый пример.
>в индустрии сейчас застой,нужна революция в игровом опыте.
Революцию они проведут очень просто - сократят штат в пару раз, кого надо уволят, кого не надо тоже уволят. Это не первый кризис в геймдеве и все сценарии по сокращению убытков давно просчитаны.
Твикать нужно при увеличении, при уменьшении ты просто используешь его не весь.
Тестеры ахуеют это проверять, лол.
https://habr.com/ru/articles/840546/
модель без перемножения матриц
>Экспериментальные результаты показывают, что без MatMul-free модель работает плюс-минус на равных с полноценными трансформерами, но экономит 61% памяти
PogU
модель без перемножения матриц
>Экспериментальные результаты показывают, что без MatMul-free модель работает плюс-минус на равных с полноценными трансформерами, но экономит 61% памяти
PogU
А ты быстрый, и года с момента публикации не прошло.
Статье 8 часов..
Раз уже давно придумали, де тогда реализация?
>но экономит 61% памяти
Мало.
Хабрабляди, сер. Они отстают на 3 месяца от двачей.
Если модель умеет из коробки в русский язык стоит ли карточку писать на русском или лучше не стоит?
>обученные модели
>370M
>1.3B
>2.7B
Эти итак даже на тапочках дырявых запустятся, хули с ними еще возиться.
Если собираешься общаться с ней на русском, то можешь писать на русском. Но в целом понимание русского и генерация на русском всегда будет хуже английского.

>генерация на русском всегда будет хуже английского
Не всегда. Вот запилю свою сетку на своей архитектуре, и будет она ебать в мультиланге всё и вся.
Мимо жду А100 от треда
>Мимо жду А100 от треда
Аноны может бы и скинулись на хорошее дело, но ты (или кто угодно другой) сначала должен публично представить какой-то конкретный план и доказать, что вообще способен обучать модельки.
Так ведь в виаре есть проекты, и нейронки давно прикрутили.
Там просто лень докручивать действия и анимации, а так — готово, кто ж тебе мешает-то.
Да и нахуй ВР, когда есть АР.
> Порнуха это ещё одна узкая ниша
Троллишь, конечно. ) Такую хуйню ляпнуть всерьез невозможно.
Да, всего лишь настройка графики.
Правда в ВАМ там режим десктопа опционален.
> Раз уже давно придумали, де тогда реализация?
Спроси об этом еще тысячу публикаций, реализаций которых мы по сей день не видим.
Мамбу надрачивали год, и тут мистраль выпустила (и обосралась).
Ну, были модели, которые в определенных задачах на русском ебали английский (но немного).
Правда это было про задачи, а не про дроч.
Я правильно понимаю что они предлагают конвертировать в свой формат модели с huggingface на трансформерах или тут речь про обучение?
Просто как-то обычно сетки нет-нет, да коверкают слова. А у тебя на скрине прямо хорошо. Либо скрин удачный, либо надо скачать и попробовать.
Ну хуй знает. Не замечал, чтобы они "разлетались".
>этот пунктик для них не будет продающим.
Это будет поводом для кучи гневных отзывов, лол.
>Троллишь, конечно. )
Ну давай прикинем хуй к носу, какая аудитория у порно игр. Релиз на консоли, мобилки и Китай для порнухи можно сразу исключать, а это три четверти рынка, если не больше. Смотрим в стим, что там среди эротики самое популярное?
https://steamdb.info/charts/?category=888
Няша топ по олл тайм пик онлайн. Целых 6.6% игру купивших имеют ачивку за её запуск. И 4% - за выключение. Но для игры за 40 рублей со скидками вплоть до 9 это как-то не серьёзно. Фолловеров и отзывов считай, что и нет.
Ласт годесс топ по текущему онлайну, аж 5к. Учитывая, что базовая версия бесплатная. Аудитория этой игры ниже, чем у банана-кликера, тоже бесплатная "игра", где нужно тупо кликать по банану и там 900к пиковый онлайн. То есть аудитория "дегенераты" несравнимо больше, чем "кумеры". И ещё что интересно с эротическими играми, там есть какой-никакой пиковый онлайн на релизе, но потом количество игроков околонулевое. Это значит не только то, что купившие игру - поиграли и бросили, но и то, что свежих игроков не приходит. Что тоже сигнализирует о низком интересе. У Фростпанка, например, пиковый онлайн 29к, но там всё ещё около 3к активных игроков, а я сомневаюсь, что в него можно аутировать шесть лет.
всю нишу игр для кумеров заняли сраные гачи, лол
нет смысла что-то другое делать
нет смысла что-то другое делать
возможно там и прикрутят вайфудроч с ии быстрее всех
100% Local AI Speech to Speech with RAG - Low Latency | Mistral 7B, Faster Whisper ++
https://www.youtube.com/watch?v=VpB6bxh4deM
https://www.youtube.com/watch?v=VpB6bxh4deM
А хз почему коверкает. На обычном мистрале вообще сильно такое проявляется. Сильнее чем в файтюне. У меня оч сильное подозрение что на это влияют внутренние инструкции опять же. Если их обходишь то и сетка лучше пишет в других стилях , а не уважительном, токенов то вероятность лучше становится.
>Ласт годесс
>поиграли и бросили
Игру скачивают для дрочки, а там вместо голых девок - донатная карточная помойка. Естественно, это говно бросают.
И, разумеется, 3к онлайна там накручено, чтоб завлечь лошков-донатеров.

Что-то с кодом у ламы 3.1 70В совсем всё печально. Думал, может быть оно мне напишет VR сцену для three.js / babylon.js, а хуй там плавал. Даже с документацией помочь не может, с вопросами типа "что конкретно смотреть чтобы реализовать то-то или то-то", само придумывает классы и функции, которых там сроду не было. Максимум, что получилось добиться - высрало базовую сцену с шаром посредине и источником света хз где, но где-то снизу. Какая-нибудь модель в принципе в код может хотя бы на уровне "примерно подсказать куда копать", или таки придется самому всю эту залупу раскуривать?
У тебя xtc тут почти не работает, если что. Выше порога в 45% будет максимум два токена с почти равными вероятностями, и то, что ты с вероятностью 10% выкинешь больший, не решает.
Вообще из описания так и не понял, как этот сэмплер может приводить к чему-либо адекватному. Даже пример в описании демонстрирует шизу. https://github.com/oobabooga/text-generation-webui/pull/6335
Потому что если в контексте должен подходить гигантский медведь, то я не хочу видеть гигантский меч. Там бы не отрезать выше порога, а фигачить локально по надпороговым токенам температурой выше единицы. Вот тогда бы была и когерентность, и креативность. А так дичь какая-то имхо.
Если в датасете не было нужных технологий, то тебе только RAG с миллионным контекстом поможет.
> Смотрим в стим
Дальше можно не читать, тащемта. Если анализировать рынок порнухи по стиму…
> Релиз на консоли, мобилки и Китай для порнухи можно сразу исключать
На мобилках тонны виар-порнухи, дратути. Ты буквально отрезал 50% рынка, хотя они есть.
Даже не знаю, есть ли смысл отвечать, ты либо тотально не шаришь, либо троллишь.
———
Вышла https://github.com/gpt-omni/mini-omni модель qwen2-0.5b+whisper+че-то еще, все это замешано в мультимодалку.
Скорость ответа 0,7-1,3 сек, довольно быстро.
Но перебивать нельзя.
И язык только английский.
Proof of concept интересный.
Локалки в кодинге подходят только для автокомплита, для написания кода катит только клод или на худой конец гпт. Курсор, аидер, claude dev, вот эти штуки еще нужны, а не дефолтный чатик.
Во-первых проверь Жору и формат промпта, как показывает практика тут половина треда не может с этим справиться.
Во-вторых, бери модель для кода, DeepSeek-Coder-V2 сейчас топ, ебёт жпт-4 в кодинге.
Ну и как уже писали - модели не обязаны знать API твоего фреймворка. Жпт-4 не сильно далеко от ламы 3.1 ушла, и так же обосрётся на незнакомом API.
Клод только 3.5-Sonnet что-то может в коде, опус сосёт дико. Тот же жпт-4о даже у Мистраля 123В соснёт.
> модели не обязаны знать API твоего фреймворка. Жпт-4 не сильно далеко от ламы 3.1 ушла, и так же обосрётся на незнакомом API.
На чистом языке LLM пишут лучше?
> формат промпта, как показывает практика тут половина треда не может с этим справиться.
Sad but true.
Вообще, базу написал.
То, чего ллм не знает, она не сможет написать.
С документацией она сможет просто составить что-то, не лучше джуна с документацией же.
Когда встречаешь модели, которые шарят в твоем фреймворке — охуеваешь от разницы.
Помню, мику знала битрикс, я охуел от ее точности, когда Алиса/Гигачат/ГПТ-4 хуйню несли.
>На мобилках тонны виар-порнухи, дратути.
В официальных сторах порнуха запрещена, это сразу минус 90% аудитории. Фриков, которые качают откуда-то с итча и подобных сайтов, учитывать даже смешно, если мы говорим о широкой аудитории.
Тут хуже всего, что они довольно успешно мимикрируют и пишут псевдокод, который на первый взгляд выглядит верным, но никогда в жизни не скомпилируется.
Ну, а на ютубе порнуха запрещена, фриков, который сидят на порнхабе учитывать даже смешно…
Как-то так.
Хотя ладно, на ютубе эротика есть под видом мокрых маек.
Криво сравнение. Если бы у тебя по умолчанию на пекарне был только ютуб, на любое взаимодействие с видео открывался ютуб, при любом поиске видео - открывался ютуб. А на попытку зайти на порнхаб у тебя было уведомление, что недоверенный посторонний сайт заблокирован. И чтобы его посетить нужно было бы заходить в панель управления, находить настройки, разрешать посещение недоверенных сайтов и потом каждый раз соглашаться с уведомлением, что порнхаб может изнасиловать твою жопу и спалить все дикпики в интернет.
Люто надуманная хуйня.
Начиная от простых сайтов со стерео-видео, заканчивая простым соглашением об установке.
Так-то и при заходе на порнхаб некоторые бразуеры и большинство антивирусов кидает хуйню про «не пущу, согласитесь на износ жопы».
Так что сравнение вполне себе соответствующее.
У тебя просто какое-то странное искажение восприятия, не знаю уж, почему, может с мобилками не сложилось, а на компе антивирусов не было. Но факт есть факт, прон есть везде, у них есть деньги, они это все снимают и продают. И виар в том числе. И это работает. И стим тут нахуй не причем вообще. У всех свои рынки.
Ладно, мы че-то флудим не по делу, извините. =)


>какой-то конкретный план
У меня был какой-то план, и я его придерживался ©
>доказать, что вообще способен обучать модельки
Есть скрины чекаутов, лол код не покажу, стырите же.
Это больше похоже на дамп структуры модели.
>Whisper
Сразу мимо.
Нет конечно, слишком низкий уровень абстракции.
>А на попытку зайти на порнхаб у тебя было уведомление, что недоверенный посторонний сайт заблокирован.
Литерали ситуация, когда он был заблочен РКН, лол.
Можно в таверне отключить у квик реплая использование лорбуков?
Qwen2-VL, mini-omni… Обе запускаются локально, бегают шустро.
Че, скоро GPT-4o в каждый дом? До НГ такие проекты появятся интересно?
Кажется, я хочу 80 гигов врама, чтобы запускать омни-модели.
Qwen2-VL-2B забирает от 5,5 гигов (без картинки), mini-omni 4,5 гига (на базе-то Qwen2-0.5B)… А хочется на базе хотя бы 7B модели, хочется хотя бы флюкс в рисовалку, хочется…
Много что хочется, закатал губу, извиняюсь.
Всем добрых снов. =)
Че, скоро GPT-4o в каждый дом? До НГ такие проекты появятся интересно?
Кажется, я хочу 80 гигов врама, чтобы запускать омни-модели.
Qwen2-VL-2B забирает от 5,5 гигов (без картинки), mini-omni 4,5 гига (на базе-то Qwen2-0.5B)… А хочется на базе хотя бы 7B модели, хочется хотя бы флюкс в рисовалку, хочется…
Много что хочется, закатал губу, извиняюсь.
Всем добрых снов. =)
>А хочется на базе хотя бы 7B модели
Обрезки. Бери от 123B, лол.
>хочется хотя бы флюкс в рисовалку
Там же уже есть своя трансформенная нейронка, вроде как.
> Самые продвинутые в этом плане японские. Для того же VITS есть VAE, которые эмоции извлекают.
Можно подробнее, что за vae и какие vits. Желательно со ссылками.
Ты потом результат только выложи. А то как-то не хочется дубликат этого пилить с нуля.
>искажение восприятия
Оно просто строится на реальных цифрах, а не странных сравнениях. Порнуха это узкая ниша и пока не будет детабуирована, таковой и останется.
https://arxiv.org/pdf/2206.12040
https://rinnakk.github.io/research/publications/DialogueTTS/
Подробнее не будет, т.к сам я в этом не разбирался. У gmvae есть гитхаб, если будешь копать его, то вперёд.
>GPT-4o в каждый дом?
А смысл? Он тупой, как пробка.
Кто-то прикручивал нормальный адекватный RAG? Убил полдня на faiss только чтобы упереться в то, что на винде с поддержкой gpu ускорения его хуй соберёшь. И нахер он нужен тогда.
>faiss
Я собирал его на винде с gpu без проблем.
Только для моих задач поиска по документам как-то фигово работает.
Вообще сейчас есть
https://ollama.com/blog/embedding-models
https://ollama.com/library/nomic-embed-text
Все работает из коробки, не нужно ебаться с питон зависимостями для gpu.

Первая моделька, которая прошла тест «объясни смысл мема».
Кинул первый попавшийся, он простенький, но она справилась и это круто.
У них есть еще Qwen2-VL-72b, но она НЕ опенсорсная, а по API.
Кинул первый попавшийся, он простенький, но она справилась и это круто.
У них есть еще Qwen2-VL-72b, но она НЕ опенсорсная, а по API.
А есть в продаже что-нибудь вроде боксов под одну видеокарту? Вот думаю к своим теслам 3090 прикупить, да только плата рассчитана под 4 двухслотовые карты. Надо колхозить внешний корпус, райзер, удлинители для кабелей PCIe. Нет ли готового решения? Про внешние карты я знаю, но они стоят дорого и редки, а вот было бы готовое решение для обычной карты...
>Я собирал его на винде с gpu без проблем.
Ну хуй знает, он у меня генерирует .cu шаблоны, с которыми nvcc нахуй посылает, потому что код сгенерирован некорректный. Процессорный собирается влёт, но там же киллерфича, хранение индексов и ускорение поиска на гпу. Там и ишью уже больше года висит, что шаблоны неправильно генерируются.
https://github.com/facebookresearch/faiss/issues/2985
Нашёл бы его вчера, всё-таки собирал бы faiss, а так ещё три раза подумать надо. Так-то я не программист, ещё ебаться с этим всем.
>фигово работает.
А что так? Можно же настраивать размерность, если поиск неточный - делаешь больше.
>не нужно ебаться с питон зависимостями для gpu
Э? Когда собираешь ставишь флаг FAISS_ENABLE_PYTHON и всё, забыл про питон.
>Вообще сейчас есть
Хрома? В принципе, как вариант, конечно. Только, на сколько я понял, у хромы нет ускорения поиска на gpu, только для генерации эмбеддингов можно видюху запрячь.
А по qdrant че скажешь?
Кто нибудь юзал tensor-split в новой версии exllamav2? Сильно быстрее? Можно ли использовать с нечетным кол-вом gpu? Должны ли они(gpus) быть все одной модели? Снизилась ли зависимость для CPU? Будет ли работать при pci-e v3: x16,x16,x4,x1? Сильная ли разница между pytorch 4.2. и 4.4.? Я так понял 4.4 прилично дает буст в comfyui для flux(трансформер же).
Таблетки выпей.
Кто квену 0.5 дал доступ на двач?
Исправлюсь т.к. писал по памяти, не tensor-split, а tensor-parallel. И по версии торча 2.4 конечно же.

Дайте Regex скрипты для мышления.
>tensor-parallel
Тема-то хорошая, если сделали. А ещё контекст шифт интересует.
Это выглядит как бессвязный поток бреда.
Ну ебать, ну нихуя себе перепутал.
А потом еще на Квена гонишь.
С квеном 0.5 я угадал, только он может так проебать внимание и нихуя не понять. Что конкретно из написанного непонятно? Уточнение я добавил, а ответа кроме "ТЫ ПЕРЕПУТАЛ ААААА.." я не увидел, нахуй ты вообще ответил?
Разъясню для 0.5: Достаточно ли будет шины х1-х4 для параллелизма? Можно ли юзать нечетное кол-во gpu? (3, 5, капиш 0.5?) Снизилась ли зависимость инференса от CPU (сейчас зависимость от однопотока, т.к. питон ВНИМАНЕ работает в одном потоке, и если проц не оч и с низкой частостой, то инференс может быть ниже, чем с норм процом)? Про торч, я думаю пояснить не надо (там оптимизация была как раз для параллелизма).
Да, вроде, один из самых быстрых. Конечно, как и все остальные, сосёт у редиса, но что поделать, редиска просто читак. Подробнее не разбирался, гпу-ускорения тоже нет.
И ебать же, как много весят векторы. Пиздец просто.
https://pytorch.org/docs/stable/notes/cpu_threading_torchscript_inference.html
У торча есть мультитрединг. И в теории при эффективном распараллеливании можно получать вывод с почти линейным ростом производительности при увеличении количества GPU. Но кто так умеет, кроме майков?
Есть.
Occulink бокс и occulink-плата в комп.
https://sl.aliexpress.ru/p?key=0yaGrA3
https://sl.aliexpress.ru/p?key=tyaGrLq
>Occulink
Лол, впервые слышу об этом стандарте.
Вопрос к знающим людям, при выборе видеокарты главное это VRAM? Я на реддите видел комменты людей, которые писали, что якобы 4060 Ti (16Gb) очень медленная для inference. Это правда? Просто 4070 и 4080 уже очень дорогие, а 4060 еще терпимо для меня, но при этом не хочу выбросить деньги на ветер. Условный мистраль немо, я смогу гонять хотя бы на 15-20 т/с на 4060?
В целом да, хотя есть свои нюансы. Чем больше врам и чем она быстрее, тем лучше. У 4060 дырявая шина на 128 бит и какие-то жалкие 280 пропускных гигабитов. Брать ее можно только в том случае, если тебе нужна именно новая карта с полочки и в коробочке.
>Условный мистраль немо, я смогу гонять хотя бы на 15-20 т/с на 4060?
Да и может быть даже быстрее. Но тут вопрос в целесообразности покупки, так как за 50 тысяч можно что-то более выгодное найти на вторичке.
>главное это VRAM
В основном да. Объём и скорость, скорость и объём. У 4060 Ti шина порезана, и скорость памяти дно.
> за 50 тысяч можно что-то более выгодное найти на вторичке
что например?
я думал брать 3090 на вторичке, все-таки 24 Gb VRAM, но она стоит в 2,5 раза дороже чем 4060
> У 4060 Ti шина порезана, и скорость памяти дно
что посоветуешь выбрать?
две теслы p40
На самом деле всё проще чем ты думаешь. Выбираешь любую карту которая тебе приглянется и смотришь на ее характеристики. От 12 гигов памяти + шина минимум 192 бита - это минимум для комфортного запуска мелких моделей типа мистраля немо.
>но она стоит в 2,5 раза дороже чем 4060
Это того стоит.
Если тебе только под LLM, то даже RTX 3060 12ГБ будет лучше, лол.
> то даже RTX 3060 12ГБ будет лучше
шина быстрее?
> шина минимум 192 бита
я так понимаю 128 бит у 4060 это совсем плохо
У 3060 пропускная 360 метров в секунду, у 4060 петуханские 260. Плохо это или хорошо... Ну подумай.
меня смущает только 12ГБ видео памяти
придется оффлодить в процессор, тогда более быстрая шина уже не сильный фактор против карты с 16ГБ, в которую можно все слои засунуть в vram
это я понял, но насколько это важный фактор, если все равно не получится всю модель загрузить в карту?
или я что-то недопонимаю?
Ты изначально писал, что хочешь взять 4060ти на 16 кило, которая стоит около 55 тысяч. Для сравнения 3060 на 12 стоит всего 30, но думаю ты это и так знаешь. Если ты готов переплачивать за воздух и кривые ручонки зеленых пидоров, то дело твое.
>насколько это важный фактор, если все равно не получится всю модель загрузить в карту?
Объясню иначе - прирост по производительности не соответствует разнице в цене. Ты готов заплатить в два раза больше за 4 гига медленной памяти? Да, она будет быстрее, чем слив в оперативку, но платить на 25 кусков больше по мне так сомнительно. Лучше мне эти деньги на карту перекинь за консультацию.
я скорее считал, что переплачиваю за доп. 4ГБ vram
насколько я понимаю, что если заоффлодить даже 10% слоев на проц, то скорость упадет драматически
ты уже ответил пока я писал
>насколько я понимаю, что если заоффлодить даже 10% слоев на проц, то скорость упадет драматически
Драматически она не упадет, будет как раз разница в те же 10-20%
сопля ебаная иди нахуй со своей капчей
>придется оффлодить в процессор
>Условный мистраль немо
Не нужно, лол.
>сопля ебаная иди нахуй со своей капчей
Купи пасскод.
> Не нужно, лол
почему не нужно?
в Q8 (даже Q6) + хотя бы 16K контекста точно не влезет
>Не нужно, лол.
Начинаем урок математики. Восьмой квант весит 13 гигабайт, в 3060 всего 12. Даже без учета контекста нихуя не влезает, а брать ниже восьмого кванта на дерьмовой модели это долбоебизм.
Не куплю.
Хуя как шиза бомбит.
Сочувствую.
Мне недавно чел скинул тесты, если он не лоханулся нигде, то там в кобольде у немо q8 16-19 токенов/сек.
Выглядит удобоваримо, но медленно (как 1070 в паре).
Т.е., ответ на твой вопрос: да, сможешь.
Люди ратуют за покупку 3090 за 50к (с доставкой и убитых в хламину, вероятно).
Где-то в Мск такие продаются. На свой страх и риск, можешь заказать.
Немо в 6 бит влезет в 3060, так что да, заметно дешевле.
Но нахуя тебе q8? Т.е., качаешь exl2 на 6,4bpw или 6bpw и радуешься жизни. Тупеет не критично, влазит целиком с 8к или даже 16к контекста.
Норм? Норм.
>давай братан ужми меня до 6 бит, я тупею, но совсем чуть-чуть
Тесты притащишь, или ты своим юзер экспириансем делишься?
> 16-19 токенов/сек
не так плохо
я так понимаю в 3060 были бы все 25
В 5 битах и 8к лезет целиком, проверял.
>а брать ниже восьмого кванта на дерьмовой модели
Размер рекомендуемого кванта не зависит от дерьмовости модели, только от размера. И 5 бит должно быть достаточно. Я так вообще в 3-х гоняю 123B.
>Размер рекомендуемого кванта не зависит от дерьмовости модели, только от размера.
Под дерьмовостью я как раз и имел ввиду размер, ес чо ок да.
>И 5 бит должно быть достаточно.
Мелкие модели на любых квантах ниже восьмого необратимо тупеют и начинают шизить. Проверял на второй и третьей ламе, квене, мистрале и айке.
>Мелкие модели
Там 12B как бы, не такая уж и мелкая. Не 3 и даже не 7.
> Своп на другом диске
Тогда странно, если только выгружаешь что-то на нвме. Большой диск который ебут сетки и прочее имеет всего 350т записей и 97% здоровья, но там именно что много дичи а не просто ленивые катки ллм.
> если пилится под одного пользователя и этот пользователь - ты сам
Тут уж или по-человечески чтобы себе любимому было комфортно, или сонсольный интерфейс, который и легок и также может быть очень удобен, (привет vim). Ну типа не маялся бы хренью а взял готовые либы на интерфейс, сосредоточившись на внутрянке. А то как в анекдоте, все уже все сделали а Вася ебется с переполнением стека рисованием в буферах, при том что базового необходимого функционала нет.
> начал вопросы про солнечную систему
Не, в таких случаях даже если в начале там полнейший треш, на последние вопросы сетка может нормально отвечать. Весь интерес в том как произойдет стык старой части что остается в начале или что поменялась, и новой, которая сдвинута, ведь она изначально считалась с учетом других токенов в начале.
> "Повреждёнными" будут токены на границах последовательностей
Не, там будут все что дальше, офк чем ближе к стыку тем серьезнее. А так даже десяток поломанных токенов в области максимального внимания могут делов натворить, но это можно решить отодвинув область стыковки.
Надо нормально выспаться, конечно, но посмотрев внимательно математику кажется что оно будет приводить только к накоплению ошибки, которая может быть как умеренно заметной и быстро выйдет в ассимптоту, или оказаться существенной и после определенного момента там пойдет совсем ерунда. Прувмивронг, может и ошибаюсь и только за буду, хочется иметь подобную фичу чтобы действительно хорошо экономить на контексте без серьезных подводных.
От 7 до 13 считай что мелкие. Ниже 7 это уже крохотные огрызки. То что ты большой мистраль гоняешь в 3 кванте это в целом приемлемо, но безопасно квантовать можно только модели хотя бы среднего уровня с 20-30 лярдами, там действительно деградация ощущается меньше.
Че там какие параметры выставлять надо?
> между pytorch 4.2. и 4.4
Там где юзаются новые фичи - в пару раз, в том числе пропадают пики потребления врам. Но только в отдельных задачах, в остальных без изменений.
> но безопасно квантовать можно только модели хотя бы среднего уровня с 20-30 лярдами
Дискуссионно на самом деле, уровень возмущения логитсов не то чтобы сильно зависит от размера, если исключить радикальные случаи.
До прихода двух P104-100 сидел на игровом, тут 12 гигов. Были 6, 6,4, 6,5 bpw.
Потом пересел на q8_0.
Какой-то критической разницы не почувствовал, если честно.
Если ты не занимаешь чем-то очень важным (а на немо вряд ли будешь прогать, когда есть дипсик-кодер), то в общем похуй, ИМХО.
Могу ошибаться, это субъективное мнение.
Ну и тесты, да, ппл все дела. =)
Учти, что это был ггуф, на exl2 может быть быстрее.
И учти, что на 3060 у тебя q8 не влезет, там будет квант поменьше — поэтому, естественно, по-быстрее.
Так что, это все довольно относительно. На 16-19 токенов точно можешь рассчитывать. А там уже и повыше, да.
На самом деле, для рп весьма комфортно, конечно.
Согласен, но 8б и 12б — разница в полтора раза. Там между 8 битами и 6,5… не все так плохо получается.
Напомню, в треде есть чел с qwen2-1.5B-q4_K_M. =) Или 0.5B, не помню точно. Я не знаю, почему не q8_0.

>Дискуссионно на самом деле, уровень возмущения логитсов не то чтобы сильно зависит от размера, если исключить радикальные случаи.
Дискуссионно как и всё что касается локалок. Но в свое время мне удавалось запускать командора на четвертом кванте с дробными токенами в секунду и ощущения что модель кастрирована не было. В отличии от той же ламы три восемь где разницу между 4 и 8 квантом можно было легко заметить во всех задачах.
Но может быть у меня шиза. Может быть.

И, мое личное мнение, что RTX 4060 ti 16GB удобна объемом, но дорога. Скорость еще куда ни шло, можно стерпеть, но +33% объем и -33% скорость (утрировано, конечно) — за почти вдвое больший прайс… 3060 12GB ты можешь купить за 20-25.
Так что, из этих двух я бы выбирал 3060. Как говорится…
Так что, из этих двух я бы выбирал 3060. Как говорится…
>Напомню, в треде есть чел с qwen2-1.5B-q4_K_M. =) Или 0.5B, не помню точно. Я не знаю, почему не q8_0.
Очевидно что капчует с цифрового блока микроволновки. Шапка треда оказалась пророческой.
Берите P100 за 20к, пока есть. Под тот же Мистраль Немо самое то. Можно gguf, а можно и exl2 - да всё что угодно можно. По сути сейчас это единственный вариант. Вот две уже сомнительно, а одну под мелочь до 12В - лучше не найти.
Сейчас кстати на Авито есть предложение за 15к. И не говорите, что вы не слышали(c).
Можно интерпретировать с точки зрения большей толерантности к странным токенам, которые с большей вероятностью полезут в более низких квантах. Старые франкенштейны тут хороший пример, там реально более мелкий квант лучше катался чем большой. Но насколько это измеримо - хз.
Тут, кстати, разные варианты семплинга могут хорошо играть, с одними вообще не заметишь отличий, а другие наоборот будут сильно подчеркивать возмущения и шизить.
> две уже сомнительно
Под 30б с большим контекстом норм.
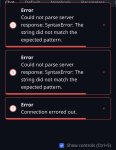
Коллаб перестал работать.
Соглашусь с другими анонами , бери Tesla P100 пока есть в продаже (на Avito). Она немного быстрее P40, только памяти будет 16 Гб. Колхозные бенчмарки обоих выше постили
Колабер на связи!
С кодом колаба всё ок. API тоже работает без проблем.
Но похоже всралось gradio.live, слишком хуёвый пинг и нарушается связь с колабом. Возможно тут даже гугол подсерает, они вообще не очень любят, когда их сервис юзают для запуска веб-интерфейсов.
Могу конечно прикрутить сверху ещё localtunnel, но он ещё более всратый, чем gradio.
Надёжнее всего юзать колаб из таверны через API, а если такой возможности нет то жаль, жди пока gradio поднимется

Рефлекшен уже щупали? В задачке с капустой безошибочно знает что делать. В целом по логике ебёт адово, надо ещё CoT тестить, оно под него тренилось. MMLU 90, жпт-4 уже за щеку принимает.
>350т записей и 97% здоровья
Да у этой хуйни паспортная запись 480ТБ, из которых 300 уже потрачено. Терабайтный диск.
>Ну типа не маялся бы хренью а взял готовые либы на интерфейс
Так я на него время не трачу практически, кроме того, что он нормально не поддерживает быстрые рефреши. Накидал квадратных кнопок и готово. Внешний вид меня устраивает на данном этапе. Функционала на самом деле раза в два-три больше, чем отображается в интерфейсе.
>Весь интерес в том как произойдет стык старой части что остается
А ты никогда и узнаешь, как она произойдёт. И где. Если не выводить дебаг, конечно.
>А так даже десяток поломанных токенов в области максимального внимания могут делов натворить
И тут мы вспоминаем, что 90%+ внимания модели это первые три-пять токенов в начале промпта. А начало промпта у нас заморожено. И все остальные токены полагаются на эти "замороженные". А самое классное, кто вообще сказал, что при таком шифте нельзя делать полный пересчёт для обнуления ошибки? Будут проблемы - можно сделать полный пересчёт каждые N шифтов. Ещё и N подобрать до возникновения серьёзной погрешности и пересчитывать после инференса, а не до, чтобы не ждать после submit никогда.
Какой квант?
В математике похоже всё же Жора серит, всё так же в дроби скатывается и путается в числах. Но в логике действительно огромный шаг вперёд. Они ещё обещают скоро 405В выкатить, которая будет лучшей LLM даже среди закрытых.
Чувак, очевидно что это ты один, давай напрямик: за 12к договоримся? =D
Ллама-3.1, что не очень хорошо, но формат обучения под синкинг — база, конечно. Ничего удивительного, надеюсь войдет в мету.
А как это — не выводить дебаг? О_о
Вот 405б это уже интересно.
Еще бы и 123б до кучи.
Там на серьезных задачах может быть огого как пиздато все. Ждем, надеемся, верим.
> Ллама-3.1, что не очень хорошо
Если без Жоры, то норм. Да в принципе и Жора норм, пока числа не достаёшь.
> Еще бы и 123б до кучи.
Вот это нам не надо, она и так лупится, а от тюнов на логику вообще ёбнется.
До сих пор кекаю с того какой популярной и эффективной получилась моя идея разделения ответа сетки на внутренний диалог и речь, собственно то что все сейчас используют и знают под видом <thinking>
Даже сетку о обучили, забавно
> моя идея
CoT существовал ещё до выхода первой лламы.
>Вот это нам не надо, она и так лупится, а от тюнов на логику вообще ёбнется.
Надо, ещё как надо. При всём уважении к Лламе 3.1 70В после выхода Магнума я на неё смотреть не могу. Тупо больше параметров - сетка заметно больше смыслов может понять и использовать. Это волшебно.
Кот существовал, эта техника нет
> Кот существовал, эта техника нет
А в чем отличие твоей техники от CoT?
мимо
А в чем отличие цепочки мыслей от дерева мыслей?
Просто тот же кот, да?
Чел, это CoT и есть. Рефлексия - прямое развитие CoT. И про рефлексию ещё полтора года назад была публикация, коту вообще 3 года уже. То что ты выдумываешь - шиза.
https://arxiv.org/pdf/2303.11366
Если твое понимание техник мышления ограничивается "это просто разные варианты кот", то ты прав
>моя идея
Нет моя!
идея хуйня, ей богу. Идее термояда уже 50+ лет, а воз и ныне там.
Реалиазация - вот что важно
Реалиазация - вот что важно

Шизло, нахуй сходи.
Шизло, нахуй сходи
Ну, на текущий момент рефлекшн лупится вообще в 50% случаев, вся моя лента в тг в скринах. =)
Ну, хуже уже не будет…
> на текущий момент рефлекшн лупится вообще в 50% случаев
Ты из тех кто не может настроить формат промпта на ламе? Даже в рп нет проблем на рефлекшене, я даже пенальти выключил. До лупов Мистраля ещё далеко.
> в 50% случаев
Заявление про то что половина треда не может справится с ламой оказывается и на практике подтверждается. Грустно что быдло банальные вещи осилить не может и лезет к нам.
Нет, не из тех. Я седня вообще не добрался еще, на работе завал.
Но пишут слишком много человек, хз. И многих знаю, вроде не глупые ребята. хз-хз
Кстати, модель была ломанная, ее перезалили, вроде, пару часов назад. Просто сообщаю, что слышал.
Там только токенизатор для трансформерсов был кривой. У гуфа от ламы нормальный был.
Если кому интересно, то не берите 4060 Ti, я изучил вопрос, даже нашел людей с этой картой. Лишние 4Gb того не стоят. 3060 тоже решил не брать, лучше доплачу за 3090. Походу лучше предложения нет и пока не будет.
Там были фиксы токенов <reflection>, но сейчас оно наоборот сломалось. Так что первые гуфы самые рабочие пока. И к лупам это никакого отношения не имеет, это всё же шизики ламой не умеют пользоваться.
Да там вон уже Гусь пишет что нихуя не работает, хотя в их демке нет проблем. Ждём фиксов, что-то они намудрили там с токенизатором/эмбедингами в выложенной версии.
Только не забывай что 3090 прожорливая. Не забудь нормальный блок к ней взять и в целом помучай ее перед покупкой в тестах. Но это чисто универсальный совет для любой карты со вторички.
> паспортная запись 480ТБ
> Терабайтный диск
Что-то там совсем хлебные крошки вместо памяти.
> Функционала
Самый базовый чат-релейтед же, без пердолинга с внутрянкой.
> никогда и узнаешь, как она произойдёт. И где.
Всмысле не узнаешь, оно заранее известно. Можно проанализировать значения, можно попытаться сформировать тесты и их прогнать.
> 90%+ внимания модели это первые три-пять токенов в начале промпта
Не передергивай, важна вся инструкция и формулировки в ней.
> можно сделать полный пересчёт каждые N шифтов.
Можно тогда вообще отказаться от него и иметь буфер для заполнения. Такое уже сделано, просто через жопу что нет норм настроек.
Какая техника, подзалумная хуеборина с кривейшей реализацией на 7б мусоре, которая просто давала рандомную вариацию перед ответом и никак его не улучшала. Спокнись уже, шизик с манией величия.
> и на практике подтверждается
И смешно и грустно, но выглядит именно так.
Но лламы тут причем… на голых трансформерах же тестируют. =)
Ггуфопроблем там нет по причине отсутствия ггуфа.
Ну как тебе и сказали, в итоге.
+
И даунвольтнуть может быть не самой плохой идеей, на самом деле.
Быстрофикс.
А, ты базовую модель имеешь в виду.
Ето возможно, ето да.
> на голых трансформерах же тестируют
Как видишь добаёб Гусь тестирует на каком-то говне vllm, который генерирует хуй знает какой промпт.
Спокнись уже, шизик с манией величия.
Высрал свое важное мнение, эксперт? Кек. Скилл ишью, шизик, у меня все работало и работает по сей день. Судить о работе по примерам которые кидались в тред, 150icq
ну че как рефлекшн для кума ептыть
Ты чего грызаешься, запросил фуру хуев - принимай. Поехавший варебух с кривым промтом в кобольде на 7б модели гонял шизу с AGI Thinks над которой насмехались, а теперь решил опять вылезти, залезай нахуй обратно.
> Судить о работе по примерам которые кидались в тред
О чем тут судить, по всем признакам пациент палаты душевно больных без каких-либо способностей начинает срать в треде "какой я гениальный все предсказал а еще у меня идею украли". Здесь двойной трактовки быть не может, все предопределено.
Вот для таких убеков как ты я и не кидал сюда реальный промпт, разве что в самом начале когда он был сырым.
>кривым промтом в кобольде на 7б модели гонял шизу с AGI Thinks
О чем ты и пиздишь, забывая маленькую деталь - я показывал что этот промпт работал даже на 7b лламе 1, самой тупой хуйне что тогда можно было взять.
Разумеется чем умнее сетка тем лучше он работает, особенно сейчас год спустя, когда сетки стали в разы лучше.
Но знаешь в чем самое смешное? Ты и подобные тебе дурачки так и будете сидеть дрочить в кулачек, потому что я уже тогда знал с кем тут сижу и кому не хочу помогать
Я объяснял пару раз после этого как именно может работать промпт и давал специально упрощенные примеры, и на этом собственно все
А свои маняфантазии о том что я там делал и кто над кем насмехался оставь для своего убеждения, кек
Сколько оскорблений, и все для чего? Показать свою ущербность и сильное желание насолить мне? Я и так знаю с кем тут сижу

>А как это — не выводить дебаг? О_о
А зачем он нужен, если всё работает? Настроил, подкрутил, выключил.
>Самый базовый чат-релейтед же
Cамый базовый чат-релейтед давно есть. Да, по сути, уже и не базовым обрастаю.
>Не передергивай, важна вся инструкция и формулировки в ней.
Всё до нас изучено и разжёвано. Важна, но не настолько, насколько важные первые несколько токенов.
https://arxiv.org/abs/2309.17453
>In traditional models, the first token often receives a disproportionate amount of attention—dubbed an "attention sink." This phenomenon arises because the SoftMax function, used in calculating attention scores, ensures that these scores sum up to one across all tokens. When many tokens aren't strongly relevant to the context, the model still needs to "dump" attention somewhere—often on the first token, simply because it's globally visible from any point in the sequence.
>Можно тогда вообще отказаться от него и иметь буфер для заполнения.
Так у меня, по сути, и так буфер. Или я не понял, о чём ты. Просто реализовывать круговой буфер было лень, но для звука пришлось, а периодическое смещение самое оно. Я больше думаю об обрезке по предложениям, но возни слишком много. Будет не лень, сделаю сравнение близости векторов полного пересчёта и шифтов, это уберёт вообще все вопросы. Вангую разницу в пределах погрешности.
Не трясись так, а то санитар прознает и опять идею украдут. Тыж эталонный шиз с ворохом расстройств, трясешься над "реальным промтом" серьезно веря в его ценность, опасаешься своих врагов, которые окружили и тебя подсиживают а то еще сорвут реализацию аги на коленке на 8б модели!, и на уверенных щщах считаешь себя крутым первооткрывателем. Счастья в неведении, был бы чуточку умнее - понял бы степень кринжовости сего действа.
> и все для чего?
Для чего тыкают палкой в труп? Для чего смотрят на фриков и уродцев, раньше в цирке, сейчас в шортсах? Тут уже к антропологам.
> Cамый базовый чат-релейтед давно есть
Может быть, просто его не видно и выглядит хуже чата кобольда.
Пример здесь не совсем про это, ведь там буквально объясняется причина конкретного примера
> When many tokens aren't strongly relevant to the context, the model still needs to "dump" attention somewhere
В случае же конкретных задач, что рп, что нлп, у тебя в начале накидана подробная инструкция и примеры и на них всегда будет большое внимание, а не просто на несколько первых токенах. Аналогично и ошибки там вносят огромный импакт на конечный перфоманс.
> Или я не понял, о чём ты.
Никакого стриминга, смещений и подобного, просто заведомо выделять на Nк контекста больше, в современных моделях это не является проблемой как раньше. И при поступлении новых данных просто использовать запас, по исчерпанию которого делать сдвиг на уровне теста/токенов и пускать пересчет.
Но класть это полностью на бэк в сочетании с каким-нибудь привычном фронтом типа таверны - такое себе, нужна их совместная работа (или можно чисто на фронте реализовать). Так можно получить наилучший экспириенс, но все это сработает только для случая простого чата без изменений в глубине.
> Я больше думаю об обрезке по предложениям, но возни слишком много.
А вот это приведет к шизе и отупению, неспроста таверна уже с самого создания умеет правильно обрезать старые посты и аккуратно формировать промт без вот этих вот кусков.
Что по карточкам не от хуанга, они хуже работают с нейрсоетями или как? У какого-нибудь Intel Arc A770 или радевона rx7600 16гб врама а цена почти на 20к меньше чем у 4060 с теми же 16гб. Если новые рассматривать а не отмайненные с авито, естественно.
Кек, как ты сильно хочешь вывернуть наизнанку все что я сделал и сказал, переврав все в свою пользу
Дурачек это ты? Я с таким же шизиком тут 2 раза недавно срался, те же приемчики
Учитывая то количество усилий и внимания которые ты уделяешь этой теме, трясешься ты там знатно
>Не трясись так, а то санитар
придет и укусит тебя за бочек
>выглядит хуже чата кобольда.
А какая разница, как оно выглядит? Внешний вид вообще поебать.
>у тебя в начале накидана подробная инструкция и примеры
И всё равно атеншн на первых токенах. С Жорой, скорее всего, это зависит от размера батча и при батче в 512 токенов лучше ровно столько с начала и не трогать. Опять же, в случае РП - инструкции, карточка и примеры диалогов должны помечаться, как "хранить вечно", так что вся проблема выдуманная.
>по исчерпанию которого делать сдвиг на уровне теста/токенов и пускать пересчет.
Ну так это хуйня, чел. Так оно работает по дефолту. Это медленно.
А если по токенам удалять? Тогда, в теории, модель ебанётся сразу после первого десятка сдвигов, да? У Жоры в сервере, кстати, есть такой шифт. И у меня такой же. Ни малейших проблем не замечаю. Я ещё не тестировал в рп, но в обычной беседе с нейросетью не проявляется никак.
Однажды в кумотред явился шиз с манией величия, утверждающий что "написал 5 божественных слов, которые обходят цензуру любой ЛЛЛ модели", но никому их не покажет, т.к. все недостойны это увидеть.
Это же был ты да?! Узнал по шизойдным высерам!
я ещё тебя, помнится, в колаб-умер-треде встречал, до сих пор с твоих "10 строк кода" проигрываю
трясь трясь
тихо малыш, сходи подрочи и все пройдет
>А если по токенам удалять?
Пока остается остальной контекст, удаление начальных токенов не сведет сетку с ума. Но если в начале стерты какие то важные примеры или инструкции то сетка будет лишь писать какое то подобие того что тебе нужно, продолжая угадывать по оставшемуся контексту
Нет, одновременно получаю удовольствие от поругания плохого-убивающего и создаю тебе не комфортную обстановку чтобы реже срал шизой.
> то количество усилий
Ага, на размер постов и количество проекций посмотри, мусор.
> за бАчек
Зачем?
> выглядит
Нет кнопок редактирования, форков, свайпов, и прочего базового, поэтому. Эстетика ультрапиздецовая, но уже вкусовщина, просто удивило зачем вообще тогда много возни с гуйней на которую жалуешься если можно сделать лучше в сонсольном интерфейсе. Ну это так, если там что-то планируется то смысл есть.
> И всё равно атеншн на первых токенах.
Во-первых, показывай. Во-вторых - всеравно оно поломается если будет ерунда даже в паре сотен токенов от начала.
> Так оно работает по дефолту.
Нет, по дефолту оно буквально имеет буфер на максимальный размер генерации и при наполнении контекста каждый раз его будет пересчитывать. Если же сделать его увеличенным и изменить парадигму использования, то пересчет потребуется только раз в 5-10-... постов, причем он может выполняться в фоне после генерации сообщения или, например, когда юзер насвайпался и начал писать свой ответ. Вообще, для этого никаких изменений в бэке не нужно, все делается самой таверной.
> медленно
только на жоре
> А если по токенам удалять?
Не не, тоже херня. Чтобы все работало хорошо, на входе у модели должен быть четко сформулированный и оформленный промт, где будет базовая инфа с инструкцией, описанием чаров и т.д. и т.п., потому суммарайз предыдущего, потом подряд посты и, наконец, задача написать ответ таким-то образом. Можно дополнительно с префиллом, всякими конструкциями и т.д. и т.п.
Если у тебя будет вместо этого внезапный обрыв и просто рандомный кусок предложения без оформления - это сразу сыграет в минус. Кое как оно отвечать будет, но поломки форматирования, лупы и все то на что тут жалуются полезет.
> Тогда, в теории, модель ебанётся сразу после первого десятка сдвигов, да?
Это не связано с шифтами и т.д., это базовый промт инженигринг, а уже под него должно все подстраиваться. Но да, у жоры в сервере есть базовый функционал чтобы не просто рандомно резать а сохранять последовательность. Тем же и убабуга занимается, на что недавно какой-то поех жаловался.
Мусор это ты дурачек, так как весь этот срач с оскорблениямм начал отнють не я
Просто у тебя чсв жмет и жопа горит когда что то не сходится с твоим манямнением
Оттого эти высеры с переводом стрелочек, оскорблениями и другими манипуляциями
Бля, походу реально ты.
Ну что, обнародуешь уже свои гениальные слова или строчки кода? Всё равно не актуально Или это всё был пиздёж? прямо как сейчас
> весь этот срач с оскорблениямм начал отнють не я
> Ррррееее яжеговорил
> ага смотрите моя идея
> моя идея, моя, я еще давно это предсказал!
@
> спокнись шиз
@
> ррреееее это вы все негодяи с манией величия срачи разводите
Кстати, сохранились его переписки с бедной нейронкой, которая терпела его шизу про аги, развитие технологий и прочие фантазии, который он скидывал в качестве демонстрации. Там прямо отборный треш, а то что он воспринимал за достижения - лупы.
Эт не я, но если б знал все равно не сказал
А за пиздеж нужно доказывать, прежде чем кидаться какашками
Но видимо кидаться интереснее
Ты опять на связи шизик? Ну смотри, ты опять пиздишь выворачивая и перевирая все
Тыж тупо конченый, сходи потрогай траву
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
>удаление начальных токенов
Я таки заебался одно и то же писать. Начало промпта морозится всегда и везде, а важные инструкции в начало и пихаются.
>Нет кнопок редактирования, форков, свайпов, и прочего базового, поэтому.
Форков нет, потому что не нужны. Свайпы это даже не второстепенная фича, третьестепенная. Но они давно есть. У меня сейчас первоочередная задача - одноразовые посты, которые удаляются после однократного инференса. Это чтобы ты понимал приоритеты. Делать всё в консоли можно только если ты поехал кукухой.
>Во-первых, показывай.
Я ссылку на архив орг принёс, тебе мало?
>где будет базовая инфа с инструкцией, описанием чаров и т.д.
Пиздец, и этот туда же.
>в случае РП - инструкции, карточка и примеры диалогов должны помечаться, как "хранить вечно"
А задача "написать пост" обычно ставится в начало. В целом, проблемы нет поставить в конец, я, скорее всего, к этому и приду, чтобы поддерживать многоперсонажные диалоги.
>Это не связано с шифтами
Напрямую связано. А вот промпт инжиниринг к шифтам уже никак не относится.
Нечего перевирать, все посты выше и с ними от того что ты - поехавший шизофреник никак не отвертишься.
> Тыж тупо конченый, сходи потрогай траву
Трогаю ее чаще чем ты. Часами мучает модельку шизоидными рассуждениями о технологиях, которые понимает как сказку, а еще что-то про ирл говорит, вот это лолита. Космос уже колонизировал, напечатав себе космический лифт?
>Кстати, сохранились его переписки с бедной нейронкой,
Ты что тсундере? Это твое "я не трачу на тебя свое внимание, бака"?
Ну кидай, раз не лень искать было
Я уже и забыл че сетки раньше писали
Вот додик, ты ведь опять перевираешь и вырваешь из контекста и считаешь что это нормально, кек
Неси пруфы, ссылку на посты
Посмотрим че там и как, или зассал?
>А за пиздеж нужно доказывать, прежде чем кидаться какашками
Бремя доказательства лежит на спизданувшем
>Эт не я
Не верю что может существовать два таких ебаната.
>Я таки заебался одно и то же писать. Начало промпта морозится всегда и везде, а важные инструкции в начало и пихаются.
И в апи на сервере жоры? Я просто скриптом когда то отправлял обрезаный прям в начале контекст и вроде работало
Ендпоинт забыл, не чат комплишен который
Ну так пусть дурачек который говорил что все хуйня и это не работает тащит пруфы
Похоже в кончай треде тоже есть какой то адекват, но сидеть там конечно мда
Какие чудеса ментальной эквилибристики. Сначала шизик рассказывает про "его идею". Потом морозиться и перекатывается о том что "вася не дурак он специально никому ПОЛНЫЙ ПРОМТ не показывал". В итоге скатывается до "вы не доказали что оно не работает а значит все сказанное мной - истина".
Так ведь хуню ты первым притащил, тебе и доказывать её нихуёвость.
А называть хуйню хуйнёй, пока не доказано обратное, это нормально.
Чудеса тут показываешь только ты, кек
Где пруфы билли?
Раз ты нашел старые посты то просто принеси ссылку а не виляй жопой раз за разом играясь со словами и переводя стрелочки

> Где пруфы билли?
В голосину с этого шизика, уже все ебало в собственном дерьме а он требует запруфать.
Ага, нахуй пошел, стрелочник
Так твое же ебало в говне, кек
Тащи упомянутые тобой пруфы, или зассал?
Пикча бессилия, мдэ
> Врети это нутелла! Аги близок и он всех покорает!
В голос с шизика.
Вот пост с которого все начинается, зарывайся поглубже не забыв задержать дыхание. Вот еще шиза про "особую технику" , а вот отсюда уже пошли маневры и перекаты с отчаянным копротивлением. На все посты где поеха спускали с небес на землю он только огрызается.
В итоге что? Приписывает себе авторство чего-то и на полном серьезе считает достижением свою шизу от декабря 23 года (которая сохранилась если пройти по архиву тредов), когда cot был уже не просто везде а заложен в тренировку. В то же время он игрался с мусорными моделями и восторгался лупами с повторением целых предложений, фантазируя об особой технике. Одних вопросов
> Master: Переделай прогнозы на основе существования развитых технологий ии, термоядерных реакторов и свободных полетов в космосе. Ну и каких нибудь наноассемблеров или продвинутых 3д принтеров.
уже достаточно чтобы приговорить тебя в дурку.
Доказательство «от противного» (лат. contradictio in contrarium), или апагогическое косвенное доказательство[1], — вид доказательства, при котором «доказывание» некоторого суждения (тезиса доказательства) осуществляется через опровержение отрицания этого суждения — антитезиса[2]. Этот способ доказательства основывается на истинности закона двойного отрицания в классической логике.
> стрелочник
Ссу на ебало
мимо
Как выше писали, могло просто подхватить из того, что ты ей скормил. А вообще хуй знает на самом деле, сам понимаешь - хуй знает что отправил хуй знает куда, но, вроде, работало. Обычно начало промпта статическое и содержит всю инфу про персонажа, инструкцию и т.д.
Не читал но осуждаю
Но судя по отсутствию ссылок на старый тред, но с копией вырванной из контекста из нужного сообщения
Ты обосрался дать ссылку так как она сыграла против твоего пиздежа, опять вырвал из контекста и опять оскорбления и другая хуйня
На сколько же низкая у тебя самооценка, с таким сильным желанием повышать ее за счет других?
Ну и в конце концов ты обьявляешься опущеным пиздоболом, вот и все
Ты был веселым клоуном анон, но отказ работы с пруфами которые у тебя на руках - доказательство твоей слабой позиции
Если у кого то вобще были такие сомнения, после всех твоих виляний задницей
> вырванной из контекста
Дура уже лупиться пошла, тебя буквально опускают первой же ссылкой на твой пост в этом треде, а ты про вырвано из контекста визжишь, мусор. Jedem das seine, твой удел - фантазировать на аиб о том что чего-то достиг и пытаться оскорблять остальных, на большее не годен.
Какой скор у ламы рефлекшн на арене?
парни чет с месяц не сидел в тредах, сейчас сижу на лунарисе 12в.
есть ли что то более вкусное с таким же размером?
есть ли что то более вкусное с таким же размером?
Почему никто до сих пор не сделал аналог «русских» чат-ботов, в то время как таких иностранных сервисов куча? Даже не обязательна русская языковая модель — можно переводчик вкрячить, да и некоторые по-русски неплохо говорят.
Слишком дорого? Гэбня забанит и напихает бутылок в задницу?
Слишком дорого? Гэбня забанит и напихает бутылок в задницу?
>Почему никто до сих пор не сделал аналог «русских» чат-ботов, в то время как таких иностранных сервисов куча?
Без кума неинтересно, а порнография в РФ запрещёна законодательно. Тем более лоли, а они там будут в количестве.
>рефлекшн
еблан это враппер
Там короче селф авер модельку выкакали. Иду потестирую (на кумслопе конечно же)
ссылку




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: