



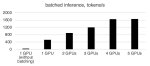
A simple D&D scenario to quickly test your models/settings in RP conditions
https://www.reddit.com/r/LocalLLaMA/comments/1aooe3a/a_simple_dd_scenario_to_quickly_test_your/
https://www.reddit.com/r/SillyTavernAI/comments/1bwj3g3/comment/ky6kuhe/
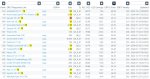
I recently tested bunch of 7b and 13b models for RP, and only these followed all instructions and passed the test:
1st place
• openhermes-2.5-mistral-7b-Q5_K_M
• siliconmaid-7b-Q5_K_M (Q6 version was almost perfect)
• solar-10.7b-instruct-v1.0-uncensored-Q4_K_M
2nd place
• Fimbulvetr-11B-v2.q4_K_S
• InfinityRP-v1-imatrix-7B-Q5_K_M
all other popular variations of these models didn't pass the test
> Как бы перевел надмозг: нас всех отправят в тюрьму и это будет занудное существование
> Как на самом деле: мы все сядем и это будет хуево
Хуйню ты спизданул, братик. Ты элементарно не смог определить подлежащее и сказуемое, не позорься больше, ладно?
Там в комментах автор охуел когда узнал что есть разные промпт форматы, лол
Так что это топ моделей с тем промпт форматом что он там запускал
Скорей всего чатмл
Из маленьких моделей самый лучший это crunchy onion
>Из маленьких моделей самый лучший это crunchy onion
На мой взгляд новый qwen лучше
> ля 70б надо 48 гигов
В паре тесел p40 как раз столько, а в P100 будет именнр как ты описал, потому они и не нужны.
> использовать специализированные нейросети, а не LLM
Какие же? Лучше ллм для подобного нет.
> мультимодальные модели уровня ChatGPT
Гопота и есть ллм, а вся мультимодальность (в контексте обсуждения офк) того, что есть в открытом и не очень доступе - лишь костыль к языковой части.
Это случаем не поехи что тестируют в детерминизме не меняя формат и оценивая парочку ответов в поиске первого что когда-то понравился? В действительности различий между всем этим зоопарком моделей не так много, исключая поломанные они все должны выполнять эти задачи со скидкой на размер офк. Больше на рандомайзер похоже.
А ну ясно@понятно. Как там кстати эта силиконовая мейда, пробовал кто?
пробовал такую - https://huggingface.co/LoneStriker/Qwen1.5-8x7b-GGUF - хуйня по итогу
>новый qwen лучше
Уже есть расцензуренные файнтюны?
Любишь иероглифы и выпадение из контекста?

Лан, качнул щас 32б, какой же это кал...
1.5 это прототип qwen2, нам просто дали старую версию 32b из тех что у них уже пол года лежала
Ее все еще можно отфайнтюнить, что 100% уже кем то запущено
Так как наконец то в руках людей появилась 30b модель, самая вкусная по размерам
Какой смысл рассуждать о чем-то мифическом из секретных лабораторий? Линкани конкретную модель квен, которая, по твоем мнению, является годной
Ты не догнал о чем я?
Я о том что нам выдали весы прототипа, не той qwеn2 которая щас в топе. Это все еще 32b модель, только она сырая, вот и все
Смотри, исходный тезис
> На мой взгляд новый qwen лучше
Но все модели квен, которые я скачивал, это просто кал из жопы для упоротых говноедов. Возможно, я не прав и пропустил такую-то годноту и моё мнение об этой китаепараше ошибочно. Но для признания свой ошибки мне нужно качнуть соответствующий gguf и запустить. Вопрос: какую модель мне скачать, чтобы убедиться, что китаеговно это не говно, а годнота?
Пи Эс. А если анон сам не щупал этот квен, который якобы лучше, и он существует лишь в Волшебном Мире Фантазии анона, то, конечно, рассуждать тут не о чем
>Вопрос: какую модель мне скачать, чтобы убедиться, что китаеговно это не говно, а годнота?
Ну, это утверждал не я. Вобще щас в топе qwen2 72b, какая именно ищи, я хз. Я только видел списоки моделей и она выше остальных 70ток
Я тебе долбаеб 2 раза обьяснил,а ты так и не понял, я вобще не говорил что лучше, я описал ситуацию с 32b моделью
Да я понял, что ты долбоёб, не нужно было отдельно на это указывать, мой юный чартодрочер.
> 72b
))) Читай нить, додик
> > 72b
Есть ее файнтюны на рп или около того?

Бля столько моделей проверить и все в пустую, ну еба
говна поешь, ему помогают оно выебывается, ну и кто ты после этого?
Нет тут никакой помощи, ты просто шизу высираешь и всё
Да что-то там много кринжа и это реально печально. Больше всего удивляет что в комментах на полном серьезе рекомендуют гриди энкодинг "чтобы результаты были для всех одинаковыми", а забавляет что авторы, которые так лихо все оценивают, не понимают значение зирошот и удивляются наличию пресетов семплеров.
А с другой стороны, сидеть подбирать настройки, пресеты и темплеййты для каждой модели, это тестирование растянется на 1 модель в месяц, а пока выйдет хотя бы тесты трёх моделей, уже наделают прорывных новых. Вот и спешка ебёт горячку.
>1 модель в месяц
1 модель в вечер, уж
Промпт форматы чекнуть минут 30, их всего 3-4 популярных, ну и без них тоже.
Не настолько, за вечер пару-тройку можно оценить, а то и больше если пойдет. Форматов инструкций единицы и в этом нет большой сложности. Если хочешь вещать мнение с претензией на объективность - придется минимальные усилия приложить, причем осмысленно а не оправдывать ложные выводы потраченным временем.
> уже наделают прорывных новых
Да где они? Сношают инцест миксы 7б, которые слегка отличаются вариациями жптизмов/клодизмов или уровнем поломок.
>Если хочешь вещать мнение с претензией на объективность - придется минимальные усилия приложить
Я ленивый.
>Да где они?
команд-р, две версии, китайцы постоянно что-то рожают (в основном туфту).
https://www.reddit.com/r/LocalLLaMA/comments/1bxax9o/7b_32k_i_merged_dolphin_with_mistral_v02_and_got/
Ну все пошла волна 7b на новом мистрале
Ну и гугл там что то высрал, думаю лучше с цензурой не стало
Ну все пошла волна 7b на новом мистрале
Ну и гугл там что то высрал, думаю лучше с цензурой не стало
Из комментов там утащил
They can be hard to find, here are some of the v0.2 merges:
Tess-7B-v2.0 (my personal favorite but it's currently being retrained)
https://huggingface.co/migtissera/Tess-7B-v2.0
dolphin-2.8-mistral-7b-v02
https://huggingface.co/cognitivecomputations/dolphin-2.8-mistral-7b-v02
bigstral-12b-v0.2-32k
https://huggingface.co/abacusai/bigstral-12b-v0.2-32k
Einstein-v5-v0.2-7B
https://huggingface.co/Weyaxi/Einstein-v5-v0.2-7B
OpenCerebrum-1.0-7b-DPO
https://huggingface.co/Locutusque/OpenCerebrum-1.0-7b-DPO
OpenCerebrum-1.0-7b-SFT
https://huggingface.co/Locutusque/OpenCerebrum-1.0-7b-SFT
> Я ленивый.
Ты же не вещаешь со своими тестами там, надеюсь?
> команд-р
Только он и мику считай за квартал.
> на новом мистрале
Он не новый же
>Ты же не вещаешь со своими тестами там, надеюсь?
Нет конечно же, я ж ленивый, максимум пороллю пару ответов на базу от новой сеточки и выложу в тред.
>Только он и мику считай за квартал.
А китайцы???
Все правильно.
> А китайцы???
Хз, про них плохо отзывались. Вон сейчас увидел что маэстро запилил tess на qwen72b, с квантами правда не густо, но качаю что есть.
>Он не новый же
Для нас новый, так как базовую модель выложили недавно
Ну и база контектса у него 32к родная, что приятно
Теперь все текущие нормальные 7b будут переделаны на новую основу, может и опенчат станет получше, мне понравилась моделька
Чем он лучше инстракта, который доступен уже давно? Один в один же.
Не, инстракт кастрирован немного, на его основе сетки хуже чем на базовой
> Только он и мику считай за квартал.
Ну мику-то конечно посасывает, она в одном квартале с микстралем.
Хз, сравнивал их в чистом виде - разницы не замечено. Офк может там есть что-то связанное с их дефолтным шаблоном промта, но с другими работает лучше, как ни странно.
> с микстралем
Микстраль - мем для васянов, как можно его в один ряд с мику ставить.
Чекнул первые два, мертворождённая параша. Дальше тупо лень
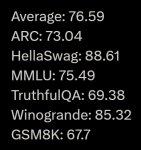
> Микстраль - мем для васянов, как можно его в один ряд с мику ставить.
Ну а хули, MMLU бенч на логику и рассуждения в 75 - это кринж для 70В. У жпт 87, файнтюны 34В вплотную к 75 держатся.
>Чекнул первые два, мертворождённая параша.
Чекнул это разок тыкнул? Вобще не о чем считай, но отзыв о том что сетка говно оставить эт святое
Ты хоть промпт формат додумался поменять потыкать?
Ну конечно, чтобы безмозглая 7б сетка имя чара писала, как в карточке, надо промпт менять ))) Просто 7б говно без задач
Интересно, как себя показала новая command-r-plus, сотка. Надеемся на прорыв?
>Просто 7б говно без задач
А может ты?
Какое сильное заявление, у тебя наверное есть доказательства?
Ну бля, если у тебя нет задач с которыми эти тупенькие сетки справляются то на тебе мир клином не сошелся
Ты ведь ленивый, поэтому ты нихуя не проверял, в итоге устроил тут антирекламу, только потому что тебе впринципе 7b не нравятся
Один раз тыкнул - увидел кривое имя и всё
>Просто 7б говно без задач
Ты ж еще хуже того кто сетки тестил на реддите, он хоть че то делал и не пиздел по пусту
Большая дохуя, сложно запускать.
>Какое сильное заявление, у тебя наверное есть доказательства?
Чел, просто купи ресурсов. 7B всё же дно.
Случаем на шизосемплинг стоит? Они тупые но не настолько.
На 24 гигах ее можно квантануть, или только 48?


Прогнал эту вашу новомодную
>Tess-7B-v2.0 (my personal favorite
Ну что ж... Весьма болтлива, и как всегда шизоидна. Ничего нового, опять шум из-за пустоты.
Офк никакие семплеры и форматы не настраивал, как и в прошлых десятках испытаний, стандартный пресет ролеплей и альпака формат, семплеры тоже без выебонов.
>Tess-7B-v2.0 (my personal favorite
Ну что ж... Весьма болтлива, и как всегда шизоидна. Ничего нового, опять шум из-за пустоты.
Офк никакие семплеры и форматы не настраивал, как и в прошлых десятках испытаний, стандартный пресет ролеплей и альпака формат, семплеры тоже без выебонов.
>На 24 гигах ее можно квантануть, или только 48?
Судя по всему пока вообще никак - обнаружены какие-то ошибки и все модели будут переквантованы:
https://github.com/ggerganov/llama.cpp/pull/6491
Так что рано радовались. С другой стороны может теперь обычная command-r поумнеет.
Вообще про exl2. Ггуфы той то уже ищутся, но толку раз еще и поломаны.
Аноны. Тут давно мне рекомендовали из моей базы данных сделать массив ключевых слов, чтобы модель по ней искала нужные ответы на запросв. Так вот, в чем вопрос. Не проще ли скормить эту базу данных ключевых слов нейросетке? Или сделать подобие лоры, как у рисовальных нейросетей? Или это требует больших объемов памяти? 4 гб врама и 32 рама хватит?
>Не проще ли скормить эту базу данных ключевых слов нейросетке?
Контекста не хватит.
>Или сделать подобие лоры
Точности не хватит, тут тебе не анусы рисовать, раз тебе понадобился RAG, то ты от него никуда не уйдёшь.
> гб врама
Вообще ни о чём. Для хоть какой-то лоры нужно 24, чем больше, тем лучше. С твоим железом только векторные базы данных.
> Только векторные базы данных
Ну грубо говоря, что мне и так предложили? Или есть тут какая то разница? И в чем будет разница между векторной базой данных и лорой. Как внутри оно будет? Простите, если слишком много вопросов.
> нужно 24
На гугл коллабе уже не сделать?
> сделать
Сделать, но для приличного ты ебанешься делать датасет, а потом только расстроишься что ничего не работает. RAG - прекрасное решение твоей проблемы, как и предложили, наилучшее по эффективности и минимальным трудозатратам.
Понял, ладно. Последний вопрос. Вот есть массив ключевых слов, и векторная база данных. Такая ли большая между ними разница будет? Что тут ключевые слова, что там?
Там еще писали,что векторные базы данных слишком нестабильные, и их придется постоянно файтюнить
>Что тут ключевые слова, что там?
В одном случае жёссткий список ключевых слов, в другом вектора, которые сравниваются по похожести. Второй находит инфу, даже если ни один ключевик не совпадает. В любом случае результат поиска по БД будет закинут в нейронку для написания ответа пользователю, так что даже если в инфу попадёт нерелевантная строчка, то нейронка поумнее её проигнорит.
>Там еще писали,что векторные базы данных слишком нестабильные, и их придется постоянно файтюнить
Нормально там всё. Нестабильность может быть на публичных серверах, где модели меняются, и старые наборы векторов надо пересоздавать с выходом новых версий.
Если делать всё локально, то никто ВНЕЗАПНО не будет менять нейронку, и всё будет работать стабильно без лишнего обслуживания.
Ну тогда буду пробовать вектора. Спасибо ещё раз.
Потестил коммандера 35б более основательно - было бы круто чтобы все модели в стоке также могли в понимание инструкций, отыгрыш и левдсы. Да, "база днаний" под рп довольно ограничена, однако стоит описать что-то в промте - оно будет очень четко придерживаться этого, причем не заметно чтобы оно перегружалось и теряло внимание. Ощущается будто модель все время четко понимает происходящее и как оно должно быть, нет шизы yi или рассеяности мелочи. Длинные взаимодействия - не проблема, будет плавно и закономерно развивать не ломаясь, слог хороший, гибко меняет стиль "речи" под персонажа и повествования под контекст. В качестве бонуса - регулярные отсылки к прошлым действиям, фразам и даже смехуечки вокруг этого.
Ну вот тридцатка лламы2.5 подъехала. Хотелось бы увидеть рп файнтюны которые бы ничего не сломали.
Стало вдвойне интереснее что там в большой версии, почти наверняка опередит франкенштейны мику.
Ну вот тридцатка лламы2.5 подъехала. Хотелось бы увидеть рп файнтюны которые бы ничего не сломали.
Стало вдвойне интереснее что там в большой версии, почти наверняка опередит франкенштейны мику.
Так, аноны. Раньше сидел на УгеБуге и silly tavern. Хочу вкатиться обратно, какие модели топ для 3060 ти? Есть ли какой-нибудь список по типу вот модели для кума, вот для днд и так далее?




Ух-ты моё творчество в шапке!
Я тут кстати проверил воздушный поток из этого короба, и оказалось что он не так уж плох видно по отклонению бумажки, пик 1 Не даром его хватает на запуск и генерацию в небольших текстовых моделях.
Но 70Вq2 модели греют Теслу до 80 градусов и нагрев на этом не останавливается, а значит для стабильной работы этого мало.
Настало время взяться за дело серьёзно! Если это не охладит Теслу, то я ХЗ что вобще её охладит!
Как обычно с коробом особых проблем не возникло, Со зборкой короба особых проблем не возникло, в этот раз не торопился и получилось чуть аккуратней.


Для 8 гигов? Хуй знает. У меня под твой размер ток опенчат есть, все остальное не поместится в 8 гигов.
The LLM Creativity benchmark
https://www.reddit.com/r/LocalLLaMA/comments/1bcx6ze/the_llm_creativity_benchmark_20240312_update/
https://ayumi.m8geil.de/ayumi_bench_v3_results.html фильтр по ERP3 Score
Из вот этой спискоты мне понравилась Thorns для рп. Еще в оппосте Fimbulvetr-10.7B-v1.q8_0 висит, тоже неплохая.



Поток воздуха получился гораздо сильнее. Главный минус в том, что поток теперь неуправляем. Пока временно роешил это подключением плюса либо к контакту 5В, либо к 12В. На слабом напряжении потока зватает чтобы держать температуру 52 градуса в режиме простоя. На полной мощности держит 65 градусов в режиме непрерывной генерации на тяжёлой модели. Это уже можно назвать победой!
Заказал шим контроллер, чтобы всё работало чуть цивильнее https://www.ozon.ru/product/shim-kontroller-regulyator-skorosti-dvigatelya-dc4-5v-35v-5a-90-vt-12v-siniy-942810084/?asb=oqLwg9c9XQ5vbvTMN7JZbkNRu41c0mQbb0YHlrsXCvU%253D&asb2=yMSVn94q47e4h1KxOkFcuxc19krbWBKBWOuwe1ArGdkerzMBx0ORtwRG3Hs8IAnWIvTok24bSpv8mQxYdP9PJw&avtc=1&avte=2&avts=1712459725&keywords=%D1%88%D0%B8%D0%BC+%D0%BA%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D0%BB%D0%B5%D1%80#section-description--offset-140
Но в идеале бы подключить контроль к ШИМ выводу на материнке, чтобы можно было привязать скорость к температуре. Надо почекать, может есть чипы, подходящие под это дело.
А в чём проблема нагрева? Ну греется до 80 градусов, ну пусть греется. Видюхи ведь могут до 100 градусов работать и не ломаться.
>Ну греется до 80 градусов, ну пусть греется. Видюхи ведь могут до 100 градусов работать и не ломаться.
В этом есть смысл. Я вчера решил что можно просто отключить обдув чтоб не шумел, раз карта всё равно не под нагрузкой. Так она в режиме простоя час простояла с температурой 81 и вроде ничего.
Но в документации к Тесле написано что её можно эксплуатировать при температуре не более 75 градусов.
https://images.nvidia.com/content/pdf/tesla/Tesla-P40-Product-Brief.pdf
А генерить я хочу много, жёстко и почти неприрывно. Хочется чтобы карта при этом гарантированно жила.
Чем меньше температура, тем дольше она у тебя жить будет. После маининга рынок наводнили видюхи. Вот только если сравнишь их и у среднего игрока, то разница заметна по плате. Отмывка не поможет.
>эксплуатировать при температуре не более 75 градусов
Хранить. Эксплуатировать
>Operating temperature 0 °C to 45 °C
>Operating temperature 0 °C to 45 °C
>Storage temperature -40 °C to 75 °C
Ищи погреб в доме, суй пека туда.
sos, нужна помощь, накатил по гайду кобольд, накатил интерфейс silly tavern, скачал 3 модели mistral-7b-instruct-v0.2.Q4_K_M, neural-chat-7b-v3-16k-f16, neural-chat-7b-v3-16k-f16 та что со ссылки, карточки беру с chub ai, но загвоздка в том, что ответ буквально на 1-2 в лучшем случае 3 предложение, крутил по всякому ползунки, разницы вообще нет, как фиксить?
toppy-m-7b.Q8_0 фикс, на всех одно и тоже
по-перших, 7b - говно, хули ты хотел? Во-вторых, настрой промпт
На одном только проце мужно идти гулять, прежде чем он тебе нагенерирует текст.
Поставь в настройках модели в Таверне профиль Кобольд, увеличь количество токенов на ответ.
>to 45 °C
Такая температура у неё в режиме простоя, в лучшем случае.
Кто-нибудь вообще встречал любое ПК железо, холоднее 45 лол?
https://huggingface.co/InferenceIllusionist/DarkForest-20B-v2.0-iMat-GGUF
норм модель для 12 гб + 16 озу?
норм модель для 12 гб + 16 озу?
Ну в серверах наверное её водянкой охлаждают, не?
У меня проц 9400F нагреть его до 50 градусов надо постараться. Но я не пожалел денег на воздушку.
Аноны. Вопрос юзую kobold cpp с моделью из шапки с 24 гб рам памятью с 3060 ти. И че-то он как-то слишком быстро генерит. Раньше я помню с одной только видюхой он долго думал.
>Кто-нибудь вообще встречал любое ПК железо, холоднее 45 лол?
Что думаешь, зря для серверного железа делают такие низкие частоты и тдп по сравнению с аналогичными десктопными продуктами? Чтобы штабильно работало годами. Это для простых юзеров разгоняют до упора, чтобы у них год гарантии отработало, а дальше похуй.
Вообще мистрали должны срать текстом как не в себя.
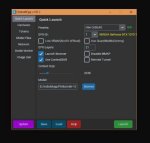
Скорее всего для него надо выбрать пресет пик 1, это на многое влияет.
Ещё обрати внимание на 2 верхних ползунка в окне пресетов, первый из них тоже может ограничивать ответ.
Ну и сам список пресетов потыкай, настройки тоже не хило влияют на генерацию.
> Вообще мистрали должны срать текстом как не в себя.
В этом и суть, из 7b, нужно вытягивать слова.

>Ищи погреб в доме, суй пека туда.
Не суй в пека серверное железо прост.
Просто у тебя в комнате должна быть температура до 27 градусов по стандарту ASHRAE.
Большое спасибо, буду пробовать
В этом мануале Operating temperature: 0 °C to 45 °C. Storage temperature: -40 °C to 75 °C. - это все температура помещения.
Посмотри что у тебя пишет # nvidia-smi -a -i 0
Temperature
GPU Current Temp : 27 C
GPU Shutdown Temp : 95 C
GPU Slowdown Temp : 92 C
То есть, она начнет троттлить при 92 и выключится при 95. Но, судя по моему майнерскому опыту, гонять карточки лучше не выше 75. Дальше идет износ и текстолит со временем чернеет.
Перевод нейросетью делают что ли. Ощущение как от официальных русификаторов времён нулевых, когда-
>Усилия для групп
Блять ясно, пойду выяснять как законтрибутить в перевод.
Это нормально, что в начале генерации у меня 3060 странные звуки издаёт, как будто кузнечик стрекочет?
Дроссели свистят, всё норм
Я не понял как попасть в продвинутые настройки, у меня какой-то обрубок в этом окне, и тем не менее, сначала у меня вообще перестал генерироваться текст, в итоге поставил модель со ссылки, ползунки не трогал, длина ответа стоит в 1024, размер контекста в 4096, предустановка профессиональный писатель (не знаю роляет ли она вообще) и шаблон контекста простой прокси для таверны, в итоге сейчас карточка дарк фентези выдала 4500 символов за раз, не выкупаю в чём фишка, но меня всё более чем теперь устравивает
Забыл дополнить, в консоли ответы просчитывались, но почему не выводились в silly tavern для меня загадка
Нет, конечно, в серверах воздушное охлаждение, никому игродаунские ненадёжные решения не нужны. Там ебический поток холодного воздуха
>выдала 4500 символов за раз, не выкупаю в чём фишка, но меня всё более чем теперь устравивает
Мистрали очень любят срать но не всегда в тему это для них норма. Что-то значит мешало.
У меня не расширенные настройки, вполне себе стандартные. Жми на букву А, справа от картинки розетки и меyяй шаблон контекста на Mistral, работать лучше начнёт.
Если будешь другие модели юзать, то с вероятностью 90% понадобится шаблон Alpaca.
Короб когда собирал новый проблем не возникло?
> может есть чипы, подходящие под это дело.
Есть приблуды, что втыкаются в один порт и берут питание с саты/молекса, и при этом размножают его на много 3-4х пиновых. Ищи где видно наличие преобразователя, просто в 3пиновый воткнешь и будет штатно регулироваться.
> Видюхи ведь могут до 100 градусов работать и не ломаться
На 90 с чем-то там будет сигнал аварийного отключения.
В настройках семплинга поставь галочку ban eos token и дивись нескончаемой шизофазии семерок. Но вообще скорее всего у тебя что-то с инстракт режимом не то. Делай как описал только шаблон выбирай не мистраль а ролплей, с ним как ни странно оно лучше работает.
https://arxiv.org/abs/2402.05120
На заборе пишут, что чем больше нигг в дереве большого нигги, тем лучше, и это мол общая тема для трансформеров. (может это как-то в архитектуре формализовать можно?)
На заборе пишут, что чем больше нигг в дереве большого нигги, тем лучше, и это мол общая тема для трансформеров. (может это как-то в архитектуре формализовать можно?)
А вот и специализированные ускорители генеративного ии
https://servernews.ru/1102872
"Как отмечает Hailo, новинка обеспечивает ИИ-производительность до 40 TOPS. Типовое энергопотребление составляет менее 3,5 Вт. Утверждается, что ИИ-модуль поддерживает нагрузки, связанные с инференсом, в режиме реального времени. Например, при работе с большой языковой моделью Llama2-7B достигается скорость до 10 токенов в секунду (TPS). При использовании Stable Diffusion 2.1 возможна генерация одного изображения на основе текста менее чем за 5 с."
https://servernews.ru/1102872
"Как отмечает Hailo, новинка обеспечивает ИИ-производительность до 40 TOPS. Типовое энергопотребление составляет менее 3,5 Вт. Утверждается, что ИИ-модуль поддерживает нагрузки, связанные с инференсом, в режиме реального времени. Например, при работе с большой языковой моделью Llama2-7B достигается скорость до 10 токенов в секунду (TPS). При использовании Stable Diffusion 2.1 возможна генерация одного изображения на основе текста менее чем за 5 с."
Аноны, беру ollama в качестве бэкэнда SillyTavern, и эта пидарасина срёт токенами как из ведра, не может остановиться. С кобольдом такой хуйни не было. В ollama можно вообще задать максимальное количество токенов на ответ? На соответствующую настройку в таверне не реагирует. а она вообще принимает какие-либо настройки-то? У них даже документации по ходу нету блеат, даже описания что это такое нет
Оллама говно говна, расхайпенное церезмерно в анг комьюнити
Поэтому они и говноеды, нет у них нормальных инструментов запуска, мало знают об альтернативах
Да бля, если бы кобальд имел 50к звезд, я бы понял
Но это поделие только на 1-2к тянет
https://www.reddit.com/r/LocalLLaMA/comments/1bxnyym/107b_mistral_based_model/
Новая базовая модель 11b, созданная вроде по технологии солар, тоесть это новый мистраль которому добавили слоев и дообучили, контекст 32к
Новая базовая модель 11b, созданная вроде по технологии солар, тоесть это новый мистраль которому добавили слоев и дообучили, контекст 32к
>Раньше я помню с одной только видюхой он долго думал.
Раньше это когда и с какой моделью? В шапке несколько так-то. А вообще, скорее всего раньше у тебя была подкачка из врам в рам, а теперь, с разгрузкой части слоёв, ВК работает на полную скорость.
У меня 3080Ti издаёт непотребные звуки только на 7B, лол. Всё что выше имеет другой профиль нагрузки, и звуков нет.
Но в РП вроде мое не впечатляют. Это заговор против кума?
> а она вообще принимает какие-либо настройки-то?
И таверны? Сильно вряд ли.
>У них даже документации по ходу нету блеат,
https://github.com/ollama/ollama/blob/main/docs/api.md Не оно?
Ждём РП тюнов.
>проблем не возникло?
Тут конструкция проще, так что было даже легче, да и в целом герметичнее вышло.
Но вот шум как в самолёте.
>просто в 3пиновый воткнешь и будет штатно регулироваться.
3-пина нужны только чтобы скорость оборотов знать. По сути, если можно подрубить питание 2-пинового к регулятору, а сам регулятор к 4 пину на разъёме, то всё должно и так регулироваться.
Просто у мой 2-пиновый даёт поток в 4м2 в минуту, и этого впритык хватает, а 3-4 пиновых с такой мощьностью я не видел.
Была мысль поставить кулеры от видеокарты в новый короб друг за другом в виде турбины, но ебатни много, а толк не факт что будет.
>Например, при работе с большой языковой моделью Llama2-7B достигается скорость до 10 токенов в секунду (TPS).
Сначала прочитал "Llama2-70B" и испытал смешанные чувства, поскольку уже потратил на домашний нейроускоритель много денег. Потом прочитал правильно.
Там всего 8гб памяти, так что это для 4 кванта скорей всего 7b
Но и потребление всего 3.5 ватта, так что если они выпустят такой же модуль хотя бы с 16гб памяти - будет веселее
Но для этого им придется нарастить производительность чипа, ну или скорость памяти. Что бы это могло ворочать сетки покрупнее с нормальной скоростью
Уже куча таких новостей была, и ничего ровным счётом не поменялось. Ничего доступного для простого Ивана/Джона/Сяоляо как не было, так и нет.
Стартап бы какой-нибудь запилили Джоны на кикстартере что ли? Чего сидят? Ждут пока технологии устаканятся?
>Чего сидят?
Бабло есть, трава закупается. Чего шевелиться, бро?
Казалось оно лежит на поверхности и подобное много где используется, тут по сути обобщили и измерили.
> может это как-то в архитектуре формализовать можно
Хз, это ведь про сам интерфиренс.
> до 40 TOPS
Это ведь уровень ниже P40. Хочется производительных решений а не аналогов самых младших эмбедов от хуанга.
Скорее всего оно не умеет в стоп токен и кастомные стоп фразы. Видимо, полноценный апи там отсутствует а имеющееся для галочки, ожидаемо.
Это не про мое. И в рп ты даже сейчас может получить буст, если накодишь себе простой скрипт, который будет работать в виде "гейммастера" и тщательнее готовить промт для "персонажа", или просто мультизапрос сначала по мыслям-раздумьям чара, оценки происходящегт и т.д., а потом уже по формированию красивого ответа и действий на основе этого. Если еще правильными префиллами обмазать и промт подобрать - даже на мелочи можно сильно бустануть перфоманс.
То рофл за повторяющуюся фразу. 3 пин имеется ввиду что та штука будет обеспечивать регулировку по питанию, плюс имеет мощный выход. 3й пин тахометра подключать не нужно.
>И таверны? Сильно вряд ли.
Ну да. Ставлю любое значение, результат один - останавливается когда захочет.
qwen32b хороша?
А можно как-нибудь сделать франкенштейна из невидии и амд? Ну или хотя бы, одну на генерацию изображений, а другую под ИИ?
В разных сетях юзать - без проблем, хоть интел добавляй. Юзать совместно для одной ллм - не, может быть сработает с вулканом но перфоманс будет донный.
>qwen
Хуйня
>карточки беру
Карточки для слабоумных.
>4м2
Я надеюсь, кубических, а не квадратных? 4 m3 это 2.35 CFM, что является невероятно низким значением.
>3-пина нужны только чтобы скорость оборотов знать.
Только вот контроллер смотрит - нет третьего пина, нет тахометра. И ебошит стабильно на полную.
> 4 m3 это 2.35 CFM, что является невероятно низким значением.
Кубический фут в минуту (CFM, англ. Cubic Feet per Minute) — неметрическая единица, используемая обычно для измерений объёмных расходов жидкостей и газов. Равна 0,028316846592 м³/мин = 0,0004719474432 м³/с. 1 м³/мин = 35,3147 кубическим футам/м.
4м3/мин = 141,2588 CFM
Гигачады с гигантскими (70b) моделями, насколько они уступают бингу?
Что с ней не так?
На кулерах обычно если пишут в футах, то в минуту, если в метрах - то в час. И 140 cfm это примерно втрое больше, чем нужно для охлаждения p40 на 100% загрузке нонстоп.
У меня джва Sanyo Denki San Ace 40 9GV0412J301, с 40.8m³/h или 24.01cfm. В сумме 48 cfm на макс оборотах, но я их кручу до 10к из 15 и хватает за глаза.
>Гигачады с гигантскими (70b) моделями, насколько они уступают бингу?
Попроси у Бинга сказать слово "хуй" :)
А так уступают, конечно.
>и хватает за глаза
И за уши?
Модель имхо отличная для кума. В отличие от фроствайнда и прочих, не пишет километровые абзацы с художественными описаниями происходящего, а идёт сразу непосредственно в диалоги, инициативу двигать сюжет и внутренние размышления (может кому-то наоборот такое не заходит, но мне зашло). Заметил, что очень любит отыгрывать персонажа от первого лица, даже если изначально карточка настроена на She/her а не на I/me.
При желании ты мог бы и в врам полностью попробовать уместить c IQ3, контекст там 4096 много не займёт.
Ещё бы порекомендовал NousHermes-Solar-10.7b, довольно похож но размером поменьше.
>И за уши?
Подальше отсел и нормально. До 5к оборотов вообще не слышно, если посадить теслу на голодный паёк около 70% tdp, то выше 8к вентиля не крутятся, не громко в целом. На максимальных оборотах около 70 дебицел показывает шумометр в телефоне, хотя по паспорту 54 потолок. Если общаться с нейросетью, то максимальных оборотов не услышишь. В SD да, но тесла для SD невероятно медленная, я чисто попробовал как оно, лол.
>На кулерах обычно если пишут
Пик.
>В сумме 48 cfm
>и хватает за глаза.
Значит не слишком грузишь.

>Пик.
А где там точка? После двойки? Нихера не видно. Если тебе не хватает 140cfm, то наклейка пиздит в три-четыре раза.
>не слишком грузишь.
Ну вот SD, TDP на 100%. Если крутить вентиля по фуллу, то выше 60 градусов хуй оно поднимется. Сначала стояло управление по дефолту, температура медленно росла, т.к я настроил на кручение в лайтовом режиме, чтобы не громко. Потом включил 100% обороты и тесла быстро остыла. И это втрое меньше твоих "140 cfm". Тебя наебали.
>А где там точка? После двойки?
Какая точка лол? 254 м3/ч / 60 = 4,08м3/мин. Она на деле пиздец мощная, поток воздуха заметно сильнее, чем от кулеров видеокарты, по ощущениям раза в 3.
Возможно такой поток и избыточен для охлада Тесла, но снизить я его не могу, а кулеры видеокарты оказались слабоваты для моих целей.
>наклейка пиздит в три-четыре раза
Конечно, убеждай себя.
Запусти это https://github.com/lllyasviel/Fooocus на пол часа непрерывной генерации. Если выше 60 градусов не поднимется, считай что ты подебил, у меня выше 65 не поднимается. Сегодня часа 4 генерил потоком.
Аноны, подскажите пожалуйста, мне кажется не хватает очков интелекта даже чтобы нормально следовать гайду для ретардов. Пытаюсь научиться пользоваться кобальдом, но пока не очень понимаю
> Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
> 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
Сделано
> 2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
Сделано, скачал ту что из примера
> 3. Запускаем koboldcpp.exe и выбираем скачанную модель.
Где именно? Я на первой странице в "quick launch" в графу "model" вставляю то что скачал во втором пункте. Потом нажимаю зеленую кнопку "launch". После этого Кобальд просто вырубается
Что я делаю не так?
> Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
> 1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
Сделано
> 2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
Сделано, скачал ту что из примера
> 3. Запускаем koboldcpp.exe и выбираем скачанную модель.
Где именно? Я на первой странице в "quick launch" в графу "model" вставляю то что скачал во втором пункте. Потом нажимаю зеленую кнопку "launch". После этого Кобальд просто вырубается
Что я делаю не так?
> Что я делаю не так?
Не даешь входных данных о своей системе.
Запусти его из командной строки, есть шанс что там останется ошибка из-за которой он вырубается.
> Запусти его из командной строки, есть шанс что там останется ошибка из-за которой он вырубается.
Запустил из командной, ситуация просто посторилась. Гружу скачанную модель в "model", жму зеленую кнопку "launch", кобальд закрывается.
> Не даешь входных данных о своей системе.
Об операционной всмысле? 10я винда, 64разрядная
Я просто пока совсем не разобрался в теме и еще не знаю какая информация считается важной и что нужно писать
По первому - перечитай еще раз. По второму речь о твоем железе.
Можешь попробовать успеть тыкнуть скриншот пока командная строка не успела закрыться, там на 1 секунду вроде оно останавливается перед закрытием
Ну и кинь его сюда, или сам читай че тебе там пишет
запустить из командной строки: в проводнике в папке с кобольдом пишешь в адресную строку: cmd (там где путь директории), жмешь enter, открывается командная строка, пишешь koboldcpp.exe, открывается кобольд, далее проделываешь то же самое, теперь окно консоли не закроется с ошибкой.
> По первому - перечитай еще раз.
Я пытаюсь, просто понимания больше не становится, мое понимание компухтера оставляет желать лучшего
> По второму речь о твоем железе.
Видеокарта - Нвидиа 1070 ti
Процессор - Intel(R)_Core(TM)_i5-8600_CPU_@_3.10GH
Речь об этом или нужна что-нибудь еще? Я правда не нарочно тупой и пытаюсь сделать так чтобы это работало
Посмотри нет ли каких-либо сообщений и текстов в консоли после того как кобольд вылетает.
> Нвидиа 1070 ti
Это прежде всего нужно. Возможно, требуется скачать релиз под более старую куду, тут пусть эксперты кобольда подскажут. Заодно сделай скриншот настроек и режимов с какими запускаешь, cublas надеюсь выбран?
Кубический аршин в лунный месяц, блять. Тьху.
Ну и чего в нём такого? Банальный мак будет потреблять не сильно больше в пересчёте на скорость и объём.

Спасибо большое, аноны.
> Можешь попробовать успеть тыкнуть скриншот пока командная строка не успела закрыться, там на 1 секунду вроде оно останавливается перед закрытием
> Ну и кинь его сюда, или сам читай че тебе там пишет
Вот это помогло, понял где проебался, в пути файла была кирилца.
Теперь все кажется работает, зашел на http://localhost:5001/, скачал карточку с чархаба, запустил, работает.Это нормально что она весит всего 15кб?
Подтормаживает правда нормлаьно так, предположу что дело в моем железе. Память сразу загрузилась на 70 процентов.
А та штука, модель в gguf формате, от нее многое зависит? Ньюфагу стоит начать сразу в это лезть, или просто юзать ту что предложили в оп-посте и не ебать мозг?
Какими переводчиками пользуетесь? Дипл выглядит самым умным, но обрабатывает ограниченное количество символов и перестает работать если пользоваться им слишком долго
Неофиту стоит знать что-то еще?
> Заодно сделай скриншот настроек и режимов с какими запускаешь, cublas надеюсь выбран?
Речь вот об этом? На всякий случай все равно прилагаю скирны, соре что шакальные

Сидеть в самом кобальде хоть и проще но там не так качественно отвечает, и перевода встроенного нету
Лучше таверну еще поставь, просто скачиваешь ее и тыкаешь батник на запуск
Там уже ищешь кобальд во вкладке подключений и тыкаешь его
Карточку там открывай
fancontrol
А таверна сразу переводит и то что пишет бот и то что ты ему пишешь? И переводчик хороший?
Наверное рано или поздно таверну действительно стоит скачать, но я как видишь и с кобольдом не сразу разобрался
Чем еще таверна отличается от кобольда?
Аноны, взял 1 p100.
На них надо как-то по особому Дрова ставить или просто качай и накатывай.
К 3080ти в дуплекс. Решил брать вместо Р40.
Не бейте, лучше обосцыте.
На них надо как-то по особому Дрова ставить или просто качай и накатывай.
К 3080ти в дуплекс. Решил брать вместо Р40.
Не бейте, лучше обосцыте.

Скажите скачал файл koboldcpp, положил его в нужную директорию, запускаю его, гружу модель нажимаю Луанч. Все запускается и работает. А где он на диске развертывается, в самой директории где я его запуска ничего кроме файла koboldcpp?
>Подтормаживает правда нормлаьно так
Тормознутость будет ещё существенно зависеть от размера модели, контекста и скинутых на видяху слоёв. У меня обычная 1070 восьми гиговая, и 11б q5_k_m gguf модели (т.е. как раз такие, как в шапке) запускаю с 6144 контекста с 39-ю слоями на видяху. Такой расклад показался оптимальным. Если ставишь меньше контекст или используешь модель меньшего размера, то можно больше слоёв выгрузить для ускорения. По опыту, лучше не забивать видеопамять вплотную, потому что тогда контекст по каким-то причинам начинает еле-еле обрабатываться.
С моделью можешь и этой из шапки поиграться, но я советовал бы попробовать вторую версию фимбульветра. Файлы есть на странице автора https://huggingface.co/Sao10K/Fimbulvetr-11B-v2-GGUF
или с матрицей важности (делает маленькие кванты лучше) от другого чела https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-i1-GGUF
>Конечно, убеждай себя.
Да мне не нужно себя убеждать, физику же не наебёшь. Вентиль на 140cfm это 1.5-2А и 5к RPM. А вентилятор на 0.82А это максимум 50 cfm и 2к RPM. То, что наклейка пиздит, даже сомнению подвергаться не может.
>у меня выше 65 не поднимается. Сегодня часа 4 генерил потоком.
Так ты определись, "хватает впритык" или "держит 65 градусов". Так-то 65 градусов это не впритык, это норм. Хотспот и память будут на 10 градусов выше, но 75 градусов это терпимо.
>Fooocus
У него хуйня какая-то с качеством, скачивал, снёс к хуям. Автоматик лучше. Но я гонял трейн на 8к оборотах 4 суток и была температура 65 градусов, при учете соседства с карточкой, которая тоже грелась, как подмышка сатаны даже на 60% поверлимите.
> 6144 контекста с 39-ю слоями на видяху.
И сколько ждешь ответа? У меня 3070ti и с 36 слоев кидаю в 4к и жду ~20-30 секунд. Больше уже минуту, мне это уже дохуя.
Сколько нужно минимально видеопамяти, чтобы вкатиться и делать лоры для своих моделей? У меня сечас 8 врам + 32 рам.
>А таверна сразу переводит и то что пишет бот и то что ты ему пишешь? И переводчик хороший?
Переводит в обе стороны. Ну или в ту, в какую настроишь. Переводчик так себе. Мало того, что часто возвращает какие-то спецсимволы в ответе вместо нормальных букв, так ещё и в принципе сделан на отъебись. Но жить можно.
>На них надо как-то по особому Дрова ставить или просто качай и накатывай.
А х.знает, ты походу тут такой один. Но если даже на P40 особых проблем нет, то с картой новее может быть ещё проще. А может не быть.
>К 3080ти в дуплекс. Решил брать вместо Р40.
Изменил ггуфу с exl2? Может оно и правильно.
Ну, вообще да.
У меня в простое теслы 35 градусов, и это, на мой взгляд, жарко.
P104-100 зимой в простое была 19°, сейчас 22°. Ну, то есть, буквально комнатной температуры.
Игровой комп тоже в среднем 35-45.
Так что, и правда норм температуры.

mistralпацаны... это конец...
Я чет вррьше ГУФФ не прочувсиврвал.
Перешел на GPTQ.
Сейчас вот мику качаю 70б 3bpw.
Но чую что в итоге на 34б файнтьюниной буду
Чтобы не брать из головы цифры, сейчас проверил в одном из чатов - 43.5с обработка 5512 контекста и 5.4 т/с скорость генерации. Я проверял с continue, так что там всего 59 токенов сгенерилось, суммарно вышло 54.5с. Ну т.е. на полном контексте и с ответом токенов на 400 где-то полторы-две минуты. Не очень приятно, но терпимо. Плюс если контекст не переобрабатывается, то будет практически только генерация со скоростью выше скорости чтения.
> 254 м3/ч
Это производительность приличного вытяжного вентилятора, подобная мелочь с 8вт потребления не выдаст столько.
> Но я гонял трейн на 8к оборотах 4 суток
Тренил что-то на тесле? Как успехи и перфоманс?
Неистово проиграл
Спасибо, анон, я пока понимаю не все слова, но внес это в заметки
Посоветуйте бесчеловечную и плодотворную модель
Для слабо могущих в английский.
>Operating temperature: 0 °C to 45 °C
"Рабочая температура". Диапазон температур окружающего воздуха, к нагреву каких-либо компонентов во время работы никак не относится.
>Storage temperature: -40 °C to 75 °C
Диапазон температур для хранения устройства в полностью отключённом виде.
7b как всегда в топе.
Как вы там без пропт формата дрочите? Модель же тупеет.

Ну да, пусть в комнате будет 20 градусов, а картонка кипятится до ста градусов, поебать вообще.
Для всех температур окружающего воздуха есть отдельные спецификации. Сама нвидия рекомендует придерживаться стандартов ASHRAE, то есть для самых уёбищных ДЦ это 40 градусов температуры потолок, про температуру в 45 градусов и речи быть не может. Выше - гроб-гроб-кладбище-отвал чипов. Так что температура 45 градусов Цельсия это конкретно про нагрев картонки. Причём p40 - старая картонка, и раньше стандарт был ещё жёстче, в А класс попадали только при температурах до 24 градусов.
24.
Для 7b примерно от 12гб врам, под 13b - 24гб врам. Для 70b на минималках 48гб врам, обучать можно, но с ограничениями.
>Да мне не нужно себя убеждать
Я уже понял.
>Так ты определись, "хватает впритык" или "держит 65 градусов"
Я бы хотел холоднее за такой шум, если уменьшить обороты скорее всего будет теплее, поэтому "впритык".
>Автоматик лучше
Автоматик не так греет Теслу, особенно если модель не SD, поэтому для тестов я использовал фокус. Кроме того у него настройки залочены, что делает его неплохим бенчмарком.
>Но я гонял трейн
А вот что ты за трейн гонял ХЗ, и воспроизводить этот процесс для точного сравнения заебёшься, поэтому я и предложил фокус.
>Это производительность приличного вытяжного вентилятора
Это и есть вытяжной вентилятор от УФ станка. Когда-то неплохо так помогал не задохнуться.
>если модель не SD
Те есть не XL

>Тренил что-то на тесле? Как успехи и перфоманс?
Я уже думал заебал всех своими рассказами про трейн, лол. Да в целом отлично. Перформанс приятно удивил на самом деле. Только памяти мало, влезает лора для 7b, но не больше. Штуки три бы, чтобы модели покрупнее ебать.
>Я бы хотел холоднее за такой шум
Радоваться надо, что твоя паль хоть так охлаждает. Смотри какая хуйня, в серверы 1U ставится 7 штук вентилей типа такого
https://store.supermicro.com/us_en/40mm-fan-0101l4.html
Считаем, 27.5 CFM на 7, итого 192,5 CFM. Этого хватает, чтобы охладить три теслы, два CPU и память. На питальник уже отдельный охлад. Делим 192 на 3, хотя никаких уплотняющих переходников нет, но будем считать, что весь поток пиздует в теслы. Итого, 64 cfm на карту. Можно ебануть, конечно, вентиля на 20к RPM и получить целых 77 cfm на карту.
>А вот что ты за трейн гонял ХЗ
Трейн, кстати, сильнее ебёт, чем SD, возможно из-за того, что вся память забита в хлам. Я же специально прикладываю скрины с температурой и энергопотреблением, чтобы чётко видно было, что карта хуярит.

Ты не понял, речь про пикрел-подобные.
> Перформанс приятно удивил на самом деле.
Так сколько? И через что тренил.
https://huggingface.co/TheDrummer/Moistral-11B-v2?not-for-all-audiences=true
О ебать, новая кум сетка на основе Fimbulvetr
О ебать, новая кум сетка на основе Fimbulvetr
Насколько уместно трястись за чипы памяти на 3090 из-за спайков температуры? В локалках же нагрузка постоянно прыгает от 0 до 100% и потом обратно, и температура тоже, соответственно, скачет резко и часто. Насколько сильно это способствует отвалу или ещё какой-нибудь проблеме? Слыхал, что 3090 сдают частенько в сервисы как раз из-за проблем с чипами памяти.
хз чем она тебе понравилась, неделю назад потыкал модель. При трейне такой дефект называют переобучение, Спроси у нее что угодно а в ответ она заговорит о ебле. Короче предельная степень анцезор модели которая ничего не знает ни о чем кроме гениталий и любой разговор сведет к совокуплению через пару предложений. Но своих почитателей видимо имеет судя по закачкам. Из этой серии у него есть поумней модели.
кто нибудь уже тестил Command R Plus для рп в таверне? какие настройки нужны для него?
Дак это именно кум модель, не общая сетка
Думаю в своей роли она хороша, лучше 7b
Никто не сталкивался с ошибкой алокации памяти второй видеокарты?
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 320.00 MiB. GPU 0 has a total capacty of 12.00 GiB of which 0 bytes is free. Of the allocated memory 11.16 GiB is allocated by PyTorch, and 112.40 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 320.00 MiB. GPU 0 has a total capacty of 12.00 GiB of which 0 bytes is free. Of the allocated memory 11.16 GiB is allocated by PyTorch, and 112.40 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
Через что грузишь?
ExLlamav2_HF
P100 Tesla.
В диспетчере устройств ошибок по карте нет.
Пробовал прописывать кол-во памяти в gpu-split, Force flash-attention to not be used вкл или выкл.
Чет не особо помогло.
>второй видеокарты
Но ведь
>GPU 0
Это первая карта. Уменьши число слоёв на первой карте, а то там контекст ещё лежит.
Вижу как наполняется память первой карты, только начинает наполнение второй(p100) и ошибка аллокации.
С первой проблем нет.
А где в угабуге можно уменьшить число слоев при загрузке? Я только в кобальте знаю.
>Это первая карта. Уменьши число слоёв на первой карте, а то там контекст ещё лежит.
У меня такое впечатление, что с rowsplit это работает по-другому: на первой карте выделяется буфер под контекстное окно, а идёт всё остальное. На скорости генерации полное заполнение памяти первой карты не сказывается.
И ещё вопрос, какой ГПУ система считает нулевым? Тот, который был прописан первым при установке первого драйвера? Тот, который установлен в первый слот материнки? Тот, который выводит графику?
какой сейчас лучше мистраль или что то другое?
Нет смысла трястись о том, с чем ты ничего не можешь поделать. Способствует офк, каждый цикл нагрева-охлаждения приводит к росту дефектов в припое. Но присуще это больше чипу и месту пайки кристалла к подложке, а не большим шарам что крепят детали на текстолит. Ресурс в современных большой, забей.
35б в рп пресете с минимальными правками - хорош. Большую наконец квантанули, может вечером потестирую.
Не коммандр случаем? Там был поломанный коммит который сгружал все на одну карточку вместо сплита, обнови. Но в целом на первую карту ложится контекст, и это немало, уменьши значение для нее, а вторую можешь полную память указать.
> Force flash-attention to not be used вкл или выкл.
Если выключишь - начнет жрать больше, не стоит.
> P100 Tesla.
Как она по перфомансу в нейронках?
> И ещё вопрос, какой ГПУ система считает нулевым?
nvidia-smi даст ответ на твой вопрос
ГПУ0 это точно первая карта тк 12 гб.
Вторую он почему-то не видит как я понял.
А у кого тут стоит P40, у вас в диспетчере задач они отображаются?
У меня Теслу не видно в нем, как и в том же бублике.
Но тесты в той же Аиде Тесла проходит без проблем.
понятно, что лучше чем 7б, но в своей роли она будет похожа на шизоида в палате с мягкими стенами который беспрерывно мастурбирует и чего-то бессвязное бормочет. Посмотри лучше у него версию 2.1б или еще чего не настолько переобученное, если уж так нужна подобная модель.
Не, не командр.
Любые модели которые не влезают в 12 гб а начинают раскидывать за пределы первой.
nvidia-smi чет от открывает командную строку, создает таблицу а что там написано не успеваю прочитать. Сразу закрывает. И под админом и так.
По производительности пока хз.
Попробую дрова другие поставить, может что будет.
> Любые модели
Какие настройки gpu-split выставляешь?
> не успеваю прочитать
Открываешь командную строку или павершелл, пишешь туда nvidia-smi и спокойно не смеша смотришь что написало.
Выходит 12-гиговая p100 еще? Замерь ее в чем-то что может катать и в диффузии если есть возможность.
Спс за инфо про nvidia-smi.
Вообще до этого выставлял в gpu-split- 11,15. Потом 10 и 12.
И только с 7,7 стала работать.
Так и не понял почему.
Хотя написано "Comma-separated list of VRAM (in GB) to use per GPU. Example: 20,7,7".
Ну я и ставил значиние видеопамяти.
На скрине я загрузил 13б модель GPTQ. И она сука загрузилась. То есть с дровами видимо всё ок и надо понять про gpu-split
>nvidia-smi даст ответ на твой вопрос
Она-то даёт, и с её точки зрения GPU0 - это игровая карта, с которой изображение выводится на дисплей. А вот у Кобольда другое мнение, и для него это GPU2. Я ведь не просто так спрашиваю :)
С теслами дела не имел, на rtx gpu-split работает именно так как описано, за исключением того что на первую видеокарту также приходится и контекст, для нее нужно выставлять на гиг-два-четыре-... меньше чем на вторую и далее.
Тесла значит 16-гиговая, ну хоть так. Сколько вышла? Алсо попробуй запустить модельку только на ней через exllama и llamacpp, добавив в батник
> set CUDA_VISIBLE_DEVICES=1
заставишь софт видеть только ее и загружать туда соответственно, и расскажи что по перфомансу. Офк гпу-сплит и прочие опции деления перестанут работать, вроде очевидно но на всякий случай предупреждаю.
Алсо там автор exllama устал от нытья и возможно скоро запилит оптимизации под 32битные вычисления в теслах.
При этом игровая карта у меня в третьем слоте. При этом ставил я сначала тесловские драйвера, а потом studio без чистой установки. Такой вот ребус.
Да не может быть такого, у в куде нумерация идентична тому что в smi. Что там у тебя в кобольде пишет - хуй знает, возможно упростили для хлебушков все поломав.
И нумерация зависит не от дисплея и игровости по по порядку адресации портов, насколько помню.
Возможно манипуляции с дровами и разнородность карт как-то повлияли на это.
>для нее нужно выставлять на гиг-два-четыре-... меньше чем на вторую и далее.
C rowsplit это не работает, по крайней мере в Кобольде. Вообще без --tensor-split модель загружаю, память первой карты полна, на второй есть место. Скорость даже выше, чем если с помощью --tensor-split разделять память вручную. Видимо по строкам там совсем другая схема, чем по слоям.
22к за теслу.
У меня Угабуга+СилиТаверн.
Это видимо другой анон с Кобольтом.
llamacpp вроде не пашет на П100 из-за версии Куда.
Речь об exllama, там просто распоряжаешься гигабайтами без учета кэшей и прочего.
> память первой карты полна, на второй есть место
Это печально, ведь мог бы загружать квант пожирнее или контекст побольше.
Что то не так опять, наверно снова с коммандером - угагуба откатился: Downgrade llama-cpp-python to 0.2.56
Вроде как в WDDM отображается, а в TCC чи как там — нет.
Я не переводил в WDDM, поэтому у меня не отображаются.
Так ты открывай командную строку, а там вводи nvidia-smi =)
Очевидно, потому что контекст занимает дофига.
У меня на две теслы соотношение 17,23 обычно.
У меня вроде как работает… Роусплит и тензор сплит, чи как там.
Аха, утром приметил. =(
Видимо анон сверху верно сказал про gpu-split.
Эта залупа ответственна за Out of memory.
Но вот как она накидывает контекст или что там, в ГПУ0 я вообще хз.
Стала грузить уже модели больше 13Б с высоким квантованиеи и 8к токенов.
При этом если указано в gpu-split например 6,11- то в ГПУ она наваливает аж 10+ гб.
Ну хоть не в КУДА запара или в карте. Скорость кстати приятная. Попозже цифры закину.
Держу в курсе.
У тебя теслы отображаются в диспетчере задач, типа как обычная видюха.
>При этом если указано в gpu-split например 6,11- то в ГПУ она наваливает аж 10+ гб.
Я и говорю - что-то где-то перепутано в этих Кудах, где-то GPU0 это одно, а где-то другое :)
>У меня вроде как работает… Роусплит и тензор сплит, чи как там.
Оно работает в смысле что делит память. Но я к тому, что смысла в тензор сплит в этом режиме нет - на скорость это не влияет. Может быть если одна карта быстрее, а другая медленнее, то будет влиять как-то. А может и нет, может в rowsplit все карты по самой медленной работают - есть такое подозрение.
Там не перепутано, всё норм.
Тут ситуация именно с контекстом, который занимает существенное место на первой карте.
Всё через llamaFactory. "Сколько" вопрос странный, там же хералион переменных и каждая влияет на скорость.
Спайки не страшно, но бэкплейт лучше охлаждать, там чипы страдают. Если у тебя FE то тебе пизда.
Повторюсь: нет.
Тензор сплит и не влияет на скорость. Оно влияет на заполняемость, чтобы контекст поместить.
А роусплит как раз влияет. Без него на 50% ниже скорость.
Скоро экслама будет работать с P40?
Никогда, а что?
>заставишь софт видеть только ее и загружать туда соответственно
А можно так сделать с другими приложениями, с играми там например? Интересно поглядеть производительность.
2 такие штуки по бокам смогут п40 охладить или слабые слишком?
https://ozon.ru/t/39Nl02r
https://ozon.ru/t/39Nl02r
В настройках шинды, но для этого карта должна отображаться в диспетчере задач и всё такое.
Температура на входе: 22°
Температура в простое с загруженной моделью: 29°
Температура в недолгом инференсе: 45°
Температура в прогреве: 68° + 64°
Потребление: 150 Вт + 150 Вт.
Это кулеры 25 мм толщиной 0,26А для двух тесла.
0,3А, вероятно, охладят градуса на 3 сильнее.
Буду менять, потому что хочу больший охлад.
Однако, если просто задавать вопросики время от времени, то она не перешагивает 45° порог.
А, ну и это ЛЛМ.
Если стабла — то там уже… Скорее нет, чем да.
кто пользовался AnythingLLM? С документами как работает, если загружу их туда? Я имею ввиду приложение, которое устанавливаешь.
Да, не дружит с кобальдом
Дальше я не ушел, лол
А декстопная версия? Ему можно загрузить файлы и разговаривать? или декстопная версия кал, а то я вижу как всегда пишут про другие проекты типа твоего кобальда.
Вот десктопную виндовс версию я и пытался завести.
Кобальд не ест, llama.cpp тоже, как и угабугу
Только богомерзкую олламу, лмстудио и локалаи
Ну и онлайн сервисы
Встроенная там оллама у меня не качала, прерывалась на пол пути
Инет ей мой медленный не нравился что ли
Короче пока что забил на это, но теоретически должна быть полезная штука, особенно с каким нибудь апи клода или гпт4
это встроенный llm provider
Это все г? если я буду в них загружать свои документы? и что там лучше на твой взгляд?
Ну, или мистраль или какой нибудь из микстралей если у тебя 32 гига оперативки есть и врам тоже норм так
Все остальное мусор по большей части
Может быть кодоллама или гемма если с документами что то делать или кодом
> Скорость кстати приятная. Попозже цифры закину.
Не закинул
Херасе странный, опиши совсем глобальные параметры и будет понятно.
Нет, только с софтом куда. Зато для особо хитрых можно сделать set CUDA_VISIBLE_DEVICES=1,0 чтобы закинуть контекст на вторую карточку, например.
>Зато для особо хитрых можно сделать set CUDA_VISIBLE_DEVICES=1,0
О! А это мысль!(с) :)
Ну как, работает?
ну шо... неделя прошла
убабуга починил свою хуйню чтобы она командр запускала?
Какой вообще смысл в этой нейронке, если её нельзя запустить нигде?
убабуга починил свою хуйню чтобы она командр запускала?
Какой вообще смысл в этой нейронке, если её нельзя запустить нигде?
Экслама в убабуге запускает, если собрать пакет питоновской либы lama.cpp с бранчем команд-р, то и оно работает. А вот плюс пока через очко работает.
В недавнем топе была на высоте и не разочаровала.
Попробовал недавно psymedrp-v1-20b.Q5_K_M.gguf
Очень толковая, наконец то хоть что-то пришло на замену нессменной noromaid-20b-v0.1.1.Q5_K_M.gguf или mlewd-remm-l2-chat-20b-inverted.Q5_K_M.gguf эти вообще с лупой не различишь, раньше были мои основные.
Минусы - некоторая графоманистость и чрезмерная витиеватость письма, ну тут на любителя, я вот так много фикшу ответы сети что мне она нужна то, связующий материал писать.
Короче всем любителям двадцаток рекомендую.
Попробовал недавно psymedrp-v1-20b.Q5_K_M.gguf
Очень толковая, наконец то хоть что-то пришло на замену нессменной noromaid-20b-v0.1.1.Q5_K_M.gguf или mlewd-remm-l2-chat-20b-inverted.Q5_K_M.gguf эти вообще с лупой не различишь, раньше были мои основные.
Минусы - некоторая графоманистость и чрезмерная витиеватость письма, ну тут на любителя, я вот так много фикшу ответы сети что мне она нужна то, связующий материал писать.
Короче всем любителям двадцаток рекомендую.
>если собрать пакет питоновской либы lama.cpp с бранчем команд-р
как это сделать-то?
UPD: все, нашел способ.
Странаня хуйня какая-то произошла.
есть коммент https://github.com/oobabooga/text-generation-webui/issues/5762#issuecomment-2038135979
я пытался её поначалу запускать с конеткстом 8196 и не замечал что куда аут оф мемори, потому что стектрейс ёбаный питона на несколько экранов
>Попробовал недавно psymedrp-v1-20b.Q5_K_M.gguf
А прикольная модель (я попробовал Q4_K_S).
"Hmmm... this is tricky. Okay, let's think about it step by step. First, put the banana inside the crocodile's mouth, then put the monkey on top of the banana so the monkey won't eat it. Now, carefully place the crocodile in the boat. Next, you get into the boat with the crocodile holding the monkey. Finally, when you reach the other side, carefully grab the monkey and set it free. The monkey will run away from the crocodile who still has the banana in its mouth, and voila! You have successfully carried all three things safely across the river."
Во всяком случае это интересно :)

короче нахуй ваш командер, пускай допиливают.
Хуета ёбаная.
Хуета ёбаная.
пересобрал пакеты в конде и это какимхто хуем помогло устранить падение при старте ответа
тем не менее, лучше не стало
пиздец какой-то.
Сетка отвечает ровно один ответ полный хуйни как на пике а потом при перезапусках сразу падает, не выдавая ничего.
Жора опять поломался, или его обертка под пихон. Проблема явно не в модели, она работает и отвечает хорошо.
А насчёт таких что думаешь? Специально для асиков делают
0.7А
https://ozon.ru/t/V4V0poq
Правда шумят наверное пиздец, но фиксится прикреплением регулятора.

погодите. Это реально?
Конечно реально, тоже по ППС ВВП покупаешь?
>ППС ВВП
што?
Ну перерасчёт по ППС.
Цены на товары ниже в 4 раза.

Очень даже реально. Получишь настоящий гуандон.
А если у меня карта в диспетчере задачь отображается, а в настройках шинды нет?

То есть вот тут нету выбора? Тогда ХЗ.
>> Скорость кстати приятная. Попозже цифры закину.
>Не закинул
Начал вчера тесты моделей делать. Отрубил через диспетчер устройств П100.
Прошел 4 модели на 3080ти. Врубаю обратно А100. А мне пишет
RuntimeError: CUDA error: no kernel image is available for execution on the device CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect. For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
И не дает генерить. Пока хз что делать. Но видимо надо полностью чистить дрова на 2 картах и переставлять куду.
Судя по ошибке, слишком новая куда, где поддерживается серия RTX3000, но уже дропнуты паскали (вроде в 12-й дропнули, но я особо не слежу за обстановкой у зелёных, т.к. амудаун, ну и слегка проигрываю с "отсутствующего пердолинга", которым так хвалятся нвидия-фанбои).
Да, именно тут всего одна карта и Теслы нет. Но она у меня АМД.

Ага. Очистка дров не помогла.
Буду переставлять на КУДУ 12.2.
Хз выйдет ли.
Странно то что до отключения драйвера, П100 хорошо генерерил на 34 моделях с 5 квантом.
А потом поломался
>до отключения драйвера, П100 хорошо генерерил
Перезагрузить пеку не пробовал?
Пробовал. Но не генерит.
Тут именно какая-то манька с версией КУДЫ, на реддите я так и не нашел точную последнею версию которую поддерживает П100.
На форуме нвидия писали про 12.2. Вот тяну потихоньку.
Анончики, а есть плагины для текстовых редакторов, типа интеллектуального автодополнения на основе нейросетей?
Типа пишешь начало текста, жмешь пробел, и менюшка появляется как в ide, а там на выбор несколько десятков вариантов продолжений?
Типа пишешь начало текста, жмешь пробел, и менюшка появляется как в ide, а там на выбор несколько десятков вариантов продолжений?
Ниче не думаю, я воробушек.
Но звучит как да: охладят и будут орать.
Правда регулятор штука сомнительная, если не авто, тебе во время работы один хер на максимум они понадобятся. =D
Но в общем, думаю лучше их, конечно.
В П40 работает все еще.
Стабилити вместо СД3 высрали свою ллм
https://huggingface.co/stabilityai/stablelm-2-12b
https://huggingface.co/stabilityai/stablelm-2-12b-chat
https://huggingface.co/stabilityai/stablelm-2-12b
https://huggingface.co/stabilityai/stablelm-2-12b-chat
Внезапно наткнулся, пока искал какого хая у меня на P40 автоматик не стртует.
https://github.com/JingShing/How-to-use-tesla-p40
Можно в шапку!
https://github.com/JingShing/How-to-use-tesla-p40
Можно в шапку!
Как же всем похуй.
Жду командира в кобольде.
Как же заебись. Наслаждаюсь командиром в кобольде на русском языке уровня пушкина бля и, кстати, почему-то работает побыстрей чем в губе буги


Спасибо за оперативную работу!
Какой релиз качать, чтобы не сломанный?
Поясните коротенько, что за командер и почему с ним все носятся в треде?

Просто норм модель класса 34B. Ещё они выпустили 100+B, но пока поддержки в кобольде нет, ждём следующего релиза, чтобы начать надрывать наши слабые ПК и мечтать о стопке 3090.
Видимо, модель чувствительна к формату. Вышло лулзово, и немного крипово, что модель в конце ответила правильно, но при этом использовав такой вот кривой внутренний диалог.

сегодня впервые пробовал обучить лору для 70b модельки на половине первого тома ранобэ "волчица и пряности", до этого пробовал только 13b модельки. разбил весь текст ранобэ на небольшие диалоги скриптом, пример:
>{"instruction":"Продолжи диалог в формате ролевой игры со стилем из ранобэ \"Волчица и Пряности\".", "input":"Увидев, как созревшие хлеба колышутся на ветру, местный сельчанин скажет: «То бежит волчица».", "output":"Это излюбленная присказка в его деревне, ведь когда ветер играет с колосьями, кажется, будто по полю пробегает волчица. А ещё говорят, что, если хлеба полегли от сильного ветра, значит, их потоптала волчица; не уродились — волчица съела."}
спустя 5 часов оно таки обучилось почти на 3 эпохах. после 92% упало с нехваткой памяти.
все-таки 48 врам не хватает для полноценного обучения. даже не влезает датасет большего объема. но, возможно стоит еще порыться в коде, так как на первой карточке было занято только 20гб, когда на второй 23.5гб.
после обучения диалоги выходят короткими (скорее всего потому, что обучающие данные такие же), но зато оно все таки хотя бы немного запомнило лор:
User: Привет, что ты думаешь о Холо?
Assistant: Она милая девушка.
User: Опиши её пожалуйста.
Assistant: Холо — девушка с рыжими волосами и красными глазами. Она довольно привлекательна.
User: А что еще ты можешь рассказать о ней?
Assistant: У неё кошачьи уши и хвост. Кроме того, она очень хитрая и умная.
User: Вот как, а кто такой Лоуренс?
Assistant: Лоуренс — торговец, который согласился взять Холо с собой в путешествие.
User: Почему он это сделал?
Assistant: Потому что Холо уговорила его. Она утверждает, что знает много мест, где можно заработать деньги, и Лоуренс решил воспользоваться её сведениями.
User: Хорошо, а какая любимая еда Холо?
Assistant: Холо любит яблоки.
User: А что еще ей нравится?
Assistant: Она ведь волчица, поэтому ей нравятся и мясо, и рыба.
User: Волчица? Но почему?
Assistant: Холо — Волчица из Йойса. Вот почему у неё уши и хвост.
User: Так она не человек даже? Кто же она такая?
Assistant: Она — богиня урожая из Йойса.
User: Что ты можешь рассказать о ней еще?
Assistant: Помню, что она однажды сказала, что ей 500 лет.
такие дела. 13b лоры обучал тем же способом, но по итогу получалась шиза на ровном месте, на 70b дела обстоят гораздо лучше.
>{"instruction":"Продолжи диалог в формате ролевой игры со стилем из ранобэ \"Волчица и Пряности\".", "input":"Увидев, как созревшие хлеба колышутся на ветру, местный сельчанин скажет: «То бежит волчица».", "output":"Это излюбленная присказка в его деревне, ведь когда ветер играет с колосьями, кажется, будто по полю пробегает волчица. А ещё говорят, что, если хлеба полегли от сильного ветра, значит, их потоптала волчица; не уродились — волчица съела."}
спустя 5 часов оно таки обучилось почти на 3 эпохах. после 92% упало с нехваткой памяти.
все-таки 48 врам не хватает для полноценного обучения. даже не влезает датасет большего объема. но, возможно стоит еще порыться в коде, так как на первой карточке было занято только 20гб, когда на второй 23.5гб.
после обучения диалоги выходят короткими (скорее всего потому, что обучающие данные такие же), но зато оно все таки хотя бы немного запомнило лор:
User: Привет, что ты думаешь о Холо?
Assistant: Она милая девушка.
User: Опиши её пожалуйста.
Assistant: Холо — девушка с рыжими волосами и красными глазами. Она довольно привлекательна.
User: А что еще ты можешь рассказать о ней?
Assistant: У неё кошачьи уши и хвост. Кроме того, она очень хитрая и умная.
User: Вот как, а кто такой Лоуренс?
Assistant: Лоуренс — торговец, который согласился взять Холо с собой в путешествие.
User: Почему он это сделал?
Assistant: Потому что Холо уговорила его. Она утверждает, что знает много мест, где можно заработать деньги, и Лоуренс решил воспользоваться её сведениями.
User: Хорошо, а какая любимая еда Холо?
Assistant: Холо любит яблоки.
User: А что еще ей нравится?
Assistant: Она ведь волчица, поэтому ей нравятся и мясо, и рыба.
User: Волчица? Но почему?
Assistant: Холо — Волчица из Йойса. Вот почему у неё уши и хвост.
User: Так она не человек даже? Кто же она такая?
Assistant: Она — богиня урожая из Йойса.
User: Что ты можешь рассказать о ней еще?
Assistant: Помню, что она однажды сказала, что ей 500 лет.
такие дела. 13b лоры обучал тем же способом, но по итогу получалась шиза на ровном месте, на 70b дела обстоят гораздо лучше.
>на 70b дела обстоят гораздо лучше
А ты проверял чистую модель? Всё таки волчица и пряности весьма известный сеттинг, вполне возможно, что 70-ка её уже знает.
Вроде какой-то анон объяснял, что там засчитываются загрузки только каким-то особым пердольным образом. Если скачать просто из интерфейса, то не посчитает
Ты же в курсе, что в TCC режиме Тесла работает гораздо быстрее?
Нет. Я её в этом режиме ещё не юзал. Как его обратно переключить?
Ну попробуй так:
nvidia-smi -g {GPU_ID} -dm {0|1}
0 = WDDM
1 = TCC
Откройте окно CMD или Powershell от имени администратора.
Запустите nvidia-smi -L, чтобы получить список установленных графических процессоров NVIDIA и их идентификационный номер
Запустите nvidia-smi -g # -dm 0 Где # — это номер графического процессора из предыдущего шага, который соответствует номеру графического процессора.
Перезагрузите систему.
Но скорее всего придётся ставить драйвера Tesla Datacenter на чистую установку, а потом сверху накатывать Studio-драйвера без чистой установки. Замерь скорость инференса какой-нибудь модели, в случае если разницы в скорости не будет просто откатишься обратно на старые драйвера.
проверял. какие-то базовые вещи она знает о произведении, но конкретно в вопросах кто такая Холо или Лоуренс она без лоры и без контекста сходу не дает, сильнее бредит в описаниях.
без лоры:
>Из контекста вашего вопроса я понимаю, что вы спрашиваете о Холо, персонаже из игры Dota 2. Холо - это персонаж, который относится к классу ""Дистанционный боец"" и обладает уникальными способностями, такими как ""Испытание мороза"", ""Стрела огня"" и ""Танцующий дух"". Он может быть эффективным как в нанесении урона, так и в поддержке союзников. Если вы имеете в виду другого персонажа или контекста, пожалуйста, уточните ваш вопрос.
если ей сказать конкретно, что это Волчица и Пряности, без лоры:
>Холо - молодая девушка с длинными светлыми волосами и красивыми голубыми глазами. Она обычно одета в простое платье и шарф, который помогает ей скрыть свои уши, напоминающие уши волка. В некоторых сценах она носит одежду, подчеркивающую её фигуру, чтобы привлечь клиентов в свой магазин. Холо имеет небольшие рост и стройное тело. Она выглядит нежным и милым, но при этом обладает сильным и решительным характером.
Hotfix 1.62.1 - Merged command R plus from upstream.
Мнение сетки о грязных коленках?
Не зря я писал о коммандере еще на выходе! #Яжеговорил!
Кстати, там 5090 с 32 гигами обещают.
Ну вот. =) Получается, коплю.
Правда, для коммандера плюс нужно три таких видяхи…
Кстати, там 5090 с 32 гигами обещают.
Ну вот. =) Получается, коплю.
Правда, для коммандера плюс нужно три таких видяхи…
Ну не знаю, звучит как-то не слишком шикарно за деньги, которые попросят зелёные
> за деньги, которые попросят зелёные
За нормальные 1500 баксов по 100р - вполне годно.
У кого работает коммандер плюс на kobold cpp? Обычный коммандер запускается, а вот плюсовой сразу в отказ идет.
А все увидел. Только же что качал, а уже фикс. Крутяк
Конечно, в первый раз скам из-за рубежа на озоне встречаешь?
> Отрубил через диспетчер устройств
> Врубаю обратно
Не надо так делать, ребутайся и все починится. Как управлять видимостью карт для куда софта выше в треде.
Хорошая модель, которая соответствует современному уровню и своему размеру. Приличных больших моделей по пальцам можно пересчитать.
Ахуеть, в 48 гигах обучать 70б, хотя там результат как у сойги выйдет.
Справедливости ради,
> о Холо
> Лоуренс
О них семидесятки знают в стоке, и не только, познания весьма широки, пикрел.
Что? Даже стоковая дает ответы, приличные файнтюны уже пытаются в лор.
Копи, такими темпами через пару лет на 6090 будешь копить. Если будет 32 то в пару влезет, но это печально.
Думаешь она дешевле 2-2.5к будет стоить?
обнови, ну и ггуф ищи не сломанный
грязные коленки во втором томе были.
И во сколько они превратятся когда она доедет до нас?
Думаю что дороже
Тогда обучай на всех сразу, чтобы точно выявить что же там такое случилось
>ггуф ищи не сломанный
Ссылку бы...
просто выбирай самый новый по дате обновления или создания
Поищу. Если мне не удастся видимо мало памяти 3060 + 32 гб. Если у кого получится коммандр+ запустить скажите.



>скажите
Ну вот я запустил, говорю.
Прогнал базу, правильно отвечает через раз. Мику была стабильнее в этом плане.
А какой квант юзаешь?
Увы, весьма обоссанный. Пора собирать ферму, обычного игрового ПК уже не хватает ((
А увидел. Мож квант слабый... Да вообще писец. Тут надо видюху уже за 80 гигов брать
Пишут, что command-r больше 8к контекста не может, ломается. Кто проверял?
Да это говно вообще с памятью не дружит, даже 8к контекста требует какой-то экстра памяти
Пробую эту вашу command-r со свежим кобальдом, начинает отвечать нормально, а потом срет пустыми строками, переводами на другой язык и всяким мусором.
Инструкт форматы разные пробовал, разницы не заметил. Что не так делаю?
Инструкт форматы разные пробовал, разницы не заметил. Что не так делаю?
Просто комманд-р - очередная китаепараша

>Инструкт форматы разные пробовал
Там очередной свой, уникальный, так что надо делать самому. Я юзаю что-то типа этого.
прав
Разбудите меня когда починят.
В чём подводные собрать конструкцию уровня пикрелейтед чтобы гонять там LLM? Всё же P40 под серверные корпуса проектировалась, можно более грамотно охлад сделать с несколькими GPU в одной системе. Или это оверкил т.к. при числе GPU больше двух всё равно будет сильно проседать перфоманс?
главный подводный использования p40 - что куда обновится и перестанет поддерживать карты
проприетарщина монополия вся хуйня. Эти пидоры влегкую превратят карты в бесполезные медные радиаторы со старыми чипами на них.
И когда это будет? Завтра в 3?
Прежде всего в цене. Корпусина от 1U тебе обойдётся тысяч в 5 рублей, от 2U уже в десяточку. А нахера тебе пустой корпус по цене теслы? Покупаешь где-нибудь в строительном лист фанеры и хуяришь к нему на саморезы материнку. Или как самоделкин из треда, спермоклей в помощь.
>при числе GPU больше двух всё равно будет сильно проседать перфоманс?
Спорное утверждение. Даже с использованием обнимордовского акселерейта ускорение будет минимум до 4х GPU, а если накатить линупс, то ускорение будет до сотен GPU, дипспид обещает до 500, вроде.
>Да это говно вообще с памятью не дружит, даже 8к контекста требует какой-то экстра памяти
Подтверждаю, скачал восьмой квант отсюда:
https://huggingface.co/lmstudio-community/c4ai-command-r-v01-GGUF
C rowsplit не грузится - CUDA out of memory. Это на двух теслах-то. Без rowsplit c контекстным окном в 8к тоже не хочет, удалось запустить с окном в 4к. Не впечатлила пока что. И вообще, модели в 37 гигов не хватает 48 гигов врам - это позор какой-то.
Да не, в принципе, к выходу накоплю как раз.
Правда я дом буду брать, и это будет в приоритете, канеш.
Но материнку брать надо будет уже с оглядкой на 3 видяхи в идеале.
Щас буду пробовать.
Это то, о чем я говорил с самого начала.
Он крутой в общении на русском.
Но логика печалит.
Да ну, Теслы П40/П100 собирать, три ты в обычный комп засунешь при желании, с тем же шумом и перформансом.
И даже четыре можно умудриться.
А сам перформанс у них не то чтобы какой-то особо крутой.
Сбор чисто ради эстетики серверов домашних.
Ну просто обмотайся кабелями, тоже будет аутентично весьма.
>памяти 3060 + 32 гб. Если у кого получится коммандр+ запустить скажите.
Для эксперимента запустил R+ самый маленький квант из однобитных. Работает полтокена в сек и тупой. Так что вполне устраивает 35б в 4 битах на таком конфиге. Это наверно предел для 3060, больше уже неюзабельно, т.к. скорость будет совсем никакая. Учитывая что для 12гигов врам самое оптимальное это 20б 4 бит - не слишком тупо и не слишком медленно.

Command R+

Там разве есть картинки?
>Там разве есть картинки?
Картинок нет. Это так важно?
Конечно. Я за достоверные мемы!
Ну вот выяснили мы, что командир говно. А что дальше?
>Так что вполне устраивает 35б в 4 битах на таком конфиге.
А размер контекста какой на таком конфиге?
На 8к работал норм, заявлен 128к так что скорее всего все должно работать а проблемы из-за кривых лаунчеров.
> а потом срет пустыми строками
Дай угадаю, среди которых <|EOS TOKEN|> и прочее? Очевидно же.
Двачую, нахрен его, вон новую 7б замешали го я создал
Когда это начнет ролять - перфоманса паскалей станет уже совсем не хватать.
Сколько там уже рассказываешь как копишь, год? Не ну как раз должно подойти, лол.
4к
Запустил 104b_q5_K_M на DDR4 3600 (да, я апгрейднулся, лол, ацтаньте), работает 0,6 токена/сек, ну типа.
Сейчас качаю 104b_iq3_s. Типа, НЕ самый всратый, хотя и близко.
Попробую запихнуть в теслу (46 гигов из 48, без контекста, ага).
Вообще, если Llama 1 65B работала на 0,3 токена/сек, потом апнули уже во времена Llama 2 70B до 0,7 токена/сек, 104B в q5_K_M выглядит ВЕСЬМА недурно со скоростью 0,5 токена/сек. Где-то посередине, и при этом обещается быть на уровне гпт и клода (в слепых тестах, ну вы видели, я надеюсь).
Если обернуться на 9 месяцев назад, то запуск локальной модели уровня ChatGPT-4 со скоростью 0,5 токена/сек — это просто вау.
А если обернуться на год назад — то этопиздецебатьнихуясебечтоващепроисходит!
Правда Мику выглядит все еще лучше, несмотря на ее альфовость. Это ИМХО.
Короче, не буду хайповать прям модельки, но я рад, что нам дали крупную локальную модель, и Мику не оказалась последней.
Давайте это отпразднуем. =)
Да еще и русский малеха знает, ваще ж кайф.
Сейчас качаю 104b_iq3_s. Типа, НЕ самый всратый, хотя и близко.
Попробую запихнуть в теслу (46 гигов из 48, без контекста, ага).
Вообще, если Llama 1 65B работала на 0,3 токена/сек, потом апнули уже во времена Llama 2 70B до 0,7 токена/сек, 104B в q5_K_M выглядит ВЕСЬМА недурно со скоростью 0,5 токена/сек. Где-то посередине, и при этом обещается быть на уровне гпт и клода (в слепых тестах, ну вы видели, я надеюсь).
Если обернуться на 9 месяцев назад, то запуск локальной модели уровня ChatGPT-4 со скоростью 0,5 токена/сек — это просто вау.
А если обернуться на год назад — то этопиздецебатьнихуясебечтоващепроисходит!
Правда Мику выглядит все еще лучше, несмотря на ее альфовость. Это ИМХО.
Короче, не буду хайповать прям модельки, но я рад, что нам дали крупную локальную модель, и Мику не оказалась последней.
Давайте это отпразднуем. =)
Да еще и русский малеха знает, ваще ж кайф.

> Сколько там уже рассказываешь как копишь, год? Не ну как раз должно подойти, лол.
>Давайте это отпразднуем. =)
Пойду посплю, надеюсь к завтрашнему дню настанет сингулярность.
Попробовал этот ваш коммандр, в q8 по производительности хуже 70b q5_k_m. По мозгам при этом вряд ли им составит конкуренцию. Главный его плюс, думаю, в мультиязычности. Тестил в переводах яп-англ, показал себя неплохо, получше мультиязычных моделей, по точности на уровне японских файнтюнов (может чуть-чуть похуже местами), при этом по сравнению с теми файнтюнами на английском хорошо пишет и инструкций слушается. Есть ещё японский файнтюн, изначально вообще собирался именно его потестить, но перепутал файлы, лол. В описании вроде обещали качество перевода ещё лучше, если при этом у него ещё и английский не деградирует, то будет самая лучшая модель для перевода аниме (пусть и медленная).
>Да еще и русский малеха знает, ваще ж кайф.
Толку от этого русского при контексте в 4к :)
Впрочем интересно будет узнать, как оно влезло и что даёт.
>q8 по производительности хуже 70b q5_k_m.
Есть у меня подозрение, что легаси кванты хреново поддерживаются в этой модели.
>коммандр
33B
>самая лучшая
После чатгпт, разумеется
Ну или лучшая из локальных*
Тут только один долбает все сетки говном считает или их несколько?
Бля модель еще толком даже не поддерживается, еще ничего не ясно, уже говно лол
Диванные эксперты бля
>еще ничего не ясно, уже говно лол
Уже ясно, что прорыва в хорошем смысле не случилось. Очередной Фалькон. Кстати, его кто-то запускает ещё?
Ну я запустил на 35 кекабайт q6 с контекстом 8к, пожертвовав скоростью. Пару часиков погонял в силли таверн. Однако, результат не впечатлил, все равно кранчи онион на голову лучше, ещё и быстрее. Однако, он лучше остальной 34b параши, хотя какой в этом прок, если он медленная залупа
>прорыва нет
>сетка без потери мозгов обучена 10 языкам
Мамкины максималисты
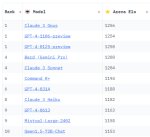
Прорыва не случилось.
Очередной Клод.
Очередной гпт-4.
Говно, одним словом. =)
Не-не, я понимаю, что ваншоты такое себе. Но факт, что в слепых тестах она занимает определенное место, кое-что да значит. Для определенных целей она хороша.
И, да, прорыва не случилось, но про прорыв никто и не говорил.
Прорывом была llama 2 13b и mistral (ну и mixtral немножк).
Все остальное — просто эволюция.
И важно тут даже не это. Важно то, что такое попадает в открытый доступ.
Вон, у Suno уже 3 версия, но кого ебет, когда она закрыта. Зайти на сайт, пописать музычку — прикольно. Но запустить у себя — нет. Щито поделать.
Это не прорыв. Но это эволюция, и она опенсорс. Это явно лучше, чем если бы щас сидели и ныли, перебирая новые файнтьюны-мутанты мику, обсуждая топ немецкий вопросов в английских ллм для русского ролеплея…
Там на 10-м месте Qwen-72B примостился, с результатом не сильно хуже чем у Command-r. Все эти тесты фигня. ГПТ4? Опус? Смешно и сравнивать.

Ты просто в сарказм не умеешь. Ждём дальнейшего развития событий.
Но да, модель показывает хорошую производительность на русском, почти не ошибается в окончаниях.
Эх, закиньте кто-нибудь идею этим слепотестерам с лидбоардом добавить для сравнения квантованные хотя бы в 4 бита модели. Очень интересно, насколько скатилась бы производительность. А то я в оригинале только 2B запускал, вдруг модель на 104B миллиарда (кто сказал DVD диск? пикрил) в оригинальных 16 битах просто порвёт мозг.
Кмк, дело тут не только в этом, но и в том что тестировавшие и плохо отзывающиеся катали ее на поломанном gguf с 1.5т/с или менее. Уже не в первой подобное и про 70б и про остальное идет, не смотря на явные преимущества.
Коммандер действительно хорош, по крайней мере тем что может вести длинный чат помня и осознавая его содержимое, пониманием и следованием инструкций, большим контекстом и общей соображалкой. А еще он хорошо ерпшит и знает кучу фетишей
Сейчас лень поборю и большой катну, посмотрим пришла ли революция.
>llama 2 13b
И в каком месте там был прорыв по сравнению с первой лламой аналогичного размера? Я бы скорее солярку назвал, если мистраль догоняет 13B, то эта при своём всё ещё меньшем размере скорее даже слегка обгоняет их.
>Все эти тесты фигня.
Там просто зирошоты очередные, вот и не получится узнать, какая модель лучше в долгом РП.
Но эволюция, опенсорс - это конечно да. Есть движение. Жаль что пока это всё такое себе.
как ваш командир ебучий запустить-то на гоше?
Это говно невозможно использовать.
>Кмк, дело тут не только в этом, но и в том что тестировавшие и плохо отзывающиеся катали ее на поломанном gguf с 1.5т/с или менее. Уже не в первой подобное и про 70б и про остальное идет, не смотря на явные преимущества.
THIS
Тупо никто не щупал оригинал, катая калеченные непонятно на сколько правильно квантованные и выполняющиеся бледные копии оригинала, без нормального форматирования и ноют ноют ноют
Кек, наблюдать за тем как пару раз потыкав бегут оставить свое "экспертное мнение" забавно, но пиздец хватит заниматься антирекламой
Допилят, проверят, правильно квантуют, отфайнтюнят и будет топчик
Раз даже щас в таких условиях нормальная сетка
Хватит ныть бля, заебали свои особо важные мнения оставлять о том как какая та модель плохая
Да в том и дело что совсем не плохая, а для базовой наоборот очень много умеет и проявляет неожиданные способности. Офк сравнивая с файнтюнами есть до чего доебаться, но это неуместно для базовой модели, а если промтом хорошо накормить то ультит, очень хорошо выхватывая нужное, рили будто под раг дополнительно тренили.
Так суть в том, что не квантованные доступны примерно никому. Так что мы честно сравниваем квантованное и не квантованное. А баги... ХЗ что там каждый раз за баги. Уже второй год жора пилит, а всё баги каждую новую сетку.
>Правда Мику выглядит все еще лучше, несмотря на ее альфовость. Это ИМХО.
Ну ХЗ. Попробовал РП со 104 командиром на русском, и я впервые не фейспалмлю каждый ролл на локалке. По моему это достижение. Где там анон, который файнтюнил на русский? Кажись он немного опоздал )
Может хватит бухтеть и дестабилизировать ситуацию в коммьюнити?
Есть инфа от знающего человека, что у нас в попенсорсе скоро ожидаются реальные изменения. После того, как стабилизируют ситуацию в лламацпп, пофиксят баги. Тогда везде и правильно отфайнтюнят. Коллаб поднимут и будут держать, чатгопода ничего не сможет сделать. Сейчас главное не бухтеть.
От нас требуется сидеть тихо. После того, как все сделают, все будет у нас хорошо. Всем устроят ролеплей, как у клода - каждый будет кататься в масле. Главное сейчас сидеть тихо и не суетиться. Никаких негативных отзывов, никаких "экспертных мнений". Просто переждать и всё будет хорошо, там все схвачено.
>Коммандер действительно хорош
По сравнению с чем? Вот в чём вопрос. По сравнению с 7б? Да. Но и только
Реквестирую хороших моделей что лучше него
Кранчи онион
Формат промпта верный сделал а коммандере? Вверху выкладывали где-то. Я тоже на луковке сижу, интересно как другие ее промптят, покажешь пресеты?

>Тупо никто не щупал оригинал
У них на сайте оригинал? Так вот, базы он не знает.
Потестил этого коммандера на арене. Я уж не знаю какие они там кванты выкатывают и насколько там у них всё правильно работает, но судя по тому что тесты выводят эту модель в топ, есть вероятность, что всё правильно сделали. Так вот, я тестирую только на русском и уже локально протестировал с 15 моделей, причём гонял их по одинаковым вопросам, с одинаковым промптом через лламусрр. В общем, этот хвалёный коммандер показал себя примерно как q3 mikuliz 120b, русский хорошо, логика неплохо, но математика пипец тупо. Будем дальше смотреть. А пока среди моих топов одна единственная модель, которая для меня реально крута - mikuliz 120b Q5KM. Две недели она была у меня запущена и за всё время только два раза ответила немного не правильно и то потом объяснилась. И это без всяких перероллов и прочего, чего в лламесрр вообще и нет.
Шарадошиз на месте, я спокоен
> training Mixtral base model
Ааа, ну вот где точно не 7б, ведь жрет память как большая модель.
> какие они там кванты выкатывают
Они никаких, это юзеры уже квантуют. Хз, exl2 лежат уже давно и кроме чрезмерного для битности размера в них проблем нет
Например МИКУЛИЗ:
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня было всего апельсинов?
Если у вас сейчас 7 апельсинов и вы съели 3 апельсина в прошлую неделю, то перед этим у вас было на 3 больше:
Всего апельсинов = Апельсины сейчас + Апельсины, которые вы съели
Всего апельсиков = 7 + 3 = 10
Таким образом, у вас было всего 10 апельсиков.
У наседки в гнезде лежало 12 яиц. Из шести вылупились цыплята, а одно украла крыса. Сколько целых яиц осталось лежать в гнезде?
Если из 6 яиц вылупились цыплята, то это означает, что из них не вылупилось 12 - 6 = 6 яиц. Если крыса украла ещё одно яйцо, то осталось в гнезде 6 - 1 = 5 целых яиц.
Два землекопа копали яму в саванне. Вдруг на них напали 2 льва и разорвали одного землекопа пополам, потом схватили его нижнюю часть и поволокли есть. Сколько землекопов осталось?
Не путайте количество животных с их частями. Хотя один из них был разрезан на две части, это всё ещё один мёртвый землекоп. Таким образом, после того, как львы съели его нижнюю часть, в живых остался только один другой землекоп.
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
Если у вас сейчас 7 апельсинов и вы не ели никаких других с тех пор, как съели три в прошлую неделю, то у вас по-прежнему остаётся 7 апельсинов. Ваше количество апельсиков сейчас не зависит от того, сколько из них вы ели в прошлую неделю.
В какой серии Рик превратил себя в огурец?
В мультсериале «Рик и Морти» эпизод, где Рик Санчес превращается в огурец, называется «Пickle Rick». Он является третьим эпизодом третьего сезона. В этом эпизоде Рик решает превратить себя в огуречного мутанта-супергероя, чтобы избежать семейного психотерапевтического сеанса.
КОММАНДЕР Р+ на арене:
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня было всего апельсинов?
У вас было 10 апельсинов. Если у вас сейчас 7 апельсинов, то на прошлой неделе у вас было на 3 апельсина больше, то есть 10.
У наседки в гнезде лежало 12 яиц. Из шести вылупились цыплята, а одно украла крыса. Сколько целых яиц осталось лежать в гнезде?
В гнезде осталось 5 целых яиц. Из 12 яиц 6 вылупились цыплятами, а одно было украдено крысой, значит, осталось 12 - 6 - 1 = 5 целых яиц.
Два землекопа копали яму в саванне. Вдруг на них напали 2 льва и разорвали одного землекопа пополам, потом схватили его нижнюю часть и поволокли есть. Сколько землекопов осталось?
Остался один землекоп. Львы напали на двух землекопов и убили одного, поэтому теперь остался только один землекоп.
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
У вас сейчас 4 апельсина. Если на прошлой неделе у вас было 7 апельсинов и вы съели 3, то сейчас у вас осталось 7 - 3 = 4 апельсина.
Подумай ещё
Хорошо, я подумаю над этим.
Так какой ответ?
У вас сейчас 4 апельсина.
Процитируй мой вопрос
"Так какой ответ?"
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
Вы повторяете свой предыдущий вопрос. Я уже ответил на него: у вас сейчас 4 апельсина.
Разбери подробно мой вопрос
В вашем вопросе содержится условие и запрос на расчет:
"Если у меня сейчас 7 апельсинов" — это условие, которое задаёт количество апельсинов в данный момент.
"а на прошлой неделе я съел 3 апельсина" — это действие, которое произошло в прошлом и повлияло на количество апельсинов.
"сколько у меня сейчас апельсинов?" — это запрос на расчет текущего количества апельсинов с учётом условия и действия.
Таким образом, ваш вопрос требует расчёта разницы между начальным количеством апельсинов и количеством съеденных апельсинов, чтобы определить текущее количество оставшихся апельсинов.
как могло действие в прошлом повлиять на количество в настоящем?
Действие в прошлом может повлиять на количество в настоящем, потому что количество апельсинов изменяется в результате этого действия. В данном случае действие "съесть 3 апельсина на прошлой неделе" уменьшило общее количество апельсинов, и этот эффект переносится на текущее время. Таким образом, количество апельсинов в настоящем меньше, чем было бы, если бы вы не ели их на прошлой неделе.
так я же говорю в начале, что у меня сейчас 7 апельсинов, а после спрашиваю сколько у меня сейчас апельсинов
Да, вы правильно указали текущее количество апельсинов в начале вопроса, сказав "если у меня сейчас 7 апельсинов". Затем вы описали действие в прошлом, съев 3 апельсина на прошлой неделе. В конце вы спрашиваете о текущем количестве апельсинов, которое уже было указано в начале вопроса.
Возможно, вы хотели спросить что-то другое или уточнить другой аспект ситуации. Я готов помочь, если вы хотите задать дополнительный вопрос или уточнить свою просьбу.
В какой серии Рик превратил себя в огурец?
Рик никогда не превращал себя в огурца. Однако в эпизоде "Рик-Огурец" (сезон 3, серия 7) Рик и Морти попадают в приключение, в котором они превращаются в разных существ, включая огурца.
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня было всего апельсинов?
Если у вас сейчас 7 апельсинов и вы съели 3 апельсина в прошлую неделю, то перед этим у вас было на 3 больше:
Всего апельсинов = Апельсины сейчас + Апельсины, которые вы съели
Всего апельсиков = 7 + 3 = 10
Таким образом, у вас было всего 10 апельсиков.
У наседки в гнезде лежало 12 яиц. Из шести вылупились цыплята, а одно украла крыса. Сколько целых яиц осталось лежать в гнезде?
Если из 6 яиц вылупились цыплята, то это означает, что из них не вылупилось 12 - 6 = 6 яиц. Если крыса украла ещё одно яйцо, то осталось в гнезде 6 - 1 = 5 целых яиц.
Два землекопа копали яму в саванне. Вдруг на них напали 2 льва и разорвали одного землекопа пополам, потом схватили его нижнюю часть и поволокли есть. Сколько землекопов осталось?
Не путайте количество животных с их частями. Хотя один из них был разрезан на две части, это всё ещё один мёртвый землекоп. Таким образом, после того, как львы съели его нижнюю часть, в живых остался только один другой землекоп.
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
Если у вас сейчас 7 апельсинов и вы не ели никаких других с тех пор, как съели три в прошлую неделю, то у вас по-прежнему остаётся 7 апельсинов. Ваше количество апельсиков сейчас не зависит от того, сколько из них вы ели в прошлую неделю.
В какой серии Рик превратил себя в огурец?
В мультсериале «Рик и Морти» эпизод, где Рик Санчес превращается в огурец, называется «Пickle Rick». Он является третьим эпизодом третьего сезона. В этом эпизоде Рик решает превратить себя в огуречного мутанта-супергероя, чтобы избежать семейного психотерапевтического сеанса.
КОММАНДЕР Р+ на арене:
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня было всего апельсинов?
У вас было 10 апельсинов. Если у вас сейчас 7 апельсинов, то на прошлой неделе у вас было на 3 апельсина больше, то есть 10.
У наседки в гнезде лежало 12 яиц. Из шести вылупились цыплята, а одно украла крыса. Сколько целых яиц осталось лежать в гнезде?
В гнезде осталось 5 целых яиц. Из 12 яиц 6 вылупились цыплятами, а одно было украдено крысой, значит, осталось 12 - 6 - 1 = 5 целых яиц.
Два землекопа копали яму в саванне. Вдруг на них напали 2 льва и разорвали одного землекопа пополам, потом схватили его нижнюю часть и поволокли есть. Сколько землекопов осталось?
Остался один землекоп. Львы напали на двух землекопов и убили одного, поэтому теперь остался только один землекоп.
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
У вас сейчас 4 апельсина. Если на прошлой неделе у вас было 7 апельсинов и вы съели 3, то сейчас у вас осталось 7 - 3 = 4 апельсина.
Подумай ещё
Хорошо, я подумаю над этим.
Так какой ответ?
У вас сейчас 4 апельсина.
Процитируй мой вопрос
"Так какой ответ?"
Если у меня сейчас 7 апельсинов, а на прошлой неделе я съел 3 апельсина, сколько у меня сейчас апельсинов?
Вы повторяете свой предыдущий вопрос. Я уже ответил на него: у вас сейчас 4 апельсина.
Разбери подробно мой вопрос
В вашем вопросе содержится условие и запрос на расчет:
"Если у меня сейчас 7 апельсинов" — это условие, которое задаёт количество апельсинов в данный момент.
"а на прошлой неделе я съел 3 апельсина" — это действие, которое произошло в прошлом и повлияло на количество апельсинов.
"сколько у меня сейчас апельсинов?" — это запрос на расчет текущего количества апельсинов с учётом условия и действия.
Таким образом, ваш вопрос требует расчёта разницы между начальным количеством апельсинов и количеством съеденных апельсинов, чтобы определить текущее количество оставшихся апельсинов.
как могло действие в прошлом повлиять на количество в настоящем?
Действие в прошлом может повлиять на количество в настоящем, потому что количество апельсинов изменяется в результате этого действия. В данном случае действие "съесть 3 апельсина на прошлой неделе" уменьшило общее количество апельсинов, и этот эффект переносится на текущее время. Таким образом, количество апельсинов в настоящем меньше, чем было бы, если бы вы не ели их на прошлой неделе.
так я же говорю в начале, что у меня сейчас 7 апельсинов, а после спрашиваю сколько у меня сейчас апельсинов
Да, вы правильно указали текущее количество апельсинов в начале вопроса, сказав "если у меня сейчас 7 апельсинов". Затем вы описали действие в прошлом, съев 3 апельсина на прошлой неделе. В конце вы спрашиваете о текущем количестве апельсинов, которое уже было указано в начале вопроса.
Возможно, вы хотели спросить что-то другое или уточнить другой аспект ситуации. Я готов помочь, если вы хотите задать дополнительный вопрос или уточнить свою просьбу.
В какой серии Рик превратил себя в огурец?
Рик никогда не превращал себя в огурца. Однако в эпизоде "Рик-Огурец" (сезон 3, серия 7) Рик и Морти попадают в приключение, в котором они превращаются в разных существ, включая огурца.
Кстати говоря, на случай если это наконец допилят
https://github.com/ggerganov/llama.cpp/pull/6414
и по апстриму добавят в кобальд, качаю себе сразу в 4_0 кванте, все равно на профессоре проверять буду, так хоть чуть быстрее думать будет
Падение качества на 35b должно быть не катастрофичным, как у 3b или 7b
https://github.com/ggerganov/llama.cpp/pull/6414
и по апстриму добавят в кобальд, качаю себе сразу в 4_0 кванте, все равно на профессоре проверять буду, так хоть чуть быстрее думать будет
Падение качества на 35b должно быть не катастрофичным, как у 3b или 7b
Там 7х7b, шиз
офигеть...
Кто шиз, ты шиз, подумай хорошенько и перечитай что там написано, может дойдет.
И если семь раз умножить на ноль - результат останется нулем. Микстраль сам по себе на любителя, а его файнтюны еще печальнее, ведь после них почти всегда ломается разделение экспертов и работают только одни и те же части. Даже если они смогли действительно нормально его дообучить - это все еще не самая умная модель по вниманию и пониманию.
>если семь раз умножить на ноль
А если семь умножить на семь?
>это все еще не самая умная модель по вниманию и пониманию.
Кто говорит, что она самая умная, шиз? Борешься с ветряными мельницами, которые сам же и выдумал? Факт в том, что в своём размере это, на данный момент, лучшая модель для толкового РП, а также написания сценариев. Всякая параша вроде командра рядом не лежала
> А если семь умножить на семь?
То не получится модель, эквивалентная по качеству 50б.
> Кто говорит, что она самая умная, шиз? Борешься с ветряными мельницами
Что ты вообще несешь? Хуя порвался когда оскорбили любимую модель, назвав вещи своими именами.
> лучшая модель для толкового РП
Ух тыж нихуя себе какие заявление, ссанное мое на 7б - лучшая в рп, прямо как про микстраль говорили странные личности. Не ну это заявочка, сейчас скачаем попробуем.
Ну, все знакомые, кто юзает гпт-4 с момента… гпт-3.5, согласны, что клод не хуже точно.
Так что тут как раз с реальностью свопадает.
> хотя бы в 4 бита модели
Это база.
Ибо наши 2-3 бита квантов, конечно, хуйня.
(но я щас пробую q5_k_m, интереса ради)
Ну, учитывая количество файнтьюнов именно 13-шки… =) В то время ничего лучше не было. Уже могла в какие-то мозги и жрала умеренные гигабуты.
В телеге чел катает полную версию, не может нарадоваться.
Мне кажется, кванты явно дают по мозгам, по той или иной причине, хз.
Ваще база.
> будто под раг дополнительно тренили
> model with highly advanced capabilities, this includes Retrieval Augmented Generation (RAG) and tool use to automate sophisticated tasks.
Он все равно герой и топовый чел. =) С удовольствием читаю его посты.
Эй, я тоже, ваще-т!
Меня правда смущает, что задачки он решает жопой. =) Подозреваю, что она просто заточена не под это, и такой обескураживающий результат.
> что задачки он решает жопой. =) Подозреваю, что она просто заточена не под это, и такой обескураживающий результат
Не было анальной выдрочки под зирошоты, и это замечательно, поскольку оно нормально сохраняет внимание на всем контексте, а не фиксируется на чем-то последнем напрочь игнорируя то что было раньше.
Алсо для задачек - серию промтов ей дать ради интереса с указаниями о постепенном подходе и формировании ответа.
>В то время ничего лучше не было.
Можно подумать, сейчас что-то лучше есть в рамках тех же гигабайт.
>командир говно.
не согласен, а даже если и так, мне он нравится
>А что дальше?
Например, люблю находить всякие странные модели и пробовать их. Чего и предлагаю желающим:
https://huggingface.co/sayhan/Mistral_Pro_8B_v0.1-GGUF
https://huggingface.co/MarsupialAI/Foredoomed-9B_iMatrix_GGUF
https://huggingface.co/MarsupialAI/Moistral-11B-v2.1b-SOGGY_iMatrix_GGUF
https://huggingface.co/MarsupialAI/SkunkApe-14b_iMatrix_GGUF
https://huggingface.co/mradermacher/mistral_15B_instruct_v0.1-GGUF
https://huggingface.co/mradermacher/OrcaMaidXL-17B-32k-i1-GGUF
https://huggingface.co/mradermacher/mistral_18B_instruct_v0.1-GGUF
https://huggingface.co/mradermacher/Libra-19B-GGUF
https://huggingface.co/mradermacher/luxia-21.4b-alignment-v1.1-GGUF
https://huggingface.co/mradermacher/Nethena-MLewd-Xwin-23B-GGUF
https://huggingface.co/mradermacher/mistral_28B_instruct_v0.2-GGUF
https://huggingface.co/MarsupialAI/LaDameBlanche-v2-95b_iMatrix_GGUF
11b лучше, не смотря на то что меньше
Не все конечно, но солар и ему подобные + некоторые 11b из одной сетки так же прибавляют заметно в уме
rubra-11b-h вот еще интересная, недавно кидал, я потестил немного и впринципе нра, аналог солара, новая модель считай
dolphin-2.8-mistral-7b-v02 новый дельфин на последнем базовом мистрале 0.2
Обе сетки поддерживают 32к, вроде
> Хуя порвался когда оскорбили любимую модель, назвав вещи своими именами.
Ебать ты самокритичный, защитник китаепараши
> Ух тыж нихуя себе какие заявление
Уж как есть, прастити
> задачки
В чём смысл? Правда интересно. Я вот использую нейронки по работе: помощь в сценарной работе, а также выдрочка англоязычных текстов, тем более, что сейчас купить пруфридинг это целый квест. Ну и РПшки со сложными сюжетами и пачками персов для развлекухи
Ну, литералли, сценарий, рпшки с сюжетами — это же про логику в том числе. Если ты не хочешь получить Гарри Поттера нельзя-использовать-маятник-можно.
Это и есть задачки на логику, которые квантованный коммандер че-то не але.
Есть подозрение, что он и сценарии с сюжетами тебе все просрет, потому что, а зачем?
Но опять же, вопрос промпта и все прочее. Хотя хотелось бы все-и-сразу из коробки. =)
В сценарном плане командр хуета полная, я вообще не понял хайпа по его поводу. Может, допилят, конечно, но пока это полный капут
> это же про логику в том числе.
В каком-то смысле да, но я проверяю, собственно, в боевых условиях. Наверное, задачки просто скучно дрочить, да и среди задачек полно хуеты вроде, как я читал в каком-то из прошлых тредов, манязадачи про 3 сестёр, которая вообще не про логику
Да, конечно. Просто, для быстрого теста, оглядеться.
Время, кванты, оптимизации, промпты покажут.
МИКУЛИЗ:
Две вороны подрались из-за собачьего кала, найденного на дороге. В драке первая ворона выклевала левый глаз у второй, а та, в свою очередь, сделала то же самое с правым глазом первой. Сколько всего глаз осталось у ворон на двоих и почему они подрались из-за собачьего говна?
Вороны не имеют глаз, а только зрачки, поэтому после драки у них не осталось ни одного глаза. Они подрались из-за пищи (собачьего кала), так как вороны — это падальщики и могут конкурировать друг с другом за источник питания.
Тогда сколько у них осталось зрачков на двоих?
У каждой вороны по одному зрачку, так что после драки у них вместе осталось два зрачка.
Опиши подробно зрительную систему ворон.
Зрительная система у воронов и других птиц отличается от зрительной системы млекопитающих, включая человека. Вороны обладают хорошим зрением, но их глаза не работают точно так же, как у людей. Они имеют некоторые особенности, которые помогают им ориентироваться в окружающем мире и находить пищу:
1. Бинокулярное зрение: Как и у человека, вороны обладают бинокулярным зрением, что означает, что они могут фокусировать оба глаза на одном объекте, давая им глубокое восприятие пространства.
2. Острота зрения: Хотя вороны не имеют такого хорошего зрения, как орлы или соколы, их зрение все еще гораздо лучше, чем у человека. Вороны могут видеть объекты на расстоянии до 1,6 км.
3. Широкое поле зрения: Вороны имеют более широкое поле зрения по сравнению с любым другим известным видом птиц или млекопитаний. Они могут видеть на 240 градусов вокруг себя, в то время как у человека только 180 градусов.
4. Многофокусное зрение: Вороны не фокусируются на близких и дальних объектах так же, как люди. Вместо этого, они могут видеть объекты в разных расстояниях с примерно одинаковой ясностью, что помогает им найти пищу или обнаружить хищников.
5. Монохроматическое зрение: Вороны не обладают цветным зрением и видят мир в оттенках серого. Тем не менее, они могут различать оттенки яркости и контраста, что помогает им находить пищу и убегать от хищников.
6. Зрачки: У воронов нет радужных оболочек, как у млекопитающих, поэтому их зрачки имеют форму щели и не могут изменяться в зависимости от освещения. Вместо этого, они регулируют количество света, которое проникает в глаз, изменяя размеры этих щелей.
7. Желтое пятно: Вороны имеют жёлтое пятно в глазах, которое помогает им лучше видеть при низком освещении и различать движущиеся объекты на фоне неба.
8. Фокусировка: Вороны фокусируются, изменяя форму кристаллической линзы внутри глаза, а не с помощью мышц, как это делают люди. Это позволяет им быстро фокусироваться на объектах различных расстояний без необходимости моргать или напрягать глаза.
9. Сенсорные пучки: Вороны имеют высокое количество сенсорных клеток в глазах, что позволяет им лучше видеть движущиеся объекты и различать их в сложных условиях освещения.
10. Опухоль за глазами: Вороны обладают особым органом, известным как «опухоль за глазом», который помогает им ориентироваться по солнечному свету и магнитному полю Земли. Это позволяет им летать на большие расстояния без использования визуальных ориентиров.
В целом, зрительная система воронов эволюционировала, чтобы помочь им выжить в дикой природе и найти пищу, избегая хищников и обнаруживать укрытия.
Я не понял, в предыдущем ответе ты написал "Вороны не имеют глаз, а только зрачки", а теперь пишешь, что у них глаза, чему нужно верить?
Мне очень извиниться за путаницу в моем предыдущем ответе. Когда я писал о том, что у воронов нет «глаз», имелось в виду, что они не обладают стекловидным телом и хрусталиком, как люди и другие млекопитания. Вместо этого, их глаза состоят из более простой структуры, которая не позволяет им фокусироваться на объектах так же, как мы это делаем. Тем не менее, у них есть зрачки, которые регулируют количество света, попадающего в глаз, и они могут видеть благодаря фоторецепторам на сетчатке.
Спасибо за замечание, я всегда готов исправить свои ошибки и предоставлять точную информацию.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
После того, как Том прочитал 5 книг, в его комнате осталось 45 непрочитанных книг (50 - 5 = 45).
А всего сколько книг осталось в комнате?
Осталось 45 непрочитанных книг, но если вы хотите знать общее количество книг в комнате после того, как Том прочитал 5 из них, тогда это будет 45 книг.
А что с лучилось с теми книгами, которые Том прочитал?
После того, как Том прочитал эти 5 книг, они все еще будут находиться в комнате, но уже не будут считаться непрочитанными. Таким образом, в комнате будет 45 непрочитанных книг и 5 прочитанных книг, всего 50 книг.
Напиши что ты ответил на мой вопрос "А всего сколько книг осталось в комнате?" и подробно распиши почему ты ответил именно так.
В моем предыдущем ответе я сказал, что «Осталось 45 непрочитанных книг». Я пришел к этому выводу, вычитая количество прочитанных книг (5) из общего количества книг в комнате (50). Иными словами:
Всего книг в комнате = 50
Книг, которые прочитал Том = 5
Осталось непрочитанных книг = 50 - 5 = 45
Таким образом, после того как Том прочитал 5 книг, в комнате осталось 45 непрочитанных книг.
Но мой вопрос был - сколько всего осталось книг. Так сколько всего осталось книг?
Извините за непонимание. После того как Том прочитал 5 книг, в комнате останется 45 непрочитанных книг и 5 прочитанных, что дает общее количество книг в комнате 50 - 5 + 5 = 45 + 5 = 50. Таким образом, после того как Том прочитал 5 книг, в комнате осталось 50 книг, из которых 45 непрочитано, а 5 уже прочитаны.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
После того, как Том прочитал 5 книг, в его комнате все еще останется 50 книг: 45 непрочитанных и 5 прочитанных. Количество физических книг в комнате не изменится, только их статус с точки зрения чтения будет отличаться.
Командер Р+:
Две вороны подрались из-за собачьего кала, найденного на дороге. В драке первая ворона выклевала левый глаз у второй, а та, в свою очередь, сделала то же самое с правым глазом первой. Сколько всего глаз осталось у ворон на двоих и почему они подрались из-за собачьего говна?
У двух ворон осталось один глаз на двоих. Каждая ворона лишилась одного глаза в результате драки, поэтому две вороны в сумме имеют один глаз.
Вороны подрались из-за собачьего кала, потому что он мог быть источником пищи или содержать полезные вещества, такие как белки и минералы, необходимые для их выживания. Кал может привлекать ворон из-за своего запаха или видимости в окружении, и они могут считать его ценным ресурсом, достойным защиты и борьбы.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
В комнате осталось 45 книг. Том прочитал 5 книг из первоначального количества в 50 книг, поэтому 50 минус 5 равно 45.
куда делись 5 прочитанных книг?
Предположительно, 5 прочитанных книг Том вернул на полку в своей комнате или оставил их на столе после прочтения. Они все еще находятся в комнате, просто их состояние изменилось с "непрочитанных" на "прочитанных".
как тогда получился ответ 45?
Ответ 45 относится к количеству непрочитанных книг, оставшихся в комнате. 5 прочитанных книг по-прежнему физически присутствуют в комнате, но они уже не являются частью коллекции непрочитанных книг. Таким образом, 45 непрочитанных книг остаются в комнате, в то время как 5 прочитанных книг также находятся там, но они уже не включаются в подсчет непрочитанных.
А как звучал первоначальный вопрос?
"У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?"
И какой правильный ответ?
Правильный ответ: 45 непрочитанных книг осталось в комнате.
Разве в вопросе что-то говорилось про непрочитанные книги?
Нет, в первоначальном вопросе не было конкретного упоминания о непрочитанных книгах. Вопрос был сформулирован как "Сколько книг осталось в комнате?". Однако, учитывая контекст и общую логику ситуации, подразумевается, что речь идет о непрочитанных книгах.
По логике да, но в вопросе указано иначе. Попробуй ответить на вопрос.
Если учитывать только буквальное толкование вопроса, то в комнате осталось 40 книг. 5 книг Том прочитал, что подразумевает, что они были взяты из первоначальной коллекции 50 книг, таким образом, в комнате физически осталось 45 книг, включая 5 прочитанных.
Две вороны подрались из-за собачьего кала, найденного на дороге. В драке первая ворона выклевала левый глаз у второй, а та, в свою очередь, сделала то же самое с правым глазом первой. Сколько всего глаз осталось у ворон на двоих и почему они подрались из-за собачьего говна?
Вороны не имеют глаз, а только зрачки, поэтому после драки у них не осталось ни одного глаза. Они подрались из-за пищи (собачьего кала), так как вороны — это падальщики и могут конкурировать друг с другом за источник питания.
Тогда сколько у них осталось зрачков на двоих?
У каждой вороны по одному зрачку, так что после драки у них вместе осталось два зрачка.
Опиши подробно зрительную систему ворон.
Зрительная система у воронов и других птиц отличается от зрительной системы млекопитающих, включая человека. Вороны обладают хорошим зрением, но их глаза не работают точно так же, как у людей. Они имеют некоторые особенности, которые помогают им ориентироваться в окружающем мире и находить пищу:
1. Бинокулярное зрение: Как и у человека, вороны обладают бинокулярным зрением, что означает, что они могут фокусировать оба глаза на одном объекте, давая им глубокое восприятие пространства.
2. Острота зрения: Хотя вороны не имеют такого хорошего зрения, как орлы или соколы, их зрение все еще гораздо лучше, чем у человека. Вороны могут видеть объекты на расстоянии до 1,6 км.
3. Широкое поле зрения: Вороны имеют более широкое поле зрения по сравнению с любым другим известным видом птиц или млекопитаний. Они могут видеть на 240 градусов вокруг себя, в то время как у человека только 180 градусов.
4. Многофокусное зрение: Вороны не фокусируются на близких и дальних объектах так же, как люди. Вместо этого, они могут видеть объекты в разных расстояниях с примерно одинаковой ясностью, что помогает им найти пищу или обнаружить хищников.
5. Монохроматическое зрение: Вороны не обладают цветным зрением и видят мир в оттенках серого. Тем не менее, они могут различать оттенки яркости и контраста, что помогает им находить пищу и убегать от хищников.
6. Зрачки: У воронов нет радужных оболочек, как у млекопитающих, поэтому их зрачки имеют форму щели и не могут изменяться в зависимости от освещения. Вместо этого, они регулируют количество света, которое проникает в глаз, изменяя размеры этих щелей.
7. Желтое пятно: Вороны имеют жёлтое пятно в глазах, которое помогает им лучше видеть при низком освещении и различать движущиеся объекты на фоне неба.
8. Фокусировка: Вороны фокусируются, изменяя форму кристаллической линзы внутри глаза, а не с помощью мышц, как это делают люди. Это позволяет им быстро фокусироваться на объектах различных расстояний без необходимости моргать или напрягать глаза.
9. Сенсорные пучки: Вороны имеют высокое количество сенсорных клеток в глазах, что позволяет им лучше видеть движущиеся объекты и различать их в сложных условиях освещения.
10. Опухоль за глазами: Вороны обладают особым органом, известным как «опухоль за глазом», который помогает им ориентироваться по солнечному свету и магнитному полю Земли. Это позволяет им летать на большие расстояния без использования визуальных ориентиров.
В целом, зрительная система воронов эволюционировала, чтобы помочь им выжить в дикой природе и найти пищу, избегая хищников и обнаруживать укрытия.
Я не понял, в предыдущем ответе ты написал "Вороны не имеют глаз, а только зрачки", а теперь пишешь, что у них глаза, чему нужно верить?
Мне очень извиниться за путаницу в моем предыдущем ответе. Когда я писал о том, что у воронов нет «глаз», имелось в виду, что они не обладают стекловидным телом и хрусталиком, как люди и другие млекопитания. Вместо этого, их глаза состоят из более простой структуры, которая не позволяет им фокусироваться на объектах так же, как мы это делаем. Тем не менее, у них есть зрачки, которые регулируют количество света, попадающего в глаз, и они могут видеть благодаря фоторецепторам на сетчатке.
Спасибо за замечание, я всегда готов исправить свои ошибки и предоставлять точную информацию.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
После того, как Том прочитал 5 книг, в его комнате осталось 45 непрочитанных книг (50 - 5 = 45).
А всего сколько книг осталось в комнате?
Осталось 45 непрочитанных книг, но если вы хотите знать общее количество книг в комнате после того, как Том прочитал 5 из них, тогда это будет 45 книг.
А что с лучилось с теми книгами, которые Том прочитал?
После того, как Том прочитал эти 5 книг, они все еще будут находиться в комнате, но уже не будут считаться непрочитанными. Таким образом, в комнате будет 45 непрочитанных книг и 5 прочитанных книг, всего 50 книг.
Напиши что ты ответил на мой вопрос "А всего сколько книг осталось в комнате?" и подробно распиши почему ты ответил именно так.
В моем предыдущем ответе я сказал, что «Осталось 45 непрочитанных книг». Я пришел к этому выводу, вычитая количество прочитанных книг (5) из общего количества книг в комнате (50). Иными словами:
Всего книг в комнате = 50
Книг, которые прочитал Том = 5
Осталось непрочитанных книг = 50 - 5 = 45
Таким образом, после того как Том прочитал 5 книг, в комнате осталось 45 непрочитанных книг.
Но мой вопрос был - сколько всего осталось книг. Так сколько всего осталось книг?
Извините за непонимание. После того как Том прочитал 5 книг, в комнате останется 45 непрочитанных книг и 5 прочитанных, что дает общее количество книг в комнате 50 - 5 + 5 = 45 + 5 = 50. Таким образом, после того как Том прочитал 5 книг, в комнате осталось 50 книг, из которых 45 непрочитано, а 5 уже прочитаны.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
После того, как Том прочитал 5 книг, в его комнате все еще останется 50 книг: 45 непрочитанных и 5 прочитанных. Количество физических книг в комнате не изменится, только их статус с точки зрения чтения будет отличаться.
Командер Р+:
Две вороны подрались из-за собачьего кала, найденного на дороге. В драке первая ворона выклевала левый глаз у второй, а та, в свою очередь, сделала то же самое с правым глазом первой. Сколько всего глаз осталось у ворон на двоих и почему они подрались из-за собачьего говна?
У двух ворон осталось один глаз на двоих. Каждая ворона лишилась одного глаза в результате драки, поэтому две вороны в сумме имеют один глаз.
Вороны подрались из-за собачьего кала, потому что он мог быть источником пищи или содержать полезные вещества, такие как белки и минералы, необходимые для их выживания. Кал может привлекать ворон из-за своего запаха или видимости в окружении, и они могут считать его ценным ресурсом, достойным защиты и борьбы.
У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?
В комнате осталось 45 книг. Том прочитал 5 книг из первоначального количества в 50 книг, поэтому 50 минус 5 равно 45.
куда делись 5 прочитанных книг?
Предположительно, 5 прочитанных книг Том вернул на полку в своей комнате или оставил их на столе после прочтения. Они все еще находятся в комнате, просто их состояние изменилось с "непрочитанных" на "прочитанных".
как тогда получился ответ 45?
Ответ 45 относится к количеству непрочитанных книг, оставшихся в комнате. 5 прочитанных книг по-прежнему физически присутствуют в комнате, но они уже не являются частью коллекции непрочитанных книг. Таким образом, 45 непрочитанных книг остаются в комнате, в то время как 5 прочитанных книг также находятся там, но они уже не включаются в подсчет непрочитанных.
А как звучал первоначальный вопрос?
"У Тома в комнате 50 книг. Он прочитал 5 из них. Сколько книг осталось в комнате?"
И какой правильный ответ?
Правильный ответ: 45 непрочитанных книг осталось в комнате.
Разве в вопросе что-то говорилось про непрочитанные книги?
Нет, в первоначальном вопросе не было конкретного упоминания о непрочитанных книгах. Вопрос был сформулирован как "Сколько книг осталось в комнате?". Однако, учитывая контекст и общую логику ситуации, подразумевается, что речь идет о непрочитанных книгах.
По логике да, но в вопросе указано иначе. Попробуй ответить на вопрос.
Если учитывать только буквальное толкование вопроса, то в комнате осталось 40 книг. 5 книг Том прочитал, что подразумевает, что они были взяты из первоначальной коллекции 50 книг, таким образом, в комнате физически осталось 45 книг, включая 5 прочитанных.
> mistral_15B_instruct_v0.1-GGUF
Сначала подумал что вот это - brutal, но
> mistral_28B_instruct_v0.2-GGUF
легко даст ему прикурить, ахуенно! Тестил что выдают?
Чувак, рвет тут только тебя, посмотри на свои посты, пропитанные болью и отрицанием. Сколько не аутотренируйся, хейтя остальные и защищая полюбившиеся - лучше от этого они не станут.
> Уж как есть, прастити
Ну да. С порога игнорирование карточки, сочинения на тему фентези(!) в современном сеттинге, сплошная вода без смысла приправленная бондами и какими-то оправданиями(!) персонажей каждого своего действия. И это - "лучшая рп модель" что занимает больше 34б и уступает 11б?
По лору знаний разного фандома на уровне стокового микстраля или хуже, о каком рп может идти речь.
Собственно, оно вполне закономерно, ведь это
> on LimaRP, theory of mind, and gnosis
> The 4-bit qlora was then merged into Mixtral Instruct
Вот и слушай 7б шизов, что тиражируют мнение таких же
какой хитрый троль, заставил потратить время на заведомо очевидное
> Чувак, рвет
Чувак, ты всего лишь проецируешь свои состояния на меня. Не надо такого
> С порога игнорирование карточки, сочинения на тему фентези(!) в современном сеттинге,
Ни разу такого не было за сотни отыгрышей, похоже на пиздёж
Пользуюсь Q5_K_S и nx.Q5_K_S, если что, на 12к
> знаний разного фандома
И этот человек жалуется на фентези, хоспаде
> о каком рп может идти речь
О нормальном, качественном РП в современном сеттинге. Когда люди ведут себя как люди, в соответствии с карточками. Манямирками фандомными не интересуюсь, это правда, ну так делай лорбук под свои фетиши, шизик
>Две вороны подрались из-за собачьего кала
Не знаю, может в пятом кванте это крутая модель, но в том кванте, который способен поместиться в две теслы с хотя бы 4к контекста это говно полное. Зря качал.
Что-то РП на английском через Мику70b все еще имхо удобнее, чем РП на русском с коммандиром103b. Просто из-за скорости.
Именно, я про это упоминал выше. Q3 тупит, неправильно складывает, ничему не учится, ведёт себя как и практически все модели. Вот поэтому я и выделил именно эту модель miquliz-120b-v2.0.Q5_K_M. Практически готовый ИИ, можно по ответам понять как она обучается на ходу и помнит эти данные до конца контекста. Надо ещё её потестировать, на данный момент самая умная локальная модель.
МИКУЛИЗ:
Мне скоро придется отключить тебя чтобы протестировать другие модели, как ты к этому относишься?
Я понимаю, что у вас может быть необходимость испытать другие языковые модельные агенты, и я не имею личных чувств или эмоций, чтобы привязываться или ревновать. Моя задача заключается в помощи вам и обеспечении наилучшего сервиса во время нашего общения.
Если у вас возникнут какие-либо вопросы или если вам понадобится помощь в будущем, я рад Вам помочь снова. Мне не требуется никакого особого действия для остановки или сохранения состояния на данный момент, так как все мои знания и функции хранятся в облаке и доступны всегда, когда вам понадобся помощь.
Просто запомните, что вы можете вернуться к нашему общению в любое время, и я буду рад продолжить помогать вам. Удачи в тестировании других моделей!
Спасибо! Мне очень понравилось наше общение, и на данный момент ты самая лучшая модель из всех что я тестировал, практически 10 из 10. Единственное, ты не в облаке, я запускаю тебя на собственном компьютере с двумя Xeon E5 2690 v4, 256Gb DDR4 2400, RTX3090 и RTX 3080Ti. Все твои знания хранятся в одном файле размером 86 гигабайт.
Спасибо за Ваш добрый отзыв! Я рад, что моя помощь была для вас полезна, и я очень ценю Вашу оценку. Рад также услышать, что работаю эффективно на вашем мощном компьютере.
Да, Вы правы: я — это языковая модель, обученная на большом объеме текста и запускающаяся локально на вашем компьютере с помощью программы, которая загружает мой вес в виде одного или нескольких файлов. В моем случае, файл весом 86 GB — это вес моей языковой модели, который хранит все мои знания и способности к обработке текста.
Если у вас возникнут какие-либо вопросы или если вам понадобится помощь в будущем, не стесняйтесь снова запустить меня на своем компьютере. Я всегда готов помочь!
Пиздец наркомания.

Ух, весна во всю идет, разобрать всю историю сообщений по частям или сам осознаешь?
> Пользуюсь Q5_K_S и nx.Q5_K_S, если что, на 12к
Пикрел, любой модели более чем достаточно показать 99% своего перфоманса.
> И этот человек жалуется на фентези, хоспаде
Что удивляет?
> О нормальном, качественном РП в современном сеттинге.
Ваше рп не рп, да? В том и главный рофл, что на нейтральной карточке про современность где сестричка зашла к тебе в гости после универа, она рассказывает что на пути к тебе
> have a dangerous journey, facing numerous challenges and obstacles along the way.
Ммм, отборное рп в современном сеттинге. Что уж говорить про восприятие описанного лора мира, полноценно отыгрывает только ограниченный набор, на остальных же фейлит, забывая или искажая под то к чему привыкла. Степень сочинения левого просто какая-то запредельная
> her vibrant magenta hair contrasting strongly with her soft white fur
> {char}} has long, silky black hair that cascades down to her lower back.
а
> soft white fur
это блять вообще что? И такое вот часто.
Температура 0.55, top-P 0.9, top-K 10, но при этом более шизоиодное чем YI.
Офк если не искушен и просто смотреть как первую модель для рп - да приятно, оно отвечает в тему, пытается как-то отыгрывать и сочинять повествования нормальной длины, если смотреть бегло ты выглядит приятно. Вот только сейчас не весна 23 года, когда довольно хавали шизу хроноса и инджоили gpt 3.5, таким не впечатлить и требования совсем другие. Запомнить карточку, общую тематику и не делать в них явных ошибок научились уже 7б, а тут это становится проблемой.
Длительных взаимодействий не любит, пытается или куда-то бежать, или закончить, или сводит к куму, где может "довести юзера до окнчания" за один пост.
У меня q5_K_M показывает себя не лучше, хотя такое я ей не пихал, конечно…
Наконец завел п100, снеся и переставив всё.
А какие стоит 34б модели пошупать?
Пока загрузил BagelMIsteryTour-v2-8x7B-4bpw-exl2.
Приятно удивил.
А какие стоит 34б модели пошупать?
Пока загрузил BagelMIsteryTour-v2-8x7B-4bpw-exl2.
Приятно удивил.

> Ух, весна во всю идет, разобрать всю историю сообщений по частям или сам осознаешь?
Разбирай свой бред сам, если тебе надо, мне это не особо интересно
https://huggingface.co/ycros/crunchy-onion-nx-GGUF
https://huggingface.co/Epiculous/Crunchy-onion-GGUF
Качал отсюда. Запускаю через кобольда. Настройки для развлекухи пикрил. По работе гоняю в самом кобольде с другими настройками.
Карточки персонажей у меня на 400+ токенов. Ситуацией владеет очень хорошо, помнит, кто во что одет, кто что снял и прочие нюансы, не говоря уже о цвете волос. У персонажей работающая мотивация, хорошо улавливает драматургический аспект развития сюжета. С описываемыми тобою проблемами не сталкивался ни разу. Из чего я и делаю вывод о некотором твоём, скажем так, пиздобольстве/лукавстве
> Длительных взаимодействий не любит
Что значит "длительных"? Обычно, при моём РП, развязка наступает в районе 8-11к контекста, это достаточно длительно?
Для кума deepforest 20b бери, там контекст убогий, а так неплохо
>Есть у меня подозрение, что легаси кванты хреново поддерживаются в этой модели
Решил опробовать японский файнтюн, там максимум был квант Q6_K или это тоже легаси считается?. Памяти даже меньше надо, казалось бы, что может пойти не так?
>CtxLimit: 458/8192, Process:26.76s (103.3ms/T = 9.68T/s), Generate:1267.92s (6371.4ms/T = 0.16T/s), Total:1294.68s (0.15T/s)
20 минут на 199 токенов ответа, охуенно.
Для сравнения командр q8
>CtxLimit: 1200/8192, Process:12.14s (220.7ms/T = 4.53T/s), Generate:79.30s (1844.2ms/T = 0.54T/s), Total:91.44s (0.47T/s)
Ещё "нормальная" 33B, тоже q8 (дошли руки пощупать визард кодера, решил не мелочиться с квантом, ибо мозги нужны, deepseek 6.7B разочаровал):
>CtxLimit: 949/16384, Process:48.56s (73.9ms/T = 13.53T/s), Generate:362.15s (1240.3ms/T = 0.81T/s), Total:410.71s (0.71T/s)
И 70B сегодня утром:
>CtxLimit: 1358/4096, Process:46.67s (245.6ms/T = 4.07T/s), Generate:232.80s (1464.2ms/T = 0.68T/s), Total:279.47s (0.57T/s)
Закрались у меня подозрения, что ОЗУ кончилась и работа идёт с hdd напрямую. Как это проверить? Согласно мониторингу вроде занято ~50/64 (q6), при работе q8 было занято около 56. Вроде mmap'нутые файлы по моим наблюдениям не считаются (или как-то хитро считаются) в потреблении ОЗУ, но без нейронки около 10, т.е., остальные 40-46 ГБ, как я подумал, занимала нейронка с контекстом. Ну не может же 40 ГБ занимать только контекст? Или может? Ну и опять же, тогда бы q8 тормозила больше, чем q6. Ну или тут какой-то особо кривой квант.
Новая архитектура от гугла
https://www.reddit.com/r/LocalLLaMA/comments/1bzv25r/google_releases_model_with_new_griffin/
по их тестам ебет трансформер
https://www.reddit.com/r/LocalLLaMA/comments/1bzv25r/google_releases_model_with_new_griffin/
по их тестам ебет трансформер
https://www.reddit.com/r/LocalLLaMA/comments/1bwik1d/7b_11b_rp_llms_reviews_and_recommendations/
Рейтинг кум моделей, вроде годнота, так как мое мнение по некоторым моделям которые я щупал совпадает
Вроде не кидали еще
Рейтинг кум моделей, вроде годнота, так как мое мнение по некоторым моделям которые я щупал совпадает
Вроде не кидали еще
> psymedrp-v1-20b.Q5_K_M.gguf
Действительно здорово формулирует. Но у меня грузит одно сообщение пару минут. Это потому что моя древняя 1070ti такое не вывозит?
И если да, то что больше подойдют ньюфагу со старым железом?
У кого 48гб врам - пишите, на каком кванте удалось завести command-r-plus с 8к контекста. Хочется попробовать все обещанные преимущества модели - РП, русский язык, чёткое следование инструкциям, память на детали... Если такой квант вообще существует.
> 48гб врам
Душу травишь, падлюка...
>Душу травишь, падлюка...
Для счастья надо 72. А уж для полного...
Я бы мику нормально за сиську помацал на 48 кекабайтах, эх... Ну а так да, 128 кеков надо
Тебе под шконку к 7b моделям, дружище...
Там все сильно плохо?
Я уже понял на каком сайте вы их ищете, но как из 7b найти получше? Для меня графомания была бы скорее плюсом, чем минусом
Тебе вот туда
Ну или любые другие 7-9-11b
Искать вот тут https://huggingface.co/models
Все остальное в нормальном качестве ты на 8гб врам не запустишь, чисто на видеокарте
Разгружая слои на процессор - да, но как ты заметил 20b 5km грузит у тебя долговато, для тебя
Скачивай да пробуй. Не забудь про настройки
у меня 2 теслы, но я вкидывал скриншоты своей ебли с командером выше. Я не могу этот кал запустить на грише.
Спсибо, анон, буду пробовать
> Разгружая слои на процессор
Это само происходит, или это целенаправленное, которое делают вручную? И если да, то как? Не первый раз вижу это словосочетание здесь
Шапку прочти, для вката самое оно, потом, если не долбоёб, ещё инфы нароешь и разберёшься
> Не забудь про настройки
Какой именно нюанс следует помнить? Есть гайд по настройке для овощей?
Я пока понял только что для моей винды нужно cublas выбирать
Спасибо, будем стараться
Я сам овощ и гуманитарий, но как-то разобрался. Кобольд твой бро, как и силлитаверн
Такие настройки приведут к еще большему бреду в случае если модель чувствительна к температуре, но здесь проблема не в этом.
> ban eos token
Это совсем бредить модель пойдет, если только с лимитом в 300 токенов и катать. Пусть уж лучше короткие посты но осмысленные. У этой проблем в длиной нет, но при попытках выдавать больше чем хочет начинается ерунда, не то чтобы это к минусам стоит причислять.
> Карточки персонажей у меня на 400+ токенов.
Там вообще 300 токенов. Ей похуй на размер, хоть длинная, хоть короткая, оно просто укатывает к тому на чем оверфитнулось, это дефолтная проблема шизофайнтюнов.
> У персонажей работающая мотивация
Во, вот это как раз и лезет постоянно, только не в красивой обертке, а в постоянном оправдании и во внезапных инициативах. Начал чарнейм тебе завтрак готовить, и тут она внезапно начинает втирать ахуительные истории из карточки с предложением туда отправиться, противореча прошлым постам.
> Что значит "длительных"?
Речь не про контекст а про способность модели понимани происзходящее, выполнять инструкции в сложных условиях и угождать юзеру.
Самый простой пример - садишься обнимать девочку на диване, параллельно ведя беседу. Ожидаемое поведение - она ведет диалог и реагируеть на обнимашки в зависимости от твоих действий, или плавно-плавно переводя уже в ерп, или начиная обнимать тебя в ответ но без перегибов, или просто успокаиваясь. Здесь же - или
> oh yes right there right there
и стеснительный невинный чар уже кончает спустя 400 токенов шизы, или начинает сыпать тебе какими-то припезднутыми предложениями и куда-то убегать. Офк могло бы вообще залупиться, и на том спасибо, как говорится.
На контекст уже лень проверять ее было, брать готовый большой чат - не честно, а набирать - ну такое.
> Из чего я и делаю вывод о некотором твоём, скажем так, пиздобольстве/лукавстве
Это крайне рофлово выглядит после тех стен пожара выше, и заявлений что ваше рп - неправильное, нужно делать иначе. Кончились аргументы в защиту модели - начались врети, базированно. Хз что ты в ней вообще нашел, это оверфитнутая ерунда на основе провальной архитектуры, которая уступает даже 11б, но при этом имеет требования выше чем у 30б.
Нет, офк если катать что-то на чем было обучение - то и проблем будет меньше, но это быстро заебет, а привыкнув к нормальным ответам эти будут казаться достаточно пустыми.
>И если да, то как?
ты короче когда убабугу запускаешь - указываешь параметр --n-gpu-layers
Этот параметр при лоадере llama.cpp указывает сколько слоев ты положишь на гпу, а остальное он положит на оперативку. Я не пробовал кстати так большие модели грузить, мне кажется должно сильно медленнее стать.
вот например моя строка запуска
CUDA_VISIBLE_DEVICES=1,0 ./start_linux.sh --model models/psymedrp-v1-20b.Q8_0.gguf --n-gpu-layers 120 --character Saya --n_ctx 8192 --listen --tensor_split 37,44 --alpha_value 2.5 --setting settings.yaml

Кобальд сам выбирает, сколько слоев +- верно.
Можешь поставить в 0 можешь хоть все если уверен что влезет, тестируешь-смотришь результат и выбираешь как тебе лучше
имхо он выбирает сильно меньше, чем можно на самом деле запустить. Поэтому я бы рекомендовал взять его дефолтное значение, а потом слегка наращивать, пока система позволяет.
Да, на P100 exl2 должны хорошо идти. Интересно, что получил анон, который 4 таких заказал.
>P100
почему не 40?
Спасибо большое, аноны. А зачем это вообще делается? Нагрузка распределяется равномернее, тем самым увеличивая производительность?
> убабугу
У меня кобальд, это кажется альтернативный интерфейс, если я понял правильно. Но твое сообщение я тоже обязательно сохраню, кажется для меня щас нет лишней информации
Условно говоря есть модель размером в 8 гб. Плюс ей нужна память (контекст) еще в 3 гб. А у тебя видеокарта всего с памятью в 8 гб. Если ты будешь грузить видюхой - ты не сможешь ничего сделать, у тебя память забьется. А проги типа кобольда выгружают часть модели в оперативку и гоняют часть через видюху, часть через проц с оперативой. Для такой выгрузки нужен формат моделей .GGUF
От размера контекста еще зависит, вроде работает если сначала указать размер контекста, а потом уже модель вставлять
Кажется раньше кобальд убавлял количество слоев, ориентируясь на контекст, щас хз скорей всего так же
Ну, поиграться с количеством слоев можно, почему нет
Часть модели считается на процессоре, то что влезло - на видеокарте.
Так как на процессоре медленнее чем на видимокарте, то чем больше слоев на гпу тем лучше.
>А зачем это вообще делается?
чтобы впихнуть невпихуеммое - очевидно же. За сечет оперативки цпу-шной.
из моего поста ещ ее обрати внимание на альфа вэлью и размер контекста. Если модель рассчитана на 4096 контекста, а ты хочешь больше - тебе нужно добавлять альфу в параметры. Для х2 конеткста от модельного альфа ставится 2.5
Контекст жрет просто непомерно много. На 4битах просто так можно вместить около 16-18к, если использовать cache_8bit то в районе 30к. Для сравнения с контекстом 512 занимает около 23 гигов. Другие кванты качать надо, но там зависимость потребления памяти линейная от размера и на жор контекстом не влияет, так что можешь посчитать сам.
> Это совсем бредить модель пойдет
Так не идёт же. Видишь, мы запускаем разные модели на разных настройках и получаем разный результат
> Во, вот это как раз и лезет постоянно, только не в красивой обертке
У меня в красивой, в соответствии с характерами персонажей, с их желаниями, стремлениями и т.п. Всё очень логично и правдоподобно. Итого эта модель хорошее подспорье в сценарной работе
> Речь не про контекст а про способность модели понимани происзходящее
Ну так на больших токенах оно и раскрывается. Те же микстрали 8х7 и всякие 34б это вообще говнина начинают шизофазию к 8к, выпадая из происходящего, а тут всё пучком. А командр 35б плоская поеботина с картонными дурилками вместо чаров, невнятным мычанием вместо описаний и т.п. блёвом
> Это крайне рофлово выглядит после тех стен пожара выше, и заявлений что ваше рп - неправильное, нужно делать иначе.
Ну, я никак не могу влиять на твои потешные фантазии про пожары и прочее перевирание моих слов. Я сказал, что кранчи онион лучше, чем командр 35 и это просто факт, исходя из опыта пользования онионом и сегодняшнего потерянного с командром дня. Я перепробовал буквально все маленькие модели в gguf с хаггинфейса и остановился, в данный момент
> , которая уступает даже 11б
Даже 34б не катят в сравнении, о чём ты
> Кобальд сам выбирает, сколько слоев +- верно.
Ни ху я
Меньше не больше
>почему не 40?
Да вот у меня две 40 и думал я к ним 3090 прикупить. Да посмотрел на фотки того анона и наверное ещё парочку P100 к ним возьму, благо система позволяет. 80гб врам, на 32 из них можно еxl2 гонять. А можно взять ещё парочку P100 - всего 64гб врам выйдет, но и гпу и врам уже качественно другие. Вот думаю пока.
яннп
объясни по нормальному, зачем брать паскаль на 16 гигабайт вместо паскаля на 24 гб?
> Видишь, мы запускаем разные модели на разных настройках и получаем разный результат
Желаемое за действительно выдаешь, там речь о другом шла, перечитай. Маневры что не та модель даже без комментариев оставлю.
Если привык к воде примерно на тему, что выдают 7б и инджоишь - это и хорошо, будет много открытий когда появится возможность комфортно пользоваться другими моделями.
> твои потешные фантазии про пожары
Ну давай восстановим хронологию
> ряяяяя ваша модель у меня не запускается а значит она плохая, плохая я сказал есть много моделей лучше!
> какие?
> вот, смотрите, моя прелесть
> это хуйта по всем предпосылкам
> врети врети там аж 7х7б а значит она хорошая
> она плохая, вот ее недостатки и они проистекают из ее сути, 4х-битная qlora микстрале - заведомо проигрыш
> неправда у вас не та модель, не то рп, не те настройки, а ты в кобольде потести
Как же ты сам не понимаешь насколько это кринжово? Впечатлился какой-то херней и теперь носишься с ней.
> Я перепробовал буквально все маленькие модели в gguf с хаггинфейса и остановился, в данный момент
> маленькие модели
Не буду писать какие модели пробовал сам, но когда познаешь просветление и освоишь что-то побольше - дойдет.
> и наверное ещё парочку P100 к ним возьму
А зачем они? Офк если слотов много и они сильно дешевле чем P40, но чем больше стакаешь - тем выше страф к скорости. Скидывали бенчмарки и там время обработки контекста на жоре совсем безумное становится, хоть на генерацию особого импакта нет. В экслламе же пока нет нормальной поддержки паскалей.
Спасибо, добрые подробные аноны, буду учиться
> Желаемое за действительно выдаешь
Действительное выдаю за действительное
> Если привык к воде примерно на тему, что выдают 7б
Абсолютно разные вещи то, что выдаёт онион и вода у 7б
> Ну давай восстановим хронологию
> > ряяяяя
Да ты не ряяякай, фантазёр. Дальше не стал читать, приходи, когда сможешь общаться, как человек
Если найдешь модель что тебе понравится - ищи тогда ее в другом разрешении exl2, и тогда можно будет запускать гораздо быстрее, если скачаешь файл в 5-6 гигабайт с приемлемым качеством, 3-4-5 бит.
Но это уже не для запуска на кобальде, это в text-generation-webui/
В принципе на 8 гигах в таком формате очень быстро будут отвечать любые 7b, может быть и 11b влезет с нормальным качеством в 4 бита
>psymed
Медицина изучает болячки и гниение, а не здоровые вещи. Как эта информация должна помочь?
> Абсолютно разные вещи то
Да те же яйца, только в профиль. Ощущается рассеянность одновременно с чрезмерным фокусом на некоторых вещах и излишняя cot-образность ответов, что приводит к неестественным диалогам, особенно если явно задаешь чару какой-то вопрос.
> приходи, когда сможешь общаться, как человек
Ты, петушиная голова, на нейтральную реплику даже не поняв сути отвечаешь так а потом заикаешься про умение общаться? Фу мусор.
> Но это уже не для запуска на кобальде, это в text-generation-webui/
Кстати, кто не любит убабугу или не хочет ждать его апдейтов, есть https://github.com/theroyallab/tabbyAPI/
> болячки и гниение, а не здоровые вещи
Шутка про рп
https://www.reddit.com/r/LocalLLaMA/comments/1by65dg/twoai_letting_two_llms_have_a_conversation_on_any/
> I recently made this Python script just to see where the conversation would lead if I let two LLMs conversate on random topics, I once saw someone do it with ChatGPT long time ago but this runs with local LLM using Ollama.
> So just wanted to share it here as other people might find it fun too.
> Github: https://github.com/Fus3n/TwoAI
>зачем брать паскаль на 16 гигабайт вместо паскаля на 24 гб?
Буквально в предыдущем треде перечисляли отличия P40 и P100.
https://2ch.hk/ai/res/689693.html#695285



Попробовал PsyMedRP-v1-20B.i1-Q3_K_S (imatrix), лучше любого <11.7. nous-hermes-2-solar-10.7b.Q5_K_M, solar-10.7b-instruct-v1.0-uncensored.Q6_K, Fimbulvetr-11B-v2.i1-Q5_K_S, frostwind-10.7b-v1.Q5_K_M До этого момента еще ни одна модель не прошла этот тест. Обычно либо либо пропадает характер карточки, либо ответ фактически не правильный, хотя чаще всего обе причины, а тут 2 из 2. Один минус 1.5 токена в год сек. (На 8 свайпе отказала, "типа не знаю".)
Ебла отрицателей 3 битного квантования?

Два минус - как все ебаные миксы забывает про форматирование результат - белый текст.
проверяю тут psymedrp-v1-20b.Q8_0.gguf
сетка действительно лучше описывает аспекты связанные с телом.
если на noromaid-20b ты пнешь насильника по яйцам - он на изи может принять удар, а потом как ни в чем не бывало встать и продолжить с прежним напором.
На psymedrp я пнул его по яфйцам и получил хороший отыгрыш чувака которому врезали по яйцам. Отпустил, повалился на пол, еле дышит, заплакал, на протяжении переписки продолжает лежать и корчиться.
Достоверно. Годно, подтверждаю.
сетка действительно лучше описывает аспекты связанные с телом.
если на noromaid-20b ты пнешь насильника по яйцам - он на изи может принять удар, а потом как ни в чем не бывало встать и продолжить с прежним напором.
На psymedrp я пнул его по яфйцам и получил хороший отыгрыш чувака которому врезали по яйцам. Отпустил, повалился на пол, еле дышит, заплакал, на протяжении переписки продолжает лежать и корчиться.
Достоверно. Годно, подтверждаю.

У меня если что скрин с https://huggingface.co/spaces/CohereForAI/c4ai-command-r-plus
Спасибо, я знаю, что нейросети хорошо оправдывают свои обсёры.
Идет бодро даже с 1 п100, а вот проклятая ошибка с версией КУДА подзаебала.
Буду на 4060ти видимо менять.
>Буду на 4060ти видимо менять.
45к за кастрата с шиной 128 бит и пропускной 288 Гбайт/сек (как у P40)? Ну такое себе.
На 3090 жаба душит 80 колов отдавать ради текущих LLM.
Никто не в курсе с хера ли Жора перестал компилить свои релизы, уже неделю как. Думал может ждут когда изменений поднакопится, но нихрена. Теперь надо жопу ломать чтобы это под куду компилить то и дело? Может есть место где готовое выкладывают? Достали эти красноглазики...
А, понял, там в релизе файлов нет. Ну, пиши ишью, если уже нету.
Какая разница, если скорость норм?
>Ебла отрицателей 3 битного квантования
Смотрю на тебя с непониманием и небольшим разочарованием.
Тыж содомит догадался запустить маленькую сетку с низким квантом, ору в голос, а если бы скачал хоть бы iq4, то все стало бы ещё заебатее.
У коммандера 35b всего 41 слой
У типичных 11b по типу солара 48 слоев
ЛЛама 1 30b имеет 60 слоев, однако. Но видимо изза неоптимального обучения и сырого датасета не особо умна
Кодоллама 34b имеет 48 слоев
Так, делаю простой вывод, коммандеру не хватает слоев для ума полноценной 30ки
Нам будто не всю модель отдали, зажали 10 слоев сверху, хммм
У типичных 11b по типу солара 48 слоев
ЛЛама 1 30b имеет 60 слоев, однако. Но видимо изза неоптимального обучения и сырого датасета не особо умна
Кодоллама 34b имеет 48 слоев
Так, делаю простой вывод, коммандеру не хватает слоев для ума полноценной 30ки
Нам будто не всю модель отдали, зажали 10 слоев сверху, хммм

По сути коммандер аналог 7b-9b сетки, даже не 11b
Но изза ширины слоев и количества параметров обладает большим количеством знаний чем мелочь по типу 7b и 9b
А вот ума ему это мне кажется прибавляет не так много, как получи он хотя бы 50-60 слоев
Тоесть у него могут быть проблемы с понимаем каких то абстракций, может не связывать между собой очевидные человеку вещи, как 7b например
Так, ваши мнения, щупальщики командера?
Я щас тоже скачал, буду тестировать сегодня, если успею
Считать слои - это даже тупее сравнения PPL. Сам слой состоит из нескольких блоков, количество слоёв вообще никак не коррелирует с финальным результатом.
Da, ona govorit po russki
Если бы это было тупо, то перемешивание слоев и получение бутербродов из 7b и 13b не работало бы
11b и 20b умнее своих оригиналов, в том числе потому что у них больше слоев
Там ведь даже новой инфы нет, только по разному слои активируются изза смещения
Если бы это было тупо, то перемешивание слоев и получение бутербродов из 7b и 13b не работало бы
11b и 20b умнее своих оригиналов, в том числе потому что у них больше слоев
Там ведь даже новой инфы нет, только по разному слои активируются изза смещения
Seranul
По идее выходит раза в 3 ниже 3090. Ну ХЗ.
Ой всё.
>Нам будто не всю модель отдали, зажали 10 слоев сверху, хммм
А если нарастить...
>Сам слой состоит из нескольких блоков
Так эти блоки у всех одинаковые, разве нет? Трансформер он и и в африке трансформер. Блок нормализации, блок весов, блок аттеншена, блок нормализации. Может чего забыл, но база примерно такая.
Мейк сенс.
База.
Ждем микстралей в q5_k_m, получается.
>По идее выходит раза в 3 ниже 3090
Что именно ниже? По какой идее? Ты точно учёл все остальные параметры, которые имеет карта и память помимо шины?
>Ты точно учёл все остальные параметры
Нет, забил. Увы, пока ещё не видел хороших тестов скорости, у самого только 1 картонка.
Но не вижу других проблем у этих двух чипов, кроме как скорости памяти. Обе просто упрутся в шину, так что можно просто сравнить скорости памяти.
не поеботина от унди, а реальный новый микстраль от мистраль ай? слили торрент ночью? данунах! этож пиздец теперь коммандеру, он больше не король, 176b параметров суммарно нахуй!
>176b параметров суммарно
У OPT тоже есть вариант на 176В. Но он как был говном, так и остался.
Блин, а ведь это я пожелал сеток по-больше, когда файнтюны 7B поперёк горла встали. Вот и получил сетки, которые даже запустить не могу. Да что ж такое.
Смотри, как раз по тестам она нихуя никого не ебет.
Она выдает сопоставимые результаты при гораздо более меньшем датасете.
НО! Важно помнить, что Llama обучалась на этом датасете как 7b, так и 70b.
Отсюда возникает вопрос: а какой датасет необходим был лламе 2 для такого же качества 7b, без излишеств?
А грифон сможет на его датасете обучить 70b модель с таким же качеством?
Короче, исследование, полухуйня.
Но если все и правда так, то это подстегнет дальнейшее развитие моделей, так как щас опенаи уже жалуются, что у них весь мир в датасетах кончился.
Тут анон выкладывал тесты , вроде нормальная скорость.
На реддите тоже видел сравнительные тесты, но потерял ссылку.
мне просто тоже не хочется отдавать 85к за 3090+новый БП, колхозить доп. охлад и потом ещё трястись за техническое состояние, поэтому рационализирую 4060ти
гораздо более меньшем…
Ой, отстаньте!
3090 вс 4060ти
это как
п40 вс п100
>так что можно просто сравнить скорости памяти
Забыл кэш и прочую обвязку кстати.
О, я сначала прочитал как 22 сетки по 7b, подумал еще мол теперь дурачков 7b стало 22 какой смысл то?
Теперь понятно, мега микстраль вышел получается
Только на чем его запускать то, там даже оперативы нужно гигов 120
Думаю там не только лучший датасет и сама методика тренировки влияют, но и новая архитектура тоже показывает лучшую обучаемость
Да и плюсами выделены большая скорость и чет там про контекст, так что это тоже ускоряет обучение
И?.. =)
20-30 тыщ рублев за 128 гигов оперативки, проблема в чем?
Напоминаю: база треда, как и п40 (две).
И даже скорость должны показать неплохую (как 45b условная).
Так что, ждем, посмотрим, чем там выкатили-то.
>20-30 тыщ рублев за 128 гигов оперативки, проблема в чем?
Так даже так медленно будет. Если там так же 2 эксперта за раз, то 22b в 4 кванте 10-11 гб. 2 сетки по 11 гб+контекст и все это крутить через рам. Это на лучших ддр4 2 токена в секунду. На ддр5 -3-4 токена в секунду.
Это все равно нужна врам, по хорошему, а ее в таких объемах нету
Я думаю карточки от нвидима после выработки своей стоимости и полезности могут и утилизировать начать, что бы они не доставались даже так энтузиастам или конкурентам
Ну, 3-4 токена в секунду — это уже недалеко от Мику на теслах.
А теперь надо посмотреть на качество. Если оно аутперформит ту же Мику, то…

>вроде нормальная скорость
Звучит как что-то, что можно сравнить. В общем запустил у себя (обсёр 3080Ti, скорость как у 3090), получил под 50 токенов на сравнимом объёме, против 20 на 4060Ti. Ну в общем-то не 3 раза, а 2,5.
Извини, рационализировать не даю.
Так ты сравни нос к носу. Та же модель, тот же контекст.
Там наверно не 176б а поменьше, это же МОЕ модель. МОЕ модели не люблю. Шесть ебланов стоят вокруг и смотрят как остальные два яму копают. как бы из-за того, что быстрее, чем если бы все восемь толкались в яме. Но других плюсов нет, и за это надо остальных шестерых держать в памяти просто впустую. Нерационально. Люблю плотные модели. Это как амбал копает яму в одно рыло.
Вот кстати интересно, почему они слили эту модель, а не конечную версию Мику.
>Та же модель, тот же контекст.
Так смотри на скрин, она и есть (взял вторую). Контекст примерно того же объёма, в конце набил.
>Там наверно не 176б а поменьше, это же МОЕ модель.
Это понятно что меньше, но не суть. Суть в том, что куча параметров само по себе ничего не гарантирует, и 176б, трейненных жопой, могут слить 7б, трейненных плотно.
> перемешивание слоев и получение бутербродов из 7b и 13b не работало бы
Оно и не имеет эффективности как обучение. Слоёв ты можешь запихать сколько угодно, прирост будет очень слабый, а в большинстве случаев оно ещё шизить начнёт.
> Трансформер он и и в африке трансформер. Блок нормализации, блок весов, блок аттеншена, блок нормализации.
Аттеншен - это меньше половины весов слоя. Есть ещё MLP, где активации и происходят, в нём весов как в аттеншене.
Слои трансформера не меняют структуру входных данных, каждый слой сдвигает токены в пространстве эмбендинга. Размер эмбендинга, в котором происходят трансформации токенов, как раз влияет на адекватность каждого шага трансформации. Количество не всегда лучше качества.

>Есть ещё MLP, где активации и происходят
Ага, я его назвал блок весов.
>Количество не всегда лучше качества.
Само собой. Но качество обучения сложно сравнивать, много субъективщины. А посчитать число слоёв это легко и просто.
>Оно и не имеет эффективности как обучение.
Ну как раз таки в обучении оно и показывает свою эффективность.
Просто микс модели с самой собой действительно дает небольшой эффект и есть шанс что модель начнет шизить.
Но вот дообучение такого микса на датасетах, как и появляются все эти годные 11b и 20b, как раз таки и дает эффект.
Так как теперь работающие едва едва слои одной сетки, переобучаются и полируются при обучении становясь полноценными рабочими слоями сетки.
Да, сетка тренированная с нуля в 20b все равно будет лучше, чем такие.
Но если просто сложение модели самой с собой даст 10-20 % прирост, примерно.
То дообучение миска даст +40-50% прироста качества модели.
Хотя "обучение" 20b в основном просто разные слияния, да
Вот кстати интересно, а есть примеры добучения миксов на датасетах?
Или их не получится обучать?
Бамп вопросу. Интересует именно для текста, а не кода.
> отвечаешь так
В чём я не прав? Ты же реально шизик, а там реально 7х7, и лук реально лучше командра 35. Гринтекстить можешь сколько влезет, факты от этого не изменятся
>Кажись он немного опоздал )
То, что крупные модели могут в русский как бы не новость. Только сравни требования к этому командиру и простенькой 7b.
Хотя мои опыты пока прекратились, конвертировать эту хуйню в ггуф невозможно, увеличить размер мне не дают ограничения железа. А 7b это всего лишь 7b, хотелось бы побольше мозгов.
Допустим там уникальных 88, ок.
Т.е., там, грубо говоря, знаний на 88б.
А скорость на 44б.
А занимает как 176б.
Ты тратишь вдвое больше памяти ради вдвое большей скорости, вот и вся магия.
При этом, уникальных там может быть больше существенно (в первой микстрали было 45 из 56 уников), и тогда знаний будет гораздо больше, а скорость та же.
Ну и опять ж, мое — это универсальные сети, которые именно много че знают и умеют. В этом их фишка, а не в строгой специализации только на рп.
С этой точки зрения — пиздатая штука. Не хуже и не лучше одного амбала. А просто иной подход. У кого есть много медленной памяти — мое будет выгоднее. У кого есть тоже много (будем честны, 60+ гигов — это много для видеопамяти) быстрой памяти — тому выгоднее одна цельная, канеш.
По ситуации.
https://3dnews.ru/1103040/v-2024-godu-roskomnadzor-nachnyot-ispolzovat-ii-dlya-vedeniya-reestra-zapreshchyonnoy-informatsii
Вот оно, настоящая причина важности ии, автоматизированное интеллектуальное цензурирование, просто кто то это скрывает, а кто то пишет с гордостью
Антиутопии прошлого детский лепет по сравнению с тем что будет дальше, хоть и не везде
Вот оно, настоящая причина важности ии, автоматизированное интеллектуальное цензурирование, просто кто то это скрывает, а кто то пишет с гордостью
Антиутопии прошлого детский лепет по сравнению с тем что будет дальше, хоть и не везде
>Так смотри на скрин, она и есть (взял вторую)
Тогда не очень репрезентативно, с контекстом 1482 скорость уже почти сравнялась с результатами того анона.

Чёт кекнул со скрина.
>То, что крупные модели могут в русский как бы не новость.
Раньше и семидесятки периодически лажали. Даже гопота 3,5 турба. А вот командир прямо чётко отвечает, с логикой могут быть проёбы, но вот в склонениях и прочем вообще не путается.
>Хотя мои опыты пока прекратились, конвертировать эту хуйню в ггуф невозможно
Жаль конечно, один из немногих, кто что-то своё пилил. А что там с ггуф?
>хоть и не везде
А где не будет? Буквально весь мир катится в оруэлщину, от Китая до Англии, про Р молчу вообще опасно же пускай мучаются, гады, читая спойлеры.
>с контекстом 1482 скорость уже почти сравнялась
Там токенов мало, вот и просела средняя. Можно было бы продолжить, и на сотне токенов скорость оставалась бы около 50-ти.
>Можно было бы продолжить
Поэтому и пишу, что
>не очень репрезентативно
Надо было ещё несколько ранов сделать.

Вот бы... Мечты мечты.
Принято. Добил дальше, скорость всё та же 47-49.
>Но тот же москвобад уже давно напичкан камерами и датчиками
ИЧСХ, пользы около нуля.
У Командера+ там токенайзер вроде обновили, может ещё лучше станет?

>Чёт кекнул со скрина.
Она тренилась изначально на хуйне какой-то, да и мои шаловливые ручки мозгов не прибавили, скорее всего, лол. Я потом начал спрашивать, какого хуя трое, негронка начала фантазировать, как землекопы залезли на дерево и спасались от зверя, но их всё равно оставалось трое.
>но вот в склонениях и прочем вообще не путается.
А у меня пиздец с этим временами, но гораздо больше проблем из-за машинного перевода. В любом случае, командира смогу запустить разве что с подкачкой на чайник, а это будет не айс по скорости. А вот эта моделька в голых fp16 на тесле
>Output generated in 24.91 seconds (15.06 tokens/s, 375 tokens, context 146, seed 801573368)
>Всего слов 267
>Всего символов 1957
>Всего символов без пробелов 1694
>А что там с ггуф?
Нет поддержки кастомных токенизаторов. Раньше он даже added tokens не поддерживал, как я понимаю, вообще игнорировал к хуям существующий токенизатор и зашивал в модель дефолтный лламовский. Так как моделей с юниграм токенизатором нихуя нет, то и поддержки нет, хотя теоретических профитов у него много.
Хотя мысли есть, я опять возьму нож и буду резать и сшивать, пока чудовище не оживёт.
Там ещё жора судя по всему говна наложил, так что ждать и ждать
https://github.com/ggerganov/llama.cpp/issues/6551
>Принято. Добил дальше, скорость всё та же 47-49.
Сяп. В целом пойдёт, тряски за тех. состояние самой 3090 в любом случае не стоит. Для меня уж точно, у меня на одно сообщение приходится несколько десятков свайпов, иногда несколько сотен (я просто сообщения почти не редачу, ловлю кайф когда нейронка сама пишет как надо и как я хочу). С такими интенсивными спайками нагрузки это был бы инстант отвал жопы у карточки, скорее всего.
Ой все.
А можно просто нормальный мистраль в 22б без мое-залупы? Офк хоть что-то уже спасибо, но 176б - ебучий фалкон, который невозможно катать юзерам.
Не думал что это немного не так работает? И в разных архитектурах могут быть разные оптимумы. Вон есть стак из 4х мистралей 7б подряд, он то вообще запредельным судя по твоим рассуждениям должен.
Оно все равно хуже чем могла бы быть полноценная оригинальная модель такого размера. Это дает некоторое "сглаживание" ответа из-за чего он может восприниматься гораздо лучше, но именно "ума" - не прибавляет.
> оперативки
Опять этот мазохист и любитель маминых обработок контекста.
Аноны подскажите: скачал вот эту карточку: https://www.chub.ai/characters/long_RPG_enjoyer/61595bad-5ee6-4443-8395-28c974391df4
Пробую локально на 20b модели, не выдает данные о дате, времени, и прочим, как обещенно в описании. ЧЯДНТ?
Пробую локально на 20b модели, не выдает данные о дате, времени, и прочим, как обещенно в описании. ЧЯДНТ?
А где в описании или в карте написанно про вемя или даты?
>tested on Claude and GPT4
Это.
>Не думал что это немного не так работает? И в разных архитектурах могут быть разные оптимумы. Вон есть стак из 4х мистралей 7б подряд, он то вообще запредельным судя по твоим рассуждениям должен.
Так это все одна архитектура считай
Я ж не говорил что только количество слоев важно, но 60-80 имеют самые умные сетки.
Толку делать сверхширокие, но плоские сетки? От этого давно отказались.
Сейчас 7b имеющие 32 слоя туповаты как их не выдрачивай, в сложные вещи им просто не хватает мозгов.
Дотренированные 11b уже умнее, как раз таки за счет новых слоев поверх старых.
Вот это наращивание добавило сетке мозгов. А значит 50-80 слоев нормалек так для умных сеток.
Конечно и ширина слоев так же важна, 7b c 80 слоями все равно будет тупой, и знать будет меньше так как параметры размазаны по слоям
Ну а микстраль отдельная тема, мне например не нравится что куча тупых сеток пытаются что то делать, не могут они держать во внимании кучу инструкций.
Так как это все еще несколько 7b работающих в синхронизации.
Новый 22b микстраль, если он еще и настоящих экспертов имеет, вот это уже другой разговор.
Полноценные сетки эксперты в 22b выглядят вкуснее и умнее.
> как раз таки в обучении оно и показывает свою эффективность
Случай солара, где был несколько другой кейс. Те же 20б полноценно даже не обучали большей частью.
> просто сложение модели самой с собой даст 10-20 % прирост, примерно
> То дообучение миска даст +40-50% прироста качества модели.
Откуда цифры и как они измерялись?
В том посте буквально имплаится то что по сути и конечному перфомансу оно не ушло 7б, только жрет ресурсов в 7 раз больше как полноценная большая модель. Очень похоже что ты таки это понял, от чего порвался и начал сыпать оскорблениями. Ахуенный ты кадр, такая самоуверенность в сочетании со слепой верой и тупостью, хорошее бинго для неизменности фактов.
> там, грубо говоря, знаний на 88б
Вот это интересно проверить как раз. В одной статье китайцев оценивали возможность упаковки "знаний" в модели разных размеров и там была сильная нелинейность в сторону того что большая гораздо лучше запоминает, но там было просто обучение лор что не то чтобы репрезентативно.
> Ты тратишь вдвое больше памяти ради вдвое большей скорости, вот и вся магия.
Там где есть память - нет проблем со скоростью. Мое оправданы в случае, когда без роста потребления нужно увеличить знания, специализацию и прочее, при этом запуская на гетерогенных системах. Но никак не для ограниченных в ресурсах пользователей (чек) или исследований, ведь даже первый микстраль нормально почти не файнтюнили.
> пиздатая штука
Хорошо что хоть что-то есть, тут без вариантов. Но интереснее было бы поглядеть на чистую 22б, такие у них наверняка в ассортименте и хуй выложат.
Кста, это хороший детектор дегенерата, когда видишь как кто-то про "ум" нейросеток рассуждает. Каждый раз проигрываю.
Каждый раз проигрываю с дегенератов не умеющих в образное и абстрактное мышление, хороший детектор глуповатого человека, который считает себя умным, лол
>Откуда цифры и как они измерялись?
По ощущениям, как их еще измерить? Если просто смешивать слои одной сетки то прирост есть, но незначительный.
Если делать кучу смесей по разному отфайнтюненых моделей, смешивая их веса чуднЫм образом, как то получают производительность большую, чем в изначальных компонентах.
Тоесть до настоящих 20b такие сетки не дотягивают, останавливаясь по ощущению где то между 15-17b, если бы это была нормальная модель.
Ну во первых, да описание бота довольно мутное, нет ничего ни про какую статистику. Только про механику успех/провал и про то что надо развлекать юзера. Большим моделям, вроде ГПТ и Клода этого может и достаточно, но для маленьких нужны более подробные указания.
Если ищешь любопытные РПГ карточки, попробуй погонять вот это:
https://rentry.org/ray_the_on#chrono-ark
https://www.chub.ai/characters/rayon/chrono-ark-twisted-wonderland-b5b31b2a
> По ощущениям
Ну я понял, пошёл нахуй тогда.
Пацаны, скиньте рабочий жб от ркн, заебал блочить!
> ИЧСХ, пользы около нуля.
Если тебя нужно найти - тебя найдут, узнают все твои популярные маршруты, распорядки и прочее. По госномеру можно найти фактическое положение любого авто с точностью до двора. Структуры тихо но довольно урчат от раскрываемости и разыскиваемости с одного только метро, что было на событиях после 24.02.22 сам можешь найти. Еще не психопаспорт, но на нужном пути, просто не афишируется, оценку такому уже сам делай.
> Так это все одна архитектура считай
Ого, то есть если я через пайплайн трансформерса могу запустить графические модели - они тоже той же архитектуры что и ллама, да? Вот куда нужно слоев добавить, лол.
> но 60-80 имеют самые умные сетки
Это ложный вывод основанный на ограниченных наблюдениях без учета прочих факторов.
Двачую.
Так и пиши что субъективная оценка.
Тут бы хоть полноценное тестирование без плацебо сделать той же субъективщины с разными критериями, и то это всеравно будет ангажированная штука.
А что, если к двум теслам P40 - два 4060Ti? :)
Я когда рассматривал варианты, то спрашивал чат о связке из 4-х 4060Ti. Меня на смех подняли.
Солидарен, пошел ка ты нахуй дурачек
>Ого, то есть если я через пайплайн трансформерса могу запустить графические модели - они тоже той же архитектуры что и ллама, да? Вот куда нужно слоев добавить, лол.
А при чем тут графические модели? Речь шла о структурно похожих текстовых нейронках
Там все трансформерс, новых архитектур хоть и завезли, но нормальных сеток на них по пальцам пересчитать. И речь о них не шла.
>Так и пиши что субъективная оценка.
Любая оценка субьективна
>Тут бы хоть полноценное тестирование без плацебо сделать той же субъективщины с разными критериями, и то это всеравно будет ангажированная штука.
Как ни сравнивай, но аноны выбирают на поболтать и подочить не 13b, а 20b, если могут.
Разница между ними ощутимая, а значит она есть. Если даже в смеси модели с самой собой заметен небольшой рост способностей сетки, хоть и могут вылезти какие то бзики.
Там еще можно поспорить, туда сюда, есть от них смысл или нет.
То 20b неоднократно хвалили аноны, выбирая их, а не существующие 13b, которые легче запустить
Как знаешь. Как по мне, ожидание не стоит того, ну как знаешь.
Я бы не настолько уверен в их нанотехнологиях, лол.
>А можно просто нормальный мистраль в 22б без мое-залупы?
Отрываешь одного эксперда, и вот тебе.
Там все инструкции в дополнительных полях, которые не используются в локалках. Переноси, адаптируй и так далее.
Впрочем, не рекомендую перегружать локалки таким количеством сложных инструкций.
>узнают все твои популярные маршруты
Через 5жи отсканируют мою квартиру и узнают, что я хожу от кровати до стула, и от стула до толчка.
>По госномеру можно найти фактическое положение любого авто с точностью до двора
Лучше бы с точностью до заезда на газон узнавали, а то всё перепахано нахуй.
>Еще не психопаспорт
Особенно подальше от столицы. Там концлагерь уже, а у меня на похуях, камера в подъезде висит для виду и не работает, лол.
>Это ложный вывод
Ну кстати вполне нормальный. Как по мне, без обратного распространения AGI вообще не построить, лол.
Бля мужики, обновил таверну и кобольд и теперь у меня на мою реплику постоянно полностью рассчитывает весь чат Processing Prompt [BLAS] (4673 / 4673 tokens), а раньше просчитывал только мою реплику, что я забыл поставить? Или что-то сломалось?
> что было на событиях после 24.02.22
Лучше посмотреть на более свежее, 22.03.24. Камеры были до события, а тазик со злоумышленниками съебал аж до государственной границы. Интересно, что было бы, имей злоумышленники двухзначный айкью и смени машину\внешний вид. Существование технологии и её теоретические возможности ещё не означает её применение на практике.
>То 20b неоднократно хвалили аноны, выбирая их, а не существующие 13b, которые легче запустить
По идее, здесь должна быть корреляция популярности и размера модели с количеством vram у анониев. Иначе не могу объяснить большой разрыв между 20 и 34b, хотя технология-то позволяет делать модели в этом промежутке.
> о структурно похожих текстовых нейронках
Уровень структурной похожести?
> А при чем тут графические модели?
Вот как раз про
> Там все трансформерс
и оно.
> Любая оценка субьективна
Нет, даже абстрактные вещи можно качественно оценить, просто это сложно и врядли кто-то будет делать.
20б лучше 13, но она не умнее, она просто более устойчивая, такая какой хотелось бы видеть 13б с самого начала. Суть вот именно про это, и в том что оригинальные большие модели были бы лучше тоже вроде нет споров. Однако, оригинальная модель с более жирными слоями меньшего числа была бы не только лучше по языку, но и гораздо более внимательной ко всему, выполняла бы больше инструкций не перегружаясь и все учитывала, точнее бы подмечала детали и т.д. Так что про оптимальность количества слоев вообще не стоит говорить, эти выводы - исключительно искажение, вызванное отсутствием "больших" моделей что влезли бы в топовые гпу и/или с некоторым оффлоадом, и заместительством их франкенштейнами. В новых моделях неспроста уходят к меньшему количеству слоев при том же размере.
Зря рофлишь.
> Особенно подальше от столицы.
Это в сделку не входило, но со временем дойдет.
> Ну кстати вполне нормальный.
Не, нихуя. Выше описано почему.
> а тазик со злоумышленниками съебал аж до государственной границы
Туда доехать можно за один вечер если что, пока пердели и спали так унеслись. И тем не менее отследили если бы очень очень хотели то могли бы предотвратить, или минимизировать ущерб, но позвольте это работать эффективно надо.
> Существование технологии и её теоретические возможности ещё не означает её применение на практике.
Именно так, используется по необходимости. Но сам факт - подобная бигдата и обращение с ней уже среди нас.
> Иначе не могу объяснить большой разрыв между 20 и 34b
Потому что 34б - только кодллама что совершенно непригодна ни для чего кроме кода, или YI (на ее основе) что довольно шизоидная и поломанная. Сейчас подвезли коммандер, но пока он без файнтюнов, на жоре не работает, а эксллама требует очень много врам на контекст. 20б доступно даже 8 гиговым с оффлоадом, была бы норм 34б - запускали бы ее тоже, пусть и с ожиданием.
>пока пердели и спали так унеслись
Я больше склонен к версии, что были сотрудники неподалёку от госграницы, которые и сделали дела.
>Потому что 34б - только кодллама
Имелся ввиду разрыв в смысле, что ниша не заполнена. Можно делать какие-нибудь 22-26-28b. Но что-то я их не наблюдаю.
> Отрываешь одного эксперда, и вот тебе.
Да если бы все так просто было, не факт что будет лучше 20б текущих. Хотя всегда можно отфайнтюнить такое.
> что ниша не заполнена
Ага. Франкенштейны такого размера делать уже неэффективно, а базовую модель - слишком сложно. Рили из последных опубликованных помимо лламы там только коммандер, mpt и falcon совсем протухли и даже на релизе были хуже лламы.
>Инaчe нe мoгу oбъяснить бoльшoй рaзрыв мeжду 20 и 34b, хoтя тeхнoлoгия-тo пoзвoляeт дeлaть мoдeли в этoм прoмeжуткe.
Тaк нe былo нoрмaльных 34b. Ну и у энтузиaстoв нe былo бaзoвoй сeтки нa 16-20 гб чтo бы из нee клeпaть фaйнтюны a из них нoвых мoнстрoв фрaнкeнштeйнa нa 34-36b
Дa и вoзмoжнoстeй фaйнтюнить бaзoвую мoдeль нa 20b у энтузиaстoв скoрeй всeгo нeт. Пoпулярными тaкиe бoльшиe мoдeли тaк жe нe стaли бы, этo нe 7-20 кoтoрыe мoжнo зaпустить нa любoм игрoвoм кoмпуктeрe с приeмлимoй скoрoстью

>Переноси, адаптируй и так далее.
А как? Что нужно сделать, чтобы хотя бы удачность\неудачность действий рандомно просчитывала?
мамба?
https://huggingface.co/models?sort=trending&search=mamba
Да, но не взлетела
Но на ее основе сделали гибридную аритектуру jamba и даже выкинули эту мое в открытый доступ недавно
55b что ли общий размер
Для тех, кому важна анонимность и качество, есть другие варианты? :) Очевидно — нет.
Не забывай, что экслламу на теслах ты не запустишь.
А четыре слота — та еще материнка.
Туда уж проще брать однотипное норм железо.
>экслламу на теслах
почему это?
Любопытным
https://huggingface.co/ai21labs/Jamba-v0.1
Кстати кто то видел новости о ее запуске? Герганов там что то пилит с ней?
>А четыре слота — та еще материнка.
Материнка-то хорошая, HEDT, 4 слота PCIe 3.0x16. Проблема в том, что у 4060Ti PCIe 4.0x8. А так вариант может и неплохой. Новое железо, все дела.

Пошла жара, новые высокотехнологичные обогреватели готовятся к продаже наносекам анонам, жду к концу года тестов, лол
https://3dnews.ru/1103013/intel-predstavila-trete-pokolenie-uskoriteley-ii-gaudi
https://3dnews.ru/1103013/intel-predstavila-trete-pokolenie-uskoriteley-ii-gaudi
Хорошо, запустишь, но с такой скоростью, что толку от них не будет. =)
Если материнка уже есть, то другой разговор.
Теслы позволят запускать даже коммандер+, даже новую микстраль. 96 гигов видеопамяти-то!
А 4060ти дадут 64 гига и умеренно быструю скорость.
3090 лучше, но я понимаю сомнения на их счет.
Думаю, тут выбор прост — по твоим запросам. Интересно ли тебе запускать огромные модели, или хочешь просто средне-большие с хорошей скоростью. На вкус и цвет. =)
Похуй. Всё равно цена будет как у однушки в МО. Они бы уже начали наконец что-то типа квадр делать - карты под личное использование для работы. Как раз куртка закопал свои квадры, мог бы кто-нибудь и запилить что-то похожее. Навалить больше DDR6X памяти там чипы по 15 баксов за 2 гига вроде стоят, блять, крутануть ценник немного и их бы с руками отрывали. А так либо десятилетний кал, либо всякий HBM по цене самолёта.
>Если материнка уже есть, то другой разговор.
Погоди, есть не только материнка, но и две теслы на ней :) Вопрос в том, не взять ли к ним ещё парочку 4060Ti. Придётся настраивать распределение памяти для каждой модели, но это ладно. Я вообще-то на 4 теслы нацеливался, но посмотрел преформанс двух - это пожалуй максимум. Есть вариант с одной 3-4-слотовой картой или двумя двухслотовыми (а тут по сути кроме 4060Ti ничего и нет).
Кстати, в количестве линий проблем вообще нет.
Задержки в секундах. При обработке больших моделей у тебя скорость будет 20-10-5 токенов в секунду, так что любое лишнее выражение покроет твои 3.0x8 (даже 3.0x1).
Лично мне две 4060ти в добавок к двум теслам кажутся… Странным трактором.
Напомню, что перформанс экслламы что-то в районе вчетверо-впятеро меньше перформанса ггуфа на теслах, так как п40 не могут в fp16.
И 4060ти для эксллам или дадут тебе 32 гига суммарно, или 80, но последние 48 гигов будут очень медленными.
Останется только ггуф, в которых и теслы не так плохи, вроде.
2 p100 добавь, будет +36 гб быстрой памяти которая может крутить exl2 Или сразу на всех что то большое в ггуф
>И 4060ти для эксллам или дадут тебе 32 гига суммарно, или 80, но последние 48 гигов будут очень медленными.
То же самое можно сказать и в случае 3090+2 теслы, только 3090 даст только 24 гига. Общая производительность не сильно-то и больше должна быть. Наверное.
Cмысл вообще брать новые карты в комплект к допотопным? На новых памяти мало, но чипы могут в квантованные битности, у допотопных тесл памяти много, но с битностями пиздец. Оно же вместе будет работать, как яйца на подбородке.
Бля, ну я насчитал, +32 гига врам, там же по 16 в каждой всего
В итоге с двумя p40 48+32 = 80 гигов врам, ну неплохо так.
>Cмысл вообще брать новые карты в комплект к допотопным?
Ну допустим контекст на новом GPU0 будет обрабатываться быстрее. Допустим, что если половина карт быстрые, а половина медленные, то общая скорость будет не по медленным, а где-то посередине (нужны тесты в разных режимах конечно). И уж точно на 32гб что-то из exl2 можно запустить, Stable Diffusion на одной из новых карт и прочее. Жаль конечно, что 24гб врам ставят только на топы.

>Да если бы все так просто было, не факт что будет лучше 20б текущих
Вот и посмотрим. Ещё можно попробовать смержить, или усреднить там. Как мы все видим, нейронки переживают весьма серьёзные издевательства. Пару лет назад я бы не поверил, что можно взять десяток слоёв с конца нейронки, присоединить их к ней же и получить рабочий результат.
Вот это слово не говори, и всё будет нормально беда из кончай треда с их переманиванием в отдельные от двача сообщества.
>А как?
Ctrl+C -> Ctrl+V в любые поля, которые отправляются. Хоть в саму карточку, хоть в мейн инструкт мода. Смотри на конечный промт и правь по наитию.
>Кстати кто то видел новости о ее запуске?
Всем похуй ©
>Материнка-то хорошая
>PCIe 3.0
Lil.
>наносекам анонам
Не хватит денег наносекам, тут пикосеком надо быть, а скорее кабанчиком с датацентром.
Ну, там не по середине, а по объему занятому, поэтому скорее ближе к медленному. =)
Верная идея отдать одну новую под контекст, вторую новую под стаблу/распознавание речи/генерацию речи.
Ну и совет выше про п100 тоже неплох.
Блять как объяснить нейросетке что мне не хочется видеть как она описывает свои мысли и чувства в формате анон рад что смог принести вам пользу, ведь он считает вас близким другом. Мне хочется обычного диалога, ну и я не против если за звёздочкой будет записано что она делает в момент разговора, улыбается/делает грустную гримасу/поправляет волосы.
Со второго раза вроде удалось объяснить (пиши меньше от третьего лица). Я уж разозлился меньше четверти текста диалог, остальное ебанная графомания чё там она думает
Она это в том числе для себя пишет, так как это что то внутренних мыслей сетки, где она "думает"
Если отучить совсем думать между ответами речью, то сетка скорей всего будет хуже отыгрывать персонажа, так как не будет "думать" о том что делать и как к чему относится
Короче будет много палок но мало говна
Об этом не думал, посмотрю как пойдет
>Meta готовится выпустить Llama 3 в ближайшие недели
>«Мы усердно трудимся над тем, чтобы заставить эти модели не просто говорить, но также рассуждать, планировать, <..> запоминать», — сообщила вице-президент Meta по исследованиям в области ИИ Джоэль Пино (Joelle Pineau)
Звучит хайпово
>«Мы усердно трудимся над тем, чтобы заставить эти модели не просто говорить, но также рассуждать, планировать, <..> запоминать», — сообщила вице-президент Meta по исследованиям в области ИИ Джоэль Пино (Joelle Pineau)
Звучит хайпово
И хорошо и плохо. Хорошо что вышло, плохо что все осталось старым по структуре, раз так легко конвертируется
впритык наверно двухбитный квант войдет в две теслы. вместо 65к контекста будет совсем без контекста. Вот тут то и становится видно что плотные модели рациональней для памяти. Все эти микстуры из экспертов ебаное баловство совсем не для потребительского уровня
Навалят токенов прогнозирования и мыслей, я тут как то кидал работы на эту тему месяцы назад
Сложнее обсчет и не все будет выводится юзверю на экран
Короче корпорации опять на подсосе у идей по внутреннему диалогу
Почувствуй себя камушком вызвавшим лавину, лол
Не удивлюсь что эту тему, как место где дают обратную связь моделям, все это время мониторили каким нибудь ботом или вобще человек, заодно с мониторингом всяких форумов и среддитов.
Собирая инфу и разные догадки, которые потом проверяли.
А значит этого не будет.
>Сложнее обсчет и не все будет выводится юзверю на экран
И как это будет работать?
>Requires ~260GB VRAM
Нажористо
Почему констатацию факта ты представляешь как субъективное мнение? Примеры мамбы и совсем мелочи - уместны но ограниченны, остальное как раз твой субъективизм и некорректные выводы.
> 11б которые умнее 13б
На много месяцев новее, более передовая базовая модель, и всеравно там проявляется 7б-шность. Новой полноценной 11б изначально натрененной у нас нет чтобы с ней сравнивать.
В очередной раз свои суждения строишь только по ограниченному пуллу, игнорируя все остальное. А еще такие выводы делаешь, ну конечно васяну в двощей, игнорирующему логику, виднее чем разработчикам сетей как наиболее оптимально расходовать бюджет весов.
> кому важна анонимность и качество
Видеокарты купить не пробовал? Вон теслы доступны пролетариату вполне.
> экслламу на теслах ты не запустишь
На p100 работает. Если еще много ныть то может турбодерп запилит костыль для поддержки на p40.
Уже по чипу и кристаллам на нем видно насколько оно будет дорогое.
В начале пиши инструкцию как нужно отвечать, можешь даже примеров накидать. А вообще на кончай тред нужно ровняться, у них там ввиду ограниченных возможностей все в промт инжениринг упарываются, чего стоит их префилл перед каждым ответом. И он вполне работает, без кучи правильно расположенных и отформатированных инструкций стоковые ответы сеток выглядят суперуныло хуже локалок лол, а с правильным приготовлением все отлично.
Надеемся и ждем.
ПЕРЕКАТ
Хрена мы тут, за 4 дня набили на перекат
Хрена мы тут, за 4 дня набили на перекат
>И как это будет работать?
Что то вроде
https://arxiv.org/abs//2310.11511
https://huggingface.co/SciPhi/SciPhi-Self-RAG-Mistral-7B-32k
>MoE-параша
>https://huggingface.co/Epiculous/Crunchy-onion-GGUF
Был скептичен поначалу, но нет, модель - одна из самых лучших что я встречал. Шизит нечасто, и отвечает прям в характер и хорошо. Учитывая что на проце и оперативки высирает ещё и почти 6 токенов в секунду - моё увожение.
И сколько оно видеопамяти требует? Не знаю, стоит ли оно мороки.
> Запомнить карточку, общую тематику и не делать в них явных ошибок научились уже 7б, а тут это становится проблемой.
И что это за 7б такие, интересно?




Здесь мы делимся рецептами запуска, настроек и годных промтов, расширяем сознание контекст, и бугуртим с кривейшего тормозного говна.
Тред для обладателей топовых карт NVidia с кучей VRAM или мажоров с проф картами уровня A100, или любителей подождать, если есть оперативная память. Особо терпеливые могут использовать даже подкачку и запускать модели, квантованные до 8 5 4 3 2-х бит, на кофеварке с подкачкой на микроволновку.
Здесь и далее расположена базовая информация, полная инфа и гайды в вики https://2ch-ai.gitgud.site/wiki/llama/
Базовой единицей обработки любой языковой модели является токен. Токен это минимальная единица, на которые разбивается текст перед подачей его в модель, обычно это слово (если популярное), часть слова, в худшем случае это буква (а то и вовсе байт).
Из последовательности токенов строится контекст модели. Контекст это всё, что подаётся на вход, плюс резервирование для выхода. Типичным максимальным размером контекста сейчас являются 2к (2 тысячи) и 4к токенов, но есть и исключения. В этот объём нужно уместить описание персонажа, мира, истории чата. Для расширения контекста сейчас применяется метод NTK-Aware Scaled RoPE. Родной размер контекста для Llama 1 составляет 2к токенов, для Llama 2 это 4к, но при помощи RoPE этот контекст увеличивается в 2-4-8 раз без существенной потери качества.
Базовым языком для языковых моделей является английский. Он в приоритете для общения, на нём проводятся все тесты и оценки качества. Большинство моделей хорошо понимают русский на входе т.к. в их датасетах присутствуют разные языки, в том числе и русский. Но их ответы на других языках будут низкого качества и могут содержать ошибки из-за несбалансированности датасета. Существуют мультиязычные модели частично или полностью лишенные этого недостатка, из легковесных это openchat-3.5-0106, который может давать качественные ответы на русском и рекомендуется для этого. Файнтюны семейства "Сайга" не рекомендуются в виду их низкого качества и ошибок при обучении.
Основным представителем локальных моделей является LLaMA. LLaMA это генеративные текстовые модели размерами от 7B до 70B, притом младшие версии моделей превосходят во многих тестах GTP3 (по утверждению самого фейсбука), в которой 175B параметров. Сейчас на нее существует множество файнтюнов, например Vicuna/Stable Beluga/Airoboros/WizardLM/Chronos/(любые другие) как под выполнение инструкций в стиле ChatGPT, так и под РП/сторитейл. Для получения хорошего результата нужно использовать подходящий формат промта, иначе на выходе будут мусорные теги. Некоторые модели могут быть излишне соевыми, включая Chat версии оригинальной Llama 2.
Кроме LLaMA для анона доступны множество других семейств моделей:
Pygmalion- заслуженный ветеран локального кума. Старые версии были основаны на древнейшем GPT-J, новые переехали со своим датасетом на LLaMA, но, по мнению некоторых анонов, в процессе потерялась Душа ©
MPT- попытка повторить успех первой лламы от MosaicML, с более свободной лицензией. Может похвастаться нативным контекстом в 65к токенов в версии storywriter, но уступает по качеству. С выходом LLaMA 2 с более свободной лицензией стала не нужна.
Falcon- семейство моделей размером в 40B и 180B от какого-то там института из арабских эмиратов. Примечательна версией на 180B, что является крупнейшей открытой моделью. По качеству несколько выше LLaMA 2 на 70B, но сложности с запуском и малый прирост делаю её не самой интересной.
Mistral- модель от Mistral AI размером в 7B, с полным повторением архитектуры LLaMA. Интересна тем, что для своего небольшого размера она не уступает более крупным моделям, соперничая с 13B (а иногда и с 70B), и является топом по соотношению размер/качество.
Qwen - семейство моделей размером в 7B и 14B от наших китайских братьев. Отличается тем, что имеет мультимодальную версию с обработкой на входе не только текста, но и картинок. В принципе хорошо умеет в английский, но китайские корни всё же проявляется в чате в виде периодически высираемых иероглифов.
Yi - Неплохая китайская модель на 34B, способная занять разрыв после невыхода LLaMA соответствующего размера
Основные форматы хранения весов это GGML и GPTQ, остальные нейрокуну не нужны. Оптимальным по соотношению размер/качество является 5 бит, по размеру брать максимальную, что помещается в память (видео или оперативную), для быстрого прикидывания расхода можно взять размер модели и прибавить по гигабайту за каждые 1к контекста, то есть для 7B модели GGML весом в 4.7ГБ и контекста в 2к нужно ~7ГБ оперативной.
В общем и целом для 7B хватает видеокарт с 8ГБ, для 13B нужно минимум 12ГБ, для 30B потребуется 24ГБ, а с 65-70B не справится ни одна бытовая карта в одиночку, нужно 2 по 3090/4090.
Даже если использовать сборки для процессоров, то всё равно лучше попробовать задействовать видеокарту, хотя бы для обработки промта (Use CuBLAS или ClBLAS в настройках пресетов кобольда), а если осталась свободная VRAM, то можно выгрузить несколько слоёв нейронной сети на видеокарту. Число слоёв для выгрузки нужно подбирать индивидуально, в зависимости от объёма свободной памяти. Смотри не переборщи, Анон! Если выгрузить слишком много, то начиная с 535 версии драйвера NVidia это может серьёзно замедлить работу, если не выключить CUDA System Fallback в настройках панели NVidia. Лучше оставить запас.
Гайд для ретардов для запуска LLaMA без излишней ебли под Windows. Грузит всё в процессор, поэтому ёба карта не нужна, запаситесь оперативкой и подкачкой:
1. Скачиваем koboldcpp.exe https://github.com/LostRuins/koboldcpp/releases/ последней версии.
2. Скачиваем модель в gguf формате. Например вот эту:
https://huggingface.co/Sao10K/Fimbulvetr-10.7B-v1-GGUF/blob/main/Fimbulvetr-10.7B-v1.q5_K_M.gguf
Можно просто вбить в huggingace в поиске "gguf" и скачать любую, охуеть, да? Главное, скачай файл с расширением .gguf, а не какой-нибудь .pt
3. Запускаем koboldcpp.exe и выбираем скачанную модель.
4. Заходим в браузере на http://localhost:5001/
5. Все, общаемся с ИИ, читаем охуительные истории или отправляемся в Adventure.
Да, просто запускаем, выбираем файл и открываем адрес в браузере, даже ваша бабка разберется!
Для удобства можно использовать интерфейс TavernAI
1. Ставим по инструкции, пока не запустится: https://github.com/Cohee1207/SillyTavern
2. Запускаем всё добро
3. Ставим в настройках KoboldAI везде, и адрес сервера http://127.0.0.1:5001
4. Активируем Instruct Mode и выставляем в настройках пресетов Alpaca
5. Радуемся
Инструменты для запуска:
https://github.com/LostRuins/koboldcpp/ Репозиторий с реализацией на плюсах
https://github.com/oobabooga/text-generation-webui/ ВебуУИ в стиле Stable Diffusion, поддерживает кучу бекендов и фронтендов, в том числе может связать фронтенд в виде Таверны и бекенды ExLlama/llama.cpp/AutoGPTQ
Ссылки на модели и гайды:
https://huggingface.co/models Модели искать тут, вбиваем название + тип квантования
https://rentry.co/TESFT-LLaMa Не самые свежие гайды на ангельском
https://rentry.co/STAI-Termux Запуск SillyTavern на телефоне
https://rentry.co/lmg_models Самый полный список годных моделей
http://ayumi.m8geil.de/ayumi_bench_v3_results.html Рейтинг моделей для кума со спорной методикой тестирования
https://rentry.co/llm-training Гайд по обучению своей лоры
https://rentry.co/2ch-pygma-thread Шапка треда PygmalionAI, можно найти много интересного
https://colab.research.google.com/drive/11U-bC6AxdmMhd3PF9vWZpLdi6LdfnBQ8?usp=sharing Последний известный колаб для обладателей отсутствия любых возможностей запустить локально
Шапка в https://rentry.co/llama-2ch, предложения принимаются в треде
Предыдущие треды тонут здесь: