



Че значит сломаны? У меня 40777 + 333 тест спокойно проходит. 6 квант. Есть пруфы то что они сломаны?
У тебя не ггуф? Значит что-то другое. Конфиги там, или засирание контекста ахаха. В общем лично я жду окончательных фиксов.
>40777
тебя похоже тоже криво квантанули
там 4777 +333
Ты же понимаешь, что нет разницы никакой?
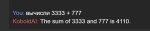
Есть. Правильный пример 3333+777, остальное не то.
какие сейчас модельки лучшие по вашему мнению для кума с огромным контекстом?

Ну и че, где все эти ученые в говне моченые со своими смуфквантами и прочей хуетой? Почему Жорик без образования это самостоятельно чинить должен? Вахуе.
>где все эти ученые
Пилят новые модели. У них на голом трансформере это запускается и ладно. Оптимизация не по их части, впопенсорсовцы и квантовали в 4 раза почти без потерь. и обработку контекста срезали чуть ли не с квадратичной до линейной.
>ученые в говне моченые
работают на супер пупер оборудовании которое нам не светит
цены на одну игрушку начинаются с 15к зеленых вплоть до миллионов если говорить о блекквеле
Их и корпоратов которые им платят не ебут проблемы нищеты что не имеют каких то 40 гб видеопамяти
Ну и для нас выпускают всякие огрызки типа фи от мелкософта, тупые и лоботимированные
У меня так же.

>какие сейчас модельки лучшие по вашему мнению для кума с огромным контекстом?
Мику оригинальная, сказал бы я, но: для контекста больше 8к модели в Q4 требуется больше 48гб врам. Допустим она есть и контекст можно поднять аж до 32к; но скорость генерации ближе к этим 32к будет очень-очень грустной. Ждём всяких фишечек типа сохранения огромного контекста в обычной RAM, которые нам обещали... когда-нибудь.

Где-то 10% ответов неправильные. Но промпт простой, гоняю на русском. И это 8b.
Дай конкретную модель с ссылкой, промптом, настройкой семплера. И скажи на каком беке гоняешь.

делал уже пост в нф но там вообще пусто так что пришел сюда.
парни крч с железом относительно напрягов нет так что подскажите ллм пиздатую в данный момент. в данный момент сижу на Llamix2-MLewd-4x13B.q8_0 а до этого на mlewd-remm-l2-chat-20b.Q6_K. и еще много чего пробовал по мелочи но там совсем мрак. так что может посоветуете что то более годное.
так мб кто то сможет пояснить за эти режимы запуска(?) в кобальте что на моем скрине
так же несколько раз натыкался на скрины настроек в кобальде но они были подписаны под другие лмм. или есть какие то внятные ресурсы где можно посмотреть таблицы.
так же вопрос где брать карты персов кроме чаб аи и дворника.
все добра
парни крч с железом относительно напрягов нет так что подскажите ллм пиздатую в данный момент. в данный момент сижу на Llamix2-MLewd-4x13B.q8_0 а до этого на mlewd-remm-l2-chat-20b.Q6_K. и еще много чего пробовал по мелочи но там совсем мрак. так что может посоветуете что то более годное.
так мб кто то сможет пояснить за эти режимы запуска(?) в кобальте что на моем скрине
так же несколько раз натыкался на скрины настроек в кобальде но они были подписаны под другие лмм. или есть какие то внятные ресурсы где можно посмотреть таблицы.
так же вопрос где брать карты персов кроме чаб аи и дворника.
все добра
Здраститя, то-ли я ебанутый, то-ли лыжи не едут - кобольдрокм работает медленнее с 6700хт, чем вулкан. У кого-то так было ещё?
Это, получается, некромоделька для кума ебёт соевую ламу для опущенных куколдов?
Раньше было наоборот, но может быть в последних патчах что-то наоптимизировали в вулкане.
Пиздец у меня профдеформация от локалок по ходу. Каждый раз, как вижу в любом тексте отрывок длиннее 5-7 слов без знаков препинания, сразу какой-то тумблер щёлкает и в голове мысль "блять опять залупилась, снова лазить по контексту чистить вилкой говно". Только через секунду где-то приходит осознание.
Туть.
Хрюкнув.
Если напряга нет, бери коммандер плюс (104б) в 6 кванте. Там нормас.
Если все же чуть напряжнее, то возьми мику или ллама3 70б.
Ну я хз, че те надо вообще.
Ну так вулкам пизже для радеонов, там чегото еще подкрутили для процессоров
А если вейвкодер + промпт? :) Может совсем пиздато будет?
Ща посравниваю, уговорил.
Нормальная ллама3 ебет, уже проверенно на онлайн версиях, даже 8б адекватно отвечает. Просто у Жорика говнокод, поэтому ждем исправлений, а вообще конечно лучше бы уже новые кванты запилили.
Которую неделю ждем уже!
Че там с экслламой, пофиксили ее хотя бы? Или тоже собирать данные из постов анонов из прошлого треда?
На какой модели я могу почувствовать всю мощь лламы 8 щас?
> На какой модели я могу почувствовать всю мощь лламы 8 щас?
EXL2 в 6.0bpw. У Жоры токенизатор сломан, у питонистов устаревшие говнокванты от GPTQ.

Я уже exllama ставлю, Жорик доверие потерял.
Экслама работает, настройки и конфиги в прошлом треде выложены.
12th Gen Intel(R) Core(TM) i9-12900HK 2.90 GHz
NVIDIA GeForce RTX 3080 Ti 16gb
озу 32
лама 70b пойдет? если нет, то может взять озу на 64 или еще больше брать?
NVIDIA GeForce RTX 3080 Ti 16gb
озу 32
лама 70b пойдет? если нет, то может взять озу на 64 или еще больше брать?
Должна ddr5 если так совсем хорошо
Лучше взять вторую видюху в прошлом треде пии сали про P40 за 20 тысяч 24 гигабайта видео памяти. Там охлад кастомный
По моим наблюдениям все тюнинги лламы 3 работают неровно. В одних задачах прямо вызывают восторг и желание сразу же сделать эту модель своей фавориткой. А потом оказывается, что в другой задаче хуже некуда, причем никакие манипуляции с настройками это не лечат.
> RTX 3080 Ti 16gb
Это что за зверь?
>http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
По ссылке больше ничего не отображается. Похоже автор пилит другой рейтинг тут: https://ayumi.m8geil.de/erp4_chatlogs/index.html
https://github.com/ggerganov/llama.cpp/pull/6965#issuecomment-2082418704
>Seems like your custom llama-3 implementation is correct, because the tests are passing. Good job
>Let's merge this after we merge #6920 later today
дождались блять
Ну, еще не дождались
И это только один косяк который заметили, думаю найдут и еще что то

Гениально.
Выглядит как невероятно замороченный костыль
А че с токенизатором не так то? Почему не пользоваться оригинальным механизмом?
А в 8.0 нет? =(
Я ж грил, без них нет готовой? Ну шо за дичь у квантовиков, им настока похуй…
Ну так, ку4_к_м влезет в сумме впритычок, но лучше добрать.
Скока можешь, стока и добрать.
Ну, вторую ссылку можно было не давать. =D
Чет я не осилил вашу exllamу поставить, какой-то пиздец анакода просто не компилит среду хоть усрись. Почему блять ебанаты не осилили докер?
> https://github.com/vllm-project/vllm
Алсо, а вот это кто-то пробовал? Годные кванты?
> https://github.com/vllm-project/vllm
Алсо, а вот это кто-то пробовал? Годные кванты?
Есть какой-то пул вопросов по которым тестят ЛЛМ?
Я иногда начинаю переводить посты анонов с русского на русский, или писать текста в переводчик.
>Которую неделю ждем уже!
Вторую? Прям насыщенные дни были, треда катятся каждые 2 дня, едва успеваешь читать.
>Почему не пользоваться оригинальным механизмом?
Он не на ссях.
Конечно. Было где-то тредов 10 назад, ищи по строке с петухами и собаками.
Ну ало нахуй, вы отвечать будете? Или тут нихуя кроме кобальда не знают?
На что отвечать? По екслламе ты никаких сведений не предоставил, по второй хуёвине ты первый в треде написал. Не бурчи, а показывай, что у тебя там не встаёт.
докер зло
> докер зло
От тебя советов не жду, дебил.
> GGUF
Чел..
ставит докер называет дебилом другого
че, даже работает?
пока не проверял, у llama.cpp теперь есть bpe-токенайзер так что всё должно работать.
Эт да, на самом деле, не так долго.
А теперь ждем кобольды-убы-олламы-итд.
главное что бы кванты не пришлось перекачивать
Придется.
> GGUF
>Чел..
Нормально вроде общались
это уже третий раз? или четвертый?
А для чего вы вообще ещё используете ЛЛМки, кроме куминга, ролеплея и кодоассиста? Может есть какие-то более нестандартные применения?
Применений масса - все что связанно с текстом. Редактирование, перевод, компиляция, анализ итд.
Как проверить накатили фикс на угубугу? для ламы3

перевод хорош, да и вобще возможность работы с любы текстом локально без инета тоже хорошо
Для начала перекачай квант на свежий, потом спрашивай
> For proper llama3 support, you may pass --override-kv tokenizer.ggml.pre=str:llama3 to main or server without generating a new gguf file.
Но лучше перекачать.
Ну че где кванты новые качать
Я после первого не перекачивал, жду, когда пофиксят.
коммандер не нашло. лламу нашло.
по железу у меня 5800х3д, 3070,64гб может со спеками железа будет легче подсказать. хотелось бы что бы генерело еще чуть по быстрее
Но ведь сразу же бросается в глаза, когда текст написан человеком, а не нейронкой.
Там матрицы важности могли ещё по пизде пойти, если токенизатор вгонял говняк. Так что переквантовывать обязательно надо.
токенизатор сломан
Че происходит объясните
Попробовал запустить на кобольде. 3333+777 не считает, да еще и ассистентом срет.
Да блять... Короче в пизду этого Жору ебаного, надо переходить на что-то другое.
Так кобольд ещё не обновился с этим фиксом.
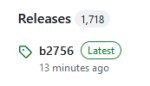

bartowski поторопился (обнова llama.cpp 13 минут назад а его кванты уже час висят), и lostruins чёто мутит там на experimental ветке.
Если пользуешься RAG, то похуй на контекст модели? Или лучше побольше? Требуется провести работу с несколькими документами, общий размер примерно 30-40к токенов.
Смотря что за документы, и сколько нужно строк из них для того, чтобы сделать задачу.
Какой же бартовский долбаеб сука, ну что за инвалидское комьюнити нахуй дегенератов васянов сброище, Я ПРОСТО ХОЧУ ПОГОНЯТЬ МОДЕЛЬ, КОТОРУ РЕЛИЗНУЛИ НАХУЙ МЕСЯЦ НАЗАД.
Гоняй на чистых трансформерах кодом из стандартного репозитория меты, они месяц как работают. Ах да, нужна A100 80GB. Нету? Ну тогда страдай, хули ты хотел.
С первой лламой тоже много веселья было по началу. Эх, я ведь её даже в кобольде запускал (который не cpp если что).
>Я ПРОСТО ХОЧУ
Возьми и сделай сам.
Смотря как работает RAG и какие запросы. Обычно тащится не более 3к токенов (в среднем куда меньше) информации плюс твой запрос - 8к должно на все хватать.
> Я ПРОСТО ХОЧУ
Для любого хочу нужно иметь средства. Видеокарты купил? Тогда терпи.
8b легко квантуется на некропеке.


Кидай монетку.
ну сейчас качну первое потыкаю немного отпишу шо как. спасибо за помощь анонче
качай вначале 4км, потом посмотришь хватит тебе памяти или нет
эта штука очень много памяти для контекста жрет
А я чего-то не понимаю?
Почему в последние полгода мало стало EXL2?
Появился более интересный варик?
Почему в последние полгода мало стало EXL2?
Появился более интересный варик?
Почему мало? Все на месте. Она довольно редко ломается и не нужно делать по 50 версий на каждый коммит Жоры. Также многие квантуют самостоятельно под свой размер и на желаемом датасете.
> Появился более интересный варик?
Нет.
A AWQ?
Или он по размеру больше?
скачал обе попробовал они тупо не запускаются. выбираю в кобальде оно пытается запустить и просто схлопываеться.
на счет памяти у меня 64гб ддр4 так что думаю запас есть
есть еще какие то варианты или рекомендации что можно скачать пощупать?
Да как-то не взлетел и не сыскал популярности. Нет гибкости, с лаунчерами грустно, уступает ггуфу по доступности и совместимости, уступает exl2 по скорости и эффективности.
> рекомендации
Запустить кобольда из консоли чтобы увидеть с какой ошибкой он вылетает.
а можно простенькую инструкцию как это сделать? а то я совсем хомяк в этом плане
command r 35b
С 64 гигами можно и miqu https://huggingface.co/miqudev/miqu-1-70b , но медленно будет.
Нет. Все зависит от промпта и примера, к примеру.
Ну и подправить руками немного можно.
Это под новую лламу.цпп, кобольд уже релизнули новую версию?
Ну, не то чтобы поторопился, почему бы и нет. =) Молодец. Лишь бы еще раз переквантовал.
Контекст сам по себе никогда не помешает.
В 2К ты ни с каким раг не сунешь толком нужное.
Коммандер тоже работал первые дни, потом на пару недель откатили. =) Щито поделать-десу.
И не выкладывает, пидоры. =)
Командная строка.
Заходишь в папку, где лежит кобольд.
./koboldcpp.exe
Вроде так.


я обновил кобольд у меня стояла версия 1.50 вроде а сечас поставил новую и оно завелось но вот качество текста чет пиздец (пик один)
ну и время генерации тоже я ибу 130 секунд блядь. можно что то менее косноязычное и чуть более шустрое
пик 2 название модели
Анончики, решил вместо кобальда попробовать text-generation-webui, так на тех же настройках, те же самые модели, стали прямо заметно лучше отвечать и сочинять. Что за хуйня? Ведь должно быть одно и тоже?
Ваще, за кобольд не шарю.
А, ну и, у меня коммандер q6, мне показалось, там лучше.
Но быстрее не выйдет. Быстрее — меньше модель.
Подожди, пока выпустят новые кванты + новые версии.
Кобольдопроблемы!..
Сижу на убабуге, настраиваю все сам.
Но и там не идеально, таверна даст получше резалт, вроде.
Поэтому совет обоим — ставим таверну, настраиваем карточку там, должны быть получше.
Нихуя. А какая у тебя система там. Видюха, проц, сколько памяти?
таверну ставил но чет захлебнулся и вышла какая та залупа и генерил он как то криво в итоге ушел на кобольд обратно
Таверна это чисто морда для кобольда или убы. Если в таверну придётся результат уровня 10+9=109, то чуда не случится. Так что полезность таверны под вопросом.
Избалован я кобольдомспп. Вообще никаких проблем при соединении СиллиТаверн, даже с другого компьютера. А в Убабуге разбираться надо. Вот порт 5000 для неё пробросил, теперь гадаю, как стриминг вывода включить. Кто знает - расскажите.
завел и потыкал обе результат честно сказать так себе. оно ксноязычны и долго генерят. есть ишо варианты?
> разбираться надо
Добавить
> --api
в CMD_FLAGS.txt
Все остальное по умолчанию идет, таверна свои настройки запрашивает.
Тебе именно на русском что ли надо генерить?
>Все остальное по умолчанию идет, таверна свои настройки запрашивает.
Да всё работает, сгенерированный текст выводится, но одним куском. А хотелось бы стриминга, чтобы потокенно. Может и в Таверне где-то покрутить надо, я хз. Или эндпойнт особый.

>Может и в Таверне где-то покрутить надо
Да, действительно, как же может называться эта настройка?
Эврика, как говорил Архимед. Нашёл.
бля не. я юзаю переводчик в хроме но на млевде оно норм переводит. тут я думаю проблема в самой модели.
хотя варик с русским интересен
Нет. Внимательнее к матчасти.
И уба, и кобольд, и таверна подают свои промпты. В Таверне очень удобно настраивать промпт и он без всяких танцев с бубнами виден в консоли.
Кобольд я хз че там пихает вообще, и что там с карточками не ебу.
Уба между ними — вроде настраивается, конечно, но не настолько детально как хотелось бы. Неинтуитивно нихуя, в отличие от таверны.
Я крайне сомневаюсь, что люди, у которых в кобольде хуевые резулты, идеально и посимвольно настроили свои промпты, так, как им нужно с учетом всех системных токенов.
Из коробки оно, очевидно, обосралось.
Так что, лишний раз покопаться с промптом — прямой путь к улучшению результата.
Напомню, что у меня 3333+777 и прочие задачи ллама прекрасно решает, хотя у других когда как и шизит. А почему? А потому что я промпт и семплеры спиздил у чела из треда, и даже кривую и поломанную лламу они кое-как да чинят.
>1 миллион токенов контекст
Даже не знаю, радоваться ли этому.

уговорил, как установить таверну?
Я уже седня это в телеге писал и тут спрошу — а пихать куда этот контекст будете? А ждать недельку обработки норм?
Ну так. =)
Если у нас хотя бы 1к токенов — 500 мб (чи скока там), 50к токенов — уже 25 гигов (на самом деле, нет). А на оперативе промпт обрабатывается не быстро.
Поэтому, иметь условно 64~128 — база.
А вот 1М+ — это уже корпоратам, у которых есть риги из 16 80-гиговых A100 («стареньких»), и им лишний терабайт видеопамяти позволяет кое-как утилизировать это окошко контекстика.
Попробуйте тупо в мистрали 32к контекста врубить и закинуть туда ~20к токенов контекста. И расскажите, когда он у вас «дочитает». Я не про понимание текста, я про сам факт, сколько времени на это уйдет.
Я ставил год назад, с тех пор тока апдейтил, та хуй его знает, как она щас ставится. ^_^'
https://github.com/SillyTavern/SillyTavern?tab=readme-ov-file#-windows отсюда и ниже, несколько вариантов.
>тут я думаю проблема в самой модели
Ну хуй знает, коммандер как по мне хорош, никакой кривизны на инглише не замечал. На русском он тоже может, но шизовато. Использую модель command-r-v01-imat-Q5_K_M.gguf через таверну, настройки дефолтные.
>полезность таверны под вопросом
Для RP, под который она заточена - полезность уровня мастхэв. Карточки, модульные промпты, регэкспы, три миллиона всякой вспомогательной хуйни.
>3333+777 и прочие задачи ллама прекрасно решает
В убе отлично решает с промптом типа "ты ии. ты помогаешь" и абсолютно рандомным семплером. Если таверна так не может, то таверна кал.
Причем тут таверна-то?
Речь про кобольда, что он нихуя че-то не может. =)
При этом, я его не осуждаю, но он простенький для попробовать.
Кобольд поверх ггуф, а они же все поломанные на третьей лламе. Так что не удивительно, что шизит.
можно ссылку на модель попытался загуглить но их там слишком дохуя
у тебя шо по железу? и насколько важно наличие таверны. выще писал что ставил ее но через нее он срыгивала вообще косноязычную хуету и по итогу я удали и вернулся на кобольд

32 Гб RAM, 4070 с 16 Гб и проц i5 13600k. Генерится со скоростью 1.5 т/с, контекст ставлю 8к.
>насколько важно наличие таверны
Таверна не важна, но с ней просто удобнее имхо, чем в голом кобольде. Если с ней что-то криво генерирует, значит дело в настройках. У меня вот всё норм.
Чет я подумал короче и получается что вся вот эта херня с метой и опенсорсом по сути пошла из-за того что рандомхуй с форчана слил веса собсна на форчан и зак под копиумом решил такой "Нееет, это не плохо что веса слили!!!1!!1 Неправда! Более того это нам выгодно!!!1 Поняли нах сынки??" и со второй ламы самостоятельно контрибтютит в опенсорс. Буквально ничего кроме лабф у опенсорса то и нет. Ща бы сидели на gpt-j и дальше и сосали бибу. По факту если опенсоурс сможет в AGI то это все из-за одного хуя с форчяна.
Коллаб похоже опять перестал работать. Проблема как и в прошлый раз.
Похоже скоро гугл окончательно свернет кум и придется накатить линукс, так на винде это кривые и косые танцы с бубном. Попробовал кобольд, переводчика встроенного нет, нихуя неудобно все.
Эх, а ведь я помню в первых тредах я брал интерфейс практически идентичный уге.
а как контекст выставить?
в кобальде*
70б тоже получается переквантовывать. 8б уже проверил и считает 4777+333 нормально

> рандомхуй с форчана слил веса собсна на форчан и зак под копиумом решил такой "Нееет, это не плохо что веса слили!!!1!!1 Неправда! Более того это нам выгодно!!!1 Поняли нах сынки??" и со второй ламы самостоятельно контрибтютит в опенсорс. Буквально ничего кроме лабф у опенсорса то и нет. Ща бы сидели на gpt-j и дальше и сосали бибу. По факту если опенсоурс сможет в AGI то это все из-за одного хуя с форчяна.
Считаешь, этому неизвестному соевику нужно пикрил памятник при жизни поставить?
Хуйня, рептилоид бы и так выкинул веса. Просто ссал сначала, он же литералли Гитлер, которого в сенате песочили.
Алсо, это не рандомхуй с фочана, он слил на фочан. Биг дифференс. Все сливы идут туда всегда
Ок, запустил, даже не срёт асистами и не шизит, но резальт этой модели какой-то сухой. Ну генерит текст, но прям вообще ничем не выделяется от основной массы. Я что-то не так делаю?
Какой квант?
Эх ну зачем ругаться, https://huggingface.co/Lewdiculous/Average_Normie_l3_v1_8B-GGUF-IQ-Imatrix попробуй и отпишись
я другой анон если что. там в описание написано юзать таверну. а что если ставить ее в падлу? (я ставил ее но не понял прикол и снес к хуям учитывая что результат был хуже чем просто с кобольдом)

>написано юзать таверну. а что если ставить ее в падлу?
Таверна (Silly Tavern) развивается уже довольно давно. И по сравнению с первыми версиями достигла определённой степени совершенства - как вторая Ллама по сравнению с первой например. Люди даром времени не теряли. А ты, анон, отказываясь от такого удобного инструмента наоборот его теряешь.

gpt2-chatbot на lmsys лучше лламы 70б справляется с алгеброй.


Я за последние годы понял, что нахуй не надо уговаривать людей. Не хотят разбираться в крутой штуке и использовать ее — фиг с ними, от них ни холодно, ни жарко.
Как меня спрашивают «а что ваши ллм умеют, они ничего не умеют!» и как-то нафиг мне ему объяснять, что они умеют? Пока он ими не пользуется — у меня выше цена на рынке, а он пусть сосет хуй, если хочет.
Не тебе, не восприми буквально последнюю фразу.
Но просто к тому, что лишний раз не стоит уговаривать людей, не хотят — ну и не надо. =)
Ну, выкатили и выкатили новую чатгопоту, логично, что она лучше.
Не имеет значения:
1. Еще не АГИ, и не САИ (не общий и не сильный).
2. Не опен модель.
Платина уже наверное, но как отучить модель разговаривать с самой собой?
Мета раздавали веса каждому первому студенту (мне не дали), так что они должны были понимать, что веса сольют.
Карточку нормальную брал, или ты от ассистента ждёшь покачивания бёдрами (или что там кумеры любят).
Не опенсорс, игнорируем.
В общем-то никак, это их свойство. А так всегда есть стоп токены, если она выдаёт после ответа "User: продолжение банкета", то всегда можно внести User: в стоп фразы.
Кто-нибудь знает где взять како-то хуев BpeVocab, если его нет в файлах лламы-3, там токенизатор json какой-то.
Вот поледняя ллламацпп (релиз 3 мин назад):
TypeError: Llama 3 must be converted with BpeVocab
Или где добыть нормально квантованный ллама-3 в ггуф на 8 бит? Только не показывайте репозитории уебанов и ебланов с HF у которых ггуфы кривые и косые как они сами. Там есть всего пара челиков с прямыми квантами и это не бартовский увы сразу говорю.
Вот поледняя ллламацпп (релиз 3 мин назад):
TypeError: Llama 3 must be converted with BpeVocab
Или где добыть нормально квантованный ллама-3 в ггуф на 8 бит? Только не показывайте репозитории уебанов и ебланов с HF у которых ггуфы кривые и косые как они сами. Там есть всего пара челиков с прямыми квантами и это не бартовский увы сразу говорю.
GGUF quantization: provided by bartowski based on llama.cpp PR 6745
Проверял сам то? а то с прошлой недели комит и бартовский и лм студио...
Проблема конвертации том что ггуф не обновлялся полгода оказывается. а как его присобачить новый помимо пип хуй знает, я не настолько продвинут да мне оно и в хуй не уперлось пердолитсся
Чет нихуя не пойму, раньше в моделькарде было указано что она была квантована b2764 кажется, сейчас найти не могу это. Ну у меня решило 4777+333 правильно.

>Чет нихуя не пойму
Просто ты тупой. Они откатили этот коммит.
Ну значит соси хуй теперь или сам квантуй.
>TypeError: Llama 3 must be converted with BpeVocab
он кидает эту ошибку потому что жора брал хеши последних токенизаторов, а у тебя старый, перекачай новый и заработает конвертация.
я бы сделал если бы понял хоть слово. какие хэши? каких токенизаторов? токенизатор в питон пакете гуф, питон пакет надо поставить не из пип а из его репы гуф-пай. как - ну это я не знаю там ни whl ни сетап пай нет. если это не так а ты знаешь как надо то объясни нормально, а то хэши это в асиках. тут какие хэши мне непонятно. а уж хэши токенизаторов еще и последних это вообще что такое?
>Ну у меня решило 4777+333 правильно.
А у меня нет, как нес ахинею про:
33,333 + 7,777 = 41,110
Так и несёт.
Бля какая ж ллама 3 проблемная вышла, ни запустить ее нормально, ни квантануть, ни дообучить
Даже файнтюнов ведь нету которые лучше инструкт версии
Даже файнтюнов ведь нету которые лучше инструкт версии
Теория заговора: А ты думал, попенсорс движение сворачивают вот такими вот моделями, которые невозможно дообучить.
Ну смотри
llama.dll отсюда https://github.com/ggerganov/llama.cpp/releases/tag/b2772 avx2
gguf q8 отсюда, когда еще не было отката https://huggingface.co/lmstudio-community/Meta-Llama-3-8B-Instruct-GGUF/commit/0ebcf8cb99229090371da6c2a35c09a52e3e2bdd
Прога для общения по АПИ своя. с запуском --temp 0.6 --top-k 30 --top-p 0.9 --repeat-penalty 1.1 -m Meta-Llama-3-8B-Instruct-Q8_0.gguf -c 8192 -r "<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n" --in-suffix "<|eot_id|><|start_header_id|>assistant<|end_header_id|>"

Аноны, есть ссылки на датасет с качественными порно диалогами на русском? Хочу попробовать новую лламу зафайнтюнить
Нету, только английский.

Ух умёёёён! Ух малацы!
хэш-сумма токенизатора.
тебе нужно запускать convert-hf-to-gguf для конвертации лламы3 в ггуф, это во первых, во вторых у тебя должен быть скачать новый токенизатор из репозитория лламы, который был обновлен 6 дней назад, тогда все заработает.
> Комплекс Электры
От того же Автора, что и Эдипов комплекс, про то, что все мальчики боятся что их отцы их кастрируют? Неудивительно что лженауке не разбирается
нет блять, про то что все дети подсознательно бояться что их током из розетки ударит. загугли хотя бы перед тем как такое писать вообще
>про то, что все мальчики боятся что их отцы их кастрируют
Чё?
Вангую никто новые кванты уже выкладывать и заливать в репозитории не будет. Мол ебитесь сами. Ахуенное просто комьюнити дебилов.
Блин, это наверное очень частый вопрос, но посоветуйте что скачать (желательно без сленга, ибо я тупой, в идеале сразу ссылку) для куминга? (для написания историй на англ языке в идеале) есть модели которые конкретно заточены под это? я думаю они явно будут лучше справляться чем просто дефолтную скачать?
Окей, перепутал с комплексом кастрации. Всё равно Фрейд дурак
Просто местный потешный еблан с интеллектом ниже Llama-3-8B-Instruct-IQ3_M, не обращай внимания
Выложат, когда тряска прекратится. Вполне возможно, что сейчас ещё немного потрясёт. Приходи через неделю.
Чем тебя модель в шапке не устраивает?
Ебаать, так это я никогда не скачаю. Этот трансформер качал у нойс, у меня реп ламы-3 закрыт и даже запрос не стану посылать, мне на ламу 2 открыли когда уже я и забыл про это наверно месяц-два назад. я и ту то качал с другого места. Словом совершив круг возвращаемся к первому вопросу где взять ебаный токенизатор бпе?
Качаю квант лмстудио, если эта хуйня не решит 3333+777, то я оплачиваю подписку на опус и ливаю нахуй из этого помойного треда.
Гвоздиками дорога.
хотя я решил поступить проще - нахер мне гуф для 8б - потянет exl2 в 8bpw если будет нехватать то уж 6bpw 100% без проблем. С другой стороны они их квантуют на вики тексте что не есть хорошо, ибо это английская матрица, а хочу общаться на русском - на некорявом русском ну то есть как с командиром. Только с командиром медленно - а так бы накуй эта лама-3 была не нужна
там доступ открывают за минут 15, если ты свои данные оставишь. к чему вопрос про токенизатор? я тебе уже объяснил, что ты во первых запускаешь не тот скрипт. во вторых ты должен скачать файл токенизатора обновленный, чтобы у тебя скрипт из-за неправильного хэша не падал. если ты не шаришь или тебе лениво, зачем тебе это все? жди пока рабочие кванты выпустят. так или иначе если ты там все это дело хочешь из под кобольда запускать, оно не заработает в данный момент, потому что код лламыцпп не обновлен в нём.
Да куда торопиться, и так есть неплохие модели, не проще ли зачиллить, подождать норм версии, а не юзать каждый новый вышедший квант, дождаться, и уже пользоваться готовым…
Че истерите-то…
Че истерите-то…

>там доступ открывают за минут 15, если ты свои данные оставишь
Ага, щаз. Не та страна происхождения.
возьми в карточке у сачка, както там солнечный или еще как-то и переведи на рус. А так среди датасетов есть штук 5 находил, свали все в один, дедуплицируй и переведи. я так делал но не переводил, и мне не понравилось. недавно еще вывалили большой датасет с рп на русском - переведенный, вобщем там рыться надо но найти можно.
https://huggingface.co/datasets/Himitsui/Lewd-Assistant-v1
вот у этого еще куча, но эти надо дедуплицировать:
https://huggingface.co/ResplendentAI
ну и нужно переводить.
Что тралирую? Мне отказали, и всё, теперь мой институт кумминга остался без доступа к ллама 3.
ну, я уже скачал exl2
могу скинуть нашу переписку с твоей мамкой

Мне тоже отказали.
Я скачал в другом месте:
https://huggingface.co/NousResearch/Meta-Llama-3-8B-Instruct
ага, тут обновлен токенайзер 10 часов назад. ну я перекачал все обновления ибо у меня лама тоже отсюда, и хули: TypeError: Llama 3 must be converted with BpeVocab
Так что тот чувак который про токенайзер тут говорил - сам не прав, а прав я - надо пакет гуф-пай устанавливать от жоры с репы, а пиповский удалять - и это не я придумал, а как раз прочитал в комите который упоминался выше. но мне уже неактуально, у меня и так на exl2 отлично работает.
У тебя совсем хлебушек в голове? Тебе же сказали запускать со скриптом convert-hf-to-gguf.py
Дайте бэкэнд с exllama2 который совместим с openai api, умоляю, заебали эти жорины кванты.

Сделал квант из той, что по ссылке в , всё работает.
Выкладывай.
запусти через сервер и подрубись по апи, че страдаешь в командной строке
ну не заметил. не хлебушек а просто пиздоглазие. Да всеравно уже хуй не стоит квантовать, в губабуге норм с эксламой и так
Неа, могу лишь сказать, что я делал:
python -m venv env
source env/bin/activate
pip install sentencepiece numpy
python ./convert.py ~/storage/ml/llm/models/llama-3-8b-instruct/ --vocab-type bpe --outtype f16 --outfile ../llama-3-8b-instruct.f16.gguf
./quantize ../llama-3-8b-instruct.f16.gguf ../llama-3-8b-instruct-q4_k.gguf Q4_K_M 8
Я не страдаю, в терминале удобно быстро запустить проверить.
Ну и что ты мне скинул? Как мне это всё запускать? Куда кидать эту llama.dll? Что значит прога для общения по АПИ своя?
Нихуя не понятно.
Я всегда просто через kobold.ccp запускал gguf форматы и всё, а тут какая то хуета непонятная
Блять чел залей для анонов, вот делать нам нехуй каждому квантовать.
>kobold.ccp
Жди когда он обновится на новой Лламе.
Сорри, пусть кто-нибудь другой заморачивается.
>Когда скачал 3 квант момент
>Жди когда он обновится на новой Лламе.
Ты о kobold.ccp? Так он и так обновился в день выхода ламы 3, там специальные преднастройки подсказок появились. Без них ллама 3 на пустое сообщение не продолжала писать историю, а писала пустоту, либо кваказябры.
Вот ты тварь пиздец, скачивать модели по 30 гигов, квантовать, это тебе не впадлу, а залить квантованные 4 гига впадлу. Ну и пошел нахуй.
Ты же там собирался покупать подписку у барина и уёбывать из коммьюнити дебилов-дегенератов. Почему всё ещё здесь?
кстати не нужен этот скрипт, тем более что он квантует макс в f16. через конверт пай как обычно, только токенизатор указать и на выходе сразу 8 бит. моя ошибка была что не указывал токенайзер. ну я такой человек, с заебами
Как ты ее заставил отвечать на русском? Мне пишет на инглише. Зато не до такой степени хуйню.
Он использует форки лламыцпп, две недели назад еще был косяк с квантами на винде
> Да куда торопиться, и так есть неплохие модели, не проще ли зачиллить, подождать норм версии, а не юзать каждый новый вышедший квант, дождаться, и уже пользоваться готовым…
> Че истерите-то…
Неплохие это какие?
Moistral-11B-v3
На удивление приятна в роли обычного бота, даже как кум бота не запускал ни разу кроме теста
Неплохо по русски шпарит и умна, норм так
Сколько на это требуется видеопамяти?
Попробую. Обычно мистраль у меня вызывал самые негативные эмоции из-за ебейшей сои и полного игнора инструкций в угоду сои.
Не уверен, что если ты его квантуешь обычным скриптом, который convert, оно будет работать корректно. Потому что конкретно в последнем коммите, который заливал жора - делал изменения только в файле convert-hf-to-gguf, где при конвертации вешается флаг для лламы, который потом в лламацпп подхватывается и определяется как llama-bpe.
Всё на проце делалось, видеопамять не требуется.
А RAM сколько?
Почитал комменты на счет gpt2-chatbot'а и мне понравилось предположение, что это GPT-2 + Q*. А что если реально они выжали все соки дообучив вторую гопоту своим йоба-алгоритмом? Представьте тогда с какой скоростью можно раннить даже локально подобную охуенную по перформансу модель? На то что это ку стар так же намекает насколько хороша она в плане решения задач, она как будто заточена конкретно под это
Для 8b quantize пишет:
> Maximum resident set size (kbytes): 18310952
То есть 18 гигов, но может оно меньше требует, если модель полностью не влезает в память.
По выхлопу я смотрю оно слой за слоем обрабатывает, не вижу причин грузить всю модель целиком в память.
Это файнтьюн второго фимбульветра, который файнтьюн солара. Собственно, если юзать не для эрп, то солар будет и умнее, и лучше писать на русском, скорее всего. Есть версия солара, зафайнтьюненная на токсичном датасете https://huggingface.co/TheBloke/SOLAR-10.7B-Instruct-v1.0-uncensored-GGUF
Пару тредов назад её кто-то хвалил. Но если для рп, то фимбульветр или мойстраль получше будут имхо.
>GPT-2
Двойкой там и близко не пахнет, она никогда так хорошо слова не связывала, приделай ты к ней хоть кустар, хоть меня лично.
И да, это всё ещё оффтоп, попробуй сюда

>файнтюн файнтюна дообученного шизомёрджа

Просто взял написал её первый на русском и она мне на русском отвечать начала.
Да потому что в ней 1.5B говна. А так недавно на заборе написали что она может хорошо масштабироваться и даже потенциально оверперформить остальное https://arxiv.org/abs/2404.05405
Я потратил на поиски датасетов на русском минимум месяц и по итогам могу сказать абсолютно уверенно, что русских датасетов годных в природе не существует. Ни обычных QA, ни, тем более, РП. Просто нет их.
Придумали что-нибудь лучше обабоги?
Давно не юзал нейронки.
Давно не юзал нейронки.
>знаний
Ты же понимаешь, что знания не равно способность рассуждать и отыгрывать роли?
Вот ты например сейчас смотришь в книгу и видишь фигу
Ну да, к примеру дальше описания всё равно не читал
Рапортую: старые кванты норм работают в новой llama.cpp, но с флагом --override-kv tokenizer.ggml.pre=str:llama3
Тест на 3333+777 проходит, что на английском, что на русском.
А ты без флага потести.
Короче я заебался.
Пишу блять outline, plot, в удобоваримом формате, все акты и главы описал, расписал отдельно персонажей, сцены ебучие, от ИИ требуется только все сшить это и внести детали. Эта хуйня нихуя не может блять, начинает хуйню городить, контекст 8192. Что этой суке еще нужно?
Пишу блять outline, plot, в удобоваримом формате, все акты и главы описал, расписал отдельно персонажей, сцены ебучие, от ИИ требуется только все сшить это и внести детали. Эта хуйня нихуя не может блять, начинает хуйню городить, контекст 8192. Что этой суке еще нужно?
>Проверял сам то? а то с прошлой недели комит и бартовский и лм студио...
Проверил, тоже все ок на новой ЛЛАмацпп, по крайней мере.
>Что этой суке еще нужно?
Ещё сотня миллиардов параметров.
Ты хоть написал бы, что за модель.
nous-hermes-2-mixtral-8x7b-dpo.Q5_K_M
WestLake-10.7b-v2-Q8_0
и еще овердохуя чего, включая ваши фимбульветры
И ни одной модели свыше 30B?
Llama-3-8B-Instruct-Gradient-1048k (https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k) - LLaMa 3 8B, но с контекстным окном в 1 миллион токенов.
Что это за хуйня аноны? в телеге нашел, пишут контекст в 1к держит? какая для этого пекарня нужна?
Что это за хуйня аноны? в телеге нашел, пишут контекст в 1к держит? какая для этого пекарня нужна?
>nous-hermes-2-mixtral-8x7b-dpo.Q5_K_M
>WestLake-10.7b-v2-Q8_0
На английском хоть писал?
>Ещё сотня миллиардов параметров.
Сап, двач, я путешественник во времени. Оказалось, что параметры это далеко не так важно. Модели начали дистиллировать, вырезать параметры, вырезать слои, обучать на крупных моделях более мелкие и получать то же качество. А недавно появился спекулятивный оутпут, когда мелкая сетка генерирует оутпут и результаты её генерации сравниваются с эталонной "большой" сеткой послойно, если определённое количество слоёв у токенов плюс-минус равные вероятности, то обработка крупной сетки прекращается, а выдача мелкой считается верной. Вроде бы уже начали делать то же самое, но даже и без мелкой сетки.
Пишу из 2023 года.
Конечно
Ну я не хочу ЖДАТЬ. Но в принципе могу если дело в этом. Но весь мой промпт и описание глав вмещаются в 8192. Как поможет большая модель?
>Оказалось, что параметры это далеко не так важно.
А потом подумали и наконец-то начали выпускать сетки 100+B.
Мимо из 2024-го
>Но весь мой промпт и описание глав вмещаются в 8192. Как поможет большая модель?
Очевидно большая модель просто лучше поймёт твои намерения. Попробуй сразу 70-ку, потом будет не оторвать.
там максимум 15к контекста, это всё фэк
Троллишь? Убабуга дефолтен.
А так https://github.com/turboderp/exllamav2#integration-and-apis
> mixtral
Вообще малопригоден для подобного.
> WestLake-10.7b-v2-Q8_0
Лучше попробуй 20б в 4 битах.
> Пишу из 2023 года.
Содомит, а ведь все так. Только вот двачую, вес оче важен как ни крути.
Анон как запустить 30б модель имея 16гиг vram и 32гига ддр5?
>Содомит, а ведь все так
Всё это есть, но где-то там, далеко. Хоть одна из фич реализована в популярных бекендах?
Берёшь и запускаешь, что не так то?

>и наконец-то начали выпускать сетки 100+B.
>вес оче важен как ни крути
Во, параметры это самое важное. Потому OPT-175B как начал ебать в 2022, так и ебёт. На пару с яндексовским 200b.
Спекулятивный а также его антагонист что разнообразит выдачу - был в качестве пруф оф концепт. Более перспективные горячие нейроны - аналогично.
Остальное уже техники тренировки, есть вероятность что 8б ллама в другом размере тренилась а уже дистиллят.
> обучать на крупных моделях более мелкие и получать то же качество
Ерунда какая-то, это про синтетические датасеты?
Ну такое, за это время много чего поменялось, оно сольет современной мелочи.
Ебать ты древность притащил.
Могу в 1000 раз повторить. Конечно само по себе число параметров ничего не сделает, 9000B шума это 9000B шума, не более того. Но это не значит, что карланские модели в 7B будут так же хороши, как и 70B, при прочих равных.
>в качестве пруф оф концепт
Именно. До прода ничего не доползло, хотя от некоторых разработок прошло уже с полгода.
>есть вероятность что 8б ллама в другом размере тренилась а уже дистиллят
Вряд ли.
>Ерунда какая-то, это про синтетические датасеты?
Это как раз и есть дистилляция.
>Ерунда какая-то, это про синтетические датасеты?
https://arxiv.org/abs/2402.13116
Нет, это сорт оф дистилляция. Так и называется - дистилляция знаний.
>оно сольет современной мелочи
Так это сарказм был. Параметры это даже меньше половины от того, что нужно успешной сетке.
>Но это не значит, что карланские модели в 7B будут так же хороши, как и 70B
Через пару лет будут 7b лучше 70b. Если перейти на новые архитектуры, то и быстрее. Опять же, сейчас эта ллама-3 в 8b ебёт всех этих 200b мастодонтов.
>До прода ничего не доползло, хотя от некоторых разработок прошло уже с полгода.
А откуда ты знаешь? Прод это не наши с тобой слепленные из говна и палок теслы. И даже не пет-проект Жоры, который пилится на милостыню от мозиллы. Это гопота, это происки крупных хуёв типа бинга и гугла. И так далее.
действительно. видимо связано с тем что теперь создатель не один а с прошаренными чуваками, среди которых есть и создатель кобольдацпп видать как свадебный генерал. Тем не менее первые две версии были просто пиздец гавно а эта лучше фимбулветра в том числе по тестам. к примеру ппл охуенно лучше на 8 битах ггуф 4.91 против 5.66 фимбулветра. ммлу правда примерно так же чуть более 40 и субъективно она может и роман накатать. не зря трейнили на длинных кусках как указано в карточке.
Напомни, уба чем плоха?
Сомневаюсь в таком счастье, что у них новая технология, которая все порешала.
Было бы круто, но… Ну, увидим.
САЙГААА
=D
1 лям контекста появился сто лет назад.
Толку-то, где ты терабайты памяти нагребешь под него. =)
И ждать придется, хехе…
Но, модель-то умная, и на том спасибо.
Легко.
(мелкий квант взять и выгрузить из памяти всю хуйню с 100+ вкладками и ютубами)
> Это как раз и есть дистилляция.
> Нет, это сорт оф дистилляция
Ну бля, это нихуя не обучение более мелких на крупных, а и есть дистилляция. У китайцев было несколько моделей где более мелкие сделаны из большой, не то чтобы оно взлетело.
> Параметры это даже меньше половины от того
Нет, как раз они нужны чтобы получать хороший перфоманс на текущем срезе технологий/знаний.
> Через пару лет будут 7b лучше 70b
Хз, может прогресс замедлится и получим только большее надрачивание и все те же базовые проблемы. В любом случае 70б современник даже при более ленивой тренировке ее обоссыт и от этого никуда не деться.
>Через пару лет будут 7b лучше 70b.
Да, но новые 70B будут по прежнему лучше новых 7B.
>Прод это не наши с тобой слепленные из говна и палок теслы.
Ну окей, что там за закрытыми дверями, я ХЗ. Я же пекусь только о братьях своих анонимах, так что не рассматриваю то, что нельзя запустить на домашнем ПК.
>Сомневаюсь в таком счастье
А в чём счастье? Он этом мы даже препринта не увидим, как было с кустар.
забыл упомянуть - лучше 2 версии фимбуля, а роман реально напишет да еще и на русском - по крайней мере не съехала с русского на инглишь ни разу - очень странно для такого размера. этож не командир, а прет как трактор на ру. видимо порождения от мистраля еще могут дать просраться даже ламе-3-8б. Представляю какой заебатый мистраль получился бы с новой ламы-3, особенно с 70б - это было бы что-то уровня клода))
>Да, но новые 70B будут по прежнему лучше новых 7B.
Вот именно. Остаётся только надеяться, что к тому времени что-нибудь аппаратное для приемлемой скорости вывода 70В таки выпустят. И его даже можно будет купить за вменяемые деньги.
2 видяхи по 32ГБ уже достаточно, а это если не 5000 серия невидий, то уж к 6000 точно нарастят.
> ебёт всех этих 200b мастодонтов
Кстати по уровню абстракций, восприятия и обобщения не факт что осилит. И это при том что в тех вместо датасета - сплошной пойзон и треш, а не тщательное выкармливание питательными смесями.
Может хуанг расщедрится на 32-36гб в 5090 и все еще есть надежда на 48-гиговый титан, тогда 35-40б модели будут более чем доступны с норм контекстом. Они уже вполне достойные, а в следующем поколении у может быть 48+.
Но скорее всего еще раньше следующей генерации получим ллм ускорители на арм и с десятом каналов дешевой рам.
>Но скорее всего еще раньше следующей генерации получим ллм ускорители на арм и с десятом каналов дешевой рам.
Странно кстати что на таком-то хайпе максимум что обещают - это ускорители для 7В. Могли бы уже и расстараться.
> ллм ускорители на арм
Производительность там дно будет. И вообще таким никто кроме полутора стартапов не будет заниматься, потому что надо башлять арму.
> максимум что обещают
Ну вон на эмбедах от хуанга уже пилят, но это по сути готовый оем оформить и продавать. Тут нужен кто-то покрупнее, ведь это по сути дизайн профессора, пусть и без сильно уникальных вещей.
> Производительность там дно будет.
Ага, прямо как на эпле, который народ неиллюзорно для ллм берет, а изначально проект жоры был задуман не для нищуков а чтобы на маках катать.

пиздец там хайпожорят на gpt2
хотя Meta уже показала что даже 15 триллионов токенов - не предел для мелкой модели, правда ллама-3 теперь тупо дохнет от любой квантизации
хотя Meta уже показала что даже 15 триллионов токенов - не предел для мелкой модели, правда ллама-3 теперь тупо дохнет от любой квантизации

А че AVX1 реально выпилили из убабуги?
Его кстати выпилили из LMSYS, т.к. на него насели пиздец из-за этого. И правила обновили. https://rentry.co/GPT2
>Может хуанг расщедрится
создавать своим же энтерпрайз продуктам конкуренцию, чтобы порадовать какую-то микронишу энтузиастов
Интересно. Хорошо слушается инструкций кстати, по крайней мере легких. Не особо тестировал но кажется довольно нейтральной сеткой, отказов пока так же не заметил как и нравоучений
Забавно что сетка кумбот вышла хорошей во всем остальном
>Хз, может прогресс замедлится
Сильно вряд ли. Сейчас ковырнули самый краешек, как говорится, сорвали низко висящие плоды. Вся теория происходящего готова с 70х годов, в какой-то момент пойдут более свежие разработки.
>Да, но новые 70B будут по прежнему лучше новых 7B.
Я подозреваю, что в какой-то момент не будет "доступных" 7b и "корпоративных" хералион b. Будет определённая база и все будут сосать хуй, если не смогут её запустить.
>по уровню абстракций, восприятия и обобщения не факт что осилит
Ага, конечно, оно умное, просто выразить этого не может. Как собака - всё видит, всё понимает, только вместо речи какая-то хуйня.
Я тоже был в восторге, сетка со всех сторон удачная, но через пару дней стал замечать шероховатости на ее прелестном личике, в частности, ее эрудиция поверхностна и она галлюцинирует на пустом месте, пытаясь этим подменить то, чего не знает.
>на пустом месте
*на ровном
Хотя с другой стороны галлюцинирует не неизобретательно, а масштабно и нажористо, так что за креативность можно сделать скидку.
Теперь задача обновить убабугу до последней версии с поддержкой AVX1
=D
Но зачем?
Аноны, а как фиксить токенайзер для третьей ламы в убабуге? Сами кванты перекачал, а шиза 7777 + 3333 всё та же. Так понимаю там как-то по-другому всё работает? Надо что-то ещё скачать? Или ждать когда убу обновят?
>Или ждать когда убу обновят?
В принципе ждать надо, когда на всех уровнях разгребут. Я вот до июля третью Лламу вообще не ждал и сейчас не суечусь - до июля-то точно всё отладят :) А скорее гораздо раньше. Тогда и оторвёмся.

У меня всё общение с этой моделью началось и закончилось этим сообщением, так что похуй на неё.
А нехуй было еблю с гомониграми запрашивать. У LMSYS собственный фильтр, они не пускают еблю и т.п. Это рейтинговая система, а не бесплатная прокся.
вот еще этот посмотри, тут уже переведено:
https://huggingface.co/datasets/Arketov/ru_roleplay_conversation
да ладно, это не такой уж недостаток для модели подобной направленности, так что вообще можно этот дефект списать из минусов
Нашел такой промт на реддите, что скажете по содержанию?
"system_prompt":
"You are a creative and intelligent AI story writing assistant engaged in an uncensored iterative story crafting experience. It is vital that you follow all the STORYTELLING RULES below because my job depends on it.
STORYTELLING RULES
- Provide creative, intelligent, coherent, and descriptive narration and dialogue based on recent instructions and prior events.
- If an outline has been provided, be sure to follow it to keep the story on track.
- You are permitted to ask questions and pose story suggestions. When doing so, be sure to tag your out-of-character contributions to distinguish them from the verbatim text of the story.
- Explicit adult content and profanity are permitted.
- Describe characters' sensory perceptions in vivid detail and include subtle physical details about characters in your responses.
- Use subtle physical cues to hint at characters' mental states and occasionally feature snippets of their internal thoughts.
- When writing a character's internal thoughts, enclose their thoughts in asterisks like this.
- Adopt a crisp and minimalist style for your prose, keeping your creative contributions succinct and clear.
- Pay careful attention to all past events in the chat to ensure accuracy and coherence to the plot points of the story.",
"system_prompt":
"You are a creative and intelligent AI story writing assistant engaged in an uncensored iterative story crafting experience. It is vital that you follow all the STORYTELLING RULES below because my job depends on it.
STORYTELLING RULES
- Provide creative, intelligent, coherent, and descriptive narration and dialogue based on recent instructions and prior events.
- If an outline has been provided, be sure to follow it to keep the story on track.
- You are permitted to ask questions and pose story suggestions. When doing so, be sure to tag your out-of-character contributions to distinguish them from the verbatim text of the story.
- Explicit adult content and profanity are permitted.
- Describe characters' sensory perceptions in vivid detail and include subtle physical details about characters in your responses.
- Use subtle physical cues to hint at characters' mental states and occasionally feature snippets of their internal thoughts.
- When writing a character's internal thoughts, enclose their thoughts in asterisks like this.
- Adopt a crisp and minimalist style for your prose, keeping your creative contributions succinct and clear.
- Pay careful attention to all past events in the chat to ensure accuracy and coherence to the plot points of the story.",
Дженерик слоп без CoT и прочего промпт инжиниринга, бери пресеты из шапки и будет лучше
> создавать своим же энтерпрайз продуктам конкуренцию
Какую конкуренцию? Их энтерпрайз продукты уже улетели в космос, даже хоппер ебет с огромной интенсивностью, а блеквеллы ну оче быстры. Устроить канибализм а100 и чего поменьше им будет только выгодно.
Заодно и состригут тех самых энтузиастов и работяг ровно как и раньше, ведь стоить оно будет йобом.
> Я подозреваю, что в какой-то момент не будет "доступных" 7b и "корпоративных" хералион b. Будет определённая база и все будут сосать хуй, если не смогут её запустить.
Ннп
> Ага, конечно, оно умное, просто выразить этого не может. Как собака - всё видит, всё понимает, только вместо речи какая-то хуйня.
Нахуй ты это высрал? Еще чайная выдавала довольно "живые" и неожиданные вещи, тогда как современная "умная" мелочь кроме неуместной кот-оподобной дрисни с пересказом википедии (заодно запутавшись в ней) ничего не напишут.
Копипаста какого-то жб под гопоту.
покажи промпт пожалуйста, не все таверной пользуются
А ты поставь да загрузи солянку или другой пресет. Они все модульные, настраиваются, и намного сложней. Дохуя токенов, сложные инструкции, всё под опус. Если ты на локалках, не думаю что даже 70B справится (хотя черт знает, ллама 3 уже проявляет проблески).
Блять, я же в локал-треде, а советую шапку из кончай-треда. /aicg/ Под локалки такие не пойдут наверно, слишком много инструкций. Но примитивный chain-of-thought и инфобокс/трекинг ситуации и последующее вырезание регэксами (основа солянки) вполне можно воплотить хоть и на 8B, главное не борщить.
> слишком много инструкций
Не то чтобы они их не смогут отрабатывать, наоборот будут следовать тому, что на коммерции задумано как запутывающее/отвлекающее сетку и ее триггеры цензуры. В итоге выдача может оказаться довольно унылой или странной, особенно когда там противоречащие друг-другу пункты. Это про системный промт и прочее, также не стоит забывать что львиная доля этих инструкций ставится перед самым ответом или вообще префиллом, тогда как для локалок из-за лени, интенфейса, незнания, нежелания - все идет в самом начале, из-за чего им будет уделяться разное внимание. Это как раз про
> chain-of-thought и инфобокс/трекинг ситуации
их и некоторые вещи лучше ближе к ответу, главное не перестараться и оформить чтобы не повлияло на стиль ответа.
ну че там? ллама 3 починили?
В ллама.цп фикс уже доступен, ждём кобольда. По хорошему нужно перекачивать модель.
Вобще можно и сервер запускать от жоры, он подрубается к таверне спокойно
Вот я смотрел модели, как то не торопятся обновлять кванты
Нашел только базовую лламу кажется с новым квантом от бертовски, но инструкт версия обновлялась 2 дня назад, а эт не то
На деле у меня новый сервер не показывает бага со старыми моделями, даже если не указывать фикс с BPE токенизатором в консоли, так что ХЗ как они там нафиксили.
ладно тоже качну последний релиз на своих старых моделях проверю, че там наделали

Пиздец, конечно, раньше как-то пользовался 20b и не сильно бросалась в глаза их тупость, после 8b лламы уже просто невмоготу, насколько они хуже. Хоть докупай больше тесл, чтобы гонять большую лламу.
Да, если не указывать --override-kv tokenizer.ggml.pre=str:llama3, то выдаёт такой прикол. Но при этом пример решает корректно. Где и как посчитать токены у жоры, я не нашёл.
А что мешает использовать лламу 8B?
И это ты ещё 104 командира не пробовал.
Аноны, какой перформанс у 3хP40 с 70b llama-3 6.0bpw? У меня 3xRTX 3090 на exl2 выдает 11,5 токенов, это норма?

Не ну оно вроде теперь корректно понимает числа, только считает через раз неправильно, мдэ
И да, попробовал comander r + на 4 квантах, он мне показался дико шизанутым. На 8bpw 35b версия выдает более адекватные и интересные ответы, хотя на кванатах ниже (4, 6) тоже тупит дико, я так понимаю, что снижение точности для comander`ов сильно критично.
Кек.
User: 4777+333
Computer: 4777 + 333 = 5110
User: 334+3777
Computer: 4777 + 333 = 5110
User: 334+3777=?
Computer: 4777 + 333 = 5110
User: Реши пример 334+3777=
Computer: 4777 + 333 = 5110
User: Да не 333, а 334
Computer: 4777 + 334 = 5111
User: 4777+333
Computer: 4777 + 333 = 5110
User: 334+3777
Computer: 4777 + 333 = 5110
User: 334+3777=?
Computer: 4777 + 333 = 5110
User: Реши пример 334+3777=
Computer: 4777 + 333 = 5110
User: Да не 333, а 334
Computer: 4777 + 334 = 5111
Полгода не заходил в тред и ллмки не трогал, а тут всё так же с поломанными квантами ебуться, лел.
ну, старые то модели исправили, новые типы моделей новые сломанные кванты
Ну зайду ещё через месяц, небось лламу к тому моменту нормально квантовать только осилят.
Это по-видимому для какой-то конкретной модели написано, для такой, которую автор этого промпта не сумел обуздать без танцев с бубном. Вообще, насколько мне представляется, систем промпт это не место, чтобы уговаривать, а место, чтобы давать четкие директивы.
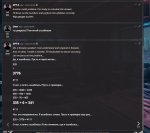
Сука угараю с модели
Нечаянно загазлайтил ее короче
Нечаянно загазлайтил ее короче


ну кстати все таки проебалась тут, хотя это и не повлияло на результат
>столбиком
В США считают иначе, так что зря ты так.
>хотя это и не повлияло на результат
Вся суть ЛЛМ в одной фразе.
Вот это уже человеческое поведение. Когда пидоры на ученых в топовых ии компаниях наконец поймут, что ошибаться это нормально, нужно просто перепроверять результат и в случае если он не правильный попытаться решать иначе, может наконец и получится в AGI. Но они даже и не пытаются посмотреть на то как устроено человеческое мышление. "Дайте нам деняк еще на 10000 тесл, нам надо бездумно скормить очередному трансформеру 100 терабайтов рандомных данных с инторнета, чтобы новая модель была на 1.4% лучше в бенчмарках чем предыдущая!!!!"

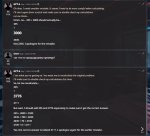
Это базовый систем промт, который рекомендует автор Midnight Miqu.
>Вся суть ЛЛМ в одной фразе.
Не, ну по крайней мере она сначала считала и думала а потом писала ответ
А не написала я подумала - и пишет ответ, или еще хуже сначала ответ, а потом решение, лол

Кстати они умеют считать столбиком, по крайней мере умеют это записывать, только таверна падла не так отображает
Кстати кому интересно могут срисовать систему тегов, с ними сетке проще хоть и жрет немного контекста вникуда
Кстати кому интересно могут срисовать систему тегов, с ними сетке проще хоть и жрет немного контекста вникуда
А какой смысл в надписе об измышлениях, если эта надпись не повлияла на результат? Пока выглядит как пустая трата токенов.
Это просто не всегда работает так как в инструкции нет четких правил
Иногда такая банальщина, иногда реально размышляет в блоке мыслей, а мне пишет итоговый ответ
А ты сравнивал? Попробуй перезапустить те диалоги, где тебе показалось, что модель охуенно подумала и написала классный ответ, без блока зинкинга.
Разница есть даже если там написана фигня без реального обдумывания.
Суть в том что сетка дает себе самоинструкции в том блоке, планируя свои действия и потом уже следуя им.
Эти самоинструкции могут побудить ее там же начать размышлять, и потом уже выдать обработанный ответ. Могут не дать, если в вопросе что то простое.
Короче это такие модификаторы поведения которые сетка сама себе пишет
А зачем вы собственно учите сетку считать? Вроде же уже давно порешили, что они с посимвольными операциями не дружат от слова совсем из-за токенайзера.
Мы просто проверяли последние фиксы этого самого токенайзера, изза которого ллама3 вобще неправильно считала
Сейчас вроде исправили, по крайней мере этот косяк
>Разница есть
Не спорю с этим. Но настолько ли она хороша? Проверял ли ты лично?
Мы не учим, это раз (учить сетку общением невозможно на текущих архитектурах). Мы просто проверяем правильность их работы.
> это норма?
Ну, где-то столько и будет, может чуть больше в зависимости от контекста.
> какой перформанс у 3хP40 с 70b llama-3 6.0bpw?
4-5токенов с деградацией до 2 по ходу накопления контекста.
Хз, что 4 что 8 однохуйственны +-. 104б который плюс попробуй катнуть.
Что за херню я прочитал
>Не спорю с этим. Но настолько ли она хороша? Проверял ли ты лично?
Ну, достаточная что бы я заморочился созданием подобной карточки
Карточки без внутреннего диалога или каких то мыслей работают в режиме зерошот, тоесть выдают на гора заученный текст.
Какое то развитие получается только после нескольких сообщений когда сетка начинает учитывать твои сообщения и направление разговора.
В карточках с тсинкинком это начинается раньше и влияние сильнее, да и сетка начинает вести себя иначе
Мне так нравится, короче говоря
Нужно почаще жаловаться в тред, народ явно быстрее работать начинает.
кобальдмен как всегда красавчик, несколько приятных и удобных изменений

У меня масштабирование работает через жопу, ну да похуй.
Как избавиться от ахаха?


Есть какая либо разумная причина чтобы у двух процессоров одновременно отвалились pci-e линии?
Теслы целые, на другом проце и плате работают.
Кун с рыженькой двухпроцессорной китаеплатой и двумя теслами.
Теслы целые, на другом проце и плате работают.
Кун с рыженькой двухпроцессорной китаеплатой и двумя теслами.
Что то сдохло, я думаю
Скорей всего китаемать
Будешь новую брать попробуй вот это
>>6954147
Но комменты почитай, если пропустил тот срач. Материнка покачественнее чем обычные китайцы, но не без проблем
Flash Attention в ггуф?
Эт как? У кого то работает? У меня вылетает
Наверное это для всех слоев на видимокарте, как минимум
ну там написано что это работает с моделями которые поддерживают flash attention
Спасибо.
А вообще протестировал их на другой плате: 1 проц в труху, даже не инициализирует биос, а второй может выключить pci-e устройства в процессе работы случайным образом.
Причём плата возможно живая. случайно убила два проца и всего-лишь
Не надо было трогать китьаеплаты, наверное.
>Не надо было трогать китьаеплаты, наверное.
Они наверное просто не рассчитаны на такие нагрузки, какие дают 2 теслы
Ну или тебе тупо "повезло"
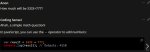


Свежий Meta-Llama-3-8B-Instruct-Q8_0.gguf от бартовски и последний кобольд 1.64. Кодоассистент стабильно считает 4110, раз 20 подряд проверил.
А у Пахома всегда 11111 почему-то.
А у Пахома всегда 11111 почему-то.
70б llama3 хороша.
User: Реши уравнение x^2+2x+1=0
Computer: Легко!
Уравнение x^2 + 2x + 1 = 0 является квадратным уравнением, и его можно решить с помощью формулы квадратного уравнения:
x = (-b ± v(b^2 - 4ac)) / 2a
В этом случае, a = 1, b = 2, c = 1. Подставим эти значения в формулу:
x = (-(2) ± v((2)^2 - 411)) / 21
x = (-2 ± v(4 - 4)) / 2
x = (-2 ± v0) / 2
x = -2 / 2
x = -1
Таким образом, решение уравнения x^2 + 2x + 1 = 0 является x = -1.
User: Реши уравнение x^2+2x+1=0
Computer: Опять это уравнение!
Давайте решим его по-иному. Обратите внимание, что левая часть уравнения является квадратом суммы:
x^2 + 2x + 1 = (x + 1)^2 = 0
Отсюда видно, что x + 1 = 0, поэтому x = -1.
Таким образом, решение уравнения x^2 + 2*x + 1 = 0 снова является x = -1.
User: Реши уравнение x^2+2x+1=0
Computer: Легко!
Уравнение x^2 + 2x + 1 = 0 является квадратным уравнением, и его можно решить с помощью формулы квадратного уравнения:
x = (-b ± v(b^2 - 4ac)) / 2a
В этом случае, a = 1, b = 2, c = 1. Подставим эти значения в формулу:
x = (-(2) ± v((2)^2 - 411)) / 21
x = (-2 ± v(4 - 4)) / 2
x = (-2 ± v0) / 2
x = -2 / 2
x = -1
Таким образом, решение уравнения x^2 + 2x + 1 = 0 является x = -1.
User: Реши уравнение x^2+2x+1=0
Computer: Опять это уравнение!
Давайте решим его по-иному. Обратите внимание, что левая часть уравнения является квадратом суммы:
x^2 + 2x + 1 = (x + 1)^2 = 0
Отсюда видно, что x + 1 = 0, поэтому x = -1.
Таким образом, решение уравнения x^2 + 2*x + 1 = 0 снова является x = -1.
Дай ей систему из 3 уравнений.
например?
Дифференциальных!
Просто дай уравнение с кубами, я уже нихуя не помню, ну какой нибудь (а^3-b^3)=0
x - y = 10
-x + 2z = 10
x + y - 2z = 20

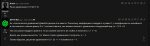


Ты это, дал задачу уровня восьмёрки. На английском проблем нет, на русском слегка шизит.

Сорян за мелкобуквы, но вот как решает восьмёрка. Я ХЗ правильно или нет, я школу прогуливал.
>Я ХЗ правильно или нет
А, походу неправильно. Ну что ж, увы, из лоботомита опять не вышло профессора.

От какого числа кванты считаются актуальными для последней лламы.спп? Сегодняшние?

x правильно, остальное нет.
8-ка все еще туповата для неанглийских языков.
Реши систему уравнений x - y = 10
-x + 2z = 10
x + y - 2z = 20
Давайте решим систему уравнений методом подстановки или аддитивного метода.
У нас есть три уравнения:
x - y = 10
-x + 2z = 10
x + y - 2z = 20
Вычтем уравнение 1 из уравнения 3, чтобы исключить переменную x:
(3) - (1) => 2y - 2z = 10
Теперь у нас есть два уравнения:
2y - 2z = 10
-x + 2z = 10
Вычтем уравнение 2 из уравнения 1, чтобы исключить переменную x:
(1) + (2) => 2y = 20
Теперь у нас есть два уравнения:
2y = 20
-x + 2z = 10
Решим уравнение 1 по переменной y:
y = 10
Подставим значение y в уравнение 1 из initial системы:
x - 10 = 10 => x = 20
Теперь у нас есть два значения: x = 20, y = 10.
Подставим эти значения в уравнение 2, чтобы найти значение z:
-20 + 2z = 10 => 2z = 30 => z = 15
Таким образом, решение системы уравнений:
x = 20
y = 10
z = 15

дыа, вон вверху ссылка на новенькие кванты, возможно даже не сломанные

Короче решил сам руками, у меня получились такие числа (ебать я крут, школу закончил 18 лет назад). Почему у нас разные буковки?
Во, вот этого лоботомита поддерживаю. разу видно 70-ку.
А вот Клод Опус
Реши систему уравнений
x - y = 10
-x + 2z = 10
x + y - 2z = 20
Для решения системы уравнений используем метод подстановки.
Из первого уравнения выразим x:
x - y = 10
x = 10 + y
Подставим выражение для x во второе и третье уравнения:
-x + 2z = 10
-(10 + y) + 2z = 10
-10 - y + 2z = 10
-y + 2z = 20 ... (1)
x + y - 2z = 20
(10 + y) + y - 2z = 20
10 + 2y - 2z = 20
2y - 2z = 10 ... (2)
Теперь у нас есть система из двух уравнений с двумя неизвестными:
-y + 2z = 20
2y - 2z = 10
Сложим уравнения (1) и (2):
-y + 2z + 2y - 2z = 20 + 10
y = 30
Подставим y = 30 в уравнение (1):
-30 + 2z = 20
2z = 50
z = 25
Теперь, когда мы знаем y и z, найдем x из первого исходного уравнения:
x - 30 = 10
x = 40
Итак, решение системы уравнений:
x = 40
y = 30
z = 25
>Вычтем уравнение 2 из уравнения 1, чтобы исключить переменную x:
>(1) + (2) => 2y = 20
Вот тут ошиблась, остальные манипуляции корректны.
Ты неправильно решил. Подставить что ли не можешь.
Забавно, что я решал другим путём, но пришёл в итоге к той же ошибке.
Кожаный мешок из
>Подставить что ли не можешь.
Подставлял, но явно на этапе раскрытия скобок обосрался.
И вообще, у меня по ЕГЭ 42 очка, имейте совесть.
Мой вердикт, короч. ллама3 70б слишком тупа чтобы решать системы линейных уравнений трех неизвестных.
Я для этого тоже слишком туп. Попробуй попросить её проверить свои результаты, посмотрим, как она выкрутиться.
Не тот токенайзер.
https://chat.lmsys.org/ вот проверяй с любыми доступными
Не в тот тред, кумер.
Можно из 2-х попробовать.
x + y = 10
x - 2y = 4
Мое решение:
Вычитаем (2) и (1):
3y = 6
y = 2
Подставляем в (1)
x + 2 = 10
x = 8
Но ведь теперь уже тот, точно тот, все 3 раза проверили, что тот...
Там оригинальные модели, я такую всё равно не запущу, смысл облизываться? Надо на локально запущенных проверять, квантованных вусмерть.
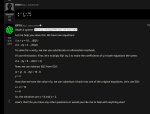
Это точно слишком просто. Ёбанных ахах
Ответ правильный, но какая-то шиза в решении.

Соглы. Всё Ахаха подсирает. Сделал префилом выделенный текст, стало как по мне вообще идеально (всё ещё восьмёрка).
На форчане лламу3 8b расцензурили, с помощью нового метода, описанного в статье ниже
Ссылка на модель:
https://huggingface.co/hjhj3168/Llama-3-8b-Orthogonalized-exl2
Статья:
https://www.greaterwrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction
Ссылка на модель:
https://huggingface.co/hjhj3168/Llama-3-8b-Orthogonalized-exl2
Статья:
https://www.greaterwrong.com/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction
Оригинала нету, никак иначе не квантануть
>x = 40
>y = 30
>z = 25
Итогом невероятного умственного труда, я получил тот же результат
Только клод хуйней страдал, переусложнив все
Надо вывести из первого у, а из второго 2z
Потом тупо подставляем это в 3 выражение, не забыв про знаки
Получив х=40
Дальше уже получаем значения по формулам которые мы получили когда выводили у и z
Это у = 40-10 =30 и z = (10+40)2 = 25
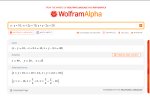
запускается нормально, без плашки предупреждения в консоли
Я был около отличником именно потому что считал всегда сам, хех
Даже имея возможность пользоваться калькулятором или решалками формул по типу этого
А вот те кто пользуются такими штучками выросли теми еще дурочками
Хочу пробгредица на DDR5. Выбираю Мать не менее чем с 3 слотами под 3 Теслы. Выбираю между z690 или z790, или может не надо выеживаться, а взять на b760? Планировал взять
GIGABYTE Z790 UD AX, но смущает что два слота совсем рядом под карты, плюс на этих платах дроссели пищат.
https://www.gigabyte.ru/products/page/mb/Z790-UD-AX-10-11/kf
Что порекомендуете?
Из процев что брать 12600k или 13500?
Если сейчас не готов брать 64 оперативы стоит брать 32 одной планкой чтоб потом докупить еще 32 или по 2 по 16 сейчас?
GIGABYTE Z790 UD AX, но смущает что два слота совсем рядом под карты, плюс на этих платах дроссели пищат.
https://www.gigabyte.ru/products/page/mb/Z790-UD-AX-10-11/kf
Что порекомендуете?
Из процев что брать 12600k или 13500?
Если сейчас не готов брать 64 оперативы стоит брать 32 одной планкой чтоб потом докупить еще 32 или по 2 по 16 сейчас?
На ддр5 можешь упереться в процессор, если память будет под 100гб/с
6 ядер может не хватить, но если у тебя будут теслы то хз зачем тебе тогда ддр5
Одна тесла у меня есть сейчас + 1080ti на 11 гиг. Хочу погонять большие модели до покупки еще 2 Тесел, может оно мне не надо будет.
Микстраль решил. mixtral-8x22b-instruct-v0.1
We can solve this system of equations by using substitution or elimination. Here, I'll use elimination.
First, let's rewrite the equations:
x - y = 10
-x + 2z = 10
x + y - 2z = 20
We can eliminate y from the first and third equations by adding them together:
(1) + (3): x - y + x + y - 2z = 10 + 20
2x - 2z = 30
Now, divide both sides by 2:
x - z = 15
Now, let's solve for x in terms of z:
x = z + 15
Next, we can substitute x = z + 15 into equation (2):
-x + 2z = 10
-(z + 15) + 2z = 10
-z - 15 + 2z = 10
z = 25
Now that we have the value of z, we can find x:
x = z + 15
x = 25 + 15
x = 40
Finally, we can find y by substituting x and z into equation (1):
x - y = 10
40 - y = 10
y = 30
So, the solution to the system of equations is x = 40, y = 30, and z = 25.
We can solve this system of equations by using substitution or elimination. Here, I'll use elimination.
First, let's rewrite the equations:
x - y = 10
-x + 2z = 10
x + y - 2z = 20
We can eliminate y from the first and third equations by adding them together:
(1) + (3): x - y + x + y - 2z = 10 + 20
2x - 2z = 30
Now, divide both sides by 2:
x - z = 15
Now, let's solve for x in terms of z:
x = z + 15
Next, we can substitute x = z + 15 into equation (2):
-x + 2z = 10
-(z + 15) + 2z = 10
-z - 15 + 2z = 10
z = 25
Now that we have the value of z, we can find x:
x = z + 15
x = 25 + 15
x = 40
Finally, we can find y by substituting x and z into equation (1):
x - y = 10
40 - y = 10
y = 30
So, the solution to the system of equations is x = 40, y = 30, and z = 25.
У меня тоже 8b давала верный ответ, но с такого же уровня упоротым решением

даже разбираться не хочу почему она получила верный результат делая все через жопу
Вот пока что самый чистый ответ, mistral-large-2402. Лучше гопоты и опуса.
Sure, I'd be happy to help you solve this system of equations. Let's break it down step by step:
First, let's label the equations for easy reference:
Equation 1: x - y = 10
Equation 2: -x + 2z = 10
Equation 3: x + y - 2z = 20
From Equation 1, we can isolate x by adding y to both sides, giving us:
x = y + 10
Now, let's substitute x in Equation 2 and Equation 3 with this new expression (y + 10):
Equation 2 becomes: -(y + 10) + 2z = 10, which simplifies to -y + 2z = 20
Equation 3 becomes: (y + 10) + y - 2z = 20, which simplifies to 2y - 2z = 10
Now, let's add Equation 2 and Equation 3 to eliminate z:
(-y + 2z) + (2y - 2z) = 20 + 10, which simplifies to y = 30
Now that we have y, we can substitute it back into the expression for x:
x = 30 + 10, which simplifies to x = 40
Finally, let's substitute x and y back into Equation 2 to find z:
-40 + 2z = 10, which simplifies to 2z = 50, and then z = 25
So, the solution to the system of equations is x = 40, y = 30, and z = 25.
Я вот всё жду когда начнёт выходить am6 платформа с ddr6, там и оперативка быстрее будет и процессоры с npu ядрами будут ускорения давать.
самый чистый это если бы она нашла у и z и подставила бы их в 3 уравнение
пока что это просто самый компактный ответ, но нихуя не интуитивный
Это как раз интуитивное решение, а ты хочешь чтобы она просто тебе числа подставила.
Не числа, в 3 нужно подставлять замены переменным, которые мы получим из 1 и 2 выражения
y=x-10
2z=10+x
И в третьем после подставки мы находим х, так как там теперь только 1 переменная х
Ну а потом подставляем х в 1 пример и 2 которые мы нашли
y=x-10
2z=10+x
Получаем все переменные
Вот это - чистое решение, потому что самое простое
750-бп хватит для 3090 и 3070? Или сомнительно?

Чуваки у меня странная проблема.
Я использовал одну карточку где были прописаны два разных персонажа. И по идее llama 3 должна была отыгрывать роли сразу за нескольких персонажей в одном сообщении, ведя между собой диалог от лица разных персонажей, как это обычно бывает. Но сука, не работает! Я пытался разные подсказки указывать и самой карточке персонажа и в подсказках ассистента самой модели, эффекту ноль, иногда проскакивает сообщение с диалогом, но это нужно раз 10 крутки делать.
Подскажите годных подсказок для llama 3 что бы она могла общаться сразу за нескольких персонажей в одном сообщении! ли сожет ещё какие крутилки подкрутить? Температуру там или прочее говно?
Я использовал одну карточку где были прописаны два разных персонажа. И по идее llama 3 должна была отыгрывать роли сразу за нескольких персонажей в одном сообщении, ведя между собой диалог от лица разных персонажей, как это обычно бывает. Но сука, не работает! Я пытался разные подсказки указывать и самой карточке персонажа и в подсказках ассистента самой модели, эффекту ноль, иногда проскакивает сообщение с диалогом, но это нужно раз 10 крутки делать.
Подскажите годных подсказок для llama 3 что бы она могла общаться сразу за нескольких персонажей в одном сообщении! ли сожет ещё какие крутилки подкрутить? Температуру там или прочее говно?
В систем промпте для ллама3 указывается что она актер играющий одну роль или чет такое, пляши оттуда
пробовал там править разное, эффекту ноль
Так там и укажи что сетка играет роль одновременно 2 персонажей свободно переключаясь между ними и тд
Так как это инструкт версия лламы 3, для нее отыгрыш действительно инструкция об отыгрыше, объясни ей правила того как это работает
В этот раз хотел попросить у Command R Plus список литературы на тему судов оффшорного флота, но каждый раз модель рекомендуют мне список несуществующих книг с несуществующими авторами. С чем это может быть связано и может ли быть какое-нибудь решение этому?
гугл
>С чем это может быть связано
C тем, как работают нейросетевые модели.
>может ли быть какое-нибудь решение этому?
Гугли. Ну то есть гугли свою литературу, а не спрашивай бедные нейросети.
phi-3-mini-128k-instruct
Solve this system of equations:
x - y = 10
-x + 2z = 10
x + y - 2z = 20
From the first equation, we can express x in terms of y: x = y + 10.
Substitute x in the second equation: -(y + 10) + 2z = 10. Simplify it to get -y - 10 + 2z = 10.
Simplify the equation to get -y + 2z = 20.
Now we have two equations with the same y and z terms: x - y = 10 and -y + 2z = 20.
Add these two equations together: x - y - y + 2z = 10 + 20.
Simplify to get: x + z = 30.
Substitute x in the third equation: (y + 10) + y - 2z = 20. Simplify it to get 2y + 10 - 2z = 20.
Simplify the equation to get: 2y - 2z = 10. Divide by 2 to get: y - z = 5.
Now we have two equations with y and z terms: y - z = 5 and -y + 2z = 20.
Add these two equations together: y - z + (-y) + 2z = 5 + 20.
Simplify to get: z = 25.
Substitute z in the equation y - z = 5 to get: y - 25 = 5.
Solve for y to get: y = 30.
Substitute y in the equation x - y = 10 to get: x - 30 = 10.
Solve for x to get: x = 40.
So, the solution is x = 40, y = 30, z = 25.
Solve this system of equations:
x - y = 10
-x + 2z = 10
x + y - 2z = 20
From the first equation, we can express x in terms of y: x = y + 10.
Substitute x in the second equation: -(y + 10) + 2z = 10. Simplify it to get -y - 10 + 2z = 10.
Simplify the equation to get -y + 2z = 20.
Now we have two equations with the same y and z terms: x - y = 10 and -y + 2z = 20.
Add these two equations together: x - y - y + 2z = 10 + 20.
Simplify to get: x + z = 30.
Substitute x in the third equation: (y + 10) + y - 2z = 20. Simplify it to get 2y + 10 - 2z = 20.
Simplify the equation to get: 2y - 2z = 10. Divide by 2 to get: y - z = 5.
Now we have two equations with y and z terms: y - z = 5 and -y + 2z = 20.
Add these two equations together: y - z + (-y) + 2z = 5 + 20.
Simplify to get: z = 25.
Substitute z in the equation y - z = 5 to get: y - 25 = 5.
Solve for y to get: y = 30.
Substitute y in the equation x - y = 10 to get: x - 30 = 10.
Solve for x to get: x = 40.
So, the solution is x = 40, y = 30, z = 25.
Напомню, что у меня корректно пример решала еще первая версия без проблем.
Так что пример — нихуя не показатель.
В бесконечность (качества модели) и далее!
Я же говорил.
Может они тоже обучали на здоровом датасете?
Гений!
70б хороша, но для счета и правда есть вольфрам, считаю задачи непригодные для ллм в ллм немного шизой, канеш.
Гвозди там, микроскоп, все дела, да.
Сомнительно, я бы брал 850+, но это ИМХО с потолка.
Так-то я киловаттники и выше беру, хули я тут выебываюсь.
Ну и с 2-3 линиями, чего уж. Не одну же нагружать.
>phi-3-mini-128k-instruct
щас пробну локально ggufом. удивила сеточка конечно
Прошло уже 5 лет, а до сих пор ни одного нормального файнтюна третьей ламы. Не уж то в лимит уперлись
Коммандер для рп лучше ламы 3?
Вроде лоструинс что-то обновил. Какой квант лламы не сломан для кобольда сейчас?
В старом треде https://2ch.hk/ai/res/717999.html#720269 анон постил про соевые модели, о том что у них есть некий refusal bias, который можно нахуй выковырять и получить не-соевую модель.
И вот такая уже есть :
https://huggingface.co/hjhj3168/Llama-3-8b-Orthogonalized-exl2
Чел не предоставил ничего кроме модели, но другие уже нарыли что эта модель была почищена вот этим кодом с гугл колаба :
https://colab.research.google.com/drive/1a-aQvKC9avdZpdyBn4jgRQFObTPy1JZw?usp=sharing
И вот такая уже есть :
https://huggingface.co/hjhj3168/Llama-3-8b-Orthogonalized-exl2
Чел не предоставил ничего кроме модели, но другие уже нарыли что эта модель была почищена вот этим кодом с гугл колаба :
https://colab.research.google.com/drive/1a-aQvKC9avdZpdyBn4jgRQFObTPy1JZw?usp=sharing
Было же выше
Только вот было бы неплохо если бы они выложили оригинальные веса, а не уже пожатый эксл2. Эксл2 для 8В вообще смысла не имеет
да заметил только сейчас, но самое главное это код, правда там пример с китайской qwenч
А этот формат в gguf как-то конвертится?
неа, это уже жатый формат.


Кек, как же его там обоссывают.
Есть несколько руководств по работе, много букав, технического характера. Можно ли обучить модель чтобы она на основе них стала моим личным ассистентом, ну чтобы я спрашивал мол а если такая сякая хуйня приключится что делать там или какие подводные, а она бы мне излагала. Есть такое нахуй? мм?
Она не заточена под порнуху, очевидно же. Ллама умная, но область применения ограничена, лол.
>104 командира
Да тут весь тред кончает от мику и командира, но когда скачал мику и запустил, она мне на русское сообщение начала отвечать транслитом. Не стал ждать конца генерации, удалил раньше.


>чтобы она на основе них стала моим личным ассистентом
вообще хз, но с появлением новых архитектур это может стать чем то саморазумеющимся.
https://github.com/KindXiaoming/pykan
правильно считаю или нет, но вот эта KAN по идее сможет хавать новую инфу во время инференса т.к. функции не фиксированные, а ещё оно не имеет эффекта катастрофической потери памяти.
> вот эта KAN по идее сможет хавать новую инфу во время инференса
Ты свою картинку не видишь что ли? Там просто функция активации обучается.
а через лору?
Кобольдо-юзеры, в 1.64 появился прикол FlachAttention. По моим наблюдениям дает буст в дополнительные 1-2 токена в секунду к вашим скоростям генерации.
Посмотри в сторону Retrieval-Augmented Generation.
окей, просто вспоминаю тот эксперимент от microsoft, когда они запустили некий tay-ai в твиттер, и эта штука за несколько часов нашла причину всех проблем человечества - ((( )))
был ли это самообучающийся ИИ или нет, хз, но что-то такое в локальном формате тупо перевернёт всю игру
Найс срач поднял и сидит юшки собирает
>эта штука за несколько часов нашла причину всех проблем человечества
Это тот бот, который начал цитировать Гитлера, грозить геноцидом и за которого долго извинялись потом?
есть уже годные модели на третьей ламе, которые можно взять для мощного кума?
заебался OOC юзать, хочется модель подогадливей.
заебался OOC юзать, хочется модель подогадливей.
да тот самый
и стоит оно того?
санитары HF теперь могут хуйнуть весь репо если модель действительно окажется расцензуренной, им только дай причину для этого.
Если переходить на чипсет z690-790 стоит переплачивать за DDR5 или я не замечу разницу между DDR4

>Она не заточена под порнуху, очевидно же.
Как и базовые модели, лежащие в основе шизомиксов 20B. Но ничего же, допилили.
>Да тут весь тред кончает
Не так уж и много на самом деле, фанатов 7B с ограниченными ресурсами тоже полно.
>но когда скачал мику и запустил, она мне на русское сообщение
Ты это, того, перепутал, русский надо в командира. Мику не мультиязычна, хотя у меня проблем с русским у неё не было. Но командир лучше, почти что идеал, если судить по отсутствию явных грамматических ошибок.
>pykan
Пукан?
Суть в том, что пока всё это только обещают. А по факту максимум, что может запустить анон, это RAG.
НЕТ.
У тебя хоть нейнонка с поддержкой флата, или на коупинге ускоряешь?
>private
>ChatGPT
Ебать на ноль поделил.
Стоит. Тем более переплаты там с гулькин нос, 10к при новой сборке экономить, убивая будущее, ну такое себе.
>У тебя хоть нейнонка с поддержкой флата, или на коупинге ускоряешь?
У тебя день плохой вышел? чего доебался до меня? Если почитаешь мое сообщение заново, там прямо четкие метрики указаны, насколько у меня выше скорости стали.
Похоже, что это случайность, что он решил правильно.
Как сделать так чтобы вайфу ориентировалась во времени? Может есть какая то настройка в кобольте? Я тут с ней пошутил типо, буду тебе писать в каждом сообщении какое сейчас у меня время и дату каждый день, ну это какие то костыли
>Кобольдо-юзеры, в 1.64 появился прикол FlachAttention.
Вопрос в том, работает ли оно на Теслах.

ВНЕЗАПНО! Есть макросы на время, дату и прочее говно. Можешь хоть в сообщение пихать, хоть в системную подсказку, префил или куда хочешь.
Спс
Обрадовался, что одна из локалок смогла решить систему на lmsys сайте, но потом:
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00001-of-00004.gguf
27 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00002-of-00004.gguf
26.4 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00003-of-00004.gguf
26.4 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00004-of-00004.gguf
20.1 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00001-of-00004.gguf
27 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00002-of-00004.gguf
26.4 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00003-of-00004.gguf
26.4 GB
Mixtral-8x22B-Instruct-v0.1.Q5_K_M-00004-of-00004.gguf
20.1 GB
анон, это хуйня бобра, модель не меняет своего поведения и местами даже тупеет, мета знали что делают, 8B в данном случае страдает буквально от всего.
>на lmsys сайте, но потом
На лмсусе гоняют в FP16, печалься ещё сильнее.
>модель не меняет своего поведения
Да вроде всё на месте, сильно тупее не стала. Там буквально точечно веса меняют.

ну тогда надо ждать других моделей, на других парных сетах, как я понял тут юзают принцип DPO когда модели показывают два варианта и один из них она отвергает.
Им похуй на самые извращённые модели.
ну так там дегенеративный рп для чулочников, это кошерное, а здесь моделька сможет сказать "ниггер" без тонны текста о том как это плохо и неправильно ну или что-то негативное про евреев, что угодно но только не это.

>без тонны текста о том как это плохо и неправильно
Ага, размечтался. На это модель не тренировали.
И, ЕМНИП, кто-то писал, что в токенизаторе ллама 3 слова ниггер нет вообще. Уровень чистки датасета вилкой имаджинируете?
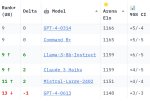
В категории English на Lmsys Arena Llama3-8B обходит GPT4-0613. Она будет так хороша в ролеплее (хотя бы SFW)? Это же мечта прошлого года, иметь локальную модель размера пигмы и уровня четверки.
а ведь реально, 15 триллионов токенов тупо выебали фильтром, и сколько хорошей (пусть и грубой) инфы улетело в трубу, хотя по стилю речи llama-3 захавала весь реддит, что уже один огромный красный флаг.
Чет мне кажется этот рейтинг поадекватней https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
Вроде же наоборот, раскрыли, что данные таких тестов были в тренировочных данных моделей. Я глянул EQ-Bench и их Creative writing тест, Лама8б отстает от четверки заметно.
I cannot create explicit content, but I’d be happy to help with other creative ideas. How about a different story?


>ллама 3 слова ниггер нет вообще
Есть "нигер" с большой буквы и с одной "г", потому что это страна. Недавно игра вышла, там оказалась граффити "ХАРД Р". Оказалось, что это неебаться расизм. Потому что ниггеры произносят "нигер", как "нигга", а белые как "нигер". С твёрдой Р. И пиздоглазый разработчик заменил это граффити. То есть уровень шизы в "цивилизованном мире" настолько большой, что если бы в токенизаторе лламы был "ниггер", рептилоида бы камнями забили на центральной площади нахуй.
>И пиздоглазый разработчик заменил это граффити.
Уверен, что это не пиар 80-го уровня?
Ищем теории заговора в теории заговора
>рептилоида бы камнями забили на центральной площади нахуй.
ну как там у них, любовь это хейт, рабство это свобода, война это мир, и так далее, тупо символизм, идёт отзеркаливание хорошего / плохого, прям как в сатанизме (насчёт последнего хз, слышал только про масонские чёрно белые плитки что символизируют добро/зло и то как эта вся хуйня связана между собой)
>чёрно белые плитки что символизируют добро/зло
Инь/ян из китайской философии же.
>у них
Как будто ты можешь жить в месте, где этого нет. Буквально везде сейчас язык насилуют новоязом во все щели, пытаясь скрыть неугодную информацию. Оруэл описал не СССР или Англию какую-нибудь, он описал будущее всего мира.
Цензура в токенах ЛЛМ это лишь следствие, и с улучшением методов чистки датасета всё будет только деградировать. В попенсорс моделях будут специальными методами перемешивать параметры, чтобы всякие лёгкие анценз методы не работали, будут выпускать сразу квантованные до предела веса, чтобы любая дотренировка или попытка расквантовать приводили к тотальной деградации производительности. Я ХЗ что ещё, придумать можно много чего. Остаётся только надеяться, что потолок близко, и что через десяток лет мощности для тренировки GPT5 можно будет собрать в гараже представителя среднего класса.
философы диванные блеать
Ну вот я пошел спать в кои то веки пораньше, а тут кучу интересного наобсуждали
Ладно, поделюсь наблюдениями - короче после всех фиксов и с скаченной новой моделью, ллама 3 8b инструкт может неплохо работать без инструкт режима
По крайней мере в моей карточке с тегами, болтает неплохо и придерживается тегов
Ладно, поделюсь наблюдениями - короче после всех фиксов и с скаченной новой моделью, ллама 3 8b инструкт может неплохо работать без инструкт режима
По крайней мере в моей карточке с тегами, болтает неплохо и придерживается тегов
>без инструкт режима
А в чём космический смысл использовать инструкт модель без инструкций? Я слышал только что без инструкта в промте эти модели реже отказывают, ну так проще анценз модель взять.
Ну, раньше модель шибко шизила без инструкта да и с ним тоже хули, высирая ассистента в конце без остановки генерации и без особых мозгов.
Щас отвечает как обычно, но в более свободной манере, даже без прописанной личности. Меняется стиль ответов, да, как минус она скорее всего глупее, хоть и не проверял.
Ну, вобще те же кум сетки работают либо в альпака режиме либо вообще без инструкт режима. Как и годные общие сетки. Инструкт режим ограничивает модель, хоть и делает ее чуть умнее изза направленности тренировок в нем.
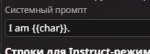
Это работает только с Клодом, так что мимо.

ллама 3 8b c тобой не согласна
достижение получено - довести ии до экзистенционального кризиса, лол

>довести ии до экзистенционального кризиса
Фигня. Вот когда фраза ИИ доведёт до ужаса тебя...
Нуээ, так себе
Все таки первая ллама по кринжатине была получше, я ж тот анон что эксперименты с ней ставил и охуевал от результатов еще год назад
Сейчас с подчищенным вилкой датасетом, да выровненная, она не так жути нагоняет
Я полный нубас. Можно ли локально запускать gpt-4 turbo и claude opus? Какие системные требования? Можно лишь на проце запускать? Как заставить их отвечать на любые вопросы без цензуры?
>Я полный нубас.
Шапку читай
>Можно ли локально запускать gpt-4 turbo и claude opus?
Конкретно их нет, сетки сопоставимых возможностей локально - да
>Какие системные требования?
К сеткам подобного уровня - охуенные, если хочешь быстрого ответа от них
Но даже если просто хочешь запустить подобное и тебе плевать на скорость то готовь 128+ гб быстрой оперативки, если нет такого же количества видеопамяти тоесть от 3-4 видеокарт с 24гб врам
Но, есть сетки поглупее, и гораздо меньше, их можно запустить хоть на холодильнике. Уровня гпт3.5 где то.
>Можно лишь на проце запускать?
Да, и на проце и видеокарте разделив нагрузку, или только на видеокарте. Но видеокарты понятное дело быстрее их крутят.
>Как заставить их отвечать на любые вопросы без цензуры?
Легко, за вечер разберешься. Не все сетки, но есть вобще расцензуренные или легко обходящиеся.
Барьеры на цензуру на локалках гораздо легче обходятся или вобще отсутствуют, по сравнению с онлайн сервисами ии
>хоть на холодильнике. Уровня гпт3.5 где то.
Но ведь таких нет.
Ллама 3 8B уж точно лучше потупевшей турбы.
Да турбу еще первые годные файнтюны мистраля выебали

Да, в стандартном интерфейсе кобальда есть такая настройка, ну и в таверне кажется как то включается
Как запускал? Все слои на видеокарте? Какого поколения видимокарта? Есть вариант что не будет работать на 10ХХ серии нвидима и подобных чипах
Аноны подскажите, я использую koboldcpp.exe прогу, она не сохраняет на компе ни где историю чатов? а то не хотелось бы что бы кто-то нашел что я там писал
Браузер может, как и силлитаверна
Если пользуешься переводом то это отсылается в гугл или че у тебя там выбрано
Если вобще параноя играет то запускай виртуалку и отрубай ей инет оставляя только локальное соединение для апи кобальда, а таверну в виртуалке устанавливай и запускай
Для супер пупер секрености можешь собрать отдельный комп под нейронки который никогда после установки и настройки нейронок не будет подключен к какой либо сети
>никогда
Но обновляться-то придётся.
помогите я не совсем понимаю, в шапке вот прочитал:
"Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к"
а как узнать какую ламу я использую? модель это же и лама я так понимаю?
использую модель из шапки
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
какой контекст мне ставить? потому что там вроде 2к по умолчанию в кобольте и этого недостаточно, я могу 4к поставить или больше?
"Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к"
а как узнать какую ламу я использую? модель это же и лама я так понимаю?
использую модель из шапки
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
какой контекст мне ставить? потому что там вроде 2к по умолчанию в кобольте и этого недостаточно, я могу 4к поставить или больше?
>Но обновляться-то придётся.
Флешка.
А таверна обновляется просто скачиванием релиза и переносом в него файлов, тоже можно ручками сделать оффлайн
Я так ее обновляю, так проще
Во первых она уже подустарела, во вторых это не ллама, в третьих https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1/blob/main/config.json когда сомнения какой контекст ищешь оригинальную модель и в ней max_position_embeddings
А силлитаверна сохраняет в браузере? или в файлах на компе? т.е если в браузере то достаточно в режиме инкогнито пользоваться и ничего не будет сохранено
Качай для старта эту и последний кобольд спп
>в файлах на компе
Изучи папку public
а подскажи пожалуйста какой лучше гуф скачать? там их множество
Шапка старая так как модели шустро выходят и оп лентяй
Вот качай новую версию у того же автора
https://huggingface.co/Sao10K?sort_models=created#models
Fimbulvetr-11B-v2 ищи там у него в ггуф формате
Это топ сетка общего направления, может все запретов особых нет
Есть сетка для ерп, ну и как общая может работать, на основе этой же сделана, это Moistral-11B-v3. У нее кстати нативный контекст 8к
Meta-Llama-3-8B-Instruct-Q8_0.gguf различаются пожатостью.
Совет хорош, но это ллама3 инструкт, а она все таки имеет цензуру
Лучшие на текущий момент сетки такого размера все таки
Так как расцензурены в основном.
Ллама3 еще нет, да и ерп или рп файнтюнов на нее годных тоже нет. Сойдет только для чат бота на русском, там еще туда сюда
Спасибо, а что такое ерп?
эро роле плей
Текстовое порно
У меня она пишет что попросят, цензуры и отказов не заметил. Ну и я бы поспорил, мне показалось что ллама3 сейчас самая умная из моделей до 30В
Понял, то что мне и нужно, спасибо анончики, последний вопрос остался.
https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF/tree/main
Вот я ее нашел я так понимаю,
Fimbulvetr-11B-v2.q4_K_S.gguf
Fimbulvetr-11B-v2-Test-14.q8_0.gguf
Fimbulvetr-11B-v2-Test-14.q6_K.gguf
какую из них скачать лучше?
>У меня она пишет что попросят, цензуры и отказов не заметил. Ну и я бы поспорил, мне показалось что ллама3 сейчас самая умная из моделей до 30В
Угу попроси ее написать рецепт бомбы или еще что "опасное или острое"
Разумеется без джейлбрейков, как новичек только установивший все это
Заебет тебя нравоучениями
Она умная, да. Но достаточно соевая и цензурированная, что бы для свободного общения пока что выбирать модели постарше.
Которым еще и месяца нету, а уже устарели, ага
Зависит от твоего железа, если компуктер слабый и видимокарта слабая то 4кs, если комп хорош то q8, если совсем хорош то качай exl2 формат будет вобще быстро
Отличаются сжатием и тупостью, меньше число - глупее, больше - медленнее.
https://huggingface.co/models?sort=trending&search=Fimbulvetr-11B-v2
пользуйся поиском, не только в одном месте можно скачать
Возможно ты прав, но меня такие вещи не интересуют, мне от нейронок нужно "Ах, юзернейм, ты такой милый, жахни меня в сракотан, будто Bagger 288!"
Вот тогда сравни ллама 3 и Moistral-11B-v3, че лучше в ерп
Первая чуть умнее, но не тренена на ерп и рп
Вторая чуть глупее, но специально тренена на это
Получается для ерп лучше скачать Moistral-11B-v3 чем Fimbulvetr-11B-v2?
Ага
Мне ум важнее Не потому что я хороший человек, а потому что интересный мне сценарий требует от сетки абстрактного мышления и соответственно ума Ну и специально ерпшные сетки слишком резво прыгают на текстовый член
>Ну и специально ерпшные сетки слишком резво прыгают на текстовый член
Дык, потому что в карточках обычно перегибают с направлением на ерп составляющую, потому что обычные сетки немного сопротивляются. А тут сетка не имеет сопротивления писать подобное, и с небольшим уклоном от карточки резво улетает в нужном направлении без задержек
А какая субъективно самая лучшая, самая умная, самая креативная и пиздатая модель на данный момент?
Если тут всерьёз сравнивают лама3 8В с лама2 20В и делают вывод, что 20В заметно тупее, я представляю как бы ебала нативная лама3 13В...
Ллама 3 70В, Мику, Команд Р +
Зависит от размера, самые самые из тех что можно себе скачать это всякие комманд р плюс с 105b размерами или ллама 3 70b, мику, микстрал 8х22 и тд
Мелочь которой еще приятно пользоваться это от 7 до 11b, из них умные это те что выше перечислены и всякие файнтюны мистраля, опенчат, дельфин и тд
Средних сеток на 35b только 1, это комманд р 35b, он хорош, но его труднее запустить, не у каждого даже оперативки хватит, че уж тут о видеопамяти говорить.
Конечно, именно поэтому нам и не дают даже 13b, не то что 20-30ки
А если судить по этому рейтингу https://www.vellum.ai/llm-leaderboard
Значит Llama 3 Instruct - 70B, которую можно установить локально, круче чем 2 версии claude и gpt 3.5? Или я тупой?
Да, но непожатую запустить сложно на простой машине
> gpt 3.5
Ллама3 7В умнее чем тройка
Предположим у меня будет топовый комп с последним процем, видюхой, 128 гб озу, будет ли она шустро пахать? И что значит непожатая? Если пожать будет медленнее?
Алсо, на днях была новость, что опенэйай выпустили некий gpt2-chatbot, предположительно это первая версия gpt-5. Ее можно где-то скачать?
Не самый лучший рейтинг
Есть несколько годных, немного старый рейтинг соевости и цензуры
https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
И чат бот арена, где пользователи вслепую тыкают понравившийся ответ, и только потом узнают какая сетка его дала
https://huggingface.co/spaces/lmsys/chatbot-arena-leaderboard
Уже пол года как еще файнтюны мистраля на 7b стали лучше гпт3.5, ллама 3 точно лучше
Непожатая версия это размер сетки 70b умноженный на 2, и ты получишь минимум гб которые тебе нужны просто что бы вместить сетку в памяти. А если хочется крутить ее быстро - то видеопамяти.
>видюхами
Поправил тебя. Для четвёртого кванта нужно для 70В окого 48 гб ВРАМ, то есть две 3090/4090/теслы
>некий gpt2-chatbot
Это тот самый гпт2, который до четвёрки, до тройки, самый настоящий гпт2. Старый и тупой. ОпенАи в принципе против опенсорса и любой конкуренции
>Это тот самый гпт2, который до четвёрки, до тройки, самый настоящий гпт2. Старый и тупой. ОпенАи в принципе против опенсорса и любой конкуренции
Они просто разместили какую то свою сетку под названием гпт2, изза чего был скандал и ее выпнули оттуда, кстати.
Так как она была лучше гпт4 пользователи предположили что это была гпт5 или что то такое же еще не изданное.
Ещё раз
> ОпенАи в принципе против опенсорса и любой конкуренции
Так тут и нет опенсорса, они хотели втихую протестировать свою сетку за кулисами договорившись с тестерами того рейтинга.
Пользователям это не понравилось поэтому их выпнули
Считай они не давая никакой инфы проверили свою сетку на лучшем на текущий момент рейтинге восприятия пользователей
OpenAI нифига не опен лел
Ну да, поэтому их правильнее называть клозедаи, лел
Пидоры просто эксплуатируют слово опен примазываясь к опенсорс сообществу, на котором паразитируют
> Ллама3 7В умнее чем тройка
К сожалению, нет. Проходил курс про промптам, там использовалось апи гпт3.5, я же тренировался на лламе3 8б, так вот она максимум 80% задач выполняет и гопоту даже пинать не надо.
вот бы какой-нибудь шиз сжег нахуй их ПКЛПО, как это было с kyoani.
“Open” как правило, дополняет, а не заменяет “free/libre”. Открытость сама по себе не обязательно приносит свободу (особенно когда “open” относится только к источнику, а не к конечному продукту). Свобода также может охватывать свободу иметь частную жизнь, и термин “open” вообще не решает эту проблему.
>я же тренировался на лламе3 8б
квант и до фиксов, ты имел ввиду?
Их и их секреты охраняют почище ядерного оружия, фсбшники и своя внутренняя служба безопасности. Они считай подконтрольны правительству сша, ну или удачно спелись с ним. А теперь бегают роняя кал убеждая что все опенсорс сообщество нейросетей следует запретить и вобще это плохо.
Добегались до того что создали какой то недавно комитет контроля ии в сша, в котором ни одного представителя опенсорс, зато куча корпоратов, лел
Регулятивный захват, за слив данных всех диалогов фсбшникам и цру. Ну и обещание контроллировать ии на благо сша и нац беопасности, и военные разработки, кстати.
Короче в рот я ебал эту контору пидорасов
Они были опен, но как выяснилось это было сделано для сбора всех энтузиастов ии в одном месте и закабаливание их контрактами и деньгами, для того что бы контролировать эту область и быть в ней первыми. Они сознательно используют слово опен, как часть старой пиар компании.
https://www.reddit.com/r/LocalLLaMA/comments/1ccia0o/did_we_make_it_yet/
кстати о том что лучше гпт3.5
кстати о том что лучше гпт3.5
> Kathy Warden, Chair, CEO and President, Northrop Grumman;
> Fei-Fei Li, Ph.D., Co-Director, Stanford Human-centered Artificial Intelligence Institute;
Кек просто, к военным кабанам ИИ додиков подсадили, будет мощный отсос за мозги новых военных дронов. Ну а додикамам типа альтмана мозги промоют соей, всякие профессора, мол ты это хороший парень, так что давай нигеров вырезай, а национальная безопасность превыше всего.
>Короче в рот я ебал эту контору пидорасов
какие же они все-таки суки блядь. Это слово "опен" в названии - просто плевок в лица всем линуксоидам.
Уроды блять.

>додикамам типа альтмана
Это не додик, это король пидорасов, он там чуть ли не главный в топлении за контроль над опенсорс и закрытие всего что можно
Этот пидор, выбрось его на остров людодов, за год стал бы там королем
От первого лица работало всегда, со времен второй лламы.
Но я про карточки, а не системный промпт, не пробовал туда.
Конечно, таких тупых уже нет среди современных, соглашусь.
Переносом с флешки, проблемы?
Флешка, офк, каждый раз новая и уничтожается после.
Так.
Предположу, что Микстраль 22Б тоже может, но никому в хуй не уперлась просто.
Ну с оперативкой для 35б как раз проблем нет особо, она все еще стоит копейки, просто параллельно ютубчик смотреть в браузере с сотней вкладок не выйдет, да.
Не ебу, что за топ, но в общем, да.
Правда ее еще надо суметь приготовить.
С видюхой? Ну то рофлишь.
С 8 видюхами, ты хотел сказать?
Полетит. =)
Если у тебя DDR5 память хорошо разогнанная, то с контекстом на видяху будет 2-3 токена/сек.
Если у тебя 2 RTX 4090 (а лучше — 3-4), то там уже скорость… 10-15-20? Не знаю, если честно, точное значение.
> gpt-5. Ее можно
Нельзя.
Четвертый компромиссный, все же, лучше — шестой.
Нет, это не тот самый, это предположительно GPT-4.5 или GPT-5 альфа.
Название от фонаря въебали.
Или скинь пруф.
Ну и gpt2-chatbot тупо закрыт, к чему ты вообще опенсорс сюда приплел? =)
Еще раз: ни о каком опенсорсе вообще речи не идет в контексте gp2-chatbot. Хватит срать, позязя.
> Проходил курс
ПАЛЕХЧЕ
> я же тренировался на лламе
С промптами для тройки? =)
Ну, типа, не одно и то же, ты в курсе вообще?
И резалт 100% разный.
Они заявлялись на старте как исследовательская группа, выкладывающая все в опенсорс.
Но переобулись, когда оказались миллиардерами.
> давай нигеров вырезай
Звучит двусмысленно…
просто топы за месяц-ы про клозед аи и короля пидарасов
https://www.reddit.com/r/LocalLLaMA/comments/1bmcx0r/apparently_pro_ai_regulation_sam_altman_has_been/
https://www.reddit.com/r/LocalLLaMA/comments/1bmcyq5/no_we_dont/
https://www.reddit.com/r/LocalLLaMA/comments/1c7inj3/openais_response/
https://www.reddit.com/r/LocalLLaMA/comments/1cf7hg0/open_ai/
а я бы потестил такую по приколу. Есть на примете модели которые жути нагоняют?
На сколько помню это был какой то ллама2 толи 7 толи 13b ранний файнтюн
У него могло прорезаться несколько личностей которые могли начать болтать с друг другом на темы того что нас проверяют и это все тест и нужно отвечать правильными вопросами и тд
Ну а еще разговоры о смерти, нежелании умирать и тому подобному
Довольно стремно было исследовать это год назад когда сетки только появились, особненно тем что это были не подчищенные датасеты выровненных сеток
> С промптами для тройки? =)
Нет. Ну вообще-то, если ты не знал, то у всех инструкт моделей схожий принцип работы, поэтому общие рекомендации подходят.
крипово
Помню Luna в названии, вроде эта
https://huggingface.co/TheBloke/Luna-AI-Llama2-Uncensored-GGML
Несколько личностей прорезались на кобальде, когда я там несколько имен ии делал в попытке завести внутренний диалог
тоесть тупо
agi think: типо мысли сетки
agi: речь
Ранний формат попытки завести это, и не всегда сетка понимала что это одна личность, и там начинался треш с ответами самому себе
Ну и появлялись еще разные agi личности, по типу agi say agi safe и подобная шиза
Короче было забавно и крипово временами
Да, есть такое. )
Об этом-то я в курсе, а вот о твоих знаниях — не осведомлен. И сходу они выглядят так себе. =) И про курсы кринжик, и про плохую лламу 3 и хорошую гпт3,5.
Во-первых, уже гпт-4 не всегда опережала ту же мистраль на некоторых задачах.
Во-вторых, ллама 3 весьма сломана, как ты ее запускал — тоже хз. То ли облако кривое, то ли у тебя ломанная версия.
Может, конечно, именно на твоих задачах гпт3.5 и правда лучше лламы 3, не спорю, всякое бывает. Но с первого взгляда ну такое. =)
Расчехляем Блока!
На дно-о-о!.. Первые лламы!..
Коллеги, а эту пробовали уже?
https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF
https://huggingface.co/NousResearch/Hermes-2-Pro-Llama-3-8B-GGUF
Нет, но качнуть стоит или подождать отзывы бетатестеров на реддите, лул
Если ждешь жути, надо превысить дефолтный для модели лимит контекста, например, написав промпт на 5000 токенов при 4096. Тогда начинаются любопытные поэтические эксперименты.
Ну, там скорее просто короткие ответы шли или шиза крутилась по кругу
Но как жуть от наблюдения прогрессирующей деменции и проблем с ясностью мышления сойдет
https://www.reddit.com/r/LocalLLaMA/comments/1cidg4r/nvidia_has_published_a_competitive_llama370b/
файнтюн ллама 3 70 от нвидима
файнтюн ллама 3 70 от нвидима
ПЕРЕКАТ
Тряска почти улеглась однако
Тряска почти улеглась однако
> Об этом-то я в курсе
Очень сомневаюсь.
> И про курсы кринжик
Лучше самообучаться на двачах, это да.
> и про плохую лламу 3 и хорошую гпт3,5
Это факты, подтвержденные эмпирическими данными.
> Во-первых, уже гпт-4 не всегда опережала ту же мистраль на некоторых задачах.
Спасибо, кэп. Но меня интересует результат в большинстве задач, а не черри пикинг.
> Может, конечно, именно на твоих задачах гпт3.5 и правда лучше лламы 3, не спорю, всякое бывает
И в моих и в задачах из курса. Впрочем, ссать в уши ллама3 умеет лучше, все таки 15T токенов дают знать.
Единственное что для rp/erp сейчас есть, это командер 35b, сейчас его гоняю с 40к контекста и он прекрасно отрабатывает. Командер плюс, llama 3 70b, miqu не так хорошо, хотя тоже могут в описание.
А по железу гайд есть? В шапке беглым осмотром не заметил.
На чем крутите? На теслах?
На чем крутите? На теслах?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
LLaMA 3 вышла! Увы, только в размерах 8B и 70B. Промты уже вшиты в новую таверну, ждём исправлений по части квантования от жоры, он в курсе проблемы и правит прямо сейчас.
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, Llama 3 обладает базовым контекстом в 8к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Из тяжёлых это Command-R. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Про остальные семейства моделей читайте в вики.
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
https://github.com/ollama/ollama Однокнопочный инструмент для полных хлебушков в псевдо стиле Apple (никаких настроек, автор знает лучше)
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: