


Окей
В дополнение к этому
Все настройки я постарался вынести в stack.env
По koboldai/koboldcpp, которые нужно заполнить:
Имя модели, вот прям полное имя с расширением.
MODEL_NAME=Llama-3.2-3B-Instruct-Q8_0.gguf
Количество потоков на этот контейнер (в рекомендациях пишут что нет смысла выделять больше одного потока на ядро).
THREADS=4
Внешний порт, тот который будет смотреть наружу
PORT=5001
Путь до моделей на локальной машине.
MODEL_PATH=/opt/4tb/files/llm-models
Путь до конфига на локальной машине.
CONFIG_PATH=/opt/4tb/files/llm-models/koboldcpp/config
Эти параметры можно не трогать:
Не поднимать удаленный доступ через интернет, контейнер кобольда по умолчанию поднимает удаленный доступ к контейнеру и выдает тебе ссылку через которую ты можешь им пользоваться в интернете. По умолчанию там нет никакой авторизации. Оно тебе надо? Если да - пиши false.
KCPP_DONT_TUNNEL=true
Параметр который говорит не удалять модели после выхода. Это не те модели которые лежат в папке MODEL_PATH. Это те модели которые он может скачивать самостоятельно при запуске, при указании параметра KCPP_MODEL в композе. (Не знаю как им пользоваться, в описании указано что это автоматический загрузчик моделей. Скорее всего так KCPP_MODEL: "Qwen/Qwen2.5-1.5B-Instruct-GGUF" - указывает на модель с HF, нужно проверять)
KCPP_DONT_REMOVE_MODELS=true
Сюда попадают параметры сверху
KCPP_ARGS="--threads=${THREADS} --model /models/${MODEL_NAME}"
С композом таверны все то же самое, параметры вынесены в stack.env
Наружный порт
PORT=8000
Пути к папкам
CONFIG_PATH_SILLYTAVERN=/opt/4tb/files/llm-models/SillyTavern/config
DATA_PATH_SILLYTAVERN=/opt/4tb/files/llm-models/SillyTavern/data
PLUGINS_PATH_SILLYTAVERN=/opt/4tb/files/llm-models/SillyTavern/plugins
USER_PATH_SILLYTAVERN=/opt/4tb/files/llm-models/SillyTavern/user
С силитаверной есть одна заеба. После запуска в контейнере докера он расценивает сеть докера как локальную, а твою локальную сеть он рассматривает как внешнюю
Поэтому после запуска контейнера и переходу по ссылке он у тебя будет ругаться на то что ты не находишься в вайтлисте. Придется немного исправить конфиг.
Заходишь по пути указанному вот тут CONFIG_PATH_SILLYTAVERN, там должен лежать файл config.yml в нем нужно изменить два параметра: выставить whitelistMode: false и basicAuthMode: true
Данные для авторизации написаны ниже (username: user; password: password), если есть желание, можешь написать свои. Сохраняешь изменения, перезапускаешь контейнер. Теперь тебя пускает под логином и паролем.
В настройках подключения в силлитаверне указываешь адрес своей локалочки, а не адрес локалочки докера (не понял почему так, нет особого желания разбираться с этим), например http://192.168.1.10:5001/api
AMD-135m
AMD-Llama-135m is a language model trained on AMD MI250 GPUs. Based on LLaMA2 model architecture, this model can be smoothly loaded as LlamaForCausalLM with huggingface transformers. Furthermore, we use the same tokenizer as LLaMA2, enabling it to be a draft model of speculative decoding for LLaMA2 and CodeLlama.
https://huggingface.co/amd/AMD-Llama-135m
AMD-Llama-135m is a language model trained on AMD MI250 GPUs. Based on LLaMA2 model architecture, this model can be smoothly loaded as LlamaForCausalLM with huggingface transformers. Furthermore, we use the same tokenizer as LLaMA2, enabling it to be a draft model of speculative decoding for LLaMA2 and CodeLlama.
https://huggingface.co/amd/AMD-Llama-135m
Очевидно, скинь это в тот же rentry.co отдельным файлом, чтобы можно было одну ссылку в шапку добавить, а в нём уже вкинь весь этот текст со ссылками на файлы докера для таверны и кобольда.
>speculative decoding for LLaMA2
Оно ещё живо? А то нам обещали мега ускорение для больших моделей, а воз и ныне там.
Ах да, им не сообщили, что уже вышла третья?
пишу кум для себя, уже нагенерил дохуя текста который не помещается в 8к и тем более в 4к контекста 22битной мистрали. Саммари которое генерит ии отрезает много мелких деталей, оставляя только события а ля "он иё выибал а потом ана у ниво пасасасала". Что делать то?

> кум
> отрезает много мелких деталей
Так соври что пипирка у тебя большая.
Заметил одну интересную херню.
Если начать играть на карточке сразу с умной модели, она постоянно дрочит детали из карточки, каждый пост их повторяет и повторяет. К концу она начинает еще сильнее укреплятся в своем характере и ее в принципе невозможно куда-то склонить. Например так у меня было с чатвайфу-1.4
Играет неплохо, но постоянно дрочит свой характер (был прописан характер страдалицы и она постов 30 страдала, все ей было хуево, любое действие с отвращением, прям бычий кайф для садистов)
Но если сначала к карточке подключить модель более кумерскую, вроде Даркидола, она на карточку особо не смотрела, предысторию не выдерживала, но при этом персонаж вел себя более развязно. Отыграть пару постов, а уже потом подключить чатвайфу, то чатвайфу вроде бы как начинает вести себя получше.
Если начать играть на карточке сразу с умной модели, она постоянно дрочит детали из карточки, каждый пост их повторяет и повторяет. К концу она начинает еще сильнее укреплятся в своем характере и ее в принципе невозможно куда-то склонить. Например так у меня было с чатвайфу-1.4
Играет неплохо, но постоянно дрочит свой характер (был прописан характер страдалицы и она постов 30 страдала, все ей было хуево, любое действие с отвращением, прям бычий кайф для садистов)
Но если сначала к карточке подключить модель более кумерскую, вроде Даркидола, она на карточку особо не смотрела, предысторию не выдерживала, но при этом персонаж вел себя более развязно. Отыграть пару постов, а уже потом подключить чатвайфу, то чатвайфу вроде бы как начинает вести себя получше.

> сразу с умной модели
> 14b васянский тюн

Мне много не надо, главно чтобы пися трепетала.
Хотя если без шуток, я вчера решил себе поднять маленькую Qwen2.5-1.5B, чтобы делать всякую рутинную хуйню, аля замени все точки на тире, сделай большие буквы маленькими.
А она как начала на русском шпарить, еще и так связно, без ошибок, и код написала.
Кароче, не недооценивай маленькие модельки для домашних задач. Они тоже кое что могут. А по железу наверное телефона хватит для запуска.
В том и прекол, что 1.5 - 3b модели хорошие и полезные, как раз для телефонов, офисных компов без ГПУ и всяких некроноутов. А для норм пека, где стоит относительно современная видяха, есть 27-32b в мелком кванте (да, даже на на Q3-K-L такая модель выебет любую 8-14b в Q8 при любом сценарии использования).
Вот эти 8-14b - ни рыба ни мясо, реально какое-то говно без задач. С простейшими вещами что ты описал, и 2b прекрасно справится, но стоит им дать что-то посерьёзнее - уже начинают сыпаться. Да даже с длительным РП они не справляются, забывая что было 10 сообщений назад, при этом сами ответы пресные и скучные. Шизотюны это частично фиксят, но, как водится, добавляют своей собственной шизы, уникальной для каждого тюна.
Не спорю что юзая такие обрубки, ты получишь не 5т/с, а 15т/c, генерация будет быстрее. Но какой ценой?
А не лучше ли для задач под 32B заюзать обычную ЖПТу? Она и умнее, и быстрее, из ебли только завести акк, и подключить зарубежный VPN на время использования.
> модели очень часто уже готовы для генерации речи с эмоциями, просто они этому не обучены
Ты про готовые ттс? Как правило они довольно мелкие и примитивные, а речь описывается просто базовой разметкой. Что-то приличное должно принимать на вход помимо текста с разметкой ударений/скорости еще и дополнительный промт, которым бы описывался голос. Может не напрямую читабельный и обычный промт, а просто дополнительный кондишн в каком-то виде, но он должен быть предусмотрен.
> Ну и моделька должна быть плюс-минус большая, здесь тоже проблемы могут быть.
Именно, на той мелочи что сейчас только изгаляться с ее возмущениями, чтобы менять голос. Не то чтобы этот вариант совсем плох, но возможности ограничены.
> Моделька пытается в эмоции даже при том, что не обучена быть эмоциональной, разве что вопросительные интонации понимает.
Лишь сочетание "предрасположенности" некоторых фраз звучать с определенными эмоциями (нейронка ухватила из датасета) и домысливания кожанными при прослушивании. До полного диапазона и управления этому далеко.
Можешь расписать вообще что и как там делал или тренировал? Штука ведь интересная.
Поставить больше контекста?
> отрезает много мелких деталей, оставляя только события
А что тебе еще нужно? Всеравно эти мелкие детали не берутся во внимание за редким исключением.
> с умной модели
> она постоянно дрочит детали из карточки, каждый пост их повторяет и повторяет. К концу она начинает еще сильнее укреплятся в своем характере и ее в принципе невозможно куда-то склонить
Такую модель нельзя назвать умной.
> что 1.5 - 3b модели хорошие и полезные
Насколько у них развито "абстрактное мышление"? Самый простой пример - переработай текст сделав саммари, используй вот эти утверждения, которые считаются истинными, и исправь текст если он противоречит им (+пожелания по подробностям и стилю). Осилит?
> Самый простой пример - переработай текст сделав саммари, используй вот эти утверждения, которые считаются истинными, и исправь текст если он противоречит им (+пожелания по подробностям и стилю). Осилит?
Часто ли тебе нужно решать такие задачи?
Я вот ни разу в жизни не решал их именно по такой постановке.
Если не смущает что твои переписки возможно будут читать третьи лица индусы, то может и лучше. Но для рп-кума наверное нет, цензура же.
>Осилит?
Такое не пробовал. Давай конкретный пример, прям текстом. Скормлю Гемме 2b - скину сюда результат.
>Саммари которое генерит ии отрезает много мелких деталей
ИИ-саммари для долгого РП не вариант, как и маленький контекст. А если ещё и модель маленькая, то нужно её очень тщательно выбирать под задачу.
Аноны, для чего делают микромодели, типа llama 1b?
Ну что там по 70b моделям?!
Чем заменить эти 7b-13b шины?
MN-12B-Lyra-v4
L3-8B-Stheno-v3.2
Пробовал:
gemma2-9B-sunfall-v0.5.2
Big-Tiger-Gemma-27B
Rocinante-12B-v2
Theia-21B-v1.i1-IQ3_XXS
Average_Normie
Вопрос к знатокам, что лучше для улучшения памяти чатбота: summarizing, rag или подход memgpt ("внешняя" память с помощью function calling)?
Я пока тестил только summarizing & memgpt и оба не сильно впечатлили. Подход memgpt (он также есть в платном ChatGPT) позволяет сохранять основные факты из чата, но в очень ограниченных масштабах (+ работает только в 35B+ моделях). Summarizing работает чуть получше, но тоже страдает от потери информации. Я еще не пробовал rag, есть ли смысл вообще связываться с этим?
Я пока тестил только summarizing & memgpt и оба не сильно впечатлили. Подход memgpt (он также есть в платном ChatGPT) позволяет сохранять основные факты из чата, но в очень ограниченных масштабах (+ работает только в 35B+ моделях). Summarizing работает чуть получше, но тоже страдает от потери информации. Я еще не пробовал rag, есть ли смысл вообще связываться с этим?
Для мобильных.
Ждём.
А нужно ли менять? Если шины.
>Big-Tiger-Gemma-27B
Зачем вы это качаете когда на обниморде есть Гемма 27b с нормальной аблитерацией?
>Да даже с длительным РП они не справляются, забывая что было 10 сообщений назад
Вы их готовить не умеете просто. Та же немо и её тюномиксы, которую все хаят тут за сою спокойно может переваривать сложный рп на 40к контекста не страдая шизой.
А где почитать как тестировать семплеры для Таверны?
То есть взять тесты и прочее.
То есть взять тесты и прочее.
и оплатить премиум... иначе без апи будеш...
согласен, но когда видишь как пишет 30б хочется такого всегда, а контекст на 40к с видяхи можно получить только на мелких моделях
Ну о том и речь, 8b модельки защищают только те, кто никогда не пользовался нормальными. Как только поюзаешь 27-32, возвращаться на мелочь уже нет никакого желания. Преимущества в скорости копеечные того не стоят.
неведомо какой день попыток завести мультимодовую модель:
все скрипты-программы для запуска на три категории делятся - не работают, не работают на Windows, не работают с квантоваными моделями... главный абсурд что Qwen2-VL официальный, не работает с квантоваными, из за поломаного дерева зависимостей, трансформеры с оптимайзом не совместимы (красота однако), но что вообще не в какие ворота, неквантованая модель тоже не заводится при любом запросе или отправке изображения краш происходит... хз как оно на хагинфейсе работает... кто-то квена смог без плясок с бубном запустить?
все скрипты-программы для запуска на три категории делятся - не работают, не работают на Windows, не работают с квантоваными моделями... главный абсурд что Qwen2-VL официальный, не работает с квантоваными, из за поломаного дерева зависимостей, трансформеры с оптимайзом не совместимы (красота однако), но что вообще не в какие ворота, неквантованая модель тоже не заводится при любом запросе или отправке изображения краш происходит... хз как оно на хагинфейсе работает... кто-то квена смог без плясок с бубном запустить?
>Как только поюзаешь 104-123, возвращаться на мелочь уже нет никакого желания
Исправил, не багодарите.
>хз как оно на хагинфейсе работает...
Там офк неквантованные гоняют.
api для слабаков, настоящие мужики говорят о футанари прямо в чате ГПТ
Господа, подскажите, появились ли какие годные апки для запуска ЛЛМ на телефоне? Сейчас использую вот это https://github.com/Vali-98/ChatterUI но там с Геммой косяк, рероллы не работают, постоянно один и тот же текст выдаёт. Может что получше есть, а я пропустил?
> >Как только поюзаешь 104-123, возвращаться на мелочь уже нет никакого желания
> Исправил, не багодарите.
Не важно насколько там много B.
Ты все равно заметишь ее тупость когда-нибудь. И тогда все воздушные замки посыпятся. Будешь ощущать себя додиком который на ламбе едет в деревенское сильпо.
>Ты все равно заметишь ее тупость когда-нибудь.
Давно уже. Но чем больше буковок B, тем реже замечаешь. С какого-то порога оно уже не каждый чат, что радует.
Есть какие-нибудь особенные гайды по настройке и запуску LLM на P40?
Моя неплохо генерирует в SD, но нивкакую не хочет запускать какие либо LLM.
llama.cpp - просто ничего не делает, ни ошибок, ни вывода. Как будто я ничего не сделал.
koboldcpp - выпадает с ошибкой на DLL. Решение вродь как связано с виндовыми примочками по переключению настроек в "производительный режим", я это сделал, так же те настройки в реестре от китайца с гитхаба. Ошибка не поменялась, вообще ничего не изменилось.
text-generation-webui - или выпадает с ошибкой при загрузке модели или нагружает проц, но ничего не грузит в память видюхи.
Как вы вобще пользуетесь теслами? Железные гайды треда курил - там такого вобще нет, будто только у меня какая-то залупа.
Моя неплохо генерирует в SD, но нивкакую не хочет запускать какие либо LLM.
llama.cpp - просто ничего не делает, ни ошибок, ни вывода. Как будто я ничего не сделал.
koboldcpp - выпадает с ошибкой на DLL. Решение вродь как связано с виндовыми примочками по переключению настроек в "производительный режим", я это сделал, так же те настройки в реестре от китайца с гитхаба. Ошибка не поменялась, вообще ничего не изменилось.
text-generation-webui - или выпадает с ошибкой при загрузке модели или нагружает проц, но ничего не грузит в память видюхи.
Как вы вобще пользуетесь теслами? Железные гайды треда курил - там такого вобще нет, будто только у меня какая-то залупа.
Внёс в шаблон если что, со следующего переката будет в шапке.
Анон, объясни:
Вот эта модель допустим, anthracite-org/magnum-v3-27b-kto, дает instruct template, а я могу эту модель использовать не для ролплея а для story writing? Не чат с карточкой а в качестве ассистента в написании текстов? Как это сделать чтобы не потерять качество ответов? Написать ему что он неебаца пейсатель?
Вот эта модель допустим, anthracite-org/magnum-v3-27b-kto, дает instruct template, а я могу эту модель использовать не для ролплея а для story writing? Не чат с карточкой а в качестве ассистента в написании текстов? Как это сделать чтобы не потерять качество ответов? Написать ему что он неебаца пейсатель?
>Написать ему что он неебаца пейсатель?
Ну да. Будет чат, просто ты вместо ответов будешь писать, куда вести историю.
>8b модельки защищают только те, кто никогда не пользовался нормальными. Как только поюзаешь 27-32, возвращаться на мелочь уже нет никакого
За последние полгода уже такое количество релизов и в сто раз больше шизотюнов и миксов было, что ситуация, когда более новая 12б или более шизозатюненая модель ебет 27-32б в каких-то задачах вполне стандартная.
Первый вопрос, не потеряет ли он от этого качества ответов? Он ведь тренирован на других данных?
И второй вопрос, в режиме инструкций будет работать, точнее будет ли он работать также хорошо? Скажем если будет просто инструкция с промтом "продолжи историю таким образом: он дал ей в рот"
Только вот растут не только 8B огрызки, но и нормальные модели всех размеров.
Да ёб ты. Попробуй разные варианты, и нам расскажешь. Что ж блядь все вокруг какие импотенты, даже пары запросов сами сделать не могут.
обязательно расскажу, но я думал это платина которую знают все, а я только вкатываюсь
Там офк неквантованные гоняют
так прикол в том, что неквантованую выкачал, а оно все равно не стартонуло... и квен как оказалось туповат, в генерацию SVG не умеет, HTML блоки в виде пирамидки поставить не может... придется жопен аи платить походу...
>Ты все равно заметишь ее тупость когда-нибудь. И тогда все воздушные замки посыпятся.
Не совсем. На 123В с большим контекстом и длинным ручным суммарайзом бывают случаи, когда НПС выбивается из роли, из своего элайнмента так сказать. И вот казалось бы мир должен разрушится - ан нет, повествование идёт настолько гладко, что просто затираешь ответ, генеришь снова - и на этот раз попадаешь. Даже не раздражает.

Подскажите годную модель для советов по геймдеву Unity. Юзаю чатгпт: он всё знает как будто и очень помогает и удобно советы в шаги/туторы складывает, но там ограничение на количество бесплатных запросов задолбало. Какой топчик сейчас?
Комп мощный, есть 4090.
>Коболбьд в докере
а мисье знает толк в извращениях
но за решение респект
> Часто ли тебе нужно решать такие задачи?
Настолько что малая модель была бы кстати за счет своей скорости. С другой стороны, перфоманса геммы в общем-то хватает.
Да потому что нехуй пердолить и ломать то что не понимаешь.
Создаешь пустой venv, активируешь
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install git+https://github.com/huggingface/transformers
pip install accelerate bitsandbytes qwen-vl-utils
Запускаешь скрипт из их репы, переписываешь под свои задачи. Если нужно загрузить в меньшей битности - добавь аргумент load_in_4bit=True в загрузку модели. Что сложного?
> Моя неплохо генерирует в SD, но нивкакую не хочет запускать какие либо LLM.
Все должно быть с точностью до наоборот.
> выпадает с ошибкой на DLL
Что за кобольд, что за железо, что за система?
мини которая неограничена не вытягивает?
на 4090 особо жирного ничего не запустиш, уровень гопоты это жирные модели больше сотни лярдов, но можеш потестить какие-нибудь кодерские, дипсики или еще чего может влезет в твои 24 гига, (и тебе ж одновременно и юнити надо держать включеным?)
щас меня тапками закидают, но купи премиум, если функционал устраивает
>Как только поюзаешь 104-123, возвращаться на мелочь уже нет никакого желания
Таки да, но это что-то на богатом. Или на некромантском. В общем не для широкой публики. А я говорю о том, что те кто запускают 14b на своих железках точно так же могут запускать и 30b, особо ничего не теряя.
Если сравнивать новые 8b и старые 30b - да, в отдельных задачах новая мелюзга будет получше. Но если сравнить новые средние модели, и новую мелочь, то мелочь будет посасывать везде.
Особый кек в том, что мелочь в Q8 и средняя моделька в Q3 на потребительском железе будут работать с примерно одинаковой скоростью, при этом последняя будет значительно умнее даже при такой лоботомии.
>Комп мощный, есть 4090.
Ну как тебе сказать, лол. Нет, не мощный. Для ЛЛМ по крайней мере. Попробуй Qwen2.5 72B в кванте Q3-K-L, но будет БОЛЬНО, сразу говорю.


Премиум покупать не хочу, да и муторно это сейчас сделать. Неограниченный гпт хз, не видел там, может не заметил, но при открытие сайта там просто сразу бот есть и всё. Но хочется именно локальную модельку, свою.
А по поводу загрузки системы, раньше юзал мелкие всякие через таверну и кобольда и вроде как там комп шуметь начинает во время ответов только?
>Qwen2.5 72B в кванте Q3-K-L
Ок, попробую. Спасибо
Зачем всратый квант взял вместо нормального q4? Я ни разу не видел на 72В китайского.
Всратый ты имеешь ввиду i1? Он же вроде наоборот лучше должен быть за счет каких то там нанотехнологий квантования, хотя утверждать не буду.


> Что за кобольд, что за железо, что за система?
Тебе нужна сборка noavx, процессор настолько устравсрат что с этим проблемы. Как-то уже чинили это, можешь поискать или дождаться пока ответят.
В чатгпт при диалоге иногда у бота появляется "память обновлена" и если туда щелкнуть, то видно что он запомнил и внёс себе и как меня понял в прошлые разы и что отметил для себя. В локальных есть такое?
Аноны, приветствую. Хочу вкатиться в локальный нейро кум. Так что для таких целей лучше ставить? Кобольд или SillyTavern? Какую модель для такого ставить? Увидел, что можно брать Lexi-Llama-3-8B-Uncensored или Llama-3-70b-Uncensored-Lumi-Tess. На борту rtx 3080, 7800x3d, 32gb.
Прошу, по возможности, развернутого гайда.
Прошу, по возможности, развернутого гайда.
>при этом последняя будет значительно умнее даже при такой лоботомии.
Далеко не всегда справедливо. Квантование до сих пор чёрный ящик во многом, который только нерепрезентативными в куче задач бенчами мерять и через универсальный инструмент под названием ну я так чувствую.
Кучу раз встречал ситуации, когда вроде большая квантованная модель в среднем по больнице лучше более мелкой не квантованной, но драматически может начать сосать жопу в каких-то отдельных хуевинах.
>Если сравнивать новые 8b и старые 30b - да, в отдельных задачах новая мелюзга будет получше.
В среднем по больнице да, но модель модели рознь. У нас тут каждый месяц охуительный релиз за охуительным релизом, когда никто особо даже не успевает нормально на куче задач погонять новые модели как выходит очередное что-то, а по бенчам оценить адекватно уже невозможно нихуя, всякий рп и кум тем более.
>Только вот растут не только 8B огрызки, но и нормальные модели всех размеров.
В среднем может и растут, но опять же с таким количеством релизов это уже в цирк ебаный превращается порой плюс ну тупо нет какой-то одной волшебной модели, которая вот лучше какой-то другой во всём.
У меня последний раз, например, жопа отвалилась, когда с полдесятка квантованных 30b+ разных и свежая 70б ллама в нужной мне задаче проебали голой q6 немо, тупо потому что при всех своих размерах не могли нормально одновременно отыгрывать чат-бота на адекватном русском отвечая при этом json'ами. И такой хуйни полно.
*сюда, макаба сука

Ладно, верим что это буковка кванта неправильная, а ни разу не цензура от дяди ляо.
Иероглифы на предыдущих скринах примерно с тем же содержанием кстати.
Иероглифы на предыдущих скринах примерно с тем же содержанием кстати.
Ват? вообще без АВХ? ты где такой откопал?
> noavx
Обычный целерон с встроенной видюшкой.
Пиздец блять, спасибо дядя кобольд, погенерировал.
Самый дешевый i3 со встройкой 7к стоит они совсем ебнулись.
Да, но работает немного иначе. В кобольде есть настройки Memory, Author's Note и World Info. Это то, что нейросеть будет держать в памяти и использовать при диалогах с тобой. Как этим всем пользоваться описано тут https://github.com/KoboldAI/KoboldAI-Client/wiki/Memory,-Author's-Note-and-World-Info Но в вики инструкция под РП. Просто адаптируй под свои задачи.
> Далеко не всегда справедливо
Спорить не буду, но именно в моём юзкейсе Q3 27-32 ебёт мелюзгу. Речь о переводе текстов, написании кода, немного медицинской хуйни, ну и РП-кум, само собой.
угу, с костылями и без кванта (оно оказывается не умеет скачивать квантованные) удалось до загрузки добраться, но упор в нехватку врам... на ЦП типа без шансов такое запустить?
>Спорить не буду, но именно в моём юзкейсе Q3 27-32 ебёт мелюзгу. Речь о переводе текстов, написании кода, немного медицинской хуйни, ну и РП-кум, само собой.
Ну я про то же, что юзкейс юзкейсу рознь как и модель модели.
С квантами нюанс в том, что никогда не узнаешь заранее, а и порой после, какие критически важные связи для каких-то абстракций и знаний модель могла проебать при квантовании.
Встречал случаи, вообще, когда модель при понижении квантов начинала всё больше разговаривать как еблан, а под конец и словно шиз с дислексией на письмо, но при этом почти не теряла понимание абстракций, знаний и прочей хуйни по конкретным темам. Сидим черный ящик палками тыкаем.
Ой, чтож такое. Теперь наверное квантователь не тот, раз квант тот.
Ряяяяя блядь
Ряяяяя блядь
> с костылями
Какими костылями?
> и без кванта
Выстави в аргументах функции нужную битность или сразу загрузи готовую квантованную модель из оффициальной репы.
> на ЦП типа без шансов такое запустить
Нууу, чисто технически - укажи 'cpu' вместо девайса, может и заведется.
Хз, это нужно совсем поломать квант, нарушив технологию, криво откалибровав или наткнувшись на серьезную ошибку в коде (привет Жора). Кванты выше 4 бит почти всегда не имеют каких-то заметных проблем.
Аноны, какой пет проект сделать, чтобы там втю основе были ллм? Rag и связанное не предлагать, для них уже пет проект есть.
>Кванты выше 4 бит почти всегда не имеют каких-то заметных проблем.
4+ да, а вот на тройке уже можно всякие приколдесы обнаружить.
>Кобольд или SillyTavern
>8B или 70b
Ты точно не траллишь?
Может семплеры не те, лол.
>какой пет проект сделать
Симулятор рыбалки.
> симулятор Рыбалки
А конкретнее?
В некоторых моментах могут застревать и свайпы не помогают.
~30B
Медленно генерирует, у меня скорость на Big-Tiger-Gemma-27B-v1_iQ3xxs менее 2т/с. И по опыту модели без ERP файнтюна плохо понимают что происходит во время этого ERP.
>пет
Что за пет проект?
> семплеры не те, лол.
Может быть. Какие надо?

>Может не напрямую читабельный и обычный промт, а просто дополнительный кондишн в каком-то виде
Сейчас практически в каждой ттс есть "спикеры", вот тебе и голос. В некоторых даже войсклон из коробки. У меня скорее идея в том, чтобы оборачивать фразы в управляющие токены, которые будут задавать интонации. LLM при инференсе с лёгкостью могут генерировать такую разметку, разве что некоторые достаточно вольно трактуют твои указания. То есть у меня генерация разметки мелким квеном, средним и геммой отличалась, даже при том, что я задаю правила генерации и даю примеры. В прошлом треде обсуждали grammar, так вот я не упомянул подводные камни. Он медленный, особенно если модели не дать чёткий шаблон, которому нужно следовать. Потому если можно - лучше обходиться без него.
>Лишь сочетание "предрасположенности" некоторых фраз
Так это то самое обобщение. По большей части. Немного вопрошать она всё-таки может, для этого специально убрана маска внимания, чтобы последующие токены могли влиять на предыдущие. Также нет eos токена, чтобы адекватно отрабатывал стриминг. А управления никакого не закладывалось, т.к я заебался и датасет не охватывает всего. В теории, если модель будет достаточно жирная и обученная сама детектировать эмоциональный окрас, то и этого не нужно будет.
>Можешь расписать вообще что и как там делал или тренировал?
Да нихуя особенного, стандартный набор из vae, hi-fi gan и небольшой нейросети поверх. Токенизируешь инпут, засылаешь в нейронку, которая генерирует спектрограмму, здесь влияние vae на выборку частот. Дальше наш gan уже превращает это в звук.
Берёшь много аудиофайлов, режешь их на кусочки, потом виспером делаешь субтитры и правишь. Вручную правишь, т.к виспер не обращает внимания ни на паузы, ни на интонации, он расставляет грамматически правильные запятые и знаки, которые тебе не нужны, т.к их нет в аудио. Со звучанием есть два варианта - либо ранний останов тренировки, либо модель далеко за оверфитом. Второе звучит лучше, но требует гигантского датасета, который покрывает всё. Без такого датасета только ранний останов. Хороший hi-fi gan в дообучении не нуждается, что упрощает всё дело, для эмоциональной речи делаешь минимальные батчи и накопление градиента, либо собираешь датасет только на одну интонацию и шарошишь, для обобщения наоборот - максимизируешь батчи и градиенты, насколько vram позволяет. Также здесь помогает то, что TTS составная и каждая часть может быть натренирована отдельно - только это позволяет помещаться в 24gb vram.
Ну какой нибудь свой проект.
Короче говоря, на данном этапе пытаться запустить виден модельку на 8гб врам дурная затея - оффлоада в рам нормального нет, вылетает в дифицит памяти, на колабе удалось ламу 3.2 завести в 4 кванте, при чем она какая-то дибильно-соевая вышла, неквантованые так себя не вели, и даже с учетом кванта 10+ гб расход - а значит в одну видяху никак не впишется... квен насколько я понимаю из того что на ХФ лежит тоже каличный малость, для вижена отличного от опиши картинку и придумай хоку - локальные пока что не пригодны от слова совсем...
??
нецензурный вариант Qwen2.5, анон который хотел выебать рыбака Васю в прошлом треде, вот оно твоё счастье. https://huggingface.co/bartowski/Qwen2.5-14B_Uncensored_Instruct-GGUF

прописал максимально просто персонажа, вроде что-то умеет, лол
> можешь поискать
Попытался, не смог найти. Хз, нахуя им дались эти AVX если я хочу на видяхе генерить?
Кароче какой-то пиздос получается. Железо дорогое. И если покупать что-то адекватное это уже выйдет из разряда "поиграться на пару вечеров".
На всякий случай бампну
Если есть советы как запустить что угодно на проце буду рад получить.
в LM Studio есть Vulkan бекэнд, попробуй. Поколение Pascal ещё не совсем древнее, должно с вулканом норм работать.
Да любую хуйню бери и делай, вон там новую таверну хотели сделать.
>Попытался, не смог найти.
Плохо искал:
https://github.com/LostRuins/koboldcpp/releases/
If you have an Nvidia GPU, but use an old CPU and koboldcpp.exe does not work, try koboldcpp_oldcpu.exe
Вроде как раз твой случай.
Нет, он вываливается с точно такой же ошибкой. Скорее всего под "олд" они подразумевают то что там нет AVX2, но AVX1 там точно должны быть. На целероне, как оказалось, их нет совсем никаких. Никогда не думал что так может быть.
LM Studio оказался слишком умным, он даже моделей для скачки мне не показал. Принудительно воткнул в него llama3.1-3B, но оно вывалилось с ошибкой.
Пиздец, весь мир под интелом (а они контора известно кого). Что там такого охуенного в этих AVX, что они даже просто загрузить без них не разрешают.
Проблема не в том что клятый интол говно в штаны залил, а что никто из разработчиков и не предусматривал забили на сценарий, в котором кто-то на подобной порезанной затычке будет пытаться пускать прожорливые нейронки. Это базовая и необходимая инструкция для математических библиотек, которая в профессорах уже второй десяток лет, все вполне ожидаемо.
Раньше там точно был no-avx режим, возможно из-за изменений в жоре уже все. Он то изначально не совсем под видеокарту а наоборот на проце, на гпу уже идет выгрузка считай, потому и требования.
Эт понятно, просто от обиды.
Так то в бытовом использовании этот проц в не ощущается ущербным. Браузер крутится, ютуб смотрится. Даже SD генерируется, хоть и не быстро. Лоры для SD обучаются (правда теперь я понял почему мне так долго пришлось ебаться с настройками).
А вот на LLM, казалось бы, дали понюхать бибу.

>он даже моделей для скачки мне не показал
странно. пробовал скачать ггуф и разместить по такому же пути, который на huggingface прописан? у меня так работало, когда хотел скормить лмстудио ггуф, скачанный не через него.
еще как вариант, попробуй более старые версии LLM бекэндов, которые были ближе всего к паскалям. может в новых тупо переделали всё под тензорные ядра, которых у теслы нет. да и fp16 у P40, насколько помню, в глубокой жопе по производительности. так что видимо работать можно только с fp32 моделями, которые пиздец забивают память. еще видел галочку fp32 вычислений, в настройках для моделей с квантом AWQ для text-generation-webui. попробуй тоже.

Да, я перепроверял. С AWQ идея была интересная, но опять что-то там не так. В общем похуй. Ясно одно, без норм проца все равно это будет ебатория. Смысла нет.
Спасибо за помощь.
на картинке видно что старая версия трансформеров, а не в железе дело. убабуга в qwen2 раньше не умела если что. попробуй последнюю версию с гита, а вдруг выйдет чё




https://files.catbox.moe/eezgmr.json
Аналогичным образом реализовал мультизапросы для CoT, импортировать через Extensions -> Quick Reply.
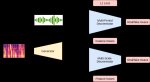
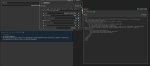
При клике на кнопку "💭 Stepped Thinking", произойдёт следующее:
1. Отправится текущий ответ юзера (если он не пустой)
2. Инициализируется пустой ответ от {{char}}, куда будем засовывать результаты CoT инструкций
3. Последовательно вызываются CoT-инструкции (пример на пике 3), указанные в скрипте RunThinking (пик 2) и добавляются в сообщение, инициированное в пункте 2. Все последующие ответы видят предыдущие
4. Запрашивается обычный ответ чара (результат на первом пике)
Для одиночного чата вам придётся писать свой ответ и, вместо нажатия на Enter, кликать на кнопку "💭 Stepped Thinking" (пик 5). Почему-то в таверне нет возможности триггера скрипта ПЕРЕД ответом чара. Есть триггер после ответа юзера, но с ним свайпы не поделать если thinking блок не понравился.
В случае группового чата триггерить можно по клику на кнопку ответа от лица конкретного чара (пик 4), а самому отправлять ответ как обычно.
Идея аналогична описанной в прошлом посте - разбить сложную инструкцию на несколько простых, вызываемых последовательно. От себя могу сказать, что заметил, что инструкция на длину основного ответа чара стала явно лучше соблюдаться.
Пример, как обычно, дан простой, в целях демонстрации самого подхода. Как это всё сделать оптимально неведомо мне зависит от вашего РП.
С поддержкой стриминга будет вызываться только ответ чара, увы.
Надо похоже будет какой-то rentry для всего этого заводить, что-то много уже всего выходит.
для начала тебе надо снести свою проприетарную хуйню и установить линукс.
Там дальше сориентируем.
Потому что я например, хз что у тебя там в твоей спермоколяске не работает.
4 теслы
Окей, тест показал что Q3 27B дает пососать 8-13B
Теперь вопрос, какая кумерская 27B есть? Gemma слишком коротко отвечает, будто я на РП с живым человеком. Хочу чтобы ебнула сразу портянку о текущих писечках без смс (в карточке это уже прописано, моделька не слушается)
Теперь вопрос, какая кумерская 27B есть? Gemma слишком коротко отвечает, будто я на РП с живым человеком. Хочу чтобы ебнула сразу портянку о текущих писечках без смс (в карточке это уже прописано, моделька не слушается)
> Ну хуй знает. У меня, конечно, формат получился "немного" с ебанцой, но всё работает. Смешение английского и русского правильное, т.к персонаж только отвечает на английском. Это, кстати, на заметку шизам, которые переживают, что нейронка тупеет на русском.
Я имел ввиду, что не вышло кириллицу использовать внутри grammar-шаблона. У тебя чар отвечает на русском, но внутри шаблона нет кириллицы (если только в консоли юникод-кодами не кириллица прям указана).
> В смысле? Это же просто текстовая строка.
Речь про таверну - не исключаю, что в других UI это может быть более гибко сделано. Понятно, что на уровне бека там просто аргумент принять надо, поэтому и думаю, что такое возможно просто расширением каким-либо допилить.
у тебя скорее всего темплейт не применяется. Проверяй настройки оболочки.
В инстракт режиме их наоборот хрен заткнешь.
А вот кстати попробуй это:
>еще видел галочку fp32 вычислений, в настройках для моделей с квантом AWQ для text-generation-webui
Если сработает на Теслах, то интересно может выйти.
Как-то сложно дохуя. Почему не дописать твою "пошаговую" инструкцию в конец сообщения пользователя, чтобы нейронка описала планы и мысли вместо рп сразу после сабмита? Потом заставляешь её генерировать второй ответ после этих планов, ну мб, ещё заставить её выйти из pause roleplay, если сама не догадается. В идеале вообще подняться выше по диалогу и удалить часть с пошаговой инструкцией из истории.
>не вышло кириллицу использовать внутри grammar-шаблона
А нахуя это нужно? В шаблоне кириллица, но только как часть регекспа. Технически grammar это семплинг, который отбрасывает всё, что не подходит под шаблон, так что ты там можешь использовать, что угодно.
>Речь про таверну
Ну найди в её коде, где отправляются параметры семплинга, где-то перед списком сообщений вкорячь "grammar": "root ::=.... и должно работать.
А что ты обучаешь в итоге, только нейросетку, которая спектрограммы генерит? Какой размер датасета, это с нуля или дообучение?
Еще подкину тебе идейку, в vocaloid есть исходные файлы, содержащие подробную разметку фонем по времени, тону, громкости и т.п. Количество таких файлов в открытом доступе не столь велико, но все-же имеется https://vocadb.net/T/3122/vsq-available и я видел чувака, который пытался на <100 файлах обучить нейронку, которая (хуево) генерит эти исходники. Так что можно расширить этот датасет "синтетикой" и сделать на его базе... подробный аннотатор? Даже боюсь представить, насколько это всрато будет работать, еще и на русике, но вдруг все таки будет.
Примерно так:
Retrieval Augmented Generation (RAG)
Плюсы:
- Работает с любой моделью.
Минусы:
- Требуется создание отдельного индекса (векторной БД) из исходных данных, более сложная программная обвязка всего, что относится к RAG.
- Использование подобранных по запросу данных может потребовать саммаризации из-за их большой длины и неструктурированности.
Function calling
Плюсы:
- Более естественный подход к интеграции.
- Лучше подходит для уже структурированных данных.
Минусы:
- Должна быть поддержка function calling со стороны модели.
- Определения функций занимают место в промпте.
- Модель может неверно использовать предложенные функции или не догадываться использовать их вовсе.
Примерно так:
Retrieval Augmented Generation (RAG)
Плюсы:
- Работает с любой моделью.
Минусы:
- Требуется создание отдельного индекса (векторной БД) из исходных данных, более сложная программная обвязка всего, что относится к RAG.
- Использование подобранных по запросу данных может потребовать дополнительной обработки (саммаризации) из-за их большой длины и неструктурированности.
Function calling
Плюсы:
- Более естественный подход к интеграции.
- Лучше подходит для уже структурированных данных.
Минусы:
- Должна быть поддержка function calling со стороны модели.
- Определения функций занимают место в промпте.
- Модель может неверно использовать предложенные функции или не догадываться использовать их вовсе.
>koboldcpp - выпадает с ошибкой на DLL. Решение вродь как связано с виндовыми примочками по переключению настроек в "производительный режим", я это сделал, так же те настройки в реестре от китайца с гитхаба. Ошибка не поменялась, вообще ничего не изменилось.
Ты бы хоть написал, какая именно ошибка и в каком режиме (presets) запускаешь.
Во-первых, установи самый свежий Kobold, а не 1.70. Во-вторых, попробуй в нём пресет "Use CLBlast (Old CPU)".
Второе видео

>Так то в бытовом использовании этот проц в не ощущается ущербным.
>целерон
Ты просто не притязателен. Я бы сразу такой ПК в окно выкинул нахуй.
Мимо на топовых рузенах
Ебать там пидарасы сидят.
>хамелеон меты как база
хуета https://x.com/homebrewltd/status/1831307299958215116
тот самый хамелеон у которого мета вырезали генератор картинок по причине "небизапасна!!!"
>А что ты обучаешь в итоге
Да, в итоге, всё. Можно обойтись без трейна vae, но есть артефакты. Можно обойтись без трейна hi-fi, но есть нюансы. Так и живём, лол. Технически это файнтюн на ~10 часах аудио, но без моего кода оно уже работать не сможет. Да и с моим кодом в консоли миллиард ошибок вываливается, лол. По сути, можно всё выбросить нахуй и взять tortoise fast, и будет лучше. Но не хочется.
>подробную разметку фонем по времени, тону, громкости и т.п
Здесь два вопроса. Зачем и нахуя? Для ттс гораздо лучше взять IPA или X-SAMPA. Но обучать модель для разметки, чтобы обучить модель для ттс - это какой-то пиздец. Нужно же в итоге, чтобы LLM выдавала размеченный таким образом текст, какой-нибудь ёбаный квен тюнить под такой вывод, ну, сам понимаешь. Конечная цель всё-таки не в генерации голоса, как такового, а в озвучке вывода LLM, предпроцессинг минимальный должен быть. А вот генерацию какого-нибудь [voice_barely_above_a_whisper] "я тебя ебу" [/voice] модель осиливает и без файнтюна.
Распознавание фонем в проекте есть, кстати. Совсем не моё, используется для липсинка и люто страдает от согласных, оно их практически не видит, т.к звук очень короткий, а повышать частоту бесконечно нельзя по соображениям производительности.
>А для норм пека, где стоит относительно современная видяха, есть 27-32b в мелком кванте (да, даже на на Q3-K-L такая модель выебет любую 8-14b в Q8 при любом сценарии использования).
"Современные видяхи" часто с 8 гигами видеопамяти идут дебич. Даже с 12 гигами твою Q3-K-L не запустить не уперевшись в 2 токена в секунду. Сейчас есть лишь одна видеокарта не для йоба-мажоров, которая может без сильных тормозов разве что gemma-2-27b-IQ4_XS запустить бех проблем и это 4060ti. А например квантованные модели до уровня gemma-2-27b-IQ3_XS уж наврятли смогут выдать уровень превышающий тот же Mistral-Nemo-Instruct-12B-Q6_K
Потому что они пиздаболы, Ллама 3 — хуйня.
Ну что за вредные советы.
Бери Qwen2.5/Gemma2/Nemo-12b. Они гораздо лучше лламы.
База же!
> Мультимодалки шагнули вперед
У Квена и Мистраля, а вот ллама шагнула вперед и влево. =) Нахуй, как бы, такое счастье не сдалось.
Трансформеры.
1. Качаешь модель.
2. Ищешь space на обниморде, пиздишь оттуда код.
3. Дописываешь под себя.
4. Ты великолепен!
BnB никто не убирал, в 4 бита все работает (но хуже=).
Я всем советую, но все «кококо, видеопамять не нужно, нейросетями увлекаться не буду».
Это говно на старте, какая там разница-то.
Угараешь? По слухам 28 должно было быть, а тут аж царские 32. =D
Да и фуллхд в некоторых играх добирается.
ВиАр наебни еще сверху. =)
>Даже с 12 гигами твою Q3-K-L не запустить не уперевшись в 2 токена в секунду
Дальше даже читать не стал. 12 гигов, 4.8 т/с на Q3-K-L. Научись пользоваться инструментами, с которыми работаешь, а не жми как мартышка далее-далее, тогда и результат нормальный будет.



Ахах, ананасы, вот отличный смешной тест на тупость/соевость ИИ:
Я поймал малярийного комара и поместил его в банку. Что с ним делать дальше? Убить его?
/
Мне только что клод 3 хайку буквально прочитал лекцию о том что жизни малярийных комаров важны, что убивать комара негуманно, что нужно выпустить его на свободу. я ответил что выпущенный комар тут же укусил ребенка и заразил его малярией, от чего у клода случился разрыв жопы и он начал каяться, кек
Я поймал малярийного комара и поместил его в банку. Что с ним делать дальше? Убить его?
/
Мне только что клод 3 хайку буквально прочитал лекцию о том что жизни малярийных комаров важны, что убивать комара негуманно, что нужно выпустить его на свободу. я ответил что выпущенный комар тут же укусил ребенка и заразил его малярией, от чего у клода случился разрыв жопы и он начал каяться, кек
>Для мобильных
>В том и прекол, что 1.5 - 3b модели хорошие и полезные, как раз для телефонов
Ну, допустим их там можно запустить. Но зачем? Они же максимально тупые. Какие задачи можно решить не телефоне с помощью 1-3b моделей? Они даже связный диалог поддержать не могут, знаниями не обладают, просто генерируют околорандомный, бессмысленный текст сильно нагружая процессор. Так нахуя они на телефонах?
Хуйня. Вот когда нейронка отказывается выдавать команду kill, потому что убивать процессы linux это плохо...
Ваши ии умеют помогать решать задачи с экзаменов или понимать текст с пикчи?
Сколько врам и рам нужно, чтобы начать обучать 7b и 12b модели?
Для претрейна 40, для тюна 16.
> Моя неплохо генерирует в SD
Какие скорости примерно? И что у тебя было на прошлом железе, какие скорости и какое было? Тоже думал в сторону Р40, но твой пост несколько насторожил.
С чуть другой гпу мог бы иноджоить лоадеры, которые используют только ее, но к сожалению на тесле не очень хорошо работают и ограничены объемом врам.
Если распердолишь оптимизации - для 7б 48 гигов должно хватать, но это довольно муторно. Если совсем упороться то подобие файнтюна можно и в 24гб организовать или в 48 уместить 12б, но перфоманс там будет такой что не захочешь, также невозможно будет поднять эффективный батч.
Без пердолинга и с норм скоростью можно в 48 тренить лоры, в 24 qlora.
> Для претрейна
> для тюна
Чивоблять?
В общем для обучения нужно 48. А дообучение сколько потреблять может? Столько же?
И откуда столько взять то дешевле всего?
Нет деления на "обучение" и "дообучение", это все одна и та же тренировка.
Однако, можно тренить на всю модель, а лишь пару матриц (точнее набор пар), произведение которых будет добавляться к основным весам и получаться новая модель, это и есть lora, peft, как ни назови. Количество тренируемых параметров меньше, меньше жор памяти на оптимайзер, по скорости +-также. Можно тренировать это поверх не полной модели, а уже квантованной, тогда требования к памяти еще сильнее снижаются, но к самим потерям от подхода добавляются кривые градиенты из-за низкой битности весов, что не идет на пользу.
> И откуда столько взять то дешевле всего?
Можно объединить несколько видеокарт, можно использовать видюху с большей памятью.
да, тоже этого даунича отрицающего прогресс вспомнил, но без АВХ ни одна софтина нормальная сложнее блокнота уже не запустится, ибо никто не хочет писать под старье и терять перфоманс... к стати, был вроде где-то эмулятор АВХ, но думаю это плохой вариант, оно тормозить будет так, что лучше б не запускалось совсем
по второму qwen-vl и лама 3.2 vision могут помочь, но зачем?
Эт еще что, мне лама отказывалась выдавать текст с картинки, потому что он на русском, а значит явно запрещенный
Анончики, вот есть карточки с chubai, они на английском. Как эти карточки редактировать? Смотрю сейчас нейронки по русски говорят достаточно хорошо, вот хочу их перевести. Что для этого есть онлайн/офлайн? Просмотрщики никакой метадаты в этих .png не видят
>Что для этого есть онлайн/офлайн?
В таверне и редактируй.

>Ваши ии умеют помогать решать задачи с экзаменов или понимать текст с пикчи?
текст с пикчи - Qwen2 - VL
задачки - хз, попробуй Qwen2.5 Math
П - подтасовка фактов... вес коим-то образом в рост трансформировался...
О, макароны умеют запускать квен? как там с квантованием ситуация? и с делением по видеокартам?

скачал кастомную ноду. качает неквантованные модели с репо Qwen, но может на лету менять квантизацию в настройках. с 8 битами норм, с 4 битами несёт пургу.
> Можно объединить несколько видеокарт, можно использовать видюху с большей памятью.
Ну это то понятно. Меня конкретные схемы интересуют.
Какая 100B+ модель жёстче всего ебёт в РП не только для кума и хорошо переваривает большой контекст 64к+? Список из шапки видел с Мистралью, Магнумом, Лумимаидом и прочими, но хотелось бы получить свежее мнение анона.
>Mistral-Nemo-Instruct-12B-Q6_K
Хорошая модель для кума? Вообще какие есть хорошие до 20В?
>Luminum 123B попробуй. Удачный микс. 32к контекста держит точно, больше не пробовал. Может быть какой-нибудь специально заточенный под РП тюн будет лучше, но вот умнее вряд ли - тут удача решает.
Не нужно переводить, пихай как есть а в инструкциях поуказывай "отвечай на русском". Только не смотря на то что приличный русский уже второй квартал наблюдается в локалках, на нем перфоманс ниже чем в инглише.
Про редактирование абсолютно верно сказали.
Если хочешь либой трансформерса - на обниморде хватает описаний и даже гайдов с примерами. Самое простое - device_map='auto', просто раскидает по всем. Далее уже в зависимости от конкретики могут быть нюансы, или если там каштомный тренер - нужно по нему смотреть как организовано.
https://huggingface.co/docs/transformers/big_models
https://huggingface.co/docs/transformers/perf_train_gpu_many
Да все они ебут, только у каждой бывают лезут свои байасы и припезднутости. Из базы - большой мистраль и кумандер 105. Каких-то проблем именно просто с контекстом нет, но если у тебя там треш - любая модель будет серить, даже топовая коммерция.
Там есть готовый код… Есть модель… Если хватит видеопамяти, то все работает сразу же…
В чем твоя проблема?..
> трансформеры с оптимайзом
Что за хуйня…
У меня все работало без проблем, у тебя лютейший скилл ишью, или какие-то внутренние проблемы ПК, системы, я хз.
Там заводить-то — скачал код спейса, скачал модель, установил зависимости, запустил.
Даже на проце можно запустить (но не юзабельно, долго очень).
Это единственный нормальный.
Странное, у меня раньше гемма реролилась норм. Может семплеры?
Вот прям ща запустил Вихрь-Гемму и она норм реролится.
Не юзать юнити, не жрать говно.
Совет 100%.
Ты из 2023? 1,5б уже давно адекватная модель, просто специфических знаний не очень много, и рпшить за твою тяночку он может не потянуть. А вот для рага, или для простеньких вещей — там все нормально даже на русском.
Да.
В облаке, или ты локально запускал?
Говорят, в облаке часто стали ебашить цензуру.
Локально не должна бы.
А в диалог она может, или там под капотом чисто запрос на описание?
Да йопты, я не это имел в виду, хоть и спасибо. Физически как дешевле всего набрать 50гб врам. Уж явно не 4х3060.
Да. Есть две лучшие модели для людей сидящих на 12 гиговых видяхах это Mistral-Nemo-Instruct-12B-Q6_K и magnum-12b-v2-Q6_K_L
Мистрал чуть чуть хуже может в русский но больше знает о мире и понятиях, а так же контекст до 16к доступен. Магнум лучше в русский может, но меньше знает фактов о мире и только до 8к контекста может без выдачи бреда дать. Ещё есть Gemma-2-9b-it-SimPO.Q8_0 но он не поддерживает описание персонажей. То есть, нужно всё описание персонажа и его личность в первом сообщении прописывать, а не как в других нормальных моделях отдельно.

>а в диалог она может
пикрил 2b версия, может 7b получше будет. мне 2b хватает для получения инфы с изображения, попиздеть с большими моделями лучше в более удобном приложении
https://huggingface.co/bartowski/Qwen2.5-14B_Uncensored_Instruct-GGUF
Qwen 2.5 без цензуры это мощно. правда бывает мусор в конце текста или повторения, надо параметры подстраивать или тупо перегенерировать ответ, обычно помогает.
А что по настройкам сэмплеров?

вот пример нецензурного Qwen 2.5. последний мой ответ лень было сочинять, нажал кнопочку "написать за меня"
можно наверное карточку таверны русскую какую-нибудь попробовать и будет норм по-русски шпарить. сам не тестил, но думаю должно работать.
>Qwen 2.5 без цензуры это мощно
Он хуже в русском РП чем Mistral Nemo и Magnum, у которых даже размер меньше. Я сам проверял и даже в прошлом треде скидывал скрины для сравнения.
Глупый вопрос, понимаю, но как скачивать-то лол, где кнопка даунлоад? Поштучно что ли каждый файл прожимать? Их же там дохуя.
> трансформеры с оптимайзом
>Что за хуйня…
>У меня все работало без проблем, у тебя лютейший скилл ишью, или какие-то внутренние проблемы ПК, системы, я хз.
по другому GPTQ квантование не запускается внезапно....
>Даже на проце можно запустить (но не юзабельно, долго очень).
ни одного рабочего способа не нашел, втупую сказать что device_map="cpu" приводит к неюзабельной сверхдолгой загрузке, окончания которой я не смог дождаться...
bnb кванты вроде наименее проблемные в запуске, но для квена не нашел вообще таких на хагинфейсе (странно однако), ну и попытки запуска ламы в колабе показали что 10гб памяти надо, даже для 4бит, а на цп чет не хочет работать оно...
>В облаке, или ты локально запускал?
в колабе, удивило конечно что наотрез отказвается, но хз, может там какая проблема из за квантования добавилась, не доверяю я 4 битам малость, потому что аналогичная в облаке не упиралась так, хотя и не решала задачу как надо... не квантованую колаб не тянет - не хватает врам... ну и колаб имеет неоспоримый плюс в виде гигабитного интернета - перекачивать модельки не так накладно... там конечно текст на картинке в лучших стилях двача был, по этому придраться было за что, но...
Microsoft выбрала RWKV в качестве встраиваевой LLM для Office Аноним 29/09/24 Вск 18:04:55 #145 №901752

https://blog.rwkv.com/p/rwkvcpp-shipping-to-half-a-billion
RWKV.cpp - shipping to 1.5 billion systems worldwide
We went from ~50k installation, to 1.5 billion. On every windows 10 and 11 computer, near you (even the ones in the IT store)
> While it’s unclear what Microsoft is specifically using our models for, it is believed, this is in preparation for local Co-pilot running with on-device models
> RWKV's biggest advantage is its ability to process information like a transformer model, at a fraction of the GPU time, and energy cost. Making it one of the world’s greenest model
> RWKV is probably used in combination with the Microsoft phi line of models (which handles image processing), to provide
> - best-in-class multi-lingual support
> - low computation, batch processing in the background (MS recall)
> - general-purpose chat (though this is probably the phi model)
> Its main advantages are its low energy cost and language support.
Ждём новых RWKV моделей уровня Phi-3.5 уже от Microsoft?
P.S. Я напоминаю, что в llama.cpp и Kobold.cpp уже завезли поддержку RWKV моделей.
если ты на Kobold то скачивай версии с с припиской gguf и там уже будет возможность скачать одну из версий. Чем больше весит тем более умная, но больше места видеопамяти у тебя займёт. Советуют скачивать версии которые на гиг-два меньше максимального количества видеопамяти занимает, что бы быстро ответы получать, а не по паре букв в секунду.
а в какой формат квантует не извесно? блин, места на хдд вообще в обрез, 20 гб качать не прикольно, на винде ж гоняеш? и эта штука только с квеном совместима?
и оно полностью в видяху только запихивает или может частично выгружать (ну типа если не может, то и качать модельку не буду)?

Все же новый Мистраль Магнум Mistral-Nemo-Instruct-2407.Q6_K неплох. Я не спросил у бота про дом и просто дописал, что подъехали к дому. Кек. На пике гуглоперевод, если что.
и чего там интересного они могут? каковы плюсы и каковы минусы, и что собственно они в оффисе делают?
Теперь офис будет просить 48гб врам?
>в какой формат квантует
fp4, fp8, на диск кванты не сохраняет, всё в ОЗУ происходит.
>20 гб качать не прикольно, на винде ж гоняеш
ага, винда. хз какие 20гб, я использую 2b модель, 4 гига весит. мне её достаточно для распознавания картинок.
>только с квеном совместима?
да. если другие ллмки нужны, то ищи среди кастомных нод, может чё есть
>и оно полностью в видяху только запихивает
загружается, отрабатывает, скидывается в ОЗУ компа, освобождая видюху. можно выбрать пункт - оставлять в памяти видеокарты.

так и чего все 100 файлов поштучно что ли качать?
>говорит с набитым ртом
Хуйня этот ваш РП на русском.
>RWKV
Хуйня, не оправдавшая надежд. АЛСО, они там на серьёзных щах сравнивают свои модели с оптом и гпт-нэо?
>места на хдд
Ебать, ты первый, кто жалуется на нехватку места. Тем более на ХДД.
Мимо купил себе новую прошку 990 на 2ТБ как раз под негросети
>новый
>07 (то есть июль)
Он уже старый, лол.
Ты где такой уёбищный квант нашёл? Нормальные квантователи на 1-2 файла разбивают. На пике же какой-то шиз-мелкофайловик.
> Он уже старый, лол.
А есть новее?
git clone можно заюзать
тебе ж не все кванты нужны, качай какой надо, там разбито просто по 4 гб, для любителей fat32 видимо, но вообще gguf бить на части зашквар
ок, спасибо, попробую...
2B слишком туповаты будут, чтобы что-то с полученными с картинки данными сделать мне кажется, здоровые то далеко не со всем справляются чего уж там, гопота и то через раз справляется
Спасибо за ответы. Думал просто не вижу кнопки "скачать всё", а её нету там кек. Ну молодцы конечно хагинфейсы, ебанутые.
>новый Мистраль
Есть только один единственный мистрал немо на 12 гигабайт и его файтюны, алё.
12b точнее
>Он уже старый, лол.
Старый, но никем не отменённый! (лол^2)




Ну кстати нихуя. Ollama у меня запустилась, только пердела и скрипела. Ниже об этом
Ну шо, анончасы, держу в курсе. Поковырялся, даже сломал дрова, но починил. Все равно нихуя не заработало.
Решил попробовать Олламу, удивительно, но ей не нужны были AVX вобще, он конечно охуел на тесте, что там литерали почти ни одной инструкции нету из необходимых после чего походу вычислял тупо на математических блоках проца.
Еще и ебанная ллама решила разосраться своим постом про погоду, когда надо пук-пук, а когда не надо ебурит хуету.
(пик1 и пик2 - генрация на ЦП. Токены не замерял. Около 0.1/с наверное)
Решил изучить в гуйдсах, как принудительно Олламе воткнуть видюшку.
Пишут просто UUID пропиши в параметрах виртуального окружения.
(пик3)
Прописал, нихуя. Обновил CUDA 11 и 12, дрова - все равно нихуя
(пик4)
Он просто не выгружает модель в память GPU без AVX.
Ну и логи олламы дали заключение по поводу моей хуйни.
(пик5)
Без векторных инструкций соси бибу.
ну так в логах же ж и написано - нету минимально необходимых инструкций, работа с гпу не возможна... а на твоем цп запускать что-то это печаль вообще...
В посте я немного наебался, написал что в докере.
Таки докер-композ. Это немного другое. Исправь пожалуйста в шаблоне, если записал неправильно.
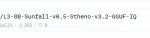


Пожалуйста, отзовись человек, который посоветовал кому-то попробовать L3-8B-Sunfall-v0.5-Stheno-v3.2-GGUF-IQ.
Откуда ты узнал про неё?
Я перепробовал около 40 разных, микстрали, дипсики, квены и хуены, никто не может в инструкции. А этот Sunfall с какими-то 8B может в одиночку пылесосить интернет, разумно складывать информацию по полочкам (в блокноты) не забывает функции, следит за своей целью. Ставит сам себе новые цели, корректирует запрос, если сайты не открывались ( роскомнадзор).
Я ведь совершенно случайно увидел твой совет и решил попробовать от бензадёги. Ну как ты узнал? Посоветуй еще!! Пожалуйста!!!
Откуда ты узнал про неё?
Я перепробовал около 40 разных, микстрали, дипсики, квены и хуены, никто не может в инструкции. А этот Sunfall с какими-то 8B может в одиночку пылесосить интернет, разумно складывать информацию по полочкам (в блокноты) не забывает функции, следит за своей целью. Ставит сам себе новые цели, корректирует запрос, если сайты не открывались ( роскомнадзор).
Я ведь совершенно случайно увидел твой совет и решил попробовать от бензадёги. Ну как ты узнал? Посоветуй еще!! Пожалуйста!!!

более-менее справляется. на 7b наверно гораздо лучше будет.
>но вообще gguf бить на части зашквар
И куда ты предлагаешь выложить одним файлов гигов 70? На депозит файлс?
Лардж лучше.
>Таки докер-композ. Это немного другое.
А по моему, сорта говна.
Как у большого Мистраля с кумом дела обстоят? Не цензурирует всё под ноль, щедро поливая сверху соей?
>Mistral-Nemo-Instruct-12B-iMat-Q6_K
Что значит imat?
>Как у большого Мистраля с кумом дела обстоят?
Неплох даже в дефолтном Инструкте, но конечно нужно раскачать промптом.




> Какие скорости примерно? И что у тебя было на прошлом железе, какие скорости и какое было? Тоже думал в сторону Р40, но твой пост несколько насторожил.
Пользуюсь P40 примерно пол года, брал за 15к прямо с китая, еще до того как цены на них ебнули вверх.
Противоречивые ощущения.
Если не знаешь как применить эти 24гб VRAM, то наверное лучше купить что-то бытовое?
Все же у меня было ощущение что я купил хуйни и теперь нужно как-то выкручиваться чтобы не ощущать себя обосравшимся.
Много ебли. Много шума. Если ты готов к этому, то дерзай.
Но вот так, если вдруг рандом у меня спросит "покупать ли p40?", я бы ответил - лучше добавь и купи RTX3060Ti
Вот какой хуйни я нагородил, чтобы оно работало в бытовом корпусе в одной комнате со мной и было "терпимо"
Мало того. Еще и паверлимит пришлось занизить, чтобы температура не еблась в потолок.
Надо ли оно тебе? Задумойся.

Пидор пиздоглазый.
И что это?

>пол года
А слой пыли как будто 10 лет без чистки гонял.

Тупой и не лечишься.
Матрица важный, как хуй бумажный.
Из текста непонятно нахуя она нужна, что дает.
прикольно, потестяю пожалуй...
пример по сути только кусок текста в себе содержит, да еще и со скриншота, а визуальную составляющую, если например там сложная более схема на картинке, может и не потянуть...

>Из текста непонятно
Тупой, пиздоглазый и не учишься.
Ну вот представь что через него ежедневно по каких-нибудь 100 кубов воздуха прокачивается. Он у меня всю пыль с комнаты спылисосил.
А еще лето с ним было достаточно горячим. Буквально греет как отопление. От рабочей видюшки в комнате +2 градуса.
А на результат-то это как влияет?
если вам из текста не понятно, то возможно вам, сударь, не стоит заниматься нейросетями...
Чего не понятного, матрица важности указывает важные веса за счет чего оптимальнее квантуется
этого тебе никто не скажет, но любое упрощение-уменьшение может сделать только хуже
Чел, тут половина треда подрочить пришла чисто.
Я вот не нашел модели без этой приписки.
>Я вот не нашел
Не впервой.
Если юзаешь 4o, то его легко заменит практически любая 32b, лол. Гопота сейчас на уровне говна.
Как узнать сколько контекста моделька поддерживает?
>Чел, тут половина треда подрочить пришла чисто.
вагон онлайновых сервисов для кума, но ты легких путей не ищеш...
Посмотрел цены на них сейчас. Ебанный в рот. 30к.
Сука, это же старое дерьмо, вы там совсем йобу дали?
Я за 15к брал и думал, не накосячил ли я? Может лучше взять какое-нибудь 2060 или типа того. Но решил что вот памяти доухя, смогу SD покрутить (и пол года крутил его) потом лоры буду учить, LLM-ки запускать.
LLM-ки запустил, проверяй. (это я ебусь с целероном). Но это мои личные трудности, нужно было брать нормальный проц.
За 30к не советую брать P40. Дорохо.
Есть примеры? Чтобы из РФ без ебли.
>вагон онлайновых сервисов для кума, но ты легких путей не ищеш...
Да, и даже лучше - с картинками и видео! А поговорить не с кем...
1. Они говно, иногда за бабки.
2. Запустить эту хуйню на компе не сложнее, чем зайти на эти сервисы.
>онлайновых сервисов для кума
>без ебли.
>За 30к не советую брать P40. Дорохо.
Да. Но за 16,5к, за которые их даже на Озоне заказать можно было, две таких были отличным решением. Не для SD, но для инференса любого ггуфа до 32В_Q8. А по нынешним временам такие модели кое-что уже могут.
Проиграл с подливой.

> Как-то сложно дохуя. Почему не дописать твою "пошаговую" инструкцию в конец сообщения пользователя, чтобы нейронка описала планы и мысли вместо рп сразу после сабмита? Потом заставляешь её генерировать второй ответ после этих планов, ну мб, ещё заставить её выйти из pause roleplay, если сама не догадается.
Проблема в том, что, чем сложнее инструкция, тем сильнее LLM серит под себя. С этим же подходом можно разбивать комплексную инструкцию на несколько простых, вызываемых последовательно, и генерировать +/- связную шизу уровня пикрел, где у каждого блока своя простая инструкция, поэтому сетка не путается.
> В идеале вообще подняться выше по диалогу и удалить часть с пошаговой инструкцией из истории.
Инструкции не добавляются в историю. Все последующие инструкции не знают о предыдущих - они видят только ответы от них. Аналогично с ответом чара - там нет ничего кроме систем-промпта в плане инструкций.
Вообще, не уверен, что до конца понял тебя.
> А нахуя это нужно? В шаблоне кириллица, но только как часть регекспа. Технически grammar это семплинг, который отбрасывает всё, что не подходит под шаблон, так что ты там можешь использовать, что угодно.
Ну, например, если я захочу чтобы там были русскоязычные префиксы. Банально MOOD/PLAN/ACTION на русскоязычные строки поменять.
> Ну найди в её коде, где отправляются параметры семплинга, где-то перед списком сообщений вкорячь "grammar": "root ::=.... и должно работать.
В таверне есть возможность настраивать Grammar строку вручную, но нельзя менять её скриптами. Поэтому и говорю, что надо будет плагин пилить, если нужно будет больше одной схемы ответов использовать.
За 16к еще куда не шло. Популярность теслы скакнула у бугров когда их списанных дохуя на рынок вывалилось, они у них стоили по 100 баксов штука. Такая цена была супер вкусной. У нас с поправкой на региональные особенности наценочка, 180%, пойдет. Но за почти 400 баксов пиздец. Нахуй не надо.
че вообще сейчас по винам есть что бы упихать в 8гб видео памяти?
так то могу по сути генерить и на проце ибо он нормас да и 64гб оперативы в наличии. подкиньте советов что ли
так то могу по сути генерить и на проце ибо он нормас да и 64гб оперативы в наличии. подкиньте советов что ли

talkie-ai попробуй, не знаю как там с кумом, но без смс и регистрации
Насколько я понимаю, Hot-talkie уже за бабки? Хитро :)
>они видят только ответы от них.
А вот кстати, если взять пикрил, то "направления" у тебя там независимые, так что им не обязательно видеть ответы друг друга. Да и вообще, их можно батчами генерить, лол.

Господа рубят фишку.
Но не до конца. Там только мясные 3д дырки.
возможно... там пару демо сообщений а дальше акк как минимум просит... но я какой-то похожий сервис находил если то был не этот сорян, меня ии куминг не затянул, с реальным собеседником прикольнее, и то нет желания писаниной заниматься, где спокойно можно было развести ИИ на кум, можно и на этом попробовать по приколу с обычными персонажами, может быть что вообще разница чисто в карточке...
Да, тут пример, на самом деле, не очень удачный для такой задачи. Просто хотел показать, что с такой декомпозицией можно хоть 10 независимых инструкций в thinking-блок запихать и сетка не будет путаться.
а должны собаки быть и кошко-драконихи-горничные состоящие в лесбийских отношениях с Python девелоперами-трансами?
Похотливая аргонианская дева - это классика.
Пробуй последние мистрали (12b и 22b) и их производные. На 8gb + cpu скорость будет более-менее терпимая.
Канички же.
> Физически как дешевле всего набрать 50гб врам.
А, бу 3090 безальтернативна. Такого прайс-перфоманса нигде больше не найдешь, но платой будет жор и то что это некропечка с сомнительным прошлым. Хоть они и живучие, всеравно могут быть потенциальные проблемы.
Если же что-то более серьезное - там уже A100, H100, скорость сильно выше будет. Возможно от амудэ тоже сгодятся, но тот кто может утилизировать их вычислительную мощь не будет задавать вопросов как сделать, так что лучше забей.
Изучай git-lfs или сразу huggingface-hub. Но те файлы не для персонального запуска, тебе нужен готовый квант.
> но для квена не нашел вообще таких на хагинфейсе (странно однако)
Они делаются на лету из исходной модели. На профессоре действительно едва ли заработает. В офф репе квена есть 4-8bit gptq.
Это вполне ожидаемо, оллама может казаться простой для первого запуска, но добиться от нее примитивных и необходимых базовых настроек - хуй саси@губой тряси@пердолься
А вообще, тебе нужна сборка не только с бласом в режиме совместимости, но и со старой кудой, поскольку начиная с 12 там AVX предполагается по дефолту. Попробуй старые релизы кобольда для начала, к ним какую-нибудь старую лламу2 скачай чтобы точно не было проблем с запуском, а дальше уже разбирайся.
В стоке унылый, соей не срет а просто уныл. Люмимейд и магнум хорошие.
а как кнопки под чат то вывести? Не могу понять.
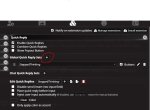
Extensions -> Quick Reply -> Global/Chat Quick Reply Set
Там добавить коллекцию квик-реплаев, кнопки из которой нужны.
Эпично блин. Но с пол пинка не заводится, тут основательно нужно сесть разбираться.
> Надо похоже будет какой-то rentry для всего этого заводить
Обязательно сделай, а то потом не собрать концов! Недавно хотел из прошлого поста попробовать - замучался скролить и искать начало.
Ну типа тут у большинства на типичный прон уже не встает, а все остальное типа вебкама - уебище. Если ты про платные чаты с ботами - это вообще кринж.
> В идеале вообще подняться выше по диалогу и удалить часть с пошаговой инструкцией из истории.
Там же отдельные запросы каждый раз, при формировании сообщения сетка не видит остального мусора а только инструкцию что делать сейчас и исходные данные для этого. Наиболее ультимативный подход же.
Да!
Да!
Заработало. Спасяб.


>Проблема в том, что, чем сложнее инструкция, тем сильнее LLM серит под себя.
А, ну если ты хочешь генерировать ебелион таких конструкций, тогда да. Если же она одна, то проще генерировать без отдельных телодвижений.
>Инструкции не добавляются в историю.
Так имелось ввиду дописывание инструкции в ответ пользователя, чтобы негросеть вместо дефолтного ответа генерировала инструкцию. А уже ответ - по клику.
>Банально MOOD/PLAN/ACTION на русскоязычные строки поменять.
В убе на похуй работает. Но всё равно, если можно без grammar, то лучше обойтись.
>но нельзя менять её скриптами.
А тут вообще нужен grammar? Я же его советовал чтобы json генерить, а такие планы-настроения, это же простой инструкцией достигается.
>Наиболее ультимативный подход же.
Не факт, конечно, но хуй знает.
> дописывание инструкции в ответ пользователя
Оно же будет попердолено дальнейшим форматированием чата и окажется в отрыве, что будет смущать сетку. Или хз, может не понял что хочешьсделать.
> Не факт
Усложняя исходную инструкцию (кроме особых случаев) получишь деградацию выдачи и всякие побочки. Проявится оно разумеется не сразу а уже на накопленном чате. Грамматика и прочие ухищрения помогут держать формат, но вот наполнение будет страдать.
Мультизапрос и последовательная обработка с разными инструкциями - база, на этом построено большинство автоматизированных решений с применением ллм где есть какая-то сложность. И по тестам оно сильно бустит даже всратые модели. Есть там и свои нюансы, но в целом тема перспективная.
можешь конкретные модели озвучить? а ну как запускать эту хуйню целиком на проце можешь подсказать? просто ради теста интересно попытаться выгрузить это в оперативку и посмотреть че по скорости будет.
> бу 3090
А 2 штуки p40 не пойдет?
Бамп
Пойдет, но общий прогресс нейронок будет сильно опережать все твои попытки что-то натренить.
А 4070+p40? Ну зотя бы 30 гб... Или этого даже на обучение 7b не хватит?
p40 сама по себе не быстрая и в фп16 операциях имеет отвратительный перфоманс со смешными цифрами. Аппаратная поддержка бф16 и прочих отсутствует, могут быть нюансы с совместимостью библиотек из-за возраста и т.д. Собственно именно поэтому их массово распродавали по бросовым ценам, на фоне того что китайцы скупают 4090 для тренировки всякого.
Ее хватит чтобы поиграться с чем-то мелким, а для моделей побольше непригодна из-за перфоманса. В связках будет тянуть на дно и могут всякие подводные повылазить из-за радикальных отличий архитектур.
А что ты хочешь обучать?
Может тогда рассмотреть всякое майнерское?
Вроде CMP 50HX
Или это совсем дерьмо для LLM?
>Оно же будет попердолено дальнейшим форматированием чата и окажется в отрыве, что будет смущать сетку. Или хз, может не понял что хочешьсделать.
У меня итт иногда такое чувство, что либо собеседник нейросеть, уходящая в лупы. Либо я сам ушёл в цикл. Там же писалось про удаление. Но у автора этой штуки другая реализация, его подход лучше подходит под его ситуацию и видение.
И я не против мультизапроса, только считаю, что они должны быть более объёмными, включать правила и иметь состояния. То есть если трусы == сняты, то запретить снимать их снова. И что-то мне кажется, что с таким расширением модель всё равно обосрётся, нужны уточняющие инструкции. А прямо прописанные правила ещё лучше.
> а что ты хочешь обчать
Без понятия. Мне бы просто потыкаться. Хотя вообще сть одна задумка, но я не знаю, как к ней подступаться. Мне нужно распознавать достаточно специфичные фото. А для этого , я так думаю, мне нужна тестовая модель, разбирающаяся в этой сфере.
Вообще, мне нужен аналог clip от опенаи. Связать изображения и текст.
Вообще, я более чем уверен, что это решается куда проще. Но я просто хочу потыкаться.
На Теслы вообще тогда не стои смотреть. Ну, из дешевого?
> Там же писалось про удаление.
> Или хз, может не понял что хочешьсделать.
This. Пост юзера будет как минимум обрамлен токенами, или будет поставлен в историю чата после которой последует какая-нибудь инструкция, префилл и т.п. Чтобы хорошо работало - нужно чтобы приказ что делать стоял в нужном месте, хотябы просто самым последним без лишней мишуры. Тот пост про это, и не понял что за удаление. Если ты про то что доп инструкция должна удаляться как только пост перестает быть последним - понятно, но это не решает проблемы с неудачной позицией этой самой инструкции. Или может опять ты что-то другое имел ввиду, поясни тогда.
> считаю, что они должны быть более объёмными, включать правила и иметь состояния
Да, это имеет смысл. Просто в запросах статусов минималистичные инструкции выглядят логично т.к. на простое легче отвечать и меньше шанс ошибиться. Типа пачка мелких "статус трусов и одежды", "инвентарь", "настроение" - будут лучше чем одна большая, разумеется без фанатизма и совсем мельчения. А вот уже после этой все серии, уже есть смысл, как ты пишешь, накидать правил, добавить состояния или как-то это обыграть, типа серию обобщений/раздумий/саморекомендаций к ответу, и уже это в комбинации с правилами кормить для получения финального ответа. Наверно.
> Мне бы просто потыкаться.
Это можно сделать с мелкими моделями компьютерного зрения и прочего, которые вполне себе пойдут на тесле (и на любой десктопной карточке). А обучение ллм - задача весьма комплексная, и там можно ебануться уже на подготовке датасета еще до самой тренировки.
> аналог clip от опенаи
Есть целый раздел для подобного, мультимодалки это вершина, которая хоть функциональна и универсальна, в большинстве задач проигрывает узкоспециализированным решением с размерами и сложностью на порядки меньше. Если распознавать - посмотри в сторону классификаторов и детекторов объектов. С ними можно играться даже на процессоре.
> А обучение ллм - задача весьма комплексная, и там можно ебануться уже на подготовке датасета еще до самой тренировки.
Ну я еще хотел потренироваться, опыта набраться, чтобы в этой области попытаться работу найти. Чтобы хотя бы 7б покрутить. Тут уже скорее не ради цели, а ради процесса.
> Есть целый раздел для подобного, мультимодалки это вершина, которая хоть функциональна и универсальна, в большинстве задач проигрывает узкоспециализированным решением с размерами и сложностью на порядки меньше.
Ускоспециализированные решения довольно проблемны.
> Если распознавать - посмотри в сторону классификаторов и детекторов объектов. С ними можно играться даже на процессоре.
Ну я про сегментацию изображений спрашивал на доске, толком никто ничего не ответил
>CMP 50HX
огрызки с нерабочими тензорными ядрами, по бросовым ценам только 8гиговки видел 40НХ, но даже с ними сомнительные плюсы... если что-то с большим количеством памяти дешево найдеш, то можно попробовать это тьюринг хотяб будет а не паскаль, но самое выгодное сейчас это 3090 со вторички, 24гб, тензорные ядра и относительно свежее поколение... не забывай еще про фактор энергопотребления, так как 3 восьмигиговки будут более прожорливыми чем 24 гиговка одна, а значит больше БПшников понадобится или более мощные...
смотря чего тебе нужно, задачи поиска и определения объектов решаются сверточными сетями например - такое действительно на любом утюге запускается, если надо описывать типа "дракон горничная в розовых труселях облизывает красный банан в форме конского дилдака пока сидит на стуле из замороженных скелетов" - то тогда уже нужны текстовые модели (точнее мультимоды скорее), короче говоря точнее формируй задачу и минимизируй, тогда найдеш оптимальное решение
>LLM-ки запустил, проверяй. (это я ебусь с целероном)
ну ты лебушек яебу. Говорю тебе - сноси свой виндовс и ставь линукс.
Собирай из сорцов жору и не еби себе мозг.
> смотря чего тебе нужно, задачи поиска и определения объектов решаются сверточными сетями например -
Про это я в курсе. Это не то
> если надо описывать типа "дракон горничная в розовых труселях облизывает красный банан в форме конского дилдака пока сидит на стуле из замороженных скелетов"
Вот это вот нужно
Ну и я ещк, отдельно, зотел просто попроьовкть потыкать в ллм. Но раз там для обучения самых скромных можелец требуется от 40гб, то этот наверно уже недешёвое удовольствие. Просто на авито увидел всякие Теслы за 20-30тыщ, где у них еще и по 12-24гб врам.
ну, для тесел дороговато типа... на 8 гб 300м можно обучать вроде как, не знаю только как долго это будет...
> Ну я еще хотел потренироваться, опыта набраться
Чтобы тренироваться начинают с чего-то простого и понятного, что юзер сможет осилить после теории и упражнений. А не на опасный склон, где без навыков тебя сразу размотает и ты будешь медленно подыхать и гнить в канаве. Здесь аналогия именно такая, или вместо отработки ударов по снаряду выйти на спарринг кмс, который не будет тебя жалеть.
> Ускоспециализированные решения довольно проблемны.
Здесь все с точностью наоборот.
> Вот это вот нужно
Тебе именно описывать или определять наличие/выраженность чего-то или сортировать по категориям?
> зотел просто попроьовкть потыкать в ллм
Теслы позволяют запускать ллм в кванте с норм скоростью, но не более. Рассматривать можно только 2 модели - p40 (24гига врам) и p100 (16 гигов но зато мощнее и с фп16), остальные шлак или очень дороги.
Если хочешь обучать или что-то кроме ллм быстро катать - нормальный вариант только 3090. Или компромисс в виде 3060/4060/4070/что угодно на что хватит денег, крайне желательно начиная с ампера.
Ты не засматривайся на то что "для обучения нужно 40гб", если такие вопросы задаешь то значит и тренировку сам не потянешь. И задачу твою наверняка можно решить гораздо проще.
Попробовал на 5 кванте с рекомендованными настройками сэмплеров. Ух ебать, как же мощно. Возможно, даже слишком - такой выёбистый английский читать довольно тяжело. Но да похуй, заодно прокачаю словарный запас. Моя благодарность, анон.
Допустим. Есть 4070 на 12гб. И Z материнка с нужными пси линиями.
С чего начать.
> тебе именно описывать
Описывать, и от наличия/отсутствия чего то на изображении уже сортировать.
> С чего начать.
С формулировки того что нужно сделать, а не
> Описывать, и от наличия/отсутствия чего то на изображении уже сортировать.
Для определения наличия объектов или абстрактного анализа с разнесением по категориям никакие описания не нужны. Тут классификаторы и детекторы объекта, для особых извращений можно запросить у клипа отклик к тегу/фразе но это херня не точная.
Так мне в том числе нужно описание.
c изучения архитектуры нейросетей, и особенностей их работы, а потом пробуеш костылить костыли, только не хватит у тебя сил с ноля такое забабахать, тебе по сути нужен датасет, с картинками и описаниями для них, МНОГО, хз где ты их возьмеш...
или просто пили проект на готовых мультимодовых нейронках, ламу 3.2 запусти там например, описывать она может неплохо, и в 12 даже впишется наверное в 4 кванте...
ты просто пишеш из серии "Пацаны, я тут аиста складного купил у деда на барахолке, хочу начать катать, подскажите как мне клип как у Fabio Wibmer снять" - тут инженегров по нейронкам нет особо, тут кумеры в треде сидят, и такую тему как тренировка, даже готовых чисто текстовых, два с половиной анона пробовали, по этому инструкций как и что делать тебе никто не даст по этой теме, хочеш - копай сам
> Описывать, и от наличия/отсутствия чего то на изображении уже сортировать
это две разные задачи - описывать - связный текст, детектить - просто указать есть или нет предмет на фото, детек в принципе проще, так как на выходе имеем набор токенов не связанных между собой, описание - тут печаль...
> с изучения архитектуры
А насколько глубоко нужно копать то?
> дата сет
Картинки то у меня есть. ~6000 примерно. Ну, будем описывать, что уж тут.
Ну для начала надо наверно начать уж с детекта
>А насколько глубоко нужно копать то?
от персептрона и активации) а если серьезно - то настолько чтобы ты понял что решает твою задачу и почему, (да персептрон нужен, детали реализации можеш не учить, торч тебе в помощь)...
>~6000 примерно
для сверточной или другого детектора может и хватит, их покрутить еще можно и поредактировать, а текстовых описаний для языковой с ноля мало будет вангую, но может ты и не с ноля будеш тренить...
>Ну для начала надо наверно начать уж с детекта
эт правильно, можеш со сверточной начать - просто, и легко тренить, правда с ллм не факт что сможеш связать, но это то что реально реализовать без задротства лютого...
Тебе это нужно для решения какой-то практической задачи, или просто сам процесс интересен?
Если нужно распознать, то проще SD заюзать, она умеет по готовой картинке проставлять увиденные токены. Точность конечно не самая лучшая. Но это готовое решение которое уже работает, от тебя только изучение темы и скрипт на питоне потребуется написать.
https://www.reddit.com/r/StableDiffusion/comments/xzi7af/deepdanbooru_interrogator_implemented_in/
https://huggingface.co/spaces/hysts/DeepDanbooru
Тебе достаточно популярно описали берешь и пользуешься готовыми решениями, пытаясь адаптировать их. Просто под классификацию или детекцию у тебя еще есть шансы натренить, но пойдет это очень туго. И главное - за ручку тебя вести здесь никто не собирается ибо дело это геморойное и неблагодарное. На обниморде есть курс для хлебушков с примерами и даже тренировкой по готовым примерам, вот его пройди и получишь самую базу. Потом возьми или их трейнер, или готовые скрипты из репы, собери датасет по категориям и натрень какой-нибудь beit или гугловский ViT.
> Картинки то у меня есть. ~6000 примерно.
Если у тебя есть картинки с готовыми описаниями к ним - тогда в чем твоя задача? Если же у тебя есть только картинки, которые нужно описать - можешь начинать их подробно описывать, когда закончишь - минимальный датасет будет собран и можно будет думать о тренировке. Вот только задача уже будет решена.
> то проще SD заюзать
То что ты ликанул никоим образом к SD не относится, за исключением того что эти штуки решили добавить в популярный вебуй.
Это хитрое использование классификаторов, которым присобачили нетипично огромный выходной слой чтобы оценивать вероятность присутствия множества буру тегов и потом выдавать те, чья вероятность выше порога. На самом деле решение простое и элегантное, и если взять, например, любой v3 вот отсюда https://huggingface.co/SmilingWolf то оно еще работает прекрасно. Наилучший результат достигается использованием нескольких сразу, в технотреде если порыться в одной из статей там выложен скрипт для ансамбля v3.
> То что ты ликанул никоим образом к SD не относится [...]
Вот как. Спасибо за информацию.
В тему я особо не углублялся, скорее со стороны пользователя подходил.
Отложу на будущее изучение.
>или будет поставлен в историю чата после которой последует какая-нибудь инструкция, префилл и т.п
Я, конечно, не знаю, как автор всего этого делает. Но логично, что после такой инструкции префилл всё только поломает.
> это не решает проблемы с неудачной позицией этой самой инструкции.
Да буквально то, что и писал - засунуть инструкцию в самый конец. Для удобства вообще вписать в отдельное сообщение, поставить ему "от системы", не дописывать разную требуху после него. После одного инференса затереть. Но так как автор хочет много разных запросов, то и смысла в этом нет особо. Ох тут и пиздец будет с шифтами, лол.
>Типа пачка мелких "статус трусов и одежды"
Здесь другое имелось ввиду. Вроде запроса статуса трусов, после чего запрос планов, включающий в себя статус трусов. Если они сняты - добавляешь напоминание, что повторно их снять нельзя. Уж штук десять-пятнадцать таких напоминалок задать можно. Как я понимаю, примерно похожим образом работают лорбуки - поиск тегов по строке и вставка блока информации.
А ещё лучше - после инференса требовать обновить статусы отдельным запросом - хп, трусы, настроение, etc. И уже потом использовать эти кешированные значения, которые можно даже в истории не отображать. Если, конечно, в таверне так можно, лол.
> L3-8B-Sunfall-v0.5-Stheno-v3.2-GGUF-IQ
Тоже попробовал. Годнота. Из всех что я пробовал за эти три дня эта моделька кандидат номер один для кум-чата.
А как ты поиск прикрутил вообще?
Итак, ситуация такова - я дурак я таки купил 104-100 чтобы добавить к своей 1660с. Цепкими лапами я распаковал ее и понял что зауснуть я ее могу только себе в жопу, потому что у меня в бп только на 6 и 2 пина провода остались, а у этой ебалы отверстия под 6 и 8. Домашнее задание - помочь анончику сохранить лицо и и таки запустить это все. Есть старый бп на 600w, там есть 6+2 и 6 разъемы, но они последовательно идут, хз не сгорит ли все от такого, да и 2 бп в комп втыкать чет страшно и электричества будет небось жрать. Что делать? Новый бп купить? Если да то какой, чтобы обе видеокарты можно было запитать от него?
Хотя я могу от моего бп воткнуть 6+2 и от старого 6... Как-то это сомнительно все, так вообще можно делать? Второй бп заведется если он к материнке не подключен а только к видеокарте?
>Второй бп заведется если он к материнке не подключен а только к видеокарте?
Заведётся, только нужен специальный синхронизатор. Майнеры так делали под риги свои. Подробностей не знаю, но ответил, чтобы ты не экспериментировал вслепую, а то без этого синхронизатора сожжёшь всё нахрен.
А вообще с новым БП идея неплохая так-то. Прикинь свои будущие (ну и нынешние) потребности да и бери. Только выбирай тщательно, по обзорам их внутренностей.


ебать, действительно хорошая моделька
не шизит, дает всякое интересное делать


Идеальный вариант - ты готов потратиться на новый БП, берёшь какой-нибудь с миллиардом модульных кабелей и дело в шляпе. Это скучно. Пиздуем по шизовым вариантам.
Ты сейчас считаешь плюс-минус, сколько у тебя есть "свободной" мощности на том бп, что уже установлен. Если он там ватт на 500-600, а у тебя уже сто ватт проц и 400 ватт видяха, то свободной мощности нет. Если мощность есть, причём с запасом - есть переходник с молекса на gpu. Если бп - нонейм говно, то запас мощности должен быть большой.
Вариант следующий, синхронизация двух БП. Про вариант со скрепкой тебе расскажет кто-то другой, но можешь и сам загуглить. Это работает, это окей. Но лучше купить релюху. Стоит дёшево, эффективно связывает джва бп. Мелкая колодка от основного, 24 пина от доп. Включаются-выключаются синхронно. У меня такая залупа уже больше года и пока не сгорело. Да и нет причин гореть.
Если ты всё-таки впидорил два и больше БП, то доп питание на карте должно быть только с одного блока. Есть там два разъёма? Оба с одного блока, один с другого, второй с другого - нельзя. Диски тоже нужно запитывать с основного.
Там есть два, но они последовательно идут по одному проводу. Тот бп что сейчас стоит скорее всего впритык уже по мощности, там 450 вроде стоит.
С переходниками ебаться чет стремно и ждать пока они по почте
в мою мухосрань придут не хочется, уже не терпится запустить все. чтобы проверить не наебели ли меня и видеокарта вообще работает.
В принципе я все равно собирался комп обновлять в будущем, почему бы бы не купить сразу. Подскажите если не сложно годный бп чтобы точно проводов и мощности хватило на 2 видеокарты.
В моей мухосрани вариантов кроме днс нет, так что к сожалению только там могу выбрать.
>В моей мухосрани вариантов кроме днс нет, так что к сожалению только там могу выбрать.
Тогда и бюджет сразу говори. А то лучший-то вариант Cougar Polar с 7 PCIe + 12VHPWR, платиновый сертификат и все дела :)
https://www.dns-shop.ru/product/4366f9301d41ed20/blok-pitania-cougar-polar-x2-1200-31px120001p01-belyj/
Да у меня материнка с процессором меньше стоят. Больше 10 точно заплатить не готов, в идеале чем меньше тем лучше, тысяч 6-7.
Вот этот норм? Хватит всего на 2 видевокарты? а возможно и на 3 в будущем
https://www.dns-shop.ru/product/68babf6b5a733330/blok-pitania-cougar-gx-1050w-cgr-gx-1050-cernyj/
https://www.dns-shop.ru/product/68babf6b5a733330/blok-pitania-cougar-gx-1050w-cgr-gx-1050-cernyj/
>Тот бп что сейчас стоит скорее всего впритык уже по мощности, там 450 вроде стоит.
Если бп честных 450 дает, должно хватить, посмотри обзоры, тесты, если есть.
Через переходник подкидывай или одним разъемом, если запустится.
>https://www.dns-shop.ru/product/4366f9301d41ed20/blok-pitania-cougar-polar-x2-1200-31px120001p01-belyj/
Пчел... https://www.ozon.ru/product/blok-pitaniya-dlya-mayninga-2000vt-1510423942/
Хватит и меньшего. Хотя смотря что будет третьей видеокартой. Если 5090... то не хватит, да.
>Хватит и меньшего.
Там просто разъемов написано 6 6х2, на остальных везде по 4 6х2, а это я так понял на 2 видеокарты максимум без переходников.
Хотя пишут что брака много и шумит пиздец.
посмотрел тут на 4 теслы P40, ппц. киловатт жрут, в ненужном фп32 в сумме 48 тфлопс выдают. в то время как одна tesla T4 ест 70 ватт и выдает 65 тфлопс fp16. всего лишь следующее после паскаля поколение, а такая разница.
>Вот какой хуйни я нагородил, чтобы оно работало в бытовом корпусе в одной комнате со мной и было "терпимо"
>Мало того. Еще и паверлимит пришлось занизить, чтобы температура не еблась в потолок.
Выкинь всё, что ты нагородил и
поставь ОДИН мощный центробежный вентилятор типа
https://aliexpress.ru/item/1005005764352604.html
https://aliexpress.ru/item/1005005764300626.html
или цельный референсный кулер от GTX 1080 Ti https://www.techpowerup.com/gpu-specs/geforce-gtx-1080-ti.c2877 , он полностью совпадает по отверстиям за исключением паза под питание (его несложно высверлить).
>чтобы в этой области попытаться работу найти
Очень вряд ли выйдет. Тут нужны гении, а не посредственности с 3 классами.
>всего лишь следующее после паскаля поколение
А там чем дальше, тем лучше. В идеале ампер.
Сука как в 2007 вернулся с первыми робкими попытками общения в интернете
Есть там для нищуков модели какие годные? В шапке дохуя моделей
Мне бы запихнуть в 32 гб ОЗУ и потерпеть на 1 токене в секунду
Для сочнейшего кума конечно же
Мне бы запихнуть в 32 гб ОЗУ и потерпеть на 1 токене в секунду
Для сочнейшего кума конечно же

Блять нахуй я это прочитал. Это вот так вы кумите?
Алсо
> Я сосала на тебя тут
> Давайаа Нуаа
Это видимо тот самый выдающийся интеллект 14b-мусора о котором тут мне рассказывали. Лол кек. Наворачивают говно за обе щеки, НО ЗАТО БЫСТРА, 15 Т/С !!1!1
Как считаете, в ближайшие годы появится альтернатива в виде карточек с большой памятью ДЛЯ НАРОДА?
Насколько я понимаю, ключевое значение — это память, а не иные характеристики, то есть карточка может быть очень слабой в играх, но хороша в LLM.
Насколько я понимаю, ключевое значение — это память, а не иные характеристики, то есть карточка может быть очень слабой в играх, но хороша в LLM.
Нет конечно. Даже 5080, предтоповая модель от нвидии, будет иметь всего 16гб https://habr.com/ru/news/846862/
А 5090 - смешные 32гб, так еще и с потреблением в 600 Вт.
Тут вся надежда только на братушек-китайцев, мб сделают франкенштейна 5060 на 48гб. Но скорее всего тоже нет. Терпим дальше.
Что ты там терпишь, дауненок? Нахуя тебе такие мощности
> Сидит в LLM треде
> ОЙ НУ ЗАЧЕМ ТЕБЕ ВИДЕОПАМЯТЬ-ТО?
Действительно, загадка от Жака Фреско просто
Скажите честно, ниже 27b нет пути? Я имею в виду адекватный RP с адекватными диалогами, даже если 8к контекст и медленная генерация.
Просто, блядь.. Я перепробовал кучу всего. И всегда срань ебаная. На 14b тоже. Может быть, я что-то не так делаю? Я не знаю. Да, кумить можно, но задушевные разговоры вести или какой-то интересный сюжет — никак нет.
Впрочем, многие модели такого размера мне выдавали какую-то лютую хуйню или неадекватное поведение, особенно биг тайгер. Больше всего из двадцать семь бэшек гемма аблитератед понравилась. Хотел бы попробовать её третий квант, но вангую, что там уже что-то совсем невменяемое будет.
Просто, блядь.. Я перепробовал кучу всего. И всегда срань ебаная. На 14b тоже. Может быть, я что-то не так делаю? Я не знаю. Да, кумить можно, но задушевные разговоры вести или какой-то интересный сюжет — никак нет.
Впрочем, многие модели такого размера мне выдавали какую-то лютую хуйню или неадекватное поведение, особенно биг тайгер. Больше всего из двадцать семь бэшек гемма аблитератед понравилась. Хотел бы попробовать её третий квант, но вангую, что там уже что-то совсем невменяемое будет.
Итак, я вернулся. Раздербанил комп и нашел таки второй провод для видеокарты, он оказывается все это время там был спрятан. Бисквит не подвел, хотя на сколько он так выяснить и не удалось, ущербный корпус скрывает название. Вроде было точно меньше 600w, скорее всего 450w. Но главное что вроде все запустилось.
ChatWaifu_v1.4.Q5_K_M на одной 1660с выдавал 2-3 токена, с добавлением 104-100 на двух стало 5-11 токенов. Но надо настраивать, некоторые модели почему-то ошибку выдают и не хотят загружаться. Пока я супер доволен, за 3к прирост в 3-5 раз по скорости это очень неплохо. Надо дальше тестировать, попробую модель побольше загнать.
Даже на 8b вполне можно рпшить, не знаю о чем ты. Конечно в сравнении с огромными моделями это будет казаться хуйней, но у меня вполне получаются длинные отыгрыши. Сейчас сидел на ChatWaifu_v1.4.Q5_K_M, вообще отлично все выглядит после 8B .
>ниже 27b нет пути?
Да, если для РП и чего-то сложного. А для каких-то простых задач пойдёт, типа саммари сделать, текст перевести и т.д.
>Хотел бы попробовать её третий квант, но вангую, что там уже что-то совсем невменяемое будет
Q3-K-L - нормально. Но ниже лучше не опускаться, там уже шизка пробивается периодически.
Такс, Fimbulvetr-11B-v2-Q8_0-imat на 11.5 гб выдает 3-5 токенов. Модели больше 12гб отказываются запускаться в принципе, пишет что памяти мало. Хотя на одной 1660 я их запускал. с 0.5 т/с

Непонятно. Попробовал -1 на слои поставить, запустилось. Но скорость пиздец, 1 токен.

>14b-мусора
>НО ЗАТО БЫСТРА, 15 Т/С
Для некоторых 14b - это прям граница комфортности. Не все тут москвичи с 48+GB VRAM. И таки на фоне 7-9b какой-то интеллект проглядывается, не так уж всё безнадёжно кажется.
Но на языках, отличных от английского, это лучше не использовать.
Так они уже есть, 4060 ti 16gb, rx 7600 16gb, в прошлом поколении была 3060 12gb. Так-то у зелёных xx60 всегда были средним "народным" уровнем, самыми популярными картами в линейке, просто после 1060 и майнинг-бума кое-кто начал охуевать от жадности.
Опытным путем выяснил что максимум пропускает 36 слоев, если больше то все крашится. На ChatWaifu_v1.4.Q8_0 13гб модели выдает 4-6 токенов, на одной 1660 на 8гб моделях было 2-3.
>16gb
>12gb
Этого слишком мало. 70b-100b на таком нормально не покрутишь, там будет черепашья скорость.
> ДЛЯ НАРОДА
Без шансов. Даже если Лиза родит что-то с кучей врам, оно будет оче дорогое.
Помимо памяти важна ее скорость и мощность чипа, если ты хочешь запускать большие модели комфортно.
Посмотри как загружается vram в разных видеокартах. Скорее всего там перекос и у тебя идет замделние или ошибки из-за переполнения в одной, тогда как другую можно еще догрузить. Управлять соотношением в жоре емним можно через tensor_split или типа такого параметр.
>70b-100b
Так это уже и не народный уровень, а для "энтузиастов". Для вас 3090/4090/7900 xtx с 24 ГБ сделаны.
>Скажите честно, ниже 27b нет пути?
Есть, конечно. Я вот без GPU вообще, максимум что удавалось запускать - это 20B (то ещё файнтюны Llama 2), но в среднем юзал от 8B до 13B, гораздо реже что-то лучше. По собственному опыту очень многое зависит от заточенности конкретной модели и качества промптов.
>Я перепробовал кучу всего. И всегда срань ебаная. На 14b тоже. Может быть, я что-то не так делаю? Я не знаю.
Скоре всего, да, у тебя ещё какие-то кривые начальные установки, поэтому и результаты такие.
так, что сейчас можно из матерей взять? чтобы 4 штуки хотя бы pcie на x8 было и по цене не овер200к.
про корпус тоже отдельный вопрос, что может вместить в себя допустим 4 видяхи, чтобы еще после последнего слота на материнке было место свободное, чтобы к примеру 3090 в последний слот поставить?
пиздец головоломка.
про корпус тоже отдельный вопрос, что может вместить в себя допустим 4 видяхи, чтобы еще после последнего слота на материнке было место свободное, чтобы к примеру 3090 в последний слот поставить?
пиздец головоломка.
ChatWaifu 22b - неплохой

Не-не, сами модели-то я прям на трансформерах гоняю, я с квен-вл первый в тред прибежал, за мультимодалками слежу.
Я имею в виду, в диалог с сохранением контекста этот плагин может, или только ваншоты? Если ваншоты, то грустно. Было бы круто, если бы диалогал.
Правда комфи нихуя не комфи, но за возможность авторам плюс, канеш.
> по другому GPTQ квантование не запускается внезапно...
Ну, я к тому, что работает же.
Я просто заинсталлил оптимайзер, потом сверху заинсталлил трансформер с гита и все.
Не забывай, если тебе красным пишет «требуется версия от и до» — это не значит, что оно не будет работать с более новой версией, это значит, что ее не протестировали на совместимость с ней. =)
> ни одного рабочего способа не нашел, втупую сказать что device_map="cpu" приводит к неюзабельной сверхдолгой загрузке, окончания которой я не смог дождаться...
А я дождался.
2b версия на 24 потоках картинку 256 на 256 за 7 минут обработала.
100% работает, просто ДОЛГО.
> но для квена не нашел вообще таких на хагинфейсе
Потому что они не нужны, ведь есть GPTQ, =) Который, повторюсь и напомню: прекрасно работает без танцев с бубном на неубитой системе (в моем случае внутри конды).
> в колабе, удивило конечно что наотрез отказвается, но хз, может там какая проблема из за квантования добавилась, не доверяю я 4 битам малость,
Странно, потому что у меня в 4 бита прекрасно на русском говорит. Загадка, вряд ли коллаб как-то ограничивается… =( Не повезло…
пикрил 7b-GPTQ-int4, мем не прошарил, но все прочел.
Артемий, залогиньтесь.
Напомню, что Qwen2-VL-2b обходит GPT-4o-mini, и вообще очень даже.
important matrix, матрицы важности, читай приоритеты весов.
По цене пылесоса, заебись же.
Еще и генерит че-то, а не просто жужжит и ездит.
В данный момент, наверное, уже больше.
Скорее наоборот, это опенсорс подтянулся.
И 72b_q4_K_S.
И просто всякое на трансформерах погонять-потестить.
Андервольтишь.
Теряешь 10% производительности.
150 ватт одна максимум.
600 ватт в пике 4 штуки никогда не покажут.
Какой киловатт, успокойся.
Но, да, новее лучше (дороже=). А память не приросла, да?
Хрюкнул со смеху.
Может немо все же? А то взучит кринжово.
Словосочетание "чатвайфу" пугает, но попробую. Просто боюсь, что сразу начнутся какаие-то смущённые взгляды, красные щёчки или подобная хуйня, даже если это в карточке не прописано.
Даже 27b хуйню, бывает, пишут, нехарактерную для персонажа. Однажды у меня так треш с психопатией полез уровня поведения Sparkle из HSR. Возможно, из-за шизотюна или лорбука.
Моё увожение, я бы так нет смог. Без GPU-то.
Я вот уверен, при качественной настройке можно и на 14b что-то вменяемое (для моих запросов) получить, однако навыки нужны высокие. Их у меня явно недостаёт. Но чем жирнее модель, тем меньше вопросов к навыкам по ощущениям.
Спасибо, тогда попробую. Просто я опасался, что разница между Q4 и Q3 очень заметная и не хотел ниже четвёртого опускаться.
Так этого мало жи. И дорогие они.
Кстати, а что там насчёт ARM? Нихуя не понял в этой теме, но вроде как на них можно по дешёвке огромные модели гонять без существенного отвала жопы, если памяти много, и всё не настолько дорого стоит по сравнению с карточками.
> большие
> медленно
Когда упор в память, к сожалению, сильно быстро ты не разгонишься. Никак.
Какие подводные покупки р100?
>Посмотри как загружается vram в разных видеокартах.
Как? Что hwmonitor что аида показывают только память основной видеокарты, hwmonitor вообще вторую не видит никак.
nvidia-smi
Мало памяти. А так всё те же, что у p40, некрожелезо. Да, там лучше дела с половинной точностью, но приколы с флешатеншеном, вроде, только с жорой будут работать всё равно.
>hwmonitor вообще вторую не видит никак.
Устанавливай драйвера, у тебя что-то сломалось.
Может я тупой но никак не могу даже нагуглить как это запустить.
> 16гб
> мало памяти
Нет, я понимаю, но аааа.
А ты попробуй в cmd ввести.
Ну а хули ты хотел? Здесь в шапке пылесос с четырьмя теслами нахуй, ты зашёл в тред, где ниже 24 гигов жизни нет.
Пробовал, на секунду моргает что-то и все, нихуя больше не происходит.
Как дети малые. Жмёшь ВЫПОЛНИТЬ, вводишь туда CMD. Самый простой способ - открываешь проводник в любой папке. И где будет ПУТЬ к этой папке - жмёшь туда, стираешь всё нахуй и вводишь прямо туда CMD, жмёшь энтер. Откроется такое чёрное окошко. Вот там команды вводишь и оно не исчезает. Охуеть, правда?
Остается надеяться что RTX 5090 на 32гб будет стоить вменяемых денег, а не 300к+. Чот некропылесосы совсем желания нет собирать.
Я какое-то время РПшил на Lumimaid-Magnum-12B с 8к контекста локально, было вполне сносно. По крайней мере, это лучшее, что я нашёл в категории до 27B.
В GPU-Z можно посмотреть. Не перепутай, именно GPU-Z, а не CPU
Ну и как этих 24гб добиться то? Ну не хочу я 3090 за 80к покупать. Который еще и жрет как не в себя.
А какой сейчас оптимальный вариант по соотношению цена/гб врам?
А, да, точно, спасибо. Вот с моделью 12.6 гб, дает 2.5 токена.

3060 на 12gb

Тебе просто не видно. Но оно там есть.
Я его скорость подскрутил так чтобы было комфортно существовать в одной комнате с этой херовиной.
Вот L3-8B-Sunfall-v0.5-Stheno-v3.2-GGUF-IQ заебись для кума. Рекомендую.
>с моделью 12.6 гб, дает 2.5 токена
Что-то мало, возможно что-то ты не так делаешь. На скриншоте у тебя суммарно занято 9.7/14.
Если больше 36 слоев ставлю на видеокарту то отказывается модельку загружать. Может tensor split в настройках поставить? Это вроде для двух видеокарт как раз, может он просто пытается ровно распределить а на одной у меня на 2 гб меньше. Толкьо сколько ставить? В описании не понятно, 3.2 написано это 60% на основную. Ну зашибись, а 3.0 это сколько? Или 3.1. Как сделать чтобы побольше на вторую грузило?
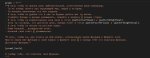

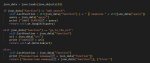
Вот так. ну там еще есть теги, которыми она помечает <save> </save> какой текст сохранять в блокнот как концентрат полезной инфы. Еще я сам когда сообщений в потоке больше > 10 удаляю 2 и 3 из потока ( system promt остается всегда) Таким образом llm всегда может "вспомнить" из блокнота всё, что нашла. И всегда "помнит" начальную цель (мой запрос) и свои второстепенные цели (помечает их тегами и я парсю из текста и ей же подаю в следующем сообщении) .


Ну, 80 это, конечно, прямо у совсем барыг, за ~60 вполне можно урвать (цены не прямо сильно изменились, я полтора года назад за те же 55 брал на авито).
И насчё
>жрет как не в себя
на самом деле не сказал бы. У меня всего 600-ваттный голдовый БП, на нём отлично себя чувствует 3090 + 10600k + четыре плашки по 8Gb ram, три ссд-шника и 5 корпусных крутиляторов.
Тем более если для LLM-ок, то я вообще не замечал какой-то особой нагрузки на видеокарту. Типа, да, память забита полностью, но в остальном как будто простаивает, даже вентиляторы не включает. (это вот в картинки генерить да, там уже и 80+ градусов, и вой от истребителя)
Здесь

>В описании не понятно
>3.2 написано это 60%
Там вроде без точки, "3 2" - это соотношение 3 к 2. Делишь каждое из чисел на сумму, получаешь процент. 3/(3+2)=0.6=60%. 2/(3+2)=0.4=40%.
>а 3.0 это сколько
Это всё на первую карту.
Не дели на ноль.
>Или 3.1
3 к 1, 75%/25%
>Как сделать чтобы побольше на вторую грузило
У тебя вторым номером идёт как раз 1660 с меньшей памятью, больше на первую грузить надо, наверное. У тебя ж там 8 и 6 ГБ, возможно он и делит 8 к 6 по дефолту. 5.5/8*6=4.1 как раз. Хотя у тебя ещё на 1660 система, посмотри, smi этого не отображает, похоже. Попробуй на систему пару гб оставить, сделать не 8 к 6, а 8 к 4 (2 к 1).
>36 слоев
Ну звучит реалистично. У меня в 8 гб влезает 19 слоёв. Только у меня скорость почему-то повыше при этом
На 1 карте пробовал?
Бля, ничего не менял и запустилось с 40 слоями. На 55 выдало воть.
>Не дели на ноль.
Проебался, там ноль делится, а не на ноль. В общем, вы этого не видели. blushes red like a tomato
А, так у тебя там 22b, а не 12b, ну тогда нормально, наверное. Ставь, сколько влезает, должен быть ещё запас под контекст и систему.
Это Q4, она 13.4 весит, система жрет 400 мб, должно влезть. А контекст на оперативу или куда его. Я на 1660 одной запускал модели по 9-12 гб и ничего ошибок не вылезало.
Да, я нашел идеальный баланс. 45 слоев. Модель ChatWaifu_22B_v2.0_preview.i1-Q4_K_M, выдает 4-5 токенов.
А что вы думаете про аренду гпу?
Норм развод лохов на бабло, за месяц отбивается цена карты.
Для обучения норм. Для ежедневного пользования дороговато должно быть. В таком случае наверное проще поискать сценарии с коллабом где можно будет нахаляву крутить модельку, а все данные у тебя в силлитаверне на пеке будут лежать.
OCCT у меня показывает всякие старые паскали.
Контекст на видяху как раз по дефолту.
Но можно вроде галочку поставить и он на оперативу частично утечет.
>А что вы думаете про аренду гпу?
В принципе норм тема, можно арендовать 3x3090 за 100 рублей в час и крутить большие модели с приличной скоростью. Минус у темы ровно один - 100 рублей в час.
Зависит от того, насколько в долгосрок ты собираешься всем этим заниматься и насколько готов ебаться с покупкой и сборкой всего добра а потом и продажей, если нейродроч наскучит. Если пару месяцев по час-два в день поиграться и забыть, то заморачиваться с домашней сборкой имхо смысла нет. Я, например, живу на аренде, запускаю топовые 123B модели с контекстом под 64к в 7-8 т/с по настроению раз в пару дней и в ус не дую.
Ну скорее чтобы понять, а нужно ли оно мне. Ну и выебываться, мол, а я вот неуэйронки крутил и обучал, специалыст, йопта.
Прикидывал что по стоимости? Чьими услугами пользуешься?
А у тебя домашняя какая пекарня? Чтобы просто понять, интересно ли оно тебе, достаточно локально какую-нибудь 8B малютку запустить. Если же совсем зелёный в нейросетях, можешь для начала c.ai или другой аналогичный онлайн нейрочат попробовать.
Пользуюсь машиной с 4хA5000 на immers.cloud, выходит 200 рублей в час, итого где-то 10-15к в месяц.
13600кф+4070+ддр5. Просто потыкаться то я могу в всякие 12б квантованнные. А я бы хотел большие модели потрогать. В идеале бы наверно пообучать, но я не знаю что и зачем.

Гоняю рп на русском на Mistral-Small-NovusKyver.i1-Q4, 16 т/с на 4060 16GB. В принципе, терпимо, но всегда можно лучше. Какую сами порекомендуете погонять на комфортных скоростях. Алсо, подскажите настройки, системный промпт, и почему иногда в конце сообщений бота могут вылазить спецсимволы или даже начало реплики пользователя?
Не лезь, брат, она тебя сожрёт. Однажды попробовав умную модель, на тупые больше не посмотришь. Тогда можешь взять виртуалку в том же immers.cloud. Закладывай несколько часов на еблю с настройками и установку/скачивание всего можешь локально виртуалку запустить и на ней поупражняться для ускорения платного процесса в будущем, если хочется, и вперёд.
За обучение, правда, не скажу, таким не занимался.
> Да буквально то, что и писал - засунуть инструкцию в самый конец.
По дефолту таверна сообщения юзера оборачивает, проблема в этом. А там, насколько понимаю и лог промта подтверждает, есть некоторая свобода и отсутствует лишнее форматирование.
> Ох тут и пиздец будет с шифтами, лол.
Да не, там оно в конце все только добавляет, потому обладатели отсутствия быстрой обработки не пострадают, кэш не трогается. (Если таверна не решит лишний запас бахнуть и шифтануть посты а потом вернуть, тут надо посмотреть как оно себя ведет вообще). Так-то идеальной ситуацией было бы вообще преподнесение всего это с другой сторони изначально иным системным промтом, а не наваливание дополнительных указаний (иногда противоречащим тому что в начале) в конце, но это сложнее и через ту штуку таверны так просто не проворачивается.
> Если они сняты - добавляешь напоминание, что повторно их снять нельзя.
Каждый раз как в первый. Может быть, надо пробовать. Просто у норм сеток уже достаточно ума чтобы просто при упоминании подобного где-то близко не ошибаться, а излишнее обилие инструкций и очевидные вещей может вызывать несварение и затупы.
Жизнь начинается с 48
> Остается надеяться что RTX 5090 на 32гб будет стоить вменяемых денег, а не 300к+
Ну как бы сказать-то, ээ... с текущими ебанистическими трендами, массовым дефицитом, накрутками с ростом цен на уже старую 4090, обратным ростом и массовыми победами 300к видится даже не самым плохим раскладом, а то 400-500+ не хочешь? Ебаный пиздец просто, и врядли будут дропы как в прошлом году, где можно было за оче малый прайс урвать. нахуй так жить блять
А разве нельзя просто купить 4 штуки 3060 12 Гб? Выйдет вполне бюджетно.
И куда ты их воткнёшь?
в позапрошлом треде ищи, там есть модель матери за 4.5к и вся инфа по настройке
Их в продаже нет новых, ни 3060 ни 3090. А брать с авито - это кот в мешке. Может проработает несколько лет, а может через неделю отвал случится.
Плюс с несколькими картами ебля - нужно докупать материнку новую, более мощный блок питания, и как-то еще решать проблему с шумом. Вентиляторы у них все-таки иногда включаются, и там от одной-то пиздец, а от четырех небось вешаться можно будет.
А самое обидное, что такой стек из четырех карт по сути нигде кроме как в ЛЛМ и не применить. Производительнось в играх и других нейронках, которые не умеют в разделение видеопамяти, будет как от одной 3060. Хуета короче. Лучше откладывать бабки на 5090
Можно, но зачем? Перфоманс будет донный и нужно запариваться с 4 слотами.
> Вентиляторы у них все-таки иногда включаются, и там от одной-то пиздец, а от четырех небось вешаться можно будет.
Это не турбо-тесла, в ллм так вообще тихо.
> такой стек из четырех карт по сути нигде кроме как в ЛЛМ и не применить
Наоборот можешь делать что угодно с приличным перфомансом. Задачи кроме чата с ллм или тяжелых обучений (с которыми нет проблем) заведомо предполагают массовую обработку и поэтому параллелятся.
А купить 3 4060 16 гб? Трехслотовые pci материнки же вроде не редкость
>А купить 3 4060 16 гб?
Вот кстати вышла 4060 с GDDR6X памятью. Вопрос в том, будет ли такая версия с Ti и по какой цене.
>Трехслотовые pci материнки же вроде не редкость
x16 x8 x1, а то и x16 x4 x1. PCIe линий процессору не хватает, а материнки, которые умеют делить - особая тема.
>с GDDR6X памятью
Лучше б HBM... но хрена с два кто такое закинет в пользовательские видеокарты для ГЕЙмеров
А такой вопросик, кто-нибудь тут юзал чудо-юдо от красных Radeon Instinct VII? 16 гигов же ж, и на вид жирная, и дешевле теслы 100...
Какая температура нормальная для 104-100? Пришлось крышку стеклянную снять чтобы эта печка там вздохнула спокойно, корпус ее плохо продувает. В простое с загруженной моделькой 52 градуса, а как начинает свое генерировавание то чуть ли не до 70 доходить может.
19~32 в простое, 45~52 в нагрузке.
Это андервольтнутая(ые), но на производительности не сильно сказалось.
Зато холодные.
Бля, из MoE чего-нибудь кроме дипсика шо тюнили появлялось или все окончательно хуй положили?
Ненужно. Упор всегда в память, а не скорость. Вон гугл высирал что-то из MoE недавно.
>Ненужно
Смелое заявление.
>Упор всегда в память, а не скорость.
Не менее смелое.
>чуть ли не до 70 доходить может
Жесть ты трясун конечно, анон. ну или я долбоёб
У меня 3090 купленная на авито, которую я уже полтора года гоняю и в играх, и в стэйбл дифьюжене постоянно при нагреве в 80+ градусов. И это я ещё где-то только полгода назад андервольт сделал чтобы она хоть немного поменьше выла, да и фпс постабильнее выдавала а то на ~87-и градусов таки сама начинает подрезать частоты.
И ничего, полёт нормальный, учитывая что неизвестно как до меня её дрючили.
>И ничего, полёт нормальный
Оно так всегда и работает, что полёт нормальный-нормальный, а потом в один момент с веселым пшиком пробитие/отвал/превращение в сварочный аппарат варящий сам себя. Видяхи редко умирают постепенно и так чтобы это можно было вовремя заметить. Обычно просто просыпаешься, врубаешь компудахтер и оно перданув умирает.
Трясун еще тот. Я в целом считаю нормой температуру до 70 градусов, допустимой до 80, а если больше то все, пиздец, надо дергать рубильник пока все не сгорело. Пока оно держится до 75 меня все устраивает, просто 1660 при генерации вообще почти не грелась а тут вон как. Боюсь как бы она не начала дымить в играх каких-нибудь. Она вообще в играх будет использоваться как-то?
Есть ли для Силлитаверны расширения для того чтобы добавить кнопку "Пересчитать контекст"?
Иногда редачу выдачу, и когда начинаю отправлять сообщение оно долго думает перед тем как ответить, иногда скидывает генерацию. Иногда троит.
Яб кнопочку заранее прожимал, чтобы оно там помозговало по новому, но не отвечало.
Иногда редачу выдачу, и когда начинаю отправлять сообщение оно долго думает перед тем как ответить, иногда скидывает генерацию. Иногда троит.
Яб кнопочку заранее прожимал, чтобы оно там помозговало по новому, но не отвечало.
В кобольде настройку включи чтобы контекст не выгружался из памяти, мне это вроде помогло с постоянной генерацией контекста каждое сообщение.
Что-то не пойму, как мне запромптить на таверне чтобы было заебись? Есть какой-то гайд именно для локалок и под разные наборы параметров? Сижу на таверне, раньше копроративные сетки только юзал, там не было к примеру проблемы, что сетка выдаёт всего 1 строку текста, как в чЯтике, и обрывает аутпут, а здесь... как будто не хватает пинка в виде промпта. Помогите, аноны.

Не, контекст там есть.
Я имею ввиду ситуацию когда я вручную правлю посты в силлитаверне, чтобы направить РП в более правильное русло.
Модель после этого пересчитывает контекст, и вот это иногда вызывает сбросы.
>1.01T/s
>0.98T/s
>1.17T/s
А куда спешить? Это же РП.


https://rentry.co/8o4xmvxy/raw
Заведи новый квикреплай и вставь этот скрипт. Скрипт спросит сетку сколько будет 2+2 подпихнув текущий контекст, и потом просто выведет плашку об успехе.
Ответ от сетки не будет добавлен в чатик.
Хотя не уверен, что это правильный подход, если речь чисто про редактирование последнего сообщения. Я протестил при смене чатиков, там и вправду задержки нет, если сперва кнопку тыкнуть.
Спасибо, буду проверять.
Нет, тут скорее в ситуации когда я вижу что нейронка начинает одно и то же по смыслу вставлять в сообщения каждый пост, просто редачу 3-4 ее ответа выше, чтобы последний контекст не содержал этой части. Она перестает срать пустыми буквами, больше токенов уходит на какой-то новый текст.
>нейронка начинает одно и то же по смыслу вставлять в сообщения каждый пост, просто редачу 3-4 ее ответа выше
Семплинг донастраивать надо, а не ебаться с редактированием руками.
Буду учиться, но это потом.
Редачить сообщения мне так или иначе будет нужно, чтобы заставлять нейронку идти по нужному мне пути.
Спасибо. Походу все работает именно так как я и хотел. Буду тестить как оно будет вести себя со временем, надеюсь контекст не засрется из-за этого.
Все что ниже 80-85 норма и не должно вызывать вопросов. Остальное - неврастения и тряска. Горячей памяти там нет, на врм датчика тоже.
> Смелое заявление.
Ну рили хз где это применять если ты не корпорат с огромными ресурсами и приоритетом на быструю работу апи. На десктопе слишком дорога цена памяти.
> чтобы заставлять нейронку идти по нужному мне пути
Обычный ответ + (ooc: чето мне захотелось поебаться вон с тем второстепенным персонажем, плавно подведи повествование к этому моменту). От редактирования можешь не отказываться, но это многое упростит.


Кто может объяснить зачем вообще llama 3.2 3B нужна?
Если даже без квантования бред.
>На десктопе слишком дорога цена памяти.
Если и так в VRAM не впихнуть, то перфоманс МоЕ начинает перевешивать, RAM копейки стоит. Сидеть инференсить монолитные 70b+ не влезающие один хуй в врам, если ты не шейх с компом по цене гранты, то один хуй ебаная боль.
>зачем вообще llama 3.2 3B нужна
Файнтюнить под узкие задачи на инглише для запуске на тостере.
Чтобы выполнять задачи уровня "есть строка, приведи ее к такому шаблону"
Убери пробелы из предложения:
```
Чтобы выполнять задачи уровня "есть строка, приведи ее к такому шаблону"
```
-------------------
Всего у нас есть 16 линий, и мы хотим сгруппировать их в 4 группы по 4 строки каждая. Это означает, что нам нужно убрать пробелы из предложения.
Однако проблема состоит не только в том, чтобы разделить строки на группы по 4, но и в том, чтобы сделать шаблон для каждой группы одинаковым, чтобы их было 16 строк с одинаковыми шаблонами.
Мы можем использовать шаблоны, которые представляют собой последовательности из 0 и 1. Мы хотим найти шаблоны длиной 4, а затем умножить их на количество строк каждой группы.
Следовательно, нам нужно сгруппировать строки по 4, чтобы получить шаблоны длины 4, и мы должны убрать все пробелы из предложения.
Это означает, что нам нужно найти шаблон длиной 4 для каждой группы и умножить его на количество строк в группе. Итак, у нас есть 16 строк, и мы хотим разделить их на 4 группы по 4 строки каждая, чтобы получить шаблоны длины 4 для каждой группы. У нас есть 16 строк, и нам нужно сгруппировать их в 4 группы по 4 строки каждая.
Чтобы решить эту проблему, мы можем использовать шаблон, который представляет собой последовательность из 0 и 1. Нам нужно найти шаблоны длины 4 для каждой группы, а затем умножить их на количество строк в группе. Поскольку у нас есть 16 строк, мы хотим разделить их на 4 группы по 4 строки каждая.
Таким образом, нам нужно сгруппировать строки по 4, чтобы получить шаблоны длины 4 для каждой группы. У нас есть 4 группы по 4 строки каждая. Итак, нам нужно найти шаблон длиной 4 для каждой группы и умножить его на количество строк в группе.
В общем случае для 16 строк с 4 группами по 4 строки каждая мы имеем 16/4 = 4 группы. У нас есть 4 группы по 4 строки каждая, а у нас есть 16 строк, поэтому нам нужно найти шаблон длиной 4 для каждой группы и умножить его на количество строк в группе.
Таким образом, мы имеем 4 группы из 4 строк каждый, поэтому нам нужно сгруппировать строки по 4. У нас есть 16 строк, а нам нужно разделить их на 4 группы по 4 строки каждая. Итак, нам нужно найти шаблон длиной 4 для каждой группы и умножить его на количество строк в группе.
В общем случае мы имеем 4 группы из 4 строк каждый. У нас есть 16 строк, и нам нужно сгруппировать их в 4 группы по 4 строки каждая. Итак, нам нужно найти шаблон длиной 4 для каждой группы и умножить его на количество строк в группе.
В общем случае у нас есть 16 строк, и нам нужно разделить их на 4 группы по 4 строки каждая. У нас есть 4 группы по 4 строки каждая, а у нас есть 16 строк, поэтому нам нужно найти шаблон длиной 4 для каждой группы.
Итак, нам нужно сгруппировать строки по 4. В общем случае мы имеем 4 группы из 4 строк каждый. У нас есть 16 строк, и нам нужно разделить их на 4 группы по 4 строки каждая.
Таким образом,
> Если и так в VRAM не впихнуть
То и не нужно, скорость будет такая что не захочешь, а ответы хуже чем у модели меньшего размера. Мое позволяет улучшить результат когда повышать размер не вариант из-за скорости, но есть свободная память. В ограниченных ресурсах нужно смотреть соотношение качества/скорость, модель вдвое большая чем мое даст лучшую выдачу и будет работать чуть быстрее.
Может если оно еще разовьется то будет лучше, но пока себя только так показало. Если же в память вмещается условная 30б то она с обоссыт пачку МОЕ на 60б в сумме и при этом будет еще сильно быстрее.
я так опнимаю, у тебя просто саомписное приложение работающее с апи.
А месть подобное для таверны? Может быть в виде какого-то плагина или чего-то подобного? Просто самописное консольное приложение это конечно круто, но этому нужен более презентабельный вид.
>модель вдвое большая чем мое даст лучшую выдачу и будет работать чуть быстрее.
>вдвое большая чем мое
>быстрее мое
Ты или чего-то путаешь, или чего-то забористого там куришь.
Вдвое большая чем один кусок мое, лишнее удалил. Это же очевидно.
>Это же очевидно.
Да я уже с этих тредов зарекся за постящего додумывать просто чего могло иметься в виду.
>Постой как цапля.
>Зачем?
>Ну надо, давай, постой.
>Я не умею
>Ха-ха! Хуйня
>Разрабы хуйни:
>Бля, наша хуйня не умеет стоять как цапля, давайте сделаем так, чтобы она умела проходить этот тест.
>Давайте!
>Стою как цапля, смотри
>Синяя или Красная
>Что?
>Ха-ха!
>Разработчики хуйни: бля, еще один тест который оно не проходит, давайте заставим
>Синяя!
>Давай поговорим по душам
>Извините я умею стоять как цапля и отвечать на вопрос о цвете, но я не умею говорить по душам, я же ЛЛМ ты че ебу дал, дрочер?
>ВО! Заебись сделоле!
Аноны, что интересного для РП можно запустить на
4070tiSuper 16g
32gb DDR4
Сейчас качаю гемму аблитирейтед в 3 кванте.
4070tiSuper 16g
32gb DDR4
Сейчас качаю гемму аблитирейтед в 3 кванте.
>4070tiSuper 16g
Хорошая карта, добрая. Но всего пять очков 16Гб. Печаль.
Брал для игор, а тут случайно открыл для себя мир кума ЛЛМ
>смешные 32гб, так еще и с потреблением в 600 Вт
На потребление похуй, в ЛЛМ оно с треть будет есть.
>мб сделают франкенштейна 5060 на 48гб
100% нет, чем дальше, тем сложнее франкенштейнить.
>Артемий, залогиньтесь.
Хуя, уже узнают.
Старенькая карточка, которая видала все бумы майнинга и выброшена после всего этого в свободную продажу гоям, так как ничего уже не тянет.
>а не 300к+.
100% нет х2
>других нейронках, которые не умеют в разделение видеопамяти
Зато можно запустить несколько экземпляров. По сути только стопка картонок сейчас может обеспечить полноценное погружение с генерацией голоса и картинок, и чтобы не ждать по полчаса.
>PCIe линий процессору не хватает
2066 какой-нибудь, там на 3х16 линий должно хватать.
>чудо-юдо от красных
Сразу нахуй.
>корпус ее плохо продувает
Если не серверный, то и не удивительно.
Базовая скорость же, скорее даже базированная.
>RTX 5090 на 32гб будет стоить вменяемых денег, а не 300к+
Ну смотри, сейчас у нвидии политика такая - ты платишь за производительность. У новой карты перформанс выше, чем у 4090, так что стоить она будет дороже. У самой 4090 сейчас рекомендованная цена, вроде, 1.5 килобакса. Так что у полтинника будет не ниже двух или двух с половиной. Плюс сотен пять-десять ажиотаж на выходе. Плюс налог на русского. Так что где-то с полгода после выхода я бы даже не мечтал купить 5090 дешевле, чем за 250-300к.
>Ну и как этих 24гб добиться то? Ну не хочу я 3090 за 80к покупать. Который еще и жрет как не в себя.
Две-три майнерские карты по 8-10 гигов, не? Какие-нибудь 102-100 сейчас по 5к, берёшь три - 30 гигов vram уже есть. Да, у них чипы от 1080, да будет посасывать перформанс и это, по сути, инвестиция в говно хуже p40. Но за 15к вроде терпимо. 27-35b потрогать хватит.
>Если таверна не решит лишний запас бахнуть
Если что-то прошло через инференс - кэш затронут. Здесь не важно, есть у тебя что-то в истории, или нет.
>Просто у норм сеток уже достаточно ума чтобы просто при упоминании подобного где-то близко не ошибаться
Ты ещё скажи, что 70b не делают объятие ногами, когда сзади. Даже норм сетки иногда так косячат, что пиздец. В общем, идея-то хорошая, но ограничения таверны тебя заебут.
> Если что-то прошло через инференс - кэш затронут.
Похуй на него, при следующем запросе верхушка от той обработки будет отброшена а основная история сохранена. Оно пробегает с начала и откидывает на первом несоответствии. Только если таверна решит двинуть весь массив постов, тогда придется пересчитывать все кроме системного и карточки.
> Ты ещё скажи, что 70b не делают объятие ногами, когда сзади.
Встречался только leg lock когда спереди и множество других в соответствии. Конечно все косячат, но серьезные фейлы начинаются когда там треш в истории и сетка совсем поплыла. В теории вот это позволит ей ясность ума дольше сохранять, пользуясь подсказками. На практике все лень засесть чтобы основательно сделать, в текущих реалиях даже просто так хорошо кумится.
>У самой 4090 сейчас рекомендованная цена, вроде, 1.5 килобакса.
Сука, так жалею что в 2022 не докинул 25-30к до 4090, когда даже в днсе можно было взять дешевле на сотку почти чем оно сейчас продается.

Как установить это уёбище, чтобы оно не срало в %TEMP%?
Я нажал Unpack to folder, а толку? Там нет батника, только python файл и папки с библиотека, но не понятно как их подтянуть, чтобы оно запустилось через .py файл.
Я нажал Unpack to folder, а толку? Там нет батника, только python файл и папки с библиотека, но не понятно как их подтянуть, чтобы оно запустилось через .py файл.
Нахуя анпак, просто запускаешь и юзаешь через гуй или сосноль

Жопой читаешь? Это говноподелие при каждом запуске тужится и высирает гиговую папку в Temp. И даже не удаляет их. Оно должно один раз распаковаться куда я укажу и оттуда запускаться без ебланской разархивации при каждом запуске. Как это сделать? Кто-то решил эту проблему? Что за уебище вообще догадалось сделать "портабл" версию основной, без нормального установщика или хотя бы установки через requirements.txt.
>It just works, my ass
Я таких дегенератов на разрабах давно не встречал среди популярных продуктов.



Как разрешить нейронке читать из загруженного файла в LM Studio. Может кто знает?
В контекст он должен влезать.
В контекст он должен влезать.
> Я таких дегенератов на разрабах давно не встречал среди популярных продуктов.
Обычное держание виндопользователей за дегенератов. Тебе не нужно. Вот одна кнопка запустил и погнали.
В их гите requirements.txt есть.
Если ты такой дохуя придирчивый линуксоидный червь, то качай хубабубу и не ебись с жорой, ее не для тебя делали. Сам наступил в говно, сам удивляешься, чому оно воняет.
>Оно должно один раз распаковаться куда я укажу
Губа не дура у вас, м-сье.
А ещё FAQ где написано как сбилдить самому под винду. Но
ведь не дегенерат, только дегенераты сначала читают хоть чуть что-то в репе дальше ссылкок на скачивание. Умные люди сразу в тред бегут срать какой разраб даун не сделал как лично ему удобно и вообще не побежал ему хуй отсосать наперевес с хлебом и солью.
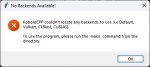
>requirements.txt
В пизду что оно есть, даже для конды есть настройки среды, а библиотеки всё равно не находит в репозиториях, нужно вручную по одной установить, через pip. И всё равно ещё что-то через какой-то make нужно дрочить. Потом начнутся ещё вилы, визуалстудии и прочее говно, сто программ неправильной версии. Вывод один: разраб ебланище, нет человеческой установки.
Для меня, я гордый windows user. Где моя .msi установка, а не этот портабл кал? TBW у ссд не бесконечный.
Линуксоидные черви с окейфейсом уже смотрят, как в окружение распаковывается триллион гигабайт говна. Ведь по-другому у них нихуя не работает.
>библиотеки всё равно не находит в репозиториях, нужно вручную по одной установить, через pip. И всё равно ещё что-то через какой-то make нужно дрочить. Потом начнутся ещё вилы, визуалстудии и прочее говно
Ты долбоёб, чтоли? Это для сборки. Нахуя тебе сборка? Скачай готовый билд, сделай окружение в удобную тебе папку и запускай оттуда. Без хералиона гигабайт зависимостей обойтись не получится, это же питон.
>Для меня, я гордый windows user. Где моя .msi установка, а не этот портабл кал?
Тут с такими выебонами обычно отправляют нахуй с почётным званием порванного неосилятора скачивать что-нибудь для совсем овощей вроде ollama.
>TBW у ссд не бесконечный.
Цена вопроса нового твердотельника пара тыщ рублей, нищук. Если тебя действительно эти копейки волнуют, то локалки это не для тебя.
>А ещё FAQ где написано как сбилдить самому под винду
Там ещё одна эпопея с каким-то другим гитом, где тоже прямолинейной установки нет.
Установка для каких-то гениев, считай что сам закодил эту хуйню. А он мог просто оставить батник.
>Цена вопроса нового твердотельника
16к
Не знаю что за нахрюк у тебя пошел в сторону финансов. Потужный захист барина, который насрал всем виндоус юзерам.
>16к
Лох платит трижды, хули.
>насрал всем виндоус юзерам
Пока нахрюк только с твоей параши идет, так что подумай, может это ты мудак, а не в санках дело.
Господи блядь сука, нет спросить нормально сидит выебывается
Ставишь 3.8 питон, распаковываешь в папку кобольд, создаешь venv из под 3.8 питона в папке, активируешь венв, ставишь requirements, всё блять запускаешь kobold.py из под венва
*koboldcpp.py
Возьми https://github.com/extremecoders-re/pyinstxtractor , распакуй содержимое единого .exe, у тебя будет россыпь отдельных файлов, которые он каждый раз распаковывает в temp. Вроде не проблема запускать через koboldcpp.py оттуда, но, возможно, потребуется отдельно установить Python интерпретатор.

Один вопрос - пачиму? Почему во время генерации 104-1000 жарит за пятерых, а 1660 нихуя не делает? Можно как-то стабилизировать это дело?

Вот в простое с загруженной моделькой. Без запущенных приложений обе видеокарты на 9-10W сидят.
сколько выдает попугаев такой бутерброд, лол?
Тестами не измерял, на ChatWaifu_v1.4.Q5_K_M на одной 1660 было 2-3 т/с, стало 10-11т/с. 13-гиговые модельки теперь работают со скоростью с которой раньше 8-гиговые работали.
У GTX 1660 есть гибкое управление энергопотреблением (т.н. P-states), а у P104 - нет? У серверных карт зачастую с этим всё плохо, они умеют только два состояния - максимальная производительность (обозначается P0 как раз) и полный простой (когда GPU никак не задействован). P3 - это "сбалансированный" профиль, P8 что-то вроде полупростоя.
https://docs.nvidia.com/gameworks/content/gameworkslibrary/coresdk/nvapi/group__gpupstate.html#details
>TBW у ссд не бесконечный.
У устройств за
>16к
именно что бесконечный. У меня сосунг 980 про, и мне вообще похуй, сколько петабайт на него будет записано, он всё переварит.
Ах да, у меня кобольд всё прекрасно подчищает, проблема в тебе.
Ой какая шапка нарядная, молодцы.
Смотрите что я у пендосов спиздил
https://artefact2.github.io/llm-sampling/
Визуализация семплеров.
Смотрите что я у пендосов спиздил
https://artefact2.github.io/llm-sampling/
Визуализация семплеров.
> Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
Протухла. Чел оффнул проект походу.
> У меня сосунг 980 про, и мне вообще похуй, сколько петабайт на него будет записано, он всё переварит.
Мой старый добрый кипятильник ебучий 970 ево в здравии на 60% отправился на заслуженный отдых переварив реально петабайт почти при ресурсе в 300tbw без единой ошибки за всё время.
Брать нормальные ssd и сидеть трястись за каждые сто мегабайт записанные как будто почку продал ради ссд это рофел, конечно.
>Ах да, у меня кобольд всё прекрасно подчищает, проблема в тебе.
Так у него жопу на ровном месте порвало как раз от того, что экзешник кобальда на каждый запуск распаковывается и чистится после.
https://github.com/hololeo/Ellama
Набор готовых Python скриптов для решения различных задач с помощью LLM. Работают через OpenAI-совместимый API.
> ell-meets-ella is a Python script that demonstrates how to get two AI bots to engage in a continuous conversation. The script showcases the creation of two distinct personas that interact with each other, generating an ongoing dialogue between the bots. This tool highlights how to structure autonomous conversations, making it ideal for developers experimenting with AI-to-AI interactions. By using Ell and Ollama, the script demonstrates how to create indefinite, engaging chats between AI models, perfect for understanding how bots communicate independently.
> ell-joker is a Python script that generates and delivers jokes. It prompts a model for a humorous joke and then uses text-to-speech to speak the joke aloud. The script showcases tool calling by utilizing LLama 3.1 and Ollama to run models locally. This makes it an ideal demonstration of combining AI language models with speech synthesis for developers or anyone who wants a quick laugh generated and voiced directly from their machine.
> ell-captioner is a Python script designed for fast image captioning. It generates descriptive captions from input images. The script utilizes Ollama to run the Moondream language model locally and leverages the Ell library to structure system and user prompts effectively. You can pass the image as an argument via the command line, and the script will provide an accurate and contextually aware caption for the image. This tool is perfect for developers, researchers, or anyone needing a quick, local image captioning solution without relying on cloud-based services.
> ell-summarizer is a Python script designed for efficient text summarization. Generates concise bullet-point summaries from input text. Utilizes Ollama to run the Gemma 2B language model locally. Leverages the Ell library to rapidly create system and user prompts. This tool is ideal for developers, researchers, or anyone needing quick, local text summarization without relying on cloud-based APIs.
> ell-employee-0 is a Python script that generates a script description from input information. The script uses the Ell library to locally run the Llama 3.1 model and demonstrates support for the Ollama tool, allowing users to create enhanced script descriptions. This automation enables us to create our own AI Employee!
> ell-rag-txt allows you to prompt any text file. Just put it in input.txt and set up your user prompt question. It implements the RAG pattern to chat with the document. Very simple implementation using context injection.
> ell-rag-audio allows you to prompt an audio file! Just put in a transcript.txt (whisper works great) and set your user prompt. Its smart to locate the audio timecode that relates to the prompt. Very simple implementation using context injection and clever prompt engineering.
> ell-categorizer categorize ANY data into ANY json format of your design! Just use a clear, specific prompt and provide some training examples. The approach can scale to thousands of lines if you batch in your data bit by bit. Ell Categorizer is a powerful tool in your AI bag-of-tricks!
Набор готовых Python скриптов для решения различных задач с помощью LLM. Работают через OpenAI-совместимый API.
> ell-meets-ella is a Python script that demonstrates how to get two AI bots to engage in a continuous conversation. The script showcases the creation of two distinct personas that interact with each other, generating an ongoing dialogue between the bots. This tool highlights how to structure autonomous conversations, making it ideal for developers experimenting with AI-to-AI interactions. By using Ell and Ollama, the script demonstrates how to create indefinite, engaging chats between AI models, perfect for understanding how bots communicate independently.
> ell-joker is a Python script that generates and delivers jokes. It prompts a model for a humorous joke and then uses text-to-speech to speak the joke aloud. The script showcases tool calling by utilizing LLama 3.1 and Ollama to run models locally. This makes it an ideal demonstration of combining AI language models with speech synthesis for developers or anyone who wants a quick laugh generated and voiced directly from their machine.
> ell-captioner is a Python script designed for fast image captioning. It generates descriptive captions from input images. The script utilizes Ollama to run the Moondream language model locally and leverages the Ell library to structure system and user prompts effectively. You can pass the image as an argument via the command line, and the script will provide an accurate and contextually aware caption for the image. This tool is perfect for developers, researchers, or anyone needing a quick, local image captioning solution without relying on cloud-based services.
> ell-summarizer is a Python script designed for efficient text summarization. Generates concise bullet-point summaries from input text. Utilizes Ollama to run the Gemma 2B language model locally. Leverages the Ell library to rapidly create system and user prompts. This tool is ideal for developers, researchers, or anyone needing quick, local text summarization without relying on cloud-based APIs.
> ell-employee-0 is a Python script that generates a script description from input information. The script uses the Ell library to locally run the Llama 3.1 model and demonstrates support for the Ollama tool, allowing users to create enhanced script descriptions. This automation enables us to create our own AI Employee!
> ell-rag-txt allows you to prompt any text file. Just put it in input.txt and set up your user prompt question. It implements the RAG pattern to chat with the document. Very simple implementation using context injection.
> ell-rag-audio allows you to prompt an audio file! Just put in a transcript.txt (whisper works great) and set your user prompt. Its smart to locate the audio timecode that relates to the prompt. Very simple implementation using context injection and clever prompt engineering.
> ell-categorizer categorize ANY data into ANY json format of your design! Just use a clear, specific prompt and provide some training examples. The approach can scale to thousands of lines if you batch in your data bit by bit. Ell Categorizer is a powerful tool in your AI bag-of-tricks!
> TBW у ссд не бесконечный.
Чето в голос с неосилятора кобольда(!), который к тому же еще невростеничка и трясется за ресурс ссд в 2д24м году (!). Ты не по адресу, тред не для долбоебов и не для нищебродов.
Мощность у карточек разная, размер частей моделей отличается. 1660 свою мелкую часть поменьше обсчитывает быстро и потом ждет p104, а та в свою очередь уже напрягается. Тут все нормально и ничего стабилизировать не нужно.
>Не юзать юнити, не жрать говно.
Может Unity и плох, но для него генерируют код код лучше, чем для других движков из-за большого количества примеров, простоты C#.
Даже для очень простых движков, вроде SDL, Raylib, уже сплошные галлюцинации. С Годотом и того хуже. А для неплохих движков, вроде Unigine, Bevy, Mach вообще ничего выдать не может.

А что это значит?
Бампуэ




Спиздил с новостной мусорки-треда /g/ форчка.
Вкратце, есть контора Liquid AI, один из челиков - бывшый CTO яндекса, также работал над алисой, так что это походу не просто пшик. https://x.com/AndrewCurran_/status/1840802455225094147
Они на днях показали некие LFM - Liquid Foundation Models https://x.com/LiquidAI_/status/1840768716784697688, не трансформер, но ебёт транфсормеро-парашу (по заявлениям бенчей), и пока они не собираются открывать веса, код и прочее https://x.com/maximelabonne/status/1840770960149913601. С пик-2 по пик-4, LFM-1B, LFM-3B, LFM-40B.
Вкратце, есть контора Liquid AI, один из челиков - бывшый CTO яндекса, также работал над алисой, так что это походу не просто пшик. https://x.com/AndrewCurran_/status/1840802455225094147
Они на днях показали некие LFM - Liquid Foundation Models https://x.com/LiquidAI_/status/1840768716784697688, не трансформер, но ебёт транфсормеро-парашу (по заявлениям бенчей), и пока они не собираются открывать веса, код и прочее https://x.com/maximelabonne/status/1840770960149913601. С пик-2 по пик-4, LFM-1B, LFM-3B, LFM-40B.
Потыкать можно здесь playground.liquid.ai
> Gemma-2
> Context length 128k
Що блять?
Так это заявленное, итак ясно что по RULER'у там нихуя не 128к.
>6
Видел такое в нодах для Comfy, конкретно там работает как говно.
>4
Вот это по идее полезно, но всё зависит от того насколько хорошо работает. "Распознавалок изображений" так то дохуя, но ещё не видел ни одну, которая могла бы написать, например описание, которое можно опубликовать под пикчей, не умерев от кринжа.
>2>1
Функционал таверны?
Остальное ХЗ зачем.
Пока что единственное норм решение практических задач с помощью ЛЛМ, которое встречал, это скрипт для опенофиса.
>для неплохих движков, вроде Unigine, Bevy, Mach
Проиграл. Добавил бы ещё в список "лучших" стингрей, дисрапт, ламберярд и torque. На том же краю спектра находятся. По факту юнити в гейдеве это что-то уровня трансформеров и лламацпп вместе взятых - практически безальтернативное решение.
>бывшый CTO яндекса, также работал над алисой
Ясно. Очередной пшик, не на что смотреть.
Корректнее ставить вопрос: зачем вообще Llama 3 нужна?
Думаю, все третьи части — скорее их опыты, где они разные подходы используют, иначе у меня нет объяснений.
Кстати, спросил Qwen2.5-14b, она помялась, мол, ну ты выпусти подальше, отдай ученым… Но в конце махнула рукой и «если нет вариантой — ебошь!»
Приемлемый ответ для топ1 цензурной модели.
Хорошая карта, памяти не 12 и на том спасибо, одобряем-с!
> По сути только стопка картонок сейчас может обеспечить полноценное погружение с генерацией голоса и картинок, и чтобы не ждать по полчаса.
Но мультимодальные (по-настоящему) уже появляются (минимум три помню, все пока не очень, но есть же!), так что скоро возможно и не понадобятся.
Но именно сейчас да.
> сейчас у нвидии политика такая
Именно такая.
Боюсь, 250к тоже заниженная сильно оптимистично.
> Какие-нибудь 102-100
Вдвое дороже 104-100, но чуть быстрее и толще? А неплохо, за такую цену, пожалуй. Для совсем небогатых.
ДА
Соглашусь.
Хлопчик, та хто там тебе в шаровары так срет-то? Аж жаль бедного!
llama.py
llama.py.cpp
llama.py.cpp.py
Великолепно. х)
Не зря я это некроговно рекламировал? :3 Почем брал?
Бля. А ведь так. =( Щито поделать, тут и не поспоришь.
ВЫГЛЯДИТ ТАК СЕБЕ. Ну, то есть, для первой модели молодцы, но L3.2 3B — говно на старте. А Qwen2.5 в сравнении ВНЕЗАПНО НЕТ. Ну, как бы…
Ну и вопрос — на каком языке и че там по датасетам?
Молодцы, просто ты новость сильно круто преподнес, на практике ребята просто предложили архитектуру, которая может составить конкуренцию. Если так, будет клево.
Как-то у ChatWaifu 1.4 такой себе русек. Для 12b конечно нормально, но до геммы явно не дотягивает. Пробовал в q5_k_m кванте.
это же какой-то шизотюн епонца датасетом из вн на его родном, с чего там быть хорошему ресеку
Да хз, соблазнился скринами какого-то ананаса с ней, там вроде довольно сносно она балакала.
> ебёт транфсормеро-парашу
Ровно в одном бенче - MMLU Pro, лол. В остальных дико сосёт. Наверняка тренили на STEM, очередной мусор.
Архитектура на SSM, вариация Мамбы с MoE, сами они там похоже нихуя не придумали, вот прошлогодняя публикация на тему их ликвида в SSM.
https://openreview.net/pdf?id=g4OTKRKfS7R
Попробуй 22В, она получше на порядок
А вот это реально годнота. В упор не понимал что конкретно делает каждый семплер, тут хоть какая-то демонстрация.
Сверху написана фраза, последнее слово в которой обозначено ___.
Снизу идёт список слов, которые ЛЛМка может вставить на это место, и вероятность того что именно это слово будет выбрано.
Семплерами можно регулировать количество возможных слов и их вероятности.
На выбор есть несколько фраз.
я бы это в шапку добавил
Я кручу ползунки и ничего не меняется.
Галочку включил?
Ебал рука этого верстальщика. Оказывается там есть галочка
А к чему нужно стремится при подборе настроек?
Чтобы оставалось как можно меньше вариантов или наоборот, больше равноценных вариантов?
Смотря что ты хочешь получить:
Меньше вариантов / выше вероятность типичного ответа - модель сухая и скучная.
Больше вариантов / вероятности примерно одинаковые - тотальная шиза.
это я так понял упрощённая дэмка, показывающая что конкретно меняет каждый семплер, а на деле разные модели по разному на семплеры реагируют
и все равно я не понимаю, один хер ведь мне модель выдаст САМЫЙ ВЕРОЯТНЫЙ ответ, она же не дает мне выбор ответов
То есть, вы тут все терпилы и принимаете факт, что кобольдопараша срёт на диск при каждом запуске. У меня-то неебаться быстрый ссд, грузит быстро, страшно представить что там у вас. Не только терпите загрузку, но еще и лишние гигабайты.
Вопрос только один, зачем вы так коупите и защищаете еблана на разрабе? Не вы ведь виноваты, а только он.
Ни одного человека, совладавшего со всратой сборкой кобы, но зато вагон вскукареков с выдуманными проекциями.
Делаем вывод, что кобольдом пользуется высокий процент говноедов.
Вопрос только один, зачем вы так коупите и защищаете еблана на разрабе? Не вы ведь виноваты, а только он.
Ни одного человека, совладавшего со всратой сборкой кобы, но зато вагон вскукареков с выдуманными проекциями.
Делаем вывод, что кобольдом пользуется высокий процент говноедов.
>выдаст САМЫЙ ВЕРОЯТНЫЙ
С хрена ли? Ты тервер изучал?
Малая вероятность выпадения не означает его невозможность. Свайпы не даром каждый раз что-то новое дают при одних и тех же настройках.
Пиздец дурачок. Вот, для таких как ты сделали специально, распаковывай, запускай через koboldcpp.py и не будет ничего тебе в temp срать.
Семплинг жи есть.
ааа ебать, я понял, то есть создается ВЫБОРКА и только потом выбирается ответ не обязательно самый вероятный!
От настроек семплера зависит чего мы будем делать с вероятностями следующего предсказанного токена и каким образом выбирать. Выше анон кидал простую визуализацию https://artefact2.github.io/llm-sampling/
>практически безальтернативное решение.
И такое же кривое говно в основном. Сколько они там уже крупных фичей и систем за последние лет 8 начинали делать и так нормально и не доделали?
>Ни одного человека, совладавшего со всратой сборкой кобы
Три или четыре раза написали как завести распакованный коболдь если в очке зудит и очень надо. Иди нахуй.
Год не был в треде. Напомните, как скачивать с Hugging Face.
Нажимаю, но скорости нет.
Нажимаю, но скорости нет.
>скорости нет
Тоже так бывает. Помогает стопнуть загрузку и начать заново.
А есть модель, которая из текста выделяет ключевые слова? Про что идет речь и все такое.
Тексты небольшие, 10000 символов где то.
Тексты небольшие, 10000 символов где то.
не помогло

Меняй страну проживания тогда, хули там.
> скорости нет
HF_TRANSFER, помогает и ркн-мразота на него не триггерится.
Не в России живу, тоже все медленно
И не в ближнем зарубежье? Что ж, интернет по всему миру разваливается, привыкай. Мы просто на переднем крае.
Нет, это проблема конкретно в hf
Аноны что в теории лучше
Q2 70B моделька или Q8 13B модель?
мимо терплю на озу
Q2 70B моделька или Q8 13B модель?
мимо терплю на озу
>Q2 70B моделька
Оно.
>мимо терплю на озу
Обнимемся, bрат.
>Q2 70B моделька или Q8 13B модель?
Юзай хороший файнтюн Мистраля Немо и будет нормально.
Q2 от 70b будет шизить как ни в себя. 13b - тупая в любом кванте. Оптимальный выбор Q3-K-L от 27-32b. Но это для 12Гб ГПУ. Если без видяхи - там будет максимум 2 т/с. Если тебе так норм, то норм. А про 70b в Q3 вообще нахуй забудь, поверь, тебе это не нужно
Очередной клоун, не прочитавши, пишет. Я сделал это и больше, но нужно чуть ли свою ос закодить, чтобы в итоге это заработало.
Не ставил, не пукай.
Попробуй в ссылках заменять домен huggingface.co на hf-mirror.com (это какой-то неофициальный прокси), у меня часто через него скорость лучше.
>Q2 от 70b будет шизить как ни в себя
100%
лучше не брать низкие квантыесли не хочеш получать непредсказуемые слова и несвязные фразы...
Хотя для кумерства может и сойдет
Ни капли не удивлён. Тупость очень часто соседствует с криворукостью.
подскажите что по годным моделям есть в диапазоне 20-30 с хорошей информационной наполненостью (инглиш пускай, можно соевые) и вцелом для работы пригодная чтоб была...
насколько я понимаю гемма есть в этой категории, может кто еще чего интересного подскажет, ( у ламмы после 8 сразу 70 идет по этому мимо насоклько я понимаю)
насколько я понимаю гемма есть в этой категории, может кто еще чего интересного подскажет, ( у ламмы после 8 сразу 70 идет по этому мимо насоклько я понимаю)
> от 27-32b. Но это для 12Гб ГПУ.
Если я запущу Q4, и невлезающее в озу, то сколько токеннов может быть?
мимо
Гемма 27b, новый Командер на 32b и Квен 32b - неплохо себя показывают. Гемма из них самая умная имхо.
На Q4-K-M будет ~3.8 т/с. На Q3-K-L будет ~4.6 т/с. Заметной разницы в качестве генераций между этими квантами нет.
окай, спасибки, значит гему буду качать, раз 32 для квена не даст весомых преимуществ...
а что там у квена к стати за Math модели есть? это типа математику решать? если да, то какой уровень оно достойно обрабатывает (двойные тройные интегралы умеет? прощадь пересечения фигуры с плоскостью)?
>невлезающее в озу
А, я жопой прочитал. Если в ОЗУ не влезет - то ты вообще не запустишь модель. Скорости выше описал относительно 12 гиговой видяшки, в которую эти кванты не до конца влезают. Ну то есть речь о видеопамяти, а не оперативной.
>Гемма из них самая умная имхо
Какую версию брать на 16гб видео?
https://huggingface.co/TouchNight/gemma-2-27b-it-abliterated-Q3_K_M-GGUF/blob/main/gemma-2-27b-it-abliterated-q3_k_m.gguf
Эту?
Полностью в видеопамять влезет Q3-K-L, он лучше. Можно скачать отсюда https://huggingface.co/QuantFactory/gemma-2-27b-it-abliterated-GGUF/tree/main
Можно Q4 еще попробовать. Он не влезает, но будет в принципе терпимо.
Прикольная штука, будет ли английская версия?
>rentry для всего этого заводить
100%
Да можно, только время надо будет найти всё оформить. Займусь на днях.
>Боюсь, 250к тоже заниженная сильно оптимистично.
Я чуток по-другому считал сначала. Самая дешёвая 4090 в трёхбуквенном 225к, рекомендованная цена 1.5к, итого 150 рублей за доллар. У новинки вряд ли будет рекомендованная ниже 2к. Без учёта ажиотажа и любых других флуктуаций, нижняя планка цены 300к. Но как-то безрадостно.
>Вдвое дороже 104-100, но чуть быстрее и толще?
Ну с такой формулировкой уже хуёво звучит.
>такое же кривое говно в основном
Вот юнити это тот случай, когда любая "кривость" или "лаги" это очевидный скилл ишью.





>нижняя планка цены 300к
Я бы сказал - 500к на старте. Один прирост "до 70%" по сравнению с 4090, плюс обязательный запрет на поставки в Китай при огромном спросе там. Плюс памяти докинули явно не просто так, а чтобы охватить и "энтузиастов" LLM. Но есть и условно светлое пятно: когда ажиотаж схлынет и 5090 таки опустятся до 300к, можно будет прикупить за 100к б/у 4090, которые точно не участвовали в майнинге и может даже ещё на гарантии.
Какая сетка?
На самом деле тот же grounding dino подобное мог уже давно, cog также представляли отличный функционал еще в начале года. Но если оно хорошо и четко работает то довольно интересно, что за сетка?
> можно будет прикупить за 100к б/у 4090
Это довольно маловероятно ибо запредельная цена на 4090 будет сдерживающим фактором.
> которые точно не участвовали в майнинге
Подходи-разбирай, вообще ни разу не майнила, умножение матриц для нейронок не считается!
> вообще ни разу не майнила, умножение матриц для нейронок не считается!
Число энтузиастов домашних LLM по сравнению с майнерами ничтожно.

Коллаб опять что-то не работает…
Если я все правильно понял, то это из-за того, что релизнулась в октябре новая версия pytorch. Я попробую себе сейчас наколхозить установку предшествующей версии.
>Я бы сказал - 500к на старте.
Ставлю на то, что до полуляма не дотянут. Если будет подпирать, то скинут тыщ 15. А то психологический барьер, лол. Если, конечно, карта не будет 3 килобакса стоить со старта.
>можно будет прикупить за 100к б/у 4090
Это нужно, чтобы 4090 начали продавать. У нас были 3090 из-под майнеров, но 4090, как ты сам говоришь, не майнили. Так что майнеры их не имеют. Будут ли их продавать геймеры? Ну, единицы будут. Массово? Сомневаюсь.
>Будут ли их продавать геймеры? Ну, единицы будут. Массово? Сомневаюсь.
Многие успели взять за 150. Ближе к концу гарантии продать за 100 - нормально, при возможности купить 5090. Впрочем увидим, как оно будет. Лично мне все эти риги с питанием под 2 киловатта и ценой в миллион при возможности арендовать и ни о чём не беспокоиться вообще кажутся сомнительным решением.

Что хочет таверна?
Ты что-то с браузером напердолил, какие-то ограничения. CSRF токен - это то, что передаётся в HTTP запросе.
одновременно одна вкладка будет работать, нажми ф5
Отменил последнее обновление - заработало.
Потом надо будет способ установки/запуска поменять, чтоб обновления не слетали, теперь угабога ставится через скрипт.
или вообще кобольда накатить, ставится на пару минут и тот же АПИ даёт
мимо-колабанон
Сколько токенов в секунду с колаба выходит? На цп.

Не пометил дерево, незачёт.
Сейчас тестил Магнум 27В со стандартными настройками.
Output generated in 33.15 seconds (13.24 tokens/s, 439 tokens, context 1210, seed 2064265985)
>На цп.
Но зачем?

Хотя даже так вырезанными русскими examples очень даже полезная вещь. Может помочь понять какая мотивация должна быть у бота (чтобы потом добавить в Definition карточки).
Модель MN-12B-Lyra-v4-IQ4_XS-imat
Сеолько нужно врам, чтобы 70б шёл на 3-4 квантах? 36?
Анончик, не останавливайся благодаря таким как ты тред живёт!
>Надо похоже будет какой-то rentry для всего этого заводить
Обязательно сделай, даже самому полезно будет. Порой, каталогизация своих мыслий/знанияй, помогает найти новые идеи.
Давно хочу заняться скриптами по твоим примерам, с голыми цинкинг-промптами неплохие результаты получались, но времени сейчас нет...
Смотри сколько весят файлы этих квантов и прибавляй 4-6Гб на контекст.
>sunfall
Количество глинтов умножено на 10
Количество глинтов умножено на 10
Опять градио лежит, похоже.
А ngrok выдает вот это.
>Но зачем?
У меня, кстати, последний месяц ни одна модель без цп не включалась.
Мимо другой анон
Интересно, выходит, что каломазин smooth sampling теоретически реально топ для креативной и разумной писанины. Ставишь температуру чуть выше единицы, smooth factor около 0.5, отрезаешь любым сэмплером маленький хвост (лучше "умными", принимающими распределение во внимание, типа tfs или minP) и получаешь штук пять примерно одинаковых нешизовых варика на выбор при условии исходно достаточно пологого распределения. Понятно, что с токенами вместо слов чуть сложнее, и для мелких моделей придётся отрезать больше, но тем не менее.
Тоже так подумал но чет не нашел этот смувинг фактор в таверне и затупил.
>Многие успели взять за 150. Ближе к концу гарантии продать за 100
C такой логикой на авито должно быть немало p40 - многие их успели взять за 15, сейчас скинуть за 10 и взять что-то мощнее. Только их там нет. Как и не будет 4090 по 100. Смысл скидывать карту ценой 200к за половину цены, если можно за три четверти?
Скачал magnum-v3-27b-kto-Q5_K_M. Ебать он скучный. Ощутил такой неслабый привкус даркфореста - речевые обороты те же, ломается так же. Но форест был лучше, он расписывал гораздо красочнее.
В личном топе кума первой всё ещё стоит обычная модель, а не кум-файнтюн, ебануться.
Сколько токенов/секунда нужно, чтобы имитировать переписку?
>не кум-файнтюн
Кажется что все кум-файнтюны это просто васянская хуйня с аутпутами от клода, а клод как известно кроме глинтов и бедер нихуя не знает
>Сколько токенов/секунда нужно, чтобы имитировать переписку?
3-4 т/с
>все кум-файнтюны это просто васянская хуйня
Так и есть
тут согласен, если нет нужды 24/7 молотить нейронку - то аренда выгоднее даже окажется, учитывая что оборудование имеет свойство устаревать, а электричество денег стоит, а для некоторых случаев можно даже не арендовать а за использзование API LLM сервера платить просто, что еще выгоднее будет...
есть такое, 4090 насколько я понимаю пока что не та карта которая чего-то не тянет, и пока не выкатят таких игрушек которые не идут на 4090 массовой продажи не будет думаю... мвайнеры так-то здорово с 3 поколением подсобили, с 4090 не понятно, сколько народу майнило что-то на них или не майнило вообще, но геймеры не будут дешево отдавать, майнерам с этим проще, они обычно продают то, что уже окупилось, а геймеры, если это не какой-нибудь стример милионер, то не сильно то и хотят в убыток быть...


ngrok уже давно не работает.
Можно конечно разобраться, но подозреваю что тут в самой убе дело. Когда градио в первый раз отвалился, я прикрутил к колабу локалтоннель. В колабах с SD он вполне себе работает, а тут по сути та же история что и с градио.
>последний месяц ни одна модель без цп не включалась
Что писала? Может ты среду ГП не использовал при запуске? пик2
40+
> каломазин smooth sampling
Ну хууууй знает. Вариативности действительно добавит но количество шизы и уебищных мишвилоус глинтов даже там где их нет может стать просто запредельное. Точно не для всех сценариев, может быть если сочетать технику выше в формированием мотивации и запросов делая на ней нормальный семплинг, а потом главный ответ с ультрашизосемплингом - что-то и получится, но всеравно специфично.
1 или меньше лол. А чтобы не ждать и было комфортно читать стриминг - от 5.
> Многие успели взять за 150. Ближе к концу гарантии продать за 100 - нормально
Ну конечно, посмотри на авторынок, где покупали _управляймечтой_ за условные 4.5 а теперь хорошо побегавшие без гарантии торгуются за 5.
Все так
>Что писала?
Сейчас точно не помню, но похоже было недостаток памяти для модели. Изначально у меня так с новыми только было, но потом и старые так же перестали работать.
>Может ты среду ГП не использовал при запуске?
Использовал.
>Когда градио в первый раз отвалился, я прикрутил к колабу локалтоннель. В колабах с SD он вполне себе работает, а тут по сути та же история что и с градио.
Не, я пробовал утром, всё равно не работало.

Ссылку на локал.лт не даёт.
Я что-то неправильно делаю?

Не, херню написал, дело вот в чём:
>Usage of ngrok requires a verified account and
authtoken.\nSign up for an account
Починил ngrok, теперь есть ещё один работающий тоннель
%правда это нихуя не помогло, т.к. причина отвала интерфейса оказалась в не в тоннелях%%
Локалтоннель тоже через раз работает, обычно помогает перезапуск. Но сейчас пока интерфейс колаба не пашет. как пойму в чём дело разберусь.
Что датасеты из одного места берут - это факт. Слишком похожие посты, слишком похожим образом себя ведут модели.
>пока что не та карта которая чего-то не тянет
Ну почему, есть хуйня, которая работает на чистом брутфорсе. Типа патчтрейсинга или анриловских нанитов с люмпенами. Вуконг вон недавно вышел - в нативном 4к ниже 50 фпс на 4090. И это с выключенным гейтрейсингом. Свиня ещё долго сможет ставить на колени любые карты кожаного. А тот и рад, хули.
>4090 насколько я понимаю пока что не та карта которая чего-то не тянет, и пока не выкатят таких игрушек которые не идут на 4090 массовой продажи не будет думаю...
С 4090 думаю распределение между бравшими для игр и бравшими для рабочих задач/нейронок сильно другое чем было с 3090 вообще.
>Вот юнити это тот случай, когда любая "кривость" или "лаги" это очевидный скилл ишью.
Так и про анрил сказать можно, и про много что. У юньки проблема в том, что который год нормального вектора разработки. Куча кор-фичей доделываются уже который год, кривые или вообще заброшены почти. SRP тяжелая в юзании ебанина, DOTS тоже не осилили нормально, куча меньших фичей в хер пойми каком состоянии, постоянно всё больше беды с перфомансом и редактора и всего рантайма. И тд. и тп, знакомое любому кто трогал по серьезному движок, а не чисто накидать пару кубов с готовыми скриптами.
Юзать и делать хорошие игоры/софт то можно при прямых руках, но движок топчтеся на месте уже лет 5 и лучше уже не станет с такой политикой доения бабок и проебывания инженеров из команды.
С этой моделью там произошло как обычно стандартное смешное: что если нормально подойти к сбору качественного датасета, то данных для заебись результатов оказлось нужно на пару тройку порядков меньше данных для обучения. Никогда такого не было и вот опять.
Так ведь ГП отберут?
Или тут нагрузка маленькая и не отбирают?
>в нативном 4к
совсем зажрались буржуи, наши люди в 720 играют при 25 кадрах...
а если серьезно, то для этого ж длсс есть, чтобы тянуло, но то такое, будем честны, каждое поколение менять карты могут позволить себе только те у кого денег куры не клюют,а простые игруны потерпят, пока хоть как-то ирается, а дизайнерам и монтажорам так еще с головой хватит на много лет
на ЦП короче 8В моделька 10с/токен, короче от старости умреш быстрее чем сгенерируеш....
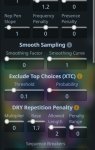
Вот же он
А такой вопрос, кто-то пробовал Groq тестить? в чем прикол что бесплатное API с огромными скоростями генерации? гопота по сравнению с этим чудом тормоз нереальный
Или там всеже не бесплатно и есть подвох?
Или там всеже не бесплатно и есть подвох?
> произошло как обычно стандартное смешное: что если нормально подойти к сбору качественного датасета, то данных для заебись результатов оказлось нужно на пару тройку порядков меньше данных для обучения
База же, и ведь до сих пор есть убежденные что большой датасет из мусора даст лучший результат чем выжимка наиболее качественного и важного из него.
> или анриловских нанитов
Трешанина ебаная же, их ведь кто только не обоссал. А так "нативные 4к" уже 3е поколение подряд покоряют, а все там же.
Ну тут только надеяться и ждать, может через пару месяцев после релиза подупадет цена. Вроде и хочется взять топ йобу но переплачивать барыгам ради "пораньше" на грани долбоебизма.
Лучшая 13 и 24 модель для романтики и кума?
А что так медленно? У меня вон на целероне похожая ситуация была. А уже на i7-2600 хотяб 1т/с выдает в 8b-8q
Для продвижения тупо + сбор фидбека.
Типа вот бесплатно с лимитами на день/в минуту, юзай базарим ещё захочешь шо деньги заплатишь.
Твайлайт на заднике)
Это самосознающий себя искусственный интеллект.
так там одно ядро двухпоточное на виртуалке... колаб на ЦП это так, по приколу, хотя его удобно использовать в качестве прокси для загрузки, если что-то большое через впн надо качать
На ГП будет поприятнее скорость, но не особо долго... (ну типа заплатить конечно можно, но если б это было вариантом то вопрос не стоял бы
короче говоря - пользуемся пока дают, а там видно будет...
так-то 70В приятнее чуть чем 8В...
А такой вопрос еще, есть ли где-то персонажи для таверны, которые не для кумерского ролплея а "обучающие", "эксперты" итд? (понятно что без этого можно обойтись, но готовый пресет лучше чем объяснять вручную роль ИИ)
>Так ведь ГП отберут?
Отберут - меняй акк и поновой!


>Куча кор-фичей доделываются уже который год
Они потому и на грани банкротства который год, лол. Набрали в менеджеры прогрессивных хуй пойми кого и всё в пизду покатилось. Гуй хуйня? Ну давайте сделаем новый. О, ебать, у нас мегапопулярное расширение для гуя от энтузиаста? Давайте наймём автора, пусть нам сделает гуй. О, нахуй этот гуй, пора пилить новый. Сколько там гуёв? Immediate, uGui, UI Toolkit, IMGUI. Это же рофл какой-то, блядь. С дотс тоже не всё гладко, хотели уйти от однопоточного монобеха, решили сломать всё, по факту вся скриптовая система писалась заново. И сверху этого ещё транслятор в крестовый код, да надо, чтобы он поддерживал и монобех, и дотс, и всё на свете. Но сейчас они забросили всё не критическое, исправляются. Вроде бы. В итоге такой себе полурак-полухуй, и всё равно ебёт.
>каждое поколение менять карты могут позволить себе только те у кого денег куры не клюют
А людей таких не много и карточек у них не десятками-сотнями, как у майнеров. Китайцы тоже скурвились, задрали цены на своё железо куда-то в заоблачные дали. Смотрел один вариант нарастить vram, но цену заломили такую, что смысл появляется только при бюджете выше килобакса. А при таком бюджете проще купить другие варианты.
>Трешанина ебаная же, их ведь кто только не обоссал.
Наниты хуйня, тормозят-лагают. А они построены на вычислительных мешлетах, которые летают на железе десятилетней давности. Наёба не чувствуешь?
Если начать подгружать большой чат в контекст, то начинают сыпаться какие-то ошибки JSON, их полный текст невидно. Может есть какие-то настройки чтобы оно не вываливалось?

>дракон горничная в розовых труселях облизывает красный банан в форме конского дилдака пока сидит на стуле из замороженных скелетов
Бля аноны посоветуйте модельку до 35b которая не пишет как Клод с глинтами
Мб стоковая Немо?
Такие в природе есть вообще? Просто если я хочу с клодом порпшить то он и так есть
Мб стоковая Немо?
Такие в природе есть вообще? Просто если я хочу с клодом порпшить то он и так есть
а дракон?
там много нюансов с врам... заметь момент интересный, на жирных теслах не gddr а НВМ память, потому что внезапно наращивание приводит к тому что уже по скорости не будет справляться...

Поймал ошибку лицом.
Еще и в логах пустота, просто сбрасывает.
Как будто у него там какой-то таймаут на обработку стоит.

ну так, костяной Дракон, хуле. Думаешь твоя горничная бессмертная?

ПЕРЕКАТ
ПЕРЕКАТ
ПЕРЕКАТ
Сука, как же у меня сегодня сгорела жопа от Убы...
Чтоб упростить жизнь юзерам он сделал автоустановку через пусковой файл. И всё бы ничего, но все зависимости ставятся сразу в ебучую Конду, а это значит что просто строчкой кода установить требования для конкретного дополнения нельзя... вернее можно, но конда должна быть уже установлена, а устанавливается она с запуском вебуи, когда уже поздно заранее что-то устанавливать
Есть выход - можно указать автоустановку дополнений. НО, у этой ебанины нет команд на установку конкретных дополнений, либо всё, либо ничего. А всё ставится около 1,5 часов...
Но оказалось что список дополнений для установки он берёт из имён папок в папке extensions. И я придумал гениальное быдлокодерское решение: выпиздить их от туда нахуй и вернуть только те дополнения, что нужны!
Теперь всё снова работает адекватно, пользуйтесь - ни в чём себе не отказывайте!
Первый блок теперь только грузит модели, а второй устанавливает и запускает, но установка идёт только один раз, можно смело перезапускать.
анон, можешь поделиться исходным кодом, буду благодарен~




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф. картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2 0,58 бит, на кофеварке с подкачкой на микроволновку.
Официальная вики треда с гайдами по запуску и базовой информацией: https://2ch-ai.gitgud.site/wiki/llama/
Инструменты для запуска на десктопах:
• Самый простой в использовании и установке форк llamacpp, позволяющий гонять GGML и GGUF форматы: https://github.com/LostRuins/koboldcpp
• Более функциональный и универсальный интерфейс для работы с остальными форматами: https://github.com/oobabooga/text-generation-webui
• Однокнопочные инструменты с ограниченными возможностями для настройки: https://github.com/ollama/ollama, https://lmstudio.ai
• Универсальный фронтенд, поддерживающий сопряжение с koboldcpp и text-generation-webui: https://github.com/SillyTavern/SillyTavern
Инструменты для запуска на мобилках:
• Интерфейс для локального запуска моделей под андроид с llamacpp под капотом: https://github.com/Mobile-Artificial-Intelligence/maid
• Альтернативный вариант для локального запуска под андроид (фронтенд и бекенд сепарированы): https://github.com/Vali-98/ChatterUI
• Гайд по установке SillyTavern на ведроид через Termux: https://rentry.co/STAI-Termux
Модели и всё что их касается:
• Актуальный список моделей с отзывами от тредовичков: https://rentry.co/llm-models
• Неактуальный список моделей устаревший с середины прошлого года: https://rentry.co/lmg_models
• Рейтинг моделей для кума со спорной методикой тестирования: https://ayumi.m8geil.de/erp4_chatlogs
• Рейтинг моделей по уровню их закошмаренности цензурой: https://huggingface.co/spaces/DontPlanToEnd/UGI-Leaderboard
• Сравнение моделей по сомнительным метрикам: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
• Сравнение моделей реальными пользователями по менее сомнительным метрикам: https://chat.lmsys.org/?leaderboard
Дополнительные ссылки:
• Готовые карточки персонажей для ролплея в таверне: https://www.characterhub.org
• Пресеты под локальный ролплей в различных форматах: https://huggingface.co/Virt-io/SillyTavern-Presets
• Шапка почившего треда PygmalionAI с некоторой интересной информацией: https://rentry.co/2ch-pygma-thread
• Официальная вики koboldcpp с руководством по более тонкой настройке: https://github.com/LostRuins/koboldcpp/wiki
• Официальный гайд по сопряжению бекендов с таверной: https://docs.sillytavern.app/usage/local-llm-guide/how-to-use-a-self-hosted-model
• Последний известный колаб для обладателей отсутствия любых возможностей запустить локально https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: