


Перекатил вопрос.
Почему всякие гайды по обучению лоры на определенный ебальник (одного человека) рекомендуют использовать 10-30 фото? Разве закинуть 100-200 фото не лучше для обучения?
Почему всякие гайды по обучению лоры на определенный ебальник (одного человека) рекомендуют использовать 10-30 фото? Разве закинуть 100-200 фото не лучше для обучения?
Принцип необходимости и достаточности
ты б еще спросил почему в зерошот моде достаточно 6 ебальников
https://huggingface.co/collections/ptx0/terminus-xl-65451893a156b3b1d1456514
Я непонел шоэта? Файнтюн или модель с нуля? Он так пишет будто с нуля тренил.
>Terminus XL Gamma is a new state-of-the-art latent diffusion model that uses zero-terminal SNR noise schedule and velocity prediction objective at training and inference time.
>Terminus is based on the same architecture as SDXL, and has the same layout. It has been trained on fewer steps with very high quality data captions via COCO and Midjourney.
Я непонел шоэта? Файнтюн или модель с нуля? Он так пишет будто с нуля тренил.
>Terminus XL Gamma is a new state-of-the-art latent diffusion model that uses zero-terminal SNR noise schedule and velocity prediction objective at training and inference time.
>Terminus is based on the same architecture as SDXL, and has the same layout. It has been trained on fewer steps with very high quality data captions via COCO and Midjourney.
Я просто не могу использовать влад автоматик или а1111, на амуде 7900 в убунту крашится драйвер на мгновение, и все графические программы перестают работать до полной перезагрузки
Комфи работает, но не нравится он мне. Признайтесь, у кого на амуде 7900 все работает, и можно генерировать два часа, какие версии, какие гайды?
Комфи работает, но не нравится он мне. Признайтесь, у кого на амуде 7900 все работает, и можно генерировать два часа, какие версии, какие гайды?
У меня есть товарищ, казуал полный,и ставить ручками эти ваши питоны-диффузеры в рот ебал, так что скачал уан-клик-инсталл модную молодёжную оболочку для нейросетей: https://github.com/LykosAI/StabilityMatrix
У неё внутре неонка Комфи, но интерфейс белого человека, а не макаронного монстра. На интерфейс комфи тоже можно переключиться в случае чего, обычным заходом по айпи.
А вообще я бы охлаждение проверил и мб андервольтинг сделал у видюхи.
Все зависит от задачи. Если цель - буквально воспроизводить фейс с минимальным изменением ракурса то такого вполне достаточно и заодно упростит подготовку датасета. Если нужно что-то более сложное или генерация остального тела то больше фоток предпочтительнее, с другой стороны здесь качество важнее количества.
А так кто знает этих шизохайперов с их вбросами и ахуительными историями. Будет неудивительно если братишки продемонстрировали где-то в статье саму возможность такого обучения, не задумываясь об оптимизации результата, а дурень увидев это принял за абсолютную истину и всюду тащит.
Файнтюны офк.
Логи хоть глянь что с драйвером ним происходит.
>Логи
Не знаю, полез, и уже 20 минут нет вылетов. Нечего добавить. Блин, а вчера ни одного нормального рана не было. Ладно, пока закрываю тему
Спс, гляну. Насчет параметров видюхи, нашел Corectrl, но в нем как-то криво настраивается, не рискну трогать
> Файнтюны офк.
Нет, это именно обученные с нуля модели на архитектуре SDXL. Но так как у них всратый датасет, то они соответственно нихуя не могут.
Просто технодемка для проверки технологий.
А зачем тогда? Как тренить модели уже известно, ничего нового. У них там линки на скрипты для файнтюна, в них что-то такое особенное - уникальное?
Применение zero-terminal SNR не ново и есть и на 1.5. Последовательный тренинг xl в разрешениях с 512 до 1024? Ну наверно норм, честно хз как тренилась оригинальная модель, сразу или с повышением. В чем суть то?
Ну очевидно что это попытка попробовать к чему приведёт
>very high quality data captions
>zero-terminal SNR noise schedule and velocity prediction objective
в архитектуре SDXL.
Это просто следствие того что цены на тренировку фундаментальных моделей резко упали (пиксарт альфа, DiT уже тренировали за копейки), вот уже отдельные энтузиасты балуются.
>Применение zero-terminal SNR не ново и есть и на 1.5.
В SDXL они не осилили ни ztsnr, ни vpred. По каким-то техническим причинам, кажется. Этот чел вот делает.
> По каким-то техническим причинам, кажется.
Вот это довольно странно, учитывая что в 2.х оно было. Возможно xl на самом деле старше чем 2.х и начала трениться до ее релиза.
На 1.5 эти вещи относительно легко добавляются файнтюном базовой модели, велика вероятность что здесь сработает тот же трюк.
Другое дело что тренировка с нуля отличается, написано о предпочтительности обширного и разнообразного датасета в начале тренировки, а смещение к качеству и усложнение наилучшим образом работает уже на более поздних ее этапах. Пока что их результат это подтверждает и усложняет оценку остального.
Кстати кто-нибудь на xdxl пробовал будку запускать, оно вообще реально без A100?

Далеко не уехал. В гугле нашел открытые проблемы, пишут про разные причины
ERROR MES failed to response msg=14
[drm:mes_v11_0_submit_pkt_and_poll_completion.constprop.0 [amdgpu]] ERROR MES failed to response msg=2
amdgpu: failed to add hardware queue to MES, doorbell=0x1216
amdgpu: MES might be in unrecoverable state, issue a GPU reset
> По каким-то техническим причинам, кажется.
Технические причины звучат примерно так: "Good morning sir, use lora, noise offset lora good, can fix everything, thank you."
https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0/blob/main/sd_xl_offset_example-lora_1.0.safetensors
> Кстати кто-нибудь на xdxl пробовал будку запускать, оно вообще реально без A100?
На 3090/4090 реально
https://github.com/recoilme/train#kohya-train-params-for-3090-with-24-ram
Но скорость пиздец конечно
Уже было?
>Stable Diffusion v1.6 Release
https://platform.stability.ai/docs/release-notes#stable-image-v1-release
>Stable Diffusion v1.6 Release
https://platform.stability.ai/docs/release-notes#stable-image-v1-release
В sd треде было
Почему доступ только через api
Без gradient_checkpointing выходит не заведется? Припоминаю что оно раза так в 1.5 скорость резало или даже больше.
А сами веса где?
SAI всегда сначала через апи дают пробовать, потом уже релизят веса
а сдхл это что было тогда?
Так, а на kaggle, если дают две Т4? accelerate, все дела?
Шта? Полторашка победила??
Надеюсь, что все штуки с когеренцией на высоких разрешениях они вынесли в отдельные слои. Чтобы с существующими миксами было проще мёржить.
> Без gradient_checkpointing выходит не заведется?
Не хватит памяти
> gradient_checkpointing
Ужасная вещь, пробовал с этим сделать лору, да, потребление памяти ниже чуть ли не в 2.5 раза, скорость всего в 1.5-2 раза была ниже, но не запомнилось практически ничего. У вас получалось с этим параметром удачно натренить что нибудь?
Есть 2 папки: с небольшим проверочным датасетом и классификационными картинками. Выставляю какие то настройки, Изображения классов на изображение экземпляра ставлю на 20, нажимаю Тренироваться - хуяк, please check your dataset directories. Что? Чего блядь? Нажимаю ещё раз Тренироваться - начинается генерация классификационных картинок.. У меня же блядь уже есть эти картинки, хули ты сука их генерируешь. Мне кажется этот dreambooth вообще не видит, что у меня есть какие-то изображения хоть в одной хоть в другой папке, всё максимально криво, во время обучения он выдает картинки которые вообще не о том, какая то потрескавшаяся штукатурка, мусор, подобие карты местности, но только не портреты людей.
Давайте помогайте кто шарит, спасайте.
Давайте помогайте кто шарит, спасайте.
Вот такая хуйня высирается
Папка с изображениями должна называться %количество повторений%_%название концепта%, например 10_proverka
Закидываешь изображения/подписи в папку, например d:\mygreatlora\10_proverka и указываешь путь датасета d:\mygreatlora
А папку с классификационными картинками с подписями как размещать?


Перекинул папки на жесткий диск с рабочего стола, теперь вроде видит классификационные картинки, по крайней мере не пытается их заново генерировать, первая генерация выдала это. В чем проёб?


Как sdxl лоры на персонажей в сравнении с 1.5 кто-нибудь сравнивал?
2d если конкретно
> с небольшим проверочным датасетом
Это тут не поможет. Про структуру папок вроде сказали, ну и пользуйся кохой а не встроенным костылем автоматика, там все сильно лучше.
Пережарил, лр снижай.
Анон, это кабздец. У меня нет апстрима. Я линуксоид во втором поколении, больше 10 лет на убунте. Я не могу жить без апстрима. Это неправильно.
Ты, может быть, меня вспомнишь. Может быть, я тебе уже даже надоел. Я треню DreamBooth на колабе от ShivamShrirao, основательно так перепиленном под мои нужды. Треню редко, в среднем раз в неделю. Не так много того, что мне хочется иметь, а датасеты собирать долго.
Так вот, у меня нет апстрима. Совсем. Шивам забросил своё поделие. Попытка воткнуть вместо его скрипта официальный, из диффузерсов - провалилась. Слишком большое расхождение. Шивам в своё время вообще не пуллреквестил, и в результате многие нужные опции реализованы совсем иначе - в его форке и в диффузерсах. Я пытаюсь сейчас всё это бэкпортнуть, но... но... диффузерсы категорически скептически настроены против того, чтобы принимать новые фичи! Вообще! Никто этого не хочет. Коха? Последний коммит 7 месяцев назад. ЛастБен? Что-то в том же духе.
Наверное, я обречен вечно страдать без апстрима. Это кара за жажду обладания тем, что мне не принадлежит.
Ты, может быть, меня вспомнишь. Может быть, я тебе уже даже надоел. Я треню DreamBooth на колабе от ShivamShrirao, основательно так перепиленном под мои нужды. Треню редко, в среднем раз в неделю. Не так много того, что мне хочется иметь, а датасеты собирать долго.
Так вот, у меня нет апстрима. Совсем. Шивам забросил своё поделие. Попытка воткнуть вместо его скрипта официальный, из диффузерсов - провалилась. Слишком большое расхождение. Шивам в своё время вообще не пуллреквестил, и в результате многие нужные опции реализованы совсем иначе - в его форке и в диффузерсах. Я пытаюсь сейчас всё это бэкпортнуть, но... но... диффузерсы категорически скептически настроены против того, чтобы принимать новые фичи! Вообще! Никто этого не хочет. Коха? Последний коммит 7 месяцев назад. ЛастБен? Что-то в том же духе.
Наверное, я обречен вечно страдать без апстрима. Это кара за жажду обладания тем, что мне не принадлежит.


Что думаете про этот Vae от OpenAI? Лица в меньшей мере распидарашивает
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13879
https://github.com/AUTOMATIC1111/stable-diffusion-webui/issues/13879
О, кстати, в автоматике в отдельной ветке реализовали
А ты быстрый. Это говно уже успели обоссать 10 раз, в автоматике передумали делать его потому что хуже обычного VAE.

Расширение, добавляющее LCM Sampler в sd-webui
Теперь lcm лору для sdxl можно использовать в автоматике!
https://github.com/light-and-ray/sd-webui-lcm-sampler
Теперь lcm лору для sdxl можно использовать в автоматике!
https://github.com/light-and-ray/sd-webui-lcm-sampler
Это всё ещё не полноценная реализация семплера, я в прошлом треде кидал сравнение с этим обрубком. По качеству всё ещё лучше частичное LCM использовать, так хоть негативы будут работать.
Негативы отрубаются при cfg 1.0
Жрёт память люто, проблемы полностью не фиксит. Вердикт: в печь. Банальные хайрез фиксы, деталеры, и прочие двухпроходные трюки работают быстрее, лучше, экономичней.
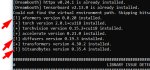
Пасаны, как лечить эту хуйню? Походу из за этого у меня dreambooth не работает, восклицательные знаки явно не просто так выставились.

Купил 3060, по бенчмаркам на англоязычных сайтах она выдаёт 12it/s. А у меня 6it/s.
Если у кого-то есть 3060, прошу сделайте тест
a house
Steps: 20, Sampler: Euler, CFG scale: 4.5, Seed: 3005468437, Size: 512x512, Model hash: 84d76a0328 (https://civitai.com/models/25694/epicrealism), Version: 1.6.1
Напишите it/s и время генерации картинки
Напишите свой set COMMANDLINE_ARGS=
Версию драйвера
Версию cuDNN
Версию PyTorch
Если у кого-то есть 3060, прошу сделайте тест
a house
Steps: 20, Sampler: Euler, CFG scale: 4.5, Seed: 3005468437, Size: 512x512, Model hash: 84d76a0328 (https://civitai.com/models/25694/epicrealism), Version: 1.6.1
Напишите it/s и время генерации картинки
Напишите свой set COMMANDLINE_ARGS=
Версию драйвера
Версию cuDNN
Версию PyTorch

6 it/s выглядит норм. Чуть больше 3 сек на генерацию, у меня так же
Скорее всего ты видел тесты нового драйвера с включенным tensorrt
Э, а че у меня сажа включилась. Бамп
xformers включил?
Да, при этом
--precision full and не работает, выдаёт ошибку
--no-half снижает производительность вдвое
> --no-half снижает производительность вдвое
Что здесь тебя удивляет, так и должно быть. Эти параметры на видеокартах белого человека не нужны.
Если судить по бенчмарку из шапки то примерно 6 итераций там и должно быть, покажи что за бенчмарки ты смотрел.
https://vladmandic.github.io/sd-extension-system-info/pages/benchmark.html
там есть без tensor rt с ебенячими показателями
плюс ещё тут смотрел 6-7 секунд у пацанов
а у меня 9-10
https://www.reddit.com/r/StableDiffusion/comments/z0f5k0/stable_diffusion_rtx_3060_12gb_vs_rtx_3060ti/
Карту проверил в бенчмарках, выдаёт что нужно, но в СД показатели ниже чем средние.
как же хочица 1.6...
А такое видал? Установил ебать дримбут, сразу пиздота непонятная началась.
Переустановил SD, получилось 7.2 - 7.5 секунд на генерацию из реддита
Хз что ещё сделать, они там не пишут какую модель используют, от модели же тоже зависит скорость?
В моём тесте получается 6,5 - 7.2 it/s, 3.2 секунды генерится картинка
Тут все ок, 6-7 it/s для 3060. Есть один с 12 it/s, но там sdp оптимизатор и большой batch size. Как я понял, это флаг на split attention, или quad attention
Можно еще в настройках до кучи token merge поставить на примерно 0.4 - даст ещё около 20% скорости
А, затупил, spd - это speed. Короче вот этот флаг:
--opt-sdp-attention May results in faster speeds than using xFormers on some systems but requires more VRAM. (non-deterministic)
А блин, затупил еще сильнее. Короче хрен знает что за sdp. В общем больше памяти жрет, не детерменистичный - это большие минусы. А судя по бенчмарку, преимущество в скорости только при большом batch size
>sdp оптимизатор
у меня с ним результат ещё хуже чем xformers
>Можно еще в настройках до кучи token merge поставить на примерно 0.4 - даст ещё около 20% скорости
Я щас буду устанавливать все игры оптимизаторы
Братишка, а объясни ещё что такое AITemplate? Его можно запустить вместе с TensorRT?
lora и tensor rt невозможно применить вместе?
Так чего там с этой лцм-лорой и мерджем?
На аниме работает? Чувствительность к негативам и цфг какая?
Контролнет, хайрезфикс, и всё такое?
Хочу понять, стоит заморачиваться или нет. 4080 в компе - это, конечно, хорошо, но если можно урезать количество шагов в 4 раза - это ж еще лучше.
P.s. кохай свой хайрезфикс запилил, мнения?
https://github.com/wcde/sd-webui-kohya-hiresfix
На аниме работает? Чувствительность к негативам и цфг какая?
Контролнет, хайрезфикс, и всё такое?
Хочу понять, стоит заморачиваться или нет. 4080 в компе - это, конечно, хорошо, но если можно урезать количество шагов в 4 раза - это ж еще лучше.
P.s. кохай свой хайрезфикс запилил, мнения?
https://github.com/wcde/sd-webui-kohya-hiresfix
>Так чего там с этой лцм-лорой и мерджем?
>На аниме работает? Чувствительность к негативам и цфг какая?
>Контролнет, хайрезфикс, и всё такое?
Всё работает. Возможно имеет тенденцию к упрощению или замыливанию фона; недавно обнаружили баг с кривым шедулером, может пофиксят. LCM оказался хорошей финишной штукой, имеет смысл генерить недопроявленную композицию на минимальном разрешении обычным методом (512х512, 4-6 шагов и т.п.), потом апскейл до рабочего разрешения и прогнать через LCM. Так получается когерентность лучше, чем чисто LDM или чисто LCM. Если с контролнетами юзать, то первый этап не нужен, можно сразу LCM.
>P.s. кохай свой хайрезфикс запилил, мнения?
Всё пиздато, работает и каши не просит.
Хуита
Возможно, надо лору конвертировать тоже. Если ты про lcm, то ее надо мержить
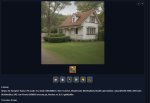
20/20 [00:02<00:00, 8.04it/s]
@echo off
set PYTHON=
set GIT=
set VENV_DIR=
set CUDA_MODULE_LOADING=LAZY
set NUMEXPR_MAX_THREADS=16
set PYTORCH_CUDA_ALLOC_CONF=garbage_collection_threshold:0.9,max_split_size_mb:512
set COMMANDLINE_ARGS=--autolaunch --opt-sdp-attention --upcast-sampling --opt-channelslast
git pull
call webui.bat
Драйвер 546.01 нвидя студио, как у всех белых людейлюдей
Cuda compilation tools, release 12.1, V12.1.105
Build cuda_12.1.r12.1/compiler.32688072_0
PyTorch второй
Вот только у меня NVIDIA GeForce RTX 2060, а после твоих мощностей мне чет расхотелось покупать что-то помощнее, когда выхлопа будет меньше
А если 150 шагов, то какая скорость? У меня была 2060Super, на ней получалось 9.2 it/s
Нажал Apply LoRA checkpoint to TensorRT model
и кажется получилось.
Если я подключаю в sd_lora LCM лору, то получается 5сек.
Если я подключаю в sd_unet TRT для лоры (не для модели, тогда работать не будет), а в sd_lora не подключаю ничего (тогда тоже работать будет), то получается 3.8 секунды.
Это оно? Или что-то не правильно?
А у тебя 2060 на 12 гб?
У тебя разница во времени из-за загрузок модели. Надо смотреть на время второй генерации после изменения модели
Очевидно, что 3060 мощнее 2060, и значит у меня какая-то проблема.
А попробуй в аргументы добавить только xformers?
С 2060 имеет смысл обновляться тогда уже на 4060 Ti и что-то выше. Или ждать следующего года, может подвезут 4060с с 12 гб для нищеты.
я несколько раз прогенерировал после изменения модели
150/150 [00:18<00:00, 7.98it/s]
Ну на этой модели столько
Da
>А попробуй в аргументы добавить только xformers?
А я не помню, какой у меня из аргументов является альтернативой для иксов, от куды. Они же в конфликт вступят.
А, тьфу, слепой я. ТОЛЬКО иксы, понял, щас
WARNING:xformers:A matching Triton is not available, some optimizations will not be enabled.
И как фиксить?
Генерит незначительно медленнее, хотя сосноль говорит, что иксы подкручены
150/150 [00:20<00:00, 7.27it/s]
> И как фиксить?
Тритон только для прыщей и в SD не используется.
У тебя там VAE какое-то подключено не стандартное, кста, попробуй генерацию без него.
Пробовал, там без разницы. Либо разница несущественная настолько, что даже не видно.
> 150/150 [00:18<00:00, 7.98it/s]
> Ну на этой модели столько
> Da
12 гб 2060 основана на 2060 super. А та в свою очередь по бенчмаркам, что кидали недавно, не отличается от 3060 в генерации
HFValidationError ( huggingface_hub.utils._validators.HFValidationError: Repo id must be in the form 'repo_name' or 'namespace/repo_name': 'путь/к/моей/модели/блять.safetensors'. Use `repo_type` argument if needed.
Какова хуя, помогите посоны. Норм запускается только на стандартной модели 1.5
Олсо как запустить тренировку из сосноли, а не из вебгуи?
Какова хуя, помогите посоны. Норм запускается только на стандартной модели 1.5
Олсо как запустить тренировку из сосноли, а не из вебгуи?
Путь/имя базовой модели неверно указал.
> Олсо как запустить тренировку из сосноли, а не из вебгуи?
Ты про что именно здесь? Там есть кнопка "печать команды", ее копируешь и вставляешь в консоль, или пишешь все параметры вручную.
> Путь/имя базовой модели неверно указал.
В том и дело что верно, прямой путь непосредственно к модели .safetensors
Если точно так же указываю стандартную 1.5 - съедает и начинает работать.
Гугл показывает схожие проблемы, например https://github.com/guoyww/AnimateDiff/issues/14#issuecomment-1635563101
>Там есть кнопка "печать команды
Кнопка есть, но начинается с accelerate что не является исполняемым файлом. И как параметр, который передается в train_network.py это не выглядит (хотя и похоже на конвейер, типа передачи вывода на ввод в другое место). Я не проверял еще это канеш, но выглядит так, как будто не заработает.
> В том и дело что верно
Прямой/обратный слеш, отдельные символы и прочее точно верные? Такое выдавало при ошибке в пути, по твоей ссылке о том же.
> но начинается с accelerate что не является исполняемым файлом.
Орли? Венв активируй и сразу станет им.
> Я не проверял еще это канеш, но выглядит так, как будто не заработает.
В фонд золотых цитат.
>Прямой/обратный слеш, отдельные символы и прочее точно верные? Такое выдавало при ошибке в пути, по твоей ссылке о том же.
У меня стандартная 1.5 лежит там же где и остальные модели. И прописывал я это не руками, а через гуй намышетыкал - тут же (почти) нельзя ошибиться.
>Венв активируй
Указать venv как PATH то есть?
>В фонд золотых цитат.
Бля ну не издевайся, консоль не поймет что такое accelerate потому что ничего об этом не знает. Она поймет максимум следующий далее train_network.py с паравозом ключей к нему, но не accelerate. Это на первый взгляд.
> Указать venv как PATH то есть?
> Бля ну не издевайся, консоль не поймет что такое accelerate потому что ничего об этом не знает
Не издеваюсь и без негатива, просто у тебя даже базовых знаний нет зато лезешь рассуждать.
По той же причине ошибка с неверным путем с вероятностью 99.5%, а прошлое могло работать вообще потому что подсасывало с обниморды по названию (да оно так может).
>просто у тебя даже базовых знаний нет
Я погуглил, я молодец, понял о чем ты. Странно, venv должен активироваться при старте вебгуя, но действительно при указании модели 1.5 я видел что
>прошлое могло работать вообще потому что подсасывало с обниморды по названию.
Но думал что это мож зависимости какие к модели, хз.
> Странно, venv должен активироваться при старте вебгуя
Так для него он активировался, но только для него а не глобально, каждый новый терминал - своя активация среды.
Ну вот и понятно стало, внимательнее будет, в первую очередь чекни чтобы слеши прямые а не обрашные были, базированная херь в шинде.
> каждый новый терминал - своя активация среды.
Я имею в виду один терминал, да. Батник с вебгуи ведь должен в т.ч. активировать venv, но при этом непонятно почему он не берет модель по прямому пути. Навскидку очень тупое предположение - потому что модели лежат в отдельной директории, но при указании прямого пути все должно работать же энивей.
Но я попробую запуск из сосноли, потому что пока гуглил - встретил мнение что это именно проблема вебгуя.
Как тренить лору на hll или на животных, как то отличается от обычного обучения или нужно какие то флаги ставить?
Какой положняк по тренировки лиц? Могу ли я мешать анфасы с профилем или одтельно тренить на анфас и на профиль?
--v_parameterization --zero_terminal_snr --scale_v_pred_loss_like_noise_pred
Tensor RT не работает с SDXL моделями? Выдаёт ошибку
Так.. Решил заняться тотальным обновлением софта, а то там хлам всякий тянется уже с релизов полугодовой давности. Вебуй для генерации вижу теперь запилили работающим без нужды засирать системный диск питоновским говном. Это хорошо.
А как быть с тренировкой лор? Гайд к скрипту традиционно начинается с "поставьте питон, поставьте ГИТ". Не сделали еще такой же установки чисто в свою папку?
А как быть с тренировкой лор? Гайд к скрипту традиционно начинается с "поставьте питон, поставьте ГИТ". Не сделали еще такой же установки чисто в свою папку?
https://github.com/serpotapov/stable-diffusion-portable
https://github.com/serpotapov/Kohya_ss-GUI-LoRA-Portable
Ты можешь сам ставить всё в свою папку, посмотри как это делает хач, или используй его сборку.
Ну какого черта в новом вебуи сделали систему сохранения промптов совсем черезжопной. Раньше выбрал в выпадающем меню, нажал применить - ВСЕ. Теперь выбираешь в меню, открываешь отдельное меню и уже оттуда применяешь. Нахрен так делать было?! Есть плагин, который схоронять может промпты нормально удобно умеет и при этом не перегружен свистоперделками типа перевода текста и ведения целой базы данных.
Нужно ли указывать pretrained model при обучении лор? Какие подводные камни у обучения с чекпоинтом и без него?
Если я указываю рандомный чекпоинт (хуй знает, пусть будет эпикреализм) в качестве pretrained model - полученная лора будет совместима с другими чекпоинтами (например с киберреалистик), или таким образом она затачивается на идеальную работу с конкретным, а со всеми другими будет хуйня?
Поясните за положняк.
Если я указываю рандомный чекпоинт (хуй знает, пусть будет эпикреализм) в качестве pretrained model - полученная лора будет совместима с другими чекпоинтами (например с киберреалистик), или таким образом она затачивается на идеальную работу с конкретным, а со всеми другими будет хуйня?
Поясните за положняк.
Чёт проиграл.
SD и NAI давно не вставляет, там нет самого главного : motion. Живой кадр, выразительная динамика, развитие и раскрытие динамической композиции в таймлайне. А так от ультра-высокого разрешения нет толку.
Васянский костыль типа deforum это не motion, а наркоманский трип. Gen-2 и та новая модель тоже нет. Хотя наработки для годных моделей давно представлены. Стабилити лоханулись, надо было пилить модель для видео вместо XL. Пусть оче базовую, но с пониманием концепта motion и temporal - остальное бы допилило комьюнити.
Васянский костыль типа deforum это не motion, а наркоманский трип. Gen-2 и та новая модель тоже нет. Хотя наработки для годных моделей давно представлены. Стабилити лоханулись, надо было пилить модель для видео вместо XL. Пусть оче базовую, но с пониманием концепта motion и temporal - остальное бы допилило комьюнити.
До этого ещё минимум год-два, если не больше, можешь залегать в спячку.
Достигнутый максимум темпоральной стабильности на сегодня это vid2vid с необходимостью обучать с нуля https://isl-org.github.io/PhotorealismEnhancement/ , для диффузии нет такого пока
Эх! А ведь дифьюжн модели будто специально предназначены для того, чтоб генерировать контент, ебейшее CGi с vfx как здесь
https://youtube.com/watch?v=Qwz5H9M8rsM
Упарывался игорем когда-то давно, интро видео как раз пример простого и грамотно сделанного моушена в компьютерной графике: освещение, камера, персонаж с гестурами. Такие пока делаются лишь спецами за бешеные деньги и спецы с навыками везде нарасхват
в марвел и голливуде, в геймдеве, на Западе и в Азии.
matplotlib не отрисовывает графики в дебаге в gradio приложении, кто-нибудь сталкивался? Как чинили?
Есть мнение, что тренить лору надо на SD / NAI (в зависимости от мясности тянки), тогда она будет совместима со всеми моделями. Но ты теоретически можешь тренить и на одном чекпоинте - тогда, теоретически, она будет на этом чекпоинте лучше, чем если тренить на SD, а на всех остальных - существенно хуже.
Но лично я не проверял.
Гит - не пихон, его нормальные люди пишут. Лично Линус, ЕМНИП, руку к его созданию приложил. Там нет зоопарка несовместимых между собой версий и вот этого всего питонячьего дерьма.
Гит не засирает твою систему, он облагораживает её, сраный ты форточник. Ставь свежайшую версию глобально и забудь про неё, она подойдёт ко всем автоматикам ещё несколько лет (а то и несколько десятков лет).
о, дримбут-братишка. няяяя...
... и повышенную когерентность на дополнительных слоях, как инпаинтинг... чтобы рррраз - и смёржил...
А в нормальное место логи можешь скидывать, типа пастебина? Это ж сука кошмар эпилептика - логи в виде видоса сука!!! Зумеры хреновы!
В сторис выложить не забудь
CUDA, говорит, кривая у тебя.
Походу, твоя тулза предпочитает тренить на тех моделях, что выложены на обниморде, а не у тебя на винте. Попробуй в качестве пути указать
admruul/anything-v3.0
и посмотри, запустится ли. Если запустится - то, возможно, дело в этом.
Убери из пути русские буквы. Кириллицу. Пробелы. И т.д. Правило 8.3, все дела!
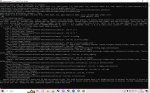
Аноны, выручайте. В программировании не шарю от слова совсем. Пару месяцев назад с кайфом генерировал всю хуйню, потом прогу снес. Ща решил снова установить, но выдает вот эту поеботу. Че делать не ебу, может из вас кто подскажет че-нить. В гугле не забанили, вообще все блять сделал из того что предлагали, все равно выдает эту срань. Уже неделю с этим ебусь, да все никак пофиксить не выходит.
Когда начинаю генерировать выдает это, забыл уточнить
Еще забыл уточнить что иногда он может сгенерировать одну пикчу, но на этом все заканчивается.
vae кривое?
--no-half в аргументы добавить?
Об этом в гайдах только ленивый не написал, пробовал конечно. Не пашет. VAE и другое ставил, и вообще выключал

Ща попробовал вписать еще раз, теперь даже начало генерировать, правда что-то в стиле этого
Давай сюда скрин настроек, особенно хэш модели. Аскотест проходил?
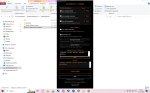
Не уверен про какие ты настройки, но предположил что это. Аскотест не проходил, ща гляну че это
Ох бля...
Погуглил немного, нихера не понял. Уточни что надо заскринить, вообще не шарю толком)
БЛЯТЬ ЭТО ТРЕД НЕ ДЛЯ НЕОСИЛЯТОРОВ - ЭТО ТЕХНО ТРЕД!
> ТЕХНО ТРЕД
И где твое техно, пчел?
Будем гонять сегодняшних неосиляторов - потеряем будущих техногуру! Всё лишнее - детям!
Настройки того места, где ты нажимаешь кнопку "генерировай".
нормальное современное искусство, чёнетак? фигачишь в NFT и продаёшь
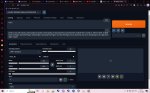
Спасибо за понимание, я просто в целом очень далек от всего этого, но очень хотел бы влиться в это все и разобраться, а тут такая хуйня. Знакомых шарящих нет, так что не придумал ничего лучше чем сюда написать. Скрин настроек вот, меня все по 100 раз, везде то же самое. Если проверку отключить, в тупую выдает черные квадраты
Это конечно заебись, но хотелось бы иметь возможность создавать не только это)
На других моделях то же самое? Нафига кфг скейл 2 выставил, кстати (стандарт - 7)? И пиздец у тебя браузер засран, конечно, я вот на отдельном генерю, без лишнего мусора. В своей васянозапускалке (которую ни один здоровый человек использовать не будет) попробуй выставить в качестве параметров --xformers --medvram --no-half-vae --precision full, а не то, что там сейчас.
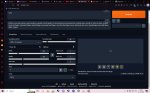
Другие модели вообще в первую очередь пробовал поставить. скейл менял когда просто параметры перебирал, смотрел мб че как работать будет. Просто перед скрином ниче специально не менял, кинул как на тот момент было. Поставил то что ты сказал, теперь вообще выдает это
Ну могу только предложить последовать путём анона из поста, с нвидия-проблемами я лично мало знаком, у меня свои, амдешные.
Спасибо, гляну как домой вернусь тогда. У кого еще будут идеи, предложите, попробую. Заранее благодарен
Галочки лишние для создания текстурок поснимай
Снеси этот малвер для васянов, клонируй репу гитом и запусти батник.
И шизу такую в негатив ставить не стоит, оно сделает только хуже.
откуда ты это скачиваете? как вы это блять вообще находите?
почему нельзя просто скачать сборку автоматика дефолтную
1. Удали это говно.
2. Скачай это.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
3.
в webui-user.bat
set COMMANDLINE_ARGS=--autolaunch --xformers
больше никаких аргументов, если карта RTX
если GTX
set COMMANDLINE_ARGS=--autolaunch --xformers --precision full --no-half
Не слушай его Тебе надо medvram и xformers. Даже gt 1030 не требует эту херню с полной точностью - это только для амудэ
>если GTX
У него GTX 1660 6GB, видно на скринах. Это говно что, уровня амуды или даже хуже, без нохалфа не пашет?
На счет xformers заработает ли на 1060 не уверен, но если не заработает - не страшно
> если GTX
Только если 1600 серия, и то там вроде это подебили большей частью. А то сейчас на паскалях сделает так и будет жаловаться насколько они медленные.
так и так только что закончил это делать. Установил стандартную версию, в батник вписал вроде все что надо. Нихуя все равно не работает. Та же хуйня абсолютно.
Да блять, раньше без этого все работало, и xformers, и вся хуйня. Вообще мозги себе не ебал. Как выше уже писал, потом переустановил через пару месяцев, и пиздец.
Вы правильно думаете, у меня 1660 стандартная.
покажи батник и скрин sd в браузере
ты прежде чем скачать дождался, что он всё скачает?
Какой версии питон?
Слушай, лучше не открывай свой пиздак, а
16серия требует --xformers --precision full --no-half
Максимальная производительность с такими настройками
medvram только замедляет работу и иногда ведёт к ошибкам, для простых генераций в нём нет никакого смысла на 6gb, его прописывать стоит только при имг2имг и апскейле
https://stability.ai/news/stable-video-diffusion-open-ai-video-model
SAI сделали видео-модель. Выглядит сравнимо с ранвеевской, те же несколько секунд относительной темпоральной стабильности. Пока только API через вейтлист.
SAI сделали видео-модель. Выглядит сравнимо с ранвеевской, те же несколько секунд относительной темпоральной стабильности. Пока только API через вейтлист.
А, стопэ, я еблан, веса сразу выпустили. Вот они https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
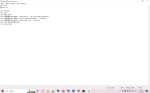
Короче, аноны, похоже это победа. Запустил нейронку буквально сделать скрин для ответа на вот это , а в итоге она заработала блять). Последнее что сделал перед тем как уйти, вписал вот это set ATTN_PRECIGION=fp16. Короче пока вроде пашет. Спасибо всем кто пытался помочь, приятно осознавать, что в трудную минуту не кинут, а помогут)
Если что можешь смело удалять все строки с commandline args кроме последней, у тебя переменная перезаписывается и xformers нету.
c lowvram модом еле помещается в 24Гб видеопамяти.
Спасибо, ух щас погенерим.
О, это хорошо. Animate diff так не может
Это для генерации ещё влезает, или я надеюсь ты про обучение 😳
Попробуй этим скриптом конвертнуть из safetensors в папочки и расскажешь как прошло
https://github.com/huggingface/diffusers/blob/main/scripts/convert_original_stable_diffusion_to_diffusers.py
cd ./diffusers
# assume you have downloaded xxx.safetensors, it will out save_dir in diffusers format.
python ./scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path xxx.safetensors --dump_path save_dir --from_safetensors
# assume you have downloaded xxx.ckpt, it will out save_dir in diffusers format.
python ./scripts/convert_original_stable_diffusion_to_diffusers.py --checkpoint_path xxx.ckpt --dump_path save_dir
Обучил лору в kohya_ss, в diffusers работает хуже чем в automatic, нужно запускать в diffusers. Что делать?

>в diffusers работает хуже чем в automatic
>Что делать?
нужно запускать в diffusers
Можно в sd next как-то убрать шуе-интерфейс, и сделать чтоб он был как stable-diffusion-webui, только с возможностью diffusers?
Можно ли в риге openposeBones в Блендере как-то зафиксировать длину рук\ног?
SD 1.6 это строго проприетарная модель? То есть можно не ждать.
Нет, просто они всегда мурыжат новые версии SD за своим апи, прежде чем релизнуть веса.
> они всегда мурыжат новые версии SD за своим апи
И когда ты такое видел? Очевидно они не будут релизить 1.6.
>И когда ты такое видел?
Блять, всегда. 1.5, 2.0, 2.1, SDXL. Сначала у них в проге и/или через апи, потом релиз весов через какое-то время.
Не пизди. 1.5 вообще не их модель, они её не релизили, это файнтюн Runway. Двуха и XL 1.0 были сразу в день релиза доступны.
> Очевидно они не будут релизить 1.6.
Какой смысл гейткипить? В ней ничего радикально нового и уникального чего нет в файнтюнах 1.5, отсутствуют и какие-то крутые коммерческие перспективы. А вот актуализировать самую массовую и популярную базовую модель - тема хорошая.
>Двуха и XL 1.0 были сразу в день релиза доступны.
То день релиза. Они долго держали веса за своей дримстудией, потом в один момент просто обозвали очередной чекпоинт релизом и выпустили.
1.5 и 1.4 - это их. 1.3, 1.2, 1.1 - вот это не их, это от CompVis
> 1.5 и 1.4 - это их.
Чел, до 1.4 - это CompVis, 1.5 - это файнтюн 1.2 силами Runway. Стабилити к первой SD имеют отношение только в виде предоставления серверов для CompVis. Они ничего сами не тренировали до 2.0.
https://huggingface.co/runwayml/stable-diffusion-v1-5
А, была еще и третья контора RunWay. Как все запутано
Блджажд, что они с таггером сотворили? Как им вообще теперь пользоваться? Почему он на базовой Deepdanbooru модели срет про какой-то tensorflow_io?
К ключу --save_state можно указать директорию сохранения? Куда сохраняется по умолчанию, с пустым ключом без указания директории?
Это про обучение лоры, если что.
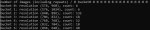
Олсо поясните почему при запуске с батника с вебгуи скорость обработки 40-50s/it, а при запуске из сосноли (с набором команд, сгенереных в вебморде) скорость 30-33it/s.
Что так тормозит при запуске вебгуи?
Олсо поясните почему при запуске с батника с вебгуи скорость обработки 40-50s/it, а при запуске из сосноли (с набором команд, сгенереных в вебморде) скорость 30-33it/s.
Что так тормозит при запуске вебгуи?
https://github.com/chengzeyi/stable-fast
Ускорятор для diffusers. Жрёт меньше памяти, работает быстрее TensorRT или AIT, при этом не требует компиляции.
Ускорятор для diffusers. Жрёт меньше памяти, работает быстрее TensorRT или AIT, при этом не требует компиляции.
> работает быстрее TensorRT
Открываю ссылку и сразу вижу что ты пиздишь. В их же бенчмарках он медленнее.
> не требует компиляции
А тебе от этого легче? Совместимости всё так же ни с чем нет. Ещё и пердоликс-онли.
> Куда сохраняется по умолчанию
В папку которая указана для выхлопа моделей, создает дирректорию соответствующую эпохе.
> Что так тормозит при запуске вебгуи?
Венвы то одинаковые? Так разницы быть не должно, с другой стороны
> 40-50s/it
Это что за дичь? Если обучаешь на 1030 то аппаратное ускорение браузера может вредить.
>В папку которая указана для выхлопа моделей
Готовых? Ок, спасибо.
>Венвы то одинаковые? Так разницы быть не должно, с другой стороны
Одинаковые, стартую оттуда, откуда же стартует вебгуи.
>Это что за дичь? Если обучаешь на 1030
На 1063. Кстати из сосноли скорость увеличилась до 29s/it за прошедшее с моего поста время.
>аппаратное ускорение браузера может вредить.
Интересно каким он тут боком. Я стартанул обучение из консоли, но при этом браузер остался открытым для параллельного двачевания.
Олсо, может подскажете мне параметры для тренировки на строго определенный ебальник? В прошлую интерацию обучения на свою еотову с 60 повторениями каждого фото генерация выдавала примерно одну очень похожую из 20 не очень похожих. Офк мне нужно полное сходство.
> В папку которая указана для выхлопа моделей
А вот хуй. Output folder указан, параметр --save_last_n_steps="1000" есть, на данный момент прогресс в полторы тысячи шагов но Output folder пуст.
Не хочу просрать четверо суток из-за броска по питанию, бсода или иного факапа.
> Одинаковые, стартую оттуда, откуда же стартует вебгуи.
Тогда разницы быть не должно, может как-то влияет особенности выгрузки врам в рам, или интерфейс жрадио на себя что-то там выделяет. Только мониторингом можно проверить.
> Интересно каким он тут боком.
Да хз, больше там нет отличий, одно и то же запускается.
> на данный момент прогресс в полторы тысячи шагов
Оно будет сохранять только каждую эпоху и даже об это напишет, шаги тут не при чем. Сколько эпох в обучении?
> четверо суток
Ты делаешь что-то неправильно, тут братишка на 1050ти тренили и там всего часов 12 выходило емнип. Лучше распердоль коллаб или купи видеокарту, 4 суток на то что должно делаться максимум минут 15 это жесть.
>может как-то влияет особенности выгрузки врам в рам
>там нет отличий, одно и то же запускается.
Вот и я про то же.
>Оно будет сохранять только каждую эпоху и даже об это напишет, шаги тут не при чем. Сколько эпох в обучении?
Эпоха одна и закончится она через 84 часа. А я хочу пощупать результат, поэтому поставил сохранение каждую 1000 шагов (аналог параметра сохранения каждые n эпох).
>Ты делаешь что-то неправильно
Я не нашел прямого мана, поэтому мне и нужна рекомендация по параметрам, или прямой конфиг. Опытным путем увидел что 60 шагов дали результат лучший чем 30, поэтому зарядил на сотню. Датасет 120 фото, 100 шагов на каждое, скорость 30s/it - вот и вырисовывается несколько суток. Впрочем, параллельно на другой пекарне учится лора с датасетом в 30 фото, и там как раз 1050 (без ти), доучится примерно к вечеру понедельника. Вощем-то у меня параметры почти все в дефолте стоят, может в этом дело, но куда крутить я не знаю.
А, ну и коллаб я конечно же не буду распердоливать, я сам себе администратор локалхоста. С видимокартой тоже пока непонятно, это сейчас я загорелся, если через полгода не пройдет - обновлюсь, иначе без задач.
> Эпоха одна
Ууу, ну земля пухом, насмотрятся своего хача а потом ебут друг друга в локалхост, лол.
> увидел что 60 шагов
О каких шагах ты говоришь, число повторений датасета?
Оптимальные параметры довольно просты и сложны, есть несколько вариантов про которые можешь в статьях из шапки почитать, вот один из них: адам8, lr unet = 2e-3, lr text = 1e-3, alpha=1, dim 32-128, число повторений подбирай так чтобы получилось 400-500 на эпоху (для 100 это будет 4-5), 10 эпох.
~15 минут разобраться, ~15 на тренировку каждой дальнейшей вместо нескольких дней на то что у владельцев 4090 уходит пара минут.
>Ууу, ну земля пухом, насмотрятся своего хача
Все так.
>О каких шагах ты говоришь, число повторений датасета?
Число повторений каждого фото. То, что задается именем директории n_datasetname.
>Оптимальные параметры довольно просты
Благодарю. Попробую при следующем обучении.
>~15 на тренировку каждой дальнейшей вместо нескольких дней
Фарш невозможно провернуть назад. Выходные у меня один хуй заняты, а в трудо-выебудни я работаю, так что скорость ебет только мою хотелку по факту. Владельцам 4090 я канеш завидую, но сам к ним смогу примкнуть лет через 5 лол, когда цена упадет до той, которую я могу безболезненно оторвать от своих финансов. Эти условные 100к я с большей охотой вложу в ремонт или влошу в фондовый срынок чем в дофаминовую морковку передергивания писюна на еотову с максимально возможной скоростью. Хотя от этого мне канеш грустно, я бы лучше морковку навернул а не вот это вот все.
>400-500 на эпоху
>10 эпох.
Что ты собрался 4000-5000 шагов тренить?
Хотя если с 2е-3... Нухз, возможно.
Я на базовое 1е-4 и 2е-5 всегда ориентируюсь, 2000-2200 шагов суммарно. И то обычно в конце уже перетрен получается, насыщение где-то на 1300-1700 начинается.
> Что ты собрался 4000-5000 шагов тренить?
Расчет был на то что он по эпохам пройдется и выберет лучшую, плюс его дженерик тнус точно запомнит. Перетрен с таким лром можно получить только на упоротом датасете, свитспот 2.5-3.5к, дальше просто бесполезно.
Хотя что там с еотовыми хз, ведь подборка их клозап фейсов вместо разнообразных пикч это тот еще пиздец вместо датасета и оно может очень рано начать ломаться.
Ээ.. Насчет количества шагов. А как быть если тренишь стиль или концепт, а там овер 300 минимум надо артов, а лучше больше. Там если по дефолту делать по 10 (как в гайдах по созданию датасетов пишут) раз на каждый арт, то выйдет овер 3000 шагов только на одну эпоху. Или вы тут про тренировку на персонажа обсуждаете где куда меньше артов надо в общем? Хотя я тренил с дофига каким количеством артов и по 3-5 эпох. Перетрен? Да, явно перетрен. Но можно просто применять Лору с весом поменьше и вполне работает нормально.
> овер 300 минимум надо артов
> по 10 (как в гайдах по созданию датасетов пишут) раз на каждый арт
Если там написано именно так и не указаны какие-то нюансы, то следует ставить под сомнение такие советы. Есть случаи где лору на стиль или даже персонажа тренят оче долго с десятками/сотнями тысяч шагов и большим числом эпох, но там в основном дадапт, хитрые шедулеры, и нет свидетельств того что это оптимально и результат качественно будет отличаться от тренировки короче.
На персонажа достаточно меньше, но и стили разные бывают, иногда с 4-х десятков такое тренируется что потом удивляешься.
> Перетрен?
По результатам смотреть надо, оно может и не оверфитнуться заметно, просто время попусту потратишь. Если же нужно снижать вес чтобы не ломало - пиздарики.
>овер 300 минимум
Это прям лютый оверкилл.
Сотни обычно вполне хватает. Может и с 40 натрениться.
Блять, арендуй 4090 на vast.ai и дрочи свой писюн со скоростью света.
Настрой колаб. Или обучи на цивите. 4 дня ходишь, лайкаешь, получаешь максимум 125 buzz в день. 500 buzz (ЕМНИП, а сейчас может и 600 уже) стОит натренить лору. Генерить вроде можно там же или на гравита и темпочтой от дядюшки Мохмала.
О, сочувствую, чувак. Там семплеры соответствуют нетривиально, в курсе? В issues diffusers на github поищи табличку. Алсо, ты точно используешь lpw pipeline? Иначе не будут работать (скобочки) [как] (в автоматике:1.07)
Либо dreambooth теми же kohya-ss/sd_scripts, в diffusers работает, брат жив, еот хороша, всем рекомендую.
Чувак, у тебя ошибка в слове preciSion
но раз работает - не трогай!
Бесплатный колаб медленный пиздос, да и платный тоже. В то время как на васте (или подобном хостинге) можно занидорага арендовать БОЛЬШОЙ УТЮГ. Например лоры для SDXL тренятся куда лучше на 48 гигах.
Я сейчас балуюсь реалтайм генерацией по нарисованной подложке в плагине для криты, в паре с копеечным планшетом это такая охуенная вещь, я прям себя рисователем с большой дороги почуствовал. Но для реалтайма надо чтобы генерация 1344х768 в SDXL была не больше секунд четырех, поэтому на медленней чем 4090 я и не смотрю. Дома у меня 3060, на ней такое не прокатит.
Тренирую лору на своём лице. Скажите, стоит ли для улыбающегося и серьёзного лица тренировать разные лоры? Стоит ли в одной лоре совмещать улыбку и серьёзное лицо?
в одну лору, но обязательно протэгать выражение лица: smile, happy, calm, serious, concentrated, worried, relaxed, etc.
Если часть фоток с очками, а часть без - очки тэгать обязательно!
я не оч по инглишу, погугли
Спасибо. А почему хачатур говорил, что теги это хуйня без задач, и не работают?
Что скажете насчёт однокартиночных лор? (не IP-Adapter)
https://civitai.com/articles/3021/one-image-is-all-you-need
https://civitai.com/articles/3021/one-image-is-all-you-need
Аноны в файле моделей, чекпоинте информация о весах хранится тоже в матрицах, или в каком-то более человекопонятном виде?
Потому что долбоёб
Херня без задач.
Надеюсь когда выложат sd 1.6 в открытый доступ, достаточно будет сделать мерж разницы с 1.5 в любой файнтюн, и тем самым генерировать в высоких разрешений без хайрез фиксов
Иначе зачем они называют ее 1.6, если у нее будет не формат 1.x моделей
Ну ты и соня. Уже давно 2.0 вложили.
Я тоже надеюсь. Более того, я тут уже полтреда как надеюсь, что хайрезность обеспечивается дополнительными слоями - как инпантинг, и мёрж там тривиален.
Но если нет, или если не выложат... Ох, анончики, объясните мне (тупому), почему никто до сих пор не натренил просто дополнительные слои на паре тысяч изображений (пусть бы только тянок, ладно) на обеспечение хайреза? Это же ведь определение гипернетворка как он есть, разве нет?..
Чем finetune отличается от dreambooth ? Я нихуя не понимаю
Dreambooth один из видов finetube
*finetune
Ребятки, я походу не дотренировал лору, можно ли продолжить с того места где я остановился? Можно ли продолжить тренировать готовую лору?
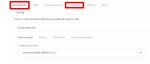
Я про это спрашиваю, в kohya_ss
Я там недавно обосрался со своей первой моделью которую более 12 часов тренировал.
Можно.
Как?) Я делаю это в программе от хрисТа
Тогда у него и спрашивай. Мы-то откуда знаем как что делать в мокропиське хача.
Ладно, скажи как в стандартной проге делать
Да-да, анонимус разрешаэ!
> что хайрезность обеспечивается дополнительными слоями
Судя по практике - такое маловероятно, для повышения резрешения достаточно дополнительной тренировки имеющейся структуры. Возможность мерджить разницу это не отменяет, но каков будет результат сказать сложно.
> до сих пор не натренил просто дополнительные слои на паре тысяч изображений
Объясни что имел ввиду, какие еще слои?
Превое - более старый традиционный способ, будка функциональнее.
Странная херня, через час использования Автоматика, скорость генерации начинает падать. Приходится перезагружать комп.


Почему результат такой уёбищный? Как нормально обучить? Хули у всех всё получается, а у меня нихуя?




Какие параметры нужно выставить чтоб обучилось нормально?
>Какие параметры нужно выставить чтоб обучилось нормально?
Оптимальные
Но автор как раз приводит задачи и демонстрирует применение.
Ты там памятники несуществующим людям собрался генерить? Шапку прочти. Чет проиграл с первой.

Так в том то и дело, что практически всё то, что он приводит, либо делается самим автоматиком "из коробки", без лоры, либо контролнетом.
Не надо писать тэги к картинке, не надо тратить время на тренировку, просто берешь и делаешь.
Хотел через img2img надрочить на обработку фото в таком стиле с прорисованными волосками, но эта хуйня какая то необучаемая. На ютубе вообще мало уроков, все делают только лоры, а нормальные модели кто делать будет!
Ресайз картинок под разрешение тренировки с сохранением соотношения сторон. Тут задаешь, какое разрешение будет минимальным/максимальным.
Кропать оно не будет, именно отресайзит.
Ну, насколько я помню эту фигню, конечно.

это сегменты какие то злоебучие, а не ресайз. разрешение тренировки у меня 768 на 1024
Вот под это разрешение оно тебе и будет ресайз делать.
Грубо говоря, если в базовых настройках 512х512 у тебя 0.26 мегапикселов, и в сете есть огромная картинка с соотношением 4:1, то отресайзит в 1024х256 под те же самые 0.26 мегапикселов.
Опять же, это то, как я эту фигню сам понимаю, исходя из данных, которые скрипт в лог по подготовленным изображениям выводит.
Вот это вот.
Тут у меня 6 повторений, всего 40 картинок. Разрешение тренировки было 768х768, с максимумом бакета на 1024.
Чёт сомнительно что такую простоту в переносе стиля и редактировании можно получить зеро-шот методами. У меня не получалось.
IPAdapter работает со входными 224х224, другие зерошот методы (референс-онли, t2i style adapter и т.п.) тоже в сравнимом, потому что все они юзают CLIP-ViT для кодировки, а он принимает ограниченное разрешение. И самое большое их ограничение - они переносят всё, нельзя нормально фильтровать, приходится изгаляться. Например если оставить перса на белом фоне сегментацией, они захавают и фон в том числе, а у него просто убираешь тег и убирается фон. А уж как это использовать для бутстрапа датасета для полноценной лоры, как он это предлагает - вообще хз.
А у него на демках чистенькая фильтрация признаков с пикчи с использованием знаний самой модели (а не CLIP-ViT), прям куда круче чем у меня когда-либо получалось. Зерошот может быть лучше конечно со временем, но конкретно текущие методы очень ограничены. Если эта хуйня действительно работает как у него написано, занимает пару минут и не требует танцев с бубном - хули бы и нет? Надо разобраться, попробовать, потестить. Никогда не подумал бы что лору можно делать из лишь одной пикчи.
> Кропать оно не будет, именно отресайзит.
Вроде как будет чтобы подогнать по кратность (по дефолту 64 вроде). Там в конце пишется ошибка, обычно оно пренебрежимо мало.
Зря максимум так близко к разрешению тренировки выставил, вон6 пикч не влезли.
Так некоторые лоры твикеры делали, но там намеренный оверфит а потом отсечка некоторых слоев.

> в мокропиське хача
Если вы вдруг не видели или не знаете, мокрописька от христа тянет билд от автоматика.
Но мокрописька от автоматика смущает вас намного реже, насколько я заметил.
Поэтому не выебывайтесь и давайте советы годные.
> мокрописька от автоматика
Довольно крупный и сложный проект, которые разрабатывается и поддерживается длительное время множеством людей. И то к ней вагон замечаний и претензий, а высказывания о забагованности уже стали мемом.
> мокрописька от христа
Подзалупная херь от глупого унтерменьша, напизженная у остальных и все равно выполненная криво. При этом создана для выполнения оче простых функций, а ца - падкие на синдром утенка кабанчики.
И на кой хер для тренировки тащить автоматика, чтобы заиметь потом конфликт зависимостей с кохой?
> давайте советы годные
Поставь любой нормальный гуи для кохи и делай все там, или вообще через консоль скриптом.
>Зря максимум так близко к разрешению тренировки выставил, вон6 пикч не влезли.
Всё влезло же.
Сложи все строки и раздели на 6 (число повторов).
240\6 = 40
Ну попробуй.
Мне что-то сомнительной кажется такая штука.
Особенно если ты собрался ее тренировать на концепт, который в модели отсутствует как таковой.

> И на кой хер для тренировки тащить автоматика, чтобы заиметь потом конфликт зависимостей с кохой?
Аллоу, маня, что коха, что сд от дружка хача ставятся сорт оф портейбл на самом деле не совсем и не срут в систему. Конфликта нет, они даже параллельно работать могут.
>Подзалупная херь от глупого унтерменьша
На самом деле ты сейчас обосрал крупный и сложный проект, который разрабатывается и поддерживается длительное время множеством людей. Потому что все, что делает мокрописька от хача - это распаковывает гит с пердоном и увязывает с ними билд от автоматика через 1,5 бат-файла, которые задают необходимые параметры сессии и дергают потроха билда автоматика.
>Поставь любой нормальный гуи для кохи
А он внезапно нормальный, кто бы мог подумать что мокрописька от хача тоже тянет "официальный" коховский билд, пикрил.
Вощем-то из этого следует что синдром утенка - у тебя, лол.
> Всё влезло же.
Часть пикч была в меньшем разрешении, другое дело что не критично.
> маня
Ай лол, любитель понюхать хачевскую сперму огрызается.
> обосрал крупный и сложный проект, который
Нет, речь про хачевские надстройки что "устанавливают и конфигурируют", это ты не разделяешь их с оригинальными.
> мокрописька от хача тоже тянет "официальный" коховский билд
А что еще она может тянуть, будто он что-то свое может создать.
> синдром утенка - у тебя
Назвать вещи своими именами? Нет, синдром утенка это защищать и оправдывать говноподелки с которых начал и уверовал.

>речь про хачевские надстройки что "устанавливают и конфигурируют"
Где? Там ничего кроме гита с питоном нет.
>будто он что-то свое может создать.
Оче хорошо. Мы разобрались что мокрописька от хача - это суть довольно крупный и сложный проект, которые разрабатывается и поддерживается длительное время множеством людей.
>говноподелки
А нет, похоже что не разобрались, опять вернулись на шаг назад. Ты где-то делишь на ноль, тебе так не кажется?
Аноны, а подскажите каую-нибудь удобную штуку для тэгирования изображений. Чтоб наглядная была.
Типа, в левой части у тебя картинка - справа плашки с тэгами. Кликаешь на плашку - тэг включается/отключается.
Ну и предварительный прогон чтоб был, как в ВД-тэггере, с разными моделями и уровнем чувствительности. Плюс с возможностью добавлять свои тэги принудительно.
WD-тэггер хорош только для полной автоматизации, вручную им работать практически невозможно.
Типа, в левой части у тебя картинка - справа плашки с тэгами. Кликаешь на плашку - тэг включается/отключается.
Ну и предварительный прогон чтоб был, как в ВД-тэггере, с разными моделями и уровнем чувствительности. Плюс с возможностью добавлять свои тэги принудительно.
WD-тэггер хорош только для полной автоматизации, вручную им работать практически невозможно.
Ох. Я в этом не очень хорошо шарю, но попробую объяснить. Знаешь, как модели по слоям мёржат? У UNet есть некие слои, в которых хранятся, собственно, веса. На разных слоях хранятся веса, отвечающие за разное. Где-то я даже картинку видел, на каком что. Соответственно, если мёржить разные слои с разным коэффициентом, то будет получаться разный результат, причём направление этого результата вроде как даже можно предсказать (уххх, алхимия! старина Фламель в гробу вертится!).
Знаешь, как из любой модели сделать инпаинтинговую? Нет, можно, конечно, и натренить - у Шивама, кажется, скрипты такие были. Но вообще-то общепринятый способ - тот самый послойный мёрж. У официальной инпаинтинговой модели есть четыре дополнительных слоя в UNet, и при мёрже A + (B - C), где А - инпаинтинговая модель, В - кастомка, С - SD1.5, эти самые инпаинтинговые слои остаются нетронутыми.
https://www.reddit.com/r/StableDiffusion/comments/zyi24j/how_to_turn_any_model_into_an_inpainting_model/
Можно ли провернуть такой же фокус, добавив слои и натренировав их обычным образом, но при залоченной модели - скажем, на разрешение 1024х1024? Если это удастся, то потом это разрешение можно будет переносить на любую полторашную модель (кроме, быть может, инпаинтинговых) без потери информации в модели, без искажения.
И я полагаю, что именно это делают гипернетворки, разве нет?..
Продолжаю мысль.
Ты спросишь: зачем мне поддержка 1024х1024 нативно, если есть хайрез фикс? А я отвечу: обучение, чуваки мои, обучение. Мы можем сколько угодно кормить адетайлер фоточками няшных рук. Но только сетка в целом сможет понять, где рука правая, а где левая, насколько разными должны быть ноги и как держать солнышко на ладошке.
Можем, я неправ и долбодятел. Это со всеми бывает. Но почему никто даже не попробовал?
> как из любой модели сделать инпаинтинговую
В ней есть допольнительные слои и добавлены лишние операции связанные с такой обработкой, это считай просто локальное возмущение имеющейся модели без существенных изменений того что она может генерировать. При том насколько улучшается перфоманс в том самом инпеинте, учитывая сочетания значительно ушедших от исходника современных моделей и древних значений в "дополнительных слоях инпеинта", и в целом целесообразность это процедуры - под вопросом.
Аналогия понятна и ожидаема, но здесь нюанс. Для получения хорошей работы в высоких разрешениях такого недостаточно, все ее части должны быть организованы таким образом, чтобы сохранять когерентность при большем количестве обрабатываемых данных. Невозможно сделать пару волшебных слоев, которые из поломанной херни вдруг сделают хорошую картинку.
Плюс в том что на возможность мерджей это, скорее всего, не повлияет и к сд 1.6 можно будет в пару кликов добавить то что было дообучено на 1.5. Но, может случиться всякое, пока не увидим ее можно только гадать.
> Ты спросишь: зачем мне поддержка 1024х1024 нативно
Странный вопрос, чем выше порог когерентности модели, офк если говорить про реальные величины а не те где нужно долго ловить удачный рандом, тем точнее она помнит и понимает мелкие детали, включая и пальцы (но панацеи тут всеравно не будет), тем более качественно можно делать апскейл. Все правильно.
> Но почему никто даже не попробовал?
Сейчас сложно найти новые файнтюны 1.5 что проводят в разрешении 512.
Нейрочелики, как дообучить модель в finetune kohya_ss ?
У меня вопрос, как сочетается опен сорс лицензия, по которой работают sai (как понимаю, она вирусная, и при всем желании они отказаться от нее не смогут), и то, что они прячут за api 1.6, и раньше прятали xl?
Это лицензии с пользователями, т.е. это только для тебя вирусная GPL или что там у них, не ебу, а SAI правообладатель и могут делать что хотят. Часто в софте делают коммерческую лицензию и вирусную для опенсорса, никто не запрещает проприетарщине иметь не совместимые между собой лицензии.
Ох, чувак, учи матчасть. И про вирусность лицензии, и про разницу копилефта и пермиссива, и вот это всё. В двух словах не объяснить. Грубо говоря, у SD - пермиссивка, не вирусная: мол, вот вам веса, творите что хотите. Или нет, анончики?..
Лицензия не опенсорс, а OpenRAIL++. Попенсорс был бы, если был бы весь процесс можно было бы реплицировать с нуля, включая точный датасет и все настройки тренировки. Ну и датасет тоже должен позволять такое использование.
А в чём проблема что прячут за api? Ну никак не совместимо. Как выпустят веса, так будет OpenRAIL++.
Так же как и лору или будку, в чём конкретно вопрос?
https://huggingface.co/stabilityai/sdxl-turbo
Вжух! SDXL-турбо, под реалтайм использование. Быстрее LCM (1-2 шага), и по словам SAI качество лучшеее.
Вжух! SDXL-турбо, под реалтайм использование. Быстрее LCM (1-2 шага), и по словам SAI качество лучшеее.
Кал какой-то. Похоже тренировалось на 512, на 1024 мутанты как на ванильной полторашке, качество говно. Мержил разницу к кастомкам - пиздец хуже LCM. Негативы не работают так же как и с LCM.
У них обратные результаты, а на 4 шагах получается что-то уровня SDXL. Собственно цель и была избавиться от LCM-мыла. Пока читаю пейпер, не вижу ничего препятствующего негативам как в LCM
На практике я не вижу этого результата. И апскейлится оно очень хуёво. XL и так такое себе по качеству картинки, а это совсем пизда.
> избавиться от LCM-мыла
Легко избавляется дополнительными 4-6 шагами хайрезфикса с Euler a.
> не вижу ничего препятствующего негативам как в LCM
Они выключены вообще в демо SAI, в принципе их нет. Если на практике включить CFG 1.5 - сразу пидорасит.
Есть демо на клипдропе
https://clipdrop.co/stable-diffusion-turbo
Выглядит очень плохо, хуже ванильной полторашки. Всё в артефактах, разрешение как у полторахи, вместо людей месиво.
ну че все идёт к тому что нейросетки будут риалтайм?
Всё идёт к тому что в следующем году полторашку изобретут второй раз. Будет реальным прорывом, глядя на то как отрицательно прогрессирует качество в последние пол года. Какая-то рекурсия, год прошёл, а стало только шакальнее, зато в 10 раз быстрее.
Какое быстрее, у меня до сих пор на CPU не идет. Не покупать же видяху.
>Сейчас сложно найти новые файнтюны 1.5 что проводят в разрешении 512.
Ага, вот только все примеры к топовым моделям сделаны на каких-нибудь 512х640 или 512х768 и потом прохайрежены. Но ладно, я могу быть долбодятлом и долбиться в глазоньки... можешь, плиз, показать хорошие, годные современные фотореалистичные модели, по качеству не уступающие фотогазму (возьмём его за точку отсчёта), которые легко сгенерят мне тянку без искажения пропорций... ну, хотя бы 649х960? 16 тянок из 16, например. С тебя сид-промпт - прочие сорцы, с меня - попытаться построить контрпример.
И как тогда, кстати, делают современные инпаинтинговые модели, которыми раздевают тянок? Тренят скриптом? Каким?..
Сколько гигов оперативки?
8, но это shared RAM
Я в крите балуюсь "реалтаймом" в 4 секунды на фрейм безо всяких ЛЦМ, и это просто охуенно, совершенно иной способ, мамины "промпт инженеры" сосут бибу. Игнорируй довена выше, он ноет абсолютно всегда.
Кстати, есть идея прикрутить подобный процесс в редактор на андроиде, с использованием облака. Рисовать пальцем. Технически будет несложно, просто нет такого же редактора на андроид чтоб сделать плагин.
Я скушал аренда-пилюлю и уже передумал покупать 4090. Покупать имеет смысл если тебе есть чем её загрузить 24/7. На деньги что нужны для 4090 и компа под неё, я могу лет 6-7 подряд генерить в темпе 2 часа в день, а там уже несколько поколений пройдёт, и заточки под новый куда компьют, и вообще всё совершенно изменится.
И при этом мне не нужна 4090 большую часть времени, обычно хватает V100 16ГБ или 3090 24ГБ, а для тренировки всё равно выгодней арендовать большой утюг вроде A100 80ГБ, т.к. можно увеличить размер батча и выйдет быстрее+дешевле чем на 4090, либо тренировать SDXL на полной точности. Так что выходит намного дешевле.
На реддите пояснили, чем civitai отбивает затраты на свой генератор. Ответ: ничем.
>Burning venture capital until they get bought by someone larger or crash, like a lot of companies
Потом продадут бизнес, а новые владельцы введут цензуру, позапрещают всё NSFW и модели с лолями типа CuteYukiMix.
Кстати, уже был похожий, охуенный сайт - который закрылся, когда сжег бабло с инвестиций. Подозреваю, что и с проектом SD, и со стабилити та же история. Эх...
>Burning venture capital until they get bought by someone larger or crash, like a lot of companies
Потом продадут бизнес, а новые владельцы введут цензуру, позапрещают всё NSFW и модели с лолями типа CuteYukiMix.
Кстати, уже был похожий, охуенный сайт - который закрылся, когда сжег бабло с инвестиций. Подозреваю, что и с проектом SD, и со стабилити та же история. Эх...
Пальцем неудобно, куда лучше небольшой планшет купить графический, с пером. Рисовать толком уметь не надо, надо просто мочь представлять картинку в голове. Хотя можно и айпад/самсунг с пером, тоже прокатит.
>Невозможно сделать пару волшебных слоев, которые из поломанной <...> сделают хорошую картинку.
Давай зададимся (пока теоретически) более простой целью. Допустим, что нам нужно уметь делать хайрезный дженерик. Одна тян, стоит/сидит, смотрит в камеру / вбок / вдаль / на тебя как на говно. Много ли тут информации надо впитать, а? Голова сверху, ноги снизу, пупок один (ну или там по количеству тянок), грудей один ряд. Горизонт слева и справа на одном уровне. Небо вверху одним куском. Ну и так далее. Возможно ли это теоретически - или я принципиально не понимаю, как работают гипернетворки?
какой денойз в им2им ставишь?
>Подозреваю, что и с проектом SD, и со стабилити та же история.
Ага, только есть нюанс. Джинна в бутылку не загнать, веса полторашки и сдохли уже в паблике, контролнет придумала не стабилити, а коммьюнити (поправьте, если неправ). Мир уже никогда не будет прежним. А бабло инвесторов... ну, это бабло инвесторов. Они знают, что идут на риск.
Братюнь, купить можно и видеокарту для ПК, а нужны именно решения для девайсов которые есть под рукой.
Рисовать умею, стилус для Wacom планшета где-то проебался лет пять назад, - да и мобильные устройства мне так-то больше нравятся.
Можно кулстори с подробностями? Оно, конечно, лучшие вещи в мире бесплатны, но о нелучших тоже неплохо бы знать. Какой страны карточка, которой платишь? Какой сервис используешь? Почём час аренды утюга?
Блять, отрыл Армению, зарывай обратно. Чугуниевая долина в таком режиме вообще десятилетиями живёт. Реальность же в том что цена тренировки резко упала и доступна / скоро будет доступна хуям простым.
> годные современные фотореалистичные модели
Предпочитаю 2д, сорян. Стоит отметить что большинство современных миксов без проблем переваривают 768х768, 800х600 и подобные разрешения и хорошо себя показывают на апскейлах.
Раньше думал что в фотораелизме там дохуя какой прогресс, но поизучав посты авторов "топовых моделей", их рекомендации, гайды и прочее сильно засомневался. Но это лишь оценочное суждение по узкой выборке, офк найдутся и хорошие мастера - моделеделы.
Натренить базовую модель в ~768, не поломав а наоборот улучшив, сделав лучшую работу с мелкими деталями и когерентность, добавив то что хочешь - не то чтобы сложно, а потом результат мерджишь по усмотрению, получая все фишки. "Повышение эффективного разрешения" возможно даже лорой сделать, будет побочный эффект если тренить в изначально большем разрешении. Офк речь о нормальной а не пиздеце с клозап лицами. Другой пример - собаки, которые заявляют 1024 базовым разрешением и относительно когерентных тней генерируют в нем.
> кстати, делают современные инпаинтинговые модели
Просто современные модели - дримбус. Инпаинтовые - мерджем разницы с древностью времен 1.4. Возможно есть более новые зафантюненные модели с теми слоями, не в курсе. Чтобы раздевать тяночку достаточно самой обычной модели без всяких доп слоев.
Хз как они работают, писали что шли поверх основной модели. Если у тебя в глубине поломалось, то обратно не соберешь, для работы в повышенном разрешении вся модель должна хорошо работать, а не иметь при себе волшебную добавку. Как раз ту самую информацию что ты описал оно должно чувствовать на большей области.
Я не он, но использую полнофункциональное API бесплатно. Не хватает лишь мелочей типа обработки видео.
Алсо, а где можно взять соответствующие датасет хотя бы на пару тысяч картинок? Можно, конечно, взять фотки одноклассниц из вконтактика заботливо мною сохранённые на винте ещё в бытность школьником, а вы что подумали? и протегать их, но такой датасет ведь будет нелегален, верно? Нельзя ведь просто так взять картинку из интернета и распространять её. Нехорошо-с, неопенсорсненько.
Набирать же генерации с цивиты... Ох, ну с анимцом ещё туда-сюда этот способ, но реалистик... Ой...
Раз бесплатно, то тем более пили кулстори. Анонимус ждёт!
>Предпочитаю 2д
Сейм.
Но для меня есть два направления, одно из них это манга-стиль. Причем ортодоксальный, без 2.5д, без "обведенного" 3д носа у персонажей.
Второе - это японские айдору и AV контент, с фотореалистичными SD моделями. Здесь задача подражать скриншотам из японских фильмов, поэтому реализм должен наоборот быть максимальным, без CG эффектов. Почему-то не перевариваю блядей как в met-art, MILF и подобные фетиши. Но японские JAV актрисы это другое, они милые. Причем, могу сразу на глаз различать японок, кореянок и китаянок - у них разное строение лиц, например кореянки немного похожи на белых. Мои любимые актрисы ирл Yua Mikamo и Yui Hatano. Ayumi Shinoda всратка, но шишка колом. Юлька вообще грудастая богиня, сразу видно еврейскую кровь.
>Mikamo
Mikami
vast.ai, другой страны + впн для оплаты, час утюга от полубакса до полутора в зависимости от утюгастости и времени суток, час обычной видюхи в 2-3 раза дешевле. Сетевой трафик не бесплатный, это тоже надо учитывать и экономить размеры. Есть ещё runpod, есть serverless апи для генерации типа comfyuiworkflows с готовым подключением комфи или modal с быстрым холодным стартом, которые берут только за загрузку, они вроде дешевле, но если нагружать дохуя то дороже.
nogpu-webui.com
Если не сможешь разобраться - значит, тебе не нужно




>Предпочитаю 2д, сорян. Стоит отметить что большинство современных миксов без проблем переваривают 768х768, 800х600 и подобные разрешения и хорошо себя показывают на апскейлах.
О, чувак, вот тебе Lametta с 1024х1024 от фуррей. Не ах какой идеал, но пикрил сделаны на ней без хайрезфикса.
https://huggingface.co/NickKolok/lametta-v2012-beastboost-2ch-fp16
Но у неё есть некие проблемы с обучаемостью с будке. Впрочем, не исключено, что это у меня проблемы с кривизной рук.
> "Повышение эффективного разрешения" возможно даже лорой сделать, будет побочный эффект если тренить в изначально большем разрешении.
Всё уже украдено придумано до нас. https://civitai.com/models/110071/hd-helper
Толком не тестил, хотя вау-эффекта не даёт.
>Всё уже украдено придумано до нас.
На аниме-моделях нифига не работает, кстати.
>nogpu-webui.com
Так со сбросом кук (в моём случае - chromium-browser --temp-profile) и на гравити можно. Какие плюсы/минусы?.. Какие подводные?
На анимэ-моделях есть BeastBoost. Про проверку которого на реалистике мне ничего не известно. Мой ноут почти успел достигнуть японского возраста согласия, но последний внезапно подняли
Некоторые выложены в публичном доступе на той же обниморде, на кагле есть коллекции и т.д., но офк на них уже тренили и качество там самое разное. Собирай самостоятельно на различных агрегаторах и потом тегай хотябы тем же клипом.
> но такой датасет ведь будет нелегален, верно?
Это серая зона в принципе, сложно доказать и на обычного пользователя всем похуй. Если так это волнует - делай свои фотографии в публичных местах, обрабатывай и используй. Можно этот процесс даже автоматизировать чтобы время не тратить, закону не противоречит. Или используй ресурсы со свободной линцензией контента, много начинающих фотографов выкладывают с такими.
> Набирать же генерации с цивиты
Только если самые отборные и удачные, иначе преумножит количество артефактов.
Эх, назвал два самых "сложных" направления из 2д. По первому проблематично собрать датасет ибо сложно сортировать чтобы остальное не подмешивалось. Но и избегать этого нельзя ибо не наберешь должного баланса и разнообразия датасета, как вариант вообще просто лорой воспользоваться поверх "униваерсальной модели". Второе уже сильно в фотореализм, но с элементами. Только пиздеть рассуждать могу, подсказать нечего, увы.
> пикрил сделаны на ней без хайрезфикса
Год назад о подобном можно было только мечтать, отличный пример.
Да, будку на колабе.
На гравити нужно регать акк, даже если и не сдетектят сразу твое временное мыло. Всё это - руками.
>назвал два самых "сложных" направления из 2д.
Щта? Это же и есть самые проработанные файнтюны. Первое Anything v3 и прочие, второе - есть реалистик модели специально для азиаток.
Чем превосходит XL?
Генерируй с dall-e 3
Да неправильно это - добиваться когерентности лорами, да извинит поздний час мой теоретизирующий максимализм. Лора - это ведь искажение весов модели, искажение, которое что-то убирает, что-то корёжит. Не должно это так работать, должно быть приращение знания! Вот жопой чую! Должен быть способ добавить информацию в модель, как это делают две самые успешные технологии в мире SD, два game changer - инпаинтинг и контролнет... Должна быть выраженная модульность.
Хотя добавить гипернетворк/слои, отвечающие за когерентность, а потом уже вместе с ними тренировать модель как единое целое на высоких разрешениях - тоже вполне себе хорошая идея. Вот сейчас что будет, если условную NAI начать тренировать на 1280х1280? Подозреваю, что полная фигня! Тут ведь был анон с датасетом под 1024, или это в SD-треде?..
Человек с высшим математическим образованием никогда не скажет "полная жопа" - он тактично уточнит, что наблюдаемая жопа - банахова.
>BeastBoost is a trick developed by Anonymous on 2ch.hk/ai/ imageboard.
RAKI SUKA
Извольте детальнее изложить причину недовольства, сударь, пока я не вызвал Вас по айпи на дуэль на пингах ?
> Первое Anything v3
Древнее зло, не соответствующее современным стандартам и недалеко ушедшее от наи, в сравнительных гридах хорошо заметно, которое вполне себе выдает 2.5+д если попросить художниками и длинными промтами на реализм.
Правильный путь - полноценный файнтюн.
> Хотя добавить гипернетворк/слои, отвечающие за когерентность
Это как добавить человеку вторую печень чтобы улучшить его мелкую моторику, никакого толку. Простая тренировка решит эту проблему. Если ты просто про изменение размеров слоев или их структуры - это уже другая модель будет, как 2.1/xl.
> Подозреваю, что полная фигня!
Если найдешь хороший сбалансированный датасет, подберешь параметры тренировки и постепенно поднимешь разрешение - будет не фигня. Только это просто лишь на словах, сделать это так чтобы при этом ничего случайно не лоботомировалось - та еще задача. Для анимца просто хайрез пикчи это меньшая из проблем.
Это шаманство с мёрджами мы тут сравнительно недавно тестировали, и лично я пришел к выводу, что не стоит оно того. Начинает выдавать картинки с разной степенью контрастности, вдобавок периодически выдавая непонятные цветовые акценты туда, где их быть не должно. Особенно сильно било синим и фиолетовым цветами. Чертовы синие собаки, их явно было слишком много в датасете оригинальной меховой модели.
Хотя возможно, что с тех пор методика мёрджа как-то поменялась. Хз.
Совместимостью со всем полторашным хозяйством, включая схемы обучения, лоры, контролнеты и т.д. Насколько там хорошая совместимость - вопрос дискуссионный, но явно лучшая, чем полное её отсутствие у сдохли.
Что не отменяет того факта, что за сдохлей может быть будущее.
Кстати, из релиза "контры" (SD 1.6) убрали хвастовство про хайрез, теперь там просто
> stable-diffusion-v1-6 has been optimized to provide higher quality 512px generations when compared to stable-diffusion-v1-5
https://platform.stability.ai/docs/release-notes#stable-image-v1-release
Насколько я понимаю, это всё тот же train-diff задом наперёд.
>Это как добавить человеку вторую печень чтобы улучшить его мелкую моторику, никакого толку.
Чего это никакого? Быстрее выводится алкоголь -> меньше трясутся руки -> лучше мелкая моторика!
Всегда знал, что бенгали - пиздаболы, лишь бы струсить бабла с инвесторов.




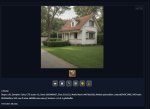
И ещё один вопрос. Как водится, ЕОТ. Тренил я её, тренил, и наконец натренил. Нагенерил много картинок. Понятно, что какие-то похожие и удачные, а какие-то... Вот пикрил1. Вроде няша, и вроде волосы такие, и причёска, и глаз столько же. Однако ж - не она!
А пикрил 2 вообще капец. И тоже не она. Пикрил3 тоже не очень-то похож - и субъективно, и объективно. Пикрил4 вобще морду помяло.
Не пропадать же нагенерённому добру? Может, его можно как-то присобачить к тренировочному датасету (с отрицательным весом? как отдельный концепт?) и повторить тренировку?..
Алсо, а как вообще валидируется успешность тренинга лица, кроме подсчёта совпадений на https://search4faces.com/search_vkwall.html ?
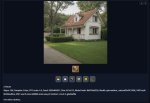
А пикрил 2 вообще капец. И тоже не она. Пикрил3 тоже не очень-то похож - и субъективно, и объективно. Пикрил4 вобще морду помяло.
Не пропадать же нагенерённому добру? Может, его можно как-то присобачить к тренировочному датасету (с отрицательным весом? как отдельный концепт?) и повторить тренировку?..
Алсо, а как вообще валидируется успешность тренинга лица, кроме подсчёта совпадений на https://search4faces.com/search_vkwall.html ?

Чет я не могу найти этот флаффирок e159, у автора этой линейки модели нет такой, либо почему всем так впадлу писать ссылки на модели, которые используют в мерджах?
>не монетизируешься
>жалуются
>монетизируешься
>снова жалуются
Ну я вот модель по ссылке потестировал - вообщем-то получше, чем в моем мердже. Когерентность не теряется, контраст постоянный.
Задники блюрит только совершенно нещадно (хотя может это косяк базовой модели, хз), ну и вообще на 1024х768 не шибко много разницы заметно, по сравнению с каким-нибудь 800х600, в котором я стандартно лоурезы генерю.
Только вот с 1024 вполне и кохаевский хайрезфикс справляется плюс-минус с теми же затратами скорости.
P.s. ради интереса посмотрел, так моя текущая модель вполне себе с 1024х768 справляется и сама по себе, ха. Вот она, польза файнтюнов.
Аноны, а кто-нибудь мега-лоры с сетами в несколько тысяч картинок тут тренил вообще? Какие настройки нужны при такой тренировке?
Вот, допустим, я тренирую, ну, скажем, деревья.
Датасет и тэги структурирую следующим образом:
В стиле_Ван-Гога__Дерево
В стиле_Ван-Гога__Дерево__Зимой
В стиле_Ван-Гога__Дерево__Летом
В стиле_Шишкина__Дерево
В стиле_Шишкина__Дерево__Зимой
В стиле_Шишкина__Дерево__Летом
Тренить, понятное дело, буду не деревья
Всё по стандарту ставить, просто повторений на каждую картинку поменьше?
Но ведь очень сильное усреднение получится? Тогда как мне бы хотелось бы чтоб лора смогла это всё разграничить, не смешивая. Чтоб была возможность суб-концепты (дерево_шишкина_зимой) вызывать поверх базового (просто какого-то усредненного дерева)
Дотренировку делать после того, как один блок-датасет ухватится? А оверфита не получится? Ведь базовый концепт (дерево) будет один.
Непонятно, вообщем.
Вот, допустим, я тренирую, ну, скажем, деревья.
Датасет и тэги структурирую следующим образом:
В стиле_Ван-Гога__Дерево
В стиле_Ван-Гога__Дерево__Зимой
В стиле_Ван-Гога__Дерево__Летом
В стиле_Шишкина__Дерево
В стиле_Шишкина__Дерево__Зимой
В стиле_Шишкина__Дерево__Летом
Тренить, понятное дело, буду не деревья
Всё по стандарту ставить, просто повторений на каждую картинку поменьше?
Но ведь очень сильное усреднение получится? Тогда как мне бы хотелось бы чтоб лора смогла это всё разграничить, не смешивая. Чтоб была возможность суб-концепты (дерево_шишкина_зимой) вызывать поверх базового (просто какого-то усредненного дерева)
Дотренировку делать после того, как один блок-датасет ухватится? А оверфита не получится? Ведь базовый концепт (дерево) будет один.
Непонятно, вообщем.
>Так же как и лору или будку, в чём конкретно вопрос?
Ну и как? Вот я обучил модель, как её туда обратно запихнуть чтоб она дообучилась с более долгим lr ?
я даже когда ставил на стоп кнопкой она потом заново с первой эпохи куячила, а не продолжала. куда жать что делать бля конкретно
> а SAI правообладатель
> А в чём проблема что прячут за api? Ну никак не совместимо. Как выпустят веса, так будет OpenRAIL++.
Так они ж не с нуля сделали, они дообучили веса, натрененые изначально вообще CompVis
> у SD - пермиссивка, не вирусная:
Я на цивите краткое описание этого open rail++ смотрел, там мержи и дообученные нельзя продавать указано. То есть уже точно не полностью свободная. Может она вирусная только в плане продажи, хз, а в плане сервиса - нет. Саму лицензию я читать, конечно же, не буду. Есть еще вариант, что создатель прошлых весов в особом порядке для них пролиценщировал
Sd корнями из MIT идет, нет? Вообще, судя по политике sai, создается впечатление, что они очень хотят закрыть свои модели. И думаю если б не вирусность, то с радостью как open ai закрыли бы. На сайте ни слова про локальное использование
> Если на практике включить CFG 1.5 - сразу пидорасит.
Плюс негативы работают не корректно. Просто рандомно меняют картинку, а не то, что указал в негативе
В командной строке у Кохи был флажок --resume, посмотри, как он работает.
в какой нахуй командной строке, у меня эта визуальная хуета автоматика
> в какой нахуй командной строке
> Stable Diffusion технотред
> в какой нахуй командной строке
Командная строка - это терминал. Консоль. PlayStation 5
Ну лично я сторонник баша, хотя вот zsh и dash тоже хвалят. Главное - не cmd
Там Linaqruf опубликовал ебейшую XL модель, го пробовать.
Анончики, хочу тренировать лору, подскажите, что такое регулярязационные изображения?
Братишка, не выебывайся и спроси иначе. Повторяй за мной: "аноны, помогите, я не знаю как в командную строку, что нужно сделать?"
Нахуй мне твоя командная строка не впёрлась, мне нужно через визуальный интерфейс автоматика как белый человек запустить дообучение, а не пердолить в линуксы
Где тут автоматик? Или пихаешь свою модель в качестве исходной и тренишь дальше с новым запуском шедулера, или через --resume как и сказали продолжаешь, но тогда шедулер продолжится и если он завершился то заново начинай.
Сука блять, что ха хуйня. Драйвер не обновлялся, дистр не обновлялся, нихуя не обновлялось, но NansException: A tensor with all NaNs was produced in Unet. This could be either because there's not enough precision to represent the picture, or because your video card does not support half type. Try setting the "Upcast cross attention layer to float32" option in Settings > Stable Diffusion or using the --no-half commandline argument to fix this. Use --disable-nan-check commandline argument to disable this check.
Да какова ж хуя, что сломалось-то бля. И ведь --no-half --no-half-vae есть, и float32 тоже попробовал выставить, и все равно залупа. Не буду же я --disable-nan-check ставить чтобы черные квадраты получать.
ГОВНО ЖОПА
Да какова ж хуя, что сломалось-то бля. И ведь --no-half --no-half-vae есть, и float32 тоже попробовал выставить, и все равно залупа. Не буду же я --disable-nan-check ставить чтобы черные квадраты получать.
ГОВНО ЖОПА
> Или пихаешь свою модель в качестве исходной
Как его туда запихать? там нет кнопки добавить другую свою
Пиздос, ты даже в гуе заблудился, даже блять мышкой натыкать не в состоянии. Кастом нажми, мудила.
Белый блять человек он, обезьяна ёбаная.
Если в тебе осталась хоть капля мужского согласись, что это было не так очевидно как ты это преподносишь. custom должен быть вынесен отдельно, а не в общем списке с моделями, это я тебе как дизайнер говорю.
>custom должен быть вынесен отдельно
>это я тебе как дизайнер говорю.
А я-то думаю, почему с каждым годом интерфейсы все всратее и всратее.
потому что их делают индусы, а не я.
Вот кстати, а треда на видеогенерацию нет, чтоль?
Или он где-то утонул?
На дипфейки вижу, а вот чисто видео - что-то нет.
А зачем он? Видеогенерация все еще кал
Настало время переустанавливать автоматик!
Действительно белый человек. Выбираешь "кастом" и потом вручную прописываешь путь к своей моделке. Чтобы не обосраться - скопируй из проводника.
Если бы эти видеогенераторы были в действительности также хороши как на промо видео.
Ну вон Имад твитнул выше, рассматривают Юнити-монетизацию для новых core-моделей. Типа если зарабатываешь этой моделью, башляешь им фиксированную плату, а для остального можешь юзать и файнтюнить как хочешь.
Ехал черрипик через черрипик.
Помнится ещё год назад кто-то показал ахуительный рил с переносом стиля голливудско-диснеевского качества, а воз и ныне там.
Заебись было бы иметь хорошую видео модель, но по демо-рилам не судят.
>Ехал черрипик через черрипик.
Как будто картинки не так генерятся, лол.
На одну хорошую - десяток-другой не очень.
НАИ в начале тоже кал был (сравнивая с текущим состоянием дел), а тред до сих пор есть.
Они пока хуже наи и даже дефолтной SD1.4
Сап, вечерний. ЕОТ. А вот пиков её косплея на конкретного персонажа в хорошем качестве - раз, два и обчёлся. Но есть шакалы а-ля 384х640 (то есть у самих фоток-то разрешение поболе будет, но они со сцены и там другие тяночки тоже есть, не такие интересные.
Вопрос: чем апскейлить? Каким апскейлером? К моим услугам все те, что есть на гравити.
Персонаж очень уж оригинальный - бульбазавр в бикини.
Вопрос: чем апскейлить? Каким апскейлером? К моим услугам все те, что есть на гравити.
Персонаж очень уж оригинальный - бульбазавр в бикини.
>Как будто картинки не так генерятся, лол.
>На одну хорошую - десяток-другой не очень.
Нет. Если меняешь сид, уже что-то не так. Черрипик это следствие ограничений, как и промпт инжиниринг, рандом непригоден для практического юзания.

>рандом непригоден для практического юзания.
При этом вся ИИ-генерация картинок построена на создании изображения из рандомного шума.
Ага.
P.s. Опять капчу поменяли. Как вот такое решать, ё-моё?!
https://twitter.com/toyxyz3/status/1729922123119104476
https://twitter.com/toyxyz3/status/1729925444596855041
Походу всё-таки придется комфи ставить и изучать.
В автоматик такого врядли завезут.
https://twitter.com/toyxyz3/status/1729925444596855041
Походу всё-таки придется комфи ставить и изучать.
В автоматик такого врядли завезут.
В интеграциях с фотошопом/критой уже давно есть.
Штош... 1050 показывала ~60it/s, 1630 показывает ~18it/s (возможно что еще немношк разгонится)
Охуеть, это даже быстрей чем на моей домашней 1063 хотя userbench показывает что она мощнее в джва раза.
Охуеть, это даже быстрей чем на моей домашней 1063 хотя userbench показывает что она мощнее в джва раза.
Как добавить вариативности в инпаинтинге? Сиды, смена шедулера не помогают. Модель генерирует результаты с минимальными изменениями
Так это давно было в плагинах под комфи, и для блендера, и для криты. Через OBS это костыль какой-то.
Деноис повысь, наверно.
>1050 показывала ~60it/s, 1630 показывает ~18it/s
Чтобля, где ты там столько итераций накопал, 4090 еле до 60it/s допукивает при всех оптимизонах
https://www.bloomberg.com/news/articles/2023-11-29/stability-ai-has-explored-sale-as-investor-urges-ceo-to-resign
Паджита хотят пидорнуть, говорят что слишком распиздяй для CEO. И SAI может продадут, но пока нет.
Паджита хотят пидорнуть, говорят что слишком распиздяй для CEO. И SAI может продадут, но пока нет.

Это хайрезфикс кохи, только вместо интерполяции конволюшеном жмут.
Тайлинг, сразу нахуй.
Там же только первая половина от кохи.
Вторая половина про Свин - это оптимизации скорости для хайрезов в основном.
Не бомби, это я ошибся перепутав показания. Не it/s а s/it то есть секунд на 1 шаг. Не стал исправлять, подумал что вы и так поймете. Пикрил 1063 из консоли (об этом нюансе я писал тут ), для 1050 и 1630 так же скорость с запуском из консоли, через гуи я ебал запускать теряя половину скорости. 1050 я уже не пруфану в любом случае, а вот 1630 завтра принесу если не забуду.
Ну и еще я на днях попробовал на интол арк А380 завестись. В вебморде запуск через openvino появился, но ебать какой же это костыль. Короче я нишмог, и ебаться особого желания не было - воткнул невидию обратно.
Шо, прям вот так с переключениями по контролнетам, с позером, в котором есть скелет, и прочими свистоперделками, типа сегментации?
Или все-таки тупо "что-то рисую, оно мне это обрабатывает"?
>Шо, прям вот так с переключениями по контролнетам, с позером, в котором есть скелет, и прочими свистоперделками, типа сегментации?
Ну да, в плагине под криту оно так и работает. Можно и скелет в векторе подвигать (и списать с позы), и IPAdapter есть, и сегментация, и хуяция, и естественно нормальный критовский инструмент доступен - кисти, слои ебошишь, перспективные гайды, трансформации и т.п. https://github.com/Acly/krita-ai-diffusion
Плагин под блендер это вообще конвертация комфи-нод в блендерные. https://github.com/AIGODLIKE/ComfyUI-BlenderAI-node/ плюс есть риг готовый https://toyxyz.gumroad.com/l/ciojz
а экстракт метод мерджа хорош, не такой ебнутый как трейн дифренс
Та не, это не совсем то, что на видео показывали.
Хотя в ФШ и того нет поди...
Блин, не хочется криту осваивать. Лениво ппц.

Новый Realistic Vision 6.0, судя по редми из беты, генерит на разрешениях 896х896, 768х1024, 640х1152 :О
Прокачка фуррями здорового человека?
https://huggingface.co/SG161222/Realistic_Vision_V6.0_B1_noVAE
Прокачка фуррями здорового человека?
https://huggingface.co/SG161222/Realistic_Vision_V6.0_B1_noVAE
>Та не, это не совсем то, что на видео показывали.
Да нет, прям то. И реалтайм, и скелеты, и всё что хошь.
https://www.youtube.com/watch?v=-QDPEcVmdLI
https://www.youtube.com/watch?v=AF2VyqSApjA
Потестил - ну смешанное впечатление. На 896х896 иногда мутации проскакивают, но редко. Но судя по рекомендуемому промпту на негатив - они выполняют дофига работы. (Там стена текста из missing limbs и т.п.), модель он обучил их воспринимать корректно
А по фотореализму - кажется стало только хуже, и до EpicPhotogasm очень далеко...
Не забыл. Вот для 1630 например
Бля. Скрин проебал, комп ребутнул. Позже принесу мб.
по ощущениям на выходе как будто лцм механики присобачили с убиранием оверхита, надо допердолить через экстрактомердж с фотогазмом и чекнуть
При тренировке ведь чем больше размер батча, тем хуже результат? (модель хуже обобщает)
Если да, можно ли это побороть?
Если да, можно ли это побороть?
Наоборот. Для LION рекомендован батчсайз 32+.
Кода нет, весов нет, нихуя нет. Когда релизнут, тогда и приходите.
Вот реальный проект https://github.com/showlab/MotionDirector — есть и код и веса.
Аноны, а никто не в курсе, как лору-слайдер натренить?
Инструкции может есть какие?
Офигенская же штука (в некоторых случаях).
Инструкции может есть какие?
Офигенская же штука (в некоторых случаях).
Ostris делает своим способом. https://github.com/ostris/ai-toolkit#lora-slider-trainer
Что-то нифига не понял из его коллаба, если честно.
Датасет куда грузить? Само генерится, чтоль, и потом на сгенерившимся тренируется?
Почему когда я ставлю Train batch size больше 1 время тренировки увеличивается, а не уменьшается? В чем смысл этих batch size тогда?
Шаред мемори?
Почему софт такое говно? Бесконечный бета-тест.
Хм. Походу так и есть.
Он генерит картинки, и потом через их сравнение (?) что-то там тренирует.
Однако Коллаб дохлый, выдает ошибку.
Какой-то кусок из софта необходимого чтоль не встал, или еще что-то?
Купи подписку на OpenAI - там все на релизе, для таких как ты
Корочи, я потренил лоры на своих еотовых на разных настройках.
Лучше всего получилось по гайду хача - больше всего похоже на оригинал из всех остальных натрененых, отдельные генерации я бы отнес к категории реальных фото. Но только лишь отдельные - все равно не идеал, я бы доучил.
А по советам из треда получилось говно, норм результаты выдавало только на 0.8-0.9, более ранние эпохи генерили анатомически верно и соответствовали промту, но черты лишь отдаленно похожи. Говно, нирикаминдую. Вы походу на своих пресетах тренили на какую-нибудь маняме, у которой из черт лица - три черточки и две закорючки.
Ух бля, чет я заебался генерить всю эту залупу, лучше бы дальше с инпейнтом развлекался.
Лучше всего получилось по гайду хача - больше всего похоже на оригинал из всех остальных натрененых, отдельные генерации я бы отнес к категории реальных фото. Но только лишь отдельные - все равно не идеал, я бы доучил.
А по советам из треда получилось говно, норм результаты выдавало только на 0.8-0.9, более ранние эпохи генерили анатомически верно и соответствовали промту, но черты лишь отдаленно похожи. Говно, нирикаминдую. Вы походу на своих пресетах тренили на какую-нибудь маняме, у которой из черт лица - три черточки и две закорючки.
Ух бля, чет я заебался генерить всю эту залупу, лучше бы дальше с инпейнтом развлекался.
Нормальная лора и должна выдавать норм результаты на 0.6-0.8
Нет. Нормальная должна работать вплоть до 1.2-1.3.
Только потом уже должны начинаться заметные косяки.
То, что работает только на 0.6-0.8 - пережарено, перетренировано, или просто закосячено.
С чего бы, лол? Твоя нормальная работа при 1.2-1.3 это недотрен..
C того, что она работает на таких числах - и выдает приемлемый результат (конечно не совсем приемлемый, с косяками, ибо все-таки перебор - но никакого сильного искажения или пережаривания картинки быть не должно).
Ну если тебе нравится, то ок. Только нормальный диапозон около 1, а 1.3 - потолок
Так о чем и речь же.
Если лора не совсем ломается на 1.3 - это значит, что базовый диапазон у нее как раз в районе единицы.
Все, что крутится на 0.6-0.8 - на единице обычно выдает лютый пережар.
Все разработчики нового AnimateAnyone - чонги Суй хуй в чай. Как же подгорает с пиздоглазой ордынской вьетнам хуйни когда она всюду лезет. Сиди бля в загоне и жри летучую мышь, ИИ - для белых людей.
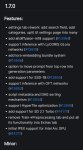
В ветке release candidate stable-diffusion-webui уже есть changlog на 1.7.0
Что за новые доп сети OFT и GLora? Про офт я пробовал понять документ по ним, вроде как типа та жа лора, только не портит какие-то концепты из основной сети. Но по примерам качественного отличия не заметил
Что за новые доп сети OFT и GLora? Про офт я пробовал понять документ по ним, вроде как типа та жа лора, только не портит какие-то концепты из основной сети. Но по примерам качественного отличия не заметил
> пробовал понять документ по ним
Нахуй вы вообще лезите туда, если буквы не понимаете?
Мужики, куда делся кроп из имг2имг на автоматике?
Что за шиз в треде?
> OFT
Новая база. Только лучше всё же COFT брать, чтоб оверфит не ебал. OFT пойдёт шизам с микродатасетами хотя лучше насемплить 2-5 вариаций капшенов, чем эпохи дрочить и ловить момент где оно перестаёт ломаться на 1.0.
> GLora
Кал, очередной способ как сделать оверфит на ещё меньшем количестве параметров, аналог лоха. Делался для LLM, за результат на графике никто не отвечает.
Какая-то новая приблуда для поз.
https://github.com/facebookresearch/detectron2/tree/main/projects/DensePose
И контролнет-модели для нее
https://civitai.com/models/120149/controlnet-for-densepose
С виду какой-то объединение openpose с depth?
https://github.com/facebookresearch/detectron2/tree/main/projects/DensePose
И контролнет-модели для нее
https://civitai.com/models/120149/controlnet-for-densepose
С виду какой-то объединение openpose с depth?
Есть ли разница в скорости генерации если устанавливать софты на HDD или SSD?
Нет. Но тягать туда-сюда модели и результаты генераций комфортнее на ссд, разумеется.
А лучше на SSD M.2 7000 Мбайт/сек. Там модели за 2-3 секунды меняются, мердж моделей идет в районе 8-10 секунд, если не меньше.
Советую Kingston FURY Renegade, по цена/качество самое то.

Можно как-то сделать чтобы контролнетовские модели не подгружались каждый раз при нажатии на генерейт? Заебывает сильно
Выключи CN. Или ты хочешь пользоваться им без моделей что ли, шиз?
Ну вот к примеру, я включил модули контролнета, нажал генерейт, он их подгружает, производит генерацию и выгружает из памяти эти модули. При следующем нажатии на генерейт все происходит по новой - ждать ~20 сек подгрузки модулей перед генерацией. Смысл этого дрочева, если я не меняю параметры и модули в контролнете? Понял о чем я, шиз?
Нахуй ты сам с собой разговариваешь, шиз? Нахуй ты кэш CN-моделей выключил в настройках и траллишь тут тупостью?
А я ничего не выключал. Зачем ты себе что-то надумываешь, шиз?
Но я теперь хотя бы знаю в какую сторону копать. Спасибо тебе, ЧСВ дебил
где 1.6
Sup!
Меня мучает такой вопрос - на сколько сильно влияет кол-во памяти в видеокарте на результат генерации в СД? У меня 3070 на 8гб, генерирую уже год, получается вроде хорошо, хотя апскейлить больше чем на 1500х1500 из-за 8гб не получается, но это не страшно, меня больше волнует сильно ли я теряю именно в качестве.
Действительно ли на одной и той же модели, промпте и даже сиде результаты будут ОЧЕНЬ разные на моей 8гб и на условной 24гб?
Просто думаю может зря я хуйней вообще занимаюсь, раз нет карточки нормальной.
Пытался найти сравнения в инете, но не нашел.
Меня мучает такой вопрос - на сколько сильно влияет кол-во памяти в видеокарте на результат генерации в СД? У меня 3070 на 8гб, генерирую уже год, получается вроде хорошо, хотя апскейлить больше чем на 1500х1500 из-за 8гб не получается, но это не страшно, меня больше волнует сильно ли я теряю именно в качестве.
Действительно ли на одной и той же модели, промпте и даже сиде результаты будут ОЧЕНЬ разные на моей 8гб и на условной 24гб?
Просто думаю может зря я хуйней вообще занимаюсь, раз нет карточки нормальной.
Пытался найти сравнения в инете, но не нашел.
>на сколько сильно влияет кол-во памяти в видеокарте на результат генерации в СД?
Нинасколько.
>Действительно ли на одной и той же модели, промпте и даже сиде результаты будут ОЧЕНЬ разные на моей 8гб и на условной 24гб?
Нет, будет то же самое.
Тогда на что именно влияет объем видеопамяти? Не просто ведь так за ним гонятся люди
На то, что влезает в него (особенно при тренировке), и на размер батча.
Очень разные результаты будут если у тебя 2 или 4 гига, medvram/lowvram меняют. В твоем же случае разница на том же сиде не будет. Для работы с большими тайлами - tiled vae используй. Тут уже достаточный размер поддерживается чтобы не было артефактов. Сложности могут быть только с контролнетами в больших разрешениях и всякими дополнительными моделями, что уже вместе с сд может не влезть.
Другое дело что перфоманс с 24 гигами если это не амд вырастет в разы, сможешь делать больше и в итоге лучше.
>Очень разные результаты будут если у тебя 2 или 4 гига, medvram/lowvram меняют.
Несёшь хуйню и рад.
Чому ты порвался? Это факт, с данными параметрами на мелких картах не воспроизвести оригинальные генерации. Будет ли средний результат в итоге лучше или хуже - хз.
Это не факт, а выдумки дегенерата, несущего хуйню и не краснеющего при этом.
https://showlab.github.io/X-Adapter/
Адаптер для полторашных лор, контролнетов и т.п. к SDXL - без переобучения. Ни весов, ни даже кода не видать.
Интересно, если это возможно то можно ли тренить лоры под SD 1.5 и юзать через такой адаптер на SDXL?
Или допустим в принципе запилить две модели - одну большую, другую маленькую, и файнтюнить маленькую, а юзать через адаптер на большой.
Наверняка результат хуйня, где-то должен быть подвох.
Адаптер для полторашных лор, контролнетов и т.п. к SDXL - без переобучения. Ни весов, ни даже кода не видать.
Интересно, если это возможно то можно ли тренить лоры под SD 1.5 и юзать через такой адаптер на SDXL?
Или допустим в принципе запилить две модели - одну большую, другую маленькую, и файнтюнить маленькую, а юзать через адаптер на большой.
Наверняка результат хуйня, где-то должен быть подвох.
Истеричка, как ты можешь объяснить то, что счастливые владельцы нищекарт не могут воспроизвести сиды нормальных генераций?
https://blog.playgroundai.com/playground-v2/
Playground v2 - новая модель на архитектуре SDXL с нуля. Заявляют качество пиздаче, насчёт следования промпту ничего не известно. Лицензия открытая.
https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic ссылка на модель, го тестить.
Playground v2 - новая модель на архитектуре SDXL с нуля. Заявляют качество пиздаче, насчёт следования промпту ничего не известно. Лицензия открытая.
https://huggingface.co/playgroundai/playground-v2-1024px-aesthetic ссылка на модель, го тестить.
Итак, вводные данные.
AMD Ryzen 7 5800X 8-Core Processor
64Gb Ram
AMDGPU RX6800
Gentoo линух
Блять, не догоняю слегка эти ваши мануалы. Пол мануала объясняется как вкорячить git с питоном на Шиндошс и на костылях деплоить ебаться с неродной системой.
Есть по простому?
С какой репы качать саму нейронку?
Из чего оно состоит? Типа оболочки которую брать на гитхабе, а потом ещё лутать запечённые датасеты? Есть вариант перевода чтобы нейронка хавала русский язык нативно? Как использовать несколько датасетов?
AMD Ryzen 7 5800X 8-Core Processor
64Gb Ram
AMDGPU RX6800
Gentoo линух
Блять, не догоняю слегка эти ваши мануалы. Пол мануала объясняется как вкорячить git с питоном на Шиндошс и на костылях деплоить ебаться с неродной системой.
Есть по простому?
С какой репы качать саму нейронку?
Из чего оно состоит? Типа оболочки которую брать на гитхабе, а потом ещё лутать запечённые датасеты? Есть вариант перевода чтобы нейронка хавала русский язык нативно? Как использовать несколько датасетов?
Бурной фантазией твоего сознания, как же ещё? Всё воспроизводится, если ты берёшь тот же самый воркфлоу и модель на той же точности, без xformers. Если у тебя не так - пруфани, ибо это экстраординарное заявление, требующее экстраординарных доказательств. Примерно как сказать что синус на 4090 может достигать четырёх, не то что на калькуляторе.
Ты что вообще пытаешься сделать, амудебил? Инференс или обучение? Если первое, то блять ставь первый попавшийся уй, там везде есть совместимость с амудой и инструкции для самых конченых.
https://github.com/AUTOMATIC1111/stable-diffusion-webui
https://github.com/comfyanonymous/ComfyUI
https://github.com/invoke-ai/InvokeAI
https://github.com/lllyasviel/Fooocus
https://github.com/easydiffusion/easydiffusion
>Есть вариант перевода чтобы нейронка хавала русский язык нативно?
Нет. Ну точнее оно немного хавает за счёт того что обучалось также и на русскоязычных кэпшенах, но нормальных результатов не жди.
>Как использовать несколько датасетов?
>лутать запечённые датасеты?
Какие блять датасеты, поехавший? Куда запечённые? Разберись чего ты хочешь, для начала.
> Бурной фантазией твоего сознания, как же ещё?
О, дефолтный наезд от чсв шиза, ты нормально общаться вообще не умеешь?
> Если у тебя не так - пруфани
У меня все в порядке, но какое-то время назад был вайн что на нищекартах сиды не воспроизводились. Было вроде то же, но с явными отличиями. Тогда же на 4х-гиговом паскале это проверил, с опциями оптимизациями памяти на выходе другая генерация. Буквально в том же автоматике с запуском по метадате, просто при смене железки и параметров.
Возможно это связано не с low/med vram а с работой всего на старых картах, но хз.
> Примерно как сказать что синус на 4090 может достигать четырёх
В военное время может достигать и 5, или быть красного цвета.
>ты нормально общаться вообще не умеешь?
Ладно бы ты просто давал некорректную инфу, но ты настаиваешь на своей правоте, когда тебе говорят что ты несёшь хуйню. Как ещё блять с такими общаться? Извините сэр, мне кажется вы неправы, сэр. Срал вам в горло, всего хорошего.
>У меня все в порядке, но какое-то время назад был вайн что на нищекартах сиды не воспроизводились.
Никогда не было такого вайна. Были дебилы, которые не разобрались как это работает, либо врубили xformers или любую другую подобную шнягу, которая давала невоспроизводимые генерации. Вот у меня блять есть 970 4ГБ на старом компе, 3060 12ГБ на новом, и арендую я 3090, 4090, или A100 когда надо, и везде всегда будет один и тот же результат.
> Ладно бы ты просто давал некорректную инфу, но ты настаиваешь на своей правоте, когда тебе говорят что ты несёшь хуйню.
Вот, это чисто про истеричные вбросы чсв шиза, знания которого кончаются на поверхностных ухватках в отличии от самоуверенности, и после очередного фейла он сливается, чтобы вскоре опять всплыть.
> я не видел значит не было и быть не может
Справедливо да
> xformers
> невоспроизводимые генерации
лол
А ведь мог бы сам погуглить ту херню, еще на гитхабе и прочих около сд ресурсах обсуждали почему нищуки не могут пройти всякие аскотесты и специальные отдельные версии для них пилили.
>Как ещё блять с такими общаться?
Да ты со всеми здесь так общаешься, обиженный в ИРЛ, видимо
Ты похоже общаешься с голосами у себя в голове, выдумывая каких-то неизвестных людей.
Так ты пруфы-то дашь, или будешь продолжать нести хуйню? Без пруфов можешь нахуй идти.
То, что можно команду стрелочками указывать, как повернуть голову или часть тела - это что-то новенькое? Или есть в контролнетах?
А еще команда поменять позу выглядит интересно, хотя возможно это работает в img2img с контролнетом, я не пробовал
>То, что можно команду стрелочками указывать, как повернуть голову или часть тела - это что-то новенькое? Или есть в контролнетах?
На это можно натренить контролнет свободно. его можно на любые пары натренить На цивите есть кастомные КН на контроль положения источников света, например. Вопрос только в том что контролнеты относительно большие. Тут новация походу в том что эта хуйня меньше по параметрам и требует датасет поменьше, её проще тренить с нуля.
>На цивите есть кастомные КН на контроль положения источников света, например.
Это лоры-слайдеры же, не контролнеты.
Больше размер памяти - больше картинка в нее помещается - больше деталей ИИ на ней нарисует. Сложно передать текстуру кожи на фуллбоди-персонаже, если у тебя картинка всего 1280х1024.
Где-то дополнительные детали - хорошо, а где-то не очень.
Хотя текстуру кое-где можно и апскейлом сделать, а вот именно детали - уже нет.
> Так ты пруфы-то дашь
Ты это серьезно? Миллион постов "почему после смены видеокарты я не могу воспроизвести сиды", "влияет ли medvram/lowvram на качество", демонстрация проблем на паскале и недотьюирангах. Плюс посты в тредах этой доски.
Держи даже разбор аскотеста где это продемонстрировано http://web.archive.org/web/20230516140252/https://imgur.com/a/DCYJCSX сраный имгур его выпилил но интернет все помнит
После ознакомления можешь в очередной раз проследовать нахуй. Каждый раз как в первый, уже бы пора чсв поубавить и вникать в вопрос перед выебонами
https://civitai.com/models/80536/ вот он. Это больше пруф ов концепт, но вообще такие вполне можно натренить полуавтоматически просто создав пары в блендере. Контролнет это довольно универсальная хрень, можешь например натренить его на парах изображение-камера и получишь крутилятор камеры, простор для экспериментов большой. Вот например https://civitai.com/models/191956/
>Ты это серьезно? Миллион постов "почему после смены видеокарты я не могу воспроизвести сиды", "влияет ли medvram/lowvram на качество", демонстрация проблем на паскале и недотьюирангах. Плюс посты в тредах этой доски.
Где блять всё это? Такое ощущение что я пытаюсь научить овоща завязывать шнурки. Ты притащил совершенно невероятное заявление, противоречащее здравому смыслу и пониманию как это работает. Это тебе надо куда-то там лезть за постами, по дефолту ты упорствующий долбоёб.
>Держи даже разбор аскотеста где это продемонстрировано http://web.archive.org/web/20230516140252/https://imgur.com/a/DCYJCSX
Что тут продемонстрировано? Вижу только беспруфный вскукарек:
>did you launch webui with the --medvram, --lowvram, or ----no-half options? if so, then you're ok, it's normal for these options to cause very slight variation in the output due to how it works.
В чём суть демонстрации?
Не отвечай мне пока не притащишь пруфы, ты заебал, не интересно мне слышать твои виляния без субстанции.
Поставь себе генту - уравненовесь свой либидо,
Гента такая классная, гента всегда нова...
завали свой выходной поток, мразь ты форточная, и воздай же ретивую хвалу Линусу нашему Торвальдсу за создание Великого Гита!
На дуэль его каналью!!!



Аноны, а можно как-то косяки с цветовыми пятнами на апскейле забороть?
Понятно, что они из-за ВАЕ вылазят, но, блин, что СДшное, что НАИшное, что всякие энифинги - они все гадят пятнами в одни и те же места. Просто где-то более заметно, а где-то менее.
Пикрил примеры: вае энифинга (клон НАИ), вае СД (840000-ema), и апскейл в то же самое разрешение, тем же самым апскейлером, но экстрой.
Вот как с таким говном бороться, если тайловый апскейл нужен?
Понятно, что они из-за ВАЕ вылазят, но, блин, что СДшное, что НАИшное, что всякие энифинги - они все гадят пятнами в одни и те же места. Просто где-то более заметно, а где-то менее.
Пикрил примеры: вае энифинга (клон НАИ), вае СД (840000-ema), и апскейл в то же самое разрешение, тем же самым апскейлером, но экстрой.
Вот как с таким говном бороться, если тайловый апскейл нужен?
Сап ананасы я лоу айку работяга с завода, скачал стейбл диффужн что бы ебать свою новенькую 4070ti, сегодня чутка ей попользовался вроде генерит что то, но я думаю надо в матчасть вкатываться что бы не тупить, пожскажите с чего начать
> работяга с завода
> что бы не тупить, пожскажите с чего начать
Начни с поиска нормальной работы
Не слушай токсика, сегодня у него месячные, срет по всем ИИ-веткам подряд.
Посмотри в соседних тредах - NAI (аниме) и SD (реализм, иллюстрации). Там в шапках очень много полезной информации.
vq-gan поробуй. Но вообще это нормальное состояние VAE. Даже если кажется нет синяков - есть желтизна на белом возле лейна. Частично пофиксить можно пересев на мыльный семплер.
Спс анончик, два чая тебе и сотен нефти
Ссылку бы еще, да где его искать.
Желтизну у линий не шибко видно (это всё-таки абсурдрес 4к уже), а вот синяки - прям в глаза бросаются. Я уже и размер тайлов пытался менять, и апскейлеры - остаются, и всё тут.
Собственно, поэтому на апскейл экстрой и перешел. Из-за таких вот косяков.
Квалифицированный токарь получает вполне на уровне айтишника. Видишь, у него на новенькую видяху есть бабло. Не училка же и не кассир.
Ого, уже похоже на обсуждение а не просто визг, красавчик, без иронии.
> Где блять всё это?
В гугле вбиваешь что-то типа "stable diffusion seed reproduction lowvram", можно сразу по гитхабу или реддиту не говоря о базированном "cuda different result on new architecture", мл инженер арендующий A100 епта. В репе автоматика ишьюсы среди которых есть немалая доля относящаяся к этому, на реддите ветки (хотя те в основном были в первом полугодии были и протухли). Там целое исследование этого запилили и было много примеров как оно может искажаться, причем чем больше операций с пикчей и сложнее тем больше разница, уходящая далеко за мелочи от xformers. Сейчас 404, можешь заняться изысканиями если есть мотивация.
> Ты притащил совершенно невероятное заявление
Оно верное, ранее были замечены проблемы с повторением пикч на старом железе которое требовало этих опций, о чем много свидетельств.
> противоречащее здравому смыслу
Противоречит только в случае если быть узколобым и не вникать. Причин для проебывания сидов здесь может быть множество, от того как (насколько корректно и без потерь) организована выгрузка частей моделей при этих опциях, до реализации работы отдельных операций в нищекартах без поддержки нужных инструкций в сочетании со всеми оптимизациями, которые уже оче давно перестали быть детерминированными, это к твоему примеру про косинус. Могут быть вообще баги в либах куды, которые никто уже не будет устранять по причине смерти той серий карт, когда находят ошибки в элементарных операциях в современном GCC уже ничего не удивляешься.
> В чём суть демонстрации?
> these options to cause very slight variation in the output
Выделил специально, глаза не видят?
> Не отвечай мне
лол


Вот уж не знаю, чего у вас там за косяки, но я сейчас взял свою генерацию, которой почти год уже (в январе на чистом сливе НАИ сделана была), закинул ее в ПНГ-инфо, тыкнул Generate, и получил 99.5% совпадение.
С тех пор чего только не поменялось. Автоматик обновлялся. Иксформерсы-хуёрмерсы, куды-приблуды. Даже комп у меня уже другой, с 2070 на 4080 пересел. Результат - пикрил.
Единственный случай, когда я столкнулся с невозможностью повторить старую картинку - это когда у меня в пнг-инфо пробилась какая-то картинка с "вирусным" параметром Eta noise seed delta, я ее отправил в т2и, и эта вот дельта у меня из-за нее в настройки скрытно прописалась. И все следующие картинки с новым параметром генерились.
Спасибо какому-то чуваку с гитхаба, который про эту штуку рассказал. С тех пор я ее в квиксеттингс автоматика вынес, висит там, ноль показывает, как и должно быть.
С тех пор чего только не поменялось. Автоматик обновлялся. Иксформерсы-хуёрмерсы, куды-приблуды. Даже комп у меня уже другой, с 2070 на 4080 пересел. Результат - пикрил.
Единственный случай, когда я столкнулся с невозможностью повторить старую картинку - это когда у меня в пнг-инфо пробилась какая-то картинка с "вирусным" параметром Eta noise seed delta, я ее отправил в т2и, и эта вот дельта у меня из-за нее в настройки скрытно прописалась. И все следующие картинки с новым параметром генерились.
Спасибо какому-то чуваку с гитхаба, который про эту штуку рассказал. С тех пор я ее в квиксеттингс автоматика вынес, висит там, ноль показывает, как и должно быть.
Попробуй kl-f8, она артефачит меньше всего, хотя полностью проблему не решает. Если не помогает - смириться. Или поправить в фотошопе используя восстанавливающую кисть, или добавив в то место участок из экстры, он хорошо получился. Вообще склейка разных частей - довольно дефолтная тема в sd, очень быстро и эффективно.
> Ссылку бы еще
https://dropmefiles.com/1ZL7b
Вроде оно, пароль стандартный, учти что его желтые артефакты могут быть даже более заметны в некоторых случаях.
Это же замечательно, а с каким железом и параметрами генерировал раньше, менялось ли что?
> с "вирусным" параметром Eta noise seed delta
Это просто смещение номера сида для повторения поведения наи.
>Попробуй kl-f8
Та же жопа, только в профиль. Что-то среднее между СД и НАИ. СД с виду даже менее заметно артефачит (по крайней мере на этой пикче).
>Вообще склейка разных частей - довольно дефолтная тема в sd, очень быстро и эффективно.
Склейка хороша, когда я саму картинку делаю.
Апскейл должен идти по принципу "тыкнул и готово", а не создавать еще больше артефактов и лишней работы.
>Вроде оно, пароль стандартный
Да, это получше. По центру и сверху артефакты почти ушли, нижний, правда, всё равно остался. Самый лучший вариант из предыдущих трех (НАИ-СД-КЛФ), но не идеал.
Странно, ну чистые же линии в оригинале, никаких особых переходов яркости нет, вся картинка такая же - а артефачит именно там.
>а с каким железом и параметрами генерировал раньше, менялось ли что?
Так я ж написал. Всё, что с начала года могло поменять - поменялось. Начиная с версии автоматика и заканчивая личным компом, виндой, и всем остальным софтом. Абсолютно две разные системы, неизменными остались только модель, вае, и те метаданные, что были прописаны в саму картинку.
>Это просто смещение номера сида для повторения поведения наи.
Вот оно и прописалось. Его ж нигде не видать, только в настройки лезть - а результат сразу заметен, как невозможность повторить старую генерацию.
Кто знает как без косяков проставить тегги и описания изображений, нужна либо программа либо что-то для автоматического тегирования без обсёров. В kohya_ss есть что-то, но качество так себе.
Что на сегодяшний день лучше всего работает?
Что на сегодяшний день лучше всего работает?
Но ведь если работа отнимает условно больше 4 часов в день, и ты вынужден жить всего пару часов вечером - это ж пиздец. Зачем вообще жить в таком случае
>В kohya_ss есть что-то, но качество так себе.
Если тебе тамошних анимублядских клип-блип теггеров не хватает, то или запускай локально CogVLM (желательны 40GB, в 24 влезает кое-как если ужаться), или бери GPT-4V. Можешь LlaVA, но она хуже обоих.
я не понял, что 40 в 24 влезает. нормально объясни по человечески чем анимублядские клип-блип теггеры отличаются от других и как эти другие найти и присобачить. там вроде как есть специальное поле, я нашёл какой то https://github.com/jmisilo/clip-gpt-captioning
вставляю ссылку туда и не работает ничего, или вставляю название, но не работает.
у меня видюха на 16гб если что.
>GPT-4V
как его брать и как всунуть?
Мимо другой анон, предполагаю не влезает по той же причине почему webui требует no-half. Т.е. из-за отсутствия операций с fp16 требует примерно в 2 раза больше памяти
>чем анимублядские клип-блип теггеры отличаются от других
Тем что не пользуются полноценными визуальными моделями. GPT-4V видит картинку и является частью GPT-4, она просто неестественно хорошо разбирает происходящее на пикчах, можно по тегам если попросить, можно натуральным языком, можешь её заставить хоть поэму в гекзаметре на древнегреческом сочинить по картинке.
>как его брать и как всунуть?
Заплатить OpenAI и юзать. Всунуть готовым образом в койя_сс никак, придется самому городить колхоз на питоне, или юзать отдельную приблуду вроде этой https://github.com/vladignatyev/bulktag
>я не понял, что 40 в 24 влезает. нормально объясни по человечески
Если не GPT-4V, то топовая локальная модель сейчас это CogVLM. Она здоровенная и хорошо видит то что на картинке, но требует 80GB (я оказывается напиздел про 40), так что тут только арендовать. A100 80GB стоит порядка 2 баксов в час на vast.ai on-demand, тебе из этого понадобится может несколько минут протегить твои картинки (смотря сколько их там конечно). А вот автотеггер тебе пилить придётся самому, готовых решений нет.
>у меня видюха на 16гб
Можешь попробовать LLaMA-13B. Она сильно лучше ссаного BLIP, но хуже даже CogVLM. Демка есть тут https://llava.hliu.cc/ , автоматических теггеров под неё не знаю, поищи, может есть.
Решений вообще без пердолинга нет, как ты думаю уже понял.
>LLaMA
LLaVA
фикс
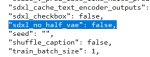
>no-half
да нет, там заёба, чтобы не было no-half нужно открыть конфиг и поставить false вместо true и тогда обучение запускается

>Великого Гита
Он теперь под мелкософтом
>Но ведь если работа отнимает условно больше 4 часов в день
Если ты на чпу и у тебя поток, а не полторы детали - вся твоя работа это настроить комплюхтер в твоем станке под деталь и опционально менять болванки/оснастку. В остальном сидишь-пердишь и периодически смеешься над дево-псами которые с мокрой жопой пытаются раскукожить схлопнувшийся кубер. Про рабов-погромистов я ваще молчу, это совсем дно.
>LLaMA-13B
Как то он странно описывает, как будто для книжки, а не для обучения.
Не думал, что описать и протеггить будет так сложно и более энергозатратно чем обучить, я думал обучение это самое сложное.
А вообще насколько влияет правильное теггирование и описание на результат тренировки? Я тренирую на людях и у меня проёб с одеждой, планирую начать делать паки с разными куртками, дождевиками, футболками и т.д. для добавления в модель по типу Realistic Vision, сейчас протеггил 50 картинок вручную методом Manual Captioning в kohya_ss
Если в это свободное время ты можешь делать свои дела на своем компе, например - тогда прям кайф
> >LLaMA-13B
> Как то он странно описывает, как будто для книжки, а не для обучения.
Это проблема не лавы, а карточки персонажа. Нужно ей чтоб в контексте были примеры того, как надо отвечать
Погодите, а что вы тут обсуждаете? В саму ламу уже добавили мультимодальность? Или это лава? Я просто забросил следить за текстовыми моделями
так и представил как греча сидит в подсобке после настройки чпу и дрочит на рисованные вагины
Не можешь. Плюс там грязно и воняет. Ну и кАЛнтингент соответствующий. Там никто не хочет работать, поэтому его окружение это скуфы и туповатые васяны с нулем интересов. Да он и сам туповатый, как видно по вопросам.



Обучил модель на сотнях мужских фото, добавил слово "дождевик" в промпт, лица неплохие, хоть и иногда растянутые бывают, но одежда полное дерьмо. Ну думаю создам пак с дождевиками и дообучу модель. В итоге получилось это, теперь модель пытается делать вместо крупных портретов моих мужиков этих манекенов с дообучения даже в полный рост кадрирование появляется и руки везде, да и вообще сами плащи выглядят почти так же хуево как и до дообучения.
Что я делаю не так?
Почему в модели realistic vision одежда выглядит нормально, а тут деформация на деформации и ещё руки везде и лысый мужик из дообучения везде появляется
Что я делаю не так?
Почему в модели realistic vision одежда выглядит нормально, а тут деформация на деформации и ещё руки везде и лысый мужик из дообучения везде появляется
Потому что капшены говно. Если нет нормальных качественных ручных капшенов, то генерируй на каждый пик по 5 капшенов в пару предложений и потом тренируй на них по очереди с батчсайзом 8-16, разрешение меньше 768 никогда не делай. Вместо кучи эпох лучше насемплить побольше капшенов. Так будет хоть какая-то генерализация и понимание у сетки что ты от неё хочешь. А так у тебя сетка в душе не ебёт что за "дождевик", может это капюшон или согнутые руки для позирования, сетке это не понятно. Ещё пробуй уменьшать размер лоры чтоб как меньше инфы влезало в неё, COFT попробуй взять или глору если датасет большой.
>Не можешь
Зависит от лояльности. Если ты не косячишь и над тобой нормальные люди - можешь сидеть-пердеть за своим ноутом, хоть дрочить, хоть вприсядку плясать. Если в руководстве сапоги - сложнее, но тоже остаются некоторые варианты, например "тестирую код для чпу к следующей партии" или "инициативно повышаю квалификацию", а сам на втором экране/вкладке вагину петровичу инпейнти вместо рта. Если твой завод режимный - тоби пизда, будешь загнивать
Но вот этот прав канеш.

>по 5 капшенов в пару предложений и потом тренируй на них по очереди с батчсайзом 8-16
Я не думаю, что большое значение имеет капшон больше одного короткого предложения, врядли оно вообще понимает контекст и все такое, у меня помимо капшенов ещё и файлы txt с теггами имеются.
Ты про тренинг батчсайз? Я его ставлю на 1 всегда, так быстрее обучается. В чем смысл ставить 8-16 ? Это же просто сколько картинок одновременно обучается, по идее должно быть быстрее если больше батчсайз, но у меня время обучения увеличивается.
>А так у тебя сетка в душе не ебёт что за "дождевик", может это капюшон или согнутые руки для позирования
Там где человек с надетым капюшоном я так и пишу, а вообще очевидно, что дождевики разных цветов, есть на молнии, а есть на кнопках, хули там не понять то.
>Ещё пробуй уменьшать размер лоры
я делаю Finetuning 768x1024
> врядли оно вообще понимает контекст и все такое
Понимает. Не прям как текстовая модель, но в какой-то степени есть понимание. И оно лучше, чем просто каша из пяти слов. Особенно когда у тебя тренируемый объект очень отличается между пиками.
> В чем смысл ставить 8-16 ?
В генерализации.
> хули там не понять то
Хотя бы указывай какие характеристики у дождевика - цвет, фасон. А иначе он так и будет думать что это самый статистически стабильный объект на пиках, а не одежда всех цветов радуги.
> Finetuning
Тогда и не спрашивай почему он обучается чему-то непонятному.
>какие характеристики у дождевика - цвет, фасон
я и указываю цвет, и на молнии он или на кнопках.
>В генерализации.
а русским языком это как?
>Тогда и не спрашивай почему он обучается чему-то непонятному.
чувак который создал модель realistic vision тоже Finetuning использовал



пиздец из меня учитель, оно даже позы повторяет

Лава. Это жуёбок очепятался я
Ну вообще кэпшены с хорошей VLM получаются очень быстро, просто нет готовых решений. Если у тебя лора, то пикч 20-50 и вручную можно затегить.
>А вообще насколько влияет правильное теггирование и описание на результат тренировки?
Максимально. Модель хавает смысл из пар картинка-текст.
>Если нет нормальных качественных ручных капшенов
Уже CogVLM даёт не менее пиздатые описания чем человек, и замечает каждую деталюху на пикче, в чём можно убедиться на их демке. Может описать позу и все объекты. Лишь изредка ошибается. Не говоря уже о гопоте-4.
Теги должны быть максимально подробные, но при этом не превышать твой выбранный лимит токенов (в кохе можно выбрать не 75 а например 225). Описывать надо каждую значимую деталь (включая фон, позы, настроения, цвета и т.п.), чтобы потом он мог генерировать без этих деталей. Если не описывать ненужное, он склеит его с нужным.
> CogVLM
На уровне лавы 1.5, хуже её файнтюнов. Обсерается в композициях сложнее клоузапа. Ручные капшены всё ещё ничего даже близко не заменит, даже жпт, у которой галлюцинации на реальных фото через раз.
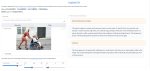

>> CogVLM
>На уровне лавы 1.5, хуже её файнтюнов. Обсерается в композициях сложнее клоузапа.
Бля, ну даже не знаю...
>даже жпт, у которой галлюцинации на реальных фото через раз.
Мне кажется ты даже не пробовал. Она охуевшие детали замечает, которые сам не сразу высмотришь, ещё и по ним какие-то вещи выводит. Ни о каких галлюцинациях через раз там даже речи не идёт. Она ошибается изредка, но в целом у неё охуенная точность и детальность, человеку надо усраться чтобы каждую картинку так описать как это делает GPT-4V.
Но не суть. Главное что при файнтюне на 10к пикч, или тренировке кучи лор, ты не будешь это всё делать вручную, это пиздец дроч. Нормальный автокэпшен это более чем годная вещь. Если бы ещё и поиск в вебе и сортировку можно было поручить нейронке, это было бы дважды охуеть.
Другая рандомная пикча, ткнул из папки все_ебанулись наугад



>Теги должны быть максимально подробные
какая разница сколько тегов если оно не может понять форму сраной куртки и пытается скопировать целиком позу человека с датасета
Ещё одна рандом пикча, результаты абсолютно несравнимые, это разного уровня модели совершенно. А на вопросы нет/да CogVLM вобще почти безупречно отвечает, если заставить хорошую LLM дополнительно переписать её ответы в виде проверочных вопросов, а потом CogVLM на них отвечать по пикче.
Впрочем даже теггинг ллавой на голову выше сраного блипа.
Бля, анон, челы с цивита как-то умудряются даже на одной пикче тренить так чтобы не повторять позы.
А что за датасет у тебя? Там одна и та же поза везде?
Чтобы оно не оверфитило датасет, нужно его разбавлять регуляризационными пикчами, штук по 5-20 на каждую пикчу датасета. Т.е. пикчи того же класса, например фотки мужиков в парке, не обязательно в дождевике. Только нельзя их генерить (во всяком случае на модели той же архитектуры), получается жопа с усилением собственных артефактов. Регуляризация помогает усреднить всю эту хурму, чтобы оно не фокусило конкретные куски из него.
Кек. Похоже я всн это время так делал, но не клал их в папку reg..
>Обучил модель на сотнях мужских фото
Ты делаешь файнтюн, будку или лору? Думаю в твоих условиях достаточно лору или ликорис сделать из 20-30 нормально подобранных и протегенных картинок (+регуляризация без дождевиков, её тегить не надо). Сотни лишь испортят дело.
Интересно, а на борушные тэги для аниме-моделей такого нет?
>Как то он странно описывает, как будто для книжки, а не для обучения.
Всё зависит от того как ты захочешь потом промптить. Хочешь натуральный язык - оно сделает тебе его по дефолту. Хочешь теги - запроси у неё теги. Это же обычный чатбот, который понимает изображения. А не специализированный теггер, который заранее знает что тебе надо.
Ёбаный насвай, неделю не запускал и хуяк ошибки.
При выборе TRT модели не генерирует
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument mat1 in method wrapper_CUDA_addmm)
хуле ему сделать надо?
При выборе TRT модели не генерирует
RuntimeError: Expected all tensors to be on the same device, but found at least two devices, cpu and cuda:0! (when checking argument for argument mat1 in method wrapper_CUDA_addmm)
хуле ему сделать надо?
CogVLM понятия не имеет о тегах данбуры (если попросить то просто ставит теги какие ей покажется нужными, но не данбуровские 1girl и т.п.). Можно попробовать расшатать GPT-4V, она может их знать. Но вряд ли, скорее нужен специфический файнтюн.
>специфический файнтюн
Вот и я так думаю.
WD-таггеры и прочие не очень хорошо картинку разбирают, к сожалению, могут просто дофига дичи накидать.
Если что-то появится - это будет просто шикарно, сразу качество тренировки лор подымется.
>специфический файнтюн.
Там на гитхабе есть описание такого. Вопрос только сколько займет по времени и какое железо надо


>регуляризационными пикчами
в файнтюнинге нет этой хуйни с регуляризационными пикчами, это тебе не дримбут.
>А что за датасет у тебя?
основной это портреты мужиков, дообучение делал на 50пикчах из дождевиков
>Сотни лишь испортят дело.
это файнтюнинг, я хочу сделать модель такого же качества как realistic vision только с улучшением, так как там лица слишком модельные получаются и через img2img похожие лица трудно воссоздать, а у меня с этим нормально, так как в датасете присутствует множество простых славянских круглых ебальников, как начнут получатся портреты с одеждой планирую добавить фото окружающей среды и всего остального, но первостепенной важности портреты конечно.
>It is recommended to use the 490px version. However, if you have limited GPU resources (such as only one node with 8* RTX 3090), you can try 224px version with model parallel.
Т.е. обучение даже шакальной 224х224 версии еле влезает в большой утюг с 192ГБ VRAM, полноценной видимо ещё больше. Риг с 4x A100 80GB SXM (т.е. объединённой в единый пул памятью) встанет тебе примерно в $7.5/час на vast.ai и дороже на других хостингах, и это ещё если в него влезет. А вот сколько времени надо это хз. Рассчитывай от получаса до 10 часов, я думаю. (чисто пальцем в небо) Можно связаться с яйцеголовыми или в иссуях на гитхабе спросить. На самом деле я думаю что модель можно урезать по точности и сократить расходы на тренировку. В общем задача под силу энтузиасту, хоть и на грани.
Конечно всё это сначала надо протестить на простеньком компе, чтобы весь датасет был в норме и все скрипты работали, прежде чем включать утюг.
кстати забавно что туториал датасет у них по решению капчи, лол
>192ГБ VRAM
Звучит больно;(
Хотя ~70 баксов не так много, можно потом на донатах отбить, наверное (но не у нас)
Что такое free-u, какая-то удудшалка для sd генераций. Норм или нет?
Потыкал. В большинстве случаев какой-то переуонтраст делает, что черные детали сливаются. В целом детали может быть лучше, но по отдельности мелкие детали похуже
По опыту использования, фрию частично помогает против нейрохуйни и бодихоррора, но средство не ультимативное и как улучшение какого-то изображения, которое хотелось бы починить работает плохо - просто другую картинку сгенерит, может и не поломанную, но другую.
Оно может сделать лучше, особенно на малых шагах. Беда в том что коэффициенты надо выбирать для каждого конкретного случая, а прямого алгоритма не существует. Это примерно такое же шаманство как латент трэвел или прямое редактирование нейронов. Можно попробовать сделать гигантские XY чарты, но всё равно оно останется непредсказуемым и оттого малоюзабельным.
Ты путаешь с гитхабом, даун. Или пруфы в visual студию!
> >Великого Гита
> Он теперь под мелкософтом
🤡 Это серьезно?
Установил по гайду, сразу всё запустилось и работало. Сегодня решил запустить через lauch, и какая-то ошибка вылезает в командой строке на секунду, так что я даже заскринить не могу. Щас запустил через файл webui-user, нажал generate и такая ошибка вылезла.
А ты думал? Каких только шизиков не бегает тут.
Причём тут гит, какие форточки, что ты несёшь, поехавший.
>и такая ошибка вылезла
В консоли-то что пишет?
кто знает что такое шаги накопления градиента и нахуй оно надо если можно просто поставить больше эпох?
Что в данный момент не позволяет создать архитектуру для нейронок как SD, но чтобы трейнить с нуля, за короткое время на небольших данных и с нужными тебе параметрами? (То бишь не зависимую от каких-либо pretrained весов с корявыми эмбедингами, при этом с базовым знанием мира, понимающая в принципе что от нее требуется, этакая pretraining-free)
> как натренировать модель без тренировки
Никак. Иди нахуй с такими дегенеративными вопросами.
Ничто не мешает этому, это называется zero-shot learning. Все эти методы трансфера стиля/концептов/объектов типа IPAdapter, reference-only controlnet и т.п. это оно и есть. Результат неизбежно хуже чем полноценная тренировка, но в долгосрочной перспективе это выигрышный путь.
> zero-shot learning
Ты хоть ознакомился бы с ним. Оно не отменяет необходимость в натренированной модели.
> типа IPAdapter
Который конечно же без тренировки работает, да? CLIP для извлечения "фичей" тоже уже без тренировки на миллиардах пиков работает?
> reference-only controlnet
Технически минимальные отличия от img2img, разница лишь в каком месте UNET применяется референс - в кросс-аттеншене, а не просто пикча на вход UNET передаётся. Без натренированного UNET это всё так же не будет работать, а от твоего референса UNET не научится рисовать то что не умеет.
> в долгосрочной перспективе это выигрышный путь
Никому не нужно такое говно. Сейчас наоборот идёт весь упор на повышение качества моделей через вариации RL, где помимо основной модели нужно ещё иметь модели для ревардов/скоров.
Я просто в глаза ебусь, думал что этот даун хочет без файнтюна, а он предлагает вообще без модели обойтись. Этого конечно не бывает.
>Никому не нужно такое говно. Сейчас наоборот идёт весь упор на повышение качества моделей через вариации RL, где помимо основной модели нужно ещё иметь модели для ревардов/скоров.
Речь об zero shot vs файнтюнинг. Зерошот на базе универсальной модели всегда будет более востребован, файнтюнят лишь из-за того что результат лучше.

> Апскейл должен идти по принципу "тыкнул и готово", а не создавать еще больше артефактов и лишней работы.
Пикрел
> Можешь LlaVA
С анимублядскими только кое как bakllava справляется, и то потом ее выдачу нужно сильно обрезать или прогонять через другую LLM. Новые мультимодалки возможно получше в этом отношении будут.
> Заплатить OpenAI и юзать.
Полноценный датасет выйдет очень дорого, но еще раньше упрешься в рейтлимиты.
> CogVLM. Она здоровенная и хорошо видит то что на картинке, но требует 80GB
> CogVLM supports 4-bit quantization now! You can inference with just 11GB GPU memory!
Пробовал кто?
> >На уровне лавы 1.5, хуже её файнтюнов. Обсерается в композициях сложнее клоузапа.
Ее бы локально пустить с нормальными настройками семплинга и промтом. Текстовая часть в этих моделях очень глупенькая и с ней надо как с ребенком ложечкой кормить, тогда отвечают.
> CogVLM понятия не имеет о тегах данбуры
Потом можно через другую llm прогнать попросив сделать теги. Но лучше сразу wd tagger из нескольких моделей.
>Новые мультимодалки возможно получше в этом отношении будут.
как их искать и где?
Речь про этот самый CogVLM и еще какая-то выходила недавно. Из легковесных - ShareGPT4V различает очень хорошо и меньше галлюцинирует, но слаб в непотребствах. Вон из llama треда их сравнение https://rentry.co/r8dg3
В перспективе наиболее рабочим вариантом может быть связка интерогейтеров, мультимодалки и LLM как в примере https://rentry.co/pvnhr
тут на основе wdtagger, clip и общения с Bakllava китайская сеть описывала пикчи и достоаточно эффективно осеивала галлюны последней и большей частью давала верное описание. На дикую графоманию описания внимания не обращай, это легко меняется промтом.
Сюда имплементировать CogVLM, ShareGPT4V, устроить сортировку по содержимому пикчи в соответствии с возможностями мультимодалок, добавить еще промежуточные этапы - легко превзойдет gpt4v в зирошоте, а то и в диалоге.
в какой последовательности и каккими калькуляционными методами лучше всего сращивать концепты моделей? допустим у нас есть реалиситиквижн и фотогазм, максимально усредненное значение можно получить через экстракцию из фотогазма в рв + рв в фотогазм и потом их вейтедсумить пополам с альфа слоем
а дальше? допустим я хочу присадить анимеконцепты, беру модель и через трейндифренс с 0.5 присаживаю, получаю уже не фотореал, а псевдо 2д, далее могу через смуфадд или долго повторяя экстракт получить более менее реалистик назад при этом сохранив концепты из аниме модели
может есть какой-то более умный метод?
а дальше? допустим я хочу присадить анимеконцепты, беру модель и через трейндифренс с 0.5 присаживаю, получаю уже не фотореал, а псевдо 2д, далее могу через смуфадд или долго повторяя экстракт получить более менее реалистик назад при этом сохранив концепты из аниме модели
может есть какой-то более умный метод?
Мультимодалки ламы с CLIP примерно все одинаковые. Cog уже лучше, но я им недавно на 12к пикч генерировал капшены - сутки вышло по времени, блять. Зато сильно лучше всего говна что до этого видел. А чистый CLIP хорош разве что вычистить мусор из датасета побыстрому, если тянешь фоточки со всяких помоек или стоков, то мусора там достаточно, приходится чистить.
Объясните тому как это запустить
https://github.com/bishopfox/unredacter
https://github.com/bishopfox/unredacter
Анон, ты про свеженький реалистиквижн, шестой? Ты если его с фотогазмом... того, ты это... выложи куда-нибудь. Интересно, потянет ли плод трудов твоих скорбных реалистиковские 768х1024.
> Мультимодалки ламы с CLIP примерно все одинаковые.
Sharegpt4v из них выделяется сильно, но у него и свой проектор не работающий с остальными. От ллавы же можно легко на любую 7б/13б подключить и она как-то будет работать.
> на 12к пикч генерировал капшены
Круто, пускал локально квантованную версию или арендовал/абузил апи? Покажи на примерах что получилось и если не стесняешься - промт запроса, было бы полезно и интересно.
> CLIP хорош разве что вычистить мусор из датасета
Ага, ему еще можно свои наборы капшнов кормить а он уже их отранжирует под каждую пикчу. Для разбивки по категориям самое то, даже с анимублядскими справляется только ссущих почему-то отправляет в safe for all ages категорию, пиздец блять
https://github.com/mlpc-ucsd/TokenCompose
Киллер-фича для SD, - она допиливает модели практически до уровня DALL-E 3. (Не считая стилистических биасов, ибо масштаб не тот.) Изображения будут точно следовать промптам после дотрейна по инновационному методу?
Киллер-фича для SD, - она допиливает модели практически до уровня DALL-E 3. (Не считая стилистических биасов, ибо масштаб не тот.) Изображения будут точно следовать промптам после дотрейна по инновационному методу?

Господа, паоменял жесткий диск в пука и установил чистую винду. Раньше использовал stable diffusion webui, но уже больше года прошло. Что сейчас принято устанавливать у анонов? И есть ли ссылка на гайд?
Уёв/движков полно, выбирай любой.
>всё тот же автоматик1111
>ComfyUI
>fooocus
>InvokeAI
>EasyDiffusion
и т.д. и т.п.
Автоматик сильно отстает от новых или если привык к нему, то нет смысла переходить на что-то другое?
> Sharegpt4v
Он же хуже балаклавы.
> что получилось
Ну Cog внезапно даже в порнуху умеет. Проёбы всё ещё частые, но это по крайней мере в пределах 10%, а не как в прошлых сетках, где буквально каждый раз проёбывается. С терминологией, конечно, надо ебаться в промпте, чтоб всякие "white substance" или "posterior" не лезли. Ещё из неприятного - у него странное понимание лежащей тянки, она должна лежать как будто спит чтобы он её назвал лежащей, а не сидящей. Проиграл что цензуру мозаикой на хуях/пиздах он понимает и даже понимает что под ней, но приписывает что она "for privacy", лол.
Вот примеры что на порнушные пики он генерит, на этих описаниях всё чётко как на пике, без галлюцинаций.
> The photo is a side-by-side comparison of a woman in two different states of undress. On the left, she is wearing a blue t-shirt and glasses, standing in an outdoor setting with trees and a body of water in the background. On the right, she is completely nude, sitting on a bed with a radiator and window curtains behind her.
> This explicit photo showcases two Asian women engaging in a passionate oral interaction inside a well-lit room with green curtains in the background. The woman on the left wears a beige turtleneck and gold earrings, while the woman on the right dons a white top. Both are visibly sweaty, suggesting intense physical activity, and both have their tongues deeply inserted into each other's mouths.
> This porn photo features a young woman with long brown hair wearing white lingerie. She is positioned in a room with floral wallpaper, sunlight streaming in from a window, and a bouquet of flowers on the floor. The woman has a heart-shaped butt plug inserted into her anus and is holding a small white object near her vagina.
> This is a close-up adult photo featuring a woman with her face covered in cum. She wears a green sleeveless top and has her finger touching her lips. The background shows a room with a dresser and a closed white door.
Не особо отстаёт, можешь ставить. Хотя новые фичи быстрее в комфи приплывают, как правило, но в автоматик тоже быстро. Ну можешь комфи поставить чисто чтоб ознакомиться как работает, принцип там иной совсем.
Есть гайд для низкоайсикьюшных по установке и настройки комфи?
Скачай@запусти батник.
https://github.com/comfyanonymous/ComfyUI#installing
Есть ещё плагины для 2Д редакторов таких как крита или фотошоп, тоже другой принцип взаимодействия с сеткой совсем.
https://github.com/Acly/krita-ai-diffusion/
Это же модель с весами, а не способ для любых моделей. Прочёл и похоже я слишком брейнлет для этого. Как-то не очень понял как оно работает и что нужно для апгрейда произвольной модели.




>man walking upside down on the ceiling
>koi fish doing a handstand on the skateboard
>yellow ball on the green box on the white plate in the park
>overturned car
Этому конечно далеко до дали-3, ололо. Многих вещей он изначально не понимает. Но тем не менее охуенно останавливает протекание токенов друг в друга и вообще в целом улучшает взаимодействие объектов. Как они это делают без огромного трансформера для кодирования текста?
а нахуя они на 1.4 делали? они ебанутые?
Они делали на 2.1, т.е. ещё более ебанутые
Господа, кто-нибудь пробовал textual inversion для sdxl натренить? На civitai их подозрительно крайне мало.
Есть персонаж, реальный человек, с не очень качественным набором фото. На 1.5 лучшие результаты получал сочетанием лоры и ти.
Есть персонаж, реальный человек, с не очень качественным набором фото. На 1.5 лучшие результаты получал сочетанием лоры и ти.
>Как они это делают без огромного трансформера для кодирования текста?
Ответ - никак, они файнтюнят на его выхлопе. Генерят пикчу по промпту, сегментируют объекты из результата на основе существительных, выделенных из промпта, и файнтюнят на этом. DreamSync выглядит лучше, там LLM на основе промпта задаёт проверочные вопросы по пикче, которые потом проверяет VLM, и на этом тренятся. Если соединить это со StyleAligned, будет пиздато.
Но все эти способы имеют один недостаток - они не научат сеть тому что она в принципе не может сгенерить, они только улучшают то что есть.
> Этому конечно далеко до дали-3
Двачую, дали вообще не может в нормальную композицию реалистика, тут бы сначала дали догнал SDXL.
Их мало потому что то TI проку мало, и их используют главным образом для негативов под SD.
>На 1.5 лучшие результаты получал сочетанием лоры и ти.
Мог бы сделать полноценный файнтюн в таком случае.
Спасибо. Попробую.
Аноны, а как можно скриптом загрузить промпт из картинки в stable-diffusion-webui? Т.е. сэмулировать перетягивание картинки в Prompt и нажатие на "Read generation...".
Скажем имеем картинку C:\123\666.PNG, запускаем скрипт - он подтягивает из неё промпт.
Суть такая, что есть дохрена картинок с "удачным" промптом, хотелось бы для кажной из них сгенерировать по 50 картинок с разным сидом.
Скажем имеем картинку C:\123\666.PNG, запускаем скрипт - он подтягивает из неё промпт.
Суть такая, что есть дохрена картинок с "удачным" промптом, хотелось бы для кажной из них сгенерировать по 50 картинок с разным сидом.
> Он же хуже балаклавы.
Не, в сценах без нсфв или где это не главный элемент он сильно лучше, может сходу четко описать сцену с большим числом объектом не сбиваясь и сохраняя консистентность выдачи, также четко выдает координаты. Его слабые места - необычные позы, стилизованное 2д, левд и подобное, в них бакллава уже лучше.
> Ну Cog внезапно даже в порнуху умеет.
По примерам весьма неплохо, это успех похоже. Через апи пробовал или локально? Настройки семплинга там сильно влияют на качество ответов и галюны. Так вот уже можно хорошо датасеты описывать и сортировать.
> они не научат сеть тому что она в принципе не может сгенерить
Вносить в нее это новое той же лорой, а в процессе обучение постепенно снижать ее вес. Разумеется с адекватной реализацией а не так топорно, но по принципу.
Exif же.
Пишешь простейший парсер и делаешь обращения по api, предварительно его включив в параметрах запуска. Описание его в репе есть.
> локально
Локально на 4090.
> Настройки семплинга там сильно влияют на качество ответов и галюны.
Влияет на внимательность к деталям, я в промпте покороче его заставляю писать, поэтому от семплинга влияет что он проигнорит. На галлюцинации не особо, с разным семплингом по ощущениям одинаковая частота проёбов. Хотелось бы, конечно, миростат заюзать, но его нет в transformers и пока лень пердолить хуки из webui. Квантование только bnb, в балаклаве удобнее было с llama.cpp.
спасибо! тоже думал насчёт файнтюна. даже попытался на runpod.io , но что-то не получилось. там есть готовый образ машины с кохьей, лора sdxl збсь тренится. файнтюн хз почему никак. думал может vram не хватает, но и на а100 с 80 гб не идёт.
локально на 8гб карте есть вариант файнтюн sdxl сделать?
Файнтюн SDXL на полной точности требует гигов 60, если не ошибаюсь. Я тоже только лоры делал, на самом деле.
Аноны, гугл полностью забанил эту тему, или в бесплатном Колабе ещё можно тренить ЛОРЫ ?
попробовал сам, работает, получилось. только очень долго. может где протупил с настройками.
15 картинок 100 повторов 10 эпох, картинки 1024*1024, xformers, full bf16, gradient checkpointing, 3 вектора, остальное не помню. на 4090 около 3 часов.
Есть предложения по правкам для шаблона? Если нет, катну завтра как есть.
>делаешь обращения по api
Вот это для меня пока непонятно
https://github.com/AUTOMATIC1111/stable-diffusion-webui/wiki/API
Все как и везде и относительно просто. Параметров изобилие, можно даже к костылям типа контролнета обращаться.
ебанул lycoris на sdxl модели, по гайду https://civitai.com/articles/908/tutorial-lycorislocon-training-using-kohyass
заебись вообще получается, причём на довольно хуевом датасете
и памяти немного хавает, на 4090 в 5 потоков не всю память сжирает, на полном бф16 с хформерами и adamw
в комфи почему-то вылетает, в фокусе норм
заебись вообще получается, причём на довольно хуевом датасете
и памяти немного хавает, на 4090 в 5 потоков не всю память сжирает, на полном бф16 с хформерами и adamw
в комфи почему-то вылетает, в фокусе норм
> Аноны, гугл полностью забанил эту тему
Гугл забанил Gradio, он больше ничего не банил. Или у нас такие пользователи технотреда, которые не знают разницы между gradio и stable diffusion?
При чем тут градио, если банят даже за скрипты, лол
Относительно недавно (ну может, с недельку назад) тренил коховскую будку - и ничего, брат жив, ягель плодоносит...
Аноны, как должен выглядеть файл CAPTION (1.txt) к прилагаемому файлу обучения (1.jpg). Читаю сейчас про тренировки и везде этот вопрос как-то опускается как будто это И ТАК ВСЕМ ОЧЕВИДНО.
Какая кодировка файла должна быть?
Допускаются ли символы новой строки "\\n" ?
Нужны ли пробелы между токенами ? Всегда ли разделитель запятая? Чувствительно ли обучение к регистру?
Короче вот так правильно?
1) token_1, token_2, token_3
Или вот так?
2) token_1,token_2,token_3
Или вот так?
3)
token_1
token_2
token_3
Какая кодировка файла должна быть?
Допускаются ли символы новой строки "\\n" ?
Нужны ли пробелы между токенами ? Всегда ли разделитель запятая? Чувствительно ли обучение к регистру?
Короче вот так правильно?
1) token_1, token_2, token_3
Или вот так?
2) token_1,token_2,token_3
Или вот так?
3)
token_1
token_2
token_3
У меня сохранились колабовские нотбуки времен когда SD только появился, там ни о каком Gradio ещё речи не было. Хочешь сказать что я могу с их помощью в колбе сейчас генерить пики и никто до этого не догадался, что надо просто интерфейс сменить?
Да и нужны ли нижние подчеркивания в токене, состоящем из нескольких слов "white_background" или "white background" ?
Они забанили внешние УИ в принципе, а реализовано это через бан скриптов по именам, кажется.
Я пробовал это делать уже после разговоров о бане автоматика. На голых diffusers. Работало, ЧСХ.
Если ты про коху, то хоть как. Весь файл будет в промпт впихнут как есть. Если используешь перемешивание токенов, то через запятую.

Вместо негативного промта прикрутили второй унет.
https://github.com/ethansmith2000/StableTwoUnet
https://github.com/ethansmith2000/StableTwoUnet
Нахуй. Зачем тратить в два раза больше VRAM? Зачем тренить отдельную модель? И самое главное - как тренить негатив, где брать консистентный говняк для такого?
> negative prediction be handled by the vase model and the positive by the finetune
Так ещё может вдруг негативные лоры переизобретут спустя пол года, лол.
>где брать консистентный говняк для такого?
В интернете, бро, в интернете. 90% всего контента - это консистентный говняк.
А еще можно нагенерить всякого. Вот уж где простор для разных абоминаций и пикч плохого качества.
Кажется мы стали забывать для чего на самом деле нужны негативы. Это не способ фиксить кривые пальцы и прочий говняк. Негативы - то чего ты не хочешь видеть на пикче, для исключения концептов с неё. Вот он тебе рисует по запросу "conductor" бортпроводницу или медную жилу. А ты пишешь "person" в негатив и он тебе рисует только медную жилу. Рисует он тебе мужика в шапке, пишешь "шапка" в негатив и он тебе рисует мужика без шапки. Рисует он тебе кучу зелени, пишешь "грин" в негатив и у тебя осень на дворе.
Что реально нужно - это негативы для зирошот хреновин вроде IPAdapter. Чтобы можно было отфильтровать то что ты НЕ хочешь брать из референса. А то оно хватает всё подряд из референсной пикчи.
> Негативы - то чего ты не хочешь видеть на пикче, для исключения концептов с неё.
Он для этого очень хуёв. Намного лучше удаление этих концептов из кросс-аттеншена через NegPiP. Негатив в этом плане плох потому что он должен знать и уметь нарисовать этот концепт. Если он рисует в позитиве хуиту не понимая что он рисует, то и негатив вычтет такую же хуиту. bad hands всегда были на грани плацебо/рандома. В 2023 году негатив используют только для стиля и каких-то общих концепций, например удалить траву/деревья/дома или типа того, когда он их рисует без твоих просьб.
>Он для этого очень хуёв.
Вот и ответ, для чего тот чел предлагает
>тратить в два раза больше VRAM
уважаемые аноны, подскажите, как повысить гибкость лоры?
лора натренена на человека. с простыми промптами результат хороший. но стоит добавить что-то посложнее, по одежде например, что-нибудь прописать в негатив - всё распидарашивает, даже лицо.
или лора для этого не подходит?
лора натренена на человека. с простыми промптами результат хороший. но стоит добавить что-то посложнее, по одежде например, что-нибудь прописать в негатив - всё распидарашивает, даже лицо.
или лора для этого не подходит?
Натренировать заново на датасете с большим количеством более подробных тэгов.
Сам датасет побольше сделать, и поразнообразнее.
Сохранять почаще, чтоб понять, на какой эпохе насыщение наступает, и использовать именно её.
Генерить без лоры, использовать только на этапе инпэинта.




Предыдущий тред:
➤ Софт для обучения
https://github.com/kohya-ss/sd-scripts
Набор скриптов для тренировки, используется под капотом в большей части готовых GUI и прочих скриптах.
Для удобства запуска можно использовать дополнительные скрипты в целях передачи параметров, например: https://rentry.org/simple_kohya_ss
➤ GUI-обёртки для sd-scripts
https://github.com/bmaltais/kohya_ss
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
https://github.com/anon-1337/LoRA-train-GUI
➤ Обучение SDXL
https://2ch-ai.gitgud.site/wiki/tech/sdxl/
➤ Гайды по обучению
Существующую модель можно обучить симулировать определенный стиль или рисовать конкретного персонажа.
✱ LoRA – "Low Rank Adaptation" – подойдет для любых задач. Отличается малыми требованиями к VRAM (6 Гб+) и быстрым обучением. https://github.com/cloneofsimo/lora - изначальная имплементация алгоритма, пришедшая из мира архитектуры transformers, тренирует лишь attention слои, гайды по тренировкам:
https://rentry.co/waavd - гайд по подготовке датасета и обучению LoRA для неофитов
https://rentry.org/2chAI_hard_LoRA_guide - ещё один гайд по использованию и обучению LoRA
https://rentry.org/59xed3 - более углубленный гайд по лорам, содержит много инфы для уже разбирающихся (англ.)
✱ LyCORIS (Lora beYond Conventional methods, Other Rank adaptation Implementations for Stable diffusion) - проект по созданию алгоритмов для обучения дополнительных частей модели. Ранее имел название LoCon и предлагал лишь тренировку дополнительных conv слоёв. В настоящий момент включает в себя алгоритмы LoCon, LoHa, LoKr, DyLoRA, IA3, а так же на последних dev ветках возможность тренировки всех (или не всех, в зависимости от конфига) частей сети на выбранном ранге:
https://github.com/KohakuBlueleaf/LyCORIS
Подробнее про алгоритмы в вики https://2ch-ai.gitgud.site/wiki/tech/lycoris/
✱ Dreambooth – выбор 24 Гб VRAM-бояр. Выдаёт отличные результаты. Генерирует полноразмерные модели:
https://rentry.co/lycoris-and-lora-from-dreambooth (англ.)
https://github.com/nitrosocke/dreambooth-training-guide (англ.)
✱ Текстуальная инверсия (Textual inversion), или же просто Embedding, может подойти, если сеть уже умеет рисовать что-то похожее, этот способ тренирует лишь текстовый энкодер модели, не затрагивая UNet:
https://rentry.org/textard (англ.)
➤ Тренировка YOLO-моделей для ADetailer:
YOLO-модели (You Only Look Once) могут быть обучены для поиска определённых объектов на изображении. В паре с ADetailer они могут быть использованы для автоматического инпеинта по найденной области.
Подробнее в вики: https://2ch-ai.gitgud.site/wiki/tech/yolo/
Не забываем про золотое правило GIGO ("Garbage in, garbage out"): какой датасет, такой и результат.
➤ Гугл колабы
﹡Текстуальная инверсия: https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_textual_inversion_training.ipynb
﹡Dreambooth: https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb
﹡LoRA [1] https://colab.research.google.com/github/Linaqruf/kohya-trainer/blob/main/kohya-trainer.ipynb
﹡LoRA [2] https://colab.research.google.com/drive/1bFX0pZczeApeFadrz1AdOb5TDdet2U0Z
➤ Полезное
Расширение для фикса CLIP модели, изменения её точности в один клик и более продвинутых вещей, по типу замены клипа на кастомный: https://github.com/arenasys/stable-diffusion-webui-model-toolkit
Гайд по блок мерджингу: https://rentry.org/BlockMergeExplained (англ.)
Гайд по ControlNet: https://stable-diffusion-art.com/controlnet (англ.)
Подборка мокрописек для датасетов от анона: https://rentry.org/te3oh
Группы тегов для бур: https://danbooru.donmai.us/wiki_pages/tag_groups (англ.)
Гайды по апскейлу от анонов:
https://rentry.org/SD_upscale
https://rentry.org/sd__upscale
https://rentry.org/2ch_nai_guide#апскейл
https://rentry.org/UpscaleByControl
Коллекция лор от анонов: https://rentry.org/2chAI_LoRA
Гайды, эмбеды, хайпернетворки, лоры с форча:
https://rentry.org/sdgoldmine
https://rentry.org/sdg-link
https://rentry.org/hdgfaq
https://rentry.org/hdglorarepo
https://gitgud.io/gayshit/makesomefuckingporn
➤ Legacy ссылки на устаревшие технологии и гайды с дополнительной информацией
https://2ch-ai.gitgud.site/wiki/tech/legacy/
➤ Прошлые треды
https://2ch-ai.gitgud.site/wiki/tech/old_threads/
Шапка: https://2ch-ai.gitgud.site/wiki/tech/tech-shapka/