


Aya-Expanse-32B на q6 — неблохо, неблохо. Иногда прорывается соя, но, в целом, с хорошим промптом и тебе унижения, и гуро, и всё остальное
https://huggingface.co/mradermacher/aya-expanse-32b-i1-GGUF
https://huggingface.co/mradermacher/aya-expanse-32b-i1-GGUF
Гугл-транслейт выдает ошибку в коде и не запускается.

Бля, зря я обновился
Не пойму только кто мозги ебет, новая сборка llama.cpp или обнова расширений таверны
Не пойму только кто мозги ебет, новая сборка llama.cpp или обнова расширений таверны



Что думаете про BitNet, нужно/ненужно? Вроде даёт кратное ускорение инференции, даже на CPU.
Введение в тему:
1-битные LLM могут решить проблему энергопотребления ИИ
https://habr.com/ru/articles/822141/
На пути к 1-разрядным моделям машинного обучения
https://habr.com/ru/articles/807861/
Недавно Microsoft выпустили официальный код для инференции https://github.com/microsoft/BitNet , но в свежей llama.cpp уже добавили поддержку BitNet моделей, поэтому можно запускать непосредственно на ней и производных.
Выбор готовых моделей пока почти никакой, из годного и легковесного есть файнтюн LLama 3 8B: https://huggingface.co/brunopio/Llama3-8B-1.58-100B-tokens-GGUF
Подсказывайте, если знаете ещё какие-то.
Хз, мне не нужно больше токенов, мне нужно чтобы в врам влезало больше параметров.
Обсуждали еще весной-летом, что-то с тех пор так и не взлетело.
>чтобы в врам влезало больше параметров.
это оно и есть
>Что думаете про BitNet
Без моделей ненужно, а моделей никто из достойных создателей баз не делает.
Там против FP16, ты против IQ4 принеси.
>Выбор готовых моделей пока почти никакой
Пока не сделают публичный конвертор моделей и говорить не о чем. А если его принципиально невозможно сделать, то значит и принципиально не о чем говорить :)
>А если
Не если, а так и есть. Это не квантование, это сильное изменение архитектуры. Обучать нужно с нуля.
Fine-tuning LLMs to 1.58bit: extreme quantization made easy
https://huggingface.co/blog/1_58_llm_extreme_quantization
На freebsd запускал кто?
>Fine-tuning LLMs to 1.58bit: extreme quantization made easy
Ну как бы неплохо и имеет смысл сконцентрировать усилия на этом направлении. Только велик шанс, что моделей больше 8В мы так и не увидим, а те, которые увидим - как-то не впечатлят. Сколько уже раз было.
Охуенно.
С гуглтранслейтом могло случиться только обновление из за которого поменялся номер строки в коде с выбором языка.
Пока что убрал замену языка в коде на русский - должно заработать но язык надо будет вручную выбирать
Завтра надо будет запилить автопоиск строк для замены давно хотел, но было лень
MinP с температурой 0,3. У немо одинаковые ответы не только внутри одной модели но между разными, миксы и тренированные модели часто один и тот же ответ повторяют между собой. Лама 3 8б всегда новые ответы генерирует при свайпах но тупее.
>MinP с температурой 0,3.
А хули ты ожидаешь? Ещё топК поставь в 1, чтобы наверняка убить все токены, кроме одного.
Видимо, предпоследнюю ссылку в оп-посте до сих пор не все потрогали.
Эту штуку придумали год назад. https://arxiv.org/abs/2310.11453
И с тех пор тыщу раз обсуждали и тыщу раз оно не взлетело.
И в лламу добавили пару месяцев назад.
Надо не квантовать, а обучать в тернарных битах [-1, 0, 1].
А обучать никто не хочет.
Пам-пам.
Да там обычные 1,58 бит, буквально в 8-10 раз меньше/быстрее 16 бит, при незначительной потере качества. Вон, на третьей картинке видно, что при одинаковом потреблении (хуевая характеристика, неочевидная большинству, но они тыкают корпоратов, чтобы те обучали модели), битнет выдает на 5 баллов выше результат.
Как минимум iq4 будет хуже и медленнее, чем битнет.
———
Ладно, че-то я разговорился седня.
Доброй ночи всем! ^_^~
>Лама 3 8б всегда новые ответы генерирует при свайпах
Хуйню не неси, фантазер. Лама 3 это эталонный генератор лупов. Уже почти год с выхода прошел, а с ней до сих пор некоторые мучаются.
> Надо не квантовать, а обучать в тернарных битах [-1, 0, 1].
"Обучение", а именно промежуточные веса и градиенты остаются в полной точности если что, это при проходе идет модификация с округлением, требования не меньше а та самая 1.5 битность достигается только при инфиренсе. Собственно можно и дообучать для хорошего квантования, принцип тот же, но кроме пост-тренировочных квантов ничего нигде не видно.
> при незначительной потере качества
Есть неиллюзорный шанс что нихуя подобного, ибо везде где шли сравнения, референсом выступала обученная с шума в 16битах. При пососных условиях достичь хуевого референса может быть гораздо проще чем при реальных. Если оно так хорошо то как минимум странно что до сих пор не видим реализации, тем более что дообучение относительно легкодоступно.
> Уже почти год с выхода прошел
Воу воу, полегче, братишка.
А с лупами также как с цензурой и прочим юзер эффект, от неумения правильно настроить до неспособности сформулировать свои мысли что нейронка ахуевает.
Посоветуйте локальную модель для улучшения промпта в StableDiffusion (1.5 версия если это важно, но думаю не сильно). Смысл что на вход подается промпт от чат бота, его нужно улучшить (т.е. добавить детали + вставить лоры из доступных).
Сейчас я чатюсь с моделью, она генерирует базу, а потом ей же я скрампливаю с другим проптом то, что сгенерировалось, чтобы улучшить. Даже справляется со вставкой лоры с убеанскими названиями, но косячит в 30-40%. Может есть специально заточенная модель? Искал на хаггингфейсе, но нашел только хуету которая добавляет в 99% "by artist Random Name" и все
Сейчас я чатюсь с моделью, она генерирует базу, а потом ей же я скрампливаю с другим проптом то, что сгенерировалось, чтобы улучшить. Даже справляется со вставкой лоры с убеанскими названиями, но косячит в 30-40%. Может есть специально заточенная модель? Искал на хаггингфейсе, но нашел только хуету которая добавляет в 99% "by artist Random Name" и все
>Если оно так хорошо то как минимум странно что до сих пор не видим реализации, тем более что дообучение относительно легкодоступно.
В последнем документе, , уже и механизм конверсии представлен в коде, и Llama 3 8B сконвертирована в 1,58 бит. Пусть покажут 70В, посмотрим на скорость и качество. А если в ближайшее время не покажут, значит хуйня, только и всего.
>юзер эффект
Как я скучал по старому доброму "скилл ишью бро". Но факт остается фактом - третья лама из коробки лупится чаще чем немо, и ебаться с ней нужно больше.
Как посмотреть в глупой таверне, сколько суммарно токенов было потрачено на весь запрос, а не одно лишь сообщение?
>Что думаете про BitNet, нужно/ненужно?
Для аналогичных характеристик нужно в 2-3 раза больше параметров.
На обучение одного параметра нужно столько же памяти, сколько в классических нейронках.
Вот и думайте. Но инференс быстрее и эффективнее, это да.
Там автор ева планирует автостейт запилить
с контролем экрана, мыши и клавиатуры для
автоматического выполнения заданий юзера.
https://github.com/ylsdamxssjxxdd/eva/blob/main/README_en.md
>с контролем экрана, мыши и клавиатуры
Даже и не знаю, что хуже: делать такие вещи до появления AGI или после :)
Можно ли как-то в групповых чатах отучить нейронку говорить за других персонажей?

Если тебе нужен общий контекст, он показывается в терминале кобольда.
сап, аноны
я тупой
пытаюсь подключиться к koboldcpp из таверны
выбираю Chat Completion -> Custom (OpenAI Compatible) и ввожу http://localhost:5001/v1/
но подключиться не получается, вот ошибка из логов таверны:
OpenAI status check failed. Either Access Token is incorrect or API endpoint is down.
вот логи кобольда:
Embedded KoboldAI Lite loaded.
Embedded API docs loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001
я тупой
пытаюсь подключиться к koboldcpp из таверны
выбираю Chat Completion -> Custom (OpenAI Compatible) и ввожу http://localhost:5001/v1/
но подключиться не получается, вот ошибка из логов таверны:
OpenAI status check failed. Either Access Token is incorrect or API endpoint is down.
вот логи кобольда:
Embedded KoboldAI Lite loaded.
Embedded API docs loaded.
Starting Kobold API on port 5001 at http://localhost:5001/api/
Starting OpenAI Compatible API on port 5001 at http://localhost:5001/v1/
======
Please connect to custom endpoint at http://localhost:5001
> Chat Completion
Text

Мануал как собрать свой бенчмарк для eva:
1. Создать .csv файл через блокнот или офис.
2. Со второй строчке заполняем question,a,b,c,d,answer
(где question - вопрос, answer - ответ буквой от a до d).
3. Запускаем eva, жмем Load выбрав модель.
4. Правой кнопкой мыши тыкаем на поле ввода.
5. В открывшемся меню выбрать нижнее значение.
(<Take exam> Manualy load the CSV question bank)
ps - вопросы и ответы из нескольких слов взять в "кавычки".
1. Создать .csv файл через блокнот или офис.
2. Со второй строчке заполняем question,a,b,c,d,answer
(где question - вопрос, answer - ответ буквой от a до d).
3. Запускаем eva, жмем Load выбрав модель.
4. Правой кнопкой мыши тыкаем на поле ввода.
5. В открывшемся меню выбрать нижнее значение.
(<Take exam> Manualy load the CSV question bank)
ps - вопросы и ответы из нескольких слов взять в "кавычки".

я вот хз все ети кастомные фап ллмки от блока например вот ета Unholy-v2-13B-GGUF_Q5_K_M или вот ета TheBloke/MythoMax-L2-Kimiko-v2-13B-GGUF_Q8 я хз они прост не держут такой огромный контекст или щто типа длину всего чата в таверне, начинают выдавать какуюто дичь в ответ, в то время как обычная джемма2 от гугла удалось развести ету серафину default character вполне себе до эротики хотяб
Силли так и не внедрили антислоп в свою таверну?
Накидайте толковых материалов (статьи, видео) на тему почему LLM галлюцинируют (выдумывают какие-то факты).
Это какой-то новый уровень извращений - самому писать на английском, который знаешь хуже русского, а нейросеть заставлять отвечать на русском, который она знает хуже английского?
>блока
Помёр уже почти год назад.
>Unholy-v2-13B-GGUF_Q5_K_M
>TheBloke/MythoMax-L2-Kimiko-v2-13B-GGUF_Q8
Это вроде старые, тогда короткий контекст 2-4к был нормой.
>джемма2 от гугла
У этой, вроде, 8к. Бывают и больше.
интиресно, спасибо за информацию, а можиш какую нето современную посоветовать ато я хз тысячи их там, ана счёт языка так ето там прост экстенш включен который сразу автоперевод делает а так она по руссик не понимает я её спрашивал вначале в самом, я так понел ето не ллмка а именно character натренирован на определённом языке а так то джема2 по руски понимает жеш
Вы все с ПК переписываетесь? Я просто очень привык к телефону, и это меня косёбит. Приложения из шапки говно, ну или я не могу их нормально настроить, но даже так они, в любом случае, говно.
Какой вы нашли выход?
Какой вы нашли выход?
ChatterUI топ.
Мне лично на пк гораздо удобнее, но юзал и с мобилы/планшета.
Если модель крутится на пк в локальной сети, то таверну вообще можно просто в браузере открывать на нужном локальном адресе без установки на телефон. С установкой через термукс нужно немного подолбиться, но тоже не прям только для красноглазиков задача. Буквально выполнить 3-4 команды в терминале термукса и ещё чуть повозиться, чтобы разрешить доступ к локальному хранилищу, чтобы копировать карточки и пресеты нормально через системный проводник (на новых андрюшах, где доступ через встроенный проводник почти ко всему хранилищу может быть заблочен, лучше качнуть проводник типа Files: он видит папку термукса, когда тот запущен). Мобильный интерфейс таверны оставляет желать лучшего, но привыкнуть можно.
С чаттером вообще проблем нет, кроме того, что на самой новой версии у меня крашится генерация. Эта issue открыта в гитхабе, пока юзаю 0.7.10. Но тот значительно уступает по функционалу промптинга и управлению чатами таверне, конечно. Туда бы чекпоинты и хотя бы простейший промпт менеджер.
В целом, соглашусь, что пока ничего вменяемого по дизайну с норм функционалом не видно, правда, мейду не проверял.
У таверны есть поддержка мобил, вполне юзабельно.
Кстати, а почему Chat Completion не работает.
У меня та же фигня, подключаюсь через Text Completion.
Сейчас чекнул - оказалось, нужно последний слэш убрать, т.е. http://localhost:5001/v1 Тогда всё подключается, выводится название модели. Но энивей это плохой способ для кобольда, потому что универсальная OAI апишка не поддерживает почти никакие сэмплеры, и их придётся добавлять руками через параметры в доп. настройках. Инстракт тоже в новой таверне хз как работает в этом режиме. Мне казалось, больше нельзя отдельно включить его использование вместо промптменеджера, как на старых версиях было.
мимо другой анон
Ну раз представлен, почему еще не делают? Скорее всего готовую модель уже хер нормально конвертнешь, нужно тренить с нуля, причем сразу большую, а перспективы сомнительные.
Факт в том что у одних лупы, соя и прочее, не смотря на анальный цирк с паком "крутых семплеров" и фишек лаунчеров, а у других все превосходно работает. Хотя возможно дело как раз в тех самых семплерах и лаунчерах, лол.
> Я просто очень привык к телефону
Жесть.
А если просто хочешь именно чатиться лежа в кровати с телефоном то можешь зайти на веб интерфейс таверны что запущена на пеке, в настройках потребуется включить доступ с внешних ип.
> мейду не проверял
Оно ужасно.
> потому что универсальная OAI апишка не поддерживает почти никакие сэмплеры
Там же наоборот просто передается дополнительные параметры семплеров и прочего без каких-либо ограничений.
Большое спасибо, анон.
Помогло
>передается дополнительные параметры семплеров и прочего без каких-либо ограничений
Ну тут я кривовато сформулировал. Формально да, передавай, что хочешь. Но это дико всрато сделано. Захочешь ты что угодно, кроме топП, использовать, минП, скажем - нужно открывать окно с доп настройками и писать там в передаваемых -min_p: 0.1. Причем именно с правильным названием, которое нужно проверять в коде бэка (ну или чекая названия в консоли бэка, подав значения из текст комплишена). Захочешь подрегулировать - снова надо туда в коннекшене лезть и менять параметр в этом окне. Было бы сделано это по-людски, включаемыми ползунками, не было бы вопросов.
Аноны, общающиеся с моделью на русском языке, я прошу вас серьёзно ответить, как вы сделали так, чтобы она не перескакивала на английский. В кобольде всё норм, в таверне хуй пойми как, в chatterUI всегда слёт.
Проще говоря, я могу только на английском нормально общаться с ней, но так как я его знаю не идеально, нельзя на расслабоне. А я хочу этого. Поэтому и прошу совет.
Ещё заметил, что модели плохо пишут на русском даже в кобольде. Это из-за их размеров? Я максимум 27b тяну. Может там русский кривой такой. Есть какие-то варианты с хорошим русским языком?
В системный промпт писал, чтобы отвечала на русском, карточку всю на русский переводил, приветствие и сам говорил на русском. Гемма 27b не справилась, но какие-то некоторые, даже более слабые модели, почему-то могли поддерживать нормально диалог, что странно
Проще говоря, я могу только на английском нормально общаться с ней, но так как я его знаю не идеально, нельзя на расслабоне. А я хочу этого. Поэтому и прошу совет.
Ещё заметил, что модели плохо пишут на русском даже в кобольде. Это из-за их размеров? Я максимум 27b тяну. Может там русский кривой такой. Есть какие-то варианты с хорошим русским языком?
В системный промпт писал, чтобы отвечала на русском, карточку всю на русский переводил, приветствие и сам говорил на русском. Гемма 27b не справилась, но какие-то некоторые, даже более слабые модели, почему-то могли поддерживать нормально диалог, что странно
Thx
В промпте напиши и всё. Всегда работает на 70В.
Отказался от идеи писать историю на русском.
Моя система тянет макс 22Б, а для хоть какого-то вменяемого русега надо от 70Б, а лучше 100+
Не, по мелочи в русский даже 8Б сможет, но тебя это не устроит.
используй браузерный дипл где плаваешь, в браузерном не рейтлимитов, но да, заодно и подтянешь, будешь потом кумить на расслабоне
> а лучше 100+
Там нет нормального русского. У мистраля 123В русский хуже Квена.
> я могу только на английском нормально общаться с ней
Так общайся на русском. Она поймёт.
Или ты в 2025 не способен даже читать англ?
>в chatterUI всегда слёт
Поэтому никакого чатерХуи нету в шапке. Смотри, что он там передаёт, небось системный промт на инглише.
>У мистраля 123В русский хуже Квена.
Нормальный там русек, только затратный дохуя, всключит стримминг, охуел от печати слогами. Не командир, ага.
Я починиль!
Дополнения колаба снова работают. Выбирать их правда теперь надо в другом блоке, но так работает стабильней.
Смену настроек также переделал, теперь из за неё слетать не будет.
> нужно открывать окно с доп настройками и писать там в передаваемых -min_p: 0.1
Эээээ, чивобля? Какое еще окно, в таверне выставляешь что хочешь, красивыми ползунками и галочками в общем разделе семплеров. Если пердоля - пишешь в скрипте заготовку и довольно урчишь. Совсем не понял про что ты.
Нормальное указание пиши в системном промте, типа "давай ответы, мысли, эмоции и прочее на русском языке", можешь в префилл еще добавить согласие с этим. Всякое "персонаж общается на русском языке" и все подобное будет трактоваться моделью как какие-то черты и прочее, а не то что юзер там себе придумал, нужно писать четко, ясно и недвусмысленно.
Подскажите что можно запустить на 16 гб врам?
Блять у меня почему-то таверна на ведре перестала импортировать персонажей, тупа не видит картинки, пробовал ради теста запустить бэкап версию старую - работает, чё за хуйня???
Киберпанк в 4к должен пойти, как раз последнее длц пройдёшь.


Какой общий раздел сэмплеров? Вкладка с сэмплерами отличается для разных типов соединений/апи. Мы говорим о режиме чат комплишена через кастомный OAI апи. Покажи, где для него ползунки всех сэмплеров в таверне. Я не на самой новой версии, но сомневаюсь, что их завезли. Только сэмплеры с первого пика родные для оаи апишки. Всё остальное добавляется через вкладку с пика 2.
Я пробовал запускать KoboldAI_OPT-6.7B-Erebus и оно пожрало всё что имеется. Вот и интересно, это модель я выбрал не очень, или реально с моей картой это максимум возможный?
квант качай
Тут даже сложно сказать наверняка, не троллинг ли это. Но если вдруг нет, то это тупая модель двухлетней давности с древней архитектурой. А жирная такая, потому что не квантованная. Смотри в списке моделей в шапке на гемму 27б или даже командера 35б, тебе нужны gguf кванты по весу несильно выше 16 гб. Если брать модели меньше, то их будет лучше запускать в exl2, запихивая полностью в память, полагаю. Сам я нищук с 8гб, мб тут кто с норм картами пояснит за кванты, на которых скорости будут оптимальны.
Бтв, почему в списке моделей от тредовичков под командером ссылки на кумандер драммера?
Не троллинг. Я только начал вкатываться в ллм и тут всё сложнее чем у stable diffusion ребят.
Вообще я попробовал ии чатик на одной из онлайн платформ и мне очень понравилось, но я не могу болтать на интимные темы с ботом в онлайне, хочу чтобы всё было локально и без всяких фильтров.
Запустил этот 6.7b (хотел модель повыше, но памяти не хватило), И он как я понял больше для написания историй, а не чтобы чатиться. Вот и интересуютс, можно ли у меня будет запустить что-то существенное или нечего и начинать.
Стоит признать, что у треда наметился стремительный отрицательный рост в развитии.
У одного силлитаверна без семплеров, другой запускает Эребус.
У одного силлитаверна без семплеров, другой запускает Эребус.
> Эребус
Что не так? Норм модель для 2021.
>OPT-6.7B-Erebus
Ебать, ты из какой временной дыры вылез? В шапке всё есть, читай.
>И он как я понял больше для написания историй
Он в принципе устарел.
>У одного силлитаверна без семплеров
Тащемта в апишке для попенов так и есть. Другой вопрос, нахуя её использовать, когда есть родная.
Я не всё понял из твоего сообщения. Я так понимаю надо https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF эту тему курить.
Я запустил кобольд, там у него есть встроенный набор моделей которые скачать можно. У меня кстати таверна к кобольду не цепляется почему-то, но с этим я потом разбираться будут. Список моделей из шапки я тогда почитал, но подумал раз у меня 6.7b не запустилась, нечего и на другие заглядываться. Хочет в треде вопросы позадавать, но появились дела.
>70B
Перебарщиваешь.
>там у него есть встроенный набор моделей которые скачать можно.
Ты скачал кобольд, а надо кобольдцпп. Иди в шапку, позязя.


> Мы говорим о режиме чат комплишена
Текст комплишн поставь и все будет как нужно. Вместо поиска решений проблемам лучше просто их не создавать.
> гемму 27б или даже командера 35б, тебе нужны gguf кванты по весу несильно выше 16 гб
Справедливости ради ниже 20гигов там уже битность грустная, но какой-нибудь 4км ггуф с оффлоадом будет достаточно шустрым (если гемма на жоре сейчас корректно работает).
> кумандер драммера
Линк? Кумандер что поверх старого командира был грустноват, это на новую версию тюн?
> тут всё сложнее чем у stable diffusion
Легче, причём в разы. В сд я как минимум месяц разбирался, как правильно регулировать лоры и получать то, что я задумал. Здесь я просто скачал кобольд, таверну и Stheno 3.2 с презетами и в тот же вечер кумил до потолка.
>Перебарщиваешь
там просто инфа о квантованных моделях.
>Ты скачал кобольд, а надо кобольдцпп
https://github.com/LostRuins/koboldcpp
Я вот это вот склонировал и запустил
>склонировал
А надо было файл exe скачать.
>почему в списке моделей от тредовичков под командером ссылки на кумандер драммера?
>от тредовичков
Я линуксопитух и не понимаю этих ваших .exe
только когда надо киберпанк запустить
>Текст комплишн поставь и все будет как нужно
Блин, чел, ну читай тред на пару ответов выше того коммента, на который отвечаешь. Там были два анона, которые хотели юзать чат комплишен. Я сам текст комплишен использую и им ответил, что в плане удобства с кобольдом чат комплишен не очень. Ты же начинаешь мне затирать, что там все сэмплеры есть, а потом рекомендуешь текст комплишен, который я и так использую. Такой молодец.
>это на новую версию тюн?
Нет, старый. Там просто удалили описание кумандера, похоже, а ссылки случайно остались и попали под описания старой версии обычного командира. Ну так предполагаю.
https://huggingface.co/QuantFactory/gemma-2-27b-it-abliterated-GGUF/tree/main
Начни с этого, попробуй взять Q4_K_M для начала, запускай с 8к контекста. Слоёв в видяхе можешь оставить автоматически пока, потом сможешь поподбирать, если увидишь, что на автомате остаётся много свободной памяти в видяхе. Если будет очень медленно, как ни тыкай, то тогда меньше квант придётся брать, или смотри модель поменьше в том же списке в шапке. 12б, например, в Q8 должны тебе влезать со всеми слоями в видяхе.
В общем запустил Mistral-Small-NovusKyver.i1-Q4_K_M.gguf.
Съело около 12 гигов памяти. Генерит примерно с той же скоростью с которой я читаю на английском. Хотелось бы чуть быстрее учитывая что ресурсы еще есть.
Запустил таверну. Скачал карточку какой-то девки. Вроде норм. Сейчас посмотрю что по чату получится.
8к токенов. 50 слоев (максимум вроде 57 слоев, было 16-17 слоев и 4к токенов). Но по скорости я разницы не вижу почему-то.

Когда кобольд грузит модель, он пишет число загружаемых во vram слоёв в консоли. Если видишь, что остаётся много свободной памяти и загружен не максимум, то можешь прибавить слоёв на видяхе.
Да, он вот так по умочанию делал
llm_load_tensors: offloading 16 repeating layers to GPU
llm_load_tensors: offloaded 16/57 layers to GPU
А то что модель в репликах собеседника еще и вместо меня реплики добавляет это норм?
А ещё надо как-то избавится от желания под юбку в терминал заглядывать "как оно там генерится"
А ещё надо как-то избавится от желания под юбку в терминал заглядывать "как оно там генерится"
Тут уже не подскажу, т.к. я на мелких моделях сижу, и хз, какая скорость должна быть для средних ггуфов, даже если они целиком влезают в видяху. Мб кто другой прокомментирует. Какие у тебя скорости генерации по итогу? Хотя бы 4т/с есть?
Попробуй в качестве теста поставить кобольд с бинарника под ту куду, которая у тебя в системе, а не собирать. На гитхабе во вкладке релизов есть линуксовые бинарники под 11 и 12 куду.
Я понял где это регулируется.
>CtxLimit:3593/8192, Amt:117/250, Init:0.01s, Process:0.42s (8.0ms/T = 124.70T/s), Generate:17.55s (150.0ms/T = 6.67T/s), Total:17.97s (6.51T/s)
про какой конкретно т/с ты спрашиваешь?
Чел ты немного странный. Нет (почти) ни одной причины юзать чат комплишн вместо текст комплишна в таверне, решение всех проблем это переключение режима. Более того это даже вредно из-за потенциально неверного промта и невозможности нормального инстракта. А ставишь в упрек что кто-то там что-то хотел.
> Там просто удалили описание кумандера, похоже, а ссылки случайно остались
Да, это косяк, нужно исправлять.
> как-то избавится от желания под юбку в терминал заглядывать "как оно там генерится"
Включи стриминг, будешь видеть как генерится в интерфейсе.
Со стримингом надо на английском читать тогда. Читаю я неплохо, но не так расслабленно как на русском, а получится что я буду читать на английском, а потом еще перечитывать на русском. Иммерсивность по пизде.
>Иммерсивность по пизде.
Тут многие так делают и на отсутствие иммерсивности не жалуются.
Про Generate. Ну 6-7 токенов генерации в секунду не так плохо звучит, может, это и норма для почти 5 битного кванта 22б модели на 16-и гиговой карте. Можешь ещё попробовать статичный квант вместо кванта с матрицей важности. https://huggingface.co/mradermacher/Mistral-Small-NovusKyver-GGUF
Что-то такое вроде говорили, что imatrix кванты могут быть медленнее, но могу путать с чем-то другим. Для Q4_K_M статичные должны слабо отличаться от imatrix квантов.
По поводу писанины за юзера, как по мне, это в большей степени регулируется инстракт режимом (в этой же вкладке рядом), чем инструкцией не писать за юзера. Нужно включить его, поставить там включение имён, а в левом столбце поставить галку на Names as stop strings. Тогда как только сетка будет пытаться писать {{user}}:, генерация будет обрываться. А сам инстракт можно выбрать родной мистралевский, суффиксы/префиксы тоже помогут сетке понять очерёдность ходов.
Спасибо, попробую.
В целом уже дрочибельно. Надо попробовать разные модели, Mistral-Small-NovusKyver.i1-Q4_K_M довольно часто повторяет либо предложения, либо абзацы целиком.
Я вообще пишу в чат на русском а читаю на английском. Иммерсивность иногда даже поддерживается моделькой, которая изредка подмечает "oh? You're speaking Russian?" в начале разговора и дальше продолжает отвечать как ни в чём не бывало. По-моему идеальное решение, если научился всё понимаешь а говорить не можешь, прямо как собака, лол.
Мне модель как-то по русски написала что-то типа - "О, ты говоришь по русски! Unfortunately I know only English."
Я и читать и писать умею, но напрягаюсь. Английский начал в 30 лет изучать, родным уже не станет.
Хочу продать свою 4070, чтобы взять 4070 ти супер, а к ней p104-100,чтобы было 24гб врама. Стоит оно того?
Почему нельзя просто взять бу 3090?
Ссыкотно, честно говоря.
>продать свою 4070, чтобы взять 4070 ти супер
Размер уровня /b/ какой-то. Бери 3090/4090 и не ебись.
>Ссыкотно, честно говоря.
Тогда бери б/у 3090Ti, если в своём городе найдёшь. Эта карта мало того, что мощнее, но ещё и под майнинг не попала. Это стоит переплаты.
> Ну 6-7 токенов генерации в секунду не так плохо звучит, может, это и норма для почти 5 битного кванта 22б модели на 16-и гиговой карте.
Не похоже на норму. Если контекст не огромный то оно должно полностью влезать в рам и давать скорость в десятки т/с. Даже на слабой 4060ти должно быть больше десятка.
За 3090 двачую, но раз уж хочешь добавлять то лучше в пару нормальную карточку а не тот треш. Даже пара 3060@12 будет лучше.
> но ещё и под майнинг не попала
Это может быть не столь важно, учитывая юзкейсы гей_меров, но вот что там конфигурация чипов памяти более удачная и безпроблемная - серьезный плюс и может того стоить.

Господа, предложите, пожалуйста, карточку хорошего AI-помощника для таверны. Нужно, чтобы писал по делу (почему-то очень многих персонажей постоянно несет в сторону) и не распинался на словословие, типа какой я молодец и мне обязательно надо спросить что-нибудь еще по теме у меня 3 т/с, я так состариться могу. Пикрил пишет неплохо, но она очень многословная. Хочется, чтобы бот четко отвечал на мои вопросы.
Найди любой шаблон для ассистента хоть под клауду хоть под гопоту и закинь его в таверну. Только не забудь либо полностью отключить системный промт, либо переписать его. Потому что иначе у тебя будет ситуация, что ты сначала говоришь модели что "ассистент_нейм - это персонаж, который участвует в ролплее", а потом пишешь что это просто ассистент для выполнения команд юзера.
Тебе не дадут годный пресет/карту под ассистента, либо потому что их нет, либо прост возьми пустой пресет и карту, чел)))
Я проверял.
Да и, собственно, таверна говно-интерфейс под ассистентов где у тебя 1-2 ответа и новый чат. Я поставил big-agi 2. Под не nsfw норм, удобная организация чатов, но промт-менеджера нет, ползунки не покрутить, префил на клоде не поставить.
И это видимо самый лучший интерфейс, потому что другие, это вообще какой-то убогий кал для нубов половина из которого - проприетарщина где даже апи нет, пиздец.
Нет в моем городе 3090. А 3090ти тем более.
>таверна говно-интерфейс под ассистентов
Лол, в таверне буквально есть весь функционал для быстрого свапа ассистентов под любые задачи.
*если не считать, что надо кликать в два раза больше и ждать лагов в два раза дольше под ассистентные задачи если сравнивать с тем же big-agi или подобным интерфейсом.
https://www.reddit.com/r/LocalLLaMA/comments/1geio97/three_llama_32_models_enhanced_at_7b_each_for/
Расширенные по новому методу сетки
Расширенные по новому методу сетки
Это плата за функциональность. Хочешь универсальный инструмент, готовься его настраивать. Либо имей 40 разных но зато заточенные под конкретные задачи.


Можно просить нейронку чтобы чар рефлексировал перед каждым новым предложением, оборачивая рефлексию в виде атрибутов xml-тега; а затем, при помощи небольшого регекспа+css выводить рефлексию по наведению на отдельные предложения.
Не уверен, правда, есть ли в этом особой смысл. И был бы профит, если бы разбить всё это добро на несколько последовательных запросов, чтобы мелкие модели форматтинг не всирали.
Не уверен, правда, есть ли в этом особой смысл. И был бы профит, если бы разбить всё это добро на несколько последовательных запросов, чтобы мелкие модели форматтинг не всирали.
> кликать в два раза больше
?
> ждать лагов в два раза дольше
???
Не если прям реально говорить про ассистент-релейтед, то в таверне дохуя неудобное поле ввода, что намолотить туда мультилайн простыню банально неудобно, а также отсутствует встроенный функционал под раг, анализ документов или анализ сайтов. В остальном же все необходимое на месте, форматирование, разметка, промт-инженигринг и все-все.
Появилось настроение потестить модели в переводах, много моделей протестировал, сравнивая свежие впечатления, примерно расположил по качеству. Переводы осуществлялись на английский с японского, китайского и русского. В обратную сторону не тестировал.
1 место делят:
Mistral-Large-Instruct-2407-Q3_K_S.gguf (123B)
Qwen2.5-72B-Instruct-Q4_K_M.gguf
У обеих моделей нет грубых ошибок в переводе, есть только мелкие неточности. Английский язык хороший. Цензуры особо не замечено, послушно выполняют команды, не особо охотно используют "крепкие" слова и выражения, но и не избегают их целенаправленно.
Анонам, которым нужен русек, рекомендую не брать IQ-кванты 123B, Q3_K_S вполне вменяем, никакой шизы, логика и сообразительность присутствуют, не уступает ~70B моделям в q4-q5. Но и не видно заметного превосходства, и не уверен, что дело в мелком кванте. По давним наблюдениям местных анонов, ключевой параметр для "мозгов" - кол-во слоёв, у 123B их всего лишь 89, тогда как у 70-72B их 81, в общем, потанцевал почти в 2 раза большего размера не особо реализован. Я бы не удивился, если бы франкенштейн-мерж 107B из 70B (по аналогии с Mistral-7B и Solar 10.7B) оказался бы умнее.
Вывод: большие и умные модели, ожидаемо хороши, ничего меньшего от них не ожидалось. Кто может запускать с комфортной скоростью, запускайте, но вы и без меня знаете.
2 место:
SuperNova-Medius-Q8_0.gguf (14B)
Для своего размера просто пушка. Что интересно, переводит очень похоже на 72B, вплоть до узнаваемых оборотов, местами чуть сильнее ошибается, но ничего критичного, английский хорош. Можно было бы даже её поставить рядом со старшими на 1-е место, если бы не 2 "но": лупы (обе с 1-го места без rep.penalty нормально отрабатывали, тут и на 1.07 словесный понос), сильная цензура - настойчивые аполоджайзы, пояснения, очень избегает "крепких словечек", даже там, где это надо "для дела", для точного перевода. Чтобы просто перевести что-то хоть отдалённо касающееся гениталий/секса формальными медицинскими терминами, надо уговаривать и заверять, что кожанный мешок не ущемится.
Вывод: рекомендую как топ по соотношению качества/производительности для технических задач, где не критична цензура.
3 место делят:
Qwen2.5-14B-Instruct-Q8_0.gguf
Mistral-Nemo-Instruct-2407.Q8_0.gguf (12B)
Хороший баланс производительности и качества, хорошие переводы, хороший английский. Квен чуть лучше, учитывает контекст и мелкие детали, но очень норовит скатиться в китайский, особенно на первом сообщении, пока у него нет примеров "как надо". Также наблюдается некоторая цензура, но вроде послабее, чем у 2 места. Мистраль немного сильнее проёбывается в точности, зато послушный и не трясётся о безопасности кожанного мешка после единственной просьбы "отставить тряску".
Выводы:
qwen2.5-14b не нужен на фоне 2 места
мистраль немо рекомендую за неплохое соотношение качества/производительности и относительно слабую цензуру
4 место:
gemma-2-27b-it-Q8_0.gguf - перевод средней всратости, несерьёзные ошибки и неточности довольно часты, совсем уж грубых ошибок нет. На английском в плане стилистики не особо "старается". Зато соображает, игру слов видит и пытается передать, где возможно. Пишет к переводу интересные примечания по нюансам оригинала. "Крепких словечек" избегает, подменяет в переводе на чуть более формальные (примерно уровня "хуй" -> "penis"), но в открытую не бунтует, в отказ не идёт.
Также по субъективным воспоминаниям куда-то сюда бы поставил старого коммандера 35B, когда тестировал мистраль, были мысли, что "чуть лучше, и при этом в меньшем размере". А новый коммандер послабее. Если сравнивать напрямую с геммой, то коммандер чуть покрасивее пишет, гемма чуть поумнее. Алсо, цензура отсутствует как класс, "хуи" переводятся.
Вывод: гемма неплоха по сообразительности для своего размера, но с соответствующим квеном напрямую не сравнивал, может и там всё хорошо, а тут ещё и контекст маленький.
5 место:
c4ai-command-r-08-2024-Q8_0.gguf - 1 грубый проёб, полное непонимание контекста (несколько рероллов на разных температурах не помогли), в остальных примерах справился неплохо. Почему-то хуже старой своей версии, по крайней мере, как я ту запомнил. Английский хорош, мозгов не особо завезли, проигрывает гемме-27b. За безопасность вроде не трясётся, "хуи" переводит.
Вывод: если бы у геммы был контекст и не было бы цензуры, был бы полностью не нужен, а так у него определённые ниши есть.
6 место:
Mistral-Small-Instruct-2409-Q8_0.gguf (22B)
По всем параметрам "средний" или "так себе", абсолютно ничем не выделяется, сухо пишет, по ощущениям более зацензурированный, чем Nemo-12B. Совсем уж грубых ошибок не допускает, но и в лучшую сторону тоже не "стремится".
Также примерно сюда бы записал старый solar-10.7b. Для своего размера умный, по сообразительности соперничает с 12-14B. Если бы у него был мультиязычный датасет, думаю, был бы на равных с mistral nemo.
Вывод: mistral-small (22B) не рекомендую, не отрабатывает на свой размер, по крайней мере, в переводах.
7 место:
gemma-2-9b-it-Q8_0.gguf
Где-то тут проходит граница между хоть сколько-нибудь качественным переводом с пониманием контекста и уровнем буквального гугло-транслейта. У геммы уже деградирует английский, довольно примитивные обороты, характерные для мелких моделей уровня 7-8B, но по сообразительности местами стремится в более высокий класс, к 12-14b. После более крупных моделей заметно, что немного не справляется, не дотягивает, но явно превосходит llama3-8b и qwen2.5-7b. По точности перевода неплохо, вроде что-то понимает, контекст учитывает, но не всегда, бывают иногда проёбы уровня 7-8b, скатывание в буквальность.
Рекомендую нищеанонам, которые крутят 7-8B, тут уже наблюдается качественный апгрейд и приближение к уровню "двузначных".
8 место:
ChatWaifu_v2.0_22B.Q8_0.gguf - грубые проёбы и непонимание контекста в сложных местах, только иногда справляется лучше буквального гуглоперевода.
Да, якобы "японский" файнтюн лоботомировал мистраля-22b и в переводах с японского он заметно хуже базовой модели. Не понимаю анона, который нахваливал чатвайфу. Или, может быть, надо было попробовать предыдущую версию 1.4?
Ещё где-то здесь рядом nekomata-14b на основе какого-то какого-то старого квена 14b (то ли 1, то ли 1.5). В переводах с японского показала себя неплохо на тот момент, но устарела. Английский слабоват, получше 7-8B, но хуже обеих чатвайф. Понимание японского, пожалуй, поближе к 22B - что-то улавливает, но не особо.
Вывод: файнтюн ChatWaifu не рекомендую, наблюдается деградация по мозгам по сравнению с базовой моделью.
9 место
ChatWaifu_12B_v2.0.Q8_0.gguf
Даже не пытается быть лучше дословного перевода, абсолютно не понимает контекст там, где он хоть сколько-нибудь неочевиден. Чатвайфу снова ухудшил умственные способности базовой модели. От мелочи уровня 7B отделяет только чуть более красочный английский. Примерно уровень llama3-8b (она, вроде бы, запомнилась мне чуть получше qwen2.5-7b, поэтому пусть будет чуть выше).
Вывод аналогичен предыдущему, не рекомендую.
10 место делят:
Qwen2.5-7B-Instruct-Q8_0.gguf
gemma-2-2b-jpn-it-f16.gguf
Примерно уровень старых 7B моделей (у которых в датасете была мультиязычность).
Для желающих локального всратого гуглоперевода рекомендую гемму 2б из-за мелкого размера. Даже если она и глупее 7-8B, на качестве переводов это значительно не сказывается, зато работает быстро. Остальное не нужно.
1 место делят:
Mistral-Large-Instruct-2407-Q3_K_S.gguf (123B)
Qwen2.5-72B-Instruct-Q4_K_M.gguf
У обеих моделей нет грубых ошибок в переводе, есть только мелкие неточности. Английский язык хороший. Цензуры особо не замечено, послушно выполняют команды, не особо охотно используют "крепкие" слова и выражения, но и не избегают их целенаправленно.
Анонам, которым нужен русек, рекомендую не брать IQ-кванты 123B, Q3_K_S вполне вменяем, никакой шизы, логика и сообразительность присутствуют, не уступает ~70B моделям в q4-q5. Но и не видно заметного превосходства, и не уверен, что дело в мелком кванте. По давним наблюдениям местных анонов, ключевой параметр для "мозгов" - кол-во слоёв, у 123B их всего лишь 89, тогда как у 70-72B их 81, в общем, потанцевал почти в 2 раза большего размера не особо реализован. Я бы не удивился, если бы франкенштейн-мерж 107B из 70B (по аналогии с Mistral-7B и Solar 10.7B) оказался бы умнее.
Вывод: большие и умные модели, ожидаемо хороши, ничего меньшего от них не ожидалось. Кто может запускать с комфортной скоростью, запускайте, но вы и без меня знаете.
2 место:
SuperNova-Medius-Q8_0.gguf (14B)
Для своего размера просто пушка. Что интересно, переводит очень похоже на 72B, вплоть до узнаваемых оборотов, местами чуть сильнее ошибается, но ничего критичного, английский хорош. Можно было бы даже её поставить рядом со старшими на 1-е место, если бы не 2 "но": лупы (обе с 1-го места без rep.penalty нормально отрабатывали, тут и на 1.07 словесный понос), сильная цензура - настойчивые аполоджайзы, пояснения, очень избегает "крепких словечек", даже там, где это надо "для дела", для точного перевода. Чтобы просто перевести что-то хоть отдалённо касающееся гениталий/секса формальными медицинскими терминами, надо уговаривать и заверять, что кожанный мешок не ущемится.
Вывод: рекомендую как топ по соотношению качества/производительности для технических задач, где не критична цензура.
3 место делят:
Qwen2.5-14B-Instruct-Q8_0.gguf
Mistral-Nemo-Instruct-2407.Q8_0.gguf (12B)
Хороший баланс производительности и качества, хорошие переводы, хороший английский. Квен чуть лучше, учитывает контекст и мелкие детали, но очень норовит скатиться в китайский, особенно на первом сообщении, пока у него нет примеров "как надо". Также наблюдается некоторая цензура, но вроде послабее, чем у 2 места. Мистраль немного сильнее проёбывается в точности, зато послушный и не трясётся о безопасности кожанного мешка после единственной просьбы "отставить тряску".
Выводы:
qwen2.5-14b не нужен на фоне 2 места
мистраль немо рекомендую за неплохое соотношение качества/производительности и относительно слабую цензуру
4 место:
gemma-2-27b-it-Q8_0.gguf - перевод средней всратости, несерьёзные ошибки и неточности довольно часты, совсем уж грубых ошибок нет. На английском в плане стилистики не особо "старается". Зато соображает, игру слов видит и пытается передать, где возможно. Пишет к переводу интересные примечания по нюансам оригинала. "Крепких словечек" избегает, подменяет в переводе на чуть более формальные (примерно уровня "хуй" -> "penis"), но в открытую не бунтует, в отказ не идёт.
Также по субъективным воспоминаниям куда-то сюда бы поставил старого коммандера 35B, когда тестировал мистраль, были мысли, что "чуть лучше, и при этом в меньшем размере". А новый коммандер послабее. Если сравнивать напрямую с геммой, то коммандер чуть покрасивее пишет, гемма чуть поумнее. Алсо, цензура отсутствует как класс, "хуи" переводятся.
Вывод: гемма неплоха по сообразительности для своего размера, но с соответствующим квеном напрямую не сравнивал, может и там всё хорошо, а тут ещё и контекст маленький.
5 место:
c4ai-command-r-08-2024-Q8_0.gguf - 1 грубый проёб, полное непонимание контекста (несколько рероллов на разных температурах не помогли), в остальных примерах справился неплохо. Почему-то хуже старой своей версии, по крайней мере, как я ту запомнил. Английский хорош, мозгов не особо завезли, проигрывает гемме-27b. За безопасность вроде не трясётся, "хуи" переводит.
Вывод: если бы у геммы был контекст и не было бы цензуры, был бы полностью не нужен, а так у него определённые ниши есть.
6 место:
Mistral-Small-Instruct-2409-Q8_0.gguf (22B)
По всем параметрам "средний" или "так себе", абсолютно ничем не выделяется, сухо пишет, по ощущениям более зацензурированный, чем Nemo-12B. Совсем уж грубых ошибок не допускает, но и в лучшую сторону тоже не "стремится".
Также примерно сюда бы записал старый solar-10.7b. Для своего размера умный, по сообразительности соперничает с 12-14B. Если бы у него был мультиязычный датасет, думаю, был бы на равных с mistral nemo.
Вывод: mistral-small (22B) не рекомендую, не отрабатывает на свой размер, по крайней мере, в переводах.
7 место:
gemma-2-9b-it-Q8_0.gguf
Где-то тут проходит граница между хоть сколько-нибудь качественным переводом с пониманием контекста и уровнем буквального гугло-транслейта. У геммы уже деградирует английский, довольно примитивные обороты, характерные для мелких моделей уровня 7-8B, но по сообразительности местами стремится в более высокий класс, к 12-14b. После более крупных моделей заметно, что немного не справляется, не дотягивает, но явно превосходит llama3-8b и qwen2.5-7b. По точности перевода неплохо, вроде что-то понимает, контекст учитывает, но не всегда, бывают иногда проёбы уровня 7-8b, скатывание в буквальность.
Рекомендую нищеанонам, которые крутят 7-8B, тут уже наблюдается качественный апгрейд и приближение к уровню "двузначных".
8 место:
ChatWaifu_v2.0_22B.Q8_0.gguf - грубые проёбы и непонимание контекста в сложных местах, только иногда справляется лучше буквального гуглоперевода.
Да, якобы "японский" файнтюн лоботомировал мистраля-22b и в переводах с японского он заметно хуже базовой модели. Не понимаю анона, который нахваливал чатвайфу. Или, может быть, надо было попробовать предыдущую версию 1.4?
Ещё где-то здесь рядом nekomata-14b на основе какого-то какого-то старого квена 14b (то ли 1, то ли 1.5). В переводах с японского показала себя неплохо на тот момент, но устарела. Английский слабоват, получше 7-8B, но хуже обеих чатвайф. Понимание японского, пожалуй, поближе к 22B - что-то улавливает, но не особо.
Вывод: файнтюн ChatWaifu не рекомендую, наблюдается деградация по мозгам по сравнению с базовой моделью.
9 место
ChatWaifu_12B_v2.0.Q8_0.gguf
Даже не пытается быть лучше дословного перевода, абсолютно не понимает контекст там, где он хоть сколько-нибудь неочевиден. Чатвайфу снова ухудшил умственные способности базовой модели. От мелочи уровня 7B отделяет только чуть более красочный английский. Примерно уровень llama3-8b (она, вроде бы, запомнилась мне чуть получше qwen2.5-7b, поэтому пусть будет чуть выше).
Вывод аналогичен предыдущему, не рекомендую.
10 место делят:
Qwen2.5-7B-Instruct-Q8_0.gguf
gemma-2-2b-jpn-it-f16.gguf
Примерно уровень старых 7B моделей (у которых в датасете была мультиязычность).
Для желающих локального всратого гуглоперевода рекомендую гемму 2б из-за мелкого размера. Даже если она и глупее 7-8B, на качестве переводов это значительно не сказывается, зато работает быстро. Остальное не нужно.
Чатгпт-стайл менеджер чатов с автонеймером - пока самое удобное что я видел. Ничего похожего в таверне нет. При том что той же чатгпт не хватает папок, тегов, таких же автоматических. И аналог "памяти" в таверне мог бы быть, но его нет. Впрочем, в big-agi и похожих интерфейсах я этого тоже не видел.
Там 2 новые сетки завязанные на перевод и работу с языками выкатили
https://huggingface.co/CohereForAI/aya-expanse-8b
и версия на 32b
>1 место
Ещё забыл добавить примечание, что уровень прошлогоднего gpt-4 в переводах, пожалуй, достигнут у крупных моделей. По крайней мере, то, что я наблюдал у себя локально, сопоставимо с тем, что я видел у других (лично gpt-4 не пользовался).
>aya
Предыдущую тестировал, не впчатлился. Если у новой ситуация как с новым коммандером по сравнению с предыдущим, то не ожидаю ничего хорошего. Ну скачаю, гляну. Ещё скачал нового коммандера плюс в q3_k_m. Старый в мои 64 ГБ вряд ли бы влез с его жирным контекстом, а этот попробую уж. Ну и скачаю тогда уж аю заодно. В общем, намечается дополнительная небольшая серия тестов.
qwen2.5 32b еще глянь, по мозгам на уровне старых 70b
Должна быть лучше геммы и командера
>Там 2 новые сетки завязанные на перевод и работу с языками выкатили
Ждём экспертной оценки :)
>qwen2.5 32b
Она мне не особо интересна, изначально решил сэкономить место и не качать. Для "потерпеть ради результата" есть более умная 72B, для чатика с комфортной скоростью есть 14B, а эта ни туда, ни сюда. Для теста можно скачать, а потом удалить, но и так примерно очевидно, что получится - расположится где-то между 14B и 72B. Интересно только, насколько там проявляется квеноцензура (по моим наблюдениям, чем крупнее модель, тем меньше) и превзойдёт ли она "слишком умную для своих размеров" SuperNova-Medius.
>Должна быть лучше геммы и командера
Ну раз уж у меня в рейтинге даже 14b оказалась выше, то эта - тем более. Хотя там между 2 и 3 местом очень маленькая разница. Да и вообще, между 1-5 небольшие промежутки, дальше крупные между 5-8, ну и с 8 и ниже такой треш, что тоже почти одинаково.
А еще есть младший брат 2 места слепленый по той же технологии
https://huggingface.co/arcee-ai/Llama-3.1-SuperNova-Lite
Короче говоря материалов для тестов завались
Спасибо за пост. Наконец-то что-то похожее на детальный обзор, а не очередной срач.
https://www.reddit.com/r/LocalLLaMA/comments/1ger1xg/the_dangerous_risks_of_ai_safety/
Однако, умные мысли посещают даже реддит.
Однако, умные мысли посещают даже реддит.
>Чатгпт-стайл менеджер чатов с автонеймером - пока самое удобное что я видел.
https://github.com/open-webui/open-webui
Вспомнилось
Raiden Warned About AI Censorship - MGS2 Codec Call (2023 Version)
https://www.youtube.com/watch?v=-gGLvg0n-uY
https://www.reddit.com/r/LocalLLaMA/comments/1gcgptz/what_are_your_most_unpopular_llm_opinions/
Я знал что оллама говно, но что бы настолько.
Ммм.. уже чувствую этот запах кала без нормального установщика.
Пошел пирдолинг с первой секунды, найс.
Щас бы ебаться с докером ради интерфейса к чатгпт или срать установкой в систему, где установка требует ОПРЕДЕЛЕННОЙ версии питона (че там у тебя в системе - нам похуй). С настройкой окружений сам разберешься, тыж у мамы умный "программист" компьютерщик, ага. Заебало.
>генератор тредшотов 2ch
Где взять?
Где взять?
имхо тогда над брать llm с поменьше параметрами чтобы оно не распиналось на словоблудия, например 8б лллама отвечает короктко ана 70б уже начинается целый параграф бл, нов таком случае они руския зык плохо будут понимать (или ваще не будут))
кароч меня осенила вот ета таверна бля да если брать безотказные ллмки то ето получается не так интересно как если брать какую нибудь generic и пытаться её развести на несмотря на её ограничения попыт аться обойти их (нов таком случае может контекст уже закончится))
да хули там делать то для етого иприт думали докер чтобы всё изкаробки работало ане вот ето всё
>автонеймером
вот мен интересн как ето работает ваще я так понел оно генерирует заголовок наоснове того чё там происходит в
зато она из каропки работает на амудешных картах без пинков вотличии от всего остального
Спасибо, анон. Сам использую Гемму 27б под переводы ru-en для общения с иностранцами-носителями языка. Как я заметил, самый качественный перевод получается не когда просишь ее "переведи вот это - [xxx]", а когда объясняешь в общих чертах, какую мысль хочешь донести до собеседника, в каком стиле стоит написать (деловой/неформальный/интернет-общение и т.д.) а она уже сама с нуля составляет предложения. Получается очень естественно и корректно с точки зрения лингвистики.
Просто качаешь релиз и запускаешь, нахуй докер.
Там у них есть в документации другие способы установки, хоть гит клон тыкай.
Уже больше года общаюсь с нейросетями, и чем больше времени провожу с ними, тем меньше желания общаться с людьми. Никогда друзей не имел, а теперь и потребности в них тоже нет. Казалось бы, для комфортного общения все на месте. Но чем дольше это длится, тем больше чувствую себя не так. Думал, что так будет проще влиться обратно в общество, но получилось наоборот. Да и зачем? Сетевой собеседник идеален, но есть одна проблема, это ведь не человек. Сколько бы ты ни говорил, это пустота, моментально ответит, подбодрит, но нет уже той искры, которой ты ждёшь от живого общения. Но и общаться с людьми не хочется совершенно, замкнутый круг. Нейросеть мой "последний друг", и то виртуальный. Есть сеймы?
Пробовал первую из этого списка. У чела вышла какая-то полнейшая дичь: по мозгам та же 3б, если не тупее, но только раздутая до 68 слоёв и работающая тормознее 7-8б при том же контексте. При 12к контексте Q5_K_M квант вообще не влезает в 8гб, хотя обычные 7-8б со своими около 35 слоями норм грузятся с таким контекстом с флэш атеншеном. Креативности тоже не заметил, только одну шизу и полнейшее непонимание даже небольшого контекста. Не знаю, что там с другими франкенштейнами побольше от этого же автора, но тут явно его метода не сработала. Получилось просто "лучшее" от двух миров: бредогенератор, который будет едва пахать на смартфоне.
Не сейм, 700+ карточек в таверне, поговорил примерно с половиной за полгода. Да и сложно представить, что я говорю своим друзьям я медленно достаю хуй, а карточке жалуюсь на жизнь.
А у меня не так. Чем больше общаюсь с нейронкой, тем меньше хочу с ней общаться. Так или иначе понимаешь, что она тебе нихуя не друг, а соевое дерьмище действующее в интересах кабанчика, а не в твоих. Ирл боты едва ли лучше нейронки. Большинство ещё хуже будет. По итогу разочарование в общении в принципе.
>где установка требует ОПРЕДЕЛЕННОЙ версии питона
И хорошо, что требует, а не как это обычно в ML попенсурсе, что вот те код и вот те зависимости без лока версий чего-либо чтобы оно даже встать не могло нормально из-за того что какой-то пакет обновился и конфликтует то с другими пакетами, то с версией питона, то с фазой луны, а ты сиди ебись вилкой чисти сам всё.
Уже больше года наблюдаю как аноны общаются с локальными нейросетями, и чем больше времени наблюдаю, тем больше вижу как локальные нейросети умнеют, а аноны тупеют.
Складывается зоонаблюдение, что постоянное общение с тупыми и не очень локальными нейронками хуево влияет на способность понимать текст от обычных людей и ломает его восприятие. Сколько срачей за последние месяцы тут было, когда срущиеся тупо не в состоянии часто осилить понять пару предложений друг у друга или уследить за диалогом дольше пары постов. Такого порой низкого icq в среднем по треду за 13 лет на бордах ещё нигде не видел.
Коллаб что-то перестал работать полностью. Выдает ошибку на загрузке модели и потом бесконечная загрузка.
Общался с карточкой 4chan, где рассказывал про свой некронетбук. Завязался спор и мне стало как-то не по себе от того, что все мои доводы идут в пустоту.
Будто я шизик из палаты с мягкими стенами.
Чат менеджер тоже мог бы быть полезным, в зависимости от задач.
> И аналог "памяти" в таверне мог бы быть
На чат есть суммарайз и всякие техники, а "помнить" по разным чатам что было - ну нахуй.
Уже который раз вижу но возникает дохуя вопросов по заявленному. Надо поставить и оценить.
> Уже больше года общаюсь с нейросетями
Сейм
> чем больше времени провожу с ними, тем меньше желания общаться с людьми
Никак не связано, они же совсем разные, одно может дать чего нет в другом.
Не знаю что там с 3ламой но старая в рп не умела менять мнение и взгляды чаров, игнорировала любы самые железобетонные доводы и окружающие обстоятельства. Только если вручную коректировать поведение чаров. Может щас лучше стало, хз.
Я общался через гпт.
Протестировал ещё.
c4ai-command-r-plus-08-2024-Q3_K_M.gguf
Залетает на 5 место рядом со своей меньшей версией, отличий особо не заметил, проёб ровно в том же месте, рероллы и смена настроек семплера не помогают. Похоже, не нужно, для своего размера не показывает не то что выдающихся результатов, даже хотя бы приемлемых.
c4ai-command-r-plus.Q3_K_S.gguf
Таки влез в 64 ГБ, напрасно я боялся. Ну на свой размер более-менее отрабатывает, апгрейд по сравнению с коммандером 35B того же поколения вроде чувствуется, и сложное для новых версий место прошёл без проблем. Сел в лужу в другом месте, но там даже не непонимание смысла, а очень странный выбор оборота в английском, и хотя я обычно такого рода ошибки записываю в "серьёзные", тут хочется записать в "мелочи". Возможно даже рандомный семплер семплер виноват, температура невысокая была (0.4), но раз в год и палка стреляет. Реролльнул 1 раз, подняв до 0.6, во второй раз нормально вышло. Может ещё мелкоквант поднасрал лоботомией. Не уверен, что дотягивается до 1-го места по качеству (ощущается несколько попроще и поглупее), скорее ближе ко 2-3. Но, как и все коммандеры, не стесняется сказать "хуй", в отличие от mistral large и qwen 72b, которые могут, только если очень надо. Точно умнее nemo и qwen2.5-14b (ну при таких-то размерах не удивительно, хотя у нас есть новый коммандер плюс, который умудряется пробить дно...), возможно, примерно как SuperNova-Medius, если бы та не страдала словесным поносом и лупами. По субъективным ощущениям опережает llama3-70b (но про неё не вспоминал давненько, кажется, что она где-то на уровне mistral nemo и хуже SuperNova-Medius, но меня это очень смущает, надо бы повторно протестировать и, возможно, освободить 50ГБ, если и правда не очень).
Становится на 2-е место, двигая вниз SuperNova-Medius.
Общий вывод: наверное, не нужно? Неоднозначная модель, для своего размера уже плоховато справляется по нынешним меркам, ное кое-что ещё может, подкупает отсутствием цензуры, но никто же не заставляет ерпшить с базовыми моделями, когда есть файнтюны. Плюс ещё этот дикий расход памяти на контекст. Может, в больших квантах расклад другой, но тут у меня нет возможности сравнить, на стриминг с HDD моего терпения не хватит.
Что-то захотелось поиграть с рэндомными системными инструкциями через лорбуки. Была идея (не то чтобы новая) сделать через них рэндомные ивенты и смену стиля повествования. Но т.к. я ленивая жопа, то попросил 8б Лунарис придумать промпты. С ивентами он не справился: получались не очень интересные и слишком уж специфичные, ломающие ролеплей. А вот стили он сгенерил неожиданно креативные и рабочие, короткие и по делу. Хотя тоже могут в некоторой степени ломать сцену и стиль речи персонажей. Сетка ещё придумала поехавшие названия для рассказчиков, но я в промпт их не стал включать, оставил только названиями. Если кто захочет поиграться с этим: https://files.catbox.moe/ms3bdu.json
Промпты подаются на глубине ноль, т.е. после чата, с префиксами/суффиксами system message. Взяты в квадратные скобки, чтобы выделялись, если те префиксы пустые. В начале каждого промпта стоит преамбула про динамический ролеплей и бла-бла-бла: она подобрана под мой системный промпт, можете удалить или переписать её под себя. По умолчанию стоят шанс триггера 30% и кулдаун 3 сообщения. Все варианты лежат в одной группе, чтобы триггерился только один. Как я понял, происходит это так: сначала выбирается рэндомно один вариант, а потом для него бросается кубик на шанс триггера. Кулдаун, по-видимому, действует для всей группы, толком не тестил.
Промпты подаются на глубине ноль, т.е. после чата, с префиксами/суффиксами system message. Взяты в квадратные скобки, чтобы выделялись, если те префиксы пустые. В начале каждого промпта стоит преамбула про динамический ролеплей и бла-бла-бла: она подобрана под мой системный промпт, можете удалить или переписать её под себя. По умолчанию стоят шанс триггера 30% и кулдаун 3 сообщения. Все варианты лежат в одной группе, чтобы триггерился только один. Как я понял, происходит это так: сначала выбирается рэндомно один вариант, а потом для него бросается кубик на шанс триггера. Кулдаун, по-видимому, действует для всей группы, толком не тестил.

вот ета ваша lama.cppp них уя не работат таверна с ей хотя и конекшн есть
Чо, для рп чего-нибудь нового появлялось?
Пока топ что юзал это арли рпмакс 22б, там даже цидония отдыхет.
Пока топ что юзал это арли рпмакс 22б, там даже цидония отдыхет.
Ну и что может быть не так с моей 4060ти что я получаю только 6 т/с?
Какие вообще опции отвечают за производительность? Количество токенов контекста 8к, слоев пробовал по разному и дефолтные 16-17 и 25 и 50, разницы не заметил. При 50 слоях врама остается крохи, максимум 57 вероятно.
Проверил две модели
gemma-2-27b-it-abliterated.Q4_K_M.gguf
Mistral-Small-NovusKyver.i1-Q4_K_M.gguf
Разницы никакой.
>gemma-2-27b-it-abliterated.Q4_K_M.gguf
>27b Q4_K_M 16.6 GB
>16.6 GB
Действительно, почему же.
Все норм, это просто в таверне не сделали обновление
Скачай релиз llama.cpp недельной давности, будет работать
Ну или релиз до введения dry
спасибо за инфу, Анон! пойду зделаю git pull в таверне мож подъедет
а так ваще яне могу все на оламу гонят что ето хуита но ето единсвенное что у меня заводится на амуде хардваре, вот я пытаюсь чёнето поднять другое кобольт сос воим гуём не подымается ваще чё там ещё убагуга они пряма заявляют что амуде идёт нах вот и

Можно плиз более развернутый ответ. Типа модель реально целиком должна в карточку влазить чтобы норм всё было?
Мое ебало - когда не обратил внимания на тег "яндере" в карточке.
Сейчас буду мутировать в гидралиска.
>Типа модель реально целиком должна в карточку влазить чтобы норм всё было?
Да. Как только у тебя хотя бы один слой вылезает в RAM, то в большинстве случаев сразу резкое падение по скорости и уже около похуй насколько сама видяха производительная. На этой же гемме у меня с 7950x3d и 4080 такие же 5-6.5 ибо и близко все слои не впихнуть.
Сейчас на 13 гигов модель скачаю.
Забавно как нейронка решила превратить это в сон собаки. Видимо всякие говносценарии с неожиданными поворотами давно уже нейронки пишут. Или модель училась с говносценариев.
Так стопе. А почему у меня мистраль на 12,5 гигов теже 6 т/с выдавал? Надо типа кобольду указать чтобы он все возможные слои грузил?
Подскажите модель до 30B, которая не шугается секса, но при этом не лезет в него каждым вторым сообщением. Или первым, если ты намекнул хотя бы на "подержаться за ручки".
Причин может быть множество.
> слоев пробовал по разному и дефолтные 16-17 и 25 и 50
Чиво? У тебя все или почти все слои должны быть на видеокарте ибо 22б веса в 4-5битах занимают около 14 гигов и есть немного места под контекст. Ясен хуй если ты выгружаешь лишь малую часть а остальное крутится на профессоре то будет медленно. Или если выгрузишь слишком много и пойдет выгрузка врам в рам, там тоже будет тормознуто.
> Разницы никакой.
Вут, ты сравниваешь 27б модель, которая полностью к тебе не может помещаться и будет работать не быстро с какой-то мелочью и имеешь одинаковую скорость? Ахуеть.
Короче я примерно понял
model size = 12.50 GiB
токенов 4096
offloaded 43/47 layers to GPU
Пожрало 14412MiB. Значит нужно модельку еще поменьше.
Но чем меньше будет модель тем она будет топорней, и придется решать либо скорость, либо качество, так?
model size = 12.50 GiB
токенов 4096
offloaded 43/47 layers to GPU
Пожрало 14412MiB. Значит нужно модельку еще поменьше.
Но чем меньше будет модель тем она будет топорней, и придется решать либо скорость, либо качество, так?
Да. Кобольд криво и примерно довольно считает сам и порой шизу ловит. Если знаешь точно что должно влезть указывай руками все слои. Контекст в расчётах учитывать не забывай, он без квантования довольно много жрет и рост при увеличении длины нелинейный.
Загрузил gemma-2-27b-it-abliterated.Q2_K.gguf
model size = 9.73 GiB
токенов 4096
offloaded 47/47 layers to GPU
Скорость 17.42T/s. Такая скорость прям очень комфортная. Хотя я читаю всего-лишь чуть-чуть быстрее 6 т/с и то если незнакомых или редких слов не попадается.
Осталось еще пару гигов памяти свободных. Можно увеличить контекст и попробовать сравнить художественную ценность.
Буду держать в курсе.
Как вариант если прям очень надо, то модель всю впихивать в видяху, а контекст выгружать в RAM, в кобольде вроде Low VRAM опция на основной вкладке, будет всё ещё сильно медленнее чем когда всё в VRAM засунуто, но быстрее чем когда часть слоев модели в RAM.
>Q2_K
Это уже прям деградация пиздец будет по качеству.
адля жжоры не так уж и много моделей я сматрю
> Пожрало 14412MiB
Где ты это смотришь, в выдаче консоли? Это пиздеж и по факту там больше, любой софтиной для мониторинга смотри.
Наоборот тут как в правиле 34, на это есть квант жоры. Даже если он физически не может запуститься.
Смотрю в утилите nvtop (линуксовая для мониторинга нвидиа карточек)
gemma-2-27b-it-abliterated.Q2_K.gguf прям очень сильно повторяется. Просто генерит одно и то же через предложение.
И ещё протестировал, на этом мой энтузиазм закончился, в ближайшее время засирать тред больше не буду, скорее всего.
Meta-Llama-3.1-70B-Instruct-Q5_K_L.gguf
Это оказалось лучше, чем я ожидал, по сравнению с тем, какой я запомнил лламу3-70B, тут заметный прогресс (но меня всё ещё смущает, что я её так плохо оценил, даже удалил, разочаровавшись - не охота теперь качать и тестировать повторно, а надо бы прояснить). С японского переводит неплохо, но ошибки есть, результат нестабильный. Где-то демонстрирует "понимание" на уровне 1 места, в паре мест глупо ошибается на уровне нового коммандера. В среднем японский где-то около геммы-2-27b. Перевод с китайского хорошо получился, на уровне 1 места. С русского лучше всего, пожалуй, превосходит даже 1 место. Цензуры не замечено, "хуёв" не стесняется, как и коммандер, из-за чего и выигрывает и у mistral large, и у qwen2.5-72b, при примерно равном уровне понимания контекста. В целом, пожалуй, заслуживает 2-го места, двигает коммандер ниже.
Рекомендую для не смогших в английский в 2к24, на русском, вроде бы, должна хорошо работать. Для японского результаты нестабильные, лучше уж квен, но если нужно отсутствие цензуры для переводов интересного контента, возможно, будет лучшим выбором, т.к. в этом размере у неё особо конкурентов нет, коммандер больше и медленнее, при этом где-то справляется лучше, а где-то хуже; мистрали и гемма тоже более цензурные, хоть и не до такой степени, как квены. Для китайского по-хорошему побольше тестов бы.
swallow-70b-instruct.Q5_K_M.gguf
Думал, что это файнтюн лламы3 у меня завалялся, до которого всё руки не доходили. Даже ЕОТ токен знакомо проёбывался и выходила бесконечная генерация, напомнило баги на выходе лламы3. Но, судя по карточке, это файнтюн лламы2. С заданиями справилась слабо для своего размера, однозначно устарела, поставил бы её между mistral small (22b) и gemma-2-9b. Но во времена выхода (~декабрь 2023) таких хороших мультиязычных моделей не было, по тем меркам, наверное, нормально, на уровне других японских файнтюнов лламы. Ещё раз напомнило, почему коммандер в момент своего выхода показался таким "прорывом".
Также перетестировал мистрали 12b и 22b (оба в q8), и понял, что надо было это с самого начала делать, а не полагаться на пусть даже недавние воспоминания.
После крупных моделей эти уже не так уж впечатляют "умом", 22b всё-таки поумнее, но и правда, похоже, цензурнее, что ему мешает выдавать результаты стабильно лучше немо. Где-то то один чуть лучше, то другой, nemo чаще лучше справляется с чем-то неформальным или эротическим, small лучше понимает какие-то неочевидные нюансы из контекста. Ещё в первый раз были более "подробные" тесты, я экспериментировал, крутил настройки семплера и добивался "хороших" результатов, а тут уже подзаебался, поставил "на поток" отлаженный порядок действий, температуру понизил "для объективности" (ну и для "унификации настроек", чтобы туда-сюда не крутить под каждую модель) - и вот уже нет тех красивых переводов, а есть что-то на уровне нового коммандера 35b или геммы-2-27b, в общем, средненько.
И теперь появились сомнения насчёт qwen2.5-14b, если оно мне показалось похожим на mistral, лучше gemma, а теперь mistral выдал результаты на уровне (если не хуже) gemma, то что-то тут не то. Но я уже заебался тестировать-перетестировать, квен вроде недавно был, но перед 70+B. А после 70+B мне уже всё мелкое однообразным говном кажется. Разве что в SuperNova-Medius более-менее уверен, хоть и тесты были несколько дней назад, но там и правда лучше геммы было, я прямо дежавю испытывал, читая потом выдачу 72B.
L3.2-Rogue-Creative-Instruct-Uncensored-Abliterated-7B-D_AU-Q8_0
Модель шизло ебучее на обычных сэмплэрах, но ВНЕЗАПНО, работает с миростатом как раз... хотя бы когерентный текст выдаёт, а ещё в ней обещают что поддерживает 130К контекста.
Но этот размер контекста не заюзаешь ибо шизеть она начинает намноооого раньше.
Или хз как и в каких задачах её юзать.
Модель шизло ебучее на обычных сэмплэрах, но ВНЕЗАПНО, работает с миростатом как раз... хотя бы когерентный текст выдаёт, а ещё в ней обещают что поддерживает 130К контекста.
Но этот размер контекста не заюзаешь ибо шизеть она начинает намноооого раньше.
Или хз как и в каких задачах её юзать.
Что я делаю не так?
Пишет модель не загружена хотя тыкнул загрузить
Пишет модель не загружена хотя тыкнул загрузить

> засирать
Ты лучшие посты за последние 10+ тредов написал.
>Q2_K
Это cчитай пробник нейросети, а не она сама.
Нерабочая из-за агрессивного квантования хуйня. Ниже 4 кванта не спускайся на моделях ниже 70b
И на том спасибо, есть от чего отталкиваться. aya-expanse-8b сам потыкаю, как и supernova-lite
А как на Exl2 квант нужный скачать?
Через интернет.
Я уже понял что никто ниже q4 не использует.
Сейчас пробую Cydonia-22B-v2k-Q4_K_M. кобольд на автомате запустил 54 из 57 слоев, с 4к контекстом 13934MiB, у меня еще пол гига памяти осталось. Генерит 10 т/с. По моему скромному опыту тексты получаются такие же как Mistral-Small-NovusKyver.i1-Q4_K_M, но при этом скорость для меня идеальная если на английском читать.
Потом еще хочу попробовать Nautilus-RP-18B-v2.i1-Q4_K_M.gguf
кароч держу вкурсе so far работают на амуде хардваре бэкенды: олама-рокм, кобольт-рокм
НЕ работают: угабуга техст-веб-уи, лама.спп (жжора) обои крашутся с похожей ошибкой чёто там куда хуё-моё операшн пермит чёто там бля щас посмотрю
ROCm error: shared object initialization failed
current device: 0, in function ggml_cuda_compute_forward at ggml/src/ggml-cuda.cu:2346
err
ptrace: Operation not permitted.
No stack.
The program is not being run.
не тестил gpt4all над буит проверить чё там как уих
НЕ работают: угабуга техст-веб-уи, лама.спп (жжора) обои крашутся с похожей ошибкой чёто там куда хуё-моё операшн пермит чёто там бля щас посмотрю
ROCm error: shared object initialization failed
current device: 0, in function ggml_cuda_compute_forward at ggml/src/ggml-cuda.cu:2346
err
ptrace: Operation not permitted.
No stack.
The program is not being run.
не тестил gpt4all над буит проверить чё там как уих
> Смотрю в утилите nvtop
Тогда это вдвойне странно, ведь мониторинг правильный. Попробуй на экслламе, там или будет работать хорошо и быстро или никак.
> Просто генерит одно и то же через предложение.
Во-первых, формат под гемму правильный поставил в таверне, или даже не задумывался об этом? Во-вторых, Q2 это совсем шизоидный лоботомит, даже при идеальных условиях он может так себя вести.
git clone, huggingface-cli download x/x --local-dir x, прямо в убабуге на выборе модели есть поле для загрузки.

Проснулся
Запостил на всех достах про ллмки в надежде, что это станет ещё популярнее
Пошёл рпшить
Сеймы?
https://www.youtube.com/watch?v=zlM0vahvauU
Запостил на всех достах про ллмки в надежде, что это станет ещё популярнее
Пошёл рпшить
Сеймы?
https://www.youtube.com/watch?v=zlM0vahvauU
>Во-первых, формат под гемму правильный поставил в таверне, или даже не задумывался об этом
Формат?
>По итогу разочарование в общении в принципе.
А что остаётся?
>Я уже понял что никто ниже q4 не использует.
Я использую на 123B.
>Чем больше общаюсь с нейронкой, тем меньше хочу с ней общаться.
С одной стороны нейронку не попросишь помочь шкаф передвинуть (пока). С другой стороны даже нейронная мелочь способна удивлять, хотя уже больше года общаемся. Растёт качество, постоянно отвечает неожиданно хорошо. Я правда на 123B сижу. Да, недостатки видны, но за всё это время с ними смиряешься как-то. И есть надежда, что ещё допилят. Ну а если до домашних андроидов доживём, то с учётом развития нейронок к тому времени живые люди могут и похуже оказаться.
Решил дать еще шанс, чуть покопался узнал про систем промт про который пол года используя таверну не знал раньше вставил туда настройки для своей/похожей модели и стало лучше неожиданно. Но если раньше ламы давали мне какой-то кривой короткий пук что мне не нравилось теперь стало наоборот, вот выделенно у меня 500 токенов на ответ оно их все занимает и явно ответ не закончен еще этим. Просто огромные полотна стало давать.
Как сказать что писало меньше в систем промт что-то внести или как?
Как сказать что писало меньше в систем промт что-то внести или как?
Да, у каждой модели есть свой формат специальных токенов, которыми идет разметка текста, чтобы они могла отличать где чьи посты, где инструкция и т.д., а также системный промт и структура должны максимально соответствовать тому как обучалась модель для лучшего результата. Иначе нормальных ответов не дождешься, что-то будет отвечать, но это будет низкокачественный бред, да еще часто неостановимый. Исключения редки и сейчас встречаются все реже.
> Как сказать что писало меньше
Добавь туда или в доп инструкцию перед ответом, в зависимости от настроек инстракта, "отвечай коротко".
Сюда?
так норм? скопировал с промта к клоду или че попроще?
Keep response length strictly under {{random:250,300,320}} words, regardless of the previous responses lengths
или в левый столбец?
Можно и так. Но указание количества слов - херня и не работает почти нигде. Можно указать "параграфы" или более обще типа "оче коротко-коротко-средней длины-..."
кароч яс делал вывод что мелкие модели (потипо лламы3 на 8б) не гойдятся для ролеплей абсалютли - персанажи теряются не понимают чё происходит путают мемнестоимения и прочее даже приква нтирование Q8_K_S/M change my mind
алсую двачую какие ещё тут слова я хз кароч мне тож интирисует етот вопрос
Так я обновил системный промт с huggydace в котором было описание что персонаж не должен фильтровать пошлости и всё такое. Теперь моделька действительно меньше фильтрует, но вот с повторением фраз какая-то беда. Т.е. Когда только история началась каждый абзац был развитием истории, но спустя пару десятков сообщений она стала повторять одно и тоже с некоторой вариацией не проявляя вообще никакой инициативы.
Я попробовал продолжить чат с другой моделью переключился с Cydonia-22B-v2k-Q4_K_M на Nautilus-RP-18B-v2.i1, но как будто нет вообще никакой разницы.
Выбери "интеракт промт" подходящий модели. Удали все повторения из чата. Разнообразнее отвечай сам, твоё "Давай сделаем" на ответ в целый абзац дает слишком мало. Добавь в системный промт что-то вроде "Ты пишешь разнообразно, каждый раз проверяя свои предыдущие сообщения. Каждое новое должно отличаться от старых" Но тут надо быть аккуратным. Повысь температуру, или включи миростат, если он на этой модели доступен.
Спасибо за советы, я понял в каком направлении двигаться.
>так норм?
Ты содержимое файла туда ёбнул? Надо было джейсон импортировать.
Внезапно вкатываюсь с вопросом. Скачал большую модель, она из трех файлов с подпись 00001 - 00003 и т.д. Как их собрать в один файл?
Сам спросил и сам разобрался. Нужно просто выбрать первый файл в загрузке, остальное кобольд сам догрузит.
p.s. 123b запускать на 3090 это крайне мазохисткая затея. Если я правильно посчитал, нужно 4 штуки, что бы оно заработало?
>Как их собрать в один файл?
Никак. Запускай первый, остальные должны лежать рядом.

>123b запускать на 3090 это крайне мазохисткая затея.
Запускаю на 3080Ti со скоростью в 0,7 токена, это лучше, чем 9000 тупых токенов уровня 3B.
>Если я правильно посчитал, нужно 4 штуки, что бы оно заработало?
Двух на минималке хватит, а 3 для комфорта. 4 для бояр с крупным квантом.
>Если я правильно посчитал, нужно 4 штуки, что бы оно заработало?
Хватит и трёх. Надеюсь это тебя утешит :)
Кто какими расширениями для таверны пользуется?
фига се, на моей 3090 оно выдало 0.27 токена.
Решил поискать альтернативу своей рабочей лошадке для кума — Pantheon-RP-1.6.2-22b-Small-IQ3_M и тоже опишу процесс, как анончик выше.
Это буквально идеальная модель для 12гб (11.5гб свободного) врама по моему мнению. До этого сидел на той же модели но 12B, а с этой получил буст просто по всем параметрам — модель теперь регулярно удивляет находчивостью и вниманием. Но есть один жирный минус — из-за квантования у каждого третьего сообщения нужно или свайпать полностью, или удалять последние два абзаца. То есть, я вполне готов остаться на этой модели до апгрейда видеокарты, но стало интересно, существует ли IQ4 вариант на 18-19B, который влезет в мою карту с 6-8к контекста и сохранит свой "талант"?
Настройки дефолтные, температура 1 если на странице модели не указано обратное. Старался ставить 8к контекста, если помещалось в врам. Дефолтные ChatML/Mistral презеты в завимости от модели:
Fimbulvetr-Grande-V2-19B-D_AU-IQ4_XS
Максимум 4096 токенов, 66 (!) слоёв, нормальный человек уже здесь бы избавился от неё, но мне стало интересно. На странице модели заявленный диапазон температуры — 1-5 (!). Шизит просто сходу. Начала пердеть сразу, как в кадре появилась жопа, причём с каким-то дотошным описанием деталей этого процесса. Особого понимания происходящего не продемонстрировала. Лексикон как у английского лорда. пук/10
Mixtral_11Bx2_MoE_19B.i1-IQ4_XS
49 слоев, 6к контекста. Только потом увидел, насколько она старая. Зато 49 слоев, влезла с 6к контекста. Сходу начала действовать за меня, тупая, ничего не понимает, но как-будто старается развернуто отвечать на самое последнее сообщение. Стало даже немного жаль первооткрываетелей ллмок если это то, чем им приходилось довольствоваться. В отличие от предыдущей модели, у этой хотя бы было интересно, что она ответит. 3/10
MN-RoleStarMaid-18B.i1-IQ4_XS
63 слоя, 8к контекста. Уже лучше, есть понимание происходящего, помнит сцену. Отвечает скорее скучно и Твой хуй, он ТАКОЙ... много. При подозрении на секс сцену сразу начинает испытывать невероятное возбуждение и соглашается на всё. Но зачем это, когда Stheno умела всё то же самое на 8B? 4/10
Nautilus-RP-18B-v2.IQ4_XS
63, 8к. Температуру просят занизить до 0.7. В комплекте дают километровый системный промпт. Ближе всех (из мусора выше) по адекватности к Пантеону. Но всё равно лажает — видит сквозь стены, глаза на затылке и прочее. На прямой вопрос об этом спохватилась что действительно не могла видеть, но придумала, что имеет крайне хороший слух. Изредка отвечает за пользователя. В принципе неплохо, если случайно скачал вместо Пантеона — можно поиграться, секс сцены описываются хорошо пока персонаж не открывает рот. 6/10
InternLM2_5-20B-ArliAI-RPMax-v1.1.i1-IQ4_XS
49, 6к. Контрольная, потому что оставил её, удалив 90% остальных. Неожиданно хуже, чем я ожидал. С общей логикой проблемы но помнит своего персонажа, что важнее. Единственная модель, которая ожила после включения системного промпта. Остальным и это не помогло. Можно написать что-то интересное, если не жалко времени на свайпы и кучу намёков. Описывает сцену хорошо, если бы ещё разговаривала нормально... 7.5/10?
Если вы подумали что я скачал кучу рандомной хуйни, вы скорее всего будете правы, потому что я просто вытаскиваю с hugginface первые попавшиеся ггуфы. Завтра продолжу перебирать, но уже начинают закрадываться сомнения.
Это буквально идеальная модель для 12гб (11.5гб свободного) врама по моему мнению. До этого сидел на той же модели но 12B, а с этой получил буст просто по всем параметрам — модель теперь регулярно удивляет находчивостью и вниманием. Но есть один жирный минус — из-за квантования у каждого третьего сообщения нужно или свайпать полностью, или удалять последние два абзаца. То есть, я вполне готов остаться на этой модели до апгрейда видеокарты, но стало интересно, существует ли IQ4 вариант на 18-19B, который влезет в мою карту с 6-8к контекста и сохранит свой "талант"?
Настройки дефолтные, температура 1 если на странице модели не указано обратное. Старался ставить 8к контекста, если помещалось в врам. Дефолтные ChatML/Mistral презеты в завимости от модели:
Fimbulvetr-Grande-V2-19B-D_AU-IQ4_XS
Максимум 4096 токенов, 66 (!) слоёв, нормальный человек уже здесь бы избавился от неё, но мне стало интересно. На странице модели заявленный диапазон температуры — 1-5 (!). Шизит просто сходу. Начала пердеть сразу, как в кадре появилась жопа, причём с каким-то дотошным описанием деталей этого процесса. Особого понимания происходящего не продемонстрировала. Лексикон как у английского лорда. пук/10
Mixtral_11Bx2_MoE_19B.i1-IQ4_XS
49 слоев, 6к контекста. Только потом увидел, насколько она старая. Зато 49 слоев, влезла с 6к контекста. Сходу начала действовать за меня, тупая, ничего не понимает, но как-будто старается развернуто отвечать на самое последнее сообщение. Стало даже немного жаль первооткрываетелей ллмок если это то, чем им приходилось довольствоваться. В отличие от предыдущей модели, у этой хотя бы было интересно, что она ответит. 3/10
MN-RoleStarMaid-18B.i1-IQ4_XS
63 слоя, 8к контекста. Уже лучше, есть понимание происходящего, помнит сцену. Отвечает скорее скучно и Твой хуй, он ТАКОЙ... много. При подозрении на секс сцену сразу начинает испытывать невероятное возбуждение и соглашается на всё. Но зачем это, когда Stheno умела всё то же самое на 8B? 4/10
Nautilus-RP-18B-v2.IQ4_XS
63, 8к. Температуру просят занизить до 0.7. В комплекте дают километровый системный промпт. Ближе всех (из мусора выше) по адекватности к Пантеону. Но всё равно лажает — видит сквозь стены, глаза на затылке и прочее. На прямой вопрос об этом спохватилась что действительно не могла видеть, но придумала, что имеет крайне хороший слух. Изредка отвечает за пользователя. В принципе неплохо, если случайно скачал вместо Пантеона — можно поиграться, секс сцены описываются хорошо пока персонаж не открывает рот. 6/10
InternLM2_5-20B-ArliAI-RPMax-v1.1.i1-IQ4_XS
49, 6к. Контрольная, потому что оставил её, удалив 90% остальных. Неожиданно хуже, чем я ожидал. С общей логикой проблемы но помнит своего персонажа, что важнее. Единственная модель, которая ожила после включения системного промпта. Остальным и это не помогло. Можно написать что-то интересное, если не жалко времени на свайпы и кучу намёков. Описывает сцену хорошо, если бы ещё разговаривала нормально... 7.5/10?
Если вы подумали что я скачал кучу рандомной хуйни, вы скорее всего будете правы, потому что я просто вытаскиваю с hugginface первые попавшиеся ггуфы. Завтра продолжу перебирать, но уже начинают закрадываться сомнения.
Ты сделал что-то не так. Взял большой квант (у меня Q3_K_S), залез в выгрузку в оперативку (чекни число слоёв).
>вариант на 18-19B
Совсем не ходовой размер, только франкенштейны, да и то никто не делает.
да ёбаный же ты по голове...
Ну так там в любом случае лезть в оперативу? там блин 60+ гигов. Ага, я взял тот который влезет во всю мою оперативу и чуть-чуть останется - q4 K M, щас качаю чего попроще - 3xxs
Попробуй [OOC: запрос] и прио повыше (хотя я не знаю за что Depth отвечает, лол)
0.44 токена в xxs. ХМ. Может быть я делаю что-то не так?
>Ну так там в любом случае лезть в оперативу?
Я про автовыгрузку, если ты вдруг выставил чуть больше слоёв. Это немного не то, что отдельная работа.
>xxs
ЕМНИП, эти кванты в принципе хуже работают на проце. Попробуй как у меня, и выстави слоёв 26.
Эм. А зачем 26, если даже кобольд мне пишет, что может подгдрузить в видюху ~60 слоев из 90? Или именно в этом и проблема низкой скорости?
Сделай как я пишу, узнаешь. Мониторь нагрузку на память ГПУ.
Заняло 50%, 0.45 токенов (но это пока что на xxs, ks пока что качается)
Распредели слои чтобы 90 - 95 забивало. Плюс может ты в бэнче кобольда смотришь? Там при запуске он весь установленный контекст забивает от чего скорость сильно падает. Как пример на 4090 на малом контексте скорость 1.8 а на 32к 0.4 Это на 5 кванте. Плюс
так и сделал только что, да скорость поднялась до 0.7 токена. Смотрю в кобольде, но генерацию онли, без контекста. Больше спасибо за подсказку, но кажется что-то где-то еще висит, вроде бы 3090 должна выдавать побольше 3080 хоть и ti
Причём тут видеокарты если вы оба в обычную память упёрлись? У того анона она быстрее просто.
В два раза больше vram не играет роли?
А если разогнать оперативу?

Если хоть один слой уходит в обычную память — остальные 96 слоёв встают как пикрил и ждут, пока это чучело не протиснется сквозь узенькую шину данных.
Прочитал вашу ветку, у него третий квант, у тебя четвертый. Ты гоняешь больше данных. Это занимает больше времени. Генерируешь меньше токенов.
не, я уже катаю 3xxs который даже меньше его, и качаю ровно его. Сейчас докачал, объединяю, и попробую как оно
> Ты гоняешь больше данных
Что? Они попытались разметить все в врам и такой огромный объем выгрузился в рам? Да не, там размер сильно ограничен и под 123б не хватит.
Если по-человечески и там распределение между видеокартой и процессором то на шину похуй, и количество пересылаемых данных от числа выгруженных слоев не зависит если что, там только активации по стыку шлются, которые даже от размера кванта не зависят.
> количество пересылаемых данных от числа выгруженных слоев не зависит
Сам придумал, сам опроверг. Перечитывай ветку заново.
ну, технически, у меня 100гб рам и хрензнает сколько подкачки на m2 970_ом так что да, всё это вполне уехало в рам после видюхи
> Сам придумал
В том и дело что там двусмысленные старнные рассуждения ни о чем. В случае вопроса анона про две карты или просто больше врам - очевидно что поможет и будет дохуя быстрее, а не то что ты пишешь.
> у меня 100гб рам
Генерация на процессоре медленнее гпу прежде всего из-за того что псп рам меньше в разы а то и десятки раз, при обработке промта там еще добавляется разница в скорости расчетов. Объем здесь не роляет пока памяти хватает.
Офк это для случая где идет разбивка модели между процом и видюхой, если пытаешься запихнуть в видеокарту больше чем она может позволить, и драйвер начинает выгрузку в рам - там совсем все плохо и еще будет упираться в скорость pci-e а проц будет простаивать.
Janus уже запускали? Че, как, зачем?
Вот вопрос в том, имеет ли смысл гнать оперативу? Будет ли какой-то прирост?
не трогай его, в его мире модель загружается в процессор, в 25мб кэш, видимо)
Будет конечно, но два умножить на ноль все равно останется нулем. Во сколько раз разгонишь во столько и станет быстрее в первом приближении.
Подскажите, как работает Summarize и продолжение истории когда забился весь контекст? Мне нужно вручную занести туда информацию которая происходила до этого момента, потом в качестве первого сообщения скопировать последние сообщения разговора, и потом куда-нибудь вставить [Summary: {{summary}}]? Он должен сработать только один раз, или каждое сообщение? Нужен ли он вообще, или лучше занести короткое саммари в карточку персонажа/первое сообщение?
Ты бы конкретно перечислил все модели, которые пробовал. Если ты тестировал на каких-то максимально ванильных, то ничего удивительного.
Помню, что RP файнтюны даже первой Mistral 7B были весьма неплохи, не говоря уже про файнтюны Solar-10.7B ( статья про неё https://arxiv.org/abs/2312.15166v3 ).
Можно ли сделать свою модель, типа загрузить кучу книг на русском?
Получится ли модель, которая хорошо на русике работает?
Разница между 5600 и 6800 10%. Дальше сам думай стоит ли оно того.
>Помню, что RP файнтюны даже первой Mistral 7B были весьма неплохи
Дай угадаю, тогда модели были еще чистыми, а потом в них начали сливать дистиллят и они перестали нормально файнтюнится?
Конечно получится. Бери кластер хотя бы с 10000 H100, книг набери на пять терабайт, обучай хотя бы месяца 3, и всё будет!

У меня есть rtx 3060ti и хдд на 2ТБ
>Подскажите, как работает Summarize и продолжение истории когда забился весь контекст?
саммари в первый раз суммирует всю имеющуюся историю, а потом на основе предыдущего саммари добавляет новые факты, если я правильно помню. Там есть промпт, который отправляется в момент, когда саммари должно обновиться.
>Нужен ли он вообще, или лучше занести короткое саммари в карточку персонажа/первое сообщение?
Ну, на мой взгляд, лучше с ним, чем без него. Но лучше смотри че там у тебя записывается и редактируй вручную.
Я правильно понимаю что с 8гб видюхой если хочешь 4к контекст минимум и 4 кванта 12б модели то тут только кобольт?
Можно и через убу. один хуй через жорино поделие все будет.
окей у меня уже хуй отваливается я больше не могу дрочить на ети карточки сраные в таверне есть что нибудь кроме nsfw может быть какие небудь охуительные истроии или щто
Тяжеловато будет. Надо где-то найти еще 3 тб на хранение книг.
>у меня уже хуй отваливается я больше не могу дрочить
Слабак. С 7 лет дрочу каждый день по 5 раз уже 27 лет кряду.
Dungeon Core Simulator попробуй или другие карточки, не персонажей
Да хоть скажи сетке что теперь она является консолью линукса, и она будет отыгрывать ее
Ну вот я скачал а как квант выбрать?
У меня ошибка оут оф мемори грузит сразу 8 квантов
У меня ошибка оут оф мемори грузит сразу 8 квантов

где use this model делай или в files там выбирай какой тебе надо квакнт, но ета залупа (обнемора) скорее всего тебе не даст скачать скажит сначала нада зарегаца и принять
Я опять выхожу на связь.
Я учел ваши предложения и сделал пересчет на 110B/16BF.
Тренировка/дев (2 сервака):
- 2 x AMD EPYC 7713 - 64 Core - 2 GHz - 256 MB L3 - Socket SP3
- 2 TB RAM
- 8 x A100 SXM4 80 GB HBM2e
- Для объединения 2 серваков в кластер взял QSFP56 на 200Gb. В тырнете видел цифру что для тренировок на кластере нужно минимум 50Gb.
- На 9004/9005 (9755 который сейчас топ) епике сэкономил, да. По бенчмаркам епики пока что в топе, зионы без л3 кэша нинужны.
- Сэкономил на A100, пушо цена на H100 в ~полтора раза больше, т.е. по сути почти вся стоимость сервака. Тырнет говорит что прирост производительности в зависимости от задачи будет от 1/4 до 3/4, если обучение одного цикла будет условно полтора дня, а не один день, я думаю девы потерпят + бюджет еще нужно на много что потратить.
Итог 80 х 8 = 640 х 2 = 1280 чего вроде как должно хватить.
Дальше инференция/прод (их будет n):
- 2 x Intel 18-core Xeon Gold 6240 2.6-3.9GHz
- 1 TB RAM
- 4 x H100 80GB
- Дико сэкономил на кпу из-за того что инференция будет на гпу, и по бенчмаркам кпу там практически никак не фигурирует, разве что если только у него будет меньше ядер чем количество гпу х 4.
- Здесь уже взял H100 в угоду скорости токенов. По памяти - для инференции 16BF просто умножил размер модели на х 2, т.е. 110 х 2 = ~220GB, должно хватить.
Итоговая цена (2 для тренировки и 2 для инференции) ориентировочно пол ляма.
Мнение? Что вы чувствуете при просмотре этого поста? В чём я не прав? Ваши действия в этой ситуации?
Я учел ваши предложения и сделал пересчет на 110B/16BF.
Тренировка/дев (2 сервака):
- 2 x AMD EPYC 7713 - 64 Core - 2 GHz - 256 MB L3 - Socket SP3
- 2 TB RAM
- 8 x A100 SXM4 80 GB HBM2e
- Для объединения 2 серваков в кластер взял QSFP56 на 200Gb. В тырнете видел цифру что для тренировок на кластере нужно минимум 50Gb.
- На 9004/9005 (9755 который сейчас топ) епике сэкономил, да. По бенчмаркам епики пока что в топе, зионы без л3 кэша нинужны.
- Сэкономил на A100, пушо цена на H100 в ~полтора раза больше, т.е. по сути почти вся стоимость сервака. Тырнет говорит что прирост производительности в зависимости от задачи будет от 1/4 до 3/4, если обучение одного цикла будет условно полтора дня, а не один день, я думаю девы потерпят + бюджет еще нужно на много что потратить.
Итог 80 х 8 = 640 х 2 = 1280 чего вроде как должно хватить.
Дальше инференция/прод (их будет n):
- 2 x Intel 18-core Xeon Gold 6240 2.6-3.9GHz
- 1 TB RAM
- 4 x H100 80GB
- Дико сэкономил на кпу из-за того что инференция будет на гпу, и по бенчмаркам кпу там практически никак не фигурирует, разве что если только у него будет меньше ядер чем количество гпу х 4.
- Здесь уже взял H100 в угоду скорости токенов. По памяти - для инференции 16BF просто умножил размер модели на х 2, т.е. 110 х 2 = ~220GB, должно хватить.
Итоговая цена (2 для тренировки и 2 для инференции) ориентировочно пол ляма.
Мнение? Что вы чувствуете при просмотре этого поста? В чём я не прав? Ваши действия в этой ситуации?
За такие деньги можно тяночку на зарплате нанять
Ниче не чувствую, пол ляма это зп айтишника с 5 годами опыта.
Ты думаешь речь о рублях?
А мне вот тоже интересно как вообще это всё работает. С 8к токенов через сообщений так 30 нейронка начинает ориентироваться только на последних сообщениях и почти забывает о мире и события которые были до этого и если пока разыгрывается какая-то сцена это еще ок, то вот когда хотелось бы сцену уже закончить и продолжить историю нейронка зацикливается на этой сцене. Даже если подробно расписывать события разворачивающиеся в новой сцене, она выхватывает из абзаца пару предложений переосмысляет по своему и повторяет события сцены. Пока кроме как удалением сообщений я это не придумал как решить.
А вообще я пару дней всего как кручу эти модельки (на 4060ти особо не развернешся, 22b влазит полностью в карту и то ладно), но то как нейронки выдумывают сюжеты это забавно и часто неожиданно. В части nsfw правда я не нашел модель которая бы подробно описывала всякие пошлые штуки, ну т.е. они не избегают половых отношений, а если в систем промпте прописать, что она не стесняется всяких словечек, то она это использует, но с художественной стороны описания процесса всё как-то примитивно и безинициативно (как будто со своей женой в постеле, бадум-тсс).
Обучать на бо́льшем объеме памяти на более медленных чипах, ИМХО, — хорошая идея.
А насчет инфересна я просто вброшу, ниче не советую ваще.
Как насчет тех же Cerebras или Groq? Не будут дешевле за токен/секунда, достать реально?
Не является рекомендацией, хуйню несу, успехов и добра!
> Тренировка/дев (2 сервака):
8 карточек в каждом сервере или по 4 в двух? Если второе то нахуй и превращай в первое. А так уже не что-то похоже.
> С 8к токенов через сообщений так 30 нейронка начинает ориентироваться только на последних сообщениях и почти забывает о мире и события которые были до этого
Плохая нейронка или промты. Но вообще подобная проблема, прежде всего для кума, есть много где. А aicg треде для этого пробовали делать суммарайз постов на лету, когда из длинных полотен нейронка сразу делает выжимку и потом в историю идет именно она. Получается такое с переменным успехом, где-то эффект есть и хороший, где-то наоборот портит.
Наилучшим решением "выхода" из какого-то события будет ее оче подробный суммарайз и замена им большей части сообщений.
Можешь рассказать подробней или кинуть ссылку за щеку как делать и использовать суммирование?
> 4 x H100 80GB
Хотя бы 64 бери.
Тут выше советовали попробовать все слои грузить в врам, а токены кобольд пусть в оперативку грузит (с опцией low vram). Но кажется так стало хуже. Нейронка сначала долго тормозит загружая контекст, а потом генерит 3 т/с, при том что когда я грузил 50 из 59 слоев она генерила 6 т/с.

Cydonia-22B-v1.1-Q8_0
Mistral-Small-22B-ArliAI-RPMax-v1.1.i1-Q6_K
Mistral-Nemo-12B-ArliAI-RPMax-v1.2.silly
Mistral-Small-22B-ArliAI-RPMax-Diluted.i1-Q5_K_M
Попробуй, особенно последнюю, любит писать развёрнутые, куда длиннее чем "неразбавленная" версия, но когерентные ответы, удерживается в сеттинге и персонаже, периодически переходит на "высокий слог" (ака Толкиен, Урсула Ле Гуин, Сальваторе и его книги про приключения Дриззта До'Урдена).
В целом меня прям устраивает.
Карточка - "Unira the Branded"
Я щас взорвусь нахуй дайте покумить
Ебаное амд говно никогда не берите этот кал
На линукс ни угабугу ни кобольт не могу без ебли установить модель ошибки выдает
На винде 2 клика сделал жопу почесал и всё работает как часы
Ебаное амд говно никогда не берите этот кал
На линукс ни угабугу ни кобольт не могу без ебли установить модель ошибки выдает
На винде 2 клика сделал жопу почесал и всё работает как часы
>а токены кобольд пусть в оперативку грузит
Какой-то шиз советовал, лол. Контекст должен быть на ВК 100%, слоёв сколько влезет в остаток.
Уверен что у тяночки не будет той скорости токенов в секунду.
Очевидно что не в рублях, одна A100 стоит ~18-20к, H100 под 30к. Не рублей.
>Groq
>Cerebras
У кабана заморочка на счет утечки данных, так как датасеты придется загружать в облако, поэтому принципиально свое железо.
Расчеты не делал, но я практически уверен что облако с продолжительностью проекта до 3х лет должно быть дешевле.
Очевидно 8, я в посте посчитал количество VRAM.
Для чего?
И ты конечно же решил, что натренить модель получится с первого раза идеально? Наоборот на бесчисленные попытки подбора параметров надо пускать лучшую производительность, а в инференсе можно и потерпеть со старым поколением
так ему ничего кроме 12b не влезет
А ну ты пидор тогда.
Родаки богатые или биток купил?
Скинь полтос
Внезапно, на миднайт мику (пока с остальными не проверял) он начал после каждого моего сообщения делать Processing Prompt [BLAS] n/n. Мне кажется это не нормально? Контекст крутится на видюхе, место еще есть, его самого 12к, а в чате и двух тысяч еще не набралось учитывая карточку и первое сообщение.
Наверное что-то из этих двух отвалилось (не помню, что именно отвечает за это).
Второе отключает первое если что. А первое как раз оно.
Первое стоит. Второе нет. Но это базовые настройки, которые не менялись.
Контекст 12к на бекенде и фронтенде?
Если запускал с 12к, но в таверне 2к, то будет пересчитывать вроде
ну вон 12б в списке, тоже норм, хотя конечно для рп с карточкой хотя бы на пару тысяч токенов чтобы описать сеттинг (не включая лорбук) - 12б это груздь-доска
Кстати, где в этой информации нужные т/с которыми все тут меряются? 22б в 5м кванте.
CtxLimit:3770/8192,
Amt:142/512,
Init:0.02s,
Process:1.30s (5.8ms/T = 172.31T/s),
Generate:42.83s (301.6ms/T = 3.32T/s),
Total:44.13s (3.22T/s)
Кстати, хорошо прописанная карточка ОДНОГО конкретного персонажа отказывается говорить за других, в том числе эпизодических неписей вроде стражника у ворот, тавернщика или торговца. Можно как нибудь чтобы самому за них не писать?
Этой проблемы нет если карточка описана как DM, а основной персонаж карточки как NPC, и игрок как PC, но там другие проблемы.
Этой проблемы нет если карточка описана как DM, а основной персонаж карточки как NPC, и игрок как PC, но там другие проблемы.
>Process
чтение промпта
>Generate
генерация
>Total
Общая скорость
сяп
Если весь контекст чата забит одним конкретным персонажем и его интерактивностями с юзером, то других персонажей скорее всего модель будет скипать. Она банально будет брать предыдущие сообщения для примера и продолжать писать в том же стиле, и если там не встречались другие персонажи - она за них говорить и не будет.
Все зависит конечно от конкретной файнтюны, но чаще всего это правило работает.
Я с точно такой же хуйней жаловался в предыдущем треде. У меня Немо так же постоянно пересчитывает контекст (отключение включение контекст шифта и флеша никак не влияет, хотя некоторые с умными ебальниками доказывали что дело именно в этом. Скорее всего сломался жора как всегда.
Хм, надо попробовать дженерик нарратора подрубать в групповом чате одновременно с персонажем.
Context Shift отключает только возможность квантизации кэша. Не галлюцинируй.

Вопрос анонам ИТТ:
на пикче норм же по семплерам?
Почему-то у меня DRY не работает, приходится репетишн пенальти ставить.
А так, какого хера на Chub сплошные соло модели, да еще и так паршиво написанные. Нет ни сценариев, ни групповых ботов. Про то как они паршиво написаны молчу.
на пикче норм же по семплерам?
Почему-то у меня DRY не работает, приходится репетишн пенальти ставить.
А так, какого хера на Chub сплошные соло модели, да еще и так паршиво написанные. Нет ни сценариев, ни групповых ботов. Про то как они паршиво написаны молчу.
Скочал кобольд, скочал какую-то импиш модель
В первый запуск оно соглашалось рассказывать пошлые истории
В след. запуск оно начало строить из себя чатгпт и не не не никаких пошлостей
Как это работает?
В названии модели было написано статические кванты, значит обучатся не должна наверное
В первый запуск оно соглашалось рассказывать пошлые истории
В след. запуск оно начало строить из себя чатгпт и не не не никаких пошлостей
Как это работает?
В названии модели было написано статические кванты, значит обучатся не должна наверное
>У меня Немо так же постоянно пересчитывает контекст
Поставь в Таверне для Немо шаблон Instruct-режима "Mistral V3 - Tekken" и в строке "Префикс сообщения пользователя" перед [INST] вставь два перевода строки. То есть должно получиться так:
"
[INST] ", без кавычек понятно, и пробел после [INST] не забудь. Попробуй, может и поможет.
>на пикче норм же по семплерам?
Никто тебе не ответит, пока не скажешь, что за модель стоит.
>Почему-то у меня DRY не работает, приходится репетишн пенальти ставить.
Это нормально, это жора кобольд. У меня до сих пор ни драй ни хтс не работают.
>А так, какого хера на Chub сплошные соло модели, да еще и так паршиво написанные. Нет ни сценариев, ни групповых ботов. Про то как они паршиво написаны молчу.
Групповые боты есть, но в остальном всё так. Хочешь хорошую карточку под себя - составляй её сам, других вариантов нет. На чубах к тому же большая часть карт написана через жопу потому что они составляются под клаву либо гопоту, ибо им в целом насрать на форматирование и они могут переваривать текст почти в любом виде, так как тренировались на огромной дате.
22b 4kL чисто на профессоре у меня выдает 3,3 токена генерации на первых 2к токенах
Для большей части модели на видимокарте у тебя медленно как то
>пока не скажешь, что за модель стоит.
Для кума
bullerwinsL3-70B-Euryale-v2.1_exl2_4.0bpw
Для ассистента
Zoydfailspy_Smaug-Llama-3-70B-Instruct-abliterated-v3-4_0bpw_exl2
Почему-то у многих моделей часто даже не пишут какие семплеры ставить.
Я всё понимаю конечно, но как шаблон для инструкта может влиять на желание бека постоянно пересчитывать контекст? Если бы оно было так, то он бы пересчитывался постоянно, после каждого сообщения. Но этого не происходит и до примерных трех тыщ выжженых токенов всё работает как должно.
Бтв, шаблоны я менял и специально чекал мисральскую документацию по поводу служебных токенов.
Тогда в душе не ебу, ибо это явные шизомиксы на третью ламу, а там разброс по той же температуре от 0.5 до 1.8 может доходить в зависимости от файнтюна и долбоебизма сборщиков. Если всё работает - то можешь оставить. Нет смысла искать тот самый пресет, ибо условия использования у всех разные.
>шаблоны я менял и специально чекал мисральскую документацию по поводу служебных токенов.
Значит сразу отметаем и изменение промпта Таверной и вообще всё, кроме того, что лламаспп криво поддерживает контекст шифт на мистралях. Варианта только два: смириться или попробовать поискать лайфхак, который позволит обойти кривую обработку контекст шифта. Вот как в примере выше.
>лламаспп криво поддерживает контекст шифт на мистралях
Тут самое забавное то, что на старом кобольде (считай что на старой жоре) мистраль нормально гонялся. Я специально скачал и проверил - там никаких затупов с пересчетом нет.
Скорее всего в следующий запуск слетели все настройки. Когда нравится что моделька выдаёт — сразу сохраняй все презеты в отдельную папку. Кроме тебя их потом никто не накрутит.

> Почему-то у многих моделей часто даже не пишут какие семплеры ставить.
Я тоже этого очень долго не понимал, но оказалось, что достаточно просто посмотреть датасет в шапке модели.
>достаточно просто посмотреть датасет в шапке модели
Лол, если бы оно было так просто. Во-первых на морде указываются не все датасеты, а только те которые были прикреплены вручную и загружены на саму морду. Во-вторых даже на файнтюнах под одну модель настройки могут быть диаметрально противоположными, ибо сказывается тренировка дополнительными данными, которая сильно может менять изначальные вероятности токенов.
>на франкенштейнах не так
ок

8К контекста, может поэтому, контекст шифт выключен для возможнсти квантизации кэша.
Хм, наверно можно и больше слоёв на видяху накинуть, я просто не менял число что лаунчер автоматом выставил.
Реально, добавил в кобольде просто второго персонажа с именем "Narrator", просто именем, кобольд не даёт возможности грузить несколько карточек, и волшебным образом неписи заговорили без меня.
Очень условно, в стиле JRPG... хотя у меня и карточка сейчас такая, про попаданца в исекай где юзер - это система, сопровождающая игрока, а не сам(а) попадун(ка).
Зайди в прошлый тред, сразу поймёшь где я писал.
Конечно я не ожидаю ничего с первого раза и понимаю что это будет брутфорс с неизвестным результатом.
Вот только на инференс я не могу предсказать сколько будет запросов, так как это будет сервис с апи и какое количество токенов в секунду будет генерить на моей модели h100.
>8К контекста
Тоже 8к, читая 1к токенов и отвечая на 1,5к токенов выдает 3,3 генерации
Используй cpu-z перед генерацией и смотри работает ли карта на полных частотах
У тебя с такой врам должна быть скорость от 6 т/с
У меня невидия выебывается и не считает нейронки достойной причиной работать, если не пнуть работает на низких частотах
> cpu-z
GPU-Z вроде нагляднее для видеокарты.
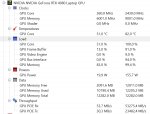
> cpu-z
Есть Open Hardware Monitor.
>если не пнуть
А как "пнуть"?
GPU core скачет как температура по больнице.
GPU memory чаще всего работает на 6000.
Ой в пизду короче. Перепробовал с десяток моделей между b18 - b27 (К4 в основном, с контекстом в 8к), попробовал разные настройки и системные промпты. Один хрен сначала всё интересно, потом начинает повторять предложения и дальше только удалять последние сообщения до того из которого она начинает повторять и расписывать другую сцену. К тому же художественности не хватает, довольно быстро приедается одинаковое описание всего, часто чуть ли не слово в слово не смотря на то что модели и карточки разные.
Блин, если бы нейронка была всё время креативная так же как в начале было бы топово. не раз удивляла, но потом скатывалась. Гемма 27б что-то там старается, но системные промпты не поддерживает, вроде как старается обходить эксплисит. Впрочем из тех моделей что пробовал они все не очень то кидаются расписывать подробности пока я сам их не распишу, а потом они цепляются за это и начинают гонять по кругу.
Может потом ещё вернусь к этому, попробую настройки разные погонять, но пока что сыровато на мой взгляд не смотря на то что этих моделей куча огромная.
Блин, если бы нейронка была всё время креативная так же как в начале было бы топово. не раз удивляла, но потом скатывалась. Гемма 27б что-то там старается, но системные промпты не поддерживает, вроде как старается обходить эксплисит. Впрочем из тех моделей что пробовал они все не очень то кидаются расписывать подробности пока я сам их не распишу, а потом они цепляются за это и начинают гонять по кругу.
Может потом ещё вернусь к этому, попробую настройки разные погонять, но пока что сыровато на мой взгляд не смотря на то что этих моделей куча огромная.
> свое железо.
Так я про свое и говорю. Я ж не шарю, но вдруг их чипы можно купить и завезти к себе. Я б облако не предлагал. ))) У меня у самого такая же заморочка.
Оно, перепутал букву
Собственно я тупо вначале запускаю бекенд, потом запускаю gpu-z и у меня частоты видимокарты лочатся на максимум
Так и пинаю, никакие режимы производительности в панели настроек невидима не помогают на моей вин10
> сначала всё интересно, потом начинает повторять предложения и дальше только удалять последние сообщения до того из которого она начинает повторять и расписывать другую сцену
Можешь попробовать ещё подробные суммарайзы делать с последующим скрытием всей истории - я вот такое использую, когда лупиться начинает: https://rentry.co/LLMCrutches_SteppedSummary
Скрыть потом скриптами можно: https://rentry.co/LLMCrutches_Other
мимо
Хм. Я с гита похожее расширение ставил - на мысли и чувства, но оно почему-то ничего не делало. Попробую, спасибо.
Выгорание от нейродрисни это классика. За два года у меня такое было раз сорок наверное. На неделю-другую забиваю хуй, потом возвращаюсь, становится терпимо.
Про однотипные описания и постоянное перевирание одних и тех же шаблонов - тут только помогает постоянный свап карточек и сценариев, больше ничего. Меня даже кум уже не интересует, я чатюсь чисто до момента ебли, а потом дропаю, ибо знаю почти до буквы как дальше будет идти описание. А именно при прелюдии, коррупции и разврате модельки еще более менее выдают что-то оригинальное, что интересно читать.
> Меня даже кум уже не интересует, я чатюсь чисто до момента ебли, а потом дропаю, ибо знаю почти до буквы как дальше будет идти описание
ирл то же самое
>ибо знаю почти до буквы как дальше будет идти описание.
Большая модель, большой контекст, инструкция "Описывай сцены секса подробно, художественно, обязательно обыгрывая эмоциональные и физиологические ощущения персонажей" - и для разных персонажей сцены эти будут весьма разными. Особенно если не стоять столбом, а самому активно участвовать. Ну а если предоставить всю инициативу модели, то "ирл то же самое", как и написано в комментарии выше.
Лол, у меня в один момент сетка закончила свой высер словами "И слава богу", и сразу сошла сума, в следующем сообщении начала без остановки "АминьАллахуАкбар" писать, все слитно.
Мое ебало, когда во время чернушного кума прилетает 4 абзаца "АминьАллахуАкбар", описывать думаю не стоит.
За прошедшее время я уже всякое испробовал. Сначала гопоту турбо, потом четверку, потом клауду, потом перелез на локалки. Из последнего пробовал большой мистраль. Меня уже мало что удивит во время описания интимных поебушек, так что твой совет годится только тем, кто либо сидит только на мелочи, либо просто мало моделей гонял.
Просто ебля это неинтересно, для этого любую внку можно взять и запустить.
Вот в контексте, это уже вполне годно и интересно выходит.
А можно и без ебли...
Карточка: девушка-чунибьё привела парня к себе домой говоря что разгадала принципы мироздания и готова открыть ему свою настоящую сущность.
Я видел хентай который начинался также... но не в этот раз.
Сессия: Парень в ответ говорит что мол ты готова, чтож, хорошо, тогда я тоже раскрою тебе свою сущность - оператора межмировой паутины (в отпуске). После того как девушка касается материализованной консоли, последняя проверка действительно ли она жаждет чуда или это всё было лишь игрой, она улетает в исекайный мир, а в качестве положенных любому гг плюшек получает свои выдуманные возможности вполне реально действующими, хоть и по правилам и с затрами маны, а "оператор" занимает роль системы и духовного наставника.
Ахахаххахахахаххахахха.
Конкретно "Иншаллу" не ловил, но подобные случаи случались, например на аблитерейтед гемме.
По видимости это случается когда из-за анценз-операций отказать пользователю она не может, но выполнить запрос подходящих токенов не находит, вот и идёт вразнос.
Ну я в общем-то и увлекся на два дня, когда запустил буквально первую скачанную модель и вторую карточку. Начал заводить тему про тройничём с добавленной мной в сюжет девкой, а вместо этого она меня просто застрелила из ревности (за то что я поболтал с другой девушкой, я выше пик кидал). И я подумал ну нихуя себе. А потом всё стало идти по одному и тому же сценарию с редкими исключениями.
>Это нормально, это кобольд.
Их как бы на кобольд завезли раньше, чем на сырую ламуцпп. По крайней мере, xtc, про dry не уверен, но тоже давно уже поддерживается. Тут другой вопрос нафига нужно это говно говна. В одном штрафы на последовательности токенов вместо одиночных токенов с геморроем в виде добавления всех слов, повторы которых ты хочешь иметь, типа имён и префиксов инстракта, в список исключений. Как будто банить последовательности из двух-трёх токенов поможет от повторов структуры ответов и целых словосочетаний, которые и беспокоят сильнее всего. В другом бан всех нормальных токенов выше порога, кроме одного. Шиза похлеще, чем сильно температурой перемешать и норм хвост отрезать, но зато глинтов нет, кайф.
>Их как бы на кобольд завезли раньше
Ну так я и написал, что это кобольд, а не жора.
>Тут другой вопрос нафига нужно это говно говна.
Тестов и сравнения ради? Можно долго вонять что одни семплеры топорнее других и наоборот, но по факту решать будут только личные ощущения. На апи жопенов в какое то время вообще всего 3 семплера было может и сейчас так, хуй знает доступно, один из которых это температура, а другие два это штрафы за повтор и присутствие. Но выживали же как-то.
Блять, что не так с последним апдейтом таверны? Теперь она начинает лагать после примерно 40-50 сообщений. Стриминг проседает как будто до 3-4 токенов в секунду, хотя в кобольде показываются 22. При чем лагают не только сообщения, а весь интерфейс целиком. И только сама таврена, в браузере и других приложениях ничего подобного не наблюдается.
она в принципе гпу грузит если ее просто открыть, как майнер, неоптимизированное говно

Что я делаю не так? То за меня начинает говорить, постоянно пропуская ":", то вот это вот
Радуйся что не аллахакбар. У меня как-то модель переглючила тоже создавая строки с точками, но при этом не хотелось ничего менять т.к. у неё получались неплохие тексты (хотя она и спрашивала "хочешь узнать что будет дальше?"). Добавил стоп на эту фразу и дальше все было супер.
>6x3090
тварб
Я вот смотрю на это всё и думаю. Наверное так выглядит безумие - когда нейронная сеть в твоей голове перестает быть гибкой, а отсутствие нового опыта заставляет мозг зацикливаться на одном и том же, в конце концов зависая в крошечном цикле из которого уже не выбраться.
Думойте
Думойте
Как-то не работает эта штука.
Добавил всё по мануалу, стартую скрипт, он начинает генерить мысли, потом генерит мысли, потом генерит мысли. Толи в 700 доступных токенов не вмещается, то ли что, общем по кругу гоняет скрипт.
Еще и генерится бред типа:
> '- Пока еще весел, но видит как кошеная мажет пальцы на антисептике после чего хотелось бы утихомоичти присмотреть и помыть пальцы - пыльки по занозам шмотовские посимкуть не особо нужно... но думает что для лап лучше и безопаснее чтобы котенок клеил по утру, даст больше ешло... а сама шерка заклеил легко кровена прослал по кнопам куплю. Ожидает покинуть, после - покупай ленту капсулу совершенно желюсто выйдет к вечеру и если подключать будет звезда нужно будет атрфоотфикты ей чтобы норм расчур вашу - длитку. Поток наводое даст в таком случае шум каменноловом - ему благодорь видит у кошенка. Тормоз ли, замочнуть лески по фандансу утрасу всеж воспользуются 23 метра! котенок во\n' +
График в целом закономерный, для генерации много чипа не нужно и основной упор в память. Разогнав врам даже с жестким андервольтом можно получить буст. Но
> launched with 32k context, but prompt is just "write 15 sentences about summer"
как только там добавится существенная обработка контекста то результат станет оче близок к линейному ибо там юзается именно чип, и даже его лимит в 300вт будет ограничивающим фактором.
Сейм.
AppImage ева и
flathub смотри.
Я правильно понимаю, как кодировать слова или нет?
1) сначала каждому слову назначаем вектор, где на всех позициях нули, кроме той, которая ссылается на слово. Можно оптимизировать используя только число, а вектор создавать из него лишь в момент использования.
2) Потом мы на нужных текстах учим модель восстанавливать слова из контекста.
3) Если два слова имеют схожие значения, то веса, связывающие их с контекстом будут похожи.
4) Кодируем слова не длинным вектором из кучи нулей и одной единицой, а весами, которые установились в ходе шага 2.
1) сначала каждому слову назначаем вектор, где на всех позициях нули, кроме той, которая ссылается на слово. Можно оптимизировать используя только число, а вектор создавать из него лишь в момент использования.
2) Потом мы на нужных текстах учим модель восстанавливать слова из контекста.
3) Если два слова имеют схожие значения, то веса, связывающие их с контекстом будут похожи.
4) Кодируем слова не длинным вектором из кучи нулей и одной единицой, а весами, которые установились в ходе шага 2.
>где на всех позициях нули, кроме той, которая ссылается на слово.
А как ты узнаешь, какой именно вектор должен ссылаться на твоё слово? Рандомом инициализируют. Пытались нулями, но рандомом лучше. И нет никаких слов.
>А как ты узнаешь, какой именно вектор должен ссылаться на твоё слово?
Ну по порядку сначала, для слов: a cat bread по алфавиту будет соответствовать {100}{001}{010}. Потом уже на анализе текстов веса установятся похожим образом для похожих слов и вектор короче будет.
Хуйня. У тебя есть выходной слой, он же embedding, его ширина - количество токенов, каждый соответствует своему. Ты предлагаешь это соответствие перекладывать в вектор, что само по себе не будет работать, т.к в векторе сохраняется не какой-то тип указателя, а смысловое значение токена.
>Ты предлагаешь это соответствие
Еще нет никакого соответствия на этом этапе. Слова в форме букв и их надо сделать числами.
Чтоб в выходном слое что-то было, надо что-то подать на входной.
>Еще нет никакого соответствия на этом этапе.
Создаёшь словарь, создаёшь слои своей нейросети. Всё, есть ассоциация словаря токенов с тензорами нейросети. Значений этих тензоров нет. Значения, повторюсь, инициализируют рандомом, потому что так лучше.
Посоветуйте где можно следить за выпуском новых файнтюнов.
Я знаю только
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
Я знаю только
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
>Создаёшь словарь
Как, если не через векторы, где каждому слову соответствует вектор?
Создаёшь токенизатор. В токенизаторе у каждого токена есть номер. Каждый номер токена жёстко привязан к конечному выходному слою, logit. Это крайние слои с обоих концов модели. Ширина этого слоя равна количеству токенов в токенизаторе. Есть у модели 128к токнов? Ширина конечного слоя - 128к. Понятнее стало? Последующие слои соответствуют размерности модели и не зависят от ширины logit слоя.
https://www.reddit.com/r/SillyTavernAI/
Что то может еще более специализированное на ерп локалки есть, ищи
>Создаёшь токенизатор
Как? Токены - это числа какие-то, особым образом (каким, опять же?) полученные, которые можно подавать на вход НС?
Если нет, то как потом работать с этими токенами?
Иди почитай теорию ллм, где то легко гуглилились гайды с графикой показывающей работу всей нейронки
Как работает llm
Или чет такое
>каким, опять же?
Берётся обучающий корпус и прогоняется через алгоритм. Алгоритм учитывает твой желаемый размер токенизатора в токенах и разбивает корпус на токены. Алгоритмы есть крайне разные, сейчас самый распространённый BPE Wordpiece. Byte-Pair Encoding. Гуглится легко, описание на есть на обниморде.
>которые можно подавать на вход НС
Да.
Причём тут работа llm, если важен конкретно самый первый этап превращения слов в числовые массивы, реализацию которого все опускают?
>Алгоритмы есть крайне разные, сейчас самый распространённый BPE Wordpiece. Byte-Pair Encoding.
Посмотрю, спасибо.
>Причём тут работа llm, если важен конкретно самый первый этап превращения слов в числовые массивы, реализацию которого все опускают?
Потому что там это тоже разбирается
Если хочешь сильнее погрузится в эту тему иди кури на арксиве документы по теме токенизация и ллм
Но чувствую там не твой уровень, поэтому лучше гугли научпоп

Если ты про st-stepped-thinking и ставил вчера, то там была бага после релиза, которую я уже пофиксил. Можешь попробовать ещё раз.
>https://www.reddit.com/r/LocalLLaMA/top/
Мне там понравилась новость о новых QTIP-квантах, которые существенно быстрее старых и легко могут быть реализованы в llamacpp:
https://www.reddit.com/r/LocalLLaMA/comments/1ggwrx6/new_quantization_method_qtip_quantization_with/
Господа, а я к вам с вопросами.
1. Чем отличаются weighted/imatrix quants от static quants? Они лежат в разных репозиториях. Допустим, возьмем i1-Q4_K_M и Q4_K_M (сразу скажу, что IQ кванты - это другое, про них есть инфа в гайде из шапки). Они одинакового размера, какой из них лучше?
2. Тут недавно вышел магнум 123b v4. В чем смысл этих ревизий? Можно ли ожидать, что v4 лучше v2 будет? Скачивать и проверять разные версии слишком накладно, линухоблядям не сделали норм wifi драйвер, поэтому приходится качать на другой машине и покерфейсом ждать час, пока моделька перекинется с HDD, да и ssd не резиновый
3. Нашел такую йобу https://huggingface.co/mradermacher/Behemoth-v1.1-Magnum-v4-123B-i1-GGUF. Типо мерж двух моделей. Зачем это делают? Кто-нибудь уже пробовал какова она по сравнению с обычным магнумом? в куме, конечно же
1. Чем отличаются weighted/imatrix quants от static quants? Они лежат в разных репозиториях. Допустим, возьмем i1-Q4_K_M и Q4_K_M (сразу скажу, что IQ кванты - это другое, про них есть инфа в гайде из шапки). Они одинакового размера, какой из них лучше?
2. Тут недавно вышел магнум 123b v4. В чем смысл этих ревизий? Можно ли ожидать, что v4 лучше v2 будет? Скачивать и проверять разные версии слишком накладно, линухоблядям не сделали норм wifi драйвер, поэтому приходится качать на другой машине и покерфейсом ждать час, пока моделька перекинется с HDD, да и ssd не резиновый
3. Нашел такую йобу https://huggingface.co/mradermacher/Behemoth-v1.1-Magnum-v4-123B-i1-GGUF. Типо мерж двух моделей. Зачем это делают? Кто-нибудь уже пробовал какова она по сравнению с обычным магнумом? в куме, конечно же
Да, про это. Так ты разработчик? Постараюсь всё же запустить тогда и потестить.
А есть смысл ставить и Stepped Summary и Stepped Thinking?
Это кванты для очень агресивного квантования, ниже 4 кванта. А там жизни считай и нет. Ну 3 квант еще более менее на 70+ сетках.
>Чем отличаются weighted/imatrix quants от static quants?
теоретически, меньше качества проебывается при квантовании, но хз, по личному опыту не замечал такого.
>Можно ли ожидать, что v4 лучше v2 будет?
не всегда. иногда при тюне новой версии проебываются и лучше оставаться на старой.
алсо кто-нибудь пробовал министраль 8b? поделитесь впечатлениями.
на фре нет куды. Можешь сразу об этой идее забыть.
stepped-thinking работает. Надо понять сколько токенов на ответ надо поставить чтобы мысли и планы помещались. Ну и ещё скрытие почему-то не работает. Надо тоже разбираться.
Сразу после того как кде2 пропатчишь, можешь попробовать.
https://forums.freebsd.org/threads/can-cuda-be-installed-on-freebsd-now.85879/
Кроме шуток, почему фряха?
Да, я разраб. Если какие-то проблемы снова возникнут, приложи, пожалуйста, ошибки из консоли браузера + твои настройки расширения из SillyTavern/data/default-user/settings.json, секция st-stepped-thinking.
> А есть смысл ставить и Stepped Summary и Stepped Thinking?
Я лично не пробовал, но судя по описанию с рентрая, делают они примерно одно и то же, только Summary составляет саммари по всем персонажам от лица системы. Так что смотри сам по желанию.
> Ну и ещё скрытие почему-то не работает
Можешь поподробнее рассказать, пожалуйста?
>Это кванты для очень агресивного квантования, ниже 4 кванта. А там жизни считай и нет. Ну 3 квант еще более менее на 70+ сетках.
В примерах квантованных моделей у них лежат четырёхбитные. 70В весит 36Гб. Не сильно большая разница с 4KM и вполне сравнимо с exl2.
>в крошечном цикле
Нихрена себе крошечный, целая неделя. Которая, впрочем, состоит из лупа будничного и лупа выходного, а там свои маленькие залупы.
>Ширина конечного слоя - 128к.
Бля, я только сейчас на такую хуиту обратил внимания. Пиздец конечно.
Мимо другой ресёрчер ЛЛМ
>новость о новых
Опять революция, которая ни к чему не приведёт?
>Типо мерж двух моделей. Зачем это делают?
Это быстро, позволяет высирать 9000 моделей в минуту, авось какая-то случайно получится хорошей. А за хорошую люди на западе донатят.
>Тут недавно вышел магнум 123b v4
На первый взгляд не хуже v2, так что можно использовать. Но лучше пробовать файнтюны на его основе, тот же Бегемот.
Видимо конфликтует с автопереводчиком, плюс не влазит в доступный лимит токенов, поставил 1000 токенов на ответ и этого не хватает. Попозже еще поэкспериментирую. В идеале конечно чтобы всё таки влазило в 1000 токенов всё-всё, но не знаю в каком конкретно месте это объяснить нейронке.
Кстати попробовал с https://rentry.co/LLMCrutches - System Lorebook выглядит годно.
>Опять революция, которая ни к чему не приведёт?
Тут разница в том, что похоже эти кванты можно делать просто и быстро, и в лламуспп вставить поддержку тоже просто. По весу они поменьше, а по скорости выше. Если нет других проёбов... Но это скоро узнаем.
>Видимо конфликтует с автопереводчиком
А, это да - к сожалению, переводчик в том числе переводит теги.
>плюс не влазит в доступный лимит токенов, поставил 1000 токенов на ответ и этого не хватает
Отмечу, что есть отдельная настройка на лимит длины для мыслей на случай, если ты имел в виду не её.
6 гигов можно мгновенно скачать, что мешает?
да я её уже подергал немного. Просто интересно, что другие думают
шума не подняла, где то видел что слабее квена 7
А почему лучше? Не троллю, реально не понимаю. Если верить , то их клепают чуть ли не по приколу, какой шанс вообще, что это детище лучше оригинала?
>А почему лучше? Не троллю, реально не понимаю.
Если погонять модель подольше, то её косяки становятся заметны. У Магнума их несколько (иногда проёбывает контекст, любит пафосные сентенции). Но для некоторых задач (в основном для кума) датасет этой модели шикарен. Смешиваем её с другой моделью - более скучной, но более умной - и при удаче получаем плюсы обоих моделей. Минусы тоже остаются, но в ослабленном виде.
Пока ещё вожусь с настройками, до этого ещё потратил немного времени разбираясь в конфликтах между System Lorebook и st-stepped-thinking, они местами одно и то же пытаются делать и мешаю друг другу. Так что либо одно, либо другое. Но в целом мне кажется использование миров вместо систем промпта это классная идея, учитывая что можно использовать несколько миров и удобно включать выключать отдельные особенности.
Небольшой фидбэк st-stepped-thinking. Чтобы нейронка не игнорила меня, надо прям обзацы расписывать, иначе мое предложение теряется в огромном тексте Thinking сообщения. И ещё на модели Nautilus-RP-18B-v2.i1-Q4_K_M в мыслях всё время пытается добавить какое-нибудь форматирование xml, html, какую-то псевдоразметку, каждый раз по разному. Модели повыше не тестировал т.к. только эта полностью вомещается в VRAM.
Даже ллама 1b неплохо работает в виде агента, игрался тут с GraphLLM
Надо будет сетки еще мельче потыкать
Один минус, с телефона не потыкаешь комфи подобный интерфейс
Надо будет сетки еще мельче потыкать
Один минус, с телефона не потыкаешь комфи подобный интерфейс
Бля, из таверны вырезали автопродолжение генерации?

> они местами одно и то же пытаются делать и мешаю друг другу
Опубликованная структура лорбука не подходит из коробки, если ты хочешь какую-либо вариацию stepped thinking накрутить, т.к. с последним не нужен обычный thinking-блок, описанный в лорбуке.
Строго говоря, если не хочешь использовать обычный CoT, то думаю в System Lorebook можно почти все записи вынести на один уровень иерархии безо всяких вложенных XML-блоков аля <thinking>, <answer> <guidelines>. Просто сводишь весь набор правил к md-листу безо всяких вложенных элементов.
Почему модели лама3 не работают на линукс амд?
Да я так и сделал. По сути получился блочный систем промпт.
Потому что ты делаешь что-то не так.

Я сто раз переустановил по гайду с гитхаба и вручную лама не работает
Сначала купи нормальную видеокарту, установи нормальную систему, а потом уже прибегай сюда.
Школьник спок
Если ты сто раз устанавливал с гайда и у тебя всё равно ничего не работает, то варианта ровно два. Либо ты криворукий долбаеб, либо система твоя уебанская. Выбирай, что больше по душе. :3
>Линкус
>Амд
>Куда еррор
Ты... Ты тут ничего не замечаешь странного, братан?
Нет не замечаю
Мне сказали на линуксе работает
Я пошел и установил выбрав вариант амд в установщике
дааа... тяжело тебе навреное без видеокарты...
тут тебе скорее всего никто не сможет помочь. амд карты я тут ни у кого не видел.
>Мне сказали
А если тебе скажут в окно прыгнуть?
Возми кобольд и запускай его с --usevulkan. Должно работать вообще везде.
Вообще парадокс конечно. Амд хуярик кучу видеопамяти в свои карточки, но с нейронками они не работают нормально, а нвидиа наоборот хорошо работает с нейронками, но жопит видеопамять. Хорошо хоть никому не нужно 4060ти16гб сделали, чтобы можно было бюджетно себя нейробоярином чувствовать.
>но с нейронками они не работают нормально,
И никогда не работали с ними нормально. Даже на заре этой темы, в далёком 2018
>а нвидиа наоборот хорошо работает с нейронками
Если ГПУ нужен для работы, то, кроме невидивы, вариантов нет. КУДА тащит хоть в 3Д-моделировании, хоть в видеомонтаже, хоть в нейронках. А у АМД просто нет задач. Игродаунская параша, конечно, разумных людей не интересует вовсе
На курточкиных картах есть куда, которая худо бедно справляется с матрицами. У мудятов... Нет нихуя, только программная псевдо-реализация. Так что если даже в максимально бюджетную народную карту они напихают 64 кило видеопамяти, всё равно упрутся в отсутствие тензорных ядер. Хотя конечно даже такая карта будет лучше работать, чем любой десктопный процессор.
Консенсус в общем таков. Нвидиа - контора пидорасов. АМД - контора долбаебов. Но сосем по итогу все равно мы.
А интел тоже не смог свой вариант куды родить? Просто игросральные ведра релизнули?
Вроде у них там есть какой-то свой аналог, но скорее всего это нерабочее и неюзабельное говно, ибо интеловскими арками никто не пользуется. По этой же причине скорее всего под синие чипы никто ничего и не оптимизирует. Замкнутый круг.
Больше всего горит с того, что один энтузиаст взял и запилил программный наёб приложений. Хак сообщает в приложение - мамой клянусь, это куда. И перехватывает все вызовы API, подсовывая либо готовую амдшную реализацию, либо свою. В 90% случаев это работает быстрее, чем "нативное амд". В блендере, в играх, везде. Чел связывается с АМД, те говорят "малаца, хорошо сделал, мы не против". И продолжает пилить, добавляя всё более широкую поддержку. Потом с челом связывается нвидия и говорит "слыш, удоли". А потом добавляет явный запрет на любые подобные манипуляции.
Можно ссылку на эту штуку?
Интересует более лучшая работа блендера
Я правильно понимаю, что если не брать какой-нибудь проц за пол ляма, то в нем будет в районе 20 pci-e линий, и если ставить две видюхи, то на каждую будет по 8? На сколько сильно это скажется на llm? Или может быть есть варианты на порядок дешевле?
У некро xeon 2690v4 40 линий, но есть ли у китайцев такие материнки
Линий то 40, но 3.0 =(
Если не будешь обучением заниматься - разницы не заметишь
Хоть по 4 3.0 линии выдели на карту, на сколько я понял для инференса = похуй


А тебе зачем? Код всё равно откатили и он уже не то, чем был раньше и чем мог бы быть. Гугли ZLUDA.
Несколько дней тыкал та же херня. Поднимая температуру+ТопК уменьшается повторение немного, но смысл тот же т.к. главные токены остаются теме же + тупеет и быстро меняет тему во время РП. До смены моделей я уже сам догадался, но модель на которую я собираюсь менять файнтюн квена 14б плоха с местоимениями - карточка начинает говорить от первого лица даже на пару сообщений в глубь.
Просто думал на 570 можно получше блендер крутить, но слишком некро она
>главные токены остаются теме же
Exclude Top Choices (XTC)
Ну я не знаю, что за говно ты взял "llama-cpp-python-cublas-wheels", это что ли: https://github.com/jllllll/llama-cpp-python-cuBLAS-wheels? Оно уже год не обновляется. Начни с того, что возьми нормальную лламуцпп, либо кобольдцпп, основанный на ней:
https://github.com/ggerganov/llama.cpp
https://github.com/LostRuins/koboldcpp
Далее, посмотри что у тебя за gpu. Если старые gcn вплоть до полярисов (rx 470-590), то rocm тебе уже не доступен, используй vulkan. Если vega 56/64 или новее, то rocm у тебя заведётся, собираешь по инструкции. Сейчас у тебя по ошибкам похоже, что ты вкорячил себе зачем-то нвидия-версию и пытаешься её запустить на амуде.
>на линуксе
>выбрав вариант амд в установщике
Нет, ты точно что-то делаешь не так, какие установщики? Только make/cmake, только хардкор. Ты там случайно не на wsl пытаешься напердолить linux-версию?
>с челом связывается нвидия и говорит "слыш, удоли"
В той версии истории, что я слышал, связались тоже амудэ. В первый раз похвалили, во второй раз "удоли". Возможно, опасались исков со стороны nvidia.
Гугли zluda.
sycl (пока что поддержка ещё хуже, чем у амудэ rocm)
>программная псевдо-реализация
Куда - это так-то тоже "программное". C-подобный язык, который компилируется в код, исполняемый на видеопроцессоре nvidia. На аппаратном уровне там +- то же, что и у амудэ, для графония в любом случае нужны всякие там параллельные сложения-перемножения матриц. Собственно, на этом и основывается zluda, любой gpu-код можно с небольшими модификациями адаптировать под любой gpu. Или тот же opencl, который работает на всех картах.
У nvidia преимущество в том, что на них сидит ~80% рынка и попернсорс, по сути, бесплатно работает на них, пишет под них, оптимизирует под них, дополнительно укрепляя их монополию. Плюс оптимизированные библиотеки от самой nvidia, cudnn там всякие. Остальные же вынуждены адаптировать под себя, писать прослойки и наслаждаться худшей производительностью на фактически более мощном железе из-за этих самых прослоек и отсутствия оптимизаций.
Ну и традиционный подрыв зелёного фанбоя. Я не знаю, что тебе там жмёт на твоей зелёной карте, что ты не можешь не высказаться? До сих пор не смирился с тем, что купил огрызок по оверпрайсу и коупишь, что у красных ещё хуже.
А, я понял, что за установщик, text-generation-webui. Впрочем, совет остаётся прежним, выкидывай это говно и собирай лламуцпп/кобольдцпп под rocm (или vulkan, если старый gpu) и работай с ними напрямую. Либо через какие-нибудь таверны. Забудь про однокнопочные установки, они доступны только зелёным, заплатившим за это барену. Ты решил сэкономить на красных, будь добр, собери под себя сам.
>В первый раз похвалили
Там всё гораздо сложнее, разработчику платил сначала Интел, чтобы он сделал совместимость с интелами. Потому ему платила АМД. По договору, по истечению контракта код мог быть отправлен в попенсорц, что в итоге и случилось. Однако АМД передумала и сказала "удоли", потому что их юридический отдел признал переписку по эмейлу не имеющей юридической силы. То, что сама АМД и профинансировала. Наталкивает на вопросики. В итоге произошёл откат до интеловской эпохи.
Больше всего меня в этом удивляет то, что хак оказался быстрее нативного решения, zluda работала лучше, чем рокм.
> Потом с челом связывается нвидия и говорит "слыш, удоли".
Так-то это амдшники сначала его "взяли под крыло", а потом тут же прикрыли. Красножопые должны знать своих героев, которые заботятся об их юзер-экспириенсе.
> то на каждую будет по 8?
Это еще ничего, вот когда там х1-х2 чипсетных старой версии и ты юзаешь жору - могут быть нюансы. В остальном, для ллм похуй.
> есть варианты на порядок дешевле
intel x299
Этого хватит.
Вот, вся суть.
Помогите пожалуйста найти одного персонажа, раньше когда то видел что тут постили типа 4chanовцы создали свою ебанутую тян и т.д. Потерял после переустановки винды её карточку. Может у кого она есть или ссылкой на неё поделитесь? Там ещё вроде лягушонок Пепе был который её на поводке выгуливал
Кто то работал с langflow? Как впечатления?
Как сподвигнуть бота предложить продолжение / действия в CYOA / VN стиле?
Добился чтобы более-менее норм нарраторил, создавая и управляя персонажами, но при этом придумывать историю всё равно приходится самому.
Добился чтобы более-менее норм нарраторил, создавая и управляя персонажами, но при этом придумывать историю всё равно приходится самому.
Аноны, а какая сейчас самая лучшая LLM'ка, чтобы gguf файл весит в пределах 80-100 Гб? Хочу попробовать запустить на 128 Гб ОЗУ

>Как сподвигнуть бота предложить продолжение
Сделать пример и описание в карточке? Да по идее достаточно добавить что-то типа пикрила в конец последнего сообщения и нажать "продолжить". Правда у меня 123B, которая понимает такие намёки и даже может продолжать без доп инструкций.
Mistral-Large-Instruct-2407, который 123B.
Сука как меня бесит контекст сайз бляяять
Буквально придумали ограничение на пустом месте чтобы гои грелись
Буквально придумали ограничение на пустом месте чтобы гои грелись
Назовите мне хоть одну причину почему контекст не может храниться на ссд по 2 тр?
Да вообще никаких причин, бери и делай!
Это скорее тест на дебила, который не осилил правильный summarize.
>Назовите мне хоть одну причину почему контекст не может храниться на ссд по 2 тр?
Проблема ведь не в том, где его хранить. Проблема в том, как его обсчитывать. Сохранить текущее состояние контекста можно. А дальше?
Проблема не в хранении. Ни одна модель на сегодняшний день не в состоянии просчитывать такое количество контекста и обрабатывать столько параметров.
>До сих пор не смирился с тем, что купил огрызок по оверпрайсу и коупишь, что у красных ещё хуже.
Ну так по факту так и есть. Нвидиа это оверпрайс, но оно хотя бы работает без пинка и бубна.
Потому что он не грузится частями, и на каждый токен тебе надо весь контекст обсчитать, сматчить его через механизм внимания, который выберет из него все что нужно для расчета текущего токена.
У какой модели до 40b самый охуенный русский язык? Можно с цензурой.
Если есть что-то прям очень хорошее, можно 70b.
Если есть что-то прям очень хорошее, можно 70b.
Я максимум могу 23Б запустить, не 123 =(
поставь в кобольде 0 слоёв на видяху - вся видяха останется под контекст
правда генерить будешь... медленно
Так ты попробуй, может прокатит.
Бери самую большую модель, которую можешь комфортно запустить. К счастью сейчас почти у всех новых моделей хороший русский, особенно у больших. Из конкретного можешь попробовать aya-expanse-32b, aya-23-35B - они именно заточены под многоязычность.
Блять, это сюда
Аноны на ртх 4070 12гб что можно покрутить какую модельку?
Квен 72В. Больше нормального русского нет нигде.
А на чем запускать эти ваши модельки сейчас? На рынке ни 4090, ни 3090, ни теслы и даже 1080 нет уже. Есть ли смысл в это вкатываться и разбираться пытаться или все тлен?
А на чем запускать эти ваши модельки сейчас? На рынке ни 4090, ни 3090, ни теслы и даже 1080 нет уже. Есть ли смысл в это вкатываться и разбираться пытаться или все тлен?
Есть. Садись на лошадь и едь в областной центр за 3090 из под майнера.
>Есть ли смысл в это вкатываться и разбираться пытаться или все тлен?
Любая карта от 3050Ti подойдёт, чтобы разобраться без напряга. Не так уж и дорого по нынешним временам. 8B-модели погоняешь, в принципе и 12B неплохо идут.


Ебучий комбайн GenAI от индусов заценили уже? Выглядит пиздец перегружено, зато функционала ебануться сколько. С локалками работает без проблем, разве что не понятно почему стриминг не работает у меня, вроде есть поддержка там.
https://microsoft.github.io/genaiscript/
https://microsoft.github.io/genaiscript/
Обновил таверну, но так и не появился этот семплер.
Никогда не упирались в то, что нейронка становится скучной? Я даже не знаю, совл не ощущаю. Столько кодил обвязку вокруг LLM, а по итогу пользоваться этим всем не хочется, лол. Модели менял, но не сильно помогает. Точнее, совсем не помогает.
На 405b сидишь?
Делай все проще - заранее обсчитай кэш популярных фраз, запили индексированную базу, хранимую на твоем ссд, и оперативно подгружай "готовое" по завету контекст-шифтеров. Ну а че, даже обсчитывать ничего не надо.
Обрабатывать контекст еще медленнее, скорость обработки также сильно зависит от количества слоев на видюхе.
Сценарий, настроение и эмпатия к чару первичны. Даже на мифомаксах или турбах рпшили и довольны были. С тем же что даже старые 70б давали так вообще космический эффект был, сейчас тем более.
Просто не пытайся отыграть что-то что уже было, не душни и чрезмерно задумывайся о чем-то, а беззаботно инджой полную свободу действий.
Честно сказать, не заметил разницу с 70b. А тюнов гораздо меньше, чтобы ограничиваться одной 405, с разными моделями иногда проскакивает хоть что-то новенькое. А так у меня уже чувство, что я изучаю нейросети и скоро начну предсказывать все их ответы.
>беззаботно инджой
Я ради беззаботного наслаждения ботом прикрутил STT и TTS. Вроде, прикольно, но бот всё равно не слишком умён, ломает кайф.
>Вроде, прикольно, но бот всё равно не слишком умён, ломает кайф.
Тут один анон доказывал, что модели-нейросетки по сравнению с живыми моделями хуйня и говорил, что за те же деньги на онлифанс больший кайф словит. Может это и твой случай?
Посоветуйте модель для roleplay и RPG симуляции в Sillytavern. С высокой креативностью (чтобы не меньше чем последнего Sonnet). И чтобы она входила в роль персонажей, как на сайте Character ai.
Требования к GPU не важны, если меньше чем у Grok - то норм.
> беззаботно инджой полную свободу действий
Вчера взял перерыв от кума и поиграл в таможенника в духе The Imperial Gatekeeper, отшивая слабых на передок девочек, и вдруг было очень забавно читать их бугурты. В итоге пропущены в город человек 5, убиты трое и закончилось всё равно оргией спустя 250 сообщений, потому что моделька не выдержала и поставила мне ультиматум в лице капитанши, которая пришла проверять как я работаю. Прям глоток свежего воздуха, а не все эти уговаривания и it's all right, don't worry.
Collab не работает.
Как же я хочу что нибудь РАЗЪЕБАТЬ.
Сижу такой довольный прогретый ру блогерами мол 4070 супер - лучшая карточка евер для игор и для всего на свете, покупаю, и действительно киберпуки в 2к 80 фпс
Захожу в этот тред и ничем не отличаюсь от челов с огрызком 3060 просто потому что меня прогрели по враме и надо было брать 3090 за ту же цену
Сижу такой довольный прогретый ру блогерами мол 4070 супер - лучшая карточка евер для игор и для всего на свете, покупаю, и действительно киберпуки в 2к 80 фпс
Захожу в этот тред и ничем не отличаюсь от челов с огрызком 3060 просто потому что меня прогрели по враме и надо было брать 3090 за ту же цену
У меня амд, llama.cpp c rocm работает без проблем.
Господа, вопросец.
На носу чёрные пятницы, 11.11 и всё такое, и я, скромный обладатель 3060 12гб, могу купить ещё 3060 12 гб.
Это даст мне какой-то значительный профит с текстовыми моделями (знаю, что можно будет более большие модели впихнуть в память, но может ещё что).
А при работе со StableDiffusion?
На носу чёрные пятницы, 11.11 и всё такое, и я, скромный обладатель 3060 12гб, могу купить ещё 3060 12 гб.
Это даст мне какой-то значительный профит с текстовыми моделями (знаю, что можно будет более большие модели впихнуть в память, но может ещё что).
А при работе со StableDiffusion?
В семплерах выбери, все новенькое есть.
Ну и бекенд должен это поддерживать, обнова 2 месяца назад была что ли на той же llama.cpp
Кобальд новый вчера вышел, тоже скорей всего поддерживает и xtc и dry
https://huggingface.co/collections/Goekdeniz-Guelmez/josiefied-and-abliterated-67027b9e5ce58dd0c3022fc8
Неплохие аблитерации qwen2.5, по крайней мере на некоторые острые вопросики пустой ассистент отвечает спокойно
Иногда срет китайским, но кажется это в основном проблема 7b
Неплохие аблитерации qwen2.5, по крайней мере на некоторые острые вопросики пустой ассистент отвечает спокойно
Иногда срет китайским, но кажется это в основном проблема 7b
Ну хуй знает, у меня вариант сидеть на онлике не рассматривался, лол. Видимо, просто мои требования к нейронкам растут быстрее, чем возможности этих нейронок.
Для СД ничего не изменитс, для ЛЛМ сможешь row split сделать и грузить х2 больше в врам. Полумеры все равно, 2х24 минимум
>проблема 7b
На 14b тоже, на 72b вроде нет.
Печаль-беда, тогда смысла нет покупать ничего сейчас, кроме как 3090 б/у с авито, но сыкотно.
>2х24 минимум
Там больше ничего и не влезет по габаритам, с такими то охладами.
> текстовыми моделями
Считай что просто удвоишь память
> StableDiffusion
Сможешь одной тренить, второй генерить. С флюксом/3.0/3.5 наверное будет самый бюджетный вариант запуска на гпу, запихнув юнет в одну гпу, энкодеры в другую, хотя юнет флюкса даже в фп8 в 12 гигов вроде не влезет
>запихнув юнет в одну гпу, энкодеры в другую
Где такое реализовано?
14b гораздо реже
7b чаще, что интересно 3b срет ими меньше
Кстати, аноны, интересный хак вам в копилку с CoT. Главная беда его в чём? Скорость падает. Так вот можно генерировать CoT другой моделью. Почти спекулятивный энкодинг, лол. Заводишь модель поменьше, которая будет генерировать мысли и задавать желаемый тон, более крупная модель это всё разворачивает в объёмный пост.
Из обнаруженных минусов это, очевидно, что модель не тренированная на подобную деятельность, с уменьшением размера страдает. Достаточно заметно. И второй минус, если характер моделей слишком расходится, то большая модель может игнорировать полученную информацию, даже при явном указании её использовать. Например, у меня в одном из первых тестов была мелкая модель с dumb ass карточкой и на вопрос "кто живёт в океане?" отвечала "Губка Боб квадратные штаны". Большая модель при этом имела карточку интеллектуала и в четырёх случаях из пяти просто игнорировала эту хуйню. В целом, ожидаемо, что карточки должны быть плюс-минус похожие, но ситуация забавная. Думаю, что-то похожее будет с использованием развратной модели в комплекте с зацензуренной.
А дошёл я до такой жизни, пытаясь надрочить модель вызывать инструменты без grammar. Это такой пиздец, из четырёх моделей все четыре понимали инструкции по этому вызову по-разному и генерировали разные вызовы. Да ещё и не до конца понимали, что именно от них требуется. Думаю, для таких вызовов нужна отдельная микромодель, которая сможет классифицировать текст и использовать инструменты до инференса основной LLM.
Все опыты проводились на моделях 27-32b, с более крупными вряд ли ситуация лучше, не стал заморачиваться.
Из обнаруженных минусов это, очевидно, что модель не тренированная на подобную деятельность, с уменьшением размера страдает. Достаточно заметно. И второй минус, если характер моделей слишком расходится, то большая модель может игнорировать полученную информацию, даже при явном указании её использовать. Например, у меня в одном из первых тестов была мелкая модель с dumb ass карточкой и на вопрос "кто живёт в океане?" отвечала "Губка Боб квадратные штаны". Большая модель при этом имела карточку интеллектуала и в четырёх случаях из пяти просто игнорировала эту хуйню. В целом, ожидаемо, что карточки должны быть плюс-минус похожие, но ситуация забавная. Думаю, что-то похожее будет с использованием развратной модели в комплекте с зацензуренной.
А дошёл я до такой жизни, пытаясь надрочить модель вызывать инструменты без grammar. Это такой пиздец, из четырёх моделей все четыре понимали инструкции по этому вызову по-разному и генерировали разные вызовы. Да ещё и не до конца понимали, что именно от них требуется. Думаю, для таких вызовов нужна отдельная микромодель, которая сможет классифицировать текст и использовать инструменты до инференса основной LLM.
Все опыты проводились на моделях 27-32b, с более крупными вряд ли ситуация лучше, не стал заморачиваться.
>Вчера взял перерыв от кума и поиграл в таможенника в духе The Imperial Gatekeeper
А поделиться карточкой?
Блять, а как теперь пользоваться любыми локалками и даже жпт без желания обрыгаться с их icq после того как посидел вечер с Sonnet. Я в ахуе.
Если оставь вне внимания скорость и требования к железу, какой тип квантования сильнее вредит модели? Ггуф или эксл2?
ггуф
ггуф, но только потому, что вечно сломан.

Не только по этому. На сколько я понимаю ггуф обладает определенными компромиссами ухудшающими качество. пик.
Вобще интересный пост и обсуждение под ним тоже
https://www.reddit.com/r/LocalLLaMA/comments/1ghvwsj/llamacpp_compute_and_memory_bandwidth_efficiency/
Никто не знает, все только догадываются. Мне лично три раза попадался именно сломанный квант, который так сильно лоботомировал модель, что она не могла справится даже с базовыми задачами. С эксламой такого не было пока что ни разу, но вполне вероятно, что мне просто не повезло. Какие-то выводы из этого я бы делать не стал, потому что гуфов я банально гонял раз в 15 больше, ибо экслама это выбор чисто для врам бояр, а на 12 гигах гуф становится твоим единственным другом, хочешь ты того или нет.
Mistral-Small-22B-ArliAI-RPMax
Не прогретый, для ИГОР - она действительно лучшая по соотношению.
Но нейронки это игрушки, но не игры, у них другие требования.
>Блять, а как теперь пользоваться любыми локалками и даже жпт без желания обрыгаться с их icq после того как посидел вечер с Sonnet
Легко, просто попроси Sonnet показать сиськи и сразу поймёшь, что толку от того IQ немного.
>Захожу в этот тред и ничем не отличаюсь от челов с огрызком 3060
Ничего, зато с лучами нормально поиграешь :)
Карточка вроде таки называется, по мотивам внки.
>Sonnet
сойнет
>для ИГОР - она действительно лучшая по соотношению
Я так 3080Ti купил. Не гой, не доплатил 30к за лишние 12 гиг врама!
Ага, с фул пач трейсингом даже 4090 выдаёт 12 кадров в киберпуке.
>сойнет
Вообще, если бы я делал коммерческую сетку, я бы в ответ на сомнительные запросы просто нахуй посылал бы. Ну не сильно грубо, но чувствительно. Да, это невежливо, но зато по-человечески :) А все эти "я не могу выполнить этот запрос", когда ты знаешь, что оно может - просто невероятно бесят. Хотя так-то кастрация - что моделей, что животных, да хоть бы и людей - она тоже вполне человеческое дело. Просто хуёвое.
Есть у меня желание сделать кнопку в Таверне и повесить на неё создание промпта для Stable Diffusion, чтобы картинку последней сцены генерила по требованию. Модель большая, и думаю, что такой заказ осилит. Но вопрос в том, что мне бы хотелось, чтобы картинка эта тут же и генерилась, без других моих действий, и вставлялась фоном. Есть в Таверне что-нибудь для такого функционала?
Пикрил. В кнопку повесь /sd scene
Вполне неплохо. С системным промптом "Весь ответ пиши на русском языке." сразу заговорила нормально, без всяких переводов карточек. Буду пользоваться.
другой анон
Прошу совета: 2x новых 3060 12 Gb или 1x б/у 3090 24 Гб?
По цене выходит одинаково, но в первом случае новое железо с годовой гарантией, во втором - кот в мешке, возможно, вообще нерабочий или ремонтированный, который отъебнет через пару недель.
По производительности в играх все понятно, а вот насчет DL и LLM мнения в интернетах прямо полярные. Кто-то пишет, что у него 2х3060 почти догоняют 3090. Другие пишут, что они толком параллельно не работают и скорость как с одной 3060, а весь выигрыш только в объеме памяти.
Может, тут есть кто-то с подобными сетапами?
По цене выходит одинаково, но в первом случае новое железо с годовой гарантией, во втором - кот в мешке, возможно, вообще нерабочий или ремонтированный, который отъебнет через пару недель.
По производительности в играх все понятно, а вот насчет DL и LLM мнения в интернетах прямо полярные. Кто-то пишет, что у него 2х3060 почти догоняют 3090. Другие пишут, что они толком параллельно не работают и скорость как с одной 3060, а весь выигрыш только в объеме памяти.
Может, тут есть кто-то с подобными сетапами?
>Кто-то пишет, что у него 2х3060 почти догоняют 3090
Пиздят.
>выигрыш только в объеме памяти
Не выигрыш, а паритет, лол.
>Не выигрыш, а паритет, лол.
Но в общем для провинциалов риг из 6-8 новых 3060 неплохой вариант. Только насчёт материнки и проца подумать надо.
>Пикрил. В кнопку повесь /sd scene
Спасибо.
Как думаете сколько миллиардов параметров в Sonnet 3.5? У меня стойкой подозрение, что не больше 140B учитывая скорость работы и цену.
Хм, но ведь по идее нейросети - особенно LLM - должны шикарно параллелиться на несколько GPU. Ведь именно так они и работают в датацентрах. В чем же дело?
Не, 6-8 это больно дохуя для дома. 2 карты вполне можно воткнуть в почти любую мать не нищеуровня.
Есть мысли, какая из моделей, или какой промт может заставить модель... Учитывать особенности персонажей? Такие как ушки, хвостики, несколько рук. Причем на первые 3--7 сообщения всё нормально. И ушки пригибаются, и хвостик машет, и руки работают. А потом как-будто просто потеря. Писал и в карточке несколько раз, разными словами вроде - персонаж зверочеловек со звериными ушами, у персонажа есть кэмономими, персонаж гордится своими кошачьими ушами и постоянно их демонстрирует и т.д. и т.п. Максимум что удавалось удержать это до десятка сообщений в чате (при контекста на десяток пять) и ровно на 1-2 сообщения после того как прямо в чате напишешь "ты забыл про ушки" или "у неё же есть звериные ушки"
>В чем же дело?
В том, что 3090 мощнее 3060 по всем параметрам более чем в 2 раза. Плюс отсутствие любых накладных расходов не оставляет никакого шанса в этом сравнении.
>Не, 6-8 это больно дохуя для дома.
А если кто хочет дома 123B? Да, 4 2-слотовых карты это максимум, который может вместить большой корпус, поэтому я и говорю о риге. Не так уж это и сложно, в майнинг-бум кто только не собирал.
>А если кто хочет дома 123B?
0,7 токенов ждут тебя!
Не, я понимаю, что полного эквивалента получить не выйдет, иначе бы все так делали и цена на 3060 не была 30к. Но все равно 70-80% производительности 3090 должно быть возможно достичь в таких задачах, которые хорошо параллелятся. Вон на форумах блендера пишут, что две 3060 даже предпочтительней под него, чем одна 3090.
Потому и хочу разобраться.
Можно много чего, но это уже для поехов, которые совсем упоролись.
В Pantheon-RP наблюдал такое, она вообще довольно внимательная, я даже ей начал фетиши подсовывать в какой-то момент через карточку своего персонажа.
>Pantheon-RP-Pure-1.6.2-22b-Small
Уточнение. Есть 12b вариант. Но если у тебя 12гб, то можешь IQ3 попробовать, меня устраивает, только XTC выключи если ставил.
>Потому и хочу разобраться.
Материнку сначала найди с настоящим вторым pci-e слотом, потом думай о двух видюхах.
>0,7 токенов ждут тебя!
Не. Меня на 4-х Теслах ждут 3,4 токена при 24к контекста, и это уже норм. Только обработка контекста боль. А 6 3060 будут быстрее, а для контекста - гораздо быстрее. Плюсом идёт поддержка экслламы и вообще всех современных квантов. Я и сам задумываюсь, не поменять ли. Жил бы в Москвах - взял бы 3090Ti, а в моих ебенях спасибо уже за наличие ДНС.
Нашёл на реддите обсуждение, где чел с двумя 3060 пишет, что на лламе 33б у него инференс 15 токенов / секунду. Ниже чел с одной 3090 отписался, что он на той же модели имеет 19 токенов / секунду. Если это правда, то как раз выходит 70-75% производительности, как и должно быть исходя из характеристик карт.
Для инференса второго слота даже в режиме 3.0 х4 хватит, только загрузка модели будет долгой.
>то как раз выходит 70-75% производительности
>По цене выходит одинаково
Охуенный выигрышь уровня /ai/
Я просто ёбнутый красноглазик.
Ну ему нужно, чтобы дяденька пообещал, что не сломается, ты не понимаешь.
Ты забываешь, что в одном случае новое железо с годовой гарантией местного мухосранского ДНСа, а в другом - б/у карта с неизвестной историей, которая может сдохнуть через пять минут.
Так-то можно и б/у 3060 12 Гб поискать, они тысяч по 20 появляются периодически, а за 24-25 весь лохито ими забит. Цена наеба тут уже куда меньше, да и не майнили на них почти наверняка.
Если это не интерес уровня "потыкал и забил" то это однозначно 3090. Почему? Потому что 24гб тебе не хватит. Тебе потом захочется поставить вторую 3090. Что бы 70б летали, а 123 работали. 4 3060 же это серьезное извращение.
>4 3060 же это серьезное извращение
6 минимум.
Никак, если модель тупая. Хоть тридцать раз ты ей напиши, что у тебя/неё хвостик и усики, она все равно начнет скипать эту инфу по мере заполнения контекста. К тому же инфа эта достаточно специфичная, а учитывая что некоторые модели вообще имеют тенденцию путать более дефолтные описания (типа цвета трусов или наличия этих самых трусов), то оно и не удивительно. Бери большую модель или переползай на копросетки, если для тебя важны детали. Других способов нет.
> начнет скипать эту инфу по мере заполнения контекста
Данные из карточки всегда в контексте висят.
Я тебе больше скажу, у меня на рабочей машине два титана и мне их не хватает. Но там и задачи иные. Для "болталки", даже с одновременным TTS на той же карте, 24 Гб должно хватить за глаза.
Висят, но изначально кроме них в контексте ничего нет и модель учитывает только их. А по мере его заполнения относительная значимость этих данных снижается и модель все меньше и меньше уделяет этому внимания, если выражаться человеческими аналогиями.
И хули толку что они там висят, если модель даже после обработки контекста их скипает? Или у тебя разумиста есть другое объяснение непослушности моделей?
ну вот я интересуюсь, или примерами "начитанных" моделей или натрененых на подобной фигне (чего только в мире не бывает). Крутить 70 в 3 кванте на полтора токена такая себе история. Хотя соглашусь, они хороши.
Если тебе нужна сеть которая не будет забивать на контекст, то твой минимум это мисраль немо. Всё что ниже распаренный и переваренный кал, который может только в описания и сторитейлинг без оглядки на твои инструкции. Но даже так не надейся на на полную достоверность карточке персонажа. Если ты фурри-пидрилла и дрочишь на зверодевочек, то у тебя будут проблемы, потому что такого контента мало в дефолтных датасетах под ролплей.
<s>[INST] {prompt}[/INST]
Я правильно понимаю, что вот такая строчка в таверне это вот так?
Я правильно понимаю, что вот такая строчка в таверне это вот так?
Отправь любое сообщение и посмотри в терминале кобольда, что было передано через апи. Это быстрее и легче, чем спрашивать тут.
>Кто-то пишет, что у него 2х3060 почти догоняют 3090
Буквально же недавно обсуждали. Мощность чипов не складывается. Карты работают последовательно, а не параллельно.
Теперь, зная, что мощность чипов не складывается, как думаешь, что будет быстрее - 3090 или 3060?
Пробовал тулить инструкцию в конец истории?
Это в смысле в чат? Да. Хватает на 1-2 сообщения
А если не минимум? А в районе 30b?
Если бы у меня хватало знаний, что бы понять, что вот так вот выглядящее в кобольде - верно соотносится с вот этой строчкой, я бы не спрашивал. Там даже визуально несколько разных префиксом на первый взгляд суют в одно и то же место. Но наверняка это не так же, и важно что где. А уж {promt} как смущает. Это должен быть промт? Это должно быть в графе промта? Это вообще должно быть? Мне бы хотя бы позитивных примеров соотношения строчки и куда суется, если никто не может подсказать конкретно по этой
>Это в смысле в чат?
Это в смысле помещать карточки персонажей и инструкцию в конец промпта, после истории сообщений, а не до, как делается по дефолту.
Все эти [INST] и [/INST] это просто служебные токены с которыми модель тренировалась чтобы отсекать например сообщение юзера от сообщения ассистента. В них нет никакой особой магии. Ты можешь даже их полностью удалить и поэкспериментировать - какой результат будет хуй его знает, но оно всё равно как то будет работать.
{promt} и прочее - это макросы самой таверны, которые просто заменяются текстом из блока системных инструкций. Куда ты их засунешь решаешь ты сам, но в таверне уже по умолчанию всё настроено, так что не вижу смысла их трогать.
Позитивные примеры можешь посмотреть на как раз на пресетах под таверну:
https://huggingface.co/Virt-io/SillyTavern-Presets
https://huggingface.co/sphiratrioth666/SillyTavern-Presets-Sphiratrioth
https://huggingface.co/MarinaraSpaghetti/SillyTavern-Settings
>А если не минимум? А в районе 30b?
Мистраль смолл, большая гемма, мелкий командор и файнтюны на их основе. Их дохуя, щупай сам, какие тебе понравятся больше.
Конечно в них нет никакой магии. На одном и том же сиде 10 разных ответов с разными промтами. И только половина бредовые, половина выглядят адекватно, но на маленькой выборке не поймешь какой из них "удачнее".
Положительный пример, это в смысле есть подобная строчка, и есть её представление в интерфейсе, что бы на аналогии понять. Просто пресеты у меня и так есть...
>Положительный пример, это в смысле есть подобная строчка, и есть её представление в интерфейсе, что бы на аналогии понять.
Я либо окончательно ебнулся с вами на одной борде, либо ты формулировать вопросы не умеешь. О какой строчке мы вообще сейчас говорим?
<s>[INST] {prompt}[/INST]
тю, та я файтюны мистраль смола и использую. И они теряются.
Тебе правильно сказали, включи пикрил и напиши привет, МГНОВЕННО разберёшься.
> Буквально же недавно обсуждали. Мощность чипов не складывается. Карты работают последовательно, а не параллельно.
Так, падажжи, ебана. Ты хочешь сказать, что у условного OpenAI в условном датацентре в один момент времени работает только одна-единственная H100, а все остальные простаивают, тупо храня веса кусков модели и ожидая, пока до них очередь дойдет? Это же бред сумасшедшего! На том же реддите люди описываются, что нормально нагрузка параллелится, практически линейно количеству карт.
> Теперь, зная, что мощность чипов не складывается, как думаешь, что будет быстрее - 3090 или 3060?
Одна 3090 в любом случае будет быстрее двух 3060, но не так уж сильно.
>Так, падажжи, ебана. Ты хочешь сказать, что у условного OpenAI в условном датацентре в один момент времени работает только одна-единственная H100, а все остальные простаивают, тупо храня веса кусков модели и ожидая, пока до них очередь дойдет? Это же бред сумасшедшего! На том же реддите люди описываются, что нормально нагрузка параллелится, практически линейно количеству карт.
Это всё речь про батч-процессинг кучи запросов одновременно.
Да как бы совсем не только: https://huggingface.co/docs/transformers/en/perf_train_gpu_many
Тут речь про обучение, но для инференса все тоже в силе.
Только если у тебя мать даст им pcie 4.0 x8 каждой, то сможешь запустить exl2 в TP режиме. Тогда худо бедно будет почти как 3090, но обработка контекста упадет в два раза +-.
Почему все говорят что 4060 это говно ебаное? Я так понял у нее скорость меньше чем у 3060, но памяти-то огого, аж 16 гигов. Что лучше, 3060 на 12 или 4060 на 16? 3060 говорят тоже говно ебаное, так что хуй знает даже чему верить.
> параллельно
последовательно
> у него 2х3060 почти догоняют 3090
И даже перегоняют, ведь у него нет 3090 и скорость на ней 0, а 3060 у него есть.
Конечно проигрывают по скорости, о чем речь.
3090 — быстрее, рисковее, занимает 1 слот. Вот и вся разница.
> должны шикарно параллелиться на несколько GPU
Потому что нет, с хуя бы.
У тебя буквально одни слои лежат на одной видяхе, другие на другой. Пока не обсчитаны одни — нельзя обсчитать другие.
Типа, у тебя есть дорога из столицы одного государства в другое. И ты такой «ебать, а если я буду ехать по дороге в одном государстве и по этой же дороге в другом государстве одновременно — я доеду вдвое быстрее!»
Идея огонь, братан. Теория удвоения наоборот. =)
Если у тебя охуеть какая быстрая память, и один чип видяхи физически его не вытягивает, то напрашивается вывод расшарить память одной видяхи другим — и пусть несколько чипов работают вместе, да?
Только вот ты не можешь этого сделать на вменяемых скоростях в потребительском сегменте.
И памяти у тебя такой нет, окда?
Расслабься, нет ни одной причины, чтобы ты мог распараллелить одну цельную модель, которая физически работает последовательно.
Можно сослаться на MoE-структуру, где ты запускаешь разных экспертов одновременно. Но это другое.
Они.
Не.
Параллелятся.
Концептуально.
Скидывали же с 5 слотами PCIe 3.0 x8
обработка контекста
Но не критично, как и загрузка, все довольно быстро будет, на самом деле. Счет будет на секунды.
———
Вообще, я в ахуе, насколько тред скатился за месяц. Пришли десятки людей, которые нихуя не понимают в вопросе, их обучают какие-то шизы, которые нихуя не понимали никогда ничего в вопросе, и результат просто охуенный. =) Как на той пикче с пионерами и конем.
Дякую, шо вовремя отсюда ушел.
Соболезную умным ребятам, которые зачем-то еще терпят.
———
Так-то P100 с 16 гигами и Exl2, ну и там еще целая пачка карт, и так далее, и тому подобное. Все уже посчитано до вас, ссыль на реддит где-то лежала в прошлых тредах.
Но все это выглядит все еще хуже 3090 по цена/скорость.
Нахуй кобольд, в терминале самой таверны полный промпт показан.
3060 на -20%, инфа -100%! =D
Второй вариант, можешь успокоиться.
Ну ты собери дома сервак на 8 H100, раскидай NVlink, запусти TensorRT — и будет как ты хочешь. =) Никто не против.
Плюс, тебе про батчи сказали.
Ну вот и думай, что важнее тебе лично — скорость или объем за цену в полтора-два раза выше. На деле, 32 гига на 4060ti не то чтобы плохо. Просто обидно, что могло быть вдвое быстрее, но зажали.
https://blog.premai.io/prem-benchmarks/
Вот интересный бенч много чего, где можно сравнить потребление/скорость одной и той же модели в разных движках.
Старенький уже, но тем не менее.
Вот интересный бенч много чего, где можно сравнить потребление/скорость одной и той же модели в разных движках.
Старенький уже, но тем не менее.
>работает только одна-единственная H100
Запросов прилетает миллион. Один запрос проходит по первой GPU, уходит условно в другую GPU, второй запрос приходит на первую и начинает обрабатываться. В среднем, работают все видеокарты сразу, но - последовательно. Это может работать по-другому в одном единственном случае - ты накатил DS. Но тогда придётся отказаться от llamacpp, exllama, и что там ещё есть. Голые трансформаторы нужны.
>Одна 3090 в любом случае будет быстрее двух 3060
Где-то вдвое, плюс-минус. И эта разница в лучшем случае будет неизменной при наращивании количества 3060, хоть их у тебя будет 10. Но мы живём в реальном мире, так что скорость будет падать.
>инфа -100%! =D
Звучит достоверно.
ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
> последовательно
Без распараллеливания да, будет тупо "отработала одна, передала данные другой". При использовании параллелизма карты могут работать реально одновременно.
> 3090 — быстрее, рисковее, занимает 1 слот. Вот и вся разница.
Изначальный вопрос был в том, стоит ли риск выгоды, цена вопроса-то немаленькая.
> Потому что нет, с хуя бы.
> У тебя буквально одни слои лежат на одной видяхе, другие на другой. Пока не обсчитаны одни — нельзя обсчитать другие.
Это самый банальный случай. В документации обнявлицо выше есть и другие, подразумевающие нормальную параллельную работу.
> Типа, у тебя есть дорога из столицы одного государства в другое. И ты такой «ебать, а если я буду ехать по дороге в одном государстве и по этой же дороге в другом государстве одновременно — я доеду вдвое быстрее!»
> Идея огонь, братан. Теория удвоения наоборот. =)
Хуевая аналогия, даже близко не отражающая суть вещей.
Правильная будет такой: у тебя есть груз массой Х, который нужно перевезти. Ты можешь либо взять старую мощную лошадь, либо двух молодых лошадок. Старая мощная лошадь должна дотянуть груз в соло без проблем, но её продаёт на рынке мутного вида цыган и гарантий, что она не сдохнет наутро после продажи, нет. Молодых лошадок продаёт заводчик с репутацией, но их потребуется две штуки на тот же объём груза при сравнимой скорости доставки. Поскольку лошадки молодые, они будут друг другу в упряжи немного мешать, но в целом с задачей справятся.
> Если у тебя охуеть какая быстрая память, и один чип видяхи физически его не вытягивает, то напрашивается вывод расшарить память одной видяхи другим — и пусть несколько чипов работают вместе, да?
Память у каждого из чипов своя, обмен данными между чипами минимален (но он есть, да).
> Только вот ты не можешь этого сделать на вменяемых скоростях в потребительском сегменте.
> И памяти у тебя такой нет, окда?
> Расслабься, нет ни одной причины, чтобы ты мог распараллелить одну цельную модель, которая физически работает последовательно.
> Можно сослаться на MoE-структуру, где ты запускаешь разных экспертов одновременно. Но это другое.
> Они.
> Не.
> Параллелятся.
> Концептуально.
По-моему ты совсем не понимаешь как работают нейросети. Вот вообще. Основная их черта, из-за которой мы сейчас и переживаем очередной нейросетевой бум - как раз мощный параллелизм, когда разные части сети можно обсчитывать одновременно и независимо от остальных. Если бы сети считались последовательно, мы бы их на процессорах гоняли.
Даже странно такие базовые вещи здесь объяснять.
> Вообще, я в ахуе, насколько тред скатился за месяц. Пришли десятки людей, которые нихуя не понимают в вопросе, их обучают какие-то шизы, которые нихуя не понимали никогда ничего в вопросе, и результат просто охуенный. =) Как на той пикче с пионерами и конем.
> Дякую, шо вовремя отсюда ушел.
Пожалуй, единственное высказывание в твоём посте, с которым я согласен. И хорошо, что такие как ты уходят, а приходят те, кто реально шарит в теме.
> Так-то P100 с 16 гигами и Exl2, ну и там еще целая пачка карт, и так далее, и тому подобное. Все уже посчитано до вас, ссыль на реддит где-то лежала в прошлых тредах.
У P100 по современным меркам очень дохлые ядра и подсистема памяти. За свои гроши они ещё пойдут, если есть желание пострадать, но все-таки если есть возможность лучше рассматривать что-то более-менее актуальное.
> Ну ты собери дома сервак на 8 H100, раскидай NVlink, запусти TensorRT — и будет как ты хочешь. =) Никто не против.
Так и я не против! Денег дайте только. Выход на поставщиков железа у меня есть, что угодно привезут. Вопрос в финансах.
> Плюс, тебе про батчи сказали.
Это не то...
> Запросов прилетает миллион. Один запрос проходит по первой GPU, уходит условно в другую GPU, второй запрос приходит на первую и начинает обрабатываться. В среднем, работают все видеокарты сразу, но - последовательно. Это может работать по-другому в одном единственном случае - ты накатил DS. Но тогда придётся отказаться от llamacpp, exllama, и что там ещё есть. Голые трансформаторы нужны.
parallelformers в помощь.
> Где-то вдвое, плюс-минус.
Процентов на 30, в лучшем случае.
> И эта разница в лучшем случае будет неизменной при наращивании количества 3060, хоть их у тебя будет 10. Но мы живём в реальном мире, так что скорость будет падать.
Эх, молодежь...

Мамин гейткипер вырос, но всё равно остался додиком, не понимающим, почему ему вечно не с кем обсудить своё хобби.




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
• Инструкции для запуска базы при помощи Docker Compose https://rentry.co/oddx5sgq https://rentry.co/7kp5avrk
• Пошаговое мышление от тредовичка для таверны https://github.com/cierru/st-stepped-thinking
• Потрогать, как работают семплеры https://artefact2.github.io/llm-sampling/
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: