



Вкот
У меня ощущение от каждого трая лоры как от вскрытия подарка каждый раз кто сейм
У меня ощущение от каждого трая лоры как от вскрытия подарка каждый раз кто сейм
> Я не уточняю, но вообще можно уточнять. Но локон норм и так.
Уточнил короче
> Че за приколы, не влезут, ток что проверил, в 1024 с букетами до 768 еле влезает один, с двумя уже на рам протик.
Сам проверил, действительно переоценил что то, вспомнил просто 11300 чтоли потребление с 2 и спизданул навскидку. 2 влезают точно, прямо сейчас проверил, а больше обычно для мелкого говна и не юзаю энивей, хоть врам и позволяет, но толку нет
> Вообще речь шла у меня в посте про 64 дименшен такто, там один батча то еле влезает, что уж говорить о двух трех.
Ну а нахер тебе такой огромный для одной еот? Хорошего человека должно быть много чтоли?
> У меня лр на юнет какраз 10 щас
Ебанись
> Вармап не юзаю, его как бы заменяет продижистепс параметр, который ищет оптимум лернинг и фризит его
Вот этот продиджистепс вообще какая то шутка. Единственный случай когда продиджи всё зажарит, это когда ты рестарт на лре сделаешь, он такое точно не любит и плавные шедулеры для него мастхев, а так он обычно если ему лр не хватает, от падения шедулера сам начинает его вверх дёргать, шедулер не до нуля обычно, а до 0.01-0.005 хорошо работает
> Не, один чел не сможет так сделать, цивит бы в помойку быстро превратился. Тут дору взяли потому что не хуй с горы сделал а нвидиеподсосы.
AYS тогда почему не сделали? Я помню там кто то, кто первую дору выложил и писал им чтобы добавили
> Это скорее алгоритм ДЛЯ ликориса. И ничеси очередной, почти полноценный файнтюн без нужды дрочить фул модель, лафа для врамлетов и гораздо меньше временных затрат.
Ты уверен? Оно тренилось когда я пробовал намного дольше, единственный плюс, что врам типо засейвит, а толку ноль, во времена поней даже оно нихуя от обычных не отличались, единственный верный способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть, ценой пиздеца по датасету, даже глора не спасала, вот всё перепробовал, прямо помню это чётко с аутизмом этим ебучим
> Ну глора это вот алгоритм репараметризации. Ты можешь эту глору вместо с дорой юзать, у них вообще разные задачи и наверно они дополнят друг друга. Кстати надо попробовать, интересно че будет, в сдскриптс вроде есть.
Я в курсе, что дора поверх других алго работает, с аутизмом ничего не помогло, опять же
> Забей место под ADOPT, другой сверхточный адам форк https://github.com/iShohei220/adopt
Да этих новых оптимайзеров как говна за баней, с каждого теперь охуевать чтоли? Вон иди попробуй фишмонгер, он ещё хлеще продиджи там по визуализации был в одном трункорде https://github.com/Clybius/Personalized-Optimizers и я на нём делал пару лор, они действительно заебись перформят, но у тебя небось не влезет в память, там 2 батч уже лучше 16гб и дольше продиджи в 2 раза, будто флюкс тренишь
Вон ещё охуевай, мемори эффишиент и фаст, потому что адам, с фичами https://github.com/lodestone-rock/torchastic
Как тред то ожил, сколько написали. Теперь читать вас и отвечать.
>Ну а нахер тебе такой огромный для одной еот? Хорошего человека должно быть много чтоли?
Ну параметризация больше моментная в работе, потенциальная точность выше, выше мощности адаптации модели и её способности захватывать более сложные паттерны в данных. Это особенно хорошо видно когда тренишь отдельные слои как в случае с билорой, выставил 1024 если ты 4090 боярин 128 и оно прям дышит сразу и в разы проще наваливает. Если оно работает с отдельными многомерными слоями то почему не работает с полными параметрами? Всегда можно отресайзить потом по финалу.
>Ебанись
А что, не запрещено - значит разрешено. Тем более работает и решает задачи.
>Вот этот продиджистепс вообще какая то шутка
Не, не шутка. Т.к. шедулера тут нет, то продижи надо пинком отрубать чтобы вызвать т.н. escape velocity и чтобы он перестал уменьшать свою полезность бесконечно, можешь тут почитать принцип https://arxiv.org/pdf/2409.20325
>шедулеры шедулер
Так речь про бесшедулерный...
>AYS тогда почему не сделали?
AYS это шедулер для семплеров же, буквально просто функция одной строчкой от лабы нвидии. Куда ее добавлять собрался?
>Ты уверен?
Ну да. Дора это такой читкод на фулпараметрик без полноценного фулпараметрика.
>Оно тренилось когда я пробовал намного дольше, единственный плюс, что врам типо засейвит, а толку ноль, во времена поней даже оно нихуя от обычных не отличались, единственный верный способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть, ценой пиздеца по датасету, даже глора не спасала, вот всё перепробовал, прямо помню это чётко с аутизмом этим ебучим
Чет я мысль твою потерял, переформулируй
>способ был зажарить нахуй модель в говно, чтобы по датасету пошёл перегар, тогда генерализация пойдёт на остальную часть
Не ну зажарить иногда бывает полезно, потом просто лорку можно поменьше весом применять и тольковыигрывать. Не с дорой конечно, т.к. там шаг влево шаг вправо от базового веса уже ощутимая потеря данных идет.
>с аутизмом ничего не помогло, опять же
Ну ты вот пишешь то не работает, то не работает, я ж вообще понятия не имею как ты тестируешь, тренируешь, какой юзкейс у этого всего. Может ты там 3000 степов на эпоху страдаешь вообще по 60 часов лору тренишь и с хоть малейшим смазом на гене отбраковываешь и начинаешь заново, а гены пускаешь на какомнибудь Dormand–Prince в миллиард шагов. У меня лично есть несколько рабочих вариантов как даже самый всратый тренинг заставить терпимо работать. Принцип тренинга же в чем вообще заключается? В том чтобы он давал результат безотносительно того как ты этот результат достигаешь. В чем проблема недотренов и перетренов? В недостатке или избытке данных и последующем денойзе этих данных. По факту дифузные модели уже с первых шагов понимают и знают калцепт который ты им кормишь, единственный вопрос в достаточности и точности данных, которые сеть получает во время тренировки дальше чтобы тюнить свои вектора, и разными способами можно заставить сетку считать, что достаточность данных для инферирования в результат на месте.
>Да этих новых оптимайзеров как говна за баней, с каждого теперь охуевать чтоли?
Да понятно что любой лох может оптимайзер сделать, но тут университет токио все дела, оптимизер без нужды тюнить параметры тренировки и с хорошей скоростью и точностью базированный на адаме.
>Вон иди попробуй фишмонгер
Давай попробую, че там как его настраивать?
>и я на нём делал пару лор, они действительно заебись перформят
Покажи + настроечки
>Вон ещё охуевай, мемори эффишиент и фаст, потому что адам
Круто, но это просто мемори эфишент мод со знижением байтов на параметр. ADOPT про другое.
> Всегда можно отресайзить потом по финалу.
Неа, не всегда, некоторые алгоритмы до сих пор не ресайзятся с сд-скриптс, полагаться можно только на лору и локон в этом плане и плане мерджей. Костыли правда я видел, для глоры той же были скрипты где то на форчонге
> Не, не шутка. Т.к. шедулера тут нет, то продижи надо пинком отрубать чтобы вызвать т.н. escape velocity и чтобы он перестал уменьшать свою полезность бесконечно, можешь тут почитать принцип https://arxiv.org/pdf/2409.20325
Ну ёпта там всё в матане, короче продиджи в стоке шедулфри через жопу работает и если эстимейшен не выключить на определённом шаге будет пиздец с нетворком?
> Так речь про бесшедулерный...
Реально не пойму в чём прикол убирать шедулер, он всегда в диапазоне двух порядков от лр нормально работает, или вообще до нуля, ладно там лр искать заёбно, но шедулер то, плюс ещё придётся ебаться с параметрами поновой искать, судя по тому что в основной репе пишут, один гемор
> AYS это шедулер для семплеров же, буквально просто функция одной строчкой от лабы нвидии. Куда ее добавлять собрался?
В генератор на сайте, куда же ещё, тоже ведь от нвидии
> Ну да. Дора это такой читкод на фулпараметрик без полноценного фулпараметрика.
Вот этот читкод сейчас полностью облажался при тренировке гойвэя впреда, с энкодером сдохло просто и пережарилось, юнет онли нан. На сам попробуй, если хочешь https://files.catbox.moe/8bpnnx.toml без доры нормально, там тольк минснр ёбнутая указана по фану проверить, с ней работает без доры и на адаме и на продиджи
> Чет я мысль твою потерял, переформулируй
Я пытался генерализовать максимально одного маняме хуйдоджника известного в узких кругах с аутизм чекпоинтом, фангдонга, он в основном к*ичек рисует, тестил на конкретном промпте, который был отдалён от того что он рисует, там была какая то кошкодевка с блюарка с огромными бидонами в купальнике, что очень отдалённо, ни один алгоритм из доступных полгода назад не выдал стиль на этом промпте, только одна лора, которую я взял с цивита работала на этом и почти всех остальных промптах, она по факту была ужарена, но я хотел повторить это, ведь ничего не работало, глянул в мету, там тренилось на похуй стоком с адамом прямиком с аутизма на малом датасете, ну сделал так же и получилось с первого раза по перформансу схоже с той, что была на циве, и та и другая по датасету выдают ужас, если кэпшен 1в1 копировать, но генерализация у них охуенная
> Ну ты вот пишешь то не работает, то не работает, я ж вообще понятия не имею как ты тестируешь, тренируешь, какой юзкейс у этого всего. Может ты там 3000 степов на эпоху страдаешь вообще по 60 часов лору тренишь и с хоть малейшим смазом на гене отбраковываешь и начинаешь заново, а гены пускаешь на какомнибудь Dormand–Prince в миллиард шагов
Ну вроде выше расписал понятно что я пытался сделать
> По факту дифузные модели уже с первых шагов понимают и знают калцепт который ты им кормишь, единственный вопрос в достаточности и точности данных, которые сеть получает во время тренировки дальше чтобы тюнить свои вектора, и разными способами можно заставить сетку считать, что достаточность данных для инферирования в результат на месте.
Это всё здорово конечно, но есть огромные байасы у чекпоинтов, тот же пони или дериватив аутизм (который ещё хуже говноговнапростоблять) практически невозможно направить в определённое русло, считай в пэинтерли стили, без лютых танцев с бубном, yd, fkey или ciloranko на них выглядят и тренятся отвратительно, а, например, на люстре заебись
> Да понятно что любой лох может оптимайзер сделать, но тут университет токио все дела, оптимизер без нужды тюнить параметры тренировки и с хорошей скоростью и точностью базированный на адаме.
Когда уже там будет оптимайзер, который сам лучшую архитектуру и датасет подберёт, а после чекпоинт натренит по запросу за часок с нуля? Ну что, как он в деле в итоге?
> Давай попробую, че там как его настраивать?
Я в рекомендуемом дефолте его гонял вообще с адамовским лром, с ним особо быстро не покрутишь и хз как будет не на впредонубе, ну смотри сам короче, конфиг такой был https://files.catbox.moe/i2ed6m.toml прикостылил к изи-скриптсам сделав из него питон пэкэдж
>Неа, не всегда, некоторые алгоритмы до сих пор не ресайзятся с сд-скриптс, полагаться можно только на лору и локон в этом плане и плане мерджей. Костыли правда я видел, для глоры той же были скрипты где то на форчонге
Ну можно по старинке смерджить лору с моделью а потом экстракцию ликориса в нужный дименшен произвести.
>короче продиджи в стоке шедулфри через жопу работает и если эстимейшен не выключить на определённом шаге будет пиздец с нетворком?
Не совсем так. Если никак не контролировать lr юнета на продигах он просто вечно будет его увеличивать. Не то что бы это было плохо, но в теории он может проскочить свитспот (шедулер фри константные) и тренить не так эффективно при определенных условиях. Это можно доджить через кучу разных параметров впрочем. Параметром продижи степс ты просто указываешь продигам шаг после которого лр обязать стать константой для него.
>Реально не пойму в чём прикол убирать шедулер,
Бесшедулерный оптим очень гибкий и реагирует на loss/градиенты, классика жесто привязана к функции шедулера (косинус хуесинус вот ето все, как барен матанского мира решил так и будет). Бесшедулер быстро реагирует на лосс, каждый шаг, классика реагирует только каждую эпоху. Очевидный плюс в меньшем количестве тюнинга конфига. Не нужен вармап.
>плюс ещё придётся ебаться с параметрами поновой искать
Да там в d0 менять только, в зависимости от того насколько агрессивно и бысттро ты хочешь обучать.
>В генератор на сайте, куда же ещё, тоже ведь от нвидии
Не, дора прям разработка мозгов из нвидии, даже в блоге у себя писали, AYS это так чисто разнообразить количество шедулеров и решить конкретную задачу.
>На сам попробуй
Странные настройки у тебя, я бы половину повыкидывал сразу.
>с энкодером сдохло просто и пережарилось, юнет онли нан.
Датасет дашь какой тренил?
>гойвэя впреда
Ой я вперды не тренил никогда, там какие-то особые условия есть?
>Ну вроде выше расписал понятно что я пытался сделать
Дай датасет крч и ссылку на лору или гены на которые ты ориентируешься по квалити, плюс ссылку на проблемный чекпоинт
>Когда уже там будет оптимайзер, который сам лучшую архитектуру и датасет подберёт, а после чекпоинт натренит по запросу за часок с нуля?
Неиронично билору тренить на одной картинке проще всего по такому запросу лол
>Ну что, как он в деле в итоге?
Адопт чисто не гонял, только в комплекте с шедфри продиги, и он даже работает. Ну консистенцию увеличивает да, сразу с первой эпохи, не говнит.
>прикостылил к изи-скриптсам сделав из него питон пэкэдж
А дай гайд кстати
Гандон на кое захардкодил применение fused_backward_pass который пиздец как повышает скорость и снижает юз врама на адафактор онли, ну что за пидераст. А между прочим фьзд изкаропки держит продижи шедулед фри. Как же пичот сука.
>дора прям разработка мозгов из нвидии, даже в блоге у себя писали
Дохуя мозгов видимо потребовалось чтобы магнитуды вынести в отдельный параметр.
ну ты ж не вынес, значит одного мозга не достаточно
> Ну можно по старинке смерджить лору с моделью а потом экстракцию ликориса в нужный дименшен произвести.
Не ну ты слышь, читы то не включай
> Не совсем так. Если никак не контролировать lr юнета на продигах он просто вечно будет его увеличивать. Не то что бы это было плохо, но в теории он может проскочить свитспот (шедулер фри константные) и тренить не так эффективно при определенных условиях. Это можно доджить через кучу разных параметров впрочем. Параметром продижи степс ты просто указываешь продигам шаг после которого лр обязать стать константой для него.
Ладно, понял короче
> Бесшедулерный оптим очень гибкий и реагирует на loss/градиенты, классика жесто привязана к функции шедулера (косинус хуесинус вот ето все, как барен матанского мира решил так и будет). Бесшедулер быстро реагирует на лосс, каждый шаг, классика реагирует только каждую эпоху. Очевидный плюс в меньшем количестве тюнинга конфига. Не нужен вармап
К классике вармап и нормальный шедулер с 1.5 не менялся, он тоже везде подходит, но в целом конечно понятно почему у меня хуита была с адамом и флюксом, я там не особо запариваясь просто оптимайзер поменял, но оставил тот же косин и лр даже не поднимал
> Да там в d0 менять только, в зависимости от того насколько агрессивно и бысттро ты хочешь обучать.
Сколько, 1e-4?
> Не, дора прям разработка мозгов из нвидии, даже в блоге у себя писали, AYS это так чисто разнообразить количество шедулеров и решить конкретную задачу.
Тоже через жопу с впредом кстати работает
> Странные настройки у тебя, я бы половину повыкидывал сразу.
Что там странного? Вообще ничего лишнего даже не стоит, чуть ли не сток. А конфиг с фишмонгером не странный а сраный, изискриптс просто калговна и там чтобы кастомный оптимайзер заюзать надо оверрайдом хуярить через экстра арг, в мету всё равно основной оптимайзер запишется, хоть он и не используется по факту
> Датасет дашь какой тренил?
Не сорян, конкретно этот не дам, я уверен там не от него зависит, любой подойдёт
> Ой я вперды не тренил никогда, там какие-то особые условия есть?
Ну теоритически только два флага включить, фактически вот доры в трейнинге и аусы в инференсе отваливаются, бета шедулеру ещё другие альфа и бета нужны, лр поменьше для тренировки лучше юзать, короче нюансов хватает, сигмы там ещё стоит крутить выше, даже кто то я видел скидывал ~35 значений для вставки в кумфи, предположительно используемых в наи
> Дай датасет крч и ссылку на лору или гены на которые ты ориентируешься по квалити, плюс ссылку на проблемный чекпоинт
На короче паком, там только две генерализуются нормально из всех, по гридам увидишь, https://litter.catbox.moe/2t6iys.7z стандартный, чекпоинт https://civitai.com/models/288584?modelVersionId=324524 датасет просто с буру сграбь, будет максимально приближённо к генерализуемым версиям
> Неиронично билору тренить на одной картинке проще всего по такому запросу лол
Вот несколько дней назад делал лору из одной картинки буквально, не стал изобретать велосипед и сделал с адамом и продиджи, справился лучше адам, более менее с такой лорой можно ещё нагенерить датасета, потом уже выёбываться
Да вот просто https://packaging.python.org/en/latest/tutorials/packaging-projects/ в доки глянул

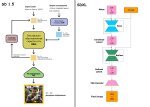
Сначала хотел спросить здесь, но решил сначала сам загуглить. Вопрос был про встроенные в комфи генераторы промтов. Вайлкарты меня заебали, особенно на флюксе который стал их очень хорошо реализует так что начинаю замечать повторы.
Оказалось есть Ollama с локальными текстовыми нейронками к которым можно подключиться через ноду в комфи. Быстро накалхозенный воркфлоу приложен.
Оказалось есть Ollama с локальными текстовыми нейронками к которым можно подключиться через ноду в комфи. Быстро накалхозенный воркфлоу приложен.
Тут тоже спрошу:
Есть ли возможность эту модель
https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
Запихнуть в wd-таггер для WebUI?
Почему-то в списке не появляется. Что-то не то делаю, но что именно - понять не могу. Я сильно тупой для всего этого программирования.
Или может какие-то другие расширения для вебуя появились?
Есть ли возможность эту модель
https://huggingface.co/SmilingWolf/wd-eva02-large-tagger-v3
Запихнуть в wd-таггер для WebUI?
Почему-то в списке не появляется. Что-то не то делаю, но что именно - понять не могу. Я сильно тупой для всего этого программирования.
Или может какие-то другие расширения для вебуя появились?
А я в убабуге запускал всякие нсфв чекпоинты из ллм треда, а в комфи апо апишке подключался (есть ноды под убабугу).
Братан, все гораздо проще
скрипт https://github.com/kohya-ss/sd-scripts/blob/dev/finetune/tag_images_by_wd14_tagger.py
тутор https://github.com/kohya-ss/sd-scripts/blob/dev/docs/wd14_tagger_README-en.md
https://pastebin.com/nuhUkepm tagger/utils.py на это поменяй
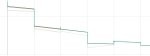
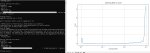
На пике три прогона на одном и том же файле конфига, два одинаковых рана, второй ран чучуть отличается. Почему так нахуй? Если сравнивать чекпоинт с красного графика то он отличается по генам с зеленого (и нихуево так отличается, композ и прочее говно в целом то же но отличается как будто другой сид). Все настройки зафиксированы. Отчего данный факап мог случиться?
Хм. Вероятно это кеш на диск или ошибки округления. +1 к страхам того что нейроговно обосралось с точностью.
>Братан, все гораздо проще
Да скриптом то я и так могу. Ну, почти - если оно с зависимостями не обосрется по какой-то причине, тогда их чинить придется.
Мне именно для вебуя решение нужно было, чтоб и протэгать, и посмотреть, что таггером навалило, и сразу в другой вкладе начать редачить.
Нашел форк таггера, в котором поддержка всех моделей реализована. Хотя модель качать заново пришлось, старую он не увидел. Ну да пофиг, работает - и хорошо.
Сохраню, на всякий случай, спасибо.
> Нашел форк таггера, в котором поддержка всех моделей реализована. Хотя модель качать заново пришлось, старую он не увидел. Ну да пофиг, работает - и хорошо.
А ссылку?
Я просто в форки перешел, и поставил тот, который обновлялся самым последним.
Вот этот:
https://github.com/67372a/stable-diffusion-webui-wd14-tagger
Как же я заебался на глазок подбирать лернинги пиздец просто еб вашу мать
Надо напердолить себе валидейшен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78
Надо напердолить себе валидейшен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78
>еверидрим
ого ебать, живые полторашкошизы
почему валидатора нет нигде больше?
Чет я заебался запускать этот валидейшен лосс, какие-то ошибки ебанутые в коде скрипта. Вроде все правильно делаю, а он не может оптимайзер загрузить из-за какого-то [doc] в скрипте трейна.
Вот есть допустим в целом для питорча https://github.com/davidtvs/pytorch-lr-finder , пытался оптимизнуть код под юнет хотя бы - хуй мне в ебало, максимум че достиг это начало тренинга и мисматч ошибки по тензорам хуензорам.
А кто-нибудь из моделеделов пробовал такую штуку проворачивать с руками:
1) собираем какой-нибудь датасет (пиздим с каггла или ещё откуда-то) с изображениями рук
2) изалекаем из него эмбеддинги, уменьшаем размерность эмбеддингов
3) кластеризуем уменьшенные эмбеддинги, присваиваем кластерам какие-нибудь рандомные хеши
4) идём уже датесет для обучения нашей SD модели, берём YOLO для детекции рук и те квадраты, что нам извлек YOLO мы классифицируем по полученным ранее кластерам (изалекаем эмбеддинги, тем же уменьшителем размерности проецируем, считаем косинусные расстояния)
5) и по результатам классификации мы в теги кладём хеш соответствующего кластера
По идее такой трюк должен существенно улучшить качество рук, но наверняка я не первый, кому она приходила в голову...
1) собираем какой-нибудь датасет (пиздим с каггла или ещё откуда-то) с изображениями рук
2) изалекаем из него эмбеддинги, уменьшаем размерность эмбеддингов
3) кластеризуем уменьшенные эмбеддинги, присваиваем кластерам какие-нибудь рандомные хеши
4) идём уже датесет для обучения нашей SD модели, берём YOLO для детекции рук и те квадраты, что нам извлек YOLO мы классифицируем по полученным ранее кластерам (изалекаем эмбеддинги, тем же уменьшителем размерности проецируем, считаем косинусные расстояния)
5) и по результатам классификации мы в теги кладём хеш соответствующего кластера
По идее такой трюк должен существенно улучшить качество рук, но наверняка я не первый, кому она приходила в голову...
>Чет я заебался запускать этот валидейшен лосс,
Так, наконецто запустил. Ну в принципе удобная штука да чтобы находить промежуток идеального лернинга для датасета. Жаль что прогоны только на ублюдских полторахо чекпоинтах.
Нахуя он тебе всрался то вообще? Вот этот форк типо может https://github.com/67372a/LoRA_Easy_Training_Scripts но там он пиздец поломанный был в стоке когда тестил, и даже через жопу хл тренил, если включить энкодеры, то он тренил только мелкий, баг или что хз, но я ебал, даже оптимайзер в стоке не работал практически ни один нормально. Включи просто продиджи и несколько датасетов натрень, он тебе всё равно покажет лр нормальный средний для того чтобы ставить с адамом
>Нахуя он тебе всрался то вообще?
Чтобы ручками не подбирать.
>Вот этот форк типо может https://github.com/67372a/LoRA_Easy_Training_Scripts
Ебать он у меня стоит, а я не заметил.
>Включи просто продиджи и несколько датасетов натрень
А я че по твоему делаю? Учитывая что у продигов достаточно своеобразные настройки то в лернинг я попал примерно на 20 прогон последний раз.
> он тебе всё равно покажет лр нормальный средний
Нет, ты не понял концепции. У продижи/продижишедулерфри есть параметр d0, который по сути управляет силой обучения. Лернингрейт самих весов и енкодера у него фиксед и настраивается отдельно. Сам d0 продижи не побирает.
>для того чтобы ставить с адамом
Я не пользуюсь адамами.
Вообще, строго говоря, та хуйнюшка которая дрочит полтораху достаточно удобная, потому что делает все быстро со вторым батчем в 512, буквально моментально 10 дестовых эпох на 200 пикчевом датасете ебашит. С хл так быстро не будет ни разу.
Лучший помощник для кодеров GitHub Copilot стал БЕСПЛАТНЫМ сегодня.
Пока открываете шампанское, пару слов о лимитах: 2000 дополнений кода и 50 сообщений к умнейшим нейронкам GPT-4o и Claude 3.5. Всё, что нужно — зайти в VSCode через аккаунт в GitHub.
Надеюсь хоть оно справится с моей задачей и портирует скрипт нормально
Пока открываете шампанское, пару слов о лимитах: 2000 дополнений кода и 50 сообщений к умнейшим нейронкам GPT-4o и Claude 3.5. Всё, что нужно — зайти в VSCode через аккаунт в GitHub.
Надеюсь хоть оно справится с моей задачей и портирует скрипт нормально
Скормил ему https://github.com/davidtvs/pytorch-lr-finder , на какойто из итераций фиксинга оно даже запустилось, но видимо развернуло мне веса в фп100500 и не влезоо ни в 32 рама ни в видяху при этом и ебнулось с ООМ. Последущие фиксы чтобы было все в фп16 к успеху пока не привели. Чисто на гпт там вообще нихуя не заработало есличе, так что копилот мощнее для кодинга определенно.
> Нет, ты не понял концепции. У продижи/продижишедулерфри есть параметр d0, который по сути управляет силой обучения. Лернингрейт самих весов и енкодера у него фиксед и настраивается отдельно. Сам d0 продижи не побирает.
Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0 и лр впринципе, он ведь и разгоняется сам по себе, а ты ему придумал новый лр подбирать, обрубив шедулер
> Я не пользуюсь адамами.
А что так? Лр от продиджи как раз ему и подходит, ну процентов 15 накинь максимум и по идее тот же эффект окажется
>Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0 и лр впринципе, он ведь и разгоняется сам по себе, а ты ему придумал новый лр подбирать, обрубив шедулер
Оптимизация времени обычная. Если ты знаешь оптимум d0 для своего датасета или любой параметр в любом другом бесшедулернике отвечающий за это то ты его указываешь и не ебешь себе мозг пока косинусное говно само себе там чето высчитает на лоу лр за 100500 часов. Это супер критично когда у тебя огромный датасет, а учитывая что дора+локр+скалар это буквально полноценный файнтюн со звездочкой позволяющий хоть 10к картинок датасет обучать, то это неебическое сохранение времени и баланс.
>А что так?
Жрет больше, чем бесшедулерник продижи, а 8бит лютая параша дли совсем нищеты Сложно доджить падение в локальный минимум. Еще и падает не в тот локальный минимум часто. Если датасет вариативный, то как-то хуево с признаками работает сопредельными и убивает вариети. Бесшедулерный адам вообще ебнутый - обучаешь хую, запоминает яички, ну это условно.
>Продиджи оригинальными авторами задумывался, чтобы не ебаться с этими д0
Кстати нет.
If the model is not training, try to keep track of d and if it remains too small, it might be worth increasing d0 to 1e-5 or even 1e-4. That being said, the optimizer was mostly insensitive to d0 in our other experiments.
> Оптимизация времени обычная
Но ты же 20 ранов сделал ебли, какая тут оптимизация времени то
> Если ты знаешь оптимум d0 для своего датасета или любой параметр в любом другом бесшедулернике отвечающий за это то ты его указываешь и не ебешь себе мозг пока косинусное говно само себе там чето высчитает на лоу лр за 100500 часов
Зачем лоу лр то? Если знаешь тот же лр с обычным адамом, то тоже самое что знать д0 с бесшедулерным. Поставь просто дефолтный 1е-4 на д0 с продиджи безшедулерным, раз уж на то пошло, или ты уже пробовал?
> Это супер критично когда у тебя огромный датасет
Когда у тебя огромный датасет, в эксперименты как то лезть не особо есть желание и хочется юзать то что точно работает нормально, ведь вот подобная
> дора+локр+скалар
Комба литералли обсирается с впредом, начиная с доры, которая нанами начинает сыпать
> 10к картинок
Вообще в лору влезет, от 100к хотя бы был бы смысл в полноценном файнтюне, но учитывая жор хля, либо сосать с мелким батчем на адаме, либо сосать с большим на адафакторе, про продиджи вообще можно забыть
> Жрет больше, чем бесшедулерник продижи
Да ну нахуй, что это за волшебная оптимизация там такая? Может и тюн даже влезет в 24, кто знает
Это кстати буквально недавно добавили https://github.com/konstmish/prodigy/commit/9396e9f1ca817b1988466f46ed40e9f993aef241 на самом деле охуеть интерес к оптимайзеру проснулся, даже начали пры пуллить и ридми обновлять, ну окей, но что 1.5, что хл, до недавнего времени действительно был инсенсетив и трогать д0 смысла не было в стоковой версии
>Но ты же 20 ранов сделал ебли, какая тут оптимизация времени то
Это меньше чем бы я потратил на другом оптимизере. Ты же понимаешь что если трен слишком медленный, или слишком быстрый, то в обоих случаях это на выходе будет замещение весов, ликинг, мутанты, сломанные веса или пережар?
>Зачем лоу лр то?
Потому что базовый лр 1е-4 это лоулр.
>Если знаешь тот же лр с обычным адамом, то тоже самое что знать д0 с бесшедулерным.
Ну так а смысл чето с адамом делать тогда? Тот же самый поиск свитспота, так еще и шедулер трахать.
>Поставь просто дефолтный 1е-4 на д0 с продиджи безшедулерным, раз уж на то пошло, или ты уже пробовал?
Да не работает так как надо. Оно может вообще не тренировать эффективно. С 1e-4 на моем датасете тренинг идет крайне медленно притом что я и лр юнета задираю чтоб побыстрее. Можно делать как ты предлагаешь и терпеть, но это не разумно и не нормально, проще свитспот для d0 найти и потом лр юнета оттюнить туда сюда - это гораздо проще.
>Когда у тебя огромный датасет, в эксперименты как то лезть не особо есть желание и хочется юзать то что точно работает нормально
Дело вкуса. Я предпочитаю точность и меньше тюнинга параметров.
>Комба литералли обсирается с впредом, начиная с доры, которая нанами начинает сыпать
Ты конечно извини, но это 99% вопрос скилишуя, я на твой пост как-то подзабил в ответе и до сих пор не тестировал впред. Вот ты там спрашивал 1е-4 или нет, откуда мне знать, у меня вообще на одном датасете свитспот на 5e-4 находится, а ты какие-то мелкие лернинги берешь вообще непонятно для какого датасета и потом говоришь что ниче неработает.
Кароче, давай сразу попути отвечу
>Что там странного?
Давай начнем с того почему у тебя дименшены одинаковые. Ты тренируешь полное замещение? Смысл? У тебя какойто-то анимушный трен кастомный, судя по всему ты какуюто анимепизду тренишь, так смысл в замещении если тебе надо оставить веса кастомной модели? Хочешь получать датасетовые картинки? Датасет ты мне не показал по количеству сколько там, но судя по степам в 2500 и лернингу в 1 там может и 250 и 25 картинок быть. Опять же непонятно почему ты говоришь про обсер впреда в контексте доры локра и скалярного слоя, если у тебя изначально вообще другое.
Дальше почему min_snr_gamma = 99? Это требование вперда или ты просто от балды ебанул? У тебя градиенты супернеустойчивые и вероятно поэтому наны, но я не уверен.
Почему lr те именно 0.25, если у тебя стоит и так низкий лернинг? Тоже от балды поделил на 4 или есть какое-то обоснование данного мува? Ты тренируешь токен или фул описание?
Зачем вармап в режиме ратио на продиги, если у тебя шедулер контролирует невозможность вечного роста лр?
Почему лосстайп l2 если он неусточив к шуму, а ты тренируешь вперд который работает со скоростью шума, повышает нестабильность и слишком сильно ебет за большие ошибки, что все вместе дает анстейбл лосс?
Почему минимальный букет 256? Эта циферка очень ситуативна и понижает качество и генерализацию на сдхл. С 2048 на макс вообще в шок выпал потому что в этом ноль смысла вообще такто. Допустим у тебя в датасете куча картинок выше 2048 и ты хочешь обрабатывать широкий рендж резолюшенов, чтобы что? У тебя базовая анимушная модель на которой ты тренишь может в 2048 искаропки? По моему мнению гораздо эффективнее было бы тогда настроить нойзофсет, мультиреснойздискант и итерации чтобы детализация/шарп остались на месте, снизив букет до дефолтных 768/1024 и увеличив стабильность градиентов наоборот таким образом, поделив альфу на 2 таким образом у тебя сохранилась бы возможность генерировать хайрезы не прибегая к шизобукету в 2048 пукселей.
Почему репитов именно 10? У тебя супермелкий датасет? Тогда зачем 2500 шагов? Это же шиза.
Зачем кешировать латенты на диск если они багуют частенько?
Косинусный шедулер конфликтует с шедулером из оптимайзера теоретически.
Зачем указан конволюшн дименшен одновременно, если у тебя и так указаны 16x16 по дименшену и альфе? Ты уверен что это не бесполезный параметр в данном случае и локон не является алиасом обычной лоры? Ты перепроверил наличие и фунциклирование конв слоев в лоре после тренинга вообще?
Почему пресет фулл вообще? У тебя мелкий датасет же судя по всему, зачем тренить дримбутлайк фул?
>от 100к хотя бы был бы смысл в полноценном файнтюне, но учитывая жор хля, либо сосать с мелким батчем на адаме, либо сосать с большим на адафакторе, про продиджи вообще можно забыть
Но количество каринок в датасете не коррелирует с оптимайзером, у тебя ж все картинки в латент переводятся просто и потом по мере дрочения юзаются. Не понял проблемы кароч и именно такого вывода по оптимайзерам.
> Вообще в лору влезет
В обычнолору нет, там по струнке магнитуд дирекшена вся дата с 10к пикч выстроится и поломается, т.к. лора либо вносит изменения большой величины + большого направления, либо изменения малой величины + малого направления.
>Может и тюн даже влезет в 24
Может и влезет, у меня нет 24 карты.
>трогать д0 смысла не было в стоковой версии
Хз, на дефолте всегда трогал...
>Дальше почему min_snr_gamma = 99
>там тольк минснр ёбнутая указана по фану проверить
А всё, отразил.
> Это меньше чем бы я потратил на другом оптимизере. Ты же понимаешь что если трен слишком медленный, или слишком быстрый, то в обоих случаях это на выходе будет замещение весов, ликинг, мутанты, сломанные веса или пережар?
Хз к чему ты это, но замещение весов будет всегда, ведь ты их обновляешь тренируя лору, ну и в инференсе накладывая потом это поверх. Ликинг, мутанты и пережар идут почти всегда в комплекте, а вот непослушность энкодера может сильно выделяться
> Потому что базовый лр 1е-4 это лоулр.
Конкретно для чего? Для того чтобы поней стукнуть и они сместили свой ебучий стиль дефолтный, да, помню что на порядок пришлось поднимать, там уже всё вышеперечисленное комплектом как раз и шло, а ниже нихуя считай и не тренилось
> на одном датасете свитспот на 5e-4 находится
Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
> а ты какие-то мелкие лернинги берешь вообще непонятно для какого датасета и потом говоришь что ниче неработает
Этот лр подходит для 90% стилей с буру для аниме моделей, ну или хотя бы частично аниме моделей, люстре кстати в стоке продиджи до 4е-4 задирает, с ней можно в стоке и прибавить в пару раз, с нубом эпсилоном ставит те же 1е-4
> Давай начнем с того почему у тебя дименшены одинаковые
Линейный и конволюшен? Хз, ну этого достаточно чтобы одну хуйню по типу стиля или чара вместить, можно даже конволюшен отключить для чара, что ты предлагаешь сменить?
> Ты тренируешь полное замещение? Смысл?
По другому не работает, смотри лоры выше, они от разных тренирователей с форчка, сработало только полное замещение, причём считай со стоковыми параметрами
> У тебя какойто-то анимушный трен кастомный, судя по всему ты какуюто анимепизду тренишь, так смысл в замещении если тебе надо оставить веса кастомной модели?
Нет, там хуйдоджник анимушный, веса базовой модели нереально стереть лорой впринципе, можно лишь сильно задавить
> Датасет ты мне не показал по количеству сколько там, но судя по степам в 2500 и лернингу в 1 там может и 250 и 25 картинок быть
50 картинок показали себя лучше, там максимум около 75 можно найти консистентных и без повторов, литералли просто на буру зайди и вбей tianliang_duohe_fangdongye, скачай всё это говно граббером, вот тебе и фулл датасет, потом только повторы фильтрани
> Опять же непонятно почему ты говоришь про обсер впреда в контексте доры локра и скалярного слоя, если у тебя изначально вообще другое.
Это вообще отдельная тема, с дорой и впредом походу надо на порядок лр уменьшать минимум, мне лень разбираться, но так в наны падает сразу обычно если огромный лр поставить не подходящий абсолютно, 1е-5 и ниже проверять надо
> Дальше почему min_snr_gamma = 99? Это требование вперда или ты просто от балды ебанул?
Нет, с впредом лосс высчитывается по другому, но если включить минснр, то "по старому", вроде ключ скейла лосса делает тоже самое, но я просто сделал это через минснр, буквально выключив эффект от него таким значением
> Почему lr те именно 0.25, если у тебя стоит и так низкий лернинг? Тоже от балды поделил на 4 или есть какое-то обоснование данного мува? Ты тренируешь токен или фул описание?
Фулл выхлоп с вд теггера, в 4 раза меньше поставил чтобы энкодер не поджигать, в 3-4 раза меньше просто из прошлых экспериментов вывел значение. Опять же, а сколько ты предлагаешь туда ставить? Равный юнету результировал в непослушности с лорой, слишком мелкий в неработающем вовсе теге, если стилей несколько в лоре
> Зачем вармап в режиме ратио на продиги, если у тебя шедулер контролирует невозможность вечного роста лр?
Вообще хз зачем я вармап до сих пор ставлю с продиджи, когда у него свой, надо было хоть сейвгвард тогда влепить чтоли или вообще убрать. Ты уверен что он "вечно" растёт? Я гонял продиджи с флюксом на константе, он максимум там один бамп делал х2 иногда и всё, в то время как когда шедулер начинает стремительный спуск посередине, с лром примерно такая же картина случается из скачков
> Почему лосстайп l2 если он неусточив к шуму, а ты тренируешь вперд который работает со скоростью шума, повышает нестабильность и слишком сильно ебет за большие ошибки, что все вместе дает анстейбл лосс?
Там и выбора то не особо много. Huber или smooth l1 лучше типо будет? Ну хз, экспериментировать опять надо, дефолт хоть как то работает вроде нормально
> Почему минимальный букет 256? Эта циферка очень ситуативна и понижает качество и генерализацию на сдхл. С 2048 на макс вообще в шок выпал потому что в этом ноль смысла вообще такто. Допустим у тебя в датасете куча картинок выше 2048 и ты хочешь обрабатывать широкий рендж резолюшенов, чтобы что? У тебя базовая анимушная модель на которой ты тренишь может в 2048 искаропки?
Это не так работает. Цифры такие элементарно чтобы не ограничивать бакеты вообще, если картинка ультравайд, либо наоборот, она попадёт в соответствующий бакет тренировочного разрешения 1536х512 и наоборот, оно не ставит разрешение 2048 во время тренировки, а крутится вокрут 1024х1024 так или иначе, такие картинки кстати энивей большая редкость
> По моему мнению гораздо эффективнее было бы тогда настроить нойзофсет, мультиреснойздискант и итерации чтобы детализация/шарп остались на месте, снизив букет до дефолтных 768/1024 и увеличив стабильность градиентов наоборот таким образом, поделив альфу на 2 таким образом у тебя сохранилась бы возможность генерировать хайрезы не прибегая к шизобукету в 2048 пукселей.
Вообще хрень какая то полная, если честно. Нойз оффсет нельзя трогать даже палкой издалека, мультирез хоть и очень полезен с эпсилоном, в впреде его трогать увы нельзя и придётся отдать всё на откуп зтснр. Ты же просто предлагаешь ужать бакеты, чтобы получить хер пойми что из датасета по итогу, вообще без понятия как он будет ресайзится и скейлится от такого, а зная кохью, ему вообще никакие ресайзы лучше не давать делать
> Почему репитов именно 10? У тебя супермелкий датасет?
Да, этот был из 15 вроде картинок, я делал лору из одной ебучей картинки итеративно
> Тогда зачем 2500 шагов?
С одной там на 500 уже прогар пошёл лютый, но с 15 уже 2500 зашло, тоже конечно прогар, но всё лишь бы сделать ещё больше для следующей итерации. А 2500 просто многочисленными эмпирическими тестами хл вывел что для стиля хороший свитспот, беря в расчёт остальные параметры того конфига, конкретно с тем датасетом этого много было, но там вери эджи кейс, так сказать, ну и концепты и чары тоже поменьше будут требовать, как и датасеты, в которых меньше 100 картинок например
> Зачем кешировать латенты на диск если они багуют частенько?
Очистить можно, если багнутся просто, почему нет впринципе
> Косинусный шедулер конфликтует с шедулером из оптимайзера теоретически
Там не до нуля косинус, а CAWR до 0.01 обычно, но ты же сам рассказываешь про стратегию "контры постоянно растущего лр", работает и довольно заебато
> Зачем указан конволюшн дименшен одновременно, если у тебя и так указаны 16x16 по дименшену и альфе?
? Чтобы добавить конволюшен слоёв
> Ты уверен что это не бесполезный параметр в данном случае и локон не является алиасом обычной лоры? Ты перепроверил наличие и фунциклирование конв слоев в лоре после тренинга вообще??
То что слои там есть это точно, ведь как минимум лора весит чуть больше, чем обычная лора с линейными слоями, должно работать, насколько эффективно хз как объективно оценить
> Но количество каринок в датасете не коррелирует с оптимайзером, у тебя ж все картинки в латент переводятся просто и потом по мере дрочения юзаются. Не понял проблемы кароч и именно такого вывода по оптимайзерам.
Никакой проблемы. Говорю просто что фулл файнтюн потребует много памяти, не каждый оптимайзер будет реально запустить, тем более с большим батчем
> В обычнолору нет, там по струнке магнитуд дирекшена вся дата с 10к пикч выстроится и поломается, т.к. лора либо вносит изменения большой величины + большого направления, либо изменения малой величины + малого направления.
Хз, я запихиваю тонны нейрокала, тегаю по разному разный нейрокал, что даёт возможность потом это контроллировать, и пока вроде нормально, конечно имеет общий паттерн нейрокаловости, но в этом и есть весь датасет, с фулл тюном не сравнивал конечно, да и туда норм батч хотя бы в 8 с адамом даже не впихнуть скорее всего. С нубом просто больше нехуй тренить считай, всё остальное с буру и так по идее в датасете было
> Может и влезет, у меня нет 24 карты.
Так что там по оптимизациям в итоге?
>но замещение весов будет всегда, ведь ты их обновляешь тренируя лору
Так альфа контролирует насколько ты дефолтные веса тюнишь. Можно избежать практического замещения оттюнив основные веса и не применяя TE, например. В локре допустим вообще факторизация и не требуется указывать дименшены вообще, кроме фактора их сокращения чтобы сделать локр универсальным или наборот только под конкретную модель, то есть по факту с помощью локра ты тюнишь веса основной модели, а не примешиваешь тренинговые веса классической лоры. И посмотреть веса и слои в локре ты тоже не сможешь, потому что их не существует.
>Ликинг, мутанты и пережар идут почти всегда в комплекте
Это неправильно подобранный лернинг, о чем я и говорю.
>а вот непослушность энкодера может сильно выделяться
К вопросу о те, то он то в целом на концепт и не нужен, клипатеншен слои ты так и так тренишь и его хватает. Я бы даже сказал что тренировать ТЕ+веса на токен сразу это какой-то нубский мув, который по факту задействуется чтобы недотрененные веса через ТЕ добирать при генерации до норм состояния, такой ред флаг на то что лернинги неправильно подобраны.
>Конкретно для чего?
Для любого небольшого датасета.
>Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
Unet тестовый на одну бабу тренился на маленьком датасете. Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
>Этот лр подходит для 90% стилей с буру для аниме моделей, ну или хотя бы частично аниме моделей, люстре кстати в стоке продиджи до 4е-4 задирает, с ней можно в стоке и прибавить в пару раз, с нубом эпсилоном ставит те же 1е-4
Но в реальности то эти лернинги не является golden так скажем. Я ж не говорю что их нельзя использовать и терпеть, я про то что идеальный лернинг который тебе в жопу говна не накинет и не потребует снижать/повышать вес применения готового продукта - это тонкая штука которую надо искать.
>Линейный и конволюшен?
Я имею в виду network_dim = 16 network_alpha = 16.0, конволюшены это другой вопрос.
>По другому не работает
Я бы поспорил и даже бы тестовый прогон сделал, но я сейчас другое треню.
>веса базовой модели нереально стереть лорой впринципе, можно лишь сильно задавить
Бля ну если так рассуждать то любой жоский файнтюн это вообще лора обмазанная поверх базовой модели, которая успешно экстрагируется. Я ж не про то.
>50 картинок показали себя лучше, там максимум около 75 можно найти консистентных и без повторов, литералли просто на буру зайди и вбей tianliang_duohe_fangdongye, скачай всё это говно граббером, вот тебе и фулл датасет, потом только повторы фильтран
Ну у тя ж есть готовый сет, скинь.
>Фулл выхлоп с вд теггера
А смысл если сам чекпоинт анимушный и хуйдожник анимушный? Думаешь сетка не разберется сама?
>в 4 раза меньше поставил чтобы энкодер не поджигать, в 3-4 раза меньше просто из прошлых экспериментов вывел значение
А че ты отдельно юнет и отдельно те не тренируешь несвязанно? Пережар происходит из-за несоответствующего схождения во время одновременной тренировки, а так это можно так костыльно обойти в целом.
>Опять же, а сколько ты предлагаешь туда ставить? Равный юнету результировал в непослушности с лорой, слишком мелкий в неработающем вовсе теге, если стилей несколько в лоре
Я бы вообще не тренировал те на стиль такто, максимум на один новый токен, не пересекающийся с основой.
>Там и выбора то не особо много. Huber или smooth l1 лучше типо будет?
Хубер будет лучше да.
>Это не так работает.
В смысле? Ты делаешь букеты по разным разрешениям с шагом 64 чтобы лишний раз не даунсейлить 2048 до 1024, чтобы изображения разных размеров букетировались друг с другом а не 256 с 2048 и не потерять детали разве нет?
Алсо у тя включено enable_bucket = true что добавляет паддинг с черными пукселями вместо скейла, я бы не скозал что это ок.
>Вообще хрень какая то полная, если честно. Нойз оффсет нельзя трогать даже палкой издалека
Я тебе рабочий вариант расписал. У меня датасет с текущей бабой состоит из мыльного говна с переебанными цветами и тонной шумов с размерами от 512 до 1024, вместе с условными --noise_offset=0.05 --multires_noise_discount=0.2 --multires_noise_iterations=7 ^ выходные гены ни в каком месте не имеют ни шумов, ни мыла ни чего бы то ни было вообще.
>Ты же просто предлагаешь ужать бакеты, чтобы получить хер пойми что из датасета по итогу, вообще без понятия как он будет ресайзится и скейлится от такого
Прекрасно будет скейлиться.
>С одной там на 500 уже прогар пошёл лютый, но с 15 уже 2500 зашло
Бля ну как по мне это ну очень дохуя, 15 картинок и 2500 шагов. Я бы не терпел так.
>но ты же сам рассказываешь про стратегию "контры постоянно растущего лр", работает
Ну может быть, я просто предположил что может конфликтовать теоретически.
>Чтобы добавить конволюшен слоёв
Не, я конкретно юзкейс конв в твоем случае. В датасете много текстурок или локальных деталей что сетка не уловит без их помощи на адаме?
>о что слои там есть это точно, ведь как минимум лора весит чуть больше, чем обычная лора с линейными слоями
Они могут быть просто пустыми.
>насколько эффективно хз как объективно оценить
Слайсишь лору на две части - одна лора чисто конв слои, вторая часть это все остальное, тестируешь.
>я запихиваю тонны нейрокала
Вот у меня датасет есть готовый на 7000 пикч с достаточно обширным универсальным концептом, до того как дору выкатили я с обычнолорами так наебался с ним, ничего путного не выходило, урезал вплоть до 1000 - все равно отсос - либо натрениваешь в датасетовские картинки, либо лезет основная модель и насилует бедную лору, хоть медленно трень хоть быстро, то есть было проще дримбудкой целый чекпоинт тренить и потом дифренс вычитать в лору, а сейчас спокойно любой размер датасета всаживается практически в любой алгоритм и лора работает как и должна - быть дополнением для модели и работать аккуратно. Это 1 в 1 как ситуация с первыми нсфв лорами на сдхл типа https://civitai.com/models/144203/nsfw-pov-all-in-one-sdxl-realisticanimewd14-74mb-version-available , где нсфв калтент как бы работает, но эта работа ужасная и ограниченная, насколько я понял там чето около 100к пикч датасета.
>Так что там по оптимизациям в итоге?
В каком смысоле?

>Вот я бы поглядел на этот датасет, результат, и с чего это тренится с таким огромным лр
>Unet тестовый на одну бабу тренился на маленьком датасете. Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
Кароче вот эта тестовая лора на 5e4, 3 эпоха всего лишь с датасетом около 10 пикч, оригинал бабцы наверно не надо показывать, просто скажу что основные признаки сетка спокойно сожрала и они на вот это пикче все полном объеме и в принципе на 5е4 дальше можно тренить было, но мне 10 пикч тренить нахер не надо было.


Ну и допом еще две пикчи.
> В локре допустим вообще факторизация и не требуется указывать дименшены вообще, кроме фактора их сокращения чтобы сделать локр универсальным или наборот только под конкретную модель, то есть по факту с помощью локра ты тюнишь веса основной модели, а не примешиваешь тренинговые веса классической лоры. И посмотреть веса и слои в локре ты тоже не сможешь, потому что их не существует.
И что тогда в файле выходном остается? Я пробовал в локр с 1.5 давно, не помню какой фактор ставил, 1000000000000 чтоли, чтобы по размеру был как обычная лора короче в 100мб, там приходилось с лр заёбываться и ставить что то типо в 4 раза больше, чем с обычной, эффекта вау не было, просто другой способ сделать одно и тоже
> К вопросу о те, то он то в целом на концепт и не нужен, клипатеншен слои ты так и так тренишь и его хватает
Концепт как раз тренят обычно включая энкодер, ведь там есть слабые или неизвестные модели токены
> который по факту задействуется чтобы недотрененные веса через ТЕ добирать при генерации до норм состояния
Был даже какой то датасет, который с энкодером лучше намного работал
> Принцип же в любом случае что чем ниже даты в датасете тем более агрессивно сетка должна хватать градиенты.
Ты не перепутал? Чем меньше датасет, тем быстрее сетка оверфитнется и тем меньший лр лучше ставить, даже выше пример, 1пикча на 500 пиздец, 15 на 2500 не полный, но пиздец, 75 уже вроде ничего на 2500, даже можно было сильнее жарить
> Я имею в виду network_dim = 16 network_alpha = 16.0, конволюшены это другой вопрос.
А, ты имеешь ввиду почему у меня дим и альфа одинаковые? Чтобы не скалировать ничего, нахуя мне лишний дампенер, когда ничего не горит, а наоборот бы натренить посильнее
> Я бы поспорил и даже бы тестовый прогон сделал, но я сейчас другое треню.
Вот если бы я увидел ту кошкодевку в стиле фангдонга, натрененную твоим суперспособом, я бы реально поверил, а так до сих пор считаю все эти алгоритмы просто самовнушением и по большей части базовых вещей и стока хватит для 90% случаев Похуй, читай ниже насчёт конфига
> ну если так рассуждать то любой жоский файнтюн это вообще лора обмазанная поверх базовой модели
Не, это щитмикс называется, лол
> Ну у тя ж есть готовый сет, скинь.
У меня он всратый, нейрокал для паддинга до 120 был добавлен, с таким точно результата не выйдет желаемого по генерализации, да и не очень хочется это заливать куда то, по понятным причинам, сграбь просто с гелбуры, зарегайся, спизди апи ключ и введи в imgbrd grabber, настройки чтобы теги вместе спиздить поставь https://files.catbox.moe/e29fq5.png
> А смысл если сам чекпоинт анимушный и хуйдожник анимушный? Думаешь сетка не разберется сама?
Разберётся конечно, просто параметры с энкодера иногда помогают дотренить, но я и сам не особо люблю идею тренить одиночный стиль с энкодером, но так получается иногда лучше
> А че ты отдельно юнет и отдельно те не тренируешь несвязанно?
Потому что это лишний гемор, когда можно просто поменьше лра поставить
> Я бы вообще не тренировал те на стиль такто, максимум на один новый токен, не пересекающийся с основой.
На мультистиль без вариантов, надо тренить уникальные токены вызова
> Хубер будет лучше да
А ты его тестил с впредом? Может он вообще не работает или через жопу
> В смысле? Ты делаешь букеты по разным разрешениям с шагом 64 чтобы лишний раз не даунсейлить 2048 до 1024, чтобы изображения разных размеров букетировались друг с другом а не 256 с 2048 и не потерять детали разве нет?
Ты делаешь букеты, чтобы пикчи сами просто ресайзнулись до разрешений, смежных твоему выбранному разрешению. Это просто границы бакетинга, если базовое разрешение 1024, всё будет просто ресайзнуто в подходящие разрешения. Если ты укажешь 1280 верхнюю границу с 1024 тренировочным, а у тебя ультравайд 3:1 5400х1800 я на самом деле хз что будет, но она скорее всего ресайзнется в ещё более мелкую хуйню, что не есть гуд
> добавляет паддинг с черными пукселями вместо скейла
Всегда юзал букетинг и ни разу не заметил эффекта этого паддинга
> --noise_offset=0.05
А теперь 2-3-4-10 таких натрень и попробуй стакнуть, охуев от того что будет происходить, мультирез кстати даже маловат, 8/0.4 вполне
> ни шумов
Не усваивает ни одна, по крайней мере аниме, сетка film grain, хоть ты выебись, вае уничтожит ещё на этапе сжатия это всё, только в фш накидывать после
> 15 картинок и 2500 шагов. Я бы не терпел так.
Так они быстрые с батчем в 1 за 15 минут и без чекпоинтинга, потому что влезает, терпеть это когда пытаться нормально натренить и вдруг узнать, что с мелким датасетом было лучше и надо крутить что то, потому что мелкие датасеты насыщаются быстрее, это тупо база
> Не, я конкретно юзкейс конв в твоем случае. В датасете много текстурок или локальных деталей что сетка не уловит без их помощи на адаме?
Любому стилю не помешают, в любом сколько нибудь выделяющемся есть какие то особенности лайна как минимум, даже в однотипном анимекале, персу не критично естественно
> Слайсишь лору на две части - одна лора чисто конв слои, вторая часть это все остальное, тестируешь.
Воркфлоу есть для такого или чем делать?
> либо натрениваешь в датасетовские картинки, либо лезет основная модель и насилует бедную лору, хоть медленно трень хоть быстро, то есть было проще дримбудкой целый чекпоинт тренить и потом дифренс вычитать в лору, а сейчас спокойно любой размер датасета всаживается практически в любой алгоритм и лора работает как и должна - быть дополнением для модели и работать аккуратно
Ну окей, если не захочешь в итоге сам фангдонга собирать и тренить, то хотя бы скинь фулл конфиг, расчехлю пони и постараюсь в адекватное сравнение с предыдущими попытками генерализации того хуйдоджника на примере той кошкодевки, используя оригинальные работы без нейрокала
> В каком смысоле?
Что делал чтобы продиджи требовал меньше врам, чем адам?
> Кароче вот эта тестовая лора на 5e4, 3 эпоха всего лишь с датасетом около 10 пикч, оригинал бабцы наверно не надо показывать, просто скажу что основные признаки сетка спокойно сожрала и они на вот это пикче все полном объеме и в принципе на 5е4 дальше можно тренить было, но мне 10 пикч тренить нахер не надо было.
Ну это шагов за 500 небось, если не меньше в 2-3 раза с таким мелким датасетом, опять же, если бы было 100, задача бы усложнилась, в отрыве от других параметров кстати довольно бесполезно знать лр, может у тебя соотношение альфы там 1/128 или дропаут какой огромный, но раз утверждаешь что есть конфиг для генерализации даже огромного количества пикч, то я бы попробовал

>Вот есть допустим в целом для питорча https://github.com/davidtvs/pytorch-lr-finder
Так, вроде заставил эту хуйню работать, с полторахой правда и оно не помещается в гпу, но работает


Заставил работать в фп16, хуй знает как но оно работает. Непонятно правда как правильно настроить лол.
Както оно странно работает, тот же прогон без изменения настроек, лосс улетел в жопу
Suggested learning rate: 1.20e-04


А всё, там рандом сид каждый раз был. Ввел фикс сид все стало повторяемым. Теперь вопрос как этой хуйней пользоваться нахуй. Кто хочет потестить?
Не ну в принципе оно ебашит нормально. Если датасет увеличивается в 2 раза, то лернинг советуемый падает как и должно быть. На батче 2 нереально за 100 итераций вызвать нестабильность градиента.
Хоть какаято польза от полторашного чекпоинта, лол, считает моментально.

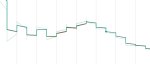
Ради теста бахнул стартовой точкой для датасета в 100 картинок 2e-3, оно мне сразу выдало повышающийся лосс, то есть определенно ниже нужно. Работает блядж!
Кароче я так понимаю основной принцип что нужно вызвать нестабильность для градиента, и примерно 10 эпох от количества картинок, то есть датасет в 100 картинок требует 1000 шагов постоянного повышения лернинга для чекинга градиентов. Щас проверим.
>Ну это шагов за 500 небось, если не меньше в 2-3 раза с таким мелким датасетом, опять же, если бы было 100, задача бы усложнилась,
139 шагов
>может у тебя соотношение альфы там 1/128
16/8 вроде, или 8/4
>дропаут
Не пользуюсь, он не нужон на продигах
>И что тогда в файле выходном остается?
локальная адаптация весов с помощью свёрточных операций, они не имеют визуализации в виде отличных друг от друга AB слоёв, буквально адаптация весов и слоев модели, а не добавление натрененных слоев как с классикой
сам состав локра сложный, я так сразу не скажу не подглядывая
>не помню какой фактор ставил, 1000000000000 чтоли, чтобы по размеру был как обычная лора короче в 100мб
Э ну там несколько не так работает, вес зависит от параметра факторизации - чем он ниже, тем больше параметров в итоговой лоре и тем больше ее вес вплоть до фактора 1 размером с полную модель, а если указать -1 то это будет минимальная лора из возможных, точно не скажу но чето около нескольких мегабайт, если не сотен килобайт. В целом там в дименшен нетворка можно хоть триллиард поставить циферку, ее главное назначение чтобы она была больше 10к с копейками чтобы факторизовать веса, если меньше поставишь то там деление не произойдет просто и тренинг не запустится.
>Концепт как раз тренят обычно включая энкодер, ведь там есть слабые или неизвестные модели токены
>Был даже какой то датасет, который с энкодером лучше намного работал
Я треню концепт на 1 токен если нужно с те. А баба сверху например вообще без те, и там клипатеншен захватил последовательность символов в качестве токена из кепшена и его можно юзать. Собсно поэтому я дрочу на правильный тренинг весов, потому что при правильном тренинге те и не нужен.
>Ты не перепутал? Чем меньше датасет, тем быстрее сетка оверфитнется и тем меньший лр лучше ставить
Нет, я все правльно скозал. Чем меньше датасет тем меньше даты для запоминания, тем выше лернинг для градиентов.
> 1пикча на 500 пиздец, 15 на 2500 не полный, но пиздец, 75 уже вроде ничего на 2500, даже можно было сильнее жарить
У нас разные эти как их пайплайны работы, у меня вообще другой опыт с моими вариантами мокрописек.
> Чтобы не скалировать ничего, нахуя мне лишний дампенер, когда ничего не горит, а наоборот бы натренить посильнее
Ну я понял что тебе выдача и знания самой модели не особо важны.
>Не, это щитмикс называется, лол
Ну как ето, можно же спокойно разницу в лору из любого файнтюна вытащить.
>У меня он всратый
Чел мне так лень заново делать когда у тебя уже есть. Мне без разницы всратый или нет, я и так со всратками работаю постоянно.
>Потому что это лишний гемор
Всего то в два раза больше времени, зато потом все работает как часеки.
>На мультистиль без вариантов, надо тренить уникальные токены вызова
Опять же спокойно можно на стиль тренировать без те, это не какаято особая магия.
>А ты его тестил с впредом? Может он вообще не работает или через жопу
Не тестил, но хуюер сам по себе мягкий и совмещает л1 и л2 в зависимости от типа ошибки.
>Ты делаешь букеты, чтобы пикчи сами просто ресайзнулись до разрешений, смежных твоему выбранному разрешению. Это просто границы бакетинга, если базовое разрешение 1024, всё будет просто ресайзнуто в подходящие разрешения. Если ты укажешь 1280 верхнюю границу с 1024 тренировочным, а у тебя ультравайд 3:1 5400х1800 я на самом деле хз что будет, но она скорее всего ресайзнется в ещё более мелкую хуйню, что не есть гуд
Ну вопервых я бы скозал что гигабукеты для сдхл уменьшают скорость сходимости, вовторых я бы не скозал что мелкая хуйня это какая-то проблема вообще для нейросеток ибо латент хуе мое, многомерное пространство признаков, что скукожилось выкукожится. Мне понравилось тренить каскад одно время когда он чучуть хайповал, там можно на ультракале из шакалов обучать достойно было.
>Всегда юзал букетинг и ни разу не заметил эффекта этого паддинга
Медленные лернинги вероятно. Если аналогично с альфой грузить пикчи которые обрабатываются как черный цвет то на высоких лернингах оно схватит и будет срать ими. Хотя опять же может это конкретный кейс альфаканалов, но я на всякий случай не букеирую со скейлом.
>А теперь 2-3-4-10 таких натрень и попробуй стакнуть
Не стакаю лоры, они же замещают друг друга, если только это не архитектрный дистиллят и лора контента.
>Не усваивает ни одна
Глора спокойно любое говно схватит и умножит.
>Так они быстрые
Какая карта?
>Воркфлоу есть для такого или чем делать?
Слои можно списком посмотреть через анализатор в кое или аналогичный скрипт, далее можно скриптом слайсить вот этим например https://github.com/ThereforeGames/blora_for_kohya ток расписать трейты под себя.
>Что делал чтобы продиджи требовал меньше врам, чем адам?
Я ниче не делал, просто наебенил себе шедулерфри.
>Вот несколько дней назад делал лору из одной картинки буквально
Как думаешь, есть смысл докидывать в датасет похожих картинок чтобы только греть оптимайзер на них? По сути просто побочные картинки в датасете, для которых будет нулевой или околонулевой лр.
Ого, я оказывается неправильно понял документацию. Надо не на уебавшийся лосс смотреть, а генерировать нисходящий лосс в начале и брать примерно середину. Интересно, то же самое дает валидейшен в евердриме, ток дольше по времени. Завтра кароч перну в гитхаб этой хуйней может кому итт пригодится.
Алсо может вы придумаете че еще можно прикрутить. Я вместо МСЕлосса хубер прихуячил например.
https://github.com/deGENERATIVE-SQUAD/stable-diffusion-lr-finder
Вот скрипт, можете погонять
Принцип работы по факту аналогичен https://medium.com/@damian0815/the-lr-finder-method-for-stable-diffusion-46053ff91f78

Запустил тренинг бофт. Лучше бы блять не запускал.

тренишь бофт
@
понимаешь что в комфе нет поддержки
да блять
@
понимаешь что в комфе нет поддержки
да блять




блять ну зато в вебуе обосраном работает конечно ебать свинья лежит там где не ждешь
ну результ бофты кароч шикарный, даже на первой эпохе ебет, взял датасет для теста из 600 пикч Cindy Shine с легалов, не тегировал
из минусов: как и случае с локром какой-то параметр или его отустствие (допустим конволюшн блоков нет ни там ни там и их в целом нельзя вкл сделать) не позволяет генерить без мутантов в нестандартных размерах, хотя основная модель позволяет, вероятно возможно надо было тренить ток атеншн, а не прям веса тюнить под 768 разрешение
ну и считает вечность конечно
3 эпоха, 453 шага с батчем 4
1 пикча с датасета, остальные лоурес гены, 4 кроп литса с нсфв контентной пикчи с расширенной песдой
еще хуйцы с порнухи все схватило нормально так и всякие позычи и нюансики детальки




> не позволяет генерить без мутантов в нестандартных размерах
То есть вот проблематика какая, первый три пикчи с разными настройками, с и без консистенси алайнерами, четвертая дефолт ген модели
Всё в 1024x1400
Если кто знает в чем прекол может быть подскажите




Не ну теоретически может быть банальный оверфит, потому что все более менее работает на весе бофта в 0.5, но тогда похожесть литса модели теряется (хотя я на нее и не тренил но все равно хочеца применять лорку на весе 1 в любом случае)


Щас бы еще понять в каком месте оверфтинулось и из-за какой настройки
Пикчи по эпохам 1 2 3, вес 0.5
>Если кто знает в чем прекол может быть подскажите
>1024x1400
Занижай разрешение, очевидно же.
ИИ имеет свойство заполнять персом все пространство, если ты ему жестко не говоришь делать обратное (т.е. в промпте много пишешь про окружение, плюс разные "ландщафтные" тэги типа изображения используешь).
Плюс потеря когерентности, ибо разрешение таки уже предельное.
И тут ты еще своей лорой говоришь рисовать исключительно тянку.
Вот у модели крыша от совокупности проблем и едет.
На более низких разрешениях, типа 1280х768 должно получше быть, даже учитывая какие-то проблемы с лорой.

Нет, ты не понял.
Модель на которой я треню натренена так что внедатасетовые размеры спокойно жрет, что я показываю пикчей 4 тут
Помимо этого дистиллят дмд2 в качестве алайнера сам по себе задизайнен на хайрезы.
Как только я применяю натрененный бофт с весом 1 начинаются мутанты на разрешении выше 1024-1280. Но если снижать влияние лоры до 0.5 то все устаканивается.
Для сравнения та же проблема с фуловым весом локра на пикче, в целом все консистентное но есть небольшая вытяжка тела, но по итогу он более лутше отрабатывает фул вес лоры. Если снижать вес, то там вообще чикипуки все.
То есть налицо проблема в тренинге, вопрос в чем именно.
Различие между конфигами локра и бофты буквально незначительно уровня отсутствия скалярного слоя у бофт и лернингов, единственное что есть у обоих - декомпрессия весов с помощью доры. Вероятность что это дора подсирает?
Так я про совокупность говорю.
На 4-м пике из поста тоже проблемы есть, просто из-за позы и заполнения кадра не такие заметные.
А ты своей лорой буквально приказываешь модели рисовать стоящую тянку на фоне стены и дивана. Да еще и на высоких разрешениях. Вот ее и вытягивает.
Когда занижаешь влияние лоры - модель рисует тянку с более корректной анатомией, так как старается отработать больше из своего датасета, а не из того, что ты натренировал. Отсюда и частичное исправление.
Другими словами, я бы не в архитектуру или настройки тренировки копал, а в то, что именно ты тренировал.
Ну или просто занизил разрешение, и посмотрел, как оно будет работать.
Если такие мутанты даже на минимальном 1024х768 будут - явно косяк в тренировочных параметрах. Если нет - значит, ты просто изнасиловал модель своим стремным сетом, и на тренировку плеваться не надо.




Касательно твоих тезисов
>ИИ имеет свойство заполнять персом все пространство, если ты ему жестко не говоришь делать обратное (т.е. в промпте много пишешь про окружение, плюс разные "ландщафтные" тэги типа изображения используешь).
Я не расписываю ничего, буквально несколько токенов вызовов уровня гирл стендинг, можно вообще без вызовов генерить.
>Плюс потеря когерентности, ибо разрешение таки уже предельное.
Зависит от базовой модели и мокрописек. Если шринк включать там все выравнивается и работает, но шринк это костыль.
>И тут ты еще своей лорой говоришь рисовать исключительно тянку.
Так датасет из тянки в модели которая полностью из тянок, даже с пустым промтом будет тянка. Ладно, давай попробуем без упоминания тянок.
skyscraper photo with car 1024x1400
Локр фул вес, локр 0.5 вес, бофт фул вес, бофт 0.5 вес
>На более низких разрешениях, типа 1280х768 должно получше быть
Так я и говорю что базовые разрешения норм.


>На 4-м пике из поста тоже проблемы есть
Нет, там нет никаких проблем. Вот тебе еще дефолт гены в еще более высоком разрешении.
>стоящую тянку на фоне стены и дивана. Да еще и на высоких разрешениях. Вот ее и вытягивает.
Можно то же самое сделать на дефолт модели и без каких-либо мутантов. В этом проблема.
>Ну или просто занизил разрешение, и посмотрел, как оно будет работать.
Ало, очевидно же что дефолт работает как надо.
>Другими словами, я бы не в архитектуру или настройки тренировки копал, а в то, что именно ты тренировал.
>Если нет - значит, ты просто изнасиловал модель своим стремным сетом, и на тренировку плеваться не надо.
Данных проблем не было на локоне и глоре.
Кароче, гпт мне сказало
Проблемы с артефактами и дублированием объектов чаще связаны с:
Некорректным масштабированием параметров LoRA.
Недостаточной адаптацией LoRA к высоким разрешениям.
Попробую кароч бакеты для начала повысить у локра.
Если мое предположение верно то тренировка глоры и локона насколько я помню была с включенными аугментациями типа --random_crop, флипы и даже колор, если щас окажется что так и есть и рандом кроп решит проблему ебаных мутантов на локре и бофт то буду очень рад
Да, проверил лоры с любыми кроп аугами (даже чисто на литсо) все они генерят не в размер спокойно без мутантов. Даже локр я оказывается уже тренил в таком ключе а потом чето все ауги убрал. Ебаный насос.
> 139 шагов
Как оно вообще в теории то должно успечь нормально пропечься, учитывая равномерное распределение таймстепов в стоке?
> чем он ниже, тем больше параметров в итоговой лоре и тем больше ее вес вплоть до фактора 1 размером с полную модель
Да, вспомнил, фактор 4 и дим дохуя ставил, чтобы получить эквивалент обычной лоры, короче не впечатлило, больше ебли, результат тот же
> Я треню концепт на 1 токен если нужно с те
А, лол, ты вообще без тегов чтоли хуяришь, ну это был полный забей на пони, когда я тестил, даже юнет онли лучше в тегами выглядел
> потому что при правильном тренинге те и не нужен
На что то одно да, а дальше нужно уже и те и разделение тегами
> У нас разные эти как их пайплайны работы, у меня вообще другой опыт с моими вариантами мокрописек.
Видимо, у меня обычно просто лора лопается, если пикч мало и неадекватный лр выставлен, поэтому абсолютно противоположный экспириенс, может дедомодели от анимушных отличаются конечно
> Ну я понял что тебе выдача и знания самой модели не особо важны.
Неиронично, я ещё не встречал ни одну хл модель, которая бы после накладывания лоры поверх не выпрямлялась бы, буквально все работают просто лучше с лорой и это какая то общая проблема шероховатости файнтюна, да и затереть там "скином" на стиль нереально, опять же повторю, особенно если специально не устраивать прогар
> Чел мне так лень заново делать когда у тебя уже есть. Мне без разницы всратый или нет, я и так со всратками работаю постоянно.
Да не в этом дело, даже очищенную версию просто заливать куда то не особо хочется, поглядел бы что там, понял бы что имею ввиду, а на буре уже валяется и стянуть любой может напиши чтоли хоть фейкомыло какое, туда хоть скину лучше
> Опять же спокойно можно на стиль тренировать без те, это не какаято особая магия.
Разделять потом как разные стили?
> Не тестил, но хуюер сам по себе мягкий и совмещает л1 и л2 в зависимости от типа ошибки.
Это смуз л1 вроде так делает, а не сам хубер, да и с впредом там в целом уже как то по другому всё с лоссом изначально
> Ну вопервых я бы скозал что гигабукеты для сдхл уменьшают скорость сходимости
Любое увеличение разрешения её снизит
> Мне понравилось тренить каскад одно время когда он чучуть хайповал, там можно на ультракале из шакалов обучать достойно было
Жаль тюнов кстати так и не появилось нормальных, в целом база не самая плохая была бы, модальная, нашли бы как тренить и врамлетам, и если надо, гигачедам с H100
> Медленные лернинги вероятно. Если аналогично с альфой грузить пикчи которые обрабатываются как черный цвет то на высоких лернингах оно схватит и будет срать ими. Хотя опять же может это конкретный кейс альфаканалов, но я на всякий случай не букеирую со скейлом.
> Не стакаю лоры, они же замещают друг друга, если только это не архитектрный дистиллят и лора контента.
Короче я в целом понял, ты на огромном лр одну вжариваешь без тегов и всё? Как она там себя показывает с другими и тд уже второстепенно, поэтому может и были проблемы с дмд от такого
> Глора спокойно любое говно схватит и умножит.
В том архиве есть глора от не самого глупого тренировщика с форчка, не схватила и не умножила, выглядит как дора обычная. Есть ещё идеи про волшебный конфиг который поможет это сделать без тупо оверврайта весов напролом? Конфиг так и не скинул кстати, в котором уверен, что сработает
> Какая карта?
4090, батч 1 лора быстрее всего делается, потому что нету штрафа от чекпоинтинга и влезает в память
> Слои можно списком посмотреть через анализатор в кое или аналогичный скрипт, далее можно скриптом слайсить вот этим например
По конкретней, какой скрипт у кохьи ты называешь анализатором и что приблизительно вписываешь в конфиг слайсера?
Если они прямо совсем одинаковые, то лучше на них тоже учить, потом проще будет датасет для некст итерации пополнять, если не совсем, то хз даже, наверное нет
> Алсо может вы придумаете че еще можно прикрутить
Хл так и не поддерживается?
Из опыта на анимекале так всрато вытягиваются если тренишь в разрешении ниже 1024, им впринципе никогда жертвовать нельзя с хл, хз что конкретно ты там напердолил
>Из опыта на анимекале так всрато вытягиваются если тренишь в разрешении ниже 1024, им впринципе никогда жертвовать нельзя с хл, хз что конкретно ты там напердолил
Это точно не разрешение, потому что вообще не вылезаю за 768 пукселей и
>Хл так и не поддерживается?
Можешь переделать спокойно под хд, там плюс минус тот же код за исключением зависимостей для полторахи, но мне в этом нужды ноль, потому что вопервых полтораха меньше весит, вовторых у нее базовое разрешение ниже для работы (хотя это и не важно вообще, тут слоп на графике же ток найти надо а не консистентное изображение), втретьих она быстрее считается, вчетвертых такто можно хоть 128x128 по разрешению выставить, впятых все перечисленное позволяет на 3060 гонять 50+ батчей за итерацию
> вообще не вылезаю за 768 пукселей
Тогда и в генерациях не вылезай за них, оно же тюнится под это разрешение
И на хл оно тот же самый лр найдёт думаешь? Только не говори, что ты полтораху на серьёзе тренишь
Этот тред нагоняет на меня тоску. Да и вся доска. Что то получается, радостный заходишь, смотришь на то ,что местные делают, и сразу какой то разочарование от собственного позора.
А ещё флюкс медленно работает, и по ощущениям, он на озу генерит, иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия
А ещё флюкс медленно работает, и по ощущениям, он на озу генерит, иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия

>Тогда и в генерациях не вылезай за них, оно же тюнится под это разрешение
Но это не так работает in vivo епт. Это если ты просто тюнишь веса под картиночки с нулем аргументов на каком-нибудь одном разрешении и упором в альфу на оптиме который падает в локальный минимум и там умирает. Можно вообще тюнить attn-mlp или attn и сохранять юзкейс модели изначальный. Или конкертные слои, как в случае билоры. У меня же юзкейс вообще другой, я где-то на какойто итерации тестинга проебал аугментационные аргументы, тупа random_crop не выставил, вероятно потому что решил перенсти латенты в кеш, а латенты с вкл кропом не работают, а он если че:
Когда включено (true):
Обрезает изображение случайным образом при его масштабировании. Полезно для нестандартных разрешений.
Изображение случайно обрезается до меньшего размера, а затем подгоняется под размер разрешения (resolution=768x768).
Это изменяет расположение объектов и может переместить объект от центра к краям изображения.
Используется для снижения переобучения на "центральных" объектах.
Включить (true) — когда нужно увеличить разнообразие расположения объектов. Например, чтобы лица или объекты могли находиться не только в центре, но и в углах. Для контекстуальных изображений.
Выключить (false) — если важно сохранить центрированное расположение объектов (например, при обучении модели для портретов или аватаров, где лицо всегда должно быть в центре).
Алсо тот же эффект без вытянутых пропорций и мутантов на хайрезах наблюдается если использовать автообрезку по ебалу, если трен на лицо.
>И на хл оно тот же самый лр найдёт думаешь?
А архитектура не важна, сам принцип алгоритма это постоянно увеличивающаяся кривая лернинга, который каждую итерацию считает лосс. Кривую обучения можно поделить на разогрев, слоп обучения, плато накопления признаков и взрыв градиентов/переобучения, задача алгоритма визуально показать в каком промежутке находится комфортный слоп обучения. Обучать в целом можно и на лернингах плато, но наиболее эффективно судя по паперам это именно промежуток слопа.
>Только не говори, что ты полтораху на серьёзе тренишь
Нет, я не шиз.
Кстати там ссану выпустили в весах умеющих в 2к + тренинг лор с гайдом https://github.com/NVlabs/Sana/blob/main/asset/docs/sana_lora_dreambooth.md https://github.com/NVlabs/Sana вот ее бы я потренил, в комфю и прочие уи еще не завезли поддержку кстати
>Как оно вообще в теории то должно успечь нормально пропечься, учитывая равномерное распределение таймстепов в стоке?
Жоско наказываешь за ошибки, задираешь лернинг юнета. Для еще более быстрой сходимости на тест можно использовать (IA)^3, который чуть ли не в 5 раз меньше требований к шагам имеет чем любой другой оптим. Алсо еще имеет значение сам оптим, адам на котором ты сидишь требует условно 1к шагов на эпоху, продиги требуют в половину меньше шагов для успешного обучения, есть еще более пизданутые по скорости схождения, но там в основном проблема с признаками и ошибка в определении локальных минимумов.
>больше ебли
Так наоборот меньше, дименшены и их отношение выставлять не надо, количество параметров управляется значением фактора.
>ты вообще без тегов чтоли хуяришь
Именно. У меня не миллионный датасет, я не треню ТЕ, устойчивые мультиконцепты это рандом в несовершенных архитектурах и поиск грааля и проще разные лоры тренить.
>ну это был полный забей на пони, когда я тестил, даже юнет онли лучше в тегами выглядел
Я паприколу киданул сложный калцепт нюши из смешариков (шарообразное нечто с глазами, сетка вообще не отдупляет че это) в пони и оно норм в целом по первым эпохам было.Так что не думаю что пони как-то разительно отличается от безтокенного обучения на базовых сдохлях. Я бы даже сказал что пони проще, т.к. сломаный текстовый енкодер позволяют втюнивать exaggerated дату, ну типа в обычносдхл сложно втюнить концепт гипербубсов размером с солнечную систему, на пони это как два пальца обоссать будет.
>а дальше нужно уже и те и разделение тегами
Я руководствуюсь тем что модель которая берется в качестве базы уже в курсе обо всех концептах датасета и модель сама все прекрасно понимает по входящим данным. То есть естетсвенно в какой-нибудь файнтюн на архитектуру смысла пихать порно нет, а в модель про порно нет смысла пихать архитектуру. VIT обрабатывает картиночку, TE уже и так полон концептов связанных с весами которые тюнятся, зачем чтото еще, если оно и так работает?
>у меня обычно просто лора лопается, если пикч мало и неадекватный лр выставлен, поэтому абсолютно противоположный экспириенс, может дедомодели от анимушных отличаются конечно
Мне кажется ты просто не юзаешь мокрые письки чтобы контролить генерализацию и конвергенцию получающейся модели на ранних этапах и ждешь у моря погоды дотренивая лору до состояния уголька, я в прошлом треде писал уже что модель уже буквально с первой эпохи обучена, но недостаток инфы не дает ей инферировать корректно, ты можешь ее пиздануть ломом и заставить выдавать корректное даже в полном недостатке признаков чтобы понять а туда ли ты обучаешь вообще. Да, это не даст тебе выложить лорочку на потеху другим пчеликам и без гайда на конкретное использование они пососут при использовании, но тебе нужен фактический тест, а не готовый продукт.
>Неиронично, я ещё не встречал ни одну хл модель, которая
Я про сохранение концептов базовой модели. Какой мне условный смысл тренить ебало еот чтобы модель делала мне ебало еот вместо контента который может модель? Никакого.
>напиши чтоли хоть фейкомыло какое, туда хоть скину лучше
[email protected]
>Разделять потом как разные стили?
Не юзать мультиконцепты стилей в одной лоре? Нейросети локальные пиздец тупые, мультиконцепты делают ток хуже, ликинги вот эти все.
>ты на огромном лр одну вжариваешь без тегов и всё?
Преимущественно да.
>Как она там себя показывает с другими и тд уже второстепенно
Ну тут смотря что с чем. Можно шизануться и одну лору на один слой аутпута натренить, а другую на соседний и бед не знать. Или тренить ток атеншены в одной лоре, а в другой ток прожекшены. Вариантов масса, но в целом да я больше 1 концептной лоры при генерации не юзаю. Ну или придумай мне юзкейс когда нужно юзать джве концептные лоры.
>поэтому может и были проблемы с дмд от такого
Не, там дмд агрился на TE, уже порешали вопросики.
>В том архиве есть глора от не самого глупого тренировщика с форчка, не схватила и не умножила, выглядит как дора обычная.
Я не смотрел состав, может там на атеншены тренились ток. В глоре целый парк адаптационных слоев, если ее фулово тренить она так все схватит что потом заебешься вилкой чистить.
>выглядит как дора обычная
Но дора это разложение весов, а не алгоритм адаптации.
>Есть ещё идеи про волшебный конфиг который поможет это сделать без тупо оверврайта весов напролом?
Атеншоны тренить?
>Конфиг так и не скинул кстати, в котором уверен, что сработает
Я ниче не скинул потому что у меня у самого нет идеального конфига, постоянно меняю всё.
>По конкретней, какой скрипт у кохьи ты называешь анализатором
Ну в kohyass есть отдельная вкладка верификации лоры, туда грузишь лору и он тебе послойно показывает состав. Отдельно должен быть скрипт.
>что приблизительно вписываешь в конфиг слайсера?
Ну если задача разделить конволюшены и все остальное, то для первого трейта будет
"1":
{
"whitelist": ["маска_конволюшенов_"],
"blacklist": []
}
а для второго
"2":
{
"whitelist": [],
"blacklist": ["маска_конволюшенов_"]
}
Во втором случае может потребоваться прописать в вайтлисте конкретно все маски нужных слоев за исключением конв, если тебе например фастфорвард слои не нужны.

Новичок, пробую подобное впервые. Поставил флюкс+ аматеур лора. Какой параметр я перекрутил, из за чего изображение такое?
выглядит просто как выкрученный на максимум вес, снизь весь лоры
>иначе минутные генерации мне вообще непонятны. Хотя это может быть из за того ,что это квантованная версия
Минута на флюхкале это еще быстро, риктифайд флоу лижет и сосет по оптимизации. У меня на 3060 в ггуфах полторы минуты ген, в то время как ммдит и ммдитх сд 3.5 50 и 20 сек соотвтественно.

> У меня на 3060 в ггуфах полторы минуты ген,
Какой квант? Воркфлоу можешь скинуть, я на своей 4070 проверю?
>Какой квант?
q4
ну хз, шифт покрути, другой семплер поставь

Флюкс ЖЁСТКО унижает мою видеокарту. Так она только в киберпанке грелась.
У меня во время техпроцесса легко в 80 градусов уходит.
Притом, генерация видео или моделей так карту не греет.
Это же хорошо. Вот у меня не греется тк флукс просто не влазит в гпу.
чет у вас вендоры кал, у меня даже при обучении нет такой печки
Видяха ещё и в разгоне


Все, это рандом кроп выключенный был виноват. Мотайте на усики что рандомкроп повышает обобщающую способность и позволяет сохранить возможность генерации хайрезов даже на меньшем размере тренировки, пикрел натренен на 768.
Потренил кароче бигасп2, ну и как будто он даже лучше для не курируемого датасета, очень хорошая стабильность и консистенция.
Лернинг по д0 стоял на 1е-4 для продижов и сета в 602 картинки, 10 эпох, на первой эпохе уже полный стиль спиздило, к пятой эпохе локальный минимал лосс и дальше уже как будто и смысла тренить нет, разве что увеличивается фиксация на конкретных превалирующих элементах датасета.
У него правда есть небольшая проблема в том что чекпоинт малость перетренирован и поэтому жарит сам по себе, особенно с убыстрялками, а реки автора вообще 2-3 по цфг. В целом это обходится мокрописьками типа шринка, но я не о том. Натренилтя значит локр, и он поправил на какой-то процент пережарку модели. Если еще на порядок опустить д0 вероятно будет еще мягче.
Лернинг по д0 стоял на 1е-4 для продижов и сета в 602 картинки, 10 эпох, на первой эпохе уже полный стиль спиздило, к пятой эпохе локальный минимал лосс и дальше уже как будто и смысла тренить нет, разве что увеличивается фиксация на конкретных превалирующих элементах датасета.
У него правда есть небольшая проблема в том что чекпоинт малость перетренирован и поэтому жарит сам по себе, особенно с убыстрялками, а реки автора вообще 2-3 по цфг. В целом это обходится мокрописьками типа шринка, но я не о том. Натренилтя значит локр, и он поправил на какой-то процент пережарку модели. Если еще на порядок опустить д0 вероятно будет еще мягче.
Щас пробую на бигаспе потренить диагональный OFT, бофт мне зашел но скорость тренинга его меня просто разыбала - аналог 3000 шагов 6 часов ебал. А диагоналка ниче так, бодро. Не понял за что отвечает парам констрейнт, но выставил 16 как дименшен нетворк. Альфу тоже нипонятно то ли в 1 надо то ли выше, оставил как с бофт 1 пока что. Еще у диагоналки есть параметр рескейлед, но тож хуй знает че делает.
Алсо понишизы, какой там файнтюн будет лучше для реалистикотренинга?


Синенький лосс диагофта, оранжевенький локр прошлый
Считается конечно быстрее чем бофт, но все равно ебнешься как долго
Ну че я могу сказать, дигофт который кофт изза аргумента уже на первой эпохе ебет и спизидл весь стиль с фоток и фигуру и немного ебало модели.
После, до. Почему до жарит? Потому что бигасп жарит, ебаное говно в виде вебуя бесоебит и вообще алайнер срет тоже.




эпохи 2 3 4 5
Хуй пойми нахуя тренить выше первой эпохи получается, мб на хайрезе там ебало консистентнее будет я хз






тест клозапа
8 эпоха, 1 эпоха, без диагофта
Ну я хуй знает кароч, да похожесть с эпохами бустится но как для стиля достаточно одной эпохи совершенно точно

Судя по графику тензорборды локальный минимум лосса был на 800 шаге, ближайшая эпоха это 755 т.е. 5, ну да в принципе похоже на модельку (напомню что на ебало я не тренировал, просто определяю где там лучшая точка схождения)
Кароче бофт и дофт/кофт/хуефт ван лав, надо долбить комфидева чтобы добавил поддержку, вебуем пользоваться невозможно нахуй
Хотя можно теоретически сконвертить офт в ликорис, надо попробовать





Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
https://github.com/bghira/SimpleTuner
Линукс онли, бэк отличается от сд-скриптс
https://github.com/Nerogar/OneTrainer
Фич меньше, чем в сд-скриптс, бэк тоже свой
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Flux
https://2ch-ai.gitgud.site/wiki/nai/models/flux/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – для SD 1.5 обучение доступно начиная с 16 GB VRAM. Ни одна из потребительских карт не осилит тренировку будки для SDXL. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
https://rentry.org/lora-is-not-a-finetune (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA https://colab.research.google.com/github/hollowstrawberry/kohya-colab/blob/main/Lora_Trainer.ipynb
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
NLP тэггер для кэпшенов T5: https://github.com/2dameneko/ide-cap-chan (gui), https://huggingface.co/Minthy/ToriiGate-v0.3 (модель), https://huggingface.co/2dameneko/ToriiGate-v0.3-nf4/tree/main (квант для врамлетов)
Оптимайзеры: https://2ch-ai.gitgud.site/wiki/tech/optimizers/
Визуализация работы разных оптимайзеров: https://github.com/kozistr/pytorch_optimizer/blob/main/docs/visualization.md
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Старая коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/badhands/makesomefuckingporn
https://rentry.org/ponyxl_loras_n_stuff - пони лоры
https://rentry.org/illustrious_loras_n_stuff - люстролоры
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/